Embed Size (px)
Citation preview

4E - Colloque GREC-O – 24 et 25 juin 2015
Les systèmes complexes face au tsunami exponentiel du numérique
Valeur et Véracité de la donnée Thierry Berthier & Bruno Teboul

Thierry Berthier est Maitre de conférences en mathématiques à l'Université de Limoges. Il effectue ses recherches au sein de la Chaire de Cybersécurité & Cyberdéfense, Saint-Cyr - Thales – Sogeti et est cofondateur du site d’analyse stratégique EchoRadar et du blog Cyberland.

Bruno Teboul est Directeur Scientifique, R&D et Innovation du groupe Keyrus, membre de la Gouvernance de la Chaire Data Scientist de l’Ecole Polytechnique et enseignant-chercheur à l'Université Paris-Dauphine.

Selon Gartner et IBM, les données massives sont caractérisées par 6 V :
- Volume- Variété- Vélocité- Visibilité- Valeur- Véracité
Nous allons évoquer la Valeur et la Véracité d’une donnée

Premiers constats…
Les 4 V (Volume, Variété, Vélocité, Visibilité) sont assez facilement mesurables.
Mesurer précisément la valeur et la véracité d’une donnée, c’est en général un problème difficile.
Valeur et Véracité de la donnée dépendent fortement du contexte et de l’instant d’évaluation.
La Valeur et la Véracité d’une donnée sont parfois indépendantes.

Premiers constats…Notre production atteindra les 40 Zo de données en 2020 ( 1 Zo = 10 puissance 21 octets ).Nos projections algorithmiques volontaires ou systémiques contribuent au déluge des données.Elles témoignent de la fusion de l’espace physique avec le cyberespace. L’information ubiquitaire renforce cette tendance.
Les projections algorithmiques des utilisateurs ont une valeur pour le data scientist.
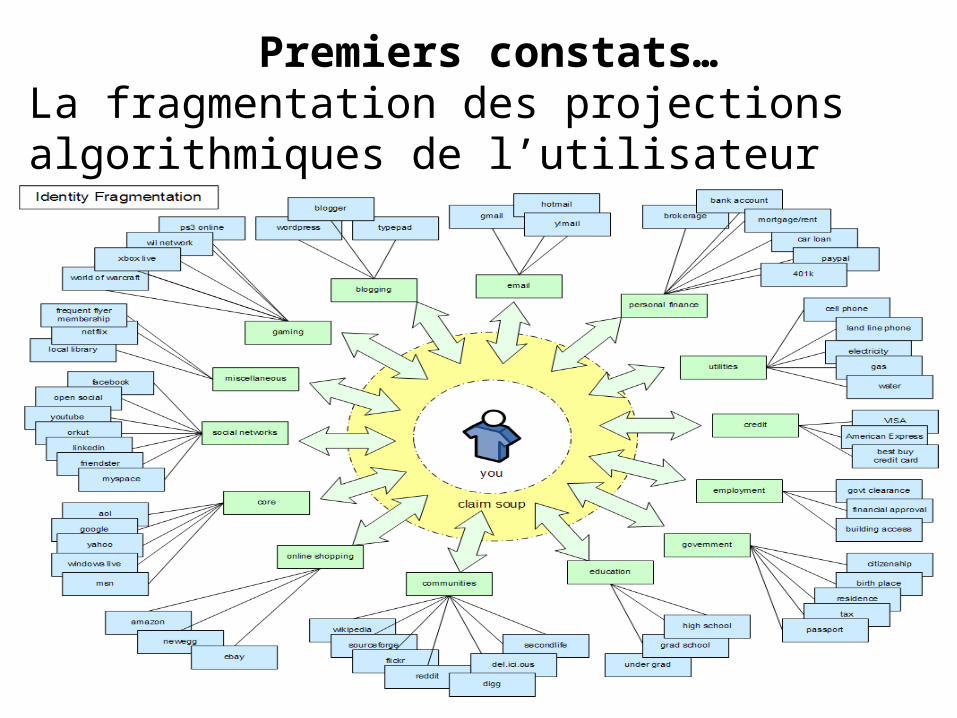
Premiers constats…La fragmentation des projections algorithmiques de l’utilisateur fragmente aussi leurs valeurs.

1 – Valeur instantanée d’interprétation ou valeur d’impact d’une donnée

Un zeste de formalisme…
Définition d’une donnée : C’est un ensemble fini de mots binaires. Un mot binaire est une suite finie formée de 0 et de 1. On note désormais D une donnée définie par : D = {M1,M2,......,Mn} où les Mj sont des mots binaires avec Mj = b1b2.....bk et bi = 0 ou 1.
Définition d’un contexte : On parlera de contexte C pour désigner un ensemble d'infrastructures humaines, physiques et algorithmiques liées entre elles par des relations et des transferts d'information assurant une cohérence systémique globale. Un contexte est constitué de groupements humains et de systèmes physiques et algorithmiques assurant son interconnexion.

Valeur instantanée d’interprétation d’une donnée
Fixons maintenant la notion de valeur d’interprétation instantanée d’une donnée D par un programme P relativement au contexte C :
Val t ( D / P, C)
Si D est une donnée accessible au contexte C, et P un programme prenant D en entrée et calculant P< D > sur un système de calcul S du contexte, on notera alors Val t ( D / P, C) la valeur à l'instant t de D relativement au contexte C et au programme P exploitant D sur C.
Val t ( D / P, C) est une valeur numérique instantanée, positive ou nulle dépendant du contexte et du programme d'exploitation.

Un premier exemple illustrant la Valeur avec Véracité
La vente de données clients par Microsoft au FBI :
Le 21 janvier 2014, la SEA (Syrian Electronic Army) publie sur son site web la copie de nombreuses factures Microsoft envoyées au FBI ainsi que des listings de données personnelles vendues. Celles-ci concernent les utilisateurs d'Outlook ou de Skype et contiennent l'identité, l'identifiant, l'adresse IP, le nom de compte en hotmail.com et le mot de passe.D'après les factures publiées par la SEA, le coût unitaire d'un jeu de données concernant un utilisateur varie entre 50 dollars et 200 dollars en fonction du contenu transmis.
La véracité des données clients vendues était certifiée par Microsoft.

Un premier exemple illustrant la Valeur avec Véracité
La vente de données clients par Microsoft au FBI : La valeur instantanée d'une donnée client D vendue par Microsoft au FBI vérifie :Val t ( D / P, C) = 200 USD pour t > 0 sur le contexte de production Microsoft.P est un programme de structuration (ou de mise au format) et de lecture de la donnée.V0 est le coût de structuration, de mise au format et de stockage de la donnée pour Microsoft.V1 désigne le prix de vente unitaire par Microsoft au FBI.V∞ est la valeur résiduelle de la donnée.

Un second exemple illustrant la Valeur sans la Véracité
L’histoire du faux tweet de la SEA qui valait 136 milliards Le 24 avril 2013, la SEA attaque le compte Twitter de l'agence Associated Press (AP). Elle en prend momentanément le contrôle et publie à 13h07 le message suivant : « Breaking : Two Explosions in the White House and Barack Obama is injured »Les 1.9 millions d'abonnés au compte Twitter d'Associated Press reçoivent le faux message posté par la SEA en le considérant comme authentique. La réaction des marchés financiers est presque immédiate : entre 13h08 et 13h10, l'indice principal de Wallstreet, le Dow Jones (DJIA) perd 145 points soit l'équivalent de 136 milliards de dollars (105 milliards d'euros) en raison notamment du trading haute fréquence (HFT) qui a interprété et « réagi » au faux tweet. Les actions Microsoft, Apple, Mobil perdent plus de 1% presque instantanément. Quelques minutes plus tard, Associated Press reprend le contrôle de son compte et publie immédiatement un tweet annonçant que le message précédent était un faux et qu'il résultait du piratage de son compte.

Valeur d’impact sans véracité
Le faux tweet de la SEA qui valait 136 milliards de dollars
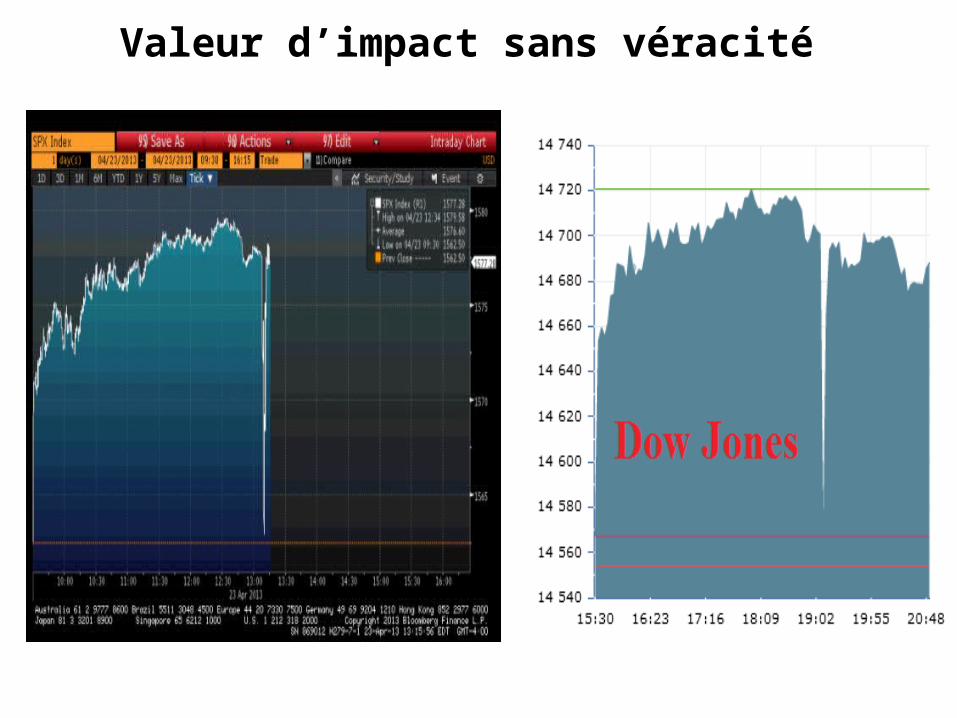
Valeur d’impact sans véracité
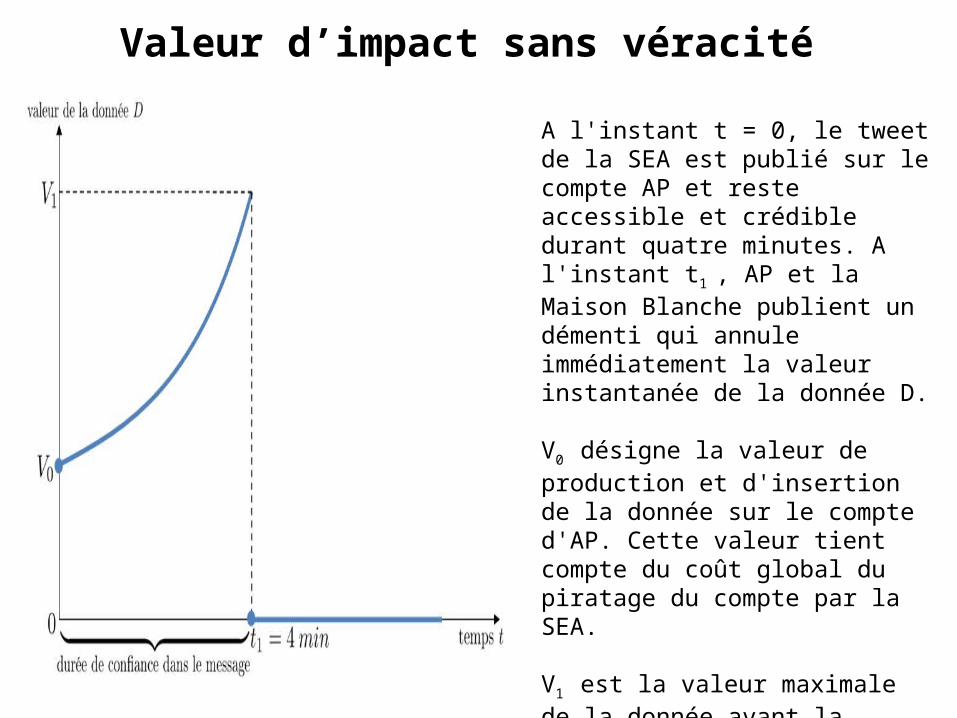
Valeur d’impact sans véracité
A l'instant t = 0, le tweet de la SEA est publié sur le compte AP et reste accessible et crédible durant quatre minutes. A l'instant t1 , AP et la Maison Blanche publient un démenti qui annule immédiatement la valeur instantanée de la donnée D. V0 désigne la valeur de production et d'insertion de la donnée sur le compte d'AP. Cette valeur tient compte du coût global du piratage du compte par la SEA. V1 est la valeur maximale de la donnée avant la reprise de contrôle du compte AP. Elle peut prendre en compte la valeur d'impact du faux tweet sur les marchés.

Valeur d’impact sans véracité
Ce que nous disent ces exemples :
La valeur d’impact d’une donnée peut être indépendante de sa Véracité.
C’est bien la confiance que l’on accorde à une donnée qui lui permet de fonder sa valeur.
Interroger la donnée, c’est d’abord évaluer la confiance qu’elle suscite, mesurer sa véracité puis sa valeur sur un contexte.

2 – Valeur d’un ensemble massif de donnée (approche par le gain)
D’où viennent les données massives ?

Définir la valeur des données massives par le gainL'idée : Pour un jeu de données massives D, on mesure le gain obtenu sur une ligne de contrainte L après exploitation de D via un système de calcul S. Une ligne de contrainte L pour une entreprise, une institution ou un laboratoire peut être temporelle (le temps nécessaire à un processus de production), spatiale (une distance, une surface à prospecter). Elle peut concerner un effectif (le nombre d'ingénieurs sur un projet) ou un coût de développement. Elle est mesurée par CL(t).
Le gain obtenu sur la ligne de contrainte L après exploitation de D par S s'écrit :
GL( D , S ) = CL ( après exploitation de D ) – CL ( avant exploitation de D )

Définir la valeur des données massives par le gain
La valeur du jeu de données D sur la ligne de contrainte L est définie par le maximum des gains obtenus lorsque l'on fait varier le système de calcul S (algorithmes et machines) :
VL( D ) = kL Max S ( GL( D , S ) )
Le facteur kL est une constante dépendant de la ligne de contrainte L. C'est un coefficient de normalisation défini pour chaque ligne de confiance. Si plusieurs lignes de contraintes sont impactées par le traitement de D, kL peut aussi représenter le poids que l'on donne à L par rapport aux autres lignes de contraintes. Il permet alors de hiérarchiser les lignes de contraintes.

Définir la valeur des données massives par le gain
Notons que calculer la valeur précise de VL(D) reviendrait à faire tourner tous les systèmes de calcul S sur l'ensemble de données D et à sélectionner celui (ou ceux) qui produisent le meilleur gain sur L.
Il s'agit donc d'une définition asymptotique de la valeur d'un ensemble de données avec laquelle on se contente d'une approximation approchant VL(D) par valeurs inférieures.
Donnons à présent deux cas concrets pour lesquels on approche la valeur d'un ensemble de données dans un contexte de traitement big data.

L’exemple des éoliennes VESTAS

L’exemple des éoliennes VESTAS
L‘analyse Big Data a permis à Vestas d’optimiser son processus d’identification des meilleurs emplacements pour implanter ses éoliennes . L’analyse des données a permis d’augmenter la production d’électricité et de réduire les coûts énergétiques.Grâce aux données massives, Vestas est en mesure de décrire avec précision le comportement du vent et de fournir une analyse de rentabilisation solide à ses clients. Le système Big Data VESTAS (IBM) induit une réduction de 97 % du temps de réponse sur les prévisions éoliennes passant de plusieurs semaines à seulement quelques heures aujourd’hui. Il réduit le coût de production par kilowattheure pour les clients et réduit le coût et l’encombrement informatique avec une diminution de 40 % de la consommation énergétique. La base de données « Vestas-Eoliennes » atteint les 24 péta-octets .

L’exemple des éoliennes VESTAS
Le logiciel IBM InfoSphere BigInsights fonctionnant sur un système IBM System x iDataPlex assiste VESTAS dans sa gestion des données météorologiques et de localisation. Ainsi, l’entreprise a diminué la résolution de base de ses grilles de données éoliennes qui passent d’une aire de 27 x 27 kilomètres à 3 x 3 kilomètres après exploitation du jeu de données. Ceci représente une réduction de 90% de l’incertitude. Ce gain donne aux dirigeants un aperçu immédiat des sites potentiels d’implantation d’éoliennes. La ligne de contrainte L est la résolution de base des grilles de données (une surface) et le gain après exploitation du jeu de données météo s’élève à :
GL( D , S ) = -720 Km2 (Ce qui représente 98 % de gain après traitement)
VL( D ) > 720 kL

L’exemple du Zoo de Cincinnati - Ohio

L’exemple du Zoo de Cincinnati - Ohio
Le zoo de Cincinnati a mis en place une structure d'analyse Big Data des données issues de capteurs et des données clients. L'image globale en temps réel de la clientèle et son interprétation ont permis d'augmenter de 25 % les dépenses des visiteurs, soit 350 000 dollars de recettes supplémentaires par an. La compréhension fine des données clients a été appliquée à l'optimisation des ressources humaines et a libéré du temps pour le personnel.La ligne de contrainte L est la dépense annuelle des visiteurs et le gain après exploitation de l’ensemble annuel des données client s’élève à :
GL( D , S ) = 350 000 usd (ce qui représente 25 % de gain annuel après traitement)
VL( D ) > 350 000 kL .

3 – Véracité de la donnée

La tentation des fausses données pour se protéger…
Selon le rapport Symantec 2015 sur la protection des données privées :
57 % des européens se déclarent inquiets quant à la sécurité de leurs informations personnelles.
81 % estiment que leurs données ont de la valeur (>1000 euros).
31 % n’hésitent plus à communiquer de fausses données pour protéger leurs données personnelles.
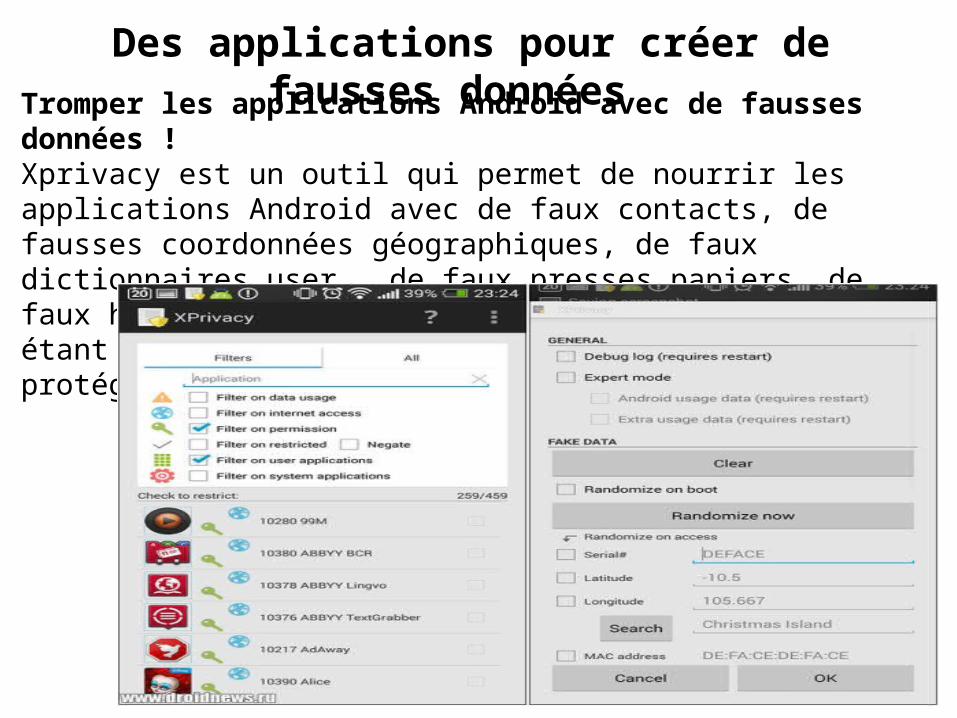
Des applications pour créer de fausses données Tromper les applications Android avec de fausses données !Xprivacy est un outil qui permet de nourrir les applications Android avec de faux contacts, de fausses coordonnées géographiques, de faux dictionnaires user, de faux presses papiers, de faux historiques d’appels, de faux SMS… L’objectif étant de créer de fausses données pour mieux protéger sa vie privée.
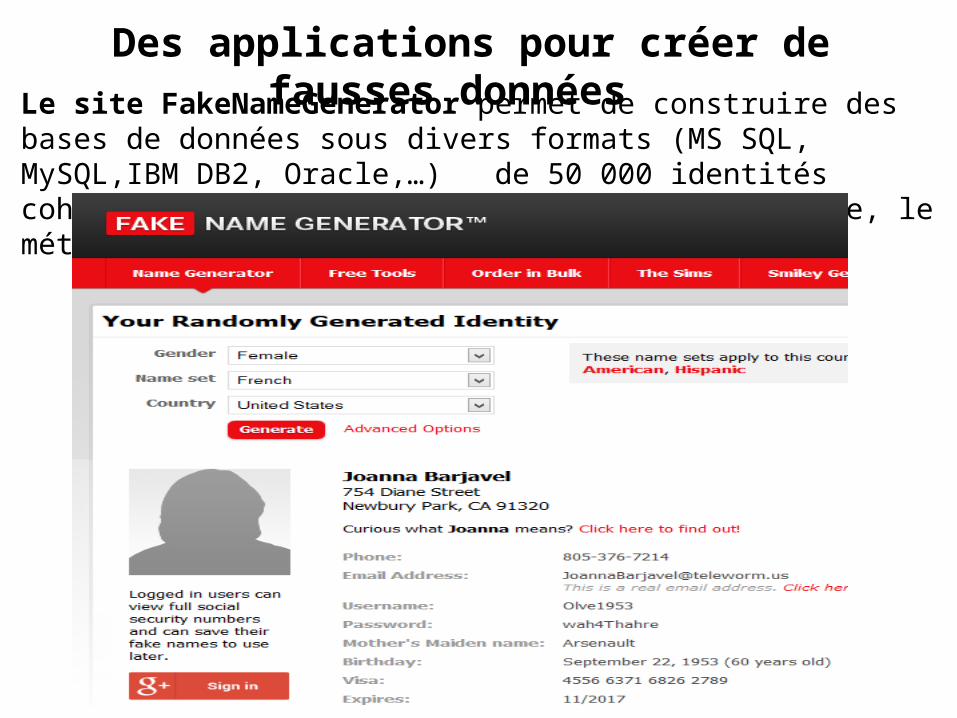
Des applications pour créer de fausses données Le site FakeNameGenerator permet de construire des bases de données sous divers formats (MS SQL, MySQL,IBM DB2, Oracle,…) de 50 000 identités cohérentes incluant l’identité, l’âge, l’adresse, le métier, etc…
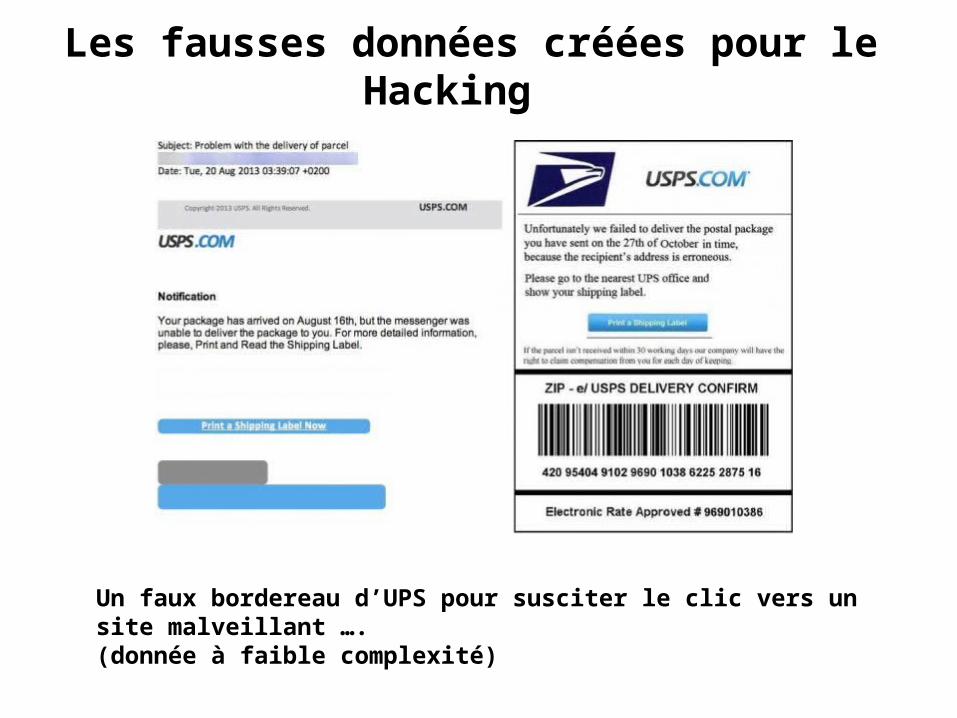
Les fausses données créées pour le Hacking
Un faux bordereau d’UPS pour susciter le clic vers un site malveillant ….(donnée à faible complexité)
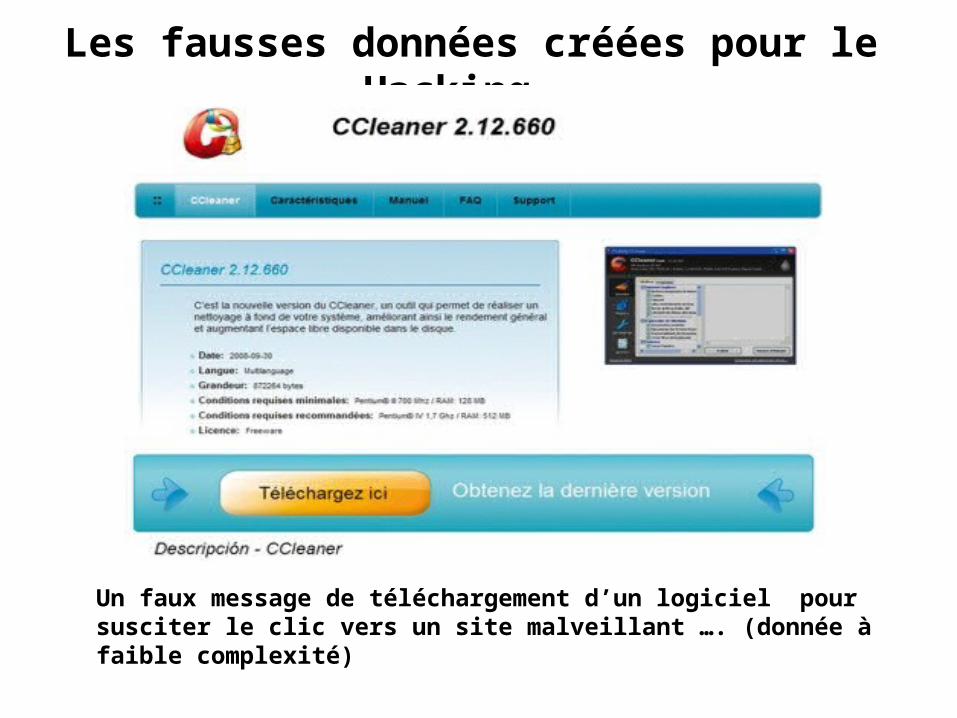
Les fausses données créées pour le Hacking
Un faux message de téléchargement d’un logiciel pour susciter le clic vers un site malveillant …. (donnée à faible complexité)
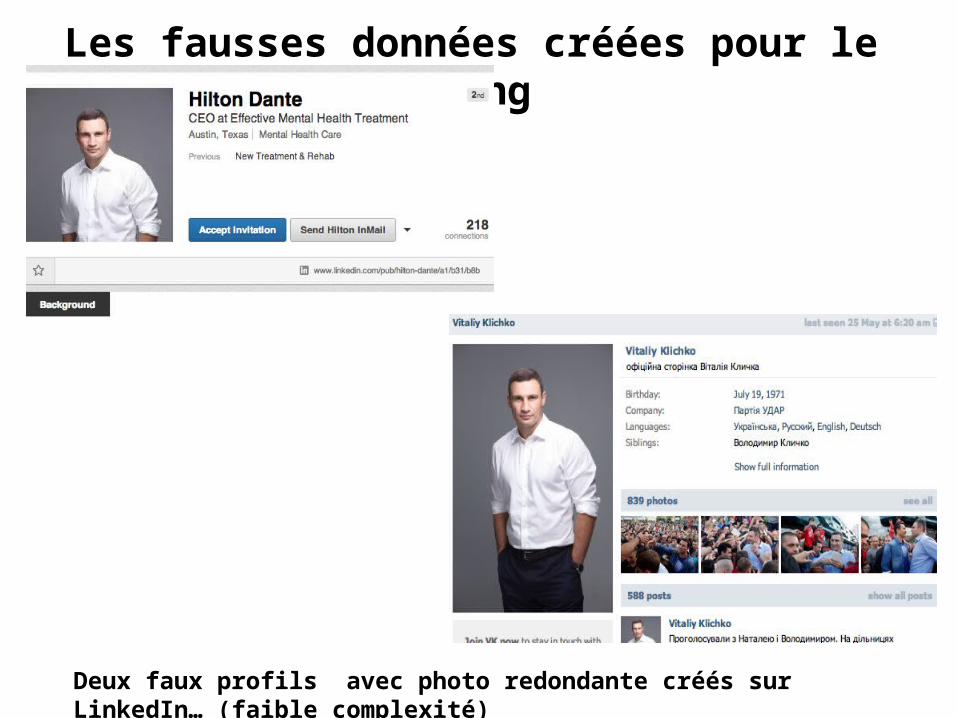
Les fausses données créées pour le Hacking
Deux faux profils avec photo redondante créés sur LinkedIn… (faible complexité)
Données fictives et hacking Dans une opération de hacking, la phase d’ingénierie sociale s’appuie de plus en plus souvent sur la création d’un ensemble de données fictives.L’objectif est d’installer la confiance auprès des cibles et de les pousser à exécuter un code viral (malware,spyware, rançonware,…).Un exemple emblématique : l’Opération Newscaster - NewsOnLine

L’OP Newscaster (forte complexité) Newscaster est une opération de cyberespionnage attribuée à l’Iran qui s’inscrit dans le durée (2012-2014) ciblant plus de 2000 personnes (USA, Europe, Israël) , des officiers supérieurs de l’US Army, des ingénieurs de l’industrie de l’armement, des membres du congrès, etc. C’est une APT longue, structurée et furtive. La première phase de l’opération s’est appuyée sur la construction d’un faux site web d’information NewsOnLine, hébergé sur des serveurs US et supervisé par une rédaction américaine fictive. Des contacts ont été noués avec les futures cibles pour qu’elles participent à la rédaction d’articles du site. Un noyau de profils fictifs américains (sur Facebook, Twitter, LinkedIn) a été construit de toute pièce pour échanger avec les cibles. La confiance s’installe durant près d’un an puis, les attaquants profitent des échanges de fichiers d’articles pour injecter des spyware sur les machines des cibles et collecter des données sensibles ou classifiées.
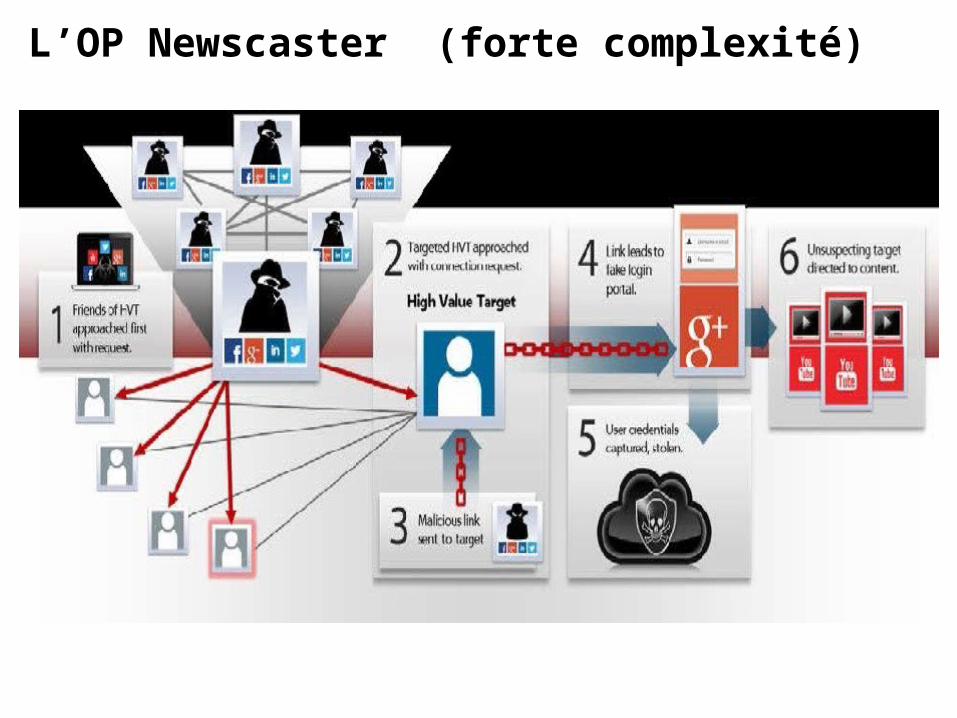
L’OP Newscaster (forte complexité)

Mesurer la confiance en une donnée ?
L'approche pragmatique consiste souvent à évaluer la probabilité de véracité d'une donnée D connaissant son émetteur, sa réputation et son historique :
p( D vraie / Émetteur, Réputation, Historique)

Mesurer la confiance en une donnée ?
il faut désormais calculer cette probabilité en tenant compte de l'éventualité d'une cyberattaque sur D, soit :
p( D vraie / Émetteur, Réputation, Historique, p( Hacking(D) ) > 0 )
C’est cette probabilité qui permet d’exprimer la confiance que l’on porte en une donnée.

Les futurs défis du Data Scientist
- Il faut évoluer vers la certification des données.- Certifier une donnée, c’est augmenter sa valeur !- L’analyse Big Data doit s’appuyer sur des données globalement certifiées. - Nous devons pouvoir détecter les corpus de données fictives pour anticiper le hacking et les cybermanipulations.
- Il faut pour cela former des Data Scientists qui possèdent une vraie culture de cybersécurité et croiser les compétences de sorte que les deux derniers V (Volume et Véracité) occupent toute leur place.
- Il faut construire des infrastructures algorithmiques dans le Big Data qui soient résilientes, antifragiles, capables d’évaluer en temps réel la véracité et la valeur des données en streaming.

Les futurs défis du Data Scientist
L'antifragilité , concept introduit par Nassim Nicholas Taleb en 2013, peut apporter une réponse efficace à la prolifération des données fictives.
Dépassant les simples notions de résistance et de résilience, l'antifragilité sous entend une amélioration régulière du système au fil des chocs subis et une capacité à profiter de l'évènement aléatoire pour se renforcer.
En matière numérique, l'antifragilité ne peut s'installer qu'à la suite d'une montée en puissance du niveau d'intelligence artificielle embarquée dans le système.
Finalement, la qualité de la donnée demeure subordonnée à l'antifragilité du système qui la produit ou la traite.

Bibliographie Report - European Commission, DG CONNECT « A European strategy on the data value chain », 2013 Report - European Commission, High Level Expert Group on Scientific Data, « Riding the Wave : How Europe can gain from the rising tide of scientific data », october 2010, IBM Report, « Vestas : Turning climate into capital with big data », 2011IBM Big Data Report, « A collection of Big Data client success stories », pp117, 2012IBM Report, « The Case for Business Analytics in Midsize Firms – Cincinnati Zoo »,pp 7-10, 2012
McKinsey Global Institute, « Big Data : The next frontier for innovation, competition, and productivity », May 2011
Rapport CIGREF «Enjeux business des données. Comment gérer les données de l'entreprise pour créer de la valeur ? », octobre 2014.
TEBOUL B. « Former des bataillons de Data Scientists à l'Ecole Polytechnique », 16 octobre 2014, Silicon, article en ligne,http://www.silicon.fr/bruno-teboul-keyrus-polytechnique-chaire-data-scientist-99428.html TEBOUL B. , AMRI T. « Les Machines pour le Big Data : Vers une Informatique Quantique et Cognitive », 2014. <hal-01096689v2>
TALEB NN. "Antifragile : les bienfaits du désordre" , Editions Les Belles Lettres, 2013

Bibliographie BERTHIER T., «Newscaster, l'opération iranienne », pp 12-14, Vérification sur Internet : quand les réseaux doutent de tout, novembre 2014, Observatoire géostratégique de l'information, IRIS. BERTHIER T., Cyberchronique – Décomposition systémique d'une cyberattaque, dissymétries et antifragilité, Publications de la chaire de cyberstratégie CASTEX, janvier 2014 BERTHIER T., Sur la valeur d'une donnée, Publications de la Chaire de cyberdéfense Saint- Cyr-Sogeti-Thales – mai 2014. KEMPF O. et BERTHIER T. - « L'armée syrienne électronique : entre cyberagression et guerre de l'information » RDN – revue de la défense nationale – « Guerre de l'information » Vol. mai 2014.
KEMPF O. et BERTHIER T. - « Ville connectée et algorithmes prédictifs », Actes de la conférence Digital Polis 2015, Paris. (à paraître). BERTHIER T. - « Projections algorithmiques et cyberespace » R2IE – revue internationale d'intelligence économique – Vol 5-2 2013 pp. 179-195.
TEBOUL B. et BERTHIER T. - « Valeur et véracité de la donnée : enjeux pour l'entreprise et défis pour le data scientist », préprint, Acte du colloque « La donnée n'est pas donnée, École Militaire, Paris, Editions Cyberstratégie, Economica.

Thierry BERTHIER -
ECHORADAR & CYBERLAND
http://cyberland.centerblog.net/
http://echoradar.eu/
https://twitter.com/echo_radar

Bruno TEBOUL - KEYRUS
www.keyrus.fr/
https://twitter.com/brunoteboul


















![Art grec[1]](https://img.pdfslide.fr/doc/110x75/55639bf0d8b42a2d538b4cb0/art-grec1.jpg)










