Embed Size (px)
Citation preview

Pachyderm,
le Big Data à
l’ère de
Docker
Enguerran DELAHAIE – Meet Up SQLI 22/06/2016 enguerran_44

Comment serait une
infrastructure d’analyse de
données si on le construisait
“from scratch” aujourdhui?
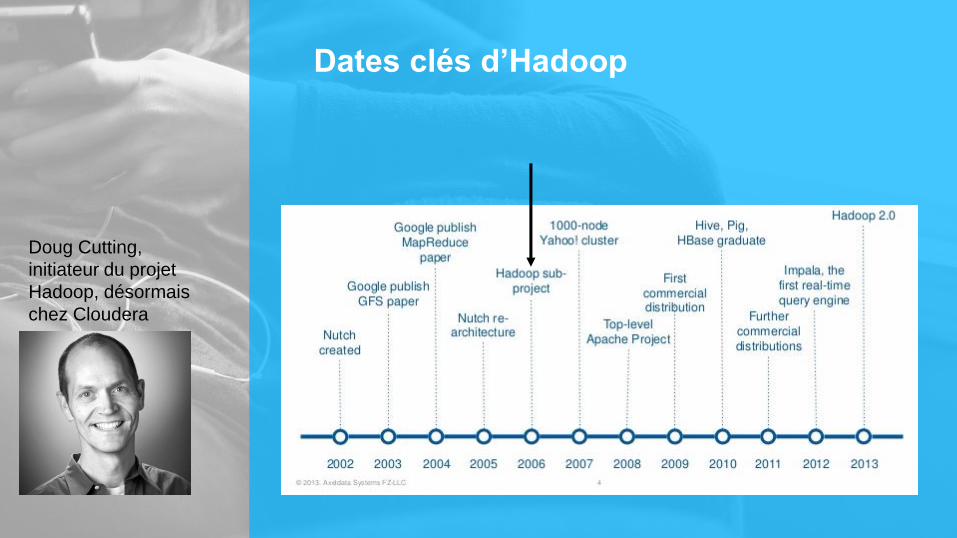
Dates clés d’Hadoop
Doug Cutting,
initiateur du projet
Hadoop, désormais
chez Cloudera

Date clés Pachyderm,Docker & Git)
Premier post sur le blog Pachyderm.io Janvier 2015
V0.5 Mars 2015 et V1.0 le 5 Mai 2016
2008 : LXC
2013 Mars : Première version en Open Source
Avril 2005 : Première version de GIT, en remplacement de BitKeeper.
(en capitalisant sur les leçons apprises à l’usage de BK)
Joe
Doliner(RethinkDb,
Airbnb)
Joseph
Zwicker(RethinkDb,
Airbnb)

Qu’est ce que Pachyderm
Big Data + Containers Docker
►Versionning pour les données stockées
►Stockage sur des systèmes de stockage Objet
(S3,GCS, Ceph)…
►Containers pour le traitement de données
►Batch ET Streaming
Pachyderm File System
Pachyderm Pipeline System
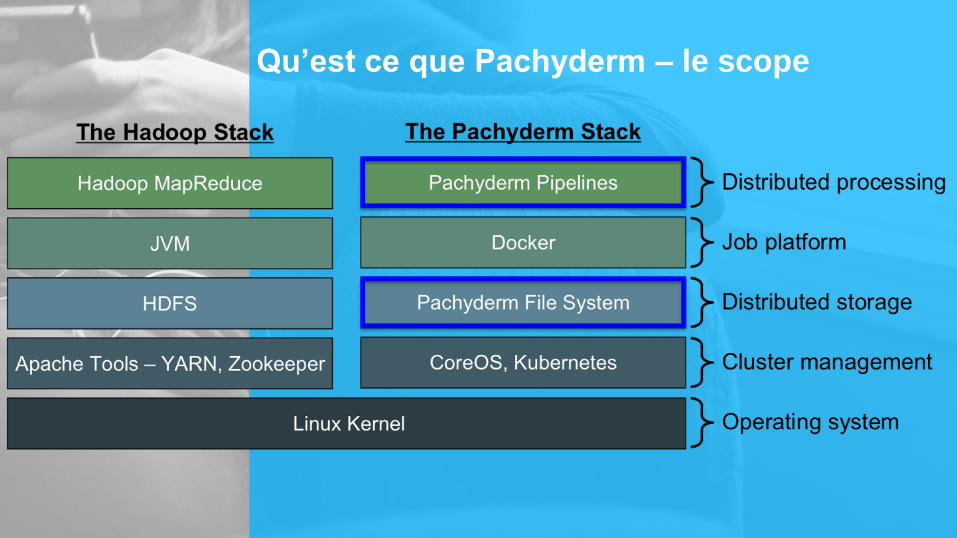
Qu’est ce que Pachyderm – le scope

Le manifeste de la Data Science
par Pachyderm
Points essentiels d’un outil de Datascience selon Pachyderm sont :
►Reproductibilité
-Des données
-De l’exécution
►Traçabilité des données
►Collaboration
►Incrémentation
►Autonomie
►Agnostique de l’Infrastructure
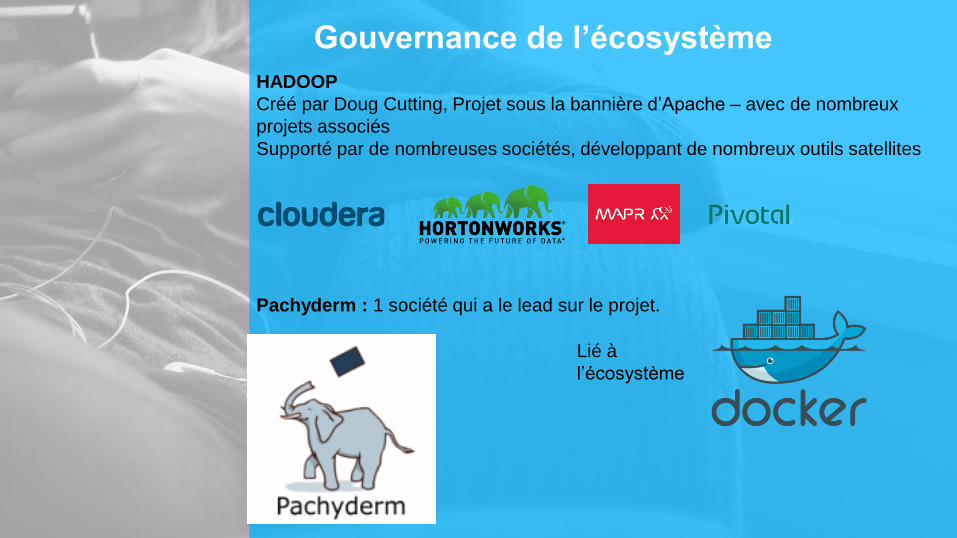
Gouvernance de l’écosystème
HADOOP
Créé par Doug Cutting, Projet sous la bannière d’Apache – avec de nombreux
projets associés
Supporté par de nombreuses sociétés, développant de nombreux outils satellites
Pachyderm : 1 société qui a le lead sur le projet.
Lié à
l’écosystème

Pachyderm File System
►Système de fichier distribué Commit Based
►En Copy On Write
(Paradigme important de Docker, et de Spark)
►Stockage de base de Pachyderm
►Versionning des données = Un GIT pour de Volumineux jeux
de données
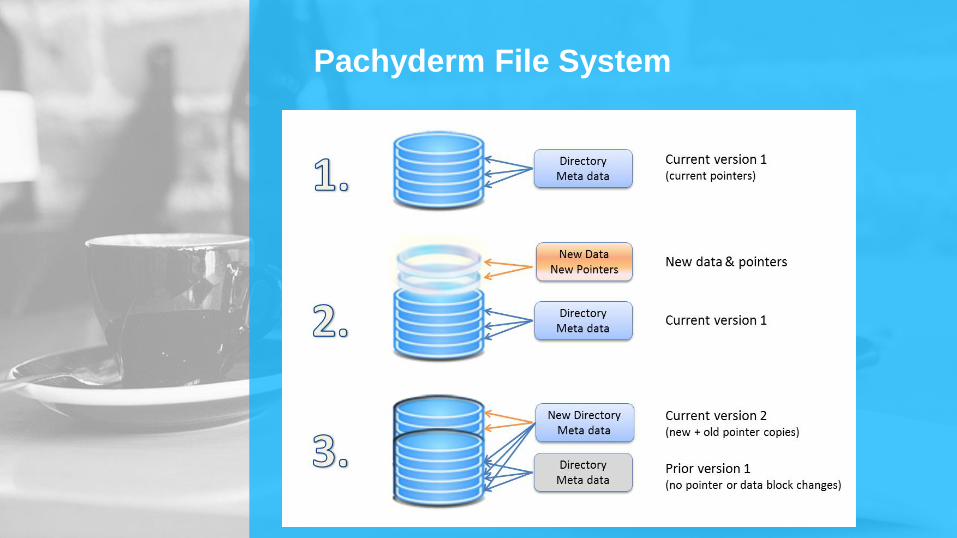
Pachyderm File System
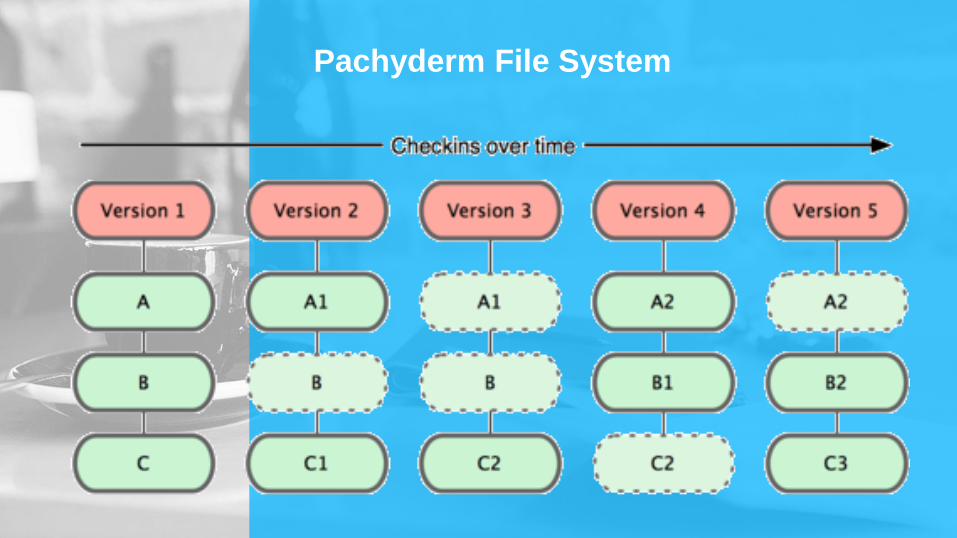
Pachyderm File System

Pachyderm Pipeline System
►Utilise l’écosystème Docker
►Agnostique d’un language
►Synergie avec le FS en Copy-on-Write (PFS)
►Resilient
►Job pipeline enregistré dans un Direct Acyclic Graph (même
structure que Git )
it’s just a container! you
can use any language or
libraries you want !

Gestion du cluster
►Hadoop
YARN – Planification des travaux et gestion des ressources
des nœuds
Zookeeper – Synchronisation de la configuration
►Pachyderm “batteries included, but removable.”
outil de gestion de cluster : Kubernetes,
Format de containerisation Docker
Etcd(CoreOs)à Gestion de la configuration
Kubernetes & Etcd de Coreos pour les tâches dévolues
à Yarn & Zookeeper sur Hadoop
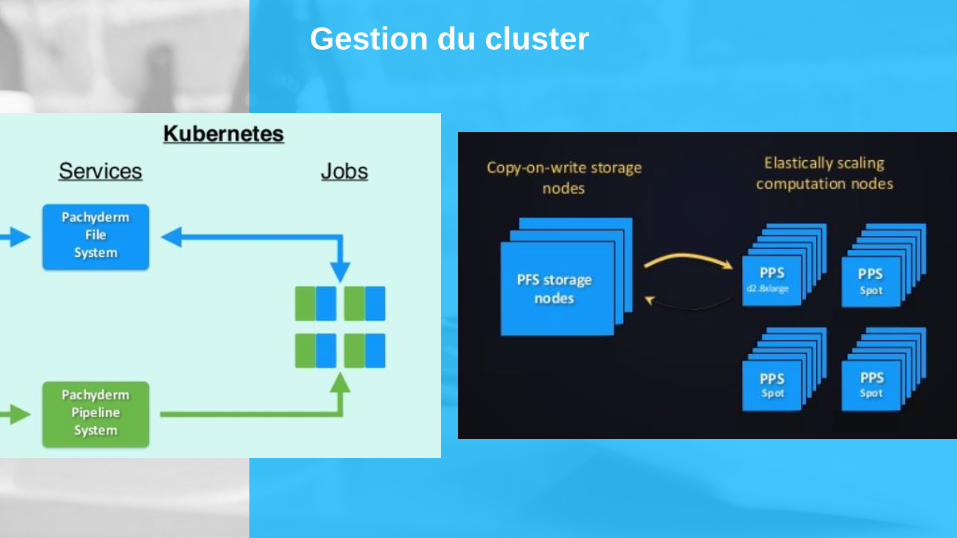
Gestion du cluster
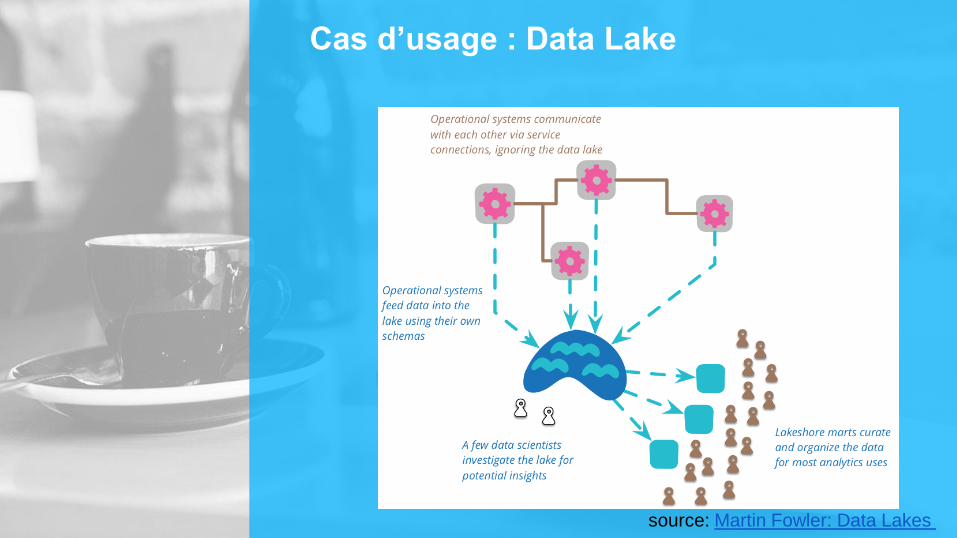
Cas d’usage : Data Lake
source: Martin Fowler: Data Lakes
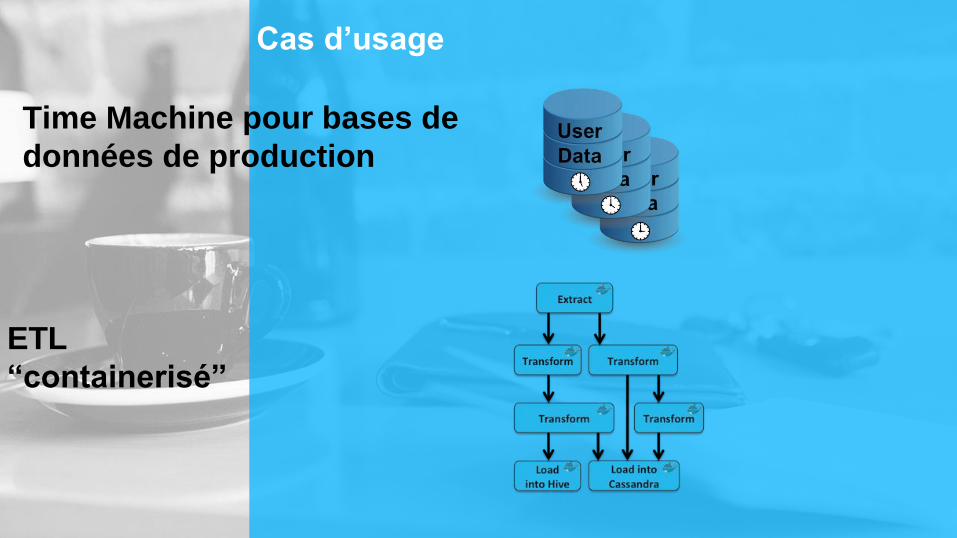
Cas d’usage
Time Machine pour bases de
données de production
ETL
“containerisé”
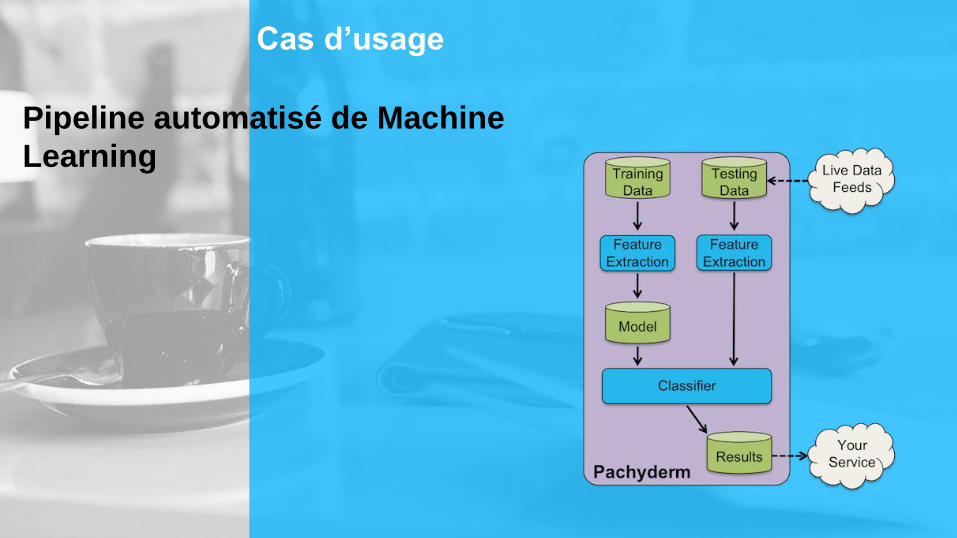
Cas d’usage
Pipeline automatisé de Machine
Learning

Prérequis à l’installation & Plateformes
Go >= 1.6
FUSE (optionel) >= 2.8.2 (pour monter PFS en local)
Kubectl (kubernetes CLI) >= 1.2.2
Pachyderm Repository
pachctl and pach-deploy
Pachyderm peut être executé sur toute plateforme que Kubernetes
supporte.
Par exemple :
►Local,
►Google Cloud Platform
►AWS
it’s just a container, you
can use any language or
libraries you want.

Merci!Des questions?













![Dyalog's [Public] Docker Containers · 2020. 11. 11. · #dyalog20 Dyalog'sDocker Containers docker run ... map TCP ports docker run -it –p 8080:8080 dyalog/jarvis Maps port 8080](https://img.pdfslide.fr/doc/110x75/60a16358bbfc10318c0191e0/dyalogs-public-docker-containers-2020-11-11-dyalog20-dyalogsdocker-containers.jpg)















