Embed Size (px)
Citation preview

Rechercheur of Prechercheur?
Een onderzoek naar de voor- en nadelen van het gebruik van Big Data bij het voorspellen van (potentiële verdachten van)
misdaden.
Door
Wouter Taal 17 augustus 2015
0

Rechercheur of Prechercheur?Een onderzoek naar de voor- en nadelen van het gebruik van Big Data bij het voorspellen van (potentiële verdachten van) misdaden.
Naam en studentnummer: Wouter Taal Emailadres: [email protected] Instituut: Hogeschool Utrecht, Faculteit Maatschappij en Recht (FMR)Opleiding: Integrale VeiligheidskundeKlas en leerjaar: IV4B, leerjaar 4Cohort: 2014-2015Afstudeerbegeleider: Dr. Ir. Anke van GorpOpdracht: Afstudeerscriptie Inleverdatum: 17 augustus 2015Versie: Definitief, versie 2
1

VoorwoordTijdens de opleiding Integrale Veiligheidskunde ben ik enthousiast geworden over het onderwerp veiligheid. Het is een thema dat continu in ontwikkeling is en op vrijwel elk vlak in de maatschappij een belangrijke rol speelt. Er zijn veel onderwerpen aan bod gekomen tijdens de studie, maar op niet alle onderwerpen wordt even diep in gegaan. Eén van die onderwerpen is veiligheid in het digitale domein. Maar dit is wel een terrein waarop de ontwikkelingen snel gaan en waar we steeds meer te maken zullen krijgen met allerlei veiligheidsvraagstukken. Vraagstukken die, ook omdat ze nieuw zijn, naar mijn mening complex en interessant zijn. Doordat er binnen de opleiding (nog) niet veel aandacht is voor de veiligheid in de digitale wereld, heb ik er voor gekozen om mijn minor te volgen aan het Lectoraat Cybersafety in Leeuwarden. Binnen het Lectoraat wordt veel onderzoek verricht naar de nieuwe problemen en vraagstukken die de komst van het internet met zich meebrengt. Tijdens de minor ben ik mij nog meer gaan interesseren voor de mogelijkheden van Big Data binnen het veiligheidsdomein. In de commerciële branche wordt al handig gebruikt gemaakt van grote hoeveelheden digitale gegevens om handelingen en gedragingen van klanten en gebruikers in kaart te brengen en verbanden te leggen. Maar wat zijn de mogelijkheden binnen het opsporingsapparaat in Nederland? Voor u ligt mijn afstudeerscriptie omtrent de mogelijkheden van het gebruik van Big Data bij het voorspellen van misdaden en potentiële verdachten van misdaden.
De afstudeerscriptie is vormgegeven aan de hand van de eisen vanuit de opleiding Integrale Veiligheidskunde, Hogeschool Utrecht. De input is op basis van kennis vanuit de opleiding, beschikbare literatuur en experts uit het werkveld die ik heb mogen interviewen. Ik wil van de gelegenheid gebruik maken om al mijn respondenten te bedanken voor hun medewerking en openhartigheid bij het beantwoorden van mijn vragen. Verder wil ik graag mijn afstudeerbegeleider Anke van Gorp bedanken voor haar goede begeleiding en enthousiasme voor mijn onderwerp.
Soest, 17 augustus 2015.
Wouter Taal
2

SamenvattingHet voorspellen van (potentiële daders van) misdaden is niet meer louter toekomst muziek. Voorspellingen doen op basis van Big Data wordt al op verschillende manieren toegepast door de overheid, maar beslissingen nemen op basis van computer berekeningen (datamining) roept nog vele vragen op. De aanleiding voor dit onderzoek is dat er een gebrek aan inzicht is wat de voor- en nadelen zijn voor het voorspellen van (potentiële verdachten van) misdaden doormiddel van Big Data.
De volgende hoofd- en deelvragen zijn geformuleerd voor het onderzoek:
Wat zijn de voor- en nadelen van Big Data gebruik bij het voorspellen van (potentiële verdachten van) misdaden?
1. Op welke manier kan Big Data gebruikt worden om aan de hand van datamining voorspellingen te doen over (potentiële verdachten van) misdaden?
2. In hoeverre bestaan er ethische en juridische bezwaren tegen het gebruik van Big Data bij het voorspellen van (potentiële verdachten van) misdaden?
3. Op welke wijze wordt er rekening gehouden met mogelijke valkuilen in relatie tot het gebruik van Big Data bij het voorspellen van (potentiële verdachten van) misdaden?
Het benutten van Big Data voor voorspellingen is een nieuwe stap binnen het intelligencegestuurd politiewerk. Als het lukt om tot goede voorspellingen te komen, kan niet alleen de politie efficiënter en effectiever ingezet worden, maar kunnen ook acties ingezet worden die leiden tot het voorkomen van misdrijven. Dit kan veel persoonlijk leed en maatschappelijke schade voorkomen. Het is uiteraard wel de kunst om te komen tot juiste voorspellingen. Dat is nog geen eenvoudige opgave.
Uit het onderzoek is gebleken dat het grootste voordeel van Big Data gebruik is, dat er aan de hand van die data verschillende voorspelmodellen zijn ontwikkeld, of nog in ontwikkeling zijn. De geïnterviewde noemen Criminaliteits Anticipatie Systeem (CAS) als voorbeeld waarbij Big Data wordt gebruikt bij het voorspellen van misdaden. Daarnaast is er nog een verzekeringsmaatschappij bezig met het ontwikkelen van een geografisch voorspelmodel van woninginbraken. Waar het gaat over het voorspellen van potentiële verdachten van misdaden worden Top600 en Prokid-plus genoemd.
Technisch gezien is er met Big Data dus al veel mogelijk, maar de vraag is moeten we dat ook willen? Hierbij gaat het over de balans vrijwillig/verplicht en de rol van de staat in de bescherming van de maatschappij ten opzichte van de vrijheid van het individu. De bezwaren spelen overigens meer waar het gaat over het voorspellen van potentiële verdachten, dan waar het gaat om het voorspellen van mogelijke misdaden als woninginbraak.
Ook ziet men het bezwaar van een overheid die allerlei privégegevens van mensen gebruikt waarmee een beeld ontstaat van een Orwelliaanse samenleving. Dit kan leiden tot een vertrouwensbreuk tussen de overheid en haar burgers (sociaal contract). De burger laat zogenaamd vrijwillig overal sporen
3

achter, maar hoe vrijwillig is dat? De burger is onwetend over wat er met die gegevens mogelijk is en wordt gedaan.
Daarnaast wordt de complexiteit van de materie in relatie tot onvoldoende kennis in de organisatie als risicofactor beschouwd. Mensen met kennis van Big Data zijn schaars en de private sector is bereid om veel te betalen voor deze kennis. Dit zou de overheid op achterstand kunnen plaatsen.
4

Wettelijke kaders voorkomen dat men doorslaat in het verzamelen van gegevens en het respecteert op deze manier de privacy van betrokkenen. Er worden echter ook belemmeringen ondervonden. Er wordt zoveel gewicht aan de kant van de privacybescherming gelegd (bewaartermijn/bewaarplicht), dat dit ten koste gaat van een efficiënte en effectieve uitvoer van de politietaken. De wetgeving loopt doorgaans achter de maatschappelijke ontwikkelingen aan, dit geldt in het bijzonder bij een terrein als Big Data waar de ontwikkelingen zo snel gaan. Ook noemt men het risico van 'de glijdende schaal': een eerste stap kan leiden tot vervolgstappen waarbij grenzen vervagen (proportionaliteit).
Naast de voor- en nadelen zijn er ook mogelijke valkuilen naar voren gekomen die, wanneer er onvoldoende bij stilgestaan wordt, om kunnen slaan in nadelen. Bij confirmation bias en interpretatiefouten lijk de menselijke factor het ‘keyword’ te zijn. Een voorspelmodel moet louter als hulpmiddel dienen voor de mens en niet andersom. Zo kan bijvoorbeeld het onderbuikgevoel van een wijkagent niet vervangen worden door een voorspelsysteem.
Function creep wordt niet als iets negatief beschouwd; het is inherent aan het gebruik van Big Data. Waar nodig wordt toestemming gevraagd om de desbetreffende gegevens te mogen gebruiken. Als toestemming wordt gegeven is er in feite geen sprake meer van function creep.
Op basis van de resultaten zijn volgende aanbevelingen geformuleerd: Kennis over het gebruiken van Big Data is schaars. Er zijn nu twee soorten
kennisniveaus. Het kennisniveau van het puur bij elkaar zoeken van data en het bij elkaar voegen, en het kennisniveau om er echt informatie uit te halen. En de laatste soort is vele malen schaarser. De schaarse hoeveelheid kennis die er nu is, lekt snel weg naar de private sector, vooral omdat daar beter wordt betaald. Vooral bij de publieke sector moet hoger worden ingezet op het vergaren en verbeteren van kennis omtrent (het gebruik van) Big Data.
Onderzoeken of voorspellingen op basis van een voorspelmodel effectiever zijn dan voorspellingen op basis van expertise en ervaring, de menselijke interpretatie van gegevens.
Het geven van voorlichting en het voeren van een maatschappelijke discussie over de voor- en nadelen van Big Data gebruik door de politie om de burgers bewust te maken en draagvlak te creëren en te blijven houden.
Onderzoek naar de mogelijkheid van een nationale databank, waarbij de burger zelf aangeeft wat er met hun persoonlijke data wel of niet mag gebeuren. Laten we nou eens aan Nederland vragen wij zij vinden wat er met hun data mag gebeuren.
5

InhoudsopgaveH1 Probleemschets............................................................................................6
1.1 Inleiding.....................................................................................................61.2 Aanleiding..................................................................................................8
H2 Doelstelling van het onderzoek...................................................................11H3 Onderzoeksvraag en deelvragen................................................................12H4 Operationalisering......................................................................................13
4.1 Big Data...................................................................................................134.2 Datamining..............................................................................................154.3 Voorspellen van (potentiële verdachten van) misdaden..........................184.4 Ethische en juridische bezwaren..............................................................224.5 Valkuilen..................................................................................................244.6 Onderzoeksmodel....................................................................................26
H5 Onderzoeksopzet........................................................................................275.1 Type onderzoek.......................................................................................275.2 Onderzoeksmethoden en analysekader...................................................27
H6 Resultaten...................................................................................................296.1 De 7 V’s van Big Data..............................................................................296.2 Big Data gebruik......................................................................................356.3 Ethische en juridische bezwaren..............................................................376.4 Valkuilen..................................................................................................44
H7 conclusies...................................................................................................497.1 Beantwoording hoofdvraag......................................................................49
H8 Discussie en aanbevelingen........................................................................538.1 Aanbevelingen.........................................................................................54
Literatuurlijst........................................................................................................55Bijlage 1 Respondenten interviews.....................................................................61Bijlage 2 Topiclijst en sturingsvragen..................................................................62
6

H1 Probleemschets1.1 Inleiding
In 2054 is er een speciale eenheid van de politie in Washington D.C., ‘Pre-Crime’ genaamd, die als doel heeft toekomstige
moordenaars te arresteren voordat ze deze moord plegen. Zij worden vervolgens zonder proces in een permanente slaapstatus gebracht. Pre-Crime baseert zich hierbij op de visioenen van drie
genetisch gemodificeerde mediums, ‘precogs’ genaamd, die foutloos de toekomst kunnen voorspellen.
Bovenstaande is de kern van de in 2002 verschenen film ‘Minority Report’. In deze film slaagt de overheid erin misdrijven te voorkomen doordat deze voorspeld kunnen worden. Hoewel deze situatie nog niet is bereikt, is het niet meer louter sciencefiction. De visioenen waarop de voorspellingen gebaseerd zijn, zijn in de huidige digitale samenleving vertaald naar Big Data en de voorspellingen worden gedaan door datascientists aan de hand van datamining-software.
Bij Big Data gaat het om zeer grote datasets die door nieuwe technologieën snel geanalyseerd en geïnterpreteerd kunnen worden (Berlo en Meijer, 2013). De technologie van tegenwoordig kan deze grote databestanden steeds beter analyseren en interpreteren. Dit zorgt ervoor dat het gedrag van mensen preciezer dan ooit geanalyseerd kan worden en daarmee ook voorspeld kan worden (Anderson, 2008; Bloem, et al, 2012). De voorspellende kracht van Big Data kan op tal van terreinen worden ingezet. Naast het gedrag kan ook een verhoogde kans op een misdrijf op een bepaalde locatie steeds beter voorspeld worden (Doeleman en Willems, 2014).
Bij Datamining draait het om verbanden leggen door de verschillende Big Data met elkaar te koppelen, zodat er nieuwe kennis ontstaat. Door diverse gegevensbestanden aan elkaar te koppelen en deze gegevensverzameling vervolgens met behulp van computerprogramma’s te doorzoeken aan de hand van bepaalde sleuteltermen of statistische verbanden, kunnen nieuwe inzichten ontstaan in bijvoorbeeld het gedrag van individuen en groepen of gebieden waar de kans groter is dat er een misdrijf gepleegd wordt (Hildebrandt en Gutwirth, 2008). De Britse filosoof Francis Bacon (1561-1626) leek zijn tijd dus ver vooruit te zijn met zijn uitspraak: “Kennis is Macht” (uit: Meditationes Sacræ (1597)). Hoe meer men weet, hoe beter men kan handelen.
Verschuiving binnen politiewerkDeze nieuwe techniek laat ook een verschuiving zien binnen het politiewerk, en dan met name in de opsporing. Waar voorheen de concentratie lag op het gebruik van informatie bij de opsporing van criminelen, is er een verschuiving te zien naar het steeds vaker gebruiken van allerlei informatie (data) bij het voorspellen van crimineel gedrag en risicovolle locaties, of anders gezegd: naar de verwachting waar een crimineel zal toeslaan. De nadruk ligt daarbij dus op het vooraf verzamelen en analyseren van data (Savič, 2014).
Deze verschuiving in de manier van denken is vertaald in de verschenen publicatie van Klerks en Kops (2009). Hierin wordt het belang van intelligencegestuurd politiewerk uitgelegd. Eén van de hoofdtaken van de politie is de opsporing van strafbare feiten (Politie, 2015). Om deze taak goed te kunnen uitvoeren heeft de politie informatie nodig uit de samenleving. Zo moeten zij bijvoorbeeld weten wat er in de samenleving gebeurt, door wie, waarom en
7

moeten zij trends in de gaten houden. Bij deze manier van werken gaat het om het bereiken van betere resultaten door voortdurend en systematisch gebruik te maken van informatie. Op deze manier krijgt de politie een goed beeld van wat er speelt in de samenleving en kan op basis van de verkregen informatie het politiewerk aangestuurd worden.
8

Dit is terug te zien in een uitspraak van commissaris Jan Boersma (2007) van de Nationale Recherche. Hij pleit voor het koppelen van politieregisters en overheidsbestanden, zoals die van de fiscus, het kadaster en de Rijksdienst voor het wegverkeer; externe bestanden van de Kamer van Koophandel en bronnen op internet waar mogelijke criminelen sporen achter gelaten hebben. Dit stelt de overheid in staat om in zekere mate grip te krijgen op de burgers door het gebruik van dataminingstechnieken (Sietsma, 2007).
Niet alleen bij intelligencegestuurd politiewerk is een verschuiving te zien naar de politie in de rol van dataverzamelaar. Dit is ook terug te zien in de vele verschenen publicaties en onderzoeken over het onderwerp 'Predictive Policing' (vrij vertaald voorspellend politiewerk). Predictive Policing vindt zijn oorsprong in de wijze waarop Wal-Mart in de Verenigde Staten inspeelde op het koopgedrag van klanten. Als er bijvoorbeeld sprake was van een weersverwachting waarbij zwaar weer werd voorspeld in een bepaalde staat, anticipeerde Wal-Mart hierop door allerlei overlevingsartikelen aan te bieden. Hierdoor werd er ingespeeld op de intuïtie van klanten om zoveel mogelijk in te slaan bij dit type weersomstandigheden (Beck, 2009). Online webshop Amazon ging nog een stap verder. Op basis van het koopgedrag van de klant werden er allerlei aanbiedingen gedaan die aansloten op recente aankopen van de desbetreffende klant. Deze voorspellingen worden gedaan door gebruik te maken van algoritmen. Een algoritme is een wiskundige formule voor het uitvoeren van een opdracht. Predictive Policing werkt ook aan de hand van deze algoritmen (Lever, 2012; Friend, 2013).
Er wordt van informatie gebruik gemaakt die afkomstig is uit meerdere databases, bijvoorbeeld demografische informatie afkomstig van het CBS in combinatie met politiegegevens (Doeleman en Willems, 2014). De informatie wordt vervolgens samengevoegd. Door hierop een analyse toe te passen kan de politie toekomstige misdaden voorspellen (Smilda, 2013). Deze analyse heeft als doel om de politie op het juiste tijdstip op de juiste locatie te laten zijn, om misdaden te voorkomen. Het intelligencegestuurd politiewerk zorgt voor informatie die gebruikt kan worden bij Predictive Policing.
Een van de bekendste voorbeelden van Predictive Policing is het inzetten van het softwarepakket PredPol door het Los Angeles Police Department, om locaties te ontdekken waar het risico op misdaad (woninginbraken, autokraken en autodiefstal) hoger is. Vervolgens krijgen deze locaties bij de diensten meer aandacht (PredPol, 2014). Ook in Nederland wordt geëxperimenteerd met Predictive Policing. In Amsterdam wordt gewerkt met het Criminaliteits Anticipatie Systeem (CAS) door wijkteams. Dit is een programma dat hetzelfde werkt als PredPol. De stad Amsterdam is opgedeeld in vakken van 125 bij 125 meter. Aan de hand van Big Data die onder andere bestaat uit aangiftes, woonlocaties van (ex)criminelen en locaties van bedrijven, wordt er een analyse gemaakt. De vakjes kleuren vervolgens geel, oranje of rood; waarbij rood een risicogebied is. Op basis van deze analyse wordt er een preventieve surveillanceroute opgesteld. De CAS kaarten richten zich op twee soorten misdaden, namelijk straatroven en inbraken (Doeleman en Willems, 2014).Wat uit deze praktijkvoorbeelden duidelijk naar voren komt, is dat het bij Predictive Policing gaat om het (geografisch) voorspellen van misdaden. Waar is de kans op een misdaad hoger dan op andere plekken? Aan de hand van deze voorspelling kan het politiewerk efficiënt ingericht worden.
Naast het gebruik van Big Data voor het voorspellen van misdaden, kunnen de grote hoeveelheden aan data ook geanalyseerd worden om potentiële
9

verdachten in kaart te brengen. Een voorbeeld hiervan is een wetsvoorstel dat Minister Opstelten van Veiligheid en Justitie in 2013 had ingediend bij de Tweede Kamer (Rijksoverheid, 2013). De kern van het wetsvoorstel was dat alle kentekens die de politie met camera's automatisch vastlegt, vier weken mogen worden bewaard om misdrijven op te sporen en voortvluchtige verdachten en veroordeelden aan te houden. Naast het kenteken en de foto van het voertuig, worden gegevens bewaard over de locatie, de datum en het tijdstip. Stichting Privacy First beschouwt het wetsvoorstel van Opstelten als een bedreiging voor de maatschappij. Privacy First voorzitter Bas Filippini zegt hierover: “... in een gezonde democratische rechtsstaat de overheid onschuldige burgers met rust dient te laten. Met dit wetsvoorstel overschrijdt de overheid die principiële grens” (Privacy First, 2013). Iedere bestuurder van een auto wordt dus op voorhand gezien als potentiële verdachte en niet pas na het begaan van een overtreding. Eenzelfde voorbeeld gaat over het opslaan van telefoongegevens door de overheid voor politieonderzoek naar ernstige misdrijven (Stoker en Thijssen, 2015). Het grote verschil met de gangbare vorm van Predictive Policing is dat het hierbij gaat om het vast leggen van gegevens van potentiële verdachten.
1.2 AanleidingInformatie over gedrag, locatie en emotie kan worden gebruikt om profielen op te stellen van potentiële verdachten van misdaden. Dit zijn in de regel abstracte, niet naar een specifieke persoon te herleiden verzamelingen gegevens die bepaalde eigenschappen vertegenwoordigen. Deze profielen kunnen alleen opgesteld worden door informatie over personen te aggregeren en te analyseren, maar vervolgens kunnen de opgestelde profielen worden toegepast op individuele personen. Dit kan ingrijpende gevolgen hebben wanneer bijvoorbeeld de verdenking onterecht is en roept vragen op over de complexiteit/selectiviteit, betrouwbaarheid van de profielen, de legitimiteit en privacy (Lodder, et al, 2014).
Complexiteit/SelectiviteitMayer-Schönberger en Cukier (2013) waarschuwen in hun boek ‘De Big Data Revolutie’ voor het ‘Minority Report’-scenario. Het gevaar dat bijvoorbeeld de overheid zich blind staart op bepaalde groepen of buurten, puur gebaseerd op de geavanceerde methoden van informatieanalyse. Dit heeft te maken met het overschatten van de voorspellende waarde (en de daaraan gekoppelde beslissingen): correlatie ≠ causaliteit.
Op zich pleit dit laatste juist voor een meer nauwkeurige afweging en besluitvorming, maar besluiten baseren puur en alleen op algoritmen blijft riskant. De vraag is welke waarde er moet worden gehecht aan de verbanden die door toepassing van speciaal ontwikkelde analytics software worden gevonden? Het leidende mantra is immers dat er verband is tussen de data, de correlatie wordt blootgelegd. Aan waarom er een verband is, dus aan de causaliteit, wordt niet of veel minder belang gehecht (Cukier en Mayer-Schönberger, 2013). Wellicht komt dit door de complexiteit. Hoe veelbelovend Big Data ook lijkt; het daadwerkelijk goed inrichten van de enorme databases die nodig zijn voor het verwerken ervan is voor velen simpelweg te complex (Stillman, 2013; Ho, 2013).
Naast de complexiteit speelt de selectiviteit een rol bij de analyses van Big Data. Welke data gebruik je wel/niet en vooral ook waarom? In de Verenigde Staten worden latino’s en donkere mensen vaker vervolgd voor het in bezit hebben of gebruiken van marihuana dan blanke mensen, terwijl blanke mensen het net zo vaak gebruiken (Levine, 2010). Omdat latino’s en donkere mensen vaker vervolgd worden, worden de databases constant gevoed met data over deze
10

bevolkingsgroepen. Gevolg hiervan is dat de politie steeds meer gebieden in de gaten gaan houden waar veel latino’s en donkere mensen woonachtig zijn. De overtredingen, in relatie tot marihuana, door blanke mensen verdwijnt op deze manier naar de achtergrond, terwijl die van de latino’s en donkere mensen constant in ontwikkeling is (Levine, 2010). Het gevaar hiervan is dat bepaalde bevolkingsgroepen/individuen onterecht onder een vergrootglas komen te liggen en als potentiële verdachten worden gezien nog voordat ze iets fout hebben gedaan (Visser, 2013).
Ook in Nederland wordt gebruik gemaakt van datamining-software die verbanden kan leggen uit grote hoeveelheden data. Dat gebeurt onder andere met het programma 'DataDetective' (Sentient, 2015). DataDetective kan correlaties ontdekken in de meest uiteenlopende gegevens, maar dit leidt soms tot foutieve conclusies die bijvoorbeeld hele bevolkingsgroepen in een kwaad daglicht stellen. Zo vond het programma een correlatie tussen de ramadan en vandalisme. Maar correlaties hoeven helemaal niet op oorzakelijke verbanden te duiden. Zo ook in dit geval: de ramadan viel in die jaren in het najaar en het vandalisme bleek bij nader inzien te maken te hebben met het afsteken van vuurwerk. Zo werd een verkeerde groep op voorhand als potentiële verdachten gekenmerkt (Visser, 2013).BetrouwbaarheidDaderprofielen van potentiële verdachten worden overal ter wereld steeds vaker gebruikt. Bij de FBI bijvoorbeeld stellen twaalf ‘profilers’ zo’n 1000 profielen per jaar op. Een daderprofiel kan zeer summier zijn. Het nut en in het bijzonder de betrouwbaarheid van deze profielen staan echter nog steeds ter discussie en blijven onderwerp van verschillende onderzoeken. Door de beperkte hoeveelheid empirisch materiaal zou aan profiling geen enkele waarde moeten worden toegekend tot er meer wetenschappelijk bewijs geleverd wordt dat profiling een meerwaarde kan betekenen. In de praktijk wordt echter vaak aangenomen dat profiling wel degelijk steun kan bieden in bepaalde politieonderzoeken (Avermaet, 2009; Koppen, 2010, p. 228).
Legitimiteit en privacyIn juni 2013 speelde Edward Snowden tienduizenden geheime documenten van de Amerikaanse inlichtingendienst NSA door aan verschillende kranten. Snowden’s onthullingen toonden aan dat veiligheidsdiensten veel meer persoonsgegevens verzamelden dan experts voor mogelijk hielden en dit maakte burgers bewust van de grote hoeveelheden persoonsgegevens die derden over hen hebben (Boon, et al, 2013). Waarom zou de NSA de enige zijn? De ontwikkeling van informatie- en communicatietechnologie en het internet zorgen voor een snel groeiende stroom aan gegevens die herleidbaar zijn tot personen. Technologische verandering zet aan tot een continue discussie over privacy (Bijlsma, et al, 2014).
In een artikel van Robert Schrijver (2014) op de website van Een Vandaag is een nieuwe vorm van informatievergaring beschreven, genaamd 'SyRi'. Hierbij worden grote hoeveelheden persoonsgegevens (Big Data) door de Nederlandse overheid gekoppeld om fraudeurs op te sporen. Het koppelen van Big Data wordt echter niet alleen gebruikt in de opsporing van fraudeurs. Sven Brinkhoff, strafrechtjurist aan de Radboud Universiteit Nijmegen, stelt dat de politie en inlichtingendiensten bij ‘een onwaarschijnlijke hoeveelheid gegevens’ kunnen als zij onderzoek doen naar een persoon of instantie (Schrijver, 2014).
Veel mensen krijgen een diep gevoel van onbehagen als onbekenden toegang hebben tot hun privé-informatie. Dit gevoel van onbehagen staat dan wel in schril contrast met het gemak waarmee mensen hun persoonsgegevens soms weggegeven. Velen gaan akkoord met privacyovereenkomsten zonder dat
11

ze goed weten wat daarin staat. In experimenten bij aankoopbeslissingen vinden veel consumenten het geen probleem om hun privé-gegevens aan de verkoper prijs te geven, zelfs wanneer dat eenvoudig te vermijden zou zijn (Bijlsma, et al, 2014; Acquisti en Grossklags, 2005, p. 26-33).
12

ResuméDe overheid wordt zich meer bewust van het feit dat het internet in zijn totaliteit inmiddels een haast oneindige hoeveelheid gegevens bevat die, wanneer zij op de juiste manier gebruikt en gecombineerd worden, een schat aan waardevolle informatie op kan leveren (Manovich, 2011). Deze data worden door alle gebruikers van het internet al dan niet bewust gecreëerd bij iedere handeling die zij online doen, zelfs wanneer zij zich niet letterlijk achter hun computer bevinden. Bijvoorbeeld wanneer zij betalen met hun creditcard, boodschappen doen met hun bonuskaart of reizen met hun OV-chipcard. Deze data worden voor verschillende doeleinden gebruikt. Er wordt geprobeerd om misdaden op te lossen, maar ook om voorspellingen te doen. Aan de ene kant het voorspellen van risicogebieden, bijvoorbeeld een verhoogde kans op woninginbraak; aan de andere kant het voorspellen van potentiële verdachten van misdaden.
Op basis van de gevonden literatuur zijn er nog veel onbeantwoorde vragen rondom het gebruik van Big Data bij de genoemde doeleinden. De aanleiding voor dit onderzoek is dan ook dat er een gebrek aan inzicht is wat de voor- en nadelen zijn voor het voorspellen van (potentiële verdachten van) misdaden door middel van Big Data. In deze scriptie wordt ingegaan op de vragen rondom complexiteit/selectiviteit, betrouwbaarheid en legitimiteit/privacy.
13

H2 Doelstelling van het onderzoek Dit hoofdstuk bevat een formulering van het doel van het onderzoek. Uit de probleemschets is gebleken dat het voorspellen van (potentiële daders van) misdaden niet louter toekomstmuziek is. Voorspellingen doen op basis van Big Data wordt al op verschillende manieren toegepast door de overheid, maar beslissingen nemen op basis van computerberekeningen (datamining) roept nog vele vragen op. Over sommige van deze vragen wordt openlijk en veelvuldig gediscussieerd (privacy), maar andere onderwerpen komen in de discussie minder aan de orde (complexiteit/selectiviteit en betrouwbaarheid). Het is van belang om hier al te vermelden dat het bij voorspellen om twee zaken kan gaan. Aan de ene kant het voorspellen van een verhoogde kans op misdaden in een bepaald gebied en aan de andere kant het voorspellen van potentiële verdachten. Dus personen die een verhoogde kans hebben om een misdaad te begaan. Hier wordt in hoofdstuk 4 ‘Operationalisatie’ dieper op in gegaan.
De doelstelling van dit onderzoek luidt:
Inzicht krijgen in de voor- en nadelen van Big Data gebruik bij het voorspellen (van potentiële verdachten) van misdaden.
14

H3 Onderzoeksvraag en deelvragenOp basis van deze doelstelling is de volgende hoofdvraag geformuleerd:
Wat zijn de voor- en nadelen van Big Data gebruik bij het voorspellen van (potentiële verdachten van) misdaden?
Op basis van bovenstaande hoofdvraag zijn de volgende deelvragen geformuleerd:
1. Op welke manier kan Big Data gebruikt worden om aan de hand van datamining voorspellingen te doen over (potentiële verdachten van) misdaden?
2. In hoeverre bestaan er ethische en juridische bezwaren tegen het gebruik van Big Data bij het voorspellen van (potentiële verdachten van) misdaden?
3. Op welke wijze wordt er rekening gehouden met mogelijke valkuilen in relatie tot het gebruik van Big Data bij het voorspellen van (potentiële verdachten van) misdaden?
15

H4 OperationaliseringIn dit hoofdstuk staat het definiëren en meetbaar maken van de centrale begrippen uit de hoofd- en deelvragen centraal. Centrale begrippen die in dit hoofdstuk geoperationaliseerd worden zijn: Big Data, Datamining, voorspellen van (potentiële verdachten van) misdaden, valkuilen, ethische en juridische bezwaren. Voordat er in Hoofdstuk 5 meer uitgelegd wordt over het type onderzoek, is het nu al van belang om te weten dat het gaat om een exploratief onderzoek.
4.1 Big DataBig Data is in deze scriptie een veelgebruikte term, maar wat behelst het precies? Over de betekenis van het begrip lijkt in redelijke mate overeenstemming te bestaan, maar een duidelijke definitie is er niet. Viktor Mayer-Schönberger en Kenneth Cukier zeggen daar in hun boek ‘De Big Data Revolutie’ (2013) het volgende over: “er bestaat geen exacte definitie van Big Data”. Zij gaan wel dieper in op de voordelen van het gebruik: “de term ‘Big Data’ verwijst naar dingen die je op een grote schaal kunt doen en die op een kleinere schaal niet mogelijk zijn, waarmee je nieuwe inzichten verkrijgt of nieuwe vormen van economische waarde creëert op een manier die invloed heeft op onder andere markten, organisaties en de relatie tussen burgers en overheden” (Mayer-Schönberger en Cukier, 2013, p. 15).
Ondanks dat Mayer-Schönberger en Cukier stellen dat er geen eenduidige definitie te geven is voor Big Data, zijn er wel definities gegeven in de literatuur. Lev Manovich (2011), professor in digitale geesteswetenschappen geeft de volgende definitie: “Big Data is a term applied to data sets whose size is beyond the ability of commonly used software tools to capture, manage, and process the data within a tolerable elapsed time. Big Data sizes are a constantly moving target currently ranging from a few dozen terabytes to many petabytes of data in a single data set”. Manovich benadrukt dat Big Data niet op een traditionele computer verzameld, beheerd en verwerkt kunnen worden. Zulke grote hoeveelheden data vragen meer computerkracht dan een gewone laptop of bijvoorbeeld een tablet. Voorheen werd er van Big Data gesproken wanneer de technologie de grootte van de data niet meer aan kon (Boyd en Crawford, 2011, p. 1; Manyika, et al., 2011). De technologie van tegenwoordig kan deze grote hoeveelheden aan data wel analyseren en interpreteren. Dit zorgt er voor dat gedrag van mensen preciezer dan ooit geanalyseerd kan worden en daarmee ook voorspeld kan worden (Anderson,2008; Bloem, et al, 2012).
4.1.1 Kenmerken Big DataManovich heeft het in zijn definitie over dusdanige grote hoeveelheden data dat deze niet met de gangbare tools behapbaar zijn (Volume). Dit kenmerk wordt ook genoemd in het onderzoeksverslag van Doug Laney (2001) voor de Meta Group. Hij heeft het echter over drie kenmerken van Big Data: Volume, Variety en Velocity. Deze drie V’s worden vandaag de dag nog altijd gebruikt bij de uitleg van Big Data (Russom, 2001, p. 6; Cukier en Mayer-Schönberger, 2013; Osseyran en Vermeend, 2014, p. 7-8).
VolumeBij het eerste kenmerk gaat het om de meest voor de hand liggende namelijk: Volume. Volume als kenmerk van Big Data betreft vooral de relatie tussen omvang en verwerkingscapaciteit. Dit aspect is aan verandering onderhevig
16

omdat het verzamelen van gegevens zal blijven toenemen, evenals de computercapaciteit voor de opslag en verwerking ervan (Russom, 2001, p. 6; Cukier en Mayer-Schönberger, 2013; Osseyran en Vermeend, 2014, p. 7-8).
17

Variety (variëteit)Bij de variëteit van de data gaat het om het gebruiken van meerdere soorten datasets, met verschillende soorten data. Daarbij kan het bijvoorbeeld gaan om de structuur van de data, tijdstip van binnenhalen en mate van openbaarheid van de data. Het verwijst dus naar de grote variatie aan soorten gegevens die wordt opgeslagen en nog moet worden verwerkt en geanalyseerd. Nieuwe soorten gegevens van sociale netwerken, communicatie tussen machines (M2M) en mobiele apparatuur komen boven op de reeds bestaande soorten gestructureerde informatie die computers genereren bij de verwerking van transacties. Voorbeelden van dergelijke nieuwe gegevenssoorten zijn: foto’s, geluids- en beeldbestanden, gps-data, medische dossiers, instrumentmetingen, logbestanden en webdocumenten. Ongestructureerde gegevens zoals spraak en sociale media maken verwerking en categorisering extra complex (Russom, 2001, p. 6; Cukier en Mayer-Schönberger, 2013; Osseyran en Vermeend, 2014, p. 7-8).
Velocity (verandersnelheid)Bij velocity draait het om hoe up-to-date de resultaten zijn, waarbij in het beste geval de data zo snel binnengehaald en geanalyseerd worden dat de analyse een weergave geeft van dit moment en waarbij deze dus real-time genoemd kunnen worden. De derde V is dus een maatstaf voor de verandersnelheid van gegevens en verwijst naar de tijdelijke waarde van de gegevens zelf (Russom, 2001, p. 6; Cukier en Mayer-Schönberger, 2013; Osseyran en Vermeend, 2014, p. 7-8).
Hoe groter de drie V’s, hoe moeilijker het is een oplossing te vinden voor de technische vraagstukken en valkuilen, maar hoe groter ook de kansen zullen zijn voor de voorspellende waarde van Big Data.
Viscosity, Virality, Veracity en ValueOsseyran en Vermeend (2014) gaan in hun boek ‘De Revolutie van Big Data’ verder dan de drie V’s van Laney. Zij hebben het over in totaal 7 V’s. De andere V’s zijn: Viscosity, Virality, Veracity en Value. Door de snelle ontwikkelingen op het gebied van sociale netwerken, mobiele technologieën, cloud puting en de integratie van communicatiekanalen zijn deze toegevoegd.
Viscosity betreft de traagheid bij het navigeren door de gegevensverzameling, bijvoorbeeld door de verscheidenheid aan bronnen of de complexiteit van de benodigde verwerking;
Virality is een maatstaf voor de snelheid waarmee gegevens zich door het netwerk verspreiden. Tijd is een belangrijk kenmerk, naast de verspreidingssnelheid. Een ander soort snelheid dus dan bij velocity;
Veracity geeft de kwaliteit en oorsprong weer om gegevens aan te merken als twijfelachtig, conflicterend of niet-zuiver, en als informatie waarvan men niet zeker weet hoe ermee om te gaan (waarheidsgetrouwheid);
Value kenmerkt welke waarde uit welke gegevens gehaald zou kunnen worden en hoe je met Big Data betere resultaten kunt krijgen uit opgeslagen gegevens (Osseyran en Vermeend, 2014, p. 8).
18

Er kan dus pas gesproken worden van Big Data wanneer aan de 7 V’s wordt voldaan en deze kenmerken gelden voor digitale informatie. Hieronder is een schematische weergave te vinden van de 7 kenmerken van Big Data. In dit onderzoek wordt gekeken wat er in de praktijk verstaan wordt onder Big Data, in welke mate er gebruik wordt gemaakt van Big Data en wat de mogelijkheden van deze grote hoeveelheden data zijn bij het voorspellen van risicoverhoogde locaties en potentiële verdachten van misdaden. Hier wordt naar gevraagd tijdens verschillende interviews met verschillende respondenten uit het werkveld.
Figuur 1: Schematische weergave 7 kenmerken Big Data.
4.2 DataminingEr zijn verschillende onderzoeken gedaan naar datamining waarbij verschillende definities worden gebruikt (Heyning en Suren, 2005; Jansen, 2006; Koffijberg, Dekkers, Homburg en Berg, 2009; Manuel, 2000; Tallir, 2008; Witte, 2008). De definitie waar alle aspecten in terug komen komt van Hildebrandt en Gutwirth (2008), en luidt als volgt:
“Gedigitaliseerde gegevensbestanden bieden de mogelijkheid gegevens op allerlei manieren te bewerken. Door diverse gegevensbestanden aan elkaar te koppelen en deze gegevensverzameling vervolgens met behulp van computerprogramma’s te doorzoeken aan de hand van bepaalde sleuteltermen of statistische verbanden, kunnen nieuwe inzichten ontstaan in bijvoorbeeld het gedrag van individuen of groepen personen. Dit geautomatiseerd doorzoeken van grote gegevensbestanden wordt datamining genoemd.”
Datamining is een onderdeel van het doorzoeken van databestanden op correlaties. Het gehele proces wordt ook wel knowledge discovery in databases (KDD) genoemd en onderscheidt zich van een zogenaamde query. Dat laatste betekent dat in een databestand gezocht wordt naar de daarin opgenomen attributen van een bepaald type data. De categorisering gaat in het geval van een query vooraf aan het doorzoeken van de data, en de zoektocht levert geen nieuwe kennis op. KDD daarentegen, produceert nieuwe patronen die worden 'ontdekt' (Zarsky, 2002-2003). KDD onderzoekt dus niet of bepaalde hypotheses bevestigd of ontkracht kunnen worden, maar genereert nieuwe hypotheses (Custers, 2004). Op die manier kunnen relaties worden ontdekt die niet eerder aan het licht zijn gekomen. In de literatuur wordt KDD ook wel het datamining-
19

proces genoemd. Deze laatste benaming wordt in deze scriptie gehanteerd, omdat in de Nederlandse literatuur vooral deze term wordt gebruikt.4.2.1 Het datamining-procesHet succes van het proces is afhankelijk van hoe grondig het proces wordt aangepakt en voorbereid. Het is niet afdoende wanneer er alleen sprake is van voldoende aanwezige data om tot conclusies te kunnen komen; deze gegevens moeten ook van een goede kwaliteit zijn en op een correcte manier worden geïnterpreteerd en verwerkt. Een veel gebruikt proces om grootschalige datamining-projecten in bedrijven te leiden is CRISP-DM, dat staat voor Cross Industry Standard Process for Data Mining. Het gehele datamining proces bestaat uit zes opeenvolgende fasen.Deze opeenvolgende fasen zijn:
1. Begrijpen van de business;2. Begrijpen van de data;3. Voorbereiding van de data;4. Modellering;5. Evaluatie;6. Presentatie van de resultaten (De Tré, 2007).
Begrijpen van de business (Business understanding)In deze eerste fase moet de doelstelling van het datamining-proces worden bepaald, moet de situatie worden beoordeeld en wordt een eerste versie van een projectplan opgesteld. Centrale vragen in deze fase zijn: Welke data wil men analyseren? Welke soorten patronen of informatie wil men verkrijgen? Welke databronnen zijn beschikbaar en volstaan deze bronnen? Welke software is voorhanden? Hoe kan het probleem worden aangepakt? (De Tré, 2007, p.374)
Begrijpen van de data (Data understanding)In deze fase is het de bedoeling dat de dataminer de informatie zo goed mogelijk weet te beschrijven en te begrijpen. Centraal staat daarbij het inzicht krijgen in de beschikbare hoeveelheid data en de kwaliteit van deze data (De Tré, 2007, p. 374; Van der Zanden, 2005).
Voorbereiding van de data (Data preparation)In deze fase worden de data voorbereid zodat men ze kan invoeren in en laten verwerken door dataminingsoftware. Daarbij kunnen de volgende stappen noodzakelijk zijn: selectie (van bijvoorbeeld variabelen), foutcontrole, foutcorrectie, integratie en transformatie (De Tré, 2007, p. 375; Van der Zanden, 2005).
Modellering (Modelling)In deze fase worden diverse modelleringtechnieken gekozen en toegepast. De gepaste technieken moeten worden geselecteerd en eventueel worden gecombineerd. Er zijn diverse technieken om een zelfde probleem op te lossen. Sommige technieken eisen een bepaalde vorm van de gegevens. Daarom is het soms nodig om terug te gaan naar de fase van het voorbereiden van de data (De Tré, 2007, p. 375; Van der Zanden, 2005).
Evaluatie (Evaluation)In deze fase daarin wordt gekeken of de gestelde doelen behaald kunnen worden met de gekozen modellen en dat er geen kwesties zijn die onvoldoende zijn onderzocht of kwesties zijn die niet zinvol zijn. Bepaalde verbanden kunnen namelijk het gevolg zijn van louter toevalligheden. In deze fase moet ook een
20

besluit genomen worden over hoe de resultaten van het project moeten worden gebruikt (De Tré, 2007, p. 375; Van der Zanden, 2005).
21

Presentatie van de resultaten (Deployment)In de laatste fase wordt bepaald op welke wijze de resultaten van het onderzoek worden ingezet (deployment). Dit kan het schrijven van een rapport inhouden of het reproduceerbaar maken van het model. In deze fase worden de resultaten dus vertaald naar een geschikte vorm voor beslissingnemers en beleidsmakers (De Tré, 2007, p. 375; Van der Zanden, 2005).
Wanneer deze 6 fasen van het datamining-proces in een model worden gezet ziet dat er als volgt uit:
Figuur 2: Het datamining-proces (Smart Vision Europe, 2013).
In deze scriptie ligt niet de nadruk op hoe de technische processen zoals het datamining-proces werken. In deze scriptie wordt datamining gezien als het proces dat gebruikt wordt om vanuit Big Data voorspellingen te kunnen doen. Er wordt in deze scriptie gekeken of en met welk doel voorspelmodellen worden gebruikt bij het voorspellen van (potentiële verdachten van) misdaden. Dit is aan de hand van interviews onderzocht.
22

4.3 Voorspellen van (potentiële verdachten van) misdadenNaast Big Data en Datamining vraagt ‘(potentiële verdachten van) misdaden’ om een nadere uitleg. Het gaat bij dit begrip om een tweedeling. Aan de ene kant het voorspellen van een verhoogde kans op misdaden in een bepaald gebied en aan de andere kant het voorspellen van potentiële verdachten. Hieronder worden beide begrippen geoperationaliseerd.
4.3.1 Voorspellen van misdadenIn de inleiding is de verschuiving binnen het politiewerk al aan bod gekomen. Bij informatiegestuurd politiewerk is een steeds nadrukkelijkere rol weggelegd voor het voorspellen van misdaden, beter bekend als Predictive Policing. In de literatuur zijn verschillende definities te vinden van Predictive Policing. Hieronder zijn twee van die definities weergeven. De eerste is uit een onderzoek van het RAND Safety and Justice Program (2013) en de tweede is van het Amerikaanse National Institue of Justice (2010).
“predictive policing is the application of analytical techniques – particularly quantitative techniques – to identify likely targets for police intervention and prevent crime or solve past crime by making statistical predictions” (Perry, et. al., 2013, p. xiii).
“Predictive policing, in essence, is taking data from disparate sources, analyzing them and then using the results to anticipate, prevent and respond more effectively to future crime” (Pearsall, 2010).
Uit deze definities kan worden gehaald dat het gaat om het verzamelen, analyseren van bestaande data, dus data uit het verleden. De resultaten kunnen worden gebruikt om te anticiperen op toekomstige criminaliteit, door te reageren met bijvoorbeeld gerichte politie-inzet. Het gaat dus om voorspellingen van wáár een misdaad, bijvoorbeeld een woninginbraak, zal plaatsvinden in de toekomst, op basis van gegevens uit het verleden. Verschillende onderzoeken laten zien dat deze gegevens uit het verleden goede voorspellers kunnen zijn voor de toekomst. Zo schreef Bernasco (2007) bijvoorbeeld een artikel in het Tijdschrift voor de Criminologie, waarin hij beschrijft dat inbrekers enige tijd na de eerste inbraak terugkeren, om gebruikmakend van eerder opgedane kennis, nogmaals hun slag te slaan. Het gaat dan niet alleen over een verhoogde kans op inbraak in hetzelfde huis, maar ook over een verhoogde kans voor nabijgelegen woningen. Ook deed J.S. Graauw (2014) onderzoek naar het tijdruimtelijk voorspellen van criminele incidenten waarin naar voren komt dat criminele incidenten niet willekeurig plaatsvinden. Zo heb je bijvoorbeeld in het weekend meer kans om slachtoffer te worden van een woninginbraak dan doordeweeks.
Er zijn dus voorspellende indicatoren te vinden in data. Aan de hand van data die onder andere bestaat uit aangiftes, woonlocaties van (ex-)criminelen en locaties van bedrijven, wordt er een analyse gemaakt. In Nederland is het Classificatie Anticipatie Systeem (CAS) een voorbeeld van de inzet van Predictive Policing. Ook in deze scriptie gaat het over Predictive Policing wanneer het gaat over het voorspellen van misdaden. Hierbij ligt de nadruk op het voorspellen van wáár, dus geografisch, er een verhoogde kans is op een misdrijf. Op deze manier kan de politiecapaciteit effectiever en efficiënter worden ingezet en aangestuurd worden.
23

4.3.2 Voorspellen van potentiële verdachtenWanneer in de literatuur gezocht wordt naar een definitie van 'potentiële verdachten', heeft de term ‘profiling’ veel raakvlakken met wat er in deze scriptie mee bedoeld wordt.
Profiling is afkomstig van de term ‘criminal profiling’. Criminal profiling is een multidisciplinaire forensische praktijk. ‘Multidisciplinair’ wijst op de voeling die criminal profiling heeft met verschillende takken van de wetenschap, zoals de criminologie, de psychologie, de psychiatrie en de forensische wetenschappen (Turvey, 2001, p. 2). ‘Forensisch’ betekent dat deze praktijk zich voordoet in een justitieel kader, met ander woorden, in opdracht van het gerecht.
De forensische praktijk van het criminal profilen omvat het proces waarbij afzonderlijke karakteristieken van daders afgeleid worden uit bijvoorbeeld de plaats delict. Deze karakteristieken vertellen meer over het gedrag, het uiterlijk, de socio-culturele afkomst en het demografisch of biologisch patroon van de dader (Kocsis, 2006, p. 2). Criminal profiling wordt vaak ‘offender profiling’, ‘behavioral profiling’, ‘crime-scene profiling’ of ‘pscychological profiling’ genoemd (Turvey, 2001, p. 1). Deze praktijk dient het opsporingsonderzoek te ondersteunen (Devroe en Vandervelde, 2005, p. 321). Hierna wordt ‘criminal profiling’ verkort profiling genoemd.
Profiling is een onderdeel van de onderzoekanalyse gericht op de dader. Onderzoekanalyse of misdrijfanalyse kan in het algemeen omschreven worden als:
“het zoeken naar, het inzichtelijk maken van en het verklaren van de mogelijke verbanden die bestaan tussen criminaliteitsgegevens onderling en tussen criminaliteitsgegevens en andere relevante gegevens, door het formuleren van bruikbare uitspraken (vaststellingen, hypothesen en aanbevelingen) met het oog op een doeltreffende praktijk van politie en justitie.” (Devroe en Vandervelde, 2005, p. 322).
Deze definitie komt overeen met wat er in deze scriptie bedoeld wordt met het begrip. Alleen ligt de nadruk op verbanden die op basis van Big Data uit het datamining-proces naar voren komen.
De onderzoekanalyse bestaat uit een reeks van diensten die worden uitgeoefend door forensische gedragsspecialisten, of in het geval van het datamining-proces door datascientists. Een van die diensten is onrechtstreekse persoonlijkheidsbeoordeling, met als einddoel het in kaart brengen van profielen van potentiële verdachten van misdaden. De onrechtstreekse persoonlijkheidsbeoordeling is het beoordelen van personen waarvan niet zeker is of zij als verdachte kunnen worden aangeduid. Profiling dient om de gedragskenmerken van de mogelijke verdachte te achterhalen, zoals hierboven reeds uiteengezet. Profiling kan nuttige antwoorden opleveren maar het zijn geen sluitende oplossingen. Het functioneert enkel als hulpmiddel dat met betrekking tot het delict meer inzicht verschaft, dat strategieën voorstelt en informatie ordent omtrent potentiële verdachten van misdaden (Ainsworth, 2000, p. 106). Een fundamenteel punt dat gemaakt moet worden is dat het begrip 'potentiële verdachten' niet juridisch is vastgelegd. Iemand is in het proces- en strafrecht een verdachte of geen verdachte. Het gaat dus om een begrip dat juridisch gezien niet kan bestaan, maar in de praktijk wel degelijk voorkomt. Het gaat dus om het in kaart brengen van mogelijke verdachten vóór een misdaad en niet om het in kaart brengen van verdachten na een misdaad.
24

Korte historische rondgangProfiling is geen nieuw verschijnsel. Een korte historische rondgang helpt om het begrip profiling beter te plaatsen in de context van vandaag de dag. Zo werd in de Oudheid al gebruik gemaakt van typerende uiterlijke kenmerken voor criminelen. Zo beschreef de Griekse dichter Homerus in de ‘Ilias’, bepaalde uiterlijke kenmerken van Thersites (een mismaakt hoofd, een scheel oog en een kreupel been) als kenmerkend voor een crimineel (Gielen, 2003, p. 130).
Ook eind Middeleeuwen (rond 1485) was profiling aanwezig in de vorm van de heksenjacht. De beslissende macht bij de heksenprocessen beschikte over een vorm van een daderprofiel, de Malleus Malificarum (letterlijk: de hamer van vrouwen die schadelijke magie bedrijven). Deze moest hen helpen heksen te herkennen. Wanneer een vrouw voldeed aan het profiel werd zij beschuldigd van hekserij (Buskes, 2006, p. 203).
Deze biologische theorieën die een link leggen tussen criminaliteit en lichamelijke kenmerken, zijn later nog verder ontwikkeld. Eén van de bekendste theorieën is die van de Italiaanse criminoloog Casare Lombroso (1911). Hij stelde vast dat een crimineel bepaalde biologische kenmerken had, die aanleiding gaven tot het plegen van criminele feiten. Hij legde verbanden tussen ras, leeftijd, geslacht, uiterlijke kenmerken, opleiding en delinquent gedrag. Er zijn drie soorten criminelen volgens Lombroso: ‘born criminals’, ‘insane criminals’ en ‘criminaloids’.
Een ‘born criminal’ is een abnormale en primitieve mensensoort die psychologisch en uiterlijk onvoldoende zijn geëvolueerd in vergelijking met de normale mens. Zo zijn typische kenmerken: een asymmetrisch gezicht, brede jukbeenderen, een plat voorhoofd, grote of kleine oren en opvallende wenkbrauwen. ‘Insane criminals’ zijn misdadigers die lijden aan een mentale of psychische stoornis. Het laatste type, ‘Criminaloids’ genaamd, zijn misdadigers zonder specifieke kenmerken die criminele feiten plegen omdat een bepaalde mentale en emotionele toestand hen daartoe dreef (Holmes en Holmes, 2002, p. 61).
Biologische verbanden en onderzoeken die hoofdzakelijk gebaseerd zijn op ooggetuigen en vermoedens werden in 1906 bekritiseerd door dr. J.B.G. Gross. Hij stelde dat dergelijke bewijsmiddelen niet betrouwbaar zijn. Het is beter om wetenschappelijke bewijzen te verzamelen. Hij benadrukte het belang van objectief onderzoek en beschreef verschillende theorieën die nog altijd aan de basis liggen van de criminologische wetenschap (Chisum en Turvey, 2011, p. 17).
In de jaren ’50 deed de Amerikaanse psychiater J.A. Brussel vooruitstrevende ontdekkingen op het gebied van criminal profiling. Zo legde hij een verband tussen misdaden gepleegd door mannen en hun relatie met hun moeder (Ramsland, 2011, p. 7).
Criminal profiling werd in 1970 voor het eerst in de praktijk toegepast binnen de FBI. In 1972 werd het FBI Behavioral Science Unit (BSU) opgericht. Nadat verschillende zaken waren opgelost door middel van criminal profiling kwamen dagelijks verzoeken van politiebureaus binnen om daderprofielen op te stellen (Turvey, 2001, p. 8).
Het schetsten van profielen wordt overal ter wereld steeds vaker gebruikt, zo ook in Nederland. Waar bij de FBI vandaag de dag 12 profilers ongeveer 1000 profielen per jaar opstellen word je op Schiphol al als potentieel terrorist gezien wanneer je je verdacht gedraagt volgens slimme camera’s (Heck, 2014). Het nut en de betrouwbaarheid van profiling staan echter nog steeds ter discussie en blijven het onderwerp van verschillende onderzoeken (Koppen, 2010, p. 228).
25

Hoe werkt profiling?FBI BSU Criminal Profile Process1. Profiling Inputs De eerste stap verzamelt input voor het profileren,
waaronder uitgebreide informatie over de misdaad en al verzameld bewijsmateriaal, zowel materiële, fysieke en digitale gegevens.
2. Decision Process Models
Deze stap analyseert de gegevens en bewijsstukken om patronen en mogelijke verbanden te bepalen met andere misdaden.
3. Crime Assessment De plaats delict wordt gereconstrueerd en geanalyseerd om de volgorde van de gebeurtenissen en andere informatie over het misdrijf te bepalen. Het kan ook zijn dat er bijvoorbeeld een digitaal tijdspad wordt geconstrueerd op basis van gevonden digitale gegevens.
4. Criminal Profile De eerste drie stappen worden gecombineerd om een crimineel profiel aan te maken; vaak de combinatie van de motieven, fysieke kwaliteiten, en de persoonlijkheid van de dader. Dit profiel wordt ook gebruikt om een ondervragingsstrategie voor verdachten op te stellen. Zie ook figuur 3.
5. The Investigation Onderzoekers en analisten gebruiken het profiel om meer van de informatie te leren en voor het identificeren van de mogelijke dader. Verdachten die overeenkomen met het profiel worden geëvalueerd. Profielen kunnen opnieuw worden overwogen of beoordeeld, met andere input als er nog geen ‘lead’ is naar een mogelijke dader.
6. The Apprehension De laatste fase treedt op wanneer de onderzoekers en/of analisten een meest voor de hand liggende verdachte selecteren die mogelijk de dader kan zijn. Een huiszoekings- of arrestatiebevel voor het individu wordt dan uitgegeven, meestal gevolgd door een proces.
De FBI BSU heeft een 6-stappen model ontwikkeld om daderprofielen te schetsen en vervolgens een misdrijf verder te onderzoeken, zie tabel 1:
26
Tabel 1: 6-stappen model profiling FBI BSU (CSIAC, 2015).

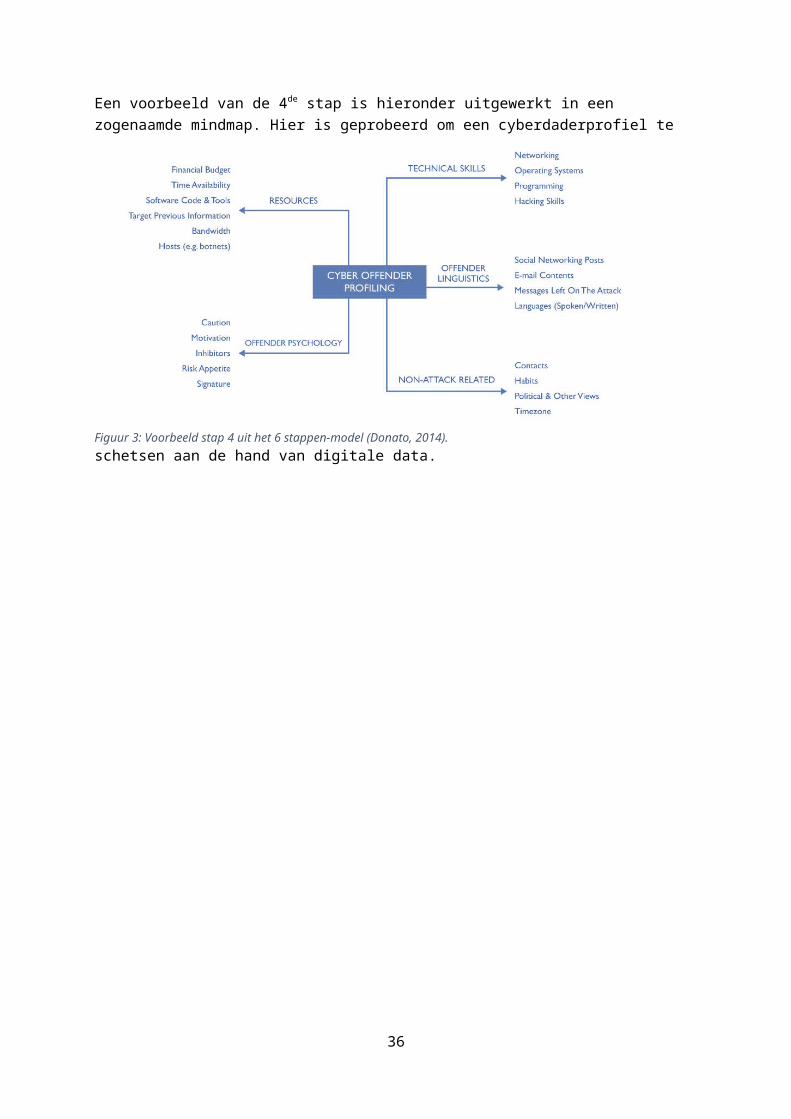
Een voorbeeld van de 4de stap is hieronder uitgewerkt in een zogenaamde mindmap. Hier is geprobeerd om een cyberdaderprofiel te schetsen aan de hand
van
digitale data.
27
Figuur 3: Voorbeeld stap 4 uit het 6 stappen-model (Donato, 2014).

In de huidige digitale wereld wordt alles geïnformatiseerd, zo ook profiling. Deze scriptie richt zich op deze laatste vorm van profiling: die in de digitale wereld. Er wordt onderzocht wat de voor- en nadelen zijn van het gebruik van Big Data, door middel van interviews met verschillende experts uit het werkveld. In de interviews wordt ook gevraagd in hoeverre potentiële verdachten van misdaden nu al in kaart worden gebracht.
4.4 Ethische en juridische bezwarenIn deze paragraaf wordt ingegaan op ethische en juridische bezwaren. In de literatuur wordt veelal gesproken over deze aspecten in combinatie met de maatschappelijke context, ook wel ethical legal social aspects (ELSA) genoemd. Bij deze maatschappelijke context (social) gaat het over de acceptatie binnen de maatschappij. Dat vraagt echter om een groot, op zichzelf staand, kwantitatief, representatief onderzoek. Daar is binnen dit onderzoek geen ruimte voor. Daarom is er voor gekozen om het alleen te hebben over de ethische en juridische bezwaren.
4.4.1 Ethische aspectenIn deze scriptie gaat het over het gebruik van Big Data voor het voorspellen van (potentiële verdachten van) misdaden. Voordat er een voorspelling gedaan kan worden moeten er eerst mensen in de gaten gehouden worden en gegevens van deze mensen opgeslagen worden. In een informatiemaatschappij als Nederland zijn we altijd en overal bereikbaar en worden onze gegevens meer en meer opgeslagen in databanken. De verwerking van deze gegevens biedt ongekende mogelijkheden voor onderzoek en innovatie en laat toe om gepersonaliseerde toepassingen aan te bieden voor gezondheidszorg, opleiding en ontspanning, maar ook voor de detectie van fraude en misdaad. Maar we riskeren het om hiervoor een hoge prijs te betalen: het risico op misbruik en het verlies van onze privacy (Preneel, 2015). Het is de vraag in hoeverre dergelijke ruime mogelijkheden tot verwerking van informatie en de daarmee gepaard gaande inbreuken op de privacy wenselijk, toelaatbaar en te rechtvaardigen zijn.
George Orwell (1948) schreef in zijn boek ‘1984’ over een samenleving waarin de overheid de burgers bewaakt via de alomtegenwoordige ‘telescreens’ die niet kunnen worden uitgeschakeld. Deze sceens waren televisie, videocamera en intercom in één. De opvattingen van de leider zijn continu op de televisie; een leider bekend onder de troostende naam ‘Big Brother’. De videocamera is uitgerust met een intercomfunctie en is bedoeld om de mensen te observeren en te corrigeren, zodra ze afwijkend gedrag vertonen, of zelfs wíllen vertonen (thoughtcrime). Het totalitaire bewind ontzegt zijn burgers elke vorm van privacy (Leukfeldt en Stol, 2012, p. 89).
Orwell omschreef een samenleving waar vandaag de dag weer naar verwezen wordt wanneer de overheid iedere burger als potentieel verdachte ziet, zoals bij de eerder genoemde voorbeelden van het bewaren van kenteken- en telefoongegevens. Wat doet het met een samenleving wanneer mensen van te voren worden ‘gebrandmerkt’ als potentiële verdachte van een misdaad? Dat is de vraag die hierbij hardop kan worden gesteld.
Vrijheid is een van de belangrijkste verworvenheden van de mens. De theorie van het sociaal contract van Jean-Jacques Rousseau (1762) gaat in op de vraag hoe vrijheid (burgers) en autoriteit (overheid) zich ten opzichte van elkaar verhouden. Volgens Rousseau is de enige reden waarom de mens zijn individuele vrijheid zou willen opgeven het feit dat zijn rechten, geluk en bezit beter kunnen
28

worden beschermd door een formele overheid dan door hemzelf, in een maatschappij waarin het recht van de sterkste geldt. Vanuit dat besef is men bereid een deel van zijn vrijheid op te geven in ruil voor bescherming van zijn rechten door een overheid.
29

De burger geeft weliswaar een deel van zijn soevereiniteit op, maar daartegenover staat dat de overheid de rechten van haar onderdanen dient te beschermen en te respecteren. Wanneer de overheid op die punten in gebreke blijft wordt het contract verbroken; er is dan immers geen sprake meer van een evenwichtssituatie van rechten en verplichtingen. Hoewel Rousseau leefde in de tijd van de Verlichting, hebben zijn ideeën in onze huidige democratische rechtsstaat nog maar weinig aan kracht ingeboet. Rechtvaardigheid speelt hierbij nog steeds ook een belangrijke rol.
In deze scriptie is in de interviews specifiek gevraagd naar de ethische aspecten rondom het gebruik van Big Data. Hierbij gaat het om vragen rondom normen/waarden en rechtvaardigheid. Wat doet het met een samenleving wanneer de overheid gegevens opslaat van zowel verdachte burgers als van niet verdachte burgers? Tot op welke hoogte is het geoorloofd om vooraf gegevens op te slaan?
4.4.2 Juridische aspectenNaast de rechtvaardigheid die bij de ethische aspecten aan bod komt, zijn er ook vragen rondom de rechtmatigheid bij het gebruik van Big Data bij het voorspellen van (potentiële verdachten van) misdaden. Binnen deze rechtmatigheid lijkt er een spanningsveld te bestaan tussen vrijheid en veiligheid. De maatschappelijke ontwikkelingen dwingen de wetgever tot het vinden van een balans tussen het effectief waarborgen van de veiligheid van de burger enerzijds en de bescherming van de privacy van diezelfde burger anderzijds (Sietsma, 2007). In Nederland is de Wet bescherming persoonsgegevens (Wbp), ook wel ‘privacywetgeving’ genoemd, de belangrijkste wettelijke regelgeving wat betreft de persoonsgegevens van de burgers. Het gaat hier om het verzamelen, gebruiken en vastleggen van persoonsgegevens. Met persoonsgegevens wordt bedoeld: “elk gegeven betreffende een geïdentificeerde of identificeerbare natuurlijke persoon” (Overheid.nl, 2015).
Een kanttekening die hierbij gemaakt moet worden is dat er weliswaar een sterke verbinding bestaat tussen persoonsgegevens enerzijds en de privacy anderzijds, maar dat er wel degelijk sprake is van een onderscheid. Enerzijds bestrijken principes als juistheid en vertrouwelijkheid ten aanzien van een behoorlijke omgang met persoonsgegevens een breder doel dan privacy alleen. Anderzijds bestrijkt privacy een breder gebied dan persoonsgegevens (Sietsma, 2007).
De Wet politiegegevens (Wpg) is een variant op de Wbp, gericht op politiegegevens. Een aantal artikelen komt letterlijk overeen met de Wbp, zoals de artikelen betreffende doelbinding, ter zake dienend, niet bovenmatig, juistheid, nauwkeurigheid en meer. Voor sommige artikelen verwijst de Wpg naar de Wbp, zoals voor uitbesteding. Het hoofddoel van beide wetten is het beschermen van de persoonlijke levenssfeer (Fasten en Paans, 2011).
30

De Wpg heeft echter een tweeledige doelstelling. Naast voldoende bescherming van de persoonlijke levenssfeer, moet hij ook voldoende ruimte bieden voor de verwerking (en verstrekking) van persoonsgegevens zodat een effectieve en efficiënte uitvoering van de politietaken mogelijk is. Onder andere het delen van gegevens binnen de politie en tussen opsporingsdiensten. Het uitgangspunt van de wet is dat er voldoende balans is tussen de twee doelstellingen (Schel, et al., 2013). Mede daarom beschrijft de Wpg in detail hoe de interactie tussen het informatiesysteem en bepaalde essentiële rollen van politiemedewerkers dient te verlopen (Fasten en Paans, 2011). Hieronder is deze balans schematisch weergegeven:Figuur 4: Schematische weergave balans tweeledige doelstelling Wpg (Schel, et al., 2013).
Naast deze balans is er nog een balans waar rekening mee gehouden moet worden wanneer het gaat om het gebruik van (persoons)gegevens: het proportionaliteitsbeginsel. Dit beginsel houdt in dat de zwaarte van het gebruikte middel, in verhouding moet staan tot het doel (Enschedé, 2008, p. 96).
In deze scriptie is onderzocht hoe rekening wordt gehouden met de privacy van burgers enerzijds bij het waarborgen van de veiligheid van diezelfde burger anderzijds. Daarnaast is getracht in kaart te brengen in hoeverre de huidige Wpg voldoende mogelijkheden of juist beperkingen biedt omtrent het gebruik van Big Data bij het voorspellen van (potentiële verdachte van) misdaden. Naar beide onderwerpen is gevraagd tijdens de interviews.
4.5 Valkuilen De term valkuilen wordt in deze scriptie gebruikt als verzamelterm voor de cognitiefout confirmation bias, interpretatiefouten (correlatie ≠ causaliteit en spurious correlations) en de systeemfout function creep. De overeenkomst tussen deze fenomenen is dat zij (kunnen) zorgen voor een zekere vervorming van de data of de uitkomsten van de bewerking van die data. Het risico bestaat vervolgens dat de uitkomsten als 100% waar worden gezien, terwijl er dus sprake is van vervorming door deze verschijnselen. In hoeverre herkent men in de praktijk deze verschijnselen/valkuilen? En op welke wijze wordt geprobeerd deze te voorkomen of tegen te gaan? Deze vragen zijn meegenomen in de interviews.
Confirmation biasDe cognitiefout confirmation bias houdt de neiging in nieuwe informatie zo te interpreteren dat die met onze bestaande theorieën, levensbeschouwing en overtuigingen overeenkomt. Informatie die niet overeenkomt met bestaande meningen of weerleggend bewijs wordt ‘disconfirming evidence’ genoemd (Dobelli, 2013, p 31).
Gilovich (1993) legt confirmation bias als volgt uit: confirmation bias verwijst naar een soort selectief denken waarbij men de neiging heeft enerzijds te letten op en te zoeken naar wat de eigen overtuiging bevestigt en anderzijds te negeren, niet zoeken naar of onderwaarderen van de relevantie van wat de
31

eigen overtuiging tegenspreekt. De meest waarschijnlijke reden hiervoor is dat het cognitief makkelijker is om om te gaan met bevestigende informatie.
Dit kan voorkomen in onschuldige proporties wanneer bijvoorbeeld iemand een nieuw dieet volgt. Wanneer hij na de eerste dag op de weegschaal gaat staan en ziet dat hij is afgevallen, komt dit door het dieet. Wanneer hij een dag later is aangekomen, dan wordt dat afgedaan als een normale schommeling en vergeet hij het. Maar bij de keuze voor welke data wel of niet gebruikt wordt voor het voorspellen van misdaden kan dit andere gevolgen hebben. Dit werd al eerder duidelijk in de inleiding met het voorbeeld over marihuanaonderzoek in Amerika, waarbij latino’s en donkere mensen onterecht vaker gevolgd werden dan blanken (Levine, 2010). Het is een onbewust proces waar wel bewust mee omgegaan kan worden door continu op zoek te gaan naar disconfirming evidence. Met andere woorden hoe wordt confirmation bias voorkomen? En hoe gaat men om met disconfirming evidence? Hier is naar gevraagd in de interviews.
32

Interpretatiefouten Naast het selecteren van data op basis van bewuste of onbewuste overtuigingen kunnen er ook ‘interpretatiefouten' optreden bij het gebruik van Big Data. Met de term interpretatiefouten wordt in deze scriptie gedoeld op ‘correlatie ≠ causaliteit’ en ‘spurrious correlations’.
In de inleiding is met het voorbeeld over de ramadan en het afsteken van vuurwerk duidelijk geworden dat correlaties niet op oorzakelijke verbanden hoeven te duiden.
Naast correlatie ≠ causaliteit bestaan er zogenoemde 'spurious correlations'. Deze valse correlaties laten een verband zien dat er niet is: hier is sprake van toeval. Er zijn inmiddels veel (leuke) voorbeelden van spurious correlations (op internet) te vinden. Zo ontdekte Tyler Vigen, die rechten studeert aan Harvard, verschillende voorbeelden van deze onechte correlaties. Hieronder is zo’n voorbeeld weergegeven:
Figuur 5: Valse correlatie (spurious correlation) verkoop margarine en aantal scheidingen (tylervigen.com, 2015).
De figuur toont een bijna perfecte correlatie tussen de verkoop van margarine en het aantal scheidingen in de Amerikaanse staat Maine. Hoewel de onderwerpen (vrijwel) niets met elkaar te maken hebben, loopt men met het ‘eindeloos’ koppelen van talloze gegevens (de crux van Big Data) het risico correlaties (en zelfs causale verbanden) te detecteren die er niet zijn (Bongers, Jager en te Velden, 2015).
Function creepNaast interpretatiefouten kunnen data ook voor iets anders gebruikt worden dan waar het in eerste instantie voor opgeslagen is. Dit is een beknopte uitleg van de term ‘function creep’. De term function creep is afkomstig uit de wereld van de technologie. Een bekend voorbeeld hiervan zijn de uitvindingen die ontwikkeld zijn voor de ruimtevaart en die later een geheel andere toepassing hebben gekregen, zoals de antiaanbaklaag in pannen, de draadloze boormachine en sportschoenen met lucht in de zolen. Inmiddels wordt de term in bredere zin gebruikt. In sommige gevallen zou je kunnen spreken van neveneffecten, die echter niet per se onvoorzien hoeven te zijn. Zo hebben de talloze veiligheidsmaatregelen na de aanslagen van 11 september 2001 onmiskenbaar de privacy van burgers aangetast, maar dat neveneffect is op de koop toe genomen, opgeofferd aan een verondersteld hoger belang. Niet toevallig is het juist in de discussie over privacybescherming dat de term function creep regelmatig opduikt. In de volgende alinea wordt hier dieper op ingegaan (Prins, 2011, p. 9-13).
33

34

Van function creep wordt niet alleen gesproken wanneer systeem A op een later tijdsstip wordt verbonden met systemen B en C die een andere functie hebben. Het is ook het proces waarbij digitale data die in eerste instantie functie X hebben, na verloop van tijd ook voor functie Y of zelfs Z worden gebruikt. Het meest bekende en besproken voorbeeld in ons land van function creep is de toepassing van biometrie (vingerafdruk) op het paspoort (Prins, 2011, p. 9-13). Aanleiding vormde een Europese verordening die als doel had het paspoort beter te beveiligen tegen fraude. Ons land koos er bij de implementatie voor de applicatie ook in te zetten voor opsporingsdoeleinden en wel via de opslag van biometrische gegevens in een landelijke databank die hiervoor gebruikt kon worden (Böhre, 2010).
In de volgende paragraaf is dit hoofdstuk schematisch weergegeven in het onderzoeksmodel.
4.6 Onderzoeksmodel
35
H5 OnderzoeksopzetIn dit hoofdstuk wordt verantwoord welke type onderzoek er gedaan is. Daarnaast zal ook de keuze voor de bepaalde onderzoeksmethoden worden beschreven. Hierbij worden de verschillende manieren van dataverzameling beschreven waarvan de resultaten hebben geholpen bij het beantwoorden van de hoofdvraag.
5.1 Type onderzoekDit betreft een exploratief kwalitatief onderzoek. Dit type onderzoek is niet gebonden aan het verzamelen van cijfermatige gegevens. Omdat het onderwerp zich in een hoog tempo door ontwikkelt betekent dit dat dit onderwerp morgen weer in een andere context kan staan. Daarom is het belangrijk dat er flexibel met de veranderende omstandigheden kan worden omgegaan tijdens het onderzoek. Dat betekent onder andere dat er tijdens de interviews gevraagd is naar relevante literatuur die een bijdrage zou kunnen leveren aan de beantwoording van de hoofd- en deelvragen. Er is ingegaan op de achtergronden van verzamelde gegevens. Centraal staat de subjectieve betekenisverlening die door de respondenten aan situaties en of begrippen is gegeven. Er is informatie verzameld in de vorm van teksten; literatuurstudie en interviews. In de volgende paragraaf wordt dieper op de onderzoeksmethoden, literatuurstudie en interviews ingegaan (Verhoeven, 2010, p. 118-119).
5.2 Onderzoeksmethoden en analysekader5.2.1 Literatuuronderzoek Literatuurstudie is een onderdeel van vrijwel ieder onderzoek voor bijvoorbeeld het in kaart brengen van de probleemstelling. In dit geval vormt literatuurstudie het hoofdbestanddeel van het onderzoek, omdat het gaat over een oriëntatie op een probleemsituatie. Hierdoor is de mogelijkheid ontstaan om de positie van het onderzoek te bepalen en is het mogelijk om richting te gegeven aan het onderzoek. Voor de literatuurstudie is het internet geraadpleegd. De wetenschappelijke databanken GoogleScholar en LexisNexis hebben de zoekbasis gevormd. Verder worden verschillende boeken, rapporten en onderzoeken gebruikt, verkregen uit de bibliotheek van de Hogeschool Utrecht en die van de Universiteit Utrecht. Door het dynamische karakter van het onderwerp kan het voorkomen dat er gaandeweg het onderzoek meer relevante literatuur naar voren komt en wordt verwerkt in het onderzoek, bijvoorbeeld omdat dit is aangegeven is door een respondent. Er is heeft dus een constante vergelijking plaatsgevonden. Er is continu gezocht naar relevante literatuur of nieuwe inzichten of berichtgevingen. Dit is gedaan om de betrouwbaarheid van de resultaten te vergroten (Verhoeven, 2010, p. 127-128; Verhoeven, 2014, 302).
5.2.2 InterviewsOpen interviewNaast literatuurstudie zijn er 9 interviews afgenomen, met in totaal 10 respondenten (1 interview met 2 personen). Om te starten met een brede oriëntatie op het onderwerp van deze scriptie is aan het begin van het onderzoek geprobeerd een open interview te houden met een onderzoeker die op dit terrein bezig is met een promotieonderzoek. Helaas bleek dit door tijdgebrek niet mogelijk. Tijd bleek een schaarse factor te zijn bij het merendeel van respondenten. Na verschillende vergeefse pogingen om een open interview te
36

mogen houden, is ervoor gekozen om het bij semigestructureerde interviews te houden. De reden hiervoor is dat er meer belang is gehecht aan de inhoudelijke interviews met kwalitatieve gegevensverzameling als hoofddoel, dan de oriëntatiefunctie van het open interview (Verhoeven, 2010, p. 124).
37

Semigestructureerde interviewsAlle 9 interviews zijn semigestructureerd van aard geweest. Bij semigestructureerde interviews is er vooraf een topiclijst/onderwerpenlijst opgesteld om het interview over bepaalde onderwerpen te laten gaan. Er is op deze wijze alle ruimte voor de eigen inbreng van de respondenten geweest. De vragen zijn voorbereid, maar in de loop van de interviews is er ruimte gelaten om de volgorde waarop de vragen worden gesteld aan te passen of vragen toe te voegen. Dit is per interview afhankelijk geweest van het verloop van het gesprek. Op voorhand is aan iedere respondent het doel van het interview uitgelegd: een open gesprek met sturende vragen waar nodig. Hiervoor is gekozen omdat het een complex onderwerp is met verschillende interpretatiemogelijkheden. Het exploratieve karakter van het onderzoek leent zich goed voor deze vorm van interviewen, omdat er op die manier een goed beeld kan worden gevormd van de huidige stand van zaken en hoe er over de verschillende onderwerpen gedacht wordt door de respondenten. Oftewel: op deze manier zijn de verschillende aspecten van het onderzoek voldoende aan bod gekomen en is er tevens ruimte gelaten voor eigen inbreng van de respondenten. Er is geprobeerd zo divers mogelijke respondenten en instanties te selecteren, opdat alle onderwerpen van dit onderzoek aan bod zouden komen (Verhoeven, 2010, p.126).
De input voor de geschikte respondenten is gekomen uit de literatuurstudie en kennis die is opgedaan vanuit de minor Cybersafety, Lectoraat Cybersafety NHL Hogeschool Leeuwarden. Daarnaast zijn er op basis van aanbevelingen uit de eerste paar interviews nog nieuwe respondenten benaderd die van meerwaarde waren voor de kwalitatieve gegevensverzameling, omdat zij specifieke kennis hadden van een bepaald domein (bijvoorbeeld ethische of juridische kwesties).
Er is in bijlage 1 een lijst bijgevoegd van de respondenten die geïnterviewd zijn. Er is aan iedere respondent gevraagd of de naam van de respondent mocht worden weergegeven in deze lijst. Wanneer de naam van een respondent ontbreekt heeft deze aangegeven liever alleen bij functie weergeven te worden, of is er geen reactie ontvangen op de vraag. Wanneer er geen reactie is ontvangen, is er voor gekozen om alleen de functie weer te geven om een eventuele weigering te respecteren.
Uitwerking Er is voorafgaand aan ieder interview aan de respondent gevraagd of het interview opgenomen mocht worden. Het zijn louter geluidsopnames geweest, dus er is geen beeldmateriaal opgenomen. Er is aan de respondenten uitgelegd dat de opnames alleen voor uitwerkingsdoeleinden dienden en, dat de opnames na de uitwerking van de interviews vernietigd zouden worden. Iedere respondent heeft hiervoor toestemming gegeven. Pas nadat er toestemming was gegeven, is de opnameapparatuur aangezet.
De interviews zijn van audio verwerkt tot tekstuele bestanden. De verdere uitwerking van de tekstuele bestanden is onder informed consent gebeurd. Deze tekstuele bestanden zijn teruggestuurd naar de respondenten ter controle en ter goedkeuring om het te mogen gebruiken. Er is wel een termijn vastgesteld om eventuele veranderingen door te voeren. Dit is gedaan om de deadline van het onderzoek niet in gevaar te laten komen of om te voorkomen dat gegevens niet gebruikt konden worden, omdat er nog op een antwoord gewacht moest worden.
Vervolgens zijn de interviewgegevens geanalyseerd en verwerkt in de resultaten van het onderzoek. Dit is gedaan op basis van de topiclijst (zie bijlage 1). De interviewgegevens zijn per hoofdonderwerp gescand. Per hoofdonderwerp zijn de gegevens uit alle interviews samengevoegd en verwerkt tot een samenhangend geheel; de resultaten. Er is dus gezocht op basis van een
38

bepaalde structuur in de interviewgegevens. Het kan echter voorkomen dat er bij de analyse van de interviewgegevens zaken naar voren komen die niet eerder ingedeeld konden worden onder een bepaald topic, maar dat deze informatie wel van belang is voor het onderzoek. Het onderzoek heeft zowel een deductief als een inductief karakter (Verhoeven, 2014, p. 302).
39

H6 ResultatenIn dit hoofdstuk wordt antwoord gegeven op de deelvragen. De resultaten zijn gebaseerd op de informatie die naar voren is gekomen uit de analyse van de antwoorden die tijdens de interviews gegeven zijn. Per paragraaf wordt de betreffende deelvraag weergegeven waarop antwoord wordt gegeven. Bij de beantwoording wordt de koppeling gemaakt met de literatuur die in de vorige hoofdstukken aan bod is gekomen. Het kan voorkomen dat op basis van de interviewgegevens ook de koppeling wordt gemaakt met nieuwe literatuur. De uitingen van de respondenten zijn volledig geanonimiseerd tijdens de uitwerking. Dat wil zeggen dat uitingen niet terug te leiden zijn naar de respondent.
6.1 De 7 V’s van Big DataVoordat er dieper op het gebruik van Big Data wordt ingegaan, worden eerst de resultaten gepresenteerd over wat er door de respondenten wordt verstaan onder Big Data. De theorie laat duidelijke indicatoren zien waaraan data moeten voldoen voordat er gesproken kan worden over Big Data. Dit zijn de 7 V’s, waarvan de 3 V’s Volume, Variety en Velocity het meest dominant zijn. Eén van de respondenten noemde ze letterlijk als antwoord: “Big Data is voor mij vooral veel, gevarieerd en met een enorme omloopsnelheid. De 3 V’s, Volume, Variety en Velocity”. Een andere respondent zei: “Er zijn natuurlijk de bekende 4 of 5 V’s, en die aspecten zitten er allemaal in”, maar welke dat dan precies zijn is niet duidelijk geworden. Over het algemeen zijn alle V’s wel aan bod gekomen, de een explicieter dan de ander.
6.1.1 VolumeWat opviel bij alle reacties is dat er overeenstemming lijkt te zijn, dat het moet gaan om zeer grote hoeveelheden data, Volume. Dat blijkt uit de volgende reacties:
“het geheel aan informatie dat je zou kunnen verzamelen over een bepaald onderwerp of in een bepaalde context. Dus eigenlijk zit er geen einde aan van hoe Big het kan worden”.
“zulke grote gegevens verzamelingen dat je dat als mens niet meer normaal kan verwerken”.
“echt alles wat er is, en wat er beschikbaar is. Dan zou je kunnen denken aan Twitter, Facebook, noem het maar op”.
“Het is zoveel data dat het met conventionele middelen niet te behappen is”.
Uit deze reacties is nog een overeenkomst te halen, namelijk dat het niet meer door een mens of conventioneel middel te verwerken is. Naast overeenkomsten blijken er ook verschil te zitten hoe er naar data gekeken wordt door de publieke en private sector. Bedrijven als Google en Facebook hebben het over aanzienlijk grotere hoeveelheden data, dan een overheidsinstantie. Die spreken in bepaalde gevallen al van Big Data als ze het over hun eigen gegevens hebben. Twee van de respondenten geven aan dat soms bij de overheid al gevonden wordt dat ze met Big Data bezig zijn wanneer het niet meer in een Excel sheet past. Een respondent verwoordde dit als volgt: “Bij gemeenten gaat het toch om kleinere hoeveelheden Big Data, omdat het toch vaak gaat over informatie die gemeenten vaak zelf in hun systemen hebben. En bij een Google gaat het over ‘het‘ internet, dat gaat dus over alle informatie, dat gaat dus over echt heel verschillende hoeveelheden aan informatie”.
40

Een ander zegt: “wat ik bijvoorbeeld nu doe is met politiegegevens, ja dat zijn wel grote databestanden, maar ik vind het niet erg Big Data”, en “we hebben te maken met een goede hoeveelheid data. We kunnen het beschouwen als een onderdeel van Big Data. Niet volledige Big Data maar nog steeds wel een goede hoeveelheid”. Er lijkt overeenstemming te zijn over dat het moet gaan over grote hoeveelheden data, maar hoe groot die data dan moeten zijn verschilt. Het hangt er dus van af aan wie je het vraagt, het gaat ook om de context. “Data is een tijdscontext afhankelijk begrip”. 6.1.2 VarietyBij de variëteit van de data gaat het om het gebruiken van meerdere soorten datasets, met behulp van verschillende soorten data (Russom, 2001, p. 6; Cukier en Mayer-Schönberger, 2013; Osseyran en Vermeend, 2014, p. 7-8). Bij Big Data moet het dus gaan om verschillende soorten data en dataverzamelingen.
Wanneer gekeken wordt naar het soort data dat wordt gebruikt bij het voorspellen, komen er een aantal antwoorden overeen. Veelal wordt er in eerste instantie gebruik gemaakt van eigen politiegegevens. Maar de politie kan bijvoorbeeld ook in systemen van gemeenten, de Kamer van Koophandel en allerlei registers. Ze kunnen bij alle openbare publieke gegevens. Dat zijn gegevens die mensen zelf openbaar op internet plaatsen. “Facebookgegevens kun je opvragen bij Facebook, Google gegevens kun je opvragen bij Google. Als jij verdachte bent en je hebt een Gmail account, dan kan ik bij Google vragen om dat account”, aldus een van de respondenten. Een ander geeft aan dat de politie ook gebruikt maakt van sociaal-economische data. Bijvoorbeeld het inkomen, hoe zo’n wijk in elkaar zit, hoeveel winkels en horeca er aanwezig is. Deze informatie is te verkrijgen via het CBS. Maar ook kunnen bijvoorbeeld kentekengegevens opgevraagd worden.
Er kan een overzicht gemaakt worden van de verschillende soorten data die naar voren zijn gekomen in de verschillende reacties.
1. Open/publieke data: veel social media, maar bijvoorbeeld ook (een deel van) CBS gegevens;
2. Data die je kunt kopen: bijvoorbeeld bij de Kamer van Koophandel of kadastergegevens;
3. Eigen/gesloten data: data die in de eigen systemen voorkomen en dus te gebruiken zijn door de betreffende instantie zelf. Deze data kunnen alleen onder bepaalde voorwaarden en na het maken van afspraken gedeeld worden met een andere partij.
6.1.3 VelocityBij velocity draait het om hoe up-to-date de resultaten zijn, waarbij in het beste geval de data zo snel binnengehaald en geanalyseerd worden, dat de analyse een weergave geeft van dit moment. Deze kunnen dus real-time genoemd worden. De derde V is dus een maatstaf voor de verandersnelheid van gegevens en verwijst naar de tijdelijke waarde van de gegevens zelf (Russom, 2001, p. 6; Cukier en Mayer-Schönberger, 2013; Osseyran en Vermeend, 2014, p. 7-8).
“Helaas is het nog steeds zo dat de meeste voorspellingen op basis van het verleden zijn. Dus als je dat op het internet gaat toepassen ga je heel veel teleurgesteld worden, want internet is nog zo dynamisch en veranderlijk dat voorspellingen uit het verleden niet zoveel zeggen over de toekomst”. Dit heeft één van de respondenten gezegd over het up-to-date zijn van de gegevens. Internetgegevens veranderen zo snel, dat wanneer je deze gaat gebruiken om een voorspelling mee te doen, je je kunt afvragen of deze gegevens nog wel voldoende up-to-date zijn. Wanneer het gaat over de tijdelijke waarde van de gegevens zelf, gaat het in de reacties ook over de bewaartermijnen van de
41
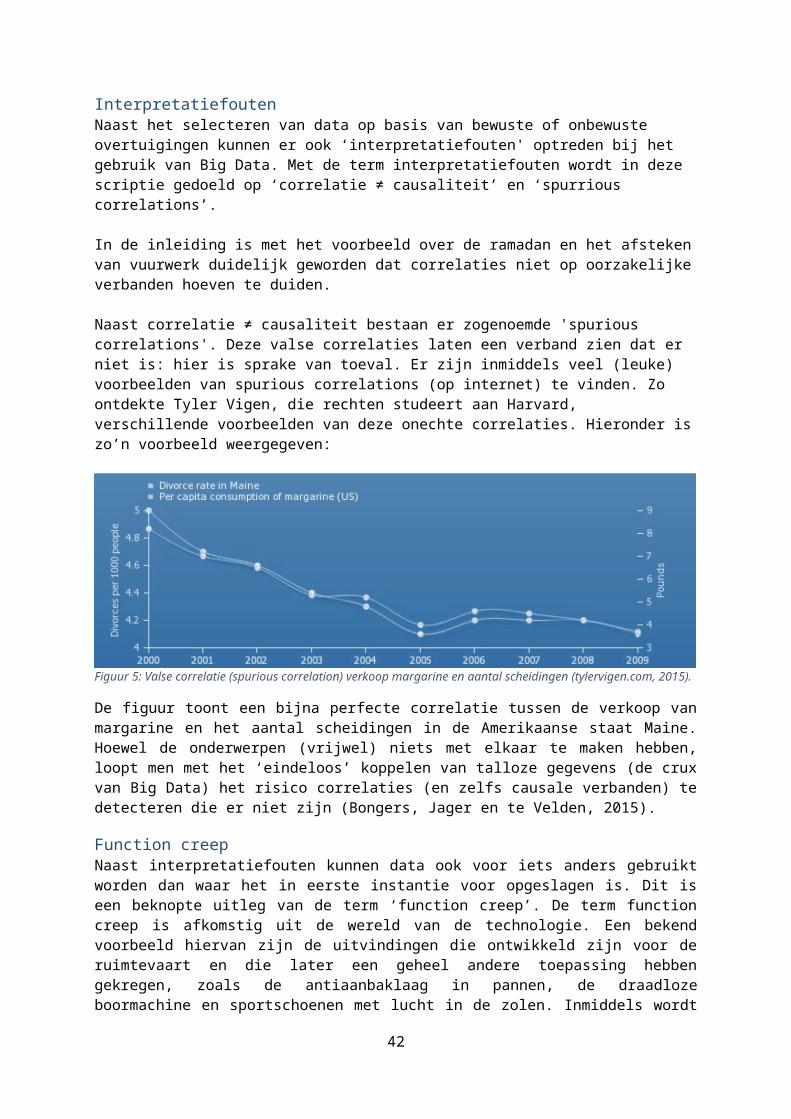
gegevens. Bij de verschillende soorten gegevens zitten verschillende soorten bewaartermijnen. Zo zit er een bewaartermijn van 4 weken op kentekengegevens (ANP, 2013). De bewaartermijn van de gegevens in de politiesystemen hangt af van het soort gegeven en het doel waarvoor je gegevens wilt inzien of gebruiken.
Over in hoeverre de data die gebruikt worden up-to-date zijn, is niet terug gekomen in de reacties van de respondenten. Maar wanneer het gaat over het gebruik van bijvoorbeeld sociaal-economische data van het CBS, kan er vanuit gegaan worden dat het CBS zelf zorgt voor het up-to-date houden van de gegevens.
42

6.1.4 ViscosityViscosity betreft de traagheid bij het navigeren door de gegevensverzameling, bijvoorbeeld door de verscheidenheid aan bronnen of de complexiteit van de benodigde verwerking (Osseyran en Vermeend, 2014).
Traagheid bij het navigeren door de gegevensverzamelingen is niet expliciet naar voren gekomen. Wel is de complexiteit van de benodigde verwerking meerdere malen naar voren gekomen als een kenmerk van het gebruik van Big Data. Een van de respondenten verwoordde dit als volgt: “ je hebt zó veel data, uit veel verschillende bronnen dat je ineens meta-analyses kan doen en patronen kan ontdekken waar je in eerste instantie niet aan had kunnen denken. En dat alleen al door het feit dat je al die data bij elkaar hebt gebracht (meervoudige data). Dat maakt het complex, want hoe relateer je dat aan elkaar en de processing/verwerking? Analyse is ook een enorme uitdaging”.
Andere respondenten voegen daar aan toe dat de omgang met Big Data zeer complex is en niet iets is dat je in een maandje onder de knie hebt en dat er binnen de politie hier nog een slag in te slaan is; door de juiste mensen aan te trekken of op te leiden. Dit is ook een aspect dat in de literatuur naar voren is gekomen. Hoe veelbelovend Big Data ook lijkt, het daadwerkelijk goed inrichten van de enorme databases die nodig zijn voor het verwerken ervan is voor velen simpelweg te complex (Stillman, 2013; Ho, 2013). Eén van de respondenten zegt hierover: “Er zijn maar heel weinig mensen met een goede Big Data kennis. Die zijn op de markt ook heel schaars. Dat is niet alleen binnen de politie zo, maar binnen de hele overheid”.
Bijna alle respondenten geven aan dat een dataminer/datascientist in de commerciële sector veel meer geld kan verdienen dan bij de overheid. “Het is een vakgebied waar je heel veel geld mee kan verdienen in de buitenwereld. Dus waarom zou je dan bij de politie gaan werken? Dat zijn dan mensen die iets voor de maatschappij willen betekenen of niet alleen maar iemand anders rijk willen maken met hun slimme ideeën”.
6.1.5 VeracityVeracity geeft de kwaliteit en oorsprong weer om gegevens aan te merken als twijfelachtig, conflicterend of niet-zuiver, en als informatie waarvan men niet zeker weet hoe ermee om te gaan (Osseyran en Vermeend, 2014). Veracity betreft dus de waarheidsgetrouwheid van gegevens.
Bij dit aspect wordt genoemd dat binnen de politie veel verschillende mensen gegevens invoeren in de systemen. Dit kan zorgen voor een bepaalde onbetrouwbaarheid bij de invoer. Daarnaast speelt de kwestie dat bepaalde gegevens uit de systemen anders geïnterpreteerd kunnen worden dan hoe ze in eerste instantie bedoeld waren.
Ook geven respondenten aan dat je kunt twijfelen aan de betrouwbaarheid van de informatie die te verkrijgen is op open bronnen. In hoeverre kun je er bijvoorbeeld van uitgaan dat wat op iemands Facebookpagina staat, waarheidsgetrouw is? Dit is een terechte vraag die een van de respondenten voorlegde in het interview. Ook de eerder genoemde kans op interpretatieverschillen kan er voor zorgen dat de gegevens aan te merken zijn als twijfelachtig.
Tenslotte is er aangegeven dat de data in de systemen niet altijd compleet zijn. Een van respondenten gaf een voorbeeld: “…een bekend voorbeeld dat iedereen altijd noemt is het volgende. Als er een bepaald incident is, moet er een begin- en eindtijd ingevuld worden. Bijvoorbeeld bij een woninginbraak, als je weet om 00:03 ging het alarm af, dan weet je: het was om 00:03. Maar als je vrijdagmiddag op vakantie ging en je komt twee weken later terug en je komt er achter dat er is ingebroken, dan weet je die tijden al niet”.
43

Wanneer deze twijfels spelen bij degene die de gegevens moet analyseren en verwerken, is er volgens meerdere respondenten de mogelijkheid om dit te controleren bij degene die verantwoordelijk is geweest voor de invoer. Ook wordt genoemd dat die foutmarge te verwaarlozen kan zijn omdat je werkt met grote hoeveelheden data.
44

6.1.6 ValueValue kenmerkt welke waarde uit welke gegevens gehaald zou kunnen worden en hoe je met Big Data betere resultaten kunt krijgen uit opgeslagen gegevens (Osseyran en Vermeend, 2014, p. 8).
Welke waarde uit gegevens gehaald kan worden hangt sterk af van het doel van waarvoor ze gebruikt worden. Bijvoorbeeld in het CAS-model is de afstand tot het woonadres van een bekende woninginbreker gebruikt als waarde. “Dat is iets dat al eerder door mensen geopperd was: er wonen hier veel inbrekers en die breken veel in hun eigen buurt in, daar moet je rekening mee houden. Is er uitgerekend wat de afstand is tot het woonadres van een bekende woninginbreker? Dat zit niet standaard in de politiesystemen, die afstand. Die is uitgerekend om te checken of dat een voorspeller zou kunnen zijn, en dat bleek ook een voorspeller te zijn”.
Er moet van tevoren goed nagedacht worden over het doel van wat je wilt voorspellen. Aan de hand daarvan kan er gekeken worden welke indicatoren daarvoor nodig zijn. Het is dus niet zo dat een systeem zelf waarde toekent aan bepaalde gegevens. Waar rekening mee gehouden moet worden, is dat veel politie-informatie in lappen tekst is en dat dat heel moeilijk is voor een computer om te verwerken. Die tekst kan tot interpretatieverschillen leiden, hetgeen ook een reden is waarom die lappen tekst maar heel beperkt gebruikt worden. Dat bevestigt een van de respondenten: “dat zijn heel complexe query’s”. In die zelfde reactie wordt in het kort uitgelegd hoe hier wel bepaalde waarden uit te halen zijn door middel van tekstmining: “…als een bepaald woord in de buurt van ander woord komt, dan zou het wel eens huiselijk geweld kunnen zijn. En dan kijkt daar nog eens een mens naar om te bevestigen dat die woorden als kenmerk huiselijk geweld gebruikt moeten worden. Dan helpt de computer eigenlijk om dat soort verkeerde administratie naar boven te halen. Maar de computer interpreteert niet de lappen tekst”.
In voorspellende modellen wordt eerder gestructureerde, vastgelegde data gebruikt. Bijvoorbeeld gegevens als tijd, datum, plek, maar ook de afstand tot het woonadres van de dichtstbijzijnde crimineel.
6.1.7 Virality Virality is een maatstaf voor de snelheid waarmee gegevens zich door het netwerk verspreiden. Tijd is een belangrijk kenmerk, naast de verspreidingssnelheid. Een ander soort snelheid dus dan bij Velocity (Osseyran en Vermeend, 2014, p. 8).
Over dit kenmerk van Big Data is niet iets expliciet terug gekomen tijdens de interviews. Men legt een wel een link met de opkomst van social media en het mobieler en het meer online zijn van de burger. Het internet wordt snel gevoed met allerlei gegevens en deze gegevens verspreiden zich heel snel en worden met veel mensen gedeeld. Eén respondent noemde als voorbeeld de korte gijzeling bij de NOS aan het begin van dit jaar: “Binnen een uur wist iedereen wie het was, waar hij woonde, noem maar op. Dat heeft een behoorlijke impact op bijvoorbeeld de ouders. Op social media wordt dat zo de wereld in gegooid. En dat ga je ook nooit meer tegenhouden want zo werkt dat tegenwoordig. Opsporingsinstanties zijn daar een stuk voorzichtiger mee”.
Respondenten geven aan dat het voor opsporingsinstanties zaak blijft om zorgvuldig met informatie van de beschikbare bronnen om te gaan. Dit geldt ook voor het delen van informatie. Er is natuurlijk een verschil tussen het gebruik door een officiële instantie en het gebruik van –soms dezelfde informatie- door burgers onderling. Zoals blijkt uit de volgende uitspraken: “als het bijvoorbeeld ergens op Twitter staat en je gebruikt het niet, dan zegt men ook: je had het wel kunnen weten want ik wist het ook want het stond op Twitter”. “…want als we er
45

dan wel uitspraken over zouden doen en het onderzoek loopt stuk, is dat toch een beetje suf. Dat wil je als slachtoffer ook niet hebben”.
46

6.1.8 Andere genoemde aspecten Big DataBij de vraag wat zij verstaan onder Big Data kwam meermaals terug dat Big Data meer is dan de 7 V’s. Het gaat ook om de slimme combinatie en toepassing van (on)gestructureerde data die als restproduct van digitale gegevensverzameling ontstaat. Uit de combinaties kunnen patronen en verbanden uitgehaald worden die voorheen niet ontdekt werden:
“En wat Big Data ook is, is dat je middels Big Data verbanden en patronen kunt gaan zien die je voorheen nooit kon zien”.
“De kern van Big Data ligt in het kunnen herkennen van patronen die je als mens niet 1, 2, 3 zou kunnen herkennen”.
“De kracht van Big Data is het leggen van verbanden”.
En dat bij Big Data de focus niet op individuen ligt: “Het interessante bij Big Data is natuurlijk: het individu verdwijnt een
beetje. Het wordt minder belangrijk dan het was…, …met Big Data worden andere dingen ook interessant. Namelijk hoe een groep werkt en hoe verschillende groepen in de maatschappij doen en wat hun preferenties zijn”.
“Je wil patronen zoeken, je wilt geen individuele kenmerken hebben, die wil je er juist zoveel mogelijk uit hebben. Dus als ik een Big Data analyse maak, is het eerste wat is doe alle persoonsgebonden ruis eruit halen”.
6.1.9 ResuméVolume
Alle respondenten zijn het wel over eens dat Big Data gaat over hele grote hoeveelheden data. Hoe groot de data precies moeten zijn, daar verschillen de meningen over. Bij de overheid wordt er al over Big Data gesproken wanneer het over de eigen data gaat. Bedrijven als Google en Facebook hebben het over alles wat op internet staat. Het lijkt dus afhankelijk van aan wie je het vraagt en in welke context. En dat je dus niet altijd over Big Data kunt spreken wanneer je in jouw ogen grote hoeveelheden data gebruikt.
Variety
Alle respondenten geven aan dat er verschillende soorten data gebruikt worden. De nadruk ligt echter wel op het gebruik van de eigen bestanden. Er wordt dus eerst gekeken wat er mogelijk is met eigen bestanden voordat er aanvullende data wordt verzameld. Hieronder zijn de verschillende soorten data weergegeven:1. Open/publieke data: veel social media, maar bijvoorbeeld ook
deel van de CBS gegevens;2. Data die je kunt kopen: bijvoorbeeld die van de Kamer van
Koophandel of kadastergegevens;3. Eigen/gesloten data: data die in de eigen systemen voorkomen
en dus te gebruiken zijn door de betreffende instantie zelf. Deze data kunnen alleen onder bepaalde voorwaarden gedeeld worden met een andere partij.
Velocity
Internetgegevens veranderen zo snel dat je je kunt afvragen of deze nog wel up-to-date zijn wanneer deze gebruikt worden om een voorspelling mee te doen. Wanneer het gaat over de tijdelijke waarde van de gegevens zelf, gaat het in de reacties ook over de bewaartermijnen van de gegevens. Hoe lang die termijn is, verschilt per soort data en het doel waarvoor de data gebruikt worden.
47

Respondenten geven aan dat er veel met eigen bestanden wordt gewerkt. Dus data uit het verleden.
48

Viscosity
Over traagheid bij het navigeren door de gegevensverzamelingen is niets expliciet naar voren gekomen. Wel is de complexiteit van de benodigde verwerking meerdere malen naar voren gekomen als een kenmerk van het gebruik van Big Data. Goede kennis omtrent Big Data gebruik is schaars. Die kennis wordt goed betaald in de commerciële sector, dat maakt het voor de overheid lastig om de juiste mensen aan te trekken.
Veracity
In de praktijk is dit terug te zien in drie dingen. 1. Interpretatie verschillen tussen invoerder en gebruiker van
gegevens;2. In hoeverre zijn gegevens van open bronnen waarheidsgetrouw?;3. Ontbrekende of incomplete data.Wanneer deze twijfels spelen bij degene die de gegevens moet analyseren en verwerken, is er volgens meerdere respondenten de mogelijkheid om dit te controleren bij degene die verantwoordelijk is geweest voor de invoer. Ook wordt genoemd dat die foutmarge te verwaarlozen kan zijn omdat je werkt met grote hoeveelheden data.
Value Er moet van te voren goed nagedacht worden over het doel; waarvoor wil je voorspelling gebruiken? Aan de hand daarvan kan gekeken worden welke indicatoren daarvoor nodig zijn. Het is dus niet zo dat een systeem zelf waarde toekent aan bepaalde gegevens. Veel politie-informatie is in lappen tekst, middels tekstmining is het wel mogelijk om daar waarden uit te halen, maar er wordt meer gestructureerde vastgelegde data gebruikt.
Virality
Over dit kenmerk van Big Data is niet iets expliciet terug gekomen tijdens de interviews. Wat wel terug is gekomen is dat op internet tegenwoordig veel sneller van alles te vinden is over een bepaald incident. Vaak al eerder dan dat de politie klaar is met haar onderzoek. Er is een belangrijk verschil tussen het gebruik door een officiële instantie en het gebruik van –soms dezelfde informatie- door burgers onderling. Dit geldt ook voor het delen van informatie.
Anders
Bij de vraag wat zij verstaan onder Big Data kwam meermaals terug Big Data meer is dan de 7 V’s. Het gaat ook om de slimme combinatie en toepassing van (on)gestructureerde data die als restproduct van digitale gegevensverzameling ontstaat. Uit de combinaties kunnen patronen en verbanden uitgehaald worden die voorheen niet ontdekt werden. En dat bij Big Data de focus niet op individuen ligt.
6.1.10 DeelconclusieDe eindconclusie van deze paragraaf is dat er ruime overeenkomsten zijn tussen wat er in de theorie wordt bedoeld met Big Data (7 V’s) en wat de respondenten hieronder verstaan. Naast de 7 V’s gaat het ook om slimme combinaties van databestanden waarbij de focus niet ligt op individuen.
49

6.2 Big Data gebruikOp welke manier kan Big Data gebruikt worden om aan de hand van datamining voorspellingen te doen over (potentiële verdachten van) misdaden?
6.2.1 Het gebruik van Big Data bij het voorspellenIn de vorige deelparagraaf is duidelijk geworden hoe er door de verschillende respondenten gedacht wordt over Big Data. In deze deelparagraaf wordt verder gegaan met de beantwoording van de deelvraag over het gebruik van Big Data bij het voorspellen.
Voorspellen van misdadenBij het voorspellen van misdaden gaat het over Predictive Policing. Dit is in de inleiding en operationalisering nader uitgelegd. Hierbij ligt de nadruk op het voorspellen van waar, dus geografisch, er een verhoogde kans is op een misdrijf. Op deze manier kan de politiecapaciteit effectiever en efficiënter worden ingezet en aangestuurd worden (Perry, et. Al., 2013, p. xiii; Pearsall, 2010).
Uit de interviews komt het Criminaliteits Anticipatie Systeem (CAS) naar voren als een systeem waarbij de politie gebruik maakt van Big Data om voorspellingen te doen van misdaden. Eén van de respondenten geeft aan dat in het landelijke model voornamelijk woninginbraken worden voorspeld. Het gaat daarbij om geografische voorspellingen waarbij gekeken wordt waar een verhoogde kans is dat er ergens een woninginbraak gepleegd wordt. Bij CAS worden berekeningen gedaan aan de hand van politiedata aangevuld met andere data. Hij legt uit wat voor soort gegevens hiervoor gebruikt worden: “…woninginbraken historie, aangevuld met CBS gegevens en afstandgegevens tot het woonadres van bekende woninginbrekers. Dus niet persoonsgegevens, maar afstandsgegevens. Je kunt bijvoorbeeld zeggen: als een woninginbreker in een straal van een kilometer van jouw huis woont, dan is er een iets verhoogde kans op een woninginbraak”.
CAS biedt uitkomst wanneer de focus ligt op grote gebieden, bijvoorbeeld de eenheid Amsterdam. “Er is niemand in Amsterdam die overzicht heeft op alles wat er in Amsterdam gebeurt. In dat geval biedt een classificatie volgens een bepaald computersysteem best wel uitkomst”. Het model is bedoeld om zo geheten flexteams aan te sturen. Dat is een pool van mensen die over de hele eenheid ingezet kunnen worden. Zij weten vaak niet wat er in een bepaald gebied allemaal speelt. Een voorspelling biedt uitkomst voor dat soort teams. Dit model zit in de pilotfase. “We zijn bezig met een landelijke pilot om het systeem naast Amsterdam bij nog vier eenheden binnen Nederland uit te voeren”.
Naast de politie is er ook een verzekeringsmaatschappij bezig met de ontwikkeling van een model om woninginbraken te voorspellen. Ook hier gaat het om een model om gebieden te voorspellen waar de kans op een woninginbraak groter is dan in andere gebieden. Zodat zij hun klanten kunnen informeren over wat zij kunnen doen tegen woninginbraken. Zij gebruiken hiervoor vooral hun eigen klantgegevens en open data, zoals een van de respondenten heeft aangegeven. Diezelfde respondent heeft daar ook nog het volgende over gezegd: “we gaan ook geen overeenkomsten aan met een andere partij om elkaars gegevens te gebruiken. Dat is natuurlijk een optie, maar we hebben er voor gekozen om dat op dit moment niet te doen. We kijken hoe ver we kunnen komen met open data. In het model dat wordt gemaakt zijn wel een aantal velden benodigd om het, in onze optiek, perfect te krijgen. Maar heb je bepaalde data niet, dan werkt het model nog steeds”.
50

Deze verzekeringsmaatschappij kijkt dus hoe ver zij kan komen wanneer alleen eigen en open data worden gebruikt. Wanneer het project slaagt, gaan zij aan de klant vragen of zij de informatie willen ontvangen. De respondent zegt hierover: “wij gaan niet zomaar klanten bestoken met informatie. Dat maakt dan onderdeel uit van het proces. Als mensen dan aangeven dat zij die informatie willen ontvangen –daar moeten zij zich dan zelf voor aanmelden- dan krijgen ze naast het inzicht in de risico’s ook tips om het risico te verkleinen”. Hij pleit er ook voor om transparanter om te gaan met data in het algemeen: “ Ik pleit ook vaak voor een soort donorregistratie. Laten we nou eens aan Nederland vragen wat zij vinden dat er met hun data mag gebeuren. Je hoort vaak: data mogen we niet naar buiten brengen. Dat weten we helemaal niet, want in mijn optiek zijn het data van onze klant en die moet daarover beslissen”. Er moet dan gedacht worden aan een soort landelijke registratieomgeving waarin je als burger kunt aangeven wat voor soort instanties jouw data, en welke data, mogen gebruiken en voor welke doeleinden.
Voorspellen van potentiële verdachtenBij het voorspellen van potentiële verdachten van misdaden gaat het over profiling. Dit is in hoofdstuk 4 Operationalisering nader uitgelegd. Het gaat daarbij om het zoeken naar, het inzichtelijk maken van en het verklaren van de mogelijke verbanden die bestaan tussen criminaliteitsgegevens onderling en tussen criminaliteitsgegevens en andere relevante gegevens, door het formuleren van bruikbare uitspraken (vaststellingen, hypothesen en aanbevelingen) met het oog op een doeltreffende praktijk van politie en justitie (Devroe en Vandervelde, 2005, p. 322).
Hieronder volgen de voorbeelden die naar voren zijn gekomen tijdens de interviews. Het gaat om de Top600 en Prokid-plus.
Top600 is een lijst die wordt opgesteld door de politie waarop de 600 meest criminele personen staan van Amsterdam. Deze personen worden geselecteerd op basis van de overeenkomst met vooraf bepaalde indicatoren. Dit wordt gebaseerd op louter politiegegevens. Een van de respondenten geeft een aantal voorbeelden van die indicatoren: “Als je bijvoorbeeld minimaal 3 keer een woningbraak pleegt, je bent minimaal 1 keer veroordeeld, en je hebt minimaal 10 politiecontacten gehad; dan zetten wij jou op de Top600. Dan ben jij voor ons iemand die aangetoond heeft dat hij crimineel is en de kans dat hij dat nog blijft doen aannemelijk is, als wij daar niet iets aan gaan doen met z’n allen”.
De Top600 is een samenwerkingsverband, waar in Amsterdam 37 organisaties aan mee werken. Naast politie, gemeente en OM zijn dat onder andere de GGD, Bureau Jeugdzorg en de Reclassering (Politieacademie, 2015). Wanneer je op deze lijst staat, word je meer gemonitord, krijg je huisbezoeken en word je vaker staande gehouden door de politie. De respondent gaat verder: “…dus we halen daar de gemeente bij, we kijken of je niet aan het werk kan, we kijken of je niet licht verstandelijk beperkt bent. Want dat zijn deze mensen vaak en dan moet je in een ander soort behandeltraject komen. Dat zijn dus allemaal dingen om die Top600 niet meer criminaliteit te laten plegen, maar om die daarmee te laten stoppen”. Er worden ook gegevens uitgewisseld over de Top600 binnen het samenwerkingsverband: “De Top600 is heel erg strak gereguleerd. Hierover zijn duidelijke afspraken gemaakt die vastgelegd zijn in convenanten”.
Het andere voorbeeld is Prokid-plus. Dat systeem gaat nog een stapje verder. Dat systeem kijkt namelijk naar de omgeving van die 600 criminelen. Er wordt
51

bijvoorbeeld gekeken of iemand broertjes of zusjes heeft. Wanneer dit het geval is, wordt er gekeken of zij in een zorg- of begeleidingstraject opgenomen kunnen worden om te voorkomen dat zij diezelfde kant op gaan als hun oudere broer of zus. “Prokid-plus is meer een methode om te voorspellen of een individu meer kans heeft om crimineel gedrag te gaan vertonen”, aldus een van de respondenten. Prokid-plus kijkt naar minderjarigen, de plus staat voor 12+. Dus 12 jaar en ouder.
Over wat het soort data betreft dat gebruikt wordt voor Prokid-plus, zegt één van de respondenten het volgende: “voor Prokid-plus weet ik dat we nu alleen nog politiedata gebruiken, maar daar zou je je kunnen voorstellen dat bijvoorbeeld gegevens over spijbelen een indicator kan zijn die je in het grote geheel mee zou willen nemen”. Er worden dus alleen nog politiedata gebruikt, maar er wordt wel nagedacht over welke gegevens deze data kunnen versterken.
52

6.2.2 Deelconclusie het gebruik van Big Data bij voorspellingenUit het onderzoek komt naar voren dat er verschillende modellen zijn ontwikkeld, of nog in ontwikkeling zijn, waarbij aan de hand van Big Data voorspellingen gedaan worden. De geïnterviewde noemen Criminaliteits Anticipatie Systeem (CAS) als voorbeeld waarbij Big Data wordt gebruikt bij het voorspellen van misdaden. Daarnaast is er nog een verzekeringsmaatschappij bezig met het ontwikkelen van een geografisch voorspelmodel van woninginbraken. Waar het gaat over het voorspellen van potentiële verdachten van misdaden worden Top600 en Prokid-plus genoemd.
Te constateren valt dat CAS en de Top600-Aanpak al in de uitvoeringsfase zitten, en dat Prokid-plus en het voorspelmodel van de verzekeringsmaatschappij nog in een meer experimentele fase verkeren.
6.3 Ethische en juridische bezwarenIn hoeverre bestaan er ethische en juridische bezwaren tegen het gebruik van Big Data bij het voorspellen van (potentiële verdachten van) misdaden?
Nu duidelijk is hoe er over Big Data gedacht wordt en hoe het in de praktijk toegepast wordt om voorspellingen te kunnen doen, wordt er in deze paragraaf gekeken naar de mogelijke juridische en ethische bezwaren. De gepresenteerde resultaten zijn op basis van uitspraken van de respondenten. Het geeft dus een weergave van hoe er door deze respondenten in de praktijk gedacht wordt over de rechtvaardigheid en rechtmatigheid omtrent het gebruik van Big Data bij de opsporing, in het bijzonder bij het voorspellen. Tot op welke hoogte is het geoorloofd om gegevens te verzamelen en op te slaan en wat mag er met de gegevens gedaan worden?
6.3.1 Ethische bezwarenHet Prokid-plus model, beschreven in de vorige paragraaf, zit nog in de experimentele fase en dat heeft een reden volgens de respondent: “Stel, je kunt, ook daar gaat het om waarschijnlijkheid, op basis van een aantal indicatoren potentiële verdachten voorspellen. Of beter gezegd, de kans dat iemand crimineel gedrag gaat vertonen is aannemelijker dan bij een ander persoon. Dan is de vraag wat je daar vervolgens mee gaat doen. En dat is het ethische vraagstuk waar de politie ook nog niet uit is”.
Daar worden wel gesprekken over gevoerd om te kijken hoe ver je daar in kan en mag gaan. De politie is zich ervan bewust dat ze heel voorzichtig om moet gaan met de gegevens en de voorspellingen die uit dat model komen. Een van de respondenten geeft aan dat de politie daar vooral een rol weggelegd ziet voor de gemeente, de zorg: “Vooral weinig politiekant, omdat dat een beetje tricky is: de politie is zich ervan bewust dat ze heel voorzichtig om moet gaan met de gegevens en de voorspellingen die uit dat model komen.” Ook al kan het zijn dat de personen die in het model naar voren komen al kleine criminaliteit hebben begaan. Maar er wordt volgens de respondent ook een goede afweging gemaakt om te kijken of het wel te rechtvaardigen is om iemand onder begeleiding te plaatsen: “…maar ook dat is weer dat je niet iemand onder begeleiding kunt plaatsen die 1 keer een winkeldiefstal heeft gepleegd. Omdat jij op basis van bepaalde indicatoren denkt dat hij wel crimineler zal gaan worden”. Er wordt dus ook geprobeerd om altijd te kijken naar het proportionaliteitsbeginsel. Past het middel wel bij -in dit geval het risico op- de daad? Een andere respondent brengt een ander gezichtspunt naar voren: “dat we te veel gaan vertrouwen op algoritmen en dat we ons daar eigenlijk achter gaan verschuilen bij het maken
53

van beslissingen. En op dit moment vooral de onnadenkendheid van mensen. Zo van: ik ga van alles, alles verzamelen en dan ga ik iets uitrekenen, zonder zich goed af te vragen of het wel mag of wel wenselijk is. The computer says so, dus dan zal het wel zo zijn”.
54

Een respondent snijdt het probleem aan dat het lastig is om een voorspelmodel voor potentiële verdachten van misdaden te toetsen. Hij geeft aan dat het heel lastig is om achteraf te concluderen of een bepaald resultaat te wijten is aan de voorspelling uit het model. Eén van de redenen is dat de politie geen referentiekader heeft. Er is in de politiegegevens bijvoorbeeld geen groep met mensen die niets fout hebben gedaan. Ook is het ethisch onverantwoord om twee willekeurige groepen op te stellen waarvan de ene groep wel een zorgtraject krijgt aangeboden en de andere groep niet. En vervolgens na een paar jaar te kijken welke van de twee groepen de meeste criminelen heeft opgeleverd, of juist de minste. Dat zou betekenen dat je een groep geen hulp hebt aangeboden, terwijl je al wel de kennis had dat het wellicht de verkeerde kant op zou gaan.
Meerdere respondenten geven dus aan dat rechtvaardigheidsvraagstukken nog een grijs gebied zijn bij het gebruik van Big Data. Het verzamelen en verwerken van gegevens lijkt dan ook niet de meest lastige stap bij het gebruik van Big Data in de opsporing, maar de stappen daarna. Is het in proportie om interventies in te zetten op basis van een voorspelling? Er is tenslotte nog niets verkeerds gedaan. Dit grijze gebiedt lijkt vooral een issue te zijn bij het voorspellen van potentiële verdachten van misdaden en minder bij de geografische voorspellingen. Wanneer je namelijk iemand verkeerd in de gaten gaat houden is dit gevoeliger dan dat je een gebied verkeerd hebt voorspeld. Men is er zich van bewust dat men heel voorzichtig om moet gaan met de gegevens en de voorspellingen die uit voorspelmodellen naar voren komen. Hierover worden binnen het veiligheidsdomein de nodige gesprekken en discussies gevoerd.
Dit geldt in het bijzonder voor het gebruik van voorspelmodellen door de politie en justitie. De politie is een overheidsinstantie die optreedt namens de samenleving om andere burgers te beschermen en heeft dus een machtspositie om de individuele vrijheid van burgers te beperken. De politie speelt ook een rol bij de afweging tussen zorg en straf. Respondenten geven voorbeelden van afwegingen van die balans:
“wat voor interventies doe je met een voorspelling? Daar zit het ethische vraagstuk. Iemand waarvan je denkt dat hij straatroven en overvallen gaat doen, maar hij heeft het nog niet gedaan, die kun je bijvoorbeeld niet vastzetten…, …maar een zorggesprek met een buurtregisseur of een wijkagent, ja daarvan kan je zeggen, dat vind ik niet heel erg ingrijpend”.
“de politie is er om de burger te beschermen en wanneer je als politie zijnde jezelf het recht toe-eigent om zomaar allemaal informatie te verzamelen van iedereen, dan gaat dat lijken op een soort Orwelliaanse samenleving”.
Een belangrijke theorie die in gaat op die balans is die van het sociaal contract van Jean-Jacques Rousseau (1762). De theorie gaat in op de vraag hoe de vrijheid (burgers) en autoriteit (overheid) zich ten opzichte van elkaar verhouden. Anno 2015 is deze discussie nog altijd actueel en die zien we ook terug bij de nieuwe mogelijkheden die de politie krijgt met de komst van Big Data.
Andrej Zwitter (2014) onderstreept dit in zijn essay waarin hij zegt dat ethici de discussie omtrent Big Data gebruik, moeten blijven aangaan om misbruik ervan te voorkomen: “When it comes to Big Data ethics, it seems not an overstatement to say that Big Data does have strong effects on assumptions about individual responsibility and power distributions. Eventually, ethicists will have to continue to discuss how we can and how we want to live in a datafied
55

world and how we can prevent the abuse of Big Data as a new found source of information and power”.
56

BewustwordingBij voorspellingen is het dus van belang dat men bewust omgaat met de voorspelmodellen en de uitkomsten daarvan. Er wordt hier veel over gediscussieerd binnen de politie. Uit verschillende reacties van de respondenten blijkt dat het kennisniveau bij de overheid nog niet op peil is als het gaat om Big Data en het gebruik daarvan.
Daarnaast zijn burgers zich onvoldoende bewust van wat zij zelf allemaal op internet zetten en dat die gegevens openbaar te verkrijgen zijn of worden doorverkocht. Dit staat weliswaar in de gebruikersvoorwaarden van bijvoorbeeld Facebook. “Maar wie leest die gebruikersvoorwaarden nou?” is een opmerking die meermaals is terug gekomen in de reacties van respondenten. “Je betaalt altijd een prijs en in dit geval is de prijs gewoon je privacy”. Men moet gaan beseffen dat Facebook en bijvoorbeeld de Albert Heijn-bonuskaart niet gratis zijn. Hans Schnitzler (2015) noemt dat in zijn boek ‘Het digitale proletariaat’, de 'digitale proletariër'. Dat is een mens van wie het hele bewustzijn, aandacht, emoties , vriendschappen, ideeën, fantasieën, tot koopwaar is gereduceerd.
Een gehoorde reden voor het tekort in dit bewustzijn is de generatiekloof op het digitale gebied. Hieronder zijn twee reacties weergegeven die dit aangeven, waar anderen zich niet verder uitlieten over de mogelijke redenen:
“Mensen van bijvoorbeeld 21 zijn zich er toch niet van bewust wat je allemaal achterlaat. Die vinden het ook allemaal maar normaal om alles van elkaar te weten. De bewustwording op het gebied van bijvoorbeeld de privacy is heel anders dan die van een oudere generatie. Ik wil niet dat we dat allemaal weten, maar mijn dochter vind dat helemaal niet erg”.
“Hoe hebben mijn ouders mij ooit kunnen opvoeden op het gebied van dataveiligheid en dat soort dingen? Zij begrijpen dat gewoon niet. Dus we hebben een groot gat tussen de generaties. En het is ook een taak om dat gat meer en meer te sluiten. Met deze nieuwe technologieën zijn de ouders niet opgegroeid. Wij groeien ermee op zonder goed de gevaren te kunnen inschatten”.
Deze generatiekloof lijkt een reden te zijn voor het gemak waarmee mensen gegevens op het internet zetten. Ze beseffen niet dat er zoveel informatie van hen online staat, omdat zij hier weinig educatie of sturing in hebben gehad van wie dan ook. “Je hebt dus een grote groep die helemaal geen computerkennis heeft en zich totaal niet realiseert wat er allemaal online staat van hen. Dan heb je een groep die zich wel realiseert dat er heel veel is, maar die hebben zoiets van: het gebeurt nog niet dat een woninginbreker een handige app heeft om te kunnen zien wie er op vakantie zijn. Ze zien er dus nog geen gevaar in”. In deze uitspraak wordt het kennistekort bevestigd; tegelijkertijd is er ook een groep die zich dit wel realiseert, maar nog geen gevaren ziet. Hier lijkt het erop dat het dus eerst mis moet gaan voordat men zich bewust wordt van de mogelijke gevaren. “Ik heb toch niets te verbergen” is een vaak gehoorde uitspraak.
Maar het lijkt er niet om te gaan wat je te verbergen hebt, maar om het bewust worden van wat je zelf allemaal aan informatie op allerlei plekken achterlaat en vrijgeeft. George Orwell had in zijn boek niet kunnen voorzien dat wij vandaag de dag zelfstandig en vrijwillig onze informatie prijsgeven. Eén van de respondenten zegt hierover: “als je het over social media hebt, dat zijn echt dingen die mensen zelf op het internet posten. Al dan niet beredeneerd, maar wel zelfstandig en niet gedwongen. Dus die brengen het zelf in de openbaarheid. Je zou het kunnen vergelijken met iemand die gewoon uit het raam schreeuwt wat hij op dat
57

moment doet. Als je dat dan doet heeft dat wel gevolgen, iedereen kan het bekijken”.
58

Toch is er al een groeiende bewustwording waar te nemen volgens sommige respondenten. Die geven aan dat burgers zich steeds bewuster worden, bijvoorbeeld door de NSA afluisterperikelen. Deze bewustwording zorgt ervoor dat burger zich steeds beter gaan beschermen. Facebookpagina’s worden steeds meer afgeschermd. Er worden op social media steeds meer besloten groepen gemaakt. Eén van de respondenten verwoordde dit als volgt: “maar dan wordt het dus interessant, want dat betekent dat Big Data er wel is, maar alleen in besloten groepen. En dan is de vraag hoe kan je bij die besloten groepen komen? Moet je dan infiltreren, kan je dan bij een bedrijf terecht dat alsnog die data heeft? Of moet je zelf iemand omkopen of is er iemand die kletst?”. Daarbij moet de politie zich weer opnieuw afvragen of een infiltratie op een Facebookpagina in proportie staat met het doel van de infiltratie.
Wanneer burgers zich bewuster worden en data beter gaan afschermen, kan dit een lastig aspect worden voor voorspellingen die gebruik maken van open data. Maar vooralsnog zou dit weinig problemen opleveren, omdat op dit moment in de voorspelmodellen vooral gebruik gemaakt wordt van eigen datasystemen en van gestructureerde data.
Daarbij komt dat het lastig is om als burger al je gegevens te beveiligen. Eén van respondenten zegt hierover: “er is zoveel data, dat het heel lastig is als individu om alles volledig geëncrypt, volledig geanonimiseerd de wereld in te laten gaan.., …zo zijn er heel veel bendes waarvan de bendeleden niet op Facebook zitten, maar hun vriendinnen, hun broertjes enzovoort allemaal wel. En die maken ineens een foto hoe ze gezellig aan het eten zijn en daar staan ze gewoon op. Dat is ook wat wij bedoelen met ‘het nieuwe DNA’. Als je het er niet zelf op zet, doet een ander het wel voor je”.
6.3.2 ResuméAls ethische bezwaren worden genoemd:
Mag je wel vertrouwen op de voorspelling? Wat doe je op basis van de uitkomsten van de voorspelling? Dit speelt
vooral ten aanzien van voorspellingen van potentiële verdachten personen. Hierbij gaat het over de balans vrijwillig/ verplicht bijvoorbeeld bij het accepteren van begeleiding en de rol van de staat in de bescherming van de maatschappij ten opzichte van de vrijheid van het individu (sociaal contract).
Het risico op een Orwelliaanse samenleving waarbij iedereen bij voorbaat verdacht is.
Het risico van de glijdende schaal: een eerste stap kan leiden tot vervolgstappen waarbij grenzen vervagen (proportionaliteit).
Er kan heel veel, maar er is (nog) onvoldoende kennis binnen de politie om hier goed mee om te gaan. Dat het kán wil nog niet zeggen dat je het moet willen. De snelheid van de technische ontwikkelingen ligt hoger dan die van de ethische discussie.
De burger is onwetend; laat zogenaamd vrijwillig overal sporen achter, maar hoe vrijwillig is dat? Er wordt nog onvoldoende expliciet aan de burger verteld wat er met hun gegevens kan worden gedaan en al wordt gedaan.
59

6.3.3 Juridische bezwarenHet is dus duidelijk geworden dat een voorspelling doen aan de hand van Big Data een complex proces is, waar specifieke kennis voor nodig is om dat te kunnen uitvoeren. Wat ook duidelijk is geworden, is dat wanneer je eenmaal een voorspelling kunt doen, de rechtvaardigheidsvragen minstens zo complex zijn. In deze paragraaf komen de resultaten over nóg een vraagstuk aan bod; de rechtmatigheid. Mag je alle gegevens zomaar gebruiken om een voorspelling te doen en wat mag je vervolgens met die resultaten? Wat zegt de wet- en regelgeving hierover?
Het antwoord dat de respondenten daarop geven is: nee. Je mag niet zomaar alle gegevens gebruiken. Verschillende respondenten hebben aangegeven dat je niet met een soort sleepnet door het internet mag gaan om data te verzamelen. En er staat bij de overheid ook geen supercomputer waarin willekeurige gegevens gestopt worden, waaruit na een bepaalde tijd allerlei verbanden, patronen en verdachte personen naar boven komen. “Eén van de dingen die de politie moet doen natuurlijk, is het handhaven van de wet, maar dat betekent dat ze zelf de wet moet volgen. En met name de privacywetgeving”. Hiermee doelt de respondent op de Wet politiegegevens (Wpg). Deze wet is in het leven geroepen om de balans te bewaren, zoals is weergegeven in figuur 4 op pagina 23. Dit figuur geeft de balans weer tussen effectieve en efficiënte uitvoering van politietaken enerzijds en de privacy van burgers anderzijds (Schel, et al. 2013).
Bijna alle respondenten refereren ook aan deze wetgeving. Het merendeel van de respondenten is het met elkaar eens wanneer zij het hebben over deze kaders bij het verzamelen van gegevens voor het voorspellen. Respondenten belichten 3 belangrijke aspecten: bescherming van de burger, toetsing door rechterlijke macht aan de (privacy)wetgeving en de legitimiteit van de bewijslast:
“die kaders zijn er natuurlijk niet zomaar, zoals ik net al zei, wij zijn er om de burger te beschermen”.
“Je hebt er niks aan om gegevens zonder toestemming binnen te halen en later gaat er een zaak door naar de bliksem”.
“ik denk dat als het niet meer toetsbaar wordt waarom jij bent opgepakt; omdat er ergens iemand is die alles bij elkaar gegooid heeft en heeft gezegd: ik vind wel dat jij een grote boef bent, of dat jij gedrag gaat vertonen waarvan wij denken dat dat niet goed is. Dat is dan een politiestaat”.
Duidelijk is dat de Wet aangeeft dat je niet zomaar allerlei informatie kunt verzamelen. Je moet een duidelijk doel hebben waarvoor je bepaalde gegevens wilt gebruiken. Wanneer je gegevens wilt delen, zowel incidenteel als structureel, moet hier toestemming voor zijn van een bevoegd gezag, bijvoorbeeld een Officier van Justitie. Voor wetenschappelijk onderzoek en statistiek moeten gegevens geanonimiseerd worden. Ook de bewaartermijn van de gegevens verschilt per doel waarvoor je het wilt gebruiken. Dat zijn enkele voorwaarden waaraan je moet voldoen wanneer je gegevens wilt opslaan en gebruiken. Deze staan ook zo vernoemd in de Wet politiegegevens (Overheid.nl, 2015a).
Zoals al eerder bekend is geworden, worden er bij het CAS-model vooral politiegegevens gebruikt. Eén van de respondenten geeft aan dat die gegevens tot op zekere hoogte gewoon gebruikt mogen worden in het CAS-model, mits het conform de Wet politiegegevens is. Moet er toch buiten die wet getreden worden om de exercitie uit te voeren, dan kan dat alleen met toestemming. De externe bronnen die gebruikt worden zijn geanonimiseerd; die gegevens zijn niet
60

herleidbaar tot specifieke personen. Daarmee geeft de respondent aan dat de privacy van personen dus niet in het geding komt.
61

Deze wettelijke kaders worden echter niet alleen als positief ervaren. De (huidige) Wpg zorgt ook voor belemmeringen bij een effectieve en efficiënte uitvoering van politietaken, in de beleving van meerdere respondenten.
Zo staan er dingen in de Wet die ruimte bieden voor eigen interpretatie, bijvoorbeeld over de omgang met internetgegevens. Eén van de respondenten zei hier het volgende over: “wetgeving heeft geen rekening gehouden met internet. Wel met de digitalisering, maar niet met internet. Wat kunnen we nou met internetdata? Daar zijn ook weer discussies over. Wat is wel of niet wenselijk, daar heeft ook iedereen weer een eigen mening over. Dat staat dus ook niet ergens vast, maar dat is een grijs gebied”. Net zoals bij de rechtvaardigheidsvragen blijkt er dus ook een grijs gebied te bestaan rondom wat wel of niet mag met internetgegevens. Een andere respondent heeft daar ook een uitspraak over gedaan: “er zijn mensen die zeggen: volgens mij mag het niet, want het staat niet in de Wet dat het mag. Aan de andere kant zijn er mensen die zeggen, het staat nergens dus het mag natuurlijk. En beide stromingen zie je ook bij de politie”.
Een ander belangrijk dilemma waar tegenaan gelopen wordt, zijn de beperkingen die de wetgeving met zich mee brengt voor de politie omtrent het Big Data gebruik. Dit wordt door verschillende respondenten als dilemma genoemd wanneer dit wordt gezet tegenover de mogelijkheden die commerciële instanties hebben. Niet alleen bedrijven zoals Google en Facebook, maar ook bijvoorbeeld privédetectives en recherchebureaus. Hieronder zijn een aantal uitspraken van respondenten weergegeven die hierop ingaan:
“Wij in ons vakgebied moeten overal toestemming voor vragen omtrent de privacy wetgeving. En daar is denk ik heel veel winst te behalen. En daar schieten wij als Nederland soms in door, vind ik”.
“Wij mogen niet zomaar dingen doen omdat er uiteindelijk een rechter gaat zeggen: hoe heb je dit dan verkregen? En als je dat niet netjes gedaan hebt, zorgt dat ervoor dat hij die persoon niet kan veroordelen. Daar hoeft een privédetective geen rekening mee te houden”.
“De belemmering is dat je voortdurend en altijd de afweging moet maken tussen het belang van de maatschappij en het belang van de verdachte. En dat is ook weer iets waarover je een discussie kunt voeren”.
“Bijvoorbeeld wanneer je een groot bedrijf hebt als Price Waterhouse Coopers, dat veel screenings moet gaan doen. Nou, Coosto (bedrijf dat zo veel mogelijk gegevens verzamelt op internet, red.) kan hun zo de benodigde gegevens verkopen. Zij hoeven ook niet met bewijzen of zo te komen, er komt geen advocaat aan te pas. En bij ons wel”.
“Het grootste probleem is dat dezelfde data worden verzameld door databrokers en deels verkopen deze databrokers de informatie ook aan het veiligheidsdomein. Dat betekent dat de private sector net zo veel, en zelfs meer informatie over ons heeft dan de publieke sector. En het probleem daarbij is dat de overheid onder vele controles zit en de private sector heeft deze controles niet. Dat is een van de problemen die ik zie”.
Er zijn twee respondenten die stellen dat overheid zelf helemaal geen externe data moet proberen te verzamelen. De ene zegt hierover: “Als ik de overheid zou zijn, dan zou ik zelf geen data van mensen die niet verdacht zijn verzamelen, met uitzondering dus van verdachte personen en waar ik dat wettelijk ook mag. In alle andere gevallen ga ik gewoon data inkopen uit de private sector. Dus van
62

mensen die mogelijk verdacht kunnen zijn. Dan ga ik naar de Googles en Facebooks toe en ga ik zeggen: ik wil alle informatie hebben over deze persoon”.
63

De ander kiest voor een andere benadering. Die pleit voor een soort donorregistratie maar dan met data. Dus een grote databank waarin gegevens staan van mensen die daar toestemming voor gegeven hebben: “Ik pleit ook vaak voor een soort donorregistratie, laten we nou eens aan Nederland vragen wat zij vinden dat er met hun data mag gebeuren”.
Maar of je die gegevens nou inkoopt of uit een landelijk database haalt maakt geen verschil, gegevens die de politie wil gebruiken vallen onder de Wpg.Daarnaast zijn er dilemma’s rondom de bewaartermijnen van gegevens. Wanneer bepaalde externe gegevens in politiebestanden komen te staan, vallen deze dus ook onder de wettelijke bewaartermijnen van de Wpg. Twee van de respondenten geven aan dat dit een goede opsporing in de weg kan staan:
“ik zou wel eens willen weten, zijn er criminele samenwerkingsverbanden die wij gemist hebben op basis van onze eigen data? We mogen namelijk maar 1 jaar terug kijken, tenzij je heel goed de doelstelling formuleert, dan mag je 5 jaar terugkijken”.
“Op dat moment zijn dat ook politiegegevens omdat ik ze met een politiedoel heb verzameld. Dus ook daarvan zal ik na maximaal 5 jaar de boel moeten wissen van de harde schijven ook al staat het nog op Facebook”.
Tenslotte een voorbeeld uit de actualiteit. Onlangs is ook de bewaarplicht opgeheven voor telecomgegevens. De kortgedingrechter in Den Haag vindt dat de Wet bewaarplicht telecommunicatiegegevens inbreuk maakt op het recht op eerbiediging van privéleven en de bescherming van persoonsgegevens (Rechtspraak.nl, 2015). Het afschaffen van de bewaarplicht heeft geleid tot “ernstige belemmeringen” in de opsporing van criminelen, aldus de Minister Veiligheid & Justitie Ard van der Steur in een brief naar de Tweede Kamer (van der Steur, 2015).
6.3.4 Deelconclusies ethische en juridische bezwarenTechnisch gezien is er met Big Data heel veel mogelijk, maar de vraag is volgens de respondenten moeten we dat ook willen? Bij het voorspellen van potentiële verdachten van misdaden zijn de gevolgen van foutieve voorspellingen groot en bovendien zit je diep in de persoonlijke levenssfeer. Het heeft ook raakvlakken met het vraagstuk rondom de verantwoordelijkheidsverdeling. Hierbij gaat het over de balans vrijwillig/verplicht bij bijvoorbeeld het accepteren van begeleiding en de rol van de staat in de bescherming van de maatschappij ten opzichte van de vrijheid van het individu. De bezwaren spelen overigens meer waar het gaat over het voorspellen van potentiële verdachten, dan waar het gaat om het voorspellen van mogelijke misdaden als woninginbraak.
Ook ziet men het bezwaar van een overheid die allerlei privégegevens van mensen gebruikt waarmee een beeld ontstaat van een Orwelliaanse samenleving. Dit kan leiden tot een vertrouwensbreuk tussen de overheid en haar burgers (sociaal contract). De burger laat zogenaamd vrijwillig overal sporen achter, maar hoe vrijwillig is dat? De burger is onwetend over wat er met die gegevens mogelijk is en wordt gedaan.
Een tweede aspect dat genoemd wordt, is de complexiteit van de materie in relatie tot onvoldoende kennis in de organisatie. Dit wordt als een risicofactor beschouwd. Mensen met kennis van Big Data zijn schaars en de markt is bereid
64

om veel te betalen voor deze kennis. Dit zou de overheid op achterstand kunnen plaatsen.
65

Bij juridische bezwaren geeft het merendeel van de respondenten aan, dat het goed is dat er binnen de wettelijke kaders gewerkt moet worden. Het voorkomt dat men doorslaat in het verzamelen van gegevens en het respecteert op deze manier de privacy van betrokkenen. Er worden echter ook belemmeringen ondervonden. Er wordt zoveel gewicht aan de kant van de privacybescherming gelegd (bewaartermijn/bewaarplicht), dat dit ten koste gaat van een efficiënte en effectieve uitvoering van de politietaken. De wetgeving loopt doorgaans achter de maatschappelijke ontwikkelingen aan, dit geldt in het bijzonder bij een terrein als Big Data waar de ontwikkelingen zo snel gaan. Ook noemt men het risico van 'de glijdende schaal': een eerste stap kan leiden tot vervolgstappen waarbij grenzen vervagen (proportionaliteit).
Er vindt wel de nodige discussie plaats over de ethische en juridische bezwaren van het gebruik Big Data bij het voorspellen van (potentiële verdachten van) misdaden.
6.4 ValkuilenOp welke wijze wordt er rekening gehouden met mogelijke valkuilen in relatie tot het gebruik van Big Data bij het voorspellen van (potentiële verdacht van) misdaden?
In deze paragraaf komen de resultaten omtrent valkuilen in relatie tot Big Data gebruik bij voorspelmodellen aan bod. De gepresenteerde resultaten zijn op basis van uitspraken van de respondenten. Er wordt daarbij een driedeling gemaakt:
cognitiefouten (zoals confirmation bias); interpretatiefouten (correlatie ≠ causaliteit en spurious correlations); systeemfouten (function creep).
Confirmation bias is een soort selectief denken, waarbij men de neiging heeft enerzijds te letten op, en te zoeken naar, wat de eigen overtuiging bevestigt en anderzijds te negeren, niet zoeken naar of onderwaarderen van de relevantie van wat de eigen overtuiging tegenspreekt (Gilovich, 1993). Een veel gemaakte interpretatiefout is dat een correlatie (er is een verband) wordt verward met causaliteit: oorzaak-gevolg relatie. Spurious correlations verwijst naar een ‘valse’ correlatie: de zogenaamde correlatie berust op louter toeval, zie het margarine voorbeeld op pagina 25.
Van function creep wordt niet alleen gesproken wanneer systeem A op een later tijdsstip wordt verbonden met systemen B en C die een andere functie hebben. Het is ook het proces waarbij digitale data die in eerste instantie functie X hebben, na verloop van tijd ook voor functie Y of zelfs Z worden gebruikt. Het meest bekende en besproken voorbeeld in ons land van function creep is de toepassing van biometrie (vingerafdruk) op het paspoort (Prins, 2011, p. 9-13).
Bij de vragen over dit onderwerp viel op dat alle respondenten meer moeite hadden om voorbeelden uit de praktijk te noemen dan bij de andere onderwerpen. Dit kan te maken hebben met de onbekendheid met de termen, maar kan ook aangeven dat dit in mindere mate onderwerp is van discussie. Na de uitleg van de begrippen (confirmation bias en function creep) kwamen er wel meer relevante reacties.
66

6.4.1 Confirmation biasWat opviel is dat bijna alle respondenten confirmation bias uiteindelijk invulden als tunnelvisie. Tunnelvisie heeft wel raakvlakken met confirmation bias; confirmation bias kan leiden tot tunnelvisie (Rassin, 2007). Confirmation bias is een onbewust proces van ieder mens in iedere situatie (Dobelli, 2013).
Het is als mens heel lastig om te kunnen doorgronden waarom er een bepaald resultaat verschijnt uit een voorspelmodel. Omdat met name de weg naar de uitkomsten niet goed begrepen kan worden is het heel lastig om daar tegenargumenten bij te bedenken (disconfirming evidence). Dat laatste zijn alle respondenten met elkaar eens. Eén van de respondenten verwoordde het als volgt: “Maar zou je dan ook kunnen zeggen dat, als je standaard gebruik maakt van een algoritme, dat je automatisch een soort van confirmation bias hebt? Want het algoritme verandert niet”. Daarmee wordt er gezegd dat een systeem altijd op zoek gaat naar dezelfde soort verbanden. Een systeem kijkt dus niet zelf kritisch naar zijn eigen algoritmen.
Een andere respondent geeft aan dat confirmation bias steeds prominenter wordt: “het gaat wel steeds meer een rol spelen, maar dan alleen bij volumedelicten. Inbraken, mishandelingen, huiselijk geweld, alles dat veel volume heeft”.
In een ander geval, bijvoorbeeld bij de opsporing van fraude, wordt er volgens een respondent niet altijd even goed gekeken naar het verhaal achter de fraude. Er wordt dan louter gezocht naar nog meer informatie die de fraude zou kunnen bevestigen. “je moet die mensen wel weer op de rit helpen. Dan moet dus voorkomen worden dat de denkfout wordt gemaakt dat je alleen nog maar gaat zoeken naar fraude, fraude en nog meer bewijzen…, …als jij een keer gejat hebt, dan betekent dat nog niet dat jij altijd een dief bent. Maar je krijgt dan wel het stempel opgedrukt dat je een dief bent. En daarvoor moet je waken, en zeker bij de politie".
De reacties geven aan dat confirmation bias vooral een rol speelt bij het voorspellen van potentiële verdachten van misdaden.
Dat confirmation bias een belangrijk onderwerp is in de Big Data wereld blijkt uit het onderzoeksrapport RECOBIA van de Community Research and Delevopment Information Service van de Europese Commissie (2015). Daaruit blijkt dat cognitieve biases een cruciale rol spelen in het werk van de inlichtingendiensten. De vraag die wordt gesteld is: hoe kan een intelligence analist een betrouwbaar rapport overhandigen aan de politieke beslissers zonder expliciet rekening te houden met confirmation bias? Volgens het onderzoek kan dat niet.
6.4.2 InterpretatiefoutenHoewel de vraagstelling open was, zijn interpretatiefouten zoals valse correlaties en het foutief duiden van een correlatie als een oorzaak-gevolg relatie niet expliciet aan de orde gekomen. Er is ook niet expliciet naar gevraagd.
Hoewel er niet expliciet naar gevraagd is, blijkt wel uit de interviews dat er veel wordt nagedacht over correlaties en causaliteit. Dit blijkt met name uit de antwoorden die gegeven zijn op de vragen op ethische bezwaren. Men realiseert zich dat foute voorspellingen en interpretatiefouten grote gevolgen kunnen hebben.
Een respondent snijdt ook nog een ander probleem aan rondom causaliteit: “Wij gaan dus proberen de voorspelling te laten falen. Dat is ook heel erg
67

ingewikkeld in de communicatie met de mensen die er uiteindelijk iets mee moeten. Die zeggen, ja maar dat klopt niet. Want als ik er ben dan gebeurt het niet. En dat is ook als we uiteindelijk iemand gaan helpen en een begeleidingstraject gaan aanbieden ,en hij wordt uiteindelijk niet crimineel, dan zeggen ze, zie je nou wel hij is niet crimineel geworden en dat hebben jullie wél voorspeld”.
Er wordt niet gezien dat een bepaald resultaat mogelijk door een voorspelling komt. 6.4.3 Function creepFunction creep is iets dat makkelijker te duiden was voor de respondenten; overigens vaak pas na uitleg van het begrip. Dat wil niet zeggen dat er geen interessante resultaten uit naar voren zijn gekomen.
Hieronder zijn een aantal quotes weergegeven, waaruit blijkt dat function creep aanwezig is in relatie tot Big Data gebruik bij voorspellingen:
“Eigenlijk is in wezen alle informatie die wij van onze partners gebruiken, een vorm van function creep. Bijvoorbeeld belastingaangiftes zijn voor de belasting, maar als de politie ze krijgt gebruiken ze die ook voor criminaliteitsbestrijding…, …en daar wordt natuurlijk nooit rekening mee gehouden.”
“Het enige wat ik kan bedenken is dat je bijvoorbeeld kentekendata voor andere doeleinden gaat gebruiken. En die gaan we koppelen met alle bekeuringen en volgens ga je kijken of je bijvoorbeeld fraude hebt. Maar volgens mij gebeurt dat niet.”
“Het doel van een aangifte is om kennis te nemen van het strafbare feit, zodat wij opsporing kunnen verrichten. Het is niet om te voorspellen waar criminaliteit gaat plaatsvinden. Dus die function creep, die zit er in die zin in”.
De één lijkt dus te zeggen dat alle informatie die gebruikt wordt voor voorspellingen onderhevig is aan function creep. Er zijn geen data opgeslagen met het doel om voorspellingen rond misdaad te doen.
De ander zegt dat alleen het gebruik van externe data function creep is, omdat bijvoorbeeld belastinggegevens niet opgeslagen zijn voor politiedoeleinden. Andere respondenten hebben geen voorbeelden genoemd of aanwijzingen kunnen geven dat function creep een rol speelt bij het gebruik van Big Data.
6.4.4 Voorkomen en tegengaan van valkuilenIn de vorige deelparagrafen is weergegeven hoe er door de respondenten gedacht wordt over de mogelijke valkuilen in relatie tot Big Data gebruik bij voorspellingen. Hieronder wordt ingegaan op de vragen hoe dit is te voorkomen of kan worden tegengegaan.
Confirmation bias en interpretatiefoutenEen veel voorkomende uitspraak is, dat er altijd een soort van menselijke factor in het beslissingsproces moet zitten. De mens kan nooit helemaal vervangen worden door een systeem dat op basis van dezelfde algoritmen voorspellingen doet. Het moet ter ondersteuning zijn en de mens moet de beslissende factor zijn. Respondenten verwoordden dat op verschillende manieren:
“ik denk dat met de huidige stand van de technologie er altijd een soort menselijke maat moet zijn om beslissingen op te baseren. Dat is ook met
68

dat geografische voorspellingssysteem, je moet niet gewoon blind ergens naar toe gaan”.
“Meestal is Big Data nog alleen sturingsinformatie om ergens te komen en ga je vervolgens kijken hoe je de zaak dicht krijgt en of de informatie en de manier waarop je alles aan elkaar linkt wel klopt. En om de zaak dicht te krijgen worden de klassieke methoden gebruikt zoals verhoor tot aan DNA aan toe”.
“Het onderbuik gevoel van een agent is op zoveel dingen gebaseerd, dat zo’n systeem niet eens de kans heeft om een poging te doen om dat beter te krijgen”.
69

“De mens ‘in het oog houden’ is nu super cruciaal. Tot aan het punt waarbij we ‘singularity’ bereikt hebben. Bij singularity gaat het erover dat alle kennis uit de hele mensheid opgeslagen is in digitale data. Kijk als we daar zijn (de voorspelling is 2045), dan kan je je afvragen wat mensen nog toevoegen. De mens voegt dan nog steeds wel wat toe met bijvoorbeeld creativiteit of emotie, maar niet meer met kennis”.
Een andere vorm van de menselijke factor is het organiseren van tegenspraak. Dat kan goed werken om confirmation bias te voor komen. Dit kwam terug in meerdere reacties. Een van de respondenten verwoordde dit krachtig: “Er wordt echt tegenspraak georganiseerd. Er wordt dan iemand aangewezen die alleen maar bij alles wat er gezegd wordt twijfel moet zaaien. Het is geen dankbare taak om dat te doen, maar ik denk wel heel erg zinnig”. Een andere respondent voegde hier aan toe dat ook het doen van navraag belangrijk kan zijn voor het voorkomen van confirmation bias. Misschien heeft iemand wel iets anders bedoeld met de informatie of is de situatie inmiddels veranderd. Een bekende inbreker kan inmiddels vast zitten of mee doen aan een verbetertraject.
Drie quotes ter illustratie: “Een voorbeeld is dat je navraag doet bij bijvoorbeeld de wijkagent, of een
analist, of de lokale informatie specialist vraagt. Verschillende mensen die er op een andere manier naar kunnen kijken”.
“om een beetje die confirmation bias eruit te halen, moet je toch echt wel even gaan kijken, als de wijkagent zegt dat het juist in een andere wijk heel mis gaat. Waarom zegt het systeem dit en de wijkagent dat, misschien heeft hij ook wel gelijk. Dan moeten we het systeem dus even laten voor wat het is en moeten we daar naar toe. En dat is prima, maar dan ga er ook tenminste een gefundeerde discussie over aan”.
“Bij groot recherche onderzoek hebben ze nu altijd tegensprekers, die kijken naar waar men de mist in is gegaan. Dat zou ook hierbij kunnen. Big Data teams opzetten en mensen langs laten komen die controleren of het wel mag wat er gebeurt. Zodat je dan van te voren al tegengas krijgt”.
Dit laatste voorbeeld kan ook een bijdrage leveren om in zekere mate rekening te houden met interpretatiefouten. Wanneer er navraag wordt gedaan wordt de kans verkleind dat bepaalde data gebruikt worden die (wellicht) met een andere intentie in de systemen zijn gezet.
Tenslotte denkt men dat het goed is om rekening te houden met verschillende expertises en achtergronden bij de samenstelling van teams die bezig zijn met voorspelmodellen en Big Data. Eén van de respondenten zei hier het volgende over: “ik denk dat het wel handig is om te zorgen dat je een heterogeen team hebt met mensen die elkaar alert houden. Anders sla je door en zeg je bij alle gegevens: geef maar”.
70

Function creepWat opvallend is bij function creep, is dat de respondenten dat in hun uitlatingen niet als iets negatiefs zien: “deze data kan ik nuttiger gebruiken of kan ik beter benutten door het ook nog voor een andere toepassing te gebruiken”.
Eén van de respondenten wees op het voorbeeld van ‘spookvoertuigen’ dat ook in de media is verschenen (Sprinkelkamp, 2008). Samengevat komt het neer op: afdeling parkeerbeheer van de dienst Toezicht rijdt door heel Amsterdam heen en scant de kentekens van alle auto’s om te kijken of ze wel of niet betaald hebben. Het interessante is dat zij ook gestolen auto’s tegen komen, maar hier pas achter komen bij het uitschrijven van de bon, 3 weken later. “Dan zijn we drie weken verder en de gestolen auto staat natuurlijk helemaal niet meer op die plek. Eigenlijk is dat heel raar, dat wij als overheid zeggen: nou ja, dat is dan maar zo. Het is veel logischer als we zeggen: ja, het is een gestolen auto. Dat betekent dat de doelstelling voor die gegevens van parkeerbeheer uitgebreid moet worden, wil je ook wat kunnen doen met die gestolen auto’s. Die aanvraag is naar de Privacycommissie gegaan en er is goedkeuring gegeven. Het is natuurlijk function creep alleen je maakt wel transparant en inzichtelijk dat je dat er ook mee gaat doen. Je ontbindt eigenlijk de function creep”.
6.4.5 Deelconclusies valkuilen en het voorkomen of tegengaan daarvanBij confirmation bias en interpretatiefouten lijk de menselijke factor het ‘keyword’ te zijn:
Er moet niet blind uitgegaan worden van wat een systeem zegt, door combinatie van klassieke methodes en nieuwe methodes aan te houden;
Rekening houden met onderbuikgevoel en ervaring van de agent op straat, deze is niet te vervangen door een systeem;
Om kritisch te blijven moet er tegenspraak georganiseerd worden (disconfirming evidence);
Verschillende expertises betrekken bij het voorspelproces en de uitkomsten;
Om na te gaan over hoe ‘zuiver’ de gegevens zijn die men wil gebruiken kan er navraag gedaan worden.
Function creep wordt niet gezien als iets negatiefs; het is inherent aan het gebruik van Big Data. Waar nodig wordt toestemming gevraagd om de desbetreffende gegevens te mogen gebruiken. Als toestemming wordt gegeven is er in feite geen sprake meer van function creep.
Tenslotte geeft het onderzoeksrapport RECOBIA van de Community Research and Delevopment Information Service van de Europese Commissie (2015) aan, dat je niet kunt spreken van een betrouwbaar rapport bij Intelligence Analysis (dus ook niet bij intelligencegestuurd politiewerk) wanneer er niet expliciet rekening is gehouden met confirmation bias.
71

H7 conclusiesIn dit hoofdstuk worden de conclusies gepresenteerd. Op basis van de beantwoording van de deelvragen in het vorige hoofdstuk kan er antwoord worden gegeven op de hoofdvraag. De antwoorden op de eerste deelvraag geven vooral een beeld van de voordelen. De nadelen zijn bij de tweede deelvraag naar voren gekomen. De laatste deelvraag geeft zicht op de mogelijke valkuilen omtrent het gebruik van Big Data bij het voorspellen van (potentiële verdachten van) misdaden.
7.1 Beantwoording hoofdvraagWat zijn de voor- en nadelen van Big Data gebruik bij het voorspellen van (potentiële verdachten van) misdaden?
Het begrip Big Data wordt in voldoende mate herkend. Er zijn ruime overeenkomsten tussen wat er in de theorie wordt bedoeld met Big Data (7 V’s) en wat de respondenten hieronder verstaan. Naast 7 V’s gaat het ook om slimme combinaties van databestanden waarbij de focus niet ligt op individuen. Tegelijkertijd geeft men aan dat de huidige door hen beschreven pratijk nog niet echt Big Data gebruik is. Zo wordt er vooral gebruik gemaakt van data uit eigen databestanden en worden er voorzichtig koppelingen met andere (externe) databestanden uitgeprobeerd.
7.1.1 VoordelenBig Data kan worden ingezet voor zowel het voorspellen van misdaden, als voor het voorspellen van potentiële verdachten van misdaden (Predictive Policing). Het benutten van Big Data voor voorspellingen is een nieuwe stap binnen het intelligencegestuurd politiewerk. Als het lukt om tot goede voorspellingen te komen, kan niet alleen de politie efficiënter en effectiever ingezet worden, maar kunnen ook acties ingezet worden die leiden tot het voorkomen van misdrijven. Dit kan veel persoonlijk leed en maatschappelijke schade voorkomen. Het is uiteraard wel de kunst om te komen tot juiste voorspellingen. Dat is nog geen eenvoudige opgave.
Uit het onderzoek komt naar voren dat er in de praktijk verschillende modellen zijn ontwikkeld, of nog in ontwikkeling zijn, waarbij aan de hand van Big Data voorspellingen gedaan worden. De geïnterviewde noemen Criminaliteits Anticipatie Systeem (CAS) als voorbeeld waarbij Big Data wordt gebruikt bij het voorspellen van misdaden. Daarnaast is er nog een verzekeringsmaatschappij bezig met het ontwikkelen van een geografisch voorspelmodel van woninginbraken. Waar het gaat over het voorspellen van potentiële verdachten van misdaden worden Top600 en Prokid-plus genoemd.
Voorspellen van misdadenCriminaliteits Anticipatie Systeem (CAS) is een systeem waarbij de politie zich richt op locaties met een verhoogd risico. CAS biedt uitkomst wanneer de focus ligt op grote gebieden. Zo kan op basis van een geografische voorspelling effectief en efficiënt omgegaan worden met de politiecapaciteit.
Naast de politie is er ook een verzekeringsmaatschappij bezig met de ontwikkeling van een model om woninginbraken te voorspellen. Ook hier gaat het om een model om gebieden te voorspellen waar de kans op een woninginbraak
72

groter is dan in andere gebieden. Zodat zij hun klanten kunnen informeren over wat zij kunnen doen om woninginbraken te voorkomen.
73

Voorspellen van potentiële verdachten van misdadenTop600 is lijst die wordt opgesteld door de politie waarop de 600 meest criminele personen staan van Amsterdam. Deze personen worden geselecteerd op basis van de overeenkomst met vooraf bepaalde indicatoren. Het voordeel is dat de politie deze 600 grootste criminelen beter in gaten kan houden.
Naast het opstellen van deze Top600 lijst wordt er nog een ander systeem ontwikkeld, Prokid-plus. Dat systeem kijkt namelijk naar de omgeving van die 600 criminelen. Bij aan die criminelen relateerde personen wordt er gekeken of zij begeleiding aangeboden kunnen krijgen om te voorkomen dat zij diezelfde kant op gaan als de crimineel.
Te constateren valt dat CAS en de Top600-Aanpak al in de uitvoeringsfase zitten, en dat Prokid-plus en het voorspelmodel van de verzekeringsmaatschappij nog in een meer experimentele fase verkeren.
7.1.2 NadelenTechnisch gezien is er met Big Data heel veel mogelijk, maar de vraag is volgens de respondenten moeten we dat ook willen? Bij het voorspellen van potentiële verdachten van misdaden zijn de gevolgen van foutieve voorspellingen groot en bovendien zit je diep in de persoonlijke levenssfeer. Het heeft ook raakvlakken met het vraagstuk rondom de verantwoordelijkheidsverdeling. Hierbij gaat het over de balans vrijwillig/verplicht en de rol van de staat in de bescherming van de maatschappij ten opzichte van de vrijheid van het individu. De bezwaren spelen overigens meer waar het gaat over het voorspellen van potentiële verdachten, dan waar het gaat om het voorspellen van mogelijke misdaden als woninginbraak.
Ook ziet men het bezwaar van een overheid die allerlei privégegevens van mensen gebruikt waarmee een beeld ontstaat van een Orwelliaanse samenleving. Dit kan leiden tot een vertrouwensbreuk tussen de overheid en haar burgers (sociaal contract). De burger laat zogenaamd vrijwillig overal sporen achter, maar hoe vrijwillig is dat? De burger is onwetend over wat er met die gegevens mogelijk is en wordt gedaan.
Een tweede aspect dat genoemd wordt, is de complexiteit van de materie in relatie tot onvoldoende kennis in de organisatie. Dit wordt als een risicofactor beschouwd. Mensen met kennis van Big Data zijn schaars en de markt is bereid om veel te betalen voor deze kennis. Dit zou de overheid op achterstand kunnen plaatsen.
Bij juridische bezwaren geeft het merendeel van de respondenten aan, dat het goed is dat er binnen de wettelijke kaders gewerkt moet worden. Het voorkomt dat men doorslaat in het verzamelen van gegevens en het respecteert op deze manier de privacy van betrokkenen. Er worden echter ook belemmeringen ondervonden. Er wordt zoveel gewicht aan de kant van de privacybescherming gelegd (bewaartermijn/bewaarplicht), dat dit ten koste gaat van een efficiënte en effectieve uitvoering van de politietaken. De wetgeving loopt doorgaans achter de maatschappelijke ontwikkelingen aan, dit geldt in het bijzonder bij een terrein als Big Data waar de ontwikkelingen zo snel gaan. Ook noemt men het risico van 'de glijdende schaal': een eerste stap kan leiden tot vervolgstappen waarbij grenzen vervagen (proportionaliteit).
74

Er vindt wel de nodige discussie plaats over de ethische en juridische bezwaren van het gebruik Big Data bij het voorspellen van (potentiële verdachten van) misdaden.
75

7.1.3 Mogelijke valkuilenNaast de voor- en nadelen zijn er ook mogelijke valkuilen naar voren gekomen. De term valkuilen wordt in deze scriptie gebruikt als verzamelterm voor de cognitiefout confirmation bias; interpretatiefouten (correlatie ≠ causaliteit en spurious correlations) en de systeemfout function creep. Deze valkuilen kunnen zich makkelijk ontwikkelen tot nadelen wanneer deze niet worden voorkomen, of wanneer ze onvoldoende worden gecompenseerd.
Bij confirmation bias en interpretatiefouten lijk de menselijke factor het ‘keyword’ te zijn:
Er moet niet blind uitgegaan worden van wat een systeem zegt, door combinatie van klassieke methodes en nieuwe methodes aan te houden;
Rekening houden met onderbuikgevoel en ervaring van de agent op straat, deze is niet te vervangen door een systeem;
Om kritisch te blijven moet er tegenspraak georganiseerd worden (disconfirming evidence);
Verschillende expertises betrekken bij het voorspelproces en de uitkomsten;
Om na te gaan over hoe ‘zuiver’ de gegevens zijn die men wil gebruiken kan er navraag gedaan worden.
Het onderzoeksrapport RECOBIA van de Community Research and Delevopment Information Service van de Europese Commissie (2015) geeft aan, dat je niet kunt spreken van een betrouwbaar rapport bij Intelligence Analysis (dus ook niet bij intelligencegestuurd politiewerk) wanneer er niet expliciet rekening is gehouden met confirmation bias.
De respondenten geven aan dat zij function creep niet als iets negatiefs beschouwen; het is inherent aan het gebruik van Big Data. Waar nodig wordt toestemming gevraagd om de desbetreffende gegevens te mogen gebruiken. Als toestemming wordt gegeven is er in feite geen sprake meer van function creep.In de volgende paragraaf is opnieuw gekeken naar het onderzoeksmodel uit paragraaf 4.6. Na de resultaten en de conclusies kan het model verder worden uitgewerkt. Er is nu te zien welke preventie maatregelen er uit het onderzoek naar voren zijn gekomen en op welke manier deelvragen en de hoofdvraag beantwoord zijn.
76

7.1.4 Onderzoeksmodel
77

H8 Discussie en aanbevelingen Hoewel er in de commerciële sector vrij veel gebruik wordt gemaakt van Big Data analyses, is het gebruik van Big Data in de publieke sector is nog een tamelijk nieuw fenomeen. Er wordt nog weinig gebruik van gemaakt en zijn nog weinig mensen die er echt verstand van hebben. Dit betekent dat het best een zoektocht was om de juiste respondenten te vinden; mensen die iets zinnigs konden zeggen over Big Data in het veiligheidsdomein. Met name waar het gaat om het gebruik van Big Data bij het voorspellen van (potentiële verdachten van) misdaden.
De bevindingen in dit onderzoek zijn dan ook gebaseerd op de informatie van een beperkte groep mensen. Dit onderzoek geeft dus mogelijk niet het hele beeld van Big Data gebruik in Nederland bij het voorspellen van (mogelijke verdachten van) misdaden.
Het is bij dit onderwerp ook best lastig gebleken om dat wat er in de literatuur gevonden is te bespreken met de respondenten. Dat kwam vooral naar voren bij het bespreken bij de deelvraag rondom de valkuilen. De gebruikte begrippen (confirmation bias en function creep) werden als term niet direct herkend, maar in de loop van het interview bleek doorgaans wel dat men over deze materie nadenkt.
Het onderwerp, gebruiken van Big Data en de relatie met de privacy ligt erg gevoelig. Ondanks dat het een gevoelig onderwerp is heeft de meerderheid van de respondenten open gesproken over de mogelijkheden van Big Data. Wellicht omdat de huidige praktijk nog geen echte Big Data toepassing is. In de nu gebruikte modellen wordt voornamelijk gebruik gemaakt van de eigen data en een koppeling met data waar men relatief makkelijk bij kan (open data; gemeentelijke registers e.d.). Ook blijkt dat er bij die modellen nog sterk rekening wordt gehouden met de menselijke factor bij het maken van de uiteindelijke beslissing.
In de toekomst kan dit nog wel gaan veranderen. Binnen de overheid wordt bij de nationale diensten zoals de AIVD en MIVD al wel gespeurd op het internet naar verdachte uitspraken en situaties. Het is dus niet zo dat wanneer de respondenten uit de interviews zeggen dat de overheid dit niet doet, dat dat ook zo is of zo blijft. Wellicht gebeurt het nog niet bij de politie, maar de overheid is daar wel degelijk mee bezig. Het is in dit onderzoek alleen niet aangetoond op wat voor manier en in welke mate. Wel is aan de orde geweest dat je voor je het weet stap voor stap verder gaat -zeker als er steeds meer kan en er steeds meer gegevens zijn- en dat dan grenzen makkelijk kunnen vervagen. Daarom moet continu de discussie gevoerd blijven worden en niet alleen achter de schermen binnen de politie en de overheid, maar moet ook het publieke debat hierover gevoerd worden.
En dan niet alleen maar over privacy en de NSA, maar juist over de verschuiving van intelligence naar de politie. Hoe ver kan je gaan met het verzamelen van informatie over burgers? Bij een moord kan je nog wel een voorstelling maken dat het daarvoor Big Data wordt ingezet. Dat is een zwaar misdrijf, maar waar ligt die grens? En wat gebeurt er vervolgens met informatie die verzameld is, niet alleen over de moordenaar, maar ook over de vrienden en familie van die moordenaar? Die zijn wellicht compleet onschuldig, maar we hebben wel gegevens over hen verzameld. Het is belangrijk voor het draagvlak van de politie
78

dat de dialoog met de burgers -juist in die veranderende context met héél veel data op allerlei plaatsen- gevoerd wordt. Hoe doen we dat met die balans van vrijheid en verantwoordelijkheid, met die balans van privacy en effectieve inzet van de politie?
Veel mensen krijgen een diep gevoel van onbehagen als onbekenden toegang hebben tot hun privé-informatie. Dit gevoel van onbehagen staat wel in schril contrast met het gemak waarmee mensen hun persoonsgegevens (soms) weggegeven. Bewustwording lijkt hierbij het sleutelwoord.
8.1 Aanbevelingen Kennis over het gebruiken van Big Data is schaars. Er zijn nu twee soorten
kennisniveaus. Het kennisniveau van het puur bij elkaar zoeken van data en het bij elkaar voegen, en het kennisniveau om er echt informatie uit te halen. En de laatste soort is vele malen schaarser. De schaarse hoeveelheid kennis die er nu is, lekt snel weg naar de private sector, vooral omdat daar beter wordt betaald. Vooral bij de publieke sector moet hoger worden ingezet op het vergaren en verbeteren van kennis omtrent (het gebruik van) Big Data.
Onderzoeken of voorspellingen op basis van een voorspelmodel effectiever zijn dan voorspellingen op basis van expertise en ervaring, de menselijke interpretatie van gegevens.
Het geven van voorlichting en het voeren van een maatschappelijke discussie over de voor- en nadelen van Big Data gebruik door de politie om de burgers bewust te maken en draagvlak te creëren en te blijven houden.
Onderzoek naar de mogelijkheid van een nationale databank, waarbij de burger zelf aangeeft wat er met hun persoonlijke data wel of niet mag gebeuren. Laten we nou eens aan Nederland vragen wij zij vinden wat er met hun data mag gebeuren.
79

LiteratuurlijstAcquisti, A. en Grossklags, J. (2005). Privacy and Rationality in Individual Decision Making. IEEE Security and Privacy, vol. 3, nr. 1, pag. 26-33.Ainsworth, P.B. (2000). Psychology and Crime: myths and reality. Harlow: Longman.Alberdingk Thijm, C. (2002). ‘Het einde van spam? Regulering van ongevraagde e-mail’. In: Privacy en Informatie 2002/6, p. 250-259.Anderson, C. (2008). The End of Theory: The Data Deluge Makes the Scientific Method Obsolete. Binnengehaald op 18 maart 2015, van: http://www.wired.com/science/discoveries/magazine/16-07/pb_theory ANP. (2013). Politie mag kentekengegevens langer bewaren. Binnengehaald op 1 juni 2015, van: http://www.nu.nl/binnenland/3189634/politie-mag-kentekengegevens-langer-bewaren.htmlAvermaet, F. van (2009). De rol van Criminal Profiling bij het ophelderen van levens- en seksuele delicten. Betekent dit een meerwaarde? Binnengehaald op 27 februari 2015, van: http://lib.ugent.be/en/catalog/rug01:001392949?i=0enq=de+rol+van+criminal+profiling Bacon, F. (1597) Meditationes Sacræ, De Hæresibus. Uitgeverij onbekend.Beck, C. (2009). Predictive policing: What we can learn from Wal-Mart and Amazon about fighting crime in a recession? Binnengehaald op 20 februari 2015, van: http://www.policechiefmagazine.org/magazine/index.cfm?fuseaction=display_archenarticle_id=1942enissue_id=112009 Berlo, D. van en Meijer, A. (2013). ‘Big Data: Overheidsbeleid in de Gekende Samenleving’, Bestuurswetenschappen 5-6, p. 163-178.Bernasco, W. (2007) Is woninginbraak besmettelijk? In: Tijdschrift voor Criminologie 2007 (49) 2.Bijlsma, M., Straathof, B. en Zwart, G. (2014). Meer keuze voor burgers. Meer ruimte voor bedrijven. Den Haag: Centraal Planbureau.Bloem, J. Doorn, M. van, Duivestein, S., Manen, T. van en Ommeren, E. van (2012). Creating clarity with Big Data. Binnengehaald op 26 februari 2015, van: http://vint.sogeti.com/wp-content/uploads/2012/07/VINT-Sogeti-on-Big-Data-1-of-4-Creating-Clarity.pdf Boersma, J. (2007). Need for Nodes. Urgentie van een nodale virtuele oriëntatie voor de toekomst van de Nederlandse politie. Apeldoorn: Politieacademie.Böhre, V. (2010). Happy landings? Het biometrische paspoort als zwarte doos. WRR-Webpublicatie nr. 46. Binnengehaald op 24 maart 2015, van: http://www.wrr.nl/fileadmin/nl/publicaties/PDF-webpublicaties/Happy_Landings_.pdf Bongers, F., Jager, C. en Velde, R. te. (2015). Big Data in onderwijs en wetenschap. Inventarisatie en essays. Geraadpleegd op 29 juli 2015, van: http://www.rijksoverheid.nl/bestanden/documenten-en-publicaties/rapporten/2015/02/24/big-data-in-onderwijs-en-wetenschap-inventarisatie-en-essays/big-data-in-onderwijs-en-wetenschap-inventarisatie-en-essays.pdf Boon, F., Derix, S. en Modderkolk, H. (2013). Document Snowden: Nederland al
80

sinds1946 doelwit van NSA. Binnengehaald op 27 februari 2015, van: http://www.nrc.nl/nieuws/2013/11/23/nederland-sinds-1946-doelwit-van-nsa/ Boyd, D. en Crawford, K. (2011) Six Provocations for Big Data. A Decade in internet Time: Symposium on the Dynamics of the internet and Society. Binnengehaald op 18 maart 2015, van: http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1926431 Buskes, C. (2006). Evolutionair denken: de invloed van Darwin op ons wereldbeeld. Amsterdam: Nieuwezijds.Chisum, W.J. en Turvey, B. (2011) Crime Reconstruction. London: Academic Press.CSIAC. (2015). Cyber Profiling: Using Instant Messaging Author Writeprints for Cybercrime Investigations. Binnengehaald op 24 maart 2015, van: https://www.csiac.org/journal_article/cyber-profiling-using-instant-messaging-author-writeprints-cybercrime-investigations Cukier, K. en Mayer-Schonberger, V. (2013). De Big Data Revolutie: Hoe de data-explosie al onze vragen gaat beantwoorden. Amsterdam: Maven Publishing.Custers, B. (2004). The Power of Knowledge. Ethical, Legal, and Technological Aspects of Data Mining and Group Profiling in Epidemiology. Nijmegen, Wolf Legal Publishers.De Tré, G. (2007) Principes van databases. Benelux: Pearson Education.Devroe, E. en Vandevelde, L. (2005). Recherche justice 1995-2003. Gent: Academia.Dobelli, R. (2013). De kunst van het heldere denken. Amsterdam: De Bezige Bij.Doeleman, R. en Willems, D. (2014). Predictive Policing – wens of werkelijkheid? In: Tijdschrift voor de Politie – jrg. 76/nr.4/5/14, p 39. Donato, L. (2014). Profiling Cyber Offenders. Binnengehaald op 24 maart 2015, van: http://www.softbox.co.uk/blog/profiling-cyber-offenders/ Enschedé, J. (2008). Beginselen van strafrecht. Deventer: Kluwer.Europese Commissie. (2015). Periodic Report Summary 1. RECOBIA (Reduction of Cognitive BIAses in Intelligence Analysis). Binnengehaald op 2 juni 2015, van: http://cordis.europa.eu/result/rcn/143686_en.html Fasten, J. en Paans, R. (2011). De Wet Politiegegevens: Revival van het Bell-La Padula model. Binnengehaald op 28 mei 2015, van: http://www.norea.nl/readfile.aspx?ContentID=70947enObjectID=981356enType=1enFile=0000037124_De_Wet_Politiegegevens.pdf Friend, Z. (2013). Predictive policing: Using technology to reduce crime. Binnengehaald op 20 februari 2015, van: http://www.fbi.gov/stats-services/publications/law-enforcementbulletin/2013/April/predictive-policing-using-technology-to-reduce-crime Gielen, G. (2003). Onaantrekkelijkheid? Beeldvorming over het belang van fysieke aantrekkelijkheid. Antwerpen: Garant.Gilovich, T. (1993) Confirmation bias. Binnengehaald op 1 juni, 2015, van: http://nederlands.skepdic.com/dict_voorkbev.htm
81

Grauw, J.S., de (2014) Tijdruimtelijk voorspellen van criminele incidenten. Binnengehaald op 28 mei 2015, van: https://www.few.vu.nl/en/Images/stageverslag-graauw_tcm39414225.pdf Heck, W. (2014) Slimme camera spot afwijkend gedrag van reizigers op Schiphol. Binnengehaald op 23 april 2015, van: http://www.nrc.nl/nieuws/2014/09/11/slimme-camera-spot-afwijkend-gedrag-van-reizigers-op-schiphol/ Hert, P. de (2011). Veiligheid en grondrechten: het belang van een evenwichtige privacypolitiek. In: Muller, E.R. (red.) Veiligheid. Alphen aan den Rijn: Kluwer, p. 610-613. Heyning, N. en Suren, W. (2005) P2P Data mining. Binnengehaald op 18 maart 2015, van: http://staff.science.uva.nl/~bredeweg/pdf/BSc/20042005/HeijingSuren.pdf
Hildebrandt, M. en Gutwirth, S. (2008). Profiling the European Citizen. Cross-disciplinary Perspectives. Dordrecht: Springer.Ho, V. (2013). Why Small Data May Be Bigger Than Big Data. Binnengehaald op 27 februari 2015, van: http://www.inc.com/victor-ho/why-small-data-may-be-bigger-than-big-data.html Holmes, R. en Holmes, S. (2002). Profiling violent crimes: an investigative tool. California: Sage Publications.Jansen, K. (2006). Data mining: het belang van de onderliggende technieken. Binnengehaald op 18 maart 2015, van: http://www.sbit.nl/ego/bestanden/Data%20mining%20het%20belang%20van%20de%20onderliggende%20technieken.pdf Klerks, P. en Kop, S. (2009). Doctrine Intellegencegestuurd politiewerk. Apeldoorn: Politieacademie.Kocsis, R. N. (2006). Criminal profiling: principles and practice. New Jersey: Humana Press.Koffijberg, J., Dekkers, S., Homburg, G. en Berg, B. van den (2009). Regioplan: Niets te verbergen en toch bang. Nederlandse burgers over het gebruik van hun gegevens in de glazen samenleving. Binnengehaald op 18 maart 2015, van: http://www.cbpweb.nl/downloads_rapporten/rap_2009_niets_te_verbergen_en_toch_bang.pdf Koops, B.J. en Vedder, A. (2001). Opsporing versus privacy. De beleving van burgers. In: IteR-reeks deel 45. Den Haag: Sdu Uitgevers.Koppen, P.J. (2010). Reizen met mijn rechter: psychologie van het recht. Deventer, Kluwer.Laney, D. (2001) 3D Data Management: Controlling Data Volume, Velocity, and Variety. In: Application Delivery Strategies, File: 949. Binnengehaald op 5 juli 2015, van: http://blogs.gartner.com/doug-laney/files/2012/01/ad949-3D-Data-Management-Controlling-Data-Volume-Velocity-and-Variety.pdf Leukfeldt, E.R. en Stol, W. Ph. (2012). Cyber Safety: An Introduction. Den Haag: Eleven International Publishing.Lever, R. (2012). ‘Predictive policing’ takes bit out of crime. Binnengehaald op 20 februari 2015, van: http://www.smh.com.au/technology/sci-tech/predictive-
82

policing-takes-bite-out-of-crime-20120730-23bg6.html Levine, H.G. (2010) Targeting Blacks for Marijuana. Binnengehaald op 1 maart 2015, van: http://www.drugpolicy.org/docUploads/Targeting_Blacks_for_Marijuana_06_29_10.pdf Lodder, A.R., Meij, L., Meulen, N.S. van der, Wisman, T.H.A en Zwinkels, C.M.M. (2014). Big Data, Big Consequences? Een verkenning naar privacy en Big Data gebruik binnen de opsporing, vervolging en rechtspraak. Amsterdam: Vrije Universiteit, Faculteit Rechtsgeleerdheid, Afdeling Transnational Legal Studies.Lombroso, C. (1911). Criminal man. New York and London: The Knickerbocker Press. Lopez, M.J.J. (2000). De mogelijkheden van data mining voor de Nederlandse politie. Binnengehaald op 18 maart 2015, van: http://www.rcm-advies.nl/Publicaties/Misdaadanalyse/De%20mogelijkheden%20van%20data%20mining.doc Manovich, L. (2011). Trending: The Promises and the Challenges of Big Social Data. In: Debates in the Digital Humanities. Minneapolis, MN: The University of Minnesota Press.Manyika, J., Cui, M., Brown, B., Bughin, J., Dobbs, R., Roxburgh, C., et al (red.). (2011). Big Data: The next frontier for innovations, competition, and productivity. McKinsey Global Institute.Orwell, G. (1948). 1984. New York: Chelsea House Publishers.
Osseyran, A. en Vermeend, W. (2014) De Revolutie van Big Data. Een verkenning van de ingrijpende gevolgen. Den Haag: Einstein Books.Overheid.nl. (2015). Wet bescherming persoonsgegevens. Binnengehaald op 2 augustus 2015, van: http://wetten.overheid.nl/BWBR0011468/geldigheidsdatum_02-08-2015 Overheid.nl. (2015a). Wet politiegegevens. Binnengehaald op 2 augustus 2015, van: http://wetten.overheid.nl/BWBR0022463/geldigheidsdatum_04-07-2015 Pearsall, B. (2010) Predictive policing: The future of Law Enforcement. Binnengehaald op 28 mei 2015, van: http://www.nij.gov/journals/266/pages/predictive.aspx Perry, W. L., McInnis, B., Price, C. C., Smith, S. C., Hollywood, J. S. (2013) The role of crime forecasting in law enforcement operations. Binnengehaald op 28 mei, van: https://www.ncjrs.gov/pdffiles1/nij/grants/243830.pdfPolitie. (2015). Politietaken. Binnengehaald op 20 februari 2015, van: http://www.politie.nl/onderwerpen/politietaken.html Politieacademie. (2015) Casus Top600-aanpak in Amsterdam. Binnengehaald op 1 juni 2015, van: https://www.politieacademie.nl/onderwijs/overdescholen/spl/overdespl/Pages/Casus-Top-600-aanpak-in-Amsterdam.aspx PredPol. (2014). How PredPol works. Binnengehaald op 21 februari 2015, van: http://www.predpol.com/how-predpol-works/Preneel, B. (2015). Privacy: Ik heb niets te verbergen. Leuven: KU Leuven and iMinds.
83

Prins, J.E.J. (2011). Function creep: over het wegen van risico’s en kansen. In: Justitiële verkenningen, Function creep en privacy jrg. 37, nr. 8, 2011. Den Haag: Boom Juridische uitgevers.Privacy First. (2013). Iedere automobilist wordt potentiële verdachte. Binnengehaald op 23 april 2015, van: https://www.privacyfirst.nl/aandachtsvelden/cameratoezicht/item/615-iedere-automobilist-wordt-potentiele-verdachte.html Ramsland, K.M. (2011). De mind of a murderer: privileged access to the demons that drive extreme violence. California: Praeger.Rassin, E. (2007). Waarom ik altijd gelijk heb: Over tunnelvisie. Schiedam: Scriptum.Rijksoverheid. (2013). Wetsvoorstel over het vastleggen van kentekens naar Tweede Kamer. Binnengehaald op 23 april 2015, van: http://www.rijksoverheid.nl/ministeries/venj/nieuws/2013/02/12/wetsvoorstel-over-het-vastleggen-van-kentekens-naar-tweede-kamer.html Rousseau, J-J. (1762). Du contrat social ou Principes du droit politiquet. Amsterdam: onbekend.Russom, P. (2011). TDWI Best Practices Report: Big Data Analystics. Renton: TDWI Research.Savič, M. (2014). Digitized methods of policing. Presentatie Minor Cybersafety, Lecoraat Cybersafety NHL Leeuwarden, bijgewoond op: 24 november 2014.Schel, R., Sibma, A., Smits, J., Struiksma, N. en Roodnat, J. (2013) Samenvatting. Glazen privacy- knelpuntenonderzoek uitvoering Wet politiegegevens (Wpg). Binnengehaald op 28 mei 2015, van: https://www.wodc.nl/images/2236-samenvatting_tcm44-527013.pdf Schnitzler, H. (2015). Het digitale proletariaat. Amsterdam/Antwerpen: De Bezige Bij.Schreuders, E. (2010). Data mining, de toetsing van beslisregels en privacy. Een juridische Odyssee naar een procedure om het toepassen van beslisregels te kunnen toetsen. In: IteR-reeks deel 48. Den Haag: Sdu Uitgevers.
84

Schrijver, R. (2014). SyRi: burgers op grote schaal doorgelicht. Binnengehaald op 25 februari 2015, van: http://www.eenvandaag.nl/binnenland/54286/syri_burgers_op_grote_schaal_doorgelicht Sentient. (2015). DataDetective. Binnengehaald op 1 maart 2015, van: http://www.sentient.nl/?ddnl Sietsma, R. (2007). Gegevensverwerking in het kader van de opsporing. Den Haag: Sdu Uitgevers.Smart Vision Europe. (2013). Data Mining Phases. Binnengehaald op 23 maart 2015, van: http://crisp-dm.eu/reference-model/ Smilda, F. (2013). Predictive policing: Big Data en voorspellend politiewerk. Geraadpleegd op 21 februari 2015, van: http://socialmediadna.nl/predictive_policing/ Sprinkelkamp, C. (2008). Speurtocht naar spookvoertuigen. Binnengehaald op 2 augustus 2015, van: http://www.telegraaf.nl/autovisie/autovisie_nieuws/20621688/__Speurtocht_naar_spookvoertuigen__.html Steur, A. van der. (2015) Stand van zaken ten aanzien van buiten werking stelling bewaarplicht telecommunicatiegegevens. Binnengehaald op 2 augustus 2015, van: http://www.rijksoverheid.nl/bestanden/documenten-en-publicaties/kamerstukken/2015/07/22/tk-stand-van-zaken-ten-aanzien-van-buiten-werking-stelling-bewaarplicht-telecommunicatiegegevens/lp-v-j-0000008679.pdf Stillman, J. (2013). Baffled By Big Data? Use ‘Small’ Data Instead. Binnengehaald op 27 februari 2015, van: http://www.inc.com/jessica-stillman/baffled-by-big-data-just-use-data-instead.html Stoker, E. en Thijssen, W. (2015) Liquidaties door afschaffing bewaarplicht ‘onoplosbaar’. Binnengehaald op 1 mei 2015, van: http://www.volkskrant.nl/binnenland/liquidaties-door-afschaffing-bewaarplicht-onoplosbaar~a3992229/ Tallir, S. (2008). Data mining: zoeken naar impliciete informatie in databases. Binnengehaald op 18 maart 2015, van: http://tallir.com/2008/thesis/THESIS.HTM Turvey, B. (2001). Criminal profiling: an introduction to behavioral evidence analysis. London, Academic Press.tylervigen.com. (2015). Spurious Correlations. Binnengehaald op 2 augustus 2015, van: http://tylervigen.com/spurious-correlations Verhoeven, N. (2010). Wat is onderzoek? Den Haag: Boom onderwijs.Verhoeven, N. (2014). Wat is onderzoek? Den Haag: Boom Lemma uitgevers.Visser, J. (2013). “Predictive policing”: bij voorbaat verdacht. Binnengehaald op 1 maart 2015, van: http://www.doorbraak.eu/predictive-policing-bij-voorbaat-verdacht/ Wegge, F. (2010). Dataminingtechnieken voor peesletselpredictie. Binnengehaald op 23 maart 2015, van: http://lib.ugent.be/fulltxt/RUG01/001/418/599/RUG01-001418599_2010_0001_AC.pdf
85

Westin, A.F. (1967). Privacy and Freedom. New York: Atheneum.Wetboek online. (2015). Wetboek van Strafvordering, Artikel 27. Binnengehaald op 1 mei 2015, van: http://www.wetboek-online.nl/wet/Sv/27.html Witte, A. de (2008). De fietsenstalling editie 8.1. Binnengehaald op 18 maart 2015, van: http://www.schoolmaster.nl/Portals/0/Downloads/Fietsenstalling/Fietsenstalling81_WEB.pdf Zanden, A. van der. (2005). Geweld(ig): datamining! Een zoektocht naar het profiel van geweldplegers met behulp van dataminingtechnieken. Binnengehaald op 8 maart 2015, van: https://www.few.vu.nl/en/Images/stageverslag-zanden_tcm39-90729.doc
86

Zarsky, T. Z. (2002-2003). “Mine Your Own Business!”: Making the Case for the Implications of the Data Mining or Personal Information in the Forum of Public Opinion. In: Yale Journal of Law and Technology: Vol. 5: Iss. 1, Article 1.Zwitter, A. (2014) Big Data Ethics. Binnengehaald op 1 juni 2015, van: http://papers.ssrn.com/sol3/Delivery.cfm/SSRN_ID2600487_code2084525.pdf?abstractid=2553758enmirid=3
87

Bijlage 1 Respondenten interviewsHieronder is een lijst weergegeven met de respondenten met wie ik een interview heb afgenomen. In overleg of bij geen antwoord op de vraag heb ik de naam van de respondent weggelaten. In deze gevallen is alleen de functie en bedrijf/instelling weergegeven van de betreffende respondent. De weergave is op alfabetische volgorde.
Andrej Zwitter: Hoogleraar ethiek en internationale politiek aan de Rijksuniversiteit Groningen en initiatiefnemer van de internationale denktank International Network Observatory, die zich richt op de ethische implicaties van de toepassing van Big Data.Arnout de Vries: Onderzoeker en Adviseur bij TNO op het gebied van social media en maatschappelijke veiligheid en auteur van het boek ‘Social Media: het nieuwe DNA’, over de rol van social media in de opsporing.Dick Willems: Dataminer bij Regionale Informatie Organisatie (RIO) Politie-eenheid Amsterdam-Amstelland en ontwerper van het Criminaliteit Anticipatie Systeem (CAS).Jeroen Groenestein: Werkzaam bij de sociale dienst, de sociale recherche. Heeft daarin inmiddels 12 jaar ervaring en werkt vanuit de gemeente Amersfoort. Hij wordt ingehuurd door de omliggende gemeentes. De omliggende gemeentes zijn Soest, Baarn, Bunschoten, Barneveld, Scherpenzeel en Woudenberg. Doet daar de onderzoeken wat betreft fraude. Heeft ook 23 jaar ervaring bij de politie. Jurist en organisatiedeskundige, gespecialiseerd in de uitwisseling van data tussen veiligheidspartners.Strategisch analist bij eenheid Oost van de politie. Haar expertise ligt vooral op veel bulk datawerken. Paul Elzinga: ontwikkelde een nieuwe methode waarmee de rapportages geautomatiseerd kunnen worden geanalyseerd. Daartoe maakte hij een model dat gebruikmaakt van een wiskundige analyse om rapportages zichtbaar te maken in de vorm van een netwerk. Deze voorstellingswijze kan nieuwe inzichten, nieuwe verdachten en nieuwe slachtoffers zichtbaar maken. Deze nieuwe analysemethode vormt in de nabije toekomst een belangrijk instrument voor informatiespecialisten binnen de politie. Het kan daarmee een belangrijke bijdrage leveren aan de resultaten van het politiewerk in Nederland. Momenteel projectleider om Big Data usescans op te zetten, waaronder een voor voorspellingen.Reinder Doeleman: Chef van Regionale Informatie Organisatie (RIO) Politie-eenheid Amsterdam-Amstelland en landelijk portefeuillehouder Business IntelligenceEen risico- en preventie expert bij Interpolis, samen met een professioneel data-engineering trainee en student van de Technische Universiteit in Eindhoven. Zij zijn bezig met een nieuw project om woninginbraken te voorspellen door het koppelen van statische en dynamische gegevens. Zodat Achmea en Interpolis hun klanten kunnen informeren wat zij kunnen doen
88

tegen woninginbraken op bepaalde locaties. Tevens draagt het bij aan de visie van Interpolis om Nederland veiliger te maken.
89

Bijlage 2 Topiclijst en sturingsvragenNetjes voorstellen en nogmaals bedanken voor de medewerking aan mijn onderzoek en vragen of het interview opgenomen mag worden om de uitwerking gemakkelijker te maken. Er zal uiteraard vertrouwelijk worden omgegaan met de en gedeelde gegevens/informatie. Alvorens ik de informatie definitief verwerk in mij onderzoek zal ik de uitwerking eerst nog naar u opsturen zodat u kunt kijken of ik het juist heb verwerkt. Vervolgens mijn onderzoek in het kort uitleggen en vragen of hij/zij nog vragen heeft over mijn onderzoek alvorens ik overga naar de interviewvragen.
Big Data Wat is uw relatie met het gebruik van Big Data voor opsporingsdoeleinden? Wat verstaat u onder Big Data? Wat is uw visie op de rol van Big Data, die steeds belangrijker/groter wordt in de opsporing? Wat is uw visie op de rol van Big Data, die steeds belangrijker/groter wordt vóórdat er
opsporing/een misdrijf plaatsvindt? o Voorspellende karakter. Het opslaan van gegevens nog voordat er een strafbaar feit zich
heeft voorgedaan, laat staan een verdachte in beeld is.
Voor- en nadelen gebruik Welke mogelijkheden zijn er om data te verkrijgen? Welke dilemma’s doen zich voor bij het gebruik van Big Data? Kent u goede en slechte voorbeelden van de toepassing van Big Data?
Ethiek Wat doet het denkt u met een samenleving wanneer de overheid gegevens opslaat van
zowel verdachte burgers als van niet (potentieel) verdachte burgers? Denkt u dat er onderscheid wordt gemaakt tussen het opslaan en gebruik van Data van
verdachte personen en niet verdachte personen (potentieel verdachten)? Tot op welke hoogte is het volgens u geoorloofd om vooraf gegevens op te slaan? In hoeverre zijn er denkt u ethische bezwaren tegen het gebruikt van Big Data bij het
voorspellen van (potentiele verdachten van) misdaden? o De balans tussen het effectief waarborgen van de veiligheid van de burger enerzijds
en de bescherming van de privacy van diezelfde burger anderzijds (Rechtvaardigheid).
Juridisch In hoeverre zijn er denkt u ethische bezwaren tegen het gebruikt van Big Data bij het
voorspellen van (potentiele verdachten van) misdaden? o Biedt de huidige wetgeving voldoende mogelijkheden of juist beperkingen omtrent
het gebruik van Big Data bij het voorspellen van (mogelijke verdachten van) misdaden?
90
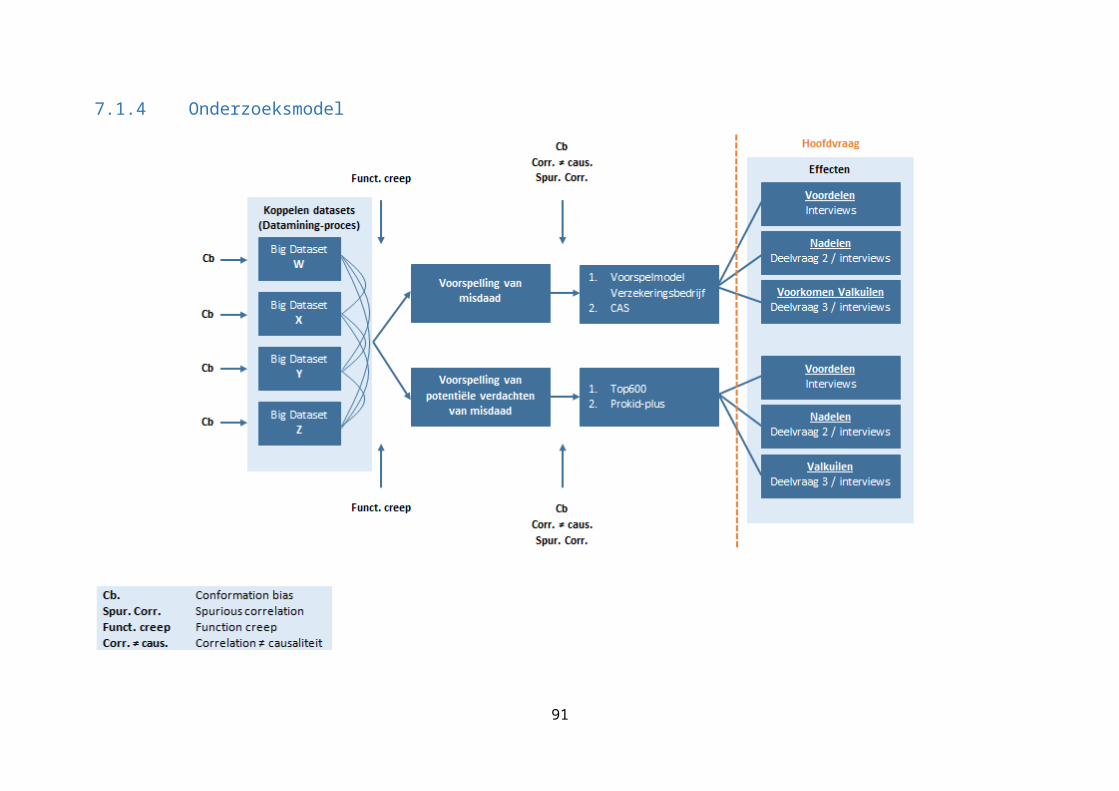
91

ValkuilenWordt er denkt u rekening gehouden met mogelijke valkuilen tijdens de opslag en verwerking van de gegevens?
Opgeslagen voor het een en later gebruikt voor het ander Verbonden met systemen die een andere functie hebben om verbanden te kunnen leggen Hoe wordt de keuze gemaakt om bepaalde gegevens wel te gebruiken en andere niet? Voorbeelden van confirmation bias en function creep erbij houden ter illustratie.
Bedanken voor zijn/haar tijd en vragen of hij/zij op de hoogte wilt worden gehouden wanneer mijn onderzoek is afgerond. Mocht er nog iets of iemand te binnen schieten waarvan u denkt dat het (nog) relevant kan zijn voor mijn onderzoek hoor ik dat graag. Ook vragen of de respondent nog interessant literatuur ter beschikking heeft over het onderwerp. Dit kan als aanvulling dienen op de gegevensverzameling
92





























