Embed Size (px)
Citation preview

i
Guide utilisateur SPSSStatistics Base 17.0

Pour plus d’informations sur les logiciels SPSS Inc., visitez notre site Web à l’adresse suivante http://www.spss.com ou contactez
SPSS Inc.233 South Wacker Drive, 11th FloorChicago, IL 60606-6412Tél : (312) 651-3000Fax : (312) 651-3668
SPSS est une marque déposée et les autres noms de produit sont des marques commerciales de SPSS Inc. pour son logicielinformatique propriétaire. La distribution ou la production de matériel décrivant ce type de logiciel est interdite sansl’autorisation écrite des propriétaires de la marque commerciale et des droits de licence dans le logiciel, et des copyrightsdans les différentes documentations.
Le LOGICIEL et sa documentation sont soumis à des DROITS RESTREINTS. L’utilisation, la reproduction ou la divulgationpar le Gouvernement des Etats-Unis est sujette à des restrictions telles qu’elles sont décrites dans la sous-division (c)(1)(ii) dela clause « The Rights in Technical Data and Computer Software », alinéa 52.227-7013. Le contractant et fabricant est SPSSInc., 233 South Wacker Drive, 11th Floor, Chicago IL 60606-6412, Etats-Unis.Brevet No. 7 023 453
Remarque générale : Les autres noms de produit mentionnés dans ce document sont utilisés à des fins d’illustration uniquementet peuvent être des marques commerciales de leurs détenteurs respectifs.
Windows est une marque déposée de Microsoft Corporation.
Apple, Mac et le logo Mac sont des marques déposées d’Apple Computer, Inc., aux Etats-Unis et dans d’autres pays.
Ce produit utilise WinWrap Basic, Copyright 1993-2007, Polar Engineering and Consulting, http://www.winwrap.com/.
Imprimé aux Etats-Unis.
Toute reproduction, tout stockage dans un système de récupération et toute transmission, même partiels, de quelque forme ou parquelque moyen que ce soit, électronique, mécanique, par photocopie, enregistrement ou autre sont interdits sans le consentementpréalable écrit de l’éditeur.

Préface
SPSS Statistics 17.0
SPSS Statistics 17.0 est un système complet d’analyse de données. SPSS Statistics peut utiliser lesdonnées de presque tout type de fichier pour générer des rapports mis en tableau, des diagrammesde distributions et de tendances, des statistiques descriptives et des analyses statistiques complexes.Ce guide, Guide utilisateur SPSS Statistics Base 17.0, documente l’interface utilisateur
graphique de SPSS Statistics. Le système d’aide installé avec le logiciel contient des exemplesd’utilisation des procédures statistiques du système SPSS Statistics Base 17.0.En outre, sous les menus et les boîtes de dialogue, SPSS Statistics utilise un langage de
commande. Certaines fonctions étendues du système sont accessibles uniquement via une syntaxede commande. (Ces fonctions ne sont pas disponibles dans la version Student.) Un guide deréférence détaillé sur la syntaxe des commandes est disponible sous deux formes différentes :guide intégré dans le système d’aide global et comme document distinct au format PDF dansCommand Syntax Reference, aussi disponible à partir du menu Aide.
Options SPSS Statistics
Les options suivantes sont fournies comme améliorations complémentaires du système de basecomplet SPSS Statistics Base (pas de la version Student) :
Le module Regression fournit des techniques d’analyse des données non adaptées aux modèlesstatistiques linéaires classiques. Il contient des procédures pour les modèles de choix binaire, larégression logistique, la pondération estimée, la régression par les doubles moindres carrés etla régression non linéaire générale.
Le module Advanced Statistics décrit les techniques souvent utilisées dans la recherchebiomédicale et expérimentale avancée. Il inclut des procédures pour les modèles linéairesgénéraux (GLM), les modèles mixtes linéaires, l’analyse des composantes de variance,l’analyse log-linéaire, la régression ordinale, la durée de vie actuarielle, l’analyse de survie deKaplan-Meier, et la régression de Cox de base et étendue.
Le module Custom Tables crée toute une gamme de rapports en tableau de qualité présentation, ycompris des tableaux croisés complexes et les affichages de données de réponses multiples.
Le module Forecasting effectue des prévisions et des analyses de séries chronologiques complètesavec plusieurs modèles d’ajustement aux courbes, des modèles de lissage et des méthodesd’estimation des fonctions autorégressives.
Le module Categories exécute des procédures de codage optimal comme l’analyse descorrespondances.
iii

Conjoint offre une manière réaliste de mesurer la façon dont les attributs du produit individuelaffectent les préférences des consommateurs et des citoyens. Avec Conjoint, il est possible demesurer facilement l’effet de compromis de chaque attribut de produits dans le contexte d’unensemble d’attributs de produits—comme le font certains consommateurs lorsqu’ils décidentde ce qu’ils vont acheter.
Le module Exact Tests calcule les valeurs p exactes pour les tests statistiques lorsque de petitséchantillons ou des échantillons distribués de façon très inégale risquent de fausser la précisiondes tests habituels. Cette option n’est disponible que sous les systèmes d’exploitation Windows.
Le module Missing Values décrit les types des données manquantes, évalue les moyennes etd’autres statistiques, et affecte des valeurs aux observations manquantes.
Le module Complex Samples permet aux chercheurs chargés d’effectuer des enquêtes (notammentd’opinion), des études de marché, ou travaillant dans le domaine de la santé, ainsi qu’auxspécialistes des sciences sociales qui utilisent une méthodologie d’étude fondée sur leséchantillons, d’incorporer leurs propres plans d’échantillonnage complexes dans l’analyse desdonnées.
Decision Trees crée un modèle d’arbre de segmentation. Elle classe les observations en groupes ouestime les valeurs d’une variable (cible) dépendante à partir des valeurs de variables (explicatives)indépendantes. Cette procédure fournit des outils de validation pour les analyses de classificationd’exploration et de confirmation.
Le module Data Preparation fournit un cliché visuel rapide de vos données. Il permet d’appliquerdes règles de validation qui identifient les valeurs de données non valides. Vous pouvez créer desrègles qui repèrent les valeurs hors plage, les valeurs manquantes et les valeurs vides. Vouspouvez également enregistrer des variables qui enregistrent les violations de règles individuelles etle nombre total de violations de règles par observation. Un ensemble limité de règles prédéfiniesque vous pouvez copier ou modifier vous est fourni.
Le module Neural Networks permet de prendre des décisions commerciales en prévoyant lademande d’un produit en fonction du prix et d’autres variables, ou en catégorisant les clients enfonction des habitudes d’achat et des caractéristiques démographiques. Les réseaux neuronauxsont des outils de modélisation de données non linéaires. Ils permettent de modéliser les relationscomplexes entre les entrées et les résultats, ou de rechercher des modèles dans les données.
Le module EZ RFM exécute l’analyse RFM (récence, fréquence, monétaire) sur des fichiers dedonnées de transaction et sur les fichiers de données client.
Amos™ (analyse de structures de moments) utilise la modélisation d’équation structurelle pourconfirmer et expliquer des modèles conceptuels qui impliquent l’attitude, les perceptions etd’autres facteurs qui entraînent un comportement.
Installation
Pour installer Base système, lancez l’assistant d’attribution de licence à l’aide du codecorrespondant fourni par SPSS Inc.. Pour plus d’informations, reportez-vous aux instructionsd’installation fournies avec le Base système.
iv

Compatibilité
SPSS Statistics est conçu pour fonctionner sur de nombreux systèmes d’exploitation. Pour plusd’informations sur la configuration minimale ou recommandée, reportez-vous aux instructionsd’installation de votre système.
Numéros de série
Le numéro de série permet de vous identifier auprès de SPSS Inc.. Vous en aurez besoin lors detout appel à SPSS Inc. pour des informations relatives au support, au paiement ou à la mise àniveau de votre système. Le numéro de série est fourni avec le système de base.
Service clients
Si vous avez des questions concernant votre envoi ou votre compte, contactez votre bureau local,dont les coordonnées figurent sur le site Web à l’adresse : http://www.spss.com/worldwide.Veuillez préparer et conserver votre numéro de série à portée de main pour l’identification.
Séminaires de formation
SPSS Inc. propose des séminaires de formation, publics et sur site. Tous les séminaires fontappel à des ateliers de travaux pratiques. Ces séminaires seront proposés régulièrement dans lesgrandes villes. Pour plus d’informations sur ces séminaires, contactez votre bureau local dont lescoordonnées sont indiquées sur le site Web à l’adresse : http://www.spss.com/worldwide.
Support technique
Les services du support technique sont disponibles pour les utilisateurs de maintenance. Lesclients peuvent contacter le support technique pour obtenir de l’aide concernant l’utilisationde SPSS Statistics ou l’installation dans le cadre de l’un des environnements matériels pris encharge. Pour contacter le support technique, visitez le site Web à l’adresse http://www.spss.comou contactez votre bureau local dont les coordonnées figurent sur le site Web à l’adresse :http://www.spss.com/worldwide. Votre nom ou celui de votre société, ainsi que le numéro desérie de votre système, vous seront demandés.
Documents supplémentairesLe module supplémentaire de procédures statistiques SPSS, créé par Marija Norušis, a
été publié par Prentice Hall. Une nouvelle version de ce manuel, mise à jour pour SPSSStatistics 17.0, est planifiée. Le module supplémentaire de procédures statistiques SPSS avancées,qui repose également sur SPSS Statistics 17.0, sera disponible prochainement. Le manueld’analyse des données SPSS Guide to Data Analysis de SPSS Statistics 17.0 est également enpréparation. L’annonce des publications disponibles uniquement auprès de Prentice Hall pourraêtre consultée sur le site Web à l’adresse : http://www.spss.com/estore (sélectionnez le pays devotre choix, puis cliquez sur Books).
v

Contenu
1 Sommaire 1
Nouveautés de la version 17.0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2Fenêtres . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
Fenêtre désignée et fenêtre active. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5Barre d’état . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6Boîtes de dialogue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6Noms de variables et étiquettes de variable dans les listes de boîtes de dialogue . . . . . . . . . . . . . 6Redimensionnement des boîtes de dialogue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7Commande des boîtes de dialogue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7Sélection de variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8Icônes Le type de données, Niveau de mesure et Liste des variables . . . . . . . . . . . . . . . . . . . . . . 8Obtenir des informations sur les variables dans les boîtes de dialogue . . . . . . . . . . . . . . . . . . . . . 9Procédures de base dans l’analyse des données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9Assistant statistique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10En savoir plus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2 Obtention d’Aide 11
Aide sur les termes utilisés dans les résultats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3 Fichiers de données 14
Ouverture de fichiers de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14Pour ouvrir un fichier de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14Types de fichier de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15Ouvrir les options de fichier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16Lecture de fichiers Excel version 95 ou ultérieure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16Lecture de fichiers Excel antérieurs ou d’autres tableurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16Lecture de fichiers dBASE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17Lecture de fichiers Stata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17Lire des fichiers de base de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18Assistant de texte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33Lecture des données de dimension . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
Informations sur les fichiers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
vi

Enregistrement des fichiers de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47Pour enregistrer des fichiers de données modifiés. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47Enregistrement des fichiers de données sous des formats externes. . . . . . . . . . . . . . . . . . . . 47Enregistrement de fichiers de données au format Excel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50Enregistrement de fichiers de données au format SAS. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51Enregistrement de fichiers de données au format Stata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52Enregistrement de sous-ensembles de variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54Export vers une base de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54Export vers Dimensions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
Protection des données d’origine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68Fichier actif virtuel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
Création d’un cache de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
4 Mode d’analyse distribuée 73
Connexion au serveur SPSS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73Ajout et modification des paramètres de connexion au serveur . . . . . . . . . . . . . . . . . . . . . . . 74Sélection, changement ou ajout de serveurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75Recherche de serveurs disponibles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
Ouverture de fichiers de données à partir d’un serveur distant . . . . . . . . . . . . . . . . . . . . . . . . . . . 77Accès aux fichiers de données en mode d’analyse locale ou distribuée . . . . . . . . . . . . . . . . . . . . 77Disponibilité des procédures en mode d’analyse distribuée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79Spécifications de chemins absolus et relatifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
5 Editeur de données 81
Affichage des données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81Affichage des variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
Pour afficher ou définir des attributs de variable . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83Noms de variable. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84Niveau de mesure des variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85Type de variable . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85Etiquettes des variables. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88Etiquettes de valeurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88Insertion de sauts de ligne dans les étiquettes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89Valeurs manquantes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89Largeur des colonnes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90Alignement de variable . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90Application d’attributs de définition de variable à plusieurs variables. . . . . . . . . . . . . . . . . . . 90Attributs de variable personnalisés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
vii

Personnaliser l’affichage des variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96Correction orthographique. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
Saisie de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97Pour entrer des données numériques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98Pour entrer des données non numériques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98Pour utiliser des étiquettes de valeur pour l’entrée de données . . . . . . . . . . . . . . . . . . . . . . . 98Restrictions concernant la valeur de données dans l’éditeur de données. . . . . . . . . . . . . . . . 99
Modification de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99Pour remplacer ou modifier les valeurs de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99Couper, copier et coller des valeurs de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99Insérer de nouvelles observations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100Insérer de nouvelles variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101Pour modifier le type de données. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
Recherche d’observations, de variables ou d’imputations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102Recherche et remplacement des valeurs d’attributs et de données. . . . . . . . . . . . . . . . . . . . . . . 104Etat de la sélection de l’observation dans l’éditeur de données . . . . . . . . . . . . . . . . . . . . . . . . . . 105Options d’affichage de l’éditeur de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105Impression de l’éditeur de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
Pour imprimer le contenu de l’Editeur de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106
6 Utilisation des sources de données multiples 107
Manipulation de base de plusieurs sources de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108Utilisation de plusieurs ensembles de données dans une syntaxe de commande . . . . . . . . . . . . 109Copie et collage d’informations entre les ensembles de données . . . . . . . . . . . . . . . . . . . . . . . . 110Attribution d’un nouveau nom aux ensembles de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110Suppression de plusieurs ensembles de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
7 Préparation des données 112
Propriétés de variable. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112Définition des propriétés de variable. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
Pour définir les propriétés de variable . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113Définition des étiquettes de valeurs et des autres propriétés de variable . . . . . . . . . . . . . . . 114Affectation du niveau de mesure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116Attributs de variable personnalisés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117Copie de propriétés de variable . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
Vecteurs de réponses multiples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119Définir des vecteurs multiréponses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
viii

Copie des propriétés de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122Pour copier des propriétés de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123Sélection des variables source et cible . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124Choix des propriétés de variable à copier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126Copie des propriétés d’ensembles de données (propriétés de fichier) . . . . . . . . . . . . . . . . . 128Résultats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
Identification des observations dupliquées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131Regroupement visuel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
Pour regrouper des variables par casiers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135Variables de regroupement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136Génération automatique de modalités regroupées par casiers . . . . . . . . . . . . . . . . . . . . . . . 139Copie de modalités regroupées par casiers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141Valeurs manquantes spécifiées dans Regroupement visuel . . . . . . . . . . . . . . . . . . . . . . . . . 142
8 Transformations de données 143
Calcul de variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143Calculer la variable : Expressions conditionnelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145Calculer la variable : Type et étiquette . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 146
Fonctions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 146Valeurs manquantes dans les fonctions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147Générateurs de nombres aléatoires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147Compter occurrences des valeurs par observation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
Compter les occurrences des valeurs par observations : Valeurs à compter . . . . . . . . . . . . 149Compter occurrences : Expressions conditionnelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 150
Valeurs de décalage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151Recodage de valeurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152Recodage de variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152
Recodage de variables : Anciennes et nouvelles valeurs . . . . . . . . . . . . . . . . . . . . . . . . . . . 153Création de variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 155
Recoder et créer de nouvelles variables : Anciennes et nouvelles valeurs . . . . . . . . . . . . . . 156Recoder automatiquement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 158Ordonner les observations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
Ordonner les observations : Types (de rangs). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162Ordonner les observations : Ex aequo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163
Assistant Date et heure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164Dates et heures dans SPSS Statistics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 166Création d’une variable date/heure à partir d’une variable chaîne . . . . . . . . . . . . . . . . . . . . 167Création d’une variable date/heure à partir d’un ensemble de variables . . . . . . . . . . . . . . . . 168
ix

Ajout de valeurs aux variables date/heure ou suppression de valeurs des variablesdate/heure. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170Extraction d’une partie d’une variable date/heure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 177
Transformation de données pour série chronologique. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179Définir des dates . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 180Créer la série chronologique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181Remplacer les valeurs manquantes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 184
Notation de données avec des modèles de prévision . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185Chargement d’un modèle enregistré . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187Affichage d’une liste de modèles chargés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189Fonctions supplémentaires avec la syntaxe de commande . . . . . . . . . . . . . . . . . . . . . . . . . 189
9 Gestion et transformations de fichiers 190
Trier les observations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 190Trier les variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191Transposer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193Fusionner des fichiers de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193Ajouter des observations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194
Ajout d’observations : Renommer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 196Ajout d’observations : Informations du dictionnaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 196Fusion de plus de deux sources de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197
Ajouter des variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197Ajouter des variables : Renommer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 199Fusion de plus de deux sources de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 199
Agréger les données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 200Agrégation de données : Fonction d’agrégation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203Agrégation de données : Nom et étiquette de variable . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203
Scinder fichier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204Sélectionner des observations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205
Sélectionner observations : Si . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 207Sélectionner observations : Echantillon aléatoire. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 208Sélectionner observations : Intervalle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 209
Pondérer les observations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 210Restructuration des données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 211
Restructuration des données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 211Assistant de restructuration des données : Sélectionner un type . . . . . . . . . . . . . . . . . . . . . 212Assistant de restructuration des données (Restructurer les variables en observations) :Nombre de groupes de variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 216Assistant de restructuration des données (Restructurer les variables en observations) :Sélectionner Variables. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 217
x

Assistant de restructuration des données (Restructurer les variables en observations):Créer des variables Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 218Assistant de restructuration des données (Restructurer les variables en observations) :Créer une variable d’index . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 220Assistant de restructuration des données (Restructurer les variables en observations) :Créer plusieurs variables d’index . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221Assistant de restructuration des données (Restructurer les variables en observations):Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 223Assistant de restructuration des données (Restructurer les observations en variables) :Sélectionner Variables. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224Assistant de restructuration des données (Restructurer les observations en variables) :Trier Données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 225Assistant de restructuration des données (Restructurer les observations en variables):Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 226Assistant de restructuration des données : Fin. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 227
10 Utilisation du résultat 229
Viewer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 229Affichage et masquage des résultats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 230Déplacement, suppression et copie de résultats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 230Changemernt de l’alignement initial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231Changement de l’alignement des items de résultat. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231Légende du Viewer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231Ajout d’éléments au Viewer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233Recherche et remplacement d’informations dans le Viewer . . . . . . . . . . . . . . . . . . . . . . . . . 234
Copie des résultats dans d’autres applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 235Pour copier et coller plusieurs éléments dans une autre application . . . . . . . . . . . . . . . . . . 236
Exporter résultats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 236Options HTML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 238Options Word/RTF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 239Options Excel. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 241Options PowerPoint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242Options PDF. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 244Options texte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 245Options graphiques uniquement. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 246Options de format des graphiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 247
Impression de documents du Viewer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 248Pour imprimer des résultats et des diagrammes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 248Aperçu avant impression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 249Attributs de page : En-têtes et pieds de page . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 250Attributs de page : Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252
xi

Enregistrement des résultats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253Pour enregistrer un document du Viewer. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 253
11 Tableaux pivotants 255
Manipulation d’un tableau pivotant . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 255Activer un tableau pivotant . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 255Pivotement de tableau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 255Modification de l’ordre d’affichage des éléments dans une dimension . . . . . . . . . . . . . . . . . 256Déplacement de lignes et de colonnes dans un élément de dimension. . . . . . . . . . . . . . . . . 256Transposer des lignes et des colonnes. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 257Groupement de lignes ou de colonnes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 257Dissociation de lignes ou de colonnes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 257Rotation des étiquettes de ligne ou de colonne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 258
Utilisation des strates . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 258Création et affichage de strates . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 258Atteindre la modalité de la strate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 261
Affichage et masquage d’éléments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 261Masquage de lignes et de colonnes dans un tableau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 261Affichage des lignes et des colonnes masquées dans un tableau. . . . . . . . . . . . . . . . . . . . . 262Masquage et affichage des étiquettes de dimension . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262Masquage ou affichage des titres de tableau. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262
Modèles de tableaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 263Pour appliquer ou enregistrer un modèle de tableau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 263Pour modifier ou créer un Modèle de tableau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 264
Propriétés du tableau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 264Pour modifier les propriétés d’un tableau pivotant . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 264Propriétés de tableau : Général . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 265Propriétés de tableau : Notes de bas de page . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 265Propriétés de tableau : Formats de cellule . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 266Propriétés de tableau : Bordures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 268Propriétés de tableau : Impression . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 269
Propriétés de la cellule . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 270Police et arrière-plan. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 271Valeur de format . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 271Alignement et marges . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 272
Notes de bas de page et légendes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273Ajout de notes de bas de page et de légendes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273Pour afficher ou masquer une légende . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 274Pour masquer ou afficher une note de bas de page dans un tableau . . . . . . . . . . . . . . . . . . 274
xii

Marque de bas de page . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 274Renuméroter les notes de bas de page . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 275
Largeur des cellules de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 275Modification de la largeur de colonne. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 275Affichage des bordures masquées dans un tableau pivotant. . . . . . . . . . . . . . . . . . . . . . . . . . . . 275Sélection de lignes et colonnes dans un tableau pivotant . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 276Impression des tableaux pivotants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 276
Contrôle des sauts de tableau pour les tableaux longs et larges. . . . . . . . . . . . . . . . . . . . . . 277Création d’un diagramme à partir d’un tableau pivotant. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 277
12 Modèles 279
Interaction avec un modèle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 279Travailler avec le Viewer de modèles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 279
Impression d’un modèle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 281Exportation d’un modèle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 281
13 Utilisation de la syntaxe de commande 282
Règles de syntaxe de commande . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 282Création d’une syntaxe depuis les boîtes de dialogue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 284
Collage d’une syntaxe depuis les boîtes de dialogue . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 284Utilisation de la syntaxe depuis le fichier de résultat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 285
Copier la syntaxe depuis le fichier de résultats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 285Utilisation de l’éditeur de syntaxe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 286
Fenêtre Editeur de syntaxe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 287Terminologie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 288Saisie semi-automatique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 289Codage par couleur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 289Points d’arrêt . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 290Signets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 292Commenter un texte. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 293Exécution d’une syntaxe de commande . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 293
Fichiers de syntaxe Unicode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 294Commandes Execute multiples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 295
xiii

14 Livre des codes 296
Onglet Résultats du livre des codes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 298Onglet Statistiques du livre des codes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 301
15 Effectifs 303
Statistiques des Effectifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 304Diagrammes des Effectifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 306Format des Effectifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 307
16 Descriptives 308
Options Descriptives. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 309Fonctionnalités supplémentaires de la commande DESCRIPTIVES . . . . . . . . . . . . . . . . . . . . . . . 310
17 Explorer 312
Statistiques d’Explorer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 314Diagrammes d’Explorer. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 315
Transformations de l’exposant d’Explorer. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 316Options d’Explorer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 316Fonctionnalités supplémentaires de la commande EXAMINE . . . . . . . . . . . . . . . . . . . . . . . . . . . 317
18 Tableaux croisés 318
Strates de tableaux croisés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 319Diagrammes en bâtons juxtaposés de tableaux croisés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 320Statistiques de tableaux croisés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 320Affichage de cellules (cases) de tableaux croisés. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 323Format de tableau croisé . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 324
xiv

19 Récapituler 325
Options de Récapituler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 327Récapituler les statistiques. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 327
20 Moyenne 330
Moyennes : Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 332
21 Cubes OLAP 335
Cubes OLAP : Statistiques. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 337Cubes OLAP : Différences . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 339Cubes OLAP : Titre . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 340
22 Tests T 341
Test T pour échantillons indépendants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 341Définir Groupes Test T pour Echantillons Indépendants . . . . . . . . . . . . . . . . . . . . . . . . . . . . 343Options Test T pour Echantillons Indépendants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 344
Test T pour échantillons appariés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 344Options test T pour échantillons appariés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 345
Test T pour échantillon unique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 346Options Test T pour échantillon unique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 347
Fonctionnalités supplémentaires de la commande T-TEST . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 348
23 ANOVA à 1 facteur 349
Contrastes ANOVA à 1 facteur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 350Tests Post Hoc ANOVA à 1 facteur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 351Options ANOVA à 1 facteur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353Fonctionnalités supplémentaires de la commande ONEWAY . . . . . . . . . . . . . . . . . . . . . . . . . . . . 354
xv

24 Analyse GLM – Univarié 355
Modèle GLM. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 357Termes construits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 357Somme des carrés. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 358
Contrastes GLM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 359Types de contraste . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 359
Diagrammes de profils GLM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 360Comparaisons post hoc GLM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 361Enregistrement GLM. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 363Options GLM. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 365Fonctionnalités supplémentaires de la commande UNIANOVA . . . . . . . . . . . . . . . . . . . . . . . . . . 366
25 Corrélations bivariées 368
Options de corrélations bivariées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 370Propriétés supplémentaires des commandes CORRELATIONS et NONPAR CORR . . . . . . . . . . . . 370
26 Corrélations partielles 372
Options Corrélations partielles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 373Fonctionnalités supplémentaires de la commande PARTIAL CORR . . . . . . . . . . . . . . . . . . . . . . . 374
27 Distances 375
Distances : Mesures de dissimilarité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 377Distances : Mesures de similarité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 378Fonctionnalités supplémentaires de la commande PROXIMITIES . . . . . . . . . . . . . . . . . . . . . . . . 378
28 Régression linéaire 380
Méthodes de sélection des variables de régression linéaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . 381Régression linéaire : Définir la règle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 383Diagrammes de régression linéaire. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 383Régression linéaire : Enregistrer de nouvelles variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 384
xvi

Statistiques de régression linéaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 387Régression linéaire : Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 388Fonctionnalités supplémentaires de la commande REGRESSION . . . . . . . . . . . . . . . . . . . . . . . . 389
29 Régression ordinale 390
Régression ordinale : Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 391Régression ordinale : Résultat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 393Régression ordinale : Emplacement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 394
Termes construits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 396Régression ordinale : Echelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 395
Termes construits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 396Fonctionnalités supplémentaires de la commande PLUM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 396
30 Ajustement de fonctions 397
Modèles d’ajustement de fonctions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 399Enregistrement de l’ajustement de fonctions. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 399
31 Régression des moindres carrés partiels 401
Modèle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 403Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 404
32 Analyse du voisin le plus proche 406
Voisins . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 410Caractéristiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 412Partitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 413Enregistrer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 415Résultats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 416Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 417Vue du modèle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 418
Espace des caractéristiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 419Importance des variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 421
xvii

Pairs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 422Distances du voisin le plus proche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 422Carte des quadrants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 423Journal d’erreur de l’espace des caractéristiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 424Journal d’erreur de sélection de k . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 425Journal d’erreur de sélection de k et des caractéristiques . . . . . . . . . . . . . . . . . . . . . . . . . 426Le tableau de classification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 426Récapitulatif d’erreur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 427
33 Analyse discriminante 428
Définition d’intervalles pour l’analyse discriminante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 430Sélection des observations pour l’analyse discriminante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 430Statistiques de l’analyse discriminante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 431Méthode pas à pas de l’analyse discriminante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 432Analyse discriminante : Classement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 433Enregistrement de l’analyse discriminante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 435Fonctionnalités supplémentaires de la commande DISCRIMINANT. . . . . . . . . . . . . . . . . . . . . . . 435
34 Analyse factorielle 436
Sélection des observations pour l’analyse factorielle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 437Descriptives d’analyse factorielle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 438Extraction d’analyse factorielle. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 439Rotation d’analyse factorielle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 441Scores d’analyse factorielle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 442Options d’analyse factorielle. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 443Fonctionnalités supplémentaires de la commande FACTOR. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 443
35 Choix d’une procédure de classification 444
36 Analyse TwoStep Cluster 446
Options de la procédure d’analyse TwoStep Cluster . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 449Diagrammes de l’analyse TwoStep Cluster . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 451Résultats de l’analyse TwoStep Cluster . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 452
xviii

37 Classification hiérarchique 454
Méthode de classification hiérarchique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 456Statistiques de la classification hiérarchique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 457Diagrammes (graphiques) de classification hiérarchique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 458Enregistrement des nouvelles variables de classification hiérarchique . . . . . . . . . . . . . . . . . . . . 458Fonctionnalités supplémentaires de la syntaxe de commande CLUSTER . . . . . . . . . . . . . . . . . . . 459
38 Nuées dynamiques 460
Efficacité de la classification en nuées dynamiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 462Itération de la classification en nuées dynamiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 462Enregistrement des analyses de classes de nuées dynamiques . . . . . . . . . . . . . . . . . . . . . . . . . 463Options d’analyses des classes de nuées dynamiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 463Fonctionnalités supplémentaires de la commande QUICK CLUSTER . . . . . . . . . . . . . . . . . . . . . . 464
39 Tests non paramétriques 465
Test du Khi-deux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 465Valeurs et intervalles théoriques du test du Khi-deux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 467Test du Khi-deux : Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 467Fonctionnalités supplémentaires de la commande NPAR TESTS (test du Khi-deux) . . . . . . . 468
Test binomial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 468Test binomial : Options. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 469Fonctionnalités supplémentaires de la commande NPAR TESTS (Test binomial) . . . . . . . . . . 470
Suites en séquences . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 470Césure des Suites en séquences . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 471Options des Suites en séquences . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 471Fonctionnalités supplémentaires de la commande NPAR TESTS (Suites en séquences) . . . . 472
Test Kolmogorov-Smirnov pour un échantillon . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 472Options du test de Kolmogorov-Smirnov pour un échantillon . . . . . . . . . . . . . . . . . . . . . . . . 473Fonctions supplémentaires de commandes NPAR TESTS (test de Kolmogorov-Smirnov pourun échantillon). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 474
Tests pour deux échantillons indépendants. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 474Types de tests pour deux échantillons indépendants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 475Définition de deux groupes d’échantillons indépendants . . . . . . . . . . . . . . . . . . . . . . . . . . . 476
xix

Tests pour deux échantillons indépendants : Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 476Fonctionnalités supplémentaires de la commande NPAR TESTS (tests pour deuxéchantillons indépendants) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 477
Tests pour deux échantillons liés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 477Types de tests pour deux échantillons liés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 478Tests pour deux échantillons liés : Options. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 479Fonctionnalités supplémentaires de la commande NPAR (Deux échantillons liés) . . . . . . . . 479
Tests pour plusieurs échantillons indépendants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 479Tests pour Plusieurs Echantillons Indépendants : Types de tests . . . . . . . . . . . . . . . . . . . . . 480Tests pour Plusieurs Echantillons Indépendants : Définir l’Intervalle . . . . . . . . . . . . . . . . . . 481Options des Tests pour Plusieurs Echantillons Indépendants . . . . . . . . . . . . . . . . . . . . . . . . 481Fonctionnalités supplémentaires de la commande NPAR TESTS (K échantillonsindépendants) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 482
Tests pour plusieurs échantillons liés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 482Tests pour plusieurs échantillons liés de types de tests . . . . . . . . . . . . . . . . . . . . . . . . . . . . 483Statistiques des tests pour plusieurs échantillons liés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 483Fonctionnalités supplémentaires de la commande NPAR TESTS (K échantillons liés) . . . . . . 483
40 Analyse des réponses multiples 484
Définition de vecteurs multiréponses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 485Tableaux de fréquences des réponses multiples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 486Tableaux croisés des réponses multiples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 488Définir Intervalles Tableaux croisés de réponses multiples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 490Options Tableaux croisés de réponses multiples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 490Fonctionnalités supplémentaires de la commande MULT RESPONSE . . . . . . . . . . . . . . . . . . . . . 491
41 Tableaux de Résultats 492
Tableaux de bord en lignes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 492Pour obtenir un rapport récapitulatif : Récapitulatifs en lignes . . . . . . . . . . . . . . . . . . . . . . . 493Format des Colonnes de données/Ventilations des Tableaux de bord . . . . . . . . . . . . . . . . . . 494Fonctions récapitulatives des Tableaux pour/Fonctions récapitulatives Finales . . . . . . . . . . 495Options de Ventilation de Tableau de Bord . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 495Options du Tableau de bord . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 496Présentation du Tableau de bord . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 497Titres du Tableau de bord. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 498
Tableaux de bord en colonnes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 498Pour obtenir un rapport récapitulatif : Récapitulatifs en colonnes . . . . . . . . . . . . . . . . . . . . 499Fonction récapitulative des Colonnes de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 500
xx

Fonction élémentaire des Colonnes de Données pour colonne de total . . . . . . . . . . . . . . . . 501Format des Colonnes du Tableau de bord . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 502Tableaux de bord en Colonnes : Options de Ventilation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 502Options des Tableaux de bord en Colonnes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 502Présentation du Tableau de bord en Colonnes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 503
Fonctionnalités supplémentaires de la commande REPORT. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 503
42 Analyse de fiabilité 504
Statistiques de l’analyse de fiabilité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 506Fonctionnalités supplémentaires de la commande RELIABILITY . . . . . . . . . . . . . . . . . . . . . . . . . 508
43 Positionnement multidimensionnel 509
Forme des données du positionnement multidimensionnel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 511Positionnement multidimensionnel : Créer une mesure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 511Modèle de positionnement multidimensionnel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 512Positionnement multidimensionnel : Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 513Fonctionnalités supplémentaires de la commande ALSCAL. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 514
44 Statistiques de ratio 515
Statistiques de ratio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 517
45 Courbes ROC 519
Courbe ROC : Options . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 520
46 Présentation de l’utilitaire de diagramme 522
Création et modification d’un diagramme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 522Construction de diagrammes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 522Modification de diagrammes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 526
xxi

Options de définition du diagramme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 529Ajout et modification de titres et de notes de bas de page . . . . . . . . . . . . . . . . . . . . . . . . . . 529Définition des options générales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 530
47 Outils 533
Informations de la variable . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 533Commentaires de fichier de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 534Groupes de Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 534Définir des groupes de variables. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 534Utiliser des groupes de variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 535Réordonner Listes Variables Cible. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 537
48 Options 538
Options générales. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 539Options Viewer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 541Options de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 542
Modification de l’affichage des variables par défaut . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 544Options monétaires (devises) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 545
Création de formats monétaires personnalisés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 546Options Etiquettes Résultats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 546Options de diagramme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 548
Données Couleurs des éléments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 549Courbes des éléments de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 549Marques des éléments de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 550Remplissages des éléments de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 551
Options tableaux pivotants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 551Options Emplacements des fichiers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 553Options script . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 554Options de l’Editeur de syntaxe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 557Options d’imputations multiples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 558
49 Personnalisation des menus et des barres d’outils 560
Editeur de menu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 560Personnalisation des barres d’outils . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 561
xxii

Montrer barres d’outils . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 561Pour personnaliser les barres d’outils . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 562
Propriétés barre d’outils . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 563Barre d’outils Modifier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 563Créer nouvel outil . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 564
50 Création et gestion de boîtes de dialogue personnalisées 566
Présentation du générateur de boîtes de dialogue personnalisées . . . . . . . . . . . . . . . . . . . . . . . 567Création d’une boîte de dialogue. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 568Propriétés de la boîte de dialogue. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 568Spécification de l’emplacement du menu d’une boîte de dialogue personnalisée . . . . . . . . . . . . 570Disposition des commandes sur le canevas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 571Création du modèle de syntaxe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 572Aperçu d’une boîte de dialogue personnalisée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 575Gestion des boîtes de dialogue personnalisées. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 575Types de commandes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 577
Liste source. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 578Liste cible . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 579Filtrage des listes de variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 580Case à cocher . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 580Boîte combinée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 581Commande Texte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 582Commande numérique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 583Commande Texte statique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 583Groupe d’éléments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 584Groupe radio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 585Groupe de cases à cocher . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 586Navigateur de fichiers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 587Bouton de boîte de dialogue de niveau inférieur. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 588
Boîtes de dialogue personnalisées pour les commandes d’extension . . . . . . . . . . . . . . . . . . . . . 589Création de versions traduites de boîtes de dialogue personnalisées . . . . . . . . . . . . . . . . . . . . . 591
51 Tâches de production 594
Options HTML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 597Options PowerPoint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 598Options PDF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 598Options Texte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 598
xxiii

Valeurs d’exécution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 599Invites utilisateur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 600Exécution de tâches de production à partir d’une ligne de commande . . . . . . . . . . . . . . . . . . . . 601Conversion des fichiers du système de production . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 602
52 Système de gestion des résultats 603
Types d’objet de sortie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 606Identificateurs de commande et sous-types de tableau. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 607Etiquettes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 608Options OMS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 609Journalisation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 614Exclusion de l’affichage des résultats du Viewer. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 615Acheminement des résultats vers des fichiers de données SPSS Statistics. . . . . . . . . . . . . . . . . 615
Exemple : Tableau bidimensionnel unique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 615Exemple : Tableaux avec strates . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 616Fichiers de données créés à partir de plusieurs tableaux . . . . . . . . . . . . . . . . . . . . . . . . . . . 617Contrôle des éléments de colonne pour contrôler les variables du fichier de données . . . . . 620Noms de variable dans les fichiers de données générés par le système de gestion desrésultats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 622
Structure de tableau OXML. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 623Identificateurs OMS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 627
Copie des identificateurs OMS à partir de la légende du Viewer. . . . . . . . . . . . . . . . . . . . . . 628
Annexe
A Convertisseur de syntaxe des commandes TABLES etIGRAPH 629
Index 632
xxiv

Chapitre
1Sommaire
SPSS Statistics vous offre un puissant système d’analyse statistique et de gestion de données dansun environnement graphique, avec des menus descriptifs et des boîtes de dialogue simples, pourfaire presque tout le travail à votre place. La plupart des tâches s’effectuent par simple pointage etcliquage de la souris.
Outre la simple interface de pointage et cliquage permettant l’analyse statistique, SPSS Statisticsoffre les fonctions suivantes :
Editeur de données : L’Editeur de données est un système polyvalent de type tableur pour définir,saisir, modifier et afficher des données.
Viewer : Le nouveau Viewer permet de parcourir les résultats, d’afficher et de masquer lesrésultats de façon sélective, de modifier l’ordre d’affichage des résultats, de déplacer des tableauxet diagrammes pour présentation depuis et vers d’autres applications.
Tableaux pivotants multidimensionnels : Vos résultats prennent vie avec les tableaux pivotantsmultidimensionnels. Explorez vos tableaux en réorganisant les lignes, colonnes et strates. Révélezdes conclusions importantes qui peuvent se perdre dans des rapports standard. Comparezfacilement les groupes en éclatant votre tableau de façon à ce qu’un seul groupe soit affiché àla fois.
Graphismes à haute résolution : L’application inclut de nombreuses caractéristiques standardcomme des diagrammes haute résolution et à secteurs unis, des diagrammes en bâtons, deshistogrammes, des diagrammes de dispersion, des graphiques 3D et plus.
Accès aux bases de données : Récupérez des informations à partir des bases de données en utilisantl’assistant de base de données au lieu d’avoir à poser des questions SQL complexes.
Transformations de données : Les fonctionnalités de transformation vous aident à rendre vosdonnées prêtes à l’analyse. Vous pouvez, entre autres, grouper les données en sous-ensembles,combiner des modalités, ajouter, agréger, fusionner, scinder et transposer des fichiers en toutefacilité.
Aide en ligne : Des didacticiels détaillés offrent un aperçu complet ; les rubriques d’aidecontextuelle des boîtes de dialogue vous guident dans les tâches spécifiques ; les définitionscontextuelles dans les résultats de tableaux pivotants expliquent les termes statistiques. L’Assistantstatistique vous aide à trouver les procédures que vous recherchez et les études de cas fournissentdes exemples concrets sur l’utilisation des procédures statistiques et l’interprétation des résultats.
Langage de commande : Vous pouvez effectuer la plupart des tâches à l’aide d’un simple clic, maisSPSS Statistics fournit également un langage de commande puissant qui vous permet d’enregistreret d’automatiser de nombreuses tâches courantes. Le langage de commande fournit égalementcertaines fonctions non disponibles dans les menus et les boîtes de dialogue.
1

2
Chapitre 1
Une documentation complète de la syntaxe de commande, intégrée dans le système d’aideglobal, est disponible dans un document PDF distinct, Command Syntax Reference, égalementdisponible à partir du menu Aide.
Nouveautés de la version 17.0
Nouvel éditeur de syntaxe. L’éditeur de syntaxe a été entièrement repensé et comprend desfonctions telles que la saisie semi-automatique, le codage par couleur, les signets et les pointsd’arrêts. Le saisie semi-automatique vous fournit une liste des noms de commande, dessous-commandes et des mots-clés, de sorte vous passiez moins de temps à vous reporter auxtableaux de syntaxe. Le codage par couleur vous permet d’identifier rapidement les termes nonreconnus ainsi que certaines erreurs de syntaxe communes. Les signets vous permettent denaviguer rapidement dans de grands fichiers de syntaxe de commande. Les points d’arrêt vouspermettent d’interrompre l’exécution à des points spécifiés afin que vous puissiez examiner lesdonnées ou les résultats avant de poursuivre. Pour plus d'informations, reportez-vous à Utilisationde l’éditeur de syntaxe dans Chapitre 13 sur p. 286.
Générateur de boîtes de dialogue personnalisées. Le générateur de boîtes de dialoguepersonnalisées vous permet de créer et de gérer des boîtes de dialogue personnalisées afin degénérer une syntaxe de commande. Vous pouvez créer des boîtes de dialogue personnaliséespour générer une syntaxe depuis plusieurs commandes, y compris des commandes d’extensionpersonnalisées mises en oeuvre dans Python ou dans R. Pour plus d'informations, reportez-vous àCréation et gestion de boîtes de dialogue personnalisées dans Chapitre 50 sur p. 566.
Support multilingue. Outre la possibilité de modifier la langue des résultats disponible dans lesversions précédentes, vous pouvez désormais modifier la langue de l’interface utilisateur. Pourplus d'informations, reportez-vous à Options générales dans Chapitre 48 sur p. 539.
Livre des codes. La procédure du livre des codes indique les informations du dictionnaire(telles que les noms de variables, les étiquettes de variables, les étiquettes de valeurs, lesvaleurs manquantes) ainsi que les statistiques récapitulatives de toutes les variables spécifiéeset les vecteurs multiréponses dans l’ensemble de données actif. Pour les variables ordinales etnominales ainsi que pour les vecteurs multiréponses, les statistiques récapitulatives comprennentles effectifs et les pourcentages. Pour les variables d’échelle, les statistiques récapitulativescomprennent la moyenne, l’écart-type et les quartiles. Pour plus d'informations, reportez-vous àLivre des codes dans Chapitre 14 sur p. 296.
Analyse du voisin le plus proche. L’analyse du voisin le plus proche est une méthode declassification d’observations en fonction de leur similarité avec les autres observations.En apprentissage automatique, elle a été développée comme une façon de reconnaître lesconfigurations de données sans avoir à recourir à une correspondance exacte avec d’autresconfigurations ou observations stockées. Les observations semblables sont proches l’une del’autre et les observations dissemblables sont éloignées l’une de l’autre. Par conséquent, ladistance entre deux observations est une mesure de leur dissemblance. Pour plus d'informations,reportez-vous à Analyse du voisin le plus proche dans Chapitre 32 sur p. 406.

3
Sommaire
Imputation multiple. La procédure d’imputation multiple procède à des imputations multiplesdes valeurs de données manquantes. Dans un ensemble de données comportant des valeursmanquantes, elle génère un ou plusieurs ensembles de données dans lesquels les valeursmanquantes sont remplacées par des estimations plausibles. Vous obtenez alors des résultatsregroupés lorsque vous exécutez d’autres procédures. La procédure récapitule également lesvaleurs manquantes dans l’ensemble de données de travail. Cette fonction est disponible dansl’option complémentaire Valeurs manquantes.
Analyse RFM. L’analyse RFM (récence, fréquence, monétaire) est une technique permettantd’identifier des clients existants qui ont plus de chances de répondre à une nouvelle offre. Cettetechnique est couramment utilisée dans le marketing direct. Cette fonction est disponible dansl’option complémentaire EZ RFM.
Améliorations de la Régression nominale. La régression nominale a été améliorée afin d’inclure desméthodes de régularisation et de rééchantillonnage afin d’estimer et d’améliorer la précision de laprévision. Ensemble, ces nouvelles méthodes rendent possible la création des modèles de pointe,même pour de grands volumes de données (où il y a davantage de variables que d’observations,comme en génomique). Cette fonction est disponible dans l’option complémentaire Modalités.
Graphique. Les visualisations graphiques sont des graphiques et des diagrammes créés à partird’un modèle de visualisation. SPSS Statistics est fourni avec des modèles de visualisationintégrés. Vous pouvez également utiliser un autre produit, SPSS Viz Designer, pour créer vospropres modèles de visualisation. Les nouveaux modèles de visualisation sont des types devisualisation fortement personnalisables.
Exportation des résultats. Davantage d’options de format d’exportation des résultats et un contrôleaccru du contenu exporté, notamment :
Réorganiser ou réduire les grands tableaux dans les documents Word. Pour plusd'informations, reportez-vous à Options Word/RTF dans Chapitre 10 sur p. 239.Créer de nouvelles feuilles de calcul ou ajouter des données à des feuilles de calcul existantesdans un classeur Excel. Pour plus d'informations, reportez-vous à Options Excel dansChapitre 10 sur p. 241.Enregistrer des spécifications d’exportation de résultats sous la forme d’une syntaxe decommande grâce à la commande OUTPUT EXPORT. Toutes les fonctions d’exportation derésultats dans la boîte de dialogue Exporter résultats sont désormais disponibles dans lasyntaxe de commande, de sorte que vous puissiez enregistrer et réexécuter vos spécificationsd’exportation et les inclure dans des tâches de production automatisées.Le système de gestion des résultats (OMS) prend désormais en charge les formats de résultatssuivants : Word, Excel, et PDF. Pour plus d'informations, reportez-vous à Système de gestiondes résultats dans Chapitre 52 sur p. 603.
Valeurs de décalage. Les valeurs de décalage permettent de créer des variables qui contiennent lesvaleurs de variables existantes à partir d’observations antérieures (décalage positif) ou ultérieures(décalage négatif). Pour plus d'informations, reportez-vous à Valeurs de décalage dans Chapitre 8sur p. 151.

4
Chapitre 1
Amélioration de l’option Agréger. Vous pouvez désormais utiliser les fonctions de la procédureAgréger sans avoir à spécifier de critère d’agrégation. Pour plus d'informations, reportez-vous àAgréger les données dans Chapitre 9 sur p. 200.
Fonction Médiane. Une fonction médiane est désormais disponible pour calculer la valeur de lamédiane sur les variables sélectionnées pour chaque observation.
Fenêtres
Il existe de nombreux types de fenêtre différents dans SPSS Statistics :
Editeur de données : L’Editeur de données affiche le contenu du fichier de données actif. Vouspouvez créer de nouveaux fichiers de données ou modifier des fichiers de données existants avecl’Editeur de données. Si vous avez plus d’un fichier de données d’ouvert, alors il y a une fenêtreéditeur de données distinctes pour chaque fichier de données.
Viewer : Tous les résultats, tableaux et diagrammes différents s’affichent dans le Viewer. Vouspouvez modifier les résultats et les enregistrer pour une utilisation ultérieure. Une fenêtre duViewer s’ouvre automatiquement la première fois que vous exécutez une procédure qui génère desrésultats.
Editeur de tableaux pivotants : Les résultats affichés dans les tableaux pivotants peuvent êtremodifiés de diverses manières grâce à l’éditeur de tableaux pivotants. Vous pouvez modifier letexte, permuter les données dans les lignes et colonnes, ajouter de la couleur, créer des tableauxmultidimensionnels, et masquer et afficher les résultats de façon sélective.
Editeur de diagrammes : Vous pouvez modifier les diagrammes à haute résolution dans les fenêtresde graphique. Vous pouvez changer les couleurs, sélectionner des polices de taille ou de typedifférent, permuter les axes horizontal et vertical, faire pivoter les diagrammes de dispersion3D, et même changer le type de diagramme.
Editeur de résultats texte : Les résultats texte qui ne sont pas affichés dans les tableaux pivotantspeuvent être modifiés grâce à l’éditeur de résultats. Vous pouvez modifier les résultats et changerles caractéristiques des polices (type, style, couleur, taille).
Editeur de syntaxe : Vous pouvez coller les choix des boîtes de dialogue dans une fenêtre desyntaxe, lorsque vos choix apparaissent sous forme de syntaxe de commande. Vous pouvez alorsmodifier la syntaxe de commande pour utiliser les fonctions spéciales qui ne sont pas disponiblesdans les boîtes de dialogue. Vous pouvez enregistrer ces commandes dans un fichier pour lesutiliser dans des sessions ultérieures.
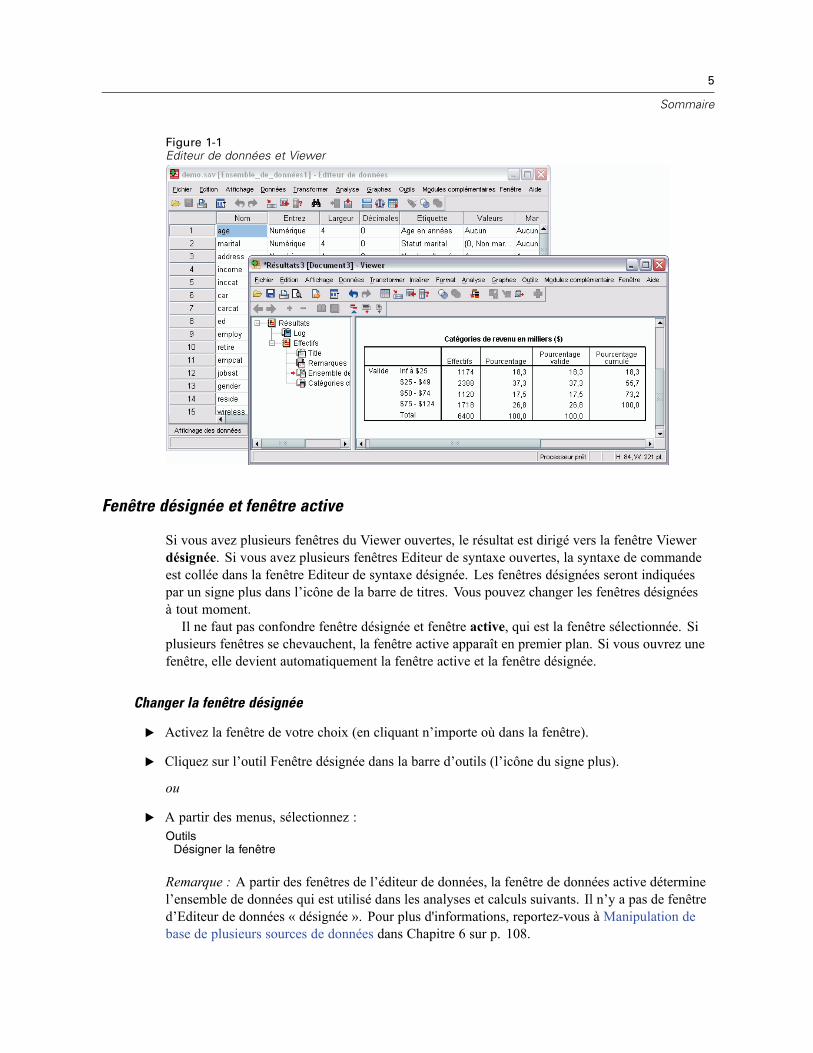
5
Sommaire
Figure 1-1Editeur de données et Viewer
Fenêtre désignée et fenêtre active
Si vous avez plusieurs fenêtres du Viewer ouvertes, le résultat est dirigé vers la fenêtre Viewerdésignée. Si vous avez plusieurs fenêtres Editeur de syntaxe ouvertes, la syntaxe de commandeest collée dans la fenêtre Editeur de syntaxe désignée. Les fenêtres désignées seront indiquéespar un signe plus dans l’icône de la barre de titres. Vous pouvez changer les fenêtres désignéesà tout moment.Il ne faut pas confondre fenêtre désignée et fenêtre active, qui est la fenêtre sélectionnée. Si
plusieurs fenêtres se chevauchent, la fenêtre active apparaît en premier plan. Si vous ouvrez unefenêtre, elle devient automatiquement la fenêtre active et la fenêtre désignée.
Changer la fenêtre désignée
E Activez la fenêtre de votre choix (en cliquant n’importe où dans la fenêtre).
E Cliquez sur l’outil Fenêtre désignée dans la barre d’outils (l’icône du signe plus).
ou
E A partir des menus, sélectionnez :Outils
Désigner la fenêtre
Remarque : A partir des fenêtres de l’éditeur de données, la fenêtre de données active déterminel’ensemble de données qui est utilisé dans les analyses et calculs suivants. Il n’y a pas de fenêtred’Editeur de données « désignée ». Pour plus d'informations, reportez-vous à Manipulation debase de plusieurs sources de données dans Chapitre 6 sur p. 108.

6
Chapitre 1
Barre d’étatLa barre d’état affichée en bas de chaque fenêtre SPSS Statistics donne les informations suivantes :
Etat de commande : Pour chaque procédure ou commande que vous exécutez, un compteurd’observations indique le nombre d’observations déjà traitées. Pour les procédures statistiques quidemandent un traitement itératif, le nombre d’itérations s’affiche.
Etat du filtre : Si vous avez sélectionné un échantillon aléatoire ou un sous-ensemble d’observationsà analyser, le message Filtre activé indique qu’un certain type de filtrage d’observations est envigueur et que l’analyse ne prend pas en compte toutes les observations du fichier de données.
Etat de la pondération : Le message Pondération activée indique qu’une variable de pondération estutilisée pour pondérer les observations prises en compte dans l’analyse.
Etat de Fichier divisé : Le message Fichier scindé activé indique que le fichier de données a étéséparé en groupes distincts pour l’analyse, d’après les valeurs d’une ou de plusieurs variables deregroupement.
Boîtes de dialogueLa plupart des sélections de menu déclenchent l’ouverture de boîtes de dialogue. Les boîtes dedialogue permettent de sélectionner des variables et des options pour effectuer des analyses.
Les boîtes de dialogue des procédures statistiques et des diagrammes comportent deux élémentsde base :
Liste des variables sources : Une liste de variables dans l’ensemble de données actif. Seuls lestypes de variables autorisés par la procédure sélectionnée apparaissent dans la liste source.L’utilisation des variables alphanumériques courtes et alphanumériques longues est limitée dansde nombreuses procédures.
Liste(s) des variables cibles : Une ou plusieurs listes indiquant les variables que vous avez choisiespour l’analyse, comme par exemple les listes de variables dépendantes et explicatives.
Noms de variables et étiquettes de variable dans les listes de boîtesde dialogue
Vous pouvez afficher soit les noms, soit les étiquettes des variables dans les listes des boîtes dedialogue. Vous pouvez également contrôler l’ordre dans lequel sont triées les variables dans leslistes de variables source.
Pour contrôler les attributs d’affichage par défaut des variables dans les listes source,choisissez Options dans le menu Edit. Pour plus d'informations, reportez-vous à Optionsgénérales dans Chapitre 48 sur p. 539.Pour modifier les attributs d’affichage de la liste de variables source dans une boîte dedialogue, cliquez avec le bouton droit de la souris sur la liste source et sélectionnez les attributsd’affichage dans le menu contextuel. Vous pouvez afficher soit les noms, soit les étiquettes desvariables (les noms sont affichés pour toutes les variables qui n’ont pas d’étiquette définie)et vous pouvez trier la liste source par ordre des fichiers, ordre alphabétique ou niveau de
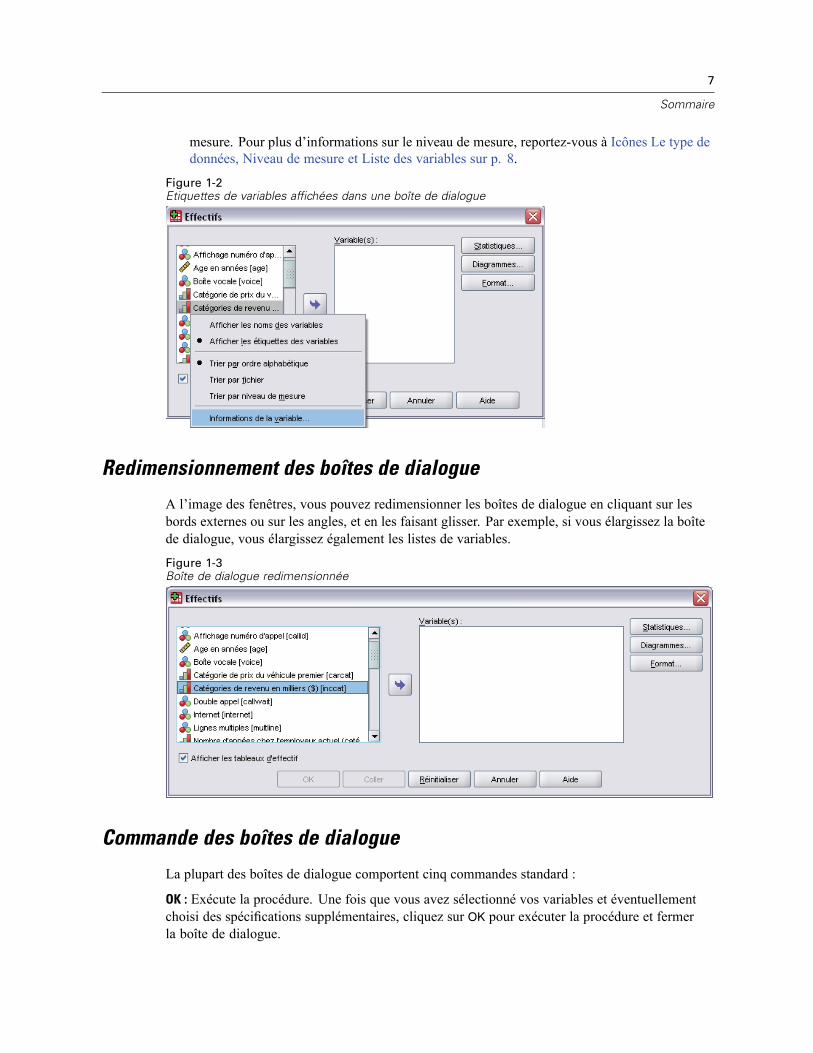
7
Sommaire
mesure. Pour plus d’informations sur le niveau de mesure, reportez-vous à Icônes Le type dedonnées, Niveau de mesure et Liste des variables sur p. 8.
Figure 1-2Etiquettes de variables affichées dans une boîte de dialogue
Redimensionnement des boîtes de dialogue
A l’image des fenêtres, vous pouvez redimensionner les boîtes de dialogue en cliquant sur lesbords externes ou sur les angles, et en les faisant glisser. Par exemple, si vous élargissez la boîtede dialogue, vous élargissez également les listes de variables.
Figure 1-3Boîte de dialogue redimensionnée
Commande des boîtes de dialogue
La plupart des boîtes de dialogue comportent cinq commandes standard :
OK : Exécute la procédure. Une fois que vous avez sélectionné vos variables et éventuellementchoisi des spécifications supplémentaires, cliquez sur OK pour exécuter la procédure et fermerla boîte de dialogue.

8
Chapitre 1
Coller : Ce bouton génère la syntaxe de commande à partir des sélections de la boîte de dialogue etcolle la syntaxe dans une fenêtre de syntaxe. Vous pouvez alors personnaliser les commandes avecd’autres fonctions SPSS qui ne sont pas disponibles à partir des boîtes de dialogue.
Restaurer : Désélectionne des variables dans la ou les listes de variables sélectionnées et remettoutes les spécifications de la boîte de dialogue et des sous-boîtes de dialogue éventuelles à l’étatpar défaut.
Annuler : Annule les modifications apportées aux paramètres de la boîte de dialogue depuis sadernière ouverture et ferme la boîte de dialogue. Au sein d’une session, les paramètres de la boîtede dialogue restent tels quels. Une boîte de dialogue conserve l’ensemble de spécifications le plusrécent jusqu’à ce que vous les ayez annulées.
Aide : Aide sensible au contexte. Ce bouton vous permet d’accéder à une fenêtre d’aide quicontient des informations sur la boîte de dialogue active.
Sélection de variables
Pour sélectionner une seule variable, sélectionnez-la simplement dans la liste des variablessource, et faites-la glisser vers la liste des variables cible. Vous pouvez également utiliser lesflèches pour déplacer les variables de la liste source aux listes cible. S’il n’y a qu’une liste devariables cible, vous pouvez double-cliquer sur des variables individuelles pour les faire passerde la liste source vers la liste cible.
Vous pouvez aussi sélectionner plusieurs variables :Pour sélectionner plusieurs variables qui sont groupées dans la liste de variables, cliquez sur lapremière puis, tout en appuyant sur Maj, cliquez sur la dernière du groupe.Pour sélectionner plusieurs variables qui ne sont pas regroupées dans la liste de variables,cliquez sur la première puis, tout en appuyant sur Ctrl, cliquez sur la variable suivante et ainside suite. (Pour Macintosh : cliquez sur la commande).
Icônes Le type de données, Niveau de mesure et Liste des variables
Les icônes affichées à côté des variables dans les listes de la boîte de dialogue fournissent desinformations sur le type de variable et le niveau de mesure.
Le type de donnéesNiveau de mesureNumérique Chaîne Date Heure
Echelle n/a
Ordinal
Nominal
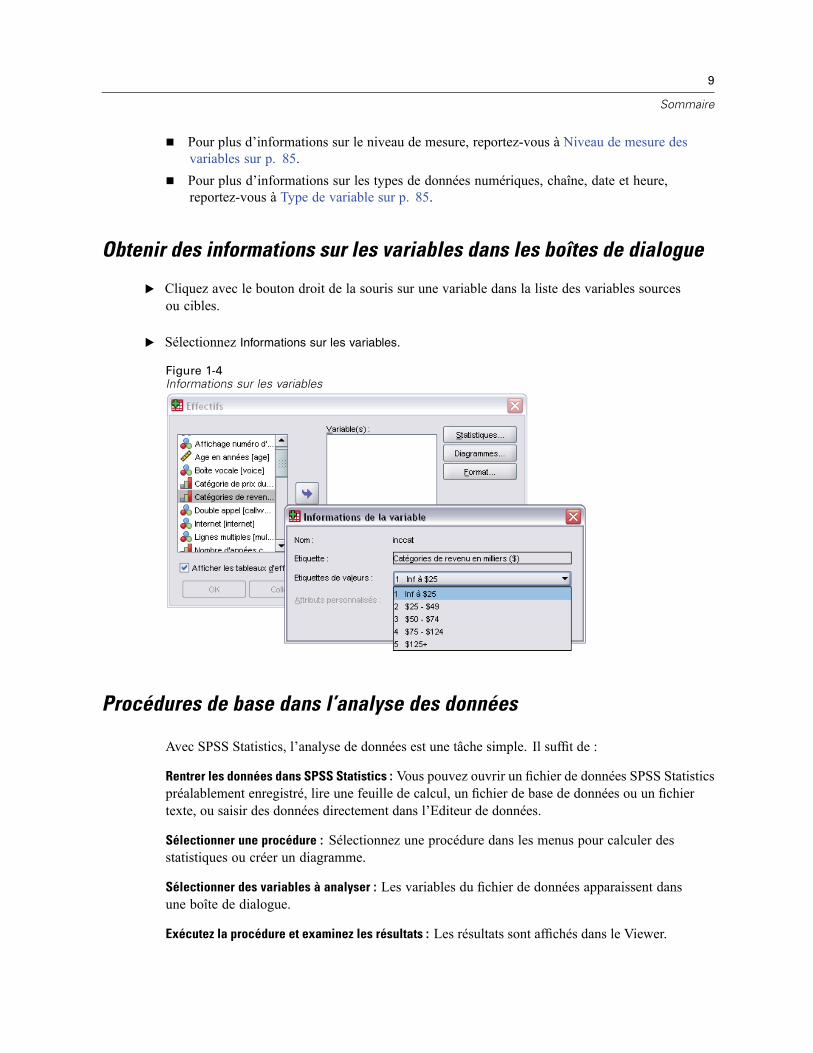
9
Sommaire
Pour plus d’informations sur le niveau de mesure, reportez-vous à Niveau de mesure desvariables sur p. 85.Pour plus d’informations sur les types de données numériques, chaîne, date et heure,reportez-vous à Type de variable sur p. 85.
Obtenir des informations sur les variables dans les boîtes de dialogue
E Cliquez avec le bouton droit de la souris sur une variable dans la liste des variables sourcesou cibles.
E Sélectionnez Informations sur les variables.
Figure 1-4Informations sur les variables
Procédures de base dans l’analyse des données
Avec SPSS Statistics, l’analyse de données est une tâche simple. Il suffit de :
Rentrer les données dans SPSS Statistics : Vous pouvez ouvrir un fichier de données SPSS Statisticspréalablement enregistré, lire une feuille de calcul, un fichier de base de données ou un fichiertexte, ou saisir des données directement dans l’Editeur de données.
Sélectionner une procédure : Sélectionnez une procédure dans les menus pour calculer desstatistiques ou créer un diagramme.
Sélectionner des variables à analyser : Les variables du fichier de données apparaissent dansune boîte de dialogue.
Exécutez la procédure et examinez les résultats : Les résultats sont affichés dans le Viewer.

10
Chapitre 1
Assistant statistique
Si vous ne connaissez pas bien SPSS Statistics ou les procédures statistiques disponibles,l’Assistant statistique peut vous aider à démarrer en vous posant des questions simples, en langagenon technique, et en vous donnant des exemples visuels qui vous aideront à sélectionner lesfonctions statistiques et de représentation graphique de base convenant le mieux à vos données.
Pour utiliser l’Assistant statistique, choisissez dans les menus d’une fenêtre SPSS Statisticsquelconque :Aide
Assistant statistique
L’Assistant statistique ne traite qu’un certain nombre de procédures du système de base. Il aété conçu pour fournir une assistance d’ordre général pour de nombreuses statistiques de baseparmi les plus courantes.
En savoir plus
Pour avoir une vue d’ensemble complète des principes de base, consultez le didacticiel en ligne.Dans un menu SPSS Statistics quelconque, choisissez :Aide
Didacticiel

Chapitre
2Obtention d’Aide
L’aide apparaît sous plusieurs formes :
Menu Aide. Le menu Aide de la plupart des fenêtres permet d’accéder au système d’aide principal,ainsi qu’aux didacticiels et aux informations de référence technique.
Rubriques. Les rubriques permettent d’accéder aux onglets Sommaire, Index et Rechercher,que vous pouvez utiliser pour chercher des rubriques d’aide particulières.Didacticiel. Instructions illustrées et détaillées étape par étape vous expliquant commentutiliser de nombreuses fonctions de base. Il n’est pas nécessaire de visualiser le didacticieldu début à la fin. Vous pouvez choisir les rubriques à visualiser, ignorer et visualiser desrubriques dans l’ordre de votre choix, et utiliser l’index ou le sommaire pour rechercher desrubriques données.Etudes de cas. Exemples pratiques indiquant comment créer différents types d’analysestatistique et comment interpréter les résultats. Les fichiers de données d’exemple utilisésdans ces cas pratiques vous sont également fournis afin que vous puissiez voir exactementcomment les résultats ont été générés. Vous pouvez choisir à partir du sommaire lesprocédures sur lesquelles vous souhaitez obtenir des informations ou rechercher des rubriquesappropriées dans l’index.Assistant statistique. Vous aide à rechercher la procédure que vous souhaitez utiliser. Une foisvos sélections effectuées, l’Assistant statistique ouvre la boîte de dialogue de la procédurestatistique, de rapport ou de diagramme qui correspond aux critères sélectionnés. L’Assistantstatistique permet d’accéder à la plupart des procédures statistiques et de rapport du systèmede base, et à de nombreuses procédures de diagramme.Command Syntax Reference. Un guide de référence détaillé sur la syntaxe des commandes estdisponible sous deux formes différentes : guide intégré dans le système d’aide global etcomme document distinct au format PDF dans Command Syntax Reference, aussi disponible àpartir du menu Aide.Algorithmes statistiques. Les algorithmes utilisés pour la plupart des procédures statistiquessont disponibles sous deux formes : intégrés dans le système d’aide global et comme documentdistinct au format PDF, disponible sur le CD des manuels. Pour connaître les liens d’accès àdes algorithmes spécifiques du système d’aide, sélectionnez Algorithmes dans le menu Aide.
Aide sensible au contexte. Plusieurs emplacements de l’interface utilisateur vous permettentd’accéder à l’aide contextuelle.
Boutons Aide de boîte de dialogue. La plupart des boîtes de dialogue disposent d’un boutonAide qui vous conduit directement à la rubrique d’aide relative à la boîte de dialogue. Larubrique d’aide fournit des informations générales et propose des liens vers les rubriquesapparentées.
11

12
Chapitre 2
Aide du menu contextuel du tableau pivotant. Cliquez avec le bouton droit de la souris sur lestermes du tableau pivotant dans le Viewer et sélectionnez Qu’est-ce que c’est ? dans le menucontextuel afin d’afficher les définitions de ces termes.Syntaxe de commande. Dans une fenêtre de synatxe de commande, positionnez le curseurn’importe où à l’intérieur du bloc de syntaxe pour une commande et appuyez sur F1 sur leclavier. Un diagramme complet de syntaxe de commande pour cette commande s’affiche.La documentation complète de la syntaxe de commande est disponible à partir des liens desrubriques liées et depusi l’onglet Contenu de l’aide.
Autres ressources
Site Web du support technique. Vous pouvez trouver des réponses à de nombreux problèmescourants à l’adresse http://support.spss.com. (Pour accéder au site Web du support technique, vousdevez entrer un ID de connexion et un mot de passe. L’URL ci-dessus vous permettra d’obtenirdes informations sur l’obtention d’un ID et d’un mot de passe.)
Developer Central. Developer Central possède des ressources pour tous les niveaux d’utilisateurset de développeurs d’applications. Téléchargez des utilitaires, des exemples graphiques,des nouveaux modules statistiques et des articles. Visitez Developer Central à l’adressehttp://www.spss.com/devcentral.
Aide sur les termes utilisés dans les résultats
Pour consulter une définition d’un terme dans les résultats du tableau pivotant du Viewer :
E Double-cliquez sur le tableau pivotant pour l’activer.
E Cliquez avec le bouton droit sur le terme dont vous souhaitez obtenir une explication.
E Sélectionnez A propos de dans le menu contextuel.
La fenêtre qui s’affiche présente une définition du terme.

13
Obtention d’Aide
Figure 2-1Glossaire du tableau pivotant activé à partir du bouton droit de la souris

Chapitre
3Fichiers de données
Les fichiers de données se présentent sous une grande diversité de formats et SPSS a été conçupour traiter nombre d’entre eux, dont :
Feuilles de calcul créées sous Excel et LotusTableaux de bases de données issus de plusieurs sources de bases de données, notammentOracle, SQLServer, Access, dBASE, etc.Fichiers texte délimités par des tabulations et autres types de fichiers texte simplesLes fichiers de données au format SPSS Statistics créés avec d’autres systèmes d’exploitationFichiers de données SYSTATFichiers de données SASFichiers de données Stata
Ouverture de fichiers de données
Outre les fichiers sauvegardés au format SPSS Statistics, vous pouvez ouvrir les fichiers Excel,SAS, Stata, ainsi que les fichiers tabulés et autres sans avoir à convertir les fichiers en un formatintermédiaire ni à entrer d’informations de définition de données.
L’ouverture d’un fichier de données le rend actif. Si un ou plusieurs fichiers de donnéesse trouvent déjà ouverts, ils restent ouverts et disponibles pour une utilisation ultérieuredans la session. Pour qu’un fichier de données ouvert devienne l’ensemble de données actif,cliquez à n’importe quel endroit de la fenêtre Editeur de données. Pour plus d'informations,reportez-vous à Utilisation des sources de données multiples dans Chapitre 6 sur p. 107.En mode d’analyse distribuée mettant en œuvre un serveur distant pour le traitement descommandes et l’exécution des procédures, les fichiers de données, dossiers et lecteursdisponibles dépendent des données accessibles sur le serveur. Le nom du serveur utilisé estindiqué dans la zone supérieure de la boîte de dialogue. Vous n’aurez accès aux fichiers dedonnées de votre ordinateur local que si vous définissez le lecteur correspondant comme unlecteur partagé et les dossiers contenant vos fichiers de données comme des dossiers partagés.Pour plus d'informations, reportez-vous à Mode d’analyse distribuée dans Chapitre 4 sur p. 73.
Pour ouvrir un fichier de données
E A partir des menus, sélectionnez :Fichier
OuvrirDonnées...
14

15
Fichiers de données
E Dans la boîte de dialogue Ouvrir données, sélectionnez le fichier à ouvrir.
E Cliquez sur Ouvrir.
Sinon, vous pouvez :Définir automatiquement la largeur de chaque variable chaîne à la valeur observée la pluslongue pour cette variable, en utilisant Réduire les largeurs de chaîne en fonction des valeursobservées. Ceci est très utile lors de la lecture de fichiers de données de page de code enmode Unicode. Pour plus d'informations, reportez-vous à Options générales dans Chapitre48 sur p. 539.Lire les noms de variable sur la première ligne des fichiers de feuilles de calcul.spécifier une plage de cellules à lire dans le cas de fichiers de feuilles de calcul.Spécifier une feuille de calcul à lire dans un fichier Excel (version Excel 95 ou supérieure).
Pour plus d’informations sur la lecture des données à partir des bases de données, reportez-vous àLire des fichiers de base de données sur p. 18. Pour plus d’informations sur la lecture des donnéesà partir des fichiers de données texte, reportez-vous à Assistant de texte sur p. 33.
Types de fichier de données
SPSS Statistics. Ouvre les fichiers de données enregistrés au format SPSS Statistics ainsi quele produit DOS SPSS/PC+.
SPSS/PC+. Ouvre les fichiers de données SPSS/PC+.
SYSTAT. Ouvre les fichiers de données SYSTAT.
SPSS Statistics Portable. Ouvre les fichiers de données sauvegardés en format portable.Sauvegarder un fichier en format portable prend bien plus de temps que de sauvegarder le fichieren format SPSS Statistics.
Excel. Ouvre les fichiers Excel.
Lotus 1-2-3. Ouvre les fichiers de données enregistrés au format 1-2-3 pour les versions 3.0 et2.0, ainsi que pour la version 1A de Lotus.
SYLK. Ouvre les fichiers de données sauvegardés en format SYLK (lien symbolique), formatutilisé par quelques applications de tableurs.
dBASE. Ouvre des fichiers de format dBASE pour dBASE IV, dBASE III ou III PLUS, ou pourdBASE II. Chaque observation est un enregistrement. Les étiquettes de variable et de valeursainsi que les spécifications de valeurs manquantes sont perdues lorsque vous sauvegardez unfichier dans ce format.
SAS. SAS versions 6–9 et fichiers de transfert SAS.
Stata. Version Stata 4–8.

16
Chapitre 3
Ouvrir les options de fichier
Lire les noms de variables : Dans le cas des feuilles de calcul, vous pouvez lire le nom des variablesà partir de la première ligne du fichier ou de la première ligne de la plage définie. En fonctionde vos besoins, vous pouvez convertir les valeurs pour créer des noms de variables valides, enn’oubliant pas de convertir les espaces en traits de soulignement.
Feuille de calcul : Les fichiers de la version Excel 95 ou supérieure peuvent contenir plusieursfeuilles de calcul. Par défaut, l’éditeur de données lit la première feuille. Pour lire une autre feuillede calcul, sélectionnez-la dans la liste déroulante.
Intervalle : Pour les fichiers de données sous forme de feuilles de calcul, vous pouvez égalementlire une plage de cellules. Utilisez la même méthode pour spécifier des intervalles de cellulescomme vous le feriez pour des applications tableur.
Lecture de fichiers Excel version 95 ou ultérieure
Les règles suivantes s’appliquent à la lecture de fichiers Excel version 95 ou ultérieure :
Type de données et largeur : Chaque colonne représente une variable. Le type et la largeur dedonnées de chaque variable sont déterminés par le type et la largeur de données dans le fichierExcel. Si la colonne contient plusieurs types de données (par exemple, des dates et des valeursnumériques), le type de données est converti en chaîne et toutes les valeurs sont lues comme desvaleurs de chaînes valides.
Cellules blanches : En ce qui concerne les variables numériques, les cellules vides sont convertiesen valeurs manquantes par défaut et identifiées par un point. En ce qui concerne les variableschaîne, un blanc est une valeur de caractère valide, et les cellules vides sont traitées comme desvaleurs de chaîne valides.
Noms des variables : Si vous lisez la première ligne du fichier Excel (ou la première ligne de laplage spécifiée) en tant que noms de variable, les valeurs qui ne sont pas conformes aux règles dedénomination de variable sont converties en noms de variable valides et les noms initiaux sontutilisés comme étiquettes de variable. Si vous ne lisez pas les noms de variables à partir du fichierExcel, des noms de variables par défaut sont affectés.
Lecture de fichiers Excel antérieurs ou d’autres tableurs
Les règles applicables à la lecture de fichiers Excel antérieurs à Excel 95 et à celle de fichiersd’autres tableurs sont les suivantes :
Type de données et largeur : Le type de données et la largeur de chaque variable sont déterminéspar la largeur de la colonne et le type de données de la première cellule de données de la colonne.Les valeurs d’autres types sont converties en valeurs manquantes par défaut. Si, dans la colonne,la première cellule de données est vide, le type général de données par défaut pour la feuille decalcul (habituellement numérique) est utilisé.

17
Fichiers de données
Cellules blanches : En ce qui concerne les variables numériques, les cellules vides sont convertiesen valeurs manquantes par défaut et identifiées par un point. En ce qui concerne les variableschaîne, un blanc est une valeur de caractère valide, et les cellules vides sont traitées comme desvaleurs de chaîne valides.
Noms des variables : Si, à partir de la feuille de calcul, vous ne pouvez pas lire le nom des variables,SPSS utilise les lettres des colonnes (A, B, C, etc.) comme noms de variable pour les fichiers Excelet Lotus. En ce qui concerne les fichiers SYLK et Excel enregistrés au format d’affichage R1C1,le programme utilise le numéro de la colonne, précédé par la lettre C (C1, C2, C3, etc.).
Lecture de fichiers dBASE
Les fichiers de base de données sont logiquement très semblables aux fichiers de données auformat SPSS Statistics. Les règles générales suivantes s’appliquent aux fichiers dBASE :
Les noms de champ sont convertis en noms de variable valides.Les signes deux points utilisés dans les noms de champ dBASE sont convertis en traits desoulignement.Les enregistrements indiqués comme devant être supprimés, mais qui n’ont pas été purgés,sont inclus. SPSS crée une nouvelle variable chaîne, D_R, qui contient un astérisque pourles observations indiquées comme devant être supprimées.
Lecture de fichiers Stata
Les règles générales suivantes s’appliquent aux fichiers de données Stata :Noms des variables : Les noms des variables Stata sont convertis en noms de variables SPSSStatistics dans un format sensible à la casse. Les noms de variable Stata qui sont identiquesmais avec une casse différente sont convertis en noms de variable valides par l’ajout d’un traitde soulignement et d’une lettre séquentielle (_A, _B, _C, ..., _Z, _AA, _AB, ..., etc.).Etiquettes de variable : Les étiquettes de variables Stata sont converties en étiquettes devariables SPSS Statistics.Les étiquettes de valeurs : Les étiquettes de valeurs Stata sont converties en étiquettes devaleurs SPSS Statistics, à l’exception des étiquettes de valeurs Stata assignées aux valeursmanquantes « étendues ».Valeurs manquantes : Les valeurs manquantes « étendues » Stata sont converties en valeursmanquantes par défaut.Conversion des dates : Les valeurs de format de date Stata sont converties en valeurs de formatde DATESPSS Statistics (j-m-a). Les valeurs de format de date de « série chronologique »Stata (semaines, mois, trimestres, etc.) sont converties au simple format numérique (F), enpréservant la valeur entière originale interne qui représente le nombre de semaines, mois,trimestres, etc. depuis le début de 1960.

18
Chapitre 3
Lire des fichiers de base de données
Vous pouvez lire des données à partir de n’importe quel format de base de données pour laquellevous avez un pilote adapté. En mode d’analyse locale, les pilotes nécessaires doivent êtreinstallés sur votre ordinateur local. En mode d’analyse distribuée (disponible avec le serveurSPSS Statistics), les pilotes doivent être installés sur le serveur distant.Pour plus d'informations,reportez-vous à Mode d’analyse distribuée dans Chapitre 4 sur p. 73.
Lire des fichiers de base de données
E A partir des menus, sélectionnez :Fichier
Ouvrir la base de donnéesNouvelle requête...
E Sélectionnez la source des données.
E Si nécessaire (selon la source de données), sélectionnez le fichier de base de données et/ou entrezun nom de connexion, un mot de passe et d’autres informations.
E Sélectionnez la (les) table(s) et les champs. Pour les sources de données OLE DB (disponiblesuniquement sous les systèmes d’exploitation Windows), vous ne pouvez sélectionner qu’untableau.
E Spécifiez toute relation existante entre vos tables.
E Eventuellement :Spécifier les critères éventuels de sélection de vos données.Ajouter une invite pour que l’utilisateur puisse y entrer un paramètre de requête.Enregistrer la requête que vous avez créée avant de l’exécuter.
Pour modifier une requête de base de données enregistrée
E A partir des menus, sélectionnez :Fichier
Ouvrir la base de donnéesModifier requête...
E Sélectionnez le fichier requête (*.spq) à modifier.
E Suivez les instructions de création d’une nouvelle requête.
Pour lire des fichiers de base de données avec des requêtes enregistrées
E A partir des menus, sélectionnez :Fichier
Ouvrir la base de donnéesExécuter requête...
E Sélectionnez le fichier requête (*.spq) à exécuter.

19
Fichiers de données
E Si nécessaire (en fonction du fichier de base de données), entrez un nom de connexion et un motde passe.
E Si la requête a une invite imbriquée, vous pourrez avoir besoin d’entrer d’autres informations (parexemple, le trimestre pour lequel vous voulez récupérer les chiffres de ventes).
Sélectionner une source de données
Dans le premier écran de l’assistant de base de données, sélectionnez le type de source de donnéesà lire.
Sources de données ODBC
Si vous n’avez pas de sources de données ODBC configurées ou si vous voulez ajouter unenouvelle source de données, cliquez sur Ajouter source données ODBC.
Sur les systèmes d’exploitation Linux, ce bouton n’est pas disponible. Les sources de donnéesODBC sont spécifiées dans odbc.ini, et les variables d’environnement ODBCINI doivent êtreparamétrées sur l’emplacement de ce fichier. Pour plus d’informations, reportez-vous à ladocumentation relative à vos pilotes de base de données.En mode d’analyse distribuée (disponible avec le serveur SPSS Statistics), ce bouton n’estpas disponible. Pour ajouter des sources de données en mode d’analyse distribuée, consultezvotre administrateur système.
Une source de données ODBC est composée de deux principaux éléments d’informations : Lepilote qui sera utilisé pour accéder aux données et l’emplacement de la base de données à laquellevous souhaitez accéder. Pour spécifier des sources de données, vous devez installer les pilotesappropriés. Pour le mode d’analyse locale, vous pouvez installer des pilote pour tout un ensemblede formats de base de données depuis le CD d’installation de SPSS Statistics.

20
Chapitre 3
Figure 3-1Assistant de base de données
Sources de données OLE DB
Pour accéder aux sources de données OLE DB (disponible uniquement sous les systèmesd’exploitation Windows), vous devez avoir installé les éléments suivants :
.NET frameworkModèle de données de dimension et accès OLE DB
Les versions des composants compatibles avec cette version peuvent être installées à partir duCD d’installation et sont disponibles dans le menu AutoPlay.
Les jointures de tables ne sont pas disponibles pour les sources de données OLE DB. Vous nepouvez lire qu’une table à la fois.Vous ne pouvez ajouter des sources de données OLE DB qu’en mode d’analyse locale.Pour ajouter des sources de données OLE DB en mode d’analyse distribuée sur un serveurWindows, consultez votre administrateur système.En mode d’analyse distribuée (disponible avec le serveur SPSS Statistics), les sources dedonnées OLE DB sont uniquement disponibles sur des serveurs Windows et .NET et le modèlede données de dimensions ainsi que l’accès OLE DB doivent être installés sur le serveur.
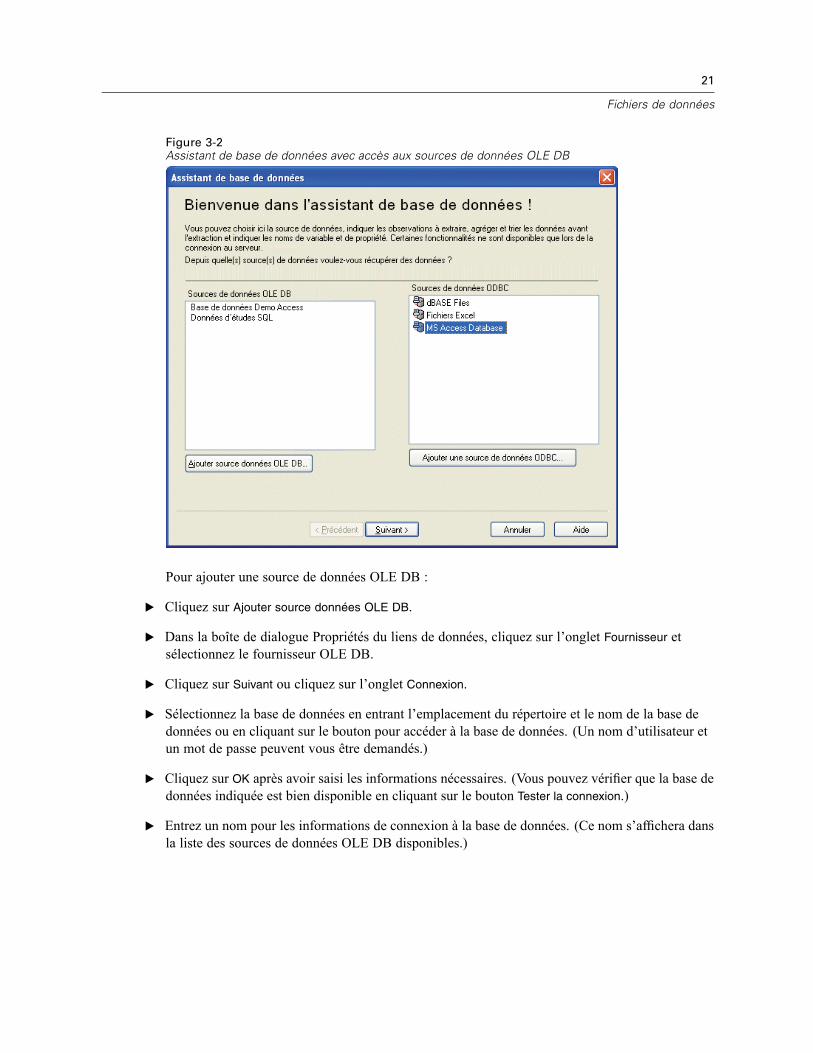
21
Fichiers de données
Figure 3-2Assistant de base de données avec accès aux sources de données OLE DB
Pour ajouter une source de données OLE DB :
E Cliquez sur Ajouter source données OLE DB.
E Dans la boîte de dialogue Propriétés du liens de données, cliquez sur l’onglet Fournisseur etsélectionnez le fournisseur OLE DB.
E Cliquez sur Suivant ou cliquez sur l’onglet Connexion.
E Sélectionnez la base de données en entrant l’emplacement du répertoire et le nom de la base dedonnées ou en cliquant sur le bouton pour accéder à la base de données. (Un nom d’utilisateur etun mot de passe peuvent vous être demandés.)
E Cliquez sur OK après avoir saisi les informations nécessaires. (Vous pouvez vérifier que la base dedonnées indiquée est bien disponible en cliquant sur le bouton Tester la connexion.)
E Entrez un nom pour les informations de connexion à la base de données. (Ce nom s’affichera dansla liste des sources de données OLE DB disponibles.)

22
Chapitre 3
Figure 3-3Boîte de dialogue Enregistrer les informations de connexion OLE DB en tant que
E Cliquez sur OK.
Cette opération vous renvoie au premier écran de l’assistant de base de données sur lequel vouspouvez ensuite sélectionner le nom enregistré à partir de la liste des sources de données OLE DBpuis passer à l’étape suivante de l’assistant.
Suppression des sources de données OLE DB
Pour supprimer le nom de certaines sources de données de la liste qui répertorie les sourcesOLE DB, supprimez le fichier UDL comportant le nom de la source de données dans :
[lecteur]:\Documents and Settings\[nom d’utilisateur]\Local Settings\ApplicationData\SPSS\UDL
Sélectionner des champs de données
L’étape Sélectionner des données contrôle les tableaux et les champs lus. Les champs base dedonnées (colonnes) sont lus comme des variables.Si une table comporte un ou plusieurs champs sélectionnés, tous ses champs seront visibles
dans les fenêtres de l’Assistant de base de données suivantes, mais seuls les champs sélectionnésdans cette boîte de dialogue seront importés comme variables. Cela vous permet de créer desjointures de tables et de spécifier les critères d’utilisation des champs que vous n’importez pas.
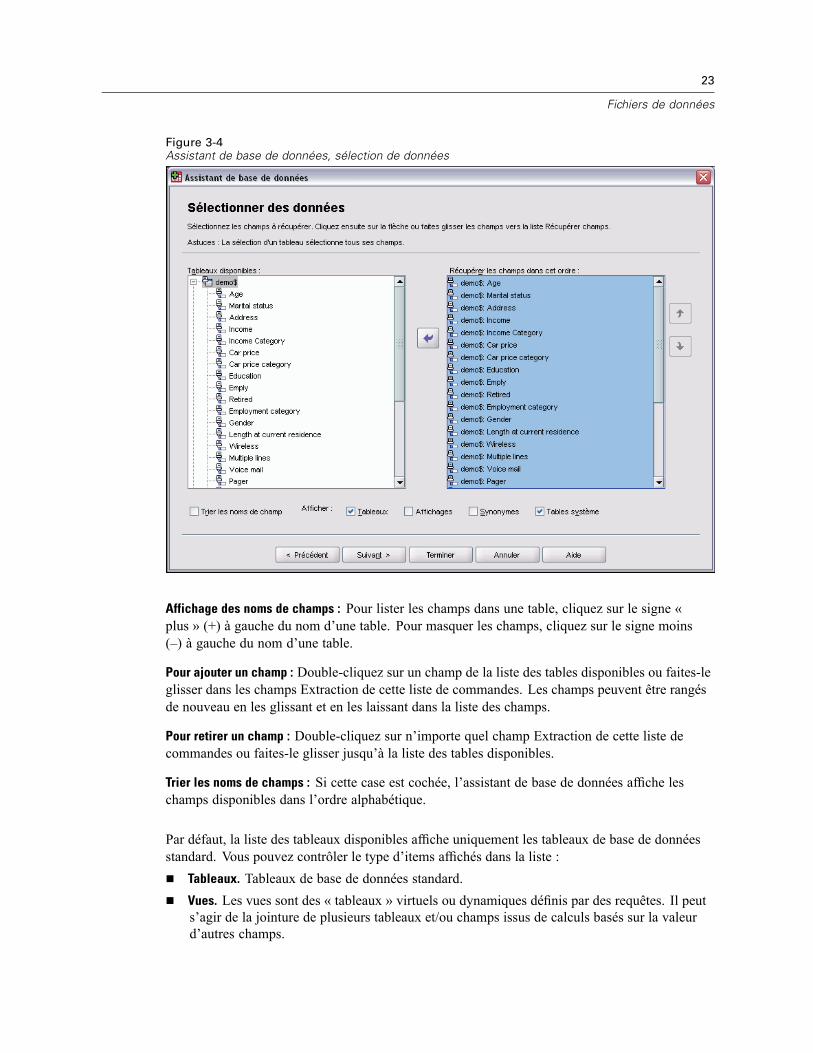
23
Fichiers de données
Figure 3-4Assistant de base de données, sélection de données
Affichage des noms de champs : Pour lister les champs dans une table, cliquez sur le signe «plus » (+) à gauche du nom d’une table. Pour masquer les champs, cliquez sur le signe moins(–) à gauche du nom d’une table.
Pour ajouter un champ : Double-cliquez sur un champ de la liste des tables disponibles ou faites-leglisser dans les champs Extraction de cette liste de commandes. Les champs peuvent être rangésde nouveau en les glissant et en les laissant dans la liste des champs.
Pour retirer un champ : Double-cliquez sur n’importe quel champ Extraction de cette liste decommandes ou faites-le glisser jusqu’à la liste des tables disponibles.
Trier les noms de champs : Si cette case est cochée, l’assistant de base de données affiche leschamps disponibles dans l’ordre alphabétique.
Par défaut, la liste des tableaux disponibles affiche uniquement les tableaux de base de donnéesstandard. Vous pouvez contrôler le type d’items affichés dans la liste :
Tableaux. Tableaux de base de données standard.Vues. Les vues sont des « tableaux » virtuels ou dynamiques définis par des requêtes. Il peuts’agir de la jointure de plusieurs tableaux et/ou champs issus de calculs basés sur la valeurd’autres champs.
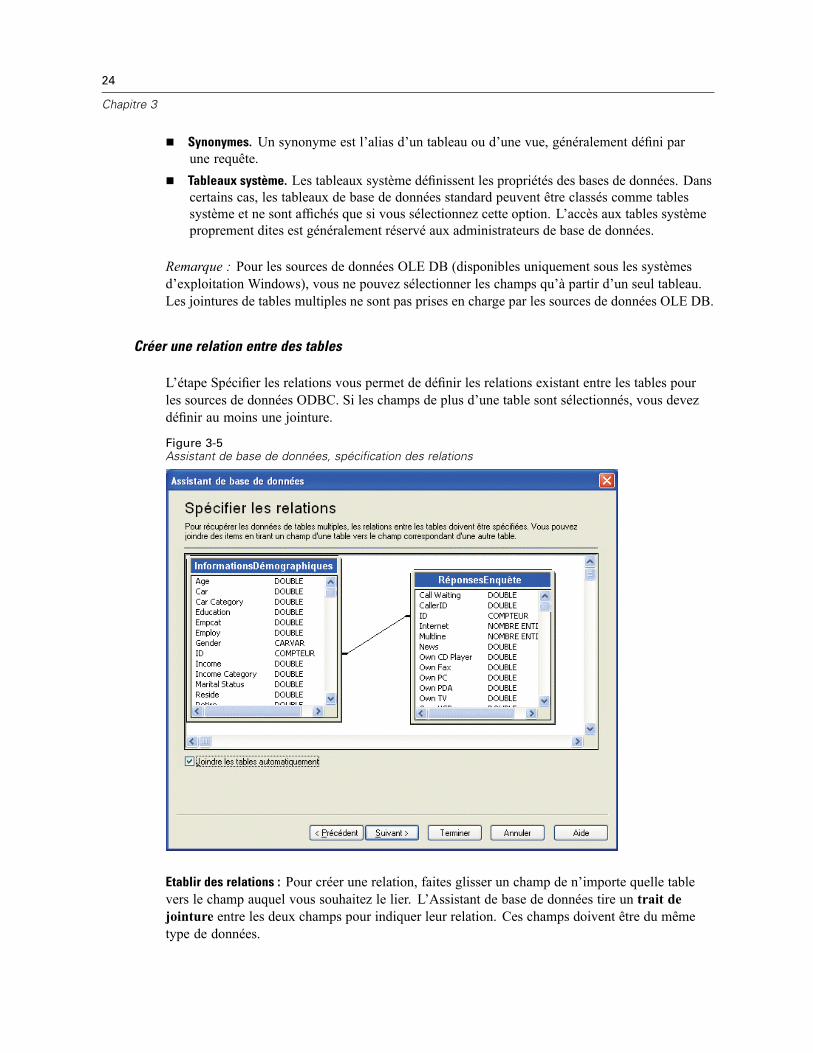
24
Chapitre 3
Synonymes. Un synonyme est l’alias d’un tableau ou d’une vue, généralement défini parune requête.Tableaux système. Les tableaux système définissent les propriétés des bases de données. Danscertains cas, les tableaux de base de données standard peuvent être classés comme tablessystème et ne sont affichés que si vous sélectionnez cette option. L’accès aux tables systèmeproprement dites est généralement réservé aux administrateurs de base de données.
Remarque : Pour les sources de données OLE DB (disponibles uniquement sous les systèmesd’exploitation Windows), vous ne pouvez sélectionner les champs qu’à partir d’un seul tableau.Les jointures de tables multiples ne sont pas prises en charge par les sources de données OLE DB.
Créer une relation entre des tables
L’étape Spécifier les relations vous permet de définir les relations existant entre les tables pourles sources de données ODBC. Si les champs de plus d’une table sont sélectionnés, vous devezdéfinir au moins une jointure.
Figure 3-5Assistant de base de données, spécification des relations
Etablir des relations : Pour créer une relation, faites glisser un champ de n’importe quelle tablevers le champ auquel vous souhaitez le lier. L’Assistant de base de données tire un trait dejointure entre les deux champs pour indiquer leur relation. Ces champs doivent être du mêmetype de données.

25
Fichiers de données
Jointure automatique de tables : Essaie de joindre automatiquement deux tables d’après les clésprimaire/étrangère, ou de mettre en correspondance le nom des champs et le type de données.
Type de jointure : Si votre pilote prend en charge les jointures externes, vous pouvez spécifier soitdes jointures internes, soit des jointures externes gauches ou droites.
Jointures internes : Une jointure interne n’inclut que les lignes dont les champs reliés sontégaux. Dans cet exemple, toutes les lignes dont les valeurs ID sont identiques dans les deuxtables seront inclues.Jointures externes : En plus des jointures internes dont les lignes correspondent une à une,vous pouvez également fusionner les tables à l’aide du système de correspondance une lignevers plusieurs en utilisant les jointures externes. Vous pouvez, par exemple, fusionner untableau contenant quelques enregistrements seulement et représentant des valeurs de donnéeset des étiquettes descriptives associées avec les valeurs d’un tableau contenant des centainesou des milliers d’enregistrements représentant des personnes interrogées. Une jointure externegauche inclut tous les enregistrements de la table de gauche et seulement les enregistrementsde la table de droite dont les champs reliés sont égaux. Dans une jointure externe droite, lajointure importe tous les enregistrements de la table de droite et seulement les enregistrementsde la table de gauche dont les champs reliés sont égaux.
Limiter les observations récupérées
L’étape Limiter les observations récupérées vous permet de spécifier les critères pour sélectionnerdes sous-groupes d’observations (lignes). Limiter les observations consiste généralement à remplirla grille de critères avec un ou plusieurs critères. Les critères consistent en deux expressions et desrelations entre elles. Celles-ci renvoient la valeur True, False ou missing pour chaque observation.
Si le résultat est vrai, l’observation est sélectionnée.Si le résultat est faux ou manquant, l’observation n’est pas sélectionnée.La plupart des critères utilisent un ou plusieurs des six opérateurs relationnels (<, >, <=, >=,= et <>).Les expressions conditionnelles peuvent inclure des noms de champs, des constantes, desopérateurs arithmétiques, des fonctions numériques et autres, des variables logiques et desopérateurs relationnels. Vous pouvez utiliser des champs que vous ne prévoyez pas d’importercomme variables.

26
Chapitre 3
Figure 3-6Assistant de base de données, limitation du nombre d’observations récupérées
Pour établir vos critères, vous avez besoin d’au moins deux expressions et d’une relation lesconnectant.
E Pour construire une expression, choisissez l’une des méthodes suivantes :Dans une cellule Expression, vous pouvez taper les noms de champs, constantes, opérateurarithmétiques, fonctions numériques et autres fonctions ou variables logiques.Double-cliquez sur le champ dans la liste des champs.Faites glisser le champ de la liste jusqu’à une cellule Expression.Sélectionnez un champ dans le menu déroulant de n’importe quelle cellule Expression active.
E Pour choisir l’opérateur relationnel (comme = or >), placez votre curseur dans la cellule Relationet saisissez l’opérateur ou sélectionnez-le dans le menu déroulant.
Si le code SQL contient des clauses WHERE avec des expressions concernant la sélection desobservations, les dates et les heures employées dans ces expressions doivent être indiquées demanière spécifique (y compris les accolades utilisées dans les exemples) :
Les littéraux de date doivent être spécifiés dans le format général {d 'aaaa-mm-jj'}.Les littéraux d’heure doivent être spécifiés dans le format général {h 'hh:mm:ss'}.

27
Fichiers de données
Les littéraux de date/d’heure (horodatages) doivent être spécifiés dans le format général{hd 'aaaa-mm-jj hh:mm:ss'}.La valeur complète de date et/ou d’heure doit être placée entre apostrophes. Les annéesdoivent comporter quatre chiffres, et les dates et heures doivent en comporter deux pourchaque partie de la valeur. Par exemple, le 1er janvier 2005, 1:05 sera exprimé comme suit :{hd '2005-01-01 01:05:00'}
Fonctions. Une sélection de fonctions SQL intégrées (arithmétique, logique, chaîne, date et heure)est fournie. Vous pouvez glisser une fonction de la liste dans une expression ou entrer n’importequelle fonction SQL valide. Consultez votre documentation sur les bases de données pour lesfonctions SQL valides. La liste des fonctions standard est disponible dans le répertoire suivant :
http://msdn2.microsoft.com/en-us/library/ms711813.aspx
Utiliser échantillon aléatoire. Cette option sélectionne un échantillon aléatoire d’observations dansla source de données. Pour les sources de données volumineuses, vous pouvez limiter le nombred’observations à un échantillon restreint et représentatif afin de réduire la durée d’exécution desprocédures. L’échantillonnage aléatoire natif, s’il est disponible pour la source de données, estplus rapide que l’échantillonnage aléatoire de SPSS Statistics ; en effet, SPSS Statistics doit lire latotalité de la source de données pour extraire un échantillon aléatoire.
Environ. Génère un échantillon aléatoire d'observations dont le nombre correspondapproximativement au pourcentage d'observations indiqué. Comme cette routine génèreune décision indépendante pseudo-aléatoire pour chaque observation, le pourcentaged'observations sélectionnées peut seulement approcher le pourcentage spécifié. Plus il y ad'observations dans le fichier de données, plus le pourcentage des observations sélectionnéessera proche de la valeur indiquée.Exactement. Sélectionne un échantillon aléatoire du nombre d'observations spécifié dansle nombre total d'observations indiqué. Si le nombre total d'observations spécifié estsupérieur au nombre total d'observations dans le fichier de données, l'échantillon contiendraproportionnellement moins d'observations que le nombre demandé.
Remarque : Si vous utilisez l’échantillonnage aléatoire, la fonction d’agrégation (disponible enmode distribué avec le serveur SPSS Statistics) n’est pas disponible.
Demander une valeur. Vous pouvez imbriquer une invite dans votre requête pour créer une requêtede paramètre. Lorsque les utilisateurs utilisent la requête, il leur est demandé d’entrer desinformations (en fonction de ce qui est précisé ici). Cette méthode peut s’avérer utile lorsque vousavez besoin par exemple de voir différents affichages des mêmes données. Par exemple, vousvoulez exécuter la même requête pour voir les chiffres de ventes des différents trimestres fiscaux.
E Placez votre curseur dans une cellule Expression et cliquez sur Demander une valeur pour créerune invite.
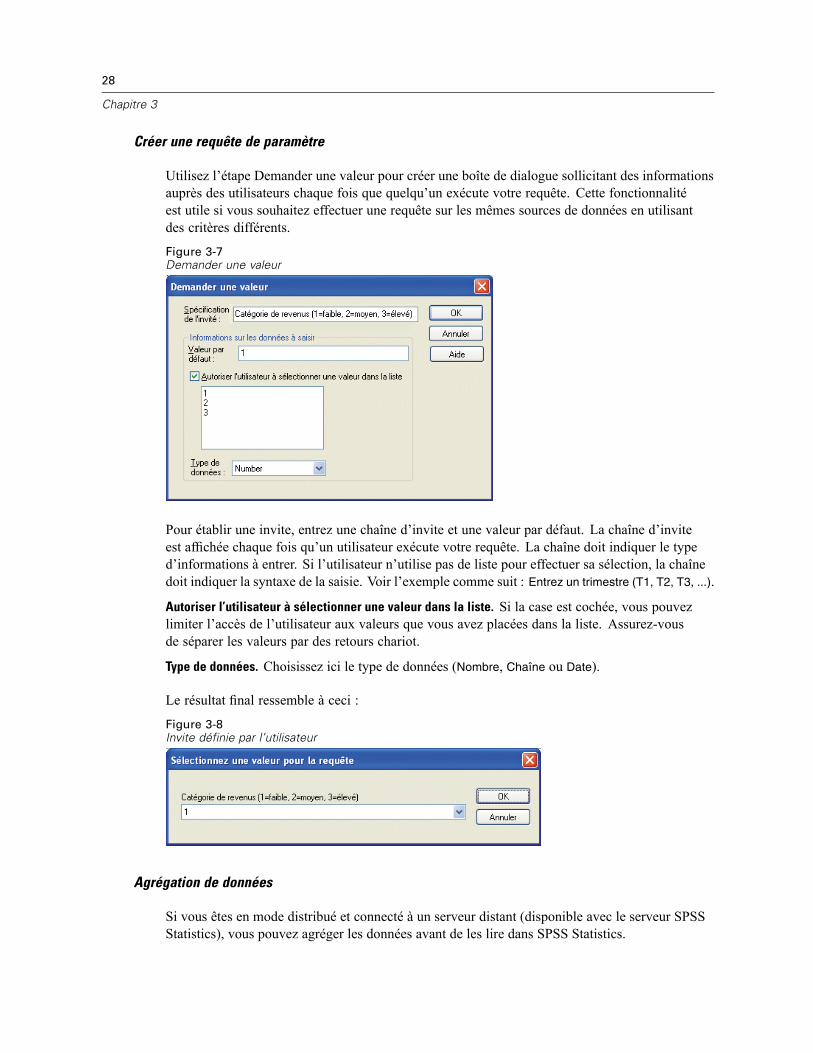
28
Chapitre 3
Créer une requête de paramètre
Utilisez l’étape Demander une valeur pour créer une boîte de dialogue sollicitant des informationsauprès des utilisateurs chaque fois que quelqu’un exécute votre requête. Cette fonctionnalitéest utile si vous souhaitez effectuer une requête sur les mêmes sources de données en utilisantdes critères différents.
Figure 3-7Demander une valeur
Pour établir une invite, entrez une chaîne d’invite et une valeur par défaut. La chaîne d’inviteest affichée chaque fois qu’un utilisateur exécute votre requête. La chaîne doit indiquer le typed’informations à entrer. Si l’utilisateur n’utilise pas de liste pour effectuer sa sélection, la chaînedoit indiquer la syntaxe de la saisie. Voir l’exemple comme suit : Entrez un trimestre (T1, T2, T3, ...).
Autoriser l’utilisateur à sélectionner une valeur dans la liste. Si la case est cochée, vous pouvezlimiter l’accès de l’utilisateur aux valeurs que vous avez placées dans la liste. Assurez-vousde séparer les valeurs par des retours chariot.
Type de données. Choisissez ici le type de données (Nombre, Chaîne ou Date).
Le résultat final ressemble à ceci :
Figure 3-8Invite définie par l’utilisateur
Agrégation de données
Si vous êtes en mode distribué et connecté à un serveur distant (disponible avec le serveur SPSSStatistics), vous pouvez agréger les données avant de les lire dans SPSS Statistics.
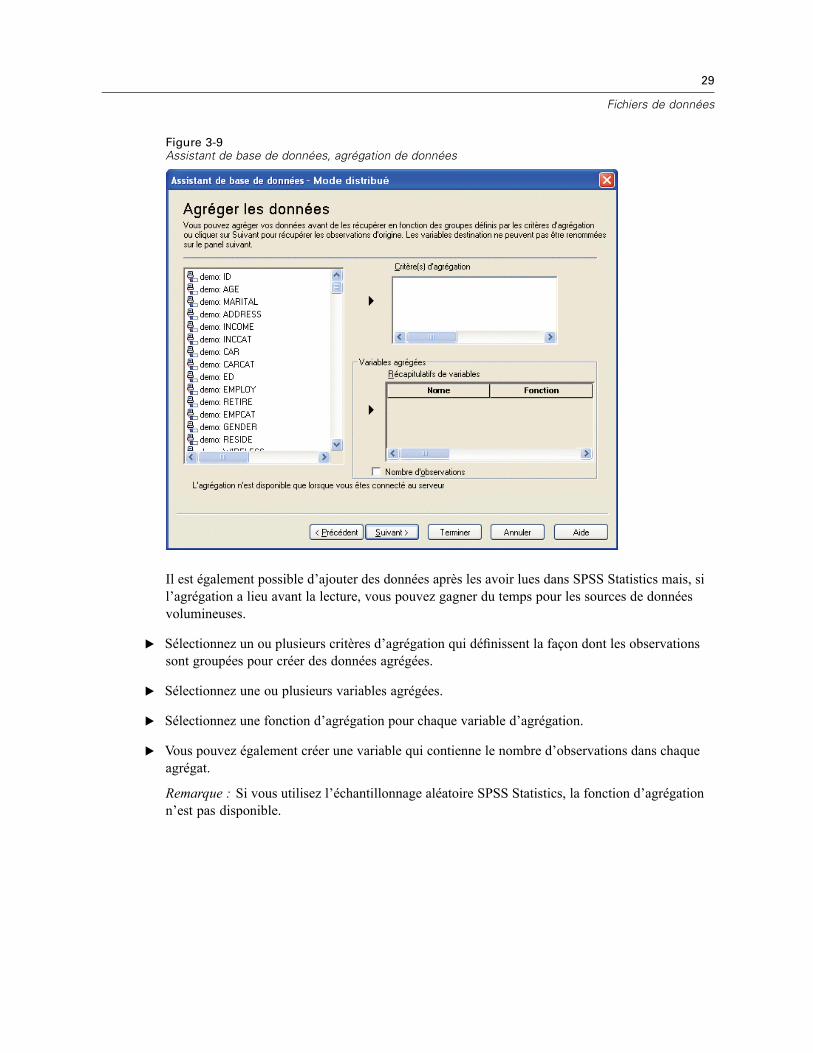
29
Fichiers de données
Figure 3-9Assistant de base de données, agrégation de données
Il est également possible d’ajouter des données après les avoir lues dans SPSS Statistics mais, sil’agrégation a lieu avant la lecture, vous pouvez gagner du temps pour les sources de donnéesvolumineuses.
E Sélectionnez un ou plusieurs critères d’agrégation qui définissent la façon dont les observationssont groupées pour créer des données agrégées.
E Sélectionnez une ou plusieurs variables agrégées.
E Sélectionnez une fonction d’agrégation pour chaque variable d’agrégation.
E Vous pouvez également créer une variable qui contienne le nombre d’observations dans chaqueagrégat.
Remarque : Si vous utilisez l’échantillonnage aléatoire SPSS Statistics, la fonction d’agrégationn’est pas disponible.

30
Chapitre 3
Définition de variables
Noms de variables et étiquettes. La totalité du nom de champ de la base de données (colonne)est utilisée en tant qu’étiquette de variable. A moins que vous ne modifiez le nom de variable,l’Assistant de base de données affecte des noms de variables à chaque colonne à partir de la basede données de l’une des manières suivantes :
Si le nom du champ de la base de données constitue un nom unique et valide de variable, ilest utilisé comme nom de variable.Si le nom du champ de la base de données ne constitue pas un champ unique et valide devariable, un nom unique est automatiquement créé.
Cliquez sur n’importe quelle cellule pour modifier le nom de variable.
Conversion des chaînes en valeurs numériques. Cochez la case Recoder en numérique d’unevariable chaîne pour la convertir automatiquement en variable numérique. Les valeurs de chaînesont converties en valeurs entières consécutives dans l’ordre alphabétique des valeurs d’origine.Les valeurs d’origine sont conservées comme étiquettes de valeurs pour les nouvelles variables.
Largeur des champs de chaînes à largeur variable. Détermine la largeur des valeurs chaîne àlargeur variable. Par défaut, la largeur est de 255 octets. Seuls les 255 premiers octets (engénéral, 255 caractères dans les langues sur un octet) sont lus. La largeur peut s’élever jusqu’à32 767 octets. Bien que vous ne souhaitiez probablement pas tronquer les valeurs chaîne, vousne voulez pas non plus spécifier une valeur importante superflue, car des valeurs trop élevéesrendent le traitement inefficace.
Réduire les largeurs de chaîne en fonction des valeurs observées. Cette option définitautomatiquement la largeur de chaque variable chaîne en fonction de la valeur observée la pluslongue.
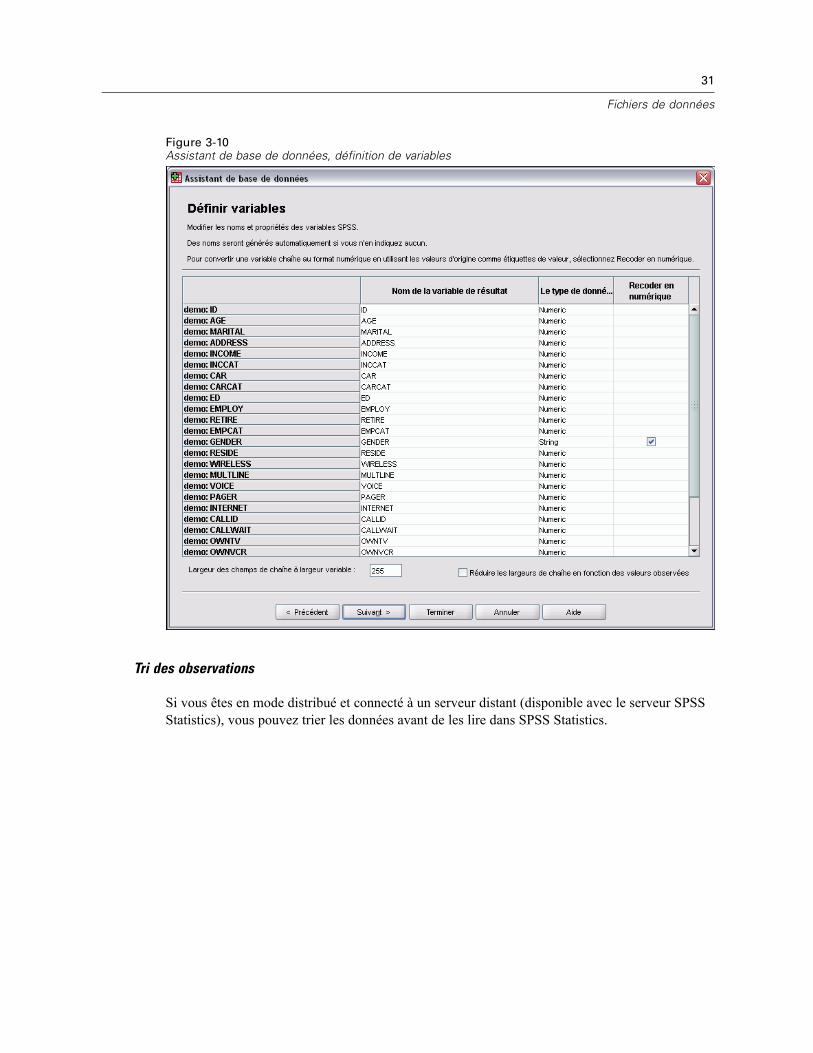
31
Fichiers de données
Figure 3-10Assistant de base de données, définition de variables
Tri des observations
Si vous êtes en mode distribué et connecté à un serveur distant (disponible avec le serveur SPSSStatistics), vous pouvez trier les données avant de les lire dans SPSS Statistics.
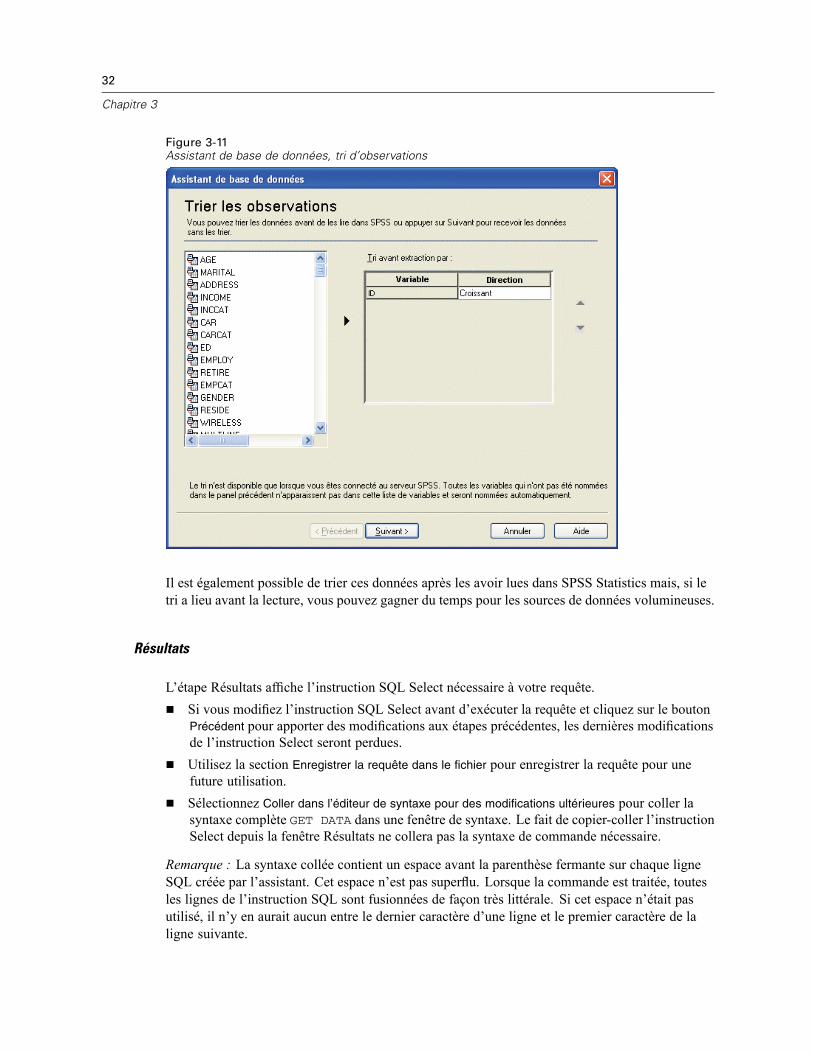
32
Chapitre 3
Figure 3-11Assistant de base de données, tri d’observations
Il est également possible de trier ces données après les avoir lues dans SPSS Statistics mais, si letri a lieu avant la lecture, vous pouvez gagner du temps pour les sources de données volumineuses.
Résultats
L’étape Résultats affiche l’instruction SQL Select nécessaire à votre requête.Si vous modifiez l’instruction SQL Select avant d’exécuter la requête et cliquez sur le boutonPrécédent pour apporter des modifications aux étapes précédentes, les dernières modificationsde l’instruction Select seront perdues.Utilisez la section Enregistrer la requête dans le fichier pour enregistrer la requête pour unefuture utilisation.Sélectionnez Coller dans l’éditeur de syntaxe pour des modifications ultérieures pour coller lasyntaxe complète GET DATA dans une fenêtre de syntaxe. Le fait de copier-coller l’instructionSelect depuis la fenêtre Résultats ne collera pas la syntaxe de commande nécessaire.
Remarque : La syntaxe collée contient un espace avant la parenthèse fermante sur chaque ligneSQL créée par l’assistant. Cet espace n’est pas superflu. Lorsque la commande est traitée, toutesles lignes de l’instruction SQL sont fusionnées de façon très littérale. Si cet espace n’était pasutilisé, il n’y en aurait aucun entre le dernier caractère d’une ligne et le premier caractère de laligne suivante.
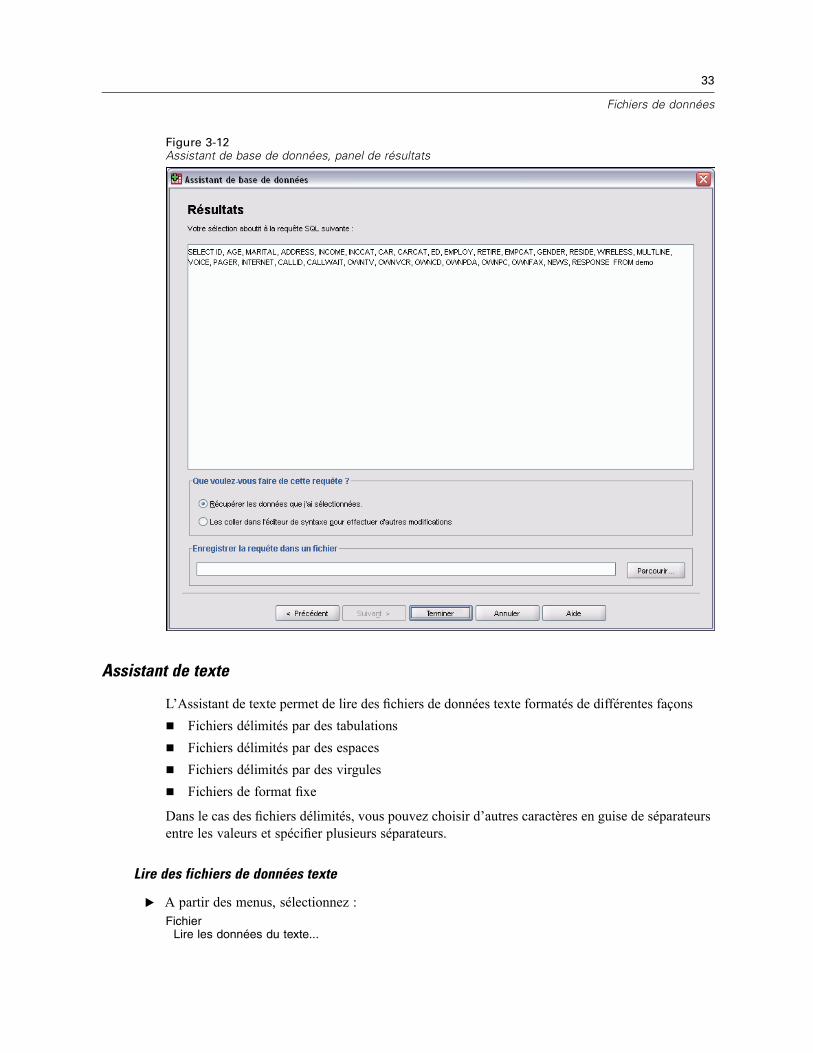
33
Fichiers de données
Figure 3-12Assistant de base de données, panel de résultats
Assistant de texte
L’Assistant de texte permet de lire des fichiers de données texte formatés de différentes façonsFichiers délimités par des tabulationsFichiers délimités par des espacesFichiers délimités par des virgulesFichiers de format fixe
Dans le cas des fichiers délimités, vous pouvez choisir d’autres caractères en guise de séparateursentre les valeurs et spécifier plusieurs séparateurs.
Lire des fichiers de données texte
E A partir des menus, sélectionnez :Fichier
Lire les données du texte...
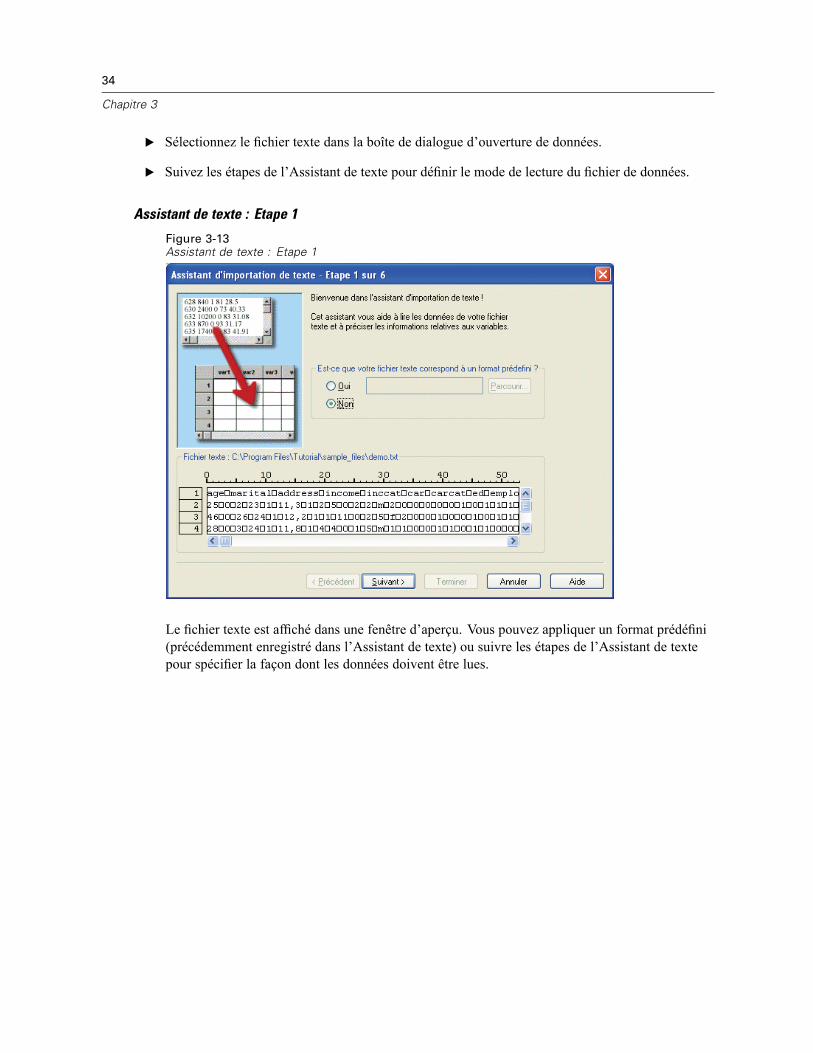
34
Chapitre 3
E Sélectionnez le fichier texte dans la boîte de dialogue d’ouverture de données.
E Suivez les étapes de l’Assistant de texte pour définir le mode de lecture du fichier de données.
Assistant de texte : Etape 1
Figure 3-13Assistant de texte : Etape 1
Le fichier texte est affiché dans une fenêtre d’aperçu. Vous pouvez appliquer un format prédéfini(précédemment enregistré dans l’Assistant de texte) ou suivre les étapes de l’Assistant de textepour spécifier la façon dont les données doivent être lues.
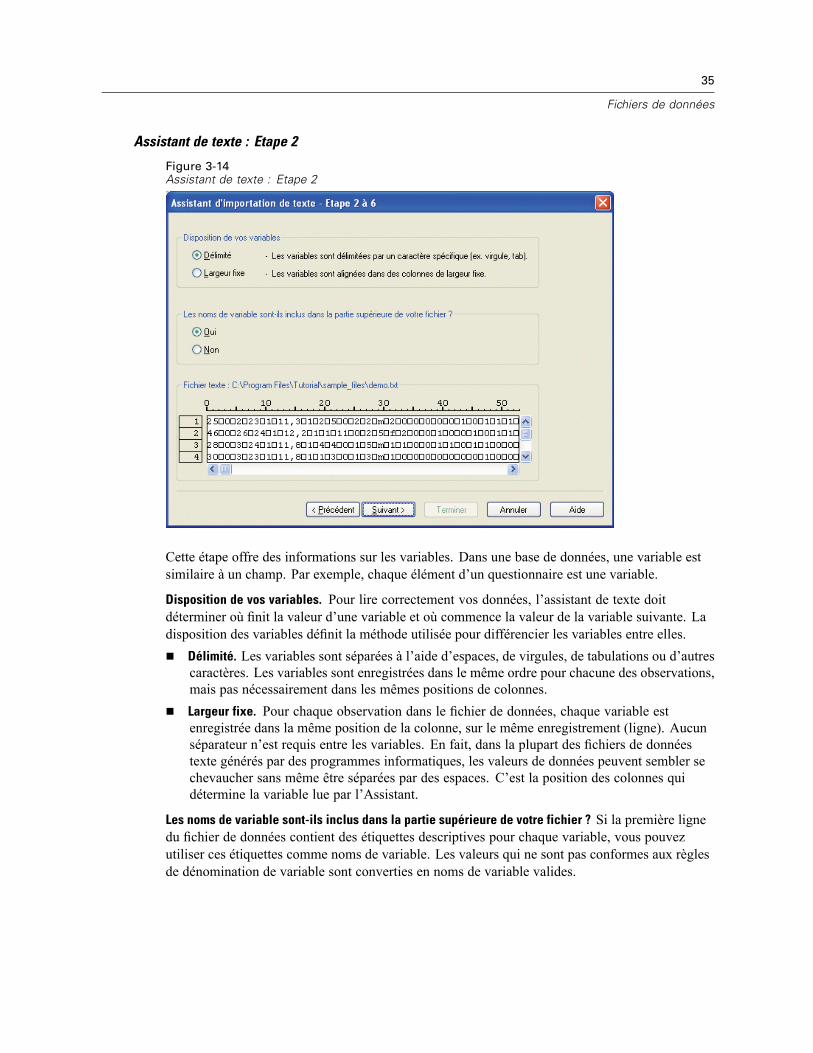
35
Fichiers de données
Assistant de texte : Etape 2
Figure 3-14Assistant de texte : Etape 2
Cette étape offre des informations sur les variables. Dans une base de données, une variable estsimilaire à un champ. Par exemple, chaque élément d’un questionnaire est une variable.
Disposition de vos variables. Pour lire correctement vos données, l’assistant de texte doitdéterminer où finit la valeur d’une variable et où commence la valeur de la variable suivante. Ladisposition des variables définit la méthode utilisée pour différencier les variables entre elles.
Délimité. Les variables sont séparées à l’aide d’espaces, de virgules, de tabulations ou d’autrescaractères. Les variables sont enregistrées dans le même ordre pour chacune des observations,mais pas nécessairement dans les mêmes positions de colonnes.Largeur fixe. Pour chaque observation dans le fichier de données, chaque variable estenregistrée dans la même position de la colonne, sur le même enregistrement (ligne). Aucunséparateur n’est requis entre les variables. En fait, dans la plupart des fichiers de donnéestexte générés par des programmes informatiques, les valeurs de données peuvent sembler sechevaucher sans même être séparées par des espaces. C’est la position des colonnes quidétermine la variable lue par l’Assistant.
Les noms de variable sont-ils inclus dans la partie supérieure de votre fichier ? Si la première lignedu fichier de données contient des étiquettes descriptives pour chaque variable, vous pouvezutiliser ces étiquettes comme noms de variable. Les valeurs qui ne sont pas conformes aux règlesde dénomination de variable sont converties en noms de variable valides.
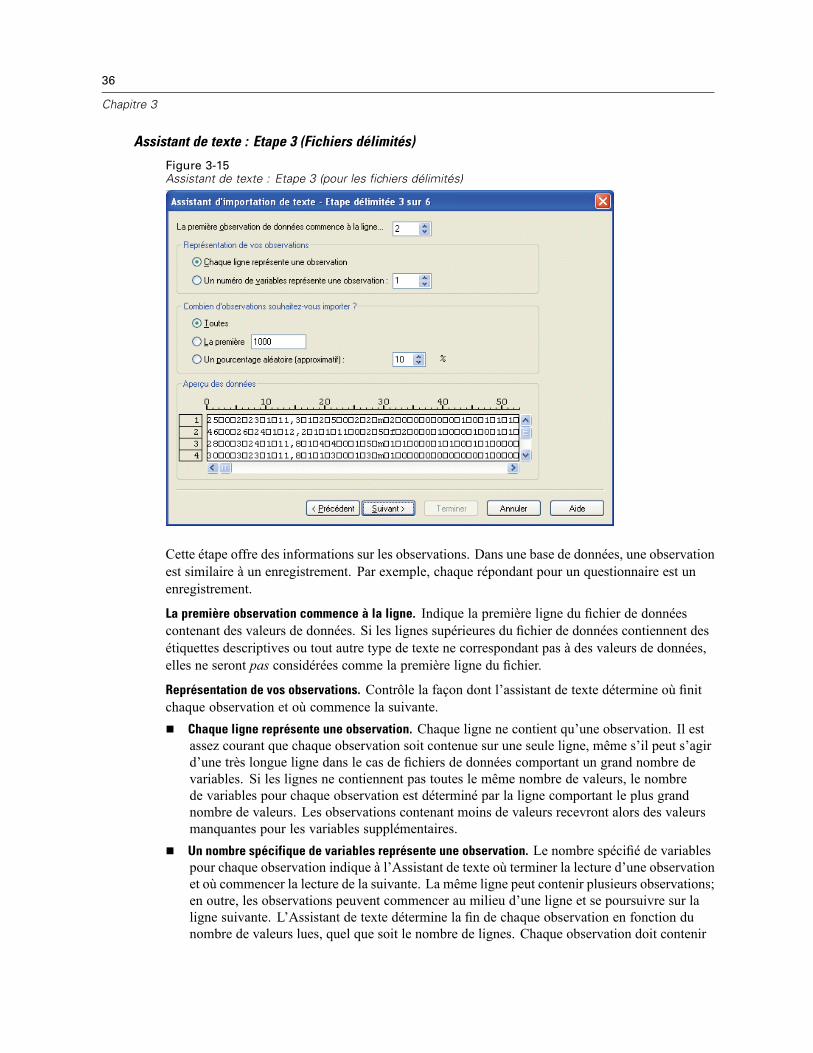
36
Chapitre 3
Assistant de texte : Etape 3 (Fichiers délimités)
Figure 3-15Assistant de texte : Etape 3 (pour les fichiers délimités)
Cette étape offre des informations sur les observations. Dans une base de données, une observationest similaire à un enregistrement. Par exemple, chaque répondant pour un questionnaire est unenregistrement.
La première observation commence à la ligne. Indique la première ligne du fichier de donnéescontenant des valeurs de données. Si les lignes supérieures du fichier de données contiennent desétiquettes descriptives ou tout autre type de texte ne correspondant pas à des valeurs de données,elles ne seront pas considérées comme la première ligne du fichier.
Représentation de vos observations. Contrôle la façon dont l’assistant de texte détermine où finitchaque observation et où commence la suivante.
Chaque ligne représente une observation. Chaque ligne ne contient qu’une observation. Il estassez courant que chaque observation soit contenue sur une seule ligne, même s’il peut s’agird’une très longue ligne dans le cas de fichiers de données comportant un grand nombre devariables. Si les lignes ne contiennent pas toutes le même nombre de valeurs, le nombrede variables pour chaque observation est déterminé par la ligne comportant le plus grandnombre de valeurs. Les observations contenant moins de valeurs recevront alors des valeursmanquantes pour les variables supplémentaires.Un nombre spécifique de variables représente une observation. Le nombre spécifié de variablespour chaque observation indique à l’Assistant de texte où terminer la lecture d’une observationet où commencer la lecture de la suivante. La même ligne peut contenir plusieurs observations;en outre, les observations peuvent commencer au milieu d’une ligne et se poursuivre sur laligne suivante. L’Assistant de texte détermine la fin de chaque observation en fonction dunombre de valeurs lues, quel que soit le nombre de lignes. Chaque observation doit contenir
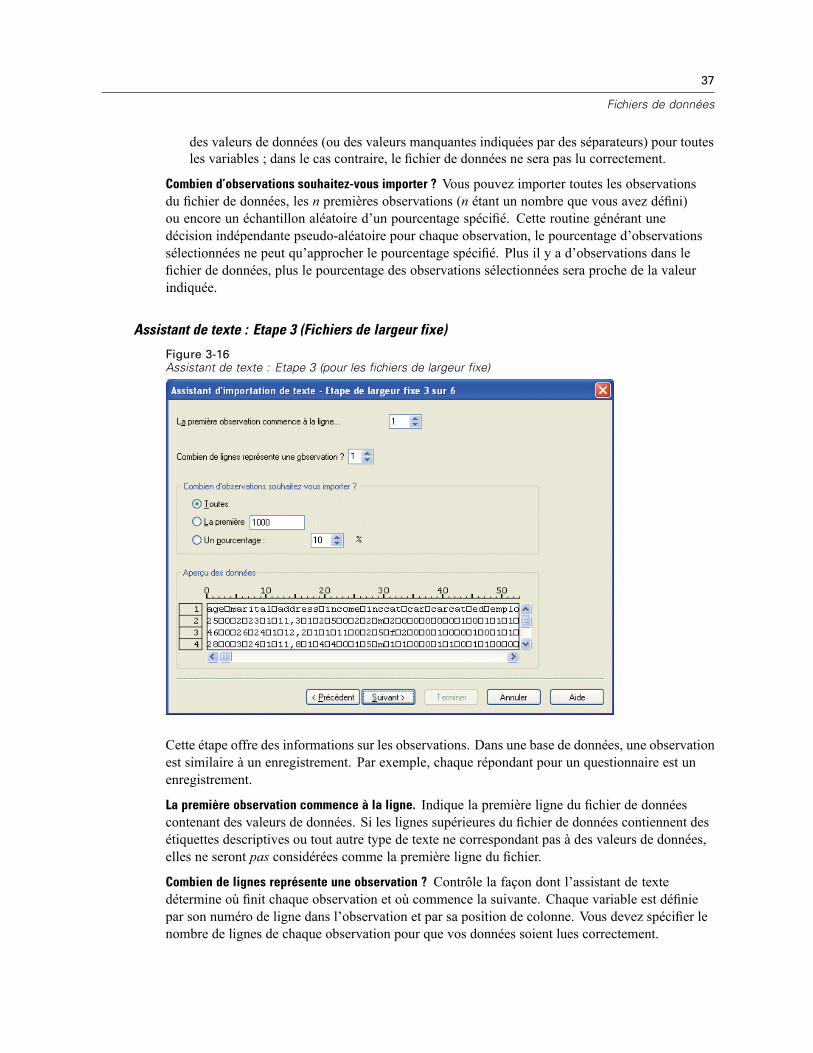
37
Fichiers de données
des valeurs de données (ou des valeurs manquantes indiquées par des séparateurs) pour toutesles variables ; dans le cas contraire, le fichier de données ne sera pas lu correctement.
Combien d’observations souhaitez-vous importer ? Vous pouvez importer toutes les observationsdu fichier de données, les n premières observations (n étant un nombre que vous avez défini)ou encore un échantillon aléatoire d’un pourcentage spécifié. Cette routine générant unedécision indépendante pseudo-aléatoire pour chaque observation, le pourcentage d’observationssélectionnées ne peut qu’approcher le pourcentage spécifié. Plus il y a d’observations dans lefichier de données, plus le pourcentage des observations sélectionnées sera proche de la valeurindiquée.
Assistant de texte : Etape 3 (Fichiers de largeur fixe)
Figure 3-16Assistant de texte : Etape 3 (pour les fichiers de largeur fixe)
Cette étape offre des informations sur les observations. Dans une base de données, une observationest similaire à un enregistrement. Par exemple, chaque répondant pour un questionnaire est unenregistrement.
La première observation commence à la ligne. Indique la première ligne du fichier de donnéescontenant des valeurs de données. Si les lignes supérieures du fichier de données contiennent desétiquettes descriptives ou tout autre type de texte ne correspondant pas à des valeurs de données,elles ne seront pas considérées comme la première ligne du fichier.
Combien de lignes représente une observation ? Contrôle la façon dont l’assistant de textedétermine où finit chaque observation et où commence la suivante. Chaque variable est définiepar son numéro de ligne dans l’observation et par sa position de colonne. Vous devez spécifier lenombre de lignes de chaque observation pour que vos données soient lues correctement.
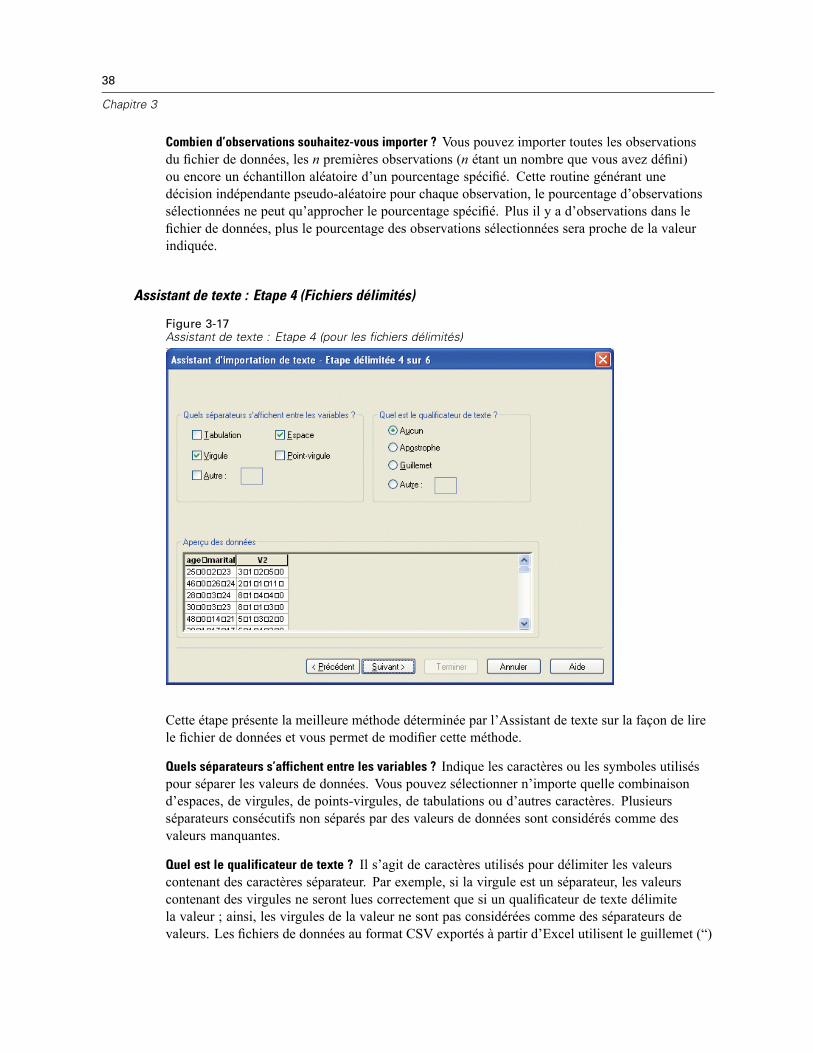
38
Chapitre 3
Combien d’observations souhaitez-vous importer ? Vous pouvez importer toutes les observationsdu fichier de données, les n premières observations (n étant un nombre que vous avez défini)ou encore un échantillon aléatoire d’un pourcentage spécifié. Cette routine générant unedécision indépendante pseudo-aléatoire pour chaque observation, le pourcentage d’observationssélectionnées ne peut qu’approcher le pourcentage spécifié. Plus il y a d’observations dans lefichier de données, plus le pourcentage des observations sélectionnées sera proche de la valeurindiquée.
Assistant de texte : Etape 4 (Fichiers délimités)
Figure 3-17Assistant de texte : Etape 4 (pour les fichiers délimités)
Cette étape présente la meilleure méthode déterminée par l’Assistant de texte sur la façon de lirele fichier de données et vous permet de modifier cette méthode.
Quels séparateurs s’affichent entre les variables ? Indique les caractères ou les symboles utiliséspour séparer les valeurs de données. Vous pouvez sélectionner n’importe quelle combinaisond’espaces, de virgules, de points-virgules, de tabulations ou d’autres caractères. Plusieursséparateurs consécutifs non séparés par des valeurs de données sont considérés comme desvaleurs manquantes.
Quel est le qualificateur de texte ? Il s’agit de caractères utilisés pour délimiter les valeurscontenant des caractères séparateur. Par exemple, si la virgule est un séparateur, les valeurscontenant des virgules ne seront lues correctement que si un qualificateur de texte délimitela valeur ; ainsi, les virgules de la valeur ne sont pas considérées comme des séparateurs devaleurs. Les fichiers de données au format CSV exportés à partir d’Excel utilisent le guillemet (“)

39
Fichiers de données
comme qualificateur de texte. Le qualificateur de texte apparaît au début et à la fin de la valeur,et délimite ainsi la valeur entière.
Assistant de texte : Etape 4 (Fichiers de largeur fixe)
Figure 3-18Assistant de texte : Etape 4 (pour les fichiers de largeur fixe)
Cette étape présente la meilleure méthode déterminée par l’Assistant de texte sur la façon de lirele fichier de données et vous permet de modifier cette méthode. Les lignes verticales présentéesdans la fenêtre d’aperçu indiquent les positions que l’Assistant de texte estime correspondreau début de chaque variable dans le fichier.Insérez, déplacez et supprimez les lignes de délimitation des variables à votre convenance pour
séparer les variables. Si plusieurs lignes sont utilisées pour chaque observation, les données serontaffichées sur une ligne pour chaque observation, les lignes suivantes étant ajoutées en fin de ligne.
Remarques :
Dans le cas de fichiers de données générés par ordinateur et présentant un flux continu de valeursde données non séparées par des espaces ni par d’autres caractéristiques distinctives, il peuts’avérer difficile de déterminer l’endroit où commence chaque variable. De tels fichiers dedonnées sont généralement associés à un fichier de définitions de données ou à toute autredescription écrite définissant la position de ligne et de colonne de chaque variable.
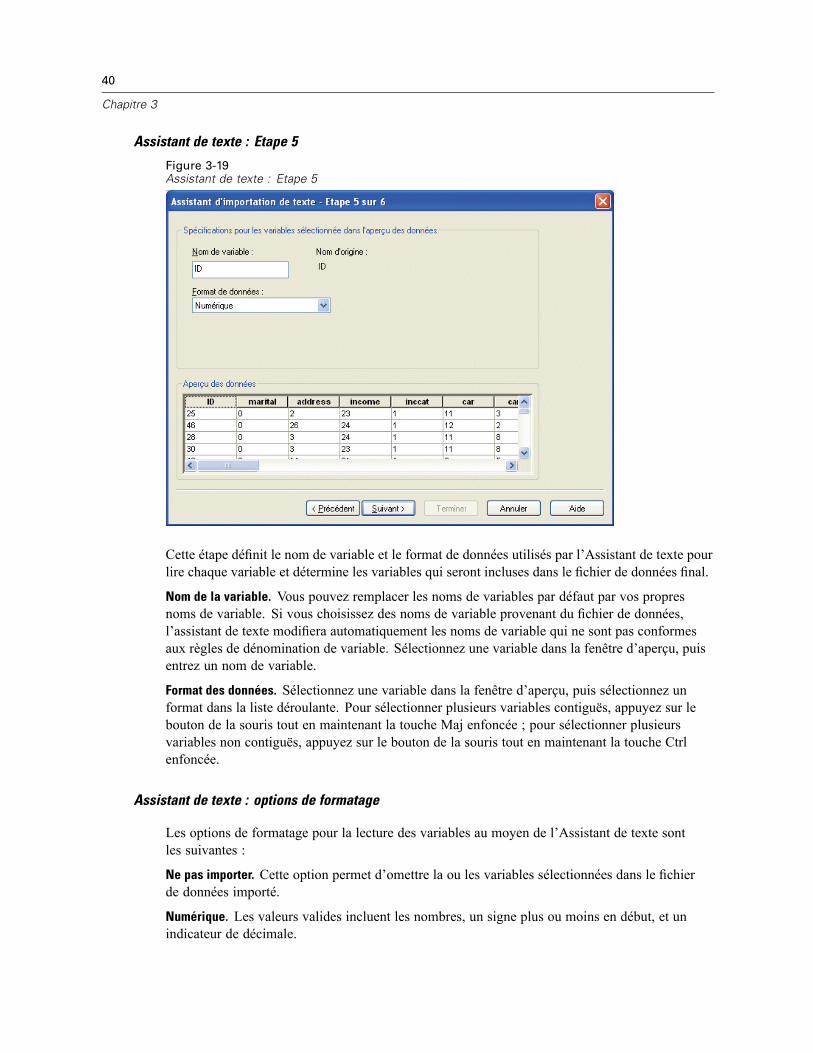
40
Chapitre 3
Assistant de texte : Etape 5
Figure 3-19Assistant de texte : Etape 5
Cette étape définit le nom de variable et le format de données utilisés par l’Assistant de texte pourlire chaque variable et détermine les variables qui seront incluses dans le fichier de données final.
Nom de la variable. Vous pouvez remplacer les noms de variables par défaut par vos propresnoms de variable. Si vous choisissez des noms de variable provenant du fichier de données,l’assistant de texte modifiera automatiquement les noms de variable qui ne sont pas conformesaux règles de dénomination de variable. Sélectionnez une variable dans la fenêtre d’aperçu, puisentrez un nom de variable.
Format des données. Sélectionnez une variable dans la fenêtre d’aperçu, puis sélectionnez unformat dans la liste déroulante. Pour sélectionner plusieurs variables contiguës, appuyez sur lebouton de la souris tout en maintenant la touche Maj enfoncée ; pour sélectionner plusieursvariables non contiguës, appuyez sur le bouton de la souris tout en maintenant la touche Ctrlenfoncée.
Assistant de texte : options de formatage
Les options de formatage pour la lecture des variables au moyen de l’Assistant de texte sontles suivantes :
Ne pas importer. Cette option permet d’omettre la ou les variables sélectionnées dans le fichierde données importé.
Numérique. Les valeurs valides incluent les nombres, un signe plus ou moins en début, et unindicateur de décimale.

41
Fichiers de données
Chaîne. Les valeurs valides incluent pratiquement tous les caractères du clavier avec des blancsimbriqués. Dans le cas des fichiers délimités, vous pouvez spécifier le nombre de caractères dela valeur (le nombre maximal étant de 32 767). Par défaut, l’Assistant de texte détermine quece nombre de caractères correspond à celui de la valeur de chaîne la plus longue pour la oules variables sélectionnées. Dans le cas des fichiers de largeur fixe, le nombre de caractèresdes valeurs de chaîne est défini par le positionnement des lignes de délimitation des variableseffectué à l’étape 4.
Date/Heure. Les valeurs valides correspondent aux dates exprimées dans les formats traditionnelsjj-mm-aaaa, mm/jj/aaaa, jj.mm.aaaa, aaaa/mm/jj, hh:mm:ss, et dans divers autres formats dedate et d’heure. Les mois peuvent être représentés par des chiffres, des chiffres romains, desabréviations à trois lettres, ou bien ils peuvent être énoncés en entier. Sélectionnez un formatde date dans la liste.
Dollar. Les valeurs valides sont des nombres précédés, en option, par un signe dollar et, égalementen option, des virgules comme séparateurs de milliers.
Virgule. Les valeurs valides correspondent aux nombres utilisant un point comme indicateurdécimal et des virgules comme séparateurs de milliers.
Point. Les valeurs valides correspondent aux nombres utilisant une virgule comme indicateurdécimal et des points comme séparateurs de milliers.
Remarque : les valeurs comportant des caractères incorrects pour le format sélectionné seronttraitées comme des valeurs manquantes. Les valeurs contenant l’un des séparateurs spécifiésseront considérées comme des valeurs multiples.
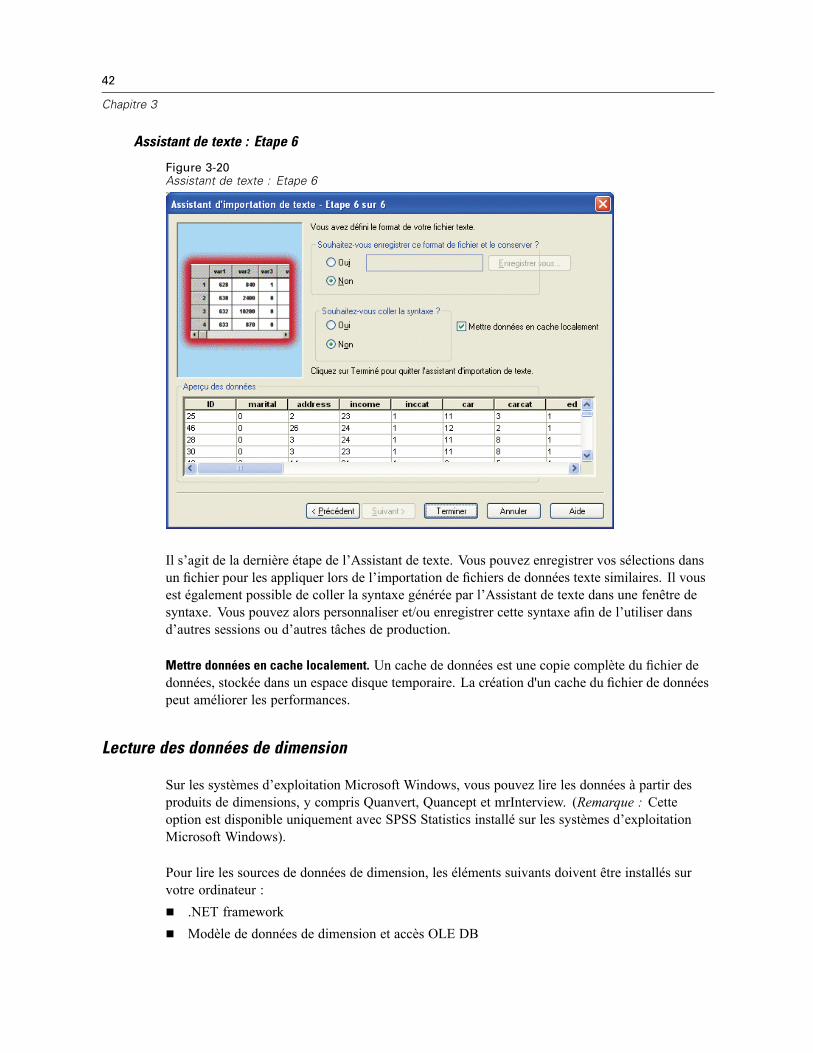
42
Chapitre 3
Assistant de texte : Etape 6
Figure 3-20Assistant de texte : Etape 6
Il s’agit de la dernière étape de l’Assistant de texte. Vous pouvez enregistrer vos sélections dansun fichier pour les appliquer lors de l’importation de fichiers de données texte similaires. Il vousest également possible de coller la syntaxe générée par l’Assistant de texte dans une fenêtre desyntaxe. Vous pouvez alors personnaliser et/ou enregistrer cette syntaxe afin de l’utiliser dansd’autres sessions ou d’autres tâches de production.
Mettre données en cache localement. Un cache de données est une copie complète du fichier dedonnées, stockée dans un espace disque temporaire. La création d'un cache du fichier de donnéespeut améliorer les performances.
Lecture des données de dimension
Sur les systèmes d’exploitation Microsoft Windows, vous pouvez lire les données à partir desproduits de dimensions, y compris Quanvert, Quancept et mrInterview. (Remarque : Cetteoption est disponible uniquement avec SPSS Statistics installé sur les systèmes d’exploitationMicrosoft Windows).
Pour lire les sources de données de dimension, les éléments suivants doivent être installés survotre ordinateur :
.NET frameworkModèle de données de dimension et accès OLE DB

43
Fichiers de données
Les versions des composants compatibles avec cette version peuvent être installées à partir duCD d’installation et sont disponibles dans le menu d’exécution automatique. Il n’est possible delire les sources de données de dimension qu’en mode d’analyse locale. Cette fonction n’est pasdisponible dans le mode d’analyse distribuée utilisant le serveur SPSS Statistics.
Pour lire les données à partir d’une source de données de dimension :
E A partir du menu de n’importe quelle fenêtre SPSS Statistics ouverte, sélectionnez :Fichier
Ouvrir les données de dimension
E Dans l’onglet Connexions des Propriétés du lien de données, spécifiez le fichier de métadonnées,le type de données d’observation et le fichier de données d’observation.
E Cliquez sur OK.
E Dans la boîte de dialogue Importation des données de dimension, sélectionnez les variables àinclure et tout critère de sélection des observations.
E Cliquez sur OK pour lire les données.
Onglet Connexions des propriétés du lien de données
Pour lire les sources de données de dimension, vous devez spécifier :
L’emplacement des métadonnées. Le fichier de document des métadonnées (.mdd) qui contient lesinformations de définition du questionnaire.
Le type des données d’observation. Le format du fichier de données d’observation. Les formatsdisponibles sont les suivants :
Fichier de données Quancept (DRS). Données d’observation dans un fichier Quancept .drs,.drz ou .dru.Base de données Quanvert. Données d’observation dans une base de données Quanvert.Base de données de dimensions (Serveur MS SQL). Les données d’observation dans unebase de données relationnelle dans SQL Server. Cette option peut être utilisée pour lire desdonnées collectées en utilisant mrInterview.Fichier de données de dimension XML. Données d’observation dans un fichier XML.
Emplacement des données d’observation. Le fichier contenant les données d’observation. Le formatde ce fichier doit être cohérent avec le type de données d’observation sélectionné.
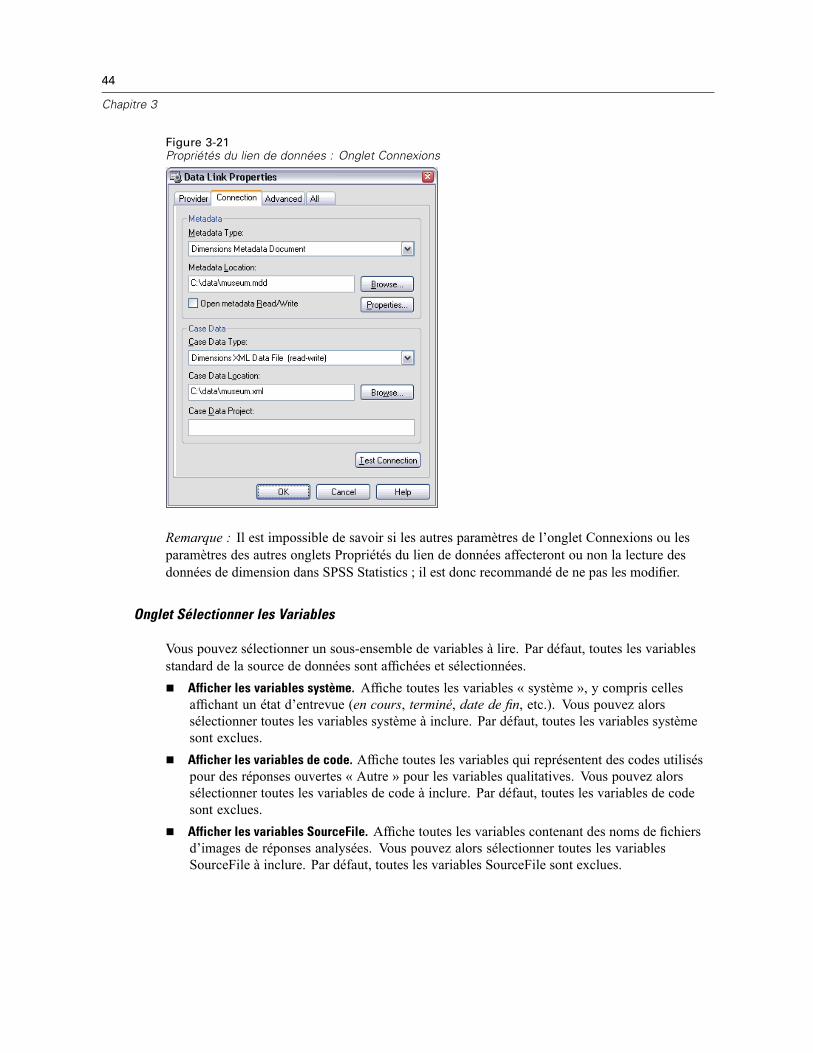
44
Chapitre 3
Figure 3-21Propriétés du lien de données : Onglet Connexions
Remarque : Il est impossible de savoir si les autres paramètres de l’onglet Connexions ou lesparamètres des autres onglets Propriétés du lien de données affecteront ou non la lecture desdonnées de dimension dans SPSS Statistics ; il est donc recommandé de ne pas les modifier.
Onglet Sélectionner les Variables
Vous pouvez sélectionner un sous-ensemble de variables à lire. Par défaut, toutes les variablesstandard de la source de données sont affichées et sélectionnées.
Afficher les variables système. Affiche toutes les variables « système », y compris cellesaffichant un état d’entrevue (en cours, terminé, date de fin, etc.). Vous pouvez alorssélectionner toutes les variables système à inclure. Par défaut, toutes les variables systèmesont exclues.Afficher les variables de code. Affiche toutes les variables qui représentent des codes utiliséspour des réponses ouvertes « Autre » pour les variables qualitatives. Vous pouvez alorssélectionner toutes les variables de code à inclure. Par défaut, toutes les variables de codesont exclues.Afficher les variables SourceFile. Affiche toutes les variables contenant des noms de fichiersd’images de réponses analysées. Vous pouvez alors sélectionner toutes les variablesSourceFile à inclure. Par défaut, toutes les variables SourceFile sont exclues.
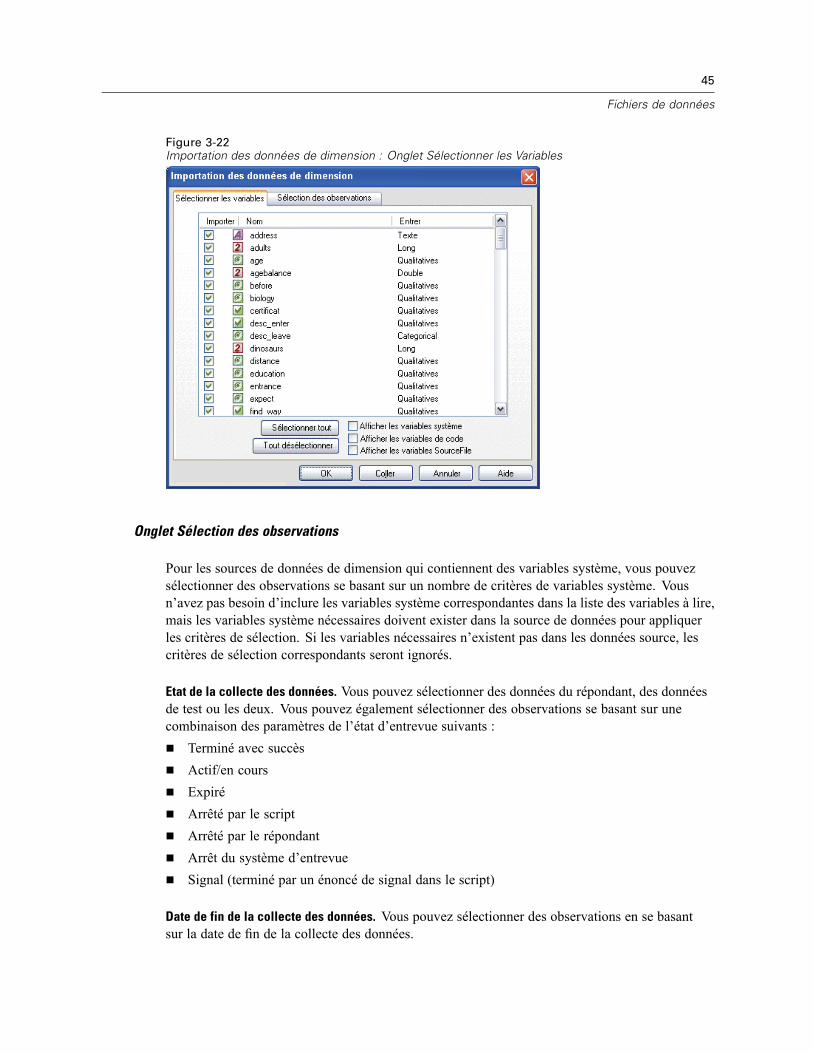
45
Fichiers de données
Figure 3-22Importation des données de dimension : Onglet Sélectionner les Variables
Onglet Sélection des observations
Pour les sources de données de dimension qui contiennent des variables système, vous pouvezsélectionner des observations se basant sur un nombre de critères de variables système. Vousn’avez pas besoin d’inclure les variables système correspondantes dans la liste des variables à lire,mais les variables système nécessaires doivent exister dans la source de données pour appliquerles critères de sélection. Si les variables nécessaires n’existent pas dans les données source, lescritères de sélection correspondants seront ignorés.
Etat de la collecte des données. Vous pouvez sélectionner des données du répondant, des donnéesde test ou les deux. Vous pouvez également sélectionner des observations se basant sur unecombinaison des paramètres de l’état d’entrevue suivants :
Terminé avec succèsActif/en coursExpiréArrêté par le scriptArrêté par le répondantArrêt du système d’entrevueSignal (terminé par un énoncé de signal dans le script)
Date de fin de la collecte des données. Vous pouvez sélectionner des observations en se basantsur la date de fin de la collecte des données.
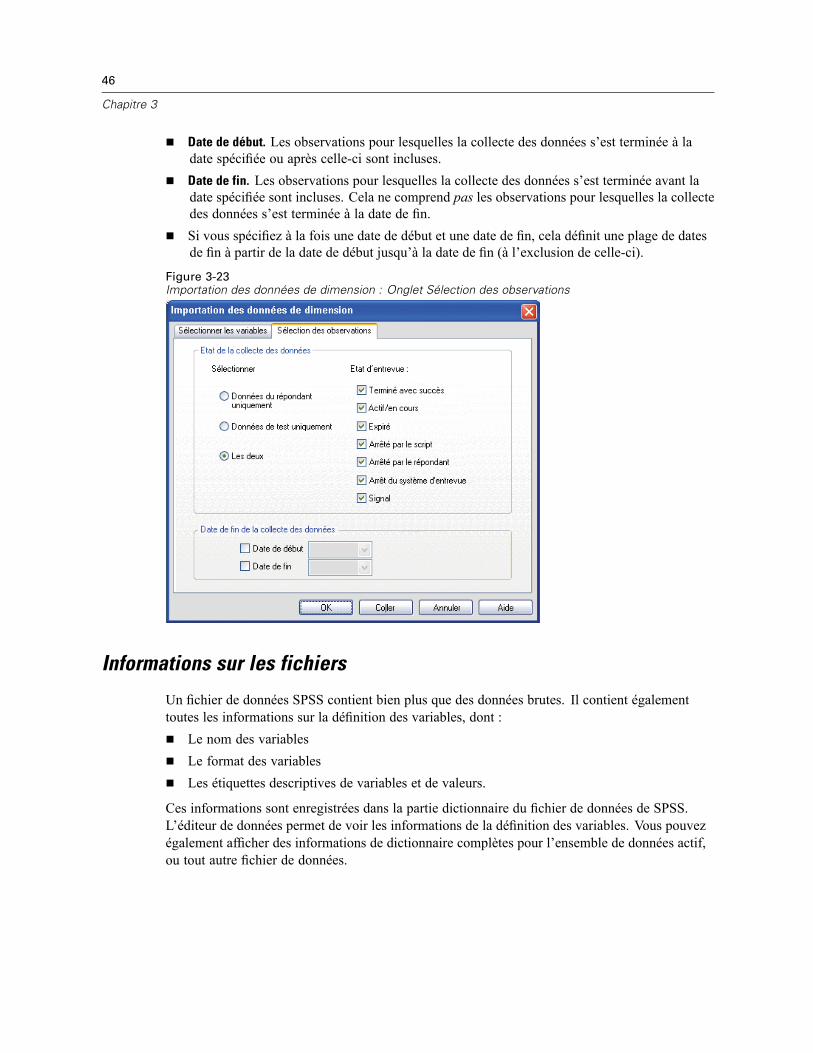
46
Chapitre 3
Date de début. Les observations pour lesquelles la collecte des données s’est terminée à ladate spécifiée ou après celle-ci sont incluses.Date de fin. Les observations pour lesquelles la collecte des données s’est terminée avant ladate spécifiée sont incluses. Cela ne comprend pas les observations pour lesquelles la collectedes données s’est terminée à la date de fin.Si vous spécifiez à la fois une date de début et une date de fin, cela définit une plage de datesde fin à partir de la date de début jusqu’à la date de fin (à l’exclusion de celle-ci).
Figure 3-23Importation des données de dimension : Onglet Sélection des observations
Informations sur les fichiers
Un fichier de données SPSS contient bien plus que des données brutes. Il contient égalementtoutes les informations sur la définition des variables, dont :
Le nom des variablesLe format des variablesLes étiquettes descriptives de variables et de valeurs.
Ces informations sont enregistrées dans la partie dictionnaire du fichier de données de SPSS.L’éditeur de données permet de voir les informations de la définition des variables. Vous pouvezégalement afficher des informations de dictionnaire complètes pour l’ensemble de données actif,ou tout autre fichier de données.

47
Fichiers de données
Pour afficher des informations sur un fichier de données
E A partir des menus de la fenêtre de l’éditeur de données, sélectionnez :Fichier
Afficher des informations sur un fichier de données
E Pour le fichier de données en cours d’utilisation, choisissez Fichier de travail.
E Pour d’autres fichiers de données, sélectionnez Fichier externe puis le fichier de données.
Les informations sur le fichier de données sont affichées dans le Viewer.
Enregistrement des fichiers de donnéesEn plus d’enregistrer les fichiers de données au format SPSS Statistics, vous pouvez enregistrerles données dans divers formats externes, notamment :
Excel et autres formats de feuille de calculFichiers délimités par des tabulations et fichiers texte CSVSASStataTableaux de base de données
Pour enregistrer des fichiers de données modifiés
E Faites en sorte que l’éditeur de données devienne la fenêtre active (cliquez n’importe où dans lafenêtre pour la rendre active).
E A partir des menus, sélectionnez :Fichier
Enregistrer
Le fichier de données modifié est enregistré, et écrase les versions précédentes du fichier.
Remarque : Un fichier de données enregistré en mode Unicode ne peut pas être lu par desversions de SPSS Statistics antérieures à la version 16.0. Pour enregistrer un fichier de donnéesUnicode dans un format pouvant être lu par des versions précédentes, ouvrez un fichier en modepage de code et enregistrez-le à nouveau. Ce fichier sera enregistré au format d’encodage basésur les paramètres régionaux en cours. Il peut y avoir une perte de données si le fichier contientdes caractères non reconnus par les paramètres régionaux en cours. Pour des informations sur lechangement du mode Unicode au mode page de code, consultez Options Générales sur p. 539.
Enregistrement des fichiers de données sous des formats externes
E Faites en sorte que l’éditeur de données devienne la fenêtre active (cliquez n’importe où dans lafenêtre pour la rendre active).
E A partir des menus, sélectionnez :Fichier
Enregistrer sous

48
Chapitre 3
E Sélectionnez un type de fichier de la liste proposée.
E Entrez un nom de fichier pour le nouveau fichier de données.
Pour écrire des noms de variable sur la première ligne d’un fichier de données de format feuille decalcul ou délimité par des tabulations :
E Cliquez sur Ecrire nom de var. dans tableur dans la boîte de dialogue Enregistrer Données sous.
Pour enregistrer les étiquettes de valeurs à la place des valeurs de données au format Excel :
E Dans la boîte de dialogue Enregistrer les données sous, cliquez sur Enregistrer les étiquettes de
valeurs lorsqu’elles sont définies à la place des valeurs de données.
Pour enregistrer les étiquettes de valeurs dans un fichier de syntaxe SAS (cette option n’est activeque si un type de fichier SAS est sélectionné) :
E Dans la boîte de dialogue Enregistrer les données sous, cliquez sur Enregistrer les étiquettes de
valeurs dans un fichier .sas.
Pour plus d’informations sur l’export des données vers des tableaux de base de données,reportez-vous à Export vers une base de données sur p. 54.
Pour plus d’informations sur l’export des données à utiliser dans les applications Dimensions,reportez-vous à Export vers Dimensions sur p. 67.
Enregistrement de données : Types de fichier de données
Vous pouvez enregistrer des données sous les formats suivants :
SPSS Statistics (*.sav). Format SPSS Statistics.Les fichiers de données enregistrés dans le format SPSS Statistics ne peuvent être lus avec lesversions du logiciel antérieures à la version 7.5. Les fichiers de données enregistrés en modeUnicode ne peuvent pas être lus par des versions de SPSS Statistics antérieures à la version16.0 Pour plus d'informations, reportez-vous à Options générales dans Chapitre 48 sur p. 539.Lorsque vous utilisez des fichiers de données ayant des noms de plus de huit octets sous 10.xou 11.x, des versions uniques de noms de variable à huit octets sont utilisées. Toutefois, lesnoms de variables originaux sont conservés pour la version 12.0 ou supérieure. Dans lesversions antérieures à la version 10.0, les noms longs originaux des variables sont perdus sivous enregistrez le fichier de données.Lorsque vous utilisez des fichiers de données avec des variables chaîne de plus de 255 octetsdans les versions de antérieures à 13.0, ces variables chaîne sont segmentées en plusieursvariables chaîne de 255 octets.
Version 7.0 (*.sav). Format version 7.0. Les fichiers de données enregistrés au format 7.0 peuventêtre lus par la version 7.0 et par les versions antérieures, mais n’incluent pas les vecteursmultiréponses définis ni les données entrées pour l’information de Windows.

49
Fichiers de données
SPSS/PC+ (*:sys). Format SPSS/PC+. Si le fichier de données contient plus de 500 variables,seules les 500 premières seront sauvegardées. En ce qui concerne les variables ayant plus d’unevaleur manquante par défaut définie, les valeurs manquantes par défaut supplémentaires serontréalignées sur la première valeur manquante par défaut.
SPSS Statistics Portable (*:por). Format portable qui peut être lu par d’autres versions de SPSSStatistics et d’autres systèmes d’exploitation. Les noms de variable sont limités à huit octets et sontautomatiquement convertis en noms à huit octets uniques si nécessaire. Dans la plupart des cas, ildevient inutile d’enregistrer les données dans un format portable car les fichiers de données auformat SPSS Statistics doivent être indépendants des plateformes et des systèmes d’exploitation.Il est impossible d’enregistrer les fichiers de données dans un format portable en mode Unicode.Pour plus d'informations, reportez-vous à Options générales dans Chapitre 48 sur p. 539.
Tabulé (*:dat). Fichiers texte avec valeurs séparées par des tabulations. (Remarque : Les caractèresde tabulation intégrés dans des valeurs de chaîne sont conservés en tant que tels dans le fichierdélimité par des tabulations. Rien ne distingue les caractères de tabulation intégrés dans desvaleurs de ceux qui séparent ces valeurs).
Délimiteur virgule (*.csv). Fichiers texte contenant des valeurs séparées par des virgules ou despoints-virgules. Si l’indicateur décimal SPSS Statistics courant est le point, les valeurs sontséparées par des virgules. Si l’indicateur décimal courant est la virgule, les valeurs sont séparéespar des points-virgules.
ASCII fixe (*:dat). Fichier texte au format fixe, qui utilise le format d’écriture par défaut pour toutesles variables. Il n’y a pas de tabulations ni d’espaces entre les champs de variables.
Excel 2007 (*.xlsx). Classeur au format XLSX de Microsoft Excel 2007 Le nombre maximum devariables est de 16 000. Toutes les variables au-delà des 16 000 premières sont ignorées. Sil’ensemble de données contient plus d’un million d’observations, plusieurs feuilles sont crééesdans le tableur.
Excel 97 à 2003 (*.xls). Tableur Microsoft Excel 97. Le nombre maximum de variables est de 256.Toutes les variables au-delà des 256 premières sont ignorées. Si l’ensemble de données contientplus de 65 356 observations, plusieurs feuilles sont créées dans le tableur.
Excel 2.1 (*:xls). Fichier de type tableur Microsoft Excel 2.1. Le nombre maximum de variables estde 256 et le nombre maximum de lignes est de 16 384.
1-2-3 Version 3.0 (*:wk3). Fichier tableur Lotus 1-2-3, version 3,0. Vous pouvez enregistrer unnombre maximum de 256 variables.
1-2-3 Version 2.0 (*:wk1). Fichier tableur Lotus 1-2-3, version 2.0. Vous pouvez enregistrer unnombre maximum de 256 variables.
1-2-3 Version 1.0 (*:wks). Fichier tableur Lotus 1-2-3, version 1A. Vous pouvez enregistrer unnombre maximum de 256 variables.
SYLK (*:slk). Format de lien symbolique pour fichiers de type tableur Microsoft Excel et Multiplan.Vous pouvez enregistrer un nombre maximum de 256 variables.
dBASE IV (*:dbf). Format dBASE IV.
dBASE III (*:dbf). Format dBASE III.
dBASE II (*:dbf). Format dBASE II.

50
Chapitre 3
SAS v7+ extension courte Windows (*.sd7). SAS version 7–8 pour Windows, format de nom defichier court.
SAS v7+ extension courte Windows (*.sas7bdat). SAS version 7–8 pour Windows, format de nomde fichier long.
SAS v7+ pour UNIX (*.ssd01). SAS v8 pour UNIX.
SAS v6 pour Windows (*.sd2). Format de fichier SAS v6 pour Windows/OS2.
SAS v6 pour UNIX (*.ssd01). Format de fichier SAS v6 pour UNIX (Sun, HP, IBM).
SAS v6 pour Alpha/OSF (*.ssd04). Format de fichier SAS v6 pour Alpha/OSF (DEC UNIX).
SAS transfert (*.xpt). Fichier de transfert SAS.
Stata Intercooled Version 8 (*.dta).
Stata Version 8 SE (*.dta).
Stata Version 7 Intercooled (*.dta).
Stata Version 7 SE (*.dta).
Stata Version 6 (*.dta).
Stata Version 4–5 (*.dta).
Enregistrement de fichier : Options
Vous pouvez écrire des noms de variables dans la première ligne des fichiers de type tableur et desfichiers séparés par des tabulations et des virgules.
Enregistrement de fichiers de données au format Excel
Vous pouvez enregistrer vos données dans un des trois formats Microsoft Excel. Excel 2.1,Excel 97, et Excel 2007.
Excel 2.1 et Excel 97 sont limités à 256 colonnes, donc seules les 256 premières variablessont incluses.Excel 2007 est limité à 16 000 colonnes, donc seules les 16 000 premières variables sontincluses.Excel 2.1 est limité à 16 384 lignes, donc seules les 16 384 premières observations sontincluses.Excel 97 et Excel 2007 sont également limités en lignes par feuille, mais les classeurspeuvent contenir plusieurs feuilles, et plusieurs feuilles sont créées si l’on dépasse le nombremaximum de feuilles individuelles.

51
Fichiers de données
Types de variable
Le tableau suivant indique la concordance des types de variable entre les données SPSS Statisticsd’origine et les données exportées dans Excel.
SPSS StatisticsType de variable Format de données ExcelNumérique 0.00; #,##0.00; ...Virgule 0.00; #,##0.00; ...Dollar $#,##0_); ...Date j-mmm-aaaaHeure hh:mm:ssChaîne Général
Enregistrement de fichiers de données au format SAS
Vos données reçoivent divers traitements spéciaux quand elles sont enregistrées en tant que fichierSAS. Ces traitements sont les suivants :
Certains caractères autorisés dans les noms de variable SPSS Statistics ne sont pas validesdans SAS, comme @, # et $. Lors de l’exportation des données, ces caractères interditssont remplacés par un trait de soulignement.Les noms de variables SPSS Statistics qui contiennent des caractères sur plusieurs octets(par exemple, caractères japonais ou chinois) sont convertis en noms de variables au formattraditionnel Vnnn, nnn correspondant à une valeur entière.Les étiquettes de variable SPSS Statistics contenant plus de 40 caractères sont tronquéesquand elles sont exportées vers un fichier SAS v6.Quand elles existent, les étiquettes de variable SPSS Statistics sont associées aux étiquettes devariable SAS. S’il n’existe aucune étiquette de variable dans les données SPSS Statistics, lenom de variable est associé à l’étiquette de variable SAS.SAS n’autorise qu’une seule valeur manquante par défaut, alors que SPSS Statistics enautorise un grand nombre. Par conséquent, toutes les valeurs manquantes par défaut de SPSSStatistics sont associées à une seule de ces valeurs dans le fichier SAS.
Enregistrement des étiquettes de valeurs
Vous pouvez choisir d’enregistrer les valeurs et les étiquettes de valeurs associées à votre fichierde données dans un fichier de syntaxe SAS. Par exemple, lorsque les étiquettes de valeurs dufichier de données cars.sav sont exportées, le fichier de syntaxe généré contient :
libname library '\name\' ;
proc format library = library ;
value ORIGIN /* Pays d'origine */
1 = 'Américaine'
2 = 'Européenne'

52
Chapitre 3
3 = 'Japonaise' ;
value CYLINDER /* Nombre de cylindres */
3 = '3 cylindres'
4 = '4 cylindres'
5 = '5 cylindres'
6 = '6 cylindres'
8 = '8 cylindres' ;
value FILTER__ /* cylrec = 1 | cylrec = 2 (FILTER) */
0 = 'Non sélectionnés'
1 = 'Sélectionnés' ;
proc datasets library = library ;
modify cars;
format ORIGIN ORIGIN.;
format CYLINDER CYLINDER.;
format FILTER__ FILTER__.;
quit;
Cette fonctionnalité n’est pas prise en charge par le fichier de transfert SAS.
Types de variable
Le tableau suivant indique la concordance des types de variable entre les données SPSS Statisticsd’origine et les données exportées dans SAS.
SPSS Statistics Type de variable Type de variable SAS Format de données SASNumérique Numérique 12Virgule Numérique 12Points Numérique 12Notation scientifique Numérique 12Date Numérique (Date) par exemple, MMJJAA10,
...Date (Heure) Numérique Time18Dollar Numérique 12Devise personnalisée Numérique 12Chaîne Caractère $8
Enregistrement de fichiers de données au format StataLes données peuvent être écrites au format Stata versions 5–8 et à la fois aux formatsIntercooled et SE (versions 7 et 8 uniquement).

53
Fichiers de données
Les fichiers de données enregistrés au format Stata version 5 peuvent être lues par un formatStata version 4.Les premiers 80 octets d’étiquettes de variable sont enregistrés comme étiquettes de variableStata.Pour les variables numériques, les premiers 80 octets d’étiquettes de valeurs sont enregistréscomme étiquettes de valeurs Stata. Pour les variables chaîne, les étiquettes de valeurs sontignorées.Pour les versions 7 et 8, les premiers 32 octets de noms de variables sensibles à la casse sontenregistrés comme noms de variables Stata. Pour les versions antérieures, les premiers huitoctets de noms de variables sont enregistrés comme noms de variables Stata. Tout caractèreautre que des lettres, des chiffres ou des traits de soulignement sont convertis en traits desoulignement.Les noms de variables SPSS Statistics qui contiennent des caractères sur plusieurs octets(par exemple, caractères japonais ou chinois) sont convertis en noms de variables au formattraditionnel Vnnn, nnn correspondant à une valeur entière.Pour les versions 5–6 et les versions Intercooled 7–8, les premiers 80 octets de valeurs chaînessont enregistrés. Pour Stata SE versions 7–8, les premiers 244 octets de valeurs chaîne sontenregistrés.Pour les versions 5–6 et les versions Intercooled 7–8, seuls les premiers 2 047 octets devariables sont enregistrés. Pour Stata SE versions 7–8, seuls les premiers 32 767 octets devariables sont enregistrés.
SPSS Statistics Type devariable
Type de variable Stata Format de données Stata
Numérique Numérique g
Virgule Numérique g
Points Numérique g
Notation scientifique Numérique g
Date*, dateheure Numérique J_m_AHeure, DHeure Numérique g (nombre de secondes)Joursem Numérique g (1–7)Mois Numérique g (1–12)Dollar Numérique g
Devise personnalisée Numérique g
Chaîne Chaîne s
*Date, Adate, Edate, SDate, Jdate, Qyr, Moyr, Wkyr
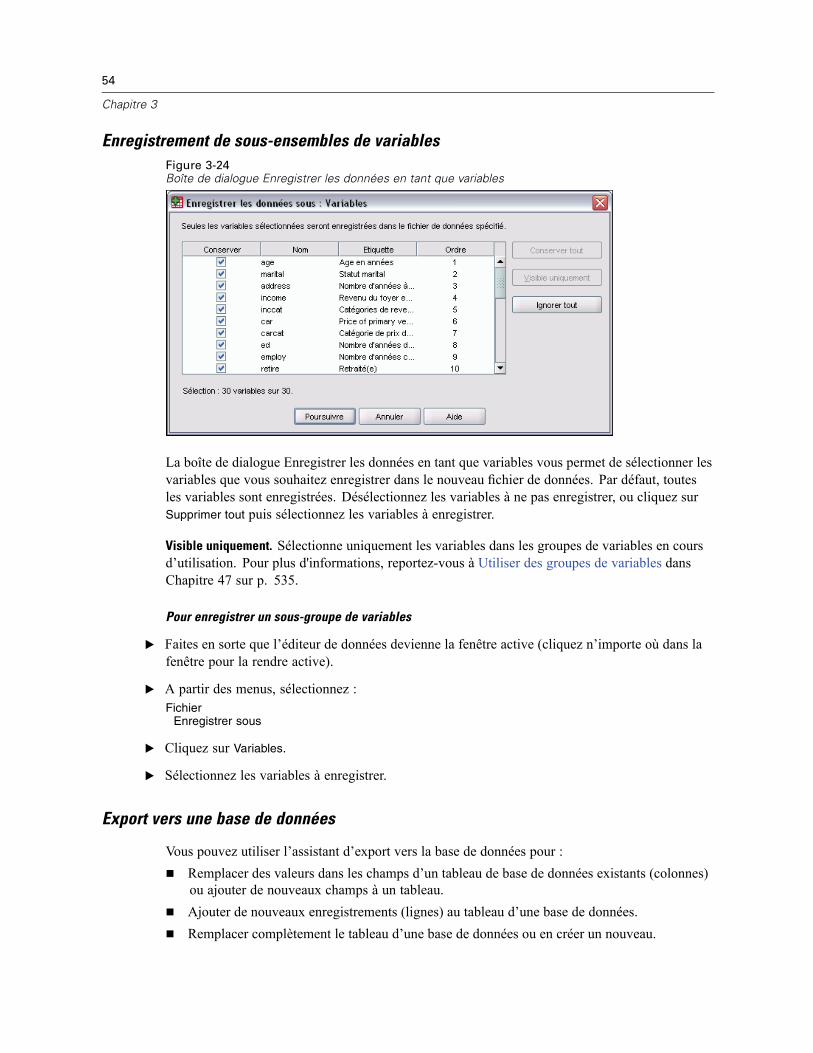
54
Chapitre 3
Enregistrement de sous-ensembles de variablesFigure 3-24Boîte de dialogue Enregistrer les données en tant que variables
La boîte de dialogue Enregistrer les données en tant que variables vous permet de sélectionner lesvariables que vous souhaitez enregistrer dans le nouveau fichier de données. Par défaut, toutesles variables sont enregistrées. Désélectionnez les variables à ne pas enregistrer, ou cliquez surSupprimer tout puis sélectionnez les variables à enregistrer.
Visible uniquement. Sélectionne uniquement les variables dans les groupes de variables en coursd’utilisation. Pour plus d'informations, reportez-vous à Utiliser des groupes de variables dansChapitre 47 sur p. 535.
Pour enregistrer un sous-groupe de variables
E Faites en sorte que l’éditeur de données devienne la fenêtre active (cliquez n’importe où dans lafenêtre pour la rendre active).
E A partir des menus, sélectionnez :Fichier
Enregistrer sous
E Cliquez sur Variables.
E Sélectionnez les variables à enregistrer.
Export vers une base de données
Vous pouvez utiliser l’assistant d’export vers la base de données pour :Remplacer des valeurs dans les champs d’un tableau de base de données existants (colonnes)ou ajouter de nouveaux champs à un tableau.Ajouter de nouveaux enregistrements (lignes) au tableau d’une base de données.Remplacer complètement le tableau d’une base de données ou en créer un nouveau.

55
Fichiers de données
Pour exporter des données vers une base de données :
E Dans les menus de la fenêtre Editeur de données du fichier de données contenant les données àexporter, sélectionnez :Fichier
Exporter vers la base de données
E Sélectionnez la source de la base de données.
E Suivez les instructions de l’assistant d’export pour exporter les données.
Création de champs de base de données à partir de variables SPSS Statistics
Lorsque vous créez des champs (ajout de champs à un tableau de base de données existant,création ou remplacement d’un tableau), vous pouvez spécifier le nom des champs, le type dedonnées et la largeur (le cas échéant).
Nom de champ : Les noms de champ par défaut sont identiques aux noms de variable SPSSStatistics. Vous pouvez modifier le nom des champs pour adopter n’importe quel nom autorisé parle format de base de données. Par exemple, de nombreuses bases de données autorisent, dansles noms de champ, des caractères interdits dans les noms de variable, notamment les espaces.C’est pourquoi un nom de variable, tel que AppelEnAttente, peut être transformé en nom dechamp Appel en attente.
Type : L’assistant d’exportation commence par attribuer des types de données en fonction destypes de données ODBC standard ou des types de données autorisés par le format de base dedonnées sélectionné le mieux adapté au format de données SPSS Statistics défini. Cependant,les bases de données peuvent distinguer les types qui n’ont pas d’équivalents directs dans SPSSStatistics, et inversement. Par exemple, la plupart des valeurs numériques dans SPSS Statisticssont stockées sous forme de valeurs à virgule flottante double précision, alors que les types dedonnées numériques de base de données incluent les valeurs flottantes (doubles), les entiers, lesréels, etc. En outre, de nombreuses bases de données n’ont pas d’équivalents aux formats d’heureSPSS Statistics. Vous pouvez opter pour n’importe quel type de données disponible dans laliste déroulante.En règle générale, le type de données de base (chaîne ou numérique) de la variable doit
correspondre à celui du champ de la base de données. En cas de non-concordance des types dedonnées que la base de données ne peut pas résoudre, une erreur est générée et aucune donnéen’est exportée dans la base de données. Par exemple, si vous exportez une variable chaîne vers unchamp de base de données ayant un type de données numérique, une erreur est générée si l’unedes valeurs de la variable chaîne contient des caractères non numériques.
Largeur : Vous pouvez modifier la largeur des types de champ chaîne (car, carvar). La largeur deschamps numériques est définie par le type de données.

56
Chapitre 3
Par défaut, les formats des variables SPSS Statistics sont mappés aux types des champs de basede données en fonction du schéma général suivant. Les types de champ réels peuvent varierselon la base de données.
Le format des variables SPSS Statistics Type de champ de base de donnéesNumérique Flottant ou DoubleVirgule Flottant ou DoublePoints Flottant ou DoubleNotation scientifique Flottant ou DoubleDate Date ou Valeurdate ou HorodatageValeurdate Valeurdate ou HorodatageHeure, DHeure Flottant ou Double (nombre de secondes)Joursem Entier (1-7)Mois Entier (1-12)Dollar Flottant ou DoubleDevise personnalisée Flottant ou DoubleChaîne Car ou Varcar
Valeurs manquantes spécifiées :
Il existe deux options de traitement des valeurs manquantes spécifiées lorsque des données issuesde variables sont exportées vers des champs de base de données :
Exporter comme valeurs valides. Les valeurs manquantes spécifiées sont traitées comme desvaleurs régulières, valides et non manquantes.Exporter les valeurs manquantes spécifiées numériques comme valeurs nulles et exporter lesvaleurs manquantes spécifiées de chaîne comme espaces. Les valeurs manquantes spécifiéesnumériques sont traitées comme les valeurs manquantes par défaut. Les valeurs manquantesspécifiées de chaîne sont converties en espaces (les chaînes ne peuvent pas être des valeursmanquantes par défaut).
Sélectionner une source de données
Dans le premier panel de l’assistant d’export vers la base de données, vous sélectionnez la sourcede données vers laquelle vous souhaitez exporter des données.

57
Fichiers de données
Figure 3-25Assistant d’export vers la base de données, sélection d’une source de données
Vous pouvez exporter des données vers toutes les sources de base de données pour lesquelles vouspossédez le pilote ODBC approprié (Remarque : l’exportation de données vers des sources dedonnées OLE DB n’est pas pris en charge).
Si vous n’avez pas de sources de données ODBC configurées ou si vous voulez ajouter unenouvelle source de données, cliquez sur Ajouter source données ODBC.
Sur les systèmes d’exploitation Linux, ce bouton n’est pas disponible. Les sources de donnéesODBC sont spécifiées dans odbc.ini, et les variables d’environnement ODBCINI doivent êtreparamétrées sur l’emplacement de ce fichier. Pour plus d’informations, reportez-vous à ladocumentation relative à vos pilotes de base de données.En mode d’analyse distribuée (disponible avec le serveur SPSS Statistics), ce bouton n’estpas disponible. Pour ajouter des sources de données en mode d’analyse distribuée, consultezvotre administrateur système.
Une source de données ODBC est composée de deux principaux éléments d’informations : Lepilote qui sera utilisé pour accéder aux données et l’emplacement de la base de données à laquellevous souhaitez accéder. Pour spécifier des sources de données, vous devez installer les pilotesappropriés. Pour le mode d’analyse locale, vous pouvez installer des pilote pour tout un ensemblede formats de base de données depuis le CD d’installation de SPSS Statistics.
Certaines sources de données exigent que vous entriez un ID de connexion et un mot de passepour pouvoir passer à l’étape suivante.
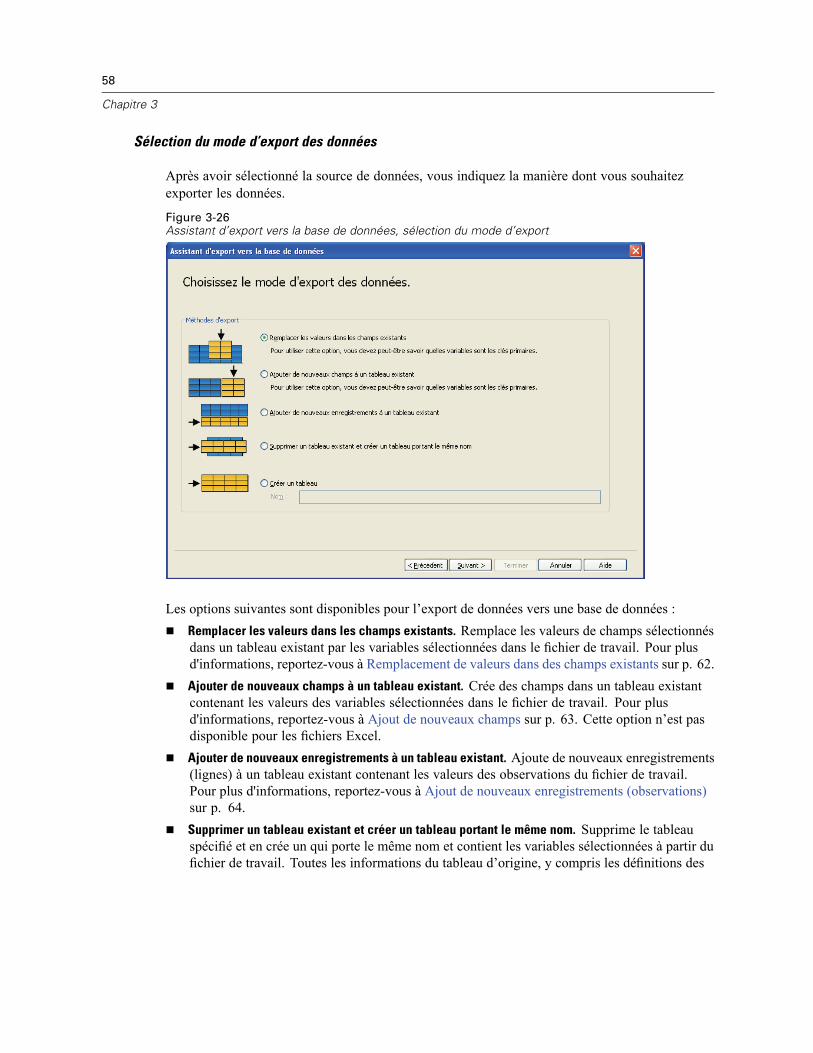
58
Chapitre 3
Sélection du mode d’export des données
Après avoir sélectionné la source de données, vous indiquez la manière dont vous souhaitezexporter les données.
Figure 3-26Assistant d’export vers la base de données, sélection du mode d’export
Les options suivantes sont disponibles pour l’export de données vers une base de données :Remplacer les valeurs dans les champs existants. Remplace les valeurs de champs sélectionnésdans un tableau existant par les variables sélectionnées dans le fichier de travail. Pour plusd'informations, reportez-vous à Remplacement de valeurs dans des champs existants sur p. 62.Ajouter de nouveaux champs à un tableau existant. Crée des champs dans un tableau existantcontenant les valeurs des variables sélectionnées dans le fichier de travail. Pour plusd'informations, reportez-vous à Ajout de nouveaux champs sur p. 63. Cette option n’est pasdisponible pour les fichiers Excel.Ajouter de nouveaux enregistrements à un tableau existant. Ajoute de nouveaux enregistrements(lignes) à un tableau existant contenant les valeurs des observations du fichier de travail.Pour plus d'informations, reportez-vous à Ajout de nouveaux enregistrements (observations)sur p. 64.Supprimer un tableau existant et créer un tableau portant le même nom. Supprime le tableauspécifié et en crée un qui porte le même nom et contient les variables sélectionnées à partir dufichier de travail. Toutes les informations du tableau d’origine, y compris les définitions des
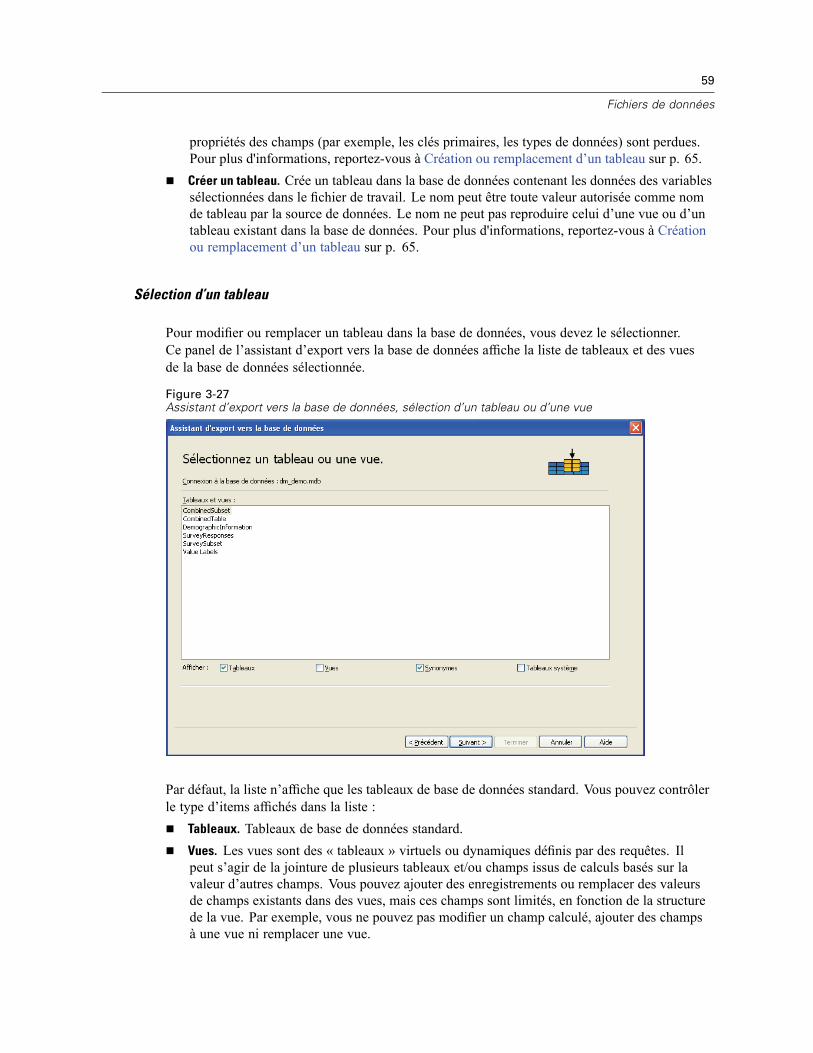
59
Fichiers de données
propriétés des champs (par exemple, les clés primaires, les types de données) sont perdues.Pour plus d'informations, reportez-vous à Création ou remplacement d’un tableau sur p. 65.Créer un tableau. Crée un tableau dans la base de données contenant les données des variablessélectionnées dans le fichier de travail. Le nom peut être toute valeur autorisée comme nomde tableau par la source de données. Le nom ne peut pas reproduire celui d’une vue ou d’untableau existant dans la base de données. Pour plus d'informations, reportez-vous à Créationou remplacement d’un tableau sur p. 65.
Sélection d’un tableau
Pour modifier ou remplacer un tableau dans la base de données, vous devez le sélectionner.Ce panel de l’assistant d’export vers la base de données affiche la liste de tableaux et des vuesde la base de données sélectionnée.
Figure 3-27Assistant d’export vers la base de données, sélection d’un tableau ou d’une vue
Par défaut, la liste n’affiche que les tableaux de base de données standard. Vous pouvez contrôlerle type d’items affichés dans la liste :
Tableaux. Tableaux de base de données standard.Vues. Les vues sont des « tableaux » virtuels ou dynamiques définis par des requêtes. Ilpeut s’agir de la jointure de plusieurs tableaux et/ou champs issus de calculs basés sur lavaleur d’autres champs. Vous pouvez ajouter des enregistrements ou remplacer des valeursde champs existants dans des vues, mais ces champs sont limités, en fonction de la structurede la vue. Par exemple, vous ne pouvez pas modifier un champ calculé, ajouter des champsà une vue ni remplacer une vue.

60
Chapitre 3
Synonymes. Un synonyme est l’alias d’un tableau ou d’une vue, généralement défini parune requête.Tableaux système. Les tableaux système définissent les propriétés des bases de données. Danscertains cas, les tableaux de base de données standard peuvent être classés comme tablessystème et ne sont affichés que si vous sélectionnez cette option. L’accès aux tables systèmeproprement dites est généralement réservé aux administrateurs de base de données.
Sélection des observations à exporter
La sélection des observations dans l’assistant d’export vers la base de données concerne toutes lesobservations, ou les observations sélectionnées via une condition de filtre définie au préalable.Si aucun filtrage d’observations n’est activé, ce panel n’apparaît pas et toutes les observationsdu fichier de travail sont exportées.
Figure 3-28Assistant d’export vers la base de données, sélection des observations à exporter
Pour plus d’informations sur la définition d’une condition de filtre pour la sélection d’observations,reportez-vous à Sélectionner des observations sur p. 205.
Mise en concordance des observations et des enregistrements
Lors de l’ajout de champs (colonnes) à un tableau existant ou lors du remplacement des valeurs dechamps existants, vous devez veiller à ce que chaque observation (ligne) du fichier de travail soitmise en concordance avec l’enregistrement de base de données qui convient.
Dans la base de données, le champ ou l’ensemble de champs identifiant de manière uniquechaque enregistrement est souvent désigné comme la clé primaire.
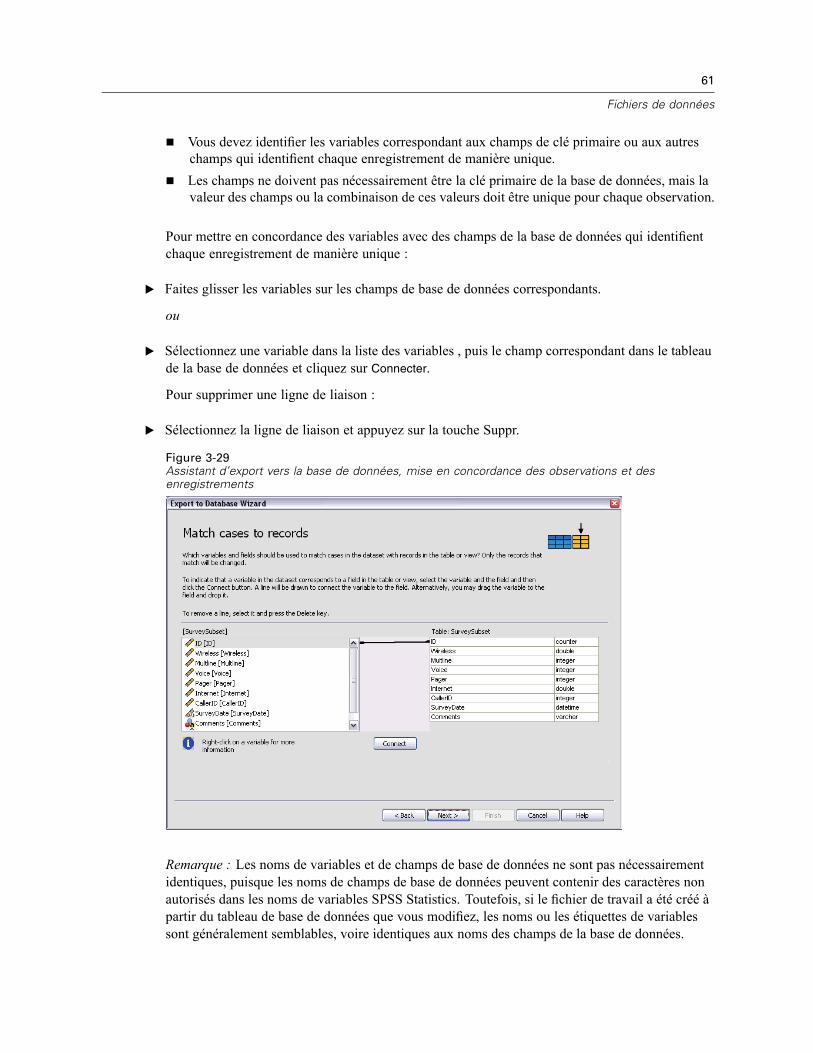
61
Fichiers de données
Vous devez identifier les variables correspondant aux champs de clé primaire ou aux autreschamps qui identifient chaque enregistrement de manière unique.Les champs ne doivent pas nécessairement être la clé primaire de la base de données, mais lavaleur des champs ou la combinaison de ces valeurs doit être unique pour chaque observation.
Pour mettre en concordance des variables avec des champs de la base de données qui identifientchaque enregistrement de manière unique :
E Faites glisser les variables sur les champs de base de données correspondants.
ou
E Sélectionnez une variable dans la liste des variables , puis le champ correspondant dans le tableaude la base de données et cliquez sur Connecter.
Pour supprimer une ligne de liaison :
E Sélectionnez la ligne de liaison et appuyez sur la touche Suppr.
Figure 3-29Assistant d’export vers la base de données, mise en concordance des observations et desenregistrements
Remarque : Les noms de variables et de champs de base de données ne sont pas nécessairementidentiques, puisque les noms de champs de base de données peuvent contenir des caractères nonautorisés dans les noms de variables SPSS Statistics. Toutefois, si le fichier de travail a été créé àpartir du tableau de base de données que vous modifiez, les noms ou les étiquettes de variablessont généralement semblables, voire identiques aux noms des champs de la base de données.

62
Chapitre 3
Remplacement de valeurs dans des champs existants
Pour remplacer des valeurs de champs existants dans une base de données :
E Dans le panel Choisissez le mode d’export des données de l’assistant d’export vers la base dedonnées, sélectionnez Remplacer les valeurs dans les champs existants.
E Dans le panel Sélectionnez un tableau ou une vue, sélectionnez le tableau de la base de données.
E Dans le panel Associer les observations aux enregistrements, faites correspondre les variables quiidentifient chaque observation de manière unique et les noms des champs de la base de donnéescorrespondants.
E Pour chaque champ dont vous souhaitez remplacer des valeurs, faites glisser la variable contenantles nouvelles valeurs vers la colonne Source de valeurs, en regard du nom de champ de basede données correspondant.
Figure 3-30Assistant d’export vers la base de données, remplacement des valeurs de champs existants
En règle générale, le type de données de base (chaîne ou numérique) de la variable doitcorrespondre à celui du champ de la base de données. En cas de non-concordance des types dedonnées que la base de données ne peut pas résoudre, une erreur est générée et aucune donnéen’est exportée dans la base de données. Par exemple, si vous exportez une variable chaînevers un champ de base de données ayant le type de données numérique (double, réel, entier),une erreur est générée si l’une des valeurs de la variable chaîne contient des caractères nonnumériques. La lettre a dans l’icône en regard d’une variable désigne une variable chaîne.Vous ne pouvez pas modifier le nom, le type ou la largeur du champ. Les attributs du champde base de données d’origine sont conservés ; seules les valeurs sont remplacées.
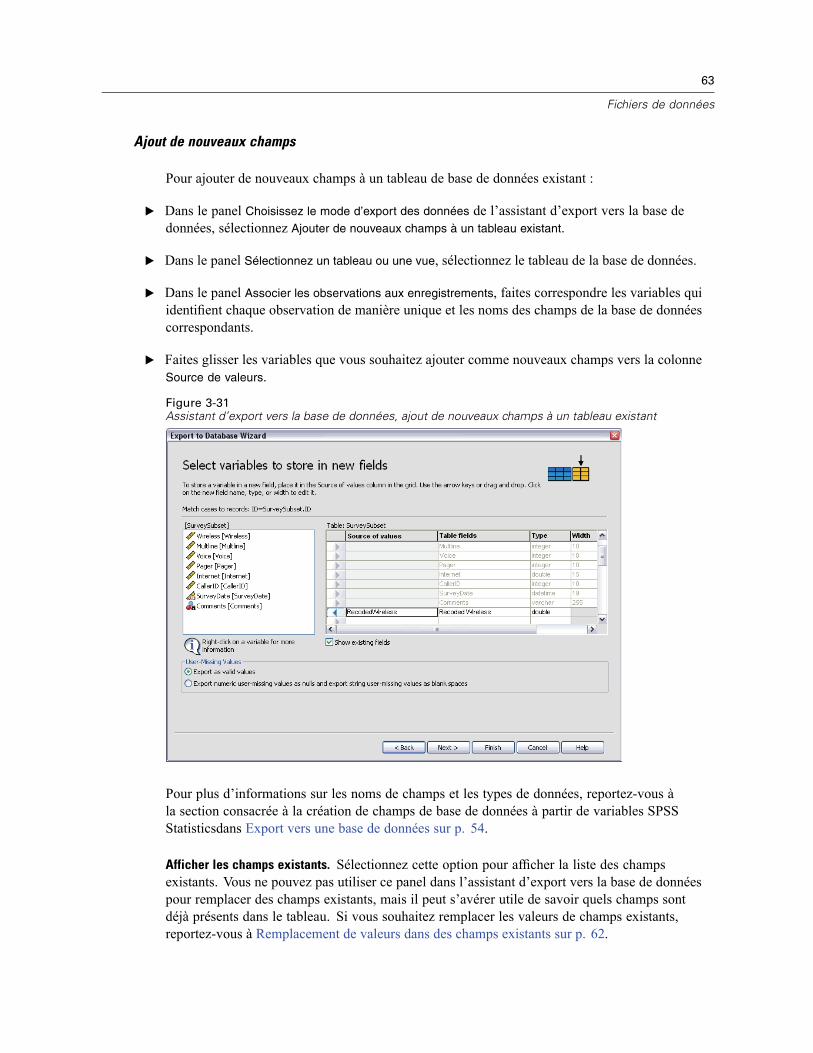
63
Fichiers de données
Ajout de nouveaux champs
Pour ajouter de nouveaux champs à un tableau de base de données existant :
E Dans le panel Choisissez le mode d’export des données de l’assistant d’export vers la base dedonnées, sélectionnez Ajouter de nouveaux champs à un tableau existant.
E Dans le panel Sélectionnez un tableau ou une vue, sélectionnez le tableau de la base de données.
E Dans le panel Associer les observations aux enregistrements, faites correspondre les variables quiidentifient chaque observation de manière unique et les noms des champs de la base de donnéescorrespondants.
E Faites glisser les variables que vous souhaitez ajouter comme nouveaux champs vers la colonneSource de valeurs.
Figure 3-31Assistant d’export vers la base de données, ajout de nouveaux champs à un tableau existant
Pour plus d’informations sur les noms de champs et les types de données, reportez-vous àla section consacrée à la création de champs de base de données à partir de variables SPSSStatisticsdans Export vers une base de données sur p. 54.
Afficher les champs existants. Sélectionnez cette option pour afficher la liste des champsexistants. Vous ne pouvez pas utiliser ce panel dans l’assistant d’export vers la base de donnéespour remplacer des champs existants, mais il peut s’avérer utile de savoir quels champs sontdéjà présents dans le tableau. Si vous souhaitez remplacer les valeurs de champs existants,reportez-vous à Remplacement de valeurs dans des champs existants sur p. 62.
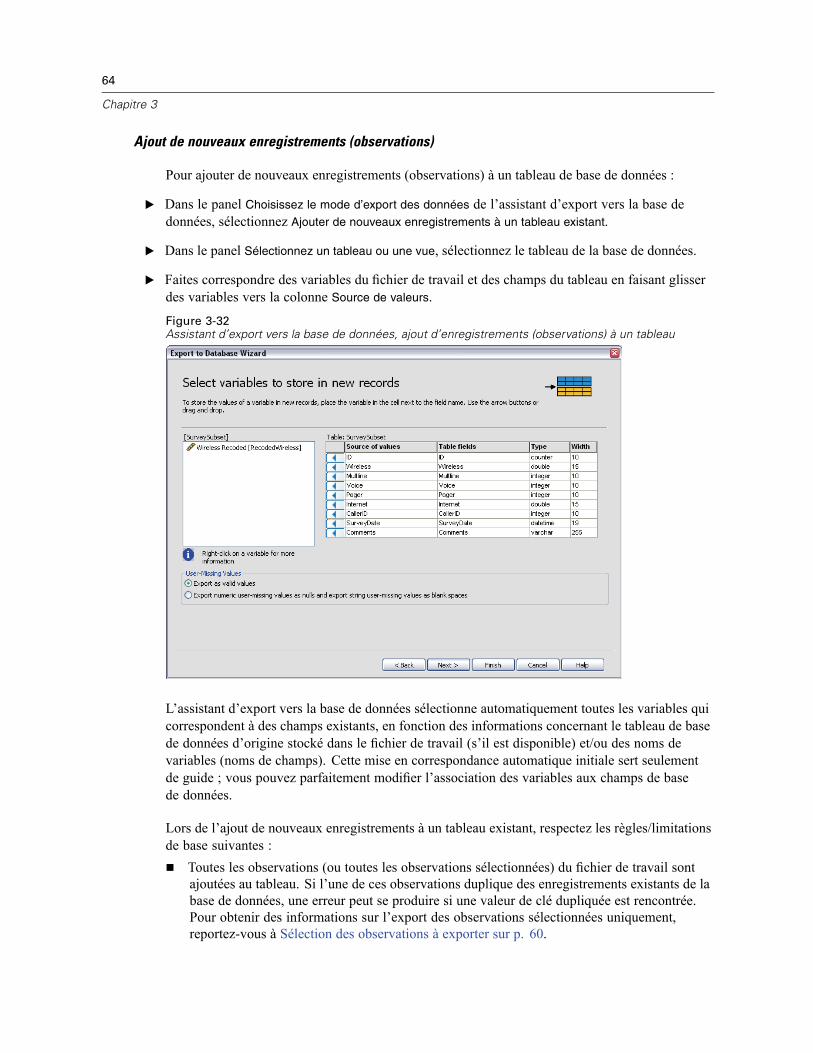
64
Chapitre 3
Ajout de nouveaux enregistrements (observations)
Pour ajouter de nouveaux enregistrements (observations) à un tableau de base de données :
E Dans le panel Choisissez le mode d’export des données de l’assistant d’export vers la base dedonnées, sélectionnez Ajouter de nouveaux enregistrements à un tableau existant.
E Dans le panel Sélectionnez un tableau ou une vue, sélectionnez le tableau de la base de données.
E Faites correspondre des variables du fichier de travail et des champs du tableau en faisant glisserdes variables vers la colonne Source de valeurs.
Figure 3-32Assistant d’export vers la base de données, ajout d’enregistrements (observations) à un tableau
L’assistant d’export vers la base de données sélectionne automatiquement toutes les variables quicorrespondent à des champs existants, en fonction des informations concernant le tableau de basede données d’origine stocké dans le fichier de travail (s’il est disponible) et/ou des noms devariables (noms de champs). Cette mise en correspondance automatique initiale sert seulementde guide ; vous pouvez parfaitement modifier l’association des variables aux champs de basede données.
Lors de l’ajout de nouveaux enregistrements à un tableau existant, respectez les règles/limitationsde base suivantes :
Toutes les observations (ou toutes les observations sélectionnées) du fichier de travail sontajoutées au tableau. Si l’une de ces observations duplique des enregistrements existants de labase de données, une erreur peut se produire si une valeur de clé dupliquée est rencontrée.Pour obtenir des informations sur l’export des observations sélectionnées uniquement,reportez-vous à Sélection des observations à exporter sur p. 60.

65
Fichiers de données
Vous pouvez utiliser les valeurs de variables créées au cours de la session comme valeurs deschamps existants, mais vous ne pouvez pas ajouter de nouveaux champs ni changer le nomdes champs existants. Pour ajouter de nouveaux champs à un tableau de base de données,reportez-vous à Ajout de nouveaux champs sur p. 63.Les champs de base de données exclus ou non appariés à une variable n’ont pas de valeur pourles enregistrements ajoutés dans le tableau de base de données. (Si la cellule Source de valeursest vide, aucune variable n’est mise en correspondance avec le champ.)
Création ou remplacement d’un tableau
Pour créer un tableau ou remplacer un tableau de base de données existant :
E Dans le panel Choisissez le mode d’export des données de l’assistant d’export, sélectionnezSupprimer un tableau existant et créer un tableau portant le même nom ou Créer un tableau et entrezle nom du nouveau tableau.
E Si vous remplacez un tableau existant, dans le panel Sélectionnez un tableau ou une vue,sélectionnez le tableau de base de données.
E Faites glisser les variables vers la colonne Variables à enregistrer.
E Vous pouvez également désigner les variables/champs qui définissent la clé primaire, modifier lenom des champs, ainsi que le type des données.
Figure 3-33Assistant d’export vers la base de données, sélection de variables pour un nouveau tableau
Clé primaire. Pour désigner des variables comme clés primaires dans le tableau d’une base dedonnées, cochez la case dans la colonne identifiée par l’icône de clé.
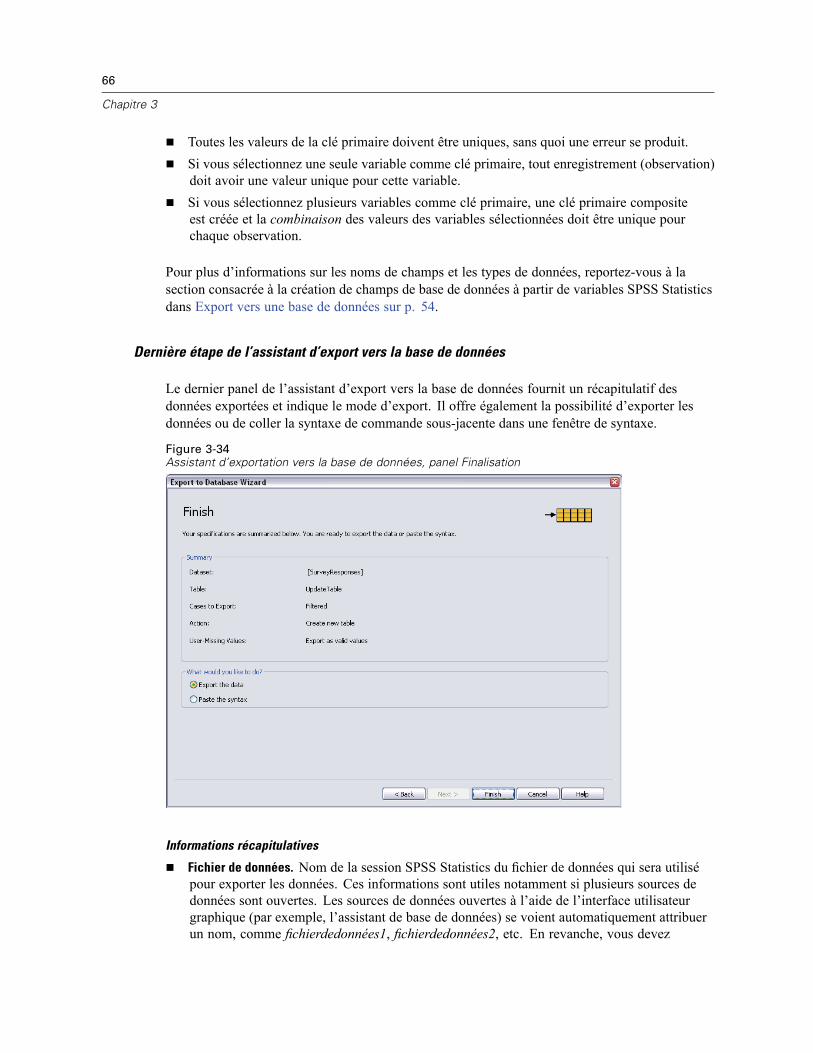
66
Chapitre 3
Toutes les valeurs de la clé primaire doivent être uniques, sans quoi une erreur se produit.Si vous sélectionnez une seule variable comme clé primaire, tout enregistrement (observation)doit avoir une valeur unique pour cette variable.Si vous sélectionnez plusieurs variables comme clé primaire, une clé primaire compositeest créée et la combinaison des valeurs des variables sélectionnées doit être unique pourchaque observation.
Pour plus d’informations sur les noms de champs et les types de données, reportez-vous à lasection consacrée à la création de champs de base de données à partir de variables SPSS Statisticsdans Export vers une base de données sur p. 54.
Dernière étape de l’assistant d’export vers la base de données
Le dernier panel de l’assistant d’export vers la base de données fournit un récapitulatif desdonnées exportées et indique le mode d’export. Il offre également la possibilité d’exporter lesdonnées ou de coller la syntaxe de commande sous-jacente dans une fenêtre de syntaxe.
Figure 3-34Assistant d’exportation vers la base de données, panel Finalisation
Informations récapitulatives
Fichier de données. Nom de la session SPSS Statistics du fichier de données qui sera utilisépour exporter les données. Ces informations sont utiles notamment si plusieurs sources dedonnées sont ouvertes. Les sources de données ouvertes à l’aide de l’interface utilisateurgraphique (par exemple, l’assistant de base de données) se voient automatiquement attribuerun nom, comme fichierdedonnées1, fichierdedonnées2, etc. En revanche, vous devez

67
Fichiers de données
explicitement attribuer un nom aux sources de données ouvertes à l’aide d’une syntaxe decommande.Tableau. Nom du tableau à modifier ou à créer.Observations à exporter. L’export concerne toutes les observations ou les observationssélectionnées par une condition de filtre définie au préalable. Pour plus d'informations,reportez-vous à Sélection des observations à exporter sur p. 60.Action. Indique comment la base de données sera modifiée (par exemple, création d’untableau, ajout de champs ou d’enregistrements à un tableau existant).Valeurs manquantes spécifiées. Les valeurs manquantes spécifiées peuvent être exportéescomme valeurs valides, ou traitées comme des valeurs manquantes par défaut pour lesvariables numériques et converties en espaces vides pour les variables chaîne. Ce paramètreest contrôlé dans le panel où vous sélectionnez les variables à exporter.
Export vers Dimensions
La boîte de dialogue Exporter vers les dimensions crée un fichier de données SPSS Statistics etun fichier de métadonnées Dimensions vous permettant de lire les données dans les applicationsDimensions, comme mrInterview et mrTables. Ceci s’avère particulièrement utile en cas de« va-et-vient » des données entre SPSS Statistics et Dimensions. Par exemple, vous pouvezlire une source de données mrInterview dans SPSS Statistics, calculer de nouvelles variableset enregistrer ces données dans un formulaire lisible via mrTables, sans pour autant perdre lesattributs des métadonnées d’origine.
Pour exporter les données à utiliser dans les applications Dimensions :
E Dans les menus de la fenêtre Editeur de données contenant les données à exporter, sélectionnez :Fichier
Exporter vers les dimensions
E Cliquez sur Fichier de données pour spécifier le nom et l’emplacement du fichier de données SPSSStatistics.
E Cliquez sur Fichier de métadonnées pour indiquer le nom et l’emplacement du fichier demétadonnées Dimensions.
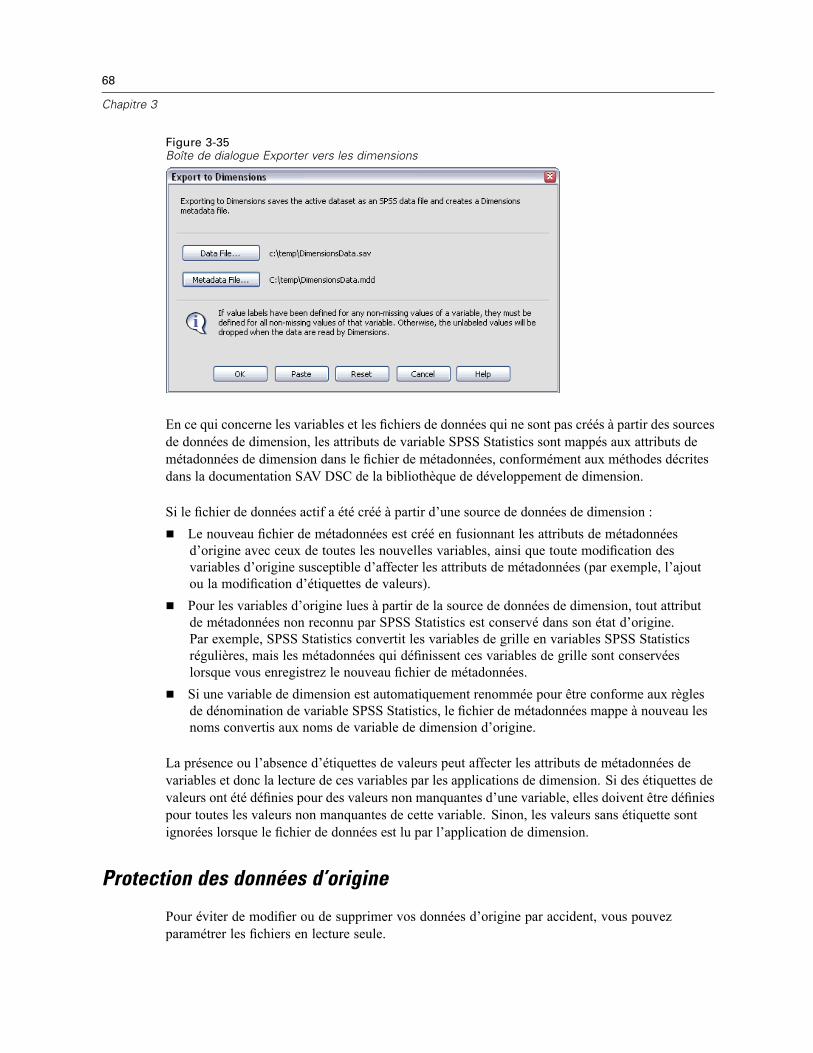
68
Chapitre 3
Figure 3-35Boîte de dialogue Exporter vers les dimensions
En ce qui concerne les variables et les fichiers de données qui ne sont pas créés à partir des sourcesde données de dimension, les attributs de variable SPSS Statistics sont mappés aux attributs demétadonnées de dimension dans le fichier de métadonnées, conformément aux méthodes décritesdans la documentation SAV DSC de la bibliothèque de développement de dimension.
Si le fichier de données actif a été créé à partir d’une source de données de dimension :Le nouveau fichier de métadonnées est créé en fusionnant les attributs de métadonnéesd’origine avec ceux de toutes les nouvelles variables, ainsi que toute modification desvariables d’origine susceptible d’affecter les attributs de métadonnées (par exemple, l’ajoutou la modification d’étiquettes de valeurs).Pour les variables d’origine lues à partir de la source de données de dimension, tout attributde métadonnées non reconnu par SPSS Statistics est conservé dans son état d’origine.Par exemple, SPSS Statistics convertit les variables de grille en variables SPSS Statisticsrégulières, mais les métadonnées qui définissent ces variables de grille sont conservéeslorsque vous enregistrez le nouveau fichier de métadonnées.Si une variable de dimension est automatiquement renommée pour être conforme aux règlesde dénomination de variable SPSS Statistics, le fichier de métadonnées mappe à nouveau lesnoms convertis aux noms de variable de dimension d’origine.
La présence ou l’absence d’étiquettes de valeurs peut affecter les attributs de métadonnées devariables et donc la lecture de ces variables par les applications de dimension. Si des étiquettes devaleurs ont été définies pour des valeurs non manquantes d’une variable, elles doivent être définiespour toutes les valeurs non manquantes de cette variable. Sinon, les valeurs sans étiquette sontignorées lorsque le fichier de données est lu par l’application de dimension.
Protection des données d’origine
Pour éviter de modifier ou de supprimer vos données d’origine par accident, vous pouvezparamétrer les fichiers en lecture seule.
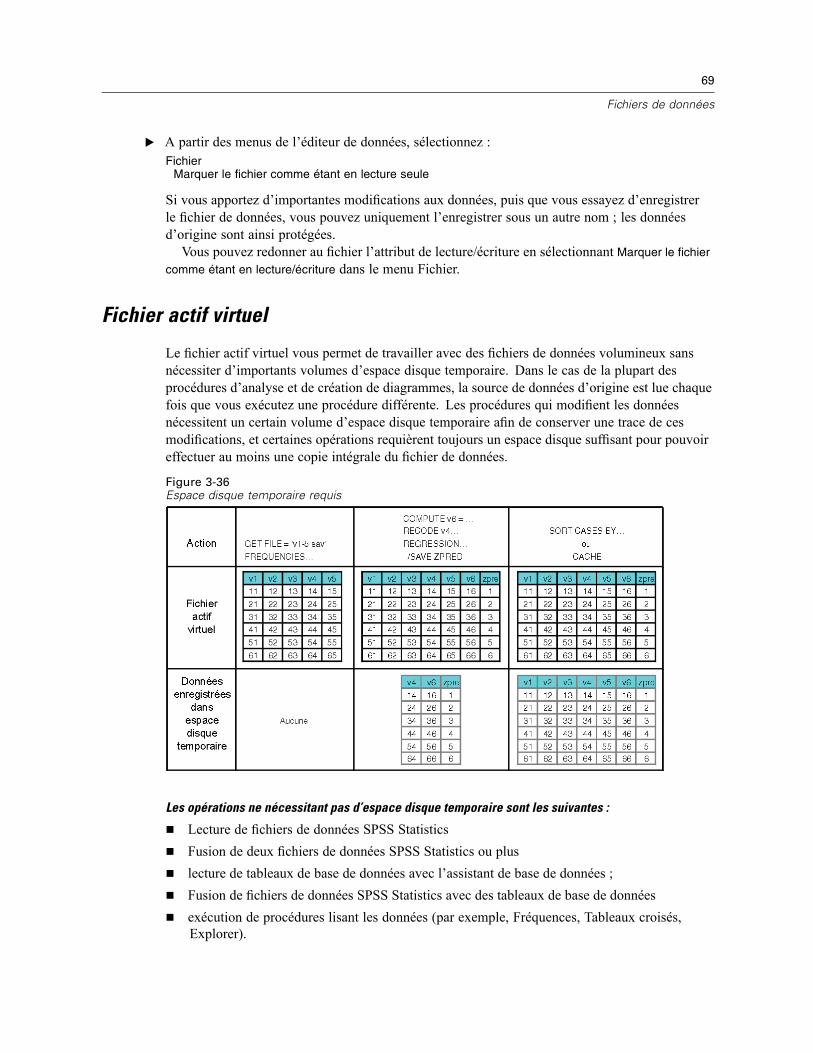
69
Fichiers de données
E A partir des menus de l’éditeur de données, sélectionnez :Fichier
Marquer le fichier comme étant en lecture seule
Si vous apportez d’importantes modifications aux données, puis que vous essayez d’enregistrerle fichier de données, vous pouvez uniquement l’enregistrer sous un autre nom ; les donnéesd’origine sont ainsi protégées.Vous pouvez redonner au fichier l’attribut de lecture/écriture en sélectionnant Marquer le fichier
comme étant en lecture/écriture dans le menu Fichier.
Fichier actif virtuel
Le fichier actif virtuel vous permet de travailler avec des fichiers de données volumineux sansnécessiter d’importants volumes d’espace disque temporaire. Dans le cas de la plupart desprocédures d’analyse et de création de diagrammes, la source de données d’origine est lue chaquefois que vous exécutez une procédure différente. Les procédures qui modifient les donnéesnécessitent un certain volume d’espace disque temporaire afin de conserver une trace de cesmodifications, et certaines opérations requièrent toujours un espace disque suffisant pour pouvoireffectuer au moins une copie intégrale du fichier de données.
Figure 3-36Espace disque temporaire requis
Les opérations ne nécessitant pas d’espace disque temporaire sont les suivantes :
Lecture de fichiers de données SPSS StatisticsFusion de deux fichiers de données SPSS Statistics ou pluslecture de tableaux de base de données avec l’assistant de base de données ;Fusion de fichiers de données SPSS Statistics avec des tableaux de base de donnéesexécution de procédures lisant les données (par exemple, Fréquences, Tableaux croisés,Explorer).

70
Chapitre 3
Les opérations créant une ou plusieurs colonnes de données dans un espace disque temporairesont les suivantes :
Calcul de nouvelles variables ;Recodage de variables existantes ;Exécution de procédures créant ou modifiant des variables (par exemple, enregistrementde prévisions dans la Régression linéaire).
Les opérations créant une copie intégrale du fichier de données dans un espace disque temporairesont les suivantes :
Lecture de fichiers Excel ;Exécution de procédures triant les données (par exemple, Trier les observations, Scinderfichier) ;Lecture des données avec la commande GET TRANSLATE ou DATA LIST ;
Utilisation de la fonctionnalité Données de mémoire cache ou de la commande CACHE ;
Ouverture depuis SPSS Statistics d’autres applications lisant le fichier de données (parexemple, AnswerTree, DecisionTime).
Remarque : La commande GET DATA assure des fonctionnalités comparables à celles de lacommande DATA LIST mais sans créer de copie intégrale du fichier de données dans un espacedisque temporaire. Dans sa syntaxe, la commande SPLIT FILE ne trie pas le fichier de donnéeset n’en crée donc pas de copie. Toutefois, pour pouvoir fonctionner correctement, cette commandenécessitent des données triées ; l’interface de boîtes de dialogue de ces procédures triera doncautomatiquement le fichier de données, aboutissant ainsi à la création d’une copie complète de cefichier. (La syntaxe de commande n’est pas disponible dans la version Student.)
Opérations créant une copie intégrale du fichier de données par défaut :
Lecture de bases de données avec l’Assistant de base de donnéesLecture de fichiers texte avec l’Assistant de texte
L’Assistant de texte offre un paramètre optionnel qui crée automatiquement un cache des données.Par défaut, cette option est sélectionnée. Pour désactiver cette option, désélectionnez la caseMettre données en cache localement. Pour l’Assistant de base de données, vous pouvez coller lasyntaxe de commande générée et supprimer la commande CACHE.
Création d’un cache de données
Bien que le fichier actif virtuel contribue à réduire considérablement le volume d’espace disquetemporaire requis, l’absence d’une copie temporaire du fichier « actif » signifie que la source dedonnées d’origine doit être lue de nouveau pour chaque procédure. Dans le cas de fichiers dedonnées volumineux provenant d’une source externe, la création d’une copie temporaire desdonnées peut améliorer les performances de lecture. Dans le cas de tableaux de données lusdans une base de données, la requête SQL qui consulte les informations de la base doit êtreréexécutée pour toute commande ou procédure nécessitant la lecture des données. Du fait quequasiment toutes les procédures d’analyse statistique et de création de diagrammes doivent lire lesdonnées, la requête SQL est réexécutée pour chaque nouvelle procédure que vous lancez, ce qui

71
Fichiers de données
risque d’entraîner un allongement considérable des temps de traitement si vous devez exécuter ungrand nombre de procédures.Si l’ordinateur sur lequel vous effectuez l’analyse (qu’il s’agisse de votre ordinateur local ou
d’un serveur distant) dispose d’un volume d’espace disque suffisant, vous pouvez éliminer denombreuses requêtes SQL et réduire ainsi les temps de traitement en créant un cache de donnéesdu fichier actif. Le cache de données est une copie temporaire de la totalité des données.
Remarque : Par défaut, l’Assistant de base de données crée automatiquement un cache dedonnées. Toutefois, si vous utilisez la commande GET DATA dans une syntaxe afin de lire unebase de données, le cache de données n’est pas créé automatiquement. (La syntaxe de commanden’est pas disponible dans la version Student.)
Pour créer un cache de données
E A partir des menus, sélectionnez :Fichier
Données de mémoire cache...
E Cliquez sur OK ou sur Cacher maintenant.
L’option OK créera un cache de données à la prochaine lecture des données (par exemple, lorsquevous exécuterez une procédure statistique). C’est l’option que vous choisirez le plus souventpuisque cette opération ne nécessite pas de passage de données supplémentaire. L’option Cacher
maintenant crée un cache de données immédiatement, ce qui généralement ne devrait pas s’avérernécessaire. L’option Cacher maintenant est surtout utile pour deux raisons :
Une source de données est « verrouillée » et ne peut être mise à jour tant que vous n’avez pasfermé la session, ouvert une autre source de données ou créé un cache des données.Pour les sources de données volumineuses, la consultation du contenu de l’onglet Affichagedes données dans l’éditeur de données s’avérera bien plus rapide si vous placez les donnéesdans un cache.
Pour mettre automatiquement des données en mémoire cache
Vous pouvez paramétrer la commande SET pour qu’elle crée automatiquement un cache dedonnées dès que vous avez apporté un certain nombre de modifications dans le fichier de donnéesactif. Par défaut, le fichier de données actif est automatiquement mis en mémoire cache après 20modifications.
E A partir des menus, sélectionnez :Fichier
NouveauSyntaxe
E Dans la fenêtre de syntaxe, tapez SET CACHE n (n correspond au nombre de modificationsapportées au fichier de données actif avant sa mise en mémoire cache).
E Dans le menu de la fenêtre de syntaxe, sélectionnez :Exécuter
Tous

72
Chapitre 3
Remarque : Vous devez définir le paramètre de cache pour chaque session. A chaque nouvellesession, la valeur est paramétrée par défaut sur 20.

Chapitre
4Mode d’analyse distribuée
Le mode d’analyse distribuée vous permet d’utiliser un autre ordinateur local que le vôtre (ou debureau) pour les tâches sollicitant la mémoire de façon intensive. Les serveurs distants utiliséspour l’analyse distribuée se révélant généralement plus puissants et plus rapides que votreordinateur local, le mode d’analyse distribuée permet de réduire considérablement les tempsde traitement. L’analyse distribuée effectuée à l’aide d’un serveur distant peut s’avérer utile sivotre travail met en œuvre :
des fichiers de données volumineux, contenant notamment des données provenant de bases dedonnées ;des tâches sollicitant la mémoire de façon intensive. Toute tâche longue à effectuer en moded’analyse locale serait ainsi mieux adaptée à une analyse distribuée.
L’analyse distribuée n’affecte que les tâches impliquant des données, telles que la lecture et latransformation de données ainsi que le calcul de nouvelles variables et de statistiques. L’analysedistribuée n’a aucun effet sur les tâches associées à la modification de résultats, telles que lamanipulation de tableaux pivotants ou la modification de diagrammes.
Remarque : L’analyse distribuée n’est disponible que si vous disposez à la fois d’une version localedu programme et d’un accès à une version serveur du même logiciel installé sur un serveur distant.
Connexion au serveur SPSS
La boîte de dialogue Connexion au serveur vous permet de sélectionner l’ordinateur qui traiteles commandes et exécute les procédures. Vous pouvez sélectionner votre ordinateur local ou unserveur distant.
73
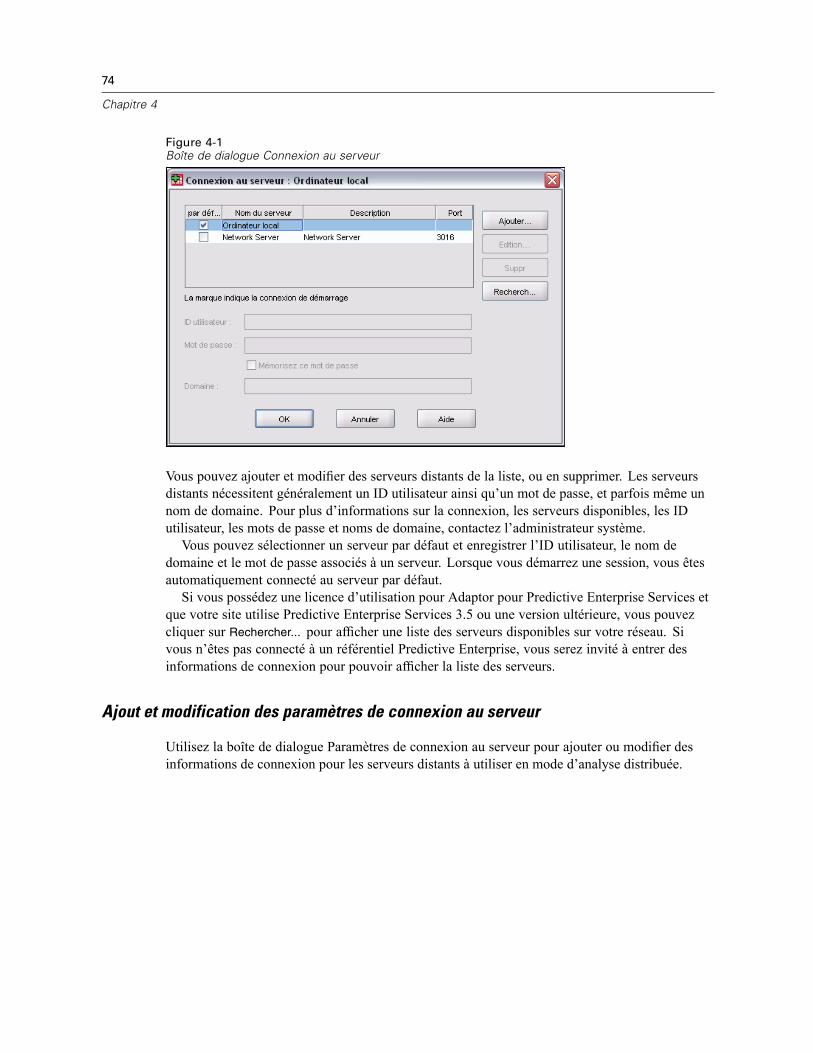
74
Chapitre 4
Figure 4-1Boîte de dialogue Connexion au serveur
Vous pouvez ajouter et modifier des serveurs distants de la liste, ou en supprimer. Les serveursdistants nécessitent généralement un ID utilisateur ainsi qu’un mot de passe, et parfois même unnom de domaine. Pour plus d’informations sur la connexion, les serveurs disponibles, les IDutilisateur, les mots de passe et noms de domaine, contactez l’administrateur système.Vous pouvez sélectionner un serveur par défaut et enregistrer l’ID utilisateur, le nom de
domaine et le mot de passe associés à un serveur. Lorsque vous démarrez une session, vous êtesautomatiquement connecté au serveur par défaut.Si vous possédez une licence d’utilisation pour Adaptor pour Predictive Enterprise Services et
que votre site utilise Predictive Enterprise Services 3.5 ou une version ultérieure, vous pouvezcliquer sur Rechercher... pour afficher une liste des serveurs disponibles sur votre réseau. Sivous n’êtes pas connecté à un référentiel Predictive Enterprise, vous serez invité à entrer desinformations de connexion pour pouvoir afficher la liste des serveurs.
Ajout et modification des paramètres de connexion au serveur
Utilisez la boîte de dialogue Paramètres de connexion au serveur pour ajouter ou modifier desinformations de connexion pour les serveurs distants à utiliser en mode d’analyse distribuée.
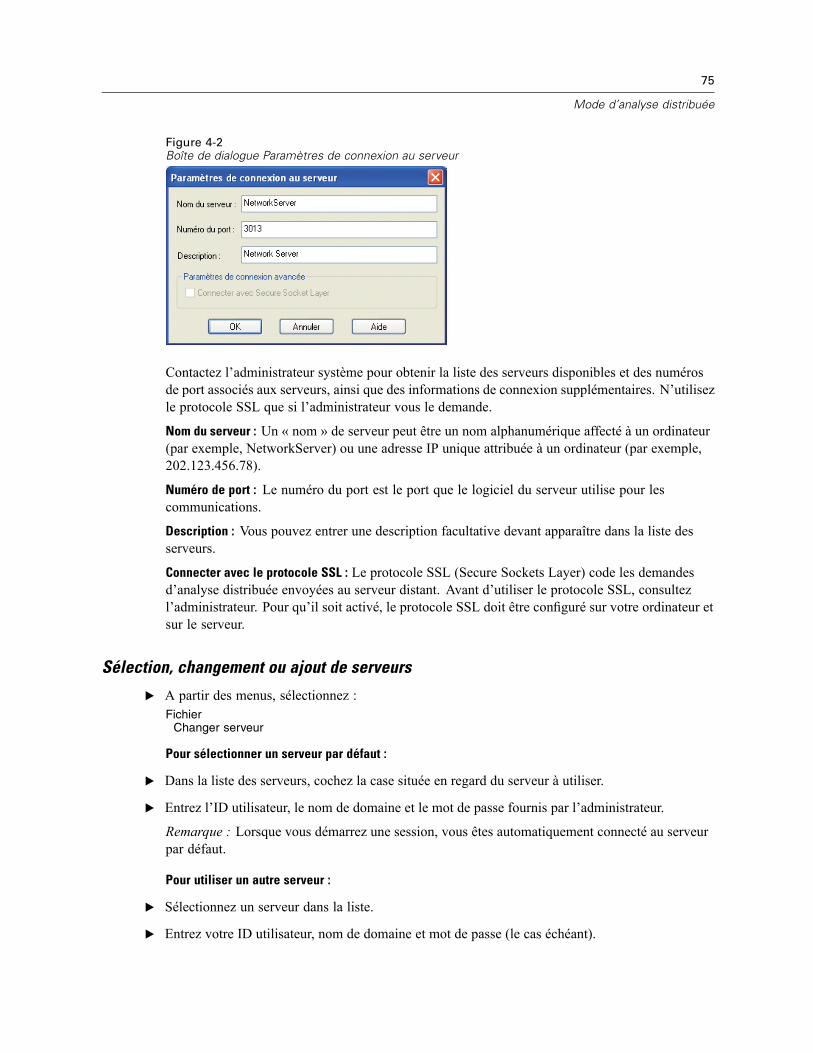
75
Mode d’analyse distribuée
Figure 4-2Boîte de dialogue Paramètres de connexion au serveur
Contactez l’administrateur système pour obtenir la liste des serveurs disponibles et des numérosde port associés aux serveurs, ainsi que des informations de connexion supplémentaires. N’utilisezle protocole SSL que si l’administrateur vous le demande.
Nom du serveur : Un « nom » de serveur peut être un nom alphanumérique affecté à un ordinateur(par exemple, NetworkServer) ou une adresse IP unique attribuée à un ordinateur (par exemple,202.123.456.78).
Numéro de port : Le numéro du port est le port que le logiciel du serveur utilise pour lescommunications.
Description : Vous pouvez entrer une description facultative devant apparaître dans la liste desserveurs.
Connecter avec le protocole SSL : Le protocole SSL (Secure Sockets Layer) code les demandesd’analyse distribuée envoyées au serveur distant. Avant d’utiliser le protocole SSL, consultezl’administrateur. Pour qu’il soit activé, le protocole SSL doit être configuré sur votre ordinateur etsur le serveur.
Sélection, changement ou ajout de serveurs
E A partir des menus, sélectionnez :Fichier
Changer serveur
Pour sélectionner un serveur par défaut :
E Dans la liste des serveurs, cochez la case située en regard du serveur à utiliser.
E Entrez l’ID utilisateur, le nom de domaine et le mot de passe fournis par l’administrateur.
Remarque : Lorsque vous démarrez une session, vous êtes automatiquement connecté au serveurpar défaut.
Pour utiliser un autre serveur :
E Sélectionnez un serveur dans la liste.
E Entrez votre ID utilisateur, nom de domaine et mot de passe (le cas échéant).

76
Chapitre 4
Remarque : Lorsque vous changez de serveur au cours d’une session, toutes les fenêtres ouvertessont automatiquement fermées. Le système vous demande d’enregistrer vos modifications avantla fermeture des fenêtres.
Pour ajouter un serveur :
E Demandez les informations de connexion du serveur à l’administrateur.
E Cliquez sur Ajouter pour ouvrir la boîte de dialogue Paramètres de connexion au serveur.
E Entrez les informations de connexion et les paramètres facultatifs, puis cliquez sur OK.
Pour modifier un serveur :
E Demandez les informations de connexion révisées à l’administrateur.
E Cliquez sur Edition pour ouvrir la boîte de dialogue Paramètres de connexion au serveur.
E Entrez les modifications et cliquez sur OK.
Pour rechercher des serveurs disponibles :
Remarque : Vous ne pouvez rechercher des serveurs disponibles que si vous possédez une licenced’utilisation pour Adaptor pour Predictive Enterprise Services et que votre site utilise PredictiveEnterprise Services 3.5 ou une version ultérieure.
E Cliquez sur Search... pour ouvrir la boîte de dialogue Search for Servers. Si vous n’êtes pasconnecté à un référentiel Predictive Enterprise, vous serez invité à fournir des informations deconnexion.
E Sélectionnez les serveurs disponibles et cliquez sur OK. Les serveurs apparaîtront maintenant dansla boîte de dialogue Connexion au serveur SPSS.
E Pour vous connecter à l’un des serveurs, suivez les instructions « Pour utiliser un autre serveur ».
Recherche de serveurs disponibles
Utilisez la boîte de dialogue Rechercher des serveurs pour sélectionner les serveurs disponiblessur votre réseau. Cette boîte de dialogue apparaît quand vous cliquez sur Search... dans la boîtede dialogue Server Login.Figure 4-3Boîte de dialogue Rechercher des serveurs

77
Mode d’analyse distribuée
Sélectionnez les serveurs et cliquez sur OK pour les ajouter à la boîte de dialogue Server Login.Bien que vous puissiez ajouter des serveurs manuellement dans la boîte de dialogue Connexionau serveur SPSS, la recherche de serveurs disponibles vous permet de vous connecter à desserveurs sans qu’il soit nécessaire de connaître le nom du serveur et le numéro de port exacts. Cesinformations sont fournies automatiquement. Toutefois, vous devez tout de même posséder lesinformations de connexion exactes, comme le nom d’utilisateur, le domaine et le mot de passe.
Ouverture de fichiers de données à partir d’un serveur distant
En mode d’analyse distribuée, la boîte de dialogue Ouvrir fichier distant remplace la boîtede dialogue Ouvrir fichier.
Le contenu de la liste des fichiers, dossiers et lecteurs disponibles dépend des donnéesaccessibles sur le serveur distant. Le nom du serveur utilisé est indiqué dans la zonesupérieure de la boîte de dialogue.En mode d’analyse distribuée, vous n’aurez accès aux fichiers de données de votre ordinateurlocal que si vous définissez le lecteur correspondant comme un lecteur partagé ou les dossierscontenant vos fichiers de données comme des dossiers partagés. Consultez la documentationrelative à votre système d’exploitation pour savoir comment « partager » les dossiers devotre ordinateur local avec le réseau serveur.Si le système d’exploitation du serveur est différent du vôtre (Windows et UNIX par exemple),vous n’aurez probablement pas accès aux fichiers de données locaux en mode d’analysedistribuée, même s’ils se trouvent dans des dossiers partagés.
Accès aux fichiers de données en mode d’analyse locale ou distribuée
L’affichage des dossiers (répertoires) et lecteurs de votre ordinateur local et du réseau dépend del’ordinateur que vous utilisez pour traiter les commandes et exécuter les procédures (qui necorrespond pas obligatoirement à l’ordinateur que vous avez en face de vous).
Mode d’analyse locale. Lorsque vous utilisez votre ordinateur local comme votre « serveur »,l’affichage des fichiers de données, dossiers et lecteurs que vous obtenez dans la boîte de dialogued’accès aux fichiers (permettant d’ouvrir les fichiers de données) est le même que celui fournidans d’autres applications ou dans l’Explorateur Windows. Vous pouvez afficher tous les fichiersde données et dossiers de votre ordinateur, ainsi que tous les fichiers et dossiers stockés sur leslecteurs réseau.
Mode d’analyse distribuée. Lorsque vous utilisez un autre ordinateur comme « serveur distant »pour exécuter les commandes et procédures, l’affichage des fichiers de données, dossiers etlecteurs correspond à celui obtenu du serveur distant. Bien que vous puissiez obtenir des noms dedossiers familiers tels que Program Files et des lecteurs portant la lettre C, il ne s’agit pas desdossiers et lecteurs de votre ordinateur, mais des dossiers et lecteurs du serveur distant.

78
Chapitre 4
Figure 4-4Affichages local et distant
En mode d’analyse distribuée, vous n’aurez accès aux fichiers de données de votre ordinateur localque si vous définissez le lecteur correspondant comme un lecteur partagé et spécifiez les dossierscontenant vos fichiers de données comme des dossiers partagés. Si le système d’exploitation duserveur est différent du vôtre (Windows et UNIX par exemple), vous n’aurez probablementpas accès aux fichiers de données locaux en mode d’analyse distribuée, même s’ils se trouventdans des dossiers partagés.L’utilisation du mode d’analyse distribuée n’équivaut pas à accéder aux fichiers de données
stockés sur un autre ordinateur de votre réseau. Vous pouvez accéder aux fichiers de donnéessitués sur d’autres disques réseau en mode d’analyse locale ou en mode d’analyse distribuée. Enmode local, vous accédez à d’autres disques à partir de votre ordinateur local. En mode distribué,vous accédez à d’autres disques réseau depuis le serveur distant.Pour savoir si vous utilisez le mode local ou le mode distribué, examinez la barre de titre
de la boîte de dialogue permettant d’accéder aux fichiers de données. Si le titre de la boîte dedialogue contient le terme Distant (comme dans Ouvrir fichier distant) ou que le libellé Serveur
distant : [nom_de_serveur] apparaît dans la zone supérieure de la boîte de dialogue, vous utilisez lemode d’analyse distribuée.

79
Mode d’analyse distribuée
Remarque : Ceci ne concerne que les boîtes de dialogue permettant d’accéder aux fichiers dedonnées (telles que Ouvrir les données, Enregistrer les données, Ouvrir la base de données etAppliquer le dictionnaire des données). Pour tous les autres types de fichier (tels que les fichiersViewer, les fichiers de syntaxe et les fichiers scripts), l’affichage local est toujours utilisé.
Disponibilité des procédures en mode d’analyse distribuée
En mode d’analyse distribuée, uniquement les procédures installées à la fois sur votre versionlocale et sur la version du serveur distant sont disponibles.Si vous avez des composants optionnels installés localement qui ne sont pas disponibles sur
le serveur distant et si vous basculez de l’ordinateur local au serveur distant, les procéduresaffectées seront supprimées des menus et des erreurs se produiront dans la syntaxe de commandecorrespondante. Vous devrez rétablir le mode local pour restaurer toutes les procédures affectées.
Spécifications de chemins absolus et relatifs
En mode d’analyse distribuée, les spécifications de chemins relatifs pour les fichiers de données etles fichiers de syntaxe de commande sont relatives au serveur utilisé et non à votre ordinateurlocal. Une spécification de chemin telle que /mydocs/mydata.sav ne désigne pas un répertoire etun fichier de votre disque local, mais un répertoire et un fichier du disque dur du serveur distant.
Spécifications de chemins UNC Windows
Avec la version serveur Windows, vous pouvez utiliser des noms de chemin UNC (UniversalNaming Convention = convention de dénomination universelle) pour accéder aux fichiers dedonnées et de syntaxe avec la syntaxe de commande. Une spécification de chemin UNC prendgénéralement la forme suivante :
\\nom_serveur\nom_partage\chemin\nom_fichier
L’élément nom_serveur est le nom de l’ordinateur contenant le fichier de données.L’élément nom_partage désigne le dossier (répertoire) de l’ordinateur défini comme dossierde partage.L’élément chemin correspond aux sous-dossiers (sous-répertoires) du dossier partagé.L’élément nom_fichier est le nom du fichier de données.
Voir l’exemple comme suit :
GET FILE='\\hqdev001\public\juillet\ventes.sav'.
Si aucun nom n’a été attribué à l’ordinateur, vous pouvez utiliser son adresse IP, comme dansl’exemple suivant :
GET FILE='\\204.125.125.53\public\juillet\ventes.sav'.
Même si vous utilisez des spécifications de chemins UNC, vous ne pouvez accéder qu’auxfichiers de données et de syntaxe installés sur des lecteurs et des dossiers partagés. Lorsque vousutilisez le mode d’analyse distribuée, les fichiers de données et de syntaxe de votre ordinateurlocal sont inclus dans le traitement.

80
Chapitre 4
Spécifications de chemins absolus UNIX
Sur les versions serveur UNIX, il n’existe aucun équivalent à la dénomination UNC. Pour tousles répertoires, vous devez indiquer un chemin d’accès absolu, commençant à la racine duserveur. Les chemins relatifs ne sont pas admis. Par exemple, si le fichier de données se trouvedans le répertoire /bin/data et que le répertoire actif est également /bin/data, la commande GETFILE='ventes.sav' n’est pas valide. Vous devez indiquer l’intégralité du chemin d’accès,à savoir :
GET FILE='/bin/ventes.sav'.INSERT FILE='/bin/salesjob.sps'.

Chapitre
5Editeur de données
L’éditeur de données fournit une méthode pratique, semblable à celle d’un tableur, permettantde créer et de modifier des fichiers de données SPSS. La fenêtre de l’éditeur de données s’ouvreautomatiquement lorsque vous lancez une session SPSS.
L’éditeur de données permet d’afficher les données de deux façons :Affichage des données. Affiche les valeurs réelles des données ou les étiquettes de valeursdéfinies.Affichage des variables. Affiche les informations de définition des variables, à savoir lesétiquettes de valeurs et de variables définies, le type des données (par exemple, chaîne, dateou valeur numérique), le niveau de mesure (nominale, ordinale ou échelle) et les valeursutilisateur manquantes.
Dans les deux affichages, vous pouvez ajouter, modifier et supprimer les informations contenuesdans le fichier de données.
Affichage des donnéesFigure 5-1Affichage des données
Un grand nombre des fonctions de l’affichage des données sont similaires à celles que proposentles tableurs. Il y a toutefois des différences importantes :
Les lignes sont des observations. Chaque ligne représente une observation. Par exemple,chaque répondant d’un questionnaire est considéré comme étant une observation.
81
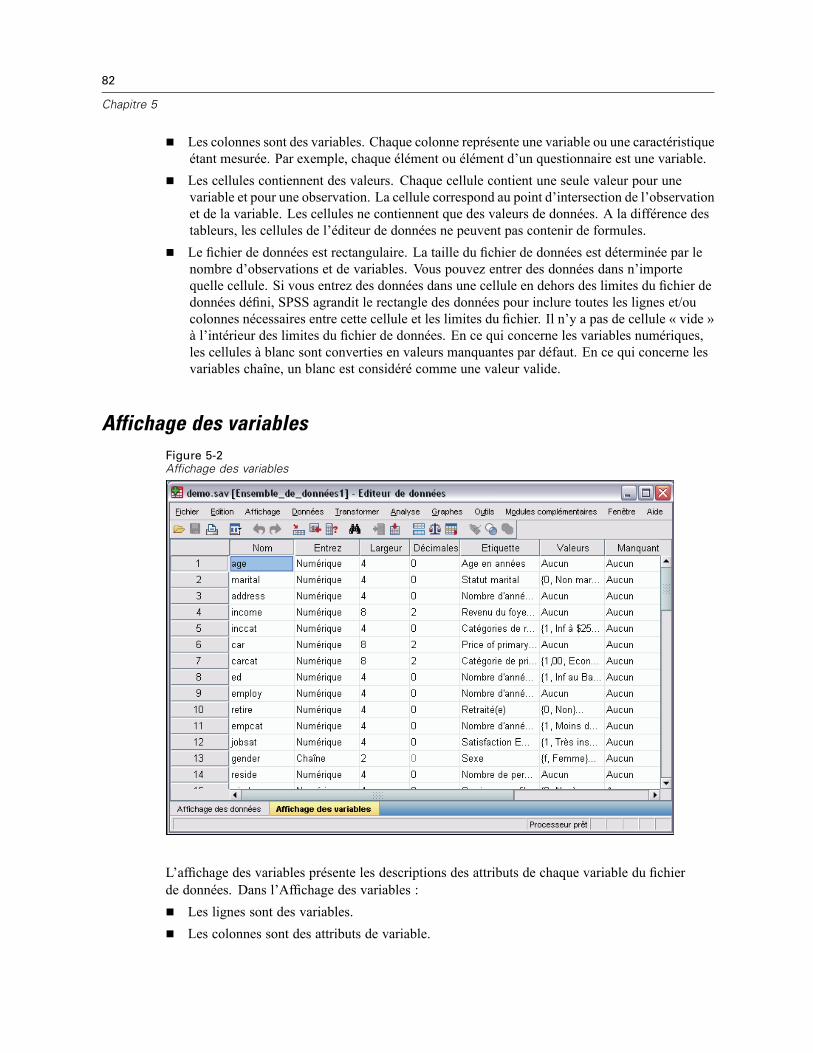
82
Chapitre 5
Les colonnes sont des variables. Chaque colonne représente une variable ou une caractéristiqueétant mesurée. Par exemple, chaque élément ou élément d’un questionnaire est une variable.Les cellules contiennent des valeurs. Chaque cellule contient une seule valeur pour unevariable et pour une observation. La cellule correspond au point d’intersection de l’observationet de la variable. Les cellules ne contiennent que des valeurs de données. A la différence destableurs, les cellules de l’éditeur de données ne peuvent pas contenir de formules.Le fichier de données est rectangulaire. La taille du fichier de données est déterminée par lenombre d’observations et de variables. Vous pouvez entrer des données dans n’importequelle cellule. Si vous entrez des données dans une cellule en dehors des limites du fichier dedonnées défini, SPSS agrandit le rectangle des données pour inclure toutes les lignes et/oucolonnes nécessaires entre cette cellule et les limites du fichier. Il n’y a pas de cellule « vide »à l’intérieur des limites du fichier de données. En ce qui concerne les variables numériques,les cellules à blanc sont converties en valeurs manquantes par défaut. En ce qui concerne lesvariables chaîne, un blanc est considéré comme une valeur valide.
Affichage des variablesFigure 5-2Affichage des variables
L’affichage des variables présente les descriptions des attributs de chaque variable du fichierde données. Dans l’Affichage des variables :
Les lignes sont des variables.Les colonnes sont des attributs de variable.

83
Editeur de données
Vous pouvez ajouter ou supprimer des variables et modifier les attributs de ces dernières, ycompris les attributs suivants :
Nom de variableLe type de donnéesLe nombre de chiffres ou de caractèresLe nombre de décimalesLes étiquettes descriptives de variables et de valeurs.Les valeurs manquantes définies par l’utilisateurLa largeur des colonnesLe niveau de mesure
Tous ces attributs sont enregistrés lorsque vous sauvegardez le fichier de données.
Vous pouvez définir les propriétés des variables dans Affichage des variables, mais vous disposezégalement de deux autres méthodes pour ce faire :
L’assistant Copier des propriétés de données permet d’utiliser un fichier de données SPSSStatistics externe ou un autre ensemble de données disponible dans la session en cours commemodèle pour définir les propriétés de fichier et de variable dans l’ensemble de données actif.Vous pouvez également utiliser des variables de l’ensemble de données actif comme modèlepour d’autres variables de l’ensemble de données actif. L’option Copier des propriétés dedonnées est disponible dans le menu Données de la fenêtre de l’éditeur de données.L’option Définir les propriétés de variable (également disponible dans le menu Donnéesde la fenêtre de l’éditeur de données) permet d’analyser vos données et de répertoriertoutes les valeurs de données uniques pour les variables sélectionnées et d’identifier lesvaleurs non étiquetées, et fournit une fonction d’étiquetage automatique. Cette méthode estparticulièrement utile pour les variables qualitatives qui utilisent des codes numériques pourreprésenter les modalités. Par exemple, 0 = Masculin, 1 = Féminin.
Pour afficher ou définir des attributs de variable
E Activez la fenêtre de l’éditeur de données.
E Double-cliquez sur un nom de variable dans la zone supérieure de la colonne dans Affichage desdonnées ou cliquez sur l’onglet Affichage des variables.
E Pour définir de nouvelles variables, entrez un nom de variable dans une ligne vierge.
E Sélectionnez les attributs à définir ou modifier.

84
Chapitre 5
Noms de variable
Les règles suivantes s’appliquent pour les noms des variables :Chaque nom de variable doit être unique ; aucune duplication n’est admise.Les noms de variable peuvent contenir jusqu’à 64 octets, le premier caractère étant unelettre ou l’un des caractères suivants : @, # ou $. Les caractères suivants peuvent êtreune combinaison de lettres, de chiffres, un point (.) et des caractères autres que ceux deponctuation. En mode page de code, soixante-quatre octets correspondent à 64 caractèresdans les langues sur un octet (anglais, français, allemand, espagnol, italien, hébreu, russe,grec, arabe et thaï par exemple) et à 32 caractères dans les langues sur deux octets (japonais,chinois et coréen par exemple). De nombreux caractères qui n’occupent qu’un seul octeten mode page de code en occupent au moins deux en mode Unicode. Par exemple, é nereprésente qu’un seul octet en mode page de code, mais en occupe deux au format Unicode.Ainsi, résumé est égal à six octets dans un fichier page de code et à huit en mode Unicode.Remarque : Les lettres incluent tout caractère autre que ceux de ponctuation utilisé dansl’écriture de mots courants dans les langues prises en charge dans le jeu de caractères dela plateforme.Les noms de variable ne doivent pas contenir d’espaces.Le caractère # au début du nom de la variable désigne une variable temporaire. Vous nepouvez créer des variables temporaires qu’avec une syntaxe de commande. Vous ne pouvezpas entrer le signe # comme premier caractère d’une variable dans une boîte de dialoguede création de variables.Le symbole $ en début de nom indique que la variable est une variable système. Vousne pouvez pas utiliser le symbole $ comme premier caractère d’une variable définie parl’utilisateur.Le point, le trait de soulignement et les caractères $, # et @ peuvent être utilisés dans les nomsde variable. Par exemple, A._$@#1 est un nom de variable valide.Evitez les noms de variable se terminant par un point car celui-ci peut être interprété commeun caractère de fin de commande. Vous ne pouvez créer des variables se terminant par unpoint que dans une syntaxe de commande. Vous ne pouvez pas créer de variables se terminantpar un point dans une boîte de dialogue de création de variables.Evitez d’utiliser des noms de variable se terminant par des traits de soulignement, étant donnéque ceux-ci peuvent entrer en conflit avec des noms de variable automatiquement créés parles commandes et les procédures.Les mots-clés réservés ne peuvent pas être utilisés pour les noms de variables : Les mots-clésréservés sont ALL, AND, BY, EQ, GE, GT, LE, LT, NE, NOT, OR, TO et WITH.Les noms de variables peuvent être définis par n’importe quelle combinaison de majuscules etde minuscules. La casse est respectée pour des raisons d’affichage.Lorsque des noms longs de variable occupent plusieurs lignes au niveau du résultat, les sautsde ligne sont segmentés au niveau des traits de soulignement, des virgules et des passagesde minuscule à majuscule.

85
Editeur de données
Niveau de mesure des variables
Vous pouvez spécifier un niveau de mesure d’échelle (données numériques sur un intervalle ouune échelle de rapport), ordinal ou nominal Les données nominales et ordinales peuvent être deschaînes de caractères (alphanumériques) ou numériques.
Nominal. Une variable peut être traitée comme étant nominale si ses valeurs représentent desmodalités sans classement intrinsèque (par exemple, le service de la société dans lequeltravaille un employé). La région, le code postal ou l'appartenance religieuse sont desexemples de variables nominales.Ordinal. Une variable peut être traitée comme étant ordinale si ses valeurs représentent desmodalités associées à un classement intrinsèque (par exemple, des niveaux de satisfactionallant de Très mécontent à Très satisfait). Exemples de variable ordinale : des scoresd'attitude représentant le degré de satisfaction ou de confiance, et des scores de classementdes préférences.Echelle. Une variable peut être traitée comme une variable d'échelle si ses valeurs représententdes modalités classées avec une mesure significative, de sorte que les comparaisons dedistance entre les valeurs soient adéquates. L'âge en années et le revenu en milliers de dollarssont des exemples de variable d'échelle.
Remarque : Pour les variables chaîne ordinales, l’ordre alphabétique des valeurs chaîne estsupposé refléter l’ordre des modalités. Par exemple, pour une variable chaîne comportant desvaleurs Faible, Moyen, Elevé, l’ordre des modalités est interprété comme Elevé, Faible ouMoyen,ce qui ne correspond pas à l’ordre correct. En règle générale, il est recommandé d’utiliser lescodes numériques pour représenter les données ordinales.
Le niveau de mesure d’échelle est affecté à toutes les nouvelles variables numériques créées lorsd’une session. Pour la lecture de données à partir de formats de fichiers externes et de fichiersde données SPSS Statistics créés avec une version antérieure à la version 8.0, l’attribution pardéfaut de niveaux de mesure est basée sur les règles suivantes :
Les variables numériques ayant moins de 24 valeurs uniques et les variables chaîne sontdéfinies comme variables nominales.Les variables numériques ayant 24 valeurs uniques ou plus sont définies comme variablesd’échelle.
Vous pouvez changer la valeur d’inclusion d’échelle/nominale pour des variables numériques dansla boîte de dialogue Options. Pour plus d'informations, reportez-vous à Options de donnéesdans Chapitre 48 sur p. 542.La boîte de dialogue Définir les propriétés de la variable, disponible à partir du menu Données,
peut vous aider à attribuer le niveau de mesure adéquat. Pour plus d'informations, reportez-vous àAffectation du niveau de mesure dans Chapitre 7 sur p. 116.
Type de variable
L’option Type de variable permet de définir le type de données pour chaque variable. Par défaut,toute nouvelle variable est numérique. Vous pouvez utiliser l’option Type de variable pour changerle type des données. Le contenu de la boîte de dialogue Type de variable dépend du type dedonnées sélectionné. Pour certains types de données, il y a des zones de texte où sont indiqués la

86
Chapitre 5
longueur et le nombre de décimales. Pour d’autres types de données, il vous suffit de sélectionnerun format dans une liste déroulante contenant des exemples.
Figure 5-3Boîte de dialogue Type de variable
Les types de données disponibles sont les suivants :
Numérique. Variable dont les valeurs sont des nombres. Les valeurs sont affichées en formatnumérique standard. L’éditeur de données accepte les valeurs numériques au format standard ousous forme de notation scientifique.
Virgule. Variable numérique dont les valeurs sont affichées avec des virgules toutes les troispositions, le point servant de séparateur décimal. L’outil éditeur de données accepte les valeursnumériques pour les variables de virgule avec ou sans virgule ou sous forme de notationscientifique. Les valeurs ne peuvent pas contenir de virgule à droite de l’indicateur décimal.
Point. Variable numérique dont les valeurs sont affichées avec des points toutes les trois positions,la virgule servant de séparateur décimal. L’outil éditeur de données accepte les valeurs numériquespour les variables de point avec ou sans point ou sous forme de notation scientifique. Les valeursne peuvent pas contenir de point à droite de l’indicateur décimal.
Notation scientifique. Variable numérique dont les valeurs sont affichées avec un E intégré et unexposant de puissance dix avec signe. L’éditeur de données accepte des valeurs numériques pourles variables de notation scientifique avec ou sans exposant. L’exposant peut être précédé d’unE ou d’un D avec ou sans signe, ou seulement d’un signe. Par exemple, 123, 1.23E2, 1.23D2,1.23E+2 et même 1.23+2.
Date. Variable numérique dont les valeurs sont affichées dans l’un des formats de date ou d’heurepossibles. Sélectionnez un format dans la liste. Vous pouvez entrer des dates avec, commeséparateur, des barres obliques, des traits d’union, des points, des virgules ou des espaces. Lavaleur du siècle pour les années à 2 chiffres est déterminée par les paramètres Options (accessiblesdepuis le menu Edition, sélectionnez Options, puis cliquez sur l’onglet Données).
Dollar. Variable numérique affichée avec le signe dollar ($), avec des virgules toutes les troispositions, le point servant de séparateur décimal. Vous pouvez entrer des valeurs de donnéesavec ou sans le signe dollar.

87
Editeur de données
Symbole monétaire. Variable numérique dont les valeurs sont affichées dans l’un des formatsmonétaires personnalisés que vous avez définis dans l’onglet Devise de la boîte de dialogueOptions. Les caractères de symbole monétaire définis ne sont pas utilisables lors de la saisie dedonnées mais sont affichés dans l’éditeur de données.
Chaîne. Variable dont les valeurs ne sont pas numériques et ne sont donc pas utilisées pour lescalculs. Ces valeurs peuvent contenir n’importe quel caractère, dans la limite de la longueurdéfinie. Les majuscules et les minuscules sont différenciées. Ce type de variable est aussi connusous le nom de variable alphanumérique.
Pour définir le type de variable
E Cliquez sur le bouton de la cellule Type de la variable à définir.
E Sélectionnez le type de données dans la boîte de dialogue Type de variable.
E Cliquez sur OK.
Formats d’entrée/d’affichage
Selon le format, les valeurs affichées dans l’affichage Données peuvent différer de celles entrées etenregistrées en interne. Voici quelques règles générales :
Pour les formats Numérique, Virgule et Point, vous pouvez entrer des valeurs avec n’importequel nombre de positions décimales (maximum 16), et la valeur entière est enregistrée.L’Affichage des données n’affiche que le nombre de décimales défini et arrondit les valeurscomportant plus de décimales. Toutefois, la valeur complète est utilisée dans tous les calculs.Pour les variables chaîne, toutes les valeurs sont cadrées à droite au maximum de la longueur.Pour une variable chaîne dont la largeur maximum est de trois, une valeur Non est enregistréecomme 'Non ' et n’est pas équivalente à ' Non'.Pour les formats de dates, vous pouvez utiliser des barres obliques, des tirets, des espaces,des virgules ou des points comme séparateurs entre les jours, les mois et les années. Pour lesmois, vous pouvez entrer des nombres, des abréviations à trois lettres ou le nom des moisen clair. Les dates de format général sous la forme jj-mmm-aa sont affichées avec des tiretsservant de séparateurs et des abréviations à trois lettres pour le mois. Les dates de formatgénéral sous la forme jj/mm/aa et mm/jj/aa sont affichées avec des barres obliques commeséparateurs et des nombres pour le mois. De manière interne, les dates sont enregistrées sousla forme d’un nombre de secondes à partir du 14 octobre 1582. La plage de siècles pour lesdates avec des années à deux chiffres est déterminée à partir des paramètres Options (dans lemenu Edition, sélectionnez Options, puis cliquez sur l’onglet Données).Pour les formats de temps, vous pouvez utiliser les deux points, des points ou des espacescomme séparateurs entre les heures, les minutes et les secondes. Les temps sont affichés avecdes deux points comme séparateurs. En interne, les temps sont enregistrés comme étantle nombre de secondes qui représente un intervalle de temps. Par exemple, 10:00:00 eststocké de manière interne comme étant 36 000, soit 60 (secondes par minute) x 60 (minutespar heure) x 10 (heures).

88
Chapitre 5
Etiquettes des variables
Vous pouvez attribuer des étiquettes de variables descriptives dont le nombre de caractères nedépasse pas 256 (128 caractères pour les langages sur deux octets). Les étiquettes de variablepeuvent contenir des espaces et des caractères réservés qui ne sont pas autorisés dans les nomsde variable.
Pour spécifier des étiquettes de variable
E Activez la fenêtre de l’éditeur de données.
E Double-cliquez sur un nom de variable dans la zone supérieure de la colonne dans Affichage desdonnées ou cliquez sur l’onglet Affichage des variables.
E Entrez l’étiquette de variable descriptive dans la cellule Etiquette de la variable.
Etiquettes de valeurs
Vous pouvez affecter des étiquettes descriptives de valeur pour chaque valeur d’une variable. Ceprocessus se révèle particulièrement utile si votre fichier de données utilise des codes numériquespour représenter des modalités non numériques (par exemple, les codes 1 et 2 pour hommeet femme).
Les étiquettes de valeurs peuvent s’élever jusqu’à 120 octets.
Figure 5-4Boîte de dialogue Etiquettes de valeurs
Pour spécifier des étiquettes de valeur
E Cliquez sur le bouton de la cellule Valeurs de la variable à définir.
E Pour chaque valeur, entrez la valeur et une étiquette.
E Cliquez sur Ajouter pour entrer l’étiquette de valeur.
E Cliquez sur OK.

89
Editeur de données
Insertion de sauts de ligne dans les étiquettes
Les étiquettes de variables ou de valeurs ont un retour à la ligne automatique dans les tableauxpivotants et les diagrammes si la cellule ou la zone n’est pas assez large pour afficher l’étiquettesur une seule ligne ; vous pouvez également modifier les résultats pour insérer des sauts de lignemanuellement si vous voulez que le saut de ligne se fasse ailleurs. Vous pouvez aussi créer desétiquettes de variable ou de valeur qui effectueront toujours un retour à la ligne en des pointsdéfinis et qui comporteront plusieurs lignes.
E Pour les étiquettes de variable, sélectionnez la cellule Etiquette de la variable dans la zoneAffichage des variables de l’éditeur de diagrammes.
E Pour les étiquettes de valeur, sélectionnez la cellule Valeurs de la variable dans la zone Affichagedes variables de l’éditeur de données, cliquez sur le bouton qui apparaît dans la cellule, puissélectionnez l’étiquette que vous souhaitez modifier dans la boîte de dialogue Etiquettes de valeurs.
E Dans l’étiquette, saisissez \n à l’endroit où vous voulez insérer un retour à la ligne.
Le \n ne s’affiche pas dans les tableaux pivotants ou les diagrammes ; il est reconnu comme uncaractère de saut de ligne.
Valeurs manquantes
L’option Valeurs manquantes permet de définir les valeurs de données spécifiées comme valeursmanquantes spécifiées par l’utilisateur. Par exemple, vous pouvez faire la distinction entreles données manquantes parce qu’une personne interrogée a refusé de répondre et les donnéesmanquantes parce que la question ne s’appliquait pas au répondant. Les valeurs des donnéesdéfinies comme valeurs utilisateur manquantes sont repérées par un indicateur en vue d’untraitement spécial et sont exclues de la plupart des calculs.
Figure 5-5Boîte de dialogue Valeurs manquantes
Vous pouvez entrer jusqu’à trois valeurs manquantes de votre choix, un intervalle de valeursmanquantes ou un intervalle plus une valeur de votre choix.Les intervalles ne peuvent être spécifiés que pour des valeurs numériques.Toutes les valeurs de chaîne, y compris les valeurs nulles ou vides, sont considérées commedes valeurs valides à moins que vous ne les définissiez comme manquantes.

90
Chapitre 5
Les valeurs manquantes pour les variables chaîne ne peuvent pas dépasser huit octets. (Il n’ya pas de limite pour la largeur définie de la variable chaîne, mais les valeurs manquantesdéfinies ne peuvent pas dépasser huit octets).Pour définir des valeurs nulles ou vides comme manquantes pour une variable chaîne, entrezun seul espace dans l’un des champs sous la sélection Valeurs manquantes discrètes.
Pour définir les valeurs manquantes
E Cliquez sur le bouton de la cellule Manquante de la variable à définir.
E Entrez les valeurs ou l’intervalle de valeurs représentant les valeurs manquantes.
Largeur des colonnes
Vous pouvez spécifier le nombre de caractères définissant la largeur des colonnes. Vous pouvezégalement modifier la largeur des colonnes dans Affichage des données en cliquant et en tirant lesbords des colonnes.
La largeur des colonnes des polices proportionnelles est basée sur la largeur moyenne descaractères. En fonction des caractères utilisés dans la valeur, un nombre plus ou moinsimportant de caractères peut être affiché dans la largeur spécifiée.La largeur des colonnes affecte seulement l’affichage des valeurs dans l’éditeur de données.Modifier la largeur de la colonne ne change pas la largeur définie d’une variable.
Alignement de variable
L’alignement contrôle l’affichage des valeurs des données et/ou des étiquettes de valeur dansAffichage des données. L’alignement par défaut est « droite » pour les variables numériqueset « gauche » pour les variables chaîne. Ce paramètre n’affecte que l’affichage d’Affichagedes données.
Application d’attributs de définition de variable à plusieurs variables
Lorsque vous avez défini les attributs de définition d’une variable, vous pouvez copier des attributset les appliquer à une ou à plusieurs variables.
L’application d’attributs de définition de variable s’effectue au moyen des opérations Copier etColler de base. Vous pouvez:
Copier un seul attribut (par exemple, les étiquettes de valeurs) et le coller dans la ou lesmêmes cellules d’attribut d’une ou de plusieurs variables.Copier tous les attributs d’une variable et les coller dans d’autres variables.Créer plusieurs variables avec tous les attributs de la copie d’une variable.

91
Editeur de données
Application d’attributs de définition de variable à d’autres variables
Pour appliquer certains attributs d’une variable définie, procédez comme suit :
E Dans l’affichage des variables, sélectionnez la cellule d’attribut que vous souhaitez appliquerà d’autres variables.
E A partir des menus, sélectionnez :Affichage
Copier
E Sélectionnez la ou les cellules d’attribut auxquelles vous souhaitez appliquer l’attribut. (Vouspouvez sélectionner plusieurs variables cible.)
E A partir des menus, sélectionnez :Affichage
Coller
Si vous collez l’attribut dans des lignes vides, de nouvelles variables sont créées avec des valeursd’attributs par défaut pour tous les attributs, à l’exception de celui que vous avez sélectionné.
Pour appliquer tous les attributs d’une variable définie, procédez comme suit :
E Dans l’affichage des variables, sélectionnez le numéro de ligne de la variable présentant lesattributs que vous souhaitez utiliser. (La totalité de la ligne est mise en surbrillance.)
E A partir des menus, sélectionnez :Affichage
Copier
E Sélectionnez le numéro de ligne de la variable à laquelle vous souhaitez appliquer les attributs.(Vous pouvez sélectionner plusieurs variables cible.)
E A partir des menus, sélectionnez :Affichage
Coller
Création de plusieurs nouvelles variables avec les mêmes attributs
E Dans Affichage des variables, cliquez sur le numéro de ligne de la variable présentant les attributsà utiliser pour la nouvelle variable. (La totalité de la ligne est mise en surbrillance.)
E A partir des menus, sélectionnez :Affichage
Copier
E Cliquez sur le numéro de la ligne vide qui se trouve sous la dernière variable définie dans lefichier de données.
E A partir des menus, sélectionnez :Affichage
Coller les variables...

92
Chapitre 5
E Dans la boîte de dialogue Coller les variables, entrez le nombre de variables à créer.
E Entrez un préfixe et un numéro de départ pour les nouvelles variables.
E Cliquez sur OK.
Les noms des nouvelles variables seront composés du préfixe spécifié et d’un numéro séquentielcommençant par le numéro spécifié.
Attributs de variable personnalisés
Outre les attributs de variable standard (par exemple, étiquettes de valeur, valeurs manquantes,niveau de mesure), vous pouvez créer des attributs de variable personnalisés. Tout comme lesattributs de variable standard, ces attributs personnalisés sont enregistrés avec les fichiers dedonnées SPSS Statistics. Par conséquent, vous pouvez créer un attribut de variable qui identifie letype de réponse pour les questions de l’enquête (par exemple, sélection simple, sélection multiple,à compléter) ou les formules utilisées pour les variables calculées.
Création d’attributs de variable personnalisés
Pour créer des attributs personnalisés :
E Dans l’Affichage des variables, à partir des menus, sélectionnez :Données
Nouvel attribut personnalisé
E Faites glisser vers la liste Variables sélectionnées les variables auxquelles vous souhaitez affecterle nouvel attribut.
E Entrez un nom pour l’attribut. Les noms d’attribut doivent suivre les mêmes règles que les nomsde variable. Pour plus d'informations, reportez-vous à Noms de variable sur p. 84.
E Entrez une valeur facultative pour l’attribut. Si vous sélectionnez plusieurs variables, la mêmevaleur leur est attribuée. Vous pouvez laisser ce champ vide et entrer des valeurs pour chaquevariable dans la vue des variables.
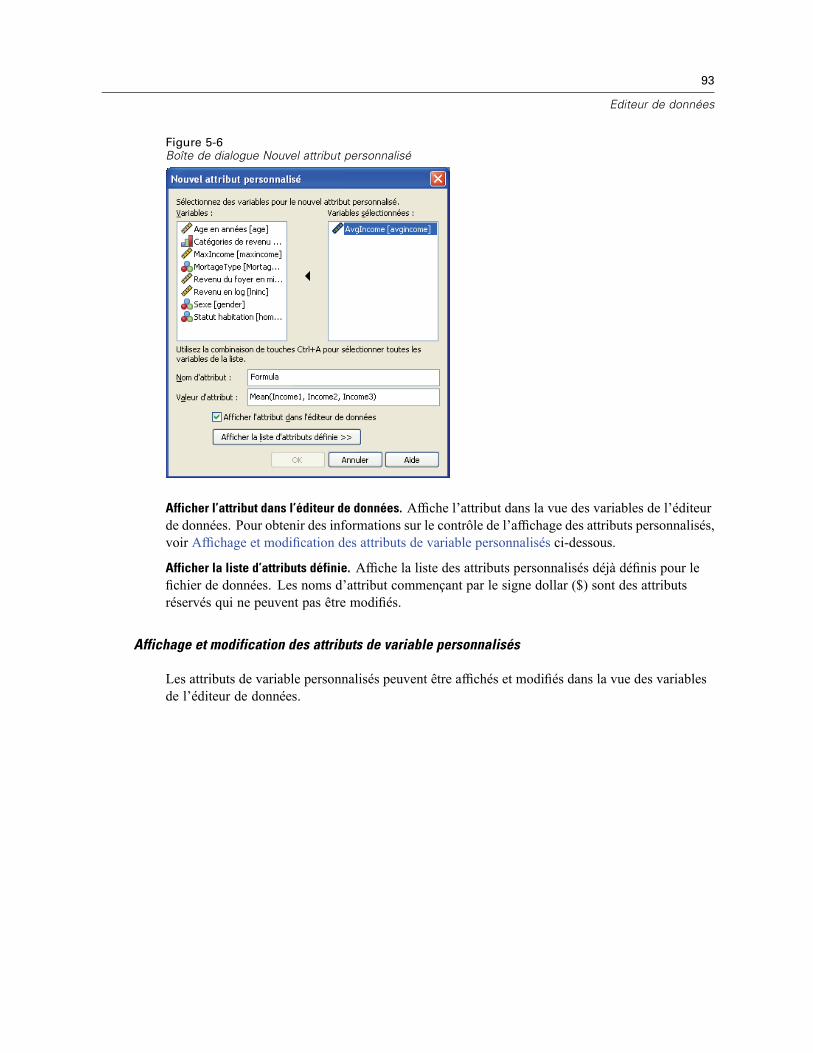
93
Editeur de données
Figure 5-6Boîte de dialogue Nouvel attribut personnalisé
Afficher l’attribut dans l’éditeur de données. Affiche l’attribut dans la vue des variables de l’éditeurde données. Pour obtenir des informations sur le contrôle de l’affichage des attributs personnalisés,voir Affichage et modification des attributs de variable personnalisés ci-dessous.
Afficher la liste d’attributs définie. Affiche la liste des attributs personnalisés déjà définis pour lefichier de données. Les noms d’attribut commençant par le signe dollar ($) sont des attributsréservés qui ne peuvent pas être modifiés.
Affichage et modification des attributs de variable personnalisés
Les attributs de variable personnalisés peuvent être affichés et modifiés dans la vue des variablesde l’éditeur de données.

94
Chapitre 5
Figure 5-7Attributs de variable personnalisés affichés dans la vue des variables
Les noms des attributs de variable personnalisés apparaissent entre crochets.Les noms d’attribut commençant par le signe dollar sont des attributs réservés qui ne peuventpas être modifiés.Une cellule vide indique que l’attribut n’existe pas pour cette variable ; la présence dumot Vide dans une cellule indique que l’attribut existe pour cette variable, mais qu’aucunevaleur ne lui a été affectée. Une fois que vous entrez du texte dans la cellule, l’attribut decette variable est associé à ce texte.Le texte Tableau... affiché dans une cellule indique que c’est un tableau d’attributs, c’est àdire, qui contient plusieurs valeurs. Cliquez sur le bouton figurant dans la cellule pour afficherla liste des valeurs.
Pour afficher et modifier des attributs de variable personnalisés
E Dans l’Affichage des variables, à partir des menus, sélectionnez :Affichage
Personnaliser l’affichage des variables...
E Cochez les attributs de variable personnalisés à afficher. (Les attributs de variables personnaliséssont ceux mis entre crochets).
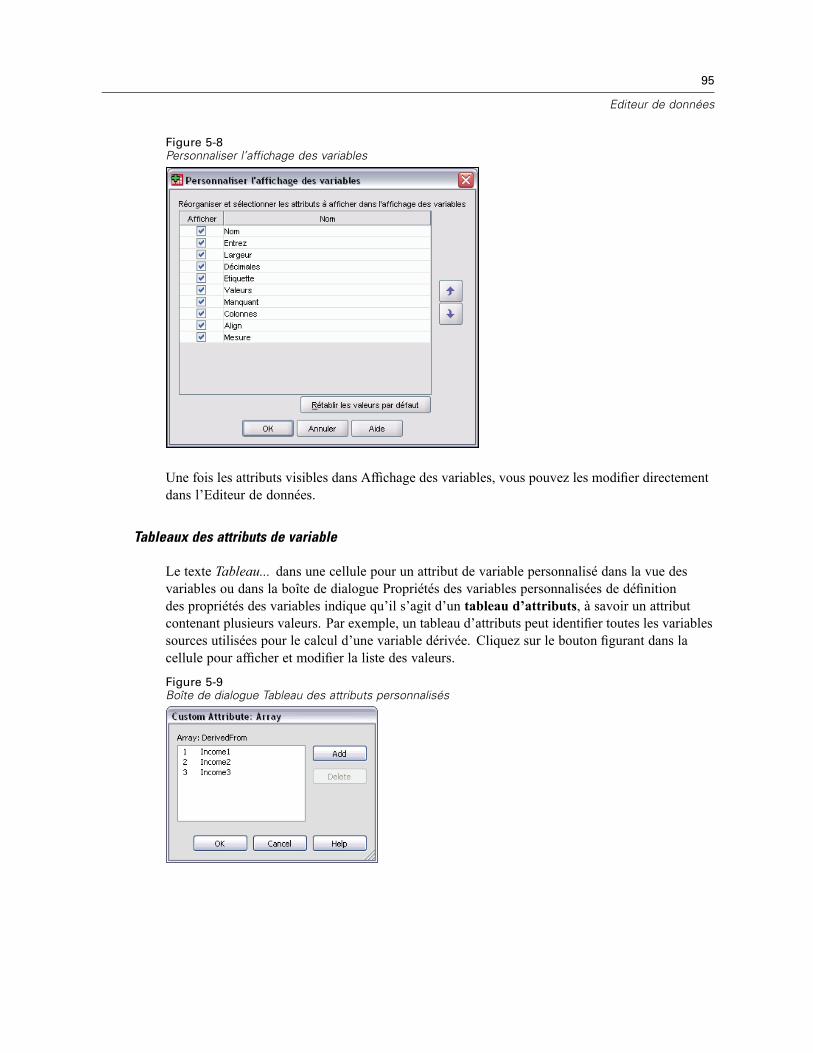
95
Editeur de données
Figure 5-8Personnaliser l’affichage des variables
Une fois les attributs visibles dans Affichage des variables, vous pouvez les modifier directementdans l’Editeur de données.
Tableaux des attributs de variable
Le texte Tableau... dans une cellule pour un attribut de variable personnalisé dans la vue desvariables ou dans la boîte de dialogue Propriétés des variables personnalisées de définitiondes propriétés des variables indique qu’il s’agit d’un tableau d’attributs, à savoir un attributcontenant plusieurs valeurs. Par exemple, un tableau d’attributs peut identifier toutes les variablessources utilisées pour le calcul d’une variable dérivée. Cliquez sur le bouton figurant dans lacellule pour afficher et modifier la liste des valeurs.
Figure 5-9Boîte de dialogue Tableau des attributs personnalisés
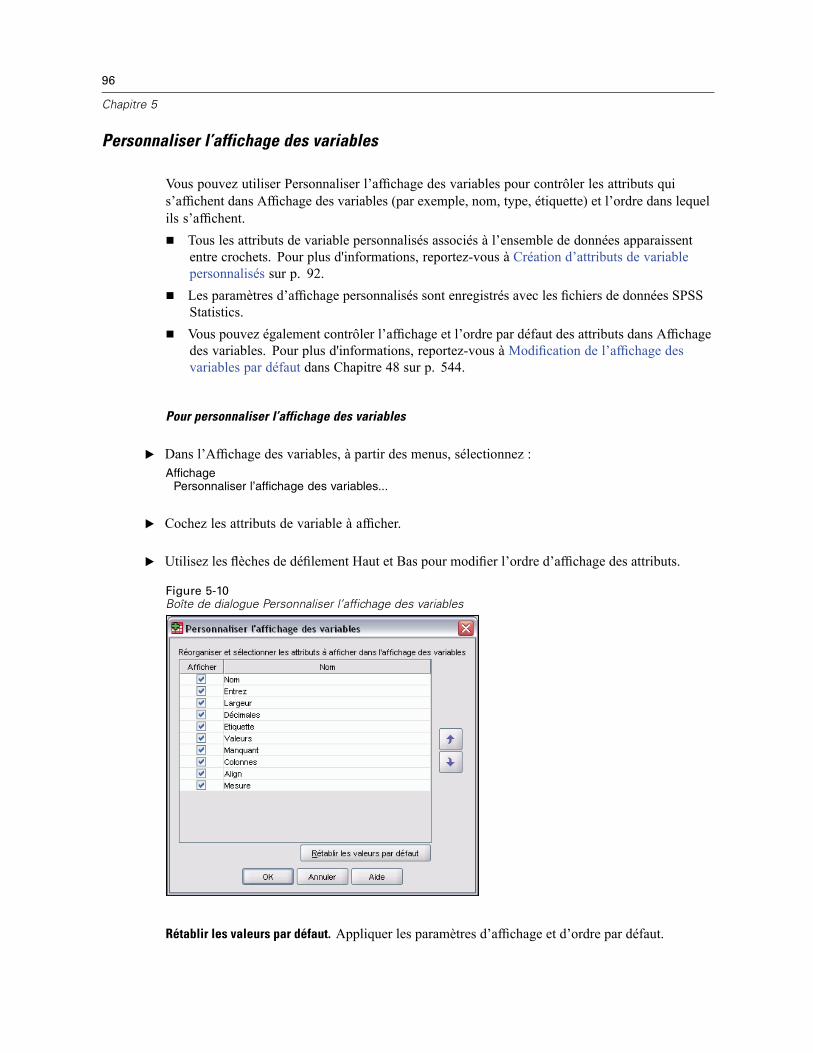
96
Chapitre 5
Personnaliser l’affichage des variables
Vous pouvez utiliser Personnaliser l’affichage des variables pour contrôler les attributs quis’affichent dans Affichage des variables (par exemple, nom, type, étiquette) et l’ordre dans lequelils s’affichent.
Tous les attributs de variable personnalisés associés à l’ensemble de données apparaissententre crochets. Pour plus d'informations, reportez-vous à Création d’attributs de variablepersonnalisés sur p. 92.Les paramètres d’affichage personnalisés sont enregistrés avec les fichiers de données SPSSStatistics.Vous pouvez également contrôler l’affichage et l’ordre par défaut des attributs dans Affichagedes variables. Pour plus d'informations, reportez-vous à Modification de l’affichage desvariables par défaut dans Chapitre 48 sur p. 544.
Pour personnaliser l’affichage des variables
E Dans l’Affichage des variables, à partir des menus, sélectionnez :Affichage
Personnaliser l’affichage des variables...
E Cochez les attributs de variable à afficher.
E Utilisez les flèches de défilement Haut et Bas pour modifier l’ordre d’affichage des attributs.
Figure 5-10Boîte de dialogue Personnaliser l’affichage des variables
Rétablir les valeurs par défaut. Appliquer les paramètres d’affichage et d’ordre par défaut.

97
Editeur de données
Correction orthographique
Étiquettes de variables et de valeurs
Pour vérifier l’orthographe des étiquettes de variables et de valeurs :
E Sélectionnez l’onglet Affichage des variables de la fenêtre Editeur de données.
E Cliquez avec le bouton droit de la souris sur la colonne Etiquettes ou Valeurs puis, dans le menucontextuel, choisissez :Orthographe
ou
E Dans l’Affichage des variables, à partir des menus, sélectionnez :Outils
Orthographe
ou
E Dans la boîte de dialogue Etiquettes de Valeurs, cliquez sur Orthographe. (Cela limite la correctionorthographique aux étiquettes de valeurs pour une variable particulière.)
La correction orthographique est limitée aux étiquettes de variables et de valeurs dans Affichagedes variables de l’éditeur de données.
Valeurs de données de chaîne
Pour vérifier l’orthographe des valeurs de données chaîne :
E Sélectionnez l’onglet Affichage des données dans l’éditeur de données.
E En option, sélectionnez une ou plusieurs variables (colonnes) à vérifier. Pour sélectionner unevariable, cliquez sur le nom de cette variable en haut de la colonne.
E A partir des menus, sélectionnez :Outils
Orthographe
Si aucune variable n’est sélectionnée dans l’Affichage des données, toutes les variables dechaîne seront vérifiées.Si l’ensemble de données ne contient pas de variables de chaîne ou qu’aucune des variablessélectionnées n’est une variable de chaîne, l’option Vérification orthographique du menuOutils est désactivée.
Saisie de donnéesDans Affichage des données, vous pouvez entrer les données directement dans l’éditeur dedonnées. Vous pouvez entrer des données dans n’importe quel ordre. Vous pouvez entrer desdonnées par observation ou par variable, pour des zones sélectionnées ou des cellules individuelles.
La cellule active est mise en surbrillance.

98
Chapitre 5
Le nom de variable et le numéro de ligne de la cellule active sont affichés dans le coinsupérieur gauche de l’éditeur de données.Lorsque vous sélectionnez une cellule et lorsque vous entrez une valeur de données, la valeurest affichée dans l’éditeur de cellules en haut de l’éditeur de données.Les valeurs de données ne sont pas enregistrées tant que vous n’avez pas appuyé sur Entrée ouque vous n’avez pas sélectionné une autre cellule.Pour entrer autre chose que des données numériques simples, vous devez d’abord définirle type de variable.
Si vous entrez une valeur dans une colonne vide, l’éditeur de données crée automatiquement unenouvelle variable et affecte un nom de variable.
Pour entrer des données numériques
E Sélectionnez une cellule dans Affichage des données.
E Entrez la valeur des données. (La valeur est affichée dans l’éditeur de cellules dans la partiesupérieure de l’éditeur de données.)
E Appuyez sur Entrée ou sélectionnez une autre cellule pour enregistrer la valeur.
Pour entrer des données non numériques
E Double-cliquez sur un nom de variable dans la zone supérieure de la colonne dans Affichage desdonnées ou cliquez sur l’onglet Affichage des variables.
E Cliquez sur le bouton de la cellule Type de la variable.
E Sélectionnez le type de données dans la boîte de dialogue Type de variable.
E Cliquez sur OK.
E Double-cliquez sur le numéro de ligne ou cliquez sur l’onglet Affichage des données.
E Pour la variable que vous venez de définir, entrez les données dans la colonne.
Pour utiliser des étiquettes de valeur pour l’entrée de données
E Si les étiquettes de valeurs n’apparaissent pas dans l’Affichage des données, choisissez dansles menus :Affichage
Etiquettes de valeurs
E Cliquez sur la cellule dans laquelle vous souhaitez entrer la valeur.
E Sélectionnez une étiquette de valeur dans la liste déroulante.
La valeur est saisie et l’étiquette de valeur est affichée dans la cellule.
Remarque : Ce processus ne fonctionne que si vous avez défini des étiquettes de valeurs pourla variable.

99
Editeur de données
Restrictions concernant la valeur de données dans l’éditeur de données
Le type et la largeur définis de la variable déterminent le type de valeur que vous pouvez entrerdans la cellule d’Affichage des données.
Si vous tapez un caractère qui n’est pas autorisé par le type de variable défini, le caractèren’est pas saisi.Pour les variables chaîne, les caractères dépassant la largeur définie ne sont pas autorisés.Pour les variables numériques, il est possible de saisir des nombres entiers dépassant la valeurdéfinie mais l’éditeur de données affichera dans la cellule une notation scientifique ou unepartie de la valeur suivie de points de suspension (…) pour indiquer que la valeur dépasse lalargeur définie. Pour afficher la valeur dans la cellule, changez la largeur définie de la variable.Remarque : Changer la largeur de la colonne n’affecte pas la largeur de la variable.
Modification de donnéesAvec l’éditeur de données, vous pouvez modifier les valeurs des données dans Affichage desdonnées de plusieurs manières. Vous pouvez:
Modifier les valeurs de donnéesCouper, copier et coller des valeurs de donnéesAjouter et supprimer des observationsAjouter et supprimer des variablesChanger l’ordre des variables
Pour remplacer ou modifier les valeurs de données
Pour supprimer l’ancienne valeur et pour entrer une nouvelle valeur
E Dans Affichage des données, double-cliquez sur la cellule. (La valeur de la cellule est affichéedans l’éditeur de cellules.)
E Modifiez la valeur directement dans la cellule ou dans l’éditeur de cellules.
E Appuyez sur Entrée ou sélectionnez une autre cellule pour enregistrer la valeur.
Couper, copier et coller des valeurs de données
Vous pouvez couper, copier et coller des valeurs individuelles de cellules ou des groupes devaleurs dans l’éditeur de données. Vous pouvez:
Déplacer ou copier la valeur d’une seule cellule dans une autre cellule.Déplacer ou copier la valeur d’une seule cellule dans un groupe de cellules.Déplacer ou copier les valeurs d’une seule observation (ligne) dans plusieurs observations.Déplacer ou copier les valeurs d’une seule variable (colonne) dans plusieurs variables.Déplacer ou copier un groupe de valeurs de cellule dans un autre groupe de cellules.

100
Chapitre 5
Conversion de données de valeurs collées dans l’éditeur de données
Si les types définis de variables des cellules source et cible ne sont pas les mêmes, SPSS essayede convertir la valeur. Si aucune conversion n’est possible, la valeur manquante par défaut estinsérée dans la cellule cible.
Conversion des formats numérique ou date en chaînes de caractères. Les formats numériques(par exemple, Numérique, Dollar, Point ou Virgule) et les formats de date sont convertis encaractères s’ils sont collés dans une cellule de variables chaîne. La valeur d’une chaîne est lavaleur numérique telle qu’elle est affichée dans la cellule. Par exemple, pour une variable dont leformat est exprimé en dollars, le signe Dollar qui est affiché devient partie intégrante de la valeurde caractères. Les valeurs qui excèdent la largeur définie de la variable chaîne sont tronquées.
Conversion de chaînes de caractères en formats numérique ou date. Les valeurs de chaînes quicontiennent des caractères acceptables pour le format numérique ou de date de la cellule cible sontconverties dans la valeur équivalente numérique ou de date. Par exemple, une valeur de caractèresde 25/12/91 est convertie en date valide si le type de format de la cellule cible est un des formatsjour-mois-année, mais elle est convertie en valeur manquante par défaut si le type de format dela cellule cible est de type mois-jour-année.
Conversion du format date en format numérique. Les valeurs de dates et de temps sont converties enun nombre de secondes si la cellule cible est d’un format numérique (par exemple, Numérique,Dollar, Point ou Virgule). Etant donné que les dates sont enregistrées en interne comme le nombrede secondes depuis le 14 octobre 1582, le fait de convertir des dates en valeurs numériquespeut résulter en des nombres très importants. Par exemple, la date du 10/29/91 a une valeurde conversion numérique de 12.908.073.600.
Conversion du format numérique en formats date ou heure. Les valeurs numériques sont convertiesen dates ou temps si la valeur représente un nombre de secondes pouvant produire une date ouun temps valides. En ce qui concerne les dates, les valeurs numériques inférieures à 86 400 sontconverties dans la valeur manquante par défaut.
Insérer de nouvelles observations
Le fait d’entrer des données dans une cellule sur une ligne blanche crée automatiquement unenouvelle observation. L’Editeur de données insère la valeur manquante par défaut pour toutesles autres variables de cette observation. S’il y a quelques lignes blanches entre la nouvelleobservation et les observations existantes, les lignes blanches deviennent également des nouvellesobservations avec des valeurs manquantes par défaut pour toutes les variables. Vous pouvezégalement insérer de nouvelles observations entre des observations existantes
Pour insérer de nouvelles observations entre des observations existantes
E Dans Affichage des données, sélectionnez n’importe quelle cellule pour l’observation (ligne)située sous la position où vous souhaitez insérer la nouvelle observation.
E A partir des menus, sélectionnez :Affichage
Insérer les observations

101
Editeur de données
Une nouvelle ligne est insérée pour cette observation et toutes les variables reçoivent la valeurmanquante par défaut.
Insérer de nouvelles variables
La saisie de données dans une colonne vide de l’affichage des données ou dans une ligne videde l’affichage des variables crée automatiquement une nouvelle variable portant un nom pardéfaut (préfixe var et numéro séquentiel) et un type de format de données par défaut (numérique).L’éditeur de données insère la valeur manquante par défaut pour toutes les observationsconcernées par la nouvelle variable. S’il existe des colonnes vides dans Affichage des données oudes lignes vides dans Affichage des variables entre la nouvelle variable et les variables existantes,ces colonnes ou lignes deviennent également de nouvelles variables avec une valeur manquantepar défaut pour toutes les observations. Vous pouvez également insérer des nouvelles variablesentre les variables existantes.
Pour insérer de nouvelles variables entre des variables existantes
E Sélectionnez n’importe quelle cellule de la variable située à droite de (pour l’Affichage desdonnées) ou au-dessous (pour l’Affichage des variables) de l’endroit où vous souhaitez insérerla nouvelle variable.
E A partir des menus, sélectionnez :Affichage
Insérer une variable
Une nouvelle variable est insérée avec la valeur manquante par défaut pour toutes les observations.
Pour déplacer des variables
E Pour sélectionner la variable, cliquez sur son nom dans Affichage des données ou sur son numérode ligne dans Affichage des variables.
E Faites glisser la variable jusqu’à son nouvel emplacement.
E Pour positionner la variable entre deux variables existantes : Dans Affichage des données,déplacez la variable sur la colonne de la variable à droite de laquelle vous souhaitez la positionnerou déplacez la variable sur la ligne de la variable sous laquelle vous souhaitez la positionnerdans Affichage des variables.
Pour modifier le type de données
Vous pouvez changer le type de données d’une variable à tout moment en utilisant la boîte dedialogue Type de variable dans Affichage des variables. L’outil Editeur de données essaiera deconvertir les valeurs existantes dans le nouveau type. Si aucune conversion n’est possible, lavaleur manquante par défaut est affectée. Les règles de conversion sont les mêmes que celles pourcoller des valeurs de données à une variable de type de format différent. Si le changement duformat des données peut avoir pour conséquence la perte des spécifications de la valeur manquante

102
Chapitre 5
par défaut ou d’étiquettes de valeurs, l’outil Editeur de données affiche une boîte d’alerte et vousdemande si vous voulez poursuivre le changement ou si vous désirez l’annuler.
Recherche d’observations, de variables ou d’imputations
La boîte de dialogue Aller à trouve le numéro (ligne) de l’observation ou le nom de variablespécifié dans l’éditeur de données.
Observations
E Pour les observations, sélectionnez les options suivantes :Affichage
Aller à l’observation
E Saisissez une valeur entière qui représente le numéro de ligne actuel dans Affichage des données.
Remarque : Le numéro de ligne actuel pour une observation particulière peut changer à cause dutri et d’autres actions.
Variables
E Pour les variables, sélectionnez les options suivantes :Affichage
Aller à la variable...
E Saisissez le nom de la variable ou sélectionnez la variable dans la liste déroulante.
Figure 5-11Boîte de dialogue Aller à
Imputations
E A partir des menus, sélectionnez :Affichage
Aller à l’imputation...
E Sélectionnez l’imputation (ou données d’origine) dans la liste déroulante proposée.
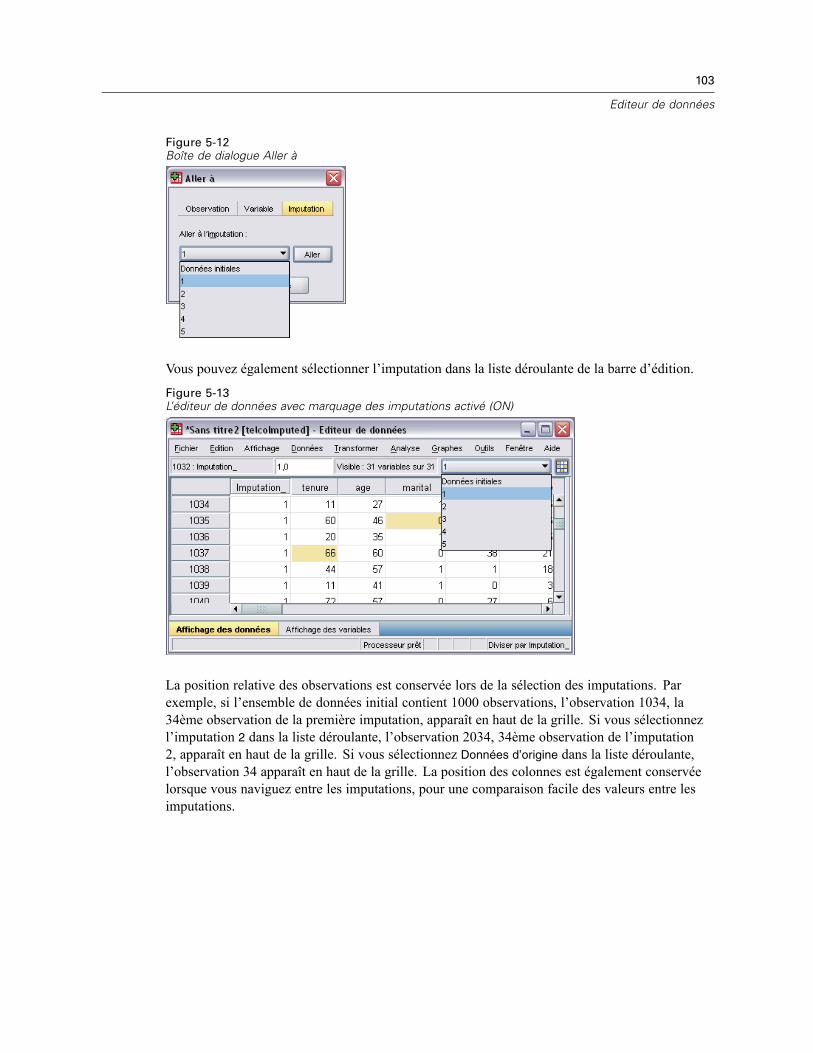
103
Editeur de données
Figure 5-12Boîte de dialogue Aller à
Vous pouvez également sélectionner l’imputation dans la liste déroulante de la barre d’édition.
Figure 5-13L’éditeur de données avec marquage des imputations activé (ON)
La position relative des observations est conservée lors de la sélection des imputations. Parexemple, si l’ensemble de données initial contient 1000 observations, l’observation 1034, la34ème observation de la première imputation, apparaît en haut de la grille. Si vous sélectionnezl’imputation 2 dans la liste déroulante, l’observation 2034, 34ème observation de l’imputation2, apparaît en haut de la grille. Si vous sélectionnez Données d’origine dans la liste déroulante,l’observation 34 apparaît en haut de la grille. La position des colonnes est également conservéelorsque vous naviguez entre les imputations, pour une comparaison facile des valeurs entre lesimputations.

104
Chapitre 5
Recherche et remplacement des valeurs d’attributs et de données
Pour trouver et/ou remplacer des valeurs de données dans Affichage des données ou des valeursd’attributs dans Affichage des variables :
E Cliquez sur une cellule dans la colonne que vous voulez rechercher. (La recherche et leremplacement de valeurs sont limités à une seule colonne.)
E A partir des menus, sélectionnez :Affichage
Chercher
ouAffichage
Remplacer
Affichage des données
Vous ne pouvez pas effectuer de recherche vers le haut dans Affichage des données. Ladirection de recherche est toujours vers le bas.Pour ce qui est des dates et des heures, les valeurs formatées telles qu’elles apparaissentdans Affichage des données sont recherchées. Par exemple, une date qui s’affiche sous laforme 10/28/2007 n’apparaîtra pas dans les résultats d’une recherche pour une date auformat 10-28-2007.Pour d’autres variables numériques, les options Contient, Commence par et Se termine parrecherchent les valeurs formatées. Par exemple, avec l’option Commence par, une valeur derecherche de 123 dollars pour une variable au format Dollar permettra de trouver 123,00dollars et 123,40 dollars mais pas 1 234. Avec l’option Cellule entière, la valeur de recherchepeut être formatée ou non (simple format numérique F), mais seules les valeurs numériquesexactes (à la précision affichée dans l’éditeur de données) correspondent.Si des étiquettes de valeurs apparaissent pour la colonne de variables sélectionnée, le textedes étiquettes est recherché, pas la valeur de données sous-jacente, et vous ne pouvez pasremplacer le texte des étiquettes.
Affichage des variables
La fonction Rechercher est uniquement disponible pour les colonnes Name, Label, Values,Missing, et d’attributs de variable personnalisés.La fonction Remplacer est uniquement disponible pour les colonnes Label, Values, et lescolonnes d’attributs personnalisés.Dans la colonne Values (étiquettes de valeurs), la chaîne de recherche peut concorder avec lavaleur de données ou une étiquette de valeur.Remarque : Le remplacement de la valeur de données supprime toutes les étiquettes de valeurprécédentes associées à cette valeur.
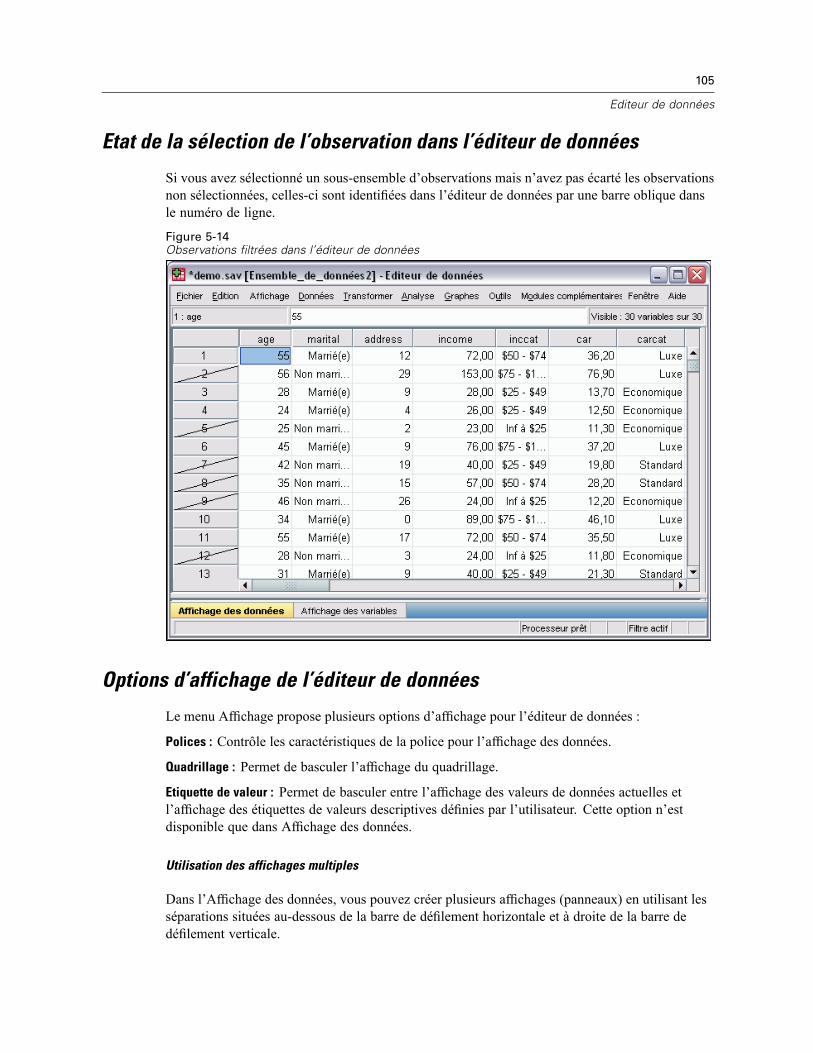
105
Editeur de données
Etat de la sélection de l’observation dans l’éditeur de données
Si vous avez sélectionné un sous-ensemble d’observations mais n’avez pas écarté les observationsnon sélectionnées, celles-ci sont identifiées dans l’éditeur de données par une barre oblique dansle numéro de ligne.
Figure 5-14Observations filtrées dans l’éditeur de données
Options d’affichage de l’éditeur de données
Le menu Affichage propose plusieurs options d’affichage pour l’éditeur de données :
Polices : Contrôle les caractéristiques de la police pour l’affichage des données.
Quadrillage : Permet de basculer l’affichage du quadrillage.
Etiquette de valeur : Permet de basculer entre l’affichage des valeurs de données actuelles etl’affichage des étiquettes de valeurs descriptives définies par l’utilisateur. Cette option n’estdisponible que dans Affichage des données.
Utilisation des affichages multiples
Dans l’Affichage des données, vous pouvez créer plusieurs affichages (panneaux) en utilisant lesséparations situées au-dessous de la barre de défilement horizontale et à droite de la barre dedéfilement verticale.

106
Chapitre 5
Vous pouvez également utiliser le menu de la fenêtre pour insérer et supprimer des séparationsde panneaux. Pour insérer des séparations :
E Dans l’Affichage de données, à partir des menus, sélectionnez :Fenêtre
Séparée
Les séparations sont insérées au-dessus et à gauche de la cellule sélectionnée.Si la cellule supérieure gauche est sélectionnée, les séparations sont insérées pour diviserl’affichage actuel en deux parties, verticalement et horizontalement.Si une cellule autre que la cellule supérieure de la première colonne est sélectionnée, uneséparation horizontale du panneau est insérée au-dessus de la cellule sélectionnée.Si une cellule autre que la première cellule de la ligne supérieure est sélectionnée, uneséparation verticale du panneau est insérée à gauche de la cellule sélectionnée.
Impression de l’éditeur de données
Un fichier de données s’imprime tel qu’il apparaît à l’écran.Les informations de l’affichage en cours sont imprimées. Dans Affichage des données, lesdonnées sont imprimées. Dans Affichage des variables, ce sont les informations de définitiondes données qui sont imprimées.Le quadrillage n’est imprimé que s’il apparaît dans l’affichage sélectionné.Les étiquettes de valeurs sont imprimées si elles apparaissent dans Affichage des données.Dans le cas contraire, ce sont les valeurs de données réelles qui sont imprimées.
Utilisez le menu Affichage dans la fenêtre de l’éditeur de données pour afficher ou masquer lequadrillage et pour activer/désactiver l’affichage des valeurs de données et des étiquettes devaleurs.
Pour imprimer le contenu de l’Editeur de données
E Activez la fenêtre de l’éditeur de données.
E Cliquez sur l’onglet correspondant à l’affichage que vous souhaitez imprimer.
E A partir des menus, sélectionnez :Fichier
Imprimer

Chapitre
6Utilisation des sources de donnéesmultiples
Avec la version 14.0, plusieurs sources de données peuvent être ouvertes en même temps, cequi permet de facilement :
Basculer entre les sources de données.Comparer les contenus des différentes sources de données.Copier et coller les données entre les sources de données.Créer de multiples sous-ensembles d’observations et/ou de variables pour analyse.Fusionner plusieurs sources de données à partir de différents formats de données (par exempledes feuilles de calcul, des bases de données ou des données texte) sans avoir à enregistrerpréalablement chaque source de données.
107

108
Chapitre 6
Manipulation de base de plusieurs sources de donnéesFigure 6-1Deux sources de données s’ouvrent en même temps
Par défaut, chaque source de données que vous ouvrez est affichée dans une nouvelle fenêtre del’éditeur de données. (Consultez Options générales pour plus d’informations sur la modificationdu comportement par défaut de manière à n’afficher qu’un ensemble de données à la fois, dansune seule fenêtre de l’éditeur de données.)
Toute source de données ouverte au préalable le reste pour utilisation ultérieure.Lorsque vous ouvrez d’abord une source de données, elle devient automatiquementl’ensemble de données actif.Vous pouvez modifier l’ensemble de données actif en cliquant simplement n’importe oùdans la fenêtre l’éditeur de données de la source de données que vous souhaitez utiliser ouen sélectionnant la fenêtre l’éditeur de données pour cette source de données à partir dumenu Fenêtre.

109
Utilisation des sources de données multiples
Seules les variables de l’ensemble de données actif sont disponibles pour analyse.
Figure 6-2Liste de variables contenant les variables dans l’ensemble de données actif
Vous ne pouvez pas modifier l’ensemble de données actif lorsque une boîte de dialogue ayantaccès aux données est ouverte (y compris toutes les boîtes de dialogue qui affichent deslistes de variables).Au moins une fenêtre éditeur de données doit être ouverte lors d’une session. Lorsque vousfermez la dernière fenêtre de l’éditeur de données, SPSS Statistics se ferme automatiquement,vous invitant au préalable à enregistrer vos modifications.
Utilisation de plusieurs ensembles de données dans une syntaxe decommande
Si vous utilisez la syntaxe de commande pour ouvrir les sources de données (par exemple GETFILE ou GET DATA), vous devez utiliser la commande DATASET NAME pour nommer de façonexplicite chaque ensemble de données afin d’avoir plusieurs sources de données ouvertessimultanément.
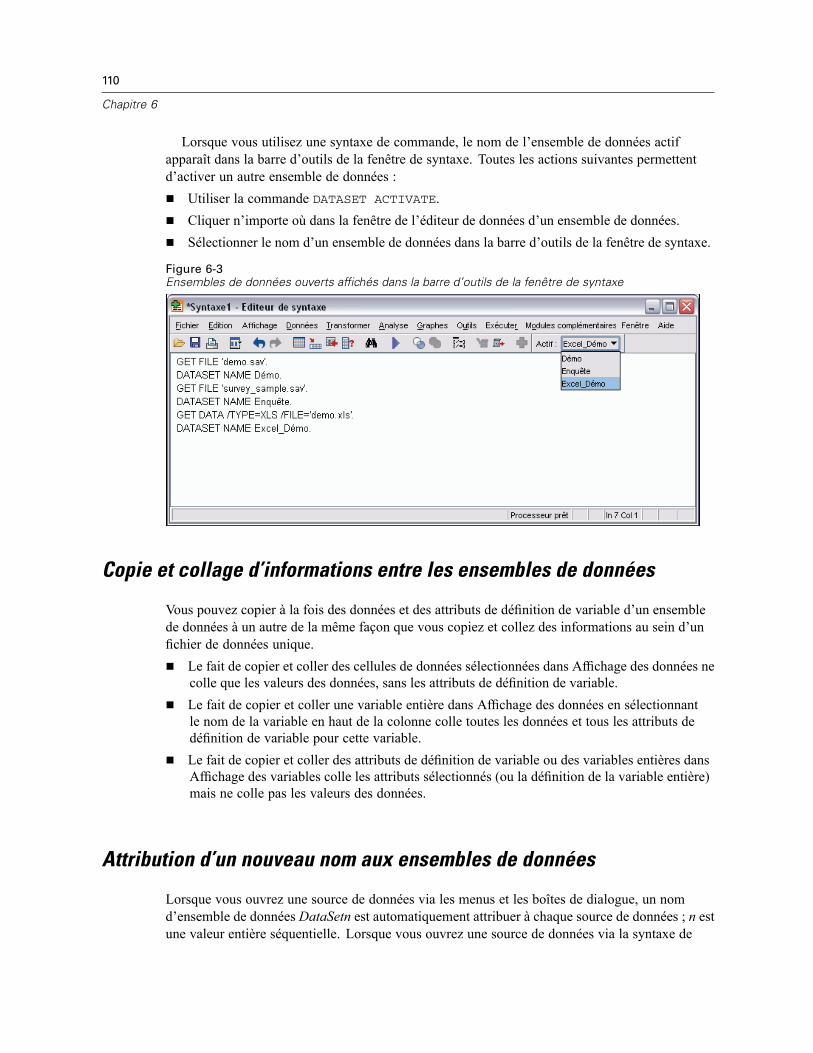
110
Chapitre 6
Lorsque vous utilisez une syntaxe de commande, le nom de l’ensemble de données actifapparaît dans la barre d’outils de la fenêtre de syntaxe. Toutes les actions suivantes permettentd’activer un autre ensemble de données :
Utiliser la commande DATASET ACTIVATE.Cliquer n’importe où dans la fenêtre de l’éditeur de données d’un ensemble de données.Sélectionner le nom d’un ensemble de données dans la barre d’outils de la fenêtre de syntaxe.
Figure 6-3Ensembles de données ouverts affichés dans la barre d’outils de la fenêtre de syntaxe
Copie et collage d’informations entre les ensembles de données
Vous pouvez copier à la fois des données et des attributs de définition de variable d’un ensemblede données à un autre de la même façon que vous copiez et collez des informations au sein d’unfichier de données unique.
Le fait de copier et coller des cellules de données sélectionnées dans Affichage des données necolle que les valeurs des données, sans les attributs de définition de variable.Le fait de copier et coller une variable entière dans Affichage des données en sélectionnantle nom de la variable en haut de la colonne colle toutes les données et tous les attributs dedéfinition de variable pour cette variable.Le fait de copier et coller des attributs de définition de variable ou des variables entières dansAffichage des variables colle les attributs sélectionnés (ou la définition de la variable entière)mais ne colle pas les valeurs des données.
Attribution d’un nouveau nom aux ensembles de données
Lorsque vous ouvrez une source de données via les menus et les boîtes de dialogue, un nomd’ensemble de données DataSetn est automatiquement attribuer à chaque source de données ; n estune valeur entière séquentielle. Lorsque vous ouvrez une source de données via la syntaxe de

111
Utilisation des sources de données multiples
commande, aucun nom d’ensemble de données n’est attribué à moins que vous en spécifiez unavec DATASET NAME. Pour fournir des noms d’ensembles de données plus descriptifs :
E Depuis les menus de la fenêtre éditeur de données pour l’ensemble de données dont vous souhaitezmodifier le nom, choisissez :Fichier
Renommer l’ensemble de données...
E Entrez un nouveau nom conforme aux règles de dénomination des variables pour l’ensemble dedonnées. Pour plus d'informations, reportez-vous à Noms de variable dans Chapitre 5 sur p. 84.
Suppression de plusieurs ensembles de données
Si vous préférez qu’un seul ensemble de données soit disponible à un moment donné et souhaitezsupprimer la fonctionnalité d’ouverture de plusieurs ensembles de données :
E A partir des menus, sélectionnez :Affichage
Options
E Cliquez sur l’onglet Général.
Sélectionnez (cochez) la case Ouvrir un seul ensemble de données à la fois.
Pour plus d'informations, reportez-vous à Options générales dans Chapitre 48 sur p. 539.

Chapitre
7Préparation des données
Une fois que vous avez ouvert le fichier de données ou saisi les données dans l’éditeur de données,vous pouvez créer des tableaux, des diagrammes et des analyses sans effectuer aucune autre tâchepréliminaire. Cependant, il existe des fonctions de préparation des données supplémentaires quipeuvent vous être utiles, y compris la possibilité de :
Affecter des propriétés de variable qui décrivent les données et déterminent le traitementdevant être appliqué à certaines valeurs.Identifier les observations pouvant contenir des informations redondantes, et les exclure desanalyses ou les supprimer du fichier de données.Créer des variables avec différentes modalités qui représentent des intervalles de valeursprovenant de variables comportant un grand nombre de valeurs possibles.
Propriétés de variable
Les données saisies dans l’Editeur de données dans l’affichage des données ou lues à partir d’unformat de fichier externe (une feuille de calcul Excel ou un fichier texte par exemple) ne sont pasdotées de certaines propriétés de variable que vous pourriez trouver très utiles, notamment :
Définition d’étiquettes de valeurs descriptives pour les codes numériques (par exemple, 0= homme et 1 = femme).Identification des codes de valeurs manquantes (par exemple, 99 = Sans objet).Attribution de niveaux de mesure (nominal, ordinal ou échelle).
Toutes ces propriétés de variable (et d’autres) peuvent être attribuées dans l’Affichage desvariables, dans l’éditeur de données. Plusieurs utilitaires peuvent également vous aider dans ceprocessus :
L’option Définir les propriétés de variable peut vous aider à définir les étiquettes de valeursdescriptives et les valeurs manquantes. Ceci est particulièrement utile pour les donnéesqualitatives dotées de codes numériques utilisés pour les valeurs de modalités.L’option Copier des propriétés de données permet d’utiliser un fichier de données SPSSStatistics existant comme modèle pour les propriétés de fichier et de variable dans le fichier dedonnées en cours. Ceci est particulièrement utile si vous utilisez fréquemment des fichiersde données au format externe ayant un contenu similaire (comme des rapports mensuels auformat Excel).
112
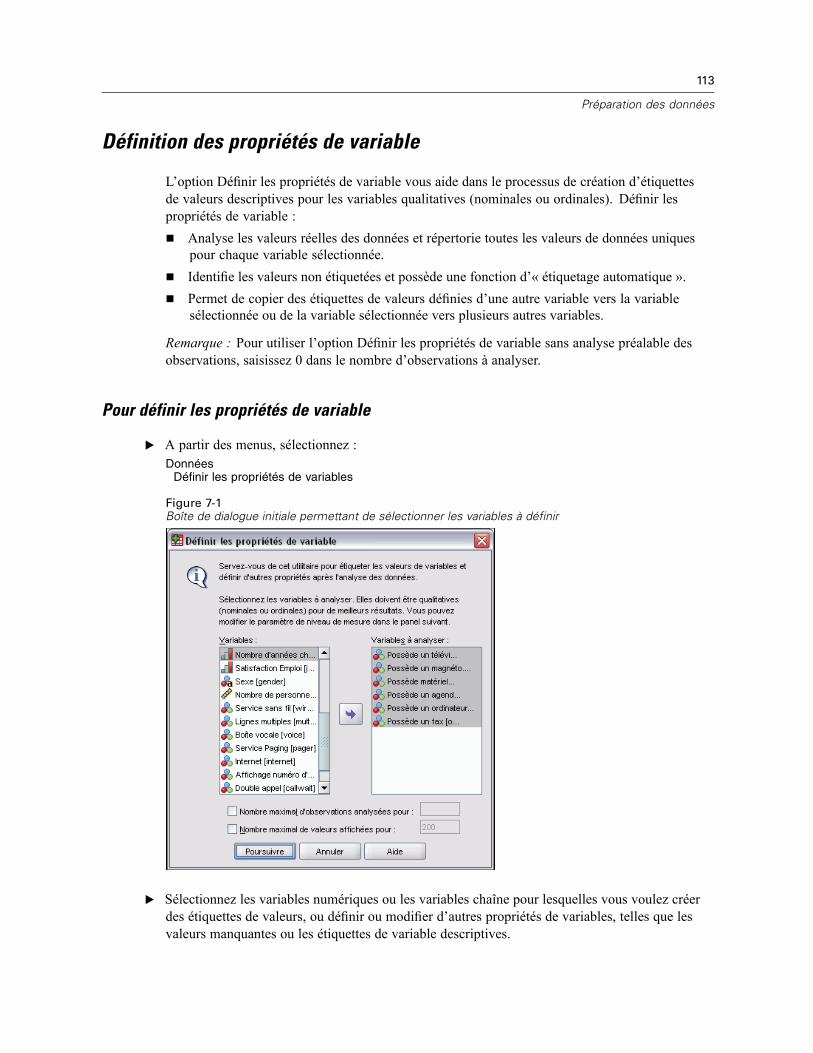
113
Préparation des données
Définition des propriétés de variable
L’option Définir les propriétés de variable vous aide dans le processus de création d’étiquettesde valeurs descriptives pour les variables qualitatives (nominales ou ordinales). Définir lespropriétés de variable :
Analyse les valeurs réelles des données et répertorie toutes les valeurs de données uniquespour chaque variable sélectionnée.Identifie les valeurs non étiquetées et possède une fonction d’« étiquetage automatique ».Permet de copier des étiquettes de valeurs définies d’une autre variable vers la variablesélectionnée ou de la variable sélectionnée vers plusieurs autres variables.
Remarque : Pour utiliser l’option Définir les propriétés de variable sans analyse préalable desobservations, saisissez 0 dans le nombre d’observations à analyser.
Pour définir les propriétés de variable
E A partir des menus, sélectionnez :Données
Définir les propriétés de variables
Figure 7-1Boîte de dialogue initiale permettant de sélectionner les variables à définir
E Sélectionnez les variables numériques ou les variables chaîne pour lesquelles vous voulez créerdes étiquettes de valeurs, ou définir ou modifier d’autres propriétés de variables, telles que lesvaleurs manquantes ou les étiquettes de variable descriptives.

114
Chapitre 7
E Spécifier le nombre d’observations à analyser afin de générer la liste de valeurs uniques. Ceci estparticulièrement utile pour les fichiers de données comportant un grand nombre d’observations,pour lesquelles une analyse complète du fichier de données prendrait beaucoup de temps.
E Spécifier une limite supérieure pour le nombre de valeurs uniques à afficher. Cette opération estparticulièrement utile pour éviter de répertorier des centaines, des milliers, voire des millions devaleurs pour les variables d’échelle (intervalle continu, rapport).
E Cliquez sur Poursuivre pour ouvrir la boîte de dialogue principale de la fonction Définir lespropriétés de variable.
E Sélectionnez une variable pour laquelle vous voulez créer des étiquettes de valeurs, ou définirou modifier d’autres propriétés de variable.
E Saisissez le texte de l’étiquette pour toutes les valeurs non étiquetées affichées dans la grilleEtiquette de valeur.
E Si vous souhaitez créer des étiquettes de valeurs pour des valeurs qui ne sont pas affichées, vouspouvez saisir les valeurs dans la colonne Valeur, sous la dernière valeur analysée.
E Répétez l’opération pour chaque variable répertoriée pour laquelle vous voulez créer des étiquettesde valeurs.
E Cliquez sur OK pour appliquer les étiquettes de valeurs et les autres propriétés de variable.
Définition des étiquettes de valeurs et des autres propriétés de variableFigure 7-2Définir les propriétés de variable, boîte de dialogue principale

115
Préparation des données
La boîte de dialogue principale de la fonction Définir les propriétés de variable donne l’informationsuivante concernant les variables analysées :
Liste des variables analysées : Pour chaque variable analysée, une coche dans la colonne Sansétiquette (U.) indique que la variable contient des valeurs qui ne possèdent pas d’étiquette devaleur.
Pour trier la liste de variables dans le but d’afficher en tête de liste toutes les variables nonétiquetées :
E Cliquez sur le titre de colonne Sans étiquette sous la liste des variables analysées.
Vous pouvez également faire un tri par nom de variable ou par niveau de mesure en cliquant sur letitre de colonne correspondant dans la liste des variables analysées.
Grille d’étiquettes de valeurs
Etiquette : Affiche toute étiquette de valeur définie. Dans cette colonne, vous pouvez ajouterou modifier des étiquettes.Valeur : Valeurs uniques pour chaque variable sélectionnée. Cette liste de valeurs uniques sefonde sur le nombre d’observations analysées. Par exemple, si vous analysez seulement les100 premières observations du fichier de données, la liste reflétera uniquement les valeursuniques présentes dans ces observations. Si le fichier de données a déjà été trié par la variableà laquelle vous voulez affecter des étiquettes de valeurs, la liste pourrait afficher beaucoupmoins de valeurs uniques qu’il n’en existe dans les données.Effectif : Nombre d’occurrences de chaque valeur dans les observations analysées.Manquant : Valeurs représentant les données manquantes. Vous pouvez modifier la désignationdes valeurs manquantes de la modalité en cochant la case. Si la case est cochée, la modalité estdéfinie en tant que modalité manquante spécifiée par l’utilisateur. Si une variable possède déjàune plage de valeurs définies comme manquantes par l’utilisateur (par exemple, 90-99), vousne pouvez ni ajouter ni supprimer des modalités de valeurs manquantes pour cette variableavec la fonction Définir les propriétés de variable. Dans l’éditeur de données, vous pouvezutiliser l’option Affichage des variables pour modifier les catégories de valeurs manquantesdes variables possédant des plages de valeurs manquantes. Pour plus d'informations,reportez-vous à Valeurs manquantes dans Chapitre 5 sur p. 89.Modifié : Indique que vous avez ajouté ou modifié une étiquette de valeur.
Remarque : Dans la boîte de dialogue initiale, si vous indiquez 0 comme nombre d’observations àanalyser, la grille Etiquette de valeur est d’abord vide, sauf pour les étiquettes de valeurs et/oules modalités de valeurs manquantes définies pour la variable sélectionnée. En outre, le boutonSuggérer du niveau de mesure est désactivé.
Niveau de mesure : Comme les étiquettes de valeurs sont particulièrement utiles pour les variablesqualitatives (nominales et ordinales), et comme certaines procédures traitent les variablesqualitatives et d’échelle différemment, il peut être important d’attribuer le niveau de mesurecorrect. Toutefois, par défaut, le niveau de mesure d’échelle est affecté à toutes les nouvellesvariables numériques. Par conséquent, de nombreuses variables normalement qualitatives peuventêtre initialement affichées en tant que variables d’échelle.
En cas de doute sur le niveau de mesure à affecter à une variable, cliquez sur Suggérer.

116
Chapitre 7
Copier les propriétés : Vous pouvez copier les étiquettes de variable ou les autres propriétés devariable à partir d’une autre variable vers la variable sélectionnée, ou à partir de la variablesélectionnée vers une ou plusieurs autres variables.
Valeurs non étiquetées : Pour créer automatiquement des étiquettes pour les valeurs non étiquetées,cliquez sur Etiquettes automatiques.
Etiquette de variable et Format d’affichage
Vous pouvez modifier l’étiquette de variable descriptive et le format d’affichage.Vous ne pouvez pas modifier le type fondamental de la variable (chaîne ou numérique).Pour les variables chaîne, vous ne pouvez modifier que l’étiquette de variable, mais pas leformat d’affichage.Concernant les variables numériques, vous pouvez changer le type numérique (nombres,dates, dollars ou autre devise), la largeur (nombre maximal de chiffres, dont les décimaleset/ou les indicateurs de regroupement) et le nombre de décimales.Pour ce qui est du format numérique de date, vous pouvez sélectionner un format de datespécifique (tel que jj-mm-aaaa, mm/jj/aa et aaaajjj).Pour un format numérique personnalisé, vous pouvez sélectionner un des cinq formats dedevise personnalisés (de CCA à CCE). Pour plus d'informations, reportez-vous à Optionsmonétaires (devises) dans Chapitre 48 sur p. 545.Un astérisque est affiché dans la colonne Valeur si la largeur indiquée est inférieure soit à celledes valeurs analysées, soit à celle des valeurs affichées, dans le cas des étiquettes de valeursdéfinies déjà existantes ou des modalités de valeurs manquantes.Un point (.) est affiché si les valeurs analysées ou les valeurs affichées (pour les étiquettesde valeurs définies déjà existantes ou pour les modalités de valeurs manquantes) ne sont pasvalides pour le type de format d’affichage sélectionné. Par exemple, une valeur numériqueinterne de moins de 86 400 n’est pas valide pour une variable format de date.
Affectation du niveau de mesure
Quand vous cliquez sur Suggérer pour le niveau de mesure dans la boîte de dialogue principaleDéfinir les propriétés de variable, la variable en cours est évaluée en fonction des observationsanalysées et des étiquettes de valeurs définies, et un niveau de mesure est suggéré dans la boîtede dialogue de suggestion d’un niveau de mesure qui apparaît. La zone Explication propose unebrève description des critères utilisés pour déterminer le niveau de mesure suggéré.
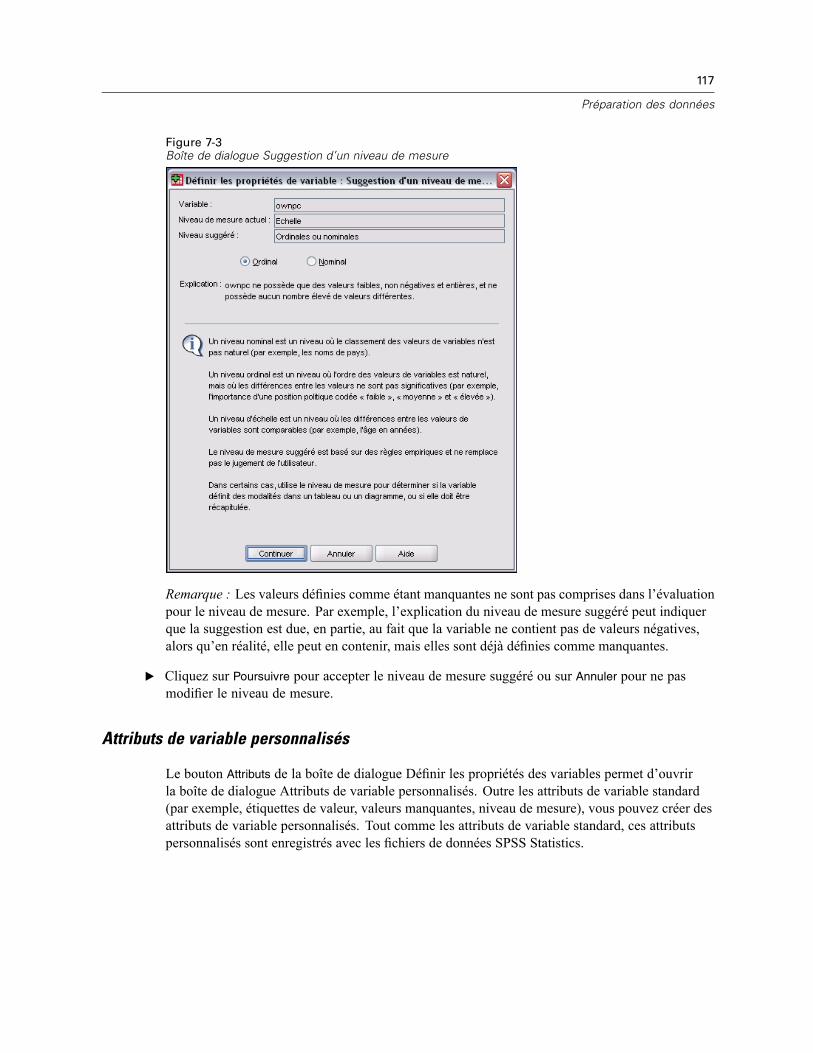
117
Préparation des données
Figure 7-3Boîte de dialogue Suggestion d’un niveau de mesure
Remarque : Les valeurs définies comme étant manquantes ne sont pas comprises dans l’évaluationpour le niveau de mesure. Par exemple, l’explication du niveau de mesure suggéré peut indiquerque la suggestion est due, en partie, au fait que la variable ne contient pas de valeurs négatives,alors qu’en réalité, elle peut en contenir, mais elles sont déjà définies comme manquantes.
E Cliquez sur Poursuivre pour accepter le niveau de mesure suggéré ou sur Annuler pour ne pasmodifier le niveau de mesure.
Attributs de variable personnalisés
Le bouton Attributs de la boîte de dialogue Définir les propriétés des variables permet d’ouvrirla boîte de dialogue Attributs de variable personnalisés. Outre les attributs de variable standard(par exemple, étiquettes de valeur, valeurs manquantes, niveau de mesure), vous pouvez créer desattributs de variable personnalisés. Tout comme les attributs de variable standard, ces attributspersonnalisés sont enregistrés avec les fichiers de données SPSS Statistics.

118
Chapitre 7
Figure 7-4Attributs de variable personnalisés
Nom : Les noms d’attribut doivent suivre les mêmes règles que les noms de variable. Pour plusd'informations, reportez-vous à Noms de variable dans Chapitre 5 sur p. 84.
Valeur : Valeur affectée à l’attribut de la variable sélectionnée.Les noms d’attribut commençant par le signe dollar sont des attributs réservés qui ne peuventpas être modifiés. Vous pouvez visualiser le contenu d’un attribut réservé en cliquant sur lebouton dans la cellule souhaitée.La présence du mot Tableau dans une cellule Valeur indique qu’il s’agit d’un tableaud’attributs, à savoir un attribut contenant plusieurs valeurs. Cliquez sur le bouton figurantdans la cellule pour afficher la liste des valeurs.
Copie de propriétés de variable
La boîte de dialogue Appliquer des étiquettes et un niveau apparaissent lorsque vous cliquez surA partir d’une autre variable ou sur Vers d’autres variables dans la boîte de dialogue principaleDéfinir les propriétés de variable. Toutes les variables analysées correspondant au type de lavariable courante (numérique ou chaîne) sont alors affichées. Dans le cas des variables chaîne, lalargeur définie doit également correspondre.

119
Préparation des données
Figure 7-5Boîte de dialogue Appliquer les étiquettes et le niveau
E Sélectionnez une seule variable dont vous allez copier les étiquettes de valeurs et les autrespropriétés de variable (sauf l’étiquette de variable).
ou
E Sélectionnez une ou plusieurs variables qui doivent recevoir les étiquettes de valeurs et les autrespropriétés de variable.
E Cliquez sur Copier pour copier les étiquettes de valeurs et le niveau de mesure.Les étiquettes de valeurs existantes et les modalités de valeurs manquantes des variablescible ne sont pas remplacées.Les étiquettes de valeurs et les modalités de valeurs manquantes des valeurs qui ne sont pasencore définies pour les variables cible sont ajoutées au groupe d’étiquettes de valeurs et demodalités de valeurs manquantes des variables cible.Le niveau de mesure des variables destination est toujours remplacé.Si la variable source ou cible possède un intervalle défini de valeurs manquantes, lesdéfinitions de valeurs manquantes ne sont pas copiées.
Vecteurs de réponses multiples
Les options Tableaux personnalisés et le Générateur de diagrammes prennent également en chargeun type spécifique de variable nommé vecteur de réponses multiples. Les vecteurs multiréponsesne sont pas réellement des « variables » au sens habituel du terme. En effet, vous ne pouvez pasles voir dans l’éditeur de données et les autres procédures ne les reconnaissent pas. Les vecteursmultiréponses utilisent plusieurs variables pour enregistrer les réponses à des questions auxquellesle répondant peut donner plusieurs réponses. Les vecteurs multiréponses sont traités comme desvariables qualitatives, et la plupart des actions appliquées à ces dernières peuvent égalementl’être aux vecteurs multiréponses.
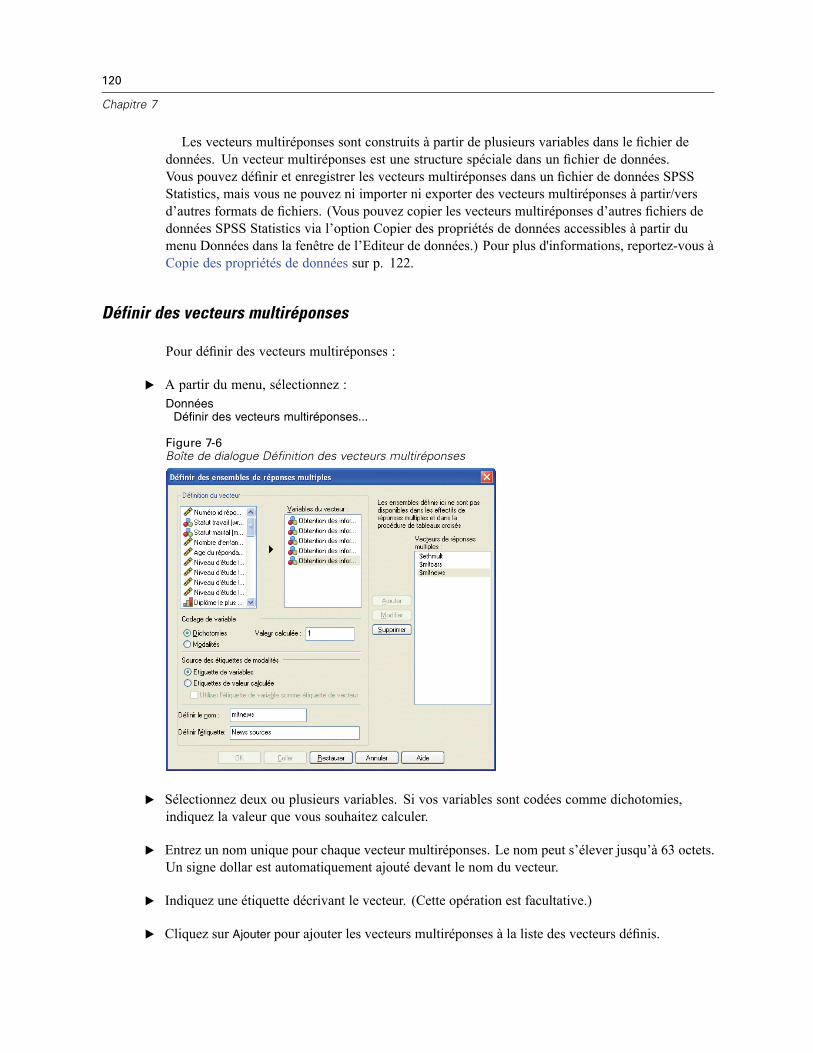
120
Chapitre 7
Les vecteurs multiréponses sont construits à partir de plusieurs variables dans le fichier dedonnées. Un vecteur multiréponses est une structure spéciale dans un fichier de données.Vous pouvez définir et enregistrer les vecteurs multiréponses dans un fichier de données SPSSStatistics, mais vous ne pouvez ni importer ni exporter des vecteurs multiréponses à partir/versd’autres formats de fichiers. (Vous pouvez copier les vecteurs multiréponses d’autres fichiers dedonnées SPSS Statistics via l’option Copier des propriétés de données accessibles à partir dumenu Données dans la fenêtre de l’Editeur de données.) Pour plus d'informations, reportez-vous àCopie des propriétés de données sur p. 122.
Définir des vecteurs multiréponses
Pour définir des vecteurs multiréponses :
E A partir du menu, sélectionnez :Données
Définir des vecteurs multiréponses...
Figure 7-6Boîte de dialogue Définition des vecteurs multiréponses
E Sélectionnez deux ou plusieurs variables. Si vos variables sont codées comme dichotomies,indiquez la valeur que vous souhaitez calculer.
E Entrez un nom unique pour chaque vecteur multiréponses. Le nom peut s’élever jusqu’à 63 octets.Un signe dollar est automatiquement ajouté devant le nom du vecteur.
E Indiquez une étiquette décrivant le vecteur. (Cette opération est facultative.)
E Cliquez sur Ajouter pour ajouter les vecteurs multiréponses à la liste des vecteurs définis.

121
Préparation des données
Dichotomies
Un vecteur de dichotomies multiples est composé de plusieurs variables dichotomiques : ils’agit de variables qui n’ont que deux valeurs possibles du type oui/non, présent/absent ousélectionné/non sélectionné. Bien que les variables peuvent ne pas être strictement dichotomiques,toutes les variables du vecteur sont codées de la même manière et la valeur comptée représente lacondition oui/présent/sélectionné.Par exemple, une enquête pose la question « Parmi les sources suivantes, quelles sont les plus
fiables dans le domaine de l’information ? » et propose cinq réponses possibles. Le répondantpeut indiquer plusieurs choix en cochant la case située en regard de chaque proposition. Lescinq réponses deviennent cinq variables dans le fichier de données, codées par 0 pour Non (nonsélectionné) et 1 pour Oui (sélectionné). Dans le vecteur de dichotomies multiples, la valeurcomptée est 1.Dans le fichier de données exemple survey_sample.sav, trois vecteurs multiréponses ont été
définis. $mltnews est un vecteur de dichotomies multiples.
E Dans la liste Vecteurs de réponses multiples, sélectionnez $mltnews en cliquant dessus.
Les variables et paramètres utilisés pour définir ce vecteur multiréponses apparaissent.La liste Variables à inclure comporte les cinq variables utilisées pour construire le vecteurmultiréponses.Le groupe Codage des variables indique que les variables sont dichotomiques.La valeur comptée est 1.
E Sélectionnez une des variables de la liste Variables à inclure en cliquant dessus.
E Cliquez avec le bouton droit de la souris sur la variable et sélectionnez Informations sur les
variables dans le menu contextuel.
E Dans la fenêtre Informations sur les variables, cliquez sur la flèche de la liste déroulante Etiquettesde valeur pour afficher la liste complète des étiquettes de valeurs définies.
Figure 7-7Informations sur la variable source à dichotomies multiples
L’étiquette de valeur indique que la variable est une dichotomie avec les valeurs 0 et 1, représentantrespectivement Non et Oui. Les cinq variables de la liste sont codées de la même façon et la valeur1 (code correspondant à Oui) est la valeur comptée pour le vecteur de dichotomies multiples.

122
Chapitre 7
Modalités
Un vecteur de modalités multiples comporte plusieurs variables, toutes codées de la même façon,souvent avec un grand nombre de modalités de réponses possibles. Par exemple, une enquêtecomporte la question « Nommez jusqu’à trois nationalités décrivant le mieux votre héritageethnique ». Des centaines de réponses sont possibles, mais pour des questions de codage, la listeest limitée aux 40 nationalités les plus courantes, le reste étant relégué dans une modalité «Autre».Dans le fichier de données, les trois choix deviennent trois variables, chacune comportant 41modalités (40 nationalités codées et une modalité « Autre »).Dans le fichier de données exemple, $ethmult et $mltcars sont des vecteurs de modalités
multiples.
Source de l’étiquette de modalité
Pour les dichotomies multiples, vous pouvez contrôler la manière dont les ensembles sontétiquetés.
Etiquettes de variable. Utilise les étiquettes de variables définies (ou les noms de variables pourles variables sans étiquette de variable définie) en tant qu’étiquettes de modalité d’ensemble.Par exemple, si toutes les variables de l’ensemble ont la même étiquette de valeur (ou pasd’étiquette de valeur définie) pour la valeur comptée (par exemple, Oui), alors vous devezutiliser les étiquettes de variables comme étiquettes de modalité d’ensemble.Etiquettes des valeurs comptées. Utilise les étiquettes de valeur définies des valeurs comptéescomme étiquettes de modalité d’ensemble. Sélectionnez cette option uniquement si toutesles variables ont une étiquette de valeur définie pour la valeur comptée et si l’étiquette de lavaleur comptée est différente pour chaque variable.Utilisez l’étiquette de variable comme étiquette d’ensemble. Si vous sélectionnez Etiquette desvaleurs comptées, vous pouvez également utiliser l’étiquette de variable pour la premièrevariable de l’ensemble avec une étiquette de variable défine comme étiquette d’ensemble. Siaucune des variables de l’ensemble ne comporte d’étiquettes de variables définies, le nom dela première variable est utilisé comme étiquette d’ensemble.
Copie des propriétés de donnéesL’assistant Copier des propriétés de données permet d’utiliser un fichier de données SPSS Statisticsexterne comme modèle pour définir les propriétés de fichier et de variable dans l’ensemble dedonnées actif. Vous pouvez également utiliser des variables de l’ensemble de données actifcomme modèle pour d’autres variables de l’ensemble de données actif. Vous pouvez:
Copier des propriétés de fichier sélectionnées à partir d’un fichier de données externe ououvrir un ensemble de données vers l’ensemble de données actif. Les propriétés de fichiercomprennent les documents, les étiquettes de fichier, les vecteurs multiréponses, les groupesde variables et la pondération.Copier des propriétés de variable sélectionnées à partir d’un fichier de données externeou ouvrir un ensemble de données vers des variables correspondantes de l’ensemble dedonnées actif. Les propriétés de variable comprennent les étiquettes de valeurs, les valeursmanquantes, le niveau de mesure, les étiquettes de variable, le format d’impression etd’écriture, l’alignement et la largeur des colonnes (dans l’éditeur de données).

123
Préparation des données
Copier des propriétés de variable sélectionnées à partir d’une variable d’un fichier de donnéesexterne, ouvrir un ensemble de données ou l’ensemble de données actif vers plusieursvariables de l’ensemble de données actif.Créer de nouvelles variables dans l’ensemble de données actif à partir de variablessélectionnées dans un fichier de données externe ou ouvrir un ensemble de données.
Lors de la copie de propriétés de données, les règles générales suivantes sont appliquées :Si vous utilisez un fichier de données externe en tant que fichier source, celui-ci doit êtreau format SPSS Statistics.Si vous utilisez l’ensemble de données actif comme fichier de données source, celui-ci doitcontenir au moins une variable. Vous ne pouvez pas utiliser un ensemble de données actifentièrement vide comme le fichier de données source.Les propriétés non définies (vides) de l’ensemble de données source ne remplacent pas lespropriétés définies dans l’ensemble de données actif.Les propriétés de variable ne sont copiées à partir de la variable source que sur des variablesd’un type correspondant : chaîne (alphanumérique) ou numérique (nombres, dates et devises).
Remarque : L’option Copier des propriétés de données remplace l’option d’application dudictionnaire de données, auparavant disponible dans le menu Fichier.
Pour copier des propriétés de données
E A partir des menus de la fenêtre de l’éditeur de données, sélectionnez :Données
Copie des propriétés de données...
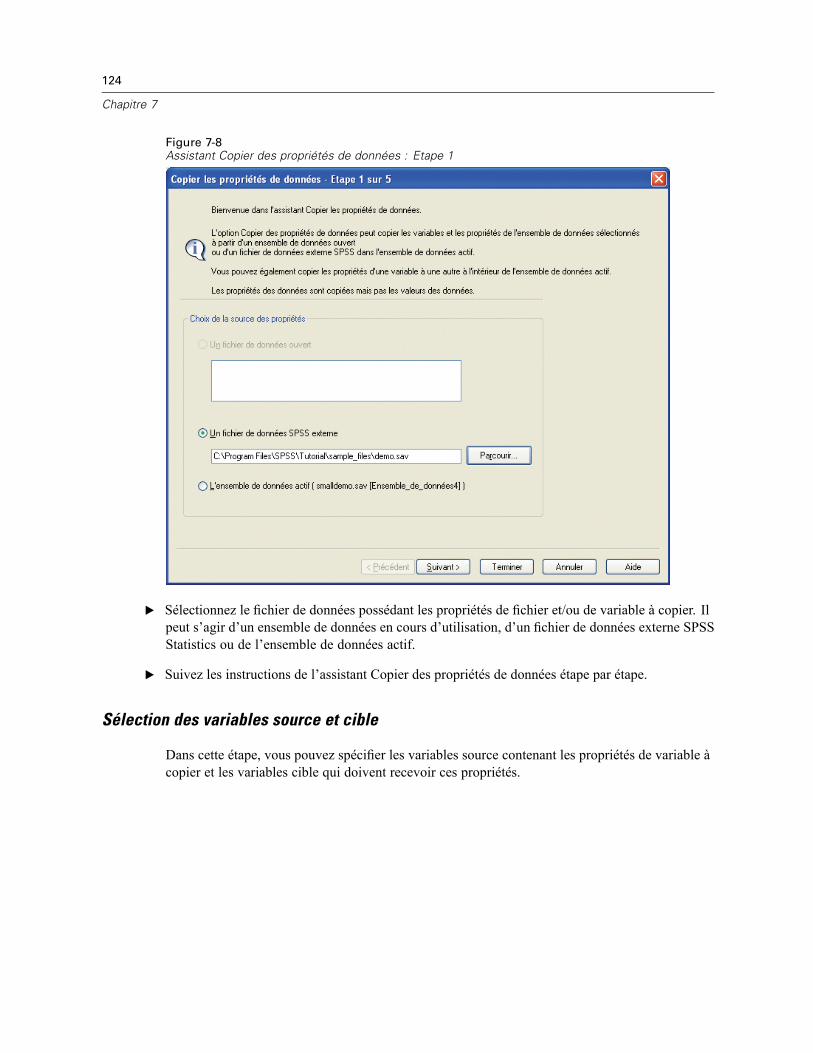
124
Chapitre 7
Figure 7-8Assistant Copier des propriétés de données : Etape 1
E Sélectionnez le fichier de données possédant les propriétés de fichier et/ou de variable à copier. Ilpeut s’agir d’un ensemble de données en cours d’utilisation, d’un fichier de données externe SPSSStatistics ou de l’ensemble de données actif.
E Suivez les instructions de l’assistant Copier des propriétés de données étape par étape.
Sélection des variables source et cible
Dans cette étape, vous pouvez spécifier les variables source contenant les propriétés de variable àcopier et les variables cible qui doivent recevoir ces propriétés.
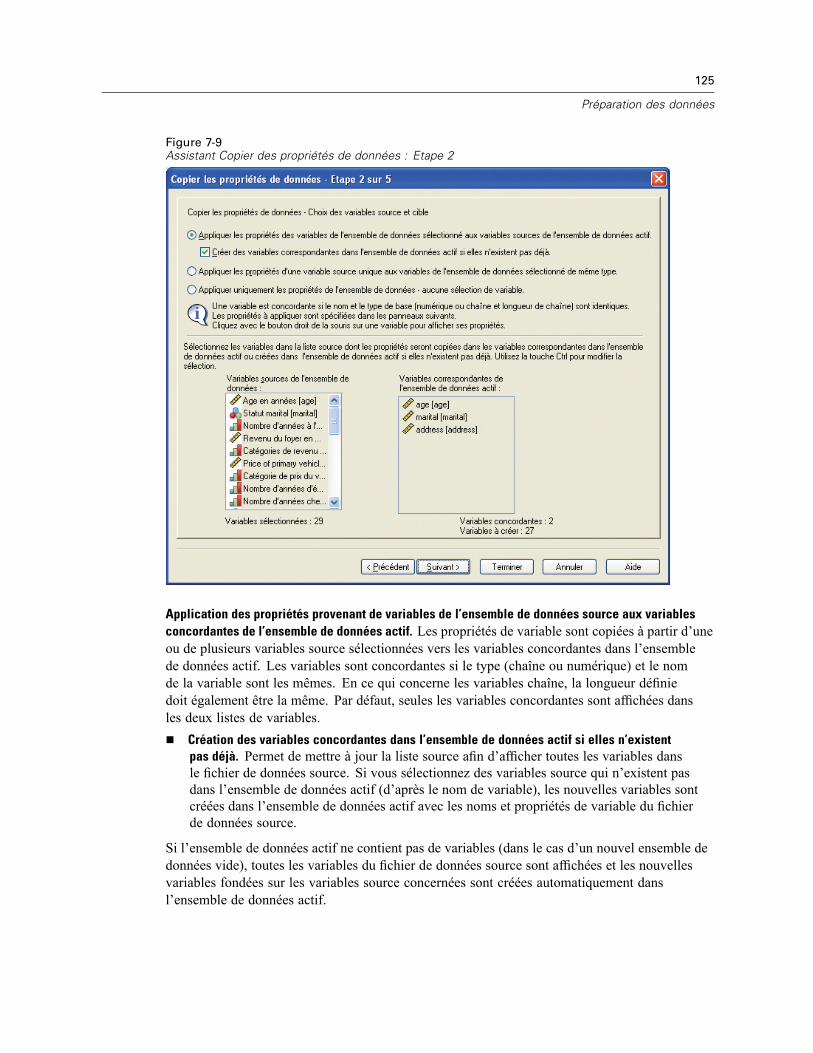
125
Préparation des données
Figure 7-9Assistant Copier des propriétés de données : Etape 2
Application des propriétés provenant de variables de l’ensemble de données source aux variablesconcordantes de l’ensemble de données actif. Les propriétés de variable sont copiées à partir d’uneou de plusieurs variables source sélectionnées vers les variables concordantes dans l’ensemblede données actif. Les variables sont concordantes si le type (chaîne ou numérique) et le nomde la variable sont les mêmes. En ce qui concerne les variables chaîne, la longueur définiedoit également être la même. Par défaut, seules les variables concordantes sont affichées dansles deux listes de variables.
Création des variables concordantes dans l’ensemble de données actif si elles n’existentpas déjà. Permet de mettre à jour la liste source afin d’afficher toutes les variables dansle fichier de données source. Si vous sélectionnez des variables source qui n’existent pasdans l’ensemble de données actif (d’après le nom de variable), les nouvelles variables sontcréées dans l’ensemble de données actif avec les noms et propriétés de variable du fichierde données source.
Si l’ensemble de données actif ne contient pas de variables (dans le cas d’un nouvel ensemble dedonnées vide), toutes les variables du fichier de données source sont affichées et les nouvellesvariables fondées sur les variables source concernées sont créées automatiquement dansl’ensemble de données actif.

126
Chapitre 7
Application des propriétés d’une variable source unique sur des variables sélectionnées de mêmetype d’un ensemble de données actif. Les propriétés d’une variable unique sélectionnée dans la listesource peuvent être appliquées à une ou à plusieurs variables sélectionnées de la liste de l’ensemblede données actif. Seules des variables du même type (numérique ou chaîne) que la variable choisiedans la liste source sont affichées dans la liste de l’ensemble de données actif. Dans le cas desvariables de chaîne, seules les chaînes de même longueur que la variable source sont affichées.Cette option n’est disponible que si l’ensemble de données actif ne contient aucune variable.
Remarque : Cette option ne vous permet pas de créer de nouvelles variables dans l’ensemblede données actif.
Application des propriétés d’un ensemble de données uniquement, sans sélection de variable. Seulesles propriétés du fichier (par exemple, les documents, les étiquettes de fichier et la pondération)sont appliquées à l’ensemble de données actif. Aucune propriété de variable n’est appliquée.Cette option n’est pas disponible si l’ensemble de données actif est également le fichier dedonnées source.
Choix des propriétés de variable à copier
Vous pouvez copier des propriétés de variable à partir des variables source vers les variablescible. Les propriétés non définies (vides) des variables source ne remplacent pas les propriétésdéfinies des variables cible.
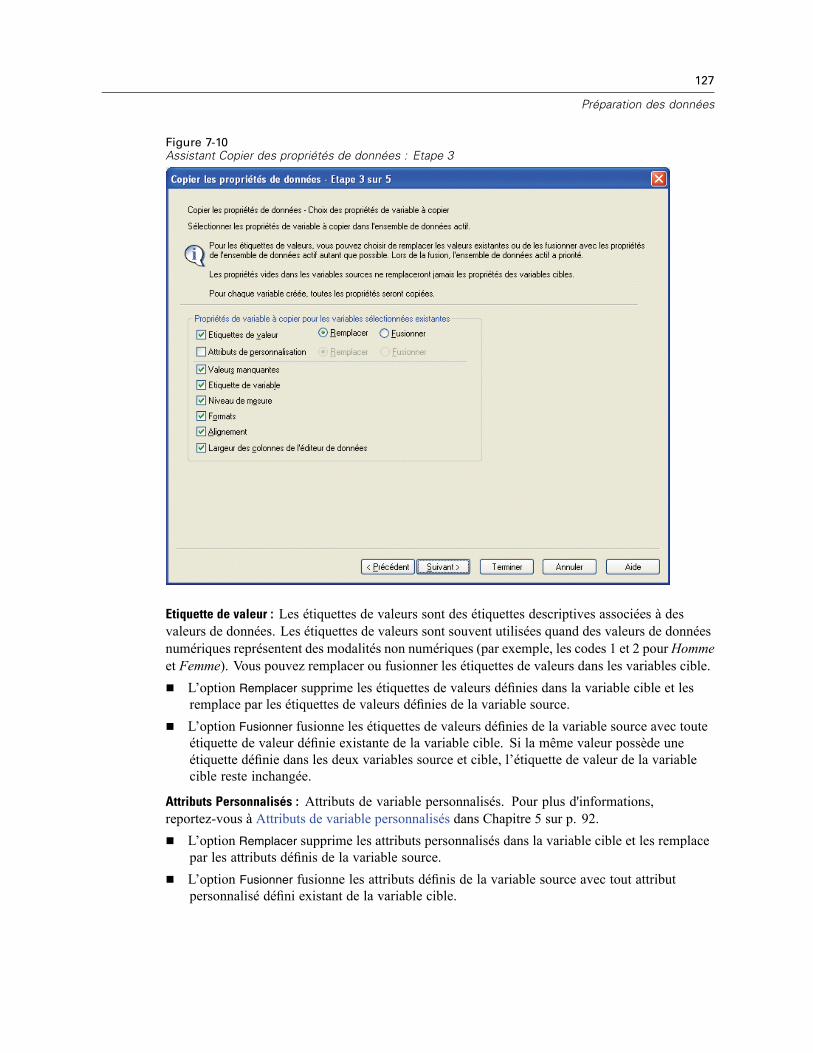
127
Préparation des données
Figure 7-10Assistant Copier des propriétés de données : Etape 3
Etiquette de valeur : Les étiquettes de valeurs sont des étiquettes descriptives associées à desvaleurs de données. Les étiquettes de valeurs sont souvent utilisées quand des valeurs de donnéesnumériques représentent des modalités non numériques (par exemple, les codes 1 et 2 pourHommeet Femme). Vous pouvez remplacer ou fusionner les étiquettes de valeurs dans les variables cible.
L’option Remplacer supprime les étiquettes de valeurs définies dans la variable cible et lesremplace par les étiquettes de valeurs définies de la variable source.L’option Fusionner fusionne les étiquettes de valeurs définies de la variable source avec touteétiquette de valeur définie existante de la variable cible. Si la même valeur possède uneétiquette définie dans les deux variables source et cible, l’étiquette de valeur de la variablecible reste inchangée.
Attributs Personnalisés : Attributs de variable personnalisés. Pour plus d'informations,reportez-vous à Attributs de variable personnalisés dans Chapitre 5 sur p. 92.
L’option Remplacer supprime les attributs personnalisés dans la variable cible et les remplacepar les attributs définis de la variable source.L’option Fusionner fusionne les attributs définis de la variable source avec tout attributpersonnalisé défini existant de la variable cible.

128
Chapitre 7
Valeurs manquantes : Les valeurs manquantes représentent des données manquantes (par exemple,98 pour Ne se prononce pas et 99 pour Sans objet). Ces valeurs possèdent également des étiquettesde valeurs définies qui décrivent ce que représentent les codes de la valeur manquante. Les valeursmanquantes définies existant dans la variable cible sont supprimées et remplacées par les valeursmanquantes définies dans la variable source.
Etiquette de variable : Les étiquettes de variable descriptive peuvent contenir des espaces et descaractères réservés qui ne sont pas autorisés dans les noms de variable. Avant de copier despropriétés d’une seule variable source sur plusieurs variables cible, plusieurs éléments sont àprendre en compte.
Niveau de mesure : Le niveau de mesure peut être nominal, ordinal ou d’échelle. Pour lesprocédures qui font une distinction entre différents niveaux de mesure, les niveaux nominal etordinal sont tous deux considérés comme qualitatifs.
Formats : Concernant les variables numériques, cette option contrôle le type numérique (nombres,dates ou devises), la largeur (nombre total de caractères affichés, dont les caractères de début etde fin, et l’indicateur décimal) et le nombre de décimales affichées. Cette option est ignoréepour les variables chaîne.
Alignement : Cette option n’affecte que l’alignement (gauche, droite, centré) de l’affichage desdonnées de l’éditeur de données.
Largeur des colonnes dans l’éditeur de données : Cette option n’affecte que la largeur des colonnesde l’affichage des données dans l’éditeur de données.
Copie des propriétés d’ensembles de données (propriétés de fichier)
Vous pouvez appliquer des propriétés choisies d’un ensemble de données global à partir dufichier de données source vers l’ensemble de données actif. (Cette option n’est pas disponible sil’ensemble de données actif est le fichier de données source.)
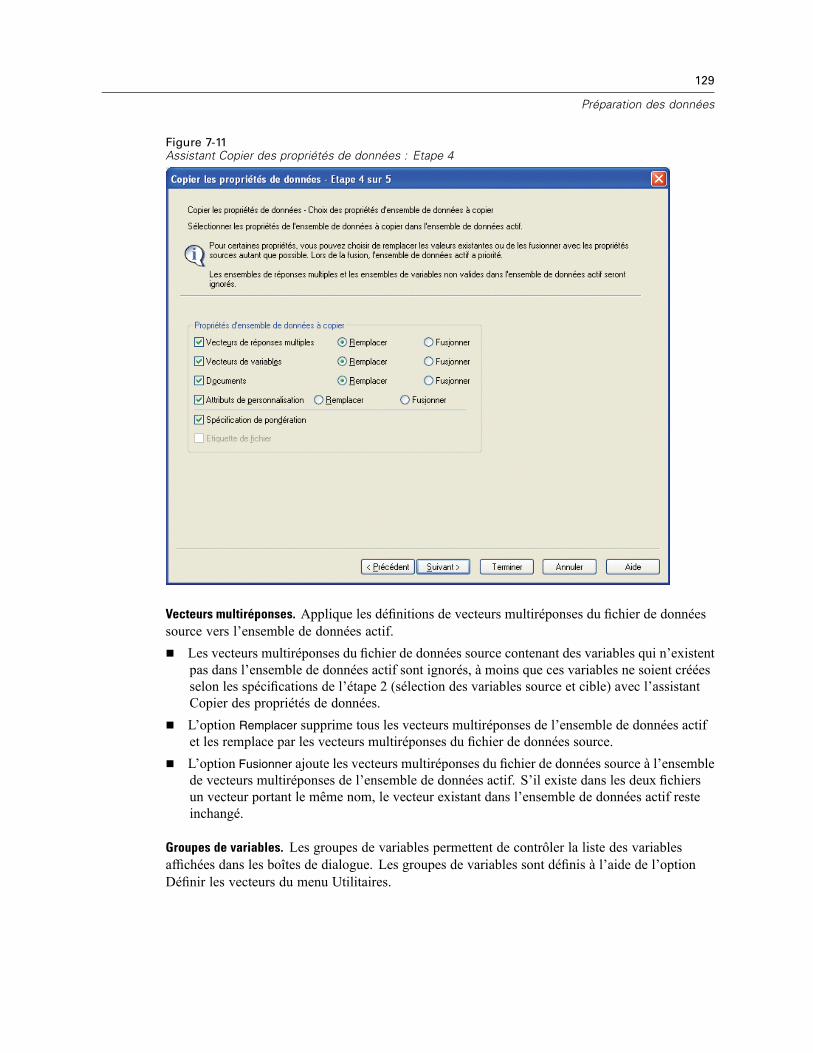
129
Préparation des données
Figure 7-11Assistant Copier des propriétés de données : Etape 4
Vecteurs multiréponses. Applique les définitions de vecteurs multiréponses du fichier de donnéessource vers l’ensemble de données actif.
Les vecteurs multiréponses du fichier de données source contenant des variables qui n’existentpas dans l’ensemble de données actif sont ignorés, à moins que ces variables ne soient crééesselon les spécifications de l’étape 2 (sélection des variables source et cible) avec l’assistantCopier des propriétés de données.L’option Remplacer supprime tous les vecteurs multiréponses de l’ensemble de données actifet les remplace par les vecteurs multiréponses du fichier de données source.L’option Fusionner ajoute les vecteurs multiréponses du fichier de données source à l’ensemblede vecteurs multiréponses de l’ensemble de données actif. S’il existe dans les deux fichiersun vecteur portant le même nom, le vecteur existant dans l’ensemble de données actif resteinchangé.
Groupes de variables. Les groupes de variables permettent de contrôler la liste des variablesaffichées dans les boîtes de dialogue. Les groupes de variables sont définis à l’aide de l’optionDéfinir les vecteurs du menu Utilitaires.

130
Chapitre 7
Les groupes du fichier de données source contenant des variables qui n’existent pas dansl’ensemble de données actif sont ignorés à moins que ces variables ne soient créées selon lesspécifications de l’étape 2 (sélection des variables source et cible) avec l’assistant Copierdes propriétés de données.L’option Remplacer supprime tous les groupes de variables existants dans l’ensemble dedonnées actif et les remplace par les groupes de variables du fichier de données source.L’option Fusionner ajoute les groupes de variables du fichier de données source à l’ensembledes groupes de variables de l’ensemble de données actif. S’il existe dans les deux fichiersun vecteur portant le même nom, le vecteur existant dans l’ensemble de données actif resteinchangé.
Documents. Remarques ajoutées au fichier de données via la commande DOCUMENT.L’option Remplacer supprime tous les documents existants dans l’ensemble de données actif etles remplace par les documents du fichier de données source.L’option Fusionner combine les documents de l’ensemble de données actif et source. Lesdocuments uniques dans le fichier source et qui n’existent pas dans l’ensemble de donnéesactif sont ajoutés à l’ensemble de données actif. Tous les documents sont ensuite triés par date.
Attributs Personnalisés. Les attributs de fichier de données personnalisés, créés en général par lacommande DATAFILE ATTRIBUTE dans la syntaxe de commande.
L’option Remplacer supprime tous les attributs du fichier de données personnalisés existantsdans l’ensemble de données actif et les remplace par les attributs du fichier de données àpartir du fichier de données source.L’option Fusionner combine les attributs du fichier de données de l’ensemble de données actifet source. Les noms d’attributs uniques dans le fichier source et qui n’existent pas dansl’ensemble de données actif sont ajoutés à l’ensemble de données actif. Si un nom d’attributidentique existe dans les deux fichiers de données, l’attribut nommé dans l’ensemble dedonnées actif reste inchangé.
Spécification de pondération. Pondère les observations à l’aide de la variable de pondérationactuelle du fichier de données source s’il existe une variable concordante dans l’ensemble dedonnées actif. Cette opération remplace toute pondération en cours dans l’ensemble de donnéesactif.
Etiquette de fichier. Etiquette descriptive appliquée à un fichier de données via la commandeFILE LABEL.
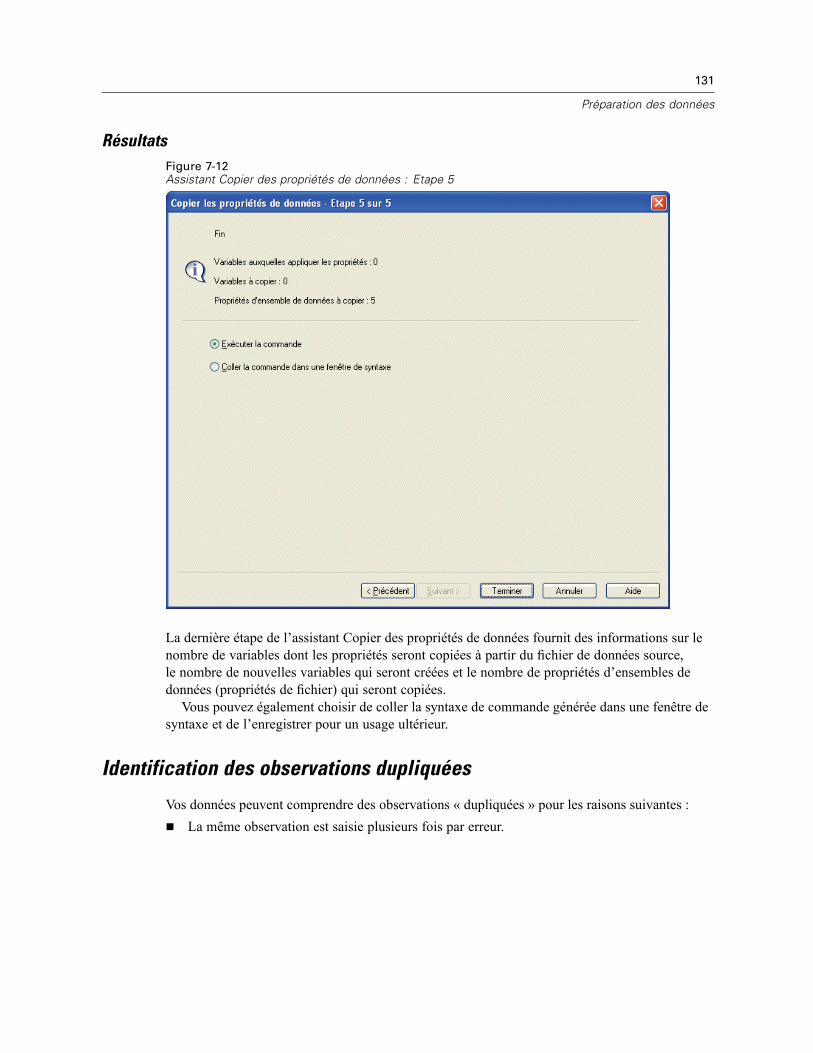
131
Préparation des données
RésultatsFigure 7-12Assistant Copier des propriétés de données : Etape 5
La dernière étape de l’assistant Copier des propriétés de données fournit des informations sur lenombre de variables dont les propriétés seront copiées à partir du fichier de données source,le nombre de nouvelles variables qui seront créées et le nombre de propriétés d’ensembles dedonnées (propriétés de fichier) qui seront copiées.Vous pouvez également choisir de coller la syntaxe de commande générée dans une fenêtre de
syntaxe et de l’enregistrer pour un usage ultérieur.
Identification des observations dupliquées
Vos données peuvent comprendre des observations « dupliquées » pour les raisons suivantes :La même observation est saisie plusieurs fois par erreur.

132
Chapitre 7
Plusieurs observations partagent la même valeur d’ID principal, mais ont des valeurs d’IDsecondaire différentes (par exemple, les membres d’une famille qui vivent tous dans la mêmemaison).Plusieurs observations représentent la même observation, mais les valeurs des variablesautres que celles qui identifient l’observation sont différentes (par exemple, plusieurs achatseffectués par la même personne ou la même société pour des produits différents ou à desheures différentes).
L’identification des observations dupliquées vous permet de définir la variable duplicate suivantvos besoins et de contrôler la détermination automatique des observations principales par rapportaux observations dupliquées.
Pour identifier et repérer les observations dupliquées
E A partir des menus, sélectionnez :Données
Identifier les observations dupliquées...
E Sélectionnez les variables qui identifient les observations concordantes.
E Sélectionnez des options dans la zone Variables à créer.
Sinon, vous pouvez :
E Sélectionner des variables pour trier les observations dans des groupes définis par les variablesdes observations concordantes sélectionnées. L’ordre de tri défini par ces variables détermine la« première » et la « dernière » observation de chaque groupe. Sinon, l’ordre utilisé est celuid’origine du fichier.
E Filtrer automatiquement les observations dupliquées afin qu’elles ne soient pas incluses dans lesrapports, les graphiques ou les calculs des statistiques.
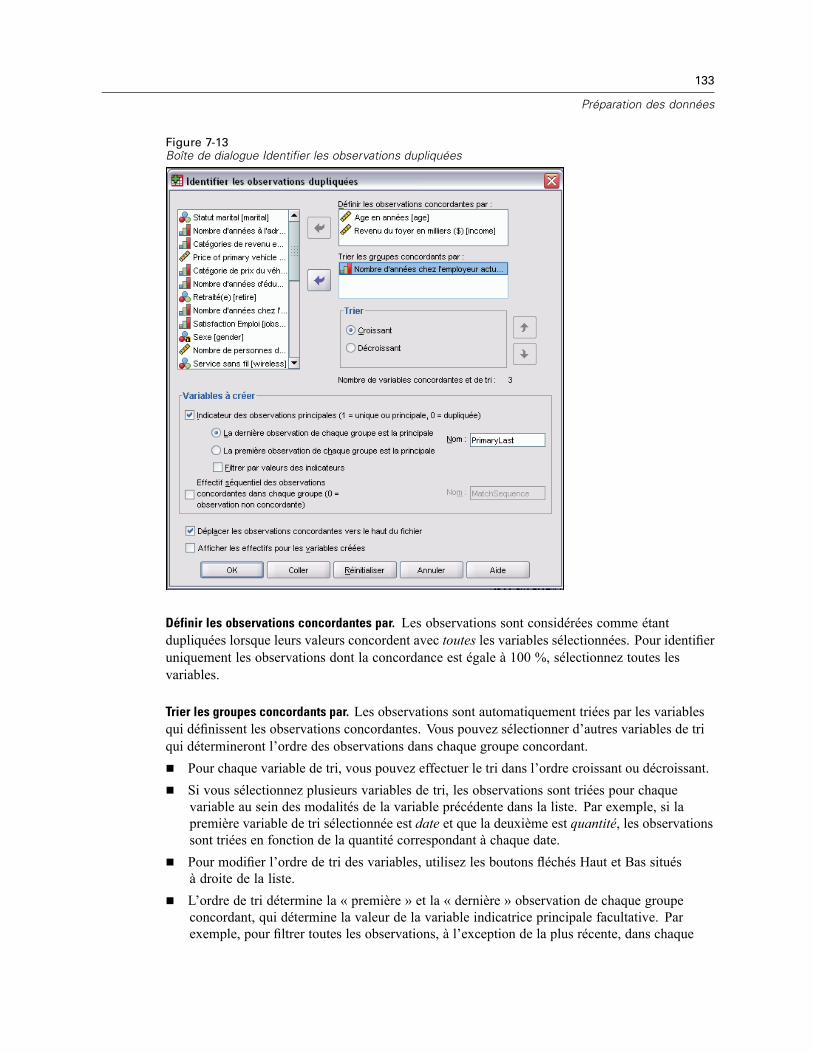
133
Préparation des données
Figure 7-13Boîte de dialogue Identifier les observations dupliquées
Définir les observations concordantes par. Les observations sont considérées comme étantdupliquées lorsque leurs valeurs concordent avec toutes les variables sélectionnées. Pour identifieruniquement les observations dont la concordance est égale à 100 %, sélectionnez toutes lesvariables.
Trier les groupes concordants par. Les observations sont automatiquement triées par les variablesqui définissent les observations concordantes. Vous pouvez sélectionner d’autres variables de triqui détermineront l’ordre des observations dans chaque groupe concordant.
Pour chaque variable de tri, vous pouvez effectuer le tri dans l’ordre croissant ou décroissant.Si vous sélectionnez plusieurs variables de tri, les observations sont triées pour chaquevariable au sein des modalités de la variable précédente dans la liste. Par exemple, si lapremière variable de tri sélectionnée est date et que la deuxième est quantité, les observationssont triées en fonction de la quantité correspondant à chaque date.Pour modifier l’ordre de tri des variables, utilisez les boutons fléchés Haut et Bas situésà droite de la liste.L’ordre de tri détermine la « première » et la « dernière » observation de chaque groupeconcordant, qui détermine la valeur de la variable indicatrice principale facultative. Parexemple, pour filtrer toutes les observations, à l’exception de la plus récente, dans chaque

134
Chapitre 7
groupe concordant, vous pouvez trier les observations du groupe dans l’ordre croissant àpartir d’une variable de date. De cette façon, la date la plus récente devient la dernière datedu groupe.
Indicateur d’observations principales. Crée une variable dont la valeur est 1 pour toutes lesobservations uniques et pour l’observation identifiée comme étant l’observation principale dechaque groupe d’observations concordantes, et 0 pour les observations dupliquées non principalesde chaque groupe.
En fonction de l’ordre de tri déterminé dans le groupe concordant, l’observation principale peutêtre la dernière ou la première observation de ce groupe. Si vous n’indiquez aucune variablede tri, l’ordre d’origine du fichier détermine celui des observations dans chaque groupe.Vous pouvez utiliser la variable indicatrice en tant que variable de filtre pour exclure lesobservations dupliquées non principales des rapports et des analyses sans les supprimer dufichier de données.
Effectif séquentiel des observations concordantes de chaque groupe. Crée une variable dont lavaleur séquentielle est comprise entre 1 et n pour les observations de chaque groupe concordant.La séquence est basée sur l’ordre en cours des observations dans chaque groupe, c’est-à-direl’ordre d’origine du fichier ou celui déterminé par les variables de tri indiquées.
Déplacer les observations concordantes vers le haut. Trie le fichier de données afin que tous lesgroupes d’observations concordantes se trouvent au début de ce fichier. Le contrôle visuel desobservations concordantes est ainsi facilité dans l’éditeur de données.
Afficher les fréquences pour les variables créées. Tableaux de fréquences indiquant le nombred’observations pour chaque valeur des variables créées. Par exemple, pour la variable indicatriceprincipale, le tableau indique le nombre d’observations dont la valeur est 0 pour cette variable (cequi indique le nombre d’observations dupliquées) et le nombre d’observations dont la valeur est 1pour cette variable (c’est-à-dire le nombre d’observations uniques et principales).
Valeurs manquantes. Pour les variables numériques, la valeur manquante par défaut est traitéecomme toute autre valeur—. Les observations disposant de la valeur manquante par défaut pourune variable d’identificateur sont traitées comme si elles disposaient de valeurs concordantes pourcette variable. Pour les variables chaîne, les observations ne disposant d’aucune valeur pourune variable d’identificateur sont traitées comme si elles disposaient de valeurs concordantespour cette variable.
Regroupement visuelLe regroupement visuel est conçu pour vous aider lors de la création de variables basées sur leregroupement des valeurs contiguës de variables dans un nombre distinct de modalités. Vouspouvez utiliser l’option Regroupement visuel pour :
Créer des variables qualitatives à partir de variables d’échelle continues. Par exemple, vouspouvez utiliser la variable d’échelle Revenu pour créer une variable qualitative contenant lestranches de revenus.Fusionner un grand nombre de modalités ordinales en un jeu de modalités plus petit. Parexemple, vous pouvez fusionner une échelle d’évaluation allant jusqu’à neuf pour obtenirtrois modalités qui représenteraient les niveaux faible, moyen et élevé.
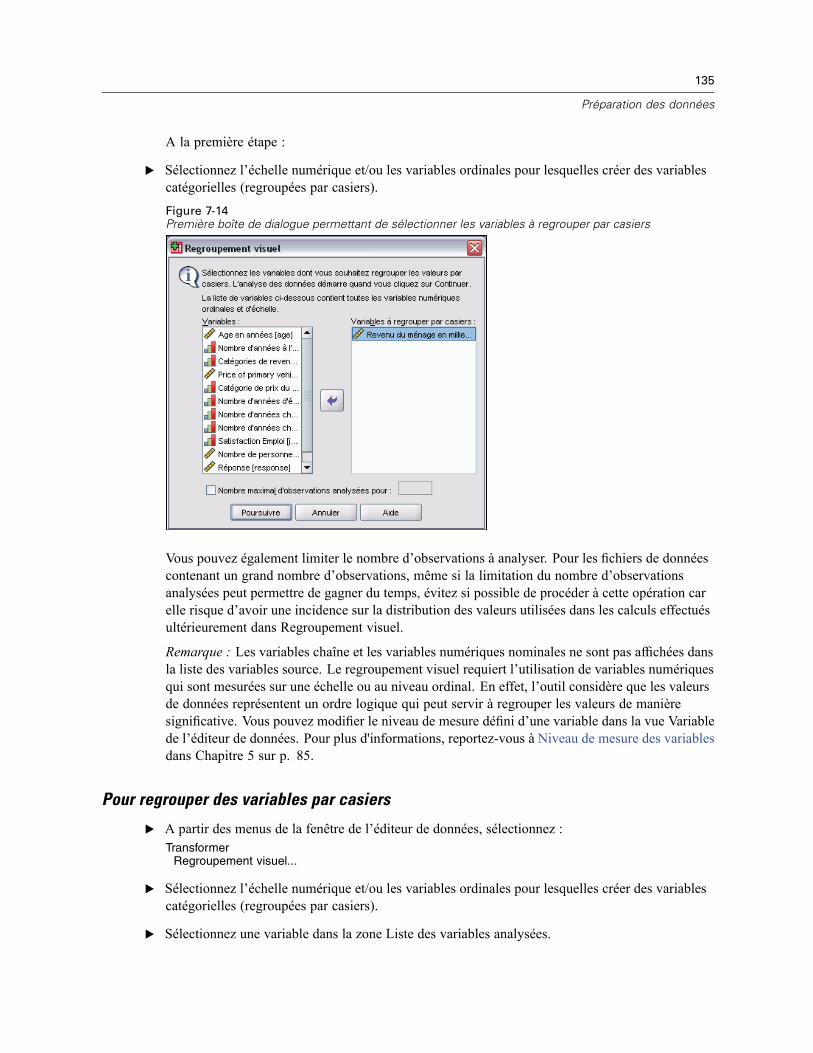
135
Préparation des données
A la première étape :
E Sélectionnez l’échelle numérique et/ou les variables ordinales pour lesquelles créer des variablescatégorielles (regroupées par casiers).
Figure 7-14Première boîte de dialogue permettant de sélectionner les variables à regrouper par casiers
Vous pouvez également limiter le nombre d’observations à analyser. Pour les fichiers de donnéescontenant un grand nombre d’observations, même si la limitation du nombre d’observationsanalysées peut permettre de gagner du temps, évitez si possible de procéder à cette opération carelle risque d’avoir une incidence sur la distribution des valeurs utilisées dans les calculs effectuésultérieurement dans Regroupement visuel.
Remarque : Les variables chaîne et les variables numériques nominales ne sont pas affichées dansla liste des variables source. Le regroupement visuel requiert l’utilisation de variables numériquesqui sont mesurées sur une échelle ou au niveau ordinal. En effet, l’outil considère que les valeursde données représentent un ordre logique qui peut servir à regrouper les valeurs de manièresignificative. Vous pouvez modifier le niveau de mesure défini d’une variable dans la vue Variablede l’éditeur de données. Pour plus d'informations, reportez-vous à Niveau de mesure des variablesdans Chapitre 5 sur p. 85.
Pour regrouper des variables par casiers
E A partir des menus de la fenêtre de l’éditeur de données, sélectionnez :Transformer
Regroupement visuel...
E Sélectionnez l’échelle numérique et/ou les variables ordinales pour lesquelles créer des variablescatégorielles (regroupées par casiers).
E Sélectionnez une variable dans la zone Liste des variables analysées.
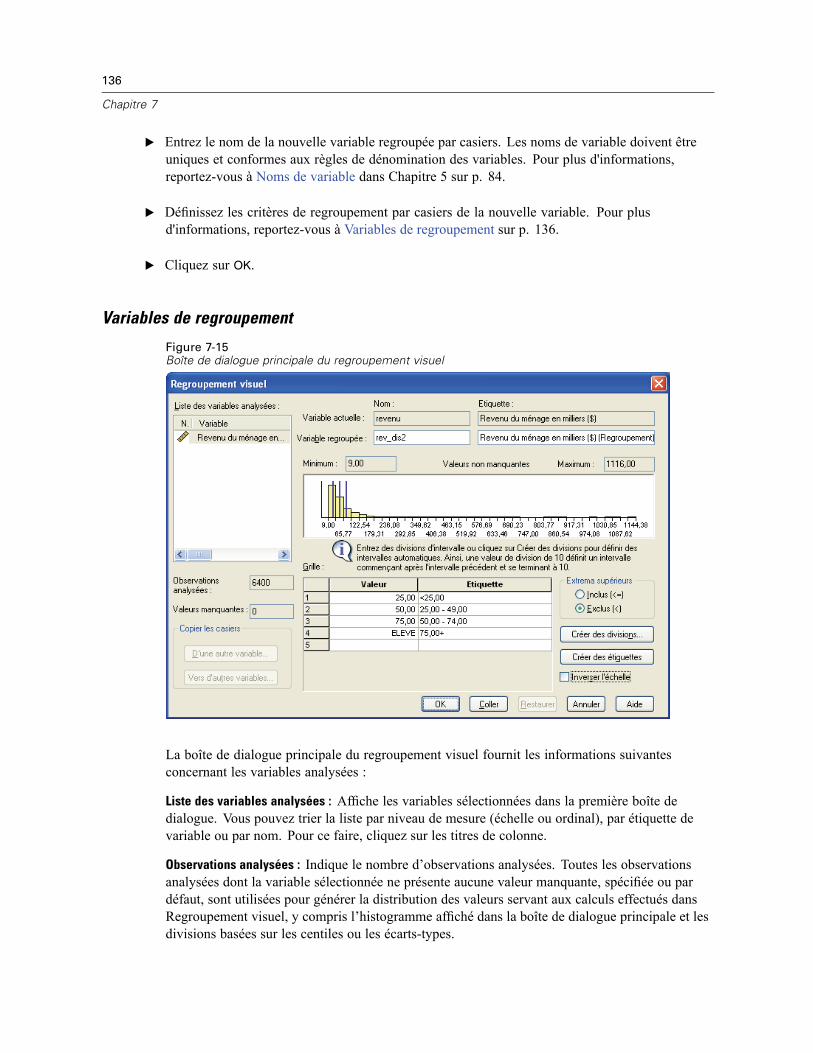
136
Chapitre 7
E Entrez le nom de la nouvelle variable regroupée par casiers. Les noms de variable doivent êtreuniques et conformes aux règles de dénomination des variables. Pour plus d'informations,reportez-vous à Noms de variable dans Chapitre 5 sur p. 84.
E Définissez les critères de regroupement par casiers de la nouvelle variable. Pour plusd'informations, reportez-vous à Variables de regroupement sur p. 136.
E Cliquez sur OK.
Variables de regroupement
Figure 7-15Boîte de dialogue principale du regroupement visuel
La boîte de dialogue principale du regroupement visuel fournit les informations suivantesconcernant les variables analysées :
Liste des variables analysées : Affiche les variables sélectionnées dans la première boîte dedialogue. Vous pouvez trier la liste par niveau de mesure (échelle ou ordinal), par étiquette devariable ou par nom. Pour ce faire, cliquez sur les titres de colonne.
Observations analysées : Indique le nombre d’observations analysées. Toutes les observationsanalysées dont la variable sélectionnée ne présente aucune valeur manquante, spécifiée ou pardéfaut, sont utilisées pour générer la distribution des valeurs servant aux calculs effectués dansRegroupement visuel, y compris l’histogramme affiché dans la boîte de dialogue principale et lesdivisions basées sur les centiles ou les écarts-types.

137
Préparation des données
Valeurs manquantes : Indique le nombre d’observations analysées contenant des valeursmanquantes par défaut et spécifiées par l’utilisateur. Les valeurs manquantes ne sont inclusesdans aucune modalité regroupée par casiers. Pour plus d'informations, reportez-vous à Valeursmanquantes spécifiées dans Regroupement visuel sur p. 142.
Variable actuelle : Nom et étiquette (si disponible) de la variable sélectionnée, qui seront utiliséscomme base pour les nouvelles variables regroupées par casiers.
Variable regroupée : Nom et étiquette facultative de la nouvelle variable regroupée par casiers.Nom : Vous devez entrer le nom de la nouvelle variable. Les noms de variable doivent êtreuniques et conformes aux règles de dénomination des variables. Pour plus d'informations,reportez-vous à Noms de variable dans Chapitre 5 sur p. 84.Etiquette : Vous pouvez saisir une étiquette descriptive à la variable jusqu’à 255 caractères.L’étiquette de variable par défaut est l’étiquette de variable (le cas échéant) ou le nom devariable de la variable source avec (Regroupé par casiers) ajouté à la fin de l’étiquette.
Minimum et Maximum : Valeurs minimales et maximales de la variable sélectionnée, basées surles observations analysées et n’incluant pas de valeurs définies en tant que valeurs manquantesspécifiées par l’utilisateur.
Valeurs non manquantes : L’histogramme affiche la distribution des valeurs non manquantes pourla variable sélectionnée, basée sur les observations analysées.
Une fois que vous avez défini les casiers de la nouvelle variable, les lignes verticales del’histogramme apparaissent afin d’indiquer les divisions définissant ces casiers.Vous pouvez cliquer sur les lignes de division, puis les déplacer vers différents emplacementsde l’histogramme, sans changer les intervalles de casiers.Vous pouvez supprimer les casiers en faisant glisser les lignes de division hors del’histogramme.
Remarque : L’histogramme (affichant les valeurs non manquantes), et les valeurs minimales etmaximales sont basés sur les valeurs analysées. Si vous n’incluez pas toutes les observations dansl’analyse, vous risquez de ne pas obtenir une distribution précise et représentative, surtout si lefichier de données a été trié par la variable sélectionnée. Si vous n’analysez pas d’observations,aucune information sur la distribution des valeurs n’est disponible.
Grille : Affiche les valeurs qui définissent les extrema supérieurs de chaque casier et les étiquettesde valeur facultatives de chaque casier.
Valeur : Valeurs qui définissent les extrema supérieurs de chaque casier. Vous pouvez entrerdes valeurs ou utiliser l’option Créer des divisions pour créer automatiquement des casiersen fonction des critères sélectionnés. Par défaut, une division dont la valeur est ELEVE estautomatiquement incluse. Ce casier contient alors toutes les valeurs non manquantes situéesau-dessus des autres divisions. Le casier défini par la division la moins élevée inclut toutes lesvaleurs non manquantes inférieures ou égales à cette valeur (ou simplement inférieures à cettevaleur, en fonction de la définition des extrema supérieurs).Etiquette : Etiquettes descriptives facultatives pour les valeurs de la nouvelle variableregroupée par casiers. Etant donné que les valeurs de la nouvelle variable sont des valeursentières séquentielles comprises entre 1 et n, les étiquettes décrivant les valeurs peuvent se

138
Chapitre 7
révéler très utiles. Vous pouvez entrer les étiquettes de valeur ou utiliser l’option Créer desétiquettes pour les créer automatiquement.
Pour supprimer un casier de la grille
E Cliquez avec le bouton droit de la souris sur la cellule Valeur ou Etiquette du casier.
E Dans le menu contextuel, sélectionnez Supprimer la ligne.
Remarque : Si vous supprimez le casier ELEVE, la valeur par défaut manquante de la nouvellevariable est attribuée à toutes les observations dont les valeurs sont supérieures à celle de ladernière division spécifiée.
Pour supprimer toutes les étiquettes ou tous les casiers définis
E Cliquez avec le bouton droit n’importe où dans la grille.
E Dans le menu contextuel, sélectionnez Supprimer toutes les étiquettes ou Supprimer toutes les
divisions.
Extrema supérieurs : Contrôle le traitement des valeurs des extrema supérieurs saisies dans lacolonne Valeur de la grille.
Inclus (<=). Les observations contenant la valeur spécifiée dans la cellule Valeur sont inclusesdans la modalité regroupée par casiers. Par exemple, si vous spécifiez les valeurs 25, 50 et 75,les observations dont la valeur est 25 seront placées dans le premier casier. En effet, ce casierinclut les observations dont les valeurs sont inférieures ou égales à 25.Exclu (<). Les observations contenant la valeur spécifiée dans la cellule Valeur ne sont pasincluses dans la modalité regroupée par casiers. Elles sont incluses dans le casier suivant. Parexemple, si vous spécifiez les valeurs 25, 50 et 75, les observations dont la valeur est 25 serontplacées dans le second casier. En effet, le premier casier inclut uniquement les observationsdont les valeurs sont inférieures à 25.
Créer des divisions : Génère automatiquement des modalités regroupées par casiers pour lesintervalles de longueur identique, les intervalles avec le même nombre d’observations ou lesintervalles basés sur les écarts-types. Cette option n’est disponible que si vous analysez au moinsune observation. Pour plus d'informations, reportez-vous à Génération automatique de modalitésregroupées par casiers sur p. 139.
Créer des étiquettes : Génère des étiquettes descriptives pour les valeurs entières séquentielles dela nouvelle variable regroupée par casiers, basées sur les valeurs se trouvant dans la grille et letraitement des extrema supérieurs (inclus ou exclus).
Inverser l’échelle : Par défaut, les valeurs de la nouvelle variable regroupée par casiers sont desvaleurs entières séquentielles croissantes comprise entre 1 et n. Inversez l’échelle pour que cesvaleurs deviennent des entiers séquentiels décroissants compris entre n et 1.
Copier les casiers : Vous pouvez copier les spécifications de regroupement par casiers à partir d’unevariable vers la variable sélectionnée ou à partir de la variable sélectionnée vers d’autres variables.Pour plus d'informations, reportez-vous à Copie de modalités regroupées par casiers sur p. 141.
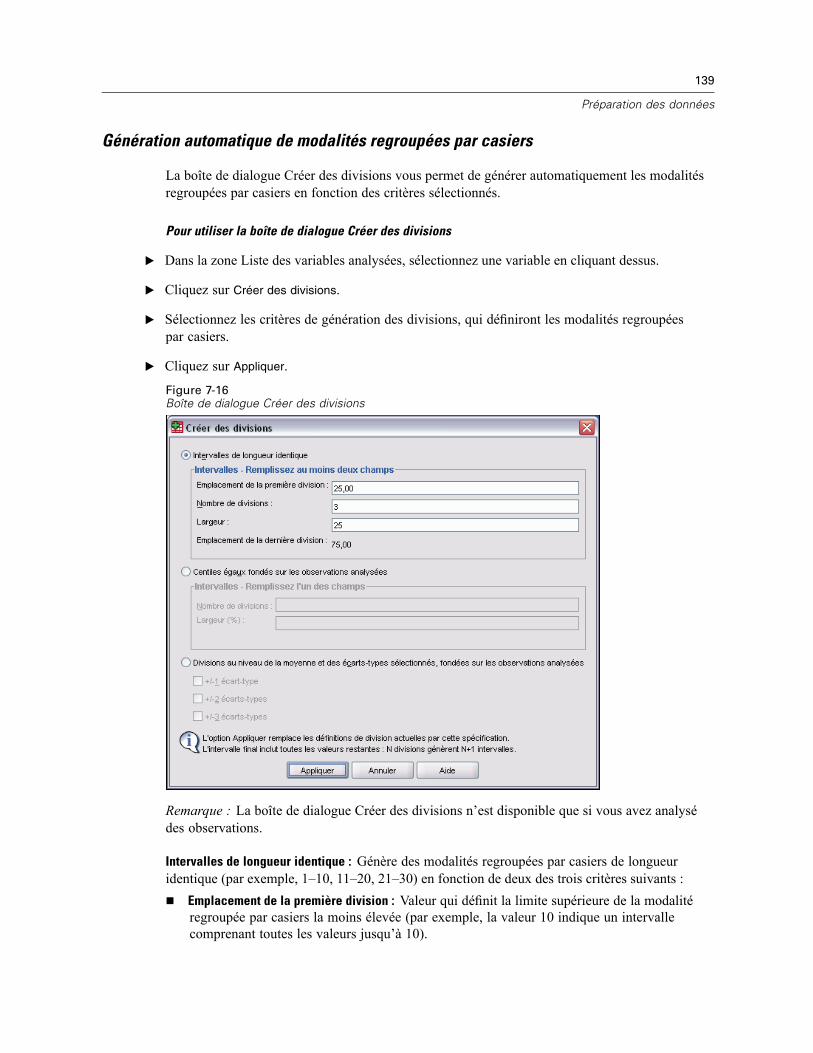
139
Préparation des données
Génération automatique de modalités regroupées par casiers
La boîte de dialogue Créer des divisions vous permet de générer automatiquement les modalitésregroupées par casiers en fonction des critères sélectionnés.
Pour utiliser la boîte de dialogue Créer des divisions
E Dans la zone Liste des variables analysées, sélectionnez une variable en cliquant dessus.
E Cliquez sur Créer des divisions.
E Sélectionnez les critères de génération des divisions, qui définiront les modalités regroupéespar casiers.
E Cliquez sur Appliquer.
Figure 7-16Boîte de dialogue Créer des divisions
Remarque : La boîte de dialogue Créer des divisions n’est disponible que si vous avez analysédes observations.
Intervalles de longueur identique : Génère des modalités regroupées par casiers de longueuridentique (par exemple, 1–10, 11–20, 21–30) en fonction de deux des trois critères suivants :
Emplacement de la première division : Valeur qui définit la limite supérieure de la modalitéregroupée par casiers la moins élevée (par exemple, la valeur 10 indique un intervallecomprenant toutes les valeurs jusqu’à 10).

140
Chapitre 7
Nombre de divisions : Le nombre de modalités regroupées par casiers correspond au nombre dedivisions, plus 1. Par exemple, 9 divisions génèrent 10 modalités regroupées par casiers.Largeur : Longueur de chaque intervalle. Par exemple, la valeur 10 regroupe les données d’âgeen années par casiers, par intervalles de 10 ans.
Centiles égaux fondés sur les observations analysées : Génère des modalités regroupées par casiersavec un nombre d’observations identique dans chaque casier (à l’aide de l’algorithme empiriquepour les centiles), en fonction de l’un des critères suivants :
Nombre de divisions : Le nombre de modalités regroupées par casiers correspond au nombre dedivisions, plus 1. Par exemple, trois divisions génèrent quatre casiers de centiles (quartiles),chacun contenant 25 % des observations.Largeur (%) : Longueur de chaque intervalle, exprimée en pourcentage du nombre total desobservations. Par exemple, la valeur 33,3 générerait trois modalités regroupées par casiers(deux divisions), chacune contenant 33,3 % des observations.
Si la variable source comporte peu de valeurs distinctes ou de nombreuses observations ayantla même valeur, vous risquez d’obtenir un nombre de casiers inférieur à celui requis. Si unedivision dispose de plusieurs valeurs identiques, ces dernières seront toutes placées dans le mêmeintervalle ; les pourcentages réels risquent donc de ne pas être strictement égaux.
Divisions au niveau de la moyenne et des écarts-types sélectionnés, fondées sur les observationsanalysées : Génère des modalités regroupées par casiers, basées sur les valeurs de la moyenne etde l’écart-type de la distribution de la variable.
Si vous ne sélectionnez pas les intervalles d’écarts-types, deux modalités regroupées parcasiers sont créées, la moyenne étant utilisée comme division entre les casiers.Vous pouvez sélectionner n’importe quelle combinaison d’intervalles d’écarts-types enutilisant un, deux et/ou trois écarts-types. Par exemple, si vous sélectionnez les trois, huitmodalités regroupées par casiers sont créées : six casiers dans un intervalle d’écarts-types,et deux casiers pour les observations supérieures ou inférieures à la moyenne de plus detrois écarts-types.
Dans une distribution normale, 68 % des observations sont comprises dans un écart-type dela moyenne, 95 %, dans deux écarts-types et 99 % dans trois écarts-types. Si la création demodalités regroupées par casiers est basée sur les écarts-types, certains casiers définis risquent dese retrouver hors de l’intervalle de données réel, voire hors de l’intervalle des valeurs possibles(par exemple, un intervalle de salaires négatif).
Remarque : Les calculs de centiles et d’écarts-types reposent sur les observations analysées. Sivous limitez le nombre d’observations analysées, les casiers obtenus risquent de ne pas contenir laproportion d’observations souhaitée, en particulier si le fichier de données est trié par variablesource. Par exemple, si vous limitez l’analyse aux 100 premières observations d’un fichier dedonnées contenant 1 000 observations et que ce fichier de données est trié dans l’ordre croissantde l’âge des répondants, vous n’obtiendrez pas quatre casiers d’âge en centiles contenant 25 % desobservations, mais plutôt trois casiers contenant chacun 3,3 % des observations et un quatrièmeen contenant 90 %.

141
Préparation des données
Copie de modalités regroupées par casiers
Si vous souhaitez créer des modalités regroupées par casiers pour plusieurs variables, vous pouvezcopier les spécifications du regroupement par casiers à partir d’une variable vers la variablesélectionnée ou à partir de la variable sélectionnée vers plusieurs variables.Figure 7-17Copie de casiers à partir de ou vers la variable actuelle
Pour copier les spécifications de regroupement par casiers
E Définissez des modalités regroupées par casiers pour une variable au moins (ne cliquez pas surOK ni sur Coller).
E Dans la zone Liste des variables analysées, cliquez sur une variable pour laquelle vous avezdéfini des modalités regroupées par casiers.
E Cliquez sur Vers d’autres variables.
E Sélectionnez les variables pour lesquelles créer des variables ayant les mêmes modalitésregroupées par casiers.
E Cliquez sur Copier.
ou
E Dans la zone Liste des variables analysées, cliquez sur la variable vers laquelle copier lesmodalités regroupées par casiers concernées.
E Cliquez sur A partir d’une autre variable.
E Sélectionnez la variable avec les modalités regroupées par casiers et définies à copier.
E Cliquez sur Copier.
Si vous avez spécifié des étiquettes de valeur pour la variable à partir de laquelle vous copiez lesspécifications de regroupement par casiers, ces étiquettes sont également copiées.

142
Chapitre 7
Remarque : Une fois que vous avez cliqué sur OK dans la boîte de dialogue principaleRegroupement visuel pour créer les variables regroupées par casiers (ou que vous avez fermé cetteboîte de dialogue d’une autre manière), vous ne pouvez pas utiliser le regroupement visuel pourcopier les modalités regroupées par casiers vers d’autres variables.
Valeurs manquantes spécifiées dans Regroupement visuel
Les valeurs définies comme valeurs manquantes spécifiées (valeurs identifiées comme codespour les données manquantes) pour la variable source ne sont pas incluses dans les modalitésregroupées par casiers de la nouvelle variable. Les valeurs manquantes utilisateur des variablessource sont copiées en tant que telles pour la nouvelle variable. Toutes les étiquettes de valeurdéfinies pour les codes de valeur manquante sont également copiées.Si un code de valeur manquante est en conflit avec l’une des valeurs de modalité regroupée
par casiers pour la nouvelle variable, le code de la valeur manquante de cette nouvelle variableest modifié : 100 est ajouté à la valeur la plus élevée de la modalité regroupée par casiers. Parexemple, si la valeur 1 est définie comme valeur manquante spécifiée de la variable source et quela nouvelle variable comporte six modalités regroupées par casiers, la valeur 106 de la nouvellevariable vient remplacer la valeur 1 de la variable source pour toutes les observations. Cette valeurdevient alors la nouvelle valeur manquante spécifiée par l’utilisateur. Si la valeur manquanteutilisateur de la variable source comporte une étiquette de valeur définie, cette dernière est utiliséecomme étiquette pour la valeur recodée de la nouvelle variable.
Remarque : Si la variable source comporte un intervalle défini de valeurs manquantes utilisateursous la forme LO-n (n étant un nombre positif), les valeurs manquantes utilisateur correspondantesde la nouvelle variable sont des nombres négatifs.

Chapitre
8Transformations de données
Dans une situation idéale, vos données brutes conviennent parfaitement pour le type d’analyseque vous désirez effectuer, et toute relation entre les variables est soit linéaire soit orthogonale.Malheureusement, c’est rarement le cas. L’analyse préliminaire peut révéler des schémas decodage peu pratiques ou des erreurs de codage, ou des transformations de données peuvents’avérer nécessaires pour déterminer la véritable relation entre les variables.Vous pouvez effectuer des transformations de données simples, comme la fusion de modalités
pour une analyse, ou des tâches plus évoluées, comme la création de nouvelles variables baséessur des équations complexes et des instructions conditionnelles.
Calcul de variables
Utilisez la boîte de dialogue Calculer pour calculer les valeurs d’une variable en fonction destransformations numériques d’autres variables.
Vous pouvez calculer les valeurs de variables numériques ou sous forme de chaîne decaractères (alphanumérique).Vous pouvez créer de nouvelles variables ou remplacer les valeurs de variables existantes.Dans le cas de nouvelles variables, vous pouvez aussi spécifier le type et l’étiquette.Vous pouvez calculer les valeurs de manière sélective pour des sous-ensembles de données enfonction de conditions logiques.Vous pouvez utiliser plus de 70 fonctions intégrées, dont des fonctions arithmétiques,statistiques, de distribution, et de chaîne.
143
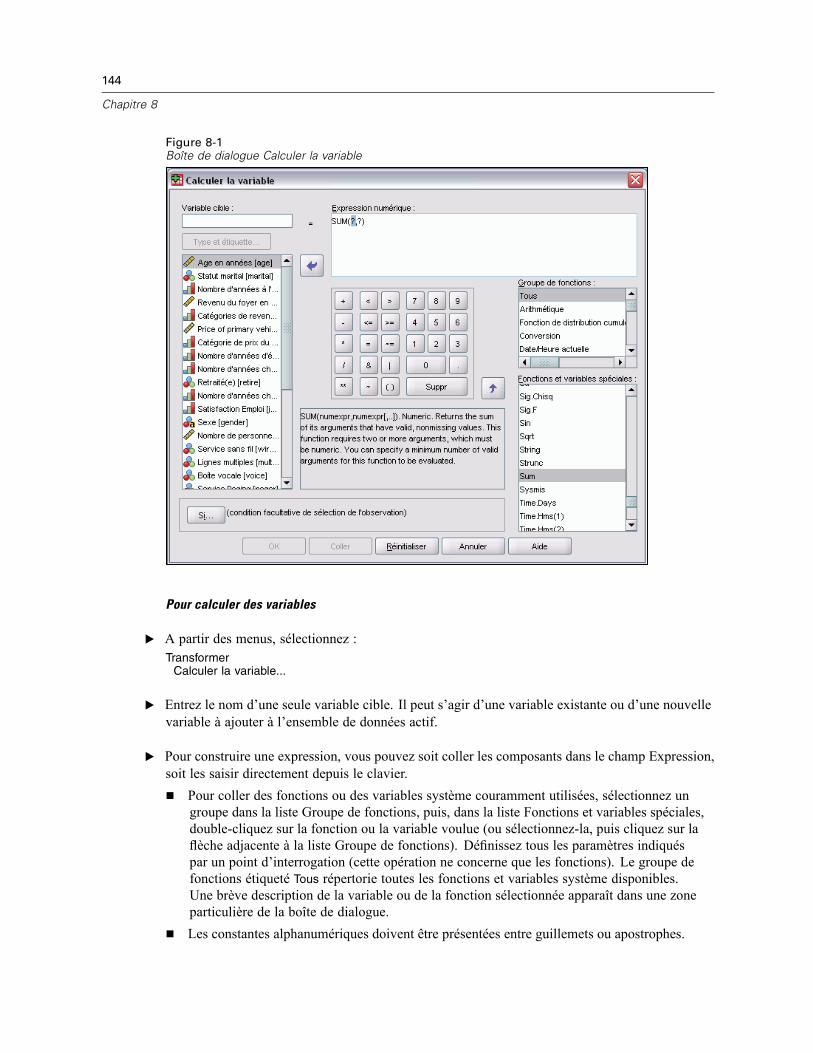
144
Chapitre 8
Figure 8-1Boîte de dialogue Calculer la variable
Pour calculer des variables
E A partir des menus, sélectionnez :Transformer
Calculer la variable...
E Entrez le nom d’une seule variable cible. Il peut s’agir d’une variable existante ou d’une nouvellevariable à ajouter à l’ensemble de données actif.
E Pour construire une expression, vous pouvez soit coller les composants dans le champ Expression,soit les saisir directement depuis le clavier.
Pour coller des fonctions ou des variables système couramment utilisées, sélectionnez ungroupe dans la liste Groupe de fonctions, puis, dans la liste Fonctions et variables spéciales,double-cliquez sur la fonction ou la variable voulue (ou sélectionnez-la, puis cliquez sur laflèche adjacente à la liste Groupe de fonctions). Définissez tous les paramètres indiquéspar un point d’interrogation (cette opération ne concerne que les fonctions). Le groupe defonctions étiqueté Tous répertorie toutes les fonctions et variables système disponibles.Une brève description de la variable ou de la fonction sélectionnée apparaît dans une zoneparticulière de la boîte de dialogue.Les constantes alphanumériques doivent être présentées entre guillemets ou apostrophes.
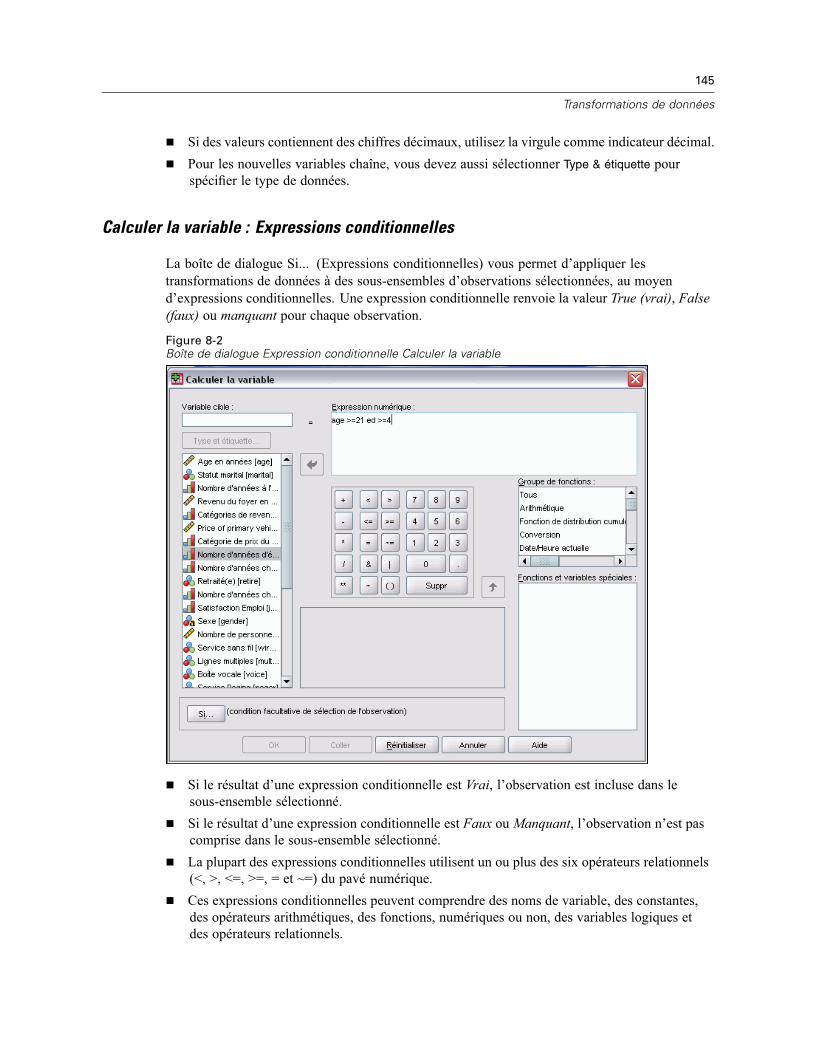
145
Transformations de données
Si des valeurs contiennent des chiffres décimaux, utilisez la virgule comme indicateur décimal.Pour les nouvelles variables chaîne, vous devez aussi sélectionner Type & étiquette pourspécifier le type de données.
Calculer la variable : Expressions conditionnelles
La boîte de dialogue Si... (Expressions conditionnelles) vous permet d’appliquer lestransformations de données à des sous-ensembles d’observations sélectionnées, au moyend’expressions conditionnelles. Une expression conditionnelle renvoie la valeur True (vrai), False(faux) ou manquant pour chaque observation.
Figure 8-2Boîte de dialogue Expression conditionnelle Calculer la variable
Si le résultat d’une expression conditionnelle est Vrai, l’observation est incluse dans lesous-ensemble sélectionné.Si le résultat d’une expression conditionnelle est Faux ou Manquant, l’observation n’est pascomprise dans le sous-ensemble sélectionné.La plupart des expressions conditionnelles utilisent un ou plus des six opérateurs relationnels(<, >, <=, >=, = et ~=) du pavé numérique.Ces expressions conditionnelles peuvent comprendre des noms de variable, des constantes,des opérateurs arithmétiques, des fonctions, numériques ou non, des variables logiques etdes opérateurs relationnels.

146
Chapitre 8
Calculer la variable : Type et étiquette
Par défaut, les nouvelles variables calculées sont numériques. Pour calculer une nouvelle variablechaîne, vous devez spécifier le type de données et sa longueur.
Etiquette : Facultatif, la longueur de l’étiquette de variable descriptive est de 255 octets maximum.Vous pouvez saisir une étiquette ou utiliser les premiers 110 caractères de l’expression de calculcomme étiquette.
Type : Les variables calculées peuvent être numériques ou alphanumériques. Les variables chaînene peuvent être utilisées dans des calculs.
Figure 8-3Boîte de dialogue Calculer la variable : Type et étiquette
Fonctions
Plusieurs types de fonctions sont prises en charge, y compris :Fonctions arithmétiquesFonctions statistiquesFonctions sur chaînesLes fonctions date et heureFonctions de distributionLes fonctions de variable aléatoireLes fonctions de valeur manquanteFonctions d’analyse (serveur SPSS Statistics uniquement)
Pour plus d’informations et pour obtenir une description détaillée de chaque fonction, tapezfonctions dans l’onglet Index du système d’aide.

147
Transformations de données
Valeurs manquantes dans les fonctions
Les fonctions et les expressions arithmétiques simples traitent les valeurs manquantes de manièredifférente. Dans l’expression :
(var1+var2+var3)/3
le résultat est manquant s’il manque une valeur dans l’une des trois variables d’une observation.
Dans l’expression :
MEAN(var1, var2, var3)
le résultat ne manque que si les valeurs des trois variables manquent dans l’observation.
Pour les fonctions statistiques, vous pouvez spécifier le nombre minimal d’arguments necomportant pas de valeurs manquantes. Pour ce faire, tapez un point et le nombre minimal après lenom de la fonction, comme suit :
MEAN.2(var1, var2, var3)
Générateurs de nombres aléatoires
La boîte de dialogue Générateurs de nombres aléatoires vous permet de sélectionner le générateurde nombres aléatoires et de définir la valeur de la séquence initiale afin que vous puissiezreproduire une séquence de nombres aléatoires.
Générateur actif. Deux types de générateur de nombres aléatoires sont disponibles :Compatible Version 12. Générateur de nombres aléatoires utilisé dans la version 12 et lesversions précédentes. Si vous avez besoin de reproduire des résultats aléatoires générésdans des versions précédentes sur la base d'une valeur de générateur spécifiée, utilisez cegénérateur de nombres aléatoires.Mersenne Twister. Générateur de nombres aléatoires plus récent et plus fiable pour lessimulations. Si la reproduction de résultats aléatoires à partir de SPSS 12 ou d'une versionantérieure n'est pas un problème, utilisez ce générateur de nombres aléatoires.
Initialisation du générateur actif. Le nombre aléatoire change chaque fois qu’ un nombre aléatoireest généré pour être utilisé dans des transformations (telles que les fonctions de distributionaléatoire), un échantillonnage aléatoire ou une pondération d’observation. Pour répliquer uneséquence de nombres aléatoires, définissez la valeur du point de départ de l’initialisation avantchaque analyse utilisant les nombres aléatoires. Il doit s’agir d’un nombre entier positif.
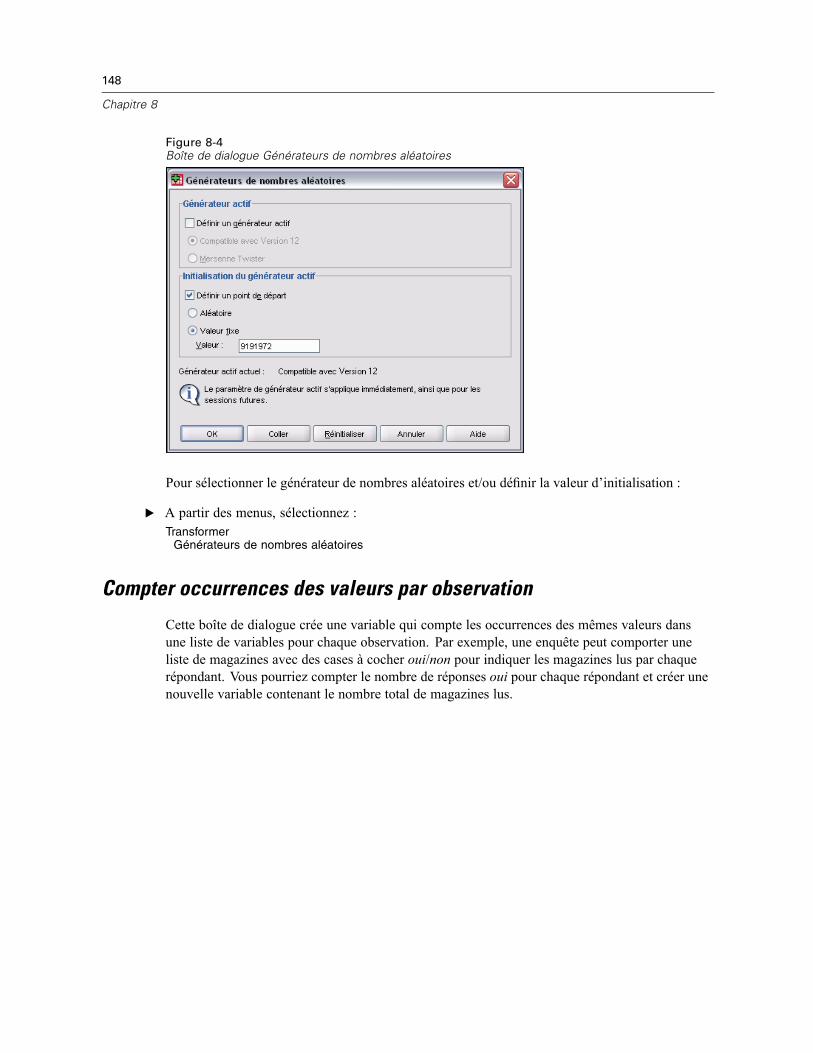
148
Chapitre 8
Figure 8-4Boîte de dialogue Générateurs de nombres aléatoires
Pour sélectionner le générateur de nombres aléatoires et/ou définir la valeur d’initialisation :
E A partir des menus, sélectionnez :Transformer
Générateurs de nombres aléatoires
Compter occurrences des valeurs par observation
Cette boîte de dialogue crée une variable qui compte les occurrences des mêmes valeurs dansune liste de variables pour chaque observation. Par exemple, une enquête peut comporter uneliste de magazines avec des cases à cocher oui/non pour indiquer les magazines lus par chaquerépondant. Vous pourriez compter le nombre de réponses oui pour chaque répondant et créer unenouvelle variable contenant le nombre total de magazines lus.
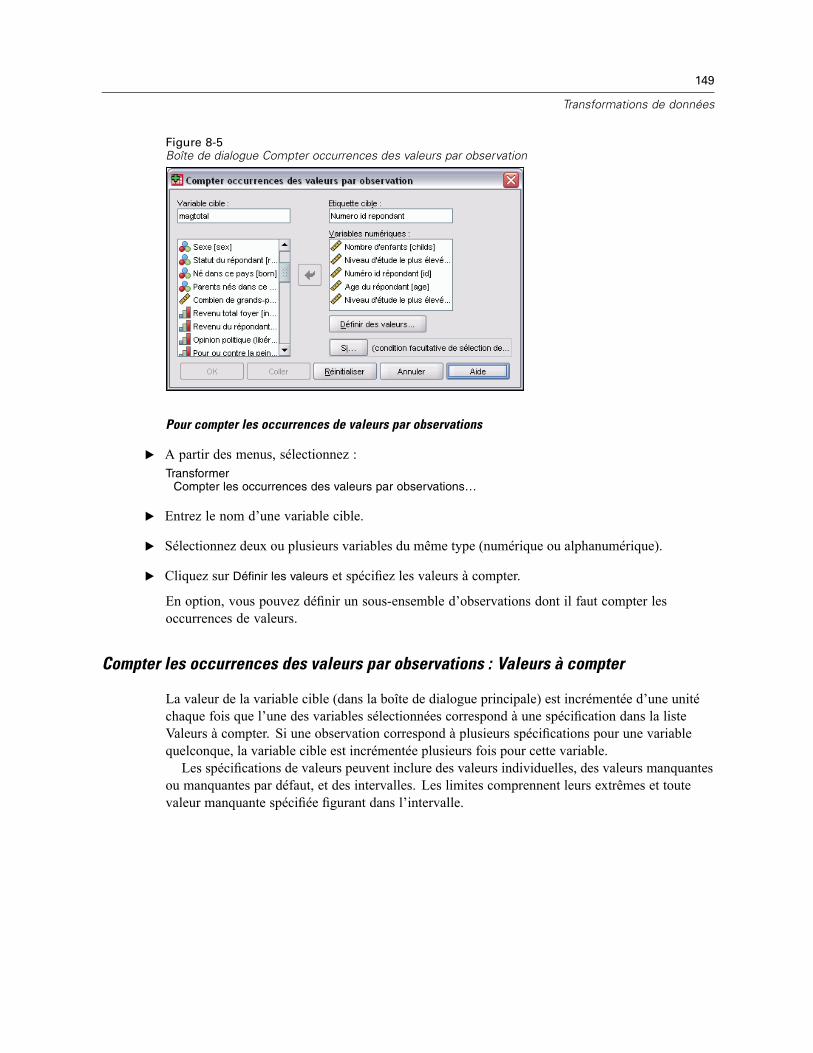
149
Transformations de données
Figure 8-5Boîte de dialogue Compter occurrences des valeurs par observation
Pour compter les occurrences de valeurs par observations
E A partir des menus, sélectionnez :Transformer
Compter les occurrences des valeurs par observations…
E Entrez le nom d’une variable cible.
E Sélectionnez deux ou plusieurs variables du même type (numérique ou alphanumérique).
E Cliquez sur Définir les valeurs et spécifiez les valeurs à compter.
En option, vous pouvez définir un sous-ensemble d’observations dont il faut compter lesoccurrences de valeurs.
Compter les occurrences des valeurs par observations : Valeurs à compter
La valeur de la variable cible (dans la boîte de dialogue principale) est incrémentée d’une unitéchaque fois que l’une des variables sélectionnées correspond à une spécification dans la listeValeurs à compter. Si une observation correspond à plusieurs spécifications pour une variablequelconque, la variable cible est incrémentée plusieurs fois pour cette variable.Les spécifications de valeurs peuvent inclure des valeurs individuelles, des valeurs manquantes
ou manquantes par défaut, et des intervalles. Les limites comprennent leurs extrêmes et toutevaleur manquante spécifiée figurant dans l’intervalle.
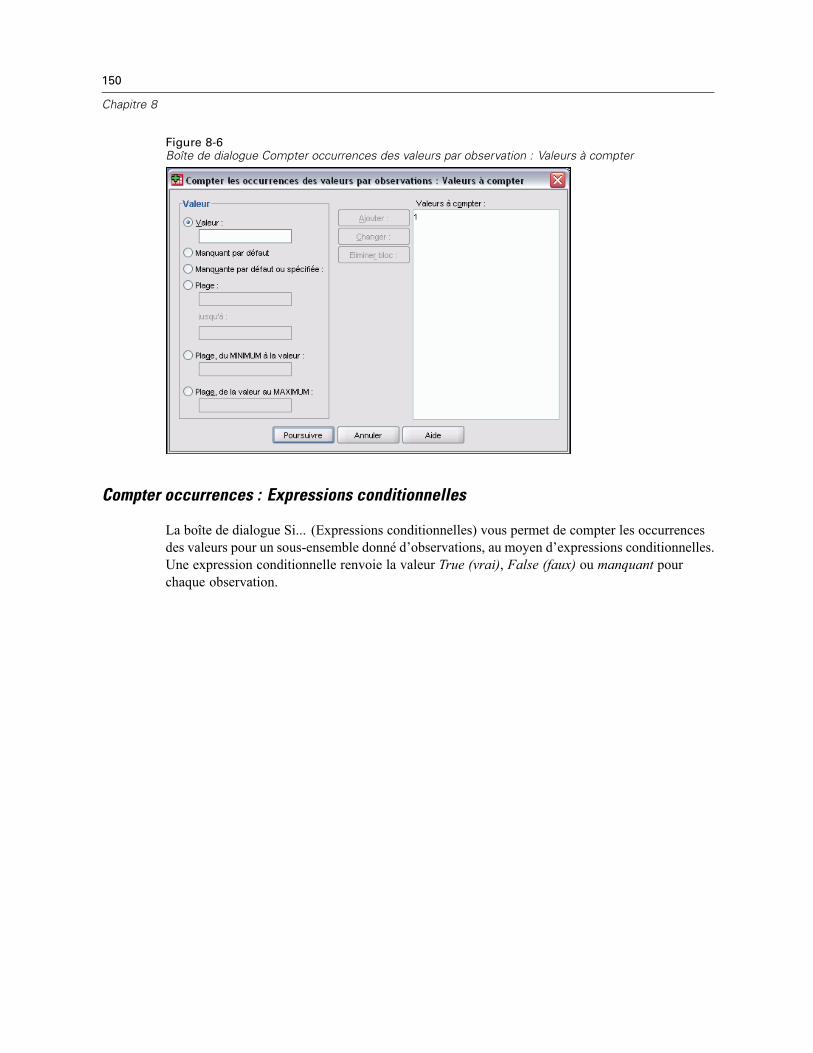
150
Chapitre 8
Figure 8-6Boîte de dialogue Compter occurrences des valeurs par observation : Valeurs à compter
Compter occurrences : Expressions conditionnelles
La boîte de dialogue Si... (Expressions conditionnelles) vous permet de compter les occurrencesdes valeurs pour un sous-ensemble donné d’observations, au moyen d’expressions conditionnelles.Une expression conditionnelle renvoie la valeur True (vrai), False (faux) ou manquant pourchaque observation.
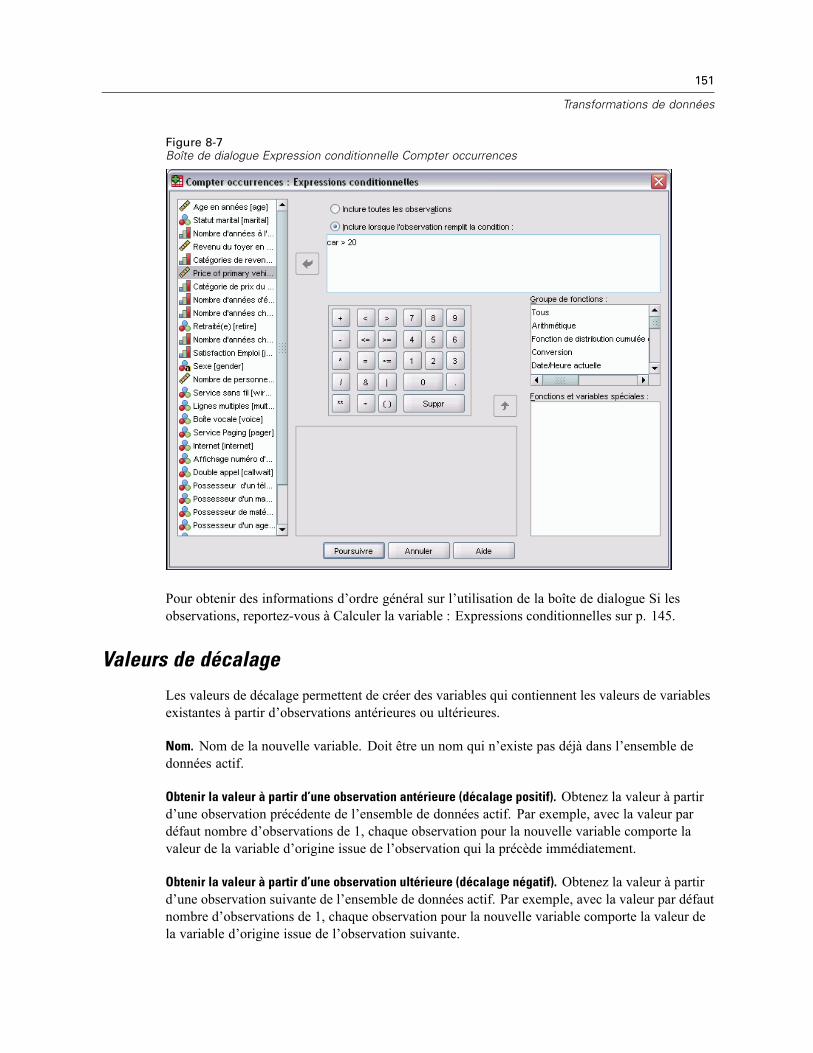
151
Transformations de données
Figure 8-7Boîte de dialogue Expression conditionnelle Compter occurrences
Pour obtenir des informations d’ordre général sur l’utilisation de la boîte de dialogue Si lesobservations, reportez-vous à Calculer la variable : Expressions conditionnelles sur p. 145.
Valeurs de décalage
Les valeurs de décalage permettent de créer des variables qui contiennent les valeurs de variablesexistantes à partir d’observations antérieures ou ultérieures.
Nom. Nom de la nouvelle variable. Doit être un nom qui n’existe pas déjà dans l’ensemble dedonnées actif.
Obtenir la valeur à partir d’une observation antérieure (décalage positif). Obtenez la valeur à partird’une observation précédente de l’ensemble de données actif. Par exemple, avec la valeur pardéfaut nombre d’observations de 1, chaque observation pour la nouvelle variable comporte lavaleur de la variable d’origine issue de l’observation qui la précède immédiatement.
Obtenir la valeur à partir d’une observation ultérieure (décalage négatif). Obtenez la valeur à partird’une observation suivante de l’ensemble de données actif. Par exemple, avec la valeur par défautnombre d’observations de 1, chaque observation pour la nouvelle variable comporte la valeur dela variable d’origine issue de l’observation suivante.

152
Chapitre 8
Nombre d’observations à décaler. Obtenez la valeur à partir de la nième observation antérieure ouultérieure, où n est la valeur indiquée. Cette valeur doit être un nombre entier non négatif.
Si le traitement du fichier scindé est activé, l’étendue du décalage se limite à chaque groupescindé. Une valeur de décalage ne peut pas être obtenue à partir d’une observation d’ungroupe scindé antérieur ou ultérieur.L’état du filtre est ignoré.La valeur de la variable de résultat est définie sur manquante par défaut pour les premièresou les dernières nièmes observations de l’ensemble de données ou du groupe scindé, où nest la valeur indiquée pour Nombre d’observations à décaler. Par exemple, l’utilisation de laméthode Décalage positif avec une valeur de 1 définit la variable de résultat sur une valeurmanquante par défaut pour la première observation de l’ensemble de données (ou premièreobservation de chaque groupe scindé).Les valeurs manquantes spécifiées par l’utilisateur sont conservées.Les informations du dictionnaire provenant de la variable d’origine, dont les étiquettes devaleurs définies et les affectations de valeurs manquantes utilisateur, sont appliquées à lanouvelle variable. (Remarque : Les attributs de variable personnalisés ne sont pas inclus).Une étiquette de variable est automatiquement générée pour la nouvelle variable qui décritl’opération de décalage qui l’a créée.
Pour créer une variable avec des valeurs décalées
E A partir du menu, sélectionnez :Transformer
Valeurs de décalage
E Sélectionnez la variable à utiliser comme source de valeurs pour la nouvelle variable.
E Entrez le nom de la nouvelle variable.
E Sélectionnez la méthode de décalage (positif ou négatif) et le nombre d’observations à décaler.
E Cliquez sur Changer.
E Répétez l’opération pour chaque variable à créer.
Recodage de valeurs
Vous pouvez modifier les valeurs de données en les recodant. Ceci est particulièrement utile pourfusionner des modalités ou les combiner. Vous pouvez recoder les valeurs à l’intérieur de variablesexistantes ou créer des variables sur la base des valeurs recodées de variables existantes.
Recodage de variables
La boîte de dialogue Recodage de variables vous permet de réaffecter les valeurs de variablesexistantes ou de fusionner des intervalles de valeurs existantes dans de nouvelles valeurs. Parexemple, vous pourriez fusionner des salaires dans des modalités d’intervalles de salaires.
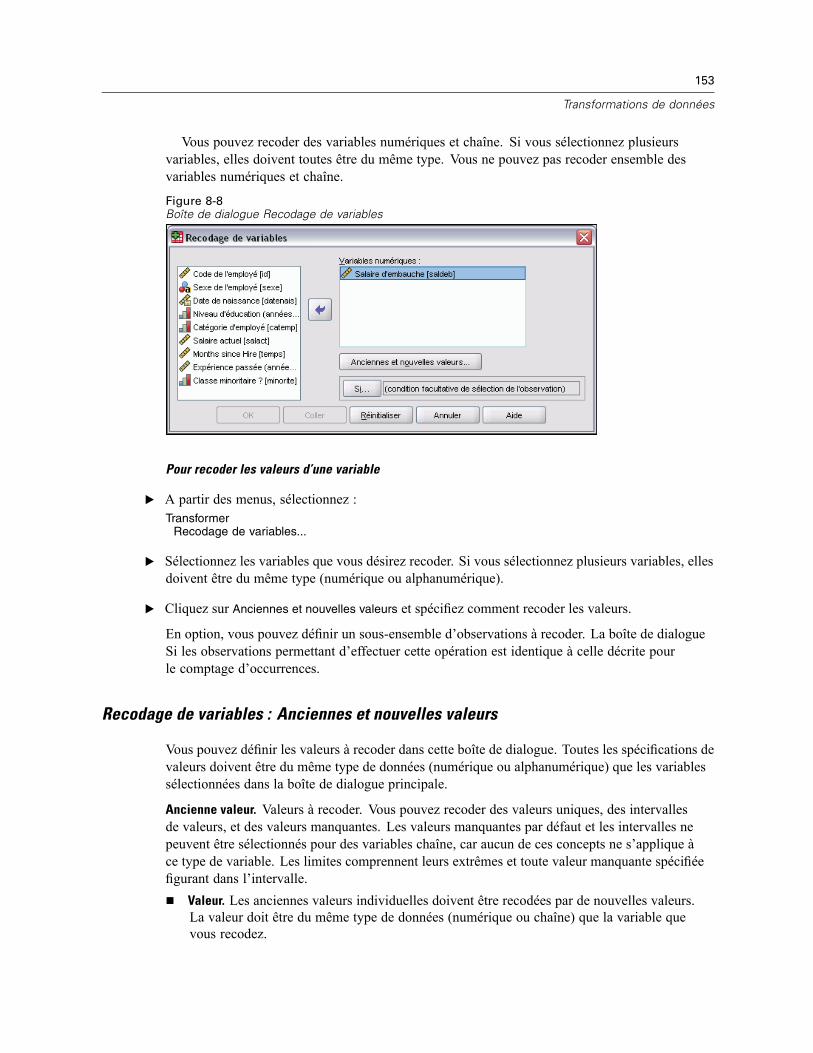
153
Transformations de données
Vous pouvez recoder des variables numériques et chaîne. Si vous sélectionnez plusieursvariables, elles doivent toutes être du même type. Vous ne pouvez pas recoder ensemble desvariables numériques et chaîne.
Figure 8-8Boîte de dialogue Recodage de variables
Pour recoder les valeurs d’une variable
E A partir des menus, sélectionnez :Transformer
Recodage de variables...
E Sélectionnez les variables que vous désirez recoder. Si vous sélectionnez plusieurs variables, ellesdoivent être du même type (numérique ou alphanumérique).
E Cliquez sur Anciennes et nouvelles valeurs et spécifiez comment recoder les valeurs.
En option, vous pouvez définir un sous-ensemble d’observations à recoder. La boîte de dialogueSi les observations permettant d’effectuer cette opération est identique à celle décrite pourle comptage d’occurrences.
Recodage de variables : Anciennes et nouvelles valeurs
Vous pouvez définir les valeurs à recoder dans cette boîte de dialogue. Toutes les spécifications devaleurs doivent être du même type de données (numérique ou alphanumérique) que les variablessélectionnées dans la boîte de dialogue principale.
Ancienne valeur. Valeurs à recoder. Vous pouvez recoder des valeurs uniques, des intervallesde valeurs, et des valeurs manquantes. Les valeurs manquantes par défaut et les intervalles nepeuvent être sélectionnés pour des variables chaîne, car aucun de ces concepts ne s’applique àce type de variable. Les limites comprennent leurs extrêmes et toute valeur manquante spécifiéefigurant dans l’intervalle.
Valeur. Les anciennes valeurs individuelles doivent être recodées par de nouvelles valeurs.La valeur doit être du même type de données (numérique ou chaîne) que la variable quevous recodez.

154
Chapitre 8
Manquant par défaut. Valeurs affectées par le programme lorsque certaines valeurs de vosdonnées sont non définies d'après le type de format spécifié, lorsqu'un champ numérique estvide ou lorsqu'une valeur résultant d'une commande de transformation n'est pas définie. Lesvaleurs manquantes par défaut numériques sont affichées sous forme de points. Les variableschaîne ne peuvent pas comporter de valeurs manquantes par défaut, puisqu'elles acceptenttous les caractères.Manquante par défaut ou spécifiée. Observations comportant des valeurs définies commevaleurs manquantes par défaut, ou comportant des valeurs inconnues et auxquelles ont étéattribuées des valeurs par défaut, comme l'indique le point (.).Intervalle. Intervalle de valeurs inclusif. Non disponible pour les variables de chaîne. Lesvaleurs manquantes spécifiées comprises dans l'intervalle sont prises en compte.Toutes les autres valeurs. Toute autre valeur restante non incluse dans l'une des spécificationsde la liste Ancienne-Nouvelle. Apparaît sous l'intitulé ELSE dans la liste Ancienne-Nouvelle.
Nouvelle valeur. Valeur unique en laquelle chaque ancienne valeur ou intervalle de valeurs estrecodé. Vous pouvez entrer une valeur ou la valeur manquante par défaut.
Valeur. Valeur dans laquelle une ou plusieurs valeurs anciennes devront être recodées. Lavaleur doit être du même type de données (numérique ou chaîne) que l'ancienne variable.Manquant par défaut. Recode les anciennes valeurs spécifiées en valeurs manquantes pardéfaut. Les valeurs manquantes par défaut ne sont pas utilisées dans les calculs, et lesobservations avec des valeurs manquantes par défaut sont exclues de nombreuses procédures.Non disponible pour les variables de chaîne.
Ancienne–>Nouvelle. Liste les spécifications qui seront utilisées pour recoder la ou les variables.Vous pouvez ajouter, modifier et supprimer des spécifications dans la liste. La liste est triéeautomatiquement, en fonction de la spécification de l’ancienne valeur, selon l’ordre suivant :valeurs uniques, valeurs manquantes, intervalles, puis toutes les autres valeurs. Si vous changezune spécification de recodage dans la liste, la procédure trie de nouveau la liste automatiquement,si nécessaire, pour conserver cet ordre.
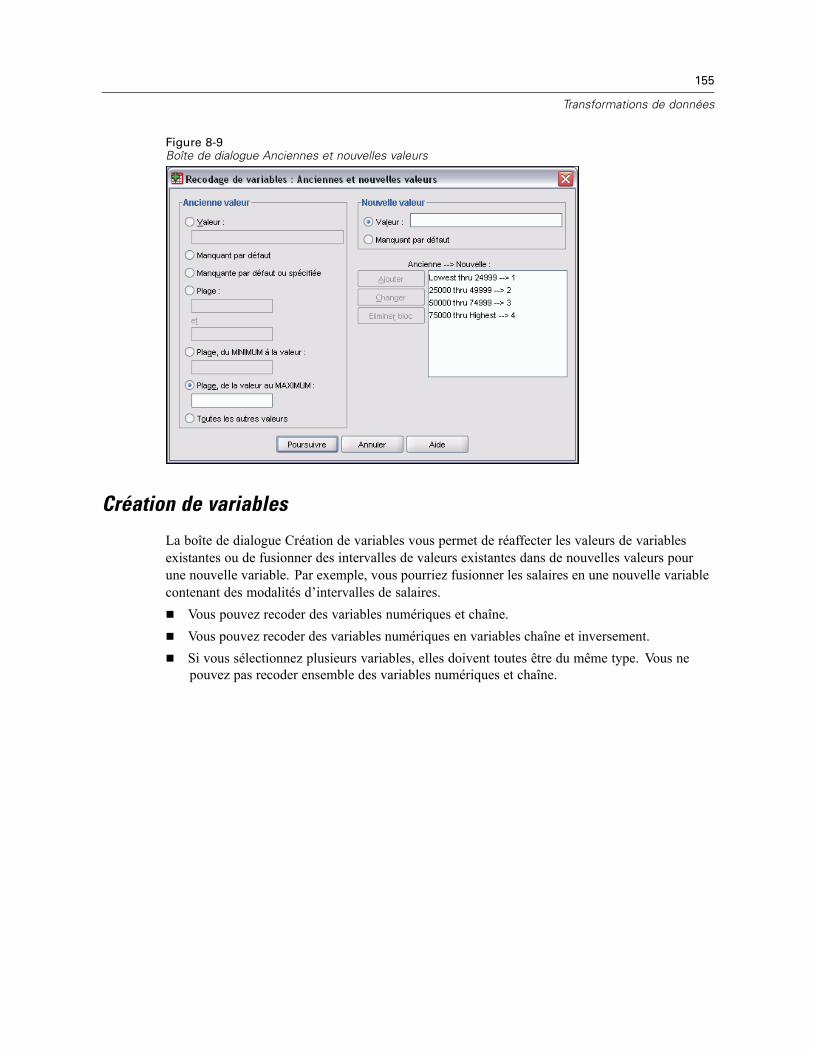
155
Transformations de données
Figure 8-9Boîte de dialogue Anciennes et nouvelles valeurs
Création de variables
La boîte de dialogue Création de variables vous permet de réaffecter les valeurs de variablesexistantes ou de fusionner des intervalles de valeurs existantes dans de nouvelles valeurs pourune nouvelle variable. Par exemple, vous pourriez fusionner les salaires en une nouvelle variablecontenant des modalités d’intervalles de salaires.
Vous pouvez recoder des variables numériques et chaîne.Vous pouvez recoder des variables numériques en variables chaîne et inversement.Si vous sélectionnez plusieurs variables, elles doivent toutes être du même type. Vous nepouvez pas recoder ensemble des variables numériques et chaîne.
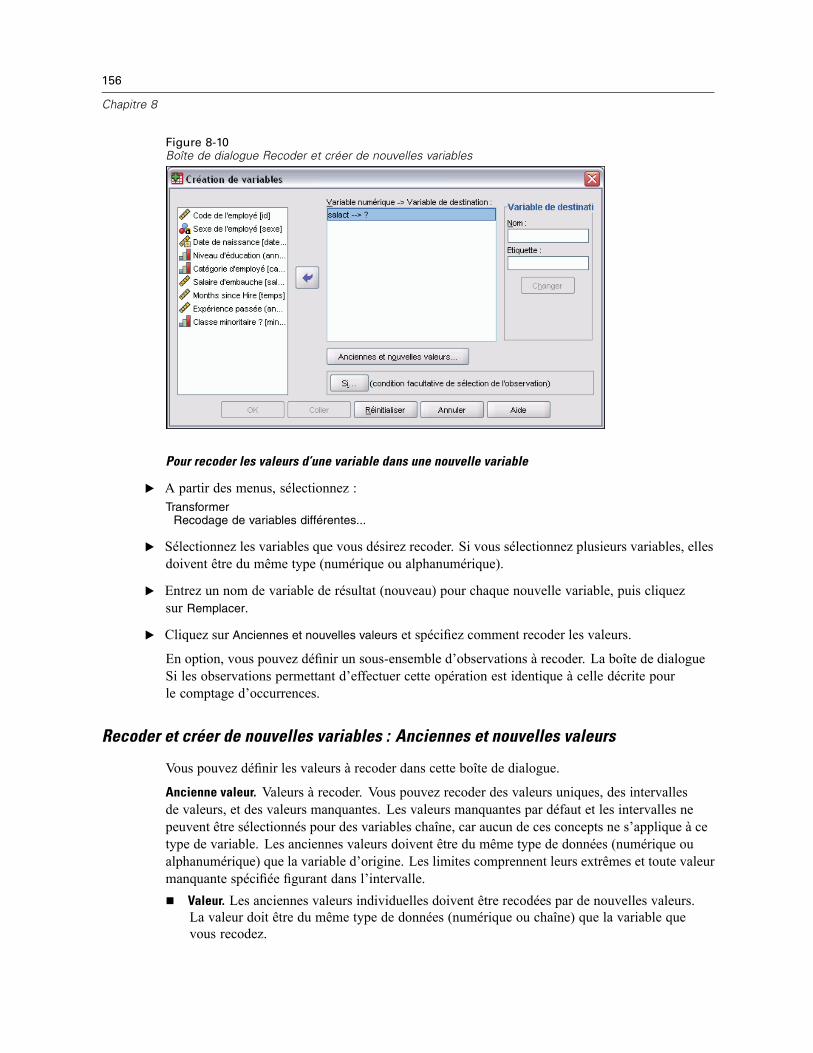
156
Chapitre 8
Figure 8-10Boîte de dialogue Recoder et créer de nouvelles variables
Pour recoder les valeurs d’une variable dans une nouvelle variable
E A partir des menus, sélectionnez :Transformer
Recodage de variables différentes...
E Sélectionnez les variables que vous désirez recoder. Si vous sélectionnez plusieurs variables, ellesdoivent être du même type (numérique ou alphanumérique).
E Entrez un nom de variable de résultat (nouveau) pour chaque nouvelle variable, puis cliquezsur Remplacer.
E Cliquez sur Anciennes et nouvelles valeurs et spécifiez comment recoder les valeurs.
En option, vous pouvez définir un sous-ensemble d’observations à recoder. La boîte de dialogueSi les observations permettant d’effectuer cette opération est identique à celle décrite pourle comptage d’occurrences.
Recoder et créer de nouvelles variables : Anciennes et nouvelles valeurs
Vous pouvez définir les valeurs à recoder dans cette boîte de dialogue.
Ancienne valeur. Valeurs à recoder. Vous pouvez recoder des valeurs uniques, des intervallesde valeurs, et des valeurs manquantes. Les valeurs manquantes par défaut et les intervalles nepeuvent être sélectionnés pour des variables chaîne, car aucun de ces concepts ne s’applique à cetype de variable. Les anciennes valeurs doivent être du même type de données (numérique oualphanumérique) que la variable d’origine. Les limites comprennent leurs extrêmes et toute valeurmanquante spécifiée figurant dans l’intervalle.
Valeur. Les anciennes valeurs individuelles doivent être recodées par de nouvelles valeurs.La valeur doit être du même type de données (numérique ou chaîne) que la variable quevous recodez.

157
Transformations de données
Manquant par défaut. Valeurs affectées par le programme lorsque certaines valeurs de vosdonnées sont non définies d'après le type de format spécifié, lorsqu'un champ numérique estvide ou lorsqu'une valeur résultant d'une commande de transformation n'est pas définie. Lesvaleurs manquantes par défaut numériques sont affichées sous forme de points. Les variableschaîne ne peuvent pas comporter de valeurs manquantes par défaut, puisqu'elles acceptenttous les caractères.Manquante par défaut ou spécifiée. Observations comportant des valeurs définies commevaleurs manquantes par défaut, ou comportant des valeurs inconnues et auxquelles ont étéattribuées des valeurs par défaut, comme l'indique le point (.).Intervalle. Intervalle de valeurs inclusif. Non disponible pour les variables de chaîne. Lesvaleurs manquantes spécifiées comprises dans l'intervalle sont prises en compte.Toutes les autres valeurs. Toute autre valeur restante non incluse dans l'une des spécificationsde la liste Ancienne-Nouvelle. Apparaît sous l'intitulé ELSE dans la liste Ancienne-Nouvelle.
Nouvelle valeur. Valeur unique en laquelle chaque ancienne valeur ou intervalle de valeurs estrecodé. Les nouvelles valeurs peuvent être numériques ou alphanumériques.
Valeur. Valeur dans laquelle une ou plusieurs valeurs anciennes devront être recodées. Lavaleur doit être du même type de données (numérique ou chaîne) que l'ancienne variable.Manquant par défaut. Recode les anciennes valeurs spécifiées en valeurs manquantes pardéfaut. Les valeurs manquantes par défaut ne sont pas utilisées dans les calculs, et lesobservations avec des valeurs manquantes par défaut sont exclues de nombreuses procédures.Non disponible pour les variables de chaîne.Copier les anciennes valeurs. Conserve l'anciennes valeur. Si certaines valeurs n'ont pas besoind'être recodées, utilisez cette option pour inclure les anciennes valeurs. Toute ancienne valeurnon spécifiée n'est pas incluse dans la nouvelle variable, et les observations avec ces valeursse verront affecter la valeur manquante par défaut de la nouvelle variable.
Variables destination sont des chaînes. Définit la nouvelle variable recodée comme une variablechaîne (alphanumérique). L'ancienne variable peut être numérique ou chaîne.
Convertir les chaînes numériques en nombres. Convertit les variables de chaîne contenant deschiffres en valeurs numériques. Les chaînes de caractères contenant autre chose que des nombreset des signes (+ ou -) sont considérées comme des valeurs manquantes par défaut.
Ancienne–>Nouvelle. Liste les spécifications qui seront utilisées pour recoder la ou les variables.Vous pouvez ajouter, modifier et supprimer des spécifications dans la liste. La liste est triéeautomatiquement, en fonction de la spécification de l’ancienne valeur, selon l’ordre suivant :valeurs uniques, valeurs manquantes, intervalles, puis toutes les autres valeurs. Si vous changezune spécification de recodage dans la liste, la procédure trie de nouveau la liste automatiquement,si nécessaire, pour conserver cet ordre.
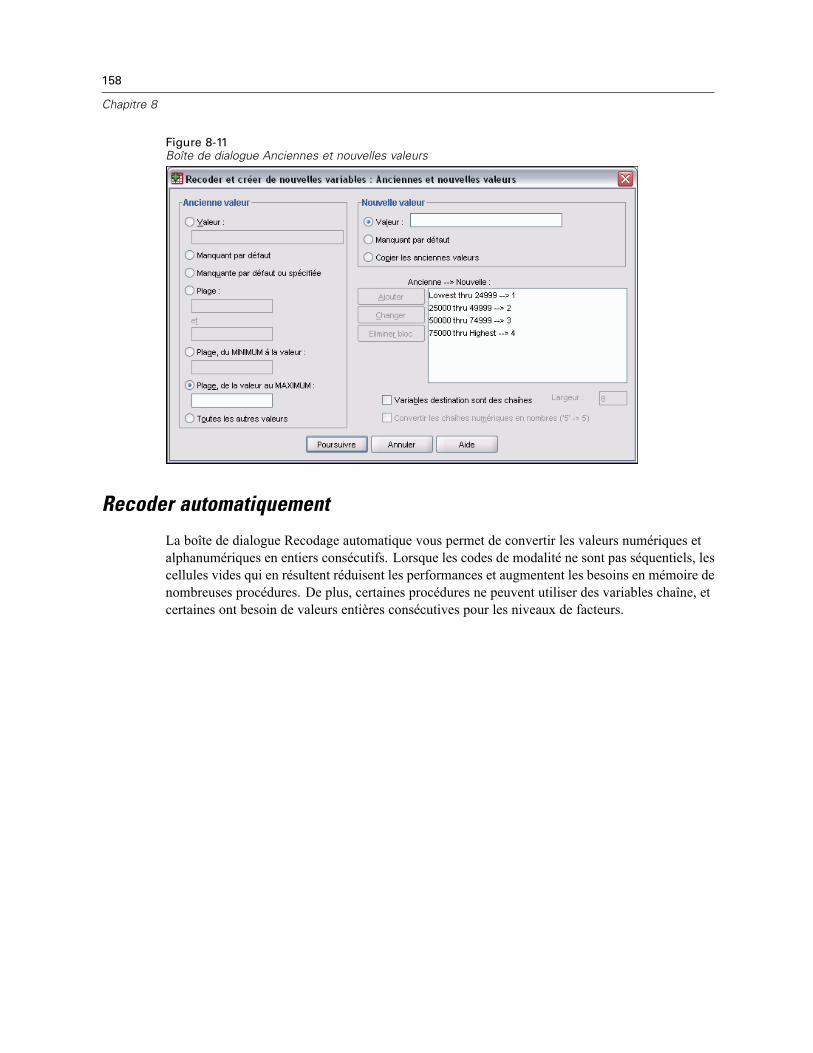
158
Chapitre 8
Figure 8-11Boîte de dialogue Anciennes et nouvelles valeurs
Recoder automatiquement
La boîte de dialogue Recodage automatique vous permet de convertir les valeurs numériques etalphanumériques en entiers consécutifs. Lorsque les codes de modalité ne sont pas séquentiels, lescellules vides qui en résultent réduisent les performances et augmentent les besoins en mémoire denombreuses procédures. De plus, certaines procédures ne peuvent utiliser des variables chaîne, etcertaines ont besoin de valeurs entières consécutives pour les niveaux de facteurs.
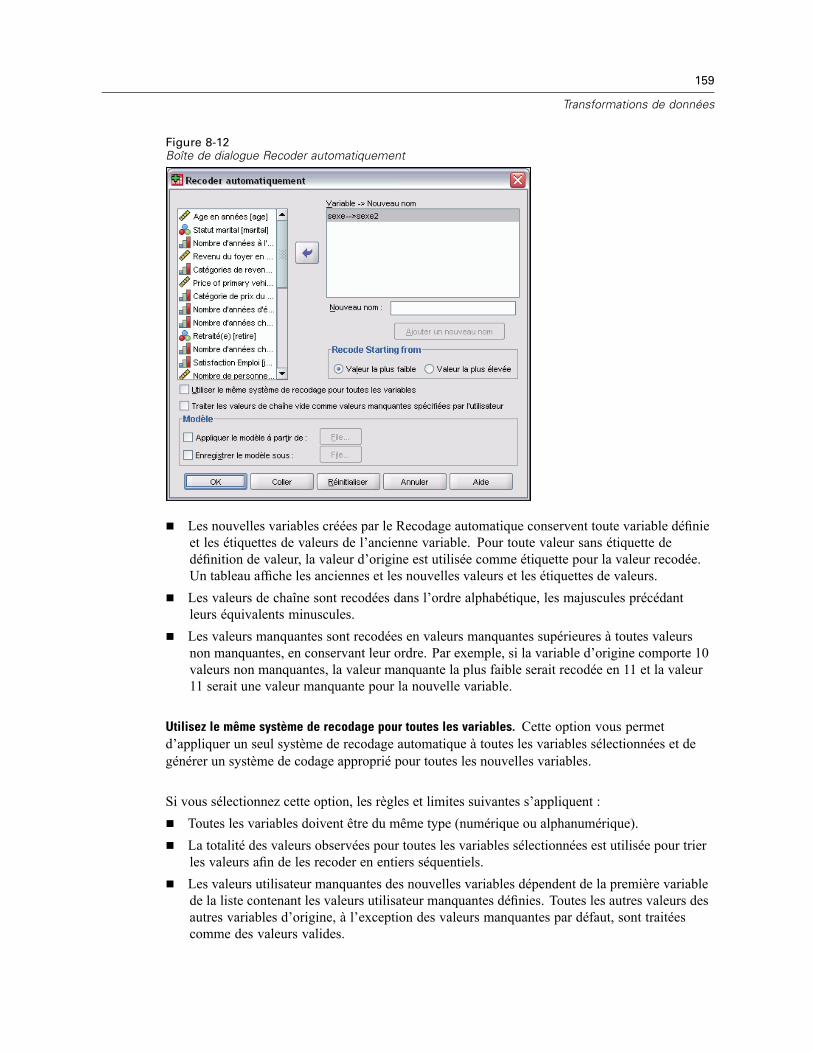
159
Transformations de données
Figure 8-12Boîte de dialogue Recoder automatiquement
Les nouvelles variables créées par le Recodage automatique conservent toute variable définieet les étiquettes de valeurs de l’ancienne variable. Pour toute valeur sans étiquette dedéfinition de valeur, la valeur d’origine est utilisée comme étiquette pour la valeur recodée.Un tableau affiche les anciennes et les nouvelles valeurs et les étiquettes de valeurs.Les valeurs de chaîne sont recodées dans l’ordre alphabétique, les majuscules précédantleurs équivalents minuscules.Les valeurs manquantes sont recodées en valeurs manquantes supérieures à toutes valeursnon manquantes, en conservant leur ordre. Par exemple, si la variable d’origine comporte 10valeurs non manquantes, la valeur manquante la plus faible serait recodée en 11 et la valeur11 serait une valeur manquante pour la nouvelle variable.
Utilisez le même système de recodage pour toutes les variables. Cette option vous permetd’appliquer un seul système de recodage automatique à toutes les variables sélectionnées et degénérer un système de codage approprié pour toutes les nouvelles variables.
Si vous sélectionnez cette option, les règles et limites suivantes s’appliquent :Toutes les variables doivent être du même type (numérique ou alphanumérique).La totalité des valeurs observées pour toutes les variables sélectionnées est utilisée pour trierles valeurs afin de les recoder en entiers séquentiels.Les valeurs utilisateur manquantes des nouvelles variables dépendent de la première variablede la liste contenant les valeurs utilisateur manquantes définies. Toutes les autres valeurs desautres variables d’origine, à l’exception des valeurs manquantes par défaut, sont traitéescomme des valeurs valides.

160
Chapitre 8
Traiter les valeurs de chaîne vide comme valeurs manquantes spécifiées par l’utilisateur. Pour lesvariables chaîne, les valeurs nulles ou vides ne sont pas traitées comme des valeursmanquantespar défaut. Cette option permet de recoder automatiquement une chaîne vide en une valeurmanquante spécifiée par l’utilisateur supérieure à la valeur non manquante la plus élevée.
Modèles
Vous pouvez enregistrer le système de recodage automatique dans un fichier de modèle, puisl’appliquer à d’autres variables et fichiers de données.Exemple : vous disposez d’un grand nombre de codes de produit alphanumériques que vous
recodez automatiquement en nombres entiers tous les mois. Toutefois, certains mois, de nouveauxcodes de produit sont ajoutés et le système de recodage automatique d’origine est modifié. Si vousenregistrez le système d’origine dans un modèle et que vous l’appliquez aux nouvelles donnéesqui contiennent le nouvel ensemble de codes, tous les nouveaux codes présents dans les donnéessont recodés automatiquement en valeurs supérieures à la dernière valeur du modèle. Le systèmede recodage automatique d’origine des codes de produit d’origine est ainsi conservé.
Enregistrer le modèle sous. Enregistre le système de recodage automatique des variablessélectionnées dans un fichier de modèle externe.
Le modèle contient des informations qui établissent une correspondance entre les valeurs nonmanquantes d’origine et les valeurs recodées.Seules les informations relatives aux valeurs non manquantes sont enregistrées dans le modèle.Les informations relatives aux valeurs utilisateur manquantes ne sont pas enregistrées.Si vous avez sélectionné plusieurs variables à recoder, mais que vous n’utilisez pas le mêmesystème de recodage automatique pour toutes les variables, ou que vous n’appliquez pas unmodèle existant lors du recodage automatique, le modèle dépend de la première variablede la liste.Si vous avez sélectionné plusieurs variables à recoder et Utiliser la même méthoded’enregistrement pour toutes les variables, et/ou que vous avez choisi Appliquer le modèle, lemodèle contient le système de recodage automatique combiné de toutes les variables.
Appliquer le modèle à partir de. Applique un modèle de recodage automatique déjà enregistré auxvariables sélectionnées pour le recodage, en ajoutant des valeurs supplémentaires de variables à lafin du système, et en conservant les relations entre les valeurs d’origine et les valeurs recodéesautomatiquement qui sont stockées dans le système enregistré.
Toutes les variables sélectionnées pour le recodage doivent être du même type (numérique oualphanumérique) et ce type doit correspondre à celui défini dans le modèle.Les modèles ne contiennent aucune information sur les valeurs utilisateur manquantes. Lesvaleurs utilisateur manquantes des variables cible dépendent de la première variable de laliste des variables d’origine contenant les valeurs utilisateur manquantes définies. Toutesles autres valeurs des autres variables d’origine, à l’exception des valeurs manquantes pardéfaut, sont traitées comme des valeurs valides.Les correspondances de valeurs du modèle sont appliquées en premier. Toutes les valeursrestantes sont recodées en valeurs supérieures à la dernière valeur du modèle, et les valeursutilisateur manquantes (qui dépendent de la première variable de la liste contenant les

161
Transformations de données
valeurs utilisateur manquantes définies) sont recodées en valeurs supérieures à la dernièrevaleur valide.Si vous avez sélectionné plusieurs variables pour le recodage automatique, le modèle estd’abord appliqué, suivi du recodage automatique combiné standard de toutes les valeurssupplémentaires détectées dans les variables sélectionnées. Un seul système de recodageautomatique standard est ainsi généré pour toutes les variables sélectionnées.
Pour recoder des variables numériques ou alphanumériques en nombres entiers consécutifs
E A partir des menus, sélectionnez :Transformer
Recoder automatiquement
E Sélectionnez des variables à recoder.
E Pour chaque variable sélectionnée, entrez un nom pour la nouvelle variable, puis cliquez surNouveau nom.
Ordonner les observations
La boîte de dialogue Ordonner les observations vous permet de créer de nouvelles variablescontenant des rangs, des scores normaux et de Savage, ainsi que des valeurs de centiles pourles variables numériques.De nouveaux noms de variables et des étiquettes de variable descriptives sont automatiquement
générées, en fonction du nom d’origine de la variable et des mesures sélectionnées. Un tableaurécapitulatif liste les variables d’origine, les nouvelles variables et les étiquettes de variable.
Sinon, vous pouvez :Ordonner les observations en ordre croissant ou décroissant.Séparez les rangs en sous-groupes en sélectionnant des variables de regroupement pour laliste Par. Les rangs sont calculés à l’intérieur de chaque groupe. Les groupes sont définis parcombinaison des valeurs des variables de regroupement. Par exemple, si vous sélectionnezsexe et minorité comme variables de regroupement, les rangs seront calculés pour chaquecombinaison de sexe et minorité.
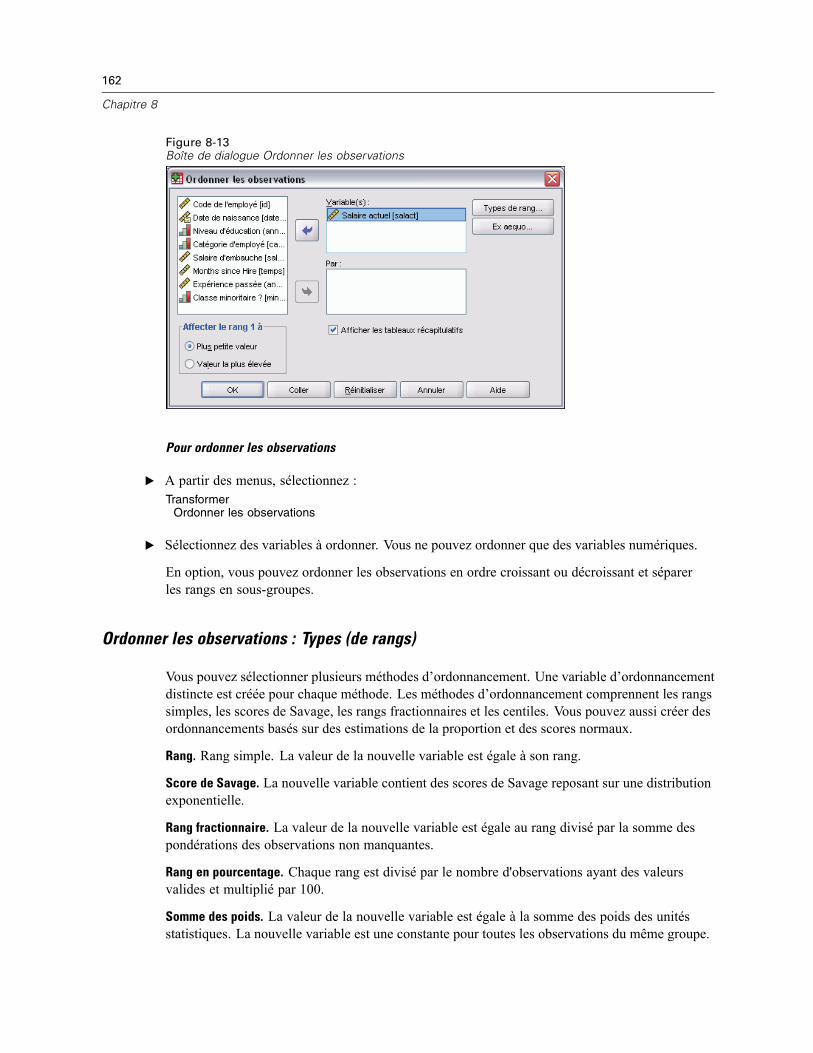
162
Chapitre 8
Figure 8-13Boîte de dialogue Ordonner les observations
Pour ordonner les observations
E A partir des menus, sélectionnez :Transformer
Ordonner les observations
E Sélectionnez des variables à ordonner. Vous ne pouvez ordonner que des variables numériques.
En option, vous pouvez ordonner les observations en ordre croissant ou décroissant et séparerles rangs en sous-groupes.
Ordonner les observations : Types (de rangs)
Vous pouvez sélectionner plusieurs méthodes d’ordonnancement. Une variable d’ordonnancementdistincte est créée pour chaque méthode. Les méthodes d’ordonnancement comprennent les rangssimples, les scores de Savage, les rangs fractionnaires et les centiles. Vous pouvez aussi créer desordonnancements basés sur des estimations de la proportion et des scores normaux.
Rang. Rang simple. La valeur de la nouvelle variable est égale à son rang.
Score de Savage. La nouvelle variable contient des scores de Savage reposant sur une distributionexponentielle.
Rang fractionnaire. La valeur de la nouvelle variable est égale au rang divisé par la somme despondérations des observations non manquantes.
Rang en pourcentage. Chaque rang est divisé par le nombre d'observations ayant des valeursvalides et multiplié par 100.
Somme des poids. La valeur de la nouvelle variable est égale à la somme des poids des unitésstatistiques. La nouvelle variable est une constante pour toutes les observations du même groupe.

163
Transformations de données
Fractiles. Les rangs sont basés sur des groupes de centiles, chaque groupe contenant à peu près lemême nombre d'observations. Par exemple, une spécification de 4 fractiles affectera une valeur de1 aux observations inférieures au 25e centile, de 2 à celles situées entre les 25e et 50e centiles, de3 à celles situées entre les 50e et 75e centiles, et de 4 à celles supérieures au 75e centile.
Estimations de la proportion. Estimations de la proportion cumulée de la distribution correspondantà un rang particulier.
Scores normaux. Ecarts z correspondant à la proportion cumulée estimée.
Formule d’estimation d’une proportion. Pour les estimations de la proportion et les scores normaux,vous pouvez sélectionner la formule d’estimation d’une proportion : Blom, Tukey, Rankit ouVan der Waerden.
Blom. Crée une variable d'ordonnancement sur la base des estimations de la proportion,qui utilise la formule (r-3/8) / (w+1/4), où r est le rang et w la somme des pondérationsd'observation.Tukey. Utilise la formule (r‑1/3) / (w+1/3), dans laquelle r est le rang et w la somme despondérations d'observation.Rankit. Utilise la formule (r‑1/2) / w. w représente le nombre d'observations et r le rang,de 1 à w.Van der Waerden. Transformation de Van der Waerden, définie par la formule r/(w+1), danslaquelle w est la somme des pondérations d'observation et r le rang, compris entre 1 et w.
Figure 8-14Boîte de dialogue Ordonner les observations : Types
Ordonner les observations : Ex aequo
Cette boîte de dialogue détermine la méthode d’affectation pour ordonner les observations ayantla même valeur que la variable d’origine.

164
Chapitre 8
Figure 8-15Boîte de dialogue Ordonner les observations : Ex aequo
Le tableau suivant montre comment les différentes méthodes affectent des rangs à des valeursex aequo.
Valeur Moyenne Plus petit Plus grand Séquentielle10 1 1 1 115 3 2 4 215 3 2 4 215 3 2 4 216 5 5 5 320 6 6 6 4
Assistant Date et heure
L’Assistant Date et heure simplifie un grand nombre de tâches courantes en relation avec lesvariables date et heure.
Pour utiliser l’Assistant Date et heure
E A partir des menus, sélectionnez :Transformer
Assistant Date et heure...
E Sélectionnez la tâche que vous souhaitez accomplir et suivez les étapes pour la définir.
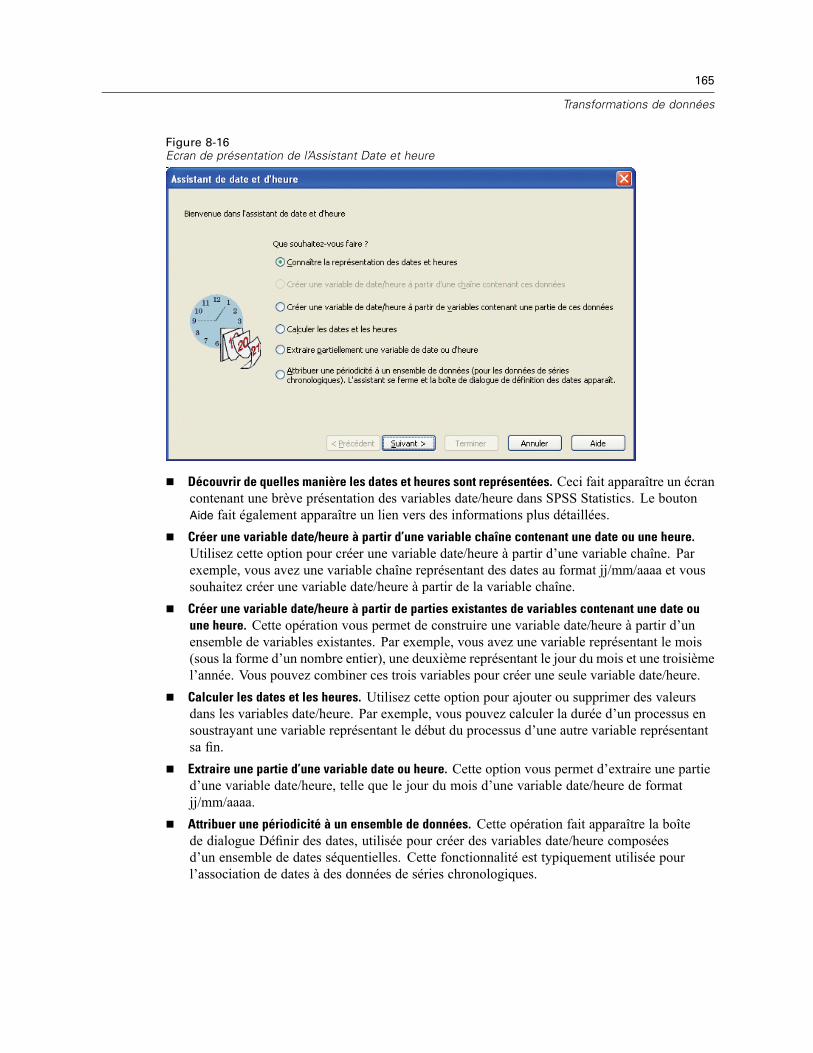
165
Transformations de données
Figure 8-16Ecran de présentation de l’Assistant Date et heure
Découvrir de quelles manière les dates et heures sont représentées. Ceci fait apparaître un écrancontenant une brève présentation des variables date/heure dans SPSS Statistics. Le boutonAide fait également apparaître un lien vers des informations plus détaillées.Créer une variable date/heure à partir d’une variable chaîne contenant une date ou une heure.Utilisez cette option pour créer une variable date/heure à partir d’une variable chaîne. Parexemple, vous avez une variable chaîne représentant des dates au format jj/mm/aaaa et voussouhaitez créer une variable date/heure à partir de la variable chaîne.Créer une variable date/heure à partir de parties existantes de variables contenant une date ouune heure. Cette opération vous permet de construire une variable date/heure à partir d’unensemble de variables existantes. Par exemple, vous avez une variable représentant le mois(sous la forme d’un nombre entier), une deuxième représentant le jour du mois et une troisièmel’année. Vous pouvez combiner ces trois variables pour créer une seule variable date/heure.Calculer les dates et les heures. Utilisez cette option pour ajouter ou supprimer des valeursdans les variables date/heure. Par exemple, vous pouvez calculer la durée d’un processus ensoustrayant une variable représentant le début du processus d’une autre variable représentantsa fin.Extraire une partie d’une variable date ou heure. Cette option vous permet d’extraire une partied’une variable date/heure, telle que le jour du mois d’une variable date/heure de formatjj/mm/aaaa.Attribuer une périodicité à un ensemble de données. Cette opération fait apparaître la boîtede dialogue Définir des dates, utilisée pour créer des variables date/heure composéesd’un ensemble de dates séquentielles. Cette fonctionnalité est typiquement utilisée pourl’association de dates à des données de séries chronologiques.

166
Chapitre 8
Remarque : Les tâches sont désactivées lorsque l’ensemble de données ne dispose pas des typesde variables requis pour accomplir la tâche. Si l’ensemble de données contient des variables sanschaîne par exemple, la tâche permettant de créer une variable date/heure à partir d’une variablechaîne ne s’applique donc pas et se trouve alors désactivée.
Dates et heures dans SPSS Statistics
Les variables représentant les dates et heures dans SPSS Statistics possèdent une variable detype numérique avec des formats d’affichage correspondant aux formats date/heure spécifiques.Ces variables sont généralement appelées variables date/heure. Une distinction est faite entreles variables date/heure représentant des dates et celles représentant des durées (par exemple20 heures, 10 minutes et 15 secondes) qui ne dépendent de la date. Ces dernières sont appeléesvariables de durée et les premières sont appelées variables date ou variables date/heure. Pour uneliste détaillée des formats d’affichage, reportez vous au paragraphe intitulé «Date and time» dansla section «Universals» de Command Syntax Reference.
Variables date et date/heure. Les variables date disposent d’un format de date tel que jj/mm/aaaa.Les variables date/heure disposent d’un format date et heure tel que jj-mmm-aaaa hh:mm:ss.Les variables date et date/heure sont enregistrées en interne en nombre de secondes depuis le14 octobre 1582. Elles sont également appelées variables de format date.
Les spécifications des années à deux ou quatres chiffres sont reconnues. Par défaut, desannées à deux chiffres représentent une plage commençant 69 années avant la date courante etfinissant 30 années après. Vos paramètres Options permettent de déterminer la plage et de laconfigurer (sélectionnez Options à partir du menu Modifier, puis cliquez sur l’onglet Données.Les tirets, points, virgules, barres obliques ou espaces peuvent être utilisés comme séparateursdans les formats jour-mois-année.Les mois peuvent être représentés par des chiffres, des chiffres romains, des abréviations àtrois lettres, ou bien ils peuvent être énoncés en entier. Les abbréviations à trois lettres et lesnoms de mois énoncés en entier doivent être en anglais. Les noms de mois d’autres languesne seront pas reconnus.
Variables de durée. Les variables de durée disposent d’un format représentant une duréetemporelle, telle que hh:mm. Elles sont enregistrées en interne en nombres de secondes sansréférence à une date en particulier.
Dans les spécifications temporelles (s’applique aux variables date/heure et durée), les deuxpoints peuvent être utilisés pour séparer les heures, les minutes et les secondes. Les heureset les minutes sont requises, les secondes restent optionnelles. Les heures peuvent êtreavoir des valeurs illimitées, cependant la valeur maximum est de 59 pour les minutes et de59,999... pour les secondes.
Date et heure actuelles. La variable par défaut $TIME contient la date et l’heure actuelles. Ellereprésente le nombre de secondes écoulées depuis le 14 octobre 1582, jusqu’à la date et l’heureauxquelles la commande de transformation utilisée pour cette variable est exécutée.
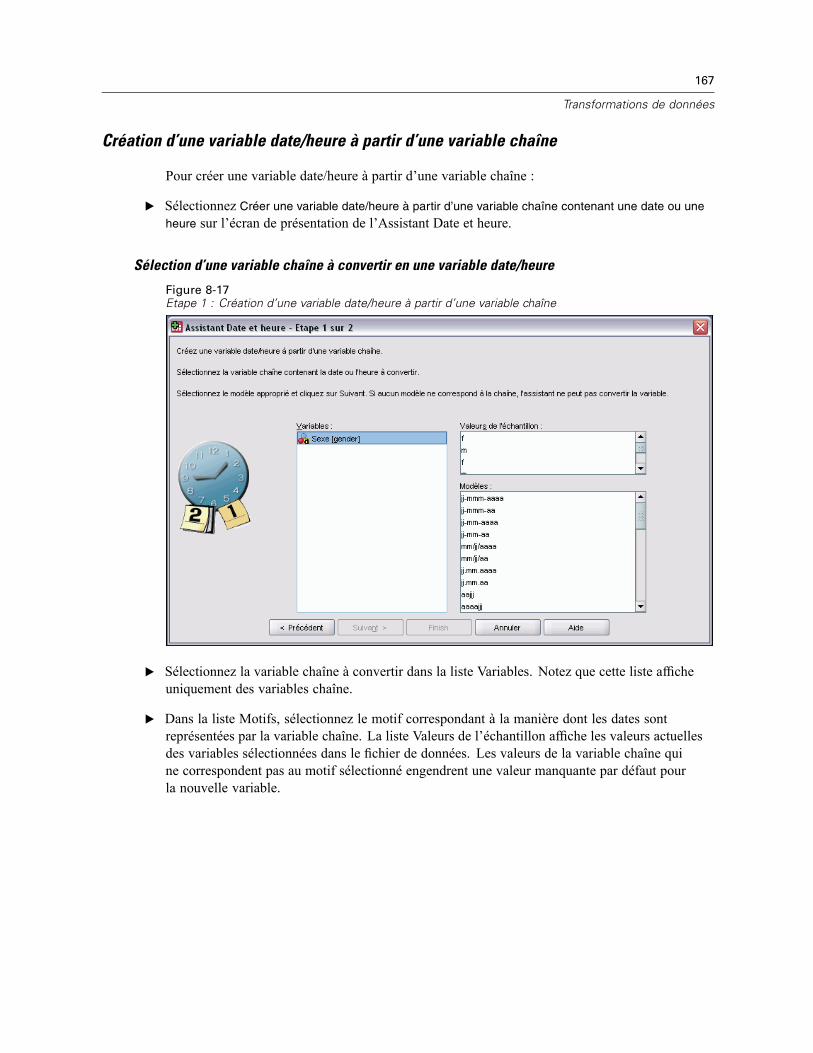
167
Transformations de données
Création d’une variable date/heure à partir d’une variable chaîne
Pour créer une variable date/heure à partir d’une variable chaîne :
E Sélectionnez Créer une variable date/heure à partir d’une variable chaîne contenant une date ou une
heure sur l’écran de présentation de l’Assistant Date et heure.
Sélection d’une variable chaîne à convertir en une variable date/heure
Figure 8-17Etape 1 : Création d’une variable date/heure à partir d’une variable chaîne
E Sélectionnez la variable chaîne à convertir dans la liste Variables. Notez que cette liste afficheuniquement des variables chaîne.
E Dans la liste Motifs, sélectionnez le motif correspondant à la manière dont les dates sontreprésentées par la variable chaîne. La liste Valeurs de l’échantillon affiche les valeurs actuellesdes variables sélectionnées dans le fichier de données. Les valeurs de la variable chaîne quine correspondent pas au motif sélectionné engendrent une valeur manquante par défaut pourla nouvelle variable.
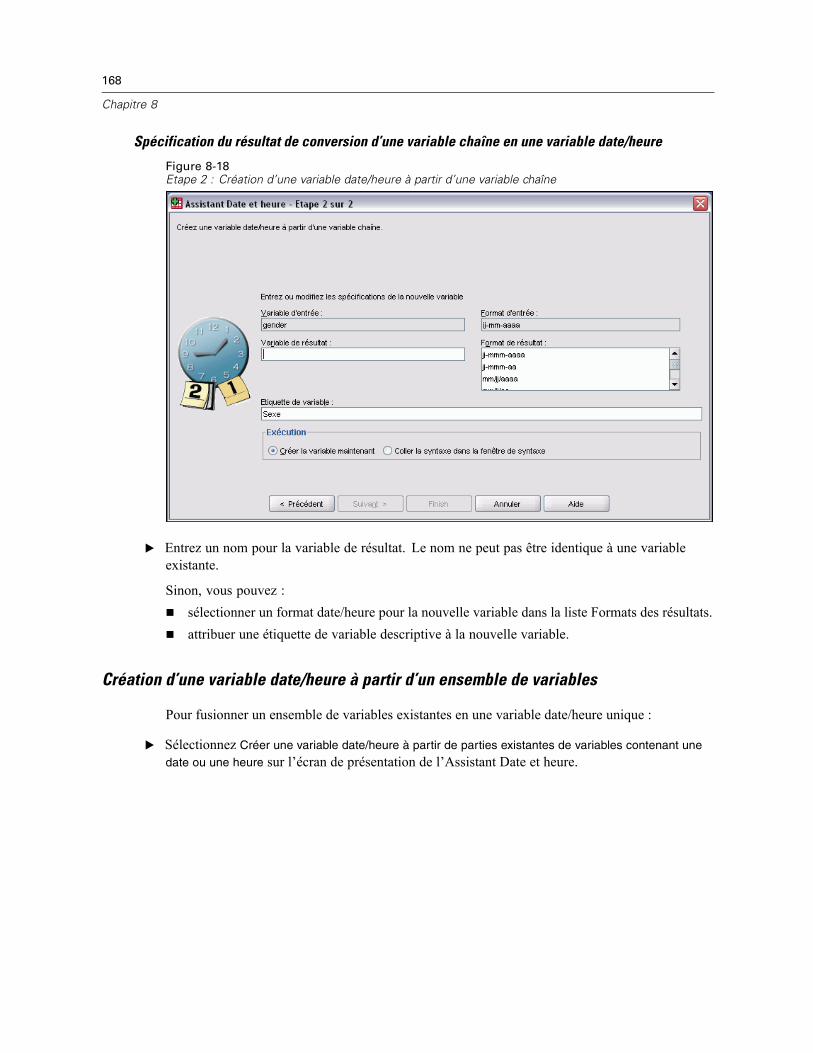
168
Chapitre 8
Spécification du résultat de conversion d’une variable chaîne en une variable date/heure
Figure 8-18Etape 2 : Création d’une variable date/heure à partir d’une variable chaîne
E Entrez un nom pour la variable de résultat. Le nom ne peut pas être identique à une variableexistante.
Sinon, vous pouvez :sélectionner un format date/heure pour la nouvelle variable dans la liste Formats des résultats.attribuer une étiquette de variable descriptive à la nouvelle variable.
Création d’une variable date/heure à partir d’un ensemble de variables
Pour fusionner un ensemble de variables existantes en une variable date/heure unique :
E Sélectionnez Créer une variable date/heure à partir de parties existantes de variables contenant une
date ou une heure sur l’écran de présentation de l’Assistant Date et heure.
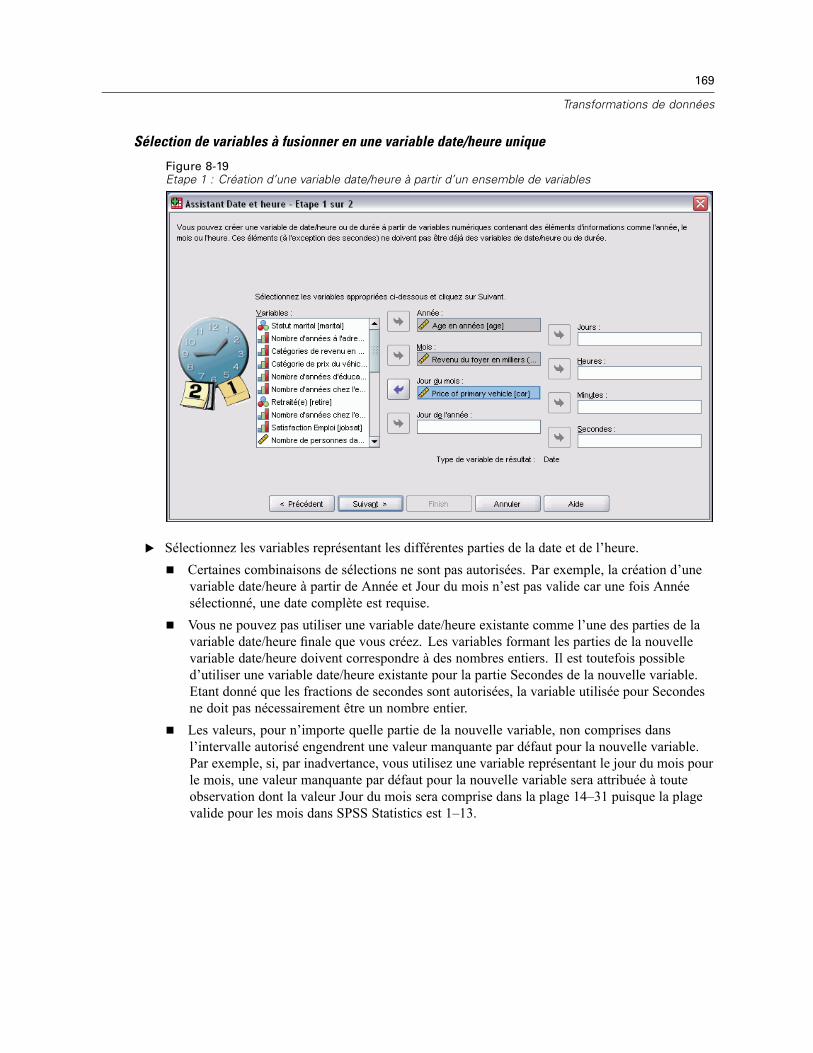
169
Transformations de données
Sélection de variables à fusionner en une variable date/heure unique
Figure 8-19Etape 1 : Création d’une variable date/heure à partir d’un ensemble de variables
E Sélectionnez les variables représentant les différentes parties de la date et de l’heure.Certaines combinaisons de sélections ne sont pas autorisées. Par exemple, la création d’unevariable date/heure à partir de Année et Jour du mois n’est pas valide car une fois Annéesélectionné, une date complète est requise.Vous ne pouvez pas utiliser une variable date/heure existante comme l’une des parties de lavariable date/heure finale que vous créez. Les variables formant les parties de la nouvellevariable date/heure doivent correspondre à des nombres entiers. Il est toutefois possibled’utiliser une variable date/heure existante pour la partie Secondes de la nouvelle variable.Etant donné que les fractions de secondes sont autorisées, la variable utilisée pour Secondesne doit pas nécessairement être un nombre entier.Les valeurs, pour n’importe quelle partie de la nouvelle variable, non comprises dansl’intervalle autorisé engendrent une valeur manquante par défaut pour la nouvelle variable.Par exemple, si, par inadvertance, vous utilisez une variable représentant le jour du mois pourle mois, une valeur manquante par défaut pour la nouvelle variable sera attribuée à touteobservation dont la valeur Jour du mois sera comprise dans la plage 14–31 puisque la plagevalide pour les mois dans SPSS Statistics est 1–13.
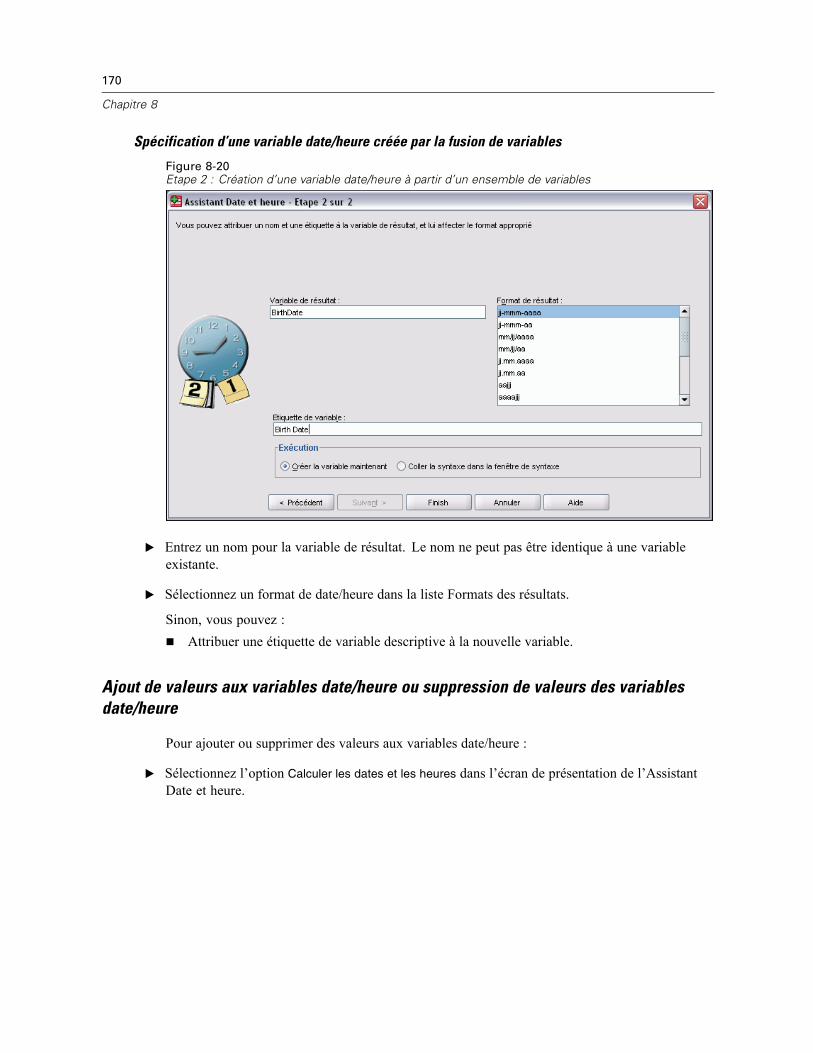
170
Chapitre 8
Spécification d’une variable date/heure créée par la fusion de variables
Figure 8-20Etape 2 : Création d’une variable date/heure à partir d’un ensemble de variables
E Entrez un nom pour la variable de résultat. Le nom ne peut pas être identique à une variableexistante.
E Sélectionnez un format de date/heure dans la liste Formats des résultats.
Sinon, vous pouvez :Attribuer une étiquette de variable descriptive à la nouvelle variable.
Ajout de valeurs aux variables date/heure ou suppression de valeurs des variablesdate/heure
Pour ajouter ou supprimer des valeurs aux variables date/heure :
E Sélectionnez l’option Calculer les dates et les heures dans l’écran de présentation de l’AssistantDate et heure.
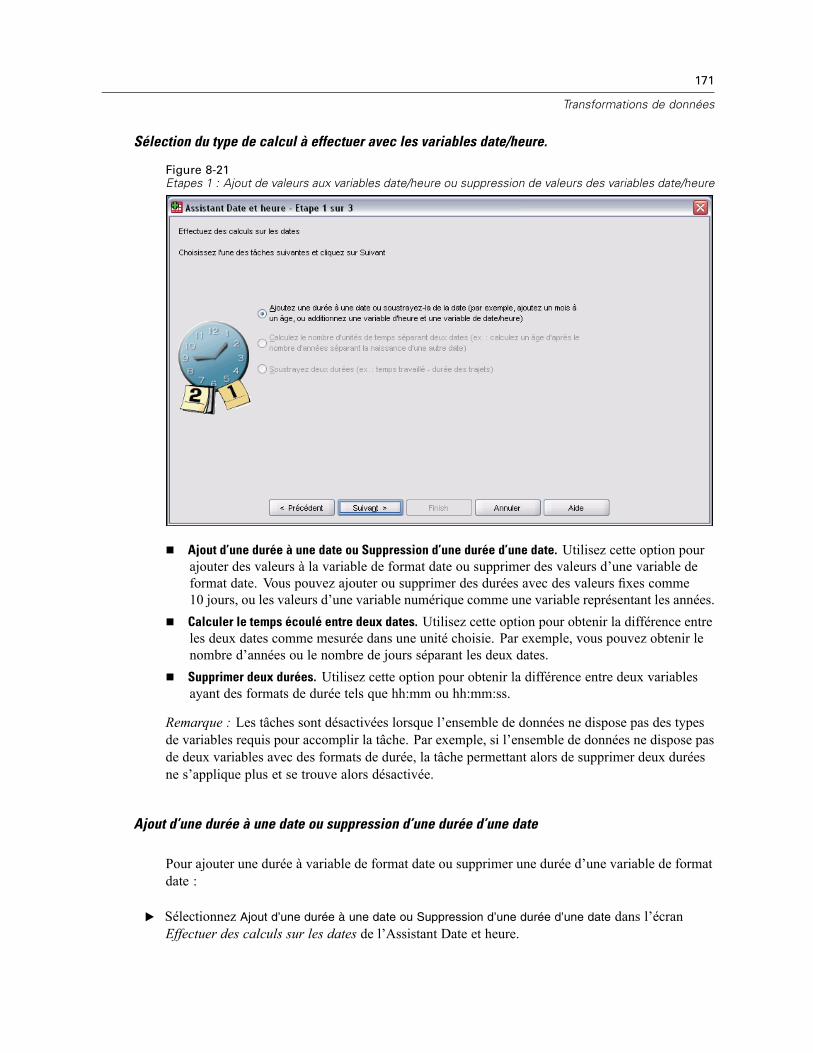
171
Transformations de données
Sélection du type de calcul à effectuer avec les variables date/heure.
Figure 8-21Etapes 1 : Ajout de valeurs aux variables date/heure ou suppression de valeurs des variables date/heure
Ajout d’une durée à une date ou Suppression d’une durée d’une date. Utilisez cette option pourajouter des valeurs à la variable de format date ou supprimer des valeurs d’une variable deformat date. Vous pouvez ajouter ou supprimer des durées avec des valeurs fixes comme10 jours, ou les valeurs d’une variable numérique comme une variable représentant les années.Calculer le temps écoulé entre deux dates. Utilisez cette option pour obtenir la différence entreles deux dates comme mesurée dans une unité choisie. Par exemple, vous pouvez obtenir lenombre d’années ou le nombre de jours séparant les deux dates.Supprimer deux durées. Utilisez cette option pour obtenir la différence entre deux variablesayant des formats de durée tels que hh:mm ou hh:mm:ss.
Remarque : Les tâches sont désactivées lorsque l’ensemble de données ne dispose pas des typesde variables requis pour accomplir la tâche. Par exemple, si l’ensemble de données ne dispose pasde deux variables avec des formats de durée, la tâche permettant alors de supprimer deux duréesne s’applique plus et se trouve alors désactivée.
Ajout d’une durée à une date ou suppression d’une durée d’une date
Pour ajouter une durée à variable de format date ou supprimer une durée d’une variable de formatdate :
E Sélectionnez Ajout d’une durée à une date ou Suppression d’une durée d’une date dans l’écranEffectuer des calculs sur les dates de l’Assistant Date et heure.

172
Chapitre 8
Sélection d’une variable date/heure et d’une durée à ajouter ou supprimer
Figure 8-22Etape 2 : Ajout ou suppression d’une durée
E Sélectionnez une variable date (ou heure).
E Sélectionnez une variable durée ou entrez une valeur d’une durée constante. Les variables utiliséespour les durées ne peuvent pas être des variables date ou des variables date/heure. Il peut s’agir devariables de durée ou de simples variables numériques.
E Sélectionnez l’unité représentée par la durée dans la liste déroulante. Sélectionnez Durée si vousutilisez une variable et que celle-ci est exprimée sous la forme d’une durée, telle que hh:mm ouhh:mm:ss.
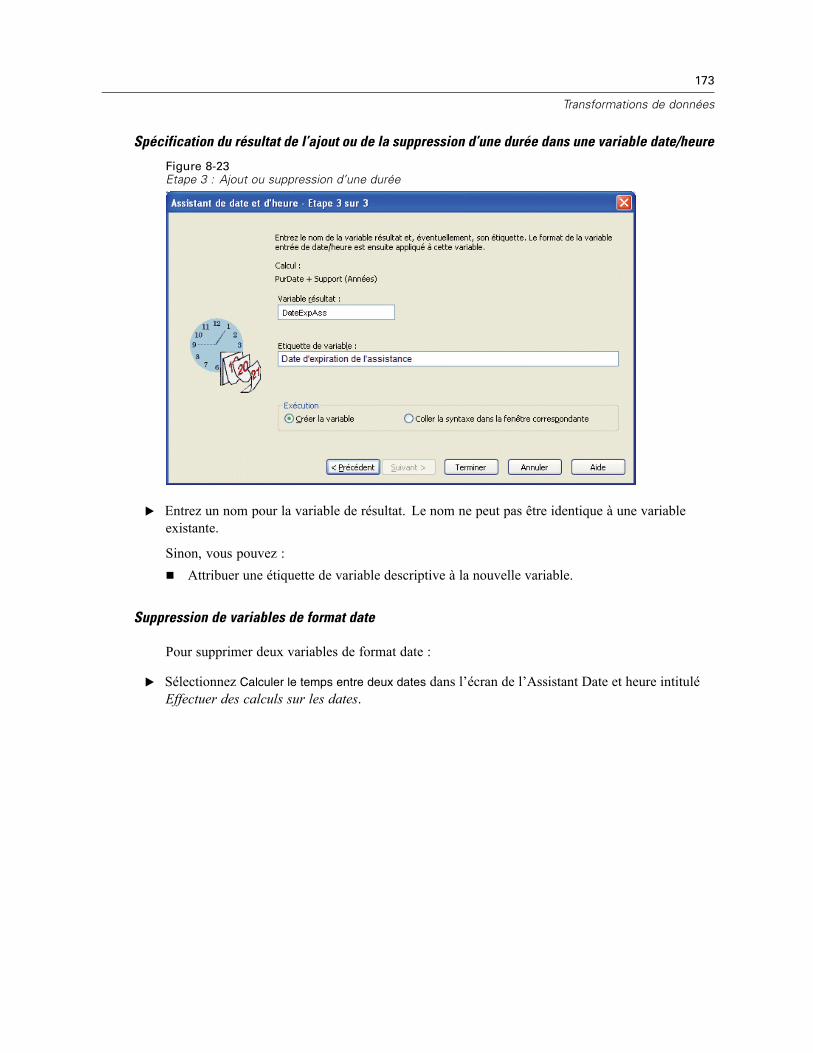
173
Transformations de données
Spécification du résultat de l’ajout ou de la suppression d’une durée dans une variable date/heure
Figure 8-23Etape 3 : Ajout ou suppression d’une durée
E Entrez un nom pour la variable de résultat. Le nom ne peut pas être identique à une variableexistante.
Sinon, vous pouvez :Attribuer une étiquette de variable descriptive à la nouvelle variable.
Suppression de variables de format date
Pour supprimer deux variables de format date :
E Sélectionnez Calculer le temps entre deux dates dans l’écran de l’Assistant Date et heure intituléEffectuer des calculs sur les dates.
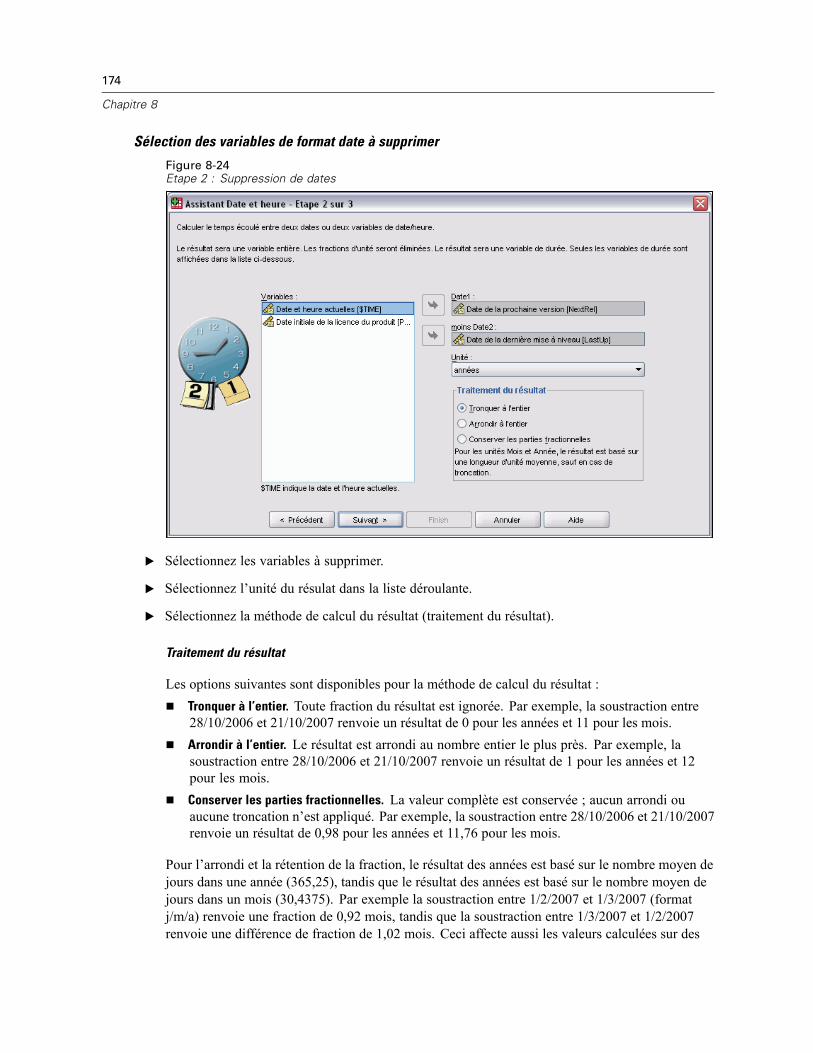
174
Chapitre 8
Sélection des variables de format date à supprimer
Figure 8-24Etape 2 : Suppression de dates
E Sélectionnez les variables à supprimer.
E Sélectionnez l’unité du résulat dans la liste déroulante.
E Sélectionnez la méthode de calcul du résultat (traitement du résultat).
Traitement du résultat
Les options suivantes sont disponibles pour la méthode de calcul du résultat :Tronquer à l’entier. Toute fraction du résultat est ignorée. Par exemple, la soustraction entre28/10/2006 et 21/10/2007 renvoie un résultat de 0 pour les années et 11 pour les mois.Arrondir à l’entier. Le résultat est arrondi au nombre entier le plus près. Par exemple, lasoustraction entre 28/10/2006 et 21/10/2007 renvoie un résultat de 1 pour les années et 12pour les mois.Conserver les parties fractionnelles. La valeur complète est conservée ; aucun arrondi ouaucune troncation n’est appliqué. Par exemple, la soustraction entre 28/10/2006 et 21/10/2007renvoie un résultat de 0,98 pour les années et 11,76 pour les mois.
Pour l’arrondi et la rétention de la fraction, le résultat des années est basé sur le nombre moyen dejours dans une année (365,25), tandis que le résultat des années est basé sur le nombre moyen dejours dans un mois (30,4375). Par exemple la soustraction entre 1/2/2007 et 1/3/2007 (formatj/m/a) renvoie une fraction de 0,92 mois, tandis que la soustraction entre 1/3/2007 et 1/2/2007renvoie une différence de fraction de 1,02 mois. Ceci affecte aussi les valeurs calculées sur des
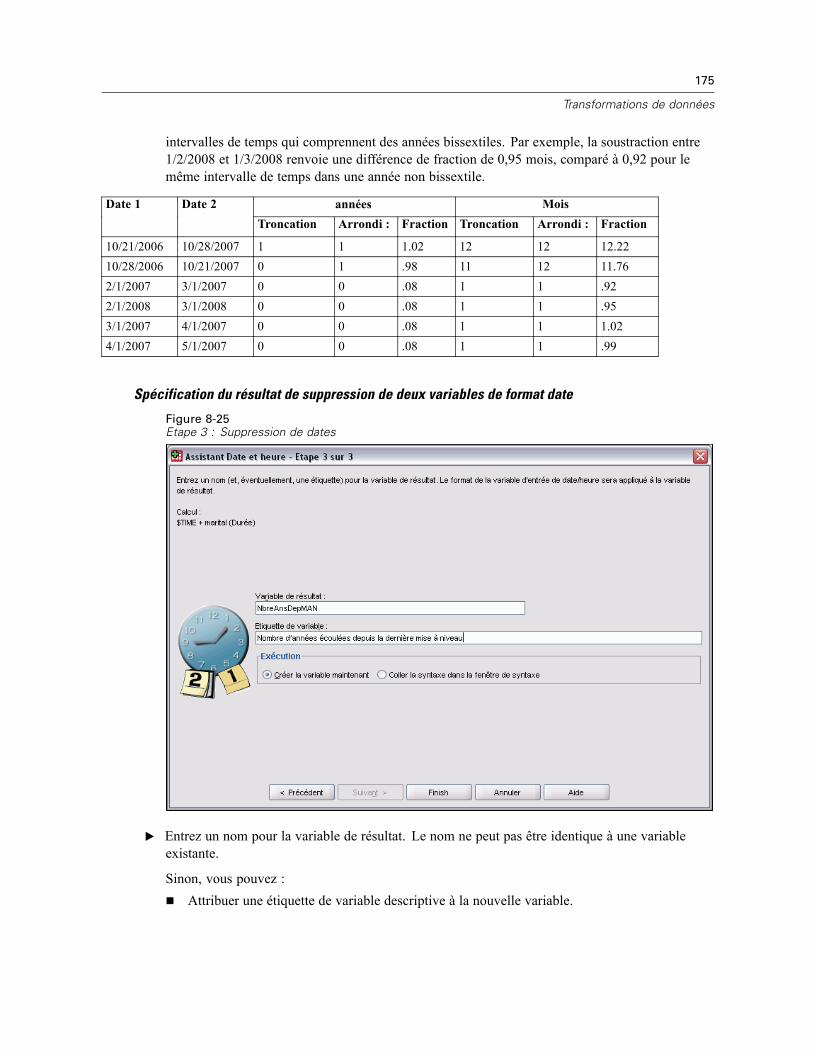
175
Transformations de données
intervalles de temps qui comprennent des années bissextiles. Par exemple, la soustraction entre1/2/2008 et 1/3/2008 renvoie une différence de fraction de 0,95 mois, comparé à 0,92 pour lemême intervalle de temps dans une année non bissextile.
années MoisDate 1 Date 2Troncation Arrondi : Fraction Troncation Arrondi : Fraction
10/21/2006 10/28/2007 1 1 1.02 12 12 12.2210/28/2006 10/21/2007 0 1 .98 11 12 11.762/1/2007 3/1/2007 0 0 .08 1 1 .922/1/2008 3/1/2008 0 0 .08 1 1 .953/1/2007 4/1/2007 0 0 .08 1 1 1.024/1/2007 5/1/2007 0 0 .08 1 1 .99
Spécification du résultat de suppression de deux variables de format date
Figure 8-25Etape 3 : Suppression de dates
E Entrez un nom pour la variable de résultat. Le nom ne peut pas être identique à une variableexistante.
Sinon, vous pouvez :Attribuer une étiquette de variable descriptive à la nouvelle variable.
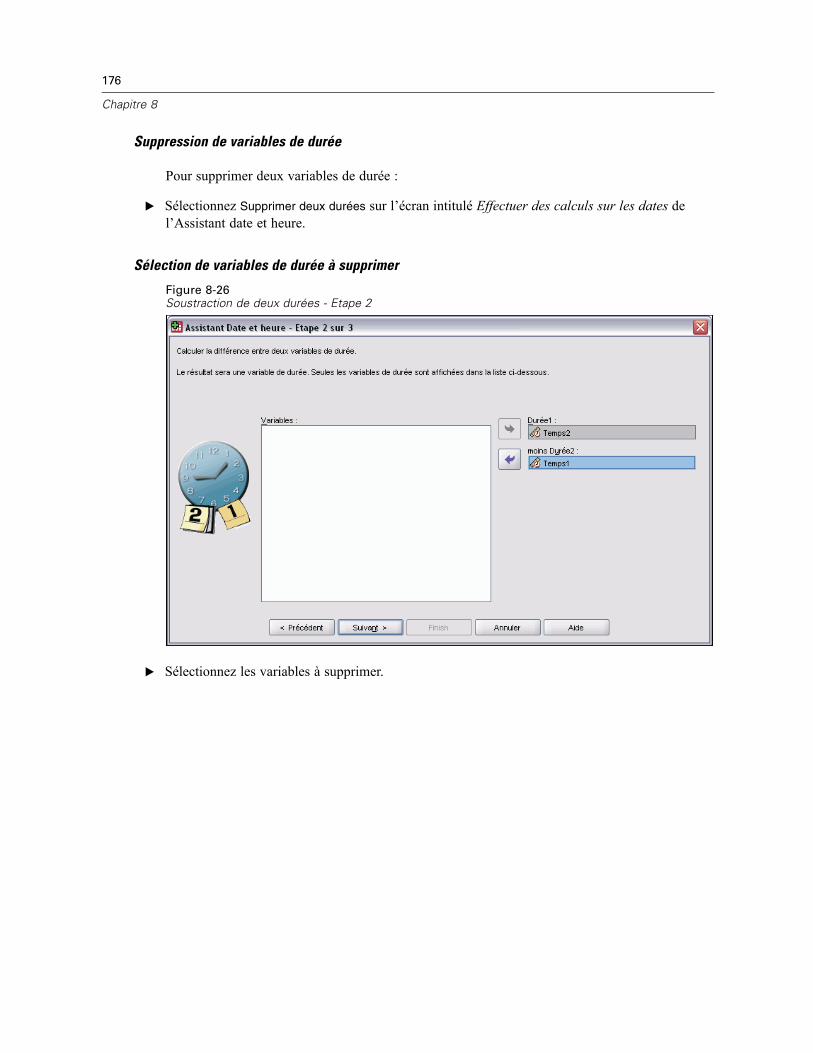
176
Chapitre 8
Suppression de variables de durée
Pour supprimer deux variables de durée :
E Sélectionnez Supprimer deux durées sur l’écran intitulé Effectuer des calculs sur les dates del’Assistant date et heure.
Sélection de variables de durée à supprimer
Figure 8-26Soustraction de deux durées - Etape 2
E Sélectionnez les variables à supprimer.
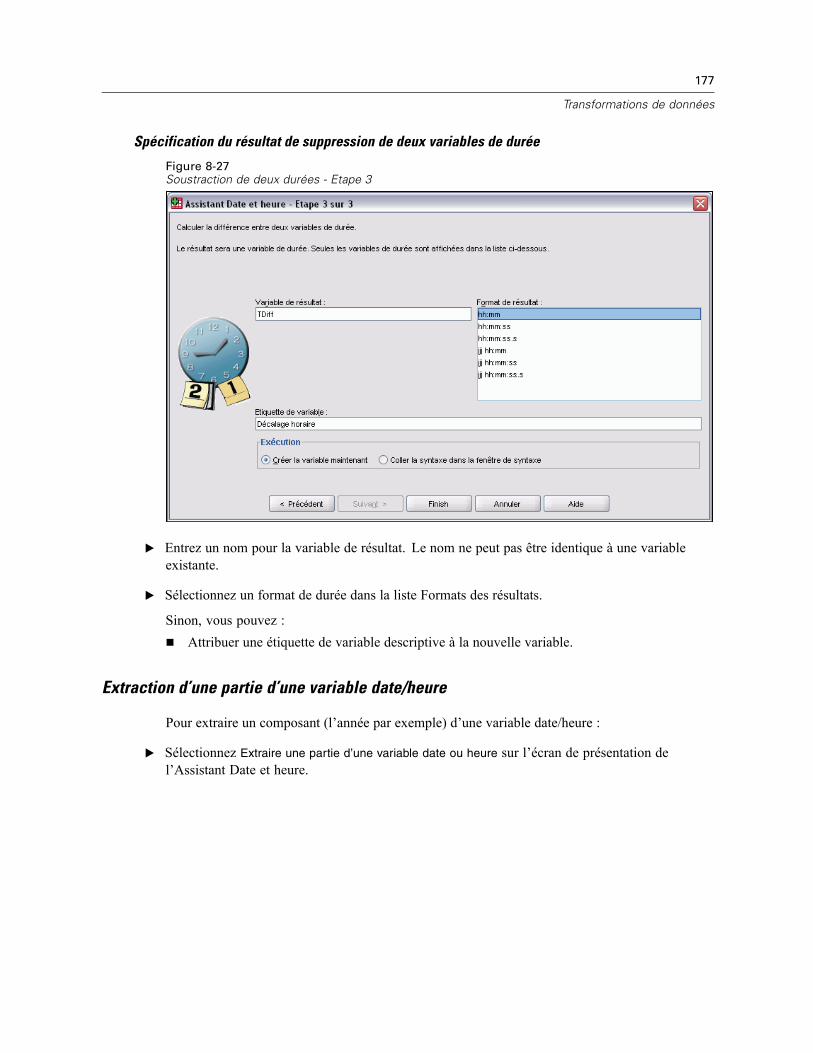
177
Transformations de données
Spécification du résultat de suppression de deux variables de durée
Figure 8-27Soustraction de deux durées - Etape 3
E Entrez un nom pour la variable de résultat. Le nom ne peut pas être identique à une variableexistante.
E Sélectionnez un format de durée dans la liste Formats des résultats.
Sinon, vous pouvez :Attribuer une étiquette de variable descriptive à la nouvelle variable.
Extraction d’une partie d’une variable date/heure
Pour extraire un composant (l’année par exemple) d’une variable date/heure :
E Sélectionnez Extraire une partie d’une variable date ou heure sur l’écran de présentation del’Assistant Date et heure.
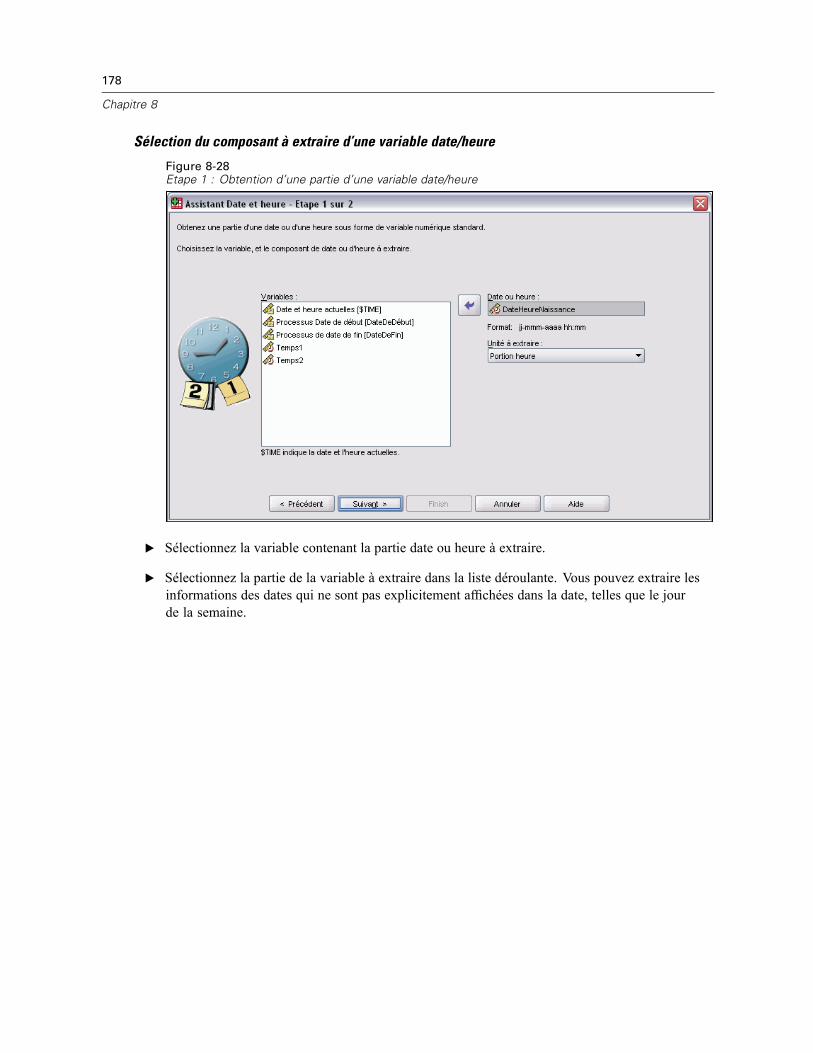
178
Chapitre 8
Sélection du composant à extraire d’une variable date/heure
Figure 8-28Etape 1 : Obtention d’une partie d’une variable date/heure
E Sélectionnez la variable contenant la partie date ou heure à extraire.
E Sélectionnez la partie de la variable à extraire dans la liste déroulante. Vous pouvez extraire lesinformations des dates qui ne sont pas explicitement affichées dans la date, telles que le jourde la semaine.
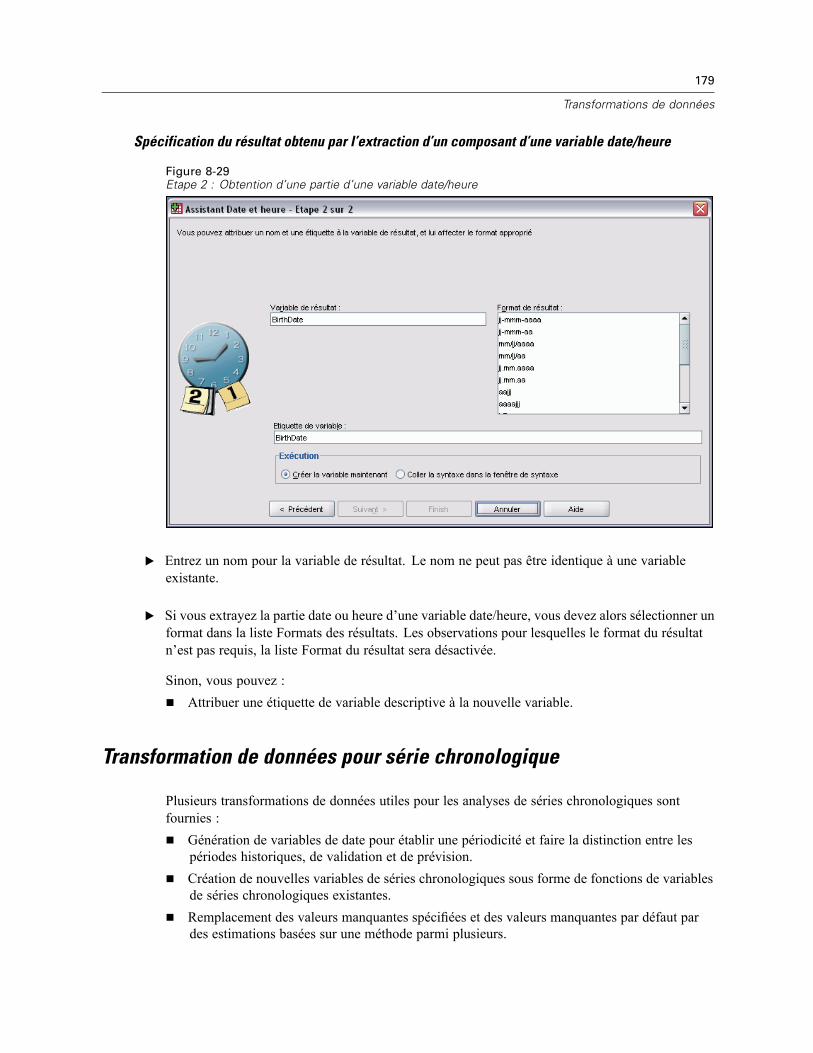
179
Transformations de données
Spécification du résultat obtenu par l’extraction d’un composant d’une variable date/heure
Figure 8-29Etape 2 : Obtention d’une partie d’une variable date/heure
E Entrez un nom pour la variable de résultat. Le nom ne peut pas être identique à une variableexistante.
E Si vous extrayez la partie date ou heure d’une variable date/heure, vous devez alors sélectionner unformat dans la liste Formats des résultats. Les observations pour lesquelles le format du résultatn’est pas requis, la liste Format du résultat sera désactivée.
Sinon, vous pouvez :Attribuer une étiquette de variable descriptive à la nouvelle variable.
Transformation de données pour série chronologique
Plusieurs transformations de données utiles pour les analyses de séries chronologiques sontfournies :
Génération de variables de date pour établir une périodicité et faire la distinction entre lespériodes historiques, de validation et de prévision.Création de nouvelles variables de séries chronologiques sous forme de fonctions de variablesde séries chronologiques existantes.Remplacement des valeurs manquantes spécifiées et des valeurs manquantes par défaut pardes estimations basées sur une méthode parmi plusieurs.

180
Chapitre 8
Une série chronologique est obtenue par mesure régulière d’une variable (ou d’un groupe devariables) sur une certaine période. Les transformations de données de séries chronologiquesexigent une structure de fichier de données dans laquelle chaque ligne représente un grouped’observations à une heure différente, et l’intervalle de temps entre les observations est uniforme.
Définir des dates
La boîte de dialogue de définition de dates permet de générer des variables de date pouvantêtre utilisées pour établir la périodicité d’une série chronologique et pour étiqueter le résultatd’analyses de séries chronologiques.
Figure 8-30Boîte de dialogue Définir des dates
Les observations sont : Définit l’intervalle de temps utilisé pour générer des dates.Non daté supprime toutes les variables de date précédemment définies. Toutes les variablesportant les noms suivants sont supprimées : année_, trimestre_, mois_, semaine_, jour_,heure_, minute_, seconde_ et date_.Personnalisé indique la présence de variables de date personnalisées créées avec la syntaxede commande (par exemple, une semaine de travail de quatre jours). Cet élément reflètesimplement l’état actuel de l’ensemble de données actif. Sa sélection dans la liste est sans effet.
La première observation est : Définit la valeur de la date de départ, qui est affectée à la premièreobservation. Des valeurs séquentielles, basées sur l’intervalle de temps, sont affectées auxobservations ultérieures.
Périodicité au niveau supérieur : Indique une variation cyclique répétitive, telle que le nombre demois dans une année ou le nombre de jours de la semaine. La valeur affichée indique la valeurmaximale que vous pouvez entrer.
Une nouvelle variable numérique est créée pour chaque composant utilisé pour définir la date. Lesnoms des nouvelles variables se terminent par un trait de soulignement. Une variable descriptivechaîne, date_, est également créée à partir des composants. Par exemple, si vous avez sélectionnésemaines, jours, heures, quatre nouvelles variables sont créées : semaine_, jour_, heure_ et date_.

181
Transformations de données
Si des variables de date ont été déjà définies, elles sont remplacées lorsque vous définissez denouvelles variables de date portant le même nom que les variables de date existantes.
Pour définir des dates pour des données de séries chronologiques
E A partir des menus, sélectionnez :Données
Définir des dates
E Sélectionnez un intervalle de temps dans la liste Les observations sont.
E Entrez les valeurs définissant la date de départ, qui détermine la date affectée à la premièreobservation.
Variables de date versus variables de format date
Les variables de date créées avec Définir les dates ne doivent pas être confondues avec lesvariables de format date, définies dans l’Affichage des variables de l’Editeur de données.Les variables de date sont utilisées pour créer une périodicité pour les données de sérieschronologiques. Les variables de format date représentent des dates et/ou des heures affichéesselon divers formats de date/heure. Les variables de date sont de simples entiers représentant lenombre de jours, de semaines, d’heures, etc., à partir d’un point de départ spécifié par l’utilisateur.En interne, la plupart des variables de format date sont stockées sous la forme du nombre desecondes écoulées depuis le 14 octobre 1582.
Créer la série chronologique
La boîte de dialogue Créer la série chronologique vous permet de créer de nouvelles variablesbasées sur des fonctions de variables numériques de séries chronologiques. Ces valeurstransformées sont utiles dans de nombreuses procédures d’analyses de séries chronologiques.Par défaut, les noms de nouvelles variables reprennent les six premiers caractères de la variable
existante utilisée pour les créer, suivis d’un trait de soulignement et d’un numéro séquentiel.Par exemple, pour la variable prix, le nom de la nouvelle variable serait prix_1. Les nouvellesvariables conservent toute étiquette de valeur définie des variables d’origine.Les fonctions disponibles, permettant de créer des variables de séries chronologiques, incluent
les fonctions de différences, de moyennes mobiles, de médianes mobiles, de décalages et dedécalage négatif.
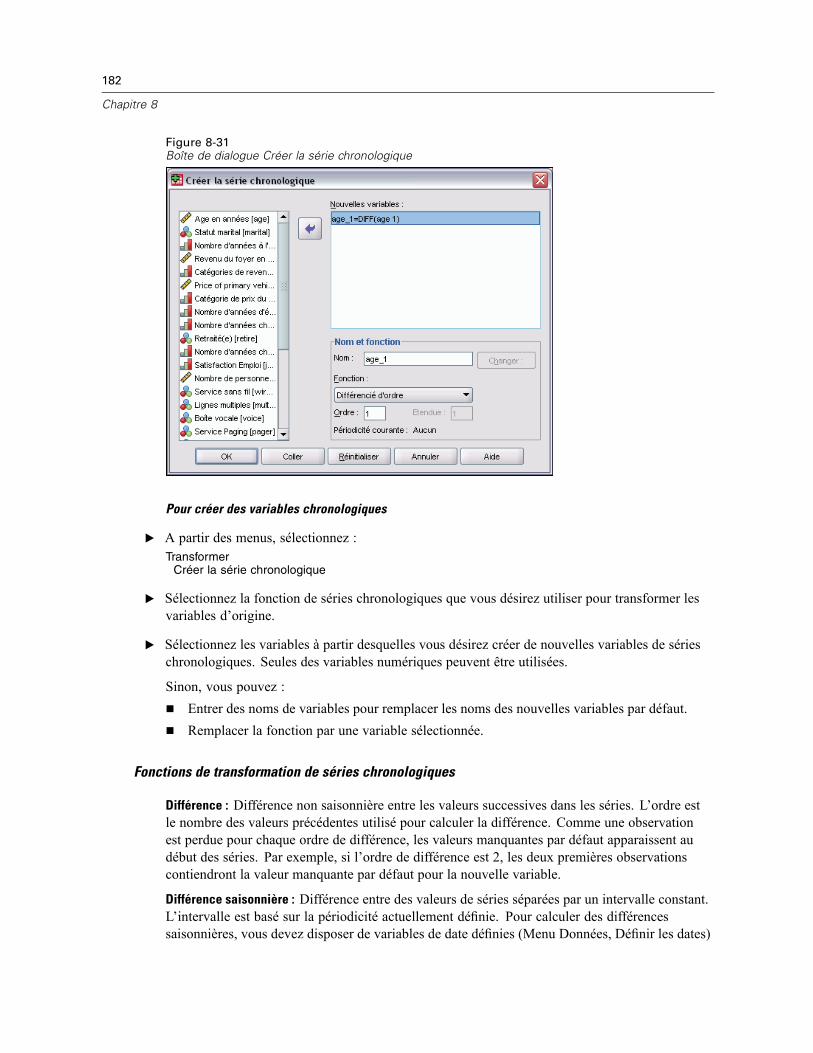
182
Chapitre 8
Figure 8-31Boîte de dialogue Créer la série chronologique
Pour créer des variables chronologiques
E A partir des menus, sélectionnez :Transformer
Créer la série chronologique
E Sélectionnez la fonction de séries chronologiques que vous désirez utiliser pour transformer lesvariables d’origine.
E Sélectionnez les variables à partir desquelles vous désirez créer de nouvelles variables de sérieschronologiques. Seules des variables numériques peuvent être utilisées.
Sinon, vous pouvez :Entrer des noms de variables pour remplacer les noms des nouvelles variables par défaut.Remplacer la fonction par une variable sélectionnée.
Fonctions de transformation de séries chronologiques
Différence : Différence non saisonnière entre les valeurs successives dans les séries. L’ordre estle nombre des valeurs précédentes utilisé pour calculer la différence. Comme une observationest perdue pour chaque ordre de différence, les valeurs manquantes par défaut apparaissent audébut des séries. Par exemple, si l’ordre de différence est 2, les deux premières observationscontiendront la valeur manquante par défaut pour la nouvelle variable.
Différence saisonnière : Différence entre des valeurs de séries séparées par un intervalle constant.L’intervalle est basé sur la périodicité actuellement définie. Pour calculer des différencessaisonnières, vous devez disposer de variables de date définies (Menu Données, Définir les dates)

183
Transformations de données
qui incluent une composante périodique (telle que les mois de l’année). L’ordre est le nombrede périodes saisonnières utilisé pour calculer la différence. Le nombre d’observations avec lavaleur manquante par défaut au début des séries est égal à la périodicité multipliée par l’ordre.Par exemple, si la périodicité courante est 12 et l’ordre 2, les 24 premières observations auront lavaleur manquante par défaut pour nouvelle variable.
Moyenne mobile centrée : Moyenne d’un intervalle de valeurs de séries entourant et incluant lavaleur courante. L’intervalle est le nombre de valeurs de séries utilisé pour calculer la moyenne.Si l’intervalle est pair, la moyenne mobile est calculée en faisant la moyenne de chaque paire demoyennes non centrées. Le nombre d’observations avec la valeur manquante par défaut au débutet à la fin des séries pour un intervalle de n est égal à n/2 pour des valeurs d’intervalles paires(n–1)/2 pour des valeurs d’intervalles impaires. Par exemple, si l’intervalle est 5, le nombred’observations avec la valeur manquante par défaut au début et à la fin des séries est 2.
Moyenne mobile précédente : Moyenne de l’intervalle de valeurs des séries précédant la valeurcourante. L’intervalle est le nombre de valeurs de séries précédentes utilisé pour calculer lamoyenne. Le nombre d’observations avec la valeur manquante par défaut au début des sériesest égal à la valeur de l’intervalle.
Médianes mobiles : Médiane d’un intervalle de valeurs de séries entourant et incluant la valeurcourante. L’intervalle est le nombre de valeurs de séries utilisé pour calculer la médiane. Sil’intervalle est pair, la médiane est calculée en faisant la moyenne de chaque paire de médianesnon centrées. Le nombre d’observations avec la valeur manquante par défaut au début et à la findes séries pour un intervalle de n est égal à n/2 pour des valeurs d’intervalles paires (n–1)/2 pourdes valeurs d’intervalles impaires. Par exemple, si l’intervalle est 5, le nombre d’observationsavec la valeur manquante par défaut au début et à la fin des séries est 2.
Somme cumulée : Somme cumulée des valeurs des séries à concurrence de la valeur courante, ycompris celle-ci.
Décalage positif : Valeur d’une observation précédente, basée sur l’ordre de décalage spécifié.L’ordre est le nombre d’observations antérieures à l’observation courante à partir de laquelle lavaleur est obtenue. Le nombre d’observations avec la valeur manquante par défaut au début desséries est égal à la valeur de l’ordre.
Décalage négatif : Valeur d’une observation ultérieure, basée sur l’ordre de décalage négatifspécifié. L’ordre est le nombre d’observations après l’observation courante à partir de laquelle lavaleur est obtenue. Le nombre d’observations avec la valeur manquante par défaut à la fin desséries est égal à la valeur de l’ordre.
Lissage : Nouvelles valeurs des séries basées sur un lisseur de données composées. Le lisseurcommence avec une médiane mobile de 4, centrée par une médiane mobile de 2. Il relisse ensuiteces valeurs en appliquant une médiane mobile de 5, puis une de 3, et du hanning (exécution demoyennes pondérées). Les résidus sont calculés par soustraction des séries lissées des sériesd’origine. Tout ce processus est ensuite répété sur les résidus calculés. Pour finir, les résidus lisséssont calculés par soustraction des valeurs lissées obtenues la première fois par le processus.On parle parfois de lissage T4253H.

184
Chapitre 8
Remplacer les valeurs manquantes
Les observations manquantes peuvent constituer un problème dans le cadre d’analyses, et il arriveque des mesures de séries ne puissent être calculées si des valeurs manquent dans les séries. Ilarrive que la valeur d’une observation donnée ne soit tout simplement pas connue. De plus, unedonnée manquante peut provenir de l’une des actions suivantes :
Chaque degré de différentiation réduit la longueur d’une série de 1.Chaque degré de différentiation saisonnière réduit la longueur d’une série d’une saison.Si vous créez de nouvelles séries contenant des prévisions relatives à la fin de la sérieexistante (en cliquant sur un bouton Enregistrer et en effectuant les choix appropriés), lesséries d’origine et les séries de résidus générées auront des valeurs manquantes pour lesnouvelles observations.Certaines transformations (la transformation log par exemple) génèrent des donnéesmanquantes pour certaines valeurs des séries d’origine.
Les données manquantes situées au début ou à la fin d’une série ne posent aucun problème : ellesréduisent simplement la longueur utile de la série. Les trous situés au milieu d’une série (donnéesmanquantes intégrées) peuvent représenter un problème beaucoup plus sérieux. L’étendue duproblème dépend de la procédure d’analyse utilisée.La boîte de dialogue Remplacer les valeurs manquantes permet de créer des variables de séries
chronologiques à partir de variables existantes, en remplaçant les valeurs manquantes par desestimations calculées selon une méthode. Par défaut, les noms de nouvelles variables reprennentles six premiers caractères de la variable existante utilisée pour les créer, suivis d’un trait desoulignement et d’un numéro séquentiel. Par exemple, pour la variable prix, le nom de la nouvellevariable serait prix_1. Les nouvelles variables conservent toute étiquette de valeur définie desvariables d’origine.
Figure 8-32Boîte de dialogue Remplacer les valeurs manquantes

185
Transformations de données
Pour remplacer les valeurs manquantes par des variables de séries chronologiques
E A partir des menus, sélectionnez :Transformer
Remplacer les valeurs manquantes
E Sélectionnez la méthode d’estimation que vous désirez utiliser pour remplacer les valeursmanquantes.
E Sélectionnez les variables dont vous voulez remplacer les valeurs manquantes.
Sinon, vous pouvez :Entrer des noms de variables pour remplacer les noms des nouvelles variables par défaut.Changer la méthode d’estimation pour une variable sélectionnée.
Méthodes d’estimation pour le remplacement de valeurs manquantes
Moyenne de la série : Remplace les valeurs manquantes par la moyenne de toute la série.
Moyenne des points voisins : Remplace les valeurs manquantes par la moyenne des valeurs validesqui les entourent. L’intervalle des points voisins est le nombre de valeurs valides au-dessus etau-dessous de la valeur manquante utilisée pour calculer la moyenne.
Médiane des points voisins : Remplace les valeurs manquantes par la médiane des valeurs validesqui les entourent. L’intervalle des points voisins est le nombre de valeurs valides au-dessus etau-dessous de la valeur manquante utilisée pour calculer la médiane.
Interpolation linéaire : Remplace les valeurs manquantes au moyen d’une interpolation linéaire.La dernière valeur valide avant la valeur manquante et la première valeur valide après la valeurmanquante sont utilisées pour l’interpolation. Si la première ou la dernière observation de la sériecomporte une valeur manquante, celle-ci n’est pas remplacée.
Tendance linéaire au point : Remplace les valeurs manquantes par la tendance linéaire de ce point.Une régression est effectuée sur la série existante selon une variable d’index d’une échelle de 1 àn. Les valeurs manquantes sont remplacées par les prévisions correspondantes.
Notation de données avec des modèles de prévision
Le processus consistant à appliquer un modèle de prévision à un ensemble de données estappelé notation des données. SPSS Statistics, Clementine et AnswerTree ont des procédurespour construire des modèles de prévision comme les modèles de régression, de classification,de segmentation et de réseau neuronal. Une fois le modèle construit, les spécifications de cedernier sont enregistrées dans un fichier XML contenant toutes les informations nécessaires pourreconstruire le modèle. Le serveur SPSS Statistics fournit alors les moyens pour lire un fichier demodèle XML et appliquer le modèle à un ensemble de données.
Exemple : Une demande de crédit est notée comme étant à risque en se basant sur différentsaspects du demandeur et du prêt en question. Le résultat de crédit obtenu à partir du modèle derisque est utilisé pour accepter ou refuser la demande de prêt.

186
Chapitre 8
La notation est traitée comme une transformation des données. Le modèle s’exprime en internecomme un ensemble de transformations numériques appliquées à un ensemble donné de variables,les variables indépendantes spécifiées dans le modèle, afin d’obtenir une prévision. En ce sens, leprocessus de notation de données avec un modèle donné est actuellement similaire à l’applicationd’une fonction, telle la fonction de racine carrée, à un ensemble de données.La notation n’est disponible qu’avec le serveur SPSS Statistics et peut être effectuée de manière
interactive par les utilisateurs travaillant en mode d’analyse distribuée. Pour la notation de largesfichiers de données, vous pouvez utiliser Batch Facility, une version exécutable distincte fournieavec le serveur SPSS Statistics. Pour obtenir plus d’informations concernant l’utilisation deBatch Facility, consultez SPSS Batch Facility User’s Guide, fourni en tant que fichier PDF surle CD du serveur SPSS Statistics.
Le processus de notation comporte les étapes suivantes :
E Chargement d’un modèle depuis un fichier au format XML (PMML).
E Calcul de vos scores comme nouvelle variable, à l’aide de la fonction ApplyModel ouStrApplyModel disponible dans la boîte de dialogue Calculer la variable.
Pour obtenir des détails au sujet des fonctions ApplyModel ou StrApplyModel, consultezExpressions de notation dans la section Expressions de transformation de Command SyntaxReference.
Le tableau suivant répertorie les procédures qui prennent en charge l’export des spécifications demodèle vers un fichier XML. Les modèles exportés peuvent être utilisés avec le serveur SPSSStatistics pour noter de nouvelles données comme décrit précédemment. La liste complètedes types de modèle pouvant être notés avec le serveur SPSS Statistics est disponible dans ladescription de la fonction ApplyModel.
Nom de la procédure Nom de la commande OptionAnalyse discriminante DISCRIMINANT BaseRégression linéaire REGRESSION BaseClassification TwoStep TWOSTEP CLUSTER BaseModèles linéaires généralisés GENLIN Advanced StatisticsModèle linéaire général des échantillonscomplexes
CSGLM Echantillonnage
Régression logistique des échantillonscomplexes
CSLOGISTIC Echantillonnage
Régression ordinale des échantillonscomplexes
CSORDINAL Echantillonnage
Régression logistique LOGISTIC REGRESSION RégressionRégression logistique multinomiale NOMREG RégressionArbre de décision TREE Tree

187
Transformations de données
Chargement d’un modèle enregistré
La boîte de dialogue Charger un modèle permet de charger des modèles de prévision enregistrésau format XML (PMML) et est seulement disponible lorsque vous travaillez en mode d’analysedistribuée. Le chargement des modèles est une première étape indispensable pour pouvoir lesutiliser afin de noter les données.
Figure 8-33Charger le résultat du modèle
Pour charger un modèle
E A partir des menus, sélectionnez :Transformer
Préparer le modèleChargement du modèle...
Figure 8-34Boîte de dialogue Préparer le modèle Charger le modèle
E Entrez un nom à associer avec ce modèle. Chaque modèle chargé doit avoir un nom unique.
E Cliquez sur Fichier et sélectionnez un fichier de modèle. La boîte de dialogue Ouvrir le fichier enrésultant affiche les fichiers disponibles en mode d’analyse distribuée. Cela comprend les fichiersde l’ordinateur sur lequel le serveur SPSS Statistics est installé et les fichiers de votre ordinateurlocal se trouvant dans des dossiers ou des lecteurs partagés.

188
Chapitre 8
Remarque : Lorsque vous notez des données, le modèle sera appliqué aux variables dansl’ensemble de données actif portant les mêmes noms que les variables du fichier de modèle. Vouspouvez lier des variables du modèle d’origine à différentes variables de l’ensemble de donnéesactif en utilisant la syntaxe de commande (voir la commande MODEL HANDLE).
Nom. Un nom utilisé pour identifier ce modèle. Les règles pour la dénomination correcte desmodèles sont les mêmes que pour les noms de variable (reportez-vous à Noms de variable dansChapitre 5 sur p. 84), en ajoutant le caractère $ comme premier caractère autorisé. Vous utilisezce nom pour indiquer le modèle lors de la notation des données avec les fonctions ApplyModelou StrApplyModel.
Fichier. Le fichier XML (PMML) contenant les spécifications du modèle.
Valeurs manquantes
Ce groupe d’options contrôle le traitement des valeurs manquantes rencontrées lors du processusde notation pour les variables indépendantes définies dans le modèle. Une valeur manquante dansle contexte de la notation réfère à l’une des options suivantes :
Une variable explicative ne contient pas de valeur. Pour les variables numériques, celacorrespond à la variable manquante par défaut. Pour les variables de chaîne, cela correspondà une chaîne nulle.La valeur a été définie comme manquante utilisateur dans le modèle, pour l’explicationdonnée. Les valeurs manquantes spécifiées dans le fichier de travail mais pas dans le modèlene seront pas traitées comme des valeurs manquantes lors du processus d’analyse.La variable indépendante est une variable catégorielle et la valeur ne fait pas partie desmodalités définies dans le modèle.
Utiliser la valeur de substitution. Tentative pour utiliser une valeur de substitution lors de lanotation d’observations avec des valeurs manquantes. La méthode pour déterminer une valeur sesubstituant à une valeur manquante dépend du modèle de prévision.
SPSS Statistics Modèles. Pour des variables indépendantes dans une régression linéaire et desmodèles discriminants, si la valeur moyenne de substitution pour les valeurs manquantes a étéspécifiée lors de la construction et l’enregistrement du modèle, alors cette valeur moyenneest utilisée à la place de la valeur manquante lors du calcul des notes et lors du processus denotation. Si cette valeur moyenne n’est pas disponible, alors la valeur manquante par défautest retournée.Modèles AnswerTree et modèles de commande TREE. Pour les modèles CHAID et ExhaustiveCHAID, le plus gros nœud enfant est sélectionné pour une variable de scission manquante. Leplus gros nœud enfant est celui possédant la plus large population parmi les nœuds enfantutilisant des observations d’échantillon d’apprentissage. Pour les modèles C&RT et QUEST,les variables de scission de substitution (le cas échéant) sont utilisées en premier. (Lesvariables de scission de substitution sont des variables de scission qui tentent de correspondreau mieux à la variable de scission originale en utilisant des variables indépendantesalternatives.) Si aucune variable de scission de substitution n’est spécifiée ou si toutes lesvariables de scission de substitution sont manquantes, le plus gros nœud enfant est utilisé.

189
Transformations de données
Modèles Clementine. Les modèles de régression linéaire sont traités comme indiqué pour lesmodèles SPSS Statistics. Les modèles de régression logistique sont traités comme indiquépour les modèles de régression logistique. Les modèles C&RT Tree sont traités commeindiqué pour les modèles C&RT sous les modèles AnswerTree.Modèles de régression logistique. Pour les covariables des modèles de régression logistique, siune valeur moyenne de la variable indépendante a été inclue dans le modèle enregistré, alorscette valeur moyenne est utilisée à la place de la valeur manquante dans le calcul des notes etles processus de notation. Si la variable indépendante est qualitative (par exemple un facteurd’un modèle de régression logistique) ou si la valeur moyenne n’est pas disponible, alors lavaleur manquante par défaut est retournée.
Utiliser la valeur manquante par défaut. Retourne la valeur manquante par défaut lors de la notationd’une observation comportant une valeur manquante.
Affichage d’une liste de modèles chargés
Vous pouvez obtenir une liste des modèles actuellement chargés. A partir des menus (uniquementdisponibles en mode d’analyse distribuée), choisissez :Transformer
Préparer le modèleLister le(s) modèle(s)
Cela génère un tableau Descriptions des modèles. Ce tableau contient une liste des modèlesactuellement chargés et inclut le nom (appelé description du modèle) assigné au modèle, son type,le chemin d’accès au fichier du modèle et la méthode utilisée pour traiter les valeurs manquantes.
Figure 8-35Liste des modèles chargés
Fonctions supplémentaires avec la syntaxe de commande
A partir de la boîte de dialogue Charger le modèle, vous pouvez coller vos sélections dans unefenêtre de syntaxe et modifier la syntaxe de commande MODEL HANDLE en résultant. Cela vouspermet de :
Lier les variables du modèle original à différentes variables de l’ensemble de données actif(avec la sous-commande MAP). Par défaut, le modèle sera appliqué aux variables dansl’ensemble de données actif portant les mêmes noms que les variables du fichier de modèle.
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.

Chapitre
9Gestion et transformations de fichiers
L’organisation des fichiers de données ne répond pas toujours idéalement à vos besoins. Vouspouvez, par exemple, combiner des fichiers, trier des données dans un ordre différent, sélectionnerdes sous-ensembles d’observations ou modifier l’unité d’analyse en regroupant les observations.De nombreuses possibilités de transformation de fichier sont disponibles, y compris la possibilitéde :
Trier les données : Vous pouvez trier les observations en fonction de la valeur de certaines variables.
Transposer des observations et des variables : Le format des fichiers de données SPSS Statistics litles lignes comme des observations et les colonnes comme des variables. Vous pouvez inverserles lignes et les colonnes et lire les données selon le bon format pour les fichiers qui présententles informations dans l’autre sens.
Fusionner des fichiers : Vous pouvez fusionner des fichiers de données (au moins deux). Vouspouvez associer des fichiers disposant des mêmes variables mais présentant des observationsdifférentes, ou l’inverse.
Sélectionner des sous-ensembles d’observations : Vous pouvez limiter votre analyse à unsous-ensemble d’observations ou effectuer des analyses simultanées sur différents sous-ensembles.
Agréger les données : Vous pouvez modifier l’unité d’analyse en agrégeant des observations enfonction de la valeur d’une ou plusieurs variables de regroupement.
Pondérer les données : Vous pouvez pondérer les observations à analyser selon la valeur d’unevariable de pondération.
Restructurer les données : Vous pouvez restructurer des données pour créer une observation (unenregistrement) à partir de plusieurs observations ou créer plusieurs observations à partir d’uneseule.
Trier les observations
Cette boîte de dialogue permet de trier les observations (lignes) du fichier en fonction des valeursd’une ou plusieurs variables de tri. Vous pouvez trier les observations par ordre croissant oudécroissant.
Si vous sélectionnez plusieurs variables de tri, les observations sont triées pour chaquevariable au sein des modalités de la variable précédente dans la liste Tri. Par exemple, sivous sélectionnez Sexe comme première variable de tri et Culture comme seconde variable
190
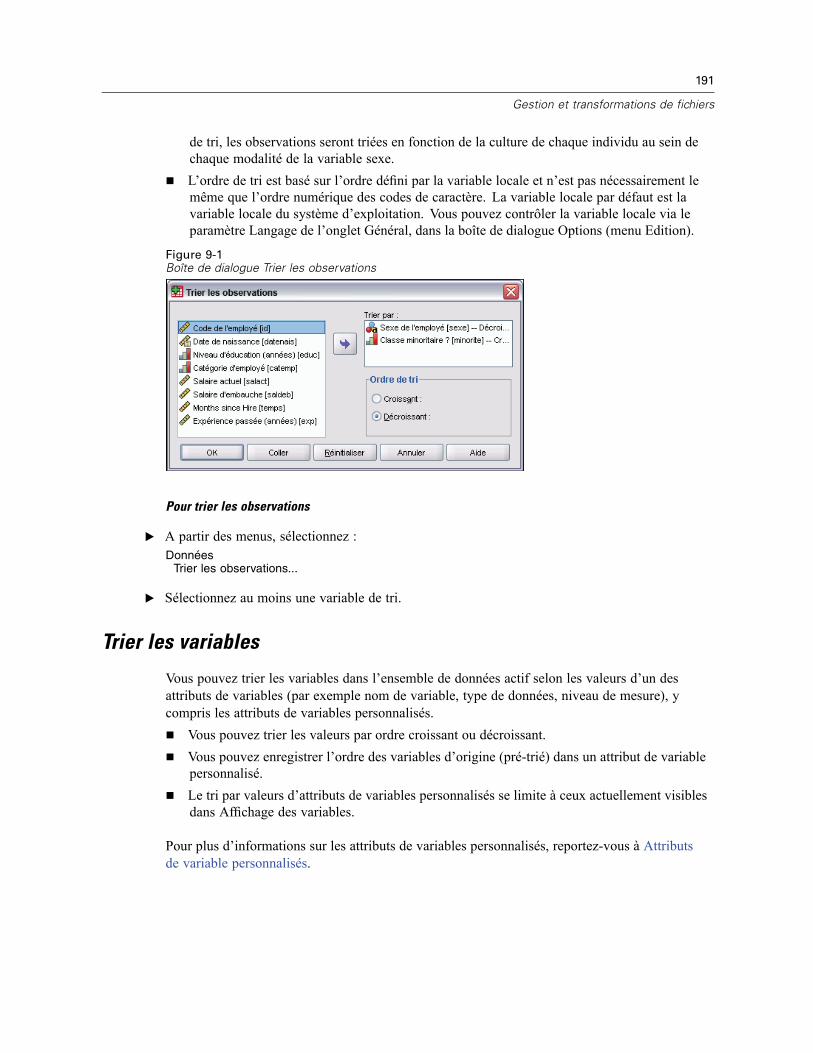
191
Gestion et transformations de fichiers
de tri, les observations seront triées en fonction de la culture de chaque individu au sein dechaque modalité de la variable sexe.L’ordre de tri est basé sur l’ordre défini par la variable locale et n’est pas nécessairement lemême que l’ordre numérique des codes de caractère. La variable locale par défaut est lavariable locale du système d’exploitation. Vous pouvez contrôler la variable locale via leparamètre Langage de l’onglet Général, dans la boîte de dialogue Options (menu Edition).
Figure 9-1Boîte de dialogue Trier les observations
Pour trier les observations
E A partir des menus, sélectionnez :Données
Trier les observations...
E Sélectionnez au moins une variable de tri.
Trier les variables
Vous pouvez trier les variables dans l’ensemble de données actif selon les valeurs d’un desattributs de variables (par exemple nom de variable, type de données, niveau de mesure), ycompris les attributs de variables personnalisés.
Vous pouvez trier les valeurs par ordre croissant ou décroissant.Vous pouvez enregistrer l’ordre des variables d’origine (pré-trié) dans un attribut de variablepersonnalisé.Le tri par valeurs d’attributs de variables personnalisés se limite à ceux actuellement visiblesdans Affichage des variables.
Pour plus d’informations sur les attributs de variables personnalisés, reportez-vous à Attributsde variable personnalisés.
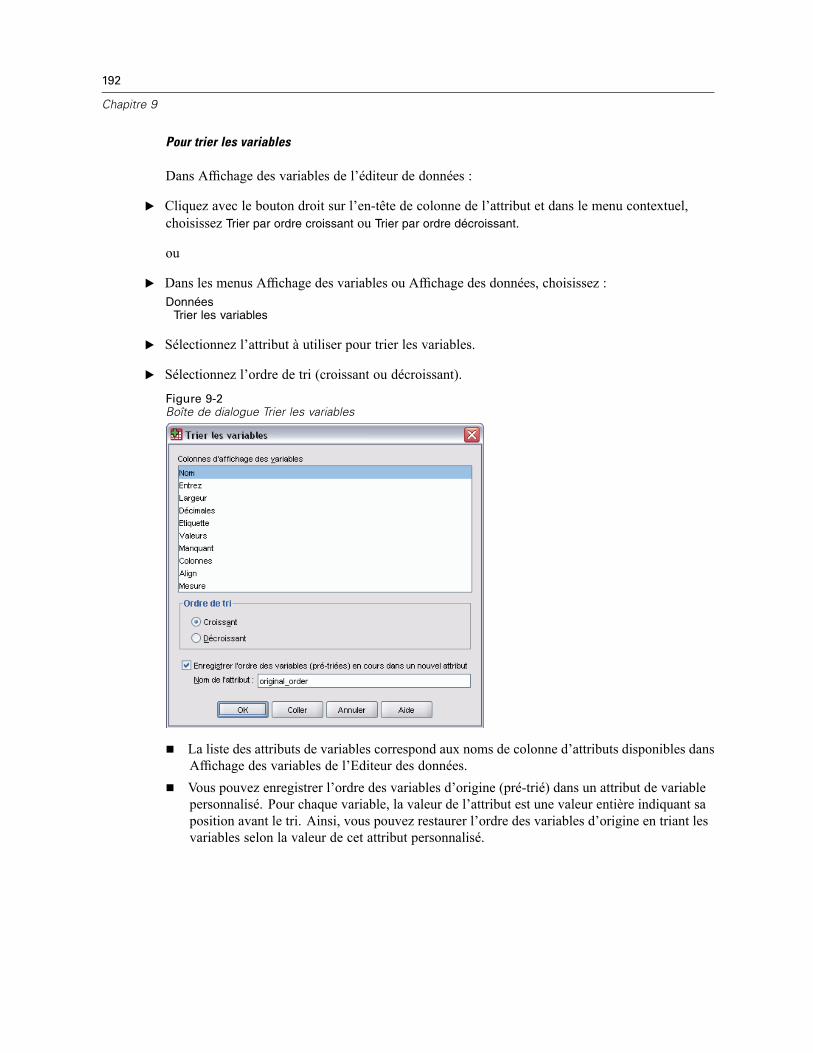
192
Chapitre 9
Pour trier les variables
Dans Affichage des variables de l’éditeur de données :
E Cliquez avec le bouton droit sur l’en-tête de colonne de l’attribut et dans le menu contextuel,choisissez Trier par ordre croissant ou Trier par ordre décroissant.
ou
E Dans les menus Affichage des variables ou Affichage des données, choisissez :Données
Trier les variables
E Sélectionnez l’attribut à utiliser pour trier les variables.
E Sélectionnez l’ordre de tri (croissant ou décroissant).
Figure 9-2Boîte de dialogue Trier les variables
La liste des attributs de variables correspond aux noms de colonne d’attributs disponibles dansAffichage des variables de l’Editeur des données.Vous pouvez enregistrer l’ordre des variables d’origine (pré-trié) dans un attribut de variablepersonnalisé. Pour chaque variable, la valeur de l’attribut est une valeur entière indiquant saposition avant le tri. Ainsi, vous pouvez restaurer l’ordre des variables d’origine en triant lesvariables selon la valeur de cet attribut personnalisé.

193
Gestion et transformations de fichiers
Transposer
La transposition permet de créer un nouveau fichier dans lequel les lignes et les colonnes du fichierinitial sont inversées pour que les observations (lignes) deviennent des variables (colonnes), etvice versa. SPSS génère automatiquement de nouveaux noms pour les variables et affiche uneliste de ces nouveaux noms.
Une nouvelle variable de type chaîne contenant le nom de variable d’origine, case_lbl, estautomatiquement créée.Si l’ensemble de données actif contient un ID (identifiant) ou une variable de nom dont lesvaleurs sont uniques, vous pouvez l’utiliser comme variable de nom et employer ses valeurscomme noms de variable dans le fichier transposé. S’il s’agit d’une variable numérique, lesnoms de variables commencent par la lettre V, suivie de la valeur numérique.Les valeurs manquantes à l’utilisateur sont converties en valeurs manquantes par défaut dansle fichier transposé. Pour conserver certaines de ces valeurs, modifiez la définition des valeursmanquantes dans l’affichage des variables de l’éditeur de données.
Pour transposer des variables et des observations
E A partir des menus, sélectionnez :Données
Transposer
E Sélectionnez au moins une variable à transposer en observation.
Fusionner des fichiers de données
SPSS vous permet de fusionner des données à partir de deux fichiers et de deux façons différentes.Vous pouvez:
Fusionner l’ensemble de données actif avec un autre ensemble de données ouvert ou avecun fichier de données au format SPSS Statistics contenant les mêmes variables mais desobservations différentes.Fusionner l’ensemble de données actif avec un autre ensemble de données ouvert ou avecun fichier de données au format SPSS Statistics contenant les mêmes observations maisdes varaibles différentes.
Pour fusionner des fichiers
E A partir des menus, sélectionnez :Données
Fusionner des fichiers
E Sélectionnez Ajouter des observations ou Ajouter des variables.
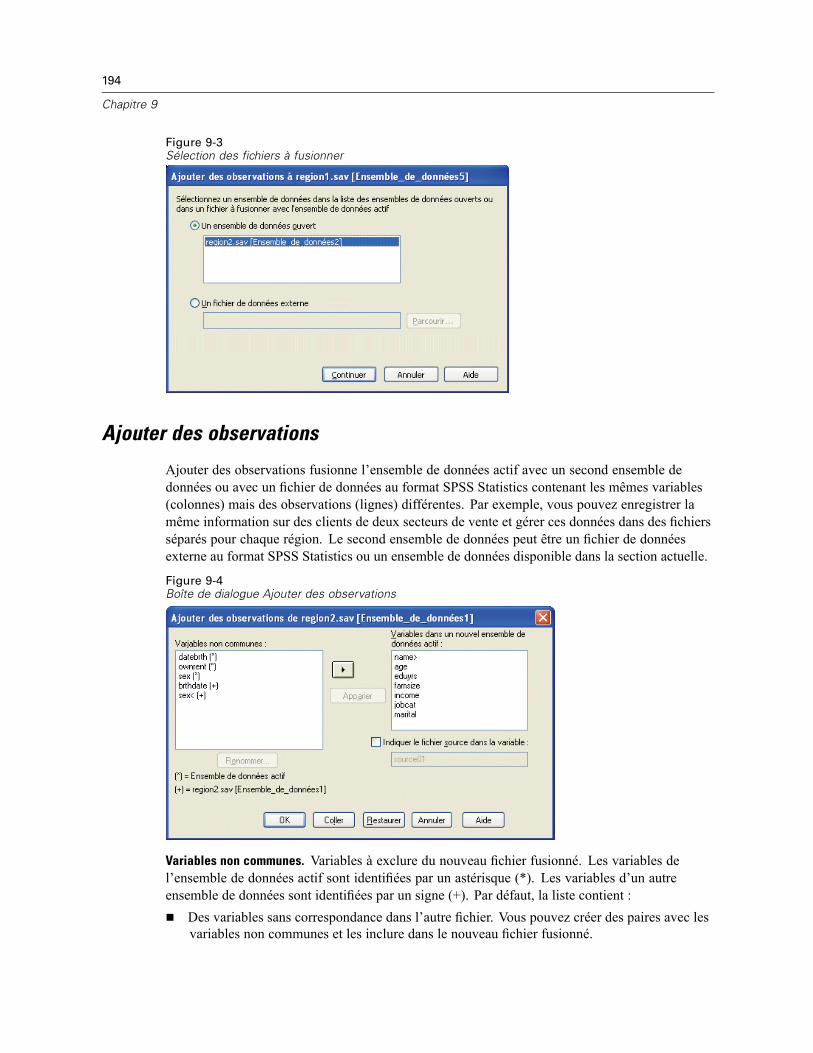
194
Chapitre 9
Figure 9-3Sélection des fichiers à fusionner
Ajouter des observations
Ajouter des observations fusionne l’ensemble de données actif avec un second ensemble dedonnées ou avec un fichier de données au format SPSS Statistics contenant les mêmes variables(colonnes) mais des observations (lignes) différentes. Par exemple, vous pouvez enregistrer lamême information sur des clients de deux secteurs de vente et gérer ces données dans des fichiersséparés pour chaque région. Le second ensemble de données peut être un fichier de donnéesexterne au format SPSS Statistics ou un ensemble de données disponible dans la section actuelle.
Figure 9-4Boîte de dialogue Ajouter des observations
Variables non communes. Variables à exclure du nouveau fichier fusionné. Les variables del’ensemble de données actif sont identifiées par un astérisque (*). Les variables d’un autreensemble de données sont identifiées par un signe (+). Par défaut, la liste contient :
Des variables sans correspondance dans l’autre fichier. Vous pouvez créer des paires avec lesvariables non communes et les inclure dans le nouveau fichier fusionné.

195
Gestion et transformations de fichiers
Des variables contenant des données numériques dans l’un des fichiers et des donnéesalphanumériques dans l’autre. Il est impossible de fusionner des variables numériques avecdes variables alphanumériques.Des variables alphanumériques de longueur différente. La longueur définie pour une variablealphanumérique doit être la même dans les deux fichiers.
Variables dans un nouvel ensemble de données actif. Variables à inclure dans le nouveau fichieractif. Par défaut, toutes les variables dont le nom et le type correspond sont ajoutées à la liste.
Vous pouvez supprimer des variables de la liste si vous ne les souhaitez pas dans le fichierfusionné.Les variables non communes incluses dans le fichier fusionné contiendront des donnéesmanquantes pour les observations du fichier qui ne les contient pas.
Indiquer le fichier source dans la variable. Indique le fichier de données source pour chaqueobservation. Cette variable a une valeur de 0 pour les observations de l'ensemble de données actifet une valeur de 1 pour les observations du fichier de données externe.
Pour fusionner des fichiers de données avec les mêmes variables mais des observations différentes
E Ouvrez au moins un des fichiers de données que vous souhaitez fusionner. Si il y a plusieursensembles de données ouverts, faites de l’un de celui dont vous souhaitez fusionner l’ensemblede données actif. Les observations de ce fichier apparaissent en premier dans le nouveau fichierfusionné.
E A partir des menus, sélectionnez :Données
Fusionner des fichiersAjouter des observations
E Sélectionnez l’ensemble de données ou le fichier de données au format SPSS Statistics à fusionneravec l’ensemble de données actif.
E Supprimez toutes les variables indésirables de la liste Variables du nouvel ensemble de donnéesactif.
E Ajouter des paires de variables de la liste des variables non communes qui représentent les mêmesinformations mais enregistrées sous des noms différents dans les deux fichiers. Par exemple, ladate de naissance peut être enregistrée sous datenais dans un fichier et né_le dans l’autre.
Sélectionner une paire de variables non communes
E Cliquez sur l’une des variables dans la liste Variables non communes.
E Tout en maintenant la touche Ctrl enfoncée, cliquez sur l’autre variable dans la liste. (Appuyez surla touche Ctrl et cliquez en même temps sur le bouton gauche de la souris.)
E Cliquez sur Apparier pour déplacer la paire de variables dans la liste Variables du nouvel ensemblede données actif. (Le nom de variable de l’ensemble de données est utilisé comme nom devariable dans le fichier fusionné.)
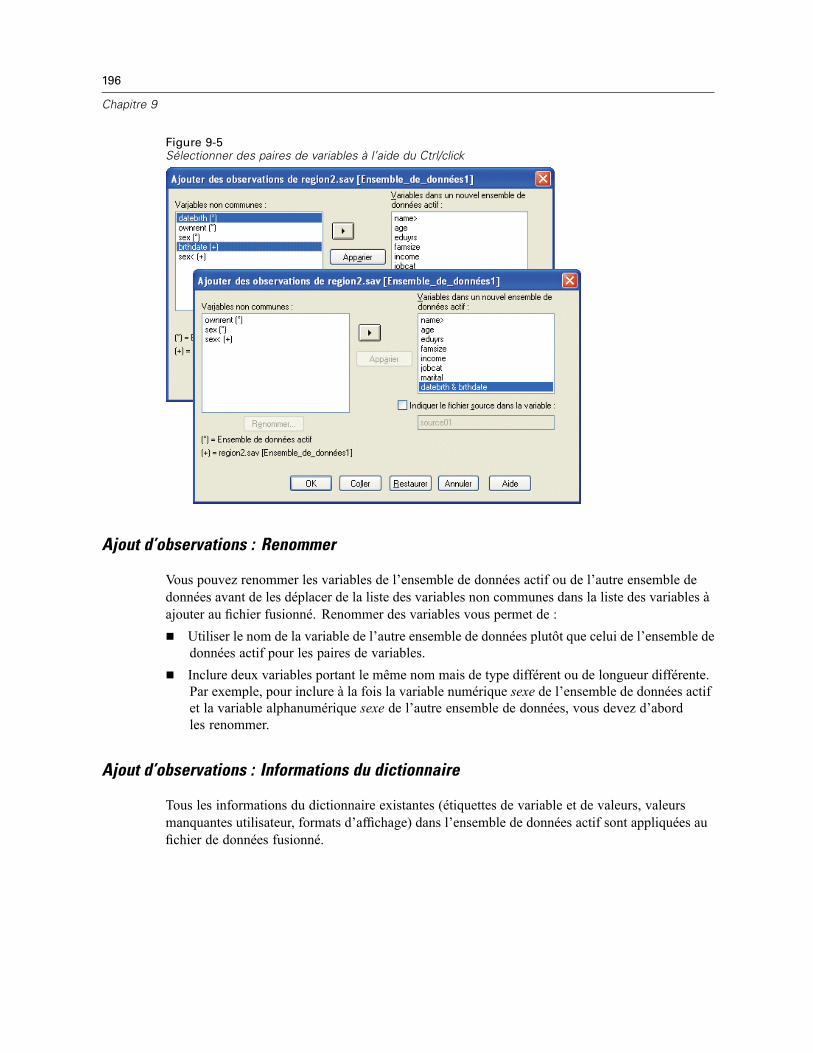
196
Chapitre 9
Figure 9-5Sélectionner des paires de variables à l’aide du Ctrl/click
Ajout d’observations : Renommer
Vous pouvez renommer les variables de l’ensemble de données actif ou de l’autre ensemble dedonnées avant de les déplacer de la liste des variables non communes dans la liste des variables àajouter au fichier fusionné. Renommer des variables vous permet de :
Utiliser le nom de la variable de l’autre ensemble de données plutôt que celui de l’ensemble dedonnées actif pour les paires de variables.Inclure deux variables portant le même nom mais de type différent ou de longueur différente.Par exemple, pour inclure à la fois la variable numérique sexe de l’ensemble de données actifet la variable alphanumérique sexe de l’autre ensemble de données, vous devez d’abordles renommer.
Ajout d’observations : Informations du dictionnaire
Tous les informations du dictionnaire existantes (étiquettes de variable et de valeurs, valeursmanquantes utilisateur, formats d’affichage) dans l’ensemble de données actif sont appliquées aufichier de données fusionné.

197
Gestion et transformations de fichiers
Si certaines informations du dictionnaire relatives à une variable ne sont pas définies dansl’ensemble de données actif, les informations du dictionnaire de l’autre ensemble de donnéess’appliquent.Si l’ensemble de données actif contient des étiquettes de valeurs non définies ou desvaleurs manquantes de type utilisateur, toutes les autres étiquettes de valeurs ou les valeursmanquantes de type utilisateur pour cette variable dans l’autre ensemble de données sontignorées.
Fusion de plus de deux sources de données
A l’aide de la syntaxe de commande, vous pouvez fusionner jusqu’à 50 ensembles de donnéeset/ou de fichiers de données. Pour plus d’informations, reportez-vous à la commande ADD FILES
dans Command Syntax Reference (accessible depuis le menu Aide).
Ajouter des variables
Ajouter des variables fusionne l’ensemble de données actif avec un autre fichier de donnéesouvert ou avec un fichier de données SPSS Statistics contenant les mêmes observations (lignes)mais des variables (colonnes) différentes. Par exemple, vous souhaitez fusionner un fichier dedonnées contenant les résultats d’un test préalable avec un autre fichier contenant les résultatsd’un test final.
Les observations doivent être présentées dans le même ordre dans les deux ensembles dedonnées.Si une ou plusieurs clés d’appariement sont utilisées pour apparier les observations, les deuxensembles de données doivent présenter ces clés d’appariement par ordre croissant.Les noms de variable du second fichier, redondants avec les noms de l’ensemble de donnéesactif, sont exclus par défaut. En effet, SPSS part du principe que ces variables contiennent desinformations redondantes.
Indiquer le fichier source dans la variable. Indique le fichier de données source pour chaqueobservation. Cette variable a une valeur de 0 pour les observations de l'ensemble de données actifet une valeur de 1 pour les observations du fichier de données externe.
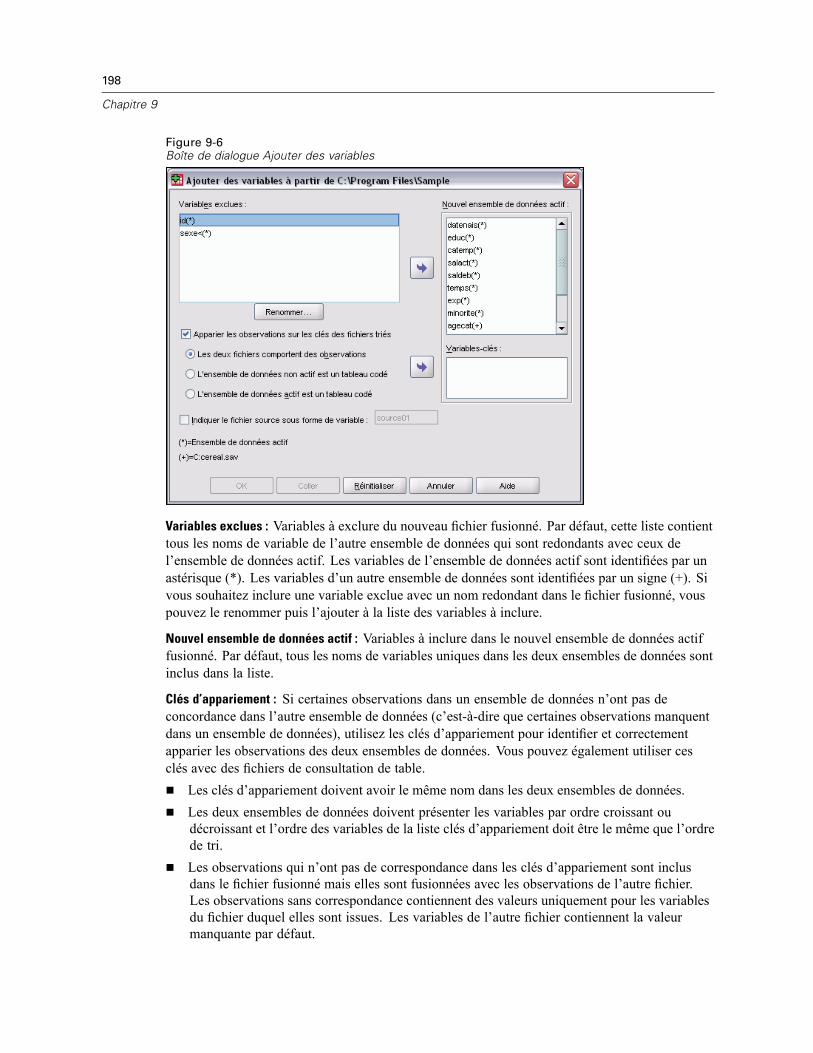
198
Chapitre 9
Figure 9-6Boîte de dialogue Ajouter des variables
Variables exclues : Variables à exclure du nouveau fichier fusionné. Par défaut, cette liste contienttous les noms de variable de l’autre ensemble de données qui sont redondants avec ceux del’ensemble de données actif. Les variables de l’ensemble de données actif sont identifiées par unastérisque (*). Les variables d’un autre ensemble de données sont identifiées par un signe (+). Sivous souhaitez inclure une variable exclue avec un nom redondant dans le fichier fusionné, vouspouvez le renommer puis l’ajouter à la liste des variables à inclure.
Nouvel ensemble de données actif : Variables à inclure dans le nouvel ensemble de données actiffusionné. Par défaut, tous les noms de variables uniques dans les deux ensembles de données sontinclus dans la liste.
Clés d’appariement : Si certaines observations dans un ensemble de données n’ont pas deconcordance dans l’autre ensemble de données (c’est-à-dire que certaines observations manquentdans un ensemble de données), utilisez les clés d’appariement pour identifier et correctementapparier les observations des deux ensembles de données. Vous pouvez également utiliser cesclés avec des fichiers de consultation de table.
Les clés d’appariement doivent avoir le même nom dans les deux ensembles de données.Les deux ensembles de données doivent présenter les variables par ordre croissant oudécroissant et l’ordre des variables de la liste clés d’appariement doit être le même que l’ordrede tri.Les observations qui n’ont pas de correspondance dans les clés d’appariement sont inclusdans le fichier fusionné mais elles sont fusionnées avec les observations de l’autre fichier.Les observations sans correspondance contiennent des valeurs uniquement pour les variablesdu fichier duquel elles sont issues. Les variables de l’autre fichier contiennent la valeurmanquante par défaut.

199
Gestion et transformations de fichiers
L’ensemble de données actif ou non actif est une table codée : Une table codée ou un fichier deconsultation de table, est un fichier dans lequel les données de chaque observation peuvents’appliquer à plusieurs observations de l’autre fichier. Par exemple, si un des fichiers contient desinformations sur les différents membres d’une famille (sexe, âge, niveau scolaire) et l’autre desinformations générales sur la famille (revenu global, taille, habitat), vous pouvez utiliser le fichiersur la famille comme fichier de consultation et appliquer les informations générales à chaquemembre de la famille dans le fichier fusionné.
Pour fusionner des fichiers avec les mêmes variables mais des observations différentes
E Ouvrez au moins un des fichiers de données que vous souhaitez fusionner. Si il y a plusieursensembles de données ouverts, faites de l’un de celui dont vous souhaitez fusionner l’ensemblede données actif.
E A partir des menus, sélectionnez :Données
Fusionner des fichiersAjouter des variables
E Sélectionnez l’ensemble de données ou le fichier de données au format SPSS Statistics à fusionneravec l’ensemble de données actif.
Sélectionnez des clés d’appariement
E Sélectionnez les variables du fichier externe (+) dans la liste des Variables exclues.
E Sélectionnez Apparier les observations sur les clés des fichiers triés.
E Ajoutez des variables à la liste des clés d’appariement.
Les clés d’appariement doivent exister à la fois dans l’ensemble de données actif et dans l’autre.Les deux ensembles de données doivent présenter les variables par ordre croissant ou décroissantet l’ordre des variables de la liste clés d’appariement doit être le même que l’ordre de tri.
Ajouter des variables : Renommer
Vous pouvez renommer les variables de l’ensemble de données actif ou de l’autre ensemble dedonnées avant de les déplacer dans la liste des variables à ajouter au fichier fusionné. Ceci estparticulièrement important si vous souhaitez inclure deux variables portant le même nom maiscontenant des informations différentes.
Fusion de plus de deux sources de données
A l’aide de la syntaxe de commande, vous pouvez fusionner jusqu’à 50 ensembles de donnéeset/ou de fichiers de données. Pour plus d’informations, reportez-vous à la commande MATCHFILES dans Command Syntax Reference (accessible depuis le menu Aide).

200
Chapitre 9
Agréger les données
L’option Agréger les données permet d’agréger des groupes d’observations de l’ensemble dedonnées actif dans des observations uniques. Elle permet également de créer dans l’ensemble dedonnées actif un nouveau fichier agrégé ou de nouvelles variables qui contiennent des donnéesagrégées. Les observations sont agrégées en fonction de la valeur de zéro ou de plusieurs critèresd’agrégation (regroupement). Si aucun critère d’agrégation n’est spécifié, l’ensemble de donnéesentier est un agrégat unique.
Si vous créez un fichier de données agrégées, il contient une observation pour chaquegroupe défini par les critères d’agrégation. Par exemple, s’il existe un critère d’agrégationcomprenant deux valeurs, le nouveau fichier de données contiendra uniquement deuxobservations. Si aucun critère d’agrégation n’est spécifié, le nouveau fichier de donnéescontient une seule observation.Si vous ajoutez des variables d’agrégation à l’ensemble de données actif, le fichier de donnéesn’est pas agrégé. Chaque observation disposant des mêmes valeurs des critères d’agrégationreçoit les mêmes valeurs pour les nouvelles variables d’agrégation. Par exemple, si le seulcritère d’agrégation est sexe, tous les hommes reçoivent la même valeur pour une nouvellevariable d’agrégation qui représente l’âge moyen. Si aucun critère d’agrégation n’est spécifié,toutes les observations reçoivent la même valeur pour une nouvelle variable d’agrégationqui représente l’âge moyen.
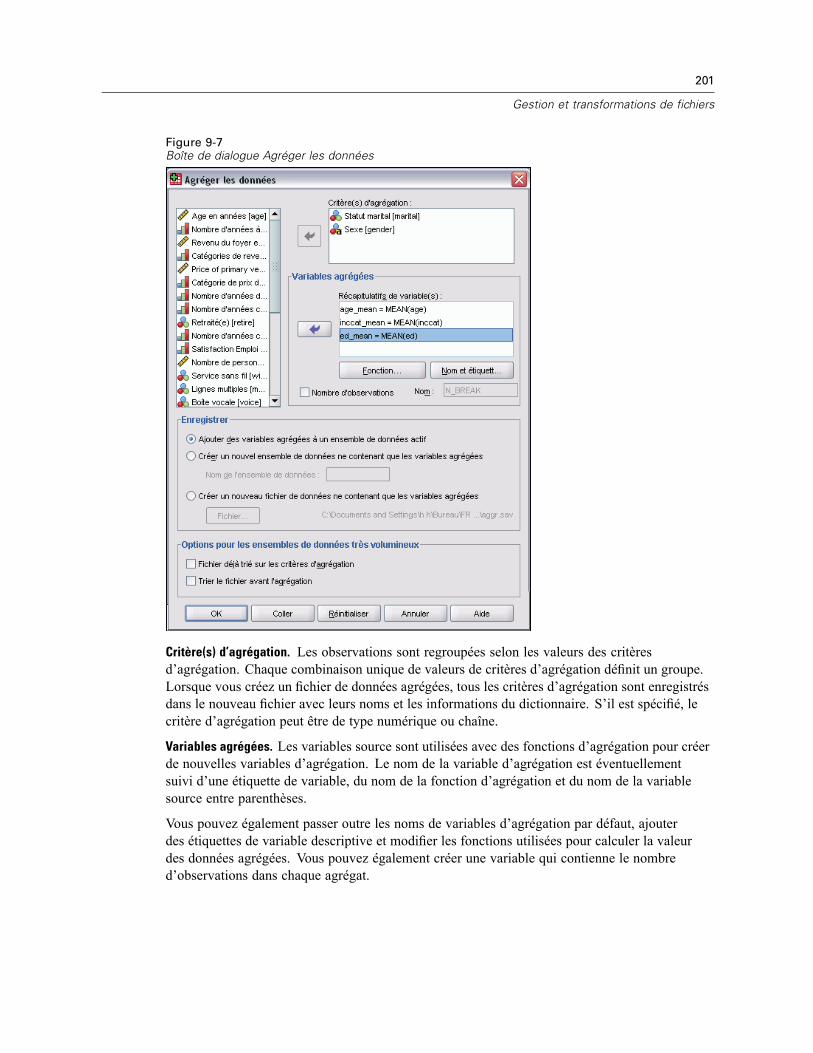
201
Gestion et transformations de fichiers
Figure 9-7Boîte de dialogue Agréger les données
Critère(s) d’agrégation. Les observations sont regroupées selon les valeurs des critèresd’agrégation. Chaque combinaison unique de valeurs de critères d’agrégation définit un groupe.Lorsque vous créez un fichier de données agrégées, tous les critères d’agrégation sont enregistrésdans le nouveau fichier avec leurs noms et les informations du dictionnaire. S’il est spécifié, lecritère d’agrégation peut être de type numérique ou chaîne.
Variables agrégées. Les variables source sont utilisées avec des fonctions d’agrégation pour créerde nouvelles variables d’agrégation. Le nom de la variable d’agrégation est éventuellementsuivi d’une étiquette de variable, du nom de la fonction d’agrégation et du nom de la variablesource entre parenthèses.
Vous pouvez également passer outre les noms de variables d’agrégation par défaut, ajouterdes étiquettes de variable descriptive et modifier les fonctions utilisées pour calculer la valeurdes données agrégées. Vous pouvez également créer une variable qui contienne le nombred’observations dans chaque agrégat.

202
Chapitre 9
Pour agréger un fichier de données
E A partir des menus, sélectionnez :Données
Agréger
E En option, sélectionnez des critères d’agrégation qui définissent la façon dont les observationssont groupées pour créer des données agrégées. Si aucun critère d’agrégation n’est spécifié,l’ensemble de données entier est un agrégat unique.
E Sélectionnez une ou plusieurs variables d’agrégation.
E Sélectionnez une fonction d’agrégation pour chaque variable d’agrégation.
Enregistrement des résultats agrégés
Vous pouvez ajouter des variables d’agrégation à l’ensemble de données actif ou créer un nouveaufichier de données agrégées.
Ajouter les variables agrégées au fichier de travail. Les nouvelles valeurs basées sur lesfonctions d'agrégation sont ajoutées à l'ensemble de données actif. Le fichier de donnéeslui-même n'est pas agrégé. Chaque observation disposant des mêmes valeurs des critèresd'agrégation reçoit les mêmes valeurs pour les nouvelles variables d'agrégation.Créer un nouvel ensemble de données ne contenant que les variables agrégées. Enregistre lesdonnées agrégées dans un nouvel ensemble de données de la session en cours. L'ensemblede données comprend les critères d'agrégation qui définissent les observations agrégées ettoutes les variables d'agrégation définies par les fonctions d'agrégation. L'ensemble dedonnées actif n'est pas affecté.Créer un nouveau fichier de données ne contenant que les variables agrégées. Enregistreles données agrégées dans un fichier de données externe. Le fichier comprend les critèresd'agrégation qui définissent les observations agrégées et toutes les variables d'agrégationdéfinies par les fonctions d'agrégation. L'ensemble de données actif n'est pas affecté.
Options de tri des fichiers de données volumineux
Pour les fichiers de données volumineux, il peut être plus judicieux d’agréger des donnéespréalablement triées.
Le fichier est déjà trié sur les variables d'agrégation. Si les données ont déja été triées en fonctiondes valeurs des critères d'agrégation, cette option permet une exécution plus rapide de la procédureet une économie de mémoire. Utilisez cette option avec précaution.
Les données doivent être triées en fonction des valeurs des critères d’agrégation, dans le mêmeordre que les critères d’agrégation indiqués pour la procédure Agréger les données.Si vous ajoutez des variables au fichier de travail, sélectionnez cette option uniquement si lesdonnées sont triées dans l’ordre croissant en fonction des critères d’agrégation.
Trier le fichier avant d'agréger. Dans de très rares cas avec des fichiers de données volumineux,il peut s'avérer nécessaire de trier le fichier de données en fonction des valeurs des critèresd'agrégation avant de procéder à l'agrégation. Cette option est déconseillée, sauf si vous rencontrezdes problèmes de mémoire/performances.
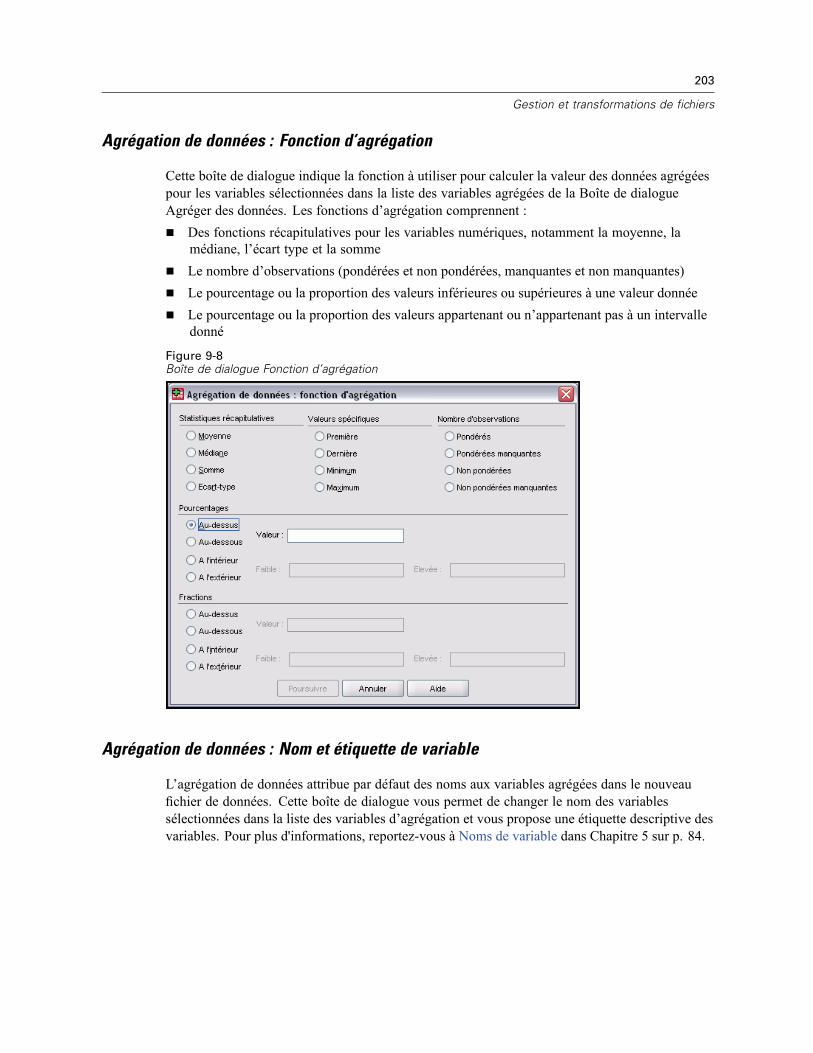
203
Gestion et transformations de fichiers
Agrégation de données : Fonction d’agrégation
Cette boîte de dialogue indique la fonction à utiliser pour calculer la valeur des données agrégéespour les variables sélectionnées dans la liste des variables agrégées de la Boîte de dialogueAgréger des données. Les fonctions d’agrégation comprennent :
Des fonctions récapitulatives pour les variables numériques, notamment la moyenne, lamédiane, l’écart type et la sommeLe nombre d’observations (pondérées et non pondérées, manquantes et non manquantes)Le pourcentage ou la proportion des valeurs inférieures ou supérieures à une valeur donnéeLe pourcentage ou la proportion des valeurs appartenant ou n’appartenant pas à un intervalledonné
Figure 9-8Boîte de dialogue Fonction d’agrégation
Agrégation de données : Nom et étiquette de variable
L’agrégation de données attribue par défaut des noms aux variables agrégées dans le nouveaufichier de données. Cette boîte de dialogue vous permet de changer le nom des variablessélectionnées dans la liste des variables d’agrégation et vous propose une étiquette descriptive desvariables. Pour plus d'informations, reportez-vous à Noms de variable dans Chapitre 5 sur p. 84.
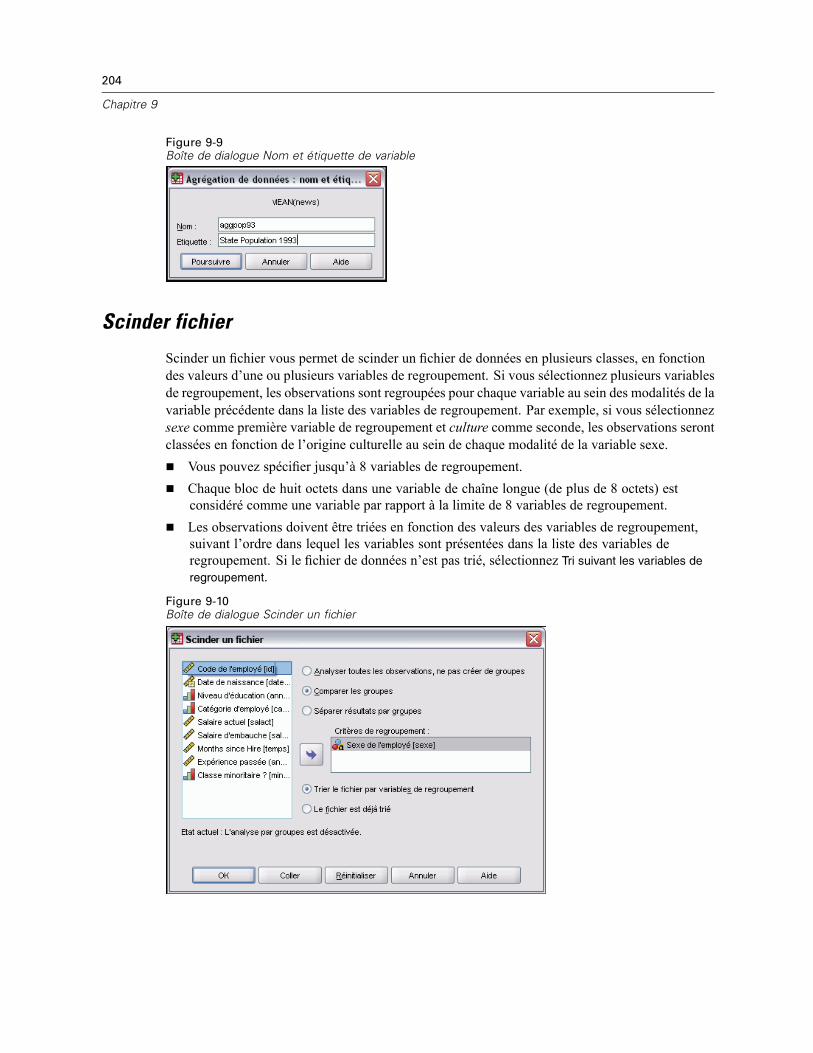
204
Chapitre 9
Figure 9-9Boîte de dialogue Nom et étiquette de variable
Scinder fichier
Scinder un fichier vous permet de scinder un fichier de données en plusieurs classes, en fonctiondes valeurs d’une ou plusieurs variables de regroupement. Si vous sélectionnez plusieurs variablesde regroupement, les observations sont regroupées pour chaque variable au sein des modalités de lavariable précédente dans la liste des variables de regroupement. Par exemple, si vous sélectionnezsexe comme première variable de regroupement et culture comme seconde, les observations serontclassées en fonction de l’origine culturelle au sein de chaque modalité de la variable sexe.
Vous pouvez spécifier jusqu’à 8 variables de regroupement.Chaque bloc de huit octets dans une variable de chaîne longue (de plus de 8 octets) estconsidéré comme une variable par rapport à la limite de 8 variables de regroupement.Les observations doivent être triées en fonction des valeurs des variables de regroupement,suivant l’ordre dans lequel les variables sont présentées dans la liste des variables deregroupement. Si le fichier de données n’est pas trié, sélectionnez Tri suivant les variables deregroupement.
Figure 9-10Boîte de dialogue Scinder un fichier

205
Gestion et transformations de fichiers
Comparer les classes : Les classes du fichier scindé sont présentées ensemble pour permettrela comparaison. En ce qui concerne les tableaux pivotants, un seul d’entre eux est créé etchaque variable du fichier scindé peut être déplacée entre les dimensions du tableau. Quantaux diagrammes, un diagramme distinct est créé pour chaque groupe du fichier scindé et cesdiagrammes sont affichés ensemble dans le Viewer.
Séparer résultats par groupes : Tous les résultats de chaque procédure sont affichés séparémentpour chaque classe du fichier scindé.
Pour scinder un fichier de données pour analyse
E A partir des menus, sélectionnez :Données
Scinder un fichier
E Sélectionnez Comparer les groupes ou Séparer résultats par groupes.
E Sélectionnez une ou plusieurs variables de regroupement.
Sélectionner des observations
Sélectionner les observations propose une série de méthodes pour sélectionner un sous-grouped’observations en fonction de certains critères qui incluent variables et expressions complexes.Vous pouvez également sélectionner un échantillon aléatoire d’observations. Les critères utiliséspour définir un sous-groupe comprennent :
Plages et valeurs de variablesPlages de dates et d’heuresNombres d’observations (lignes)Expressions arithmétiquesExpressions logiquesFonctions
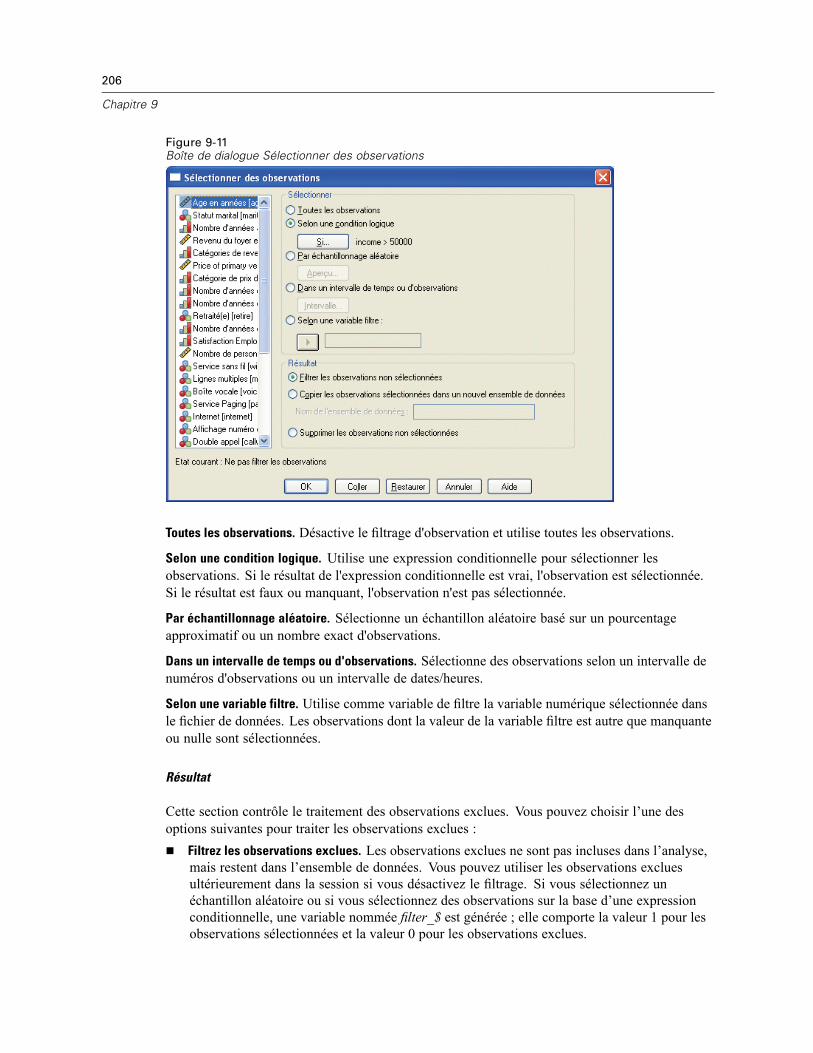
206
Chapitre 9
Figure 9-11Boîte de dialogue Sélectionner des observations
Toutes les observations. Désactive le filtrage d'observation et utilise toutes les observations.
Selon une condition logique. Utilise une expression conditionnelle pour sélectionner lesobservations. Si le résultat de l'expression conditionnelle est vrai, l'observation est sélectionnée.Si le résultat est faux ou manquant, l'observation n'est pas sélectionnée.
Par échantillonnage aléatoire. Sélectionne un échantillon aléatoire basé sur un pourcentageapproximatif ou un nombre exact d'observations.
Dans un intervalle de temps ou d'observations. Sélectionne des observations selon un intervalle denuméros d'observations ou un intervalle de dates/heures.
Selon une variable filtre. Utilise comme variable de filtre la variable numérique sélectionnée dansle fichier de données. Les observations dont la valeur de la variable filtre est autre que manquanteou nulle sont sélectionnées.
Résultat
Cette section contrôle le traitement des observations exclues. Vous pouvez choisir l’une desoptions suivantes pour traiter les observations exclues :
Filtrez les observations exclues. Les observations exclues ne sont pas incluses dans l’analyse,mais restent dans l’ensemble de données. Vous pouvez utiliser les observations excluesultérieurement dans la session si vous désactivez le filtrage. Si vous sélectionnez unéchantillon aléatoire ou si vous sélectionnez des observations sur la base d’une expressionconditionnelle, une variable nommée filter_$ est générée ; elle comporte la valeur 1 pour lesobservations sélectionnées et la valeur 0 pour les observations exclues.

207
Gestion et transformations de fichiers
Copiez les observations sélectionnées dans l’ensemble de données. Les observationssélectionnées sont copiées dans un nouvel ensemble de données ; l’ensemble de donnéesd’origine reste inchangé. Les observations exclues ne sont pas incluses dans le nouvelensemble de données et sont conservées dans leur état d’origine dans l’ensemble de donnéesd’origine.Supprimez les observations exclues. Les observations exclues sont supprimées de l’ensemblede données. Vous pouvez récupérer les observations supprimées uniquement en fermantle fichier sans enregistrer les modifications et en l’ouvrant à nouveau. La suppression desobservations est définitive si vous enregistrez les modifications apportées au fichier dedonnées.
Remarque : Si vous supprimez des observations exclues et enregistrez le fichier, vous ne pouvezpas récupérer ces observations.
Sélection d’un sous-groupe d’observations
E A partir des menus, sélectionnez :Données
Sélectionner des observations
E Sélectionnez une des méthodes de sélection d’observations.
E Spécifiez les critères de sélection des observations.
Sélectionner observations : Si
La boîte de dialogue vous permet de sélectionner des sous-ensembles d’observations à l’aided’expressions conditionnelles. Une expression conditionnelle renvoie la valeur True (vrai), False(faux) ou manquant pour chaque observation.
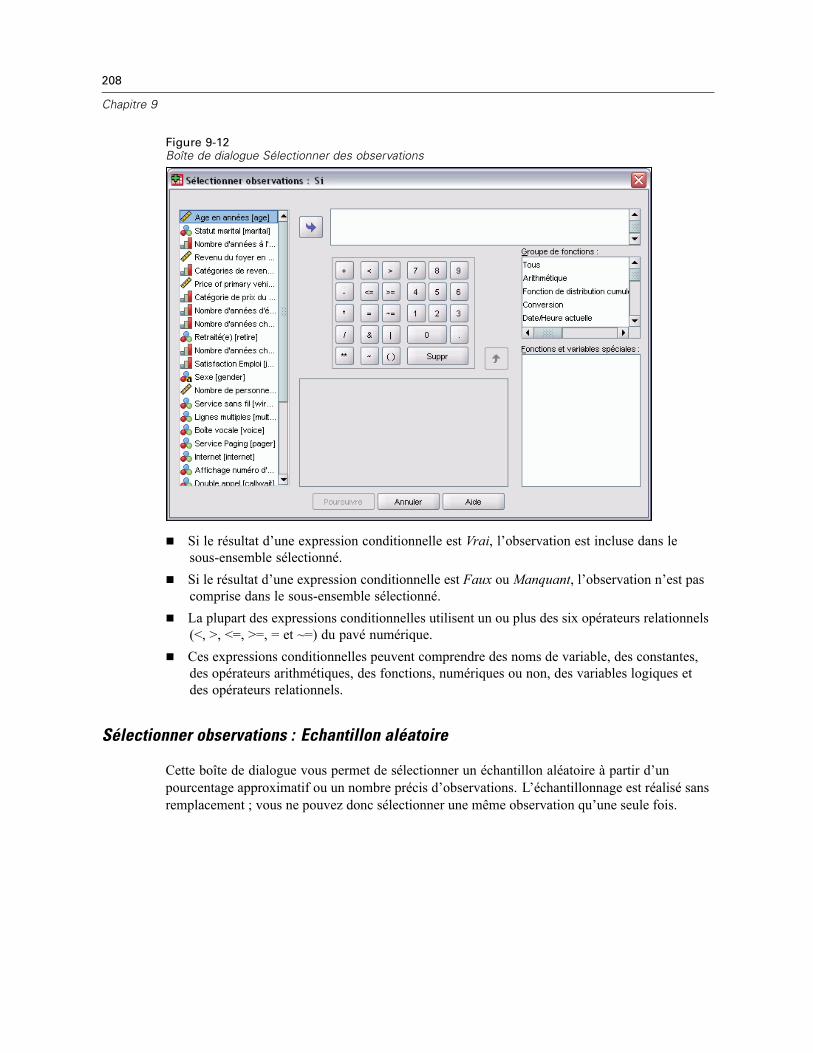
208
Chapitre 9
Figure 9-12Boîte de dialogue Sélectionner des observations
Si le résultat d’une expression conditionnelle est Vrai, l’observation est incluse dans lesous-ensemble sélectionné.Si le résultat d’une expression conditionnelle est Faux ou Manquant, l’observation n’est pascomprise dans le sous-ensemble sélectionné.La plupart des expressions conditionnelles utilisent un ou plus des six opérateurs relationnels(<, >, <=, >=, = et ~=) du pavé numérique.Ces expressions conditionnelles peuvent comprendre des noms de variable, des constantes,des opérateurs arithmétiques, des fonctions, numériques ou non, des variables logiques etdes opérateurs relationnels.
Sélectionner observations : Echantillon aléatoire
Cette boîte de dialogue vous permet de sélectionner un échantillon aléatoire à partir d’unpourcentage approximatif ou un nombre précis d’observations. L’échantillonnage est réalisé sansremplacement ; vous ne pouvez donc sélectionner une même observation qu’une seule fois.

209
Gestion et transformations de fichiers
Figure 9-13Boîte de dialogue Sélectionner observations : Echantillon aléatoire
Environ : SPSS génère un échantillon aléatoire d’observations dont le nombre correspondapproximativement au pourcentage indiqué. Comme cette routine génère une décisionindépendante pseudo-aléatoire pour chaque observation, le pourcentage d’observationssélectionnées peut seulement approcher le pourcentage spécifié. Plus il y a d’observations dans lefichier de données, plus le pourcentage des observations sélectionnées sera proche de la valeurindiquée.
Exactement : Nombre d’observations spécifié par l’utilisateur. Vous devez également indiquerle nombre d’observations à partir duquel l’échantillon sera généré. Ce deuxième nombre doitêtre inférieur ou égal au nombre total d’observations dans le fichier de données. Si ce nombredépasse le nombre total d’observations dans le fichier de données, l’échantillon contiendraproportionnellement moins d’observations que le nombre demandé.
Sélectionner observations : Intervalle
Cette boîte de dialogue vous permet de sélectionner des observations à partir d’un intervalle denuméros d’observation ou d’un intervalle de date ou de temps.
Les intervalles d’observations sont fondés sur un numéro de ligne, affiché dans l’éditeur dedonnées.Les intervalles de dates et de temps sont valables uniquement pour les séries chronologiquesdisposant de variables de date (menu Données, Définir dates).
Figure 9-14Sélectionnez la boîte de dialogue Intervalle d’observations pour un intervalle d’observations (aucunevariable de date définie ).
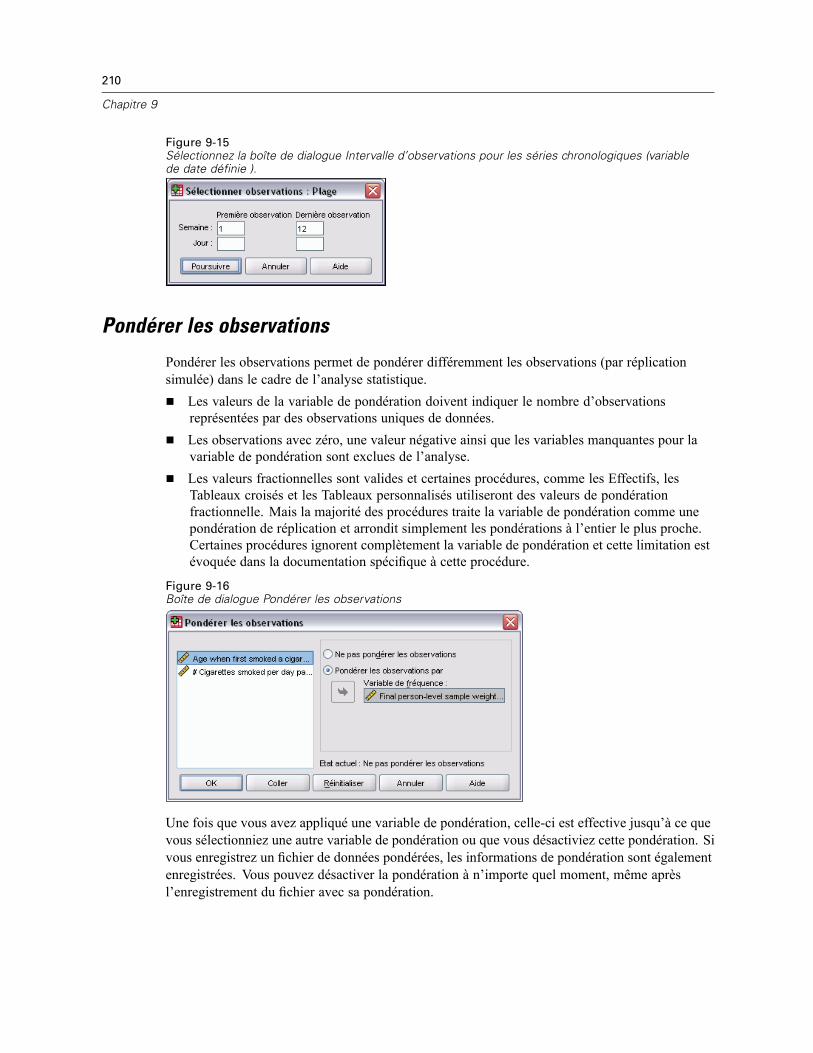
210
Chapitre 9
Figure 9-15Sélectionnez la boîte de dialogue Intervalle d’observations pour les séries chronologiques (variablede date définie ).
Pondérer les observations
Pondérer les observations permet de pondérer différemment les observations (par réplicationsimulée) dans le cadre de l’analyse statistique.
Les valeurs de la variable de pondération doivent indiquer le nombre d’observationsreprésentées par des observations uniques de données.Les observations avec zéro, une valeur négative ainsi que les variables manquantes pour lavariable de pondération sont exclues de l’analyse.Les valeurs fractionnelles sont valides et certaines procédures, comme les Effectifs, lesTableaux croisés et les Tableaux personnalisés utiliseront des valeurs de pondérationfractionnelle. Mais la majorité des procédures traite la variable de pondération comme unepondération de réplication et arrondit simplement les pondérations à l’entier le plus proche.Certaines procédures ignorent complètement la variable de pondération et cette limitation estévoquée dans la documentation spécifique à cette procédure.
Figure 9-16Boîte de dialogue Pondérer les observations
Une fois que vous avez appliqué une variable de pondération, celle-ci est effective jusqu’à ce quevous sélectionniez une autre variable de pondération ou que vous désactiviez cette pondération. Sivous enregistrez un fichier de données pondérées, les informations de pondération sont égalementenregistrées. Vous pouvez désactiver la pondération à n’importe quel moment, même aprèsl’enregistrement du fichier avec sa pondération.

211
Gestion et transformations de fichiers
Pondération dans des tableaux croisés : Plusieurs options de la procédure Tableaux croiséspermettent de gérer la pondération des observations. Pour plus d'informations, reportez-vous àAffichage de cellules (cases) de tableaux croisés dans Chapitre 18 sur p. 323.
Pondération des diagrammes de dispersion et histogrammes : Les diagrammes de dispersionet les histogrammes disposent d’une option d’activation/désactivation de la pondération desobservations, mais cela n’affecte pas les observations avec des valeurs négatives, des zéros, ouune valeur manquante pour la variable de pondération. Ces observations sont toujours exclues dudiagramme même lorsque la pondération est désactivée depuis ce diagramme.
Pour pondérer des observations
E A partir des menus, sélectionnez :Données
Pondérer les observations
E Sélectionnez Pondérer les observations par.
E Sélectionnez une variable de fréquence.
Les valeurs de la variable de fréquence servent à la pondération des observations. Par exemple,une observation ayant la valeur 3 dans la table de fréquence représente 3 observations dans lefichier des données pondérées.
Restructuration des données
Utilisez l’Assistant de restructuration des données pour restructurer les données qui sontnécessaires à la procédure choisie. L’Assistant remplace le fichier actuel par un nouveau fichier,restructuré. L’Assistant vous permet de :
Restructurer les variables sélectionnées en observationsRestructurer les observations sélectionnées en variablesTransposer toutes les données
Restructuration des données
E A partir des menus, sélectionnez :Données
Restructurer...
E Sélectionnez le type de restructuration à effectuer.
E Sélectionnez les données à restructurer.
Sinon, vous pouvez :Créer des variables d’identification qui vous permettent de faire correspondre une valeur dunouveau fichier avec la valeur du fichier d’origineTrier les données avant leur restructuration

212
Chapitre 9
Définir les options du nouveau fichierColler la syntaxe de la commande dans une fenêtre de syntaxe
Assistant de restructuration des données : Sélectionner un type
Servez-vous de l’Assistant de restructuration des données pour restructurer vos données. Dans lapremière boîte de dialogue, sélectionnez le type de restructuration à effectuer.
Figure 9-17Assistant de restructuration des données
Restructurer les variables sélectionnées en observations : Sélectionnez cette option lorsque vosdonnées comportent des groupes de colonnes apparentées que vous souhaitez faire apparaîtredans des groupes de lignes du nouveau fichier de données. Si vous choisissez cette option,l’assistant affiche les étapes relatives à l’opération de Restructuration des variables enobservations.Restructurer les observations sélectionnées en variables : Sélectionnez cette option lorsque vosdonnées comportent des groupes de lignes apparentées que vous souhaitez faire apparaîtredans des groupes de colonnes du nouveau fichier de données. Si vous choisissez cette option,

213
Gestion et transformations de fichiers
l’Assistant affiche les étapes relatives à l’opération de Restructuration des observationsen variables.Transposer toutes les données : Choisissez cette option pour transposer vos données. Dans lesnouvelles données, toutes les lignes vont être transformées en colonnes et les colonnes enlignes. La sélection de cette option entraîne la fermeture de l’Assistant de restructuration desdonnées et l’ouverture de la boîte de dialogue Transposer les données.
Choix du mode de restructuration des données
Une variable contient les informations à analyser, comme une mesure ou un résultat. Uneobservation correspond, par exemple, à un individu. Dans une structure de données simple,chaque variable correspond à une colonne de vos données et chaque observation à une ligne.Supposez que vous mesuriez les résultats obtenus à un test par tous les étudiants d’une classe.Dans ce cas, tous les résultats apparaissent dans une même colonne et une ligne est associée àchaque étudiant.Lors de l’analyse des données, vous êtes souvent amené à analyser la manière dont une
variable évolue en fonction de certaines conditions. Ces conditions peuvent correspondre à untraitement expérimental précis, à une population, à un moment en particulier, etc. Dans l’analysedes données, les conditions qui vous intéressent sont souvent appelées facteurs. Lorsque vousanalysez des facteurs, vous obtenez une structure de données complexe. Vous pouvez disposerd’informations sur une variable dans plusieurs colonnes de vos données (par exemple, une colonnepour chaque niveau d’un facteur) ou d’informations sur une observation dans plusieurs lignes (parexemple, une ligne pour chaque niveau d’un facteur). L’Assistant de restructuration des donnéesvous aide à restructurer les fichiers dont la structure de données est complexe.Les options que vous sélectionnez dans l’Assistant dépendent de la structure du fichier actuel et
de celle du nouveau fichier.
Organisation des données dans le fichier actuel : Vous pouvez organiser les données actuellesde telle sorte que les facteurs soient enregistrés dans une variable distincte (dans des groupesd’observations) ou avec la variable (dans des groupes de variables).
Groupes d’observations : Dans le fichier actuel, les variables et les conditions sont-ellesenregistrées dans des colonnes distinctes ? Par exemple :
variance factor8 19 13 21 2

214
Chapitre 9
Dans cet exemple, les deux premières lignes constituent un groupe d’observations car ellessont apparentées. Elles contiennent des données relatives au même niveau de facteur. Dans lesanalyses de données SPSS Statistics, le facteur est souvent appelé variable de regroupementlorsque les données sont structurées de cette manière.
Groupes de colonnes : Dans le fichier actuel, les variables et les conditions sont-ellesenregistrées dans la même colonne ? Par exemple :
var_1 var_28 39 1
Dans cet exemple, les deux colonnes constituent un groupe de variables car elles sontapparentées. Elles contiennent des données concernant la même variable (var_1 pour le niveau defacteur 1 et var_2 pour le niveau de facteur 2). Dans les analyses de données SPSS Statistics, lefacteur est souvent appelémesure répétée lorsque les données sont structurées de cette manière.
Organisation des données dans le nouveau fichier : La procédure d’analyse des données déterminegénéralement l’organisation des données.
Procédures nécessitant des groupes d’observations : Vous devez structurer vos donnéesen groupes d’observations pour procéder à des analyses qui requièrent une variable deregroupement. A titre d’exemple, il est possible de citer le modèle linéaire général pour lescomposantes univariées, multivariées et de variance, les modèles linéaires généraux, lesmodèles mixtes, les cubes OLAP, ainsi que le test T ou les tests non paramétriques pourles échantillons indépendants. Si vos données actuelles sont structurées en groupes devariables, sélectionnez Restructurer les variables sélectionnées en observations pour procéderà ces analyses.Procédures nécessitant des groupes de variables : Vous devez structurer vos données engroupes de variables pour procéder à des analyses de mesures répétées. A titre d’exemple,il est possible de citer le modèle linéaire général pour les mesures répétées, l’analyse par larégression de Cox à prédicteurs chronologiques, le test T pour les échantillons appariés oules tests non paramétriques pour les échantillons apparentés. Si vos données actuelles sontstructurées en groupes d’observations, sélectionnez Restructurer les observations sélectionnéesen variables pour procéder à ces analyses.
Exemple de restructuration de variables en observations
Dans cet exemple, les résultats d’un test sont enregistrés dans des colonnes distinctes pour chacundes facteurs A et B.
Figure 9-18Données actuelles utilisées pour la restructuration de variables en observations

215
Gestion et transformations de fichiers
Vous voulez réaliser un test t pour des échantillons indépendants. Vous disposez d’un groupe decolonnes comprenant score_a et score_b, mais pas de la variable de regroupement requise par laprocédure. Sélectionnez Restructurer les variables sélectionnées en observations dans l’Assistantde restructuration des données, restructurez un groupe de variables dans une nouvelle variableintitulée résultat, puis créez un index appelé groupe. Le nouveau fichier de données est illustrédans la figure suivante.
Figure 9-19Nouvelles données restructurées utilisées pour la restructuration de variables en observations
Lorsque vous exécutez le test t pour des échantillons indépendants, vous pouvez désormais utiliserl’index groupe en tant que variable de regroupement.
Exemple de restructuration d’observations en variables
Dans cet exemple, les résultats du test sont enregistrés deux fois pour chaque sujet—avantet après le traitement.
Figure 9-20Données actuelles utilisées pour la restructuration d’observations en variables
Vous voulez réaliser un test t pour des échantillons appariés. Vos données sont structurées engroupes d’observations, mais vous ne disposez pas des mesures répétées des variables appariéesrequises par la procédure. Sélectionnez Restructurer les observations sélectionnées en variables
dans l’Assistant de restructuration des données, utilisez id pour identifier les groupes de lignesdans les données actuelles, et temps pour créer le groupe de variables dans le nouveau fichier.
Figure 9-21Nouvelles données restructurées utilisées pour la restructuration d’observations en variables
Pour l’exécution du test t pour échantillons appariés, vous pouvez désormais utiliser ava et aprcomme paire de variables.

216
Chapitre 9
Assistant de restructuration des données (Restructurer les variables en observations) :Nombre de groupes de variables
Remarque : L’Assistant vous propose cette étape lorsque vous optez pour la restructuration desgroupes de variables en lignes.
Lors de cette étape, vous déterminez le nombre de groupes de variables du fichier actuel àrestructurer dans le nouveau fichier.
Nombre de groupes de variables présents dans le fichier actuel. Déterminez le nombre de groupesde variables présents dans les données actuelles. Un groupe de colonnes apparentées, appelégroupe de variables, permet d’enregistrer les mesures répétées d’une même variable dans descolonnes distinctes. Supposez que parmi les données dont vous disposez, trois colonnes, l1, l2et l3, enregistrent la largeur. Dans ce cas, vous avez un groupe de variables. Si trois autrescolonnes, h1, h2 et h3, enregistrent la hauteur, vous disposez de deux groupes de variables.
Nombre de groupes de variables à créer dans le nouveau fichier. Déterminez le nombre de groupesde variables à représenter dans le nouveau fichier. Il n’est pas nécessaire de restructurer tous lesgroupes de variables dans le nouveau fichier.
Figure 9-22Assistant de restructuration des données : Nombre de groupes de variable, étape 2
Une : L’Assistant crée une variable restructurée dans le nouveau fichier à partir d’un groupe devariables du fichier actuel.Plusieurs : L’Assistant crée plusieurs variables restructurées dans le nouveau fichier.Le nombre spécifié est utilisé à l’étape suivante, au cours de laquelle l’Assistant créeautomatiquement le nombre de variables indiqué.
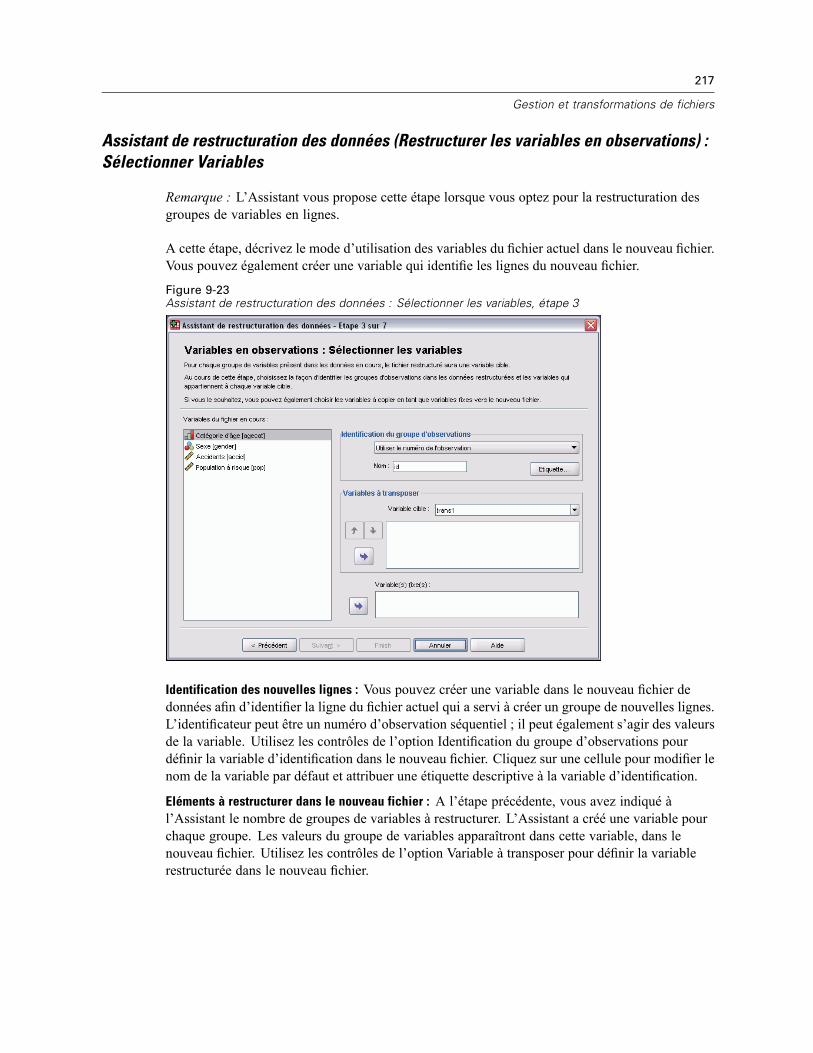
217
Gestion et transformations de fichiers
Assistant de restructuration des données (Restructurer les variables en observations) :Sélectionner Variables
Remarque : L’Assistant vous propose cette étape lorsque vous optez pour la restructuration desgroupes de variables en lignes.
A cette étape, décrivez le mode d’utilisation des variables du fichier actuel dans le nouveau fichier.Vous pouvez également créer une variable qui identifie les lignes du nouveau fichier.
Figure 9-23Assistant de restructuration des données : Sélectionner les variables, étape 3
Identification des nouvelles lignes : Vous pouvez créer une variable dans le nouveau fichier dedonnées afin d’identifier la ligne du fichier actuel qui a servi à créer un groupe de nouvelles lignes.L’identificateur peut être un numéro d’observation séquentiel ; il peut également s’agir des valeursde la variable. Utilisez les contrôles de l’option Identification du groupe d’observations pourdéfinir la variable d’identification dans le nouveau fichier. Cliquez sur une cellule pour modifier lenom de la variable par défaut et attribuer une étiquette descriptive à la variable d’identification.
Eléments à restructurer dans le nouveau fichier : A l’étape précédente, vous avez indiqué àl’Assistant le nombre de groupes de variables à restructurer. L’Assistant a créé une variable pourchaque groupe. Les valeurs du groupe de variables apparaîtront dans cette variable, dans lenouveau fichier. Utilisez les contrôles de l’option Variable à transposer pour définir la variablerestructurée dans le nouveau fichier.

218
Chapitre 9
Pour spécifier une variable structurée
E Placez dans la liste Variables à transposer les variables comprenant la liste des variablesà transformer. Toutes les variables du groupe doivent être du même type (numérique oualphanumérique).
Vous pouvez inclure une même variable plusieurs fois dans le groupe de variables (au lieu d’êtredéplacées, les variables sont copiées à partir de la liste des variables source) ; ses valeurs sontrépétées dans le nouveau fichier.
Pour spécifier plusieurs variables structurées
E Dans la liste déroulante, sélectionnez la première variable cible à définir.
E Placez dans la liste Variables à transposer les variables comprenant la liste des variablesà transformer. Toutes les variables du groupe doivent être du même type (numérique oualphanumérique). Vous pouvez inclure la même variable plusieurs fois dans le groupe devariables. (Une variable est copiée au lieu d’être déplacée à partir de la liste des variables sourceet ses valeurs sont répétées dans le nouveau fichier.)
E Sélectionnez la variable cible suivante à définir et recommencez le processus de sélection de lavariable pour toutes les variables cible disponibles.
Bien que vous puissiez inclure plusieurs fois une même variable dans un groupe de variablescible, vous ne pouvez pas l’inclure dans plusieurs groupes de variables cible.Chaque liste de groupes de variables cible doit contenir le même nombre de variables. (Lesvariables répertoriées plusieurs fois sont comptées.)Le nombre de groupes de variables cible est déterminé par le nombre de groupes de variablesque vous avez indiqué à l’étape précédente. Vous pouvez modifier le nom par défaut desvariables ici, mais pour modifier le nombre de groupes de variables à restructurer, vous devezretourner à l’étape précédente.Vous devez définir les groupes de variables (sélectionnez les variables dans la liste source)pour chaque variable cible disponible avant de passer à l’étape suivante.
Eléments à copier dans le nouveau fichier : Les variables non restructurées peuvent être copiéesdans le nouveau fichier. Leurs valeurs seront répercutées dans les nouvelles lignes. Déplacez versla liste Variable(s) fixe(s) les variables à copier dans le nouveau fichier.
Assistant de restructuration des données (Restructurer les variables en observations):Créer des variables Variables
Remarque : L’Assistant vous propose cette étape lorsque vous optez pour la restructuration desgroupes de variables en lignes.
A cette étape, indiquez si vous voulez créer des variables d’index. Un index est une nouvellevariable qui identifie de manière séquentielle un groupe de lignes d’après la variable d’origine àpartir de laquelle la nouvelle ligne a été créée.

219
Gestion et transformations de fichiers
Figure 9-24Assistant de restructuration des données : Créer des variables d’index, étape 4
Nombre de variables d’index à créer dans le nouveau fichier : Vous pouvez utiliser les variablesd’index en tant que variables de regroupement dans les procédures. Dans la plupart des cas, unevariable d’index suffit. Toutefois, si les groupes de variables de votre fichier actuel font apparaîtreplusieurs niveaux de facteur, il est recommandé de créer plusieurs index.
Une : L’Assistant crée une seule variable d’index.Plusieurs : L’Assistant crée plusieurs index. Entrez le nombre d’index à créer. Le nombrespécifié est utilisé à l’étape suivante, au cours de laquelle l’Assistant crée automatiquement lenombre d’index indiqué.Aucune : Sélectionnez cette option pour ne créer aucune variable d’index dans le nouveaufichier.
Exemple d’index unique lors de la restructuration de variables en observations
Parmi les données actuelles figurent un groupe de variables, largeur, et un facteur, temps. Lalargeur a été mesurée trois fois et enregistrée dans l1, l2 et l3.Figure 9-25Données actuelles utilisées pour un index
Vous allez restructurer le groupe de variables en une seule variable, largeur, et créer un indexnumérique. Les nouvelles données sont illustrées dans le tableau suivant.
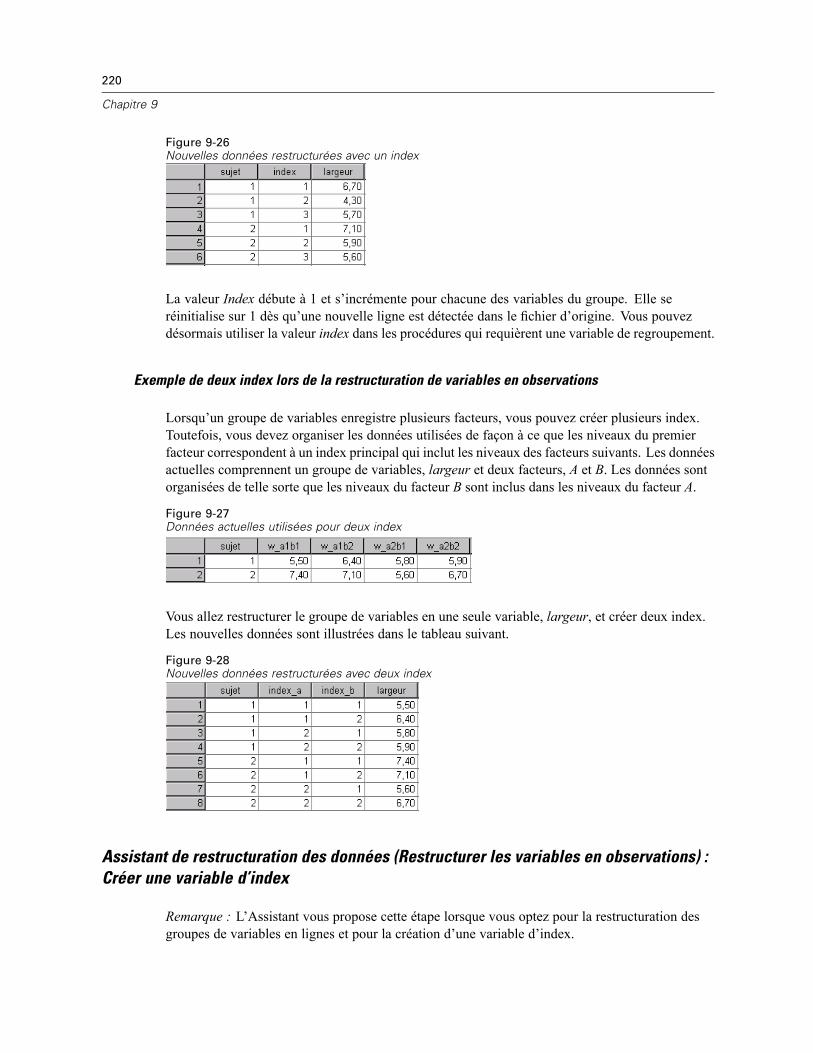
220
Chapitre 9
Figure 9-26Nouvelles données restructurées avec un index
La valeur Index débute à 1 et s’incrémente pour chacune des variables du groupe. Elle seréinitialise sur 1 dès qu’une nouvelle ligne est détectée dans le fichier d’origine. Vous pouvezdésormais utiliser la valeur index dans les procédures qui requièrent une variable de regroupement.
Exemple de deux index lors de la restructuration de variables en observations
Lorsqu’un groupe de variables enregistre plusieurs facteurs, vous pouvez créer plusieurs index.Toutefois, vous devez organiser les données utilisées de façon à ce que les niveaux du premierfacteur correspondent à un index principal qui inclut les niveaux des facteurs suivants. Les donnéesactuelles comprennent un groupe de variables, largeur et deux facteurs, A et B. Les données sontorganisées de telle sorte que les niveaux du facteur B sont inclus dans les niveaux du facteur A.
Figure 9-27Données actuelles utilisées pour deux index
Vous allez restructurer le groupe de variables en une seule variable, largeur, et créer deux index.Les nouvelles données sont illustrées dans le tableau suivant.
Figure 9-28Nouvelles données restructurées avec deux index
Assistant de restructuration des données (Restructurer les variables en observations) :Créer une variable d’index
Remarque : L’Assistant vous propose cette étape lorsque vous optez pour la restructuration desgroupes de variables en lignes et pour la création d’une variable d’index.

221
Gestion et transformations de fichiers
A cette étape, indiquez les valeurs à affecter à la variable d’index. Vous pouvez utiliser desnombres séquentiels ou le nom des variables d’un groupe de variables d’origine. Vous pouvezégalement attribuer un nom et une étiquette à la nouvelle variable d’index.
Figure 9-29Assistant de restructuration des données : Créer une variable d’index, étape 5
Pour plus d'informations, reportez-vous à Exemple d’index unique lors de la restructuration devariables en observations sur p. 219.
Nombres séquentiels : L’Assistant affecte automatiquement des numéros séquentiels en tantque valeurs d’index.Noms des variables : L’Assistant utilise les noms du groupe de variables sélectionné en tantque valeurs d’index. Choisissez un groupe de variables dans la liste proposée.Noms et étiquettes : Cliquez sur une cellule pour modifier le nom de la variable par défautet attribuer une étiquette descriptive à la variable d’index.
Assistant de restructuration des données (Restructurer les variables en observations) :Créer plusieurs variables d’index
Remarque : L’Assistant vous propose cette étape lorsque vous optez pour la restructuration desgroupes de variables en lignes et pour la création de plusieurs variables d’index.
A cette étape, indiquez le nombre de niveaux de chaque variable d’index. Vous pouvez égalementattribuer un nom et une étiquette à la nouvelle variable d’index.
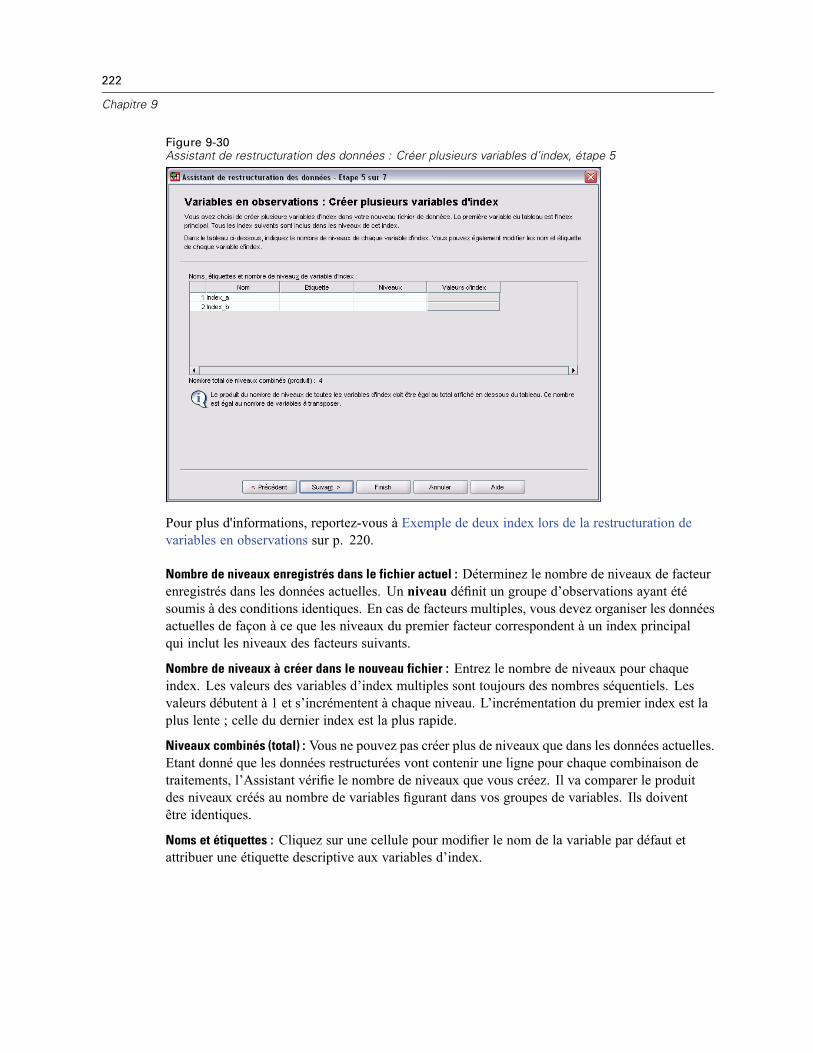
222
Chapitre 9
Figure 9-30Assistant de restructuration des données : Créer plusieurs variables d’index, étape 5
Pour plus d'informations, reportez-vous à Exemple de deux index lors de la restructuration devariables en observations sur p. 220.
Nombre de niveaux enregistrés dans le fichier actuel : Déterminez le nombre de niveaux de facteurenregistrés dans les données actuelles. Un niveau définit un groupe d’observations ayant étésoumis à des conditions identiques. En cas de facteurs multiples, vous devez organiser les donnéesactuelles de façon à ce que les niveaux du premier facteur correspondent à un index principalqui inclut les niveaux des facteurs suivants.
Nombre de niveaux à créer dans le nouveau fichier : Entrez le nombre de niveaux pour chaqueindex. Les valeurs des variables d’index multiples sont toujours des nombres séquentiels. Lesvaleurs débutent à 1 et s’incrémentent à chaque niveau. L’incrémentation du premier index est laplus lente ; celle du dernier index est la plus rapide.
Niveaux combinés (total) : Vous ne pouvez pas créer plus de niveaux que dans les données actuelles.Etant donné que les données restructurées vont contenir une ligne pour chaque combinaison detraitements, l’Assistant vérifie le nombre de niveaux que vous créez. Il va comparer le produitdes niveaux créés au nombre de variables figurant dans vos groupes de variables. Ils doiventêtre identiques.
Noms et étiquettes : Cliquez sur une cellule pour modifier le nom de la variable par défaut etattribuer une étiquette descriptive aux variables d’index.
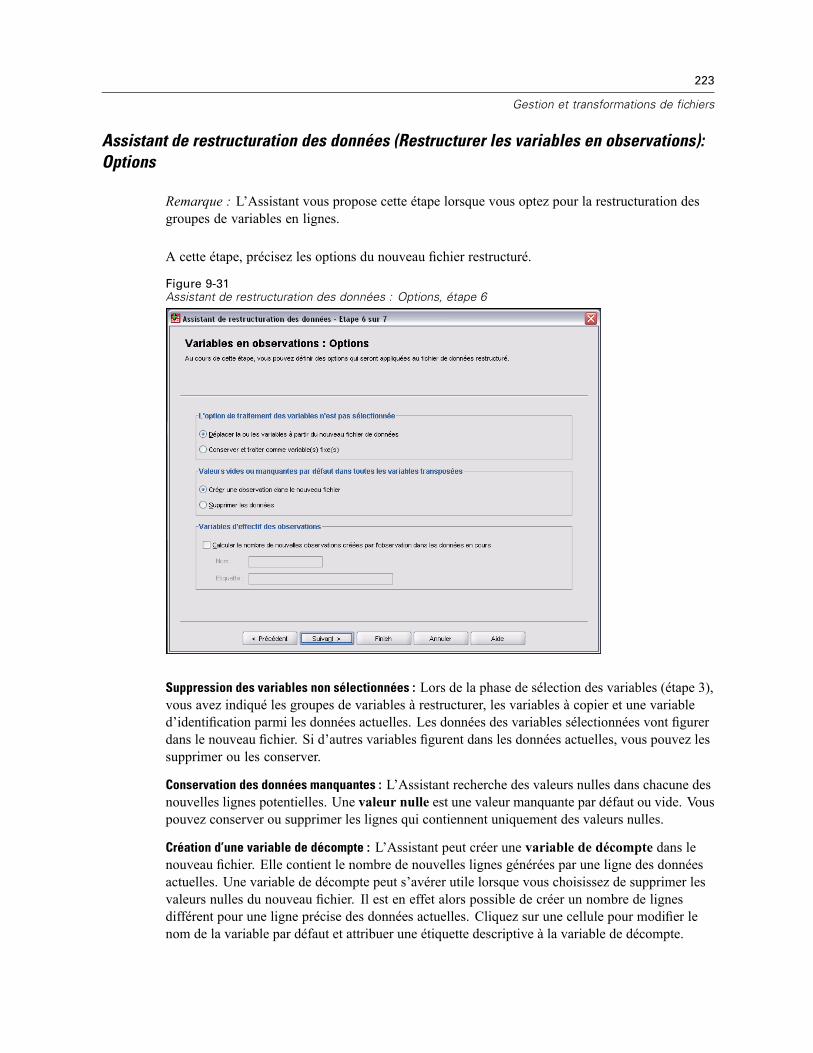
223
Gestion et transformations de fichiers
Assistant de restructuration des données (Restructurer les variables en observations):Options
Remarque : L’Assistant vous propose cette étape lorsque vous optez pour la restructuration desgroupes de variables en lignes.
A cette étape, précisez les options du nouveau fichier restructuré.
Figure 9-31Assistant de restructuration des données : Options, étape 6
Suppression des variables non sélectionnées : Lors de la phase de sélection des variables (étape 3),vous avez indiqué les groupes de variables à restructurer, les variables à copier et une variabled’identification parmi les données actuelles. Les données des variables sélectionnées vont figurerdans le nouveau fichier. Si d’autres variables figurent dans les données actuelles, vous pouvez lessupprimer ou les conserver.
Conservation des données manquantes : L’Assistant recherche des valeurs nulles dans chacune desnouvelles lignes potentielles. Une valeur nulle est une valeur manquante par défaut ou vide. Vouspouvez conserver ou supprimer les lignes qui contiennent uniquement des valeurs nulles.
Création d’une variable de décompte : L’Assistant peut créer une variable de décompte dans lenouveau fichier. Elle contient le nombre de nouvelles lignes générées par une ligne des donnéesactuelles. Une variable de décompte peut s’avérer utile lorsque vous choisissez de supprimer lesvaleurs nulles du nouveau fichier. Il est en effet alors possible de créer un nombre de lignesdifférent pour une ligne précise des données actuelles. Cliquez sur une cellule pour modifier lenom de la variable par défaut et attribuer une étiquette descriptive à la variable de décompte.
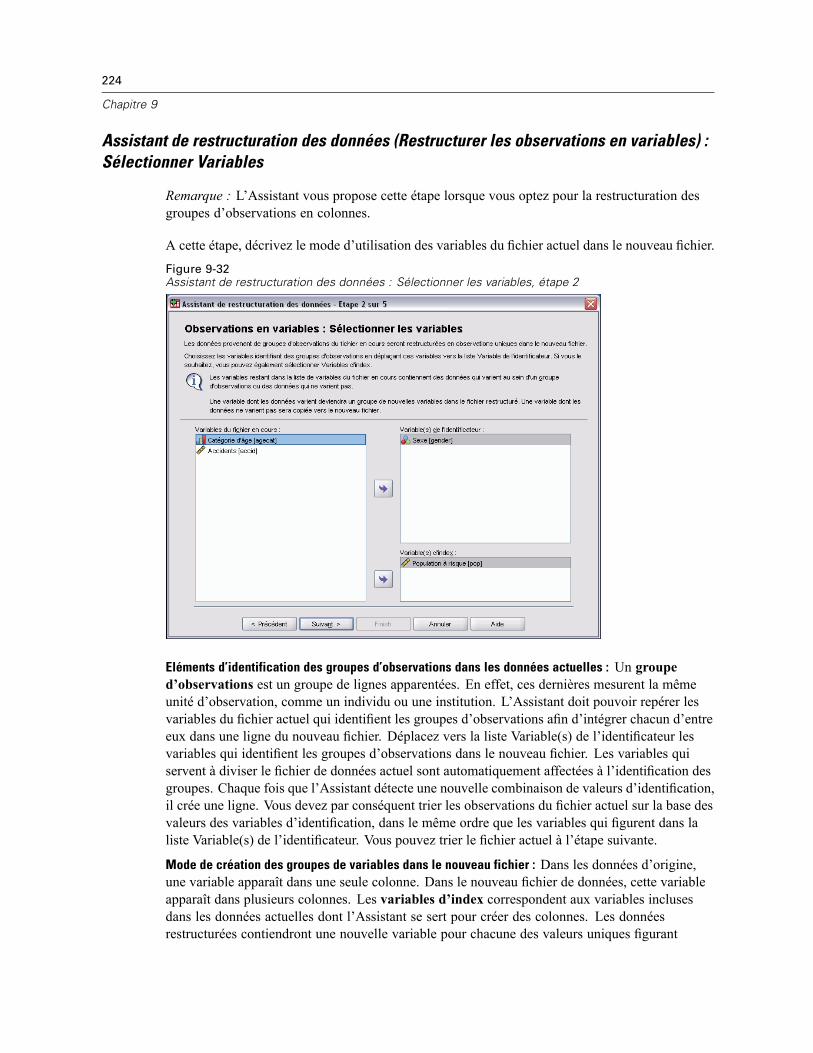
224
Chapitre 9
Assistant de restructuration des données (Restructurer les observations en variables) :Sélectionner Variables
Remarque : L’Assistant vous propose cette étape lorsque vous optez pour la restructuration desgroupes d’observations en colonnes.
A cette étape, décrivez le mode d’utilisation des variables du fichier actuel dans le nouveau fichier.
Figure 9-32Assistant de restructuration des données : Sélectionner les variables, étape 2
Eléments d’identification des groupes d’observations dans les données actuelles : Un grouped’observations est un groupe de lignes apparentées. En effet, ces dernières mesurent la mêmeunité d’observation, comme un individu ou une institution. L’Assistant doit pouvoir repérer lesvariables du fichier actuel qui identifient les groupes d’observations afin d’intégrer chacun d’entreeux dans une ligne du nouveau fichier. Déplacez vers la liste Variable(s) de l’identificateur lesvariables qui identifient les groupes d’observations dans le nouveau fichier. Les variables quiservent à diviser le fichier de données actuel sont automatiquement affectées à l’identification desgroupes. Chaque fois que l’Assistant détecte une nouvelle combinaison de valeurs d’identification,il crée une ligne. Vous devez par conséquent trier les observations du fichier actuel sur la base desvaleurs des variables d’identification, dans le même ordre que les variables qui figurent dans laliste Variable(s) de l’identificateur. Vous pouvez trier le fichier actuel à l’étape suivante.
Mode de création des groupes de variables dans le nouveau fichier : Dans les données d’origine,une variable apparaît dans une seule colonne. Dans le nouveau fichier de données, cette variableapparaît dans plusieurs colonnes. Les variables d’index correspondent aux variables inclusesdans les données actuelles dont l’Assistant se sert pour créer des colonnes. Les donnéesrestructurées contiendront une nouvelle variable pour chacune des valeurs uniques figurant

225
Gestion et transformations de fichiers
dans ces colonnes. Déplacez vers la liste Variable(s) d’index les variables qui doivent servir àla création des groupes de variables. Parmi les possibilités offertes par l’Assistant, vous pouvezégalement opter pour le tri des nouvelles colonnes par index.
Devenir des autres colonnes : L’Assistant détermine automatiquement ce que vont devenir lesvariables qui demeurent dans la liste Fichier actuel. Il vérifie pour chaque variable si les valeursdes données varient au sein d’un groupe d’observations. Si tel est le cas, l’Assistant restructure,dans le nouveau fichier, les valeurs dans un groupe de variables. Dans le cas contraire, l’Assistantcopie les valeurs dans le nouveau fichier.
Assistant de restructuration des données (Restructurer les observations en variables) :Trier Données
Remarque : L’Assistant vous propose cette étape lorsque vous optez pour la restructuration desgroupes d’observations en colonnes.
A cette étape, indiquez si vous voulez trier le fichier actuel avant de le restructurer. Chaque fois quel’Assistant détecte une nouvelle combinaison de valeurs d’identification, il crée une ligne. Vousdevez par conséquent trier les données d’après les variables identifiant les groupes d’observations.
Figure 9-33Assistant de restructuration des données : Trier les données, étape 3
Organisation des lignes dans le fichier actuel : Déterminez le mode de tri des données actuelles etles variables qui servent à identifier les groupes de variables (définis à l’étape précédente).

226
Chapitre 9
Oui : L’Assistant trie automatiquement les données actuelles par variable d’identification,dans le même ordre que les variables qui figurent dans la liste Variable(s) de l’identificateurprésentée à l’étape précédente. Sélectionnez cette option lorsque les données ne sont pastriées par variable d’identification ou lorsque vous avez des doutes à ce propos. Cette optionimplique un passage distinct des données, mais elle assure un tri adéquat des lignes dansl’optique de la restructuration.Non : L’Assistant ne trie pas les données actuelles. Sélectionnez cette option lorsque vousêtes certain que les données actuelles sont triées sur la base des variables qui identifientles groupes d’observations.
Assistant de restructuration des données (Restructurer les observations en variables):Options
Remarque : L’Assistant vous propose cette étape lorsque vous optez pour la restructuration desgroupes d’observations en colonnes.
A cette étape, précisez les options du nouveau fichier restructuré.
Figure 9-34Assistant de restructuration des données : Options, étape 4
Mode de tri des groupes de variables dans le nouveau fichier
Par variable : L’Assistant regroupe les variables créées à partir d’une variable d’origine.Par index : L’Assistant regroupe les variables en fonction des valeurs des variables d’index.

227
Gestion et transformations de fichiers
Exemple : Les variables à restructurer sont l et h, et l’index est mois :
l h mois
Le résultat du regroupement par variable est le suivant :
l.jan l.fév h.jan
Le résultat du regroupement par index est le suivant :
l.jan h.jan l.fév
Création d’une variable de décompte : L’Assistant peut créer une variable de décompte dans lenouveau fichier. Elle contient le nombre de lignes des données actuelles qui a permis de créerune ligne dans le nouveau fichier de données.
Créer des variables indicatrices : L’assistant peut utiliser les variables d’index pour créer desvariables indicatrices dans le nouveau fichier de données. Il crée une variable pour chaquevaleur unique de la variable d’index. Les variables indicatrices signalent la présence ou l’absenced’une valeur pour une observation. Une variable indicatrice a la valeur 1 si l’observation a unevaleur; sinon, elle a la valeur 0.
Exemple : La variable d’index est produit. Elle enregistre les produits achetés par un client. Lesdonnées d’origine sont les suivantes :
client produit1 poussin1 oeufs2 oeufs3 poussin
La création d’une variable indicatrice entraîne la création d’une variable pour chaque valeurunique de produit. Les données restructurées sont les suivantes :
client poussinindicateur
oeufs indicateurs
1 1 12 0 13 1 0
Dans cet exemple, les données restructurées pourraient être utilisées pour obtenir des effectifsdes produits achetés par le client.
Assistant de restructuration des données : Fin
Il s’agit de la dernière étape de l’Assistant de restructuration de données. Définissez l’objetde vos spécifications.
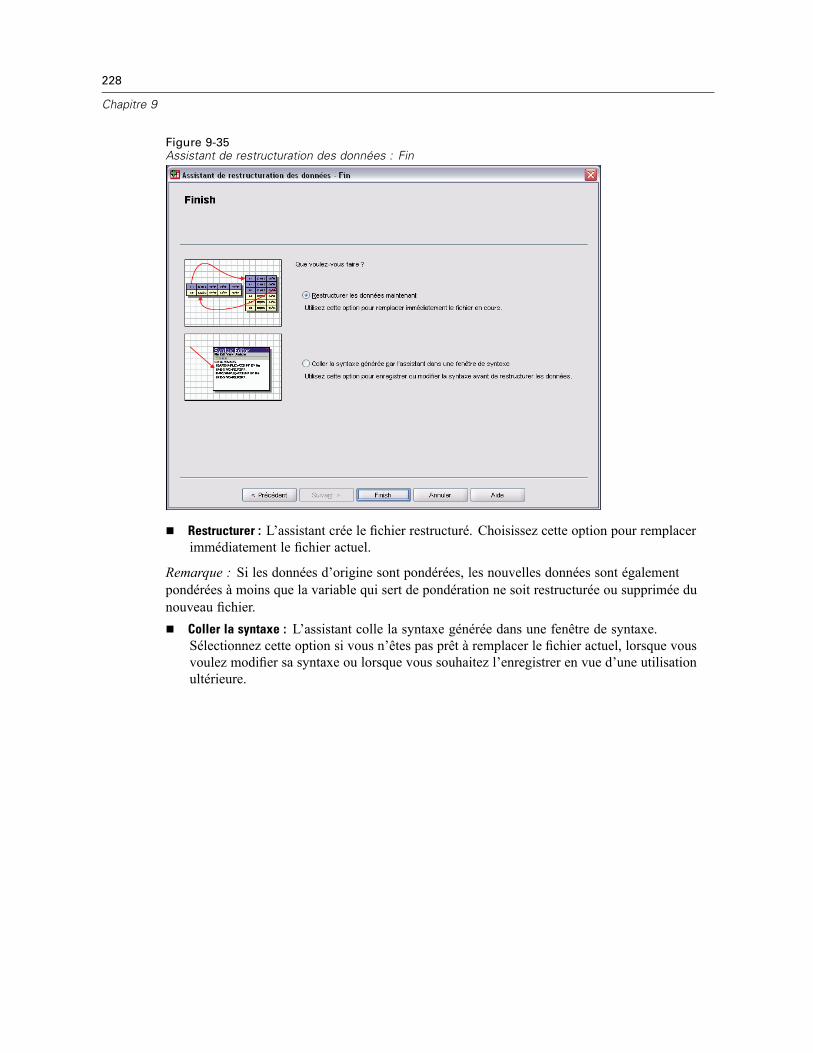
228
Chapitre 9
Figure 9-35Assistant de restructuration des données : Fin
Restructurer : L’assistant crée le fichier restructuré. Choisissez cette option pour remplacerimmédiatement le fichier actuel.
Remarque : Si les données d’origine sont pondérées, les nouvelles données sont égalementpondérées à moins que la variable qui sert de pondération ne soit restructurée ou supprimée dunouveau fichier.
Coller la syntaxe : L’assistant colle la syntaxe générée dans une fenêtre de syntaxe.Sélectionnez cette option si vous n’êtes pas prêt à remplacer le fichier actuel, lorsque vousvoulez modifier sa syntaxe ou lorsque vous souhaitez l’enregistrer en vue d’une utilisationultérieure.

Chapitre
10Utilisation du résultat
Lorsque vous lancez une procédure, les résultats sont affichés dans une fenêtre appelée le Viewer.Dans cette fenêtre, vous pouvez facilement naviguer vers le résultat que vous voulez voir. Vouspouvez également manipuler le résultat et créer un document contenant précisément le résultatvoulu.
Viewer
Les résultats sont affichés dans le Viewer. Vous pouvez utiliser le Viewer pour :Parcourir les résultats.Afficher ou masquer les tableaux et diagrammes sélectionnés.Modifier l’ordre d’affichage des résultats en déplaçant les éléments sélectionnés.Déplacer des éléments entre le Viewer et d’autres applications.
Figure 10-1Viewer
Le Viewer est divisé en deux panneaux :Le panneau gauche contient la légende du contenu du résultat.Le panneau droit contient les tableaux statistiques, les diagrammes et les textes.
229

230
Chapitre 10
Vous pouvez cliquer sur un élément affiché dans la légende pour accéder directement au tableauou au diagramme correspondant. Vous pouvez cliquer et faire glisser le bord droit de la fenêtre delégende pour modifier la largeur de la fenêtre.
Affichage et masquage des résultats
Dans le Viewer, vous pouvez sélectionner individuellement des tableaux ou les résultats d’uneprocédure pour les afficher ou les masquer. Ce processus est utile si vous voulez limiter laproportion de résultats visibles dans le panneau de contenu.
Pour masquer un tableau ou un diagramme
E Double-cliquez sur l’icône Livre de l’élément dans le panneau de légende de l’Editeur de résultats.
ou
E Cliquez sur l’élément pour le sélectionner.
E A partir des menus, sélectionnez :Affichage
Masquer
ou
E Cliquez sur l’icône Livre fermé (Masquer) dans la barre d’outils Légende.
L’icône Livre ouvert (Montrer) devient l’icône active, indiquant que l’élément est désormaismasqué.
Pour masquer les résultats de la procédure
E Cliquez sur la boîte à gauche du nom de la procédure dans le panneau de légende.
Cela masque tous les résultats de la procédure et réduit l’affichage de la légende.
Déplacement, suppression et copie de résultats
Vous pouvez réarranger les résultats en copiant, en déplaçant ou en effaçant un élément ou ungroupe d’éléments.
Pour déplacer des résultats dans l’Editeur de résultats
E Sélectionnez les éléments affichés dans le panneau de légende ou de contenu.
E Faites glisser les éléments sélectionnés dans un emplacement différent.
Pour supprimer des résultats dans l’Editeur de résultats
E Sélectionnez les éléments affichés dans le panneau de légende ou de contenu.

231
Utilisation du résultat
E Appuyez sur la touche Supprimer.
ou
E A partir des menus, sélectionnez :Affichage
Suppr
Changemernt de l’alignement initial
Par défaut, tous les résultats sont initialement alignés à gauche. Pour changer l’alignement initialdes nouveaux éléments de résultat :
E A partir des menus, sélectionnez :Affichage
Options
E Cliquez sur l’onglet Viewer.
E Dans le groupe Etat initial résultats, sélectionnez le type d’élément (par exemple : tableaupivotant, diagramme, résultats texte).
E Sélectionnez l’option d’alignement souhaitée.
Changement de l’alignement des items de résultat
E Dans le panneau de légende ou de contenu, sélectionnez les éléments à aligner.
E A partir des menus, sélectionnez :Format
Aligner à gauche
ouFormat
Centre
ouFormat
Aligner à droite
Légende du Viewer
Le panneau de légende fournit une table des matières du document Viewer. Vous pouvez utiliser lepanneau de légende pour naviguer dans votre résultat et contrôler l’affichage du résultat. La plupartdes actions dans le panneau de légende ont un effet correspondant sur le panneau de contenu.
Le fait de sélectionner un élément dans le panneau de légende affiche l’élément correspondantdans le panneau de contenu.Déplacer un élément dans le panneau de légende déplace l’élément correspondant dans lepanneau de contenu.Réduire la ligne de légende masque le résultat de tous les éléments des niveaux réduits.

232
Chapitre 10
Contrôler l’Affichage du Résultat : Pour contrôler l’affichage du résultat, vous pouvez :Développer et réduire l’affichage de la légende.Modifiez le niveau de ligne de légende pour les éléments sélectionnés.Modifier la taille des éléments dans l’affichage de la ligne de légende.Modifier la police utilisée dans l’affichage de la ligne de légende.
Pour réduire et agrandir l’affichage de légende
E Cliquez sur la boîte à gauche de l’élément de ligne de légende à réduire ou à étendre.
ou
E Cliquez sur l’élément dans la ligne de légende.
E A partir des menus, sélectionnez :Affichage
Réduire
ouAffichage
Développer
Pour modifier le niveau de légende d’un élément
E Cliquez sur l’élément dans le panneau de légende.
E Cliquez sur la flèche gauche de la barre d’outil de la Ligne de légende pour promouvoir l’élément(le déplacer vers la gauche).
ou
Cliquez sur la flèche droit de la barre d’outil de la Ligne de légende pour rétrograder l’élément(déplacer l’élément vers la droite).
ou
E A partir des menus, sélectionnez :Affichage
BordurePromouvoir
ouAffichage
BordureRétrograder
Modifier le niveau de légende est particulièrement utile après avoir déplacé des éléments dans unniveau de légende. Déplacer des éléments peut modifier le niveau de légende des éléments et vouspouvez utiliser les boutons de flèche gauche et de flèche droite dans la barre d’outils de la Lignede légende pour restaurer le niveau d’origine.

233
Utilisation du résultat
Pour modifier la taille des éléments dans la légende
E A partir des menus, sélectionnez :Affichage
Taille de la ligne de légende
E Sélectionnez la taille de la ligne de légende (Petite, Moyenne, ou Grande).
Pour modifier la police dans la légende
E A partir des menus, sélectionnez :Affichage
Police de la ligne de légende
E Sélectionnez une police.
Ajout d’éléments au Viewer
Dans le Viewer, vous pouvez ajouter des éléments tels que des titres, du nouveau texte, desdiagrammes ou des données provenant d’autres applications.
Pour ajouter un nouveau titre ou texte
Des éléments textes qui ne sont pas liés à un tableau ou un diagramme peuvent être ajoutésau Viewer.
E Cliquez sur le tableau, diagramme ou autre objet qui précédera le titre ou texte.
E A partir des menus, sélectionnez :Insérer
Nouveau titre
ouInsérer
Nouveau texte
E Double-cliquez sur le nouvel objet.
E Entrez le texte.
Pour ajouter un fichier texte
E Dans le panneau de légende ou de contenu de l’Editeur de résultats, cliquez sur le tableau,diagramme ou autre objet qui précédera le texte.
E A partir des menus, sélectionnez :Insérer
Fichier texte
E Sélectionnez un fichier texte.
Pour modifier le texte, double-cliquez dessus.
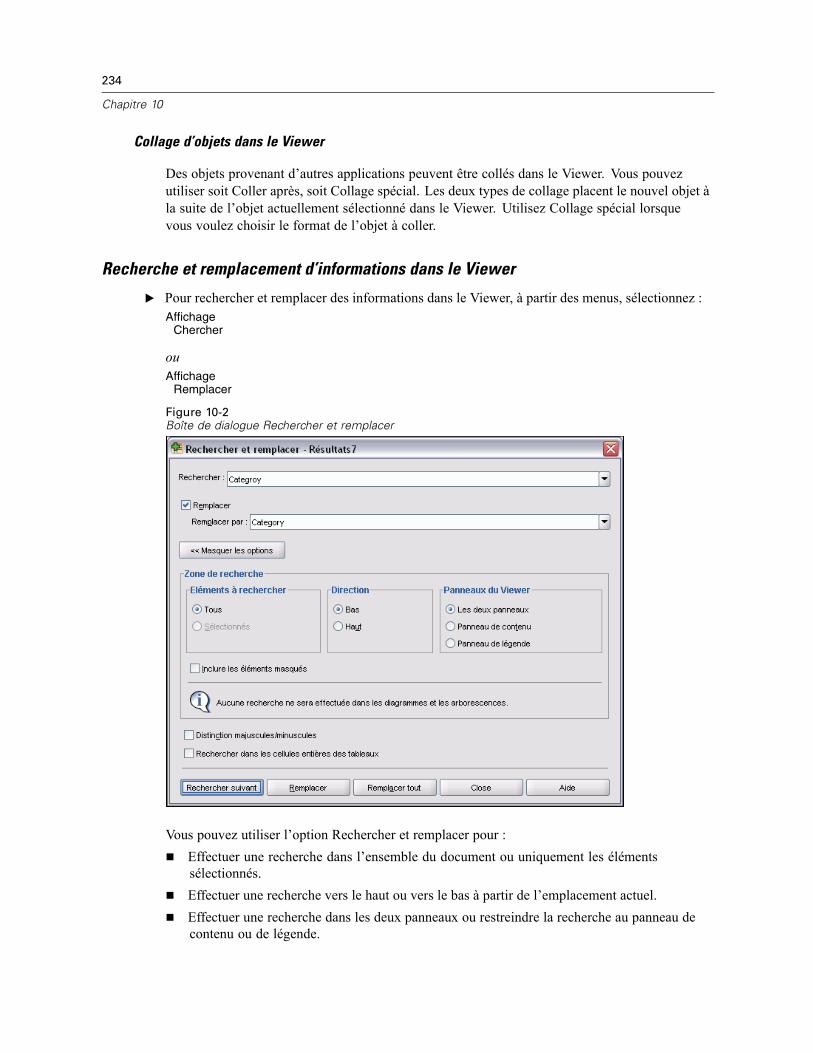
234
Chapitre 10
Collage d’objets dans le Viewer
Des objets provenant d’autres applications peuvent être collés dans le Viewer. Vous pouvezutiliser soit Coller après, soit Collage spécial. Les deux types de collage placent le nouvel objet àla suite de l’objet actuellement sélectionné dans le Viewer. Utilisez Collage spécial lorsquevous voulez choisir le format de l’objet à coller.
Recherche et remplacement d’informations dans le Viewer
E Pour rechercher et remplacer des informations dans le Viewer, à partir des menus, sélectionnez :Affichage
Chercher
ouAffichage
Remplacer
Figure 10-2Boîte de dialogue Rechercher et remplacer
Vous pouvez utiliser l’option Rechercher et remplacer pour :Effectuer une recherche dans l’ensemble du document ou uniquement les élémentssélectionnés.Effectuer une recherche vers le haut ou vers le bas à partir de l’emplacement actuel.Effectuer une recherche dans les deux panneaux ou restreindre la recherche au panneau decontenu ou de légende.

235
Utilisation du résultat
Rechercher des éléments masqués. Il s’agit de tout élément masqué dans le panneau decontenu (par exemple des tableaux de remarques masqués par défaut) ainsi que des lignes etcolonnes masquées dans les tableaux pivotants.Restreindre les critères de recherche aux résultats respectant la casse.Restreindre les critères de recherche dans les tableaux pivotants aux correspondances ducontenu global des cellules.
Eléments masqués et strates de tableau pivotant
Les strates se trouvant sous la strate actuellement visible d’un tableau pivotantmultidimensionnel ne sont pas considérées comme masquées et sont incluses dans la zone derecherche même quand les éléments masqués ne sont pas inclus dans la recherche.Les éléments masqués incluent les éléments masqués du panneau de contenu (élémentsaccompagnés d’icônes de livre fermé dans le panneau de légende ou inclus dans des blocsréduits du panneau de légende) ainsi que les lignes et colonnes de tableaux pivotantsmasquées par défaut (par exemple, les lignes et colonnes vides sont masquées par défaut) oumasquées manuellement en modifiant le tableau et en masquant de façon sélective des lignesou colonnes spécifiques. Les éléments masqués ne sont inclus dans la recherche que si vousavez explicitement sélectionné Inclure les éléments masqués.Dans les deux cas, l’élément masqué ou non visible contenant le texte ou la valeur derecherche est affiché une fois trouvé, mais cet élément revient ensuite à son état d’origine.
Copie des résultats dans d’autres applications
Les objets de sortie peuvent être copiés et collés dans d’autres applications telles que lestraitements de texte ou les tableurs. Vous pouvez coller les résultats de différentes façons. Enfonction de l’application cible, certains formats suivants (ou tous les formats) peuvent êtredisponibles :
Image (métafichier) : Les tableaux pivotants et les diagrammes peuvent être collés en tantqu’images (métafichiers). Le format image peut être redimensionné dans l’autre application, etquelquefois édité dans une mesure limitée à l’aide des outils de l’autre application. Les tableauxpivotants collés comme images conservent toutes leurs caractéristiques de bordures et de polices.Pour les tableaux pivotants, sélectionnez Fichiers dans le menu Collage spécial. Ce format n’estdisponible que sous les systèmes d’exploitation Windows.
RTF (texte enrichi) : Les tableaux pivotants peuvent être collés dans d’autres applications au formatRTF. Dans la plupart des applications, cette procédure colle le tableau pivotant en tant que tableaupouvant être modifié dans une autre application.
Remarque : Microsoft Word risque de ne pas afficher correctement les tableaux extrêmementlarges.
Bitmap : Les diagrammes et les autres graphiques peuvent être collés dans d’autres applicationsen tant que bitmaps.
BIFF : Le contenu d’un tableau peut être collé dans une feuille de calcul et conserver sa précisionnumérique. Ce format n’est disponible que sous les systèmes d’exploitation Windows.

236
Chapitre 10
Texte : Le contenu d’un tableau peut être copié et collé comme texte. Cette option peut êtreutile pour les applications telles que le courrier électronique, où l’application ne peut accepterou transmettre que du texte.
Si l’application cible prend en charge plusieurs formats disponibles, elle possède certainementun élément de menu Collage spécial vous permettant de sélectionner le format, ou elle afficheprobablement automatiquement une liste des formats disponibles.
Pour copier et coller plusieurs éléments dans une autre application
E Sélectionnez les objets dans le panneau de légende ou de contenu du Viewer.
E A partir des menus du Viewer, sélectionnez :Affichage
Copier
E Dans les menus de l’application cible, choisissez :Affichage
Coller
ouAffichage
Collage spécial
Coller. Les sorties sont copiées vers le Presse-papiers dans un certain nombre de formats.Chaque application détermine le « meilleur » format à utiliser pour Coller.Collage spécial. Les résultats sont copiés dans le Presse-papiers dans différents formats.Collage spécial vous permet de sélectionner le format voulu dans la liste des formatsdisponibles pour l’application cible.
Copie et collage des vues de modèle. Toutes les vues de modèle, y compris les tableaux, sontcollées sous forme d’images graphiques.
Copie et collage de tableaux pivotants. Lorsque des tableaux pivotants sont collés au formatWord/RTF, les tableaux trop larges pour la largeur du document seront soit ajustés ou réduits pourcorrespondre à la largeur du document, soit laissées inchangés, selon les paramètres d’optionsdu tableau pivotant. Pour plus d'informations, reportez-vous à Options tableaux pivotants dansChapitre 48 sur p. 551.
Exporter résultats
L’option d’export enregistre les résultats de Résultats aux formats HTML, texte, Word/RTF,Excel, PowerPoint (nécessite PowerPoint 97 ou une version ultérieure) et PDF. Les diagrammespeuvent également être exportés dans différents formats graphiques.
Remarque : L’exportation vers PowerPoint n’est disponible que sous les systèmes d’exploitationWindows et n’est pas disponible dans la version Student.
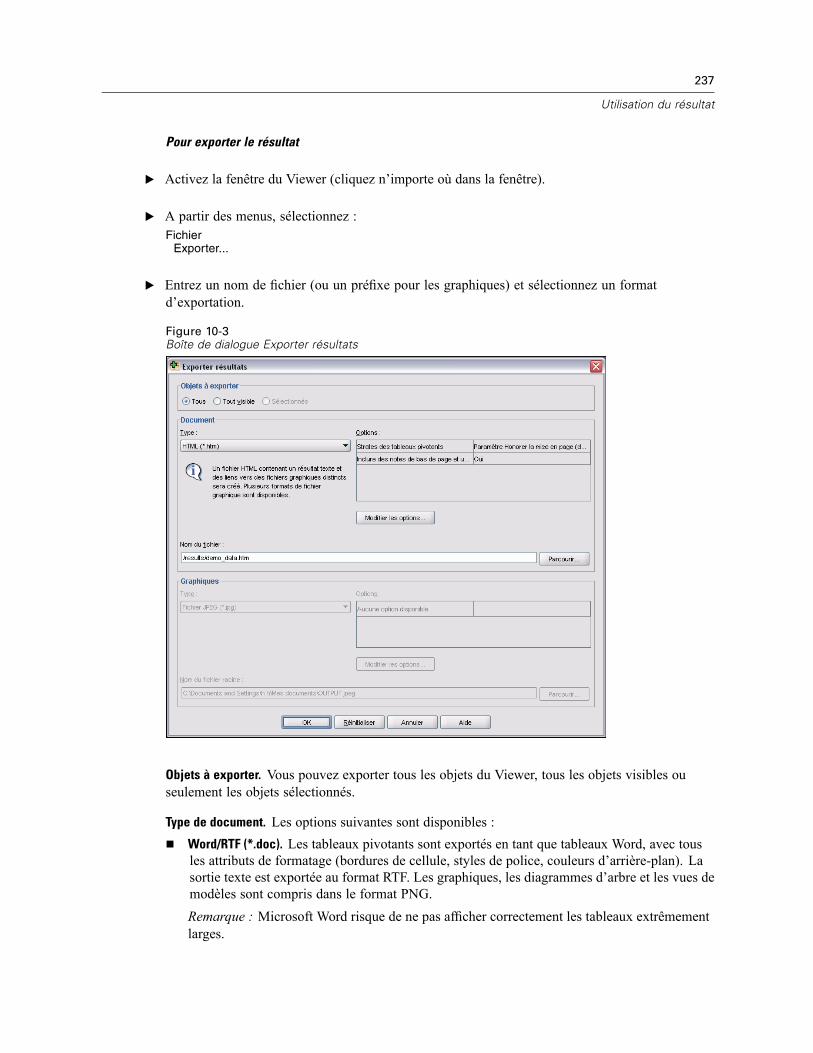
237
Utilisation du résultat
Pour exporter le résultat
E Activez la fenêtre du Viewer (cliquez n’importe où dans la fenêtre).
E A partir des menus, sélectionnez :Fichier
Exporter...
E Entrez un nom de fichier (ou un préfixe pour les graphiques) et sélectionnez un formatd’exportation.
Figure 10-3Boîte de dialogue Exporter résultats
Objets à exporter. Vous pouvez exporter tous les objets du Viewer, tous les objets visibles ouseulement les objets sélectionnés.
Type de document. Les options suivantes sont disponibles :Word/RTF (*.doc). Les tableaux pivotants sont exportés en tant que tableaux Word, avec tousles attributs de formatage (bordures de cellule, styles de police, couleurs d’arrière-plan). Lasortie texte est exportée au format RTF. Les graphiques, les diagrammes d’arbre et les vues demodèles sont compris dans le format PNG.Remarque : Microsoft Word risque de ne pas afficher correctement les tableaux extrêmementlarges.

238
Chapitre 10
Excel (*:xls). Les lignes, colonnes et cellules des tableaux pivotants sont exportées comme deslignes, colonnes et cellules Excel, avec tous les attributs de formatage (bordures de cellule,styles de police, couleurs d’arrière-plan, etc.). Le résultat texte est exporté avec tous lesattributs de police. Chaque ligne du résultat texte est une ligne dans le fichier Excel, avec lecontenu de toute la ligne dans une seule cellule. Les graphiques, les diagrammes d’arbre et lesvues de modèles sont compris dans le format PNG.HTML (*.htm). Les tableaux pivotants sont exportés comme des tableaux HTML. Les résultatstexte sont publiés au format HTML pré-formaté. Les graphiques, les diagrammes d’arbre sontintégrés par référence, et vous devez exporter les diagrammes sous un format adapté pourpermettre leur intégration dans des documents HTML (par exemple PNG et JPEG).Portable Document Format (*.pdf). Tous les résultats sont exportés tels qu’ils apparaissent dansl’aperçu avant impression, avec tous les attributs de formatage intacts.Fichier PowerPoint (*.ppt). Les tableaux pivotants sont exportés en tant que tableaux Word, puisincorporés au fichier PowerPoint dans des diapositives distinctes, à raison d’une diapositivepar tableau pivotant. Tous les attributs de formatage (bordures de cellule, styles de police,couleurs d’arrière-plan, etc.) sont conservés. Les graphiques, les diagrammes d’arbre et lesvues de modèles sont exportés au format PNG. Les résultats texte ne sont pas inclus.L’option Exporter vers PowerPoint n’est disponible que sous les systèmes d’exploitationWindows.Texte (*.txt). Les formats de résultats texte comprennent les formats texte brut, UTF-8 etUTF-16. Les tableaux pivotants peuvent être exportés en format tabulé ou avec espaces. Tousles résultats texte sont exportés en format avec espaces. Pour les graphiques, les diagrammesd’arbre et les vues de modèles, une ligne est insérée dans le fichier texte pour chaquegraphique, indiquant le nom de fichier de l’image.Aucun (diagrammes uniquement). Les formats d’exportation disponibles sont les suivants :EPS, JPEG, TIFF, PNG et BMP. Sous les systèmes d’exploitation Windows, le format EMF(métafichier amélioré) est également disponible.
Système de gestion des résultats. Vous pouvez également exporter automatiquement tous lesrésultats ou tous les types de résultats définis par l’utilisateur, tels que les fichiers texte et lesfichiers de données au format Word, Excel, PDF, HTML, text ou sous forme de fichiers de donnéesau format SPSS Statistics. Pour plus d'informations, reportez-vous à Système de gestion desrésultats dans Chapitre 52 sur p. 603.
Options HTML
Les options suivantes sont disponibles pour exporter les résultats au format HTML :
Strates des tableaux pivotants. Par défaut, l’inclusion ou l’exclusion de strates de tableauxpivotants est contrôlée par les propriétés du tableau pour chaque tableau pivotant. Vous pouvezremplacer ce paramètre et inclure toutes les strates, ou les exclure toutes sauf la strate actuellementvisible. Pour plus d'informations, reportez-vous à Propriétés de tableau : Impression dans Chapitre11 sur p. 269.
Inclure des notes de bas de page et des légendes. Contrôle l’inclusion ou l’exclusion des notes debas de page et légendes de tous les tableaux pivotants.
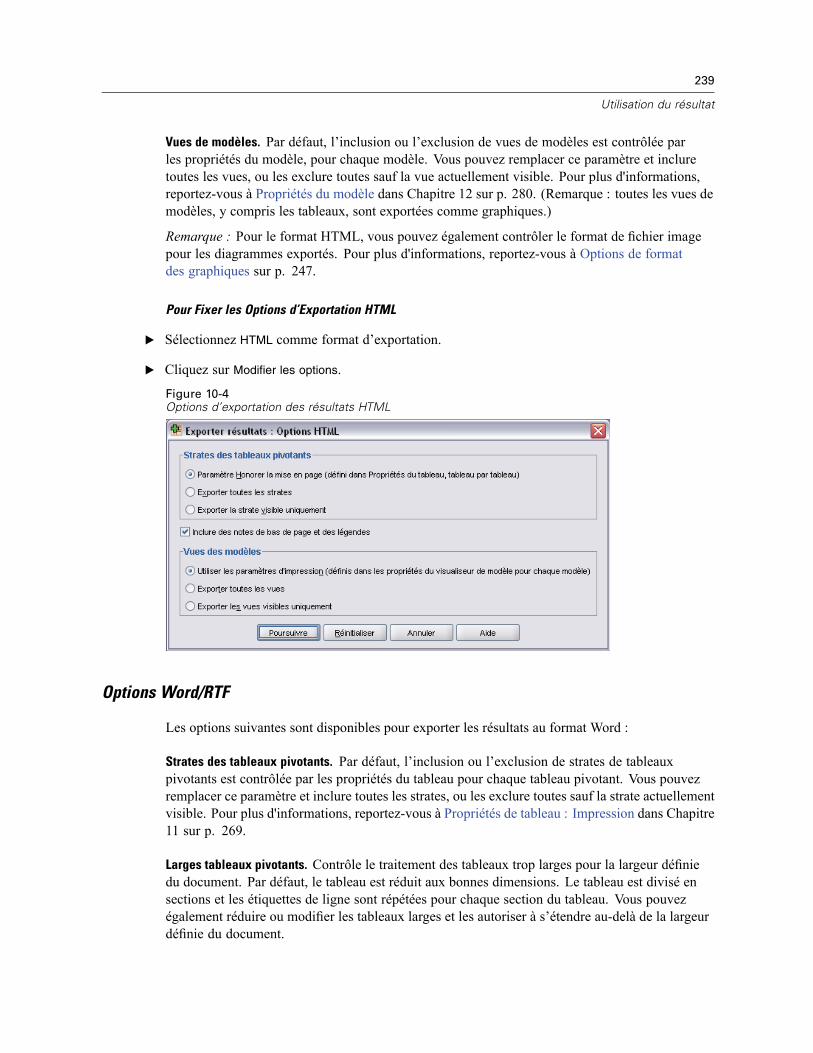
239
Utilisation du résultat
Vues de modèles. Par défaut, l’inclusion ou l’exclusion de vues de modèles est contrôlée parles propriétés du modèle, pour chaque modèle. Vous pouvez remplacer ce paramètre et incluretoutes les vues, ou les exclure toutes sauf la vue actuellement visible. Pour plus d'informations,reportez-vous à Propriétés du modèle dans Chapitre 12 sur p. 280. (Remarque : toutes les vues demodèles, y compris les tableaux, sont exportées comme graphiques.)
Remarque : Pour le format HTML, vous pouvez également contrôler le format de fichier imagepour les diagrammes exportés. Pour plus d'informations, reportez-vous à Options de formatdes graphiques sur p. 247.
Pour Fixer les Options d’Exportation HTML
E Sélectionnez HTML comme format d’exportation.
E Cliquez sur Modifier les options.
Figure 10-4Options d’exportation des résultats HTML
Options Word/RTF
Les options suivantes sont disponibles pour exporter les résultats au format Word :
Strates des tableaux pivotants. Par défaut, l’inclusion ou l’exclusion de strates de tableauxpivotants est contrôlée par les propriétés du tableau pour chaque tableau pivotant. Vous pouvezremplacer ce paramètre et inclure toutes les strates, ou les exclure toutes sauf la strate actuellementvisible. Pour plus d'informations, reportez-vous à Propriétés de tableau : Impression dans Chapitre11 sur p. 269.
Larges tableaux pivotants. Contrôle le traitement des tableaux trop larges pour la largeur définiedu document. Par défaut, le tableau est réduit aux bonnes dimensions. Le tableau est divisé ensections et les étiquettes de ligne sont répétées pour chaque section du tableau. Vous pouvezégalement réduire ou modifier les tableaux larges et les autoriser à s’étendre au-delà de la largeurdéfinie du document.
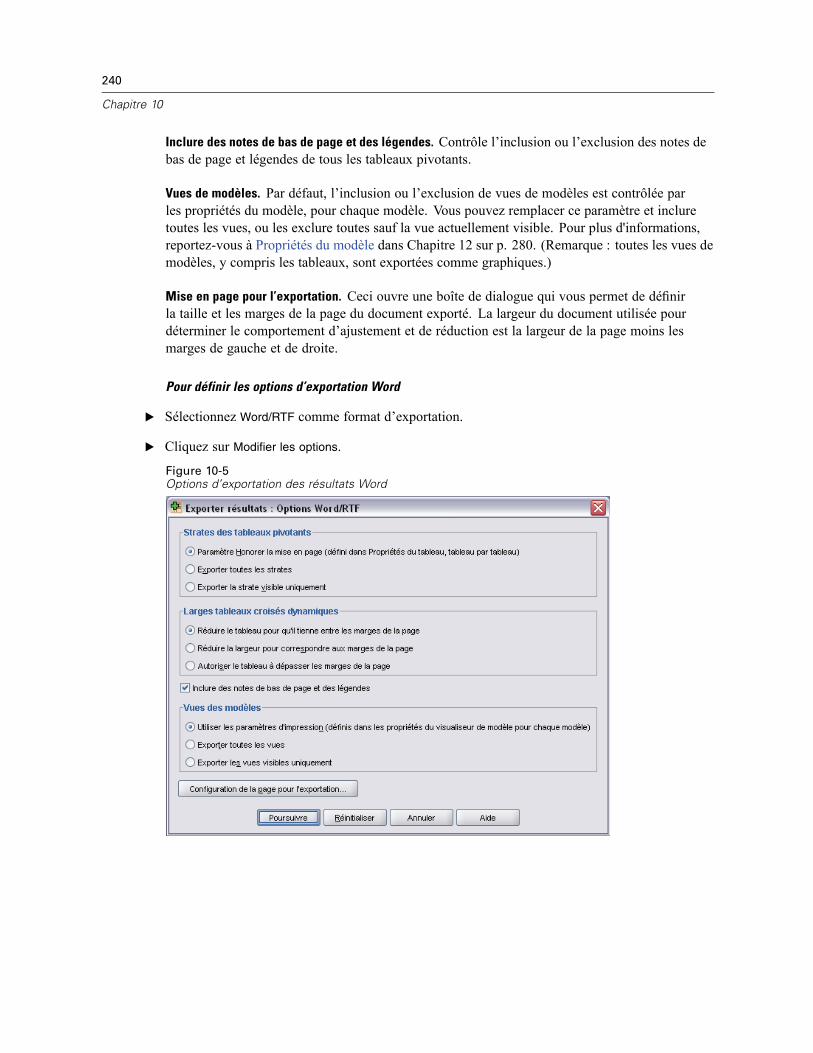
240
Chapitre 10
Inclure des notes de bas de page et des légendes. Contrôle l’inclusion ou l’exclusion des notes debas de page et légendes de tous les tableaux pivotants.
Vues de modèles. Par défaut, l’inclusion ou l’exclusion de vues de modèles est contrôlée parles propriétés du modèle, pour chaque modèle. Vous pouvez remplacer ce paramètre et incluretoutes les vues, ou les exclure toutes sauf la vue actuellement visible. Pour plus d'informations,reportez-vous à Propriétés du modèle dans Chapitre 12 sur p. 280. (Remarque : toutes les vues demodèles, y compris les tableaux, sont exportées comme graphiques.)
Mise en page pour l’exportation. Ceci ouvre une boîte de dialogue qui vous permet de définirla taille et les marges de la page du document exporté. La largeur du document utilisée pourdéterminer le comportement d’ajustement et de réduction est la largeur de la page moins lesmarges de gauche et de droite.
Pour définir les options d’exportation Word
E Sélectionnez Word/RTF comme format d’exportation.
E Cliquez sur Modifier les options.
Figure 10-5Options d’exportation des résultats Word

241
Utilisation du résultat
Options Excel
Les options suivantes sont disponibles pour exporter les résultats au format Excel :
Créez une feuille de calcul ou un classeur, ou modifiez une feuille de calcul existante. Par défaut,un nouveau classeur est créé. Si un fichier portant le même nom existe, il sera écrasé. Si vouschoisissez de créer une nouvelle feuille de calcul, si une feuille de cacul portant le même nomexiste dans le fichier spécifié, elle sera écrasée. Si vous choisissez de modifier une feuille de calculexistante, vous devez en spécifier le nom. (Cela est facultatif si vous créez une feuille de calcul).Les noms de feuille de calcul ne peuvent pas dépasser 31 caractères et ne doivent pas comporterde barre oblique, de barre oblique inversée, de crochet, de point d’interrogation ou d’astérisque.
Si vous modifiez une feuille de calcul existante, les graphiques, les modèles de vue et lesdiagrammes d’arbre ne seront pas inclus dans les résultats exportés.
Emplacement dans la feuille de calcul. Contrôle l’emplacement dans la feuille de calcul destinéaux résultats exportés. Par défaut, les résultats exportés seront ajoutés après la dernière colonneà contenu, en partant de la première ligne, sans modifier le contenu existant. C’est une bonnesolution pour ajouter de nouvelles colonnes à une feuille de calcul existante. L’ajout des résultatsexportés après la dernière ligne est une bonne solution pour ajouter de nouvelles lignes à unefeuille de calcul existante. L’ajout des résultats exportés en partant d’un emplacement de cellulespéficique écrasera le contenu dans la zone d’ajout des résultats exportés.
Strates des tableaux pivotants. Par défaut, l’inclusion ou l’exclusion de strates de tableauxpivotants est contrôlée par les propriétés du tableau pour chaque tableau pivotant. Vous pouvezremplacer ce paramètre et inclure toutes les strates, ou les exclure toutes sauf la strate actuellementvisible. Pour plus d'informations, reportez-vous à Propriétés de tableau : Impression dans Chapitre11 sur p. 269.
Inclure des notes de bas de page et des légendes. Contrôle l’inclusion ou l’exclusion des notes debas de page et légendes de tous les tableaux pivotants.
Vues de modèles. Par défaut, l’inclusion ou l’exclusion de vues de modèles est contrôlée parles propriétés du modèle, pour chaque modèle. Vous pouvez remplacer ce paramètre et incluretoutes les vues, ou les exclure toutes sauf la vue actuellement visible. Pour plus d'informations,reportez-vous à Propriétés du modèle dans Chapitre 12 sur p. 280. (Remarque : toutes les vues demodèles, y compris les tableaux, sont exportées comme graphiques.)
Pour définir les options d’exportation Excel
E Sélectionnez Excel comme format d’exportation.
E Cliquez sur Modifier les options.
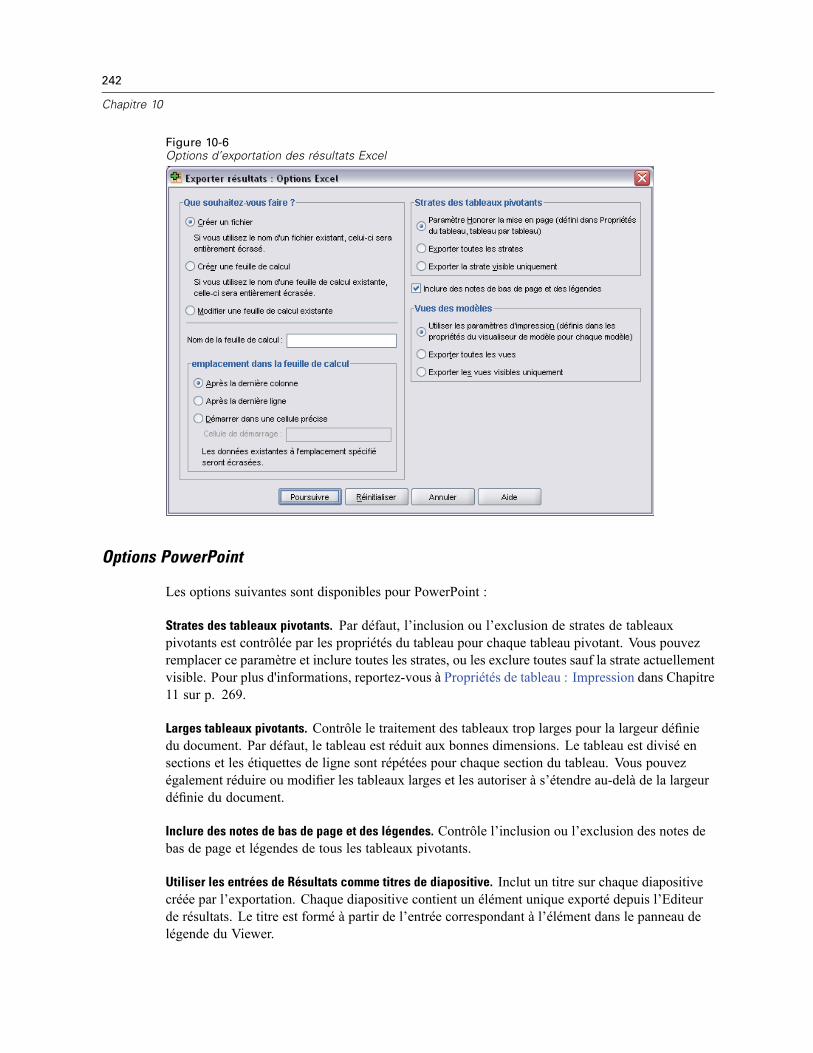
242
Chapitre 10
Figure 10-6Options d’exportation des résultats Excel
Options PowerPoint
Les options suivantes sont disponibles pour PowerPoint :
Strates des tableaux pivotants. Par défaut, l’inclusion ou l’exclusion de strates de tableauxpivotants est contrôlée par les propriétés du tableau pour chaque tableau pivotant. Vous pouvezremplacer ce paramètre et inclure toutes les strates, ou les exclure toutes sauf la strate actuellementvisible. Pour plus d'informations, reportez-vous à Propriétés de tableau : Impression dans Chapitre11 sur p. 269.
Larges tableaux pivotants. Contrôle le traitement des tableaux trop larges pour la largeur définiedu document. Par défaut, le tableau est réduit aux bonnes dimensions. Le tableau est divisé ensections et les étiquettes de ligne sont répétées pour chaque section du tableau. Vous pouvezégalement réduire ou modifier les tableaux larges et les autoriser à s’étendre au-delà de la largeurdéfinie du document.
Inclure des notes de bas de page et des légendes. Contrôle l’inclusion ou l’exclusion des notes debas de page et légendes de tous les tableaux pivotants.
Utiliser les entrées de Résultats comme titres de diapositive. Inclut un titre sur chaque diapositivecréée par l’exportation. Chaque diapositive contient un élément unique exporté depuis l’Editeurde résultats. Le titre est formé à partir de l’entrée correspondant à l’élément dans le panneau delégende du Viewer.
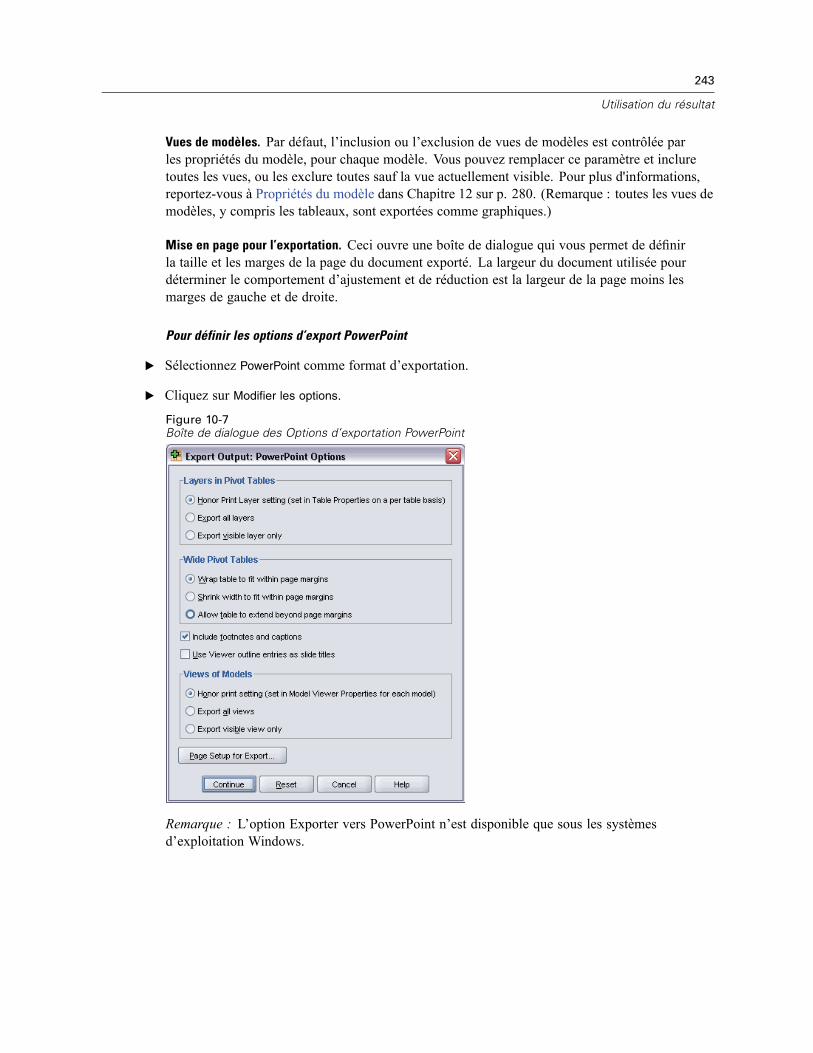
243
Utilisation du résultat
Vues de modèles. Par défaut, l’inclusion ou l’exclusion de vues de modèles est contrôlée parles propriétés du modèle, pour chaque modèle. Vous pouvez remplacer ce paramètre et incluretoutes les vues, ou les exclure toutes sauf la vue actuellement visible. Pour plus d'informations,reportez-vous à Propriétés du modèle dans Chapitre 12 sur p. 280. (Remarque : toutes les vues demodèles, y compris les tableaux, sont exportées comme graphiques.)
Mise en page pour l’exportation. Ceci ouvre une boîte de dialogue qui vous permet de définirla taille et les marges de la page du document exporté. La largeur du document utilisée pourdéterminer le comportement d’ajustement et de réduction est la largeur de la page moins lesmarges de gauche et de droite.
Pour définir les options d’export PowerPoint
E Sélectionnez PowerPoint comme format d’exportation.
E Cliquez sur Modifier les options.
Figure 10-7Boîte de dialogue des Options d’exportation PowerPoint
Remarque : L’option Exporter vers PowerPoint n’est disponible que sous les systèmesd’exploitation Windows.
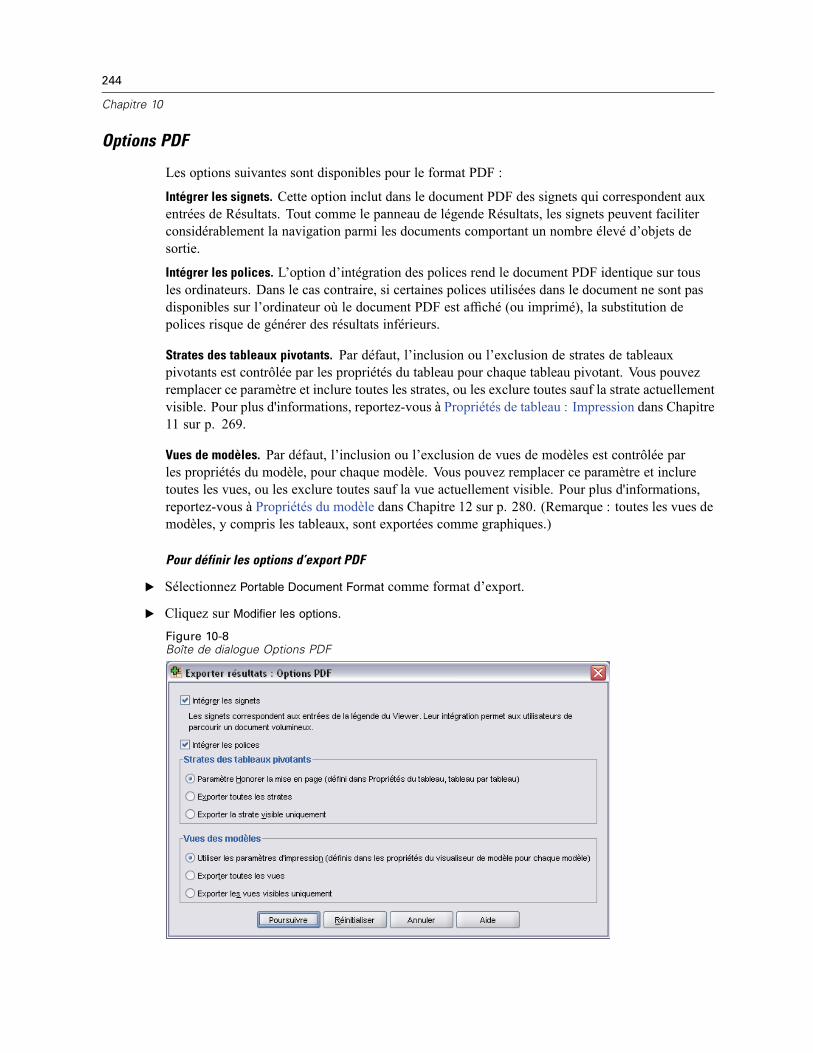
244
Chapitre 10
Options PDF
Les options suivantes sont disponibles pour le format PDF :
Intégrer les signets. Cette option inclut dans le document PDF des signets qui correspondent auxentrées de Résultats. Tout comme le panneau de légende Résultats, les signets peuvent faciliterconsidérablement la navigation parmi les documents comportant un nombre élevé d’objets desortie.
Intégrer les polices. L’option d’intégration des polices rend le document PDF identique sur tousles ordinateurs. Dans le cas contraire, si certaines polices utilisées dans le document ne sont pasdisponibles sur l’ordinateur où le document PDF est affiché (ou imprimé), la substitution depolices risque de générer des résultats inférieurs.
Strates des tableaux pivotants. Par défaut, l’inclusion ou l’exclusion de strates de tableauxpivotants est contrôlée par les propriétés du tableau pour chaque tableau pivotant. Vous pouvezremplacer ce paramètre et inclure toutes les strates, ou les exclure toutes sauf la strate actuellementvisible. Pour plus d'informations, reportez-vous à Propriétés de tableau : Impression dans Chapitre11 sur p. 269.
Vues de modèles. Par défaut, l’inclusion ou l’exclusion de vues de modèles est contrôlée parles propriétés du modèle, pour chaque modèle. Vous pouvez remplacer ce paramètre et incluretoutes les vues, ou les exclure toutes sauf la vue actuellement visible. Pour plus d'informations,reportez-vous à Propriétés du modèle dans Chapitre 12 sur p. 280. (Remarque : toutes les vues demodèles, y compris les tableaux, sont exportées comme graphiques.)
Pour définir les options d’export PDF
E Sélectionnez Portable Document Format comme format d’export.
E Cliquez sur Modifier les options.Figure 10-8Boîte de dialogue Options PDF

245
Utilisation du résultat
Autres paramètres affectant la sortie PDF
Mise en page/Attributs de page. La taille de page, l’orientation, les marges, le contenu et l’affichagedes en-têtes et bas de page, et la taille des graphiques imprimés dans les documents PDF sontcontrôlés par les options de mise en page et d’attribut de page.
Propriétés du tableau/Modèles de tableaux. Le redimensionnement de tableaux larges et/oulongs et l’impression des strates de tableau sont contrôlés par les propriétés de chaque tableau.Ces propriétés peuvent également être enregistrées dans Modèles de tableaux. Pour plusd'informations, reportez-vous à Propriétés de tableau : Impression dans Chapitre 11 sur p. 269.
Imprimante par défaut/active. La résolution (PPP) du document PDF est le paramètre de résolutioncourant de l’imprimante par défaut ou sélectionnée (qui peut être changée à l’aide de l’option Miseen page). La résolution maximale est de 1 200 ppp. Si le paramètre de résolution de l’imprimanteest supérieur, la résolution du document PDF sera de 1 200 ppp.
Remarque : Une haute résolution peut générer des résultats médiocres si les documents sontimprimés sur des imprimantes de résolution inférieure.
Options texte
Les options suivantes sont disponibles pour l’exportation de texte :
Format des tableaux pivotants. Les tableaux pivotants peuvent être exportés en format tabulé ouavec espaces. Pour le format avec espaces, vous pouvez également contrôler :
Largeur de colonne. Ajustement automatique ne permet pas un renvoi à la ligne du contenu descolonnes, et chacune d’entre elles est aussi large que la plus grande étiquette ou la plus grandevaleur de cette colonne. Personnalisé permet de définir une largeur de colonne maximale quiest appliquée à toutes les colonnes de la table, et les valeurs qui dépassent cette largeur sontrenvoyées à la ligne suivante de cette colonne.Caractère de bordure de ligne/colonne. Permet de contrôler les caractères utilisés pour créerdes bordures de ligne et de colonne. Pour supprimer l’affichage de ces bordures de ligne et decolonne , indiquez des espaces vides pour les valeurs.
Strates des tableaux pivotants. Par défaut, l’inclusion ou l’exclusion de strates de tableauxpivotants est contrôlée par les propriétés du tableau pour chaque tableau pivotant. Vous pouvezremplacer ce paramètre et inclure toutes les strates, ou les exclure toutes sauf la strate actuellementvisible. Pour plus d'informations, reportez-vous à Propriétés de tableau : Impression dans Chapitre11 sur p. 269.
Inclure des notes de bas de page et des légendes. Contrôle l’inclusion ou l’exclusion des notes debas de page et légendes de tous les tableaux pivotants.
Vues de modèles. Par défaut, l’inclusion ou l’exclusion de vues de modèles est contrôlée parles propriétés du modèle, pour chaque modèle. Vous pouvez remplacer ce paramètre et incluretoutes les vues, ou les exclure toutes sauf la vue actuellement visible. Pour plus d'informations,reportez-vous à Propriétés du modèle dans Chapitre 12 sur p. 280. (Remarque : toutes les vues demodèles, y compris les tableaux, sont exportées comme graphiques.)
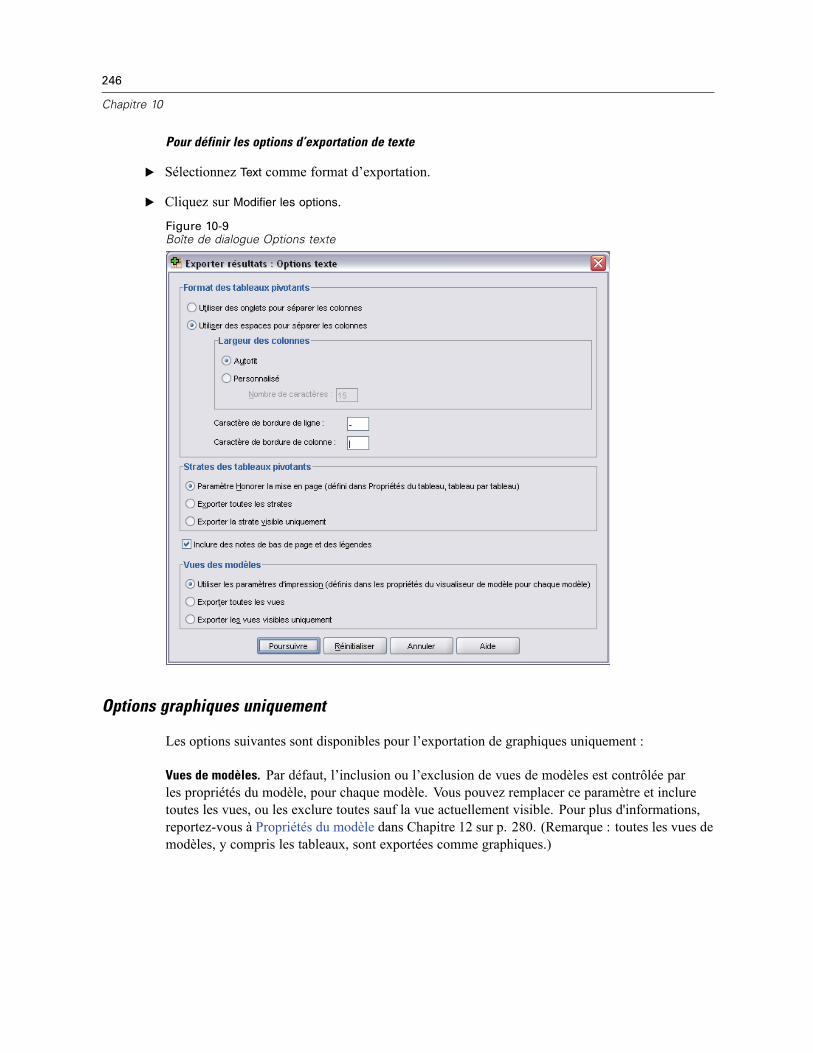
246
Chapitre 10
Pour définir les options d’exportation de texte
E Sélectionnez Text comme format d’exportation.
E Cliquez sur Modifier les options.
Figure 10-9Boîte de dialogue Options texte
Options graphiques uniquement
Les options suivantes sont disponibles pour l’exportation de graphiques uniquement :
Vues de modèles. Par défaut, l’inclusion ou l’exclusion de vues de modèles est contrôlée parles propriétés du modèle, pour chaque modèle. Vous pouvez remplacer ce paramètre et incluretoutes les vues, ou les exclure toutes sauf la vue actuellement visible. Pour plus d'informations,reportez-vous à Propriétés du modèle dans Chapitre 12 sur p. 280. (Remarque : toutes les vues demodèles, y compris les tableaux, sont exportées comme graphiques.)

247
Utilisation du résultat
Figure 10-10Options graphiques uniquement
Options de format des graphiques
Pour les documents HTML et texte ainsi que pour l’exportation de graphiques uniquement, vouspouvez sélectionner le format graphique, et, pour chaque format graphique, vous pouvez contrôlerdivers paramètres facultatifs.
Pour sélectionner le format graphique et des options pour les diagrammes exportés :
E Sélectionnez HTML, Text ou None (Graphics only) comme type de document.
E Sélectionnez un type de fichier graphique dans la liste déroulante proposée.
E Cliquez surModifier les options pour modifier les options du format de fichier graphique sélectionné.
Options d’exportation de diagrammes au format JPEGTaille d’image. Pourcentage de la taille d’origine du diagramme, jusqu’à 200 pour cent.Convertir en niveaux de gris. Convertit les couleurs en nuances de gris.
Options d’exportation de diagrammes au format BMPTaille d’image. Pourcentage de la taille d’origine du diagramme, jusqu’à 200 pour cent.Compresser l’image pour réduire la taille du fichier. Technique de compression sans perte quicrée des fichiers plus petits sans affecter la qualité de l’image.
Options d’exportation de diagrammes au format PNG
Taille d’image. Pourcentage de la taille d’origine du diagramme, jusqu’à 200 pour cent.
Profondeur des couleurs. Détermine le nombre de couleurs du diagramme exporté. Quelle quesoit la profondeur de couleur utilisée lors de l’enregistrement d’un diagramme, le nombre decouleurs du diagramme est compris entre le nombre de couleurs réellement utilisées et le nombremaximal de couleurs autorisé par la profondeur. Par exemple, si vous enregistrez un diagrammecontenant trois couleurs (rouge, blanc et noir) en mode 16 couleurs, ce diagramme conserve sestrois couleurs.

248
Chapitre 10
Lorsque le nombre de couleurs du diagramme est supérieur au nombre prévu pour cetteprofondeur, les couleurs sont converties de manière à reproduire celles du diagramme.L’option Profondeur d’écran actuelle correspond au nombre de couleurs affichées sur votreécran.
Options d’exportation de diagrammes aux formats PNG et TIFF
Taille d’image. Pourcentage de la taille d’origine du diagramme, jusqu’à 200 pour cent.
Remarque : Le format EMF (métafichier amélioré) n’est disponible que sous les systèmesd’exploitation Windows.
Options d’exportation de diagrammes au format EPS
Taille d’image. Vous pouvez spécifier la taille sous forme de pourcentage de la taille d’origine del’image (jusqu’à 200 pour cent) ou vous pouvez spécifier la largeur d’une image en pixels (lahauteur étant déterminée par la valeur de largeur et le rapport hauteur/largeur). L’image exportéeest toujours proportionnelle à celle d’origine.
Inclure une image d’aperçu TIFF. Enregistre un aperçu avec l’image EPS au format TIFF pour unaffichage dans les applications qui ne peuvent pas afficher les images EPS à l’écran.
Polices. Contrôle le traitement des polices dans les images EPS.Utiliser des polices de référence. Si les polices utilisées dans le diagramme sont disponiblessur le périphérique de sortie, elles sont utilisées. Sinon, le périphérique de sortie utilise despolices alternatives.Remplacer les polices avec courbes. Transforme les polices en données de courbe PostScript.Vous ne pouvez plus modifier le texte en tant que tel dans les applications de retouche desgraphiques EPS. Cette option est utile si les polices utilisées dans le diagramme ne sontpas disponibles sur le périphérique de sortie.
Impression de documents du Viewer
Il y a deux options pour l’impression du contenu de la fenêtre Editeur de résultats :
Tous les résultats affichés : Seuls s’impriment les éléments affichés dans le panneau de contenu.Les éléments masqués (éléments accompagnés d’une icône représentant un livre fermé dansle panneau de ligne de légende ou masqués dans les strates réduites des lignes de légende)ne s’impriment pas.
Sélection : Seuls s’impriment les éléments sélectionnés dans les panneaux de ligne de légendeet/ou de contenu.
Pour imprimer des résultats et des diagrammes
E Activez la fenêtre du Viewer (cliquez n’importe où dans la fenêtre).

249
Utilisation du résultat
E A partir des menus, sélectionnez :Fichier
Imprimer
E Choisissez les paramètres d’impression voulus.
E Cliquez sur OK pour imprimer.
Aperçu avant impression
L’Aperçu avant impression vous montre ce qui va s’imprimer sur chaque page des documentsdu Viewer. Il est conseillé d’utiliser l’Aperçu avant impression avant d’imprimer réellement undocument de l’Editeur de résultats car cela permet de détecter les éléments qui ne seront pasvisibles, tout simplement en regardant le panneau de contenu de l’Editeur de résultats, notamment :
Les sauts de pageLes strates masquées des tableaux pivotantsLes ruptures dans les tableaux de grande largeurLes en-têtes et pieds de page imprimés sur chaque page
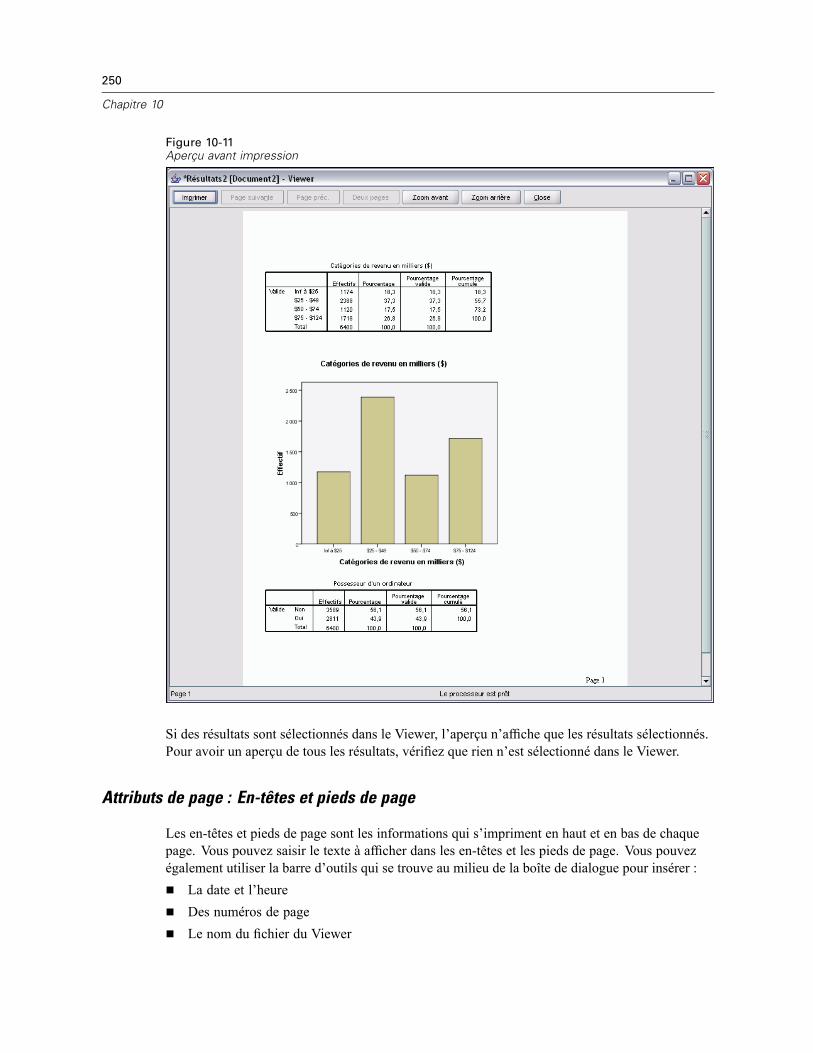
250
Chapitre 10
Figure 10-11Aperçu avant impression
Si des résultats sont sélectionnés dans le Viewer, l’aperçu n’affiche que les résultats sélectionnés.Pour avoir un aperçu de tous les résultats, vérifiez que rien n’est sélectionné dans le Viewer.
Attributs de page : En-têtes et pieds de page
Les en-têtes et pieds de page sont les informations qui s’impriment en haut et en bas de chaquepage. Vous pouvez saisir le texte à afficher dans les en-têtes et les pieds de page. Vous pouvezégalement utiliser la barre d’outils qui se trouve au milieu de la boîte de dialogue pour insérer :
La date et l’heureDes numéros de pageLe nom du fichier du Viewer
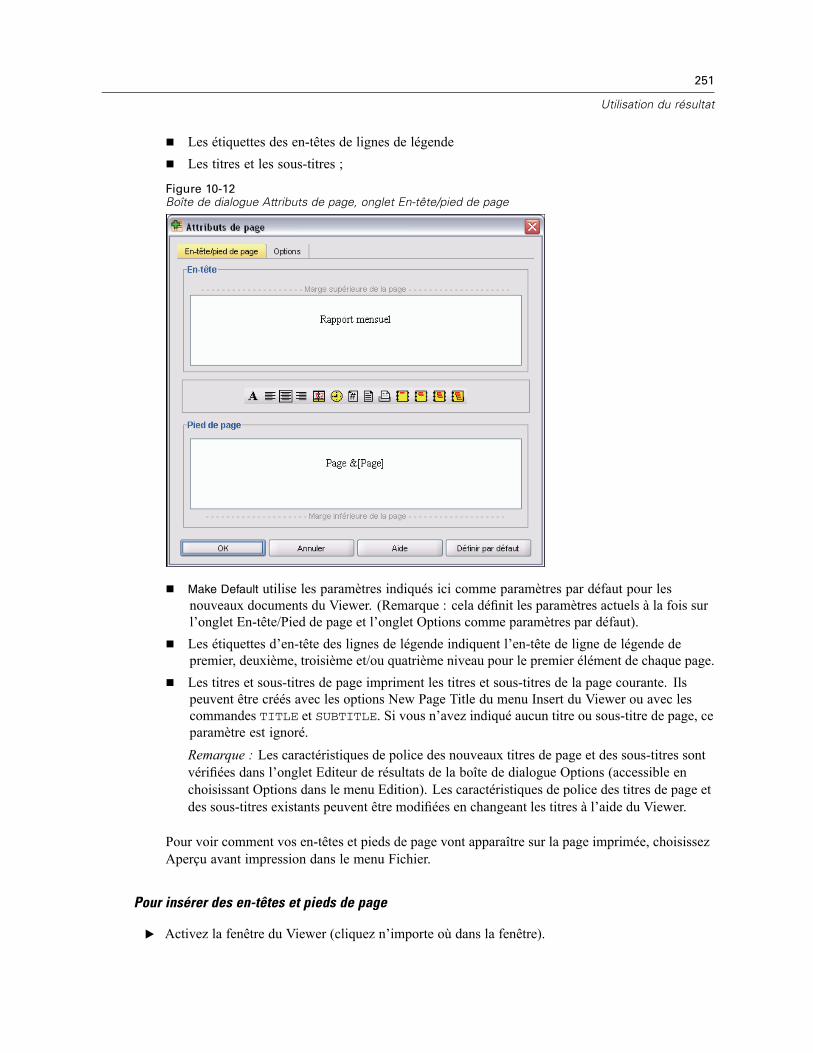
251
Utilisation du résultat
Les étiquettes des en-têtes de lignes de légendeLes titres et les sous-titres ;
Figure 10-12Boîte de dialogue Attributs de page, onglet En-tête/pied de page
Make Default utilise les paramètres indiqués ici comme paramètres par défaut pour lesnouveaux documents du Viewer. (Remarque : cela définit les paramètres actuels à la fois surl’onglet En-tête/Pied de page et l’onglet Options comme paramètres par défaut).Les étiquettes d’en-tête des lignes de légende indiquent l’en-tête de ligne de légende depremier, deuxième, troisième et/ou quatrième niveau pour le premier élément de chaque page.Les titres et sous-titres de page impriment les titres et sous-titres de la page courante. Ilspeuvent être créés avec les options New Page Title du menu Insert du Viewer ou avec lescommandes TITLE et SUBTITLE. Si vous n’avez indiqué aucun titre ou sous-titre de page, ceparamètre est ignoré.Remarque : Les caractéristiques de police des nouveaux titres de page et des sous-titres sontvérifiées dans l’onglet Editeur de résultats de la boîte de dialogue Options (accessible enchoisissant Options dans le menu Edition). Les caractéristiques de police des titres de page etdes sous-titres existants peuvent être modifiées en changeant les titres à l’aide du Viewer.
Pour voir comment vos en-têtes et pieds de page vont apparaître sur la page imprimée, choisissezAperçu avant impression dans le menu Fichier.
Pour insérer des en-têtes et pieds de page
E Activez la fenêtre du Viewer (cliquez n’importe où dans la fenêtre).

252
Chapitre 10
E A partir des menus, sélectionnez :Fichier
Attributs de page...
E Cliquez sur l’onglet En-tête/pied de page.
E Saisissez l’en-tête et/ou le pied de page devant figurer sur chaque page.
Attributs de page : Options
Cette boîte de dialogue contrôle la taille du diagramme imprimé, l’espace entre les éléments derésultat imprimés, ainsi que la numérotation des pages.
Taille imprimée diagramme : Contrôle la taille du diagramme imprimé par rapport à la tailledéfinie pour la page. Le rapport hauteur/largeur du diagramme n’est pas affecté par la taille dudiagramme imprimé. La taille globale d’un diagramme imprimé est limitée par sa hauteuret par sa largeur. Lorsque les bordures extérieures d’un tableau atteignent les bordures degauche et de droite de la page, la taille du diagramme ne peut plus augmenter pour occuperplus de hauteur.Espace entre items : Contrôle l’espace entre des éléments imprimés. Chaque tableau pivotant,diagramme et objet de texte constitue un élément distinct. Ce paramètre n’affecte pasl’affichage des éléments dans le Viewer.Commencer page : Numéros de page consécutifs commençant à partir d’un numéro spécifié.Définir par défaut : Cette option utilise les paramètres spécifiés ici comme paramètres par défautpour les nouveaux documents du Viewer. (Remarque : cela définit les paramètres actuels à lafois sur l’onglet En-tête/Pied de page et l’onglet Options comme paramètres par défaut).
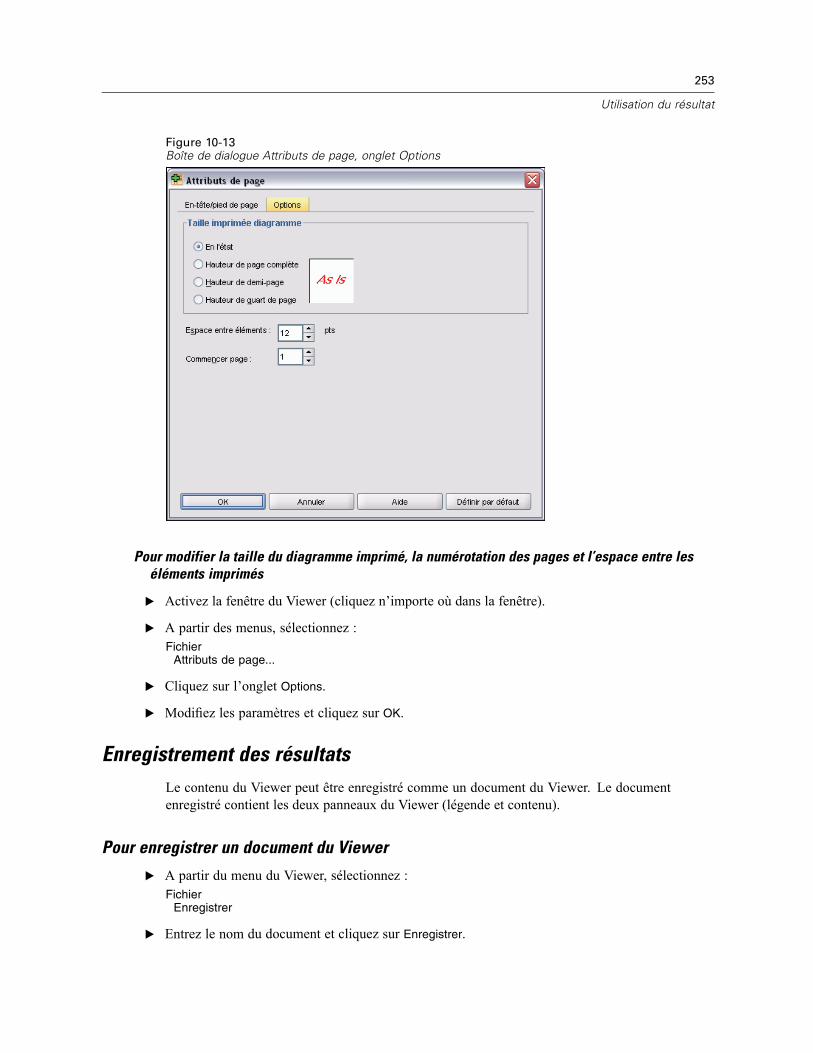
253
Utilisation du résultat
Figure 10-13Boîte de dialogue Attributs de page, onglet Options
Pour modifier la taille du diagramme imprimé, la numérotation des pages et l’espace entre leséléments imprimés
E Activez la fenêtre du Viewer (cliquez n’importe où dans la fenêtre).
E A partir des menus, sélectionnez :Fichier
Attributs de page...
E Cliquez sur l’onglet Options.
E Modifiez les paramètres et cliquez sur OK.
Enregistrement des résultatsLe contenu du Viewer peut être enregistré comme un document du Viewer. Le documentenregistré contient les deux panneaux du Viewer (légende et contenu).
Pour enregistrer un document du Viewer
E A partir du menu du Viewer, sélectionnez :Fichier
Enregistrer
E Entrez le nom du document et cliquez sur Enregistrer.

254
Chapitre 10
Pour enregistrer le résultat dans un format externe (par exemple HTML ou texte), utilisez Exporterdans le menu Fichier.

Chapitre
11Tableaux pivotants
De nombreux résultats sont présentés dans des tableaux qui peuvent être pivotés de manièreinteractive. Cela signifie que vous pouvez réarranger les lignes, colonnes et strates.
Manipulation d’un tableau pivotant
Les options de manipulation des tableaux pivotants comprennent les éléments suivants :Transposer des lignes et des colonnes.Déplacer des lignes et des colonnes.Créer des strates multidimensionnelles.Grouper et séparer des lignes et des colonnes.Afficher et masquer des lignes, des colonnes et d’autres informations.Faire pivoter des étiquettes de lignes et de colonnes.Trouver des définitions de termes.
Activer un tableau pivotant
Avant de pouvoir manipuler ou modifier un tableau pivotant, vous devez l’activer. Pour activerun tableau :
E Double-cliquez sur le tableau.
ou
E Cliquez avec le bouton droit de la souris sur le tableau puis, dans le menu contextuel, sélectionnezModifier le contenu.
E Dans le sous-menu, choisissez soit dans le Viewer soit Dans une fenêtre distincte.
Par défaut, l’activation du tableau par un double-clic ne permet pas d’activer les très grandstableaux dans la fenêtre Viewer. Pour plus d'informations, reportez-vous à Options tableauxpivotants dans Chapitre 48 sur p. 551.Si vous voulez activer simultanément plusieurs tableaux pivotants, vous devez les activerdans des fenêtres distinctes.
Pivotement de tableau
E Activez le tableau pivotant.
255

256
Chapitre 11
E A partir des menus, sélectionnez :Tableau pivotant
Structure pivotante
Figure 11-1Structure pivotante
Un tableau comporte trois dimensions : lignes, colonnes et strates. Une dimension peut contenirplusieurs éléments (ou aucun). Vous pouvez modifier l’organisation de la table en déplaçantles éléments entre les dimensions. Pour déplacer un élément, faites-le glisser vers la positionsouhaitée.
Modification de l’ordre d’affichage des éléments dans une dimension
Pour modifier l’ordre d’affichage des éléments dans une dimension de tableau (ligne, colonneou strate) :
E Si la structure pivotante n’est pas déjà activée, à partir du menu Tableau pivotant, choisissez :Tableau pivotant
Structure pivotante
E Faites-glisser les éléments dans la dimension de la structure pivotante.
Déplacement de lignes et de colonnes dans un élément de dimension
E Dans le tableau (pas la structure pivotante), cliquez sur l’étiquette de ligne ou de colonne àdéplacer.
E Faites glisser l’étiquette vers sa nouvelle position.
E Dans le menu contextuel, choisissez Insérer Avant ou Permuter.
Remarque : Assurez-vous que l’option Faire glisser pour Copier du menu Edition n’est pasactivée (cochée). Si l’option Faire glisser pour Copier est activée, désactivez-la.

257
Tableaux pivotants
Transposer des lignes et des colonnes
Si vous voulez juste retourner les lignes et les colonnes, une simple alternative permet d’utiliser lastructure pivotante :
E A partir des menus, sélectionnez :Tableau pivotant
Transposer lignes et colonnes
Cette action a le même effet que le glissement de tous les éléments de lignes dans la dimension decolonne et les éléments de colonnes dans la dimension de ligne.
Groupement de lignes ou de colonnes
E Sélectionnez les étiquettes des lignes ou des colonnes que vous voulez regrouper (cliquez etfaites glisser ou cliquez dessus tout en maintenant la touche Maj enfoncée pour sélectionnerplusieurs étiquettes).
E A partir des menus, sélectionnez :Affichage
Groupe
Une étiquette de groupe est insérée automatiquement. Double-cliquez sur l’étiquette de groupepour modifier le texte de l’étiquette.
Figure 11-2Groupes et étiquettes de lignes et de colonnes
Etiquette de groupe de colonnes
Etiquette deGroupe de Lignes
Clerical
ManagerCustodial
Female Male Total206
10
157 3632774
2784
Remarque : Pour ajouter des lignes ou des colonnes à un groupe existant, vous devez d’aborddissocier les éléments actuellement dans le groupe. Ensuite, vous pouvez créer un groupe quiinclut les éléments supplémentaires.
Dissociation de lignes ou de colonnes
E Cliquez n’importe où dans l’étiquette de groupe pour les lignes et les colonnes que vous souhaitezdégrouper.
E A partir des menus, sélectionnez :Affichage
Dissocier
Dissocier supprime automatiquement l’étiquette de groupe.

258
Chapitre 11
Rotation des étiquettes de ligne ou de colonne
Vous pouvez faire pivoter des étiquettes entre l’affichage horizontal et vertical des étiquettes decolonne les plus internes et les étiquettes de ligne les plus externes dans un tableau.
E A partir des menus, sélectionnez :Format
Faire pivoter les étiquettes des colonnes internes
ouFormat
Faire pivoter les étiquettes des lignes externes
Figure 11-3Etiquettes de colonnes pivotées
Seules les étiquettes des colonnes les plus internes et les étiquettes des lignes les plus externespeuvent être pivotées.
Utilisation des strates
Vous pouvez afficher un tableau bidimensionnel séparé pour chaque modalité ou combinaisonde modalités. Le tableau peut être imaginé comme un empilement de strates, dont seule la stratesupérieure est visible.
Création et affichage de strates
Pour créer des strates :
E Activez le tableau pivotant.

259
Tableaux pivotants
E Si la structure pivotante n’est pas déjà activée, à partir du menu Tableau pivotant, choisissez :Tableau pivotant
Structure pivotante
E Faites glisser un élément de la dimension de ligne ou de colonne vers la dimension de strate.
Figure 11-4Déplacer des modalités dans des strates
Le déplacement d’éléments vers la dimension de strate permet de créer un tableaumultidimensionnel. Toutefois, seul un « secteur » 2D est affiché. Le tableau visible est celui de lastrate supérieure. Par exemple, si une variable catégorielle oui/non figure dans la dimension de

260
Chapitre 11
strate, le tableau multidimensionnel comprend deux strates : une pour la modalité oui et l’autrepour la modalité non.
Figure 11-5Modalités en strates séparées
Modification de la strate affichée
E Sélectionnez une modalité dans la liste déroulante des strates (dans le tableau pivotant lui-même,et non la structure pivotante).
Figure 11-6Sélectionnez des strates à partir des listes déroulantes.
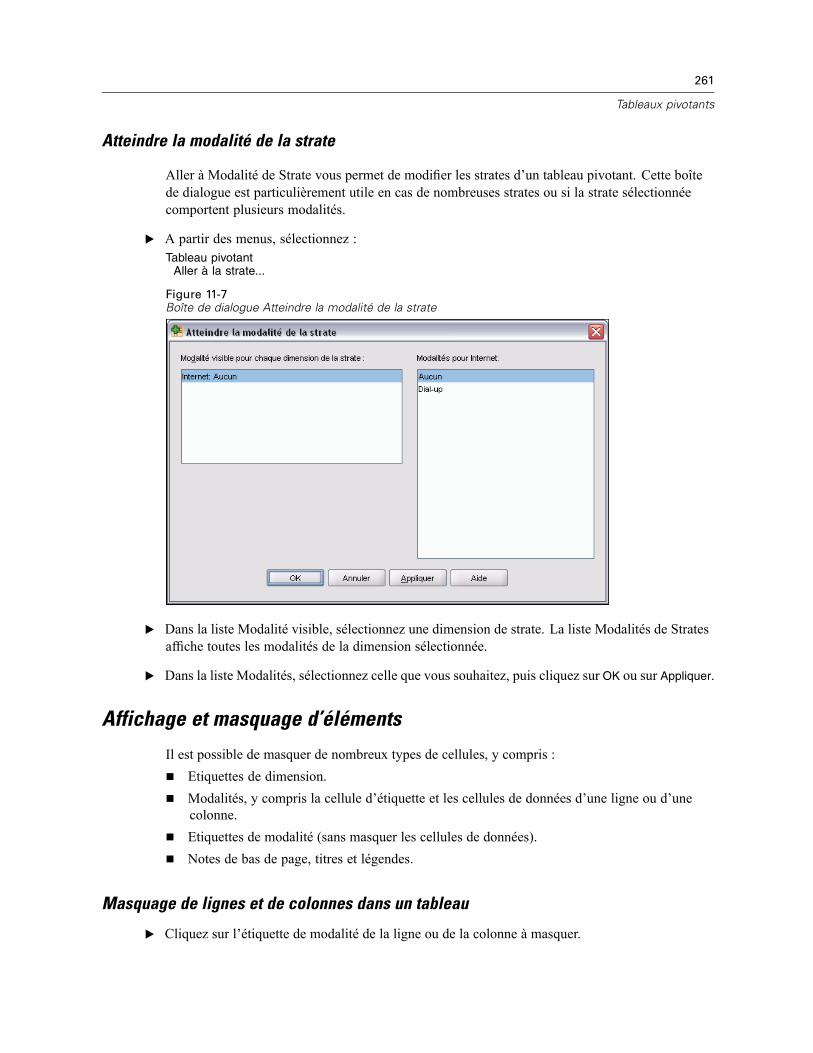
261
Tableaux pivotants
Atteindre la modalité de la strate
Aller à Modalité de Strate vous permet de modifier les strates d’un tableau pivotant. Cette boîtede dialogue est particulièrement utile en cas de nombreuses strates ou si la strate sélectionnéecomportent plusieurs modalités.
E A partir des menus, sélectionnez :Tableau pivotant
Aller à la strate...
Figure 11-7Boîte de dialogue Atteindre la modalité de la strate
E Dans la liste Modalité visible, sélectionnez une dimension de strate. La liste Modalités de Stratesaffiche toutes les modalités de la dimension sélectionnée.
E Dans la liste Modalités, sélectionnez celle que vous souhaitez, puis cliquez sur OK ou sur Appliquer.
Affichage et masquage d’éléments
Il est possible de masquer de nombreux types de cellules, y compris :Etiquettes de dimension.Modalités, y compris la cellule d’étiquette et les cellules de données d’une ligne ou d’unecolonne.Etiquettes de modalité (sans masquer les cellules de données).Notes de bas de page, titres et légendes.
Masquage de lignes et de colonnes dans un tableau
E Cliquez sur l’étiquette de modalité de la ligne ou de la colonne à masquer.

262
Chapitre 11
E A partir du menu contextuel, sélectionnez :Sélectionnez
Cellules de données et d’étiquettes
E Cliquez à nouveau avec le bouton droit sur l’étiquette de modalité et, dans le menu contextuel,sélectionnez Masquer modalité.
ou
E Dans le menu Affichage, choisissez Masquer.
Affichage des lignes et des colonnes masquées dans un tableau
E Cliquez avec le bouton droit sur une autre étiquette de ligne ou de colonne dans la mêmedimension que la ligne ou la colonne masquée.
E A partir du menu contextuel, sélectionnez :Sélectionnez
Cellules de données et d’étiquettes
E A partir des menus, sélectionnez :Affichage
Afficher toutes les modalités dans [nom de la dimension]
ou
E Pour afficher toutes les lignes et les colonnes masquées d’un tableau pivotant activé, sélectionnezdans les menus :Affichage
Montrer Tout
Cette action affiche toutes les lignes et les colonnes masquées du tableau. (Si l’option Masquer
les Lignes et Colonnes vides est sélectionnée dans les propriétés de ce tableau, une ligne ou unecolonne totalement vide reste masquée)
Masquage et affichage des étiquettes de dimension
E Sélectionnez l’étiquette de dimension ou toute étiquette de modalité dans la dimension.
E Dans le menu Affichage ou dans le menu contextuel, sélectionnez Masquer l’étiquette de dimension
ou Afficher l’étiquette de dimension.
Masquage ou affichage des titres de tableau
Pour masquer un titre :
E Sélectionnez le titre.
E Dans le menu Affichage, choisissez Masquer.
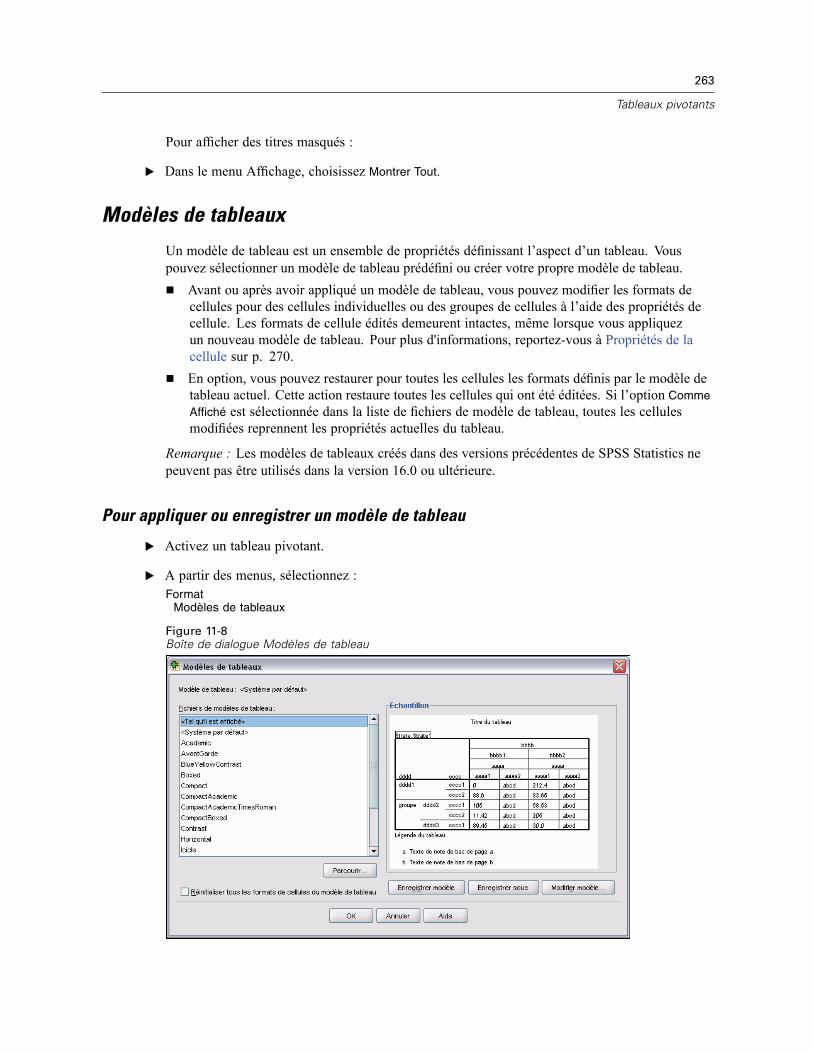
263
Tableaux pivotants
Pour afficher des titres masqués :
E Dans le menu Affichage, choisissez Montrer Tout.
Modèles de tableaux
Un modèle de tableau est un ensemble de propriétés définissant l’aspect d’un tableau. Vouspouvez sélectionner un modèle de tableau prédéfini ou créer votre propre modèle de tableau.
Avant ou après avoir appliqué un modèle de tableau, vous pouvez modifier les formats decellules pour des cellules individuelles ou des groupes de cellules à l’aide des propriétés decellule. Les formats de cellule édités demeurent intactes, même lorsque vous appliquezun nouveau modèle de tableau. Pour plus d'informations, reportez-vous à Propriétés de lacellule sur p. 270.En option, vous pouvez restaurer pour toutes les cellules les formats définis par le modèle detableau actuel. Cette action restaure toutes les cellules qui ont été éditées. Si l’option CommeAffiché est sélectionnée dans la liste de fichiers de modèle de tableau, toutes les cellulesmodifiées reprennent les propriétés actuelles du tableau.
Remarque : Les modèles de tableaux créés dans des versions précédentes de SPSS Statistics nepeuvent pas être utilisés dans la version 16.0 ou ultérieure.
Pour appliquer ou enregistrer un modèle de tableau
E Activez un tableau pivotant.
E A partir des menus, sélectionnez :Format
Modèles de tableaux
Figure 11-8Boîte de dialogue Modèles de tableau

264
Chapitre 11
E Sélectionnez un modèle de tableau dans la liste de fichiers. Pour sélectionner un fichier dans unautre répertoire, cliquez sur Parcourir.
E Cliquez sur OK pour appliquer le modèle de tableau au tableau pivotant sélectionné.
Pour modifier ou créer un Modèle de tableau
E Dans la boîte de dialogue Modèles de tableaux, sélectionnez un modèle de tableau parmi la listede fichiers.
E Cliquez sur Modifier modèle.
E Modifiez les propriétés de tableau pour obtenir les attributs souhaités et cliquez sur OK.
E Cliquez sur Enregistrer modèle pour enregistrer le modèle de tableau modifié ou sur Enregistrer
sous pour l’enregistrer comme nouveau modèle.
Modifier un modèle de tableau n’affecte que le tableau pivotant sélectionné. Un modèle de tableaumodifié n’est pas appliqué à d’autres tableaux utilisant cet Aspect, sauf si vous sélectionnez cestableaux et appliquez à nouveau le modèle de tableau.
Propriétés du tableauPropriétés de tableau vous permet de fixer les propriétés générales d’un tableau, les styles decellules pour diverses parties d’un tableau ainsi que d’enregistrer un ensemble de propriété en tantque modèle de tableau. Vous pouvez:
Contrôler les propriétés générales, telles que masquer les lignes ou les colonnes vides etajuster les propriétés d’impression.Contrôler le format et la position des marques de notes de bas de page.Déterminer des formats spécifiques pour les cellules de données, pour les étiquettes de ligne etde colonne et pour les autres zones du tableau.Contrôler la largeur et la couleur des lignes formant les bordures de chaque zone du tableau.
Pour modifier les propriétés d’un tableau pivotant
E Activez le tableau pivotant.
E A partir des menus, sélectionnez :Format
Propriétés du tableau
E Sélectionnez un onglet (Général, Notes de bas de page, Formats de cellule, Bordures ou Impression).
E Sélectionnez les options souhaitées.
E Cliquez sur OK ou sur Appliquer.
Les nouvelles propriétés sont appliquées au tableau pivotant sélectionné. Pour appliquer denouvelles propriétés de tableau à un modèle de tableau au lieu du tableau sélectionné seulement,modifiez le modèle de tableau (menu Format, Modèle de tableau).
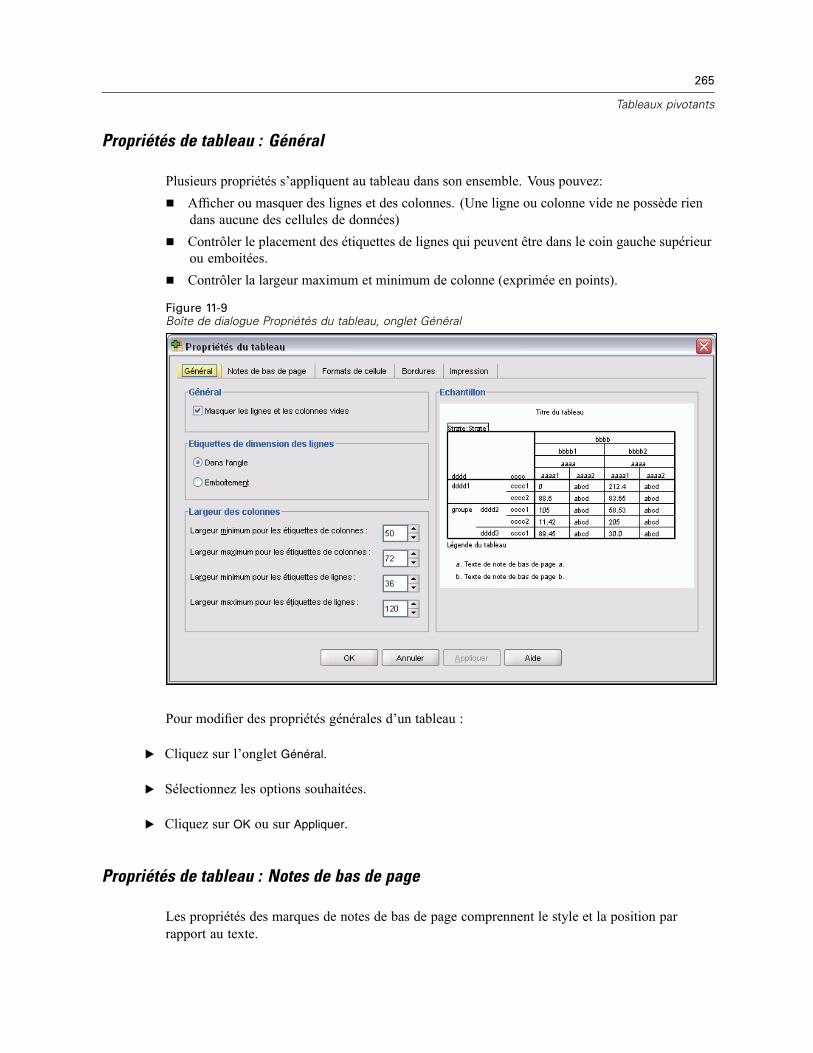
265
Tableaux pivotants
Propriétés de tableau : Général
Plusieurs propriétés s’appliquent au tableau dans son ensemble. Vous pouvez:Afficher ou masquer des lignes et des colonnes. (Une ligne ou colonne vide ne possède riendans aucune des cellules de données)Contrôler le placement des étiquettes de lignes qui peuvent être dans le coin gauche supérieurou emboitées.Contrôler la largeur maximum et minimum de colonne (exprimée en points).
Figure 11-9Boîte de dialogue Propriétés du tableau, onglet Général
Pour modifier des propriétés générales d’un tableau :
E Cliquez sur l’onglet Général.
E Sélectionnez les options souhaitées.
E Cliquez sur OK ou sur Appliquer.
Propriétés de tableau : Notes de bas de page
Les propriétés des marques de notes de bas de page comprennent le style et la position parrapport au texte.
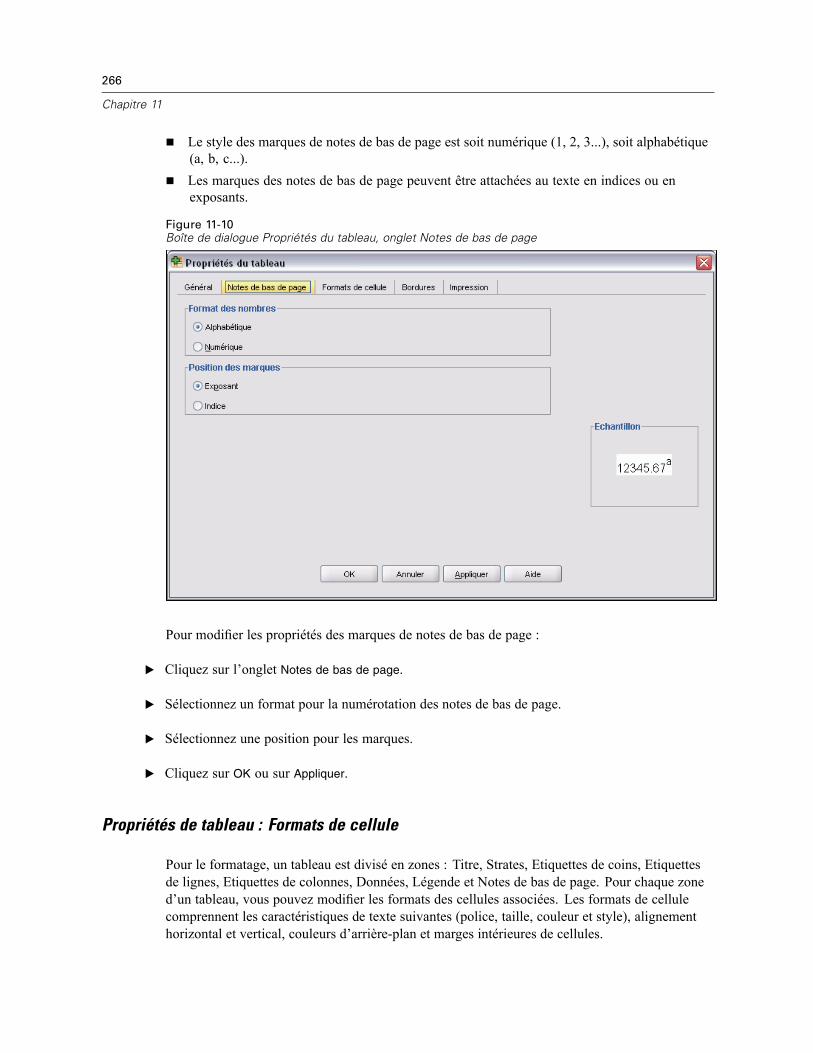
266
Chapitre 11
Le style des marques de notes de bas de page est soit numérique (1, 2, 3...), soit alphabétique(a, b, c...).Les marques des notes de bas de page peuvent être attachées au texte en indices ou enexposants.
Figure 11-10Boîte de dialogue Propriétés du tableau, onglet Notes de bas de page
Pour modifier les propriétés des marques de notes de bas de page :
E Cliquez sur l’onglet Notes de bas de page.
E Sélectionnez un format pour la numérotation des notes de bas de page.
E Sélectionnez une position pour les marques.
E Cliquez sur OK ou sur Appliquer.
Propriétés de tableau : Formats de cellule
Pour le formatage, un tableau est divisé en zones : Titre, Strates, Etiquettes de coins, Etiquettesde lignes, Etiquettes de colonnes, Données, Légende et Notes de bas de page. Pour chaque zoned’un tableau, vous pouvez modifier les formats des cellules associées. Les formats de cellulecomprennent les caractéristiques de texte suivantes (police, taille, couleur et style), alignementhorizontal et vertical, couleurs d’arrière-plan et marges intérieures de cellules.

267
Tableaux pivotants
Figure 11-11Zones d’un tableau
Les formats des cellules sont appliqués aux zones (modalités d’informations). Ce ne sont pas descaractéristiques des cellules individuelles. Cette distinction est importante lorsqu’on fait pivoterun tableau.
Par exemple,Si vous spécifiez une police en caractères gras pour un format de cellules dans les étiquettes decolonnes, celles-ci apparaîtront en caractères gras quelles que soient les informations affichéesdans la dimension de la colonne. Si vous déplacez un élément de la dimension de colonnevers une autre dimension, il ne conserve pas les caractères gras des étiquettes de colonne.Si vous appliquez les caractères gras sur les étiquettes de colonne simplement en mettant ensurbrillance les cellules dans un tableau pivotant actif et en cliquant sur le bouton Gras dela barre d’outils, le contenu de ces cellules demeurera en caractères gras quelle que soit ladimension dans laquelle vous les déplacez, et les étiquettes de colonne ne resteront pas encaractères gras pour d’autres éléments déplacés dans la dimension de colonne.
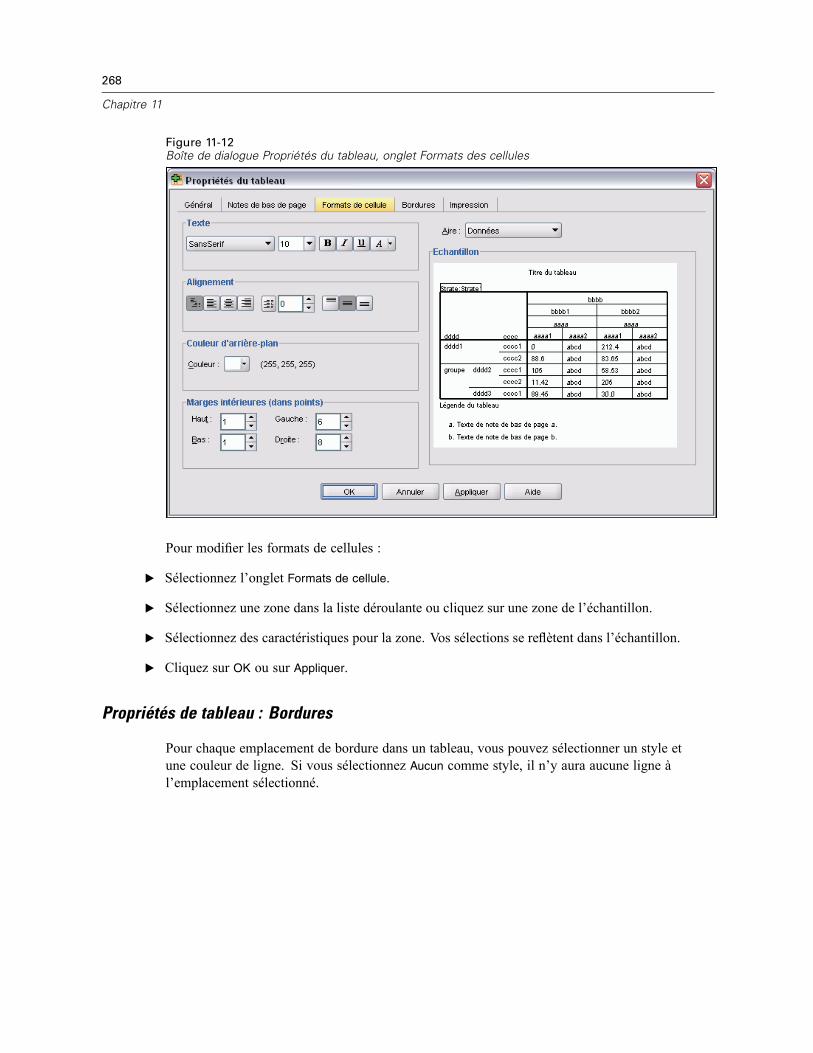
268
Chapitre 11
Figure 11-12Boîte de dialogue Propriétés du tableau, onglet Formats des cellules
Pour modifier les formats de cellules :
E Sélectionnez l’onglet Formats de cellule.
E Sélectionnez une zone dans la liste déroulante ou cliquez sur une zone de l’échantillon.
E Sélectionnez des caractéristiques pour la zone. Vos sélections se reflètent dans l’échantillon.
E Cliquez sur OK ou sur Appliquer.
Propriétés de tableau : Bordures
Pour chaque emplacement de bordure dans un tableau, vous pouvez sélectionner un style etune couleur de ligne. Si vous sélectionnez Aucun comme style, il n’y aura aucune ligne àl’emplacement sélectionné.
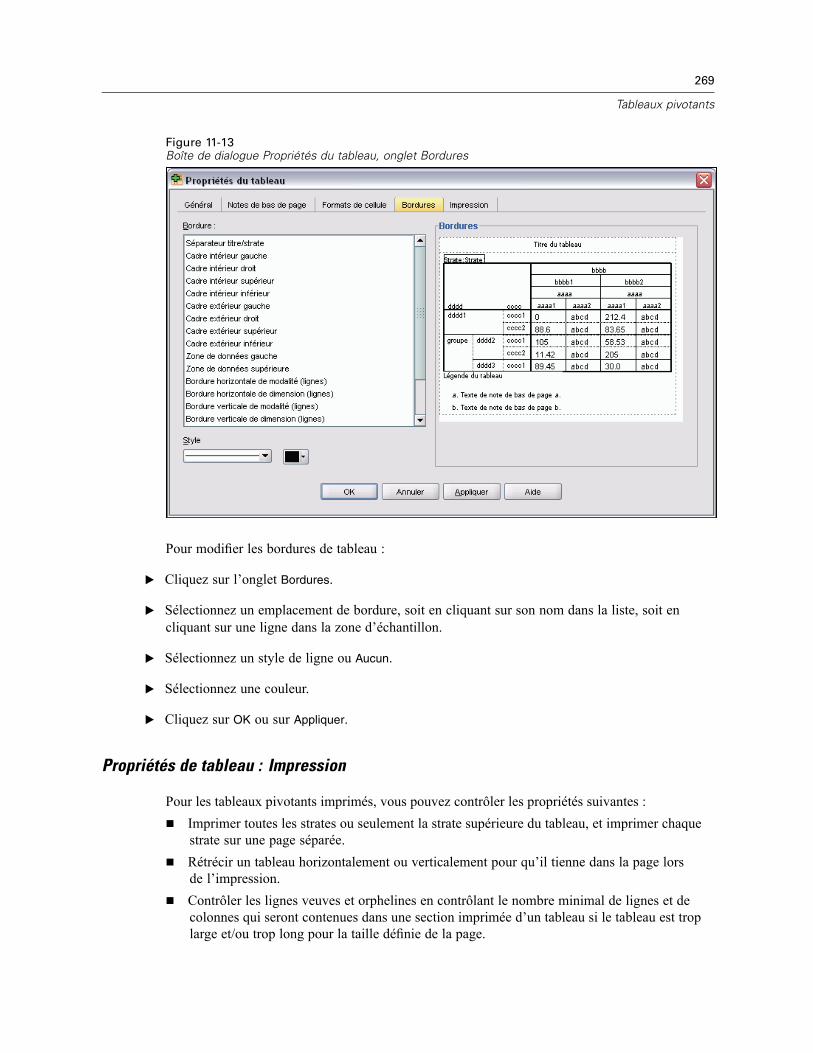
269
Tableaux pivotants
Figure 11-13Boîte de dialogue Propriétés du tableau, onglet Bordures
Pour modifier les bordures de tableau :
E Cliquez sur l’onglet Bordures.
E Sélectionnez un emplacement de bordure, soit en cliquant sur son nom dans la liste, soit encliquant sur une ligne dans la zone d’échantillon.
E Sélectionnez un style de ligne ou Aucun.
E Sélectionnez une couleur.
E Cliquez sur OK ou sur Appliquer.
Propriétés de tableau : Impression
Pour les tableaux pivotants imprimés, vous pouvez contrôler les propriétés suivantes :Imprimer toutes les strates ou seulement la strate supérieure du tableau, et imprimer chaquestrate sur une page séparée.Rétrécir un tableau horizontalement ou verticalement pour qu’il tienne dans la page lorsde l’impression.Contrôler les lignes veuves et orphelines en contrôlant le nombre minimal de lignes et decolonnes qui seront contenues dans une section imprimée d’un tableau si le tableau est troplarge et/ou trop long pour la taille définie de la page.
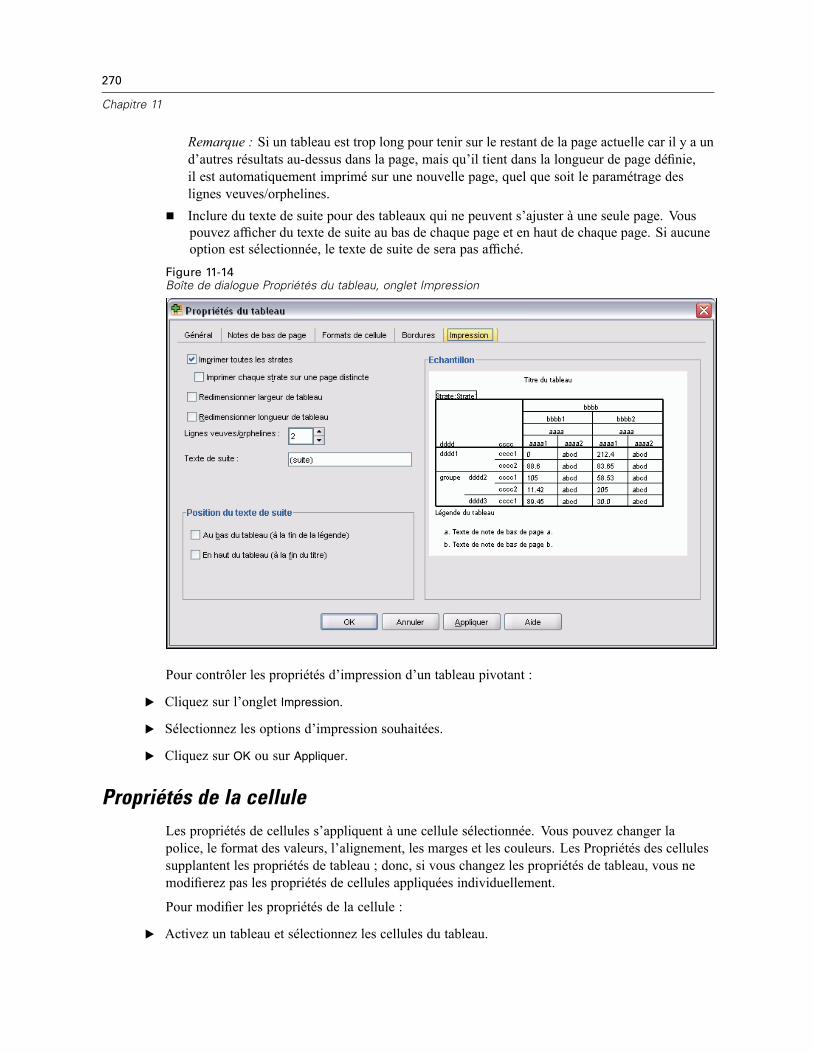
270
Chapitre 11
Remarque : Si un tableau est trop long pour tenir sur le restant de la page actuelle car il y a und’autres résultats au-dessus dans la page, mais qu’il tient dans la longueur de page définie,il est automatiquement imprimé sur une nouvelle page, quel que soit le paramétrage deslignes veuves/orphelines.Inclure du texte de suite pour des tableaux qui ne peuvent s’ajuster à une seule page. Vouspouvez afficher du texte de suite au bas de chaque page et en haut de chaque page. Si aucuneoption est sélectionnée, le texte de suite de sera pas affiché.
Figure 11-14Boîte de dialogue Propriétés du tableau, onglet Impression
Pour contrôler les propriétés d’impression d’un tableau pivotant :
E Cliquez sur l’onglet Impression.
E Sélectionnez les options d’impression souhaitées.
E Cliquez sur OK ou sur Appliquer.
Propriétés de la celluleLes propriétés de cellules s’appliquent à une cellule sélectionnée. Vous pouvez changer lapolice, le format des valeurs, l’alignement, les marges et les couleurs. Les Propriétés des cellulessupplantent les propriétés de tableau ; donc, si vous changez les propriétés de tableau, vous nemodifierez pas les propriétés de cellules appliquées individuellement.
Pour modifier les propriétés de la cellule :
E Activez un tableau et sélectionnez les cellules du tableau.
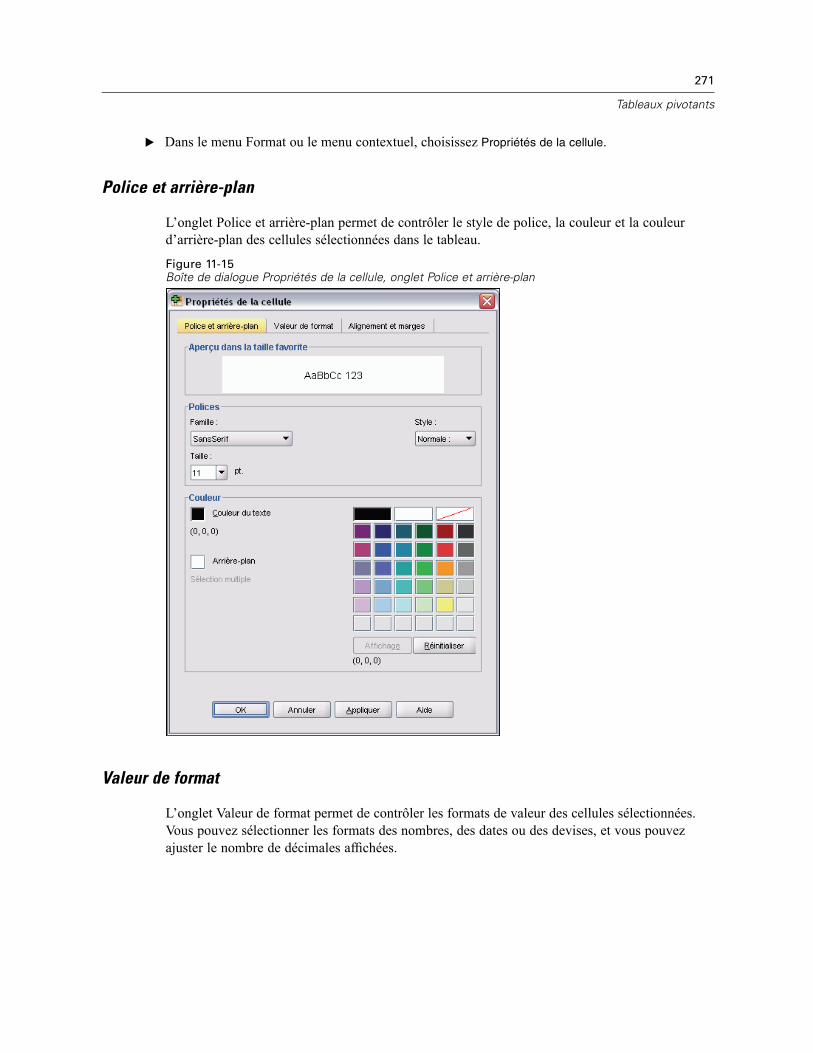
271
Tableaux pivotants
E Dans le menu Format ou le menu contextuel, choisissez Propriétés de la cellule.
Police et arrière-plan
L’onglet Police et arrière-plan permet de contrôler le style de police, la couleur et la couleurd’arrière-plan des cellules sélectionnées dans le tableau.
Figure 11-15Boîte de dialogue Propriétés de la cellule, onglet Police et arrière-plan
Valeur de format
L’onglet Valeur de format permet de contrôler les formats de valeur des cellules sélectionnées.Vous pouvez sélectionner les formats des nombres, des dates ou des devises, et vous pouvezajuster le nombre de décimales affichées.
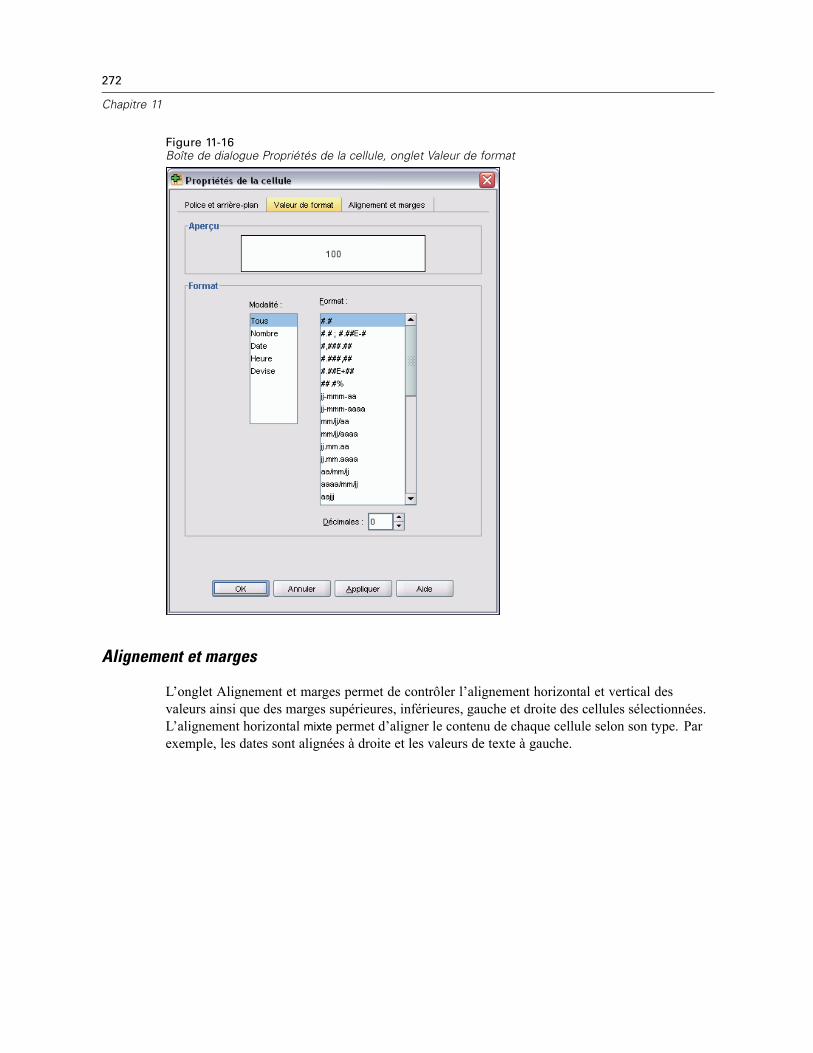
272
Chapitre 11
Figure 11-16Boîte de dialogue Propriétés de la cellule, onglet Valeur de format
Alignement et marges
L’onglet Alignement et marges permet de contrôler l’alignement horizontal et vertical desvaleurs ainsi que des marges supérieures, inférieures, gauche et droite des cellules sélectionnées.L’alignement horizontal mixte permet d’aligner le contenu de chaque cellule selon son type. Parexemple, les dates sont alignées à droite et les valeurs de texte à gauche.
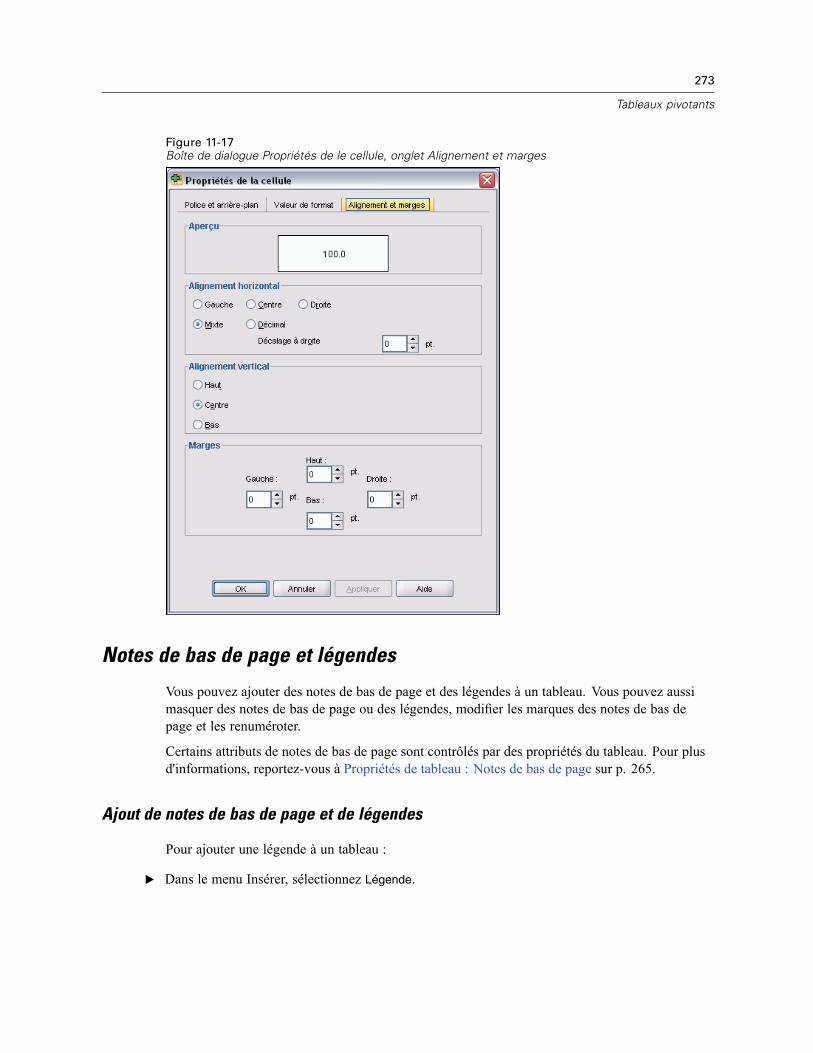
273
Tableaux pivotants
Figure 11-17Boîte de dialogue Propriétés de le cellule, onglet Alignement et marges
Notes de bas de page et légendes
Vous pouvez ajouter des notes de bas de page et des légendes à un tableau. Vous pouvez aussimasquer des notes de bas de page ou des légendes, modifier les marques des notes de bas depage et les renuméroter.
Certains attributs de notes de bas de page sont contrôlés par des propriétés du tableau. Pour plusd'informations, reportez-vous à Propriétés de tableau : Notes de bas de page sur p. 265.
Ajout de notes de bas de page et de légendes
Pour ajouter une légende à un tableau :
E Dans le menu Insérer, sélectionnez Légende.

274
Chapitre 11
Une note de bas de page peut être attachée à tout élément d’un tableau. Pour ajouter une notede bas de page :
E Cliquez sur un titre, une cellule ou une légende dans le tableau pivotant activé.
E Dans le menu Insérer, sélectionnez Note de bas de page.
Pour afficher ou masquer une légende
Pour masquer une légende :
E Sélectionnez la légende.
E Dans le menu Affichage, choisissez Masquer.
Pour afficher des légendes masquées :
E Dans le menu Affichage, choisissez Montrer Tout.
Pour masquer ou afficher une note de bas de page dans un tableau
Pour masquer une note de bas de page :
E Sélectionnez la note de bas de page.
E Dans le menu Affichage, choisissez Masquer ou dans le menu contextuel, choisissez Masquer la
note de bas de page.
Pour afficher des notes de bas de page masquées :
E Dans le menu Affichage, choisissez Afficher toutes les notes de bas de page.
Marque de bas de page
Marque de note de bas de page modifie le ou les caractères utilisés pour marquer une notede bas de page.
Figure 11-18Boîte de dialogue Marque de Note de bas de page
Pour modifier des marques de notes de bas de page :
E Sélectionnez une note de bas de page.

275
Tableaux pivotants
E Dans le menu Format, sélectionnez Marque de note de bas de page.
E Entrez un ou deux caractères.
Renuméroter les notes de bas de page
Lorsque vous avez fait pivoter un tableau en échangeant des lignes, des colonnes et des strates, lesnotes de bas de page peuvent être désactivées. Pour renuméroter les notes de bas de page :
E Dans le menu Format, sélectionnez Renuméroter les notes de bas de page.
Largeur des cellules de données
Fixer la largeur des cellules de données est utilisé pour fixer une même largeur à toutes lescellules de données.
Figure 11-19Boîte de dialogue Fixer la Largeur des Cellules de Données
Pour définir la largeur de toutes les cellules de données :
E A partir des menus, sélectionnez :Format
Largeur des cellules
E Entrez une valeur pour la largeur des cellules.
Modification de la largeur de colonne
E Cliquez et faites-glisser la bordure de colonne.
Affichage des bordures masquées dans un tableau pivotant
Pour les tableaux possédant peu de bordures visibles, vous pouvez afficher les bordures masquées.Cela peut faciliter des tâches telles que la modification de la largeur des colonnes.
E Dans le menu Affichage, choisissez Quadrillage.
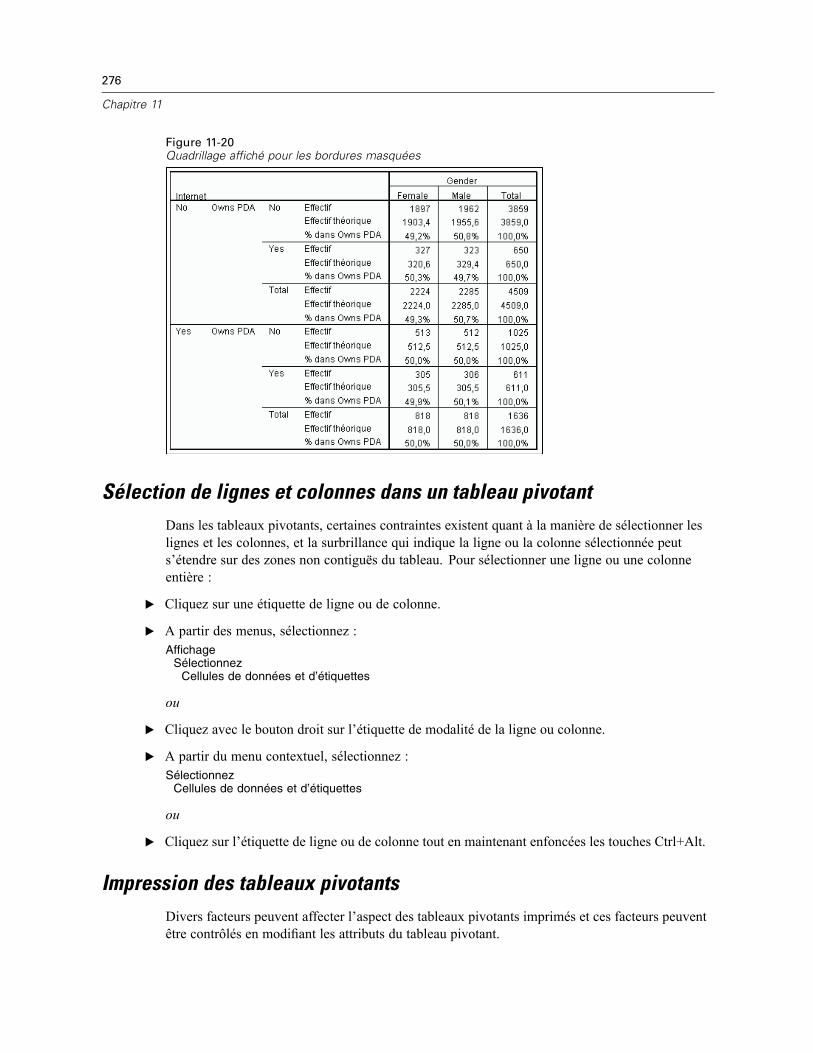
276
Chapitre 11
Figure 11-20Quadrillage affiché pour les bordures masquées
Sélection de lignes et colonnes dans un tableau pivotantDans les tableaux pivotants, certaines contraintes existent quant à la manière de sélectionner leslignes et les colonnes, et la surbrillance qui indique la ligne ou la colonne sélectionnée peuts’étendre sur des zones non contiguës du tableau. Pour sélectionner une ligne ou une colonneentière :
E Cliquez sur une étiquette de ligne ou de colonne.
E A partir des menus, sélectionnez :Affichage
SélectionnezCellules de données et d’étiquettes
ou
E Cliquez avec le bouton droit sur l’étiquette de modalité de la ligne ou colonne.
E A partir du menu contextuel, sélectionnez :Sélectionnez
Cellules de données et d’étiquettes
ou
E Cliquez sur l’étiquette de ligne ou de colonne tout en maintenant enfoncées les touches Ctrl+Alt.
Impression des tableaux pivotantsDivers facteurs peuvent affecter l’aspect des tableaux pivotants imprimés et ces facteurs peuventêtre contrôlés en modifiant les attributs du tableau pivotant.

277
Tableaux pivotants
Pour des tableaux pivotants multidimensionnels (tableaux avec strates), vous pouvez soitimprimer toutes les strates, soit simplement imprimer la strate supérieure (visible). Pour plusd'informations, reportez-vous à Propriétés de tableau : Impression sur p. 269.Pour des tableaux pivotants longs ou larges, vous pouvez automatiquement redimensionner letableau pour ajuster à la page ou contrôler la position des sauts de tableaux ou des sauts depage. Pour plus d'informations, reportez-vous à Propriétés de tableau : Impression sur p. 269.Pour les tableaux trop larges ou trop longs pour une seule page, vous pouvez contrôlerl’emplacement des sauts de tableau entre les pages.
Utilisez l’Aperçu avant impression du menu Fichier pour voir à quoi ressembleront les tableauxpivotants imprimés.
Contrôle des sauts de tableau pour les tableaux longs et larges
Les tableaux pivotants qui sont soit trop larges soit trop longs pour être imprimés dans la taillede page définie sont automatiquement divisés et sont imprimés en plusieurs sections. (Pourles tableaux larges, les différentes sections s’impriment sur la même page s’il y a de la place).Vous pouvez:
Contrôler la position à laquelle les lignes et les colonnes sont divisés les grands tableauxIndiquer les lignes et colonnes qui doivent être conservés ensemble lors de la division detableauxRedimensionner les grands tableaux pour les ajuster à la taille définie pour la page
Pour spécifier des sauts de ligne et de colonne dans les tableaux pivotants imprimés
E Cliquez sur l’étiquette de colonne à gauche de l’endroit où vous souhaitez insérer le saut ou surl’étiquette de ligne au-dessus de l’endroit où vous souhaitez insérer le saut.
E A partir des menus, sélectionnez :Format
Séparer ici
Spécification des lignes ou colonnes à conserver ensemble
E Sélectionnez les étiquettes des lignes ou colonnes que vous souhaitez conserver ensemble.(Cliquez et faites-glisser ou cliquez avec la touche Maj. enfoncée pour sélectionner plusieursétiquettes de ligne ou de colonne.)
E A partir des menus, sélectionnez :Format
Conserver ensemble
Création d’un diagramme à partir d’un tableau pivotantE Double-cliquez sur le tableau pivotant pour l’activer.
E Sélectionnez les cellules à afficher dans le diagramme.

278
Chapitre 11
E Effectuez un clic droit n’importe où dans la zone sélectionnée.
E Sélectionnez Créer un diagramme dans le menu contextuel, puis choisissez un type de diagramme.

Chapitre
12Modèles
Certains résultats sont présentés sous forme de modèles qui apparaissent dans le Viewer avecun type spéficique de visualisation. La visualisation affichée dans le Viewer n’est pas la seulevue disponible du modèle. Un modèle contient de nombreuses vues différentes. Vous pouvezactiver le modèle dans le Viewer de modèles et interagir directement avec le modèle pour affichertoutes les vues du modèle disponibles. Vous pouvez également imprimer et exporter l’ensembledes vues du modèle.
Interaction avec un modèlePour interagir avec un modèle, vous devez d’abord l’activer :
E Double-cliquez sur le modèle.
ou
E Cliquez avec le bouton droit de la souris sur le modèle puis, dans le menu contextuel, sélectionnezModifier le contenu.
E Dans le sous-menu, choisissez Dans une fenêtre séparée.
L’activation du modèle permet de l’afficher dans le Viewer de modèles. Pour plus d'informations,reportez-vous à Travailler avec le Viewer de modèles sur p. 279.
Travailler avec le Viewer de modèles
Le Viewer de modèles est un outil interactif permettant d’afficher les vues de modèles disponibleset d’en modifier l’apparence. (Pour plus d’informations sur le Viewer de modèles, reportez-vous àInteraction avec un modèle sur p. 279). Le Viewer de modèles est divisé en deux parties :
Vue principale. La vue principale apparaît à gauche dans le Viewer de modèles. La vueprincipale affiche des visualisations générales du modèle, par exemple un diagramme réseau.La vue principale peut comporter plusieurs vues de modèle. La liste déroulante située sous lavue principale vous permet de choisir une des vues principales parmi celles disponibles.Vue auxiliaire. La vue auxiliaire apparaît à droite dans le Viewer de modèles. Comparéeà la visualisation générale dans la vue principale, la vue auxiliaire affiche en général unevisualisation du modèle plus détaillée, y compris les tableaux. Tout comme la vue principale,la vue auxiliaire peut comporter plusieurs vues de modèle. La liste déroulante située sousla vue auxiliaire vous permet de choisir une des vues principales parmi celles disponibles.La vue auxiliaire peut également afficher des visualisations spécifiques pour les élémentssélectionnés dans la vue principale. Par exemple, selon le type de modèle, vous pouvez
279

280
Chapitre 12
sélectionner un noeud de variable dans la vue principale pour afficher un tableau pour cettevariable dans la vue auxiliaire.
Les visualisations spécifiques qui sont affichées dépendent de la procédure à l’origine de lacréation du modèle. Pour plus d’informations concernant l’utilisation de modèles spécifiques,reportez-vous à la documentation concernant la procédure à l’origine de la création du modèle.
Tableaux de vue de modèles
Les tableaux affichées dans le Viewer de modèles ne sont pas des tableaux pivotants. Vous nepouvez pas manipuler ces tableaux de la même manière que vous manipulez des tableaux pivotants.
Edition et exploration des vues de modèles
Par défaut, le Viewer de modèles est activé enMode Exploration. Ce mode vous permetd’interagir avec le modèle en déplaçant des éléments et en les sélectionnant pour afficher lesvisualisations associées dans la vue auxiliaire.Le Viewer de modèles comporte également unMode Edition. Ce mode vous permet d’éditer
les styles des vues de modèles. Le Viewer de modèle inclut l’Editeur de graphiques pour effectuerces modifications. Lorsque vous fermez le Viewer de modèles, toutes vos modifications serontenregistrées dans le modèle.Le menu Vue vous permet de basculer entre les modes Exploration et Edition.
Paramétrer les propriétés du modèle
À l’intérieur du Viewer de modèles, vous pouvez définir des propriétés spécifiques pour le modèle.Pour plus d'informations, reportez-vous à Propriétés du modèle sur p. 280.
Copie des vues de modèles
Vous pouvez également copier des vues de modèles individuelles à l’intérieur du Viewer demodèle. Pour plus d'informations, reportez-vous à Copie des vues de modèles sur p. 281.
Propriétés du modèle
À partir du Viewer de modèles, sélectionnez, à partir des menus :Fichier
Propriétés
Chaque modèle possède des propriétés associées qui vous permettent de spécifier quelles serontles vues à imprimer à partir du Viewer. Par défaut, seule la vue visible dans le Viewer de résultatsest imprimée. Il s’agit toujours d’une seule vue principale. Vous pouvez également spécifierque l’ensemble des vues de modèle disponibles soient imprimées. Elles regroupent l’ensembledes vues principales et l’ensemble des vues auxiliaires. Remarque : vous pouvez égalementimprimer des vues de modèles individuelles à l’intérieur du Viewer de modèles lui-même. Pourplus d'informations, reportez-vous à Impression d’un modèle sur p. 281.

281
Modèles
Copie des vues de modèles
À partir du menu Edition dans le Viewer de modèles, vous pouvez copier la vue principaleaffichée ou la vue auxiliaire affichée. Une seule vue de modèle est copiée. Vous pouvez coller lavue de modèle dans le Viewer de résultats, dans lequel la vue de modèle individuelle sera ensuitereprésentée par une visualisation qui peut être éditée dans l’Editeur de graphiques. Coller dansle Viewer de résultats vous permet d’afficher plusieurs vues de modèle simultanément. Vouspouvez également coller dans d’autres applications, la vue apparaissant sous forme d’image oude tableau selon l’application cible choisie.
Impression d’un modèle
Impression à partir du Viewer de modèles
Vous pouvez imprimer une vue de modèle unique dans le Viewer de modèles lui-même.
E Activez le modèle dans le Viewer de modèles. Pour plus d'informations, reportez-vous àInteraction avec un modèle sur p. 279.
E A partir des menus, sélectionnez :Affichage
Mode d’édition
E Dans la vue principale ou auxiliaire (selon celle que vous souhaitez imprimer), cliquez sur l’icôned’impression dans la palette d’outils Générale. (Si cette palette ne s’affiche pas, sélectionnezPalettes>Générale dans le menu Vue).
Impression à partir du Viewer de résultats
Lorsque vous imprimez à partir du Viewer de résultats, le nombre de vue imprimées pour unmodèle spécifique dépend des propriétés de ce modèle. Le modèle peut être défini sur l’impressionde la vue affichée uniquement ou sur l’ensemble des vues de modèle disponibles. Pour plusd'informations, reportez-vous à Propriétés du modèle sur p. 280.
Exportation d’un modèle
Par défaut, lorsque vous exportez des modèles à partir du Viewer de résultats, l’inclusion oul’exclusion des vues de modèle est contrôlée par les propriétés de chaque modèle. Pour plusd’informations sur les propriétés des modèles, reportez-vous à Propriétés du modèle sur p.280. Lors de l’exportation, vous pouvez remplacer ce paramètre et inclure l’ensemble des vuesde modèles ou uniquement la vue de modèle visible. Dans la boîte de dialogue Exporter lesrésultats, cliquez sur Modifier les options... dans le groupe Document. Pour plus d’informations surl’exportation et cette boîte de dialogue, reportez-vous à Exporter résultats sur p. 236. Notez quetoutes les vues de modèles, y compris les tableaux, sont exportées sous forme de graphiques.

Chapitre
13Utilisation de la syntaxe de commande
Le puissant langage de commande permet d’enregistrer et d’automatiser de nombreuses tâchescommunes. Il fournit également des fonctionnalités qui ne se trouvent ni dans les menus nidans les boîtes de dialogue.La plupart des commandes sont accessibles depuis les menus et boîtes de dialogue. Cependant,
certaines options et commandes ne sont disponibles qu’en utilisant le langage de commande.Celui-ci vous permet d’enregistrer vos travaux dans un fichier de syntaxe afin de vous permettrede relancer votre analyse à une date ultérieure ou de l’exécuter dans une opération automatiséeà l’aide d’une tâche de production.Un fichier de syntaxe de commande est un fichier texte simple contenant des commandes. Il est
possible d’ouvrir une fenêtre de syntaxe et de taper des commandes, mais il est plus simple delaisser le logiciel construire le fichier de syntaxe selon l’une des méthodes suivantes :
Copie de la syntaxe de commande à partir des boîtes de dialogue,Copie de la syntaxe à partir du fichier de résultat,Copie de la syntaxe à partir du fichier-journal.
Un guide de référence détaillé sur la syntaxe des commandes est disponible sous deux formesdifférentes : guide intégré dans le système d’aide global et comme fichier PDF distinct appeléCommand Syntax Reference, aussi disponible à partir du menu Aide.L’aide contextuelle pour la commande en cours est disponible dans une fenêtre de syntaxe en
pressant la touche F1.
Règles de syntaxe de commande
Lorsque vous exécutez des commandes à partir d’une fenêtre de syntaxe de commande lors d’unesession, vous exécutez des commandes en mode interactif.
Les règles suivantes s’appliquent aux spécifications de commandes en mode interactif :Chaque commande doit commencer sur une nouvelle ligne. Les commandes peuventcommencer dans n’importe quelle colonne d’une ligne de commande et continuer sur autantde lignes que nécessaire. Il existe néanmoins une exception : La commande END DATA doitcommencer dans la première colonne de la première ligne à la fin des données.Chaque commande doit terminer par un point servant de caractère de fin de commande.Cependant, il est préférable d’ignorer le caractère de fin sur BEGIN DATA, de façon à ce queles données linéaires soient traitées comme une seule spécification continue.
282

283
Utilisation de la syntaxe de commande
Le caractère de fin de commande doit correspondre au dernier caractère non vide d’unecommande.En l’absence d’un point servant de caractère de fin de commande, toute ligne vide estinterprétée comme un caractère de fin de commande.
Remarque : Pour que les autres modes d’exécution de commande soient compatibles entre eux(notamment les fichiers de commandes exécutés avec les commandes INSERT ou INCLUDE dansune session interactive), chaque ligne de syntaxe de commande ne doit pas dépasser 256 octets.
La plupart des sous-commandes sont séparées par des barres obliques (/). La barre obliquefigurant avant la première sous-commande de la commande est souvent facultative.Le nom des variables doit être écrit en en toute lettre.Le texte inclus dans les apostrophes ou les guillemets doit tenir sur une seule ligne.Un point (.) doit être utilisé pour indiquer les décimales, indépendamment des paramètresrégionaux ou locaux.Le nom des variables finissant par un point peut engendrer des erreurs dans les commandescréées par les boîtes de dialogue. Vous ne pouvez pas créer de tels noms de variable dans lesboîtes de dialogue ; vous devez donc éviter d’indiquer ces noms.
La syntaxe de commande respectant la casse, une abréviation de trois ou quatre lettres peut êtreutilisée pour spécifier ces commandes. Vous pouvez utiliser autant de lignes voulues pour spécifierune commande unique. Il vous est possible d’ajouter des espaces ou des sauts de ligne à presquetous les points d’insertion d’un espace vide, tels que des barres obliques, des parenthèses, desopérateurs arithmétique, ou les ajouter entre le nom des variables. Par exemple,
FREQUENCIESVARIABLES=JOBCAT GENDER/PERCENTILES=25 50 75/BARCHART.
et
freq var=jobcat gender /percent=25 50 75 /bar.
sont deux choix possibles qui génèrent les mêmes résultats.
Fichiers INCLUDE
Pour les fichiers de commande exécutés via la commande INCLUDE, les règles de syntaxe dumode de commande s’appliquent.
Les règles suivantes s’appliquent aux spécifications de commandes en mode batch :Toutes les commandes du fichier de commande doivent commencer dans la colonne 1. Vouspouvez utiliser les signes plus (+) ou moins (–) dans la première colonne si vous souhaitezindenter la spécification de commande afin de faciliter la lecture du fichier.Si plusieurs lignes sont utilisées pour une commande, la colonne 1 de chaque ligne suivantedoit être vide.Les caractères de fin de commande sont optionnels.Une ligne ne peut pas excéder 256 octets. Tout caractère supplémentaire est tronqué.
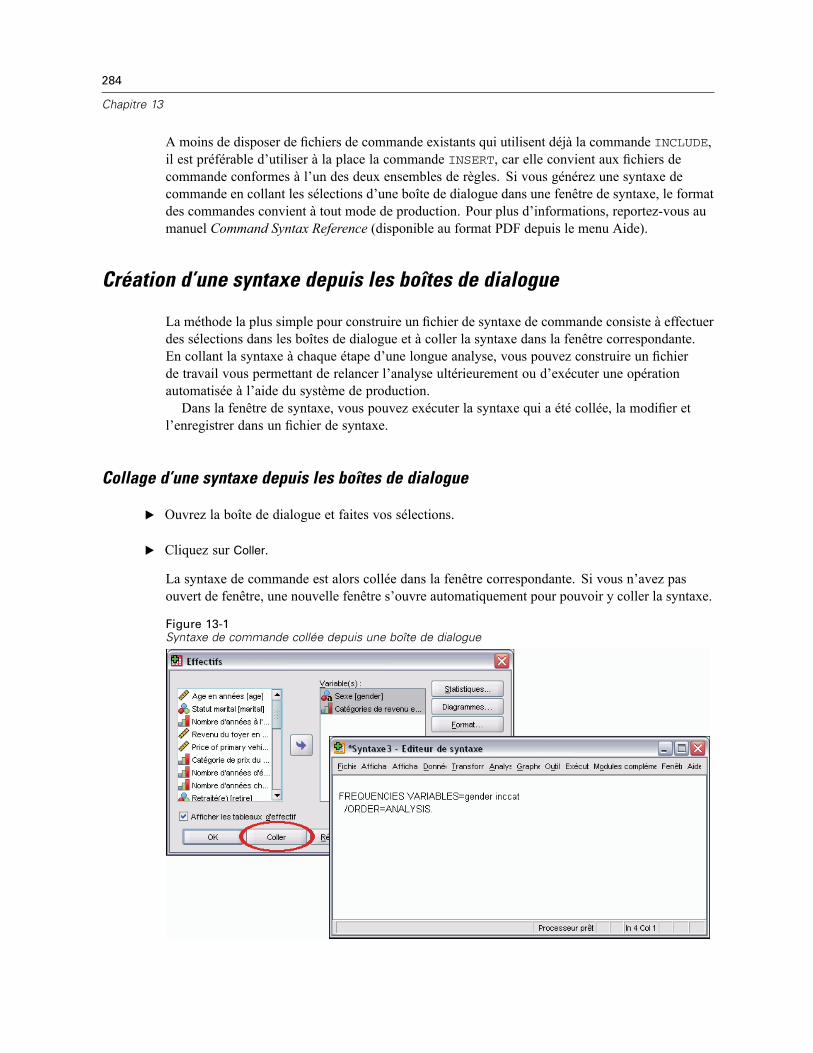
284
Chapitre 13
A moins de disposer de fichiers de commande existants qui utilisent déjà la commande INCLUDE,il est préférable d’utiliser à la place la commande INSERT, car elle convient aux fichiers decommande conformes à l’un des deux ensembles de règles. Si vous générez une syntaxe decommande en collant les sélections d’une boîte de dialogue dans une fenêtre de syntaxe, le formatdes commandes convient à tout mode de production. Pour plus d’informations, reportez-vous aumanuel Command Syntax Reference (disponible au format PDF depuis le menu Aide).
Création d’une syntaxe depuis les boîtes de dialogue
La méthode la plus simple pour construire un fichier de syntaxe de commande consiste à effectuerdes sélections dans les boîtes de dialogue et à coller la syntaxe dans la fenêtre correspondante.En collant la syntaxe à chaque étape d’une longue analyse, vous pouvez construire un fichierde travail vous permettant de relancer l’analyse ultérieurement ou d’exécuter une opérationautomatisée à l’aide du système de production.Dans la fenêtre de syntaxe, vous pouvez exécuter la syntaxe qui a été collée, la modifier et
l’enregistrer dans un fichier de syntaxe.
Collage d’une syntaxe depuis les boîtes de dialogue
E Ouvrez la boîte de dialogue et faites vos sélections.
E Cliquez sur Coller.
La syntaxe de commande est alors collée dans la fenêtre correspondante. Si vous n’avez pasouvert de fenêtre, une nouvelle fenêtre s’ouvre automatiquement pour pouvoir y coller la syntaxe.
Figure 13-1Syntaxe de commande collée depuis une boîte de dialogue
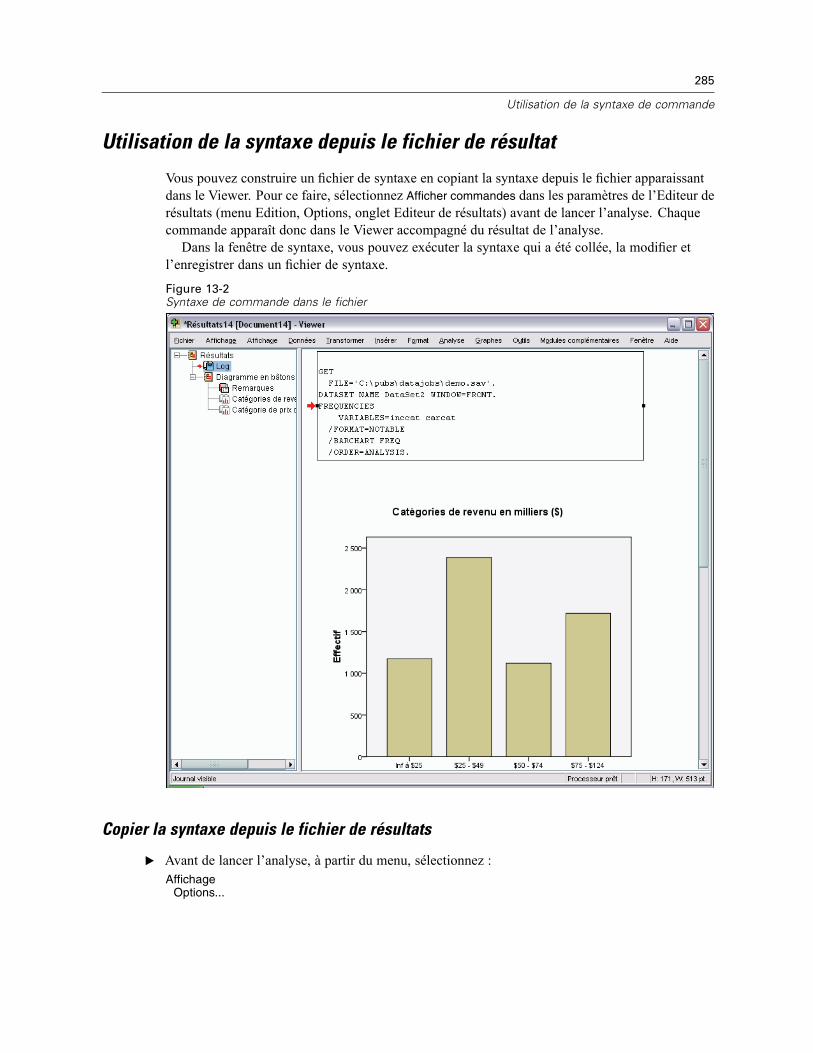
285
Utilisation de la syntaxe de commande
Utilisation de la syntaxe depuis le fichier de résultat
Vous pouvez construire un fichier de syntaxe en copiant la syntaxe depuis le fichier apparaissantdans le Viewer. Pour ce faire, sélectionnez Afficher commandes dans les paramètres de l’Editeur derésultats (menu Edition, Options, onglet Editeur de résultats) avant de lancer l’analyse. Chaquecommande apparaît donc dans le Viewer accompagné du résultat de l’analyse.Dans la fenêtre de syntaxe, vous pouvez exécuter la syntaxe qui a été collée, la modifier et
l’enregistrer dans un fichier de syntaxe.
Figure 13-2Syntaxe de commande dans le fichier
Copier la syntaxe depuis le fichier de résultats
E Avant de lancer l’analyse, à partir du menu, sélectionnez :Affichage
Options...

286
Chapitre 13
E Dans l’onglet Viewer, sélectionnez Afficher commandes.
Au cours de l’analyse, les commandes des sélections faites dans votre boîte de dialogue sontenregistrées dans le fichier.
E Ouvrez un fichier de syntaxe précédemment enregistré ou créez-en un nouveau. Pour ce faire, àpartir du menu, sélectionnez :Fichier
NouveauSyntaxe
E Dans l’Editeur de résultats, double-cliquez sur un élément du fichier pour le mettre en surbrillance.
E Sélectionnez le texte à copier.
E A partir du menu du Viewer, sélectionnez :Affichage
Copier
E Dans la fenêtre de syntaxe, à partir du menu, sélectionnez :Affichage
Coller
Utilisation de l’éditeur de syntaxe
L’éditeur de syntaxe fournit un environnement spécialement conçu pour la création, lamodification et l’exécution de la syntaxe de commande. L’éditeur de syntaxe de commandepossède les fonctionnalités suivantes :
Saisie semi-automatique. Vous pouvez sélectionner des commandes, des sous-commandes, desmots-clés et des valeurs de mot-clé à mesure que vous tapez à partir d’une liste contextuelle.Vous pouvez choisir l’option d’invite automatique ou l’affichage de la liste sur demande.Codage par couleur. Les éléments reconnus de la syntaxe de commande (commandes,sous-commandes, mots-clés et valeurs de mot-clé) sont codés par couleur afin que vouspuissez identifier les termes non reconnus d’un coup d’oeil. De plus, plusieurs erreurs desyntaxes communes, telles que des guillemets non fermées, sont codées par couleur pourune identification rapide.Points d’arrêt. Vous pouvez interrompre l’exécution d’une syntaxe de commande à des pointsspécifiés, ce qui vous permet d’examiner les données ou les résultats avant de poursuivre.Signets. Vous pouvez définir des signets qui vous permettent de naviguer rapidement dans degrands fichiers de syntaxe de commande.Exécution pas à pas. Vous pouvez exécuter une syntaxe de commande pas à pas, à raison d’unecommande à la fois, en passant à la commande suivante en un simple clic.
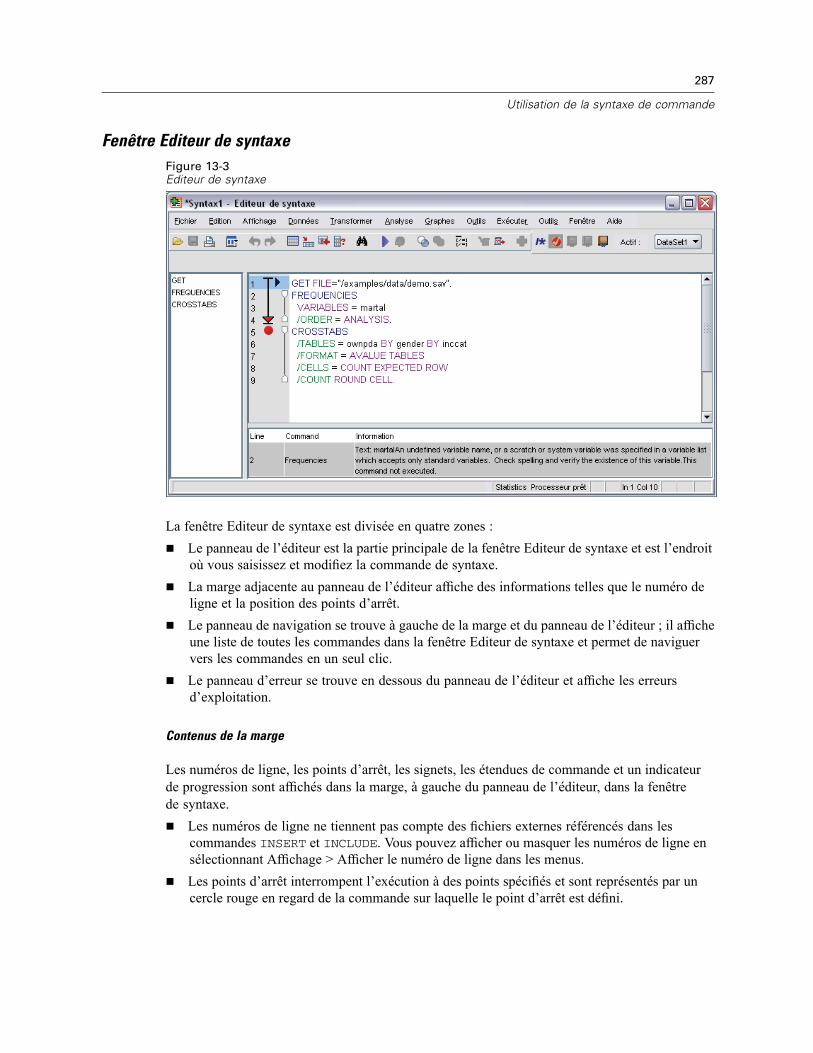
287
Utilisation de la syntaxe de commande
Fenêtre Editeur de syntaxeFigure 13-3Editeur de syntaxe
La fenêtre Editeur de syntaxe est divisée en quatre zones :Le panneau de l’éditeur est la partie principale de la fenêtre Editeur de syntaxe et est l’endroitoù vous saisissez et modifiez la commande de syntaxe.La marge adjacente au panneau de l’éditeur affiche des informations telles que le numéro deligne et la position des points d’arrêt.Le panneau de navigation se trouve à gauche de la marge et du panneau de l’éditeur ; il afficheune liste de toutes les commandes dans la fenêtre Editeur de syntaxe et permet de naviguervers les commandes en un seul clic.Le panneau d’erreur se trouve en dessous du panneau de l’éditeur et affiche les erreursd’exploitation.
Contenus de la marge
Les numéros de ligne, les points d’arrêt, les signets, les étendues de commande et un indicateurde progression sont affichés dans la marge, à gauche du panneau de l’éditeur, dans la fenêtrede syntaxe.
Les numéros de ligne ne tiennent pas compte des fichiers externes référencés dans lescommandes INSERT et INCLUDE. Vous pouvez afficher ou masquer les numéros de ligne ensélectionnant Affichage > Afficher le numéro de ligne dans les menus.Les points d’arrêt interrompent l’exécution à des points spécifiés et sont représentés par uncercle rouge en regard de la commande sur laquelle le point d’arrêt est défini.

288
Chapitre 13
Les signets marquent des lignes spécifiques dans un fichier de syntaxe de commande et sontreprésentés par un carré contenant le numéro (1 à 9) attribué au signet. En passant le curseursur l’icône d’un signet, vous affichez le numéro et le nom attribué à ce signet, s’il y en a.Les étendues de commande sont des icônes qui fournissent des indicateurs visuels du début etde la fin d’une commande. Vous pouvez afficher ou masquer les étendues de commande ensélectionnant Affichage > Afficher les étendues de commande dans les menus.La progression de l’exécution d’une syntaxe est indiquée par une flèche pointant vers lebas dans la marge et s’étirant de la première à la dernière commande exécutée. Ceciest particulièrement utile lors de l’exécution d’une syntaxe de commande contenant despoints d’arrêt et lors de l’exécution pas à pas d’une commande. Pour plus d'informations,reportez-vous à Exécution d’une syntaxe de commande sur p. 293.
Panneau de navigation
Le panneau de navigation contient une liste de toutes les commandes reconnues dans la fenêtre desyntaxe, affichées dans l’ordre dans lequel elles apparaissent dans la fenêtre. Le fait de cliquer surune commande dans le panneau de navigation positionne le curseur au début de la commande.
Vous pouvez utiliser les touches de direction Haut et Bas pour vous déplacer dans la listedes commandes ou cliquer sur une commande pour y accéder. Un double-clic sélectionnela commande.Les noms de commandes contenant certains types d’erreurs de syntaxe, telles que desguillemets non fermées, sont en rouge et en gras par défaut. Pour plus d'informations,reportez-vous à Codage par couleur sur p. 289.Le premier mot de chaque ligne de texte non reconnu est en gris.Vous pouvez afficher ou masquer le panneau de navigation en sélectionnant Affichage >Afficher le panneau de navigation dans les menus.
Panneau d’erreur
Le panneau d’erreur affiche les erreurs d’exécution survenues lors de la toute dernière exécution.Les informations de chaque erreur contiennent entre autres le numéro de ligne où l’erreur estsurvenue.Vous pouvez utiliser les touches de direction Haut et Bas pour vous déplacer dans la listedes erreurs.Le fait de cliquer sur une entrée de la liste positionne le curseur sur la ligne qui a générél’erreur.Vous pouvez afficher ou masquer le panneau d’erreur en sélectionnant Affichage > Afficher lepanneau d’erreur dans les menus.
Terminologie
Commandes. L’unité de base de la syntaxe est la commande. Chaque commande commence par lenom de la commande, qui se compose d’un, deux ou trois mots (par exemple, DESCRIPTIVES,SORT CASES, ou ADD VALUE LABELS .

289
Utilisation de la syntaxe de commande
Sous-commandes. La plupart des commandes contiennent des sous-commandes. Lessous-commandes fournissent des spécifications supplémentaires et commencent par une barreoblique suivie du nom de la sous-commande.
Mots-clés. Les mots-clés sont des termes fixes qui sont généralement utilisés dans unesous-commande afin de spécifier les options disponibles de la sous-commande.
Valeurs de mots-clé. Les mots-clés peuvent avoir pour valeur un terme fixe qui spécifie une optionou une valeur numérique.
Exemple
CODEBOOK gender jobcat salary/VARINFO VALUELABELS MISSING/OPTIONS VARORDER=MEASURE.
Le nom de la commande est CODEBOOK.VARINFO et OPTIONS sont des sous-commandes.VALUELABELS, MISSING, et VARORDER sont des mots-clés.MEASURE est une valeur de mot-clé associée à VARORDER .
Saisie semi-automatique
L’éditeur de syntaxe propose une aide sous la forme d’une saisie semi-automatique descommandes, des sous-commandes, des mots-clés et des valeurs de mots-clé. Par défaut, une listecontextuelle des termes disponibles vous est proposée. Vous pouvez afficher la liste sur demandeen appuyant sur Ctrl+barre d’espace et fermer la liste en appuyant sur la touche Echap.L’élément de menu Saisie semi-automatique du menu Outils active ou désactive l’affichage
automatique de la liste de saisie semi-automatique. Vous pouvez aussi activer ou désactiverl’affichage automatique de la liste à partir de l’onglet Éditeur de syntaxe dans la boîte de dialogueOptions. L’activation ou la désactivation de l’élément de menu Saisie semi-automatique remplacele paramètre de la boîte de dialogue Options mais n’est pas conservé d’une session à l’autre.
Remarque : La liste de saisie semi-automatique se ferme si vous saisissez un espace. Pour descommandes composées de plusieurs mots, telles que ADD FILES, sélectionnez la commandesouhaitée avant de saisir un espace.
Codage par couleur
Les couleurs de l’Editeur de syntaxe codent des éléments reconnus d’une syntaxe de commande,tels que les commandes et les sous-commandes ainsi que diverses erreurs de syntaxe telles queles guillemets ou les parenthèses non fermées. Le codage par couleur n’est pas appliqué autexte non reconnu.
Commandes. Par défaut, les commandes reconnues sont en bleu et en gras. Cependant, si uneerreur de syntaxe est reconnue à l’intérieur de la commande, telle qu’une parenthèse manquante,le nom de la commande est en rouge et en gras par défaut.

290
Chapitre 13
Remarque : Les abréviations des noms de commandes, telles que FREQ pour FREQUENCIES nesont pas en couleurs, mais elles sont valides.
Sous-commandes. Les sous-commandes reconnues sont en vert par défaut. Cependant, si un signeégal obligatoire manque dans la sous-commande ou si un signe égal non valide la suit, le nomde la sous-commande est en rouge par défaut.
Mots-clés. Les mots-clés reconnus sont en marron par défaut. Cependant, si un signe égalobligatoire manque dans le mot-clé ou si un signe égal non valide le suit, le nom du mot-clé esten rouge par défaut.
Valeurs de mots-clé. Les valeurs de mots-clé reconnues sont en rose par défaut. Les valeurs demots-clé spécifiées par l’utilisateur telles que les entiers, les nombres réels et les chaînes entreguillemets ne sont pas codées par couleur.
Commentaires. Le texte à l’intérieur d’un commentaire est en gris.
Erreurs de syntaxe. Le texte associé aux erreurs de syntaxe suivantes est en rouge par défaut.Parenthèses, crochets et guillemets manquants. Les parenthèses et les crochets manquantsà l’intérieur des commentaires et des chaînes entre guillemets ne sont pas détectés. Desguillemets simples ou doubles manquantes à l’intérieur de chaînes entre guillemets sontsyntaxiquement valides.Certaines commandes contiennent des blocs de textes qui ne sont pas des syntaxes decommande, telles que BEGIN DATA-END DATA, BEGIN GPL-END GPL , et BEGINPROGRAM-END PROGRAM . Les valeurs sans correspondance ne sont pas détectées au sein deces blocs.Lignes longues. Les lignes longues sont des lignes contenant plus de 251 caractères.Instructions de fin. Plusieurs commandes nécessitent soit une instruction END avant le caractèrede fin de commande (par exemple, BEGIN DATA-END DATA), soit une commande ENDcorrespondante à un point ultérieur dans le flux de commande (par exemple, LOOP-ENDLOOP ). Dans les deux cas, la commande est en rouge par défaut tant que l’instruction ENDn’est pas ajoutée.
Vous pouvez modifier les couleurs par défaut et le style du texte et vous pouvez activer oudésactiver le codage par couleur à partir de l’onglet Editeur de syntaxe de la boîte de dialogueOptions. Vous pouvez aussi activer ou désactiver le codage par couleur des commandes, dessous-commandes, des mots-clés et des valeurs de mots-clé en sélectionnant Outils > Codage parcouleur dans les menus. Vous pouvez activer ou désactiver le codage par couleur des erreurs desyntaxe en sélectionnant Outils > Validation. Les choix effectués dans le menu Outils remplacentles paramètres de la boîte de dialogue Options mais ne sont pas conservés d’une session à l’autre.
Remarque : Le codage par couleur de la syntaxe de commande au sein des macros n’est paspris en charge.
Points d’arrêt
Les points d’arrêt vous permettent d’interrompre l’exécution d’une syntaxe de commande à despoints spécifiés à l’intérieur de la fenêtre de syntaxe et de poursuivre l’exécution lorsque vousêtes prêt.

291
Utilisation de la syntaxe de commande
Les points d’arrêt sont définis au niveau d’une commande et interrompent l’exécution avantd’exécuter la commande.Il ne peut pas y avoir de points d’arrêt dans les blocs LOOP-END LOOP, DO IF-END IF ,DO REPEAT-END REPEAT, INPUT PROGRAM-END INPUT PROGRAM, et MATRIX-ENDMATRIX. Ils peuvent cependant être définis au début de ces blocs et interrompront alorsl’exécution avant d’exécuter le bloc.Les points d’arrêt ne peuvent pas être définis sur des lignes contenant des syntaxes decommande non-SPSS Statistics, telles que dans les blocs BEGIN PROGRAM-END PROGRAM,BEGIN DATA-END DATA et BEGIN GPL-END GPL.Les points d’arrêts ne sont pas enregistrés avec le fichier de syntaxe de commande et nesont pas inclus dans le texte copié.Par défaut, les points d’arrêt sont utilisés au cours de l’exécution. Vous pouvez activer oudésactiver l’utilisation des points d’arrêt à partir de Outils > Utiliser les points d’arrêt.
Pour insérer un point d’arrêt
E Cliquez n’importe où dans la marge à gauche du texte de la commande.
ou
E Positionnez le curseur à l’intérieur de la commande souhaitée.
E A partir des menus, sélectionnez :Outils
Activer/désactiver un point d’arrêt
Le point d’arrêt est représenté par un cercle rouge dans la marge à gauche du texte de la commandeet sur la même ligne que le nom de la commande.
Effacement de points d’arrêt
Pour effacer un seul point d’arrêt :
E Cliquez sur l’icône représentant le point d’arrêt dans la marge à gauche du texte de la commande.
ou
E Positionnez le curseur à l’intérieur de la commande souhaitée.
E A partir des menus, sélectionnez :Outils
Activer/désactiver un point d’arrêt
Pour effacer tous les points d’arrêt :
E A partir des menus, sélectionnez :Outils
Effacer tous les points d’arrêt
Reportez-vous à Exécution d’une syntaxe de commande sur p. 293 pour plus d’informationsconcernant le comportement lors de l’exécution en présence de points d’arrêt.

292
Chapitre 13
Signets
Les signets vous permettent d’accéder rapidement à des positions spécifiées dans un fichier desyntaxe de commande. Vous pouvez placer 9 signets au maximum dans un fichier donné. Lessignets sont enregistrés avec le fichier mais ne sont pas inclus lors de la copie du texte.
Pour insérer un signet
E Positionnez le curseur sur la ligne où vous voulez insérer le signet.
E A partir des menus, sélectionnez :Outils
Activer/désactiver un signet
Le prochain numéro disponible de 1 à 9 est attribué au nouveau signet. Il est représenté par uncarré contenant le numéro attribué et est affiché dans la marge à gauche du texte de la commande.
Effacement des signets
Pour effacer un seul signet :
E Positionnez le curseur sur la ligne contenant le signet.
E A partir des menus, sélectionnez :Outils
Activer/désactiver un signet
Pour effacer tous les signets :
E A partir des menus, sélectionnez :Outils
Effacer tous les signets
Renommer un signet
Vous pouvez associer un nom à un signet. Ceci s’ajoute au numéro (1 à 9) attribué au signet lorsde sa création.
E A partir des menus, sélectionnez :Outils
Renommer un signet
E Entrez un nom de signet puis cliquez sur OK.
Le nom spécifié remplace le nom existant du signet.
Navigation parmi les signets
Pour accéder au signet suivant ou précédent :
E A partir des menus, sélectionnez :Outils
Signet suivant

293
Utilisation de la syntaxe de commande
ouOutils
Signet précédent
Pour accéder à un signet spécifique :
E A partir des menus, sélectionnez :Outils
Accéder au signet
E Sélectionnez le signet souhaité.
Commenter un texte
Vous pouvez commenter des commandes entières ainsi que du texte qui n’est pas reconnu commesyntaxe de commande.
E Sélectionnez le texte souhaité. Lorsque vous sélectionnez plusieurs commandes, une commandeest commentée si une partie en est sélectionnée.
E A partir des menus, sélectionnez :Outils
Sélection de commentaire
Vous pouvez commenter une seule commande en positionnant le curseur n’importe où à l’intérieurde la commande et en cliquant sur le bouton Sélection de commentaire dans la barre d’outils.
Exécution d’une syntaxe de commande
E Mettez en surbrillance les commandes à exécuter dans la fenêtre de syntaxe.
E Cliquez sur le bouton Exécuter (en forme de triangle) dans la barre d’outils de la fenêtre del’éditeur de syntaxe. Il exécute les commandes sélectionnées ou bien la commande où se trouve lecurseur s’il n’y a pas de sélection.
ou
E Sélectionnez l’un des éléments du menu Exécuter.Tout : Exécute toutes les commandes de la fenêtre de syntaxe en utilisant tous les points d’arrêt.Sélection : Exécute les commandes actuellement sélectionnées, en utilisant tous les pointsd’arrêt. Ceci comprend toutes les commandes partiellement sélectionnées. S’il n’y a pas desélection, la commande où se trouve le curseur est exécutée.Jusqu’à la fin : Exécute toutes les commandes en commençant par la première commande de lasélection en cours jusqu’à la dernière commande de la fenêtre de syntaxe, en utilisant tous lespoints d’arrêt. Si rien n’est sélectionné, l’exécution commence à partir de la commande oùse trouve le curseur.Exécution pas à pas : Exécute la syntaxe de commande, une commande à la fois, encommençant par la première commande de la fenêtre de syntaxe (Pas à pas depuis le début)ou par la commande où est positionné le curseur (Pas à pas à partir de l’actuel). Si un texte estsélectionné, l’exécution commence à partir de la première commande de la sélection. Après

294
Chapitre 13
l’exécution d’une certaine commande, le curseur avance jusqu’à la commande suivante etvous pouvez passer à l’étape suivante en sélectionnant Poursuivre.Les blocs LOOP-END LOOP , DO IF-END IF, DO REPEAT-END REPEAT, INPUTPROGRAM-END INPUT PROGRAM, et MATRIX-END MATRIX sont traités comme descommandes uniques en exécution pas à pas. Vous ne pouvez pas poursuivre vers l’un deces blocs.Poursuivre : Poursuit une exécution arrêtée en pas à pas ou par un point d’arrêt.
Indicateur de progression
La progression de l’exécution d’une syntaxe est indiquée par une flèche pointant vers le basdans la marge, chevauchant le dernier ensemble de commandes exécutées. Par exemple, vouschoisissez d’exécuter toutes les commandes d’une fenêtre de syntaxe qui contient des pointsd’arrêt. Au premier point d’arrêt, la flèche couvre la zone de la première commande de la fenêtre àla commande avant celle contenant le point d’arrêt. Au second point d’arrêt, la flèche s’étendde la commande contenant le premier point d’arrêt jusqu’à la commande avant celle contenantle deuxième point d’arrêt.
Comportement de l’exécution avec des points d’arrêt
Si vous exécutez une syntaxe de commande contenant des points d’arrêt, l’exécution s’arrête àchaque point d’arrêt. En particulier, le bloc de la syntaxe de commande d’un point d’arrêtdonné (ou du début de l’exécution) au point d’arrêt suivant (ou à la fin de l’exécution) estsoumis à l’exécution de la même manière que si vous aviez sélectionné cette syntaxe puisExécuter > Sélection.Vous pouvez travailler avec plusieurs fenêtres de syntaxe, chacune disposant de son propre jeude points d’arrêt, mais il n’y a qu’une seule file d’attente pour l’exécution de la syntaxe decommande. Une fois qu’un bloc de syntaxe de commande a été soumis (tel que le bloc desyntaxe de commande s’étendant jusqu’au premier point d’arrêt), aucun autre bloc de syntaxede commande n’est exécuté tant que le bloc précédent n’est pas terminé, que les blocs setrouvent dans la même fenêtre de syntaxe ou dans des fenêtres de syntaxe différentes.Lorsque l’exécution est arrêtée à un point d’arrêt, vous pouvez exécuter une syntaxe decommande dans d’autres fenêtres de syntaxe et examiner les fenêtres Editeur de données etViewer. Cependant, la modification du contenu de la fenêtre de syntaxe contenant le pointd’arrêt ou la modification de la position du curseur dans cette fenêtre annule l’exécution.
Fichiers de syntaxe Unicode
En mode Unicode, le format par défaut pour l’enregistrement des fichiers de syntaxe de commandecréés ou modifiés au cours de la session est aussi Unicode (UTF-8). Les fichiers de syntaxede commande au format Unicode ne peuvent pas être lus par des versions de SPSS Statisticsantérieures à 16.0. Pour plus d’informations sur le mode Unicode, reportez-vous à Optionsgénérales sur p. 539.

295
Utilisation de la syntaxe de commande
Pour enregistrer un fichier de syntaxe dans un format compatible avec les versions antérieures :
E A partir des menus de la fenêtre de syntaxe, sélectionnez :Fichier
Enregistrer sous
E Dans la boîte de dialogue Enregistrer sous, sélectionnez Codage local dans la liste déroulanteCodage. Le codage local est déterminé par les paramètres régionaux actuels.
Commandes Execute multiples
La syntaxe collée depuis des boîtes de dialogue ou copiée depuis le journal peut contenir descommandes EXECUTE. Lorsque vous exécutez des commandes à partir d’une fenêtre de syntaxe,il est généralement inutile de faire appel aux commandes EXECUTE. Vous risquez même deralentir les performances, particulièrement avec les fichiers de données volumineux, car chaquecommande EXECUTE lit intégralement ces fichiers. Pour plus d’informations, reportez-vous à lacommande EXECUTE dans le manuel Command Syntax Reference (disponible depuis le menuAide d’une fenêtre SPSS Statistics).
Fonctions Décalage positif
Cette exception concerne les commandes de transformation qui contiennent des fonctionsDécalage positif. Dans une série de commandes de transformation ne contenant aucune commandeEXECUTE ni aucune autre commande lisant les données, les fonctions Décalage positif sontcalculées une fois toutes les autres transformations effectuées, sans tenir compte de l’ordre descommandes. Par exemple,
COMPUTE lagvar=LAG(var1).COMPUTE var1=var1*2.
et
COMPUTE lagvar=LAG(var1).EXECUTE.COMPUTE var1=var1*2.
génère différents résultats pour la valeur lagvar car la première valeur utilise la valeur transforméevar1 alors que la deuxième utilise la valeur d’origine.

Chapitre
14Livre des codes
Le livre des codes indique les informations du dictionnaire, telles que les noms de variables, lesétiquettes de variables, les étiquettes de valeurs, les valeurs manquantes, ainsi que les statistiquesrécapitulatives de toutes les variables (ou celles spécifiées) et les vecteurs multiréponses dansl’ensemble de données actif. Pour les variables ordinales et nominales ainsi que pour les vecteursmultiréponses, les statistiques récapitulatives comprennent les effectifs et les pourcentages. Pourles variables d’échelle, les statistiques récapitulatives comprennent la moyenne, l’écart-typeet les quartiles.
Remarque : Le livre des codes ignore l’état de fichier scindé. Ceci comprend les groupes defichiers scindés crées pour l’imputation multiple de valeurs manquantes (disponible dans l’optioncomplémentaire Valeurs manquantes). Pour plus d’informations sur le traitement des fichiersscindés, reportez-vous à Scinder fichier.
Pour obtenir un livre des codes
E A partir des menus, sélectionnez :Analyse
RapportsLivre des codes
E Cliquez sur l’onglet Variables.
296
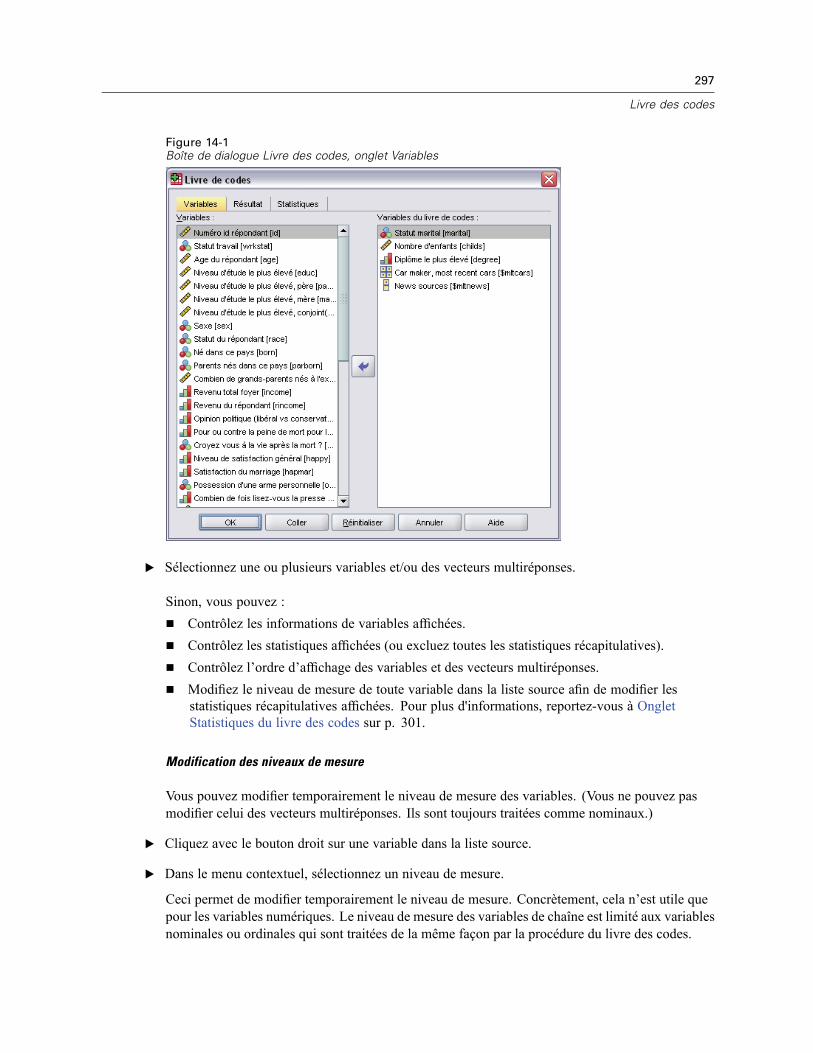
297
Livre des codes
Figure 14-1Boîte de dialogue Livre des codes, onglet Variables
E Sélectionnez une ou plusieurs variables et/ou des vecteurs multiréponses.
Sinon, vous pouvez :Contrôlez les informations de variables affichées.Contrôlez les statistiques affichées (ou excluez toutes les statistiques récapitulatives).Contrôlez l’ordre d’affichage des variables et des vecteurs multiréponses.Modifiez le niveau de mesure de toute variable dans la liste source afin de modifier lesstatistiques récapitulatives affichées. Pour plus d'informations, reportez-vous à OngletStatistiques du livre des codes sur p. 301.
Modification des niveaux de mesure
Vous pouvez modifier temporairement le niveau de mesure des variables. (Vous ne pouvez pasmodifier celui des vecteurs multiréponses. Ils sont toujours traitées comme nominaux.)
E Cliquez avec le bouton droit sur une variable dans la liste source.
E Dans le menu contextuel, sélectionnez un niveau de mesure.
Ceci permet de modifier temporairement le niveau de mesure. Concrètement, cela n’est utile quepour les variables numériques. Le niveau de mesure des variables de chaîne est limité aux variablesnominales ou ordinales qui sont traitées de la même façon par la procédure du livre des codes.
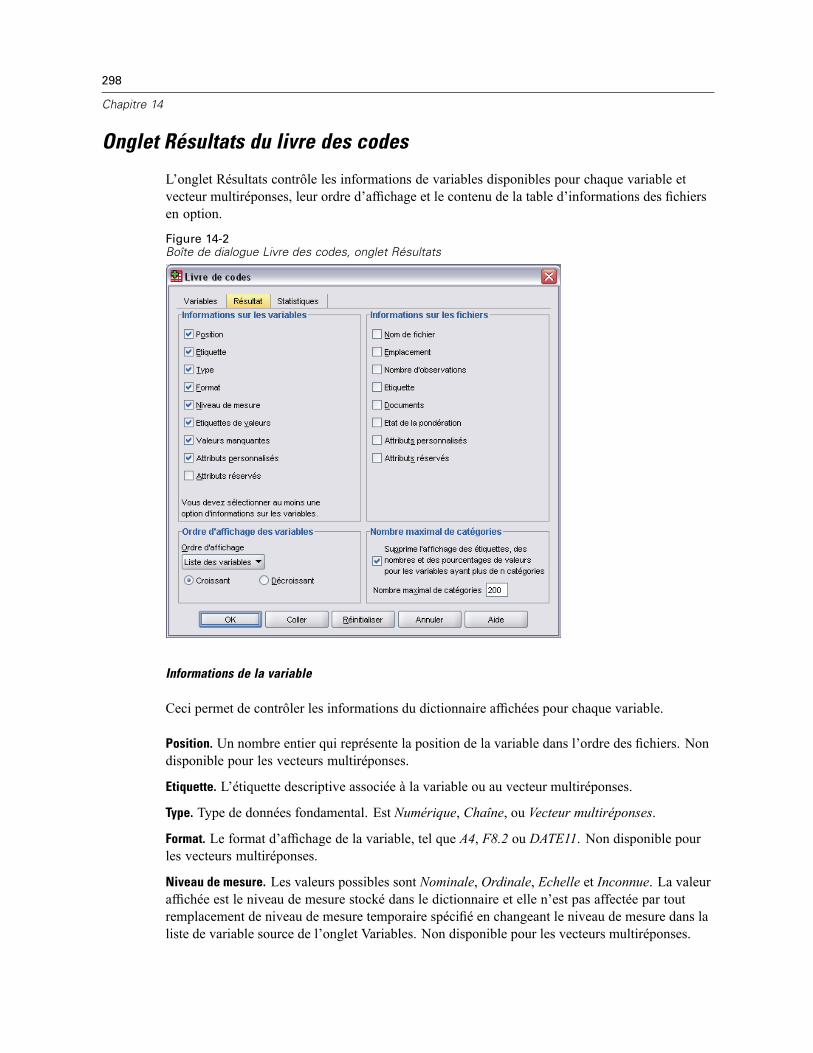
298
Chapitre 14
Onglet Résultats du livre des codes
L’onglet Résultats contrôle les informations de variables disponibles pour chaque variable etvecteur multiréponses, leur ordre d’affichage et le contenu de la table d’informations des fichiersen option.
Figure 14-2Boîte de dialogue Livre des codes, onglet Résultats
Informations de la variable
Ceci permet de contrôler les informations du dictionnaire affichées pour chaque variable.
Position. Un nombre entier qui représente la position de la variable dans l’ordre des fichiers. Nondisponible pour les vecteurs multiréponses.
Etiquette. L’étiquette descriptive associée à la variable ou au vecteur multiréponses.
Type. Type de données fondamental. Est Numérique, Chaîne, ou Vecteur multiréponses.
Format. Le format d’affichage de la variable, tel que A4, F8.2 ou DATE11. Non disponible pourles vecteurs multiréponses.
Niveau de mesure. Les valeurs possibles sont Nominale, Ordinale, Echelle et Inconnue. La valeuraffichée est le niveau de mesure stocké dans le dictionnaire et elle n’est pas affectée par toutremplacement de niveau de mesure temporaire spécifié en changeant le niveau de mesure dans laliste de variable source de l’onglet Variables. Non disponible pour les vecteurs multiréponses.

299
Livre des codes
Remarque : Le niveau de mesure des variables numériques peut être « inconnu » avant le premierpassage de données lorsque le niveau de mesure n’a pas été explicitement défini, par exemple pourla lecture de données à partir d’une source externe ou des variables récemment créées.Pour plusd'informations, reportez-vous à Niveau de mesure des variables dans Chapitre 5 sur p. 85.
Etiquettes de valeurs. Etiquettes descriptives associées à des valeurs de données spécifiques. Pourplus d'informations, reportez-vous à Etiquettes de valeurs dans Chapitre 5 sur p. 88.
Si l’option Effectif ou Pourcentage est sélectionnée dans l’onglet Statistiques, les étiquettesde valeurs définies sont comprises dans les résultats même si vous ne sélectionnez pasEtiquettes de valeur ici.Pour les vecteurs de dichotomies multiples, les « étiquettes de valeur » sont les étiquettes desvariables élémentaires du vecteur soit les étiquettes des valeurs comptées, selon la définitiondu vecteur. Pour plus d'informations, reportez-vous à Vecteurs de réponses multiples dansChapitre 7 sur p. 119.
Valeurs manquantes. Valeurs manquantes définies par l’utilisateur. Pour plus d'informations,reportez-vous à Valeurs manquantes dans Chapitre 5 sur p. 89. Si l’option Effectif ou Pourcentageest sélectionnée dans l’onglet Statistiques, les étiquettes de valeurs définies sont comprises dansles résultats même si vous ne sélectionnez pas Valeurs manquantes ici. Non disponible pourles vecteurs multiréponses.
Attributs Personnalisés. Attributs de variable personnalisés. Les résultats comprennent à la fois lesnoms et les valeurs pour tout attribut de variables personnalisé associé à chaque variable. Pourplus d'informations, reportez-vous à Création d’attributs de variable personnalisés dans Chapitre5 sur p. 92. Non disponible pour les vecteurs multiréponses.
Attributs réservés. Attributs de variables système réservés. Vous pouvez afficher les attributssystème, mais vous ne devez pas les modifier. Les noms des attributs système commencent par unsigne dollar ($) . Les attributs hors affichage, avec les noms qui commencent par « @ » ou « $@», ne sont pas inclus. Les résultats comprennent à la fois les noms et les valeurs pour tout attributsystème associé à chaque variable. Non disponible pour les vecteurs multiréponses.
Informations sur les fichiers
La table d’informations de fichiers en option peut comprendre l’un des attributs de fichierssuivants :
Nom de fichier. Nom du fichier de données SPSS Statistics. Si l’ensemble de données n’a jamaisété enregistré au format SPSS Statistics, aucun nom de fichier de données n’est disponible.(Si aucun nom de fichier n’est affiché dans la barre de titre de la fenêtre Editeur de données,l’ensemble de données actif ne comporte pas de nom de fichier).
Emplacement. Emplacement du répertoire (dossier) du fichier de données SPSS Statistics. Sil’ensemble de données n’a jamais été enregistré au format SPSS Statistics, aucun n’emplacementn’est disponible.
Nombre d’observations. Nombre d’observations dans l’ensemble de données actif. Ceci estle nombre total d’observations, y compris celles qui peuvent être exclues des statistiquesrécapitulatives en raison des conditions de filtrage.

300
Chapitre 14
Etiquette. Ceci est le fichier d’étiquette (si disponible) défini par la commande FILE LABEL.
Documents. Texte de document de fichier de données. Pour plus d'informations, reportez-vous àCommentaires de fichier de données dans Chapitre 47 sur p. 534.
Etat de la pondération. Si la pondération est activée, le nom de la variable de pondération est affiché.Pour plus d'informations, reportez-vous à Pondérer les observations dans Chapitre 9 sur p. 210.
Attributs Personnalisés. Attributs de fichiers de données personnalisés définis par l’utilisateur.Attributs de fichiers de données définis avec la commande DATAFILE ATTRIBUTE.
Attributs réservés. Attributs de fichiers de données système réservés. Vous pouvez afficherles attributs système, mais vous ne devez pas les modifier. Les noms des attributs systèmecommencent par un signe dollar ($) . Les attributs hors affichage, avec les noms qui commencentpar « @ » ou « $@ », ne sont pas inclus. Les résultats incluent les noms et les valeurs pourtout attribut de fichiers de données système.
Ordre d’affichage des variables
Les alternatives suivantes sont disponibles pour contrôler l’ordre d’affichage des variables etdes vecteurs multiréponses :
Alphabétique. Ordre alphabétique par nom de variable.
Fichier. L’ordre d’affichage des variables dans l’ensemble de données (leur ordre d’affichagedans l’Editeur de données). Dans l’ordre croissant, les vecteurs multiréponses sont affichés endernier, après toutes les variables sélectionnées.
Niveau de mesure. Trier par niveau de mesure. Ceci crée quatre groupes de tri : nominal, ordinal,échelle et inconnu. Les vecteurs multiréponses sont traités comme nominaux
Remarque : Le niveau de mesure des variables numériques peut être « inconnu » avant le premierpassage de données lorsque le niveau de mesure n’a pas été explicitement défini, par exemple pourla lecture de données à partir d’une source externe ou des variables récemment créées.
Liste des variables. L’ordre d’affichage des variables et des vecteurs multiréponses dans la liste desvariables sélectionnées de l’onglet Variables.
Nom d’attribut personnalisé. La liste des options d’ordre de tri comprend aussi le nom des attributsde variables personnalisés définis par l’utilisateur. Dans l’ordre croissant, les variables dont le trides attributs ne figure pas en haut, puis celles dont la valeur n’est pas définie pour l’attribut, puiscelles avec des valeurs définies pour l’attribut dans l’ordre alphabétique des valeurs.
Nombre maximum de modalités
Si les résultats comprennent les étiquettes de valeurs, les effectifs, ou les pourcentages pourchaque valeur unique, vous pouvez supprimer ces informations de la table si le nombre de valeursdépasse la valeur indiquée. Par défaut, ces informations sont supprimées si le nombre de valeursuniques de la variable dépasse 200.
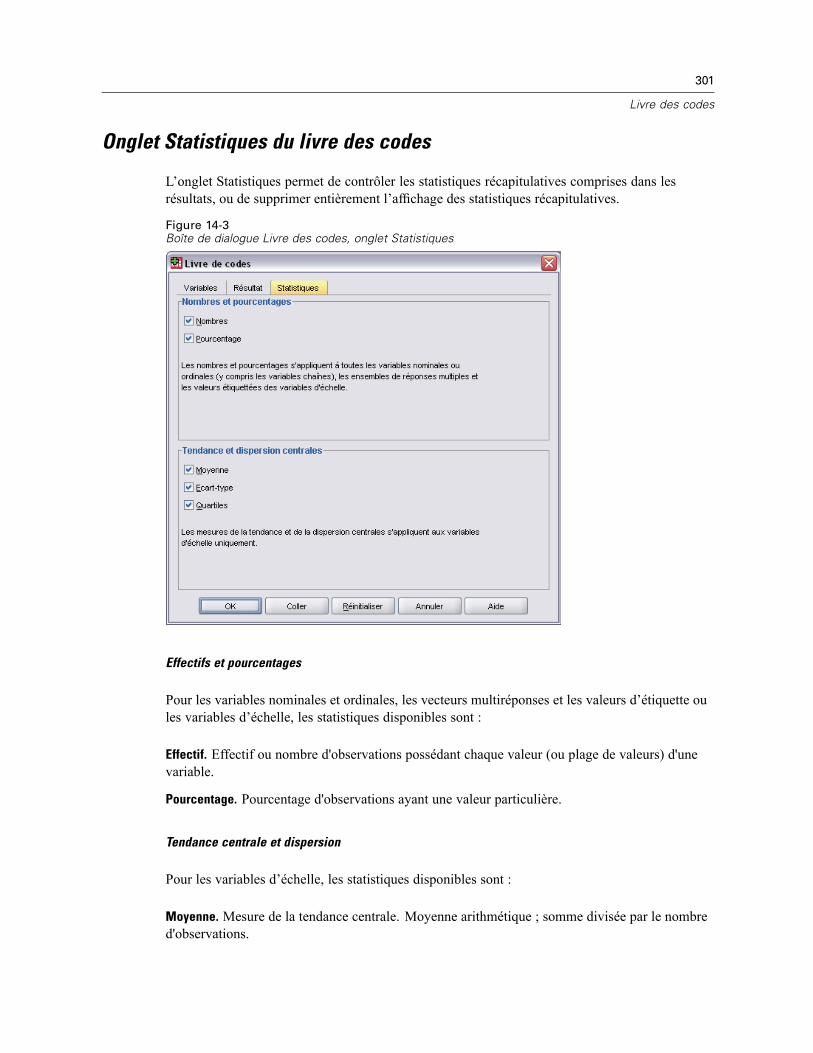
301
Livre des codes
Onglet Statistiques du livre des codes
L’onglet Statistiques permet de contrôler les statistiques récapitulatives comprises dans lesrésultats, ou de supprimer entièrement l’affichage des statistiques récapitulatives.
Figure 14-3Boîte de dialogue Livre des codes, onglet Statistiques
Effectifs et pourcentages
Pour les variables nominales et ordinales, les vecteurs multiréponses et les valeurs d’étiquette oules variables d’échelle, les statistiques disponibles sont :
Effectif. Effectif ou nombre d'observations possédant chaque valeur (ou plage de valeurs) d'unevariable.
Pourcentage. Pourcentage d'observations ayant une valeur particulière.
Tendance centrale et dispersion
Pour les variables d’échelle, les statistiques disponibles sont :
Moyenne. Mesure de la tendance centrale. Moyenne arithmétique ; somme divisée par le nombred'observations.

302
Chapitre 14
Ecart-type. Mesure de dispersion par rapport à la moyenne. Dans le cas d'une distribution normale,68 % des observations se situent à l'intérieur d'un écart-type de la moyenne et 95 % se situent àl'intérieur de deux écarts-types. Par exemple, si la moyenne d'âge est de 45 avec un écart-type égalà 10, une distribution normale verra 95 % des observations se situer entre 25 et 65.
Quartiles. Valeurs correspondant aux 25ème, 50ème et 75ème centiles.
Remarque : vous pouvez modifier temporairement le niveau de mesure associé à une variable(et par conséquent modifier les statistiques récapitulatives affichées pour cette variable) dans laliste de variables source de l’onglet Variables.

Chapitre
15Effectifs
La procédure Effectifs permet d’obtenir des affichages statistiques et graphiques qui servent àdécrire de nombreux types de variables. La procédure Effectifs peut jouer un rôle lorsque vousprenez connaissance de vos données.Pour obtenir un rapport des fréquences et un diagramme en bâtons, vous pouvez trier les
différentes valeurs par ordre croissant ou décroissant, ou bien classer les modalités en fonction deleurs fréquences. Le rapport de fréquences peut être supprimé lorsqu’une variable a plusieursvaleurs distinctes. Vous pouvez étiqueter les diagrammes avec des fréquences (par défaut)ou des pourcentages.
Exemple : Quelle est la répartition de la clientèle d’une société selon le type d’industrie dontelle fait partie ? Le résultat pourrait vous apprendre que votre clientèle est composée à 37,5 %d’organismes d’état, à 24,9 % de sociétés commerciales, à 28,1 % d’établissements universitaireset à 9,4 % du secteur de la santé. Pour des données continues et quantitatives, comme par exempleles revenus des ventes, vous pourriez constater que la moyenne de vente par produit est de 3 576 €avec un écart-type de 1 078 €.
Diagrammes et statistiques : Effectifs de fréquence, pourcentages, pourcentages cumulés,moyenne, médiane, mode, somme, écart-type, variance, étendue, valeurs minimale et maximale,erreur standard de la moyenne, asymétrie et aplatissement (avec leurs erreurs standard), quartiles,centiles choisis par l’utilisateur, diagrammes en bâtons, diagrammes en secteurs et histogrammes.
Données : Utilisez des codes numériques ou alphanumériques pour coder les variables qualitatives(mesures de niveau nominal ou ordinal).
Hypothèses : Les tabulations et les pourcentages fournissent une description utile sur les donnéesde n’importe quelle distribution, particulièrement pour les variables disposant de modalitéstriées ou non. Certaines des statistiques récapitulatives facultatives, telles que la moyenne etl’écart-type, sont fondées sur la théorie de normalité et sont appropriées pour des variablesquantitatives avec une distribution symétrique. Les statistiques de base, telles que la médiane, lesquartiles et les centiles, sont appropriées pour les variables quantitatives, qu’elles répondent ounon au critère de normalité.
Pour obtenir des tableaux de effectifs
E A partir des menus, sélectionnez :Analyse
Statistiques descriptivesEffectifs
303
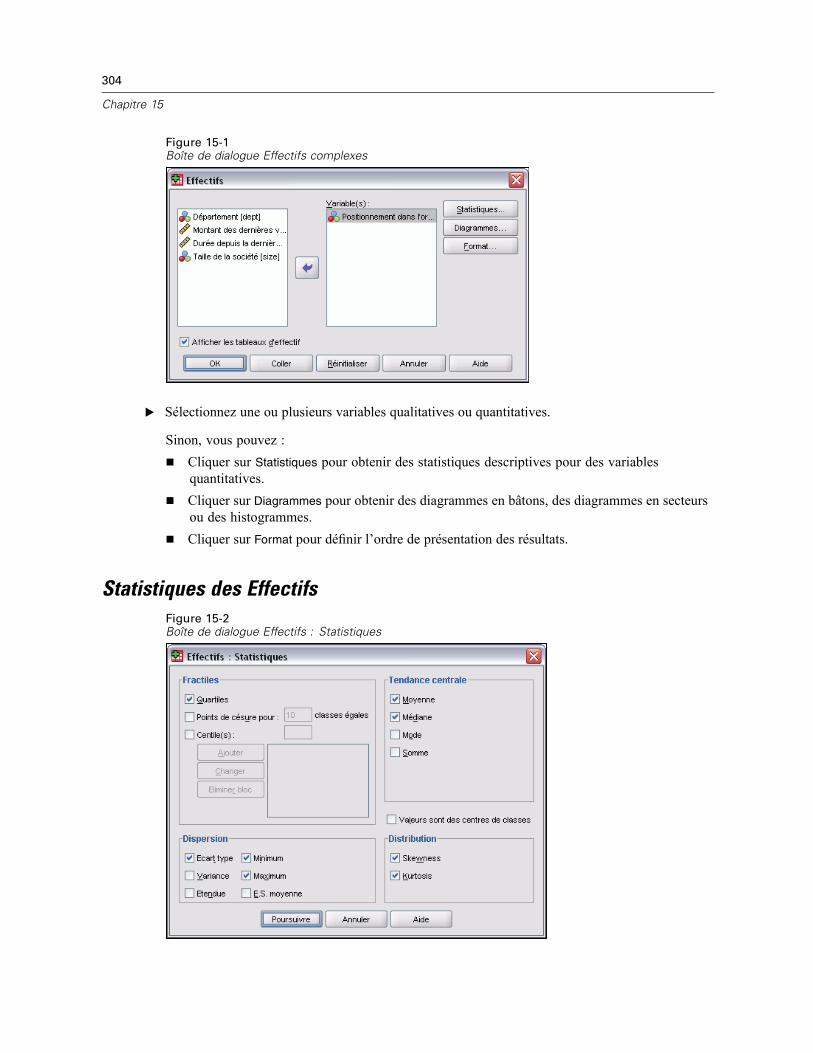
304
Chapitre 15
Figure 15-1Boîte de dialogue Effectifs complexes
E Sélectionnez une ou plusieurs variables qualitatives ou quantitatives.
Sinon, vous pouvez :Cliquer sur Statistiques pour obtenir des statistiques descriptives pour des variablesquantitatives.Cliquer sur Diagrammes pour obtenir des diagrammes en bâtons, des diagrammes en secteursou des histogrammes.Cliquer sur Format pour définir l’ordre de présentation des résultats.
Statistiques des EffectifsFigure 15-2Boîte de dialogue Effectifs : Statistiques

305
Effectifs
Fractiles : Valeurs d’une variable quantitative qui divisent les données triées en classes parcentième. Les quartiles (25ième, 50ième et 75ième centiles) divisent les observations enquatre classes de taille égale. Si vous souhaitez un nombre égal de classes différent de quatre,sélectionnez Partition en n classes égales. Vous pouvez également spécifier des centiles particuliers(par exemple, le 95ième centile, valeur au-dessus de 95 % des observations).
Tendance centrale : Les statistiques décrivant la position de la distribution comprennent laMoyenne, la Médiane, le Mode et la Somme de toutes les valeurs.
Moyenne. Mesure de la tendance centrale. Moyenne arithmétique ; somme divisée par lenombre d'observations.Médiane. Valeur au‑dessus ou au‑dessous de laquelle se trouvent la moitié des observations ;50e centile. Si le nombre d'observations est pair, la médiane correspond à la moyenne desdeux observations du milieu lorsqu'elles sont triées dans l'ordre croissant ou décroissant. Lamédiane est une mesure de tendance centrale et elle n'est pas, à l'inverse de la moyenne,sensible aux valeurs éloignées.Mode. Valeur qui revient le plus fréquemment. Si plusieurs valeurs partagent la plus grandefréquence d'occurrence, chacune d'elles constitue un mode. La procédure Effectifs ne rendcompte que du plus petit mode.Somme. Somme ou total des valeurs, pour toutes les observations n'ayant pas de valeurmanquante.
Dispersion : Les statistiques mesurant la variance ou la dispersion dans les données, comprennentl’écart-type, la variance, l’étendue, le minimum, le maximum et l’erreur standard (ES) de lamoyenne.
Ecart type. Mesure de dispersion par rapport à la moyenne. Dans le cas d'une distributionnormale, 68 % des observations se situent à l'intérieur d'un écart-type de la moyenne et 95% se situent à l'intérieur de deux écarts-types. Par exemple, si la moyenne d'âge est de 45avec un écart-type égal à 10, une distribution normale verra 95 % des observations se situerentre 25 et 65.Variance. Mesure de dispersion autour de la moyenne, égale à la somme des carrés des écartspar rapport à la moyenne, divisée par le nombre d'observations moins un. La variance semesure en unités, qui sont égales au carré des unités de la variable.Etendue. Différence entre la valeur maximale et la valeur minimale d'une variable numérique(maximum–minimum).Minimum. Valeur la plus petite d'une variable numérique.Maximum. Plus grande valeur d'une variable numérique.ES Moyenne. Mesure du degré de variation de la moyenne d'un échantillon à l'autre au seind'une même distribution. Cette mesure permet de comparer approximativement la moyenneobservée avec une valeur hypothétique (autrement dit, vous pouvez conclure que ces deuxvaleurs sont différentes si le rapport de la différence avec l'erreur standard est inférieur à -2ou supérieur à +2).
Distribution : L’Asymétrie et l’Aplatissement sont des statistiques qui décrivent la forme et lasymétrie de la distribution. Ces statistiques sont présentées avec leurs erreurs standard.

306
Chapitre 15
Asymétrie. Mesure de l'asymétrie d'une distribution. La distribution normale est symétriqueet possède une valeur d'asymétrie égale à 0. Une distribution dont la valeur d'asymétrieest positive présente une extrémité droite allongée. Une distribution caractérisée par uneimportante asymétrie négative présente une extrémité gauche plus allongée. Pour simplifier,une valeur d'asymétrie deux fois supérieure à l'erreur standard correspond à une absence desymétrie.Aplatissement. Mesure de l'étendue du regroupement des observations autour d'un pointcentral. Dans le cas d'une distribution normale, la valeur de la statistique d'aplatissement estégale à zéro. Un aplatissement positif indique que les observations sont plus regroupéeset présentent des extrémités plus longues que dans le cas d'une distribution normale. Unaplatissement négatif signifie que les observations sont moins regroupées et présentent desextrémités plus courtes.
Valeurs sont des centres de classes : Si les valeurs dans vos données représentent des centresde classes (par exemple, les âges des individus trentenaires sont représentés par le code 35),sélectionnez cette option pour estimer la médiane et les centiles des données originales, nonregroupées.
Diagrammes des EffectifsFigure 15-3Boîte de dialogue Effectifs : Diagrammes
Type de diagramme : Un diagramme en secteurs montre la participation de chaque partie àl’ensemble. Chaque secteur du diagramme correspond à un groupe défini par une simple variablede regroupement. Un diagramme en bâtons montre l’effectif de chaque valeur ou de chaquemodalité sous la forme d’un bâton distinct, ce qui vous permet de comparer les modalitésvisuellement. Un histogramme est également constitué de bâtons mais ils sont répartis à intervalleségaux. La hauteur de chaque bâton représente l’effectif des valeurs d’une variable quantitativeappartenant à l’intervalle. Un histogramme montre la forme, le centre et la dispersion de ladistribution. Si vous superposez une courbe normale sur l’histogramme, vous pouvez déterminersi les données sont distribuées normalement.
Valeurs du diagramme : Dans les diagrammes en bâtons, l’axe peut être étiqueté par fréquences oupourcentages de fréquence.
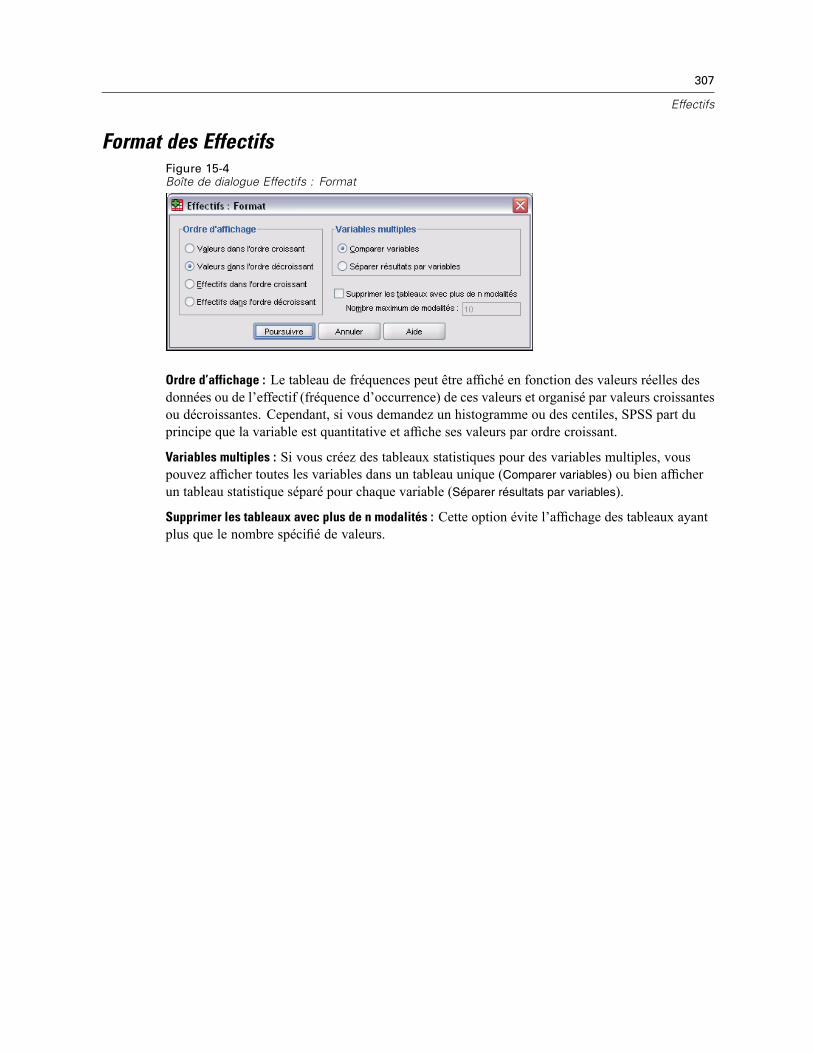
307
Effectifs
Format des EffectifsFigure 15-4Boîte de dialogue Effectifs : Format
Ordre d’affichage : Le tableau de fréquences peut être affiché en fonction des valeurs réelles desdonnées ou de l’effectif (fréquence d’occurrence) de ces valeurs et organisé par valeurs croissantesou décroissantes. Cependant, si vous demandez un histogramme ou des centiles, SPSS part duprincipe que la variable est quantitative et affiche ses valeurs par ordre croissant.
Variables multiples : Si vous créez des tableaux statistiques pour des variables multiples, vouspouvez afficher toutes les variables dans un tableau unique (Comparer variables) ou bien afficherun tableau statistique séparé pour chaque variable (Séparer résultats par variables).
Supprimer les tableaux avec plus de n modalités : Cette option évite l’affichage des tableaux ayantplus que le nombre spécifié de valeurs.

Chapitre
16Descriptives
La procédure Descriptive affiche les résumés de statistiques univariées pour plusieurs variables enun seul tableau et calcule les valeurs standardisées (scores z). Les variables peuvent être ordonnéesen fonction de la taille de leurs moyennes (en ordre ascendant ou descendant), alphabétiquementou selon l’ordre dans lequel vous avez sélectionné les variables (par défaut).Lorsque les scores z sont enregistrés, ils sont ajoutés aux données dans l’éditeur de données et
sont disponibles pour les diagrammes SPSS, les listes de données et les analyses. Lorsque lesvariables sont enregistrées avec des unités différentes (par exemple, produit domestique brut parpersonne et pourcentage de la population sachant lire et écrire), une transformation en score zplace les variables sur une échelle commune pour que la comparaison soit plus facile.
Exemple : Si chaque observation dans vos données contient les totaux des ventes quotidiennes pourchacun des membres du personnel commercial (par exemple, une entrée pour Bob, une pour Kimet une pour Brian) rapportés chaque jour pendant plusieurs mois, la procédure Descriptives peutcalculer les ventes quotidiennes moyennes pour chacun des membres du personnel et ordonner lesrésultats de la moyenne des ventes la plus élevée à la plus basse.
Statistiques : Taille de l’échantillon, moyenne, minimum, maximum, écart-type, variance,intervalle, somme, erreur standard de la moyenne, et aplatissement et asymétrie avec leurs erreursstandards (ES).
Données : Utilisez des variables numériques après les avoir visualisées graphiquement encherchant des erreurs d’enregistrement, les valeurs éloignées et les anomalies de distribution. Laprocédure Descriptives est très efficace pour les gros fichiers (milliers d’observations).
Hypothèses : La plupart des statistiques disponibles (y compris les écarts z) sont basées sur unethéorie normale et conviennent pour des variables continues (mesures de niveau d’intervalle ou derapport) avec distribution symétrique. Evitez les variables avec des modalités désordonnées oudes répartitions asymétriques. La distribution des écarts z a la même forme que celle des donnéesd’origine. Ainsi, le calcul des écarts z n’est pas une solution aux données posant des problèmes.
Pour obtenir des statistiques descriptives
E A partir des menus, sélectionnez :Analyse
Statistiques descriptivesDescriptives
308
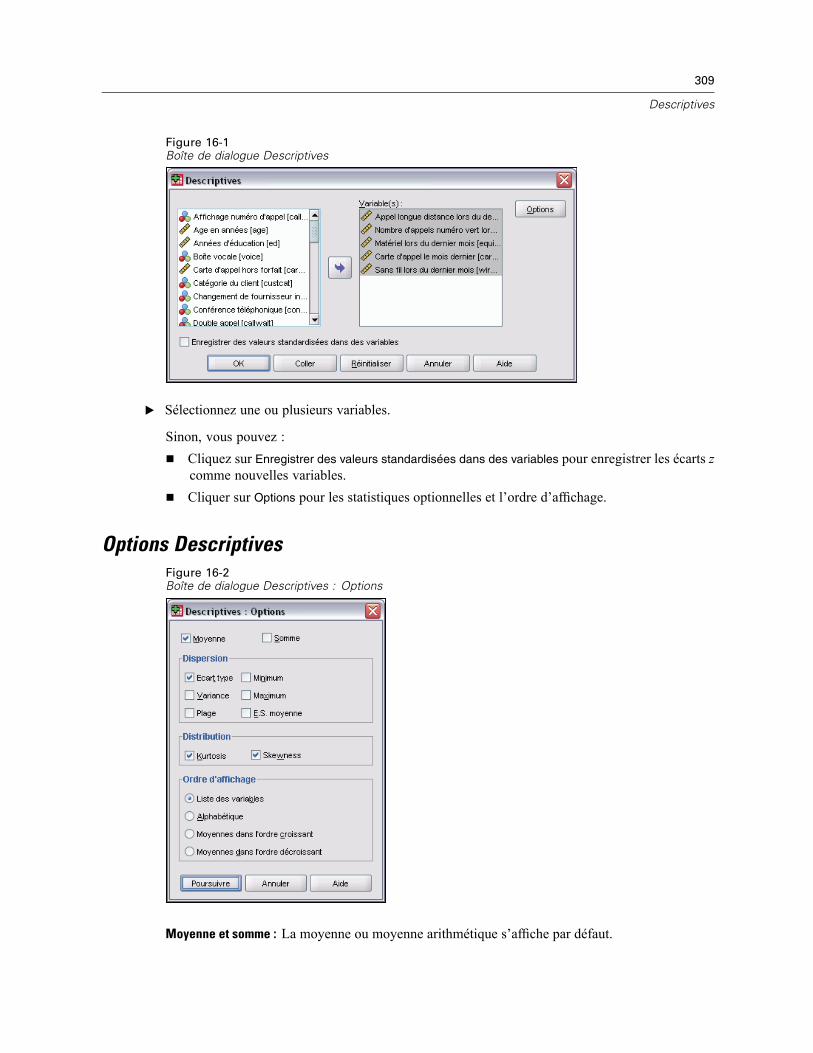
309
Descriptives
Figure 16-1Boîte de dialogue Descriptives
E Sélectionnez une ou plusieurs variables.
Sinon, vous pouvez :Cliquez sur Enregistrer des valeurs standardisées dans des variables pour enregistrer les écarts zcomme nouvelles variables.Cliquer sur Options pour les statistiques optionnelles et l’ordre d’affichage.
Options DescriptivesFigure 16-2Boîte de dialogue Descriptives : Options
Moyenne et somme : La moyenne ou moyenne arithmétique s’affiche par défaut.

310
Chapitre 16
Dispersion : Les statistiques qui mesurent l’étendue ou les variations dans les données comprennentl’écart-type, la variance, l’intervalle, le minimum, le maximum, et l’erreur standard (ES) de lamoyenne.
Ecart type. Mesure de dispersion par rapport à la moyenne. Dans le cas d'une distributionnormale, 68 % des observations se situent à l'intérieur d'un écart-type de la moyenne et 95% se situent à l'intérieur de deux écarts-types. Par exemple, si la moyenne d'âge est de 45avec un écart-type égal à 10, une distribution normale verra 95 % des observations se situerentre 25 et 65.Variance. Mesure de dispersion autour de la moyenne, égale à la somme des carrés des écartspar rapport à la moyenne, divisée par le nombre d'observations moins un. La variance semesure en unités, qui sont égales au carré des unités de la variable.Etendue. Différence entre la valeur maximale et la valeur minimale d'une variable numérique(maximum–minimum).Minimum. Valeur la plus petite d'une variable numérique.Maximum. Plus grande valeur d'une variable numérique.E.S. moyenne. Mesure du degré de variation de la moyenne d'un échantillon à l'autre au seind'une même distribution. Cette mesure permet de comparer approximativement la moyenneobservée avec une valeur hypothétique (autrement dit, vous pouvez conclure que ces deuxvaleurs sont différentes si le rapport de la différence avec l'erreur standard est inférieur à -2ou supérieur à +2).
Distribution : L’aplatissement et l’asymétrie sont des statistiques qui caractérisent la forme et lasymétrie de la distribution. Ces statistiques sont présentées avec leurs erreurs standard.
Aplatissement. Mesure de l'étendue du regroupement des observations autour d'un pointcentral. Dans le cas d'une distribution normale, la valeur de la statistique d'aplatissement estégale à zéro. Un aplatissement positif indique que les observations sont plus regroupéeset présentent des extrémités plus longues que dans le cas d'une distribution normale. Unaplatissement négatif signifie que les observations sont moins regroupées et présentent desextrémités plus courtes.Asymétrie. Mesure de l'asymétrie d'une distribution. La distribution normale est symétriqueet possède une valeur d'asymétrie égale à 0. Une distribution dont la valeur d'asymétrieest positive présente une extrémité droite allongée. Une distribution caractérisée par uneimportante asymétrie négative présente une extrémité gauche plus allongée. Pour simplifier,une valeur d'asymétrie deux fois supérieure à l'erreur standard correspond à une absence desymétrie.
Ordre d’affichage : Par défaut, les variables s’affichent dans l’ordre dans lequel vous les avezsélectionnées. En option, vous pouvez afficher les variables alphabétiquement, par moyennescroissantes ou par moyennes décroissantes.
Fonctionnalités supplémentaires de la commande DESCRIPTIVES
Le langage de syntaxe de commande vous permet aussi de :Enregistrer les coordonnées standardisées (écarts z) pour certaines variables uniquement (àl’aide de la sous-commande VARIABLES).

311
Descriptives
Spécifier le nom des nouvelles variables contenant des coordonnées standardisées (à l’aide dela sous-commande VARIABLES).Exclure de l’analyse les observations ayant des valeurs manquantes pour n’importe quellevariable (à l’aide de la sous-commande MISSING).Trier les variables affichées en utilisant la valeur d’une statistique, et pas uniquement lamoyenne (à l’aide de la sous-commande SORT).
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.

Chapitre
17Explorer
La procédure Explorer produit des résumés statistiques et des affichages graphiques pourtoutes vos observations ou séparément pour des groupes d’observations. Il existe plusieursraisons pour utiliser la procédure Explorer : le filtrage de données, l’identification des valeurséloignées, la description, la vérification d’hypothèses et la caractérisation des différences parmiles sous populations (groupes d’observations). Le filtrage de données peut vous indiquer lesvaleurs inhabituelles, les valeurs extrêmes, les trous dans les données ou d’autres particularités.L’exploration des données peut vous aider à déterminer si les techniques statistiques que vousenvisagez d’utiliser pour l’analyse de vos données sont appropriées. L’exploration peut indiquerque vous avez besoin de transformer les données si la technique nécessite une répartitiongaussienne. Vous pouvez également choisir d’utiliser des tests non paramétriques.
Exemple : Examiner la distribution des temps d’apprentissage pour les souris dans un labyrintheavec quatre programmes de renforcement. Pour chacun des quatre groupes, vous pouvez voir sila répartition des temps est approximativement gaussienne et si les quatre variances sont égales.Vous pouvez aussi identifier les observations avec les cinq plus grands et les cinq plus petitstemps. Les boîtes à moustaches et les diagrammes tige et feuille résument graphiquement larépartition des temps d’apprentissage pour chacun des groupes.
Diagrammes et statistiques : Moyenne, médiane, moyenne tronquée à 5 %, erreur standard,variance, écart-type, minimum, maximum, intervalle, intervalle interquartile, asymétrie etaplatissement avec leurs erreurs standard, intervalle de confiance pour la moyenne (et niveauxde confiance spécifiés), centiles, M-estimateur de Huber, Andrews, Hampel, Tukey, les cinqplus grandes et cinq plus petites valeurs, le Kolmogorov-Smirnov avec un seuil de significationLilliefors pour tester la normalité, et la statistique Shapiro-Wilk. Boîtes à moustaches, diagrammestige et feuille, histogrammes, diagrammes de répartition gaussienne, et dispersion/niveaux avec letest de Levene et les transformations.
Données : La procédure d’Explorer peut être utilisée pour les variables quantitatives (Mesuresde niveaux d’intervalle ou de rapport). Une variable active (utilisée pour répartir les données engroupes d’observations) doit avoir un nombre raisonnable de valeurs distinctes (modalités). Cesvaleurs peuvent être des chaînes de caractères courtes ou numériques. La variable d’étiquette parobservation, utilisée pour étiqueter les valeurs extrêmes dans les boîtes à moustache, peut être decourtes chaînes de caractères, de longues chaînes de caractères (15 premiers octets) ou numériques.
Hypothèses : La distribution de vos données ne doit pas obligatoirement être symétrique ougaussienne.
312
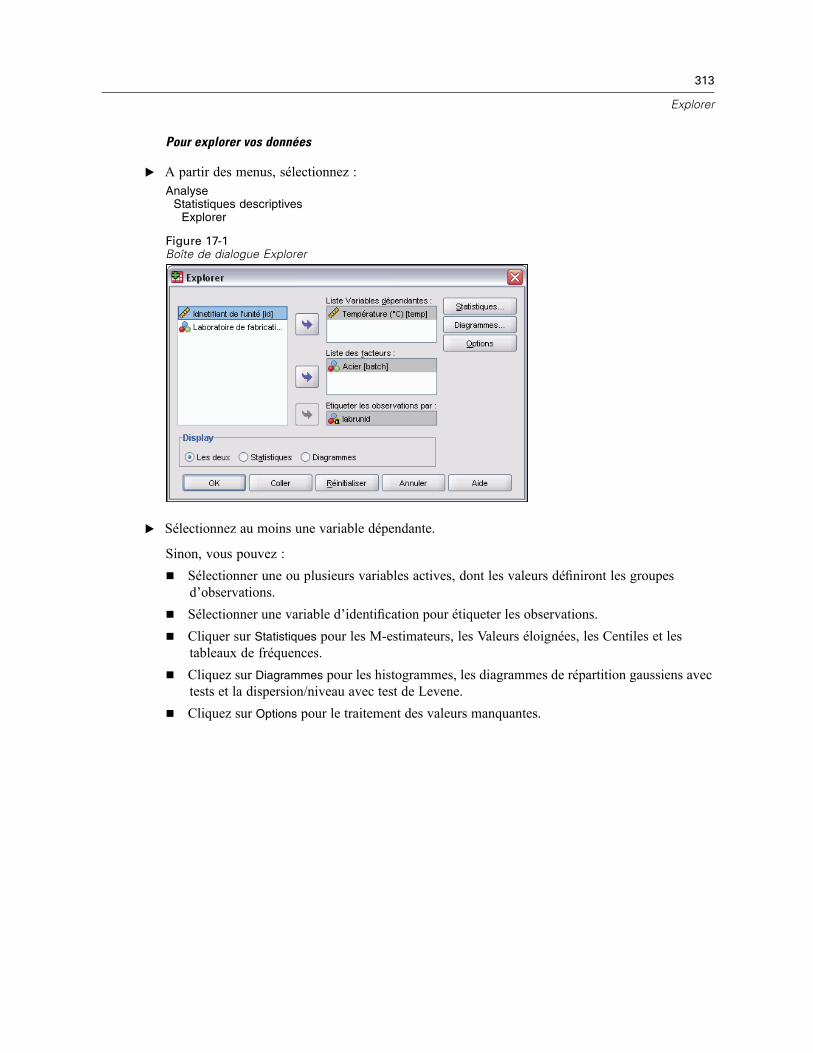
313
Explorer
Pour explorer vos données
E A partir des menus, sélectionnez :Analyse
Statistiques descriptivesExplorer
Figure 17-1Boîte de dialogue Explorer
E Sélectionnez au moins une variable dépendante.
Sinon, vous pouvez :Sélectionner une ou plusieurs variables actives, dont les valeurs définiront les groupesd’observations.Sélectionner une variable d’identification pour étiqueter les observations.Cliquer sur Statistiques pour les M-estimateurs, les Valeurs éloignées, les Centiles et lestableaux de fréquences.Cliquez sur Diagrammes pour les histogrammes, les diagrammes de répartition gaussiens avectests et la dispersion/niveau avec test de Levene.Cliquez sur Options pour le traitement des valeurs manquantes.
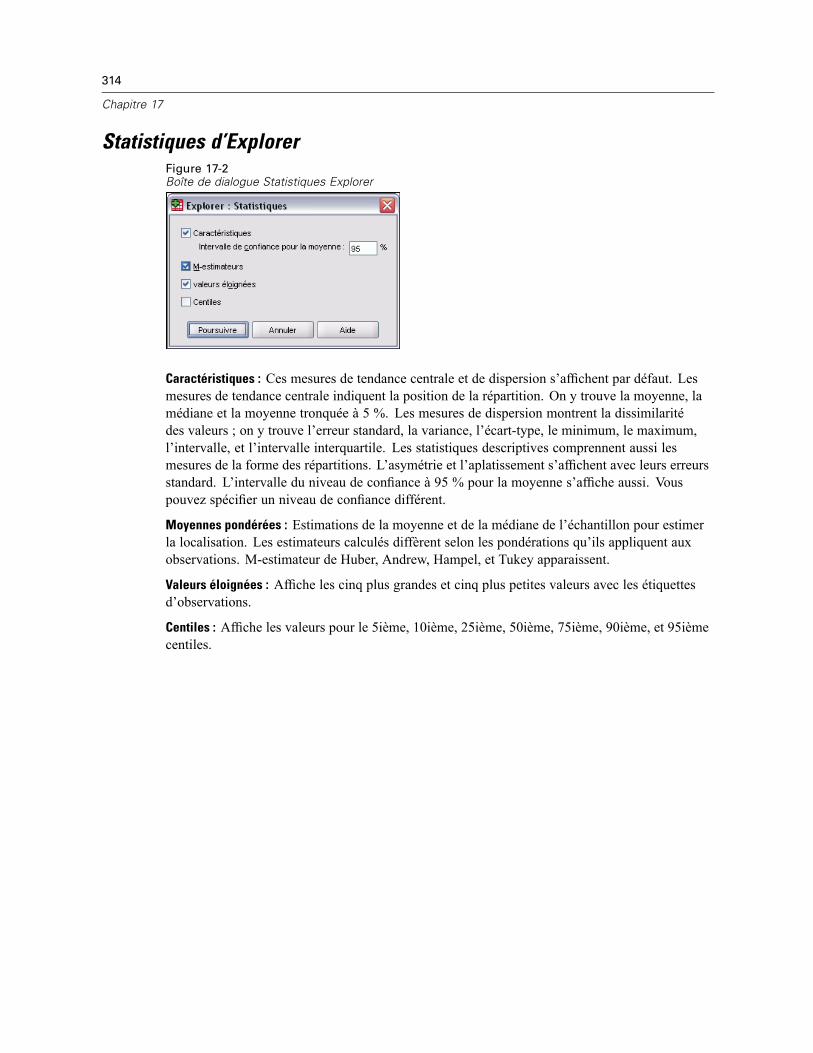
314
Chapitre 17
Statistiques d’ExplorerFigure 17-2Boîte de dialogue Statistiques Explorer
Caractéristiques : Ces mesures de tendance centrale et de dispersion s’affichent par défaut. Lesmesures de tendance centrale indiquent la position de la répartition. On y trouve la moyenne, lamédiane et la moyenne tronquée à 5 %. Les mesures de dispersion montrent la dissimilaritédes valeurs ; on y trouve l’erreur standard, la variance, l’écart-type, le minimum, le maximum,l’intervalle, et l’intervalle interquartile. Les statistiques descriptives comprennent aussi lesmesures de la forme des répartitions. L’asymétrie et l’aplatissement s’affichent avec leurs erreursstandard. L’intervalle du niveau de confiance à 95 % pour la moyenne s’affiche aussi. Vouspouvez spécifier un niveau de confiance différent.
Moyennes pondérées : Estimations de la moyenne et de la médiane de l’échantillon pour estimerla localisation. Les estimateurs calculés diffèrent selon les pondérations qu’ils appliquent auxobservations. M-estimateur de Huber, Andrew, Hampel, et Tukey apparaissent.
Valeurs éloignées : Affiche les cinq plus grandes et cinq plus petites valeurs avec les étiquettesd’observations.
Centiles : Affiche les valeurs pour le 5ième, 10ième, 25ième, 50ième, 75ième, 90ième, et 95ièmecentiles.
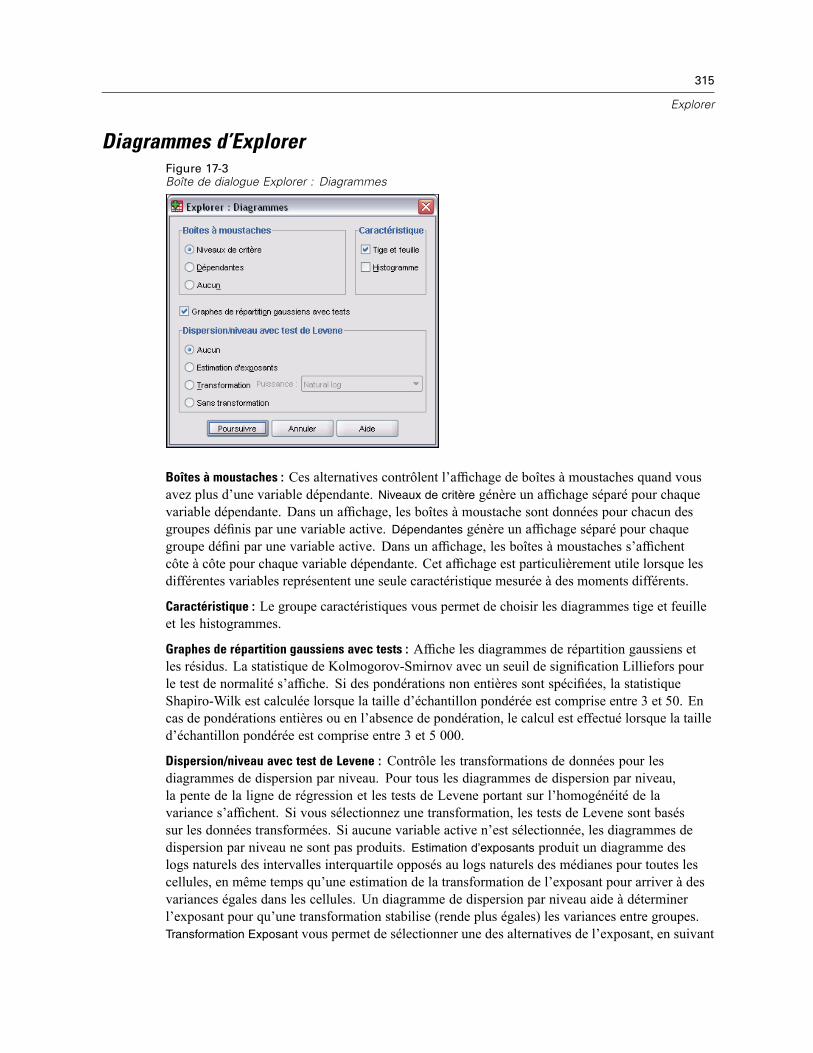
315
Explorer
Diagrammes d’ExplorerFigure 17-3Boîte de dialogue Explorer : Diagrammes
Boîtes à moustaches : Ces alternatives contrôlent l’affichage de boîtes à moustaches quand vousavez plus d’une variable dépendante. Niveaux de critère génère un affichage séparé pour chaquevariable dépendante. Dans un affichage, les boîtes à moustache sont données pour chacun desgroupes définis par une variable active. Dépendantes génère un affichage séparé pour chaquegroupe défini par une variable active. Dans un affichage, les boîtes à moustaches s’affichentcôte à côte pour chaque variable dépendante. Cet affichage est particulièrement utile lorsque lesdifférentes variables représentent une seule caractéristique mesurée à des moments différents.
Caractéristique : Le groupe caractéristiques vous permet de choisir les diagrammes tige et feuilleet les histogrammes.
Graphes de répartition gaussiens avec tests : Affiche les diagrammes de répartition gaussiens etles résidus. La statistique de Kolmogorov-Smirnov avec un seuil de signification Lilliefors pourle test de normalité s’affiche. Si des pondérations non entières sont spécifiées, la statistiqueShapiro-Wilk est calculée lorsque la taille d’échantillon pondérée est comprise entre 3 et 50. Encas de pondérations entières ou en l’absence de pondération, le calcul est effectué lorsque la tailled’échantillon pondérée est comprise entre 3 et 5 000.
Dispersion/niveau avec test de Levene : Contrôle les transformations de données pour lesdiagrammes de dispersion par niveau. Pour tous les diagrammes de dispersion par niveau,la pente de la ligne de régression et les tests de Levene portant sur l’homogénéité de lavariance s’affichent. Si vous sélectionnez une transformation, les tests de Levene sont baséssur les données transformées. Si aucune variable active n’est sélectionnée, les diagrammes dedispersion par niveau ne sont pas produits. Estimation d’exposants produit un diagramme deslogs naturels des intervalles interquartile opposés au logs naturels des médianes pour toutes lescellules, en même temps qu’une estimation de la transformation de l’exposant pour arriver à desvariances égales dans les cellules. Un diagramme de dispersion par niveau aide à déterminerl’exposant pour qu’une transformation stabilise (rende plus égales) les variances entre groupes.Transformation Exposant vous permet de sélectionner une des alternatives de l’exposant, en suivant

316
Chapitre 17
éventuellement les recommandations de l’estimation de l’exposant et de produire les diagrammesdes données transformées. L’intervalle interquartile et la médiane des données transformées sontdessinés. Sans transformation produit des diagrammes de données brutes. Ceci est équivalent àune transformation avec une puissance de 1.
Transformations de l’exposant d’Explorer
Voici les transformations de l’exposant pour les diagrammes de dispersion par niveau. Pourtransformer les données, vous devez sélectionner un exposant pour la transformation. Vous avez lechoix entre les options suivantes :
Log népérien : Transformation par log naturel. Il s’agit de la valeur par défaut.1/racine carrée : La réciproque de la racine carrée est calculée pour chaque valeur des données.Réciproque : La réciproque de chaque valeur des données est calculée.Racine carrée : La racine carrée de chaque valeur des données est calculée.Carré : Chaque valeur des données est élevée au carré.Cube : Chaque valeur des données est élevée au cube.
Options d’ExplorerFigure 17-4Boîte de dialogue Explorer : Options
Valeurs manquantes : Contrôle le traitement des valeurs manquantes.Exclure toute observation incomplète : Les observations avec des valeurs manquantes pourl’une ou l’autre des variables dépendantes ou actives sont exclues de toutes les analyses. Ils’agit de la valeur par défaut.Exclure seulement les composantes non valides : Les observations sans valeur manquante pourune variable dans un groupe (cellule) sont inclues dans l’analyse de ce groupe. L’observationpeut avoir des valeurs manquantes pour les variables utilisées dans d’autres groupes.Signaler les valeurs manquantes : Les valeurs manquantes pour les variables activessont traitées comme une modalité séparée. Tout résultat est produit pour cette modalitésupplémentaire. Les tableaux de fréquences contiennent les modalités pour les valeursmanquantes. Les valeurs manquantes pour une variable active sont inclues, mais étiquetéescomme manquantes.

317
Explorer
Fonctionnalités supplémentaires de la commande EXAMINE
La procédure Explorer utilise la syntaxe de la commande EXAMINE. Le langage de syntaxe decommande vous permet aussi de :
Demander le total des résultats et des diagrammes en complément des résultats et diagrammesrelatifs aux groupes définis par les variables actives (au moyen de la sous-commande TOTAL) ;Spécifier une échelle commune pour un groupe de boîtes à moustaches (au moyen de lasous-commande SCALE) ;Préciser les interactions des variables actives (au moyen de la sous-commande VARIABLES) ;Spécifier les centiles autres que ceux par défaut (au moyen de la sous-commandePERCENTILES) ;Calculer les centiles à l’aide de l’une des cinq méthodes possibles (au moyen de lasous-commande PERCENTILES) ;Spécifier toute transformation de l’exposant pour les diagrammes de dispersion par niveau(au moyen de la sous-commande PLOT) ;Préciser le nombre de valeurs extrêmes à afficher (au moyen de la sous-commandeSTATISTICS) ;Indiquer les paramètres pour les M-estimateurs d’un emplacement (au moyen de lasous-commande MESTIMATORS).
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.

Chapitre
18Tableaux croisés
La procédure de tableaux croisés établit des tableaux à deux entrées ou à entrées multiples etpermet 22 tests et mesures d’associations pour les tableaux à deux entrées. La structure du tableauet l’ordre des modalités déterminent quels test ou mesures effectuer.Les statistiques et les mesures d’association de tableaux croisés ne sont calculées que pour les
tableaux à deux entrées. Si vous spécifiez une ligne, une colonne et une strate de facteur (variablede contrôle), SPSS forme un tableau de statistiques et de mesures pour chaque valeur de la stratede facteur (ou une combinaison de valeurs pour deux variables de contrôle ou plus). Par exemple,si le sexe est un facteur de strate pour un tableau marié (oui, non) face à la vie (est excitante,routinière ou ennuyeuse), les résultats d’un tableau à deux entrées pour les femmes sont calculésséparément de ceux des hommes et affichés sous forme de tableaux consécutifs.
Exemple : Les clients de PME ont-ils plus de probabilités d’être rentables en ventes de services(par exemple, formation et conseil) que ceux de grandes sociétés ? A partir d’une tabulationcroisée, vous pourriez apprendre que la majorité des PME (moins de 500 salariés) génèrent desbénéfices de services élevés, alors que la majorité des grandes sociétés (plus de 2 500 salariés)rapportent des bénéfices de services bas.
Statistiques et mesures d’association : Khi-deux de Pearson, Khi-deux du rapport de vraisemblance,test d’association linéaire par linéaire, test exact de Fisher, Khi-deux corrigé de Yates, r dePearson, rho de Spearman, coefficient de contingence, phi, V de Cramér, lambdas symétriques etasymétriques, tau de Goodman et Kruskal, coefficient d’incertitude, gamma, d de Somer, tau-b deKendall, tau-c de Kendall, coefficient êta, Kappa de Cohen, estimation de risque relatif, odds ratio,test de McNemar, et statistiques de Cochran et Mantel-Haenszel.
Données : Pour définir les modalités de chaque variable du tableau, utilisez des variablesnumériques ou des variables sous forme de chaînes (huit caractères ou moins). Par exemple, poursexe, vous pouvez codifier les données avec 1 et 2, ou avec homme et femme.
Hypothèses : Des statistiques et des mesures partent du principe de modalités ordonnées (donnéesordinales) ou de valeurs quantitatives (données d’intervalle ou données de type ratio), tel quedécrit dans la section sur les statistiques. D’autres sont valides lorsque les variables du tableau ontdes modalités désordonnées (données nominales). Pour les statistiques basées sur le test Khi-deux(phi, V de Cramér, coefficient de contingence), les données doivent provenir d’un échantillonaléatoire avec une répartition multinomiale.
Remarque : Les variables ordinales peuvent être des codes numériques représentant des modalités(par exemple, 1 = faible, 2 = moyen, 3 = élevé) ou des valeurs de chaîne. Toutefois, l’ordrealphabétique des valeurs de chaîne est supposé refléter l’ordre réel des modalités. Par exemple,pour une variable chaîne comportant des valeurs Faible, Moyen, Elevé, l’ordre des modalités estinterprété comme Elevé, Faible ou Moyen, ce qui ne correspond pas à l’ordre correct. En règlegénérale, il est recommandé d’utiliser les codes numériques pour représenter les données ordinales.
318
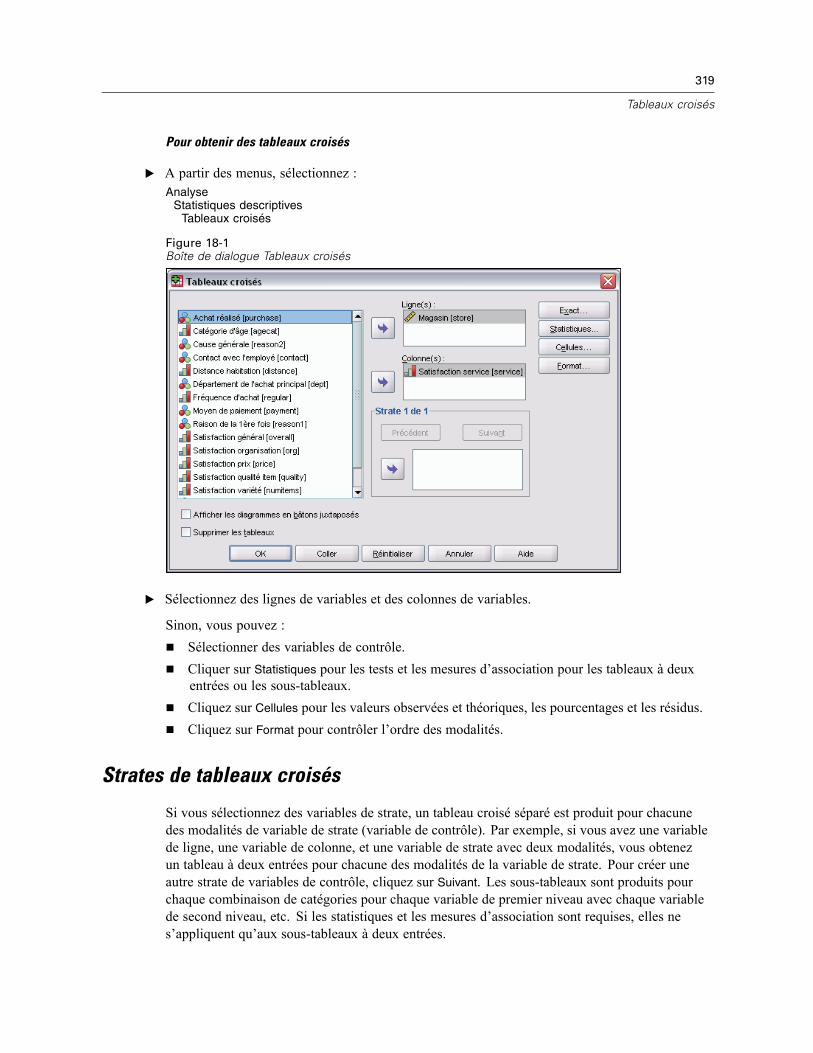
319
Tableaux croisés
Pour obtenir des tableaux croisés
E A partir des menus, sélectionnez :Analyse
Statistiques descriptivesTableaux croisés
Figure 18-1Boîte de dialogue Tableaux croisés
E Sélectionnez des lignes de variables et des colonnes de variables.
Sinon, vous pouvez :Sélectionner des variables de contrôle.Cliquer sur Statistiques pour les tests et les mesures d’association pour les tableaux à deuxentrées ou les sous-tableaux.Cliquez sur Cellules pour les valeurs observées et théoriques, les pourcentages et les résidus.Cliquez sur Format pour contrôler l’ordre des modalités.
Strates de tableaux croisés
Si vous sélectionnez des variables de strate, un tableau croisé séparé est produit pour chacunedes modalités de variable de strate (variable de contrôle). Par exemple, si vous avez une variablede ligne, une variable de colonne, et une variable de strate avec deux modalités, vous obtenezun tableau à deux entrées pour chacune des modalités de la variable de strate. Pour créer uneautre strate de variables de contrôle, cliquez sur Suivant. Les sous-tableaux sont produits pourchaque combinaison de catégories pour chaque variable de premier niveau avec chaque variablede second niveau, etc. Si les statistiques et les mesures d’association sont requises, elles nes’appliquent qu’aux sous-tableaux à deux entrées.
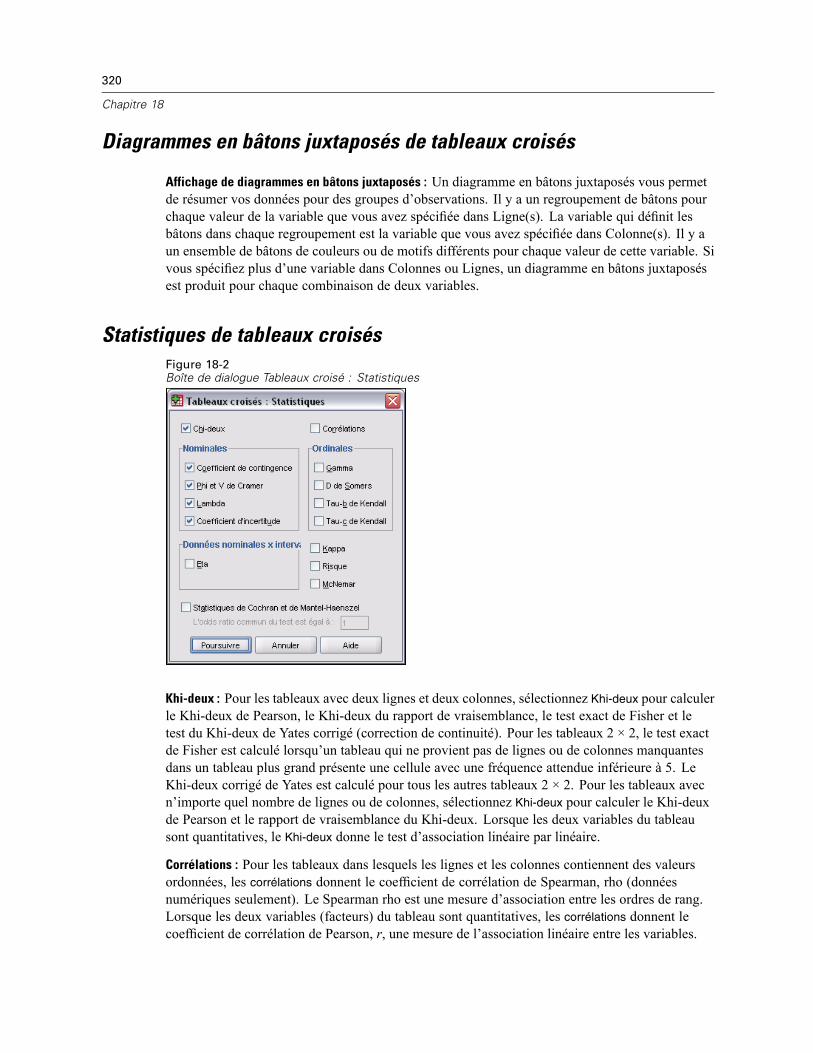
320
Chapitre 18
Diagrammes en bâtons juxtaposés de tableaux croisés
Affichage de diagrammes en bâtons juxtaposés : Un diagramme en bâtons juxtaposés vous permetde résumer vos données pour des groupes d’observations. Il y a un regroupement de bâtons pourchaque valeur de la variable que vous avez spécifiée dans Ligne(s). La variable qui définit lesbâtons dans chaque regroupement est la variable que vous avez spécifiée dans Colonne(s). Il y aun ensemble de bâtons de couleurs ou de motifs différents pour chaque valeur de cette variable. Sivous spécifiez plus d’une variable dans Colonnes ou Lignes, un diagramme en bâtons juxtaposésest produit pour chaque combinaison de deux variables.
Statistiques de tableaux croisésFigure 18-2Boîte de dialogue Tableaux croisé : Statistiques
Khi-deux : Pour les tableaux avec deux lignes et deux colonnes, sélectionnez Khi-deux pour calculerle Khi-deux de Pearson, le Khi-deux du rapport de vraisemblance, le test exact de Fisher et letest du Khi-deux de Yates corrigé (correction de continuité). Pour les tableaux 2 × 2, le test exactde Fisher est calculé lorsqu’un tableau qui ne provient pas de lignes ou de colonnes manquantesdans un tableau plus grand présente une cellule avec une fréquence attendue inférieure à 5. LeKhi-deux corrigé de Yates est calculé pour tous les autres tableaux 2 × 2. Pour les tableaux avecn’importe quel nombre de lignes ou de colonnes, sélectionnez Khi-deux pour calculer le Khi-deuxde Pearson et le rapport de vraisemblance du Khi-deux. Lorsque les deux variables du tableausont quantitatives, le Khi-deux donne le test d’association linéaire par linéaire.
Corrélations : Pour les tableaux dans lesquels les lignes et les colonnes contiennent des valeursordonnées, les corrélations donnent le coefficient de corrélation de Spearman, rho (donnéesnumériques seulement). Le Spearman rho est une mesure d’association entre les ordres de rang.Lorsque les deux variables (facteurs) du tableau sont quantitatives, les corrélations donnent lecoefficient de corrélation de Pearson, r, une mesure de l’association linéaire entre les variables.

321
Tableaux croisés
Nominal : Pour les données nominales (sans ordre intrinsèque, comme Catholique, Protestant, Juif),vous pouvez sélectionner le coefficient de contingence, le coefficient Phi et V de Cramér’s V, Lambda
(lambdas symétriques et asymétriques, et tau de Goodman et Kruskal) et le coefficient d’incertitude.Coefficient de contingence. Mesure d'association basée sur le Khi‑deux. Les valeurs sonttoujours comprises entre 0 et 1, 0 indiquant l'absence d'association entre les variables deligne et de colonne, et les valeurs proches de 1 indiquant un degré d'association élevé entreles variables. La valeur maximale possible dépend du nombre de lignes et de colonnes dansle tableau.Phi et V de Cramer. Phi est une mesure d'association calculée à partir du Khi‑deux. Elle estobtenue en divisant la statistique du Khi‑deux par la taille de l'échantillon, puis en prenantla racine carrée du résultat. Le V de Cramer est également une mesure d'association baséesur le Khi-deux.Lambda. Mesure d'association reflétant la réduction proportionnelle de l'erreur lorsque lesvaleurs de la variable indépendante sont utilisées pour prévoir la variable dépendante. Lavaleur 1 signifie que la variable indépendante prévoit parfaitement la variable dépendante. Lavaleur 0 signifie que la variable indépendante ne prévoit pas du tout la variable dépendante.Coefficient d'incertitude. Mesure d'association qui indique la réduction proportionnelle del'erreur lorsque les valeurs d'une variable sont utilisées pour prévoir celles d'une autre. Parexemple, la valeur 0,83 indique que la connaissance d'une variable réduit de 83 % l'erreur dansles prévisions de l'autre variable. Le programme calcule à la fois des versions symétriqueset asymétriques de ce coefficient.
Ordinal : Pour les tableaux dont les lignes et les colonnes contiennent des valeurs ordonnées,sélectionnez Gamma (ordre zéro pour les tableaux à 2 entrées et conditionnel pour les tableaux de3 à 10 entrées), le tau-b de Kendall et le tau-c de Kendall. Pour prévoir les modalités de colonnesà partir des modalités de lignes, sélectionnez le d de Somers.
Gamma. Mesure d'association symétrique entre deux variables ordinales. Cette mesure estsituée entre -1 et 1. Les valeurs proches d'une valeur absolue de 1 indiquent une relation forteentre les deux variables. Les valeurs proches de 0 indiquent une relation faible ou inexistante.Pour les tableaux d'ordre 2, les gammas d'ordre 0 (zéro) apparaissent. Pour les tableauxd'ordre 3 et les tableaux d'ordre n, les gammas conditionnels apparaissent.d de Somer. Mesure d'intensité de la relation entre deux variables ordinales, qui s'étend de ‑1à 1. Les valeurs proches de 1 indiquent une forte relation entre les deux variables, et cellesproches de zéro indiquent une relation faible ou inexistante entre les variables. Le d de Somerest une extension asymétrique du gamma, qui ne diffère de celui-ci que par l'inclusion dunombre de paires non liées à la variable indépendante. Le programme calcule égalementune version symétrique de cette statistique.Tau-b de Kendall. Mesure de corrélation non paramétrique pour variables ordinales ou classéesqui prend en considération les ex aequo. Le signe du coefficient indique la direction de larelation et sa valeur absolue indique sa force, les valeurs absolues les plus grandes indiquantles relations les plus fortes. Les valeurs peuvent varier de -1 à +1 mais une valeur de -1 ou de+1 ne peut toutefois être obtenue que dans des tableaux carrés.Tau-c de Kendall. Mesure d'association non paramétrique pour variables ordinales qui ne prendpas en considération les ex aequo. Le signe du coefficient indique la direction de la relation etsa valeur absolue indique sa force, les valeurs absolues les plus grandes indiquant les relations

322
Chapitre 18
les plus fortes. Les valeurs peuvent varier de -1 à +1 mais une valeur de -1 ou de +1 ne peuttoutefois être obtenue que dans des tableaux carrés.
Données nominales x intervalle : Lorsqu’une variable est qualitative et l’autre quantitative,sélectionnez Eta. La variable qualitative doit être codée numériquement.
Eta. Mesure d'association dont les valeurs sont comprises entre 0 et 1, 0 indiquant l'absenced'association entre les variables de ligne et de colonne, et les valeurs proches de 1 indiquantun degré d'association élevé. Eta convient à une variable dépendante continue mesurée surune échelle d'intervalle (par exemple, le revenu) et une variable indépendante ayant unnombre limité de modalités (par exemple, le sexe). Deux valeurs eta sont calculées : L'unetraite la variable de ligne comme variable d'intervalle et l'autre traite la variable de colonnecomme variable d'intervalle.
Kappa. Le Kappa de Cohen mesure la concordance entre les évaluations de deux évaluateursutilisés pour évaluer un même objet. La valeur 1 indique une concordance parfaite. La valeur0 indique que la concordance ne dépasse pas celle due au hasard. Le Kappa n'est disponibleque pour les tableaux dans lesquels les deux variables utilisent les mêmes valeurs de modalitéet possèdent le même nombre de modalités.
Risque. Pour les tableaux 2 x 2, mesure de la force de l'association entre la présence d'un facteur etla réalisation d'un événement. Si l'intervalle de confiance de la statistique inclut une valeur de 1, iln'existe aucune association entre le facteur et l'événement. L'odds ratio peut être utilisé commeestimation du risque relatif dans le cas où la réalisation du facteur est rare.
McNemar. Test non paramétrique pour deux variables dichotomiques liées. Il recherche leschangements de réponse en utilisant la répartition Khi-deux. Ce test est utile pour détecter leschangements avant-après dans les réponses dus à une intervention expérimentale dans les plans.Pour les tableaux carrés plus volumineux, le test McNemar-Bowker de symétrie est reporté.
Statistiques de Cochran et de Mantel-Haenszel. Les statistiques de Cochran et de Mantel‑Haenszelservent à tester l'indépendance entre une variable facteur dichotomique et une variable réponsedichotomique, selon les paramètres de covariable définis par des variables (contrôles) de strate.Remarque : alors que les autres statistiques sont calculées strate par strate, les statistiques deCochran et de Mantel-Haenszel sont calculées une seule fois pour toutes les strates.

323
Tableaux croisés
Affichage de cellules (cases) de tableaux croisésFigure 18-3Boîte de dialogue Tableaux croisés : Contenu des cases (cellules)
Pour vous aider à découvrir des types dans les données qui contribuent à un test du Khi-deuxsignificatif, la procédure de Tableaux croisés affiche les fréquences attendues et trois types derésidus (déviations) qui mesurent la différence entre les fréquences observées et les fréquencesattendues. Chaque cellule du tableau peut contenir toute combinaison d’effectifs, de pourcentageset de résidus sélectionnés.
Effectif : Nombre d’observations effectivement observées et nombre d’observations attendues siles variables de ligne et de colonne sont indépendantes l’une de l’autre.
Pourcentages : Les pourcentages peuvent s’additionner par ligne ou par colonne. Les pourcentagesdu nombre total d’observations représentées dans le tableau (une strate) sont égalementdisponibles.
Résidus : Les résidus non standardisés donnent la différence entre les valeurs observées et lesvaleurs théoriques. Les résidus standardisés et standardisés ajustés sont également disponibles.
Non standardisés. Différence entre la valeur observée et la valeur théorique. La valeurthéorique correspond au nombre d'observations attendues dans la cellule quand il n'existe pasde relation entre les deux variables. Un résidu positif indique que la cellule contient plusd'observations que si les variables de ligne et de colonne étaient indépendantes.Standardisé. Résidu, divisé par une estimation de son erreur standard. Egalement appelésrésidus de Pearson, les résidus standardisés ont une moyenne de 0 et un écart-type de 1.Standardisés ajustés. Résidu d'une cellule (valeur observée moins valeur théorique) divisé parune estimation de son erreur standard. Le résidu standardisé qui en résulte est exprimé enécarts par rapport à la moyenne.
Pondérations non entières : En général, les effectifs de cellules sont des valeurs entières, car ilsreprésentent le nombre d’observations figurant dans chaque cellule. Toutefois, si le fichier dedonnées est pondéré par une variable de pondération avec des fractions (par exemple, 1,25), les

324
Chapitre 18
effectifs de cellules peuvent également être des fractions. Vous pouvez tronquer ou arrondir lesvaleurs avant ou après le calcul des effectifs de cellules, ou utiliser des effectifs de cellules nonentiers pour l’affichage des tableaux et les calculs statistiques.
Arrondi des effectifs des cellules. Les poids des observations sont utilisés tels quels, mais lespoids accumulés dans les cellules sont arrondis avant le calcul des statistiques.Troncature des effectifs des cellules. Les poids des observations sont utilisés tels quels, maisles poids accumulés dans les cellules sont arrondis avant le calcul des statistiques.Arrondi des poids des observations. Les poids des observations sont arrondis avant leurutilisation.Troncature des poids des observations. Les poids des observations sont tronqués avant leurutilisation.Aucun ajustement. Les pondérations des observations sont utilisées telles quelles et les comptesdes cellules fractionnées sont utilisées. Toutefois, lorsque des statistiques exactes (disponiblesuniquement avec l'option Tests exacts) sont demandées, les pondérations cumulées dans lescellules sont tronquées ou arrondies avant le calcul des statistiques du test exact.
Format de tableau croiséFigure 18-4Boîte de dialogue Tableaux croisés : Format
Vous pouvez arranger les lignes par ordre croissant ou décroissant de valeur de la variable de ligne.

Chapitre
19Récapituler
La procédure Récapituler calcule les statistiques de sous-groupes pour les variables à l’intérieurdes modalités de variables de regroupement. Tous les niveaux de variables de regroupement sont àtabulation croisée. Vous pouvez choisir l’ordre dans lequel les statistiques sont affichées. Lesstatistiques Récapituler sont affichées pour chaque variable à travers toutes les modalités. Lesvaleurs des données dans chaque modalité peuvent être listées ou supprimées. Avec d’importantsfichiers de données, vous pouvez choisir de lister seulement les premières observations n.
Exemple : Quel est le montant moyen de ventes de produits par région et par secteur de clientèle?Vous pouvez découvrir que le montant moyen des ventes est légèrement plus élevé dans la régionOuest que dans les autres régions, avec des sociétés commerciales dans la région Ouest apportantle montant moyen de ventes le plus élevé.
Statistiques : Somme, nombre d’observations, moyenne, médiane, médiane groupée, erreurstandard pour la moyenne, minimum, maximum, plage, valeur de la variable pour la premièremodalité de la variable de regroupement, valeur de la variable pour la dernière modalité de lavariable de regroupement, écart-type, variance, aplatissement, erreur standard d’aplatissement,asymétrie, erreur standard d’asymétrie, pourcentage de la somme totale, pourcentage de N total,pourcentage de la somme dans, pourcentage de N dans, moyennes géométrique et harmonique.
Données : Les variables de regroupement sont des variables qualitatives dont les valeurs peuventêtre numériques ou chaîne. Le nombre de modalités doit être raisonnablement limité. Les autresvariables doivent pouvoir être classées.
Hypothèses : Certains des sous-groupes statistiques optionnels, tels que la moyenne et l’écart-typesont basés sur la théorie normale et conviennent aux variables quantitatives ayant une distributionsymétrique. Les statistiques robustes telles que la médiane et l’intervalle, conviennent auxvariables quantitatives qui confirment ou infirment l’hypothèse de normalité.
Obtenir des récapitulatifs des observations
E A partir des menus, sélectionnez :Analyse
RapportsRécapitulatif des observations
325
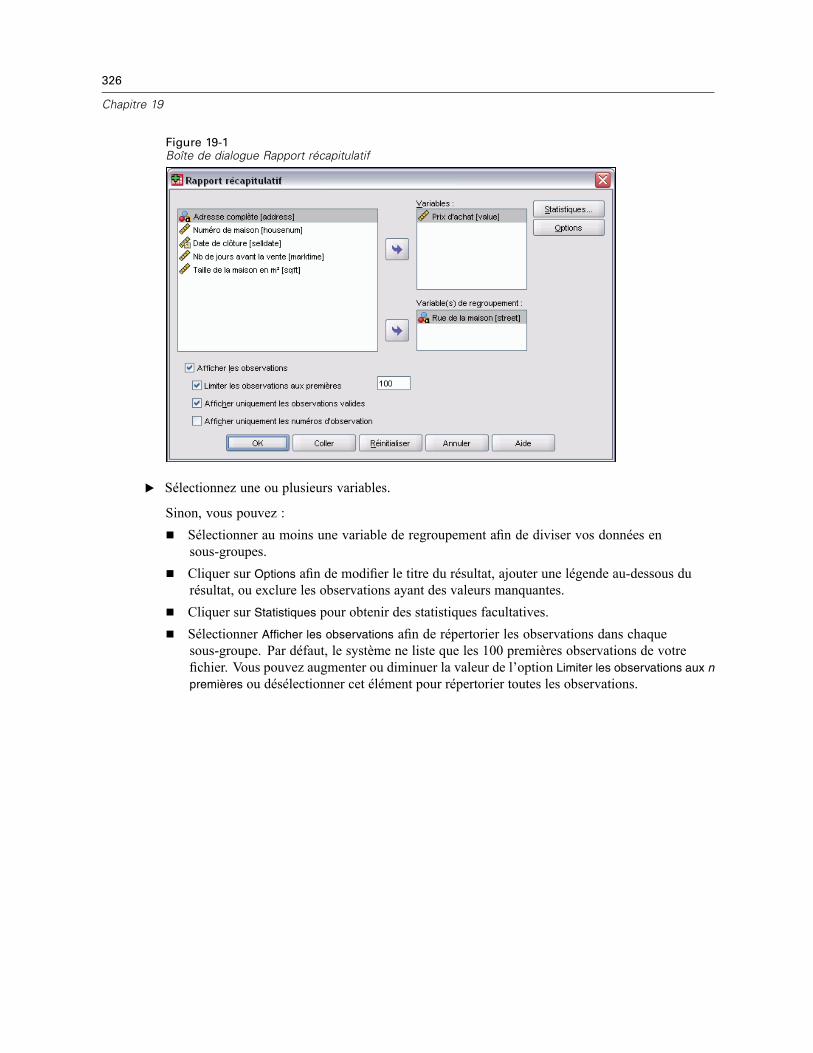
326
Chapitre 19
Figure 19-1Boîte de dialogue Rapport récapitulatif
E Sélectionnez une ou plusieurs variables.
Sinon, vous pouvez :Sélectionner au moins une variable de regroupement afin de diviser vos données ensous-groupes.Cliquer sur Options afin de modifier le titre du résultat, ajouter une légende au-dessous durésultat, ou exclure les observations ayant des valeurs manquantes.Cliquer sur Statistiques pour obtenir des statistiques facultatives.Sélectionner Afficher les observations afin de répertorier les observations dans chaquesous-groupe. Par défaut, le système ne liste que les 100 premières observations de votrefichier. Vous pouvez augmenter ou diminuer la valeur de l’option Limiter les observations aux npremières ou désélectionner cet élément pour répertorier toutes les observations.
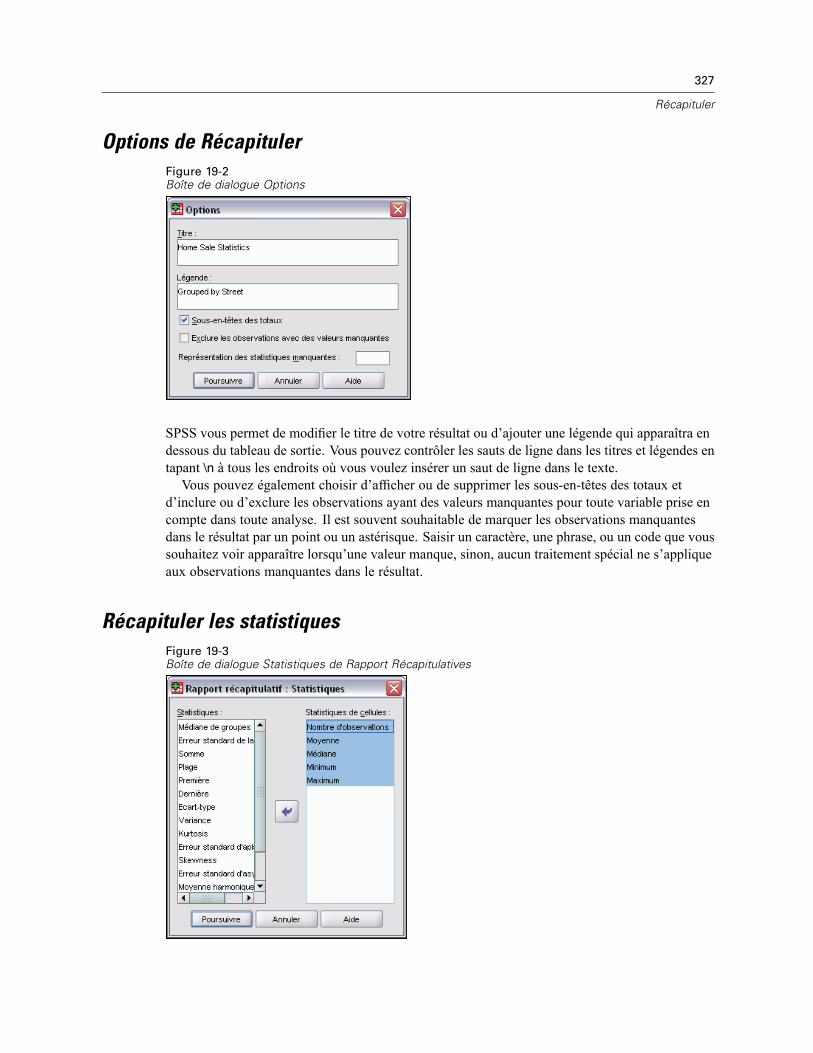
327
Récapituler
Options de RécapitulerFigure 19-2Boîte de dialogue Options
SPSS vous permet de modifier le titre de votre résultat ou d’ajouter une légende qui apparaîtra endessous du tableau de sortie. Vous pouvez contrôler les sauts de ligne dans les titres et légendes entapant \n à tous les endroits où vous voulez insérer un saut de ligne dans le texte.Vous pouvez également choisir d’afficher ou de supprimer les sous-en-têtes des totaux et
d’inclure ou d’exclure les observations ayant des valeurs manquantes pour toute variable prise encompte dans toute analyse. Il est souvent souhaitable de marquer les observations manquantesdans le résultat par un point ou un astérisque. Saisir un caractère, une phrase, ou un code que voussouhaitez voir apparaître lorsqu’une valeur manque, sinon, aucun traitement spécial ne s’appliqueaux observations manquantes dans le résultat.
Récapituler les statistiquesFigure 19-3Boîte de dialogue Statistiques de Rapport Récapitulatives

328
Chapitre 19
Vous pouvez choisir l’une des statistiques de sous-groupe suivantes pour les variables à l’intérieurde chaque modalité de chacune des variables de regroupement : Somme, nombre d’observations,moyenne, médiane, médiane groupée, erreur standard pour la moyenne, minimum, maximum,intervalle, valeur de la variable pour la première modalité de la variable de regroupement,valeur de la variable pour la dernière modalité de la variable de regroupement, écart-type,variance, aplatissement, erreur standard d’aplatissement, asymétrie, erreur standard d’asymétrie,pourcentage de somme totale, pourcentage de N total, pourcentage de la somme dans, pourcentagede N dans, moyenne géométrique, moyenne harmonique. L’ordre dans lequel les statistiquesapparaissent dans la liste Variables correspond à celui dans lequel elles seront affichées dansle résultat. Les statistiques récapitulatives sont aussi affichées pour chaque variable à traverstoutes les modalités.
Première. Affiche la première valeur rencontrée dans le fichier de données.
Moyenne géométrique. Racine nième du produit des valeurs de données, n représentant le nombred'observations.
Médiane de groupes. Médiane calculée pour les données codées dans des groupes. Par exemple,pour les données d'âge, si chaque valeur de la trentaine est codée 35, chaque valeur de laquarantaine est codée 45, etc., la médiane de groupes est la médiane calculée à partir des donnéescodées.
Moyenne harmonique. Fonction utilisée pour estimer la taille moyenne d'un groupe lorsque la tailledes échantillons diffère d'un groupe à l'autre. La moyenne harmonique correspond au nombre totald'échantillons divisé par la somme des réciproques des tailles de l'échantillon.
Aplatissement. Mesure de l'étendue du regroupement des observations autour d'un point central.Dans le cas d'une distribution normale, la valeur de la statistique d'aplatissement est égale àzéro. Un aplatissement positif indique que les observations sont plus regroupées et présententdes extrémités plus longues que dans le cas d'une distribution normale. Un aplatissement négatifsignifie que les observations sont moins regroupées et présentent des extrémités plus courtes.
Dernière. Affiche la dernière valeur rencontrée dans le fichier de données.
Maximum. Plus grande valeur d'une variable numérique.
Moyenne. Mesure de la tendance centrale. Moyenne arithmétique ; somme divisée par le nombred'observations.
Médiane. Valeur au‑dessus ou au‑dessous de laquelle se trouvent la moitié des observations ; 50ecentile. Si le nombre d'observations est pair, la médiane correspond à la moyenne des deuxobservations du milieu lorsqu'elles sont triées dans l'ordre croissant ou décroissant. La médianeest une mesure de tendance centrale et elle n'est pas, à l'inverse de la moyenne, sensible auxvaleurs éloignées.
Minimum. Valeur la plus petite d'une variable numérique.
Nombre d'observations. Nombre d'observations (ou d'enregistrements).
Pourcentage de N total. Pourcentage du nombre total d'observations dans chaque modalité.
Pourcentage de la somme totale. Pourcentage de la somme totale dans chaque modalité.
Etendue. Différence entre la valeur maximale et la valeur minimale d'une variable numérique(maximum–minimum).

329
Récapituler
Asymétrie. Mesure de l'asymétrie d'une distribution. La distribution normale est symétrique etpossède une valeur d'asymétrie égale à 0. Une distribution dont la valeur d'asymétrie est positiveprésente une extrémité droite allongée. Une distribution caractérisée par une importante asymétrienégative présente une extrémité gauche plus allongée. Pour simplifier, une valeur d'asymétriedeux fois supérieure à l'erreur standard correspond à une absence de symétrie.
Erreur standard du Kurtosis. Le rapport de l'aplatissement à son erreur standard peut servir de testde normalité (il y a anormalité si ce rapport est inférieur à ‑2 ou supérieur à +2). Une valeurd'aplatissement positive importante indique que les extrémités de la distribution sont plusallongées que celles d'une distribution normale ; une valeur d'aplatissement négative présente desextrémités plus courtes (semblables à celles d'une distribution uniforme sous forme de boîtes).
Erreur standard du Skewness. Rapport de l'asymétrie avec son erreur standard, qui peut servir detest de normalité (il y a anormalité si ce rapport est inférieur à ‑2 ou supérieur à +2). Une valeurd'asymétrie positive importante indique une extrémité allongée vers la droite ; une valeur négativeextrême produit une extrémité allongée vers la gauche.
Somme. Somme ou total des valeurs, pour toutes les observations n'ayant pas de valeur manquante.
Variance. Mesure de dispersion autour de la moyenne, égale à la somme des carrés des écarts parrapport à la moyenne, divisée par le nombre d'observations moins un. La variance se mesure enunités, qui sont égales au carré des unités de la variable.

Chapitre
20Moyenne
La procédure des moyennes calcule les moyennes de sous-groupes et les statistiques univariéescorrespondantes pour des variables dépendantes au sein des modalités d’une ou de plusieursvariables indépendantes. Vous pouvez également obtenir une analyse à un facteur de la variance,un coefficient êta et des tests de linéarité.
Exemple : Mesurez la quantité moyenne de lipides absorbée par trois différents types d’huilealimentaire et effectuez une analyse à un facteur de la variance pour voir si les moyennes divergent.
Statistiques : Somme, nombre d’observations, moyenne, médiane, médiane groupée, erreurstandard pour la moyenne, minimum, maximum, plage, valeur de la variable pour la premièremodalité de la variable de regroupement, valeur de la variable pour la dernière modalité de lavariable de regroupement, écart-type, variance, aplatissement, erreur standard d’aplatissement,asymétrie, erreur standard d’asymétrie, pourcentage de la somme totale, pourcentage de N total,pourcentage de la somme dans, pourcentage de N dans, moyennes géométrique et harmonique.Les options comportent une analyse de la variance, un coefficient êta, un coefficient êta-carré,ainsi que des tests de linéarité R et R2.
Données : Les variables dépendantes sont quantitatives et les variables indépendantes sontqualitatives. Les valeurs des variables qualitatives peuvent être soit numériques, soit des chaînes.
Hypothèses : Certains des sous-groupes statistiques optionnels, tels que la moyenne et l’écart-typesont basés sur la théorie normale et conviennent aux variables quantitatives ayant une distributionsymétrique. Les statistiques robustes, telles que la médiane, conviennent aux variables continuesqui confirment ou infirment l’hypothèse de normalité. L’analyse de la variance résiste aux écartspar rapport à la normalité, à condition que les données de chaque cellule soient symétriques.L’analyse de la variance part également du principe que les groupes sont issus de populationsayant la même variance. Pour vérifier cette hypothèse, utilisez le test d’homogénéité de la variancede Levene, disponible dans la procédure ANOVA à un facteur.
Pour obtenir des moyennes de sous-groupes
E A partir des menus, sélectionnez :Analyse
Comparer les moyennesMoyennes
330
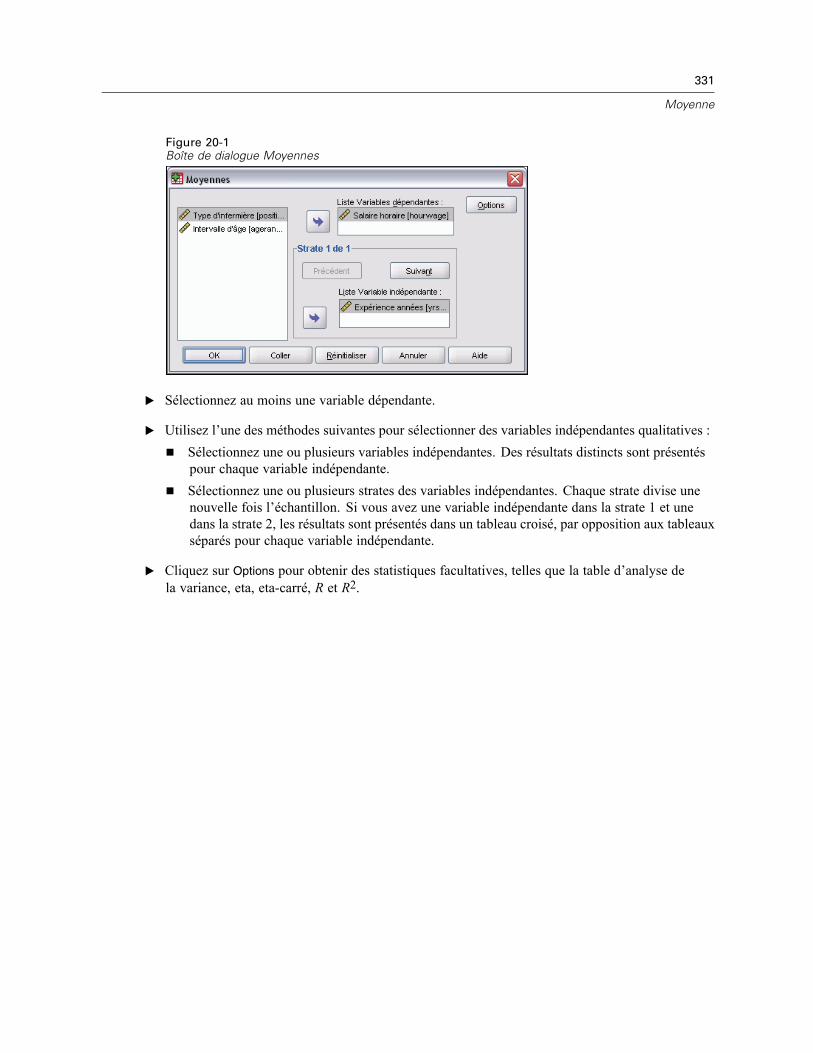
331
Moyenne
Figure 20-1Boîte de dialogue Moyennes
E Sélectionnez au moins une variable dépendante.
E Utilisez l’une des méthodes suivantes pour sélectionner des variables indépendantes qualitatives :Sélectionnez une ou plusieurs variables indépendantes. Des résultats distincts sont présentéspour chaque variable indépendante.Sélectionnez une ou plusieurs strates des variables indépendantes. Chaque strate divise unenouvelle fois l’échantillon. Si vous avez une variable indépendante dans la strate 1 et unedans la strate 2, les résultats sont présentés dans un tableau croisé, par opposition aux tableauxséparés pour chaque variable indépendante.
E Cliquez sur Options pour obtenir des statistiques facultatives, telles que la table d’analyse dela variance, eta, eta-carré, R et R2.
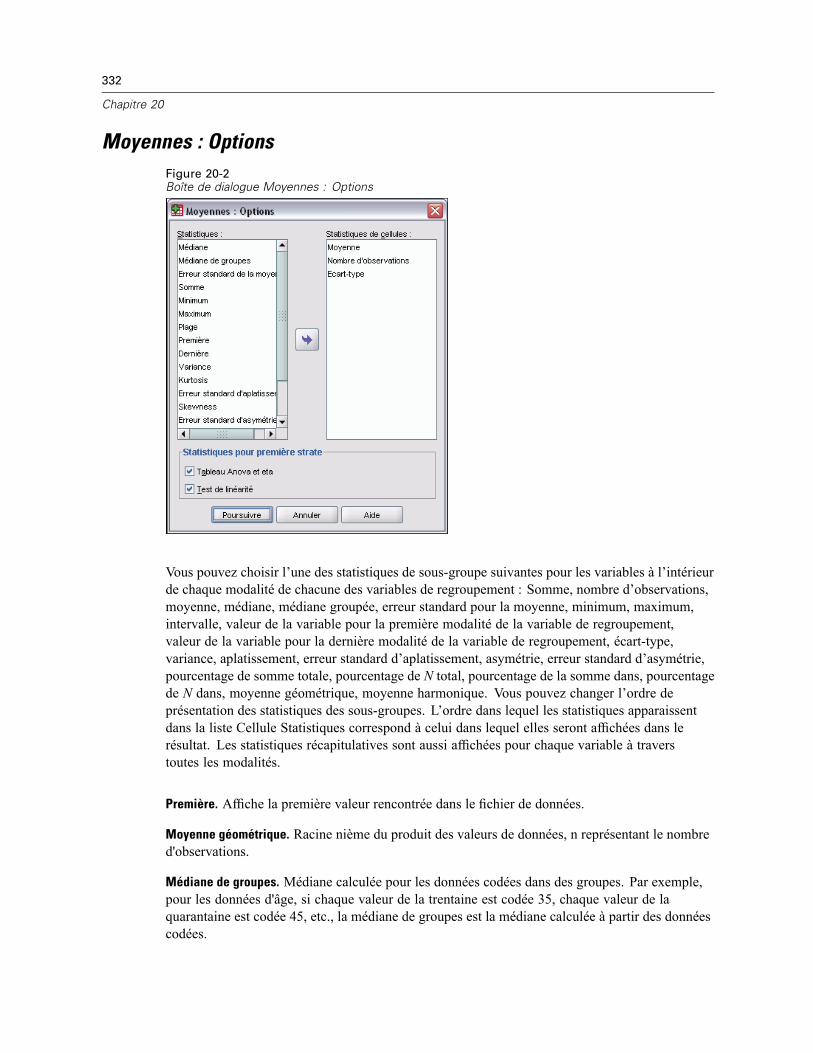
332
Chapitre 20
Moyennes : OptionsFigure 20-2Boîte de dialogue Moyennes : Options
Vous pouvez choisir l’une des statistiques de sous-groupe suivantes pour les variables à l’intérieurde chaque modalité de chacune des variables de regroupement : Somme, nombre d’observations,moyenne, médiane, médiane groupée, erreur standard pour la moyenne, minimum, maximum,intervalle, valeur de la variable pour la première modalité de la variable de regroupement,valeur de la variable pour la dernière modalité de la variable de regroupement, écart-type,variance, aplatissement, erreur standard d’aplatissement, asymétrie, erreur standard d’asymétrie,pourcentage de somme totale, pourcentage de N total, pourcentage de la somme dans, pourcentagede N dans, moyenne géométrique, moyenne harmonique. Vous pouvez changer l’ordre deprésentation des statistiques des sous-groupes. L’ordre dans lequel les statistiques apparaissentdans la liste Cellule Statistiques correspond à celui dans lequel elles seront affichées dans lerésultat. Les statistiques récapitulatives sont aussi affichées pour chaque variable à traverstoutes les modalités.
Première. Affiche la première valeur rencontrée dans le fichier de données.
Moyenne géométrique. Racine nième du produit des valeurs de données, n représentant le nombred'observations.
Médiane de groupes. Médiane calculée pour les données codées dans des groupes. Par exemple,pour les données d'âge, si chaque valeur de la trentaine est codée 35, chaque valeur de laquarantaine est codée 45, etc., la médiane de groupes est la médiane calculée à partir des donnéescodées.

333
Moyenne
Moyenne harmonique. Fonction utilisée pour estimer la taille moyenne d'un groupe lorsque la tailledes échantillons diffère d'un groupe à l'autre. La moyenne harmonique correspond au nombre totald'échantillons divisé par la somme des réciproques des tailles de l'échantillon.
Aplatissement. Mesure de l'étendue du regroupement des observations autour d'un point central.Dans le cas d'une distribution normale, la valeur de la statistique d'aplatissement est égale àzéro. Un aplatissement positif indique que les observations sont plus regroupées et présententdes extrémités plus longues que dans le cas d'une distribution normale. Un aplatissement négatifsignifie que les observations sont moins regroupées et présentent des extrémités plus courtes.
Dernière. Affiche la dernière valeur rencontrée dans le fichier de données.
Maximum. Plus grande valeur d'une variable numérique.
Moyenne. Mesure de la tendance centrale. Moyenne arithmétique ; somme divisée par le nombred'observations.
Médiane. Valeur au‑dessus ou au‑dessous de laquelle se trouvent la moitié des observations ; 50ecentile. Si le nombre d'observations est pair, la médiane correspond à la moyenne des deuxobservations du milieu lorsqu'elles sont triées dans l'ordre croissant ou décroissant. La médianeest une mesure de tendance centrale et elle n'est pas, à l'inverse de la moyenne, sensible auxvaleurs éloignées.
Minimum. Valeur la plus petite d'une variable numérique.
Nombre d'observations. Nombre d'observations (ou d'enregistrements).
Pourcentage de N total. Pourcentage du nombre total d'observations dans chaque modalité.
Pourcentage de N total. Pourcentage de la somme totale dans chaque modalité.
Etendue. Différence entre la valeur maximale et la valeur minimale d'une variable numérique(maximum–minimum).
Asymétrie. Mesure de l'asymétrie d'une distribution. La distribution normale est symétrique etpossède une valeur d'asymétrie égale à 0. Une distribution dont la valeur d'asymétrie est positiveprésente une extrémité droite allongée. Une distribution caractérisée par une importante asymétrienégative présente une extrémité gauche plus allongée. Pour simplifier, une valeur d'asymétriedeux fois supérieure à l'erreur standard correspond à une absence de symétrie.
Erreur standard du Kurtosis. Le rapport de l'aplatissement à son erreur standard peut servir de testde normalité (il y a anormalité si ce rapport est inférieur à ‑2 ou supérieur à +2). Une valeurd'aplatissement positive importante indique que les extrémités de la distribution sont plusallongées que celles d'une distribution normale ; une valeur d'aplatissement négative présente desextrémités plus courtes (semblables à celles d'une distribution uniforme sous forme de boîtes).
Erreur standard du Skewness. Rapport de l'asymétrie avec son erreur standard, qui peut servir detest de normalité (il y a anormalité si ce rapport est inférieur à ‑2 ou supérieur à +2). Une valeurd'asymétrie positive importante indique une extrémité allongée vers la droite ; une valeur négativeextrême produit une extrémité allongée vers la gauche.
Somme. Somme ou total des valeurs, pour toutes les observations n'ayant pas de valeur manquante.
Variance. Mesure de dispersion autour de la moyenne, égale à la somme des carrés des écarts parrapport à la moyenne, divisée par le nombre d'observations moins un. La variance se mesure enunités, qui sont égales au carré des unités de la variable.

334
Chapitre 20
Statistiques pour première strate
Tableau Anova et eta. Affiche un tableau d'analyse unifactorielle de la variance et calcule êta et êtacarré (mesures de l'association) pour chaque variable indépendante de la première couche.
Test de linéarité. Calcule la somme des carrés, les degrés de liberté et le carré moyen associés auxcomposants linéaires et non linéaires, ainsi que le rapport F, le R et le R-deux. La linéarité n'estpas calculée si la variable indépendante est une chaîne courte.

Chapitre
21Cubes OLAP
La procédure de Cubes OLAP (Online Analytical Processing) calcule les totaux, les moyennes etautres statistiques univariées pour des variables récapitulatives continues à l’intérieur de modalitésd’une ou plusieurs variables de regroupement qualitatives. Une strate séparée dans le tableau estcréée pour chaque modalité de chaque variable de regroupement.
Exemple : Ventes totales et moyennes pour différentes régions et lignes de produits à l’intérieur dechaque région.
Statistiques : Somme, nombre d’observations, moyenne, médiane, médiane groupée, erreurstandard pour la moyenne, minimum, maximum, intervalle, valeur de la variable pour la premièremodalité de la variable de regroupement, valeur de la variable pour la dernière modalité de lavariable de regroupement, écart-type, variance, aplatissement, erreur standard d’aplatissement,asymétrie, erreur standard d’asymétrie, pourcentage des observations totales, pourcentagede somme totale, pourcentage des observations totales dans les variables de regroupement,pourcentage de la somme totale dans les variables de regroupement, moyenne géométrique etmoyenne harmonique.
Données : Les variables récapitulatives sont quantitatives (variables continues mesurées sur uneéchelle d’intervalle ou de rapport) et les variables de regroupement sont qualitatives. Les valeursdes variables qualitatives peuvent être soit numériques, soit des chaînes.
Hypothèses : Certains des sous-groupes statistiques optionnels, tels que la moyenne et l’écart-typesont basés sur la théorie normale et conviennent aux variables quantitatives ayant une distributionsymétrique. Les statistiques robustes telles que la médiane et l’intervalle, conviennent auxvariables quantitatives qui confirment ou infirment l’hypothèse de normalité.
Pour obtenir des cubes OLAP
E A partir des menus, sélectionnez :Analyse
RapportsCubes OLAP
335
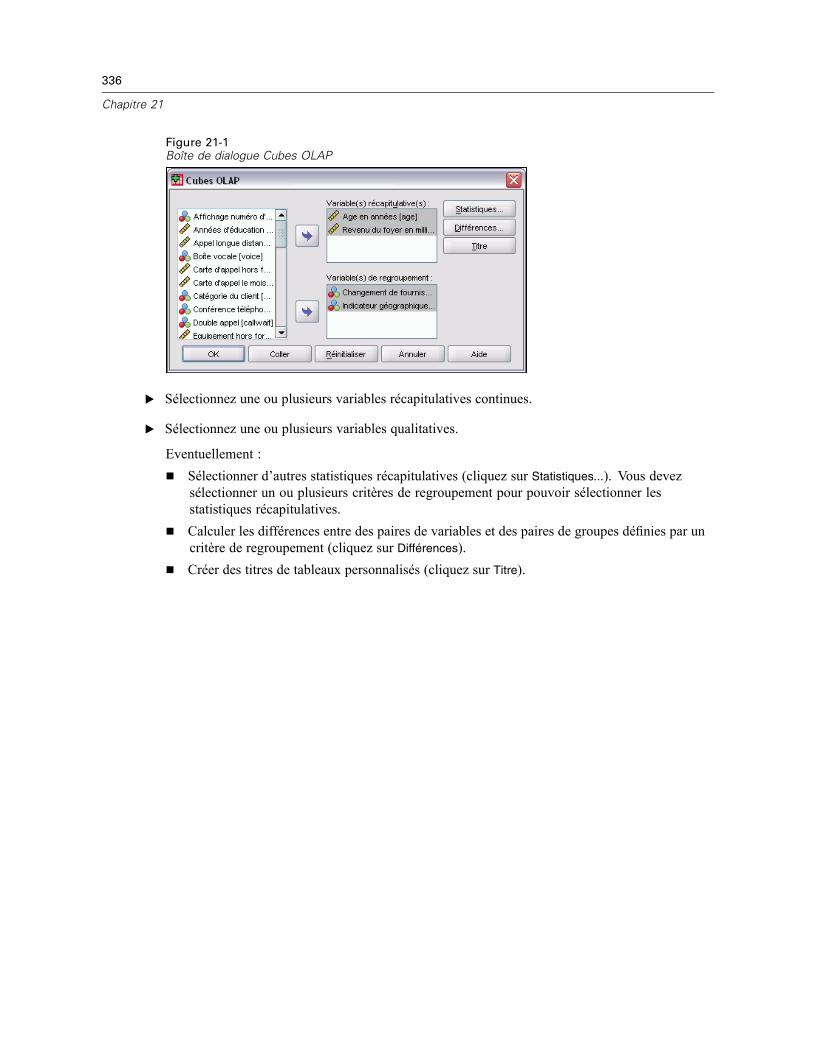
336
Chapitre 21
Figure 21-1Boîte de dialogue Cubes OLAP
E Sélectionnez une ou plusieurs variables récapitulatives continues.
E Sélectionnez une ou plusieurs variables qualitatives.
Eventuellement :Sélectionner d’autres statistiques récapitulatives (cliquez sur Statistiques...). Vous devezsélectionner un ou plusieurs critères de regroupement pour pouvoir sélectionner lesstatistiques récapitulatives.Calculer les différences entre des paires de variables et des paires de groupes définies par uncritère de regroupement (cliquez sur Différences).Créer des titres de tableaux personnalisés (cliquez sur Titre).
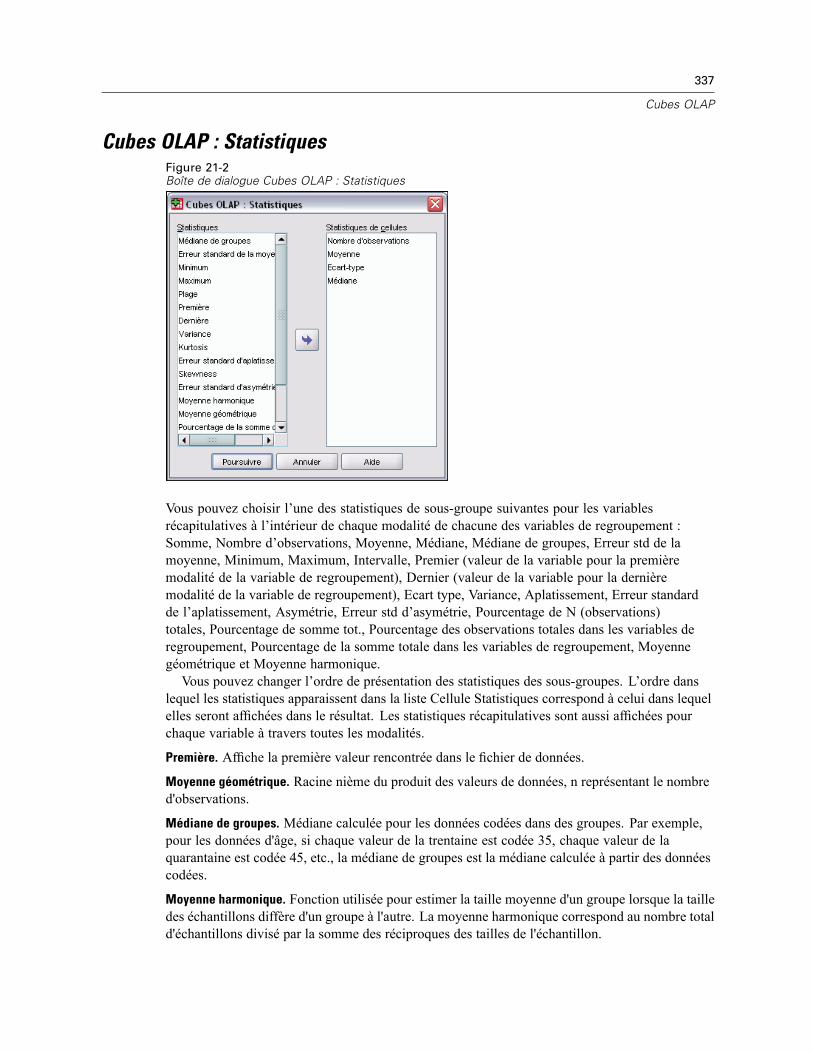
337
Cubes OLAP
Cubes OLAP : StatistiquesFigure 21-2Boîte de dialogue Cubes OLAP : Statistiques
Vous pouvez choisir l’une des statistiques de sous-groupe suivantes pour les variablesrécapitulatives à l’intérieur de chaque modalité de chacune des variables de regroupement :Somme, Nombre d’observations, Moyenne, Médiane, Médiane de groupes, Erreur std de lamoyenne, Minimum, Maximum, Intervalle, Premier (valeur de la variable pour la premièremodalité de la variable de regroupement), Dernier (valeur de la variable pour la dernièremodalité de la variable de regroupement), Ecart type, Variance, Aplatissement, Erreur standardde l’aplatissement, Asymétrie, Erreur std d’asymétrie, Pourcentage de N (observations)totales, Pourcentage de somme tot., Pourcentage des observations totales dans les variables deregroupement, Pourcentage de la somme totale dans les variables de regroupement, Moyennegéométrique et Moyenne harmonique.Vous pouvez changer l’ordre de présentation des statistiques des sous-groupes. L’ordre dans
lequel les statistiques apparaissent dans la liste Cellule Statistiques correspond à celui dans lequelelles seront affichées dans le résultat. Les statistiques récapitulatives sont aussi affichées pourchaque variable à travers toutes les modalités.
Première. Affiche la première valeur rencontrée dans le fichier de données.
Moyenne géométrique. Racine nième du produit des valeurs de données, n représentant le nombred'observations.
Médiane de groupes. Médiane calculée pour les données codées dans des groupes. Par exemple,pour les données d'âge, si chaque valeur de la trentaine est codée 35, chaque valeur de laquarantaine est codée 45, etc., la médiane de groupes est la médiane calculée à partir des donnéescodées.
Moyenne harmonique. Fonction utilisée pour estimer la taille moyenne d'un groupe lorsque la tailledes échantillons diffère d'un groupe à l'autre. La moyenne harmonique correspond au nombre totald'échantillons divisé par la somme des réciproques des tailles de l'échantillon.

338
Chapitre 21
Aplatissement. Mesure de l'étendue du regroupement des observations autour d'un point central.Dans le cas d'une distribution normale, la valeur de la statistique d'aplatissement est égale àzéro. Un aplatissement positif indique que les observations sont plus regroupées et présententdes extrémités plus longues que dans le cas d'une distribution normale. Un aplatissement négatifsignifie que les observations sont moins regroupées et présentent des extrémités plus courtes.
Dernière. Affiche la dernière valeur rencontrée dans le fichier de données.
Maximum. Plus grande valeur d'une variable numérique.
Moyenne. Mesure de la tendance centrale. Moyenne arithmétique ; somme divisée par le nombred'observations.
Médiane. Valeur au‑dessus ou au‑dessous de laquelle se trouvent la moitié des observations ; 50ecentile. Si le nombre d'observations est pair, la médiane correspond à la moyenne des deuxobservations du milieu lorsqu'elles sont triées dans l'ordre croissant ou décroissant. La médianeest une mesure de tendance centrale et elle n'est pas, à l'inverse de la moyenne, sensible auxvaleurs éloignées.
Minimum. Valeur la plus petite d'une variable numérique.
Nombre d'observations. Nombre d'observations (ou d'enregistrements).
Pourcentage de N dans. Pourcentage du nombre d'observations pour le critère de regroupementspécifié dans les modalités des autres critères de regroupement. Si vous n'avez qu'un seul critèrede regroupement, cette valeur est identique au pourcentage du nombre total d'observations.
Pourcentage de la somme dans. Pourcentage de la somme de la variable de regroupement définiedans les modalités des autres variables de regroupement. Si vous n'avez qu'un seul critère deregroupement, cette valeur est identique au pourcentage de la somme totale.
Pourcentage de N total. Pourcentage du nombre total d'observations dans chaque modalité.
Pourcentage de la somme totale. Pourcentage de la somme totale dans chaque modalité.
Etendue. Différence entre la valeur maximale et la valeur minimale d'une variable numérique(maximum–minimum).
Asymétrie. Mesure de l'asymétrie d'une distribution. La distribution normale est symétrique etpossède une valeur d'asymétrie égale à 0. Une distribution dont la valeur d'asymétrie est positiveprésente une extrémité droite allongée. Une distribution caractérisée par une importante asymétrienégative présente une extrémité gauche plus allongée. Pour simplifier, une valeur d'asymétriedeux fois supérieure à l'erreur standard correspond à une absence de symétrie.
Erreur standard du Kurtosis. Le rapport de l'aplatissement à son erreur standard peut servir de testde normalité (il y a anormalité si ce rapport est inférieur à ‑2 ou supérieur à +2). Une valeurd'aplatissement positive importante indique que les extrémités de la distribution sont plusallongées que celles d'une distribution normale ; une valeur d'aplatissement négative présente desextrémités plus courtes (semblables à celles d'une distribution uniforme sous forme de boîtes).
Erreur standard du Skewness. Rapport de l'asymétrie avec son erreur standard, qui peut servir detest de normalité (il y a anormalité si ce rapport est inférieur à ‑2 ou supérieur à +2). Une valeurd'asymétrie positive importante indique une extrémité allongée vers la droite ; une valeur négativeextrême produit une extrémité allongée vers la gauche.
Somme. Somme ou total des valeurs, pour toutes les observations n'ayant pas de valeur manquante.
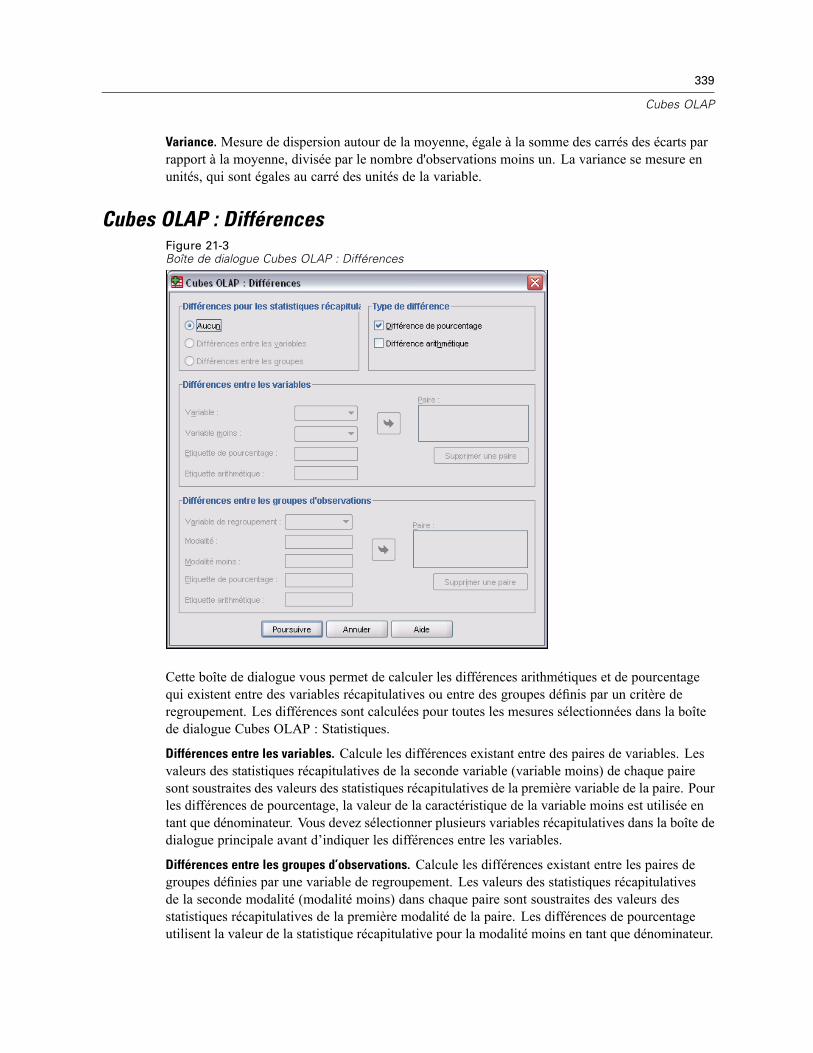
339
Cubes OLAP
Variance. Mesure de dispersion autour de la moyenne, égale à la somme des carrés des écarts parrapport à la moyenne, divisée par le nombre d'observations moins un. La variance se mesure enunités, qui sont égales au carré des unités de la variable.
Cubes OLAP : DifférencesFigure 21-3Boîte de dialogue Cubes OLAP : Différences
Cette boîte de dialogue vous permet de calculer les différences arithmétiques et de pourcentagequi existent entre des variables récapitulatives ou entre des groupes définis par un critère deregroupement. Les différences sont calculées pour toutes les mesures sélectionnées dans la boîtede dialogue Cubes OLAP : Statistiques.
Différences entre les variables. Calcule les différences existant entre des paires de variables. Lesvaleurs des statistiques récapitulatives de la seconde variable (variable moins) de chaque pairesont soustraites des valeurs des statistiques récapitulatives de la première variable de la paire. Pourles différences de pourcentage, la valeur de la caractéristique de la variable moins est utilisée entant que dénominateur. Vous devez sélectionner plusieurs variables récapitulatives dans la boîte dedialogue principale avant d’indiquer les différences entre les variables.
Différences entre les groupes d’observations. Calcule les différences existant entre les paires degroupes définies par une variable de regroupement. Les valeurs des statistiques récapitulativesde la seconde modalité (modalité moins) dans chaque paire sont soustraites des valeurs desstatistiques récapitulatives de la première modalité de la paire. Les différences de pourcentageutilisent la valeur de la statistique récapitulative pour la modalité moins en tant que dénominateur.
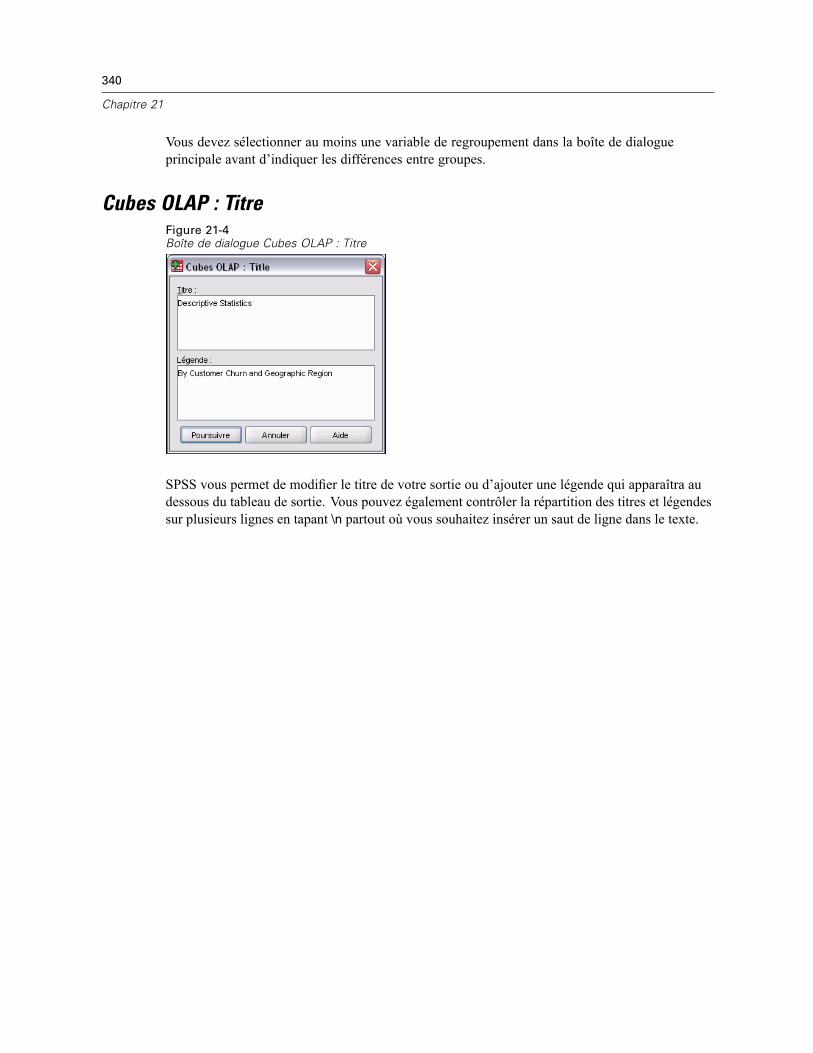
340
Chapitre 21
Vous devez sélectionner au moins une variable de regroupement dans la boîte de dialogueprincipale avant d’indiquer les différences entre groupes.
Cubes OLAP : TitreFigure 21-4Boîte de dialogue Cubes OLAP : Titre
SPSS vous permet de modifier le titre de votre sortie ou d’ajouter une légende qui apparaîtra audessous du tableau de sortie. Vous pouvez également contrôler la répartition des titres et légendessur plusieurs lignes en tapant \n partout où vous souhaitez insérer un saut de ligne dans le texte.

Chapitre
22Tests T
Il existe trois types de test t :
Test T pour échantillons indépendants (test t pour deux échantillons) : Permet de comparer lamoyenne d’une variable de deux groupes d’observations. Les statistiques descriptives pourchaque groupe et le test de Levene permettant d’obtenir l’égalité des variances sont disponiblesainsi que les valeurs t de variance égale et inégale, et qu’un intervalle de confiance de 95 % pourla différence des moyennes.
Test T pour échantillons appariés (test t dépendant) : Permet de comparer la moyenne de deuxvariables pour un seul groupe. Ce test sert aussi pour les plans d’études appariées ou de contrôled’observation. Les résultat incluent les statistiques descriptives pour les variables de test, leurscorrélations, les statistiques descriptives pour les différences appariées, le test t et un intervalle deconfiance de 95 %.
Test T pour échantillon unique : Permet de comparer la moyenne d’une variable avec une valeurconnue ou supposée. Les statistiques descriptives des variables tests sont affichées avec le test t.Un intervalle de confiance de 95 % pour la différence entre la moyenne de la variable test et lavaleur test supposée fait partie du résultat par défaut.
Test T pour échantillons indépendants
La procédure du Test T pour échantillons indépendants permet de comparer la moyenne de deuxgroupes d’observations. Idéalement, pour ce test, les sujets doivent être attribués de manièrealéatoire à deux groupes, de manière à ce que toute différence dans la réponse soit due autraitement (ou à un manque de traitement) et non pas à d’autres facteurs. Ceci n’est pas le cassi l’on compare un revenu moyen pour les hommes et les femmes. Une personne n’est pasaléatoirement désignée comme devant être un homme ou une femme. Dans de telles situations,il faut s’assurer que les différences dans les autres facteurs ne cachent pas ou n’augmententde différence significative dans les moyennes. Les différences de revenu moyen peuvent êtreinfluencées par des facteurs tels que l’éducation et non par le sexe seul.
Exemple : Les patients souffrant d’hypertension se voient assignés de façon aléatoire à un groupeplacebo et à un groupe auquel on donne un traitement. Les sujets du groupe placebo reçoiventune pilule inactive et les sujets du groupe auquel on donne un traitement reçoivent un nouveaumédicament supposé réduire l’hypertension. Après que les sujets ont suivi le traitement pendantdeux mois, le test t pour deux échantillons est utilisé pour comparer la tension artérielle moyennedu groupe placebo à celle du groupe qui suit le traitement. Chaque patient est examiné une foiset appartient à un groupe.
341
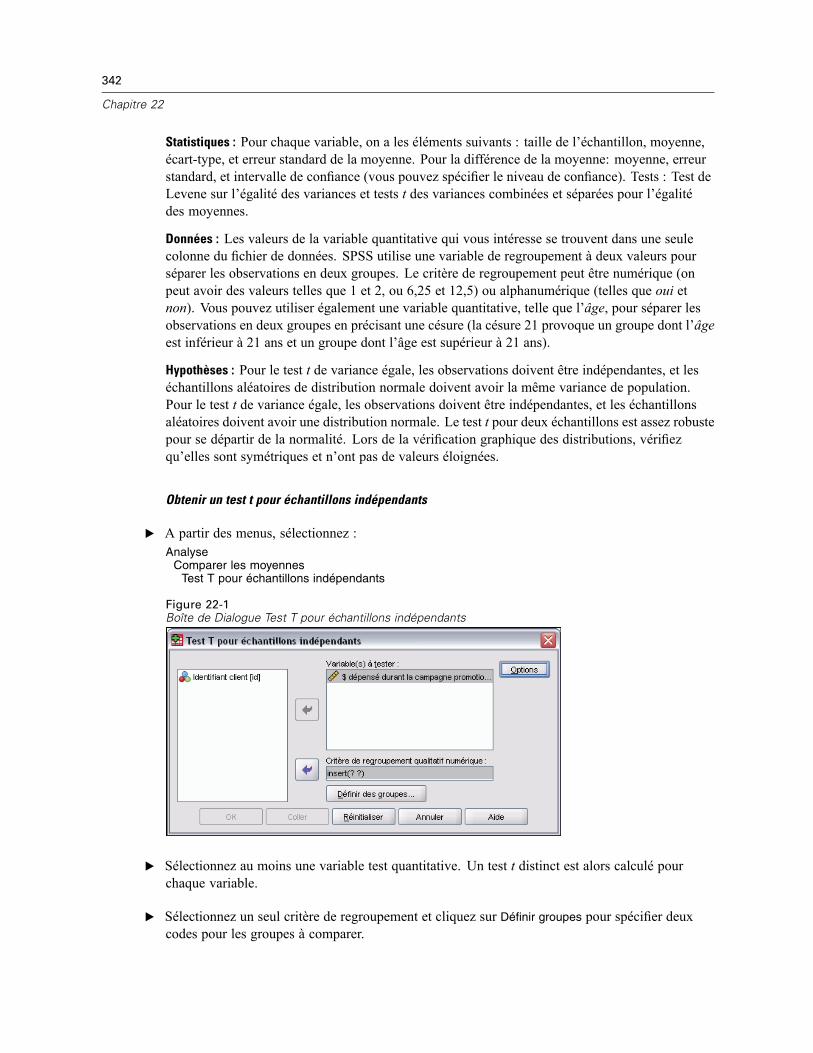
342
Chapitre 22
Statistiques : Pour chaque variable, on a les éléments suivants : taille de l’échantillon, moyenne,écart-type, et erreur standard de la moyenne. Pour la différence de la moyenne: moyenne, erreurstandard, et intervalle de confiance (vous pouvez spécifier le niveau de confiance). Tests : Test deLevene sur l’égalité des variances et tests t des variances combinées et séparées pour l’égalitédes moyennes.
Données : Les valeurs de la variable quantitative qui vous intéresse se trouvent dans une seulecolonne du fichier de données. SPSS utilise une variable de regroupement à deux valeurs pourséparer les observations en deux groupes. Le critère de regroupement peut être numérique (onpeut avoir des valeurs telles que 1 et 2, ou 6,25 et 12,5) ou alphanumérique (telles que oui etnon). Vous pouvez utiliser également une variable quantitative, telle que l’âge, pour séparer lesobservations en deux groupes en précisant une césure (la césure 21 provoque un groupe dont l’âgeest inférieur à 21 ans et un groupe dont l’âge est supérieur à 21 ans).
Hypothèses : Pour le test t de variance égale, les observations doivent être indépendantes, et leséchantillons aléatoires de distribution normale doivent avoir la même variance de population.Pour le test t de variance égale, les observations doivent être indépendantes, et les échantillonsaléatoires doivent avoir une distribution normale. Le test t pour deux échantillons est assez robustepour se départir de la normalité. Lors de la vérification graphique des distributions, vérifiezqu’elles sont symétriques et n’ont pas de valeurs éloignées.
Obtenir un test t pour échantillons indépendants
E A partir des menus, sélectionnez :Analyse
Comparer les moyennesTest T pour échantillons indépendants
Figure 22-1Boîte de Dialogue Test T pour échantillons indépendants
E Sélectionnez au moins une variable test quantitative. Un test t distinct est alors calculé pourchaque variable.
E Sélectionnez un seul critère de regroupement et cliquez sur Définir groupes pour spécifier deuxcodes pour les groupes à comparer.

343
Tests T
E Vous pouvez également cliquer sur Options pour contrôler le traitement des données manquantes etle niveau de l’intervalle de confiance.
Définir Groupes Test T pour Echantillons IndépendantsFigure 22-2Boîte de dialogue Définir groupes pour variables numériques
Pour les critères de regroupement numérique, définissez les deux groupes du test t en spécifiantdeux valeurs ou un point de séparation :
Utiliser les valeurs spécifiées : Saisissez une valeur pour le Groupe 1 et une autre pour leGroupe 2. Les observations qui ont une autre valeur sont exclues de l’analyse. Il n’est pasnécessaire que les nombres soient des entiers (par exemple, 6,25 et 12,5 sont valides).Césure : Vous avez également la possibilité de saisir un nombre qui sépare les valeurs dela variable de regroupement en deux groupes. Toutes les observations ayant des valeursinférieures à la césure constituent un groupe et les observations ayant des valeurs supérieuresou égales à la césure constituent l’autre groupe.
Figure 22-3Boîte de dialogue Définir Groupes pour les variables caractères
Pour les critères de regroupement alphanumériques, entrez une chaîne pour le Groupe 1 et uneautre pour le Groupe 2, par exemple oui et non. Les observations avec d’autres chaînes sontexclues de l’analyse.

344
Chapitre 22
Options Test T pour Echantillons IndépendantsFigure 22-4Boîte de dialogue Test T pour échantillons indépendants : Options
Intervalle de confiance : Par défaut, un intervalle de confiance de 95 % pour la différence dansles moyennes est affiché. Saisir une valeur comprise entre 1 et 99 pour demander un niveau deconfiance différent.
Valeurs manquantes : Quand vous testez plusieurs variables et que des données sont manquantespour au moins une variable, vous pouvez indiquer à la procédure les observations à inclure (ouexclure).
Exclure les observations analyse par analyse : Chaque test t utilise toutes les observations quiont des données valides pour les variables testées. La taille des échantillons peut varierd’un test à l’autre.Exclure toute observation incomplète : Chaque test t utilise seulement les observations qui ontdes données valides pour toutes les variables utilisées dans les tests t requis. La taille deséchantillons est constante durant les tests.
Test T pour échantillons appariés
La procédure du Test T pour Echantillons Appariés compare la moyenne de deux variables pourun seul groupe. Elle permet de calculer la différence de valeurs entre les deux variables pourchaque observation et de tester si la moyenne diffère de 0.
Exemple : Dans le cadre d’une étude sur l’hypertension, des mesures sont prises sur tous lespatients au début de l’étude, un traitement est administré, puis on procède à une nouvelle mesure.Par conséquent, chaque sujet est l’objet de deux mesures, souvent nommées mesures avant etaprès. Il existe une alternative à ce test, il s’agit d’une étude appariée ou de contrôle d’observationdans laquelle chaque déclaration dans le fichier de données contient la réponse du patient ainsique celle de son sujet de contrôle apparié. Dans le cadre d’une étude sur la tension artérielle,les patients et les contrôles peuvent être appariés selon l’âge (un patient âgé de 75 ans avec unmembre du groupe de contrôle âgé de 75 ans).
Statistiques : Pour chaque variable, on a les éléments suivants : moyenne, taille d’échantillon,écart-type, et erreur standard de la moyenne. Pour chaque paire de variables, on a les élémentssuivants : Corrélation, différence moyenne de moyennes, test t et intervalle de confiance pour ladifférence moyenne (vous pouvez préciser le niveau de confiance). Ecart-type et erreur standardde la différence moyenne.
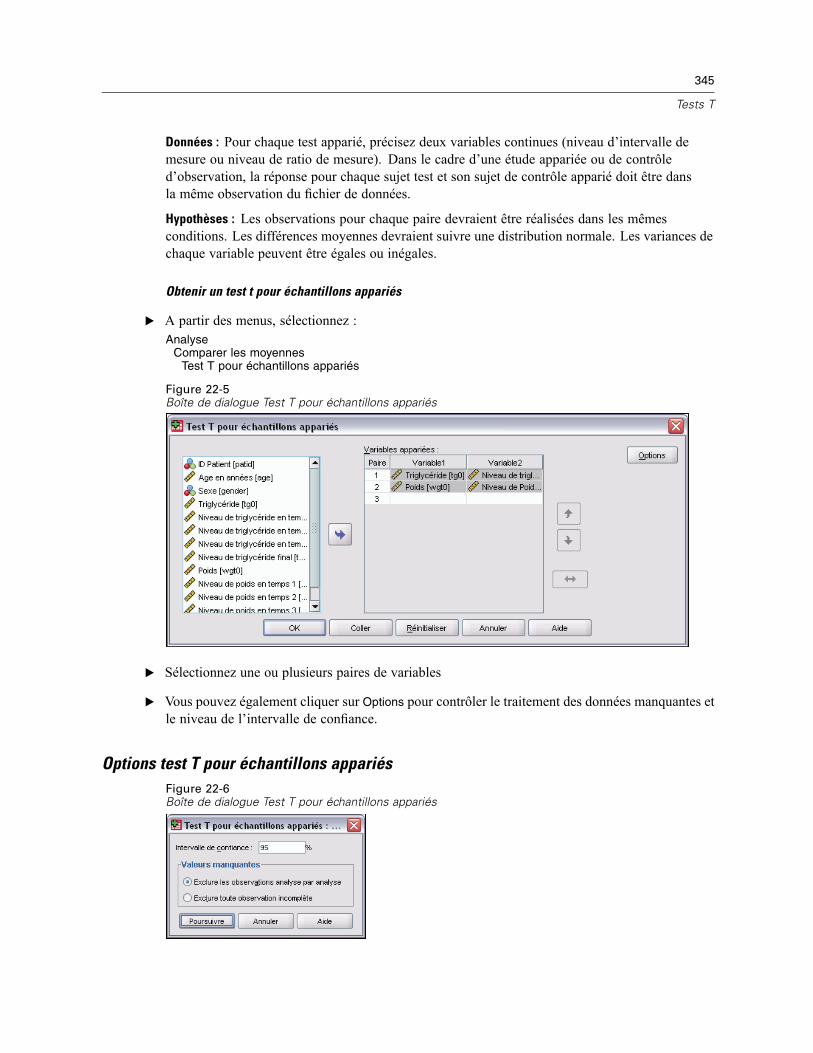
345
Tests T
Données : Pour chaque test apparié, précisez deux variables continues (niveau d’intervalle demesure ou niveau de ratio de mesure). Dans le cadre d’une étude appariée ou de contrôled’observation, la réponse pour chaque sujet test et son sujet de contrôle apparié doit être dansla même observation du fichier de données.
Hypothèses : Les observations pour chaque paire devraient être réalisées dans les mêmesconditions. Les différences moyennes devraient suivre une distribution normale. Les variances dechaque variable peuvent être égales ou inégales.
Obtenir un test t pour échantillons appariés
E A partir des menus, sélectionnez :Analyse
Comparer les moyennesTest T pour échantillons appariés
Figure 22-5Boîte de dialogue Test T pour échantillons appariés
E Sélectionnez une ou plusieurs paires de variables
E Vous pouvez également cliquer sur Options pour contrôler le traitement des données manquantes etle niveau de l’intervalle de confiance.
Options test T pour échantillons appariésFigure 22-6Boîte de dialogue Test T pour échantillons appariés

346
Chapitre 22
Intervalle de confiance : Par défaut, un intervalle de confiance de 95 % pour la différence dansles moyennes est affiché. Saisir une valeur comprise entre 1 et 99 pour demander un niveau deconfiance différent.
Valeurs manquantes : Quand vous testez plusieurs variables et que des données sont manquantespour au moins une variable, vous pouvez indiquer à SPSS les observations à inclure (ou exclure) :
Exclure les observations analyse par analyse : Chaque test t utilise toutes les observations quiont des données valides pour la paire de variables testées. La taille des échantillons peutvarier d’un test à l’autre.Exclure toute observation incomplète : Chaque test t utilise seulement les observations qui ontdes données valides pour toutes les paires de variables testées. La taille des échantillons estconstante durant les tests.
Test T pour échantillon unique
La procédure du Test T pour échantillon unique permet de tester si la moyenne d’une seulevariable diffère d’une constante spécifiée.
Exemples : Un chercheur souhaite tester si le QI moyen d’un groupe d’étudiants diffère de 100. Unfabricant céréalier prélève un échantillon de boîtes à partir d’une chaîne de production et vérifie sile poids moyen des échantillons diffère de 1,3 livres à l’intervalle de confiance 95 %.
Statistiques : Pour chaque variable test : moyenne, écart-type, et erreur standard de la moyenne.Différence moyenne entre chaque valeur de donnée et la valeur test supposée, le test t vérifie quecette différence est égale à 0 et vérifie également l’intervalle de confiance pour cette différence(vous pouvez préciser le niveau de confiance).
Données : Afin de tester les valeurs d’une variable quantitative par rapport à une valeur testsupposée, choisissez une variable quantitative et saisissez une valeur test supposée.
Hypothèses : Ce test suppose que les données sont distribuées normalement ; cependant, ce testrésiste convenablement à la normalité.
Obtenir un test t pour échantillon unique
E A partir des menus, sélectionnez :Analyse
Comparer les moyennesTest T pour échantillon unique
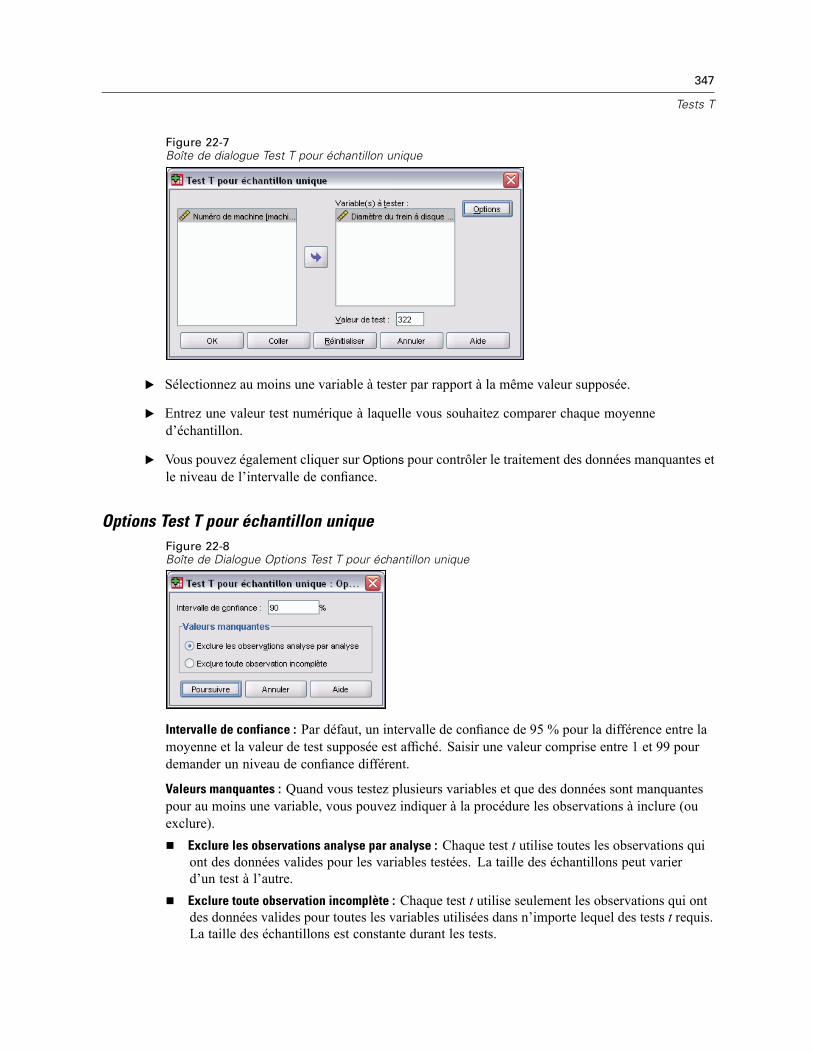
347
Tests T
Figure 22-7Boîte de dialogue Test T pour échantillon unique
E Sélectionnez au moins une variable à tester par rapport à la même valeur supposée.
E Entrez une valeur test numérique à laquelle vous souhaitez comparer chaque moyenned’échantillon.
E Vous pouvez également cliquer sur Options pour contrôler le traitement des données manquantes etle niveau de l’intervalle de confiance.
Options Test T pour échantillon uniqueFigure 22-8Boîte de Dialogue Options Test T pour échantillon unique
Intervalle de confiance : Par défaut, un intervalle de confiance de 95 % pour la différence entre lamoyenne et la valeur de test supposée est affiché. Saisir une valeur comprise entre 1 et 99 pourdemander un niveau de confiance différent.
Valeurs manquantes : Quand vous testez plusieurs variables et que des données sont manquantespour au moins une variable, vous pouvez indiquer à la procédure les observations à inclure (ouexclure).
Exclure les observations analyse par analyse : Chaque test t utilise toutes les observations quiont des données valides pour les variables testées. La taille des échantillons peut varierd’un test à l’autre.Exclure toute observation incomplète : Chaque test t utilise seulement les observations qui ontdes données valides pour toutes les variables utilisées dans n’importe lequel des tests t requis.La taille des échantillons est constante durant les tests.

348
Chapitre 22
Fonctionnalités supplémentaires de la commande T-TEST
Le langage de syntaxe de commande vous permet aussi de :Produire à la fois des tests t pour un échantillon et pour des écahntillons indépendants enexécutant une commande unique.Tester une variable avec chacune des variables d’une liste dans un test t apparié (avec lasous-commande PAIRS).
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.

Chapitre
23ANOVA à 1 facteur
La procédure de l’analyse de variance ANOVA à 1 facteur permet d’effectuer une analysede variance univariée sur une variable quantitative dépendante par une variable critère simple(indépendant). L’analyse de variance sert à tester l’hypothèse d’égalité des moyennes. Cettetechnique est une extension du test t pour deux échantillons.Déterminer que des différences existent parmi les moyennes ne vous suffit peut-être pas.
Vous voulez éventuellement savoir quelles sont les moyennes qui diffèrent. Il existe deux typesde tests pour comparer les moyennes : les contrastes a priori et les tests post hoc. Les contrastessont des tests définis avant l’expérience, et les tests post hoc sont effectués après l’expérience.Vous pouvez aussi tester les tendances à travers les modalités.
Exemple : Les beignets absorbent la graisse dans des proportions variées lorsqu’ils sont cuisinés.Une expérience est conduite à partir de l’utilisation de trois types de graisse : huile d’arachide,huile de maïs, et saindoux. L’huile d’arachide et l’huile de maïs sont des graisses non saturées, etle saindoux une graisse saturée. Non seulement vous déterminez si la quantité de graisse absorbéedépend du type de graisse utilisée, mais vous pouvez également créer un contraste a priori afin dedéterminer si le degré d’absorption de graisse diffère pour les graisses saturées et non saturées.
Statistiques : Pour chaque groupe : nombre d’observations, moyenne, écart type, erreur standardpour la moyenne, minimum, maximum et intervalle de confiance à 95 % pour la moyenne. Testde Levene pour l’homogénéité de la variance, tableau d’analyse de la variance et tests d’égalitédes moyennes pour chaque variable dépendante, contrastes a priori spécifiés par l’utilisateur ettests d’intervalle et comparaisons multiples post hoc : Bonferroni, Sidak, test de Tukey, GT2 deHochberg, Gabriel, Dunnett, test F de Ryan-Einot-Gabriel-Welsch (R-E-G-W F), test d’intervallede Ryan-Einot-Gabriel-Welsch (R-E-G-W Q), T2 de Tamhane, T3 de Dunnett, Games-Howell,test C de Dunnett, test de Duncan, Student-Newman-Keuls (S-N-K), B de Tukey, Waller-Duncan,Scheffé et différence la moins significative.
Données : Les valeurs de la variable active devraient être des nombres entiers, et la variabledépendante devrait être quantitative (niveau d’intervalle de mesures).
Hypothèses : Chaque groupe est un échantillon aléatoire indépendant extrait d’une populationnormale. L’analyse de la variance supporte les écarts à la normalité, bien que les données doiventêtre symétriques. Les groupes devraient être composés de populations à variance égale. Pourtester cette hypothèse, utiliser le test d’homogénéité de variance de Levene.
Obtenir une analyse de variance à un facteur
E A partir des menus, sélectionnez :Analyse
Comparer les moyennesANOVA à 1 facteur
349
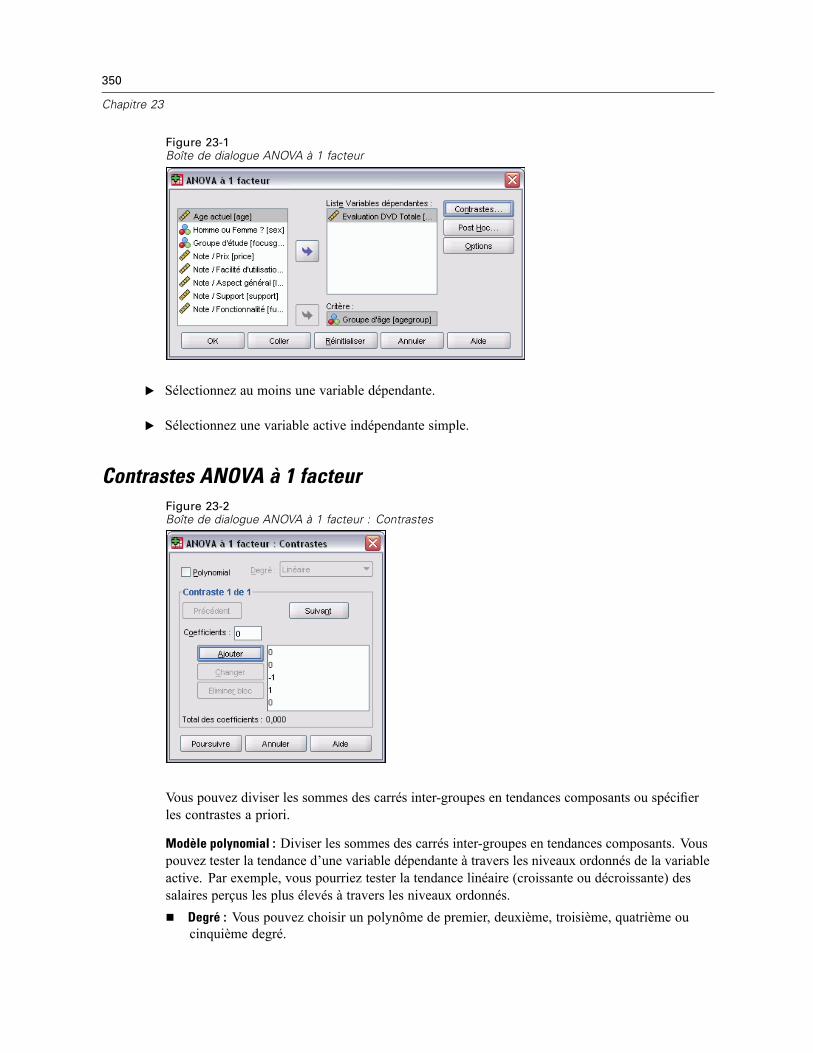
350
Chapitre 23
Figure 23-1Boîte de dialogue ANOVA à 1 facteur
E Sélectionnez au moins une variable dépendante.
E Sélectionnez une variable active indépendante simple.
Contrastes ANOVA à 1 facteurFigure 23-2Boîte de dialogue ANOVA à 1 facteur : Contrastes
Vous pouvez diviser les sommes des carrés inter-groupes en tendances composants ou spécifierles contrastes a priori.
Modèle polynomial : Diviser les sommes des carrés inter-groupes en tendances composants. Vouspouvez tester la tendance d’une variable dépendante à travers les niveaux ordonnés de la variableactive. Par exemple, vous pourriez tester la tendance linéaire (croissante ou décroissante) dessalaires perçus les plus élevés à travers les niveaux ordonnés.
Degré : Vous pouvez choisir un polynôme de premier, deuxième, troisième, quatrième oucinquième degré.
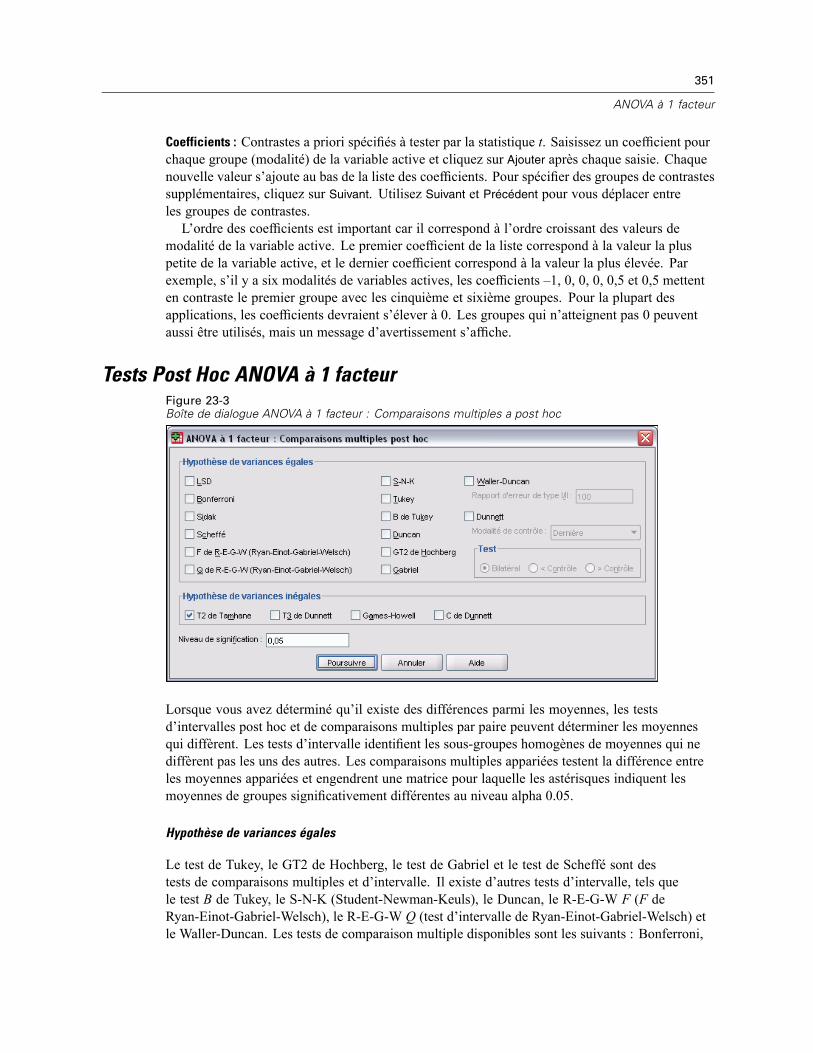
351
ANOVA à 1 facteur
Coefficients : Contrastes a priori spécifiés à tester par la statistique t. Saisissez un coefficient pourchaque groupe (modalité) de la variable active et cliquez sur Ajouter après chaque saisie. Chaquenouvelle valeur s’ajoute au bas de la liste des coefficients. Pour spécifier des groupes de contrastessupplémentaires, cliquez sur Suivant. Utilisez Suivant et Précédent pour vous déplacer entreles groupes de contrastes.L’ordre des coefficients est important car il correspond à l’ordre croissant des valeurs de
modalité de la variable active. Le premier coefficient de la liste correspond à la valeur la pluspetite de la variable active, et le dernier coefficient correspond à la valeur la plus élevée. Parexemple, s’il y a six modalités de variables actives, les coefficients –1, 0, 0, 0, 0,5 et 0,5 mettenten contraste le premier groupe avec les cinquième et sixième groupes. Pour la plupart desapplications, les coefficients devraient s’élever à 0. Les groupes qui n’atteignent pas 0 peuventaussi être utilisés, mais un message d’avertissement s’affiche.
Tests Post Hoc ANOVA à 1 facteurFigure 23-3Boîte de dialogue ANOVA à 1 facteur : Comparaisons multiples a post hoc
Lorsque vous avez déterminé qu’il existe des différences parmi les moyennes, les testsd’intervalles post hoc et de comparaisons multiples par paire peuvent déterminer les moyennesqui diffèrent. Les tests d’intervalle identifient les sous-groupes homogènes de moyennes qui nediffèrent pas les uns des autres. Les comparaisons multiples appariées testent la différence entreles moyennes appariées et engendrent une matrice pour laquelle les astérisques indiquent lesmoyennes de groupes significativement différentes au niveau alpha 0.05.
Hypothèse de variances égales
Le test de Tukey, le GT2 de Hochberg, le test de Gabriel et le test de Scheffé sont destests de comparaisons multiples et d’intervalle. Il existe d’autres tests d’intervalle, tels quele test B de Tukey, le S-N-K (Student-Newman-Keuls), le Duncan, le R-E-G-W F (F deRyan-Einot-Gabriel-Welsch), le R-E-G-W Q (test d’intervalle de Ryan-Einot-Gabriel-Welsch) etle Waller-Duncan. Les tests de comparaison multiple disponibles sont les suivants : Bonferroni,

352
Chapitre 23
test de différence significative de Tukey, Sidak, Gabriel, Hochberg, Dunnett, Scheffé et LSD(différence la moins significative).
LSD.Utilisation de tests t pour effectuer toutes les comparaisons par paire entre des moyennesde groupe. Le taux d'erreur n'est pas corrigé dans le cas de comparaisons multiples.Bonferroni. Utilise des tests t pour effectuer des comparaisons par paire entre les moyennes degroupes, mais contrôle le taux d'erreur global en spécifiant comme taux d'erreur pour chaquetest le taux d'erreur empirique divisé par le nombre total de tests. Le seuil de significationobservé est ainsi ajusté en raison des comparaisons multiples réalisées.Sidak. Test de comparaisons multiples par paire reposant sur la statistique t. Le test Sidakajuste le seuil de signification en fonction des comparaisons multiples et fournit des bornesplus étroites que le test Bonferroni.Scheffé. Exécute des comparaisons par paire simultanées pour toutes les paires de moyennespossibles. Utilise la distribution d'échantillonnage F. Peut servir à examiner toutes lescombinaisons linéaires possibles de moyennes de groupe, et pas seulement des comparaisonspar paire.F de R-E-G-W (Ryan-Einot-Gabriel-Welsch). Procédure multiple descendante deRyan‑Einot‑Gabriel‑Welsch basée sur un test F.Q de R-E-G-W (Ryan-Einot-Gabriel-Welsch). Procédure multiple descendante deRyan‑Einot‑Gabriel‑Welsch basée sur un intervalle de Student.S-N-K. Ce test effectue toutes les comparaisons de moyennes par paire, à l'aide de ladistribution des intervalles de Student. Lorsque la taille des échantillons est égale, il compareaussi les moyennes par paire dans les sous-ensembles homogènes, en utilisant une procédurepas à pas. Les moyennes sont triées dans l'ordre décroissant et les différences extrêmes sonttestées en premier.Tukey. Utilise la statistique de plages de Student pour effectuer toutes les comparaisons degroupes par paire. Fixe le taux d'erreur expérimental au niveau du taux d'erreur de l'ensemblepour toutes des comparaisons par paire.B de Tukey. Utilise la distribution de plages de Student pour effectuer des comparaisons degroupes par paire. La valeur critique est la moyenne de la valeur correspondante du test deTukey et du test de Student-Newman-Keuls.Duncan. Réalise des comparaisons par paires en suivant un ordre pas à pas identique à celuiutilisé dans le test de Student‑Newman‑Keuls, mais établit un niveau de protection du tauxd'erreur pour l'ensemble des tests, plutôt que pour chaque test en particulier. Utilise lastatistique d'intervalle de Student.GT2 de Hochberg. Test de multiples comparaisons et intervalles appariés utilisant le modulusmaximum de Student. Similaire au test de Tukey.Gabriel. Test de comparaison par paire qui utilise le modulus maximum de Student. Il est plusefficace que le GT2 de Hochberg lorsque les tailles des cellules sont inégales. Le test deGabriel offre plus de souplesse lorsque les tailles des cellules divergent beaucoup.Waller-Duncan. Test de comparaisons multiples reposant sur une statistique t et utilisantune approche bayésienne.Dunnett. Test‑t de comparaisons multiples par paires comparant un ensemble de traitements àune moyenne de contrôle unique. La dernière modalité est la modalité de contrôle par défaut.Vous pouvez également choisir la première modalité. L’option Bilatéral teste que la moyenne

353
ANOVA à 1 facteur
à un certain niveau (hormis la modalité de contrôle) du facteur n’est pas égale à celle de lamodalité de contrôle. L’option <Contrôle permet de tester si la moyenne est inférieure, à uncertain niveau du facteur, à celle de la modalité de contrôle. L’option >Contrôle permet detester si la moyenne est supérieure, à un certain niveau du facteur, à celle de la modalité decontrôle.
Hypothèse de variances inégales
Les tests de comparaison multiple qui ne supposent pas de variances égales sont le T2 deTamhane, le T3 de Dunnett, Games-Howell et le C de Dunnett.
T2 de Tamhane. Test de comparaison par paire conservatif reposant sur le test T. Ce test estopportun lorsque les variances sont inégales.T3 de Dunnett. Test des comparaisons par paires basé sur le module maximal de Student. Cetest est opportun lorsque les variances sont inégales.Games-Howell. Test des comparaisons appariées qui peut parfois être souple. Ce test estopportun lorsque les variances sont inégales.C de Dunnett. Test des comparaisons par paires basé sur l'intervalle de Student. Ce test estopportun lorsque les variances sont inégales.
Remarque : Il peut vous paraître plus facile d’interpréter le résultat à partir de tests post hoc si vousdésactivez l’option Masquer les lignes et les colonnes vides dans la boîte de dialogue Propriétés dutableau (dans le tableau pivotant activé, choisissez Propriétés du tableau dans le menu Format).
Options ANOVA à 1 facteurFigure 23-4Boîte de dialogue ANOVA à 1 facteur : Options

354
Chapitre 23
Statistiques : Choisissez une ou plusieurs des options suivantes :Caractéristique : La procédure calcule le nombre d’observations, la moyenne, l’écart type,l’erreur standard de la moyenne, le minimum, le maximum, et les intervalles de confiance à95 % pour chaque variable dépendante de chaque groupe.Effets fixes et aléatoires : La procédure affiche l’écart type, l’erreur standard et l’intervallede confiance à 95 % pour le modèle à effets fixes, ainsi que l’erreur standard, l’intervalle deconfiance à 95 % et l’estimation de la variance inter-composants pour le modèle à effetsaléatoires.Test d’homogénéité de variance : La procédure calcule la statistique de Levene pour testerl’égalité des variances de groupe. Ce test ne dépend pas de l’hypothèse de normalité.Brown-Forsythe : La procédure calcule la statistique de Brown-Forsythe pour tester l’égalitédes moyennes de groupe. Il est préférable d’utiliser cette statistique (au lieu de la statistiqueF) lorsque l’hypothèse d’égalité des variances n’est pas satisfaite.Welch : Calcule la statistique de Welch pour tester l’égalité des moyennes de groupe. Il estpréférable d’utiliser cette statistique (au lieu de la statistique F) lorsque l’hypothèse d’égalitédes variances n’est pas satisfaite.
Diagramme des moyennes : Affiche un diagramme qui représente les moyennes de sous-groupes(les moyennes de chaque groupe définies par les valeurs de la variable active).
Valeurs manquantes : Contrôle le traitement des valeurs manquantes.Exclure les observations analyse par analyse : Aucune observation avec valeur manquante n’estutilisée, que ce soit pour la variable dépendante ou pour la variable active d’une analysedonnée. De même, on n’utilise pas d’observation en dehors de l’intervalle spécifié pour lavariable active.Exclure toute observation incomplète : Les observations ayant des valeurs manquantes pourla variable active ou pour toute variable dépendante contenue dans la liste dépendante de laboîte de dialogue principale sont exclues de toutes les analyses. Si vous n’avez pas spécifié devariables multiples dépendantes, cela est sans effet.
Fonctionnalités supplémentaires de la commande ONEWAY
Le langage de syntaxe de commande vous permet aussi de :Obtenir des statistiques à effets fixes et aléatoires Ecart type, erreur standard de la moyenne etintervalles de confiance de 95 % pour le modèle à effets fixes. Erreur standard, intervallesde confiance de 95 % et estimation de la variance inter-composants pour le modèle à effetsaléatoires (en utilisant STATISTICS=EFFECTS).Spécifier les niveaux alpha pour la différence de moindre signification, tests de comparaisonmultiple Bonferroni, Duncan et Scheffé (avec la sous-commande RANGES).Ecrire une matrice des moyennes, des écarts-types et des fréquences ou lire une matrice desmoyennes, des fréquences, des variances combinées et des degrés de liberté des variancescombinées. Ces matrices peuvent être utilisées à la place des données brutes pour obtenir uneanalyse à un facteur de la variance (avec la sous-commande MATRIX).
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.

Chapitre
24Analyse GLM – Univarié
GLM – Univarié fournit un modèle de régression et une analyse de la variance pour plusieursvariables dépendantes par un ou plusieurs facteurs ou variables. Les variables actives divisentla population en groupes. Cette procédure de régression linéaire généralisée vous permet detester les hypothèses nulles à propos des effets des autres variables sur la moyenne de différentsregroupements de la variable dépendante. Vous pouvez rechercher les interactions entre lesfacteurs ainsi que les effets des différents facteurs, certains d’entre eux étant aléatoires. En outre,les effets et les interactions des covariables avec les facteurs peuvent être inclus. Pour l’analyse dela régression, les variables indépendantes (explicatives) sont spécifiées comme covariables.Vous pouvez tester les modèles équilibrés comme déséquilibrés. Un modèle est équilibré si
chaque cellule de ce modèle contient le même nombre d’observations. L’analyse GLM – Univariéteste non seulement les hypothèses mais elle produit également des estimations.Vous disposez de contrastes a priori communs pour effectuer les tests d’hypothèse. En outre,
lorsqu’un test F global se révèle significatif, vous pouvez utiliser les tests post hoc pour évaluerles différences entre les moyennes spécifiques. Les moyennes marginales estimées fournissent desestimations des valeurs moyennes estimées pour les cellules dans le modèle et les diagrammesdes profils (diagrammes d’interaction) de ces moyennes vous permettent de visualiser plusfacilement certaines des relations.Les résidus, les prévisions, la distance de Cook et les valeurs influentes peuvent être enregistrées
sous forme de nouvelles variables dans votre fichier de données pour vérifier les hypothèses.Poids WLS. Vous permet de spécifier une variable utilisée pour pondérer les observations
pour une analyse pondérée (WLS) des moindres carrés, peut-être pour compenser les différentsniveaux de précision des mesures.
Exemple : Des données sont collectées sur les différents participants au Marathon de Paris surplusieurs années. Le temps effectué par chaque participant est la variable dépendante. Les autresfacteurs comprennent le temps (froid, modéré, chaud), le nombre de mois d’entraînement, lenombre de marathons précédemment effectués et le sexe. L’âge est considéré comme co-variable.Vous devez trouver que le sexe a un effet significatif et que l’interaction du sexe avec le tempsest significatif.
Méthodes : Les sommes des carrés de type I, II, III et IV peuvent servir à évaluer les différenteshypothèses. Le type III est la valeur par défaut.
Statistiques : Tests d’intervalle post hoc et comparaisons multiples : La différence la moinssignificative, Bonferroni, Sidak, Scheffé, F multiple de Ryan-Einot-Gabriel-Welsch, l’intervallemultiple de Ryan-Einot-Gabriel-Welsch, Student-Newman-Keuls, le test de Tukey, b de Tukey,Duncan, GT2 de Hochberg, Gabriel, le test t de Waller Duncan, Dunnett (unilatéral, bilatéral), T2de Tamhane, T3 de Dunnett, Games-Howell et C de Dunnett. Statistiques descriptives : moyenne
355
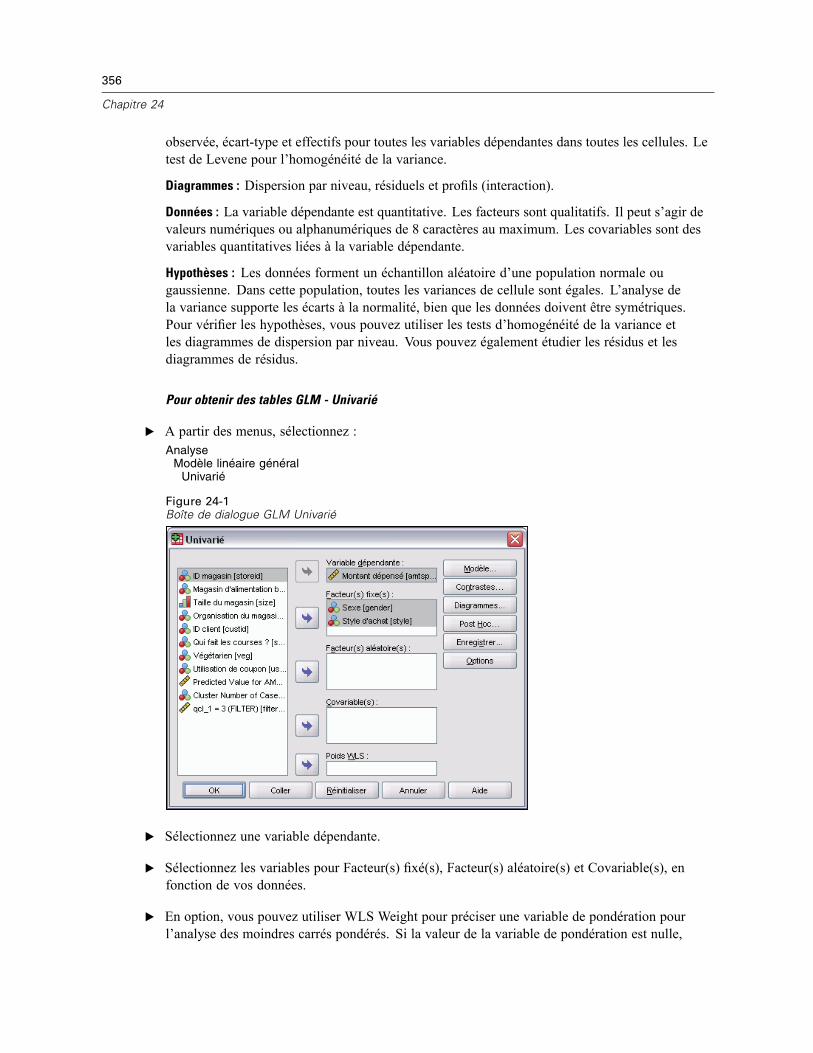
356
Chapitre 24
observée, écart-type et effectifs pour toutes les variables dépendantes dans toutes les cellules. Letest de Levene pour l’homogénéité de la variance.
Diagrammes : Dispersion par niveau, résiduels et profils (interaction).
Données : La variable dépendante est quantitative. Les facteurs sont qualitatifs. Il peut s’agir devaleurs numériques ou alphanumériques de 8 caractères au maximum. Les covariables sont desvariables quantitatives liées à la variable dépendante.
Hypothèses : Les données forment un échantillon aléatoire d’une population normale ougaussienne. Dans cette population, toutes les variances de cellule sont égales. L’analyse dela variance supporte les écarts à la normalité, bien que les données doivent être symétriques.Pour vérifier les hypothèses, vous pouvez utiliser les tests d’homogénéité de la variance etles diagrammes de dispersion par niveau. Vous pouvez également étudier les résidus et lesdiagrammes de résidus.
Pour obtenir des tables GLM - Univarié
E A partir des menus, sélectionnez :Analyse
Modèle linéaire généralUnivarié
Figure 24-1Boîte de dialogue GLM Univarié
E Sélectionnez une variable dépendante.
E Sélectionnez les variables pour Facteur(s) fixé(s), Facteur(s) aléatoire(s) et Covariable(s), enfonction de vos données.
E En option, vous pouvez utiliser WLS Weight pour préciser une variable de pondération pourl’analyse des moindres carrés pondérés. Si la valeur de la variable de pondération est nulle,
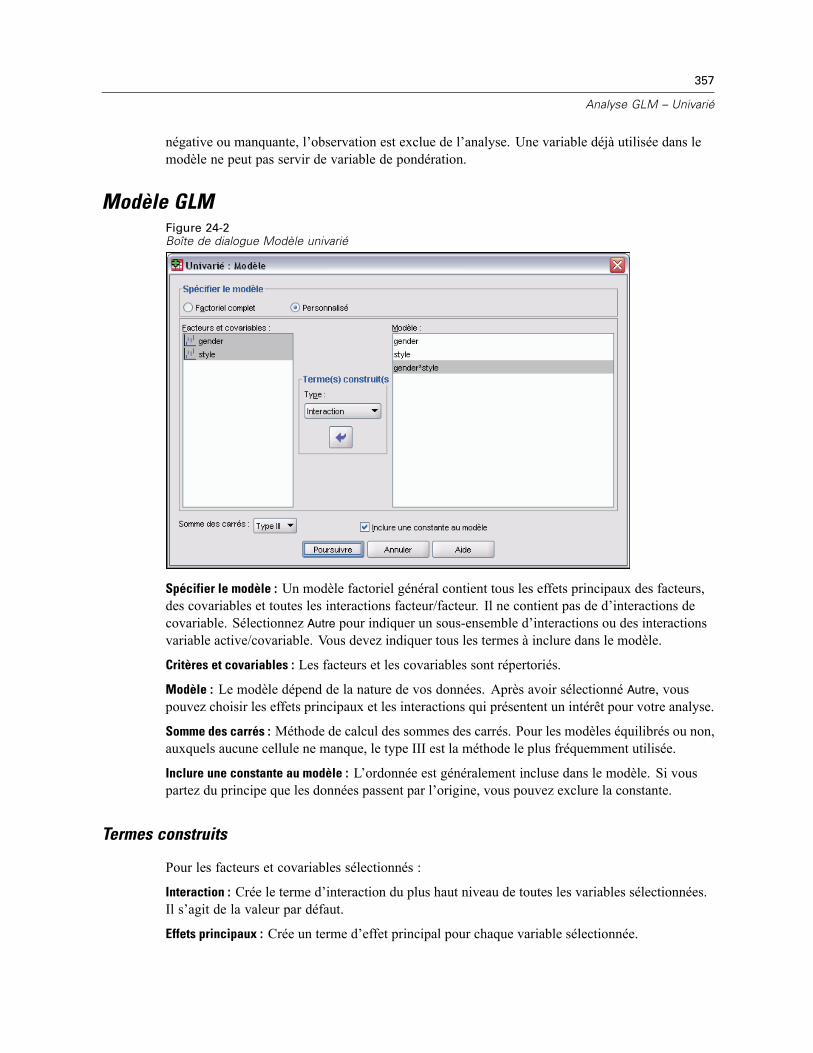
357
Analyse GLM – Univarié
négative ou manquante, l’observation est exclue de l’analyse. Une variable déjà utilisée dans lemodèle ne peut pas servir de variable de pondération.
Modèle GLMFigure 24-2Boîte de dialogue Modèle univarié
Spécifier le modèle : Un modèle factoriel général contient tous les effets principaux des facteurs,des covariables et toutes les interactions facteur/facteur. Il ne contient pas de d’interactions decovariable. Sélectionnez Autre pour indiquer un sous-ensemble d’interactions ou des interactionsvariable active/covariable. Vous devez indiquer tous les termes à inclure dans le modèle.
Critères et covariables : Les facteurs et les covariables sont répertoriés.
Modèle : Le modèle dépend de la nature de vos données. Après avoir sélectionné Autre, vouspouvez choisir les effets principaux et les interactions qui présentent un intérêt pour votre analyse.
Somme des carrés : Méthode de calcul des sommes des carrés. Pour les modèles équilibrés ou non,auxquels aucune cellule ne manque, le type III est la méthode le plus fréquemment utilisée.
Inclure une constante au modèle : L’ordonnée est généralement incluse dans le modèle. Si vouspartez du principe que les données passent par l’origine, vous pouvez exclure la constante.
Termes construits
Pour les facteurs et covariables sélectionnés :
Interaction : Crée le terme d’interaction du plus haut niveau de toutes les variables sélectionnées.Il s’agit de la valeur par défaut.
Effets principaux : Crée un terme d’effet principal pour chaque variable sélectionnée.

358
Chapitre 24
Toutes d’ordre 2 : Crée toutes les interactions d’ordre 2 possibles des variables sélectionnées.
Toutes d’ordre 3 : Crée toutes les interactions d’ordre 3 possibles des variables sélectionnées.
Toutes d’ordre 4 : Crée toutes les interactions d’ordre 4 possibles des variables sélectionnées.
Toutes d’ordre 5 : Crée toutes les interactions d’ordre 5 possibles des variables sélectionnées.
Somme des carrés
Pour ce modèle, vous pouvez choisir un type de sommes des carrés. Le type III est le plus courantet c’est la valeur par défaut.
Type I : Cette méthode est également appelée décomposition hiérarchique de la somme des carrés.Chaque terme est ajusté uniquement pour le terme qui le précède dans le modèle. La somme descarrés de type I est généralement utilisée pour :
Une analyse de la variance équilibrée dans laquelle tout effet principal est spécifié avant leseffets d’interaction de premier ordre, et chaque effet de premier ordre spécifié avant ceuxde second ordre, et ainsi de suite.Un modèle de régression polynomial dans lequel les termes d’ordre inférieur sont spécifiésavant ceux d’ordre supérieur.Un modèle par imbrication pur dans lequel le premier effet spécifié est imbriqué dans lesecond et le second spécifié dans le troisième, etc. (Cette forme d’imbrication peut êtrespécifiée par la syntaxe uniquement.)
Type II : Cette méthode calcule les sommes des carrés d’un effet dans le modèle ajusté pourtous les autres effets « appropriés ». Un effet approprié est un effet qui correspond à tous leseffets qui ne contiennent pas l’effet à étudier. La méthode des sommes des carrés de type II sertgénéralement pour :
Une analyse de la variance équilibrée.Tout modèle qui contient un effet principal uniquement.Tout modèle de régression.Un modèle par emboîtement pur. (Cette forme d’emboîtement peut être spécifiée par lasyntaxe.)
Type III : Valeur par défaut. Cette méthode calcule les sommes des carrés d’un effet dans le modèlecomme les sommes des carrés ajustée pour tout autre effet qui ne le contient pas et orthogonalà chaque effet qui le contient. Les sommes de carrés de type III présentent l’avantage essentielqu’elles ne varient pas avec les fréquences de cellule tant que la forme générale d’estimabilitéreste constante. Ce type de somme des carrés est donc souvent considéré comme utile pour lesmodèles déséquilibrés auxquels aucune cellule ne manque. Dans le modèle factoriel sans cellulemanquante, cette méthode est équivalente à la technique de Yates des carrés moyens pondérés. Laméthode des sommes des carrés de type III sert généralement pour :
Tous les modèles énumérés dans les types I et II.Tous les modèles équilibrés ou non qui ne contiennent pas de cellules vides.

359
Analyse GLM – Univarié
Type IV : Cette méthode est conçue pour une situation dans laquelle il manque des cellules. Pourchaque effet F dans le modèle, si F n’est inclus dans aucun autre effet, Type IV = Type III = TypeII. Si F est inclus dans d’autres effets, le Type IV distribue les contrastes à effectuer parmi lesparamètres dans F sur tous les effets de niveau supérieur de façon équitable. La méthode dessommes des carrés de type IV sert généralement pour :
Tous les modèles énumérés dans les types I et II.Tous les modèles équilibrés ou non qui contiennent des cellules vides.
Contrastes GLMFigure 24-3Boîte de dialogue GLM Univarié : Contrastes
Les contrastes servent à tester les différences entre les niveaux d’un facteur. Vous pouvez spécifierun contraste pour chaque facteur du modèle (dans un modèle de mesures répétées, pour chaquefacteur inter-sujets). Les contrastes représentent des combinaisons linéaires des paramètres.Le test des hypothèses est fondé sur l’hypothèse nulle LB =0, L étant la matrice des coefficients
de contraste et B le vecteur de paramètre. Lorsqu’un contraste est spécifié, une matrice L estcréée. Les colonnes de la matrice L correspondantes au facteur concordent avec le contraste. Lescolonnes restantes sont ajustées de telle sorte que la matrice L puisse être estimée.Le résultat reprend une statistique F pour chaque ensemble de contrastes. Pour les différences
de contraste, le système affiche également les intervalles de confiance simultanés de typeBonferroni fondés sur la distribution t de Student.
Contrastes possibles
Les contrastes fournis sont écart, simple, différence, Helmert, répétée et modèle polynomial. Pourles contrastes d’écart et simple, vous pouvez choisir si la modalité de référence est la premièreou la dernière.
Types de contraste
Ecart : Compare la moyenne de chaque niveau (hormis une modalité de référence) à la moyenne detous les niveaux (grande moyenne). Les niveaux du facteur peuvent être de n’importe quel ordre.

360
Chapitre 24
Simple : Compare la moyenne de chaque niveau à celle d’un niveau donné. Ce type de contrasteest utile lorsqu’il y a un groupe de contrôle. Vous pouvez prendre la première ou la dernièremodalité en référence.
Différence : Compare la moyenne de chaque niveau (hormis le premier) à la moyenne des niveauxprécédents. (Parfois appelé contrastes d’Helmert inversé.)
Helmert : Compare la moyenne de chaque niveau de facteur (hormis le dernier) à la moyennedes niveaux suivants.
Répété : Compare la moyenne de chaque niveau (hormis le premier) à la moyenne du niveausuivant.
Modèle polynomial : Compare l’effet linéaire, l’effet quadratique, l’effet cubique etc. Lepremier degré de liberté contient l’effet linéaire sur toutes les modalités, le second degré l’effetquadratique, etc. Ces contrastes servent souvent à estimer les tendances polynomiales.
Diagrammes de profils GLMFigure 24-4Boîte de dialogue GLM – Univarié : Diagrammes des protocoles
Les diagrammes des profils (diagrammes d’interaction) sont utiles pour comparer les moyennesmarginales dans votre modèle. Un diagramme des profils est une courbe dont chaque pointindique la moyenne marginale estimée d’une variable dépendante (ajustée pour les covariables)à un niveau du facteur. Les niveaux d’un second facteur peuvent servir à dessiner des courbesdistinctes. Chaque niveau dans un troisième facteur peut servir à créer un diagramme distinct.Tous les facteurs fixés et aléatoire sont disponibles pour les diagrammes. Pour les analysesmultivariées, les diagrammes des profils sont créés pour chaque variable dépendante. Dansune analyse à mesures répétées, à la fois les facteurs inter-sujets et intra-sujets peuvent êtreutilisés dans les diagrammes des profils. GLM - Multivarié et GLM - Mesures Répétées ne sontdisponibles que si vous avez installé l’option Statistiques avancées.
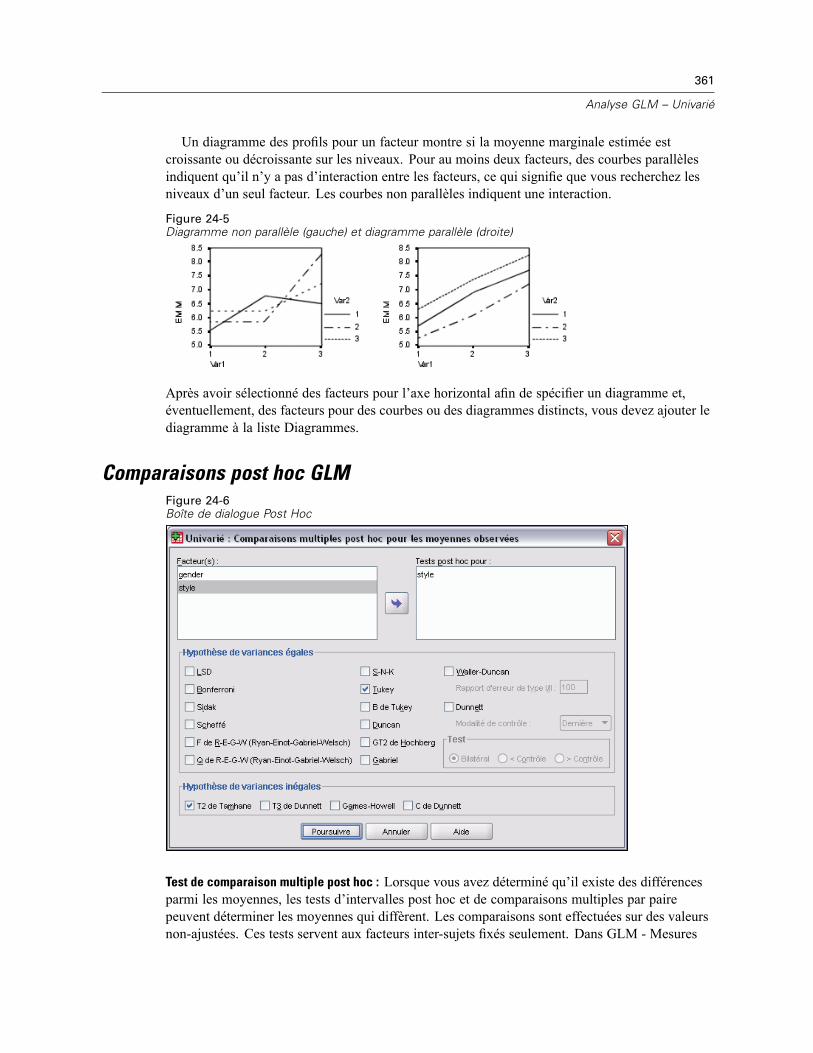
361
Analyse GLM – Univarié
Un diagramme des profils pour un facteur montre si la moyenne marginale estimée estcroissante ou décroissante sur les niveaux. Pour au moins deux facteurs, des courbes parallèlesindiquent qu’il n’y a pas d’interaction entre les facteurs, ce qui signifie que vous recherchez lesniveaux d’un seul facteur. Les courbes non parallèles indiquent une interaction.
Figure 24-5Diagramme non parallèle (gauche) et diagramme parallèle (droite)
Après avoir sélectionné des facteurs pour l’axe horizontal afin de spécifier un diagramme et,éventuellement, des facteurs pour des courbes ou des diagrammes distincts, vous devez ajouter lediagramme à la liste Diagrammes.
Comparaisons post hoc GLMFigure 24-6Boîte de dialogue Post Hoc
Test de comparaison multiple post hoc : Lorsque vous avez déterminé qu’il existe des différencesparmi les moyennes, les tests d’intervalles post hoc et de comparaisons multiples par pairepeuvent déterminer les moyennes qui diffèrent. Les comparaisons sont effectuées sur des valeursnon-ajustées. Ces tests servent aux facteurs inter-sujets fixés seulement. Dans GLM - Mesures

362
Chapitre 24
répétées, ces tests ne sont pas disponibles s’il n’y a pas de facteurs inter-sujets. Les tests decomparaisons multiples post hoc sont effectués pour la moyenne de tous les niveaux des facteursintra-sujets. Pour GLM - Multivarié, les tests post hoc sont effectués séparément pour chaquevariable dépendante. GLM - Multivarié et GLM - Mesures Répétées ne sont disponibles que sivous avez installé l’option Statistiques avancées.Les tests de différence significative de Bonferroni et Tukey servent généralement comme
tests de comparaison multiples. Le test de Bonferroni, fondé sur la statistique t de Student,ajuste le niveau de signification observé en fonction du nombre de comparaisons multiples quisont effectuées. Le test t de Sidak ajuste également le niveau de signification et fournit deslimites plus strictes que le test de Bonferroni. Le test de Tukey utilise la statistique d’intervalleselon Student pour effectuer des comparaisons par paire entre les groupes et fixe le taux d’erreurempirique au taux d’erreur du regroupement de toutes les comparaisons par paire. Lorsque voustestez un grand nombre de paires de moyennes, le test de Tukey est plus efficace que celui deBonferroni. Lorsqu’il y a peu de paires, Bonferroni est plus efficace.Le GT2 de Hochberg est similaire au test de Tukey mais il utilise un modulus maximum selon
Student. Le test de Tukey est généralement plus efficace. Le test de comparaison par paire deGabriel utilise également le modulus maximum selon Student. Il est plus efficace que le GT2 deHochberg lorsque les tailles des cellules sont inégales. Le test de Gabriel offre plus de souplesselorsque les tailles des cellules divergent beaucoup.Le test de comparaison multiple de Dunnett compare un ensemble de traitements à une
simple moyenne de contrôle. La dernière modalité est la modalité de contrôle par défaut. Vouspouvez également choisir la première modalité. Vous pouvez également choisir un test unilatéralou bilatéral. Pour tester que la moyenne à un certain niveau (hormis la modalité de contrôle) dufacteur n’est pas égale à celle de la modalité de contrôle, utilisez le test double-face. Pour testersi la moyenne est inférieure, à un certain niveau du facteur, à celle de la modalité de contrôle,sélectionnez < Contrôle. Pour tester si la moyenne est supérieure, à un certain niveau du facteur, àcelle de la catégorie de contrôle, sélectionnez > Contrôle.Ryan, Einot, Gabriel et Welsch (R-E-G-W) ont développé deux tests d’intervalles multiples
descendants. Les procédures multiples descendantes testent d’abord que toutes les moyennes sontégales. Si toutes les moyennes ne sont pas égales, l’égalité est testée sur des sous-ensemblesde moyennes. Le F de R-E-G-W est fondé sur le test F et le Q de R-E-G-W est fondé surl’intervalle selon Student. Ces tests sont plus efficaces que le test d’intervalles multiples deDuncan et Student-Newman-Keuls (procédures multiples descendantes), mais ils sont conseilléslorsque les cellules sont de taille inégale.Lorsque les variances sont inégales, utilisez le T2 de Tamhane (test de comparaisons par paire
conservatif fondé sur un test t), le T3 de Dunnett (comparaison par paire fondée sur le modulusmaximal selon Student), le test de comparaison par paire de Games-Howell (parfois flexible)ou le C de Dunnett (test de comparaison par paire fondé sur l’intervalle selon Student). Notez ques’il y a plusieurs facteurs dans le modèle, ces tests ne sont pas valides et ne seront pas produits.Le test d’intervalles multiples de Duncan, Student-Newman-Keuls (S-N-K) et le b de
Tukey sont des tests d’intervalle qui classifient les moyennes de groupe et calculent une valeurd’intervalle. Ces tests ne sont pas utilisés aussi souvent que les tests évoqués précédemment.Le test t de Waller-Duncan utilise une approche de Bayes. Ce test d’intervalle utilise la
moyenne harmonique de la taille de l’échantillon lorsque les échantillons sont de tailles différentes.

363
Analyse GLM – Univarié
Le niveau de signification du test de Scheffé est conçu pour permettre toutes les combinaisonslinéaires possibles des moyennes de groupe à tester, pas seulement par paire, disponibles danscette fonction. Il en résulte que le test de Scheffé est souvent plus strict que les autres, ce quisignifie qu’une plus grande différence de moyenne est nécessaire pour être significative.Le test de comparaison multiple par paire de différence la moins significative (LSD) est
équivalent aux divers tests t individuels entre toutes les paires des groupes. L’inconvénient dece test est qu’il n’essaie pas d’ajuster le niveau d’importance observée pour les comparaisonsmultiples.
Tests affichés : Les comparaisons par paire sont proposées pour LSD, Sidak, Bonferroni, Games etHowell, T2 et T3 de Tamhane, C et T3 de Dunnett. Des sous-ensembles homogènes pour les testsd’intervalle sont proposés pour S-N-K, b de Tukey, Duncan, F et Q de R-E-G-W et Waller. Le testde Tukey, le GT2 de Hochberg, le test de Gabriel et le test de Scheffé sont à la fois des tests decomparaison multiple et des tests d’intervalle.
Enregistrement GLMFigure 24-7Boîte de dialogue Enregistrer
Vous pouvez enregistrer les prévisions par le modèle, les résidus et les mesures associées sousforme de nouvelles variables dans l’éditeur de données. La plupart de ces variables peuvent servirà étudier les hypothèses relatives aux données. Pour enregistrer les valeurs afin de les utiliser dansune autre session SPSS Statistics, vous devez enregistrer le fichier de données en cours.
Prévisions : Valeurs que le modèle estime pour chaque observation.Non standardisés. Valeur prévue par le modèle pour la variable dépendante.

364
Chapitre 24
Pondéré. Valeurs estimées non standardisées pondérées. Disponibles uniquement lorsqu'unevariable WLS a été préalablement sélectionnée.Erreur standard. Estimation de l'écart‑type de la valeur moyenne de la variable dépendante,pour des observations ayant la même valeur pour les variables indépendantes.
Diagnostics : Mesures permettant d’identifier les observations avec des combinaisons inhabituellesde valeurs pour les variables indépendantes et les observations qui peuvent avoir un impactimportant sur le modèle.
Distance de Cook. Mesure du degré dont les résidus de toutes les observations sont modifiés siune observation donnée est exclue des calculs des coefficients de régression. Si la distancede Cook est élevée, l'exclusion d'une observation changerait substantiellement la valeurdes coefficients.Valeurs influentes. Valeurs influentes non centrées. Mesure de l'influence d'un point surl'ajustement de la régression.
Résidus : Un résidu non standardisé correspond à la valeur réelle de la variable dépendante moinsla valeur estimée par le modèle. Les résidus standardisés, selon Student et supprimés sontégalement disponibles. Si vous avez choisi une variable de pondération, les résidus standardiséspondérés sont disponibles.
Non standardisés. Différence entre la valeur observée et la valeur prévue par le modèle.Pondéré. Résolus non normalisés pondérés. Disponibles uniquement lorsqu'une variable WLSa été préalablement sélectionnée.Standardisé. Résidu, divisé par une estimation de son erreur standard. Egalement appelésrésidus de Pearson, les résidus standardisés ont une moyenne de 0 et un écart-type de 1.Studentisés. Résidu, divisé par une estimation de son écart‑type, qui varie d'une observationà l'autre, selon la distance entre les valeurs et la moyenne des variables indépendantes pourchaque observation.Supprimées. Résidu d'une observation lorsque celle‑ci est exclue du calcul des coefficients derégression. Il s'agit de la différence entre la valeur de la variable dépendante et la prévisionajustée.
Statistiques à coefficients : Ecrit une matrice variance-covariance des estimations des paramètresdu modèle dans un nouvel ensemble de données de la session en cours ou dans un fichier dedonnées externe au format SPSS Statistics. D’autre part, pour chaque variable dépendante,il y aura une ligne d’estimations, une ligne de valeurs de signification pour les statistiquest correspondant aux estimations et une ligne de degrés de liberté résiduels. Pour un modèlemultivarié, il y a les mêmes lignes pour chaque variable dépendante. Vous pouvez utiliser cesfichiers de matrice dans les autres procédures qui lisent des fichiers de matrice.
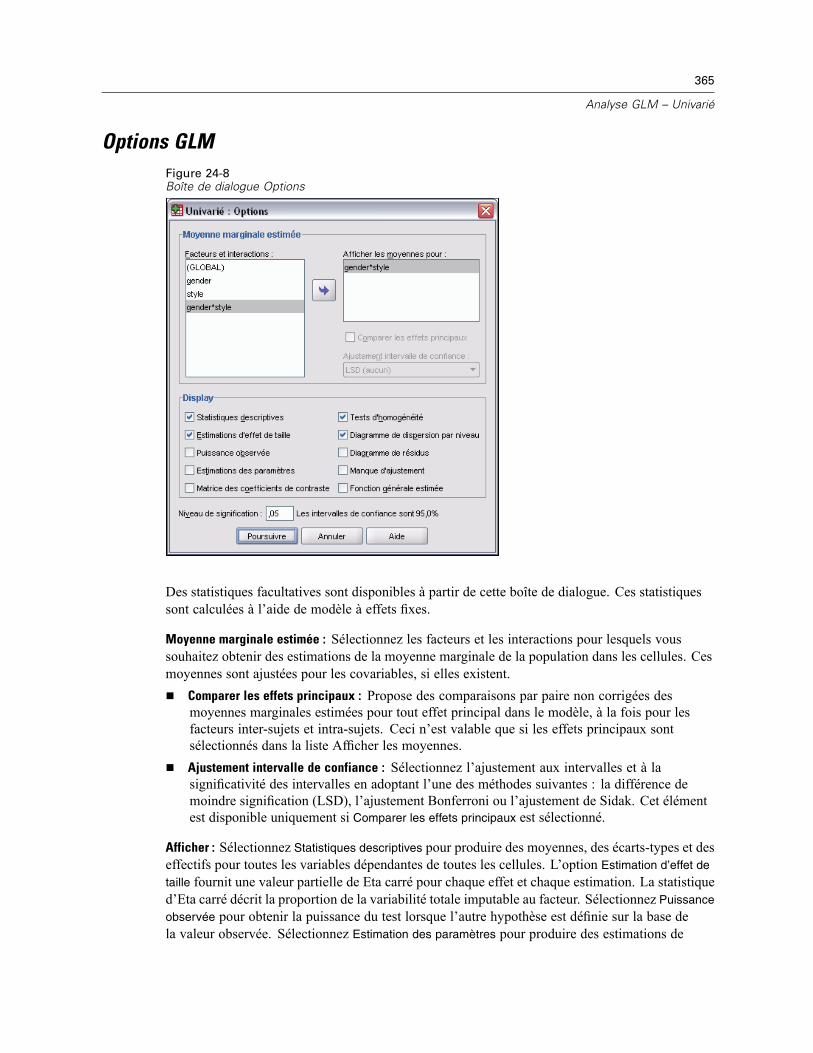
365
Analyse GLM – Univarié
Options GLMFigure 24-8Boîte de dialogue Options
Des statistiques facultatives sont disponibles à partir de cette boîte de dialogue. Ces statistiquessont calculées à l’aide de modèle à effets fixes.
Moyenne marginale estimée : Sélectionnez les facteurs et les interactions pour lesquels voussouhaitez obtenir des estimations de la moyenne marginale de la population dans les cellules. Cesmoyennes sont ajustées pour les covariables, si elles existent.
Comparer les effets principaux : Propose des comparaisons par paire non corrigées desmoyennes marginales estimées pour tout effet principal dans le modèle, à la fois pour lesfacteurs inter-sujets et intra-sujets. Ceci n’est valable que si les effets principaux sontsélectionnés dans la liste Afficher les moyennes.Ajustement intervalle de confiance : Sélectionnez l’ajustement aux intervalles et à lasignificativité des intervalles en adoptant l’une des méthodes suivantes : la différence demoindre signification (LSD), l’ajustement Bonferroni ou l’ajustement de Sidak. Cet élémentest disponible uniquement si Comparer les effets principaux est sélectionné.
Afficher : Sélectionnez Statistiques descriptives pour produire des moyennes, des écarts-types et deseffectifs pour toutes les variables dépendantes de toutes les cellules. L’option Estimation d’effet de
taille fournit une valeur partielle de Eta carré pour chaque effet et chaque estimation. La statistiqued’Eta carré décrit la proportion de la variabilité totale imputable au facteur. Sélectionnez Puissance
observée pour obtenir la puissance du test lorsque l’autre hypothèse est définie sur la base dela valeur observée. Sélectionnez Estimation des paramètres pour produire des estimations de

366
Chapitre 24
paramètres, des erreurs standard, des tests t, des intervalles de confiance et la puissance observéede chaque test. Sélectionnez Matrice des coefficients de contraste pour obtenir la matrice L.L’option des tests d’homogénéité produit le test de Levene d’homogénéité de la variance pour
chaque variable dépendante sur toutes les combinaisons de niveaux des facteurs inter-sujets,uniquement pour les facteurs inter-sujets. Les options des diagrammes de dispersion par niveauet de résidus sont utiles pour vérifier les hypothèses sur les données. Ceci n’est pas valable s’iln’y a pas de facteurs. Sélectionnez Diagrammes résiduels pour produire un diagramme résiduelobservé/estimé/standardisé pour chaque variable dépendante. Ces diagrammes sont utiles pourvérifier l’hypothèse de variance égale. Sélectionnez Manque d’ajustement pour vérifier si la relationentre la variable dépendante et les variables indépendantes peut être convenablement décrite par lemodèle. Fonction générale estimée vous permet de construire des tests d’hypothèses personnalisésbasés sur la fonction générale estimée. Les lignes de n’importe quelle matrice des coefficients decontraste sont des combinaisons linéaires de la fonction générale estimée.
Niveau de signification : Vous souhaitez peut-être ajuster le niveau de signification utilisé dansles tests post hoc et le niveau de confiance utilisé pour construire des intervalles de confiance.La valeur spécifiée est également utilisée pour calculer l’intensité observée pour le test. Lorsquevous spécifiez un niveau de signification, le niveau associé des intervalles de confiance est affichédans la boîte de dialogue.
Fonctionnalités supplémentaires de la commande UNIANOVA
Le langage de syntaxe de commande vous permet aussi de :Spécifier les effets en cascade dans un modèle (à l’aide de la sous-commande DESIGN).Spécifier les tests d’effets par rapport à une combinaison linéaire d’effets ou une valeur (àl’aide de la sous-commande TEST).Spécifier de multiples contrastes (à l’aide de la sous-commande CONTRAST).Inclure les valeurs manquantes pour l’utilisateur (à l’aide de la sous-commande MISSING).Spécifier les critères EPS (à l’aide de la sous-commande CRITERIA).Construisez une matrice L personnalisée, une matriceM ou une matrice K (à l’aide dessous-commandes LMATRIX, MMATRIX et KMATRIX).Pour les contrastes simples ou d’écart, spécifier une modalité de référence intermédiaire (àl’aide de la sous-commande CONTRAST).Spécifier les mesures pour les contrastes polynomiaux (à l’aide de la sous-commandeCONTRAST).Spécifier des termes d’erreur pour les comparaisons post hoc (à l’aide de la sous-commandePOSTHOC).Calculer les moyennes marginales estimées pour chaque facteur ou interaction de facteursparmi les facteurs de la liste (à l’aide de la sous-commande EMMEANS).Attribuer des noms aux variables temporaires (à l’aide de la sous-commande SAVE).Construire un fichier de matrice de corrélation (à l’aide de la sous-commande OUTFILE).

367
Analyse GLM – Univarié
Construire un fichier de type matrice de données qui contient les statistiques provenant de latable ANOVA inter-sujets (à l’aide de la sous-commande OUTFILE).Enregistrer la matrice du plan dans un nouveau fichier de données (à l’aide de lasous-commande OUTFILE).
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.

Chapitre
25Corrélations bivariées
La procédure de corrélations bivariées calcule le coefficient de corrélation de Pearson, le rho deSpearman et le tau-b de Kendall avec leurs seuils de signification. Les corrélations mesurentcomment les variables ou les ordres de rang sont liés. Avant de calculer un coefficient decorrélation, parcourez vos données pour rechercher les valeurs éloignées (qui peuvent provoquerdes résultats erronés) et les traces d’une relation linéaire. Le coefficient de corrélation de Pearsonest une mesure d’association linéaire. Deux variables peuvent être parfaitement liées, mais sila relation n’est pas linéaire, le coefficient de corrélation de Pearson n’est pas une statistiqueappropriée pour mesurer leur association.
Exemple : Le nombre de matchs de basket-ball remportés par une équipe est-il lié au nombremoyen de points marqués par match ? Un diagramme de dispersion indique qu’il existe unerelation linéaire. L’analyse des données de la saison NBA 1994–1995 démontre que le coefficientde corrélation de Pearson (0,581) est significatif au niveau 0,01. On peut penser que plus on agagné de matchs dans une saison, moins l’adversaire a marqué de points. Ces variables sont liéesnégativement (–0,401) et la corrélation est significative au niveau 0,05.
Statistiques : Pour chaque variable, on a les éléments suivants : nombre d’observations avecdes valeurs non manquantes, moyenne, et écart-type. Pour chaque paire de variables, on a leséléments suivants : coefficient de corrélation de Pearson, rho de Spearman, tau-b de Kendall,produits des écarts et covariance.
Données : Utilisez des variables quantitatives symétriques pour le coefficient de corrélation dePearson, et des variables quantitatives ou des variables avec des modalités ordonnées pour le rhode Spearman et le tau-b de Kendall.
Hypothèses : Le coefficient de corrélation de Pearson part du principe que chaque paire devariables est gaussienne bivariée.
Pour obtenir des corrélations bivariées
A partir des menus, sélectionnez :Analyse
CorrélationBivariée
368
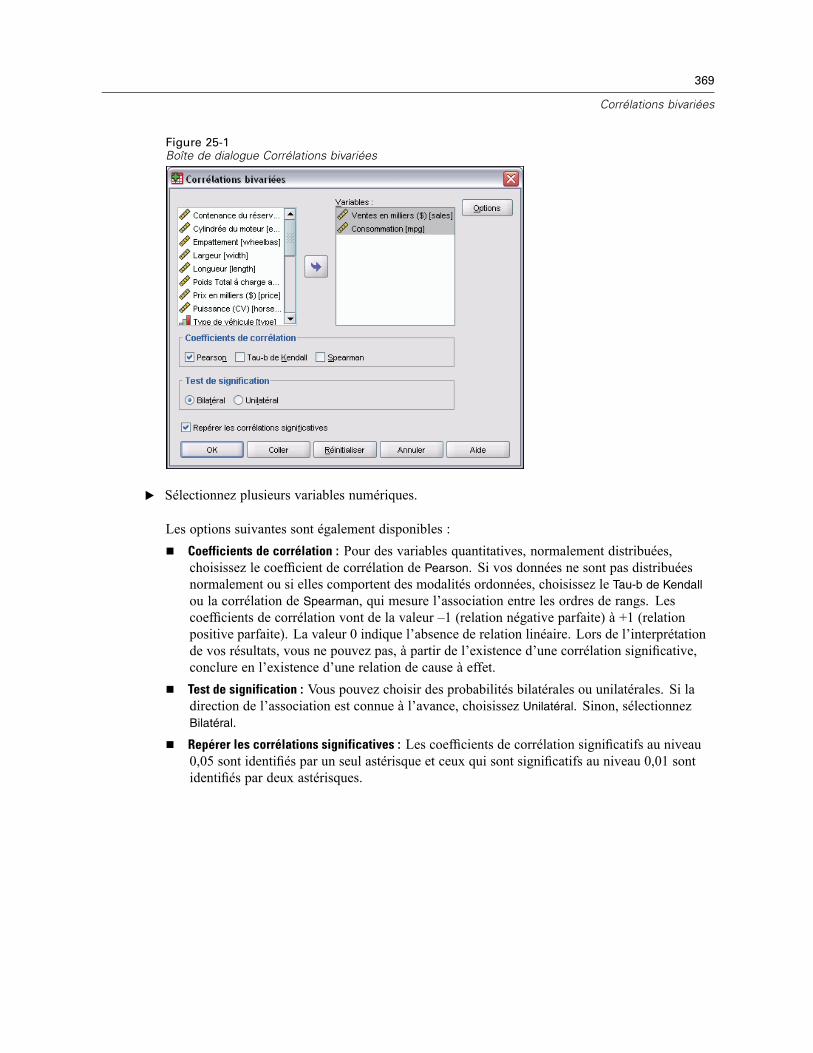
369
Corrélations bivariées
Figure 25-1Boîte de dialogue Corrélations bivariées
E Sélectionnez plusieurs variables numériques.
Les options suivantes sont également disponibles :Coefficients de corrélation : Pour des variables quantitatives, normalement distribuées,choisissez le coefficient de corrélation de Pearson. Si vos données ne sont pas distribuéesnormalement ou si elles comportent des modalités ordonnées, choisissez le Tau-b de Kendallou la corrélation de Spearman, qui mesure l’association entre les ordres de rangs. Lescoefficients de corrélation vont de la valeur –1 (relation négative parfaite) à +1 (relationpositive parfaite). La valeur 0 indique l’absence de relation linéaire. Lors de l’interprétationde vos résultats, vous ne pouvez pas, à partir de l’existence d’une corrélation significative,conclure en l’existence d’une relation de cause à effet.Test de signification : Vous pouvez choisir des probabilités bilatérales ou unilatérales. Si ladirection de l’association est connue à l’avance, choisissez Unilatéral. Sinon, sélectionnezBilatéral.Repérer les corrélations significatives : Les coefficients de corrélation significatifs au niveau0,05 sont identifiés par un seul astérisque et ceux qui sont significatifs au niveau 0,01 sontidentifiés par deux astérisques.

370
Chapitre 25
Options de corrélations bivariéesFigure 25-2Boîte de dialogue Corrélations bivariées : Options
Statistiques : Pour les corrélations de Pearson, vous pouvez choisir l’une des options suivantes(ou les deux) :
Moyennes et écarts-types : Affichés pour chaque variable. Le nombre d’observations avecvaleurs non manquantes est également affiché. Les valeurs manquantes sont examinéesvariable par variable quel que soit votre réglage des valeurs manquantes.Produits des écarts et covariances : Indiqués pour chaque paire de variables. Le produitdes écarts est égal à la somme des produits des variables moyennes corrigées. Ceci estle numérateur du coefficient de corrélation de Pearson. La covariance est une mesure nonstandardisée de la relation entre deux variables, égale au produit des écarts divisé par N–1.
Valeurs manquantes : Vous pouvez choisir l’un des éléments suivants :Exclure seulement les composantes non valides : Les observations avec des valeurs manquantespour l’une ou les deux variables d’une paire pour un coefficient de corrélation sont exclues del’analyse. Etant donné que chaque coefficient est basé sur toutes les observations ayant descodes valides pour cette paire particulière de variables, la quantité maximale d’informationsdisponibles est utilisée dans chaque calcul. Ceci peut aboutir à un jeu de coefficients basé surun nombre variable d’observations.Exclure toute observation incomplète : Les observations avec des valeurs manquantes pour unevariable sont exclues de toutes les analyses.
Propriétés supplémentaires des commandes CORRELATIONS etNONPAR CORR
Le langage de syntaxe de commande vous permet aussi de :Ecrire une f pour les corrélations de Pearson qui peut être utilisée à la place de donnéesbrutes pour obtenir d’autres analyses comme une analyse factorielle (avec la sous-commandeMATRIX).Obtenir des corrélations de chaque variable dans une liste avec chaque variable d’une secondeliste (en utilisant le mot clé WITH avec la sous-commande VARIABLES).

371
Corrélations bivariées
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.

Chapitre
26Corrélations partielles
La procédure des corrélations partielles calcule les coefficients de corrélation partielle quidécrivent le rapport linéaire entre deux variables tout en contrôlant les effets d’une ou plusieursautres variables. Les corrélations sont des mesures d’association linéaire. Deux variables peuventêtre parfaitement liées mais, si leur rapport n’est pas linéaire, un coefficient de corrélation n’estpas une statistique adaptée pour mesurer leur association.
Exemple : Existe-t-il une relation entre le financement associé aux soins de santé et les tauxd’attaque ? Contre toute attente, une étude fait état d’une corrélation positive : Lorsque lefinancement associé aux soins de santé augmente, les taux d’attaque augmentent. Cependant, lecontrôle du taux de visite aux fournisseurs de soins de santé supprime presque la corrélationpositive observée. Le financement lié aux soins de santé et les taux d’attaque sont associés demanière positive car le nombre de personnes ayant accès aux soins de santé augmente en mêmetemps que le financement. De ce fait, le nombre de maladies déclarées par les docteurs et leshôpitaux augmente également
Statistiques : Pour chaque variable, on a les éléments suivants : nombre d’observations avec desvaleurs non manquantes, moyenne, et écart-type. Matrices de corrélation partielle et simple,avec degrés de liberté et seuils de signification.
Données : Utiliser des variables quantitatives et symétriques.
Hypothèses : La procédure des Corrélations Partielles suppose que chaque paire de variablesprésente une corrélation normale.
Obtenir des corrélations partielles
E A partir des menus, sélectionnez :Analyse
CorrélationPartielle
372
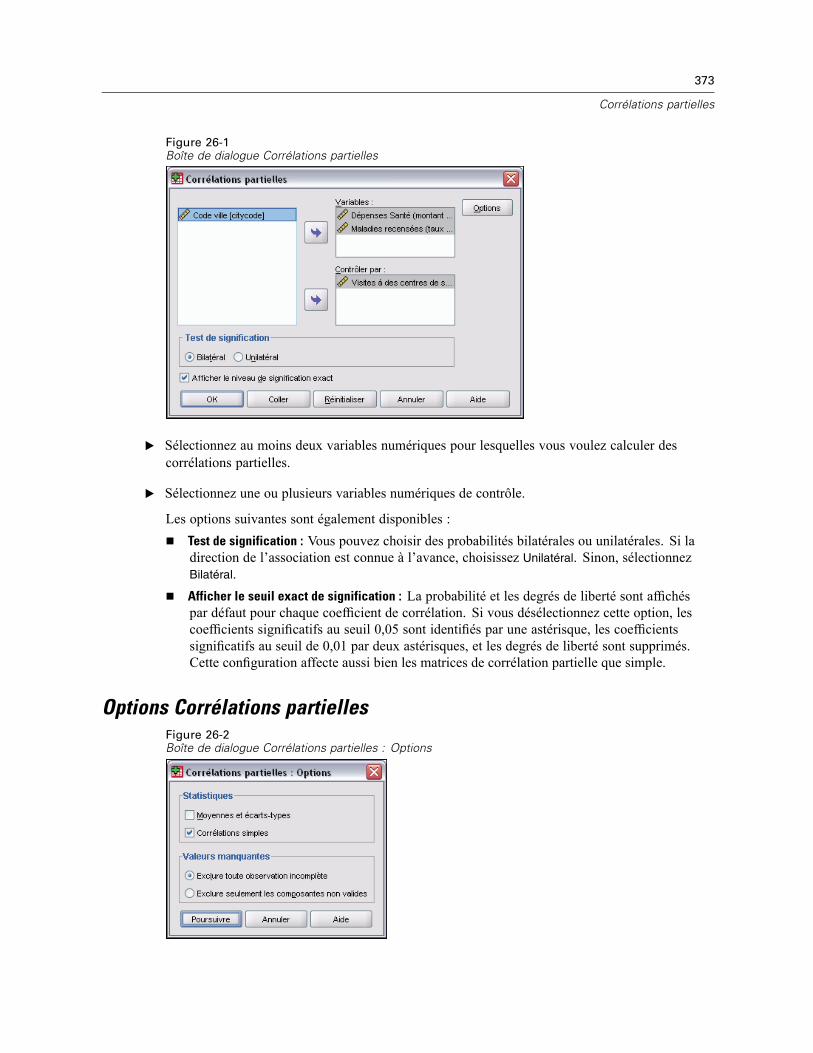
373
Corrélations partielles
Figure 26-1Boîte de dialogue Corrélations partielles
E Sélectionnez au moins deux variables numériques pour lesquelles vous voulez calculer descorrélations partielles.
E Sélectionnez une ou plusieurs variables numériques de contrôle.
Les options suivantes sont également disponibles :Test de signification : Vous pouvez choisir des probabilités bilatérales ou unilatérales. Si ladirection de l’association est connue à l’avance, choisissez Unilatéral. Sinon, sélectionnezBilatéral.Afficher le seuil exact de signification : La probabilité et les degrés de liberté sont affichéspar défaut pour chaque coefficient de corrélation. Si vous désélectionnez cette option, lescoefficients significatifs au seuil 0,05 sont identifiés par une astérisque, les coefficientssignificatifs au seuil de 0,01 par deux astérisques, et les degrés de liberté sont supprimés.Cette configuration affecte aussi bien les matrices de corrélation partielle que simple.
Options Corrélations partiellesFigure 26-2Boîte de dialogue Corrélations partielles : Options

374
Chapitre 26
Statistiques : Vous avez le choix entre les deux options suivantes :Moyennes et écarts-types : Affichés pour chaque variable. Le nombre d’observations avecvaleurs non manquantes est également affiché.Corrélations simples : Une matrice de corrélations simples entre toutes les variables, y comprisles variables de contrôle, s’affiche.
Valeurs manquantes : Vous avez le choix entre les options suivantes :Exclure toute observation incomplète : Les observations ayant des valeurs manquantes pour unevariable quelconque, y compris une variable de contrôle, sont exclues de tous les calculs.Exclure seulement les composantes non valides : Pour le calcul des corrélations simples surlesquelles se basent les corrélations partielles, une observation ayant des valeurs manquantespour une composante ou les deux composantes d’une paire de variables ne sera pas utilisée.La suppression des composantes non valides seulement utilise autant de données que possible.Le nombre d’observations peut toutefois différer selon les coefficients. Lorsque la suppressiondes composantes non valides seulement est sélectionnée, les degrés de liberté d’un coefficientpartiel donné sont basés sur le plus petit nombre d’observations utilisées dans le calcul del’une quelconque des corrélations d’ordre zéro.
Fonctionnalités supplémentaires de la commande PARTIAL CORR
Le langage de syntaxe de commande vous permet aussi de :Lire une matrice de corrélation d’ordre zéro ou écrire une matrice de corrélation d’ordre zéro(avec la sous-commande MATRIX).Obtenir des corrélations partielles entre deux listes de variables (en utilisant le mot-clé WITHdans la sous-commande VARIABLES).Obtenir des analyses multiples (avec les sous-commandes VARIABLES).Spécifier les valeurs des ordres à demander (par exemple, à la fois les corrélations partiellesde premier et de second ordre) lorsque vous avez deux variables de contrôle (avec lasous-commande VARIABLES).Supprimer les coefficients redondants (avec la sous-commande FORMAT).Afficher une matrice de corrélations simples lorsque certains coefficients ne peuvent pas êtrecalculés (avec la sous-commande STATISTICS).
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.

Chapitre
27Distances
Cette procédure permet de calculer de très nombreuses statistiques mesurant les similitudes oules différences (distances) entre des paires de variables ou d’observations. Vous pourrez ensuiteutiliser ces mesures de similarité ou de dissimilarité avec d’autres procédures, comme l’analysefactorielle, la classification ou le positionnement multidimensionnel, afin de simplifier l’analysedes fichiers de données complexes.
Exemple : Est-il possible de mesurer les similarités entre des paires de voitures en fonction decertaines caractéristiques, comme le nombre de cylindres, la consommation et la puissance ? Encalculant les similarités existant entre des voitures, vous pouvez déterminer les voitures quisont semblables et celles qui sont différentes. Dans l’optique d’une analyse plus formelle, vouspouvez appliquer une classification hiérarchique ou un positionnement multidimensionnel auxsimilarités afin d’examiner la structure sous-jacente.
Statistiques : Pour les données d’intervalle, les mesures de dissimilarité sont la distanceEuclidienne, le carré de la distance Euclidienne, la distance de Tchebycheff, la distance deManhattan (bloc), la distance de Minkowski ou une mesure personnalisée. Pour les donnéesd’effectif, les mesures sont khi-deux et phi-deux. Pour les données binaires, les mesures dedissimilarité sont la distance Euclidienne, le carré de la distance Euclidienne, l’écart de taille, ladifférence de motif, la variance, la forme, ou la mesure de Lance et Williams. Pour les donnéesd’intervalles, les mesures de similarité sont la corrélation de Pearson ou cosinus. Pour les donnéesbinaires, il s’agit des mesures suivantes : Russel et Rao, indice de Sokal et Michener, Jaccard,Dice, Rogers et Tanimoto, Sokal et Sneath 1, Sokal et Sneath 2, Sokal et Sneath 3, Kulczynski 1,Kulczynski 2, Sokal et Sneath 4, Hamann, lambda, D d’Anderberg, Y de Yule, Q de Yule, Ochiai,Sokal et Sneath 5, corrélation phi tétrachorique ou dispersion.
Pour obtenir des matrices de distance
E A partir des menus, sélectionnez :Analyse
CorrélationIndices
375
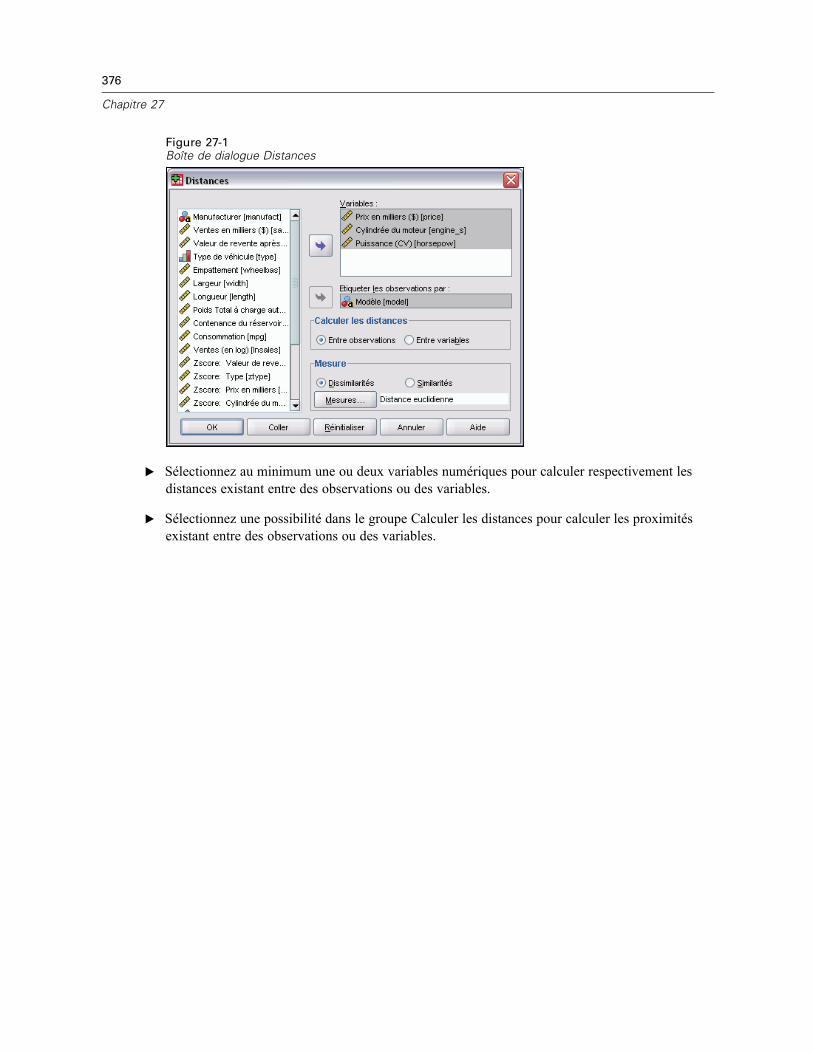
376
Chapitre 27
Figure 27-1Boîte de dialogue Distances
E Sélectionnez au minimum une ou deux variables numériques pour calculer respectivement lesdistances existant entre des observations ou des variables.
E Sélectionnez une possibilité dans le groupe Calculer les distances pour calculer les proximitésexistant entre des observations ou des variables.
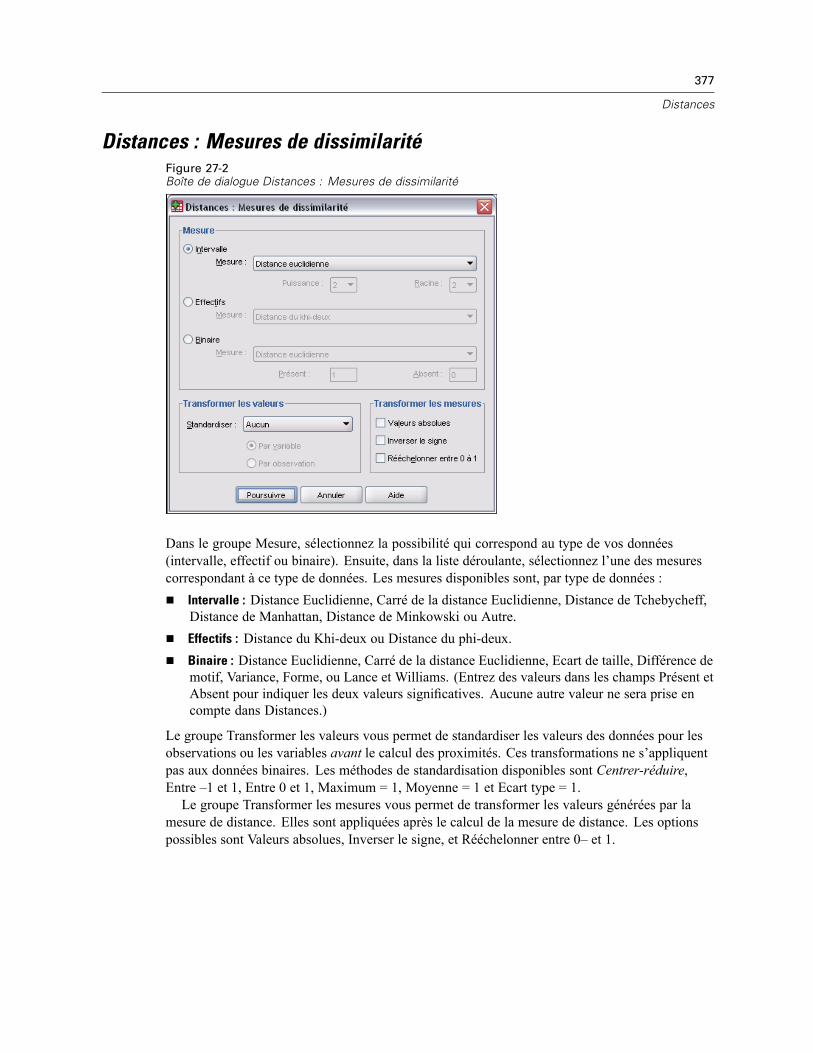
377
Distances
Distances : Mesures de dissimilaritéFigure 27-2Boîte de dialogue Distances : Mesures de dissimilarité
Dans le groupe Mesure, sélectionnez la possibilité qui correspond au type de vos données(intervalle, effectif ou binaire). Ensuite, dans la liste déroulante, sélectionnez l’une des mesurescorrespondant à ce type de données. Les mesures disponibles sont, par type de données :
Intervalle : Distance Euclidienne, Carré de la distance Euclidienne, Distance de Tchebycheff,Distance de Manhattan, Distance de Minkowski ou Autre.Effectifs : Distance du Khi-deux ou Distance du phi-deux.Binaire : Distance Euclidienne, Carré de la distance Euclidienne, Ecart de taille, Différence demotif, Variance, Forme, ou Lance et Williams. (Entrez des valeurs dans les champs Présent etAbsent pour indiquer les deux valeurs significatives. Aucune autre valeur ne sera prise encompte dans Distances.)
Le groupe Transformer les valeurs vous permet de standardiser les valeurs des données pour lesobservations ou les variables avant le calcul des proximités. Ces transformations ne s’appliquentpas aux données binaires. Les méthodes de standardisation disponibles sont Centrer-réduire,Entre –1 et 1, Entre 0 et 1, Maximum = 1, Moyenne = 1 et Ecart type = 1.Le groupe Transformer les mesures vous permet de transformer les valeurs générées par la
mesure de distance. Elles sont appliquées après le calcul de la mesure de distance. Les optionspossibles sont Valeurs absolues, Inverser le signe, et Rééchelonner entre 0– et 1.

378
Chapitre 27
Distances : Mesures de similaritéFigure 27-3Boîte de dialogue Distances : Mesures de similarité
Dans le groupe Mesure, sélectionnez la possibilité qui correspond au type de vos données(intervalle ou binaire). Ensuite, dans la liste déroulante, sélectionnez l’une des mesurescorrespondant à ce type de données. Les mesures disponibles sont, par type de données :
Intervalle : Corrélation de Pearson ou Cosinus.Binaire : Russel et Rao, Indice de Sokal et Michener, Jaccard, Dice, Rogers et Tanimoto, Sokalet Sneath 1, Sokal et Sneath 2, Sokal et Sneath 3, Kulczynski 1, Kulczynski 2, Sokal etSneath 4, Hamann, Lambda, D d’Anderberg, Y de Yule, Q de Yule, Ochiai, Sokal et Sneath 5,Corrélation phi tétrachorique ou Dispersion. (Entrez des valeurs dans les champs Présent etAbsent pour indiquer les deux valeurs significatives. Aucune autre valeur ne sera prise encompte dans Distances.)
Le groupe Transformer les valeurs vous permet de standardiser les valeurs des données pour lesobservations ou les variables avant le calcul des proximités. Ces transformations ne s’appliquentpas aux données binaires. Les méthodes de standardisation disponibles sont Centrer-réduire,Entre –1 et 1, Entre 0 et 1, Maximum = 1, Moyenne = 1 ou Ecart type = 1.Le groupe Transformer les mesures vous permet de transformer les valeurs générées par la
mesure de distance. Elles sont appliquées après le calcul de la mesure de distance. Les optionspossibles sont Valeurs absolues, Inverser le signe, et Rééchelonner entre 0– et 1.
Fonctionnalités supplémentaires de la commande PROXIMITIES
La procédure Distances utilise la syntaxe de la commande PROXIMITIES. Le langage de syntaxede commande vous permet aussi de :
Indiquez un nombre entier comme la puissance pour la mesure de distance de Minkowski.Indiquez des nombres entiers comme la puissance et la racine pour une mesure de distancepersonnalisée.

379
Distances
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.

Chapitre
28Régression linéaire
La régression linéaire estime les coefficients de l’équation linéaire, impliquant une ou plusieursvariables indépendantes, qui estiment le mieux la valeur de la variable dépendante. Par exemple,vous pouvez essayer d’estimer les ventes annuelles globales d’un commercial (la variabledépendante) à partir de variables indépendantes telles que l’âge, l’éducation et les annéesd’expérience.
Exemple : Le nombre de matches gagnés par une équipe de basket-ball au cours d’une saisonest-il lié au nombre moyen de points marqués par l’équipe à chaque match ? Un diagrammede dispersion indique que ces variables ont un lien linéaire. Le nombre de matches gagnés etle nombre moyen de points marqué par l’équipe adverse ont également un lien linéaire. Cesvariables ont une relation négative. Lorsque le nombre de matches gagnés augmente, le nombremoyen de points marqués par les adversaires diminue. A l’aide de la régression linéaire, vouspouvez modéliser la relation entre ces variables. Un bon modèle peut être utilisé pour prévoircombien de matches les équipes vont gagner.
Statistiques : Pour chaque variable, on a les éléments suivants : nombre d’observations valides,moyenne et écart-type. Pour chaque modèle : coefficients de régression, matrice de corrélations,mesures et corrélations partielles, R multiple, R2, R2 ajusté, variation de R2, erreur standardde l’estimation, tableau d’analyse de la variance, prévisions et résidus. En plus, intervalles deconfiance à 95 % pour chaque coefficient de régression, matrice variances-covariances, facteurd’inflation de la variance, tolérance, test de Durbin-Watson, mesures de distances (Mahalanobis,Cook, et valeurs influentes), DfBêta, différence de prévision, intervalles d’estimation etdiagnostics des observations. Diagrammes : dispersion, diagrammes partiels, histogrammes etdiagrammes de répartition gaussiens.
Données : Les variables dépendantes et indépendantes doivent être quantitatives. Les variablesqualitatives, comme la religion, la qualification, la zone de résidence, doivent être enregistréessous forme de variables binaires (muettes) ou sous de tout autre type de variables de contraste.
Hypothèses : Pour chaque valeur de la variable indépendante, la distribution de la variabledépendante doit être normale. La variance de la distribution de la variable dépendante doitêtre constante pour toutes les valeurs de la variable indépendante. La relation entre la variabledépendante et chaque variable indépendante doit être linéaire et toutes les observations doiventêtre indépendantes.
Obtenir une analyse de régression linéaire
E A partir des menus, sélectionnez :Analyse
RégressionLinéaire
380
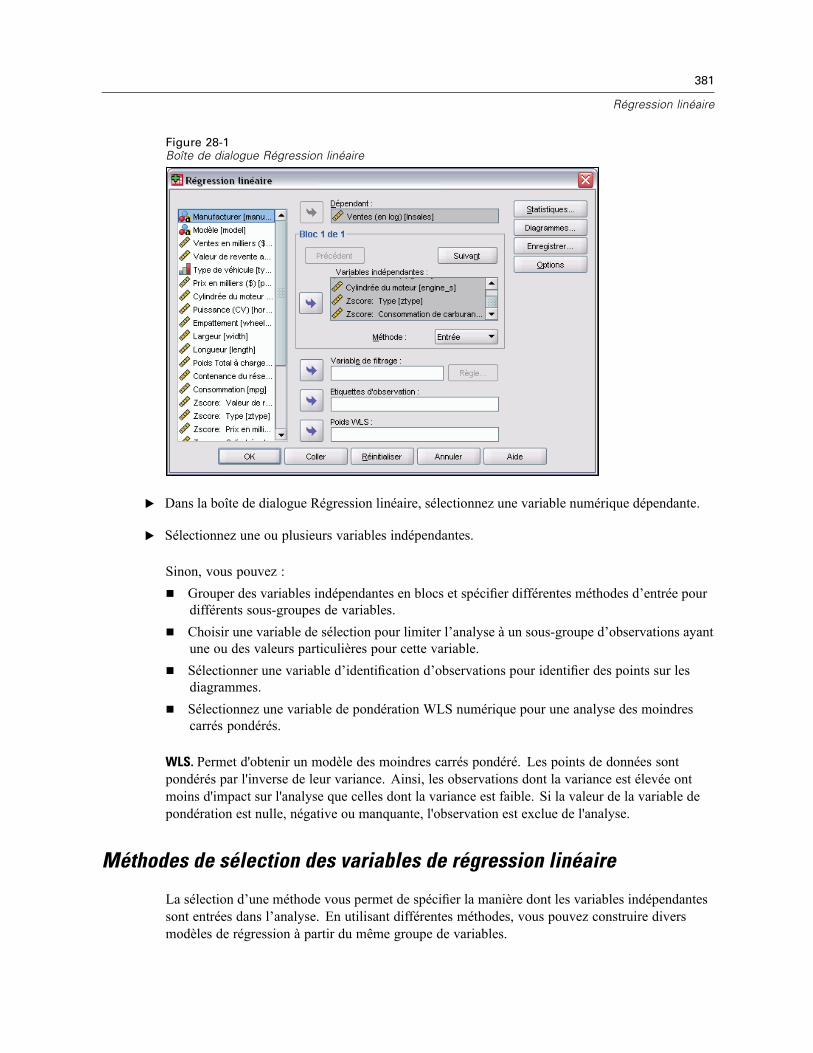
381
Régression linéaire
Figure 28-1Boîte de dialogue Régression linéaire
E Dans la boîte de dialogue Régression linéaire, sélectionnez une variable numérique dépendante.
E Sélectionnez une ou plusieurs variables indépendantes.
Sinon, vous pouvez :Grouper des variables indépendantes en blocs et spécifier différentes méthodes d’entrée pourdifférents sous-groupes de variables.Choisir une variable de sélection pour limiter l’analyse à un sous-groupe d’observations ayantune ou des valeurs particulières pour cette variable.Sélectionner une variable d’identification d’observations pour identifier des points sur lesdiagrammes.Sélectionnez une variable de pondération WLS numérique pour une analyse des moindrescarrés pondérés.
WLS. Permet d'obtenir un modèle des moindres carrés pondéré. Les points de données sontpondérés par l'inverse de leur variance. Ainsi, les observations dont la variance est élevée ontmoins d'impact sur l'analyse que celles dont la variance est faible. Si la valeur de la variable depondération est nulle, négative ou manquante, l'observation est exclue de l'analyse.
Méthodes de sélection des variables de régression linéaire
La sélection d’une méthode vous permet de spécifier la manière dont les variables indépendantessont entrées dans l’analyse. En utilisant différentes méthodes, vous pouvez construire diversmodèles de régression à partir du même groupe de variables.

382
Chapitre 28
Introduire (régression). Procédure de sélection de variables au cours de laquelle toutes lesvariables d'un bloc sont introduites en une seule opération.Pas à pas. A chaque étape, le programme saisit la variable indépendante exclue de l'équationayant la plus petite probabilité de F, si cette probabilité est suffisamment faible. Les variablesdéjà comprises dans l'équation de régression sont éliminées si leur probabilité de F devient tropgrande. Le processus s'arrête lorsqu'aucune variable ne peut plus être introduite ou éliminée.Eliminer bloc. Procédure de sélection de variables dans laquelle toutes les variables d'un blocsont supprimées en une seule étape.Elimination descendante. Procédure de sélection de variables au cours de laquelle toutes lesvariables sont entrées dans l'équation, puis éliminées une à une. La variable ayant la pluspetite corrélation partielle avec la variable dépendante est la variable dont l'élimination estétudiée en premier. Si elle répond aux critères d'élimination, elle est supprimée. Une foisla première variable éliminée, l'élimination de la variable suivante restant dans l'équation etayant le plus petit coefficient de corrélation partielle est étudiée. La procédure prend fin quandplus aucune variable de l'équation ne satisfait aux critères d'élimination.Introduction ascendante. Procédure de sélection pas à pas de variables, dans laquelle lesvariables sont introduites séquentiellement dans le modèle. La première variable considéréeest celle qui a la plus forte corrélation positive ou négative avec la variable dépendante. Cettevariable n'est introduite dans l'équation que si elle satisfait le critère d'introduction. Si lapremière variable est introduite dans l'équation, la variable indépendante externe à l'équationet qui présente la plus forte corrélation partielle est considérée ensuite. La procédures'interrompt lorsqu'il ne reste plus de variables satisfaisant au critère d'introduction.
Les valeurs de significativité dans vos résultats sont basées sur l’adéquation à un modèle unique.Par conséquent, les valeurs de significativité ne sont généralement pas valables lorsqu’on utiliseune méthode progressive (pas à pas, ascendante ou descendante).Toutes les variables doivent respecter le critère de tolérance pour être entrées dans l’équation,
quelle que soit la méthode d’entrée spécifiée. Le niveau de tolérance par défaut est 0,0001. Unevariable n’est pas entrée si elle fait passer la tolérance d’une autre variable déjà entrée dansle modèle en dessous du seuil de tolérance.Toutes les variables indépendantes sélectionnées sont ajoutées dans un seul modèle de
régression. Cependant, vous pouvez spécifier différentes méthodes d’entrée pour les sous-groupesde variables. Par exemple, vous pouvez entrer un bloc de variables dans le modèle de régressionen utilisant la sélection pas à pas, et un second bloc en utilisant la sélection ascendante. Pourajouter un second bloc de variables au modèle de régression, cliquez sur Suivant.
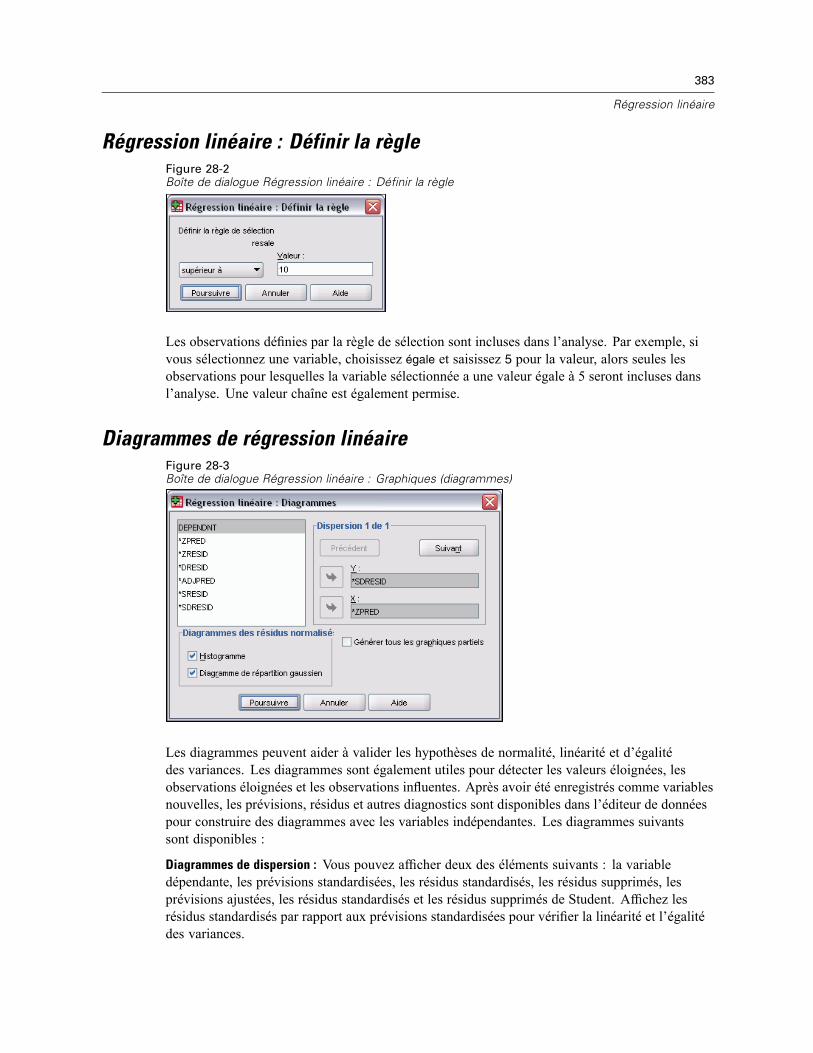
383
Régression linéaire
Régression linéaire : Définir la règleFigure 28-2Boîte de dialogue Régression linéaire : Définir la règle
Les observations définies par la règle de sélection sont incluses dans l’analyse. Par exemple, sivous sélectionnez une variable, choisissez égale et saisissez 5 pour la valeur, alors seules lesobservations pour lesquelles la variable sélectionnée a une valeur égale à 5 seront incluses dansl’analyse. Une valeur chaîne est également permise.
Diagrammes de régression linéaireFigure 28-3Boîte de dialogue Régression linéaire : Graphiques (diagrammes)
Les diagrammes peuvent aider à valider les hypothèses de normalité, linéarité et d’égalitédes variances. Les diagrammes sont également utiles pour détecter les valeurs éloignées, lesobservations éloignées et les observations influentes. Après avoir été enregistrés comme variablesnouvelles, les prévisions, résidus et autres diagnostics sont disponibles dans l’éditeur de donnéespour construire des diagrammes avec les variables indépendantes. Les diagrammes suivantssont disponibles :
Diagrammes de dispersion : Vous pouvez afficher deux des éléments suivants : la variabledépendante, les prévisions standardisées, les résidus standardisés, les résidus supprimés, lesprévisions ajustées, les résidus standardisés et les résidus supprimés de Student. Affichez lesrésidus standardisés par rapport aux prévisions standardisées pour vérifier la linéarité et l’égalitédes variances.
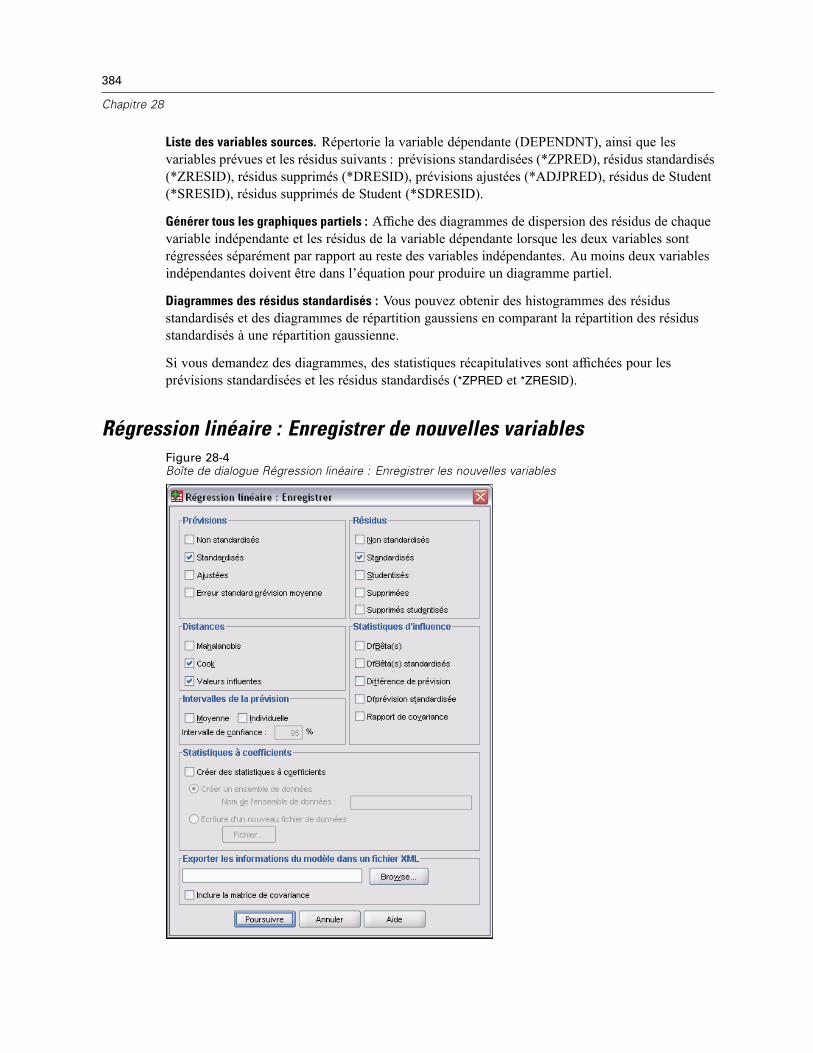
384
Chapitre 28
Liste des variables sources. Répertorie la variable dépendante (DEPENDNT), ainsi que lesvariables prévues et les résidus suivants : prévisions standardisées (*ZPRED), résidus standardisés(*ZRESID), résidus supprimés (*DRESID), prévisions ajustées (*ADJPRED), résidus de Student(*SRESID), résidus supprimés de Student (*SDRESID).
Générer tous les graphiques partiels : Affiche des diagrammes de dispersion des résidus de chaquevariable indépendante et les résidus de la variable dépendante lorsque les deux variables sontrégressées séparément par rapport au reste des variables indépendantes. Au moins deux variablesindépendantes doivent être dans l’équation pour produire un diagramme partiel.
Diagrammes des résidus standardisés : Vous pouvez obtenir des histogrammes des résidusstandardisés et des diagrammes de répartition gaussiens en comparant la répartition des résidusstandardisés à une répartition gaussienne.
Si vous demandez des diagrammes, des statistiques récapitulatives sont affichées pour lesprévisions standardisées et les résidus standardisés (*ZPRED et *ZRESID).
Régression linéaire : Enregistrer de nouvelles variablesFigure 28-4Boîte de dialogue Régression linéaire : Enregistrer les nouvelles variables

385
Régression linéaire
Vous pouvez enregistrer les prévisions, les résidus et autres statistiques utiles pour les diagnostics.Chaque sélection ajoute une ou plusieurs variables à votre fichier de données actif.
Prévisions : Valeurs prévues par le modèle de régression pour chaque observation.Non standardisés. Valeur prévue par le modèle pour la variable dépendante.Standardisé. Transformation de chaque prévision en sa forme normalisée. La prévisionmoyenne est soustraite de la prévision, et la différence est divisée par l'écart-type desprévisions. Les prévisions standardisées ont une moyenne de 0 et un écart-type de 1.Ajustées. Prévision pour une observation lorsqu'une observation est exclue du calcul descoefficients de régression.Erreur standard prévision moyenne. Erreurs standard des prévisions. Estimation de l'écart-typede la valeur moyenne de la variable expliquée pour les unités statistiques qui ont les mêmesvaleurs pour les valeurs explicatives.
Distances : Mesures permettant d’identifier les observations avec des combinaisons inhabituellesde valeurs pour les variables indépendantes et les observations qui peuvent avoir un impactimportant sur le modèle.
Mahalanobis. Mesure de la distance entre les valeurs d'une observation et la moyenne de toutesles observations sur les variables indépendantes. Une distance de Mahalanobis importanteidentifie une observation qui a des valeurs extrêmes pour des variables indépendantes.Cook. Mesure du degré dont les résidus de toutes les observations sont modifiés si uneobservation donnée est exclue des calculs des coefficients de régression. Si la distance deCook est élevée, l'exclusion d'une observation changerait substantiellement la valeur descoefficients.Valeurs influentes. Mesures de l'influence d'un point sur l'ajustement de la régression. Lavaleur influente centrée varie de 0 (aucune influence sur la qualité de l'ajustement) à (N-1)/N.
Intervalles de la prévision : Les limites supérieure et inférieure pour les intervalles de la prévisionmoyenne et individuelle.
Moyenne. Limites inférieure et supérieure (deux variables) de l'intervalle de prévision de laréponse moyenne prévue.Individuelle. Limites inférieure et supérieure (deux variables) de l'intervalle de prévision de lavariable dépendante pour une seule observation.Intervalle de confiance. Entrez une valeur comprise entre 1 et 99,99 pour spécifier le seuil deconfiance pour les deux intervalles de la prévision. Vous devez sélectionner Moyenne ouIndividuelle avant d'entrer cette valeur. Les seuils d'intervalle de confiance typiques sont 90,95 et 99.
Résidus : La valeur réelle de la variable indépendante moins la valeur prévue par l’équation derégression.
Non standardisés. Différence entre la valeur observée et la valeur prévue par le modèle.Standardisé. Résidu, divisé par une estimation de son erreur standard. Egalement appelésrésidus de Pearson, les résidus standardisés ont une moyenne de 0 et un écart-type de 1.Studentisés. Résidu, divisé par une estimation de son écart‑type, qui varie d'une observationà l'autre, selon la distance entre les valeurs et la moyenne des variables indépendantes pourchaque observation.

386
Chapitre 28
Supprimées. Résidu d'une observation lorsque celle‑ci est exclue du calcul des coefficients derégression. Il s'agit de la différence entre la valeur de la variable dépendante et la prévisionajustée.Supprimés studentisés. Résidu supprimé d'une observation, divisé par son erreur standard. Ladifférence entre le résidu supprimé de Student et le résidu de Student associé indique l'impactde l'élimination d'une observation sur sa propre prédiction.
Influences individuelles : Modification des coefficients de régression (DfBêta[s]) et des prévisions(différence de prévision) qui résulte de l’exclusion d’une observation particulière. Les valeursDfBêtas et de différence de prévision standardisées sont également disponibles ainsi que lerapport de covariance.
Différence de bêta. La différence de bêta correspond au changement des coefficients derégression qui résulte du retrait d'une observation particulière. Une valeur est calculée pourchaque terme du modèle, y compris la constante.DfBêta(s) standardisée. Différence normalisée de la valeur bêta. Modification du coefficientde régression, résultant de l'exclusion d'une observation donnée. Vous pouvez par exempleexaminer les observations ayant des valeurs absolues supérieures à 2, divisées par la racinecarrée de N, N représentant le nombre d'observations. Une valeur est calculée pour chaqueterme du modèle, y compris la constante.Différence d'ajustement. La différence d'ajustement est le changement de la prévision résultantde l'exclusion d'une observation donnée.Dfprévision standardisée. Différence normalisée de la valeur ajustée. Modification de laprévision qui résulte de l'exclusion d'une observation donnée. Vous pouvez par exempleexaminer les valeurs standardisées dont la valeur absolue est supérieure à 2 fois la racine carréede p/N, p correspondant au nombre de paramètres du modèle et N, au nombre d'observations.Rapport de covariance. Rapport entre le déterminant de la matrice de variance‑covariance siune observation donnée a été exclue du calcul des coefficients de régression et le déterminantde la matrice de covariance avec toutes les observations incluses. Si le rapport est proche de1, l'observation modifie peu la matrice de covariance.
Statistiques à coefficients : Enregistre les coefficients de régression dans un ensemble de donnéesou dans un fichier de données. Les ensembles de données sont disponibles pour utilisationultérieure dans la même session mais ne sont pas enregistrés en tant que fichiers sauf si vousle faites explicitement avant la fin de la session. Le nom des ensembles de données doit êtreconforme aux règles de dénomination de variables. Pour plus d'informations, reportez-vous àNoms de variable dans Chapitre 5 sur p. 84.
Exporter les informations du modèle dans un fichier XML : Les estimations de paramètres etleurs covariances (facultatif) sont exportées vers le fichier spécifié au format XML (PMML).SmartScore et le serveur de SPSS Statistics (produit séparé) peuvent utiliser ce fichier de modèlepour appliquer les informations du modèle à d’autres fichiers de données à des fins d’analyse.
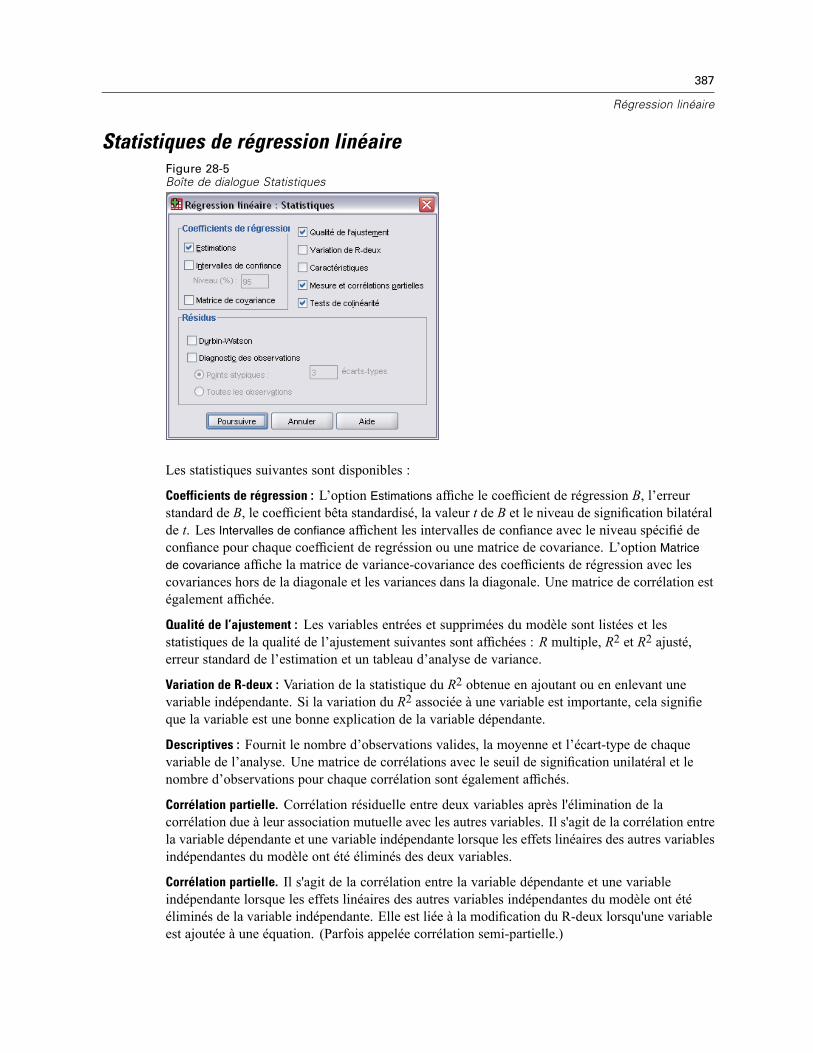
387
Régression linéaire
Statistiques de régression linéaireFigure 28-5Boîte de dialogue Statistiques
Les statistiques suivantes sont disponibles :
Coefficients de régression : L’option Estimations affiche le coefficient de régression B, l’erreurstandard de B, le coefficient bêta standardisé, la valeur t de B et le niveau de signification bilatéralde t. Les Intervalles de confiance affichent les intervalles de confiance avec le niveau spécifié deconfiance pour chaque coefficient de regréssion ou une matrice de covariance. L’option Matrice
de covariance affiche la matrice de variance-covariance des coefficients de régression avec lescovariances hors de la diagonale et les variances dans la diagonale. Une matrice de corrélation estégalement affichée.
Qualité de l’ajustement : Les variables entrées et supprimées du modèle sont listées et lesstatistiques de la qualité de l’ajustement suivantes sont affichées : R multiple, R2 et R2 ajusté,erreur standard de l’estimation et un tableau d’analyse de variance.
Variation de R-deux : Variation de la statistique du R2 obtenue en ajoutant ou en enlevant unevariable indépendante. Si la variation du R2 associée à une variable est importante, cela signifieque la variable est une bonne explication de la variable dépendante.
Descriptives : Fournit le nombre d’observations valides, la moyenne et l’écart-type de chaquevariable de l’analyse. Une matrice de corrélations avec le seuil de signification unilatéral et lenombre d’observations pour chaque corrélation sont également affichés.
Corrélation partielle. Corrélation résiduelle entre deux variables après l'élimination de lacorrélation due à leur association mutuelle avec les autres variables. Il s'agit de la corrélation entrela variable dépendante et une variable indépendante lorsque les effets linéaires des autres variablesindépendantes du modèle ont été éliminés des deux variables.
Corrélation partielle. Il s'agit de la corrélation entre la variable dépendante et une variableindépendante lorsque les effets linéaires des autres variables indépendantes du modèle ont étééliminés de la variable indépendante. Elle est liée à la modification du R-deux lorsqu'une variableest ajoutée à une équation. (Parfois appelée corrélation semi-partielle.)

388
Chapitre 28
Tests de colinéarité : La colinéarité (ou multicolinéarité) est la situation indésirable où une variableindépendante est une fonction linéaire d’autres variables indépendantes. Les valeurs propres dela matrice des produits croisés dimensionnés et non centrés, les indices de conditionnement etles proportions de décomposition de variance sont affichés ainsi que les facteurs d’inflation de lavariance (VIF) et les tolérances pour les variables individuelles.
Résidus : Affiche le test de Durbin-Watson de corrélation sérielle des résidus et le diagnostic desobservations correspondant au critère de sélection (valeurs éloignées de n écarts-types).
Régression linéaire : OptionsFigure 28-6Boîte de dialogue Régression linéaire : Options
Les options suivantes sont disponibles :
Paramètres des méthodes progressives : Ces options sont valables lorsque la méthode de sélectionascendante, descendante ou progressive a été sélectionnée. Des variables peuvent être entréesou supprimées du modèle soit en fonction de la signification (probabilité) de la valeur F, soit enfonction de la valeur F elle-même.
Utiliser la probabilité de F.Une variable est entrée dans le modèle si le seuil de signification dela valeur F est inférieur à la valeur Entrée ; la variable est éliminée si ce seuil est supérieur à lavaleur Elimination. La valeur Entrée doit être inférieure à la valeur Elimination et toutes deuxdoivent être positives. Pour introduire davantage de variables dans le modèle, diminuez lavaleur Entrée. Pour éliminer davantage de variables du modèle, réduisez la valeur Elimination.Utiliser la valeur de F. Une variable est introduite dans un modèle si sa valeur F est supérieureà la valeur Entrée et elle est éliminée si la valeur F est inférieure à la valeur Elimination.La valeur Entrée doit être supérieure à la valeur Elimination et toutes deux doivent êtrepositives. Pour introduire davantage de variables dans le modèle, réduisez la valeur duchamp Entrée. Pour éliminer davantage de variables dans le modèle, augmentez la valeur duchamp Elimination.

389
Régression linéaire
Inclure terme constant dans l’équation : Par défaut, le modèle de régression inclut un termeconstant. Désélectionner cette option force la régression jusqu’à l’origine, ce qui est rarementutilisé. Certains résultats de la régression jusqu’à l’origine ne sont pas comparables aux résultatsde la régression incluant une constante. Par exemple, R2 ne peut pas être interprété de la manièrehabituelle.
Valeurs manquantes : Vous pouvez choisir l’un des éléments suivants :Exclure toute observation incomplète : Seules les observations dont les valeurs sont validespour toutes les variables sont incluses dans les analyses.Exclure seulement les composantes non valides : Les observations pour lesquelles les donnéessont complètes pour la paire de variables corrélées sont utilisées pour calculer le coefficient decorrélation sur lequel l’analyse de régression est basée. Les degrés de liberté sont basés surle minimum N par paire.Remplacer par la moyenne : Toutes les observations sont utilisées pour les calculs, ensubstituant la moyenne de la variable aux observations manquantes.
Fonctionnalités supplémentaires de la commande REGRESSION
Le langage de syntaxe de commande vous permet aussi de :Ecrire une matrice de corrélation ou lire une matrice à la place de données brutes afin d’obtenirune analyse de régression (avec la sous-commande MATRIX).Spécifier des niveaux de tolérance (avec la sous-commande CRITERIA).Obtenir plusieurs modèles pour des variables dépendantes différentes ou identiques (avec lessous-commandes METHOD et DEPENDENT).Obtenir des statistiques supplémentaires (avec les sous-commandes DESCRIPTIVES etSTATISTICS).
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.

Chapitre
29Régression ordinale
La régression ordinale vous permet d’effectuer un modèle dont la variable dépendante est uneréponse ordinale sur un groupe de prédicteurs pouvant être soit des facteurs, soit des covariables.Le concept de régression ordinale repose sur la méthodologie de McCullagh (1980, 1998) ; voustrouverez cette procédure sous le nom de PLUM dans la syntaxe.L’analyse de la régression linéaire standard implique la réduction des différences de sommes
des carrés entre une variable de réponse (dépendante) et une combinaison pondérée des prédicteurs(variables indépendantes). Les coefficients estimés reflètent le mode d’affectation de la réponsedue aux modifications des prédicteurs. La réponse est numérique, dans le sens où les changementsde niveau de réponse sont équivalents pour l’ensemble des intervalles de réponse. Par exemple,la différence de taille existant entre une personne de 150 cm et une de 140 cm est de 10 cm, cequi correspond à la même différence existant entre une personne de 210 cm et une de 200 cm.Ces relations n’existent peut-être pas pour les variables ordinales, pour lesquelles le choix et lenombre de modalités de réponse peut être relativement arbitraire.
Exemple : La régression ordinale peut être utilisée en vue d’étudier la réaction des patients àcertaines doses de médicament. Les réactions possibles peuvent être classées en aucune, légère,modérée ou grave. La différence entre une réaction légère et une réaction modérée est difficile,voire impossible à quantifier car elle repose sur une perception. De plus, la différence entre uneréponse légère et une réponse modérée peut être supérieure ou inférieure à la différence existantentre une réponse modérée et une réponse grave.
Diagrammes et statistiques : Fréquences observées et théoriques, et fréquences cumulées, résidusde Pearson pour les fréquences cumulées, probabilités observées et théoriques, probabilitésobservées et cumulées théoriques de chaque modalité de réponse par type de covariable,corrélation asymptotique et matrices de covariance des estimations des paramètres, Khi-deux dePearson et Khi-deux du rapport de vraisemblance, qualité d’ajustement, historique des itérations,test d’hypothèses de lignes parallèles, estimations des paramètres, erreurs standard, intervalles deconfiance, statistiques de Cox et Snell, de Nagelkerke et R2 de McFadden.
Données : La variable dépendante est considérée comme ordinale, mais peut être soit numérique,soit chaîne. L’ordre est déterminé par le tri des valeurs de la variable dépendante par ordrecroissant. La plus petite valeur définit la première modalité. Les variables actives sont supposéesêtre qualitatives. Les covariables doivent être numériques. Notez que l’utilisation de plusieurscovariables continues peut engendrer la création d’un tableau volumineux de probabilités parcellule.
Hypothèses : Seule une variable de réponse est autorisée et doit donc être spécifiée. De plus, pourchaque type de valeurs distinct parmi les variables explicatives, les réponses sont supposéesêtre des variables multinomiales explicatives.
390
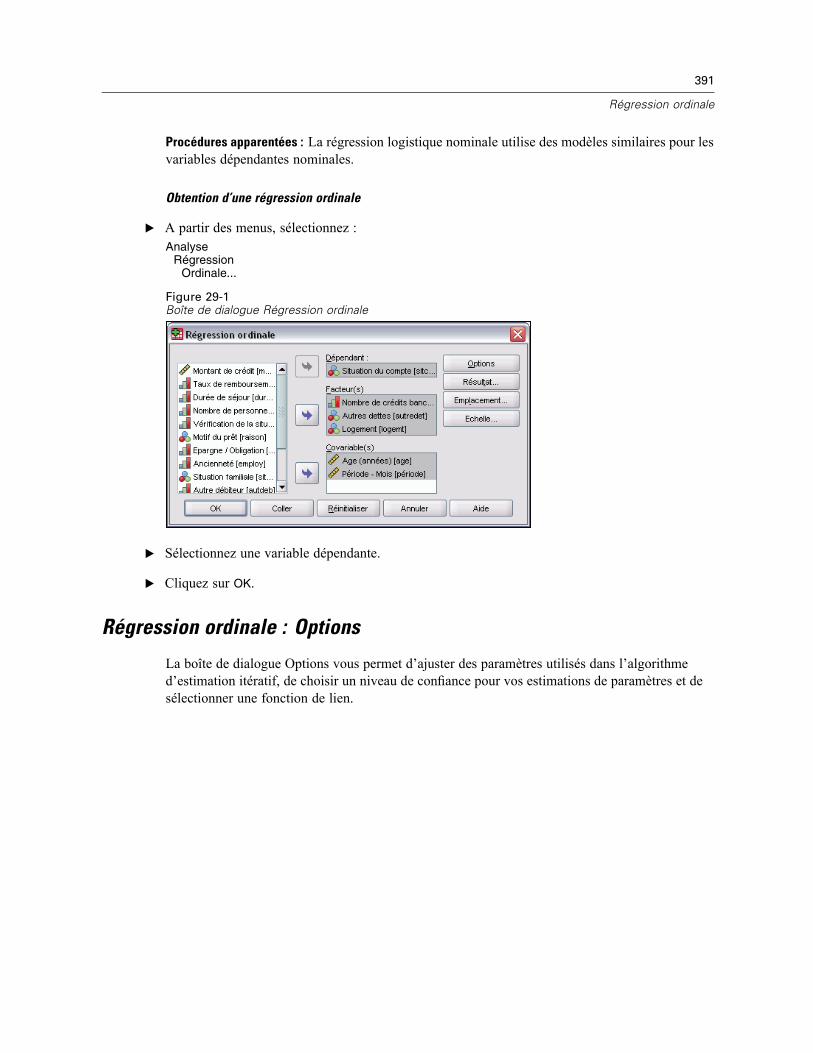
391
Régression ordinale
Procédures apparentées : La régression logistique nominale utilise des modèles similaires pour lesvariables dépendantes nominales.
Obtention d’une régression ordinale
E A partir des menus, sélectionnez :Analyse
RégressionOrdinale...
Figure 29-1Boîte de dialogue Régression ordinale
E Sélectionnez une variable dépendante.
E Cliquez sur OK.
Régression ordinale : Options
La boîte de dialogue Options vous permet d’ajuster des paramètres utilisés dans l’algorithmed’estimation itératif, de choisir un niveau de confiance pour vos estimations de paramètres et desélectionner une fonction de lien.

392
Chapitre 29
Figure 29-2Boîte de dialogue Régression ordinale : Options
Itérations : Vous pouvez personnaliser l’algorithme itératif.Nombre maximum d’itérations : Spécifiez un nombre entier non négatif. Si vous indiquez 0, laprocédure renvoie aux estimations initiales.Nombre maximum de dichotomie : Spécifiez un nombre entier positif.Convergence de log-vraisemblance : L’algorithme s’interrompt si la modification absolueou relative apportée au log-vraisemblance est inférieure à cette valeur. Le critère n’est pasutilisé si 0 est spécifié.Convergence des paramètres : L’algorithme s’interrompt si la modification absolue ou relativeapportée à chaque estimation de paramètres est inférieure à cette valeur. Le critère n’estpas utilisé si 0 est spécifié.
Intervalle de confiance : Spécifiez une valeur supérieure ou égale à 0 et inférieure à 100.
Delta : Valeur ajoutée aux fréquences zéro par cellule. Spécifiez une valeur non négative,inférieure à 1.
Tolérance singularité : Option utilisée pour vérifier les prédicteurs à haute dépendance.Sélectionnez une valeur dans la liste des options.
Fonction de lien : La fonction de lien consiste en une transformation des probabilités cumuléespermettant d’estimer le modèle. Les cinq fonctions de lien disponibles sont récapitulées dans letableau suivant.
Fonction Forme Application standardLogit log( ξ / (1−ξ) ) Modalités réparties de façon égaleLog-log complémentaire log(−log(1−ξ)) Modalités supérieures les plus
probablesLog-log négatif −log(−log(ξ)) Modalités inférieures plus
probablesProbit Φ−1(ξ) Variable de latence normalement
répartieCauchit (Cauchy inverse) tan(π(ξ−0,5)) Variable de latence avec de
nombreux extrema
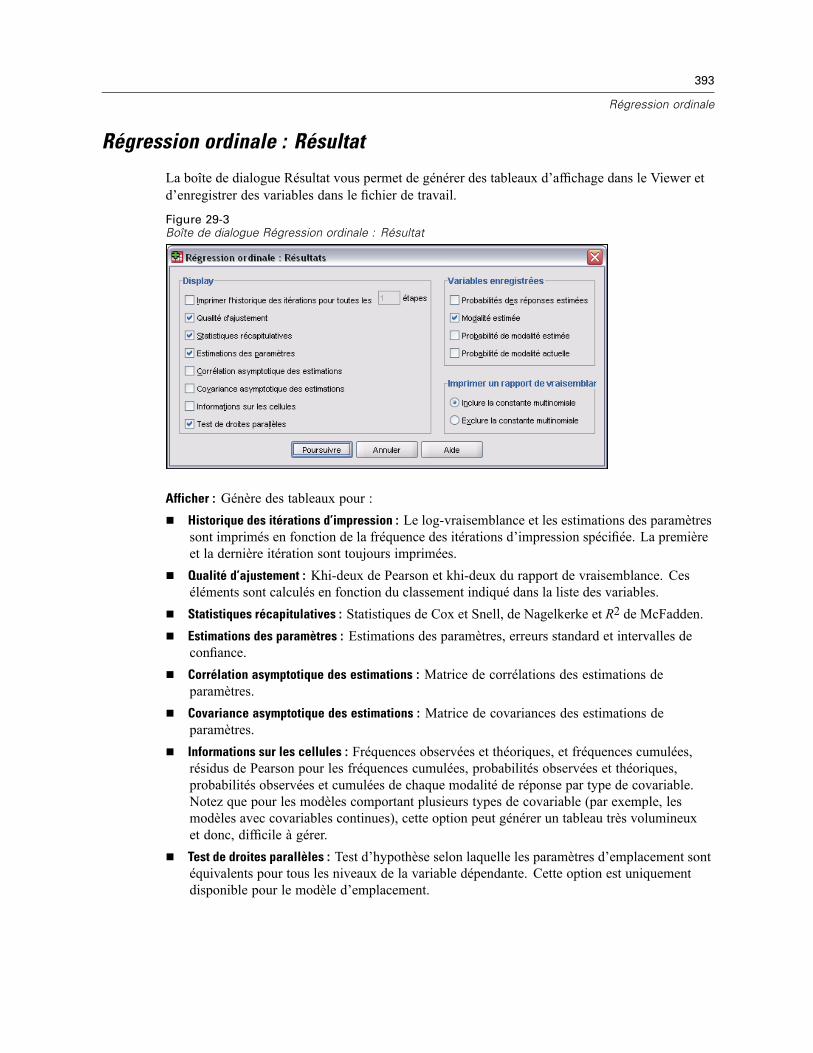
393
Régression ordinale
Régression ordinale : Résultat
La boîte de dialogue Résultat vous permet de générer des tableaux d’affichage dans le Viewer etd’enregistrer des variables dans le fichier de travail.
Figure 29-3Boîte de dialogue Régression ordinale : Résultat
Afficher : Génère des tableaux pour :Historique des itérations d’impression : Le log-vraisemblance et les estimations des paramètressont imprimés en fonction de la fréquence des itérations d’impression spécifiée. La premièreet la dernière itération sont toujours imprimées.Qualité d’ajustement : Khi-deux de Pearson et khi-deux du rapport de vraisemblance. Ceséléments sont calculés en fonction du classement indiqué dans la liste des variables.Statistiques récapitulatives : Statistiques de Cox et Snell, de Nagelkerke et R2 de McFadden.Estimations des paramètres : Estimations des paramètres, erreurs standard et intervalles deconfiance.Corrélation asymptotique des estimations : Matrice de corrélations des estimations deparamètres.Covariance asymptotique des estimations : Matrice de covariances des estimations deparamètres.Informations sur les cellules : Fréquences observées et théoriques, et fréquences cumulées,résidus de Pearson pour les fréquences cumulées, probabilités observées et théoriques,probabilités observées et cumulées de chaque modalité de réponse par type de covariable.Notez que pour les modèles comportant plusieurs types de covariable (par exemple, lesmodèles avec covariables continues), cette option peut générer un tableau très volumineuxet donc, difficile à gérer.Test de droites parallèles : Test d’hypothèse selon laquelle les paramètres d’emplacement sontéquivalents pour tous les niveaux de la variable dépendante. Cette option est uniquementdisponible pour le modèle d’emplacement.

394
Chapitre 29
Variables enregistrées : Enregistre les variables suivantes dans le fichier de travail :Probabilités des réponses estimées : Probabilités estimées sur un modèle de classement d’untype de facteur/covariable dans les modalités de réponse. Il existe autant de probabilités quede nombre de modalités de réponse.Modalité estimée : Modalité de réponse contenant la probabilité estimée maximale pour untype de facteur/covariable.Probabilité de modalité estimée : Probabilité estimée de classement d’un type defacteur/covariable au sein d’une modalité prévue. Cette probabilité représente également lemaximum de probabilités estimées du type de facteur/covariable.Probabilité de modalité actuelle : Probabilité estimée de classement d’un type defacteur/covariable au sein de la modalité actuelle.
Imprimer un rapport de vraisemblance : Commande l’affichage du rapport de log-vraisemblance.Inclure la constante multinomiale vous indique la valeur complète de la vraisemblance. Pourcomparer vos résultats parmi les produits n’incluant pas de constante, vous pouvez choisir del’exclure.
Régression ordinale : Emplacement
La boîte de dialogue Emplacement vous permet de spécifier le modèle d’emplacement de l’analyse.
Figure 29-4Boîte de dialogue Régression ordinale : Emplacement
Spécifier un modèle : Un modèle comportant des effets principaux contient des effets principaux decovariable et de facteur, mais aucun effet d’interaction. Vous pouvez créer un modèle personnalisépour définir des sous-groupes d’interactions de facteurs ou de covariables.
Facteurs/covariables : Les facteurs et les covariables sont répertoriés.
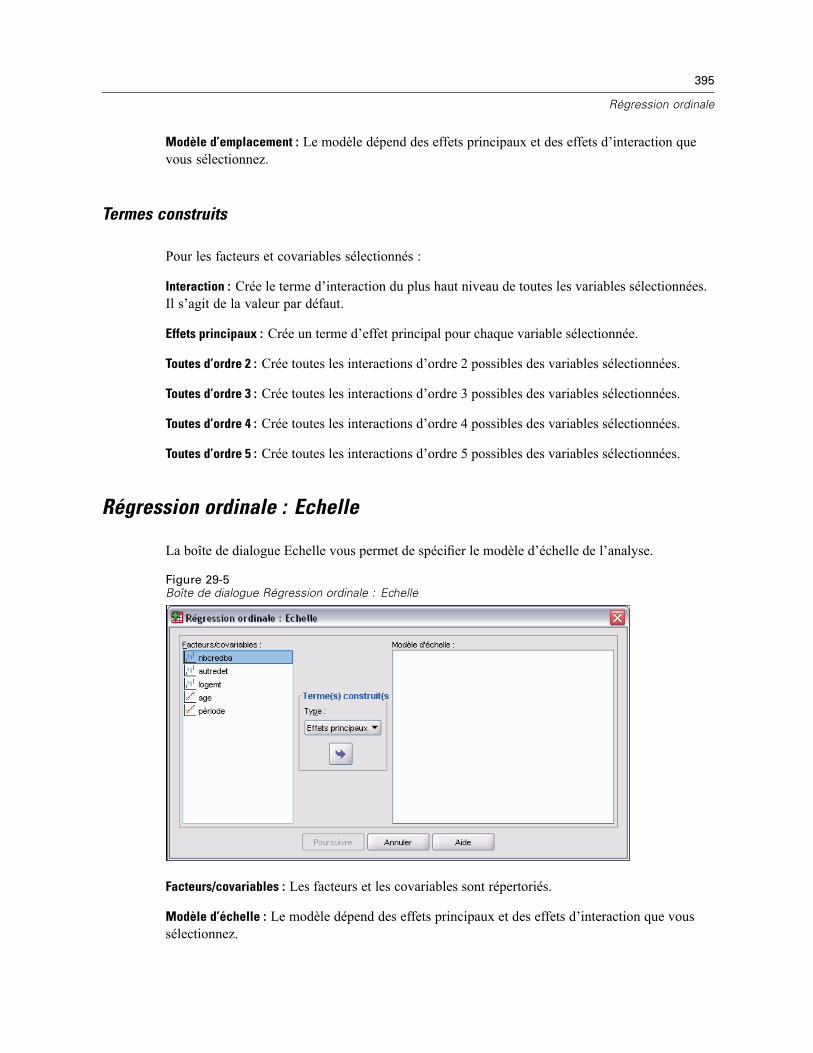
395
Régression ordinale
Modèle d’emplacement : Le modèle dépend des effets principaux et des effets d’interaction quevous sélectionnez.
Termes construits
Pour les facteurs et covariables sélectionnés :
Interaction : Crée le terme d’interaction du plus haut niveau de toutes les variables sélectionnées.Il s’agit de la valeur par défaut.
Effets principaux : Crée un terme d’effet principal pour chaque variable sélectionnée.
Toutes d’ordre 2 : Crée toutes les interactions d’ordre 2 possibles des variables sélectionnées.
Toutes d’ordre 3 : Crée toutes les interactions d’ordre 3 possibles des variables sélectionnées.
Toutes d’ordre 4 : Crée toutes les interactions d’ordre 4 possibles des variables sélectionnées.
Toutes d’ordre 5 : Crée toutes les interactions d’ordre 5 possibles des variables sélectionnées.
Régression ordinale : Echelle
La boîte de dialogue Echelle vous permet de spécifier le modèle d’échelle de l’analyse.
Figure 29-5Boîte de dialogue Régression ordinale : Echelle
Facteurs/covariables : Les facteurs et les covariables sont répertoriés.
Modèle d’échelle : Le modèle dépend des effets principaux et des effets d’interaction que voussélectionnez.

396
Chapitre 29
Termes construits
Pour les facteurs et covariables sélectionnés :
Interaction : Crée le terme d’interaction du plus haut niveau de toutes les variables sélectionnées.Il s’agit de la valeur par défaut.
Effets principaux : Crée un terme d’effet principal pour chaque variable sélectionnée.
Toutes d’ordre 2 : Crée toutes les interactions d’ordre 2 possibles des variables sélectionnées.
Toutes d’ordre 3 : Crée toutes les interactions d’ordre 3 possibles des variables sélectionnées.
Toutes d’ordre 4 : Crée toutes les interactions d’ordre 4 possibles des variables sélectionnées.
Toutes d’ordre 5 : Crée toutes les interactions d’ordre 5 possibles des variables sélectionnées.
Fonctionnalités supplémentaires de la commande PLUM
Vous pouvez personnaliser la régression ordinale en collant vos sélections dans une fenêtre desyntaxe et en modifiant la syntaxe de commande PLUM. Le langage de syntaxe de commandevous permet aussi de :
Créer des tests d’hypothèse personnalisés en spécifiant des hypothèses nulles commecombinaisons linéaires de paramètres.
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.

Chapitre
30Ajustement de fonctions
La procédure d’ajustement de fonctions produit des statistiques de régression d’ajustement defonctions et les diagrammes relatifs pour 11 modèles différents de régression d’ajustement defonctions. Un modèle différent est produit pour chaque variable dépendante. Vous pouvez aussienregistrer les prévisions, les résidus et les intervalles de la prévision comme nouvelles variables.
Exemple : Un fournisseur de services Internet suit le pourcentage dans le temps du trafic demessages électroniques infectés par un virus sur ses réseaux. Un diagramme de dispersion révèleque la relation n’est pas linéaire. Vous pouvez ajuster un modèle quadratique ou cubique enfonction des données, vérifier la validité des hypothèses et la qualité d’ajustement du modèle.
Statistiques : Pour chaque modèle : coefficients de régression, R multiples, R2, R2 ajusté, erreurstandard de la prévision, tableau d’analyse de la variance, prévisions, résidus et intervallesde prévision. Modèles : linéaire, logarithmique, inverse, quadratique, cubique, de puissance,composé, en S, logistique, de croissance et exponentiel.
Données : Les variables dépendantes et indépendantes doivent être quantitatives. Si voussélectionnez Temps à partir de l’ensemble de données actif comme variable indépendante (au lieude sélectionner une variable), la procédure Ajustement de fonctions génère une variable de tempsoù la durée entre les observations est uniforme. Si Temps est sélectionné, la variable dépendantedoit être une mesure de séries chronologiques. L’analyse des séries chronologiques nécessite unestructure de fichier de données dans lequel chaque observation (rangée) représente un ensembled’observations à des moments différents et où la durée entre les observations est uniforme.
Hypothèses : Vérifiez vos données graphiquement pour déterminer comment sont reliées lesvariables indépendantes et dépendantes (de manière linéaire ou exponentielle, etc.). Les résidusd’un bon modèle doivent être répartis aléatoirement et doivent être normaux. Si vous utilisezun modèle linéaire, les hypothèses suivantes doivent être vérifiées : pour chaque valeur de lavariable indépendante, la distribution de la variable dépendante doit être normale. La variance dela distribution de la variable dépendante doit être constante pour toutes les valeurs de la variableindépendante. La relation entre la variable dépendante et la variable indépendante doit êtrelinéaire, et toutes les observations doivent être indépendantes.
Pour obtenir un ajustement de fonctions
E A partir des menus, sélectionnez :Analyse
RégressionAjustement de fonctions
397
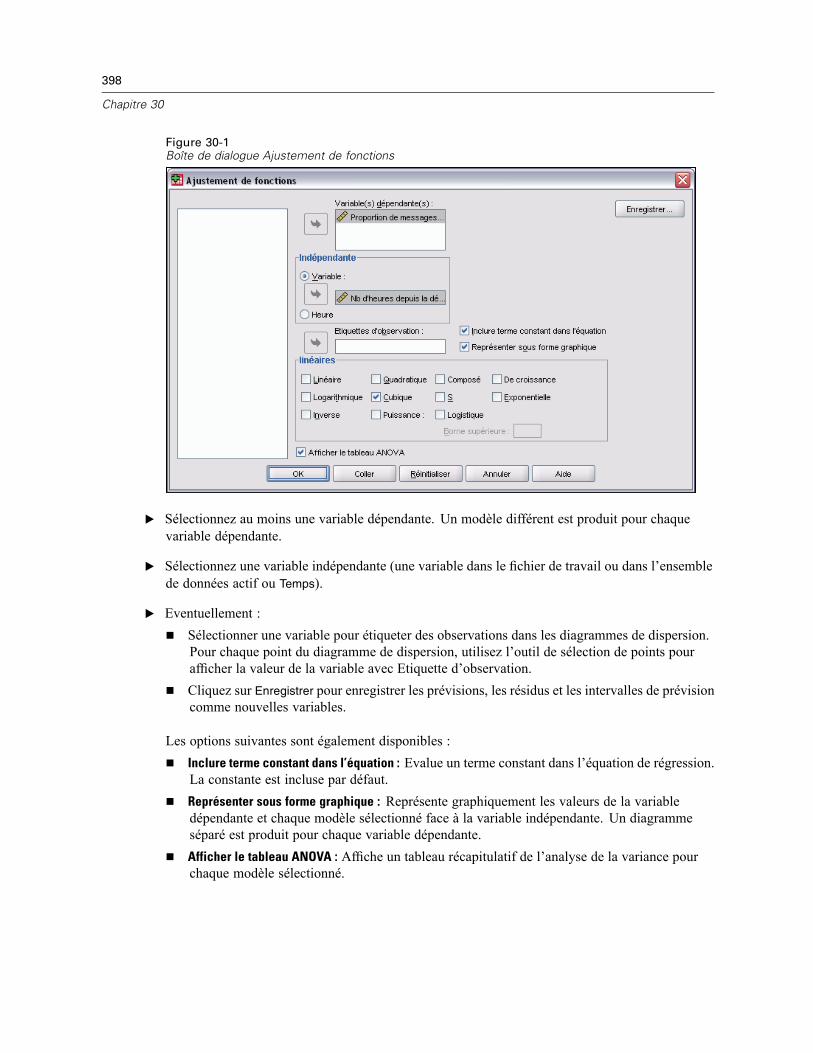
398
Chapitre 30
Figure 30-1Boîte de dialogue Ajustement de fonctions
E Sélectionnez au moins une variable dépendante. Un modèle différent est produit pour chaquevariable dépendante.
E Sélectionnez une variable indépendante (une variable dans le fichier de travail ou dans l’ensemblede données actif ou Temps).
E Eventuellement :Sélectionner une variable pour étiqueter des observations dans les diagrammes de dispersion.Pour chaque point du diagramme de dispersion, utilisez l’outil de sélection de points pourafficher la valeur de la variable avec Etiquette d’observation.Cliquez sur Enregistrer pour enregistrer les prévisions, les résidus et les intervalles de prévisioncomme nouvelles variables.
Les options suivantes sont également disponibles :Inclure terme constant dans l’équation : Evalue un terme constant dans l’équation de régression.La constante est incluse par défaut.Représenter sous forme graphique : Représente graphiquement les valeurs de la variabledépendante et chaque modèle sélectionné face à la variable indépendante. Un diagrammeséparé est produit pour chaque variable dépendante.Afficher le tableau ANOVA : Affiche un tableau récapitulatif de l’analyse de la variance pourchaque modèle sélectionné.

399
Ajustement de fonctions
Modèles d’ajustement de fonctionsVous pouvez choisir des modèles de régression d’ajustement de fonctions. Pour déterminer quelmodèle utiliser, représentez vos données sous forme graphique. Si vos variables semblent êtreliées linéairement, utilisez un modèle de régression linéaire simple. Lorsque vos variables ne sontpas liées linéairement, essayez de transformer vos données. Lorsque la transformation n’améliorepas les choses, vous devrez peut-être utiliser un modèle plus élaboré. Observez un diagramme dedispersion de vos données. Si le diagramme ressemble à une fonction mathématique que vousreconnaissez, ajustez vos données en fonction de ce type de modèle. Par exemple, si vos donnéesressemblent à une fonction exponentielle, utilisez un modèle exponentiel.
Linéaire. Modèle dont l'équation est Y = b0 + (b1 * t). Les valeurs de la série sont modéliséescomme fonction linéaire du temps.
Logarithmique. Modèle dont l'équation est Y = b0 + (b1 * ln(t)).
Inverse. Modèle dont l'équation est Y = b0 + (b1 / t).
Quadratique. Modèle dont l'équation est Y = b0 + (b1 * t) + (b2 * t**2). Le modèle quadratiquepeut être utilisé pour modéliser une série qui « décolle » ou qui s'amortit de manière oscillatoire.
Cubique. Modèle défini par l'équation Y = b0 + (b1 * t) + (b2 * t**2) + (b3 * t**3).
Exposant. Modèle dont l'équation est Y = b0 * (t**b1) ou ln(Y) = ln(b0) + (b1 * ln(t)).
Composé. Modèle dont l'équation est la suivante : Y = b0 * (b1**t) ou ln(Y) = ln(b0) + (ln(b1) * t).
En S.Modèle dont l'équation est Y = e**(b0 + (b1/t)) ou ln(Y) = b0 + (b1/t).
Logistique. Modèle dont l'équation est Y = 1 / (1/u + (b0 * (b1**t))) ou ln(1/y‑1/u)= ln (b0) +(ln(b1)*t), u étant la valeur de la borne supérieure. Après avoir sélectionné la logistique, précisezla valeur de la borne supérieure à utiliser dans l'équation de régression. La valeur doit être unnombre positif supérieur à la plus grande valeur de la variable dépendante.
Croissance. Modèle dont l'équation est Y = e**(b0 + (b1 * t)) ou ln(Y) = b0 + (b1 * t).
Exponentielle. Modèle dont l'équation est Y = b0 * (e**(b1 * t)) ou ln(Y) = ln(b0) + (b1 * t).
Enregistrement de l’ajustement de fonctionsFigure 30-2Boîte de dialogue Ajustement de fonctions : Enregistrer

400
Chapitre 30
Enregistrer les variables : Pour chaque modèle sélectionné, vous pouvez enregistrer les prévisions,les résidus (valeur observée de la variable dépendante moins la prévision du modèle) et lesintervalles de prévision (limites supérieure et inférieure). Les nouveaux noms de variable et lesétiquettes descriptives s’affichent dans un tableau dans la fenêtre de résultats.
Calculer une prévision : Si, dans l’ensemble de données actif, vous sélectionnez Temps à la placed’une variable comme variable indépendante, vous pouvez spécifier une période de prévisionau-delà de la fin de la série chronologique. Vous avez le choix entre les options suivantes :
A partir d’une estimation limitée à une période : Prévoit les valeurs pour toutes les observationsdu fichier, à partir des observations de la période d’estimation. La période d’estimation quis’affiche en bas de la boîte de dialogue est définie avec la boîte de sous dialogue Intervalle del’option Sélectionner des observations du menu Données. Si aucune période d’estimation n’aété définie, toutes les observations sont utilisées pour prévoir les valeurs.Jusqu’à : Prévoit les valeurs jusqu’à la date, l’heure ou le numéro de l’observation spécifié, àpartir des observations de la période d’estimation. Cette fonctionnalité peut être utilisée pourprévoir les valeurs au-delà de la dernière observation de la série chronologique. Les variablescourantes de date définies déterminent les zones de texte disponibles pour la spécificationde la fin de la période de prévision. Si aucune variable de date n’est définie, vous pouvezspécifier le numéro de l’observation finale.
Utilisez l’option Définir des dates... dans le menu Données pour créer des variables de date.

Chapitre
31Régression des moindres carréspartiels
La procédure de régression des moindres carrés partiels estime les modèles de régression desmoindres carrés partiels (également connus sous le nom de « projection to latent structure », PLS).La technique de prévision PLS constitue une solution de remplacement par rapport à la régressionpar les moindres carrés classiques, à la corrélation canonique ou à la modélisation d’équationstructurelle, particulièrement utile lorsque les variables indépendantes présentent une fortecorrélation ou lorsque le nombre de variables indépendantes dépasse le nombre d’observations.PLS combine des fonctionnalités d’analyse des composants principaux et la régression
multiple. Un ensemble de facteurs latents expliquant autant que possible la covariance entre lesvariables indépendantes et dépendantes est extrait. Ensuite, une étape de régression prévoit lesvaleurs des variables dépendantes à l’aide de la décomposition des variables indépendantes.
Disponibilité. PLS est une commande d’extension qui requiert l’installation du moduled’extension Python sur le système où vous prévoyez d’exécuter PLS. Le module d’extensionPLS doit être installé séparément, et le programme d’installation peut être téléchargé depuishttp://www.spss.com/devcentral.
Remarque : Le module d’extension PLS dépend du logiciel Python. SPSS Inc. n’est ni lepropriétaire ni le concédant de licence du logiciel Python. L’utilisateur de Python doit accepter lestermes de l’accord de licence Python figurant sur le site Web de Python. SPSS Inc. ne fait aucunedéclaration concernant la qualité du programme Python. SPSS Inc. ne peut en aucun cas être tenupour responsable des conséquences liées à votre utilisation du programme Python.
Tables. Proportion de variance expliquée (par facteur latent), pondérations de facteurs latents,corrélations de facteurs latents, importance de la variable indépendante dans la projection (VIP),et estimations des paramètres de régression (par variable dépendante) sont tous générés par défaut.
Diagrammes. Importance de la variable dans la projection (VIP), facteurs, pondération des troispremiers facteurs latents et distance au modèle sont tous générés depuis l’onglet Options.
Niveau de mesure. Les variables dépendantes et indépendantes (prédicteur) peuvent être échelle,nominal ou ordinal. La procédure considère que le niveau de mesure approprié a été assigné àtoutes les variables, bien que vous puissiez changer provisoirement le niveau de mesure d’unevariable en cliquant avec le bouton droit de la souris sur la variable dans la liste des variablessource, puis en sélectionnant un niveau de mesure dans le menu contextuel. Les variablesqualitatives (nominales ou ordinales) sont traitées de manière équivalente par la procédure.
Codage des variables indicatrices. La procédure recode provisoirement les variables dépendantesqualitatives via le codage un-de-c pendant la durée de la procédure. S’il existe des modalités cd’une variable, cette dernière est stockée comme vecteurs c, la première modalité étant identifiée
401
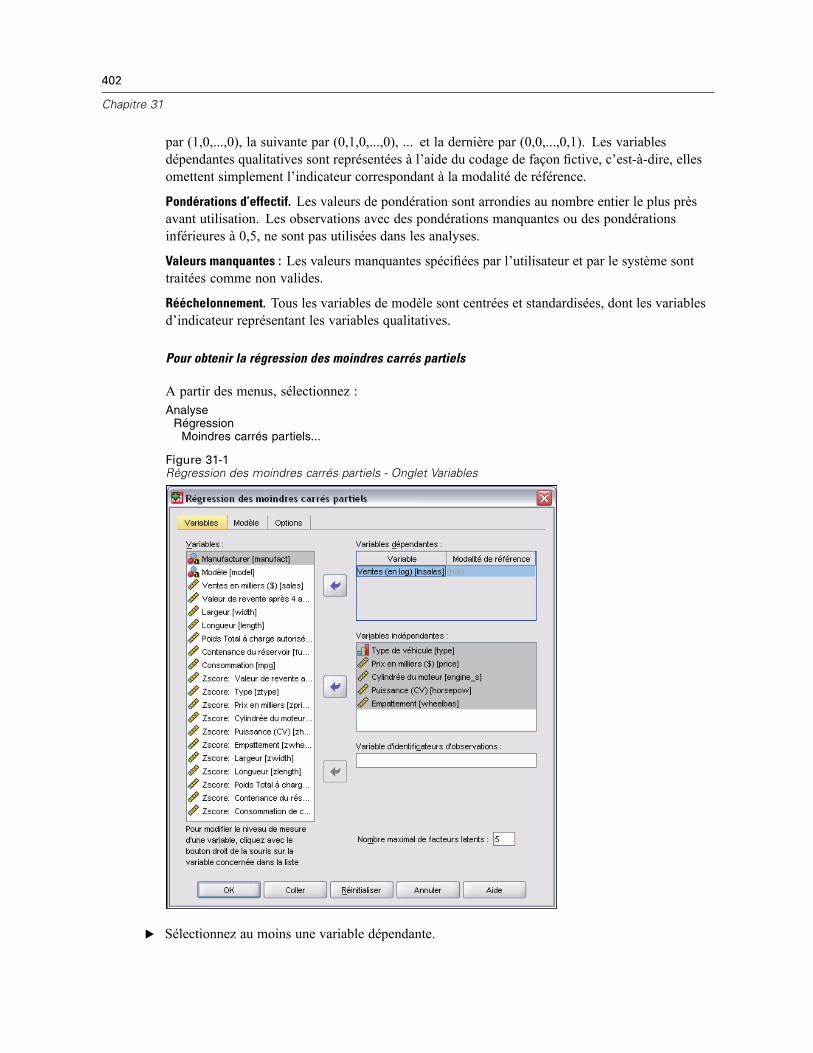
402
Chapitre 31
par (1,0,...,0), la suivante par (0,1,0,...,0), ... et la dernière par (0,0,...,0,1). Les variablesdépendantes qualitatives sont représentées à l’aide du codage de façon fictive, c’est-à-dire, ellesomettent simplement l’indicateur correspondant à la modalité de référence.
Pondérations d’effectif. Les valeurs de pondération sont arrondies au nombre entier le plus prèsavant utilisation. Les observations avec des pondérations manquantes ou des pondérationsinférieures à 0,5, ne sont pas utilisées dans les analyses.
Valeurs manquantes : Les valeurs manquantes spécifiées par l’utilisateur et par le système sonttraitées comme non valides.
Rééchelonnement. Tous les variables de modèle sont centrées et standardisées, dont les variablesd’indicateur représentant les variables qualitatives.
Pour obtenir la régression des moindres carrés partiels
A partir des menus, sélectionnez :Analyse
RégressionMoindres carrés partiels...
Figure 31-1Régression des moindres carrés partiels - Onglet Variables
E Sélectionnez au moins une variable dépendante.
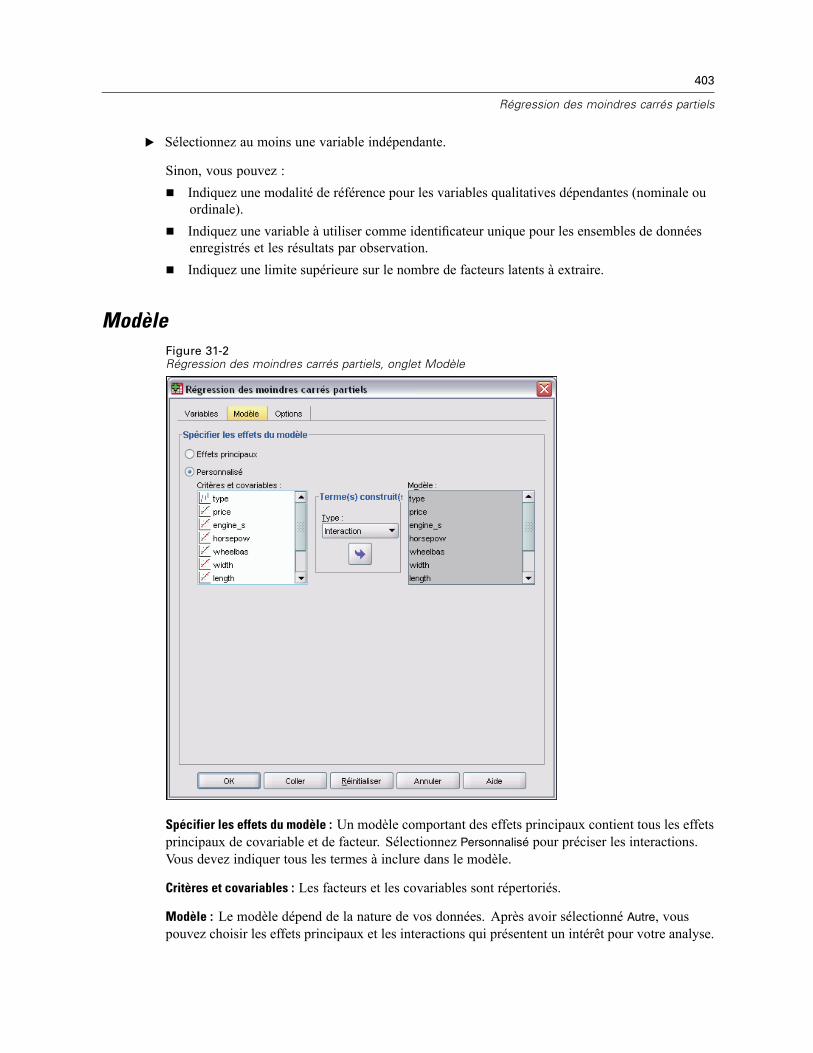
403
Régression des moindres carrés partiels
E Sélectionnez au moins une variable indépendante.
Sinon, vous pouvez :Indiquez une modalité de référence pour les variables qualitatives dépendantes (nominale ouordinale).Indiquez une variable à utiliser comme identificateur unique pour les ensembles de donnéesenregistrés et les résultats par observation.Indiquez une limite supérieure sur le nombre de facteurs latents à extraire.
ModèleFigure 31-2Régression des moindres carrés partiels, onglet Modèle
Spécifier les effets du modèle : Un modèle comportant des effets principaux contient tous les effetsprincipaux de covariable et de facteur. Sélectionnez Personnalisé pour préciser les interactions.Vous devez indiquer tous les termes à inclure dans le modèle.
Critères et covariables : Les facteurs et les covariables sont répertoriés.
Modèle : Le modèle dépend de la nature de vos données. Après avoir sélectionné Autre, vouspouvez choisir les effets principaux et les interactions qui présentent un intérêt pour votre analyse.

404
Chapitre 31
Termes construits
Pour les facteurs et covariables sélectionnés :
Interaction : Crée le terme d’interaction du plus haut niveau de toutes les variables sélectionnées.Il s’agit de la valeur par défaut.
Effets principaux : Crée un terme d’effet principal pour chaque variable sélectionnée.
Toutes d’ordre 2 : Crée toutes les interactions d’ordre 2 possibles des variables sélectionnées.
Toutes d’ordre 3 : Crée toutes les interactions d’ordre 3 possibles des variables sélectionnées.
Toutes d’ordre 4 : Crée toutes les interactions d’ordre 4 possibles des variables sélectionnées.
Toutes d’ordre 5 : Crée toutes les interactions d’ordre 5 possibles des variables sélectionnées.
OptionsFigure 31-3Régression des moindres carrés partiels, onglet Options
L’onglet Options permet d’enregistrer et de tracer des estimations de modèles pour desobservations individuelles, des facteurs latents, et des variables indépendantes.

405
Régression des moindres carrés partiels
Pour chaque type de données, indiquez le nom d’un ensemble de données. Les nomsd’ensemble de données doivent être uniques. Si vous spécifiez le nom d’un ensemble de donnéesexistant, son contenu est remplacé ; sinon, un ensemble de données est créé.
Enregistrez les estimations concernant les observations individuelles. Enregistre les estimationsde modèle par observation : les prévisions, les résidus, la distance au modèle de facteur latent,et les facteurs latents. Elle permet également de tracer les facteurs latents.Enregistrez les estimations concernant les facteurs latents. Enregistre les corrélations defacteurs latents et les pondérations de facteurs latents. Elle permet également de tracer lespondérations de facteurs latents.Enregistrez les estimations concernant les variables indépendantes. Enregistre les estimationsdes paramètres de régression et l’importance des variables dans la projection (VIP). Ellepermet également de tracer l’importance des variables dans la projection par facteur latent.
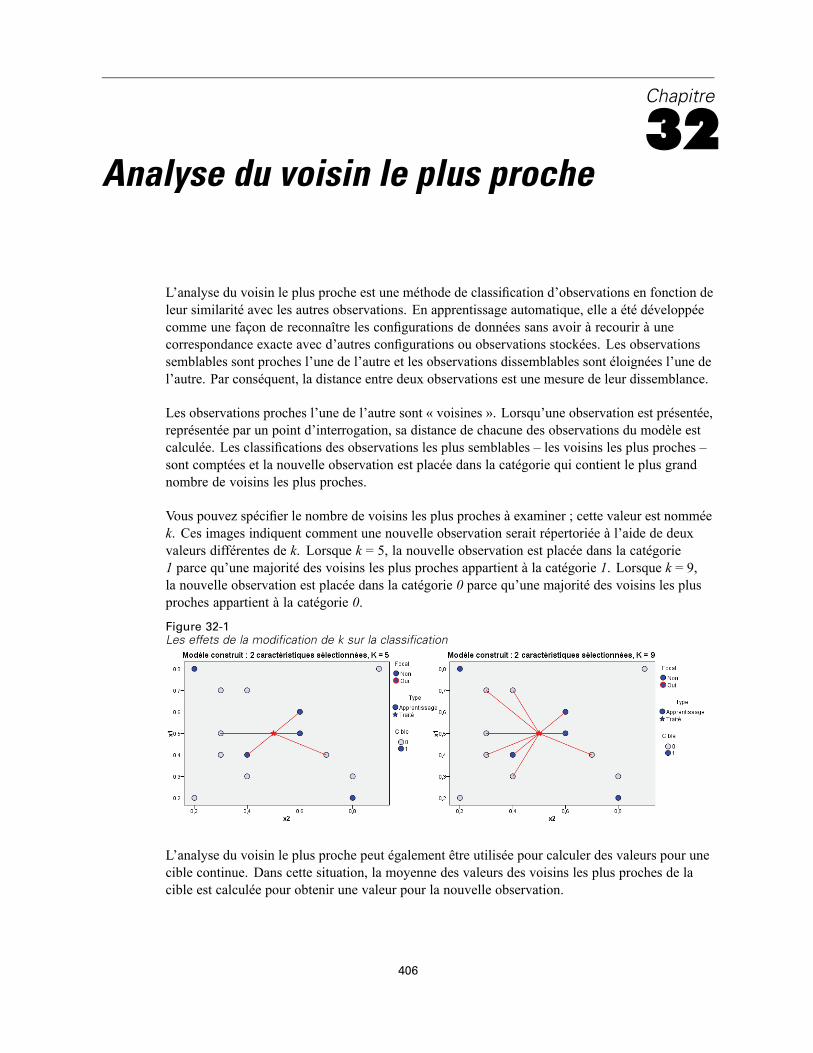
Chapitre
32Analyse du voisin le plus proche
L’analyse du voisin le plus proche est une méthode de classification d’observations en fonction deleur similarité avec les autres observations. En apprentissage automatique, elle a été développéecomme une façon de reconnaître les configurations de données sans avoir à recourir à unecorrespondance exacte avec d’autres configurations ou observations stockées. Les observationssemblables sont proches l’une de l’autre et les observations dissemblables sont éloignées l’une del’autre. Par conséquent, la distance entre deux observations est une mesure de leur dissemblance.
Les observations proches l’une de l’autre sont « voisines ». Lorsqu’une observation est présentée,représentée par un point d’interrogation, sa distance de chacune des observations du modèle estcalculée. Les classifications des observations les plus semblables – les voisins les plus proches –sont comptées et la nouvelle observation est placée dans la catégorie qui contient le plus grandnombre de voisins les plus proches.
Vous pouvez spécifier le nombre de voisins les plus proches à examiner ; cette valeur est nomméek. Ces images indiquent comment une nouvelle observation serait répertoriée à l’aide de deuxvaleurs différentes de k. Lorsque k = 5, la nouvelle observation est placée dans la catégorie1 parce qu’une majorité des voisins les plus proches appartient à la catégorie 1. Lorsque k = 9,la nouvelle observation est placée dans la catégorie 0 parce qu’une majorité des voisins les plusproches appartient à la catégorie 0.
Figure 32-1Les effets de la modification de k sur la classification
L’analyse du voisin le plus proche peut également être utilisée pour calculer des valeurs pour unecible continue. Dans cette situation, la moyenne des valeurs des voisins les plus proches de lacible est calculée pour obtenir une valeur pour la nouvelle observation.
406
407
Analyse du voisin le plus proche
Cible et caractéristiques. La cible et les caractéristiques peuvent être :Nominal. Une variable peut être traitée comme étant nominale si ses valeurs représentent desmodalités sans classement intrinsèque (par exemple, le service de la société dans lequeltravaille un employé). La région, le code postal ou l'appartenance religieuse sont desexemples de variables nominales.Ordinal. Une variable peut être traitée comme étant ordinale si ses valeurs représentent desmodalités associées à un classement intrinsèque (par exemple, des niveaux de satisfactionallant de Très mécontent à Très satisfait). Exemples de variable ordinale : des scoresd'attitude représentant le degré de satisfaction ou de confiance, et des scores de classementdes préférences.Echelle. Une variable peut être traitée comme une variable d'échelle si ses valeurs représententdes modalités classées avec une mesure significative, de sorte que les comparaisons dedistance entre les valeurs soient adéquates. L'âge en années et le revenu en milliers de dollarssont des exemples de variable d'échelle.Les variables qualitatives et ordinales sont traitées de manière équivalente par l’analysedu voisin le plus proche. La procédure considère que le niveau de mesure approprié a étéassigné à chaque variable, bien que vous puissiez changer provisoirement le niveau de mesured’une variable en cliquant avec le bouton droit de la souris sur la variable dans la liste desvariables sources, puis en sélectionnant un niveau de mesure dans le menu contextuel. Pourmodifier le niveau de mesure d’une variable de manière permanente, reportez-vous à Niveaude mesure d’une variable.
Dans la liste des variables, une icône indique le niveau de mesure et le type de données :
Le type de donnéesNiveau de mesureNumérique Chaîne Date Heure
Echelle n/a
Ordinal
Nominal
Codage des variables indicatrices. La procédure recode provisoirement les variables indépendantesqualitatives et les variables dépendantes via le codage un-de-c pour la durée de la procédure. S’ilexiste des modalités c d’une variable, la variable est stockée comme vecteurs c, la premièremodalité étant identifiée par (1,0,...,0), la suivante par (0,1,0,...,0), ... et la dernière par (0,0,...,0,1).Ce système de codage augmente le nombre de dimensions de l’espace des caractéristiques. Plus
particulièrement, le nombre total de dimensions correspond au nombre de variables indépendantesd’échelle plus le nombre de modalités sur l’ensemble des variables indépendantes qualitatives.En conséquence, ce système de codage peut provoquer un ralentissement de la formation. Sivotre formation des voisins les plus proches s’effectue très lentement, vous pouvez essayer deréduire le nombre de modalités dans vos variables indépendantes qualitatives en combinant des

408
Chapitre 32
modalités similaires ou en supprimant les observations comportant des modalités extrêmementrares avant de lancer la procédure.Tout codage un-de-c repose sur les données de formation, même si un échantillon traité est
défini (reportez-vous à Partitions). Ainsi, si l’échantillon traité contient des observations avecdes modalités de variable indépendantes absentes des données de formation, ces observationsne seront pas évaluées. Si l’échantillon traité contient des observations avec des modalités devariable dépendantes absentes des données de formation, ces observations seront évaluées.
Rééchelonnement. Les caractéristiques d’échelle sont normalisées par défaut. Le rééchelonnementrepose entièrement sur les données de formation, même si un échantillon traité est défini(reportez-vous à Partitions sur p. 413). Si vous spécifiez une variable pour définir des partitions,il est important que ces caractéristiques présentent des distributions similaires à travers leséchantillons de formation et les échantillons traités. Par exemple, utilisez la procédure Explorerpour examiner les distributions à travers les partitions.
Pondérations d’effectif. Cette procédure ignore les pondérations d’effectif.
Réplication de résultats. La procédure utilise la génération de nombres aléatoires pendantl’attribution aléatoire des partitions et les niveaux de validation croisée. Si vous souhaitezrépliquer vos résultats exactement, en plus d’utiliser les mêmes paramètres de procédure,définissez un générateur pour le Mersenne Twister (reportez-vous à Partitions sur p. 413), ouutilisez des variables pour définir les partitions et les niveaux de validation croisée.
Pour obtenir une analyse du voisin le plus proche
A partir des menus, sélectionnez :Analyse
ClassificationVoisin le plus proche...
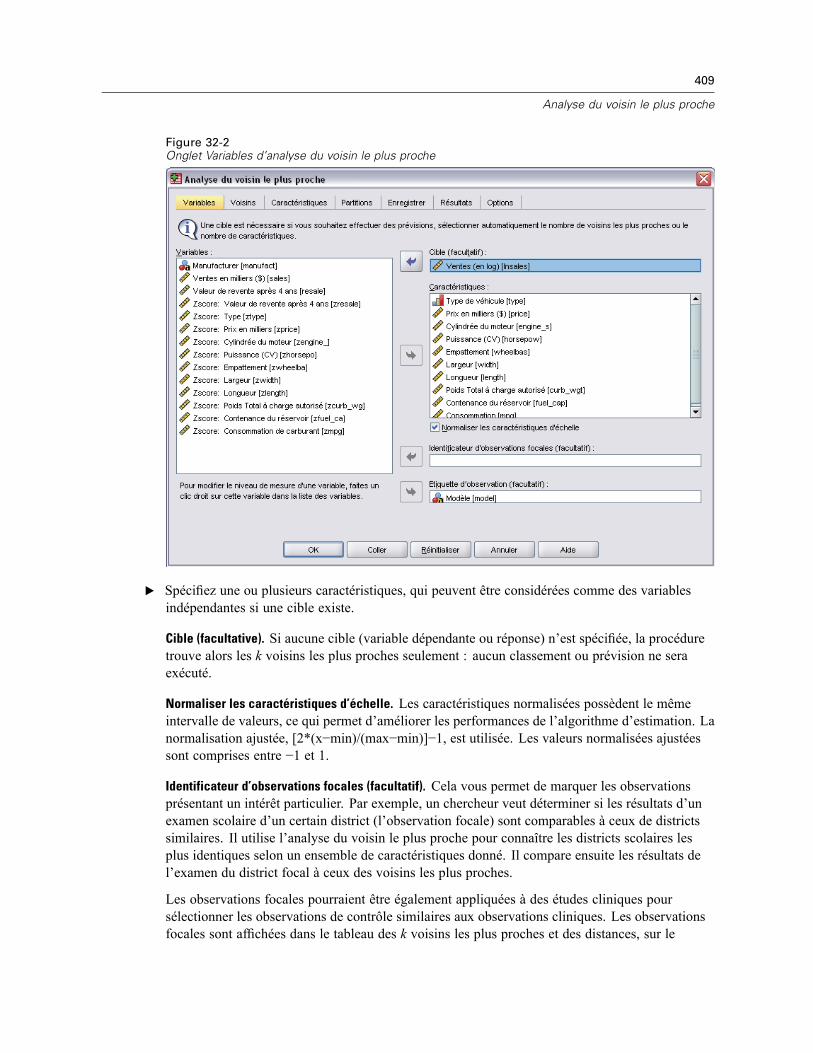
409
Analyse du voisin le plus proche
Figure 32-2Onglet Variables d’analyse du voisin le plus proche
E Spécifiez une ou plusieurs caractéristiques, qui peuvent être considérées comme des variablesindépendantes si une cible existe.
Cible (facultative). Si aucune cible (variable dépendante ou réponse) n’est spécifiée, la procéduretrouve alors les k voisins les plus proches seulement : aucun classement ou prévision ne seraexécuté.
Normaliser les caractéristiques d’échelle. Les caractéristiques normalisées possèdent le mêmeintervalle de valeurs, ce qui permet d’améliorer les performances de l’algorithme d’estimation. Lanormalisation ajustée, [2*(x−min)/(max−min)]−1, est utilisée. Les valeurs normalisées ajustéessont comprises entre −1 et 1.
Identificateur d’observations focales (facultatif). Cela vous permet de marquer les observationsprésentant un intérêt particulier. Par exemple, un chercheur veut déterminer si les résultats d’unexamen scolaire d’un certain district (l’observation focale) sont comparables à ceux de districtssimilaires. Il utilise l’analyse du voisin le plus proche pour connaître les districts scolaires lesplus identiques selon un ensemble de caractéristiques donné. Il compare ensuite les résultats del’examen du district focal à ceux des voisins les plus proches.
Les observations focales pourraient être également appliquées à des études cliniques poursélectionner les observations de contrôle similaires aux observations cliniques. Les observationsfocales sont affichées dans le tableau des k voisins les plus proches et des distances, sur le
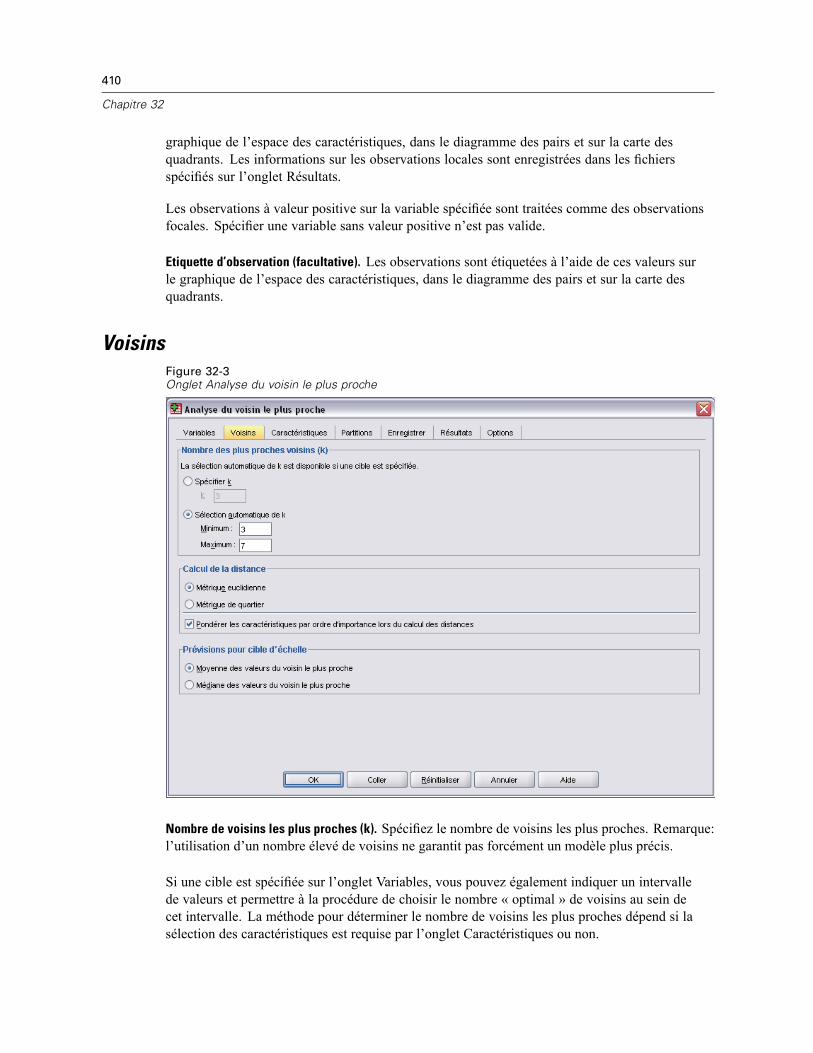
410
Chapitre 32
graphique de l’espace des caractéristiques, dans le diagramme des pairs et sur la carte desquadrants. Les informations sur les observations locales sont enregistrées dans les fichiersspécifiés sur l’onglet Résultats.
Les observations à valeur positive sur la variable spécifiée sont traitées comme des observationsfocales. Spécifier une variable sans valeur positive n’est pas valide.
Etiquette d’observation (facultative). Les observations sont étiquetées à l’aide de ces valeurs surle graphique de l’espace des caractéristiques, dans le diagramme des pairs et sur la carte desquadrants.
VoisinsFigure 32-3Onglet Analyse du voisin le plus proche
Nombre de voisins les plus proches (k). Spécifiez le nombre de voisins les plus proches. Remarque:l’utilisation d’un nombre élevé de voisins ne garantit pas forcément un modèle plus précis.
Si une cible est spécifiée sur l’onglet Variables, vous pouvez également indiquer un intervallede valeurs et permettre à la procédure de choisir le nombre « optimal » de voisins au sein decet intervalle. La méthode pour déterminer le nombre de voisins les plus proches dépend si lasélection des caractéristiques est requise par l’onglet Caractéristiques ou non.

411
Analyse du voisin le plus proche
Si oui, la sélection des caractéristiques sera alors exécutée pour chaque valeur de k dansl’intervalle requis, et le k ainsi que l’ensemble des caractéristiques l’accompagneant, avec letaux d’erreur le plus faible (ou l’erreur de la somme des carrés la plus faible si la cible estune échelle), seront sélectionnés.Si la séléction des caractéristiques n’est pas activée, alors la validation croisée de niveau Vsera utilisée pour sélectionner le nombre de voisins « optimal ». Reportez-vous à l’ongletPartitions pour contrôler l’attribution de niveaux.
Calcul de la distance. Il s’agit de la métrique employée pour spécifier la distance métrique utiliséedans la mesure de la similarité des observations.
Métrique euclidienne. La distance entre deux observations, x et y, est la racine carrée dela somme, sur toutes les dimensions, des carrés des différences entre les valeurs de cesobservations.Mesure de la distance de Manhattan. La distance entre deux observations est la somme, surtoutes les dimensions, des différences absolues entre les valeurs de ces observations. Appeléeégalement distance City Block.
Si une cible est spécifiée dans l’onglet Variables, vous pouvez également choisir de pondérer lescaractéristiques selon leur importance normalisée lors du calcul des distances. L’importance descaractéristiques pour une variable indépendante est calculée par le rapport du taux d’erreur oul’erreur de la somme des carrés du modèle avec la valeur indépendante supprimée du modèle versle taux d’erreur ou l’erreur de la somme des carrés pour le modèle entier. L’importance normaliséeest calculée par nouvelle pondération des valeurs d’importance des caractéristiques de sorte queleur somme soit égale à 1.
Prévisions pour cible d’échelle. Lorsqu’une cible d’échelle est spécifiée sur l’onglet Variables,elle détermine si la valeur prévue est calculée à partir de la valeur moyenne ou la médiane desvoisins les plus proches ou non.
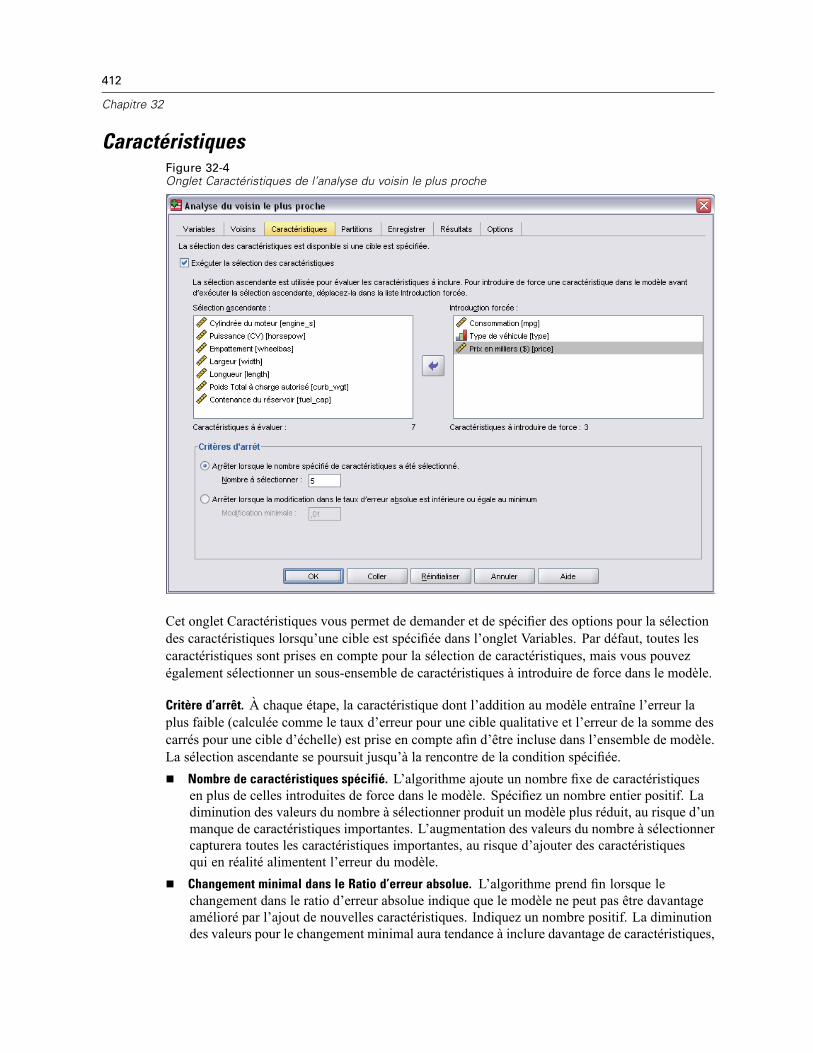
412
Chapitre 32
CaractéristiquesFigure 32-4Onglet Caractéristiques de l’analyse du voisin le plus proche
Cet onglet Caractéristiques vous permet de demander et de spécifier des options pour la sélectiondes caractéristiques lorsqu’une cible est spécifiée dans l’onglet Variables. Par défaut, toutes lescaractéristiques sont prises en compte pour la sélection de caractéristiques, mais vous pouvezégalement sélectionner un sous-ensemble de caractéristiques à introduire de force dans le modèle.
Critère d’arrêt. À chaque étape, la caractéristique dont l’addition au modèle entraîne l’erreur laplus faible (calculée comme le taux d’erreur pour une cible qualitative et l’erreur de la somme descarrés pour une cible d’échelle) est prise en compte afin d’être incluse dans l’ensemble de modèle.La sélection ascendante se poursuit jusqu’à la rencontre de la condition spécifiée.
Nombre de caractéristiques spécifié. L’algorithme ajoute un nombre fixe de caractéristiquesen plus de celles introduites de force dans le modèle. Spécifiez un nombre entier positif. Ladiminution des valeurs du nombre à sélectionner produit un modèle plus réduit, au risque d’unmanque de caractéristiques importantes. L’augmentation des valeurs du nombre à sélectionnercapturera toutes les caractéristiques importantes, au risque d’ajouter des caractéristiquesqui en réalité alimentent l’erreur du modèle.Changement minimal dans le Ratio d’erreur absolue. L’algorithme prend fin lorsque lechangement dans le ratio d’erreur absolue indique que le modèle ne peut pas être davantageamélioré par l’ajout de nouvelles caractéristiques. Indiquez un nombre positif. La diminutiondes valeurs pour le changement minimal aura tendance à inclure davantage de caractéristiques,
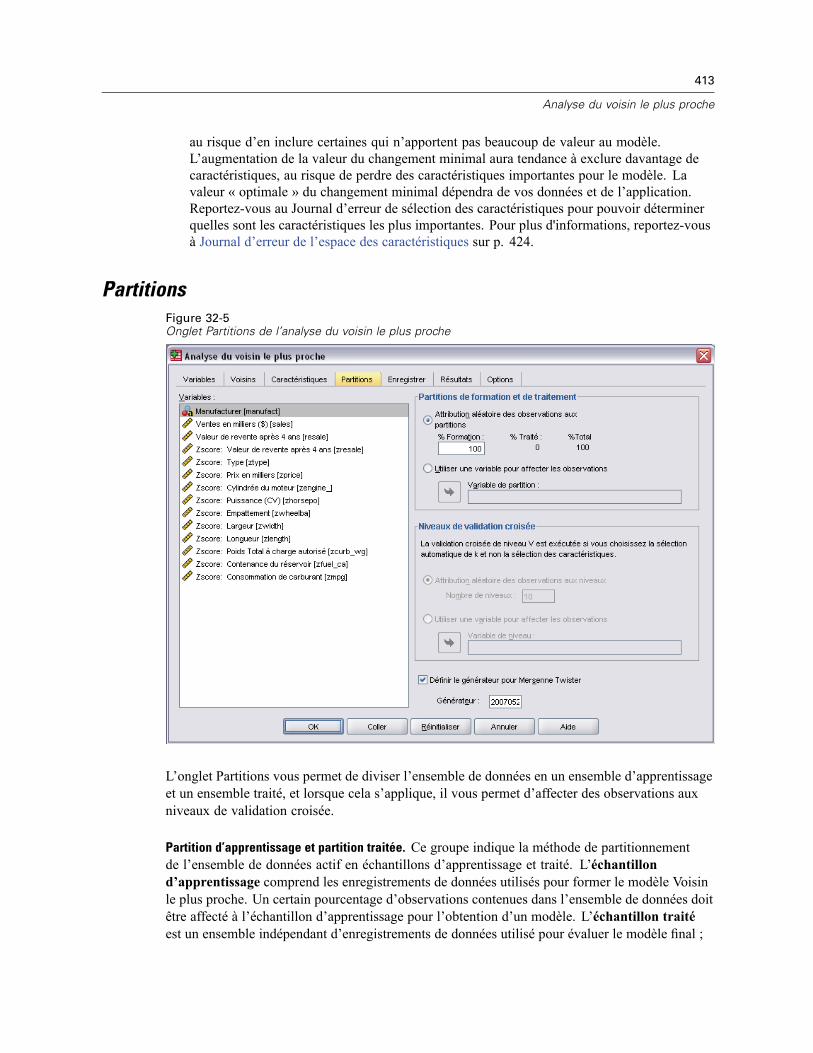
413
Analyse du voisin le plus proche
au risque d’en inclure certaines qui n’apportent pas beaucoup de valeur au modèle.L’augmentation de la valeur du changement minimal aura tendance à exclure davantage decaractéristiques, au risque de perdre des caractéristiques importantes pour le modèle. Lavaleur « optimale » du changement minimal dépendra de vos données et de l’application.Reportez-vous au Journal d’erreur de sélection des caractéristiques pour pouvoir déterminerquelles sont les caractéristiques les plus importantes. Pour plus d'informations, reportez-vousà Journal d’erreur de l’espace des caractéristiques sur p. 424.
PartitionsFigure 32-5Onglet Partitions de l’analyse du voisin le plus proche
L’onglet Partitions vous permet de diviser l’ensemble de données en un ensemble d’apprentissageet un ensemble traité, et lorsque cela s’applique, il vous permet d’affecter des observations auxniveaux de validation croisée.
Partition d’apprentissage et partition traitée. Ce groupe indique la méthode de partitionnementde l’ensemble de données actif en échantillons d’apprentissage et traité. L’échantillond’apprentissage comprend les enregistrements de données utilisés pour former le modèle Voisinle plus proche. Un certain pourcentage d’observations contenues dans l’ensemble de données doitêtre affecté à l’échantillon d’apprentissage pour l’obtention d’un modèle. L’échantillon traitéest un ensemble indépendant d’enregistrements de données utilisé pour évaluer le modèle final ;

414
Chapitre 32
l’erreur pour l’échantillon traité donne une estimation « honnête » de la capacité de prévision dumodèle parce que les observations traitées n’ont pas été utilisées pour construire le modèle.
Affecter aléatoirement des observations aux partitions. Spécifier le pourcentage d’observationsà affecter à l’échantillon d’apprentissage. Le reste est affecté à l’échantillon traité.Utiliser une variable pour affecter des observations. Indiquer une variable numérique quiaffecte chaque observation de l’ensemble de données actif à l’échantillon d’apprentissageet traité. Les observations contenant une valeur positive sur la variable sont affectées àl’échantillon d’apprentissage, celles contenant une valeur égale à 0 ou une valeur négativesont affectées à l’échantillon traité. Les observations contenant des valeurs manquantes sontexclues de l’analyse. Les valeurs manquantes spécifiées par l’utilisateur pour la variable departitionnement sont toujours considérées comme étant valides.
Niveaux de validation croisée. Le Niveau V de validation croisée est utilisé pour déterminerle « meilleur » nombre de voisins. Il n’est pas disponible en association avec la sélection decaractéristiques pour des raisons de performance.
La validation croisée divise l’échantillon en plusieurs sous échantillons, ou niveaux. Lesmodèles du voisin le plus proche sont générés en excluant à tour de rôle les données de chaquesous-échantillon. Le premier modèle est basé sur toutes les observations à l’exception de celles dupremier sous-échantillon, le deuxième modèle est basé sur toutes les observations à l’exception decelles du deuxième sous-échantillon, etc. L’erreur est estimée pour chaque modèle en appliquantle modèle au sous-échantillon exclu lors de la génération du modèle. Le « meilleur » nombre desvoisins les plus proches est celui qui produit l’erreur la plus faible sur les sous-échantillons.
Affecter aléatoirement des observations aux niveaux. Spécifier le nombre de niveaux à utiliserpour la validation croisée. Cette procédure affecte aléatoirement des observations auxsous-échantillons, numérotés de 1 à V, le nombre de sous-échantillons.Utiliser une variable pour affecter des observations. Indiquer une variable numérique qui affectechaque observation de l’ensemble de données actif à un niveau. Cette variable doit êtrenumérique et d’une valeur comprise entre 1 et V. Si une valeur manque dans cet intervalle, etque sur toutes les scissions les fichiers scindés sont activés, cela provoqusplitra une erreur.Pour plus d'informations, reportez-vous à Scinder fichier dans Chapitre 9 sur p. 204.
Définissez un générateur pour le Mersenne Twister. Définir un générateur vous permet de reproduireles analyses. Ce contrôle est essentiellement un raccourci permettant de définir le MersenneTwister comme le générateur actif et de spécifier un point de départ fixe dans la boîte de dialogueGénérateurs de nombres aléatoires. Pour plus d'informations, reportez-vous à Générateurs denombres aléatoires dans Chapitre 8 sur p. 147.
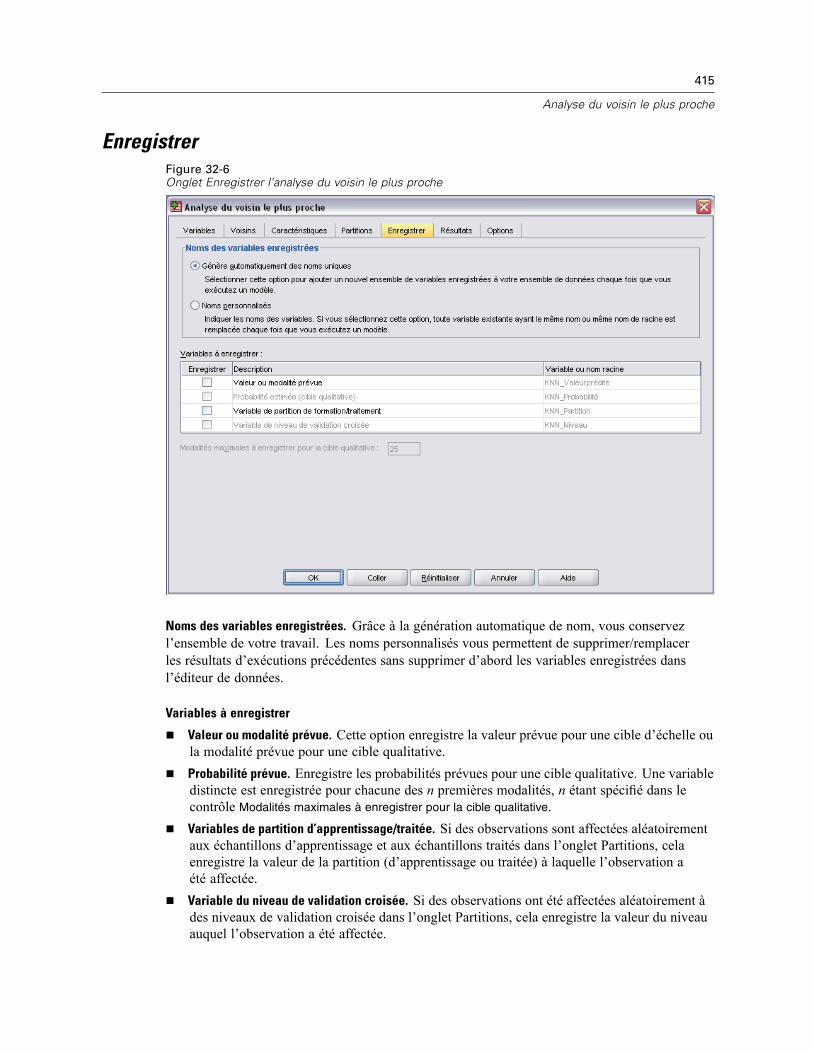
415
Analyse du voisin le plus proche
EnregistrerFigure 32-6Onglet Enregistrer l’analyse du voisin le plus proche
Noms des variables enregistrées. Grâce à la génération automatique de nom, vous conservezl’ensemble de votre travail. Les noms personnalisés vous permettent de supprimer/remplacerles résultats d’exécutions précédentes sans supprimer d’abord les variables enregistrées dansl’éditeur de données.
Variables à enregistrer
Valeur ou modalité prévue. Cette option enregistre la valeur prévue pour une cible d’échelle oula modalité prévue pour une cible qualitative.Probabilité prévue. Enregistre les probabilités prévues pour une cible qualitative. Une variabledistincte est enregistrée pour chacune des n premières modalités, n étant spécifié dans lecontrôle Modalités maximales à enregistrer pour la cible qualitative.Variables de partition d’apprentissage/traitée. Si des observations sont affectées aléatoirementaux échantillons d’apprentissage et aux échantillons traités dans l’onglet Partitions, celaenregistre la valeur de la partition (d’apprentissage ou traitée) à laquelle l’observation aété affectée.Variable du niveau de validation croisée. Si des observations ont été affectées aléatoirement àdes niveaux de validation croisée dans l’onglet Partitions, cela enregistre la valeur du niveauauquel l’observation a été affectée.
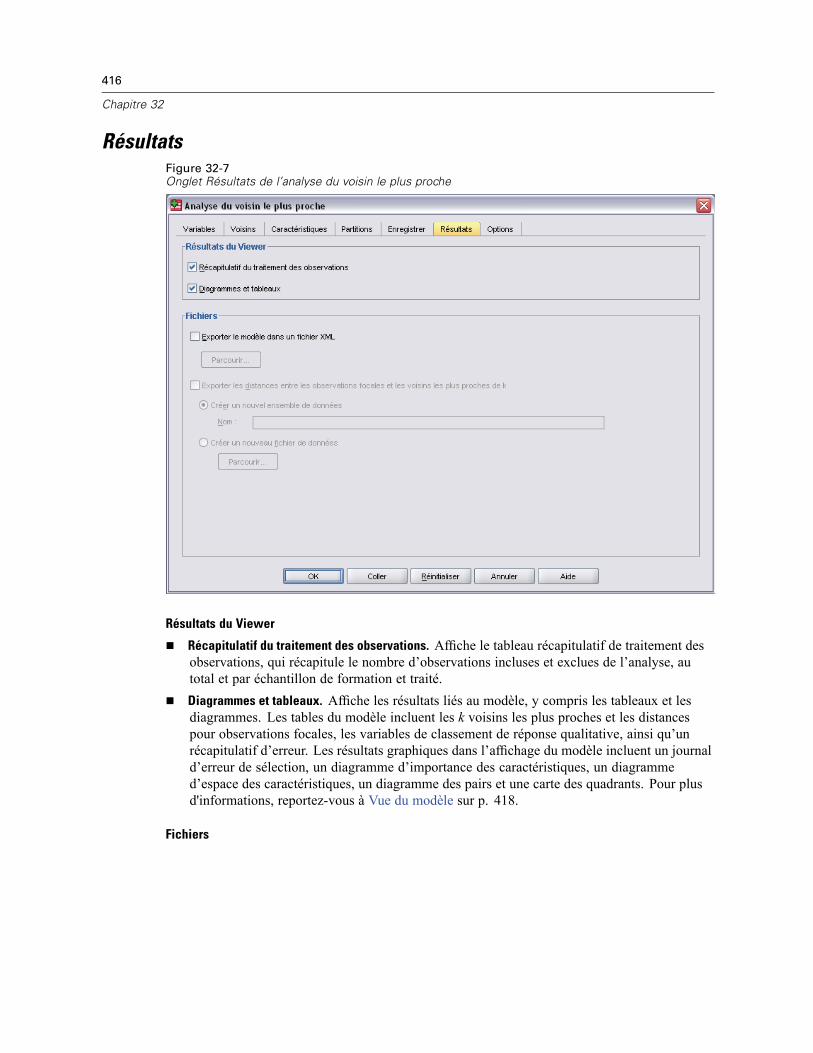
416
Chapitre 32
RésultatsFigure 32-7Onglet Résultats de l’analyse du voisin le plus proche
Résultats du Viewer
Récapitulatif du traitement des observations. Affiche le tableau récapitulatif de traitement desobservations, qui récapitule le nombre d’observations incluses et exclues de l’analyse, autotal et par échantillon de formation et traité.Diagrammes et tableaux. Affiche les résultats liés au modèle, y compris les tableaux et lesdiagrammes. Les tables du modèle incluent les k voisins les plus proches et les distancespour observations focales, les variables de classement de réponse qualitative, ainsi qu’unrécapitulatif d’erreur. Les résultats graphiques dans l’affichage du modèle incluent un journald’erreur de sélection, un diagramme d’importance des caractéristiques, un diagrammed’espace des caractéristiques, un diagramme des pairs et une carte des quadrants. Pour plusd'informations, reportez-vous à Vue du modèle sur p. 418.
Fichiers
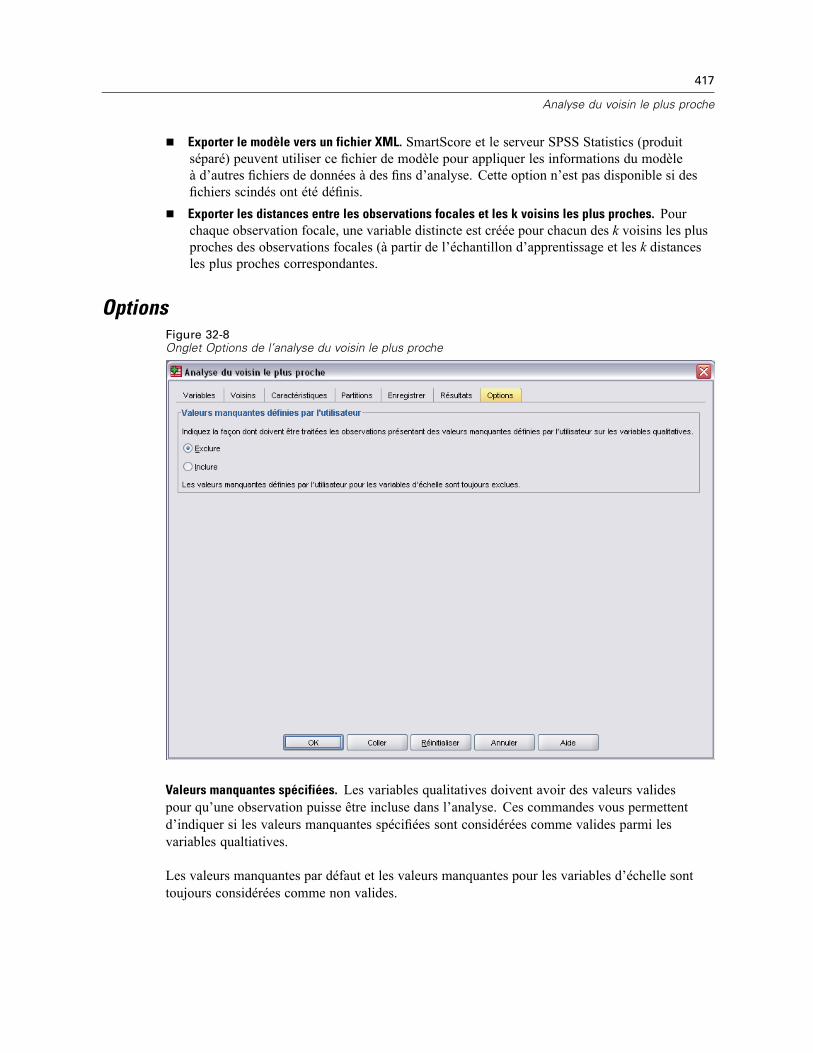
417
Analyse du voisin le plus proche
Exporter le modèle vers un fichier XML. SmartScore et le serveur SPSS Statistics (produitséparé) peuvent utiliser ce fichier de modèle pour appliquer les informations du modèleà d’autres fichiers de données à des fins d’analyse. Cette option n’est pas disponible si desfichiers scindés ont été définis.Exporter les distances entre les observations focales et les k voisins les plus proches. Pourchaque observation focale, une variable distincte est créée pour chacun des k voisins les plusproches des observations focales (à partir de l’échantillon d’apprentissage et les k distancesles plus proches correspondantes.
OptionsFigure 32-8Onglet Options de l’analyse du voisin le plus proche
Valeurs manquantes spécifiées. Les variables qualitatives doivent avoir des valeurs validespour qu’une observation puisse être incluse dans l’analyse. Ces commandes vous permettentd’indiquer si les valeurs manquantes spécifiées sont considérées comme valides parmi lesvariables qualtiatives.
Les valeurs manquantes par défaut et les valeurs manquantes pour les variables d’échelle sonttoujours considérées comme non valides.
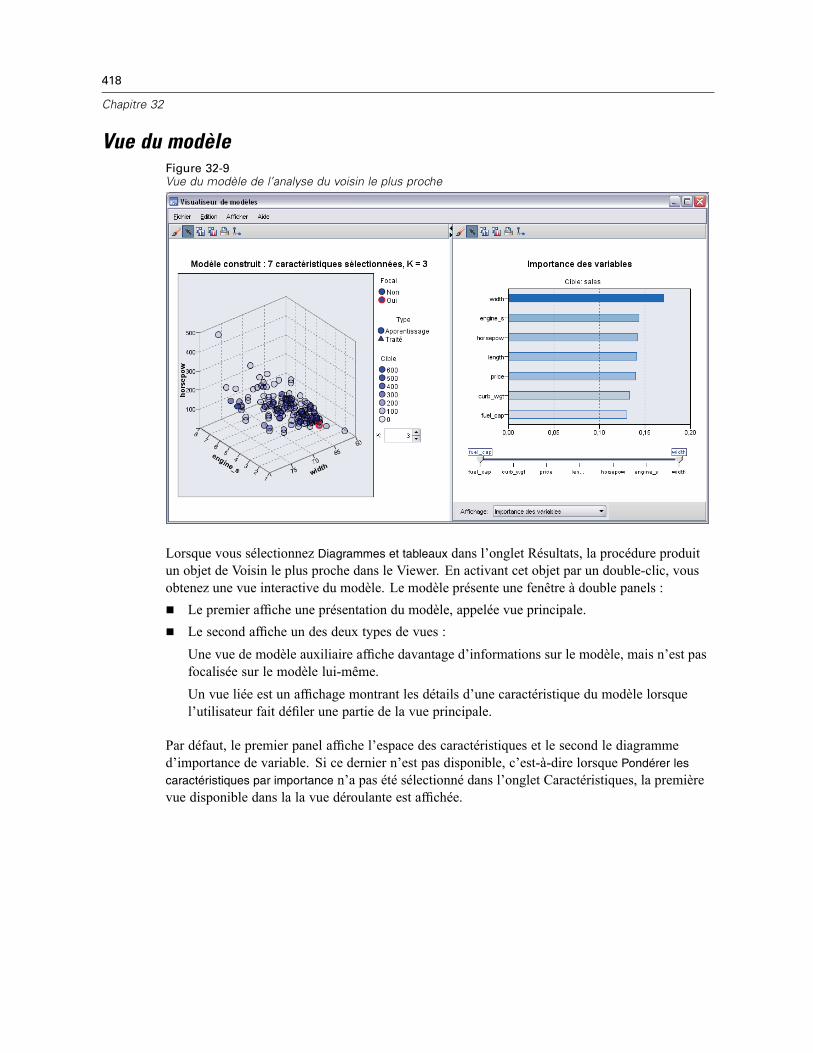
418
Chapitre 32
Vue du modèleFigure 32-9Vue du modèle de l’analyse du voisin le plus proche
Lorsque vous sélectionnez Diagrammes et tableaux dans l’onglet Résultats, la procédure produitun objet de Voisin le plus proche dans le Viewer. En activant cet objet par un double-clic, vousobtenez une vue interactive du modèle. Le modèle présente une fenêtre à double panels :
Le premier affiche une présentation du modèle, appelée vue principale.Le second affiche un des deux types de vues :Une vue de modèle auxiliaire affiche davantage d’informations sur le modèle, mais n’est pasfocalisée sur le modèle lui-même.Un vue liée est un affichage montrant les détails d’une caractéristique du modèle lorsquel’utilisateur fait défiler une partie de la vue principale.
Par défaut, le premier panel affiche l’espace des caractéristiques et le second le diagrammed’importance de variable. Si ce dernier n’est pas disponible, c’est-à-dire lorsque Pondérer les
caractéristiques par importance n’a pas été sélectionné dans l’onglet Caractéristiques, la premièrevue disponible dans la la vue déroulante est affichée.

419
Analyse du voisin le plus proche
Figure 32-10Vue déroulante de l’analyse du voisin le plus proche
Lorsqu’une vue n’a aucune information disponible, son élément texte dans la vue déroulante estdésactivé.
Pour plus d’informations sur les objets de Modèle, reportez-vous à Modèles sur p. 279.
Espace des caractéristiquesFigure 32-11Espace des caractéristiques
Le diagramme d’espace des caractéristiques est un diagramme interactif de l’espace descaractéristiques (ou un sous-espace, s’il existe plus de 3 caractéristiques). Chaque axe représenteune caractéristique du modèle, et l’emplacement des points dans le diagramme montre la valeur deces caractéristiques pour des observations dans les partitions de formation et traitée.
Clés. En plus des valeurs de caractéristiques, les points du diagramme contiennent d’autresinformations.

420
Chapitre 32
La forme indique la partition à laquelle appartient un point, Formation ou Traité. Si aucunepartition traitée n’est spécifiée, la clé ne s’affiche pas.La couleur/ombrage d’un point indique la valeur de la cible pour cette observation, avecles valeurs de couleur distinctes correspondant aux modalités d’une cible qualitative, et lesombres indiquant l’intervalle des valeurs d’une cible continue. La valeur indiquée pour lapartition de formation est la valeur observée. Pour la partition traitée, il s’agit de la valeurprévue. Si aucune cible n’est spécifiée, la clé ne s’affiche pas.Les contours plus épais indiquent que l’observation est focale. Les observations focales sontaffichées avec un lien vers les k voisins les plus proches.
Commandes et intéractivité. Un certain nombre de commandes dans le graphique vous permettentd’explorer l’espace des caractéristiques.
Vous pouvez choisir quel sous-ensemble de caractéristiques vous souhaitez afficher dans lediagramme et modifier les caractéristiques à représenter dans les dimensions.Les « Observations focales » sont tout simplement des points sélectionnés dans le diagrammede l’espace des caractéristiques. Si vous avez spécifié une variable d’observation focale, lespoints représentant les observations focales seront sélectionnées dès le début. Cependant, tousles points peuvent devenir temporairement une observation focale si vous les sélectionnez.Les commandes « habituelles » pour la sélection des points sont appliquées. Cliquer sur unpoint permet de sélectionner ce point et de desélectionner tous les autres. Cliquer sur un pointavec la touche Ctrl enfoncée ajoute ce point à l’ensemble des points sélectionnés. Les vuesliées, tels que le diagramme des pairs, sont automatiquement mis à jour en fonction desobservations sélectionnées dans l’espace des caractéristiques.Vous pouvez modifier le nombre de voisins les plus proches (k) à afficher pour les observationsfocales.Positionner le curseur sur un point du diagramme affiche une note d’aide avec la valeur del’étiquette d’observation, ou le nombre d’observations si les étiquettes d’observation ne sontpas définies, et les valeurs des cibles observées et prévues.Un bouton « Réinitialiser » vous permet de revenir à l’Espace des caractéristiques à sonétat d’origine.
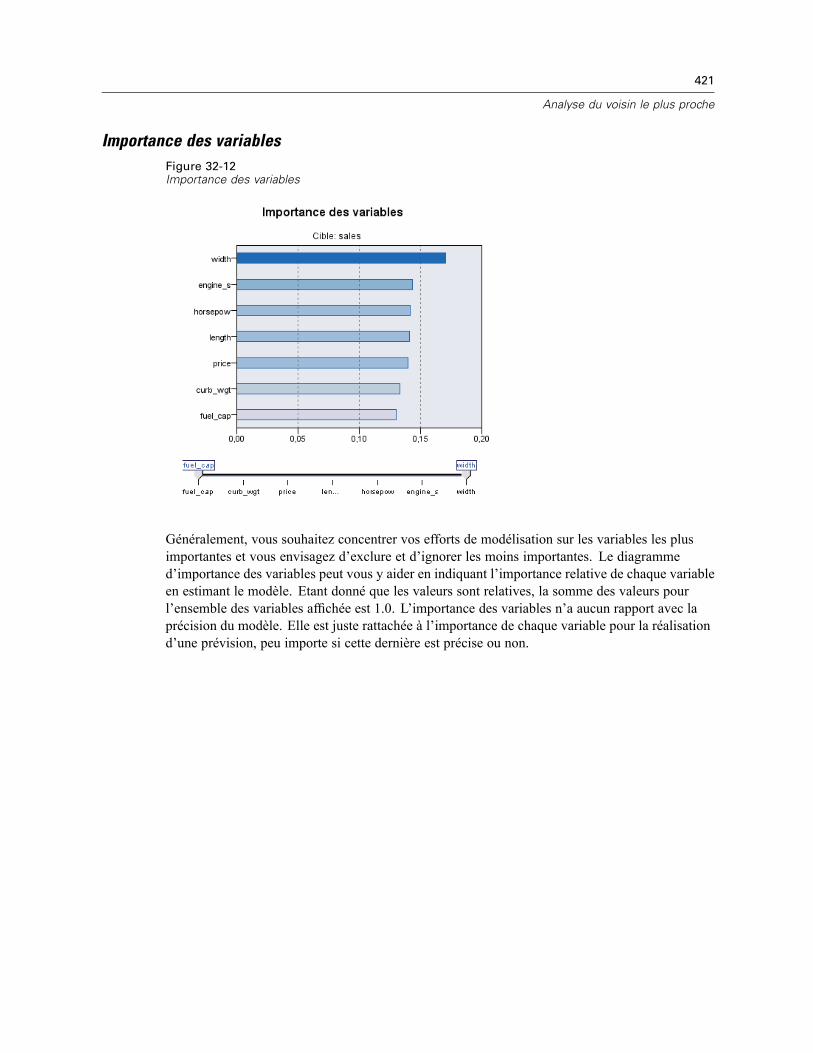
421
Analyse du voisin le plus proche
Importance des variablesFigure 32-12Importance des variables
Généralement, vous souhaitez concentrer vos efforts de modélisation sur les variables les plusimportantes et vous envisagez d’exclure et d’ignorer les moins importantes. Le diagrammed’importance des variables peut vous y aider en indiquant l’importance relative de chaque variableen estimant le modèle. Etant donné que les valeurs sont relatives, la somme des valeurs pourl’ensemble des variables affichée est 1.0. L’importance des variables n’a aucun rapport avec laprécision du modèle. Elle est juste rattachée à l’importance de chaque variable pour la réalisationd’une prévision, peu importe si cette dernière est précise ou non.

422
Chapitre 32
PairsFigure 32-13Diagramme des pairs
Ce diagramme affiche les observations focales et leurs k voisins les plus proches sur chaquecaractéristique et sur la cible. Il est disponible si une observation focale est sélectionnée dansl’espace des caractéristiques.
Comportement de lien. Le diagramme des pairs est relié à l’espace des caractéristiques de deuxmanières différentes.
Les observations sélectionnées (focales) dans l’espace des caractéristiques sont affichées dansle diagramme des pairs, ainsi que leurs k voisins les plus proches.La valeur de k sélectionnée dans l’espace des caractéristiques est utilisée dans le diagrammedes pairs.
Distances du voisin le plus procheFigure 32-14Distances du voisin le plus proche

423
Analyse du voisin le plus proche
Ce tableau affiche les k voisins les plus proches et les distances pour les observations focalesuniquement. Il est disponible si un identificateur d’observations focale est spécifié dans l’ongletVariable, et il n’affiche que les observations focales identifiées par cette variable.
Chaque ligne de :La colonne Observation focale contient la valeur de la variable d’étiquetage des observationspour l’observation focale. Si les étiquettes d’observations ne sont pas définies, cette colonnecontient le nombre d’observations de l’observation focale.La ième colonne sous le groupe des voisins les plus proches contient la valeur de la variabled’étiquetage d’observation pour le ième voisin le plus proche de l’observation focale. Si lesétiquettes d’observations ne sont pas définies, cette colonne contient le nombre d’observationdu ième voisin le plus proche de l’observation focale.La ième colonne sous le groupe Distances les plus proches contient la distance du ième voisinle plus proche de l’observation focale.
Carte des quadrantsFigure 32-15Carte des quadrants
Ce diagramme affiche les observations focales et leur k voisins les plus proches sur un diagrammede dispersion (ou nuage de points, selon le niveau de mesure de la cible) avec la cible sur l’axe yet une caractéristique d’échelle sur l’axe x, affichés sous forme de panel par caractéristique. Ilest disponible si une cible existe et si une observation focale est sélectionnée dans l’espace descaractéristiques.
Les lignes de référence sont tracées pour des variables continues, aux moyennes variablesdans la partition de formation.
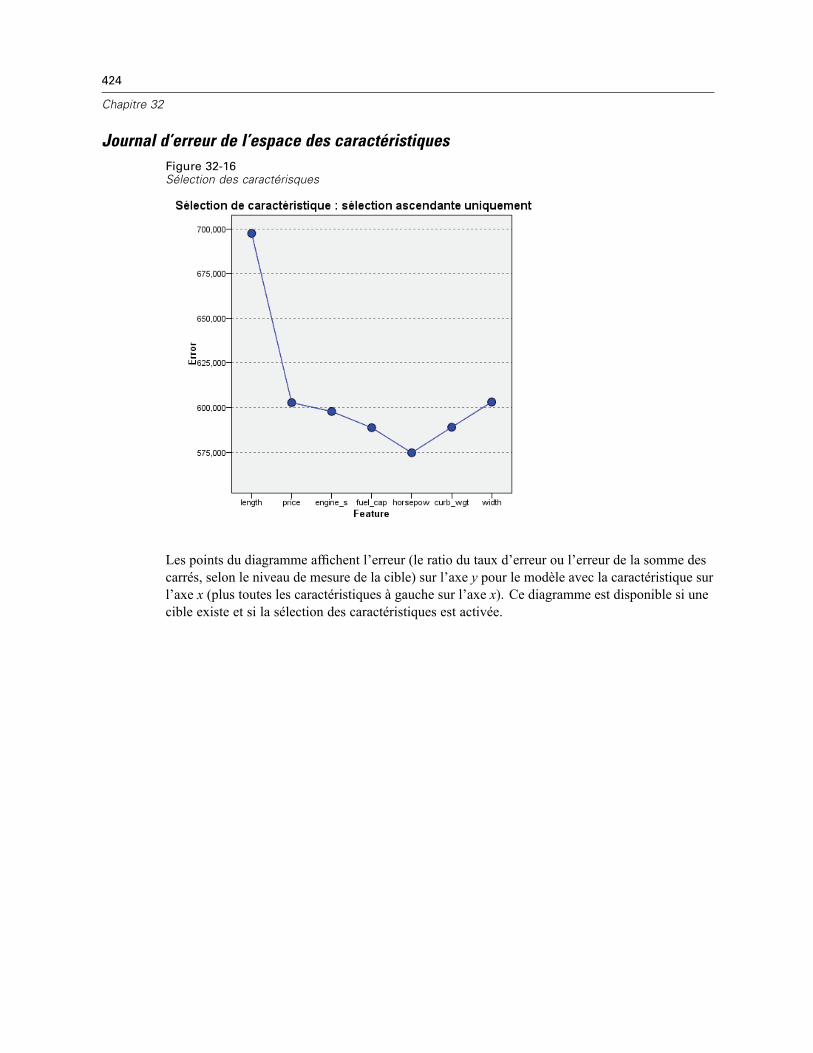
424
Chapitre 32
Journal d’erreur de l’espace des caractéristiquesFigure 32-16Sélection des caractérisques
Les points du diagramme affichent l’erreur (le ratio du taux d’erreur ou l’erreur de la somme descarrés, selon le niveau de mesure de la cible) sur l’axe y pour le modèle avec la caractéristique surl’axe x (plus toutes les caractéristiques à gauche sur l’axe x). Ce diagramme est disponible si unecible existe et si la sélection des caractéristiques est activée.
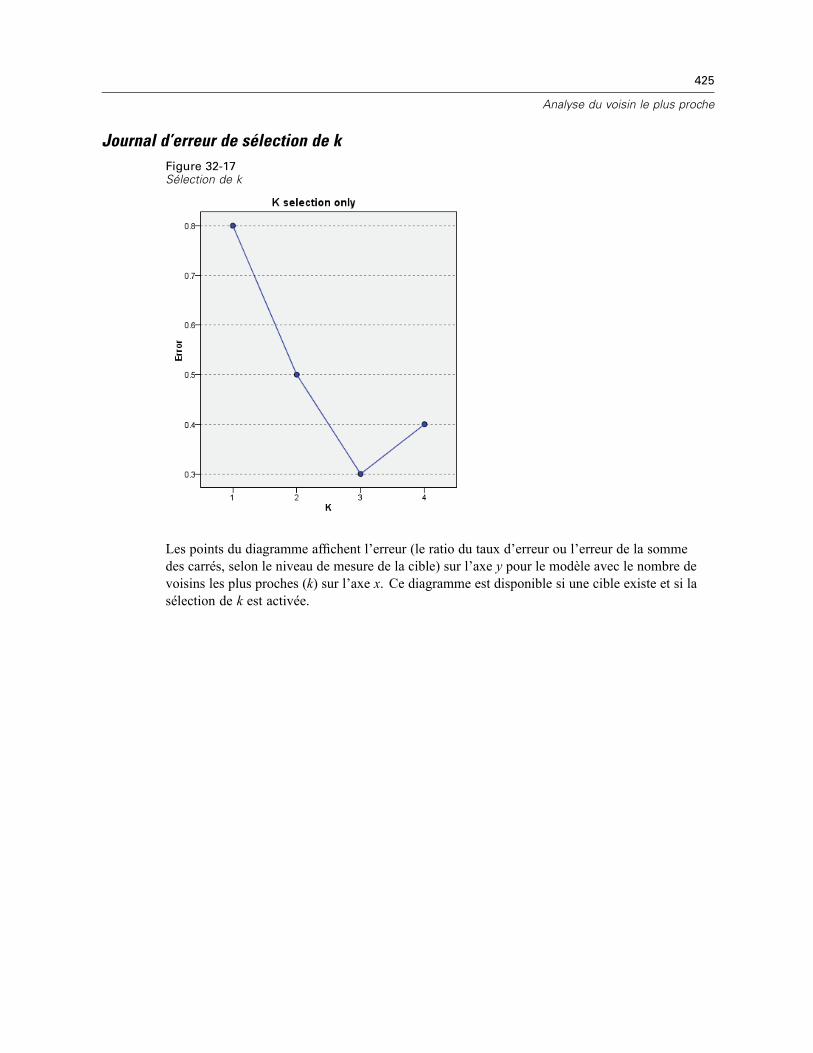
425
Analyse du voisin le plus proche
Journal d’erreur de sélection de kFigure 32-17Sélection de k
Les points du diagramme affichent l’erreur (le ratio du taux d’erreur ou l’erreur de la sommedes carrés, selon le niveau de mesure de la cible) sur l’axe y pour le modèle avec le nombre devoisins les plus proches (k) sur l’axe x. Ce diagramme est disponible si une cible existe et si lasélection de k est activée.
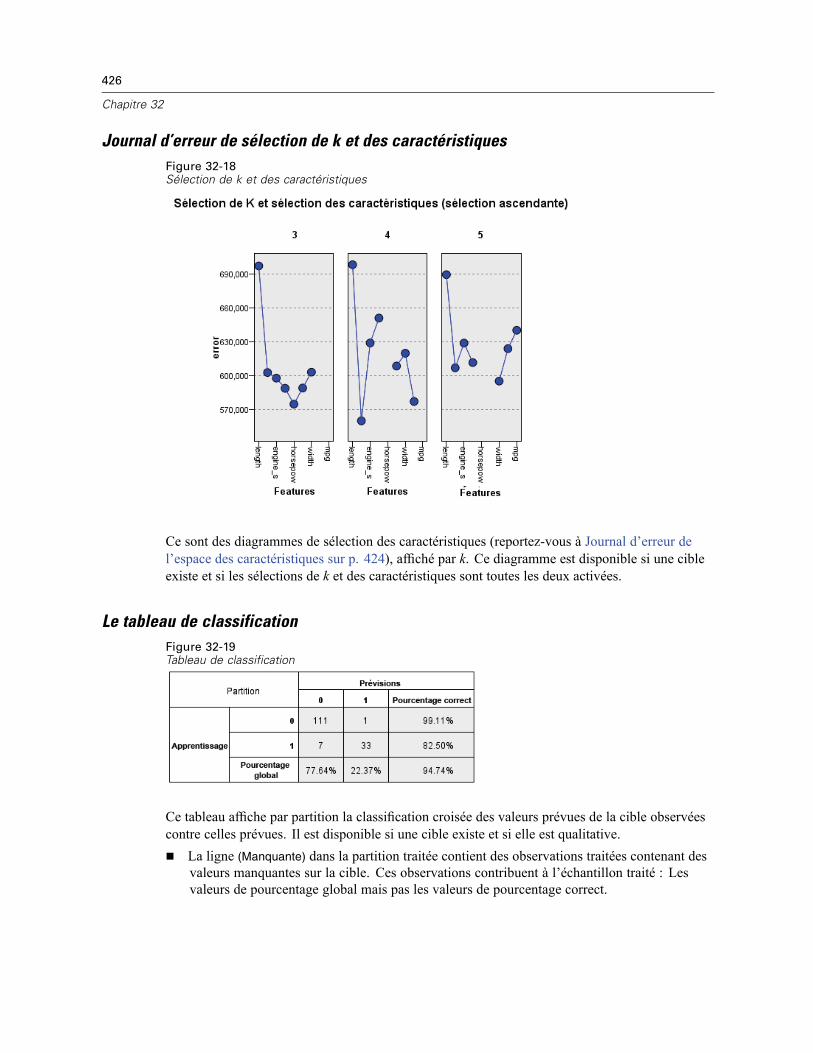
426
Chapitre 32
Journal d’erreur de sélection de k et des caractéristiquesFigure 32-18Sélection de k et des caractéristiques
Ce sont des diagrammes de sélection des caractéristiques (reportez-vous à Journal d’erreur del’espace des caractéristiques sur p. 424), affiché par k. Ce diagramme est disponible si une cibleexiste et si les sélections de k et des caractéristiques sont toutes les deux activées.
Le tableau de classificationFigure 32-19Tableau de classification
Ce tableau affiche par partition la classification croisée des valeurs prévues de la cible observéescontre celles prévues. Il est disponible si une cible existe et si elle est qualitative.
La ligne (Manquante) dans la partition traitée contient des observations traitées contenant desvaleurs manquantes sur la cible. Ces observations contribuent à l’échantillon traité : Lesvaleurs de pourcentage global mais pas les valeurs de pourcentage correct.

427
Analyse du voisin le plus proche
Récapitulatif d’erreurFigure 32-20Récapitulatif d’erreur
Ce tableau est disponible si une variable cible existe. Il affiche l’erreur associée au modèle, lasomme des carrés pour une cible cible continue et le taux d’erreur (100% − pourcentage généralcorrect) pour une cible qualitative.

Chapitre
33Analyse discriminante
L’analyse discriminante crée un modèle de prévision de groupe d’affectation. Le modèle estcomposé d’une fonction discriminante (ou, pour plus de deux groupes, un ensemble de fonctionsdiscriminantes) basée sur les combinaisons linéaires des variables explicatives qui donnent lameilleure discrimination entre groupes. Les fonctions sont générées à partir d’un échantillond’observations pour lesquelles le groupe d’affectation est connu. Les fonctions peuvent alorsêtre appliquées aux nouvelles observations avec des mesures de variables explicatives, mais degroupe d’affectation inconnu.
Remarque : la variable de groupe peut avoir plus de deux valeurs. Les codes de la variable deregroupement doivent cependant être des nombres entiers, et vous devez spécifier leur valeurminimale et maximale. Les observations dont les valeurs se situent hors des limites sont excluesde l’analyse.
Exemple : En moyenne, les habitants des pays des zones tempérées consomment plus de caloriespar jour que ceux des tropiques, et une plus grande proportion de ces habitants vit en ville.Un chercheur veut combiner ces informations en une fonction pour déterminer comment unindividu peut être différencié selon les deux groupes de pays. Le chercheur pense que la taillede la population et des informations économiques peuvent aussi être importantes. L’analysediscriminante vous permet d’estimer les coefficients de la fonction discriminante linéaire, quiressemble à la partie droite d’une équation de régression linéaire multiple. Ainsi, en utilisantles coefficients a, b, c et d, la fonction est :
D = a * climat + b * urbain + c * population + d * Produit National Brut par habitant
Si ces variables sont utiles pour établir la différence entre les deux zones climatiques, les valeursde D seront différentes pour les pays tempérés et les pays tropicaux. Si vous utilisez une méthodede sélection des variables pas à pas, vous pouvez découvrir que vous n’avez pas forcément besoind’inclure les quatre variables dans la fonction.
Statistiques. Pour chaque variable, on a les éléments suivants : moyenne, écarts-types, ANOVAà un facteur. Pour chaque analyse : Test de Box, matrice de corrélation intra-classe, matrice decovariance intra-classe, matrice de covariance de chaque classe, matrice de covariance totale. Pourchaque fonction discriminante canonique : valeur propre, pourcentage de la variance, corrélationcanonique, lambda de Wilks, Khi-deux. Pour chaque pas : probabilités à priori, coefficientsde fonction de Fisher, coefficients de fonction non standardisés, lambda de Wilks pour chaquefonction canonique.
428
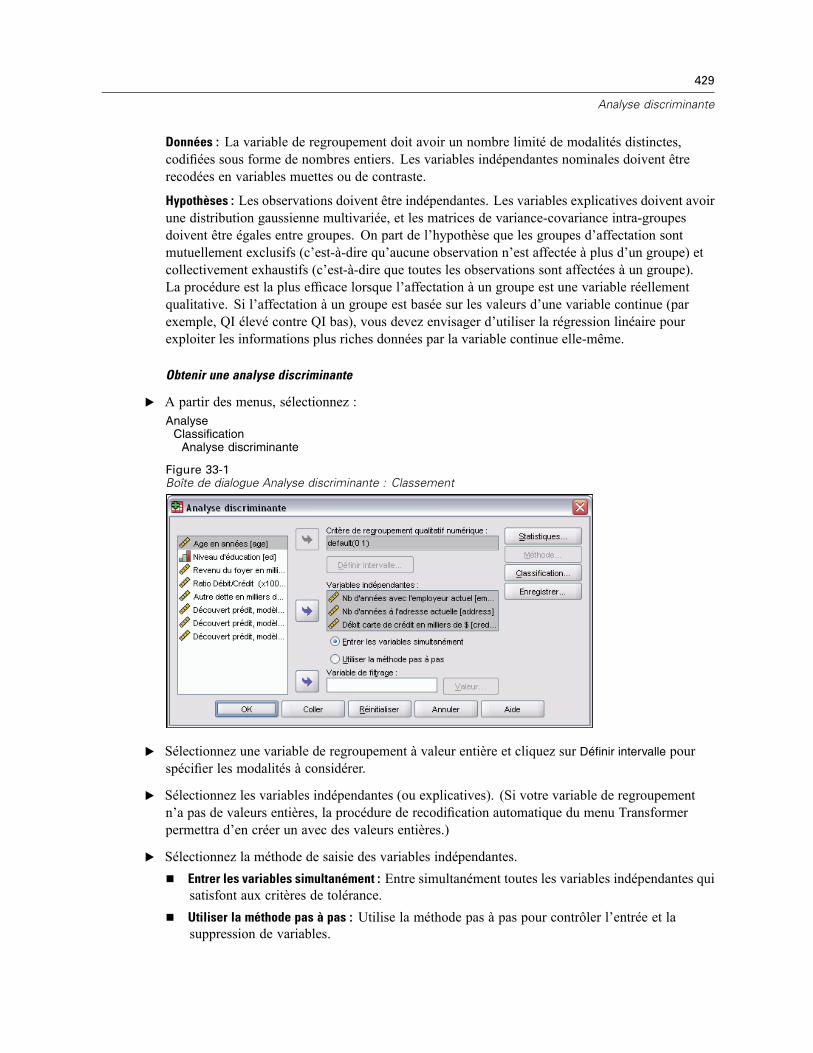
429
Analyse discriminante
Données : La variable de regroupement doit avoir un nombre limité de modalités distinctes,codifiées sous forme de nombres entiers. Les variables indépendantes nominales doivent êtrerecodées en variables muettes ou de contraste.
Hypothèses : Les observations doivent être indépendantes. Les variables explicatives doivent avoirune distribution gaussienne multivariée, et les matrices de variance-covariance intra-groupesdoivent être égales entre groupes. On part de l’hypothèse que les groupes d’affectation sontmutuellement exclusifs (c’est-à-dire qu’aucune observation n’est affectée à plus d’un groupe) etcollectivement exhaustifs (c’est-à-dire que toutes les observations sont affectées à un groupe).La procédure est la plus efficace lorsque l’affectation à un groupe est une variable réellementqualitative. Si l’affectation à un groupe est basée sur les valeurs d’une variable continue (parexemple, QI élevé contre QI bas), vous devez envisager d’utiliser la régression linéaire pourexploiter les informations plus riches données par la variable continue elle-même.
Obtenir une analyse discriminante
E A partir des menus, sélectionnez :Analyse
ClassificationAnalyse discriminante
Figure 33-1Boîte de dialogue Analyse discriminante : Classement
E Sélectionnez une variable de regroupement à valeur entière et cliquez sur Définir intervalle pourspécifier les modalités à considérer.
E Sélectionnez les variables indépendantes (ou explicatives). (Si votre variable de regroupementn’a pas de valeurs entières, la procédure de recodification automatique du menu Transformerpermettra d’en créer un avec des valeurs entières.)
E Sélectionnez la méthode de saisie des variables indépendantes.Entrer les variables simultanément : Entre simultanément toutes les variables indépendantes quisatisfont aux critères de tolérance.Utiliser la méthode pas à pas : Utilise la méthode pas à pas pour contrôler l’entrée et lasuppression de variables.

430
Chapitre 33
E Vous pouvez également sélectionner les observations avec une variable de sélection.
Définition d’intervalles pour l’analyse discriminanteFigure 33-2Boîte de dialogue Analyse discriminante : Définir intervalle
Spécifiez la valeur minimum et maximum de la variable de regroupement pour l’analyse.Les observations avec des valeurs hors de cet intervalle ne sont pas utilisées dans l’analysediscriminante mais elles sont classées dans un des groupes existants en fonction des résultats del’analyse. Les valeurs minimum et maximum doivent être des entiers.
Sélection des observations pour l’analyse discriminanteFigure 33-3Boîte de dialogue Analyse discriminante : Enregistrer
Pour sélectionner les observations pour votre analyse :
E Dans la boîte de dialogue Analyse discriminante, sélectionnez une variable de sélection.
E Cliquez sur Valeur pour entrer un entier comme valeur de sélection.
Seules les observations avec la valeur spécifiée pour la variable de sélection sont utilisées pourdériver les fonctions discriminantes. Les résultats des statistiques et de classification sontgénérés pour les observations sélectionnées et celles qui ne le sont pas. Ce processus fournit uneméthode de classification des nouvelles observations reposant sur des données existantes ou departitionnement de vos données dans un sous-ensemble de test ou de formation en vue d’effectuerune validation sur le modèle créé.

431
Analyse discriminante
Statistiques de l’analyse discriminanteFigure 33-4Boîte de dialogue Analyse discriminante: Statistiques
Descriptives. Les options disponibles sont moyennes (y compris écarts-types), ANOVA à 1 facteuret Test M de Box.
Moyennes. Affiche le total et la moyenne de chaque groupe ainsi que l'écart-type des variablesexplicatives.ANOVA à 1 facteur. Effectue pour chacune des variables indépendantes une analyse de varianceà 1 facteur pour tester l'égalité des moyennes de groupe.M de Box. Test d'égalité des matrices de covariance des classes. Pour les échantillons de taillesuffisamment importante, une valeur p non significative indique qu'il n'est pas démontréque les matrices diffèrent. Ce test est sensible aux déviations par rapport à la distributiongaussienne multivariée.
Coefficients de la fonction : Les options disponibles sont les coefficients de la classification deFisher et les coefficients non standardisés.
Fisher. Affiche les coefficients de la fonction de classification de Fisher qui peuvent êtredirectement utilisés pour la classification. Un groupe séparé de coefficients de fonctions declassification est obtenu pour chaque groupe et une observation est affectée au groupe qui a leplus grand score discriminant (valeur de fonction de classification).Non standardisés. Affiche les coefficients non normalisés de la fonction discriminante.
Matrices : Les matrices de coefficients pour variables indépendantes disponibles sont la matricede corrélation intra-classe, la matrice de covariance intra-classe, la matrice de covariance dechaque classe et la matrice de covariance totale.
Corrélations intra-classe. Affiche une matrice de corrélations intra‑classes globale, encalculant la moyenne des matrices de covariance distinctes pour tous les groupes avant decalculer les corrélations.Covariance intra-classe. Affiche une matrice de covariances intra‑classes globale, qui peutdifférer de la matrice de covariance totale. Cette matrice est obtenue en calculant la moyennedes matrices de covariances distinctes de tous les groupes.

432
Chapitre 33
Covariance de chaque classe. Affiche des matrices de covariances distinctes pour chaquegroupe.Covariance totale. Affiche la matrice de covariance de toutes les observations comme si ellesprovenaient d'un seul échantillon.
Méthode pas à pas de l’analyse discriminanteFigure 33-5Boîte de dialogue Analyse discriminante : Méthode pas à pas
Méthode : Sélectionnez la statistique à utiliser pour ajouter ou supprimer de nouvelles variables.Les options possibles sont le lambda de Wilks, la variance résiduelle, la distance de Mahalanobis,le plus petit rapport F et le V de Rao. Avec le V de Rao, vous pouvez spécifier l’augmentationminimum de V pour entrer une variable.
Lambda de Wilks. Méthode de sélection des variables pour une analyse discriminante pas àpas qui sélectionne les variables à entrer dans l'équation d'après leur capacité à faire baisserle lambda de Wilks. A chaque étape, les variables sont entrées dans l'analyse d'après leurcapacité à faire baisser le lambda de Wilks.Variance résiduelle. A chaque étape, la variable qui minimise la somme des variationsrésiduelles entre les groupes est saisie.Distance de Mahalanobis. Mesure de la distance entre les valeurs d'une observation et lamoyenne de toutes les observations sur les variables indépendantes. Une distance deMahalanobis importante identifie une observation qui a des valeurs extrêmes pour desvariables indépendantes.Plus petit rapport F.Méthode de sélection des variables en analyse pas à pas, fondée sur lamaximisation d'un rapport F calculé à partir de la distance de Mahalanobis entre des groupes.V de Rao. Mesure des différences entre des moyennes de groupes. Egalement appelée trace deLawley-Hotelling. A chaque étape, la variable qui maximise l'augmentation du V de RAOest entrée. Après avoir sélectionné cette option, entrez la valeur minimale que doit avoir unevariable pour entrer dans l'analyse.

433
Analyse discriminante
Critères : Les options disponibles sont Choisir la valeur de F et Choisir la probabilité de F. Entrez desvaleurs pour ajouter et supprimer des variables.
Choisir la valeur de F. Une variable est introduite dans un modèle si sa valeur F est supérieureà la valeur Entrée et elle est éliminée si la valeur F est inférieure à la valeur Elimination.La valeur Entrée doit être supérieure à la valeur Elimination et toutes deux doivent êtrepositives. Pour introduire davantage de variables dans le modèle, réduisez la valeur duchamp Entrée. Pour éliminer davantage de variables dans le modèle, augmentez la valeur duchamp Elimination.Choisir la probabilité de F.Une variable est entrée dans le modèle si le seuil de signification dela valeur F est inférieur à la valeur Entrée ; la variable est éliminée si ce seuil est supérieur à lavaleur Elimination. La valeur Entrée doit être inférieure à la valeur Elimination et toutes deuxdoivent être positives. Pour introduire davantage de variables dans le modèle, diminuez lavaleur Entrée. Pour éliminer davantage de variables du modèle, réduisez la valeur Elimination.
Afficher : L’option Récapitulation des étapes affiche les statistiques de toutes les variables aprèschaque étape. L’option Test F des distances entre couples affiche une matrice de rapports Fappariés pour chaque paire de groupes.
Analyse discriminante : ClassementFigure 33-6Boîte de dialogue Classement de l’analyse discriminante
Probabilités à priori : Cette option permet de déterminer si les coefficients de classification sontajustés pour une connaissance à priori de l’appartenance à une classe.
Egales pour toutes les classes. Des probabilités à priori égales sont supposées pour toutes lesclasses; ceci n’a aucun incident sur les coefficients.A calculer selon les effectifs. Les tailles de classe observées dans votre échantillon déterminentles probabilités à priori de la classe d’appartenance. Par exemple, si 50% des observationscomprises dans l’analyse appartiennent à la première classe, 25 % à la deuxième, et 25 %à la troisième, les coefficients de classification sont ajustés pour accroître la probabilitéd’affectation de la première classe par rapport aux deux autres.

434
Chapitre 33
Afficher : Les options d’affichage disponibles sont les résultats par observation, le récapitulatifet la classification par élimination.
Résultats par observation. Les codes du groupe actuel, du groupe prévu, des probabilités aposteriori et des scores discriminants sont affichés pour chaque observation.Récapitulatif. Nombre d'observations correctement et incorrectement affectées à chacune desclasses sur la base de l'analyse discriminante. Parfois appelés « matrice de confusion ».Classification par élimination :. Classement de chaque observation de l'analyse par les fonctionsdérivées de l'ensemble des observations autres que cette observation. Cette classification estégalement appelée « méthode U ».
Remplacer les valeurs manquantes par la moyenne : Sélectionnez cette option pour remplacer lavaleur manquante d’une variable indépendante par la moyenne de cette variable, mais seulementdurant la phase de classification.
Utiliser la matrice d’inertie : Vous pouvez choisir de classer les observations en utilisant unematrice de covariance intra-classe ou une matrice de covariance pour chaque classe.
Intra-classe. La matrice de covariances intra‑classes globale est utilisée pour classifier lesobservations.Classe par classe. Les matrices de covariances de chaque groupe sont utilisées pour laclassification. Comme la classification repose sur les fonctions discriminantes et pas sur lesvariables d'origine, cette option n'est pas toujours équivalente à la discrimination quadratique.
Diagrammes : Les options de diagramme disponibles sont toutes classes combinées, classe parclasse, et carte des régions d’affectation.
Toutes classes combinées. Crée un diagramme de dispersion de tous les groupes, des valeursdes deux premières fonctions discriminantes. S'il n'y a qu'une seule fonction, un histogrammeest tracé à la place.Classe par classe :. Crée des diagrammes de dispersion classe par classe pour les deuxpremières valeurs de fonction discriminante. Lorsqu'il n'y a qu'une seule fonction, deshistogrammes sont affichés à la place.Carte des régions d'affectation. Diagramme des limites servant à classifier les observationsen fonction de valeurs de fonction. Les numéros correspondent aux groupes auxquels lesobservations ont été affectées. La moyenne de chaque groupe est indiquée par un astérisqueà l'intérieur de ses limites. La carte n'est pas affichée s'il n'existe qu'une seule fonctiondiscriminante.
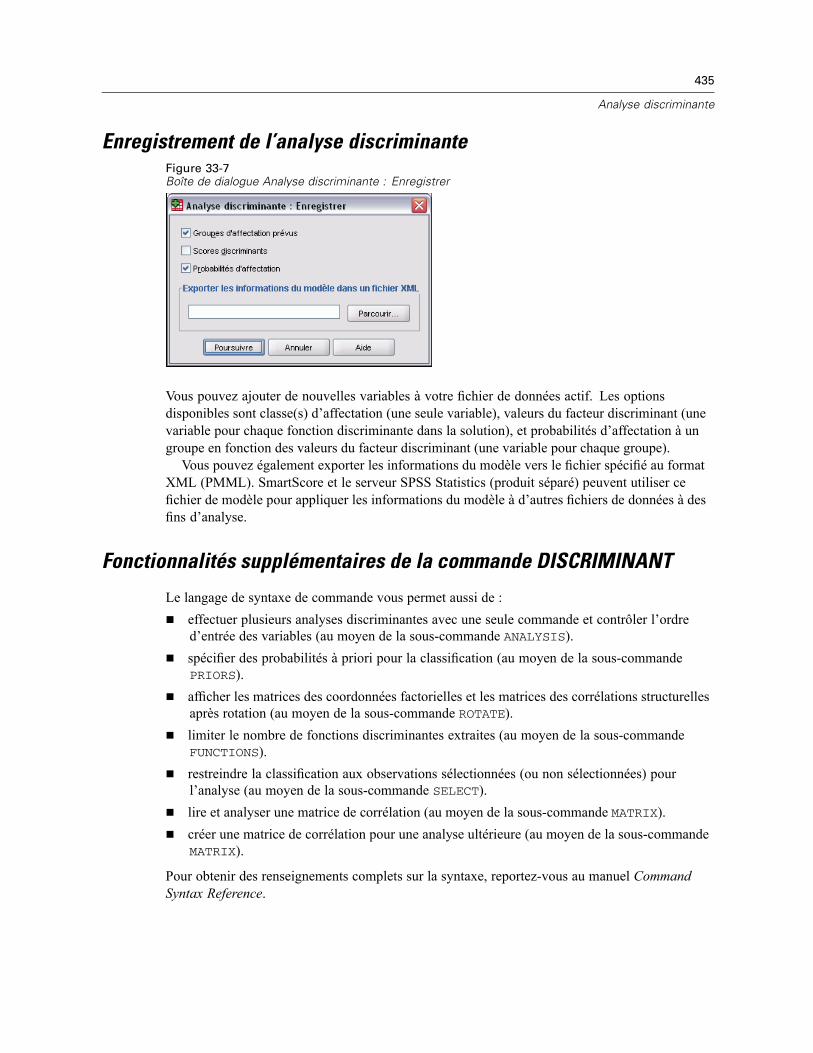
435
Analyse discriminante
Enregistrement de l’analyse discriminanteFigure 33-7Boîte de dialogue Analyse discriminante : Enregistrer
Vous pouvez ajouter de nouvelles variables à votre fichier de données actif. Les optionsdisponibles sont classe(s) d’affectation (une seule variable), valeurs du facteur discriminant (unevariable pour chaque fonction discriminante dans la solution), et probabilités d’affectation à ungroupe en fonction des valeurs du facteur discriminant (une variable pour chaque groupe).Vous pouvez également exporter les informations du modèle vers le fichier spécifié au format
XML (PMML). SmartScore et le serveur SPSS Statistics (produit séparé) peuvent utiliser cefichier de modèle pour appliquer les informations du modèle à d’autres fichiers de données à desfins d’analyse.
Fonctionnalités supplémentaires de la commande DISCRIMINANT
Le langage de syntaxe de commande vous permet aussi de :effectuer plusieurs analyses discriminantes avec une seule commande et contrôler l’ordred’entrée des variables (au moyen de la sous-commande ANALYSIS).spécifier des probabilités à priori pour la classification (au moyen de la sous-commandePRIORS).afficher les matrices des coordonnées factorielles et les matrices des corrélations structurellesaprès rotation (au moyen de la sous-commande ROTATE).limiter le nombre de fonctions discriminantes extraites (au moyen de la sous-commandeFUNCTIONS).restreindre la classification aux observations sélectionnées (ou non sélectionnées) pourl’analyse (au moyen de la sous-commande SELECT).lire et analyser une matrice de corrélation (au moyen de la sous-commande MATRIX).créer une matrice de corrélation pour une analyse ultérieure (au moyen de la sous-commandeMATRIX).
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.

Chapitre
34Analyse factorielle
L’analyse factorielle essaie d’identifier des variables sous-jacentes, ou facteurs, qui permettentd’expliquer le patron des corrélations à l’intérieur d’un ensemble de variables observées.L’analyse factorielle est souvent utilisée pour réduire un ensemble de données. L’analysefactorielle est souvent utilisée dans la factorisation, en identifiant un petit nombre de facteurs quiexpliquent la plupart des variances observées dans le plus grand nombre de variables manifestes.On peut également utiliser l’analyse factorielle pour générer des hypothèses concernant desmécanismes de causalité ou pour afficher des variables pour une analyse ultérieure (par exemple,pour identifier la colinéarité avant une analyse de régression linéaire).
La procédure d’analyse factorielle offre une très grande flexibilité :Il existe sept méthodes d’extraction de facteur.Il existe cinq méthodes de rotation, dont directe Oblimin et Promax pour les rotations nonorthogonales.Il existe trois méthodes pour calculer les facteurs, et ces facteurs peuvent être enregistrés entant que variables pour des analyses ultérieures.
Exemple : Quelle est l’attitude sous-jacente qui pousse les personnes à répondre d’une certainemanière aux questions concernant un sondage politique ? L’examen des corrélations parmi leséléments d’un sondage révèle qu’il y a des recouvrements significatifs parmi divers sous-groupesd’éléments. Les questions sur les impôts ont tendance à être en corrélation, de même que lesquestions à thèmes militaires, etc. Avec l’analyse factorielle, vous pouvez enquêter sur le nombrede facteurs sous-jacents, et, dans de nombreux cas, vous pouvez identifier le concept représentépar ces facteurs. De plus, vous pouvez calculer les facteurs pour chaque répondant, facteurs quevous pouvez utiliser pour des analyses ultérieures. Par exemple, sur la base des facteurs, vouspouvez développer un modèle logistique de régression pour prévoir le comportement de vote.
Statistiques : Pour chaque variable, on a les éléments suivants : nombre d’observationsvalides, moyenne et écart-type. Pour chaque analyse factorielle : matrice de corrélation desvariables, incluant des seuils de signification, déterminant, inverse ; les matrices des corrélationsreconstituées, incluant l’anti-image ; les solutions initiales (qualités de représentation, valeurspropres et pourcentage de variance expliqué) ; mesure d’adéquation d’échantillonnage deKaiser-Meyer-Olkin et le test de sphéricité de Bartlett ; structure avant rotation, incluant lessaturations sur les facteurs, la qualité de représentation, et les valeurs propres; structure aprèsrotation, incluant une matrice de forme après rotation et une matrice de transformation. Pourrotations obliques : type et matrices de structure après rotation ; matrice factorielle de coefficientde facteur et matrice factorielle de facteur de covariance. Diagrammes : Diagramme de valeurspropres et carte factorielle du premier, du deuxième et du troisième facteur.
436
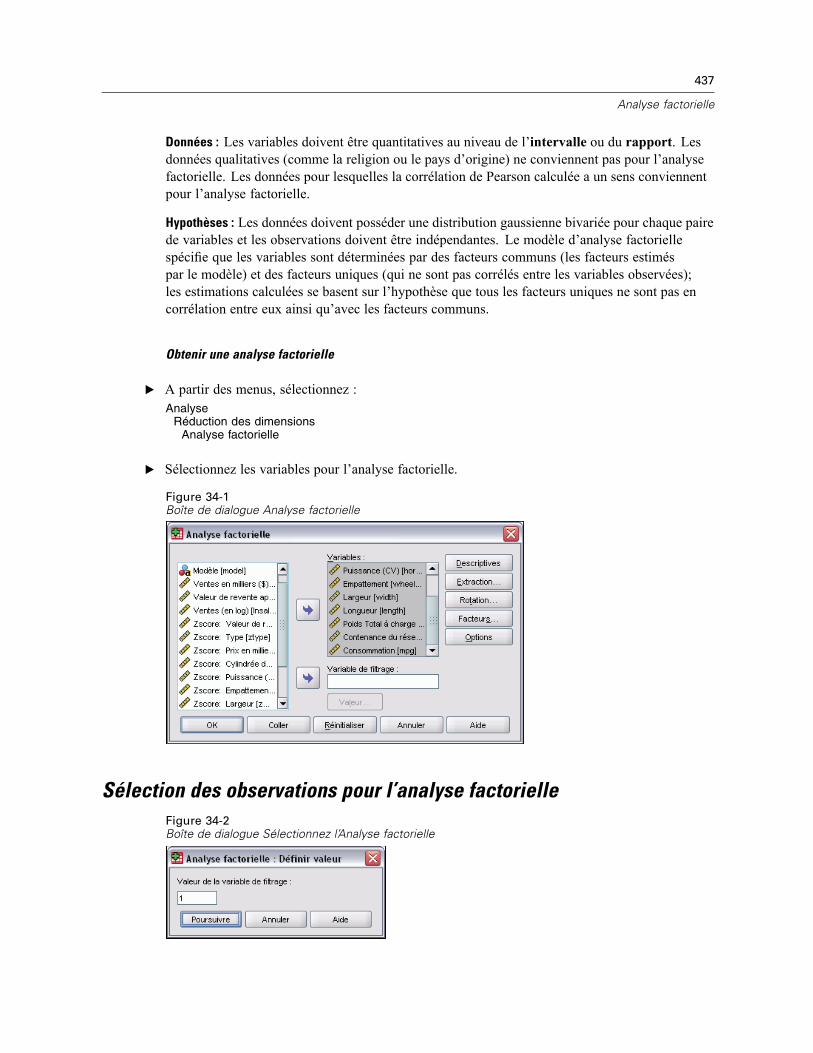
437
Analyse factorielle
Données : Les variables doivent être quantitatives au niveau de l’intervalle ou du rapport. Lesdonnées qualitatives (comme la religion ou le pays d’origine) ne conviennent pas pour l’analysefactorielle. Les données pour lesquelles la corrélation de Pearson calculée a un sens conviennentpour l’analyse factorielle.
Hypothèses : Les données doivent posséder une distribution gaussienne bivariée pour chaque pairede variables et les observations doivent être indépendantes. Le modèle d’analyse factoriellespécifie que les variables sont déterminées par des facteurs communs (les facteurs estiméspar le modèle) et des facteurs uniques (qui ne sont pas corrélés entre les variables observées);les estimations calculées se basent sur l’hypothèse que tous les facteurs uniques ne sont pas encorrélation entre eux ainsi qu’avec les facteurs communs.
Obtenir une analyse factorielle
E A partir des menus, sélectionnez :Analyse
Réduction des dimensionsAnalyse factorielle
E Sélectionnez les variables pour l’analyse factorielle.
Figure 34-1Boîte de dialogue Analyse factorielle
Sélection des observations pour l’analyse factorielleFigure 34-2Boîte de dialogue Sélectionnez l’Analyse factorielle
438
Chapitre 34
Pour sélectionner les observations pour votre analyse :
E Sélectionnez une variable de sélection.
E Cliquez sur Valeur pour entrer un entier comme valeur de sélection.
Seules les observations ayant cette valeur pour la variable de sélection sont utilisées dans l’analysefactorielle.
Descriptives d’analyse factorielleFigure 34-3Boîte de dialogue Analyse Factorielle : Descriptives
Statistiques : Les Descriptives univariées incluent la moyenne, l’écart-type et le nombred’observations valides pour chaque variable. La structure initiale affiche la qualité de représentationinitiale, les valeurs propres et le pourcentage de variance expliqué.
Matrice de corrélation : Les options disponibles sont les coefficients, les seuils de signification, lesdéterminants, les inverses, les reproduits, l’anti-image et l’indice KMO et le test de sphéricitéde Bartlett.
Indice KMO et test de sphéricité de Bartlett. Mesure de l'adéquation de l'échantillonnage deKaiser‑Meyer‑Olkin qui teste si les corrélations partielles entre les variables sont faibles. Letest de sphéricité de Bartlett teste si la matrice des corrélations est une matrice d'identité, cequi indiquerait que le modèle de facteur n'est pas adapté.Reconstituée. Matrice des corrélations estimée à partir de la solution factorielle. Les résidus(différence entre les corrélations estimées et observées) sont également affichés.Anti-image. La matrice de corrélation des anti-images contient les opposés des coefficientsde corrélation partielle ; la matrice de covariance des anti-images contient les opposés descovariances partielles. Dans un bon modèle factoriel, la plupart des éléments hors diagonaledoivent être petits. La mesure d'adéquation d'échantillonnage pour une variable est affichéesur la diagonale de la matrice de corrélation des anti-images.
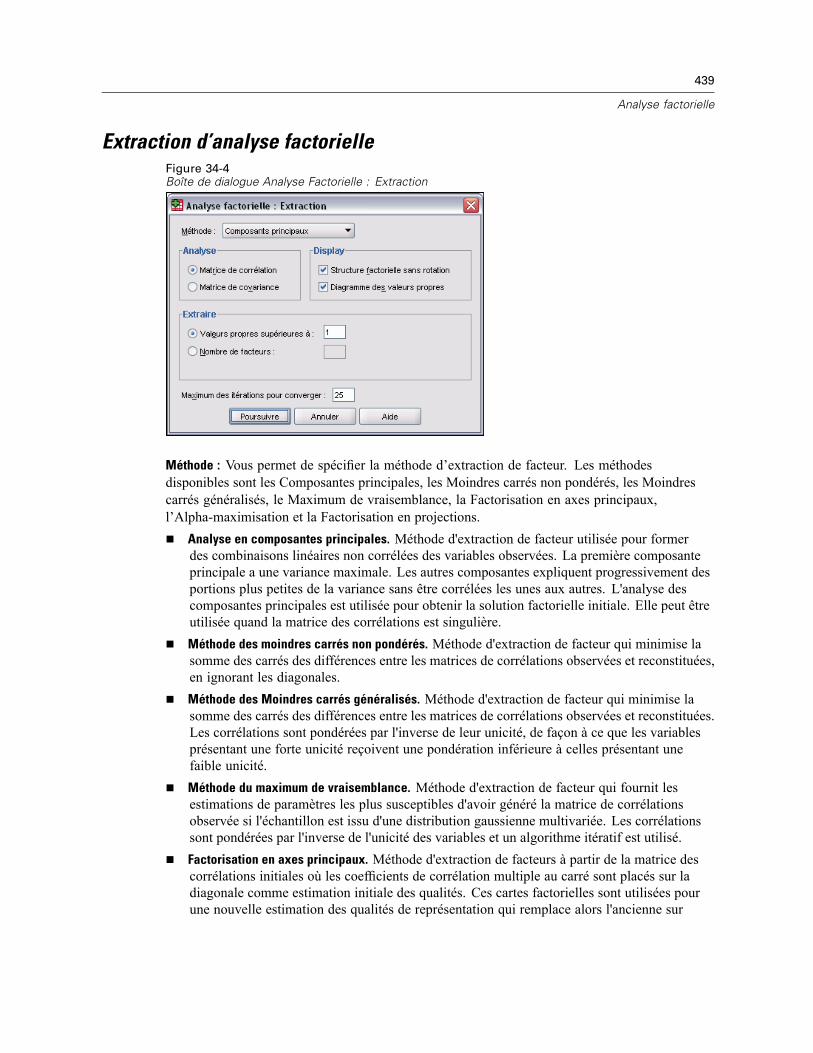
439
Analyse factorielle
Extraction d’analyse factorielleFigure 34-4Boîte de dialogue Analyse Factorielle : Extraction
Méthode : Vous permet de spécifier la méthode d’extraction de facteur. Les méthodesdisponibles sont les Composantes principales, les Moindres carrés non pondérés, les Moindrescarrés généralisés, le Maximum de vraisemblance, la Factorisation en axes principaux,l’Alpha-maximisation et la Factorisation en projections.
Analyse en composantes principales. Méthode d'extraction de facteur utilisée pour formerdes combinaisons linéaires non corrélées des variables observées. La première composanteprincipale a une variance maximale. Les autres composantes expliquent progressivement desportions plus petites de la variance sans être corrélées les unes aux autres. L'analyse descomposantes principales est utilisée pour obtenir la solution factorielle initiale. Elle peut êtreutilisée quand la matrice des corrélations est singulière.Méthode des moindres carrés non pondérés. Méthode d'extraction de facteur qui minimise lasomme des carrés des différences entre les matrices de corrélations observées et reconstituées,en ignorant les diagonales.Méthode des Moindres carrés généralisés. Méthode d'extraction de facteur qui minimise lasomme des carrés des différences entre les matrices de corrélations observées et reconstituées.Les corrélations sont pondérées par l'inverse de leur unicité, de façon à ce que les variablesprésentant une forte unicité reçoivent une pondération inférieure à celles présentant unefaible unicité.Méthode du maximum de vraisemblance. Méthode d'extraction de facteur qui fournit lesestimations de paramètres les plus susceptibles d'avoir généré la matrice de corrélationsobservée si l'échantillon est issu d'une distribution gaussienne multivariée. Les corrélationssont pondérées par l'inverse de l'unicité des variables et un algorithme itératif est utilisé.Factorisation en axes principaux. Méthode d'extraction de facteurs à partir de la matrice descorrélations initiales où les coefficients de corrélation multiple au carré sont placés sur ladiagonale comme estimation initiale des qualités. Ces cartes factorielles sont utilisées pourune nouvelle estimation des qualités de représentation qui remplace alors l'ancienne sur

440
Chapitre 34
la diagonale. Les itérations se poursuivent jusqu'à ce que les variations des qualités dereprésentation d'une itération à l'autre satisfassent le critère de convergence de l'extraction.Alpha. Méthode d'extraction de facteur qui considère les variables dans l'analyse comme unéchantillon issu de la population des variables potentielles. Cette méthode maximise l'alphade Cronbach des facteurs.Factorisation en projections. Méthode d'extraction de facteur développée par Guttman etbasée sur la théorie d'une image. La partie commune de la variable, appelée image partielle,est définie comme sa régression linéaire sur les autres variables, plutôt qu'une fonction defacteurs hypothétiques.
Analyser : Vous permet de spécifier si l’analyse porte sur une matrice de corrélation ou sur unematrice de covariance.
Matrice de corrélation. Utile si les variables de votre analyse sont mesurées selon des échellesdifférentes.Matrice de covariance. Utile lorsque vous souhaitez appliquer l’analyse factorielle à plusieursgroupes avec des variances différentes pour chaque variable.
Extraire : Vous pouvez retenir tous les facteurs dont les valeurs propres dépassent une valeurspécifique ou retenir un nombre spécifique de facteurs.
Afficher : Vous permet de demander la solution factorielle avant rotation et un diagramme desvaleurs propres.
Solution factorielle sans rotation. Affiche les corrélations factorielles sans rotation (matrice deprojections factorielles), les qualités de représentation et les valeurs propres de la solutionfactorielle.Diagramme des valeurs propres. Diagramme représentant la variance associée à chaque facteur.Permet de déterminer le nombre de facteurs à conserver. Généralement, le diagrammemontre une coupure franche entre la forte pente des facteurs élevés et la traîne graduelledu reste (valeurs propres).
Maximum des itérations pour converger : Vous permet de spécifier le nombre maximum de pas quel’algorithme peut utiliser pour estimer la solution.

441
Analyse factorielle
Rotation d’analyse factorielleFigure 34-5Boîte de dialogue Analyse factorielle : Rotation
Méthode : Vous permet de sélectionner la méthode de rotation des facteurs. Les méthodesdisponibles sont Varimax, Oblimin directe, Quartimax, Equamax ou Promax.
Méthode varimax. Méthode de rotation orthogonale qui minimise le nombre de variables ayantde fortes corrélations sur chaque facteur. Simplifie l'interprétation des facteurs.Critère oblimin direct. Méthode de rotation oblique (non orthogonale). Lorsque delta est nul(valeur par défaut), les solutions sont les plus obliques. Plus la valeur de delta est négative,moins les facteurs sont obliques. Pour remplacer la valeur nulle par défaut de delta, entrezun nombre inférieur ou égal à 0,8.Méthode quartimax. Méthode de rotation qui réduit le nombre de facteurs requis pour expliquerchaque variable. Simplifie l'interprétation des variables observées.Equamax. Méthode de rotation qui est une combinaison de la méthode Varimax (qui simplifieles facteurs) et de la méthode Quartimax (qui simplifie les variables). Le nombre de variablespesant sur un facteur et le nombre de facteurs nécessaires pour expliquer une variable sontminimisés.Rotation Promax. Rotation oblique qui permet aux facteurs d'être corrélés. Peut être calculéeplus rapidement qu'une rotation oblimin directe, aussi est-elle utile pour les vastes ensemblesde données.
Afficher : Vous permet d’inclure le résultat de la structure après rotation, et également d’afficherles cartes factorielles sur le premier, le second et le troisième facteur (Cartes factorielles).
Structure après rotation. Vous devez sélectionner une méthode de rotation pour obtenir unestructure après rotation. Pour les rotations orthogonales, la matrice de forme après rotationet la matrice de transformation factorielle sont affichées. Pour les rotations obliques, leprogramme affiche la matrice des projections factorielles, la matrice de structure et la matricedes corrélations de facteurs.Diagramme des Contributions des Facteurs. Diagramme en trois dimensions des contributionsdes trois premiers facteurs. Pour une solution à deux facteurs, un diagramme en deuxdimensions est affiché. Le diagramme n'est pas affiché si un seul facteur est extrait. Lesdiagrammes affichent des solutions ayant subi une rotation si cette dernière est demandée.

442
Chapitre 34
Maximum des itérations pour converger : Vous permet de spécifier le nombre maximum de pas quel’algorithme peut utiliser pour réaliser la rotation.
Scores d’analyse factorielleFigure 34-6Boîte de dialogue Scores de l’Analyse Factorielle
Enregistrer dans des variables : Vous permet de créer une nouvelle variable pour chaque facteurselon la structure finale.
Méthode : Les méthodes alternatives pour calculer les facteurs sont la Régression, Bartlett,et Anderson-Rubin.
Méthode de régression. Méthode d'estimation des coefficients factoriels. Les écarts obtenusont une moyenne de 0 et une variance égale au carré de la corrélation multiple entre lescoefficients factoriels estimés et les vraies valeurs du facteur. Les écarts peuvent être corrélésmême lorsque les facteurs sont orthogonaux.Facteurs de Bartlett. Méthode d'estimation des coefficients factoriels. Les résultats ont unemoyenne de 0. La somme des carrés des facteurs uniques dans la plage de variables estminimisée.Méthode d'Anderson-Rubin. Méthode d'estimation des coefficients factoriels ; variante de laméthode de Bartlett qui garantit l'orthogonalité des facteurs estimés. Les résultats obtenusaffichent une moyenne de 0 et un écart-type de 1 et ne sont pas corrélés.
Afficher la matrice des coefficients factoriels : Vous permet de montrer les coefficients par lesquelsles variables sont multipliées pour obtenir les facteurs. Cela permet également de montrer lescorrélations entre les facteurs.
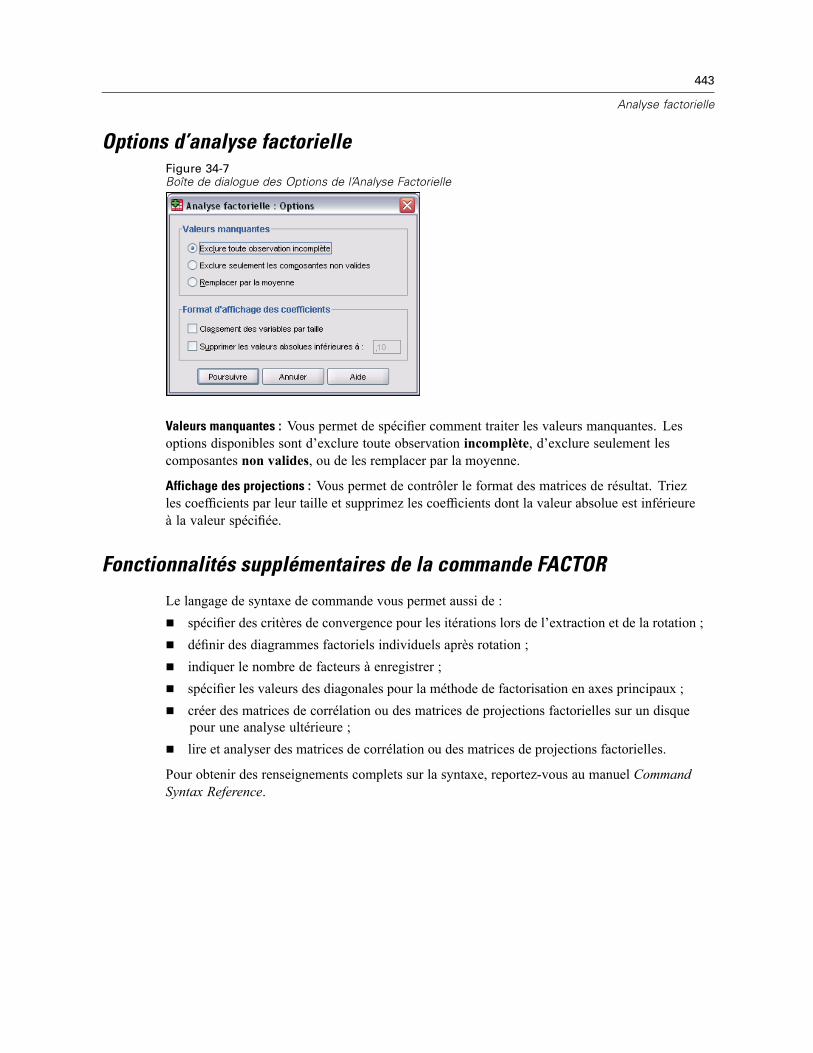
443
Analyse factorielle
Options d’analyse factorielleFigure 34-7Boîte de dialogue des Options de l’Analyse Factorielle
Valeurs manquantes : Vous permet de spécifier comment traiter les valeurs manquantes. Lesoptions disponibles sont d’exclure toute observation incomplète, d’exclure seulement lescomposantes non valides, ou de les remplacer par la moyenne.
Affichage des projections : Vous permet de contrôler le format des matrices de résultat. Triezles coefficients par leur taille et supprimez les coefficients dont la valeur absolue est inférieureà la valeur spécifiée.
Fonctionnalités supplémentaires de la commande FACTOR
Le langage de syntaxe de commande vous permet aussi de :spécifier des critères de convergence pour les itérations lors de l’extraction et de la rotation ;définir des diagrammes factoriels individuels après rotation ;indiquer le nombre de facteurs à enregistrer ;spécifier les valeurs des diagonales pour la méthode de factorisation en axes principaux ;créer des matrices de corrélation ou des matrices de projections factorielles sur un disquepour une analyse ultérieure ;lire et analyser des matrices de corrélation ou des matrices de projections factorielles.
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.

Chapitre
35Choix d’une procédure declassification
Vous pouvez effectuer des analyses de classes à l’aide de la procédure TwoStep, de la classificationhiérarchique ou des nuées dynamiques. Chaque procédure utilise un algorithme différent pour lacréation des classes, et chacune d’elles comporte des options qui ne sont pas disponibles dansles autres procédures.
Analyse du composant Classe TwoStep. La procédure Analyse du composant Classe TwoStep est laméthode privilégiée pour de nombreuses applications. Elle offre les fonctionnalités spécifiquessuivantes :
Sélection automatique du meilleur nombre de classes, en plus des mesures de sélection parmides modèles de classe.Possibilité de créer simultanément des modèles de classe sur la base de variables qualitativeset continues.Possibilité d’enregistrer le modèle de classe dans un fichier XML externe, puis de lire cefichier et de mettre à jour le modèle de classe à l’aide des données les plus récentes.
En outre, la procédure Analyse du composant Classe TwoStep permet d’analyser des fichiers dedonnées volumineux.
Classification hiérarchique. La procédure Classification hiérarchique est limitée à des fichiersde données plus petits (centaines d’objets à classer), mais offre les fonctionnalités spécifiquessuivantes :
Possibilité de classer des observations ou des variables.Possibilité de calculer plusieurs solutions possibles et d’enregistrer des classes d’affectationpour chacune de ces solutions.Plusieurs méthodes de formation de classes, de transformation de variables et de mesure dela dissimilarité entre les classes.
Tant que toutes les variables sont du même type, la procédure Classification hiérarchique peutanalyser des variables d’intervalle (continues), d’effectif ou binaires.
Nuées dynamiques. La procédure Nuées dynamiques est limitée aux données continues et exigeque vous indiquiez au préalable le nombre de classes. Elle offre néanmoins les fonctionnalitésspécifiques suivantes :
Possibilité d’enregistrer les distances à partir des centres de classes pour chaque objet.Possibilité de lire les centres de classes initiaux à partir d’un fichier SPSS Statistics etd’enregistrer les centres de classes finaux dans un fichier SPSS Statistics externe .
444

445
Choix d’une procédure de classification
En outre, la procédure Nuées dynamiques permet d’analyser des fichiers de données volumineux.

Chapitre
36Analyse TwoStep Cluster
La procédure d’analyse TwoStep Cluster est un outil d’exploration conçu pour révéler desgroupements naturels (ou classes) au sein d’un fichier de données. L’algorithme utilisé par cetteprocédure possède plusieurs fonctionnalités qui le distinguent des techniques de classificationstandard :
Gestion des données qualitatives et continues : En supposant que les variables soientindépendantes, une distribution jointe multinomiale-normale peut être placée sur des variablesqualitatives et continues.Sélection automatique du nombre de classes : En comparant les valeurs d’un critère demodèle-choix dans différentes solutions de classification, la procédure peut déterminerautomatiquement le nombre optimal de classes.Evolutivité : En construisant une arborescence de fonctionnalités de classe (CF) qui récapituleles enregistrements, l’algorithme TwoStep vous permet d’analyser des fichiers de donnéesvolumineux.
Exemple : Les entreprises du domaine des produits de consommation et du commerce de détailutilisent régulièrement des techniques de classification des données qui décrivent les habitudesd’achat, le sexe, l’âge, le niveau de revenu, etc. de leurs clients. Ces sociétés adaptent leursstratégies de marketing et de développement produit à chaque groupe de consommation afind’augmenter les ventes et de développer la fidélité à la marque.
Statistiques : Cette procédure produit des critères d’information (AIC ou BIC) par nombre declasses dans la solution, effectifs de classe pour la classification finale et statistiques descriptivespar classe pour la classification finale.
Diagrammes : Cette procédure produit des diagrammes en bâtons pour les fréquences de classe,des diagrammes en secteurs pour les fréquences de classe et des diagrammes d’importance pourles variables.
446
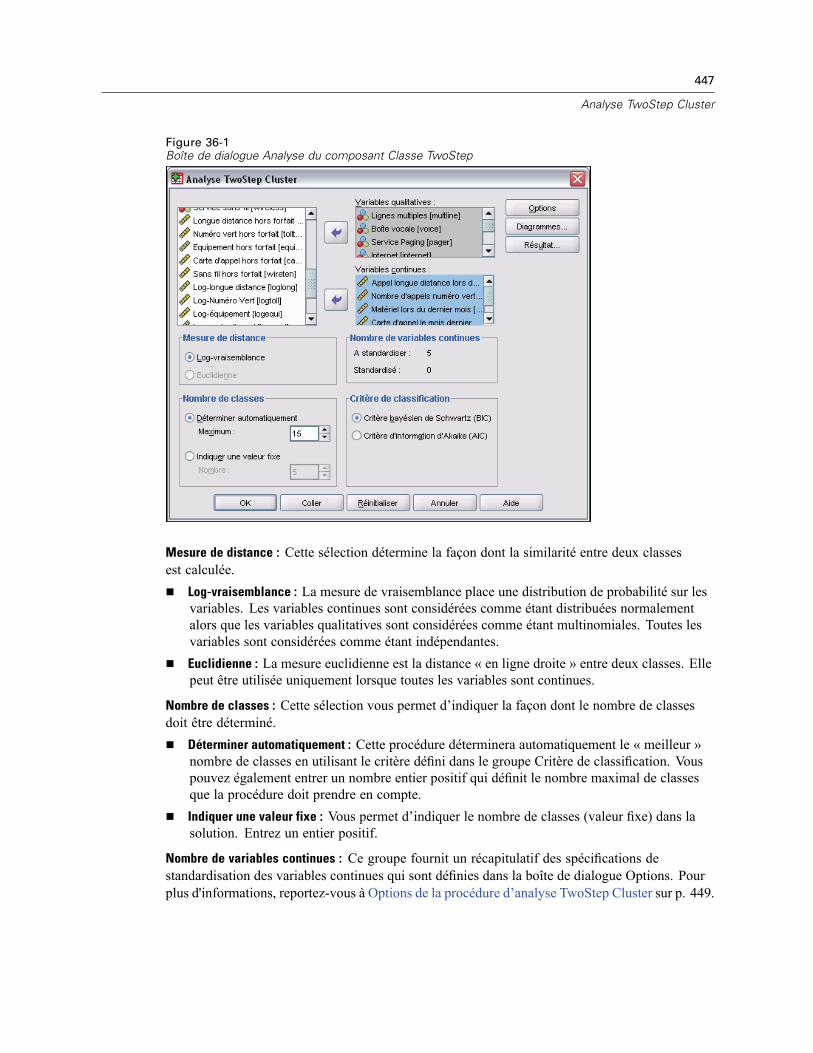
447
Analyse TwoStep Cluster
Figure 36-1Boîte de dialogue Analyse du composant Classe TwoStep
Mesure de distance : Cette sélection détermine la façon dont la similarité entre deux classesest calculée.
Log-vraisemblance : La mesure de vraisemblance place une distribution de probabilité sur lesvariables. Les variables continues sont considérées comme étant distribuées normalementalors que les variables qualitatives sont considérées comme étant multinomiales. Toutes lesvariables sont considérées comme étant indépendantes.Euclidienne : La mesure euclidienne est la distance « en ligne droite » entre deux classes. Ellepeut être utilisée uniquement lorsque toutes les variables sont continues.
Nombre de classes : Cette sélection vous permet d’indiquer la façon dont le nombre de classesdoit être déterminé.
Déterminer automatiquement : Cette procédure déterminera automatiquement le « meilleur »nombre de classes en utilisant le critère défini dans le groupe Critère de classification. Vouspouvez également entrer un nombre entier positif qui définit le nombre maximal de classesque la procédure doit prendre en compte.Indiquer une valeur fixe : Vous permet d’indiquer le nombre de classes (valeur fixe) dans lasolution. Entrez un entier positif.
Nombre de variables continues : Ce groupe fournit un récapitulatif des spécifications destandardisation des variables continues qui sont définies dans la boîte de dialogue Options. Pourplus d'informations, reportez-vous à Options de la procédure d’analyse TwoStep Cluster sur p. 449.

448
Chapitre 36
Critère de classification : Cette sélection détermine la façon dont l’algorithme de classificationautomatique détermine le nombre de classes. Vous pouvez spécifier le critère d’informationbayésien (BIC) ou le critère d’information d’Akaike (AIC).
Données : Cette procédure fonctionne avec des variables continues et qualitatives. Lesobservations représentent les objets à classer et les variables représentent les attributs sur lesquelsest basée la classification.
Tri par observation : Remarque : l’arborescence des fonctionnalités de classe et la solution finalepeuvent dépendre de l’ordre des observations. Pour réduire les effets de tri, classez les observationsde manière aléatoire. Vous pouvez obtenir différentes solutions pour lesquelles les observationsont été triées de manière aléatoire, afin de vérifier la stabilité d’une solution donnée. Lorsquecela s’avère difficile en raison de fichiers très volumineux, vous pouvez effectuer plusieurs foisl’opération sur un échantillon des observations triées de différentes manières aléatoires.
Hypothèses : La mesure de la distance de vraisemblance considère que les variables du modèle declasse sont indépendantes. De plus, chaque variable continue est considérée comme ayant unedistribution normale (gaussienne) et chaque variable qualitative comme ayant une distributionmultinomiale. Des tests internes empiriques indiquent que la procédure est assez résistante auxviolations de l’hypothèse d’indépendance et des hypothèses de distribution, mais vous devezsavoir comment ces hypothèses sont vérifiées.
Utilisez la procédure Corrélations bivariées pour tester l’indépendance de deux variablescontinues. Utilisez la procédure Tableaux croisés pour tester l’indépendance de deux variablescatégorielles.Utilisez la procédure Moyennes pour tester l’indépendance entre une variablecontinue et une variable catégorielle. Utilisez la procédure Explorer pour tester la normalité d’unevariable continue. Utilisez la procédure Test du Khi-deux pour tester si une variable catégorielle aune distribution multinomiale spécifiée.
Pour effectuer une procédure d’analyse TwoStep Cluster
E A partir des menus, sélectionnez :Analyse
ClassificationClassification TwoStep
E Sélectionnez une ou plusieurs variables qualitatives ou continues.
Sinon, vous pouvez :Ajuster les critères sur lesquels est basée la construction des classes.Sélectionner les paramètres de gestion du bruit, d’affectation de mémoire, de standardisationde variable et d’entrée de modèle de classe.Demander des tableaux et des diagrammes facultatifs.Enregistrer les résultats de modèle dans le fichier de travail ou dans un fichier XML externe.
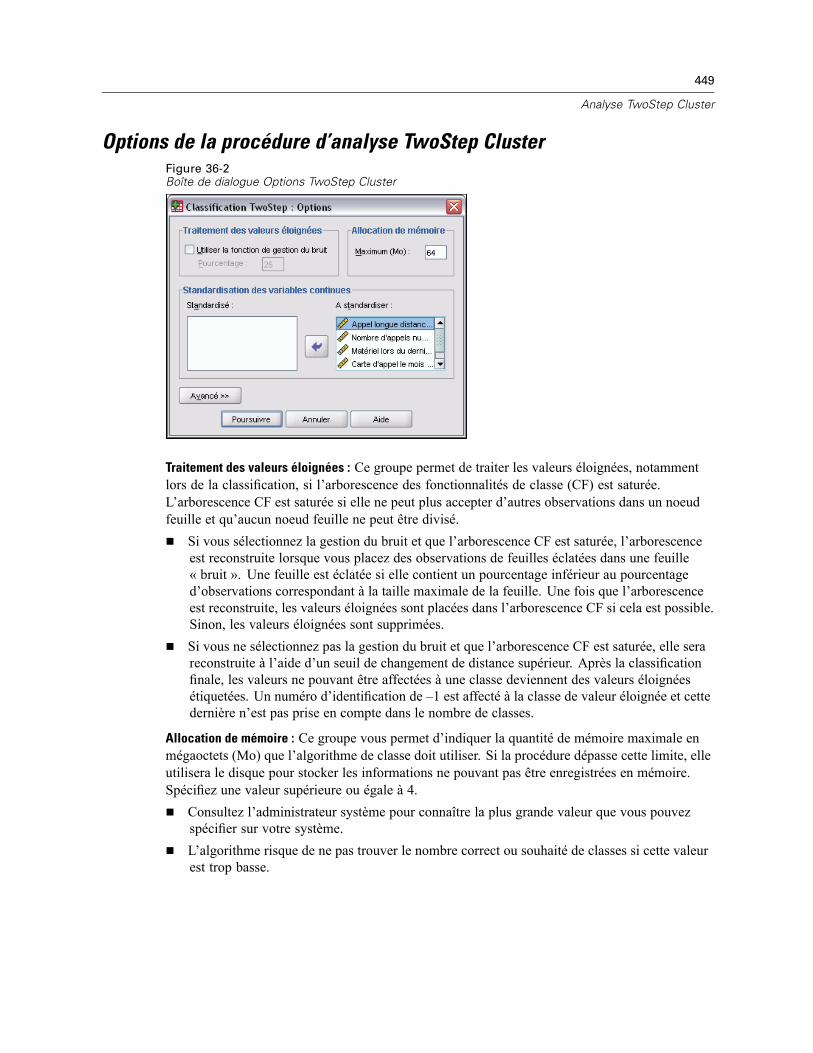
449
Analyse TwoStep Cluster
Options de la procédure d’analyse TwoStep ClusterFigure 36-2Boîte de dialogue Options TwoStep Cluster
Traitement des valeurs éloignées : Ce groupe permet de traiter les valeurs éloignées, notammentlors de la classification, si l’arborescence des fonctionnalités de classe (CF) est saturée.L’arborescence CF est saturée si elle ne peut plus accepter d’autres observations dans un noeudfeuille et qu’aucun noeud feuille ne peut être divisé.
Si vous sélectionnez la gestion du bruit et que l’arborescence CF est saturée, l’arborescenceest reconstruite lorsque vous placez des observations de feuilles éclatées dans une feuille« bruit ». Une feuille est éclatée si elle contient un pourcentage inférieur au pourcentaged’observations correspondant à la taille maximale de la feuille. Une fois que l’arborescenceest reconstruite, les valeurs éloignées sont placées dans l’arborescence CF si cela est possible.Sinon, les valeurs éloignées sont supprimées.Si vous ne sélectionnez pas la gestion du bruit et que l’arborescence CF est saturée, elle serareconstruite à l’aide d’un seuil de changement de distance supérieur. Après la classificationfinale, les valeurs ne pouvant être affectées à une classe deviennent des valeurs éloignéesétiquetées. Un numéro d’identification de –1 est affecté à la classe de valeur éloignée et cettedernière n’est pas prise en compte dans le nombre de classes.
Allocation de mémoire : Ce groupe vous permet d’indiquer la quantité de mémoire maximale enmégaoctets (Mo) que l’algorithme de classe doit utiliser. Si la procédure dépasse cette limite, elleutilisera le disque pour stocker les informations ne pouvant pas être enregistrées en mémoire.Spécifiez une valeur supérieure ou égale à 4.
Consultez l’administrateur système pour connaître la plus grande valeur que vous pouvezspécifier sur votre système.L’algorithme risque de ne pas trouver le nombre correct ou souhaité de classes si cette valeurest trop basse.

450
Chapitre 36
Standardisation de variable : L’algorithme de classification fonctionne avec des variables continuesstandardisées. Les variables continues non standardisées doivent être laissées comme étant « Astandardiser ». Pour gagner du temps et éviter trop de calculs, vous pouvez sélectionner unevariable continue déjà standardisée comme variable « Standardisées ».
Options avancées
Critères de réglage de l’arborescence CF : Les paramètres d’algorithme de classification suivantss’appliquent de façon spécifique à l’arborescence CF et doivent être modifiés avec le plus grandsoin :
Seuil de modification de distance initiale : Il s’agit du seuil initial utilisé pour construirel’arborescence CF. Si l’insertion d’une observation dans une feuille de l’arborescence CFprovoque une étroitesse inférieure au seuil, la feuille n’est pas divisée. Si l’étroitesse dépassele seuil, la feuille est divisée.Nombre maximum de branches (par noeud feuille) : Nombre maximum de noeuds enfant qu’unnoeud feuille peut contenir.Profondeur maximum de l’arborescence : Nombre maximum de niveaux que l’arborescence CFpeut contenir.Nombre maximal de noeuds : Ceci indique le nombre maximal de nœuds de l’arbre CF pouvantêtre générés par la procédure, d’après la fonction (bd+1 – 1) / (b – 1), b étant le nombremaximal de branches et d, la profondeur maximale de l’arbre. Notez qu’une arborescence CFtrop volumineuse risque d’épuiser les ressources du système et d’avoir des effets défavorablessur les performances de la procédure. Chaque noeud exige au moins 16 octets.
Mettre à jour le modèle de classe : Ce groupe vous permet d’importer et de mettre à jour un modèlede classe généré dans une analyse précédente. Le fichier d’entrée contient l’arborescence CF auformat XML. Le modèle est ensuite mis à jour avec les données du fichier actif. Vous devezsélectionner les noms des variables dans la boîte de dialogue principale dans le même ordre quecelui dans lequel ils ont été spécifiés dans l’analyse précédente. Le fichier XML demeure inchangé,sauf si vous enregistrez les informations du nouveau modèle en utilisant le même nom de fichier.Pour plus d'informations, reportez-vous à Résultats de l’analyse TwoStep Cluster sur p. 452.Si vous avez indiqué la mise à jour d’un modèle de classe, les options relatives à la génération
de l’arborescence CF spécifiées pour le modèle d’origine sont utilisées. Plus précisément, lesparamètres de mesure de la distance, de gestion du bruit, d’affectation de mémoire ou les critèresde réglage de l’arborescence CF pour le modèle enregistré sont utilisés et tous les paramètres deces options dans les boîtes de dialogue sont ignorés.
Remarque : Lorsque vous effectuez une mise à jour d’un modèle de classe, la procédure considèrequ’aucune des observations sélectionnées dans l’ensemble de données actif n’a été utilisée pourcréer le modèle de classe d’origine. La procédure considère également que les observationsutilisées dans la mise à jour du modèle sont issues de la même population d’observations utiliséepour créer le modèle d’origine. En d’autres termes, les moyennes et les variances des variablescontinues et les niveaux des variables qualitatives sont considérés comme étant identiques dansles deux groupes d’observations. Si votre « nouveau » groupe d’observations ne provient pas dela même population que votre « ancien » groupe, exécutez la procédure Analyse du composantClasse TwoStep sur les groupes d’observations combinés pour obtenir de meilleurs résultats.
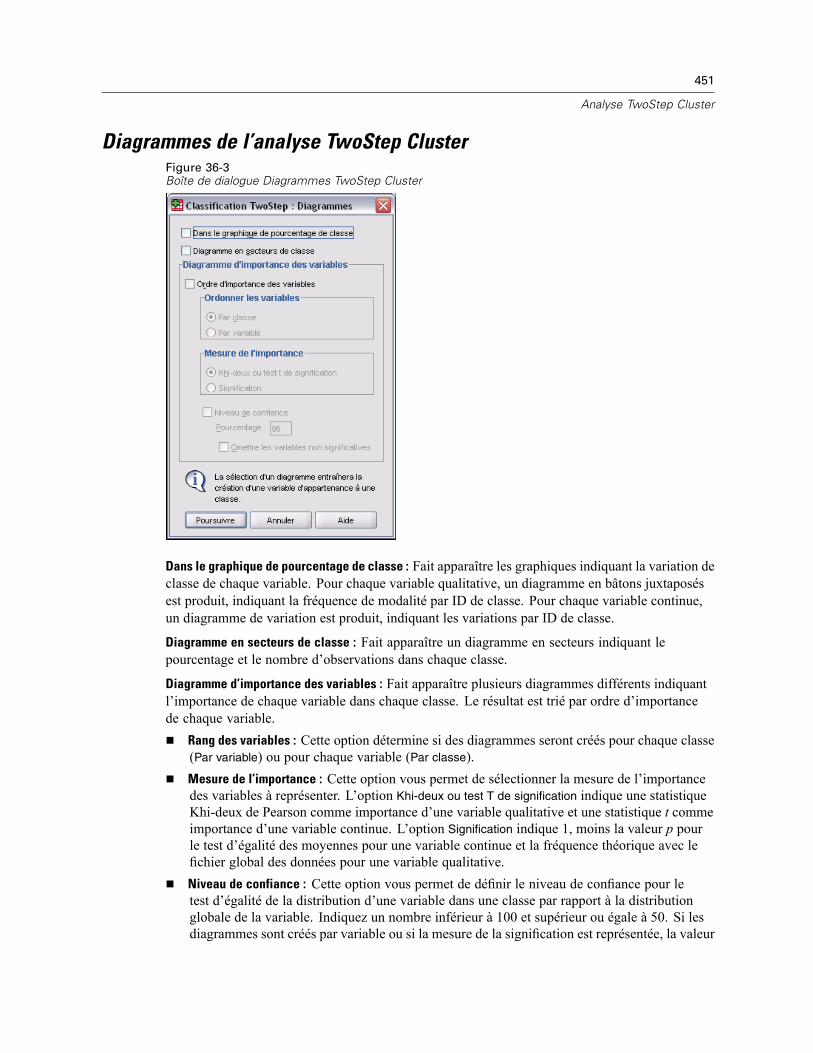
451
Analyse TwoStep Cluster
Diagrammes de l’analyse TwoStep ClusterFigure 36-3Boîte de dialogue Diagrammes TwoStep Cluster
Dans le graphique de pourcentage de classe : Fait apparaître les graphiques indiquant la variation declasse de chaque variable. Pour chaque variable qualitative, un diagramme en bâtons juxtaposésest produit, indiquant la fréquence de modalité par ID de classe. Pour chaque variable continue,un diagramme de variation est produit, indiquant les variations par ID de classe.
Diagramme en secteurs de classe : Fait apparaître un diagramme en secteurs indiquant lepourcentage et le nombre d’observations dans chaque classe.
Diagramme d’importance des variables : Fait apparaître plusieurs diagrammes différents indiquantl’importance de chaque variable dans chaque classe. Le résultat est trié par ordre d’importancede chaque variable.
Rang des variables : Cette option détermine si des diagrammes seront créés pour chaque classe(Par variable) ou pour chaque variable (Par classe).Mesure de l’importance : Cette option vous permet de sélectionner la mesure de l’importancedes variables à représenter. L’option Khi-deux ou test T de signification indique une statistiqueKhi-deux de Pearson comme importance d’une variable qualitative et une statistique t commeimportance d’une variable continue. L’option Signification indique 1, moins la valeur p pourle test d’égalité des moyennes pour une variable continue et la fréquence théorique avec lefichier global des données pour une variable qualitative.Niveau de confiance : Cette option vous permet de définir le niveau de confiance pour letest d’égalité de la distribution d’une variable dans une classe par rapport à la distributionglobale de la variable. Indiquez un nombre inférieur à 100 et supérieur ou égale à 50. Si lesdiagrammes sont créés par variable ou si la mesure de la signification est représentée, la valeur

452
Chapitre 36
du niveau de confiance apparaît sous la forme d’une ligne verticale dans les diagrammesd’importance des variables.Omettre les variables non significatives : Les variables non significatives au niveau de confiancespécifié n’apparaissent pas dans les diagrammes d’importance des variables.
Résultats de l’analyse TwoStep ClusterFigure 36-4Boîte de dialogue Résultats de l’analyse TwoStep Cluster
Statistiques : Ce groupe fournit des options d’affichage pour les tableaux des résultats de laclassification. Les statistiques descriptives et les fréquences de classe sont produites pour lemodèle de classe final alors que le tableau du critère d’information fait apparaître des résultatspour une plage de solutions de classe.
Descriptives par classe : Fait apparaître deux tableaux qui décrivent les variables dans chaqueclasse. Dans un tableau, les moyennes et les écarts-types sont indiqués pour les variablescontinues par classe. L’autre tableau indique les effectifs des variables qualitatives par classe.Fréquences de classe : Fait apparaître un tableau indiquant le nombre d’observations danschaque classe.Critère d’information (AIC ou BIC) : Fait apparaître un tableau contenant les valeurs d’AIC oude BIC en fonction du critère choisi dans la boîte de dialogue principale, pour différentsnombres de classes. Ce tableau est fourni uniquement lorsque le nombre de classes estdéterminé automatiquement. Si le nombre de classes est fixe, ce paramètre est ignoré et letableau n’est pas fourni.

453
Analyse TwoStep Cluster
Fichier de travail : Ce groupe vous permet d’enregistrer des variables dans l’ensemble de donnéesactif.
Créer une variable d’appartenance à une classe : Cette variable contient un numérod’identification de classe pour chaque observation. Le nom de cette variable est tsc_n, n étantun nombre entier positif qui indique l’ordinal de l’opération d’enregistrement de l’ensemblede données actif effectuée par cette procédure au cours d’une session.
Fichiers XML : Le modèle de classe final et l’arborescence CF représentent deux types de fichiersde résultats pouvant être exportés au format XML.
Exporter le modèle final : Le modèle de classe final est exporté vers le fichier indiqué auformat XML (PMML). SmartScore et le serveur de SPSS Statistics (produit séparé) peuventutiliser ce fichier de modèle pour appliquer les informations du modèle à d’autres fichiersde données à des fins d’analyse.Exporter l’arborescence CF : Cette option vous permet d’enregistrer l’état actuel del’arborescence de classe et de le mettre à jour ultérieurement en utilisant des données plusrécentes.

Chapitre
37Classification hiérarchique
Cette procédure tente d’identifier les classes d’observations (ou de variables) relativementhomogènes basées sur des caractéristiques sélectionnées, en utilisant un algorithme qui débuteavec chaque observation (ou variable) dans une classe séparée et qui combine les classes jusqu’àce qu’il n’en reste qu’une. Vous pouvez analyser des variables non normées ou vous pouvezchoisir parmi un assortiment de transformations standardisées. Les mesures de distance ou desimilarité sont générées par la procédure Proximities (Proximités). Les statistiques s’affichent àchaque étape pour vous aider à choisir la meilleure solution.
Exemple : Y a-t-il des classes identifiables de spectacles télévisuels qui attirent des audiencessimilaires à l’intérieur de chaque classe ? Avec une classification hiérarchique, vous pouvezreclasser les spectacles télévisuels (observations) en classes homogènes basées sur lescaractéristiques du spectateur. Cette méthode peut être utilisée pour identifier des segments à desfins commerciales. Vous pouvez aussi classer les villes (observations) en groupes homogènes pourpermettre la sélection de villes comparables afin de tester diverses stratégies commerciales.
Statistiques : Chaîne des agrégations, matrice de distances (ou des similarités) et classed’affectation pour une seule solution ou un ensemble de solutions. Diagrammes : arbreshiérarchiques et Stalactites.
Données : Les variables peuvent être des données quantitatives, binaires ou d’effectif. L’échelledes variables est un élément important : des différences d’échelle qui peuvent affecter votre(vos) solution(s) en classes hiérarchiques. Si vos variables sont d’échelles très différentes (parexemple, une variable est mesurée en dollars et l’autre est mesurée en années), vous devezenvisager de les standardiser (ceci peut être fait automatiquement avec la procédure de laclassification hiérarchique).
Tri par observation : Si des distances ex aequo ou des similitudes se présentent dans les données desaisie ou entre les classes mises à jour au cours de l’opération de jointure, la solution de classe quien résulte risque de dépendre de l’ordre des observations dans le fichier. Vous pouvez obtenirdifférentes solutions pour lesquelles les observations ont été triées de manière aléatoire, afinde vérifier la stabilité d’une solution donnée.
Hypothèses : Les mesures de distance ou de similarité utilisées doivent convenir aux donnéesanalysées (Voir la procédure Proximities (proximités) pour plus de renseignements sur le choix desmesures de distances et de similarité). Vous devez aussi inclure toutes les variables appropriéesdans votre analyse. L’omission de variables influentes peut aboutir à une solution erronée.Parce que la classification hiérarchique est une méthode d’exploration, les résultats doivent êtreconsidérés comme provisoires tant qu’ils ne sont pas confirmés avec un échantillon indépendant.
454
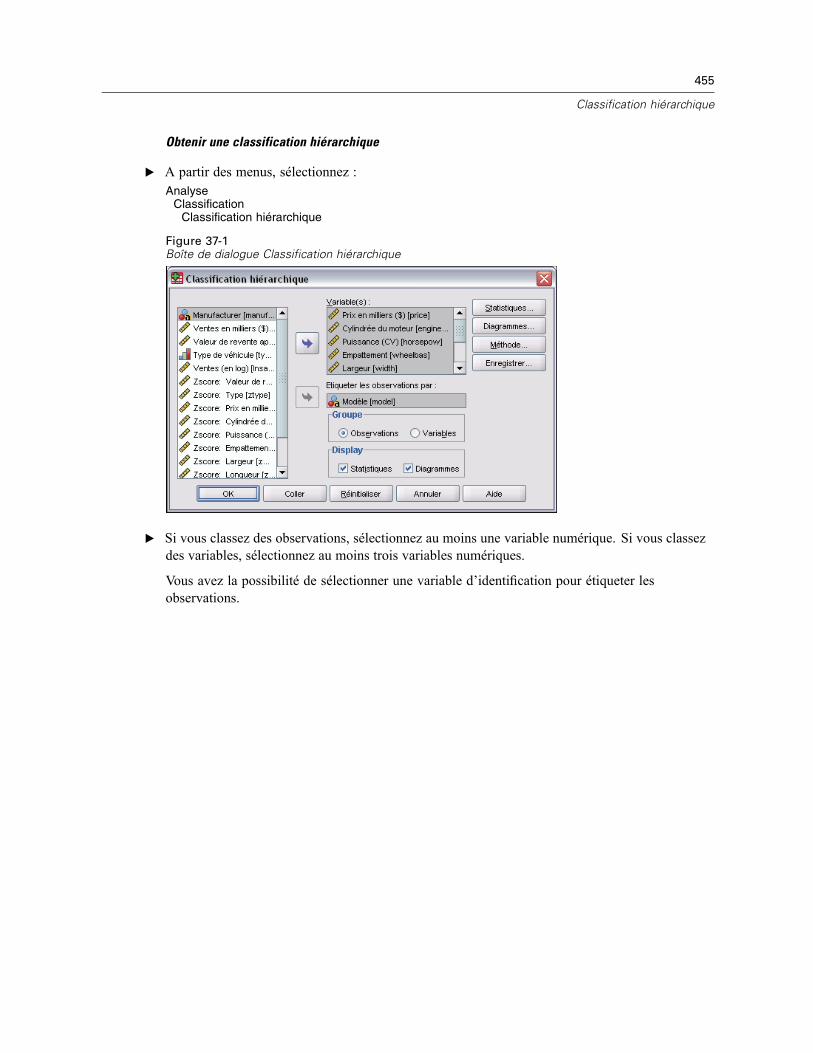
455
Classification hiérarchique
Obtenir une classification hiérarchique
E A partir des menus, sélectionnez :Analyse
ClassificationClassification hiérarchique
Figure 37-1Boîte de dialogue Classification hiérarchique
E Si vous classez des observations, sélectionnez au moins une variable numérique. Si vous classezdes variables, sélectionnez au moins trois variables numériques.
Vous avez la possibilité de sélectionner une variable d’identification pour étiqueter lesobservations.
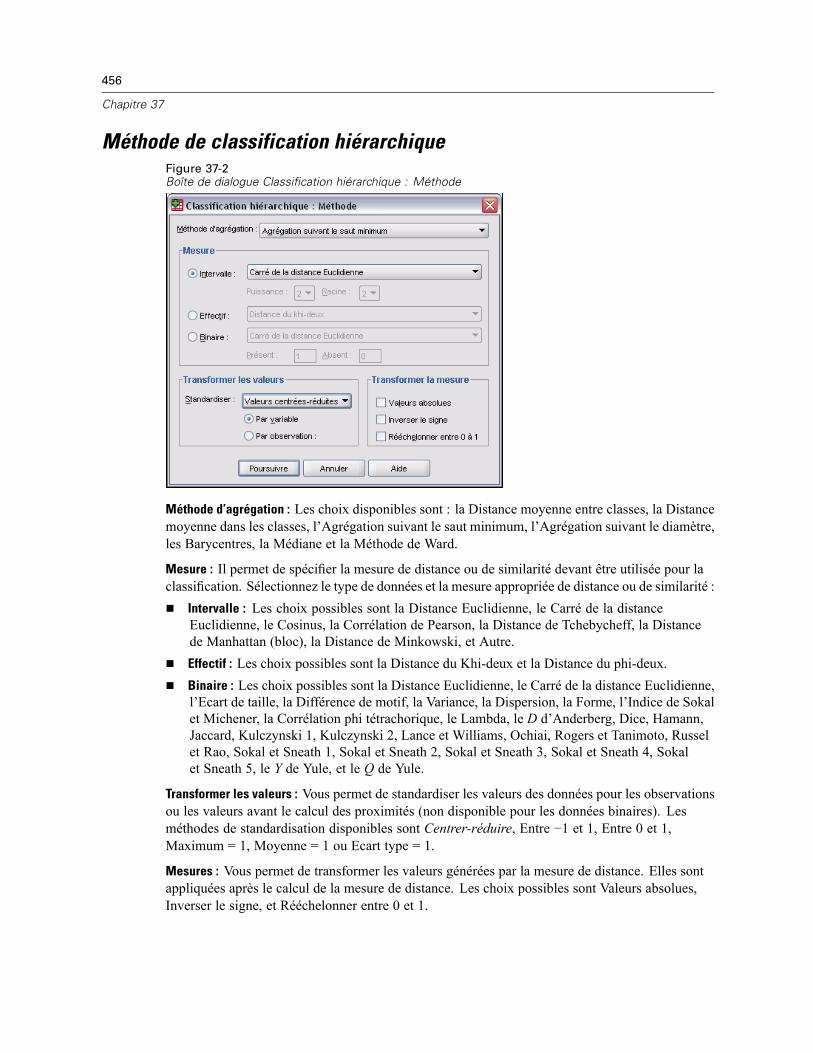
456
Chapitre 37
Méthode de classification hiérarchiqueFigure 37-2Boîte de dialogue Classification hiérarchique : Méthode
Méthode d’agrégation : Les choix disponibles sont : la Distance moyenne entre classes, la Distancemoyenne dans les classes, l’Agrégation suivant le saut minimum, l’Agrégation suivant le diamètre,les Barycentres, la Médiane et la Méthode de Ward.
Mesure : Il permet de spécifier la mesure de distance ou de similarité devant être utilisée pour laclassification. Sélectionnez le type de données et la mesure appropriée de distance ou de similarité :
Intervalle : Les choix possibles sont la Distance Euclidienne, le Carré de la distanceEuclidienne, le Cosinus, la Corrélation de Pearson, la Distance de Tchebycheff, la Distancede Manhattan (bloc), la Distance de Minkowski, et Autre.Effectif : Les choix possibles sont la Distance du Khi-deux et la Distance du phi-deux.Binaire : Les choix possibles sont la Distance Euclidienne, le Carré de la distance Euclidienne,l’Ecart de taille, la Différence de motif, la Variance, la Dispersion, la Forme, l’Indice de Sokalet Michener, la Corrélation phi tétrachorique, le Lambda, le D d’Anderberg, Dice, Hamann,Jaccard, Kulczynski 1, Kulczynski 2, Lance et Williams, Ochiai, Rogers et Tanimoto, Russelet Rao, Sokal et Sneath 1, Sokal et Sneath 2, Sokal et Sneath 3, Sokal et Sneath 4, Sokalet Sneath 5, le Y de Yule, et le Q de Yule.
Transformer les valeurs : Vous permet de standardiser les valeurs des données pour les observationsou les valeurs avant le calcul des proximités (non disponible pour les données binaires). Lesméthodes de standardisation disponibles sont Centrer-réduire, Entre −1 et 1, Entre 0 et 1,Maximum = 1, Moyenne = 1 ou Ecart type = 1.
Mesures : Vous permet de transformer les valeurs générées par la mesure de distance. Elles sontappliquées après le calcul de la mesure de distance. Les choix possibles sont Valeurs absolues,Inverser le signe, et Rééchelonner entre 0 et 1.
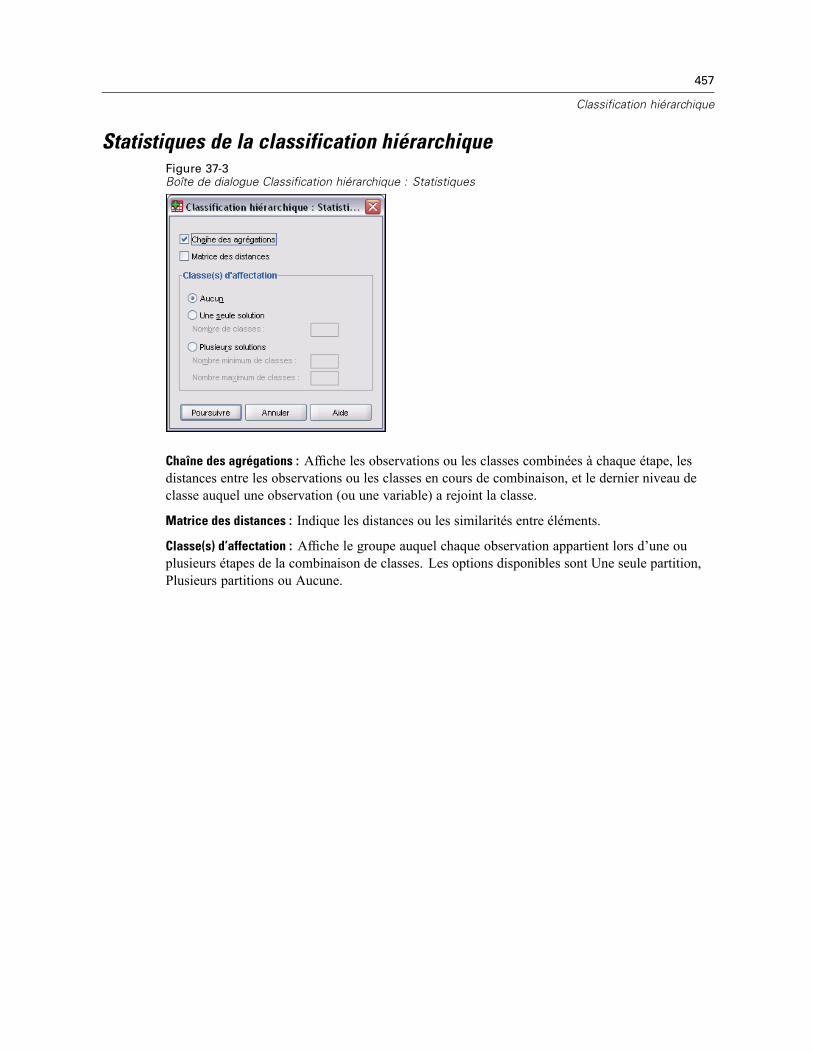
457
Classification hiérarchique
Statistiques de la classification hiérarchiqueFigure 37-3Boîte de dialogue Classification hiérarchique : Statistiques
Chaîne des agrégations : Affiche les observations ou les classes combinées à chaque étape, lesdistances entre les observations ou les classes en cours de combinaison, et le dernier niveau declasse auquel une observation (ou une variable) a rejoint la classe.
Matrice des distances : Indique les distances ou les similarités entre éléments.
Classe(s) d’affectation : Affiche le groupe auquel chaque observation appartient lors d’une ouplusieurs étapes de la combinaison de classes. Les options disponibles sont Une seule partition,Plusieurs partitions ou Aucune.
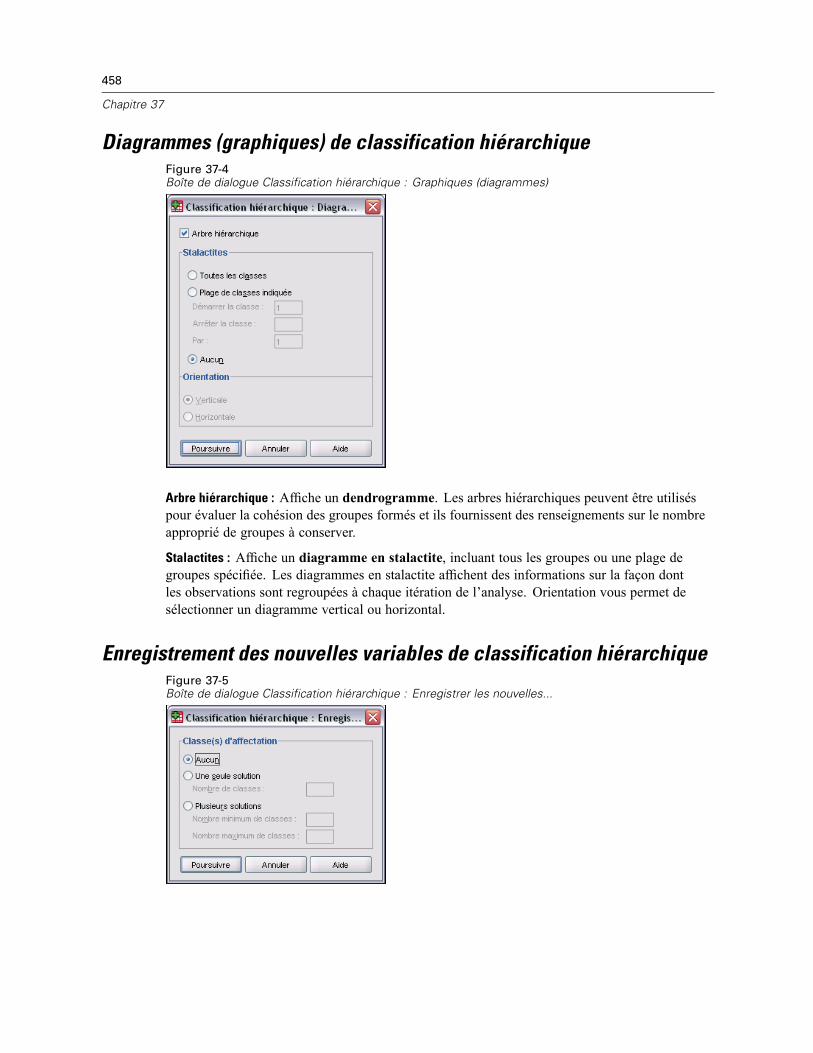
458
Chapitre 37
Diagrammes (graphiques) de classification hiérarchiqueFigure 37-4Boîte de dialogue Classification hiérarchique : Graphiques (diagrammes)
Arbre hiérarchique : Affiche un dendrogramme. Les arbres hiérarchiques peuvent être utiliséspour évaluer la cohésion des groupes formés et ils fournissent des renseignements sur le nombreapproprié de groupes à conserver.
Stalactites : Affiche un diagramme en stalactite, incluant tous les groupes ou une plage degroupes spécifiée. Les diagrammes en stalactite affichent des informations sur la façon dontles observations sont regroupées à chaque itération de l’analyse. Orientation vous permet desélectionner un diagramme vertical ou horizontal.
Enregistrement des nouvelles variables de classification hiérarchiqueFigure 37-5Boîte de dialogue Classification hiérarchique : Enregistrer les nouvelles...

459
Classification hiérarchique
Classe(s) d’affectation : Vous permet de sauvegarder les classes d’affectation pour une ou plusieursou aucune partition(s). Les variables sauvegardées peuvent alors être utilisées pour des analysesultérieures pour explorer d’autres différences entre groupes.
Fonctionnalités supplémentaires de la syntaxe de commande CLUSTER
La procédure de classification hiérarchique utilise la syntaxe de commande CLUSTER. Le langagede syntaxe de commande vous permet aussi de :
Utiliser plusieurs méthodes de classification dans une seule analyse.Lire et analyser une matrice de proximité.Ecrire une matrice de proximité à analyser ultérieurement.Indiquer des valeurs pour la puissance et la racine dans la mesure de distance personnalisée(Puissance).Spécifier les noms des variables enregistrées.
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.

Chapitre
38Nuées dynamiques
Cette procédure cherche à identifier des groupes d’observations relativement homogènes d’aprèsdes caractéristiques sélectionnées, au moyen d’un algorithme qui peut traiter de grands nombresd’observations. L’algorithme vous demande toutefois d’indiquer le nombre de classes. Vouspouvez indiquer les centres de classe initiaux si vous connaissez cette information. Vous pouvezchoisir entre deux méthodes de classement des observations, soit la mise à jour des centres declasse de façon itérative, soit la classification seule. Vous pouvez enregistrer l’appartenance à uneclasse, les informations de distance et les centres de classes finaux. Vous pouvez éventuellementindiquer une variable dont les valeurs servent à étiqueter les résultats par observations. Vouspouvez également demander des statistiques F d’analyse de la variance. Bien que ces statistiquessoient opportunistes (la procédure cherche à former des groupes qui diffèrent), la taille relativedes statistiques fournit des informations sur la contribution de chaque variable à la séparationdes groupes.
Exemple : Quels sont les groupes de programmes de télévision identifiables qui attirent despublics similaires au sein de chaque groupe ? Grâce à l’analyse des nuées dynamiques, vouspouvez classer les programmes de télévision (observations) en k groupes homogènes d’après lescaractéristiques des téléspectateurs. Cette méthode peut être utilisée pour identifier des segments àdes fins commerciales. Vous pouvez aussi classer les villes (observations) en groupes homogènespour permettre la sélection de villes comparables afin de tester diverses stratégies commerciales.
Statistiques : Solution complète : centres de classes initiaux, tableau ANOVA. Chaqueobservation: information de classe, distance au centre de classe.
Données : Les variables doivent être quantitatives au niveau intervalle ou ratio. Si vos variablessont binaires ou sont des effectifs, utilisez la procédure de classification hiérarchique.
Ordre des observations et des centres de classe initiaux : L’algorithme par défaut permettant dechoisir les centres de classe initiaux varie en fonction du tri par observation. L’option Utiliser
les nouveaux centres de la boîte de dialogue Itérer rend la solution résultante potentiellementdépendante du tri par observation, quel que soit le mode de sélection des centres de classeinitiaux. Si vous utilisez l’une de ces méthodes, vous pouvez obtenir différentes solutions pourlesquelles les observations ont été triées de manière aléatoire, afin de vérifier la stabilité d’unesolution donnée. Si vous indiquez les centres de classe initiaux et que vous n’utilisez pas l’optionUtiliser les nouveaux centres, vous évitez tout problème lié au tri par observation. Toutefois, letri des centres de classe initiaux risque d’affecter la solution, s’il existe des distances ex aequoentre les observations et les centres de classe. Pour évaluer la stabilité d’une solution donnée, vouspouvez comparer les résultats des analyses pour lesquelles les valeurs des centres initiaux ont étépermutées de différentes manières.
460
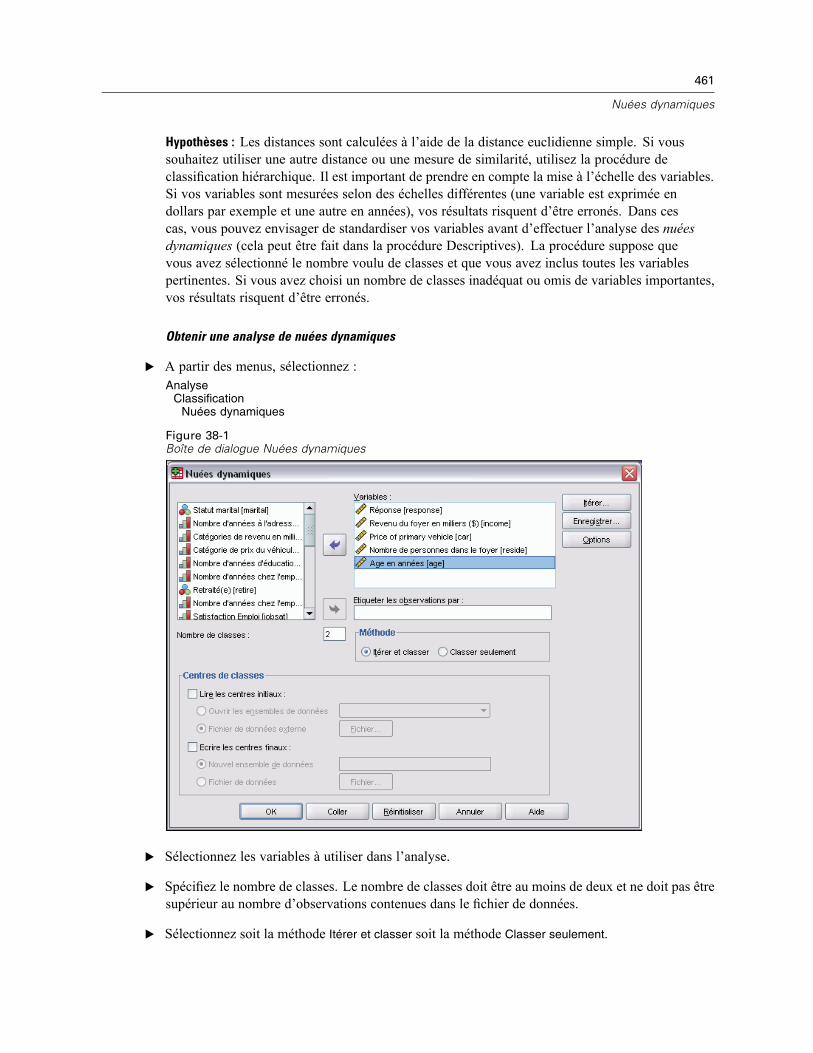
461
Nuées dynamiques
Hypothèses : Les distances sont calculées à l’aide de la distance euclidienne simple. Si voussouhaitez utiliser une autre distance ou une mesure de similarité, utilisez la procédure declassification hiérarchique. Il est important de prendre en compte la mise à l’échelle des variables.Si vos variables sont mesurées selon des échelles différentes (une variable est exprimée endollars par exemple et une autre en années), vos résultats risquent d’être erronés. Dans cescas, vous pouvez envisager de standardiser vos variables avant d’effectuer l’analyse des nuéesdynamiques (cela peut être fait dans la procédure Descriptives). La procédure suppose quevous avez sélectionné le nombre voulu de classes et que vous avez inclus toutes les variablespertinentes. Si vous avez choisi un nombre de classes inadéquat ou omis de variables importantes,vos résultats risquent d’être erronés.
Obtenir une analyse de nuées dynamiques
E A partir des menus, sélectionnez :Analyse
ClassificationNuées dynamiques
Figure 38-1Boîte de dialogue Nuées dynamiques
E Sélectionnez les variables à utiliser dans l’analyse.
E Spécifiez le nombre de classes. Le nombre de classes doit être au moins de deux et ne doit pas êtresupérieur au nombre d’observations contenues dans le fichier de données.
E Sélectionnez soit la méthode Itérer et classer soit la méthode Classer seulement.
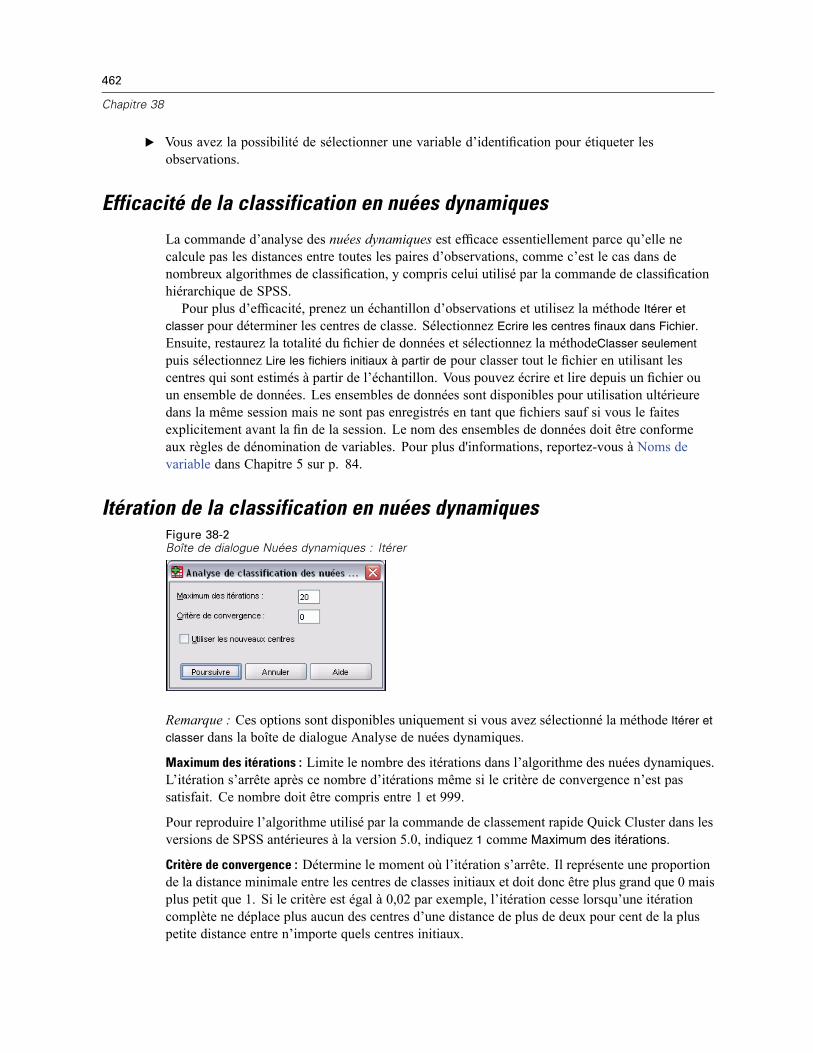
462
Chapitre 38
E Vous avez la possibilité de sélectionner une variable d’identification pour étiqueter lesobservations.
Efficacité de la classification en nuées dynamiques
La commande d’analyse des nuées dynamiques est efficace essentiellement parce qu’elle necalcule pas les distances entre toutes les paires d’observations, comme c’est le cas dans denombreux algorithmes de classification, y compris celui utilisé par la commande de classificationhiérarchique de SPSS.Pour plus d’efficacité, prenez un échantillon d’observations et utilisez la méthode Itérer et
classer pour déterminer les centres de classe. Sélectionnez Ecrire les centres finaux dans Fichier.Ensuite, restaurez la totalité du fichier de données et sélectionnez la méthodeClasser seulement
puis sélectionnez Lire les fichiers initiaux à partir de pour classer tout le fichier en utilisant lescentres qui sont estimés à partir de l’échantillon. Vous pouvez écrire et lire depuis un fichier ouun ensemble de données. Les ensembles de données sont disponibles pour utilisation ultérieuredans la même session mais ne sont pas enregistrés en tant que fichiers sauf si vous le faitesexplicitement avant la fin de la session. Le nom des ensembles de données doit être conformeaux règles de dénomination de variables. Pour plus d'informations, reportez-vous à Noms devariable dans Chapitre 5 sur p. 84.
Itération de la classification en nuées dynamiquesFigure 38-2Boîte de dialogue Nuées dynamiques : Itérer
Remarque : Ces options sont disponibles uniquement si vous avez sélectionné la méthode Itérer et
classer dans la boîte de dialogue Analyse de nuées dynamiques.
Maximum des itérations : Limite le nombre des itérations dans l’algorithme des nuées dynamiques.L’itération s’arrête après ce nombre d’itérations même si le critère de convergence n’est passatisfait. Ce nombre doit être compris entre 1 et 999.
Pour reproduire l’algorithme utilisé par la commande de classement rapide Quick Cluster dans lesversions de SPSS antérieures à la version 5.0, indiquez 1 comme Maximum des itérations.
Critère de convergence : Détermine le moment où l’itération s’arrête. Il représente une proportionde la distance minimale entre les centres de classes initiaux et doit donc être plus grand que 0 maisplus petit que 1. Si le critère est égal à 0,02 par exemple, l’itération cesse lorsqu’une itérationcomplète ne déplace plus aucun des centres d’une distance de plus de deux pour cent de la pluspetite distance entre n’importe quels centres initiaux.

463
Nuées dynamiques
Utiliser les nouveaux centres : Vous permet de demander la mise à jour des centres aprèsl’affectation de chaque observation. Si vous ne sélectionnez pas cette option, les nouveaux centresseront calculés lorsque toutes les observations auront été affectées.
Enregistrement des analyses de classes de nuées dynamiquesFigure 38-3Boîte de dialogue Nuées dynamiques : Enregistrer les nouvelles variables...
Vous pouvez enregistrer des informations sur la solution relatives aux nouvelles variables àutiliser dans les analyses ultérieures :
Classe(s) d’affectation : Crée une nouvelle variable indiquant la classe d’affectation finale dechaque observation. Les valeurs de la nouvelle variable vont de 1 au nombre de classes.
Distance au centre de classe : Crée une nouvelle variable indiquant la distance euclidienne entrechaque nouvelle variable et son centre de classification.
Options d’analyses des classes de nuées dynamiquesFigure 38-4Boîte de dialogue Nuées dynamiques : Options
Statistiques : Vous pouvez sélectionner les statistiques suivantes : Centres de classes initiaux,Tableau ANOVA, et Affectation et distances au centre.
Centres de classe initiaux. Première estimation des moyennes des variables de chacune desclasses. Par défaut, le nombre d'observations assez espacées sélectionné dans les donnéesest égal au nombre de classes. Les centres de classes initiaux sont utilisés pour une premièreclassification et sont ensuite mis à jour.

464
Chapitre 38
Tableau ANOVA.Affiche un tableau d'analyse de la variance, incluant les tests F univariés pourchacune des variables de la classification. Les tests F sont uniquement descriptifs et lesprobabilités qui en résultent ne doivent pas être interprétées. Le tableau ANOVA n'apparaîtpas si toutes les observations sont affectées à une seule classe.Affectations et distances au centre. Affiche pour chaque observation l'affectation de classefinale et la distance euclidienne entre l'observation et le centre de classe utilisé pour classerl'observation. Affiche également la distance euclidienne entre les centres de classe finaux.
Valeurs manquantes : Les options disponibles sont Exclure toute observation incomplète ou Exclure
seulement les composantes non valides.Exclure toute observation incomplète : Exclut de l’analyse les observations qui ont des valeursmanquantes pour une variable de grappe.Exclure seulement les composantes non valides : Affecte des observations aux classes baséessur des distances calculées à partir de toutes les variables n’ayant pas de valeur manquante.
Fonctionnalités supplémentaires de la commande QUICK CLUSTER
La procédure de nuées dynamiques utilise la syntaxe de commande QUICK CLUSTER. Le langagede syntaxe de commande vous permet aussi de :
Accepter les premières observations k comme centres de classes initiaux, évitant ainsi lepassage de données normalement utilisé pour les estimer.Spécifier les centres de classe initiaux directement comme faisant partie de la syntaxe decommande.Spécifier les noms des variables enregistrées.
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.

Chapitre
39Tests non paramétriques
La procédure de tests non paramétriques propose plusieurs tests qui ne nécessitent pas d’hypothèseconcernant la forme de la distribution sous-jacente.
Test Khi-deux : Tabule une variable en modalités et calcule une statistique khi-deux basée sur lesdifférences entre les fréquences observées et les fréquences attendues.
Test binomial : Compare la fréquence observée dans chaque modalité d’une variable dichotomiqueavec les fréquences attendues de la distribution binomiale.
Suites en séquence : Teste si l’ordre d’occurrence de deux valeurs d’une variable est aléatoire.
Test Kolmogorov-Smirnov pour un échantillon : Compare la fonction de distribution cumuléeobservée pour une variable avec une distribution théorique spécifiée, qui peut être normale,uniforme, exponentielle ou Poisson.
Tests de deux échantillons indépendants : Compare deux groupes d’observations d’une variable.Le test U de Mann-Whitney, le test de Kolmogorov-Smirnov pour deux échantillons, le test deréactions extrêmes Moses et les suites en séquences Wald-Wolfowitz sont disponibles.
Tests de deux échantillons liés : Compare les distributions de deux variables. Le test de Wilcoxon,le test des signes et le test de McNemar sont disponibles.
Tests de plusieurs échantillons indépendants : Compare deux groupes d’observations ou plusd’une variable. Le test de Kruskal-Wallis, le test de la médiane et le test de Jonckheere-Terpstrasont disponibles.
Tests de plusieurs échantillons liés : Compare les distributions de deux variables ou plus. Le testde Friedman, le test W de Kendall et le test Q de Cochran sont disponibles.
Les quartiles et la moyenne, l’écart-type, le minimum, le maximum, et le nombre d’observationssont disponibles pour tous les tests ci-dessus.
Test du Khi-deux
La procédure de test du Khi-deux tabule une variable en modalités et calcule une statistiqueKhi-deux. Ce test de qualité de l’ajustement compare les fréquences observées et attendues danschaque modalité pour vérifier si toutes les modalités contiennent la même proportion de valeurs ousi chaque modalité contient une proportion de valeurs spécifiées par l’utilisateur.
Exemples : Le test du Khi-deux peut être utilisé pour déterminer si un sac de bonbons contient lesmêmes proportions de bonbons bleus, marrons, verts, oranges, rouges et jaunes. Vous pouvezaussi tester si le sac de bonbons contient 5 % de bonbons bleus, 30 % de bonbons marrons, 10 %de bonbons verts, 20 % bonbons oranges, 15 % de bonbons rouges et 15 % de bonbons jaunes.
465
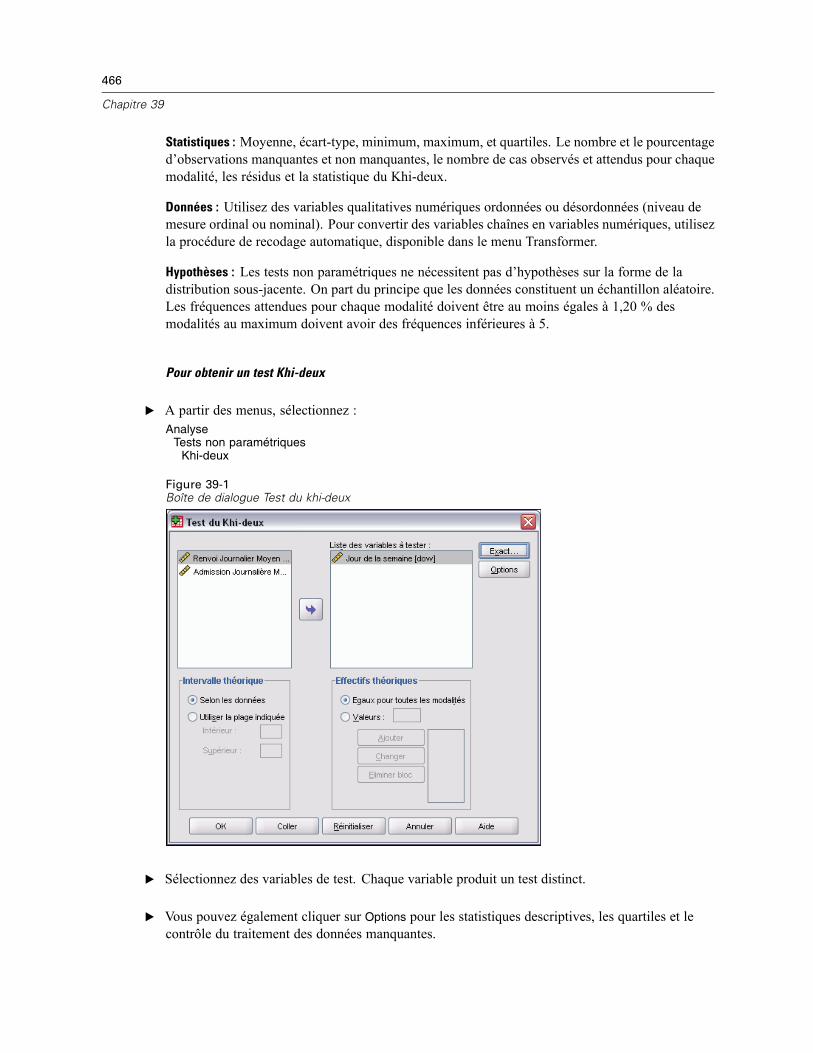
466
Chapitre 39
Statistiques : Moyenne, écart-type, minimum, maximum, et quartiles. Le nombre et le pourcentaged’observations manquantes et non manquantes, le nombre de cas observés et attendus pour chaquemodalité, les résidus et la statistique du Khi-deux.
Données : Utilisez des variables qualitatives numériques ordonnées ou désordonnées (niveau demesure ordinal ou nominal). Pour convertir des variables chaînes en variables numériques, utilisezla procédure de recodage automatique, disponible dans le menu Transformer.
Hypothèses : Les tests non paramétriques ne nécessitent pas d’hypothèses sur la forme de ladistribution sous-jacente. On part du principe que les données constituent un échantillon aléatoire.Les fréquences attendues pour chaque modalité doivent être au moins égales à 1,20 % desmodalités au maximum doivent avoir des fréquences inférieures à 5.
Pour obtenir un test Khi-deux
E A partir des menus, sélectionnez :Analyse
Tests non paramétriquesKhi-deux
Figure 39-1Boîte de dialogue Test du khi-deux
E Sélectionnez des variables de test. Chaque variable produit un test distinct.
E Vous pouvez également cliquer sur Options pour les statistiques descriptives, les quartiles et lecontrôle du traitement des données manquantes.

467
Tests non paramétriques
Valeurs et intervalles théoriques du test du Khi-deux
Intervalle théorique. Par défaut, chaque valeur distincte de la variable est définie comme modalité.Pour établir des modalités dans un intervalle spécifique, sélectionnez l’option Dans les limites
spécifiées, et indiquez les valeurs entières pour les limites inférieure et supérieure. Des modalitéssont établies pour chaque valeur entière comprise dans l’intervalle, et les observations à l’extérieurdes limites sont exclues. Par exemple, si vous spécifiez une valeur de 1 pour la limite inférieure etune valeur de 4 pour la limite supérieure, seules les valeurs entières comprises entre 1 et 4 sontutilisées pour le test du Khi-deux.
Valeurs théoriques. Par défaut, toutes les modalités ont des valeurs théoriques égales. Lesmodalités peuvent avoir des proportions attendues définies par l’utilisateur. Sélectionnez Valeurs,indiquez une valeur supérieure à 0 pour chaque modalité de variable de test et cliquez ensuite surAjouter. Chaque fois que vous ajoutez une valeur, celle-ci apparaît au bas de la liste des valeurs.L’ordre des valeurs est important. Il correspond à l’ordre croissant des valeurs des modalités de lavariable de test. La première valeur de la liste correspond à la valeur de groupe la plus basse de lavariable de test et la dernière valeur correspond à la valeur la plus élevée. Les éléments de la listedes valeurs sont additionnés et chaque valeur est ensuite divisée par cette somme pour calculer laproportion d’observations attendues dans la modalité correspondante. Par exemple, une liste devaleurs de 3, 4, 5, 4 indique les proportions attendues de 3/16, 4/16, 5/16 et 4/16.
Test du Khi-deux : Options
Figure 39-2Boîte de dialogue Test du Khi-deux : Options
Statistiques : Vous pouvez choisir l’une des statistiques récapitulatives, ou bien les deux.Caractéristique : Affiche la moyenne, l’écart-type, le minimum, le maximum, et le nombred’observations non manquantes.Quartiles : Indique les valeurs correspondant au 25ème, 50ème et 75ème centiles.
Valeurs manquantes : Contrôle le traitement des valeurs manquantes.Exclure les observations test par test : Lorsque plusieurs tests sont indiqués, chaque test esteffectué séparément selon le nombre des valeurs manquantes.Exclure toute observation incomplète : Les observations avec des valeurs manquantes pourl’une ou l’autre variable sont exclues de toutes les analyses.

468
Chapitre 39
Fonctionnalités supplémentaires de la commande NPAR TESTS (test du Khi-deux)
Le langage de syntaxe de commande vous permet aussi de :Spécifier des valeurs minimale et maximale différentes, ou des fréquences attendues pourdifférentes variables (avec la sous-commande CHISQUARE).Tester la même variable avec différentes fréquences attendues ou utiliser différentes plages(avec la sous-commande EXPECTED).
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.
Test binomial
La procédure de test binomial compare les fréquences observées des deux modalités d’unevariable dichotomique avec les fréquences que l’on peut attendre d’une distribution binomialeavec un paramètre de probabilité spécifié. Par défaut, le paramètre de probabilité pour les deuxgroupes est de 0,5. Pour modifier les probabilités, vous pouvez entrer un test de proportion pourle premier groupe. La probabilité pour le second groupe sera de 1 moins la probabilité spécifiéepour le premier groupe.
Exemple : Quand vous lancez une pièce, la probabilité de tomber sur le côté face est de 1/2. Surla base de cette hypothèse, une pièce est lancée 40 fois, et les résultats sont enregistrés (pile ouface). Du test binomial, il se peut que vous observiez que les 3/4 des lancements sont tombéssur le côté face et que le seuil de signification observé est bas (0,0027). Ces résultats indiquentqu’il est peu probable que la probabilité pour que la pièce tombe sur le côté face soit égale à 1/2.La pièce est probablement truquée.
Statistiques : Moyenne, écart-type, minimum, maximum, nombre d’observations avec des valeursnon manquantes et quartiles.
Données : Les variables testées doivent être numériques et dichotomiques. Pour convertirdes variables chaînes en variables numériques, utilisez la procédure de recodage automatique,disponible dans le menu Transformer. Une variable dichotomique est une variable qui ne peutprendre que deux valeurs possibles : oui ou non, vrai ou faux, 0 ou 1, etc. La première valeurrencontrée dans l’ensemble de données définit le premier groupe, et l’autre valeur définit ledeuxième groupe. Si les variables ne sont pas dichotomiques, vous devez spécifier une césure. Lacésure affecte les observations avec les valeurs qui sont inférieures ou égales au premier groupe etle reste des observations à un deuxième groupe.
Hypothèses : Les tests non paramétriques ne nécessitent pas d’hypothèses sur la forme de ladistribution sous-jacente. On part du principe que les données constituent un échantillon aléatoire.
Pour obtenir un test binomial
E A partir des menus, sélectionnez :Analyse
Tests non paramétriquesBinomial…
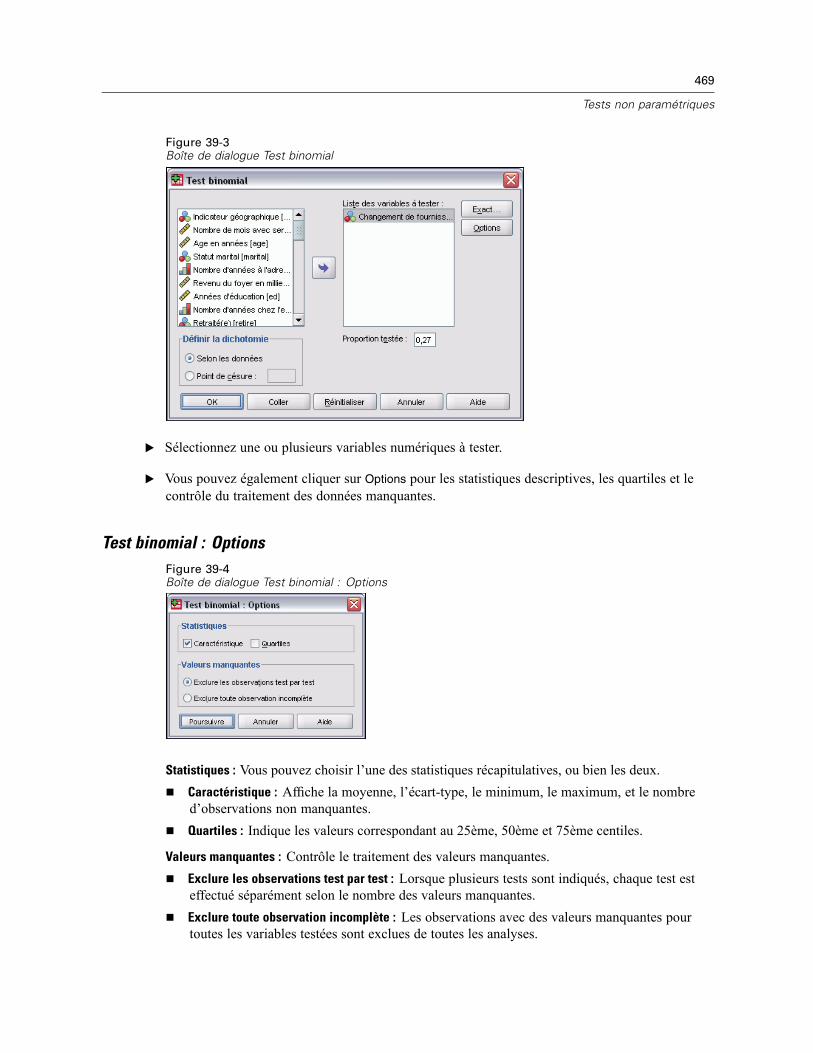
469
Tests non paramétriques
Figure 39-3Boîte de dialogue Test binomial
E Sélectionnez une ou plusieurs variables numériques à tester.
E Vous pouvez également cliquer sur Options pour les statistiques descriptives, les quartiles et lecontrôle du traitement des données manquantes.
Test binomial : OptionsFigure 39-4Boîte de dialogue Test binomial : Options
Statistiques : Vous pouvez choisir l’une des statistiques récapitulatives, ou bien les deux.Caractéristique : Affiche la moyenne, l’écart-type, le minimum, le maximum, et le nombred’observations non manquantes.Quartiles : Indique les valeurs correspondant au 25ème, 50ème et 75ème centiles.
Valeurs manquantes : Contrôle le traitement des valeurs manquantes.Exclure les observations test par test : Lorsque plusieurs tests sont indiqués, chaque test esteffectué séparément selon le nombre des valeurs manquantes.Exclure toute observation incomplète : Les observations avec des valeurs manquantes pourtoutes les variables testées sont exclues de toutes les analyses.

470
Chapitre 39
Fonctionnalités supplémentaires de la commande NPAR TESTS (Test binomial)
Le langage de syntaxe de commande vous permet aussi de :Sélectionner des groupes spécifiques (et en exclure d’autres) lorsqu’une variable comporteplus de deux modalités (avec la sous-commande BINOMIAL).Spécifier différentes césures ou probabilités pour différentes variables (avec la sous-commandeBINOMIAL).Tester la même variable avec différentes césures ou probabilités (avec la sous-commandeEXPECTED).
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.
Suites en séquences
La procédure Suites en séquences teste si l’ordre d’occurrence de deux valeurs d’une variable estaléatoire. Une séquence est une suite d’observations semblables. Un échantillon comportant tropou trop peu de séquences suggère que l’échantillon n’est pas aléatoire.
Exemples : Supposons que 20 personnes soient sondées pour déterminer si elles achèteraientun produit donné. On peut douter que l’échantillon soit aléatoire si toutes les personnes sontdu même sexe. Les suites en séquences peuvent être utilisées pour déterminer si l’échantillona été tiré au hasard.
Statistiques : Moyenne, écart-type, minimum, maximum, nombre d’observations avec des valeursnon manquantes et quartiles.
Données : Les variables doivent être numériques. Pour convertir des variables chaînes en variablesnumériques, utilisez la procédure de recodage automatique, disponible dans le menu Transformer.
Hypothèses : Les tests non paramétriques ne nécessitent pas d’hypothèses sur la forme de ladistribution sous-jacente. Utilisez des échantillons à distribution de probabilité continue.
Pour obtenir un test de suites
E A partir des menus, sélectionnez :Analyse
Tests non paramétriquesSéquences
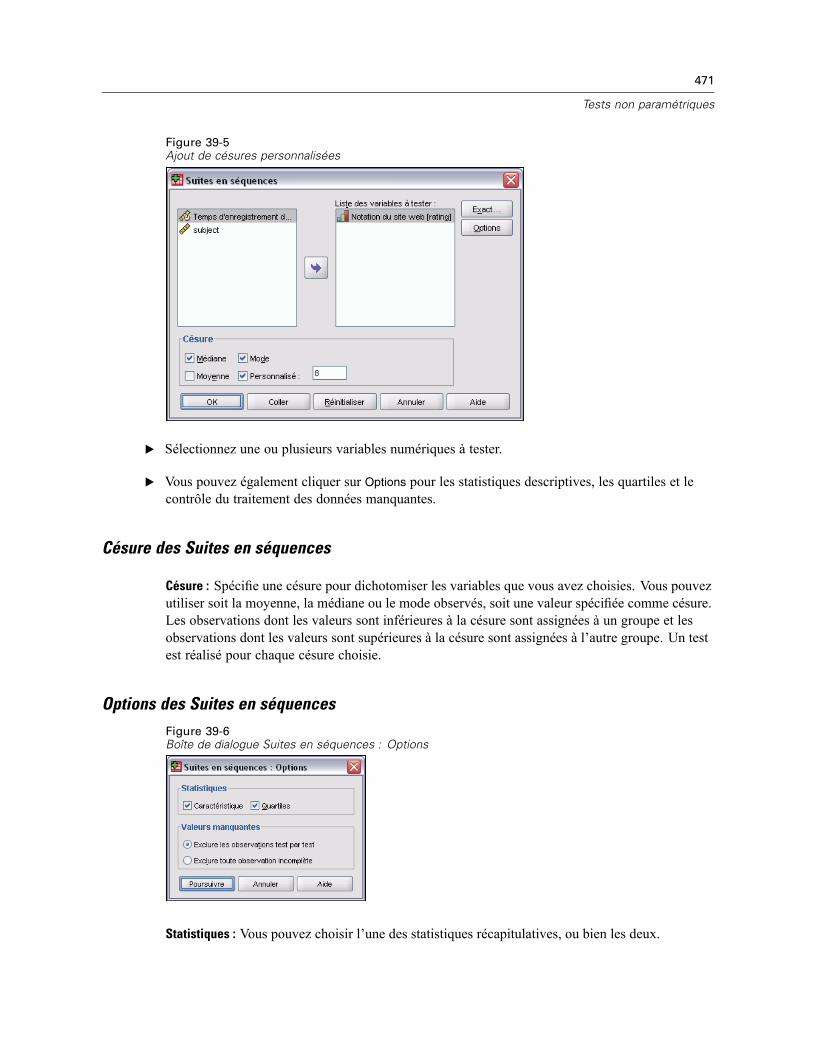
471
Tests non paramétriques
Figure 39-5Ajout de césures personnalisées
E Sélectionnez une ou plusieurs variables numériques à tester.
E Vous pouvez également cliquer sur Options pour les statistiques descriptives, les quartiles et lecontrôle du traitement des données manquantes.
Césure des Suites en séquences
Césure : Spécifie une césure pour dichotomiser les variables que vous avez choisies. Vous pouvezutiliser soit la moyenne, la médiane ou le mode observés, soit une valeur spécifiée comme césure.Les observations dont les valeurs sont inférieures à la césure sont assignées à un groupe et lesobservations dont les valeurs sont supérieures à la césure sont assignées à l’autre groupe. Un testest réalisé pour chaque césure choisie.
Options des Suites en séquencesFigure 39-6Boîte de dialogue Suites en séquences : Options
Statistiques : Vous pouvez choisir l’une des statistiques récapitulatives, ou bien les deux.

472
Chapitre 39
Caractéristique : Affiche la moyenne, l’écart-type, le minimum, le maximum, et le nombred’observations non manquantes.Quartiles : Indique les valeurs correspondant au 25ème, 50ème et 75ème centiles.
Valeurs manquantes : Contrôle le traitement des valeurs manquantes.Exclure les observations test par test : Lorsque plusieurs tests sont indiqués, chaque test esteffectué séparément selon le nombre des valeurs manquantes.Exclure toute observation incomplète : Les observations avec des valeurs manquantes pourl’une ou l’autre variable sont exclues de toutes les analyses.
Fonctionnalités supplémentaires de la commande NPAR TESTS (Suites en séquences)
Le langage de syntaxe de commande vous permet aussi de :Spécifier différentes césures pour différentes variables (à l’aide de la sous-commande RUNS).Tester la même variable par rapport à différentes césures personnalisées (à l’aide de lasous-commande RUNS).
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.
Test Kolmogorov-Smirnov pour un échantillon
Le test de Kolmogorov-Smirnov pour un échantillon compare la fonction de distribution cumuléeobservée d’une variable avec une distribution théorique spécifiée, qui peut être normale, uniforme,de Poisson ou exponentielle. Le Z de Kolmogorov-Smirnov est calculé à partir de la plus grandedifférence (en valeur absolue) entre les fonctions de distribution cumulées observées et théoriques.Le test de qualité de l’ajustement contrôle si les observations peuvent avoir été raisonnablementdéduites de la distribution spécifiée.
Exemple : La plupart des tests paramétriques nécessitent des variables distribuées normalement.Le test de Kolmogorov-Smirnov pour un échantillon permet de vérifier qu’une variable (parexemple Revenu) est distribuée normalement.
Statistiques : Moyenne, écart-type, minimum, maximum, nombre d’observations avec des valeursnon manquantes et quartiles.
Données : Utilisez des variables quantitatives (mesure d’intervalle ou de rapport).
Hypothèses : Le test de Kolmogorov-Smirnov part du principe que les paramètres de la distributionà tester sont précisés a priori. Cette procédure estime les paramètres à partir d’un échantillon.L’échantillon de moyenne et l’échantillon d’écart type sont les paramètres pour une distributionnormale. Les valeurs minimum et maximum de l’échantillon définissent l’intervalle de ladistribution uniforme, l’échantillon de moyenne est le paramètre pour la distribution de Poisson etl’échantillon de l’écart-type est le paramètre pour la distribution exponentielle. La puissance dutest à détecter les abandons de la distribution hypothétique peut être sérieusement diminuée. Pourle test d’une distribution normale avec des paramètres estimés, considérez le test K-S Lillieforsajusté (disponible dans la procédure d’exploration).
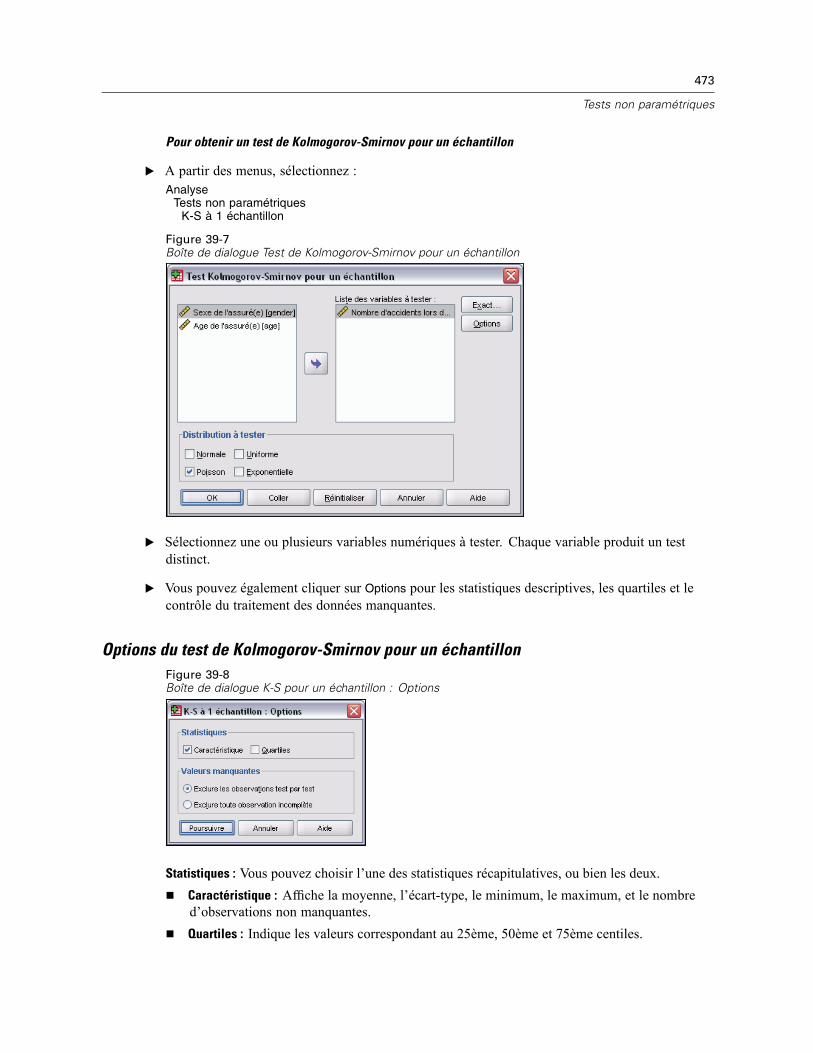
473
Tests non paramétriques
Pour obtenir un test de Kolmogorov-Smirnov pour un échantillon
E A partir des menus, sélectionnez :Analyse
Tests non paramétriquesK-S à 1 échantillon
Figure 39-7Boîte de dialogue Test de Kolmogorov-Smirnov pour un échantillon
E Sélectionnez une ou plusieurs variables numériques à tester. Chaque variable produit un testdistinct.
E Vous pouvez également cliquer sur Options pour les statistiques descriptives, les quartiles et lecontrôle du traitement des données manquantes.
Options du test de Kolmogorov-Smirnov pour un échantillonFigure 39-8Boîte de dialogue K-S pour un échantillon : Options
Statistiques : Vous pouvez choisir l’une des statistiques récapitulatives, ou bien les deux.Caractéristique : Affiche la moyenne, l’écart-type, le minimum, le maximum, et le nombred’observations non manquantes.Quartiles : Indique les valeurs correspondant au 25ème, 50ème et 75ème centiles.

474
Chapitre 39
Valeurs manquantes : Contrôle le traitement des valeurs manquantes.Exclure les observations test par test : Lorsque plusieurs tests sont indiqués, chaque test esteffectué séparément selon le nombre des valeurs manquantes.Exclure toute observation incomplète : Les observations avec des valeurs manquantes pourl’une ou l’autre variable sont exclues de toutes les analyses.
Fonctions supplémentaires de commandes NPAR TESTS (test de Kolmogorov-Smirnovpour un échantillon)
Le langage de syntaxe de commande vous permet également de spécifier des paramètres pour ladistribution du test (avec la sous-commande K-S).
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.
Tests pour deux échantillons indépendants
La procédure des tests pour deux échantillons indépendants compare deux groupes d’observationsen fonction d’une variable.
Exemple : De nouveaux appareils dentaires qui sont censés être plus confortables, avoir uneapparence plus agréable et provoquer des progrès plus rapides pour le redressage des dents ont étédéveloppés. Pour savoir si les nouveaux appareils doivent être portés aussi longtemps que lesanciens, 10 enfants sont choisis de façon aléatoire pour porter les anciens appareils et 10 autrespour porter les nouveaux appareils. Le test U de Mann-Whitney peut par exemple vous montrerque les sujets portant les nouveaux appareils ne doivent pas les porter aussi longtemps que lessujets utilisant les anciens appareils.
Statistiques : Moyenne, écart-type, minimum, maximum, nombre d’observations avec des valeursnon manquantes et quartiles. Tests : U de Mann-Whitney, réactions extrêmes de Moses, Z deKolmogorov-Smirnov, suites de Wald-Wolfowitz.
Données : Utilisez des variables numériques qui peuvent être ordonnées.
Hypothèses : Utilisez des échantillons indépendants, aléatoires. Le test U de Mann-Whitney exigeque les deux échantillons testés soient de forme semblable.
Pour effectuer les tests pour deux échantillons indépendants
E A partir des menus, sélectionnez :Analyse
Tests non paramétriques2 échantillons indépendants
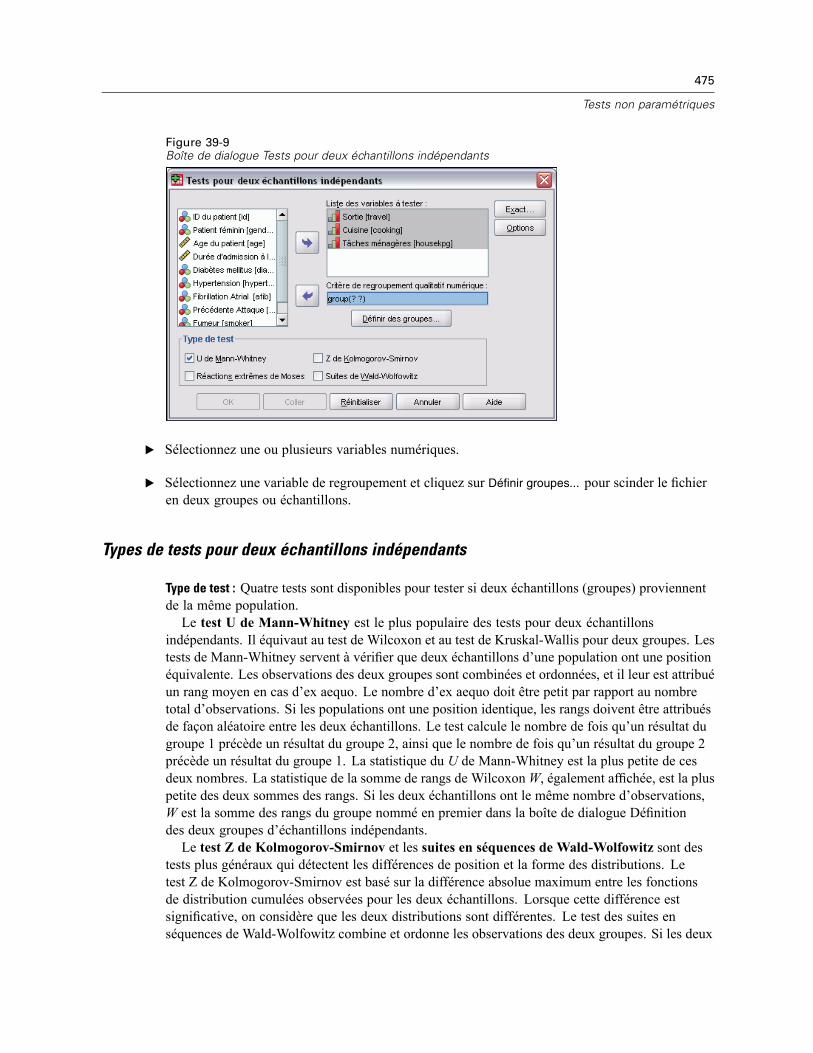
475
Tests non paramétriques
Figure 39-9Boîte de dialogue Tests pour deux échantillons indépendants
E Sélectionnez une ou plusieurs variables numériques.
E Sélectionnez une variable de regroupement et cliquez sur Définir groupes... pour scinder le fichieren deux groupes ou échantillons.
Types de tests pour deux échantillons indépendants
Type de test : Quatre tests sont disponibles pour tester si deux échantillons (groupes) proviennentde la même population.Le test U de Mann-Whitney est le plus populaire des tests pour deux échantillons
indépendants. Il équivaut au test de Wilcoxon et au test de Kruskal-Wallis pour deux groupes. Lestests de Mann-Whitney servent à vérifier que deux échantillons d’une population ont une positionéquivalente. Les observations des deux groupes sont combinées et ordonnées, et il leur est attribuéun rang moyen en cas d’ex aequo. Le nombre d’ex aequo doit être petit par rapport au nombretotal d’observations. Si les populations ont une position identique, les rangs doivent être attribuésde façon aléatoire entre les deux échantillons. Le test calcule le nombre de fois qu’un résultat dugroupe 1 précède un résultat du groupe 2, ainsi que le nombre de fois qu’un résultat du groupe 2précède un résultat du groupe 1. La statistique du U de Mann-Whitney est la plus petite de cesdeux nombres. La statistique de la somme de rangs de WilcoxonW, également affichée, est la pluspetite des deux sommes des rangs. Si les deux échantillons ont le même nombre d’observations,W est la somme des rangs du groupe nommé en premier dans la boîte de dialogue Définitiondes deux groupes d’échantillons indépendants.Le test Z de Kolmogorov-Smirnov et les suites en séquences de Wald-Wolfowitz sont des
tests plus généraux qui détectent les différences de position et la forme des distributions. Letest Z de Kolmogorov-Smirnov est basé sur la différence absolue maximum entre les fonctionsde distribution cumulées observées pour les deux échantillons. Lorsque cette différence estsignificative, on considère que les deux distributions sont différentes. Le test des suites enséquences de Wald-Wolfowitz combine et ordonne les observations des deux groupes. Si les deux

476
Chapitre 39
échantillons proviennent de la même population, les deux groupes doivent être dispersés defaçon aléatoire dans tout le classement.Le test des réactions extrêmes de Moses part du principe que la variable expérimentale
influence certains sujets dans une direction et d’autres sujets dans la direction opposée. Le testvérifie les réponses extrêmes par rapport à un groupe de contrôle. Ce test permet d’étudierl’intervalle du groupe de contrôle et de mesurer à quel point les valeurs extrêmes du groupeexpérimental influencent l’amplitude lorsque ce test est associé au groupe de contrôle. Le groupede contrôle est défini par la valeur du groupe 1 dans la boîte de dialogue Définition des deuxgroupes d’échantillons indépendants. Les observations des deux groupes sont combinées etordonnées. L’intervalle du groupe de contrôle se calcule en effectuant la différence entre les rangsdes valeurs les plus grandes et les plus petites du groupe de contrôle plus 1. Puisque des valeurséloignées peuvent occasionnellement et facilement fausser l’intervalle d’amplitude, 5 % desobservations de contrôle sont filtrées automatiquement à chaque extrémité.
Définition de deux groupes d’échantillons indépendantsFigure 39-10Boîte de dialogue Tests pour deux échantillons indépendants : Définir groupes
Pour scinder le fichier en deux groupes ou échantillons, indiquez un nombre entier pour legroupe 1 et une autre valeur pour le groupe 2. Les observations avec d’autres valeurs sontexclues de l’analyse.
Tests pour deux échantillons indépendants : OptionsFigure 39-11Boîte de dialogue Deux échantillons indépendants : Options
Statistiques : Vous pouvez choisir l’une des statistiques récapitulatives, ou bien les deux.Caractéristique : Indique la moyenne, l’écart-type, le minimum, le maximum, et le nombred’observations sans valeurs manquantes.Quartiles : Indique les valeurs correspondant au 25ème, 50ème et 75ème centiles.
Valeurs manquantes : Contrôle le traitement des valeurs manquantes.

477
Tests non paramétriques
Exclure les observations test par test : Lorsque plusieurs tests sont indiqués, chaque test esteffectué séparément selon le nombre des valeurs manquantes.Exclure toute observation incomplète : Les observations avec des valeurs manquantes pourl’une ou l’autre variable sont exclues de toutes les analyses.
Fonctionnalités supplémentaires de la commande NPAR TESTS (tests pour deuxéchantillons indépendants)
Le langage de syntaxe de commande vous permet également de spécifier le nombre d’observationsdevant être filtrées pour le test de Moses (avec la sous-commande MOSES).
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.
Tests pour deux échantillons liés
La procédure des tests pour deux échantillons liés compare les distributions pour deux variables.
Exemple : En général, une famille qui vend sa maison perçoit-elle le prix demandé ? En appliquantle test de Wilcoxon aux données de 10 foyers, vous apprendrez que sept familles perçoiventmoins que le prix demandé, qu’une famille perçoit plus que le prix demandé et que deux famillesperçoivent le prix demandé.
Statistiques : Moyenne, écart-type, minimum, maximum, nombre d’observations avec des valeursnon manquantes et quartiles. Tests : Classement Wilcoxon, Signe, McNemar. Si l’option Testsexacts est installée (disponible uniquement sous les systèmes d’exploitation Windows), le testd’Homogénéité marginale est alors disponible.
Données : Utilisez des variables numériques qui peuvent être ordonnées.
Hypothèses : Bien qu’aucune distribution particulière ne soit supposée pour les deux variables, onpart du principe que la distribution de la population des différences liées est symétrique.
Pour obtenir des tests pour deux échantillons liés
E A partir des menus, sélectionnez :Analyse
Tests non paramétriques2 échantillons liés
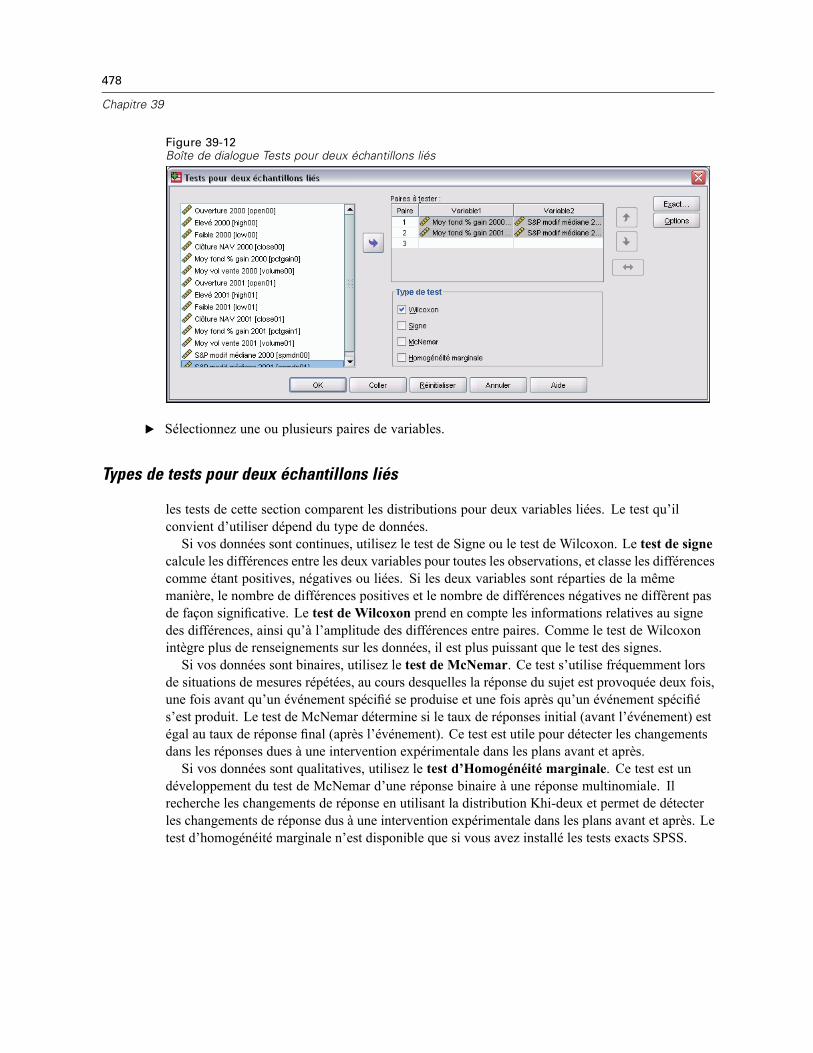
478
Chapitre 39
Figure 39-12Boîte de dialogue Tests pour deux échantillons liés
E Sélectionnez une ou plusieurs paires de variables.
Types de tests pour deux échantillons liés
les tests de cette section comparent les distributions pour deux variables liées. Le test qu’ilconvient d’utiliser dépend du type de données.Si vos données sont continues, utilisez le test de Signe ou le test de Wilcoxon. Le test de signe
calcule les différences entre les deux variables pour toutes les observations, et classe les différencescomme étant positives, négatives ou liées. Si les deux variables sont réparties de la mêmemanière, le nombre de différences positives et le nombre de différences négatives ne diffèrent pasde façon significative. Le test de Wilcoxon prend en compte les informations relatives au signedes différences, ainsi qu’à l’amplitude des différences entre paires. Comme le test de Wilcoxonintègre plus de renseignements sur les données, il est plus puissant que le test des signes.Si vos données sont binaires, utilisez le test de McNemar. Ce test s’utilise fréquemment lors
de situations de mesures répétées, au cours desquelles la réponse du sujet est provoquée deux fois,une fois avant qu’un événement spécifié se produise et une fois après qu’un événement spécifiés’est produit. Le test de McNemar détermine si le taux de réponses initial (avant l’événement) estégal au taux de réponse final (après l’événement). Ce test est utile pour détecter les changementsdans les réponses dues à une intervention expérimentale dans les plans avant et après.Si vos données sont qualitatives, utilisez le test d’Homogénéité marginale. Ce test est un
développement du test de McNemar d’une réponse binaire à une réponse multinomiale. Ilrecherche les changements de réponse en utilisant la distribution Khi-deux et permet de détecterles changements de réponse dus à une intervention expérimentale dans les plans avant et après. Letest d’homogénéité marginale n’est disponible que si vous avez installé les tests exacts SPSS.

479
Tests non paramétriques
Tests pour deux échantillons liés : OptionsFigure 39-13Boîte de dialogue Tests pour deux échantillons liés : Options
Statistiques : Vous pouvez choisir l’une des statistiques récapitulatives, ou bien les deux.Caractéristique : Indique la moyenne, l’écart-type, le minimum, le maximum, et le nombred’observations sans valeurs manquantes.Quartiles : Indique les valeurs correspondant au 25ème, 50ème et 75ème centiles.
Valeurs manquantes : Contrôle le traitement des valeurs manquantes.Exclure les observations test par test : Lorsque plusieurs tests sont indiqués, chaque test esteffectué séparément selon le nombre des valeurs manquantes.Exclure toute observation incomplète : Les observations avec des valeurs manquantes pourl’une ou l’autre variable sont exclues de toutes les analyses.
Fonctionnalités supplémentaires de la commande NPAR (Deux échantillons liés)
Le langage de syntaxe de commande vous permet également de tester une variable avec chaquevariable d’une liste.
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.
Tests pour plusieurs échantillons indépendants
La procédure de Tests pour Plusieurs Echantillons Indépendants compare deux groupesd’observations ou plus sur une variable.
Exemple : Trois marques d’ampoules 100 watts diffèrent-elles par leur durée moyenne defonctionnement ? A partir de l’analyse de variance d’ordre 1 de Kruskal-Wallis, vous apprendrezpeut-être que les trois marques diffèrent par leur durée de vie moyenne.
Statistiques : Moyenne, écart-type, minimum, maximum, nombre d’observations avec des valeursnon manquantes et quartiles. Tests : H de Kruskal-Wallis, médiane.
Données : Utilisez des variables numériques qui peuvent être ordonnées.
Hypothèses : Utilisez des échantillons indépendants, aléatoires. Le test du H de Kruskal-Wallisnécessite que les échantillons testés soient de forme similaire.
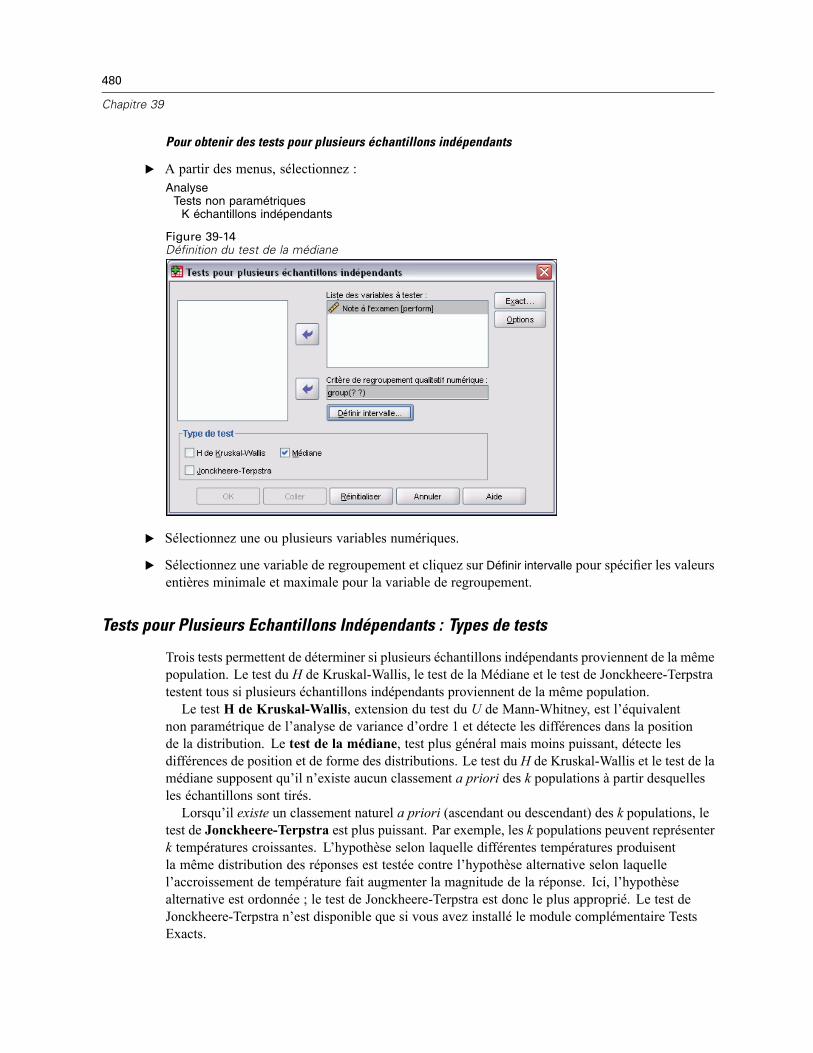
480
Chapitre 39
Pour obtenir des tests pour plusieurs échantillons indépendants
E A partir des menus, sélectionnez :Analyse
Tests non paramétriquesK échantillons indépendants
Figure 39-14Définition du test de la médiane
E Sélectionnez une ou plusieurs variables numériques.
E Sélectionnez une variable de regroupement et cliquez sur Définir intervalle pour spécifier les valeursentières minimale et maximale pour la variable de regroupement.
Tests pour Plusieurs Echantillons Indépendants : Types de tests
Trois tests permettent de déterminer si plusieurs échantillons indépendants proviennent de la mêmepopulation. Le test du H de Kruskal-Wallis, le test de la Médiane et le test de Jonckheere-Terpstratestent tous si plusieurs échantillons indépendants proviennent de la même population.Le test H de Kruskal-Wallis, extension du test du U de Mann-Whitney, est l’équivalent
non paramétrique de l’analyse de variance d’ordre 1 et détecte les différences dans la positionde la distribution. Le test de la médiane, test plus général mais moins puissant, détecte lesdifférences de position et de forme des distributions. Le test du H de Kruskal-Wallis et le test de lamédiane supposent qu’il n’existe aucun classement a priori des k populations à partir desquellesles échantillons sont tirés.Lorsqu’il existe un classement naturel a priori (ascendant ou descendant) des k populations, le
test de Jonckheere-Terpstra est plus puissant. Par exemple, les k populations peuvent représenterk températures croissantes. L’hypothèse selon laquelle différentes températures produisentla même distribution des réponses est testée contre l’hypothèse alternative selon laquellel’accroissement de température fait augmenter la magnitude de la réponse. Ici, l’hypothèsealternative est ordonnée ; le test de Jonckheere-Terpstra est donc le plus approprié. Le test deJonckheere-Terpstra n’est disponible que si vous avez installé le module complémentaire TestsExacts.

481
Tests non paramétriques
Tests pour Plusieurs Echantillons Indépendants : Définir l’IntervalleFigure 39-15Boîte de dialogue Plusieurs échantillons indépendants : Définir l’intervalle
Pour définir l’intervalle, entrez des valeurs entières pour Minimum et Maximum qui correspondentà la modalité la plus basse et à la plus haute du critère de regroupement. Les observations dontles valeurs se trouvent à l’extérieur des limites sont exclues. Par exemple, si vous spécifiez unevaleur minimale de 1 et une valeur maximale de 3, seules les valeurs entières comprises entre1 et 3 seront utilisées. La valeur minimale doit être inférieure à la valeur maximale, et les deuxvaleurs doivent être spécifiées.
Options des Tests pour Plusieurs Echantillons IndépendantsFigure 39-16Boîte de dialogue Plusieurs échantillons indépendants : Options
Statistiques : Vous pouvez choisir l’une des statistiques récapitulatives, ou bien les deux.Caractéristique : Indique la moyenne, l’écart-type, le minimum, le maximum, et le nombred’observations sans valeurs manquantes.Quartiles : Indique les valeurs correspondant au 25ème, 50ème et 75ème centiles.
Valeurs manquantes : Contrôle le traitement des valeurs manquantes.Exclure les observations test par test : Lorsque plusieurs tests sont indiqués, chaque test esteffectué séparément selon le nombre des valeurs manquantes.Exclure toute observation incomplète : Les observations avec des valeurs manquantes pourl’une ou l’autre variable sont exclues de toutes les analyses.
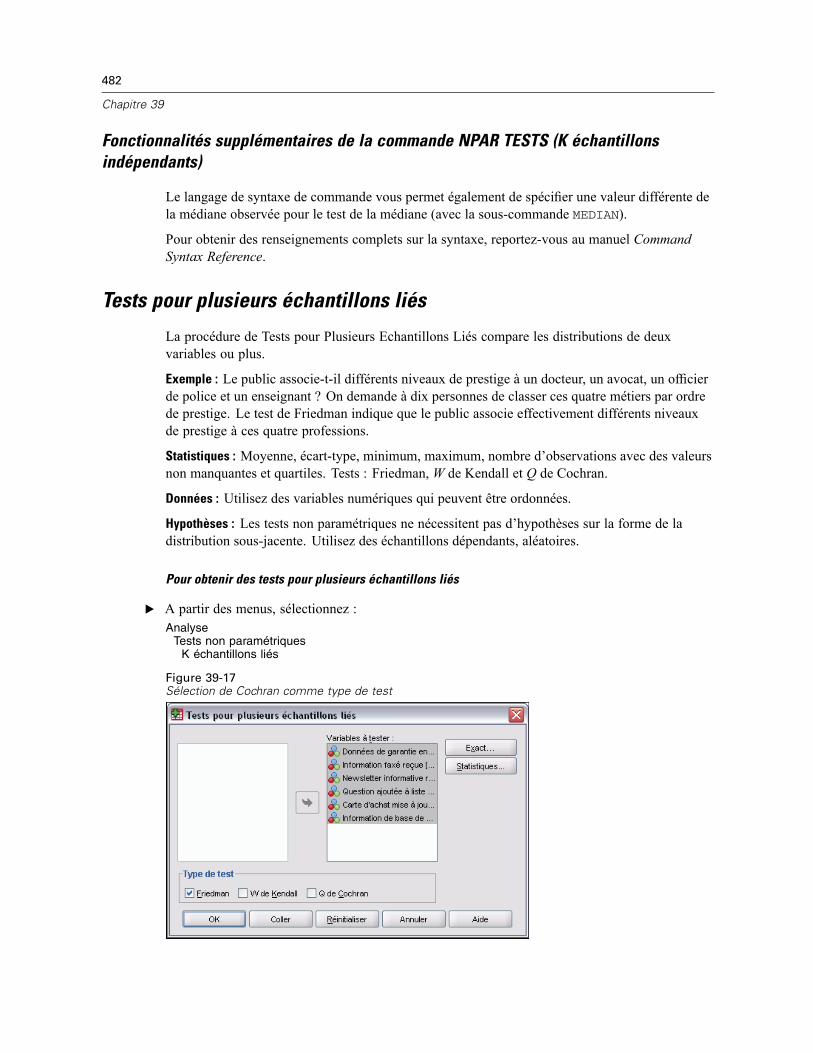
482
Chapitre 39
Fonctionnalités supplémentaires de la commande NPAR TESTS (K échantillonsindépendants)
Le langage de syntaxe de commande vous permet également de spécifier une valeur différente dela médiane observée pour le test de la médiane (avec la sous-commande MEDIAN).
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.
Tests pour plusieurs échantillons liés
La procédure de Tests pour Plusieurs Echantillons Liés compare les distributions de deuxvariables ou plus.
Exemple : Le public associe-t-il différents niveaux de prestige à un docteur, un avocat, un officierde police et un enseignant ? On demande à dix personnes de classer ces quatre métiers par ordrede prestige. Le test de Friedman indique que le public associe effectivement différents niveauxde prestige à ces quatre professions.
Statistiques : Moyenne, écart-type, minimum, maximum, nombre d’observations avec des valeursnon manquantes et quartiles. Tests : Friedman, W de Kendall et Q de Cochran.
Données : Utilisez des variables numériques qui peuvent être ordonnées.
Hypothèses : Les tests non paramétriques ne nécessitent pas d’hypothèses sur la forme de ladistribution sous-jacente. Utilisez des échantillons dépendants, aléatoires.
Pour obtenir des tests pour plusieurs échantillons liés
E A partir des menus, sélectionnez :Analyse
Tests non paramétriquesK échantillons liés
Figure 39-17Sélection de Cochran comme type de test

483
Tests non paramétriques
E Sélectionnez deux variables numériques ou plus à tester.
Tests pour plusieurs échantillons liés de types de tests
Trois tests sont disponibles pour comparer les distributions de plusieurs variables liées.Le test de Friedman est l’équivalent non paramétrique d’un plan de mesures répétées sur un
échantillon ou d’une analyse de variance d’ordre 2 avec une observation par cellule. Le testde Friedman teste l’hypothèse nulle selon laquelle k variables liées proviennent de la mêmepopulation. Pour chaque observation, les variables k sont classées de 1 à k. La statistique detest est basée sur ces classements.Le testW de Kendall est une standardisation de la statistique de Friedman. Le test W de
Kendall peut être interprété comme le coefficient de concordance, qui est une mesure de l’accordentre les évaluateurs. Chaque observation est un juge ou un indicateur, et chaque variable est unepersonne ou un élément jugé. Pour chaque variable, la somme des rangs est calculée. Le W deKendall se situe entre 0 (pas d’accord) et 1 (accord total).Le Q de Cochran est identique au test de Friedman mais s’applique lorsque toutes les réponses
sont binaires. Ce test est une extension du test de McNemar à K échantillons. Le Q de Cochranteste l’hypothèse nulle selon laquelle plusieurs variables dichotomiques liées ont la mêmemoyenne. Les variables sont mesurées sur le même individu ou sur des individus comparables.
Statistiques des tests pour plusieurs échantillons liésFigure 39-18Boîte de dialogue Statistiques pour Plusieurs Echantillons Liés
Vous pouvez choisir les statitistiques.Caractéristique : Indique la moyenne, l’écart-type, le minimum, le maximum, et le nombred’observations sans valeurs manquantes.Quartiles : Indique les valeurs correspondant au 25ème, 50ème et 75ème centiles.
Fonctionnalités supplémentaires de la commande NPAR TESTS (K échantillons liés)Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.

Chapitre
40Analyse des réponses multiples
Deux procédures sont proposées pour l’analyse des vecteurs comportant plusieurs variablesdichotomiques ou plusieurs modalités. La procédure Fréquences multiréponses affiche lestableaux de fréquences. La procédure des Tableaux croisés multiréponses affiche des tableauxcroisés à deux ou trois dimensions. Avant d’utiliser l’une de ces procédures, vous devez définirdes vecteurs multiréponses.
Exemple : Cet exemple illustre l’utilisation des éléments multiréponses dans une étude demarché. Ces données sont fictives et ne doivent pas être considérées comme réelles. Unecompagnie aérienne est parfois amenée à interroger les passagers d’un trajet donné pour évaluer laconcurrence. Dans cet exemple, American Airlines veut savoir si ses passagers utilisent d’autrescompagnies aériennes pour couvrir le trajet Chicago-New York et connaître l’importance relativedes horaires et du service dans le choix d’une compagnie aérienne. L’hôtesse distribue à chaquepassager un court questionnaire lors de l’embarquement. La première question est la suivante:Entourez toutes les compagnies aériennes par lesquelles vous avez effectué au moins un vol dansles six derniers mois parmi American, United, TWA, USAir et d’autres. Il s’agit d’une question àréponses multiples, car le passager peut entourer plus d’une réponse. Cependant, cette question nepeut pas être codée directement, parce qu’une variable SPSS ne peut avoir qu’une valeur pourchaque cas. Vous devez utiliser plusieurs variables pour mapper les réponses à chaque question.Ceci peut être fait de deux manières. L’une consiste à définir une variable correspondant à chaquechoix possible (par exemple, American, United, TWA, USAir et d’autres). Si le passager entoureUnited, le numéro de code 1 est affecté à la variable united, sinon c’est le code 0 qui lui estaffecté. Il s’agit de la méthode de codage de variables à dichotomie multiple. L’autre méthodepermettant de mapper les réponses est la méthode des modalités multiples, où vous devezestimer le nombre maximal de réponses possibles à la question et définir le même nombre devariables, avec des codes correspondant à la compagnie aérienne empruntée. En utilisant unéchantillon de questionnaires, vous vous apercevrez peut-être que personne n’a emprunté plus detrois compagnies différentes pour ce trajet. Qui plus est, vous vous rendrez compte que, du fait dela déréglementation des compagnies aériennes, 10 autres compagnies figurent dans la modalitéAutre. A l’aide de la méthode multiréponses, vous pouvez définir trois variables, codées commesuit : 1 = american, 2 = united, 3 = twa, 4 = usair, 5 = delta, etc. Si un passager entoure Americanet TWA, la première variable porte le code 1, la seconde le code 3, et la troisième un code sansvaleur. Un autre passager a peut-être entouré American et ajouté Delta. Ainsi, la première variableporte le code 1, la seconde le code 5, et la troisième un code sans valeur. Si vous utilisez laméthode des dichotomies multiples, d’un autre côté, vous finissez par vous retrouver avec 14variables différentes. Les deux méthodes de codage sont possibles dans le cadre de cette enquête.Cependant, votre choix dépendra de la répartition des réponses.
484

485
Analyse des réponses multiples
Définition de vecteurs multiréponses
La procédure de définition de vecteurs multiréponses regroupe des variables itemaires dans desvecteurs de dichotomies ou de modalités, pour lesquels vous pouvez obtenir des tableaux defréquences et des tableaux croisés. Vous pouvez définir jusqu’à 20 vecteurs multiréponses.Chaque vecteur doit avoir un nom unique. Pour éliminer un vecteur, sélectionnez-le dans la listedes vecteurs multiréponses et cliquez sur Eliminer. Pour modifier un vecteur, sélectionnez-le dansla liste, modifiez-en les caractéristiques et cliquez sur Changer.Vous pouvez coder vos variables itemaires sous forme de dichotomies ou de modalités. Pour
utiliser des variables dichotomiques, sélectionnez Variables dichotomiques afin de créer un vecteurde dichotomies multiples. Entrez une valeur entière dans Valeur comptée. Chaque variable ayantau moins une occurrence de la valeur comptée devient une modalité du vecteur de dichotomiesmultiples. Sélectionnez Modalités pour créer un vecteur de modalités multiples ayant le mêmeintervalle de valeurs que les variables qui le composent. Entrez des nombres entiers pour leminimum et le maximum de l’intervalle des modalités du vecteur de modalités multiples. SPSStotalise chaque valeur entière contenue dans l’intervalle pour toutes les variables qui le composent.Les modalités vides ne sont pas tabulées.A chaque vecteur multiréponses doit être attribué un nom unique de 7 caractères maximum. La
procédure ajoute un signe dollar ($) devant le nom que vous avez attribué. Les noms réservéssuivants ne doivent pas être utilisés : casenum, sysmis, jdate, date, time, length et width. Le nomdu vecteur multiréponses doit uniquement être utilisé dans les procédures multiréponses. Vous nepouvez pas faire référence aux noms des vecteurs multiréponses dans les autres procédures. Atitre facultatif, vous pouvez entrer une étiquette de variable décrivant le vecteur multiréponses.Cette étiquette peut comporter jusqu’à 40 caractères.
Définir des vecteurs de réponses multiples
E A partir des menus, sélectionnez :Analyse
Réponses multiplesDéfinir des groupes
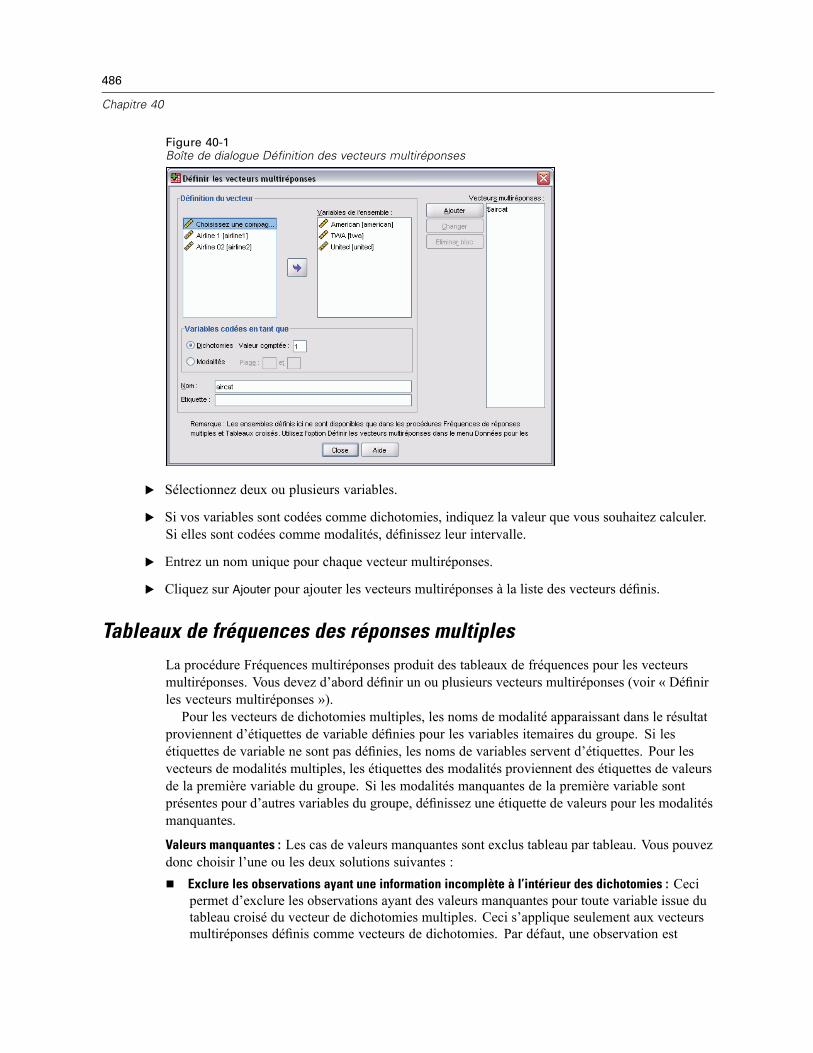
486
Chapitre 40
Figure 40-1Boîte de dialogue Définition des vecteurs multiréponses
E Sélectionnez deux ou plusieurs variables.
E Si vos variables sont codées comme dichotomies, indiquez la valeur que vous souhaitez calculer.Si elles sont codées comme modalités, définissez leur intervalle.
E Entrez un nom unique pour chaque vecteur multiréponses.
E Cliquez sur Ajouter pour ajouter les vecteurs multiréponses à la liste des vecteurs définis.
Tableaux de fréquences des réponses multiplesLa procédure Fréquences multiréponses produit des tableaux de fréquences pour les vecteursmultiréponses. Vous devez d’abord définir un ou plusieurs vecteurs multiréponses (voir « Définirles vecteurs multiréponses »).Pour les vecteurs de dichotomies multiples, les noms de modalité apparaissant dans le résultat
proviennent d’étiquettes de variable définies pour les variables itemaires du groupe. Si lesétiquettes de variable ne sont pas définies, les noms de variables servent d’étiquettes. Pour lesvecteurs de modalités multiples, les étiquettes des modalités proviennent des étiquettes de valeursde la première variable du groupe. Si les modalités manquantes de la première variable sontprésentes pour d’autres variables du groupe, définissez une étiquette de valeurs pour les modalitésmanquantes.
Valeurs manquantes : Les cas de valeurs manquantes sont exclus tableau par tableau. Vous pouvezdonc choisir l’une ou les deux solutions suivantes :
Exclure les observations ayant une information incomplète à l’intérieur des dichotomies : Cecipermet d’exclure les observations ayant des valeurs manquantes pour toute variable issue dutableau croisé du vecteur de dichotomies multiples. Ceci s’applique seulement aux vecteursmultiréponses définis comme vecteurs de dichotomies. Par défaut, une observation est

487
Analyse des réponses multiples
considérée manquante pour un vecteur de dichotomies multiples si aucune de ses variablescomposantes ne contient de valeur comptée. Les cas de valeurs manquantes pour certainesvariables, mais pas toutes, sont inclus dans les tabulations du groupe si au moins une variablecontient la valeur comptée.Exclure toute observation ayant une information incomplète à l’intérieur des modalités : Celapermet d’exclure les observations ayant des valeurs manquantes pour toute variable provenantdu tableau croisé du vecteur des modalités multiples. Ceci s’applique seulement aux vecteursmultiréponses définis comme des vecteurs de modalités. Par défaut, une observation estconsidérée manquante pour un vecteur de modalités multiples si aucune de ses composantesn’a de valeurs valides à l’intérieur de l’intervalle défini.
Exemple : Chaque variable créée à partir d’une question de l’enquête est une variable élémentaire.Pour analyser un élément multiréponses, vous devez combiner les variables dans l’un des deuxtypes de vecteurs multiréponses : vecteur de modalités multiples ou vecteur de dichotomiesmultiples. Par exemple, si dans une enquête, une compagnie aérienne vous demande la compagnie(American Airlines, United Airlines ou TWA) que vous avez empruntée au cours des six derniersmois, si vous utilisez des variables dichotomiques et avez défini un vecteur de dichotomiesmultiples, chacune des trois variables du vecteur devient une modalité de la variable deregroupement. Les effectifs et les pourcentages correspondant aux trois compagnies aérienness’affichent dans un tableau de fréquences. Si vous découvrez qu’aucun des répondants n’amentionné plus de deux compagnies, vous pouvez créer deux variables, chacune ayant trois codes,un par compagnie aérienne. Si vous définissez un vecteur de modalités multiples, les valeurssont tabulées et les mêmes codes sont ajoutés dans toutes les variables élémentaires. Le vecteur devaleurs résultant est le même que pour chacune des variables itemaires. Par exemple, 30 réponsespour United représentent la somme des cinq réponses United pour la compagnie aérienne 1 etdes 25 réponses United pour la compagnie 2. Les effectifs et les pourcentages correspondant auxtrois compagnies aériennes s’affichent dans un tableau de fréquences.
Statistiques : Tableaux de fréquences contenant des effectifs, des pourcentages de réponses, despourcentages de cas, le nombre de cas valables, et le nombre de cas manquants.
Données : Utilisez des vecteurs multiréponses.
Hypothèses : Les effectifs et pourcentages représentent une description utile des données den’importe quelle distribution.
Procédures apparentées : La procédure Définir Vecteurs multiréponses vous permet de définirdes vecteurs multiréponses.
Pour obtenir des tableaux de fréquences de réponses multiples
E A partir des menus, sélectionnez :Analyse
Réponses multiplesFréquences
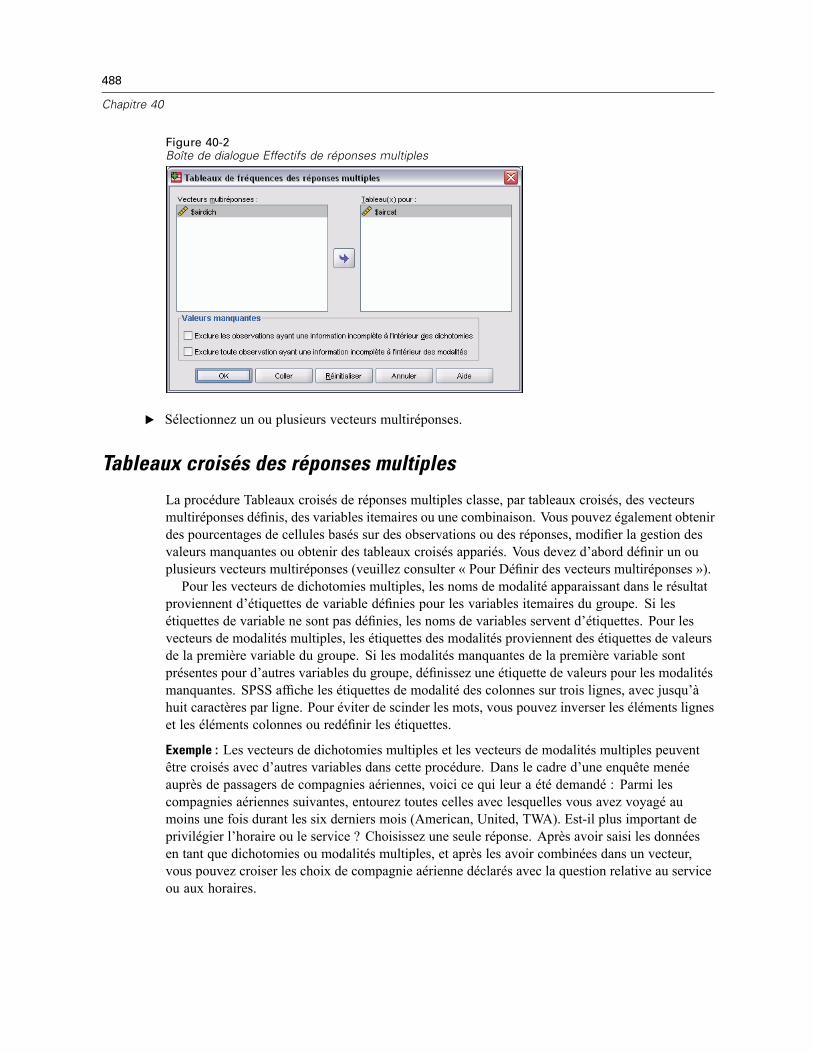
488
Chapitre 40
Figure 40-2Boîte de dialogue Effectifs de réponses multiples
E Sélectionnez un ou plusieurs vecteurs multiréponses.
Tableaux croisés des réponses multiples
La procédure Tableaux croisés de réponses multiples classe, par tableaux croisés, des vecteursmultiréponses définis, des variables itemaires ou une combinaison. Vous pouvez également obtenirdes pourcentages de cellules basés sur des observations ou des réponses, modifier la gestion desvaleurs manquantes ou obtenir des tableaux croisés appariés. Vous devez d’abord définir un ouplusieurs vecteurs multiréponses (veuillez consulter « Pour Définir des vecteurs multiréponses »).Pour les vecteurs de dichotomies multiples, les noms de modalité apparaissant dans le résultat
proviennent d’étiquettes de variable définies pour les variables itemaires du groupe. Si lesétiquettes de variable ne sont pas définies, les noms de variables servent d’étiquettes. Pour lesvecteurs de modalités multiples, les étiquettes des modalités proviennent des étiquettes de valeursde la première variable du groupe. Si les modalités manquantes de la première variable sontprésentes pour d’autres variables du groupe, définissez une étiquette de valeurs pour les modalitésmanquantes. SPSS affiche les étiquettes de modalité des colonnes sur trois lignes, avec jusqu’àhuit caractères par ligne. Pour éviter de scinder les mots, vous pouvez inverser les éléments ligneset les éléments colonnes ou redéfinir les étiquettes.
Exemple : Les vecteurs de dichotomies multiples et les vecteurs de modalités multiples peuventêtre croisés avec d’autres variables dans cette procédure. Dans le cadre d’une enquête menéeauprès de passagers de compagnies aériennes, voici ce qui leur a été demandé : Parmi lescompagnies aériennes suivantes, entourez toutes celles avec lesquelles vous avez voyagé aumoins une fois durant les six derniers mois (American, United, TWA). Est-il plus important deprivilégier l’horaire ou le service ? Choisissez une seule réponse. Après avoir saisi les donnéesen tant que dichotomies ou modalités multiples, et après les avoir combinées dans un vecteur,vous pouvez croiser les choix de compagnie aérienne déclarés avec la question relative au serviceou aux horaires.
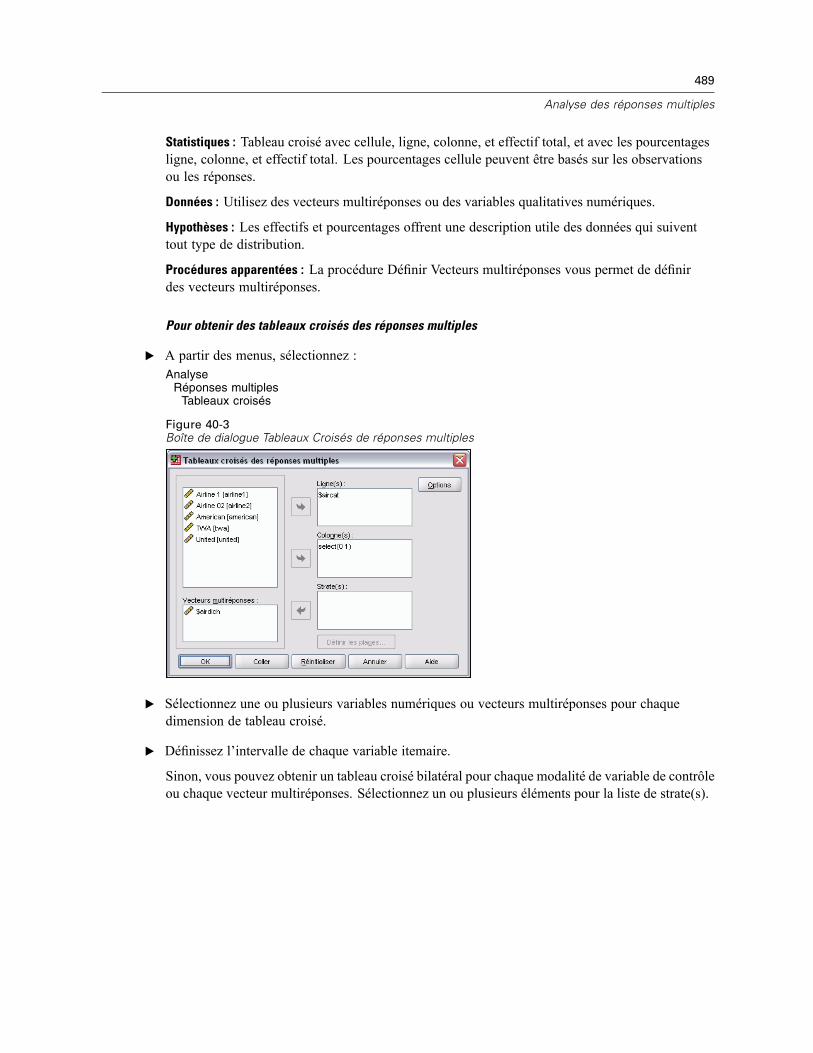
489
Analyse des réponses multiples
Statistiques : Tableau croisé avec cellule, ligne, colonne, et effectif total, et avec les pourcentagesligne, colonne, et effectif total. Les pourcentages cellule peuvent être basés sur les observationsou les réponses.
Données : Utilisez des vecteurs multiréponses ou des variables qualitatives numériques.
Hypothèses : Les effectifs et pourcentages offrent une description utile des données qui suiventtout type de distribution.
Procédures apparentées : La procédure Définir Vecteurs multiréponses vous permet de définirdes vecteurs multiréponses.
Pour obtenir des tableaux croisés des réponses multiples
E A partir des menus, sélectionnez :Analyse
Réponses multiplesTableaux croisés
Figure 40-3Boîte de dialogue Tableaux Croisés de réponses multiples
E Sélectionnez une ou plusieurs variables numériques ou vecteurs multiréponses pour chaquedimension de tableau croisé.
E Définissez l’intervalle de chaque variable itemaire.
Sinon, vous pouvez obtenir un tableau croisé bilatéral pour chaque modalité de variable de contrôleou chaque vecteur multiréponses. Sélectionnez un ou plusieurs éléments pour la liste de strate(s).
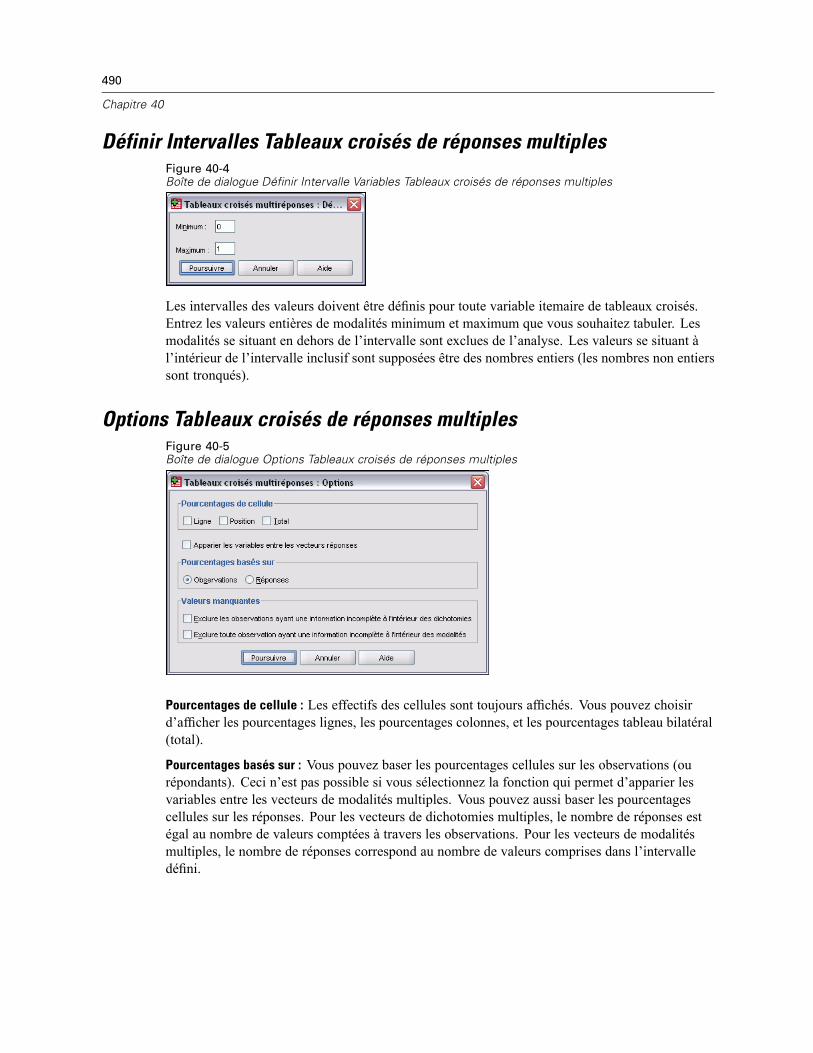
490
Chapitre 40
Définir Intervalles Tableaux croisés de réponses multiplesFigure 40-4Boîte de dialogue Définir Intervalle Variables Tableaux croisés de réponses multiples
Les intervalles des valeurs doivent être définis pour toute variable itemaire de tableaux croisés.Entrez les valeurs entières de modalités minimum et maximum que vous souhaitez tabuler. Lesmodalités se situant en dehors de l’intervalle sont exclues de l’analyse. Les valeurs se situant àl’intérieur de l’intervalle inclusif sont supposées être des nombres entiers (les nombres non entierssont tronqués).
Options Tableaux croisés de réponses multiplesFigure 40-5Boîte de dialogue Options Tableaux croisés de réponses multiples
Pourcentages de cellule : Les effectifs des cellules sont toujours affichés. Vous pouvez choisird’afficher les pourcentages lignes, les pourcentages colonnes, et les pourcentages tableau bilatéral(total).
Pourcentages basés sur : Vous pouvez baser les pourcentages cellules sur les observations (ourépondants). Ceci n’est pas possible si vous sélectionnez la fonction qui permet d’apparier lesvariables entre les vecteurs de modalités multiples. Vous pouvez aussi baser les pourcentagescellules sur les réponses. Pour les vecteurs de dichotomies multiples, le nombre de réponses estégal au nombre de valeurs comptées à travers les observations. Pour les vecteurs de modalitésmultiples, le nombre de réponses correspond au nombre de valeurs comprises dans l’intervalledéfini.

491
Analyse des réponses multiples
Valeurs manquantes : Vous avez le choix entre les deux options suivantes :Exclure les observations ayant une information incomplète à l’intérieur des dichotomies : Cecipermet d’exclure les observations ayant des valeurs manquantes pour toute variable issue dutableau croisé du vecteur de dichotomies multiples. Ceci s’applique seulement aux vecteursmultiréponses définis comme vecteurs de dichotomies. Par défaut, une observation estconsidérée manquante pour un vecteur de dichotomies multiples si aucune de ses variablescomposantes ne contient de valeur comptée. Les observations ayant des valeurs manquantespour certaines, mais pas toutes, les variables sont incluses dans les tableaux croisés du groupesi au moins une variable contient la valeur comptée.Exclure toute observation ayant une information incomplète à l’intérieur des modalités : Celapermet d’exclure les observations ayant des valeurs manquantes pour toute variable provenantdu tableau croisé du vecteur des modalités multiples. Ceci s’applique seulement aux vecteursmultiréponses définis comme des vecteurs de modalités. Par défaut, une observation estconsidérée manquante pour un vecteur de modalités multiples si aucune de ses composantesn’a de valeurs valides à l’intérieur de l’intervalle défini.
Par défaut, lorsque vous croisez deux vecteurs de modalités multiples, SPSS tabule chaquevariable du premier groupe avec chaque variable du second groupe et additionne les effectifs dechaque cellule. Par conséquent, certaines réponses peuvent apparaître plus d’une fois dans untableau. Vous pouvez choisir l’option suivante :
Apparier les variables entre les vecteurs réponses : Cela permet d’apparier la première variable dupremier groupe avec la première variable du second groupe, etc. Si vous sélectionnez cette option,SPSS base les pourcentages cellules sur les réponses plutôt que sur les répondants. On ne peutapparier les vecteurs de dichotomies multiples ou les variables itemaires.
Fonctionnalités supplémentaires de la commande MULT RESPONSE
Le langage de syntaxe de commande vous permet aussi de :Obtenir des tableaux croisés ayant jusqu’à cinq dimensions (avec la sous-commande BY).Modifier les options de formatage du résultat, y compris la suppression des étiquettes devaleurs (avec la sous-commande FORMAT).
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.

Chapitre
41Tableaux de Résultats
Les listes d’observations et les statistiques descriptives sont des outils de base permettant d’étudieret de présenter des données. Vous pouvez obtenir les listes d’observations à l’aide de l’éditeur deDonnées ou de la procédure Récapituler, les effectifs de fréquence et les statistiques descriptives àl’aide de la procédure Fréquences, et les statistiques de sous-population à l’aide de la procédureMoyennes. Chacune de ces procédures utilise un format destiné à rendre les informations claires.Si vous souhaitez afficher les informations dans un format différent, les procédures Tableaux debord en lignes et Tableaux de bord en colonnes vous permettent de contrôler la présentationdes données.
Tableaux de bord en lignes
Tableaux de bord en lignes produit des tableaux de bord dans lesquels différentes statistiquesrécapitulatives sont disposées en lignes. Les listes d’observations sont également disponibles,avec ou sans statistiques récapitulatives.
Exemple : Une société possédant une chaîne de magasins conserve des dossiers sur les employéscomprenant le salaire, l’ancienneté, le magasin et le service où chaque employé travaille.Vous pourriez générer un tableau de bord fournissant les informations individuelles sur lesemployés (liste) divisées par magasin et par division (critères d’agrégation), avec les statistiquesrécapitulatives (par exemple, salaire moyen) pour chaque magasin, division et par division danschaque magasin.
Variables en colonnes : Donne la liste des variables de tableau pour lesquelles vous voulez obtenirdes listes d’observations ou des statistiques récapitulatives, et contrôle le format d’affichagedes Variables en colonnes.
Variables de ventilation : Donne la liste des critères d’agrégation optionnels qui divisent le tableaude bord en groupes et contrôle les statistiques récapitulatives et les formats d’affichage descolonnes de ventilation. Pour les critères d’agrégation multiples, il y aura un groupe séparé pourchaque modalité de chaque critère d’agrégation à l’intérieur des modalités du critère d’agrégationprécédent dans la liste. Les critères d’agrégation doivent être des variables qualitatives discrètesqui divisent les observations en un nombre limité de modalités significatives. Les valeursindividuelles de chaque critère d’agrégation apparaissent, triées, dans une colonne séparée àgauche des Variables en colonnes.
Tableau de bord : Contrôle les caractéristiques globales du tableau de bord, y compris lesstatistiques récapitulatives globales, l’affichage des valeurs manquantes, la numérotation despages et les titres.
492

493
Tableaux de Résultats
Afficher les observations : Affiche les valeurs réelles (ou les étiquettes de valeurs) des variablesde Variables en colonnes pour chaque observation. La liste produite peut être nettement pluslongue qu’un tableau de bord.
Aperçu : N’affiche que la première page du tableau de bord. Cette option est utile pour avoir unaperçu du format de votre tableau sans traiter le tableau entier.
Les données sont déjà triées : Pour les rapports avec critères d’agrégation, le fichier de donnéesdoit être trié par valeur des critères d’agrégation avant de générer le tableau de bord. Si votrefichier de données est déjà trié par valeur des critères d’agrégation, vous pouvez gagner du tempsde traitement en sélectionnant cette option. Cette option est particulièrement utile après avoir vuun aperçu du tableau.
Pour obtenir un rapport récapitulatif : Récapitulatifs en lignes
E A partir des menus, sélectionnez :Analyse
RapportsTableaux de bord en lignes
E Sélectionnez une ou plusieurs variables pour les variables en colonnes. Une colonne est généréedans le tableau de bord pour chaque variable sélectionnée.
E Pour les tableaux triés et affichés par sous-groupe, sélectionnez une ou plusieurs variables pour lescritères d’agrégation.
E Pour les tableaux avec statistiques récapitulatives de sous-groupe définies par des critèresd’agrégation, sélectionnez le critère d’agrégation dans la liste Variables de ventilation et cliquezsur Tableau récapitulatif dans le groupe Variables de ventilation pour spécifier les mesuresrécapitulatives.
E Pour les tableaux avec statistiques récapitulatives globales, cliquez sur Tableau récapitulatif pourspécifier les mesures récapitulatives.

494
Chapitre 41
Figure 41-1Boîte de dialogue Tableaux de bord en lignes
Format des Colonnes de données/Ventilations des Tableaux de bord
Les boîtes de dialogue Format contrôlent les titres et largeurs des colonnes, l’alignement du texteet l’affichage des valeurs de données ou des étiquettes de valeurs. Format colonne de donnéescontrôle le format des Variables en colonnes du côté droit de la page du tableau de bord. Formatcolonne de ventilation contrôle le format des Colonnes de ventilation du côté gauche.
Figure 41-2Boîte de dialogue Tableau de bord : Format colonne de données
Titre de la colonne : Pour la variable sélectionnée, contrôle le titre de la colonne. Les titreslongs sont automatiquement ajustés dans la colonne. Utilisez la touche Entrée pour insérermanuellement des sauts de lignes aux endroits où vous voulez ajuster les titres.

495
Tableaux de Résultats
Position des valeurs dans la colonne : Pour la variable sélectionnée, contrôle l’alignement desvaleurs de données ou des étiquettes de données dans la colonne. L’alignement des valeurs ou desétiquettes n’affecte pas l’alignement des titres de colonnes. Vous pouvez soit indenter le contenude la colonne d’un nombre de caractères donné, soit centrer le contenu de la colonne.
Contenu de la colonne : Pour la variable sélectionnée, contrôle l’affichage soit des valeurs dedonnées, soit des étiquettes de valeurs définies. Les valeurs de données sont affichées pour toutesles valeurs qui ne possèdent pas d’étiquette de valeur définie. (Non disponible pour les Variablesen colonnes dans les Tableaux de bord en colonnes)
Fonctions récapitulatives des Tableaux pour/Fonctions récapitulatives Finales
Les deux boîtes de dialogue Fonctions récapitulatives contrôlent l’affichage des statistiquesrécapitulatives pour les agrégats et pour l’ensemble du tableau de bord. L’option Fonctionsrécapitulatives contrôle les statistiques de sous-groupe pour chaque modalité définie par lescritères d’agrégation. Fonctions récapitulatives Finales contrôle les statistiques globales affichéesà la fin du tableau de bord.
Figure 41-3Boîte de dialogue Tableau de bord : Fonction récapitulative
Les statistiques récapitulatives disponibles sont la somme des valeurs, la moyenne des valeurs, lavaleur minimale, la valeur maximale, le nombre d’observations, le pourcentage d’observationssituées au-dessus ou en dessous d’une valeur spécifiée, le pourcentage d’observations comprises àl’intérieur d’un intervalle donné de valeurs, l’écart-type, l’aplatissement, la variance et l’asymétrie.
Options de Ventilation de Tableau de Bord
Options de Ventilation contrôle l’espacement et la pagination des informations de modalité deventilation.

496
Chapitre 41
Figure 41-4Boîte de dialogue Options de Ventilation des Tableaux de bord
Gestion des pages : Contrôle l’espacement et la pagination des modalités du critère d’agrégationsélectionné. Vous pouvez spécifier un nombre de lignes vides entre les modalités de ventilation oucommencer chaque modalité de ventilation sur une nouvelle page.
Lignes à sauter avant fonctions élémentaires : Contrôle le nombre de lignes vides entre les étiquettesou les données des modalités de ventilation et les statistiques récapitulatives. Cette option estparticulièrement utile pour les tableaux de bords combinés incluant des listes d’observationsindividuelles et des statistiques récapitulatives pour les modalités de ventilation ; dans ces tableaux,vous pouvez insérer des espaces entre les listes d’observations et les statistiques récapitulatives.
Options du Tableau de bord
Options du Tableau de bord contrôle le traitement et l’affichage des valeurs manquantes et lanumérotation des pages du tableau de bord.
Figure 41-5Boîte de dialogue Tableau de bord : Options
Exclure les observations avec des valeurs manquantes : Elimine (du tableau de bord) touteobservation avec des valeurs manquantes pour l’une des variables du tableau de bord.
Représentation des valeurs manquantes : Vous permet de spécifier le symbole représentant lesvaleurs manquantes dans le fichier de données. Ce symbole ne peut comporter qu’un seul caractèreet sert à représenter les valeurs manquantes par défaut et les valeurs manquantes utilisateur.
Paginer à partir de : Vous permet de spécifier un numéro pour la première page du tableau de bord.

497
Tableaux de Résultats
Présentation du Tableau de bord
Présentation du Tableau de bord contrôle la largeur et la longueur de chaque page du tableau debord, l’emplacement du tableau sur la page et l’insertion de lignes vides et d’étiquettes.
Figure 41-6Boîte de dialogue Tableau : Présentation
Mise en page : Contrôle les marges de page exprimées en lignes (haut et bas) et en caractères(gauche et droite), et reporte l’alignement à l’intérieur des marges.
Titres et bas de page : Contrôle le nombre de lignes séparant les titres et les pieds de page ducorps du tableau de bord.
Variables de ventilation : Contrôle l’affichage des colonnes de ventilation. Si des critèresd’agrégation multiples sont spécifiés, ils peuvent être affichés en colonnes séparées ou dans lapremière colonne. Placer tous les critères d’agrégation dans la première colonne produit untableau de bord plus étroit.
Titres des colonnes : Contrôle l’affichage des titres de colonnes, y compris le soulignement destitres, l’espacement entre les titres et le corps du tableau, et l’alignement vertical des titres decolonnes.
Lignes de variables en colonnes et étiquettes de ventilation : Contrôle l’emplacement desinformations de Variables en colonnes (valeurs de données et/ou statistiques récapitulatives) parrapport aux étiquettes de ventilation au début de chaque modalité de ventilation. La première lignedes informations de Variables en colonnes peut commencer soit sur la même ligne que l’étiquettede modalité de ventilation, soit un nombre donné de lignes après cette étiquette. (Non disponiblepour les Tableaux de bord en colonnes)

498
Chapitre 41
Titres du Tableau de bord
Titres du Tableau de bord contrôle le contenu et l’emplacement des titres et pieds de page dutableau de bord. Vous pouvez spécifier jusqu’à dix lignes de titre et jusqu’à dix lignes de pieds depage, avec des composants justifiés à gauche, centrés et justifiés à droite sur chaque ligne.
Figure 41-7Boîte de dialogue Tableau : Titres
Si vous insérez des variables dans les titres ou les pieds de page, l’étiquette de valeur actuelle oula valeur de la variable est affichée dans le titre ou le pied de page. Dans les titres, l’étiquette devaleur correspondant à la valeur de la variable au début de la page est affichée. Dans les pieds depage, l’étiquette de valeur correspondant à la valeur de la variable à la fin de la page est affichée.S’il n’y a aucune étiquette de valeur, la valeur réelle est affichée.
Variables spéciales : Les variables spéciales DATE et PAGE vous permettent d’insérer la dateactuelle ou le numéro de page dans l’une des lignes d’un en-tête ou d’un pied de page. Si votrefichier de données contient des variables nommées DATE ou PAGE, vous ne pouvez pas utiliserces variables dans les titres ou les pieds de page des tableaux.
Tableaux de bord en colonnes
Tableaux de bord en colonnes produit des tableaux de bord dans lesquels différentes statistiquesrécapitulatives apparaissent en colonnes séparées.
Exemple : Une société possédant une chaîne de magasins conserve des dossiers sur les employéscomprenant le salaire, l’ancienneté et le service où chaque employé travaille. Vous pourriezgénérer un tableau de bord fournissant des statistiques récapitulatives sur les salaires (par exemplemoyenne, minimum, maximum) pour chaque division.

499
Tableaux de Résultats
Variables en colonnes : Fournit la liste des variables du tableau de bord pour lesquelles vous voulezdes statistiques récapitulatives et contrôle le format d’affichage et les statistiques récapitulativesaffichées pour chaque variable.
Variables de ventilation : Fournit la liste des critères d’agrégation optionnels qui divisent le tableaude bord en groupes et contrôle les formats d’affichage des colonnes de ventilation. Pour lescritères d’agrégation multiples, il y aura un groupe séparé pour chaque modalité de chaque critèred’agrégation à l’intérieur des modalités du critère d’agrégation précédent dans la liste. Les critèresd’agrégation doivent être des variables qualitatives discrètes qui divisent les observations enun nombre limité de modalités significatives.
Tableau de bord : Contrôle les caractéristiques globales du tableau de bord, y compris l’affichagedes valeurs manquantes, la numérotation des pages et les titres.
Aperçu : N’affiche que la première page du tableau de bord. Cette option est utile pour avoir unaperçu du format de votre tableau sans traiter le tableau entier.
Les données sont déjà triées : Pour les rapports avec critères d’agrégation, le fichier de donnéesdoit être trié par valeur des critères d’agrégation avant de générer le tableau de bord. Si votrefichier de données est déjà trié par valeur des critères d’agrégation, vous pouvez gagner du tempsde traitement en sélectionnant cette option. Cette option est particulièrement utile après avoir vuun aperçu du tableau.
Pour obtenir un rapport récapitulatif : Récapitulatifs en colonnes
E A partir des menus, sélectionnez :Analyse
RapportsTableaux de bord en colonnes
E Sélectionnez une ou plusieurs variables pour les variables en colonnes. Une colonne est généréedans le tableau de bord pour chaque variable sélectionnée.
E Pour modifier la mesure récapitulative d’une variable, sélectionnez la variable dans la listeVariables en colonnes et cliquez sur Tableau récapitulatif.
E Pour obtenir plus d’une mesure récapitulative pour une variable, sélectionnez la variable dansla liste source et déplacez-la dans la liste Variables en colonnes plusieurs fois, une fois pourchaque mesure récapitulative que vous souhaitez.
E Pour afficher une colonne contenant la somme, la moyenne, le rapport ou une autre fonction decolonnes existantes, cliquez sur Insérer le total. Une variable appelée total est alors placée dans laliste Variables en colonnes.
E Pour les tableaux triés et affichés par sous-groupe, sélectionnez une ou plusieurs variables pour lescritères d’agrégation.
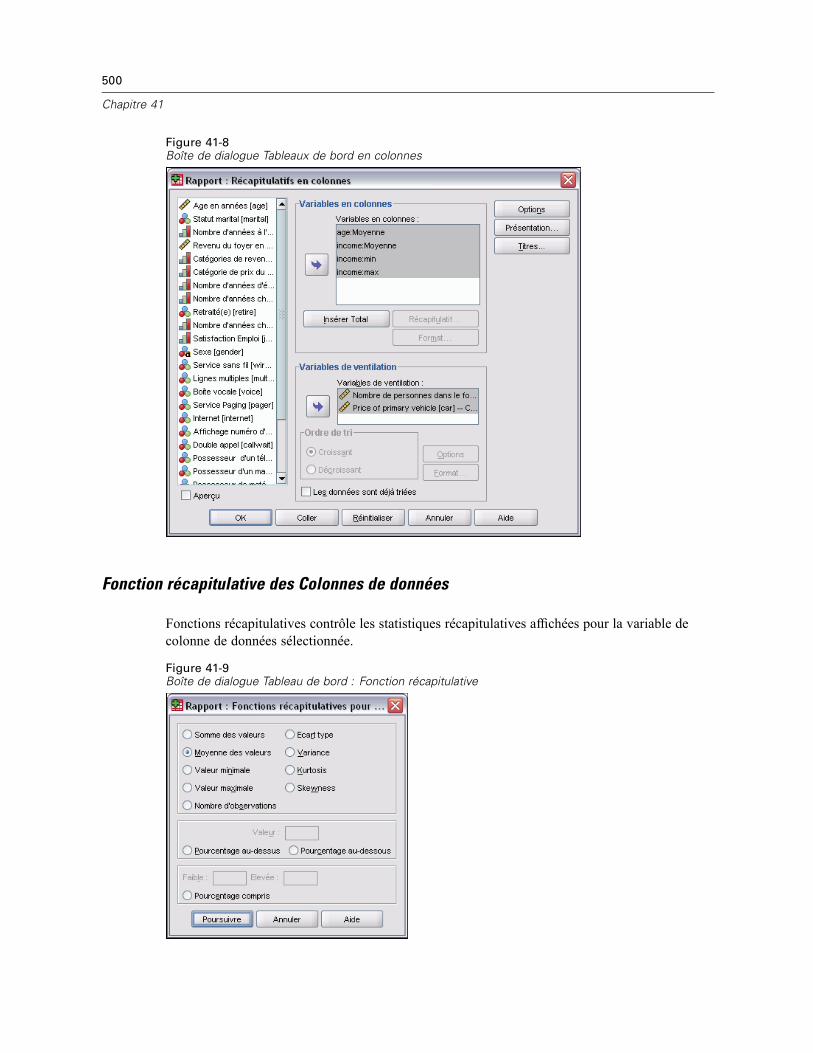
500
Chapitre 41
Figure 41-8Boîte de dialogue Tableaux de bord en colonnes
Fonction récapitulative des Colonnes de données
Fonctions récapitulatives contrôle les statistiques récapitulatives affichées pour la variable decolonne de données sélectionnée.
Figure 41-9Boîte de dialogue Tableau de bord : Fonction récapitulative
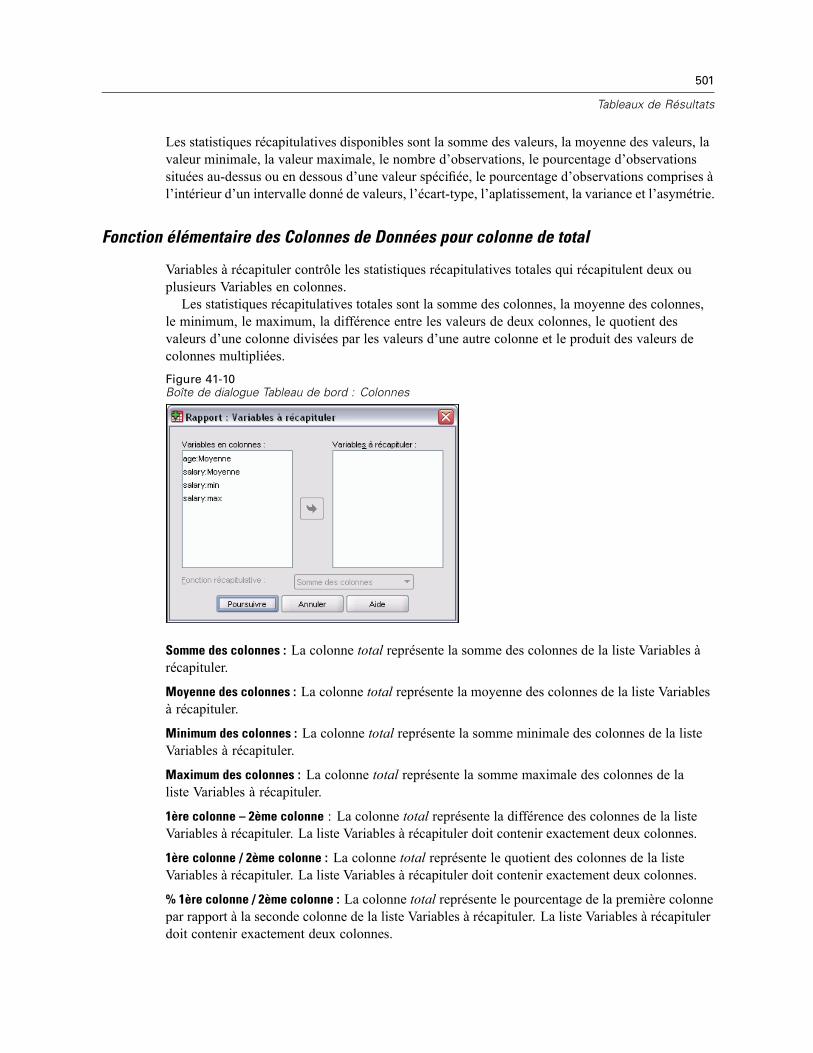
501
Tableaux de Résultats
Les statistiques récapitulatives disponibles sont la somme des valeurs, la moyenne des valeurs, lavaleur minimale, la valeur maximale, le nombre d’observations, le pourcentage d’observationssituées au-dessus ou en dessous d’une valeur spécifiée, le pourcentage d’observations comprises àl’intérieur d’un intervalle donné de valeurs, l’écart-type, l’aplatissement, la variance et l’asymétrie.
Fonction élémentaire des Colonnes de Données pour colonne de total
Variables à récapituler contrôle les statistiques récapitulatives totales qui récapitulent deux ouplusieurs Variables en colonnes.Les statistiques récapitulatives totales sont la somme des colonnes, la moyenne des colonnes,
le minimum, le maximum, la différence entre les valeurs de deux colonnes, le quotient desvaleurs d’une colonne divisées par les valeurs d’une autre colonne et le produit des valeurs decolonnes multipliées.Figure 41-10Boîte de dialogue Tableau de bord : Colonnes
Somme des colonnes : La colonne total représente la somme des colonnes de la liste Variables àrécapituler.
Moyenne des colonnes : La colonne total représente la moyenne des colonnes de la liste Variablesà récapituler.
Minimum des colonnes : La colonne total représente la somme minimale des colonnes de la listeVariables à récapituler.
Maximum des colonnes : La colonne total représente la somme maximale des colonnes de laliste Variables à récapituler.
1ère colonne – 2ème colonne : La colonne total représente la différence des colonnes de la listeVariables à récapituler. La liste Variables à récapituler doit contenir exactement deux colonnes.
1ère colonne / 2ème colonne : La colonne total représente le quotient des colonnes de la listeVariables à récapituler. La liste Variables à récapituler doit contenir exactement deux colonnes.
% 1ère colonne / 2ème colonne : La colonne total représente le pourcentage de la première colonnepar rapport à la seconde colonne de la liste Variables à récapituler. La liste Variables à récapitulerdoit contenir exactement deux colonnes.
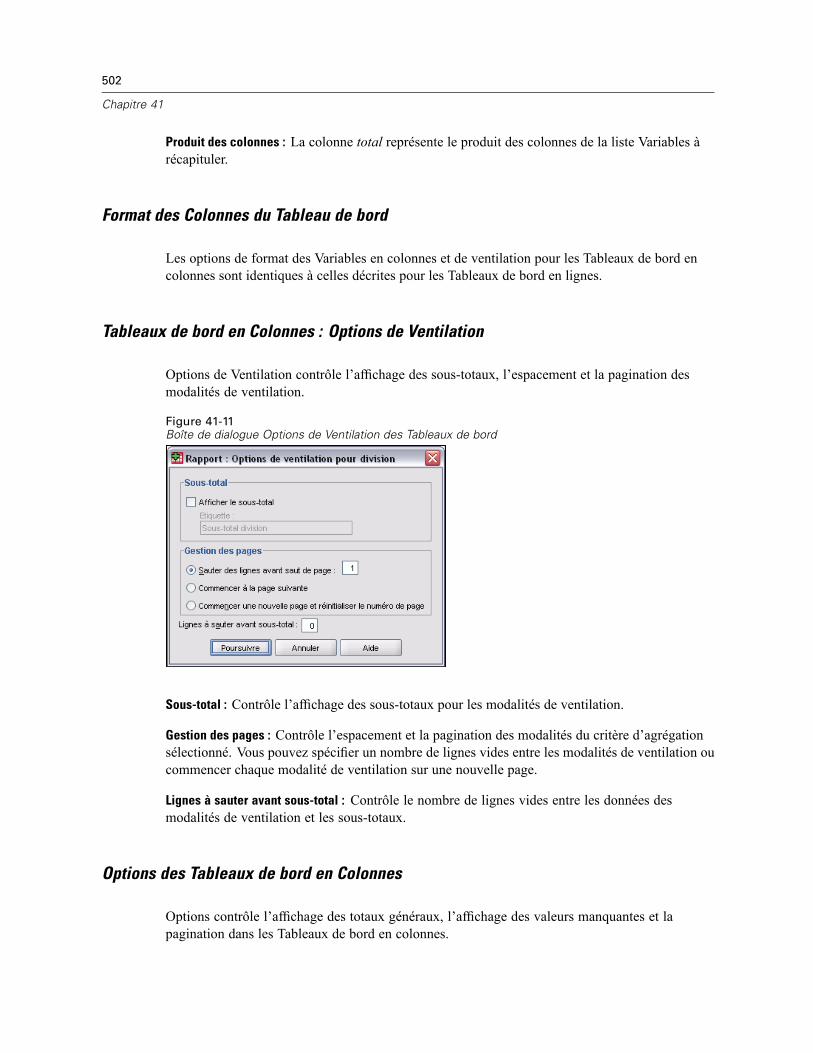
502
Chapitre 41
Produit des colonnes : La colonne total représente le produit des colonnes de la liste Variables àrécapituler.
Format des Colonnes du Tableau de bord
Les options de format des Variables en colonnes et de ventilation pour les Tableaux de bord encolonnes sont identiques à celles décrites pour les Tableaux de bord en lignes.
Tableaux de bord en Colonnes : Options de Ventilation
Options de Ventilation contrôle l’affichage des sous-totaux, l’espacement et la pagination desmodalités de ventilation.
Figure 41-11Boîte de dialogue Options de Ventilation des Tableaux de bord
Sous-total : Contrôle l’affichage des sous-totaux pour les modalités de ventilation.
Gestion des pages : Contrôle l’espacement et la pagination des modalités du critère d’agrégationsélectionné. Vous pouvez spécifier un nombre de lignes vides entre les modalités de ventilation oucommencer chaque modalité de ventilation sur une nouvelle page.
Lignes à sauter avant sous-total : Contrôle le nombre de lignes vides entre les données desmodalités de ventilation et les sous-totaux.
Options des Tableaux de bord en Colonnes
Options contrôle l’affichage des totaux généraux, l’affichage des valeurs manquantes et lapagination dans les Tableaux de bord en colonnes.
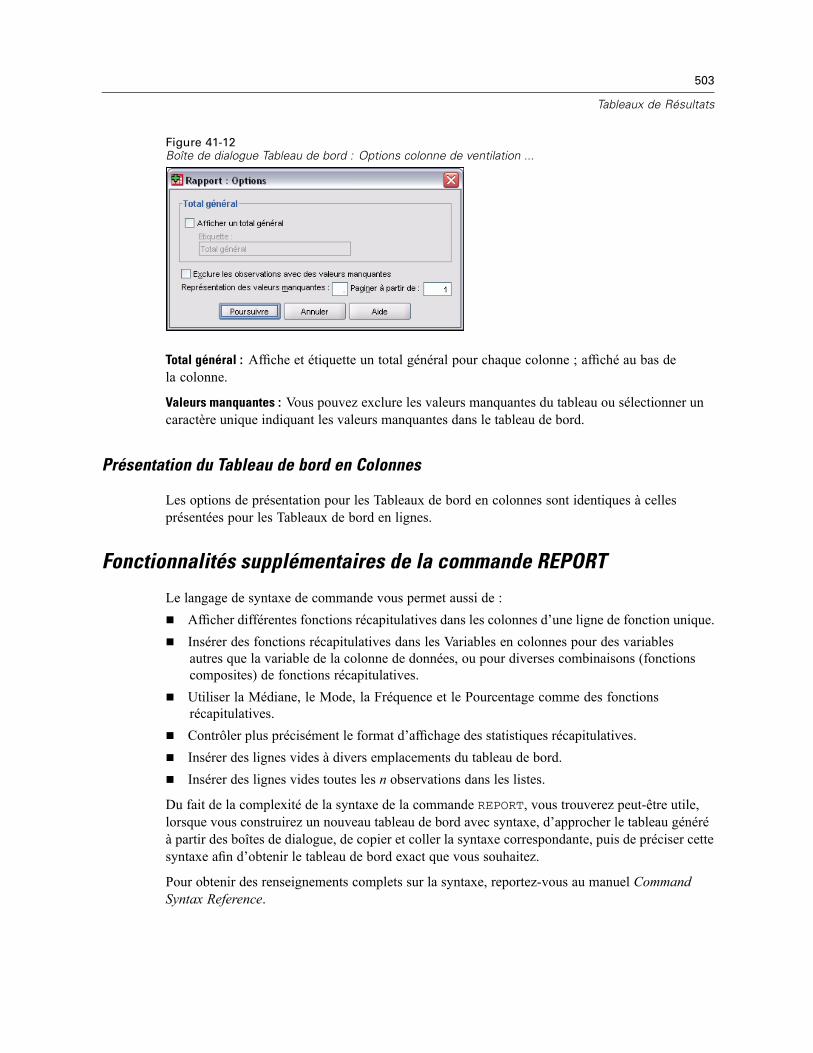
503
Tableaux de Résultats
Figure 41-12Boîte de dialogue Tableau de bord : Options colonne de ventilation ...
Total général : Affiche et étiquette un total général pour chaque colonne ; affiché au bas dela colonne.
Valeurs manquantes : Vous pouvez exclure les valeurs manquantes du tableau ou sélectionner uncaractère unique indiquant les valeurs manquantes dans le tableau de bord.
Présentation du Tableau de bord en Colonnes
Les options de présentation pour les Tableaux de bord en colonnes sont identiques à cellesprésentées pour les Tableaux de bord en lignes.
Fonctionnalités supplémentaires de la commande REPORT
Le langage de syntaxe de commande vous permet aussi de :Afficher différentes fonctions récapitulatives dans les colonnes d’une ligne de fonction unique.Insérer des fonctions récapitulatives dans les Variables en colonnes pour des variablesautres que la variable de la colonne de données, ou pour diverses combinaisons (fonctionscomposites) de fonctions récapitulatives.Utiliser la Médiane, le Mode, la Fréquence et le Pourcentage comme des fonctionsrécapitulatives.Contrôler plus précisément le format d’affichage des statistiques récapitulatives.Insérer des lignes vides à divers emplacements du tableau de bord.Insérer des lignes vides toutes les n observations dans les listes.
Du fait de la complexité de la syntaxe de la commande REPORT, vous trouverez peut-être utile,lorsque vous construirez un nouveau tableau de bord avec syntaxe, d’approcher le tableau généréà partir des boîtes de dialogue, de copier et coller la syntaxe correspondante, puis de préciser cettesyntaxe afin d’obtenir le tableau de bord exact que vous souhaitez.
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.

Chapitre
42Analyse de fiabilité
L’analyse de fiabilité vous permet d’étudier les propriétés des échelles de mesure et des élémentsqui les constituent. La procédure d’analyse de fiabilité calcule plusieurs mesures fréquemmentutilisées de la fiabilité de l’échelle et propose également des informations sur les relations entre lesdifférents éléments de l’échelle. Les coefficients de corrélation intra-classe peuvent être utiliséspour calculer les estimations de fiabilité inter-coefficients.
Exemple : Mon questionnaire mesure-t-il de façon fidèle la satisfaction de la clientèle ? L’analysede la fiabilité vous permet de déterminer dans quelle mesure les éléments de votre questionnairesont liés les uns aux autres et vous procure un indice général de la consistance ou de la cohérenceinterne de l’échelle dans son ensemble. Elle vous permet enfin d’identifier les éléments qui posentproblème et qu’il faudrait exclure de l’échelle.
Statistiques : Descriptions de chaque variable et pour l’échelle, statistiques récapitulatives sur leséléments, corrélations et covariances entre éléments, prévisions de fiabilité, tableau d’ANOVA,coefficients de corrélation intra-classe, T2 d’Hotelling et test d’additivité de Tukey.
Modèles : Les modèles suivants de fiabilité sont disponibles :Alpha (Cronbach) : Il s’agit d’un modèle de cohérence interne, fondé sur la corrélationmoyenne entre éléments.Split-half : Ce modèle fractionne l’échelle en deux et examine la corrélation entre les deuxparties.Guttman : Ce modèle calcule les limites minimales de Guttman pour une fiabilité vraie.Parallèle : Ce modèle part de l’hypothèse que tous les éléments ont des variances égales et desvariances d’erreur égales en cas de réplication.Parallèle strict : Ce modèle se fonde sur les mêmes hypothèses que le modèle parallèle maisenvisage également que tous les éléments ont la même moyenne.
Données : Les données peuvent être dichotomiques, ordinales ou constituer des intervalles, maiselles doivent être codées en numérique.
Hypothèses : Les observations doivent être indépendantes, les erreurs ne doivent pas être corréléesentre éléments. Chaque paire d’éléments doit avoir une distribution gaussienne bivariée. Leséchelles doivent être additives, de sorte que chaque élément est linéairement relié au total.
Procédures apparentées : Si vous souhaitez explorer la dimensionnalité des éléments de votreéchelle (pour voir si plusieurs éléments de base sont nécessaires au modèle des calculs), utilisezAnalyse factorielle ou Positionnement multidimensionnel. Pour identifier des groupes homogènesde variables, utilisez la classification hiérarchique pour classer les variables.
504
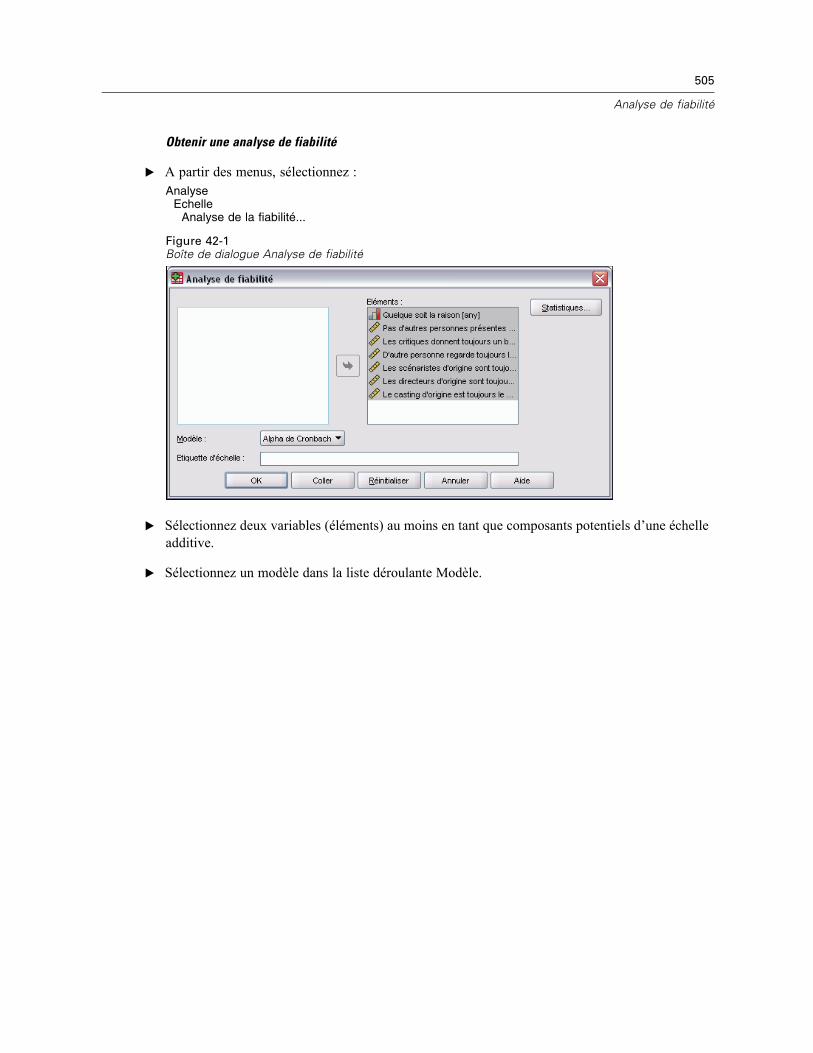
505
Analyse de fiabilité
Obtenir une analyse de fiabilité
E A partir des menus, sélectionnez :Analyse
EchelleAnalyse de la fiabilité...
Figure 42-1Boîte de dialogue Analyse de fiabilité
E Sélectionnez deux variables (éléments) au moins en tant que composants potentiels d’une échelleadditive.
E Sélectionnez un modèle dans la liste déroulante Modèle.
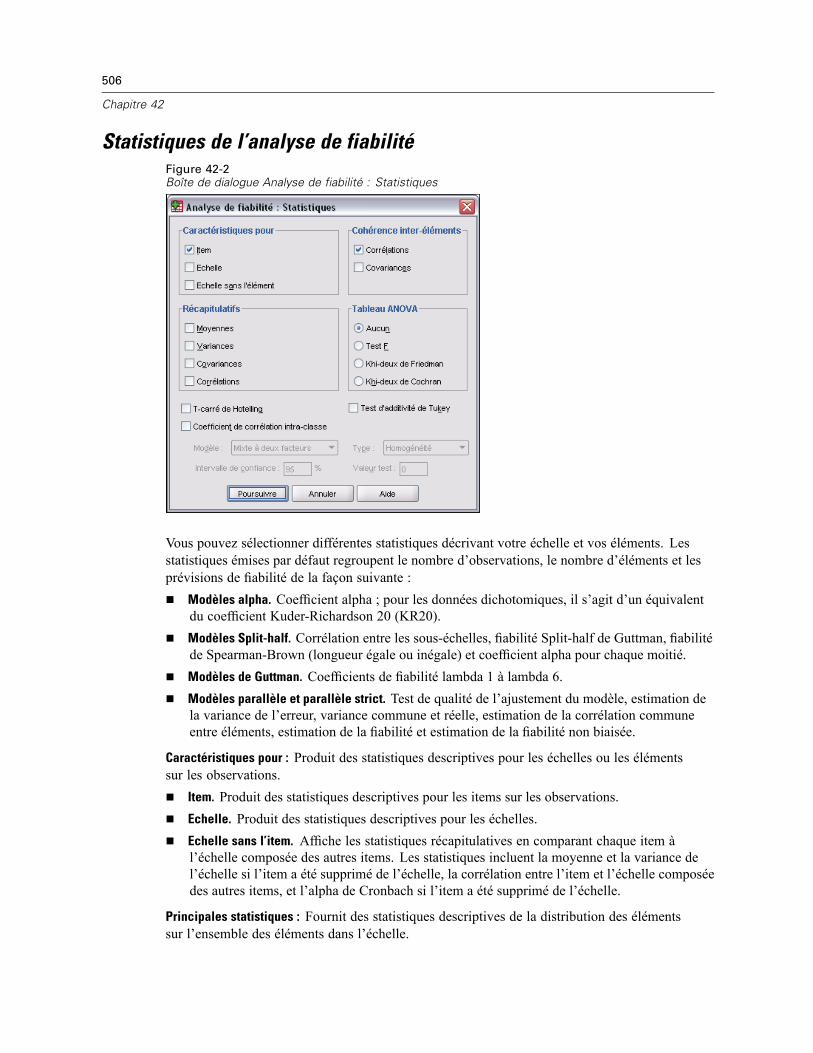
506
Chapitre 42
Statistiques de l’analyse de fiabilitéFigure 42-2Boîte de dialogue Analyse de fiabilité : Statistiques
Vous pouvez sélectionner différentes statistiques décrivant votre échelle et vos éléments. Lesstatistiques émises par défaut regroupent le nombre d’observations, le nombre d’éléments et lesprévisions de fiabilité de la façon suivante :
Modèles alpha. Coefficient alpha ; pour les données dichotomiques, il s’agit d’un équivalentdu coefficient Kuder-Richardson 20 (KR20).Modèles Split-half. Corrélation entre les sous-échelles, fiabilité Split-half de Guttman, fiabilitéde Spearman-Brown (longueur égale ou inégale) et coefficient alpha pour chaque moitié.Modèles de Guttman. Coefficients de fiabilité lambda 1 à lambda 6.Modèles parallèle et parallèle strict. Test de qualité de l’ajustement du modèle, estimation dela variance de l’erreur, variance commune et réelle, estimation de la corrélation communeentre éléments, estimation de la fiabilité et estimation de la fiabilité non biaisée.
Caractéristiques pour : Produit des statistiques descriptives pour les échelles ou les élémentssur les observations.
Item. Produit des statistiques descriptives pour les items sur les observations.Echelle. Produit des statistiques descriptives pour les échelles.Echelle sans l’item. Affiche les statistiques récapitulatives en comparant chaque item àl’échelle composée des autres items. Les statistiques incluent la moyenne et la variance del’échelle si l’item a été supprimé de l’échelle, la corrélation entre l’item et l’échelle composéedes autres items, et l’alpha de Cronbach si l’item a été supprimé de l’échelle.
Principales statistiques : Fournit des statistiques descriptives de la distribution des élémentssur l’ensemble des éléments dans l’échelle.

507
Analyse de fiabilité
Moyennes. Statistiques récapitulatives pour les moyennes d'élément. Les moyennes d'élémentminimale, maximale et intermédiaire sont affichées, ainsi que le rapport de la moyennemaximale à la moyenne minimale.Variances. Statistique récapitulative des variances d'élément. Les valeurs de variancemaximale, minimale et moyenne sont affichées, ainsi que la plage et la variance des variancesd'élément, et le rapport entre les variances d'élément maximale et minimale.Covariances. Statistiques récapitulatives pour les covariances inter élément. Les covariancesentre éléments minimale, maximale et intermédiaire sont affichées, ainsi que l'intervalle etla variance des covariances entre éléments, et le rapport de la covariance entre élémentsmaximale à la covariance minimale.Corrélations. Statistiques récapitulatives pour les corrélations inter élément. Les corrélationsentre éléments minimale, maximale et intermédiaire sont affichées, ainsi que l'intervalle etla variance des corrélations entre éléments, et le rapport de la corrélation entre élémentsmaximale à la corrélation minimale.
Cohérence inter-items : Produit des matrices de corrélations et de covariances entre éléments.
Tableau ANOVA : Produit des tests de moyennes égales.Test F. Affiche un tableau d’analyse de la variance des mesures répétées.Khi-deux de Friedman. Affiche le test de Friedman (khi-deux) et le coefficient de concordancede Kendall. Cette option convient aux données organisées sous forme de rangs. Le test dukhi-deux remplace le test F habituel dans le tableau ANOVA.Khi-deux de Cochran. Affiche la valeur Q de Cochran. Cette option est appropriée pour lesdonnées dichotomiques. Le Q de Cochran remplace le test F habituel dans le tableau ANOVA.
T-carré de Hotelling : Produit un test multivarié basé sur l’hypothèse nulle que tous les élémentssur l’échelle ont la même moyenne.
Test d’additivité de Tukey : Produit un test basé sur l’hypothèse qu’il n’y a pas d’interactionmultiplicative entre les éléments.
Coefficient de corrélation intra-classe : Produit des mesures d’homogénéité ou de cohérencedes valeurs par observation.
Modèle : Sélectionnez le modèle de calcul du coefficient de corrélation intra-classe. Lesmodèles disponibles sont Mixte à deux facteurs, Aléatoire à deux facteurs et Aléatoire à unfacteur. Sélectionnez Mixte à deux facteurs lorsque les effets de population sont aléatoireset les effets d’item sont fixes, sélectionnez Aléatoire à deux facteurs lorsque les effets depopulation et les effets d’items sont aléatoires, ou sélectionnez Aléatoire à un facteur lorsqueles gens effectuent un facteur.Type : Sélectionnez le type d’index. Les types disponibles sont Homogénéité et Cohérenceabsolue.Intervalle de confiance : Spécifiez le niveau de l’intervalle de confiance. La valeur par défautest 95 %.Valeur test : Spécifiez la valeur hypothétique du coefficient pour le test d’hypothèse. Il s’agitde la valeur par rapport à laquelle la valeur observée est comparée. La valeur par défaut est 0.

508
Chapitre 42
Fonctionnalités supplémentaires de la commande RELIABILITY
Le langage de syntaxe de commande vous permet aussi de :Lire et analyser une matrice de corrélation.Enregistrer une matrice de corrélation à analyser ultérieurement.Spécifier un fractionnement autre qu’en deux moitiés égales quant au nombre d’élémentspour la méthode Split-half.
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.

Chapitre
43Positionnement multidimensionnel
Le positionnement multidimensionnel tente de déterminer une structure dans un ensemble demesures de distance entre objets ou observations. Pour cela, il affecte les observations à despositions particulières dans un espace conceptuel (à deux ou trois dimensions généralement) detelle sorte que les distances entre les points dans l’espace correspondent le mieux possible auxdissimilarités données. Dans la plupart des cas, les dimensions de cet espace conceptuel peuventêtre interprétées et utilisées pour mieux comprendre les données.Si vous avez mesuré objectivement les variables, vous pouvez utiliser le positionnement
multidimensionnel comme technique de factorisation (le Positionnement multidimensionnelcalcule pour vous les distances à partir des données multivariées, le cas échéant). Lepositionnement multidimensionnel peut également s’appliquer à des estimations subjectives dedissimilarité entre objets ou concepts. D’autre part, le positionnement multidimensionnel peutgérer les informations de dissimilarité provenant de plusieurs sources, comme c’est le cas lorsqu’ily a plusieurs indicateurs ou plusieurs répondants au questionnaire.
Exemple : Comment les gens perçoivent-ils les relations entre différentes voitures ? Si les donnéesque vous obtenez de vos répondants indiquent des évaluations de similarité entre différentesmodèles, le positionnement multidimensionnel peut servir à identifier les dimensions qui décriventles perceptions des consommateurs. Vous pouvez trouver, par exemple, que le prix et la taille duvéhicule définissent un espace à deux dimensions qui tient compte des similarités reportées parles répondants.
Statistiques : Pour chaque modèle : matrice des données, positionnement optimisé des données dela matrice, stress S (de Young), stress S (de Kruskal), RSQ, coordonnées des stimuli, stress moyenet RSQ pour chaque stimulus (modèles RMDS). Pour les modèles des différences individuelles :pondérations des sujets et indice de singularité pour chaque sujet. Pour chaque matrice dans lesmodèles de positionnement multidimensionnel répliqués : stress et RSQ pour chaque stimulus.Diagrammes : coordonnées des stimulus (à deux ou trois dimensions), diagramme de dispersiondes disparités par rapport aux distances.
Données : Si vos données sont dissemblables, toutes les dissemblances doivent être quantitativeset mesurées avec les mêmes unités et échelles. Si vos données sont multivariées, les variablespeuvent être quantitatives, binaires mais peuvent aussi être des données d’effectif. Lepositionnement des variables est un enjeu de taille : les différences de positionnement peuventaffecter votre solution. Si vos variables présentent de grandes différences de positionnement (parexemple, si une variable est mesurée en dollar et l’autre en année), vous devez envisager de lesstandardiser (et cela automatiquement par la procédure de positionnement multidimensionnel).
509
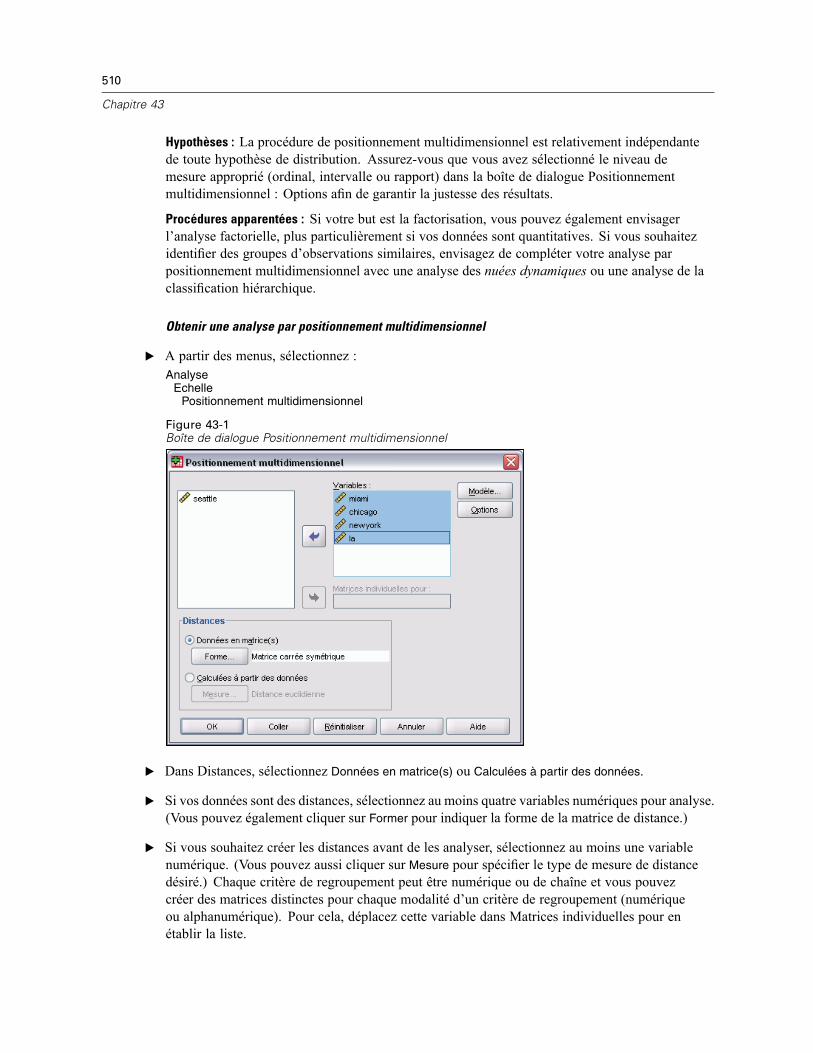
510
Chapitre 43
Hypothèses : La procédure de positionnement multidimensionnel est relativement indépendantede toute hypothèse de distribution. Assurez-vous que vous avez sélectionné le niveau demesure approprié (ordinal, intervalle ou rapport) dans la boîte de dialogue Positionnementmultidimensionnel : Options afin de garantir la justesse des résultats.
Procédures apparentées : Si votre but est la factorisation, vous pouvez également envisagerl’analyse factorielle, plus particulièrement si vos données sont quantitatives. Si vous souhaitezidentifier des groupes d’observations similaires, envisagez de compléter votre analyse parpositionnement multidimensionnel avec une analyse des nuées dynamiques ou une analyse de laclassification hiérarchique.
Obtenir une analyse par positionnement multidimensionnel
E A partir des menus, sélectionnez :Analyse
EchellePositionnement multidimensionnel
Figure 43-1Boîte de dialogue Positionnement multidimensionnel
E Dans Distances, sélectionnez Données en matrice(s) ou Calculées à partir des données.
E Si vos données sont des distances, sélectionnez au moins quatre variables numériques pour analyse.(Vous pouvez également cliquer sur Former pour indiquer la forme de la matrice de distance.)
E Si vous souhaitez créer les distances avant de les analyser, sélectionnez au moins une variablenumérique. (Vous pouvez aussi cliquer sur Mesure pour spécifier le type de mesure de distancedésiré.) Chaque critère de regroupement peut être numérique ou de chaîne et vous pouvezcréer des matrices distinctes pour chaque modalité d’un critère de regroupement (numériqueou alphanumérique). Pour cela, déplacez cette variable dans Matrices individuelles pour enétablir la liste.
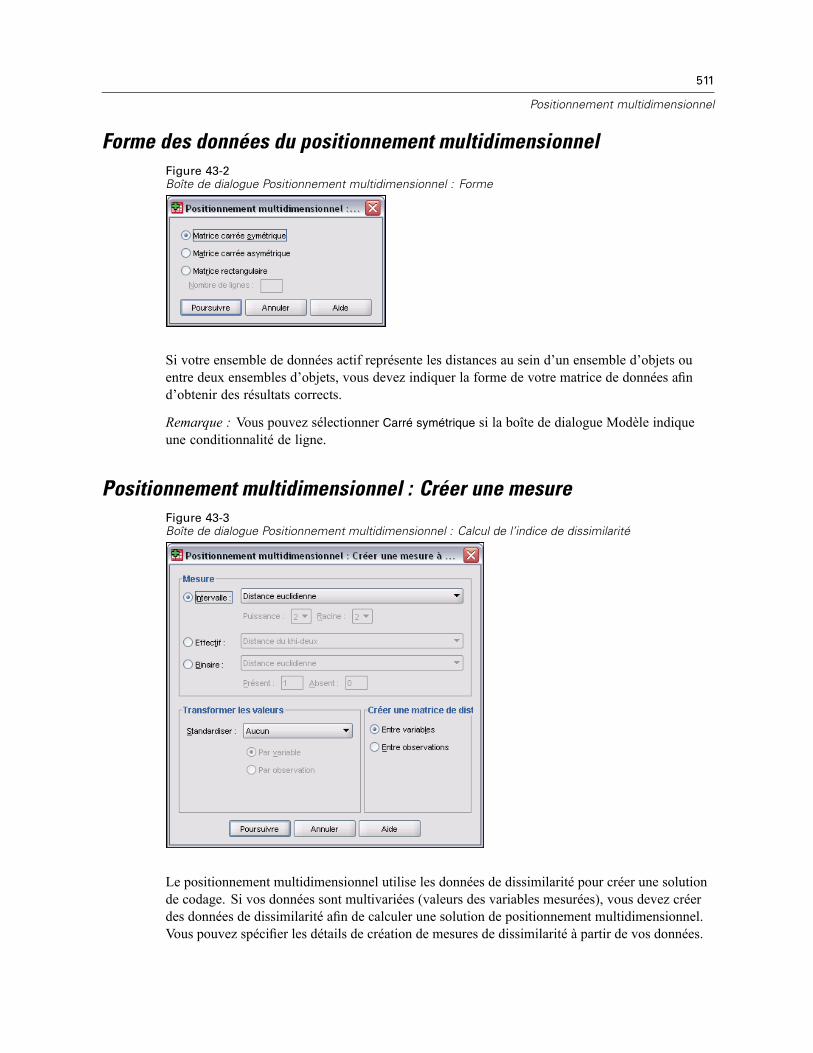
511
Positionnement multidimensionnel
Forme des données du positionnement multidimensionnelFigure 43-2Boîte de dialogue Positionnement multidimensionnel : Forme
Si votre ensemble de données actif représente les distances au sein d’un ensemble d’objets ouentre deux ensembles d’objets, vous devez indiquer la forme de votre matrice de données afind’obtenir des résultats corrects.
Remarque : Vous pouvez sélectionner Carré symétrique si la boîte de dialogue Modèle indiqueune conditionnalité de ligne.
Positionnement multidimensionnel : Créer une mesureFigure 43-3Boîte de dialogue Positionnement multidimensionnel : Calcul de l’indice de dissimilarité
Le positionnement multidimensionnel utilise les données de dissimilarité pour créer une solutionde codage. Si vos données sont multivariées (valeurs des variables mesurées), vous devez créerdes données de dissimilarité afin de calculer une solution de positionnement multidimensionnel.Vous pouvez spécifier les détails de création de mesures de dissimilarité à partir de vos données.
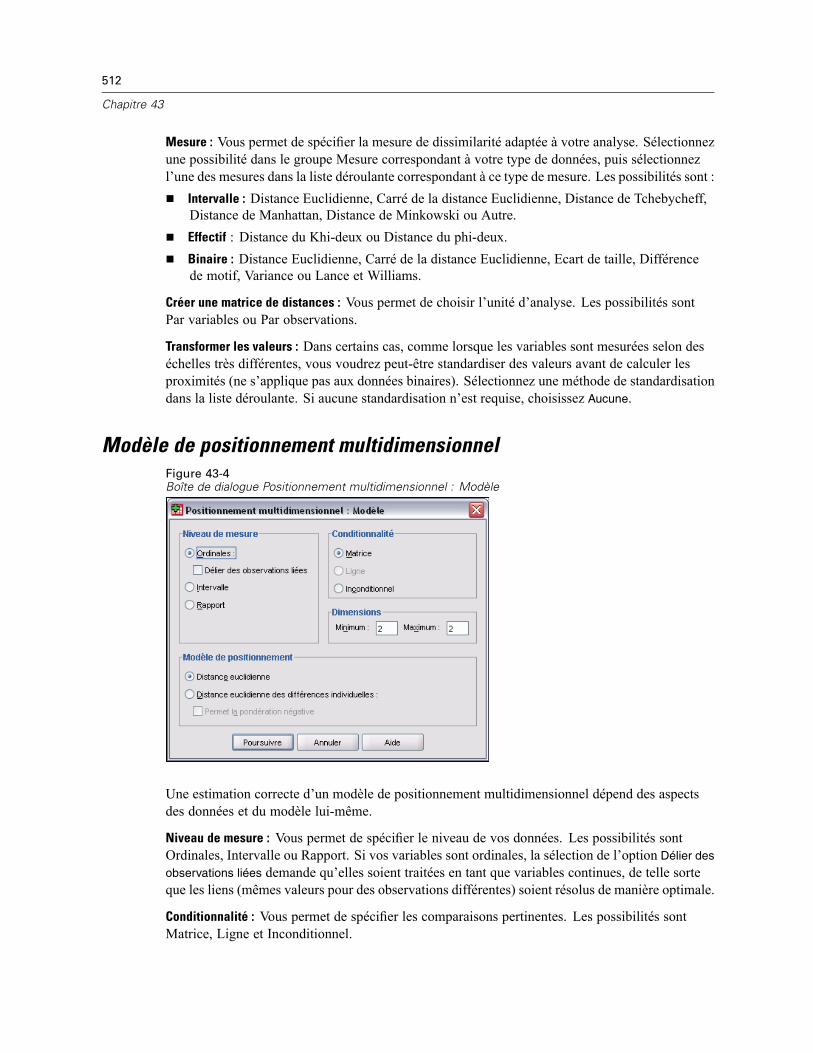
512
Chapitre 43
Mesure : Vous permet de spécifier la mesure de dissimilarité adaptée à votre analyse. Sélectionnezune possibilité dans le groupe Mesure correspondant à votre type de données, puis sélectionnezl’une des mesures dans la liste déroulante correspondant à ce type de mesure. Les possibilités sont :
Intervalle : Distance Euclidienne, Carré de la distance Euclidienne, Distance de Tchebycheff,Distance de Manhattan, Distance de Minkowski ou Autre.Effectif : Distance du Khi-deux ou Distance du phi-deux.Binaire : Distance Euclidienne, Carré de la distance Euclidienne, Ecart de taille, Différencede motif, Variance ou Lance et Williams.
Créer une matrice de distances : Vous permet de choisir l’unité d’analyse. Les possibilités sontPar variables ou Par observations.
Transformer les valeurs : Dans certains cas, comme lorsque les variables sont mesurées selon deséchelles très différentes, vous voudrez peut-être standardiser des valeurs avant de calculer lesproximités (ne s’applique pas aux données binaires). Sélectionnez une méthode de standardisationdans la liste déroulante. Si aucune standardisation n’est requise, choisissez Aucune.
Modèle de positionnement multidimensionnelFigure 43-4Boîte de dialogue Positionnement multidimensionnel : Modèle
Une estimation correcte d’un modèle de positionnement multidimensionnel dépend des aspectsdes données et du modèle lui-même.
Niveau de mesure : Vous permet de spécifier le niveau de vos données. Les possibilités sontOrdinales, Intervalle ou Rapport. Si vos variables sont ordinales, la sélection de l’option Délier des
observations liées demande qu’elles soient traitées en tant que variables continues, de telle sorteque les liens (mêmes valeurs pour des observations différentes) soient résolus de manière optimale.
Conditionnalité : Vous permet de spécifier les comparaisons pertinentes. Les possibilités sontMatrice, Ligne et Inconditionnel.

513
Positionnement multidimensionnel
Dimensions : Vous permet de spécifier la dimensionnalité de la ou des solutions de positionnement.Une seule solution est calculée pour chaque nombre de l’intervalle. Indiquez des nombres entiersentre 1 et 6. La valeur minimale 1 n’est autorisée que si vous sélectionnez l’option Distance
Euclidienne comme modèle de positionnement. Pour n’obtenir qu’une seule solution, indiquez lemême nombre en tant que minimum et maximum.
Modèle de positionnement : Vous permet de spécifier les hypothèses sous lesquelles lepositionnement est effectué. Les possibilités existantes sont Distance Euclidienne ou DistanceEuclidienne des différences individuelles (connue également en tant que INDSCAL). Pour lemodèle Distance Euclidienne des différences individuelles, vous pouvez sélectionner l’optionPermet la pondération négative, si cela convient à vos données.
Positionnement multidimensionnel : OptionsFigure 43-5Boîte de dialogue Positionnement multidimensionnel : Options
Vous pouvez spécifier les options de votre analyse par positionnement multidimensionnel.
Afficher : Vous permet d’afficher les différents types d’affichage. Les options possibles sontDiagrammes des stimuli, Diagrammes des sujets, Matrice des données et Récapitulatif des optionsdu modèle.
Critères : Vous permet de déterminer quand l’itération doit s’interrompre. Pour modifier lesvaleurs par défaut, entrez des valeurs pour la Convergence du stress S, le Minimum du stress S etle Maximum des itérations.
Traiter les dissimilarités inférieures à n comme des valeurs manquantes : Ces distances sont excluesde l’analyse.

514
Chapitre 43
Fonctionnalités supplémentaires de la commande ALSCAL
Le langage de syntaxe de commande vous permet aussi de :Utiliser trois types de modèles supplémentaires, ASCAL, AINDS et GEMSCAL dans ladocumentation relative au Positionnement multidimensionnel.Effectuer des transformations polynomiales sur l’intervalle et les données de type ratio.Analyser les similarités (plutôt que les distances) avec des données ordinales.Analyser les données nominales.Enregistrer diverses matrices de coordonnées et de pondération dans des fichiers et les relirepour l’analyse.Contraindre le dépliage multidimensionnel.
Pour obtenir des renseignements complets sur la syntaxe, reportez-vous au manuel CommandSyntax Reference.

Chapitre
44Statistiques de ratio
La procédure Statistiques de ratio permet d’obtenir la liste exhaustive des statistiquesrécapitulatives qui servent à décrire le rapport entre deux variables d’échelle.Vous pouvez trier le résultat sur la base des valeurs d’une variable de regroupement, dans
l’ordre croissant ou décroissant. Vous pouvez supprimer le rapport des statistiques de ratio dans ledocument de sortie et enregistrer les résultats dans un fichier externe.
Exemple : Le rapport existant entre le prix estimatif et le prix de vente des maisons est-il uniformedans chacun de ces cinq comtés ? D’après les résultats, vous pouvez conclure que la distributiondes rapports varie considérablement d’un comté à l’autre.
Statistiques : Médiane, moyenne, moyenne pondérée, intervalles de confiance, coefficient dedispersion (COD), coefficient de variation avec médiane centrée, coefficient de variation avecmoyenne centrée, différentiel lié au prix (PRD), écart-type, écart absolu moyen (AAD), intervalle,valeurs minimale et maximale, et index de concentration calculés pour un intervalle ou unpourcentage défini par l’utilisateur dans le rapport médian.
Données : Utilisez des codes numériques ou alphanumériques pour coder les variables deregroupement (mesures de niveau nominal ou ordinal).
Hypothèses : Vous devez utiliser des variables d’échelle acceptant les valeurs positives pour lesvariables qui définissent le numérateur et le dénominateur du rapport.
Pour obtenir des statistiques de ratio
E A partir des menus, sélectionnez :Analyse
Statistiques descriptivesRatio
515
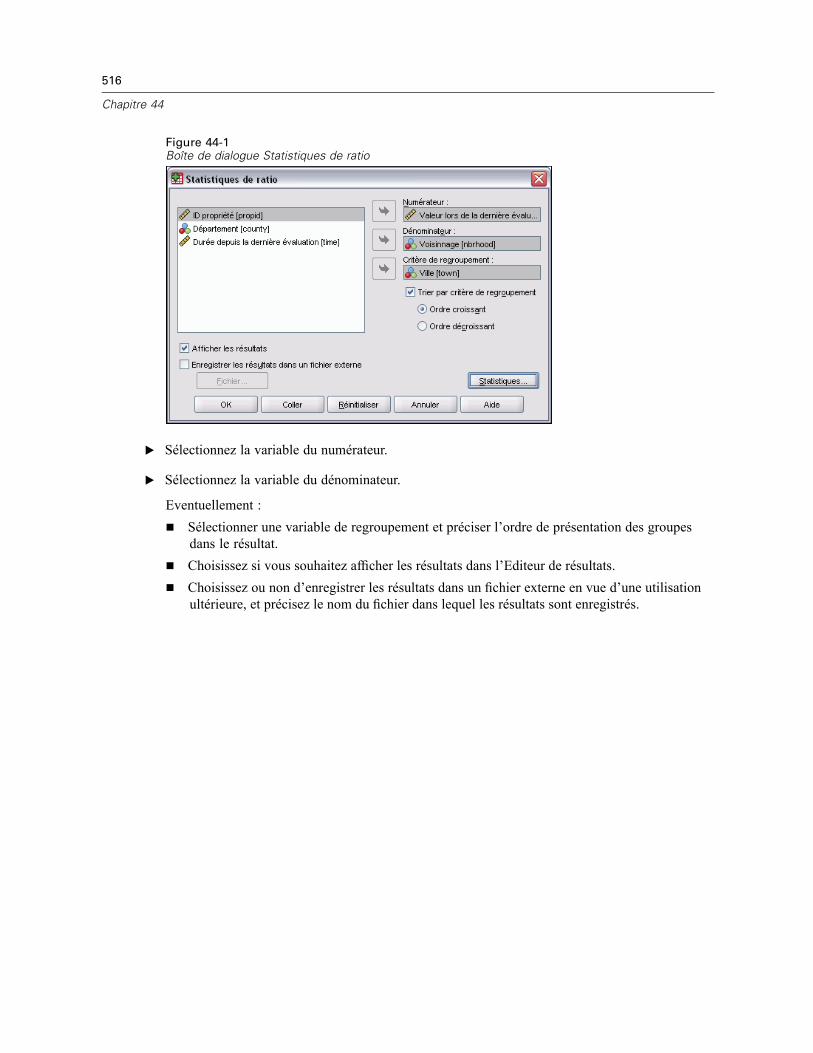
516
Chapitre 44
Figure 44-1Boîte de dialogue Statistiques de ratio
E Sélectionnez la variable du numérateur.
E Sélectionnez la variable du dénominateur.
Eventuellement :Sélectionner une variable de regroupement et préciser l’ordre de présentation des groupesdans le résultat.Choisissez si vous souhaitez afficher les résultats dans l’Editeur de résultats.Choisissez ou non d’enregistrer les résultats dans un fichier externe en vue d’une utilisationultérieure, et précisez le nom du fichier dans lequel les résultats sont enregistrés.

517
Statistiques de ratio
Statistiques de ratioFigure 44-2Boîte de dialogue Statistiques de ratio
Tendance centrale : Les mesures de tendance centrale sont des statistiques qui décrivent ladistribution des rapports.
Médiane : La valeur telle que le nombre de ratios inférieurs à cette valeur est identique aunombre de ratios supérieurs à cette valeur.Moyenne : Résultat de la somme des ratios divisée par le nombre total de ratios.Moyenne pondérée : Résultat de la division de la moyenne du numérateur par la moyenne dudénominateur. La moyenne pondérée correspond également à la moyenne des ratios pondéréepar le dénominateur.Intervalles de confiance : Affiche les intervalles de confiance de la moyenne, de la médianeet de la moyenne pondérée (si demandée). Affectez une valeur supérieure ou égale à 0 etinférieure à 100 au niveau de confiance.
Dispersion : Ces statistiques permettent de mesurer le degré de variation, ou de répartition, auniveau des valeurs observées.
AAD : L’écart absolu moyen est égal à la somme des écarts absolus des ratios relatifs à lamédiane, divisée par le nombre total de ratios.COD : Le coefficient de dispersion résulte de l’expression de l’écart moyen absolu enpourcentage de la médiane.PRD : Le différentiel lié au prix, ou index de régressivité, résulte de la division de la moyennepar la moyenne pondérée.

518
Chapitre 44
Médiane centrée COV : Le coefficient de variation avec médiane centrée résulte de l’expressionde la racine de la moyenne des carrés de l’écart par rapport à la médiane en pourcentagede la médiane.Moyenne centrée COV : Le coefficient de variation avec moyenne centrée résulte del’expression de l’écart-type en tant que pourcentage de la moyenne.Ecart type : L’écart-type est la racine carrée positive de la somme des carrés des écarts desratios relatifs à la moyenne divisée par le nombre total des ratios moins un.Intervalle : Résultat de la soustraction du ratio minimal au ratio maximal.Minimum : Le minimum est le plus petit ratio.Maximum : Le maximum est le plus grand ratio.
Index de concentration : Le coefficient de concentration mesure le pourcentage des ratios comprisdans un intervalle. Vous pouvez le calculer de deux manières :
Ratios entre : Dans ce cas, vous définissez l’intervalle de manière explicite en précisant lesvaleurs minimale et maximale. Entrez les valeurs des proportions inférieure et supérieure,puis cliquez sur Ajouter pour obtenir un intervalle.Ratios dans : Dans ce cas, vous définissez l’intervalle de manière implicite en indiquantle pourcentage de la médiane. Entrez une valeur comprise entre 0 et 100, et cliquez surAjouter. La limite inférieure de l’intervalle est égale à (1 – 0,01×valeur)×médiane et la limitesupérieure est égale à (1 + 0,01×valeur)×médiane.

Chapitre
45Courbes ROC
Cette procédure constitue un moyen efficace d’évaluer les performances des méthodes declassement ne mettant en œuvre qu’une seule variable à deux modalités et utilisées pour laclassification des sujets.
Exemple : Une banque envisage de classer correctement ses clients en modalités, à savoir ceux quiassumeront ou non le remboursement de leur prêt. Des méthodes particulières sont développéesafin de supporter la prise de décision. Les courbes ROC peuvent être utilisées pour évaluer lemode de fonctionnement optimal de ces méthodes.
Statistiques : La zone inférieure à la courbe ROC comporte un intervalle de confiance ainsi queles coordonnées de cette courbe. Diagrammes : Courbe ROC
Méthodes : L’estimation de la zone située sous la courbe ROC peut être calculée de façonparamétrique ou non à l’aide du modèle exponentiel binégatif.
Données : Les variables de test sont quantitatives. Les variables de test se composent souvent desprobabilités issues d’une analyse discriminante, d’une régression logistique ou des scores indiquéssur une échelle arbitraire et spécifiant la « force de conviction » d’un indicateur lorsqu’un sujetse rapporte à l’une ou l’autre des modalités. La variable d’état peut être d’un type quelconqueet indique la véritable modalité à laquelle un sujet appartient. La valeur de la variable d’étatindique la modalité à considérer comme positive.
Hypothèses : Les nombres croissants d’une échelle d’indicateurs confirment que le sujet appartientà une modalité, tandis que les nombres décroissants d’une échelle confirment qu’il appartient àune autre modalité. L’utilisateur doit choisir la direction positive. On suppose également que lavéritable modalité à laquelle chaque sujet appartient est connue.
Pour obtenir une courbe ROC
E A partir des menus, sélectionnez :Analyse
Courbe ROC...
519
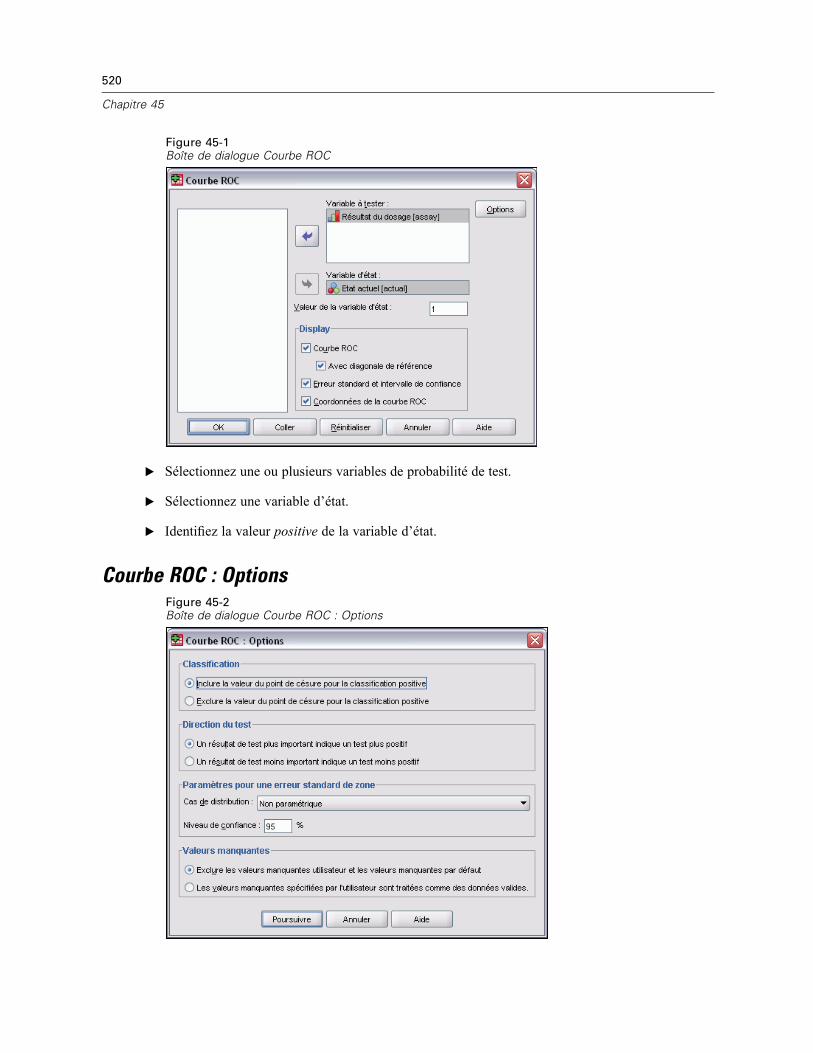
520
Chapitre 45
Figure 45-1Boîte de dialogue Courbe ROC
E Sélectionnez une ou plusieurs variables de probabilité de test.
E Sélectionnez une variable d’état.
E Identifiez la valeur positive de la variable d’état.
Courbe ROC : OptionsFigure 45-2Boîte de dialogue Courbe ROC : Options

521
Courbes ROC
Vous pouvez indiquer les options suivantes pour votre analyse ROC :
Classification : Permet de spécifier si la valeur du point de césure doit être incluse ou exclue lorsd’une classification positive. Ce paramètre n’a pas de conséquence sur le résultat.
Direction du test : Permet de spécifier la direction de l’échelle en fonction de la modalité positive.
Paramètres pour une erreur standard de zone : Vous permet de spécifier la méthode utilisée pourestimer l’erreur standard de la zone située sous la courbe. Les méthodes disponibles sont desvaleurs exponentielles non paramétriques et bi-négatives. Vous permet également de définir leniveau de l’intervalle de confiance. Les valeurs de l’intervalle se situent entre 50,1 % et 99,9 %.
Valeurs manquantes : Vous permet de spécifier comment traiter les valeurs manquantes.

Chapitre
46Présentation de l’utilitaire dediagramme
Les procédures du menu Diagrammes et de nombreuses procédures du menu Analyse permettentde créer des diagrammes et des graphiques haute résolution. Ce chapitre présente l’utilitairede diagramme.
Création et modification d’un diagramme
Avant de créer un diagramme, vous devez disposer de données dans l’éditeur de données. Vouspouvez saisir les données directement dans l’éditeur de données, ouvrir un fichier de données déjàenregistré ou lire une feuille de calcul, un fichier de données délimité par des tabulations ou unfichier de base de données. L’élément Didacticiel du menu Aide propose des exemples en lignede création et de modification de diagramme ; le système d’aide en ligne explique commentcréer et modifier tous les types de diagrammes.
Construction de diagrammes
Le Générateur de diagrammes permet de créer des diagrammes à partir de diagrammes prédéfinisde la galerie ou à partir de composants spécifiques (par exemple, des axes et des barres). Pourcréer un diagramme, faites glisser les éléments de base ou les diagrammes de la galerie, puisdéposez-les sur le canevas, qui est la zone située à droite de la liste Variables dans la boîte dedialogue Générateur de diagrammes.Lors de la création du diagramme, le canevas en affiche l’aperçu. Bien que l’aperçu utilise des
étiquettes de variable et des niveaux de mesure définis, il n’affiche pas vos données réelles. Ilutilise en revanche des données générées de façon aléatoire pour effectuer un croquis approximatifdu diagramme.Les nouveaux utilisateurs préfèrent utiliser la galerie. Pour obtenir des informations sur
l’utilisation de la galerie, reportez-vous à Construction d’un diagramme à partir de la galeriesur p. 523.
Pour lancer le Générateur de diagrammes
E A partir des menus, sélectionnez :Graphes
Générateur de diagrammes
La boîte de dialogue Générateur de diagrammes apparaît.
522
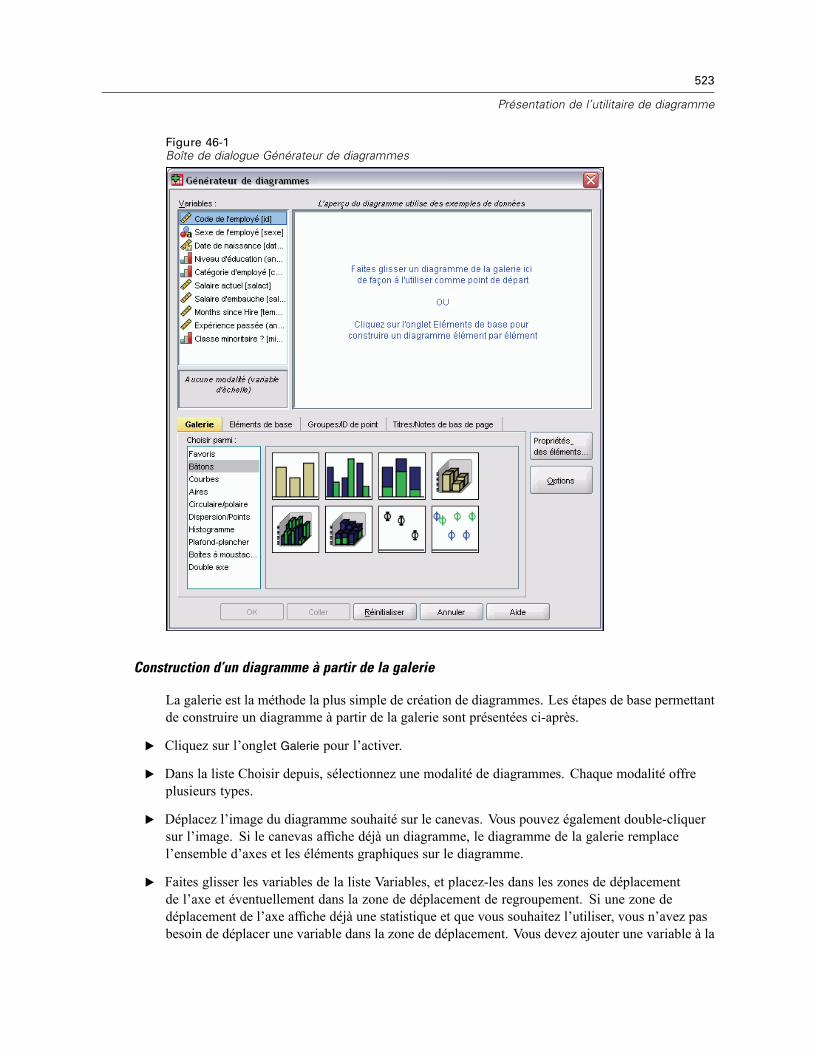
523
Présentation de l’utilitaire de diagramme
Figure 46-1Boîte de dialogue Générateur de diagrammes
Construction d’un diagramme à partir de la galerie
La galerie est la méthode la plus simple de création de diagrammes. Les étapes de base permettantde construire un diagramme à partir de la galerie sont présentées ci-après.
E Cliquez sur l’onglet Galerie pour l’activer.
E Dans la liste Choisir depuis, sélectionnez une modalité de diagrammes. Chaque modalité offreplusieurs types.
E Déplacez l’image du diagramme souhaité sur le canevas. Vous pouvez également double-cliquersur l’image. Si le canevas affiche déjà un diagramme, le diagramme de la galerie remplacel’ensemble d’axes et les éléments graphiques sur le diagramme.
E Faites glisser les variables de la liste Variables, et placez-les dans les zones de déplacementde l’axe et éventuellement dans la zone de déplacement de regroupement. Si une zone dedéplacement de l’axe affiche déjà une statistique et que vous souhaitez l’utiliser, vous n’avez pasbesoin de déplacer une variable dans la zone de déplacement. Vous devez ajouter une variable à la
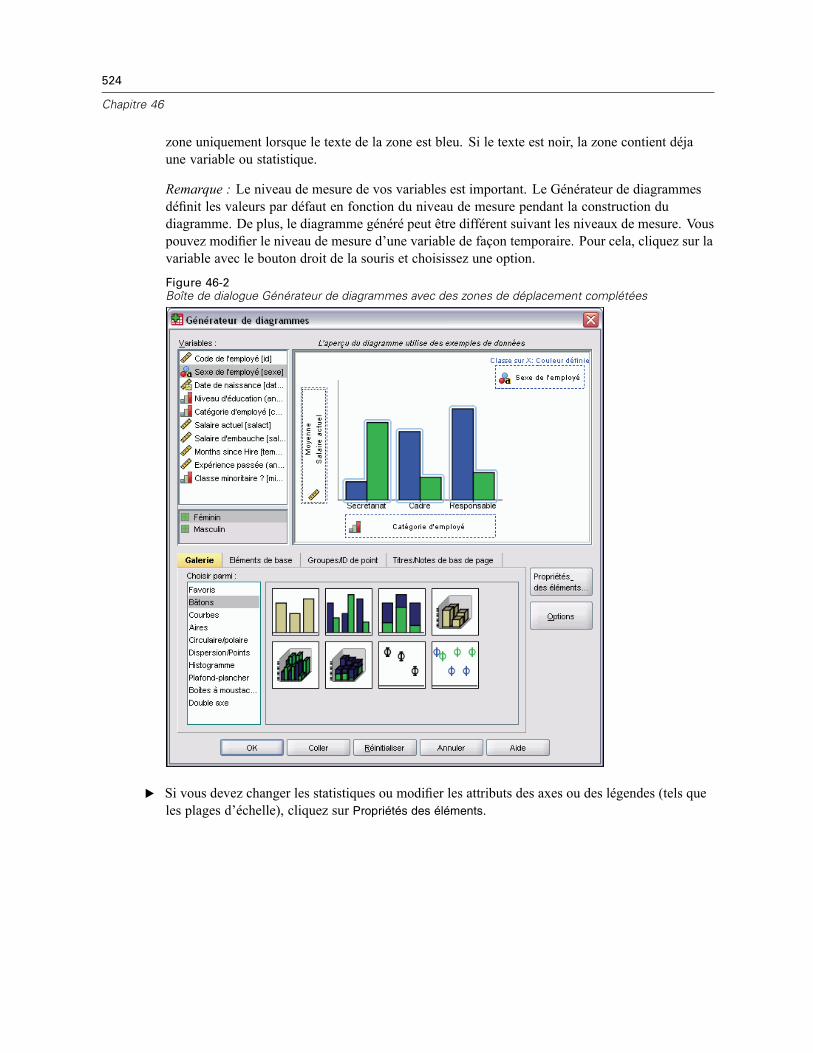
524
Chapitre 46
zone uniquement lorsque le texte de la zone est bleu. Si le texte est noir, la zone contient déjaune variable ou statistique.
Remarque : Le niveau de mesure de vos variables est important. Le Générateur de diagrammesdéfinit les valeurs par défaut en fonction du niveau de mesure pendant la construction dudiagramme. De plus, le diagramme généré peut être différent suivant les niveaux de mesure. Vouspouvez modifier le niveau de mesure d’une variable de façon temporaire. Pour cela, cliquez sur lavariable avec le bouton droit de la souris et choisissez une option.
Figure 46-2Boîte de dialogue Générateur de diagrammes avec des zones de déplacement complétées
E Si vous devez changer les statistiques ou modifier les attributs des axes ou des légendes (tels queles plages d’échelle), cliquez sur Propriétés des éléments.
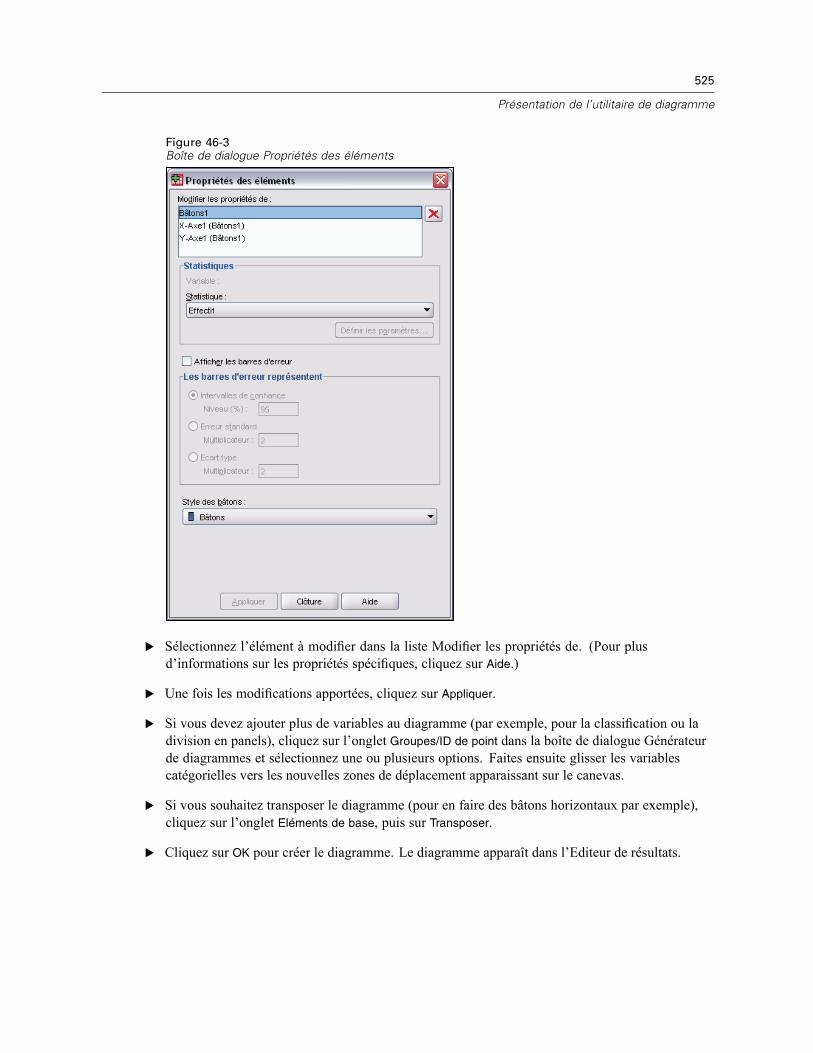
525
Présentation de l’utilitaire de diagramme
Figure 46-3Boîte de dialogue Propriétés des éléments
E Sélectionnez l’élément à modifier dans la liste Modifier les propriétés de. (Pour plusd’informations sur les propriétés spécifiques, cliquez sur Aide.)
E Une fois les modifications apportées, cliquez sur Appliquer.
E Si vous devez ajouter plus de variables au diagramme (par exemple, pour la classification ou ladivision en panels), cliquez sur l’onglet Groupes/ID de point dans la boîte de dialogue Générateurde diagrammes et sélectionnez une ou plusieurs options. Faites ensuite glisser les variablescatégorielles vers les nouvelles zones de déplacement apparaissant sur le canevas.
E Si vous souhaitez transposer le diagramme (pour en faire des bâtons horizontaux par exemple),cliquez sur l’onglet Eléments de base, puis sur Transposer.
E Cliquez sur OK pour créer le diagramme. Le diagramme apparaît dans l’Editeur de résultats.

526
Chapitre 46
Figure 46-4Diagramme en bâtons affiché dans la fenêtre du Viewer
Modification de diagrammes
L’éditeur de diagrammes dispose d’un environnement puissant et convivial vous permettant depersonnaliser vos diagrammes et d’explorer vos données. L’éditeur de diagrammes possède lesfonctionnalités suivantes :
Une interface utilisateur simple et intuitive. A l’aide des menus, des menus contextuels et desbarres d’outils, vous pouvez sélectionner rapidement certaines parties de vos diagrammes etles modifier. Vous pouvez également saisir du texte à l’intérieur des diagrammes.De nombreuses options statistiques et de formatage. Vous pouvez faire votre choix dans unegamme complète de styles et d’options statistiques.De nombreux outils d’exploration puissants. Vous avez différents moyens d’explorer vosdonnées ; vous pouvez les étiqueter, les réorganiser et les faire pivoter. Vous pouvez modifierles types de diagramme et les rôles des variables dans le diagramme. Vous pouvez égalementy ajouter des lignes de distribution, d’ajustement, d’interpolation et de référence.Des modèles flexibles pour obtenir un aspect et un comportement logiques. Vous pouvez créerdes modèles personnalisés et vous en servir pour créer facilement des diagrammes avecl’aspect et les options que vous voulez. Par exemple, si vous voulez que les étiquettes des
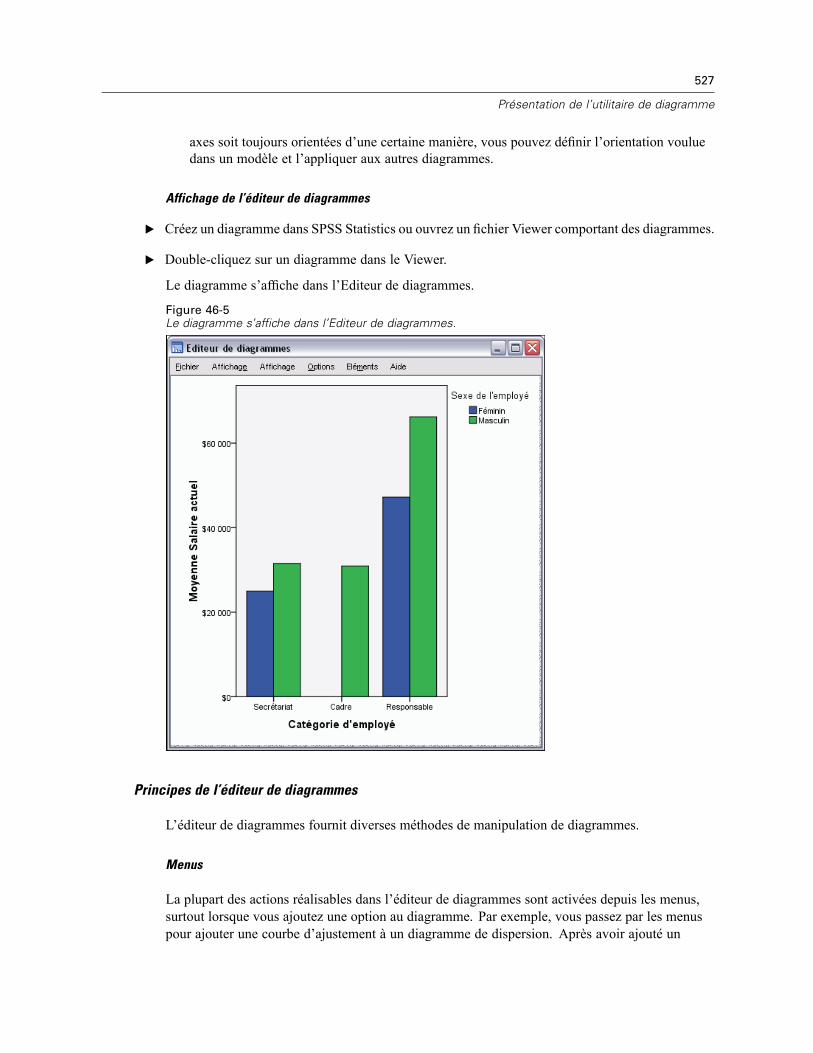
527
Présentation de l’utilitaire de diagramme
axes soit toujours orientées d’une certaine manière, vous pouvez définir l’orientation vouluedans un modèle et l’appliquer aux autres diagrammes.
Affichage de l’éditeur de diagrammes
E Créez un diagramme dans SPSS Statistics ou ouvrez un fichier Viewer comportant des diagrammes.
E Double-cliquez sur un diagramme dans le Viewer.
Le diagramme s’affiche dans l’Editeur de diagrammes.
Figure 46-5Le diagramme s’affiche dans l’Editeur de diagrammes.
Principes de l’éditeur de diagrammes
L’éditeur de diagrammes fournit diverses méthodes de manipulation de diagrammes.
Menus
La plupart des actions réalisables dans l’éditeur de diagrammes sont activées depuis les menus,surtout lorsque vous ajoutez une option au diagramme. Par exemple, vous passez par les menuspour ajouter une courbe d’ajustement à un diagramme de dispersion. Après avoir ajouté un
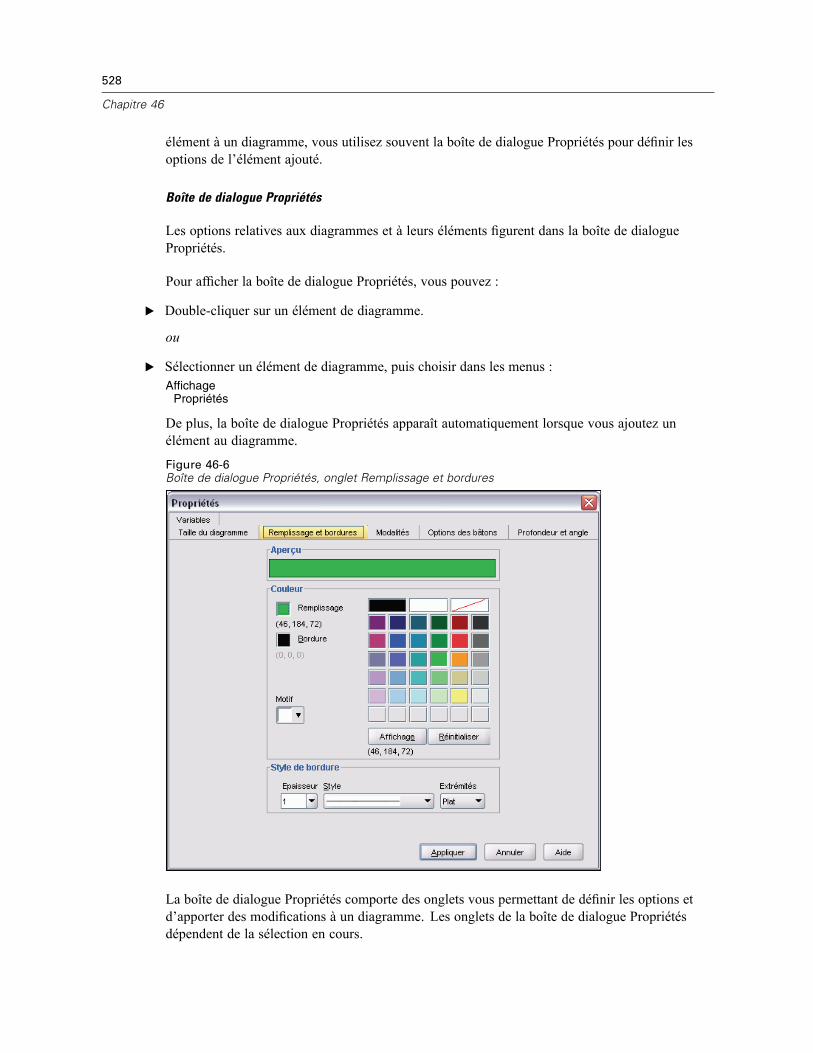
528
Chapitre 46
élément à un diagramme, vous utilisez souvent la boîte de dialogue Propriétés pour définir lesoptions de l’élément ajouté.
Boîte de dialogue Propriétés
Les options relatives aux diagrammes et à leurs éléments figurent dans la boîte de dialoguePropriétés.
Pour afficher la boîte de dialogue Propriétés, vous pouvez :
E Double-cliquer sur un élément de diagramme.
ou
E Sélectionner un élément de diagramme, puis choisir dans les menus :Affichage
Propriétés
De plus, la boîte de dialogue Propriétés apparaît automatiquement lorsque vous ajoutez unélément au diagramme.
Figure 46-6Boîte de dialogue Propriétés, onglet Remplissage et bordures
La boîte de dialogue Propriétés comporte des onglets vous permettant de définir les options etd’apporter des modifications à un diagramme. Les onglets de la boîte de dialogue Propriétésdépendent de la sélection en cours.

529
Présentation de l’utilitaire de diagramme
Certains onglets comportent un aperçu afin de vous donner une idée du résultat desmodifications sur la sélection, une fois qu’elles sont appliquées. Cependant, le diagrammen’intègre pas les modifications tant que vous n’avez pas cliqué sur Appliquer. Vous pouvezapporter des modifications dans plusieurs onglets avant de cliquer sur Appliquer. Si vous avez àchanger la sélection pour modifier un élément différent dans le diagramme, cliquez sur Appliquer
avant de changer la sélection. Si vous ne cliquez pas sur Appliquer avant de changer la sélection, lefait de cliquer sur Appliquer ultérieurement appliquera les changements uniquement aux élémentsactuellement sélectionnés.En fonction de la sélection, seuls certains paramètres seront disponibles. L’aide de chaque
onglet précise ce que vous devez sélectionner pour que les onglets apparaissent. Si plusieurséléments sont sélectionnés, vous pouvez uniquement modifier les paramètres communs à tous ceséléments.
Barres d’outils
Les barres d’outils comportent des raccourcis pour certaines des fonctionnalités de la boîtede dialogue Propriétés. Par exemple, au lieu d’utiliser l’onglet Texte de la boîte de dialoguePropriétés, vous pouvez vous servir de la barre d’outils Edition pour modifier la police et lestyle du texte.
Enregistrement des modifications
Les modifications apportées au diagramme sont enregistrées lorsque vous fermez l’Editeur dediagrammes. Le diagramme modifié est ensuite affiché dans le Viewer.
Options de définition du diagramme
Lorsque vous définissez un diagramme dans le Générateur de diagrammes, vous pouvez ajouterdes titres et modifier les options de création du diagramme.
Ajout et modification de titres et de notes de bas de page
Vous pouvez ajouter des titres et des notes de bas de page au diagramme pour en faciliterl’interprétation. Le Générateur de diagrammes affiche également automatiquement lesinformations des diagrammes de variation dans les notes de bas de page.
Pour ajouter des titres et des notes de bas de page
E Cliquez sur l’onglet Titres/Notes de bas de page.
E Sélectionnez un ou plusieurs titres et notes de bas de page. Le canevas affiche du texte pourindiquer que ces titres et notes de bas de page ont été ajoutés au diagramme.
E Utilisez la boîte de dialogue Propriétés de l’élément pour modifier le texte des titres/notes debas de page.

530
Chapitre 46
Pour supprimer un titre ou une note de bas de page
E Cliquez sur l’onglet Titres/Notes de bas de page.
E Désélectionnez le titre ou la note de bas de page à supprimer.
Pour modifier le texte d’un titre ou d’une note de bas de page
Lorsque vous ajoutez des titres et des notes de bas de page, vous ne pouvez pas modifier leur textedirectement dans le diagramme. Comme avec les autres éléments du Générateur de diagrammes,effectuez les modifications dans la boîte de dialogue Propriétés des éléments.
E Cliquez sur Propriétés des éléments si la boîte de dialogue Propriétés des éléments ne s’affiche pas.
E Sélectionnez un titre, un sous-titre ou une note de bas de page (par exemple Titre 1) dans la listeModifier les propriétés de.
E Dans la zone de contenu, tapez le texte associé avec le titre, le sous-titre ou la note de bas de page.
E Cliquez sur Appliquer.
Définition des options générales
Le Générateur de diagrammes offre des options générales pour le diagramme. Ces optionss’appliquent à l’ensemble du diagramme, plutôt qu’à un élément donné du diagramme. Lesoptions générales comprennent la gestion des valeurs manquantes, les modèles, la taille desdiagrammes et les retours à la ligne dans les panels.
E Cliquez sur Options.
E Modifiez les options générales. Les détails relatifs aux options sont les suivants.
E Cliquez sur Appliquer.
Valeurs manquantes spécifiées :
Critères d’agrégation.Si des valeurs manquantes figurent dans les variables utilisées pour définirdes modalités ou des sous-groupes, sélectionnez Inclure de sorte que les modalités des valeursutilisateur manquantes (valeurs identifiées comme manquantes par l’utilisateur) soient inclusesdans le diagramme. Ces modalités agissent également en tant que critères d’agrégation lors ducalcul de la statistique. Les modalités « manquantes » figurent sur l’axe de modalités ou dans lalégende et se traduisent par exemple par l’ajout d’un bâton supplémentaire, d’un secteur dans lesdiagrammes en secteurs. S’il n’existe aucune valeur manquante, les modalités « manquantes »n’apparaissent pas.Si vous avez sélectionné cette option et que vous ne voulez plus afficher ces valeurs une
fois le diagramme tracé, ouvrez ce dernier dans le Générateur de diagrammes, puis choisissezPropriétés dans le menu Modifier. L’onglet Modalités permet de déplacer vers la liste Excluesles modalités à supprimer. Notez cependant que les statistiques ne sont pas recalculées si vouscachez les modalités « manquantes ». Ainsi, une statistique de pourcentage prendra toujours encompte les modalités « manquantes ».
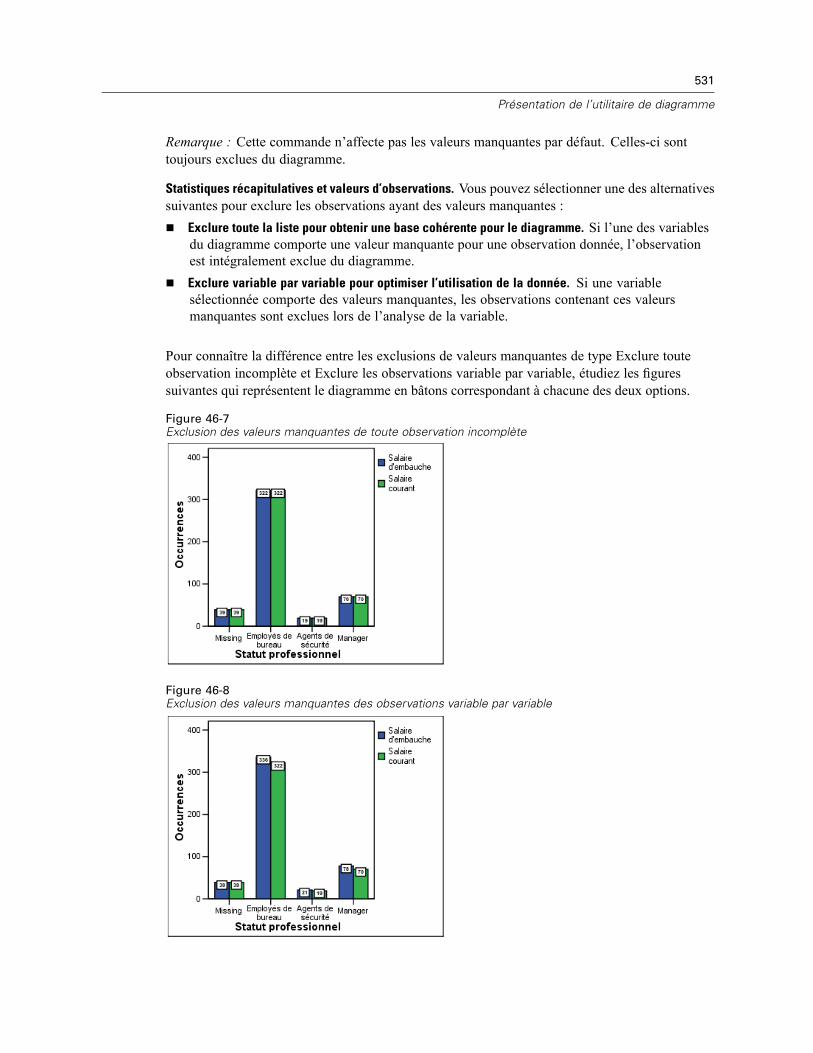
531
Présentation de l’utilitaire de diagramme
Remarque : Cette commande n’affecte pas les valeurs manquantes par défaut. Celles-ci sonttoujours exclues du diagramme.
Statistiques récapitulatives et valeurs d’observations. Vous pouvez sélectionner une des alternativessuivantes pour exclure les observations ayant des valeurs manquantes :
Exclure toute la liste pour obtenir une base cohérente pour le diagramme. Si l’une des variablesdu diagramme comporte une valeur manquante pour une observation donnée, l’observationest intégralement exclue du diagramme.Exclure variable par variable pour optimiser l’utilisation de la donnée. Si une variablesélectionnée comporte des valeurs manquantes, les observations contenant ces valeursmanquantes sont exclues lors de l’analyse de la variable.
Pour connaître la différence entre les exclusions de valeurs manquantes de type Exclure touteobservation incomplète et Exclure les observations variable par variable, étudiez les figuressuivantes qui représentent le diagramme en bâtons correspondant à chacune des deux options.
Figure 46-7Exclusion des valeurs manquantes de toute observation incomplète
Figure 46-8Exclusion des valeurs manquantes des observations variable par variable

532
Chapitre 46
Les données comprennent quelques valeurs système manquantes (vides) dans les variables pourSalaire actuel et Catégorie d’emploi. Dans d’autres observations, la valeur 0 a été saisie etdéfinie comme manquante. L’option Afficher les groupes définis par des valeurs manquantes étantsélectionnée pour les deux diagrammes, la modalité Manquant est ajoutée aux types de posteaffichés. Dans chaque diagramme, les valeurs de la fonction récapitulative Nombre d’observationsfigurent dans les étiquettes des bâtons.26 observations des deux diagrammes comportent une valeur manquante par défaut pour le
type de poste occupé, et 13 la valeur manquante utilisateur (0). Dans le diagramme avec exclusionde toute observation incomplète, le nombre d’observations est identique pour les deux variablesde chaque regroupement de bâtons. En effet, si une valeur est manquante, l’observation estexclue pour toutes les variables. Dans le diagramme avec exclusion des observations variable parvariable, le nombre d’observations non manquantes de chaque variable d’une modalité donnée estreprésenté indépendamment des valeurs manquantes dans les autres variables.
Modèles
Un modèle de diagramme vous permet d’appliquer les attributs d’un diagramme à un autre.Lorsque vous ouvrez un diagramme dans Chart Editor, vous pouvez l’enregistrer en tant quemodèle. Vous pouvez ensuite appliquer ce modèle en l’indiquant au moment de sa création ouultérieurement en l’appliquant dans l’éditeur’ de diagrammes.
Modèle par défaut. Il s’agit du modèle spécifié par les options. Vous pouvez accéder à cesoptions en sélectionnant Options dans le menu Edition de l’éditeur de données, puis en cliquantsur l’onglet Diagrammes. Le modèle par défaut est appliqué en premier, ce qui signifie que lesautres modèles peuvent le remplacer.
Fichiers de modèle. Cliquez sur Ajouter pour spécifier un ou plusieurs modèles à l’aide de laboîte de dialogue standard de sélection de fichier. Ils sont appliqués en fonction de leur ordred’apparition. Les modèles situés à la fin de la liste peuvent ainsi remplacer les modèles situésau début de la liste.
Taille des diagrammes et panels
Taille du diagramme. Spécifiez un pourcentage supérieur ou inférieur à 100 pour agrandir ou réduirele diagramme, respectivement. Le pourcentage est fonction de la taille de diagramme par défaut.
Panels. En présence de nombreuses colonnes de panel, sélectionnez Réorganiser les panels pourque les panels puissent occuper plusieurs lignes au lieu d’être contraints de tenir sur une seule. Lespanels sont réduits pour tenir impérativement sur une ligne, sauf si cette option est sélectionnée.
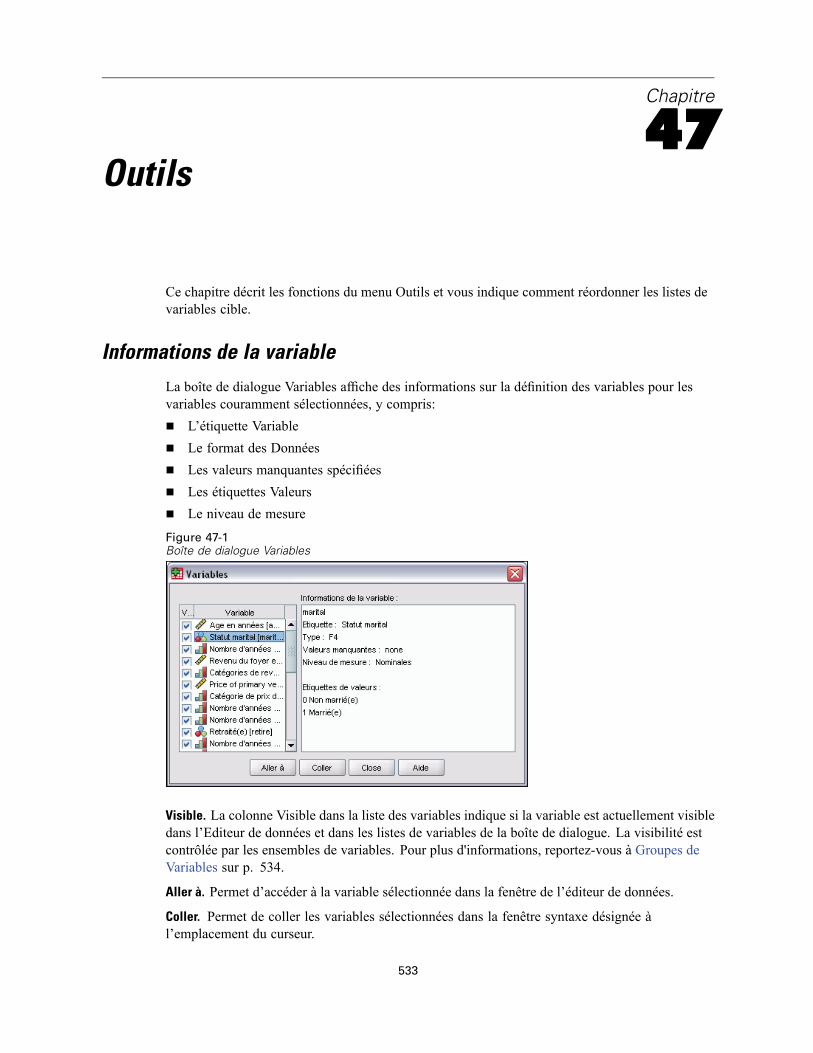
Chapitre
47Outils
Ce chapitre décrit les fonctions du menu Outils et vous indique comment réordonner les listes devariables cible.
Informations de la variable
La boîte de dialogue Variables affiche des informations sur la définition des variables pour lesvariables couramment sélectionnées, y compris:
L’étiquette VariableLe format des DonnéesLes valeurs manquantes spécifiéesLes étiquettes ValeursLe niveau de mesure
Figure 47-1Boîte de dialogue Variables
Visible. La colonne Visible dans la liste des variables indique si la variable est actuellement visibledans l’Editeur de données et dans les listes de variables de la boîte de dialogue. La visibilité estcontrôlée par les ensembles de variables. Pour plus d'informations, reportez-vous à Groupes deVariables sur p. 534.
Aller à. Permet d’accéder à la variable sélectionnée dans la fenêtre de l’éditeur de données.
Coller. Permet de coller les variables sélectionnées dans la fenêtre syntaxe désignée àl’emplacement du curseur.
533

534
Chapitre 47
Pour modifier les définitions de variables, utilisez l’affichage des variables dans l’éditeur dedonnées.
Pour obtenir des informations sur les variables
E A partir des menus, sélectionnez :Outils
Variables
E Sélectionnez la variable dont vous souhaitez afficher les informations de définition variable.
Commentaires de fichier de données
Vous pouvez inclure des commentaires descriptifs dans le fichier de données. Pour les fichiers dedonnées au format SPSS Statistics, les commentaires sont enregistrés avec le fichier de données.
Pour ajouter, modifier, supprimer ou afficher les commentaires de fichier de données
E A partir des menus, sélectionnez :Outils
Commentaires de fichier de données
E Pour afficher les commentaires dans le Viewer, sélectionnez Afficher les commentaires dans la sortie.
Les commentaires ne sont pas limités en longueur, mais ne doivent pas dépasser 80 octets (engénéral, cela correspond à 80 caractères dans les langues sur un octet) par ligne. Les lignes sontautomatiquement interrompues par un renvoi à la ligne suivante à partir de 80 caractères. Lapolice utilisée pour afficher les commentaires est celle utilisée pour les résultats texte de manière àdonner une représentation fidèle de l’affichage dans le Viewer.Un cachet de date (la date actuelle entre parenthèses) est automatiquement ajouté à la fin de la
liste des commentaires dès que vous modifiez un commentaire ou que vous en ajoutez un. Cecipeut entraîner des ambiguïtés au niveau des dates associées aux commentaires lorsque vousmodifiez un commentaire ou que vous insérez un nouveau commentaire entre deux commentairesexistants.
Groupes de Variables
Vous pouvez limiter le nombre de variables affichées dans l’Editeur de données et dans les listesde variables des boîtes de dialogue. Pour cela, définissez et utilisez des groupes de variables. Ceciest particulièrement utile pour les fichiers de données avec un grand nombre de variables. Lespetits groupes de variables facilitent la recherche et la sélection des variables pour votre analyse.
Définir des groupes de variables
La procédure Définir des groupes de variables crée des sous-ensembles de variables à afficherdans l’éditeur de données et dans les listes de variables de boîtes de dialogue. Les groupes devariables définis sont enregistrés avec les fichiers de données au format SPSS Statistics.
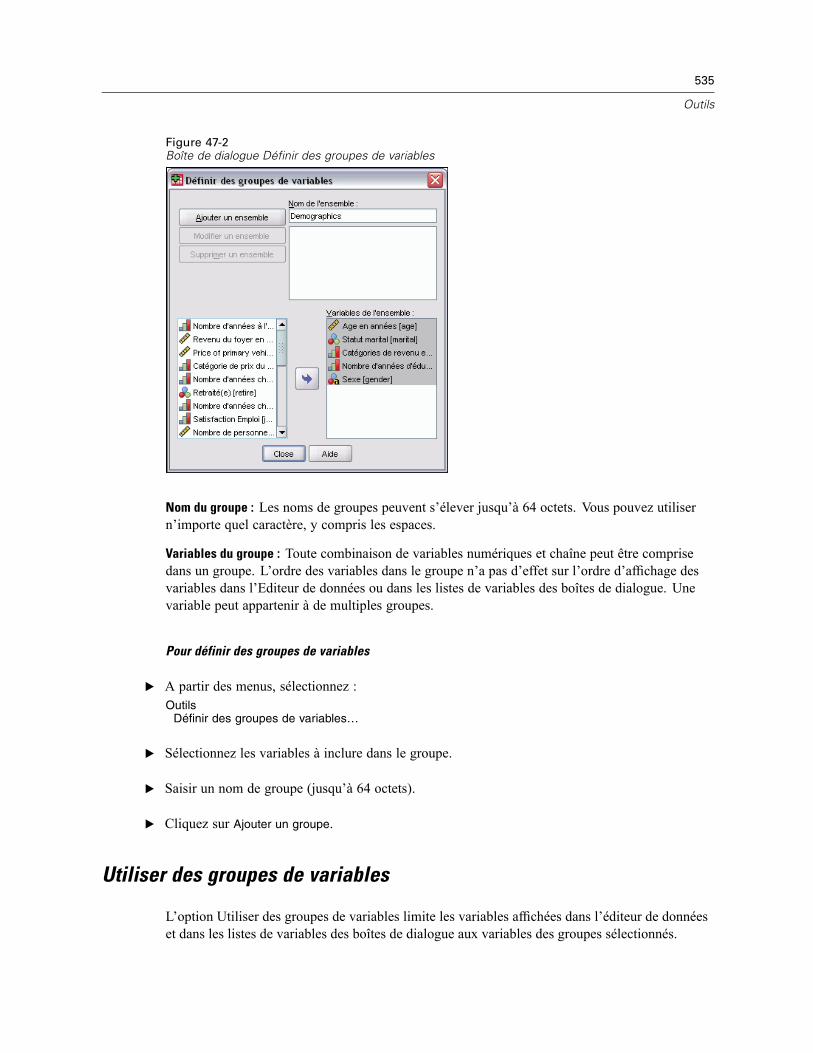
535
Outils
Figure 47-2Boîte de dialogue Définir des groupes de variables
Nom du groupe : Les noms de groupes peuvent s’élever jusqu’à 64 octets. Vous pouvez utilisern’importe quel caractère, y compris les espaces.
Variables du groupe : Toute combinaison de variables numériques et chaîne peut être comprisedans un groupe. L’ordre des variables dans le groupe n’a pas d’effet sur l’ordre d’affichage desvariables dans l’Editeur de données ou dans les listes de variables des boîtes de dialogue. Unevariable peut appartenir à de multiples groupes.
Pour définir des groupes de variables
E A partir des menus, sélectionnez :Outils
Définir des groupes de variables…
E Sélectionnez les variables à inclure dans le groupe.
E Saisir un nom de groupe (jusqu’à 64 octets).
E Cliquez sur Ajouter un groupe.
Utiliser des groupes de variables
L’option Utiliser des groupes de variables limite les variables affichées dans l’éditeur de donnéeset dans les listes de variables des boîtes de dialogue aux variables des groupes sélectionnés.

536
Chapitre 47
Figure 47-3Boîte de dialogue Utiliser des groupes de variables
Le groupe de variables affiché dans l’Editeur de données et dans les listes des boîtes dedialogue recense tous les groupes sélectionnés.Une variable peut être incluse dans plusieurs groupes sélectionnés.L’ordre des variables dans les groupes sélectionnés et celui des groupes même n’ont pasd’effet sur l’ordre d’affichage des variables dans l’Editeur de données ni dans les listes devariables des boîtes de dialogue.Bien que les groupes de variables définis soient enregistrés avec les fichiers de données auformat SPSS Statistics, les groupes intégrés par défaut sont rétablis dans la liste des groupessélectionnés chaque fois que vous ouvrez le fichier de données.
La liste des groupes de variables disponibles inclut tous les groupes de variables définis pour lefichier de données actif, ainsi que deux autres groupes intégrés :
ALLVARIABLES : Ce groupe contient toutes les variables du fichier de données, y compris lesnouvelles variables créées pendant une session.NEWVARIABLES : Ce groupe contient seulement les nouvelles variables créées pendant lasession.Remarque : Même si vous enregistrez le fichier de données après avoir créé des variables,celles-ci sont incluses dans le groupe NEWVARIABLES jusqu’à ce que vous fermiez et ouvriezde nouveau le fichier de données.
Vous devez sélectionner au moins un groupe de variables. Si vous sélectionnez le groupeALLVARIABLES, les autres groupes sélectionnés n’ont aucun effet concret puisque ce groupecontient toutes les variables.
Pour sélectionner les groupes de variables à afficher
E A partir des menus, sélectionnez :Outils
Utiliser des groupes de variables…

537
Outils
E Sélectionnez les groupes de variables définis qui contiennent les variables que vous souhaitez voirapparaître dans l’Editeur de données et dans les listes de variables des boîtes de dialogue.
Pour afficher toutes les variables
E A partir des menus, sélectionnez :Outils
Afficher toutes les variables
Réordonner Listes Variables Cible
Les variables apparaissent dans les listes cible de la boîte de dialogue dans l’ordre dans lequel ellessont sélectionnées à partir de la liste source. Si vous souhaitez modifier l’ordre des variables d’uneliste cible—mais que vous ne souhaitez pas désélectionner toutes les variables et les resélectionnerdans le nouvel ordre—vous pouvez faire remonter et redescendre les variables dans la liste cible àl’aide de la touche Ctrl (Macintosh : touche Commande) et les touches flèches Haut et Bas. Vouspouvez déplacer simultanément les variables multiples si elles sont attenantes (regroupées). Vousne pouvez pas déplacer les groupes de variables non attenantes.

Chapitre
48Options
Les commandes Options permettent de contrôler un grand nombre de paramètres, y compris :le journal de session qui enregistre toutes les commandes exécutées dans chaque sessionl’ordre d’affichage des variables dans les listes source des boîtes de dialogueles éléments affichés et masqués dans les nouveaux résultatsModèle de tableau pour les nouveaux tableaux pivotants.les formats monétaires personnalisés (devises)
Pour modifier les paramètres d’options
E A partir des menus, sélectionnez :Affichage
Options...
E Cliquez sur les onglets correspondant aux paramètres que vous souhaitez modifier.
E Modifiez les paramètres.
E Cliquez sur OK ou sur Appliquer.
538
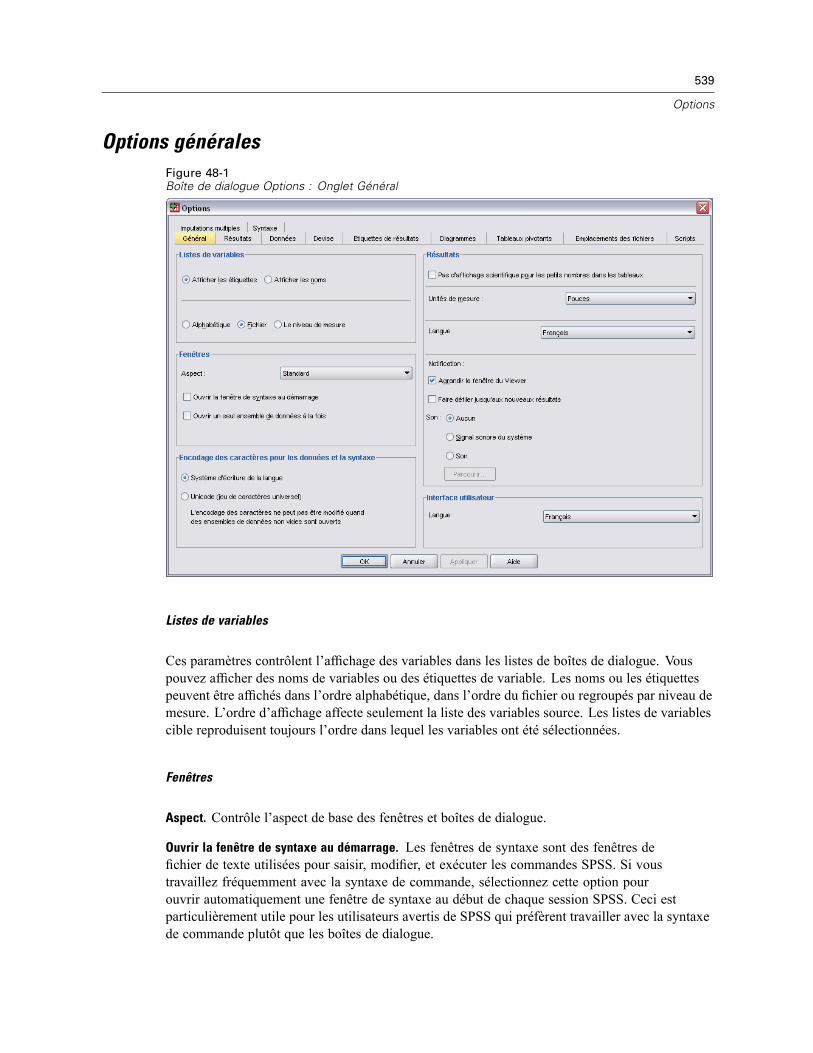
539
Options
Options généralesFigure 48-1Boîte de dialogue Options : Onglet Général
Listes de variables
Ces paramètres contrôlent l’affichage des variables dans les listes de boîtes de dialogue. Vouspouvez afficher des noms de variables ou des étiquettes de variable. Les noms ou les étiquettespeuvent être affichés dans l’ordre alphabétique, dans l’ordre du fichier ou regroupés par niveau demesure. L’ordre d’affichage affecte seulement la liste des variables source. Les listes de variablescible reproduisent toujours l’ordre dans lequel les variables ont été sélectionnées.
Fenêtres
Aspect. Contrôle l’aspect de base des fenêtres et boîtes de dialogue.
Ouvrir la fenêtre de syntaxe au démarrage. Les fenêtres de syntaxe sont des fenêtres defichier de texte utilisées pour saisir, modifier, et exécuter les commandes SPSS. Si voustravaillez fréquemment avec la syntaxe de commande, sélectionnez cette option pourouvrir automatiquement une fenêtre de syntaxe au début de chaque session SPSS. Ceci estparticulièrement utile pour les utilisateurs avertis de SPSS qui préfèrent travailler avec la syntaxede commande plutôt que les boîtes de dialogue.

540
Chapitre 48
Ouvrir un seul ensemble de données à la fois. Ferme la source de données actuellement ouvertechaque fois que vous ouvrez une source de données différente à l’aide des menus et boîtes dedialogue. Par défaut, chaque fois que vous utilisez les menus et boîtes de dialogue pour ouvrir unenouvelle source de données, cette source de données s’ouvre dans une nouvelle fenêtre éditeur dedonnées, et toutes les autres sources de données ouvertes dans d’autres fenêtres éditeur de donnéesrestent ouvertes et disponibles pendant la session jusqu’à ce qu’elles soient explicitement fermées.
La sélection de cette option prend effet immédiatement mais ne ferme aucun ensemble de donnéesouvert au moment où le paramètre a été modifié. Ce paramètre n’a aucun effet sur les sources dedonnées ouvertes à l’aide de la syntaxe de commande, qui dépend des commandes DATASET pourcontrôler plusieurs ensembles de données.Pour plus d'informations, reportez-vous à Utilisationdes sources de données multiples dans Chapitre 6 sur p. 107.
Encodage des caractères pour les fichiers de données et de syntaxe
Cette option contrôle le comportement par défaut pour déterminer l’encodage pour la lecture etl’écriture de fichiers de données et de fichiers de syntaxe. Vous ne pouvez modifier ce paramètreque quand aucune source de données n’est ouverte, et le paramètre reste activé pour les sessionssuivantes jusqu’à ce qu’il soit explicitement modifié.
Système d’écriture de la langue. Utilisez le paramètre régional en cours pour déterminerl’encodage pour la lecture et l’écriture de fichiers. On parle de mode page de code.Unicode (jeu de caractères universel). Utilisez l’encodage Unicode (UTF-8) pour la lecture etl’écriture de fichiers. Ce mode est appelé mode Unicode.
Il existe un certain nombre d’implications importantes concernant le mode Unicode et les fichiersUnicode.
Les fichiers de données SPSS Statistics et les fichiers de syntaxe enregistrés au formatd’encodage Unicode ne doivent pas être utilisés avec des versions de SPSS Statisticsantérieures à la version 16.0. Pour les fichiers de syntaxe, vous pouvez spécifier l’encodagequand vous enregistrez le fichier. Pour les fichiers de données, vous devez ouvrir le fichier dedonnées en mode page de code puis l’enregistrer à nouveau si vous voulez lire le fichier avecdes versions antérieures.Quand les fichiers de données de page de code sont lus en mode Unicode, la largeur définiede toutes les variables chaîne est triplée. Pour définir automatiquement la largeur de chaquevariable chaîne à la valeur observée la plus longue pour cette variable, sélectionnez Réduireles largeurs de chaîne en fonction des valeurs observées dans la boîte de dialogue Ouvrir lesdonnées.
Résultat
Pas d’affichage scientifique pour les petits nombres dans les tableaux : Supprime l’affichagescientifique pour les petites valeurs décimales dans le résultat. Les valeurs décimales très petitessont affichées au format suivant : 0 (ou 0,000).
Unités de mesure : Système de mesure utilisé (Points, Pouces, ou Centimètres) pour spécifier lesattributs tels que les marges de cellules du tableau pivotant, les largeurs de cellules et l’espaced’impression entre les tableaux
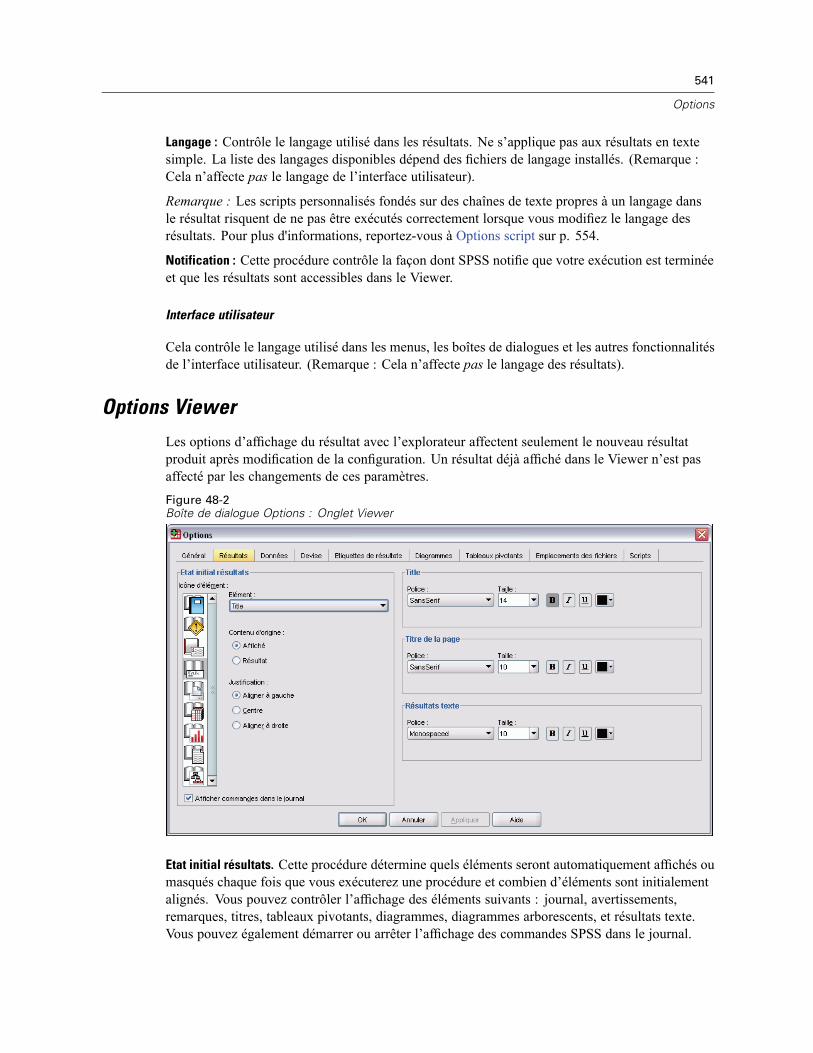
541
Options
Langage : Contrôle le langage utilisé dans les résultats. Ne s’applique pas aux résultats en textesimple. La liste des langages disponibles dépend des fichiers de langage installés. (Remarque :Cela n’affecte pas le langage de l’interface utilisateur).
Remarque : Les scripts personnalisés fondés sur des chaînes de texte propres à un langage dansle résultat risquent de ne pas être exécutés correctement lorsque vous modifiez le langage desrésultats. Pour plus d'informations, reportez-vous à Options script sur p. 554.
Notification : Cette procédure contrôle la façon dont SPSS notifie que votre exécution est terminéeet que les résultats sont accessibles dans le Viewer.
Interface utilisateur
Cela contrôle le langage utilisé dans les menus, les boîtes de dialogues et les autres fonctionnalitésde l’interface utilisateur. (Remarque : Cela n’affecte pas le langage des résultats).
Options ViewerLes options d’affichage du résultat avec l’explorateur affectent seulement le nouveau résultatproduit après modification de la configuration. Un résultat déjà affiché dans le Viewer n’est pasaffecté par les changements de ces paramètres.
Figure 48-2Boîte de dialogue Options : Onglet Viewer
Etat initial résultats. Cette procédure détermine quels éléments seront automatiquement affichés oumasqués chaque fois que vous exécuterez une procédure et combien d’éléments sont initialementalignés. Vous pouvez contrôler l’affichage des éléments suivants : journal, avertissements,remarques, titres, tableaux pivotants, diagrammes, diagrammes arborescents, et résultats texte.Vous pouvez également démarrer ou arrêter l’affichage des commandes SPSS dans le journal.
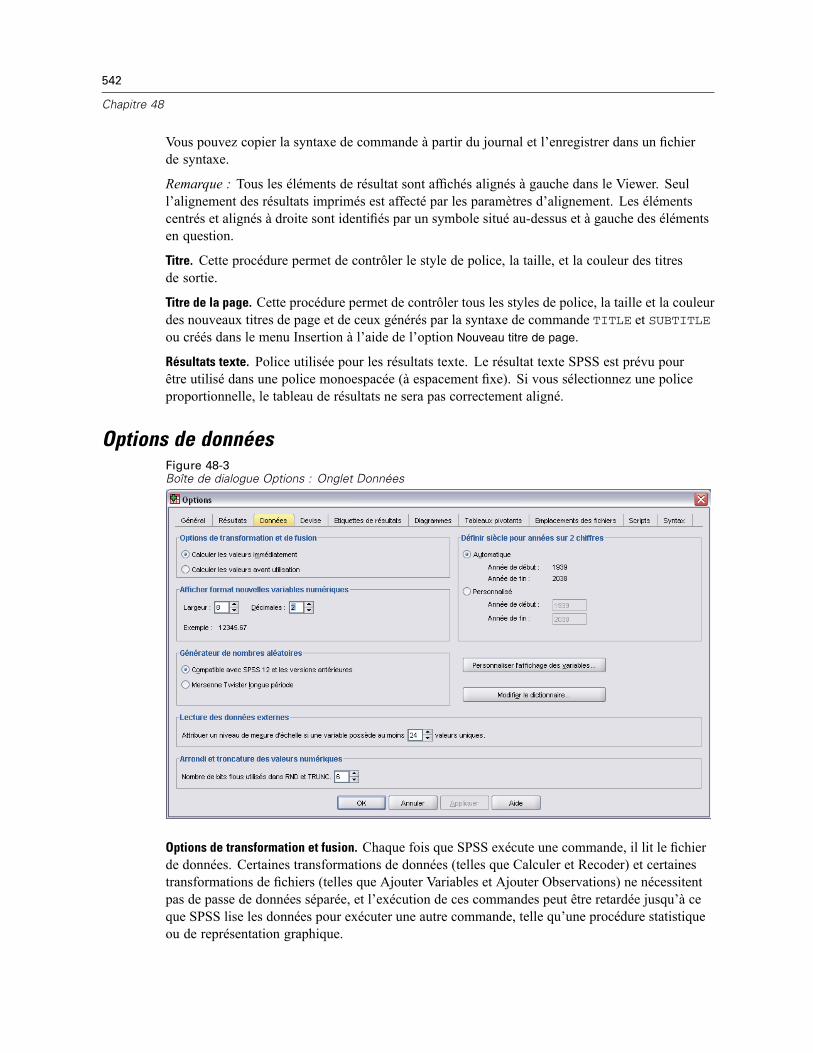
542
Chapitre 48
Vous pouvez copier la syntaxe de commande à partir du journal et l’enregistrer dans un fichierde syntaxe.
Remarque : Tous les éléments de résultat sont affichés alignés à gauche dans le Viewer. Seull’alignement des résultats imprimés est affecté par les paramètres d’alignement. Les élémentscentrés et alignés à droite sont identifiés par un symbole situé au-dessus et à gauche des élémentsen question.
Titre. Cette procédure permet de contrôler le style de police, la taille, et la couleur des titresde sortie.
Titre de la page. Cette procédure permet de contrôler tous les styles de police, la taille et la couleurdes nouveaux titres de page et de ceux générés par la syntaxe de commande TITLE et SUBTITLEou créés dans le menu Insertion à l’aide de l’option Nouveau titre de page.
Résultats texte. Police utilisée pour les résultats texte. Le résultat texte SPSS est prévu pourêtre utilisé dans une police monoespacée (à espacement fixe). Si vous sélectionnez une policeproportionnelle, le tableau de résultats ne sera pas correctement aligné.
Options de donnéesFigure 48-3Boîte de dialogue Options : Onglet Données
Options de transformation et fusion. Chaque fois que SPSS exécute une commande, il lit le fichierde données. Certaines transformations de données (telles que Calculer et Recoder) et certainestransformations de fichiers (telles que Ajouter Variables et Ajouter Observations) ne nécessitentpas de passe de données séparée, et l’exécution de ces commandes peut être retardée jusqu’à ceque SPSS lise les données pour exécuter une autre commande, telle qu’une procédure statistiqueou de représentation graphique.

543
Options
Pour les fichiers de données volumineux dont la lecture des données peut être longue, vouspouvez sélectionner Calculer les valeurs avant utilisation pour différer l’exécution et réduire letemps de traitement. Lorsque cette option est sélectionnée, les résultats des transformationseffectuées via des boîtes de dialogue comme Calculer la variable n’apparaissent pasimmédiatement dans l’éditeur de données. Les variables créées par les transformationsapparaissent sans valeur de données. Vous ne pouvez pas modifier les valeurs de données dansl’éditeur de données alors que certaines transformations sont en attente. Toute commandelisant les données, telle qu’une procédure statistique ou de représentation graphique, exécuteles transformations en attente et met à jour les données affichées dans l’éditeur de données.Vous pouvez également utiliser l’option Exécuter les transformations en attente du menuTransformer.Avec la valeur par défaut de l’option Calculer les valeurs immédiatement, lorsque vous collezune syntaxe de commande à partir d’une boîte de dialogue, une commande EXECUTE estcollée après chaque commande de transformation. Pour plus d'informations, reportez-vous àCommandes Execute multiples dans Chapitre 13 sur p. 295.
Afficher format nouvelles variables numériques. Cette procédure permet de contrôler la largeurd’affichage par défaut et le nombre de positions décimales par défaut des nouvelles variablesnumériques. Il n’existe pas de format d’affichage par défaut pour les nouvelles variables chaînes.Si une valeur est trop grande pour le format d’affichage spécifié, les premières décimales sontarrondies et les valeurs sont ensuite converties en notation scientifique Les formats d’affichagen’affectent pas les valeurs de données internes. Par exemple, la valeur 123456.78 peut être arrondieà 123457 pour l’affichage, mais la valeur originale non arrondie est utilisée pour tout calcul.
Définir siècle pour années sur 2 chiffres. Définit l’intervalle d’années pour les variables de formatde date entrés et/ou affichés avec des années à deux chiffres (par exemple,10/28/86, 29-OCT-87).Le paramétrage de l’intervalle automatique est basé sur l’année en cours, commençant 69 annéesavant et finissant 30 années après l’année en cours (ajouter l’année en cours donne un intervalletotal de 100 années). Pour un intervalle personnalisé, l’année de fin est automatiquementdéterminée en fonction de la valeur que vous entrez pour l’année de début.
Générateur de nombres aléatoires. Deux types de générateur de nombres aléatoires sontdisponibles :
Compatible Version 12. Générateur de nombres aléatoires utilisé dans la version 12 et lesversions précédentes. Si vous avez besoin de reproduire des résultats aléatoires générésdans des versions précédentes sur la base d'une valeur de générateur spécifiée, utilisez cegénérateur de nombres aléatoires.Mersenne Twister. Générateur de nombres aléatoires plus récent et plus fiable pour lessimulations. Si la reproduction de résultats aléatoires à partir de SPSS 12 ou d'une versionantérieure n'est pas un problème, utilisez ce générateur de nombres aléatoires.
Lecture des données externes. Pour la lecture de données à partir de formats de fichiers externeset de fichiers de données créés avec des versions précédentes de SPSS Statistics (antérieuresà la version 8.0), vous pouvez spécifier le nombre minimum de valeurs de données pour unevariable numérique utilisé pour classer la variable en tant que variable d’échelle ou nominale. Lesvariables avec moins que le nombre spécifié de valeurs uniques sont classées comme nominales.

544
Chapitre 48
Arrondi et troncation des valeurs numériques. Pour les fonctions RND et TRUNC, ce paramètrecontrôle le seuil par défaut des valeurs arrondies qui sont très près d’une limite d’arrondi. Ceparamètre est spécifié comme un nombre de bits et est défini sur 6 au moment de l’installation ; cequi doit être suffisant pour la plupart des applications. Le paramétrage du nombre de bits sur 0génère les mêmes résultats que dans la version 10. La valeur 10 donne les mêmes résultats quedans les versions 11 et 12.
Pour la fonction RND, ce paramètre indique le nombre de bits les moins significatifs parlesquels la valeur à arrondir risque de ne pas atteindre le seuil d’arrondi souhaité. Par exemple,pour l’arrondi d’une valeur entre 1,0 et 2,0 au nombre entier le plus près, ce paramètre indiquece qui manque à la valeur pour atteindre 1,5 (le seuil pour l’arrondi à 2,0).Pour la fonction TRUNC, ce paramètre indique le nombre de bits les moins significatifs parlesquels la valeur à tronquer risque de ne pas atteindre le seuil d’arrondi le plus près avanttroncation. Par exemple, pour la troncation d’une valeur entre 1,0 et 2,0 au nombre entier leplus près, ce paramètre indique ce qui manque à la valeur pour atteindre 2,0 (arrondi à 2,0).
Personnaliser l’affichage des variables. Contrôle l’affichage par défaut et l’ordre des attributs dansl’option Variable View. Pour plus d'informations, reportez-vous à Modification de l’affichagedes variables par défaut sur p. 544.
Modifier le dictionnaire. Contrôle la langue du dictionnaire utilisé pour vérifier l’orthographe deséléments dans Variable View. Pour plus d'informations, reportez-vous à Correction orthographiquedans Chapitre 5 sur p. 97.
Modification de l’affichage des variables par défaut
Vous pouvez utiliser Personnaliser l’affichage des variables pour contrôler les attributs quis’affichent dans Affichage des variables (par exemple, nom, type, étiquette) et l’ordre dans lequelils s’affichent.
Cliquez sur Personnaliser l’affichage des variables.
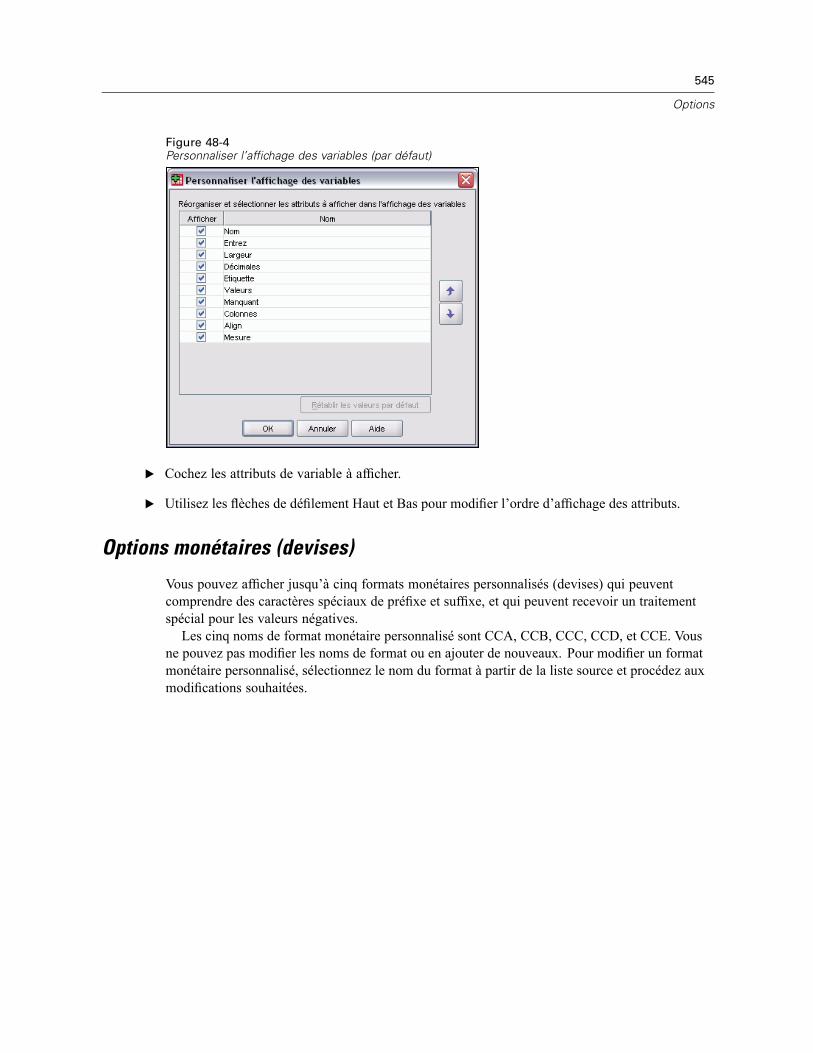
545
Options
Figure 48-4Personnaliser l’affichage des variables (par défaut)
E Cochez les attributs de variable à afficher.
E Utilisez les flèches de défilement Haut et Bas pour modifier l’ordre d’affichage des attributs.
Options monétaires (devises)
Vous pouvez afficher jusqu’à cinq formats monétaires personnalisés (devises) qui peuventcomprendre des caractères spéciaux de préfixe et suffixe, et qui peuvent recevoir un traitementspécial pour les valeurs négatives.Les cinq noms de format monétaire personnalisé sont CCA, CCB, CCC, CCD, et CCE. Vous
ne pouvez pas modifier les noms de format ou en ajouter de nouveaux. Pour modifier un formatmonétaire personnalisé, sélectionnez le nom du format à partir de la liste source et procédez auxmodifications souhaitées.
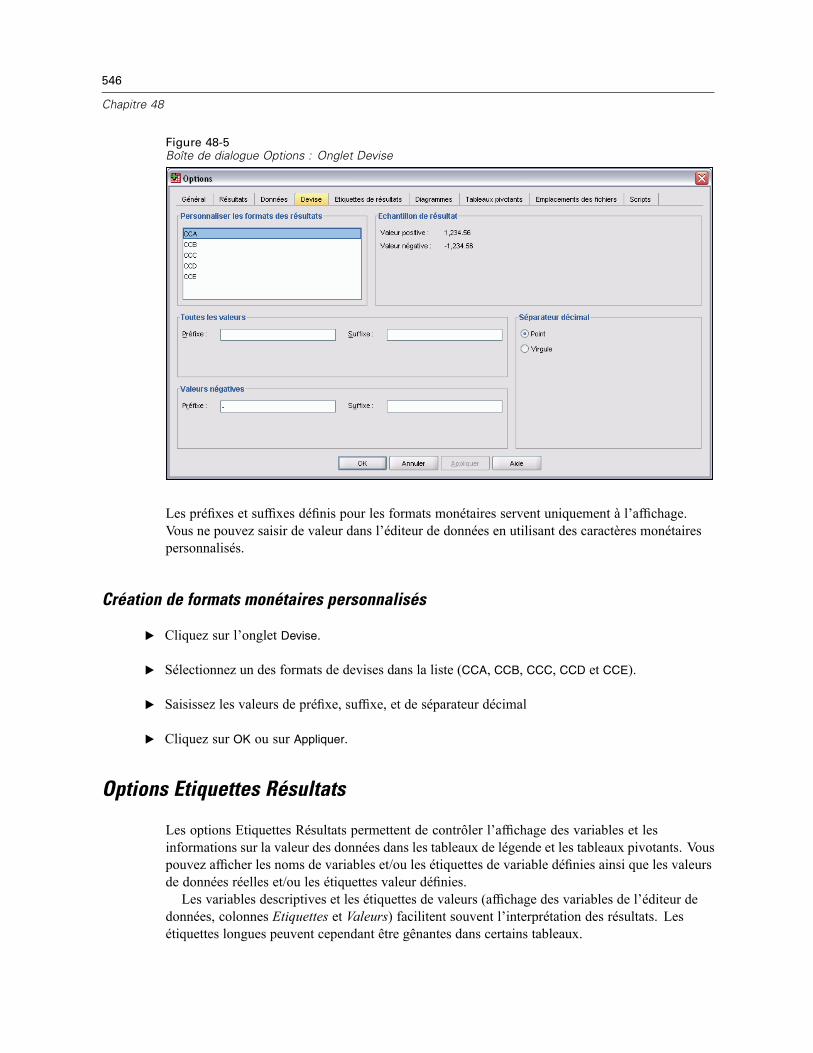
546
Chapitre 48
Figure 48-5Boîte de dialogue Options : Onglet Devise
Les préfixes et suffixes définis pour les formats monétaires servent uniquement à l’affichage.Vous ne pouvez saisir de valeur dans l’éditeur de données en utilisant des caractères monétairespersonnalisés.
Création de formats monétaires personnalisés
E Cliquez sur l’onglet Devise.
E Sélectionnez un des formats de devises dans la liste (CCA, CCB, CCC, CCD et CCE).
E Saisissez les valeurs de préfixe, suffixe, et de séparateur décimal
E Cliquez sur OK ou sur Appliquer.
Options Etiquettes Résultats
Les options Etiquettes Résultats permettent de contrôler l’affichage des variables et lesinformations sur la valeur des données dans les tableaux de légende et les tableaux pivotants. Vouspouvez afficher les noms de variables et/ou les étiquettes de variable définies ainsi que les valeursde données réelles et/ou les étiquettes valeur définies.Les variables descriptives et les étiquettes de valeurs (affichage des variables de l’éditeur de
données, colonnes Etiquettes et Valeurs) facilitent souvent l’interprétation des résultats. Lesétiquettes longues peuvent cependant être gênantes dans certains tableaux.
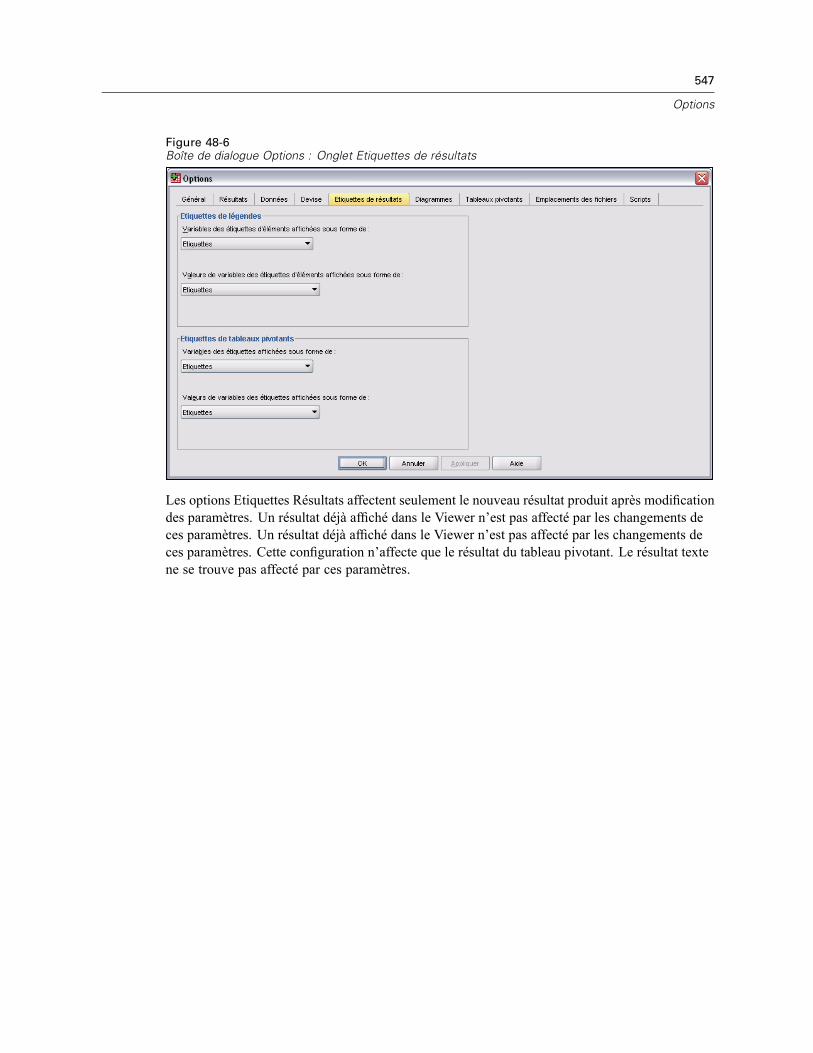
547
Options
Figure 48-6Boîte de dialogue Options : Onglet Etiquettes de résultats
Les options Etiquettes Résultats affectent seulement le nouveau résultat produit après modificationdes paramètres. Un résultat déjà affiché dans le Viewer n’est pas affecté par les changements deces paramètres. Un résultat déjà affiché dans le Viewer n’est pas affecté par les changements deces paramètres. Cette configuration n’affecte que le résultat du tableau pivotant. Le résultat textene se trouve pas affecté par ces paramètres.
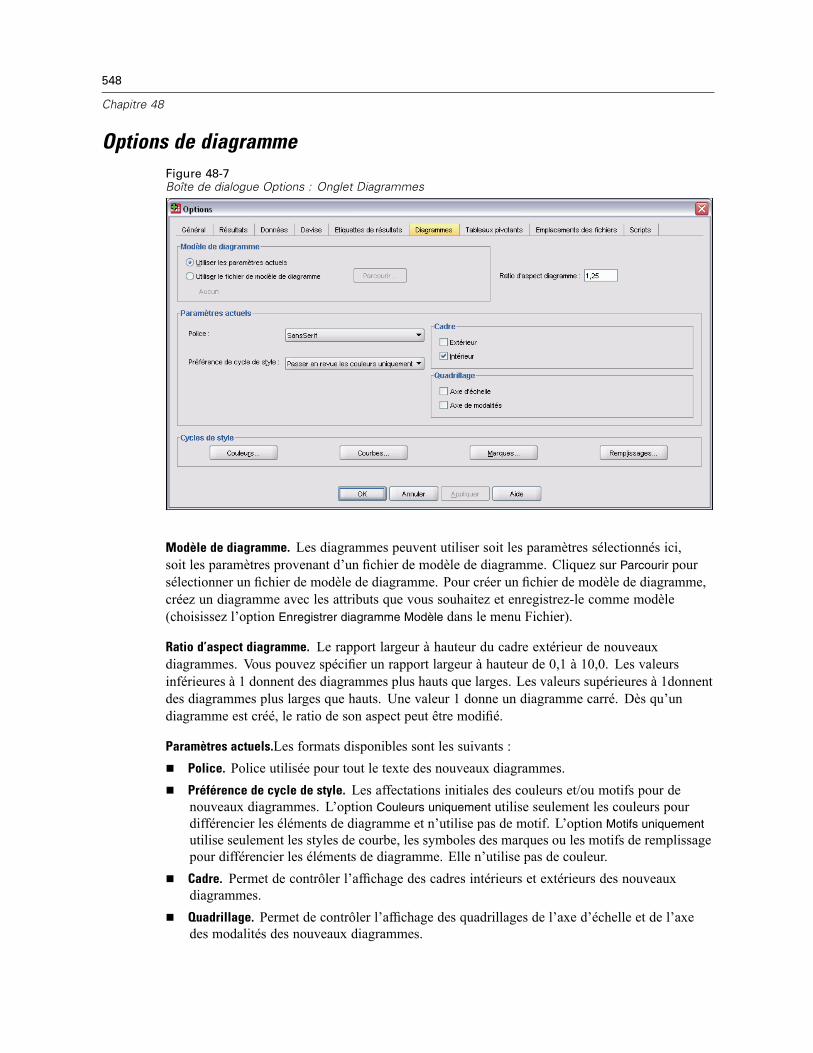
548
Chapitre 48
Options de diagrammeFigure 48-7Boîte de dialogue Options : Onglet Diagrammes
Modèle de diagramme. Les diagrammes peuvent utiliser soit les paramètres sélectionnés ici,soit les paramètres provenant d’un fichier de modèle de diagramme. Cliquez sur Parcourir poursélectionner un fichier de modèle de diagramme. Pour créer un fichier de modèle de diagramme,créez un diagramme avec les attributs que vous souhaitez et enregistrez-le comme modèle(choisissez l’option Enregistrer diagramme Modèle dans le menu Fichier).
Ratio d’aspect diagramme. Le rapport largeur à hauteur du cadre extérieur de nouveauxdiagrammes. Vous pouvez spécifier un rapport largeur à hauteur de 0,1 à 10,0. Les valeursinférieures à 1 donnent des diagrammes plus hauts que larges. Les valeurs supérieures à 1donnentdes diagrammes plus larges que hauts. Une valeur 1 donne un diagramme carré. Dès qu’undiagramme est créé, le ratio de son aspect peut être modifié.
Paramètres actuels.Les formats disponibles sont les suivants :Police. Police utilisée pour tout le texte des nouveaux diagrammes.Préférence de cycle de style. Les affectations initiales des couleurs et/ou motifs pour denouveaux diagrammes. L’option Couleurs uniquement utilise seulement les couleurs pourdifférencier les éléments de diagramme et n’utilise pas de motif. L’option Motifs uniquementutilise seulement les styles de courbe, les symboles des marques ou les motifs de remplissagepour différencier les éléments de diagramme. Elle n’utilise pas de couleur.Cadre. Permet de contrôler l’affichage des cadres intérieurs et extérieurs des nouveauxdiagrammes.Quadrillage. Permet de contrôler l’affichage des quadrillages de l’axe d’échelle et de l’axedes modalités des nouveaux diagrammes.

549
Options
Cycles de style : Personnalise les couleurs, les styles de ligne, les symboles de marque et les motifsde remplissage pour les nouveaux diagrammes. Vous pouvez changer l’ordre des couleurs et desmotifs utilisés lors de la création d’un diagramme.
Données Couleurs des éléments
Précisez l’ordre dans lequel les couleurs doivent être utilisées pour les éléments de données(comme les bâtons et les marques) de votre nouveau diagramme. Les couleurs sont utilisées dèsque vous effectuez une sélection incluant l’option Couleur dans la zone de groupe Préférence decycle de style de la boîte de dialogue principale Options de diagramme.Par exemple, si vous créez un diagramme en bâtons juxtaposés comprenant deux groupes,
et que vous sélectionnez Couleurs puis motifs dans la boîte de dialogue principale Options dediagramme, les deux premières couleurs de la liste des diagrammes regroupés sont utiliséescomme couleurs des bâtons du nouveau diagramme.
Pour modifier l’ordre d’utilisation des couleurs
E Sélectionnez Diagramme simple, puis sélectionnez une couleur utilisée pour les diagrammes sansmodalités.
E Sélectionnez Diagramme regroupé pour modifier le cycle des couleurs des diagrammes avecmodalités. Pour modifier la couleur d’une modalité, sélectionnez la modalité concernée, puischoisissez une couleur dans la palette.
Sinon, vous pouvez :insérer une nouvelle modalité avant la modalité sélectionnée ;déplacer une modalité sélectionnée ;supprimer une modalité sélectionnée ;paramétrer la séquence sur la valeur par défaut ;modifier une couleur en sélectionnant son puits, puis en cliquant sur Edition.
Courbes des éléments de données
Précisez l’ordre dans lequel les styles doivent être utilisés pour les éléments de données de lacourbe de votre nouveau diagramme. Les styles de courbe sont utilisés si votre diagramme inclutdes éléments de données de courbe et que vous effectuez une sélection incluant l’option Typesdans la zone de groupe Préférence de cycle de style de la boîte de dialogue principale Optionsde diagramme.Par exemple, si vous créez un diagramme curviligne comprenant deux groupes, et que vous
sélectionnez Motifs uniquement dans la boîte de dialogue principale Options de diagramme, lesdeux premiers styles de la liste des diagrammes regroupés sont utilisés comme motifs des courbesdu nouveau diagramme.

550
Chapitre 48
Pour modifier l’ordre d’utilisation des styles de lignes
E Sélectionnez Diagramme simple, puis sélectionnez un style de courbe utilisé pour les diagrammescurvilignes sans modalités.
E Sélectionnez Diagramme regroupé pour modifier le cycle des motifs des diagrammes curvilignesavec modalités. Pour modifier le style de courbe d’une modalité, sélectionnez la modalitéconcernée, puis choisissez un style de courbe dans la palette.
Sinon, vous pouvez :insérer une nouvelle modalité avant la modalité sélectionnée ;déplacer une modalité sélectionnée ;supprimer une modalité sélectionnée ;paramétrer la séquence sur la valeur par défaut ;
Marques des éléments de données
Précisez l’ordre dans lequel les symboles doivent être utilisés pour les éléments de données desmarques de votre nouveau diagramme. Les styles de marque sont utilisés si votre diagrammeinclut des éléments de données de marque et que vous effectuez une sélection incluant l’optionTypes dans la zone de groupe Préférence de cycle de style de la boîte de dialogue principaleOptions de diagramme.Par exemple, si vous créez un diagramme de dispersion comprenant deux groupes, et que vous
sélectionnez Motifs uniquement dans la boîte de dialogue principale Options de diagramme, lesdeux premiers symboles de la liste des diagrammes regroupés sont utilisés comme marques dunouveau diagramme.
Pour modifier l’ordre d’utilisation des styles de marques
E Sélectionnez Diagramme simple, puis sélectionnez un symbole de marque utilisé pour lesdiagrammes sans modalités.
E Sélectionnez Diagramme regroupé pour modifier le cycle des motifs des diagrammes avecmodalités. Pour modifier le symbole de marque d’une modalité, sélectionnez la modalitéconcernée, puis choisissez un symbole dans la palette.
Sinon, vous pouvez :insérer une nouvelle modalité avant la modalité sélectionnée ;déplacer une modalité sélectionnée ;supprimer une modalité sélectionnée ;paramétrer la séquence sur la valeur par défaut.

551
Options
Remplissages des éléments de données
Précisez l’ordre dans lequel les styles de remplissage doivent être utilisés pour les éléments dedonnées de bâton et d’aire de votre nouveau diagramme. Les styles de remplissage sont utilisés sivotre diagramme inclut des éléments de données de bâton et d’aire, et que vous effectuez unesélection incluant l’option Types dans la zone de groupe Préférence de cycle de style de la boîte dedialogue principale Options de diagramme.Par exemple, si vous créez un diagramme en bâtons juxtaposés comprenant deux groupes,
et que vous sélectionnez Motifs uniquement dans la boîte de dialogue principale Options dediagramme, les deux premiers styles de la liste des diagrammes regroupés sont utilisés commemotifs de remplissage des bâtons du nouveau diagramme.
Pour modifier l’ordre d’utilisation des styles de remplissage
E Sélectionnez Diagramme simple, puis sélectionnez un motif de remplissage utilisé pour lesdiagrammes sans modalités.
E Sélectionnez Diagramme regroupé pour modifier le cycle des motifs des diagrammes avecmodalités. Pour modifier le motif de remplissage d’une modalité, sélectionnez la modalitéconcernée, puis choisissez un motif de remplissage dans la palette.
Sinon, vous pouvez :insérer une nouvelle modalité avant la modalité sélectionnée ;déplacer une modalité sélectionnée ;supprimer une modalité sélectionnée ;paramétrer la séquence sur la valeur par défaut.
Options tableaux pivotants
Les options de tableaux pivotants définissent le modèle de tableau par défaut utilisé pour denouveaux résultats de tableaux pivotants. Le modèle de tableau peut contrôler une variétéd’attributs de tableaux pivotants, y compris l’affichage et la largeur du quadrillage; le style depolice, la taille, la couleur; et la couleur de fond.
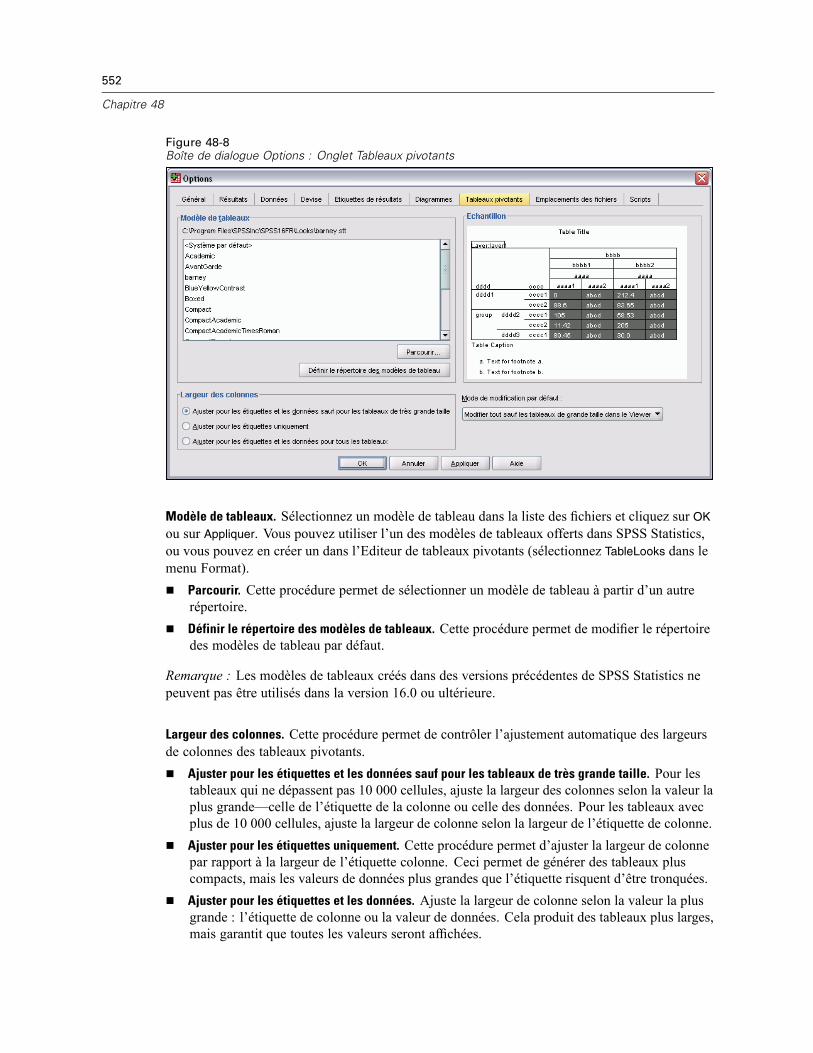
552
Chapitre 48
Figure 48-8Boîte de dialogue Options : Onglet Tableaux pivotants
Modèle de tableaux. Sélectionnez un modèle de tableau dans la liste des fichiers et cliquez sur OK
ou sur Appliquer. Vous pouvez utiliser l’un des modèles de tableaux offerts dans SPSS Statistics,ou vous pouvez en créer un dans l’Editeur de tableaux pivotants (sélectionnez TableLooks dans lemenu Format).
Parcourir. Cette procédure permet de sélectionner un modèle de tableau à partir d’un autrerépertoire.Définir le répertoire des modèles de tableaux. Cette procédure permet de modifier le répertoiredes modèles de tableau par défaut.
Remarque : Les modèles de tableaux créés dans des versions précédentes de SPSS Statistics nepeuvent pas être utilisés dans la version 16.0 ou ultérieure.
Largeur des colonnes. Cette procédure permet de contrôler l’ajustement automatique des largeursde colonnes des tableaux pivotants.
Ajuster pour les étiquettes et les données sauf pour les tableaux de très grande taille. Pour lestableaux qui ne dépassent pas 10 000 cellules, ajuste la largeur des colonnes selon la valeur laplus grande—celle de l’étiquette de la colonne ou celle des données. Pour les tableaux avecplus de 10 000 cellules, ajuste la largeur de colonne selon la largeur de l’étiquette de colonne.Ajuster pour les étiquettes uniquement. Cette procédure permet d’ajuster la largeur de colonnepar rapport à la largeur de l’étiquette colonne. Ceci permet de générer des tableaux pluscompacts, mais les valeurs de données plus grandes que l’étiquette risquent d’être tronquées.Ajuster pour les étiquettes et les données. Ajuste la largeur de colonne selon la valeur la plusgrande : l’étiquette de colonne ou la valeur de données. Cela produit des tableaux plus larges,mais garantit que toutes les valeurs seront affichées.
553
Options
Mode de modification par défaut. Contrôle l’activation des tableaux pivotants dans la fenêtre duViewer ou dans une fenêtre séparée. Par défaut, le fait de double-cliquer sur un tableau pivotantactive tout sauf les tableaux de grande taille dans la fenêtre du Viewer. Vous pouvez choisird’activer les tableaux pivotants dans une fenêtre séparée ou de sélectionner une définition de taillequi ouvrira de plus petits tableaux pivotants dans la fenêtre du Viewer et de plus grands tableauxpivotants dans une fenêtre séparée.
Copie des tableaux larges dans le Presse-papiers au format texte enrichi (format RTF). Lorsque destableaux pivotants sont collés au format Word/RTF, les tableaux trop larges pour la largeur dudocument seront ajustés ou réduits pour correspondre à la largeur du document, soit ils serontinchangés.
Options Emplacements des fichiers
Les options de l’onglet Emplacements des fichiers permettent de contrôler l’emplacement pardéfaut qu’utilisera l’application pour l’ouverture et l’enregistrement de fichiers au début de chaquesession, l’emplacement du fichier journal,l’emplacement du dossier temporaire, et le nombre defichiers qui apparaissent dans la liste des fichiers récemment utilisés.
Figure 48-9Boîte de dialogue Options : Onglet Emplacements des fichiers

554
Chapitre 48
Dossiers de démarrage pour les boîtes de dialogue Ouvrir et Enregistrer
Dossier spécifié. Le dossier spécifié est utilisé comme emplacement par défaut au début dechaque session. Vous pouvez indiquer plusieurs emplacements par défaut pour les fichiers dedonnées et autres (non-données).Dernier dossier utilisé. Le dernier dossier utilisé pour ouvrir ou enregistrer des fichiers lors dela session précédente est utilisé comme dossier par défaut au début de la session suivante.Ceci s’applique aux fichiers de données et autres (non-données).
Ces paramètres ne s’appliquent qu’aux boîtes de dialogue pour l’ouverture et l’enregistrement defichiers, et le « dernier fichier utilisé » est déterminé par la dernière boîte de dialogue utilisée pourouvrir ou enregistrer un fichier. Les fichiers ouverts ou enregistrés par le biais de la syntaxe decommande n’ont aucun effet sur—et ne sont pas affectés par—ces paramètres. Ces paramètresne sont disponibles qu’en mode analyse locale. En mode d’analyse distribuée avec connexionà un serveur distant (requiert un serveur SPSS Statistics), vous ne pouvez pas contrôler lesemplacements du dossier de démarrage.
Journal de session
Vous pouvez utiliser le journal de session pour enregistrer automatiquement les commandesexécutées dans une session. Celui-ci comprend les commandes saisies et exécutées dans lesfenêtres de syntaxe, ainsi que les commandes générées par les choix de boîte de dialogue. Vouspouvez modifier le fichier-journal et réutiliser les commandes dans d’autres sessions. Vous pouvezactiver ou désactiver la fonction journal, ajouter au fichier-journal ou l’écraser et sélectionner lenom et l’emplacement du fichier-journal. Vous pouvez copier la syntaxe de commande à partir dufichier journal et l’enregistrer dans un fichier de syntaxe.
Dossier temporaire
Cette option contrôle l’emplacement des fichiers temporaires créés au cours d’une session. Enmode distribué (disponible avec la version serveur), cette option n’affecte pas l’emplacement desfichiers de données temporaires. En mode distribué, l’emplacement des fichiers temporairesest contrôlé par la variable d’environnement SPSSTMPDIR, qui ne peut être définie que surl’ordinateur exécutant la version serveur du programme. Si vous devez modifier l’emplacementdu répertoire temporaire, contactez votre administrateur système.
Liste des fichiers récemment utilisés
Cette procédure permet de contrôler le nombre de fichiers récemment utilisés qui apparaissentdans le menu Fichier.
Options script
Utilisez l’onglet Scripts pour indiquer le langage de script par défaut et les autoscripts que vousvoulez utiliser. Vous pouvez utiliser les scripts pour automatiser de nombreuses fonctions dansSPSS, y compris la personnalisation des tableaux pivotants.
555
Options
Figure 48-10Boîte de dialogue Options : Onglet Scripts
Remarque : Les utilisateurs d’une ancienne version de Sax Basic doivent convertir manuellementtous les autoscripts personnalisés. Les autoscritps installés avec des versions antérieures à 16.0sont disponibles sous la forme d’un ensemble de fichiers de script distincts dans le sous-répertoireSamples du répertoire où SPSS Statistics est installé. Par défaut, aucun élément de résultat n’estassocié aux autoscripts. Vous devez associer manuellement tous les autoscripts aux éléments derésultat souhaités, comme indiqué ci-dessous.
Langage de script par défaut. Le langage de script par défaut détermine l’éditeur de script lancélors de la création de scripts. Il indique aussi le langage par défaut dont le fichier exécutablesera utilisé pour exécuter les autoscripts. Les langages de script disponibles dépendent de votreplateforme. Pour Windows, les langages de script disponibles sont Basic, qui est installé avec lesystème de base, et le langage de programmation Python. Pour toutes les autres plateformes, lescript est disponible avec le langage de programmation Python.
Remarque : Pour activer la fonction de script avec le langage de programmation Python, vousdevez installer Python et le plug-in d’intégration SPSS Statistics-Python séparément. Ce langagen’est pas installé avec le système de base, mais est disponible sur le CD d’installation pourWindows. Le plug-in d’intégration SPSS Statistics-Python est disponible sur le CD d’installationpour toutes les plateformes..
Activer l’autoscript. Cette case vous permet d’activer ou de désactiver l’autoscript. L’autoscriptest activé par défaut.
Autoscript de référence. Script facultatif appliqué à tous les nouveaux objets du Viewer avantqu’aucun autre autoscript ne soit appliqué. Indiquez le fichier de script à utiliser comme autoscriptde référence ainsi que le langage dont le fichier exécutable sera utilisé pour exécuter le script.

556
Chapitre 48
Pour appliquer des autoscripts à des éléments de résultat
E Dans la grille Identificateurs de commande, sélectionnez une commande qui génère des élémentsde résultat auxquels les autoscripts seront appliqués.
La colonne Objets, dans la grille Objets et Scripts, affiche une liste des objets associés à lacommande sélectionnée. La colonne Script affiche tout script existant pour la commandesélectionnée.
E Indiquez un script pour un élément affiché dans la colonne Objets. Cliquez sur la cellule Scriptcorrespondante. Entrez le chemin d’accès au script ou cliquez sur les points de suspension pouraccéder au script.
E Indiquez le langage dont le fichier exécutable sera utilisé pour exécuter le script. Remarque : Lelangage sélectionné n’est pas affecté par la modification du langage de script par défaut.
E Cliquez sur Appliquer ou sur OK.
Pour supprimer des associations à des autoscripts
E Dans la grille Objets et Scripts, cliquez sur la cellule de la colonne Script correspondant au script àdissocier.
E Effacez le chemin d’accès au script puis cliquez sur n’importe quelle autre cellule dans la grilleObjets et Scripts.
E Cliquez sur Appliquer ou sur OK.
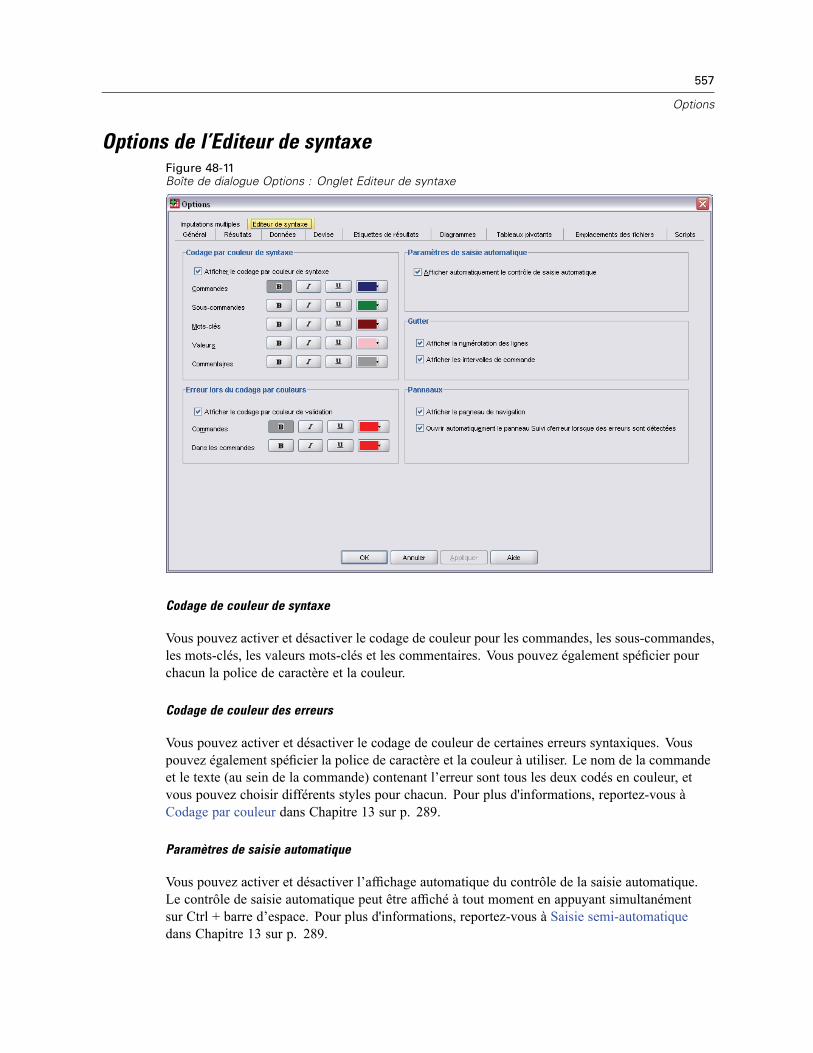
557
Options
Options de l’Editeur de syntaxeFigure 48-11Boîte de dialogue Options : Onglet Editeur de syntaxe
Codage de couleur de syntaxe
Vous pouvez activer et désactiver le codage de couleur pour les commandes, les sous-commandes,les mots-clés, les valeurs mots-clés et les commentaires. Vous pouvez également spéficier pourchacun la police de caractère et la couleur.
Codage de couleur des erreurs
Vous pouvez activer et désactiver le codage de couleur de certaines erreurs syntaxiques. Vouspouvez également spéficier la police de caractère et la couleur à utiliser. Le nom de la commandeet le texte (au sein de la commande) contenant l’erreur sont tous les deux codés en couleur, etvous pouvez choisir différents styles pour chacun. Pour plus d'informations, reportez-vous àCodage par couleur dans Chapitre 13 sur p. 289.
Paramètres de saisie automatique
Vous pouvez activer et désactiver l’affichage automatique du contrôle de la saisie automatique.Le contrôle de saisie automatique peut être affiché à tout moment en appuyant simultanémentsur Ctrl + barre d’espace. Pour plus d'informations, reportez-vous à Saisie semi-automatiquedans Chapitre 13 sur p. 289.
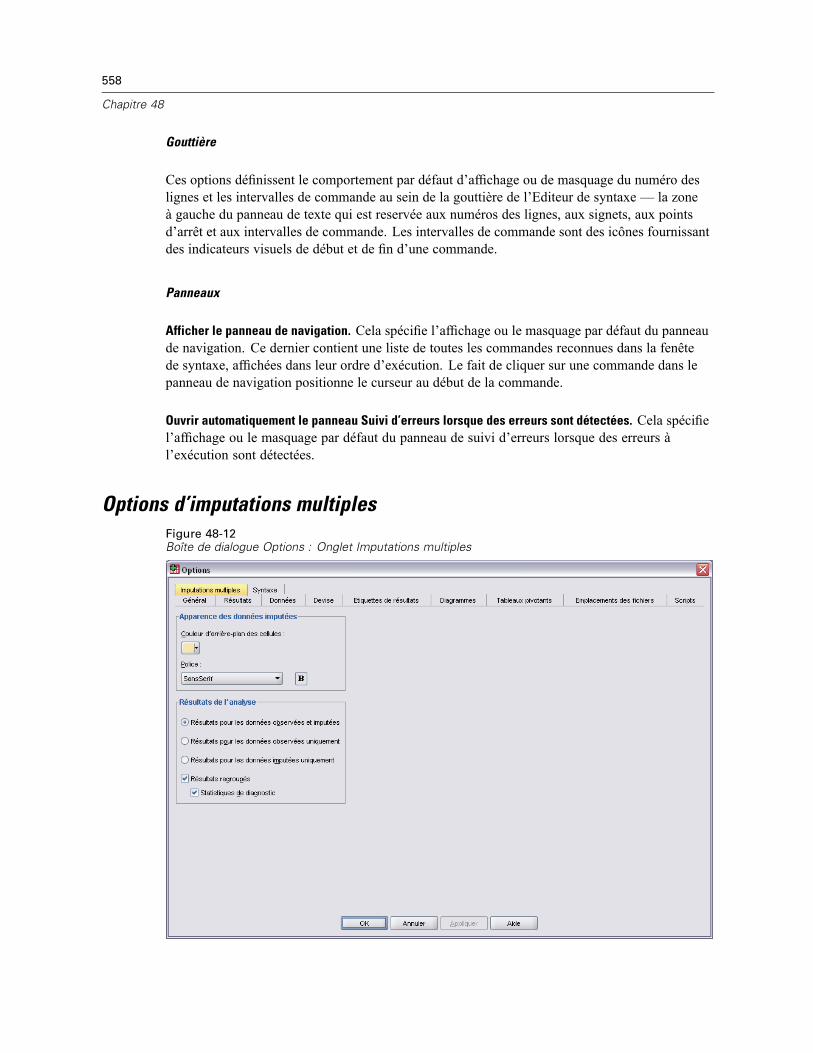
558
Chapitre 48
Gouttière
Ces options définissent le comportement par défaut d’affichage ou de masquage du numéro deslignes et les intervalles de commande au sein de la gouttière de l’Editeur de syntaxe — la zoneà gauche du panneau de texte qui est reservée aux numéros des lignes, aux signets, aux pointsd’arrêt et aux intervalles de commande. Les intervalles de commande sont des icônes fournissantdes indicateurs visuels de début et de fin d’une commande.
Panneaux
Afficher le panneau de navigation. Cela spécifie l’affichage ou le masquage par défaut du panneaude navigation. Ce dernier contient une liste de toutes les commandes reconnues dans la fenêtede syntaxe, affichées dans leur ordre d’exécution. Le fait de cliquer sur une commande dans lepanneau de navigation positionne le curseur au début de la commande.
Ouvrir automatiquement le panneau Suivi d’erreurs lorsque des erreurs sont détectées. Cela spécifiel’affichage ou le masquage par défaut du panneau de suivi d’erreurs lorsque des erreurs àl’exécution sont détectées.
Options d’imputations multiplesFigure 48-12Boîte de dialogue Options : Onglet Imputations multiples

559
Options
L’onglet Imputations multiples contrôle deux sortes de préférences asssociées aux imputationsmultiples :
L’apparence des données imputées. Par défaut, les cellules contenant des données imputéesauront un arrière-plan d’une autre couleur que celui des cellules contenant des donnéesnon-imputées. Cette différence d’apparence des données imputées devrait faciliter la navigationdans les ensembles de données et la recherche de ces cellules. Vous pouvez modifier la couleurd’arrière-plan par défaut des cellules, la police et afficher les données imputées en gras.
Résultats d’analyse. Ce groupe contrôle le type de résultats du Viewer produits lorsqu’un ensemblede données à imputation multiple est analysé. Par défaut, les résultats seront produits pourl’ensemble de données d’origine (pré-imputation) et pour chacun des ensembles de donnéesimputés. De plus, pour ce genre de procédures qui prennent en charge le regroupement dedonnées imputées, des résultats combinés finaux seront générés. Lorsqu’un regroupement univariésera effectué, les diagnostiques de regroupement seront également affichés. Mais vous pouvezsupprimer tous les résultats que vous ne désirez pas voir.
Pour définir les options d’imputation multiple
A partir du menu, sélectionnez :Affichage
Options
Cliquez sur l’onglet Imputation multiple.

Chapitre
49Personnalisation des menus et desbarres d’outils
Editeur de menu
Vous pouvez utiliser l’éditeur de menu pour personnaliser vos menus SPSS. Avec l’éditeur demenu vous pouvez :
Ajouter des éléments de menus qui exécutent des scripts SPSS personnalisés.Ajouter des éléments de menu qui exécutent des fichiers de syntaxe de commande SPSS.Ajouter des éléments de menu qui lancent d’autres applications et envoient automatiquementdes données SPSS vers d’autres applications.
SPSS peut envoyer des données vers d’autres applications dans les formats suivants : SPSSStatistics, Excel, Lotus 1-2-3, séparés par des tabulations et dBASE IV.
Pour ajouter des éléments aux menus
E A partir des menus, sélectionnez :Affichage
Editeur de menu
E Dans la boîte de dialogue Editeur de menu, double-cliquez sur le menu dans lequel vous voulezrajouter un nouvel élément ou cliquez sur l’icône en forme de signe plus.
E Sélectionnez l’élément de menu au-dessus duquel vous voulez qu’apparaisse le nouvel élément.
E Cliquez sur Insérer élément pour insérer un nouvel élément de menu.
E Sélectionnez le type de fichier du nouvel élément (fichier de script, fichier de syntaxe decommande ou application externe).
E Cliquez sur Parcourir pour sélectionner un fichier à attacher à l’élément de menu.
560
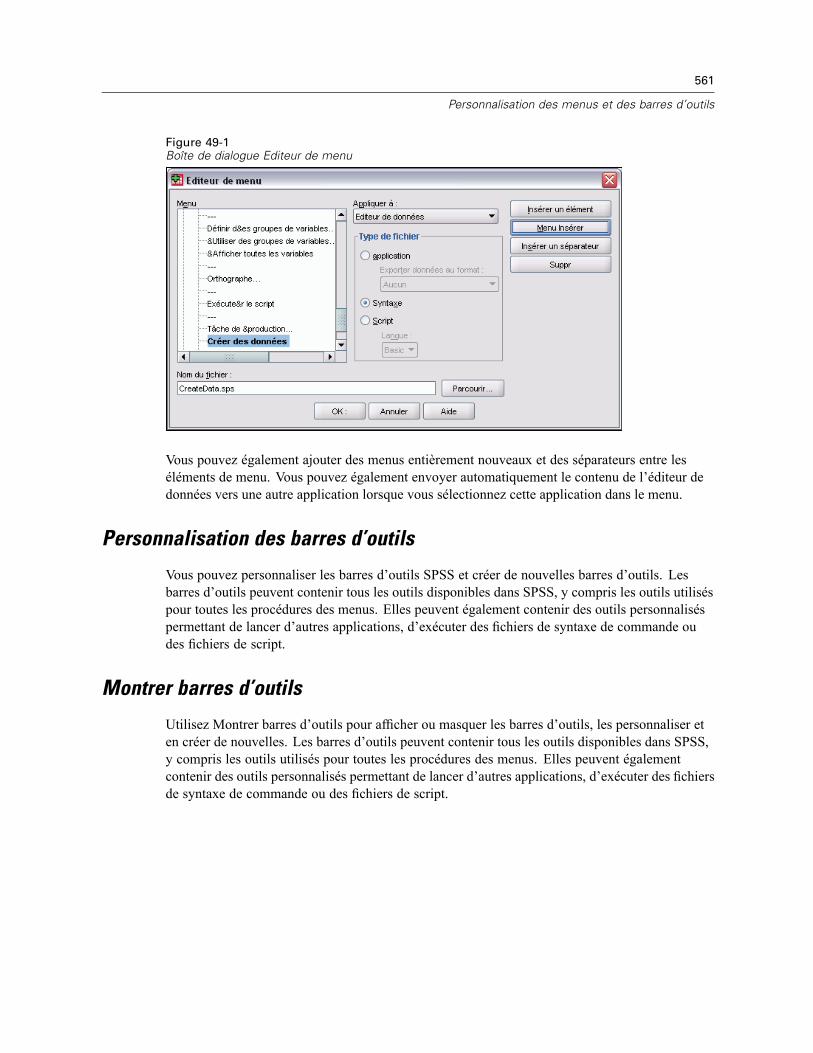
561
Personnalisation des menus et des barres d’outils
Figure 49-1Boîte de dialogue Editeur de menu
Vous pouvez également ajouter des menus entièrement nouveaux et des séparateurs entre leséléments de menu. Vous pouvez également envoyer automatiquement le contenu de l’éditeur dedonnées vers une autre application lorsque vous sélectionnez cette application dans le menu.
Personnalisation des barres d’outils
Vous pouvez personnaliser les barres d’outils SPSS et créer de nouvelles barres d’outils. Lesbarres d’outils peuvent contenir tous les outils disponibles dans SPSS, y compris les outils utiliséspour toutes les procédures des menus. Elles peuvent également contenir des outils personnaliséspermettant de lancer d’autres applications, d’exécuter des fichiers de syntaxe de commande oudes fichiers de script.
Montrer barres d’outils
Utilisez Montrer barres d’outils pour afficher ou masquer les barres d’outils, les personnaliser eten créer de nouvelles. Les barres d’outils peuvent contenir tous les outils disponibles dans SPSS,y compris les outils utilisés pour toutes les procédures des menus. Elles peuvent égalementcontenir des outils personnalisés permettant de lancer d’autres applications, d’exécuter des fichiersde syntaxe de commande ou des fichiers de script.

562
Chapitre 49
Figure 49-2Boîte de dialogue Montrer barres d’outils
Pour personnaliser les barres d’outilsE A partir des menus, sélectionnez :
AffichageBarres d’outils
Personnaliser
E Sélectionnez la barre d’outils que vous voulez personnaliser et cliquez sur Modifier, ou cliquez surNouveau pour créer une nouvelle barre d’outils.
E Pour les nouvelles barres d’outils, indiquez le nom de la barre, sélectionnez les fenêtres danslesquelles vous voulez qu’elles apparaissent et cliquez sur Modifier.
E Sélectionnez un élément dans la liste Modalités pour afficher les outils disponibles dans cettemodalité.
E Faites glisser et lâchez les outils que voulez inclure dans la barre d’outils affichée dans la boîte dedialogue.
E Pour supprimer un outil dans une barre d’outils, le faire glisser n’importe où en dehors de labarre d’outils affichée dans la boîte de dialogue.
Pour créer un outil personnalisé pour ouvrir un fichier, exécuter un fichier de syntaxe decommande ou exécuter un script :
E Cliquez sur Nouvel outil dans la boîte de dialogue Modifier barre d’outils.
E Indiquez une étiquette décrivant l’outil.
E Sélectionnez l’action que vous voulez affecter à l’outil (ouvrir un fichier, exécuter un fichier desyntaxe de commande ou exécuter un script).
E Cliquez sur Parcourir pour sélectionner un fichier ou une application à associer à l’outil.

563
Personnalisation des menus et des barres d’outils
Les nouveaux outils s’affichent dans la modalité définie par l’utilisateur, qui peut aussi contenirdes éléments de menu définis par l’utilisateur.
Propriétés barre d’outils
Utilisez Propriétés des barres d’outils pour sélectionner les types de fenêtres dans lesquelles vousvoulez voir apparaître la barre d’outils sélectionnée. Cette boîte de dialogue sert aussi à créer desnoms ou de nouvelles barres d’outils.
Figure 49-3Boîte de dialogue Propriétés barre d’outils
Pour définir des propriétés des barres d’outils
E A partir des menus, sélectionnez :Affichage
Barres d’outilsPersonnaliser
E Pour les barres d’outils existantes, cliquez sur Modifier, puis sur Propriétés dans la boîte de dialogueModifier barre d’outils.
E Pour les nouvelles barres d’outils, cliquez sur Nouvel outil.
E Sélectionnez les types de fenêtres dans lesquelles vous voulez voir apparaître la barre d’outils.Pour les nouvelles barres d’outils, indiquez aussi un nom de barre.
Barre d’outils Modifier
Utilisez la boîte de dialogue Modifier barre d’outils pour personnaliser les barres d’outilsexistantes et en créer de nouvelles. Les barres d’outils peuvent contenir tous les outils disponiblesdans SPSS, y compris les outils utilisés pour toutes les procédures des menus. Elles peuventégalement contenir des outils personnalisés permettant de lancer d’autres applications, d’exécuterdes fichiers de syntaxe de commande ou des fichiers de script.
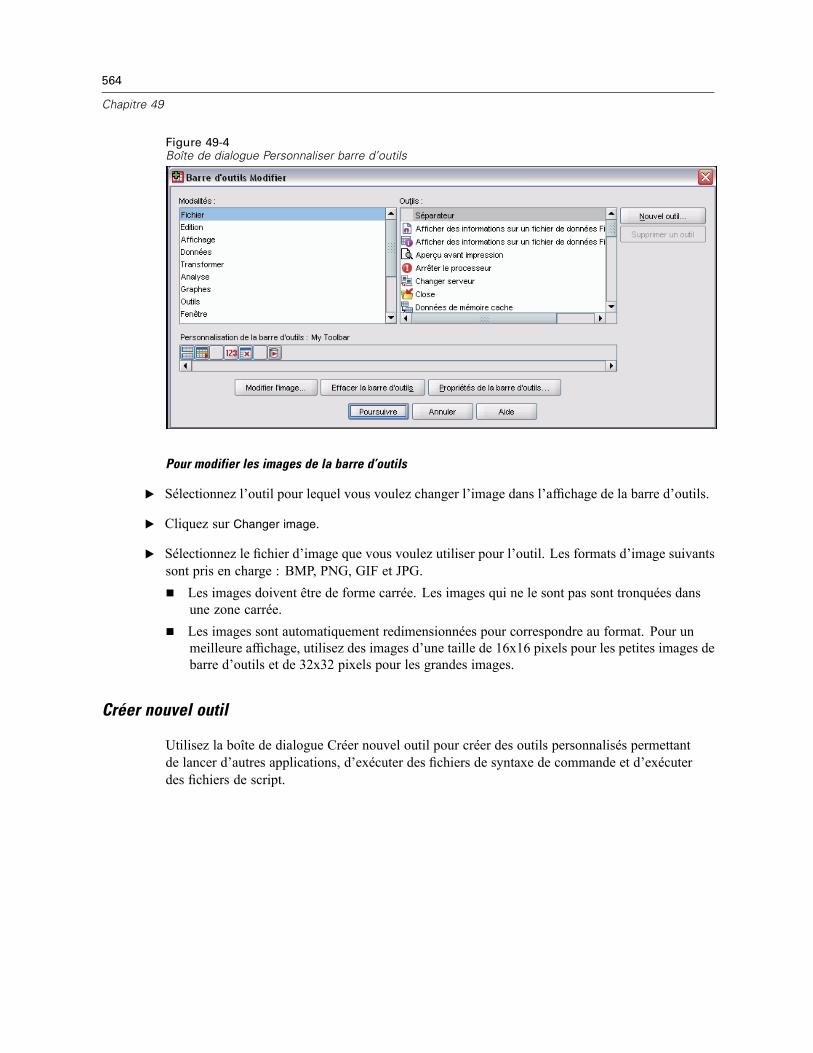
564
Chapitre 49
Figure 49-4Boîte de dialogue Personnaliser barre d’outils
Pour modifier les images de la barre d’outils
E Sélectionnez l’outil pour lequel vous voulez changer l’image dans l’affichage de la barre d’outils.
E Cliquez sur Changer image.
E Sélectionnez le fichier d’image que vous voulez utiliser pour l’outil. Les formats d’image suivantssont pris en charge : BMP, PNG, GIF et JPG.
Les images doivent être de forme carrée. Les images qui ne le sont pas sont tronquées dansune zone carrée.Les images sont automatiquement redimensionnées pour correspondre au format. Pour unmeilleure affichage, utilisez des images d’une taille de 16x16 pixels pour les petites images debarre d’outils et de 32x32 pixels pour les grandes images.
Créer nouvel outil
Utilisez la boîte de dialogue Créer nouvel outil pour créer des outils personnalisés permettantde lancer d’autres applications, d’exécuter des fichiers de syntaxe de commande et d’exécuterdes fichiers de script.
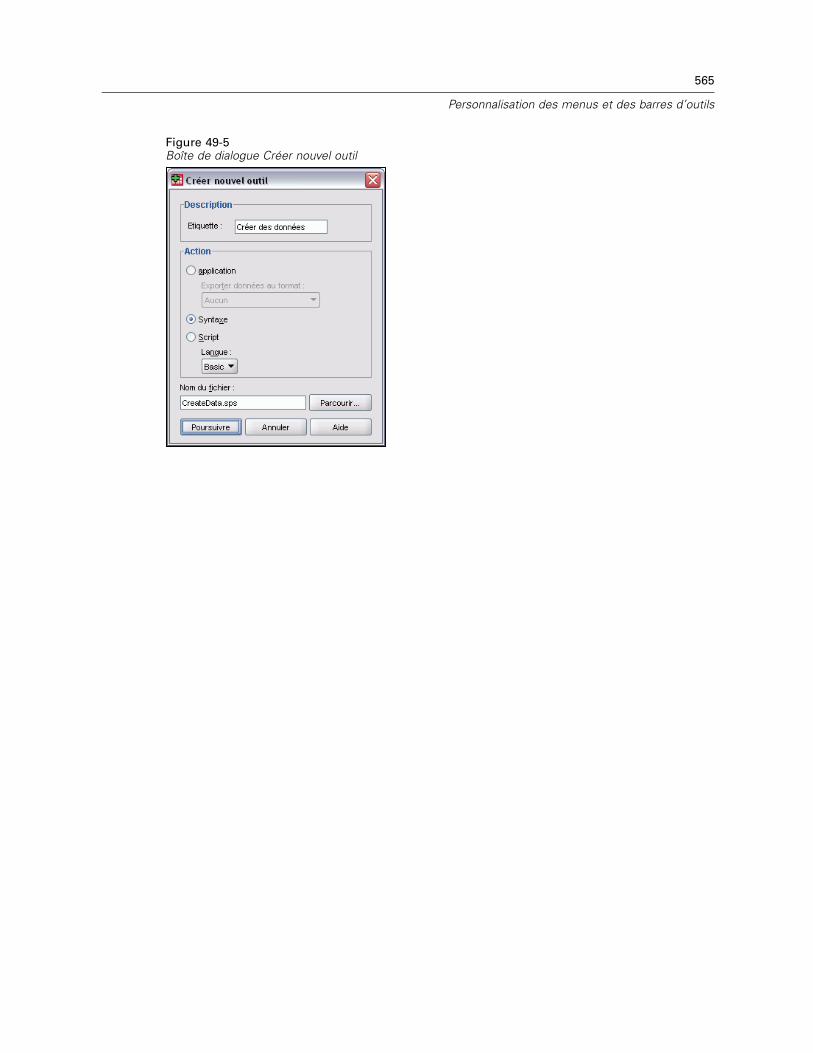
565
Personnalisation des menus et des barres d’outils
Figure 49-5Boîte de dialogue Créer nouvel outil

Chapitre
50Création et gestion de boîtes dedialogue personnalisées
Le générateur de boîtes de dialogue personnalisées vous permet de créer et de gérer des boîtesde dialogue personnalisées afin de générer une syntaxe de commande. Grâce au générateur deboîtes de dialogue personnalisées, vous pouvez :
Créer votre propre version d’une boîte de dialogue pour une procédure SPSS Statisticsintégrée. Par exemple, vous pouvez créer une boîte de dialogue pour la procédure Effectifsqui autorise l’utilisateur uniquement à sélectionner le groupe de variables et qui génère unesyntaxe de commande avec des options prédéfinies qui normalisent les résultats.Créer une interface utilisateur qui génère une syntaxe de commande pour une commanded’extension. Les commandes d’extension sont des commandes SPSS Statistics définies parl’utilisateur implémentées soit dans le langage de programmation Python ou R. Pour plusd'informations, reportez-vous à Boîtes de dialogue personnalisées pour les commandesd’extension sur p. 589.Ouvrir un fichier contenant la spécification d’une boîte de dialogue (vraisemblablement crééepar un autre utilisateur) et ajouter la boîte de dialogue à votre installation de SPSS Statistics,en procédant éventuellement à vos propres modifications.Enregistrer la spécification d’une boîte de dialogue personnalisée de sorte que d’autresutilisateurs puissent l’ajouter à leur installation de SPSS Statistics.
Pour lancer le générateur de boîtes de dialogue personnalisées
E A partir des menus, sélectionnez :Outils
Générateur de boîtes de dialogue personnalisées
566
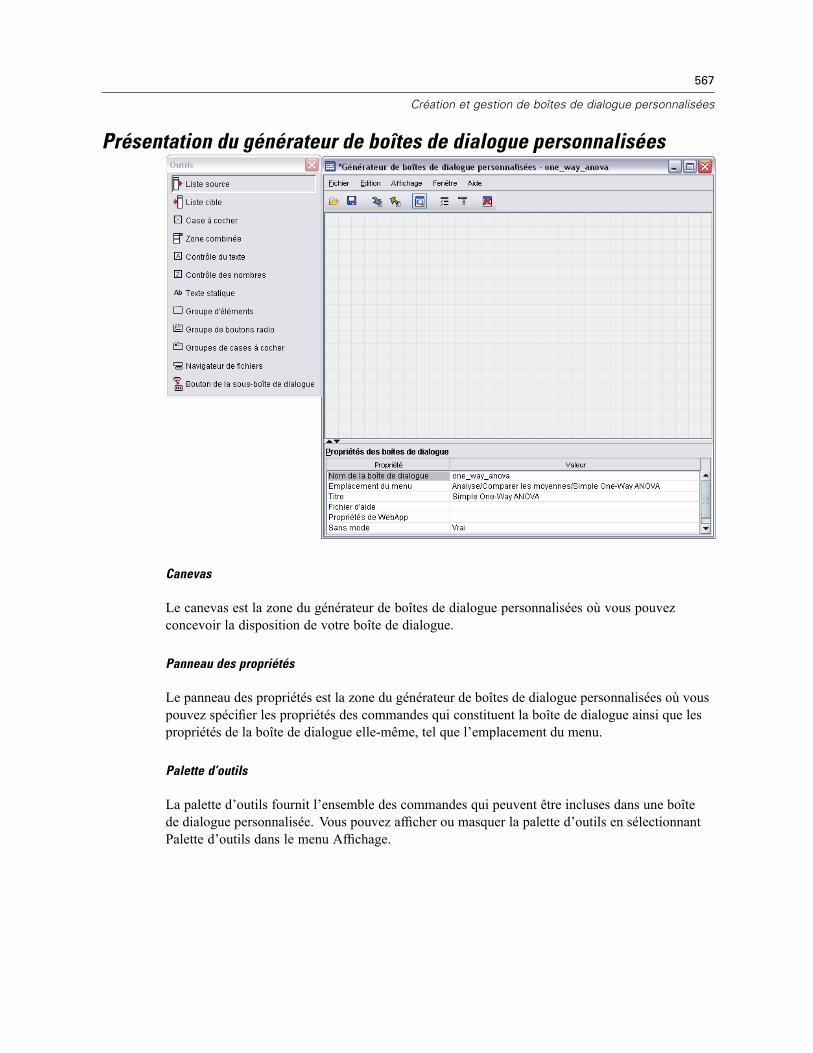
567
Création et gestion de boîtes de dialogue personnalisées
Présentation du générateur de boîtes de dialogue personnalisées
Canevas
Le canevas est la zone du générateur de boîtes de dialogue personnalisées où vous pouvezconcevoir la disposition de votre boîte de dialogue.
Panneau des propriétés
Le panneau des propriétés est la zone du générateur de boîtes de dialogue personnalisées où vouspouvez spécifier les propriétés des commandes qui constituent la boîte de dialogue ainsi que lespropriétés de la boîte de dialogue elle-même, tel que l’emplacement du menu.
Palette d’outils
La palette d’outils fournit l’ensemble des commandes qui peuvent être incluses dans une boîtede dialogue personnalisée. Vous pouvez afficher ou masquer la palette d’outils en sélectionnantPalette d’outils dans le menu Affichage.

568
Chapitre 50
Création d’une boîte de dialogueLes étapes de base impliquées dans la création d’une boîte de dialogue sont :
E Spécifier les propriétés de la boîte de dialogue même, telles que le titre qui apparaît lorsque laboîte de dialogue est lancée et l’emplacement du nouvel élément de menu de la boîte de dialogue àl’intérieur des menus de SPSS Statistics. Pour plus d'informations, reportez-vous à Propriétésde la boîte de dialogue sur p. 568.
E Spécifier les commandes, telles que les listes de variables source et cible qui constituent laboîte de dialogue et toutes les boîtes de dialogue de niveau inférieur. Pour plus d'informations,reportez-vous à Types de commandes sur p. 577.
E Créer le modèle de syntaxe qui spécifie la syntaxe de commande que la boîte de dialogue doitgénérer. Pour plus d'informations, reportez-vous à Création du modèle de syntaxe sur p. 572.
E Installer la boîte de dialogue dans SPSS Statistics et/ou enregistrer la spécification de la boîtede dialogue dans un fichier (.spd ) de package de boîtes de dialogue personnalisées. Pour plusd'informations, reportez-vous à Gestion des boîtes de dialogue personnalisées sur p. 575.
Vous pouvez afficher l’aperçu de votre boîte de dialogue pendant sa création. Pour plusd'informations, reportez-vous à Aperçu d’une boîte de dialogue personnalisée sur p. 575.
Propriétés de la boîte de dialoguePour afficher et définir les propriétés de la boîte de dialogue :
E Cliquez dans le canevas sur toute zone qui se trouve à l’extérieur des commandes. Comme il n’y aaucune commande sur le canevas, les propriétés de la boîte de dialogue sont toujours visibles.
Nom de la boîte de dialogue. La propriété Nom de la boîte de dialogue est obligatoire et spécifieun nom unique à associer à la boîte de dialogue. Il s’agit du nom utilisé pour identifier la boîtede dialogue lors de son installation ou de sa désinstallation. Afin de réduire la possibilité d’unconflit de noms, vous pouvez attribuer un préfixe au nom de la boîte de dialogue à l’aide d’unidentifiant de votre entreprise, tel qu’une URL.
Emplacement du menu. Cliquez sur le bouton points de suspension (...) pour ouvrir la boîtede dialogue Emplacement du menu qui vous permet de spécifier le nom et l’emplacement del’élément de menu destiné à la boîte de dialogue. L’ajout de l’emplacement d’un menu pour unenouvelle boîte de dialogue personnalisée ou la modification de l’emplacement du menu d’uneboîte de dialogue personnalisée installée nécessitent le redémarrage de SPSS Statistics.
Titre. La propriété Titre spécifie le texte à afficher dans la barre de titre de la boîte de dialogue.
Fichier d’aide. La propriété Fichier d’aide est optionnelle et spécifie le chemin vers un fichierd’aide destiné à la boîte de dialogue. Il s’agit du fichier qui est exécuté lorsque l’utilisateur cliquesur le bouton Aide de la boîte de dialogue. Les fichiers d’aide doivent être au format HTML. Lebouton Aide de la boîte de dialogue est masqué en temps réel si aucun fichier d’aide n’y est associé.
Tous les fichiers de prise en charge tels que les fichiers d’images et les feuilles de style doiventêtre stockés avec le fichier d’aide principal une fois que la boîte de dialogue a été installée. Pardéfaut, les spécifications d’une boîte de dialogue personnalisée installée sont stockées dans le

569
Création et gestion de boîtes de dialogue personnalisées
dossier ext/lib/<Nom de la boîte de dialogue> du répertoire d’installation (situé dans la racine durépertoire d’installation de Windows et de Linux, et dans le répertoire Contents/bin du grouped’applications pour Mac. Les fichiers de prise en charge doivent se trouver dans le répertoireracine du dossier et non dans des sous-dossiers. Ils doivent être ajoutés manuellement à tous lesfichiers de packages de boîtes de dialogue personnalisées que vous créez pour la boîte de dialogue.
Si vous avez spécifié d’autres emplacements pour les boîtes de dialogue installées (à l’aide de lavariable d’environnement SPSS_CDIALOGS_PATH ) vous devez stocker tous les dossiers de priseen charge dans le dossier <Nom de la boîte de dialogue> à l’emplacement approprié. Pour plusd'informations, reportez-vous à Gestion des boîtes de dialogue personnalisées sur p. 575.
Remarque : Lorsque vous travaillez avec une boîte de dialogue ouverte à partir d’un fichier depackage (.spd) de boîtes de dialogue personnalisées, la propriété Fichier d’aide pointe vers undossier temporaire associé au fichier .spd. Toute modification apportée au fichier d’aide doit êtreeffectuée sur la copie située dans le dossier temporaire.
Propriétés WebApp. Elles vous permettent d’associer un fichier de propriétés à cette boîte dedialogue pour une utilisation destinée au développement de petites applications clientes déployéessur le Web.
Non modale. Spécifie si la boîte de dialogue est modale ou non modale. Si une boîte de dialogueest modale, elle doit être fermée avant que l’utilisateur ne puisse interagir avec les fenêtres del’application principale (Données, Résultats et Syntaxe) ou avec d’autres boîtes de dialogueouvertes. Les boîtes de dialogues non modales n’ont pas de contraintes. La valeur par défautest non modale.
Syntaxe. La propriété de syntaxe spécifie le modèle de syntaxe utilisé pour créer la syntaxe decommande générée par la boîte de dialogue en temps réel. Cliquez sur le bouton points desuspension (...) pour ouvrir le modèle de syntaxe. Pour plus d'informations, reportez-vous àCréation du modèle de syntaxe sur p. 572.

570
Chapitre 50
Spécification de l’emplacement du menu d’une boîte de dialoguepersonnalisée
Figure 50-1Boîte de dialogue Emplacement du menu du générateur de boîtes de dialogue personnalisées
La boîte de dialogue Emplacement du menu vous permet de spécifier le nom et l’emplacementde l’élément du menu d’une boîte de dialogue personnalisée. L’ajout de l’emplacement d’unmenu pour une nouvelle boîte de dialogue personnalisée ou la modification de l’emplacementdu menu d’une boîte de dialogue personnalisée installée nécessitent le redémarrage de SPSSStatistics. Les éléments de menu des boîtes de dialogue personnalisées n’apparaissent pas dansl’Editeur de menu de SPSS Statistics.
E Double-cliquez sur le menu dans lequel vous voulez rajouter l’élément pour la nouvelle boîte dedialogue ou cliquez sur l’icône en forme de signe plus. Vous pouvez aussi ajouter des éléments aumenu de premier niveau étiqueté Personnalisé (situé entre les éléments Graphiques et Outils), quin’est disponible que pour les éléments de menu associés à des boîtes de dialogue personnalisées.
Si vous souhaitez créer des menus personnalisés ou des sous-menus, utilisez l’Editeur de menu.Pour plus d'informations, reportez-vous à Editeur de menu dans Chapitre 49 sur p. 560. Notezcependant que d’autres utilisateurs de votre boîte de dialogue devront créer manuellement lemême menu ou sous-menu à partir de leur Editeur de menu, faute de quoi la boîte de dialogue seraajoutée à leur menu personnalisé.
Remarque : La boîte de dialogue Emplacement du menu affiche l’ensemble des menus, y comprisceux de tous les modules complémentaires. Assurez-vous d’ajouter l’élément de menu pourvotre boîte de dialogue personnalisée à un menu auquel vous ou les utilisateurs finaux de votreboîte de dialogue pourront accéder.

571
Création et gestion de boîtes de dialogue personnalisées
E Sélectionnez l’élément de menu au-dessus duquel vous voulez qu’apparaisse l’élément de lanouvelle boîte de dialogue. Une fois que l’élément est ajouté, vous pouvez utiliser les boutonsDéplacer vers le haut et Déplacer vers le bas pour le repositionner.
E Saisissez un titre pour l’élément du menu. Les titres d’un menu ou d’un sous-menu donnédoivent être uniques.
E Cliquez sur Ajouter.
Sinon, vous pouvez :Ajouter un séparateur au-dessus ou en dessous du nouvel élément du menu.Spécifiez le chemin vers une image qui s’affiche à côté de l’élément du menu de la boîte dedialogue personnalisée. Les type d’images gérés sont gif et png. La taille de l’image nepeut pas excéder 16 x 16 pixels.
Disposition des commandes sur le canevas
Vous pouvez ajouter des commandes à une boîte de dialogue personnalisée en les faisant glisserdepuis la palette d’outils sur le canevas. Afin d’assurer la cohérence avec les boîtes de dialogueintégrées, le canevas est divisé en trois colonnes fonctionnelles dans lesquelles vous pouvezplacer des commandes.
Figure 50-2Structure du canevas
Colonne de gauche. La colonne de gauche est essentiellement destinée à une commande de listesource. Toutes les commandes qui ne sont ni des listes cible ni des boutons de boîte de dialogue deniveau inférieur peuvent être placées dans la colonne de gauche.
Colonne centrale. La colonne centrale peut contenir toutes les commandes qui ne sont ni des listescible ni des boutons de boîte de dialogue de niveau inférieur.
Colonne de droite. La colonne de droite ne peut contenir que des boutons de boîte de dialoguede niveau inférieur.

572
Chapitre 50
Bien qu’elles ne soient pas affichées sur le canevas, chaque boîte de dialogue contient les boutonsOK, Coller, Annuler et Aide situés en bas de la boîte de dialogue. La présence et l’emplacementde ces boutons sont automatiques, néanmoins, le bouton Aide est masqué si aucun fichier d’aiden’est associé à la boîte de dialogue (comme spécifié par la propriété du fichier d’aide dans lespropriétés de la boîte de dialogue).
Vous pouvez modifier l’ordre vertical des commandes au sein d’une colonne en les faisantglisser vers le haut ou vers le bas, mais la position exacte des commandes sera automatiquementdéterminée pour vous. À l’exécution, les commandes seront correctement redimensionnées lorsquela boîte de dialogue sera elle-même redimensionnée. Des commandes telles que des listes sourceet des listes cible se développent automatiquement afin de remplir l’espace disponible entre elles.
Création du modèle de syntaxe
Le modèle de syntaxe spécifie la syntaxe de commande à générer par la boîte de dialoguepersonnalisée. Une boîte de dialogue personnalisée unique peut générer une syntaxe de commandepour n’importe quel nombre de commandes SPSS Statistics intégrées ou de commandesd’extension.Le modèle de syntaxe peut consister en un texte statique qui est généré systématiquement et en
identificateurs de commande qui sont remplacés en temps réel par les valeurs des commandesde la boîte de dialogue personnalisée associée. Par exemple, des noms de commande et desspécifications de sous-commande qui ne dépendent pas d’une saisie par l’utilisateur sontconsidérés comme du texte statique, tandis que le groupe de variables spécifiées dans une listecible est représenté par l’identificateur de commande de la commande de liste cible.
Pour créer un modèle de syntaxe
E À partir du menu du Générateur de boîtes de dialogue personnalisées, sélectionnez :Affichage
Modèle de syntaxe
(ou cliquez sur le bouton points de suspension (...) dans le champ de propriété de syntaxe despropriétés de la boîte de dialogue)
E Pour une syntaxe de commande statique qui ne dépend pas de valeurs spécifiées par l’utilisateur,saisissez la syntaxe de la même manière que dans l’éditeur de syntaxe.
E Ajoutez des identificateurs de commandes dans le format %%Identificateur%% auxemplacements où vous souhaitez insérer une syntaxe de commande générée par des commandes,où Identificateur est la valeur de la propriété Identificateur de cette commande. Vouspouvez effectuer une sélection à partir d’une liste des identificateurs de commande disponibles enappuyant sur Ctrl+barre d’espace. Si vous saisissez manuellement des identificateurs, conservezles espaces car tous les espaces des identificateurs sont pris en compte.
Au moment de l’exécution chaque identificateur est remplacé par la valeur actuelle de la propriétéde syntaxe de commande associée pour toutes les commandes qui ne sont ni des cases à cocherni des groupes de cases à cocher. Pour les cases à cocher et les groupes de cases à cocher,l’identificateur est remplacé par la valeur actuelle de la propriété de syntaxe Cochée ou Non

573
Création et gestion de boîtes de dialogue personnalisées
cochée de la commande associée, en fonction de l’état actuel de la commande (cochée ou noncochée). Pour plus d'informations, reportez-vous à Types de commandes sur p. 577.
Exemple : Inclusion de valeurs dans le modèle de syntaxe au moment de l’exécution
Envisagez une version simplifiée de la boîte de dialogue Effectifs qui ne contient qu’unecommande de liste source et une commande de liste cible et qui génère une syntaxe de commandede la forme suivante :
FREQUENCIES VARIABLES=var1 var2.../FORMAT = NOTABLE/BARCHART.
Le modèle de syntaxe à générer pourrait ressembler à :
FREQUENCIES VARIABLES=%%target_list%%/FORMAT = NOTABLE/BARCHART.
%%target_list%% représente la valeur de la propriété de l’identificateur pour la commandede liste cible. Au moment de l’exécution elle est remplacée par la valeur actuelle de lapropriété de syntaxe de commande.La définition de la propriété de syntaxe de commande de liste cible qui doit être%%ThisValue%% indique qu’au moment de l’exécution, la valeur actuelle de la propriété serala valeur de la commande, laquelle représente le groupe de variables dans la liste cible.
Exemple : Inclusion d’une syntaxe de commande à partir de commandes de conteneur
À partir de l’exemple précédent, envisagez d’ajouter une boîte de dialogue Statistiques de niveauinférieur qui contient un unique groupe de cases à cocher qui permet à l’utilisateur de spécifier unemoyenne, un écart type, un minimum et un maximum. Supposez que les cases à cocher soientcontenues dans une commande de groupe d’éléments, comme illustré sur la figure suivante.
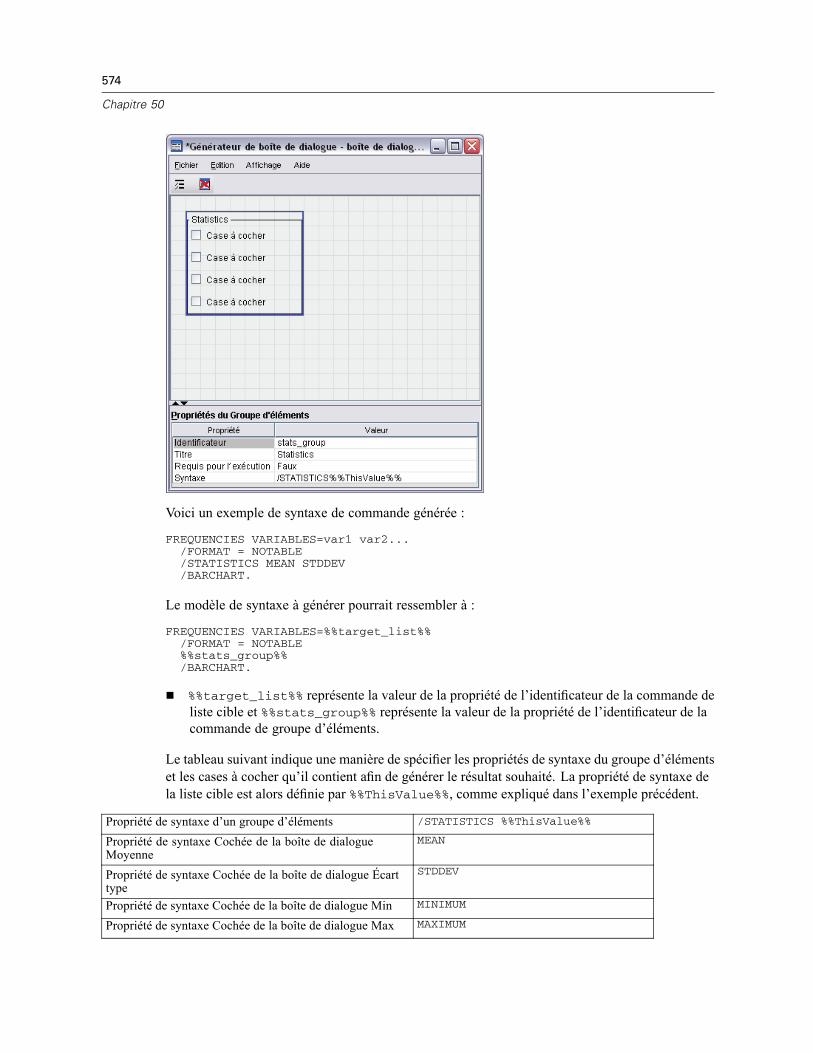
574
Chapitre 50
Voici un exemple de syntaxe de commande générée :
FREQUENCIES VARIABLES=var1 var2.../FORMAT = NOTABLE/STATISTICS MEAN STDDEV/BARCHART.
Le modèle de syntaxe à générer pourrait ressembler à :
FREQUENCIES VARIABLES=%%target_list%%/FORMAT = NOTABLE%%stats_group%%/BARCHART.
%%target_list%% représente la valeur de la propriété de l’identificateur de la commande deliste cible et %%stats_group%% représente la valeur de la propriété de l’identificateur de lacommande de groupe d’éléments.
Le tableau suivant indique une manière de spécifier les propriétés de syntaxe du groupe d’élémentset les cases à cocher qu’il contient afin de générer le résultat souhaité. La propriété de syntaxe dela liste cible est alors définie par %%ThisValue%%, comme expliqué dans l’exemple précédent.
Propriété de syntaxe d’un groupe d’éléments /STATISTICS %%ThisValue%%
Propriété de syntaxe Cochée de la boîte de dialogueMoyenne
MEAN
Propriété de syntaxe Cochée de la boîte de dialogue Écarttype
STDDEV
Propriété de syntaxe Cochée de la boîte de dialogue Min MINIMUM
Propriété de syntaxe Cochée de la boîte de dialogue Max MAXIMUM

575
Création et gestion de boîtes de dialogue personnalisées
Au moment de l’exécution %%stats_group%% est remplacé par la valeur actuelle de la propriétéde syntaxe de commande du groupe d’éléments. Spécifiquement, %%ThisValue%% est remplacépar une liste de valeurs, séparées par des blancs, de la propriété de syntaxe Cochée ou Non cochéepour chaque case en fonction de son état (cochée ou non cochée). Puisque nous n’avons spécifiédes valeurs que pour la propriété de syntaxe Cochée, seules les cases cochées contribuent à%%ThisValue%% . Par exemple, si l’utilisateur coche les cases de la moyenne et de l’écarttype, la valeur au moment de l’exécution de la propriété de syntaxe pour le groupe d’élémentsest /STATISTICS MEAN STDDEV .
Si aucune case n’est cochée, la propriété de syntaxe de commande de groupe d’éléments est vide etla syntaxe de commandes générée ne contient aucune référence à %%stats_group%%. Cela peutêtre ou ne pas être souhaitable. Par exemple, même si aucune case n’est cochée, il est possibleque vous souhaitiez générer la sous-commande STATISTICS. Cela est réalisable en référant lesidentificateurs des cases à cocher directement dans le modèle de syntaxe, comme dans :
FREQUENCIES VARIABLES=%%target_list%%/FORMAT = NOTABLE/STATISTICS %%stats_mean%% %%stats_stddev%% %%stats_min%% %%stats_max%%/BARCHART.
Aperçu d’une boîte de dialogue personnalisée
Vous pouvez afficher l’aperçu de la boîte de dialogue actuellement ouverte dans le générateurde boîtes de dialogue personnalisées. La boîte de dialogue s’affiche et fonctionne comme elle leferait si elle était exécutée à partir de menus dans SPSS Statistics.
Les listes de variables source sont renseignées à l’aide de variables fictives qui peuvent êtredéplacées vers des listes cible.Le bouton Coller colle la syntaxe de commande dans la fenêtre de syntaxe désignée.Le bouton OK ferme l’aperçu.Si un fichier d’aide est justifié, le bouton Aide est activé et ouvre le fichier spécifié. Si aucunfichier d’aide n’est spécifié, le bouton d’aide est désactivé lors de l’aperçu, et masqué lors del’exécution de la boîte de dialogue actuelle.
Pour afficher l’aperçu d’une boîte de dialogue personnalisée :
E À partir du menu du Générateur de boîtes de dialogue personnalisées, sélectionnez :Fichier
Aperçu d’une boîte de dialogue
Gestion des boîtes de dialogue personnalisées
Le générateur de boîtes de dialogue personnalisées vous permet de gérer des boîtes de dialoguepersonnalisées que vous ou d’autres utilisateurs ont créées. Vous pouvez installer, désinstaller oumodifier des boîtes de dialogue installées et vous pouvez enregistrer les spécifications d’une boîtede dialogue personnalisée dans un fichier externe ou ouvrir un fichier contenant les spécificationsd’une boîte de dialogue personnalisée afin de procéder à des modifications. Les boîtes dedialogues personnalisées doivent être installées avant de pouvoir être utilisées.

576
Chapitre 50
Installation d’une boîte de dialogue personnalisée
Vous pouvez installer la boîte de dialogue actuellement ouverte dans le générateur de boîtes dedialogue personnalisées ou vous pouvez installer une boîte de dialogue à partir d’un fichier (.spd)de package des boîtes de dialogue personnalisées. La réinstallation d’une boîte de dialogueexistante remplace la version existante.
Pour installer la boîte de dialogue actuellement ouverte :
E À partir du menu du Générateur de boîtes de dialogue personnalisées, sélectionnez :Fichier
Installer
Pour procéder à l’installation à partir d’un fichier de package des boîtes de dialoguepersonnalisées :
E A partir des menus, sélectionnez :Outils
Installer une boîte de dialogue personnalisée
Pour utiliser une nouvelle boîte de dialogue personnalisée, vous devez redémarrer SPSS Statistics.La réinstallation d’une boîte de dialogue existante ne nécessite pas de redémarrage à moinsque l’emplacement du menu ait été modifié.
Par défaut, l’installation d’une boîte de dialogue nécessite des droits d’écriture dans lerépertoire d’installation de SPSS Statistics. Si vous ne disposez pas de droits d’écriture pour cerépertoire ou si vous souhaitez stocker ailleurs des boîtes de dialogue installées, vous pouvezspécifier un ou plusieurs autres emplacements en définissant la variable d’environnementSPSS_CDIALOGS_PATH. Les chemins spécifiés dans SPSS_CDIALOGS_PATH , lorsqu’ilsexistent, ont la priorité sur le répertoire d’installation de SPSS Statistics. Pour des emplacementsmultiples, séparez chacun d’eux par un point-virgule sous Windows et par deux-points sousLinux et Mac.
Ouverture d’une boîte de dialogue personnalisée installée
Vous pouvez ouvrir une boîte de dialogue personnalisée que vous avez déjà installée ce qui vousautorise à la modifier et/ou à l’enregistrer de manière externe afin qu’elle puisse être distribuée àd’autres utilisateurs.
E À partir du menu du Générateur de boîtes de dialogue personnalisées, sélectionnez :Fichier
Ouvrir une boîte de dialogue installée
Remarque : Si vous ouvrez une boîte de dialogue installée afin de la modifier, la sélectiond’Installation de fichier la réinstalle et remplace la version existante.
Désinstallation d’une boîte de dialogue personnalisée
E À partir du menu du Générateur de boîtes de dialogue personnalisées, sélectionnez :Fichier
Désinstaller

577
Création et gestion de boîtes de dialogue personnalisées
Enregistrement d’un fichier de package des boîtes de dialogue personnalisées
Vous pouvez enregistrer les spécifications d’une boîte de dialogue personnalisée dans un fichierexterne, ce qui vous permet de distribuer la boîte de dialogue à d’autres utilisateurs ou d’enregistrerdes spécifications pour une boîte de dialogue qui n’est pas encore installée. Les spécifications sontenregistrées dans un fichier (.spd ) de package de boîtes de dialogue personnalisées.
E À partir du menu du Générateur de boîtes de dialogue personnalisées, sélectionnez :Fichier
Enregistrer
Ouverture d’un fichier de package de boîtes de dialogue personnalisées
Vous pouvez ouvrir un fichier de package de boîtes de dialogue personnalisées contenant lesspécifications d’une boîte de dialogue personnalisée, ce qui vous permet de modifier la boîte dedialogue et de la réenregistrer ou de l’installer.
E À partir du menu du Générateur de boîtes de dialogue personnalisées, sélectionnez :Fichier
Ouvrir
Copie manuelle d’une boîte de dialogue personnalisée installée
Par défaut, les spécifications d’une boîte de dialogue personnalisée installée sont stockées dans ledossier ext/lib/<Nom de la boîte de dialogue> du répertoire d’installation (situé dans la racine durépertoire d’installation de Windows et de Linux, et dans le répertoire Contents/bin du grouped’applications pour Mac). Vous pouvez copier ce dossier au même emplacement relatif dansune autre instance de SPSS Statistics et il sera reconnu comme une boîte de dialogue installéelors de l’exécution de la prochaine instance.
Si vous avez spécifié d’autres emplacements pour les boîtes de dialogue installées (à l’aide dela variable d’environnement SPSS_CDIALOGS_PATH ) vous devez copier le dossier <Nomde la boîte de dialogue> à l’autre emplacement approprié.Si d’autres emplacements de boîtes de dialogue installées ont été définis pour l’instance deSPSS Statistics dans laquelle vous procédez à la copie, vous pouvez procéder à la copie dansn’importe lequel des emplacements spécifiés et la boîte de dialogue sera reconnue comme uneboîte de dialogue installée lors de l’exécution de la prochaine instance.
Types de commandesLa palette d’outils fournit l’ensemble des commandes qui peuvent être ajoutées dans une boîte dedialogue.
Liste source : Une liste de variables source dans l’ensemble actif de données. Pour plusd'informations, reportez-vous à Liste source sur p. 578.Liste cible : Une cible pour les données transférées depuis la liste source. Pour plusd'informations, reportez-vous à Liste cible sur p. 579.Case à cocher : Une case unique à cocher. Pour plus d'informations, reportez-vous à Case àcocher sur p. 580.

578
Chapitre 50
Boîte combinée : Une boîte combinée destinée à la création de listes déroulantes. Pour plusd'informations, reportez-vous à Boîte combinée sur p. 581.Commande de texte : Une zone de texte qui accepte la saisie d’un texte arbitraire. Pour plusd'informations, reportez-vous à Commande Texte sur p. 582.Commande numérique : Une zone de texte limitée à la saisie de valeurs numériques. Pour plusd'informations, reportez-vous à Commande numérique sur p. 583.Commande de texte statique : Une commande destinée à afficher du texte statique. Pour plusd'informations, reportez-vous à Commande Texte statique sur p. 583.Groupe d’éléments : Un conteneur destiné à grouper un ensemble de commandes, tel qu’unensemble de cases à cocher. Pour plus d'informations, reportez-vous à Groupe d’élémentssur p. 584.Groupe radio : Un groupe de boutons radio. Pour plus d'informations, reportez-vous à Grouperadio sur p. 585.Groupe de cases à cocher : Un conteneur destiné à un ensemble de commandes activéesou désactivées, en tant que groupe, par une seule case à cocher. Pour plus d'informations,reportez-vous à Groupe de cases à cocher sur p. 586.Navigateur de fichiers : Une commande destinée à naviguer dans le système de fichierspour ouvrir ou fermer un fichier. Pour plus d'informations, reportez-vous à Navigateur defichiers sur p. 587.Bouton de boîte de dialogue de niveau inférieur : Un bouton destiné à lancer une boîte dedialogue de niveau inférieur. Pour plus d'informations, reportez-vous à Bouton de boîtede dialogue de niveau inférieur sur p. 588.
Liste source
La commande Liste de variables sources affiche la liste des variables à partir de l’ensemble actifde données disponible pour l’utilisateur final de la boîte de dialogue. Vous pouvez afficher toutesles variables à partir de l’ensemble actif de données (par défaut) ou vous pouvez filtrer la listeselon le type ou le niveau de mesure : par exemple, des variables numériques qui ont un niveau demesure d’échelle. L’utilisation d’une commande Liste source implique l’utilisation d’une ou deplusieurs commandes Liste cible. La commande Liste source possède les propriétés suivantes :
Identificateur. L’identificateur unique pour le contrôle.
Titre. Un titre facultatif qui apparaît au dessus du contrôle. Dans le cas de titres à plusieurs lignes,utilisez \n pour spéficier les sauts de ligne.
Note d’aide. Le texte de la note d’aide facultative qui s’affiche lorsque l’utilisateur positionneson curseur sur le contrôle. Le texte spécifié n’apparaît que lorsque le curseur passe sur la zonede titre de la commande. Le fait de faire passer le curseur sur les variables répertoriées affichele nom de la variable et l’étiquette.
Touche mnémonique. Un caractère facultatif dans le titre à utiliser comme raccourci clavierdu contrôle. Ce caractère est souligné dans le titre. Le raccourci est activé en appuyant surAlt+[touche mnémonique] Mac ne prend pas en charge les touches mnémoniques.

579
Création et gestion de boîtes de dialogue personnalisées
Transferts de variable. Spécifie si des variables transférées à partir de la liste source vers uneliste cible demeurent dans la liste source (copier les variables) ou si elles sont supprimées de laliste source (déplacer les variables).
Filtre à variables. Vous permet de filtrer l’ensemble des variables affichées dans la commande.Vous pouvez filtrer selon le type de variable et le niveau de mesure et vous pouvez spécifier queplusieurs ensembles de réponses sont inclus dans la liste des variables. Cliquez sur le boutonpoints de suspension (...) pour ouvrir la boîte de dialogue Filtrer. Pour plus d'informations,reportez-vous à Filtrage des listes de variables sur p. 580.
Remarque : La commande Liste source ne peut pas être ajoutée à une boîte de dialogue de niveauinférieur.
Liste cible
La commande Liste cible définit une cible pour les variables transférées depuis la liste de source.L’utilisation de la commande Liste cible suppose la présence d’une commande Liste source.Vous pouvez spécifier le fait qu’une seule variable peut être transférée à la commande ou queplusieurs variables peuvent y être transférées et vous pouvez appliquer une contrainte au type devariables qui peuvent être transférées à la commande : par exemple, uniquement des variablesnumériques avec un niveau de mesure nominal ou ordinal. La commande Liste cible possède lespropriétés suivantes :
Identificateur. L’identificateur unique pour le contrôle. Il s’agit de l’identificateur à utiliser lors duréférencement du contrôle dans le modèle de syntaxe.
Titre. Un titre facultatif qui apparaît au dessus du contrôle. Dans le cas de titres à plusieurs lignes,utilisez \n pour spéficier les sauts de ligne.
Note d’aide. Le texte de la note d’aide facultative qui s’affiche lorsque l’utilisateur positionneson curseur sur le contrôle. Le texte spécifié n’apparaît que lorsque le curseur passe sur la zonede titre de la commande. Le fait de faire passer le curseur sur les variables répertoriées affichele nom de la variable et l’étiquette.
Type de listes cible. Spécifie si des variables multiples ou une variable unique peuvent êtretransférées à la commande.
Touche mnémonique. Un caractère facultatif dans le titre à utiliser comme raccourci clavierdu contrôle. Ce caractère est souligné dans le titre. Le raccourci est activé en appuyant surAlt+[touche mnémonique] Mac ne prend pas en charge les touches mnémoniques.
Nécessaire à l’exécution. Spécifie si une valeur est ou non requise dans ce contrôle pour quel’exécution soit effectuée. Si Vrai est spécifié, les boutons OK et Coller seront désactivés jusqu’à cequ’une valeur soit spécifiée pour ce contrôle. Si Faux est spécifié, l’absence de valeur dans cecontrôle n’aura pas d’effet sur l’état des boutons OK et Coller. La valeur par défaut est True (vrai) .
Filtre à variables. Vous permet d’appliquer une contrainte sur les types de variables qui peuvent êtretransférées à la commande. Vous pouvez appliquer une contrainte par type de variable et niveaude mesure et vous pouvez spécifier si des ensembles de réponses multiples peuvent être transférésà la commande. Cliquez sur le bouton points de suspension (...) pour ouvrir la boîte de dialogueFiltrer. Pour plus d'informations, reportez-vous à Filtrage des listes de variables sur p. 580.

580
Chapitre 50
Syntaxe. Spécifie la syntaxe de commande générée par ce contrôle lors de l’exécution et quipeut être insérée dans le modèle de syntaxe.
Vous pouvez spécifier n’importe quelle syntaxe de commande valide et vous pouvez utiliser\n pour les sauts de ligne.La valeur %%ThisValue%% spécifie la valeur de la commande au moment de l’exécution, quicorrespond à la liste des variables transférées à la commande. Il s’agit de la valeur par défaut.
Remarque : La commande Liste cible ne peut pas être ajoutée à une boîte de dialogue de niveauinférieur.
Filtrage des listes de variablesFigure 50-3Boîte de dialogue Filtrer
La boîte de dialogue Filtrer, associé aux listes source et cible de variables, vous permet defiltrer les types de variables à partir de l’ensemble actif de données qui s’affiche dans les listes.Vous pouvez aussi spécifier si des ensembles de réponses multiples associés à l’ensemble actifde données sont inclus. Les variables numériques comprennent tous les formats numériquesà l’exception des formats de date et d’heure.
Case à cocher
La commande Case à cocher est une simple case à cocher qui peut générer une syntaxe decommande différente selon les états coché ou non coché. La commande Case à cocher possède lespropriétés suivantes :
Identificateur. L’identificateur unique pour le contrôle. Il s’agit de l’identificateur à utiliser lors duréférencement du contrôle dans le modèle de syntaxe.
Titre. L’étiquette qui est affichée avec la case à cocher. Dans le cas de titres sur plusieurs lignes,utilisez \n pour spécifier les fins de ligne.

581
Création et gestion de boîtes de dialogue personnalisées
Note d’aide. Le texte de la note d’aide facultative qui s’affiche lorsque l’utilisateur positionneson curseur sur le contrôle.
Touche mnémonique. Un caractère facultatif dans le titre à utiliser comme raccourci clavierdu contrôle. Ce caractère est souligné dans le titre. Le raccourci est activé en appuyant surAlt+[touche mnémonique] Mac ne prend pas en charge les touches mnémoniques.
Valeur par défaut. L’état par défaut de la case à cocher : coché ou non coché.
La syntaxe Cochée ou Non cochée. Spécifie la syntaxe de commande qui est générée lorsque lacommande est cochée et lorsqu’elle n’est pas cochée. Pour inclure la syntaxe de commandedans le modèle de syntaxe, utilisez la valeur de la propriété Identificateur. La syntaxe générée, àpartir de la propriété de syntaxe Cochée ou Non cochée, est insérée aux positions spécifiées del’identificateur. Par exemple, si l’identificateur est checkbox1, à l’exécution, les instances de%%checkbox1%% dans le modèle de syntaxe sont remplacées par la valeur de la propriété desyntaxe cochée si la case est cochée et par la propriété de syntaxe non cochée si la case n’estpas cochée.
Vous pouvez spécifier n’importe quelle syntaxe de commande valide et vous pouvez utiliser\n pour les sauts de ligne.
Boîte combinée
La commande Boîte combinée vous permet de créer une liste déroulante qui peut générer unesyntaxe de commande spécifique à l’élément sélectionné de la liste. La commande Boîte combinéepossède les propriétés suivantes :
Identificateur. L’identificateur unique pour le contrôle. Il s’agit de l’identificateur à utiliser lors duréférencement du contrôle dans le modèle de syntaxe.
Titre. Un titre facultatif qui apparaît au dessus du contrôle. Dans le cas de titres à plusieurs lignes,utilisez \n pour spéficier les sauts de ligne.
Note d’aide. Le texte de la note d’aide facultative qui s’affiche lorsque l’utilisateur positionneson curseur sur le contrôle.
Éléments de liste. Cliquez sur le bouton points de suspension (...) pour ouvrir la boîte de dialoguePropriétés des éléments de liste, qui vous permet de spécifier les éléments de liste de la commandeBoîte combinée.
Touche mnémonique. Un caractère facultatif dans le titre à utiliser comme raccourci clavierdu contrôle. Ce caractère est souligné dans le titre. Le raccourci est activé en appuyant surAlt+[touche mnémonique] Mac ne prend pas en charge les touches mnémoniques.
Syntaxe. Spécifie la syntaxe de commande générée par ce contrôle lors de l’exécution et quipeut être insérée dans le modèle de syntaxe.
La valeur %%ThisValue%% spécifie la valeur de la commande au moment de l’exécution,qui correspond à la valeur de la propriété de syntaxe pour l’élément de liste sélectionné. Ils’agit de la valeur par défaut.Vous pouvez spécifier n’importe quelle syntaxe de commande valide et vous pouvez utiliser\n pour les sauts de ligne.

582
Chapitre 50
Spécification d’éléments de liste destinés à des Boîtes combinées
La boîte de dialogue Propriétés d’éléments de liste vous permet de spécifier les éléments de listed’une commande de boîte combinée.
Identificateur. Un identificateur unique destiné à l’élément de liste.
Nom. Le nom qui s’affiche dans la liste déroulante pour cet élément de liste. Le nom est unchamp obligatoire.
Défaut. Spécifie si l’élément de liste est l’élément par défaut à afficher dans la boîte combinée.
Syntaxe. Spécifie la syntaxe de commande générée si l’élément de liste est sélectionné.Vous pouvez spécifier n’importe quelle syntaxe de commande valide et vous pouvez utiliser\n pour les sauts de ligne.
Vous pouvez ajouter un nouvel élément de liste dans la ligne vierge en dessous de la liste existante.La saisie de propriétés différentes de l’identificateur génère un identificateur unique que vouspouvez conserver ou modifier. Vous pouvez supprimer un élément de liste en cliquant sur lacellule Identificateur de l’élément et en appuyant sur supprimer.
Commande Texte
La commande Texte est une simple zone de texte qui peut accepter une saisie arbitraire quipossède les propriétés suivantes :
Identificateur. L’identificateur unique pour le contrôle. Il s’agit de l’identificateur à utiliser lors duréférencement du contrôle dans le modèle de syntaxe.
Titre. Un titre facultatif qui apparaît au dessus du contrôle. Dans le cas de titres à plusieurs lignes,utilisez \n pour spéficier les sauts de ligne.
Note d’aide. Le texte de la note d’aide facultative qui s’affiche lorsque l’utilisateur positionneson curseur sur le contrôle.
Touche mnémonique. Un caractère facultatif dans le titre à utiliser comme raccourci clavierdu contrôle. Ce caractère est souligné dans le titre. Le raccourci est activé en appuyant surAlt+[touche mnémonique] Mac ne prend pas en charge les touches mnémoniques.
Contenu de texte. Spécifie si les contenus sont arbitraires ou si la zone de texte doit contenir unechaîne conforme aux règles des noms de variables SPSS Statistics .
Valeur par défaut. Le contenu par défaut de la zone de texte.
Nécessaire à l’exécution. Spécifie si une valeur est ou non requise dans ce contrôle pour quel’exécution soit effectuée. Si Vrai est spécifié, les boutons OK et Coller seront désactivés jusqu’à cequ’une valeur soit spécifiée pour ce contrôle. Si Faux est spécifié, l’absence de valeur dans cecontrôle n’aura pas d’effet sur l’état des boutons OK et Coller. La valeur par défaut est False (faux) .
Syntaxe. Spécifie la syntaxe de commande générée par ce contrôle lors de l’exécution et quipeut être insérée dans le modèle de syntaxe.

583
Création et gestion de boîtes de dialogue personnalisées
Vous pouvez spécifier n’importe quelle syntaxe de commande valide et vous pouvez utiliser\n pour les sauts de ligne.La valeur %%ThisValue%% spécifie la valeur de la commande au moment de l’exécution, quicorrespond au contenu de la zone de texte. Il s’agit de la valeur par défaut.
Commande numérique
La commande numérique est une zone de texte destinée à saisir une valeur numérique et possèdeles propriétés suivantes :
Identificateur. L’identificateur unique pour le contrôle. Il s’agit de l’identificateur à utiliser lors duréférencement du contrôle dans le modèle de syntaxe.
Titre. Un titre facultatif qui apparaît au dessus du contrôle. Dans le cas de titres à plusieurs lignes,utilisez \n pour spéficier les sauts de ligne.
Note d’aide. Le texte de la note d’aide facultative qui s’affiche lorsque l’utilisateur positionneson curseur sur le contrôle.
Touche mnémonique. Un caractère facultatif dans le titre à utiliser comme raccourci clavierdu contrôle. Ce caractère est souligné dans le titre. Le raccourci est activé en appuyant surAlt+[touche mnémonique] Mac ne prend pas en charge les touches mnémoniques.
Type numérique. Spécifie toutes les limitations concernant la saisie. La valeur Réel spécifie qu’iln’y a aucune restriction sur la valeur saisie si ce n’est celle d’être une valeur numérique. La valeurEntier spécifie que la valeur doit être un entier.
Valeur par défaut. La valeur par défaut, le cas échéant.
Valeur minimale. La valeur minimale autorisée, le cas échéant.
Valeur maximale. La valeur maximale autorisée, le cas échéant.
Nécessaire à l’exécution. Spécifie si une valeur est ou non requise dans ce contrôle pour quel’exécution soit effectuée. Si Vrai est spécifié, les boutons OK et Coller seront désactivés jusqu’à cequ’une valeur soit spécifiée pour ce contrôle. Si Faux est spécifié, l’absence de valeur dans cecontrôle n’aura pas d’effet sur l’état des boutons OK et Coller. La valeur par défaut est False (faux) .
Syntaxe. Spécifie la syntaxe de commande générée par ce contrôle lors de l’exécution et quipeut être insérée dans le modèle de syntaxe.
Vous pouvez spécifier n’importe quelle syntaxe de commande valide et vous pouvez utiliser\n pour les sauts de ligne.La valeur %%ThisValue%% spécifie la valeur de la commande au moment de l’exécution, quicorrespond à la valeur numérique. Il s’agit de la valeur par défaut.
Commande Texte statique
La commande Texte statique vous permet d’ajouter un bloc de texte à votre boîte de dialogue etpossède les propriétés suivantes :
Identificateur. L’identificateur unique pour le contrôle.

584
Chapitre 50
Titre. Le contenu par défaut du bloc de texte. Dans le cas d’un contenu sur plusieurs lignes, utilisez\n pour spécifier les fins de ligne.
Groupe d’éléments
La commande Groupe d’éléments est un conteneur d’autres commandes qui vous permet degrouper et de contrôler la syntaxe générée à partir de plusieurs commandes. Par exemple, vousdisposez d’un ensemble de cases à cocher qui spécifie des paramètres optionnels pour unesous-commande, mais vous ne souhaitez générer la syntaxe de la sous-commande que si aumoins une case est cochée. Cela s’effectue en utilisant une commande Groupe d’éléments entant que conteneur pour les commandes de cases à cocher. Les types suivants de commandespeuvent être contenus dans un groupe d’éléments : case à cocher, boîte combinée, commande detexte, commande de nombre, texte statique, groupe de boutons radio et navigateur de fichiers. Lacommande Groupe d’éléments possède les propriétés suivantes :
Identificateur. L’identificateur unique pour le contrôle. Il s’agit de l’identificateur à utiliser lors duréférencement du contrôle dans le modèle de syntaxe.
Titre. Un titre optionnel pour le groupe. Dans le cas de titres sur plusieurs lignes, utilisez \n pourspécifier les fins de ligne.
Nécessaire à l’exécution. True (vrai) indique que les boutons OK et Coller sont désactivés jusqu’àce qu’au moins une commande du groupe génère une syntaxe de commande. Si False (faux) estspécifié, l’absence de syntaxe d’exécution à partir de cette commande n’a aucun effet sur l’étatdes boutons OK et Coller. La valeur par défaut est False (faux) .
Par exemple, le groupe est composé d’un ensemble de cases à cocher dont chacune ne génèrequ’une syntaxe à l’état coché. Si Nécessaire à l’exécution est configuré sur True (vrai) et qu’aucunedes autres cases n’est cochée, OK et Coller sont désactivés.
Syntaxe. Spécifie la syntaxe de commande générée par ce contrôle lors de l’exécution et quipeut être insérée dans le modèle de syntaxe.
Vous pouvez spécifier n’importe quelle syntaxe de commande valide et vous pouvez utiliser\n pour les sauts de ligne.Vous pouvez inclure des identificateurs pour toutes les commandes contenues dans le grouped’éléments. Au moment de l’exécution les identificateurs sont remplacés par une syntaxegénérée par les commandes.La valeur %%ThisValue%% génère une liste, dont les éléments sont séparés par des blancs,de la syntaxe générée par chaque commandes du groupe d’éléments dans l’ordre danslequel ils apparaissent dans le groupe (de haut en bas). Il s’agit de la valeur par défaut. Si%%ThisValue%% est spécifié et qu’aucune syntaxe n’est générée par aucune des commandesdu groupe d’éléments, le groupe d’éléments, dans sa totalité, ne génère aucune syntaxe decommande.

585
Création et gestion de boîtes de dialogue personnalisées
Groupe radio
La commande Groupe radio est un conteneur destiné à un ensemble de boutons radio et possèdeles propriétés suivantes :
Identificateur. L’identificateur unique pour le contrôle. Il s’agit de l’identificateur à utiliser lors duréférencement du contrôle dans le modèle de syntaxe.
Titre. Un titre optionnel pour le groupe. Si elle est omise, la bordure du groupe n’est pas affichée.Dans le cas de titres sur plusieurs lignes, utilisez \n pour spécifier les fins de ligne.
Note d’aide. Le texte de la note d’aide facultative qui s’affiche lorsque l’utilisateur positionneson curseur sur le contrôle.
Boutons radio. Cliquez sur le bouton points de suspension (...) pour ouvrir la boîte de dialoguePropriétés du groupe radio, qui vous permet de spécifier les propriétés des boutons radio aussibien que d’ajouter ou de supprimer des boutons du groupe.
Syntaxe. Spécifie la syntaxe de commande générée par ce contrôle lors de l’exécution et quipeut être insérée dans le modèle de syntaxe.
Vous pouvez spécifier n’importe quelle syntaxe de commande valide et vous pouvez utiliser\n pour les sauts de ligne.La valeur %%ThisValue%% spécifie la valeur du groupe de boutons radio au moment del’exécution, qui correspond à la valeur de la propriété de syntaxe pour le bouton radiosélectionné. Il s’agit de la valeur par défaut.
Définition de boutons radio
La boîte de dialogue Propriétés du groupe de boutons radio vous permet de spécifier un groupe deboutons radio.
Identificateur. Un identificateur unique destiné au bouton radio.
Nom. Le nom qui apparaît en regard du bouton radio. Le nom est un champ obligatoire.
Note d’aide. Le texte de la note d’aide facultative qui s’affiche lorsque l’utilisateur positionneson curseur sur le contrôle.
Touche mnémonique. Un caractère optionnel du nom à utiliser en tant que mnémonique. Lecaractère spécifié doit se trouver dans le nom.
Défaut. Spécifie si le bouton radio représente la sélection par défaut.
Syntaxe. Spécifie la syntaxe de commande générée si le bouton radio est sélectionné.Vous pouvez spécifier n’importe quelle syntaxe de commande valide et vous pouvez utiliser\n pour les sauts de ligne.
Vous pouvez ajouter un nouveau bouton radio dans la ligne vierge en dessous de la liste existante.La saisie de propriétés différentes de l’identificateur génère un identificateur unique que vouspouvez conserver ou modifier. Vous pouvez supprimer un bouton radio en cliquant sur la celluleIdentificateur du bouton et en appuyant sur supprimer.

586
Chapitre 50
Groupe de cases à cocher
La commande Groupe de cases à cocher est un conteneur destiné à un ensemble de commandesactivées ou désactivées, en tant que groupe, par une seule case à cocher. Les types suivantsde commandes peuvent être contenus dans un groupe de cases à cocher : case à cocher, boîtecombinée, commande de texte, commande de nombre, texte statique, groupe de boutons radio etnavigateur de fichiers. La commande Groupe de cases à cocher possède les propriétés suivantes :
Identificateur. L’identificateur unique pour le contrôle. Il s’agit de l’identificateur à utiliser lors duréférencement du contrôle dans le modèle de syntaxe.
Titre. Un titre optionnel pour le groupe. Si elle est omise, la bordure du groupe n’est pas affichée.Dans le cas de titres sur plusieurs lignes, utilisez \n pour spécifier les fins de ligne.
Titre de case à cocher. Une étiquette optionnelle qui est affichée avec la case à cocher de contrôle.Gère \n pour spécifier les fins de ligne.
Note d’aide. Le texte de la note d’aide facultative qui s’affiche lorsque l’utilisateur positionneson curseur sur le contrôle.
Touche mnémonique. Un caractère facultatif dans le titre à utiliser comme raccourci clavierdu contrôle. Ce caractère est souligné dans le titre. Le raccourci est activé en appuyant surAlt+[touche mnémonique] Mac ne prend pas en charge les touches mnémoniques.
Valeur par défaut. L’état par défaut de la case à cocher de contrôle : coché ou non coché.
La syntaxe Cochée ou Non cochée. Spécifie la syntaxe de commande qui est générée lorsque lacommande est cochée et lorsqu’elle n’est pas cochée. Pour inclure la syntaxe de commandedans le modèle de syntaxe, utilisez la valeur de la propriété Identificateur. La syntaxe générée, àpartir de la propriété de syntaxe Cochée ou Non cochée, est insérée aux positions spécifiées del’identificateur. Par exemple, si l’identificateur vaut checkboxgroup1, à l’exécution, les instancesde %%checkboxgroup1%% dans le modèle de syntaxe sont remplacés par la valeur de la propriétéde syntaxe cochée si la case est cochée et par la propriété de syntaxe non cochée si la case n’estpas cochée.
Vous pouvez spécifier n’importe quelle syntaxe de commande valide et vous pouvez utiliser\n pour les sauts de ligne.Vous pouvez inclure des identificateurs pour toutes les commandes contenues dans le groupede cases à cocher. Au moment de l’exécution les identificateurs sont remplacés par unesyntaxe générée par les commandes.La valeur %%ThisValue%% peut être utilisée dans la propriété de syntaxe Cochée ou Noncochée. Elle génère une liste, dont les éléments sont séparés par des blancs, de la syntaxegénérée par chaque commande du groupe de cases à cocher dans l’ordre dans lequel ellesapparaissent dans le groupe (de haut en bas).Par défaut, la propriété de syntaxe cochée possède la valeur %%ThisValue%% et la propriétéde syntaxe non cochée est vierge.

587
Création et gestion de boîtes de dialogue personnalisées
Navigateur de fichiers
La commande Navigateur de fichiers se compose d’une zone de texte destinée à un chemin defichier et d’un bouton de navigation qui ouvre une boîte de dialogue standard de SPSS Statisticspour ouvrir ou fermer un fichier. La commande Navigateur de fichiers possède les propriétéssuivantes :
Identificateur. L’identificateur unique pour le contrôle. Il s’agit de l’identificateur à utiliser lors duréférencement du contrôle dans le modèle de syntaxe.
Titre. Un titre facultatif qui apparaît au dessus du contrôle. Dans le cas de titres à plusieurs lignes,utilisez \n pour spéficier les sauts de ligne.
Note d’aide. Le texte de la note d’aide facultative qui s’affiche lorsque l’utilisateur positionneson curseur sur le contrôle.
Touche mnémonique. Un caractère facultatif dans le titre à utiliser comme raccourci clavierdu contrôle. Ce caractère est souligné dans le titre. Le raccourci est activé en appuyant surAlt+[touche mnémonique] Mac ne prend pas en charge les touches mnémoniques.
Utilisation du système de fichiers. Spécifie si la boîte de dialogue lancée par le bouton de navigationest appropriée pour l’ouverture ou l’enregistrement de fichiers. La valeur Ouvrir indique que laboîte de dialogue de navigation valide l’existence du fichier spécifié. La valeur Enregistrer indiqueque la boîte de dialogue de navigation ne valide pas l’existence du fichier spécifié.
Type de navigateur. Spécifie si la boîte de dialogue de navigation est utilisée pour sélectionner unfichier (trouver un fichier) ou pour sélectionner un dossier (trouver un dossier).
Filtre à fichiers. Cliquez sur le bouton points de suspension (...) pour ouvrir la boîte dedialogueFiltre à fichiers qui vous permet de spécifier les types de fichiers disponibles pour la boîtede dialogue Ouvrir ou Enregistrer. Tous les types de fichiers sont autorisés par défaut.
Type de système de fichiers. En mode d’analyse distribuée, il spécifie si la boîte de dialogueparcourt le système de fichiers dans lequel le serveur SPSS Statistics est en cours d’exécution oule système de fichiers de votre ordinateur local : Serveur pour parcourir le système de fichiersdu serveur, Client pour parcourir le système de fichiers de votre ordinateur local. La propriétén’a aucun effet sur le mode d’analyse locale.
Nécessaire à l’exécution. Spécifie si une valeur est ou non requise dans ce contrôle pour quel’exécution soit effectuée. Si Vrai est spécifié, les boutons OK et Coller seront désactivés jusqu’à cequ’une valeur soit spécifiée pour ce contrôle. Si Faux est spécifié, l’absence de valeur dans cecontrôle n’aura pas d’effet sur l’état des boutons OK et Coller. La valeur par défaut est False (faux) .
Syntaxe. Spécifie la syntaxe de commande générée par ce contrôle lors de l’exécution et quipeut être insérée dans le modèle de syntaxe.
Vous pouvez spécifier n’importe quelle syntaxe de commande valide et vous pouvez utiliser\n pour les sauts de ligne.La valeur %%ThisValue%% spécifie la valeur de la zone de texte à l’exécution, qui correspondau chemin du fichier, spécifié manuellement ou renseigné par la boîte de dialogue denavigation. Il s’agit de la valeur par défaut.

588
Chapitre 50
Filtre de type de fichiers
Figure 50-4Boîte de dialogue Filtre de fichiers
La boîte de dialogue Filtre de fichiers vous permet de spécifier les types de fichiers affichés dansles listes déroulantes Fichiers de type et Enregistrer sous pour les boîtes de dialogue Ouvrir etEnregistrer accédées à partir de la commande Navigateur du système de fichiers. Tous les typesde fichiers sont autorisés par défaut.
Pour spécifier des types de fichiers qui ne sont pas explicitement répertoriés dans la boîte dedialogue :
E Sélectionnez Autre.
E Saisissez un nom de type de fichier.
E Saisissez un type de fichier de la forme *.suffixe : par exemple, *.xls . Vous pouvez spécifierplusieurs types de fichiers, chacun étant séparé par un point-virgule.
Bouton de boîte de dialogue de niveau inférieur
La commande Bouton de boîte de dialogue de niveau inférieur spécifie un bouton pour lelancement d’une boîte de dialogue de niveau inférieur et fournit un accès aux générateur deboîtes de dialogue pour la boîte de dialogue de niveau inférieur. Le bouton Boîte de dialogue deniveau inférieur possède les propriétés suivantes :
Identificateur. L’identificateur unique pour le contrôle.
Titre. Le texte affiché dans le bouton.
Note d’aide. Le texte de la note d’aide facultative qui s’affiche lorsque l’utilisateur positionneson curseur sur le contrôle.
Boîte de dialogue de niveau inférieur. Cliquez sur le bouton points de suspension (...) pour ouvrirle générateur de boîtes de dialogue personnalisées pour la boîte de dialogue de niveau inférieur.Vous pouvez aussi ouvrir le générateur en double-cliquant sur le bouton Boîte de dialoguede niveau inférieur.

589
Création et gestion de boîtes de dialogue personnalisées
Touche mnémonique. Un caractère facultatif dans le titre à utiliser comme raccourci clavierdu contrôle. Ce caractère est souligné dans le titre. Le raccourci est activé en appuyant surAlt+[touche mnémonique] Mac ne prend pas en charge les touches mnémoniques.
Remarque : La commande Bouton de boîte de dialogue de niveau inférieur ne peut pas êtreajoutée à une boîte de dialogue de niveau inférieur.
Propriétés de la boîte de dialogue pour une boîte de dialogue de niveau inférieur
Pour afficher et définir les propriétés d’une boîte de dialogue de niveau inférieur :
E Ouvrez la boîte de dialogue de niveau inférieur en double-cliquant sur le bouton de la boîtede dialogue de niveau inférieur dans la boîte de dialogue principale ou cliquez une fois sur lebouton de la boîte de dialogue de niveau inférieur et cliquez sur les points de suspension (...) de lapropriété Boîte de dialogue de niveau inférieur.
E Dans la boîte de dialogue de niveau inférieur, cliquez sur le canevas dans la zone à l’extérieurdes commandes. Comme il n’y a aucune commande sur le canevas, les propriétés d’une boîte dedialogue de niveau inférieur sont toujours visibles.
Boîte de dialogue de niveau inférieur. L’identificateur unique de la boîte de dialogue de niveauinférieur. La propriété Nom de la boîte de dialogue de niveau inférieur est obligatoire.
Remarque : Si vous spécifiez le nom de la boîte de dialogue de niveau inférieur en tantqu’identificateur dans le modèle de syntaxe (comme dans %%My Sub-dialog Name%%) il estremplacé au moment de l’exécution par une liste, dont les éléments sont séparés par des blancs, dela syntaxe générée par chaque commande de la boîte de dialogue de niveau inférieur, dans l’ordredans lequel ils apparaissent (de haut en bas et de gauche à droite).
Titre : Spécifie le texte à afficher dans la barre de titre de la boîte de dialogue de niveau inférieur.La propriété Titre est optionnelle mais recommandée.
Fichier d’aide. Spécifie le chemin vers un fichier d’aide optionnel destiné à la boîte de dialogue deniveau inférieur. Il s’agit du fichier qui est exécuté lorsque l’utilisateur clique sur le bouton Aide dela boîte de dialogue de niveau inférieur, et ce peut-être le même fichier d’aide spécifié pour la boîtede dialogue principale. Les fichiers d’aide doivent être au format HTML. Voir la description de lapropriété Fichier d’aide des Propriétés de la boîte de dialogue pour de plus amples informations.
Syntaxe. Cliquez sur le bouton points de suspensions (...) pour ouvrir le modèle de syntaxe. Pourplus d'informations, reportez-vous à Création du modèle de syntaxe sur p. 572.
Boîtes de dialogue personnalisées pour les commandes d’extensionLes commandes d’extension sont des commandes SPSS Statistics définies par l’utilisateur et quisont implémentées dans le langage de programmation Python ou R. Une fois déployée dansune instance de SPSS Statistics, une commande d’extension est exécutée de la même manièrequ’une commande SPSS Statistics intégrée.
Vous pouvez utiliser le générateur de boîtes de dialogue personnalisées pour créer des boîtes dedialogue destinées à des commandes d’extension et vous pouvez installer des boîtes de dialoguepersonnalisées pour des commandes d’extension créées par d’autres utilisateurs.

590
Chapitre 50
Création de boîtes de dialogue personnalisées pour des commandes d’extension
Qu’une commande d’extension soit écrite par vous ou par un autre utilisateur, vous pouvez créerune boîte de dialogue personnalisée pour celle-ci. Le modèle de syntaxe de la boîte de dialoguedoit générer la syntaxe de commande destinée à la commande d’extension. Si la boîte de dialoguepersonnalisée est destinée à votre seul usage, installez la boîte de dialogue. En admettant que lacommande d’extension soit déjà déployée sur votre système, vous serez en mesure d’exécuter lacommande pour la boîte de dialogue installée.
Si vous créez une boîte de dialogue personnalisée pour une commande d’extension et que voussouhaitez la partager avec d’autres utilisateurs, vous devez enregistrer les spécifications de la boîtede dialogue dans un fichier (.spd) de package de boîtes de dialogue personnalisée et distribuer cefichier. Le fichier de package de boîte de dialogue personnalisée ne contient pas les spécificationsde la commande d’extension même, mais uniquement les spécifications de la boîte de dialoguepersonnalisée. Vous devrez fournir séparément à l’utilisateur final le fichier XML qui spécifie lasyntaxe de commande d’extension et le code d’implémentation écrit en Python ou en R.
Installation de commandes d’extension avec les boîtes de dialogue personnalisées associées
Une commande d’extension avec une boîte de dialogue personnalisée associée comporte troiséléments : un fichier XML qui spécifie la syntaxe de commande ; un fichier de code (un modulePython ou un package R) qui implémente la commande et un fichier de package de boîtes dedialogue personnalisées qui contient les spécifications de la boîte de dialogue personnalisée.
Fichier de package de boîtes de dialogue personnalisées. Installez le fichier de package de boîtesde dialogue personnalisées à partir de l’élément Installer une boîte de dialogue personnaliséedans le menu Outils.
Fichier de spécification de syntaxe XML et Code d’implémentation. Le fichier XML spécifiant lasyntaxe de commande d’extension et le code d’implémentation (module Python ou package R)doivent tous deux être placés dans le répertoire extensions du répertoire d’installation de SPSSStatistics. Pour Mac, le répertoire d’installation se rapporte au répertoire Sommaire dans le grouped’applications SPSS Statistics.
Si vous ne disposez pas de droits d’écriture pour le répertoire d’installation de SPSS Statisticsou si vous souhaitez stocker ailleurs le fichier XML et le code d’implémentation, vous pouvezspécifier un ou plusieurs autres emplacements en définissant la variable d’environnementSPSS_EXTENSIONS_PATH. Les chemins spécifiés dans SPSS_EXTENSIONS_PATH,lorsqu’ils existent, ont la priorité sur le répertoire d’installation de SPSS Statistics. Pourdes emplacements multiples, séparez chacun d’eux par un point-virgule sous Windows etpar deux-points sous Linux et Mac.Pour une commande extension implémentée en Python, vous pouvez toujours stocker lemodule Python associé dans un emplacement du chemin de recherche de Python, tel que lerépertoire site-packages de Python.Pour une commande d’extension implémentée dans R, le package R contenant le coded’implémentation doit être installé dans le répertoire contenant le fichier de spécification desyntaxe XML. Par ailleurs, vous pouvez toujours l’installer dans l’emplacement par défautde la plateforme associée (par exemple R_Home/library sous Windows, où R_Home estl’emplacement d’installation de R et library un sous-répertoire de cet emplacement. Pour

591
Création et gestion de boîtes de dialogue personnalisées
obtenir de l’aide concernant l’installation des packages R, consultez le guide d’installation etd’administrations de R fournit avec R.
Pour de plus amples informations concernant la création de commandes d’extension, consultezl’article « Écriture SPSS Statistics de commandes d’extension », disponible auprès de DeveloperCentral à http://www.spss.com/devcentral . Vous pouvez aussi consulter le chapitre Commandesd’extension dans Programmation et gestion de données pour SPSS Statistics, disponible au formatPDF auprès de http://www.spss.com/spss/data_management_book.htm .
Création de versions traduites de boîtes de dialogue personnaliséesVous pouvez créer des versions traduites de boîtes de dialogue personnalisées pour toutesles langues prises en charge par SPSS Statistics. Vous pouvez traduire toutes les chaînes quis’affichent dans une boîte de dialogue personnalisée ainsi que les fichiers d’aide optionnels.
Pour traduire des chaînes de boîte de dialogue
E Faites une copie du fichier de propriétés associé à la boîte de dialogue. Le fichier de propriétéscontient toutes les chaînes traduisibles associées à la boîte de dialogue. Par défaut, il se trouvedans le dossier ext/lib/<Nom de la boîte de dialogue> du répertoire d’installation de SPSSStatistics (situé dans la racine du répertoire d’installation de Windows et de Linux, et dans lerépertoire Contents/bin du groupe d’applications de SPSS Statistics 17.0 pour Mac). La copiedoit se trouver dans le même dossier et non dans un sous-dossier.
Si vous avez spécifié d’autres emplacements pour les boîtes de dialogue installées (à l’aide dela variable d’environnement SPSS_CDIALOGS_PATH ) la copie doit se trouver dans le dossier<Nom de la boîte de dialogue> à l’autre emplacement approprié. Pour plus d'informations,reportez-vous à Gestion des boîtes de dialogue personnalisées sur p. 575.
E Renommez la copie en <Nom de la boîte de dialogue>_<identificateur de langue>.properties, enutilisant les identificateurs de langue du tableau ci-dessous. Par exemple, si le nom de la boîte dedialogue est mydialog et que vous souhaitez créer une version japonaise de la boîte de dialogue,les fichiers des propriétés traduites doivent avoir pour nom mydialog_ja.properties . Les fichiersdes propriétés traduites doivent être ajoutés manuellement à tous les fichiers de package de boîtede dialogue que vous créez pour la boîte de dialogue.
E Ouvrez les nouveaux fichiers de propriétés à l’aide d’un éditeur de texte qui prend en chargel’encodage UTF8, tel que le bloc-notes de Windows ou l’application TextEdit pour Mac. Modifiezles valeurs associées aux propriétés qui doivent être traduites, mais ne modifiez pas les noms despropriétés. Les propriétés associées à une commande spécifique ont pour préfixe l’identificateurde la commande. Par exemple, la propriété Note d’aide d’une commande dont l’identificateuroptions_button est options_button_tooltip_LABEL. Les propriétés de titre sont simplementnommées <identificateur>_LABEL, comme dans options_button_LABEL. Les deux-points utiliséspour les valeurs de propriété doivent être échappés, comme dans \:.
Lorsque la boîte de dialogue est exécutée, SPSS Statistics recherche un fichier de propriétés dontl’identificateur de langue correspond à la langue actuelle, comme spécifié dans la liste déroulanteLangues de l’onglet Général de la boîte de dialogue Options. Si aucun fichier de propriétés n’estprouvé, le fichier par défaut <Nom de boîte de dialogue>.propriétés est utilisé.

592
Chapitre 50
Pour traduire le fichier d’aide
E Faites une copie du fichier d’aide associé à la boîte de dialogue et traduisez le texte dans lalangue souhaitée. La copie doit se trouver dans le même répertoire que le fichier d’aide et nondans un sous-répertoire. Le fichier d’aide doit se trouver dans le dossier ext/lib/<Nom de laboîte de dialogue> du répertoire d’installation de SPSS Statistics (situé à la racine du répertoired’installation de Windows et de Linux, et sous le répertoire Contents/bin du groupe d’applicationsde SPSS Statistics 17.0 pour Mac.
Si vous avez spécifié d’autres emplacements pour les boîtes de dialogue installées (à l’aide dela variable d’environnement SPSS_CDIALOGS_PATH ) la copie doit se trouver dans le dossier<Nom de la boîte de dialogue> à l’autre emplacement approprié. Pour plus d'informations,reportez-vous à Gestion des boîtes de dialogue personnalisées sur p. 575.
E Renommez la copie en <Fichier d’aide>_<identificateur de langue>, en utilisant lesidentificateurs de langue du tableau ci-dessous. Par exemple, si le fichier d’aide est myhelp.htm etque vous souhaitez créer une version allemande de ce fichier, le fichier d’aide traduit doit êtrenommémyhelp_de.htm. Les fichiers d’aide traduits doivent être ajoutés manuellement à tous lesfichiers de packages de boîte de dialogue que vous créez pour la boîte de dialogue.
Si d’autres fichiers tels que des fichiers d’image doivent aussi être traduits, vous devez modifiermanuellement les chemins appropriés dans le fichier d’aide principal afin qu’ils pointent vers lesversions traduites qui doivent être stockées avec les versions originales.
Lorsque la boîte de dialogue est exécutée, SPSS Statistics recherche un fichier d’aide dontl’identificateur de langue correspond à la langue actuelle, comme spécifié dans la liste déroulanteLangues de l’onglet Général de la boîte de dialogue Options. Si aucun fichier n’est trouvé, lefichier d’aide spécifié pour la boîte de dialogue (le fichier spécifié dans la propriété Fichier d’aidedes propriétés de la boîte de dialogue) est utilisé.
Identificateurs de langue
de Allemandfr Anglaises Espagnolfr Françaisit Italienja Japonaisko Coréenpl Polonaisru Russezh_cn Chinois simplifiézh_tw Chinois traditionnel
Remarque : Le texte des boîtes de dialogue personnalisées et des fichiers d’aide n’est pas limitéaux langues prises en charge par SPSS Statistics. Vous êtes libre d’écrire le texte des boîtes dedialogue et des aides dans n’importe quelle langue sans avoir à créer de propriétés ni de fichiers

593
Création et gestion de boîtes de dialogue personnalisées
d’aide propres à la langue. Tous les utilisateurs de votre boîte de dialogue verront alors le textedans cette langue.

Chapitre
51Tâches de production
Les tâches de production permettent d’automatiser l’exécution de SPSS Statistics. Le programmefonctionne seul et prend fin après avoir exécuté la dernière commande, ce qui vous permetd’exécuter d’autres tâches pendant qu’il fonctionne ou de programmer l’heure d’exécution dela tâche de production. Les tâches de production sont utiles si vous exécutez souvent le mêmeensemble d’analyses longues, telles que des rapports hebdomadaires.Les tâches de production utilisent des fichiers de syntaxe de commande pour indiquer à SPSS
Statistics la marche à suivre. Un fichier de syntaxe de commande est un fichier texte simplecontenant une syntaxe de commande. Vous pouvez utiliser n’importe quel éditeur de textepour créer ce fichier. Vous pouvez également générer une syntaxe de commande en collant lessélections de la boîte de dialogue dans une fenêtre de syntaxe ou en modifiant le fichier-journal.Pour plus d'informations, reportez-vous à Utilisation de la syntaxe de commande dans Chapitre13 sur p. 282.
Pour créer une tâche de production :
E A partir des menus d’une fenêtre quelconque, sélectionnez :Outils
Tâche de production
594
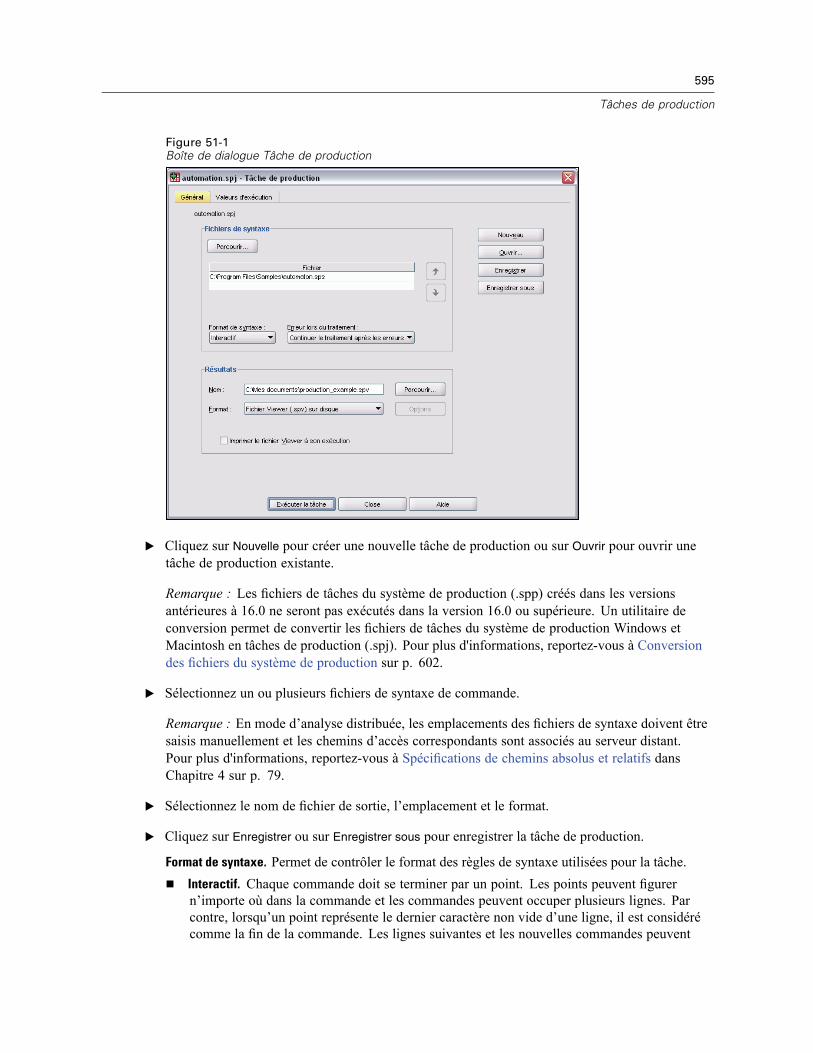
595
Tâches de production
Figure 51-1Boîte de dialogue Tâche de production
E Cliquez sur Nouvelle pour créer une nouvelle tâche de production ou sur Ouvrir pour ouvrir unetâche de production existante.
Remarque : Les fichiers de tâches du système de production (.spp) créés dans les versionsantérieures à 16.0 ne seront pas exécutés dans la version 16.0 ou supérieure. Un utilitaire deconversion permet de convertir les fichiers de tâches du système de production Windows etMacintosh en tâches de production (.spj). Pour plus d'informations, reportez-vous à Conversiondes fichiers du système de production sur p. 602.
E Sélectionnez un ou plusieurs fichiers de syntaxe de commande.
Remarque : En mode d’analyse distribuée, les emplacements des fichiers de syntaxe doivent êtresaisis manuellement et les chemins d’accès correspondants sont associés au serveur distant.Pour plus d'informations, reportez-vous à Spécifications de chemins absolus et relatifs dansChapitre 4 sur p. 79.
E Sélectionnez le nom de fichier de sortie, l’emplacement et le format.
E Cliquez sur Enregistrer ou sur Enregistrer sous pour enregistrer la tâche de production.
Format de syntaxe. Permet de contrôler le format des règles de syntaxe utilisées pour la tâche.Interactif. Chaque commande doit se terminer par un point. Les points peuvent figurern’importe où dans la commande et les commandes peuvent occuper plusieurs lignes. Parcontre, lorsqu’un point représente le dernier caractère non vide d’une ligne, il est considérécomme la fin de la commande. Les lignes suivantes et les nouvelles commandes peuvent

596
Chapitre 51
commencer n’importe où sur une nouvelle ligne. Voici les règles « interactives » appliquéeslorsque vous sélectionnez et exécutez des commandes dans une fenêtre de syntaxe.Commande. Chaque commande doit commencer au début d’une nouvelle ligne (aucunespace vide avant le début de la commande) et les lignes suivantes doivent commencer parun décrochement d’au moins un espace. Pour mettre en retrait de nouvelles commandes,vous pouvez entrer le signe plus, un tiret ou un point pour le premier caractère au début dela ligne, puis mettre en retrait la commande réelle. Le point à la fin de la commande estoptionnel. Ce paramètre est compatible avec les règles de syntaxe des fichiers de commandequi accompagnent la commande INCLUDE.Remarque : N’utilisez pas l’option Commandeh si vos fichiers de syntaxe contiennent lasyntaxe de commande GGRAPH qui inclut les instructions GPL. Les instructions GPL ne sontexécutées qu’avec des règles interactives.
Erreur lors du traitement. Permet de contrôler le traitement des conditions d’erreur dans la tâche.Continuer le traitement après les erreurs. Les erreurs figurant dans la tâche n’arrêtent pasautomatiquement le traitement des commandes. Les commandes des fichiers de tâches deproduction sont traitées comme une partie du flux de commandes normal et le traitementdes commandes se poursuit normalement.Arrêter le traitement immédiatement. Le traitement des commandes s’arrête lorsque la premièreerreur d’un fichier de tâches de production est détectée. Ce paramètre est compatible avec lecomportement des fichiers de commande qui accompagnent la commande INCLUDE.
Résultats. Contrôle le nom, l’emplacement et le format des résultats des tâches de production. Lesoptions de format suivantes sont disponibles :
Fichier Viewer (.spv) sur disque. Les résultats sont enregistrés au format Viewer de SPSSStatistics dans l’emplacement de fichier indiqué.Fichier Viewer (.spv) dans le référentiel PES. Cette opération requiert l’option Adaptor pourEnterprise Services.Rapports Web (.spv) dans le référentiel PES. Cette opération requiert l’option Adaptor pourEnterprise Services.Word/RTF (*.doc). Les tableaux pivotants sont exportés en tant que tableaux Word, avec tousles attributs de formatage (bordures de cellule, styles de police, couleurs d’arrière-plan). Lasortie texte est exportée au format RTF. Les graphiques, les diagrammes d’arbre et les vues demodèles sont compris dans le format PNG.Remarque : Microsoft Word risque de ne pas afficher correctement les tableaux extrêmementlarges.Excel (*:xls). Les lignes, colonnes et cellules des tableaux pivotants sont exportées comme deslignes, colonnes et cellules Excel, avec tous les attributs de formatage (bordures de cellule,styles de police, couleurs d’arrière-plan, etc.). Le résultat texte est exporté avec tous lesattributs de police. Chaque ligne du résultat texte est une ligne dans le fichier Excel, avec lecontenu de toute la ligne dans une seule cellule. Les graphiques, les diagrammes d’arbre et lesvues de modèles sont compris dans le format PNG.

597
Tâches de production
HTML (*.htm). Les tableaux pivotants sont exportés comme des tableaux HTML. Les résultatstexte sont publiés au format HTML pré-formaté. Les graphiques, les diagrammes d’arbre sontintégrés par référence, et vous devez exporter les diagrammes sous un format adapté pourpermettre leur intégration dans des documents HTML (par exemple PNG et JPEG).Portable Document Format (*.pdf). Tous les résultats sont exportés tels qu’ils apparaissent dansl’aperçu avant impression, avec tous les attributs de formatage intacts.Fichier PowerPoint (*.ppt). Les tableaux pivotants sont exportés en tant que tableaux Word, puisincorporés au fichier PowerPoint dans des diapositives distinctes, à raison d’une diapositivepar tableau pivotant. Tous les attributs de formatage (bordures de cellule, styles de police,couleurs d’arrière-plan, etc.) sont conservés. Les graphiques, les diagrammes d’arbre et lesvues de modèles sont exportés au format PNG. Les résultats texte ne sont pas inclus.L’option Exporter vers PowerPoint n’est disponible que sous les systèmes d’exploitationWindows.Texte (*.txt). Les formats de résultats texte comprennent les formats texte brut, UTF-8 etUTF-16. Les tableaux pivotants peuvent être exportés en format tabulé ou avec espaces. Tousles résultats texte sont exportés en format avec espaces. Pour les graphiques, les diagrammesd’arbre et les vues de modèles, une ligne est insérée dans le fichier texte pour chaquegraphique, indiquant le nom de fichier de l’image.
Imprimer le fichier Viewer à son exécution. Envoie le fichier de résultats Viewer final versl’imprimante une fois la tâche de production terminée.
Exécuter la tâche. Permet d’exécuter la tâche de production dans une session distincte. Cetteopération s’avère particulièrement utile pour le test des nouvelles tâches de production avantde les déployer.
Tâches de production avec commandes OUTPUT
Les tâches de production utilisent les commandes OUTPUT telles que OUTPUT SAVE, OUTPUTACTIVATE et OUTPUT NEW. Les commandes OUTPUT SAVE exécutées au cours d’une tâche deproduction écrivent le contenu des documents de résultat spécifiés aux emplacements indiqués.Ceci s’ajoute au fichier de résultats créé par la tâche de production. Lorsque vous utilisez OUTPUTNEW pour créer un document de résultats, il est recommandé de l’enregistrer explicitement avec lacommande OUTPUT SAVE.Le fichier de résultats de la tâche de production est composé du contenu du document de
résultats actif tel qu’il est à la fin de la tâche. Pour les tâches contenant les commandes OUTPUT,le fichier résultat ne contient pas nécessairement tous les résultats créés durant la session. Parexemple, supposez que la tâche de production se compose d’un certain nombre de procéduressuivies d’une commande OUTPUT NEW, elle-même suivie d’autres procédures, mais sans autrescommandes OUTPUT. La commande OUTPUT NEW définit un nouveau document de résultatsactif. A la fin de la tâche de production, il contiendra uniquement les résultats des procéduresexécutées après la commande OUTPUT NEW.
Options HTMLOptions de tableau. Aucune option de tableau n’est disponible pour le format HTML. Tous lestableaux pivotants sont convertis en tableaux HTML.

598
Chapitre 51
Options d’image. Les types d’images disponibles sont les suivants : EPS, JPEG, TIFF, PNG etBMP. Sous les systèmes d’exploitation Windows, le format EMF (métafichier amélioré) estégalement disponible. Vous pouvez aussi mettre à l’échelle la taille de l’image (de 1% à 200 %).
Options PowerPoint
Options de tableau. Vous pouvez utiliser les entrées de Résultats comme titres de diapositive.Chaque diapositive contient un seul élément de résultat. Le titre est formé à partir de l’entréecorrespondant à l’élément dans le panneau de légende du Viewer.
Options d’image. Vous pouvez mettre à l’échelle la taille de l’image (de 1% à 200 %). (Toutes lesimages sont converties en PowerPoint au format TIFF.)
Remarque : Le format PowerPoint n’est disponible que sur les systèmes d’exploitation Windowset requiert PowerPoint 97 ou supérieur.
Options PDFIntégrer les signets. Cette option inclut dans le document PDF des signets qui correspondent auxentrées de Résultats. Tout comme le panneau de légende Résultats, les signets peuvent faciliterconsidérablement la navigation parmi les documents comportant un nombre élevé d’objets desortie.
Intégrer les polices. L’option d’intégration des polices rend le document PDF identique sur tousles ordinateurs. Dans le cas contraire, si certaines polices utilisées dans le document ne sont pasdisponibles sur l’ordinateur où le document PDF est affiché (ou imprimé), la substitution depolices risque de générer des résultats inférieurs.
Options Texte
Options de tableau. Les tableaux pivotants peuvent être exportés en format tabulé ou avec espaces.Pour le format avec espaces, vous pouvez également contrôler :
Largeur de colonne. Ajustement automatique ne permet pas un renvoi à la ligne du contenu descolonnes, et chacune d’entre elles est aussi large que la plus grande étiquette ou la plus grandevaleur de cette colonne. Personnalisé permet de définir une largeur de colonne maximale quiest appliquée à toutes les colonnes de la table, et les valeurs qui dépassent cette largeur sontrenvoyées à la ligne suivante de cette colonne.Caractère de bordure de ligne/colonne. Permet de contrôler les caractères utilisés pour créerdes bordures de ligne et de colonne. Pour supprimer l’affichage de ces bordures de ligne et decolonne , indiquez des espaces vides pour les valeurs.
Options d’image. Les types d’images disponibles sont les suivants : EPS, JPEG, TIFF, PNG etBMP. Sous les systèmes d’exploitation Windows, le format EMF (métafichier amélioré) estégalement disponible. Vous pouvez aussi mettre à l’échelle la taille de l’image (de 1% à 200 %).
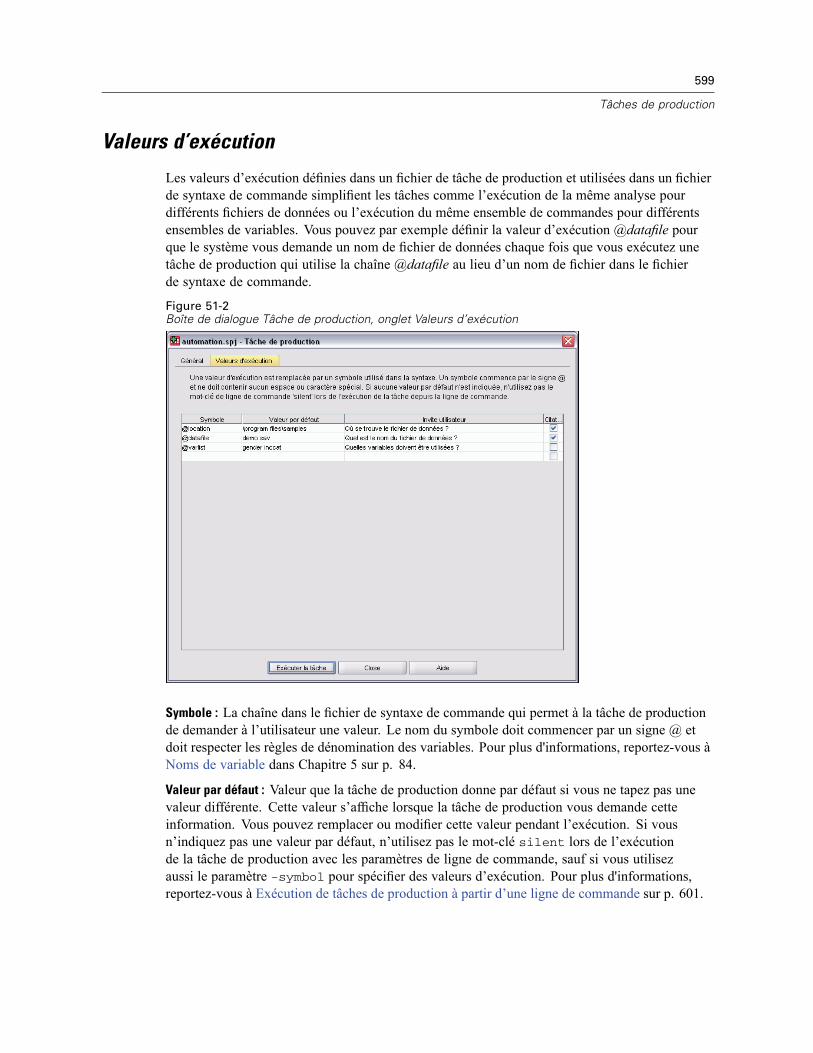
599
Tâches de production
Valeurs d’exécution
Les valeurs d’exécution définies dans un fichier de tâche de production et utilisées dans un fichierde syntaxe de commande simplifient les tâches comme l’exécution de la même analyse pourdifférents fichiers de données ou l’exécution du même ensemble de commandes pour différentsensembles de variables. Vous pouvez par exemple définir la valeur d’exécution@datafile pourque le système vous demande un nom de fichier de données chaque fois que vous exécutez unetâche de production qui utilise la chaîne@datafile au lieu d’un nom de fichier dans le fichierde syntaxe de commande.
Figure 51-2Boîte de dialogue Tâche de production, onglet Valeurs d’exécution
Symbole : La chaîne dans le fichier de syntaxe de commande qui permet à la tâche de productionde demander à l’utilisateur une valeur. Le nom du symbole doit commencer par un signe @ etdoit respecter les règles de dénomination des variables. Pour plus d'informations, reportez-vous àNoms de variable dans Chapitre 5 sur p. 84.
Valeur par défaut : Valeur que la tâche de production donne par défaut si vous ne tapez pas unevaleur différente. Cette valeur s’affiche lorsque la tâche de production vous demande cetteinformation. Vous pouvez remplacer ou modifier cette valeur pendant l’exécution. Si vousn’indiquez pas une valeur par défaut, n’utilisez pas le mot-clé silent lors de l’exécutionde la tâche de production avec les paramètres de ligne de commande, sauf si vous utilisezaussi le paramètre -symbol pour spécifier des valeurs d’exécution. Pour plus d'informations,reportez-vous à Exécution de tâches de production à partir d’une ligne de commande sur p. 601.
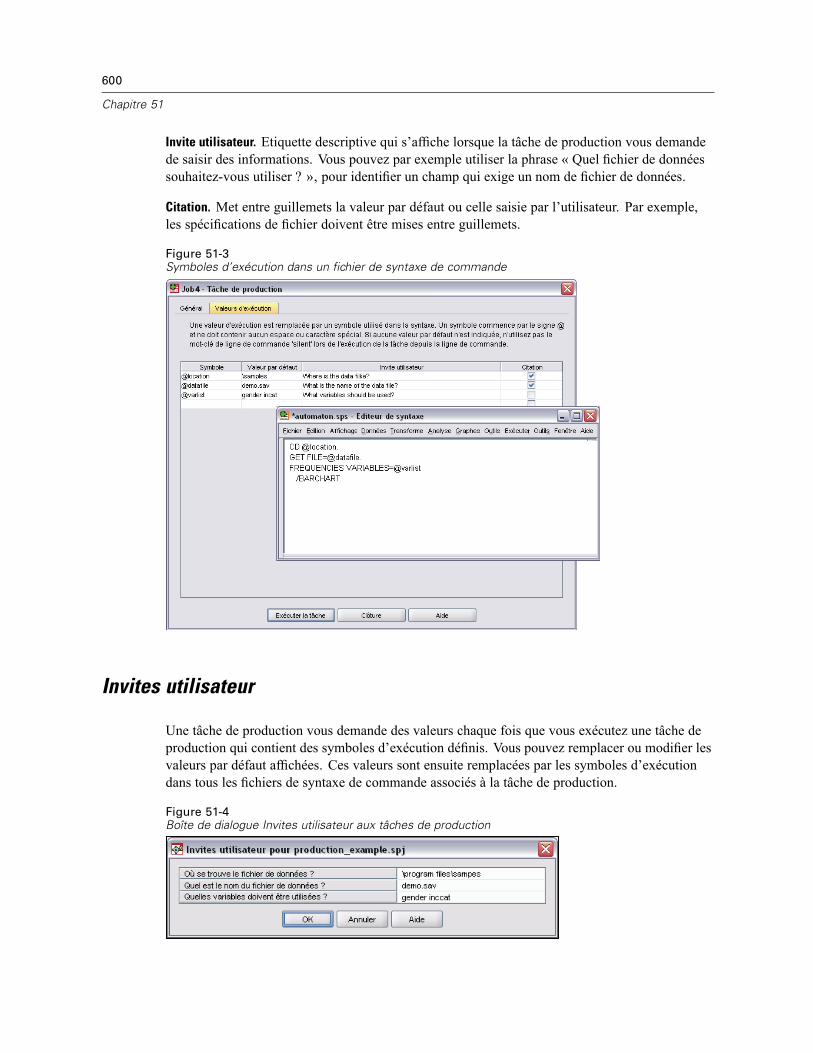
600
Chapitre 51
Invite utilisateur. Etiquette descriptive qui s’affiche lorsque la tâche de production vous demandede saisir des informations. Vous pouvez par exemple utiliser la phrase « Quel fichier de donnéessouhaitez-vous utiliser ? »‚ pour identifier un champ qui exige un nom de fichier de données.
Citation. Met entre guillemets la valeur par défaut ou celle saisie par l’utilisateur. Par exemple,les spécifications de fichier doivent être mises entre guillemets.
Figure 51-3Symboles d’exécution dans un fichier de syntaxe de commande
Invites utilisateur
Une tâche de production vous demande des valeurs chaque fois que vous exécutez une tâche deproduction qui contient des symboles d’exécution définis. Vous pouvez remplacer ou modifier lesvaleurs par défaut affichées. Ces valeurs sont ensuite remplacées par les symboles d’exécutiondans tous les fichiers de syntaxe de commande associés à la tâche de production.
Figure 51-4Boîte de dialogue Invites utilisateur aux tâches de production

601
Tâches de production
Exécution de tâches de production à partir d’une ligne de commande
Les paramètres de ligne de commande permettent de programmer des tâches de production pourqu’elles soient exécutées automatiquement à certaines périodes données, en utilisant les utilitairesde programmation disponibles dans votre système d’exploitation. Le format de base de l’argumentde ligne de commande est le suivant :
statistics filename.spj -production
En fonction de la méthode d’appel de la tâche de production, vous devrez peut être incluredes chemins de répertoire pour le fichier exécutable statistiques (figurant dans le répertoired’installation de l’application) et/ou le fichier de tâche de production.
Vous pouvez exécuter des tâches de Production à partir d’une ligne de commande à l’aide desboutons suivants :
-production [prompt|silent]. Démarrez l’application en mode production. Les mots-clés prompt etsilent spécifient s’il faut afficher la boîte de dialogue qui demande les valeurs d’exécution sielles sont précisées dans la tâche. Le mot-clé prompt est la valeur par défaut et affiche la boîtede dialogue. Le mot-clé silent supprime cette boîte de dialogue. Si vous utilisez le mot-clésilent, vous pouvez définir les symboles d’exécution à l’aide du commutateur -symbol. Sinon,la valeur par défaut est utilisée. Les commutateurs -switchserver et -singleseat sontignorés lors de l’utilisation du commutateur -production.
-symbol <values>. Liste des paires symbole-valeur utilisées dans la tâche de production. Chaquenom de symbole commence par @. Les valeurs qui contiennent des espaces doivent être misesentre guillemets. Les règles d’inclusion de guillemets ou d’apostrophes dans les valeurs littéraleschaîne peuvent varier selon le système d’exploitation. Toutefois, mettre une chaîne qui inclutdes guillemets simples ou apostrophes entre guillemets doubles fonctionne généralement (parexemple, “'une valeur entre guillemets'”).
Pour exécuter des tâches de production sur un serveur distant en mode d’analyse distribuée, vousdevrez peut être aussi spécifier les informations de connexion au serveur :
-server <inet:hostname:port>. Le nom ou l’adresse IP et le numéro de port du serveur. Uniquementsous Windows.
-user <name>. Un nom d’utilisateur valide. Si un nom de domaine est nécessaire, Faites précéderle nom d’utilisateur d’un nom de domaine et d’une barre oblique (\). Uniquement sous Windows.
-password <password>. Le mot de passe de l’utilisateur. Uniquement sous Windows.
Exemple
statistics \production_jobs\prodjob1.spj -production silent -symbol @datafile /data/July_data.sav
Cet exemple suppose que vous exécutez la ligne de commande depuis le répertoired’installation, pour qu’aucun chemin ne soit nécessaire au fichier exécutable statistiques.Cet exemple suppose aussi que la tâche de production indique que la valeur pour@datafiledoit être mise entre parenthèse (case Citation de l’onglet Valeurs d’exécution), pour qu’aucunguillemet ne soit nécessaire lorsque vous spécifiez le fichier de données sur la ligne decommande. Sinon, vous devrez indiquer une valeur comparable à '/data/July_data.sav' pour

602
Chapitre 51
inclure des guillemets avec les spécifications de fichier de données, puisque que ces dernièresdoivent être mises entre guillemets dans la syntaxe de commande.Le chemin de répertoire de l’emplacement de la tâche de production utilise la barre obliqueinverse de Windows. Sous Macintosh et Linux, utilisez des barres obliques. Les barresobliques dans la spécification de fichier de données entre guillemets fonctionnent sur tous lessystèmes d’exploitation puisque cette chaîne entre guillemets est insérée dans le fichier desyntaxe de la commande. Et donc, les barres obliques sont acceptables dans des commandesqui comprennent des spécifications de fichiers (par exemple, GET FILE, GET DATA, SAVE)sur tous les systèmes d’exploitation.Le mot-clé silent permet de supprimer toute invite utilisateur dans la tâche de production,et le paramètre -symbol permet d’insérer le nom de fichier de données et l’emplacemententre guillemets chaque fois que le symbole d’exécution@datafile figure dans les fichiers desyntaxe de commande inclus dans la tâche de production.
Conversion des fichiers du système de production
Les fichiers de tâches du système de production (.spp) créés dans les versions antérieures à 16.0ne seront pas exécutés dans la version 16.0 ou supérieure. Pour les fichiers de tâche du systèmede production Windows et Macintosh créés dans les versions antérieures, vous pouvez utiliserprodconvert, figurant dans le répertoire d’installation, pour convertir ces fichiers en nouveauxfichiers de tâche de production (.spj). Exécutez prodconvert à partir d’une fenêtre de commande àl’aide des spécifications suivantes :
[installpath]\prodconvert [filepath]\filename.spp
où [installpath] est l’emplacement du dossier dans lequel SPSS Statistics est installé et [filepath]est l’emplacement du dossier où figure le fichier de tâche de production d’origine. Un nouveaufichier avec le même nom, mais avec l’extension .spj est créé dans le même dossier que le fichierd’origine. (Remarque : si le chemin contient des espaces, mettez entre guillemets chaque cheminet spécification de fichier. Dans les systèmes d’exploitation Macintosh, utilisez des barres obliquesau lieu des barres obliques inverses.)
Limites
Les formats de diagramme WMF et EMF ne sont pas pris en charge. Le format PNG estprivilégié.Les options d’exportation Sortie document (sans diagrammes), Diagrammes seuls et Rien nesont pas prises en charge. Tous les objets résultats, pris en charge par le format sélectionné,sont inclus.Les paramètres du serveur distant sont ignorés. Pour spécifier les paramètres du serveurdistant pour l’analyse distribuée, vous devez exécuter la tâche de production à partir d’uneligne de commande, en utilisant les paramètres correspondants pour indiquer les optionsdu serveur. Pour plus d'informations, reportez-vous à Exécution de tâches de production àpartir d’une ligne de commande sur p. 601.Les paramètres de Publier sur le Web sont ignorés.
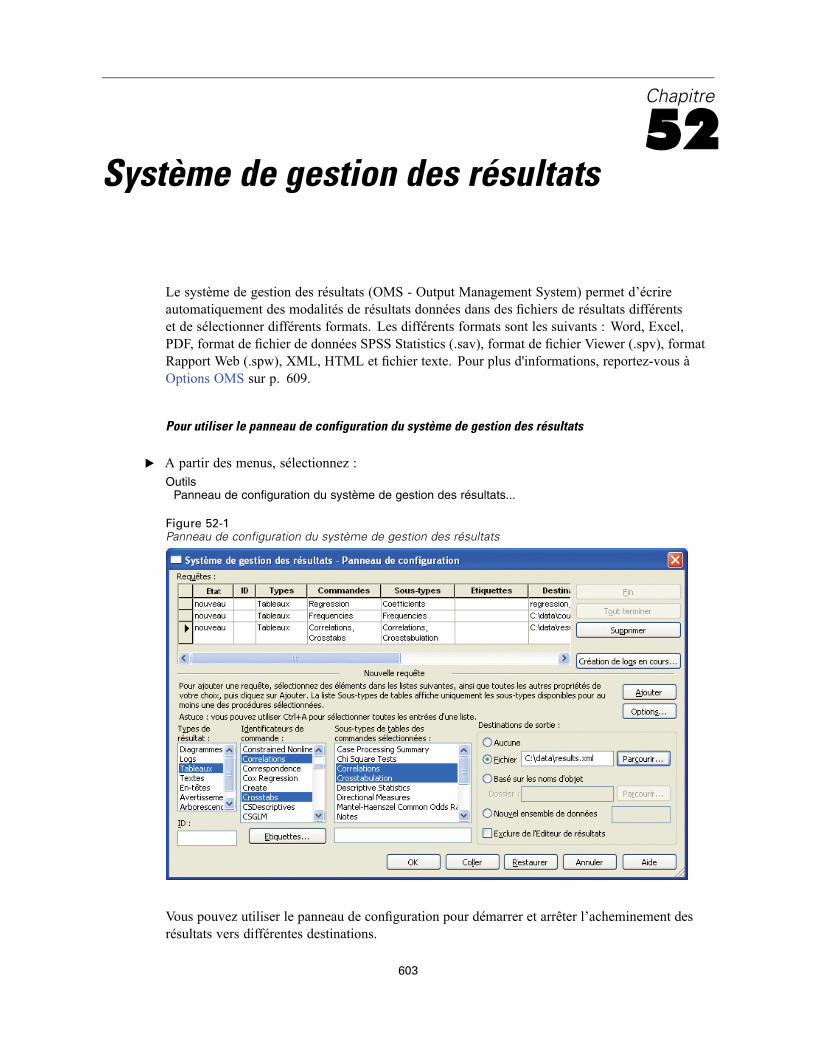
Chapitre
52Système de gestion des résultats
Le système de gestion des résultats (OMS - Output Management System) permet d’écrireautomatiquement des modalités de résultats données dans des fichiers de résultats différentset de sélectionner différents formats. Les différents formats sont les suivants : Word, Excel,PDF, format de fichier de données SPSS Statistics (.sav), format de fichier Viewer (.spv), formatRapport Web (.spw), XML, HTML et fichier texte. Pour plus d'informations, reportez-vous àOptions OMS sur p. 609.
Pour utiliser le panneau de configuration du système de gestion des résultats
E A partir des menus, sélectionnez :Outils
Panneau de configuration du système de gestion des résultats...
Figure 52-1Panneau de configuration du système de gestion des résultats
Vous pouvez utiliser le panneau de configuration pour démarrer et arrêter l’acheminement desrésultats vers différentes destinations.
603

604
Chapitre 52
Chaque requête OMS reste active jusqu’à ce qu’elle soit interrompue explicitement ou jusqu’àla fin de la session.Un fichier de destination spécifié dans une requête OMS est indisponible pour les autresprocédures et les autres applications jusqu’à la fin de la requête OMS.Lorsqu’une requête OMS est active, les fichiers de destination spécifiés sont stockés enmémoire (RAM). Les requêtes OMS actives qui écrivent une grande quantité de résultats dansdes fichiers externes risquent donc de consommer beaucoup de mémoire.Plusieurs requêtes OMS sont indépendantes les unes des autres. Les mêmes résultatspeuvent être acheminés vers différents emplacements dans plusieurs formats en fonction desspécifications des différentes requêtes OMS.L’ordre des objets de sortie dans une destination particulière est l’ordre dans lequel ils ont étécréés, déterminé par l’ordre et l’exécution des procédures à l’origine des résultats.
Pour ajouter de nouvelles requêtes OMS
E Sélectionnez les types de résultats (tableaux, diagrammes, etc.) à inclure. Pour plus d'informations,reportez-vous à Types d’objet de sortie sur p. 606.
E Sélectionnez les commandes à inclure. Si vous souhaitez inclure tous les résultats, sélectionneztous les éléments de la liste. Pour plus d'informations, reportez-vous à Identificateurs decommande et sous-types de tableau sur p. 607.
E Pour les commandes qui produisent des résultats sous forme de tableaux pivotants, sélectionnezles types de tableau spécifiques à inclure.
La liste affiche uniquement les tableaux disponibles dans les commandes sélectionnées ; touttype de tableau disponible dans une ou plusieurs des commandes sélectionnées apparaît dans laliste. Si aucune commande n’est sélectionnée, tous les types de tableau sont affichés. Pour plusd'informations, reportez-vous à Identificateurs de commande et sous-types de tableau sur p. 607.
E Pour sélectionner des tableaux en fonction des étiquettes et non des sous-types, cliquez surEtiquettes. Pour plus d'informations, reportez-vous à Etiquettes sur p. 608.
E Cliquez sur Options pour spécifier le format des résultats (par exemple, fichier de données SPSSStatistics, XML, HTML). Par défaut, le format XML de sortie est utilisé. Pour plus d'informations,reportez-vous à Options OMS sur p. 609.
E Spécifiez une destination pour les résultats :Fichier. Tous les résultats sélectionnés sont acheminés dans un fichier unique.Basés sur les noms des objets. Le résultat est acheminé vers plusieurs fichiers de destinationbasés sur des noms d’objet. Un fichier séparé est créé pour chaque objet de résultat, avec unnom de fichier basé sur les noms des sous-type de tableau ou sur les étiquettes des tableaux.Entrez le nom du dossier de destination.Nouvel ensemble de données. Pour les résultats au format de fichier de données SPSSStatistics, vous pouvez les acheminer vers un ensemble de données. L’ensemble de donnéesest disponible pour utilisation ultérieure dans la même session mais n’est pas enregistré entant que fichier sauf si vous le faites explicitement avant la fin de la session. Cette option estdisponible uniquement pour les résultats au format de fichier de données SPSS Statistics. Le

605
Système de gestion des résultats
nom des ensembles de données doit être conforme aux règles de dénomination de variables.Pour plus d'informations, reportez-vous à Noms de variable dans Chapitre 5 sur p. 84.
E Eventuellement :Exclure les résultats sélectionnés du Viewer. Si vous sélectionnez Exclure de l’Editeur derésultats, les types de résultat de la requête OMS n’apparaîtront pas dans la fenêtre du Viewer.Si plusieurs requêtes OMS actives comprennent les mêmes types de résultat, l’affichage deces types de résultat dans le Viewer est déterminé par la requête OMS la plus récente qui lescontient. Pour plus d'informations, reportez-vous à Exclusion de l’affichage des résultats duViewer sur p. 615.Affecter une chaîne d’ID à la requête. Toutes les requêtes se voient automatiquement attribuerune valeur d’ID et vous pouvez remplacer la chaîne d’ID par défaut par un ID descriptif. Celapeut être utile si vous disposez de plusieurs requêtes actives que vous souhaitez identifierfacilement. Les valeurs d’ID que vous affectez ne peuvent pas commencer par le signedollar ($).
Voici quelques astuces pour sélectionner plusieurs éléments dans une liste :Pour sélectionner tous les éléments d’une liste, appuyez sur les touches Ctrl+A du clavier.Pour sélectionner plusieurs éléments contigus, cliquez dessus tout en maintenant la toucheMaj enfoncée.Pour sélectionner plusieurs éléments non contigus, cliquez dessus tout en maintenant la toucheCtrl enfoncée.
Pour interrompre des requêtes OMS ou pour les supprimer
Les nouvelles requêtes OMS et les requêtes OMS actives sont affichées dans la liste Requêtes,la plus récente apparaissant en première position. Vous pouvez modifier la largeur des colonnesd’information en faisant glisser les bordures et vous pouvez parcourir la liste horizontalementpour voir davantage d’informations sur une requête particulière.La présence d’un astérisque (*) après le terme Actif dans la colonne Etat signale une requête
OMS créée avec une syntaxe de commande comprenant des fonctions non disponibles dans lepanneau de configuration.
Pour interrompre une requête OMS active spécifique :
E Dans la liste des requêtes, cliquez sur la cellule d’une ligne pour la requête.
E Cliquez sur Fin.
Pour interrompre toutes les requêtes OMS actives :
E Cliquez sur Tout terminer.
Pour supprimer une nouvelle requête (une requête ajoutée mais pas encore active) :
E Dans la liste des requêtes, cliquez sur la cellule d’une ligne pour la requête.
E Cliquez sur Supprimer.
Remarque : Les requêtes OMS actives ne sont interrompues que lorsque vous cliquez sur OK.

606
Chapitre 52
Types d’objet de sortie
Il existe différents types d’objet de sortie :
Diagrammes : Cela inclut les diagrammes réalisés avec le Générateur de diagrammes, lesprocédures de création de diagrammes et les diagrammes réalisés par des procédures destatistiques (par exemple, un diagramme en bâtons créé par la procédure Effectifs).
En-têtes. Objets Texte intitulés Titre dans le panneau de légende du Viewer. Les objets texted’en-tête ne sont pas inclus avec le format de sortie XML.
Journaux. Objets Texte Journal. Les objets Journal contiennent certains types de message d’erreuret d’avertissement. Selon vos paramètres Options (menu Edition, Options, onglet Editeur derésultats), les objets Journal peuvent également contenir la syntaxe de commande exécutéependant la session. Les objets Journal sont intitulés Journal dans le panneau de légende du Viewer.
Modèles. Objets de sortie affichées dans le Viewer de modèles. Un objet modèle unique peutcontenir plusieurs vues du modèle, y compris à la fois des tableaux et des diagrammes.
Tables. Objets Résultats qui se présentent sous forme de tableaux pivotants dans l’Editeur derésultats (y compris les tableaux Notes). Les tableaux sont les seuls objets de sortie qui peuventêtre acheminés au format de fichier de données SPSS Statistics (.sav).
Textes. Objets Texte qui ne sont pas des journaux ou des en-têtes (y compris les objets étiquetésRésultats texte dans le panneau de légende de l’Editeur de résultats).
Arbres. Diagrammes de modèle d’arbre produits par l’option Arbre de décision.
Avertissements. Les objets Avertissement contiennent certains types de message d’erreur etd’avertissement.
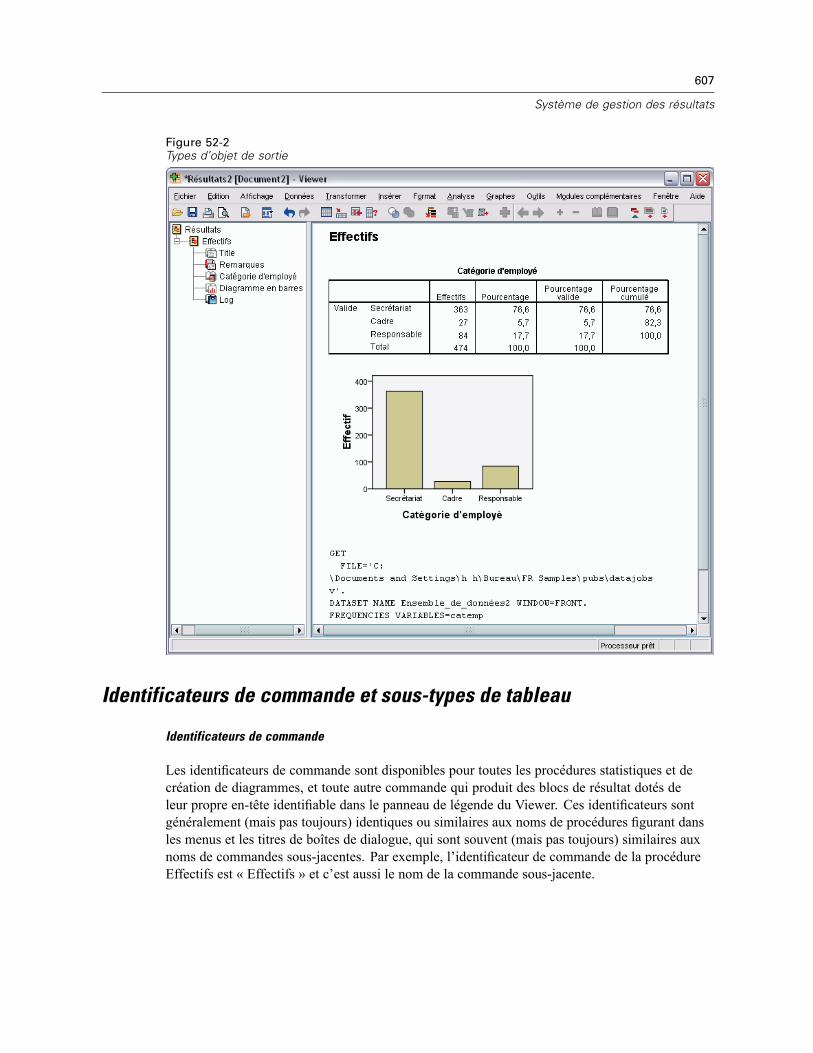
607
Système de gestion des résultats
Figure 52-2Types d’objet de sortie
Identificateurs de commande et sous-types de tableau
Identificateurs de commande
Les identificateurs de commande sont disponibles pour toutes les procédures statistiques et decréation de diagrammes, et toute autre commande qui produit des blocs de résultat dotés deleur propre en-tête identifiable dans le panneau de légende du Viewer. Ces identificateurs sontgénéralement (mais pas toujours) identiques ou similaires aux noms de procédures figurant dansles menus et les titres de boîtes de dialogue, qui sont souvent (mais pas toujours) similaires auxnoms de commandes sous-jacentes. Par exemple, l’identificateur de commande de la procédureEffectifs est « Effectifs » et c’est aussi le nom de la commande sous-jacente.

608
Chapitre 52
Toutefois, dans certains cas, le nom de la procédure, l’identificateur de commande et/ou le nomde la commande ne sont pas tous similaires. Par exemple, toutes les procédures dans le sous-menuTests non paramétriques (à partir du menu Analyse) utilisent la même commande sous-jacente etl’identificateur de commande est identique au nom de cette commande : Npar Tests.
Sous-types de tableau
Les sous-types sont les différents types de tableau pivotant qui peuvent être générés. Certainssous-types sont produits par une seule commande, d’autres peuvent être produits par plusieurscommandes (bien que les tableaux risquent de ne pas se ressembler). Les noms des sous-typesde tableau sont généralement assez descriptifs. Toutefois, leur nombre peut être assez élevé(notamment si vous avez sélectionné un grand nombre de commandes) et/ou deux sous-typespeuvent avoir des noms très proches.
Recherche d’identificateurs de commande et de sous-types de tableau
Si vous avez un doute, vous pouvez rechercher des identificateurs de commande et des noms desous-type de tableau dans la fenêtre du Viewer :
E Exécutez la procédure pour générer des résultats dans le Viewer.
E Cliquez avec le bouton droit de la souris sur l’item dans le panneau de légende de l’Editeur derésultats.
E Sélectionnez Copier l’identificateur de commande OMS ou Copier le sous-type de table OMS.
E Collez l’identificateur de commande ou le nom de sous-type de tableau copié dans un éditeur detexte (comme une fenêtre Editeur de syntaxe, par exemple).
Etiquettes
Comme alternative aux noms de sous-type de tableau, vous pouvez sélectionner des tableauxsur la base du texte affiché dans le panneau de légende de l’Editeur de résultats. Vous pouvezégalement sélectionner d’autres types d’objets en fonction de leur étiquette. Vous pouvez utiliserdes étiquettes pour différencier des tableaux de même type dans lesquels le texte de la légendereflète un attribut de l’objet de sortie particulier (par exemple, les noms de variable ou lesétiquettes). Cependant, il existe un certain nombre de facteurs qui peuvent avoir une incidencesur le texte de l’étiquette :
Si le traitement du fichier scindé est activé, l’identification des classes de fichier scindé peutêtre ajoutée à l’étiquette.Les étiquettes qui comprennent des informations sur les variables ou les valeurs sont affectéespar le paramétrage des options des étiquettes de résultat (menu Edition, Options, ongletEtiquettes Résultats).Les étiquettes sont affectées par le paramètre lié à la langue des résultats (menu Modifier,Options, onglet Général).

609
Système de gestion des résultats
Pour spécifier les étiquettes à utiliser pour identifier les objets Résultat
E Dans le panneau de configuration du système de gestion de résultats, sélectionnez un ou plusieurstypes de résultats, puis une ou plusieurs commandes.
E Cliquez sur Etiquettes.Figure 52-3Boîte de dialogue Etiquettes OMS
E Entrez l’étiquette exactement telle qu’elle apparaît dans le panneau de légende de la fenêtre del’Editeur de résultats. Vous pouvez également cliquer avec le bouton droit de la souris sur l’itemdans la légende, sélectionner Copier l’étiquette OMS et coller l’étiquette copiée dans le champ detexte Etiquette.
E Cliquez sur Ajouter.
E Répétez l’opération pour chaque étiquette à inclure.
E Cliquez sur Poursuivre.
Caractères génériques
Vous pouvez utiliser l’astérisque (*) comme dernier caractère de la chaîne d’étiquette. Toutes lesétiquettes qui commencent par la chaîne spécifiée (astérisque exclu) seront sélectionnées. Cetteopération fonctionne uniquement lorsque l’astérisque est le dernier caractère, car les astérisquespeuvent apparaître comme des caractères valides dans une étiquette.
Options OMSVous pouvez utiliser la boîte de dialogue Options OMS pour :
Spécifier le format des résultats.Indiquez le format d’image (pour les formats de résultats de sortie HTML et XML).Indiquer quels éléments de dimension de tableau doivent aller dans la dimension de ligne.Inclure une variable qui identifie le numéro de tableau séquentiel qui est la source de chaqueobservation (pour le format de fichier de données SPSS Statistics).
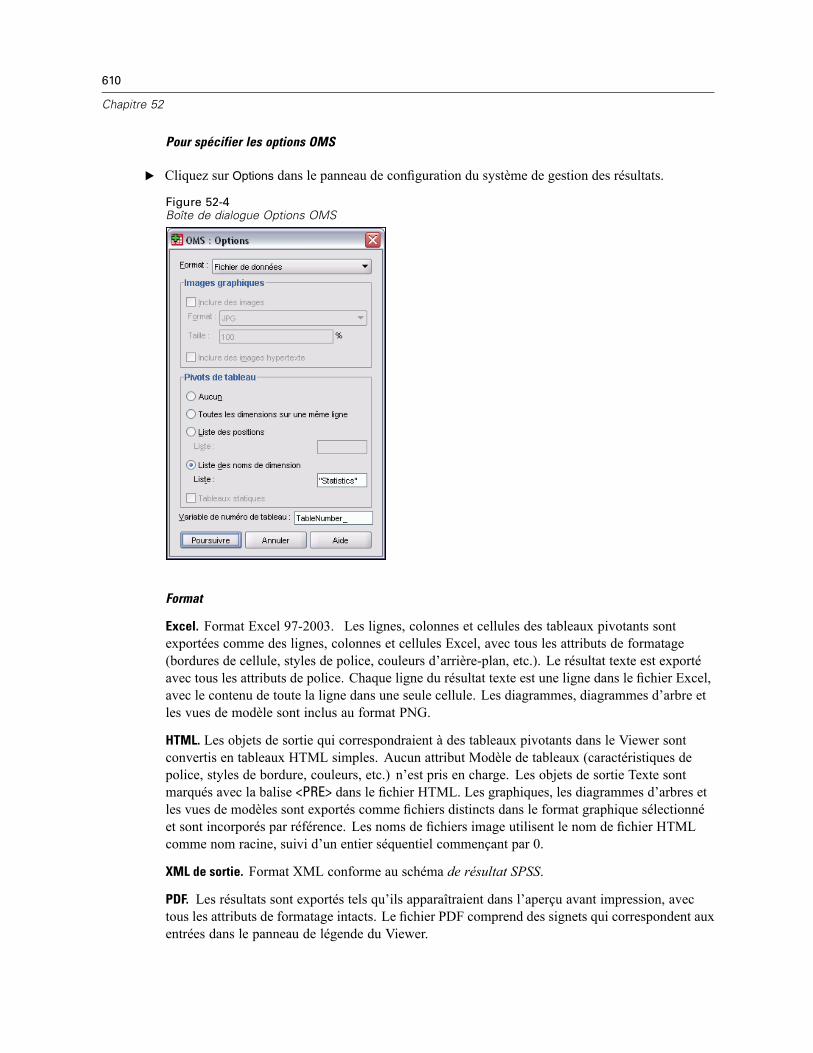
610
Chapitre 52
Pour spécifier les options OMS
E Cliquez sur Options dans le panneau de configuration du système de gestion des résultats.
Figure 52-4Boîte de dialogue Options OMS
Format
Excel. Format Excel 97-2003. Les lignes, colonnes et cellules des tableaux pivotants sontexportées comme des lignes, colonnes et cellules Excel, avec tous les attributs de formatage(bordures de cellule, styles de police, couleurs d’arrière-plan, etc.). Le résultat texte est exportéavec tous les attributs de police. Chaque ligne du résultat texte est une ligne dans le fichier Excel,avec le contenu de toute la ligne dans une seule cellule. Les diagrammes, diagrammes d’arbre etles vues de modèle sont inclus au format PNG.
HTML. Les objets de sortie qui correspondraient à des tableaux pivotants dans le Viewer sontconvertis en tableaux HTML simples. Aucun attribut Modèle de tableaux (caractéristiques depolice, styles de bordure, couleurs, etc.) n’est pris en charge. Les objets de sortie Texte sontmarqués avec la balise <PRE> dans le fichier HTML. Les graphiques, les diagrammes d’arbres etles vues de modèles sont exportés comme fichiers distincts dans le format graphique sélectionnéet sont incorporés par référence. Les noms de fichiers image utilisent le nom de fichier HTMLcomme nom racine, suivi d’un entier séquentiel commençant par 0.
XML de sortie. Format XML conforme au schéma de résultat SPSS.
PDF. Les résultats sont exportés tels qu’ils apparaîtraient dans l’aperçu avant impression, avectous les attributs de formatage intacts. Le fichier PDF comprend des signets qui correspondent auxentrées dans le panneau de légende du Viewer.

611
Système de gestion des résultats
SPSS Statistics Fichier de données. Il s’agit d’un format de fichier binaire. Tous les types d’objetde sortie autres que les tableaux sont exclus. Chaque colonne d’un tableau devient une variabledans le fichier de données. Pour utiliser un fichier de données créé avec le système OMS au coursde la même session, vous devez interrompre la requête OMS active pour pouvoir ouvrir le fichierde données. Pour plus d'informations, reportez-vous à Acheminement des résultats vers desfichiers de données SPSS Statistics sur p. 615.
Texte : Texte séparé par des espaces. Les résultats sont écrits au format texte, les résultats entableaux étant alignés avec des espaces pour les polices à espacement fixe. Les diagrammes,diagrammes d’arbre et les vues de modèle sont exclus.
Texte à onglets. Texte délimité par des tabulations. Pour les résultats affichés en tant que tableauxpivotants dans le Viewer, des tabulations délimitent les éléments de colonne des tableaux. Leslignes de bloc de texte sont écrites telles quelles ; le système ne tente pas de les diviser avec destabulations aux emplacements appropriés. Les diagrammes, diagrammes d’arbre et les vues demodèle sont exclus.
Fichier Viewer. Ceci est le même format utilisé lorsque vous enregistrez le contenu d’une fenêtreViewer.
Fichier rapport Web. Ce format de fichier de résultats est conçu pour être utilisé avec PredictiveEnterprise Services. Il est pratiquement le même que le format Viewer SPSS Statistics, si ce n’estque les diagrammes d’arbre sont enregistrés comme images statiques.
Word/RTF. Les tableaux pivotants sont exportés en tant que tableaux Word, avec tous les attributsde formatage (bordures de cellule, styles de police, couleurs d’arrière-plan). La sortie texte estexportée au format RTF. Les diagrammes, diagrammes d’arbre et les vues de modèle sont inclusau format PNG.
Images graphiques
Pour les formats HTML et XML de sortie, vous pouvez inclure des diagrammes, des diagrammesd’arbres et des vues de modèle sous forme de fichiers d’image. Un fichier image est créé pourchaque graphique et/ou diagramme d’arbre.
Pour le format de document HTML, les balises <IMG SRC='filename'> standard sontcomprises dans le document HTML pour chaque fichier image.Pour le format de document XML de sortie, le fichier XML contient un élément chart avec unattribut ImageFile de format général <chart imageFile="filepath/filename"/>pour chaque fichier image.Les fichiers image sont enregistrés dans un sous-répertoire (dossier) distinct. Le nom dusous-répertoire est le nom du fichier de destination sans extension et contenant le suffixe_files. Par exemple, si le fichier de destination est julydata.htm, le sous-répertoire des imagesest intitulé julydata_files.
Format : Les formats d’images disponibles sont PNG, JPG, EMF, BMP et VML.Le format EMF (métafichier amélioré) n’est disponible que sous les systèmes d’exploitationWindows.Le format d’image VML n’est disponible qu’avec le format de document HTML.

612
Chapitre 52
Le format image VML ne crée pas de fichiers image distincts. Le code VML qui génèrel’image est intégré dans le fichier HTML.Le format d’image VML n’inclut pas de diagrammes d’arbre.
Taille : Vous pouvez mettre à l’échelle la taille de l’image (de 10% à 200 %).
Inclure des images hypertexte. Pour le format de document HTML, cette option permet de créerdes info-bulles d’images hypertexte qui affichent des informations pour certains éléments dugraphique, comme la valeur du point sélectionné sur un diagramme curviligne ou un bâton surun diagramme en bâtons.
Pivots de tableau
Pour les résultats Tableau pivotant, vous pouvez spécifier le ou les éléments de dimension quidoivent apparaître dans les colonnes. Tous les autres éléments de dimension apparaissent dans leslignes. Pour le format de fichier de données SPSS Statistics, les colonnes du tableau deviennentdes variables et les lignes, des observations.
Si vous spécifiez plusieurs éléments de dimension pour les colonnes, ils sont emboîtés dansles colonnes dans l’ordre dans lequel ils sont répertoriés. Pour le format de fichier de donnéesSPSS Statistics, les noms de variable sont construits par les éléments de colonne emboîtés.Pour plus d'informations, reportez-vous à Noms de variable dans les fichiers de donnéesgénérés par le système de gestion des résultats sur p. 622.Si un tableau ne contient aucun des éléments de dimension répertoriés, tous les éléments dedimension de ce tableau apparaissent dans les lignes.Les pivots de tableau spécifiés ici n’ont aucun effet sur les tableaux affichés dans l’Editeur derésultats.
Chaque dimension d’un tableau (ligne, colonne, strate) peut contenir aucun, un ou plusieurséléments. Par exemple, un tableau croisé bidimensionnel simple contient un seul élément dedimension de ligne et un seul élément de dimension de colonne, chacun contenant l’une desvariables utilisées dans le tableau. Vous pouvez utiliser des arguments de position ou des « noms »d’élément de dimension pour spécifier les éléments de dimension à placer dans la dimensionde colonne.
Toutes les dimensions en lignes. Créé une ligne unique pour chaque tableau. Pour les fichiers dedonnées au format SPSS Statistics, cela implique que chaque tableau correspond à une observationunique et tous les élements du tableau à des variables.
Liste des positions. La forme générale d’un argument de position est une lettre indiquant laposition par défaut de l’élément (C pour colonne, L pour ligne ou S pour strate), suivie d’un entierpositif indiquant la position par défaut au sein de cette dimension. Par exemple, L1 indiquel’élément de dimension de ligne le plus externe.
Pour spécifier plusieurs éléments à partir de plusieurs dimensions, séparez les dimensions parun espace (par exemple, R1 C2).

613
Système de gestion des résultats
La lettre de dimension suivie par ALL indique tous les éléments de cette dimension dans leurordre par défaut. Par exemple, CALL équivaut au comportement par défaut (utilisation detous les éléments de colonne dans leur ordre par défaut pour créer des colonnes).CALL LALL SALL (ou LALL CALL SALL, etc.) placent tous les éléments de dimensiondans les colonnes. Pour le format de fichier de données SPSS Statistics, cela crée uneligne/observation par tableau dans le fichier de données.
Figure 52-5Arguments de position de ligne et de colonne
Liste des noms de dimension. Alternative aux arguments de position, vous pouvez utiliser les« noms » d’élément de dimension qui sont les étiquettes de texte apparaissant dans le tableau.Par exemple, un tableau croisé bidimensionnel simple contient un seul élément de dimension deligne et un seul élément de dimension de colonne, tous deux dotés d’étiquettes basées sur lesvariables de ces dimensions, plus un seul élément de dimension de strate intitulé Statistiques (sile français est la langue de sortie).
Les noms d’élément de dimension peuvent varier en fonction de la langue de sortie et/ou desparamètres qui affectent l’affichage des noms de variable et/ou des étiquettes dans les tableaux.Chaque nom d’élément de dimension doit apparaître entre apostrophes ou entre guillemets.Pour spécifier plusieurs noms d’élément de dimension, séparez-les par un espace.
Les étiquettes associées aux éléments de dimension ne sont peut-être pas toujours évidentes.
Pour afficher tous les éléments de dimension et leurs étiquettes pour un tableau pivotant
E Double-cliquez sur le tableau dans le Viewer pour l’activer.
E A partir des menus, sélectionnez :Affichage
Montrer Tout
et/ou
E Si les structures pivotantes ne sont pas affichées, sélectionnez les option suivantes dans les menus :Tableau pivotant
Structure pivotante
Les étiquettes d’élément sont affichées dans la structure pivotante.

614
Chapitre 52
Figure 52-6Noms d’élément de dimension affichés dans le tableau et les structures pivotantes
Journalisation
Vous pouvez enregistrer l’activité OMS dans un journal au format XML ou texte.Le journal effectue le suivi de toutes les nouvelles requêtes OMS de la session, mais il n’inclutpas les requêtes OMS déjà actives avant que vous demandiez un journal.Le fichier journal en cours est interrompu si vous en indiquez un nouveau ou si vousdésélectionnez l’option Activité du log OMS.
Pour spécifier la journalisation OMS :
E Cliquez sur Journalisation dans le panneau de configuration du système de gestion des résultats.

615
Système de gestion des résultats
Exclusion de l’affichage des résultats du Viewer
La case à cocher Exclure du Viewer affecte l’ensemble des résultats sélectionnés dans la requêteOMS en supprimant l’affichage de ces résultats de la fenêtre du Viewer. Cette fonctionnalité estsouvent utile pour les tâches de production qui génèrent un grand nombre de résultats et si vousn’avez pas besoin des résultats sous la forme d’un document du Viewer (fichier .spv). Vouspouvez également l’utiliser pour supprimer l’affichage d’objets de résultats particuliers que vousne souhaitez jamais voir apparaître, sans acheminer les autres résultats vers un fichier et un formatexternes.
Pour supprimer l’affichage de certains objets de sortie sans acheminer les autres résultats vers unfichier externe :
E Créez une requête OMS identifiant les résultats indésirables.
E Sélectionnez Exclure du Viewer.
E Pour la destination des résultats, sélectionnez Fichier en prenant soin de laisser vide le champFichier.
E Cliquez sur Ajouter.
Les résultats sélectionnés sont exclus du Viewer, alors que tous les autres résultats sont affichésnormalement dans le Viewer.
Acheminement des résultats vers des fichiers de données SPSSStatistics
Un fichier de données au format SPSS Statistics est composé de variables réparties dans lescolonnes et d’observations réparties dans les lignes. Ceci est le format dans lequel les tableauxpivotants sont convertis en fichiers de données :
Les colonnes du tableau sont les variables du fichier de données. Les noms de variable validessont construits à partir des étiquettes de colonne.Les étiquettes de ligne du tableau deviennent des variables portant des noms génériques (Var1,Var2, Var3, etc.) dans le fichier de données. Les valeurs de ces variables sont les étiquettesde lignes du tableau.Trois variables d’identificateur de tableau sont automatiquement incluses dans le fichier dedonnées : Command_, Subtype_ et Label_. Toutes trois sont des variables chaîne. Les deuxpremières variables correspondent aux identificateurs de commande et de sous-type. Pourplus d'informations, reportez-vous à Identificateurs de commande et sous-types de tableau surp. 607. Label_ contient le texte du titre de tableau.Les lignes du tableau deviennent des observations dans le fichier de données.
Exemple : Tableau bidimensionnel unique
Dans le cas le plus simple (un tableau bidimensionnel unique), les colonnes du tableau deviennentles variables et les lignes deviennent les observations du fichier de données.

616
Chapitre 52
Figure 52-7Tableau bidimensionnel unique
Les trois premières variables identifient le tableau source par commande, sous-type et étiquette.Les deux éléments qui définissent les lignes du tableau (valeurs de la variable Sexe et Mesuresstatistiques) se voient affecter les noms de variable génériques Var1 et Var2. Dans les deuxcas, il s’agit de variables chaîne.Les étiquettes de colonne du tableau sont utilisées pour créer des noms de variable valides. Enl’occurrence, ces noms de variables sont basés sur les étiquettes des trois variables d’échellereprises dans le tableau. Si les variables ne sont pas dotées d’étiquettes ou si vous choisissezd’afficher les noms de variables à la place des étiquettes en tant qu’étiquettes de colonnesdu tableau, les noms de variables du nouveau fichier de données sont identiques à ceux dufichier de données source.
Exemple : Tableaux avec strates
Outre les lignes et les colonnes, un tableau peut également contenir une troisième dimension : ladimension de strate.

617
Système de gestion des résultats
Figure 52-8Tableau avec strates
Dans le tableau, la variable intitulée Classification des minorités définit les strates. Dans lefichier de données, deux variables supplémentaires sont créées : une qui identifie l’élément destrate et une autre qui identifie les modalités de cet élément.Comme pour les variables créées à partir des éléments de ligne, les variables créées à partirdes éléments de strate sont des variables chaîne portant des noms génériques (le préfixeVar suivi d’un numéro séquentiel).
Fichiers de données créés à partir de plusieurs tableaux
Lorsque plusieurs tableaux sont acheminés vers le même fichier de données, chacun d’entre euxest ajouté au fichier de données selon le même principe que la fusion de fichiers de données quiconsiste à ajouter les observations d’un fichier de données à un autre (menu Données, Fusionnerdes fichiers, Ajouter des observations).
Chaque tableau suivant ajoute des observations au fichier de données.Si les étiquettes de colonne des tableaux sont différentes, chaque tableau peut égalementajouter des variables au fichier de données, avec des valeurs manquantes pour les observationsprovenant des autres tableaux qui ne comportent pas de colonne dotée d’une étiquetteidentique.
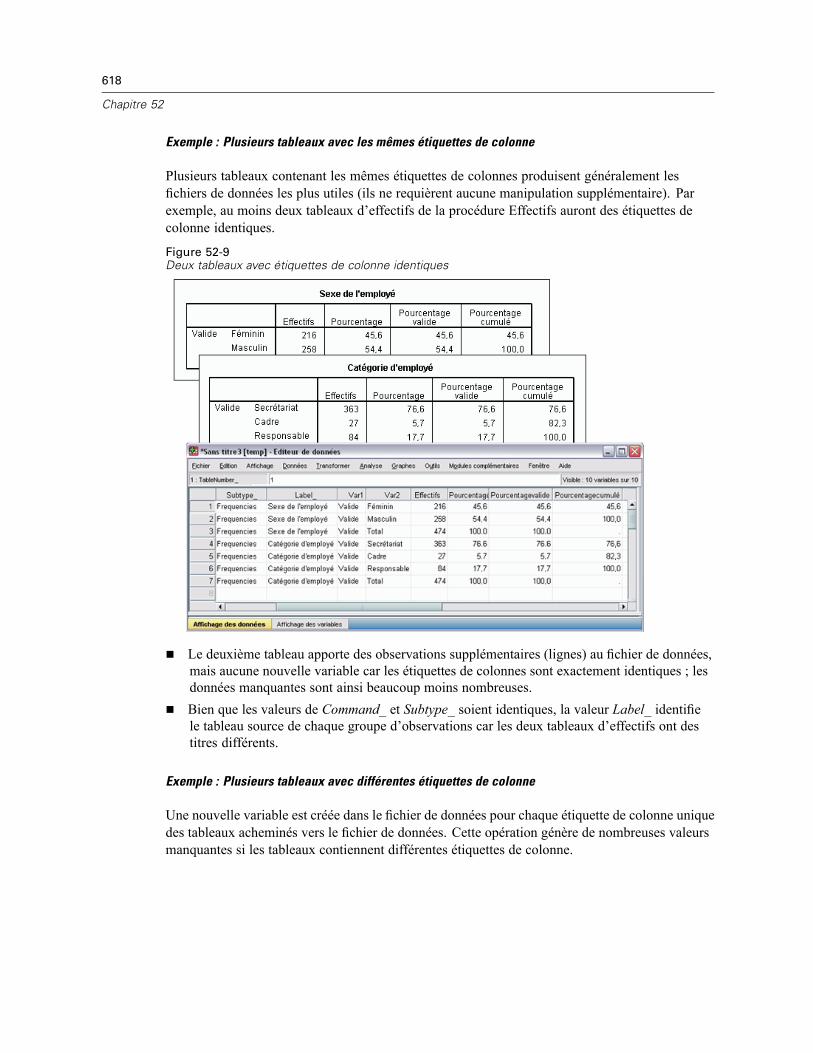
618
Chapitre 52
Exemple : Plusieurs tableaux avec les mêmes étiquettes de colonne
Plusieurs tableaux contenant les mêmes étiquettes de colonnes produisent généralement lesfichiers de données les plus utiles (ils ne requièrent aucune manipulation supplémentaire). Parexemple, au moins deux tableaux d’effectifs de la procédure Effectifs auront des étiquettes decolonne identiques.
Figure 52-9Deux tableaux avec étiquettes de colonne identiques
Le deuxième tableau apporte des observations supplémentaires (lignes) au fichier de données,mais aucune nouvelle variable car les étiquettes de colonnes sont exactement identiques ; lesdonnées manquantes sont ainsi beaucoup moins nombreuses.Bien que les valeurs de Command_ et Subtype_ soient identiques, la valeur Label_ identifiele tableau source de chaque groupe d’observations car les deux tableaux d’effectifs ont destitres différents.
Exemple : Plusieurs tableaux avec différentes étiquettes de colonne
Une nouvelle variable est créée dans le fichier de données pour chaque étiquette de colonne uniquedes tableaux acheminés vers le fichier de données. Cette opération génère de nombreuses valeursmanquantes si les tableaux contiennent différentes étiquettes de colonne.
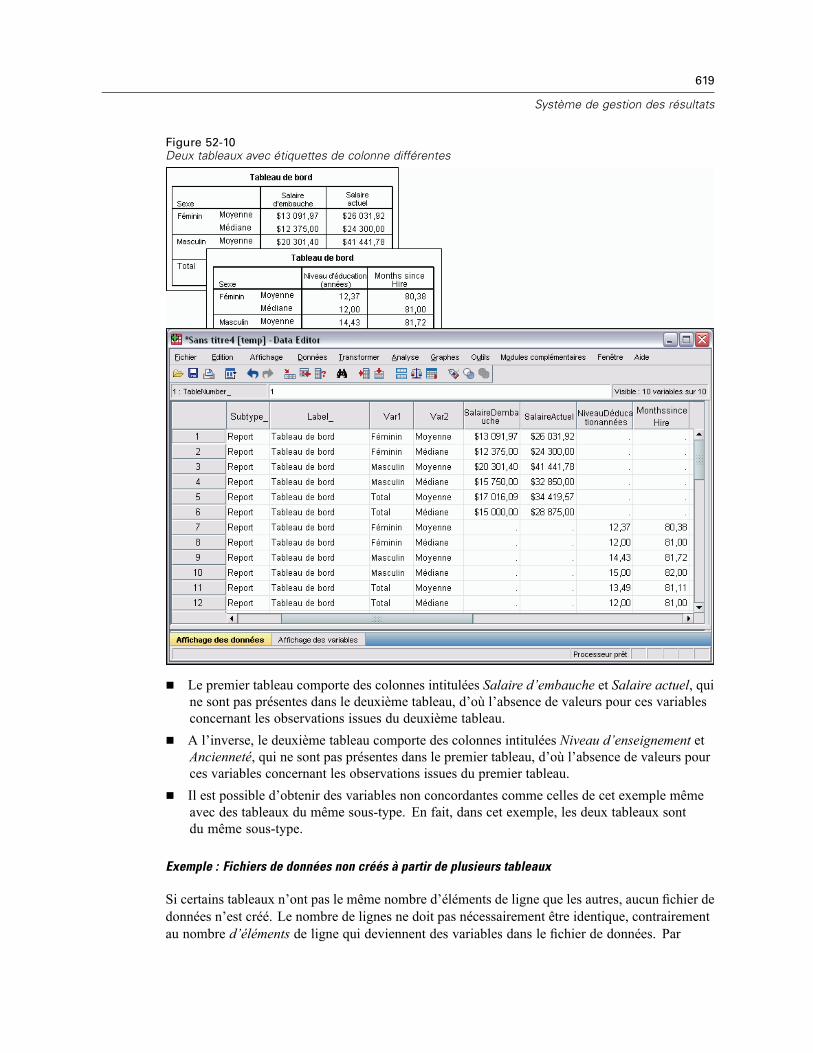
619
Système de gestion des résultats
Figure 52-10Deux tableaux avec étiquettes de colonne différentes
Le premier tableau comporte des colonnes intitulées Salaire d’embauche et Salaire actuel, quine sont pas présentes dans le deuxième tableau, d’où l’absence de valeurs pour ces variablesconcernant les observations issues du deuxième tableau.A l’inverse, le deuxième tableau comporte des colonnes intitulées Niveau d’enseignement etAncienneté, qui ne sont pas présentes dans le premier tableau, d’où l’absence de valeurs pources variables concernant les observations issues du premier tableau.Il est possible d’obtenir des variables non concordantes comme celles de cet exemple mêmeavec des tableaux du même sous-type. En fait, dans cet exemple, les deux tableaux sontdu même sous-type.
Exemple : Fichiers de données non créés à partir de plusieurs tableaux
Si certains tableaux n’ont pas le même nombre d’éléments de ligne que les autres, aucun fichier dedonnées n’est créé. Le nombre de lignes ne doit pas nécessairement être identique, contrairementau nombre d’éléments de ligne qui deviennent des variables dans le fichier de données. Par
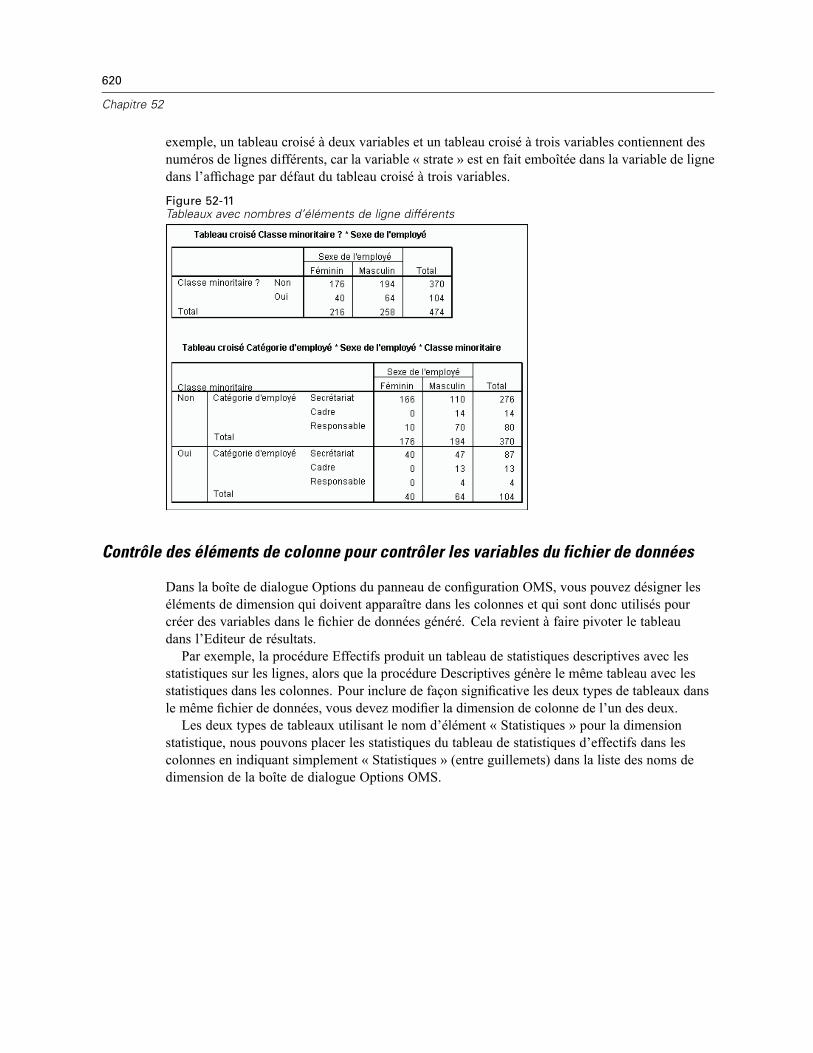
620
Chapitre 52
exemple, un tableau croisé à deux variables et un tableau croisé à trois variables contiennent desnuméros de lignes différents, car la variable « strate » est en fait emboîtée dans la variable de lignedans l’affichage par défaut du tableau croisé à trois variables.
Figure 52-11Tableaux avec nombres d’éléments de ligne différents
Contrôle des éléments de colonne pour contrôler les variables du fichier de données
Dans la boîte de dialogue Options du panneau de configuration OMS, vous pouvez désigner leséléments de dimension qui doivent apparaître dans les colonnes et qui sont donc utilisés pourcréer des variables dans le fichier de données généré. Cela revient à faire pivoter le tableaudans l’Editeur de résultats.Par exemple, la procédure Effectifs produit un tableau de statistiques descriptives avec les
statistiques sur les lignes, alors que la procédure Descriptives génère le même tableau avec lesstatistiques dans les colonnes. Pour inclure de façon significative les deux types de tableaux dansle même fichier de données, vous devez modifier la dimension de colonne de l’un des deux.Les deux types de tableaux utilisant le nom d’élément « Statistiques » pour la dimension
statistique, nous pouvons placer les statistiques du tableau de statistiques d’effectifs dans lescolonnes en indiquant simplement « Statistiques » (entre guillemets) dans la liste des noms dedimension de la boîte de dialogue Options OMS.
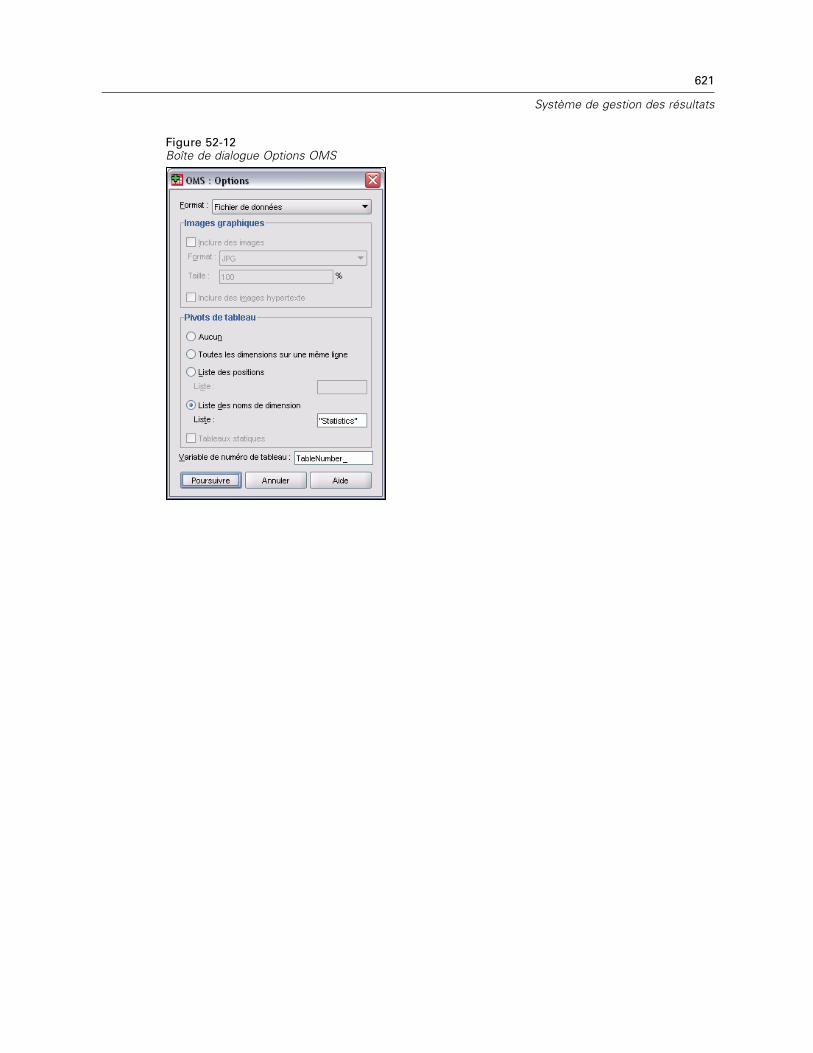
621
Système de gestion des résultats
Figure 52-12Boîte de dialogue Options OMS

622
Chapitre 52
Figure 52-13Combinaison de différents types de tableau dans un fichier de données par pivotement des élémentsde dimension
Des valeurs sont manquantes dans certaines variables, car les structures des tableaux ne sonttoujours pas exactement identiques aux statistiques des colonnes.
Noms de variable dans les fichiers de données générés par le système de gestiondes résultats
Le système OMS construit des noms de variable uniques et valides à partir des étiquettes decolonne :
Des noms de variables génériques sont attribués aux éléments de ligne et de strate (le préfixeVar suivi par un numéro séquentiel).Les caractères non autorisés dans les noms de variable (comme l’espace ou les parenthèses)sont supprimés. Par exemple, le nom « Cette étiquette (de colonne) » devient la variable« Cetteétiquettedecolonne ».Si l’étiquette commence par un caractère autorisé dans les noms de variable, mais pas commepremier caractère (par exemple, un chiffre), le symbole @ est inséré comme préfixe. Parexemple, « 2ème » devient la variable «@2ème ».

623
Système de gestion des résultats
Les traits de soulignement et les virgules à la fin des étiquettes sont supprimés des noms devariable obtenus. Les traits de soulignement situés à la fin des variables Command_, Subtype_et Label_ générées automatiquement ne sont pas supprimés.Si plusieurs éléments figurent dans la dimension de colonne, les noms de variable sontconstruits par la combinaison des étiquettes de modalité avec des traits de soulignemententre ces étiquettes. Les étiquettes de groupe ne sont pas incluses. Par exemple, si VarB estemboîté sous VarA dans les colonnes, vous obtenez des variables de type ModA1_ModB1, etnon VarA_ModA1_VarB_ModB1.
Figure 52-14Noms de variable construits à partir d’éléments de tableau
Structure de tableau OXML
Le format Output XML (OXML) est un format XML conforme au schéma de résultat spss.Pour obtenir une description détaillée du schéma, reportez-vous à la section relative au schémade résultats dans le système d’aide.
Les identificateurs de sous-type et de commande OMS sont utilisés comme valeurs desattributs command et subType au format OXML. Voir l’exemple comme suit :
<command text=Frequencies command=Frequencies...><pivotTable text=Gender label=Gender subType=Frequencies...>
Les valeurs d’attribut command et subType OMS ne sont pas affectées par la langue de sortieni par les paramètres d’affichage des étiquettes/noms de variable ou des valeurs/étiquettesde valeur.Le langage XML respecte la casse. La valeur d’attribut subType « effectifs » n’est pasidentique à la valeur d’attribut subType « Effectifs ».

624
Chapitre 52
Toutes les informations affichées dans un tableau sont contenues dans les valeurs d’attributen OXML. Au niveau de chaque cellule, OXML est composé d’éléments « vides » quicontiennent des attributs mais pas de « contenu » autre que celui des valeurs d’attribut.En OXML, la structure de tableau est représentée ligne par ligne ; les éléments qui représententles colonnes sont emboîtés dans les lignes et les différentes cellules sont emboîtées dansles éléments de colonne :
<pivotTable...><dimension axis='row'...><dimension axis='column'...>
<category...><cell text='...' number='...' decimals='...'/>
</category><category...>
<cell text='...' number='...' decimals='...'/></category>
</dimension></dimension>
...</pivotTable>
L’exemple précédant est une représentation simplifiée de la structure qui présente les relationsdescendant/ancêtre de ces éléments. Cependant, l’exemple ne présente pas nécessairement lesrelations parent/enfant car il y a généralement insertion d’autres niveaux d’éléments emboîtés.Le schéma suivant illustre un simple tableau d’effectifs et la représentation OXML complète de
ce tableau.
Figure 52-15Tableau d’effectifs simple
Figure 52-16OXML pour tableau d’effectifs simple
<?xml version=1.0 encoding=UTF-8?><outputTreeoutputTree xmlns=http://xml.spss.com/spss/oms
xmlns:xsi=http://www.w3.org/2001/XMLSchema-instancexsi:schemaLocation=http://xml.spss.com/spss/omshttp://xml.spss.com/spss/oms/spss-output-1.0.xsd><command text=Frequencies command=FrequenciesdisplayTableValues=label displayOutlineValues=labeldisplayTableVariables=label displayOutlineVariables=label><pivotTable text=Gender label=Gender subType=FrequenciesvarName=gender variable=true>

625
Système de gestion des résultats
<dimension axis=row text=Gender label=GendervarName=gender variable=true><group text=Valid><group hide=true text=Dummy><category text=Female label=Female string=fvarName=gender><dimension axis=column text=Statistics><category text=Frequency><cell text=216 number=216/></category><category text=Percent><cell text=45.6 number=45.569620253165 decimals=1/></category><category text=Valid Percent><cell text=45.6 number=45.569620253165 decimals=1/></category><category text=Cumulative Percent><cell text=45.6 number=45.569620253165 decimals=1/></category></dimension>
</category><category text=Male label=Male string=m varName=gender><dimension axis=column text=Statistics><category text=Frequency><cell text=258 number=258/></category><category text=Percent><cell text=54.4 number=54.430379746835 decimals=1/></category><category text=Valid Percent><cell text=54.4 number=54.430379746835 decimals=1/></category><category text=Cumulative Percent><cell text=100.0 number=100 decimals=1/></category></dimension>
</category></group><category text=Total><dimension axis=column text=Statistics><category text=Frequency><cell text=474 number=474/></category><category text=Percent><cell text=100.0 number=100 decimals=1/></category><category text=Valid Percent><cell text=100.0 number=100 decimals=1/></category>
</dimension></category></group>

626
Chapitre 52
</dimension></pivotTable></command>
</outputTree>
Comme vous pouvez le constater, un petit tableau simple produit une quantité importante decode XML. En effet, le code XML contient des informations non apparentes dans le tableaud’origine, des informations qui ne sont peut-être même pas disponibles dans le tableau d’origine etune certaine quantité de redondances.
Le contenu du tableau tel qu’il apparaîtrait dans un tableau pivotant dans le Viewer est contenudans les attributs de texte. Voir l’exemple comme suit :
<command text=Frequencies command=Frequencies...>
Les attributs de texte peuvent être affectés par la langue de sortie et par les paramètres quiinfluencent l’affichage des noms/étiquettes de variable et des valeurs/étiquettes de valeur.Dans cet exemple, la valeur d’attribut texte diffère selon la langue de sortie, alors que lavaleur d’attribut commande reste identique, quelle que soit cette langue.Que les variables ou les valeurs des variables soient utilisées dans des étiquettes de ligne oude colonne, le code XML contiendra un attribut text et une ou plusieurs valeurs d’attributsupplémentaires. Voir l’exemple comme suit :
<dimension axis=row text=Gender label=Gender varName=gender>...<category text=Female label=Female string=f varName=gender>
Dans le cas d’une variable numérique, l’attribut string est remplacé par l’attribut number.L’attribut label est présent uniquement si la variable ou les valeurs disposent d’étiquettesdéfinies.Les éléments <cell> qui contiennent des valeurs de cellule pour les nombres contiendrontl’attribut text> et une ou plusieurs valeurs d’attribut supplémentaires. Voir l’exemple commesuit :
<cell text=45.6 number=45.569620253165 decimals=1/>
L’attribut nombre est la valeur numérique non arrondie réelle et l’attribut décimales indique lenombre de décimales affichées dans le tableau.
Les colonnes étant emboîtées dans les lignes, l’élément de modalité qui identifie chaquecolonne est répété pour chaque ligne. Par exemple, comme les statistiques sont affichées dansles colonnes, l’élément <category text=Frequency> apparaît trois fois dans le code XML : unefois pour la ligne Homme, une fois pour la ligne Femme et une fois pour la ligne de total.

627
Système de gestion des résultats
Identificateurs OMSLa boîte de dialogue Identificateurs OMS vous aide à écrire la syntaxe de commande OMS.Vous pouvez l’utiliser pour coller une commande et des identificateurs de sous-type sélectionnésdans une fenêtre de syntaxe de commande.Figure 52-17Boîte de dialogue Identificateurs OMS
Pour utiliser la boîte de dialogue Identificateurs OMS
E A partir des menus, sélectionnez :Outils
Identificateurs OMS...
E Sélectionnez les identificateurs de commande ou de sous-type souhaités. (Pour sélectionnerplusieurs identificateurs dans chaque liste, cliquez dessus tout en maintenant la touche Ctrlenfoncée.)
E Cliquez sur Coller commandes et/ou sur Coller sous-types.La liste des sous-types disponibles dépend des commandes sélectionnées. Si plusieurscommandes sont sélectionnées, la liste des sous-types disponibles regroupe tous les sous-typesdisponibles pour les commandes sélectionnées. Si aucune commande n’est sélectionnée,tous les sous-types sont répertoriés.Les identificateurs sont collés dans la fenêtre de syntaxe de commande désignée, àl’emplacement actuel du curseur. Si aucune fenêtre de syntaxe de commande n’est ouverte,une nouvelle fenêtre de syntaxe est automatiquement ouverte.Lorsqu’un identificateur de commande et/ou de sous-type est collé, il est mis entre guillemetscar la syntaxe de la commande OMS requiert des guillemets.Les listes d’identificateurs des mots-clés COMMANDS et SUBTYPES doivent être mises entrecrochets. Par exemple :
/IF COMMANDS=['Crosstabs' 'Descriptives']SUBTYPES=['Crosstabulation' 'Descriptive Statistics']

628
Chapitre 52
Copie des identificateurs OMS à partir de la légende du Viewer
Vous pouvez copier et coller les identificateurs de sous-type et de la commande OMS dans lafenêtre de légende du Viewer.
E Dans le panneau de légende, cliquez avec le bouton droit de la souris sur l’entrée correspondant àl’item concerné.
E Sélectionnez Copier l’identificateur de commande OMS ou Copier le sous-type de table OMS.
Cette méthode est différente de celle liée à la boîte de dialogue Identificateurs OMS pour laraison suivante : L’identificateur copié n’est pas automatiquement collé dans une fenêtre desyntaxe de commande. Il est simplement copié dans le Presse-papiers ; vous pouvez le coller àl’emplacement de votre choix. Etant donné que les valeurs des identificateurs de commande et desous-type sont identiques aux valeurs des attributs de commande et de sous-type correspondantesdans les résultats au format XML (OXML), cette méthode de copier/coller peut vous être utilelorsque vous écrivez des transformations XSLT.
Copie d’étiquettes OMS
Au lieu de copier des identificateurs, vous pouvez copier des étiquettes pour les utiliser avec lemot-clé LABELS. Vous pouvez utiliser des étiquettes pour différencier des diagrammes ou destableaux de même type dans lesquels le texte de la légende reflète un attribut de l’objet de sortieparticulier (par exemple, les noms de variables ou les étiquettes). Cependant, il existe un certainnombre de facteurs qui peuvent avoir une incidence sur le texte de l’étiquette :
Si le traitement du fichier scindé est activé, l’identification des classes de fichier scindé peutêtre ajoutée à l’étiquette.Les étiquettes qui comprennent des informations sur les variables ou les valeurs sont affectéespar les paramètres d’affichage des noms de variables/étiquettes et des valeurs/étiquettes devaleurs dans le panneau de légende (menu Modifier, Options, onglet Etiquettes Résultats).Les étiquettes sont affectées par le paramètre lié à la langue des résultats (menu Modifier,Options, onglet Général).
Pour copier des étiquettes OMS
E Dans le panneau de légende, cliquez avec le bouton droit de la souris sur l’entrée correspondant àl’item concerné.
E Sélectionnez Copier l’étiquette OMS.
Comme pour les identificateurs de commande et de sous-type, les étiquettes doivent apparaîtreentre guillemets et la liste entre crochets. Par exemple :
/IF LABELS=['Catégorie d'emploi' 'Niveau d'enseignement']

Annexe
AConvertisseur de syntaxe descommandes TABLES et IGRAPH
Si vous avez des fichiers de syntaxe de commande qui contiennent la syntaxe TABLES que voussouhaitez convertir en syntaxe CTABLES et/ou la syntaxe IGRAPH que vous souhaitez convertiren syntaxe GGRAPH, un simple programme utilitaire est fourni pour vous aider à démarrer leprocessus de conversion. Cependant, il existe des différences significatives entre les fonctions deTABLES et CTABLES et entre IGRAPH et GGRAPH. Il est probable que le programme utilitaire nepuisse pas convertir certaines de vos tâches de syntaxe TABLES et IGRAPH ou génère une syntaxeCTABLES et GGRAPH produisant des tableaux et des diagrammes ne ressemblant pas de près auxoriginaux produits par les commandes TABLES et IGRAPH. Pour la plupart des tableaux, vouspouvez modifier la syntaxe convertie pour produire un tableau ressemblant de près à l’original.
Le programme utilitaire est conçu pour :Créer un nouveau fichier de syntaxe à partir d’un fichier de syntaxe existant. Le fichier desyntaxe d’origine n’est pas modifié.Convertir uniquement des commandes TABLES et IGRAPH dans le fichier de syntaxe. Lesautres commandes du fichier ne sont pas modifiées.Garder la syntaxe TABLES et IGRAPH d’origine dans la forme commentée.Identifier le début et la fin de chaque bloc de conversion à l’aide de commentaires.Identifier les commandes de syntaxe TABLES et IGRAPH qui ne peuvent pas être converties.Convertir les fichiers de syntaxe de commande qui respectent les règles de syntaxe du modeinteractif ou du mode de production.
Ce programme utilitaire ne peut pas convertir de commandes contenant des erreurs. Leslimitations suivantes s’appliquent également.
Limitations de TABLES
Le programme utilitaire peut convertir des commandes TABLES de façon incorrecte dans certainscas, y compris les commandes TABLES contenant :
Des noms de variables entre parenthèses avec les initiales « sta » ou « lab » dans lasous-commande TABLES si la variable est elle-même entre parenthèses—par exemple,var1 par (statvar) par (labvar). Ils seront interprétés en tant que mots-clé(STATISTICS) et (LABELS).Les sous-commandes SORT qui utilisent les abbréviations A ou D pour indiquer un ordrecroissant ou décroissant. Celles-ci seront interprétées comme des noms de variables.
629

630
Annexe A
Le programme utilitaire ne peut pas convertir les commandes TABLES contenant :Des erreurs de syntaxe.Des sous-commandes OBSERVATION qui font référence à une plage de variables utilisant lemot-clé TO (par exemple var01 TO var05).Les valeurs littérales de chaîne divisées en segments séparés par des signes « plus » (parexemple TITLE "My" + "Title").Les appels macro qui seraient des syntaxes TABLES non valides en l’absence d’extension demacro. Puisque le convertisseur ne prolonge pas les appels macro, il les traite comme simpleélément de la syntaxe standard TABLES.
Le programme utilitaire ne convertit pas les commandes TABLES contenues dans les macros. Lesmacros ne sont pas affectées par le processus de conversion.
Limitations de IGRAPH
IGRAPH a été modifié de manière significative dans la version 16. En raison de ces modifications,certaines sous-commandes et mots clés dans la syntaxe IGRAPH créés avant cette version peuventne pas être disponibles. Consultez la section IGRAPH dans leGuide de référence sur la syntaxe descommandes pour l’historique de révision complet.Le programme utilitaire de conversion peut générer une syntaxe supplémentaire stockée dans
le mot clé INLINETEMPLATE dans la syntaxe GGRAPH. Ce mot clé est uniquement créé par leprogramme de conversion. Sa syntaxe n’est pas destinée à être modifiée par les utilisateurs.
Utilisation du programme utilitaire de conversion
Le programme utilitaire de conversion, SyntaxConverter.exe, figure dans le répertoired’installation. Il est conçu pour s’exécuter à partir d’une invite de commande. Une commandeprend généralement la forme suivante :
syntaxconverter.exe [path]/inputfilename.sps [path]/outputfilename.sps
Vous devez exécuter cette commande à partir du répertoire d’installation.
Si les noms de répertoire contiennent des espaces, incluez le chemin d’accès et le nom du fichierentre guillemets comme ci-après :
syntaxconverter.exe /myfiles/oldfile.sps /new files/newfile.sps
Règles de syntaxe de commande en mode interactif et en mode de production
Le programme utilitaire de conversion peut convertir des fichiers de commandes qui utilisent lesrègles de syntaxe du mode interactif et du mode de production.

631
Convertisseur de syntaxe des commandes TABLES et IGRAPH
Interactif. Les règles de syntaxe du mode interactif sont les suivantes :Chaque commande commence sur une nouvelle ligne.Chaque commande se termine par un point (.).
Mode de production. Le système de production et les commandes des fichiers accessible via lacommande INCLUDE dans un fichier de commande différent utilisent les règles de syntaxe dumode de production :
Chaque commande doit commencer sur la première colonne d’une nouvelle ligne.Les lignes suites doivent être en retrait d’un espace au moins.Le point à la fin de la commande est optionnel.
Si vos fichiers de commande utilisent les règles de syntaxe du mode de production et necontiennent pas de points à la fin de chaque commande, vous devez inclure le bouton de ligne decommande -b (ou /b) lorsque vous exécutez SyntaxConverter.exe, comme ci-après :
syntaxconverter.exe -b /myfiles/oldfile.sps /myfiles/newfile.sps
Script du convertisseur de syntaxe (Windows uniquement)
Sous Windows, vous pouvez également exécuter le convertisseur de syntaxe avec le scriptSyntaxConverter.wwd, situé dans le répertoire Echantillons du répertoire d’installation.
E A partir des menus, sélectionnez :Outils
Exécuter le script
E Accédez au répertoire Echantillons puis sélectionnez SyntaxConverter.wwd.
Cela ouvrira une simple boîte de dialogue dans laquelle vous pourrez spécifier les noms etemplacements des anciens et nouveaux fichiers de syntaxe.

Index
Access (Microsoft), 19Affectation de mémoireDans l’analyse TwoStep Cluster, 449
Affichage, 230, 262, 274, 561Barres d’outils, 561Etiquettes de dimension, 262Légendes, 274Lignes ou colonnes, 262Notes de bas de page, 274Résultats, 230Titres, 262
Affichage des données, 81Affichage des variables, 82personnalisation, 96, 544
affichages/panneaux multipleséditeur de données, 105
agrégation de donnéesFonctions d’agrégation, 203
Agrégation de données, 200Noms de variable et étiquettes, 203
Aide en ligne, 11Assistant statistique, 10
Ajout d’étiquettes de groupe, 257Ajustement de fonctions, 397Analyse de la variance, 397Enregistrement de prévisions, 399Enregistrement de résidus, 399Enregistrement d’intervalles de prévision, 399Inclusion de la constante, 397Modèles, 399Prévision, 399
algorithmes, 11Alignement, 90, 231, 541éditeur de données, 90Résultats, 231, 541
Alpha de CronbachDans l’analyse de fiabilité, 504, 506
Alpha-maximisation, 439Analyse de données, 9Etapes de base, 9
Analyse de fiabilité, 504Caractéristiques, 506Coefficient de corrélation intra-classe, 506Corrélations et covariances entre éléments, 506Exemple, 504Fonctionnalités supplémentaires, 508Kuder-Richardson 20, 506statistiques, 504, 506T2 de Hotelling , 506Tableau ANOVA, 506Test d’additivité de Tukey, 506
Analyse de la varianceAjustement de fonctions, 397Dans ANOVA à 1 facteur, 349Dans la régression linéaire, 387Dans Moyennes, 332
Analyse de séries chronologiquesPrévision, 399Prévision d’observations, 399
Analyse discriminante, 428Coefficients de la fonction, 431Critères, 432Définition d’intervalles, 430Diagrammes, 433Distance de Mahalanobis, 432Enregistrement des variables du classement, 435Exemple, 428Exportation des informations du modèle, 435Fonctionnalités supplémentaires, 435Lambda de Wilks, 432Matrice de covariance, 433Matrices, 431Méthodes de l’analyse discriminante, 432Méthodes pas à pas, 428Options d’affichage, 432–433Probabilités a priori, 433Sélection d’observations, 430statistiques, 428, 431Statistiques descriptives, 431V de Rao , 432Valeurs manquantes, 433Variables de regroupement, 428Variables indépendantes, 428
Analyse du voisin le plus proche, 406enregistrement de variables, 415Options, 417partitions, 413Résultats, 416sélection des caractéristiques, 412voisins, 410vue du modèle, 418
Analyse en composantes principale, 436, 439Analyse factorielle, 436Aperçu, 436Cartes factorielles, 441Convergence, 439, 441descriptives, 438Exemple, 436Facteurs, 442Fonctionnalités supplémentaires, 443Format d’affichage des projections, 443Méthodes de rotation, 441Méthodes d’extraction, 439
632

633
Index
Sélection d’observations, 437statistiques, 436, 438Valeurs manquantes, 443
Analyse multiréponsesTableau croisé, 488Tableaux croisés des réponses multiples, 488tableaux de fréquences, 486Tableaux de fréquences des réponses multiples, 486
Analyse TwoStep Cluster, 446Diagrammes, 451Enregistrer dans le fichier de travail, 452Enregistrer dans le fichier externe, 452Options, 449statistiques, 452
AndrewDans Explorer, 314
Années, 542valeurs à deux chiffres, 542
ANOVADans ANOVA à 1 facteur, 349dans GLM - Univarié, 355Dans Moyennes, 332Modèle, 357
ANOVA à 1 facteur, 349Comparaisons multiples, 351Contrastes, 350Contrastes polynomiaux, 350Fonctionnalités supplémentaires, 354Options, 353statistiques, 353Tests post hoc, 351Valeurs manquantes, 353Variables actives, 349
AplatissementDans Explorer, 314Dans Fréquences, 304Dans les cubes OLAP, 337Dans les tableaux de bord en colonnes, 500Dans les tableaux de bord en lignes, 495Dans Moyennes, 332Dans Récapituler, 327Descriptives, 309
Arbres hiérarchiquesClassification hiérarchique, 458
Assistant statistique, 10Association linéaire par linéaireTableaux croisés, 320
AsymétrieDans Explorer, 314Dans Fréquences, 304Dans les cubes OLAP, 337Dans les tableaux de bord en colonnes, 500Dans les tableaux de bord en lignes, 495Dans Moyennes, 332Dans Récapituler, 327Descriptives, 309
attribution d’un nouveau nom aux ensembles de données,110attributsattributs de variable personnalisés, 92
Attributs de variable, 90–91Copie et collage, 90–91personnalisé, 92
attributs de variable personnalisés, 92attributs personnalisés, 92Autoscripts, 554
B de TukeyDans ANOVA à 1 facteur, 351GLM, 361
Barre d’état, 6Barres d’outils, 561, 563–564Affichage dans des fenêtres différentes, 563Affichage et masquage, 561Création, 561, 563Création d’outils, 564personnalisation, 561, 563
bases de données, 18–19, 22, 24–25, 28, 30, 32ajout de nouveaux champs à un tableau, 63ajout d’enregistrements (observations) à un tableau, 64Clause Where, 25Conversion des chaînes en valeurs numériques, 30Création de relations, 24création d’un tableau, 65Définition de variables, 30Demander une valeur, 28Echantillonnage aléatoire, 25Enregistrement, 54Enregistrement de requêtes, 32Expressions conditionnelles, 25Jointures de tables, 24Lecture, 18–19, 22Microsoft Access, 19mise à jour, 54remplacement de valeurs dans des champs existants, 62remplacement d’un tableau, 65Requêtes de paramètres, 25, 28sélection de fichiers de données, 22Sélection d’une source de données, 19Spécification de critères, 25Syntaxe SQL, 32Vérification des résultats, 32
boîtes à moustachesComparaison des niveaux de facteur, 315Comparaison des variables, 315Dans Explorer, 315
Boîtes de dialogue, 8, 534–535, 539Affichage des étiquettes de variable, 6, 539Affichage des noms de variable, 6, 539commandes, 7Définition de groupes de variables, 534icônes de variables, 8Informations sur les variables, 9

634
Index
Ordre d’affichage des variables, 539Réordonnance de listes cible, 537Sélection de variables, 8Utilisation de groupes de variables, 535Variables, 6
BonferroniDans ANOVA à 1 facteur, 351GLM, 361
Bordures, 268, 275Affichage des bordures masquées, 275
Bouton Aide, 7Bouton Annuler, 7Bouton Coller, 7Bouton OK, 7Bouton Restaurer, 7
C de DunnettDans ANOVA à 1 facteur, 351GLM, 361
Calcul de variables, 143Calcul de nouvelles variables chaîne, 146
Caractéristiquesstatistiques, 309
Carré de la distance euclidienneDistances, 377
carte des quadrantsdans l’analyse du voisin le plus proche, 423
Cartes factoriellesDans Analyse factorielle, 441
Cellules de tableaux pivotants, 266, 274–275Affichage, 261Formats, 266Largeurs, 275Masquage, 261
CentilesDans Explorer, 314Dans Fréquences, 304
Centrage de résultats, 231, 541ClassificationChoix d’une procédure, 444Classification hiérarchique, 454Dans Courbe ROC, 519Efficacité, 462Nuées dynamiques, 460
Classification hiérarchique, 454Arbres hiérarchiques, 458Chaîne des agrégations, 457Classes d’affectation, 457–458Classification de variables, 454Classification d’observations, 454Diagrammes en stalactite, 458Enregistrement de nouvelles variables, 458Exemple, 454Fonctionnalités supplémentaires, 459Matrices de distance, 457Mesures de distance, 456Mesures de similarité, 456
Méthodes de classification, 456Orientation du diagramme, 458statistiques, 454, 457Transformation de mesures, 456Transformation de valeurs, 456
codage local, 294Coefficient alphaDans l’analyse de fiabilité, 504, 506
Coefficient de contingenceTableaux croisés, 320
Coefficient de corrélation de SpearmanCorrélations bivariées, 368Tableaux croisés, 320
Coefficient de corrélation intra-classeDans l’analyse de fiabilité, 506
Coefficient de corrélation par rangCorrélations bivariées, 368
Coefficient de corrélation rCorrélations bivariées, 368Tableaux croisés, 320
Coefficient de dispersion (COD)Dans les statistiques de ratio, 517
Coefficient de variation (COV)Dans les statistiques de ratio, 517
Coefficient d’incertitudeTableaux croisés, 320
Coefficients bêtaDans la régression linéaire, 387
Coefficients de régressionDans la régression linéaire, 387
Colonne de totalDans les tableaux de bord, 501
colonnes., 275–276Modification de la largeur des tableaux pivotants, 275Sélection dans les tableaux pivotants, 276
commandes d’extensionboîtes de dialogue personnalisées, 589
Comparaison des groupesDans les cubes OLAP, 339
Comparaison des variablesDans les cubes OLAP, 339
Comparaisons multiplesDans ANOVA à 1 facteur, 351
Comparaisons multiples post hoc, 351Comptage d’occurrences, 148Connexion à un serveur, 73ContrastesDans ANOVA à 1 facteur, 350GLM, 359
Contrastes à la précédenteGLM, 359
Contrastes de HelmertGLM, 359
Contrastes déviationGLM, 359
Contrastes différenceGLM, 359

635
Index
Contrastes polynomiauxDans ANOVA à 1 facteur, 350GLM, 359
Contrastes simplesGLM, 359
ConvergenceAnalyse de classification des nuées dynamiques, 462Dans Analyse factorielle, 439, 441
convertisseur de syntaxe, 629Correction pour la continuité de YatesTableaux croisés, 320
Corrélation de PearsonCorrélations bivariées, 368Tableaux croisés, 320
CorrélationsCorrélations bivariées, 368Dans Corrélations partielles, 372Ordre zéro, 373Tableaux croisés, 320
Corrélations bivariéesCoefficients de corrélation, 368Fonctionnalités supplémentaires, 370Options, 370Seuil de signification, 368statistiques, 370Valeurs manquantes, 370
Corrélations partielles, 372Corrélations simples, 373Dans la régression linéaire, 387Fonctionnalités supplémentaires, 374Options, 373statistiques, 373Valeurs manquantes, 373
Corrélations simplesDans Corrélations partielles, 373
couleur d’arrière-plan, 271Couleurs de tableaux pivotants, 268Bordures, 268
Courbe ROC, 519Diagrammes et statistiques, 520
création de diagrammes, 522critères d’agrégationDans Agréger les données, 200
CTABLESconversion de la syntaxe de la commande TABLES enCTABLES, 629
Cubes OLAP, 335statistiques, 337Titres, 340
DTableaux croisés, 320
D de SomersTableaux croisés, 320
Data Editorplusieurs fichiers de données ouverts, 539
DATA LIST, 69et GET DATA, 69
Décomposition hiérarchique, 358Définir les vecteurs multiréponses, 485Définition des étiquettes, 485Définition des noms, 485Dichotomies, 485Modalités, 485
définition de variablesApplication d’un dictionnaire des données, 122Etiquettes de valeurs, 113
Définition de variables, 83, 85, 88–91, 113Copie et collage d’attributs, 90–91Etiquettes de valeurs, 88Etiquettes de variable, 88Modèles, 90–91Types de données, 85Valeurs manquantes, 89
Déplacement de lignes et de colonnes, 256DernierDans les cubes OLAP, 337Dans Moyennes, 332Dans Récapituler, 327
Descriptives, 308Enregistrement des écarts z, 308Fonctionnalités supplémentaires, 310Ordre d’affichage, 309
Diagnostic des observationsDans la régression linéaire, 387
diagramme de l’espace des caractéristiquesdans l’analyse du voisin le plus proche, 419
Diagramme de répartition gaussienDans Explorer, 315Dans la régression linéaire, 383
Diagramme de répartition hors tendanceDans Explorer, 315
diagramme d’importanceDans l’analyse TwoStep Cluster, 451
diagrammes, 230, 236, 277, 522, 548Aperçu, 522Copie dans d’autres applications, 236Création, 522Création à partir de tableaux pivotants, 277Dans Courbe ROC, 519Etiquettes d’observations, 397exportation, 236Générateur de diagrammes, 522Masquage, 230Modèles, 530, 548Rapport hauteur/largeur, 548retours à la ligne dans les panels, 530taille, 530Valeurs manquantes, 530
Diagrammes de dispersionDans la régression linéaire, 383
Diagrammes de profilsGLM, 360

636
Index
Diagrammes des résidusdans GLM - Univarié, 365
Diagrammes d’importance des variablesDans l’analyse TwoStep Cluster, 451
Diagrammes dispersion/niveauDans Explorer, 315dans GLM - Univarié, 365
Diagrammes en bâtonsDans Fréquences, 306
diagrammes en secteursDans Fréquences, 306
Diagrammes en stalactiteClassification hiérarchique, 458
Diagrammes interactifs, 236Copie dans d’autres applications, 236
Diagrammes partielsDans la régression linéaire, 383
Diagrammes tige et feuilleDans Explorer, 315
Dictionnaire, 46Livre des codes, 296
Dictionnaire des donnéesApplication à partir d’un autre fichier, 122
Différence de bêtaDans la régression linéaire, 384
Différence de prévisionDans la régression linéaire, 384
Différence la moins significativeDans ANOVA à 1 facteur, 351GLM, 361
Différence significative de TukeyDans ANOVA à 1 facteur, 351GLM, 361
Différences entre les groupesDans les cubes OLAP, 339
Différences entre les variablesDans les cubes OLAP, 339
Différentiel lié au prix (PRD)Dans les statistiques de ratio, 517
Distance de CookDans la régression linéaire, 384GLM, 363
Distance de MahalanobisAnalyse discriminante, 432Dans la régression linéaire, 384
Distance de Manhattandans l’analyse du voisin le plus proche, 410Distances, 377
Distance de MinkowskiDistances, 377
Distance de TchebycheffDistances, 377
Distance du Khi-deuxDistances, 377
Distance euclidiennedans l’analyse du voisin le plus proche, 410Distances, 377
distance Manhattandans l’analyse du voisin le plus proche, 410
Distances, 375Calcul des distances existant entre des observations, 375Calcul des distances existant entre des variables, 375Exemple, 375Fonctionnalités supplémentaires, 378Mesures de dissimilarité, 377Mesures de similarité, 378statistiques, 375Transformation de mesures, 377–378Transformation de valeurs, 377–378
distances du voisin le plus prochedans l’analyse du voisin le plus proche, 422
DivisionDivision dans les colonnes de tableaux, 501
Division de tableaux, 277Contrôle des sauts de tableau, 277
Données de dimension, 42Enregistrement, 67
Données de séries chronologiquesCréation de variables de séries chronologiques, 181Définition de variables de date, 180Fonctions de transformation, 182Remplacement de valeurs manquantes, 184Transformations de données, 179
Données pondérées, 227Et fichiers des données restructurées, 227
Données qualitatives, 116Conversion de données d’intervalle en modalitésdiscrètes, 134
Données séparées par des espaces, 33
Ecart absolu moyen (AAD)Dans les statistiques de ratio, 517
Ecart zDescriptives, 308Enregistrement sous forme de variables, 308Ordonner les observations, 162
Ecart-typeDans Explorer, 314Dans Fréquences, 304dans GLM - Univarié, 365Dans les cubes OLAP, 337Dans les statistiques de ratio, 517Dans les tableaux de bord en colonnes, 500Dans les tableaux de bord en lignes, 495Dans Moyennes, 332Dans Récapituler, 327Descriptives, 309
échantillon aléatoirebases de données, 25Sélection, 208
Echantillon aléatoire, 25Génération de nombres aléatoires, 147
échantillon d’apprentissagedans l’analyse du voisin le plus proche, 413

637
Index
échantillon traitédans l’analyse du voisin le plus proche, 413
échantillonnageEchantillon aléatoire, 208
Echantillons liés, 477, 482Echelle, 85Dans l’analyse de fiabilité, 504Dans le positionnement multidimensionnel, 509Niveau de mesure, 85, 116
Editeur de diagrammes, 526propriétés, 527
éditeur de données, 83, 90, 97–101, 105–106, 560Affichage des données, 81Affichage des variables, 82affichages/panneaux multiples, 105Alignement, 90Définition de variables, 83Déplacement de variables, 101Impression, 106Insertion de nouvelles observations, 100Insertion de nouvelles variables, 101Largeur de colonne, 90Modification de données, 99–100Modification du type de données, 101Observations filtrées, 105Options d’affichage, 105Restrictions concernant la valeur de données, 99Saisie de données, 97Saisie de données non numériques, 98Saisie de données numériques, 98
Editeur de données, 81Envoi de données vers d’autres applications, 560plusieurs fichiers de données ouverts, 107
éditeur de syntaxe, 286codage par couleur, 289commentaire d’un texte, 293étendues de commande, 287numéros de ligne, 287Options, 557points d’arrêt, 287, 290, 293saisie semi-automatique, 289Signets, 287, 292
éditeur de syntaxe commande, 286codage par couleur, 289commentaire d’un texte, 293étendues de commande, 287numéros de ligne, 287Options, 557points d’arrêt, 287, 290, 293saisie semi-automatique, 289Signets, 287, 292
Effectif observéTableaux croisés, 323
Effectif théoriqueTableaux croisés, 323
Effectifs, 303diagrammes, 306
Formats, 307Ordre d’affichage, 307statistiques, 304Suppression de tableaux, 307
Elimination descendanteDans la régression linéaire, 381
emplacements des fichierscontrôle des emplacements des fichiers par défaut, 553
emplacements des fichiers par défaut, 553En-têtes, 250Enregistrement de diagrammes, 236, 247–248Fichiers BMP, 236, 247Fichiers EMF, 236Fichiers EPS, 236, 248Fichiers JPEG, 236, 247Fichiers PICT, 236Fichiers PNG, 247Fichiers PostScript, 248Fichiers TIFF, 248Métafichiers, 236
enregistrement de fichiersFichiers de données, 47–48Fichiers de données SPSS Statistics, 47Requêtes de fichiers de base de données, 32
Enregistrement de fichiers, 47–48contrôle des emplacements des fichiers par défaut, 553
Enregistrement des résultats, 236, 242, 245Format Excel, 236, 241Format HTML, 236Format PDF, 236, 244Format PowerPoint, 236, 242Format texte, 236, 245Format Word, 236, 239HTML, 236, 238
ensembles de donnéesrenommer, 110
Erreur standardDans Courbe ROC, 520Dans Explorer, 314Dans Fréquences, 304Descriptives, 309GLM, 363, 365
Erreur standard d’aplatissementDans les cubes OLAP, 337Dans Moyennes, 332Dans Récapituler, 327
Erreur standard d’asymétrieDans les cubes OLAP, 337Dans Moyennes, 332Dans Récapituler, 327
Erreur standard de la moyenneDans les cubes OLAP, 337Dans Moyennes, 332Dans Récapituler, 327
Espace disque, 69–70Temporaire, 69–70
Espace disque temporaire, 69–70

638
Index
Estimation de l’intensité des effetsdans GLM - Univarié, 365
Estimations de Blom, 162Estimations de la proportionOrdonner les observations, 162
Estimations de puissancedans GLM - Univarié, 365
Estimations de Rankit, 162Estimations de Tukey, 162Estimations de Van der Waerden, 162Estimations des paramètresdans GLM - Univarié, 365Régression ordinale, 393
êtaDans Moyennes, 332Tableaux croisés, 320
Eta carrédans GLM - Univarié, 365Dans Moyennes, 332
Etapes de base, 9Etiquettes, 257et noms de sous-type dans le système OMS, 608Insertion d’étiquettes de groupe, 257Suppression, 257
Etiquettes de groupe, 257Etiquettes de valeurs, 88, 98, 105, 113, 546Application à plusieurs variables, 118Copie, 118Dans des fichiers de données fusionnés, 196éditeur de données, 105enregistrement dans des fichiers Excel, 47Insertion de sauts de ligne, 89Panneau de légendes, 546Tableaux pivotants, 546Utilisation pour la saisie de données, 98
étiquettes de variableDans des fichiers de données fusionnés, 196
Etiquettes de variable, 88, 539, 546Boîtes de dialogue, 6, 539Insertion de sauts de ligne, 89Panneau de légendes, 546Tableaux pivotants, 546
Etude appariéeTest T pour échantillons appariés, 344
Etude de contrôle d’observationTest T pour échantillons appariés, 344
exclusion de résultats du Viewer avec OMS, 615EXECUTE (commande)Collée depuis les boîtes de dialogue, 295
Explorer, 312Diagrammes, 315Fonctionnalités supplémentaires, 317Options, 316statistiques, 314Transformations de l’exposant, 316Valeurs manquantes, 316
export de données, 47
ExportationModèles, 281
Exportation de diagrammes, 236, 247–248, 594Production automatisée, 594
Exportation de données, 560Ajout d’éléments de menu pour l’exportation de données,560
Exportation de résultats, 236, 242, 245Format Excel, 236, 241, 609Format HTML, 236Format PDF, 236, 244, 609Format PowerPoint, 236Format texte, 609Format Word, 236, 239, 609HTML, 238OMS, 603
F de R-E-G-W (Ryan-Einot-Gabriel-Welsch)Dans ANOVA à 1 facteur, 351GLM, 361
F multiple de Ryan-Einot-Gabriel-WelschDans ANOVA à 1 facteur, 351GLM, 361
Facteur d’inflation de la varianceDans la régression linéaire, 387
Facteurs, 442Facteurs d’Anderson-Rubin, 442Facteurs de Bartlett, 442Factorisation en axes principaux, 439Factorisation en projections, 439Fenêtre active, 5Fenêtre désignée, 5Fenêtres, 4Fenêtre active, 5Fenêtre désignée, 5
Fenêtres d’aide, 11Fiabilité de Spearman-BrownDans l’analyse de fiabilité, 506
Fiabilité Split-halfDans l’analyse de fiabilité, 504, 506
Fichier actif, 69–70Création d’un fichier actif temporaire, 70Fichier actif virtuel, 69Mise en mémoire cache, 70
Fichier actif temporaire, 70Fichier actif virtuel, 69fichier de modèlechargement de modèles enregistrés pour noter desdonnées, 187
fichier-journal, 553fichiers, 233Ajout d’un fichier texte dans le Viewer, 233Ouverture, 14
Fichiers BMP, 236, 247Exportation de diagrammes, 236, 247
Fichiers dBASE, 14, 17, 47–48Enregistrement, 47–48

639
Index
Lecture, 14, 17fichiers de donnéesEnregistrement, 47–48informations sur les dictionnaires, 46Informations sur les fichiers, 46Ouverture, 14–15Retournement, 193Transposition, 193
Fichiers de données, 14–15, 33, 46–48, 54, 70, 77, 212ajout de commentaires, 534Amélioration des performances pour des fichiersvolumineux, 70Dimensions, 42Enregistrement de sous-ensembles de variables, 54enregistrement des résultats en tant que fichiers dedonnées SPSS Statistics, 603mrInterview, 42plusieurs fichiers de données ouverts, 107, 539protection, 68Quancept, 42Quanvert, 42Restructuration, 212Serveurs distants, 77Texte, 33
Fichiers de feuille de calcul, 14, 16, 50Ecriture de noms de variable, 50Lecture des noms de variable, 16Lecture des plages, 16Ouverture, 16
fichiers de syntaxe de commande, 294Fichiers de syntaxe de commande Unicode, 294Fichiers délimités par des tabulations, 14, 16, 33, 47–48, 50Ecriture de noms de variable, 50Enregistrement, 47–48Lecture des noms de variable, 16Ouverture, 14
Fichiers délimités par des virgules, 33Fichiers EPS, 236, 248Exportation de diagrammes, 236, 248
Fichiers Excel, 14, 16, 48, 560Ajout d’éléments de menu pour l’envoi de données versExcel, 560Enregistrement, 47–48enregistrement d’étiquettes de valeurs au lieu de valeurs,47Ouverture, 14, 16
Fichiers JPEG, 236, 247Exportation de diagrammes, 236, 247
Fichiers Lotus 1-2-3, 14, 47–48, 560Ajout d’éléments de menu pour l’envoi de données versLotus, 560Enregistrement, 47–48Ouverture, 14
Fichiers PNG, 236, 247Exportation de diagrammes, 236, 247
fichiers portablesnoms de variable, 48
Fichiers PostScript (encapsulés), 236, 248Exportation de diagrammes, 236, 248
Fichiers SASEnregistrement, 47Ouverture, 14
fichiers sppconversion en fichiers spj, 602
Fichiers Stata, 17Enregistrement, 47Lecture, 14Ouverture, 17
Fichiers SYSTAT, 14Ouverture, 14
Fichiers TIFF, 248Exportation de diagrammes, 236, 248
Fonction Décalage négatif, 151, 182Fonction Décalage positif, 151Fonction Différence, 182Fonction Différence saisonnière, 182Fonction Lissage, 182Fonction Médiane mobile, 182Fonction Moyenne mobile centrée, 182Fonction Moyenne mobile précédente, 182Fonction Somme cumulée, 182fonctions, 146Traitement des valeurs manquantes, 147
Format chaîne, 85format CSVenregistrement des données, 48lecture de données, 33
format de fichier de données SPSS Statisticsacheminement des résultats dans un fichier de données,609, 615
format de fichier SAVacheminement des résultats dans un fichier de donnéesSPSS Statistics, 609, 615
Format dollar, 85, 87Format ExcelExportation de résultats, 236, 241, 609
Format fixe, 33Format libre, 33Format numérique, 85, 87Format PDFExportation de résultats, 609
Format point, 85, 87Format PowerPointExportation de résultats, 236
Format virgule, 85, 87Format WordExportation de résultats, 236, 239, 609tableaux larges, 236
FormatageColonnes dans les tableaux de bord, 494
Formats d’affichage, 87Formats de dateannées à deux chiffres, 542
Formats d’entrée, 87

640
Index
Formats monétaires, 545Formats monétaires personnalisés, 85, 545Fréquences cumuléesRégression ordinale, 393
Fréquences de classeDans l’analyse TwoStep Cluster, 452
Fréquences observéesRégression ordinale, 393
Fréquences théoriquesRégression ordinale, 393
fusion de modalités, 134Fusion des fichiers de donnéesAffectation d’un nouveau nom aux variables, 196Fichiers avec observations différentes, 194Fichiers avec variables différentes, 197informations sur les dictionnaires, 196
gammaTableaux croisés, 320
Gamma de Goodman et KruskalTableaux croisés, 320
Générateur de boîtes de dialogue personnalisées, 566aperçu, 575boîte combinée, 581boîtes de dialogue personnalisées pour les commandesd’extension, 589bouton de boîte de dialogue de niveau inférieur, 588case à cocher, 580commande groupe d’éléments, 584commande numérique, 583commande texte, 582commande texte statique, 583éléments de liste de boîte combinées, 582emplacement du menu, 570enregistrement des spécifications des boîtes de dialogue,575fichier d’aide, 568fichiers (spd) de package des boîtes de dialoguepersonnalisées, 575filtrage des listes de variables, 580filtre de type fichier, 588groupe cases à cocher, 586groupe de boutons radio, 585groupe radio, 585installation de boîtes de dialogue, 575liste cible, 579liste source, 578modèle de syntaxe, 572modification des boîtes de dialogue installées, 575navigateur de fichiers, 587ouverture des fichiers des spécifications des boîtes dedialogue, 575propriétés de boîte de dialogue, 568propriétés de boîte de dialogue de niveau inférieur, 589règles de présentation, 571traduction de boîtes de dialogue et de fichiers d’aide, 591
Générateur de diagrammes, 522Galerie, 523
Génération de nombres aléatoires, 147Gestion des pagesDans les tableaux de bord en colonnes, 502Dans les tableaux de bord en lignes, 496
Gestion du bruitDans l’analyse TwoStep Cluster, 449
GET DATA, 69et DATA LIST, 69et GET CAPTURE, 69
GGRAPHconversion de IGRAPH en GGRAPH, 629
GLMDiagrammes de profils, 360Enregistrement de matrices, 363Enregistrement de variables, 363Modèle, 357Somme des carrés, 357Tests post hoc, 361
GLM - Univarié, 355, 366Affichage, 365Contrastes, 359Diagnostics, 365Moyennes marginales estimées, 365Options, 365
graphique comparatif, 277Groupement de lignes ou de colonnes, 257Groupes de variables, 534–535Définition, 534Utilisation, 535
GT2 de HochbergDans ANOVA à 1 facteur, 351GLM, 361
H de Kruskal-WallisTests pour deux échantillons indépendants, 479
HistogrammesDans Explorer, 315Dans Fréquences, 306Dans la régression linéaire, 383
Historique des itérationsRégression ordinale, 393
HTML, 236, 238Exportation de résultats, 236, 238
ICC. Voir Coefficient de corrélation intra-classe, 506IcônesBoîtes de dialogue, 8
identificateurs de commande, 607IGRAPHconversion de IGRAPH en GGRAPH, 629
import de données, 14, 18importance des variablesdans l’analyse du voisin le plus proche, 421
impression, 248–250, 252Aperçu avant impression, 249

641
Index
diagrammes, 248En-têtes et pieds de page, 250Espace entre les éléments de résultat, 252Numéros de page, 252Résultats texte, 248Strates, 248Tableaux pivotants, 248Taille des diagrammes, 252
Impression, 106, 265, 269, 277Contrôle des sauts de tableau, 277Données, 106Modèles, 281Redimensionnement de tableaux, 265, 269Strates, 265, 269
Imputation multipleOptions, 558
imputationsRecherche dans l’éditeur de données, 102
Index de concentrationDans les statistiques de ratio, 517
Informations sur les fichiers, 46Informations sur les variables, 533Insertion d’étiquettes de groupe, 257Intervalle multiple de Ryan-Einot-Gabriel-WelschDans ANOVA à 1 facteur, 351GLM, 361
Intervalles de confianceDans ANOVA à 1 facteur, 353Dans Courbe ROC, 520Dans Explorer, 314Dans la régression linéaire, 387Enregistrement dans la régression linéaire, 384GLM, 359, 365Test T pour échantillon unique, 347Test T pour échantillons appariés, 345Test T pour échantillons indépendants, 344
Intervalles de prévisionEnregistrement dans la régression linéaire, 384Enregistrement dans l’ajustement de fonctions, 399
ItérationsAnalyse de classification des nuées dynamiques, 462Dans Analyse factorielle, 439, 441
jointure externe, 24jointure interne, 24Journal de session, 553Justification, 231, 541Résultats, 231, 541
KappaTableaux croisés, 320
Kappa de CohenTableaux croisés, 320
Khi-deux, 465Association linéaire par linéaire, 320Correction pour la continuité de Yates, 320Indépendance, 320
Intervalle théorique, 467Options, 467Pearson :, 320Rapport de vraisemblance, 320statistiques, 467Tableaux croisés, 320Test à un échantillon, 465Test exact de Fisher, 320Valeurs manquantes, 467Valeurs théoriques, 467
Khi-deux de PearsonRégression ordinale, 393Tableaux croisés, 320
Khi-deux du rapport de vraisemblanceRégression ordinale, 393Tableaux croisés, 320
KR20Dans l’analyse de fiabilité, 506
Kuder-Richardson 20 (KR20)Dans l’analyse de fiabilité, 506
LAG (fonction), 182LambdaTableaux croisés, 320
Lambda de Goodman et KruskalTableaux croisés, 320
Lambda de WilksAnalyse discriminante, 432
Langagemodification du langage de l’interface utilisateur, 539Modification du langage des résultats, 539
langage de commande, 282Largeur de colonne, 90, 265, 275, 551Contrôle de la largeur maximale, 265Contrôle de la largeur par défaut, 551Contrôle de la largeur pour texte avec retour automatiqueà la ligne, 265éditeur de données, 90Tableaux pivotants, 275
Légende, 231–232Dans le Viewer, 231Développement, 232Modification des niveaux, 232Réduction, 232
Légendes, 273–274LienRégression ordinale, 391
Lignes, 276Sélection dans les tableaux pivotants, 276
Lissage T4253H, 182Liste des observations, 325Listes cible, 537Listes de variables, 537Réordonnance de listes cible, 537
Livre des codes, 296Résultats, 298statistiques, 301

642
Index
LSD de FisherGLM, 361
M-estimateur de HuberDans Explorer, 314
M-estimateur redescendant de HampelDans Explorer, 314
M-estimateursDans Explorer, 314
Masquage, 230, 261–262, 274, 561Barres d’outils, 561Etiquettes de dimension, 262Légendes, 274Lignes et colonnes, 261Notes de bas de page, 274Résultats d’une procédure, 230Titres, 262
masquage (exclusion) de résultats du Viewer avec OMS,615Matrice de corrélationAnalyse discriminante, 431Dans Analyse factorielle, 436, 438Régression ordinale, 393
Matrice de covarianceAnalyse discriminante, 431, 433Dans la régression linéaire, 387GLM, 363Régression ordinale, 393
Matrice de transformationDans Analyse factorielle, 436
Matrice des projections factoriellesDans Analyse factorielle, 436
MaximumComparaison des colonnes de tableaux, 501Dans Explorer, 314Dans Fréquences, 304Dans les cubes OLAP, 337Dans les statistiques de ratio, 517Dans Moyennes, 332Dans Récapituler, 327Descriptives, 309
Maximum de vraisemblanceDans Analyse factorielle, 439
médianeDans Explorer, 314Dans Fréquences, 304Dans les cubes OLAP, 337Dans les statistiques de ratio, 517Dans Moyennes, 332Dans Récapituler, 327
Médiane de groupesDans les cubes OLAP, 337Dans Moyennes, 332Dans Récapituler, 327
Mémoire, 539menus, 560personnalisation, 560
Mesure de dissimilarité de Lance et Williams, 377Distances, 377
Mesure de distance du Phi-deuxDistances, 377
Mesure d’écart de la tailleDistances, 377
Mesure d’écart de structuresDistances, 377
Mesures de distanceClassification hiérarchique, 456dans l’analyse du voisin le plus proche, 410Distances, 377
Mesures de la dispersionDans Explorer, 314Dans Fréquences, 304Dans les statistiques de ratio, 517Descriptives, 309
Mesures de la distributionDans Fréquences, 304Descriptives, 309
Mesures de la tendance centraleDans Explorer, 314Dans Fréquences, 304Dans les statistiques de ratio, 517
Mesures de similaritéClassification hiérarchique, 456Distances, 378
Métafichiers, 236Exportation de diagrammes, 236
Méthodes de sélection, 276Sélection de lignes et de colonnes dans des tableauxpivotants, 276
Microsoft Access, 19MinimumComparaison des colonnes de tableaux, 501Dans Explorer, 314Dans Fréquences, 304Dans les cubes OLAP, 337Dans les statistiques de ratio, 517Dans Moyennes, 332Dans Récapituler, 327Descriptives, 309
mise à l’échelleTableaux pivotants, 265, 269
Mise en mémoire cache, 70Fichier actif, 70
Mise en page, 250, 252En-têtes et pieds de page, 250Taille des diagrammes, 252
Modalité de référenceGLM, 359
modeDans Fréquences, 304
Mode distribué, 73–74, 77, 79Accès aux fichiers de données, 77chemins relatifs, 79Procédures disponibles, 79

643
Index
Modèle composéAjustement de fonctions, 399
Modèle cubiqueAjustement de fonctions, 399
Modèle de croissanceAjustement de fonctions, 399
Modèle de GuttmanDans l’analyse de fiabilité, 504, 506
Modèle de puissanceAjustement de fonctions, 399
Modèle d’échelleRégression ordinale, 395
Modèle d’emplacementRégression ordinale, 394
Modèle en SAjustement de fonctions, 399
Modèle exponentielAjustement de fonctions, 399
Modèle inverseAjustement de fonctions, 399
Modèle linéaireAjustement de fonctions, 399
Modèle logarithmiqueAjustement de fonctions, 399
Modèle logistiqueAjustement de fonctions, 399
Modèle parallèleDans l’analyse de fiabilité, 504, 506
Modèle parallèle strictDans l’analyse de fiabilité, 504, 506
Modèle quadratiqueAjustement de fonctions, 399
Modèles, 90–91, 279, 530, 548activation, 279copie, 281Définition de variable, 90–91diagrammes, 530Diagrammes, 548Exportation, 281Impression, 281interaction, 279propriétés, 280Utilisation d’un fichier de données externe commemodèle, 122Viewer de modèles, 279
Modèles de tableaux, 263–264Application, 263Création, 264
Modèles factoriels completsGLM, 357
Modèles personnalisésGLM, 357
Modification de données, 99–100Modification de l’ordre des lignes et des colonnes, 256Moindres carrés généralisésDans Analyse factorielle, 439
Moindres carrés non pondérésDans Analyse factorielle, 439
moindres carrés pondérésDans la régression linéaire, 380
moyenneDans ANOVA à 1 facteur, 353Dans Explorer, 314Dans Fréquences, 304Dans les cubes OLAP, 337Dans les statistiques de ratio, 517Dans les tableaux de bord en colonnes, 500Dans les tableaux de bord en lignes, 495Dans Moyennes, 332Dans Récapituler, 327Des colonnes de tableaux multiples, 501Descriptives, 309Sous-groupe, 330, 335
Moyenne, 330Options, 332statistiques, 332
Moyenne géométriqueDans les cubes OLAP, 337Dans Moyennes, 332Dans Récapituler, 327
Moyenne harmoniqueDans les cubes OLAP, 337Dans Moyennes, 332Dans Récapituler, 327
Moyenne pondéréeDans les statistiques de ratio, 517
Moyenne tronquéeDans Explorer, 314
Moyennes des groupes, 330, 335Moyennes des sous-groupes, 330, 335Moyennes marginales estiméesdans GLM - Univarié, 365
Moyennes observéesdans GLM - Univarié, 365
mrInterview, 42MultiplicationMultiplication dans les colonnes de tableaux, 501
Newman-KeulsGLM, 361
Niveau de mesure, 85, 116Définition, 85icônes des boîtes de dialogue, 8
Nombre d’observationsDans les cubes OLAP, 337Dans Moyennes, 332Dans Récapituler, 327
Nombre maximal de branchesDans l’analyse TwoStep Cluster, 449
Nominal, 85Niveau de mesure, 85, 116

644
Index
noms de variable, 84, 539affichage des noms de variables longs dans les résultats,84Boîtes de dialogue, 6, 539fichiers portables, 48généré par le système de gestion des résultats, 622noms de variables d’observation mixtes, 84Règles, 84troncation des noms de variable longs dans les versionsprécédentes, 48
notationaffichage de modèles chargés, 189chargement de modèles enregistrés, 187modèles pris en charge pour l’export et la notation, 185
Notation scientifique, 85, 539Suppression dans le résultat, 539
Notes de bas de page, 265, 273–275diagrammes, 529Marques, 265, 274Renumérotation, 275
Nouvelles fonctionnalitésversion 17.0, 2
Nuées dynamiquesAperçu, 460Classes d’affectation, 463Critères de convergence, 462Distances entre les classes, 463Efficacité, 462Enregistrement des informations sur les classes, 463Exemples, 460Fonctionnalités supplémentaires, 464Itérations, 462Méthodes, 460statistiques, 460, 463Valeurs manquantes, 463
Numéros de port, 74Numérotation des pages, 252Dans les tableaux de bord en colonnes, 502Dans les tableaux de bord en lignes, 496
observationsla pondération, 210Sélection de sous-groupes, 205, 207, 209Tri, 190
Observations, 100, 212Insertion de nouvelles observations, 100Recherche dans l’éditeur de données, 102recherche des observations dupliquées, 131Restructuration en variables, 212
observations dupliquées (enregistrements)recherche et filtrage, 131
Observations filtrées, 105éditeur de données, 105
OMS, 603, 627contrôle des pivots de tableau, 609, 620exclusion des résultats du Viewer, 615format de fichier de données SPSS Statistics, 609, 615
format de fichier SAV, 609, 615Format Excel, 609Format PDF, 609Format texte, 609Format Word, 609identificateurs de commande, 607noms de variable dans les fichiers SAV, 622sous-types de tableau, 607types d’objet de sortie, 606utilisation de XSLT avec OXML, 628XML, 609, 623
Options, 539, 541–542, 545–546, 548, 551, 553–554, 557Affichage des variables, 544années à deux chiffres, 542diagrammes, 548Données, 542éditeur de syntaxe, 557Etiquettes résultats, 546Générales, 539imputation multiple, 558Modèle de tableau pivotant, 551Monnaie, 545Répertoire temporaire, 553scripts, 554Viewer, 541
Options de diagramme, 548Ordinal, 85Niveau de mesure, 85, 116
Ordonnancement des observations, 161Centiles, 162Rangs fractionnaires, 162Scores de Savage, 162Valeurs ex aequo, 163
Ordre d’affichage, 256orthographe, 97Dictionnaire, 542
Outil visuel de regroupement en bandes, 134Ouverture de fichiers, 14–18, 33contrôle des emplacements des fichiers par défaut, 553Fichiers dBASE, 14, 17Fichiers de données, 14–15Fichiers de données texte, 33Fichiers de feuille de calcul, 14, 16Fichiers délimités par des tabulations, 14Fichiers Excel, 14, 16Fichiers Lotus 1-2-3, 14Fichiers Stata, 17Fichiers SYSTAT, 14
OXML, 628
Paires de variables, 212Création, 212
pairsdans l’analyse du voisin le plus proche, 422
Paramètres de ligne de commande, 601Tâches de production, 601

645
Index
PDFExportation de résultats, 236, 244
Performances, 70Mise en mémoire cache des données, 70
PhiTableaux croisés, 320
Pieds de page, 250Pivotementcontrôle avec OMS pour les résultats exportés, 620
plageDans Fréquences, 304Dans les cubes OLAP, 337Dans les statistiques de ratio, 517Dans Moyennes, 332Dans Récapituler, 327Descriptives, 309
PlumRégression ordinale, 390
plusieurs fichiers de données ouverts, 107, 539suppression, 111
Polices, 105, 233, 271éditeur de données, 105Panneau de légendes, 233
Pondération d’observationsPondérations fractionnelles dans des tableaux croisés,210
Pondération d’observations, 210Positionnement multidimensionnel, 509Conditionnalité, 512Création de matrices de distance, 511Critères, 513Définition de la forme des données, 511Dimensions, 512Exemple, 509Fonctionnalités supplémentaires, 514Mesures de distance, 511Modèles de positionnement, 512Niveaux de mesure, 512Options d’affichage, 513statistiques, 509Transformation de valeurs, 511
pourcentagesTableaux croisés, 323
Pourcentages en colonneTableaux croisés, 323
Pourcentages en ligneTableaux croisés, 323
Pourcentages totauxTableaux croisés, 323
PowerPoint, 242exportation du résultat au format PowerPoint, 242
PremierDans les cubes OLAP, 337Dans Moyennes, 332Dans Récapituler, 327
PrévisionAjustement de fonctions, 399
PrévisionsEnregistrement dans la régression linéaire, 384Enregistrement dans l’ajustement de fonctions, 399
Prévisions pondéréesGLM, 363
Production automatisée, 594Profondeur d’arborescenceDans l’analyse TwoStep Cluster, 449
programmation avec le langage de commande, 282propriétés, 264–265Tableaux, 265Tableaux pivotants, 264
propriétés de cellule, 271–272ProximitésClassification hiérarchique, 454
Q de CochranDans les tests pour plusieurs échantillons liés, 483
Q de R-E-G-W (Ryan-Einot-Gabriel-Welsch)Dans ANOVA à 1 facteur, 351GLM, 361
quadrillage, 275Tableaux pivotants, 275
Qualité de l’ajustementRégression ordinale, 393
Quancept, 42Quanvert, 42QuartilesDans Fréquences, 304
R multipleDans la régression linéaire, 387
R2Dans la régression linéaire, 387Dans Moyennes, 332modification R2, 387
R2 ajustéDans la régression linéaire, 387
R2 de Cox et SnellRégression ordinale, 393
R2 de McFaddenRégression ordinale, 393
R2 de NagelkerkeRégression ordinale, 393
Rapport de covarianceDans la régression linéaire, 384
Rapport hauteur/largeur, 548récapitulatif d’erreurdans l’analyse du voisin le plus proche, 427
Récapituler, 325Options, 327statistiques, 327
rechercher et remplacerdocuments du Viewer, 234
Recodage de valeurs, 134, 152–153, 155–156, 158RégressionDiagrammes, 383

646
Index
Régression linéaire, 380Régression multiple, 380
Régression des moindres carrés partiels, 401exporter des variables, 404Modèle, 403
Régression linéaire, 380Blocs, 380Diagrammes, 383Enregistrement de nouvelles variables, 384Exportation des informations du modèle, 384Fonctionnalités supplémentaires, 389Méthodes de sélection des variables, 381, 388Pondérations, 380Résidus, 384statistiques, 387Valeurs manquantes, 388Variable de sélection, 383
Régression multipleDans la régression linéaire, 380
Régression ordinale , 390Fonctionnalités supplémentaires, 396Lien, 391Modèle d’échelle, 395Modèle d’emplacement, 394Options, 391statistiques, 390
regroupement en bandes, 134regroupement par casiers, 134Remplacement de valeurs manquantesInterpolation linéaire, 185Médiane des points voisins, 185Moyenne de la série, 185Moyenne des points voisins, 185Tendance linéaire, 185
Répertoire temporaire, 553Définition de la position en mode local, 553Variable d’environnement SPSSTMPDIR, 553
Réponses multiplesFonctionnalités supplémentaires, 491
Résidu non standardiséGLM, 363
RésidusEnregistrement dans la régression linéaire, 384Enregistrement dans l’ajustement de fonctions, 399Tableaux croisés, 323
Résidus de PearsonRégression ordinale, 393
Résidus de StudentDans la régression linéaire, 384
Résidus standardisésDans la régression linéaire, 384GLM, 363
Résidus supprimésDans la régression linéaire, 384GLM, 363
Restructuration des données, 211–212, 214–221, 223–227Aperçu, 211
Création de plusieurs variables d’index pour larestructuration des variables en Observations, 221Création de variables d’index pour la restructuration desvariables en observations, 218Création d’une variable d’index pour la restructurationdes variables en observations, 220Et données pondérées, 227Exemple de deux index lors de la restructuration devariables en observations, 220Exemple de restructuration de variables en observations,214Exemple de restructuration d’observations en variables,215Exemple d’index unique lors de la restructuration devariables en observations, 219Groupes de variables pour la restructuration de variablesen observations, 216Options de restructuration des variables en observations,223Options de restructuration d’observations en variables,226Sélection de données pour la restructuration de variablesen observations, 217Sélection de données pour la restructurationd’observations en variables, 224Tri de données pour la restructuration d’observationsen variables, 225Types de restructuration, 212
Résultats, 229–231, 235–236, 253, 541Affichage, 230Alignement, 231, 541Centrage, 231, 541Collage dans d’autres applications, 235copie, 230Copie dans d’autres applications, 236déplacement, 230Enregistrement, 253exportation, 236Masquage, 230Modification du langage des résultats, 539Suppression, 230Viewer, 229
résultats de diagrammes, 236Retour à la ligne automatique, 265Contrôle de la largeur de colonne pour texte avec retourautomatique à la ligne, 265étiquettes de variable et de valeur, 89
RhoCorrélations bivariées, 368Tableaux croisés, 320
RisqueTableaux croisés, 320
risque relatifTableaux croisés, 320
Rotation d’étiquettes, 258Rotation equamaxDans Analyse factorielle, 441

647
Index
Rotation oblimin directeDans Analyse factorielle, 441
Rotation quartimaxDans Analyse factorielle, 441
Rotation VarimaxDans Analyse factorielle, 441
Saisie de données, 97–98Non numérique, 98numérique, 98Utilisation d’étiquettes de valeurs, 98
Sauts de ligneétiquettes de variable et de valeur, 89
Sauts de tableau, 277Scores de Savage, 162Scores normauxOrdonner les observations, 162
scripts, 560, 564Ajout aux menus, 560Exécution avec les boutons de la barre d’outils, 564langage par défaut, 554
Sélection ascendanteDans la régression linéaire, 381dans l’analyse du voisin le plus proche, 412
sélection de kdans l’analyse du voisin le plus proche, 425
sélection de k et des caractéristiquesdans l’analyse du voisin le plus proche, 426
sélection des caractéristiquesdans l’analyse du voisin le plus proche, 424
sélection des observationsEchantillon aléatoire, 208En fonction de critères de sélection, 207Intervalle de temps, 209Plage de dates, 209Plage d’observations, 209
Sélection d’observations, 205Sélection progressiveDans la régression linéaire, 381
sélectionner des observations, 205séparation de fenêtreéditeur de données, 105
séparation de panneauéditeur de données, 105
Serveurs, 73–74Ajout, 74Connexion, 73Modification, 74Noms, 74Numéros de port, 74
Serveurs distants, 73–74, 77, 79Accès aux fichiers de données, 77Ajout, 74chemins relatifs, 79Connexion, 73Modification, 74Procédures disponibles, 79
Seuil initialDans l’analyse TwoStep Cluster, 449
sommeDans Fréquences, 304Dans les cubes OLAP, 337Dans Moyennes, 332Dans Récapituler, 327Descriptives, 309
Somme des carrés, 358GLM, 357
sous-groupes d’observationsEchantillon aléatoire, 208Sélection, 205, 207, 209
Sous-titresdiagrammes, 529
Sous-totauxDans les tableaux de bord en colonnes, 502
sous-types, 607et étiquettes, 608
sous-types de tableau, 607et étiquettes, 608
StandardisationDans l’analyse TwoStep Cluster, 449
Statistique de Brown-ForsytheDans ANOVA à 1 facteur, 353
Statistique de CochranTableaux croisés, 320
Statistique de Durbin-WatsonDans la régression linéaire, 387
Statistique de Mantel-HaenszelTableaux croisés, 320
Statistique de WelchDans ANOVA à 1 facteur, 353
Statistique RDans la régression linéaire, 387Dans Moyennes, 332
Statistiques de ratio, 515statistiques, 517
Statistiques descriptivesDans Explorer, 314Dans Fréquences, 304dans GLM - Univarié, 365Dans l’analyse TwoStep Cluster, 452Dans les statistiques de ratio, 517Dans Récapituler, 327Descriptives, 308
Strates, 248, 258, 261, 265, 269Affichage, 258, 261Création, 258impression, 248Impression, 265, 269Tableaux croisés, 319Tableaux pivotants, 258
StressDans le positionnement multidimensionnel, 509
Stress SDans le positionnement multidimensionnel, 509

648
Index
Student-Newman-KeulsDans ANOVA à 1 facteur, 351GLM, 361
Suites de Wald-WolfowitzTests pour deux échantillons indépendants, 475
Suites en séquencesCésures, 470–471Fonctionnalités supplémentaires, 472Options, 471statistiques, 471Valeurs manquantes, 471
Suppression de plusieurs commandes EXECUTE dans lesfichiers de syntaxe, 295Suppression de résultats, 230Suppression d’étiquettes de groupe, 257Syntaxe, 282, 293, 563, 594accès à Command Syntax Reference, 11Collage, 284Exécution, 293Exécution de la syntaxe de commande avec les boutonsde la barre d’outils, 563Fichier de résultat, 285fichier-journal, 295Fichiers de syntaxe de commande Unicode, 294Règles de syntaxe, 282Règles des tâches de production, 594
Syntaxe de commande, 282, 293, 560, 564, 594accès à Command Syntax Reference, 11Ajout aux menus, 560Collage, 284Exécution, 293Exécution avec les boutons de la barre d’outils, 564Fichier de résultat, 285fichier-journal, 295Règles de syntaxe, 282Règles des tâches de production, 594
Système de gestion des résultats (OMS), 603, 627Système de mesure, 539Système de production, 539conversion des fichiers en tâches de production, 602Utilisation de la syntaxe de commande à partir d’unfichier-journal, 539
T2 de HotellingDans l’analyse de fiabilité, 504, 506
T2 de TamhaneDans ANOVA à 1 facteur, 351GLM, 361
T3 de DunnettDans ANOVA à 1 facteur, 351GLM, 361
table de consultation, 197Tableau croiséMultiréponses, 488Tableaux croisés, 318
tableau de classementdans l’analyse du voisin le plus proche, 426
Tableaux, 277Alignement, 272Contrôle des sauts de tableau, 277conversion de la syntaxe de la commande TABLES enCTABLES, 629couleur d’arrière-plan, 271Marges, 272Polices, 271propriétés de cellule, 271–272
Tableaux croisés, 318Affichage de cellules, 323Diagrammes en bâtons juxtaposés, 320Formats, 324Pondérations fractionnelles, 210statistiques, 320Strates, 319Suppression de tableaux, 318Variables de contrôle, 319
Tableaux croisés des réponses multiples, 488Appariement des variables entre les vecteurs, 490Définition des plages de valeurs, 490Pourcentages basés sur les observations, 490Pourcentages basés sur les réponses, 490Pourcentages dans les cellules, 490Valeurs manquantes, 490
Tableaux de bordColonne de total, 501Comparaison des colonnes, 501Division des valeurs de colonnes, 501Multiplication des valeurs de colonnes, 501Tableaux de bord en colonnes, 498Tableaux de bord en lignes, 492Totaux composites, 501
Tableaux de bord en colonnes, 498Colonne de total, 501Fonctionnalités supplémentaires, 503Format de colonne, 494Gestion des pages, 502Mise en page, 497Numérotation des pages, 502Sous-totaux, 502Total général, 502Valeurs manquantes, 502
Tableaux de bord en lignes, 492Critères d’agrégation, 492Espacement de ventilation, 495Fonctionnalités supplémentaires, 503Format de colonne, 494Gestion des pages, 495Mise en page, 497Numérotation des pages, 496Pieds de page, 498Séquences de tri, 492Titres, 498Valeurs manquantes, 496Variables dans les titres, 498Variables en colonnes, 492

649
Index
Tableaux de contingence, 318tableaux de fréquencesDans Explorer, 314Dans Fréquences, 303
Tableaux de fréquences des réponses multiples, 486Valeurs manquantes, 486
tableaux largescollage dans Microsoft Word, 235
Tableaux personnalisésconversion de la syntaxe de la commande TABLES enCTABLES, 629
Tableaux pivotants, 230, 235–236, 248, 255–258, 261,263–266, 268–269, 275–277, 551Affichage des bordures masquées, 275Affichage et masquage des cellules, 261Ajustement de la largeur de colonne par défaut, 551Alignement, 272Bordures, 268Collage dans d’autres applications, 235Collage sous forme de tableaux, 235Contrôle des sauts de tableau, 277Copie dans d’autres applications, 236couleur d’arrière-plan, 271Création de diagrammes à partir de tableaux, 277Déplacement de lignes et de colonnes, 256Dissociation de lignes ou de colonnes, 257Exportation au format HTML, 236Formats de cellule, 266Groupement de lignes ou de colonnes, 257Impression de grands tableaux, 277Impression de strates, 248Insertion d’étiquettes de groupe, 257Largeur des cellules, 275Légendes, 273–274Manipulation, 255Marges, 272Masquage, 230Modèle de tableau par défaut des nouveaux tableaux,551Modification, 255Modification de l’aspect, 263Modification de l’ordre d’affichage, 256Notes de bas de page, 273–274Pivotement, 255Polices, 271propriétés, 264propriétés de cellule, 271–272Propriétés des notes de bas de page, 265Propriétés générales, 265quadrillage, 275Redimensionnement à des fins d’ajustement à la page,265, 269Rotation d’étiquettes, 258Sélection de lignes et de colonnes, 276Strates, 258Suppression d’étiquettes de groupe, 257Texte de suite, 269
Transposition de lignes et de colonnes, 257Utilisation d’icônes, 255
TABLESconversion de la syntaxe de la commande TABLES enCTABLES, 629
Tâches de production, 594, 599–601conversion des fichiers du système de production, 602exécution de plusieurs tâches de production, 601Exportation de diagrammes, 594Fichiers de résultat, 594Paramètres de ligne de commande, 601Programmation des tâches de production, 601Règles de syntaxe, 594Remplacement de valeurs dans des fichiers de syntaxe,599
Tailles, 233Dans la légende, 233
Tau de Goodman et KruskalTableaux croisés, 320
Tau de KruskalTableaux croisés, 320
Tau-bTableaux croisés, 320
Tau-b de KendallCorrélations bivariées, 368Tableaux croisés, 320
Tau-cTableaux croisés, 320
Tau-c de Kendall , 320Tableaux croisés, 320
Termes construits, 357, 396Termes d’interaction, 357, 396Test binomial, 468Dichotomies, 468Fonctionnalités supplémentaires, 470Options, 469statistiques, 469Valeurs manquantes, 469
Test d’additivité de TukeyDans l’analyse de fiabilité, 504, 506
Test de comparaison par paire de GabrielDans ANOVA à 1 facteur, 351GLM, 361
Test de comparaison par paire de Games et HowellDans ANOVA à 1 facteur, 351GLM, 361
Test de FriedmanDans les tests pour plusieurs échantillons liés, 483
Test de la médianeTests pour deux échantillons indépendants, 479
Test de LeveneDans ANOVA à 1 facteur, 353Dans Explorer, 315dans GLM - Univarié, 365
Test de LillieforsDans Explorer, 315

650
Index
Test de McNemarTableaux croisés, 320Tests pour deux échantillons liés, 477
test de SchefféDans ANOVA à 1 facteur, 351GLM, 361
Test de Shapiro-WilksDans Explorer, 315
Test de sphéricité de BartlettDans Analyse factorielle, 438
Test de WilcoxonTests pour deux échantillons liés, 477
Test des droites parallèlesRégression ordinale, 393
Test des réactions extrêmes de MosesTests pour deux échantillons indépendants, 475
Test des signesTests pour deux échantillons liés, 477
Test d’Homogénéité marginaleTests pour deux échantillons liés, 477
Test d’intervalle multiple de DuncanDans ANOVA à 1 facteur, 351GLM, 361
Test exact de FisherTableaux croisés, 320
Test Kolmogorov-Smirnov pour un échantillon, 472Distribution à tester, 472Fonctionnalités supplémentaires, 474Options, 473statistiques, 473Valeurs manquantes, 473
Test M de BoxAnalyse discriminante, 431
Test Tdans GLM - Univarié, 365Test T pour échantillon unique, 346Test T pour échantillons appariés, 344Test T pour échantillons indépendants, 341
Test t de DunnettDans ANOVA à 1 facteur, 351GLM, 361
Test t de SidakDans ANOVA à 1 facteur, 351GLM, 361
test t de Student, 341Test t de Waller-DuncanDans ANOVA à 1 facteur, 351GLM, 361
Test t dépendantTest T pour échantillons appariés, 344
test t pour deux échantillonsTest T pour échantillons indépendants, 341
Test T pour échantillon unique, 346Fonctionnalités supplémentaires, 348Intervalles de confiance, 347Options, 347Valeurs manquantes, 347
Test T pour échantillons appariés, 344Options, 345Sélection de variables appariées, 344Valeurs manquantes, 345
Test T pour échantillons indépendants, 341Définition de groupes, 343Intervalles de confiance, 344Options, 344Valeurs manquantes, 344Variables chaîne, 343Variables de regroupement, 343
Tests de colinéaritéDans la régression linéaire, 387
Tests de l’indépendanceKhi-deux, 320
Tests de linéaritéDans Moyennes, 332
Tests de normalitéDans Explorer, 315
Tests d’homogénéité de la varianceDans ANOVA à 1 facteur, 353dans GLM - Univarié, 365
Tests non paramétriquesKhi-deux, 465Suites en séquences, 470Test Kolmogorov-Smirnov pour un échantillon, 472Tests pour deux échantillons indépendants, 474Tests pour deux échantillons liés, 477Tests pour plusieurs échantillons indépendants, 479Tests pour plusieurs échantillons liés, 482
Tests pour deux échantillons indépendants, 474Définition de groupes, 476Fonctionnalités supplémentaires, 477Options, 476statistiques, 476Types de test, 475Valeurs manquantes, 476Variables de regroupement, 476
Tests pour deux échantillons liés, 477Fonctionnalités supplémentaires, 479Options, 479statistiques, 479Types de test, 478Valeurs manquantes, 479
Tests pour plusieurs échantillons indépendants, 479Définition de l’intervalle, 481Fonctionnalités supplémentaires, 482Options, 481statistiques, 481Types de test, 480Valeurs manquantes, 481Variables de regroupement, 481
Tests pour plusieurs échantillons liés, 482Fonctionnalités supplémentaires, 483statistiques, 483Types de test, 483

651
Index
texteExportation de résultat en tant que texte, 609
Texte, 33, 233, 236, 245Ajout au Viewer, 233Ajout d’un fichier texte dans le Viewer, 233Exportation de résultat en tant que texte, 236, 245Fichiers de données, 33
Texte de suite, 269Pour les tableaux pivotants, 269
Texte d’étiquette vertical, 258Titres, 233Ajout au Viewer, 233Dans les cubes OLAP, 340diagrammes, 529
ToléranceDans la régression linéaire, 387
Totaux générauxDans les tableaux de bord en colonnes, 502
traitement d’un fichier scindé, 204Transformations conditionnelles, 145Transformations de données, 542Calcul de variables, 143fonctions, 146Ordonnancement des observations, 161Recodage de valeurs, 152–153, 155–156, 158Retardement de l’exécution, 542Séries chronologiques, 179, 181Transformations conditionnelles, 145Variables chaîne, 146
transformations de fichiersAgrégation de données, 200Fusion des fichiers de données, 197Pondération d’observations, 210Transposition des variables et des observations, 193Tri d’observations, 190
Transformations de fichiers, 211–212Fusion des fichiers de données, 194Restructuration des données, 211–212traitement d’un fichier scindé, 204
Transposition de lignes et de colonnes, 257Transposition des variables et des observations, 193TriVariables, 191
tri des variables, 191Tri d’observations, 190TukeyDans Explorer, 314
Types de données, 85, 87, 101, 545Définition, 85Devise personnalisée, 85, 545Formats d’affichage, 87Formats d’entrée, 87Modification, 101
types d’objet de sortiedans OMS, 606
U de Mann-WhitneyTests pour deux échantillons indépendants, 475
Unicode, 14, 47
VTableaux croisés, 320
V de CrameréTableaux croisés, 320
V de RaoAnalyse discriminante, 432
Valeurs de décalage, 151Valeurs éloignéesDans Explorer, 314Dans la régression linéaire, 383Dans l’analyse TwoStep Cluster, 449
valeurs extrêmesDans Explorer, 314
Valeurs influentesDans la régression linéaire, 384GLM, 363
Valeurs manquantes, 89, 530Corrélations bivariées, 370Dans Analyse factorielle, 443Dans ANOVA à 1 facteur, 353Dans Corrélations partielles, 373Dans Courbe ROC, 520Dans Explorer, 316Dans la régression linéaire, 388dans l’analyse du voisin le plus proche, 417Dans les suites en séquences, 471Dans les tableaux croisés des réponses multiples, 490Dans les tableaux de bord en colonnes, 502Dans les tableaux de bord en lignes, 496Dans les tableaux de fréquences des réponses multiples,486Dans Test Kolmogorov-Smirnov pour un échantillon,473Définition, 89diagrammes, 530Fonctions, 147Remplacement dans des données de sérieschronologiques, 184Test binomial, 469Test du Khi-deux, 467Test T pour échantillon unique, 347Test T pour échantillons appariés, 345Test T pour échantillons indépendants, 344Tests pour deux échantillons indépendants, 476Tests pour deux échantillons liés, 479Tests pour plusieurs échantillons indépendants, 481Variables chaîne, 89
Valeurs manquantes spécifiées par l’utilisateur, 89Valeurs propresDans Analyse factorielle, 438–439Dans la régression linéaire, 387
Valeurs standardiséesDescriptives, 308

652
Index
Variable de sélectionDans la régression linéaire, 383
Variable d’environnement SPSSTMPDIR, 553Variables, 8, 83, 101, 212, 533–534, 539Affectation d’un nouveau nom aux fichiers de donnéesfusionnés, 196Boîtes de dialogue, 6Définition, 83Définition de groupes de variables, 534déplacement, 101Informations sur la définition, 533Informations sur les variables dans les boîtes de dialogue,9Insertion de nouvelles variables, 101Ordre d’affichage dans les boîtes de dialogue, 539Recherche dans l’éditeur de données, 102Recodage, 152–153, 155–156, 158Restructuration en observations, 212Sélection dans des boîtes de dialogue, 8Tri, 191
Variables chaîne, 89, 98Boîtes de dialogue, 6Calcul de nouvelles variables chaîne, 146Recodage en nombres entiers consécutifs, 158Saisie de données, 98segmentation des chaînes longues dans les versionsprécédentes, 48Valeurs manquantes, 89
Variables de contrôleTableaux croisés, 319
Variables de dateDéfinition pour des données de séries chronologiques,180
variables de format date, 85, 87, 542ajouter ou soustraire des variables date/heure, 164créer une variable date/heure à partir d’un ensemble devariables, 164créer une variable date/heure à partir d’une variablechaîne, 164extraire une partie de la variable date/heure, 164
Variables de regroupement, 212Création, 212
Variables d’échelleregroupement par casiers pour créer des variablesqualitatives, 134
Variables d’environnement, 553SPSSTMPDIR, 553
VarianceDans Explorer, 314Dans Fréquences, 304Dans les cubes OLAP, 337Dans les tableaux de bord en colonnes, 500Dans les tableaux de bord en lignes, 495Dans Moyennes, 332Dans Récapituler, 327Descriptives, 309
vecteurs multiréponsesDéfinition, 120Dichotomies multiples, 120Livre des codes, 296Modalités multiples, 120
Viewer, 229–233, 252–253, 541, 546Affichage des étiquettes de valeurs, 546Affichage des étiquettes de variable, 546Affichage des noms de variable, 546Affichage des valeurs de données, 546Déplacement du résultat, 230Développement de la ligne de légende, 232Enregistrement du document, 253Espace entre les éléments de résultat, 252exclusion de types de résultat avec OMS, 615Légende, 231Masquage de résultats, 230modification de la police de la légende, 233Modification des niveaux de la ligne de légende, 232Modification des tailles de la légende, 233Options d’affichage, 541Panneau de légende, 229Panneau de résultats, 229Réduction de la ligne de légende, 232Suppression de résultats, 230
Viewer de modèles, 279Viewer.rechercher et remplacer des informations, 234
Vitesse, 70Mise en mémoire cache des données, 70
vue du modèledans l’analyse du voisin le plus proche, 418
W de KendallDans les tests pour plusieurs échantillons liés, 483
XMLacheminement des résultats au format XML, 609enregistrement des résultats sous forme de fichiers XML,603résultat OXML depuis OMS, 628structure de tableau au format OXML, 623
XSLTutilisation avec OXML, 628
Z de Kolmogorov-SmirnovDans Test Kolmogorov-Smirnov pour un échantillon,472Tests pour deux échantillons indépendants, 475





























