Embed Size (px)
Citation preview

Mémoire
Pour l’Obtention du Diplôme de
Post Graduation Spécialisée
PRÉSENTÉ PAR ACEF MOHAMED
THEME
UTILISATION DU MODELE MAPREDUCE DANS LES
DIFFERENTS SYSTEMES NOSQL: ETUDE COMPARATIVE
Soutenu le : .. / .. / 2015 Devant le jury composé de :
Président: B. Beldjilali Professeur, Université d’Oran 1, Ahmed Ben Bella
Directeur de mémoire : G. Belalem Professeur, Université d’Oran 1, Ahmed Ben Bella
Examinatrice: N. Taghezout MCA, Université d’Oran 1, Ahmed Ben Bella
Code : …/…
اإلعالم اآلليقسم Département d’Informatique

Dédicaces
A mes parents,
A ma femme,
A ma fille Taghrid Ibtihal,
A mon fils Ahmed Yacine,
A mon fils Maemoun Abdelmounaim,
A mes frères et mes sœurs,
Je vous aime !
Mohamed.

Remerciements
Je remercie ALLAH le tout puissant, maître des cieux et de la terre, qui m’a éclairé le
chemin et permis de mener à bien ce travail.
Je remercie mon encadreur Monsieur BELALEM Ghalem pour ces précieux conseils, sa
disponibilité, la confiance qu’il m’a toujours témoigné, et ce tout au long de l’élaboration du
présent travail.
Je remercie les membres de jury d’avoir accepté de siéger et de juger mon travail.
Je remercie également;
mes enseignants de l’université d’Oran,
le Directeur du CPE,
Monsieur BOUHADDA Abdelkader, chef de département TSO,
Monsieur BABA Ahmed Amine, chef de département TQI,
mes collègues du département TSO,
mes collègues du département TQI,
mes collègues du CPE,
Mr BEKKOUCHE Abdelmadjid,
Mr SALHI Ali et sa famille,
pour leurs aides et encouragements jusqu’à la finalisation de ce travail.

SOMMAIRE
INTRODUCTION GENERALE ........................................................................................................3
Chapitre I. Le BIG DATA et le Cloud Computing ..........................................................................4
I.1. Le BIG DATA ...........................................................................................................................5
I.1.1. Introduction .......................................................................................................................5
I.1.2. Définition ...........................................................................................................................5
I.1.3. L’origine des données ......................................................................................................7
I.1.4. Les principaux acteurs ......................................................................................................7
I.1.5. Les enjeux technologiques ................................................................................................8
I.1.6. Les secteurs d’activités ......................................................................................................8
I.1.7. Le stockage .......................................................................................................................10
I.1.8. Le traitement et l’analyse ................................................................................................10
I.2. LE CLOUD COMPUTING ....................................................................................................10
I.2.1.Définition ..........................................................................................................................10
I.2.2. Les différents services .....................................................................................................11
I.2.3. Les formes de déploiement du Cloud Computing ..........................................................11
I.3. Conclusion ..............................................................................................................................13
Chapitre II. Le NoSQL .....................................................................................................................14
II.1. Introduction ..........................................................................................................................15
II.2. Notions préliminaires ...........................................................................................................15
II.2.1. Les propriétés ACID ......................................................................................................16
II.2.2. Scalabilité .......................................................................................................................17
II.2.3. Le Théorème CAP [5]................................................................................................17
II.2.4. L’émergence du NoSQL ................................................................................................18
II.2.5. Types de base NoSQL ...............................................................................................20
II.2.6. Les propriétés de « BASE ».......................................................................................24
II.2.7. Les avantages et les inconvénients du NoSQL .......................................................24
II.3. MapReduce ..........................................................................................................................26
II.3.1. Introduction ....................................................................................................................26
II.3.2. Principe de MapReduce.................................................................................................26
II.3.3. Le modèle de programmation.................................................................................27

II-4 Conclusion .............................................................................................................................29
Chapitre III. HADOOP, HBASE, MONGODB ET YCSB. ............................................................30
III.1. Introduction .........................................................................................................................31
III.2. HADOOP .............................................................................................................................31
III.2.1. Historique ......................................................................................................................31
III.2.2. Présentation d’Hadoop ................................................................................................31
III.2.3. HDFS..............................................................................................................................35
III.2.4. Le composant MapReduce ...........................................................................................37
III.3. HBASE..................................................................................................................................39
III.3. 1. Présentation de Hbase .................................................................................................39
III.3. 2. Architecture de HBASE ...............................................................................................39
III.4. MONGODB .........................................................................................................................41
III.4.1. Présentation de MongoDB ...........................................................................................41
III.4.2. Modèle de données .......................................................................................................41
III.4.3. Architecture ...................................................................................................................42
III.4.4. Le composant Mapreduce ............................................................................................43
III.4.5. Réponse au CAP ...........................................................................................................44
III.5. YCSB : Le Benchmark Yahoo ..............................................................................................44
III.6. Conclusion ...........................................................................................................................45
Chapitre IV. IMPLEMENTATION ET EXPERIMENTATION ....................................................46
IV.1. Introduction .........................................................................................................................47
IV.2. Première partie ....................................................................................................................47
IV.2.1. Installation de Hadoop, HBASE, MongoDB et YCSB ................................................47
IV.2.1.1.Configuration ..............................................................................................................47
IV.2.1.2. Installation d’Hadoop en mode Single Node ..........................................................48
IV.2.1.3. Installation de HBASE ...............................................................................................56
IV.2.1.4. Installation de MongoDB ..........................................................................................59
IV.2.1.5. Comparaison des propriétés système ......................................................................61
IV.2.1.6. Installation de YCSB ..................................................................................................62
IV.3. Deuxième partie : Analyse des tests ..................................................................................64
IV.3.1. Introduction ..................................................................................................................64
IV.3.2. Tests et analyse des résultats .......................................................................................65

IV.3.3. Deuxième cas : Environnement distribué (Cloud) .....................................................77
IV.4. Conclusion : .........................................................................................................................88
CONCLUSION GENERALE ...........................................................................................................89
Référence : ........................................................................................................................................91
Résumé .............................................................................................................................................93

INTRODUCTION

3
INTRODUCTION GENERALE
Nous sommes confrontés depuis quelques années à de nouvelles technologies qui
envahissent le monde de l’information et l’internet. Cette situation nous oblige à prendre les
défis, de connaitre et maîtriser ces « nouvelles sciences » afin de nous permettre de s’adapter
aux changements forcés par cette « révolution scientifique » semblable à celle du XVII siècle.
Beaucoup de concepts « inséparables » dominent actuellement le monde de l’IT. On entend
souvent de « Cloud Computing » ; la « mode » technologique actuelle, hébergeant un « Big
Data » sous forme de « NoSQL » et traité par un simple programme « MapReduce » dans des
« clusters » distribués partout dans le monde.
Ce manuscrit met le point sur ces concepts; et définie la relation qui les relient, en étudiant
deux solutions caractérisées par l’implémentation dans leurs noyaux du même algorithme
« MapReduce », il s’agit de HBASE et MongoDB. Nous essayerons de comparer entre ces deux
solutions. L²’objectif est de donner une conclusion bénéfique aux acteurs intéressés.
Nous commençons, dans les deux premiers chapitres, de donner les définitions et les
descriptions des concepts considérés comme état de l’art pour cette étude. A savoir le « Big
Data », le « Cloud Computing », « Le NoSQL », et l’Algorithme « MapReduce ».
Le troisième chapitre est consacré à la présentation des outils : Hadoop, HBASE, MongoDB, et
YCSB.
Le quatrième chapitre montre la comparaison des résultats déduits à partir de l’évaluation des
performances de chaque base de données, et nous terminerons notre manuscrit par une
conclusion générale et quelques perspectives.

4
Chapitre I
Le BIG DATA,
et le Cloud Computing

5
I.1. Le BIG DATA
I.1.1. Introduction
En quelques années, le volume des données exploité par les entreprises a
considérablement augmenté. Émanant de sources diverses (transactions, systèmes
d’information automatisés, réseaux sociaux,...), elles sont souvent susceptibles de croître très
rapidement.
Lorsqu’on parle de manipulation de gros volume de données, on pense généralement à des
problématiques sur le volume des données et sur la rapidité de traitement de ces données.
L'idée derrière le "Big Data" est de pouvoir traiter ce grand volume de données.
La première partie de ce chapitre consistera donc à expliquer ce sujet.
D’une autre part, et depuis la création de la technologie de l'internet, une nouvelle tendance
vient de dominer la technologie de l’IT, il s'agit du Cloud Computing . Et afin de mettre le
point sur cette technologie, nous allons consacrer la deuxième partie de ce chapitre pour
présenter ce nouveau marché.
I.1.2. Définition
Le terme «Big Data » est apparu il y’a quelques années pour expliquer un domaine
issu d’une révolution dans la manière de traitement des données. Plusieurs définitions ont été
données.
On trouve principalement la définition donnée par Wikipédia, indiquant qu’il s’agit d’une
“expression anglophone utilisée pour désigner des ensembles de données qui deviennent
tellement gros qu’ils en deviennent difficiles à travailler avec des outils classiques de gestion
de base de données”.[W1]
On trouve d’autres définitions qui peuvent être considéré comme des critiques données à la
définition de Wikipédia. En disant que « Le Big Data est avant tout un terme marketing. À
dire vrai, il recouvre un ensemble de concepts et d'idées pas clairement définis. En se tenant à

6
l'étymologie du terme, Big Data voudrait dire « grosses données ». Or, la problématique des «
grosses données », ou données ayant un volume important, n'est pas nouvelle. [1]
Depuis plus de 30 ans, nous sommes confrontés à des volumes importants de données. Cela
fait presque dix ans que la problématique de gestion des gros volumes de données se pose
dans les métiers de la finance, de l’indexation Web et de la recherche scientifique. Pour y
répondre, l’approche historique a été celle des offres de DataWarehouse.
… En somme, le Big Data, ce serait plutôt des besoins et des envies nouvelles émanant de l'idée de
mieux utiliser ces données qui commencent à s'entasser dans nos DataWarehouse. ».[1]
Le Big Data est défini ; donc ; par rapport à la manière avec laquelle les grandes masses de
données peuvent être traitées et exploitées de façon optimale.
Le concept de Big Data se caractérise par plusieurs aspects. De nombreux responsables
informatiques et autorités du secteur tendent à définir le Big Data selon trois grandes
caractéristiques : Volume, Vitesse et Variété, soit les trois « V ».[1]
- Volume
Le Big Data est associé à un volume de données vertigineux, se situant actuellement entre
quelques dizaines de téraoctets (1 téraoctet=212 octets) et plusieurs péta-octets (1 péta-octets =
215 octets) en un seul jeu de données. Les entreprises, tous secteurs d’activité confondus,
devront trouver des moyens pour gérer le volume de données en constante augmentation qui
est créé quotidiennement.
- Vitesse
La vitesse décrit la fréquence à laquelle les données sont générées, capturées et partagées. Les
entreprises doivent appréhender la vitesse non seulement en termes de création de données,
mais aussi sur le plan de leur traitement, de leur analyse et de leur restitution à l'utilisateur en
respectant les exigences des applications en temps réel.
- Variété
La croissance de la variété des données est largement la conséquence des nouvelles données
multi structurelles et de l'expansion des types de données. Aujourd’hui, on trouve des
capteurs d'informations aussi bien dans les trains, les automobiles ou les avions, ajoutant à
cette variété.

7
Alex Popescu [2] ajoute à cela un quatrième “V”, celui de “variabilité” :
- Variabilité: le format et le sens des données peut varier au fil du temps.
I.1.3. L’origine des données
Les données traitées par le Big Data proviennent notamment [3]:
o du Web: les textes, les images, les vidéos, et tous ce qui peut figurer sur les pages
Web.
o plus généralement, de l’internet et des objets communicants: réseaux de
capteurs, journaux des appels en téléphonie;
o des sciences: génomique, astronomie, physique subatomique, etc.;
o données commerciales
o données personnelles (ex: dossiers médicaux);
o données publiques (open data).
Ces données sont localisées généralement dans les Data Warehouses d’entreprises ou chez les
fournisseurs du Cloud. Ce qui facilite leur traitement en utilisant des méthodes adaptées à ces
architectures. On peut citer par exemple l’algorithme MapReduce.
I.1.4. Les principaux acteurs
Les acteurs sont les organismes qui « produisent » du Big Data, et dans la plupart des
cas ce sont leurs fondateurs.
« Les principales innovations du domaine trouvent leur origine chez les leaders du Web [3]:
Google (MapReduce et BigTable), Amazon (Dynamo, S3), Yahoo! (Hadoop, S4), Facebook
(Cassandra, Hive), Twitter (Storm, FlockDB), LinkedIn (Kafka, SenseiDB, Voldemort),
LiveJournal (Memcached), etc.
La Fondation Apache est ainsi particulièrement active dans ce domaine, en lançant ou en
recueillant plus d’une dizaine de projets, matures ou en incubation: Hadoop,

8
Lucene/Solr,Hbase, Hive, Pig, Cassandra, Mahout, Zookeeper, S4, Storm, Kafka, Flume,
Hama, Giraph, etc.
Outre les sociétés du Web, le secteur scientifique et plus récemment les promoteurs de l’Open
Data (et de sa variante, l’Open Linked Data, issu du Web Sémantique), sont également
historiquement très ouverts à l’Open Source, et ont logiquement effectué des contributions
importantes dans le domaine du Big Data.
I.1.5. Les enjeux technologiques
Pour beaucoup d’entreprises, le Big Data représente de nouveaux enjeux qu’il faut envisager,
mais il faut aussi étudier les risques induits.
D’après Michael Stonebraker [3] « “Il y a beaucoup de bruit autour du Big Data. Ce concept a
plusieurs significations en fonction du type de personnes. Nous pensons que la meilleure
façon de considérer le Big Data est de penser au concept de trois V. Big Data peut être
synonyme de gros volume, du teraoctet au petaoctet. Il peut également signifier la rapidité
[Velocity, NDLR] de traitement de flux continus de données. Enfin, la troisième signification:
vous avez à manipuler une grande variété de données, de sources hétérogènes. Vous avez à
intégrer entre mille et deux mille sources de données différentes et l’opération est un calvaire.
La vérité est que le Big Data a bien trois significations et que les éditeurs n’en abordent qu’une
à la fois. Il est important de connaître leur positionnement pour leur poser les bonnes
questions.”
I.1.6. Les secteurs d’activités
Actuellement, le Big Data est considéré souvent comme un chemin inévitable par les secteurs
économiques, industriels et sociaux dans le monde. Plusieurs organismes et chercheurs
s’intéressent à connaitre les impacts de ce nouveaux concept dans l’avenir.
« Ces secteurs d’activité, qui ont été les premiers à s’intéresser au Big Data, peuvent être
séparés en deux groupes : ceux pour qui le Big Data répond à des besoins historiques de leur
activité, et ceux pour qui il ouvre de nouvelles opportunités. »[1]
La première catégorie regroupe :
- Les Banques.
- La Télécommunication.

9
- Les Médias Numériques.
- Les Marchés Financiers.
Et dans la deuxième catégorie on trouve :
- Les Services Publics
- Le Marketing :
- La Santé :
« …. mais d’autres commencent à s’y intéresser, notamment la Recherche, la Police ou encore
les Transports. »[1]
Afin de répondre à cette demande, de nombreux fournisseurs de technologie de Big Data sont
apparus. Parmi les secteurs d’activités qui s’intéressent aux Big Data, les plus connus sont les
entreprises d’informatiques. Qui sont les « créateurs » des technologies Big Data. Parmi elles :
Microsoft, IBM, Microstrategy, Hurence et TeraData.
Mais de nombreuses autres entreprises utilisent des solutions de Big Data proposées par les
entreprises d’informatiques (figure I.1). Parmi elles, on retrouve différents secteurs d’activité
tels que :
- les télécoms : SFR ;
- les réseaux sociaux : Facebook ;
- des sociétés de services : Amazon Web Services ;
- des sociétés d’analyses : HPCC Systems, 1010 Data, Quantivo, Opera solutions…
Figure. I.1. Les différents secteurs d’activités du BIG DATA

10
I.1.7. Le stockage
Les difficultés de présentation et stockage de données dans les Data Warhouses vu
leurs formes, types et tailles gênent leur exploitation adéquate. La technique utilisée est
l’instauration des bases de données NoSQL.
Les bases NoSQL visent à passer à l’échelle de manière horizontale en relâchant les conditions
fortes de transactionnalité (ACID - atomiques, cohérentes, isolées et durables) attendues des
bases traditionnelles, et en renonçant au modèle relationnel (voir Chapitre 2).
I.1.8. Le traitement et l’analyse
L’architecture distribuée implantée pour le stockage et le traitement des données Big
Data présente un obstacle qui ralenti considérablement le temps espéré par les utilisateurs.
Une technique dite « MapReduce », qui a été utilisée au début par Google, est actuellement
intégrée dans plusieurs solutions Big Data.
MapReduce est à l’origine une technique de programmation connue de longue date en
programmation fonctionnelle, mais surtout un Framework développé par Google en 2004.
La deuxième partie du chapitre 2 est consacré à la présentation de l’algorithme
« MapReduce ».
I.2. LE CLOUD COMPUTING
Depuis sa création, la technologie de l'Internet se développe d’une manière
exponentielle. Actuellement, une nouvelle « tendance » est dominante, il s'agit du Cloud
Computing. Cette technologie, s'appuie sur le WEB 2.0, offre des occasions aux sociétés de
réduire les coûts d'exploitation des logiciels par leurs utilisations directement en ligne.[4]
Dans ce chapitre nous allons présenter les notions fondamentales du Cloud Computing, ses
enjeux, ses évolutions et son utilité.
I.2.1.Définition
Le CloudComputing, « littéralement l'informatique dans les nuages » est un concept
qui consiste à «rendre accessible et exploitable des données et des applications à travers un
réseau. Ce terme désigne à la fois les applications en tant que services sur Internet et le
matériel et logiciels qui permettent de fournir ces services ».[4]

11
I.2.2. Les différents services
Le concept « Cloud Computing » est utilisé pour désigner des services, on distingue trois
"catégories" de services fournis :
Infrastructure as a service : IaaS
Platform as a service : PaaS
Software as a service : Saas
IAAS
Il s’agit de la mise à disposition, à la demande, de ressources d’infrastructures dont la plus
grande partie est localisée à distance dans des Data Center.
PAAS
PAAS désigne les services visant à proposer un environnement complet permettant de
développer et déployer des applications.
SAAS
Il s'agit des plateformes du nuage, regroupant principalement les serveurs mutualisés et
leurs systèmes d'exploitation. En plus de pouvoir délivrer des logiciels.
I.2.3. Les formes de déploiement du Cloud Computing
Nous distinguons trois formes de Cloud Computing: Le Cloud publique, également le
premier apparu, le Cloud privé et le Cloud hybride qui est en fait la combinaison des deux
premiers.
Le Cloud publique
Le principe est d'héberger des applications, en général des applications Web, sur un
environnement partagé avec un nombre illimité d'utilisateurs. La mise en place de ce type de
Cloud est gérée par des entreprises tierces (exemple Amazon, Google, etc.). Les fournisseurs
du Cloud publique les plus connus sont Google et Amazon.
Ce modèle est caractérisé par :
- Demande de lourds investissements pour le fournisseur de services.
- Offre un maximum de flexibilité.
- N’est pas sécurisé.

12
Le Cloud privé
C'est un environnement déployé au sein d'une entreprise en utilisant les infrastructures
internes de l’entreprise, et en utilisant des technologies telles que la virtualisation.
Les ressources sont détenues et contrôlées par le département informatique de l’entreprise.
Eucalyptus, OpenNebula et OpenStack sont des exemples de solution pour la mise en place
du Cloud privé.
Le Cloud hybride
En général, on entend par Cloud hybride la cohabitation et la communication entre un Cloud
privé et un Cloud publique dans une organisation partageant des données et des applications.

13
I.3. Conclusion
Nous avons tenté dans ce premier chapitre de comprendre les concepts de «Big Data »
et de « Cloud Computing ». Ces notions préliminaires aideront à mieux comprendre le
contexte de traitement de nouveaux types données difficile à être classer dans les bases de
données relationnel. Les systèmes de gestion de bases de données NoSQL appariaient ces
dernières années pour solutionner ce problème.
Nous avons présenté dans la deuxième partie de ce chapitre la technologie du Cloud
Computing ainsi que les types de services Cloud connus jusqu'à présent.
Nous allons présenter dans le chapitre suivant d’autres concepts qui ont une relation directe
avec le Big Data et le Cloud Computing. Il s’agit du NoSQL et l’algorithme « MapReduce ».

14
Chapitre II.
Le NoSQL

15
II.1. Introduction
On ne peut pas parler de Big Data sans citer le NoSQL, Not Only SQL. Il est venu pour
solutionner les difficultés rencontrées pendant la gestion des données classées « Big Data »
avec les systèmes SGBD relationnels.
Nous allons donner dans ce chapitre quelques notions préliminaires qui vont faciliter la
comprenions et la présentation des bases de données NoSQL.
En fin du chapitre, nous allons présenter l’algorithme « MapReduce » qui est devenu
actuellement le noyau des procédures intégrés dans la plupart des systèmes de gestion de
bases de données NoSQL.
II.2. Notions préliminaires
Une base de données (BDD) est un dispositif dans lequel il est possible de stocker des
données de manière structurée ou semi-structurée et avec le moins de redondances possibles.
Accessibles par des programmes employés par plusieurs utilisateurs.
Une base de données peut être soit locale, soit répartie. Dans ce dernier cas, les informations
sont stockées sur des machines distantes et accessibles par le réseau. L’accès aux données doit
être géré par des droits accordés aux utilisateurs.
L'avantage majeur des bases de données réparties est la possibilité de pouvoir être accédées
simultanément par plusieurs utilisateurs.
Les bases de données sont gérées par un système appelé « système de gestion de base de
données », abrégé SGBD. C’est un logiciel dont les tâches sont principalement l’accès aux
données, l’insertion de données, l’autorisation des accès aux informations simultanément à de
multiples utilisateurs ainsi que la manipulation des données présentes dans la base.
Suite aux limites du modèle hiérarchique et du modèle réseaux qui sont apparus au début
pour implémenter la représentation physique des données ; le modèle relationnel est
actuellement le SGBD le plus répandu. Dans ce modèle, les informations sont décomposées et
organisées dans des matrices à deux dimensions (ligne-colonne) appelées relations ou tables.
La manipulation de ces données se fait selon la théorie mathématique des opérations
d’algèbre relationnelle telles que l’intersection, la jointure ou le produit cartésien.

16
La manipulation répondue dans le monde de plusieurs types et formes de données et sur
plusieurs plateformes impose deux « critères » de mesure de performances: Les propriétés
ACID et la « Scalabilité».
II.2.1. Les propriétés ACID
Lorsque des transactions sont effectuées, les SGBD de type hiérarchique, réseau et
relationnel fonctionnent selon les contraintes dites ACID.
ACID est un acronyme qui veut dire « Atomicity », « Consistancy », « Isolation » et «
Durability ». Une transaction est réalisée avec succès si elle respecte ces quatre contraintes.
Voici une description détaillée de celles-ci [W2] :
« Atomicity » (Atomicité) :
Lorsqu’une transaction est effectuée, toutes les opérations qu’elle comporte doivent être
menées à bien : en effet, en cas d’échec d’une seule des opérations, toutes les opérations
précédentes doivent être complètement annulées, peu importe le nombre d’opérations déjà
réussies. En résumé, une transaction doit s’effectuer complètement ou pas du tout. Voici un
exemple concret : une transaction qui comporte 3000 lignes qui doivent être modifiées ; si la
modification d’une seule des lignes échoue, alors la transaction entière est annulée.
L’annulation de la transaction est toute à fait normale, car chaque ligne ayant été modifiée
peut dépendre du contexte de modification d’une autre, et toute rupture de ce contexte
pourrait engendrer une incohérence des données de la base.
« Consistancy » (Cohérence) :
Avant et après l’exécution d’une transaction, les données d’une base doivent toujours être
dans un état cohérent. Si le contenu final d’une base de données contient des incohérences,
cela entraînera l’échec et l’annulation de toutes les opérations de la dernière transaction. Le
système revient au dernier état cohérent. La cohérence est établie par les règles fonctionnelles.
« Isolation » (Isolation) :
La caractéristique d’isolation permet à une transaction de s’exécuter en un mode isolé. En
mode isolé, seule la transaction peut voir les données qu’elle est en train de modifier, c’est le
système qui garantit aux autres transactions exécutées en parallèle une visibilité sur les
données antérieures. Ce fonctionnement est obtenu grâce aux verrous système posés par le
SGBD. Prenons l’exemple de deux transactions A et B : lorsque celles-ci s’exécutent en même

17
temps, les modifications effectuées par A ne sont ni visibles, ni modifiables par B tant que la
transaction A n’est pas terminée et validée par un « commit ».
« Durability » (Durabilité) :
Toutes les transactions sont lancées de manière définitive. Une base de données ne doit pas
afficher le succès d’une transaction pour ensuite remettre les données modifiées dans leur état
initial. Pour ce faire, toute transaction est sauvegardée dans un fichier journal afin que, dans le
cas où un problème survient empêchant sa validation complète, elle puisse être correctement
terminée lors de la disponibilité du système.
II.2.2. Scalabilité
La « scalabilité » est le terme utilisé pour définir l’aptitude d’un système à maintenir
un même niveau de performance face à l’augmentation de charge ou de volumétrie de
données, par augmentation des ressources matérielles.
Il y a deux façons de rendre un système extensible :
La « scalabilité » horizontale
Le principe de la « scalabilité » horizontale consiste à simplement rajouter des serveurs en
parallèle.
La « scalabilité » verticale
Elle consiste à augmenter les ressources d’un seul serveur, comme par exemple le
remplacement du CPU par un modèle plus puissant ou par l’augmentation de la capacité de
la mémoire RAM.
Ces deux critères; ACID et scalabilité ; sont limités par le théorème CAP qui signifie
«Coherence», «Availability» et «Partition tolerance», aussi connu sous le nom de théorème de
Brewer [6].
II.2.3. Le Théorème CAP [5]
Ce théorème, formulé par Eric Brewer en 2000 et démontré par Seth Gilbert et Nancy Lych
en 2002, énonce une conjecture qui définit qu’il est impossible, sur un système informatique
de calcul distribué, de garantir en même temps les trois contraintes suivantes :

18
« Coherence » (Cohérence) :
Tous les clients du système voient les mêmes données au même instant.
« Availibility » (Haute disponibilité) :
Un système est dit disponible si toute requête reçue par un nœud retourne un résultat. Bien
évidemment le nœud en question ne doit en aucun cas être victime de défaillance.
« Partition tolerance » (Tolérance à la partition) :
Un système est dit tolérant à la partition s’il continue à répondre aux requêtes de manière
correcte même en cas de panne autre qu’une panne totale du système.
Seuls deux des trois contraintes peuvent être respectés en même temps
Fig. II.1. Théorème de CAP
II.2.4. L’émergence du NoSQL
Le volume de données de certaines entreprises est augmenté considérablement durant
ces dernières années. L’informatisation croissante de traitement en tout genre a eu pour
conséquence une augmentation exponentielle de ce volume de données qui se compte
désormais en pétaoctets, les anglo-saxon l’ont nommé le Big Data (Voir Chapitre 1).
La gestion de ces volumes de données est donc devenue un problème que les bases de
données relationnelles n’ont plus été en mesure de gérer ; la raison suite à laquelle est apparus
le NoSQL comme solution plus performante par rapport aux systèmes de gestion des bases de
données relationnels.

19
Beaucoup d'organisations doivent stocker de grandes quantités de données, la plupart des
SGBD relationnel actuels ne permettent plus de répondre aux besoins de stockage et de
traitement de ces grandes quantités.
Le besoin fondamental auquel répond le NoSQL est la performance. Afin de résoudre les
problèmes liés au « Big Data », les développeurs de sociétés telles que Google et Amazone ont
procédé à des compromis sur les propriétés ACID des SGBDR. Ces compromis sur la notion
relationnelle ont permis aux SGBDR de se libérer de leurs freins à la scalabilité horizontale.
Un autre aspect important du NoSQL est qu’il répond au théorème de CAP qui est plus
adapté pour les systèmes distribués.[5]
Ce sont les grands acteurs du Web tels que Google, Amazon, Linkedin et Facebook qui ont
solutionné leurs problèmes en développant, en parallèle de leurs activités primaire, leurs
propres SGBD NoSQL. A l’heure actuelle, la quasi-totalité des sites à fort trafic utilisent des
SGBD NoSQL.[6]
Un des premiers buts des systèmes NoSQL est de renforcer la « scalabilité » horizontale, il faut
pour cela que le principe de tolérance au partitionnement soit respecté, ce qui exige l’abandon
soit de la cohérence, soit de la haute disponibilité.[6]
Le NoSQL ou « Not Only SQL » est un mouvement très récent (2009), qui concerne les bases
de données.
L’idée du mouvement est simple : proposer des alternatives aux bases de données
relationnelles pour coller aux nouvelles tendances et architectures du moment, notamment le
Cloud Computing.[7]
Les axes principaux du NoSQL sont une haute disponibilité et un partitionnement horizontal
des données, au détriment de la consistance. Alors que les bases de données relationnelles
actuelles sont basées sur les propriétés ACID (Atomicité, Consistance, Isolation et Durabilité).
Un SGBDR pour répondre aux exigences de performance face aux gros volumes de données,
doit se retourner vers du matériel de plus en plus rapide et à l'ajout de mémoire. Le NoSQL,
pour sa part, pour gérer la « montée en charge » se réfère à la répartition de la charge sur les
systèmes de Cloud Computing. Il s'agit la de composant de NoSQL qui fait d'elle une solution
peu coûteuse pour les grands ensembles de données.

20
II.2.5. Types de base NoSQL
Il existe une diversité d’approches NoSQL classées en quatre catégories. Ces différents
systèmes NoSQL utilisent des technologies fortes distinctes spécifiques à différentes solutions
[7. Voici quelques exemples]:
Orientées colonnes : HBase, Hyper table, Cassandra et BigTable
Orientées graphes (Euler) : Neo4J16
Orientées clé-valeur : Voldemort , Dynamite et Riak
Orientées document : MongoDB, CouchDB.
Ces différents modèles de structure sont décrits comme suit :
Base de données Orientée Clé- valeur
Cette structure est très adaptée à la gestion des caches ou pour fournir un accès rapide aux
informations [W3]. La base de données de type clé-valeur est considérée comme la plus
élémentaire. Son principe est très simple, chaque valeur stockée est associée à une clé unique.
C’est uniquement par cette clé qu’il sera possible d’exécuter des requêtes sur la valeur.
Souvent assimilé à une « hashmap » distribuée, le système de base de données de type
clé/valeur est probablement le plus connu et le plus basique que comporte la mouvance
NoSQL. [6]
La structure de l’objet stocké est libre et donc à la charge du développeur de l’application. Un
avantage considérable de ce type de base de données est qu’il est très facilement extensibles,
on parle donc de scalabilité horizontale.
Fig. II.2. Schéma d’une Base de données Orientée Clé-valeur

21
La structure de l’objet est libre et le plus souvent laissé à la charge du développeur de
l’application (par exemple XML, JSON, ...), la base ne gérant généralement que des chaînes
d’octets. [7]
La communication avec la base de données se résume aux opérations basiques que sont PUT,
GET, UPDATE et DELETE. La plupart des bases de données de type clé/valeur disposent
d’une interface HTTP REST qui permet de procéder très facilement à des requêtes depuis
n’importe quel langage de développement.
Ces systèmes sont donc principalement utilisés comme dépôt de données à condition que les
types de requêtes nécessitées soient très simples. On les retrouve comme système de stockage
de cache ou de sessions distribuées, particulièrement là où l’intégrité des données est non
significative. Aujourd’hui, les solutions les plus connues ayant adoptées le système de couple
clé-valeur sont Voldemort (LinkedIn), Redis et Riak. [5]
Les bases de données orientées colonnes
Les bases de données orientées colonnes ont été conçues par les géants du web afin de faire
face à la gestion et au traitement de gros volumes de données s’amplifiant rapidement de
jours en jours.
Ce modèle ressemble à première vue à une table dans un SGBDR à la différence qu’avec une
BD NoSQL orientée colonne, le nombre de colonnes est dynamique.
En effet, dans une table relationnelle, le nombre de colonnes est fixé dès la création du schéma
de la table et ce nombre reste le même pour tous les enregistrements dans cette table. Par
contre, avec ce modèle, le nombre de colonnes peut varier d’un enregistrement à un autre ce
qui évite de retrouver des colonnes ayant des valeurs NULL.
Le concept de base est décrit comme suit :
- Column : c’est l’entité de base qui représente un champ de données. Toutes les
colonnes sont définies par un couple clé/valeur
- Super column : c’est une colonne qui contient d’autres colonnes
- Column family : elle est considérée comme un conteneur de plusieurs colonnes ou
super-colonnes
- Row : c’est l’identifiant unique de chaque ligne de colonne
22
- Value : c’est le contenu de la colonne. Cette valeur peut très bien être une colonne
elle-même.
Ce type de structure permet d’être plus évolutif et flexible ; cela vient du fait qu’on peut
ajouter à tout moment une colonne ou une super-colonne à n’importe quelle famille de
colonnes.
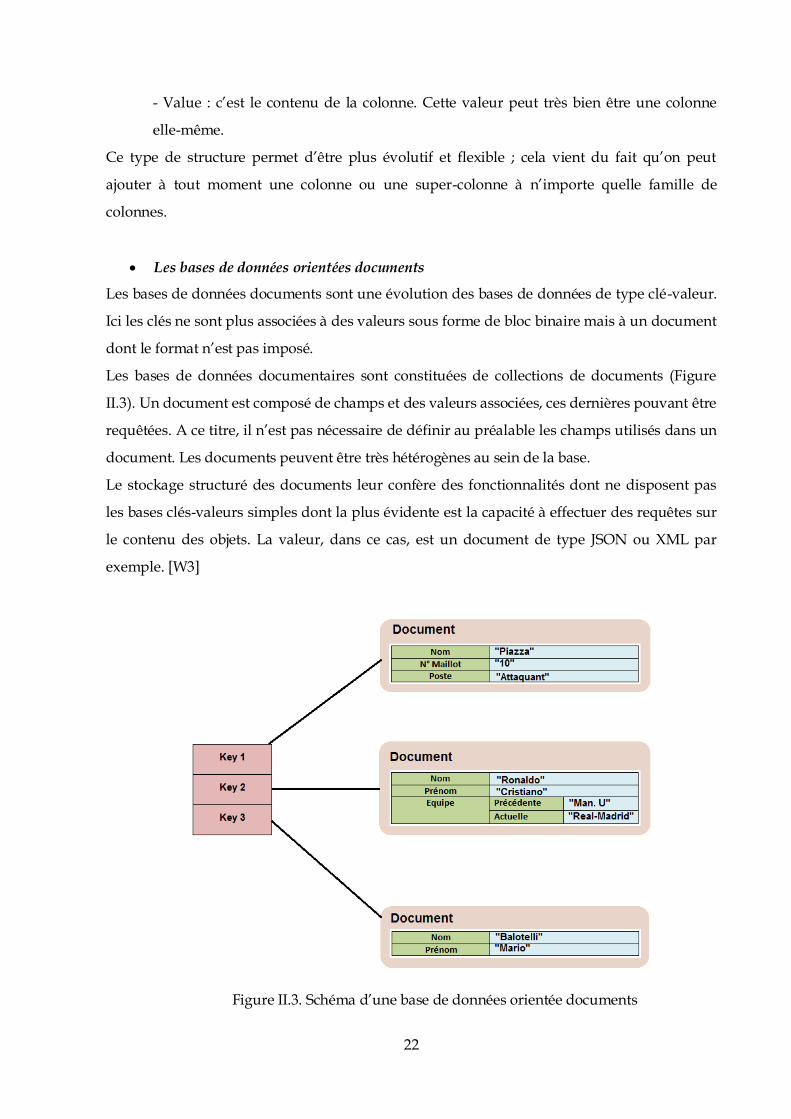
Les bases de données orientées documents
Les bases de données documents sont une évolution des bases de données de type clé-valeur.
Ici les clés ne sont plus associées à des valeurs sous forme de bloc binaire mais à un document
dont le format n’est pas imposé.
Les bases de données documentaires sont constituées de collections de documents (Figure
II.3). Un document est composé de champs et des valeurs associées, ces dernières pouvant être
requêtées. A ce titre, il n’est pas nécessaire de définir au préalable les champs utilisés dans un
document. Les documents peuvent être très hétérogènes au sein de la base.
Le stockage structuré des documents leur confère des fonctionnalités dont ne disposent pas
les bases clés-valeurs simples dont la plus évidente est la capacité à effectuer des requêtes sur
le contenu des objets. La valeur, dans ce cas, est un document de type JSON ou XML par
exemple. [W3]
CLE …Figure II.3. Schéma d’une base de données orientée documents

23
L’avantage des bases de données documents est de pouvoir récupérer un ensemble
d’informations structurées hiérarchiquement depuis une clé. Une opération similaire dans le
monde relationnelle équivaudrait à plusieurs jointures de table.[5]
Les bases de données orientées graphe
Bien que les bases de données de type clé-valeur, colonne, ou document tirent leur principal
avantage de la performance du traitement de données, les bases de données orientées graphe
permettent de résoudre des problèmes très complexes qu’une base de données relationnelle
serait incapable de faire. [6]
Ce modèle de représentation des données se base sur la théorie des graphes. Il s’appuie sur la
notion de nœuds, de relations et de propriétés qui leur sont rattachées (Figure II.4).
Ce modèle facilite la représentation du monde réel, ce qui le rend adapté au traitement des
données des réseaux sociaux
Ces bases permettent la modélisation, le stockage ainsi que le traitement de données
complexes reliées par des relations. Ce modèle est composé d’un :
Moteur de stockage pour les objets : c’est une base documentaire où chaque entité de
cette base est nommée nœud.
Mécanisme qui décrit les arcs : c’est les relations entre les objets, elles contiennent des
propriétés de type simple (integer, string, date,...).
Figure II.4. Schéma d’une base de données Orientées graphe.

24
II.2.6. Les propriétés de « BASE »
Dans la première partie de ce chapitre consacrée aux notions préliminaires, nous avons
vu les propriétés ACID auxquelles doivent répondre les SGBD de type relationnel. Les SGBD
NoSQL par contre doivent vérifier les propriétés dites propriétés de BASE.
Le principe de BASE est le fruit d’une réflexion menée par Eric Brewer (Théorème de CAP).
Les caractéristiques de BASE sont fondées sur les limites que montrent les SGBD
relationnelles. Voici sa description[6] :
Basically Available (Disponibilité basique) :
Même en cas de désynchronisation ou de panne d’un des nœuds du cluster, le système reste
disponible selon le théorème CAP.
Soft-state (Cohérence légère) :
Cela indique que l’état du système risque de changer au cours du temps, sans pour autant que
des données soient entrées dans le système. Cela vient du fait que le modèle est cohérent à
terme.
Eventual consistancy (Cohérence à terme) :
Cela indique que le système devient cohérent dans le temps, pour autant que pendant ce laps
de temps, le système ne reçoive pas d’autres données.
II.2.7. Les avantages et les inconvénients du NoSQL
Plusieurs avantages peuvent être associés aux systèmes NoSQL, nous pouvons citer par
exemple :
o La « scalabilité » horizontale :
Aujourd’hui, la rapidité en lecture/écriture ainsi que la haute disponibilité sont devenues des
critères indispensables. C’est pourquoi les bases de données NoSQL répondent entièrement à
ce besoin. Elles ont été conçues pour répandre les données de manière transparente sur
plusieurs nœuds et ainsi former un cluster. Les performances qu’offrent la «scalabilité »
horizontale peuvent même être atteintes avec des serveurs bas de gamme, ce qui rend la
structure plus économique. [6]
La scalabilité horizontale offre d’autres avantages non négligeables, comme une grande
tolérance aux pannes où les coûts réduits relatifs à l’achat du matériel (plus besoin d’acheter
de serveurs extrêmement puissants).

25
o Gros volume de données (Big Data)
NoSQL est plus évolutif. C’est en effet l’élasticité de ses bases de données NoSQL qui le rend
si bien adapté au traitement de gros volumes de données.
o Economique
Les bases de données NoSQL ont tendance à utiliser des serveurs bas de gammes dont le coût
est moindre afin d’équiper les « clusters ». Les serveurs destinés aux bases de données NoSQL
sont généralement bon marché et de faible qualité, contrairement à ceux qui sont utilisés par
les bases relationnelles. De plus, la très grande majorité des solutions NoSQL sont Open–
Source, ce qui reflète d’une part une économie importante sur le prix des licences.
o Plus flexible
N’étant pas enfermée dans un seul et unique modèle de données, une base de données
NoSQL est beaucoup moins restreinte qu’une base SQL. Les applications NoSQL peuvent
donc stocker des données sous n’importe quel format ou structure, et changer de format en
production.
o Le Cloud Computing
NoSQL et le Cloud s’associent de façon naturelle. En effet, le Cloud Computing répond
extrêmement bien aux besoins en matière de scalabilité horizontale que requièrent les bases de
données NoSQL. En plus la pluparts des solutions Cloud sont basés sur le NoSQL.
Néanmoins, l’inconvénient majeur est que les SGBD relationnel occupent actuellement la
grande partie du marché mondial, ce qui implique une lenteur dans l’adoption des solutions
NoSQL par les décideurs IT. Dans le monde NoSQL, presque tous les développeurs sont en
apprentissage avec la technologie.
Ces inconvénients vont disparaitre après quelques années vu la tendance mondiale vers les
SGBD NoSQL.

26
II.3. MapReduce
II.3.1. Introduction
Le traitement des données par un SGBD NoSQL est caractérisé par son stockage dans
des supports distribués appelés «Clusters» d’une part, et d’autre part par la quantité
gigantesque des données. Ce qui exige une fragmentation (décomposition) des données et
leurs traitements simultanés (en parallèle), en plus, la finalité est de regrouper les résultats. Ce
traitement de données de façon distribuée soulève certaines questions : Comment distribuer le
travail entre les serveurs ? Comment synchroniser les différents résultats ? Comment gérer
une panne d’une unité de traitement ?
Une des solutions proposées est l’utilisation de l’algorithme « Map Reduce ».
Il ne s’agit pas d’un élément de base de données, mais d’un modèle de programmation
s’inspirant des langages fonctionnels et plus précisément du langage Lisp. Il permet de traiter
une grande quantité de données de manière parallèle, en les distribuant sur divers nœuds
d’un Cluster. Ce mécanisme a été mis en avant par Google en 2004 et a connu un très grand
succès auprès des sociétés utilisant des DataCenter telles que Facebook ou Amazon. [5]
MapReduce est un patron d'architecture de développement informatique, popularisé (et non
inventé) par Google, dans lequel sont effectués des calculs parallèles, et souvent distribués, de
données potentiellement très volumineuses, typiquement supérieures en taille à 1 téraoctet.
[W4]
II.3.2. Principe de MapReduce
Le principe de MapReduce est simple (voir Figure II-5): il s’agit de découper une tâche
manipulant un gros volume de données en plusieurs tâches traitant chacune un sous-
ensemble de ces données. Dans la première étape (Map) les tâches sont donc dispatchées sur
l’ensemble des nœuds. Chaque nœud traite un ensemble des données. Dans la deuxième
étape, les résultats sont consolidés pour former le résultat final du traitement (Reduce).
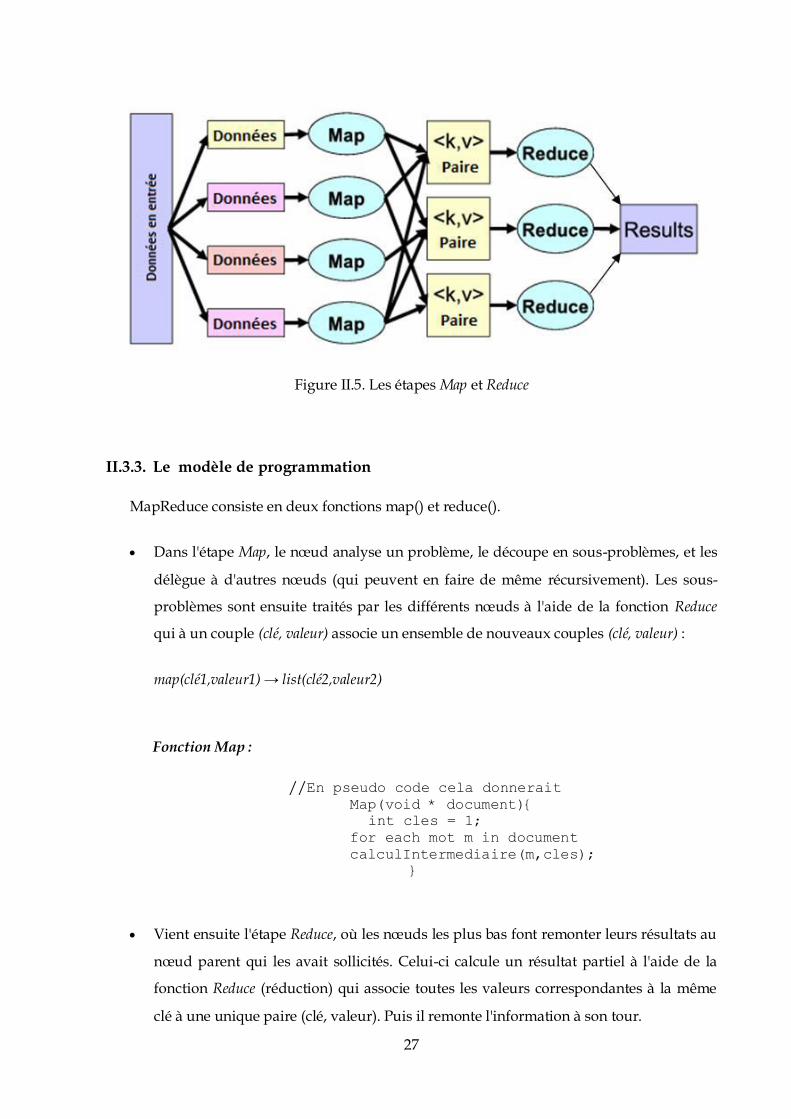
27
Figure II.5. Les étapes Map et Reduce
II.3.3. Le modèle de programmation
MapReduce consiste en deux fonctions map() et reduce().
Dans l'étape Map, le nœud analyse un problème, le découpe en sous-problèmes, et les
délègue à d'autres nœuds (qui peuvent en faire de même récursivement). Les sous-
problèmes sont ensuite traités par les différents nœuds à l'aide de la fonction Reduce
qui à un couple (clé, valeur) associe un ensemble de nouveaux couples (clé, valeur) :
map(clé1,valeur1) → list(clé2,valeur2)
Fonction Map :
//En pseudo code cela donnerait Map(void * document){
int cles = 1;
for each mot m in document
calculIntermediaire(m,cles);
}
Vient ensuite l'étape Reduce, où les nœuds les plus bas font remonter leurs résultats au
nœud parent qui les avait sollicités. Celui-ci calcule un résultat partiel à l'aide de la
fonction Reduce (réduction) qui associe toutes les valeurs correspondantes à la même
clé à une unique paire (clé, valeur). Puis il remonte l'information à son tour.

28
À la fin du processus, le nœud d'origine peut recomposer une réponse au problème qui lui
avait été soumis :
reduce(key2,list(valeur2))→ list(valeur2)
Fonction Reduce :
//En pseudo code cela donnerait
Reduce(entier cles, Iterator values){
int result = 0;
for each v in values
result += v;
}
MapReduce peut être utilisé pour un grand nombre d'applications, dont grep distribué, tri
distribué, inversion du graphe des liens Web, vecteur de terme par hôte, statistiques d'accès
au Web, construction d'index inversé, classification automatique de documents, apprentissage
automatique. [W4]
Le MapReduce a émergé en 2004 comme un important modèle de programmation pour les
applications utilisant d’énormes quantités de données grâce à sa répartition efficace du travail
sur différents nœuds de calcul. Il commence notamment à être utilisé dans le Cloud
Computing, car son nombre de données stockées et manipulées ne cesse de croître. Il est donc
nécessaire d'avoir un moyen d'améliorer le traitement des données au sein du Cloud. [W4]

29
II-4 Conclusion
Nous avons montré dans ce chapitre les différents types de bases de données NoSQL
avec leurs différents domaines d’utilisation.
Nous avons présenté en fin du chapitre l’algorithme MapReduce, et nous avons expliqué ses
composants et son fonctionnement.
Le chapitre suivant sera consacré à présenter deux solutions NoSQL. Le but est de comparer
leur performance et d’arriver, en cas de besoin, à en choisir la bonne solution pour les
circonstances liées au type de données choisies et au type de traitement exécuté sur ces
données.

30
Chapitre III.
HADOOP, HBASE, MONGODB
ET YCSB.

31
III.1. Introduction
Nous nous intéresserons particulièrement dans ce chapitre aux technologies HBASE,
MongoDB, et Hadoop le framework Java destiné aux applications distribuées et à la gestion
intensive des données. Ce sont des technologies récentes, encore relativement peu connues du
grand public mais auxquelles nous associons déjà des grands noms parmi lesquels : Facebook,
Yahoo ou encore Twitter.
Nous présentons en fin de chapitre l’outil Yahoo ! Cloud Serving Benchmark (YCSB) qui un
générateur de banque d'essais (benchmark en anglais) pour les bases de données NoSQL sur
Cloud Computing.
III.2. HADOOP
III.2.1. Historique
Doug Cutting l’un des fondateurs de Hadoop, travaillant à l’époque sur le
développement de Apache Lucene, cherchait une solution quant à la distribution du
traitement de Lucene afin de bâtir le moteur d’indexation web Nutch. Il décidait donc de
s’inspirer de la publication de Google sur leur système de fichier distribué GFS (Google File
System). Premièrement, renommer NDFS, il sera rebaptisé HDFS pour Hadoop Distributed
File System [5].
III.2.2. Présentation d’Hadoop
Hadoop est un ensemble de logiciels et d’outils qui permettent de créer des
applications distribuées. C’est une plate-forme logicielle open-source, écrite en Java et fondée
sur le modèle MapReduce de Google et les systèmes de fichiers distribués (HDFS). Elle permet
de prendre en charge les applications distribuées en analysant de très grands ensembles de
données.
Hadoop est utilisé particulièrement dans l’indexation et le tri de grands ensembles de
données, le data mining, l’analyse de logs, et le traitement d’images. Le succès de Google lui
est en partie imputable. En 2001, alors qu’il n'en est encore qu'à ses balbutiements sur le
marché des moteurs de recherche, le futur géant développe ce qui inspira les composants
phares d'Hadoop: MapReduce, Google BigTable et Google BigFiles (futur Google File System).
Ces deux points forment l’écosystème Hadoop, écosystème fortement convoité et qui se
trouve au centre de l’univers du Big Data [10].

32
Hadoop fait partie des projets de la fondation de logiciel Apache depuis 2009. Il est destiné à
faciliter le développement d’applications distribuées et scalables, permettant la gestion de
milliers de nœuds ainsi que des pétaoctets de données.
En 2011, Yahoo! crée Horton works, sa filiale dédiée à Hadoop. L'entreprise se concentre sur le
développement et le support d'Apache Hadoop. De la même manière, Cloudera, créé au
début de l'année 2009, se place comme l'un des plus gros contributeurs au projet Hadoop, au
côté de MapR (2009) et Hortonworks.
Typologie d’un cluster Hadoop
Hadoop repose sur un schéma dit « maître-esclave » et peut être décomposé en cinq éléments.
(Fig III.1) :
Le nom du noeud (Name Node) : Le « Name Node » est la pièce centrale dans le HDFS, il
maintient une arborescence de tous les fichiers du système et gère l’espace de nommage. Il
centralise la localisation des blocs de données répartis sur le système. Sans le « Name Node»,
les données peuvent être considérées comme perdues car il s’occupe de reconstituer un fichier
à partir des différents blocs répartis dans les différents « Data Node ». Il n’y a qu’un «Name
Node» par cluster HDFS.
Le gestionnaire de tâches (Job Tracker) : Il s’occupe de la coordination des tâches sur les
différents clusters. Il attribue les fonctions de MapReduce aux différents « TaskTrackers ». Le
« Job Tracker » est un « Daemon » cohabitant avec le « Name Node » et ne possède donc
qu’une instance par cluster.
Le moniteur de tâches (Tasktracker) : Il permet l’exécution des ordres de mapReduce, ainsi
que la lecture des blocs de données en accédant aux différents « Data Nodes ». Par ailleurs, le
« TaskTracker » notifie de façon périodique au « Job Tracker » le niveau de progression des
tâches qu’il exécute, ou alors d’éventuelles erreurs pour que celui-ci puisse reprogrammer et
assigner une nouvelle tâche Un « TaskTracker est un « Deamon » cohabitant avec un « Data
Node », il y a un donc un « TaskTracker » par « Data Node ».
Le noeud secondaire (Secondarynode) : N’étant initialement pas présent dans l’architecture
Hadoop, celui-ci a été ajouté par la suite afin de répondre au problème du point individuel de
défaillance (SPOF- Single point of failure). Le « Secondary Node » va donc périodiquement
faire une copie des données du « Name Node » afin de pouvoir prendre la relève en cas de
panne de ce dernier.

33
Le nœud de données (Data Node) : Il permet le stockage des blocs de données. Il
communique périodiquement au « Name Node » une liste des blocs qu’il gère. Un HDFS
contient plusieurs noeuds de données ainsi que des réplications d’entre eux. Ce sont les
nœuds esclaves [5].
Figure III.1 Architecture d’un Cluster Hadoop
Un Cluster Hadoop peut être constitué de machines hétérogènes, que ce soit au niveau du
hardware comme au niveau software (système d’exploitation). Cependant il est bien plus
simple d’administrer un cluster de type homogène [5].
Hadoop est aujourd’hui l’un des outils les plus pertinents pour répondre aux problèmes du
Big Data [5]. C’est la première technologie qui vient à l’esprit lorsque l’on évoque aujourd’hui
ce sujet [11].

34
Les points forts d’Hadoop se résument dans ses caractéristiques suivantes :
- évolutif, car pensé pour utiliser plus de ressources physiques, selon les besoins, et de
manière transparente ;
- rentable, car il optimise les coûts via une meilleure utilisation des ressources
présentes;
- souple, car il répond à la caractéristique de variété des données en étant capable de
traiter différents types de données ;
- et enfin, résilient, car pensé pour ne pas perdre d'information et être capable de
poursuivre le traitement si un nœud du système tombe en panne [10].
Hadoop n’a pas été conçu pour traiter de grandes quantités de données structurées à grande
vitesse. Cette mission reste largement l’apanage des grands systèmes de Datawarehouse et de
Datamart reposant sur des SGBD traditionnelles et faisant usage de SQL comme langage de
requête. La spécialité d’Hadoop, ce serait plutôt le traitement à très grande échelle de grands
volumes de données non structurées tels que des documents textuels, des images, des fichiers
audio,… même s’il est aussi possible de traiter des données semi-structurées ou structurées
avec Hadoop [11].
Exemple d’usage
Ce qui fait la spécificité de Hadoop est qu’il est conçu pour traiter un énorme volume de
données en un temps record. A titre d’exemple, les Laboratoires de Yahoo! ont trié
l’équivalent de 500 GB de données en 59 secondes sur un Cluster de 1400 nœuds (Avril 2009).
Sa vocation première est donc d’implémenter des traitements batchs performants,
particulièrement lorsqu’ils impliquent un volume de données très important. En dehors de
Yahoo!, citons les cas d’utilisation de deux sociétés prestigieuses :
La plateforme musicale Last.fm met en œuvre Hadoop pour générer les statistiques
hebdomadaires (Tops artistes et Top titres) ou mesurer les tendances musicales.
Facebook l’utilise pour la production de rapports à usage interne, comme la
performance des campagnes publicitaires opérées par la plateforme sociale, ou des
statistiques diverses (croissance du nombre des utilisateurs, consultation des pages,
temps moyen de consultation du site, etc.) [W4].

35
III.2.3. HDFS
HDFS (Hadoop Distributed File System) est un système de fichiers distribué, inspiré
du système GFS développé par Google. Il se démarque des autres systèmes de fichier
distribués par sa grande tolérance aux fautes [8] et le fait qu’il soit conçu pour être déployé sur
des machines à faible coût. HDFS fournit un haut débit d’accès aux données et est adapté pour
les applications qui nécessitent de grands groupes de données. Il a été à l’origine conçu pour
le projet de moteur de recherche web Apache Nutch [9].
HDFS a une architecture de type maître/esclave. Un Cluster HDFS est constitué d’un unique
NameNode, un serveur maître qui gère le système de fichier et notamment les droits d’accès
aux fichiers. A cela s’ajoute des DataNodes, en général un par nœud dans le Cluster, qui gère le
stockage des données affectés au nœud sur lequel elle se trouve (Voir Figure III.2).
HDFS est conçu pour tourner sur des machines simples sous GNU/linux, et est programmé
en Java. Toute machine qui dispose de Java peut donc faire tourner un NameNode ou un
DataNode. Les nœuds communiquent entre eux via SSH. Il faut donc entrer la clé publique de
chaque DataNode dans le fichier authorized_keys du NameNode, afin qu’il puisse se connecter
aux autres nœuds via SSH sans avoir besoin de taper un mot de passe à chaque fois [9].
Figure III.2. Schéma HDFS
Le NameNode dispose d’un fichier de configuration dans lequel il entre l’adresse de chaque
machine sur laquelle tourne un DataNode, et se connecte ensuite à chacune de ces machines
36
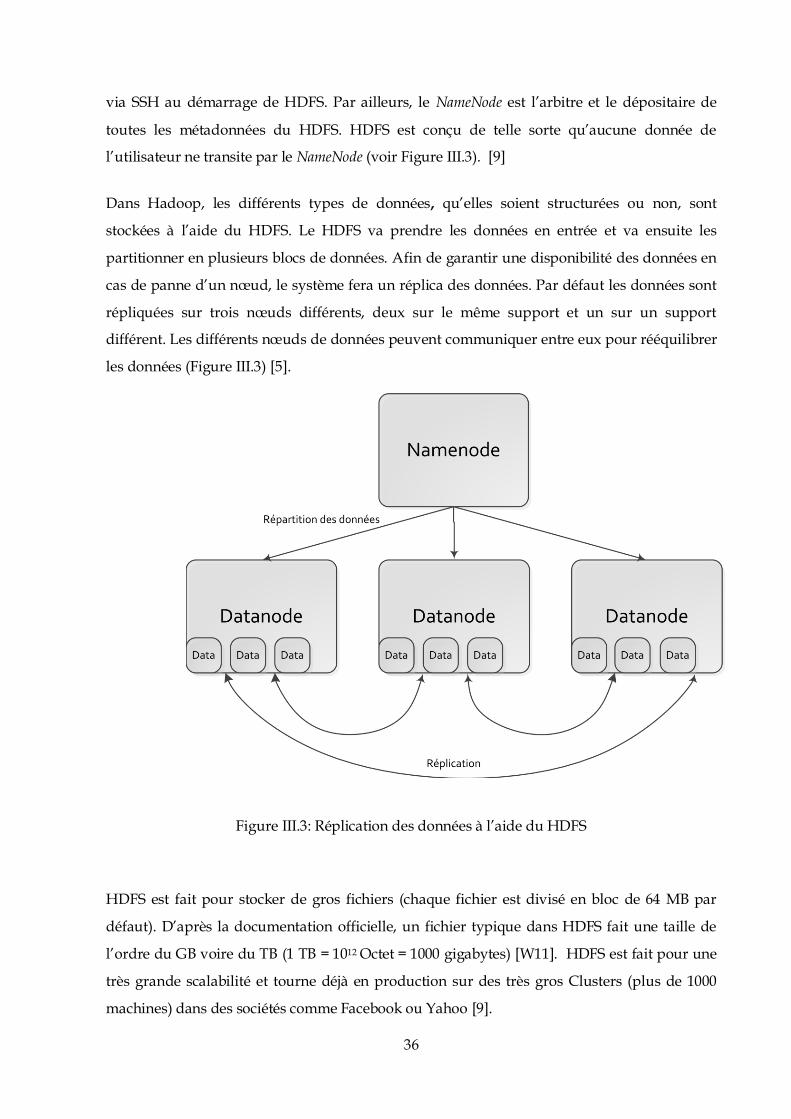
via SSH au démarrage de HDFS. Par ailleurs, le NameNode est l’arbitre et le dépositaire de
toutes les métadonnées du HDFS. HDFS est conçu de telle sorte qu’aucune donnée de
l’utilisateur ne transite par le NameNode (voir Figure III.3). [9]
Dans Hadoop, les différents types de données, qu’elles soient structurées ou non, sont
stockées à l’aide du HDFS. Le HDFS va prendre les données en entrée et va ensuite les
partitionner en plusieurs blocs de données. Afin de garantir une disponibilité des données en
cas de panne d’un nœud, le système fera un réplica des données. Par défaut les données sont
répliquées sur trois nœuds différents, deux sur le même support et un sur un support
différent. Les différents nœuds de données peuvent communiquer entre eux pour rééquilibrer
les données (Figure III.3) [5].
Figure III.3: Réplication des données à l’aide du HDFS
HDFS est fait pour stocker de gros fichiers (chaque fichier est divisé en bloc de 64 MB par
défaut). D’après la documentation officielle, un fichier typique dans HDFS fait une taille de
l’ordre du GB voire du TB (1 TB = 1012 Octet = 1000 gigabytes) [W11]. HDFS est fait pour une
très grande scalabilité et tourne déjà en production sur des très gros Clusters (plus de 1000
machines) dans des sociétés comme Facebook ou Yahoo [9].
37
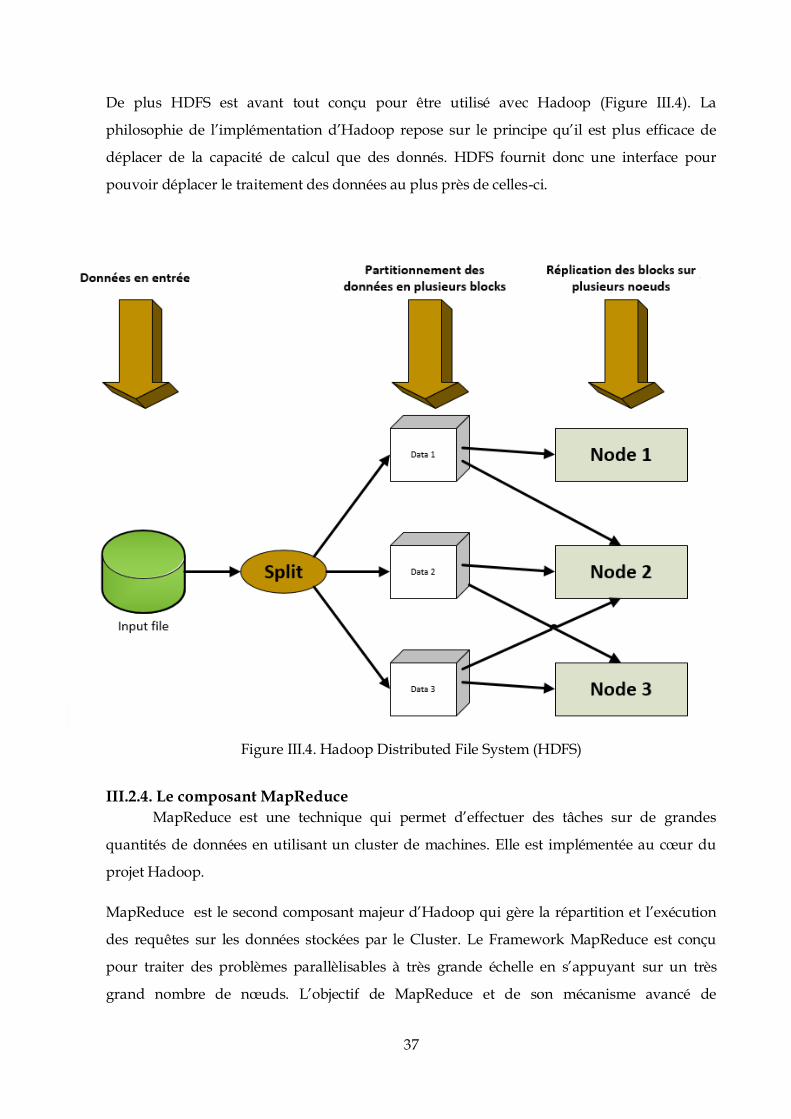
De plus HDFS est avant tout conçu pour être utilisé avec Hadoop (Figure III.4). La
philosophie de l’implémentation d’Hadoop repose sur le principe qu’il est plus efficace de
déplacer de la capacité de calcul que des donnés. HDFS fournit donc une interface pour
pouvoir déplacer le traitement des données au plus près de celles-ci.
Figure III.4. Hadoop Distributed File System (HDFS)
III.2.4. Le composant MapReduce
MapReduce est une technique qui permet d’effectuer des tâches sur de grandes
quantités de données en utilisant un cluster de machines. Elle est implémentée au cœur du
projet Hadoop.
MapReduce est le second composant majeur d’Hadoop qui gère la répartition et l’exécution
des requêtes sur les données stockées par le Cluster. Le Framework MapReduce est conçu
pour traiter des problèmes parallèlisables à très grande échelle en s’appuyant sur un très
grand nombre de nœuds. L’objectif de MapReduce et de son mécanisme avancé de
38
distribution de tâches est de tirer parti de la localité entre données et traitements sur le même
nœud de façon à minimiser l’impact des transferts de données entre les nœuds du Cluster sur
la performance [11].
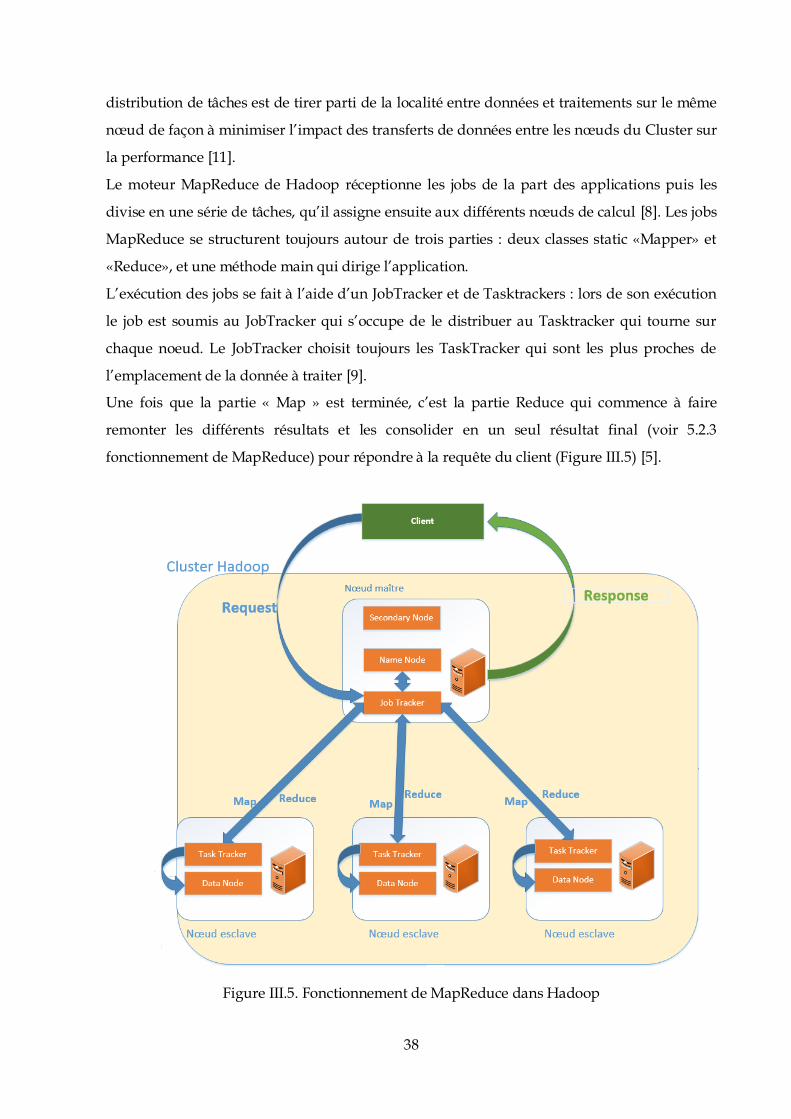
Le moteur MapReduce de Hadoop réceptionne les jobs de la part des applications puis les
divise en une série de tâches, qu’il assigne ensuite aux différents nœuds de calcul [8]. Les jobs
MapReduce se structurent toujours autour de trois parties : deux classes static «Mapper» et
«Reduce», et une méthode main qui dirige l’application.
L’exécution des jobs se fait à l’aide d’un JobTracker et de Tasktrackers : lors de son exécution
le job est soumis au JobTracker qui s’occupe de le distribuer au Tasktracker qui tourne sur
chaque noeud. Le JobTracker choisit toujours les TaskTracker qui sont les plus proches de
l’emplacement de la donnée à traiter [9].
Une fois que la partie « Map » est terminée, c’est la partie Reduce qui commence à faire
remonter les différents résultats et les consolider en un seul résultat final (voir 5.2.3
fonctionnement de MapReduce) pour répondre à la requête du client (Figure III.5) [5].
Figure III.5. Fonctionnement de MapReduce dans Hadoop

39
III.3. HBASE
III.3. 1. Présentation de Hbase
HBase est un système de gestion de base de données NoSQL distribué, écrit en Java,
disposant d'un stockage structuré pour les grandes tables. Il est sous LicenceApache.
La société américaine Cloudera distribue une édition de Hadoop et HBase avec support
nommée Cloudera Enterprise.
HBase est utilisé par des acteurs comme Facebook pour stocker tous les messages de ce réseau
social, ce qui représentait en 2009 plus de 150 téraoctets de nouvelles données par mois [W6].
HBase est inspirée des publications de Google sur BigTable, de type base de données orientée
colonnes basées sur une architecture maître/esclave, et capable de gérer d'énormes quantités
d'informations (plusieurs milliards de lignes par table). Il s'installe généralement sur le
système de fichiers HDFS d'Hadoop pour faciliter la distribution. Il est utilisé lors d’un besoin
à un accès aléatoire pour lecture- écriture en temps réel au Big Data.
L'objectif de ce projet est l'hébergement de très Grandes tables des milliards de lignes et des
millions de colonnes. HBase conserve un grand nombre de fichiers ouverts en même temps
[12].
Mark Zuckerberg a annoncé le 15novembre2010 que Facebook allait désormais utiliser HBase
en remplacement de Cassandra [W7].
Parmi les points forts de Hbase, nous trouvons ; son utilisation pour le Big Data, sa solidité
de la conception et excellente tolérance au partitionnement. La propriété ACID est garantie
sur une ligne (c'est-à-dire plusieurs familles de colonnes) depuis HBase 0.92 [W6].
III.3. 2. Architecture de HBASE
Contrairement au SGBD orienté ligne (SGBD relationnel), les données sont stockées
sous forme de colonne. On retrouve deux types de composants pour HBase : le composant
maître appelé «HMaster», qui contient le schéma des tables de données, et les nœuds esclaves
appelés «Region Server», qui gèrent des sous-ensembles de tables, appelés « Region ».

40
HBase est généralement utilisé sur un ensemble de machines, ou cluster, et utilise le système
de fichier HDFS. Les données des tables sont stockées sur les nœuds « DataNode» (HDFS) par
les nœuds de type « Region Server »(HBASE).
La Figure III.6 présente le fonctionnement général d'HBase. Les tables sont stockées en
orientation par colonne. Chaque table est constituée d'un ensemble de familles de colonnes
(regroupements logiques de colonnes). Sur chaque famille de colonnes il est possible d'ajouter
des colonnes. Les lignes des tables sont partitionnées en plusieurs régions. Lors de la création
d'une table, une seule région est créée, elle est ensuite automatiquement divisée en sous-
parties lorsque sa taille atteint un seuil limite.
Le rôle du master est la gestion des régions. Zookeeper est un outil permettant de coordonner
des services distribués, c'est lui qui permettra de faire le lien entre le master et le système de
fichier distribué HDFS.
Figure III.6. Schéma de HBASE.

41
III.4. MONGODB
III.4.1. Présentation de MongoDB
MongoDB est une base de données orientée documents open-source qui fournit de
hautes performances, haute disponibilité, et une scalabilité automatique [15]. Développé
depuis 2007 par 10gen (une société de logiciel), MongoDB est un système de gestion de base
de données orientée document. Ecrit en C++ et distribué sous licence AGPL (licence libre), elle
est très adaptée aux applications Web. MongoDB a été adoptée par plusieurs grands noms de
l’informatique, tels que Foursquare, SAP, ou bien même GitHub [5].
MongoDB utilise des fichiers au format BSON, un dérivé du JSON. Comparé à ce dernier, le
BSON a été pensé pour faciliter le scan des données. Un enregistrement dans MongoDB est
un document, qui est une structure de données composée de paires de champs et de valeur.
Les valeurs des champs peuvent inclure d'autres documents, des tableaux et des tableaux de
documents [15].
Fonctionnant comme une architecture distribuée centralisée, il réplique les données sur
plusieurs serveurs avec le principe de maître-esclave, permettant ainsi une plus grande
tolérance aux pannes. La répartition et la duplication de document est faite de sorte que les
documents les plus demandés soient sur le même serveur et que celui-ci soit dupliqué un
nombre de fois suffisant [15].
Par sa simplicité d’utilisation du point de vue de développement client, ainsi que ces
performances remarquables, MongoDB est l’une de base de données orientées document la
plus utilisé [5].
III.4.2. Modèle de données
Le modèle de données de MongoDB est de type orienté documents. Un document,
l'unité basique de MongoDB, est un ensemble ordonné de paires clé-valeur. Il est identifié par
son nom.
Un ensemble de documents (et peut donc être vu comme une table SQL) forment ce que nous
appelons une collection. Les documents d'une collection peuvent avoir des formes très
différentes. MongoDB ne pose aucune restriction quant aux documents contenus dans une
même collection. A la différence d'une table SQL, le nombre de champs des documents d'une
même collection peut varier d'un document à l'autre.

42
Une base de données MongoDB est un conteneur pour les collections (tout comme une base
dedonnées SQL contient des tables) avec ses propres permissions [13].
III.4.3. Architecture
Il existe quatre différents modes de fonctionnement pour MongoDB [14]:
- Single : Le mode Single sert à faire fonctionner une base de données sur un seul
serveur.
- Replication Master / Slave : Dans Le mode Master/Slave ; le serveur fonctionne en
tant que maître et s'occupe des demandes des clients. En plus il s'occupe de répliquer
les données sur le serveur esclave de façon asynchrone. L'esclave est présent pour
prendre la place du maître si ce dernier se tombe en panne. L'avantage premier de
cette structure permet de garantir une forte cohérence des données, car seul le maître
s'occupe des clients. Aucune opération n'est faite sur l'esclave, hormis quand le maître
envoie les mise à jours [14].
- Replica Set : (Voir Figure III.7) Le Replica Sets fonctionne avec plusieurs nœuds
possédant chacun la totalité des données, de la même manière qu'un réplica. Ces
différents nœuds vont alors élire un nœud primaire, qui peut s'apparenter à un maître.
Il faut qu'un nœud obtienne la majorité absolue afin d'être élu. Dans le cas où un nœud
n'obtiendrait pas la majorité, le processus de vote recommencerait à zéro. De plus, une
priorité peut être donnée à chaque nœud afin de lui donner plus de poids lors de
l'élection. Un serveur arbitre peut être inséré dans le système. Ce dernier n'aura
aucune donnée mais participera aux élections afin de pouvoir garantir la majorité
absolue [14].

43
- Sharding : Le Sharding est une surcouche qui est basée sur du Master / Slave ou du
Replica Sets.
Les Shards : Ce sont un groupe de serveurs en mode Master / Slave ou Réplica
Sets.
Les mongos : Ce sont des serveurs qui savent quelles données se trouvent dans
quel Shard et leur donnent des ordres (lecture, écriture).
Les Config Servers : Ils connaissent l'emplacement de chaque donnée et en
informent les mongos. De plus, ils organisent la structure des données entre les
Shards.
Le Sharding sert à partager les données entre plusieurs Shard, chaque Shard devant
stocker une partie des données [14].
III.4.4. Le composant Mapreduce
Dans une opération de MapReduce, MongoDB applique la phase de map pour chaque
document d'entrée (les documents de la collection qui correspondent à la condition de
requête). La fonction map retourne des paires clé-valeur. Pour les clés qui ont plusieurs
valeurs, MongoDB applique la phase Reduce, qui recueille et condense les données agrégées.
MongoDB stocke ensuite les résultats dans une collection. En option, la sortie de la fonction
reduce peut passer à travers une fonction de finalisation traitement des résultats.
Toutes les fonctions de Mapreduce dans MongoDB sont des scripts Java qui sont exécutés
dans le processus de MongoDB. Les opérations Mapreduce prennent les documents d'une
unique collection comme entrée, et peuvent effectuer un tri arbitraire et de limitation avant de
commencer l'étape map. Mapreduce peut retourner les résultats d'une opération sous forme
d’un document, ou peut écrire les résultats dans des collections. Les collections d'entrée et de
la sortie peuvent être fragmentées.
En résumé, les opérations de MapReduce utilisent des fonctions JavaScript pour l’étape map,
et associe les valeurs à une clé. Si une clé a de multiples valeurs mappées à elle, l'opération
reduce réduit les valeurs de la clé à un seul objet. L'utilisation de fonctions JavaScript permet
la flexibilité des opérations Mapreduce [W8].

44
III.4.5. Réponse au CAP
MongoDB, de par son architecture dans un système distribué, et qui dans chaque mode utilise
toujours un nœud maître, a tendance à privilégier l'intégrité par rapport à la disponibilité [14].
MongoDB se différencie des bases de données relationnelles avec sa récupération automatique
d'erreurs dans le cas où un serveur maître viendrait à être indisponible, via le système
d'élection où les esclaves vont s'élire entre eux. Elle permet également de gérer des
transactions en deux phases et permet de revenir en arrière en cas d'erreur afin de garantir
l'isolation des données. De plus, de nombreux CMS (Content Management System) ont
également fait des portages sur MongoDB, car cette dernière se prête bien aux applications
Web [15].
III.5. YCSB : Le Benchmark Yahoo
Yahoo propose un outil très puisant (YCSB : Yahoo ! Cloud Serving Benchmark) qui se
présente comme une nouvelle méthodologie de bancs d'essais (benchmark en anglais) pour
les bases de données NoSQL sur Cloud.
YCSB est un excellent outil pour comparer les performances SGBD NoSQL. Il supporte
l’exécution des tests de chargement en parallèle des variables (benchmark), pour évaluer
l’insertion, la mise à jour, et la suppression des enregistrements.
Dans chaque test on peut configurer le nombre d'enregistrements à charger, le nombre
d’opérations à effectuer, et la proportion de lecture et d'écriture. Il est donc facile à utiliser
pour tester différents scénarios de charge d’enregistrements et d’opérations.
Les tests utilisent des charges de travail (Workload ) avec des paramètres de de référence
différents pour chaque Workload. Par exemple :
● Workload A: 50% de lectures, 50% de mises à jour.
● Workload B: 95% de lectures, 5% des mises à jour.
● Workload C: 100% de lectures.
● Workload F: simule read-modify-write.
● Workload D: insère des enregistrements, avec des lectures des données récemment insérées.
● Workload E: insère des enregistrements, et interroge les plages d'enregistrements.
Chaque Workload effectue généralement 1000 opérations et mesure la latence moyenne par
type d'opération, ainsi que le débit total de toutes les opérations. Ces Workload peuvent être
modifié et personnalisé suivant la nature des résultats attendues des tests.

45
III.6. Conclusion
Dans ce chapitre nous avons présenté les outils utilisés dans la partie implémentation et
expérimentation citée dans le chapitre IV. En l’occurrence, Hadoop, HBASE, MongoDB, et
YCSB.
Nous avons présenté l’architecture, les caractéristiques techniques et les composants de
chaque système. L’objectif était de donner aux lecteurs une idée sur ces outils, leur domaine
d’utilisation, et leur mode de fonctionnent ; afin de leur permettre le suivi et la compréhension
le fond de notre travail qui consiste à comparer les performances des systèmes SGBD NoSQL :
HBASE et MongoDB.
La comparaison de L’évaluation de performance l’analyse de résultat est présentée dans le
chapitre IV.

46
Chapitre IV.
IMPLEMENTATION ET
EXPERIMENTATION

47
IV.1. Introduction
Ce chapitre est consacré aux étapes d’installation des composants Hadoop, HBASE et
MongoDB, et se termine avec une analyse des résultats obtenus à partir des tests, afin
d’arriver à une évaluation globale de performances.
Dans la première partie, vous trouverez les étapes d’installation de Hadoop, HBASE et
MongoDB, et l’outil de Benchmarking YCSB.
La deuxième partie est consacrée à l’analyse des résultats obtenus à partir de nos
expérimentations dans le cas d’une architecture Single Node.
Pour le second cas - l’architecture distribuée sur un Cloud Computing- nous avons fait une
analyse à partir d’une étude publiée et réalisée sur la base de tests effectués dans cet
environnement.
L’évaluation des performances va se porter sur deux niveaux :
1- Niveau 1 : temps d’exécution : il consiste à mesurer le temps d’exécution des
demandes lorsqu'une base de données est en charge (Workloads). La lenteur
d’exécution des demandes est fortement liée au débit du système SGBD NoSQL et
reste un obstacle pour augmenter la performance.
2- Niveau 2 : évolutivité: Le plus grand indice de vente chez les fournisseurs Cloud est
leur capacité à ajouter de nouveaux serveurs (nœuds) en cas de besoin. Le but est de
savoir l’impact d’évolutivité sur les performances des SGBD NoSQL.
IV.2. Première partie
IV.2.1. Installation de Hadoop, HBASE, MongoDB et YCSB
IV.2.1.1.Configuration
PC portable, HP Probook 4740s ;
Processeur : Intel Core i5-2450M [email protected]
Type OS : 64 Bits
RAM : 6 Go
Disque : 732 Go

48
Système d’exploitation : Ubuntu 14.10
Hadoop 1.0.4
HBASE 0.94.8
MongoDB 2.6.7
YCSB 0.1.4
IV.2.1.2. Installation d’Hadoop en mode Single Node
Dans ce chapitre, nous allons montrer l’installation d’un cluster Hadoop Single-Node version
1.0.4 sur Ubuntu 14.10 LTS.
L’installation de Hadoop-1.0.4 est réalisé à en suivant les étapes suivantes :
1- Installation de JAVA.
Le composant java est un outil indispensable pour l’exécution des jobs Hadoop écrits sous
forme de javascript. Nous commençons par une mise à jour du système Ubuntu.
$ sudo apt-get update
Ensuite, nous avons installé la version récente de java à l’aide de la commande :
$ sudo apt-get install default-jdk
Et pour vérifier la version de java :
$ java -version
java version "1.7.0_65"
OpenJDKRuntimeEnvironment (IcedTea 2.5.3) (7u71-2.5.3-0ubuntu1)
OpenJDK 64-Bit Server VM (build 24.65-b04, mixed mode)
Initialement ; les utilisateurs d’Hadoop doivent être définis. Afin de leurs attribuer les
permissions d’utilisation de Hadoop.
Pour cela, nous devons créer un groupe d’utilisateurs avec tous les droits sur Hadoop.
$ sudo addgroup hadoop
$ sudo adduser --ingroup hadoop hduser
Hduser est l’utilisateur crée dans notre cas pour gérer Hadoop.
La gestion des droits est très stricte dans les systèmes Linux. A cet effet ; la création d’une clé
SSH pour notre utilisateur hduser est obligatoire.

49
Création est installation des certificats SSH :
Hadoop nécessite un accès SSH pour gérer ses nœuds, c’est à dire les machines distantes ainsi
que notre machine locale.
Pour notre configuration à un nœud unique (Single Node) , nous avons donc besoin de
configurer l'accès SSH à localhost :
acef@pcubuntu01:~$ su - hduser
hduser@pcubuntu01:~$ ssh-keygen -t rsa -P ""
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hduser/.ssh/id_rsa):
Created directory '/home/hduser/.ssh'.
Your identification has been saved in /home/hduser/.ssh/id_rsa.
Your public key has been saved in /home/hduser/.ssh/id_rsa.pub.
The key fingerprint is:
9b:82:ea:58:b4:e0:35:d7:ff:19:66:a6:ef:ae:0e:d2 hduser@pcubuntu01
The key's randomart image is:
……..
Afin que Hadoop peut utiliser SSH sans demander un mot de passe à chaque accès ; nous
avons besoin d’ajouter la clé nouvellement créée à la liste des clés autorisées. Pour cela nous
devons taper la commande suivante :
hduser@pcubuntu01:~$ cat $HOME/.ssh/id_rsa.pub >>
$HOME/.ssh/authorized_keys
Nous pouvons vérifier si SSH fonctionne:
hduser@pcubuntu01:~$ ssh localhost
The authenticity of host 'localhost (::1)' can't be established.
RSA key fingerprint is
d7:87:25:47:ae:02:00:eb:1d:75:4f:bb:44:f9:36:26.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'localhost' (RSA) to the list of known
hosts.
Pour installer Hadoop-1.0.4, nous l’avons téléchargé à partir du site Apache. Après l’extraction, le dossier hadoop est déplacé vers /usr/local.
$ cd /usr/local
$ sudo tar xzf hadoop-1.0.4.tar.gz
$ sudo mv hadoop-1.0.3 hadoop
$ sudo chown -R hduser:hadoop hadoop
Réglage des fichiers de paramètres
Les fichiers suivants devront être modifiés pour terminer la configuration d’Hadoop:

50
1. ~/.bashrc
2. /usr/local/hadoop/etc/hadoop/hadoop-env.sh
3. /usr/local/hadoop/etc/hadoop/core-site.xml
4. /usr/local/hadoop/etc/hadoop/mapred-site.xml.template
5. /usr/local/hadoop/etc/hadoop/hdfs-site.xml
1. ~/.bashrc:
Avant de modifier le fichier .bashrc dans notre répertoire personnel, nous devons trouver le
chemin où Java a été installée pour définir la variable d'environnement JAVA_HOME en
utilisant la commande suivante:
$ update-alternatives --config java
There isonly one alternative in link group java (providing
/usr/bin/java): /usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java
Nothing to configure.
Maintenant, nous pouvons ajouter les lignes suivantes à la fin de ~ / .bashrc
# Set Hadoop-related environment variables
export HADOOP_HOME=/usr/local/hadoop
# Set JAVA_HOME (we will also configure JAVA_HOME directly for Hadoop
later on)
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
# Some convenient aliases and functions for running Hadoop-related
commands
unalias fs &> /dev/null
alias fs="hadoop fs"
unalias hls &> /dev/null
alias hls="fs -ls"
# If you have LZO compression enabled in your Hadoop cluster and
# compress job outputs with LZOP (not covered in this tutorial):
# Conveniently inspect an LZOP compressed file from the command
# line; run via:
#
# $ lzohead /hdfs/path/to/lzop/compressed/file.lzo
#
# Requires installed 'lzop' command.
#
lzohead () {
hadoop fs -cat $1 | lzop -dc | head -1000 | less
}
# Add Hadoop bin/ directory to PATH
export PATH=$PATH:$HADOOP_HOME/bin
2. /usr/local/hadoop/etc/hadoop/hadoop-env.sh
Nous devons définir JAVA_HOME en modifiant le fichier hadoop-env.sh :

51
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
L’ajout de la déclaration ci-dessus dans le fichier hadoop-env.sh assure que la valeur de la
variable JAVA_HOME sera disponible pour Hadoop chaque fois qu'il est mis en marche.
3. /usr/local/hadoop/etc/hadoop/core-site.xml:
Le fichier /usr/local/hadoop/etc/hadoop/core-site.xml contient les propriétés de
configuration utilisées par Hadoop au démarrage.
Premièrement nous devons créer un dossier de travail pour Hadoop.
$ sudo mkdir -p /app/hadoop/tmp
$ sudo chown hduser:hadoop /app/hadoop/tmp
# ...and if you want to tighten up security, chmod from 755 to 750...
$ sudo chmod 750 /app/hadoop/tmp
Ensuite il faut modifier le fichier /usr/local/hadoop/etc/hadoop/core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/app/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:54310</value>
<description>The name of the default file system. A URI whose
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri's authority is used
to
determine the host, port, etc. for a filesystem.</description>
</property>
4. /usr/local/hadoop/etc/hadoop/mapred-site.xml
Le fichier mapred-site.xml est utilisé pour spécifier dans quel cadre est utilisée MapReduce.
Nous devons entrer le contenu suivants dans le bloc <configuration></configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:54311</value>

52
<description>The host and port that the MapReduce job tracker runs
at. If "local", then jobs are run in-process as a single map
and reduce task.
</description>
</property>
5. /usr/local/hadoop/etc/hadoop/hdfs-site.xml
Le fichier /usr/local/hadoop/etc/hadoop/hdfs-site.xml doit être configuré pour chaque hôte
du cluster qui va l’utiliser. Il est utilisé pour spécifier les répertoires qui seront utilisés comme
NameNode et DataNode sur cette hôte.
Ouvrez le fichier et entrez le contenu suivant entre <configuration></ configuration> :
<property>
<name>dfs.replication</name>
<value>1</value>
<description>Default block replication.
The actual number of replications can be specified when the file is
created.
The default is used if replication is not specified in create time.
</description>
</property>
Formater le nouveau système de fichier HDFS pour Hadoop :
hduser@pcubuntu01:~$ /usr/local/hadoop/bin/hadoop namenode -format
L’écran suivant s’affiche :
.../hadoop-hduser/dfs/name has been successfully formatted.
************************************************************
SHUTDOWN_MSG: Shutting down NameNode at ubuntu/127.0.1.1
************************************************************/
6- Lancement d’Hadoop
Maintenant il est temps de démarrer le cluster Hadoop Single-Node nouvellement installé.
Nous pouvons lancer (start-dfs.sh et start-yarn.sh) ou start-all.sh.
hduser@pcubuntu01:~$ /usr/local/hadoop/bin/start-all.sh
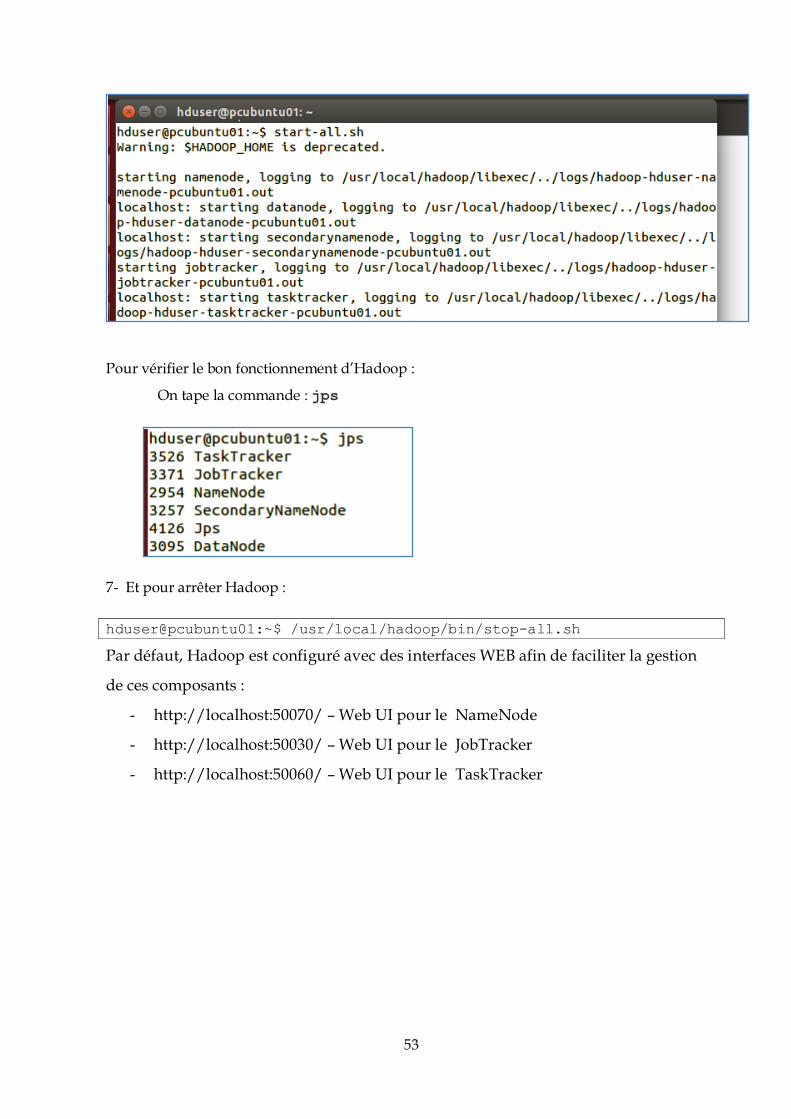
53
Pour vérifier le bon fonctionnement d’Hadoop :
On tape la commande : jps
7- Et pour arrêter Hadoop :
hduser@pcubuntu01:~$ /usr/local/hadoop/bin/stop-all.sh
Par défaut, Hadoop est configuré avec des interfaces WEB afin de faciliter la gestion
de ces composants :
- http://localhost:50070/ – Web UI pour le NameNode
- http://localhost:50030/ – Web UI pour le JobTracker
- http://localhost:50060/ – Web UI pour le TaskTracker
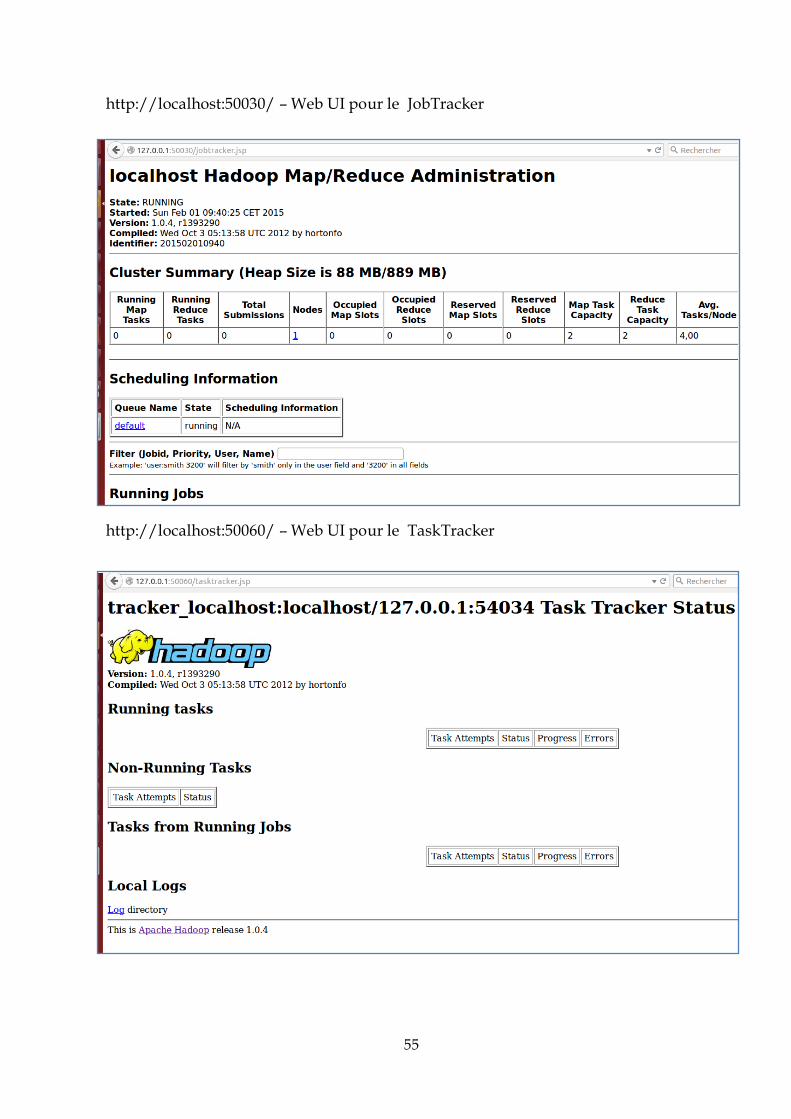
55
http://localhost:50030/ – Web UI pour le JobTracker
http://localhost:50060/ – Web UI pour le TaskTracker

56
IV.2.1.3. Installation de HBASE
L’installation de HBASE est très facile à réaliser. Il faut choisir une version stable
conforme à la configuration disponible.
Les étapes à suivre pour effectuer l’installation :
1- Télécharger HBASE, version stable, depuis le site :
http://www.apache.org/dyn/closer.cgi/hbase/.
2- Extraire le fichier téléchargé dans le chemin /usr/local
$ cd /usr/local
$ sudo tar xzf hbase-0.90.4.tar.gz
$ sudo mv hbase-0.90.4 hbase
$ sudo chown -R hduser:hadoop hbase
3- Modifier le fichier ~/.bashrc en ajoutant les lignes :
# Set Hadoop-related environment variables
export HADOOP_HOME=/usr/local/hadoop
export HBASE_HOME=/usr/local/hbase
# Add Hadoop bin/ directory to PATH
export PATH=$PATH:$HADOOP_HOME/bin:$HBASE_HOME/bin
4- Modifier le fichier /usr/local/hbase/conf/hbase-site.xml
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:54310/hbase</value>
<description>The directory shared by RegionServers.
</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>The replication count for HLog and HFile
storage. Should not be greater
than HDFS datanode count.
</description>
</property>
</configuration>
5- Remarque : Il faut modifier le fichiers /etc/hosts pour éviter des erreurs de
fonctionnement da HBASE :
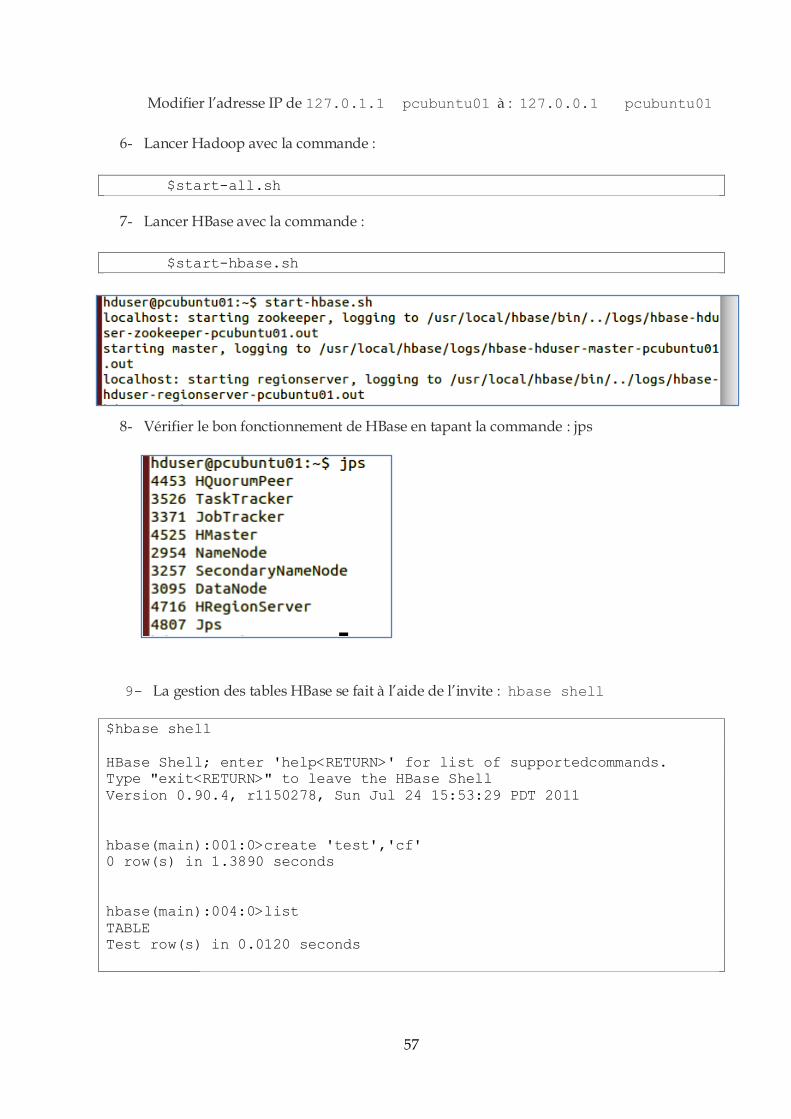
57
Modifier l’adresse IP de 127.0.1.1 pcubuntu01 à : 127.0.0.1 pcubuntu01
6- Lancer Hadoop avec la commande :
$start-all.sh
7- Lancer HBase avec la commande :
$start-hbase.sh
8- Vérifier le bon fonctionnement de HBase en tapant la commande : jps
9- La gestion des tables HBase se fait à l’aide de l’invite : hbase shell
$hbase shell
HBase Shell; enter 'help<RETURN>' for list of supportedcommands.
Type "exit<RETURN>" to leave the HBase Shell
Version 0.90.4, r1150278, Sun Jul 24 15:53:29 PDT 2011
hbase(main):001:0>create 'test','cf'
0 row(s) in 1.3890 seconds
hbase(main):004:0>list
TABLE
Test row(s) in 0.0120 seconds
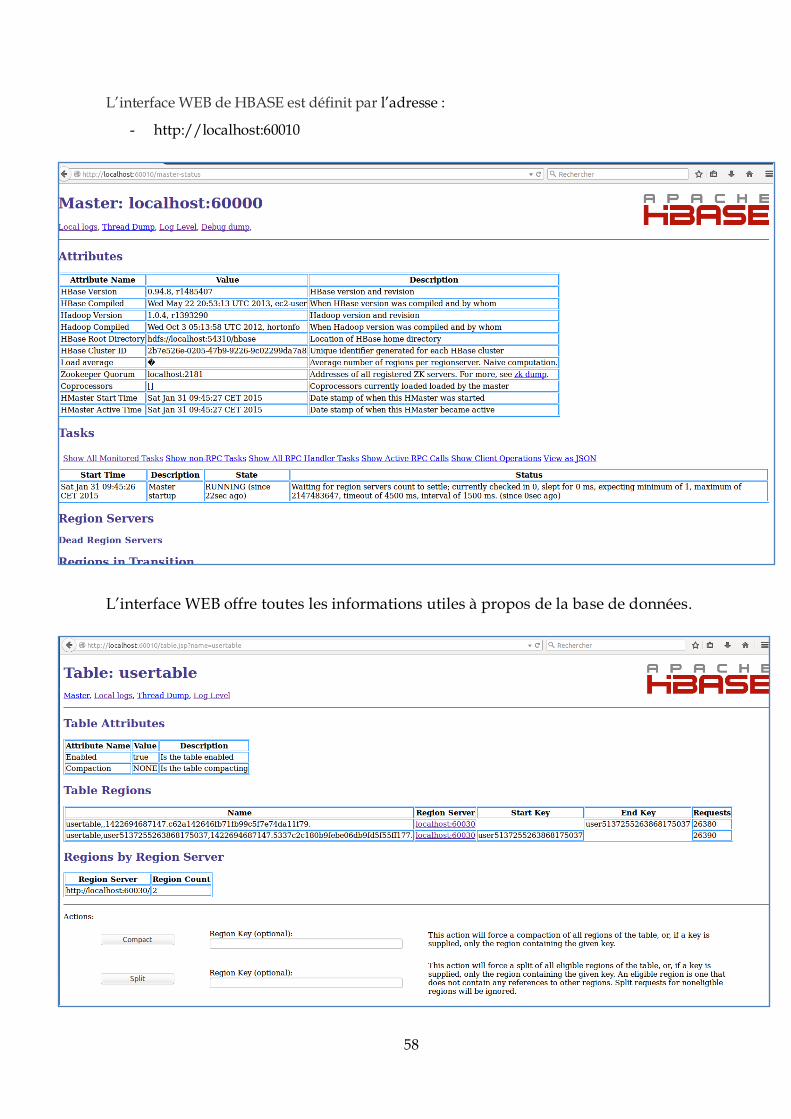
58
L’interface WEB de HBASE est définit par l’adresse :
- http://localhost:60010
L’interface WEB offre toutes les informations utiles à propos de la base de données.

59
IV.2.1.4. Installation de MongoDB
Les étapes d’installation figurent dans la page WEB :
http://docs.mongodb.org/manual/tutorial/install-mongodb-on-linux/
L’installation dans le cas d’un système Linux 64 bits se résume dans les étapes suivantes :
1- Télécharger MongoDB :
curl -O http://downloads.mongodb.org/linux/mongodb-linux-x86_64-
2.6.7.tgz
2- Extraire le fichier téléchargé :
tar -zxvf mongodb-linux-x86_64-2.6.7.tgz
3- Copier le dossier mongodb-linux-x86_64-2.6.7 dans l’emplacement Mongodb :
mkdir -p mongodb
cp -R -n mongodb-linux-x86_64-2.6.7/ mongodb
4- Ajouter la ligne suivante au fichier ~/.bashrc
export PATH=/home/hduser/mongodb/bin:$PATH
5- Créer le dossier /data/db
mkdir -p /data/db
6- Lancer MongoDB avec la commande :
Mongod -rest
L’option –rest permet de lance l’interface WEB qui peut être obtenu par l’adresse :
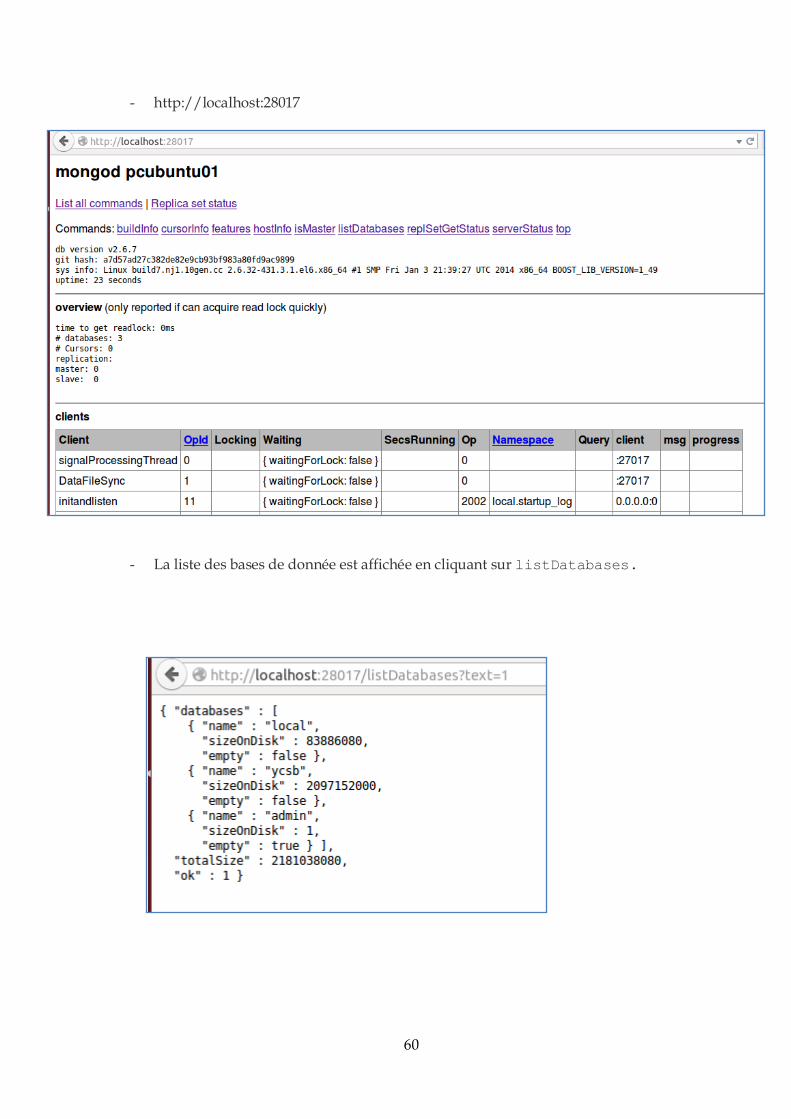
60
- http://localhost:28017
- La liste des bases de donnée est affichée en cliquant sur listDatabases.
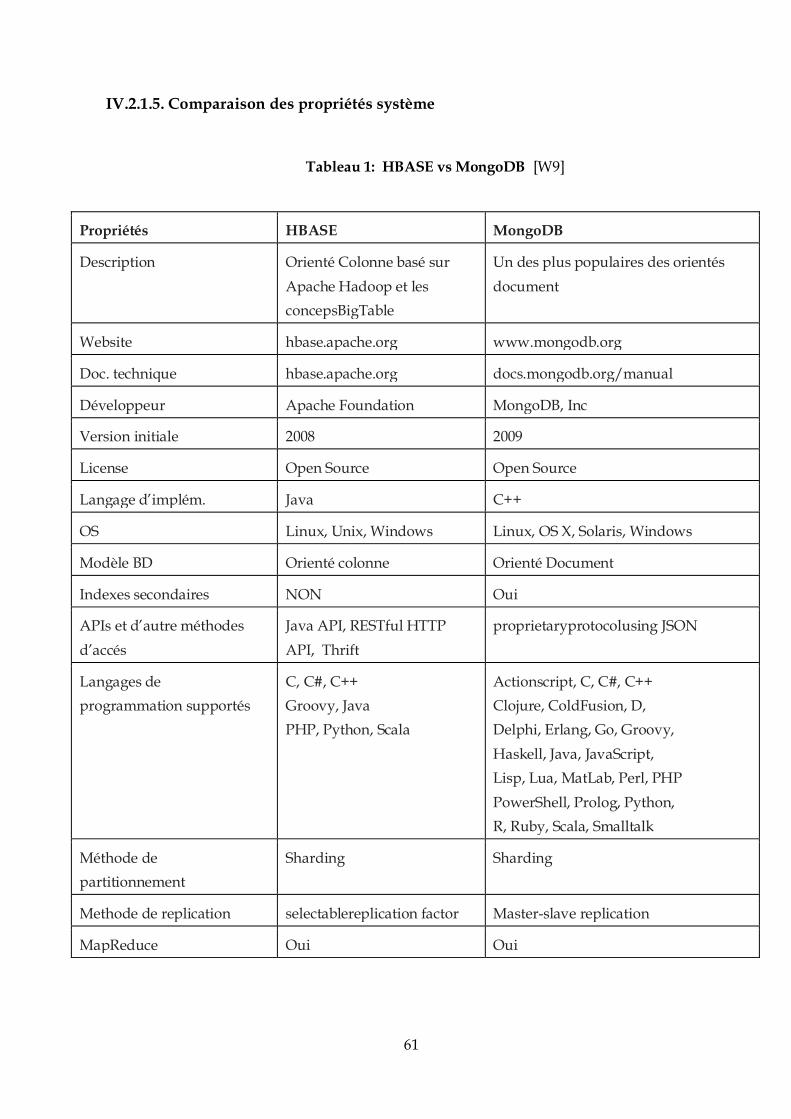
61
IV.2.1.5. Comparaison des propriétés système
Tableau 1: HBASE vs MongoDB [W9]
Propriétés HBASE MongoDB
Description Orienté Colonne basé sur
Apache Hadoop et les
concepsBigTable
Un des plus populaires des orientés
document
Website hbase.apache.org www.mongodb.org
Doc. technique hbase.apache.org docs.mongodb.org/manual
Développeur Apache Foundation MongoDB, Inc
Version initiale 2008 2009
License Open Source Open Source
Langage d’implém. Java C++
OS Linux, Unix, Windows Linux, OS X, Solaris, Windows
Modèle BD Orienté colonne Orienté Document
Indexes secondaires NON Oui
APIs et d’autre méthodes
d’accés
Java API, RESTful HTTP
API, Thrift
proprietaryprotocolusing JSON
Langages de
programmation supportés
C, C#, C++
Groovy, Java
PHP, Python, Scala
Actionscript, C, C#, C++
Clojure, ColdFusion, D,
Delphi, Erlang, Go, Groovy,
Haskell, Java, JavaScript,
Lisp, Lua, MatLab, Perl, PHP
PowerShell, Prolog, Python,
R, Ruby, Scala, Smalltalk
Méthode de
partitionnement
Sharding Sharding
Methode de replication selectablereplication factor Master-slave replication
MapReduce Oui Oui
62
IV.2.1.6. Installation de YCSB
1- Télécharger la source YCSB avec la commande :
~$ gitclone http://github.com/brianfrankcooper/YCSB.git
2- Accéder au dossier YCSB et compiler avec la commande :
/YCSB/ mvn clean package
3- Après la phase de compilation ; copier et extraire le fichier ycsb-0.1.4.tar.gz se trouvant
dans le dossier /YCSB/distribution/ vers un emplacement de votre choix
Exécution des tests avec l’outil YCSB.
Test de HBASE
- Pour tester HBase, nous commençons par la phase de chargement (Load process). Taper :
hduser@pcubuntu01:~/ycsb-0.1.4$ bin/ycsb load hbase -P
workloads/workloada -p columnfamily=f1 -p recordcount=600000 -s >
loadh.dat
Le message suivant s’affiche pour indiquer le temps d’exécution du chargement (Load
process).
Loading workload... Starting test. 0 sec: 0 operations; 10 sec: 131095 operations; 13108,19 current ops/sec; [INSERT AverageLatency(us)=68,84] 20 sec: 234099 operations; 10297,31 current ops/sec; [INSERT AverageLatency(us)=98,74] 30 sec: 369877 operations; 13577,8 current ops/sec; [INSERT AverageLatency(us)=72,27] 40 sec: 486927 operations; 11705 current ops/sec; [INSERT AverageLatency(us)=78,94] 50 sec: 561839 operations; 7490,45 current ops/sec; [INSERT AverageLatency(us)=138,5] 54 sec: 600000 operations; 8226,13 current ops/sec; [INSERT AverageLatency(us)=125,09]
- Pour l’exécution du Workload :
hduser@pcubuntu01:~/ycsb-0.1.4$ bin/ycsb run hbase -P workloads/workloada -p columnfamily=f1 -p recordcount=600000 -s > rha.datPour tester MongoDB avec YCSB :

63
- Le temps d’exécution des opérations est affiché dans l’écran :
Loading workload... Starting test. 0 sec: 0 operations; 2 sec: 1000 operations; 442,28 current ops/sec; [UPDATE AverageLatency(us)=87,59] [READ AverageLatency(us)=4199,08]
Test de MongoDB
- Pour tester MongoDB, nous commençons par Load process :
hduser@pcubuntu01:~/ycsb-0.1.4$ bin/ycsb load mongodb -P
workloads/workloada -p recordcount=600000 -s > loadm.da
- Le temps des opérations du chargement s’affiche à l’écran:
Loading workload...
Starting test.
0 sec: 0 operations;
10 sec: 35224 operations; 3517,12 current ops/sec; [INSERT
AverageLatency(us)=271,46]
20 sec: 69417 operations; 3417,59 current ops/sec; [INSERT
AverageLatency(us)=285,98]
30 sec: 103515 operations; 3409,46 current ops/sec; [INSERT
AverageLatency(us)=287,16]
40 sec: 134375 operations; 3086 current ops/sec; [INSERT
AverageLatency(us)=317,35]
…………………
110 sec: 341262 operations; 2663,43 current ops/sec; [INSERT
AverageLatency(us)=369,1]
120 sec: 374153 operations; 3289,1 current ops/sec; [INSERT
AverageLatency(us)=285,67]
130 sec: 405036 operations; 3087,99 current ops/sec; [INSERT
AverageLatency(us)=328,89]
140 sec: 436248 operations; 3121,2 current ops/sec; [INSERT
AverageLatency(us)=315,09]
150 sec: 467971 operations; 3171,98 current ops/sec; [INSERT
AverageLatency(us)=308,4]
160 sec: 495816 operations; 2784,5 current ops/sec; [INSERT
AverageLatency(us)=352,09]
170 sec: 520900 operations; 2508,15 current ops/sec; [INSERT
AverageLatency(us)=393]
180 sec: 554563 operations; 3366,3 current ops/sec; [INSERT
AverageLatency(us)=291,19]
190 sec: 586224 operations; 3165,78 current ops/sec; [INSERT
AverageLatency(us)=309,9]
194 sec: 600000 operations; 2944,85 current ops/sec; [INSERT
AverageLatency(us)=332,82]

64
- L’étape de l’exécution se lance après la commande :
hduser@pcubuntu01:~/ycsb-0.1.4$ bin/ycsb run mongodb -P
workloads/workloada -p recordcount=600000 -s > rma.dat
- Le résultat du test est le suivant :
Loading workload...
Starting test.
0 sec: 0 operations;
0 sec: 1000 operations; 1798,56 current ops/sec; [UPDATE
AverageLatency(us)=482,79] [READ AverageLatency(us)=279,77]
IV.3. Deuxième partie : Analyse des tests
IV.3.1. Introduction
Les objectifs ciblés dans ce chapitre sont les évaluations de performance de HBASE et
MongoDB qui sont analysés sur deux niveaux :
L’évaluation de performance dans une architecture nœud unique (Single Node).
Et l’évaluation de performance dans une architecture distribuée hébergée par un
environnement Cloud.
Dans le premier cas, nous avons réalisé nos expériences présentées dans ce chapitre sous
forme de test de scénarios (Benchmarks) en utilisant l’utilitaire YCSB. Ces tests sont exécutés
sur les bases de données HBASE et MongoDB.
Les résultats des tests sont notés et suivis par des explications et des commentaires.
Afin de renforcer la validation des résultats de nos expériences, nous avons pris comme cadre
de rapprochement les résultats publiés dans l’article « EXPERIMENTAL EVALUATION OF
NOSQL DATABASES » écrit par Veronika Abramova, Jorge Bernardino et Pedro Furtado
[16].
Les résultats obtenues par Veronika Abramova et son équipe dans leur article [16] sont en
global plus lentes par rapport à nos résultats. La configuration utilisée dans leur expérience
était: VM Ubuntu 32 bits 2 Go de RAM, hébergée dans un PC 32 bits Windows 7 avec 4 GO
RAM. Notre configuration était : Ubuntu 14.10, PC 64 Bits, i5 CORE, 6 GO RAM.

65
Pour le deuxième cas, celui de l’expérimentation dans un environnement distribué, et à cause
de la difficulté d’implémenter ce genre d’expériences, due au manque d’infrastructures Cloud
à notre niveau; nous nous somme limité uniquement sur les résultats publiés par DATASTAX
CORPORATION dans son livre blanc « Benchmarking Top NoSQLDatabases », publié en
février 2013 [17]. .
IV.3.2. Tests et analyse des résultats
IV.3.2.1. Première étude : Evaluation dans un Single Node Cluster
Initialisation
Nous avons commencé par initialiser l’outil YCSB avec 8 Workloads afin de rendre les
scénarios plus significatifs [16]:
• Workload A: Mise à jour lourde, se compose d'un rapport de 50% Read /50% Update ;
• Workload B: Lire Partiellement, Il consiste en un rapport de 95% Read /5% Update ;
• Workload C: Lecture seule, ce workload est 100% Read;
• Workload D: Ce Workload se compose de 95% Read /5% Insert ;
• Workload E: Se compose d'un rapport de 95% Scan /5% Insert ;
• Workload F: Ce workload se compose d'un rapport de 50% Read /50% Read-Modify-Write ;
• Workload G: Se compose d'un rapport de 5% Read /95% Update ;
• Workload H: Ce workload est composé de 100% Update.
Evaluation de performance
Dans ce paragraphe, nous présentons et analysons les résultats de chargement de 600000
enregistrements générés par YCSB. Nous présentons également le temps d'exécution des
Workloads enregistré pendant les opérations de lecture, écriture, et mises à jour.
Chargement de données (LoadProcess)
Nous commençons par l’étape de chargement des donnés (Load Process).
Les résultats obtenus après le lancement du Workload Load sont les suivants :
- Le journal de chargement généré par YCSB pour HBASE :

66
YCSB Client 0.1
Command line: -db com.yahoo.ycsb.db.HBaseClient -P
workloads/workloada -p columnfamily=f1 -p recordcount=600000 -s -load
[OVERALL], RunTime(ms), 54644.0
[OVERALL], Throughput(ops/sec), 10980.162506405095
[INSERT], Operations, 600000
[INSERT], AverageLatency(us), 88.99416833333333
[INSERT], MinLatency(us), 4
[INSERT], MaxLatency(us), 2639999
[INSERT], 95thPercentileLatency(ms), 0
[INSERT], 99thPercentileLatency(ms), 0
[INSERT], Return=0, 600000
[INSERT], 0, 599843
[INSERT], 1, 6
[INSERT], 2, 2
[INSERT], 999, 0
[INSERT], >1000, 10
- Le journal de chargement généré par YCSB pour MongoDB :
YCSB Client 0.1
Command line: -db com.yahoo.ycsb.db.MongoDbClient -P
workloads/workloada -p recordcount=600000 -s -load
new database url = localhost:27017/ycsb
mongo connection created with localhost:27017/ycsb
[OVERALL], RunTime(ms), 189957.0
[OVERALL], Throughput(ops/sec), 3158.6095800628564
[INSERT], Operations, 600000
[INSERT], AverageLatency(us), 310.31195
[INSERT], MinLatency(us), 65
[INSERT], MaxLatency(us), 2379463
[INSERT], 95thPercentileLatency(ms), 0
[INSERT], 99thPercentileLatency(ms), 0
[INSERT], Return=0, 600000
[INSERT], 0, 598502
[INSERT], 1, 132
[INSERT], 2, 66
[INSERT], 3, 7
[INSERT], 4, 3
[INSERT], 5, 2
[INSERT], 6, 0
…………
[INSERT], 997, 0
[INSERT], 998, 0
[INSERT], 999, 0
[INSERT], >1000, 5

67
Figure IV.1. Temps de chargement.
La Figure IV.1 montre les temps d'exécution pendant le chargement de 600000
enregistrements dans les deux bases de données. Nous avons constaté que durant le
chargement de 600000 enregistrements, le meilleurs temps d’insertion a été présenté par
HBASE avec un temps de chargement de seulement 54644,0 ms contre 189957,0 ms pour
MongoDB.
Cela signifie que HBASE était plus rapide que MongoDB pendant la phase de chargement. La
cause est le fait que HBASE ne nécessite pas de grande quantité de mémoire pendant
l’exécution des opérations de chargement initial. [16]
La figure suivante montre le résultat publié par Veronika Abramova et son équipe dans
l’article « EXPERIMENTAL EVALUATION OF NOSQL DATABASES ». [16] La différence de
performance entre les deux bases reste très proche de notre résultat. Dans la figure IV.1.1
HBASE était plus performant pendant le chargement.
0,0
20000,0
40000,0
60000,0
80000,0
100000,0
120000,0
140000,0
160000,0
180000,0
200000,0
MongoDB HBASE
Temps de chargement (ms)
SGBD NoSQL
Load process time (ms)
MongoDB 189957,0
HBASE 54644,0

68
Workload A (50%/50% de Read / Update )
- Le journal de l’exécution du Workload A par MongoDB :
YCSB Client 0.1
Command line: -db com.yahoo.ycsb.db.MongoDbClient -P
workloads/workloada -p recordcount=600000 -s -t
new database url = localhost:27017/ycsb
mongo connection created with localhost:27017/ycsb
[OVERALL], RunTime(ms), 533.0
[OVERALL], Throughput(ops/sec), 1876.172607879925
[UPDATE], Operations, 503
[UPDATE], AverageLatency(us), 398.9244532803181
[UPDATE], MinLatency(us), 207
[UPDATE], MaxLatency(us), 8803
[UPDATE], 95thPercentileLatency(ms), 0
[UPDATE], 99thPercentileLatency(ms), 1
[UPDATE], Return=0, 503
[UPDATE], 0, 496
[UPDATE], 1, 3
[UPDATE], 2, 0
…………….
……………
[READ], 999, 0
[READ], >1000, 0
- Le journal de l’exécution du Workload A par HBASE :
YCSB Client 0.1
Command line: -db com.yahoo.ycsb.db.HBaseClient -P
workloads/workloada -p columnfamily=f1 -p recordcount=600000 -s -t
[OVERALL], RunTime(ms), 2261.0
[OVERALL], Throughput(ops/sec), 442.2821760283061
[UPDATE], Operations, 492
[UPDATE], AverageLatency(us), 87.59349593495935
[UPDATE], MinLatency(us), 45
[UPDATE], MaxLatency(us), 358
[UPDATE], 95thPercentileLatency(ms), 0
[UPDATE], 99thPercentileLatency(ms), 0
[UPDATE], Return=0, 492
[UPDATE], 0, 492
[UPDATE], 1, 0
[UPDATE], 2, 0
[UPDATE], 3, 0
………..
[UPDATE], 999, 0
[UPDATE], >1000, 0
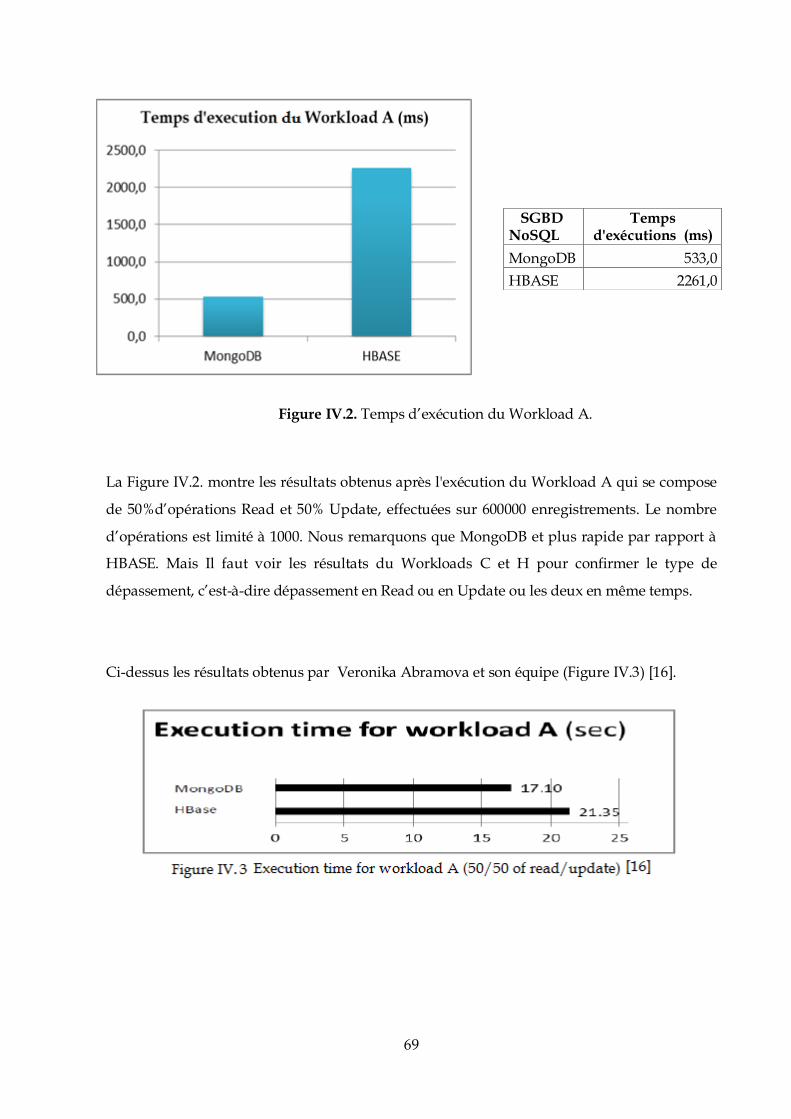
69
Figure IV.2. Temps d’exécution du Workload A.
La Figure IV.2. montre les résultats obtenus après l'exécution du Workload A qui se compose
de 50%d’opérations Read et 50% Update, effectuées sur 600000 enregistrements. Le nombre
d’opérations est limité à 1000. Nous remarquons que MongoDB et plus rapide par rapport à
HBASE. Mais Il faut voir les résultats du Workloads C et H pour confirmer le type de
dépassement, c’est-à-dire dépassement en Read ou en Update ou les deux en même temps.
Ci-dessus les résultats obtenus par Veronika Abramova et son équipe (Figure IV.3) [16].
SGBD NoSQL
Temps d'exécutions (ms)
MongoDB 533,0
HBASE 2261,0
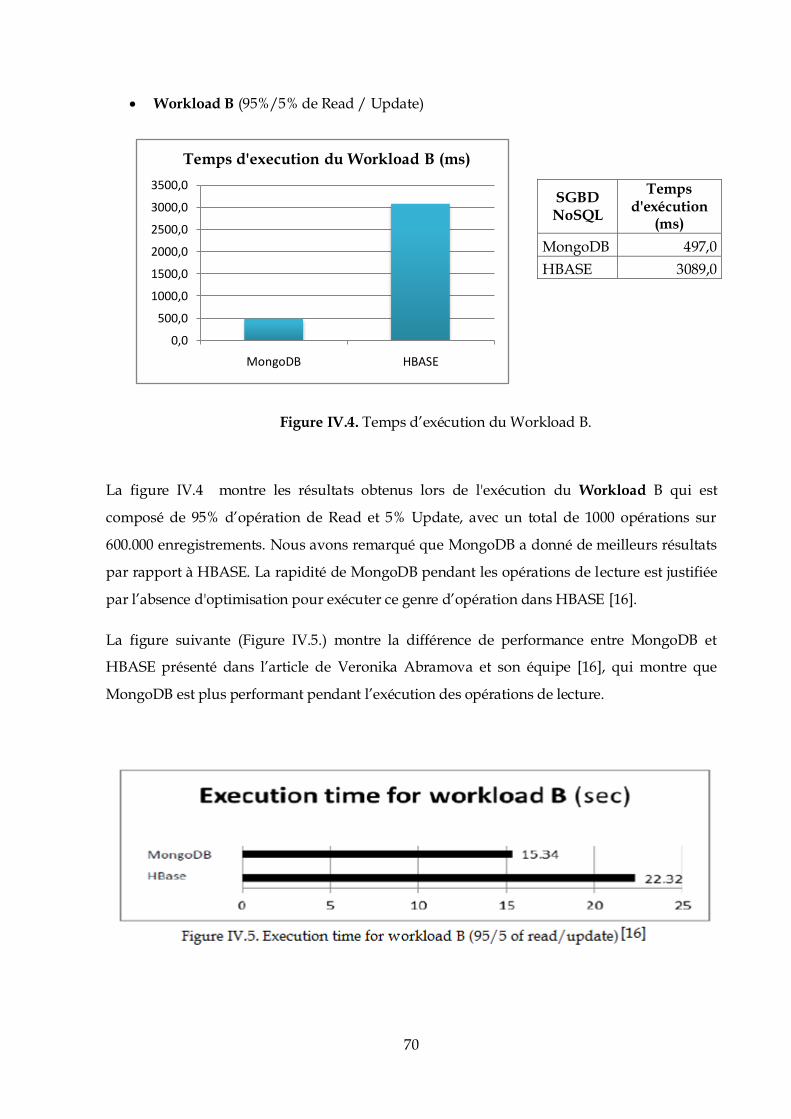
70
0,0
500,0
1000,0
1500,0
2000,0
2500,0
3000,0
3500,0
MongoDB HBASE
Temps d'execution du Workload B (ms)
Workload B (95%/5% de Read / Update)
Figure IV.4. Temps d’exécution du Workload B.
La figure IV.4 montre les résultats obtenus lors de l'exécution du Workload B qui est
composé de 95% d’opération de Read et 5% Update, avec un total de 1000 opérations sur
600.000 enregistrements. Nous avons remarqué que MongoDB a donné de meilleurs résultats
par rapport à HBASE. La rapidité de MongoDB pendant les opérations de lecture est justifiée
par l’absence d'optimisation pour exécuter ce genre d’opération dans HBASE [16].
La figure suivante (Figure IV.5.) montre la différence de performance entre MongoDB et
HBASE présenté dans l’article de Veronika Abramova et son équipe [16], qui montre que
MongoDB est plus performant pendant l’exécution des opérations de lecture.
SGBD NoSQL
Temps d'exécution
(ms)
MongoDB 497,0
HBASE 3089,0
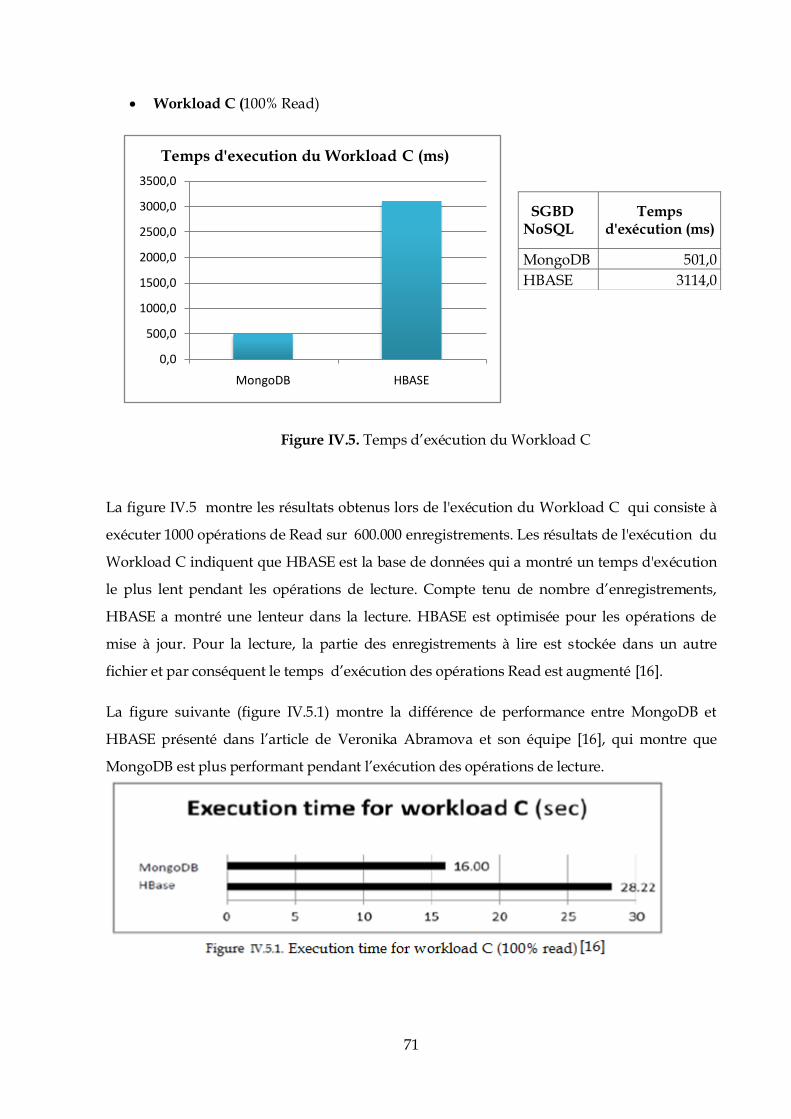
71
0,0
500,0
1000,0
1500,0
2000,0
2500,0
3000,0
3500,0
MongoDB HBASE
Temps d'execution du Workload C (ms)
Workload C (100% Read)
Figure IV.5. Temps d’exécution du Workload C
La figure IV.5 montre les résultats obtenus lors de l'exécution du Workload C qui consiste à
exécuter 1000 opérations de Read sur 600.000 enregistrements. Les résultats de l'exécution du
Workload C indiquent que HBASE est la base de données qui a montré un temps d'exécution
le plus lent pendant les opérations de lecture. Compte tenu de nombre d’enregistrements,
HBASE a montré une lenteur dans la lecture. HBASE est optimisée pour les opérations de
mise à jour. Pour la lecture, la partie des enregistrements à lire est stockée dans un autre
fichier et par conséquent le temps d’exécution des opérations Read est augmenté [16].
La figure suivante (figure IV.5.1) montre la différence de performance entre MongoDB et
HBASE présenté dans l’article de Veronika Abramova et son équipe [16], qui montre que
MongoDB est plus performant pendant l’exécution des opérations de lecture.
SGBD NoSQL
Temps d'exécution (ms)
MongoDB 501,0
HBASE 3114,0
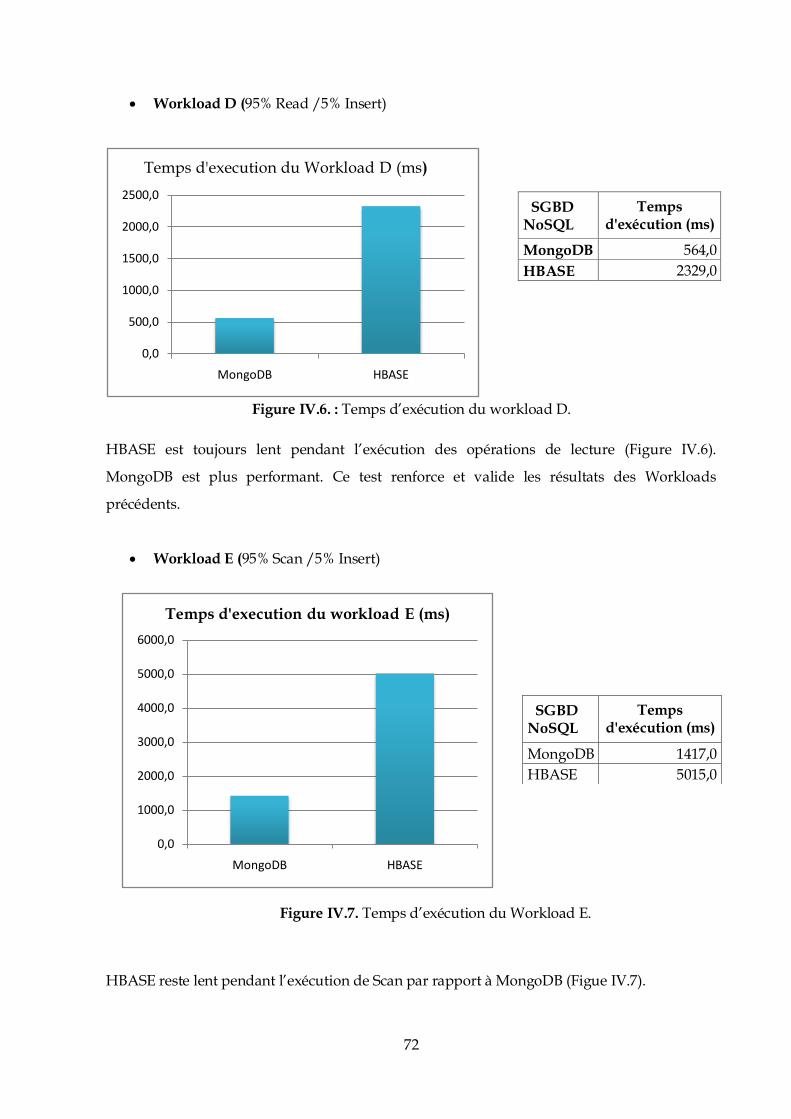
72
Workload D (95% Read /5% Insert)
Figure IV.6. : Temps d’exécution du workload D.
HBASE est toujours lent pendant l’exécution des opérations de lecture (Figure IV.6).
MongoDB est plus performant. Ce test renforce et valide les résultats des Workloads
précédents.
Workload E (95% Scan /5% Insert)
Figure IV.7. Temps d’exécution du Workload E.
HBASE reste lent pendant l’exécution de Scan par rapport à MongoDB (Figue IV.7).
SGBD NoSQL
Temps d'exécution (ms)
MongoDB 564,0
HBASE 2329,0
SGBD NoSQL
Temps d'exécution (ms)
MongoDB 1417,0
HBASE 5015,0
0,0
500,0
1000,0
1500,0
2000,0
2500,0
MongoDB HBASE
Temps d'execution du Workload D (ms)
0,0
1000,0
2000,0
3000,0
4000,0
5000,0
6000,0
MongoDB HBASE
Temps d'execution du workload E (ms)

73
Workload F (50% Read /50% Read-Modify-Write )
Figure IV.8. Temps d’exécution de Workload F.
La Figure IV.8 montre les résultats obtenus après l'exécution du Workload F qui est Read/
Read-Modify-Write. 1000 opérations ont été exécutées sur 600000 enregistrements stockés.
Dans ce Workload les enregistrements sont lus en premier lieu, mis à jour après et ensuite
sauvegardés. Nous constatons que HBASE a montré une performance inférieure en raison de
ca difficulté de lecture par rapport à la mise à jour [16].
La figure suivante (figure IV.9) montre les résultats donnée par l’article [16].
SGBD NoSQL
Temps d'exécution
(ms)
MongoDB 716,0
HBASE 2615,0
0,0
500,0
1000,0
1500,0
2000,0
2500,0
3000,0
MongoDB HBASE
Temps d'execution de workload F (ms)
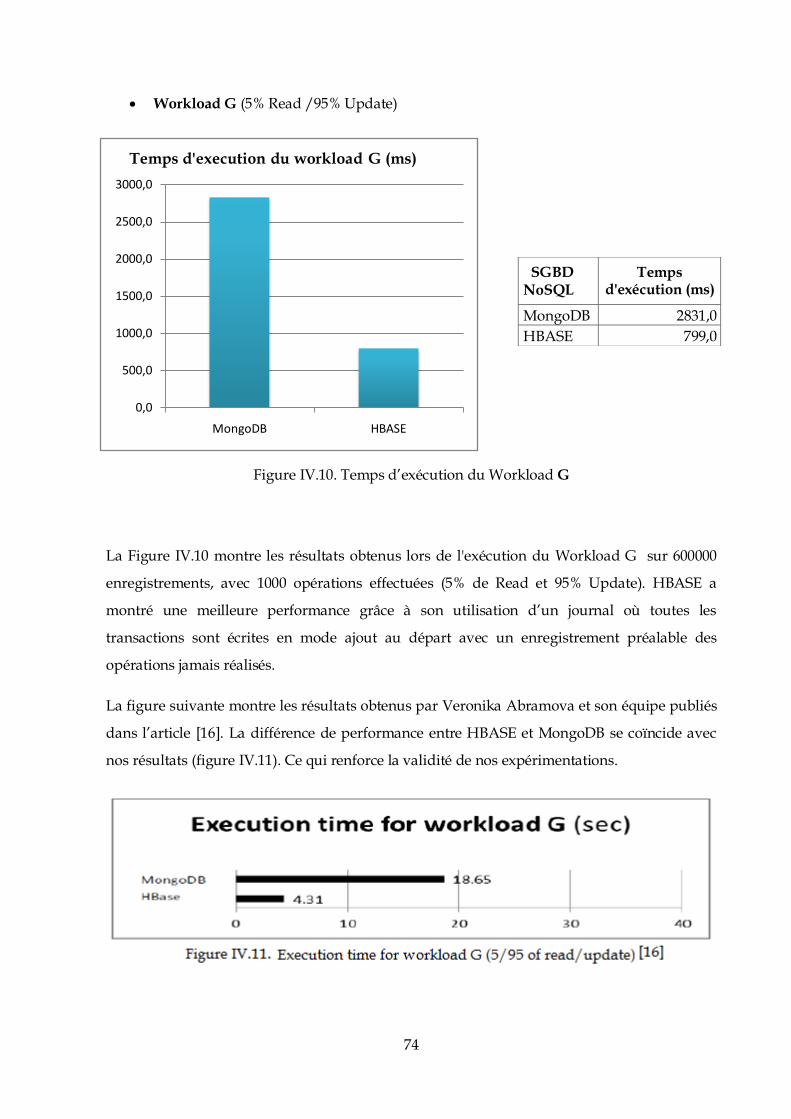
74
Workload G (5% Read /95% Update)
Figure IV.10. Temps d’exécution du Workload G
La Figure IV.10 montre les résultats obtenus lors de l'exécution du Workload G sur 600000
enregistrements, avec 1000 opérations effectuées (5% de Read et 95% Update). HBASE a
montré une meilleure performance grâce à son utilisation d’un journal où toutes les
transactions sont écrites en mode ajout au départ avec un enregistrement préalable des
opérations jamais réalisés.
La figure suivante montre les résultats obtenus par Veronika Abramova et son équipe publiés
dans l’article [16]. La différence de performance entre HBASE et MongoDB se coïncide avec
nos résultats (figure IV.11). Ce qui renforce la validité de nos expérimentations.
SGBD NoSQL
Temps d'exécution (ms)
MongoDB 2831,0
HBASE 799,0
0,0
500,0
1000,0
1500,0
2000,0
2500,0
3000,0
MongoDB HBASE
Temps d'execution du workload G (ms)
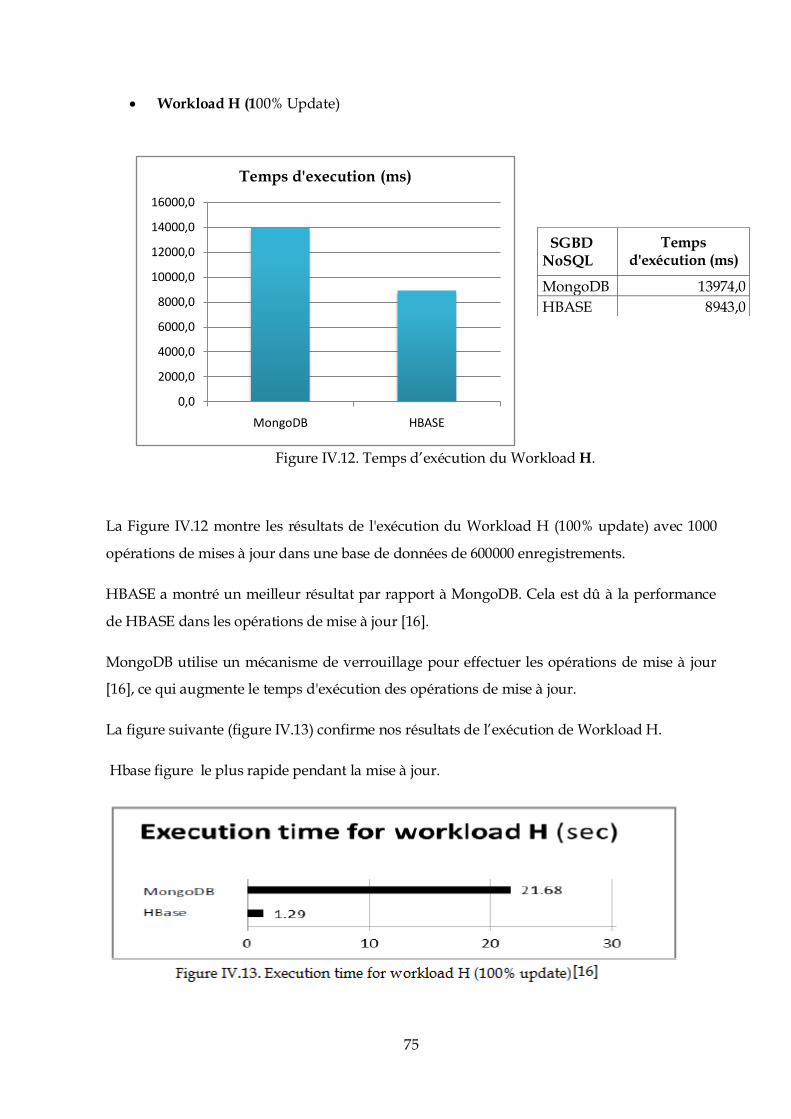
75
Workload H (100% Update)
Figure IV.12. Temps d’exécution du Workload H.
La Figure IV.12 montre les résultats de l'exécution du Workload H (100% update) avec 1000
opérations de mises à jour dans une base de données de 600000 enregistrements.
HBASE a montré un meilleur résultat par rapport à MongoDB. Cela est dû à la performance
de HBASE dans les opérations de mise à jour [16].
MongoDB utilise un mécanisme de verrouillage pour effectuer les opérations de mise à jour
[16], ce qui augmente le temps d'exécution des opérations de mise à jour.
La figure suivante (figure IV.13) confirme nos résultats de l’exécution de Workload H.
Hbase figure le plus rapide pendant la mise à jour.
SGBD NoSQL
Temps d'exécution (ms)
MongoDB 13974,0
HBASE 8943,0
0,0
2000,0
4000,0
6000,0
8000,0
10000,0
12000,0
14000,0
16000,0
MongoDB HBASE
Temps d'execution (ms)
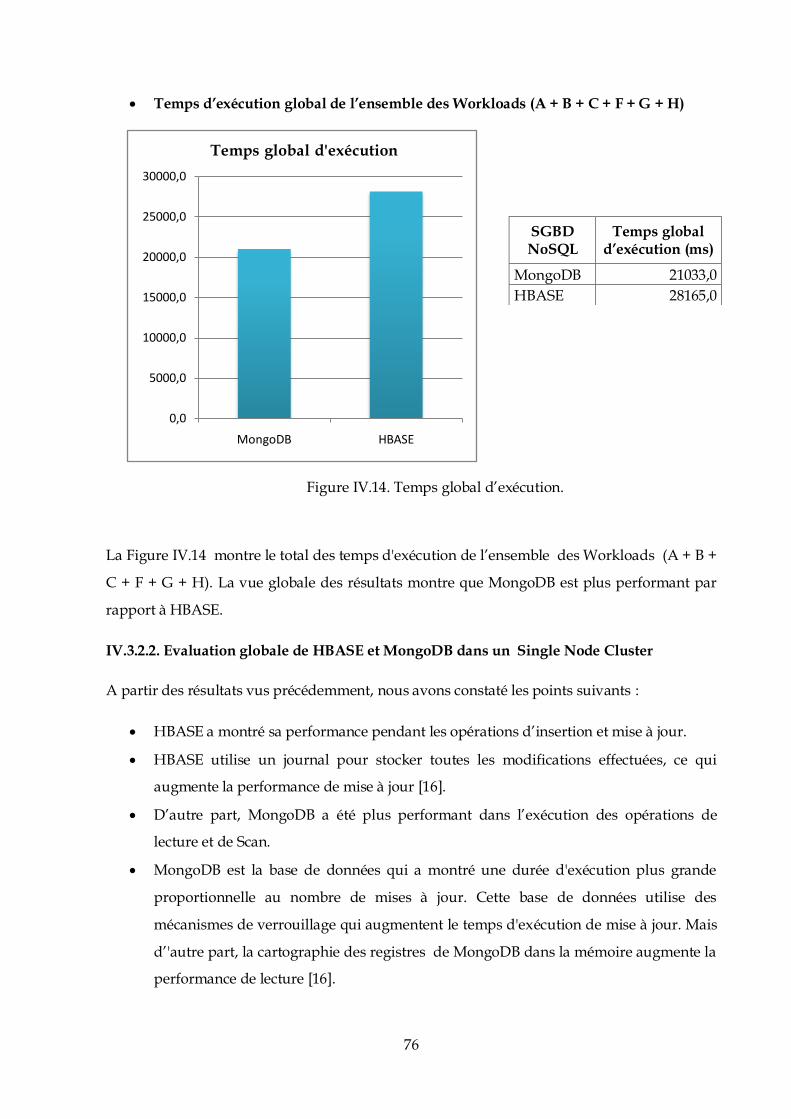
76
0,0
5000,0
10000,0
15000,0
20000,0
25000,0
30000,0
MongoDB HBASE
Temps global d'exécution
Temps d’exécution global de l’ensemble des Workloads (A + B + C + F + G + H)
Figure IV.14. Temps global d’exécution.
La Figure IV.14 montre le total des temps d'exécution de l’ensemble des Workloads (A + B +
C + F + G + H). La vue globale des résultats montre que MongoDB est plus performant par
rapport à HBASE.
IV.3.2.2. Evaluation globale de HBASE et MongoDB dans un Single Node Cluster
A partir des résultats vus précédemment, nous avons constaté les points suivants :
HBASE a montré sa performance pendant les opérations d’insertion et mise à jour.
HBASE utilise un journal pour stocker toutes les modifications effectuées, ce qui
augmente la performance de mise à jour [16].
D’autre part, MongoDB a été plus performant dans l’exécution des opérations de
lecture et de Scan.
MongoDB est la base de données qui a montré une durée d'exécution plus grande
proportionnelle au nombre de mises à jour. Cette base de données utilise des
mécanismes de verrouillage qui augmentent le temps d'exécution de mise à jour. Mais
d’'autre part, la cartographie des registres de MongoDB dans la mémoire augmente la
performance de lecture [16].
SGBD NoSQL
Temps global d’exécution (ms)
MongoDB 21033,0
HBASE 28165,0

77
IV.3.3. Deuxième cas : Environnement distribué (Cloud)
En plus de nos expérimentations sur les SGBD NoSQL dans un environnement
SingleNode Cluster, et afin d’arriver à une évaluation de performance significative, nous
avions besoin d’étudier les capacités de HBASE et MongoDB dans un environnement Cloud
caractérisé par un traitement de Big Data.
Le Cloud Computing est l’environnement dédié à l’exploitation des systèmes de gestion de
bases de données NoSQL basées sur l’architecture distribuée qui traitent de grandes masses
de données.
L’insuffisance des moyens techniques nous a poussé à chercher d’autres références ayants
une haute crédibilité scientifique relatives à notre sujet. Le livre blanc « Benchmarking Top
NoSQLDatabases » publié par DataStax en Février 2013 [17] fournit une profonde étude sur
l’évaluation de performance de plusieurs bases de données NoSQL.
Ce livre blanc est le fruit d’une étude menée par End Point Corporation, une société de conseil
et de base de données Open-source, pour le compte de DataStax. L’objectif était d’effectuer des
Benchmarks sur trois différentes SGBD NoSQL : Cassandra, HBASE et MongoD [17].
Le livre blanc « Benchmarking Top NoSQLDatabases » présente les résultats obtenues à partir
des tests de Benchmarking sur Cassendra, HBASE et MongoDB dans un environnement
Cloud. Les résultats sont publiés sous forme de tableaux de mesures avec des graphes.
Pour notre étude de cas, nous nous étions limités uniquement sur les résultats relatifs à
HBASE et MongoDB.
Configuration initiale
End Point a dirigé le test sur Amazon Web Services instances EC2 qui est un service Cloud. Et
pour plus d’exactitude, les tests ont été effectués trois fois différentes dans trois jours
différents. Chaque test est effectué dans une nouvelle instance AWS [17].
Les tests ont été réalisés exclusivement sur les instances de type m1.xlarge (15 Go de RAM et
4 cœurs CPU), avec un stockage local de l’instance pour plus de performance [17] .
Les instances AMI (Amazon Machine Image) utilisent Ubuntu 12.04 LTS avec Oracle Java 1.6
installé.
Configuration de HBASE :
L’instance HBASE utilise la version stable 0.94.3 de HBASE et la version stable Hadoop 1.1.1
installé à partir de http://archive.apache.org/dist/hadoop/core/hadoop-1.1.1/,

78
Configuration de MongoDB :
La version stable 2.2.2 a été installée dans l’instance MongoDB, à partir de
http://downloads-distro.mongodb.org/repo/ubuntu-upstart.
Les Workloads testés :
1. Read-mostly workload, basé sur YCSB’sworkload B: 95% Read / 5% Update
2. Read/write combination, basé sur YCSBsworkload A: 50% Read / 50% Update.
3. Write-mostly workload: 99% update/ 1% Read.
4. Read/scan combination: 47% Read, 47% de Scan, 6% Update.
5. Read/write combination with scans: 25% Read, de 25% Scan, 25% Update, 25% Insert.
6. Read latest workload, basé sur YCSB workload D: 95% Read / 5% Insert.
7. Read-modify-write, basé sur YCSB workload F: 50% Read 50% de Read-modify-write.
Pour chaque enregistrement, le nombre de champs est fixé à 20 afin d’avoir 2 KB par
enregistrement. Le nombre d’opérations est limité à 900000. Le nombre d’enregistrement a été
calculé sur la base du nombre d'instances de données demandées pour le test. 15M
d’enregistrements (de 30 Go) par DataNode.
Résultats de Chargement de données (Loading data).
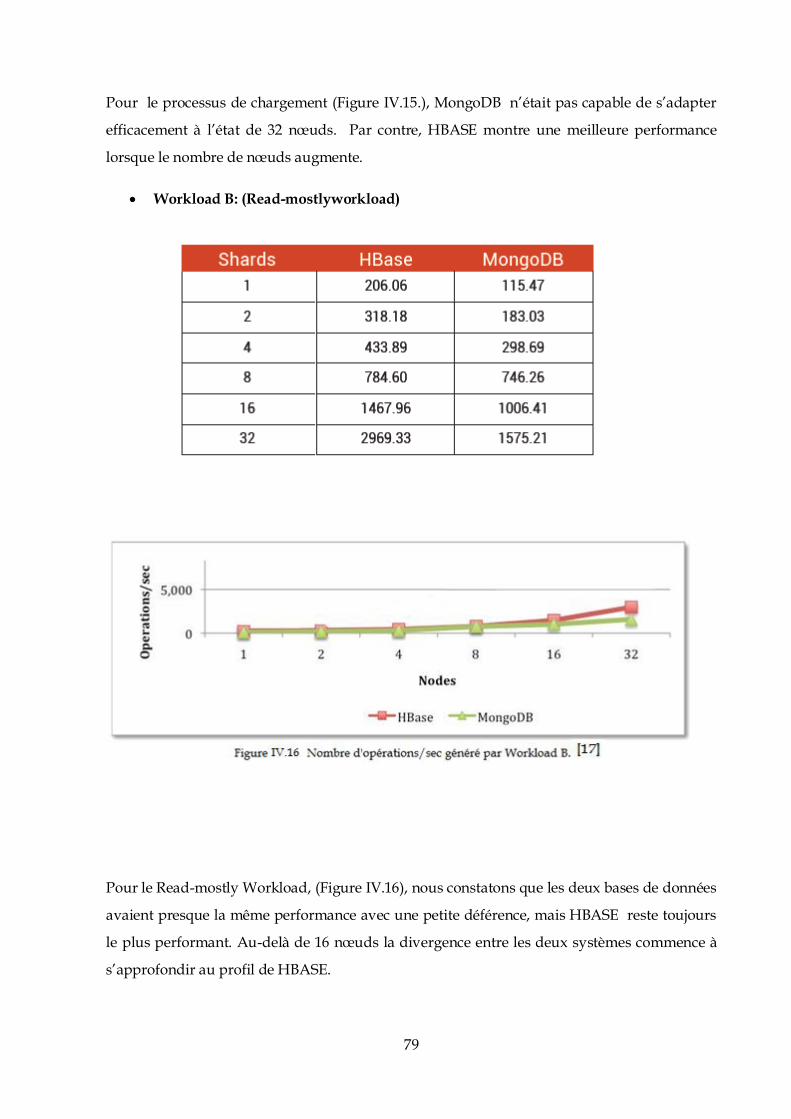
79
Pour le processus de chargement (Figure IV.15.), MongoDB n’était pas capable de s’adapter
efficacement à l’état de 32 nœuds. Par contre, HBASE montre une meilleure performance
lorsque le nombre de nœuds augmente.
Workload B: (Read-mostlyworkload)
Pour le Read-mostly Workload, (Figure IV.16), nous constatons que les deux bases de données
avaient presque la même performance avec une petite déférence, mais HBASE reste toujours
le plus performant. Au-delà de 16 nœuds la divergence entre les deux systèmes commence à
s’approfondir au profil de HBASE.
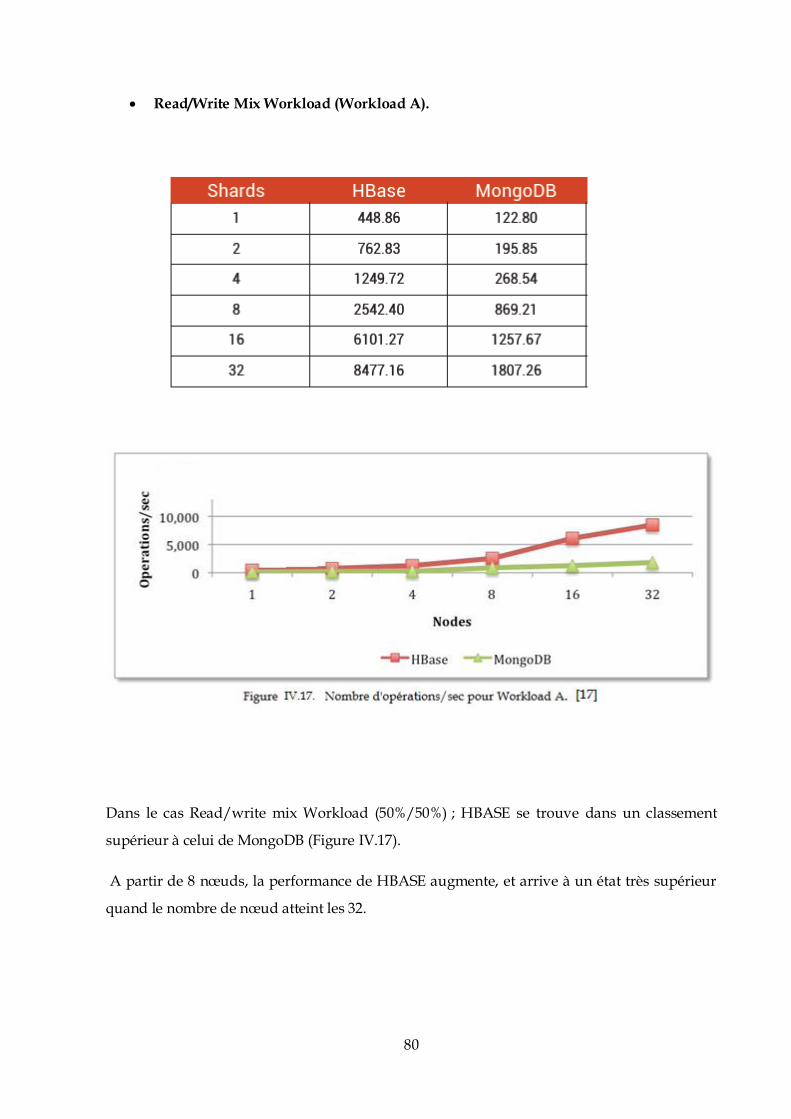
80
Read/Write Mix Workload (Workload A).
Dans le cas Read/write mix Workload (50%/50%) ; HBASE se trouve dans un classement
supérieur à celui de MongoDB (Figure IV.17).
A partir de 8 nœuds, la performance de HBASE augmente, et arrive à un état très supérieur
quand le nombre de nœud atteint les 32.
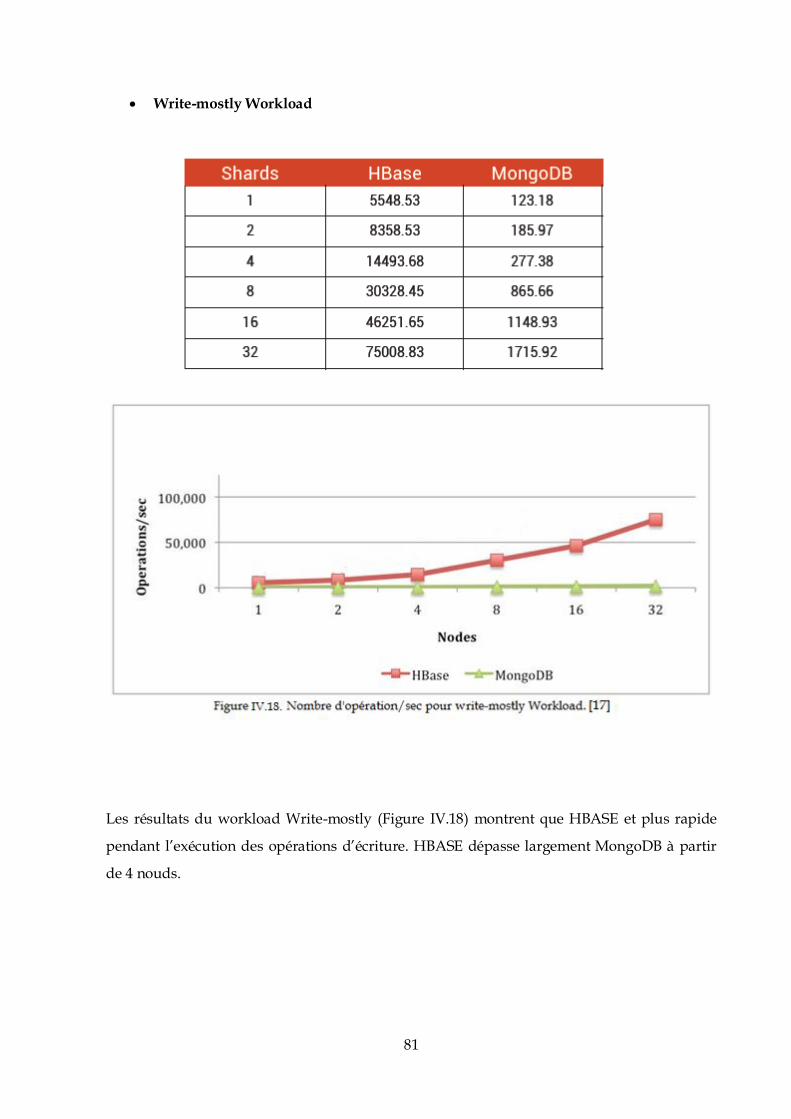
81
Write-mostly Workload
Les résultats du workload Write-mostly (Figure IV.18) montrent que HBASE et plus rapide
pendant l’exécution des opérations d’écriture. HBASE dépasse largement MongoDB à partir
de 4 nouds.
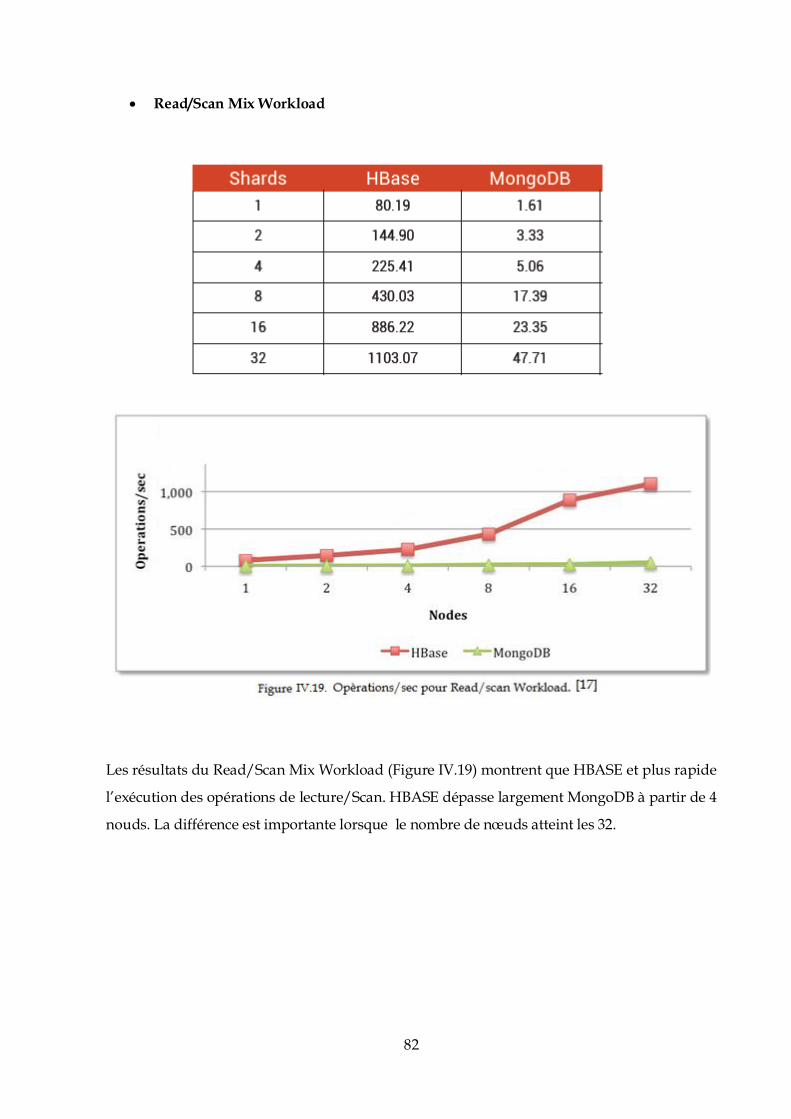
82
Read/Scan Mix Workload
Les résultats du Read/Scan Mix Workload (Figure IV.19) montrent que HBASE et plus rapide
l’exécution des opérations de lecture/Scan. HBASE dépasse largement MongoDB à partir de 4
nouds. La différence est importante lorsque le nombre de nœuds atteint les 32.
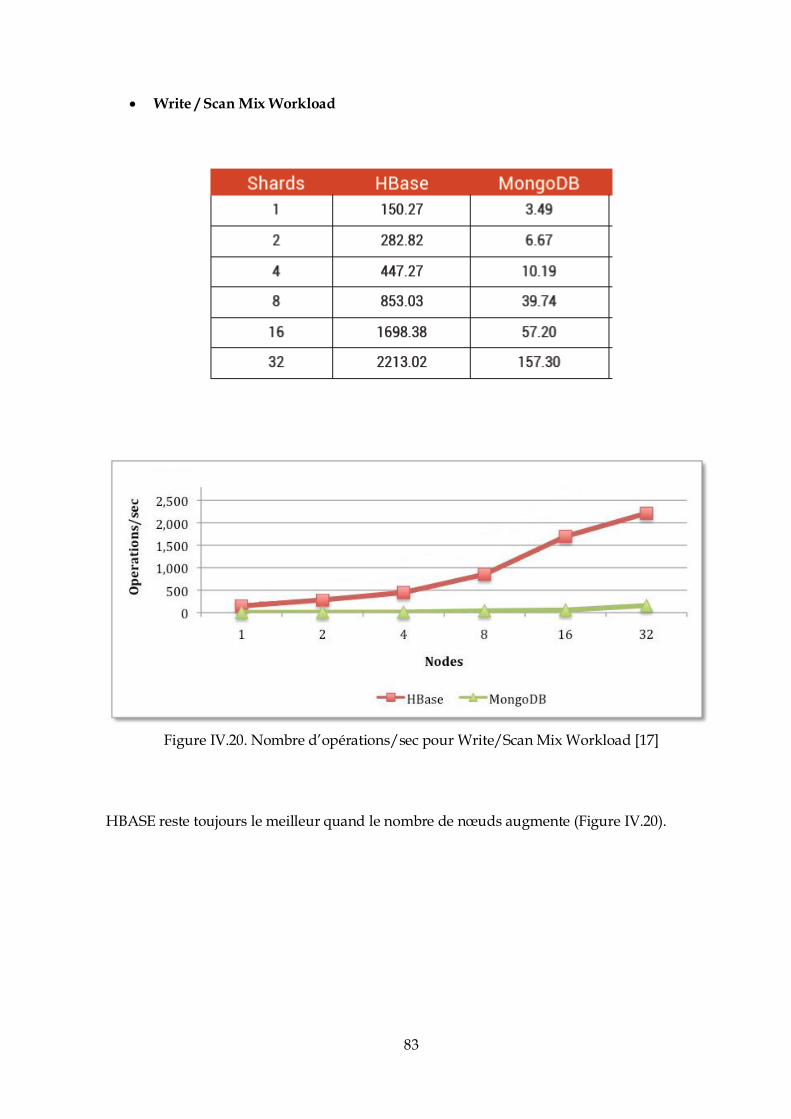
83
Write / Scan Mix Workload
Figure IV.20. Nombre d’opérations/sec pour Write/Scan Mix Workload [17]
HBASE reste toujours le meilleur quand le nombre de nœuds augmente (Figure IV.20).
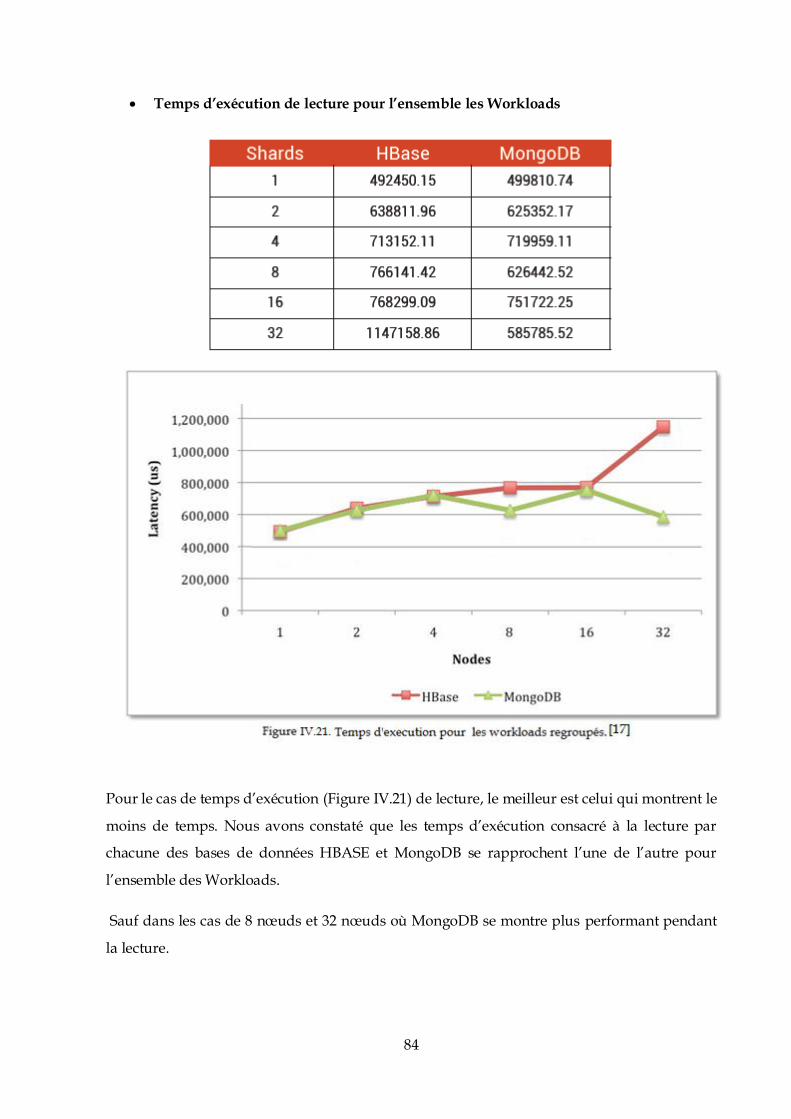
84
Temps d’exécution de lecture pour l’ensemble les Workloads
Pour le cas de temps d’exécution (Figure IV.21) de lecture, le meilleur est celui qui montrent le
moins de temps. Nous avons constaté que les temps d’exécution consacré à la lecture par
chacune des bases de données HBASE et MongoDB se rapprochent l’une de l’autre pour
l’ensemble des Workloads.
Sauf dans les cas de 8 nœuds et 32 nœuds où MongoDB se montre plus performant pendant
la lecture.
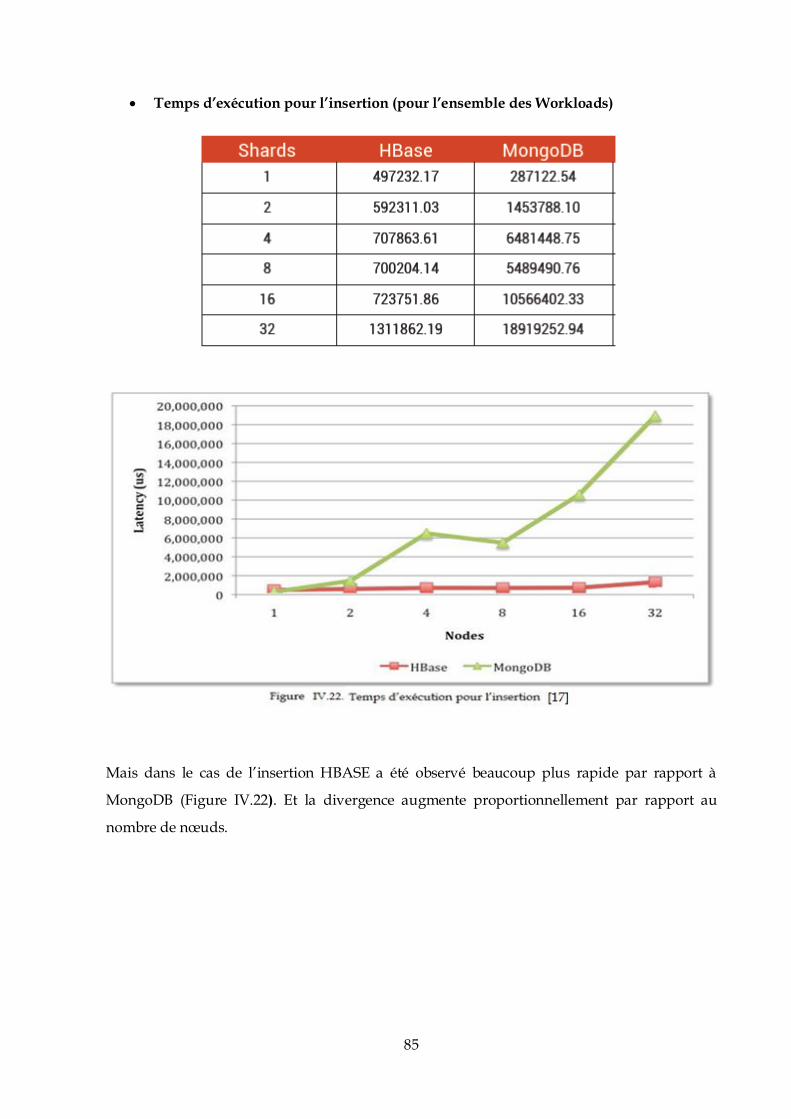
85
Temps d’exécution pour l’insertion (pour l’ensemble des Workloads)
Mais dans le cas de l’insertion HBASE a été observé beaucoup plus rapide par rapport à
MongoDB (Figure IV.22). Et la divergence augmente proportionnellement par rapport au
nombre de nœuds.
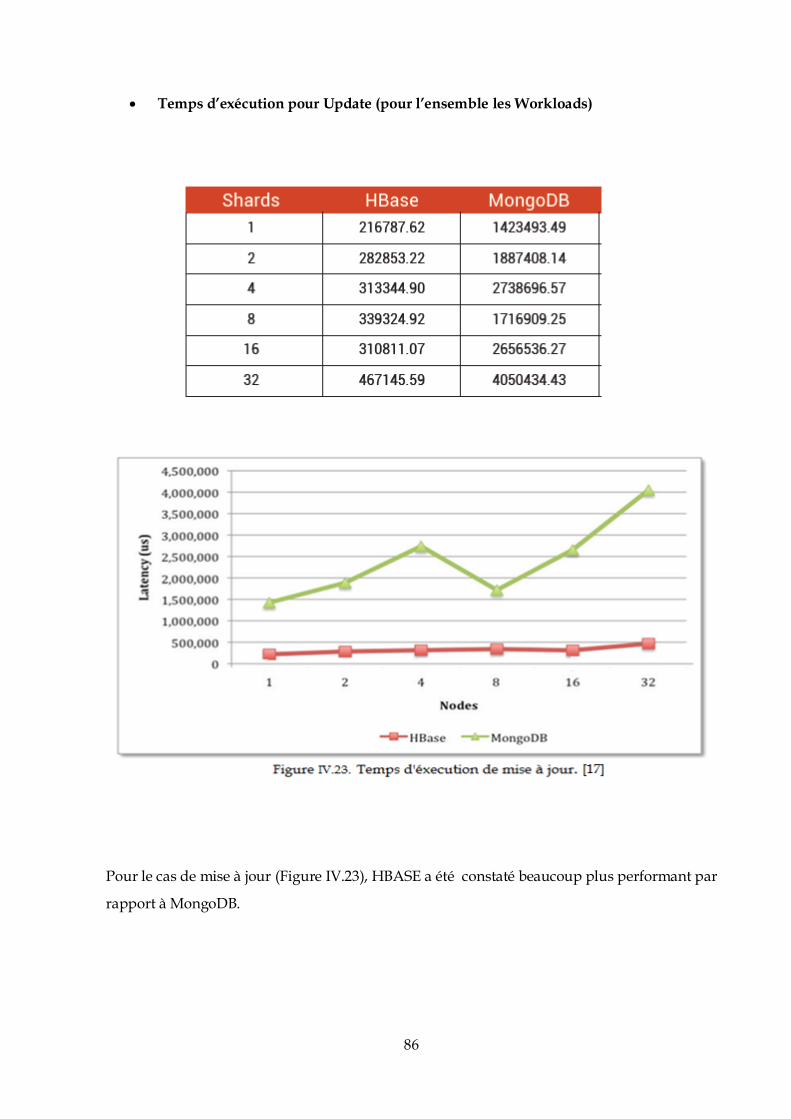
86
Temps d’exécution pour Update (pour l’ensemble les Workloads)
Pour le cas de mise à jour (Figure IV.23), HBASE a été constaté beaucoup plus performant par
rapport à MongoDB.
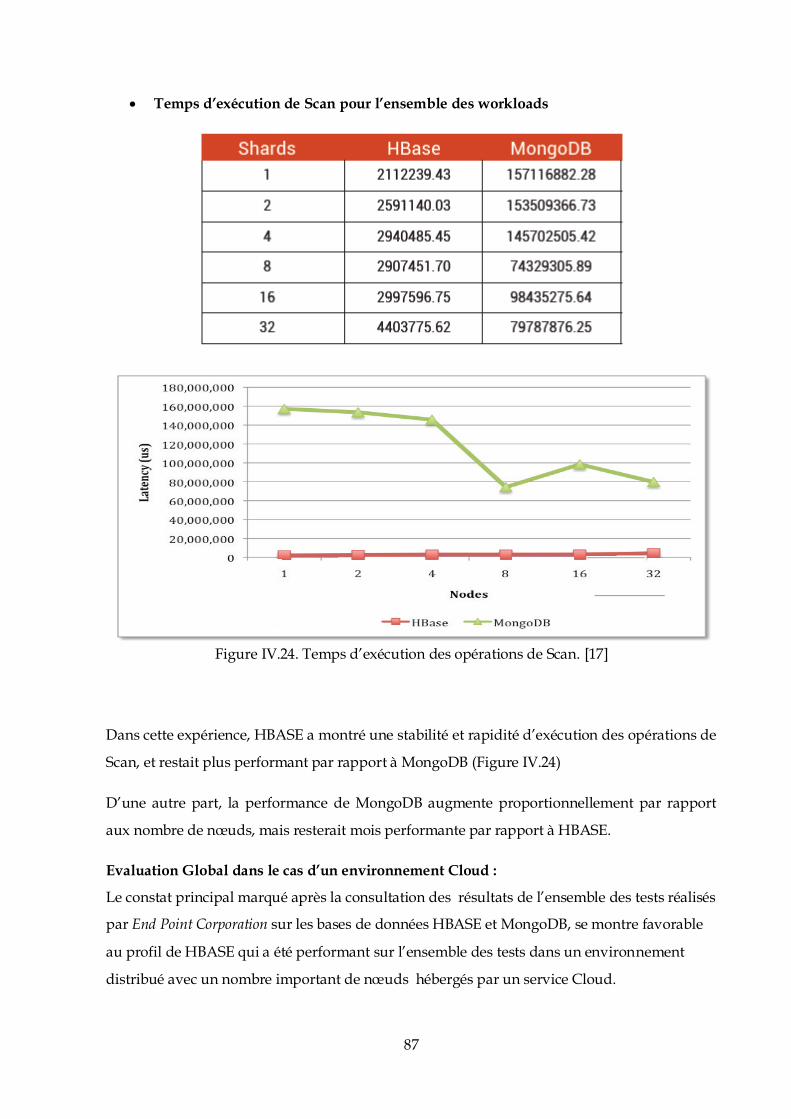
87
Temps d’exécution de Scan pour l’ensemble des workloads
Figure IV.24. Temps d’exécution des opérations de Scan. [17]
Dans cette expérience, HBASE a montré une stabilité et rapidité d’exécution des opérations de
Scan, et restait plus performant par rapport à MongoDB (Figure IV.24)
D’une autre part, la performance de MongoDB augmente proportionnellement par rapport
aux nombre de nœuds, mais resterait mois performante par rapport à HBASE.
Evaluation Global dans le cas d’un environnement Cloud :
Le constat principal marqué après la consultation des résultats de l’ensemble des tests réalisés
par End Point Corporation sur les bases de données HBASE et MongoDB, se montre favorable
au profil de HBASE qui a été performant sur l’ensemble des tests dans un environnement
distribué avec un nombre important de nœuds hébergés par un service Cloud.

88
IV.4. Conclusion :
Les tests réalisés dans ce chapitres ont aidé à connaitre des résultats intéressants liés à la
performance de deux différents types de bases de données NoSQl, orienté colonne (HBASE),
et orienté document (MongoDB).
La diversité des environnements réservés aux tests, Single Node et distribué, a enrichi la base
de résultats et a permis une meilleure analyse.
Dans le premier cas, le Single Node, nous avons constaté que MongoDB et globalement plus
performant par rapport à HBASE pendant la lecture, Scan et lecture/ écriture.
HBASE de son coté, était performant pendant l’insertion et la mise à jour.
Mais dans le cas d’une architecture distribuée (Cloud) caractérisé par un nombre important de
nœuds ; nous avons remarqué que HBASE a montré de bons résultats lorsque le nombre de
nœuds dépassent les 8 nœuds. Nous constatons donc que HBASE reste la bonne solution à
choisir entre ces deux systèmes SGBD NoSQL en cas d’une solution distribuée.

89
CONCLUSION GENERALE
L’objectif de ce travail était de comparer les performances de HBASE et MongoDB.
Deux systèmes de gestion de bases de données Not Only SQL. Nous avons commencé, dans
le premier chapitre, par définir les thèmes liés à ce travail. Précisément, nous avons présenté
les concepts de Big Data et de Cloud Computing.
Avant d’entamer la phase d’implémentation et expérimentation des solutions choisies pour
l’évaluation de performance, nous avons jugé important de faire connaitre deux concepts;
NoSQL et Mapreduce. Le deuxième chapitre était consacré à des notions préliminaires sur ces
concepts.
Dans le troisième chapitre nous avons défini les caractéristiques de Hadoop, HBASE et
MongoDB. L’utilité de Hadoop était d’implémenter le système de fichiers HDFS pour faciliter
l’exploitation de HBASE.
Nous avons présenté à la fin du chapitre III l’outil Yahoo YCSB utilisé dans notre travail
pour tester les bases de données NoSQL HBASE et MongoDB.
Le quatrième chapitre était consacré à l’implémentation. Nous avons donné les étapes
d’installation de Hadoop, HBASE, MongoDB et YCSB. Ensuite, nous avons présenté les
résultats obtenus après l’élaboration des tests avec YCSB. La comparaison de performance
entre HBASE et MongoDB a été faite par démonstration de graphes contenant les mesures
trouvées, et suivi par des commentaires argumentant les résultats.
Nous estimons qu’avec la domination de l’Internet dans presque tous les secteurs, industriels,
medias, communication, et même familial, les technologies de Big Data sont aujourd’hui en
plein essor. Dans les prochaines années, nous estimons que ces technologies seront de plus en
plus utilisées pour répondre à de nouvelles problématiques pour la gestion de données. Nous
avons constaté que les systèmes NoSQL sont des solutions idéales pour gérer les grands
volumes de données qui caractérisent le Big Data.
En étudiant HBASE et MongoDB dans ce projet, nous avons conclu que le choix d’une
utilisation de chaque SGBD parmi les deux dépend de la réalité de la situation dans laquelle
se trouvent les données. En effet le type de données et leur traitement sont des indices
important pour définir laquelle des deux solutions utiliser. La fréquence estimée de lecture,
écriture, la mise à jour, et la taille des données sont les facteurs essentiels pour la sélection des
solutions NoSQL.

90
PERSPECTIVES
Actuellement la tendance vers une favorisation d’une solution NoSQL précise est loin d’être
réalisée à cause de nombre important de systèmes de gestion de base de données NoSQL
existants. Plusieurs solutions open-source et payantes sont présentées aux acteurs des
différents secteurs liés au Big Data.
A ce propos, une comparaison entre les différentes familles des solutions NoSQL, clé valeur,
orienté documents, orienté colonne et orienté graphe, dans un environnement Cloud ; restera
comme un travail très recommandé qui peut apporter une aide et un support aux intéressés
de Big Data et de Cloud Computing.

91
Référence :
- Livres électroniques
[1] SRS Day,Rapport d’étude sur le Big Data, SRS Day 2012.
[2] Alex Popescu “Big Data Causes Concern and Big Confusion. A Big Data
definition to Help Clarify the Confusion”, 27 Fevrier 2012.
[3] Stefane Fermigier, BIG DATA & OPEN SOURCE: UNE CONVERGENCE
INÉVITABLE, 2012.
[4] Olivier BENDAVID, Bi in the Cloud, 18/06/10.
[5] Adriano Girolamo PIAZZA, NoSQL Etat de l’art et benchmark Travail, 2013
[6] Matteo DI MAGLIE, Adoption d’une solution NoSQL dans l’entreprise, 12
septembre 2012.
[7] KOUEDI Emmanuel, Approche de migration d’une base de données
relationnelle vers une base de données NoSQL orientée colonne, 2012.
[8] Intel Corporation, Maîtriser les technologies Big Data pour
obtenir des résultats en quasi-temps réel, 2013.
[9] Julien Gerlier et Siman Chen,
Prototypage et évaluation de performances d’un service de traçabilité avec une
architecture distribuée basée sur Hadoop, 2011
[10] Mickaël CORINUS, Rapport d’étude sur le Big Data, 2012
[11] TechTarget, Tout savoir sur Hadoop : Vulgarisation de la technologie et les
stratégies de certains acteurs, 2014
[12] Yifeng Jiang, HBase Administration Cookbook, Août 2012
[13] Nicolas Degroodt, L'élasticité des bases de données sur le cloud computing, 2011.
[14] Lionel HEINRICH, Architecture NoSQL et réponse au Théorème CAP, 26 octobre 2012
[15] Mongodb Org., MongoDB Documentation Release 2.6.7, 13 Janvier 2015.
[16] EXPERIMENTAL EVALUATION OF NOSQL DATABASES, Veronika Abramova1,
Jorge Bernardino1,2 and Pedro Furtado2, International Journal of Database
Management Systems, Vol.6, No.3, June 2014.

92
[17] Benchmarking Top NoSQL Databases, White Paper by DATASTAX CORPORATION,
Février 2013.
- Sites internet [W1] http://fr.wikipedia.org/wiki/big_data, 20/12/2014
[W2] http://fr.wikipedia.org/wiki/Transaction_informatique, 02/02/2014.
[W3] http://blog.xebia.fr/2010/04/21/nosql-europe-tour-dhorizon-des-bases-de-donnees-
nosql/, Avril 2012
[W4] http://fr.wikipedia.org/wiki/MapReduce, 28/11/2014.
[W5] http://blog.inovia-conseil.fr/, 28/11/2014
[W6] http://hbase.apache.org/, 28/11/2014
[W7] http://www.journaldunet.com/developpeur/outils/comparatif-des-bases-nosql/,
20/12/2014
[W8] http://fr.wikipedia.org/wiki/HBase, 20/12/2014
[W9] http://docs.mongodb.org/manual/, 20/12/2014
[W10] http://db-engines.com/en/system/HBase%3BMongoDB ; 25/01/2015.
[W11] http://en.wikipedia.org/wiki/Terabyte

93
Résumé
Le Big Data est un ensemble de technologies basées sur les bases de données NoSQL
qui permettent de traiter de très grands volumes de données informatiques. Les bases NoSQL
sont de nouvelles bases de données qui ont vu le jour pour la plupart il y a 5 ou 6 ans. Il sont
vu par les grandes entreprises du domaine informatique comme de nouvelles solutions
permettant de répondre à leurs besoins d'évolutivité.
Le but de ce travail est d'expliquer l'architecture des différentes bases NoSQL
disponibles sur le marché. Et de voir d’une façon plus approfondi deux d’entre elles, HBASE
et MongoDB, pour arriver à une analyse de performance utile en utilisant YCSB, un outil très
connus pour sa puissance de test et utilisé dans plusieurs travaux d’évaluation des bases de
données NoSQL. La finalité est de connaître les performances de chacun de deux bases de
donnés et d’effectuer une comparaison à partir des résultats des tests générés par YCSB.