Embed Size (px)
Citation preview

Info
Bd
D
Info Algèbre relationnelle et bases de données PTSI
Algèbre relationnelle et bases de données
L’objectif de ce chapitre est de présenter de manière formelle et succincte les notions et le vocabulaire utile en base
de données.
1. Introduction
1.1. Stockage et gestion des données
Dans beaucoup d’applications, il est nécessaire de conserver des données pour pouvoir les réutiliser :
⋄ les réseaux sociaux,
⋄ à Ginette : élèves, notes, profs, emploi du temps...,
⋄ CDI (Titre, auteur, éditeur, cote),
⋄ marathon de Paris,
⋄ sécurité sociale / mutuelles,
⋄ location de voitures / réservation de billets d’avion,
⋄ entreprise : client, produits, commandes, factures.
Pour stocker (conserver ou enregistrer en évitant les redondances) et traiter (interroger et transformer) ces données,
on utilise des bases de données (BD), ou database (DB) en anglais.
La gestion d’une base de données pose des problèmes complexes et elle est assurée par des logiciels spécialisés : lessystèmes de gestion de bases de données : SGBD (en anglais DBMS pour database management system).
Le fonctionnement de ces logiciels est basé sur une architecture trois-tiers. Il s’agit d’un modèle logique d’architecture
applicative qui vise à modéliser une application comme un empilement de trois couches logicielles (étages, niveaux,tiers ou strates) dont le rôle est clairement défini :
⋄ L’accès aux données persistantes : correspondant aux données qui sont destinées à être conservées sur la durée,
voire de manière définitive. Cette fonction est généralement réalisée par un serveur.
⋄ Le traitement des données : correspondant à la mise en œuvre de l’ensemble des règles de gestion. Cette fonction
est réalisée par le client, installé sur une autre machine.
⋄ La présentation des données : correspondant à l’affichage, la restitution sur le poste de travail, le dialogue avec
l’utilisateur. Cette fonction est typiquement réalisée par un navigateur Web sur une tablette ou un laptop.
Lycée SainteGeneviève 2019/2020 page 1/22
Info Algèbre relationnelle et bases de données PTSI
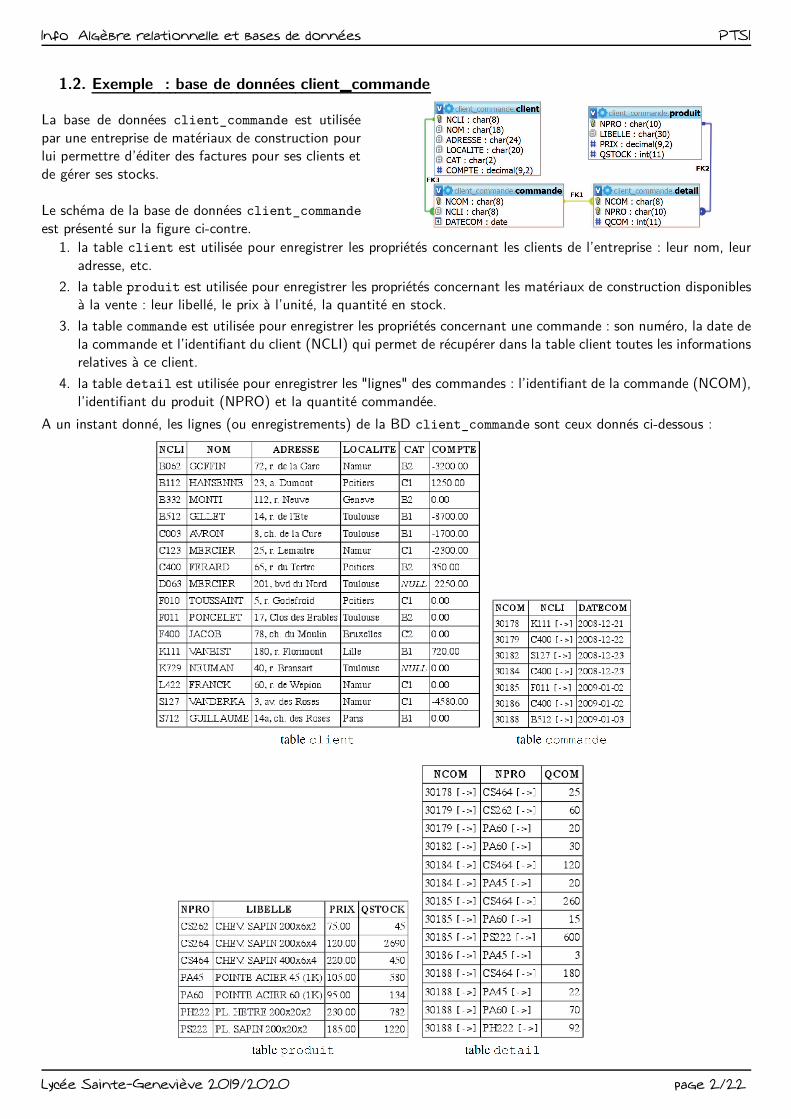
1.2. Exemple : base de données client_commande
La base de données client_commande est utilisée
par une entreprise de matériaux de construction pourlui permettre d’éditer des factures pour ses clients et
de gérer ses stocks.
Le schéma de la base de données client_commande
est présenté sur la figure ci-contre.
1. la table client est utilisée pour enregistrer les propriétés concernant les clients de l’entreprise : leur nom, leur
adresse, etc.
2. la table produit est utilisée pour enregistrer les propriétés concernant les matériaux de construction disponiblesà la vente : leur libellé, le prix à l’unité, la quantité en stock.
3. la table commande est utilisée pour enregistrer les propriétés concernant une commande : son numéro, la date de
la commande et l’identifiant du client (NCLI) qui permet de récupérer dans la table client toutes les informationsrelatives à ce client.
4. la table detail est utilisée pour enregistrer les "lignes" des commandes : l’identifiant de la commande (NCOM),
l’identifiant du produit (NPRO) et la quantité commandée.
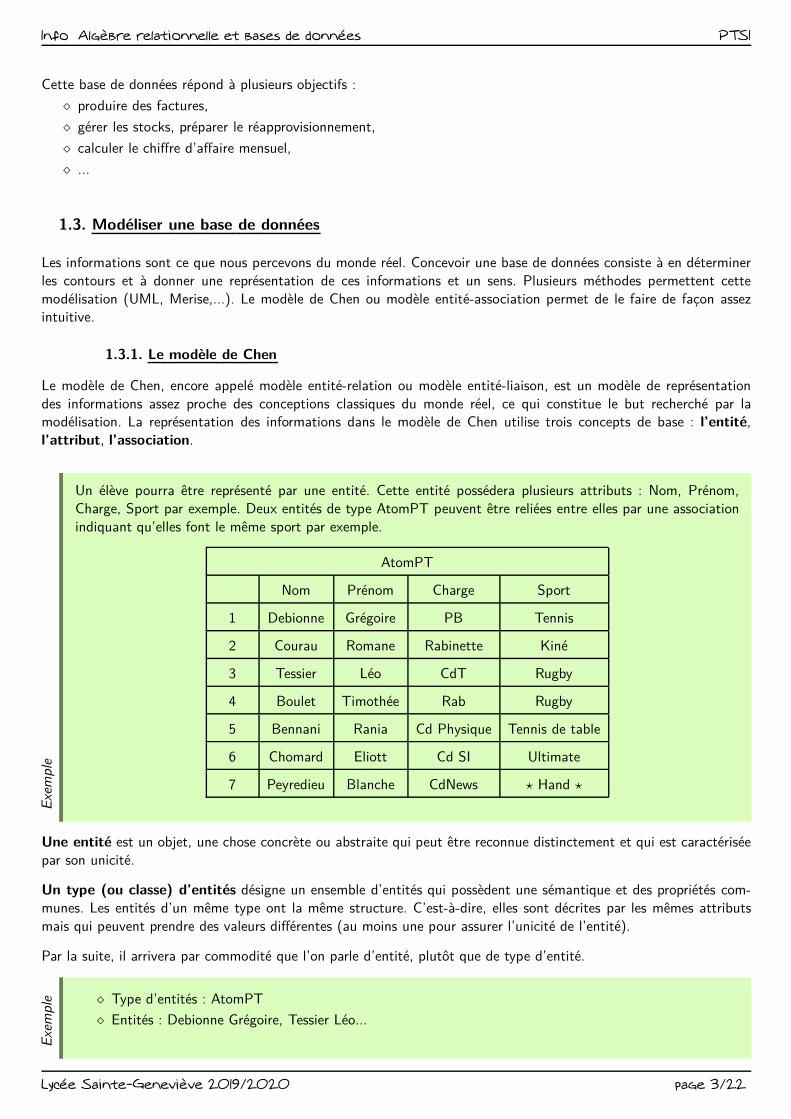
A un instant donné, les lignes (ou enregistrements) de la BD client_commande sont ceux donnés ci-dessous :
Lycée SainteGeneviève 2019/2020 page 2/22
Info Algèbre relationnelle et bases de données PTSI
Cette base de données répond à plusieurs objectifs :
⋄ produire des factures,
⋄ gérer les stocks, préparer le réapprovisionnement,
⋄ calculer le chiffre d’affaire mensuel,
⋄ ...
1.3. Modéliser une base de données
Les informations sont ce que nous percevons du monde réel. Concevoir une base de données consiste à en déterminer
les contours et à donner une représentation de ces informations et un sens. Plusieurs méthodes permettent cette
modélisation (UML, Merise,...). Le modèle de Chen ou modèle entité-association permet de le faire de façon assezintuitive.
1.3.1. Le modèle de Chen
Le modèle de Chen, encore appelé modèle entité-relation ou modèle entité-liaison, est un modèle de représentation
des informations assez proche des conceptions classiques du monde réel, ce qui constitue le but recherché par lamodélisation. La représentation des informations dans le modèle de Chen utilise trois concepts de base : l’entité,
l’attribut, l’association.
Exe
mple
Un élève pourra être représenté par une entité. Cette entité possédera plusieurs attributs : Nom, Prénom,
Charge, Sport par exemple. Deux entités de type AtomPT peuvent être reliées entre elles par une association
indiquant qu’elles font le même sport par exemple.
AtomPT
Nom Prénom Charge Sport
1 Debionne Grégoire PB Tennis
2 Courau Romane Rabinette Kiné
3 Tessier Léo CdT Rugby
4 Boulet Timothée Rab Rugby
5 Bennani Rania Cd Physique Tennis de table
6 Chomard Eliott Cd SI Ultimate
7 Peyredieu Blanche CdNews ⋆ Hand ⋆
Une entité est un objet, une chose concrète ou abstraite qui peut être reconnue distinctement et qui est caractérisée
par son unicité.
Un type (ou classe) d’entités désigne un ensemble d’entités qui possèdent une sémantique et des propriétés com-
munes. Les entités d’un même type ont la même structure. C’est-à-dire, elles sont décrites par les mêmes attributs
mais qui peuvent prendre des valeurs différentes (au moins une pour assurer l’unicité de l’entité).
Par la suite, il arrivera par commodité que l’on parle d’entité, plutôt que de type d’entité.
Exe
mple ⋄ Type d’entités : AtomPT
⋄ Entités : Debionne Grégoire, Tessier Léo...
Lycée SainteGeneviève 2019/2020 page 3/22

Info Algèbre relationnelle et bases de données PTSI
Un type d’attribut ou attribut est une caractéristique (ou propriété) associée à un type d’entité et susceptible d’être
enregistrée dans la base de données. Une entité est définie par un ensemble d’attributs.
Exe
mple Si l’on considère le type d’entités AtomPT, le type d’attribut Charge sera une fonction associant chaque entité
de type AtomPT à une chaîne de caractères représentant sa charge.
Un type d’association ou association ou encore relation est un lien entre plusieurs entités. Elle se compose
généralement d’un verbe.
Exe
mple
L’éleve d’AtomPT Romane Courau colle avec le Colleur M. Flieller.L’éleve d’AtomPT Timothée Boulet pratique le Sport Rugby.
Une clé (ou identifiant) d’un type d’entité est un ensemble minimal d’attributs qui permet d’identifier chaque entité
ou association de manière unique. Les clés seront décrites paragraphe 4.
1.3.2. Première approche d’une base de données
Une base de données est un ensemble de tables
⋄ chaque table correspond à un type d’entité et a un nom unique,
⋄ chaque table contient les données relatives à des entités de même nature,
⋄ chaque ligne (nuplet ou enregistrement) d’une table décrit les données relatives à une entité,
⋄ chaque colonne d’une table est un attribut et décrit une propriété des entités.
⋄ les lignes d’une table sont distinctes (ce sont des entités).
⋄ les noms de table et de colonnes constituent le schéma de la base.
⋄ les lignes constituent le contenu de la base.
Dès qu’il y a un nombre important de tables reliées entre elles et comportant un grand nombre de données (lignes), il
est indispensable de se munir d’un formalisme permettant de structurer et d’exploiter de manière efficace toutes ces
données. Nous allons pour cela introduire et utiliser le formalisme de l’algèbre relationnelle.
2. Langage SQL (Structured Query Language)
Un Système de Gestion de Base de Données (SGBD) est un logiciel (ou un ensemble de logiciels) permettant de
manipuler les données d’une base de données. Manipuler, c’est-à-dire sélectionner et afficher des informations tirées
de cette base, modifier des données, en ajouter ou en supprimer (ce groupe de quatre opérations étant souvent appelé
"CRUD", pour Create, Read, Update, Delete).
Un langage spécifique a été développé pour interagir avec les bases de données à partir de requêtes. Il s’agit du langage
SQL (Structured Query Language). Ce langage permet de traduire simplement les opérateurs de l’algèbre relation-
nelle en utilisant des mots clés explicites. Il est utilisé par de nombreux SGBD (MySQL, MariaDB, PostgreSQL, SQLite).
Lycée SainteGeneviève 2019/2020 page 4/22

Info Algèbre relationnelle et bases de données PTSI
Le langage de bases de données SQL est composé de deux sous-langages :
⋄ SQL DDL (Data Definition Language) : pour la définition et la modification des structures (table colonne,
contrainte). Les instructions sont CREATE, ALTER et DROP.
⋄ SQL DML (Data Manipulation Language) : pour l’extraction et la modification des données. Les instructionssont SELECT, INSERT, DELETE et UPDATE.
Une instruction SQL constitue une requête (query) c’est-à-dire la description d’une opération que le SGBD soit exécuter.
Une requête SQL peut être écrite en utilisant le clavier, générée à partir d’une interface graphique, ou importée à partir
d’un fichier.
Le résultat de l’exécution d’une requête peut apparaître à l’écran avec des éventuels messages d’erreurs. Une requête
peut également être envoyée par un programme (Python) au SGBD.
Toutes les requêtes SQL commencent par le mot clé SELECT et terminent par un point virgule.
SQ
L SELECT modèle FROM voitures WHERE carburant="Diesel";
Une requête SELECT simple contient trois parties principales :
1. la clause SELECT précise le nom des colonnes dont on veut récupérer les valeurs dans le résultat de la requête.
2. la clause FROM indique la table ou les tables sur lesquelles portent la requête. Toutes les colonnes de la clauseSELECT doivent appartenir à une des tables de la clause FROM.
3. la clause WHERE spécifie les conditions de sélections des valeurs du résultat de la requête.
L’exécution d’une requête SELECT produit un résultat qui est une table volatile car ses lignes sont envoyées à
l’écran mais cette table n’est pas créée dans la base de données.
Rq
Les commandes SQL sont conventionnellement écrites en majuscules mais ne sont pas sensibles à la casse
(différence majuscule/minuscule).
Par contre, les champs (par exemple voitures sont sensibles à la casse).
3. Les bases de l’algèbre relationnelle
3.1. La représentation plane
On appelle représentation plane la présentation de données sous la forme d’un tableau à deux entrées. Prenons pour
exemple une liste de véhicules ci-dessous.
marque modèle carburant cylindrée ( cm3)
1 Citroën C4 Picasso Diesel 1997
2 Citroën C4 Picasso Essence 1598
3 Volkswagen Jetta Essence 1197
4 Volkswagen Jetta Diesel 1598
5 Porsche 911 Carrera Essence 3436
6 Porsche 911 GT3 RS Essence 3996
Lycée SainteGeneviève 2019/2020 page 5/22

Info Algèbre relationnelle et bases de données PTSI
Dans une base de données relationnelle, l’information est organisée dans des tableaux à deux dimensions
appelés relations ou tables. Une base de données consiste en une ou plusieurs relations.
3.2. Définitions
Un tableau de données est appelé relation. Une relation est composée d’un ensemble de lignes appelées nuplets (ou
enregistrements ou entités).On appelle relation, ou table, associée à un schéma relationnel S, un ensemble de nuplets correspondant aux diffé-
rentes valeurs prises par les attributs. Cette relation est notée R(S).
• Chaque ligne (ici chaque voiture) est un nuplet (ou enregistrement ou entité) :
(Citroën, C4Picasso, Diesel, 1997).
• Les noms des colonnes (marque, modèle,...) sont appelés les attributs Au de la relation et sont distincts deux
à deux.
(marque, modèle, carburant, cylindrée)
• Une telle représentation est appelée un schéma noté S.Le schéma relationnel peut ainsi se mettre sous la forme : S = (A1, . . . , Au).
Les différents attributs peuvent prendre leurs valeurs dans des ensembles appelés domaines des attributs notés
dom(Au). Il est d’usage de représenter un schéma relationnel en rappelant le domaine de chaque attribut :
S = ((A1, dom(A1)) . . . , (Au, dom(Au))) .
Ainsi, dans le cas des listes de véhicules, le schéma relationnel serait :
S = ((marque, {Citroën, Renault, ..., Porsche}), (modèle, T exte), (carburant, {Essence, Diesel}), (cylindrée,N)).
On appelle relation, ou table, associée à un schéma relationnel S, un ensemble de nuplets correspondant aux diffé-
rentes valeurs prises par les attributs. Cette relation est notée R(S).
On notera B ∈ S pour signifier que B est un des attributs de S. De même, on notera X ⊂ S pour signifier que X
est un sous-nuplet de S.
Exe
mple
On considère le schéma relationnel :
S = (marque, modèle, carburant, cylindrée)
⋄ B = (modèle) est un attribut de S,
⋄ X = (marque, modèle) est un sous élément de S.
Lycée SainteGeneviève 2019/2020 page 6/22
Info Algèbre relationnelle et bases de données PTSIE
xem
ple
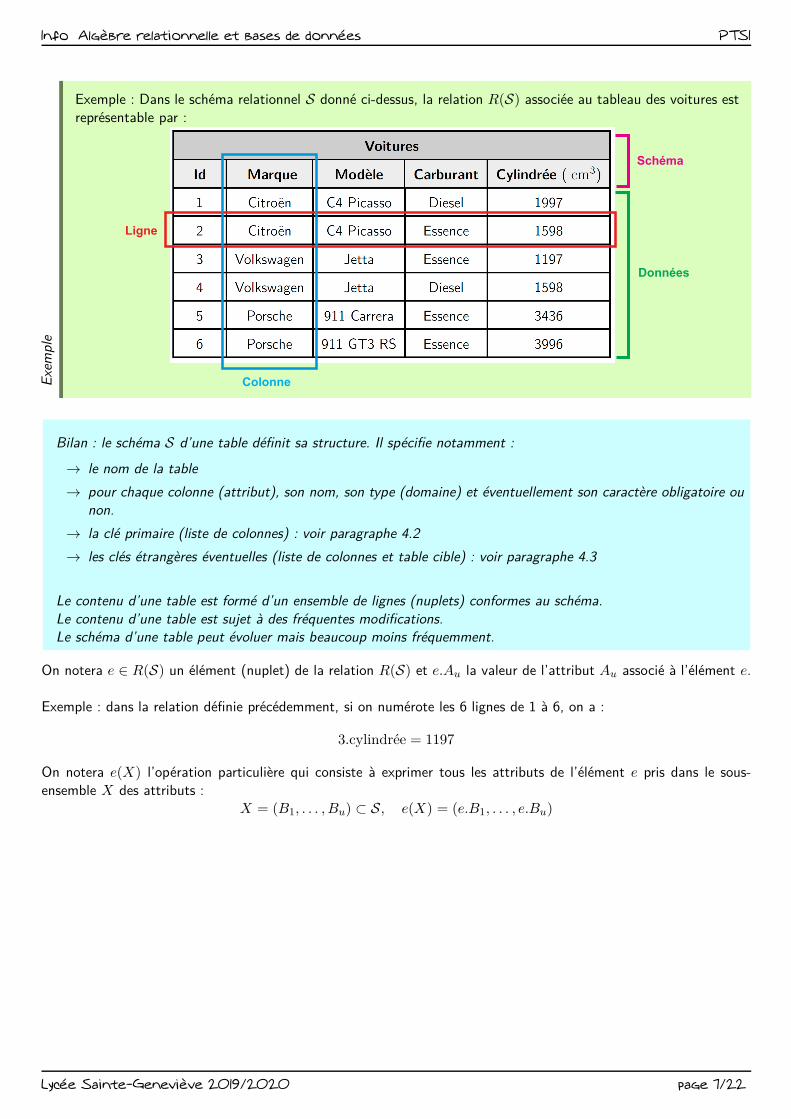
Exemple : Dans le schéma relationnel S donné ci-dessus, la relation R(S) associée au tableau des voitures est
représentable par :
Ligne
Colonne
Données
Schéma
Bilan : le schéma S d’une table définit sa structure. Il spécifie notamment :
→ le nom de la table
→ pour chaque colonne (attribut), son nom, son type (domaine) et éventuellement son caractère obligatoire ou
non.
→ la clé primaire (liste de colonnes) : voir paragraphe 4.2
→ les clés étrangères éventuelles (liste de colonnes et table cible) : voir paragraphe 4.3
Le contenu d’une table est formé d’un ensemble de lignes (nuplets) conformes au schéma.
Le contenu d’une table est sujet à des fréquentes modifications.Le schéma d’une table peut évoluer mais beaucoup moins fréquemment.
On notera e ∈ R(S) un élément (nuplet) de la relation R(S) et e.Au la valeur de l’attribut Au associé à l’élément e.
Exemple : dans la relation définie précédemment, si on numérote les 6 lignes de 1 à 6, on a :
3.cylindrée = 1197
On notera e(X) l’opération particulière qui consiste à exprimer tous les attributs de l’élément e pris dans le sous-
ensemble X des attributs :X = (B1, . . . , Bu) ⊂ S, e(X) = (e.B1, . . . , e.Bu)
Lycée SainteGeneviève 2019/2020 page 7/22

Info Algèbre relationnelle et bases de données PTSI
3.3. Projection
3.3.1. Formalisme relationnel
La projection d’une relation consiste à ne conserver que certains attributs pour tous les éléments. Soit R une relationde schéma S et X ⊂ S. On appelle projection de R selon X la relation :
πX(R) = {e(X) | e ∈ R}
Exe
mple
La projection de la relation voitures sur les attributsmarque et modèle est :
πmarque, modèles (voitures)
marque modèle
Citroën C4 Picasso
Volkswagen Jetta
Porsche 911 Carrera
Porsche 911 GT3 RS
Suite à une projection, on peut obtenir des entités
identiques. Pour éviter cet affichage on pourra utiliserla clause DISTINCT.
Rq
Une projection diminue le nombre de colonnes (attributs). Le résultat d’une projection est une relation qui n’a
pas le même schéma que la relation de départ.
3.3.2. Commande SQL
La projection consiste à sélectionner certains attributs d’une relation, ce qui se traduit en langage SQL par :
SQ
L SELECT marque , modèle FROM voitures ;
Il est possible d’obtenir tous les éléments d’une table avec * :
SQ
L SELECT * FROM voitures ;
La commande ci-dessus affiche le tableau en entier.
Lycée SainteGeneviève 2019/2020 page 8/22
Info Algèbre relationnelle et bases de données PTSI
3.4. Sélection simple
3.4.1. Formalisme relationnel
La sélection (ou restriction) consiste à choisir les éléments (nuplets) de la relation vérifiant une certaine condition.Soit R une relation de schéma S. A un attribut du schéma S : A ∈ S. Et a une valeur possible de A. On appelle
sélection de R selon A = a la relation :
σA=a(R) = {e ∈ R | e.A = a}
Rq
Si le domaine de A le permet (nombres entiers ou flottants), la sélection peut également porter sur une
inégalité :σA≤a(R) = {e ∈ R | e.A ≤ a}
Exe
mple
Dans la relation voitures, la sélection des voitures Diesel donne :
σcarburant=”Diesel”(voitures)
marque modèle carburant cylindrée ( cm3)
Citroën C4 Picasso Diesel 1997
Volkswagen Jetta Diesel 1598
Rq
La sélection élimine des lignes mais garde le même nombre de colonnes.
Le résultat d’une sélection est une nouvelle relation de même schéma que la relation de départ.
Exe
mple
Dans la même relation, la sélection des voitures de plus de 1, 7 L de cylindrée s’écrit :
σcylindrée≥1700(voitures)
marque modèle carburant cylindrée ( cm3)
Citroën C4 Picasso Diesel 1997
Porsche 911 Carrera Essence 3436
Porsche 911 GT3 RS Essence 3996
Lycée SainteGeneviève 2019/2020 page 9/22

Info Algèbre relationnelle et bases de données PTSI
3.4.2. Commande SQL
On utilise encore la commande SELECT associée au mot clé WHERE pour imposer la (ou les) condition(s).
Le mot clé SELECT permet de réaliser à la fois les projections et les sélections.
Les deux exemples ci-dessus s’écriraient donc :
SQ
L
SELECT * FROM voitures WHERE carburant="Diesel";SELECT * FROM voitures WHERE cylindrée >=1700;
On peut alors combiner aisément la sélection avec une projection, pour afficher par exemple la liste des modèlesexistant en version diesel :
SQ
L SELECT modèle FROM voitures WHERE carburant="Diesel";
3.5. Opérateurs ensemblistes usuels
3.5.1. Formalisme relationnel
Si deux relations ont le même schéma relationnel, il est possible de leur appliquer des opérateurs ensemblistes.
Parmi ceux-ci, on aura principalement recours à l’union, l’intersection et la différence.
Pour cette partie, on considère deux relations vendeur1 et vendeur2 contenant les listes de véhicules proposés par deuxconcessionnaires.
vendeur1
marque modèle carburant cylindrée
Mercedes C200 Essence 1796
Mercedes C200 Diesel 2143
Subaru Impreza Essence 1994
Subaru Impreza Diesel 1998
Renault Twingo Essence 1149
Fiat 500 Essence 1242
Fiat 500 Diesel 1248
vendeur2
marque modèle carburant cylindrée
Mercedes C63 AMG Essence 6208
Mercedes C200 Essence 1796
Subaru Impreza Essence 1994
Subaru WRX STI Essence 2457
Bugatti Veyron Essence 7993
Renault Twingo Essence 1149
Abarth 500 Essence 1368
Fiat 500 Diesel 1242
Lycée SainteGeneviève 2019/2020 page 10/22

Info Algèbre relationnelle et bases de données PTSI
⋄ L’union vendeur1 ∪ vendeur2 est une relation
comprenant l’ensemble des nuplets (éléments) ap-partenant à vendeur1 ou vendeur2 (avec élimination
des doublons éventuels) : vendeur1 ∪ vendeur2 :
vendeur1 ∪ vendeur2
marque modèle carburant cylindrée
Mercedes C63 AMG Essence 6208
Mercedes C200 Essence 1796
Mercedes C200 Diesel 2143
Subaru Impreza Essence 1994
Subaru Impreza Diesel 1998
Subaru WRX STI Essence 2457
Bugatti Veyron Essence 7993
Renault Twingo Essence 1149
Abarth 500 Essence 1368
Fiat 500 Diesel 1242
Fiat 500 Essence 1242
Fiat 500 Diesel 1248
⋄ L’intersection vendeur1 ∩ vendeur2 est une relation
comprenant l’ensemble des nuplets (éléments)appartenant à vendeur1 et vendeur2 : vendeur1 ∩
vendeur2
vendeur1 ∩ vendeur2
marque modèle carburant cylindrée
Mercedes C200 Essence 1796
Subaru Impreza Essence 1994
Renault Twingo Essence 1149
Fiat 500 Diesel 1242
⋄ La différence vendeur1 - vendeur2 est une relation
comprenant l’ensemble des éléments appartenant à
vendeur1 mais pas à vendeur2 : vendeur1 - vendeur2
vendeur1
marque modèle carburant cylindrée
Mercedes C200 Diesel 2143
Subaru Impreza Diesel 1998
Renault Twingo Essence 1149
Fiat 500 Diesel 1248
3.5.2. Commande SQL
⋄ L’union est réalisée avec le mot clé UNION :
SQ
L SELECT * FROM vendeur1 UNION SELECT * FROM vendeur2 ;
⋄ L’intersection est réalisée avec le mot clé INTERSECT :
SQ
L SELECT * FROM vendeur1 INTERSECT SELECT * FROM vendeur2 ;
⋄ La différence est réalisée avec le mot clé EXCEPT :
SQ
L SELECT * FROM vendeur1 EXCEPT SELECT * FROM vendeur2 ;
Lycée SainteGeneviève 2019/2020 page 11/22

Info Algèbre relationnelle et bases de données PTSI
3.5.3. Application à la sélection composée
Comme chaque sélection donne une nouvelle relation, on peut utiliser les opérations ensemblistes sur les sélections
pour exprimer des conditions complexes.
Exe
mple
Pour obtenir la liste des véhicules essence de cylindrée inférieure à 1, 5 L proposés par le vendeur1 :
⋄ En notation relationnelle :
σcarburant=”essence”(vendeur1) ∩ σcylindrée<1500(vendeur1)
⋄ En langage SQL :
SQ
L
SELECT * FROM vendeur1 WHERE carburant="Essence" INTERSECT
SELECT * FROM vendeur1 WHERE cylindrée <1500;
Et on peut aussi combiner plusieurs conditions avec les mots clés AND et OR :
SQ
L SELECT *FROM vendeur1 WHERE carburant="Essence" AND cylindrée<1500;
3.6. Renommage
Le renommage sert à changer temporairement le nom d’un attribut. Ce renommage n’affecte que la requête en cours
(en vue de l’affichage) mais ne modifie pas la structure relationnelle.
Exe
mple
Pour afficher la liste des véhicules proposés par le vendeur 1 avec des noms de colonne en anglais :
SQ
L SELECT marque AS Brand , modèle AS Model , carburant AS Fuel FROM vendeur1 ;
vendeur1
Brand Model Fuel
Mercedes C200 Essence
Mercedes C200 Diesel
Subaru Impreza Essence
Subaru Impreza Diesel
Renault Twingo Essence
Fiat 500 Essence
Fiat 500 Diesel
Lycée SainteGeneviève 2019/2020 page 12/22

Info Algèbre relationnelle et bases de données PTSI
3.7. Tri des données
Il est possible de trier les données renvoyées par n’importe quelle opération (projection, sélection,...) grâce à ORDER
BY, selon un ordre ascendant (ASC) ou descendant (DESC).
SQ
L SELECT * FROM vendeur1 WHERE carburant ="Diesel" ORDER BY marque ASC ;
Cette requête permet d’obtenir l’ensemble des véhicules diesel proposés par le vendeur1 triés par ordre alphabétique
croissant de la marque.
Rq
Il est possible d’effectuer un tri sur plusieurs attributs en les séparant par une virgule :
SQ
L SELECT *FROM relation ORDER BY attr1 , attr2 ASC ;
Dans ce cas, les données sont d’abord triées selon l’attribut attr1, les cas d’égalité sont triés avec l’attribut
attr2.
4. Clé
4.1. Définition
Une ligne dans une table regroupe des informations sur une entité. Une des propriétés importante dans une table est
de pouvoir identifier de manière unique une ligne à l’aide d’une clé (key en anglais) ou identifiant.
Une clé peut être composée de une ou plusieurs colonnes de la table.
Soit R une relation de schéma S et K ⊂ S On dit que K est une clé pour R si et seulement si pour tout élémente1 ∈ R et e2 ∈ R, on a :
e1(K) = e2(K) ⇒ e1 = e2
Exe
mple Considérons à nouveau la relation voitures. L’attribut marque ou l’ensemble ( marque, modèle) ne consti-
tuent pas des clés pour la relation car par exemple deux voitures ont pour attributs (Volkswagen, Jetta).
En revanche, l’ensemble (modèle, carburant) est bien une clé pour la relation.
Lycée SainteGeneviève 2019/2020 page 13/22
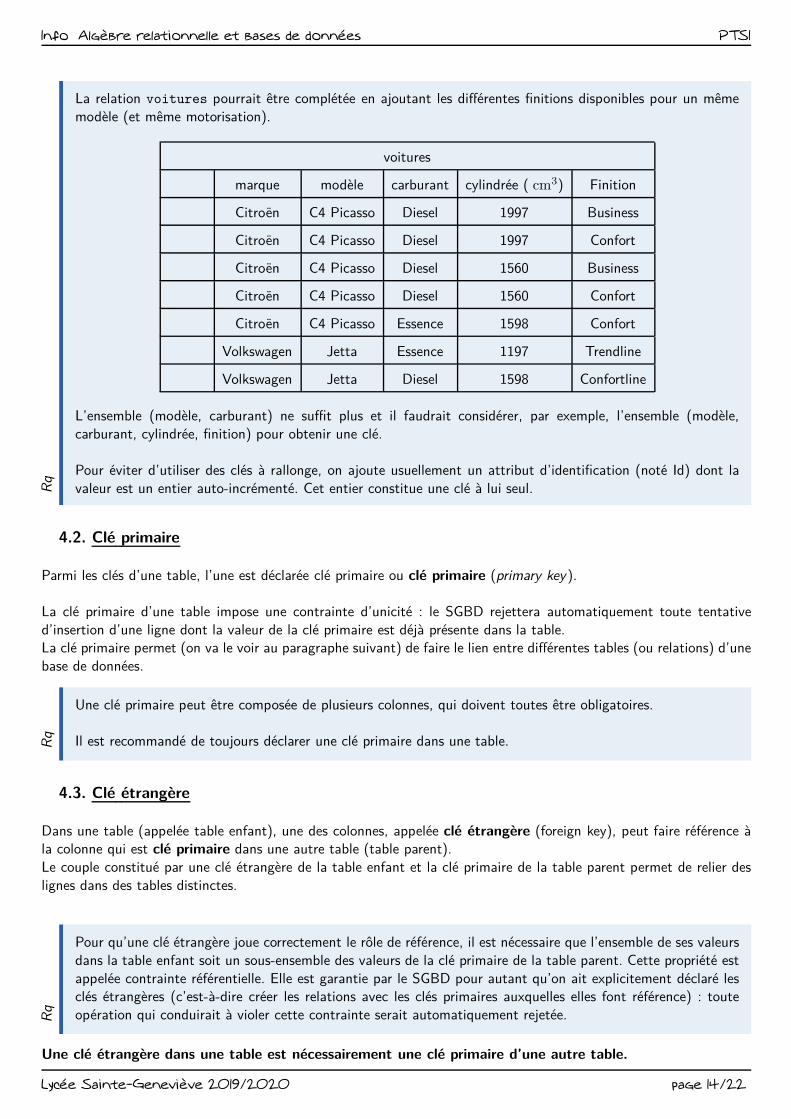
Info Algèbre relationnelle et bases de données PTSIR
q
La relation voitures pourrait être complétée en ajoutant les différentes finitions disponibles pour un même
modèle (et même motorisation).
voitures
marque modèle carburant cylindrée ( cm3) Finition
Citroën C4 Picasso Diesel 1997 Business
Citroën C4 Picasso Diesel 1997 Confort
Citroën C4 Picasso Diesel 1560 Business
Citroën C4 Picasso Diesel 1560 Confort
Citroën C4 Picasso Essence 1598 Confort
Volkswagen Jetta Essence 1197 Trendline
Volkswagen Jetta Diesel 1598 Confortline
L’ensemble (modèle, carburant) ne suffit plus et il faudrait considérer, par exemple, l’ensemble (modèle,
carburant, cylindrée, finition) pour obtenir une clé.
Pour éviter d’utiliser des clés à rallonge, on ajoute usuellement un attribut d’identification (noté Id) dont la
valeur est un entier auto-incrémenté. Cet entier constitue une clé à lui seul.
4.2. Clé primaire
Parmi les clés d’une table, l’une est déclarée clé primaire ou clé primaire (primary key).
La clé primaire d’une table impose une contrainte d’unicité : le SGBD rejettera automatiquement toute tentative
d’insertion d’une ligne dont la valeur de la clé primaire est déjà présente dans la table.La clé primaire permet (on va le voir au paragraphe suivant) de faire le lien entre différentes tables (ou relations) d’une
base de données.
Rq
Une clé primaire peut être composée de plusieurs colonnes, qui doivent toutes être obligatoires.
Il est recommandé de toujours déclarer une clé primaire dans une table.
4.3. Clé étrangère
Dans une table (appelée table enfant), une des colonnes, appelée clé étrangère (foreign key), peut faire référence àla colonne qui est clé primaire dans une autre table (table parent).
Le couple constitué par une clé étrangère de la table enfant et la clé primaire de la table parent permet de relier des
lignes dans des tables distinctes.
Rq
Pour qu’une clé étrangère joue correctement le rôle de référence, il est nécessaire que l’ensemble de ses valeurs
dans la table enfant soit un sous-ensemble des valeurs de la clé primaire de la table parent. Cette propriété est
appelée contrainte référentielle. Elle est garantie par le SGBD pour autant qu’on ait explicitement déclaré lesclés étrangères (c’est-à-dire créer les relations avec les clés primaires auxquelles elles font référence) : toute
opération qui conduirait à violer cette contrainte serait automatiquement rejetée.
Une clé étrangère dans une table est nécessairement une clé primaire d’une autre table.
Lycée SainteGeneviève 2019/2020 page 14/22
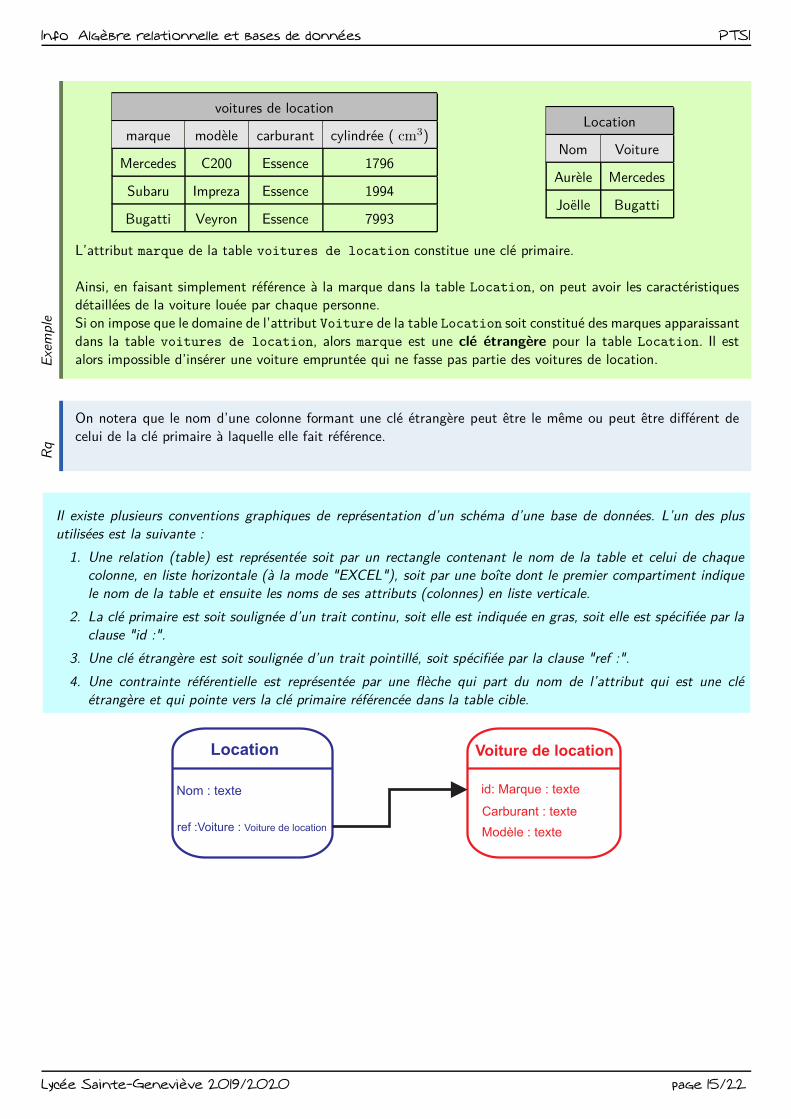
Info Algèbre relationnelle et bases de données PTSIE
xem
ple
voitures de location
marque modèle carburant cylindrée ( cm3)
Mercedes C200 Essence 1796
Subaru Impreza Essence 1994
Bugatti Veyron Essence 7993
Location
Nom Voiture
Aurèle Mercedes
Joëlle Bugatti
L’attribut marque de la table voitures de location constitue une clé primaire.
Ainsi, en faisant simplement référence à la marque dans la table Location, on peut avoir les caractéristiquesdétaillées de la voiture louée par chaque personne.
Si on impose que le domaine de l’attribut Voiture de la table Location soit constitué des marques apparaissant
dans la table voitures de location, alors marque est une clé étrangère pour la table Location. Il est
alors impossible d’insérer une voiture empruntée qui ne fasse pas partie des voitures de location.
Rq
On notera que le nom d’une colonne formant une clé étrangère peut être le même ou peut être différent de
celui de la clé primaire à laquelle elle fait référence.
Il existe plusieurs conventions graphiques de représentation d’un schéma d’une base de données. L’un des plus
utilisées est la suivante :
1. Une relation (table) est représentée soit par un rectangle contenant le nom de la table et celui de chaquecolonne, en liste horizontale (à la mode "EXCEL"), soit par une boîte dont le premier compartiment indique
le nom de la table et ensuite les noms de ses attributs (colonnes) en liste verticale.
2. La clé primaire est soit soulignée d’un trait continu, soit elle est indiquée en gras, soit elle est spécifiée par la
clause "id :".
3. Une clé étrangère est soit soulignée d’un trait pointillé, soit spécifiée par la clause "ref :".
4. Une contrainte référentielle est représentée par une flèche qui part du nom de l’attribut qui est une clé
étrangère et qui pointe vers la clé primaire référencée dans la table cible.
Location
Nom : texte
ref :Voiture : Voiture de location
Voiture de location
id: Marque : texte
Modèle : texte
Carburant : texte
Lycée SainteGeneviève 2019/2020 page 15/22

Info Algèbre relationnelle et bases de données PTSI
5. Opérations plus évoluées
Les opérations définies jusqu’à présent n’étaient applicables qu’à une seule relation ou à deux relations de mêmeschéma relationnel. Les opérateurs suivants permettent de croiser les informations présentes dans plusieurs tables de
formats différents.
5.1. Produit cartésien
Le produit cartésien R × R′ de deux relations R et R′, de schémas quelconques, consiste à associer tous les éléments
de R avec tous les éléments de R′.
Exe
mple
Elèves
Nom_eleve
Romane
Hortense
Ombeline
Claire
Rania
Blanche
Philippine
Professeurs
Nom_professeur
Merle
Cid
Bourrigan
Bay
Gonzalez
Elèves × Professeurs
Romane Merle
Romane Cid
Romane Bourrigan
Romane Bay
Romane Gonzalez
Hortense Merle
Hortense Cid
Hortense Bourrigan
Hortense Bay
Hortense Gonzalez
. . . . . .
Le produit cartésien est obtenu très simplement en langage SQL en utilisant une projection de deux relations :
SQ
L SELECT * FROM Elèves , Professeurs ;
La division cartésienne existe en algèbre relationnelle pour des raisons de complétude mais elle est absente des langages
de requête.
5.2. Jointure
Pour extraire des données corrélées stockées dans deux tables ayant au moins un attribut en commun, on utilise
une jointure.
Cette jointure permet de construire une table fictive en couplant chaque ligne de la première table avec chaque ligne
de la seconde table (concaténation) tout en respectant la condition de jointure (attribut en commun).
Soient R(S) et R′(S ′) deux relations de schémas disjoints. Soient A ∈ S et A′ ∈ S ′ tels que dom(A) = dom(A′).
L’opération
R[
A = A′]
= R ⊲⊳A=A′ R′ ={
e ∈ R × R′ | e.A = e.A′}
= σA=A′(R × R′)
est appelée jointure symétrique de R et R′ selon (A, A′).
On peut voir une jointure simple résultant de deux opérations successives :
⋄ un produit cartésien des deux tables
⋄ puis une sélection sur la table R × R′ à partir du critère de sélection (l’attribut sélectionné en commun)
Lycée SainteGeneviève 2019/2020 page 16/22
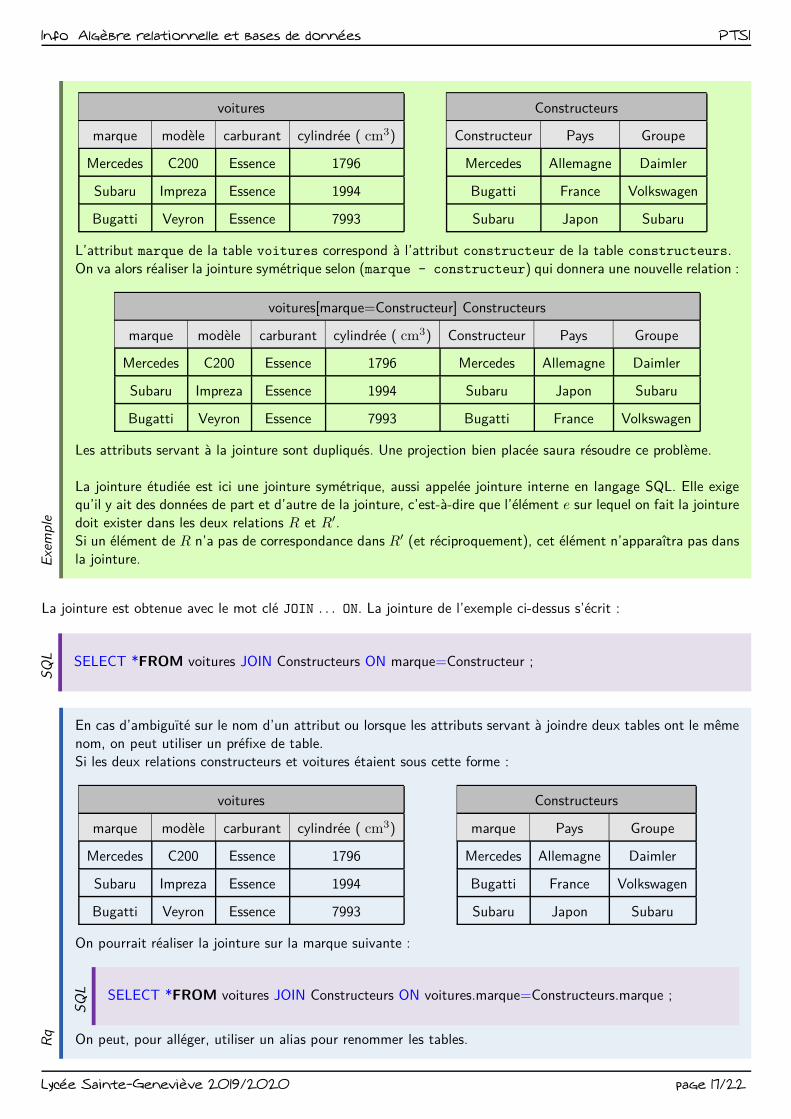
Info Algèbre relationnelle et bases de données PTSIE
xem
ple
voitures
marque modèle carburant cylindrée ( cm3)
Mercedes C200 Essence 1796
Subaru Impreza Essence 1994
Bugatti Veyron Essence 7993
Constructeurs
Constructeur Pays Groupe
Mercedes Allemagne Daimler
Bugatti France Volkswagen
Subaru Japon Subaru
L’attribut marque de la table voitures correspond à l’attribut constructeur de la table constructeurs.
On va alors réaliser la jointure symétrique selon (marque - constructeur) qui donnera une nouvelle relation :
voitures[marque=Constructeur] Constructeurs
marque modèle carburant cylindrée ( cm3) Constructeur Pays Groupe
Mercedes C200 Essence 1796 Mercedes Allemagne Daimler
Subaru Impreza Essence 1994 Subaru Japon Subaru
Bugatti Veyron Essence 7993 Bugatti France Volkswagen
Les attributs servant à la jointure sont dupliqués. Une projection bien placée saura résoudre ce problème.
La jointure étudiée est ici une jointure symétrique, aussi appelée jointure interne en langage SQL. Elle exigequ’il y ait des données de part et d’autre de la jointure, c’est-à-dire que l’élément e sur lequel on fait la jointure
doit exister dans les deux relations R et R′.
Si un élément de R n’a pas de correspondance dans R′ (et réciproquement), cet élément n’apparaîtra pas dans
la jointure.
La jointure est obtenue avec le mot clé JOIN . . . ON. La jointure de l’exemple ci-dessus s’écrit :
SQ
L SELECT *FROM voitures JOIN Constructeurs ON marque=Constructeur ;
Rq
En cas d’ambiguïté sur le nom d’un attribut ou lorsque les attributs servant à joindre deux tables ont le même
nom, on peut utiliser un préfixe de table.
Si les deux relations constructeurs et voitures étaient sous cette forme :
voitures
marque modèle carburant cylindrée ( cm3)
Mercedes C200 Essence 1796
Subaru Impreza Essence 1994
Bugatti Veyron Essence 7993
Constructeurs
marque Pays Groupe
Mercedes Allemagne Daimler
Bugatti France Volkswagen
Subaru Japon Subaru
On pourrait réaliser la jointure sur la marque suivante :
SQ
L SELECT *FROM voitures JOIN Constructeurs ON voitures.marque=Constructeurs.marque ;
On peut, pour alléger, utiliser un alias pour renommer les tables.
Lycée SainteGeneviève 2019/2020 page 17/22

Info Algèbre relationnelle et bases de données PTSIR
q
On peut aussi rencontrer une requête de la forme suivante lorsque les attributs des 2 tables considérées sont
identiques (syntaxe hors programme) :SELECT * FROM voitures JOIN constructeurs USING marque ;
5.3. Agrégation
Les opérations étudiées jusqu’à présent sont des fonctions scalaires : elles s’appliquent à chaque ligne ou nuplet indé-pendamment.
Les fonctions d’agrégation regroupent les lignes pour effectuer une opération.
Les fonctions d’agrégation classiques sont :
⋄ comptage(A) : compte le nombre d’éléments d’attribut A,
⋄ max(A) (resp. min(A)) : renvoi le plus grand (resp. le plus petit) élément de A,
⋄ somme(A) : donne la somme des éléments de A,
⋄ moyenne(A) : donne la valeur moyenne des éléments de A.
5.3.1. Formalisme relationnel
Pour toutes les explications qui suivent, on va travailler avec la relation suivante :
voitures
marque modèle carburant cylindrée ( cm3)
Mercedes C63 AMG Essence 6208
Mercedes C200 Essence 1796
Mercedes C200 Diesel 2143
Subaru Impreza Essence 1994
Subaru Impreza Diesel 1998
Subaru WRX STI Essence 2457
Bugatti Veyron Essence 7993
Renault Twingo Essence 1149
Abarth 500 Essence 1368
Fiat 500 Essence 1242
Fiat 500 Diesel 1248
Lors de la réalisation d’une agrégation, on doit distinguer deux opérations distinctes :
• l’application de la fonction d’agrégation.
• le regroupement éventuel des valeurs.
Lycée SainteGeneviève 2019/2020 page 18/22

Info Algèbre relationnelle et bases de données PTSI
• Application des fonctions d’agrégation sans regroupement
A une relation R donnée, on peut appliquer des fonctions d’agrégation à un ou plusieurs attributs et obtenir ainsi des
statistiques globales sur cette table.
L’agrégation de la relation R en appliquant la fonction f à l’attribut A se note de la manière suivante :
γf(A)(R).
Exe
mple
Si on cherche la plus grande cylindrée dans la relation voitures :
γmax(cylindrée)(voitures)
max(cylindrée)
7993
Il est possible d’appliquer de plusieurs fonctions d’agrégation à une même relation.
On considère :
⋄ les attributs B1, . . . , Bn ∈ S ,
⋄ les fonctions d’agrégation f1, . . . , fn.
La relation obtenue par application des fonctions f1, . . . , fn aux attributs B1, . . . , Bn ∈ S est notée :
γf1(B1),...,fn(Bn)(R).
Exe
mple
Si on cherche les cylindrées extrêmes dans la relation voitures :
γmax(cylindrée),min(cylindrée)(voitures)
max(cylindrée) min(cylindrée)
7993 1149
Lycée SainteGeneviève 2019/2020 page 19/22

Info Algèbre relationnelle et bases de données PTSI
• Application des fonctions d’agrégation avec regroupement
Au lieu d’appliquer la fonction d’agrégation à la totalité de la table, il est possible de regrouper les éléments selon un
ou plusieurs attributs pour ensuite appliquer la fonction à chacun des regroupements.
Commençons par un exemple pour voir ce que peut donner un tel regroupement.Si on cherche les cylindrées moyennes pour chaque marque, il faut appliquer le calcul de la moyenne aux éléments
ayant comme attribut commun la marque :
marque γmoy(cylindrée)(voitures)
marque moy(cylindrée)
Mercedes 3382,33
Subaru 2149,67
Bugatti 7793
Renault 1149
Abarth 1368
Fiat 1245
Soient R(S) une relation, A1, . . . , An, B1, . . . , Bm ∈ S et f1, . . . , fm des fonctions d’agrégation. On note
A1, ..., Anγf1(B1),...,fm(Bm)
la relation obtenue
⋄ en regroupant les valeurs de R qui sont identiques sur les attributs A1, . . . , An,
⋄ et en définissant de nouveaux attributs fi(Bi) pour ces valeurs regroupées pour tout i ∈ [1, m] par applicationde la fonction d’agrégation fi sur chacun de ces agrégats sur l’attribut Bi.
• Application des fonctions d’agrégation avec sélection en amont ou en aval
Il est tout à fait possible de composer l’agrégation avec une sélection :
⋄ en amont : A1, ..., Anγf1(B1),...,fm(Bm) ◦ σU (R).
La sélection σU est effectuée avant l’agrégation. Elle porte donc sur la relation R et la condition U porte sur les
attributs de R.
On commence par faire une sélection des lignes ou nuplets, puis on applique à cette sélection la fonction d’agrégation
(ou les fonctions d’agrégation) avec ou sans regroupement.
⋄ en aval : σU ◦A1, ..., Anγf1(B1),...,fm(Bm)(R).
La sélection σU est effectuée après l’agrégation. Elle porte donc sur la relation γ et la condition U porte sur les
attributs de γ.
On applique la fonction d’agrégation sur la table entière, puis on applique la sélection.
Lycée SainteGeneviève 2019/2020 page 20/22

Info Algèbre relationnelle et bases de données PTSIR
q
Dans la mesure du possible, il faut toujours réaliser les sélections en amont, car cela limite le nombre de valeurs
à considérer dans l’agrégation.Cependant, lorsque l’on désire sélectionner en fonction du résultat des fonctions d’agrégation, il est obligatoire
de le faire en aval.
5.3.2. Commande SQL
Les fonctions f sont les suivantes :
fonction d’agrégation Langage SQL
comptage COUNT
maximum MAX
minimum MIN
moyenne AVG
somme SUM
• Agrégation simple, sans regroupement
La traduction de γf(A)(R) en langage SQL se fait avec :
SQ
L SELECT f (A) FROM R ;
Ainsi, la recherche de la cylindrée maximale dans la table voitures s’écrit :
SQ
L SELECT MAX (cylindrée) FROM voitures ;
La recherche de la cylindrée minimale et de la cylindrée maximale dans la table voitures s’écrit :
SQ
L SELECT MIN (cylindrée), MAX (cylindrée) FROM voitures ;
• Agrégation avec regroupement - Commande : GROUP BY
Pour appliquer une fonction d’agrégation f à un attribut B pour des regroupements A : Aγf(B)(R), on utilise lacommande GROUP BY :
SQ
L SELECT A , f (Bm) FROM R GROUP BY A ;
Lycée SainteGeneviève 2019/2020 page 21/22

Info Algèbre relationnelle et bases de données PTSI
L’expression générale : A1, ..., Anγf1(B1),...,fm(Bm)(R) :
SQ
L SELECT A1 , . . . , An , f1 (B1) , . . . , fm (Bm) FROM R GROUP BY A1 , . . . , An ;
L’affichage des cylindrées moyennes par marque s’obtient avec la requête suivante :
SQ
L SELECT marque , AVG (cylindrée) FROM voitures GROUP BY marque ;
• Fonctions d’agrégation avec sélection en amont ou en aval
⋄ La sélection en amont se fait comme une sélection classique, c’est-à-dire avec le mot clé WHERE.
A1, ..., Anγf1(B1),...,fm(Bm) ◦ σU (R) s’obtient avec :
SQ
L
SELECT A1 , . . . , An , f1 ( B1 ) , . . . , fm ( Bm ) FROM R WHERE U GROUP BY
A1 , . . . , An ;
L’affichage des cylindrées moyennes par marque des voitures de carburant essence s’obtient avec la requête
suivante :
SQ
L
SELECT marque , AVG (cylindrée) FROM voitures WHERE carburant =
"Essence" GROUP BY marque ;
Rq
Attention à l’ordre des mots clés. WHERE porte sur la relation R. Il doit donc être juste après l’instruction
FROM R et avant l’instruction de regroupement.
⋄ La sélection en aval se fait avec le mot clé HAVING.
σU ◦A1, ..., Anγf1(B1),...,fm(Bm)(R) s’obtient avec :
SQ
L
SELECT A1 , . . . , An , f1 ( B1 ) , . . . , fm ( Bm ) FROM R GROUP BY A1 , . . . , An
HAVING U ;
L’affichage des cylindrées moyennes supérieures à 1500 par marque des voitures s’obtient avec la requête suivante :
SQ
L SELECT marque , AVG (cylindrée) FROM voitures GROUP BY marque HAVING AVG (cylindrée) >1500;
Rq
HAVING porte sur le résultat de la fonction d’agrégation. Il doit donc être placé à la fin de l’instruction toujours
après un GROUP BY.
Lycée SainteGeneviève 2019/2020 page 22/22





























