Embed Size (px)
Citation preview

BNF101STRUCTURE D’UNE BASE DE DONNEES
LE MODELE RELATIONNEL

INTRODUCTION
Une base de données (BD) est un ensemble structuré d'information qui peut être utilisé simultanément par plusieurs utilisateurs grâce aux fonctions offertes par un composant logiciel appelé système de gestion de bases de données (SGBD).
Cet ensemble structuré d'information peut modéliser un univers réel composé d'objets interliés comme par exemple représenter l'univers de vente d'une société.Les objets d'un même type constituent une entité et le lien entre deux entités est appelé association. Entité et association peuvent être décrites par un ensemble de caractéristiques.La description des entités et des associations se fait en utilisant l'un des modèles connus sur lesquel s'appuient aussi les SGBD:
INTRODUCTION (suite)
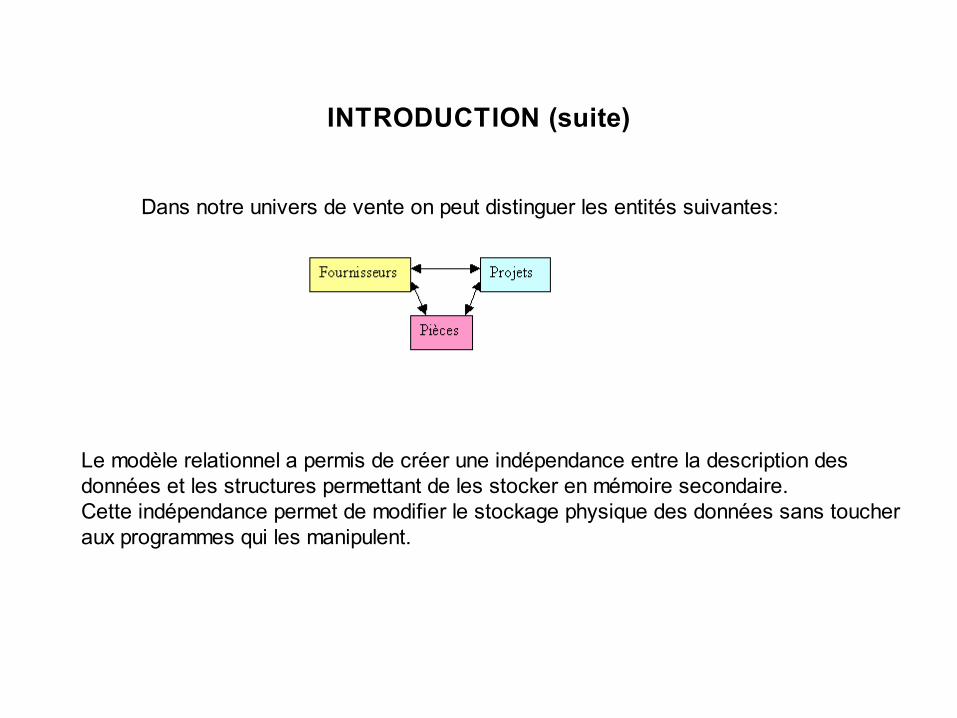
Dans notre univers de vente on peut distinguer les entités suivantes:
Le modèle relationnel a permis de créer une indépendance entre la description des données et les structures permettant de les stocker en mémoire secondaire.Cette indépendance permet de modifier le stockage physique des données sans toucher aux programmes qui les manipulent.

LE MODELE RELATIONNEL
Le modèle relationnel consiste à représenter aussi bien les entités que les liens (associations) à l'aide de relations appelées tables. Chaque table décrit alors une partie de l'univers concerné.
Une table est une structure tabulaire dont les colonnes, appelées attributs, correspondent aux caractéristiques de l'entité. Les lignes sont généralement appelées occurence, tuples ou n-uplets, ils correspondent aux objets de l'univers.
Tout attribut est désigné par un nom et caractérisé par un domaine. Un domaine est un type de données.
LE MODELE RELATIONNEL
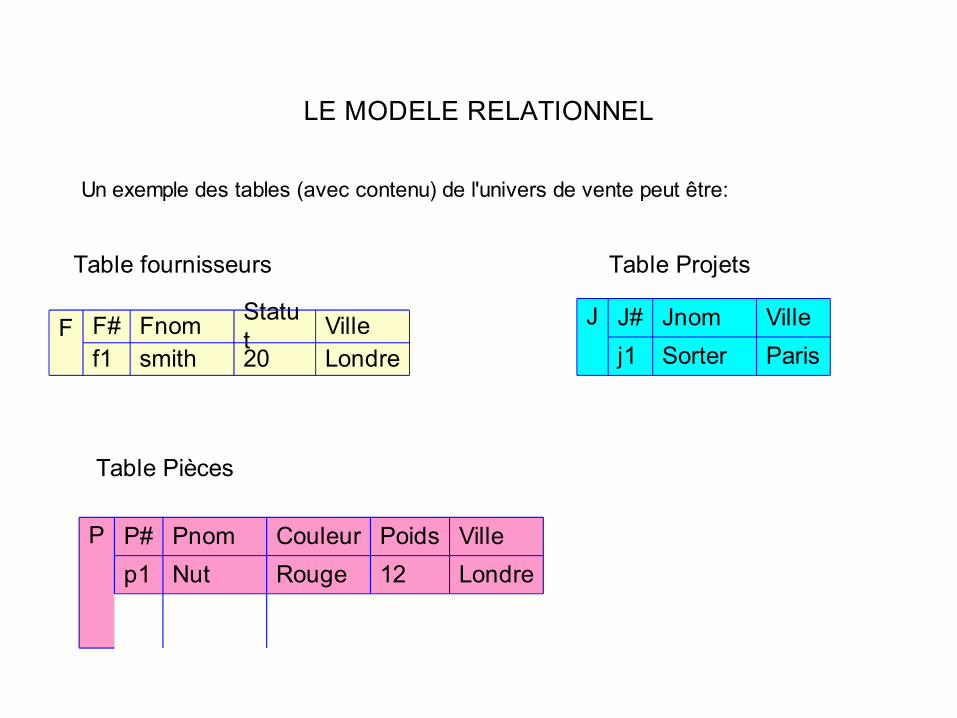
Un exemple des tables (avec contenu) de l'univers de vente peut être:
Table fournisseurs
Londre20smithf1VilleStatu
tFnomF#F
Table Projets
ParisSorterj1VilleJnomJ#J
Table Pièces
Londre12RougeNutp1VillePoidsCouleurPnomP#P
LE MODELE RELATIONNEL
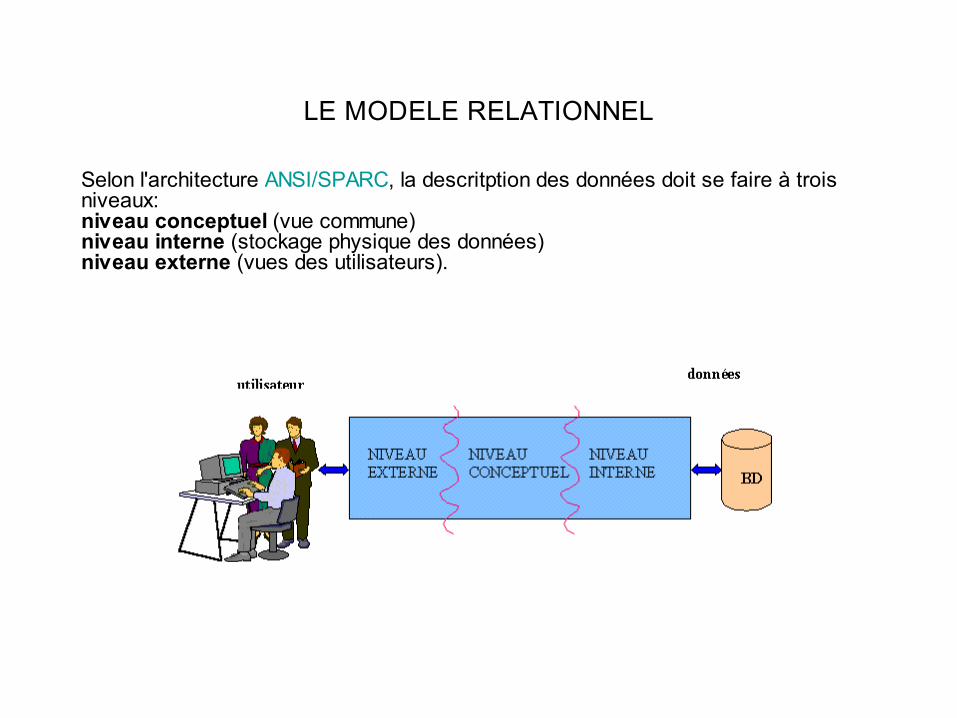
Selon l'architecture ANSI/SPARC, la descritption des données doit se faire à trois niveaux: niveau conceptuel (vue commune)niveau interne (stockage physique des données) niveau externe (vues des utilisateurs).

LE NIVEAU CONCEPTUEL
Le niveau conceptuel correspond à la phase de description de l'univers réel représenté par la base de données en utilisant les concept du modèle choisi. Il s'agit de décrire:
1) les entités du monde réel: ce sont les objets pouvant être identifiés distinctement, comme par exemple les entités Fournisseur, Pièce et Projet .
2) les attributs: ce sont les caractéristiques ou propriétés des entités, les attributs de l'entité Projet déja recensée peuvent être:
VilleJnomJ#
Un attribut peut être obligatoire ou facultatif, mais tout attribut a un domaine de valeurs

LE NIVEAU CONCEPTUEL
3) les relations : qu'on peut aussi nomer associations, elles représentent les liens existants entre les entités. Elles sont caractérisées, comme les entités, par un nom et des attributs.Une relation (souvent notée R) peut aussi être considérée comme un sous-ensemble d’un produit cartésien de domaines.Pour une relation on distingue le degré d’une relation qui peut être défini comme le nombre de facteurs de ce produit cartésien.
4) les cardinalités : la cardinalité est le nombre de participation d’entité à une relation.
Cardinalité un à un : si et seulement si par exemple un employé ne peut être directeur que dans un seul département et un département n’a qu’un seul employé comme directeur.
Cardinalité un à plusieurs : un département peut occuper plusieurs employés qui réalisent différentes fonctions mais chaque employé ne fait partie que d’un seul département.
Cardinalité plusieurs à plusieurs : un type de produit peut être fabriqué en plusieurs usines et une usine peut fabriquer plusieurs types de produits.

LE NIVEAU CONCEPTUEL
Pour une relation on peut aussi distinguer ses contraintes d'intégrité.Une contrainte d'intégrité associée à une relation concerne les règles de manipulation ou de gestion d'une relation avec les autres.C'est une propriété du monde que l'on va modéliser comme par exemple le fait qu'un employé a un chef et un seul. 5) les clef : parmi tous les attributs de l’entité, la clef (appelée aussi identifiant) est un attribut ou un ensemble d’attributs permettant de déterminer une et une seule occurence à l’intérieur de l’ensemble. La clef identifie sans ambiguité et de façon unique chaque n-uplet.On distingue deux classes de clefs: Clé primaire: ensemble d’attributs dont les valeurs permettent de distinguer les tuples les uns des autres, ces identifiants sont souvent soulignés lors des représentations schématique, comme par exemple le numéro d'une pièce ou le numéro du passeport.Clé étrangère: attribut qui est clé primaire d’une autre relation. Ainsi pour connaître le fournisseur de chaque produit il faut par exemple ajouter l’attribut numéro de fournisseur à la relation pièce.
La phase conceptuelle se termine par la génération du schéma conceptuel .

LE NIVEAU INTERNE
Dans ce niveau les entités du schéma conceptuel sont transformées en tableaux à deux dimensions. Dans cette phase il s'agit de spécifier comment les objets recensés au niveau supérieur seront stockés sur mémoire secondaire et comment on y accède. C'est une traduction du schéma conceptuel (schéma Entité/Association) en schéma relationnel ou relations.Les entités et associations seront transformées en table. Au cours de cette phase on parlera d'enregistrements, de mémoire, de fichier et d'index.On se situe juste au dessus de la couche physique (blocs, pages mémoire).
Cette phase génère le schéma interne.

LE NIVEAU EXTERNE
Dans cette phase il s'agit d'indiquer la façon avec laquelle les utilisateurs voient les entités du schéma conceptuel dans leur manipulation de la base, on parle alors de vue.
Ces différentes vues sont décrites à l'aide de schéma externes ou sous-schéma.On identifie un schéma externe par groupe d’utilisateurs pour définir la vue de la base pour ces utilisateurs. Dans ce niveau on est proche de l'utilisateur, final qui gère les rapports avec les programmes d'application.Cette distinction des niveaux permet d'assurer certaines indépendances entre données et traitements :- indépendance physique: modifier l'organisation physique des données n'oblige pas de réercire les programmes qui les manipulent.- indépendance logique: modifier le schéma conceptuel n'oblige pas à modifier les programmes d'application. Toutefois on peut être amené à modifier le schéma externe.- indépendance par rapport aux stratégies d'accès : un programme d'application ne se soucie pas du comment on accède à telle donnée.
LA NORMALISATION
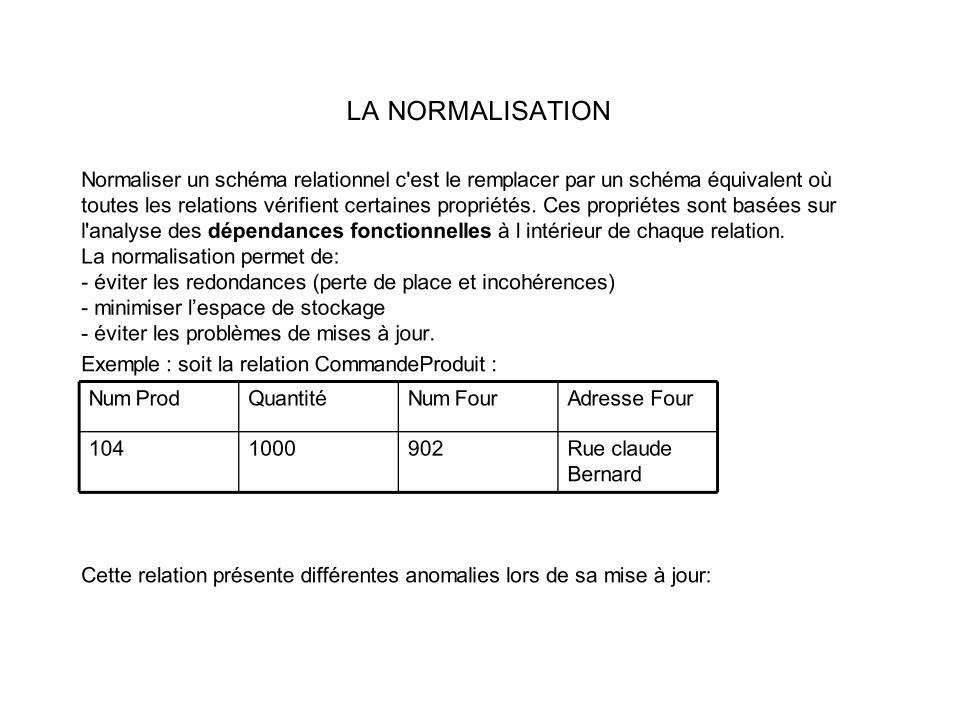
Normaliser un schéma relationnel c'est le remplacer par un schéma équivalent où toutes les relations vérifient certaines propriétés. Ces propriétes sont basées sur l'analyse des dépendances fonctionnelles à l intérieur de chaque relation.La normalisation permet de:- éviter les redondances (perte de place et incohérences)- minimiser l’espace de stockage- éviter les problèmes de mises à jour.Exemple : soit la relation CommandeProduit :
Cette relation présente différentes anomalies lors de sa mise à jour:
Rue claude Bernard
9021000104
Adresse FourNum FourQuantitéNum Prod

LA NORMALISATION
- Anomalies de modification:Si on souhaite modifier l'adresse d un fournisseur, il faut le faire pour tous les tuples concernés (produits qu'il fournit).- Anomalies d insertion: Pour ajouter un nouveau fournisseur, il faut obligatoirement fournir des valeurs pour NumProd et Quantité(ajouter un nouveau produit).- Anomalies de suppression : La suppression par exemple du produit 104 fait perdre toutes les informations concernant le fournisseur 902.
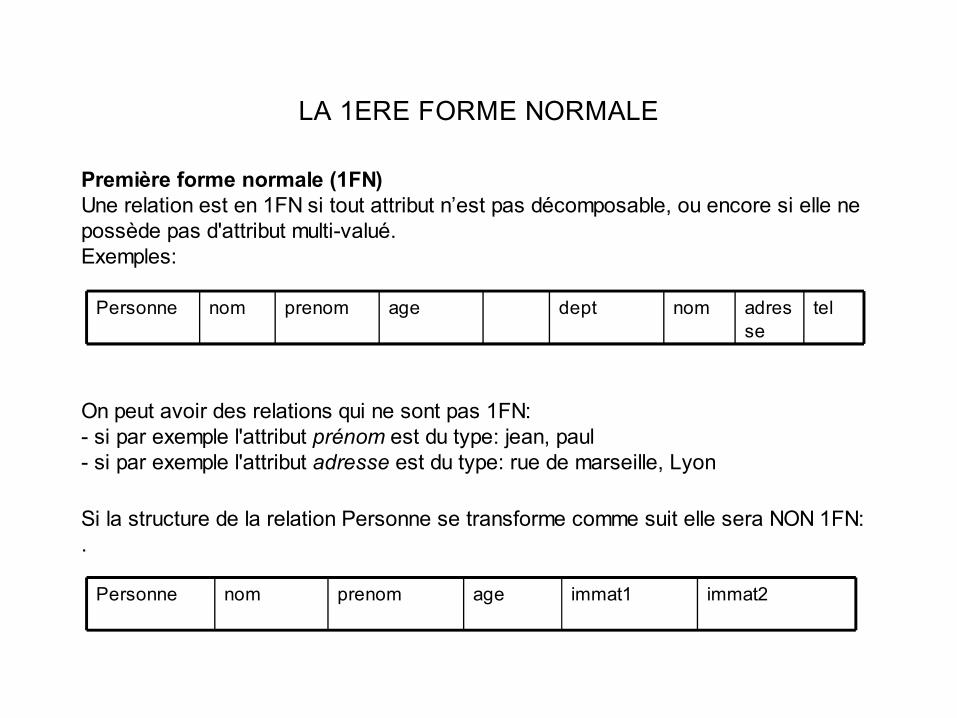
LA 1ERE FORME NORMALE
Première forme normale (1FN)Une relation est en 1FN si tout attribut n’est pas décomposable, ou encore si elle ne possède pas d'attribut multi-valué.Exemples:
On peut avoir des relations qui ne sont pas 1FN:- si par exemple l'attribut prénom est du type: jean, paul- si par exemple l'attribut adresse est du type: rue de marseille, Lyon
Si la structure de la relation Personne se transforme comme suit elle sera NON 1FN:.
adresse
telnomdeptageprenomnomPersonne
immat2immat1ageprenomnomPersonne

LA 1ERE FORME NORMALE
les problèmes posés par cette structure sont:- on ne peut pas enregistrer plus de deux véhicules- si la personne ne possède qu un seul véhicule, Immat 2 prend de la place inutilement
Pour résoudre ce cas on peut proposer de créér une nouvelle table pour l'attribut multi-valué:1. On créé une nouvelle relation contenant un attribut (une valeur de l'attribut multi-valué)2. On fait le lien entre la nouvelle relation et la première relation en ajoutant à la nouvelle relation la clé primaire de la première relation3. Ce nouvel attribut est une clé externe Nouveau schéma en 1FN et ce en considérant deux tables :
Immatricule
NumPersVéhiculeageprénomnomNumPersPersonne

LA 2eme FORME NORMALE
Deuxième forme normale (2FN)
Une relation est en 2FN si:Elle est en 1FN, Tout attribut, non clef primaire, est dépendant de la clef primaire.Exemple de relation en 1FN mais pas en 2FN :
NomEmployéFonctionNumEmployéNumProjetProjet
Problèmes- on ne peut enregistrer un employé que s'il participe à un projet - si un employé participe à plusieurs projets, on doit répéter les informations sur cet employé (redondance et problèmes de m-à-j)
Une solution peut être proposée qui consiste à extraire la dépendance fonctionnelle:1. On créé une nouvelle relation contenant l'attribut déterminé par une partie de la clé primaire 2. La clé primaire de la nouvelle relation est cette partie de la clé

LA 2EME FORME NORMALE
NumEmployé est à la fois clé primaire et clé externe dans ProjetOn peut aussi étudier d'autres relations comme :
villerueDate naissance
PrénomNomNumClient
CLIENT
NomEmployé
Numprojet
projet FonctionNomEmployé
NumEmployé
Employé
Cette relation est en 2FN par contre la suivante n'est pas en 2FN
villeN° FOURNISSEURquantitéN° PRODUIT
COMMANDE_PRODUIT
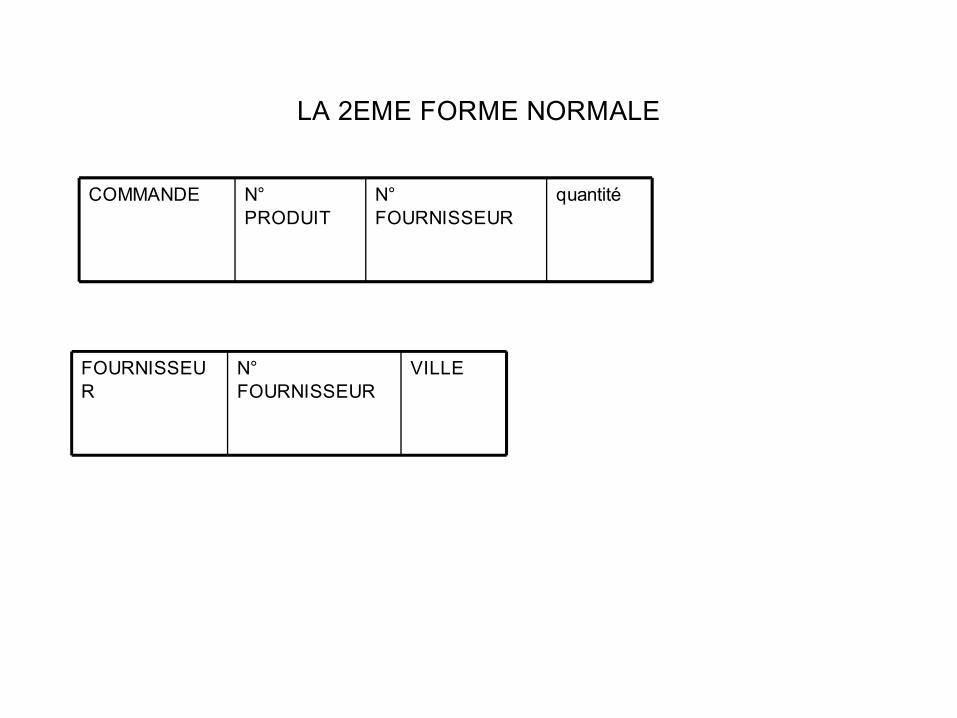
LA 2EME FORME NORMALE
quantitéN° FOURNISSEUR
N° PRODUIT
COMMANDE
VILLEN° FOURNISSEUR
FOURNISSEUR

LA 3EME FORME NORMALE
NUMSERVICE
NOMSERVICE
NOM EMPLOYE
NUM EMPLOYE
EMPLOYE
Troisième forme normale (3FN)
Une relation est en 3FN si: Elle est en 2FN,Il n’existe aucune DF entre deux attributs non clef primaire
Exemple : relation en 2FN mais pas en 3FN

LA 3EME FORME NORMALE
NOM SERVICENUM SERVICESERVICE
Problèmes - Nom du service répété pour tous ses employés (redondance) - Si on ajoute une information sur le service, il faut la rajouter dans tous les tuples des employés du service Solution : on extrait la dépendance fonctionnelle :
1. On créé nouvelle relation contenant l'attribut déterminé par l'attribut non-clé (partie droite de la DF) 2. La clé primaire de la nouvelle relation est l'attribut déterminant (partie gauche de la DF)3. Cette clé primaire devient une clé externe dans l'ancienne relation
NUMSERVICE
NOM EMPLOYE
NUM EMPLOYE
EMPLOYE

Pourquoi des langages de manipulation de données relationnelles? La structure des relations étant semblable à celle des tableaux en mémoire centrale, on peut se demander pourquoi avoir inventé des langages spéciaux d'interrogation et de mise à jour pour les relations.
Avec un tel concept l'utilisateur est obligé d'apprendre un autre langage spécifique des bases de données.Le problème est que sans ces langages algébriques les programmes des utilisateurs doivent connaître l'organisation des tuples dans les relations pour accéder plus rapidement aux informations dont ils ont besoin.
Par exemple, si la relation Etudiant est triée selon les noms des étudiants, un programme efficace cherchant des informations sur l'étudiante Zazi, partira de la fin de la relation.
LE LANGAGE ALGEBRIQUE

Le résultat est que l'indépendance - recherchée dans les SGBDs - entre les programmes et les données n'est plus réalisée. Les utilisateurs doivent connaître l'organisation des données (existence de tri, d'index,....). D'autre part tout changement dans cette organisation impliquera des changements dans les programmes des utilisateurs.
Les langages de manipulation de données (LMD) doivent donc être aussi conceptuels que possible, c'est-à-dire ne porter que sur les concepts du schéma (relations, attributs, domaines) et ignorer tout de l'organisation interne des relations. Ils doivent aussi être efficaces, avec des temps de réponse courts même si la base de données est très grande. Aussi les LMD offrent-ils un éventail de fonctions limité à celles qu'on sait optimiser, mais assez vaste pour permettre d'exprimer la plupart des requêtes.
LE LANGAGE ALGEBRIQUE (SUITE)

Le modèle relationnel a été à l'origine proposé avec deux LMD de base, l'algèbre relationnelle et le calcul des tuples, équivalents en puissance et qui ont fixé l'ensemble des fonctions que tout LMD relationnel doit offrir.
En plus des fonctions de l'algèbre ou du calcul, ces LMD offrent généralement des possibilités de mise à jour de la base de données, et d'utilisatin d'expressions arithmétiques et de fonctions d'agrégation telles que cardinalité, somme, minimum, maximum et moyenne.
L'intérêt de l'algèbre relationnelle est multiple:- l'algèbre a identifié les opérateurs fondamentaux d'utilisation d'une base de données relationnelle,
- ces opérateurs ont défini les principales fonctions à optimiser dans les SGBD relationnels,
- l'algèbre a donné naissance à des LMD pour les utilisateurs. SQL est le LMD relationnel le plus répandu du fait que c'est la seule norme existante pour les LMD relationnels.
LANGAGE DE MANIPULATION DE DONNEE ALGEBRIQUE

L’algèbre relationnelle est un ensemble d'opérateurs qui, à partir d'une ou deux relations existantes, créent en résultat une nouvelle relation temporaire (c'est-à-dire qui a une durée de vie limitée, généralement la relation est détruite à la fin du programme utilisateur ou de la transaction qui l'a créée).
La relation résultat a exactement les mêmes caractéristiques qu'une relation de la base de données et peut donc être manipulée de nouveau par les opérateurs de l'algèbre.
Formellement l'algèbre comprend: - cinq opérateurs de base: sélection, projection, union, différence et produit,- un opérateur syntaxique, renommer, qui ne fait que modifier le schéma et pas les tuples.
L’ALGEBRE RELATIONNEL

A partir de ces opérateurs, d'autres opérateurs ont été proposés qui sont équivalents à la composition de plusieurs opérateurs de base. Ces nouveaux opérateurs, appelés opérateurs déduits, sont des raccourcis d'écriture, qui n'apportent aucune fonctionnalité nouvelle, mais qui sont pratiques pour l'utilisateur lors de l'écriture des requêtes.
Nous présentons les opérateurs de base et renommer ainsi que les opérateurs déduits les plus fréquents:intersection, jointure naturelle, thêta jointure et division.
Les opérateurs de l'algèbre peuvent être regroupés en deux classes:
- les opérateurs provenant de la théorie mathématique sur les ensembles : union, intersection, différence, produit;
- les opérateurs définis spécialement pour les bases de données relationnelles: sélection, projection, jointure, division et renommage.
L’ALGEBRE RELATIONNEL (SUITE)

Projection pOn peut la représenter schématiquement comme: Relation * Liste d'attributs -> Relation. La notation utilisée est : PROJY(R) ou pY(R) Elle ne conserve que les types d'attributs (colonnes) Y de la relation et supprime les doublons.
Cet opérateur construit une relation résultat où n'apparaissent que certains attributs de la relation initiale ou encore en termes de tableau, cela revient à extraire certaines colonnes.
Exemple avec la relation R représentée par la table COMMANDE:
LES OPERATEURS :La projection

Sélection s
Cet opérateur construit une relation résultat où n'apparaissent que certains tuples de la relation initiale, en termes de tableau, cela revient à extraire certaines lignes. Les tuples retenus sont ceux satisfaisant une condition explicite, appelée prédicat de sélection.
Schématiquement la relation peut être représentée comme suit: Relation* Expression Logique -> Relation.
La notation utilisée est : SELECT C(R) ou s C (R).
La sélection ne conserve de la relation que les tuples (lignes) qui vérifient l'expression logique sur noms d'attributs (construite avec les opérateurs logiques ¬, ̂et les comparaisons =, <, >). Le schéma relationnel est conservé comme le montre l'exemple de la relation R suivante:
LES OPERATEURS :La sélection

Le Produit Cartésien
Le produit cartésien entre relations peut être schématiquement représenté par: Relation * Relation -> Relation
On peut trouver les notations suivantes : PROD(R1, R2) ou R1* R2
Il est à remarquer que l'on doit renommer les types d'attributs que R1 et R2 ont en commun, puis on concatène chaque tuple de la relation R1 avec chaque tuple de la relation R2 pour former l'extension.
Remarques : - On doit renommer les types d'attributs en double. - On obtient toutes les combinaisons possibles.
LES OPERATEURS :Le produit cartésien

La têta-jointure
Schématiquement la T-jointure peut être représentée par:Relation * Relation * T-Expression -> Relation.
On peut noter cela par : JOIN T-Expression (R,S) ou bien R T-Expression S.
La jointure est la superposition de tout enregistrement de R avec un enregistrement de S dans laquelle on ne garde que les tuples qui vérifient la T-Expression.
Remarque : Comme pour le produit cartésien, on renommera les types d'attributs communs à R et à S.
LES OPERATEURS :La têta jointure





























