Embed Size (px)
Citation preview

CONSERVATOIRE NATIONAL DES ARTS ET MÉTIERSCENTRE RÉGIONAL DE LORRAINE
CENTRE D’ENSEIGNEMENT DE METZ
CONCEPTION ET DÉPLOIEMENT D’UNEGRILLE DE CONTRÔLE DE PROCESSUS
PHYSIQUES
MÉMOIRE EN INFORMATIQUE
PRÉSENTÉ PAR
SABATIER Fabrice
Soutenu à Metz le 6 septembre 2004
JURY
Président : Monsieur Jean-Pierre ARNAUD,
Membres : Monsieur Stéphane VIALLE, Professeur PrincipalMonsieur Laurent Watrin,Monsieur Claude Lhermitte,Monsieur Hervé Frezza-Buet.

Table des matières i
Remerciements
Mes remerciements vont tout particulièrement à :
Monsieur Stéphane VIALLE, chercheur et enseignant à SUPELEC, pour ses conseils en programma-tion
Monsieur Hervé FREZZA-BUET, chercheur et enseignant à SUPELEC, pour ses conseils sur l’utili-sation de la bibliothèque de commandes du Koala
L’équipe système informatique de SUPELEC

Table des matières ii
Table des matières
Introduction v
1 Les « Grilles » de calcul et de ressources 11.1 Les besoins et l’enjeux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.1.1 La Grille d’information . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.1.2 La Grille de calcul . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.1.3 L’ingénierie concourante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 L’historique du « Grid computing » . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.3 Le concept de Grille . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.4 Quelques exemples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.4.1 Les projets européens DATAGRID et EGEE . . . . . . . . . . . . . . . . . . . . 61.4.2 Le projet européen EUROGRID . . . . . . . . . . . . . . . . . . . . . . . . . . 91.4.3 La plate-forme RNTL e-Toile . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.5 Notre projet de Grille de contrôle de processus physiques . . . . . . . . . . . . . . . . . 12
2 Le GridRPC et DIET 152.1 Le GridRPC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.1.1 Le modèle de base . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.2 L’architecture de DIET . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.2.1 Les composants de DIET . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192.2.2 Le fonctionnement général de DIET . . . . . . . . . . . . . . . . . . . . . . . . 20
3 Application robotique et architecture client-serveur initiale 233.1 L’application robotique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.1.1 Description . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233.1.2 Sa plate-forme matérielle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233.1.3 Ses modules logiciels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.1.3.1 Le module de localisation . . . . . . . . . . . . . . . . . . . . . . . . 243.1.3.2 Le module de navigation . . . . . . . . . . . . . . . . . . . . . . . . 25
3.2 L’architecture client-serveur de contrôle du robot . . . . . . . . . . . . . . . . . . . . . 273.2.1 Vue d’ensemble . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 273.2.2 Qu’est-ce que la bibliothèque nono? . . . . . . . . . . . . . . . . . . . . . . . . 27
3.2.2.1 Principe de base de la bibliothèque nono . . . . . . . . . . . . . . . . 293.2.2.2 Structure de la bibliothèque nono . . . . . . . . . . . . . . . . . . . . 293.2.2.3 Le protocole de la bibliothèque nono . . . . . . . . . . . . . . . . . . 313.2.2.4 L’annuaire de ressources . . . . . . . . . . . . . . . . . . . . . . . . 323.2.2.5 Réveil du serveur lors de la réception de nouvelles requêtes . . . . . . 33
3.2.3 Qu’est-ce que la bibliothèque koala? . . . . . . . . . . . . . . . . . . . . . . . . 333.2.3.1 Structure de la bibliothèque koala . . . . . . . . . . . . . . . . . . . . 343.2.3.2 Création d’une application cliente . . . . . . . . . . . . . . . . . . . . 38

Table des matières iii
3.2.4 Qu’est-ce que la bibliothèque nonovideo? . . . . . . . . . . . . . . . . . . . . . 393.2.4.1 Structure de la bibliothèque nonovideo . . . . . . . . . . . . . . . . . 39
4 Conception d’une nouvelle architecture logicielle adaptée à une Grille 424.1 Vue d’ensemble de l’environnement de Grille expérimentale . . . . . . . . . . . . . . . 43
4.1.1 Les caractéristiques du robot . . . . . . . . . . . . . . . . . . . . . . . . . . . . 434.1.2 L’application robotique expérimentée . . . . . . . . . . . . . . . . . . . . . . . 444.1.3 La configuration du VPN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 444.1.4 L’environnement de Grille . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 454.1.5 Les services de la Grille expérimentale . . . . . . . . . . . . . . . . . . . . . . 45
4.2 L’architecture du logiciel de Grille . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 454.3 La Grille orientée serveur de robots . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.3.1 Les besoins spécifiques pour contrôler le robot . . . . . . . . . . . . . . . . . . 464.3.2 Le service d’annuaire de ressources . . . . . . . . . . . . . . . . . . . . . . . . 474.3.3 L’utilisation de buffers d’historique . . . . . . . . . . . . . . . . . . . . . . . . 47
4.3.3.1 Élaboration du mécanisme de concurrence . . . . . . . . . . . . . . . 484.3.3.2 Algorithme de mémorisation . . . . . . . . . . . . . . . . . . . . . . 49
5 Déploiement et installation d’une Grille multi-sites 555.1 Réseaux privés virtuels . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
5.1.1 IPSec . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 585.1.1.1 Architecture d’IPsec . . . . . . . . . . . . . . . . . . . . . . . . . . . 595.1.1.2 Principe de fonctionnement . . . . . . . . . . . . . . . . . . . . . . . 61
5.1.2 Types d’utilisations possibles . . . . . . . . . . . . . . . . . . . . . . . . . . . 625.1.2.1 Équipement fournissant IPsec . . . . . . . . . . . . . . . . . . . . . . 625.1.2.2 Modes de fonctionnement . . . . . . . . . . . . . . . . . . . . . . . . 64
5.1.3 Les projets Open Source IPsec . . . . . . . . . . . . . . . . . . . . . . . . . . . 645.1.4 Sécurisation de l’accès au VPN . . . . . . . . . . . . . . . . . . . . . . . . . . 645.1.5 Architecture sécurisée de notre Grille . . . . . . . . . . . . . . . . . . . . . . . 65
5.2 Protocole d’accès au service d’annuaire . . . . . . . . . . . . . . . . . . . . . . . . . . 655.2.1 Les concepts de LDAP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 665.2.2 Le protocole LDAP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 665.2.3 Le modèle de données arborescentes . . . . . . . . . . . . . . . . . . . . . . . . 66
5.2.3.1 Les attributs des entrées . . . . . . . . . . . . . . . . . . . . . . . . . 675.2.4 Le partitionnement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
5.2.4.1 Le service « referral » . . . . . . . . . . . . . . . . . . . . . . . . . . 685.2.4.2 Le service « replication » . . . . . . . . . . . . . . . . . . . . . . . . 69
5.2.5 L’annuaire de notre Grille locale . . . . . . . . . . . . . . . . . . . . . . . . . . 695.3 Déploiement de l’environnement de Grille DIET . . . . . . . . . . . . . . . . . . . . . 70
5.3.1 Déploiement des services CORBA . . . . . . . . . . . . . . . . . . . . . . . . . 705.3.2 Déploiement et configuration de DIET . . . . . . . . . . . . . . . . . . . . . . . 71
6 API - Application Programming Interface 736.1 Principes de l’API côté client . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
6.1.1 Les appels GridRPC de l’API . . . . . . . . . . . . . . . . . . . . . . . . . . . 746.1.2 L’algorithmique de Grille . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
6.2 Architecture de l’API côté client . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 756.2.1 Structure type d’un client pour un service de haut niveau . . . . . . . . . . . . . 756.2.2 Description du service de localisation . . . . . . . . . . . . . . . . . . . . . . . 766.2.3 Description du service de navigation . . . . . . . . . . . . . . . . . . . . . . . . 80

Table des matières iv
6.2.4 Description du service de mesure de luminosité . . . . . . . . . . . . . . . . . . 826.2.5 Extensibilité de notre API côté client . . . . . . . . . . . . . . . . . . . . . . . 84
6.3 Conception d’une application robotique de Grille . . . . . . . . . . . . . . . . . . . . . 856.4 Principes de l’API côté serveur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 886.5 Architecture de l’API côté serveur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
6.5.1 Structure type d’un service de haut niveau . . . . . . . . . . . . . . . . . . . . . 896.5.2 Agencement des différentes classes . . . . . . . . . . . . . . . . . . . . . . . . 91
7 Expérimentations et performances 937.1 Les expérimentations de la redondance . . . . . . . . . . . . . . . . . . . . . . . . . . . 947.2 Les performances mesurées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
7.2.1 Performances sur la Grille locale . . . . . . . . . . . . . . . . . . . . . . . . . . 967.2.2 Performances sur la Grille déployée . . . . . . . . . . . . . . . . . . . . . . . . 99
7.2.2.1 Comparaison à une exécution « classique » . . . . . . . . . . . . . . . 997.2.2.2 Performances de la Grille à travers l’Internet . . . . . . . . . . . . . . 100
8 Conclusion et perspectives 102
Annexe 103
A Publication pour la conférence internationale WETICE-2004 103
B Les principaux schémas UML des bibliothèques nono, koala et nonovideo 104B.1 Diagramme de déploiement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105B.2 Consultation de l’annuaire des ressources . . . . . . . . . . . . . . . . . . . . . . . . . 106B.3 Établissement d’une connexion en mode directe . . . . . . . . . . . . . . . . . . . . . . 107B.4 Traitement des caractères de réveil . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108B.5 La méthode DataTransfer() - première partie . . . . . . . . . . . . . . . . . . . . . . . 109B.6 La méthode DataTransfer() - seconde partie . . . . . . . . . . . . . . . . . . . . . . . . 109B.7 Initialisation du client koala pour la ressource configurable . . . . . . . . . . . . . . . . 111B.8 Initialisation du client koala pour le contrôle de la ressource . . . . . . . . . . . . . . . 112B.9 Initialisation de la ressource de commande . . . . . . . . . . . . . . . . . . . . . . . . . 113B.10 Initialisation de la ressource configurable . . . . . . . . . . . . . . . . . . . . . . . . . 114
C Les mécanismes de sécurité d’IPsec 115C.1 Authentication Header (AH) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
C.1.1 Encapsulating Security Payload (ESP) . . . . . . . . . . . . . . . . . . . . . . . 116C.2 La gestion des clés pour IPsec : ISAKMP et IKE . . . . . . . . . . . . . . . . . . . . . . 118
C.2.1 ISAKMP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118C.2.1.1 Indépendance vis à vis des mécanismes : les domaines d’interprétation
et les phases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119C.2.1.2 Indépendance vis à vis du protocole de gestion des clés : la construc-
tion des messages par blocs . . . . . . . . . . . . . . . . . . . . . . . 119C.2.2 IKE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 120
C.2.2.1 Phase 1 : Main Mode et Aggressive Mode . . . . . . . . . . . . . . . 120C.2.2.2 Phase 2 : Quick Mode . . . . . . . . . . . . . . . . . . . . . . . . . . 121C.2.2.3 Les groupes : New Group Mode . . . . . . . . . . . . . . . . . . . . . 122C.2.2.4 Phases et modes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122

Introduction v
D Installation de FreeS/WAN sur un noyau 2.4 123D.0.3 Installations des commandes IPsec . . . . . . . . . . . . . . . . . . . . . . . . . 124D.0.4 Test de l’installation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
E Création des certificats X.509 125E.0.4.1 Création de l’autorité de certification . . . . . . . . . . . . . . . . . . 126E.0.4.2 Création du certificat de la passerelle . . . . . . . . . . . . . . . . . . 127E.0.4.3 Signature du certificat de la passerelle . . . . . . . . . . . . . . . . . 127
E.0.5 Mise en place de la passerelle . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
F Installation du VPN 129F.0.6 Configuration de la passerelle . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
F.0.6.1 Le fichier /etc/ipsec.conf . . . . . . . . . . . . . . . . . . . . . . . . 129F.0.6.2 Le fichier /etc/ipsec.secrets . . . . . . . . . . . . . . . . . . . . . . . 131
F.0.7 Configuration du poste distant situé en Italie . . . . . . . . . . . . . . . . . . . . 131F.0.7.1 Le fichier /etc/ipsec.conf . . . . . . . . . . . . . . . . . . . . . . . . 131F.0.7.2 Le fichier /etc/ipsec.secrets . . . . . . . . . . . . . . . . . . . . . . . 133
F.0.8 Connexion d’un poste distant à la Grille . . . . . . . . . . . . . . . . . . . . . . 133
G Sécurisation de la passerelle 135
H Fichiers de configuration de DIET 137H.1 L’agent maître - MA (sfMA1.cfg) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137H.2 L’agent local - LA (sfLA1.cfg) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138H.3 Le serveur démon - SeD (sfSeD1.cfg) . . . . . . . . . . . . . . . . . . . . . . . . . . . 139H.4 Le client (sfClient.cfg) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 139
I Script de lancement des agents 140

Introduction vi
Introduction
Le calcul sur une Grille est vu comme le moyen d’avenir pour obtenir des ressources de calcul « àla demande ». Les applications qui en bénéficient pour le moment sont généralement des applicationstrès gourmandes en temps de calcul. Ce sont des simulations numériques, des calculs d’algèbre linéaire,des modélisations de structures, etc. Par contre, aucune de ces applications ne concerne la distributionau sein d’une Grille informatique d’applications « interactives » accompagnées de contraintes de temps.C’est-à-dire celles où des flots de données (permanents) entrent dans l’application alors que d’autres enressortent, et où une vitesse de traitement minimale est imposée par la vitesse des flots de données au lieud’être fixée par la puissance de traitement disponible. Ces applications sont par exemple toutes celles quiconcernent le contrôle de processus physiques, comme l’analyse de signaux en provenance de capteurset le réglage en conséquence des commandes du dispositif.
Utiliser la Grille comme on utilise le réseau électrique, où il suffirait de connecter son « appareil »d’un côté au secteur électrique pour avoir de l’énergie et de l’autre côté à la Grille de calcul pour avoirla puissance de calcul nécessaire à son fonctionnement, est la perceptive que s’est donné l’équipe deSupélec.
C’est pourquoi une première approche a été réalisée dans ce sens en portant une application robotiquesur une Grille de PC standard, PC multiprocesseurs et cluster de PC. Grâce aux travaux précédemmentréalisés avec l’Ensam, nous disposions d’une application où les robots peuvent se déplacent jusqu’àrejoindre une position fixée, en effectuant tout d’abord une auto-localisation basée sur une détection pa-noramique de marques artificielles, puis en calculant une trajectoire minimisant les glissements entre laposition courante et l’objectif (module qui demande encore à être amélioré). La Grille nous a permisd’utiliser plus de machines que nécessaire afin d’être tolérant aux pannes et d’accélérer les calculs enfaisant appel à des machines plus puissantes que l’ordinateur portable typiquement utilisé ou que lesordinateurs que l’on peut raisonnablement dédier aux robots.
Par la suite, cette architecture de Grille testée sur un seul robot « KOALA » et sur deux pays européensservira de base à la prochaine étape : le déploiement de différents « services de contrôle de processusphysiques » à travers une Grille étendue à l’Europe, afin de permettre de contrôler une multitude deprocessus physiques diversifiés (robot Hercule, moteurs, capteurs, etc.) tout en respectant une politiquede gestion des services permettant un équilibrage de charge et une tolérance aux pannes. Le portage decette architecture sur une plate-forme comme Globus sera étudiée après cette expérimentation à grandeéchelle.

Mémoire d’ingénieur CNAM 1
Chapitre 1
Les « Grilles » de calcul et de ressources
Un des éléments importants dans l’évolution des technologies de l’information, lié à la convergencedes télécommunications, de l’informatique et de l’audiovisuel, est que l’ensemble de l’information dontnous disposons ou que nous générons (données, textes, images, vidéo, etc.) est maintenant numérique.Ainsi nous nous trouvons face à une explosion de la quantité d’informations directement accessiblevia les réseaux de communication. La maîtrise et le traitement de ces informations sont devenus unenjeu stratégique de tout premier ordre pour toutes les organisations tant industrielles que publiques ouassociatives.
Face à une concurrence de plus en plus grande, les entreprises doivent faire preuve du maximum deréactivité dans la conception de nouveaux produits ou services, l’adaptation de leurs outils de productionou la mise en œuvre de solutions spécifiques à la demande. Dans ce contexte, les outils informatiques demodélisation et de simulation sont à la base de leur compétitivité.
Ces deux remarques démontrent l’importance de disposer, dans les meilleures conditions, de moyensadaptés pour le stockage, la transmission et le traitement de l’information et pour la mise en œuvre de lapuissance de calcul nécessaire. Or, aujourd’hui, on constate que, suivant la loi de Moore [1], la puissancede traitement des processeurs croit très rapidement et est facilement accessible au travers de PC ou destations de travail. Ces puissances de traitement sont globalement extrêmement sous-utilisées, et ainsi lesentreprises ou organisations disposent de réserve importante de puissance qu’elles souhaitent utiliser. Parailleurs, des réseaux de communication à haut débit ont été installés ou sont en cours de déploiement, àl’exemple de l’initiative GÉANT [2] permettant de disposer, au niveau des organismes de recherche, d’unréseau à 10 Gigabits. Cette organisation des moyens disponibles et des besoins en terme de puissance detraitement et de capacité de stockage accompagne le développement des Grilles informatiques.

Mémoire d’ingénieur CNAM 2
10 Gbit/s
2,5 Gbit/s
622 Mbit/s
34-155 Mbit/s
'
FIG. 1.1 – Le réseau GÉANT
1.1 Les besoins et l’enjeux
1.1.1 La Grille d’information
La maîtrise et la disponibilité des informations par l’accès à de très grandes bases d’informationsréparties géographiquement et à des capacités de traitement adaptées (data-mining par exemple) est unenjeu essentiel pour toutes les organisations. Ces informations peuvent être d’origine et de type trèsvariés. A titre d’exemple, on peut indiquer les bases de données expérimentales issues de grandes expé-riences scientifiques (physique des particules, biologie, observation spatiale, etc.) ou résultant d’actionsspécifiques telles que les données commerciales ou économiques, les bases de données textuelles prove-nant de publications ou de centre de documentation, maintenant largement interconnectés, les bases dedonnées techniques, etc.
Les quantités de données stockées ou générées peuvent atteindre aujourd’hui des grandeurs de l’ordredu petabyte [3] ou plus, nécessitant des capacités de stockage inaccessibles pour un organisme seul. Parailleurs, il apparaît souvent inutile de devoir rapatrier en un même lieu l’ensemble des données alors queseule une faible partie est nécessaire pour le traitement envisagé. Un système de partage « intelligent »de ces données est nécessaire.
1.1.2 La Grille de calcul
Les techniques de simulation et les outils de conception de nouveaux produits ou systèmes apportentune différenciation concurrentielle forte en permettant la réduction des coûts et du temps de mise aupoint. Avec les outils de PLM (Product Lifecycle Management) on s’oriente vers le concept d’entre-prise numérique. La complexité des systèmes considérés, la nécessité de coupler plusieurs phénomènes(thermique, structure, fluides, etc.) ou de prendre en compte des géométries 3D complexes induisentdes besoins de puissance de calcul pouvant atteindre plusieurs téraflops. L’objectif est de résoudre soitdes systèmes couplés d’équations aux dérivées partielles par diverses méthodes numériques (différencesfinies, volumes finis, éléments finis, Monte-Carlo, méthodes particulaires, etc.) soit de grands systèmesalgébro-différentiels et de disposer de capacités de pré et post traitement adaptées intégrant des tech-niques de réalité virtuelle.

Mémoire d’ingénieur CNAM 3
Parmi les grands défis nécessitant de telles puissances de calcul, on peut citer les modèles météo etles études sur le changement climatique global, les simulations ab-initio de matériaux dans les domainesscientifiques, les simulations et outils de conception en aéronautique, automobile, chimie ou nucléairepour ne citer que quelques exemples industriels, sans oublier les domaines de la finance, notamment avecles calculs de risque et de la santé [4].
1.1.3 L’ingénierie concourante
De plus en plus souvent, dans le cadre de grands projets, les entreprises doivent collaborer entre ellesà partir de sites géographiquement répartis, mettre en commun des bases de données ou de connaissances,des descriptions 3D d’objets complexes, des outils de modélisation ou de simulation... Ces probléma-tiques se retrouvent en particulier dans des secteurs tels que l’aéronautique, l’espace ou l’automobileentre maître d’œuvre, équipementiers et fournisseurs. L’objectif est, par une mise en commun en perma-nence de moyens, de données et d’outils dans le cadre d’une « organisation virtuelle » (une Grille), deréduire considérablement les temps et coûts de conception. Ainsi la Grille apparaît comme une architec-ture des systèmes d’information particulièrement bien adaptée aux nouvelles organisations du travail etdes entreprises.
1.2 L’historique du « Grid computing »
Le terme de « Grid computing » apparaît en 1998, plusieurs définition circulent, nous présentonsrapidement les principales.
Une première définition présente le Grid computing comme la suite du « meta computing » : Unpeu avant 1998 où deux projets américains ont expérimenté l’utilisation conjointe de plusieurs super-ordinateurs répartis en différents sites des USA. Il s’agit des projets CASA [5] de simulations intensivesde phénomènes chimiques et météorologiques, et SF [6] (Synthetic Force) de simulation interactive deguerre pour l’armée américaine.
An o perator’ s primary i nteraction with theconsole is t hrough the touch-sensitive displayscreens. All four consoles in an OM are identical
LE GE ND1. OPE N SHE L TE R V IE W OF OPE R AT IONS M ODU L E 5. POW E R GE NE R AT OR2. L OC AL AN/ TPS-7 5 R ADA R S 6. OT HE R MC E3. M ANNE D OPE R AT IONS M ODU L E S 7. AI R FIE L D4. R EMOTE R ADAR 8. TA DIL TO AWACS
Synthetic
B attlespace
FIG. 1.2 – les projets SF et CASA
Le « meta computing » regroupe l’ensemble des techniques permettant d’utiliser plusieurs super-ordinateurs au sein d’une même application, en tenant compte des temps de communications sur desréseaux longue distance lors de la conception de l’application. L’extension de cette technique à un grandnombre de super-ordinateurs, prenant en compte les problèmes de répartition et d’équilibrage de charge,et réalisant une tolérance aux pannes, constitue l’une des approches du Grid computing.
Une deuxième définition est donnée par les fondateurs du Grid computing (Ian Foster et Karl Kessel-man), qui font une analogie avec les grilles de gaz, d’eau et d’électricité [7]. Aujourd’hui la plupart des

Mémoire d’ingénieur CNAM 4
maisons européennes sont raccordées au réseau d’électricité, au réseau d’eau courante et au réseau degaz. Peu importe où est produit cette électricité, cette eau ou ce gaz. Il en arrive suffisamment dans toutesles maisons. Il suffit de se raccorder à ces réseaux. Derrière ces réseaux de tuyaux se trouvent égalementdes réservoirs de stockage, des centres de production, des artères à haut débit entre les principaux centrede production et de stockage, puis des artères à plus faible débit pour atteindre les particuliers. On peutenvisager la même démarche en informatique : disposer chez sois d’une prise de raccordement de sonordinateur au réseau informatique, mais pas seulement pour y trouver des données comme sur Internet,mais pour y trouver de la puissance de calcul et de l’espace de stockage. On aurait alors une Grille infor-matique, comme l’on a des grilles d’électricité, d’eau et de gaz. On serait alors capable de répondre plussouplement aux besoin des utilisateurs en globalisant les ressources.
FIG. 1.3 – Une Grille informatique, comme l’on a des grilles d’électricité
Ainsi, derrière ce concept, se cachent deux approches : la virtualisation des ressources (une vision àlong terme) et la distribution de calculs lourds (déjà opérationnelle).
Les difficultés techniques à relever sont légion et les acteurs de ce marché devront se mettre d’accordsur des standards communs afin de favoriser l’interopérabilité des Grilles de calcul et la formation deGrilles inter-entreprises. Les Grilles en cours de déploiement se limitent en effet à des projets isolésregroupant très peu de partenaires et reposant souvent sur des plates-formes technologiques propriétaires.
Aujourd’hui, il s’agit d’un empilement d’intergiciel (middleware) évoluant vers une architectureorientée services web et visant à faire communiquer chaque nœud de la Grille (calculateurs, baies destockage, instruments scientifiques, etc.) au travers d’un réseau à haut débit. Toutefois, des problèmesde sécurité restent à résoudre. Authentification et chiffrement s’imposent. Pour sa part, Globus, le projetle plus avancé, propose un système de type PKI 1 pour authentifier les serveurs, les utilisateurs et lesprocessus.
Enfin, une troisième définition du « Grid computing » correspond à certains projets très médiatisés,comme « seti@home », qui font travailler de concert des centaines de milliers de PC. Cette activité hau-tement parallèle fonctionne à travers Internet car les différentes tâches ne communiquent pas entre elles.Il s’agit d’application « embarassingly parallel », où chaque nœud de la Grille exécute une version com-plète du programme avec certains paramètres ou un certain jeu de données. L’ensemble des exécutionsde la Grille permet de réaliser la totalité des calculs plus rapidement. La distribution d’une application de« lancer de rayon » sur le réseau du campus de Metz de Supélec est un exemple d’application « embaras-singly parallel » : chaque portion de l’image peut être calculée indépendamment des autres. Un simpleréseau Ethernet peut alors suffire pour réaliser cette distribution de calculs.
1. Public Key Infractructure ou en français Infrastructure de Gestion de Clés IGC.

Mémoire d’ingénieur CNAM 5
D’autres définition existe pour d’autres types de Grilles informatiques, comme les Grilles d’infor-mation, les Grilles d’environnements,... Mais nous pouvons résumer toutes ces définitions par celle duministère français de la recherche : Globalisation des Ressources Informatiques et des Données (GRID).
1.3 Le concept de Grille
Le concept de Grille a été mis au point pour répondre aux différents besoins évoqués précédemmenten optimisant au maximum l’utilisation des moyens de traitement et de stockage disponibles.
Il a pour objet de fournir, de manière transparente et sure, à des communautés d’intérêt (organisationvirtuelle), l’accès à des moyens de traitement et de stockage hétérogènes distribués géographiquement,permettant de disposer de capacités difficilement accessibles, individuellement ou incompatibles avec lesmoyens financiers d’une telle structure.
Un système de Grille repose sur les éléments suivants :– des moyens matériels, systèmes de traitement et de calcul (PC, stations de travail, clusters, etc.) et
systèmes de stockage;– des mécanismes de communication par des réseaux haut-débit reliant les différents centres;– des services de Grilles réunis au sein d’un intergiciel;– des boites à outils génériques (outils de visualisation, bibliothèques de données, etc.);– des logiciels d’applications spécifiques adaptés à l’architecture de Grille.
L’intergiciel est la brique de base regroupant l’ensemble des éléments logiciels pour la mise en œuvred’une Grille. Il comprend notamment les fonctions suivantes :
– le partage et l’allocation des différentes ressources de la Grille suivant des critères techniques deperformance, mais également des critères économiques et d’éventuelles contraintes utilisateurs;
– l’exécution, l’ordonnancement et l’administration de la Grille, intégrant toutes les fonctions demonitoring et de gestion en termes de facturation notamment;
– l’ensemble des procédures de sécurisation de la Grille, notamment les outils d’authentification desutilisateurs, la gestion des restrictions d’accès, la confidentialité des données et des résultats;
– les outils collaboratifs permettant aux divers acteurs de travailler ensemble et d’échanger docu-ments, données, logiciels, résultats, etc., en garantissant la cohérence de ceux-ci au cours de l’en-semble des manipulations;
– les outils d’évaluation des performances et de mesure de la qualité de service;– les outils de développement et les interfaces utilisateurs pour le déploiement des différentes appli-
cations.Ces intergiciels s’appuient sur des protocoles standards de l’Internet tels que FTP (File Transfer proto-col), LDAP (Ligth Directory Acccess Protocol), HTTP (Hypertext Transfert Protocol). Parmi les intergi-ciels les plus utilisés actuellement il faut citer les outils GLOBUS, LEGION et UNICORE.

Mémoire d’ingénieur CNAM 6
FIG. 1.4 – Logiciel de supervision de Grille utilisant l’intergiciel LEGION
Le développement de ces intergiciels fait l’objet d’une très grande activité tant au niveau recherchequ’industriel notamment dans le cadre du GGF (Global GRID Forum). Une initiative très importanteappelée OGSA (Open Grid Services Architecture) a été récemment lancée pour assurer la convergenceentre les technologies de Grilles et les technologies de Web Services, notamment WSDL (Web ServicesDescription Language) et définir ainsi des standards pour des services distribués. L’initiative OGSA seprolonge aujourd’hui par « WSRF » ( Web Services Resource Framework) qui sera au cœur de Globus 4
Actuellement, les entreprises boudent encore ces projets coûteux et difficiles à mettre en œuvre. Ellespréfèrent des Grilles internes qui leur permettent d’optimiser leurs cycles CPU dormants en recourantà des technologies de calcul distribué identiques à celles utilisées par le Décrypthon qui a permis l’éta-blissement de la carte de 500 000 protéines du vivant ou le très médiatique « Seti@home » qui, pour larecherche de signaux extra-terrestres, a réussi, en récupérant sur des milliers de PC les cycles processeursinutilisés, à générer une puissance de 33, 79 Téraflops.
1.4 Quelques exemples
Aujourd’hui de très nombreux projets de Grille sont en cours de développement dans le monde. Ils’agit d’un axe majeur des actions proposées dans le cadre du 6e Programme Cadre de Recherche et deDéveloppement (PCRD) de l’Union Européenne et de plus en plus expérimentations industrielles sonten cours.
1.4.1 Les projets européens DATAGRID et EGEE
Le projet DATAGRID [8] était un projet européen (5e PCRD) pour la mise en place d’une Grillede stockage et d’analyse de données issues de grandes expériences scientifiques. Le projet, issu d’uneinitiative du CERN, a réunit six partenaires principaux (CERN, CNRS, ESRIN, INFN, NIKHEF, PPARC)et quinze partenaires associés dont trois industriels (CS Communication et Systèmes, DATAMAT et IBM-UK).

Mémoire d’ingénieur CNAM 7
DataGrid Testbed
Dubna
Moscow
RAL
Lund
Lisboa
Santander
Madrid
Valencia
Barcelona
Paris
Berlin
Lyon
Grenoble
Marseille
BrnoPrague
Torino
Milano
BO-CNAF
PD-LNL
Pisa
Roma
Catania
ESRIN
CERN
HEP sites
ESA sites
IPSL
Estec KNMI
Testbed Sites
FIG. 1.5 – le projet européen DataGrid
Le projet DATAGRID avait pour principaux objectifs :– de développer un intergiciel open-source fondé sur l’outil GLOBUS ,– de déployer des testbeds à grande échelle,– de valider le concept de Grille sur différents démonstrateurs.
Trois grandes applications ont servies à valider ce projet 2 :
Physique des particules
L’objectif est de traiter les données qui seront fournies par les expériences avec le nouveau collision-neur LHC (Large Hadron Collider) en cours de montage au CERN.
Le LHC est un accélérateur permettant la collision entre protons et ions à des énergies jamais atteintesaujourd’hui, ceci devant recréer les conditions initiales de l’univers après le « Big Bang ». Les différentsdétecteurs du LHC fournissent une énorme quantité de données (environ 3,5 Petabytes par an), donnéesdevant être stockées, accessibles et traitées par la communauté mondiale des physiciens des particulesregroupant en Europe plus de 250 instituts et dans le reste du monde plus de 200 instituts.
2. Aujourd’hui DATAGRID se poursuit par un nouveau projet appelé EGEE (Enabling Grids for E-science in Europe) quireprend les deux premières applications à savoir la physique des particules et la Bio-informatique.

Mémoire d’ingénieur CNAM 8
FIG. 1.6 – le collisionneur LHC
Cette problématique requiert des besoins de stockage et de traitement inaccessibles à une seule orga-nisation et seule une architecture de type Grille peut y répondre.
Bio-informatique
Le domaine de la bio-informatique est caractérisé par son interdisciplinarité (biologie moléculaire,calcul scientifique, technologies de l’information, gestion de données, etc.)
Il manipule de très grandes bases de données réparties à travers le monde (les bases de donnéesconnaissent une croissance exponentielle depuis plusieurs années).
Les architectures de Grilles doivent permettre de répondre aux problèmes d’organisation des données,d’accès à celles-ci (en prenant en compte les aspects de distribution et de réplications) et de traitementde ces données (data-mining).
Observation de la terre
L’objectif de cette application est le stockage, la distribution et le traitement des données fourniespar les satellites d’observation ERS 1/2 et ENVISAT. A titre d’exemple le satellite d’observation de laterre ENVISAT fournira un volume de 500 Go de données par jour. Le concept « Grille » doit permettred’accroître la disponibilité de ces données, de fournir un moyen de retraiter les archives de données etd’autoriser l’utilisation de traitements complexes de fusion de données, d’analyse et de modélisationde celles-ci. Un premier système fonctionne sur plus de dix sites en Europe regroupant plus de 4 000chercheurs.

Mémoire d’ingénieur CNAM 9
FIG. 1.7 – le satellite d’observation de la terre ENVISAT
1.4.2 Le projet européen EUROGRID
Le projet EUROGRID était un projet européen (5e PCRD) pour le développement des technologiesde Grille autour du calcul haute performance. Le projet dont le coordinateur était la société allemandePALLAS, regroupe six centres de calcul haute performance dont le centre IDRIS du CNRS et deuxgrands utilisateurs (GIE, EADS, CCR et Deutsche Wetterdienst). Le projet s’appuyait sur l’intergicielUNICORE de la société PALLAS. Les principales applications mises en œuvre étaient :
– la simulation en recherche biomoléculaire,– les modèles de prédiction météorologique, notamment les modèles atmosphériques régionaux,– le couplage de codes d’IAO, notamment pour des applications dans le domaine de l’aéronautique,– la simulation « multiphysique ».
LRZ: SR 8000, VPP, LC*
RUS: SX-5, 2xLC*
FZJ: 2xT3E,SV1, LC*
ZIB: T3E, Sun
DWD: IBM SP, SGI
RUKA: IBM SP
PC²: LC*
TUD: T3E, SGI
Pallas: Sun
Fujitsu: VPP, Sun
*LC = Linux Cluster
FZJ
ZIBPC2
TUD
LRZ
DWD
RUKA
RUS
FIG. 1.8 – Le réseau Grille utilisant l’intergiciel UNICORE en Allemagne
Au niveau européen il convient également de signaler l’initiative GRIDSTART dont l’objectif est deconsolider les avancées européennes dans les technologies de Grille et de stimuler le développement

Mémoire d’ingénieur CNAM 10
des Grilles dans tous les domaines scientifiques, industriels et grand public. Ils associent la plupart desprojets européens (AVO, CROSSGRID, DAMIEN, DATAGRID, DATATAG, EGSO, EUROGRID, GRIA,GRIDLAB, GRIP).
FIG. 1.9 – Le projet européen EUROGRID
1.4.3 La plate-forme RNTL e-Toile
Le projet e-Toile est une plate-forme financée par le RNTL (Réseau National des Technologies Lo-gicielles ). Ce projet vient de se terminer.
Journées RNTL 2003 13
VTHD
3 Gb/s
VTHD
3 Gb/s
ursa-major
ursus-0 à ursus-9ursa-minor
CEA
serveur1
node1 à node6
node7 à node10
EDF
Sirius-vthd
6 icluster
ID-IMAG
IRISA
antares2 à
antares4
antares1
SUN-Grenoble
cobalt-31 à
cobalt-39saturne
mercure
PRiSM
node-001 à
node-006cocteau
nas
SUN-Lyon
ls1 à ls16 gasp-front
IBCPsupervision réseau
et administration
ressources de testUREC
3 qos
RESO
6 tamanoir
LIP
poi0 à poi23
tortue
poi
kwad
ENS-LYON
CERN
Plate-forme de production Plate-forme de tests
noeuds actifs
FIG. 1.10 – Le projet e-Toile
Il réunit de grands acteurs français de la recherche et de l’industrie dans le domaine des Grilles(CNRS, INRIA, ENS Lyon, CEA, EDF, France Télécom, SUN France, CS-Communication et Systèmes).Les objectifs du projet peuvent se résumer comme suit :
– mettre à la disposition de la communauté scientifique française une plate-forme d’expérimenta-tion d’une Grille de calcul s’appuyant sur RENATER (Réseau National de Télécommunications

Mémoire d’ingénieur CNAM 11
pour la Technologie, l’Enseignement et la Recherche) et VTHD (Vraiment Très Haut Débit). Cetteplate-forme devait permettre de valider les travaux de recherche sur l’intergiciel et de tester desapplications dans les domaines du calcul intensif et du traitement de grandes quantités de données;
– développer un intergiciel prototype 3 intégrant les travaux les plus récents en réseaux actifs, DSM(Distributed Shared Memory), allocation de ressources et sécurité;
– favoriser la valorisation de cette technologie dans les grands domaines scientifiques et industrielsen préparant une démarche de type GRID Service Provider.
2,5 Gbit/s
622 Mbit/s
155 Mbit/s
Boucleen Ile
de France
Connexion
vers les DOM-TOM
Guadeloupe
Guyane
La Réunion
Nouvelle Calédonie
Martinique
Tahiti
Connexion
Asie Pacifique
Connexion vers
l'Internet
Mondial
GEANT
Connexion vers les réseaux
de la Recherche
Europe, Amérique...
NR
NRI
Rennes
Corté
Besançon
Caen
Nantes Dijon
Poitiers
Limoges
Clermont -Ferrand
Lyon
Marseille
Bordeaux
Strasbourg
Lille
Rouen Compiègne
Reims
Nancy
Orléans
SFINX
accès à l'Internet en France
ToulouseNice
Grenoble
Montpellier
Réseau pour l'Enseignement Supérieur, la Recherche et la TechnologieRéseau pour l'Enseignement Supérieur, la Recherche et la Technologie
Mayotte
Pau
FIG. 1.11 – Le réseau RENATER
Trois applications nécessitant l’accès à de grandes puissances de calcul ont été testées :– des problèmes d’optimisation combinatoire à partir de la bibliothèque Bob (Bibliothèque d’Opti-
misation avec Branch-and-bound) développée par le laboratoire PRISM (université de VersaillesSaint Quentin). Il s’agit de traiter des arbres de quelques milliards de sommets;
– un logiciel de dynamique moléculaire avec potentiels empiriques lissés par des calculs ab initioet un atelier de neutronique composé d’un modèle de données métier et d’une solution génériqued’enchaînement de codes de calcul développé par EDF;
– deux applications dans les domaines de la physique nucléaire pour la simulation de données del’expérience ALICE [9] et des sciences du vivant pour des problèmes de dynamique moléculaire.
Le projet e-Toile ce termine cette année et son expérience servira au nouveau projet Grid’5000 [10].Grid’5000 est une plateforme mis en place pour la recherche dans le domaine des Grilles. Dix labora-toires sont impliqués afin de fournir une plate-forme dédiée, permettant aux développeurs de la com-munauté Grille de valider les différents niveaux logiciels acteurs de la mise en œuvre des technologiesGrille. L’objectif est de fournir une plate-forme de huit sites composés de clusters de 256 à 1 000 CPUsconnectés par Renater à 1Gbit/s (étendu à 10 Gbit/s par la suite).
3. Ces travaux se sont réalisés en étroite complémentarité avec l’ACI GRID du ministère de la recherche.

Mémoire d’ingénieur CNAM 12
FIG. 1.12 – Le projet Grid’5000
1.5 Notre projet de Grille de contrôle de processus physiques
Au départ de ce projet, une application robotique client-serveur a été développée pour permettre à unrobot de type « KOALA » de se déplacer et de se localiser dans un environnement clôt. L’objectif final dece projet, est de permettre de connecter n’importe quel processus physique sur une Grille de ressources,en fournissant les outils et l’architecture nécessaire. Une Grille de calcul a été mise en place au sein deSupélec, composée de mono et quadriprocesseur Intel Xéon. Le projet prévoit quatre phases qui sont :
Phase 1 : Test de performance à travers Internet
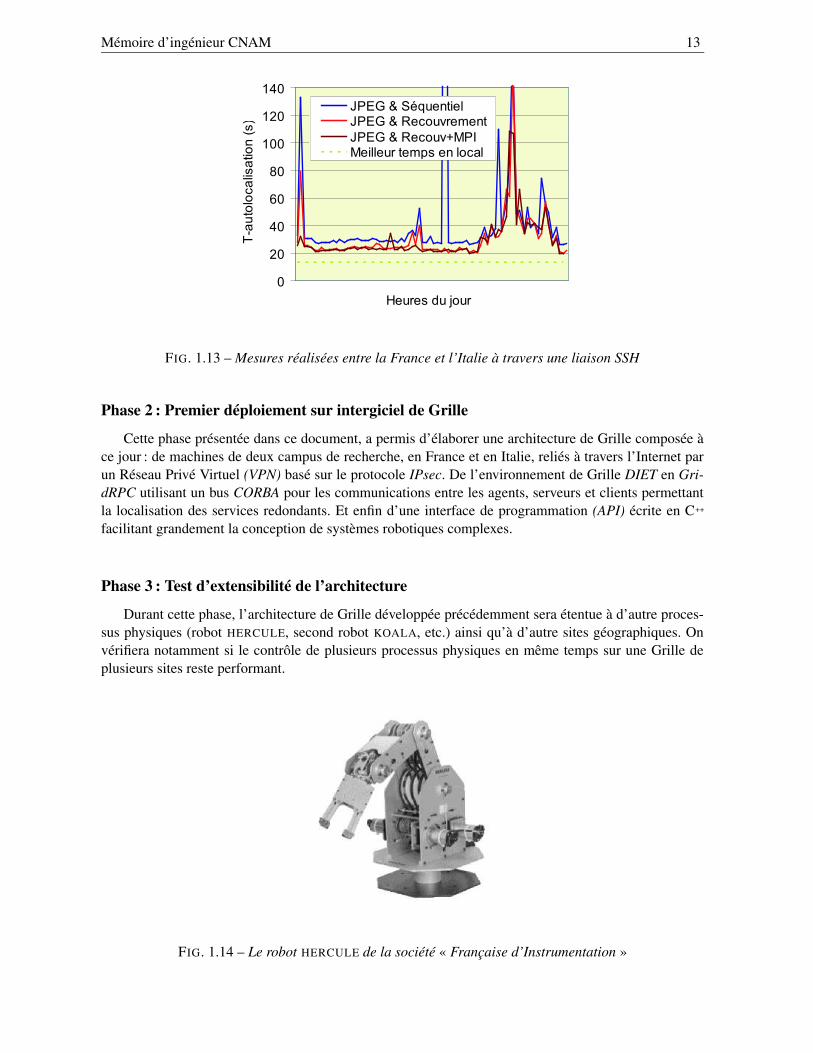
Lors de la première phase, une attention toute particulière a été portée à l’optimisation de la routined’auto-localisation qui se répète fréquemment lors de longs parcours (optimisation de la liaison série,utilisation du multithreading, de l’hyperthreading, de la parallélisation sur cluster, et du recouvrementdes temps de communication, des temps de calcul, et des temps des mouvements mécaniques).
Un déploiement de l’application sur une liaison pair à pair (lien direct sur un tunnel SSH) avec l’Italie,a montré qu’il était possible de contrôler le robot à travers l’Internet avec un ralentissement acceptable àcertaines heures.
Mémoire d’ingénieur CNAM 13
0
20
40
60
80
100
120
140
Heures du jour
T-a
uto
loca
lisa
tio
n (
s)
JPEG & SéquentielJPEG & Recouvrement
JPEG & Recouv+MPIMeilleur temps en local
FIG. 1.13 – Mesures réalisées entre la France et l’Italie à travers une liaison SSH
Phase 2 : Premier déploiement sur intergiciel de Grille
Cette phase présentée dans ce document, a permis d’élaborer une architecture de Grille composée àce jour : de machines de deux campus de recherche, en France et en Italie, reliés à travers l’Internet parun Réseau Privé Virtuel (VPN) basé sur le protocole IPsec. De l’environnement de Grille DIET en Gri-dRPC utilisant un bus CORBA pour les communications entre les agents, serveurs et clients permettantla localisation des services redondants. Et enfin d’une interface de programmation (API) écrite en C++
facilitant grandement la conception de systèmes robotiques complexes.
Phase 3 : Test d’extensibilité de l’architecture
Durant cette phase, l’architecture de Grille développée précédemment sera étentue à d’autre proces-sus physiques (robot HERCULE, second robot KOALA, etc.) ainsi qu’à d’autre sites géographiques. Onvérifiera notamment si le contrôle de plusieurs processus physiques en même temps sur une Grille deplusieurs sites reste performant.
FIG. 1.14 – Le robot HERCULE de la société « Française d’Instrumentation »

Mémoire d’ingénieur CNAM 14
Phase 4 : Passage à Globus
Le projet se terminera par une première transposition de l’architecture de Grille sur une plate-formeGlobus. Cette opération a été retardée à la phase 4, car elle est jugée relativement lourde, et notre planétait d’obtenir rapidement une Grille opérationnelle permettant les expérimentations.

Mémoire d’ingénieur CNAM 15
Chapitre 2
Le GridRPC et DIET
La gestion de ressources est une clé fondamentale pour le développement d’environnements de Grilleefficaces. Plusieurs approches co-existent sur les plates-formes d’intergiciel d’aujourd’hui. Le grain decalcul ainsi que les dépendances entre les calculs ont une grande influence sur le choix du logiciel.
La première approche fournit à l’utilisateur une vue uniforme des ressources. C’est le cas de GLO-BUS qui fournit des communications MPI transparentes (avec MPICH-G2) entre les nœuds distants,mais ne gère pas la répartition de charge entre ces nœuds. C’est également à l’utilisateur de développerun code qui prendra en considération l’hétérogénéité de l’architecture de la Grille.
Une deuxième approche fournit un accès semi-transparent aux serveurs de calcul en soumettant lestravaux aux serveurs dédiés. Ce modèle est connu sous le nom de modèle Fournisseur de Services Appli-catifs (Application Service Provider - ASP) où les fournisseurs offrent, pas nécessairement gratuitement,des ressources de calcul (matériel et logiciel) aux clients de la même façon que les fournisseurs d’Internetoffrent des ressources du réseau mondial aux clients. La granularité programmée de ce modèle est plutôtgrossière. Un des avantages de cette approche est que les utilisateurs finaux n’ont pas besoin d’être desexperts en programmation parallèle pour bénéficier des hautes performances des programmes et ordina-teurs parallèles. Ce modèle est étroitement lié au classique paradigme d’Appel de Procédures Distribuées(Remote Procedure CAll - RPC). Sur une plate-forme de la Grille, le RPC (ou GridRPC [11, 12]) offreun accès simple aux ressources disponibles, depuis un navigateur Web, un Environnement de Résolutionde Problèmes (Problem Solving Environment - PSE), ou un simple programme client écrit en C, Fortran,ou Java.
Dans un contexte de Grille, cette approche exige que la mise en œuvre des intergiciels facilitentl’accès du client aux ressources éloignées. Dans l’approche ASP, une façon commune pour les clientsde demander des ressources pour résoudre leur problème, est de soumettre une demande à l’intergiciel.Les intergiciels trouveront le serveur le plus approprié pour résoudre le problème soumis par le client enutilisant un logiciel spécifique. Plusieurs environnements, appelés habituellement NES (Network EnablesServers), ont implémenté ce paradigme : NetSolve [13], Ninf [14], NEOS [15], OmniRPC [16], et plusrécemment DIET développé dans le projet GRAAL. Le point commun entre ces environnements résidedans les cinq éléments qui les composent : les clients, les serveurs, les bases de données (pour la gestiondes ressources logicielles et hardware), les moniteurs et enfin les ordonnanceurs. Les clients soumettentdes requêtes de résolutions de calculs aux serveurs trouvés par le NES. Le NES planifie les demandessur les différents serveurs en utilisant les informations de performances obtenues par les moniteurs etstockées dans une base de données.
2.1 Le GridRPC
Bien que la Grille de calcul soit perçue comme l’infrastructure de calcul de la prochaine génération,son adoption finale est entachée par des questions du type : « comment programmer (d’une façon simple)

Mémoire d’ingénieur CNAM 16
sur une Grille? ».Actuellement, l’infrastructure d’intergiciel la plus populaire, à savoir le toolkit Globus, fournit les
éléments essentiels par des services de bas niveau, tel la sécurité / authentification, l’exécution de tâches,un service d’annuaire, etc. Bien que ces services soient d’une nécessité absolue particulièrement pour lesupport d’une plate-forme commune et pour faire abstraction des différences des machines de la Grilledans le but d’interopérabilité, on s’accorde à dire qu’il existe un fossé entre les services de Grille etl’abstraction du niveau de programmation utilisé communément.
Cela est semblable aux débuts de la programmation parallèle, où les outils de développement etd’abstraction disponibles étaient sous forme de bibliothèques de bas niveau tel l’échange des messages(de bas niveau), et/ou les bibliothèques de threads. Dans un sens métaphorique, programmer seulementet directement par dessus les E/S de Globus peut être envisagé comme une programmation parallèleperformante utilisant uniquement l’API Linux sur un cluster. Par tous les moyens, il y eu plusieurs essaisde fournir un modèle de programmation ou un langage approprié à la Grille. Beaucoups de ces effortsont été rassemblés et catalogués par le Groupe de Recherche en Modèle de Programmation Avancée(Advanced Programming Models Research Group) du GGF (Global Grid Forum [17]) . Un modèle deprogrammation particulier qui s’est montré être viable est le mécanisme RPC adapté pour la Grille, ouGridRPC.
Quelques systèmes représentatifs du GridRPC sont Netsolve et Ninf. Historiquement, ces deux pro-jets sont nés en même temps. En revanche, parce qu’il y a des différences dans les différents protocoleset les APIs, l’interopérabilité entre les deux systèmes est plutôt pauvre. Il y a eut des tentatives pourobtenir l’interopérabilité entre ces deux systèmes par une translation de protocole via une sorte de proxyadaptateur [14], mais pour des raisons techniques le support complet des caractéristiques mutuelles s’estavéré très difficile.
En fait, le besoin d’un standard unifié de GridRPC devenait peu à peu apparent, dans le même espritque la standardisation de MPI basée sur les expériences passées avec différents systèmes de passage demessages, a conduit à l’adoption d’une programmation parallèle portable à grande échelle sur MPPs etcluster.
2.1.1 Le modèle de base
Le modèle d’interaction entre un client et une plate-forme offrant l’accès à des applications surla grille se fait sur le modèle de l’appel de fonction (ou d’invocation de service) puisque ce modèleest supposé répandu, donc maîtrisé, chez un grand nombre d’utilisateurs. En effet, dans ce contexte,un client peut souhaiter accéder aux applications soit en réalisant une simple soumission de problème,soit en donnant une suite de requêtes. Dans le premier cas, il sera possible d’offrir un maximum deconfort par la soumission à travers une interface graphique ou WEB. Dans le second cas, des langagesde programmation de haut niveau tels que scilab peuvent convenir et utiliser la plate-forme, comme dansSCILAB [18]. Dans les deux cas, le modèle suppose la possibilité de soumettre plusieurs requêtes entreune phase d’initialisation et une phase de terminaison du client.
lookup
Client
Registry
Service
handle
call
results
register

Mémoire d’ingénieur CNAM 17
FIG. 2.1 – Le modèle de base GridRPC
Le modèle de référence des travaux du GridRPC-WG est représenté dans la figure 2.1. Les fonction-nalités choisies sont basiques, nous les retrouvons donc dans de nombreux autres systèmes, en particulierles systèmes de RPC plus généraux. Dans la phase d’initialisation, un serveur déclare ses applicationsauprès d’un service d’enregistrement (Registry). Par la suite, un client contacte ce Registry pour y recher-cher un service. Il obtient en retour un identificateur (handle) donnant accès à l’application recherchée.Le client utilise ensuite cet identificateur pour appeler le serveur qui lui retourne éventuellement unrésultat.
Ce modèle de base permet d’identifier les rôles attribués à chacun des intervenants. Il est nécessairede compléter ce modèle par la définition de structures de données permettant l’identification et les in-teractions entre les composants de ce modèle. Ainsi, dans la terminologie du GridRPC, un descripteurde service est un function handle. Ce function handle représente la correspondance entre la chaîne decaractères qu’est le nom d’une fonction et l’instance d’un service proposé par un serveur spécifique. Unefois cette correspondance établie entre une fonction et un serveur, à l’initialisation du function handle,tous les appels utilisant ce function handle seront exécutés sur le serveur identifié.
Au niveau des appels aux serveurs deux modèles sont possibles. Le premier est synchrone. Il per-met de mettre en œuvre la sémantique classique d’appel de procédure à distance, c’est à dire que leclient est bloqué jusqu’à la fin de l’exécution de sa fonction, en attente de ses résultats. Cependant,les plates-formes de Grilles étant destinées à permettre l’exécution de calcul important, le modèle syn-chrone apparaît évidemment trop restrictif. Il n’est pas envisageable de demander à un utilisateur debloquer une application dans un calcul qui peut durer plusieurs jours. Il est donc naturel de trouver danscette interface des possibilités d’attente différée du résultat d’une exécution, d’où le modèle d’invocationasynchrone. L’interface GridRPC définit donc le session ID comme l’identificateur d’un appel non blo-quant. Ce session ID est utilisé dans l’interface pour permettre aux utilisateurs de manipuler leurs appelsnon bloquants : en obtenir l’état, attendre la fin d’une exécution, arrêter une exécution ou pour vérifier lescodes d’erreur générés. Il faut noter qu’un effort particulier à été réalisé afin de définir des codes d’erreuret les retours de fonctions.
2.2 L’architecture de DIET
DIET signifie Boîte à outils d’Ingénierie Interactive et Distribuée (Distributed Interactive Enginee-ring Toolbox). C’est une boîte à outils pour développer facilement des systèmes Fournisseur de ServicesApplicatifs sur les plates-formes de Grille, basé sur le schéma Client/Agent/Serveur. Les agents sont lesordonnanceurs de cette boîte à outils. Dans DIET, les demandes des utilisateurs sont servies via le RPC.DIET suit l’API GridRPC défini dans le Forum de la Global Grid.
Mémoire d’ingénieur CNAM 18
Page web, Scilab, Matlab,...
Interface haut niveau
DIE T (C++/CORBA)
Ordonnanceur DIE T
Niveau utilisateur
Niveau développeur
DIE T (C++/CORBA)
Niveau développeurServeur DIE T
(DI E T )
(DI E T )
Programme C/C++, F ortran, Java, ...
Niveau développeur
(A pplication)A pplication
DIE T (C++/CORBA)
Client DIE T Niveau développeur
Niveau applicatif
Programme C/C++, F ortran, Java, ...
Niveau applicatif
(DI E T )
Programme C/C++, F ortran, Java, ...
Client applicatif
Serveur applicatif
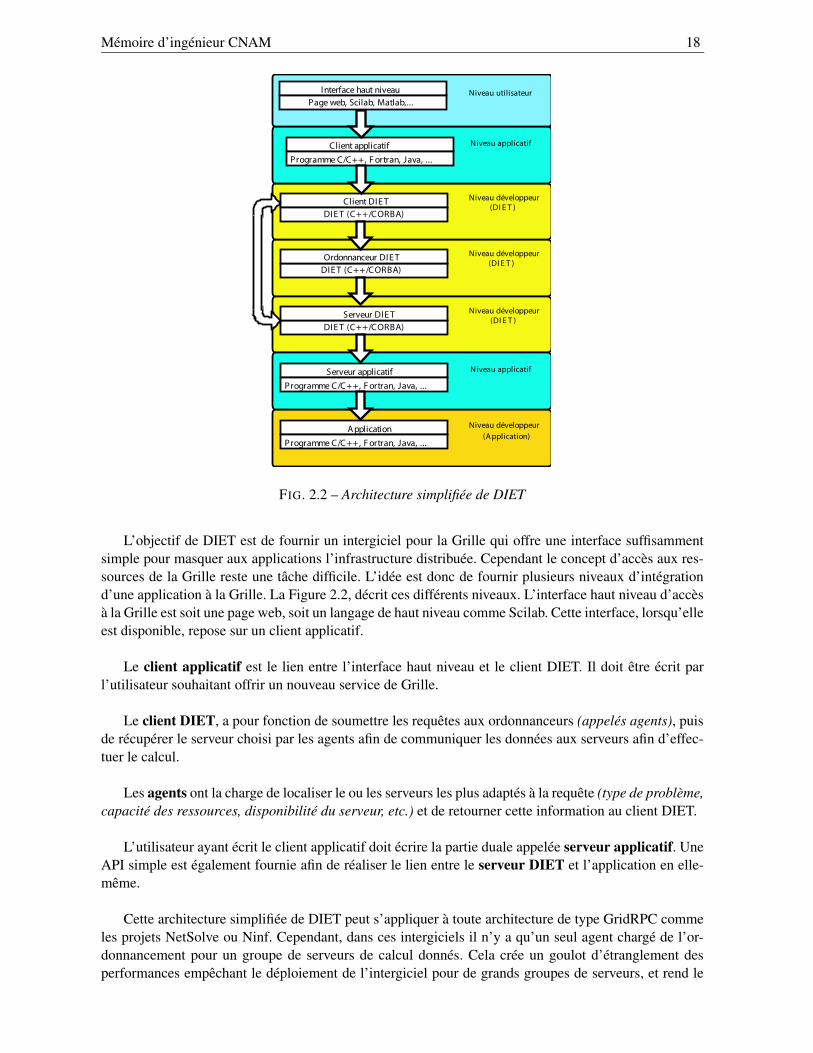
FIG. 2.2 – Architecture simplifiée de DIET
L’objectif de DIET est de fournir un intergiciel pour la Grille qui offre une interface suffisammentsimple pour masquer aux applications l’infrastructure distribuée. Cependant le concept d’accès aux res-sources de la Grille reste une tâche difficile. L’idée est donc de fournir plusieurs niveaux d’intégrationd’une application à la Grille. La Figure 2.2, décrit ces différents niveaux. L’interface haut niveau d’accèsà la Grille est soit une page web, soit un langage de haut niveau comme Scilab. Cette interface, lorsqu’elleest disponible, repose sur un client applicatif.
Le client applicatif est le lien entre l’interface haut niveau et le client DIET. Il doit être écrit parl’utilisateur souhaitant offrir un nouveau service de Grille.
Le client DIET, a pour fonction de soumettre les requêtes aux ordonnanceurs (appelés agents), puisde récupérer le serveur choisi par les agents afin de communiquer les données aux serveurs afin d’effec-tuer le calcul.
Les agents ont la charge de localiser le ou les serveurs les plus adaptés à la requête (type de problème,capacité des ressources, disponibilité du serveur, etc.) et de retourner cette information au client DIET.
L’utilisateur ayant écrit le client applicatif doit écrire la partie duale appelée serveur applicatif. UneAPI simple est également fournie afin de réaliser le lien entre le serveur DIET et l’application en elle-même.
Cette architecture simplifiée de DIET peut s’appliquer à toute architecture de type GridRPC commeles projets NetSolve ou Ninf. Cependant, dans ces intergiciels il n’y a qu’un seul agent chargé de l’or-donnancement pour un groupe de serveurs de calcul donnés. Cela crée un goulot d’étranglement desperformances empêchant le déploiement de l’intergiciel pour de grands groupes de serveurs, et rend le

Mémoire d’ingénieur CNAM 19
système peu résistant aux erreurs. De plus, la mort du processus agent rend inutilisable la plate-formetoute entière. Pour résoudre ces problèmes, DIET se propose de répartir le travail de l’agent selon unenouvelle organisation. Il est ainsi remplacé par un ensemble d’agents organisés selon deux approches :une approche multi-agents de type pair à pair (peer to peer) améliorant la robustesse du système associéet une approche hiérarchique favorisant l’efficacité de l’ordonnancement. Cette répartition du rôle del’agent offre divers avantages :
– une meilleure répartition de la charge entre les différents agents,– une plus grande stabilité du système (si un des éléments venait à s’arrêter, les autres éléments
pourraient se réorganiser pour le remplacer),– une gestion simplifiée en cas de passage à l’échelle (l’administration de chaque groupe de serveurs
et des agents associés peut être déléguée).Un serveur DIET est également appelé SeD (Server Daemon). Nous avons ensuite une hiérarchie
(organisée de manière arborescente) d’agents dont les LA (Leader Agents) et les MA (Master Agents).Plusieurs hiérarchies pourront co-exister au sein de DIET, différents MA seront alors connectés soit enCORBA, soit via un système pair à pair.
MA MA
MA MA
LA
Client
LA LA
MAMA
SeDMA: Master AgentLA : Local AgentSeD: Server Daemon
FIG. 2.3 – Une hiérarchie d’agents DIET
2.2.1 Les composants de DIET
Les différents composants de l’architecture logiciel sont les suivants :
Le client
Lorsque l’on évoque le client, il s’agit du client applicatif qui utilise DIET pour résoudre des pro-blèmes. Plusieurs clients peuvent se connecter à DIET. Un problème peut être soumis de manière syn-chrone (le client reste en attente du résultat) ou de manière asynchrone (le contrôle est rendu au pro-gramme après la soumission).

Mémoire d’ingénieur CNAM 20
L’agent maître (Master Agent - MA)
Un MA est directement relié aux clients. Il reçoit des requêtes de calcul des clients et choisit un (ouplusieurs) SeD qui sont capables de résoudre le problème en un temps raisonnable. Un MA possède lesmêmes informations qu’un LA, mais il a une vue globale (et de haut niveau) de tous les problèmes quipeuvent être résolus et de toutes les données qui sont distribuées dans tous ses sous-arbres afin d’accélérerla recherche d’un SeD capable de résoudre une requête.
L’agent local (Local Agent - LA)
Un LA compose un niveau hiérarchique dans les agents DIET. Il peut être le lien entre un MA et unSeD, deux LA ou un LA et SeD. Son but est de diffuser les requêtes et les informations entre les MA etles SeD. Il tient à jour une liste des requêtes en cours de traitement et, pour chacun de ses sous-arbres,le nombre de serveurs pouvant résoudre un problème donné, ainsi que des informations à propos desdonnées.
Le serveur démon (Server Daemon - SeD)
Un SeD est le point d’entrée d’un serveur de calcul. Il gère l’ensemble des ressources qui lui sontallouées. Il peut s’agir d’un processeur, comme d’un cluster (dans le cas d’applications parallèles). Iltient à jour une liste des données disponibles sur un serveur (éventuellement avec leur distribution etle moyen d’y accéder), une liste des problèmes qui peuvent y être résolus, et toutes les informationsconcernant sa charge (charge CPU, mémoire disponible, taille du disque, etc.).
2.2.2 Le fonctionnement général de DIET
Un nouveau client de DIET doit d’abord contacter le Master Agent le plus approprié (suivant saproximité dans le réseau). Une fois que son Master Agent est identifié, le client peut lui soumettre unproblème. Pour choisir le serveur le plus approprié pour résoudre ce problème, le Master Agent propageune requête dans ses sous-arbres afin de trouver à la fois les données impliquées (parfois issues decalculs précédents et ainsi déjà présentes sur certains serveurs) et les serveurs capables de résoudrel’opération demandée. Ensuite, le Master Agent renvoie l’adresse du serveur choisi au client et effectuele transfert des données persistantes impliquées dans le calcul. Le client communique ses données localesau serveur et alors la résolution du calcul peut être effectuée. Les résultats pourront être renvoyés au clienten fonction du problème.
La phase d’initialisation
La Figure 2.4 décrit chaque étape de la mise en œuvre d’une architecture DIET simple. La plate-forme est construite en suivant la hiérarchie, chaque composant étant connecté à son père. Le MA est lepremier composant qui est démarré 1© . Il est alors en attente de la connexion d’un agent ou de requêtesen provenance des clients.

Mémoire d’ingénieur CNAM 21
MA MA MA MA MA
Cl
LA LA LA
LA
LA
LA
1 2 3 4 5
FIG. 2.4 – Initialisation d’un système DIET
Lors de son initialisation le LA vient s’inscrire auprès du MA 2© . Deux types de composants peuventalors connectés à ce LA : soit un SeD 3© soit un autre LA pour ajouter un niveau de hiérarchie à la branche4© . Lorsque le SeD s’enregistre à un LA, la liste des services qu’il fournit est publiée, c’est-à-dire que la
liste des services disponibles est diffusée dans la hiérarchie du LA jusqu’au MA. Finalement, lorsqu’unclient souhaite accéder à une ressource de la plate-forme, il contacte un MA 5© afin de récupérer laréférence (ou une liste de référence) du meilleur serveur (ou des meilleurs serveurs) et se connecteensuite directement à ce SeD pour effectuer le transfert des données et le calcul.
L’architecture de la hiérarchie est décrite au travers des fichiers de configuration de chacun des com-posants. En effet, chaque composant a dans son fichier le nom de son parent (exception faite pour lesMA). Afin de donner un ordre d’idée nous envisageons le déploiement d’une hiérarchie à l’échelle d’undomaine tel qu’une université, les clients de ce domaine auront de fait les droits nécessaires pour l’accèsaux ressources. Les LA peuvent quant à eux être déployés au niveau des laboratoires de cette univer-sité. Chaque laboratoire pouvant alors administrer les ressources qui lui sont propres et les déclarer auLA. Cette administration hiérarchique de la plate-forme facilite le déploiement à l’échelle de la Grille,puisque chaque modification locale ne provoque pas de perturbation à l’ensemble de la plate-forme.
Le traitement des requêtes
Dans cette section nous considérons que l’architecture décrite dans la section 2.2 comprend plusieursserveurs capables de résoudre le même problème (ce qui est souvent le cas) et que ce problème peut êtrerésolu sur un seul serveur. L’exemple présenté figure 2.5 correspond à la soumission d’un problème F ()utilisant les données A et B.
S111 S112 S122
S31 S32S21
B
F()
A F()
S123S121
CL IE NTF(A,B)
MA
L A 1 L A 2 L A 3
L A 12L A 11
FIG. 2.5 – Exemple de soumission de problème

Mémoire d’ingénieur CNAM 22
L’algorithme présenté ici décrit la procédure réalisée par le MA afin de sélectionner le serveur pourrépondre à la requête. Cette décision se déroule en quatre étapes :
– Le MA propage la requête du client dans les sous-arbres où des serveurs disposent du service.Dans la version actuelle chaque agent sait dans quelles branches il peut-être intéressant de fairesuivre la requête. Cette méthode à l’avantage de limiter les communications mais pose quelquesproblèmes de cohérence dans le cas de hiérarchie profonde.
– Chaque serveur qui dispose du service et qui reçoit cette requête va exécuter Fast 1 pour estimer letemps de calcul nécessaire et transmet cette estimation à son père (le LA).
– En cas de succès, chaque LA de l’arbre reçoit une ou plusieurs estimations des serveurs. A chaqueniveau de la hiérarchie un ordonnancement des serveurs est effectué jusqu’au MA.
– Une fois au MA, ce dernier effectue la décision finale et communique au client le serveur sélec-tionné (ou une liste de serveurs).
Pour la résolution du problème en lui-même, le client se connecte au serveur choisi, il envoie lesdonnées locales et spécifie si le résultat doit être gardé sur le serveur pour un futur calcul ou s’il doitrevenir au client. Le transfert des données persistantes est réalisé à ce moment.
1. Fast (Fast’s Agent System Timer) est un outil de modélisation des performances dynamiques dans un environnement demetacomputing.

Mémoire d’ingénieur CNAM 23
Chapitre 3
Application robotique et architectureclient-serveur initiale
3.1 L’application robotique
3.1.1 Description
En septembre 2003, l’équipe SIDP 1 de Supélec dispose d’un robot mobile capable au démarrage,de se repérer seul dans son environnement équipé de marques de recalage, puis de calculer sa trajectoireentre son point de départ et sa destination souhaitée grâce à une application robotique parallélisée réaliséepar Alexandru IOSUP [19] au cours de son stage de fin d’étude.
La localisation de ce point de départ réutilise les travaux effectués jusqu’à maintenant sur le robot encollaboration avec l’ENSAM, à savoir l’étude sur la détection de marques de recalage réalisée par VincentRIEGER [20] lors de son Studienarbeit en 2000, puis l’étude sur la localisation de Cyrille ROUSSEL [21]au cours de son stage de DEA en 2001. Le calcul de la trajectoire jusqu’à la destination souhaitée faitsuite au travail de Matthieu MASSONNEAU (Échange Franco-Allemand ENSAM 2003).
3.1.2 Sa plate-forme matérielle
L’environnement dans lequel évolue le robot est un plan structuré (4m× 2m). Il est délimité par desmurs d’environ 30 cm de hauteur. Le sol est recouvert d’un matériau s’apparentant au linoléum, doncrelativement glissant.
Marque P-Similaire
FIG. 3.1 – Environnement dans lequel évolue le robot
1. Systèmes Intelligents Distribués et Parallèles.

Mémoire d’ingénieur CNAM 24
L’environnement (cf. figure 3.1) est inconnu pour le robot mais balisé grâce à des marques P-Similairessituées sur les murs. Cet environnement peut inclure des obstacles si nécessaire (pour inclure et expéri-menter un module de contournement d’obstacles). Le robot utilisé est un KOALA de la société K-TEAM
de 30× 30× 30 cm (cf. figure 3.2). Il dispose de six roues qui lui permettent de se déplacer à la manièred’un tank. Les pneus sont en caoutchouc souple. Pour prévenir toutes collisions avec l’environnement, lerobot est équipé de seize capteurs infrarouges disposés sur son pourtour. Le KOALA possède égalementune caméra C.C.D., montée sur une tourelle deux axes. Cette caméra fournit des images à la carte d’ac-quisition de l’ordinateur embarqué (PC104) ou externe (PC classique). Enfin un capteur odométrique 2
permet de connaître la position du robot par rapport à sa position précédente. On verra apparaître une er-reur de localisation lorsque les roues glissent sur le sol, car le capteur odométrique relève un déplacementdifférent de la réalité.
carte de controle de la caméra
capteurs infrarouges
caméra
FIG. 3.2 – Robot KOALA
3.1.3 Ses modules logiciels
L’application robotique est composée d’un assemblage de deux modules dédiés qui sont :– un module de localisation (scan panoramique, filtrage des marques artificielles détectées, triangu-
lation, interpolation de Newton-Raphson);– un module de navigation (suivi de courbes de Dubins et Mouaddib).
3.1.3.1 Le module de localisation
Ce module permet au robot de se localiser dans un environnement de test (cf. figure 3.1). Afin deréaliser cela, l’application robotique utilise un système de marques artificielles P-Similaire développépar Daniel SCHARSTEIN en 1999 [22]. Ces marques sont composées d’une représentation graphiqued’une fonction P-Similaire et d’un nombre sous forme d’un code barre (cf. figure 3.1). Détecter desmarques P-Similaires est un système très robuste puisqu’il est théoriquement insensible à l’orientationdes marques et à l’angle de vision, et que ces marques artificielles n’existent pas dans la nature. Mais, il ya tout de même des conditions à respecter (les distances minimales et maximales, l’orientation limite et laqualité de l’image). La routine de localisation retourne un triplet (x, y, θ), représentant respectivement,la position du robot sur l’axe des x, des y et son orientation par rapport à l’axe d’origine Ox.
2. L’odométrie est une méthode de « mesure » relative fondée sur la relation entre la rotation des roues et le déplacement durobot.

Mémoire d’ingénieur CNAM 25
Le processus de localisation est nécessaire chaque fois que le robot s’est déplacé sur une longuedistance ou a effectué une rotation sur lui-même. Il est constant en terme de besoin de puissance decalcul.
Premièrement, les positions des marques sont lues à partir d’un fichier au lancement du processus.Alors, dix sept scans sont nécessaires pour réaliser un scan panoramique, avec un changement d’orien-tation de caméra de 20◦ pour chaque nouvelle capture d’image. L’acquisition et le traitement de l’imagese font selon trois étapes :
1. Deux images de différentes résolutions sont capturées pour chaque position de la caméra (détectionde près ou de loin des marques). Nous somme forcé de faire cela car l’objectif de la caméra (en« œil de poisson ») déforme les objets trop proches ou trop éloignés, rendant indétectable lesmarques artificielles.
2. Chaque image est scrutée ligne par ligne, et une première liste des marques détectées est établie.3. La caméra est tournée dans une nouvelle position. L’angle de rotation de la caméra a été fixé
expérimentalement à 20◦. Cela assure que la détermination de la position réelle du robot est suffi-samment précise pour un nombre raisonnable d’images à traiter.
Pour compléter la routine de localisation, deux étapes supplémentaires sont nécessaires :1. A la fin de tout scan panoramique, la liste des marques trouvées est filtrée pour éliminer celles
détectées plusieurs fois à des positions différentes ou pour enlever celles n’appartenant pas à labase de données. De telles erreurs de détection arrivaient encore assez fréquemment en septembre2003.
2. Finalement, si au moins trois marques sont détectées, une triangulation optimisée, basée sur latriangulation classique et l’optimisation itérative de Newton-Raphson [23], est calculée.
En résumé, la routine de localisation est composée d’un scan panoramique, d’un filtrage des marquesartificielles détectées, d’une triangulation et d’une interpolation de Newton-Raphson :
Filtrage
des marquesTriangulation
Interpolation
Newton−RaphsonScan panoramique
PositionDirection+− +−1 cm, 2°
FIG. 3.3 – Déroulement d’une localisation dont le résultat est sous forme d’un triplet (x, y, θ)
3.1.3.2 Le module de navigation
Ce module permet au robot de se déplacer d’un point à un autre, tout en évitant au maximum deglisser. Pour réaliser cela, deux algorithmes ont été considérés : l’un basé sur les courbes de Dubins etl’autre sur les courbes de Mouaddib. Les deux algorithmes essayent de calculer des trajectoires tenantcompte de la manœuvrabilité du robot, tout spécialement sur la courbure minimale lors des rotations, etassurent aussi que la position finale du robot soit précisément celle désirée (sans glissement).
Trajectoire de Dubins Trajectoire de Mouaddib
FIG. 3.4 – Trajectoires théoriques de Dubins et de Mouaddib
Les trajectoires de Mouaddib commencent par une ligne droite, puis un arc de cercle et enfin seterminent par une ligne droite (cf. figure 3.4). Nous considérons uniquement les trajectoires de Dubins

Mémoire d’ingénieur CNAM 26
qui commencent par un arc de cercle puis se poursuivent par une ligne droite et se terminent en arc decercle (cf. figure 3.4).
La différence entre ces deux algorithmes, se trouve entre la longueur des trajectoires (celles de Dubinssont plus courtes) et dans le nombre de degrés que le robot parcourt lors des rotations (sur ce sujet, lestrajectoires de Mouaddib sont généralement meilleures). Le module décide alors du choix à retenir enfonction de critères définis par l’utilisateur. Il assure alors au robot d’obtenir les commandes appropriéespour suivre la trajectoire.
Malheureusement ce module a soulevé un nombre important de problèmes, aussi bien en conception,qu’en implémentation et ne fonctionne pas encore dans tous les cas. C’est pourquoi un module de navi-gation beaucoup plus simple a été développé par Yannick BOYÉ au cours de son stage précédent le mien(été 2003).
Pour aller d’un point A à un point B, alors que le robot est initialement le long de la flèche au pointA, on commence 1© par faire une rotation sur lui-même (ce qui n’est pas du tout optimal, car l’on a unfort glissement dû à la rotation du robot sur lui-même). Puis 2© on suit la trajectoire jusqu’au point B.Éventuellement, on peut 3© orienter le robot en B suivant un angle différent grâce à une seconde rotationsur lui-même; mais cette rotation peut aussi être effectuée au début du prochain appel à la routine denavigation.
1
2 3
A
B
Position finale
Position initiale
FIG. 3.5 – Déplacement du robot KOALA selon le module de navigation simplifiée
Nota : le module respecte la convention choisie par le module précédent à savoir que le triplet repré-sentant la position finale est toujours (0, 0, 0) (ce qui implique des changements de repères à chaquenouvelle navigation) (cf. figure 3.6). Malgré tout, ce choix se justifie par une éventuelle portabilité ducode sur une future version du module utilisant les courbes de Mouaddib et de Dubins.
(10,10,0)
(210,10,−pi/2)
(0,0,0)
(O,x,y)
Position de départ Position finale
Changement de repère
Position finale
Position de départ
(0,−200,pi/2)
(O,x,y)
FIG. 3.6 – Exemple de changement de repère

Mémoire d’ingénieur CNAM 27
3.2 L’architecture client-serveur de contrôle du robot
3.2.1 Vue d’ensemble
Le système de pilotage du robot s’appuie sur un modèle en couches composé ainsi :– la couche nono est responsable de l’acheminement des informations entre l’application cliente et
le robot;– la couche koala est responsable du contrôle des différents organes du robot (tel que la tourelle
dans la partie Kreb, les roues et les capteurs infra-rouge dans la partie Koala);– la couche nonovideo elle, est responsable de la capture d’images ou de séquences vidéo.
NONO
KOALA NONOVIDEOKrebKoala
FIG. 3.7 – Modèle en couches
Le robot KOALA communique avec le client applicatif : celui-ci envoie des commandes (sur les mo-teurs, la tourelle, la caméra, ou les capteurs) par l’intermédiaire d’un ordinateur serveur et reçoit enretour des informations sur ce qui se passe du côté du robot.
Client Serveur Robot Koala
Liaison sérieLiaison Ethernet/Internet
commandes
données
commandes
données
Vidéo
Moteurs
Capteurs
FIG. 3.8 – Architecture client-serveur de contrôle du robot
3.2.2 Qu’est-ce que la bibliothèque nono?
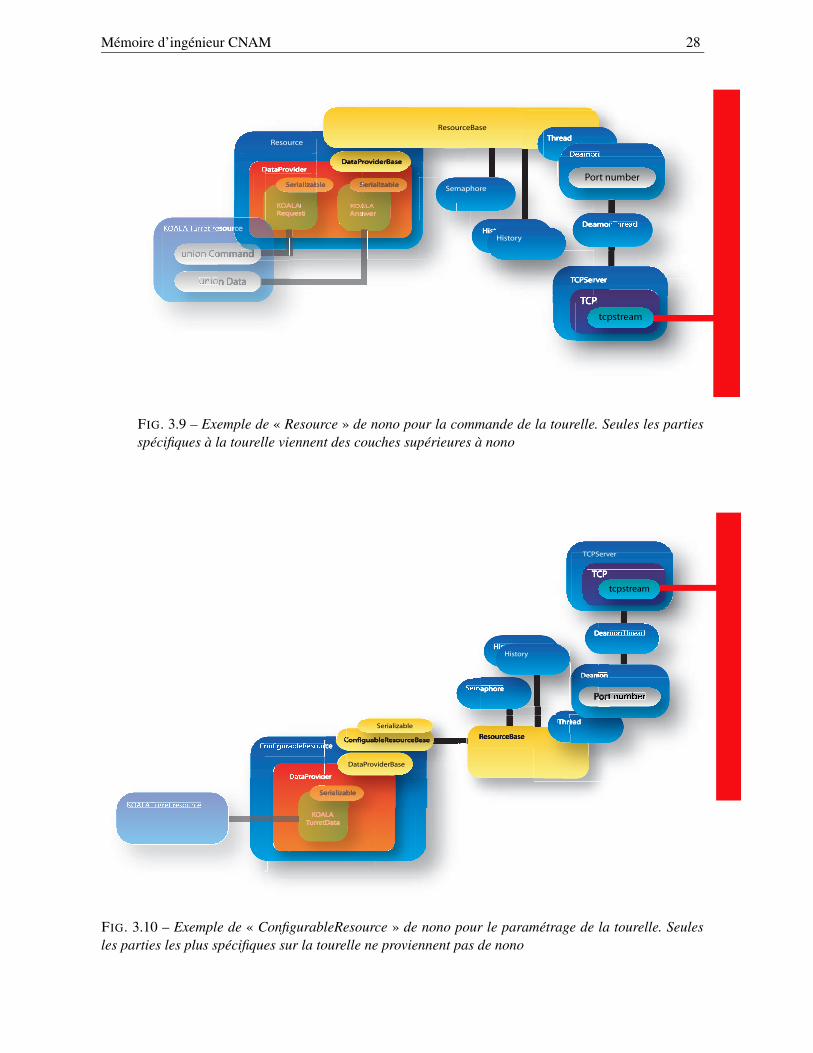
La bibliothèque nono, conçue au départ pour contrôler à distance le pilotage d’un robot, permetde réaliser facilement des applications de type client-serveur, avec une particularité : le serveur est unserveur de ressources. Ces ressources, qui correspondent à différents devices présents sur le serveur (portsérie, commandes du robot, commandes de la tourelle, capture video...), peuvent être adressées par leclient afin d’être contrôlées ou interrogées à distance. On distingue deux sortes de ressources :
– la première (cf. figure 3.9) pour le pilotage des devices (elle porte le nom de « Resource »). Ellecontient les deux objets de la couche supérieure (ici, en autre, celles de la bibliothèque koala)responsables du contenu des questions/réponses. Le mécanisme de dialogue étant assuré par lesdifférentes parties rattachés à la ressource de base;
– la seconde (cf. figure 3.10) pour la configuration des paramètres des devices (elle porte le nomde « ConfigurableResource »). Elle contient un objet de la couche supérieure responsable desparamètres physiques de la ressource.
Mémoire d’ingénieur CNAM 28
Resource
ResourceBase
Semaphore
Port number
tcpstream
History
FIG. 3.9 – Exemple de « Resource » de nono pour la commande de la tourelle. Seules les partiesspécifiques à la tourelle viennent des couches supérieures à nono
DataProviderBase
tcpstream
TCPServer
History
Serializable
FIG. 3.10 – Exemple de « ConfigurableResource » de nono pour le paramétrage de la tourelle. Seulesles parties les plus spécifiques sur la tourelle ne proviennent pas de nono

Mémoire d’ingénieur CNAM 29
Cette bibliothèque, élaborée par Hervé FREZZA-BUET, repose sur la GNU Common C++ développéepar Open Source Telecom Corporation. Cette dernière confère le support des threads et des sockets TCPutilisés pour la gestion des connexions des clients au serveur.
3.2.2.1 Principe de base de la bibliothèque nono
La bibliothèque nono, met en place un protocole de questions/réponses par l’intermédiaire de deuxobjets « sérialisables » dont l’un contient les commandes à traiter (la question) par la ressource concernéeet l’autre le résultat de ce traitement (la réponse). Ainsi en adaptant ces deux objets 3 à nos besoins, nouspouvons aisément contrôler des ressources distantes (dans notre cas, les organes du robot).
3.2.2.2 Structure de la bibliothèque nono
La bibliothèque nono se compose de deux parties : une pour le côté client et l’autre pour le côtéserveur.
Le côté client
Sur le diagramme de classes ci-après, on peut remarquer la classe paramétrable Client, laquelle dérivede la classe ClientBase. C’est à travers la classe Client que les couches supérieures (koala, nonovideo)peuvent faire transiter les données (méthode DataTransfer()). La classe ClientBase est composéed’agrégat de la classe DataProviderBase et de la classe TCPClient. Elle permet ainsi de transmettre(méthode SendRequest()) et de recevoir (méthode RecvData()) les questions/réponses quelquessoient leurs contenus. Quant à la classe TCPClient, elle permet d’établir une connexion TCP sur leserveur distant (méthode open()) et de verrouiller/déverrouiller l’accès au device associé (méthodesLock() et Unlock() de la classe TCP).
3. La bibliothèque koala définit l’objet Request contenant la structure Command et l’objet Answer contenant la structureData pour réaliser le dialogue avec le robot au travers d’une liaison série.

Mémoire d’ingénieur CNAM 30
Communicator(from nono)
<<Interface>>
TCP
TCP()<<virtual>> ~TCP()<<virtual>> Out()<<virtual>> In()<<virtual>> Lock()<<virtual>> Unlock()<<virtual>> Close()<<virtual>> Ok()
(from nono)
tcpstream(from ost)
#tcp
TCPClient
_host_name : std::string_port : int
TCPClient()<<virtual>> ~TCPClient()<<virtual>> Open()SetHost()GetHostName()GetPort()
(from nono)
DataProviderBase(from nono)
<<Interface>>
ClientBase
_key : std::string_main_port : int
ClientBase()Com()StartCom()Wait()<<virtual>> Connect()<<virtual>> Connect()<<virtual>> DataTransfer()<<virtual>> Disconnect()<<virtual>> ~ClientBase()
(from nono)
-com
#_provider
REQUESTDATA
DataProvider
_d : DATA_r : REQUEST
Data()DataProvider()Request()<<virtual>> RecvData()<<virtual>> RecvRequest()<<virtual>> SendData()<<virtual>> SendRequest()<<virtual>> ~DataProvider()
(from nono)
REQUESTDATA
Client
Request : REQUESTData : DATA
Client(server_key : std::string)<<virtual>> ~Client( : void)Request( : void) : REQUEST&Data( : void) : DATA&
(from nono)
-prov
FIG. 3.11 – Diagramme de classes UML - côté client
Le côté serveur
La partie « serveur de ressources » est assurée par la classe Server (cf. figure 3.12). Elle gère l’an-nuaire des ressources (resource directory), les connexions multiples des applications clientes (serveurmultithreadé) et la possibilité d’entrer en mode « programmation interactive » des ressources (méthodeInteractiveConfig()). Le mécanisme de gestion de l’annuaire permet d’enregistrer aussi biendes objets de type Resource que des objets de type ConfigurableResource. Le premier servant pourcommander un device distant (les roues du robot, la tourelle, etc), et le second pour paramétrer cemême device dans le mode « programmation interactive » ou à partir d’un fichier de configuration(/etc/Koala.config). Les classes Resource et ConfigurableResource 4 sont composées d’un agré-gat de la classe DataProviderBase. Elles permettent ainsi de recevoir (méthode RecvRequest()) etde retransmettre (méthode SendData()) les objets « sérialisés » quelques soient leurs contenus.
4. La classe ConfigurableResource hérite de la classe Serializable afin de permettre la lecture/écriture d’une ressource confi-gurable (par exemple la ressource RobotData).
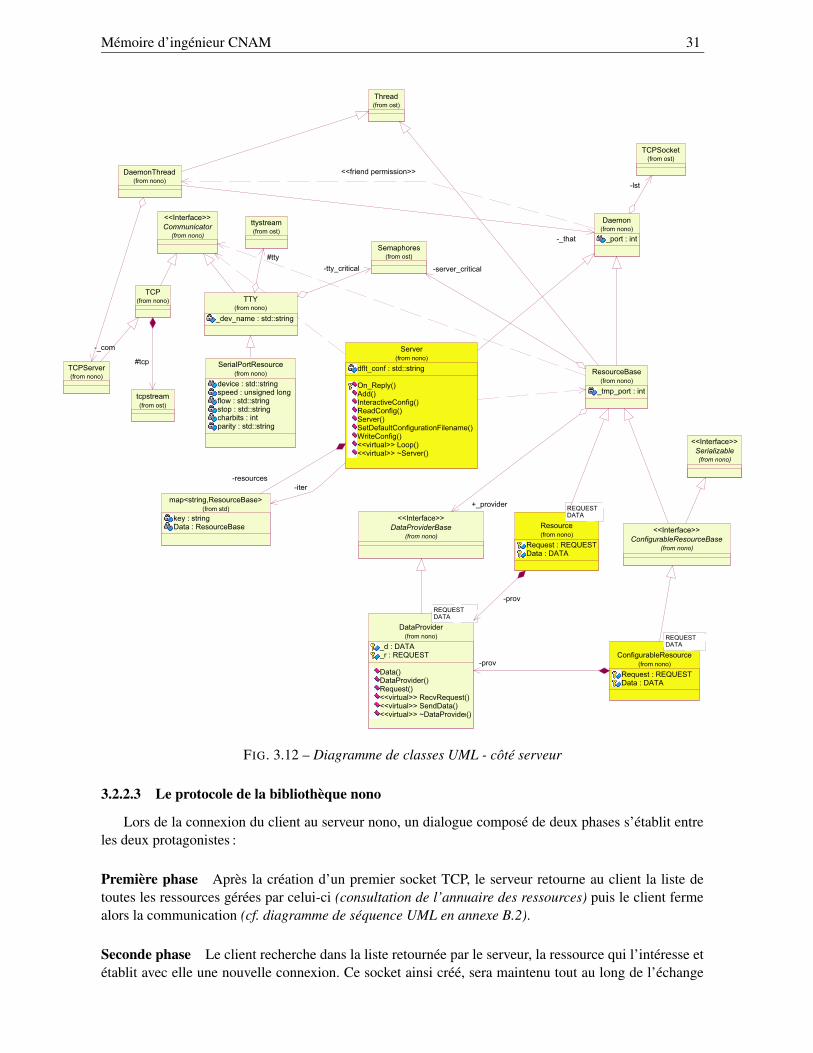
Mémoire d’ingénieur CNAM 31
Communicator(from nono)
<<Interface>>
ConfigurableResourceBase(from nono)
<<Interface>>
Serializable(from nono)
<<Interface>>
SerialPortResource
device : std::stringspeed : unsigned longflow : std::stringstop : std::stringcharbits : intparity : std::string
(from nono)
Thread(from ost)
tcpstream(from ost)
TCP(from nono)
#tcpTCPServer(from nono)
TCPSocket(from ost)
DaemonThread(from nono)
-_com
Daemon
_port : int
(from nono)
-lst
-_that
<<friend permission>>
map<string,ResourceBase>
key : stringData : ResourceBase
(from std)
Server
dflt_conf : std::string
On_Reply()Add()InteractiveConfig()ReadConfig()Server()SetDefaultConfigurationFilename()WriteConfig()<<virtual>> Loop()<<virtual>> ~Server()
(from nono)
-resources
-iter
ttystream(from ost)
TTY
_dev_name : std::string
(from nono)
#tty
DataProviderBase(from nono)
<<Interface>>
Semaphores(from ost)
-tty_critical
ResourceBase
_tmp_port : int
(from nono)
+_provider
-server_critical
REQUESTDATA
ConfigurableResource
Request : REQUESTData : DATA
(from nono)
REQUESTDATA
Resource
Request : REQUESTData : DATA
(from nono)
REQUESTDATA
DataProvider
_d : DATA_r : REQUEST
Data()DataProvider()Request()<<virtual>> RecvRequest()<<virtual>> SendData()<<virtual>> ~DataProvider()
(from nono)
-prov
-prov
FIG. 3.12 – Diagramme de classes UML - côté serveur
3.2.2.3 Le protocole de la bibliothèque nono
Lors de la connexion du client au serveur nono, un dialogue composé de deux phases s’établit entreles deux protagonistes :
Première phase Après la création d’un premier socket TCP, le serveur retourne au client la liste detoutes les ressources gérées par celui-ci (consultation de l’annuaire des ressources) puis le client fermealors la communication (cf. diagramme de séquence UML en annexe B.2).
Seconde phase Le client recherche dans la liste retournée par le serveur, la ressource qui l’intéresse etétablit avec elle une nouvelle connexion. Ce socket ainsi créé, sera maintenu tout au long de l’échange

Mémoire d’ingénieur CNAM 32
entre le client et la ressource correspondante au device distant. (cf. diagramme de séquence UML enannexe B.3).
A la suite de cette connexion, le client va indiquer le mode de transfert souhaité :– le « mode bufferisé » où toutes les réponses du device distant seront mémorisées sur le serveur
(envoi du caractère de réveil « nonobufSTART_DATA_TRANSFER » suivi par le numéro queprendra le premier buffer et le nombre de buffers souhaités);
– le « mode direct » sans mémorisation des réponses (envoi du caractère de réveil«nonoSTART_DATA_TRANSFER » suivi par le numéro de buffer à zéro et le nombre de bufferssouhaités à un);
– le « mode personnalisé » où le protocole d’échange de données est défini dans l’application cliente(envoi du caractère de réveil « nonoSTART_CUSTOM » suivi par le numéro de buffer à zéro et lenombre de buffers souhaités à un).
3.2.2.4 L’annuaire de ressources
La classe Server de nono est composée d’un conteneur 5 renfermant la liste des ressources ainsidisponibles. La méthode Add() permet alors d’ajouter de nouvelles ressources lors du lancement del’application serveur (tels que la vidéo, le port série, la tourelle, etc.).
Server : SApplication
server : Server resources : map
resources[key]=resourceStore the ("key",resource) pair into the map contener
Add("key", resource)
operator[]( "key")
operator=( resource)
count( "Key")use count method to know if "key" key is already included in the contener (0= none)0
FIG. 3.13 – Diagramme de séquence de l’ajout d’une nouvelle ressource
Au démarrage de l’application serveur, des ressources sont ajoutées à l’annuaire comme expliquéprécédemment, puis par l’intermédiaire d’un appel à la méthode Loop() de la classe Server de la bi-bliothèque nono (cf. figure 3.14) chaque ressource passe en écoute sur son propre port 6 TCP (premièreboucle while de la méthode Loop()). Mais c’est seulement lors de l’appel à la méthode start() dela classe Thread de la Common C++ que la thread associée à la ressource passe réellement à l’écouted’une connexion d’un client. Puis par l’intermédiaire de la méthode Loop() de la classe Daemonde la bibliothèque nono, le service d’annuaire va être mis en place. Dans un premier temps, l’ob-jet TCPSocket est créé et initialisé avec l’adresse IP et le numéro de port TCP à écouter (construc-teur TCPSocket(address,port)). Puis l’objet Daemon attend une connexion d’un client (mé-thode isPendingConnection()). Lorsque celle-ci se présente, il crée une thread (constructeurDaemonThread(this)), et la lance pour dialoguer avec le client, parallèlement à la présente exécu-tion qui elle, va s’empresser d’attendre le client suivant (méthode isPendingConnection() de laboucle while).
5. Ce conteneur est implémenté par la classe map<string,ResourceBase>.6. Le numéro de port est calculé à partir du numéro de port du serveur d’annuaire auquel vient s’ajouter le numéro de rang
de la ressource dans l’annuaire.

Mémoire d’ingénieur CNAM 33
main
server : Server
: Daemon
*rsc : ResourceBase
lst : TCPSocket
*thrd : DaemonThread
thr : Thread
lst
Define the resource port
Start daemon to listen
Start all deamon resources contened in ResourceBase contener.
Server()
Loop(port)
Daemon()
RscStart()
RscHasNext()
RscNext(name)
While loop
End loop
SetPort(port)
Ready()
start( )
Loop(port)
TCPSocket(address,port)
Thread( )
start( )
While loop
End loop
Used to wait for pending connection requests
DaemonThread(this)
isPendingConnection( )
start( )
start( )
~TCPSocket( )
Really, wait for a connection from a client
Create a new thread when a client is just connecting and wait for a new connection from another client
Create a new thread to manage the connection of the client
FIG. 3.14 – Diagramme de séquence de la méthode Loop()
Le client peut alors se connecter directement à la ressource désirée (cf. diagramme de séquence UMLen annexe B.3).
3.2.2.5 Réveil du serveur lors de la réception de nouvelles requêtes
Le client envoie avant chaque requête, un caractère de réveil qui permet :– la sélection du mode d’échange des données (direct, bufferisé ou personnalisé);– l’exécution de la méthode On_Reply() du côté serveur par le mécanisme de la bibliothèque
Common C++ qui est responsable de la gestion des threads.Ainsi la méthode On_Reply() va procéder aux étapes suivantes (cf. diagramme de séquence UML enannexe B.4) :
1. initialisation des buffers pour le mode bufferisé (lors de la connexion du client uniquement);2. verrouillage/déverrouillage de l’accès à la ressource;3. traitement des données transmises par le client (méthodes Answer(), DataTransfer() ou
DataTransfer_Buf());4. ou effacement des buffers (si le caractère de réveil nonoFLUSH_HISTORY est reçu);
3.2.3 Qu’est-ce que la bibliothèque koala?
Cette bibliothèque, qui est une sur-couche de la bibliothèque nono (cf. figure 3.7), permet de gérerles organes mécaniques du robot KOALA tels que :
– la rotation de la tourelle sur deux axes;

Mémoire d’ingénieur CNAM 34
– le mouvement des six roues;– l’état des capteurs infrarouge.
3.2.3.1 Structure de la bibliothèque koala
La bibliothèque koala se décompose en deux parties : une côté client, une côté serveur.
Le côté client
Sur le diagramme de classes ci-après, on peut remarquer les classes Client<Request,Answer> (pa-rente de la classe Client) et Client<int,RobotData> (parente de la classe RobotClient) qui sont élaboréesà partie de la classe paramétrable Client de la bibliothèque nono (cf. figure 3.11).
La première sera utilisée lors de dialogue de bas-niveau avec les organes de mouvement du robot,tandis que la seconde servira à piloter ces même organes (commandes de haut-niveau) :
koala::RobotClient *robot = new koala::RobotClient(); // high-level controller... // for the Koala robotrobot->GoTo(SpeedLeftRows,SpeedRightRows); // we ask for motion
FIG. 3.15 – Exemple d’une commande de haut niveau
La classe RobotData contiendra les informations sur la configuration des organes de mouvement etles classes Request et Answer serviront respectivement pour commander les organes et recevoir la ré-ponse de ceux-ci.La classe de plus bas niveau Client de la bibliothèque koala servira pour envoyer des micro-commandesdirectement compréhensives par le micro-kernel du robot (la traduction est réalisée lors de la « sériali-sation » de l’objet Request) :
koala::Client *koala = new koala::Client(); // The client for koala control
union koala::Command command; // The commandunion koala::Data data; // The received data.
...// Move: first, we set counters to 0command.type=koala::SetPosition;command.set_pos.pos.left=0;command.set_pos.pos.right=0;if(!koala->DataTransfer()) std::cerr << "Transfer failed !" << std::endl;
// Then, we ask for motioncommand.type=koala::GoTo;std::cin >> command.go_to.pos.left >> command.go_to.pos.right;if(!koala->DataTransfer()) std::cerr << "Transfer failed !" << std::endl;
FIG. 3.16 – Exemple de commandes de bas niveau
Après configuration des différents champs de la structure Command, le programme transfert lesdonnées au serveur (méthode DataTransfer()) puis attend la réponse en retour (cf. diagramme deséquence UML en annexe B.5 et B.6).

Mémoire d’ingénieur CNAM 35
Nota : nous retrouvons le même principe pour la gestion de la tourelle où les classes TurretData 7,Request et Answer de l’espace de nommage Kreb sont utilisées.
7. Au lieu de la clase RobotData de l’espace de nommage Koala.
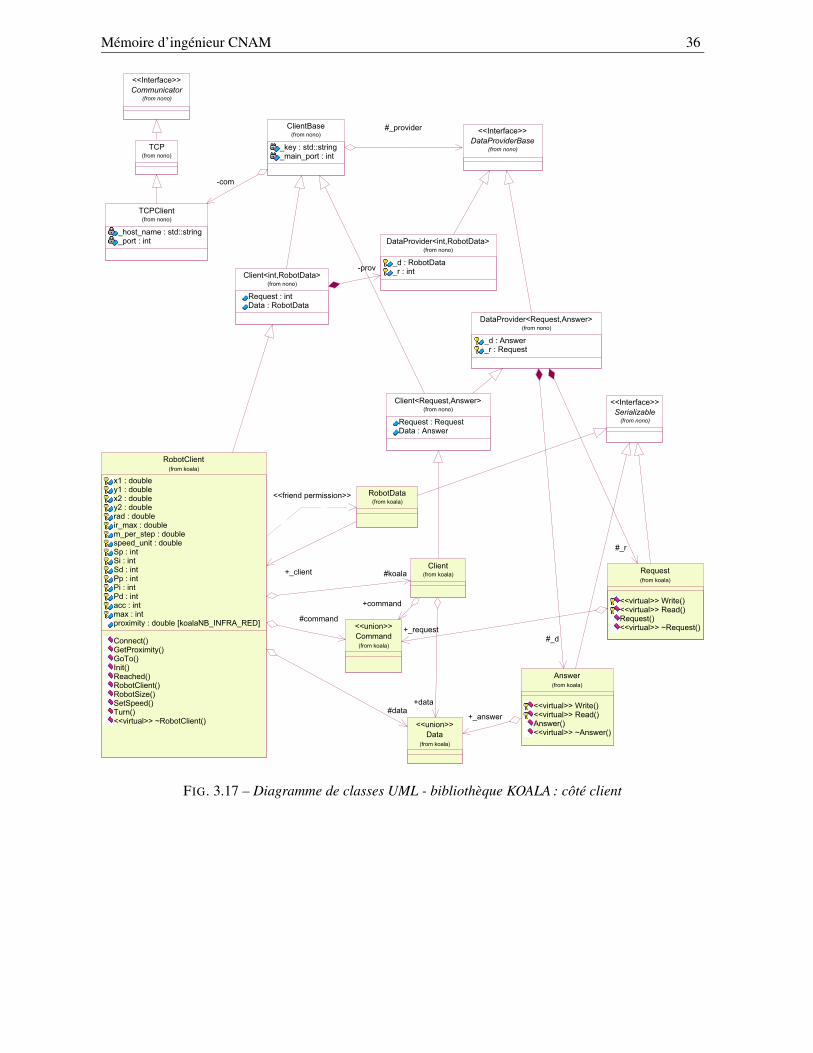
Mémoire d’ingénieur CNAM 36
Serializable(from nono)
<<Interface>>
TCP(from nono)
Communicator(from nono)
<<Interface>>
Client<Request,Answer>
Request : RequestData : Answer
(from nono)
DataProviderBase(from nono)
<<Interface>>ClientBase
_key : std::string_main_port : int
(from nono)#_provider
TCPClient
_host_name : std::string_port : int
(from nono)
-com
DataProvider<Request,Answer>
_d : Answer_r : Request
(from nono)
Request
<<virtual>> Write()<<virtual>> Read()Request()<<virtual>> ~Request()
(from koala)
#_r
Answer
<<virtual>> Write()<<virtual>> Read()Answer()<<virtual>> ~Answer()
(from koala)
#_dCommand(from koala)
<<union>> +_request
Data(from koala)
<<union>>+_answer
Client(from koala)
+command
+data
RobotData(from koala)
RobotClient
x1 : doubley1 : doublex2 : doubley2 : doublerad : doubleir_max : doublem_per_step : doublespeed_unit : doubleSp : intSi : intSd : intPp : intPi : intPd : intacc : intmax : intproximity : double [koalaNB_INFRA_RED]
Connect()GetProximity()GoTo()Init()Reached()RobotClient()RobotSize()SetSpeed()Turn()<<virtual>> ~RobotClient()
(from koala)
#command
#data
#koala+_client
Client<int,RobotData>
Request : intData : RobotData
(from nono)
DataProvider<int,RobotData>
_d : RobotData_r : int
(from nono)
-prov
<<friend permission>>
FIG. 3.17 – Diagramme de classes UML - bibliothèque KOALA : côté client

Mémoire d’ingénieur CNAM 37
Le côté serveur
Au niveau du serveur, deux ressources sont disponibles afin de permettre d’une part de paramétrer leséquipements du robot et d’autre part de contrôler celui-ci à distance (cf. diagrammes de séquence UMLen annexe B.9 et B.10).
ConfigurableResourceBase(from nono)
<<Interface>>
DataProviderBase(from nono)
<<Interface>>
Serializable(from nono)
<<Interface>>
ConfigurableResource<int,int>
Request : intData : int
(from nono)
TTY
_dev_name : std::string
(from nono)
ResourceBase
_tmp_port : int
(from nono)
DataProvider<Request,Answer>
_d : Answer_r : Request
(from nono)
Request(from koala)
#_r
Answer(from koala)
#_d
Command(from koala)
<<union>>+_request
Data(from koala)
<<union>>+_answer
SerialPortResource
device : std::stringspeed : unsigned longflow : std::stringstop : std::stringcharbits : intparity : std::string
(from nono)
Resource
BadProtocol()<<virtual>> ComputeDataFromReq()Resource()<<virtual>> ~Resource()
(from koala)
-command
-data
-_device
Resource<Request,Answer>
Request : RequestData : Answer
(from nono)
FIG. 3.18 – Diagramme de classes UML - bibliothèque KOALA : côté serveur (ressource de contrôle desroues)
Sur le diagramme de classes côté serveur de la ressource de contrôle des roues (cf. figure 3.18), onpeut distinguer la ressource (classe Resource) chargée d’acheminer les commandes destinées au robot(grâce à la classe Request) et de retourner à l’application cliente la réponse à sa requête (classe Answer).Elle s’appuie sur le protocole de nono par l’héritage de la classe Resource<Request,Answer>.
La méthode ComputeDataFromReq() (classe Resource) permet le dialogue de bas niveau réa-lisé entre l’application serveur et le hardware du robot au travers une liaison série (cf. diagramme deséquence UML en annexe B.6).
Sur le diagramme de classes côté serveur de la ressource de configuration des roues (cf. figure 3.19),la classe RobotResource contient les informations de configuration des organes de mouvement du ro-bot. L’application cliente pourra consulter ces informations au moyen de la classe RobotData (elle sera« sérialisée » pour transiter entre le client et le serveur)

Mémoire d’ingénieur CNAM 38
Serializable(from nono)
<<Interface>>
ConfigurableResourceBase(from nono)
<<Interface>>
RobotData(from koala)
RobotResource
x1 : doubley1 : doublex2 : doubley2 : doublerad : doubleir_max : doublem_per_step : doublespeed_unit : doubleSp : intSi : intSd : intPp : intPi : intPd : intacc : intmax : int
<<virtual>> ComputeDataFromReq()RobotResource()<<virtual>> ~RobotResource()<<virtual>> Write()<<virtual>> Read()<<virtual>> WriteType()<<virtual>> ConfigDialog()<<virtual>> DisplayConfig()
(from koala)
+_resource
<<friend permission>>
DataProvider<int,RobotData>
_d : RobotData_r : int
(from nono)ConfigurableResource<int,RobotData>
Request : intData : RobotData
(from nono)-prov
ResourceBase(from nono)
DataProviderBase(from nono)
<<Interface>>+_provider
FIG. 3.19 – Diagramme de classes UML - bibliothèque KOALA : côté serveur (ressource de configurationdes roues)
Nota : nous retrouvons le même principe pour la gestion de la tourelle où les classes TurretData 8,Request et Answer de l’espace de nommage Kreb sont utilisées.
3.2.3.2 Création d’une application cliente
L’application cliente commence par créer tous les objets impliqués dans le mécanisme de transfertdes données sur TCP/IP (objets TCPClient, TCP et tcpstream) (cf. diagramme de séquence UML en an-nexe B.7).Puis poursuit par la création de l’objet responsable de l’acheminement des informations de configuration(objet DataProvider<int,RobotData>). Enfin, elle termine par la mise en place du mécanisme de com-mande/réponse réalisé au moyen des objets Request, Answer et DataProvider<Request,Answer> (cf. diagramme de séquence UML en annexe B.8).
8. Au lieu de la clase RobotData de l’espace de nommage Koala.

Mémoire d’ingénieur CNAM 39
3.2.4 Qu’est-ce que la bibliothèque nonovideo?
Cette bibliothèque, sur-couche de la bibliothèque nono (cf. figure 3.7), permet la capture d’imagesou de séquences vidéo provenant de la caméra embarquée sur le robot KOALA.
3.2.4.1 Structure de la bibliothèque nonovideo
Comme la bibliothèque Koala, la bibliothèque nonovideo se décompose aussi en deux parties : unepour le côté client et l’autre pour le côté serveur.
Le côté client
Sur le diagramme de classes, on retrouve le même principe que la bibliothèque koala, c’est à direla classe Client<VideoReq,VideoDataClient> qui découle de la classe paramétrable Client de la biblio-thèque nono (cf. figure 3.11). Grâce à la méthode set_RTJ_quality() de la classe VideoClient, ilest alors possible de choisir la qualité de l’image (compressée au format JPEG) et de réaliser des cap-tures d’images (méthode update_img()) ou des séquences vidéo (méthodes start_capture() etend_capture())
VideoClient
Q : intpol : int
transcheck()VideoClient()get_frame()update_img()update_img()get_img()start_capture()end_capture()save()savePGM()get_w()get_h()get_format()get_size()scale()rotate180()set_RTJ_quality()set_scale_policy()
(from nonovideo)
Serializable(from nono)
<<Interface>>
ImgBuffer
ok : int [NONOV_NBFORMAT]Aframe : intw : inth : int
(from nonovideo)Client<VideoReq,VideoDataClient>
Request : VideoReqData : VideoDataClient
(from nono)
VideoReq
key : charw : inth : inttype : intframe : intQ : intpol : int
(from nonovideo)
<<friend permission>>
VideoDataClient
capok : int
(from nonovideo)
<<friend permission>>
#ib
DataProvider<VideoReq,VideoDataClient>
_d : VideoDataClient_r : VideoReq
(from nono)
-prov
#_r
#_d
FIG. 3.20 – Diagramme de classes UML - bibliothèque NONOVIDEO : côté client

Mémoire d’ingénieur CNAM 40
Le côté serveur
Au niveau du serveur, deux ressources sont disponibles afin de permettre d’une part de paramétrerla source vidéo provenant de la carte d’acquisition (classe V4lConfig, méthode ConfigDialog()) etd’autre part de réaliser les acquisitions vidéos (classe VideoResource, méthode ComputeDataFromReq())stockées dans la classe vector<MImgBuffer>.
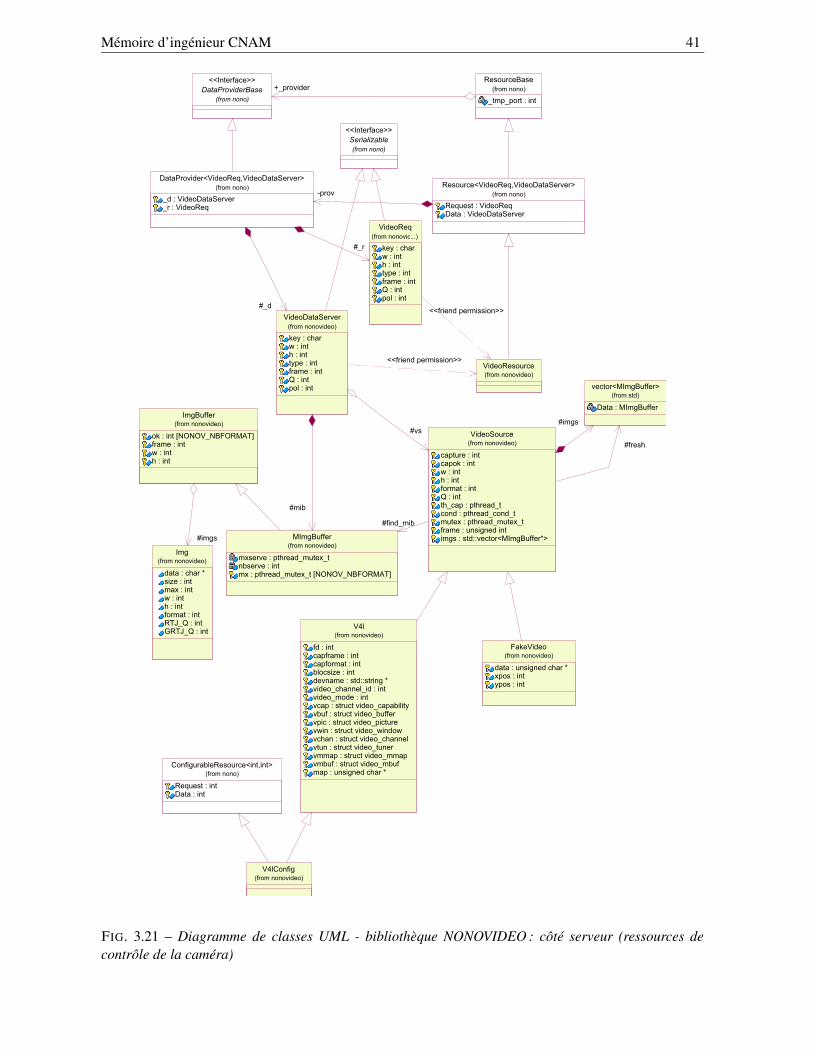
Mémoire d’ingénieur CNAM 41
VideoResource(from nonovideo)
V4lConfig(from nonovideo)
V4l
fd : intcapframe : intcapformat : intblocsize : intdevname : std::string *video_channel_id : intvideo_mode : intvcap : struct video_capabilityvbuf : struct video_buffervpic : struct video_picturevwin : struct video_windowvchan : struct video_channelvtun : struct video_tunervmmap : struct video_mmapvmbuf : struct video_mbufmap : unsigned char *
(from nonovideo)
FakeVideo
data : unsigned char *xpos : intypos : int
(from nonovideo)
ImgBuffer
ok : int [NONOV_NBFORMAT]frame : intw : inth : int
(from nonovideo)
Img
data : char *size : intmax : intw : inth : intformat : intRTJ_Q : intGRTJ_Q : int
(from nonovideo)
#imgs
Serializable
(from nono)
<<Interface>>
ResourceBase
_tmp_port : int
(from nono)DataProviderBase
(from nono)
<<Interface>>+_provider
Resource<VideoReq,VideoDataServer>
Request : VideoReqData : VideoDataServer
(from nono)
VideoReq
key : charw : inth : inttype : intframe : intQ : intpol : int
(from nonovid...)
<<friend permission>>
DataProvider<VideoReq,VideoDataServer>
_d : VideoDataServer_r : VideoReq
(from nono)-prov
#_r
MImgBuffer
mxserve : pthread_mutex_tnbserve : intmx : pthread_mutex_t [NONOV_NBFORMAT]
(from nonovideo)
VideoDataServer
key : charw : inth : inttype : intframe : intQ : intpol : int
(from nonovideo)
<<friend permission>>
#mib
#_d
vector<MImgBuffer>
Data : MImgBuffer
(from std)
VideoSource
capture : intcapok : intw : inth : intformat : intQ : intth_cap : pthread_tcond : pthread_cond_tmutex : pthread_mutex_tframe : unsigned intimgs : std::vector<MImgBuffer*>
(from nonovideo)
#find_mib
#vs#imgs
#fresh
ConfigurableResource<int,int>
Request : intData : int
(from nono)
FIG. 3.21 – Diagramme de classes UML - bibliothèque NONOVIDEO : côté serveur (ressources decontrôle de la caméra)

Mémoire d’ingénieur CNAM 42
Chapitre 4
Conception d’une nouvelle architecturelogicielle adaptée à une Grille
Au cours de ces dernières années, de nombreuses recherches ont été menées sur l’utilisation d’In-ternet comme réseau support pour le contrôle distant d’un robot et des études existes sur les effets desfacteurs tels les délais de temps incertains, la perte de données et les problèmes de sécurité [24, 25].Mais, lorsque nous parlons de robots autonomes, le problème est plus complexe. Un robot autonome nefait pas que simplement exécuter des ordres. Il doit être capable de décider entre un grand nombre dequestions, et généralement il a besoin d’une plus grande puissance de calcul que celle disponible par sonprocesseur embarqué. Avec ce genre de robot, cela prend tout son sens de distribuer les calculs amontssur différentes machines, y compris celles, situées dans des laboratoires partenaires éloignés.
Citons quelques situations typiques qui ont besoin de calculs distribués et dé-localisés :– certaines applications robotiques, mais pas toutes sont très consommatrices de calculs et ont besoin
pour cela d’une machine puissante et très chère. Étant donné que ce n’est pas un cas courant, il n’estpas commode de consacrer une machine parallèle ou un cluster au système robotique. Pour pallierà ce problème, nous recherchons sur notre LAN, ou chez des laboratoires partenaires éloignés, unemachine puissante, lorsque nous en avons besoin;
– certaines applications robotiques sont composées de modules totalement concurrents qui travaillentsur les mêmes données. Le traitement entier peut ralentir le robot, nous pouvons donc les découperen différentes tâches et les distribués sur différentes machines;
– une solution basée sur une machine unique n’est pas tolérante aux pannes. Pour être sûr que lamission du robot ne va pas échouer, nous pouvons lancer de multiples copies de l’application surdifférentes machines. Lorsqu’un échec interviendra sur l’une des plus rapide, la mission du robotralentira mais continuera tout de même, ainsi contrôlé par une plus lente;
– lorsque l’on utilise des ressources non dédiées, un ralentissement variable peut apparaître selonla charge. Basculer dynamiquement d’une machine à une autre peut être une solution pour évitercette surcharge;
– nous pouvons souhaiter partager notre système robotique avec nos partenaires, mais ne pas vouloirleurs allouer toutes nos ressources de calcul. Il est souhaitable qu’ils puissent exécuter leurs appli-cations robotiques sur leurs propres machines, en dirigeant nos robots depuis leurs laboratoires;
Plusieurs systèmes peuvent être construits sur des mécanismes classiques de client-serveur à traversdes tunnels cryptés (comme les liens SSH) sur l’Internet. Mais actuellement les Grilles de calcul et deressources sont en pleine émergence et pourraient être une solution intéressante à notre objectif. LesGrilles ont l’ambition de devenir des environnements distribués confortables, cachant l’hétérogénéité etla complexité des systèmes distribués [26, 27] et notre collaboration avec des partenaires éloignés sembletout à fait convenir à la philosophie des Grilles. En tout cas nos applications renferment trois points quipeuvent poser problème dans un environnement de Grille. En premier, ils doivent interagir fréquemment

Mémoire d’ingénieur CNAM 43
avec les sondes du robot et ses moteurs, et pas seulement s’exécuter en mémoire avec des Entrées/Sortieslimitées. En second, ils doivent s’exécuter lorsque le robot l’exige, et ceci indépendamment de la chargede la Grille. En troisièmement, ils doivent prendre en considération la synchronisation parce que lesrobots sont composés de plusieurs organes bougeant et agissant en parallèle.
Dans ce chapitre nous discutons de l’intérêt et des difficultés d’exécuter des applications robotiquesur une Grille de calcul et de ressources. Notre premier objectif est d’évaluer s’il est réellement possibled’utiliser une Grille pour améliorer le contrôle distribué de robots autonomes. Le second objectif est dedévelopper une architecture de Grille adaptée à nos besoins, et composée de modules de bas niveau pourcontrôler un robot, d’un intergiciel de Grille et de services de Grille de haut niveau.
4.1 Vue d’ensemble de l’environnement de Grille expérimentale
Notre environnement de test actuel est composé d’un robot, d’un ensemble de PCs mono et multi-processeur situés à Supélec (à Metz en France), d’un PC mono-processeur à l’Université de Salerne (enItalie), d’un VPN qui relie toutes ces machines à travers Internet et de l’environnement de Grille DIET.
Serveur du robot
Serveurs de calculs
monoprocesseur
Serveurs de calculs
Passerelle et pare-feu
VPN
Routeur Routeur
PC client
Fast et Gigabit
EthernetINTERNET
Liaison série
Serveur de calculs
Pare-feu
VPN (IPsec) + bus CORBA + Environnement DIET (GridRPC)
Université Salerne Italie
FIG. 4.1 – Vue d’ensemble de l’environnement de Grille expérimentale
4.1.1 Les caractéristiques du robot
Nous avons utilisé un robot KOALA de la société de la K-TEAM. Il possède ses propres contrôleursembarqués lui permettant de piloter ses différents organes, et il est contrôlé à distance par un PC externedédié, relié à lui à travers une liaison série. Ce PC héberge le serveur du Koala et toutes les applicationsrobotique sont clientes de lui. Comme explosé plus loin, ce serveur a été modifié pour être adapté à unenvironnement de Grille.

Mémoire d’ingénieur CNAM 44
FIG. 4.2 – Liaison entre le serveur et le robot KOALA
4.1.2 L’application robotique expérimentée
Cette application porte sur des robots qui naviguent à l’intérieur d’environnements dynamiques où ilsne peuvent pas utiliser d’itinéraires simplement prédéterminées. Quelques obstacles inattendus peuventapparaître. Nous supposons que des repères artificiels sont installés aux coordonnées connues. Quand ondémarre, le robot, il réalise un scan panoramique (déplace la tourelle de la caméra), détecte des repères,calcule une triangulation optimisée, et s’auto-localise [23]. Il peut alors calculer une trajectoire théoriquepour circuler avec précision (cf. §3.1.3).
Points d'arrêt avec scan panoramique et localisation
Robot Obstacle inattendu
FIG. 4.3 – Robot autonome suivant une longue trajectoire
Les auto-localisations sont calculées à des positions intermédiaires afin de compenser les erreurssurvenues durant de longues trajectoires et lorsque des obstacles inattendus sont détectés. Les imagestransmises depuis le serveur Koala jusqu’aux clients sont optimisées en utilisant la compression JPEG.
4.1.3 La configuration du VPN
Un VPN basé sur IPsec [28] a été installé pour supporter le bus Corba exigé par l’environnementde Grille DIET. IPsec implémente les deux protocoles AH (Authentication Header) et ESP (Encapsu-

Mémoire d’ingénieur CNAM 45
lating Security Payload), ainsi les paquets IPsec peuvent traverser les routeurs intermédiaires d’Internetcomme s’ils étaient de simples paquets IP. Seul le port 500/udp doit être ouvert sur la passerelle de desti-nation, afin que les politiques de sécurité les plus restrictives soient compatibles avec les connexions descomposants de la Grille (cf. §5.1).
4.1.4 L’environnement de Grille
L’environnement de Grille que nous utilisons est DIET (Distributed Interactive Engineering Tool-box). Il peut être considéré comme un environnement de résolution de problèmes sur une Grille, basésur un bus Corba et suivant un schéma Client/Agent/Serveur. Dans ce schéma, un client est une appli-cation qui soumet un problème à la Grille à travers une hiérarchie d’agents. Les agents possèdent uneliste des serveurs tournant sur la Grille et choisissent le meilleur pour répondre à la requête du client.Généralement un agent fait ses choix d’après la mesure des performances produite par un logiciel deprédiction supervisant les ressources de la Grille et donnant des informations sur la charge de travail, labande passante, etc.
Enfin, DIET supporte les appels GridRPC synchrones et asynchrones [12].
4.1.5 Les services de la Grille expérimentale
Deux modules de pilotage de l’application robotique ont été re-développés pour l’environnement deGrille : la localisation (basé sur un scan panoramique) et la navigation. Ce sont des modules d’usagecourant, qui permettent de construire des applications robotique de base. Ce sont donc, les premiersservices de Grille de haut niveau que nous avons rendu effectifs.
4.2 L’architecture du logiciel de Grille
La figure 4.4 montre les différents niveaux du logiciel de notre Grille pour contrôler le robot. Ausommet, l’application de Grille est pratiquement semblable à une application classique, incluant quelquescommandes de haut niveau du robot, tel que la « Localisation » ou la « Navigation » qui sont implémentéspar les services de Grille. S’il y a besoin, l’utilisateur peut appeler concurremment ces services de hautniveau, mais son succès dépendra de sa capacité à coordonner les différents organes du robot!
middleware de grilleServices de
Serveur du robot
Robot
de haut−niveauServices de grille
de bas−niveauServices de grille
Application robotique de la grille
ProtocoleInternet Ethernet
Protocole
Middleware VPN(basé sur IPsec)
Middleware DIET (grille)(basé sur un bus Corba)
API de DIET (GridRPC)
du robot sur la grilleAppels GridRPC redondants
Commandes de haut−niveau
Commandes robotiques composéesCommandes robotiques simplesCommandes robotiques de la liaison série
Sockets TCPSockets TCPPilote du port série
de résultats des commandesControle des buffers
de résultats des commandesControle des buffers
Applications de grille
FIG. 4.4 – Les niveaux du software de Grille pour le contrôle du robot
Les services de Grille de haut niveau sont implémentés en utilisant les appels GridRPC. Selon leservice, sa mise en œuvre peut faire un simple appel synchrone à un service de bas niveau (pour contrô-ler uniquement une fonction du robot), un simple appel asynchrone à un service de bas niveau (pour

Mémoire d’ingénieur CNAM 46
contrôler un organe du robot en parallèle d’autres services), ou plusieurs appels asynchrones concou-rants aux services de bas niveau, par exemple pour lancer des calculs redondants sur différents serveursde la Grille. Quand un service de haut niveau lance un calcul redondant, il attend seulement la fin d’unappel GridRPC, en ignorant ou annulant les autres appels. Tous ces détails de programmation de Grillesont cachés à l’utilisateur qui peut ainsi se concentrer sur des problèmes robotiques. Les services de basniveau de notre Grille sont divisés en deux groupes :
– les services de l’intergiciel de Grille;– les services du robot constitués de trois sous niveaux :
un service de transcription des commandes sur la liaison série,un protocole client-serveur bufferisé qui permet à des tâches différentes et redondantes d’ac-
céder concurremment au serveur du robot à travers des sockets TCP,un pilote de liaison série qui tourne sur la machine du serveur du robot.
Tout ces services robot de bas niveau sont appelés depuis des processus distribués à travers la Grille,lesquels sont supportés par l’intergiciel de Grille. Cet intergiciel est composé de l’environnent de GrilleDIET, du VPN basé sur IPsec, et des liens de bas et de haut niveau des services de Grille.
Le déploiement de notre architecture logicielle de Grille est illustré par la figure 4.5. Le programmede l’utilisateur (l’application cliente) tourne sur le PC client (un PC de base), et appelle des servicesde Grille de haut niveau qui, à leur tour, font appel au GridRPC. Ils contactent des agents DIET lancésquelque part sur la Grille pour connaître les adresses des serveurs de calcul les plus adaptés. Ensuite,le programme de l’utilisateur contacte directement ces serveurs pour obtenir des services de Grille. Cescommunications traversent le VPN qui utilise le protocole de DIET sur un bus Corba.
Alors, chaque serveur de calcul qui a besoin d’accéder au robot établit une communication directeavec le serveur du koala. Ces communications traversent aussi le VPN, mais utilisent les sockets TCP aulieu du protocole DIET basé sur Corba. De cette façon, les images conséquentes de la caméra, prises parle serveur du robot, sont envoyées aux serveurs de Grille à travers des sockets TCP en évitant le codageCorba. Lorsque ces serveurs les traitent, seuls de petits résultats (tel que les localisations calculées) sontretournés à la machine cliente de l’utilisateur à travers le bus Corba.
4.3 La Grille orientée serveur de robots
4.3.1 Les besoins spécifiques pour contrôler le robot
D’un point de vue informatique, un robot est un ensemble de périphériques indépendants (roue,tourelle de la caméra, caméra, sondes infrarouges...) qui travaillent habituellement en parallèle et sesynchronisent au besoin. Donc, chaque organe du robot est considéré comme une ressource qui peut êtreaccessible à travers un service. Le serveur du robot regroupe des services tous élémentaires en rapportavec les différents organes du robot. Il est composé de plusieurs sous-serveurs, un par organe du robot (cf.figure 4.5), attaché à différents ports. Chaque sous-serveur est un serveur multithreadé afin de pouvoirservir plusieurs clients en même temps, et peut verrouiller sa ressource au besoin. Par exemple, plusieursclients (en réalité les serveurs de calcul de la Grille) peuvent se connecter en parallèle à la caméra pourfaire différentes acquisitions d’images et traiter ces images pendant le mouvement du robot, mais un seuldes clients peut commander un moteur à la fois.

Mémoire d’ingénieur CNAM 47
- service de navigation 1
- service de localisation 1
Service DIET B
PC serveur de calculs
- service de navigation 2
- service de localisation 2
Service DIET C
PC serveur de calculs
Master Agent
Local Agent
PC DIET de la grille
programme client
- service de navigation 1
- service de localisation 1
Service DIET A
PC serveur de calculs
Port série image roueAnnuaire
des ressourcesthreads
buffers
d'historique
PC serveur du robot
Serveur du robot: serveur multithreadé & bufferisé driver port série (objet)
France Italie
1. VPN-Corba-DIET
2. VPN-Corba-DIET2. VPN
Corba
DIET
4. VPN-TCP3. VPN-TCP
VPN
Liaison série
FIG. 4.5 – Mapping des serveurs et des services de la Grille
4.3.2 Le service d’annuaire de ressources
Les numéros de ports des services dépendent de la configuration du PC serveur du robot. Les servicesde calcul de haut niveau de la Grille doivent se connecter aux différents ports du PC serveur du robotpour exiger des services variés.
Pour améliorer l’indépendance entre le serveur du robot et les serveurs de calcul de la Grille (enréalité les clients du serveur du robot), le serveur du robot inclut un service d’annuaire de ressources (cf.figure 4.5). Les clients doivent connaître uniquement le numéro du port de ce service, leurs renvoyantainsi la liste de toutes les ressources disponibles et leur numéro de port associé. De plus, la mise àjour du serveur du robot (c.-à-d. la mise à jour d’un service de Grille de bas niveau) n’entraîne pas dechangement sur les services de haut niveau de la Grille.
4.3.3 L’utilisation de buffers d’historique
Lorsque des calculs redondants sont lancés, le robot doit exécuter une fois et une seule chaque ac-tion mais doit retourner les mêmes valeurs subséquentes des sondes à tous les clients redondants. Poursatisfaire à ces contraintes nous avons introduit des buffers d’historique dans le serveur du robot : unbuffer par ressource et par algorithme contrôlant la ressource. Quand un serveur de calcul de la Grillese connecte au serveur du robot et interroge un service, il envoie un numéro d’identification d’exécutionsuivi d’un ensemble de commandes de la liaison série pour être retransmises au robot par le serveur durobot (plus précisément par le sous-serveur attaché à la ressource). Les serveurs de calcul de Grille re-dondants exécuteront le même algorithme et enverront ainsi le même numéro d’identication d’exécution.Lorsqu’il reçoit une nouvelle demande de bas niveau, le serveur du robot la transmet au robot et stocke lerésultat dans le buffer associé à cette exécution. Lorsqu’il reçoit de nouveau la même demande d’un autreserveur de calcul de la Grille qui est en retard, il retourne simplement à ce serveur le résultat entreposédans le buffer.

Mémoire d’ingénieur CNAM 48
Les buffers ont une dimension limitée, et les serveurs de calcul les plus lents de la Grille qui de-mandent une exécution trop ancienne sont rejetés et finalement annulés. Cependant, les serveurs lentsobtiennent leurs résultats bien plus vite parce qu’ils ne doivent pas attendre les actions du robot. Donc,en réalité, peu de serveurs sont repoussés et annulés. De plus, si la charge du réseau change pendantl’exécution, le serveur de calcul de la Grille qui envoie le premier la prochaine nouvelle demande peutaussi changer. Dans ce cas le serveur du robot poursuit, contrôlé par le nouveau serveur de calcul le plusrapide de la Grille. Ce mécanisme mène à améliorer la tolérance aux pannes et à un équilibrage de charge(load balancing).
4.3.3.1 Élaboration du mécanisme de concurrence
Le mécanisme décrit précédemment et mis en œuvre sur le serveur du robot est en soi très simple :
1. on distingue le mode bufferisé du mode direct (sans buffers) par un caractère de réveil envoyé auserveur du robot (cf. §3.2.2.3);
2. chaque message reçu du client doit appartenir à un numéro d’algorithme;3. chaque message reçu contient un numéro de séquencement croissant;4. le premier message reçu dont le numéro d’algorithme est x1 et le numéro de séquencement s1
est envoyé à la ressource pour être exécuté par l’organe associé. Le résultat est alors stocké puisretourné au client;
5. le second message reçu dont le numéro d’algorithme est x1 et le numéro de séquencement s1 n’estpas interprété par l’organe. On retourne directement au client le résultat précédemment stocké dansl’historique.
Réflexion sur le choix de stockage des réponses
Deux possibilités s’ouvre à nous :– le stockage de toutes les réponses des transactions passées à une ressource pour un algorithme
donné;– le stockage optimisé des réponses en ne bufferisant qu’une seule fois une réponse qui se répète n
fois;Le second point semble plus intéressant mais pose des problèmes lors de l’utilisation de boucles dans
l’application client. Prenons le cas de ce programme :
int i=0;
MoveRobot(10);while(!reached()){
i++;printf("nombre itération: %d",i);
}
FIG. 4.6 – Exemple de programme qui pose problème
Effectivement si l’on exécute une seconde fois le programme, le nombre d’itérations affichées ne serapas le même puisque l’on ne mémorise que la dernière réponse. Il est donc impossible de garantir par ceprocédé qu’un algorithme s’exécute à l’identique lors de chaque appel.
Autre problème, certaines méthodes attendent le changement d’état d’un capteur physique (exemplela méthode reached()). il faudrait donc mettre en place un système qui bloque l’archivage des résultats

Mémoire d’ingénieur CNAM 49
jusqu’à un changement d’état du capteur pour enfin ne retenir que le dernier état de celui-ci. Lors d’unedemande de plusieurs clients redondants, le mécanisme ne sera pas certain de savoir s’il doit interrogerle capteur pour contrôler son changement d’état ou s’il doit simplement retourner aux clients un étatprécédent de celui-ci.
Si l’on considère la possibilité d’imbriquer ces différentes méthodes dans des boucles, il devient trèsdifficile de distinguer entre le moment où il faut interroger le capteur et celui où il faut retourner l’étatprécédent.
Par souci de robustesse de l’algorithme, nous avons décidé de ne retenir que la première possibi-lité de stockage des réponses, à savoir : mémoriser tous les résultats pour chaque ressource et numérod’algorithme donné au détriment de la place mémoire consommée.
4.3.3.2 Algorithme de mémorisation
Pour implémenter cet algorithme, il faut modifier légèrement le fonctionnement de la couche « nono »qui est responsable de l’acheminement des données entre le client et le robot KOALA et de doter denouvelles fonctions aux couches supérieures (koala, nonovideo).
Au niveau du serveur nono
Lorsque l’on étudie le déroulement d’une transaction entre le client et le serveur nono, on s’aperçoitque tout ce passe au niveau de la classe ResourceBase dans la méthode On_Reply() (cf. diagrammede séquence en annexe B.4). C’est elle qui est activée après l’établissement du socket TCP sur demandedu client (utilisation de la méthode Connect() de la classe Client) puis qui traite, jusqu’à la libérationde la connexion, les nouveaux messages arrivés (boucle while sur le diagramme de séquence). Par l’in-termédiaire de la méthode DataTransfer(), elle réceptionne la question, la traite et enfin retourne laréponse au client tend que la connexion reste active.
Ainsi, en ajoutant un premier traitement lors de l’activation de cette méthode (cf. figure 4.7), il estpossible de déterminer les besoins du client lors de l’utilisation du mode bufferisé (nombres d’algo-rithmes à bufferiser et numéro du premier de la série) et de le distinguer du mode direct (nombresd’algorithmes à zéro et numéro du premier à un). On ajoute à la suite la création des buffers souhaités(boucle for du diagramme de séquence UML), puis au moyen du caractère de réveil qui précède chaquetransaction (entre autre « nonobufSTART_DATA_TRANSFER »), il est possible de déterminer si cellereçue doit être traitée par le mode de mémorisation ou directement par le device associé. Et finalement,la numérotation de chaque transaction permettra de retrouver celles déjà traitées auparavant ou d’établirque c’est une nouvelle commande à traiter par l’algorithme de mémorisation.
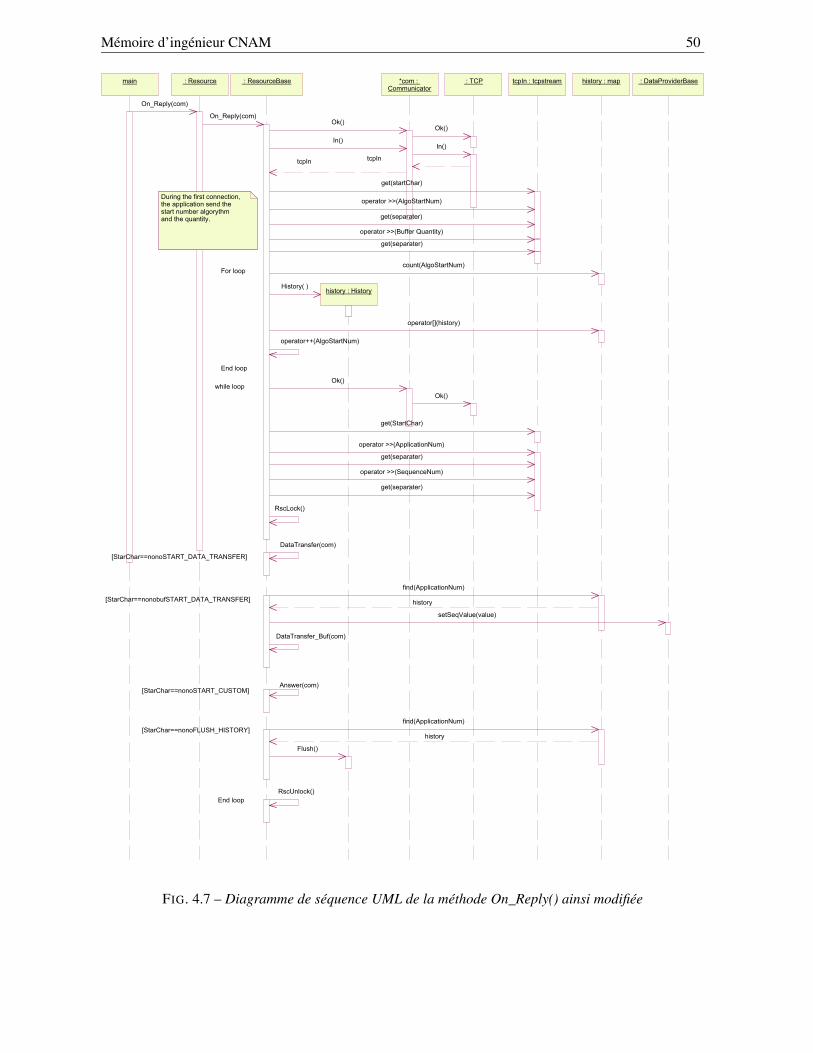
Mémoire d’ingénieur CNAM 50
main : Resource : ResourceBase
history : History
*com : Communicator
: TCP tcpIn : tcpstream history : map : DataProviderBase
On_Reply(com)
On_Reply(com)Ok()
Ok()
In()In()
tcpIntcpIn
get(startChar)
operator >>(AlgoStartNum)
get(separater)
operator >>(Buffer Quantity)
get(separater)
count(AlgoStartNum)
History( )
operator[](history)
operator++(AlgoStartNum)
Ok()
Ok()
get(StartChar)
operator >>(ApplicationNum)
get(separater)
operator >>(SequenceNum)
get(separater)
RscLock()
DataTransfer(com)
[StarChar==nonoSTART_DATA_TRANSFER]
[StarChar==nonobufSTART_DATA_TRANSFER]
find(ApplicationNum)
history
setSeqValue(value)
DataTransfer_Buf(com)
[StarChar==nonoSTART_CUSTOM]Answer(com)
[StarChar==nonoFLUSH_HISTORY]
find(ApplicationNum)
history
Flush()
RscUnlock()
During the first connection, the application send the start number algorythm and the quantity.
For loop
End loop
while loop
End loop
FIG. 4.7 – Diagramme de séquence UML de la méthode On_Reply() ainsi modifiée

Mémoire d’ingénieur CNAM 51
Élaboration de la classe History
Afin d’implémenter le mécanisme de mémorisation, une classe History a été ajoutée à la struc-ture de la bibliothèque nono (cf. figure 4.8). Elle regroupe toutes les méthodes nécessaires à la gestiond’un buffer. Ainsi chaque instance de cette classe sera associée à un numéro d’algorithme afin de dé-finir plusieurs buffers pour une même ressource (l’association est réalisée par le tableau de hachagemap<int,history> où la clé représente le numéro d’algorithme et la donnée une instance de laclasse History) .
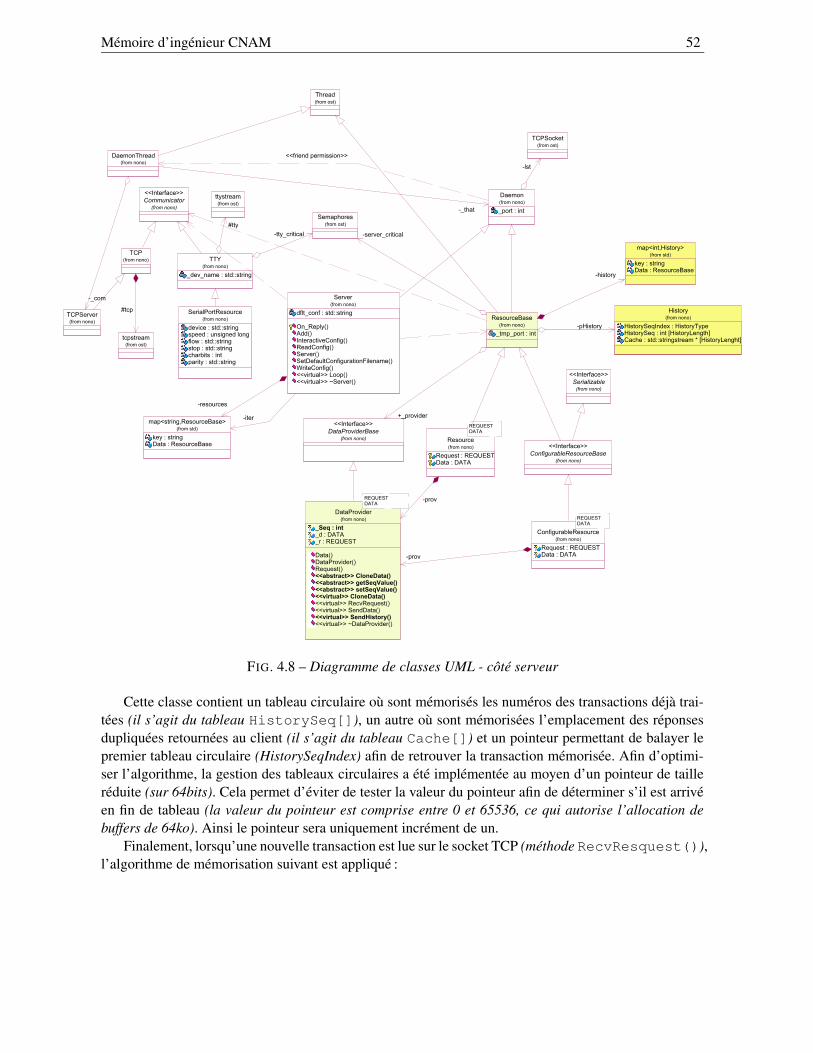
Mémoire d’ingénieur CNAM 52
Communicator(from nono)
<<Interface>>
ConfigurableResourceBase(from nono)
<<Interface>>
Serializable(from nono)
<<Interface>>
SerialPortResource
device : std::stringspeed : unsigned longflow : std::stringstop : std::stringcharbits : intparity : std::string
(from nono)
Thread(from ost)
tcpstream(from ost)
TCP(from nono)
#tcpTCPServer(from nono)
TCPSocket(from ost)
DaemonThread(from nono)
-_com
Daemon
_port : int
(from nono)
-lst
-_that
map<string,ResourceBase>
key : stringData : ResourceBase
(from std)
Server
dflt_conf : std::string
On_Reply()Add()InteractiveConfig()ReadConfig()Server()SetDefaultConfigurationFilename()WriteConfig()<<virtual>> Loop()<<virtual>> ~Server()
(from nono)
-resources
-iter
ttystream(from ost)
TTY
_dev_name : std::string
(from nono)
#tty
History
HistorySeqIndex : HistoryTypeHistorySeq : int [HistoryLength]Cache : std::stringstream * [HistoryLenght]t
(from nono)
DataProviderBase(from nono)
<<Interface>>
Semaphores(from ost)
-tty_critical
map<int,History>
key : stringData : ResourceBase
(from std)
ResourceBase
_tmp_port : int
(from nono) -pHistory
+_provider
-server_critical
-history
<<friend permission>>
REQUESTDATA
ConfigurableResource
Request : REQUESTData : DATA
(from nono)
REQUESTDATA
Resource
Request : REQUESTSData : DATA
(from nono)
REQUESTDATA
DataProvider
_Seq : int_d : DATA_r : REQUEST
Data()DataProvider()Request()<<abstract>> CloneData()<<abstract>> getSeqValue()<<abstract>> setSeqValue()<<virtual>> CloneData()<<virtual>> RecvRequest()<<virtual>> SendData()<<virtual>> SendHistory()<<virtual>> ~DataProvider()
(from nono)
-prov
-prov
FIG. 4.8 – Diagramme de classes UML - côté serveur
Cette classe contient un tableau circulaire où sont mémorisés les numéros des transactions déjà trai-tées (il s’agit du tableau HistorySeq[]), un autre où sont mémorisées l’emplacement des réponsesdupliquées retournées au client (il s’agit du tableau Cache[]) et un pointeur permettant de balayer lepremier tableau circulaire (HistorySeqIndex) afin de retrouver la transaction mémorisée. Afin d’optimi-ser l’algorithme, la gestion des tableaux circulaires a été implémentée au moyen d’un pointeur de tailleréduite (sur 64bits). Cela permet d’éviter de tester la valeur du pointeur afin de déterminer s’il est arrivéen fin de tableau (la valeur du pointeur est comprise entre 0 et 65536, ce qui autorise l’allocation debuffers de 64ko). Ainsi le pointeur sera uniquement incrément de un.
Finalement, lorsqu’une nouvelle transaction est lue sur le socket TCP (méthode RecvResquest()),l’algorithme de mémorisation suivant est appliqué :
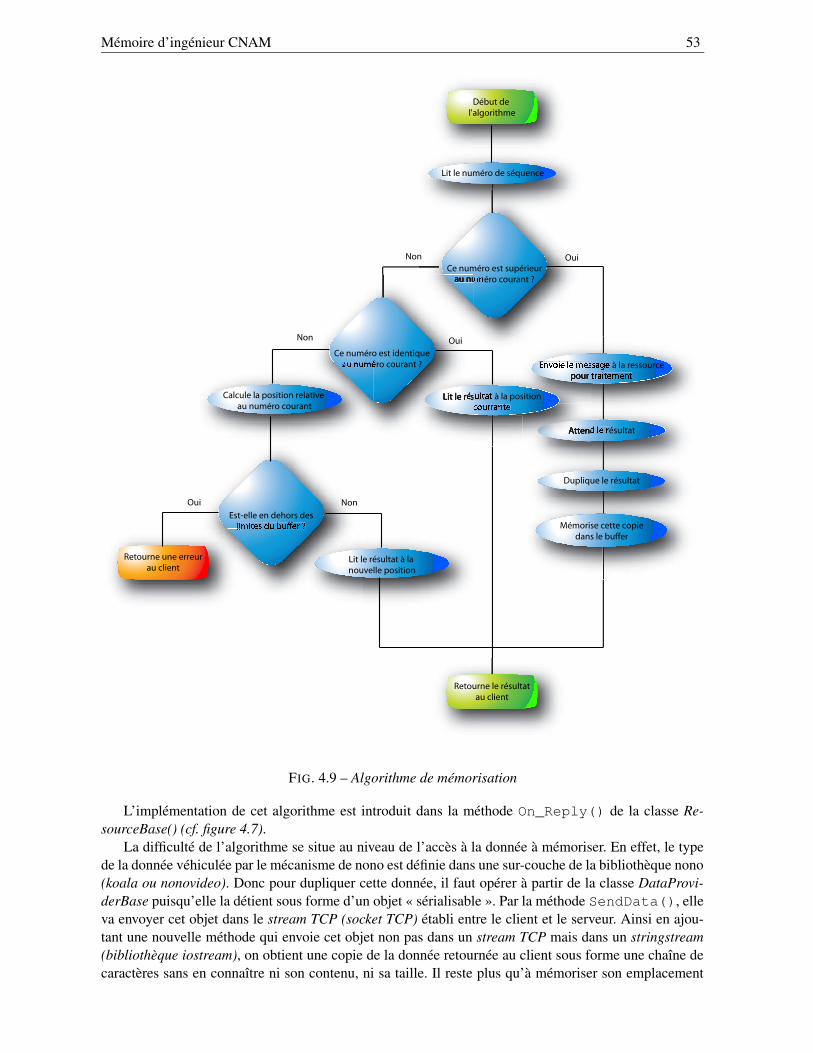
Mémoire d’ingénieur CNAM 53
Lit le numéro de séquence
à la ressource
ésultat
Duplique le résultat
Mémorise cette copie
dans le buffer
à la position
Ce numéro est supérieur
éro courant ?
Ce numéro est identique
ro courant ?
Calcule la position relative
au numéro courant
Est-elle en dehors des
Lit le résultat à la
nouvelle position
Retourne une erreur
au client
Retourne le résultat
au client
Oui Non
Oui
Oui
Non
Non
Début de
l'algorithme
FIG. 4.9 – Algorithme de mémorisation
L’implémentation de cet algorithme est introduit dans la méthode On_Reply() de la classe Re-sourceBase() (cf. figure 4.7).
La difficulté de l’algorithme se situe au niveau de l’accès à la donnée à mémoriser. En effet, le typede la donnée véhiculée par le mécanisme de nono est définie dans une sur-couche de la bibliothèque nono(koala ou nonovideo). Donc pour dupliquer cette donnée, il faut opérer à partir de la classe DataProvi-derBase puisqu’elle la détient sous forme d’un objet « sérialisable ». Par la méthode SendData(), elleva envoyer cet objet dans le stream TCP (socket TCP) établi entre le client et le serveur. Ainsi en ajou-tant une nouvelle méthode qui envoie cet objet non pas dans un stream TCP mais dans un stringstream(bibliothèque iostream), on obtient une copie de la donnée retournée au client sous forme une chaîne decaractères sans en connaître ni son contenu, ni sa taille. Il reste plus qu’à mémoriser son emplacement
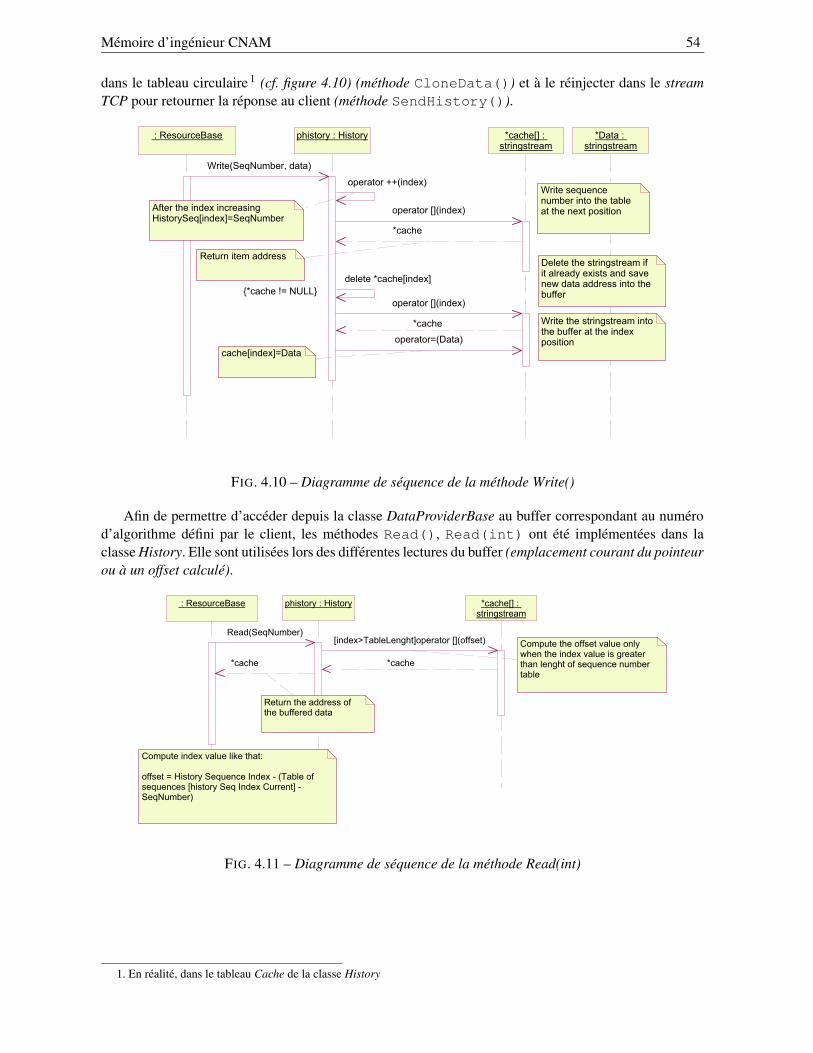
Mémoire d’ingénieur CNAM 54
dans le tableau circulaire 1 (cf. figure 4.10) (méthode CloneData()) et à le réinjecter dans le streamTCP pour retourner la réponse au client (méthode SendHistory()).
: ResourceBase phistory : History *cache[] : stringstream
*Data : stringstream
Write(SeqNumber, data)
operator ++(index)
operator [](index)
delete *cache[index]
After the index increasingHistorySeq[index]=SeqNumber
cache[index]=Data
*cache
operator [](index)
*cache
operator=(Data)
{*cache != NULL}
Write sequence number into the table at the next position
Delete the stringstream if it already exists and save new data address into the buffer
Write the stringstream into the buffer at the index position
Return item address
FIG. 4.10 – Diagramme de séquence de la méthode Write()
Afin de permettre d’accéder depuis la classe DataProviderBase au buffer correspondant au numérod’algorithme défini par le client, les méthodes Read(), Read(int) ont été implémentées dans laclasse History. Elle sont utilisées lors des différentes lectures du buffer (emplacement courant du pointeurou à un offset calculé).
: ResourceBase phistory : History *cache[] : stringstream
*cache*cache
Read(SeqNumber)[index>TableLenght]operator [](offset)
Compute index value like that:
offset = History Sequence Index - (Table of sequences [history Seq Index Current] - SeqNumber)
Return the address of the buffered data
Compute the offset value only when the index value is greater than lenght of sequence number table
FIG. 4.11 – Diagramme de séquence de la méthode Read(int)
1. En réalité, dans le tableau Cache de la classe History

Mémoire d’ingénieur CNAM 55
Chapitre 5
Déploiement et installation d’une Grillemulti-sites
Notre Grille de calcul et de ressources est composée d’un réseau support (ici un réseau ethernet engigabit) et de différents PC (voir tableau 5.1) tournant sur le système d’opération Linux 2.4.20 (RedHat9).
Serveur du robot
Pentiums quadri XEON
Pentiums mono XEON
ETHERNET
GIGABIT
RESEAU LOCAL
INTERNET
Serveur
DHCP DNS LDAP
Passerelle
pare-feu
routeur
AMD ATHLONGrille locale
Supélec à Metz
Unisa en Italie
Nom de la Caractéristique du processeur Cache RAMmachine (Ko) (Mo)
gserver 1 x AMD Athlon(tm) 1,4GHz 256 1000ggate 1 x AMD Athlon(tm) 500MHz 64 190quadx1-2 4 x Intel XEON PIII 700 MHz 2048 512quadx3 4 x Intel XEON PIV 2,50GHz 2048 1000monox1-4 1 x Intel XEON PIV 2,40GHz 512 512monox5-8 1 x Intel XEON PIV 2,40GHz 512 1000
FIG. 5.1 – Implantation de la Grille locale
Pour se connecter sur chaque PC, un système de gestion de comptes centralisés (au moyen du proto-cole LDAP décrit au paragraphe 5.2) a été installé sur le serveur de la Grille locale (appelé gserver) qui

Mémoire d’ingénieur CNAM 56
sert déjà de serveur DHCP et DNS.La gestion des ressources quant à elle est réalisée grâce à l’environnement de grille DIET (décrit au
paragraphe 5.3) au moyen de différents agents (agent maître ou local) et du bus CORBA (implémentépar omniORB). Le déploiement des ressources à l’extérieur de la Grille locale est effectué au travers d’unréseau privé virtuel (décrit au paragraphe 5.1) par l’intermédiaire d’une passerelle sécurisée.
5.1 Réseaux privés virtuels
Après avoir effectué des tests de notre application sur notre Grille locale, nous avons voulu étendrenotre système avec d’autres laboratoires partenaires, afin de dé-localiser la reprise de contrôle du robot etde mettre en évidence une contrainte de temps lors du transport des commandes. (utilisation de l’Internetcomme réseau support).
RESEAU LOCAL
Client DIET
Services DIET
de localisation
GRILLE LOCALE
FIG. 5.2 – Topologie de notre Grille locale
Pour réussir le déploiement de notre architecture de Grille (CORBA-DIET) à d’autres sites distants,il faut tenir compte des futur problèmes rencontrés :
– le premier problème se situe au niveau de l’adressage de notre Grille; en effet son adressage est detype 192.168.x.x, or cette plage d’adresses est réservée pour les réseaux locaux (adresses privées),donc non routable sur internet.
Ce problème considéré seul, pourrait être résolu en mettant en place le système de translationd’adresse (Network Address Translator NAT) à l’entrée/sortie de la Grille;
– le second problème est dû au nombre de ports TCP utilisées, d’une part au niveau du serveur durobot pour dialoguer avec les différents ressources (établissement de sockets TCP sur des portsfixes), et d’autre part au niveau des échanges entre CORBA et DIET (ports supérieurs à 1024 ). Ilest donc nécessaire de prévoir, sur les pare-feux rencontrés, l’ouverture de plus d’une dizaine deports fixes et d’autoriser l’ouverture des ports TCP supérieurs à 1024 pour permettre à CORBAet DIET de renvoyer leurs résultats au client. Malheureusement chaque administrateur de site à sapropre politique de sécurité.

Mémoire d’ingénieur CNAM 57
Une solution serait d’utiliser du tunnelling 1 (tunnel SSH) entre les sites. Mais dans la versionactuelle d’omniORB (implémentation de CORBA sous Linux), les objets mémorisés sont référencéspar un identifiant composé d’un identifiant objet, mais aussi de l’adresse IP et du port TCP de samachine hôte. Ce qui pose problème lors de la réponse du serveur DIET au client à travers de cetype de tunnel (cf. figure 5.3).
4. Réponse vers l’objet 127.0.0.1:6543... et non pas
1. enregistrement de l’objet client
2. indique le servicedisponible pourtraiter la requete
3. soumet la requete
193.26.226.2:6544...
2809 6543 6544 2809
Serveur DIET
Serveur SSH
193.26.226.3
Référence objet
127.0.01:6543...
CORBA
Serveur SSH
193.26.226.1
Client DIET
4. réponseClient SSH
127.0.0.1
193.26.226.2
127.0.0.1 127.0.0.1
FIG. 5.3 – Problème lié à l’enregistrement des objets dans omniORB
– le troisième problème est de pouvoir restreindre l’accès à notre système de contrôle de robot. Il estnécessaire que seuls les utilisateurs authentifiés/autorisés puissent avoir accès aux services offertspar notre système.
La solution à ce problème seul, serait de mettre en place des connexions SSL sur les différentsservices disponibles.
Après réflexion sur ces problèmes soulevés, la solution globale la plus appropriée est la mise en placed’un VPN (Virtual Private Network, réseau privé virtuel) reliant tous les sites distants à notre Grillelocale.
1. Technique consistant à créer un « tunnel » entre deux points du réseau en appliquant une transformation aux paquets àune extrémité (généralement, une encapsulation dans un protocole approprié) et en les reconstituant à l’autre extrémité.

Mémoire d’ingénieur CNAM 58
INTERNET
de navigation
Second service DIET
de localisation
Services DIET
de navigation
Premier service DIET
de localisation
GRILLE LOCALE
FIG. 5.4 – Topologie de notre Grille déployée
A la base, les VPN étaient majoritairement utilisés pour relier plusieurs réseaux privés distants en unseul par le biais d’un réseau qui n’est pas de confiance, tout en garantissant un minimum de confidentialitéet de sécurité. Sont venus s’ajouter à tout cela des travailleurs itinérants (aussi appelés Road Warrior) etdes besoins de sécurité dans les réseaux sans fil. Dans ce contexte, IPsec a représenté la solution idéale :un standard qui permet de créer des VPN en utilisant les implémentations 2 de différents constructeurs. Aprésent, il est nativement implémenté dans IPv6, et apparaît par conséquent comme l’avenir naturel descommunications sécurisées.
5.1.1 IPSec
Le terme IPsec (IP Security Protocol) désigne un ensemble de mécanismes destinés à protéger letrafic au niveau d’IP (IPv4 ou IPv6). Les services de sécurité offerts sont :
– l’intégrité 3 en mode non connecté;– l’authentification de l’origine des données;– la protection contre le rejeu 4;– la confidentialité (confidentialité des données et protection partielle contre l’analyse du trafic).
Ces services sont fournis au niveau de la couche IP (cf. figure 5.5 ci-après), offrant donc une protectionpour IP et tous les protocoles de niveau supérieur. Optionnel dans IPv4, IPsec est obligatoire pour touteimplémentation de IPv6.
2. Anglicisme, de to implement : mettre en œuvre, réaliser.3. Service de sécurité qui consiste à s’assurer que seules les personnes autorisées pourront modifier un ensemble de données.
Dans le cadre de communications, ce service consiste à permettre la détection de l’altération des données durant le transfert.4. Action consistant à envoyer un message intercepté précédemment, en espérant qu’il sera accepté comme valide par le
destinataire.

Mémoire d’ingénieur CNAM 59
sportTran
Couches liaison
et physique
IP
IPsec (AH et ESP)
Transport
(TCP, UDP)
Clés IKEProtocoles
applicatifs
Applications
FIG. 5.5 – Modèle TCP/IP avec support d’IPsec
IPsec est développé par un groupe de travail du même nom à l’IETF (Internet Engineering TaskForce), groupe qui existe depuis 1992. Une première version des mécanismes proposés a été publiéesous forme de RFC 5 en 1995, sans la partie de gestion des clés. Une seconde version, qui comporte enplus la définition du protocole de gestion des clés IKE, a été publiée en novembre 1998. Mais IPsec resteune norme non figée qui fait en ce moment même l’objet de multiples « brouillons d’Internet »(Internetdrafts).
5.1.1.1 Architecture d’IPsec
Pour sécuriser les échanges ayant lieu sur un réseau TCP/IP, il existe plusieurs approches, en parti-culier en ce qui concerne le niveau auquel est effectué la sécurisation :
– niveau applicatif (mails chiffrés par exemple),– niveau transport (TLS/SSL, SSH...),– ou encore au niveau physique (boîtiers chiffrant toutes les données transitant par un lien donné).
IPsec, quant à lui, vise à sécuriser les échanges au niveau de la couche réseau.
Les mécanismes AH et ESP Pour cela, IPsec fait appel à deux mécanismes de sécurité pour le traficIP : les « protocoles » AH et ESP, qui viennent s’ajouter au traitement IP classique :
– Authentication Header (AH) est conçu pour assurer l’intégrité et l’authentification des datagrammes 6
IP sans chiffrement des données (i.e. sans confidentialité). Le principe de AH est d’adjoindre audatagramme IP classique un champ supplémentaire sans modifier l’en-tête IP, permettant ainsi à laréception, de vérifier l’authenticité des données incluses dans le datagramme (cf. annexe C.1).
5. Littéralement, « Appel à commentaires » (Request For Comment) . C’est en fait un document décrivant un des aspectsd’Internet de façon relativement formelle (généralement, spécification d’un protocole). Ces documents sont destinés à êtrediffusés à grande échelle dans la communauté Internet et servent souvent de référence. On peut les trouver sur la plupart dessites FTP.
6. Les datagrammes sont des paquets totalement indépendants les uns des autres et circulant en mode non connecté. Parexemple, les paquets d’IP et ceux d’UDP sont des datagrammes. Chaque paquet de type datagramme transite à travers le réseauavec l’ensemble des informations nécessaires à son acheminement, et notamment les adresses de l’expéditeur et du destinataire.Le routage étant effectué séparément pour chaque datagramme, deux datagrammes successifs peuvent donc suivre des cheminsdifférents et être reçus par le destinataire dans un ordre différent de celui d’émission. De plus, en cas de problème dans le réseau,des datagrammes peuvent être perdus. Le destinataire doit donc réordonner les datagrammes pour reconstituer les messages etcontrôler qu’aucun datagramme n’est perdu.

Mémoire d’ingénieur CNAM 60
Authentifié
(excepté pur les champs variables de l’en−tete)
Après application de AH
En−tete IPd’origine
Données(protocole de niveau supérieur)AH
FIG. 5.6 – Authentication Header
– Encapsulating Security Payload (ESP) a pour rôle premier d’assurer la confidentialité, mais peutaussi assurer l’authenticité des données. Le principe de ESP est de générer, à partir d’un data-gramme IP classique, un nouveau datagramme dans lequel les données et éventuellement l’en-têteoriginal sont chiffrés (cf. annexe C.1.1).
En−tete IPd’origine
Données(protocole de niveau supérieur)
TrailerESP d’authentification
Données
Chiffré (confidentialité)
Authentifié
Après application de ESP
En−teteESP
FIG. 5.7 – Encapsulating Security Payload
Ces mécanismes peuvent être utilisés seuls ou combinés pour obtenir les fonctions de sécurité dési-rées.
La notion d’association de sécurité Les mécanismes mentionnés ci-dessus font bien sûr appel à lacryptographie, et utilisent donc un certain nombre de paramètres (algorithmes de chiffrement utilisés,clés, mécanismes sélectionnés, etc...) sur lesquels les tiers communicants doivent se mettre d’accord.Afin de gérer ces paramètres, IPsec a recours à la notion d’association de sécurité 7 (Security Association,SA).
Une SA est unidirectionnelle ; en conséquence, protéger les deux sens d’une communication classiquerequiert deux associations, une dans chaque sens. Les services de sécurité sont fournis par l’utilisationsoit de AH soit de ESP. Si AH et ESP sont tous deux appliqués au trafic en question, deux SA (voir plus)sont créées ; on parle alors de paquet (bundle) de SA.
Chaque association est identifiée de manière unique à l’aide d’un triplet composé de :– L’adresse de destination des paquets,– L’identifiant du protocole de sécurité utilisé (AH ou ESP),– Un encodage des paramètres de sécurité (Security Parameter Index, SPI 8).Pour gérer les associations de sécurité actives, on utilise une « base de données des associations de
sécurité » (Security Association Database, SAD). Elle contient tous les paramètres relatifs à chaque SAet sera consultée pour savoir comment traiter chaque paquet reçu ou à émettre.
La gestion des clés et des associations de sécurité Comme nous l’avons mentionné au paragrapheprécédent, les SA contiennent tous les paramètres nécessaires à IPsec, notamment les clés utilisées. UneSA peut être configurée manuellement dans le cas d’une situation simple, mais la règle générale est
7. Une association de sécurité IPsec est une « connexion » simplexe qui fournit des services de sécurité au trafic qu’elletransporte. On peut aussi la considérer comme une structure de données servant à stocker l’ensemble des paramètres associés àune communication donnée.
8. Un SPI est un bloc de 32 bits qui, associé à une adresse de destination et au nom d’un protocole de sécurité (par exempleAH ou ESP), identifie de façon unique une association de sécurité (SA). Le SPI est transporté dans chaque paquet de façon àpermettre au destinataire de sélectionner la SA qui servira à traiter le paquet. Le SPI est choisi par le destinataire à la créationde la SA.

Mémoire d’ingénieur CNAM 61
d’utiliser un protocole spécifique qui permet la négociation dynamique des SA et notamment l’échangedes clés de session.
D’autre part, IPv6 n’est pas destiné à supporter une gestion des clés « en bande », c’est-à-dire oùles données relatives à la gestion des clés seraient transportées à l’aide d’un en-tête IPv6 distinct. Aulieu de cela on utilise un système de gestion des clés dit « hors bande », où les données relatives à lagestion des clés sont transportées par un protocole de couche supérieure tel que UDP ou TCP. Cecipermet le découplage clair du mécanisme de gestion des clés et des autres mécanismes de sécurité. Ilest ainsi possible de substituer une méthode de gestion des clés à une autre sans avoir à modifier lesimplémentations des autres mécanismes de sécurité.
Le protocole de négociation des SA développé pour IPsec s’appelle « protocole de gestion des clés etdes associations de sécurité pour Internet » (Internet Security Association and Key Management Protocol,ISAKMP). ISAKMP est en fait inutilisable seul : c’est un cadre générique qui permet l’utilisation deplusieurs protocoles d’échange de clé et qui peut être utilisé pour d’autres mécanismes de sécurité queceux d’IPsec. Dans le cadre de la standardisation d’IPsec, ISAKMP est associé à une partie des protocolesSKEME et Oakley pour donner un protocole final du nom d’IKE (Internet Key Exchange).
Politiques de sécurité Les protections offertes par IPsec sont basées sur des choix définis dans une« base de données de politique de sécurité » (Security Policy Database, SPD). Cette base de données estétablie et maintenue par un utilisateur, un administrateur système ou une application mise en place parceux-ci. Elle permet de décider, pour chaque paquet, s’il se verra apporter des services de sécurité, seraautorisé à passer outre ou sera rejeté.
La SPD contient une liste ordonnée de règles, chaque règle comportant un certain nombre de critèresqui permettent de déterminer quelle partie du trafic est concernée. Les critères utilisables sont l’ensembledes informations disponibles par le biais des en-têtes des couches IP et transport. Ils permettent de définirla granularité selon laquelle les services de sécurité sont applicables et influencent directement le nombrede SA correspondantes. Dans le cas où le trafic correspondant à une règle doit se voir attribuer des servicesde sécurité, la règle indique les caractéristiques de la SA (ou paquet de SA) correspondante : protocoles,modes, algorithmes requis...
5.1.1.2 Principe de fonctionnement
Le schéma ci-dessous représente tous les éléments présentés précédemment, ainsi que leurs positionset leurs interactions.
Administrateur
ISAKMPSKEMEOakleyD.O.I.
I.K.E.
Application
Protocole applicatif(HTTP,FTP,POP...)
Sockets
Transport (TCP, UDP)
IP / IPsec (AH, ESP)
Liaison
S.P.D.
S.A.D.
Configure
Alertes
Négocie,modifie,
supprime Pointe vers
Consulte
Consulte
Demande création SA
FIG. 5.8 – Organisation d’IPsec sur une passerelle

Mémoire d’ingénieur CNAM 62
On distingue deux situations :– Trafic sortant
Lorsque la « couche » IPsec reçoit des données à envoyer, elle commence par consulter labase de donnée des politiques de sécurité (SPD) pour savoir comment traiter ces données. Si cettebase lui indique que le trafic doit se voir appliquer des mécanismes de sécurité, elle récupère lescaractéristiques requises pour la SA correspondante et va consulter la base des SA (SAD). Si la SAnécessaire existe déjà, elle est utilisée pour traiter le trafic en question. Dans le cas contraire, IPsecfait appel à IKE pour établir une nouvelle SA avec les caractéristiques requises.
– Trafic entrantLorsque la couche IPsec reçoit un paquet en provenance du réseau, elle examine l’en-tête
pour savoir si ce paquet s’est vu appliquer un ou plusieurs services IPsec et si oui quelles sontles références de la SA. Elle consulte alors la SAD pour connaître les paramètres à utiliser pour lavérification et/ou le déchiffrement du paquet. Une fois le paquet vérifié et/ou déchiffré, la SPD estconsultée pour savoir si l’association de sécurité appliquée au paquet correspondait bien à cellerequise par les politiques de sécurité. Dans le cas où le paquet reçu est un paquet IP classique, laSPD permet de savoir s’il a néanmoins le droit de passer. Par exemple, les paquets IKE sont uneexception. Ils sont traités par IKE, qui peut envoyer des alertes administratives en cas de tentativede connexion infructueuse.
5.1.2 Types d’utilisations possibles
Après avoir vu comment est constitué IPsec et comment il fonctionne, nous allons maintenant nousintéresser aux différentes façons de l’utiliser. Un point important à retenir est que le fait d’intervenir auniveau réseau rend la sécurisation totalement transparente pour les applications.
5.1.2.1 Équipement fournissant IPsec
IPsec peut être utilisé au niveau d’équipements terminaux ou au niveau de passerelles de sécurité 9
(security gateway), permettant ainsi des approches de sécurisation lien par lien comme de bout en bout.Trois configurations de base sont possibles :
9. Une passerelle de sécurité est un système intermédiaire (par exemple un routeur ou un garde-barrière) qui agit commeinterface de communication entre un réseau externe considéré comme non fiable et un réseau interne de confiance. Elle fournit,pour les communications traversant le réseau non fiable, un certain nombre de services de sécurité.

Mémoire d’ingénieur CNAM 63
Passerelle de sécurité
IPsec
Réseau deconfiance
Passerelle de sécurité
IPsec
Réseau deconfiance
Réseaunon fiable
Equipement terminal
IPsec
Passerelle de sécurité
IPsec
Réseau deconfiance
Equipement terminal
IPsec
non fiableRéseau
non fiableRéseau
IPsec
Equipement terminal
FIG. 5.9 – Différentes configurations possibles suivant l’équipement mettant IPsec en œuvre
La première situation est celle où l’on désire relier des réseaux privés distants par l’intermédiaired’un réseau non fiable, typiquement Internet. Les deux passerelles de sécurité permettent ici d’établir unréseau privé virtuel (Virtual Private Network).
La deuxième situation correspond au cas où l’on désire fournir un accès sécurisé au réseau internepour des postes nomades. Le réseau non fiable peut être Internet, le réseau téléphonique...
Enfin, dans la troisième situation, deux tiers désirent communiquer de façon sécurisée mais n’ontaucune confiance dans le réseau qui les sépare.
On peut également imaginer des configurations plus complexes où plusieurs associations de sécu-rité, apportant éventuellement des services de sécurité différents, se succéderaient ou se superposeraientpartiellement :
Réseau deconfiance
Réseau deconfiance
IPsec
Réseaunon fiable
IPsec IPsec
Association de sécurité 1
Association de sécurité 2
IPsec
Réseaunon fiable
IPsec
Association de sécurité 1 Association de sécurité 2
IPsecPasserelle de sécurité
Passerelle de sécurité
FIG. 5.10 – Exemples de double utilisation d’IPsec

Mémoire d’ingénieur CNAM 64
Dans les exemples ci-dessus, la première association peut servir à assurer les services de sécuritérequis par la politique de sécurité externe (authentification et confidentialité par exemple), et la secondeà assurer les services requis par la politique de sécurité interne (authentification vis-à-vis de l’hôte finalpar exemple).
5.1.2.2 Modes de fonctionnement
Pour chacun des mécanismes de sécurité d’IPsec, il existe deux modes :– le mode transport,– le mode tunnel.En mode transport, seules les données en provenance du protocole de niveau supérieur et transportées
par le datagramme IP sont protégées. Ce mode n’est utilisable que sur des équipements terminaux ; eneffet, en cas d’utilisation sur des équipements intermédiaires, on courrait le risque, suivant les aléas duroutage, que le paquet atteigne sa destination finale sans avoir traversé la passerelle sensée le déchiffrer.
En mode tunnel, l’en-tête IP est également protégé (authentification, intégrité et/ou confidentialité) etremplacé par un nouvel en-tête. Ce nouvel en-tête sert à transporter le paquet jusqu’à la fin du tunnel, oùl’en-tête original est rétabli. Le mode tunnel est donc utilisable à la fois sur des équipements terminaux etsur des passerelles de sécurité. Ce mode permet d’assurer une protection plus importante contre l’analysedu trafic, car il masque les adresses de l’expéditeur et du destinataire final.
5.1.3 Les projets Open Source IPsec
Pour notre application, nous souhaitions absolument une implémentation libre d’IPsec sur un sys-tème linux 10. Voici la liste correspondante à nos exigences :
– Cerberus 0.5 12/05/2000 : c’est un projet abandonné;– ipsec_tunnel : implémentation complète d’IPsec mais seulement pour créer des tunnels (pas de
support des certificats 11);– FreeS/WAN : implémentation d’IPsec la plus utilisée sous Linux (sous licence GPL).
Nous avons retenu FreeS/WAN pour l’avancée du projet et son dynamisme (notamment lors de la cor-rection de bogues).
Plus de précisions sur son utilisation et son installation, sont disponibles en annexe D.
5.1.4 Sécurisation de l’accès au VPN
Il est nécessaire de laisser passer le trafic IPsec au niveau des routeurs et des pare-feux. Cela concerne :– le protocole 17 (UDP) et le port 500 (isakmp) : échange des clés;– le protocole 50 (ESP) : IPsec avec chiffrement;– le protocole 51 (AH) : IPsec sans chiffrement.Il n’est plus possible d’effectuer du filtrage au niveau du routeur ou du pare-feu lorsque le trafic IPsec
transite dans un tunnel chiffré. De même les détecteurs d’intrusion ne verront rien. Toutefois, ce n’est pasparce que l’interlocuteur est connu et authentifié qu’il faut renoncer à tout contrôle. A ce sujet rappelonsque ce n’est pas une personne physique qui est authentifiée mais une machine ce qui offre moins degaranties. Il est donc judicieux d’effectuer un filtrage à la sortie du tunnel lorsque l’on retrouve de l’IPclassique non chiffré (cf. annexe G). Cela peut se faire en interposant un routeur ou pare-feu entre lapasserelle et le réseau interne ou bien directement sur la passerelle en utilisant les possibilités de filtrageoffertes par le noyau (commande iptables).
10. Un système openBSD aurait été plus judicieux pour la sécurité mais moins abordable par l’administrateur du réseauhabitué à Linux.
11. Document électronique qui renferme la clé publique d’une entité, ainsi qu’un certain nombre d’informations la concer-nant, comme son identité. Ce document est signé par une autorité de certification ayant vérifié les informations qu’il contient.
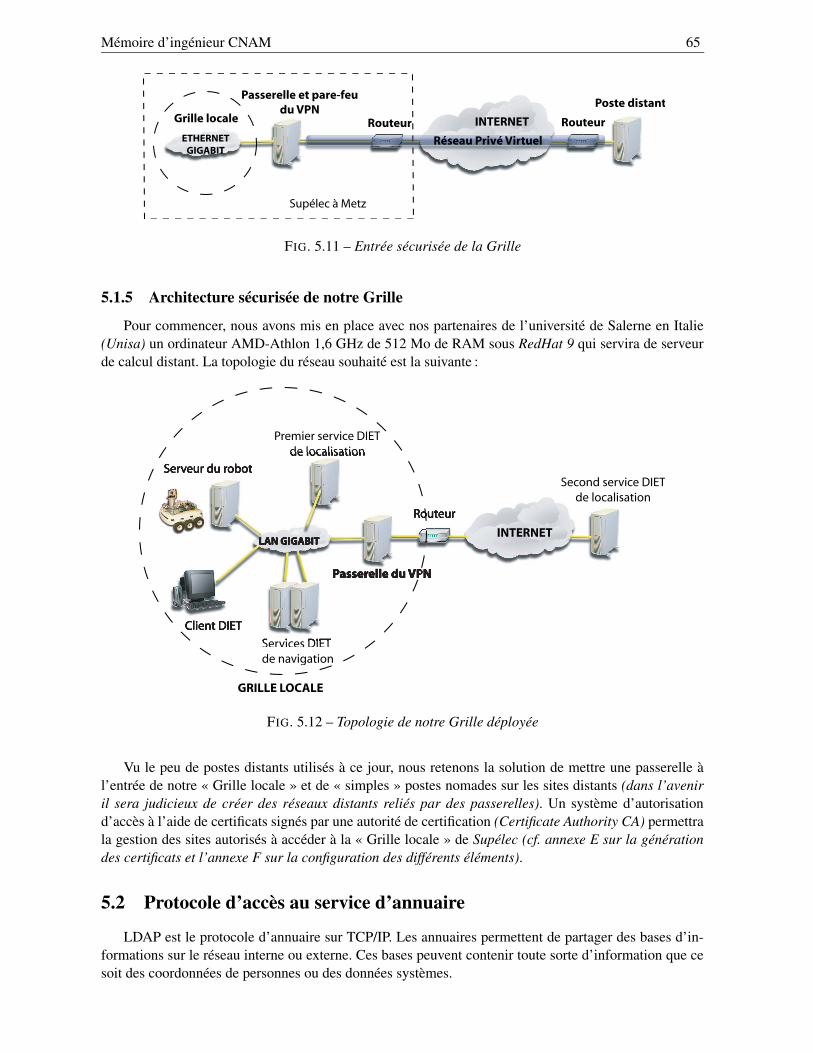
Mémoire d’ingénieur CNAM 65
Grille locale INTERNET
Réseau Privé Virtuel
Passerelle et pare-feu
du VPN
Supélec à Metz
Routeur Routeur
Poste distant
ETHERNET
GIGABIT
FIG. 5.11 – Entrée sécurisée de la Grille
5.1.5 Architecture sécurisée de notre Grille
Pour commencer, nous avons mis en place avec nos partenaires de l’université de Salerne en Italie(Unisa) un ordinateur AMD-Athlon 1,6 GHz de 512 Mo de RAM sous RedHat 9 qui servira de serveurde calcul distant. La topologie du réseau souhaité est la suivante :
INTERNET
de navigation
Second service DIET
de localisation
Services DIET
de navigation
Premier service DIET
de localisation
GRILLE LOCALE
FIG. 5.12 – Topologie de notre Grille déployée
Vu le peu de postes distants utilisés à ce jour, nous retenons la solution de mettre une passerelle àl’entrée de notre « Grille locale » et de « simples » postes nomades sur les sites distants (dans l’aveniril sera judicieux de créer des réseaux distants reliés par des passerelles). Un système d’autorisationd’accès à l’aide de certificats signés par une autorité de certification (Certificate Authority CA) permettrala gestion des sites autorisés à accéder à la « Grille locale » de Supélec (cf. annexe E sur la générationdes certificats et l’annexe F sur la configuration des différents éléments).
5.2 Protocole d’accès au service d’annuaire
LDAP est le protocole d’annuaire sur TCP/IP. Les annuaires permettent de partager des bases d’in-formations sur le réseau interne ou externe. Ces bases peuvent contenir toute sorte d’information que cesoit des coordonnées de personnes ou des données systèmes.

Mémoire d’ingénieur CNAM 66
Un annuaire électronique est une base de donnée spécialisée, dont la fonction première est de retour-ner un ou plusieurs attributs d’un objet grâce à des fonctions de recherche multi-critères. Contrairement àun SGBD, un annuaire est très performant en lecture mais l’est beaucoup moins en écriture. Sa fonctionpeut être de servir d’entrepôt pour centraliser des informations et les rendre disponibles, via le réseau àdes applications, des systèmes d’exploitation ou des utilisateurs. Lightweight Directory Access Protocol(LDAP) est né de la nécessaire adaptation du protocole DAP (protocole d’accès au service d’annuaireX500 de l’OSI) à l’environnement TCP/IP. Initialement frontal d’accès à des annuaires X500, LDAP estdevenu en 1995, un annuaire natif (standalone LDAP) sous l’impulsion d’une équipe de l’université duMichigan (logiciel U-M LDAP).
5.2.1 Les concepts de LDAP
LDAP est un protocole d’annuaire standard et extensible. Il fournit :
– le protocole permettant d’accéder à l’information contenue dans l’annuaire,– un modèle d’information définissant le type de données contenues dans l’annuaire,– un modèle de nommage définissant comment l’information est organisée et référencée,– un modèle fonctionnel qui définit comment on accède à l’information ,– un modèle de sécurité qui définit comment données et accès sont protégés,– un modèle de duplication qui définit comment la base est répartie entre serveurs,– des APIs pour développer des applications clientes,– LDIF, un format d’échange de données.
5.2.2 Le protocole LDAP
Le protocole définit comment s’établit la communication client-serveur. Il fournit à l’utilisateur descommandes pour se connecter ou se déconnecter, pour rechercher, comparer, créer, modifier ou effacerdes entrées. Des mécanismes de chiffrement (SSL ou TLS) et d’authentification (SASL), couplés à desmécanismes de règles d’accès (ACL) permettent de protéger les transactions et l’accès aux données.
La plupart des logiciels serveurs LDAP proposent également un protocole de communication serveur-serveur permettant à plusieurs serveurs d’échanger leur contenu et de le synchroniser (replication service)ou de créer entre eux des liens permettant ainsi de relier des annuaires les uns aux autres (referral service).
La communication client-serveur est normalisée par l’IETF dans la version actuelle, la 3, du protocoleLDAP (RFC2251).
Contrairement à d’autres protocoles d’Internet, comme HTTP, SMTP ou NNTP, le dialogue LDAPne se fait pas en ASCII mais utilise le format de codage Basic Encoding Rule (BER).
5.2.3 Le modèle de données arborescentes
Les serveurs LDAP sont conçus pour stocker une grande quantité de données mais de faible volumeet pour accéder en lecture très rapidement à celles-ci grâce au modèle hiérarchique. Les données LDAPsont structurées dans une arborescence hiérarchique qu’on peut comparer au système de fichier Unix.Chaque nœud de l’arbre correspond à une entrée de l’annuaire ou directory service entry (DSE) et ausommet de cette arbre, appelé Directory Information Tree (DIT), se trouve la racine ou suffixe (cf. figure5.13). Ce modèle est en fait repris de X500, mais contrairement à ce dernier, conçu pour rendre un serviced’annuaire mondial (ce que le DNS fait par exemple pour les noms de machines de l’Internet), l’espacede nommage d’un annuaire LDAP n’est pas inscrit dans un contexte global.

Mémoire d’ingénieur CNAM 67
dc=Supelec,dc=fr
ou=People ou=Groups
uid=Sabatier cn=infosys
o=Supelec,c=fr (norme X.500)dc=Supelec,dc=fr (RFC2247)
types de base:
Utilisé pour créer une structurehiérarchique organisée
Utilisateur Objet
FIG. 5.13 – Exemple de sommet d’un arbre LDAP (voir 5.2.3.1 pour détails de syntaxe)
Les entrées correspondent à des objets abstraits ou issus du monde réel, comme une personne, uneimprimante, ou des paramètres de configuration. Elles contiennent un certain nombre de champs appelésattributs dans lesquelles sont stockées des valeurs. Chaque serveur possède une entrée spéciale, appeléeroot directory specific entry (rootDSE) qui contient la description de l’arbre et de son contenu.
5.2.3.1 Les attributs des entrées
Chaque entrée est constituée d’un ensemble d’attributs (paires clé/valeur) permettant de caractériserl’objet que l’entrée définit. Il existe deux types d’attributs :
– Les attributs normaux : ceux-ci sont les attributs habituels (nom, prénom, ...) caractérisant l’objet;– Les attributs opérationnels : ceux-ci sont des attributs auxquels seul le serveur peut accéder afin de
manipuler les données de l’annuaire (dates de modification, etc.)Une entrée est indexée par un nom distinct (DN, distinguished name) permettant d’identifier de ma-
nière unique un élément de l’arborescence.Un DN se construit en prenant le nom de l’élément, appelé Relative Distinguished Name (RDN,
c’est-à-dire le chemin de l’entrée par rapport à un de ses parents), et en lui ajoutant l’ensemble des nomdes entrées parentes. Il s’agit d’utiliser une série de paires clé/valeur permettant de repérer une entrée demanière unique. Voici une série de clés généralement utilisées :
– dc (Domain component), il s’agit d’une chaîne contenant le nom de domaine;– c (Country), il s’agit du nom du pays;– uid (userid), il s’agit d’un identifiant unique obligatoire;– cn (common name), il s’agit du nom de la personne;– givenname, il s’agit du prénom de la personne;– sn (surname), il s’agit du surnom de la personne;– o (organization), il s’agit de l’entreprise de la personne;– ou (organizational unit), il s’agit du service de l’entreprise dans laquelle la personne travaille;– mail, il s’agit de l’adresse de courrier électronique de la personne (bien évidemment);– ...

Mémoire d’ingénieur CNAM 68
Ainsi un Distinguished Name sera de la forme :
dn: uid=sabatier_fab, ou=People, dc=Supelec,dc=frcn=Sabatiergivenname=Fabrice
Le Relative Distinguished Name étant ici "uid=sabatier_fab".Ainsi, on appelle « schéma » l’ensemble des définitions d’objets et d’attributs qu’un serveur LDAP
peut gérer. Cela permet par exemple de définir si un attribut peut posséder une ou plusieurs valeurs.D’autre part, un attribut nommé objectclass permet de définir les attributs qui sont obligatoires ou facul-tatifs...
5.2.4 Le partitionnement
Il consiste à séparer les données de l’annuaire sur plusieurs serveurs. Il peut être imposé par le volumed’entrées à gérer, leur gestion répartie sur plusieurs sites, les types d’accès au réseau physique ou le moded’organisation de la société. Séparer les données ne veut pas dire forcément les dissocier : les standardsLDAP et X500 définissent des moyens de les relier (recoller). Ce sont les services referral et replication.
5.2.4.1 Le service « referral »
Les méthodes permettant de créer des liens entre des partitions d’annuaires sont appelées les know-ledge references. Ce sont des mécanismes qui permettent de relier virtuellement des arbres entre eux, enindiquant à quel point de branchement d’un arbre vient se raccrocher un autre DIT (immediate superiorknowledge reference) et inversement quels sont les arbres qui viennent se raccrocher à tel ou tel point debranchement du sien (subordinate reference).
Ces liaisons permettent à un serveur de faire suivre les requêtes des utilisateurs lorsque l’objet re-cherché n’appartient pas à l’arbre qu’il gère. La résolution de nom est le mécanisme par lequel un serveurdétermine quel objet de sa base est désigné par le DN qu’un client lui fournit. Si le DN est bien dans soncontexte de nommage, il exécute la requête du client (search, modify, bind...), sinon il renvoie un signal« object not found ». Si l’objet n’est pas dans son espace de nommage, le serveur utilise alors ses liensknowledge reference soit pour faire suivre la requête vers le serveur qui peut fournir l’objet, soit pourindiquer au client lequel contacter.
ldap.metz.supelec.fr
ldap.gif.supelec.fr
ou=People ou=Aliases dc=metzou=Group dc=grid
dc=ese−metz,dc=fr
dc=ese−gif,dc=fr
... dc=metz
FIG. 5.14 – Lien entre la base LDAP de Gif et celle de Metz

Mémoire d’ingénieur CNAM 69
5.2.4.2 Le service « replication »
La duplication (replication) consiste à recopier le contenu de tout ou partie de son arbre sur un autreserveur. Elle peut être utilisée pour rapprocher le service des utilisateurs (serveur et clients sur le mêmeréseau physique), répartir la charge sur plusieurs serveurs (load balancing) ou importer dans son arbredes entrées gérées sur un autre serveur. La duplication est, à terme, un passage obligé car elle permetd’améliorer la rapidité et la sûreté de fonctionnement du service d’annuaire.
ldap.metz.supelec.fr
gserver.grid.metz.supelec.fr
dc=grid
uid=Sabatier
ou=People ou=Group dc=griduse
ou=Group ou=People
dc=ese−metz,dc=fr
ou=People ou=Aliases dc=metzou=Group
dc=grid
uid=Sabatier
ou=People ou=Group dc=griduse
ou=Group ou=People
cn=replicator
dc=ese−metz,dc=fr
FIG. 5.15 – Duplication de la branche grid sur les deux serveurs
On pourra choisir de dupliquer un arbre entier ou seulement un sous arbre ou même, comme il estprévu dans le standard X500, une partie des entrées et de leurs attributs qu’on aura spécifiés via un filtredu genre :
– « on ne duplique que les objets de type personne »– « on ne duplique que les attributs non confidentiels » (annuaire interne vs annuaire externe)
Il existe plusieurs manières de synchroniser les serveurs - mise à jour totale ou incrémentale - et plusieursstratégies de duplications - single-master replication (un serveur maître en lecture-écriture les serveursreplica étant lecture seule) ou multiple-master replication (plusieurs maîtres qui se synchronisent mu-tuellement). En général la duplication se fait en temps-réel, ce qui peut être pénalisant dans le cas degros transferts de données, on peut alors fixer le délai de synchronisation, certains serveurs permettantde lancer celle-ci à heure fixe (scheduling replication).
5.2.5 L’annuaire de notre Grille locale
L’annuaire de la Grille locale (implantée physiquement sur le serveur gserver) est composé d’unerecopie de la sous-branche grid de l’annuaire principal de Supélec et d’une branche contenant les comptesutilisateurs restreints à la Grille (sous-branche griduse).

Mémoire d’ingénieur CNAM 70
Arborescence sur le serveur
du réseau local de SupélecArborescence sur le serveur
du réseau de la << grille >>
Branche identique
(réplication)
FIG. 5.16 – Arborescence LDAP de Supélec et de la Grille
Ainsi, certains utilisateurs peuvent se connecter au réseau entier de Supélec à Metz, tandis que d’autrepeuvent uniquement accéder au réseau Grille.
Le service de réplication est utilisé pour mettre à jour le serveur LDAP de Supélec à Metz et leserveur LDAP de la Grille locale. Alors que le service referral permet de relier les différents campus deSupélec entre eux (Gif, Rennes et Metz).
5.3 Déploiement de l’environnement de Grille DIET
DIET implante le standard GridRPC et permet de réaliser des RPC synchrone ou asynchrone à traversune plate-forme distribuée (voir chapitre 2.1). Toutes les communications internes de la plate-formeDIET sont assurées par un bus CORBA. Ainsi tout le mécanisme de DIET repose sur lui, en particulier,les dialogues entres les agents (maîtres ou locaux) et les services de Grille. Les implémentations deCORBA couramment supportées par DIET sont :
– omniORB 3 qui dépend de Python 1.5;– omniORB 4 qui lui dépend de la version 2.1 ou supérieure de Python.
L’avantage de la version 4, exceptée le fait qu’elle soit plus facile à installer, est qu’elle supporte en-tièrement le protocole SSL permettant ainsi, de sécuriser les transactions CORBA. Afin de déployer lesservices CORBA de omniORB, seul un fichier de configuration et un répertoire des fichiers de « logs »sont nécessaires.
5.3.1 Déploiement des services CORBA
Pour mettre en œuvre un bus CORBA, un seul service est nécessaire : le service de nommage. Ceservice, assuré par un serveur de noms, doit être impérativement démarré avant toutes entités DIET, afinque celles-ci puissent s’enregistrer auprès de lui sous une référence de la forme <hôte:port>.

Mémoire d’ingénieur CNAM 71
Le serveur de noms omniNames
Pour lancer le serveur de noms d’omniORB, il suffit simplement de taper la commande :
~ > omniNames -start
Fri Dec 13 14:46:02 2002:
Starting omniNames for the first time.Wrote initial log file.Read log file successfully.Root context is IOR:010000002b00000049444c3a6f6d672e6f72672f436f734e616d696e672f4e616d696e67436f6e746578744578743a312e300000010000000000000060000000010102000d0000003134302e37372e31332e34360000fa0a0b0000004e616d6553657276696365000200000000000000080000000100000000545441010000001c00000001000000010001000100000001000105090101000100000009010100Checkpointing Phase 1: Prepare.Checkpointing Phase 2: Commit.Checkpointing completed.
A présent, le service de nommage écoute sur le port par défaut (port 2809) et attend la connexionéventuelle d’un client.
Les clients CORBA
Chaque entité DIET (application cliente, agents et serveur de calcul) a besoin de se connecter au ser-veur de noms de CORBA. C’est de cette façon que les services se découvrent les uns les autres. L’adressedu serveur de noms d’omniORB est indiquée dans un fichier de configuration (/etc/omniORB.conf).
[root@quadx1 root]# /usr/local/bin/dietAgent /usr/local/cfgs/sfMA1.cfg &
Master Agent MA1 started.Root LocMgr MA1Loc started.
[root@quadx1 root]# /usr/local/bin/dietAgent /usr/local/cfgs/sfLA1.cfg &
Local Agent LA1 started.Local LocMgr LA1Loc started.
5.3.2 Déploiement et configuration de DIET
Un fichier de configuration (cf. annexe H) est nécessaire au lancement d’une entité DIET. On y trouveentre autre :
– le niveau de traçabilité;– le nom de l’agent maître;– le nom de l’agent local;– le lien avec un agent maître (s’il s’agit d’un agent local);– le port d’écoute utilisé par les agents et les services DIET (port 2809).

Mémoire d’ingénieur CNAM 72
Script de démarrage de DIET
Afin de faciliter l’initialisation de l’environnement de Grille DIET lors de la mise au point des ser-vices de Grille, j’ai mis en place un script bash qui permet le lancement du serveur de noms puis desagents maîtres et des agents locaux lors du démarrage de la machine. Ce script reprend les principes desservices Unix (conforme à la norme System V) à savoir la possibilité de démarrer, redémarrer et enfinarrêter ce service par la commande : service agents start|restart|stop (cf. annexe I).
Serveur du robot
Serveur DIET (SeD)
Pentiums mono XEON
ETHERNET
GIGABIT
RESEAU LOCAL
INTERNET
Passerelle
pare-feu
routeur
AMD ATHLONGrille locale
Supélec à Metz
Unisa en Italie
Serveur DIET
(SeD)
Client DIET
Serveur de noms
omniNames
et
agents DIET (MA & LA)
BUS CORBA
FIG. 5.17 – Exemple de déploiement sur notre Grille

Mémoire d’ingénieur CNAM 73
Chapitre 6
API - Application Programming Interface
La simplicité de programmation pour l’utilisateur ainsi que la robustesse du système final, ont étédeux objectifs fondamentaux dans notre démarche. Ainsi l’Application Programming Interface API-RobGrid se veut la plus simple possible tout en dissimulant les mécanismes complexes de contrôle durobot et les appels à la Grille de calcul (lors de la tolérance aux pannes en autre). Dans son ensemble,elle reprend une architecture de type client-serveur compatible GridRPC où seule la partie cliente estnécessaire à l’utilisateur. Quant à la partie serveur, elle sert de structure à la mise en place des servicesexistants (service de localisation et de navigation) ainsi qu’aux développements de nouveaux servicesde haut niveau.
(ex: localisation,navigation,lightness, ...)
API RobGrid
Services de bas niveau
Interface DIET de haut niveauServices de Grille de haut niveau
API DIET (GridRPC)
Application robotique de la GrilleApplications de Grille
FIG. 6.1 – Détails de l’architecture de Grille de haut niveau
La partie consacrée à l’application cliente a été toute particulièrement étudiée pour correspondreaux besoins de l’utilisateur. Elle reprend pour l’instant sous forme d’une bibliothèque, les deux modulesprincipaux 1 à la conception d’une application robotique à savoir : la localisation et la navigation du robot.
6.1 Principes de l’API côté client
Lorsque l’on reprend une structure d’un programme client sous DIET, on constate qu’il faut toutd’abord initialiser une session DIET (fonction diet_initialize()), puis la libérer lorsque le pro-gramme n’a plus besoin d’envoyer de requêtes à la Grille (fonction diet_finalize()). Cette fonc-tionnalité est reprise dans le concept de l’API grâce à la classe Session.
1. Le module « mesure de la luminosité » a été développé pour démontrer la modularité de notre API lors de l’utilisation deplusieurs services de haut niveau en même temps.

Mémoire d’ingénieur CNAM 74
Session
Session()~Session()Start()
(from RobGrid)
FIG. 6.2 – La classe Session
Elle encapsule donc ces deux fonctions : l’une dans la méthode Start(), l’autre dans le destructeur~Session(). Ainsi tout programme écrit en C++ utilisant l’API sera structuré de cette façon :
// Création d’un handle de session pour contrôler les communications entre// l’application et les services de GrilleSession *session = new Session();
...session->Start(); // Démarrage d’une session de communications...
delete session; // Ferme la session de communications
De même, il est nécessaire de définir des profiles sous DIET afin de préciser la nature des don-nées échangées entre chaque service de la Grille utilisé et le programme client (autant de profiles quede services désirés). Dans l’API RobGrid, cette contrainte a disparue. En effet, tous les profiles d’unmodule de haut niveau ont été regroupés dans une même classe. Ainsi la classe LocalizationClientcontient la définition de tous les profiles servant à demander au robot de se localiser (tableaux de typediet_profile_t *).
LocalizationClient
LocProfile : diet_profile_t* [MAX_Servers]LocRobConnectProfile : diet_profile_t* [MAX_Servers]LocRobDiscProfile : diet_profile_t* [MAX_Servers]LocFlushProfile : diet_profile_t* [MAX_Servers]
(from RobGrid)
FIG. 6.3 – Attributs de la classe LocalizationClient
6.1.1 Les appels GridRPC de l’API
Afin de permettre le lien entre l’application utilisateur et les services de Grille disponibles, tout lemécanisme d’appel compatible GridRPC a été regroupé dans une classe dédiée : la classe ClientBase.Par son utilisation sous forme d’héritage, il est alors possible de réaliser des appels aux services suivantdifférentes possibilités :
– en mode synchrone avec attente du premier résultat disponible (méthode Call_or());– en mode synchrone avec attente que tous les services interrogés répondent (méthode Call_and());– en mode asynchrone sans attendre de réponse (méthode AsyncCall()).
Afin de connaître la fin d’une opération demandée à un service au moyen d’un appel en mode asynchrone,il est possible d’utiliser la méthode Probe() dans une boucle itérative.

Mémoire d’ingénieur CNAM 75
ClientBase
_NBServer : intSrvRst : diet_reqID_t [MAX_Servers]AlgoNum : intServProfileNum : intActSrvNum : int
Call_or()AsynCall()Call_and()Flush()Probe()ClientBase()~ClientBase()
(from RobGrid)
FIG. 6.4 – La classe ClientBase
6.1.2 L’algorithmique de Grille
Avant de pouvoir demander au robot de se déplacer ou de se localiser au moyen des services adé-quates, toute une algorithmique de Grille doit être mise en place. Ainsi lors de la création des objetsclients, l’API fait appelle à des « sous-services » qui sont totalement masqués à l’utilisateur :
1. demande d’établissement de la connexion TCP directe entre le service et le serveur du robot;2. demande d’initialisation de l’organe du robot (tourelle, caméra, odométrie...).
Ces deux opérations sont réalisées lors de l’appel à un sous-service de connexion propre au service deplus haut niveau. Par convention, le numéro d’identifiant d’algorithme à l’exécution a été défini à 1 pourtous les sous-services de connexion. Ainsi la séquence d’initialisation entière du robot est mémoriséedans le buffer associé au numéro de l’algorithme 1 (cela permet de connecter/déconnecter des servicesau serveur du robot sans pour autant réinitialiser physiquement le robot).
Un autre point important dans cet algorithme, est qu’une plage composée de trois numéros d’algo-rithme est réservée pour chaque service de haut niveau :
– le service de localisation de haut niveau à la plage de 2 à 4;– le service de mesure de luminosité de haut niveau à la plage de 5 à 7;– le service de navigation de haut niveau à la plage de 8 à 10.
Ainsi, à chaque nouvel appel à l’un de ces services de haut niveau, ce numéro évolu dans son rang afind’effacer le futur buffer utilisé et de conserver le précédent buffer contenant l’historique des réponsesdes services les plus rapides. Le mécanisme de concurrence des commandes du robot est de cette façonparfaitement implémenté puisque sur les trois buffers seules les deux précédents sont interrogés par lesclients retardataires.
Enfin, pour terminer, un sous-service de déconnexion à pour rôle d’effacer le buffer qui contient laséquence d’initialisation du robot et de libérer la communication directe (socket TCP) entre le service dehaut niveau et le serveur du robot. Ce sous-service est automatiquement appelé lors de la destruction desobjets clients.
6.2 Architecture de l’API côté client
6.2.1 Structure type d’un client pour un service de haut niveau
Un client type de services de haut niveau est composé des trois catégories de méthodes suivantes :– la méthode de connexion et d’initialisation du service de haut niveau (Connect());– les méthodes d’appel au service de haut niveau (Call(), AsyncCall());

Mémoire d’ingénieur CNAM 76
– les méthodes de consultation du service de haut niveau (GetResult(), Probe()).Toutes ces méthodes sont implémentées et spécifiques au service de haut niveau implémenté. Par exemple,la méthode Call() prendra ou non des paramètres suivant si elle est implémentée dans le service de lo-calisation (pas de paramètre) ou dans le service de navigation (paramètre de type PolarCoordinates). Parl’héritage de la classe ClientBase, tout nouveau service pourra accéder à la Grille par simple utilisationdes méthodes tels que Call_or(), Call_and(), AsyncCall() et Probe().
ServiceClient
Variable : doubleServiceFlushProfile : diet_profile_t* [MAX_Servers]ServiceProfile : diet_profile_t* [MAX_Servers]ServiceRobConnectProfile : diet_profile_t* [MAX_Servers]ServiceRobDiscProfile : diet_profile_t* [MAX_Servers]
~ServiceClient()AsynCall()Call()Connect()EraseNextBuffer()GetResult()ServiceClient()Serviceprofile_init()Probe()
(from RobGrid)
FIG. 6.5 – La classe « type » d’un service de haut niveau
6.2.2 Description du service de localisation
Au sein de la classe LocalizationClient sont rassemblés tous les éléments nécessaires à l’initialisationdu service de localisation, à son exécution et à la libération des ressources du robot utilisées. C’est parson intermédiaire qu’il est possible de connaître la position exacte du robot à l’arrêt.
LocalizationClient
LocProfile : diet_profile_t* [MAX_Servers]LocRobConnectProfile : diet_profile_t* [MAX_Servers]LocRobDiscProfile : diet_profile_t* [MAX_Servers]LocFlushProfile : diet_profile_t* [MAX_Servers]
Locprofile_init()EraseNextBuffer()LocalizationClient()~LocalizationClient()Connect()GetResult()Probe()Call()AsynCall()
(from RobGrid)
ClientBase(from RobGrid)
FIG. 6.6 – La classe LocalizationClient

Mémoire d’ingénieur CNAM 77
Constructeur : LocalizationClient()
Paramètres d’appel :– Nombre de redondances souhaitées pour ce service (jusqu’à 5 maximums).– Nom du fichier contenant la position des marques artificielles (par défaut "LandmarkPosi-
tion.txt").
Description : Création d’une instance de la classe LocalizationClient.
main : ClientApplication
loc : LocalizationClient
: ClientBase
LocalizationClient(2)
ClientBase(2)
FIG. 6.7 – Diagramme de séquence UML du constructeur
Constructeur : ~LocalizationClient()
Paramètres d’appel : aucun.
Description : Destruction de l’instance de la classe LocalizationClient.
main : ClientApplication
loc : LocalizationClient
: ClientBase
~LocalizationClient()Flush(LocFlushProfile[0],FasterSrvNumber)
Call_or(LocRobDiscProfile[0])
Call the faster flush service
Call disconnect sub-services
~ClientBase( )
FIG. 6.8 – Diagramme de séquence UML du destructeur
Méthode : Connect()
Paramètres d’appel : aucun.Paramètres de retour : aucun.
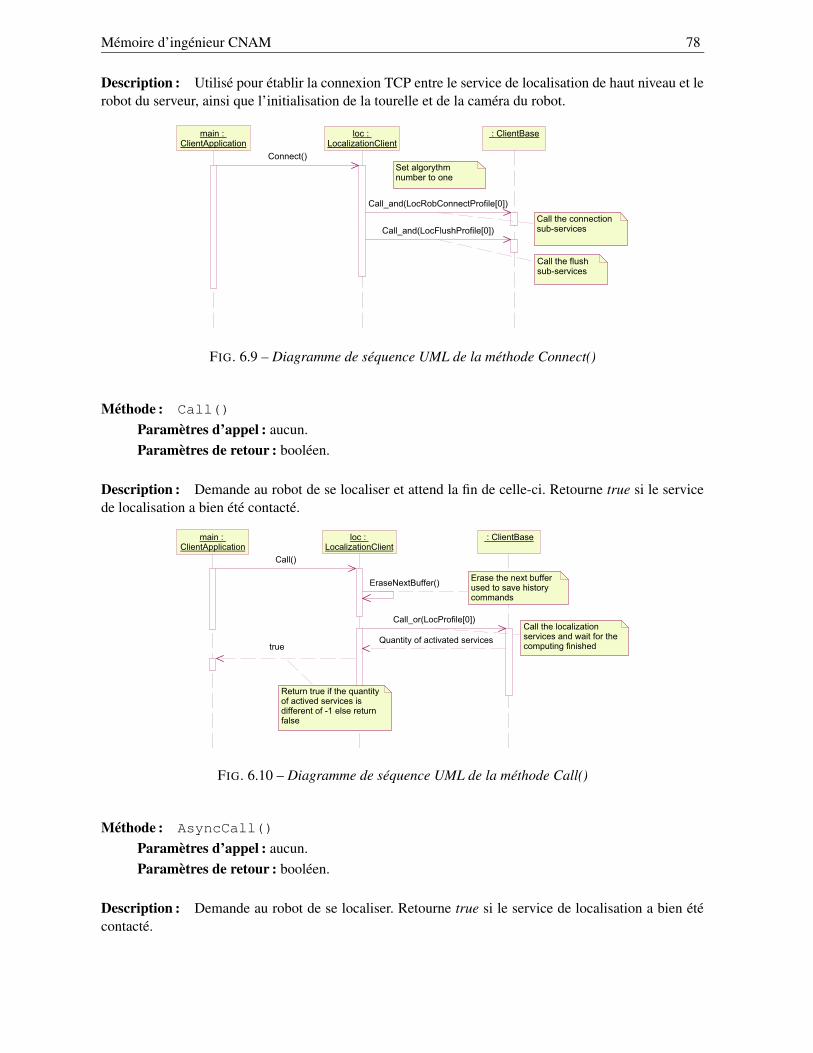
Mémoire d’ingénieur CNAM 78
Description : Utilisé pour établir la connexion TCP entre le service de localisation de haut niveau et lerobot du serveur, ainsi que l’initialisation de la tourelle et de la caméra du robot.
main : ClientApplication
loc : LocalizationClient
: ClientBase
Connect()
Call_and(LocRobConnectProfile[0])
Call_and(LocFlushProfile[0])
Set algorythm number to one
Call the connection sub-services
Call the flush sub-services
FIG. 6.9 – Diagramme de séquence UML de la méthode Connect()
Méthode : Call()
Paramètres d’appel : aucun.Paramètres de retour : booléen.
Description : Demande au robot de se localiser et attend la fin de celle-ci. Retourne true si le servicede localisation a bien été contacté.
main : ClientApplication
loc : LocalizationClient
: ClientBase
Erase the next buffer used to save history commands
Call the localization services and wait for the computing finished
Call()
Call_or(LocProfile[0])
EraseNextBuffer()
trueQuantity of activated services
Return true if the quantity of actived services is different of -1 else return false
FIG. 6.10 – Diagramme de séquence UML de la méthode Call()
Méthode : AsyncCall()
Paramètres d’appel : aucun.Paramètres de retour : booléen.
Description : Demande au robot de se localiser. Retourne true si le service de localisation a bien étécontacté.

Mémoire d’ingénieur CNAM 79
main : ClientApplication
loc : LocalizationClient
: ClientBase
Erase the next buffer used to save history commands
Call the localization services
trueQuantity of activated services
Return true if the quantity of actived services is different of -1 else return false
AsynCall()
EraseNextBuffer()
AsynCall(LocProfile[0])
FIG. 6.11 – Diagramme de séquence UML de la méthode AsyncCall()
Méthode : Probe()
Paramètres d’appel : aucun.Paramètres de retour : booléen.
Description : Demande au service de localisation s’il a terminé. Retourne true si c’est le cas.
main : ClientApplication
loc : LocalizationClient
: ClientBase
true
finished service number
Probe()
Probe(ActivedSrvQuantity)
Return true when finished service number is different from -1 else return false
Quantity of activated redundant services
FIG. 6.12 – Diagramme de séquence UML de la méthode Probe()
Méthode : GetResult()
Paramètres d’appel : aucun.Paramètres de retour : structure de type PolarCoordinates.
Description : Demande au service de localisation le résultat de la localisation sous forme d’une struc-ture de type PolarCoordinates contenant le tripet (x, y, θ).

Mémoire d’ingénieur CNAM 80
main : ClientApplication
loc : LocalizationClient
GetResult()
PolarCoordinates structure
FIG. 6.13 – Diagramme de séquence UML de la méthode GetResult()
6.2.3 Description du service de navigation
Au sein de la classe NavigationClient sont rassemblés tous les éléments nécessaires à l’initialisationdu service de navigation, à son exécution et à la libération des ressources du robot utilisées. C’est par sonintermédiaire qu’il est possible de déplacer le robot vers un point donné.
ClientBase(from RobGrid)
NavigationClient
NavProfile : diet_profile_t* [MAX_Servers]NavRobConnectProfile : diet_profile_t* [MAX_Servers]NavRobDiscProfile : diet_profile_t* [MAX_Servers]NavFlushProfile : diet_profile_t* [MAX_Servers]navStartabscissa : doublenavStartordinate : doublenavStartangle : doublenavEndabscissa : doublenavEndordinate : doublenavEndangle : double
Navprofile_init()EraseNextBuffer()NavigationClient()~NavigationClient()GetResult()Probe()Call()AsynCall()Connect()
(from RobGrid)
FIG. 6.14 – La classe NavigationClient
Constructeur : NavigationClient()
Paramètres d’appel :– Nombre de redondances souhaitées pour ce service (jusqu’à 5 maximums).
Description : Création d’une instance de la classe NavigationClient.

Mémoire d’ingénieur CNAM 81
Constructeur : ~NavigationClient()
Paramètres d’appel : aucun.
Description : Destruction de l’instance de la classe NavigationClient.
Méthode : Connect()
Paramètres d’appel : aucun.Paramètres de retour : aucun.
Description : Utilisé pour établir la connexion TCP entre le service de navigation de haut niveau et leserveur du robot, ainsi que l’initialisation de l’odométrie et des capteurs infrarouges.
Méthode : Call()
Paramètres d’appel : structure de type PolarCoordinates.Paramètres de retour : booléen.
Description : Demande au robot de se déplacer jusqu’au point dont les coordonnées sont passés par lastructure de type PolarCoordinates et attend la fin de celui-ci. Retourne true si le service de navigation abien été contacté.
Méthode : AsyncCall()
Paramètres d’appel : structure de type PolarCoordinates.Paramètres de retour : booléen.
Description : Demande au robot de se déplacer jusqu’au point dont les coordonnées sont passés par lastructure de type PolarCoordinates. Retourne true si le service de navigation a bien été contacté.
Méthode : Probe()
Paramètres d’appel : aucun.Paramètres de retour : booléen.
Description : Demande au service de navigation s’il a terminé. Retourne true si c’est le cas.
Méthode : GetResult()
Paramètres d’appel : aucun.Paramètres de retour : double.
Description : Demande au service de navigation la distance réellement parcourue (en millimètre). Re-tourne une distance négative si un obstacle a été rencontré sur le parcours.

Mémoire d’ingénieur CNAM 82
6.2.4 Description du service de mesure de luminosité
Au sein de la classe LightnessClient sont rassemblés tous les éléments nécessaires à l’initialisationdu service de mesure de luminosité, à son exécution et à la libération des ressources du robot utilisées.C’est par son intermédiaire qu’il est possible de mesurer la luminosité moyenne d’une image prise dansun angle de vue donnée.
ClientBase(from RobGrid)
LightClient
lightAngle : doubleLightFlushProfile : diet_profile_t* [MAX_Servers]LightProfile : diet_profile_t* [MAX_Servers]LightRobConnectProfile : diet_profile_t* [MAX_Servers]LightRobDiscProfile : diet_profile_t* [MAX_Servers]
~LightClient()AsynCall()Call()Connect()EraseNextBuffer()GetResult()LightClient()Lightprofile_init()Probe()
(from RobGrid)
FIG. 6.15 – La classe LightClient
Constructeur : LightClient()
Paramètres d’appel :– Nombre de redondances souhaitées pour ce service (jusqu’à 5 maximums).
Description : Création d’une instance de la classe LightClient.
Constructeur : ~LightClient()
Paramètres d’appel : aucun.
Description : Destruction de l’instance de la classe LightClient.
Méthode : Connect()
Paramètres d’appel : aucun.Paramètres de retour : aucun.
Description : Utilisé pour établir la connexion TCP entre le service de mesure de haut niveau et leserveur du robot, ainsi que l’initialisation de la tourelle et de la caméra vidéo.

Mémoire d’ingénieur CNAM 83
Méthode : Call()
Paramètres d’appel : double.Paramètres de retour : booléen.
Description : Demande au robot de positionner la tourelle suivant l’angle passé en paramètre, de cap-turer une image, de calculer sa luminosité moyenne, et d’attendre la fin de l’opération. Retourne true sile service de mesure a bien été contacté.
Méthode : AsyncCall()
Paramètres d’appel : double.Paramètres de retour : booléen.
Description : Demande au robot de positionner la tourelle suivant l’angle passé en paramètre, de cap-turer une image, et de calculer sa luminosité moyenne. Retourne true si le service de mesure a bien étécontacté.
Méthode : Probe()
Paramètres d’appel : aucun.Paramètres de retour : booléen.
Description : Demande au service de mesure de luminosité s’il a terminé. Retourne true si c’est le cas.
Méthode : GetResult()
Paramètres d’appel : aucun.Paramètres de retour : double.
Description : Demande au service de mesure de luminosité la valeur calculée.

Mémoire d’ingénieur CNAM 84
ClientBase
_NBServer : intSrvRst : diet_reqID_t [MAX_Servers]AlgoNum : intServProfileNum : intActSrvNum : int
Call_or()AsynCall()Call_and()Flush()Probe()ClientBase()~ClientBase()
(from RobGrid)
LightClient
lightAngle : doubleLightFlushProfile : diet_profile_t* [MAX_Servers]LightProfile : diet_profile_t* [MAX_Servers]LightRobConnectProfile : diet_profile_t* [MAX_Servers]LightRobDiscProfile : diet_profile_t* [MAX_Servers]
~LightClient()AsynCall()Call()Connect()EraseNextBuffer()GetResult()LightClient()Lightprofile_init()Probe()
(from RobGrid)
LocalizationClient
LocProfile : diet_profile_t* [MAX_Servers]LocRobConnectProfile : diet_profile_t* [MAX_Servers]LocRobDiscProfile : diet_profile_t* [MAX_Servers]LocFlushProfile : diet_profile_t* [MAX_Servers]
Locprofile_init()EraseNextBuffer()LocalizationClient()~LocalizationClient()Connect()GetResult()Probe()Call()AsynCall()
(from RobGrid)NavigationClient
NavProfile : diet_profile_t* [MAX_Servers]NavRobConnectProfile : diet_profile_t* [MAX_Servers]NavRobDiscProfile : diet_profile_t* [MAX_Servers]NavFlushProfile : diet_profile_t* [MAX_Servers]navStartabscissa : doublenavStartordinate : doublenavStartangle : doublenavEndabscissa : doublenavEndordinate : doublenavEndangle : double
Navprofile_init()EraseNextBuffer()NavigationClient()~NavigationClient()GetResult()Probe()Call()AsynCall()Connect()
(from RobGrid)
Session
Session()~Session()Start()
(from RobGrid)
FIG. 6.16 – Diagramme de classes UML - côté client
6.2.5 Extensibilité de notre API côté client
Pour ajouter de nouveaux services à notre API, il suffira de définir de nouvelles classes contenantsles implémentations spécifiques des méthodes précédemment évoquées tout en héritant celles définiesdans la classe ClientBase.
Mémoire d’ingénieur CNAM 85
ClientBase
_NBServer : intSrvRst : diet_reqID_t [MAX_Servers]AlgoNum : intServProfileNum : intActSrvNum : int
Call_or()AsynCall()Call_and()Flush()Probe()ClientBase()~ClientBase()
(from RobGrid)
LightClient(from RobGrid)
SrvClient
SrvProfile : diet_profile_t* [MAX_Servers]SrvRobConnectProfile : diet_profile_t* [MAX_Servers]SrvRobDiscProfile : diet_profile_t* [MAX_Servers]SrvFlushProfile : diet_profile_t* [MAX_Servers]
Srvprofile_init()EraseNextBuffer()SrvClient()~SrvClient()Connect()GetResult()Probe()Call()AsynCall()
(from RobGrid)
NavigationClient(from RobGrid)
Session
Session()~Session()Start()
(from RobGrid)
FIG. 6.17 – Structure de l’API RobGrid côté client
6.3 Conception d’une application robotique de Grille
Pour illustrer notre API, voici un exemple de ce que pourrait être une application robotique utilisantnotre API-RobGrid :
Points d'arrêt avec scan panoramique et localisation
Robot
3
2
4
5 6
7
Marques P-Similaires
1

Mémoire d’ingénieur CNAM 86
FIG. 6.18 – Trajectoire programmée composée de 6 points de passage et de 7 localisations
Après l’initialisation des différents organes du robot, celui-ci procède à une première localisation.Le résultat de cette localisation est alors affiché à l’écran. Puis l’on demande au robot de rejoindre unnouvel emplacement tout en mesurant la luminosité ambiante (les résultats sont affichés à l’écran). Unefois arrivé au point prévu, il exécute une nouvelle localisation. Et ainsi de suite jusqu’au 6e point où iltermine par une localisation.
Code source en C++ de la trajectoire programmée//// Programme de démonstration de l’API-RobGrid//
#include "robotclient.h" // Définition de notre API côté client#include <stdio.h> // Appels standards du système#include <unistd.h> // Pour la fonction sleep()
// Définitions des trajectoires et des angles d’arrivée du robot#define SHORT_TRACE sqrt(700*700+375*375)#define LONG_TRACE sqrt(1200*1200+750*750)#define ANGLE_TRACE atan(700/375)
using namespace RobGrid; // Définition de l’espace de nommage
int main(int argc, char **argv) // Début du programme principal{PolarCoordinates position; // Structure utilisée pour lire le résultat
// de la localisationbool AngleToggle=false; // drapeau utilisé pour changer le sens de rotation
// de la tourelledouble lightAngle=0; // valeur de l’angle de positionnement de la tourelle
// Coordonnées des 6 points de passagePolarCoordinates Point[]= {{-375,0,0},{-SHORT_TRACE,0,-ANGLE_TRACE},{-375,0,ANGLE_TRACE},{LONG_TRACE,0,ANGLE_TRACE},{-375,0,-ANGLE_TRACE},{-SHORT_TRACE,0,-ANGLE_TRACE}};
// Création d’un handle de session pour contrôler les communications// entre l’application robotique et les services de GrilleSession *session = new Session();
// Allocation des services de haut niveau de Grille// avec la définition du nombre de redondance pour le serviceLocalizationClient *loc = new LocalizationClient(2,"LandmarkPosition.txt");NavigationClient *nav = new NavigationClient(2);LightClient *light = new LightClient(1);
// Démarre la communication entre l’application cliente et les services// précédemment spécifiés

Mémoire d’ingénieur CNAM 87
session->Start();
// Connexion TCP entre les services de Grille et le serveur du robot,// initialisation des ressources du robot et des buffersloc->Connect();light->Connect();nav->Connect();
// Boucle sur les 6 points de passage de la trajectoire programméefor (int i=0; i<6; i++){
loc->AsynCall(); // Demande au robot de se localiserstd::cout << "wait localization "; // et affiche l’état en courswhile (loc->Probe()==false) // Boucle durant toute la phase de localisation
{ // Affiche une ligne de dièse pendant la phase de localisationsleep(1); // Attend une secondestd::cout << "#"; // puis affiche un dièse à l’écran
}std::cout << std::endl; // Passe à la ligne suivante
position=loc->GetResult(); // Lit le résultat de la localisation puis l’affichestd::cerr << "x=" << position.x << " y=" << position.y << " theta="
<< position.theta << std::endl;
// Déplace alors le robot vers le point suivant tout en mesurant la// luminosité moyenne de l’entouragenav->AsynCall(Point[i]);while (nav->Probe()==false) / Boucle durant toute la phase de déplacement du robot
{ // Mesure la luminosité tout les PI/8 d’angle dans un sens puis dans l’autrelight->Call(lightAngle);std::cout << "lightness= " << light->GetResult() << std::endl;// Change le sens de rotation une fois arrivée en butté
if(lightAngle>PI/4 || lightAngle<-PI*3.9/4)AngleToggle=(AngleToggle)?false:true;
lightAngle+=(AngleToggle)?-PI/8:PI/8; // Augmente ou diminue l’angle de PI/8
}
// Lit alors la distance parcourruedouble distance=nav->GetResult();// Puis l’affiche à l’écranstd::cout << "distance=" << distance << std::endl;
}
// Demande une dernière localisation au robotif(loc->Call()==true)
{position=loc->GetResult();std::cout << "x=" << position.x << " y=" << position.y << " theta="
<< position.theta << std::endl;}
else std::cerr << "Diet localization Error !" << std::endl;
// Déconnection des services de Grille du serveur du robot et effacement

Mémoire d’ingénieur CNAM 88
// des buffers d’initialisationdelete loc;delete light;delete nav;delete session;
return 0; // Fin du programme principal}
Dans ce programme, on commence par créer un handle de session pour contrôler les communicationsentre l’application robotique et les services de haut niveau de la Grille. Ensuite, vient la création desdifférents objets clients pour chaque service désiré. Le paramètre du constructeur permet de spécifierle nombre nécessaire d’instances des services concurrents. Par exemple, nous utilisons deux instancespour les services critiques (localisation et navigation). Chaque objet client encaspule totalement lesmécanismes de communication de Grille utilisés dans DIET. L’étape suivante consiste à démarrer lasession DIET, laquelle démarre les communications entre l’application et les services de Grille.
Chaque objet client demande une connexion entre le service de haut niveau adéquate et le serveurdu robot. Cela établie une connexion TCP directe, initialise les devices physiques du robot et alloue lesbuffers associés aux ressources.
Plusieurs services peuvent être simultanément connectés au serveur du robot. Chaque service peutalors être appelé au moyen de son objet client en mode synchrone (light->Call()) ou en modeasynchrone (nav->AsyncCall()). Tous les services redondants de la Grille sont appelés concur-remment. Une méthode de l’API RobGrid permet de tester si une opération asynchrone s’est terminée(nav->Probe()). Les appels redondants sont considérés finis aussitôt que l’une des instances des ser-vices de Grille a terminée. Le service de Grille gagnant est alors identifié, pendant que les autres sontannulés ou ignorés.
Le client d’un service redondant peut alors lire le résultat provenant de celui-ci (loc->GetResult()).Au final, les objets clients et la session DIET sont supprimés : chaque service est contacté pour qu’il ef-face le buffer lui correspondant au niveau du serveur du robot et une phase de déconnexion est alorsengagée.
6.4 Principes de l’API côté serveur
Cette partie de l’API s’adresse uniquement au développeurs désireux de concevoir de nouveauxservices pour le contrôle du robot et non plus à des utilisateurs concentrés sur l’aspect robotique dudéveloppement. Elle est considérée comme une « structure de base », une sorte de « boîte à outils » pourconcevoir des services de haut niveau.
Ainsi tous les services de bas niveau du robot ont été rassemble au sein de la classe RobotBase. Ellecontient les méthodes nécessaires à initialisation et au contrôle du robot et à la gestion des historiques decommandes.

Mémoire d’ingénieur CNAM 89
RobotBase
device : nono::SerialPort*robot : koala::RobotClient*koalaraw : koala::Client*turret : kreb::TurretClient*video : VideoClient*kcmdCommand : union koala::CommandkdatData : union koala::DataAppVerboseLevel : intRobServerName : char [255]RobServerPort : intServerNumber : int
RobSetServerName()RobSetPortNumber()AppDefaultInit()<<const>> WaitRobot()<<const>> TurnRobot()<<const>> StopRobot()CheckTransfer()SerialInit()RobInit()RobFinalize()<<const>> RobSetAlgoNum()<<const>> RobKoalaInit()<<const>> RobFlushOne()<<const>> RobFlush()GetServNum()RobTurretInit()RobTurretFinalize()<<const>> RobTurretSetAlgoNum()<<const>> ResetTurret()<<const>> RobTurretFlushOne()<<const>> RobTurretFlushAll()<<const>> RobSetTurretAngle0()<<const>> RobSetTurretAngle_nowait()<<const>> RobWaitTurret()<<const>> RobGetYData()<<const>> RobGetTurretAngle()<<const>> RobGetMinTurretAngle()<<const>> RobGetMaxTurretAngle()<<static>> RobScaleGrayscaleImage()RobotBase()~RobotBase()
(from RobotGrid)
FIG. 6.19 – La classe RobotBase
De la même manière, la classe DietServer, rassemble les services de bas niveau de la Grille. Ellereprend sous forme de la méthode Loop(), la fonction diet_SeD() élaborée dans l’API de DIET.
DietServer
Profile : diet_profile_desc_t *NameService : char [255]
DietServer()~DietServer()<<const>> Loop()<<const>> Loop()
(from RobotGrid)
FIG. 6.20 – La classe DietServer
6.5 Architecture de l’API côté serveur
6.5.1 Structure type d’un service de haut niveau
Un service de haut niveau est composé de deux classes dont une est responsable du dialogue avec lesservices de bas niveau de la Grille (par exemple la classe NavigationServer) et l’autre est responsable dudialogue avec les services de bas niveau du robot (par exemple la classe HighLevelNav).

Mémoire d’ingénieur CNAM 90
RobotBase(from RobotGrid)
HighLevelNav
<<const>> AppUsage()<<const>> AppInfo()<<const>> AppPrintInit()AppCommandLineParsing()DummyGoLine()HighLevelNav()HighLevelNav()~HighLevelNav()DummyGo()
(from RobotGrid)NavigationServer
<<static>> solve_flush()<<static>> solve_disconnection()<<static>> solve_connection()<<static>> solve_Navigation()CreateServices()NavigationServer()NavigationServer()~NavigationServer()
(from RobotGrid)
-$_navigation
<<friend permission>>
DietServer(from RobotGrid)
FIG. 6.21 – Les classes NavigationServer et HighLevelNav
La classe principale
Dans la classe responsable du dialogue avec les services de bas niveau de la Grille, sont rassemblesla définition des différents profiles nécessaires à la description des sous-services implémentés (méthodeCreateServices()). La particularité de cette classe est qu’elle contient les méthodes exécutées parl’intergiciel de Grille lors de l’appel des services par l’application cliente. C’est pourquoi, il est impératifde définir ces méthodes comme étant des méthodes statiques afin de pouvoir passer leur adresse auxfonctions GridRPC contenues dans l’API de DIET.
LocalizationServer
FilePath : char [255]
<<static>> solve_flush()<<static>> solve_disconnection()<<static>> solve_connection()<<static>> solve_Localization()CreateServices()LocalizationServer()LocalizationServer()~LocalizationServer()
(from RobotGrid)
FIG. 6.22 – La classe LocalizationServer
La classe parente
Dans la classe responsable du dialogue avec les services de bas niveau du robot, sont rassembles lesméthodes nécessaires pour le paramétrage, l’initialisation et l’exécution du service dédié.

Mémoire d’ingénieur CNAM 91
HighLevelLoc
<<const>> AppUsage()<<const>> AppInfo()<<const>> AppPrintInit()AppCommandLineParsing()HighLevelLoc()HighLevelLoc()~HighLevelLoc()
(from RobotGrid)
FIG. 6.23 – La classe HighLevelLoc
6.5.2 Agencement des différentes classes
Sur le diagramme de classes ci-après, il apparaît clairement que tous les services de haut niveau telsla localisation, la navigation et la mesure de luminosité sont structurés de la même manière. Ainsi laclasse principale d’un service de haut niveau (par exemple la classe NavigationServer pour le service denavigation) hérite de la classe DietServer pour dialoguer avec la Grille et utilise la classe responsable dudialogue avec les services de bas niveau du robot (par exemple la classe HighLevelNav) qui elle hérite dela classe parente RobotBase. Les mécanismes d’héritage et de « classe amie » (friend class) permettentdonc le lien entre le serveur du robot et l’intergiciel de Grille.
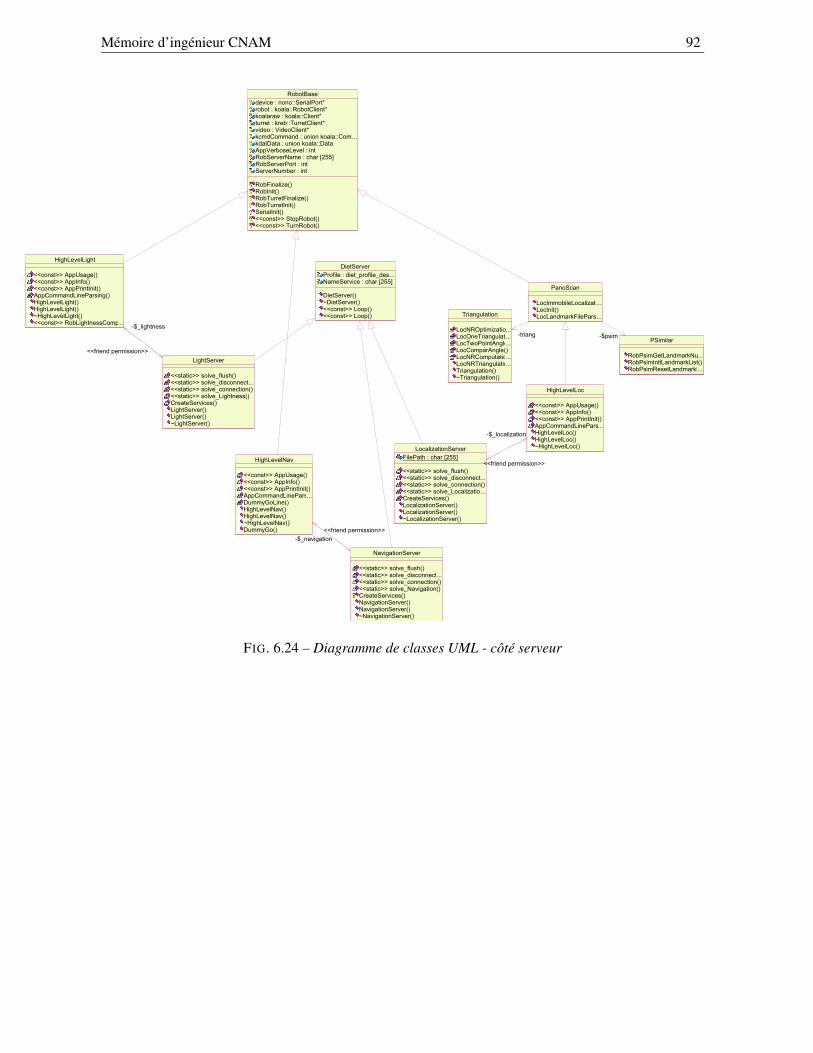
Mémoire d’ingénieur CNAM 92
DietServer
Profile : diet_profile_des...NameService : char [255]
DietServer()~DietServer()<<const>> Loop()<<const>> Loop()
LightServer
<<static>> solve_flush()<<static>> solve_disconnect...<<static>> solve_connection()<<static>> solve_Lightness()CreateServices()LightServer()LightServer()~LightServer()
HighLevelLight
<<const>> AppUsage()<<const>> AppInfo()<<const>> AppPrintInit()AppCommandLineParsing()HighLevelLight()HighLevelLight()~HighLevelLight()<<const>> RobLightnessComp...
<<friend permission>>
-$_lightness
RobotBase
device : nono::SerialPort*robot : koala::RobotClient*koalaraw : koala::Client*turret : kreb::TurretClient*video : VideoClient*kcmdCommand : union koala::Com...kdatData : union koala::DataAppVerboseLevel : intRobServerName : char [255]RobServerPort : intServerNumber : int
RobFinalize()RobInit()RobTurretFinalize()RobTurretInit()SerialInit()<<const>> StopRobot()<<const>> TurnRobot()
PSimilar
RobPsimGetLandmarkNu...RobPsimInitLandmarkList()RobPsimResetLandmarkL...
PanoScan
LocImmobileLocalizati...LocInit()LocLandmarkFilePars...
-$psim
Triangulation
LocNROptimizatio...LocOneTriangulati...LocTwoPointAngle...LocComparAngle()LocNRComputatio...LocNRTriangulatio...Triangulation()~Triangulation()
-triang
LocalizationServer
FilePath : char [255]
<<static>> solve_flush()<<static>> solve_disconnect...<<static>> solve_connection()<<static>> solve_Localizatio...CreateServices()LocalizationServer()LocalizationServer()~LocalizationServer()
HighLevelLoc
<<const>> AppUsage()<<const>> AppInfo()<<const>> AppPrintInit()AppCommandLinePars...HighLevelLoc()HighLevelLoc()~HighLevelLoc()
-$_localization
<<friend permission>>
NavigationServer
<<static>> solve_flush()<<static>> solve_disconnect...<<static>> solve_connection()<<static>> solve_Navigation()CreateServices()NavigationServer()NavigationServer()~NavigationServer()
HighLevelNav
<<const>> AppUsage()<<const>> AppInfo()<<const>> AppPrintInit()AppCommandLinePars...DummyGoLine()HighLevelNav()HighLevelNav()~HighLevelNav()DummyGo()
-$_navigation
<<friend permission>>
FIG. 6.24 – Diagramme de classes UML - côté serveur

Mémoire d’ingénieur CNAM 93
Chapitre 7
Expérimentations et performances
Afin d’expérimenter notre API et de procéder à des mesures de performances, nous avons de nouveaudéployé notre Grille de calcul sur deux sites à travers un VPN. Une application robotique très simple aété développée pour démontrer les possibilités des différents services de haut niveau déjà élaborés. Lecode source a été largement commenté dans le chapitre 6. Ainsi le robot suit une trajectoire programméepassant par 6 points définis. A chaque point de passage, il opère une localisation puis rejoint le suivant.Tout en se déplaçant, la tourelle positionne la caméra à différents angles de vue et une moyenne calculéede la luminosité ambiante est retournée au client.
Points d'arrêt avec scan panoramique et localisation
Robot
3
2
4
5 6
7
Marques P-Similaires
1
FIG. 7.1 – Trajectoire programmée du robot
Les appels aux services critiques (localisation et navigation) sont assurés par des services redondants.L’un des services de localisation se situe dans la Grille locale de Supélec, tandis que l’autre est situé àl’université de Salerne en Italie.

Mémoire d’ingénieur CNAM 94
Serveur du robot
Serveurs de calculs
monoprocesseur
Serveurs de calculs
Passerelle et pare-feu
VPN
Routeur Routeur
PC client
Fast et Gigabit
EthernetINTERNET
Liaison série
Serveur de calculs
Pare-feu
VPN (IPsec) + bus CORBA + Environnement DIET (GridRPC)
Université Salerne Italie
FIG. 7.2 – Vue d’ensemble de l’environnement de Grille de test
L’ensemble de la Grille déployée est composée des machines suivantes :
Nom de la Caractéristique du processeur Cache RAMmachine (Ko) (Mo)
gserver 1 x AMD Athlon(tm) 1,4GHz 256 1000ggate 1 x AMD Athlon(tm) 500MHz 64 190quadx1-2 4 x Intel XEON PIII 700 MHz 2048 512quadx3 4 x Intel XEON PIV 2,50GHz 2048 1000monox1-4 1 x Intel XEON PIV 2,40GHz 512 512monox5-8 1 x Intel XEON PIV 2,40GHz 512 1000pinocchio 1 x AMD Athlon(tm) 1,6GHz 256 512gdev1 (poste client) 1 x Intel Pentium IV 1,60GHz 256 256portable (poste client) 1 x Intel Celeron 650MHz 256 512
TAB. 7.1 – Liste des PCs composant les tests de performances
7.1 Les expérimentations de la redondance
Afin de tester notre environnement de programmation de Grille, nous avons développé une applica-tion utilisant les appels redondants de la Grille pour les services de localisation et de navigation. Le robotse déplace d’un point à un autre, procède à un scan panoramique et détermine sa localisation à chaquepoint du parcours.

Mémoire d’ingénieur CNAM 95
Arrêt du service de localisation en cours d'exécution
3
2
4
5 6
7
1
Relance du service de localisation
4
FIG. 7.3 – Parcours programmé du robot
La caméra du robot était à la fois contrôlée par deux serveurs DIET (un en France et l’autre enItalie). A cause du sur-coût des communications lors de la traversée d’internet, le serveur DIET local(en France) était toujours le premier à contrôler le robot, pendant que l’autre récupérait uniquement lesrésultats. Nous avons « arrêté » le serveur DIET local à différents points du trajet et alors le mouvementde la caméra du robot s’est stoppé net puis il est reparti dans un mouvement plus lent mais cette fois-ci contrôlé par le serveur DIET distant (en Italie). Lorsque que nous avons relancé le serveur DIETdans la Grille locale, l’application client a rappelé ce serveur avec succès, et le contrôle de la caméra aautomatiquement accéléré.
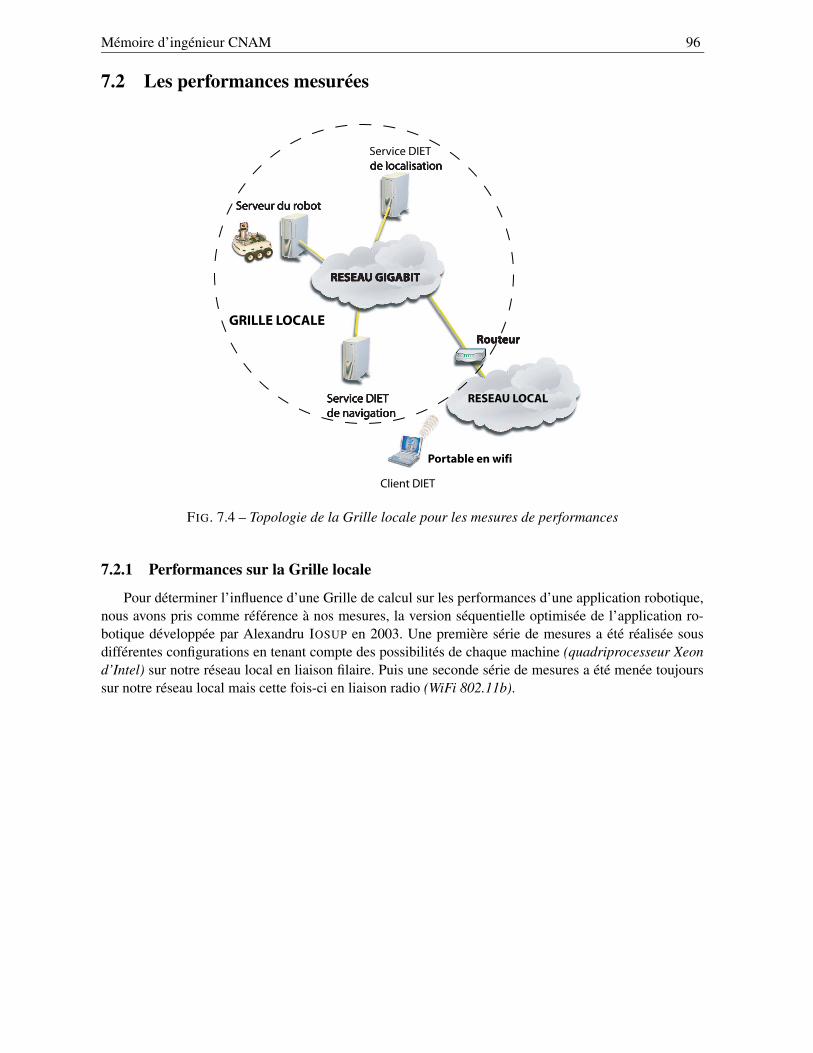
Mémoire d’ingénieur CNAM 96
7.2 Les performances mesurées
RESEAU LOCAL
Client DIET
Service DIET
de localisation
GRILLE LOCALE
Portable en wifi
FIG. 7.4 – Topologie de la Grille locale pour les mesures de performances
7.2.1 Performances sur la Grille locale
Pour déterminer l’influence d’une Grille de calcul sur les performances d’une application robotique,nous avons pris comme référence à nos mesures, la version séquentielle optimisée de l’application ro-botique développée par Alexandru IOSUP en 2003. Une première série de mesures a été réalisée sousdifférentes configurations en tenant compte des possibilités de chaque machine (quadriprocesseur Xeond’Intel) sur notre réseau local en liaison filaire. Puis une seconde série de mesures a été menée toujourssur notre réseau local mais cette fois-ci en liaison radio (WiFi 802.11b).
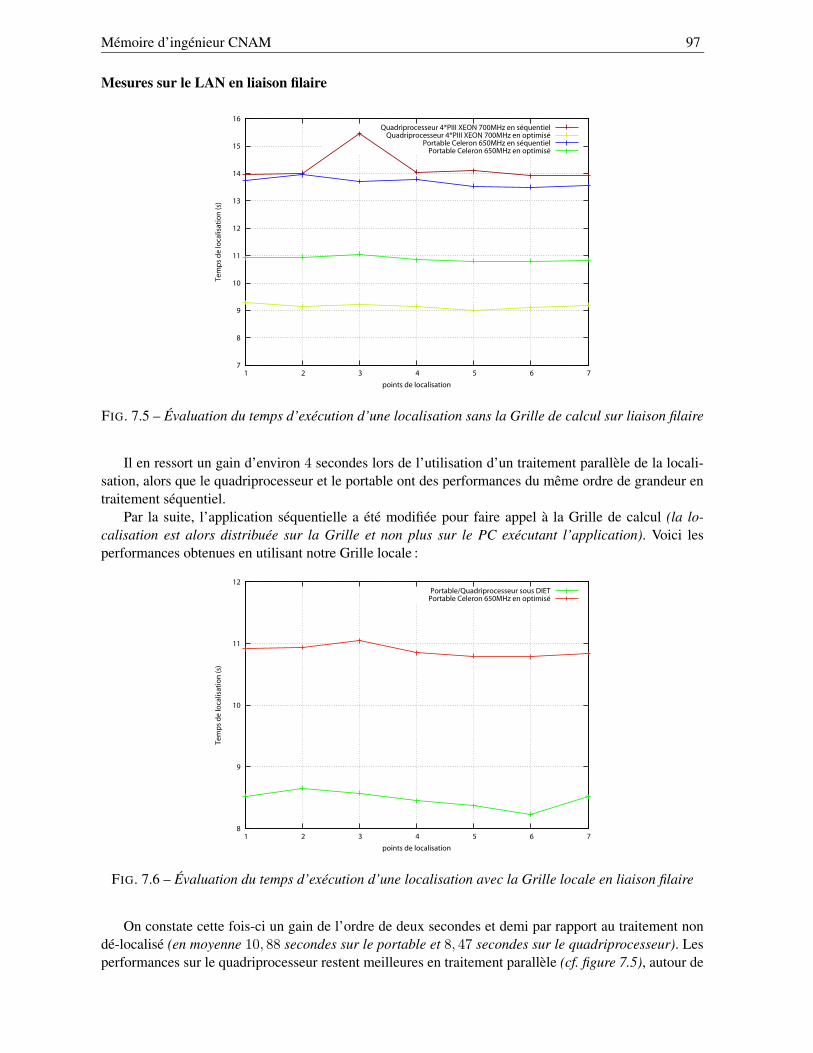
Mémoire d’ingénieur CNAM 97
Mesures sur le LAN en liaison filaire
7
8
9
10
11
12
13
14
15
16
1 2 3 4 5 6 7
Te
mp
s d
e lo
cali
sati
on
(s)
points de localisation
Quadriprocesseur 4*PIII XEON 700MHz en séquentielQuadriprocesseur 4*PIII XEON 700MHz en optimisé
Portable Celeron 650MHz en séquentielPortable Celeron 650MHz en optimisé
FIG. 7.5 – Évaluation du temps d’exécution d’une localisation sans la Grille de calcul sur liaison filaire
Il en ressort un gain d’environ 4 secondes lors de l’utilisation d’un traitement parallèle de la locali-sation, alors que le quadriprocesseur et le portable ont des performances du même ordre de grandeur entraitement séquentiel.
Par la suite, l’application séquentielle a été modifiée pour faire appel à la Grille de calcul (la lo-calisation est alors distribuée sur la Grille et non plus sur le PC exécutant l’application). Voici lesperformances obtenues en utilisant notre Grille locale :
8
9
10
11
12
1 2 3 4 5 6 7
Te
mp
s d
e lo
cali
sati
on
(s)
points de localisation
Portable/Quadriprocesseur sous DIETPortable Celeron 650MHz en optimisé
FIG. 7.6 – Évaluation du temps d’exécution d’une localisation avec la Grille locale en liaison filaire
On constate cette fois-ci un gain de l’ordre de deux secondes et demi par rapport au traitement nondé-localisé (en moyenne 10, 88 secondes sur le portable et 8, 47 secondes sur le quadriprocesseur). Lesperformances sur le quadriprocesseur restent meilleures en traitement parallèle (cf. figure 7.5), autour de
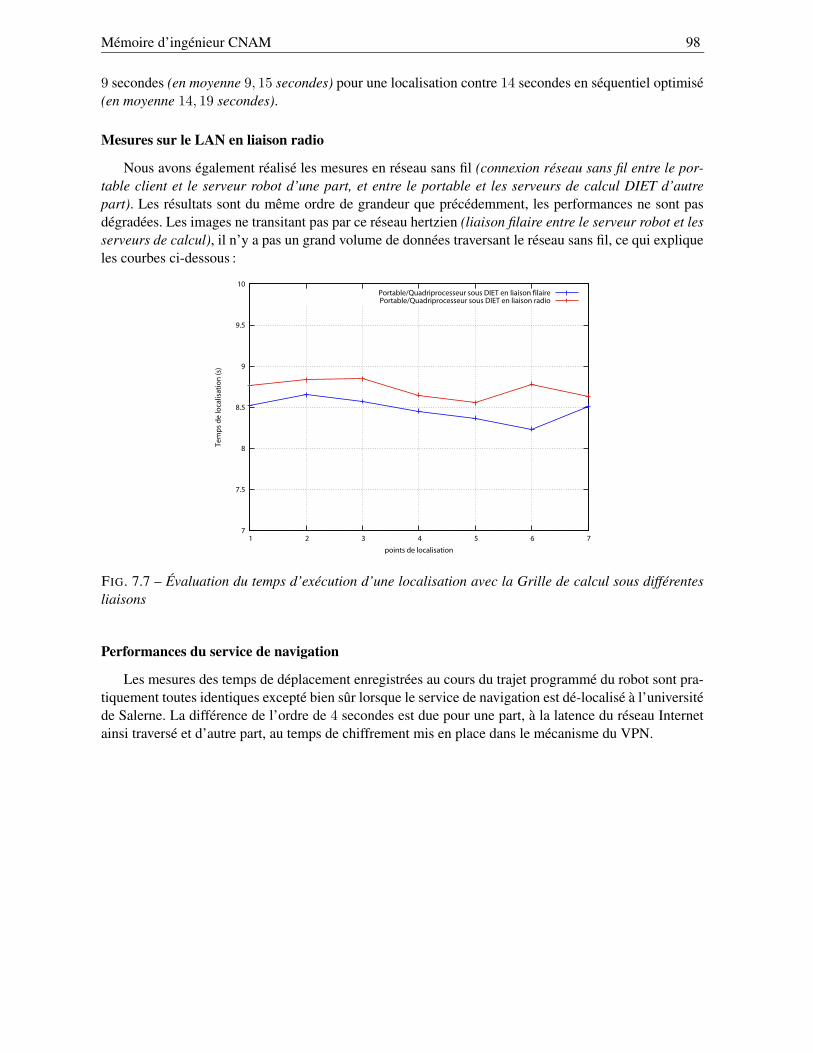
Mémoire d’ingénieur CNAM 98
9 secondes (en moyenne 9, 15 secondes) pour une localisation contre 14 secondes en séquentiel optimisé(en moyenne 14, 19 secondes).
Mesures sur le LAN en liaison radio
Nous avons également réalisé les mesures en réseau sans fil (connexion réseau sans fil entre le por-table client et le serveur robot d’une part, et entre le portable et les serveurs de calcul DIET d’autrepart). Les résultats sont du même ordre de grandeur que précédemment, les performances ne sont pasdégradées. Les images ne transitant pas par ce réseau hertzien (liaison filaire entre le serveur robot et lesserveurs de calcul), il n’y a pas un grand volume de données traversant le réseau sans fil, ce qui expliqueles courbes ci-dessous :
7
7.5
8
8.5
9
9.5
10
1 2 3 4 5 6 7
Te
mp
s d
e lo
cali
sati
on
(s)
points de localisation
Portable/Quadriprocesseur sous DIET en liaison filairePortable/Quadriprocesseur sous DIET en liaison radio
FIG. 7.7 – Évaluation du temps d’exécution d’une localisation avec la Grille de calcul sous différentesliaisons
Performances du service de navigation
Les mesures des temps de déplacement enregistrées au cours du trajet programmé du robot sont pra-tiquement toutes identiques excepté bien sûr lorsque le service de navigation est dé-localisé à l’universitéde Salerne. La différence de l’ordre de 4 secondes est due pour une part, à la latence du réseau Internetainsi traversé et d’autre part, au temps de chiffrement mis en place dans le mécanisme du VPN.
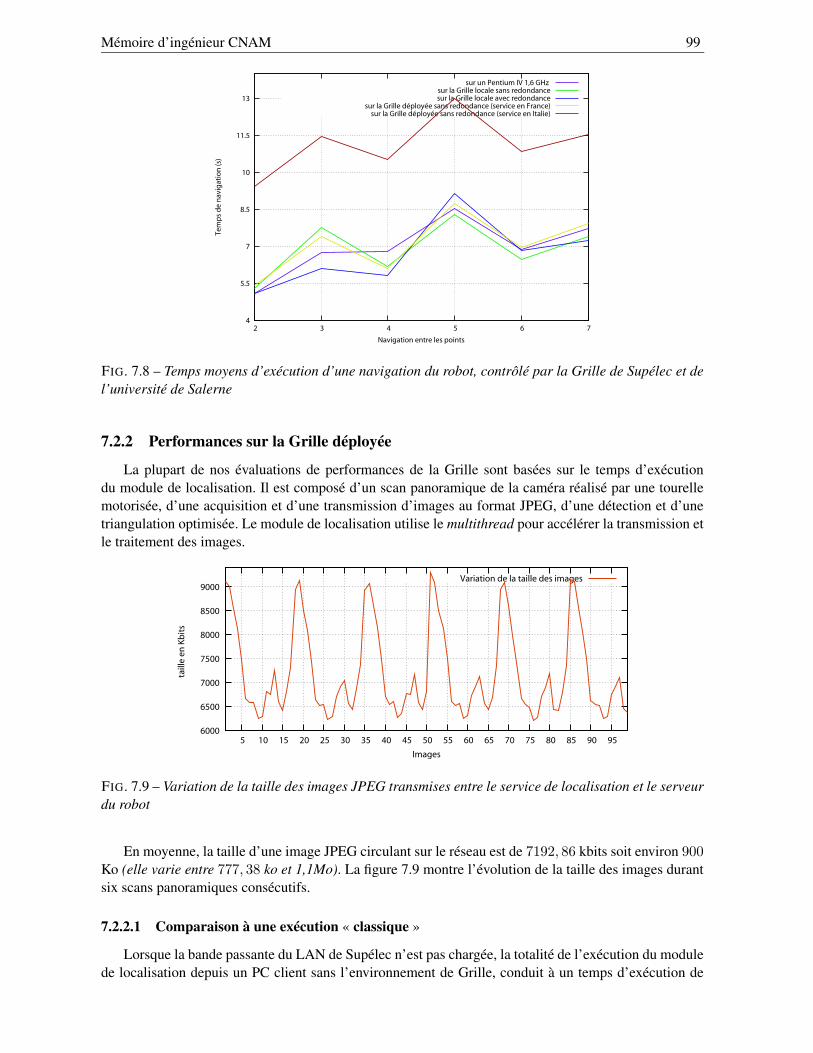
Mémoire d’ingénieur CNAM 99
4
5.5
7
8.5
10
11.5
13
2 3 4 5 6 7
Te
mp
s d
e n
av
iga
tio
n (
s)
Navigation entre les points
sur un Pentium IV 1,6 GHz sur la Grille locale sans redondancesur la Grille locale avec redondance
sur la Grille déployée sans redondance (service en France)sur la Grille déployée sans redondance (service en Italie)
FIG. 7.8 – Temps moyens d’exécution d’une navigation du robot, contrôlé par la Grille de Supélec et del’université de Salerne
7.2.2 Performances sur la Grille déployée
La plupart de nos évaluations de performances de la Grille sont basées sur le temps d’exécutiondu module de localisation. Il est composé d’un scan panoramique de la caméra réalisé par une tourellemotorisée, d’une acquisition et d’une transmission d’images au format JPEG, d’une détection et d’unetriangulation optimisée. Le module de localisation utilise le multithread pour accélérer la transmission etle traitement des images.
6000
6500
7000
7500
8000
8500
9000
5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95
tail
le e
n K
bit
s
Images
Variation de la taille des images
FIG. 7.9 – Variation de la taille des images JPEG transmises entre le service de localisation et le serveurdu robot
En moyenne, la taille d’une image JPEG circulant sur le réseau est de 7192, 86 kbits soit environ 900Ko (elle varie entre 777, 38 ko et 1,1Mo). La figure 7.9 montre l’évolution de la taille des images durantsix scans panoramiques consécutifs.
7.2.2.1 Comparaison à une exécution « classique »
Lorsque la bande passante du LAN de Supélec n’est pas chargée, la totalité de l’exécution du modulede localisation depuis un PC client sans l’environnement de Grille, conduit à un temps d’exécution de
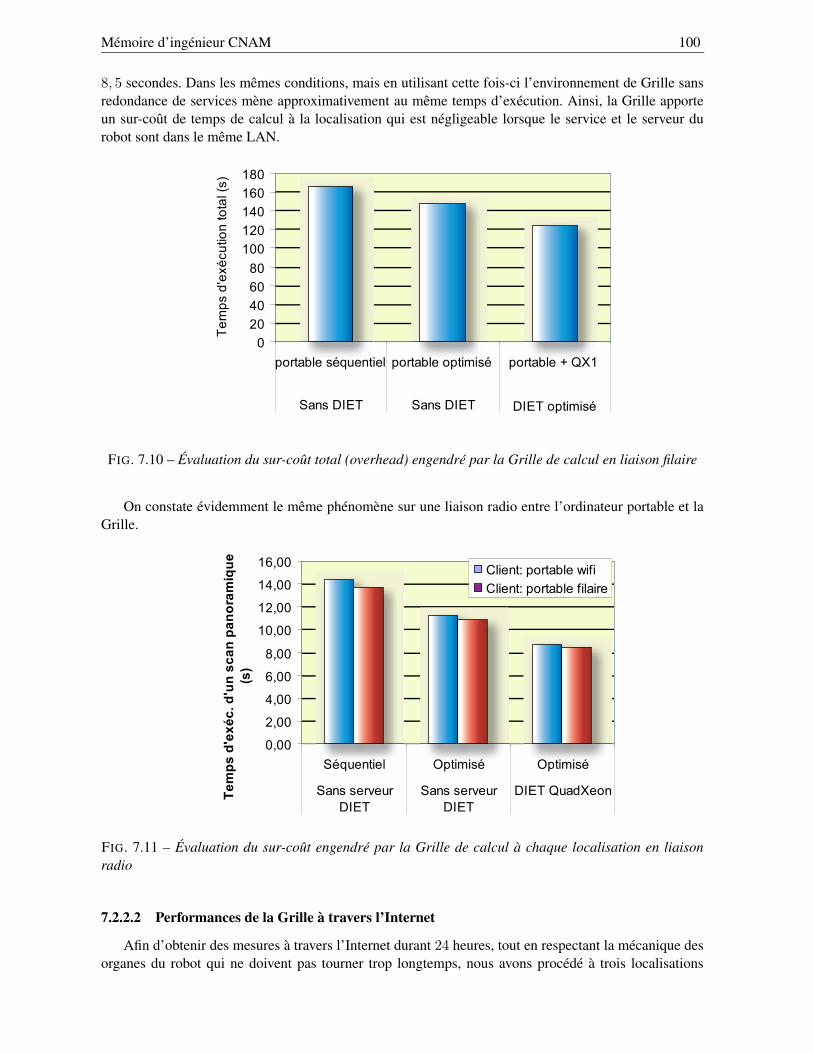
Mémoire d’ingénieur CNAM 100
8, 5 secondes. Dans les mêmes conditions, mais en utilisant cette fois-ci l’environnement de Grille sansredondance de services mène approximativement au même temps d’exécution. Ainsi, la Grille apporteun sur-coût de temps de calcul à la localisation qui est négligeable lorsque le service et le serveur durobot sont dans le même LAN.
0
20
40
60
80
100
120
140
160
180
portable séquentiel portable optimisé portable + QX1
Sans DIET Sans DIET DIET optimisé
Te
mp
s d
'exé
cu
tio
n to
tal (s
)
FIG. 7.10 – Évaluation du sur-coût total (overhead) engendré par la Grille de calcul en liaison filaire
On constate évidemment le même phénomène sur une liaison radio entre l’ordinateur portable et laGrille.
0,00
2,00
4,00
6,00
8,00
10,00
12,00
14,00
16,00
Séquentiel Optimisé Optimisé
Sans serveur
DIET
Sans serveur
DIET
DIET QuadXeonTe
mp
s d
'ex
éc
. d
'un
sc
an
pa
no
ram
iqu
e
(s)
Client: portable wifi
Client: portable filaire
FIG. 7.11 – Évaluation du sur-coût engendré par la Grille de calcul à chaque localisation en liaisonradio
7.2.2.2 Performances de la Grille à travers l’Internet
Afin d’obtenir des mesures à travers l’Internet durant 24 heures, tout en respectant la mécanique desorganes du robot qui ne doivent pas tourner trop longtemps, nous avons procédé à trois localisations
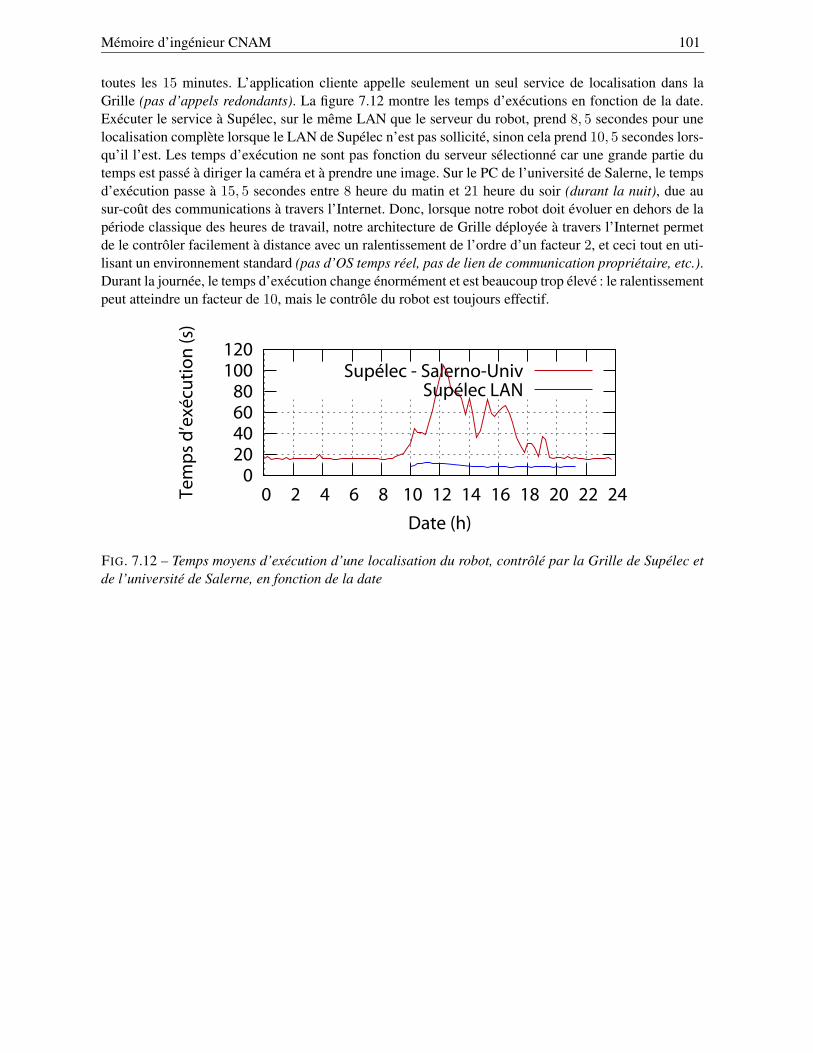
Mémoire d’ingénieur CNAM 101
toutes les 15 minutes. L’application cliente appelle seulement un seul service de localisation dans laGrille (pas d’appels redondants). La figure 7.12 montre les temps d’exécutions en fonction de la date.Exécuter le service à Supélec, sur le même LAN que le serveur du robot, prend 8, 5 secondes pour unelocalisation complète lorsque le LAN de Supélec n’est pas sollicité, sinon cela prend 10, 5 secondes lors-qu’il l’est. Les temps d’exécution ne sont pas fonction du serveur sélectionné car une grande partie dutemps est passé à diriger la caméra et à prendre une image. Sur le PC de l’université de Salerne, le tempsd’exécution passe à 15, 5 secondes entre 8 heure du matin et 21 heure du soir (durant la nuit), due ausur-coût des communications à travers l’Internet. Donc, lorsque notre robot doit évoluer en dehors de lapériode classique des heures de travail, notre architecture de Grille déployée à travers l’Internet permetde le contrôler facilement à distance avec un ralentissement de l’ordre d’un facteur 2, et ceci tout en uti-lisant un environnement standard (pas d’OS temps réel, pas de lien de communication propriétaire, etc.).Durant la journée, le temps d’exécution change énormément et est beaucoup trop élevé : le ralentissementpeut atteindre un facteur de 10, mais le contrôle du robot est toujours effectif.
0 20 40 60 80
100 120
0 2 4 6 8 10 12 14 16 18 20 22 24Te
mp
s d
’ex
écu
tio
n (
s)
Date (h)
Supélec - Salerno-UnivSupélec LAN
FIG. 7.12 – Temps moyens d’exécution d’une localisation du robot, contrôlé par la Grille de Supélec etde l’université de Salerne, en fonction de la date

Mémoire d’ingénieur CNAM 102
Chapitre 8
Conclusion et perspectives
Cette architecture de Grille que nous avons développée est composée à ce jour : de machines dedeux campus de recherche, en France et en Italie, reliés à travers l’Internet par un Réseau Privé Virtuel(VPN) basé sur le protocole IPsec. De l’environnement de Grille DIET en GridRPC utilisant un busCORBA pour les communications entre les agents, serveurs et clients permettant la localisation des ser-vices redondants. Et enfin d’une interface de programmation (API) écrite en C++ facilitant grandement laconception de systèmes robotiques complexes.
Les services de bas niveau du robot supportent la concurrence des commandes de contrôle grâce à unsystème de mémorisation des résultats traités, permettant de surcroît, la redondance des services critiquesde haut niveau tels que les services de localisation et de navigation.
La simplicité et la flexibilité de l’API permettent d’une part, de combiner l’utilisation de plusieursservices élémentaires indépendants des un des autres qui pourront se synchronisés lorsque que ceci estnécessaire, et d’autre part, de compléter la liste des services disponibles en développants facilement denouveaux modules, grâce à une « sémantique » de service.
Nous avons conçu et expérimenté une architecture de Grille où les communications avec les servicesde bas niveau passent par le VPN mais pas par le bus CORBA. Ce sont des connexions directes par socketqui transfèrent efficacement les données encombrantes comme des images vidéo. En revanche, les com-munications avec les services de haut niveau empruntent bien le bus CORBA et le protocole de DIET.Grâce à ce protocole de communication, les ralentissements mesurées lors du contrôle du robot à traversInternet restent inférieures à un facteur de 2 aux « heures creuses ». Cela, permet d’utiliser les différentssites de la Grille pour héberger des calculs redondants et obtenir une tolérance aux pannes avec un ralen-tissement acceptable. Une Grille de contrôle de processus à travers Internet semble donc réalisable.
Dans l’avenir, la Grille déployée sera étendue à d’autres sites grâce à de nouveaux partenaires quifédèrent déjà à ce projet, fournissant ainsi encore plus de ressources dé-localisées. Puis, dans un premiertemps, le nombre de robot contrôlé par l’architecture de Grille sera augmenté de deux autres robots. Dèslors que le nombre de processus physiques gérés augmentera, une politique de gestion de la redondancedes calculs devra être développée. On limitera ainsi le nombre de tâches lancées simultanément surla Grille, et on optimisera le placement des services redondants pour assurer une bonne tolérance auxpannes.

Mémoire d’ingénieur CNAM 103
Annexe A
Publication pour la conférenceinternationale WETICE-2004
F. Sabatier and A. De Vivo and S. Vialle. Grid Programming for Disributed Remote Robot Control.13th IEEE International Workshops on Enabling Technologies: Infrastructures for Collaborative Enter-prises (WETICE-2004), Modena, Italy. June 2004 (à paraître).

Mémoire d’ingénieur CNAM 104

Mémoire d’ingénieur CNAM 105
Annexe B
Les principaux schémas UML desbibliothèques nono, koala et nonovideo
B.1 Diagramme de déploiement
Robot KOALA server
Koalanonovideonono
Robot KOALA client
koalanonovideonono
Robot
TCP/IP
Serial link
File: \\Portable\DISK D (D)\Robot\nono-2.11.mdl 11:23:02 samedi 20 mars 2004 Deployment Diagram Page 1
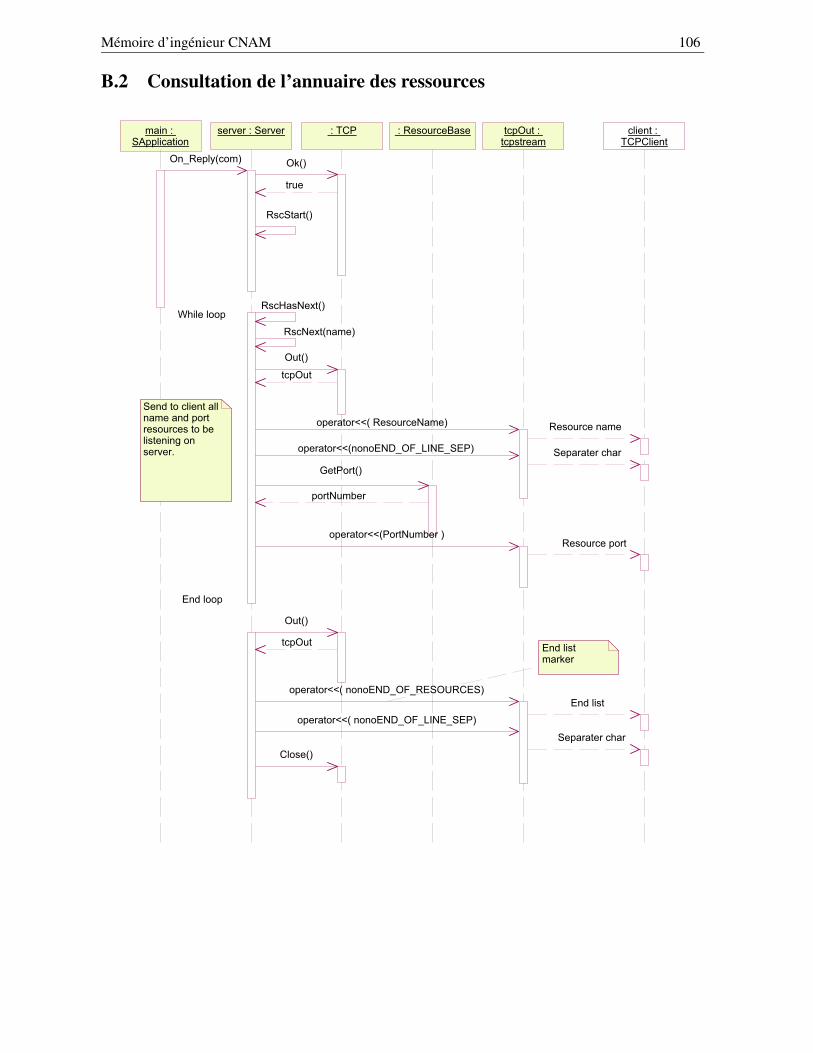
Mémoire d’ingénieur CNAM 106
B.2 Consultation de l’annuaire des ressources
main : SApplication
server : Server : TCP : ResourceBase tcpOut : tcpstream
client : TCPClient
portNumber
End list marker
Resource name
Resource port
End list
Separater char
Separater char
Send to client all name and port resources to be listening on server.
On_Reply(com)
RscHasNext()
RscNext(name)
Ok()
Out()
Close()
GetPort()
operator<<( ResourceName)
operator<<(nonoEND_OF_LINE_SEP)
operator<<(PortNumber )
operator<<( nonoEND_OF_RESOURCES)
operator<<( nonoEND_OF_LINE_SEP)
true
RscStart()
tcpOut
Out()
tcpOut
While loop
End loop
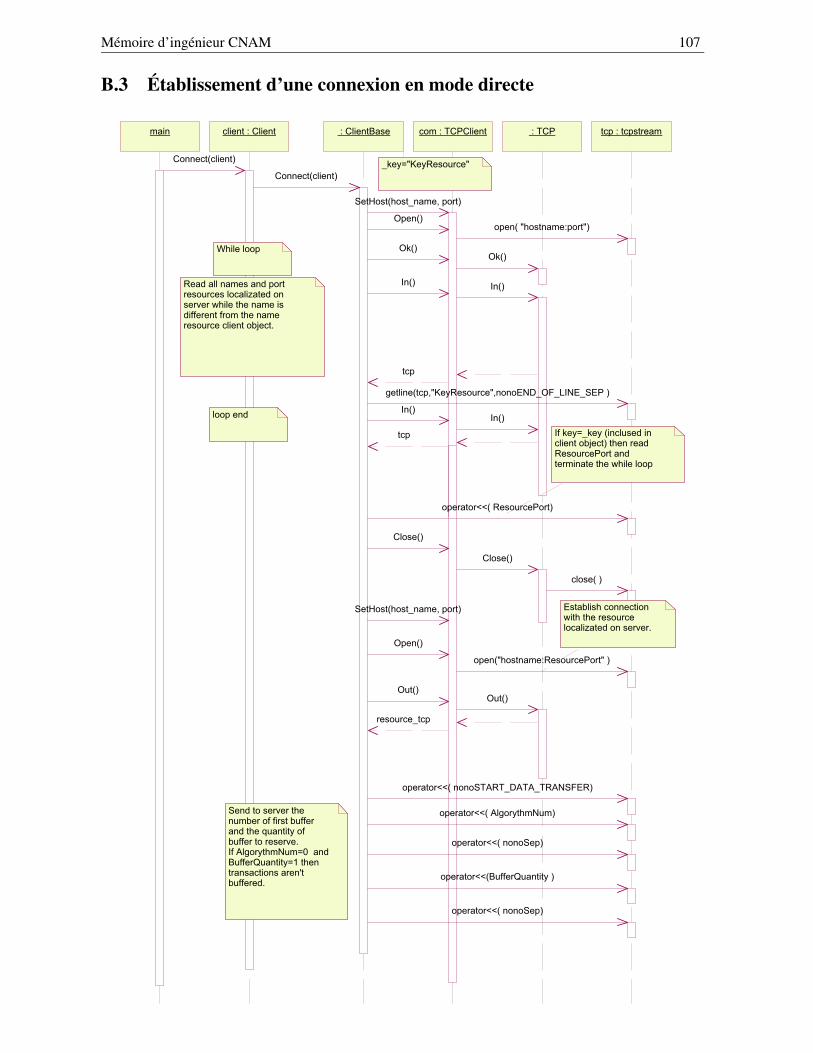
Mémoire d’ingénieur CNAM 107
B.3 Établissement d’une connexion en mode directe
main client : Client : ClientBase com : TCPClient : TCP tcp : tcpstream
resource_tcp
Send to server the number of first buffer and the quantity of buffer to reserve.If AlgorythmNum=0 and BufferQuantity=1 then transactions aren't buffered.
Establish connection with the resource localizated on server.
If key=_key (inclused in client object) then read ResourcePort and terminate the while loop
While loop
loop end
Read all names and port resources localizated on server while the name is different from the name resource client object.
tcp
_key="KeyResource"Connect(client)
Connect(client)
SetHost(host_name, port)
Open()
Ok()
In()
Close()
SetHost(host_name, port)
Open()
Out()
In()
Ok()
In()
tcp
Close()
Out()
In()
open( "hostname:port")
operator<<( ResourcePort)
close( )
open("hostname:ResourcePort" )
operator<<( nonoSTART_DATA_TRANSFER)
operator<<( AlgorythmNum)
operator<<( nonoSep)
operator<<(BufferQuantity )
operator<<( nonoSep)
getline(tcp,"KeyResource",nonoEND_OF_LINE_SEP )
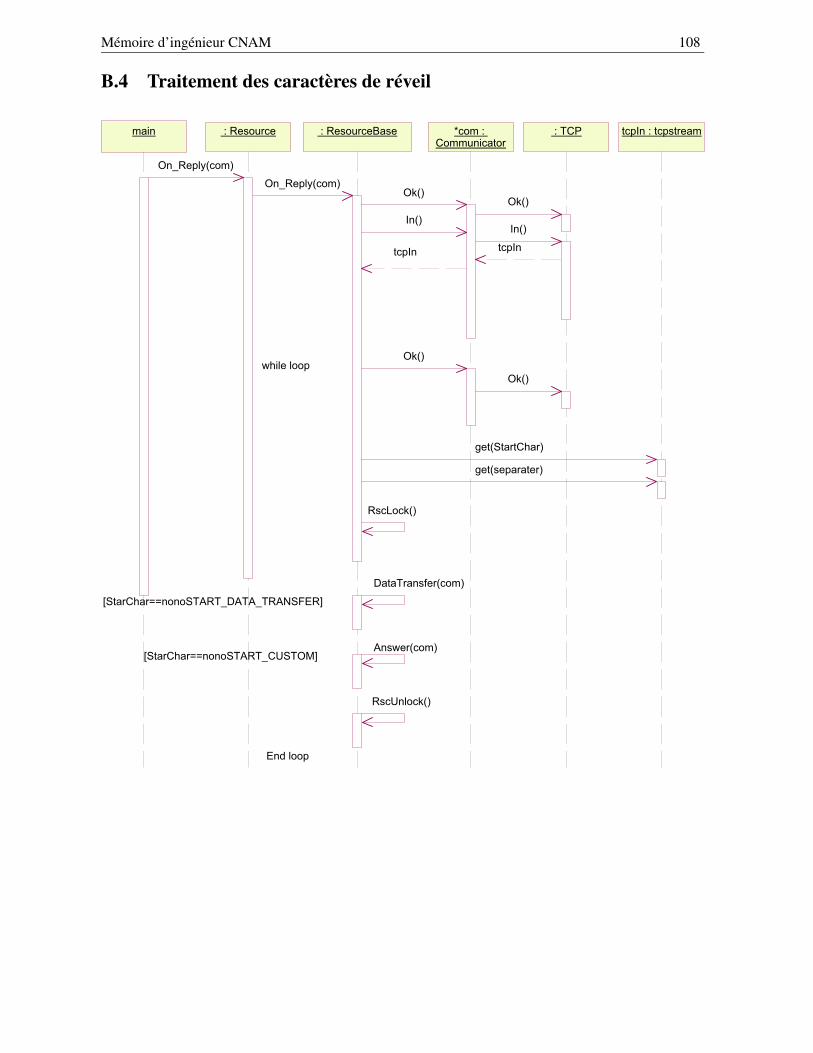
Mémoire d’ingénieur CNAM 108
B.4 Traitement des caractères de réveil
main : Resource : ResourceBase *com : Communicator
: TCP tcpIn : tcpstream
tcpIntcpIn
[StarChar==nonoSTART_DATA_TRANSFER]
[StarChar==nonoSTART_CUSTOM]
while loop
End loop
On_Reply(com)
On_Reply(com)
RscLock()
DataTransfer(com)
Answer(com)
RscUnlock()
Ok()
In()
Ok()
Ok()
In()
Ok()
get(StartChar)
get(separater)

Mémoire d’ingénieur CNAM 109
B.5 La méthode DataTransfer() - première partie
AppClient : Client
: Client : ClientBase prov : DataProvider<Request,Answer>
com : TCPClient : TCP ClientTCPOut : tcpstream
SrvTCPIn : tcpstream AppServer : SApplication : Serializable
DataTransfer()DataTransfer()
Indicate the mode selectionned:- Buffering mode if algorythm number is greater than 0- else direct mode
Send serializable object to server
Ok()Ok()
truetrue
Out()Out()
tcpOuttcpOut
operator << (nonoSTART_DATA_TRANSFER)
operator << (AlgoNumber)
operator <<(nonoSEP)
operator << (SequenceNumber)
operator <<(nonoSEP)
Ok()Ok()
Out()Out()
SendRequest(SrvTCPOut)
operator << (request)
operator <<(nonoSEP)
Write(ClientTCPOut)
B.6 La méthode DataTransfer() - seconde partie

Mémoire d’ingénieur CNAM 110
SrvTCPIn : tcpstream AppServer : SApplication
: Resource<Request,Answer> : ResourceBase com : TCPServer
: TCP prov : DataProvider<Request,Answer> : Serializable
: Resource serial_device : SerialPortResource
: TTY ttyOut : ttystream ttyIn : ttystream
Receive serializable object from server
On_Reply(SrvTCPIn)On_Reply(SrvTCPIn)
Ok()Ok()
truetrue
In()In()
SrvTCPInSrvTCPIn
get(start_char)
operator >>(AlgoNumber)
operator >>(nonoSEP)
operator >>(Sequence Number)
operator >>(nonoSEP)
RscLock()
Ok()Ok()
truetrue
RecvRequest(SrvTCPIn)
In()In()
SrvTCPInSrvTCPIn
Ok()Ok()
Lock()
Ok() Ok()
WriteMMAHeader()
Out()
Out()
ttyOut
ttyOut
operator << ("I,")
operator << (command.ad_in.number)
operator << ("\n")
EatMMAHeader(answer)
{GetADInput command}
In()In()
ttyInttyIn
operator >> (data.ad_in.value)
get(Separater)
get(CR_char)
get(LF_char)
ComputeDataFromReq()
operator >>(request)
operator >>(nonoSEP)
Unlock()
Read(SrvTCPIn)
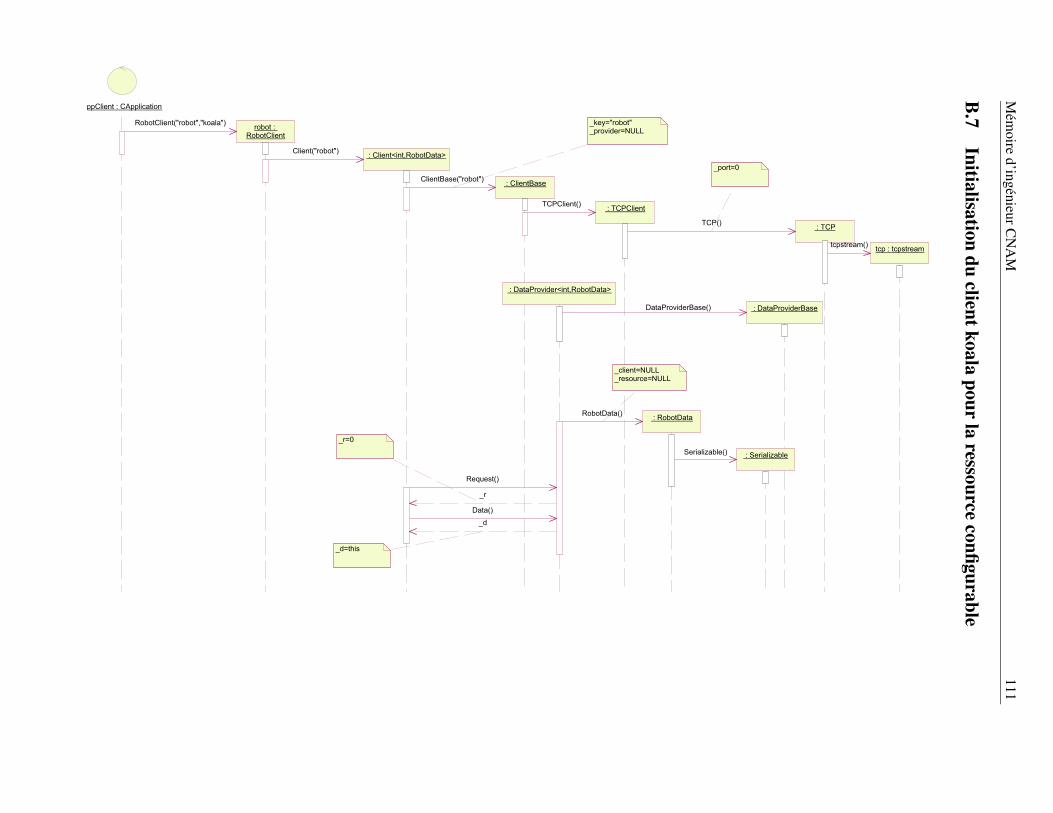
Mém
oired’ingénieurC
NA
M111
B.7
Initialisationdu
clientkoalapour
laressource
configurableppClient : CApplication
robot : RobotClient
: Client<int,RobotData>
: ClientBase
: DataProvider<int,RobotData>
: TCPClient
: RobotData
: DataProviderBase
: TCP
tcp : tcpstream
: Serializable
_r=0
_d=this
_client=NULL_resource=NULL
_key="robot"_provider=NULL
_port=0
RobotClient("robot","koala")
Client("robot")
ClientBase("robot")
TCPClient()
TCP()
tcpstream()
RobotData()
Serializable()
Request()
_r
Data()
_d
DataProviderBase()
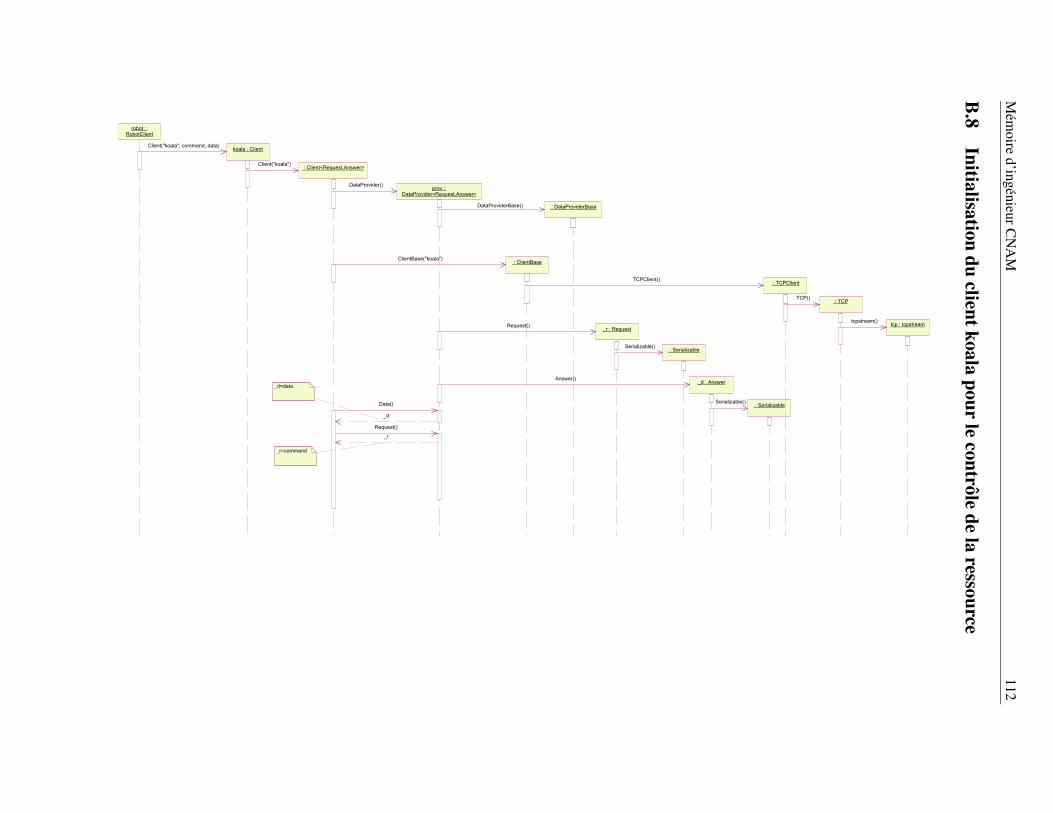
Mém
oired’ingénieurC
NA
M112
B.8
Initialisationdu
clientkoalapour
lecontrôle
dela
ressource
robot : RobotClient
koala : Client
: Client<Request,Answer>
prov : DataProvider<Request,Answer>
: ClientBase
: DataProviderBase
_r : Request
: Serializable
_d : Answer
: Serializable
: TCPClient
: TCP
tcp : tcpstream
_r=command
_d=data
Request()
_r
Data()
_d
Client("koala", command, data)
Client("koala")
ClientBase("koala")
TCPClient()
TCP()
tcpstream()
DataProvider()
DataProviderBase()
Request()
Serializable()
Answer()
Serializable()
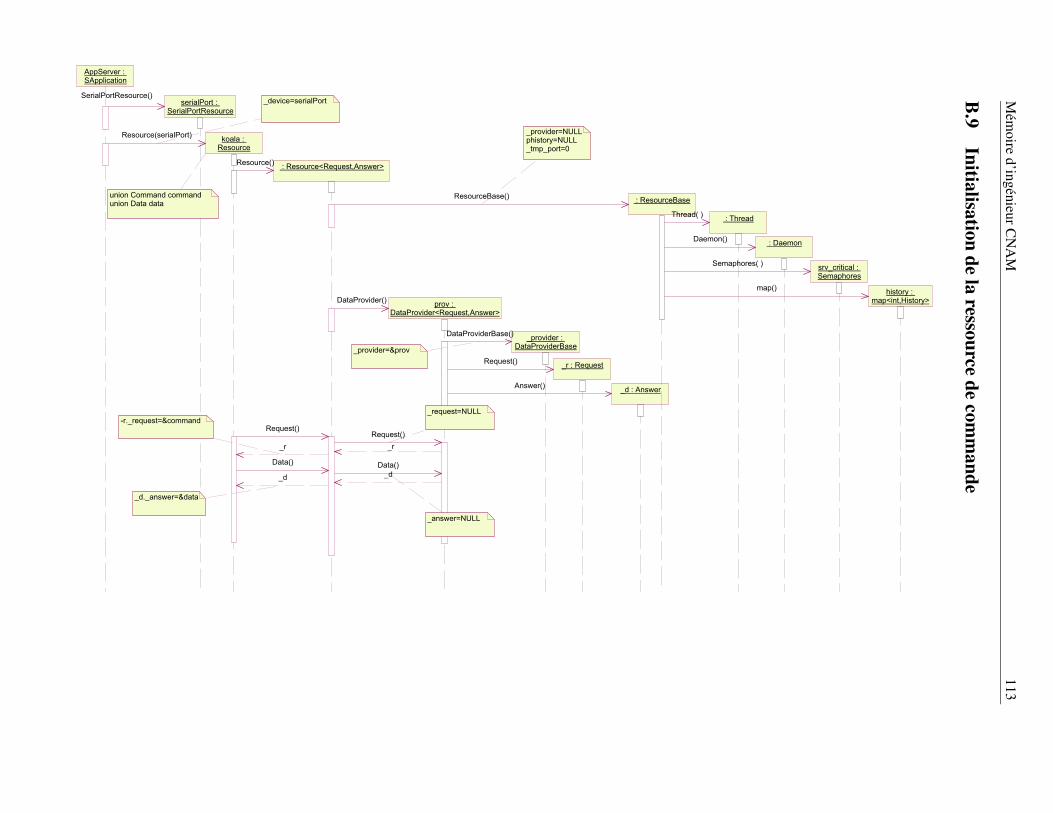
Mém
oired’ingénieurC
NA
M113
B.9
Initialisationde
laressource
decom
mande
AppServer : SApplication
serialPort : SerialPortResource
koala : Resource
_r : Request
_d : Answer
: ResourceBase
: Thread
prov : DataProvider<Request,Answer>
: Daemon
_provider : DataProviderBase
srv_critical : Semaphores
history : map<int,History>
: Resource<Request,Answer>
SerialPortResource()
Resource(serialPort)
Thread( )
Daemon()
Semaphores( )
map()
DataProviderBase()
Request()
Answer()
Resource()
ResourceBase()
-r._request=&command
_d._answer=&data
Request()
DataProvider()
Request()
_r_r
Data() Data()
_d_d
_device=serialPort
union Command commandunion Data data
_provider=&prov
_provider=NULLphistory=NULL_tmp_port=0
_request=NULL
_answer=NULL
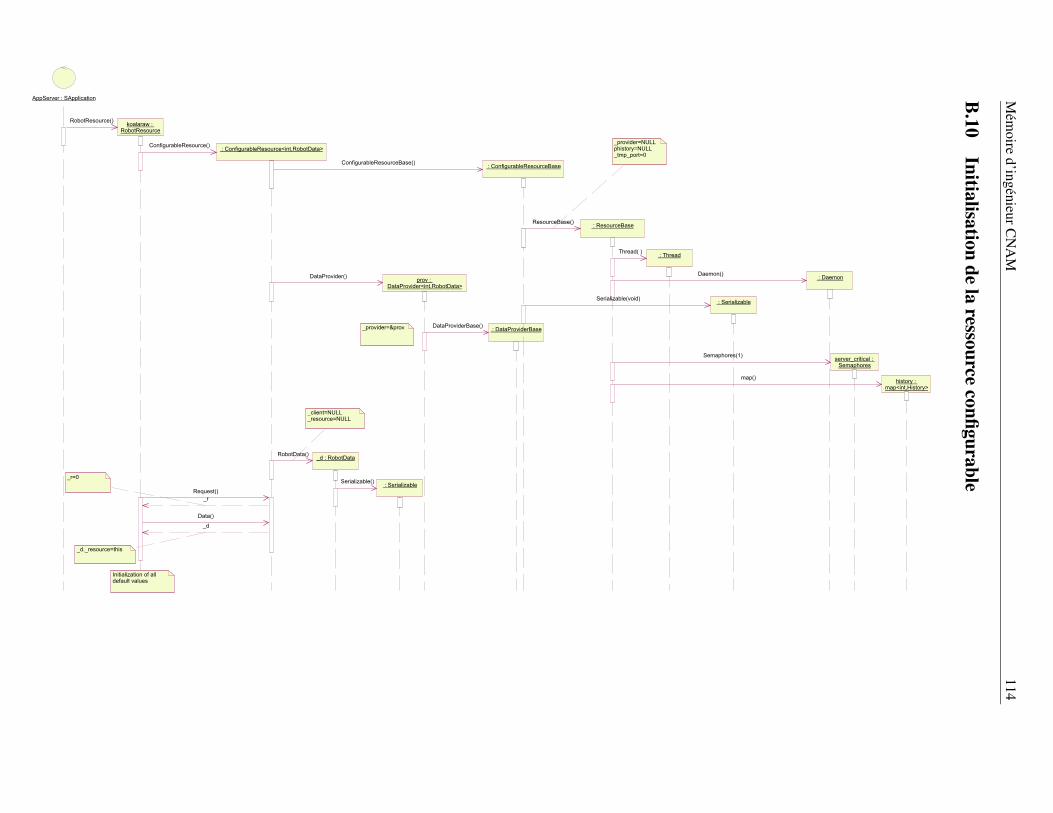
Mém
oired’ingénieurC
NA
M114
B.10
Initialisationde
laressource
configurableAppServer : SApplication
koalaraw : RobotResource
: ConfigurableResource<int,RobotData>
_d : RobotData
: Serializable
prov : DataProvider<int,RobotData>
: DataProviderBase
: ConfigurableResourceBase
: ResourceBase
: Thread
: Daemon
server_critical : Semaphores
history : map<int,History>
: Serializable
RobotResource()
ConfigurableResourceBase()
ConfigurableResource()
RobotData()
Serializable()
_client=NULL_resource=NULL
Request()
_r
Data()
_d
_r=0
_d._resource=this
Initialization of all default values
_provider=NULLphistory=NULL_tmp_port=0
ResourceBase()
Thread( )
Daemon()
Semaphores(1)
DataProvider()
DataProviderBase()
map()
_provider=&prov
Serializable(void)

Mémoire d’ingénieur CNAM 115
Annexe C
Les mécanismes de sécurité d’IPsec
C.1 Authentication Header (AH)
AH assure l’intégrité des données en mode non connecté, l’authentification de l’origine des donnéeset, de façon optionnelle, la protection contre le rejeu.
L’absence de confidentialité dans AH permet de s’assurer que ce standard pourra être largementrépandu sur l’Internet, y compris dans les endroits où l’exportation, l’importation ou l’utilisation duchiffrement dans des buts de confidentialité est restreint par la loi. Cela constitue l’une des raisons del’utilisation de deux mécanismes distincts.
Dans AH, intégrité et authentification sont fournies ensembles, à l’aide d’un bloc de données sup-plémentaire adjoint au message à protéger. Ce bloc de données est appelé « valeur de vérification d’in-tégrité » (Integrity Check Value, ICV 1),terme générique pour désigner soit un code d’authentificationde message 2 (Message Authentication Code, MAC), soit une signature numérique 4. Pour des raisonsde performances, les algorithmes proposés actuellement sont tous des algorithmes de scellement 5 (coded’authentification de message et non signature).
La protection contre le rejeu se fait grâce à un numéro de séquence ; elle n’est disponible que si IKEest utilisé, car en mode manuel aucune « ouverture de connexion » ne permet d’initialiser le compteur.
Voici l’organisation de l’en-tête d’authentification :
Longueur Réservé
Index des paramètres de sécurité (SPI)
En−tete suivant^
Données d’authentification (longueur variable)
Numéro de séquence
FIG. C.1 – Format de AH
1. « Valeur de vérification d’intégrité ». Cette valeur est calculée par l’expéditeur sur l’ensemble des données à protéger.L’ICV est alors envoyée avec les données protégées. En utilisant le même algorithme, le destinataire recalcule l’ICV sur lesdonnées reçues et la compare à l’ICV originale. Si elles se correspondent, il en déduit que les données n’ont pas été modifiées.
2. Résultat d’une fonction de hachage 3 à sens unique à clé secrète. L’empreinte dépend à la fois des données et de la clé ;elle n’est donc calculable que par les personnes connaissant la clé. Adjointe aux données sur lesquelles elle a été calculée, ellepermet de vérifier leur authenticité (authentification + intégrité).
4. « Données ajoutées à une unité de données, ou transformation cryptographique d’une unité de données, permettant à undestinataire de prouver la source et l’intégrité de l’unité de données et protégeant contre la contrefaçon (par le destinataire, parexemple). » [ISO 7498-2].
5. Mécanisme de sécurité permettant d’assurer l’intégrité et l’authentification de l’origine des données.

Mémoire d’ingénieur CNAM 116
L’expéditeur calcule les données d’authentification à partir de l’ensemble des champs invariants dudatagramme IP final, AH compris, ce qui permet d’étendre l’authentification au SPI et au numéro deséquence notamment. Les champs variables (TTL, routage...) et le champ destiné à recevoir les donnéesd’authentification sont considérés comme égaux à zéro pour le calcul. Les données d’authentificationsont alors adjointes au paquet IP par le biais de l’en-tête d’authentification (AH). Le récepteur vérifiel’exactitude de ces données à la réception.
Les figures ci-dessous indiquent la position de AH et le service apporté en fonction du mode choisi(transport ou tunnel).
En−tete IPd’origine
Données(protocole de niveau supérieur)
Avant application de AH
Authentifié
Après application de AH
En−tete IPd’origine
(excepté pour les champs variables de l’en−tete)
Données(protocole de niveau supérieur)AH
FIG. C.2 – Position de AH en mode transport (IPv4)
Données(protocole de niveau supérieur)d’origine
En−tete IPen−tete IP
En−tete IPd’origine
Données(protocole de niveau supérieur)
Avant application de AH
Authentifié
Après application de AH
(excepté pour les champs variables du nouvel en−tete)
AHNouvel
FIG. C.3 – Position de AH en mode tunnel (IPv4)
Les algorithmes par défaut que doit fournir toute réalisation d’IPsec pour AH sont HMAC-MD5 etHMAC-SHA-1.
C.1.1 Encapsulating Security Payload (ESP)
ESP peut assurer, au choix, un ou plusieurs des services suivants :– confidentialité (confidentialité des données et protection partielle contre l’analyse du trafic si l’on
utilise le mode tunnel),– intégrité des données en mode non connecté et authentification de l’origine des données, protection
contre le rejeu.La confidentialité peut être sélectionnée indépendamment des autres services, mais son utilisation sansintégrité/authentification (directement dans ESP ou avec AH) rend le trafic vulnérable à certains typesd’attaques actives qui pourraient affaiblir le service de confidentialité. Comme dans AH, authentification

Mémoire d’ingénieur CNAM 117
et intégrité sont deux services qui vont de pair et que l’on désigne souvent sous le terme « authentifica-tion » ; ils sont fournis par l’utilisation d’une ICV (en pratique, un MAC). La protection contre le rejeune peut être sélectionnée que si l’authentification l’a été et que IKE est utilisé. Elle est fournie par unnuméro de séquence que le destinataire des paquets vérifie.
Contrairement à AH, où l’on se contentait d’ajouter un en-tête supplémentaire au paquet IP, ESPfonctionne suivant le principe de l’encapsulation : les données originales sont chiffrées puis encapsuléesentre un en-tête et un trailer. Voici l’organisation de ESP :
Index des paramètres de sécurité (SPI)
Numéro de séquence
Charge utile(vecteur d’initialisation éventuel + données chiffrées)
Longueur de bourrage En−tete suivantBourrage
Données d’authentification
En−tete ESP
Charge utile
Authentification ESP
Trailer ESP
FIG. C.4 – Format de ESP
Le champ bourrage peut être nécessaire pour les algorithmes de chiffrement par blocs ou pour alignerle texte chiffré sur une limite de 4 octets.
Les données d’authentification ne sont présentes que si ce service a été sélectionné.Voyons maintenant comment est appliquée la confidentialité dans ESP. L’expéditeur :
1. Encapsule, dans le champ « charge utile » de ESP, les données transportées par le datagrammeoriginal et éventuellement l’en-tête IP (mode tunnel).
2. Ajoute si nécessaire un bourrage.3. Chiffre le résultat (données, bourrage, champs longueur et en-tête suivant).4. Ajoute éventuellement des données de synchronisation cryptographiques (vecteur d’initialisa-
tion 6) au début du champ « charge utile ».Si elle a été sélectionnée, l’authentification est toujours appliquée après que les données ne soient
chiffrées. Cela permet, à la réception, de vérifier la validité du datagramme avant de se lancer dans lacoûteuse tâche de déchiffrement. Contrairement à AH, l’authentification dans ESP est appliquée uni-quement sur le « paquet » (en-tête + charge utile + trailer) ESP et n’inclut ni l’en-tête IP ni le champd’authentification.
Les figures ci-dessous indiquent la position de ESP et les services apportés en fonction du modechoisi (transport ou tunnel).
6. Bloc de valeur quelconque servant à initialiser un chiffrement avec chaînage de blocs, et donc à faire en sorte que deuxmessages identiques donnent des cryptogrammes distincts.

Mémoire d’ingénieur CNAM 118
En−tete IPd’origine
Données(protocole de niveau supérieur)
Avant application de ESP
En−tete IPd’origine
Données(protocole de niveau supérieur)
TrailerESP d’authentification
Données
Chiffré (confidentialité)
Authentifié
Après application de ESP
En−teteESP
FIG. C.5 – Position de ESP en mode transport (IPv4)
En−tete IPd’origine
Données(protocole de niveau supérieur)
Avant application de ESP
Données(protocole de niveau supérieur)
TrailerESP d’authentification
Donnéesen−tete IPNouvel
Après application de ESP
En−tete IPd’origine
Chiffré (confidentialité)
Authentifié
En−teteESP
FIG. C.6 – Position de ESP en mode tunnel (IPv4)
Les algorithmes prévus pour être utilisés avec ESP sont :– Confidentialité : DES triple (obligatoire), DES, AES et NULL pour le cas ou le chiffrement n’est
pas souhaité.– Authentification : HMAC-MD5 (obligatoire), HMAC-SHA-1 (obligatoire) et NULL pour le cas
où l’authenticité n’est pas sélectionnée.
C.2 La gestion des clés pour IPsec : ISAKMP et IKE
IKE (Internet Key Exchange) est un système développé spécifiquement pour IPsec qui vise à fournirdes mécanismes d’authentification et d’échange de clés adaptés à l’ensemble des situations qui peuventse présenter sur l’Internet. Il est composé de plusieurs éléments : le cadre générique ISAKMP et unepartie des protocoles Oakley et SKEME. Lorsqu’il est utilisé pour IPsec, IKE est de plus complété par un« domaine d’interprétation » pour IPsec.
C.2.1 ISAKMP
Nous avons vu au début de cette présentation que l’apport de services de sécurité passait par l’utilisa-tion d’associations de sécurité qui permettent de définir les paramètres (clés, protocoles...) nécessaires àla sécurisation d’un flux donné. ISAKMP (Internet Security Association and Key Management Protocol)a pour rôle la négociation, l’établissement, la modification et la suppression des associations de sécuritéet de leurs attributs.

Mémoire d’ingénieur CNAM 119
C.2.1.1 Indépendance vis à vis des mécanismes : les domaines d’interprétation et les phases
ISAKMP est un cadre générique indépendant des mécanismes en faveur desquels la négociation alieu. En effet, ISAKMP est a priori utilisable pour négocier, sous forme d’associations de sécurité, lesparamètres relatifs à n’importe quels mécanismes de sécurité : IPsec, TLS... Il est en effet prévu poursupporter la négociation de SA pour n’importe quel protocole de niveau supérieur ou égal à IP.
Ceci est possible grâce à la façon dont les négociations ont lieu. Tout d’abord, ISAKMP est prévupour fonctionner indépendamment des mécanismes pour lesquels il travaille : les données relatives à lagestion des clés seront transportées à part. ISAKMP peut être implémenté directement au-dessus d’IP, ouau-dessus de tout protocole de la couche transport. Il s’est notamment vu attribuer le port 500 sur UDPpar l’IANA.
Ensuite, ISAKMP définit un cadre pour négocier les associations de sécurité, mais n’impose rienquant aux paramètres qui les composent. Un document appelé « domaine d’interprétation » (Domainof Interpretation, DOI) doit définir les paramètres négociés et les conventions relatives à l’utilisationde ISAKMP dans un cadre précis. Un identificateur de DOI est utilisé pour interpréter le contenu desmessages ISAKMP. La [RFC 2407] définit le DOI pour l’utilisation de ISAKMP avec IPsec.
Enfin, ISAKMP comporte deux phases, qui permettent une séparation nette de la négociation des SApour un protocole donné et de la protection du trafic propre à ISAKMP :
– Durant la première phase, un ensemble d’attributs relatifs à la sécurité est négocié, les identi-tés des tiers sont authentifiées et des clés sont générées. Ces éléments constituent une première« association de sécurité », dite SA ISAKMP. Contrairement aux SA IPsec, la SA ISAKMP estbidirectionnelle. Elle servira à sécuriser l’ensemble des échanges ISAKMP futurs.
– La seconde phase permet de négocier les paramètres de sécurité relatifs à une SA à établir pour lecompte d’un mécanisme de sécurité donné (par exemple AH ou ESP). Les échanges de cette phasesont sécurisés (confidentialité, authenticité...) grâce à la SA ISAKMP. Celle-ci peut bien sûr êtreutilisée pour négocier plusieurs SA destinées à d’autres mécanismes de sécurité.
Les paramètres de la SA ISAKMP peuvent être propres à ISAKMP seulement, ou comporter égalementdes éléments propres à un protocole de sécurité donné et définis dans le DOI correspondant. Dans lepremier cas, on parlera de Generic ISAKMP SA, et celle-ci pourra servir pour la négociation de SA pourn’importe quel protocole de sécurité. Dans le second cas, la SA ISAKMP ne pourra être utilisée que pournégocier une SA dépendant du même DOI.
C.2.1.2 Indépendance vis à vis du protocole de gestion des clés : la construction des messages parblocs
ISAKMP est également indépendant de la méthode de génération des clés et des algorithmes dechiffrement et d’authentification utilisés. Il est donc indépendant de tout protocole d’échange de clé,ce qui permet de séparer clairement les détails de la gestion des associations de sécurité des détails del’échange de clé. Différents protocoles d’échange de clé, présentant des propriétés différentes sont ainsiutilisables avec ISAKMP.
Ceci est possible à cause du fait que ISAKMP n’impose pas un déroulement fixe, basé sur la définitiond’un ensemble de messages limité. ISAKMP est plutôt une sorte de « kit de construction », puisqueles messages d’ISAKMP sont constitués d’un en-tête suivi d’un nombre variable de blocs. Ces blocs(payloads en anglais) sont les briques de base d’ISAKMP.
Chaque message ISAKMP commence par un en-tête (ISAKMP Header) de longueur fixe. Celui-ci comprend notamment deux cookies, l’initiator cookie et le responder cookie, qui, en plus du rôleclassique de protection contre le déni de service 7 (anti-clogging), permettent d’identifier l’association desécurité ISAKMP en cours (contrairement aux autres SA, elle n’est pas identifiée pas un SPI).
7. « Impossibilité d’accès à des ressources pour des utilisateurs autorisés ou introduction d’un retard pour le traitementd’opérations critiques. » [ISO 7498-2]

Mémoire d’ingénieur CNAM 120
Un champ Exchange Type permet de connaître le type d’échange en cours et donc de connaîtrel’organisation et le nombre des messages.
L’en-tête ISAKMP comprend également un champ, Next Payload, qui indique le type du premier blocdu message. Chaque bloc commence à son tour par un en-tête propre, qui indique la longueur du bloccourant et le type du bloc suivant. Le dernier bloc du message indique 0 comme type de bloc suivant. Laconstruction des messages ISAKMP repose donc sur le chaînage de blocs.
C.2.2 IKE
Si le DOI IPsec précise le contenu des blocs ISAKMP dans le cadre d’IPsec, IKE en revanche utiliseISAKMP, pour construire un protocole pratique. Le protocole de gestion des clés associé à ISAKMP dansce but est inspiré à la fois d’Oakley et de SKEME. Plus exactement, IKE utilise certains des modes définispar Oakley et emprunte à SKEME son utilisation du chiffrement à clé publique pour l’authentification etsa méthode de changement de clé rapide par échange d’aléas. D’autre part, IKE ne dépend pas d’un DOIparticulier mais peut utiliser tout DOI.
IKE comprend quatre modes :– le mode principal (Main Mode),– le mode agressif (Aggressive Mode),– le mode rapide (Quick Mode)– le mode nouveau groupe (New Group Mode).
Main Mode et Aggressive Mode sont utilisés durant la phase 1, Quick Mode est un échange de phase 2.New Group Mode est un peu à part : ce n’est ni un échange de phase 1, ni un échange de phase 2, mais ilne peut avoir lieu qu’une fois une SA ISAKMP établie ; il sert à se mettre d’accord sur un nouveau groupepour de futurs échanges Diffie-Hellman.
C.2.2.1 Phase 1 : Main Mode et Aggressive Mode
Les attributs suivants sont utilisés par IKE et négociés durant la phase 1 : un algorithme de chiffre-ment, une fonction de hachage, une méthode d’authentification et un groupe pour Diffie-Hellman.
Trois clés sont générées à l’issue de la phase 1 : une pour le chiffrement, une pour l’authentificationet une pour la dérivation d’autres clés. Ces clés dépendent des cookies, des aléas échangés et des valeurspubliques Diffie-Hellman ou du secret partagé préalable. Leur calcul fait intervenir la fonction de hachagechoisie pour la SA ISAKMP et dépend du mode d’authentification choisi. Pour connaître les formulesexactes, référez-vous à [RFC 2409].
Composé de six messages, Main Mode est une instance de l’échange ISAKMP Identity ProtectionExchange :
– Les deux premiers messages servent à négocier les paramètres IKE : algorithme de chiffrement,fonction de hachage, méthode d’authentification des tiers et groupe pour Diffie-Hellman.
3 DES
SHA
RSA Sig
DH group 2
DES
SMD5
Pre-shared
DH group 1
Choix 1 Choix 2
Proposition
3 DES
SHA
RSA Sig
DH group 2
Sélection
Négociation des
paramètres IKE
FIG. C.7 – Main Mode : exemple de premier échange
Les quatre méthodes d’authentification possibles sont la signature numérique, deux formesd’authentification par chiffrement à clé publique et l’utilisation d’un secret partagé préalable.

Mémoire d’ingénieur CNAM 121
– Les deux seconds messages permettent l’établissement d’un secret partagé via l’utilisation du pro-tocole Diffie-Hellman.
Valeur publique DHNombre aléatoire
(requete CERT)
Valeur publique DHNombre aléatoire
(requete CERT)
Génération de valeurs DH et d’aléas
Calcul du secret partagé
FIG. C.8 – Main Mode : second échange
Le secret partagé sert à dériver des clés de session, deux d’entre elles étant utilisées pourprotéger la suite des échanges avec les algorithmes de chiffrement et de hachage négociés précé-demment.
– Les deux derniers messages servent à l’authentification des échanges et notamment des valeurspubliques.
Alice@wonderland
Empreinte/signature
sur l'ensemble des
données échangées
ipsec.supelec.fr
Empreinte/signature
sur l'ensemble des
données échangées
Authentification
mutuelle
Bob
signé CA
Alice
signé CA
FIG. C.9 – Main Mode : troisième échange
Aggressive Mode est une instance de l’échange ISAKMP Aggressive Exchange : il combine les échangesdécrits ci-dessus pour Main Mode de façon à ramener le nombre total de messages à trois.
Dans ces deux cas, la méthode choisie pour l’authentification influence le contenu des messages etla méthode de génération de la clé de session 8. Les quatre méthodes d’authentification possibles sont lasignature numérique, deux formes d’authentification par chiffrement à clé publique et l’utilisation d’unsecret partagé préalable. La [RFC 2408] détaille les messages échangés dans chaque cas et les formulesde calcul des signatures et empreintes.
C.2.2.2 Phase 2 : Quick Mode
Les messages échangés durant la phase 2 sont protégés en authenticité et en confidentialité grâce auxéléments négociés durant la phase 1. L’authenticité des messages est assurée par l’ajout d’un bloc HASHaprès l’en-tête ISAKMP, et la confidentialité est assurée par le chiffrement de l’ensemble des blocs dumessage.
Quick Mode est utilisé pour la négociation de SA pour des protocoles de sécurité donnés commeIPsec. Chaque négociation aboutit en fait à deux SA, une dans chaque sens de la communication.
Plus précisément, les échanges composant ce mode ont le rôle suivant :
– Négocier un ensemble de paramètres IPsec (paquets de SA)
8. Clé ayant une durée de vie très limitée, généralement à une session. Les clés de session sont généralement des cléssecrètes, utilisées pour chiffrer les données transmises, et que les tiers communicants génèrent en début de communication.

Mémoire d’ingénieur CNAM 122
– Échanger des nombres aléatoires, utilisés pour générer une nouvelle clé qui dérive du secret généréen phase 1 avec le protocole Diffie-Hellman. De façon optionnelle, il est possible d’avoir recours àun nouvel échange Diffie-Hellman, afin d’accéder à la propriété de Perfect Forward Secrecy 9, quin’est pas fournie si on se contente de générer une nouvelle clé à partir de l’ancienne et des aléas.
– Identifier le trafic que ce paquet de SA protégera, au moyen de sélecteurs (blocs optionnels IDi etIDr ; en leur absence, les adresses IP des interlocuteurs sont utilisées).
Les échanges composant ce mode sont les suivants :Ou, en terme de composition des messages par blocs :
C.2.2.3 Les groupes : New Group Mode
Le groupe à utiliser pour Diffie-Hellman peut être négocié, par le biais du bloc SA, soit au coursdu Main Mode, soit ultérieurement par le biais du New Group Mode. Dans les deux cas, il existe deuxfaçons de désigner le groupe à utiliser :
– Donner la référence d’un groupe prédéfini : il en existe actuellement quatre, les quatre groupesOakley (deux groupes MODP et deux groupes EC2N).
– Donner les caractéristiques du groupe souhaité : type de groupe (MODP, ECP, EC2N), nombrepremier ou polynôme irréductible, générateurs...
C.2.2.4 Phases et modes
Au final, le déroulement d’une négociation IKE suit le diagramme suivant :
Quick ModePFS
− mode Secret partagé− mode Chiffrement asymétrique− mode Signature
MODE AGRESSIF
Quick Mode Quick Mode Quick ModePFS
− mode Secret partagé− mode Chiffrement asymétrique− mode Signature
MODE PRINCIPAL
IKE Phase 1
IKE Phase 2
Premier tunnel IKE
Tunnel IPsec 1 Tunnel IPsec n
DEBUT
FIG. C.10 – Négociation d’IKE
9. Propriété d’un protocole d’échange de clef selon laquelle la découverte, par un attaquant, du ou des secrets à long termeutilisés ne permet pas de retrouver les clefs de sessions.

Mémoire d’ingénieur CNAM 123
Annexe D
Installation de FreeS/WAN sur un noyau2.4
Nous allons ajouter le support d’IPsec dans le noyau Linux. Pour se faire, il faut télécharger lecode source du noyau 2.4.xx (suivant la dernière version supportée par FreeS/WAN) puis l’installer (parapt-get ou rpm -vih kernel-source...).
apt-get install kernel-source#2.4.20-24.9
Ensuite, nous avons besoin de télécharger le patch permettant le support du chiffrement X.509 à cetteadresse :
ftp://ftp.xs4all.nl/pub/crypto/freeswan/kernpatch/
Ainsi ce patch s’applique au moyen des commandes suivantes :
[root@station root]# cd /usr/src/linux-2.4[root@station linux-2.4]# zcat freeswan-2.04.k2.4.patch.gz | patch -l -s -p1
Nous pouvons à présent compiler le noyau Linux :
[root@station linux-2.4]# make mrproper[root@station linux-2.4]# make xconfig
Cette dernière commande va lancer le menu de configuration du kernel. Dans la rubrique Networking options,il faudra sélectionner l’option IP Security Protocol (FreeS/WAN IPEC) ainsi que toutes les op-tions filles.
[root@station linux-2.4]# make dep[root@station linux-2.4]# make bzImage (création du noyau)[root@station linux-2.4]# make modules (création des modules)[root@station linux-2.4]# make modules_install
Une fois terminer, procédons à l’installation du nouveau noyau
[root@station linux-2.4]# cp arch/i386/boot/bzImage /boot/vmlinuz-2.4.20-24.9custom[root@station linux-2.4]# mkinitrd -f /boot/initrd-2.4.20-24.9custom.img 2.4.20-24.9custom
Il reste à modifier le chargeur de noyau (ici LILO), en ajoutant ces quelques lignes au fichier /etc/lilo.conf
image=/boot/vmlinuz-2.4.20-24.9customlabel="linux-ipsec"

Mémoire d’ingénieur CNAM 124
initrd=/boot/initrd-2.4.20-24.9custom.imgread-onlyappend="root=LABEL=/"
Tapons alors la commande lilo pour mettre en place le chargeur de noyau puis redémarrons lamachine.
D.0.3 Installations des commandes IPsec
Voilà, à cette étape notre système supporte le protocole IPsec. Mais pour le mettre en œuvre, il resteencore à télécharger les rpms contenant les outils 1 destinés à notre version de noyau à l’adresse suivante :
http://download.freeswan.ca/freeswan-x509/RedHat-RPMs/2.04/
Par exemple :- freeswan-module-2.04_x509_1.4.8_2.4.20_24.9-0.i386.rpm- freeswan-userland-2.04_x509_1.4.8_2.4.20_24.9-0.i386.rpm
D.0.4 Test de l’installation
Pour tester que tout fonctionne correctement, nous allons d’abord démarrer le service par la com-mande :
[root@station root]# ipsec setup start
Puis lancer, une vérification interne par la commande :
[root@station root]# ipsec verify
Nous obtenons les messages suivants si tout fonctionne correctement :
Version check and ipsec on-path [OK]Checking for KLIPS support in kernel [OK]Checking for RSA private key (/etc/ipsec.secrets) [OK]Checking that pluto is running [OK]
1. Ces utilitaires ne fonctionneront correctement qu’avec RedHat car ils sont très sensibles aux variations du kernel.

Mémoire d’ingénieur CNAM 125
Annexe E
Création des certificats X.509
Pour créer les certificats d’autorisations d’accès à notre réseau Grille, nous allons utiliser les scriptsPerl mis à notre disposition dans le répertoire /usr/share/ssl/misc.
Afin de coller à nos exigences, le fichier /usr/share/ssl/openssl.cnf a été modifié ainsi :
default_days = 1825 (365) =>le certificat sera valide pendant 5 ansdefault_bits = 2048 (1024) =>défini la longueur de la clé à 2048 bitssubjectAltName=IP:$ENV::CERTIP =>utilise l’adresse IP contenu dans la variable CERTIPpour définir le nom du certificat
Ainsi, la dernière ligne fait appelle à une extension de SSL (norme v3) afin d’ajouter l’adresse IP aucertificat. Au lieu d’avoir un nom DN de la forme « C=FR, ST=France, L=Metz, O=Supelec,OU=Education,CN=gateway/[email protected] » comme identi-fiant, le certificat sera accessible par l’adresse IP de la machine auquelle le certificat est rattaché .
Certificate:Data:
Version: 3 (0x2)Serial Number: 3 (0x3)Signature Algorithm: md5WithRSAEncryptionIssuer: C=FR, ST=France, L=Metz, O=Supelec, OU=Education,CN=ca.lan.net/[email protected]
Not Before: Dec 15 08:32:32 2003 GMTNot After : Dec 12 08:32:32 2013 GMT
Subject: C=FR, ST=France, L=Metz, O=Supelec, OU=Education,CN=gateway/[email protected] Public Key Info:
Public Key Algorithm: rsaEncryptionRSA Public Key: (2048 bit)
Modulus (2048 bit):00:c2:78:54:86:a0:1e:04:4d:f0:e2:5b:d7:82:dc:...8d:53
Exponent: 65537 (0x10001)X509v3 extensions:
X509v3 Basic Constraints:CA:FALSENetscape Comment:OpenSSL Generated CertificateX509v3 Subject Key Identifier:E3:40:4F:BE:45:DB:68:B3:67:1E:53:A9:9E:82:5B:F2:F9:18:FC:55

Mémoire d’ingénieur CNAM 126
X509v3 Authority Key Identifier:keyid:54:FB:87:BD:E8:9A:F8:A7:7F:12:97:5F:16:D0:F7:8D:FD:A8:02:BEDirName:/C=FR/ST=France/L=Metz/O=Supelec/OU=Education/CN=ca.lan.net/[email protected]:00
X509v3 Subject Alternative Name:IP Address:192.168.30.1
Signature Algorithm: md5WithRSAEncryption56:dc:f3:5a:c1:fd:91:0e:ed:f1:a0:d6:a6:5e:57:b8:84:a5:...e0:5f:6e:69
FIG. E.1 – Exemple de certificat avec l’extension de la version 3 de SSL
Ce qui permet de simplifier grandement la configuration de la passerelle (une seule section « conn »au lieu d’une par identifiant de certificat).
Pour mettre en place le système d’authentification, nous avons besoin de créer 1 un certificat pourl’Autorité de Certification (Certificate Authority CA) , un pour la passerelle VPN (dans notre cas, ils’agit de la même machine) et un pour chaque poste distant autorisé à se connecter au VPN.Remarque : toutes les opérations de création de certificats doivent être réalisées par l’administrateur duréseau.
E.0.4.1 Création de l’autorité de certification
Voici la commande à saisir dans une console en tant que root :
[root@station root]# cd /usr/share/ssl/misc[root@station root]# ./CA -newca
Cette dernière étape va permettre de créer une autorité de certification, ainsi que son certificat auto-signé. A la question :CA certificate filename (or enter to create)il faudra taper ENTREE et répondre aux questions posées par la suite (les réponses sont données à titred’exemple) :CA certificate filename (or enter to create)
Making CA certificate ...Using configuration from /usr/share/ssl/openssl.cnfGenerating a 2048 bit RSA private key...................................................................................+++..............................+++writing new private key to ’./demoCA/private/cakey.pem’Enter PEM pass phrase:<ex: ca@phrase>Verifying password - Enter PEM pass phrase:<confirmation du mot de passe précédent>-----You are about to be asked to enter information that will be incorporatedinto your certificate request.What you are about to enter is what is called a Distinguished Name or a DN.There are quite a few fields but you can leave some blankFor some fields there will be a default value,If you enter ’.’, the field will be left blank.-----
1. C’est une opération à effectuer qu’une seule fois lors de l’installation.

Mémoire d’ingénieur CNAM 127
Country Name (2 letter code) [GB]:FRState or Province Name (full name) [Berkshire]:FranceLocality Name (eg, city) [Newbury]:MetzOrganization Name (eg, company) [My Company Ltd]:SupelecOrganizational Unit Name (eg, section) []:Division InformatiqueCommon Name (eg, your name or your server’s hostname) []:gatewayCA.vpn.netEmail Address []:[email protected]
E.0.4.2 Création du certificat de la passerelle
Une fois le certificat du CA créé, il faut créer celui de la passerelle VPN :
[root@station root]# export CERTIP=192.168.130.1 (adresse IP de la passerelle coté extérieur)[root@station root]# ./CA -newreq
Using configuration from /usr/share/ssl/openssl.cnfGenerating a 2048 bit RSA private key...............................................+++.....................................................................+++writing new private key to ’newreq.pem’Enter PEM pass phrase:<ex: vpngw@phrase>Verifying password - Enter PEM pass phrase:<confirmation du mot de passe précédent>-----You are about to be asked to enter information that will be incorporatedinto your certificate request.What you are about to enter is what is called a Distinguished Name or a DN.There are quite a few fields but you can leave some blankFor some fields there will be a default value,If you enter ’.’, the field will be left blank.-----Country Name (2 letter code) [GB]:FRState or Province Name (full name) [Berkshire]:FranceLocality Name (eg, city) [Newbury]:MetzOrganization Name (eg, company) [My Company Ltd]:SupelecOrganizational Unit Name (eg, section) []:Division InformatiqueCommon Name (eg, your name or your server’s hostname) []:gateway.vpn.netEmail Address []:[email protected] enter the following ’extra’ attributesto be sent with your certificate requestA challenge password []:An optional company name []:Request (and private key) is in newreq.pem
Le fichier newreq.pem nouvellement créé, contient à la fois le certificat et sa clé privée.
E.0.4.3 Signature du certificat de la passerelle
Il faut ensuite signer le certificat, le renommer et le copier au bonne endroit :
[root@station root]# ./CA -sign
Using configuration from /usr/share/ssl/openssl.cnfEnter PEM pass phrase:<mot de passe CA>Check that the request matches the signatureSignature okThe Subjects Distinguished Name is as follows

Mémoire d’ingénieur CNAM 128
countryName :PRINTABLE:’FR’stateOrProvinceName :PRINTABLE:’France’localityName :PRINTABLE:’Metz’organizationName :PRINTABLE:’Supelec’organizationalUnitName:PRINTABLE:’Division Informatique’commonName :PRINTABLE:’gateway.vpn.net’emailAddress :IA5STRING:’[email protected]’Certificate is to be certified until Nov 12 07:49:49 2003 GMT (1825 days)Sign the certificate? [y/n]:y
1 out of 1 certificate requests certified, commit? [y/n]yWrite out database with 1 new entriesData Base UpdatedSigned certificate is in newcert.pem
A cette dernière étape, le mot de passe demandé est celui du CA. Le fichier newcert.pem contientalors le certificat signé de la passerelle.Nota : ces deux dernières opérations seront à renouveler pour chaque poste distant (poste nomade) auto-risé à rejoindre notre VPN (un certificat signé par poste).
E.0.5 Mise en place de la passerelle
Il nous reste à mettre en place ce certificat et sa clé privée dans les répertoires prévus à cet effet parFreeS/WAN.
[root@station root]# mv newcert.pem /etc/ipsec.d/certs/gateway.cert[root@station root]# mv newreq.pem /etc/ipsec.d/private/gateway.key
Pour terminer, il faut retirer le certificat non signé, du fichier de la clé privée en éditant le fichiergateway.key et en supprimant la section correspondant à :
------BEGIN CERTIFICAT REQUEST-------xxxxxxxxxxx?.-------END CERTIFICAT REQUEST---------
Il ne doit rester que la section :
-----BEGIN RSA PRIVATE KEY-------xxxxx?-------END RSA PRIVATE KEY---------
Pour vérifier que le certificat présenté par la passerelle au poste distant, a bien été signé par l’autoritéde certification (CA), IKE utilise le certificat du CA pour récupérer la clé publique et pour contrôler lavalidité de ce dernier. C’est pourquoi le fichier ca.cert doit être présent sur la passerelle ainsi que surles postes distants.
[root@station root]# cp demoCA/cacert.pem /etc/ipsec.d/cacerts/ca.cert
Pour une raison ou une autre, il est tout à fait possible de retirer le droite à un poste distant de seconnecter à notre VPN. Pour ceci, il convient de révoquer son certificat et de mettre à jour la liste descertificats révoqués publiée lors de l’établissement de la connexion par IKE. La commande suivante gé-nère cette fameuse liste :
[root@station root]# openssl ca -gencrl -out /etc/ipsec.d/crls/crl.pem

Mémoire d’ingénieur CNAM 129
Annexe F
Installation du VPN
F.0.6 Configuration de la passerelle
Il faut configurer au minimum les fichiers /etc/ipsec.conf et /etc/ipsec.secrets.
F.0.6.1 Le fichier /etc/ipsec.conf
Ce fichier est composé de deux parties :– une partie globale (indiquée par la directive config setup);– une partie « connexions spécifiques » (indiquée par la directive conn ).
A noter que les sections config setup et conn %default (connexion par défaut) sont globalesmais certaines valeurs indiquées peuvent être outre-passées dans les sections définissant les différentesconnexions du VPN.# /etc/ipsec.conf - FreeS/WAN IPsec configuration file
version 2.0 # conforms to second version of ipsec.conf specification
# basic configurationconfig setup
# Mode debug.klipsdebug=none# Mode debug pour IKEplutodebug=none# Interface utilisée pour les tunnelsinterfaces="ipsec0=eth0"# L’identification d’un participant doit être uniqueuniqueids=yes# IKE est lancépluto=yes
# Configuration par défaut d’une connexionconn %default
# Nombre de tentatives pour négocier une connexionkeyingtries=5# Temps maximum d’une connexion avant re-négociation du SAikelifetime=1h# Temps maximum d’une connexion pour une clékeylife=24h# Adresse IP de la passerelleleft=192.168.130.1# Réseau local à protégerleftsubnet=192.168.100.0/24

Mémoire d’ingénieur CNAM 130
# Fichier du certificat de la passerelleleftcert=gateway.cert# Type de la clé publique d’authentificationleftrsasigkey=%cert# Authentification par certificatsauthby=rsasig
# Connexion d’un poste isoléconn roadwarriors
# Toute adresse IPright=%any# Fichier du certificat du poste distantrightcert=roadwarrior.cert# Connexion chargée sur demandeauto=add
Par convention, on s’accorde pour que :– tous les paramètres débutant par left concernent les paramètres locaux;– tous les paramètres débutant par right concernent les paramètres distants;
192.168.100.0/24
193.24.226.253
193.68.130.0/24
193.68.130.253
193.68.130.1
Réseau local
Réseau grille
Réseaux de Supélec
Internet
���
���
���
���
Gdev2Gdev1
Monox
Router
Quadx
Passerelle
GServer
FIG. F.1 – Plan d’adressage de la Grille
La première ligne définit la version du fichier de configuration. Ensuite, on trouve la configurationglobale avec les modules de débbugage, l’interface utilisée pour les tunnels et l’utilisation de pluto (im-plémentation de IKE). On rencontre alors plusieurs sections conn. La première définit une section deconnexion par défaut. Ces informations seront utilisées pour toutes les autres connexions définies dansle fichier, en tant que valeurs par défaut. Nous définissons le nombre d’essais maximum 1 autorisé pournégocier une connexion (SA). Puis nous définissons la durée maximale d’une SA, ainsi que la durée maxi-male d’une clé de session. Nous arrivons aux données sur les adresses des participants du VPN. Le cotégauche (la machine locale) avec son adresse IP, le sous réseau à protéger (ici un réseau de classe C) et
1. Une valeur à zéro définit un nombre infini.

Mémoire d’ingénieur CNAM 131
le chemin d’accès au fichier contenant le certificat. Nous définissons que le coté droit (le poste distant)sera authentifié par une clé publique de type certificat X.509 signé.
Et enfin, la section suivante définit une communication spécifique, appelée « roadwarriors » (le côtédroit de la connexion VPN). Nous avons l’adresse de la composante droite (toute adresse IP valide), puisle chemin d’accès au fichier de certificat des machines distantes (ce certificat est envoyé par IKE lors dela négociation de connexion). L’absence de la directive rightid permet d’identifier le poste distant parson adresse IP (d’où la nécessité d’inclure l’adresse IP dans le certificat).
Dans notre cas, toutes les machines qui présenteront un certificat signé par l’autorité de certificationqui possède le certificat ca.cert, seront authentifiées et autorisées à se connecter au VPN. Ainsi sur lapasserelle, nous n’avons pas besoin de stocker les certificats des hôtes autorisés.
Grille locale
INTERNET
Réseau Privé Virtuel
Passerelle du VPN
Supélec à Metz Unisa en Italie
CA
signé CAItalie
signé CA
Passerelle
signé CAPasserelle
signé CAListe descertificatsrévoqués
CA
signé CA
Liste descertificatsrévoqués
Routeur Routeur
Poste nomade
ETHERNET
GIGABIT
FIG. F.2 – Architecture de notre VPN
F.0.6.2 Le fichier /etc/ipsec.secrets
Ce fichier doit uniquement contenir cette ligne :: RSA gateway.key "passphrase"
ou: RSA gateway.key %prompt
Ainsi, ce fichier référence la clé privée de type RSA de la machine locale (ici la passerelle). La se-conde formulation permet d’éviter la présence de la « passphrase » en clair dans le fichier (cela peut-être gênant sur un ordinateur portable servant de poste nomade). Il faudra alors utiliser la commandeipsec auto rereadsecrets après chaque redémarrage d’IPsec pour saisir la « passphrase ».
F.0.7 Configuration du poste distant situé en Italie
F.0.7.1 Le fichier /etc/ipsec.conf
Le fichier /etc/ipsec.conf se présente comme ceci :# /etc/ipsec.conf - FreeS/WAN IPsec configuration file
version 2.0 # conforms to second version of ipsec.conf specification
# basic configurationconfig setup
# Mode debug.klipsdebug=none# Mode debug pour IKEplutodebug=none# Interface utilisée pour les tunnelsinterfaces="ipsec0=eth0"# L’identification d’un participant doit être uniqueuniqueids=yes

Mémoire d’ingénieur CNAM 132
# IKE est lancépluto=yes
# Add connections here.# Configuration par defaut d’une connexionconn %default
# Nombre de tentatives pour négocier une connexionkeyingtries=5# Temps maximum d’une connexion avant re-négociation du SAikelifetime=1h# Temps maximum d’une connexion pour une clékeylife=24h# Adresse IP de la passerelle localeleftnexthop=192.21.228.254# Adresse IP du poste localleft=192.21.228.78# Réseau local à protégerleftsubnet=192.21.228.78/32# Fichier du certificat du posteleftcert=roadwarrior.cert# Type de la clé publique d’authentificationleftrsasigkey=%cert# Authentification par certificatsauthby=rsasig
# Connexion du poste isoléconn road
# Adresse IP de la passerelleright=193.168.130.1# Réseau protégé par la passerellerightsubnet=192.168.100.0/24# Fichier du certificat de la passerellerightcert=gateway.cert# Connexion chargée sur demandeauto=add
On retrouve la même définition que le fichier présent sur la passerelle sauf pour la partie adresses IP etnom du certificat (leftcert=roadwarrior.cert).
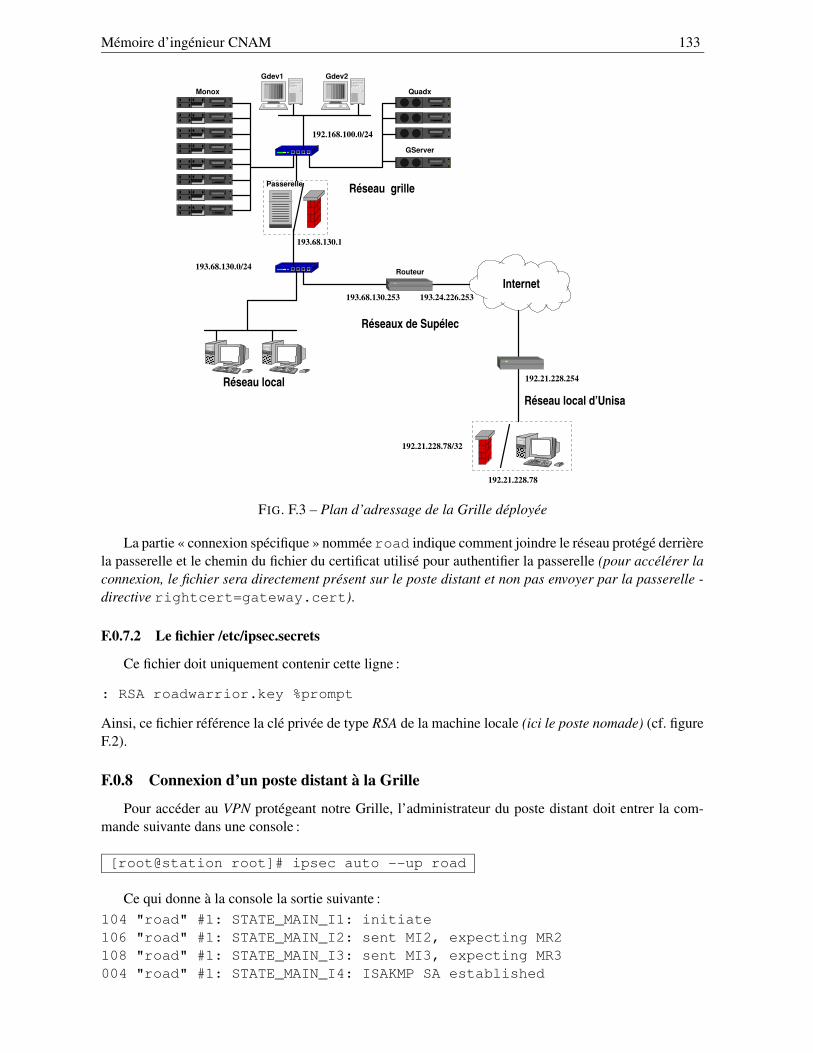
Mémoire d’ingénieur CNAM 133
192.168.100.0/24
193.24.226.253
193.68.130.0/24
193.68.130.253
193.68.130.1
Réseau local
Réseau grille
Réseaux de Supélec
192.21.228.78
192.21.228.254
192.21.228.78/32
Internet
Réseau local d’Unisa
���
���
���������
���
Gdev2Gdev1
Monox Quadx
Passerelle
GServer
Routeur
FIG. F.3 – Plan d’adressage de la Grille déployée
La partie « connexion spécifique » nommée road indique comment joindre le réseau protégé derrièrela passerelle et le chemin du fichier du certificat utilisé pour authentifier la passerelle (pour accélérer laconnexion, le fichier sera directement présent sur le poste distant et non pas envoyer par la passerelle -directive rightcert=gateway.cert).
F.0.7.2 Le fichier /etc/ipsec.secrets
Ce fichier doit uniquement contenir cette ligne :
: RSA roadwarrior.key %prompt
Ainsi, ce fichier référence la clé privée de type RSA de la machine locale (ici le poste nomade) (cf. figureF.2).
F.0.8 Connexion d’un poste distant à la Grille
Pour accéder au VPN protégeant notre Grille, l’administrateur du poste distant doit entrer la com-mande suivante dans une console :
[root@station root]# ipsec auto --up road
Ce qui donne à la console la sortie suivante :104 "road" #1: STATE_MAIN_I1: initiate106 "road" #1: STATE_MAIN_I2: sent MI2, expecting MR2108 "road" #1: STATE_MAIN_I3: sent MI3, expecting MR3004 "road" #1: STATE_MAIN_I4: ISAKMP SA established

Mémoire d’ingénieur CNAM 134
112 "road" #2: STATE_QUICK_I1: initiate004 "road" #2: STATE_QUICK_I2: sent QI2, IPsec SA established{ESP=>0xd5631de5 <0xcfcffb92}
Il est alors possible de vérifier le bon fonctionnement du VPN depuis le poste distant, en lançant unsimple ping vers une machine présente dernière la passerelle.
[root@station root]# ping 192.168.100.2
Envoi d’une requête ’ping’ sur 192.168.100.2 avec 32 octets de données :
Réponse de 192.168.100.2 : octets=32 temps=47 ms TTL=126Réponse de 192.168.100.2 : octets=32 temps=31 ms TTL=126Réponse de 192.168.100.2 : octets=32 temps=31 ms TTL=126Réponse de 192.168.100.2 : octets=32 temps=32 ms TTL=126
Remarque : une fois les testes de bon fonctionnement réalisés avec succès, il convient de configurerIPsec pour que le poste distant se connecte automatiquement lors du démarrage de celui-ci (il suffit deremplacer la directive auto=add par auto=start dans le ficher de configuration).

Mémoire d’ingénieur CNAM 135
Annexe G
Sécurisation de la passerelle
Voici les règles de filtrage (sous forme d’un script bash) du pare-feu présent sur la passerelle :#!/bin/sh# Script de définition des règles de filtrage de la passerelle VPN# sous iptables
# Interface du réseau protégé par le VPNint=eth1
# Accès extérieur de la passerelleext=eth0
# Par défaut, on interdit tout en entrée et en sortieiptables -P INPUT DROPiptables -P OUTPUT DROPiptables -P FORWARD ACCEPT
# On accepte tout sur le localhost (127.0.0.1).iptables -A INPUT -i lo -j ACCEPTiptables -A OUTPUT -o lo -j ACCEPT
# On autorise tout sur le réseau 192.168.100.0 :iptables -A INPUT -s 192.168.100.0/24 -j ACCEPTiptables -A OUTPUT -d 192.168.100.0/24 -j ACCEPTiptables -A FORWARD -s 192.168.100.0/24 -j ACCEPT
# On autorise l’utilisation du protocole icmpiptables -A INPUT -i $ext -p icmp --icmp-type 0 -j ACCEPTiptables -A INPUT -i $ext -p icmp --icmp-type 8 -j ACCEPTiptables -A INPUT -i $ext -p icmp --icmp-type 3 -j ACCEPTiptables -A OUTPUT -p icmp --icmp-type 0 -j ACCEPTiptables -A OUTPUT -p icmp --icmp-type 8 -j ACCEPTiptables -A OUTPUT -p icmp --icmp-type 3 -j ACCEPT
# On autorise l’utilisation du DNS en interneiptables -A INPUT -i $int --protocol udp --source-port 53 -j ACCEPTiptables -A OUTPUT -o $int --protocol udp --destination-port 53 -j ACCEPTiptables -A INPUT -i $int --protocol tcp --source-port 53 -j ACCEPTiptables -A OUTPUT -o $int --protocol tcp --destination-port 53 -j ACCEPT
# On autorise le DHCP pour configurer l’interface externeiptables -A INPUT -i $ext -p udp --dport 67:68 --sport 67:68 -j ACCEPT

Mémoire d’ingénieur CNAM 136
# On autorise IKE à négocier sur le port 500iptables -A INPUT -p udp -i $ext --sport 500 --dport 500 -j ACCEPTiptables -A OUTPUT -p udp -o $ext --sport 500 --dport 500 -j ACCEPT
# on autorise l’encryptage et l’authentification ESPiptables -A INPUT -p 50 -i $ext -j ACCEPTiptables -A OUTPUT -p 50 -o $ext -j ACCEPT
# On accepte les connexions SSHiptables -A INPUT -i $ext --protocol tcp --destination-port 22 -m state--state NEW,ESTABLISHED -j ACCEPTiptables -A OUTPUT -o $ext --protocol tcp --source-port 22 -m state--state ESTABLISHED -j ACCEPT
# On autorise les connexions établies ou devant s’établir dont le port est supérieur à 1024iptables -A INPUT -i $ext -p tcp --sport 1024:65535 --dport 1024:65535 -m state--state ESTABLISHED -j ACCEPTiptables -A OUTPUT -o $ext -p tcp --sport 1024:65535 --dport 1024:65535 -m state--state NEW,ESTABLISHED,RELATED -j ACCEPT
Il suffit de taper la commande ./firewall.sh pour mettre en place le pare-feu. Pour sauvegarderla configuration et permettre ainsi son chargement lors d’un prochain redémarrage du système, il faututiliser la commande suivante :
[root@station root]# iptables-save > /etc/sysconfig/iptables

Mémoire d’ingénieur CNAM 137
Annexe H
Fichiers de configuration de DIET
H.1 L’agent maître - MA (sfMA1.cfg)#****************************************************************************## traceLevel for the DIET agent:# 0 DIET prints only warnings and errors on the standard error output.# 1 [default] DIET prints information on the main steps of a call.# 5 DIET prints information on all internal steps too.# 10 DIET prints all the communication structures too.# >10 (traceLevel - 10) is given to the ORB to print CORBA messages too.#****************************************************************************#
traceLevel = 10
#****************************************************************************## (*) agentType: Master Agent or Local Agent ? As there is only one excutable# for both agent types, it is COMPULSORY to specify the type of this agent.#****************************************************************************#
agentType = DIET_MASTER_AGENT # or MA
#****************************************************************************## (*) name: the name of this MA. The ORB configuration files of the clients# and the children of this MA (LAs and SeDs) must point at the same CORBA# Naming Service as the one pointed at by the ORB configuration file of# this agent.#****************************************************************************#
name = MA1
#****************************************************************************## endPoint: the listening port of the agent. If not specified, let the ORB# get a port from the system (if the default 2809 was busy)#****************************************************************************#
#endPoint = 2809
#****************************************************************************## fastUse: if set to 0, all LDAP and NWS parameters are ignored, and all# requests to FAST are disabled (when DIET is compiled with FAST). This is# useful for testing a DIET platform without deploying an LDAP base nor an# NWS platform.

Mémoire d’ingénieur CNAM 138
#****************************************************************************#
fastUse = 0
#****************************************************************************## ldapUse: 0 tells FAST not to look for the services in an LDAP base.# ldapBase: <host:port> of the LDAP base that stores FAST-known services.# ldapMask: the mask which is registered in the LDAP base.# Actually, no LDAP request is performed on an agent.#****************************************************************************#
ldapUse = 0#ldapBase = quadx1:9050#ldapMask = dc=LIP,dc=ens-lyon,dc=fr
#****************************************************************************## nwsUse: 0 tells FAST not to use NWS for its comm times forecasts.# nwsNameserver: <host:port> of the NWS nameserver.# nwsForecaster: <host:port> of the NWS forecaster.#****************************************************************************#
nwsUse = 0nwsNameserver = quadx1.grid.metz.supelec.fr:9056nwsForecaster = quadx1.grid.metz.supelec.fr:9055
H.2 L’agent local - LA (sfLA1.cfg)traceLevel = 10
#****************************************************************************## (*) agentType: Master Agent or Local Agent ? As there is only one excutable# for both agent types, it is COMPULSORY to specify the type of this agent.#****************************************************************************#
agentType = DIET_LOCAL_AGENT # or LA
#****************************************************************************## (*) name: the name of this LA. The ORB configuration files of the clients# and the children of this MA (LAs and SeDs) must point at the same CORBA# Naming Service as the one pointed at by the ORB configuration file of# this agent.#****************************************************************************#
name = LA1
#****************************************************************************## (*) parentName: the name of the agent to which the LA will register. This# agent must have registered at the same CORBA Naming Service that is# pointed to by your ORB configuration.#****************************************************************************#
parentName = MA1
fastUse = 0ldapUse = 0nwsUse = 0

Mémoire d’ingénieur CNAM 139
nwsNameserver = quadx1.grid.metz.supelec.fr:9056nwsForecaster = quadx1.grid.metz.supelec.fr:9055
H.3 Le serveur démon - SeD (sfSeD1.cfg)traceLevel = 10
#****************************************************************************## (*) parentName: the name of the agent to which the SeD will register. This# agent must have registered at the same CORBA Naming Service that is# pointed to by your ORB configuration.#****************************************************************************#
parentName = LA1
fastUse = 0ldapUse = 0nwsUse = 0nwsNameserver = quadx1:9056nwsForecaster = quadx1:9055
H.4 Le client (sfClient.cfg)traceLevel = 10
#****************************************************************************## (*) MAName: the name of the Master Agent to which the client will connect.# This agent must have registered at the same CORBA Naming Service that is# pointed to by your ORB configuration.#****************************************************************************#
MAName = MA1
#****************************************************************************## useAsyncAPI: if set to 0, you will not be able to use the asynchronous# client API (diet_call_*_async), and then your client will be more# performant. Defaults to 1.#****************************************************************************#useAsyncAPI = 1

Mémoire d’ingénieur CNAM 140
Annexe I
Script de lancement des agents
#!/bin/bash## Agents: Start the Agents Diet Daemon## description: This is a daemon which handles agents diet \### processname: /usr/local/bin/dietAgent##
# Sanity checks.[ -f /usr/local/bin/dietAgent ] || exit 0[ -f /usr/bin/omniNames ] || exit 0[ -x /usr/local/cfgs ] || exit 0
# Source function library.. /etc/rc.d/init.d/functions
PID_FILE=/var/run/dietAgents.pidRETVAL=0prog="Diet Agents"
function start() {echo -n $"Starting $prog: "/usr/bin/omniNames >/dev/null 2>&1 &/usr/local/bin/dietAgent /usr/local/cfgs/sfMA1.cfg >/dev/null &sleep 1/usr/local/bin/dietAgent /usr/local/cfgs/sfLA1.cfg >/dev/null &sleep 1/usr/local/bin/dietAgent /usr/local/cfgs/sfLA2.cfg >/dev/null &sleep 1/usr/local/bin/dietAgent /usr/local/cfgs/sfLA3.cfg >/dev/null &RETVAL=$?if [ $RETVAL -eq 0 ]; thensuccess $"$prog startup"
elsefailure $"$prog start"
fiechoreturn $RETVAL

Mémoire d’ingénieur CNAM 141
}
function stop() {echo -n $"Stopping $prog: "killall dietAgentkillall omniNamesRETVAL=$?if [ $RETVAL -eq 0 ]; then
success $"$prog shutdown"else
failure $"$prog shutdown"fiechoreturn $RETVAL
}
function restart() {stopsleep 1start
}
# See how we were called.case "$1" in
start)startRETVAL=$?;;
stop)stopRETVAL=$?;;
status)status dietAgentRETVAL=$?;;
restart)restartRETVAL=$?;;
*)echo $"Usage: $0 {start|stop|status|restart}\n" "$0"RETVAL=1;;
esacexit $RETVAL

Mémoire d’ingénieur CNAM 142
Bibliographie
[1] G.E. Moore. Cramming more components into integrated circuits. Electronics, 38(8), April 1965.[2] K. Amako J. Apostolakis H. Araujo P. Arce M. Asai D. Axen S. Banerjee G. Barrand et al. S. Agos-
tinelli J. Allison. Geant4 a simulation toolkit. Nuclear Instruments and Methods in Physics Re-search Section A: Accelerators, Spectrometers, Detectors and Associated Equipment, 506:250–303,July 2003. GEANT http://www.dante.net/server/show/.
[3] F. Hernandez. Infrastructures de grilles, Juillet 2004. slide:http://www.metz.supelec.fr/metz/personnel/vialle/GridUSe2004/index.html.
[4] J.L. Rognon. La grille tente de trouver sa place dans l’entreprise. Le Monde Informatique, 1010,Janvier 2004.
[5] A. Kuppermann. The geometric phase in reaction dynamics. In The Geometric Phase in ReactionDynamics, pages 411–472. Marcel Dekker, New York, 1996.
[6] George G. R. Brooks R. Bell H. Breitbach R. Steffes R. Bruhl C. Synthetic forces in the air forcecommand and control distributed mission training environment, current and future. In Proceedingsof the Eighth Conference on Computer Generated Forces and Behavioral Representation, volume 8,pages 319–331, Orlando FL, 1999. Marcel Dekker.
[7] I. Foster C. Kesselman S. Tuecke. International J. The anatomy of the grid: Enabling scalablevirtual organizations. Supercomputer Applications, 15(3), 2001. Defines Grid computing and theassociated research field, proposes a Grid architecture, and discusses the relationships between Gridtechnologies and other contemporary technologies.
[8] Heinz Stockinger Mehnaz Hafeez, Asad Samar. A data grid prototype for distributed data produc-tion in cms. Technical report, ACAT2000, October 2000. VII International Workshop on AdvancedComputing and Analysis Techniques in Physics Research.
[9] Forestier B. Expérience ALICE pour l’étude des collisions d’ions lourds ultra-relativistes au CERN-LHC. PhD thesis, UNIVERSITE BLAISE PASCAL - CLERMONT-FERRAND II, December2003.
[10] Groupe de réflexion. Grid’5000 plate-forme de recherche expérimentale en informatique, Juillet2003. http://www.lri.fr/ fci/Grid5000/.
[11] S. Matsuoka and H. Casanova. Network-Enabled Server Systems and the Computatio-nal Grid. http://www.eece.unm.edu/ dbader/grid/WhitePapers/GF4-WG3-NES-whitepaper-draft-000705.pdf, July 2000. Grid Forum, Advanced Programming Models Working Group whitepaper(draft).
[12] Keith Seymour, Hidemoto Nakada, Satoshi Matsuoka, Jack Dongarra, Craig Lee, and Henri Casa-nova. Overview of gridrpc: A remote procedure call api for grid computing. In Manish Parashar,editor, Grid Computing - GRID 2002, Third International Workshop, Baltimore, MD, USA, Novem-ber 18, 2002, Proceedings, volume 2536 of LNCS, pages 274–278. Springer, 2002.
[13] D. Arnold, S. Agrawal, S. Blackford, J. Dongarra, M. Miller, K. Sagi, Z. Shi, and S. Vadhiyar.Users’ Guide to NetSolve V1.4. Computer Science Dept. Technical Report CS-01-467, Universityof Tennessee, Knoxville, TN, July 2001. http://www.cs.utk.edu/netsolve/.

Mémoire d’ingénieur CNAM 143
[14] H. Nakada, M. Sato, and S. Sekiguchi. Design and Implementations of Ninf: towards a GlobalComputing Infrastructure. Future Generation Computing Systems, Metacomputing Issue, 15(5–6):649–658, 1999. http://ninf.apgrid.org/papers/papers.shtml.
[15] M.C. Ferris, M.P. Mesnier, and J.J. Mori. NEOS and Condor: Solving Optimization ProblemsOver the Internet. ACM Transaction on Mathematical Sofware, 26(1):1–18, 2000. http://www-unix.mcs.anl.gov/metaneos/publications/index.html.
[16] M. Sato, M. Hirano, Y. Tanaka, and S. Sekiguchi. OmniRPC: A Grid RPC Facility for Cluster andGlobal Computing in OpenMP. Lecture Notes in Computer Science, 2104:130–136, 2001.
[17] GridRPC Working Group. https://forge.gridforum.org/projects/gridrpc-wg/.[18] E. Caron, S. Chaumette, S. Contassot-Vivier, F. Desprez, E. Fleury, C. Gomez, M. Goursat, E. Jean-
not, D. Lazure, F. Lombard, J.-M. Nicod, L. Philippe, M. Quinson, P. Ramet, J. Roman, F. Rubi,S. Steer, F. Suter, and G. Utard. Scilab to Scilab//, the OURAGAN Project. Parallel Computing,11(27):1497–1519, OCT 2001.
[19] A. Iosup. Parallelization and grid integration of a mobile robotics application, 2003. BucharestUPolitehnica student.
[20] V. Rieger, 2000. Studienarbeit ENSAM-SUPELEC.[21] C. Roussel. Conception d’un système de navigation pour un robot mobile basé sur la détection des
marques p-similaires, 2001. Stage de DEA ENSAM-SUPELEC.[22] D. Scharstein and A. Briggs. Fast recognition of self-similar landmarks. In In IEEE Workshop on
Perception for Mobile Agents, pages 4–18, June 1999. Fort Collins CO.[23] A. Siadat and S. Vialle. Robot localization, using p-similar landmarks, optimized triangulation and
parallel programming. 2nd IEEE International Symposium on Signal Processing and InformationTechnology, 2002. Marrakesh.
[24] R.C. Luo K.L. Su S.H. Shen K.H. Tsai. Networked intelligent robots through the internet: Issuesand opportunities. In Proceedings of IEEE Special Issue on Networked Intelligent Robots Throughthe Internet, volume 91, June 2003.
[25] L. Frangu C. Chiculita. A web based remote control laboratory. In 6th World Multiconference onSystemics, Cybernetics and Informatics, Orlando, Florida, July 2002.
[26] I. Foster and C. Kesselman. The grid : Blueprint for a new computing infrastructure, 1998. MorganKaufmann publisher.
[27] I. Foster C. Kesselman J. Nick S. Tuecke. Grid services for distributed system integration, 2002.Computer,35(6).
[28] N. Doraswamy and D. Harkins. Ipsec: The new security standard for the internet, intranets, andvirtual private networks, 1999. Prentice-Hall.

Résumé
• Conception et déploiement d’une Grille de contrôle de processus physiques.
Mémoire d’ingénieur C.N.A.M. Metz,M. Fabrice Sabatier Spécialité Informatique.
La plupart des applications portées et exécutées sur une Grille informatiques sont de gros calculs quel’on souhaite exécuter en « batch » sur un réseau de super-ordinateurs, ou sur un très grand réseau de PCsi les calculs sont indépendants. Beaucoup de travaux ont déjà été fait dans ce sens. En revanche, peude projets concernent la distribution au sein d’une Grille informatique d’applications « interactives » ac-compagnées de contraintes de temps. C’est-à-dire des applications où des flots de données (permanents)entrent dans l’application alors que d’autres en ressortent, et où une vitesse de traitement minimale estimposée par la vitesse des flots de données au lieu d’être fixée par la puissance de traitement disponible.
Notre équipe à Supélec a choisi d’aborder la problématique des Grilles de ressources informatiquespour des applications interactives, en expérimentant une application de robotique autonome sur une Grillede PC. Une Grille de ressources permet d’utiliser plus de machines que nécessaire afin d’être tolérantaux pannes, et d’accélérer les calculs en faisant appel à des PC multiprocesseurs plus puissants que l’or-dinateur de l’utilisateur ou que les ordinateurs que l’on peut raisonnablement dédier à la plate-formerobotique.
L’objectif final de ce projet est de pouvoir lancer une application robotique sur une Grille de calculdepuis un simple PC standard tel un portable en liaison radio, et de disposer d’une bibliothèque simplede programmation d’applications interactives sur une Grille.
Notre plate-forme de test, est composé de machines de deux campus de recherche, en France et enItalie, reliés par un VPN, sous l’environnement DIET en GridRPC. Finalement, nos travaux prouventqu’une solution de Grille est utilisable pour notre application robotique et procure une bonne toléranceaux pannes.
Mots clés :
Architecture de Grille - programmation de Grille - système distribué - contrôle de robot distribué - mesurede performance.
Keywords :
Grid architecture - Grid programming - distributed system - remote robot control - performance measu-rement.