Embed Size (px)
Citation preview

Cours de Statistique
G. Marcou, P. Jost
7 juillet 2011

2

Chapitre 1
Régressions Linéaires
Ce chapitre est dédié à l'élaboration et à la validation de modèles linéaires.Partant de modèles particulièrement simple à un seul facteur, le cas de plu-sieurs facteurs sera ensuite abordé. La validation des modèles sera étudiéedans le détail.
1.1 Modèle mathématique de propriétés chimi-
ques et physico-chimiques
On appelle modèle mathématique toute fonction destinée à représenterles variations d'une propriété chimique ou physico-chimique. Ces fonctionsmettent en relation des quantités accessibles à l'utilisateur, appelés facteurs
explicatifs, du modèle et, le plus souvent, une propriété particulièrement in-téressante, appelée variable expliquée. Les données ainsi structurées, on dé-signe par Xl les facteurs explicatifs et par Y la variable expliquée. Le modèlemathématique suppose qu'il existe une fonction f(Xl) = Y + R reliant lesvariations de la variable expliquée aux variations des facteurs explicatifs, aubruit R près. Le bruit est une composante inexpliquée de la variable Y , quiidéalement doit être modélisée par une distribution gaussienne.
En général, ces facteurs sont considérés comme des variables aléatoires.Chaque réalisation de ces variables prend la forme d'un ensemble de valeursqui peuplent, le plus souvent, une ligne dans un tableau de données. Ellessont donc identi�ées par un indice i et notées en minuscules. Ainsi, la réali-sation i sera désignée par l'ensemble des valeurs xli prises par les l variablesaléatoires Xl et la valeur yi prise par la variable aléatoire Y . Ces réalisations,en pratique, sont souvent les enregistrements de mesures expérimentales.
La détermination du modèle mathématique doit répondre à trois exi-gences.
3

4 CHAPITRE 1. RÉGRESSIONS LINÉAIRES
1. Déterminer quelles fonctions f sont plausibles.
2. Parmis les fonctions f possibles, il faut trouver la meilleure. Il fautdonc savoir ce que peut être une meilleure fonction.
3. Il faut en�n, un algorithme permettant de la trouver.
Dans ce chapitre, seules les fonctions linéaires seront abordées. La meil-leure fonction sera toujours celle qui minimise l'erreur quadratique moyenne.En�n, une équation sera dérivée pour construire la fonction optimale.
1.1.1 L'erreur quadratique moyenne
Il faut au moins un critère d'optimalité pour choisir parmi toutes lesfonctions possibles, celle qui doit être retenue. On considère alors la partieinexpliquée, le bruit R introduit plus haut. Il correspond à l'erreur, l'écartentre la valeur prévue par le modèle fθ(xli) pour une donnée i et la variableexpliquée yi. On l'appelle le résidu, ri. Pour une réalisation d'une expérience,xli, yi, le résidu ri correspondant se dé�nit par la relation :
ri = yi − fθ(xli) (1.1)
Le critère d'optimalité est une fonction des résidus pour un modèle et unesérie de données expérimentales : C(|ri|). Cette fonction est choisie pour êtrepetite si les résidus sont petits en valeur absolue et grande s'ils sont grands.Cette fonction retourne ses valeurs dans Rm
+ , c'est à dire qu'elle peut renvoyeréventuellement m réels positifs. Le plus souvent, on impose qu'un seul réelsoit retourné. Dans ce cas, cette fonction est appelée le risque empirique.
Le choix de cette fonction de risque empirique est crucial et fait l'objet denombreux développements mathématiques récents dans le cadre de la théo-rie de l'utilité ou encore la théorie de l'apprentissage statistique. Cependant,depuis le 19ème siècle, une fonctionnelle s'est imposée car elle rend le pro-blème abordable avec des outils analytiques tout à fait courants. Il s'agit dela somme des carrés des erreurs (noté SSE, pour Sum of Squared Errors) qui,pour N observations s'écrit :
SSE =N∑i=1
r2i (1.2)
C'est cette fonction que l'on minimise dans le cadre de ce cours. En touterigueur on lui préfère l'erreur quadratique moyenne :
r2 =1
N
N∑i=1
r2i (1.3)

1.1. MODÈLE MATHÉMATIQUE 5
mais ces expressions di�èrent par des termes qui sont constants pour unmême problème et les solutions trouvées ne di�èrent pas.
Le problème posé ici est donc de choisir les paramètres θk pour que laSSE soit la plus petite possible. Le problème de modélisation devient doncun problème d'optimisation, de minimisation du risque empirique.
Il faut noter que ce choix de fonctionnelle est critiqué depuis longtemps.On reproche essentiellement deux défauts à cette fonction :
� elle est dominée par les résidus les plus grands (parfois désignés parle terme � outlier �) qui, le plus souvent, correspondent à des donnéesexpérimentales erronées ;
� elle est convexe partout.
1.1.2 Application : le modèle a�ne
Ce modèle est basé sur une fonction a�ne, c'est à dire un fonction choisieparmi la classe des fonctions de la forme fθ(x) = θ0 + θ1x. Dans ce problème,on cherche une relation entre les valeurs observées xi (explicative) et yi (ex-pliquée). On cherche donc à optimiser θ0 et θ1, c'est-à-dire parmi toutes lesvaleurs possibles, celles qui minimisent le SSE. Ces valeurs seront notées θ∗0et θ∗1.
exemple
Dans ce cas pratique, il faut étalonner un appareil de concentration par�uorescence sur un ensemble d'échantillon de concentration connue absolue-ment. Les données sont rassenblées dans le tableau 1.1.
Intens. de �uorescence (ua) 2.2 4.9 9.1 12.4 17.1 21.4 24.6Concentration, pg.ml−1 0 2 4 6 8 10 12
Tab. 1.1 � Etalonnage d'un appareil dosimétrique par �uorescence.
Une premier modèle possible est de considérer que l'intensité de la �uo-rescence n'a aucun lien avec la concentration : θ1 = 0. Dans ce cas, la concen-tration mesuré n'est qu'une �uctuation autour de la moyenne : θ0 = 13.7.L'erreur quadratique moyenne r2 = 59.95. En ayant choisi les valeurs op-timales θ∗0 = 1.51 et θ∗1 = 1.93 on aurait trouvé une erreur quadratiquemoyenne r2 = 0.22. La fonction a�ne fθ∗(X) explique donc mieux les don-nées que toute fonction a�ne fθ(X) utilisant d'autres valeurs des paramètresθ0 et θ1.

6 CHAPITRE 1. RÉGRESSIONS LINÉAIRES
1.1.3 Fonctions plausibles : modèles linéaires
Étant donné un ensemble de facteurs explicatifs, on autorise toutes lestransformations/combinaisons gk(Xl) possibles de ces facteurs du momentque celles-ci sont intégralement connues et déterminées à priori. Si on a dé�niK tranformations, les fonctions plausibles sont alors de la forme :
fθ(Xl) =K∑k=1
θkgk(Xl) (1.4)
Les fonctions parmis lesquelles choisir le modèle sont indexées par unesérie de nombres θ. Ces nombres sont appelés les paramètres du modèle.Quand on parle de modèle � linéaires � on ne fait pas référence aux facteursexplicatifs, mais aux paramètres de la fonction. C'est à dire que :
fθ1+θ2(Xl) = fθ1(Xl) + fθ2(Xl) (1.5)
Les facteurs explicatifs et leurs manipulations doivent suivre en généralun schéma inductif. En d'autres termes, des connaissances ou des hypothèsesphysico-chimiques sont utilisées pour choisir les facteurs explicatifs et lesfonctions gk utilisées.
exemple
Dans ce nouvel exemple, on cherche à relier la viscosité dynamique de laglycérine avec la température. Les données sont rassenblées dans le tableau1.2.
T (°C) -42 -36 -25 -20 -15.4 -10.8 -4.2
η (cp) 6.71106 2.05106 2.62105 1.34105 6.65104 3.55104 1.49104
T (°C) 0 6 15 20 25 30
η (cp) 12110 6260 2330 1490 954 629
Tab. 1.2 � Viscosités dynamiques de la glycérine en fonction de la tempéra-ture.
La modélisation de la viscosité en fonction de la température par unedroite est grossière. En revanche, un modèle a�ne du logarithme de la vis-cosité en fonction de la température semble plus judicieux (�gure 1.1). Lelogarithme de la viscosité est la variable expliquée : y = ln(η). La variableexplicative est la température, x = T . Un premier modèle purement linéaire,y = θ0 + θ1x donne une erreur quadatique moyenne élevée, r2 = 0.18 ua2 -enutilisant les valeurs optimales θ∗0 = 9.62 et θ∗1 = −0.124).
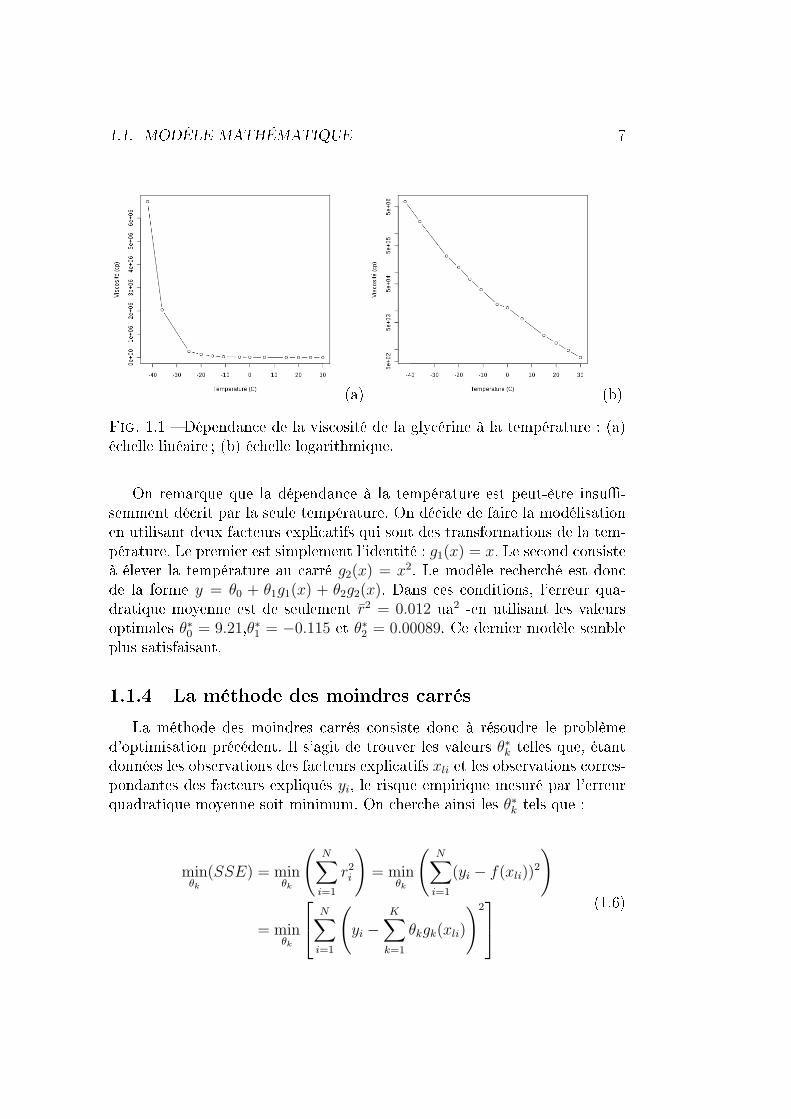
1.1. MODÈLE MATHÉMATIQUE 7
(a) (b)
Fig. 1.1 � Dépendance de la viscosité de la glycérine à la température : (a)échelle linéaire ; (b) échelle logarithmique.
On remarque que la dépendance à la température est peut-être insu�-semment décrit par la seule température. On décide de faire la modélisationen utilisant deux facteurs explicatifs qui sont des transformations de la tem-pérature. Le premier est simplement l'identité : g1(x) = x. Le second consisteà élever la température au carré g2(x) = x2. Le modèle recherché est doncde la forme y = θ0 + θ1g1(x) + θ2g2(x). Dans ces conditions, l'erreur qua-dratique moyenne est de seulement r2 = 0.012 ua2 -en utilisant les valeursoptimales θ∗0 = 9.21,θ∗1 = −0.115 et θ∗2 = 0.00089. Ce dernier modèle sembleplus satisfaisant.
1.1.4 La méthode des moindres carrés
La méthode des moindres carrés consiste donc à résoudre le problèmed'optimisation précédent. Il s'agit de trouver les valeurs θ∗k telles que, étantdonnées les observations des facteurs explicatifs xli et les observations corres-pondantes des facteurs expliqués yi, le risque empirique mesuré par l'erreurquadratique moyenne soit minimum. On cherche ainsi les θ∗k tels que :
minθk
(SSE) = minθk
(N∑i=1
r2i
)= min
θk
(N∑i=1
(yi − f(xli))2
)
= minθk
N∑i=1
(yi −
K∑k=1
θkgk(xli)
)2 (1.6)

8 CHAPITRE 1. RÉGRESSIONS LINÉAIRES
Pour résoudre ce problème, il su�t donc d'annuler simultanément les Kdérivées partielles de cette expression relativement aux paramètres θk.
1.1.5 Explicitation de la méthode des moindres carrés
A�n de rendre plus concret le concept, deux exemples sont proposés.Dans un premier temps, le cas d'une fonction linéaire d'une variable estconsidéré : y = θ1x. Ensuite, ce cas sera développé en supposant un facteuradditionnel constant : y = θ0x0 +θ1x1 avec x0 constant et égal à 1 pour toutela série de données. Ce formalisme visant à ajouter une colonne constanteaux facteurs explicatifs est préférée car le traitement de la constante devientalors indistingable de celui des autres paramètres du modèle.
Modèle linéaire
Dans le cadre du modèle linéaire, y = θ1x1, une seul facteur explicatif, X1
est retenu et aucune transformation n'est envisagé, ce qui implique g1(x1i) =x1i et K = 1. Les équations 1.13, 1.14 et 1.15 deviennent :
SSE(θ1) =N∑i=1
(x1iθ1 − yi)2 (1.7)
∂SSE
∂θ1
= 2N∑i=1
(x1i(x1iθ1 − yi) = 0 (1.8)
θ∗1 =
∑Ni=1 x1iyi∑Ni=1 x1ix1i
(1.9)
Modèle a�n
Dans le cadre du modèle a�n, y = θ1x1+θ0, une seul facteur explicatif,X1
est retenu et aucune transformation n'est envisagé, ce qui implique g1(x1i) =x1i et K = 1. En revanche, le paramètre θ0 est considéré comme associé à unfacteur explicatif constant de valeur x0i = 1 pour tout i ∈ {1, . . . , N}. Leséquations 1.13, 1.14 et 1.15 deviennent :
SSE(θ0, θ1) =N∑i=1
(x1iθ1 + x0iθ0 − yi)2 (1.10)

1.1. MODÈLE MATHÉMATIQUE 9∂SSE
∂θ0
= 2N∑i=1
x0i (x1iθ1 + x0iθ0 − yi) = 0
∂SSE
∂θ1
= 2N∑i=1
x1i (x1iθ1 + x0iθ0 − yi) = 0
(1.11)
θ∗0 =
∑Ni=1 x1ix0i
∑Ni=1 x1iyi −
∑Ni=1 x0iyi
∑Ni=1 x
21i
−∑N
i=1 x20i
∑Ni=1 x
21i +
(∑Ni=1 x1ix0i
)2
θ∗1 =−∑N
i=1 x20i
∑Ni=1 x1iyi +
∑Ni=1 x1ix0i
∑Ni=1 x0iyi
−∑N
i=1 x20i
∑Ni=1 x
21i +
(∑Ni=1 x1ix0i
)2
(1.12)
Le traitement symétrique de la constante θ0 par rapport au paramètre θ1
donne aux expression un caractère symétrique plus agréable. Bien sûr, cesexpressions peuvent être simpli�ées puisque
∑Ni=1 x
20i = N ,
∑Ni=1 x0ix1i =∑N
i=1 x1i et∑N
i=1 x0iyi =∑N
i=1 yi.
Application Pratique
Ici, on considère un cas arbitraire (tableau 1.3) que l'on souhaite modéliserpar une fonction de la forme y = f(x) = θ0 + θ1x.
xi 0 1 2 3yi 4 2 1 -1
Tab. 1.3 � Exemple arbitraire.
Les résidus sont pour chaque exemple :
1.1.6 Formalisme matriciel
L'accumulation des indices et des sommes explicites est très dommageableà la lisibilité du problème. Aussi on lui préfère un formalisme matriciel. Dansce cas, [G] désigne le tableau à N lignes et K colonnes des valeurs prisentpar les fonctions gk(xli) ; [Y ] la matrice colonne des N observations de lapropriété à modéliser et [θ] la matrice colonne des K paramètres. Ainsi :
SSE(θ) = ‖[Y ]− [G][θ]‖2 (1.13)
L'annulation simultanée de toutes les dérivées par rapport aux θk impliquealors l'équation vectorielle :

10 CHAPITRE 1. RÉGRESSIONS LINÉAIRES
[G]T ([Y ]− [G][θ]) = 0 (1.14)
Le vecteur de paramètre [θ∗] satisfait donc l'équation :
[θ∗] = ([G]T [G])−1[G]T [Y ] (1.15)
Cette solution nécessite encore le calcul et l'inversion de la matrice [G]T [G]ce qui demande de l'ordre de N×K×K opérations. Ceci fait de la régressionlinéaire l'une des méthodes numériques les plus complexes. C'est pourquoi,entre autres, de très nombreuses alternatives lui sont préférées.
Application Pratique
L'exemple précédent est ici repris avec cette notation dans l'équation 1.16.
[X] =
0123
, [Y ] =
421−1
, [G] =
1 01 11 21 3
, [θ] =
[θ0
θ1
](1.16)
L'équation 1.14, en pratique, est transcrite dans l'équation 1.17 :
[1 1 1 10 1 2 3
]
4− θ0
2− θ0 − θ1
1− θ0θ1
−1− θ0 − 3θ1
=
0000
, (1.17)
On retrouve le système ??.
1.1.7 Interprétation géométrique
L'estimateur des paramètres [θ∗] étant dé�ni, on peut regarder les va-leurs prédites par le modèle pour le jeu de données considéré. Il dé�nit unvecteur [Y ]. Les valeurs prévues par le modèle pour chaque données sontbien entendu di�érentes des valeurs observées de la propriété modélisée. Laprédiction, même sur les données utilisées pour construire le modèle, n'estjamais parfaite.
Il est intéressant de remarque que :
[Y ] = [G][θ] = [G]([G]T [G])−1[G]T [Y ] = [PH ][Y ] (1.18)
L'opérateur, la matrice, [PH ] est appelé opérateur chapeau, ou � hat ope-rator � en anglais. Il permet de mettre en évidence que les données prédites

1.2. MAXIMUM DE VRAISEMBLANCE 11
par le modèles sont en fait une projection du vecteur [Y ], sur un sous-espacevectoriel de dimension K, des facteurs explicatifs. La notion importante estque l'opérateur [PH ] est un opérateur de projection. Cet opérateur :
[PH ] = [G]([G]T [G])−1[G]T (1.19)
joue un rôle important dans l'analyse des modèles de régression linéaire par laméthode des moindres carrés. Il est facile de véri�er que [PH ] est un opérateurde projection, c'est-à-dire qu'il possède la propriété suivante :
[PH ]2 = [PH ] (1.20)
Il est également utile de véri�er que :
[PH ]T = [PH ] (1.21)
1.1.8 Remarques
Une fois le problème posé, la méthode des moindres carrés décrit un algo-rithme pour le résoudre. Les paramètres calculés à l'aide de cette méthode nepeuvent pas être considérés comme des quantités absolues. Ajouter, suppri-mer, ou remplacer certaines données par de nouvelles induisent des résultatsnumériques di�érents -mais comparables. En somme, les paramètres du mo-dèle doivent être considérés comme des réalisations d'un tirage de variablesaléatoires. On dit aussi que ce sont des estimateurs des paramètres de l'équa-tion.
1.2 Maximum de vraisemblance : l'hypothèse
gaussienne
Il existe plusieurs autres approches qui conduisent à l'algorithme desmoindres carrés pour une régression linéaire. Le principe du maximum devraisemblance est particulièrement utile car il met en avant une inférencefondemmentale sur les résidus, les erreurs de modélisation : ceux-ci doiventobéir à une loi normale centrée.
1.2.1 Maximum de vraisemblance
Soit une variable aléatoire X obéissant à une loi de probabilité p(X|[θ]),dé�nie aux paramètres [θ] près, représentés par un vecteur. Une série d'ex-

12 CHAPITRE 1. RÉGRESSIONS LINÉAIRES
périences indépendantes permet de générer un ensemble de N résultats ξ ={xl, l = 1 . . . N}.
La probabilité d'obtenir un ensembe Ξ de résultats, P (Ξ|[θ]), dépendantdonc des paramètres [θ]. La vraisemblance des paramètres [θ], noté L([θ]|ξ)est la probabilité d'obtenir exactement l'échantillon ξ, étant donné le vecteurdes paramètres [θ] :
L([θ]|ξ) ≡ P (Ξ = ξ|[θ]) (1.22)
L'indépendance des expériences permet en outre de factoriser cette pro-babilité :
L([θ]|ξ) =N∏l=1
p(X = xl|[θ]) (1.23)
Le principe du maximum de vraisemblance consiste à considérer que l'évè-nement Ξ = ξ était le plus probable, le plus vraissemblable, compte tenu desparamètres [θ]. Il revient donc à rechercher les valeurs des paramètres [θ] quimaximisent la probabilité P (Ξ = ξ|[θ]), c'est-à-dire la vraisemblance :
[θ∗] = arg max[θ]
(P (Ξ = ξ|[θ])) = arg max[θ]
(L([θ]|Ξ = ξ)) (1.24)
En pratique, le produit est jugé gênant pour les opérations analytiques etle logarithme de cette expression lui est préféré. C'est donc, généralement lemaximum du logarithme de la vraisemblance qui est recherchée, qui coincidebien sûr avec celui de la vraisemblance :
[θ∗] = arg max[θ]{log (L([θ]|Ξ = ξ))} = arg max
[θ]
{N∑l=1
log (p(X = xl|[θ]))
}(1.25)
1.2.2 Régression
Dans le cas de la régression, une observation est constitué d'un vecteurde M variables aléatoires, les facteurs explicatifs, desquels dépend une va-riable aléatoire, la variable expliquée : ([X], Y ). L'ensemble des réalisationsest notée Ξ = {([x]i, yi), i ∈ {1 . . . N}}, pour jeu de données contenant Nobservations. La variable expliquée est reliée aux facteurs explicatifs par un

1.2. MAXIMUM DE VRAISEMBLANCE 13
modèle Y = f([X], [θ]) +R, possédant K paramètres θk réunis dans un vec-teur [θ]. Le modèle peut donc être vu comme un moyen de substituer l'étudedu jeu de données ΞR = {Ri, i ∈ {1 . . . N}} au jeu de données initiales Ξ.
L'hypothèse fondemmentale est que l'erreur résiduelle suit une distribu-tion de probabilité normale de moyenne nulle et de variance constante σ2,N (0, σ2) et que chaque observation est indépendante. Il est alors immédiatque la vraisemblance de ΞR est :
L([θ],ΞR) =N∏i=1
P (Ri|[θ]) =N∏i=1
N (yi − f([x]i, [θ]), σ2) (1.26)
C'est également la vraisemblance du jeu de données Ξ considérant le mo-dèle f de paramètres [θ]. Le principe du maximum de vraisemblance est iciaussi malaisé en raison du produit ; il est préférable de maximiser le loga-rithme de la vraisemblance :
[θ∗] = arg max[θ]
(N∑i=1
log(N (yi − f([x]i, [θ]), σ
2)))
= arg max[θ]
(N∑i=1
log
(1√2πσ
e−(yi−f([x]i,[θ]))
2
2σ2
)) (1.27)
Donc,
[θ∗] = arg max[θ]
(− 1
2σ2
N∑i=1
(yi − f([x]i, [θ]))2 −N log(
√2πσ)
)(1.28)
Cette opération est équivalente à chercher le minimum de la SSE :
[θ∗] = arg min[θ]
(N∑i=1
(yi − f([x]i, [θ]))2
)(1.29)
Il s'agit donc de l'algorithme des moindres carrés.
1.2.3 Remarques
L'algorithme des moindres carrés se déduit donc d'un ensemble de sup-positions concernant la loi de probabilité à laquelle doivent obéir les résidusdu modèle reliant la variable observée aux facteurs explicatifs. Le principe devraisemblance est néanmoins un principe très fort puisqu'il suppose que laprobabilité de réalisation de l'ensemble des observations du jeu de donnéesest maximale.

14 CHAPITRE 1. RÉGRESSIONS LINÉAIRES
Ce principe peut cependant être a�aibli en considérant non plus les para-mètres [θ∗] optimaux mais plutôt des variables aléatoires [θ] possédant leurspropres lois et leurs propres paramètres qui sont postulés a priori. Ceux-cisont alors pris en compte directement dans l'expression de la vraisemblance,ce qui modi�e les expressions à optimiser et les solutions des algorithmes.
Cette sophistication constitue la base d'un domaine extrèmement produc-tif des statistiques appelé l'inférence bayésienne.
1.3 Validation
Le modèle étant construit, il minimise le risque empirique. Il reste encoreà considérer sa capacité prédictive, c'est-à-dire à émettre des estimations rai-sonnables de la variable expliquée pour de nouvelles séries de valeurs desfacteurs explicatifs. Par ailleurs, le modèle peut être utilisé pour illustrer lebien fondé d'une théorie physico-chimique. Une théorie exprimant un cer-tain nombre de relations, celles-ci doivent être confortées par l'expérience.Typiquement, cela impose de démontrer que statistiquement, les paramètresdu modèle sont di�érents de 0. Les réponses classiques à ces questions fontdes hypothèses fortes quant à la dispersion des résidus. Celle-ci doit doncelle-aussi être étudiée.
1.3.1 Distribution des résidus
Même si l'objectif d'un modèle n'est pas toujours d'être interprété, il estcependant supposé qu'il existe de � vraies � valeurs pour les paramètres d'unmodèle linéaire. L'estimation des paramètres issus d'un algorithme tel que lesmoindres carrés doit être sans biais, c'est-à-dire que ces paramètres devraientêtre considérés comme des variables aléatoires dont les espérances sont lesvraies valeurs et dont la variance diminue avec la quantité d'information.
La conséquence principale est que les résidus doivent être :
1. indépendants,
2. centrés,
3. de même variance (homoscédasticité) σ2,
4. gaussiens.
En e�et, chaque résidu est alors considéré comme une réalisation d'unevariable aléatoire associée à une ensemble de valeurs des facteurs explicatifs.Les conditions précédentes traduisent simplement le fait que si l'un de cesrésidus n'est pas centré, il existe une erreur qui est en moyenne non nulle, quiest donc systématique ; si les réalisations de ces variables aléatoires dépendent

1.3. VALIDATION 15
des valeurs prises pour d'autres valeurs des facteurs explicatifs ou que leurvariance en dépend, c'est qu'il existe encore des possibilités de modélisationqui n'ont pas encore été exploitées.
La dernière hypothèse sur les résidus est plutôt une généralité qui sejusti�e par le théorème central limite. C'est d'ailleurs une hypothèse fon-dammentale pour certaines approches conduisant à cet algorithme.
Ces hypothèses étant posées, la variance σ2 des résidus est estimée par larelation, faisant intervenir le nombre de données N et le nombre de paramè-tres K :
σ2 =1
N −K
N∑i=1
r2i (1.30)
Les résidus considérés comme un vecteur [R] de variables aléatoires dedimension N , pour N réalisations des facteurs explicatifs, ont pour moyenne(espérance) et variance :
E([R]) = 0 (1.31)
V ([R]) = σ2(1− [PH ]) (1.32)
(1.33)
Il faut noter que la variance d'un vecteur aléatoire est une matrice. Parailleurs, les résidus constituant la partie inexpliquée de la variable expliquée,ils forment un vecteur orthogonal aux prédictions du modèles. Il est aisé devéri�er que :
[R]T [Y ] = 0 (1.34)
Ceci étant dit, l'estimateur de la variance des résidus σ2 joue un rôle par-ticulièrement important. En premier lieu, la racine carrée de la variance esttrès proche de l'erreur quadratique moyenne (� Root Mean Squared Error �en anglais, avec l'acronyme RMSE) :
RMSE =
√√√√ 1
N
N∑i=1
(yi − yi)2 (1.35)
Cette quantité est l'une des plus utilisées pour évaluer l'intérêt prédic-tif d'un modèle, l'autre étant l'erreur absolue moyenne (� Mean AbsoluteError � en anglais, avec l'acronyme MAE) :

16 CHAPITRE 1. RÉGRESSIONS LINÉAIRES
MAE =1
N
N∑i=1
|yi − yi| (1.36)
qui est considérée comme un peu plus �dèle parce que moins a�ectée parles erreurs de prédiction les plus importantes.
En second lieu, pour revenir à des distributions de probabilité tabulées,on préférera utiliser des quantités standardisées plutôt que de travailler avecles résidus bruts. Celles-ci sont appelés résidus studentisés (ou normalisés) :
zri =1
σ√
1− [PH ]iiri (1.37)
Pour faire le point, l'ensemble des résidus ri calculés à partir du jeu dedonnées doit être considéré comme autant de réalisations d'une seule et mêmeloi normale centrée de variance σ2. Ce point conditionne dans une large me-sure la validité de toutes les a�rmations statistiques qui sont ensuite faitessur la qualité et la validité du modèle.
Il importe donc de véri�er que les résidus studentisés suivent une loigaussienne. Il faut alors se référer aux test de normalité (par exemple le testde Shapiro-Wilk ou le test d'adéquation du χ2). Une méthode graphiqueassez parlante est la droite de Henry.
1.3.2 Droite de Henry
Il s'agit d'une représentation graphique de l'adéquation d'un échantillonavec la loi normale. Les étapes de sa constructions sont assez immédiates :
1. Choisir un exemple de l'échantillon, xi.
2. Estimer la probabilité p = P (X < xi). Une courbe des e�ectifs cumuléspeut être utilisée à cette �n.
3. Calculer zi, le quantile de la distribution normale centré réduiteN (0, 1),correspondant à la probabilité p.
4. Reporter sur un graphe le point (zi, xi).
5. Retirer l'exemple xi de l'échantillon.
6. Reprendre au point 1.
Si l'échantillon suit e�ectivement une loi normale, de moyenne et l'écart-type estimés m et s, alors zi ≈ xi−m
set les points du graphe doivent se
répartir sur une droite de pente 1/s et d'ordonnée à l'origine −m/s. Quandl'hypothèse de normalité de l'échantillon est prise en défaut, la répartitiondes points n'est plus linéaire.

1.3. VALIDATION 17
La droite de Henry est donc une méthode graphique assez immédiate pourillustrer le caractère normal des résidus.
1.3.3 Coe�cients de corrélation, de détermination et de
Fisher
Il est ici particulièrement utile d'utiliser un point de vue géométrique. Ilest clair que les vecteurs des prédictions et des résidus sont orthogonaux etque le facteur prédit est la somme des vecteurs des prédictions et des résidus :
[Y ] = [Y ] + [R] = [X][θ] + [R] (1.38)
[R]T [Y ] = 0 (1.39)
Dans ces conditions, le théorème de Pythagore permet d'écrire que :
‖[Y ]‖2 = ‖[Y ]‖2 + ‖[R]‖2 (1.40)
Sans perte de généralité, il est possible de soustraire à [Y ] et [Y ], le vecteur[y], ne contenant que la valeur moyenne du facteur prédit y :
‖[Y ]− [y]‖2 = ‖[Y ]− [y]‖2 + ‖[R]‖2 (1.41)
Chaque élément de cette équation a une interprétation. Il y a d'abordla somme des carré totale des écarts à la moyenne de la série de mesure dufacteur expliqué (SCT ) :
SCT = ‖[Y ]− [y]‖2 =N∑i=1
(yi − y)2 (1.42)
Celle-ci se divise en une partie expliquée par le modèle (SCE) :
SCE = ‖[Y ]− [y]‖2 =N∑i=1
(yi − y)2 (1.43)
et une partie résiduelle (SCR), inexpliquée :
SCR = ‖[R]‖2 =N∑i=1
r2i (1.44)
Ce qui est résumé par la relation :
SCT = SCE + SCR (1.45)

18 CHAPITRE 1. RÉGRESSIONS LINÉAIRES
Ces sommes interviennent dans di�érents calculs de variance. La variancetotale, VT :
VT =1
N − 1SCT =
1
N − 1
N∑i=1
(yi − y)2 (1.46)
Pour N mesures, le nombre de degrés de liberté est ici de N − 1. Ensuitela variance expliquée, VE :
VE =1
KSCE =
1
K
N∑i=1
(yi − y)2 (1.47)
Les K paramètres sont tous indépendants et doivent tous être considéréscomme les degrés de liberté de la prédiction. En�n, la variance résiduelle,VR :
VR =1
N −KSCE =
1
N −K
N∑i=1
(yi − yi)2 (1.48)
Ici, le nombre de degrés de liberté est N −K. Notez que le nombre K deparamètres inclut une éventuelle constante dans le modèle.
Coe�cient de corrélation
Etant données un vecteur de propriété et un vecteur de prédiction, l'un despremiers moyens de comparaison géométrique est de véri�er leur colinéarité.Pour cela, il su�t de calculer le cosinus de l'angle entre les deux vecteurs etde véri�er qu'il est proche de 1. Le carré de ce cosinus est appelé coe�cientde corrélation, R2
c :
R2c =
([Y ]T [Y ])2
‖[Y ]‖2‖[Y ]‖2(1.49)
L'orthogonalité de [Y ] et de [R] implique que le triangle formé par lestrois vecteurs [Y ], [Y ] et [R] est rectangle dont l'hypoténuse est [Y ], ce quia été utilisé plus haut. La dé�nition même de l'angle opposé à [R], formépar les vecteurs [Y ] et [Y ] veut donc que le coe�cient de corrélation puisses'exprimer de la façon suivante :
R2c =‖[Y ]‖2
‖[Y ]‖2(1.50)
Ce coe�cient de corrélation est souvent optimiste sur la qualité de larégression. Il ne fait pas d'habitude l'objet d'un test statistique.

1.3. VALIDATION 19
1.3.4 Coe�cient de détermination
C'est pourquoi on lui préfère une autre mesure, mettant en relation lavariance expliquée par rapport à la variance totale. Cette mesure est appeléecoe�cient de détermination :
R2d =‖[Y ]− [y]‖2
‖[Y ]− [y]‖2(1.51)
Il faut ici remarquer que le produit scalaire de [R] avec un vecteur constanttel que [y], dont toutes les composantes sont égales, est nul en moyenne.En e�et, cette opération revient à multiplier l'estimateur de la moyenne desrésidus avec une constante. Cette propriété étant admise, les vecteurs [Y ]−[y],[Y ] − [y] et R forment un nouveau triangle rectangle dont l'hypoténuse est[Y ] − [y]. Le théorème de Pythagore permet de reformuler le coe�cient dedétermination :
R2d = 1− [R]2
‖[Y ]− [y]‖2= 1−
∑Ni=1(yi − yi)2∑Ni=1(yi − y)2
(1.52)
C'est cette dernière expression qui est considérée comme la dé�nition cor-recte du coe�cient de détermination. Il est important de remarquer que cesexpressions pour le coe�cient de détermination ne sont équivalentes qu'enmoyenne. Si la première exprime nécessairement le carré d'un cosinus, en pra-tique, la seconde peut parfois prendre des valeurs négatives pour des modèlesparticulièrement mauvais.
Le coe�cient de détermination étant nécessairement inférieur ou égal à1, il est rare qu'il fasse l'objet de tests statistiques. Ces test sont en e�etun peu plus compliqués et, au demeurant, équivalents aux tests de Fisherdiscutés plus loin. Néanmoins, c'est la mesure la plus couramment utiliséepour estimer la qualité descriptive d'une modèle.
1.3.5 Coe�cient de détermination ajusté
La qualité descriptive d'un modèle est sa capacité à reproduire les don-nées initiales. En fait, plus il y a de paramètres dans un modèle linéaire, plusil est simple de décrire les données. Malheureusement, les modèles sont alorsfortement a�ectés par le bruit expérimental présent dans le jeu de donnéesétudié. En conséquence, les modèles se généralisent moins bien, leurs capaci-tés prédictives se détériorent quand on ajoute des paramètres. Ce phénomèneest appelé sur-apprentissage (� over�tting � en anglais). C'est pourquoi unemodi�cation du coe�cient de détermination, appelée coe�cient de détermi-
nation ajusté, R2a, existe :

20 CHAPITRE 1. RÉGRESSIONS LINÉAIRES
R2a = 1− N − 1
N −K[R]2
‖[Y ]− [y]‖2(1.53)
Cependant, l'intéret de cette mesure est très restreint car la protectionqu'il o�re contre le sur-apprentissage est extrèmement faible. En pratiqueson usage est donc déconseillé.
1.3.6 Incertitude sur les paramètres d'un modèle
Une régression linéaire doit en général faire la preuve que les éléments uti-lisés par la modélisation ont une réelle utilité. Les paramètres du modèle sontdonc considérés comme des variables aléatoires. L'hypothèse que le vecteur[θ] des paramètres suit une loi Gaussienne. Pour un vecteur, une loi Normaleest caractérisé par une moyenne, estimée par les paramètres calculés pourle modèle, et une matrice de covariance, [Σ] de rang K. La matrice [Σ] estestimée à partir de la relation suivante :
[Σ] = ([G]T [G])−1σ2 (1.54)
Un élément i, j de cette matrice s'interpète à l'aide des variables aléatoiresΘi et Θj représentant les paramètres i et j du modèle. Ce sont les moyennesdes produits des écarts à leurs moyennes respectives des deux variables aléa-toires :
E ((Θi − E(Θi))(Θj − E(Θj))) = [Σ]ij (1.55)
La question se pose donc de l'intervalle de con�ance qui entoure les es-timateurs des paramètres de la régression. En e�et, un paramètre n'a desens statistique que si son signe est connu avec certitude, si 0 n'est pas dansl'intervalle de con�ance. Autrement, il est incorrect de le considérer dans lemodèle et doit donc en être retiré.
Sous l'hypothèse que les résidus se distribuent selon une loi Normale cen-trée de variance σ2, l'intervalle de con�ance pour un paramètre θi fait inter-venir le facteur de student tN−K(1− α/2) pour N −K degrés de libertés etune con�ance α :[
θi −tN−K(1− α/2)σ√
[([G]T [G])−1]ii, θi +
tN−K(1− α/2)σ√[([G]T [G])−1]ii
](1.56)
La demi-largeur de l'intervalle de con�ance, ∆θi, est :
∆θi =tN−K(1− α/2)σ√
[([G]T [G])−1]ii(1.57)

1.3. VALIDATION 21
La calcul de l'interval de con�ance, autrement que dans des cas extrè-mements simples est une tâche assez pénible mais qui est très simplementréalisée par un ordinateur.
1.3.7 Test de Fisher et comparaison de deux modèles
Le test le plus utilisé pour l'analyse de la qualité d'un modèle de régressionlinéaire est le test de Fisher. Étant acquis que les résidus sont centrés, onse demande si la variance résiduelle qu'ils représentent est signi�cativementplus petite que la variance expliquée. En somme, le modèle doit avoir été enmesure de décrire la majeure partie des �uctuations du facteur expliqué.
Il s'agit donc de comparer la variance expliquée à la variance résiduelledans un rapport habituellement désigné par F :
F =VEVR
=N −KK
∑Ni=1(yi − y)2∑Ni=1(yi − yi)2
(1.58)
Il apparaît que, si les résidus suivent une loi normale, F suit une loi deFisher, dons les degrés de liberté sont K et N −K. Ceci permet d'utiliser untest paramétrique. Etant donné un degré de con�ance α, il permet d'a�rmerque F est su�samment grand pour conclure que la variance expliquée estbien signi�cative par rapport à la variance résiduelle. Le modèle est doncconsidéré comme ajustant correctement les données si :
F > F(K,N −K, 1− α) (1.59)
Il s'agit d'un test classique sur les variances.La comparaison de deux modèles se fait en général sur la base des mesures
F1 et F2
Comparaison de modèles
Dans ce cas, il s'agit de savoir si la di�érence entre les prédictions desdeux modèles est signi�cative ou non. Comme ces di�érences sont fonctionsdes données et des unités de mesures, on se réfère à l'erreur, aux résidusdu modèle le plus compliqué. Si deux modèles sont trouvés équivalents, onpréférera utiliser le plus simple. La complexité d'un modèle de régressionlinéaire se mesure au nombre de ses paramètres. A complexité égale, on utiliseles résidus du modèle dont les résidus sont les plus petits.
En pratique, deux modèles M1 et M2 sont considérés, ayant respective-ment K1 et K2 paramètres, conduisant à deux séries de prédictions [Y1] et[Y2], des variances expliquées VE1 et VE2, et des sommes de carrés des résidus

22 CHAPITRE 1. RÉGRESSIONS LINÉAIRES
SCR1 et SCR2. Il est supposé que K1 > K2 et si K1 = K2, alors il fau-dra supposer que SCR1 < SCR2. La distance des prédictions des modèles,comparé à l'erreur de prédiction du plus complexe, est donc :
F =‖[Y1]− [Y2]‖2
SCR1
=N −K1
K1 −K2
∑Ni=1(y1i − y2i)
2∑Ni=1(y1i − y)2
(1.60)
Encore une fois, cette mesure suit un loie de Fisher ce qui permet deconclure, au seuil de con�ance α, qu'un modèle est mieux ajusté si :
F > F(K1−K2, N −K1, 1− α) (1.61)
Il faut ici noter que si le modèle plus simple est la moyenne de la propriétéexpliquée, alors F et les tests statistiques sont identiques à ceux décrits pourestimer la qualité de l'ajustement d'un modèle linéaire. En d'autres termes,estimer la qualité de l'ajustement d'une régression linéaire revient à démon-trer que celui-ci est meilleur qu'un simple calcul de la moyenne du facteurprédit.
En pratique, cette approche a du sens dans le cas de modèles emboîtés. Ondit qu'un modèle M2 est emboité dans le modèle M1 si tous les facteurs ex-plicatifs de M2 sont contenus dans les facteurs explicatifs de M1. Autrement,la sélection d'un � meilleur � modèle est très délicate : �nalement ils portentune information di�érente. Il est donc recommandé de conserver tous les mo-dèles non-emboités qui satisfont individuellement les critères de validation.Il doivent alors tous être utilisés conjointement, dans une sorte de modèlemoyen. Cette approche fait l'objet de recherches en apprentissage automa-tique qui désigne un tel ensemble de modèles par le terme méta-modèles.
1.3.8 Prédiction et erreurs de prédiction
L'objectif d'un modèle est d'être utilisé pour prédire la valeur du facteurexpliqué, étant donné un nouvel ensemble de valeurs des facteurs explicatifs.De nouvelles données, xN+1,l sont founies conduisant à de nouvelles évalua-tions de fonctions gk(xN+1,l) qui sont introduites dans le modèle linéaire etproduit une nouvelle valeur yN+1 = f(gk(xN+1,l)). Le vecteur constitué parles k évaluations gk(xN+1,l) est noté [G]N+1.
La question est maintenant d'estimer l'intervalle autour de la valeur pré-dite, dans laquelle on attend la vrai valeure, celle qui serait mesuré si onfaisait l'expérience.
Étant donnée l'hypothèse de Normalité sur les résidus et un vecteur[G]N+1 calculé à partir de nouvelles valeurs des facteurs explicatifs [X]N+1,la vraie valeur est attendue, avec une con�ance α, dans l'intervalle :

1.4. CONCLUSION 23
[yN+1−tN−K(1− α/2)σ√
[G]TN+1([G]T [G])−1[G]N+1 + 1,
yN+1 + tN−K(1− α/2)σ√
[G]TN+1([G]T [G])−1[G]N+1 + 1](1.62)
De même que pour une mesure expérimentale, une prédiction délivrée parun modèle mathématique ne devrait jamais être délivrée sans un intervallede con�ance.
1.4 Conclusion
Ce chapitre a présenté les grandes lignes de la régression multilinéaireutilisant l'algorithme des moindres carrés. Il faut retenir :
1. Les grandes étapes d'un processus de modélisation
2. Ce que représente une régression multilinéaire
3. Les notions de risque empirique et d'erreur quadratique moyenne
4. L'algorithme des moindres carrés
5. L'opérateur chapeau
6. Ce qu'est une vraisemblance et le principe du maximum de vraisem-blance
7. Les hypothèses réalisées sur les résidus d'un modèle
8. Ce que sont une RMSE et une MAE
9. Les di�érents coe�cents de corrélation et de détermination
10. Le critère d'ajustement de Fisher
11. Comment comparer des modèles
12. Les intervalles de con�ance sur les paramètres d'un modèles
13. L'intervalle de con�ance sur la prédiction d'un modèle
La suite du cours s'attachera à décrire des techniques plus avancées pourla sélection de variables, la construction de variables pertinentes, des algo-rithmes plus avancés de régression et comment utiliser la régression dans lecas de problèmes de classi�cation.





























