Embed Size (px)
Citation preview

信息检索与搜索引擎Introduction to Information Retrieval
GESC1007
Philippe Fournier-Viger
Full professor
School of Natural Sciences and Humanities
Spring 20211

Last week
We have discussed about:
◦ Index construction
◦ Index compression
Website: Videos, PPTs…
2
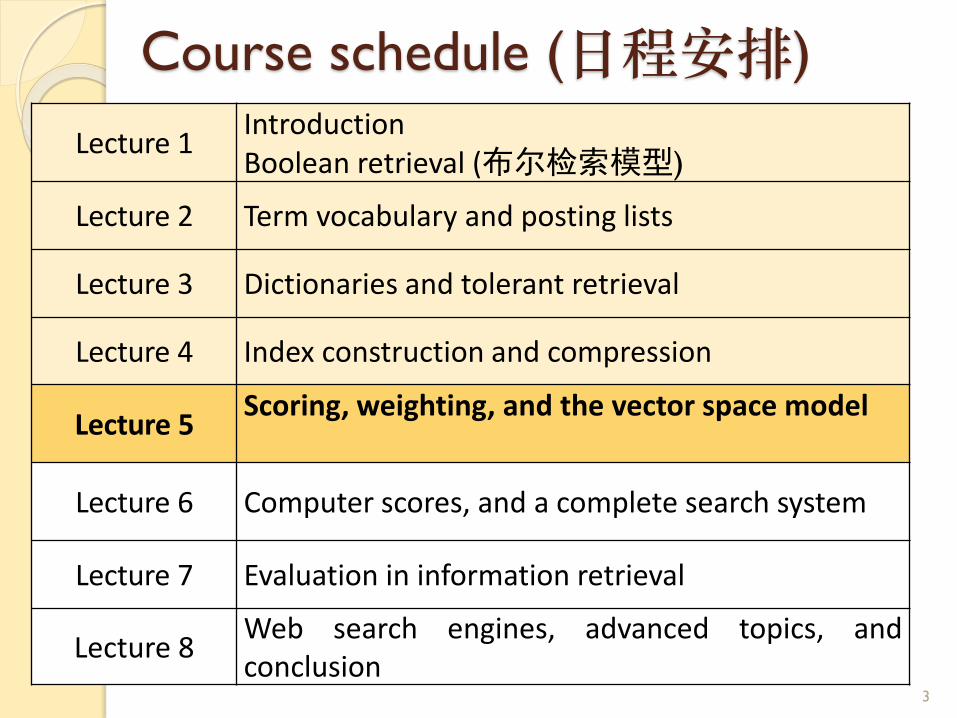
Course schedule (日程安排)
3
Lecture 1IntroductionBoolean retrieval (布尔检索模型)
Lecture 2 Term vocabulary and posting lists
Lecture 3 Dictionaries and tolerant retrieval
Lecture 4 Index construction and compression
Lecture 5Scoring, weighting, and the vector space model
Lecture 6 Computer scores, and a complete search system
Lecture 7 Evaluation in information retrieval
Lecture 8 Web search engines, advanced topics, andconclusion

CHAPTER 6:
SCORING, TERM
WEIGHTING AND
THE VECTOR SPACE MODEL
4pdf p146

Introduction
5
Until now, we have only discussed
Boolean queries (布尔查询)
Shenzhen AND Beijing
car AND rental AND NOT buy
For each query, a document matches the query
or not.
(e.g. each document contains
“Shenzhen AND Beijing” or does not)

Introduction
For small document collections, a Boolean
query may retrieve few documents.
Query = HITSZ AND Basketball AND Football
Only three documents!

Introduction
7
For large document collections (e.g. Web),
the number of documents matching a query may
be huge.
Query = Beijing AND Restaurants
5 million webpages !

Introduction
8
For large document collections, a user may not be
able to look at all the results.
the user may not want or may not have time
to look at 5 million webpages
Thus, a search engine such as Baidu should not
show all the documents to the user.

Introduction
A search engine should:
◦ calculate a score for each document
indicating its relevance for the query.
◦ presents documents to the user by
decreasing order of relevance
(using a score得分).
◦ In other words, the most relevant documents
are presented first.
9
Example →

10
Shenzhen airport
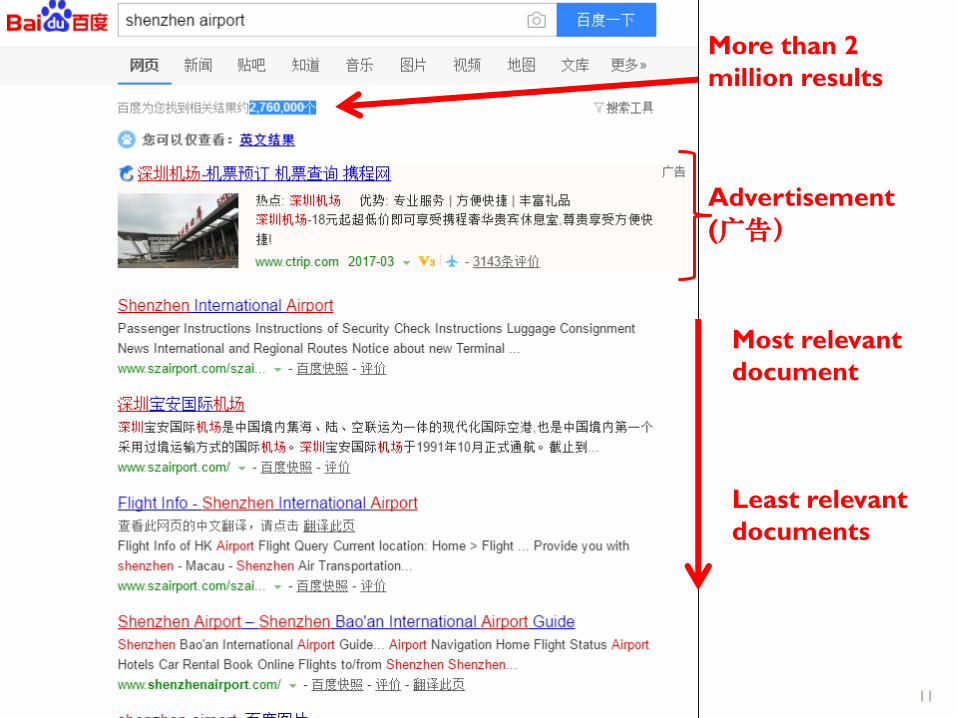
11
More than 2
million results
Most relevant
document
Least relevant
documents
Advertisement
(广告)

The structure of a document
Documents typically contains:
◦ Text
◦ Pictures, videos, and other information
A document may also contain data about the document itself
(metadata -元数据).
Example →
12

Example of metadata (元数据)
FieldAuthor:
Title:
Date of publication:
Date of creation:
Language:
…
13
Values
Shakespeare
Bla Bla Bla
1900/01/01
1899/0101
English
…
Metadata may consist of values for various
fields.
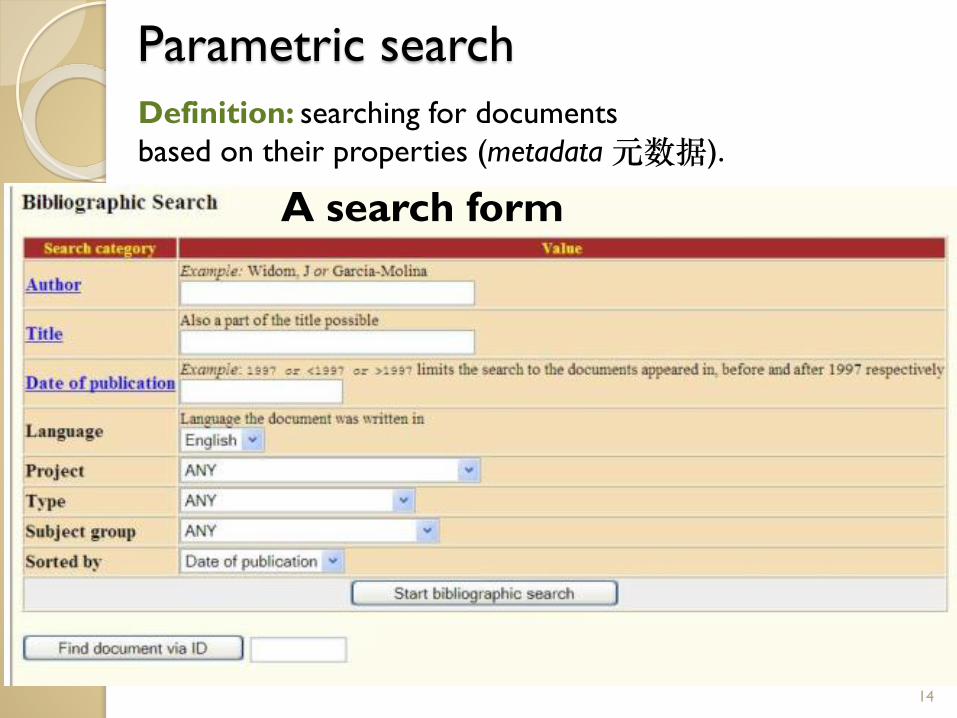
Parametric search
Definition: searching for documents
based on their properties (metadata元数据).
14
A search form
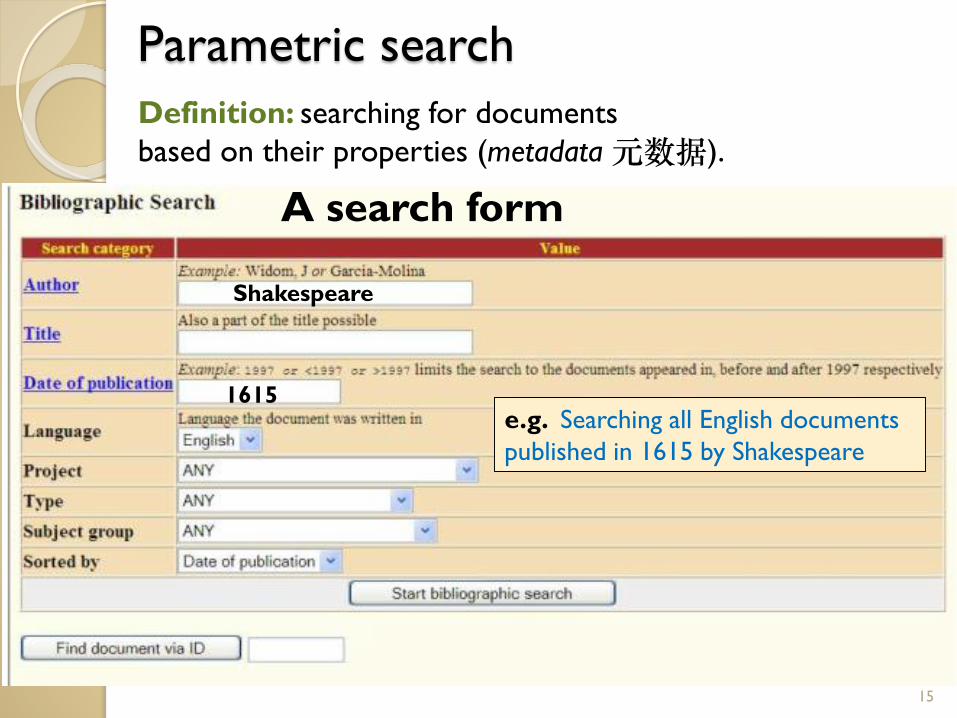
Parametric search
Definition: searching for documents
based on their properties (metadata元数据).
15
e.g. Searching all English documents
published in 1615 by Shakespeare
A search form
1615
Shakespeare

Another example“Find documents authored by Shakespeare in 1601, containing the word “England”
Author = “Shakespeare”Publication year = 1601Body contains “England”
How to find documents for this query?
Find documents containing “England” using a dictionary.
When searching using the dictionary, only retrieve the documents having the field values specified by the query (Author = Shakespeare, Year = 1601)
16

Search forms
Search forms have two types of components:
Field: takes a value from a limited set of values
Zone: the user can write any text
17
Publication date:
Title:
Keywords:
Abstract:
Field
Zones
Travel to Beijing

Indexes for fields and zones
It is easy to create an index for a field (field
index) because the set of terms to use for
searching is restricted and small.
2010, 2011, 2012….
It is more difficult to create a zone index because
all possible terms must be considered.
there can be many!
How to create a “zone index” ?
→
18
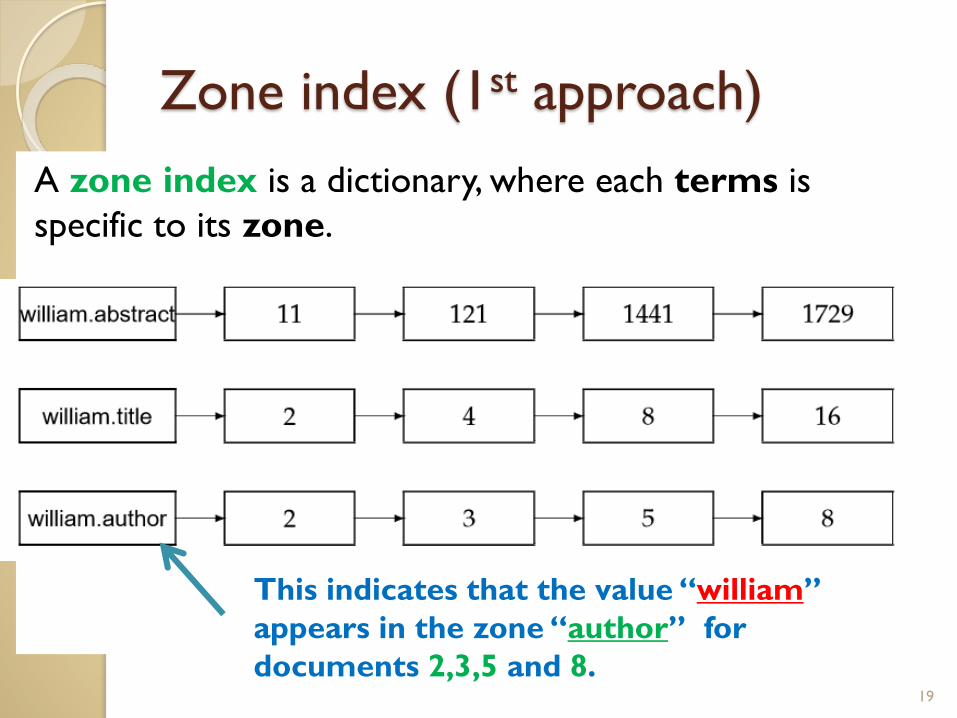
Zone index (1st approach)
A zone index is a dictionary, where each terms is
specific to its zone.
19
This indicates that the value “william”
appears in the zone “author” for
documents 2,3,5 and 8.
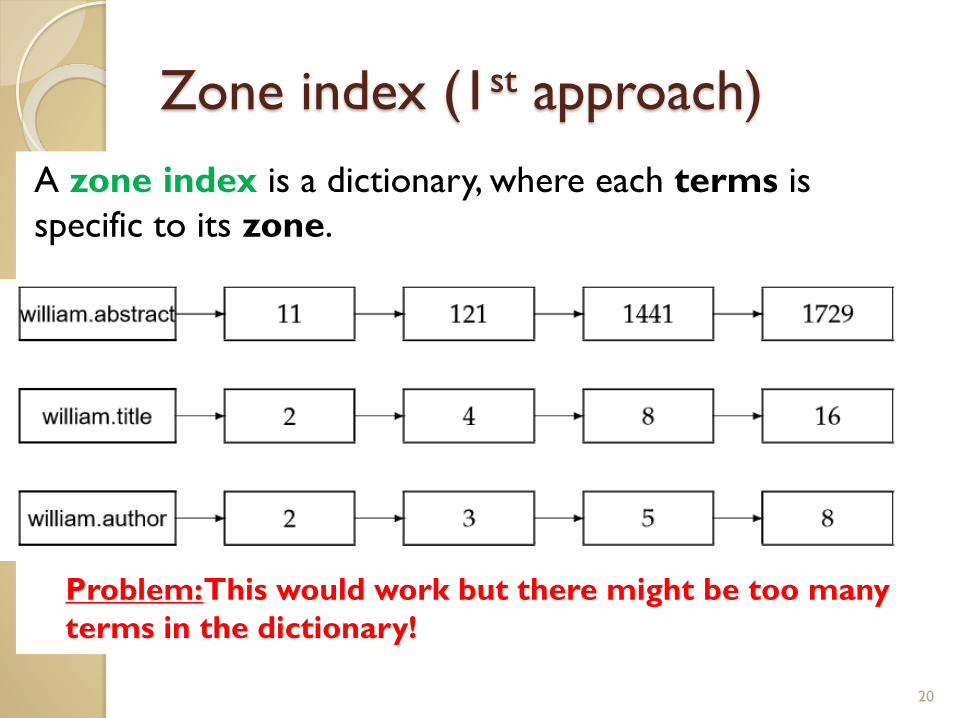
Zone index (1st approach)
A zone index is a dictionary, where each terms is
specific to its zone.
20
Problem: This would work but there might be too many
terms in the dictionary!

Zone index (2nd approach)
Another way of representing a zone index is the
following:
21
This indicates that the value “william” appears in
the zone “author” and in the “title” of document 2

Zone index (2nd approach)
Another way of representing a zone index is the
following:
22
Is it better?
• The number of terms in the dictionary is
reduced…
• But the posting lists may be longer
• Useful to search for terms appearing
anywhere in the document (title, author etc.)

Ranking documents using a zone index
A zone index is useful for rankingdocuments from most relevant to least relevant.
This technique is called:“weighted zone scoring”.
A score between 0 and 1 will be assigned to each document.
1 = highly relevant0 = irrelevant document
23Note: “Weighted zone scoring” is also called “Ranked Boolean retrieval”

How to assign scores?
The score of a document:
The overall score of a document is
the sum of the scores of its zones.
Each zone of a document contributes
to the document’s score if the query
matches the zone,
Weights may be assigned to each zone
to indicate their relative importance.
(title may be more important than
author name)
24

Example
A collection of documents with three zones:
author, title and body
25
author:
title:
body:

Example
We can set the weights as follow:
weight of “author” = 0.2
weight of “title” = 0.3
weight of “body” = 0.5
26
author:
title:
body:

Example
We can set the weights as follow:
weight of “author” = 0.2
weight of “title” = 0.3
weight of “body” = 0.5
27
author:
title:
body:
Thus, a match in the author zone does not change
much the overall score, the title zone somewhat
more, and the body is the most important zone.

ExampleWe will search for documents using this query:
QUERY = Shakespeare
28

Exampleweight of “author” = 0.2
weight of “title” = 0.3
weight of “body” = 0.5
If a document D1 contains “Shakespeare” in the title and body, its overall score is :
0 + 0.3 + 0.5 = 0.8
If a document D2 contains “Shakespeare” only in the body, its overall score is :
0 + 0 + 0.5 = 0.5
Thus, document D1 is ranked higher than document D2.
29
QUERY = Shakespeare

How to calculate scores using a zone index?
e.g.: query: “william”
Using the index, we can quickly find all the documents containing “william”.
The information in the postling list(s), allows calculating the score of each document:
Doc 2: 0.2 + 0.3 = 0.5Doc 3: 0.2
Doc 4: 0.3Doc 5: 0.2
30

How to choose the weights?
So how do we choose the weights?
Different weights will result in different rankings
of documents.
Weights could be set by a human expert.
31
weight of “author” = 0.2
weight of “title” = 0.3
weight of “body” = 0.5
weight of “author” = 0.4
weight of “title” = 0.4
weight of “body” = 0.2
Which one is better?

How to choose the weights?
But often, the weights are “learned”
automatically using “machine learning
methods” (机器学习方法).
The idea is to try to find the best weights
automatically.
32

How does it works?We have a set of training examples:
a query + some documents + a relevance judgment on
each document
Relevance judgement: {relevant, non_relevant} or a score.
33
The query matches the title
of this document
0 = no 1 = yes
The query matches
the body of this
document
0 = no 1 = yes

How does it works?
The weights are then “learned” from these examples so that they will approximate the relevance judgments in the examples.
Let’say that: relevant = 1 non_relevant = 0
What should be the weights?
weight of body = ? 0.5 ? 0.6 ? 0.3?
weight of title = ? 0.5 ? 0.4 ? 0.7 ?
It is an optimization problem (优化问题). We should find the weights that provide the best approximation (minimizes the error).
34

TERM FREQUENCY AND WEIGHTING
35

Introduction
Until now, we have considered that a term
appears or does not appear in a document.
We did not consider how often a term appears in
a document!
«shenzhen » appears 3 times in webpage 1
«shenzhen » appears 30 times in webpage 2
36
We need to consider term frequency !
(how many times a term appears)

Free text queries
Users of a search engine like Baidu will often search using a
list of keywords (terms) as query.
e.g. shenzhen airport schedule
This query is said to contains three terms or keywords.
This type of query is called a «free form query »
No Boolean operators are used.
37

Scoring documents for free text queries
To answer free text queries, the score of a
document should be based on:
◦ which keywords appear in the document,
◦ how many times they appear in the
document
38

Scoring documents for free text queries
Simple approach: The score of a document is the sum of the number of occurrences of each term in that document (Term Frequency –TF -词频).
QUERY: shenzhen aiport
DOCUMENT: Shenzhen is a big city, founded in 1979. Shenzhen has an aiport. There is also a few ports in Shenzhen
SCORE = 3 + 1 = 4
39
3 times «shenzhen »
+ 1 time «airport »

Bag of word model (词袋模型)
This approach for scoring document is
called the «bag of word model »
because it does not consider the order
between words.
40

All words are equally important?
No!
Example: airports in Shenzhen
The word «in » is a very common word that is
in general not important (it is a stop word 停用词). We may ignore it.
41

Problem with term frequency
all terms are viewed as equally important by the previous approach.
words that are very frequent will not allow to discriminate between documents.
e.g. documents related to the automobile industry will likely all contain the word «auto »
42

Solution
Idea: we want to assign smaller weights to terms
that are very frequent.
Inverse document frequency (IDF) of a term:
(逆文档频率)
43
IDFt = log (𝐍
𝐃𝐅𝐭)
N = number of documents in the collection
DFt = number of documents containing the term
(document frequency)

Example
N = 806, 791 documents
44
IDFt = log (𝐍
𝐃𝐅𝐭)
45

How to combine document
frequency and term frequency?
To score each term in a document, a
popular measure is TF-IDF
TF = term frequency
IDF = inverse document frequency
46
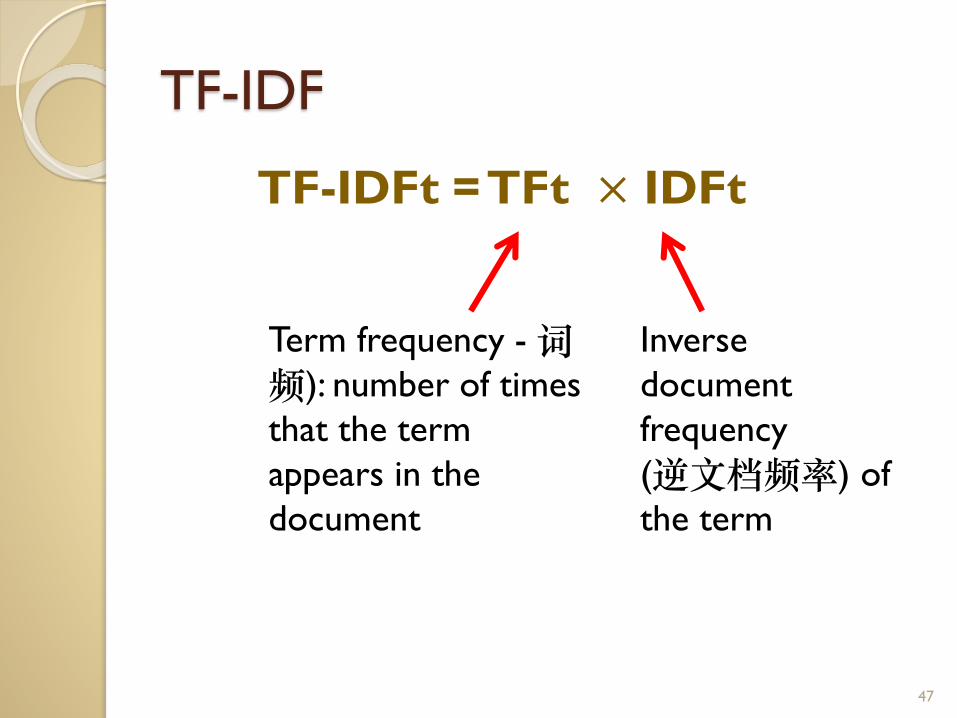
TF-IDF
47
TF-IDFt = TFt × IDFt
Term frequency -词频): number of times
that the term
appears in the
document
Inverse
document
frequency
(逆文档频率) of
the term

TF-IDF
For a document, a term will get:
a high score if it appears many
times in the document but rarely
in other documents.
a lower score if the term appears
few times in the document, or if it
appears in many documents
a low score if the term appears in
almost all documents
48

To score a document for a query
Based on the TF-IDF, we can calculate the score of a document for a query:
Score(query, document) = sum of the TD-IDF of all terms in the query for that
document.
Consider the query: Shenzhen Beijing
Score(Shenzhen + Beijing, Doc1) =
TD-IDFShenzhen + TD-IDFBeijing
49

THE VECTOR SPACEMODEL FOR SCORING
50

Vector model (矢量模型)
The vector space model is a way of
representing documents that is often used
in information retrieval.
Each document is represented as a
vector (矢量).
51
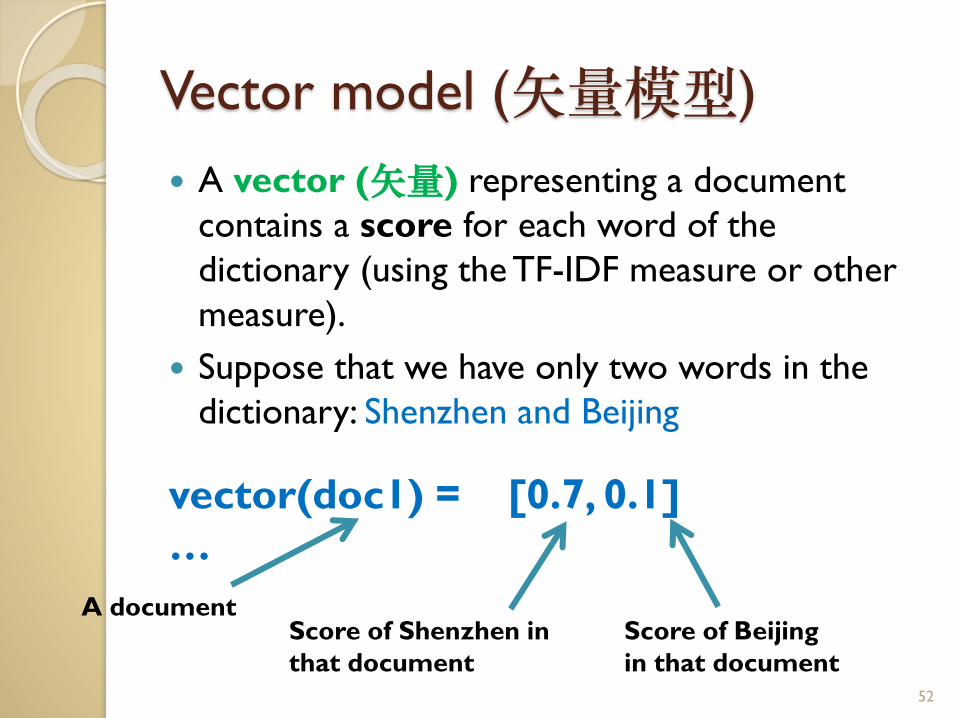
Vector model (矢量模型)
A vector (矢量) representing a document
contains a score for each word of the
dictionary (using the TF-IDF measure or other
measure).
Suppose that we have only two words in the
dictionary: Shenzhen and Beijing
vector(doc1) = [0.7, 0.1]
…
52
Score of Shenzhen in
that document
Score of Beijing
in that document
A document
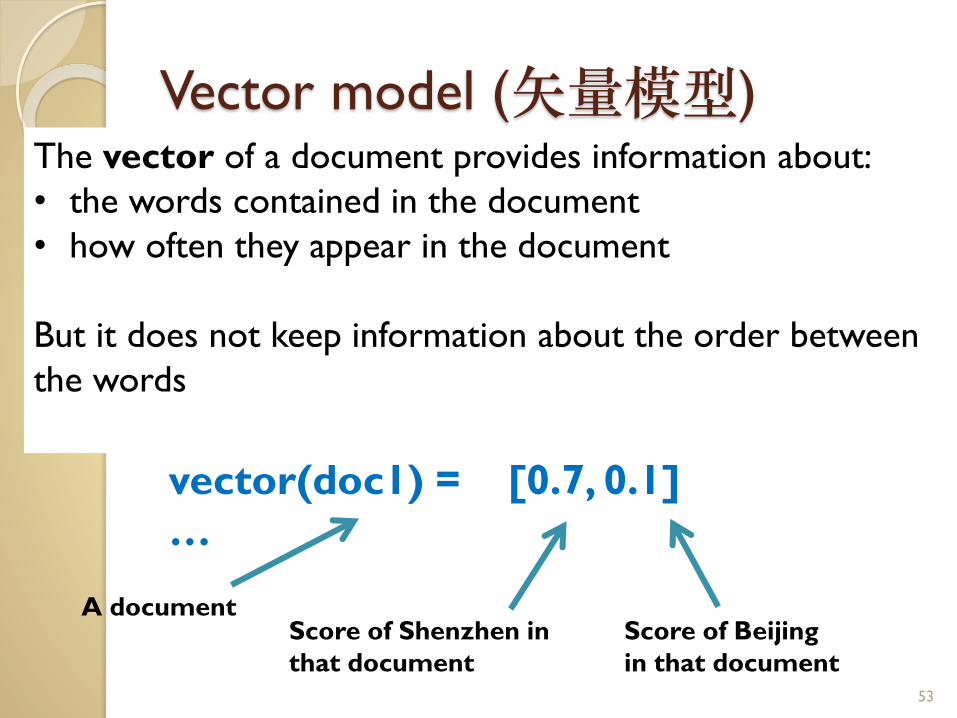
Vector model (矢量模型)
vector(doc1) = [0.7, 0.1]
…
53
Score of Shenzhen in
that document
Score of Beijing
in that document
A document
The vector of a document provides information about:
• the words contained in the document
• how often they appear in the document
But it does not keep information about the order between
the words

Vector model (矢量模型)
The collection of all documents can be
viewed as a set of vectors.
vector(doc1) = [0.4, 0.5]
vector(doc2) = [0.7, 0.1]
vector(doc3) = [0.4, 0.8]
vector(doc4) = [0.7, 0.9]
…
… …
..
54
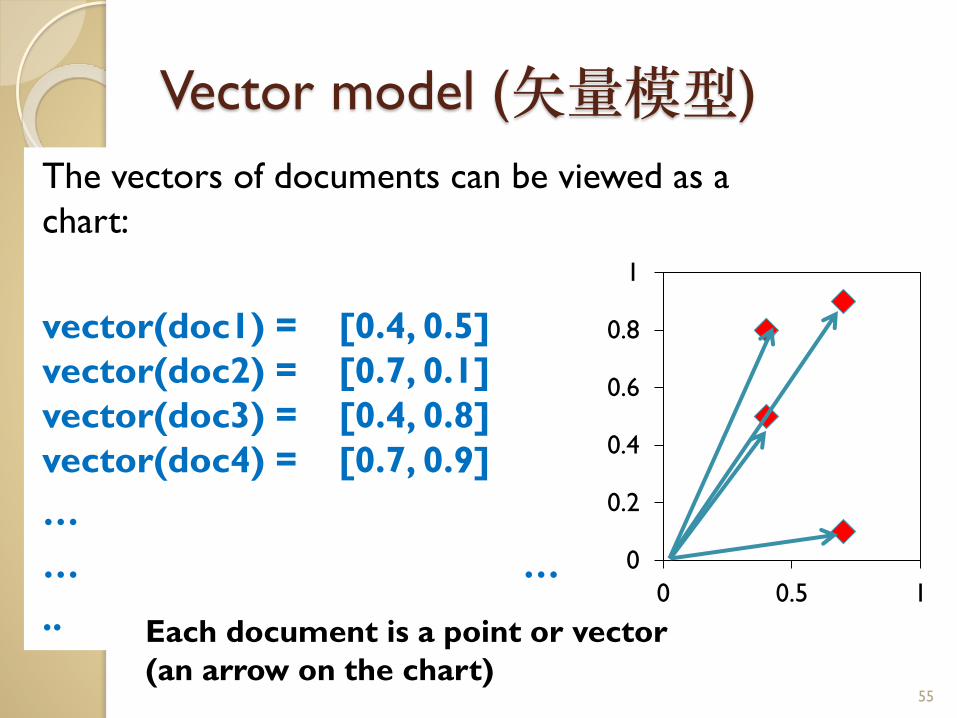
Vector model (矢量模型)
The vectors of documents can be viewed as a
chart:
vector(doc1) = [0.4, 0.5]
vector(doc2) = [0.7, 0.1]
vector(doc3) = [0.4, 0.8]
vector(doc4) = [0.7, 0.9]
…
… …
..
55
0
0.2
0.4
0.6
0.8
1
0 0.5 1
Each document is a point or vector
(an arrow on the chart)

Vector model (矢量模型)
The vectors of documents can be viewed as a
chart:
vector(doc1) = [0.4, 0.5]
vector(doc2) = [0.7, 0.1]
vector(doc3) = [0.4, 0.8]
vector(doc4) = [0.7, 0.9]
…
… …
..
56
0
0.2
0.4
0.6
0.8
1
0 0.5 1
In our case, we have two dimensions (2D) because we
assume that two words “Shenzhen” and “Beijing” are
the only words in the dictionary

Vector model (矢量模型)
The vectors of documents can be viewed as a
chart:
vector(doc1) = [0.4, 0.5]
vector(doc2) = [0.7, 0.1]
vector(doc3) = [0.4, 0.8]
vector(doc4) = [0.7, 0.9]
…
… …
..
57
0
0.2
0.4
0.6
0.8
1
0 0.5 1
If we create the vectors using 3 words, we would
have 3 dimensions (3D) instead, and so on…

Similarity between documents
Using the vector space model, we can try to calculate
how similar two documents are.
58
Intuitively, two
documents are
expected to be
similar if their
vectors are close
to each other
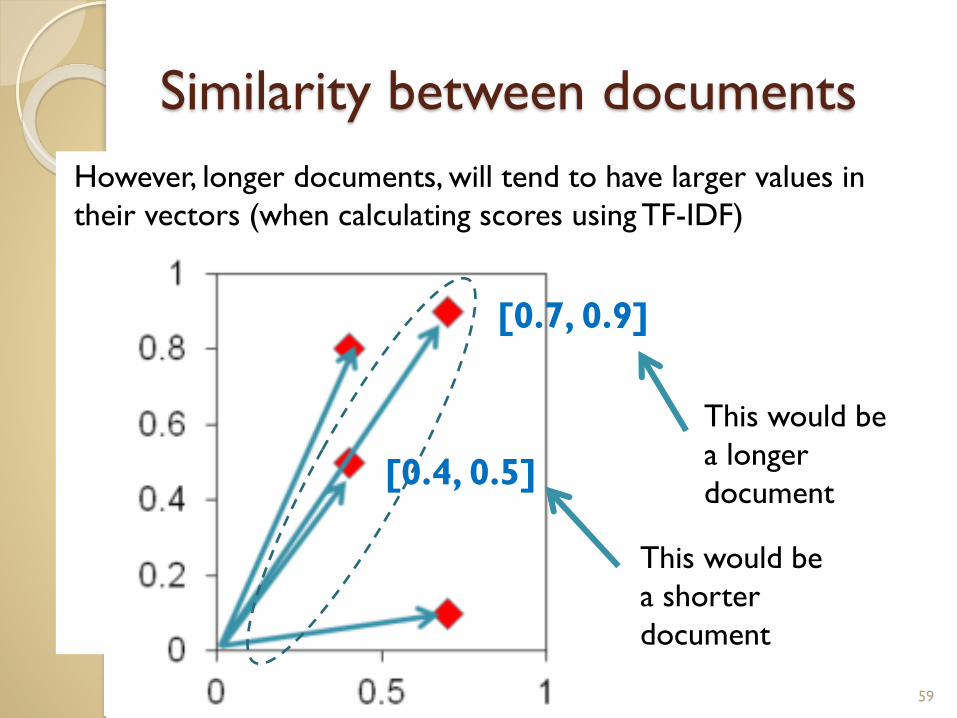
Similarity between documents
However, longer documents, will tend to have larger values in
their vectors (when calculating scores using TF-IDF)
59
[0.7, 0.9]
[0.4, 0.5]
This would be
a longer
document
This would be
a shorter
document

Similarity between documents
How to calculate the similarity between two
vectors while considering the length of
documents?
Solution: calculate the cosine similarity (余弦相似度 ) of two documents d1 and d2.
Example →
60
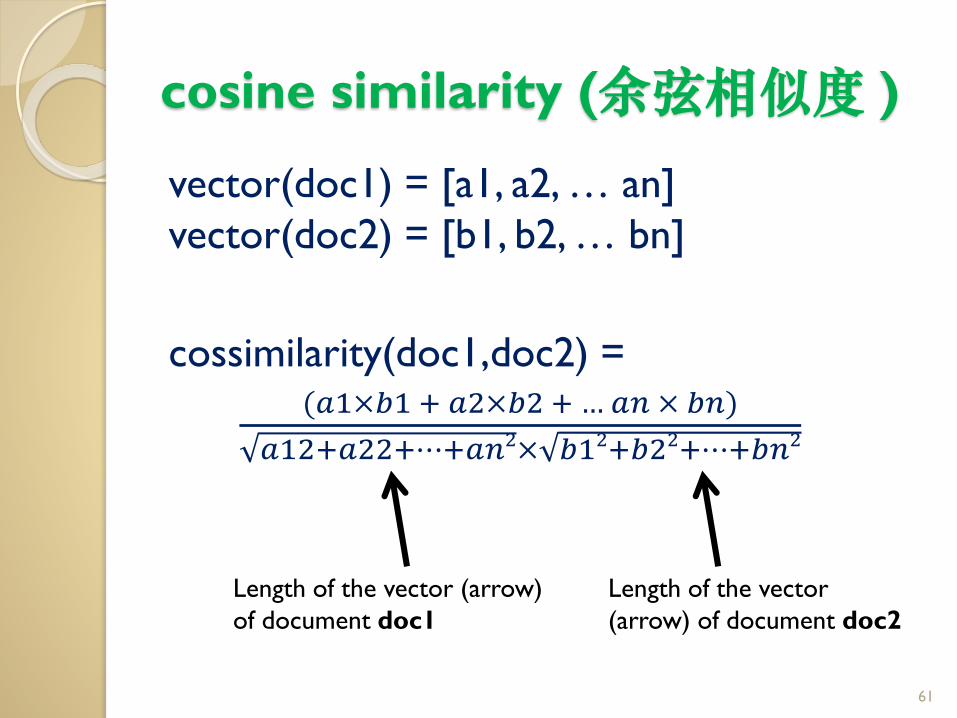
cosine similarity (余弦相似度 )
vector(doc1) = [a1, a2, … an]
vector(doc2) = [b1, b2, … bn]
cossimilarity(doc1,doc2) = (𝑎1×𝑏1 + 𝑎2×𝑏2 + … 𝑎𝑛 × 𝑏𝑛)
𝑎12+𝑎22+⋯+𝑎𝑛2× 𝑏12+𝑏22+⋯+𝑏𝑛2
61
Length of the vector (arrow)
of document doc1
Length of the vector
(arrow) of document doc2

If we use the standard math notation:
𝑑𝑜𝑐1 = [a1, a2, … an]
𝑑𝑜𝑐2 = [b1, b2, … bn]
cossimilarity(𝑑𝑜𝑐1, 𝑑𝑜𝑐2) = 𝑑𝑜𝑐1 ∙𝑑𝑜𝑐2
|𝑑𝑜𝑐1||𝑑𝑜𝑐2|
62
Length
of this
vector
Length
of this
vector
dot
product

Example – 3 documents
63
We will use the Term frequency (TF) measure
instead of TF-IDF for the vectors
We will consider three documents with the
following term frequencies:
| 𝑑𝑜𝑐1| = 30.56 | 𝑑𝑜𝑐2| = 46.86 | 𝑑𝑜𝑐3| = 41.30

Example – 3 documents
64
• Then, we length-normalize each vector.
• This means to divide each values in a vector
Ԧv by the length of the vector | Ԧv |
With these values, we could easily calculate the
cosine similarity between any documents….

Example – 3 documents
…
We will not do all the calculations!
What is important is that we can now
calculate the similarity between two
vectors (documents)
65

Queries as vectors
Just like documents, a query can be
represented as a vector.
Example: assume a dictionary of three
words: affection, jealous, gossip
The query: jealous gossip
can be viewed as a vector:
vector(query) = [0, 0.7, 0.7]
66

Queries as vectors
The score of a document for a query can be
defined as the cosine similarity between the
query and the document.
score(query,document) =
cossimilarity(query, document)
67
query

Queries as vectors
Using this approach, a document may have a
high score for a query even if it does not
contain all the query terms
Note: in practice, we can use TF, TF-IDF or
other measures for calculating the scores of
terms in documents.
68

Queries as vectors (cont’d)
To search for documents:
◦ Calculate the cosine similarity between the query
and each document.
◦ Show only the documents to the user that have the
highest similarity with the query
69
top 10
documents

Queries as vectors (cont’d)
However, calculating the similarity between a
query and all documents is time-consuming!
We want a search engine to be fast!
70
top 10
documents

Computing vector scores
1) Set the score of all documents to 0.
2) For each query term t :
◦ calculate the weight of the query term t.
◦ obtain the posting list of t.
◦ increase the score of each document appearing in the posting list of t.
3) Divide the score of each document by its vector length.
4) Show the documents having the highest score to the user.
71
Some details…

Computing vector scores
A key observation is that:
If we have multiple computers, we can
calculate the score using several
computers working in parallel.
Each computer may score different
documents for a same query.
72
Some details…

SUMMARY
73

Term frequency (TF): (词频) how many times
a term appears in a document
Document frequency (DF) (文档频率):
how many documents contain a term in a
collection of documents.
74
Inverse document frequency (IDF) of a term t:
(逆文档频率)
IDFt = log (𝐍
𝐃𝐅𝐭)
N = number of documents in the collection
DFt = document frequency of the term t

Conclusion
Today, we discussed chapter 6 about
weighted Boolean retrieval.
We will continue next week…
The PPT slides are on the website.
75

References
Manning, C. D., Raghavan, P., Schütze, H.
Introduction to information retrieval. Cambridge:
Cambridge University Press, 2008
76





























