Embed Size (px)
Citation preview

MASTER MENTION GEOMATIQUE
DEVELOPPEMENT D’UNE METHODOLOGIE POUR LA
CONSTRUCTION DE CARTES D’OCCUPATION DU SOL DE
L’ILE DE LA REUNION
Mónica María Londoño Villegas
Stage effectué entre le 6 Mars et le 6 Septembre
Soutenance le 11 septembre 2017
Maître de stage :
Stéphane Dupuy (UMR-TETIS, CIRAD)
Tuteur-enseignant:
Jean-François Girres (Université Paul-Valéry)

2
REMERCIEMENTS
Tout d’abord je tiens à remercier Stéphane Dupuy, mon maître de stage et Raffaele Gaetano,
développeur de la chaîne de traitement, pour m’avoir fait confiance pour participer à cet
important projet, ainsi que pour leur attention, orientation et appui constants.
Je remercie également toutes les personnes qui font partie du CIRAD pour m’avoir permis de
travailler dans un environnement de travail agréable et collaboratif, notamment l’équipe
ARTISTS à La Réunion pour leurs conseils, leur aide et accompagnement.
Aux personnes du projet GABIR pour m’avoir accueillie et de la SAFER pour les informations
fournies.
Aux professeurs des trois instituts d’enseignement à Montpellier et aux membres du jury.
Merci à ma famille qui depuis La France et La Colombie m’ont toujours aidé sans conditions,
pour m’avoir encouragé et appuyé à chaque moment.
Finalement à mon copain et camarade du Master Bertrand Richard dont le soutien, l’amour et la
confiance m’ont été indispensables pendant ces deux années de Master.

3
TABLE DE MATIERES
INTRODUCTION ................................................................................................................................ 4
1. PRESENTATION DU PROJET ..................................................................................................... 5
1.1. Contexte institutionel : LE CIRAD, L’UMR-TETIS ET LE PROJET GABIR .............................. 5
1.2. Contexte de l’occupation du sol à l’île de La Réunion ...................................................... 6
1.3. Description de l’approche méthodologique : une classification supervisée orientée-objet ........ 9
1.4. Antécédents de la méthode dans le cadre de L’UMR-TETIS ........................................... 13
2. MATERIELS ET METHODE ....................................................................................................... 15
2.1. Les ressources informatiques ......................................................................................... 15
2.2. Les ressources en imagerie ............................................................................................. 17
2.3. Méthode .......................................................................................................................... 19
3. RESULTATS ET DISCUSSION.................................................................................................... 29
4. CONCLUSIONS ET PERSPECTIVES ........................................................................................... 34
BIBLIOGRAPHIE .............................................................................................................................. 37
LISTE D’ANNEXES ........................................................................................................................... 38
RESUME .......................................................................................................................................... 46

4
INTRODUCTION
Le CIRAD1 et plus particulièrement l’UMR-TETIS2 est partenaire de projets menés à l’échelle
mondiale reliés à la caractérisation et au suivi de zones agricoles en utilisant des ressources et
méthodes en télédétection. Cela avec l’objectif de générer des informations d’occupation du sol
précises pour améliorer la capacité de décision de la communauté mondiale face aux problématiques
de sécurité alimentaire et des effets du changement climatique sur les systèmes agricoles. Au travers
de ces projets, différentes méthodes ont été testées pour classifier des images satellites et générer
de façon automatique des cartes d’occupation du sol, en tirant profit des nouvelles ressources en
imagerie satellitaire, de plus en plus précises, accessibles et adaptées au suivi des zones agricoles. Les
méthodes affinées au travers de ces projets ont permis le développement de chaînes de traitement
pour la classification d’images satellites dans les pays du nord et les pays du sud.
La chaîne de traitement testée dans le cadre de ce stage, développée au sein de l’UMR-TETIS,
est conçue pour faire face aux problématiques de la caractérisation de l’occupation du sol dans les
« pays du sud », localisés notamment dans la zone tropicale, où la couverture nuageuse est très
importante et le paysage caractérisé par une forte hétérogénéité des cultures. Ainsi, cette chaîne de
traitement cherche à profiter du potentiel qu’offrent les séries temporelles d’images à haute
résolution spatiale (HRS) Sentinel-2, de libre accès, dont l’information radiométrique et les
résolutions spatiales et temporelles sont particulièrement adaptées pour les études qui portent sur
le type et la dynamique de la végétation, notamment pour la caractérisation et le suivi des systèmes
agricoles. La série temporelle d’images est complétée par des images Landsat-8 afin d’augmenter le
nombre d’images disponibles face aux problèmes de la couverture nuageuse. D’autre part, cette
chaîne de traitement adopte une approche orientée objet, en incluant des images à très haute
résolution spatiale (THRS) utilisées afin de générer des objets qui sont ensuite classés en utilisant
notamment l’information fournie par la série temporelle d’images HRS.
À l’échelle de La Réunion, le développement de méthodes automatiques pour la génération
de cartes d’occupation du sol s’avère indispensable pour combler les besoins d’information pour
l’aménagement du territoire de l’île. Le projet GABIR3, source de financement du stage, vise à
proposer des solutions pour améliorer la gestion de la biomasse à La Réunion. Une des tâches de ce
projet consiste à identifier les sources et puits de biomasse dans les zones agricoles. Ainsi la
possibilité de compter sur une méthode automatique pour la génération de cartes d’occupation du
sol pourrait apporter des bénéfices à long terme. L’information ainsi obtenue serait très utile en tant
que complément des sources d’information disponibles actuellement, dont le principal est constitué
par la BOS4, fournie par la DAAF5, dont la mise à jour dépend en grande partie des déclarations des
agriculteurs dans le cadre de la politique agricole commune.
Le but de mon stage est donc d’appliquer la chaîne de traitement Sitsproc, conçue au sein de
l’UMR-TETIS, dans le but de tester sa performance et de contribuer à son adaptation dans le contexte
de La Réunion afin de développer une méthode pour la production de cartes d’occupation du sol du
territoire de l’île.
1 Centre de coopération internationale en recherche agronomique pour le développement
2 Unité Mixte de Recherche « Territoires, environnement, télédétection et information spatiale »
3 Gestion Agricole des Biomasses à l’échelle de la Réunion
4 Base agricole de l’Occupation du sol
5 Direction de l’Alimentation, de l’Agriculture et de la Forêt de La Réunion

5
1. PRESENTATION DU PROJET
1.1. CONTEXTE INSTITUTIONEL : LE CIRAD, L’UMR-TETIS ET LE PROJET GABIR
Le CIRAD est un organisme français de recherche agronomique et de coopération
internationale pour le développement durable des régions tropicales. Il est sous la tutelle du
ministère de l’éducation nationale, de l’Enseignement supérieur et de la Recherche, et du
ministère des Affaires étrangères et du développement international. Avec ses partenaires du
sud, dans plus de 100 pays du monde, le CIRAD « produit et transmet des nouvelles
connaissances pour accompagner l’innovation et le développement agricole ». Son statut et son
expérience lui permettent aussi de nourrir les débats sur les principaux enjeux de l’agriculture au
niveau mondial6.
Le CIRAD est structuré en 33 unités de recherche dont l’UMR-TETIS (Territoires,
environnement, télédétection et information spatiale). Cette unité de recherche implémente
une approche intégrée pour le traitement de l’information spatiale au service de la gestion
durable des systèmes agro-environnementaux et du développement territorial7. Ainsi cette
unité est partenaire de différentes initiatives liées au développement de méthodes pour
exploiter l’information fournie par des images satellites pour ainsi améliorer le suivi et la
caractérisation des espaces agricoles du monde entier.
A la Réunion, les recherches menées par le CIRAD sont organisées au sein de 4 dispositifs de
programmation en partenariat, dont celui de « Services et impacts des activités agricoles en
milieu tropical »8, auquel est rattaché le projet GABIR. Ce dispositif porte sur 3 axes d’action, à
savoir : le recyclage des nutriments et maîtrise des flux de contaminants, la production et
valorisation de la biomasse à des fins alimentaires et non-alimentaires, et l'analyse et le
traitement de l'information spatiale pour l'aide à la production agricole et la gestion du
territoire.
Le but du projet GABIR est d’améliorer l’autonomie des exploitations, notamment du secteur
agricole, en proposant des solutions innovantes pour la gestion et la valorisation de la biomasse
à l’échelle de l’île de La Réunion, sous le principe d’une gestion circulaire et durable des effluents
d’élevage et d’autres produits résiduels organiques et des cultures. Ce projet est coordonné par
le CIRAD qui le mène en partenariat avec plusieurs acteurs impliqués, parmi lesquels se trouvent
la Chambre d’Agriculture de la Réunion, l’Institut Régional de la Recherche Agronomique (INRA),
la SAFER, la DAAF, la Fédération Régionale des Coopératives Agricoles de La Réunion (FRCA) et
l’Université de La Réunion9
6 Site internet CIRAD. http://www.cirad.fr/qui-sommes-nous/le-cirad-en-bref. Consulté en juillet 2017.
7 Site internet CIRAD. http://www.cirad.fr/nos-recherches/unites-de-recherche/tetis. Consulté en juillet 2017.
8 Site internet CIRAD La Réunion- Mayotte. https://reunion-mayotte.cirad.fr/recherche-en-partenariat/dispositifs-de-
recherche/services-et-impacts-des-activites-agricoles. Consulté en juillet 2017. 9 Source : CIRAD et al. 2016. Description synthétique du projet GABIR.

6
1.2. CONTEXTE DE L’OCCUPATION DU SOL A L’ILE DE LA REUNION
La Réunion est une île tropicale de 2510 km2 de surface qui est localisée dans le sud-ouest de
l’Océan Indien, 800 km à l’est de Madagascar, par 55° 30’ de longitude est et 21°05’ de latitude
sud. Cette île est un des départements d’outre-mer de la France, et son territoire est distribué en
24 communes dont la préfecture est à Saint-Denis.
Il s’agit d’une île volcanique très montagneuse, qui possède une variété de microclimats
inhabituels pour un territoire de cette taille (Raunet, 1991). Le relief, La grande diversité des
écosystèmes mais également la complexité des espaces agricoles, amplement distribués en
dehors du Parc National, font de la Réunion un territoire unique.
La population de l’île, estimée en 844 741 personnes10, se trouve localisé notamment vers le
littoral, distribuée sur plusieurs villes et villages. Il existe aussi des agglomérations urbaines dans
le haut plateau de l’île (à la Plaine des Cafres et la Plaine de Palmistes) et dans deux des trois
cirques situés dans la moitié ouest de ce territoire. Une portion de la population est aussi
dispersée dans les zones rurales.
Figure 1. Carte de localisation et territoire de l’Île de La Réunion
1.2.1. Relief et climat
L’un des traits caractéristiques de l’île de La Réunion est son relief qui a permis l’inscription
de ce territoire au Patrimoine Mondial de l’UNESCO. Les formes des Pitons, Cirques et Remparts
10
INSEE, recensement de la population 2013.

7
définissent un paysage unique au monde. Etant donné que l’île est en réalité le sommet d’un
volcan de 7000 m d’altitude placé sur le fond marin, l’un des plus actifs dans le monde, les
formations particulières sont le résultat d’une géomorphologie très dynamique influencée par
des éruptions qui peuvent se succéder à raison d’une ou plusieurs par an, et par une forte
érosion. Anciennement, l’activité volcanique se situait aux alentours du Piton des Neiges, qui
constitue le point le plus haut de l’île à 3 069 m d’altitude, et les trois cirques qui entourent ce
sommet correspondent à des anciens cratères effondrés. Actuellement les éruptions se
concentrent dans le complexe volcanique autour du Piton de la Fournaise, à l’est de l’île (Nehlig
& Bucelle 2005, Raunet 1991).
Par rapport au climat, La Réunion possède un régime assez instable, déterminé par son
caractère insulaire, sa localisation tropicale, son relief et la direction dominante du vent. Le
climat se caractérise ainsi par de très forts gradients de pluviosité (depuis 600 mm jusqu’à 9000
mm), des périodes cycloniques violentes et un fort gradient de température liée à l’altitude
(Raunet 1991). Les alizés, arrivant du sud-est, amènent les nuages chargés d’humidité qui
rencontrent dans leur passage les montagnes, déclenchant ainsi des pluies fréquentes vers cette
portion de l’île et une forte présence des nuages. Ce phénomène apporte également un climat
beaucoup plus sec ver l’ouest de l’île. On peut ainsi différencier une saison plus pluvieuse qui
s’étend de novembre jusqu’à avril et qui coïncide avec la période la plus chaude : l’été austral.
1.2.2. Les zones cultivées
La zone cultivée se trouve notamment dans une bande d’amplitude variable aux alentours
du littoral qui est interrompue dans la partie est de l’ile, zone couverte par des coulées de lave
récentes et qui est protégée par le Parc National de La Réunion. Les cultures s’étendent aussi
vers la plaine localisée entre les deux sommets de l’île et à l’intérieur de deux des cirques :
Salazie et Cilaos. Dans le cirque de Mafate, l’activité agricole est minimale en raison des
difficultés d’accès à cette zone.
La culture dominante de l’île est la canne à sucre, spécifiquement en-dessous de 800 m
d’altitude, et correspond à 24 000 ha soit 57% de la surface agricole utilisée11. Au-dessus de
cette limite les prairies prédominent et elles s’étendent jusqu’à 1700 m d’altitude
approximativement. Dans l’île il existe des prairies pâturées et des prairies « fauchées »
destinées à l’extraction et au stockage de foin pour l’alimentation du bétail.
D’autres cultures occupent une surface importante comme l’ananas, la banane, les vergers
et les cultures maraichères. Ces dernières correspondent habituellement à des parcelles
composées par une mosaïque de petites surfaces de différents types de légumes (carotte,
betterave, chou-fleur, brocoli, choux, tomate, haricot, lentille, poivron, oignon, etc). Les cultures
de maraichage sont souvent réalisées sous des serres en plastique.
La présence de quelques cultures est influencée par la région et les microclimats. Parmi les
vergers, le letchi prédomine dans le nord-est de l’île, autour de Saint-Benoît et Sainte-Rose, les
11
Site internet Chambre d’Agriculture Réunion. http://www.reunion.chambagri.fr/spip.php?rubrique56. Consulté en juillet 2017.

8
manguiers abondent dans le sud-ouest, spécialement aux alentours de Saint-Paul, et les agrumes
sont très concentrés dans le sud, surtout vers la commune de Petite Île. La distribution de
quelques cultures est restreinte à certains endroits comme les lentilles à Cilaos, les haricots à
l’Entre-Deux, le curcuma à la Pleine des Grègues (Saint-Joseph) et la pomme de terre dans la
zone haute du Tampon. Dans le cas de la cristophine, même si cette plante a tendance à envahir
les zones agricoles en friche et les bords de route, elle est seulement cultivée de manière
systématique dans le cirque de Salazie.
Les plantations forestières de cryptomeria, destinées à la production de bois, sont aussi
importantes dans la zone cultivée. Celles-ci se trouvent généralement localisées dans des zones
contigües à la forêt naturelle, et c’est la seule culture présente au-delà de 1700 m d’altitude.
1.2.3. Les zones naturelles
Bien que le but du projet GABIR ne soit pas l’identification des zones naturelles, leur prise en
compte dans la démarche est indispensable afin que l’algorithme de classification puisse les
différencier des zones agricoles.
Les friches, type d’occupation du sol très intéressante à la mission de la SAFER,
correspondent à des zones cultivables mais non cultivées ou abandonnées qui sont en
conséquence couvertes par de la végétation en transition. Ainsi, parmi les friches on peut
trouver des zones de savane herbacée, savane arbustive ou même des forêts dont le
comportement sur les images se confond avec la végétation naturelle des zones protégées. La
classification des zones couvertes par la végétation naturelle permettrait ainsi d’extraire les
friches à l’aide d’un croisement avec des informations reliées à l’aménagement du territoire
condensées par la SAFER dans une couche de « terres cultivables ».
Le paysage naturel de l’île constitue une mosaïque très hétérogène, non seulement à cause
de la variabilité climatique (humidité, température) et topographique, mais aussi comme
résultat des perturbations, d’origines naturelles (éruptions, glissements de terrain) et humaines.
L’arrivée de l’homme au milieu du XVIIème siècle, notamment avec la culture de canne à sucre
à partir du début du XIXème siècle, a produit de profondes transformations sur le paysage de l’île,
puisque la végétation d’origine a été détruite dans les zones propices au développement des
activités agricoles et à l’établissement des équipements humains. Ainsi, plusieurs espèces
introduites se sont répandues dans certaines zones de l’île, prenant la place des plantes
indigènes. Parmi ces espèces, la vigne marronne, qui tend à envahir la place des écosystèmes
naturels, fait actuellement l’objet de recherches et de mesures pour diminuer son impact sur la
végétation naturelle.
Les forêts naturelles sont notamment présentes dans la zone comprise dans le Parc National
de la Réunion, sur les endroits où l’altitude et la pente permettent le développement de cet
écosystème. Parmi ceux-ci, les plus représentatifs sont le reboisement d’Acacia decurrens et
d’Acacia heterophylla (Tamarins), et le bois de couleurs (Raunet 1991). Les forêts naturelles

9
longent aussi les ravines, mélangées à des cultures de vergers, et le littoral sur quelques
endroits, où dominent les Vacoas (Pandanus spp.) et les Filaos (Casuarina equisetofolia).
À partir d’une certaine altitude et dans quelques zones soumises récemment à des éruptions
la végétation est formée notamment par des savanes arbustives. Vers l’ouest de l’île, près du
littoral, les savanes arbustives et herbacées abondent parmi la végétation naturelle, et dans ce
cas elles sont dominées par des espèces introduites envahissantes adaptées aux climats secs (i.e.
Leucaena). Les savanes herbacées sont aussi présentes dans les zones naturelles plates
d’altitude où le niveau phréatique empêche le développement de la végétation vers des savanes
arbustives, ainsi que dans les murailles situées dans des zones sèches où le manque d’humidité
et la forte pente ne permettent pas le développement d’une végétation dense (i.e. Mafate).
Les sols minéraux sont aussi assez représentatifs de l’île, et ils correspondent aux coulées de
lave de différentes compositions et ancienneté, localisées dans l’enclos du Piton de la Fournaise,
au Piton des Neiges, à l’est de l’ile et vers le littoral. Les sols minéraux sont aussi présents sous
forme de roches massives, galets et sable dans le lit des rivières et ravines, et vers la plage, ainsi
que dans les zones découvertes par les glissements de terrain à cause de la forte pente.
1.3. DESCRIPTION DE L’APPROCHE METHODOLOGIQUE : UNE CLASSIFICATION SUPERVISEE
ORIENTEE-OBJET
La classification des images satellites part du principe que les éléments qui forment la
surface de la terre possèdent des propriétés particulières qui permettent de les différencier les
uns des autres sur les images. Parmi ces propriétés, la réflectance au niveau de pixel dans les
différentes bandes d’un capteur constitue l’unité fondamentale sur laquelle sont basées toutes
les approches de classification d’images optiques.
L’approche orienté pixel s’appuie seulement sur la valeur de chaque unité minimale de
l’image pour faire la classification. Ainsi, les pixels d’une image sont affectés à une classe en
fonction seulement de sa valeur de réflectance dans les différentes bandes ou néocanaux prises
comme variables de la classification. Néanmoins, les objets ne correspondent souvent pas à un
seul type de valeur radiométrique mais sont constitués de plusieurs couleurs (exemple d’une
parcelle de vigne constituée d’une alternance de pixels de sol nu et de végétation). Ces objets ne
sont donc pas seulement reconnaissables sur une image à partir de la réponse spectrale des
pixels individuels, mais aussi grâce à la sémantique contenue dans des objets formés par des
groupes de pixels et les relations entre eux (Baatz & Schäpe 2000). C’est la raison qui a motivé le
développement de l’approche orienté objet, qui commence par faire une partition de l’image en
entités, qui correspondent à des groupes de pixels ayant des propriétés relativement
homogènes, dans un processus appelé « segmentation ». L’approche orienté-objet s’avère
souvent plus efficace que l’approche orienté-pixel, surtout dans des paysages très hétérogènes
(Lebourgeois et al. 2017, Peña-Barragán et al. 2011).

10
La classification des objets issus de la segmentation peut être faite en prenant comme
référence des parcelles de vérité terrain, lesquelles servent à extraire les caractéristiques des
différentes classes visées sur les images ; dans ce cas on parle d’une classification supervisée.
1.3.1. Prétraitement des images
L’utilisation des images pour la classification implique la réalisation de prétraitements
conçus pour faire que les informations fournies par les images soient les plus précises possibles
et qu’elles représentent au mieux la réalité du paysage. Les prétraitements consistent, en
général, à faire des corrections radiométriques, des améliorations de la résolution spatiale et des
corrections géométriques.
Les corrections radiométriques comprennent un passage de la valeur des pixels à
réflectance, qui constitue la valeur physique qui reflète les propriétés optiques des cibles. L’idéal
serait d’éliminer les effets atmosphériques et calculer ainsi la réflectance TOC (Top of Canopy),
mais c’est un processus très compliqué car les données nécessaires sur les conditions
atmosphériques ne sont souvent pas disponibles dans les pays tropicaux. Nous avons donc
décidé de n’utiliser que des images du niveau TOA (Top of Atmosphere).
Le pansharpening, permet d’améliorer la résolution spatiale des images multispectrales par
rapport à une bande panchromatique (lorsque les capteurs en disposent). Cette bande
panchromatique possède une résolution spectrale plus basse parce qu’elle s’étend sur une
région vaste du spectre électromagnétique mais la taille du pixel est plus précise que dans le cas
des bandes multispectrales.
Les corrections géométriques consistent à faire une orthorectification de l’image pour
corriger les effets du relief, à l’aide d’un modèle numérique du terrain et des informations du
capteur. Lorsqu’il s’agit d’études qui portent sur des séries temporelles d’images, surtout quand
elles proviennent de capteurs différents, la mise en correspondance des informations contenues
sur les images par rapport à une image de référence (recalage) s’avère nécessaire.
1.3.2. La segmentation
Obtenir une segmentation satisfaisante de l’image en objets représentatifs est indispensable
pour aboutir ensuite à de bons résultats de classification. Néanmoins, ce n’est pas une tâche
simple et pour cette raison plusieurs méthodes ont été développées par différents experts.
Parmi celles-ci, la segmentation Multiresolution, proposée par Baatz & Schäpe (2000), crée les
objets en utilisant un algorithme de segmentation par croissance de régions, partant de l’unité
minimale (le pixel), dans un processus itératif qui cherche à minimiser l’hétérogénéité à
l’intérieur des segments générés, sur la base d’un critère radiométrique et d’un autre spatial. Le
critère radiométrique est basé sur la réponse spectrale des pixels tandis que l’hétérogénéité
spatiale est basée sur la forme des objets, spécifiquement la relation entre la surface et le
périmètre (Happ et al. 2010). La croissance des régions pour la formation de segments est ainsi
influencée par 3 paramètres définis par l’utilisateur :

11
L’échelle : ce paramètre est relié au degré d’hétérogénéité accepté pour fusionner des
segments. Il influence ainsi la taille de ceux-ci.
La forme : ce paramètre, qui varie entre 0 et 1, est relié à l’importance de la forme
contre la couleur. Une valeur de 0 donne toute l’importance à la couleur tandis que 0,5
confère la même importance au deux.
Compacité : variant entre 0 et 1, ce paramètre privilégie des formes plus compactes
lorsque sa valeur s’approche de 1, et des formes sinueuses dans le cas contraire.
L’utilisation des algorithmes de segmentation sur des images THRS implique des risques de
saturation de mémoire en raison de la taille de ces données. Afin d’éviter ce problème il existe
des algorithmes de segmentation qui permettent de faire une partition en tuiles de l’image,
lesquelles sont ensuite traitées indépendamment. Cette partition est faite en suivant le contour
des objets pour éviter la production d’artéfacts dans les bords des tuiles (Madhavi et al. 2017,
Happ et al. 2010).
1.3.3. L’extraction des variables pour la classification
Les variables de la classification sont calculées sur des caractéristiques des images, dont les
principales correspondent aux différentes bandes et indices radiométriques qui apportent des
informations utiles à différencier les objets en classes. Ces variables sont souvent calculées sur
des séries temporelles d’images afin d’inclure la variation temporelle des classes. Aussi, d’autres
caractéristiques telles que la texture (calculée sur des images THRS), l’altitude et la pente
(calculées à partir de modèles numériques de terrain –MNT-), peuvent fournir des informations
supplémentaires pour la classification (Lebourgeois et al. 2017, Peña-Barragán et al. 2011).
La variable la plus souvent utilisée est la moyenne des caractéristiques calculées sur les
objets issus de la segmentation, ainsi que sur les parcelles d’apprentissage utilisées pour la
modélisation, lorsqu’il s’agit d’une classification supervisée.
Les indices radiométriques sont obtenus à partir d’équations appliquées à la valeur des
pixels dans bandes différentes, dans le but de tirer profit des particularités du comportement
radiométrique de différents types d’objets. Par exemple le NDVI (indice normalisé de végétation)
utilise la haute réflectance de la végétation dans le proche infrarouge et sa basse réflectance
dans le rouge ; plus dense et vigoureuse est la végétation, plus cette tendance s’accentue.
La texture constitue une des caractéristiques importantes pour l’identification des objets sur
les images ; cette variable apporte des informations sur la distribution spatiale des pixels.
Haralick (1973) propose plusieurs indices pour mesurer la texture, calculés à partir d’une fenêtre
glissante dont on choisit la dimension et basés sur des matrices de dépendance de la variation
de gris dans des régions voisines de l’image. L’ensemble des variables fournit des informations
sur le contraste, l’homogénéité, l’existence des patrons dans les objets, ainsi que sur la
complexité et la nature des transitions de gris. D’autre part, les informations calculées sur les
MNT peuvent contribuer à l’identification des classes dont la localisation est restreinte à une
certaine altitude et/ou de pente.

12
1.3.4. Classification des objets issus de la segmentation
Les différentes variables extraites ainsi sur les différentes sources de données (série
d’images HRS, image THRS, MNT) permettent tout d’abord la génération d’un modèle de
classification. Dans le cas de la classification supervisée, ce modèle est construit à partir d’une
base de données d’apprentissage formée par des parcelles de types d’occupation du sol ciblés,
obtenues à partir de photo-interprétation ou de relevés de terrain, pour chacune desquelles les
variables sont calculées.
Pour calculer le modèle de classification il existe des options différentes d’algorithmes parmi
lesquels se trouve Random Forest. Ce type de modèle, développé par Breiman (2001), est une
méthode qui part de la création d’une « forêt » d’arbres de prédiction dont la combinaison
produit le résultat final de classification. Les arbres sont construits sur des sous-espaces de la
zone d’étude et à chaque nœud seulement quelques variables, sélectionnées de façon aléatoire,
sont disponibles pour faire une partition binaire. La classe de chaque objet est déterminée, après
l’application du modèle prédicteur des arbres, au travers d’un « Majority voting ». Dans la
structuration des arbres presque toutes les observations (données d’apprentissage) sont
utilisées au moins une fois, sauf une partie qui est destinée à l’estimation de la précision du
modèle. Les principaux paramètres du modèle sont le nombre maximal d’arbres dans la forêt et
la profondeur maximale de l’arbre (reliée au nombre de variables prises en compte). Random
Forest a l’avantage d’être facile à paramétrer et d’être performant dans le cas où un nombre
élevé de variables est utilisé. Enfin, implémenté sur le logiciel R, Random Forest permet
d’évaluer l’importance des variables et des différentes sources d’information dans la prédiction
des classes (Li et al. 2016, Rodriguez-Galiano et al. 2011, Cutler et al. 2007, Liaw & Wiener
2002).
1.3.5. Validation de la classification
La validation d’une classification supervisée est faite à l’aide d’une matrice de confusion qui
permet de confronter les résultats de la classification à un jeu de données de référence, qui doit
être différent des données utilisées pour faire la modélisation de la classification. Cette matrice
permet d’évaluer la précision de la classification (globale et par classe), et de détecter les
confusions entre classes. Les principaux indices calculés à partir de la matrice générée sont :
Pour la validation globale :
Précision globale (Overall accuracy index): c’est la proportion de données de validation
bien classées par la classification.
𝑃𝑟é𝑐𝑖𝑠𝑖𝑜𝑛 𝑔𝑙𝑜𝑏𝑎𝑙𝑒 = 𝑛𝑜𝑚𝑏𝑟𝑒 𝑡𝑜𝑡𝑎𝑙 𝑑𝑒 𝑝𝑖𝑥𝑒𝑙𝑠 (𝑜𝑢 𝑝𝑎𝑟𝑐𝑒𝑙𝑙𝑒𝑠) 𝑐𝑜𝑟𝑟𝑒𝑐𝑡𝑒𝑚𝑒𝑛𝑡 𝑐𝑙𝑎𝑠𝑠é𝑠
𝑛𝑜𝑚𝑏𝑟𝑒 𝑡𝑜𝑡𝑎𝑙 𝑑𝑒 𝑝𝑖𝑥𝑒𝑙𝑠 (𝑜𝑢 𝑝𝑎𝑟𝑐𝑒𝑙𝑙𝑒𝑠) 𝑑𝑒 𝑙𝑎 𝑏𝑎𝑠𝑒 𝑑𝑒 𝑑𝑜𝑛𝑛é𝑒𝑠 𝑑𝑒 𝑣𝑎𝑙𝑖𝑑𝑎𝑡𝑖𝑜𝑛
Indice de Kappa (Kappa index) : le test de kappa mesure le niveau d’accord d’une
classification. Une valeur de 1 correspond à un niveau d’accord parfait, alors que 0
indique que le niveau d’accord obtenu n’est pas différent d’un accord aléatoire
(Rosenfield & Fitzpatrick-Lins 1986).

13
Pour la validation par classe :
Précision de l’utilisateur (Precision of classe) : c’est la proportion de données de
validation affectées à une classe qui correspondent vraiment à cette classe :
𝑃𝑟é𝑐𝑖𝑠𝑖𝑜𝑛 𝑑𝑒 𝑙′𝑢𝑡𝑖𝑙𝑖𝑠𝑎𝑡𝑒𝑢𝑟 =𝑛𝑜𝑚𝑏𝑟𝑒 𝑑𝑒 𝑝𝑖𝑥𝑒𝑙𝑠 (𝑜𝑢 𝑝𝑎𝑟𝑐𝑒𝑙𝑙𝑒𝑠) 𝑐𝑜𝑟𝑟𝑒𝑐𝑡𝑒𝑚𝑒𝑛𝑡 𝑎𝑡𝑡𝑟𝑖𝑏𝑢é𝑠 à 𝑙𝑎 𝑐𝑙𝑎𝑠𝑠𝑒 𝑖
𝑛𝑜𝑚𝑏𝑟𝑒 𝑑𝑒 𝑝𝑖𝑥𝑒𝑙𝑠 (𝑜𝑢 𝑝𝑎𝑟𝑐𝑒𝑙𝑙𝑒𝑠) 𝑎𝑓𝑓𝑒𝑐𝑡é𝑠 à 𝑙𝑎 𝑐𝑙𝑎𝑠𝑠𝑒 𝑖
Précision du producteur (Recall of class): c’est la proportion de données d’une classe
dans le jeu de validation, qui a été bien classée :
𝑃𝑟é𝑐𝑖𝑠𝑖𝑜𝑛 𝑑𝑢 𝑝𝑟𝑜𝑑𝑢𝑐𝑡𝑒𝑢𝑟 =𝑛𝑜𝑚𝑏𝑟𝑒 𝑑𝑒 𝑝𝑖𝑥𝑒𝑙𝑠 (𝑜𝑢 𝑝𝑎𝑟𝑐𝑒𝑙𝑙𝑒𝑠)𝑐𝑜𝑟𝑟𝑒𝑐𝑡𝑒𝑚𝑒𝑛𝑡 𝑎𝑡𝑡𝑟𝑖𝑏𝑢é𝑠 à 𝑙𝑎 𝑐𝑙𝑎𝑠𝑠𝑒 𝑖
𝑛𝑜𝑚𝑏𝑟𝑒 𝑑𝑒 𝑝𝑖𝑥𝑒𝑙𝑠 (𝑜𝑢 𝑝𝑎𝑟𝑐𝑒𝑙𝑙𝑒𝑠) 𝑞𝑢𝑖 𝑎𝑝𝑝𝑎𝑟𝑡𝑖𝑒𝑛𝑛𝑒𝑛𝑡 à 𝑙𝑎 𝑐𝑙𝑎𝑠𝑠𝑒 𝑖
F-Score : c’est la moyenne harmonique des précisions par classe
𝑓 − 𝑠𝑐𝑜𝑟𝑒 = 2 ∗(𝑝𝑟é𝑐𝑖𝑠𝑖𝑜𝑛 𝑢𝑡𝑖𝑙𝑖𝑠𝑎𝑡𝑒𝑢𝑟) ∗ (𝑝𝑟é𝑐𝑖𝑠𝑖𝑜𝑛 𝑝𝑟𝑜𝑑𝑢𝑐𝑡𝑒𝑢𝑟)
(𝑝𝑟é𝑐𝑖𝑠𝑖𝑜𝑛 𝑢𝑡𝑖𝑙𝑖𝑠𝑎𝑡𝑒𝑢𝑟 + 𝑝𝑟é𝑐𝑖𝑠𝑖𝑜𝑛 𝑝𝑟𝑜𝑑𝑢𝑐𝑡𝑒𝑢𝑟)
1.4. ANTECEDENTS DE LA METHODE
L’équipe TETIS du CIRAD est partenaire dans des projets menés à l’échelle mondiale afin de
développer des méthodes automatiques pour classifier des images satellites à des fins de suivi
des zones agricoles.
Un des projets dans lesquels le CIRAD est partenaire est le JECAM12 qui constitue la partie
recherche et développement de GEOCLAM13, initiative conçue pour renforcer la capacité de la
communauté internationale à faire des prédictions précises et efficaces sur la productivité des
systèmes agricoles dans le monde. Son objectif est d’améliorer les systèmes d’alerte précoces
pour mieux lutter contre l’insécurité alimentaire (Bontemps et al. 2015). Le but de JECAM est
d’unifier des approches pour réaliser le suivi des systèmes agricoles mondiaux et améliorer les
pratiques culturales. L’expérience est menée dans une série de 12 sites pilotes représentant
différents types de pratiques agricoles. Les données terrain récoltées sur ces sites sont mises à la
disposition des partenaires et sont utilisées pour tester des méthodes de classification14.
Plusieurs travaux ont été publiés à partir des résultats dérivés de cette expérience. Parmi
ceux-ci, Bontemps et al. (2015) ont consolidé une base de données de séries temporelles
d’images HRS et de données terrain, pour 12 sites pilotes, afin de contribuer à préparer le terrain
pour l’exploitation d’images qui seraient disponibles après le lancement du premier satellite de
Sentinel-2. Ensuite, Inglada et al. (2015) ont testé une méthode de classification orienté-pixel
12
Joint Experiment of Crop Assessment and Monitoring 13
Global Agricultural Monitoring 14
Site internet du projet JECAM. http://www.jecam.org/?/project-overview/france-OSR-2017. Consulté en Juillet 2017

14
avec Random Forest pour la production de cartes d’occupation du sol à partir d’images SPOT4 et
Landsat-8, dans les mêmes 12 sites pilotes, trouvant de bons résultats, sauf pour Madagascar et
le Burkina Faso. Ensuite, Lebourgeois et al. (2017) ont testé une méthode de classification
orienté-objet, en utilisant le même type de classificateur, pour la production de cartes
d’occupation du sol agricole à Madagascar, à partir d’une série temporelle formée par des
images HRS SPOT5 et Landsat-8 et d’une couverture d’images THRS Pléiades.
Les différentes expérimentations menées sur ces sites ont motivé le développement de deux
chaînes pour le traitement automatique d’images satellites dans le cadre du Centre d’expertise
scientifique « Occupation du Sol Opérationnelle » (CES OSO) du pole THEIA. La première est la
chaîne IOTA-2, développé par le CESBIO15, adaptée à la classification de l’occupation du sol
testée notamment sur l’ensemble de la Métropole avec une approche orienté-pixel. La chaîne
Sitsproc, qui est utilisée dans ce stage, est conçue pour le traitement orienté-objet des images
concernant la classification de l’occupation du sol dans les pays du sud. Ces chaînes de
traitement, qui intègrent plusieurs algorithmes pour l’application de diverses méthodes de
télédétection, sont différenciées notamment par le type d’approche de classification sur lequel
elles sont basées.
15
Site internet du Système d’Information Environnemental de CESBIO. http://osr-cesbio.ups-tlse.fr/~oso/

15
2. MATERIELS ET METHODE
La méthode est basée sur l’application de la chaîne de traitement Sitsproc mettant en œuvre
une classification orientée objet de type supervisée et utilisant une image à très haute résolution
spatiale (THRS) et une série temporelle d’images à haute résolution spatiale (HRS). La
construction de la base de données de vérité terrain ainsi que quelques autres manipulations
ont dû être faites en dehors de la chaîne de traitement. Dans ce cas, nous avons entre autres
utilisé QGis ainsi que la boite à outils Orfeo Toolbox (OTB).
Par rapport aux ressources utilisées, il est important de noter que tous les logiciels et
presque la totalité des images sont de libre accès. Les images SPOT6/7 ne le sont pas, mais le
CIRAD, parmi d’autres institutions, peut bénéficier d’un accès facilité à ces données dans le cadre
du projet GEOSUD.
2.1. LES RESSOURCES INFORMATIQUES
2.1.1. La chaîne de traitement SITSPROC
La structure de Sistsproc est développée en langage Python et elle fait appel à plusieurs
librairies de ce même langage de programmation. Dans cette chaîne sont intégrés des modules
de ressources destinées au traitement de l’information spatiale, notamment celles issues de la
télédétection, telles que GDAL, OTB et d’autres modules développés de manière indépendante.
La chaîne de traitement en développement au sein de l’UMR-TETIS, notamment par Raffaele
Gaetano, adopte une méthode basée sur l’expérience accumulée lors d’études réalisées par
cette unité de recherche dans le cadre de projets liés au suivi et à la caractérisation de
l’occupation du sol dans les « pays du sud ». Dans le cadre de ce stage, la chaîne de traitement
est appliquée sur l’île de la Réunion mais les mêmes traitements sont effectués sur d’autres sites
afin d’en évaluer la généricité. Des ajustements à faire sur la chaîne se sont avérés nécessaires
lors de son application et ceux-ci étaient communiqués à son développeur qui identifiait et
faisait les modifications pertinentes sur les algorithmes.
Du point de vue de l’utilisateur, la chaîne de traitement est structurée en 4 algorithmes qui
doivent être lancés indépendamment, à partir d’une fenêtre de commandes OSGeo4W
(disponible dans le dossier de QGis et configurée dans l’étape d’installation de la chaîne), ainsi
que par un fichier de configuration qui doit être renseigné. Les algorithmes sont les suivants :
getLandsat-8.py et getSentinel-2.py : génèrent des fichiers intermédiaires pour le
téléchargement des images Sentinel-2 et Landsat-8, en fonction des paramètres définis
par l’utilisateur.
genProcessScript.py : génère le fichier ProcessScript.bat qui doit être lancé pour faire le
prétraitement de la série temporelle d’images ainsi que la création des masques de
nuages.

16
launchChain.py : permet de lancer le cœur principal de la chaîne de traitement, lequel est
divisé en 6 étapes qui peuvent être exécutées de manière indépendante :
Étape 0 : prétraitement de l’image THRS (Conversion à TOA/raster virtuel/Pansharpening)
Étape 1 : Segmentation de l’image THRS
Étape 2 : Recalage de la série temporelle d’images HRS sur l’image THRS
Étape 3 : Extraction des caractéristiques de la série temporelle
Étape 4 : Statistiques zonales des caractéristiques (calcul des variables)
Étape 5 : Modélisation de la classification
Étape 6 : Classification
Toute la démarche nécessaire pour l’installation de la chaîne de traitement est décrite en
détail dans sa notice d’utilisation. D’abord il faut installer le logiciel QGis, disponible
gratuitement sur leur site internet, puis plusieurs dépendances : Wget, un build personnalisé
d’Orfeo Toolbox (OTB), un module de calcul de masques de nuages/ombres pyhton-fmask, un
module python appelé Rios et le programme Git pour l’installation et mise à jour de la chaîne.
La configuration de la chaîne de traitement se fait grâce au fichier d’extension .cfg qui se
trouve dans le dossier de la chaîne de traitement. Ce fichier permet de définir plusieurs
paramètres qui conviennent à l’utilisateur et qui sont répartis en plusieurs rubriques :
Configuration général, Configuration Sentinel-2, Configuration Landsat-8, Configuration de la
scène THRS, Recalage THRS - Série temporelle, Configuration de l’entraînement (modélisation de
la classification), configuration du résultat de la classification et caractéristiques additionnelles.
2.1.2. Orfeo ToolBox
OTB est un logiciel de libre accès initié par le CNES en 2006 et qui est constamment en
développement. Sa structure est constituée d’une librairie avec une série d’algorithmes
construits en langage C++ qui servent au traitement des ressources issues de la télédétection16.
L’utilisation des modules d’OTB peut se faire de plusieurs manières :
Par ligne de commande. Dans ce cas, nous utilisons la fenêtre de commandes OSGeo4W,
contenue dans le dossier de QGis.
Sur QGIS, accessible depuis la fenêtre de boîte à outils.
Sur l’interface graphique MAPLA, disponible dans le dossier d’OTB de la version
téléchargeable sur le site Internet.
OTB permet également aux développeurs la création de classes d’OTB afin d’étendre les
possibilités de traitements. Pour cette raison, on utilise dans ce travail une version personnalisée
16
Site internet OTB. https://www.orfeo-toolbox.org/. Consulté en Juillet 2017.

17
qui contient quelques classes qui n’ont pas été créées par les développeurs d’OTB, mais par
d’autres personnes qui suivent le protocole d’OTB.
2.1.3. QGis
L’installation de QGis nous fournit la fenêtre de commandes OSGeo4W sur laquelle sont
lancés les algorithmes de la chaîne de traitement, ainsi que les commandes d’OTB utilisées
indépendamment. La chaîne de traitement utilise certains modules de bibliothèques mis à
disposition par QGis (par exemple GDAL). L’interface de QGis, en tant que logiciel de SIG, nous a
permis de faire plusieurs démarches de la méthodologie ; par exemple, la création de la base de
données de vérité terrain et la création de mosaïques de l’image THRS.
2.2. LES RESSOURCES EN IMAGERIE
La chaîne de traitement utilise des images de trois satellites différents : (i) la série
temporelle d’images à haute résolution spatiale (HRS), formée par des images Sentinel-2 et
Landsat-8 ; ces dernières sont utiles en tant que complément des images Sentinel-2 pour
contourner les problèmes de la couverture nuageuse qui empêche l’exploitation de toute la série
Sentinel-2 disponible dans l’intervalle de temps défini, et (ii) une image à très haute résolution
spatiale (THRS) utilisée pour faire la segmentation et extraire quelques caractéristiques pour la
classification. Dans notre cas il s’agit d’une image SPOT6.
Sentinel-2 est une constellation de satellites de l’Agence Spatiale Européenne (ESA) qui fait
partie d’un programme de suivi de l’environnement (programme Copernicus). Ces deux satellites
sont placés à 180° l’un de l’autre. Le premier satellite, Sentinel-2A, a été lancé le 23 juin 2015 et
le deuxième, Sentinel-2B, le 7 mars 2017. Le premier satellite permet de revisiter le même
endroit tous les 10 jours, mais une image est disponible tous les 5 jours depuis que le deuxième
satellite a été lancé2.
Les bandes multispectrales de Sentinel-2 offrent beaucoup de potentiel dans les études de
l’environnement, en permettant le calcul de divers indices17. L’information captée par ce satellite
s’avère très utile pour la foresterie et l’agriculture. Ces images permettent également le suivi de
la croissance de la végétation, la cartographie du changement d’occupation du sol, le suivi des
forêts au niveau mondial, de la pollution des eaux et des catastrophes naturelles18.
Les images Sentinel-2 possèdent 12 bandes spectrales qui comprennent une plage du
spectre qui va du visible jusqu’au moyen infrarouge, avec des résolutions spatiales de 10, 20 et
60 m. Les trois bandes dans le « red-edge » fournissent des informations importantes sur l’état
de la végétation4.
17
http://www.sentinel-hub.com/data_sources. Consulté en Août 2017. 18
Site internet de l’ESA. http://www.esa.int/Our_Activities/Observing_the_Earth/Copernicus/Sentinel-2/Introducing_Sentinel-2
18
LANDSAT est un ancien programme développé par l’Agence Spatiale Américaine (NASA), qui
fonctionne depuis 1972. Le satellite le plus récent, Landsat-8, a été lancé en 2013. Les images
ont des applications en agriculture, cartographie, géologie, foresterie, aménagement de
territoires, suivi et éducation14. Landsat-8 comprend une bande panchromatique, avec une
résolution radiométrique limité mais d’une taille de pixel de 15 m, alors que la résolution
spatiale des bandes multispectrales est de 30 m.
SPOT est une famille de satellites de l’Agence Spatiale Française (CNES) dont le premier a été
lancé en 1985. SPOT6 et SPOT7, fabriqués et exploités par Airbus DS, ont été lancés
respectivement en septembre 2012 et juin 2014. Ils garantissent la disponibilité des données à
très haute résolution jusqu’à 2024 avec une couverture mondiale. Ces images ont des
applications en défense, agriculture, cartographie et suivi de l’environnement. Ces images sont
constituées par 4 bandes multispectrales (bleu, vert, rouge et proche infrarouge) de 6 m de
résolution spatiale et une bande panchromatique de 1,5 m19.
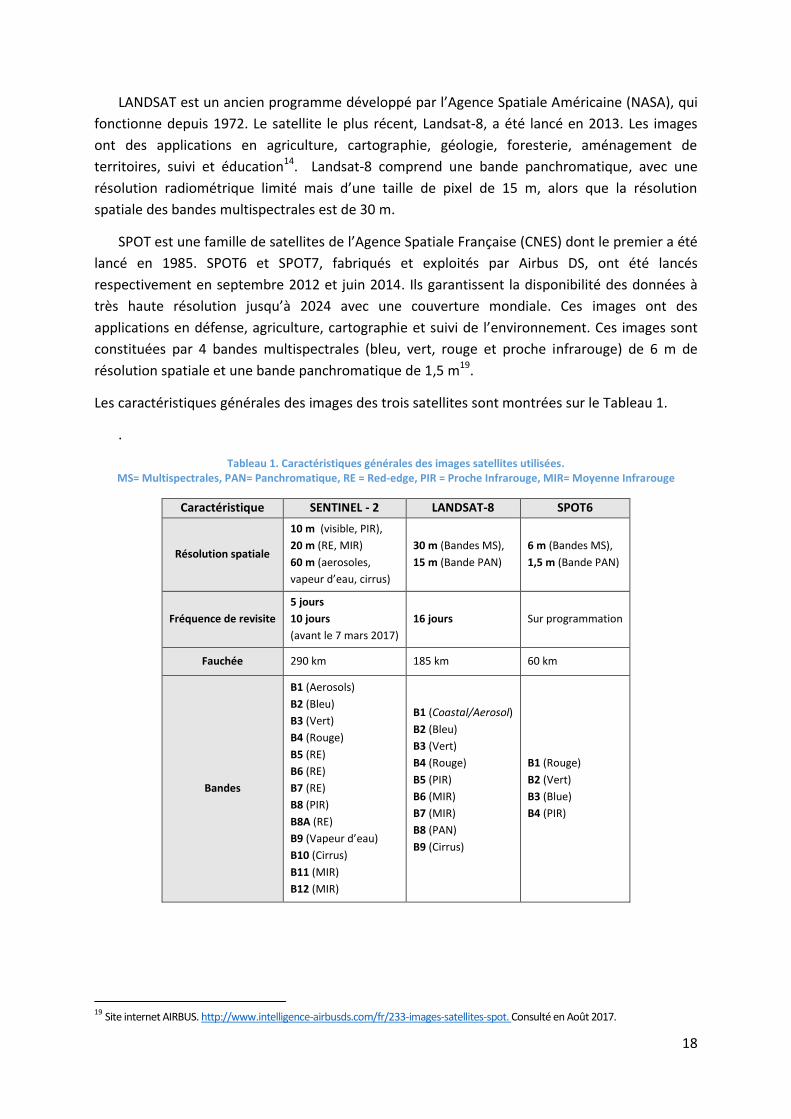
Les caractéristiques générales des images des trois satellites sont montrées sur le Tableau 1.
.
Tableau 1. Caractéristiques générales des images satellites utilisées. MS= Multispectrales, PAN= Panchromatique, RE = Red-edge, PIR = Proche Infrarouge, MIR= Moyenne Infrarouge
Caractéristique SENTINEL - 2 LANDSAT-8 SPOT6
Résolution spatiale
10 m (visible, PIR),
20 m (RE, MIR)
60 m (aerosoles,
vapeur d’eau, cirrus)
30 m (Bandes MS),
15 m (Bande PAN)
6 m (Bandes MS),
1,5 m (Bande PAN)
Fréquence de revisite
5 jours
10 jours
(avant le 7 mars 2017)
16 jours Sur programmation
Fauchée 290 km 185 km 60 km
Bandes
B1 (Aerosols)
B2 (Bleu)
B3 (Vert)
B4 (Rouge)
B5 (RE)
B6 (RE)
B7 (RE)
B8 (PIR)
B8A (RE)
B9 (Vapeur d’eau)
B10 (Cirrus)
B11 (MIR)
B12 (MIR)
B1 (Coastal/Aerosol)
B2 (Bleu)
B3 (Vert)
B4 (Rouge)
B5 (PIR)
B6 (MIR)
B7 (MIR)
B8 (PAN)
B9 (Cirrus)
B1 (Rouge)
B2 (Vert)
B3 (Blue)
B4 (PIR)
19
Site internet AIRBUS. http://www.intelligence-airbusds.com/fr/233-images-satellites-spot. Consulté en Août 2017.

19
2.3. METHODE
La Figure 2 présente les étapes impliquées dans la démarche méthodologique, ainsi que les
outils informatiques utilisés. Ces étapes sont ensuite décrites.
Figure 2. Schéma de la méthode suivi et les ressources utilisés pour la classification des images
2.3.1. Construction de la base de données terrain
La base de données terrain est formée par des polygones qui constituent des échantillons de
différents types d’occupation du sol présents dans l’île et qui ont été utilisés dans l’analyse. Pour
sélectionner les classes, quelques critères ont été pris en compte comme la possibilité
d’identifier le type d’occupation sur l’image, sa représentativité en termes de surface et une
taille des parcelles adaptée à la résolution des images disponibles.
La construction de la base de données de vérité terrain a été effectuée sur l’image SPOT6,
mais cela a impliqué l’utilisation de plusieurs sources d’information de référence :
Base de données d’occupation du sol 2014 : la BOS constitue la principale source
d’information d’occupation du sol dans l’île. Elle est élaborée par la Direction de
l’Alimentation, de l’Agriculture et de la Forêt de La Réunion (DAAF). Cette base de
données est formée par les parcelles de la Surface Agricole Utilisée. Sa mise à jour se
réalise annuellement sur la base des déclarations faites par les agriculteurs qui reçoivent
des aides financières pour leurs exploitations. Nous avons utilisé la BOS 2014 parce qu’au
premier semestre de 2017 c’était la dernière version disponible.

20
Expertise des collègues du CIRAD – La Réunion
Sorties terrain : en total nous avons réalisé 3 sorties terrain lors desquelles nous avons
pris des points GPS des cultures trouvées sur les parcours. Cela nous a permis d’identifier
l’apparence des certaines cultures sur l’image, ainsi que d’identifier les localisations où
sont restreintes ou concentrées quelques types d’occupation du sol.
Orthophotographies de l’IGN20 des années 2011 et 2013 : Ces images sont disponibles
dans le site AWARE du CIRAD et elles peuvent être chargées comme couche WMS sur
QGIS21. Nous avons utilisé cette source d’information en vérifiant que l’occupation du sol
n’avait pas changé par rapport à la date de la prise de l’image THRS.
Nous avons fait attention à ce que les parcelles comprennent seulement des pixels de la classe
visée et à éviter l’effet de bord laissant une bordure entre la limite du polygone et le contour de
la parcelle (Figure 3)
Figure 3. Exemple de parcelles de la base de données terrain
Les classes d’occupation du sol ont été organisées dans un système de nomenclature
emboitée inspirée du projet JECAM (Tableau 2). Pour chaque type d’occupation du sol et pour
tous les niveaux, un code provisionnel en format entier a été créé. Cette démarche est
indispensable puisque l’algorithme de classification ne gère pas les catégories ordinales.
20
Institute National de l’Information Géographique et Forestière 21
Pour plus d’information consulter le manuel utilisateur d’AWARE. CIRAD 2016. Disponible sur http://aware.cirad.fr/static/user_manual/Manuel_Utilisateur_AWARE.pdf

21
Tableau 2. Nomenclature utilisée pour faire la classification
Niveau 1 Niveau 2 Niveau 3 Niveau 4
Zone cultivée
Cultures annuelles et pluriannuelles
Cultures maraichères
Cristophine
Ananas
Curcuma
Pomme de terre
Autres cultures maraichères
Cultures sucrières Canne à sucre
Canne replantée
Cultures de rente Géranium
Cultures ligneuses Vergers
Mangue
Letchi
Agrumes
Cocotier
Banane
Plantations forestières Cryptomeria
Prairies Prairies Prairies
Zone non cultivée
Végétation naturelle
Forêt naturelle Forêt naturelle
Savane arbustive Savane arbustive
Vigne marronne
Savane herbacée savane herbacée
Sols minéraux Sols minéraux Sols minéraux
Surfaces construites Surfaces construites Surfaces construites
Cultures sous serre Cultures sous serre
Eau Eau Eau
Ombres Ombres Ombres
La base de données de vérité terrain a été divisée en deux couches : une couche
d’apprentissage et une couche de validation. Pour cela nous avons utilisé l’outil de QGis
« sélection aléatoire depuis des sous-ensemble ». Dans notre cas nous avons sélectionné 20%
des parcelles par classe pour la validation.
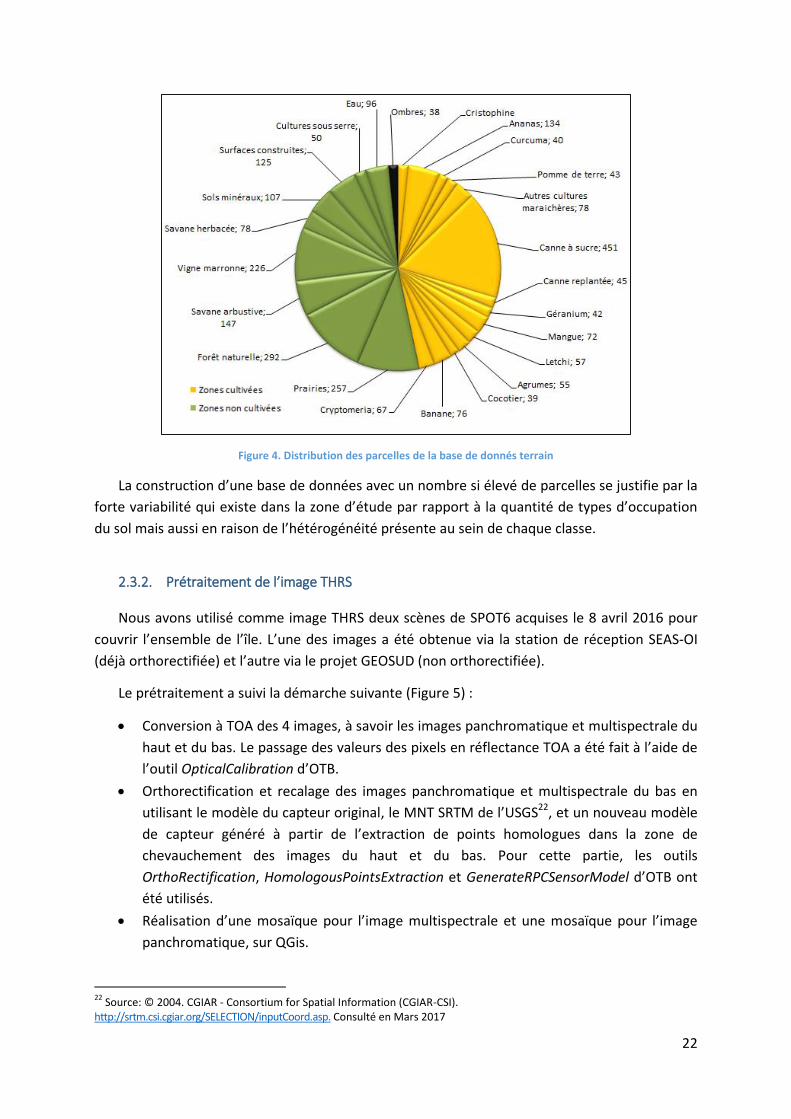
La base de données de vérité terrain est formée par 2650 polygones dont l’ensemble
représente 1% de la surface de la zone d’étude. La distribution du nombre de parcelles par classe
est montrée sur la Figure 4.
22
Figure 4. Distribution des parcelles de la base de donnés terrain
La construction d’une base de données avec un nombre si élevé de parcelles se justifie par la
forte variabilité qui existe dans la zone d’étude par rapport à la quantité de types d’occupation
du sol mais aussi en raison de l’hétérogénéité présente au sein de chaque classe.
2.3.2. Prétraitement de l’image THRS
Nous avons utilisé comme image THRS deux scènes de SPOT6 acquises le 8 avril 2016 pour
couvrir l’ensemble de l’île. L’une des images a été obtenue via la station de réception SEAS-OI
(déjà orthorectifiée) et l’autre via le projet GEOSUD (non orthorectifiée).
Le prétraitement a suivi la démarche suivante (Figure 5) :
Conversion à TOA des 4 images, à savoir les images panchromatique et multispectrale du
haut et du bas. Le passage des valeurs des pixels en réflectance TOA a été fait à l’aide de
l’outil OpticalCalibration d’OTB.
Orthorectification et recalage des images panchromatique et multispectrale du bas en
utilisant le modèle du capteur original, le MNT SRTM de l’USGS22, et un nouveau modèle
de capteur généré à partir de l’extraction de points homologues dans la zone de
chevauchement des images du haut et du bas. Pour cette partie, les outils
OrthoRectification, HomologousPointsExtraction et GenerateRPCSensorModel d’OTB ont
été utilisés.
Réalisation d’une mosaïque pour l’image multispectrale et une mosaïque pour l’image
panchromatique, sur QGis.
22
Source: © 2004. CGIAR - Consortium for Spatial Information (CGIAR-CSI). http://srtm.csi.cgiar.org/SELECTION/inputCoord.asp. Consulté en Mars 2017

23
Fusion des mosaïques des images panchromatique et multispectrale, au travers d’un
pansharpening, afin d’obtenir une image unique et complète de l’île avec la résolution
radiométrique de l’image multispectrale et la taille du pixel de l’image panchromatique.
Figure 5. Prétraitement de l’image THRS
Bien que l’étape 0 de la chaîne de traitement ait été conçue pour faire la conversion à TOA et
le pansherpening pour l’image THRS, ces deux étapes ont été faites autrement. Dans le cas de la
conversion à TOA, cela était nécessaire puisque nous utilisions deux images, alors que la chaîne
n’était prévue que pour une seule. Pour le pansharpening, nous avons trouvé que la méthode
Bayésienne, utilisée par la chaîne de traitement, ne convenait pas au cas de La Réunion puisque
elle produit des pixels de « no –data » dans la bande du proche infrarouge au niveau de chaque
bâtiment. Nous avons donc utilisé un autre algorithme disponible sur la boîte à outils d’OTB
(Bundle to Perfect Sensor).
2.3.3. Acquisition et prétraitement de la série temporelle d’images HRS
La série temporelle d’images Sentinel-2 et Landsat-8 a été téléchargée sur le site d’Amazon
web services au travers d’un algorithme annexe à la chaîne de traitement qui permet d’acquérir
les images en fonction d’une période de dates et d’un pourcentage maximal de nuages, parmi
d’autres paramètres définis par l’utilisateur. L’algorithme découpe chaque image en utilisant
une couche de type vecteur délimitant la zone d’étude.
Les prétraitements de la série temporelle Landsat-8 et Sentinel-2 sont également réalisés par
un des algorithmes annexes à la chaîne de traitement. Pour Landsat-8 les prétraitements
correspondent à la conversion en réflectance TOA, la concaténation de bandes (layer stack) et le
pansharpening (avec la méthode bayésienne), et pour les images Sentinel-2, le rééchantillonage
des bandes à 10 m de résolution et la concaténation des bandes ; les images Sentinel-2 étant
déjà en réflectance TOA au moment du téléchargement. L’algorithme de prétraitement créé
24
également un masque de nuages et d’ombres pour chaque image de la série temporelle à l’aide
du module Python f-mask23.
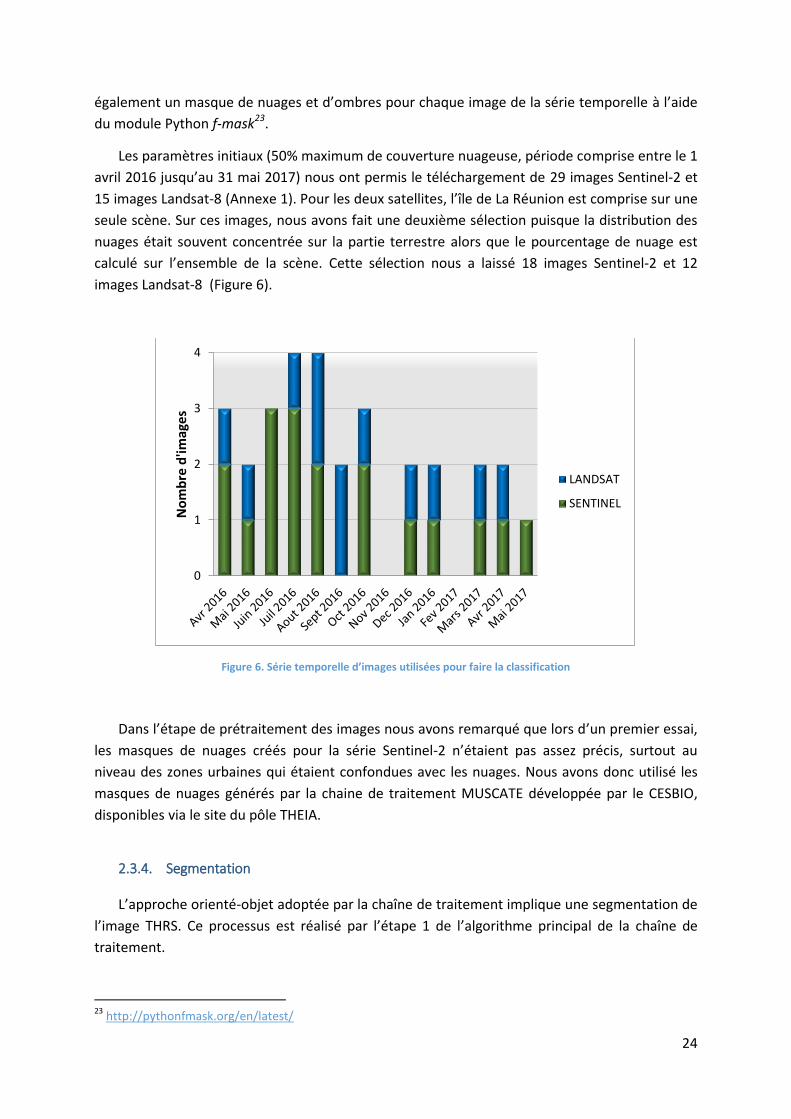
Les paramètres initiaux (50% maximum de couverture nuageuse, période comprise entre le 1
avril 2016 jusqu’au 31 mai 2017) nous ont permis le téléchargement de 29 images Sentinel-2 et
15 images Landsat-8 (Annexe 1). Pour les deux satellites, l’île de La Réunion est comprise sur une
seule scène. Sur ces images, nous avons fait une deuxième sélection puisque la distribution des
nuages était souvent concentrée sur la partie terrestre alors que le pourcentage de nuage est
calculé sur l’ensemble de la scène. Cette sélection nous a laissé 18 images Sentinel-2 et 12
images Landsat-8 (Figure 6).
Figure 6. Série temporelle d’images utilisées pour faire la classification
Dans l’étape de prétraitement des images nous avons remarqué que lors d’un premier essai,
les masques de nuages créés pour la série Sentinel-2 n’étaient pas assez précis, surtout au
niveau des zones urbaines qui étaient confondues avec les nuages. Nous avons donc utilisé les
masques de nuages générés par la chaine de traitement MUSCATE développée par le CESBIO,
disponibles via le site du pôle THEIA.
2.3.4. Segmentation
L’approche orienté-objet adoptée par la chaîne de traitement implique une segmentation de
l’image THRS. Ce processus est réalisé par l’étape 1 de l’algorithme principal de la chaîne de
traitement.
23
http://pythonfmask.org/en/latest/
0
1
2
3
4
No
mb
re d
'imag
es
LANDSAT
SENTINEL

25
L’algorithme de segmentation utilisé par la chaîne de traitement est celui de Baatz & Schäpe
(2000), pour lequel l’utilisateur doit définir 3 paramètres : échelle, forme et compacité. Sur la
version personnalisée d’OTB il existe deux outils qui permettent de faire la segmentation avec
cet algorithme : GenericRegionMerging et LSGRM (Large scale generic region merging). La
première, applicable à des images de petite taille, nous a permis de faire des essais de
segmentation sur des extraits d’image d’une taille de 1000 m x 1000 m approximativement, afin
de trouver la combinaison des paramètres qui s’adapte le mieux à notre image THRS. Le
deuxième outil, LSGRM, est celui adopté par la chaîne, qui applique le même algorithme
GenericRegionMerging mais en faisant une partition préliminaire de l’image en tuiles, en
fonction de la capacité de la mémoire RAM disponible sur l’ordinateur. Cette partition en tuiles
permet le traitement d’images de grande taille, comme c’est le cas de l’image THRS qui couvre
toute l’île.
Après plusieurs essais de segmentation, nous avons choisi la combinaison de paramètres
suivante : Echelle : 230, Forme : 0,5 et Compacité : 0,7.
Un aperçu de la segmentation est montré sur la Figure 7.
Figure 7. Aperçu de la segmentation produite avec les paramètres choisis. Source : Image SPOT6 du 8 avril 2016 (©2016 - AIRBUS DS - All rights reserved Diffusion SEAS-OI)
Après cette étape, la base de données d’apprentissage est intersectée avec la couche
résultant de la segmentation. Cela avec l’objectif d’avoir des parcelles d’apprentissage plus
homogènes du point de vue des critères de segmentation. C’est cette couche de données
d’apprentissage fractionnées qui va être utilisée par la chaîne de traitement dans les étapes
suivantes de sa méthode.

26
2.3.5. Recalage des images HRS sur l’image THRS
Le recalage de la série temporelle d’images Sentinel-2 et Landsat-8 est réalisé lors de l’étape
2 de la chaîne de traitement. Ce recalage prend comme référence l’image SPOT6. Ce processus,
similaire à celui décrit pour l’orthorectification d’une des scènes de l’image THRS, est basé sur la
création d’un nouveau modèle de capteur qui est généré à partir des points homologues extraits
sur les images de la série temporelle par rapport à l’image THRS.
2.3.6. Extraction des caractéristiques
L’extraction des caractéristiques, ainsi que le remplissage de trous sur les images, est fait par
l’étape 3 de l’algorithme principal de la chaîne de traitement.
Dans notre cas, la plupart des caractéristiques sur lesquelles les variables sont calculées
correspondent aux valeurs des indices radiométriques produits sur la série temporelle d’images
Landsat-8 et Sentinel-2, ainsi que plusieurs de ses bandes radiométriques. Les indices
radiométriques sont calculés pour chacune des images de la série temporelle, sauf le RNDVI (red-
edge NDVI) qui est adapté seulement aux images Sentinel-2. Nous avons également inclus les
bandes spectrales de l’image THRS.
D’autres variables ont été ajoutées : (i) plusieurs indices de texture basés sur l’image SPOT6
panchromatique et calculés avec l’algorithme de Haralick et al. (1973) implémenté sur OTB
(l’outil SelectiveHaralickTextures). Après plusieurs tests, nous avons choisi une fenêtre glissante
de 11 pixels et les indices « Energy », « Entropy » et « Contrast » parmi les 7 indices proposés ;
(ii) l’altitude et les pentes calculées à partir du MNT produit par IGN (MNT Litto3D® d’une
résolution spatiale de 5m).
Dans le fichier de configuration de la chaîne de traitement, l’utilisateur peut choisir les
bandes et les indices de la série temporelle qui l’intéressent ; pour l’instant la chaîne de
traitement permet de calculer de façon automatique 5 indices pour les images Landsat-8 et 6
indices dans les cas de Sentinel-2. Les autres caractéristiques peuvent être ajoutées en mettant
leur chemin de fichier sur ce fichier de configuration.
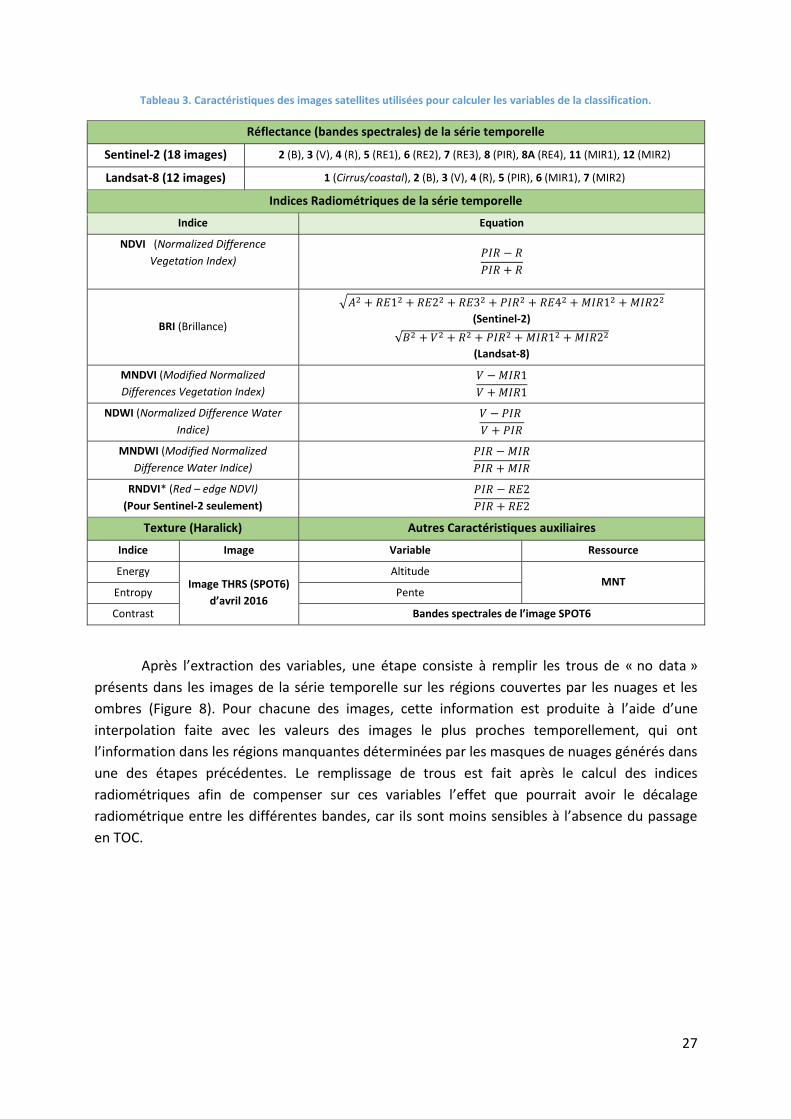
Les différentes caractéristiques sur lesquelles les variables ont été calculées sont montrées
sur le Tableau 3.
27
Tableau 3. Caractéristiques des images satellites utilisées pour calculer les variables de la classification.
Réflectance (bandes spectrales) de la série temporelle
Sentinel-2 (18 images) 2 (B), 3 (V), 4 (R), 5 (RE1), 6 (RE2), 7 (RE3), 8 (PIR), 8A (RE4), 11 (MIR1), 12 (MIR2)
Landsat-8 (12 images) 1 (Cirrus/coastal), 2 (B), 3 (V), 4 (R), 5 (PIR), 6 (MIR1), 7 (MIR2)
Indices Radiométriques de la série temporelle
Indice Equation
NDVI (Normalized Difference
Vegetation Index)
𝑃𝐼𝑅 − 𝑅
𝑃𝐼𝑅 + 𝑅
BRI (Brillance)
√𝐴2 + 𝑅𝐸12 + 𝑅𝐸22 + 𝑅𝐸32 + 𝑃𝐼𝑅2 + 𝑅𝐸42 + 𝑀𝐼𝑅12 + 𝑀𝐼𝑅22
(Sentinel-2)
√𝐵2 + 𝑉2 + 𝑅2 + 𝑃𝐼𝑅2 + 𝑀𝐼𝑅12 + 𝑀𝐼𝑅22
(Landsat-8)
MNDVI (Modified Normalized
Differences Vegetation Index)
𝑉 − 𝑀𝐼𝑅1
𝑉 + 𝑀𝐼𝑅1
NDWI (Normalized Difference Water
Indice)
𝑉 − 𝑃𝐼𝑅
𝑉 + 𝑃𝐼𝑅
MNDWI (Modified Normalized
Difference Water Indice)
𝑃𝐼𝑅 − 𝑀𝐼𝑅
𝑃𝐼𝑅 + 𝑀𝐼𝑅
RNDVI* (Red – edge NDVI)
(Pour Sentinel-2 seulement)
𝑃𝐼𝑅 − 𝑅𝐸2
𝑃𝐼𝑅 + 𝑅𝐸2
Texture (Haralick) Autres Caractéristiques auxiliaires
Indice Image Variable Ressource
Energy Image THRS (SPOT6)
d’avril 2016
Altitude MNT
Entropy Pente
Contrast Bandes spectrales de l’image SPOT6
Après l’extraction des variables, une étape consiste à remplir les trous de « no data »
présents dans les images de la série temporelle sur les régions couvertes par les nuages et les
ombres (Figure 8). Pour chacune des images, cette information est produite à l’aide d’une
interpolation faite avec les valeurs des images le plus proches temporellement, qui ont
l’information dans les régions manquantes déterminées par les masques de nuages générés dans
une des étapes précédentes. Le remplissage de trous est fait après le calcul des indices
radiométriques afin de compenser sur ces variables l’effet que pourrait avoir le décalage
radiométrique entre les différentes bandes, car ils sont moins sensibles à l’absence du passage
en TOC.

28
Figure 8. Exemple du remplissage des trous produits par les nuages sur la bande 2 de l’image Sentinel-2 du 17 avril 2016.
2.3.7. Statistiques zonales
Il s’agit de l’étape 4 de la chaîne de traitement.
Cette étape consiste à calculer les variables de la classification pour toutes les parcelles de la
base de données d’apprentissage ainsi que pour les objets issus de la segmentation. Chaque
variable correspond à la moyenne de la valeur des pixels pour chaque caractéristique. Pour
l’instant, la chaîne de traitement calcule seulement la moyenne, mais d’autres variables, comme
l’écart type, ont été utilisées dans d’autres études.
2.3.8. Classification
La classification est divisée en deux étapes : la modélisation et la prédiction, faites par les
étapes 5 et 6 de la chaîne de traitement. D’un côté, l’étape 5 réalise une modélisation de la
classification à partir des valeurs des variables des parcelles d’apprentissage. L’étape 6 classifie
les objets issus de la segmentation, en utilisant le modèle de prédiction.
La chaîne de traitement utilise pour la modélisation le module d’OTB TrainVecteurClassifier.
Le modèle de classification, ainsi que les paramètres du modèle, sont définis dans le fichier de
configuration de la chaîne de traitement. Le modèle utilisé pour faire la classification est Random
Forest avec comme paramètres une profondeur maximale de l’arbre de 10 et un nombre
maximal d’arbres dans la forêt de 400.
Pour faire la classification, la chaîne de traitement effectue une prédiction des classes sur les
objets issus de la segmentation en utilisant l’outil VectorClassifier d’OTB.
2.3.9. Validation de la classification
L’évaluation de la classification est basée sur un jeu de données de validation qui correspond
à 20% des parcelles de la base de données de vérité terrain, pour chaque classe. La construction
de la matrice de confusion a été réalisée avec l’outil ComputeConfusionMatrix d’OTB. Une
évaluation visuelle de la classification a également été réalisée afin de repérer les sources
d’erreur.
29
3. RESULTATS ET DISCUSSION
Les résultats de précision globale de la classification sont montrés pour les 4 niveaux de la
nomenclature dans le Tableau 4. On remarque une précision croissante du niveau 4 vers le
niveau 1 de la nomenclature, ce qui s’explique par l’élimination de la fraction de confusion
existant entre les classes qui sont regroupées, pour un niveau déterminé.
Tableau 4. Précision globale et indice de Kappa résultants de la classification dans le 4 niveau de la nomeclature
Indice de précision Niveau 1 Niveau 2 Niveau 3 Niveau 4
Indice de Kappa 0,9 0,88 0.87 0.86
Précision globale 95,0% 91,0% 89,0% 87,8%
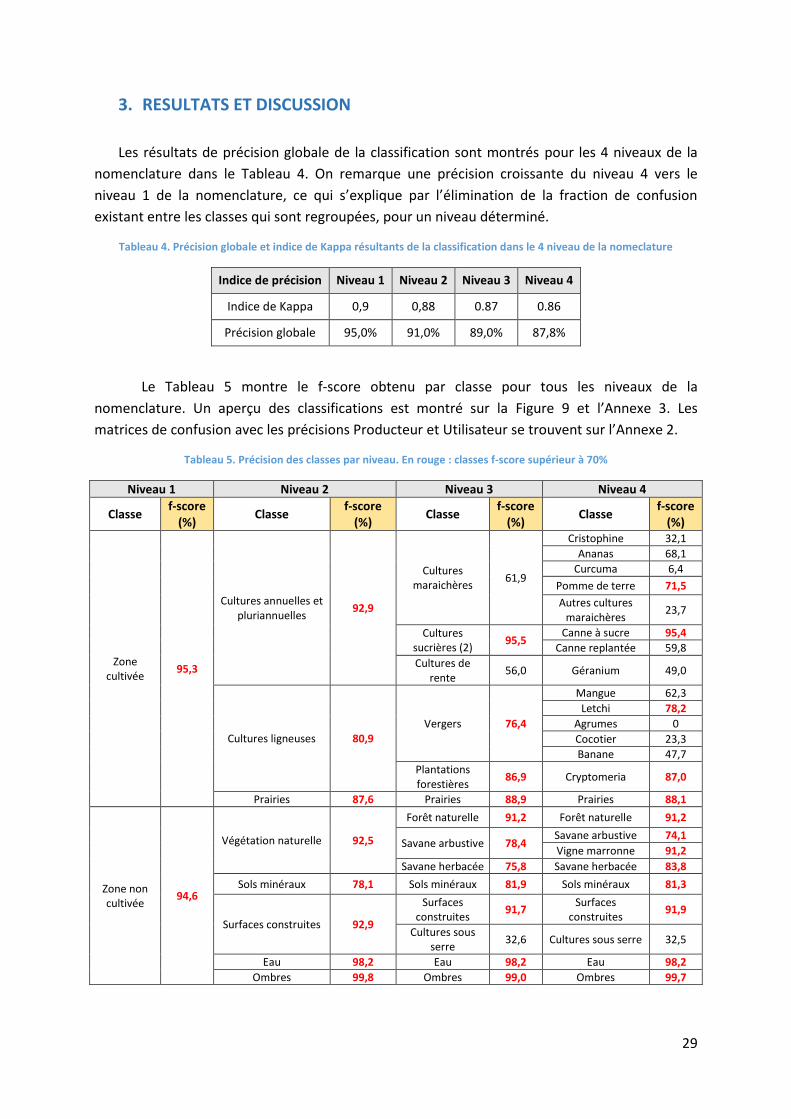
Le Tableau 5 montre le f-score obtenu par classe pour tous les niveaux de la
nomenclature. Un aperçu des classifications est montré sur la Figure 9 et l’Annexe 3. Les
matrices de confusion avec les précisions Producteur et Utilisateur se trouvent sur l’Annexe 2.
Tableau 5. Précision des classes par niveau. En rouge : classes f-score supérieur à 70%
Niveau 1 Niveau 2 Niveau 3 Niveau 4
Classe f-score
(%) Classe
f-score (%)
Classe f-score
(%) Classe
f-score (%)
Zone cultivée
95,3
Cultures annuelles et pluriannuelles
92,9
Cultures maraichères
61,9
Cristophine 32,1
Ananas 68,1
Curcuma 6,4
Pomme de terre 71,5
Autres cultures maraichères
23,7
Cultures sucrières (2)
95,5 Canne à sucre 95,4
Canne replantée 59,8
Cultures de rente
56,0 Géranium 49,0
Cultures ligneuses 80,9 Vergers 76,4
Mangue 62,3
Letchi 78,2
Agrumes 0
Cocotier 23,3
Banane 47,7
Plantations forestières
86,9 Cryptomeria 87,0
Prairies 87,6 Prairies 88,9 Prairies 88,1
Zone non cultivée
94,6
Végétation naturelle 92,5
Forêt naturelle 91,2 Forêt naturelle 91,2
Savane arbustive 78,4 Savane arbustive 74,1
Vigne marronne 91,2
Savane herbacée 75,8 Savane herbacée 83,8
Sols minéraux 78,1 Sols minéraux 81,9 Sols minéraux 81,3
Surfaces construites 92,9
Surfaces construites
91,7 Surfaces
construites 91,9
Cultures sous serre
32,6 Cultures sous serre 32,5
Eau 98,2 Eau 98,2 Eau 98,2
Ombres 99,8 Ombres 99,0 Ombres 99,7
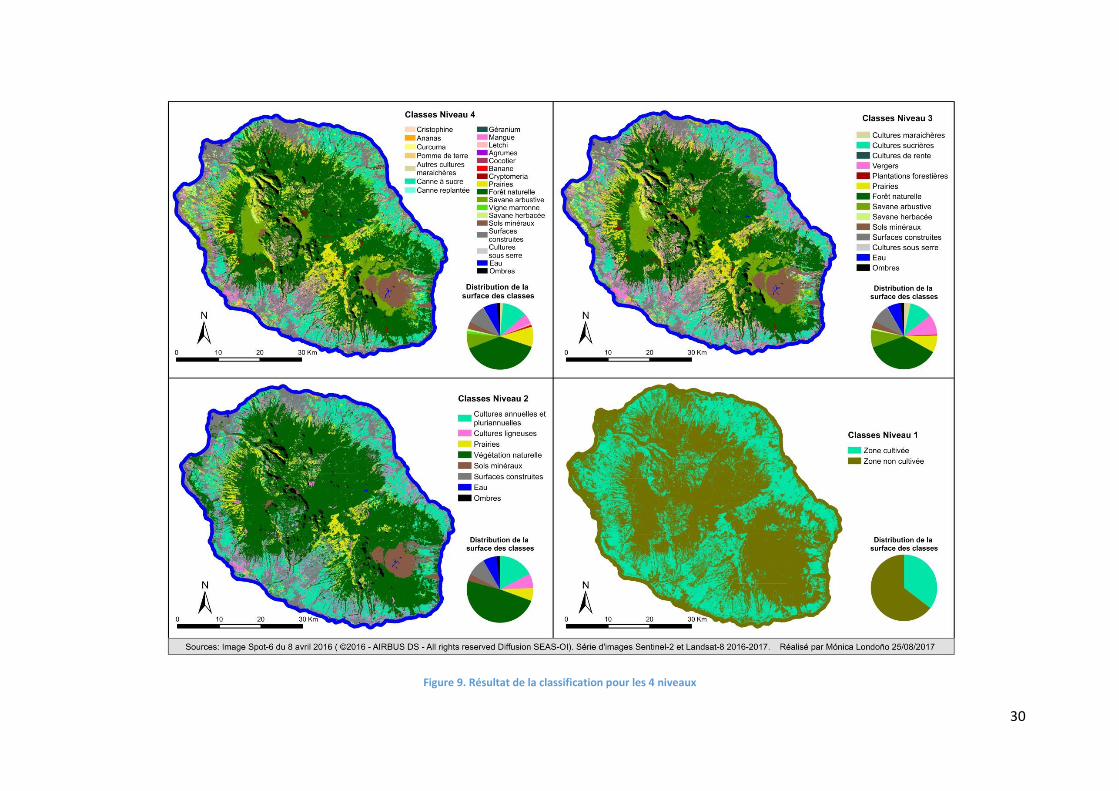
30
Figure 9. Résultat de la classification pour les 4 niveaux

31
La précision pour toutes les classes des niveaux 1 et 2 montre un f-score supérieur à 70%
(Tableau 5), alors que pour le niveau 3, seules les classes « cultures maraichères », « cultures de
rente » et « cultures sous serre » présentent un f-score inférieur à cette valeur (respectivement
69,2%, 56% et 32,6%). La Figure 9 montre que la proportion des vergers augmente par rapport
au niveau 4 au détriment de la canne à sucre, ce qui peut s’expliquer par l’inclusion dans la
classe « vergers » de la banane, culture très similaire à la canne sur l’image.
Les meilleures précisions (f – score) pour le niveau 4 ont été obtenues pour les classes
« canne à sucre » (95%), « forêt naturelle » (91%), « vigne marronne » (91%), « surfaces
construites » (91%) et « prairies » (88%). Ces classes correspondent aux classes majoritaires en
termes de surface sur la zone d’étude. Sur la Figure 9, on observe que les résultats de la
classification s’ajustent à la distribution générale d’occupation du sol sur l’île. En termes
généraux, les zones cultivées sont bien différenciées des zones naturelles et des surfaces
construites, et la zone dominée par la canne à sucre se distingue bien de celle où prédominent
les prairies. La Figure 10 illustre cela mais aussi la bonne détection des zones urbaines.
Figure 10. Différenciation de la zone de canne à sucre, des prairies et des zones urbaines dans la classification
Il existe néanmoins une tendance à la surestimation des classes majoritaires qui peut
être due à plusieurs raisons. D’un côté, les algorithmes tendent à classer comme telles d’autres
classes qui leur ressemblent en termes radiométriques, ce qui peut s’expliquer par la
configuration de la base de données, qui favorise en nombre et distribution de parcelles les
classes les plus représentatives. Pour la canne à sucre, une zone de confusion importante se
situe vers l’est de l’île, où des savanes arbustives ont été classées en canne (Figure 11). On peut
observer que dans ce cas, cela coïncide avec le décalage radiométrique localisé à l’endroit où les
deux scènes SPOT6 se rejoignent. Les bandes radiométriques ont donc dû participer de manière
importante dans la classification sur cet endroit. En effet, dans cette zone, la plupart des images
de la série temporelle sont couvertes par les nuages.

32
Figure 11. Confusion de savanes arbustives avec zones cultivées, notamment canne à sucre
Sur la Figure 11, il est possible d’apercevoir aussi une confusion des sols minéraux avec
les zones urbaines, phénomène qui est présent aussi sur quelques endroits situés au fond des
ravines. Les cultures sous serres ont aussi été confondues avec les zones urbaines, ce qui se voit
à la faible Précision Producteur de cette classe (18,6%) sur la matrice de confusion (Annexe 3A).
Par rapport aux prairies, la source principale de surestimation est générée notamment
par la ressemblance radiométrique avec les savanes herbacées et arbustives sur quelques zones
spécifiques (Figure 12) et avec certaines cultures maraichères, en particulier la cristophine et le
curcuma.
Figure 12. Confusion des savanes herbacées avec prairies dans les remparts du cirque de Mafate

33
Par rapport aux autres cultures, la pomme de terre ainsi que les vergers de letchi et les
plantations de cryptomeria ont eu des précisions supérieures à 70% (respectivement 74,5%,
77,4% et 87%). Même si les cultures d’ananas n’ont pas atteint cette précision (69,2%), des
parcelles ont été bien identifiées dans les zones où cette culture est la plus concentrée (Figure
13). La plupart des confusions par rapport à cette dernière culture correspond à des cas de
parcelles classées comme canne à sucre.
Figure 13. Zone de cultures d’ananas
Dans les figures précédentes, on remarque une surestimation des vergers de manguiers.
La plupart des confusions a lieu avec les autres vergers (agrumes, cocotiers) et avec les savanes
arbustives. D’une part, cela s’explique par la forte présence de cette culture à proximité de la
végétation qui longe les ravines, mais aussi dans les zones urbaines, aux alentours des maisons
dans les zones rurales et dans les bords des parcelles cultivées. D’autre part, les erreurs de
classification peuvent s’expliquer par la grande variation radiométrique de cette culture. C’est
également le cas avec la classe « autres cultures maraichères ».
Concernant les cultures de banane, la précision du producteur est de 91% alors que la
précision de l’utilisateur n’est que de 30%. Leur forte ressemblance radiométrique avec d’autres
classes majoritaires, notamment avec la canne à sucre, fait qu’elles sont souvent mal reconnues.

34
4. CONCLUSIONS ET PERSPECTIVES
Pendant ce stage, nous avons accompli l’objectif de tester la chaîne de traitement Sitsproc.
Cela nous a permis de générer une première classification mais aussi de faire évoluer certains
aspects de la méthodologie, liés aux spécificités de la Réunion. Les résultats de la classification
sont comparables à ceux obtenus sur d’autres sites sur des zones tropicales (Madagascar,
Burkina Faso et Brésil). Cela montre que la méthode et les outils informatiques mis en œuvre par
la chaîne de traitement, ainsi que les ressources en imagerie utilisées, pour la plupart gratuits,
ont beaucoup de potentiel pour la production automatique de cartes d’occupation du sol sur des
contextes variés. Le développement de cette méthode se positionne ainsi comme une
contribution importante dans le cadre des efforts menés par l’UMR-TETIS pour le suivi des zones
agricoles dans le monde.
L’application de la méthode nous a permis de réaliser une première classification basée
sur une nomenclature à 4 niveaux. Pour le niveau le plus détaillé, nous avons obtenu une
précision globale de 86% et un indice de Kappa de 87,8%. Ces indicateurs s’améliorent pour les
niveaux les moins détaillés de la nomenclature.
Les cultures dominantes dans la zone agricole (canne à sucre et prairies) ont présenté
des précisions supérieures à 85%, et parmi les autres cultures il y a trois classes (letchi, pomme
de terre et cryptomeria) dont le f-score est supérieur à 70%. Parmi les autres classes, même si
elles ont une précision inférieure, les résultats montrent que leur identification serait
améliorable en affinant la méthode. Les zones naturelles et les surfaces construites ont de bons
résultats de classification, ce qui montre que ces zones pourraient être isolées dès le départ afin
de construire un masque pour ne travailler que sur les agricoles.
La mise en place et l’adaptation de la chaîne de traitement ont pris beaucoup de temps.
Il a en effet été nécessaire d’effectuer des ajustements. Ceci était prévisible car il s’agissait de la
première expérimentation sur un nouveau site (la chaîne ayant été mise au point sur le site du
Burkina Faso). Il s’agit évidemment d’une contrainte car nous n’avons pas eu le temps de tester
d’autres stratégies utilisées en télédétection permettant d’affiner la méthode et ainsi les
résultats de classification. Il était toutefois très important, afin de valider la méthode, de la
tester dans un nouvel environnement de travail et sur un nouveau site.
Des post-traitements sont envisagés afin d’améliorer le résultat de la classification. D’un
côté des règles basées sur la localisation (par exemple pente, altitude couche de terres
cultivables, Parc Nationale de La Réunion) pourraient être appliquées pour la différenciation de
certaines classes. Il serait également possible d’appliquer des traitements de morphologie
mathématique pour améliorer le contour des objets et généraliser la classification afin d’éliminer
des petites zones mal classées au milieu de classes majoritaires et adapter la classification sur la
base d’une surface minimale cartographiable.

35
Comme expliqué dans l’introduction, la chaîne de traitement rassemble les briques
développées sur différents sites d’étude gérés par l’équipe TETIS. Elle est encore en cours de
développement et certaines fonctionnalités vont prochainement être incorporées. Voici
quelques évolutions en préparation évoquées dans l’article de Lebourgeois et al. 2017 :
L’utilisation de l’algorithme Random Forest disponible sur R permet d’évaluer
l’importance des différentes variables utilisées pour la classification. Ceci permet de faire
une optimisation de variables et contribue à éliminer le bruit, à améliorer la classification
et à diminuer le temps de traitement
La validation croisée consiste à partitionner la base de données terrain en données
d’apprentissage et données de validation. Random Forest permet de tester un grand
nombre de fois chacune des parcelles de la base en les utilisant selon les tests comme
des parcelles de validation et d’apprentissage. L’implémentation de cette fonction dans
la chaîne permettra d’exploiter au mieux la base de données.
Lors des traitements préliminaires réalisés sur le site de Madagascar (Lebourgeois et al.
2017), une approche hiérarchique de classification avait produit de meilleurs
résultats. Cette approche consiste à faire la classification dans le niveau le moins détaillé
de la nomenclature et à restreindre la classification des niveaux suivants aux domaines
isolés dans le niveau précédent. Puisque cela implique une partition de la zone d’étude,
cela s’avérerait utile pour réduire la variabilité et ainsi favoriser la production de
meilleurs résultats. Cependant, il faudrait obtenir de très bons résultats de classification
dans le niveau le moins détaillé pour ne pas transférer d’erreurs aux autres niveaux de la
classification. Les bons résultats obtenus pour les niveaux supérieurs de la nomenclature
dans notre cas montrent que cela serait applicable à la Réunion. Une approche basée sur
une classification hiérarchique pourrait être combinée avec une définition d’une
nomenclature qui regroupe les classes en fonction de leurs ressemblances sur l’image.
L’amélioration des sources d’informations offre également beaucoup de potentiel pour
améliorer les classifications. La possibilité d’obtenir des images corrigées au niveau de
réflectance Top of canopy diminuerait les décalages radiométriques existants entre les
différentes images de la série temporelle qui peuvent avoir un impact négatif sur l’étape de
remplissage des trous résultants du découpage des zones couvertes par les nuages.
L’amélioration de la détection des nuages sur les images Landsat-8 serait aussi à envisager.
Depuis quelques mois, la chaîne de prétraitement MAJA (issue de la chaine MUSCATE mise au
point par le CESBIO) est disponible. Elle permet d’effectuer des prétraitements performants sur
les images Landsat-8 mais surtout Sentinel-2 (passage en TOC et masques de nuages en tenant
compte de données historiques). Il est envisagé de l’intégrer prochainement dans la chaîne
Sitsproc afin de travailler sur des données plus fiables.

36
Les images du satellite Sentinel-2B commencent à être diffusées. L’accès à ces données
permettra de compter sur un plus grand nombre d’images (une image tous les 5 jours au lieu
d’une image tous les 10 jours). Dans les pays tropicaux, c’est un aspect important pour
augmenter la probabilité d’images sans nuages. Pendant le stage, nous avons testé la production
d’une classification n’utilisant que les variables issues de la série temporelle (images Sentinel-2
et Landsat-8) au niveau le plus détaillé. Le résultat montre un indice de Kappa inférieur de
seulement 0,2 par rapport à celui obtenu avec toutes les variables. Ceci montre la forte
participation de la série temporelle d’images HRS dans la prédiction des classes.
L’utilisation des images Pléiades en remplacement de SPOT6 comme images THRS,
permettrait, avec une meilleure résolution spatiale, d’améliorer les objets issus de la
segmentation et par conséquent les résultats de classification pour certaines classes (vergers,
maraichage…).
Enfin, la base de données de vérité terrain, élaborée pendant ce stage, pourra être
utilisée dans des études futures (sous réserve de mise à jour) pour actualiser la carte
d’occupation du sol.

37
BIBLIOGRAPHIE
Baatz, M.; Schäpe, A. 2000. Multiresolution Segmentation: An Optimization Approach for High
Quality Multi-scale Image Segmentation. Proceedings of the Angewandte Geographische
Information Sverarbeitung XII, Heidelberg, Allemagne, 5–7 July 2000: 12–23.
Bontemps, S.; Arias, M.; Cara, C.; Dedieu, G.; Guzzonato, E.; Hagolle, O.; Inglada, J.; Matton, N.;
Morin, D.; Popescu, R. et al. 2015. Building a Data Set over 12 Globally Distributed Sites to
Support the Development of Agriculture Monitoring Applications with Sentinel-2. Remote Sens. 7:
16062–16090.
Breiman, L. 2001. Random forests. Mach. Learn. 45: 5–32.
Cutler, D.R.; Edwards, T.C.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. 2007.
Random forests for classification in ecology. Ecology 88: 2783–2792.
Happ, P.N.; Ferreira, R.S.; Bentes, C.; Costa, G. A. O. P. & Feitosa, R. Q. 2010. Multiresolution
segmentation: a parallel approach for high resolution image segmentation in multicore
architectures. The International Archives of the Photogrammetry, Remote Sensing and Spatial
Information Sciences. Vol. XXXVIII-4/C7.
Haralick, R.M.; Shanmugam, K.; Dinstein, I. 1973 Textural features for image classification. IEEE
Trans. Syst. Man Cybern., SMC-3: 610–621.
Inglada, J.; Arias, M.; Tardy, B.; Hagolle, O.; Valero, S.; Morin, D.; Dedieu, G.; Sepulcre, G.;
Bontemps, S.;Defourny, P.; et al. 2015. Assessment of an operational system for crop type map
production using high temporal and spatial resolution satellite optical imagery. Remote Sens. 7:
12356–12379.
Lebourgeois, V. ; Dupuy, S. ; Vintrou, C. ; Ameline, M. ; Butler, S. ; Bégué, A. 2017 Combined
Random Forest and OBIA Classification Scheme for Mapping Smallholder Agriculture at Different
Nomenclature Levels Using Multisource Data (Simulated Sentinel-2 Time Series, VHRS and DEM).
Remote Sens. 9, 259.
Li, M.; Ma, L.; Blaschke, T.; Cheng, L.; Tiede, D. 2016. A systematic comparison of different
object-based classification techniques using high spatial resolution imagery in agricultural
environments. Int. J. Appl. Earth Obs. Geoinf: 49, 87–98
Liaw, A. & Wiener, M. Classification and regression by Random Forest. R News 2002, 2, 18–22.
Madhavi, S. & T.Swathi, 2016. Statistical Region Merging Algorithm for Segmenting Very High
Resolution Images. International Journal & Magazine of Engineering, Technology, Management
and Research. 3, 11: 126-132
Nehlig, P. & Bucelle, M. 2005. Connaissance géologique de La Réunion. Livret de l’enseignant.
Kit Pédagogique Sciences de la Terre. Région Réunion. 85 pp.
Peña-Barragán, J.M.; Ngugi, M.K. ; Plant, R.E. ; Six, J. 2011. Object-based crop identification
using multiple vegetation indices, textural features and crop phenology. Remote Sensing of
Environment. 115: 1301–1316
Raunet, M. 1991. Le milieu physique et les sols de l’île de La Réunion : conséquences pour la
mise en valeur agricole. CIRAD. Région Réunion. 438 p.
Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanch, J. P. 2011. An
assessment of the effectiveness of a random forest classifier for land-cover classification. Journal
of Photogrammetry and Remote Sensing 67: 93–104
Rosenfield, G.H.; Fitzpatrick-Lins, K. 1986. A coefficient of agreement as a measure of thematic
classification accuracy. Photogramm. Eng. Remote Sens. 52: 223–227.

38
LISTE D’ANNEXES
ANNEXE 1. Série temporelle d’images Sentinel-2 et Landsat-8 téléchargées initialement. ......... 39
ANNEXE 2 (A). Matrice de confusion de la classification pour le niveau 4. ................................... 40
ANNEXE 2 (B). Matrice de confusion de la classification pour le niveau 3 .................................... 41
ANNEXE 2 (C). Matrice de confusion de la classification pour le niveau 2. ................................... 42
ANNEXE 3 (A). Résultat de la classification pour le niveau 4. ........................................................ 43
ANNEXE 3 (B). Résultat de la classification pour le niveau 3. ........................................................ 44
ANNEXE 3 (C). Résultat de la classification pour le niveau 2. ........................................................ 45
ANNEXE 3 (D). Résultat de la classification pour le niveau 1. ........................................................ 46
39
ANNEXE 1. Série temporelle d’images Sentinel-2 et Landsat-8 téléchargées initialement. Cadre vert : Images Sentinel-2, Cadre bleu : Images Landsat-8. Texte en rouge : Images exclues de l’analyse.
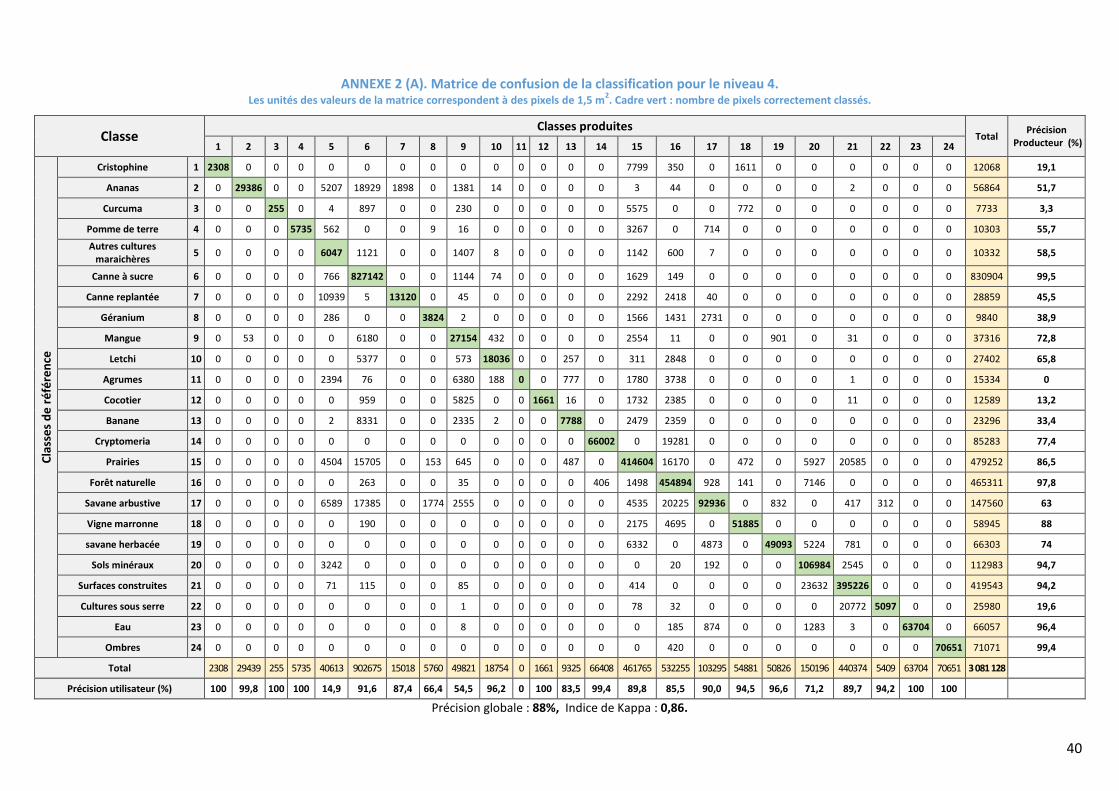
40
ANNEXE 2 (A). Matrice de confusion de la classification pour le niveau 4. Les unités des valeurs de la matrice correspondent à des pixels de 1,5 m
2. Cadre vert : nombre de pixels correctement classés.
Classe Classes produites
Total Précision
Producteur (%) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
Cla
sse
s d
e r
éfé
ren
ce
Cristophine 1 2308 0 0 0 0 0 0 0 0 0 0 0 0 0 7799 350 0 1611 0 0 0 0 0 0 12068 19,1
Ananas 2 0 29386 0 0 5207 18929 1898 0 1381 14 0 0 0 0 3 44 0 0 0 0 2 0 0 0 56864 51,7
Curcuma 3 0 0 255 0 4 897 0 0 230 0 0 0 0 0 5575 0 0 772 0 0 0 0 0 0 7733 3,3
Pomme de terre 4 0 0 0 5735 562 0 0 9 16 0 0 0 0 0 3267 0 714 0 0 0 0 0 0 0 10303 55,7
Autres cultures maraichères
5 0 0 0 0 6047 1121 0 0 1407 8 0 0 0 0 1142 600 7 0 0 0 0 0 0 0 10332 58,5
Canne à sucre 6 0 0 0 0 766 827142 0 0 1144 74 0 0 0 0 1629 149 0 0 0 0 0 0 0 0 830904 99,5
Canne replantée 7 0 0 0 0 10939 5 13120 0 45 0 0 0 0 0 2292 2418 40 0 0 0 0 0 0 0 28859 45,5
Géranium 8 0 0 0 0 286 0 0 3824 2 0 0 0 0 0 1566 1431 2731 0 0 0 0 0 0 0 9840 38,9
Mangue 9 0 53 0 0 0 6180 0 0 27154 432 0 0 0 0 2554 11 0 0 901 0 31 0 0 0 37316 72,8
Letchi 10 0 0 0 0 0 5377 0 0 573 18036 0 0 257 0 311 2848 0 0 0 0 0 0 0 0 27402 65,8
Agrumes 11 0 0 0 0 2394 76 0 0 6380 188 0 0 777 0 1780 3738 0 0 0 0 1 0 0 0 15334 0
Cocotier 12 0 0 0 0 0 959 0 0 5825 0 0 1661 16 0 1732 2385 0 0 0 0 11 0 0 0 12589 13,2
Banane 13 0 0 0 0 2 8331 0 0 2335 2 0 0 7788 0 2479 2359 0 0 0 0 0 0 0 0 23296 33,4
Cryptomeria 14 0 0 0 0 0 0 0 0 0 0 0 0 0 66002 0 19281 0 0 0 0 0 0 0 0 85283 77,4
Prairies 15 0 0 0 0 4504 15705 0 153 645 0 0 0 487 0 414604 16170 0 472 0 5927 20585 0 0 0 479252 86,5
Forêt naturelle 16 0 0 0 0 0 263 0 0 35 0 0 0 0 406 1498 454894 928 141 0 7146 0 0 0 0 465311 97,8
Savane arbustive 17 0 0 0 0 6589 17385 0 1774 2555 0 0 0 0 0 4535 20225 92936 0 832 0 417 312 0 0 147560 63
Vigne marronne 18 0 0 0 0 0 190 0 0 0 0 0 0 0 0 2175 4695 0 51885 0 0 0 0 0 0 58945 88
savane herbacée 19 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6332 0 4873 0 49093 5224 781 0 0 0 66303 74
Sols minéraux 20 0 0 0 0 3242 0 0 0 0 0 0 0 0 0 0 20 192 0 0 106984 2545 0 0 0 112983 94,7
Surfaces construites 21 0 0 0 0 71 115 0 0 85 0 0 0 0 0 414 0 0 0 0 23632 395226 0 0 0 419543 94,2
Cultures sous serre 22 0 0 0 0 0 0 0 0 1 0 0 0 0 0 78 32 0 0 0 0 20772 5097 0 0 25980 19,6
Eau 23 0 0 0 0 0 0 0 0 8 0 0 0 0 0 0 185 874 0 0 1283 3 0 63704 0 66057 96,4
Ombres 24 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 420 0 0 0 0 0 0 0 70651 71071 99,4
Total 2308 29439 255 5735 40613 902675 15018 5760 49821 18754 0 1661 9325 66408 461765 532255 103295 54881 50826 150196 440374 5409 63704 70651 3 081 128
Précision utilisateur (%) 100 99,8 100 100 14,9 91,6 87,4 66,4 54,5 96,2 0 100 83,5 99,4 89,8 85,5 90,0 94,5 96,6 71,2 89,7 94,2 100 100
Précision globale : 88%, Indice de Kappa : 0,86.
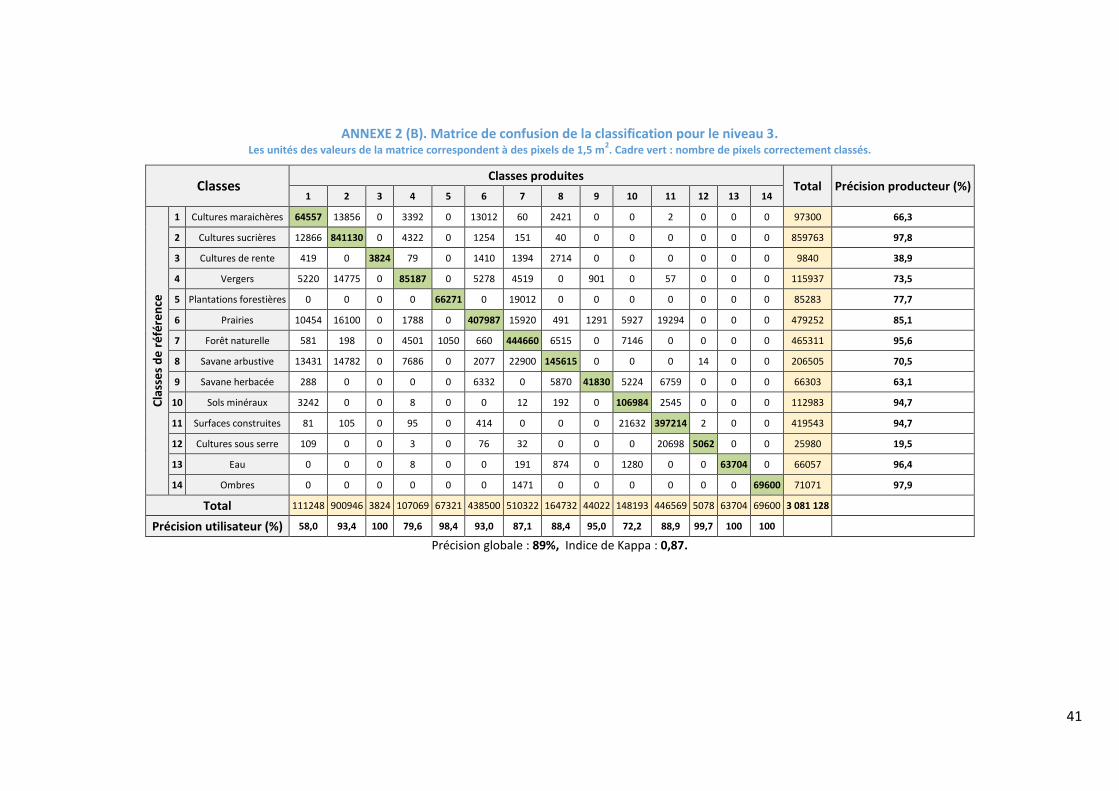
41
ANNEXE 2 (B). Matrice de confusion de la classification pour le niveau 3. Les unités des valeurs de la matrice correspondent à des pixels de 1,5 m
2. Cadre vert : nombre de pixels correctement classés.
Classes Classes produites
Total Précision producteur (%) 1 2 3 4 5 6 7 8 9 10 11 12 13 14
Cla
sse
s d
e r
éfé
ren
ce
1 Cultures maraichères 64557 13856 0 3392 0 13012 60 2421 0 0 2 0 0 0 97300 66,3
2 Cultures sucrières 12866 841130 0 4322 0 1254 151 40 0 0 0 0 0 0 859763 97,8
3 Cultures de rente 419 0 3824 79 0 1410 1394 2714 0 0 0 0 0 0 9840 38,9
4 Vergers 5220 14775 0 85187 0 5278 4519 0 901 0 57 0 0 0 115937 73,5
5 Plantations forestières 0 0 0 0 66271 0 19012 0 0 0 0 0 0 0 85283 77,7
6 Prairies 10454 16100 0 1788 0 407987 15920 491 1291 5927 19294 0 0 0 479252 85,1
7 Forêt naturelle 581 198 0 4501 1050 660 444660 6515 0 7146 0 0 0 0 465311 95,6
8 Savane arbustive 13431 14782 0 7686 0 2077 22900 145615 0 0 0 14 0 0 206505 70,5
9 Savane herbacée 288 0 0 0 0 6332 0 5870 41830 5224 6759 0 0 0 66303 63,1
10 Sols minéraux 3242 0 0 8 0 0 12 192 0 106984 2545 0 0 0 112983 94,7
11 Surfaces construites 81 105 0 95 0 414 0 0 0 21632 397214 2 0 0 419543 94,7
12 Cultures sous serre 109 0 0 3 0 76 32 0 0 0 20698 5062 0 0 25980 19,5
13 Eau 0 0 0 8 0 0 191 874 0 1280 0 0 63704 0 66057 96,4
14 Ombres 0 0 0 0 0 0 1471 0 0 0 0 0 0 69600 71071 97,9
Total 111248 900946 3824 107069 67321 438500 510322 164732 44022 148193 446569 5078 63704 69600 3 081 128
Précision utilisateur (%) 58,0 93,4 100 79,6 98,4 93,0 87,1 88,4 95,0 72,2 88,9 99,7 100 100
Précision globale : 89%, Indice de Kappa : 0,87.
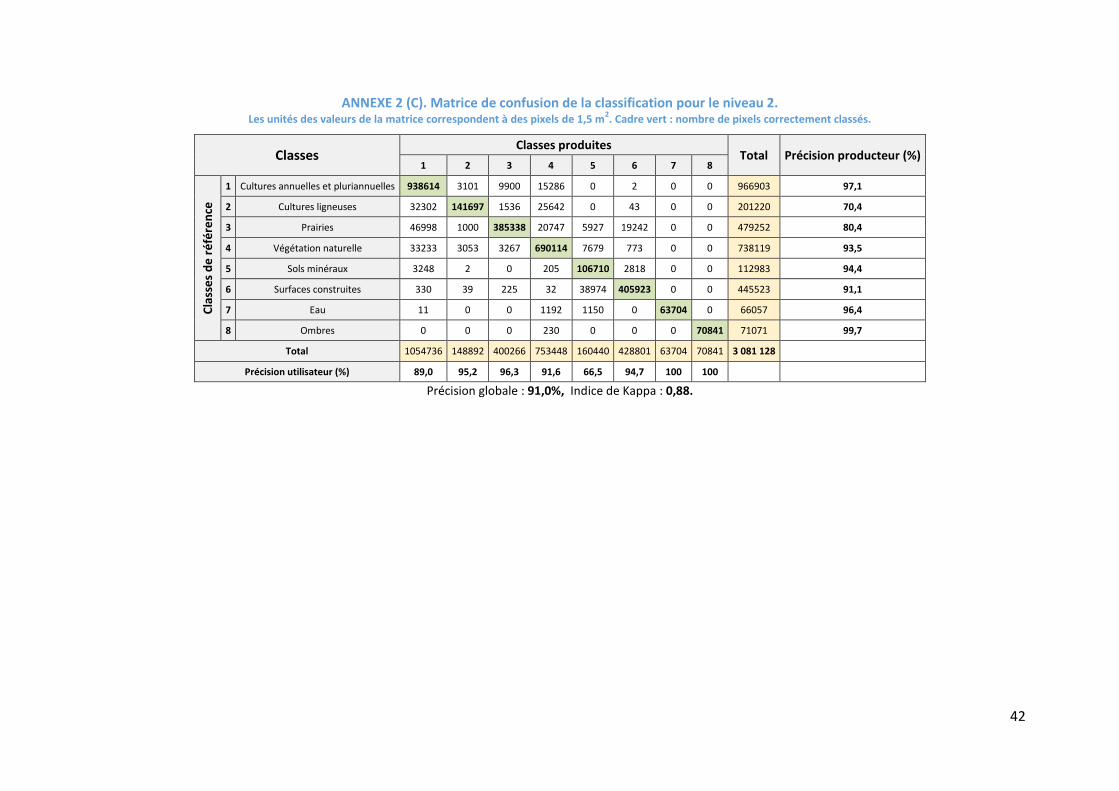
42
ANNEXE 2 (C). Matrice de confusion de la classification pour le niveau 2. Les unités des valeurs de la matrice correspondent à des pixels de 1,5 m
2. Cadre vert : nombre de pixels correctement classés.
Classes Classes produites
Total Précision producteur (%) 1 2 3 4 5 6 7 8
Cla
sse
s d
e r
éfé
ren
ce
1 Cultures annuelles et pluriannuelles 938614 3101 9900 15286 0 2 0 0 966903 97,1
2 Cultures ligneuses 32302 141697 1536 25642 0 43 0 0 201220 70,4
3 Prairies 46998 1000 385338 20747 5927 19242 0 0 479252 80,4
4 Végétation naturelle 33233 3053 3267 690114 7679 773 0 0 738119 93,5
5 Sols minéraux 3248 2 0 205 106710 2818 0 0 112983 94,4
6 Surfaces construites 330 39 225 32 38974 405923 0 0 445523 91,1
7 Eau 11 0 0 1192 1150 0 63704 0 66057 96,4
8 Ombres 0 0 0 230 0 0 0 70841 71071 99,7
Total 1054736 148892 400266 753448 160440 428801 63704 70841 3 081 128
Précision utilisateur (%) 89,0 95,2 96,3 91,6 66,5 94,7 100 100
Précision globale : 91,0%, Indice de Kappa : 0,88.
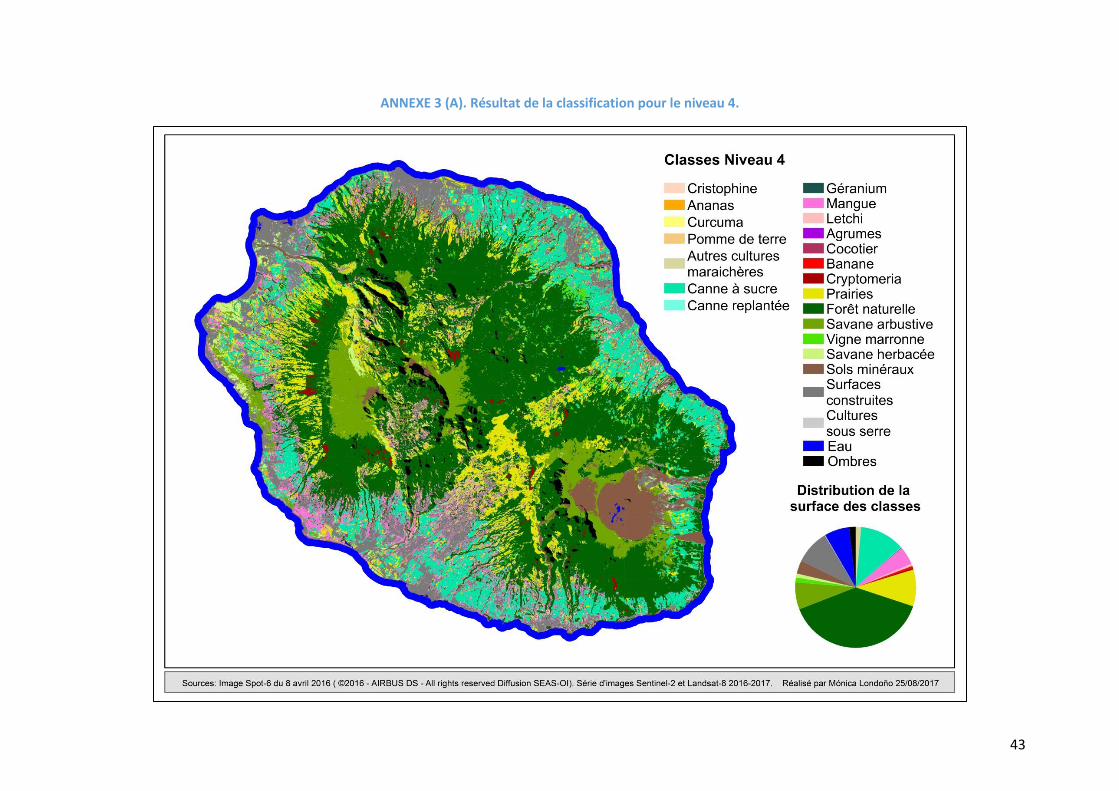
43
ANNEXE 3 (A). Résultat de la classification pour le niveau 4.
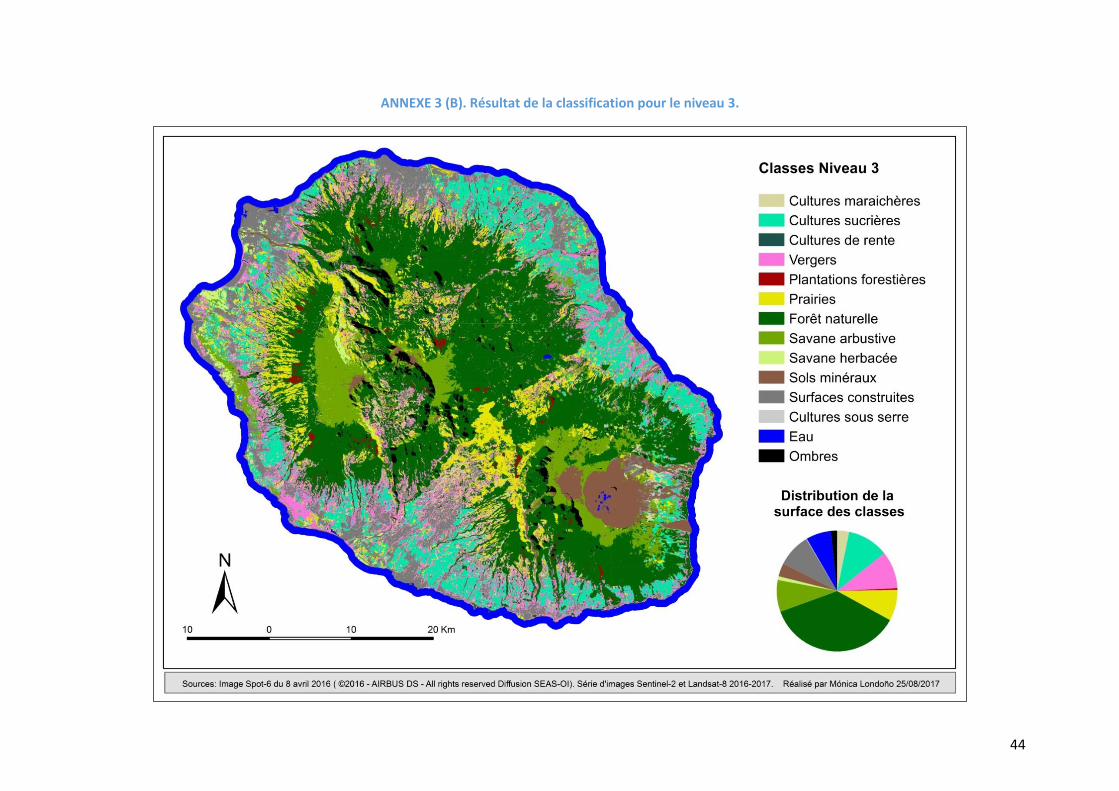
44
ANNEXE 3 (B). Résultat de la classification pour le niveau 3.
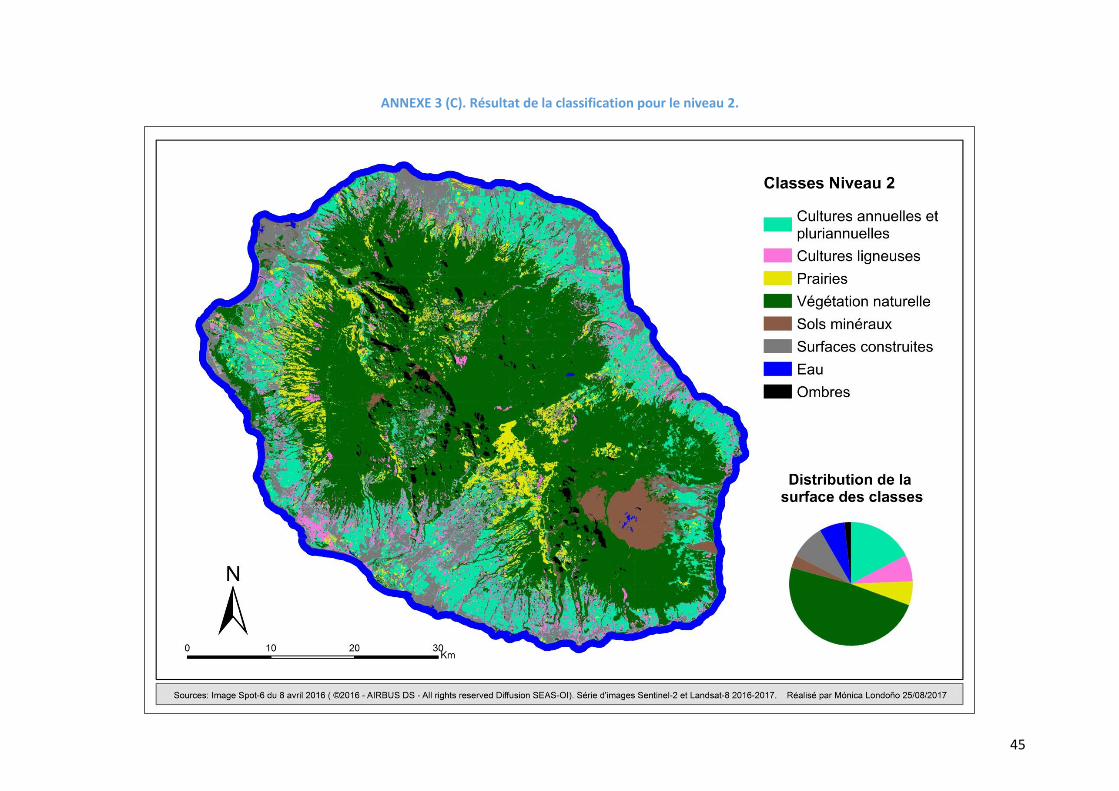
45
ANNEXE 3 (C). Résultat de la classification pour le niveau 2.
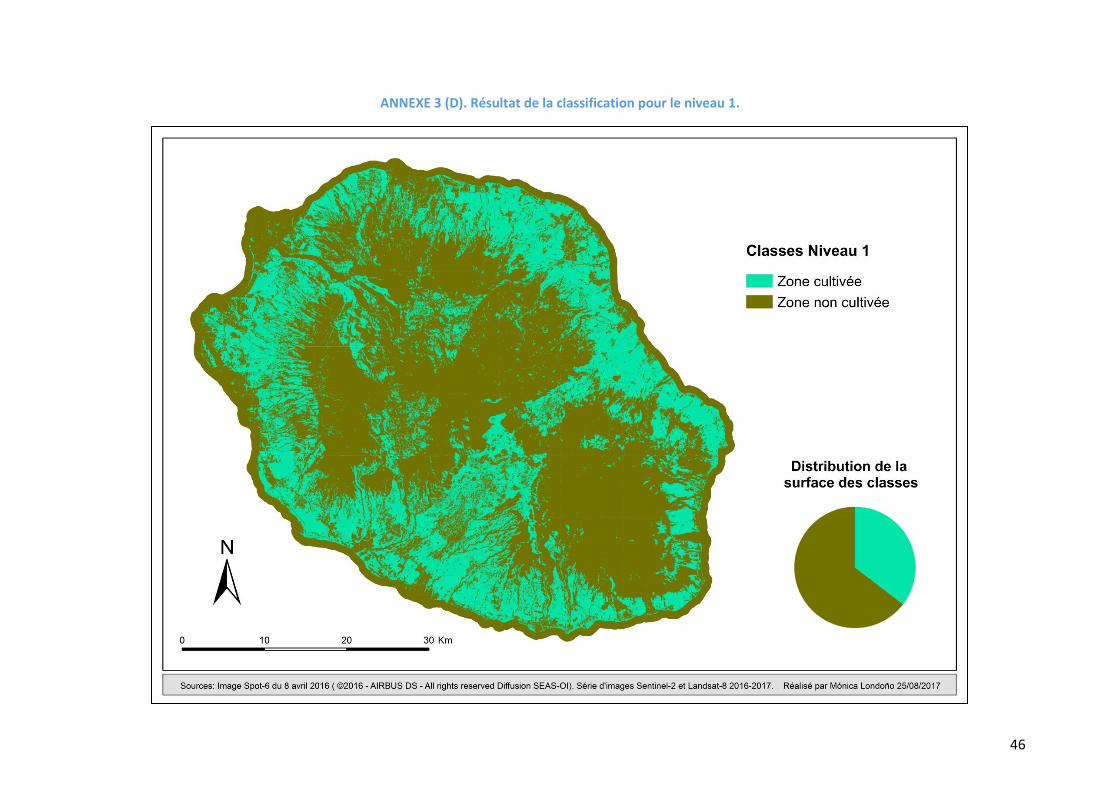
46
ANNEXE 3 (D). Résultat de la classification pour le niveau 1.

47
RESUME
L’UMR-TETIS du CIRAD est partenaire dans des projets reliés au développement de méthodes de
classification automatique d’images satellites pour le suivi des zones agricoles dans le monde. Dans ce cadre,
une chaîne de traitement pour la génération de cartes d’occupation du sol est en train d’être développée. Elle
est conçue pour utiliser une série temporelle d’images à haute résolution spatiale Sentinel-2 et Landsat-8,
combinée à une image à très haute résolution spatiale SPOT6/7 pour produire, avec une méthode orientée
objets et un algorithme de classification supervisé, des cartes d’occupation du sol agricole pour les pays du sud.
Au cours du stage cette chaîne de traitement a été appliquée au cas de l’île de La Réunion, dont le
paysage se caractérise par une grande diversité de zones naturelles et de cultures. Dans la zone agricole, les
cultures prédominantes sont la canne à sucre et les prairies, mais l’arboriculture et le maraichage occupent une
place importante.
À l’échelle de La Réunion, le développement d’une méthode de classification supervisée pour la
génération de cartes d’occupation du sol s’avère intéressante pour le projet GABIR, source de financement du
stage. Ce projet cherche des solutions innovantes pour le traitement des déchets de biomasse à l’échelle de
l’île. Les cartes d’occupation du sol ont aussi un intérêt pour d’autres institutions chargées de l’aménagement
du territoire.
L’application de la méthode nous a permis la réalisation d’une première classification basée sur une
nomenclature à 4 niveaux. Pour le niveau le plus détaillé, nous avons obtenu une précision globale de 86% et
un indice de Kappa de 87,8%. Ces indicateurs s’améliorent pour les niveaux les moins détaillés de la
nomenclature. Les classes ayant une meilleure précision correspondent en général aux types d’occupation qui
prédominent dans l’île, comme la canne à sucre, les pâturages et les forêts.
L’application de la méthodologie à un nouveau site d’étude et les résultats obtenus nous ont permis
d’en évaluer la robustesse et l’adaptation.
ABSTRACT
The CIRAD UMR-TETIS research unit is a partner in projects related to the development of automatic
classification methods of satellite imagery for the monitoring of agricultural areas in the world. In this context,
a processing chain for the generation of land use maps is being developed. It is designed to use a time series of
high spatial resolution Sentinel-2 and Landsat-8 images, combined with a very high spatial resolution SPOT6/7
image to produce, with an object-oriented method and a supervised classification algorithm, crop maps in
tropical countries.
During my internship, this processing chain was applied to the case of La Reunion Island, whose
landscape is characterized by a great diversity of natural areas and crops. In the agricultural zone, the
predominant crops are sugar cane and grassland, but fruit crops and vegetables represent an important area.
At La Reunion island scale, the development of a supervised classification method for the generation
of land use maps is interesting for the GABIR project, source of funding for the internship. This project seeks
innovative solutions for the treatment of biomass waste on the island scale. Land use maps are also of interest
to other institutions related to territorial planning.
The application of the method allowed to carry out a first classification based on a 4-level
nomenclature. For the most detailed level we obtained an overall accuracy of 86% and a Kappa index of 87.8%.
These indicators are higher for aggregated nomenclature. Classes with highest precisions generally correspond
to the predominant land uses on the island, such as sugarcane, pasture and forests.
The application of the methodology on La Reunion Island and the results obtained allowed us to
evaluate its robustness and adaptation.





























