Embed Size (px)
DESCRIPTION
Une implantation de la juxtaposition parallèle. Frédéric Gava JFLA’2006. Contexte. Implicite. Explicite. Parallélisation Automatique. Patrons. Data-parallélisme. Extensions parallèles. Programmation Concurrente. Programmation parallèle. Projets. 2002-2004 ACI Grid - PowerPoint PPT Presentation
Citation preview

Frédéric GavaJFLA’2006
Une implantation de la
juxtaposition parallèle
2/24
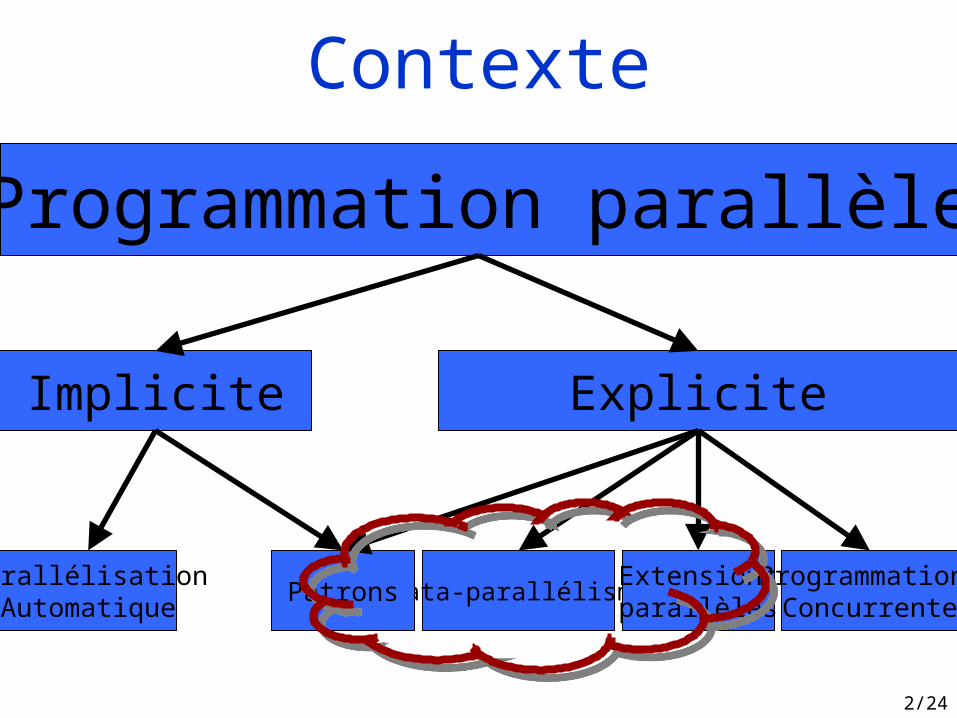
Programmation parallèle
Implicite Explicite
Data-parallélismeExtensionsparallèles
Programmation Concurrente
ParallélisationAutomatique
Patrons
Contexte

3/24
Projets
2002-2004
ACI Grid
Conception de bibliothèques parallèles et Grid pour OCaml avec des applications pour les SGBD et le calcul numérique.
2004-2007
ACI « jeunes chercheurs »
Produire un environnement de programmation parallèle où les programmes pourront être certifiés et exécutés de manière sûre.

4/24
Plan
I. Le modèle BSP et BSML « plat »
II. Compositions parallèlesa. La superposition
b. La juxtaposition
III. Implantation de la juxtaposition et performances
IV. Conclusion et futurs travaux

5/24
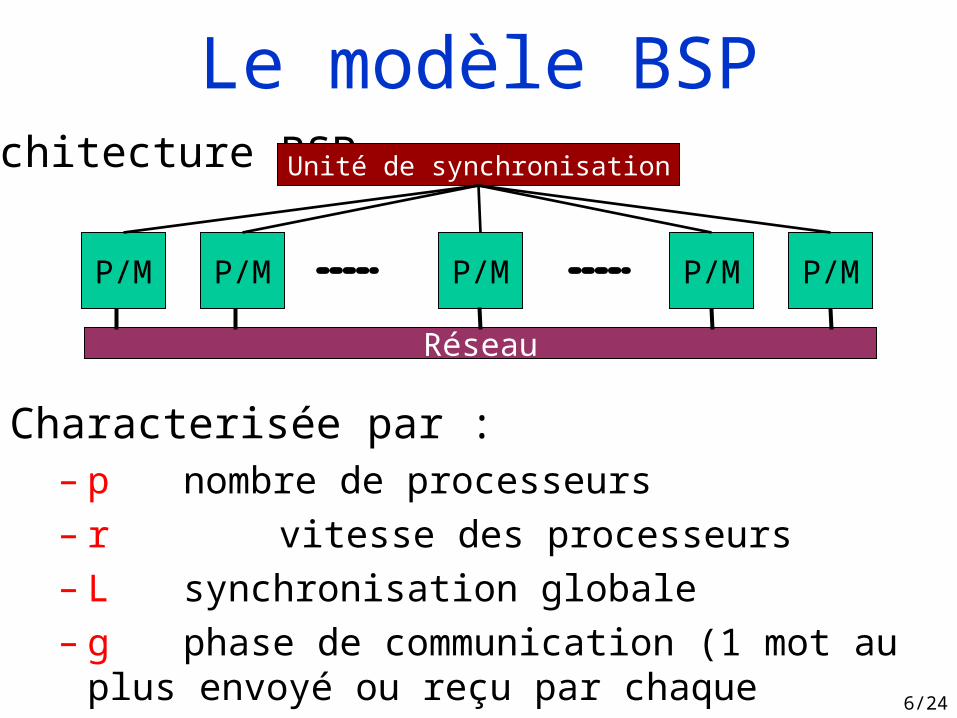
Le modèle BSP et BSML « plat »
6/24
Characterisée par :– p nombre de processeurs– r vitesse des processeurs– L synchronisation globale– g phase de communication (1 mot au plus envoyé ou
reçu par chaque processeur)
Architecture BSP:
Le modèle BSP
P/M P/M P/M P/M P/M
Réseau
Unité de synchronisation
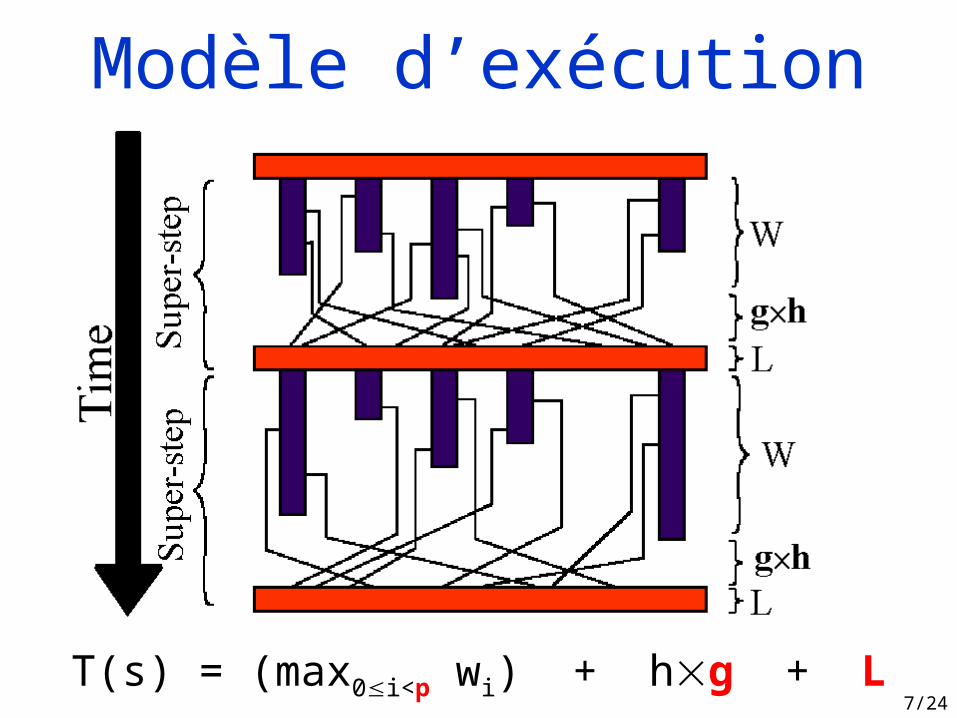
7/24T(s) = (max0i<p wi) + hg + L
Modèle d’exécution

8/24
Extension data-parallèle explicite de ML basée sur le modèle BSP
Parallélisme structuré, langage fonctionnel et prédictions des coûts BSP
Permet l’implantation de patrons
Bibliothèque pour le langage OCaml
4 primitives pour manipuler une structure distribuée de données appelée « vecteur parallèle » :
1. Création d’un vecteur (suivant le PID du processeur)
2. Application parallèle point-à-point (asynchrone)
3. Communication synchrone entre les composantes d’un vecteur
4. Projection synchrone de valeurs (d’un vecteur)
Le langage BSML
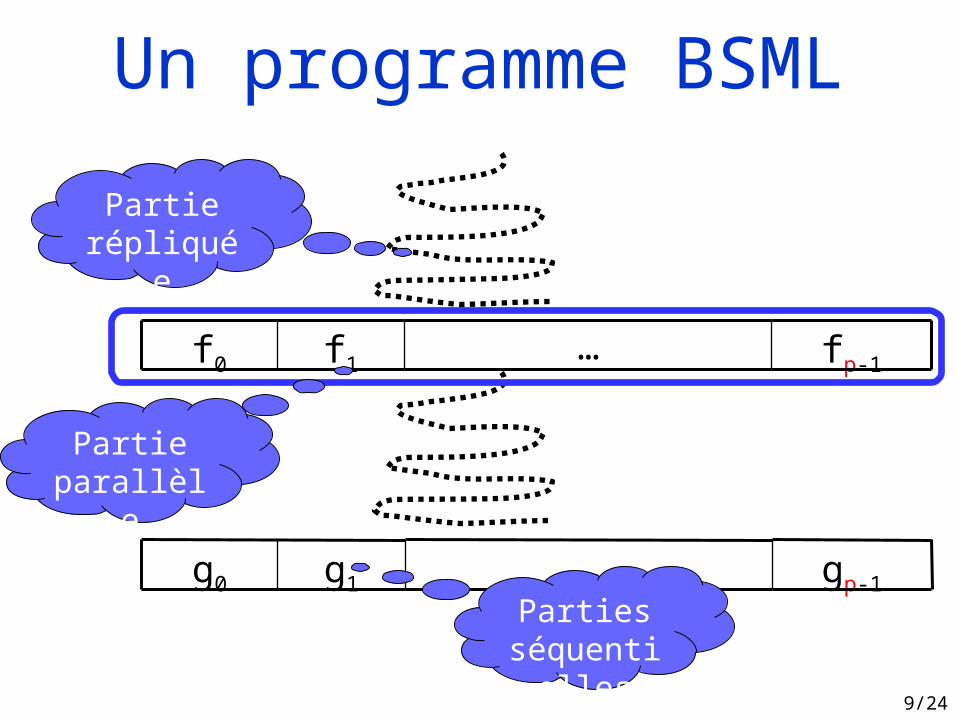
9/24
fp-1…f1f0
gp-1…g1g0
Partieparallèle
Partiesséquentielle
s
Partierépliquée
Un programme BSML

10/24
Compositions parallèles

11/24
Plusieurs programmes sur une même machine
2 nouvelles primitives de compositions :1. Superposition2. Juxtaposition
– Algorithmes BSP « diviser-pour-régner »
Multi-programmation

12/24
super : (unit (unit )
super E1 E2 = (E1 (), E2())
Fusion des communications/synchronisations par l’utilisation de super-threads
Préserve le modèle d’exécution BSP
Purement fonctionnelle
Superposition parallèle
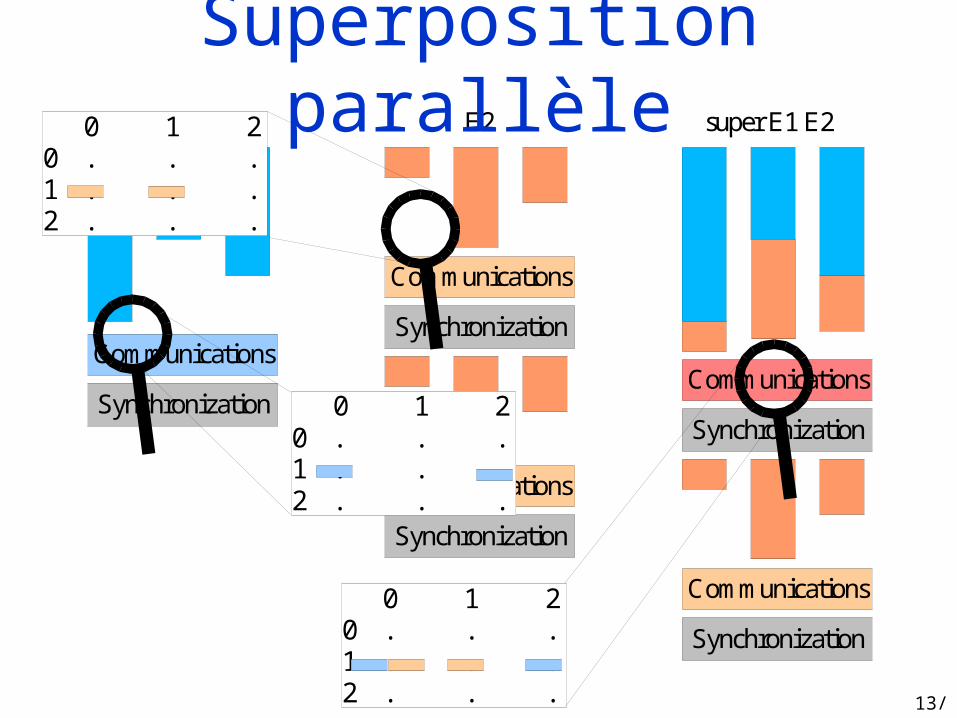
13/24
Communications
Synchronization
Communications
Synchronization
Communications
Synchronization
Communications
Synchronization
Communications
Synchronization
E1 E2 super E1 E2
0 1 20 . . .1 . . .2 . . .
0 1 20 . . .1 . . .2 . . .
0 1 20 . . .1 . . .2 . . .
Superposition parallèle

14/24
Juxtaposition parallèle
Création de 2 « sous-machines »
juxta : int(unitpar(unitpar)par
Fusion des communications/synchronizations pour chaque « sous-machine » ; préserve le modèle d’exécution BSP
Effet de bord sur le nombre de processeurs
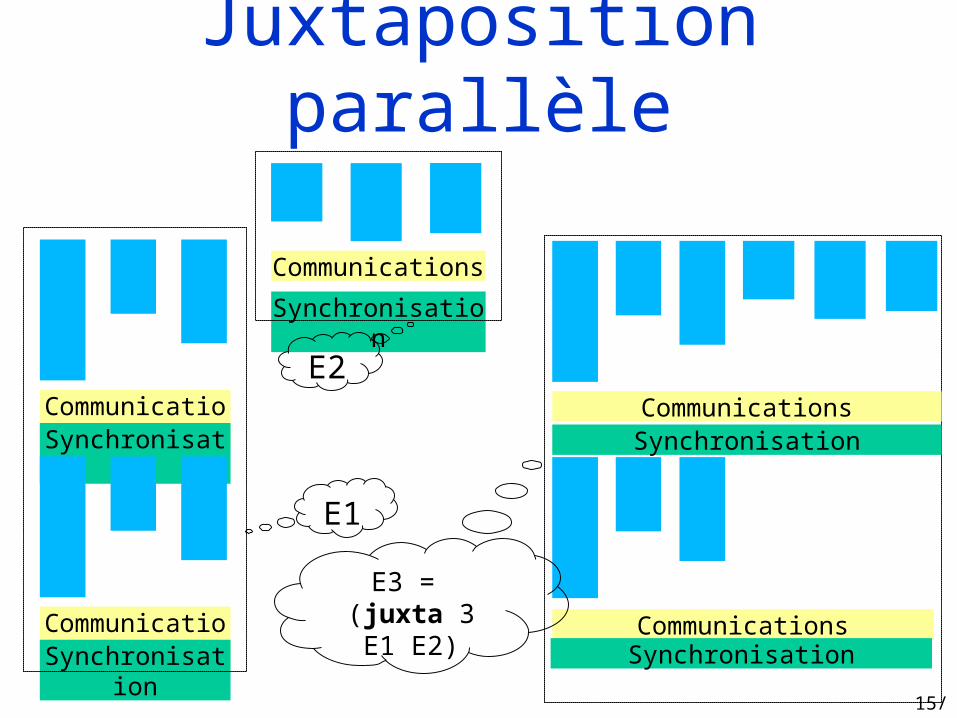
15/24
Juxtaposition parallèle
CommunicationsSynchronisation
CommunicationsSynchronisation
E1
Communications
Synchronisation
E2CommunicationsSynchronisation
CommunicationsSynchronisation
E3 = (juxta 3 E1 E2)

16/24
Implantation et performances

17/24
Implantation 2 références contenant le nombre de processeurs d’une « sous machine » et le PID du processeur « réel » qui est le processeur 0 de la sous-machine
Créations de vecteurs « non complets »
Applications point-à-point « partielles »
Communications en simulant le nombre de processeur (restauration à chaque super-étape du nombre de processeur de la « sous-machine »)
Chaque « sous-machine » de la juxtaposition dans un super-thread

18/24
Exemplecalcul parallèle des
préfixesscan: ( par par
scan (+) <v0, …, vp-1>
= <v0, v0+v1, …, v0+v1+…+ vp-1>
scan (+) <v0, …, vm>= < w0 , … , wm >
scan (+) <vm+1, …, vp-1>=<wm+1 , … , wp+1>
< w0 , … , wm , wm+wm+1, … , wm+wp+1>= <v0, v0+v1, v0+…+vm, v0+…+vm+1,…, v0+…+vp-1>

19/24
Juxta versus Super
Code avec juxtaposition : 8 lignes
Code avec superposition : 12 lignes
Code directe : 6 lignes
20/24
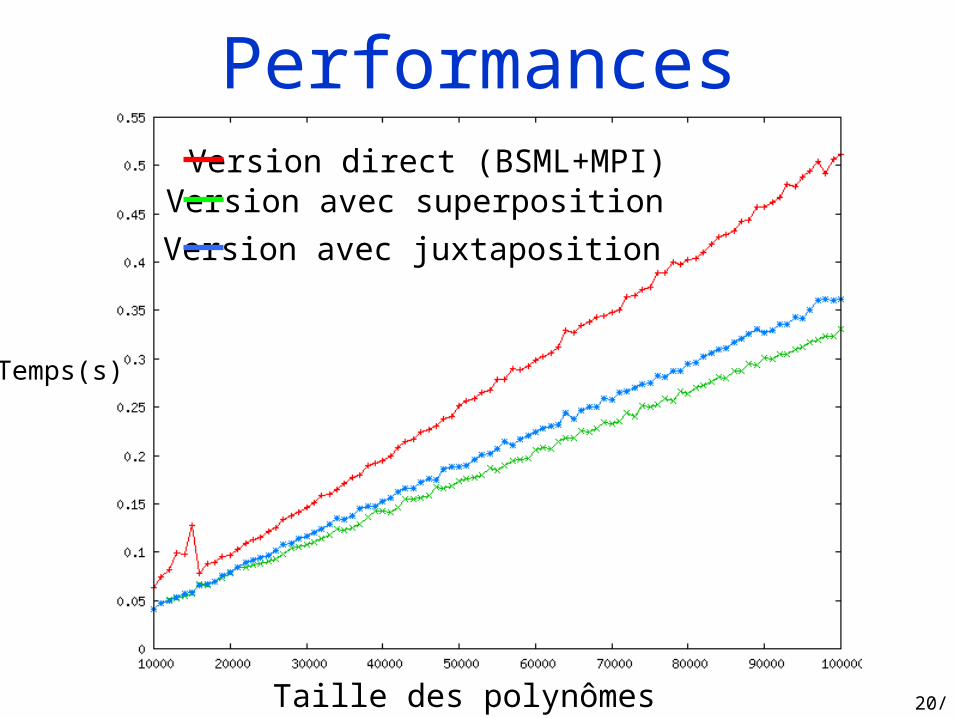
Performances
Taille des polynômes
Temps(s)
Version direct (BSML+MPI)Version avec superposition
Version avec juxtaposition

21/24
Conclusion et travaux
futurs

22/24
Conclusion
BSML = ML + BSP
Superposition = primitive de composition parallèle
Juxtaposition = fonction utile pour les algorithmes « diviser-pour-régner » parallèles
La superposition + traits impératifs simule la juxtaposition
Performances similaires

23/24
Pour ce travail :
La juxtaposition peut-elle simuler la superposition ?
La superposition sans les traits impératifs peut-elle simuler la juxtaposition ? Preuve ? Avec les mêmes coûts BSP ?
Implantation de plus gros algorithmes diviser-pour-régner BSP
En général :
Outils pour la preuve de programmes impératifs BSP
Outils d’analyses statiques pour la prédiction des performances
Application pour la conception d’un « modèle checker » BSP pour les réseaux de Petri de haut-niveau
Futurs travaux

Merci de votre attention





























