Embed Size (px)
Citation preview

HEH, Campus Technique
Institut Supérieur Industriel de Mons
Traitement de l’informationBases de données
Synthèse
Ce document a été rédigé en LATEXLe 27 décembre 2014
Auteur :Corky Maigre *[*]** (FPMs 173)[email protected]
TB3ETI3ème Bachelier ISIMs
Ir. Ing. S.Cremer
Année Académique 2014-2015

Table des matières
I Bases de données 2
1 Introduction aux bases de données 31.1 Définition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 Système de gestion de bases de données (SGBD) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.2.1 Concepts de base . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Les différentes structures 62.1 Bases de données hiérarchiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.2 Bases de données réseaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.3 Bases de données relationnelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.3.1 NoSQL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.4 Bases de données orientées objet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.5 Bases de données semi-structurées . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.6 Bases de données multidimensionnelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.7 Bases de données multimédia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.8 Bases de données décisionnelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.9 Bases de données géographiques (SIG) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.10 Bases de données factuelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3 Langage Merise 103.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103.2 Schéma conceptuel (MCD) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3.2.1 Entités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103.2.2 Relations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113.2.3 Degré de relation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113.2.4 Cardinalités . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.2.5 Démarche de conception . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.2.6 Remarques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.2.7 Dépendance fonctionnelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.2.8 Contrainte d’intégrité fonctionnelle (CIF) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.3 Schéma logique (MLD) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133.4 Schéma physique (MPD) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133.5 Normalisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.5.1 Première forme normale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133.5.2 Deuxième forme normale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143.5.3 Troisième forme normale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1

Première partie
Bases de données
2

Chapitre 1
Introduction aux bases de données
Avant, avec les fichiers plats, on stockait les données dans des fichiers textes qui ne sont pas des bases de données.L’utilisateur devait connaître l’organisation des fichiers et développer des programmes complexes spécifiques de lec-ture et écriture pour pouvoir lire et modifier les informations. À chaque nouvelle version de l’application, l’utilisateurdevait créer de nouveaux codes, l’application était donc rigide et il se pouvait qu’il crée de nouveaux fichiers avecdes informations déjà présentes dans les autres fichiers, les données étaient alors redondantes.
Les applications étaient rigides, contraignantes, et leur mise en oeuvre (développement) était longue et coûteuse.Les données étaient mal définies, mal désignées, redondantes, peu accessible de manière ponctuelle, et peu fiables.
Afin d’avoir des systèmes d’informations globaux, cohérents, directement accessibles, et des réponses immédiatesaux requêtes demandées, on a inventé le concept de base de données.
1.1 DéfinitionUne base de données (BD), ou database (DB) en anglais, est une entité dans laquelle il est possible de stocker desdonnées de façon structurée et avec le moins de redondance possible. Elle se traduit physiquement par un ensemblede fichiers sur un disque.Une base de données est un ensemble d’informations sur un sujet qui est exhaustif, non redondant, structuré, etpersistant.Elle permet de mettre des données à disposition de plusieurs utilisateurs simultanément.
Figure 1.1 – Schématisation d’une base de données.
Il existe deux types de base de données :Base de données locale : base de données utilisable sur une machine par une personne (poste monopole).Base de données répartie : bases de données liées à un serveur et utilisable sur plusieurs machines, donc par
plusieurs personnes.
3

1.2 Système de gestion de bases de données (SGBD)Le Sytsème de Gestion de Bases de Données (SGBD), ou DataBase Management System (DBMS) est un ensemblede services (applications logicielles) permettant de gérer et contrôler les bases de données au niveau des donnéesainsi qu’au niveau des utilisateurs :
– simplifier l’accès aux données– autoriser l’accès aux informations à de multiples utilisateurs– manipuler les données présentes dans la base de données (insertion, suppression, modification)
Figure 1.2 – Système de gestion de bases de données.
Les objectifs de la SGBD sont :
• Indépendance physique : la façon dont les données sont définies doit être indépendante des structures destockage utilisées.
• Indépendance logique : un ensemble de données peut être vu différemment par des utilisateurs différents.
• Manipulabilité : pouvoir accéder aux données via des langages faciles (SQL)
• Efficacité des accès aux données : optimiser le temps de réponse et minimiser le nombre d’accès au disques.
• Administration centralisée des données
• Non redondance des données : chaque donnée ne doit être présente qu’une seule fois dans la base afind’éviter des problèmes lors des mises à jours.
• Cohérence des données : données soumises à des contraintes d’intégrité.
• Partageabilité des données : permettre d’accéder en lecture et écriture aux même données en même tempspar plusieurs utilisateurs.
• Sécurité des données : associer des droits d’accès à chaque utilisateur.
• Résistance aux pannes : récupérer une base de donnée dans un état sain (soit annuler soit terminer lescommandes en cours).
4

1.2.1 Concepts de base
Pour atteindre les objectifs d’indépendance physique et d’indépendance logique, la norme ANSI/SPARC a définitrois niveaux de description des données.
Figure 1.3 – Concepts de base.
Niveau externe (ES)
Le niveau externe ou niveau vue représente les interfaces utilisateurs de l’application finale, c’est la couche logiciellequi va faire la connexion entre les différents utilisateurs et le SGBD. L’utilisateur concerné est le simple utilisateur.
Niveau conceptuel (CS)
Le niveau conceptuel décrit la structure de toutes les données de la base, leurs propriétés, sans se soucier de l’im-plémentation physique ni de la façon dont chaque groupe de travail voudra s’en servir. L’utilisateur concerné est leconcepteur.
On utilise deux langages :1. Langage de description de données (LDD)
Il permet de réaliser le schéma conceptuel qui est la description de la structure des données (Merise ou UML).2. Langage de manipulation des données (LMD)
Il sert à manipuler la structure des données (SQL).
Niveau interne ou physique (IS)
Le niveau interne définit la représentation interne (stockage) de la base de données (disques, fichiers, ...). La repré-sentation interne physique concerne le type de données (réel, entier, booléen, ...).Il définit l’application du CS sur le IS (principe d’indépendance). L’utilisateur concerné est l’administrateur.
5

Chapitre 2
Les différentes structures
2.1 Bases de données hiérarchiquesUne base de données hiérarchique est une base de données dont le système de gestion lie les enregistrements dansune structure arborescente où chaque enregistrement n’a qu’un seul possesseur.
Cette structure a largement été utilisée dans les premiers systèmes de gestion de base de données de type mainframe.Elle rencontre des limites quand il s’agit de décrire des structures complexes.
Figure 2.1 – Base de données hiérarchique (liaisons 1-N)
2.2 Bases de données réseauxUne base de données réseau est une base de données décrite sur un modèle réseau qui permet de définir des associa-tions entre tous les types d’enregistrements.
Cette structure est une extension du modèle hiérarchique où les liens entre objets peuvent exister sans restric-tion. Pour accéder à une donnée, il faut connaître le chemin donc les liens, ce qui rend les programmes dépendantsde la structure de données.
Figure 2.2 – Base de données réseau (liaisons 1-N)
6

2.3 Bases de données relationnellesUne base de données relationnelle est une base de données inventée en 1970 par Edgar Frank Codd et définie par destables de données hétérogènes qui permettent d’établir des relations entre elles. C’est la plus utilisée actuellementavec le langage SQL.
Figure 2.3 – Base de données relationnelle.
2.3.1 NoSQL
Le NoSQL est utilisé pour les grosses base de données (Facebook, Google, ...).
Figure 2.4 – Représentation du NoSQL.
2.4 Bases de données orientées objetUne base de données orientée objet est une base de données où les données sont représentées sous forme d’objets.
7

Figure 2.5 – Base de données orientée objet.
2.5 Bases de données semi-structuréesUne base de données semi-structurée est une base de données hétérogènes où le schéma ne présente aucune contraintesur la base. Elle se base sur une structure offerte par le langage XML pour stocker des données de volumes importantset les repérer. Il n’y a pas de SGBD, elle a donc de mauvaises performances mais elle est flexible.
Un document XML peut être considéré comme une base de données uniquement au sens le plus strict de l’ex-pression, à savoir une collection de données. Le langage XML se distingue des fichiers plats et présente certainsavantages. Il est auto-descriptif (balises), portable (Unicode), et peut décrire des données sous la forme d’un arbreou d’un graphe. Son inconvénient est qu’il est verbeux, donc l’accès aux données est lent à cause du parsing et de laconversion du texte. L’organisation des données en XML reste cependant hiérarchique.
1 <exemple>2 <h1 langue=" f r a n ç a i s ">Mes CD</h1>3 <album langue=" a n g l a i s ">4 <a r t i s t e>Madonna</ a r t i s t e>5 <t i t r e>American L i f e</ t i t r e>6 <annee>2000</annee>7 </album>8 <album>9 <a r t i s t e>Oasis</ a r t i s t e>
10 <t i t r e>Heathen Chemistry</ t i t r e>11 <annee>2001</annee>12 </album>13 <album langue=" a n g l a i s ">14 <a r t i s t e>U2</ a r t i s t e>15 <t i t r e>Vert igo</ t i t r e>16 <annee>2005</annee>17 </album>18 </exemple>
2.6 Bases de données multidimensionnellesUne base de données multidimensionnelle est une base de données modélisée par un tableau à plusieurs dimensions.Le modèle représente les données sur plusieurs axes (3 en général), ce qui nous donne un hypercube dont chaqueélément peut être défini par plusieurs catégories.
En réalité, une base multidimensionnelle est contenue dans une seule table dont chaque cellule est caractérisée parune dimension (type, date, lieu, groupe) et une mesure (quantité descriptive). Elle est souvent formée par agrégatsde bases hétérogènes ou non pouvant être relationnelles.
8

Figure 2.6 – Base de données multidimensionnelle.
2.7 Bases de données multimédiaUne base de données multimédia est une base de données consacrée au stockage et à l’organisation de données mul-timédia (son, image, vidéo). Elle peut s’appuyer sur différentes architectures de bases de données comme le modèlerelationnel et le modèle objet.
Ces bases de données ne sont pas encore très courantes car on rencontre quelques problèmes pour l’indexationde leur contenu et les recherches par contenu. L’approche classique consiste à renseigner des mots-clés décrivantles caractéristiques principales des documents stockés. Les limitations évidentes sont le manque de précision de ladescription et l’impossibilité de faire des recherches sur des informations existantes dans les documents mais nonpertinentes du point de vue de l’indexation. Une autre approche serait de disposer d’une indexation dynamiquepar l’application d’opérateurs de traitement d’image ou de traitement du signal. L’objectif serait de décomposer lesdocuments en entités élémentaires structurées et reliées entre elles, de manière à ce que l’indexation permettre deretrouver soit des formes (structures) soit des objets (entités) soit des combinaisons des deux.
2.8 Bases de données décisionnellesUne base de données décisionnelle est une base de données utilisées en lecture intensive dont le contenu provientde l’ensemble des bases de données de production. Toutes les données complexes provenant de tout département del’entreprise sont filtrées, croisées, et reclassées dans un entrepôt de données central qui va permettre aux responsablesde l’entreprise et aux analystes de prendre connaissance des données à un niveau global et ainsi prendre des décisionsplus pertinentes. Par exemple, les bases de données multidimensionnelles sont généralement utilisées de manièredécisionnelle.
2.9 Bases de données géographiques (SIG)Une base de données géographique est une base de données qui permet de gérer des données alphanumériques spa-tialement localisées ainsi que des données graphiques permettant d’afficher ou d’imprimer des plans et des cartes.Cette structure couvre les usages d’activités géomatiques de traitement et diffusion de l’information géographique.
Le rôle du système d’information géographique (SIG) est de proposer une représentation plus ou moins réalistede l’environnement spatial en se basant sur des primitives graphiques telles que des points, des vecteurs (arcs), despolygones, ou des maillages (raster). À ces primitives sont associées des informations qualitatives ou tout autreinformation textuelle.
2.10 Bases de données factuellesUne base de données factuelle est une base de données qui regroupe des données établies et attestées concernantun domaine (chimie, physique, médecine, ...). Elle peut intégrer des données non textuelles, dans ce cas on parle debanque de données.
9

Chapitre 3
Langage Merise
3.1 DéfinitionsAvant de programmer une base de données, il faut établir un schéma conceptuel ou « concept map » en anglais afinde visualiser les liens entre les entités. Un schéma conceptuel est une représentation graphique, réalisée avec Meriseou UML, d’un ensemble de concepts reliés entre eux qui sert à décrire le fonctionnement d’une base de données. Lesconcepts sont connectés par des lignes fléchées décrivant la relation qui existe entre ces concepts.
Merise signifiant Méthode d’Etude et de Réalisation Informatique pour les Systèmes d’Entreprise est un langagede spécification le plus répandu dans la communauté de l’informatique des systèmes d’information et plus particu-lièrement dans le domaine des bases de données. Une représentation Merise permet de valider des choix par rapportaux objectifs, de quantifier les solutions retenues, de mettre en oeuvre des techniques d’optimisation, et enfin deguider jusqu’à implémentation. Il est reconnu comme standard et devient un outil de communication facile réalisantune modélisation précise et formelle.
La méthode Merise a l’avantage de séparer les données (statique du système) et les traitements (dynamique dusystème), elle est donc parfaitement adaptée à la modélisation des problèmes abordés d’un point de vue fonctionnel.L’expression conceptuelle des données conduit à une modélisation des données en entités et en associations.
L’établissement du schéma de données avec Merise se fait en trois étapes :1. Modèle conceptuel de données (MCD)2. Modèle logique de données (MLD)3. Modèle physique de données (MPD)
3.2 Schéma conceptuel (MCD)Le modèle conceptuel des données décrit les entités du monde réel, en termes d’objets, de propriétés et de relations,indépendamment de toute technique d’organisation et d’implémentation des données. Ce modèle se concrétise parun schéma entités-associations représentant la structure du système d’information, du point de vue des données.
3.2.1 Entités
Les entités sont des objets concrets (ex : livre, individu) ou abstraits (ex : compte bancaire) que l’on peut identifier.Un ensemble d’entités peut être représenté par une entité type (ex : un élève pour l’ensemble des élèves). Une entitétype est représentée par une table où les attributs sont des champs. Chaque entité est caractérisée par des propriétésappelées attributs parmi lesquels on définit un identifiant unique appelé clé primaire (primary key).
L’identifiant clé primaire peut être de trois types :– clé primaire naturelle : identifiant naturel (ex : email d’une personne)→ Beaucoup de possibilités mais perfor-
mances de comparaison nulles.– clé primaire artificielle : identifiant de type INTEGER créé par une incrémentation (232 possibilités).– clé primaire composée : identifiant composé (ex : enseigne + localité d’une entreprise).
Une « occurrence » ou un enregistrement dans une entité est également appelé « tuple ».
10
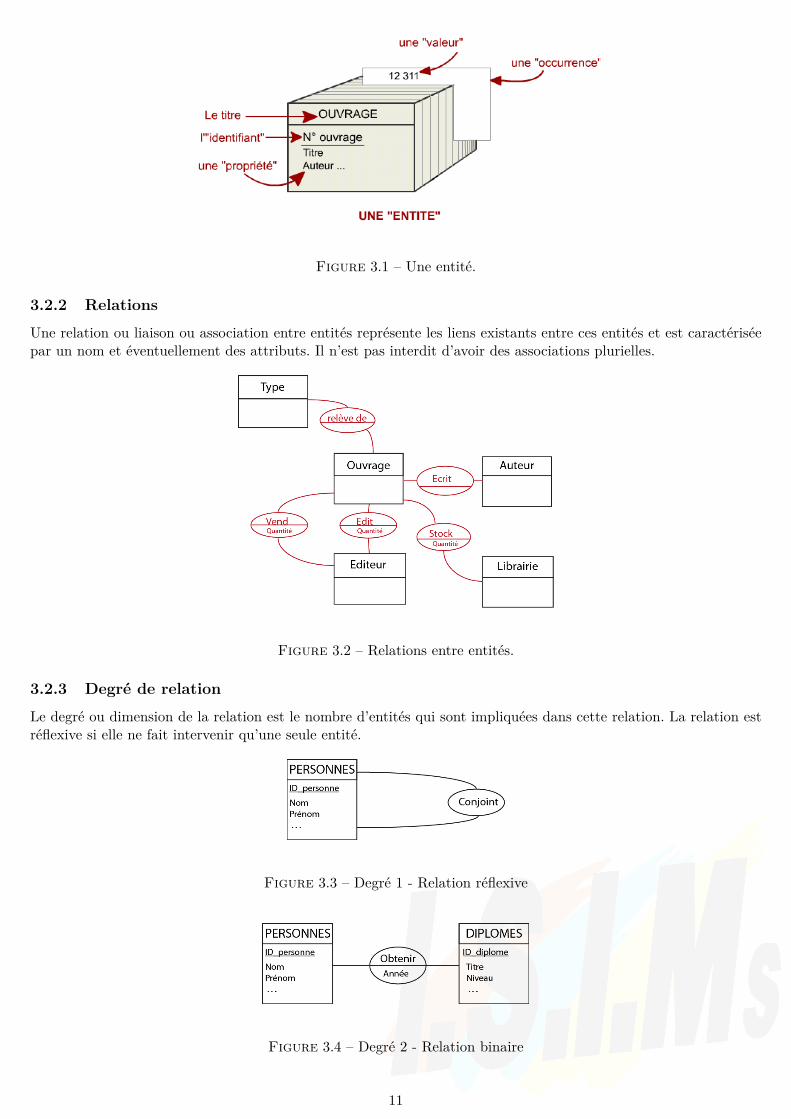
Figure 3.1 – Une entité.
3.2.2 Relations
Une relation ou liaison ou association entre entités représente les liens existants entre ces entités et est caractériséepar un nom et éventuellement des attributs. Il n’est pas interdit d’avoir des associations plurielles.
Figure 3.2 – Relations entre entités.
3.2.3 Degré de relation
Le degré ou dimension de la relation est le nombre d’entités qui sont impliquées dans cette relation. La relation estréflexive si elle ne fait intervenir qu’une seule entité.
Figure 3.3 – Degré 1 - Relation réflexive
Figure 3.4 – Degré 2 - Relation binaire
11

Figure 3.5 – Degré 3 - Relation ternaire
3.2.4 Cardinalités
Les cardinalités sont le nombre d’occurrences défini par un couple min,max qui caractérise la relation. La cardinalitéminimale peut être 0 ou 1 tandis que la cardinalité maximale peut être 1 ou N.
Une cardinalité minimale à 0 signifie qu’il se peut qu’aucune occurrences de l’entité ne soit reliée à l’association.Une cardinalité minimale à 1 signifie qu’il faut au moins une occurrence de l’entité qui soit reliée à l’association.Une cardinalité maximale à 1 signifie qu’il y aura au plus une occurrence de l’entité qui est reliée à l’association.Une cardinalité maximale à N signifie qu’il se peut qu’il y ait plusieurs occurrences de l’entité qui soient reliées àl’association.
Figure 3.6 – Modèle conceptuel de données en Merise.
3.2.5 Démarche de conception
1. Etablir la liste des entités2. Déterminer les attributs de chaque entité3. Etablir les relations entre les différentes entités4. Définir les cardinalités des relations5. Vérifier la cohérence et la pertinence du schéma obtenu
3.2.6 Remarques
Il faut essayer de limiter le nombre d’entités en fusionnant celles qui ont trop d’attributs en commun. Dans unerelation, on peut ajouter des attributs si cette dernière est de type N,N. Lorsque la relation est de type 1,1, onfusionne les deux entités car il s’agit d’une erreur de conception.Un tuple est un néologisme basé sur le terme mathématique N-uplet étant Table Uplet.Un n-uplet est une collection ordonnée de n objets.Un t-uple est un enregistrement dans une table (une entité).
3.2.7 Dépendance fonctionnelle
On dit qu’il existe une dépendance fonctionnelle entre un attribut A1 et un attribut A2 (A1 → A2), si connaissantune valeur de A1 on ne peut lui associer qu’une seule valeur de A2. On dit aussi que A1 détermine A2. A1 est lasource de la dépendance fonctionnelle et A2 le but.
12

Si la valeur d’un attribut est souvent rencontrée, on crée une entité pour entrer les différentes valeurs commeattribut. Ainsi, cela permet de changer rapidement en cas de fautes d’orthographe dans la valeur, il suffit de changerà un seul endroit. On évite donc la redondance.
La seule dépendance fonctionnelle admissible au sein d’une entité est celle qui fait que la clé primaire est source ettous les autres champs doivent en être le but.
3.2.8 Contrainte d’intégrité fonctionnelle (CIF)
La contrainte d’intégrité fonctionnelle se définit par le fait que l’une des entités participant à l’association est com-plètement déterminée par la connaissance d’une ou plusieurs autres entités participant dans cette même association.
Les associations directes qui peuvent être définies par des associations intermédiaires doivent être retirées du modèle.
3.3 Schéma logique (MLD)Le modèle logique de données précise le modèle conceptuel par des choix organisationnels. Il s’agit d’une transcrip-tion du MCD dans un formalisme adapté à une implémentation ultérieure, au niveau physique, sous forme de basede données relationnelle ou réseau, ou autres. Les choix techniques d’implémentation (choix d’un SGBD) ne seronteffectués qu’à l’étape suivante.
On passe du modèle conceptuel au modèle logique en remplaçant les relations par des flèches.
Dans le cas des relations 1-N, il faut créer une clé secondaire appelée clé étrangère (foreign key) où l’identifiantest précédé par un "#" et du côté du 1.Dans le cas des relations N-N, il faut créer une nouvelle entité appelée table intermédiaire avec deux clés étrangèresdont l’association forme la clé primaire composée de cette dernière.
Figure 3.7 – Modèle logique de données en Merise.
3.4 Schéma physique (MPD)Le modèle physique de données permet d’établir la manière concrète dont le système sera mis en place (SGBD retenu).Dans ce modèle, on précise le format de stockage des données on optimise les performances en dénormalisant le MLD.
C’est l’étape qui consiste à modifier le MLD afin d’implémenter la base de données dans le système informatique.
3.5 NormalisationIl existe des règles de normalisation afin d’aider le concepteur à éviter certaines erreurs de modélisation de sa basede données. Ces règles permettent de faciliter les mises à jour de la BD et d’éliminer les redondances.
3.5.1 Première forme normale
Les conditions pour avoir une première forme normale sont :– Tous les attributs non clé doivent être en dépendance fonctionnelle avec la clé.– Tout attribut ne doit contenir qu’une valeur atomique (non décomposable).
13

3.5.2 Deuxième forme normale
Les conditions pour avoir une deuxième forme normale sont :– Être en première forme normale.– Tout attribut n’appartenant pas à la clé doit dépendre totalement et non partiellement de la clé.
3.5.3 Troisième forme normale
Les conditions pour avoir une troixième forme normale sont :– Être en deuxième forme normale.– Tout attribut non clé ne doit pas dépendre d’un attribut non clé.
14