Embed Size (px)
Citation preview

2
Plan
• Intégration de données• Architectures d’intégration
– Approche matérialisée – Approche virtuelle
• Médiateurs– Conception et intégration– Traitement des requêtes– Systèmes existants
• Médiation et architectures P2P

3
Intégration de données
• Contexte • Caractéristiques• Taxonomie des systèmes existants• Processus d’intégration de données
4
Problématique
Globalisation des données et des ressources
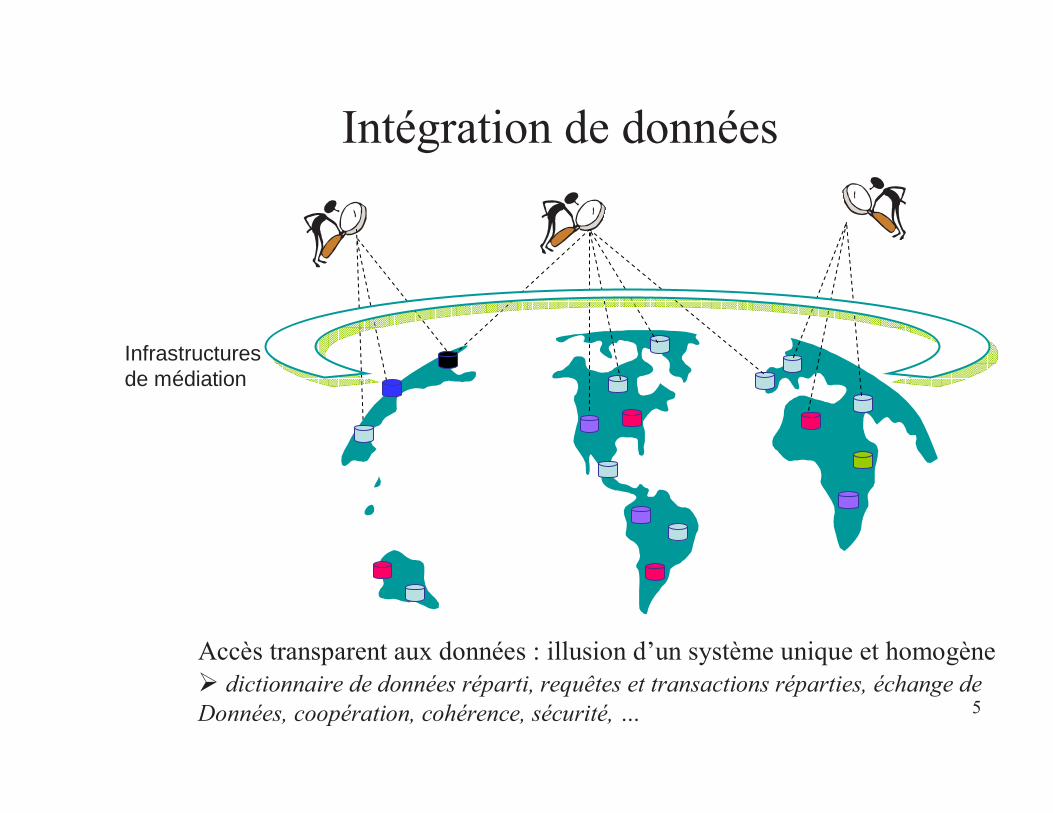
5
Intégration de données
Infrastructuresde médiation
Accès transparent aux données : illusion d’un système unique et homogènedictionnaire de données réparti, requêtes et transactions réparties, échange de
Données, coopération, cohérence, sécurité, …

6
Contexte
• Sources d’informations nombreuses et très diversifiées (SGBD R, SGBDO, XML, fichiers texte, pages Web, etc.)
• Différents modes de consultation– Langages et modes de requêtes différents (SQL, moteurs de
recherche, programme d’applications…)– Différentes façons de répondre (différentes présentations
du résultat) : pages Web, tableurs, relations…• Différents interactions avec la source
– Protocoles de communication (JDBC, ODBC, IIOP)– Différentes interfaces
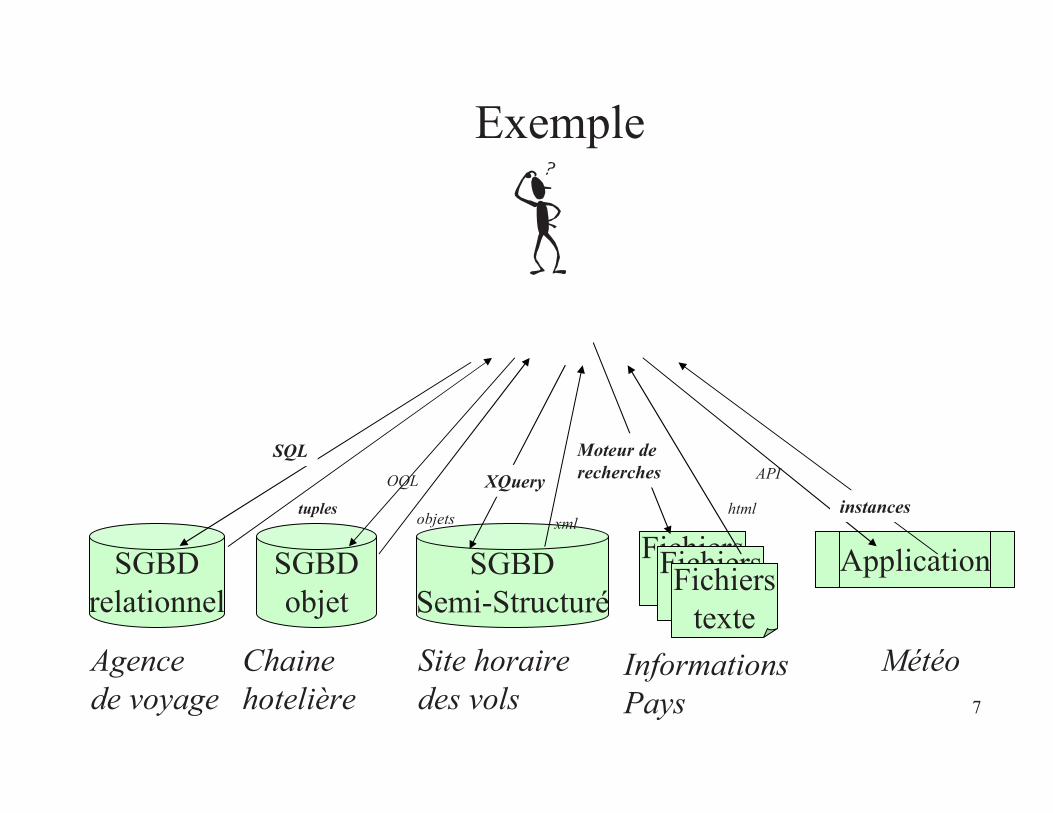
7
Exemple
SGBDrelationnel
ApplicationSGBDobjet
SGBDSemi-Structuré
Agencede voyage
Chainehotelière
Site horairedes vols
InformationsPays
Météo
FichierstexteFichiers
texteFichiers
texte
SQLXQueryOQL API
Moteur derecherches
instancestuples objets xmlhtml

8
Intégration de données
Fournir un accès (requêtes, éventuellement mises à jour)uniforme (les sources sont transparentes à l’utilisateur)à des sources (pas seulement des BD)multiples (même 2 est un problème)autonomes (sans affecter le comportement des sources)hétérogènes (différents modèles de données, schémas)structurées ( ou au moins semi-structurées)
9
Caractéristiques des sources
• Distribution• Hétérogénéité• Autonomie• Interopérabilité
Distribution
HétérogénéitéAutonomie
Interopérabilité

10
Distribution
• Les données sont stockées sur des supports répartis géographiquement.
• Offre disponibilité et amélioration des temps d’accès. • Pbs:
– Localiser la (ou les) source(s) contenant les données pertinentes.
– Tenir compte de la puissance des sources et de leur charge
– Les sources peuvent être temporairement indisponibles

11
Hétérogénéité
• L’hétérogénéité concerne les données, les modèles et les langages.
• Système homogène : • même logiciel gérant les données sur tous les sites • même modèle de données• même univers de discours
• Système hétérogène :• n’adhère pas à toutes les caractéristiques d’un système
homogène• langages de programmation et d’interrogation différents,
modèles différents, SGBD différents

12
Hétérogénéité des données
• Sémantique– Signification, interprétation ou utilisation différente de la
même donnée– Types de relations sémantiques
• R1 identique à R2 : même constructeur, même concept• R1 équivalente à R2 : constructeurs différents, même concept• R1 compatible avec R2 : ni identiques, ni équivalents• R1 incompatible avec R2 : contradictoires
• Structurelle

13
Hétérogénéité des données
• Sémantique• Structurelle
– Représentation différente des mêmes concepts dans des bases différentes
– Conflits de noms, types de données, attributs, unités

14
Autonomie• Conception : sources locales avec des
• modèles de données propres,• langage d’interrogation• Interprétation sémantique des données, contraintes, fonctions …
• Communication : les sources de données locales décident quand et comment répondre aux questions d’autres sources
• Exécution : pas d’information provenant des sources locales sur
• l’ordre d’exécution des transactions locales ou des opérations externes
• pas de distinction entre les opérations locales et globales• Association :
• connexion et déconnexion des sources• partage de données et des fonctions

15
Interopérabilité
• Systèmes interopérables :• échange de messages et de requêtes• fonctionnent comme une unité pour une tâche commune• partagent les fonctions• Communiquent même avec des composants internes
incompatibles• Propriétés fondamentales à tout système interopérable :
– Distribution– Hétérogénéité– Autonomie
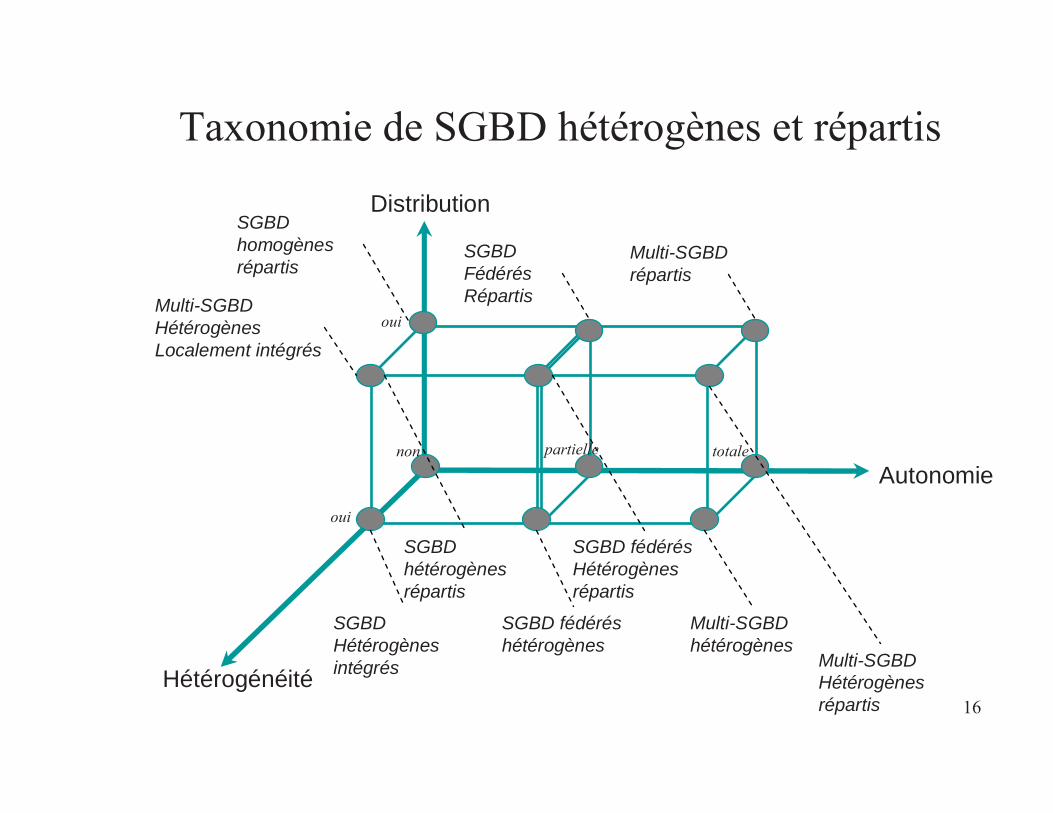
16
Taxonomie de SGBD hétérogènes et répartis
Autonomie
Hétérogénéité
Distribution
SGBDFédérés Répartis
Multi-SGBDrépartis
Multi-SGBDhétérogènes
Multi-SGBDHétérogènesrépartis
SGBD fédérésHétérogènesrépartis
SGBD hétérogènes répartis
SGBD fédéréshétérogènes
SGBD Hétérogènesintégrés
SGBD homogènes répartis
Multi-SGBDHétérogènesLocalement intégrés
non
oui
totalepartielle
oui
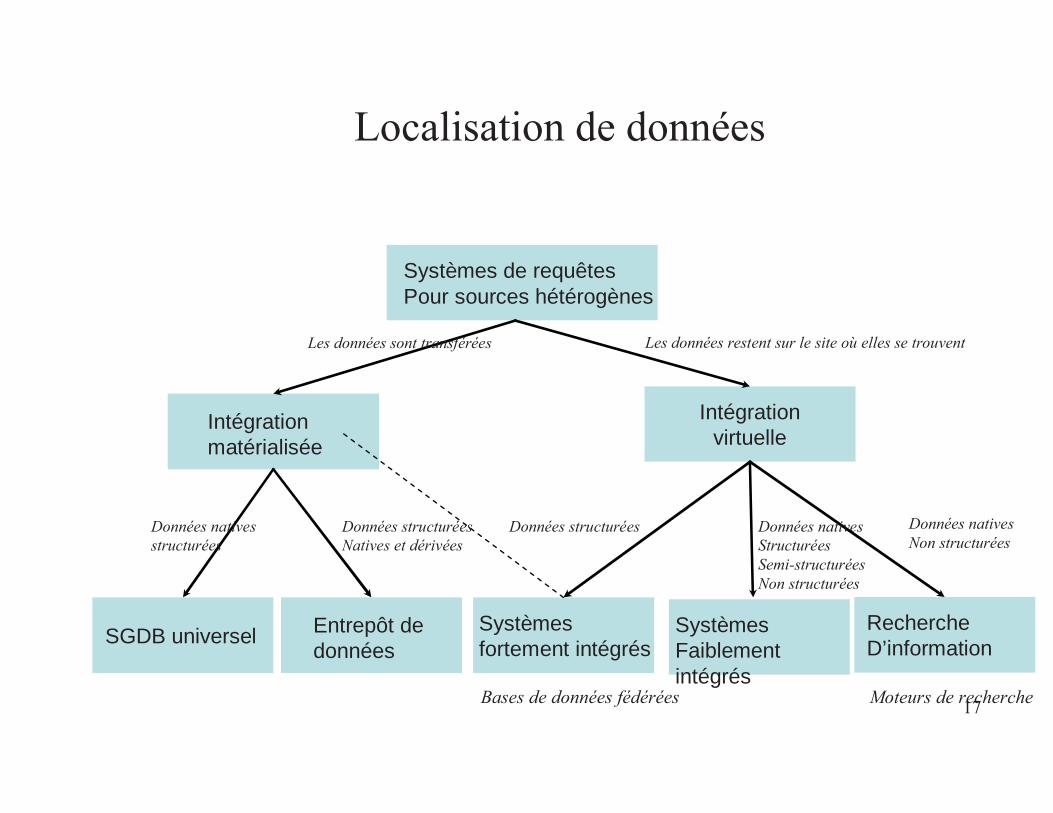
17
SGDB universel Entrepôt de données
Systèmes fortement intégrés
RechercheD’information
SystèmesFaiblement intégrés
Systèmes de requêtesPour sources hétérogènes
Intégrationvirtuelle
Intégration matérialisée
Localisation de données
Bases de données fédérées Moteurs de recherche
Les données sont transférées Les données restent sur le site où elles se trouvent
Données nativesstructurées
Données structuréesNatives et dérivées
Données nativesNon structurées
Données structurées Données nativesStructuréesSemi-structuréesNon structurées
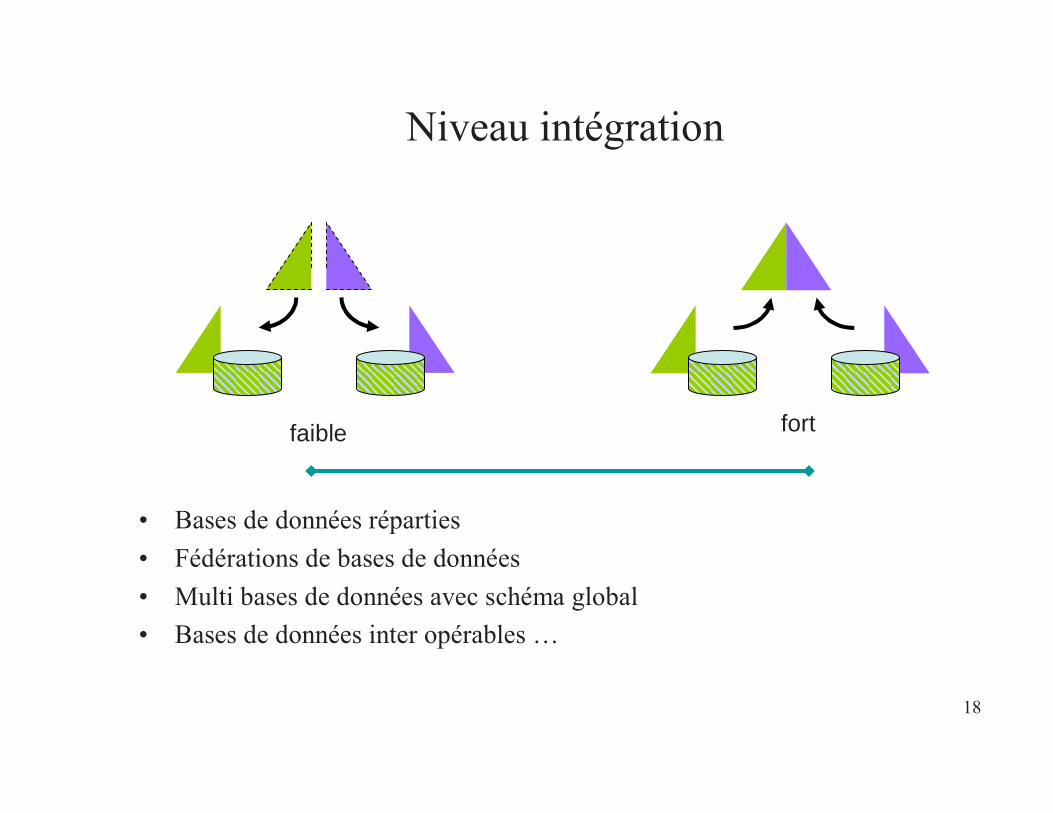
18
Niveau intégration
• Bases de données réparties• Fédérations de bases de données• Multi bases de données avec schéma global• Bases de données inter opérables …
faible fort

19
Processus d’Intégration
Processus semi automatisable permettant d’intégrer des données structurellement et sémantiquement hétérogènes.
Problème ancien (voir état de l’art dans A.P.Sheth and J.A Larson. Federated database systems for managing distributed, heterogeneous, andautonomous databases. ACM Computing Surveys, 22(1):183-236, Mars 90).
Pbs : hétérogénéité des modèles de données, des puissances d’expression, des modélisations.
Un système d’intégration comprend 4 tâches principales :- intégration de schéma- fusion de données- traduction de requêtes- réécriture de requêtes

20
Intégration de schéma
– Pré intégration• Analyse des schémas :
– identification des éléments semblables dans les schémas initiaux, et description des liens inter-schémas.
– unifier les types en correspondance en un schéma intégré et produire les règles de traduction associées entre le schéma intégré et les schémas initiaux.
• Ordre d’intégration• Définition de contraintes globales
– Comparaison• Identification de relations entre attributs• Homonymes, synonymes, types de données, dépendances• Propriétés (assertions) de correspondance inter schémas
(dépendances d’inclusion, exclusion, union)• S’assurer que l’ensemble d’assertions est cohérent et minimum.

21
Fusion de données
– Mise en conformité : résolution de conflits• Classification : les populations du monde réel représentées par les
deux types sont différentes.• Description : les types ont des ensembles différents de propriétés• Structure : les concepts utilisés pour décrire les types sont différents• Hétérogénéité : les modèles de données utilisés sont différents. • Données : des instances en correspondance ont des valeurs
différentes pour des propriétés en correspondance.
– Regroupement et restructuration : mise en forme d’objets dans la vue intégrée

22
Représentation des aspects sémantiques
• Logique de description
• Méta attributs et valeurs à représentation d’un contexte
• Dictionnaires de données à vocabulaire utilisé dans les bases de données
• Ontologies décrivant des domaines de discours (concepts, relations, valeurs)

23
Architectures d’intégration
• Intégration matérialisée– Les données provenant des sources à intégrer sont stockées
sur un support spécifique (entrepôt de données).– L’interrogation s’effectue comme sur une BD classique
(relationnelle).
• Intégration virtuelle– Les données restent dans les sources– Les requêtes sont faites sur un schéma global, puis
décomposées en sous-requêtes sur les sources. Les différents résultats des sources sont de la requête sont combinés pour former le résultat final.
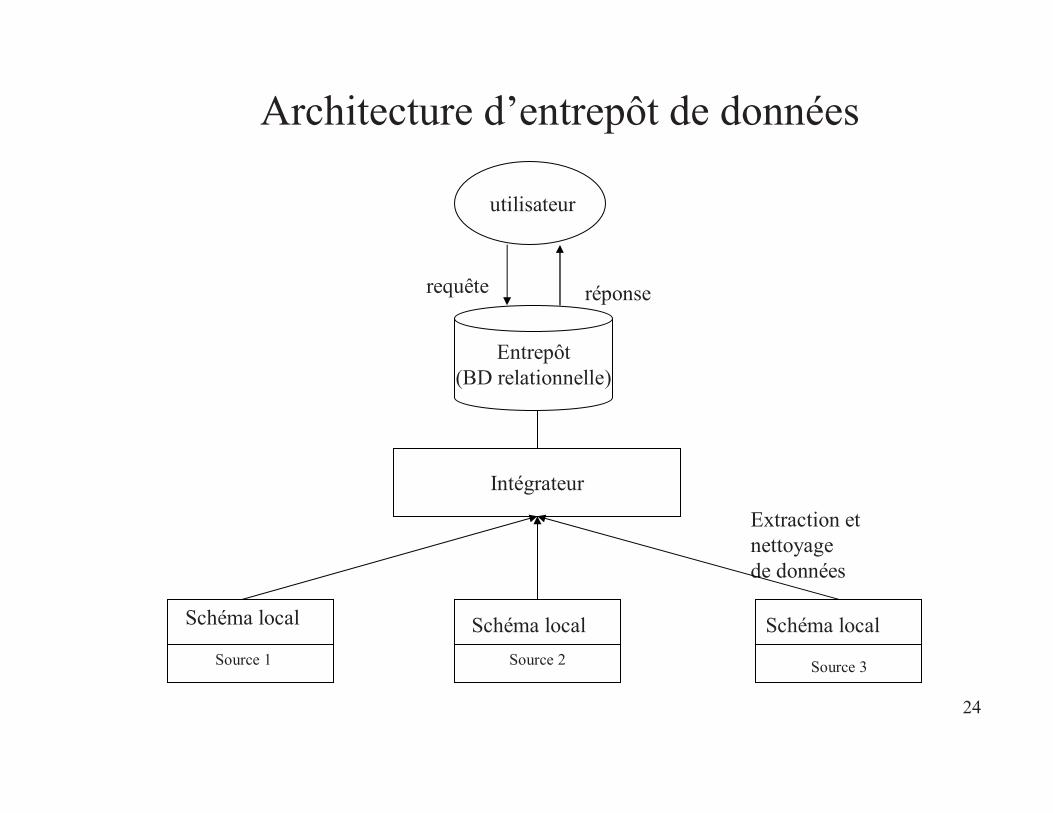
24
Architecture d’entrepôt de données
Intégrateur
Entrepôt(BD relationnelle)
requête réponse
Schéma local Schéma local Schéma local
Extraction et nettoyagede données
utilisateur
Source 1 Source 2 Source 3
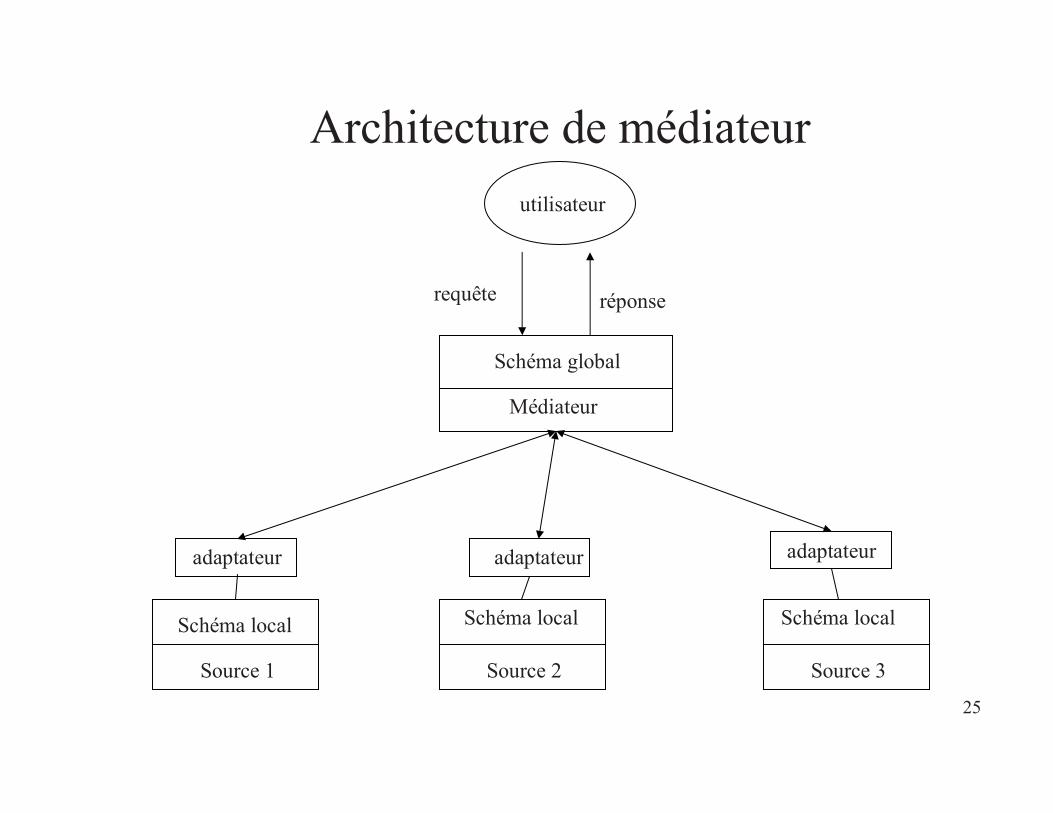
25
Architecture de médiateur
Schéma global
Schéma local
Source 1
Schéma local
Source 2
Schéma local
Source 3
Médiateur
requête réponse
utilisateur
adaptateuradaptateur adaptateur

26
Matérialisé vs. virtuel
• Architectures matérialisées– Bonnes performances– Données pas toujours fraîches– Nettoyage et filtrage des données
• Architectures virtuelles– Les données sont toujours fraîches– Traitement de requêtes peut être coûteux– Défi principal : performances

27
Entrepôts de données

28
Motivations
• Réconciliation sémantique– Dispersion des sources de données au sein d’une entreprise– Différents codage pour les mêmes données– L’entrepôt rassemble toutes les informations au sein d’un unique
schéma– Conserve l’historique des données
• Performance– Les données d’aide à la décision nécessitent une autre organisation
des données– Les requêtes complexes de l’OLAP dégradent les performances
des requêtes OLTP.• Disponibilité
– La séparation augmente la disponibilité– Une bonne façon d’interroger des sources de données dispersées
• Qualité des données

29
Systèmes légués
• gros système, critique, sur environnement ancien. Souvent peu documenté. Interactions entre les différents modules peu claires. Très cher à maintenir.
• Il faut l'intégrer (migration) au système actuel (Entrepôt) = architecture cible.• Contraintes : migration sur place, garder opérationnel, corriger et améliorer
pour anticiper, le moins de changements possibles (diminuer le risque), flexible sur les évolutions futures, utiliser les technologies modernes.
• Approche classique : tout réécrire dans l'architecture cible– promesses à tenir dans des conditions changeantes– problème de transfert de très gros fichiers (plusieurs jours) dans
système critique– gros projet, retard mal vus, risque d'abandon
• Approche incrémentale : – isoler des sous-systèmes a migrer– établir des passerelles pour que les modules déjà migrés puissent
communiquer avec les modules encore dans le système légué(traducteur de requêtes et de données).
– coordonner les mises à jour pour garder la cohérence.
30
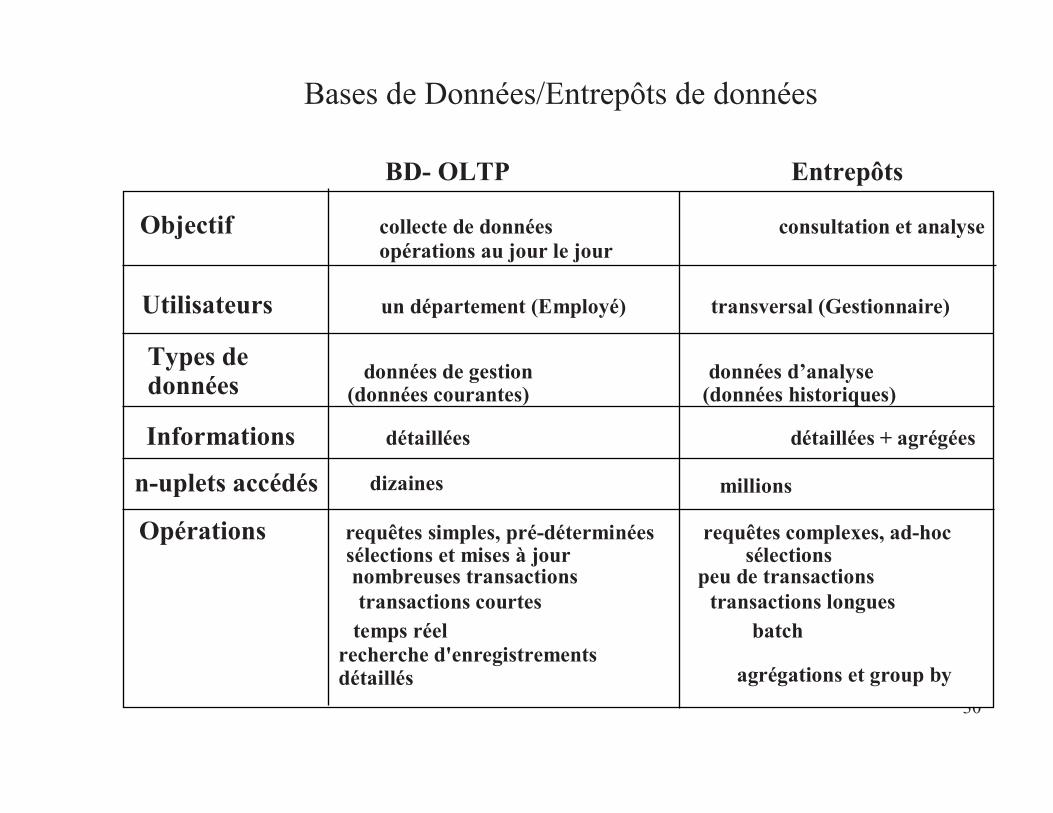
Bases de Données/Entrepôts de données
BD- OLTP Entrepôts
Objectif collecte de données consultation et analyseopérations au jour le jour
Utilisateurs un département (Employé) transversal (Gestionnaire)
Types dedonnées données de gestion données d’analyse
(données courantes) (données historiques)
Informations détaillées détaillées + agrégées
Opérations requêtes simples, pré-déterminées requêtes complexes, ad-hocsélections et mises à jour sélectionsnombreuses transactions peu de transactionstransactions courtes transactions longues
temps réel batchrecherche d'enregistrementsdétaillés agrégations et group by
n-uplets accédés dizaines millions

31
Bases de données/Entrepôts de données
Un entrepôt recouvre un horizon bien plus long dans le tempsque les systèmes de production.
Il inclut de nombreuses bases de données «travaillées» de façon àdéfinir les données uniformément.
Il est optimisé pour répondre à des questions complexes pour décideurset analystes.

32
Bases de données / Entrepôts
Les entrepôts sont physiquement séparés des systèmes de production,pour des raisons de
Performance : les données des systèmes de production ne sont pas organisées pour pouvoir répondre efficacement aux requêtes des systèmes d’aide à la décision. Même les requêtes simples peuvent dégrader sérieusement les performances.
Accès aux données : un entrepôt doit pouvoir accéder aux données uniformément, quelle que soit la provenance des données.
Formats des données : les données des entrepôts sont transformées,et doivent être disponibles sous un format simple et unique.
Qualité des données: les données d’un DW sont propres et validées. La qualité des données est vue au sens large du décisionnel, et ne peut être réalisée qu’après comparaison avec d’autres éléments.

33
Caractéristiques
Dans un entrepôt, les données sont
• orientées par sujets : Les données organisées par sujet (clients, vendeurs, production,etc.) contiennent seulement l'information utile à la prise de décision. Les systèmes opérationnels sont plutôt orientés autour des traitements et des fonctions.
• intégrées :Les données, provenant de différentes sources (systèmes légués) sont souvent structurées et codées de façons différentes. L'intégration permet d'avoir une représentation uniforme, cohérente et transparente. Lorsque les données sont agrégées, il faut s’assurer que l’intégration est correcte.
• historiques :Un datawarehouse contient des données "anciennes", datant de plusieurs années, utilisées pour des comparaisons, des prévisions, etc.
• non volatiles :Une fois chargées dans le datawarehouse, les données ne sont plus modifiables. Ellessont uniquement accessibles en lecture (pour l'instant...).

34
Fonctions des entrepôts
• Récupérer les données existantes des différentes sources
• Référencer les données de manière uniforme
• Stocker les données (notamment historisées)
• Mettre à disposition les données pour :
•interrogation•visualisation•analyse
35
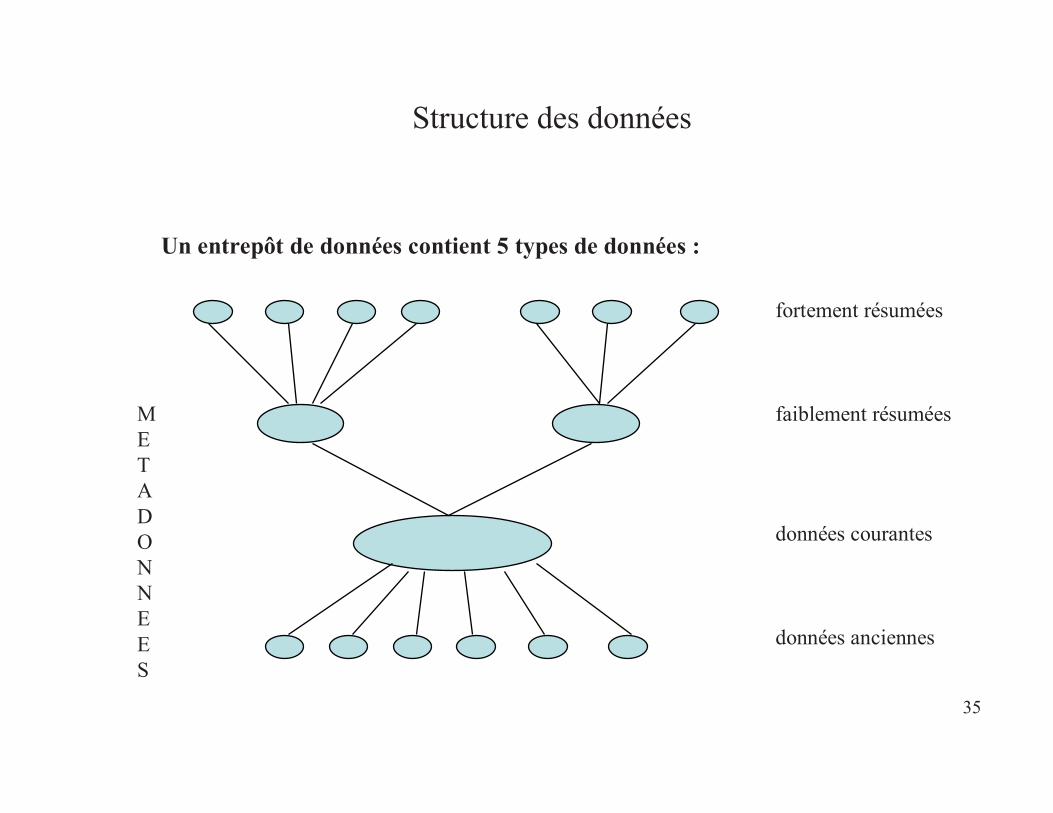
Structure des données
Un entrepôt de données contient 5 types de données :
fortement résumées
faiblement résumées
données courantes
données anciennes
METADONNEES

36
Métadonnées
• Les métadonnées jouent un rôle central dans l'alimentation de l’entrepôt
• Ce sont les "données sur les données".
• Elles sont utilisées lors de l'extraction, l'agrégation, la transformation, le filtrage et le transfert des données.
• Le méta-modèle constitue le référentiel unique:
• utilisateurs, profils et droits• applications• modèles de données, structure des données• règles d'agrégation et de calcul
37
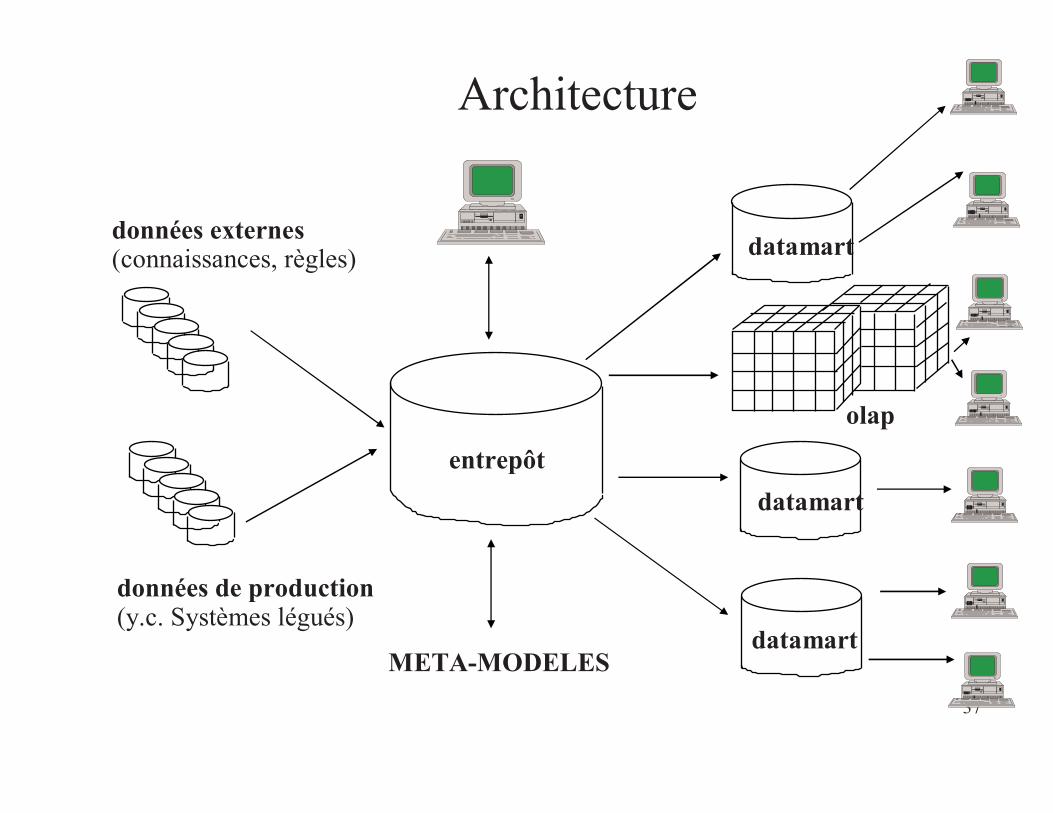
Architecture
entrepôt
datamart
datamart
datamart
olap
données de production(y.c. Systèmes légués)
données externes (connaissances, règles)
META-MODELES

38
Architecture à 3 niveaux
• Serveur de la BD de l’entrepôt– Presque toujours relationnel
• Data marts /serveur OLAP– Relationel (ROLAP)– Multidimensionel (MOLAP)
• Clients– Outils d’interrogation et de rapports– Outils d’analyse et d’aide à la décision

39
Construction d’un entrepôt de données
1. Acquisition:Extraction : collection de données utilesPréparation : transformation des caractéristiques des données
du système opérationnel dans le modèle de l’entrepôtChargement : nettoyage (élimination des dupliqués, incomplétudes,
règles d’intégrité, etc.) et chargement dans l’entrepôt (trier, résumer, calculs,index).
2. Stockage :Les données sont chargées dans une base de données pouvanttraiter des applications décisionnelles.
3. Restitution des données :Il existe plusieurs outils de restitution (tableaux de bord, requêteursSQL, analyse multidimensionnelle, data mining ...)
Trois phases principales

40
Maintenance• Les données de l’entrepôt sont stockées sous forme de vues
matérialisées sur les différentes sources de données.• Quand répercuter les mises à jour des sources ?
– À chaque modification ?– Périodiquement ?– À définir par l’administrateur
• Comment les répercuter ?– Tout recompiler périodiquement ?– Maintenir les vues de façon incrémentale
• Détecter les modifications (transactions, règles actives, etc.)• Les envoyer à un intégrateur qui détermine les vues concernées,
calcule les modifications et les répercute.

41
Outils d’extraction de données
• Les requêteurs génèrent des requêtes SQL ad hoc (GQL, Reporter, Impromptu).• Les tableaux de bord prédéfinis, consultables à l’écran, génèrent des états
• Les outils de data mining permettent d’extraire des informations implicitesde la base. Ils utilisent des techniques de classification, de segmentation, d’apprentissage symbolique et numérique, des statistiques, des réseaux neuronaux.(Enterprise Miner, Intelligent Miner, KnowledgeSeeker, STATlab,...)
• Les analyseurs permettent de gérer les données multidimensionnelles (Outils OLAP: Explorer, PowerPlay, Metacube Explorer, ...)
(histogrammes, camemberts, ...)

42
Evolution
Les entrepôts sont amenés à évoluer souvent et considérablement.La taille d'un entrepôt croît rapidement (de 20giga à 100giga en 2 ans).
Pourquoi ?- nouvelles données (extension géographique, changement de fréquence deshistoriques, changement du niveau de détail, etc.)- ajout de nouveaux éléments de données au modèle (l'ajout d'un attributpour 2millions de n-uplets représente une augmentation considérable!)- création de nouveaux index, résumés- ajout de nouveaux outils (générateurs de requêtes, outils OLAP, etc.)- nouveaux utilisateurs- complexité des requêtes
Comment garantir l'extensibilité, la disponibilité, la maintenabilité ?

43
Evolution
Les prototypes ne sont guère utiles (ne dépassent pas 20giga), les estimations sont souvent erronées...Trois aspects majeurs sont concernés :
la base de données doit être extensible, disponible (plus de batch),facilement gérable (optimisation, indexation, gestion du disque automatiques).le middleware (gestionnaire de transactions, gestionnaire d'accès,...)doit être performant et cohérent. Là aussi, extensibilité, disponibilité, facilité de gestion.
l'intégration des outils doit se faire avec un souci de compatibilité.Les outils doivent être conformes au plus grand nombre de standards.

44
Problèmes ouverts dans les DW
• Alimentation des entrepôts : 1/3 de la taille du projet. Simplifier le processus pour en alléger le coût.
• Maintenance : maintenir des vues matérialisées. Pb de cohérence. Pb de mise à jour à travers les vues.
• Intégration de schéma : les différentes sources ont des schéma différents, le DW doit avoir un schéma global unique. Comment faire ?
• Effet taille : les DW grossissent "`à vue d'oeil" (victimes de leur succès), vers des tera-octets. Comment gérer cela ? Les solutions actuelles seront-elles viables ?
• Coût d'un DW prohibitif pour les petites entreprises. Commencer par ne faire que des data-marts et les intégrer peu à peu...