Embed Size (px)
Citation preview

Intérêt, principes de mise en œuvre et
précautions d’emploi des
modèles d’équations structurelles
en psychologie
Jacques JuhelUniversité Rennes 2
CRPCC (E.A. 1285)
56ème Congrès de la SFP - Université de Strasbourg 2-4 septembre 2015

Les modèles d’équations structurelles
offrent un cadre méthodologique
extrêmement flexible

Un cadre méthodologique utilisable par une recherche
structurale
A partir d’une certaine façon de « comprendre » un phénomène
complexe, le psychologue :
• choisit le niveau d’observation et d’analyse associée du phénomène ;
• représente ses hypothèses sous la forme d’un système de relations entre les
variables considérées ;
• déduit de ces hypothèses les contraintes imposées aux paramètres d’un
certain modèle statistique ;
• recueille des données empiriques sur un échantillon de participants ;
• estime les paramètres du modèle statistique spécifié et teste sa capacité à
reproduire l’organisation des données ;
• discute les hypothèses substantielles mises à l’épreuve à partir des résultats
du modèle qui, parmi tous ceux testés, reconstruit « le mieux » les données.
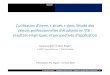
Vlaeyen, J.W., & Linton, S.J. (2000). Fear-avoidance and its consequences in chronic musculoskeletal pain : A state of the art.
Pain, 85, 317-332.
Exemple 1 – Rôle de l’instabilité émotionnelle et des affects
négatifs dans le modèle peur-évitement en douleur chronique
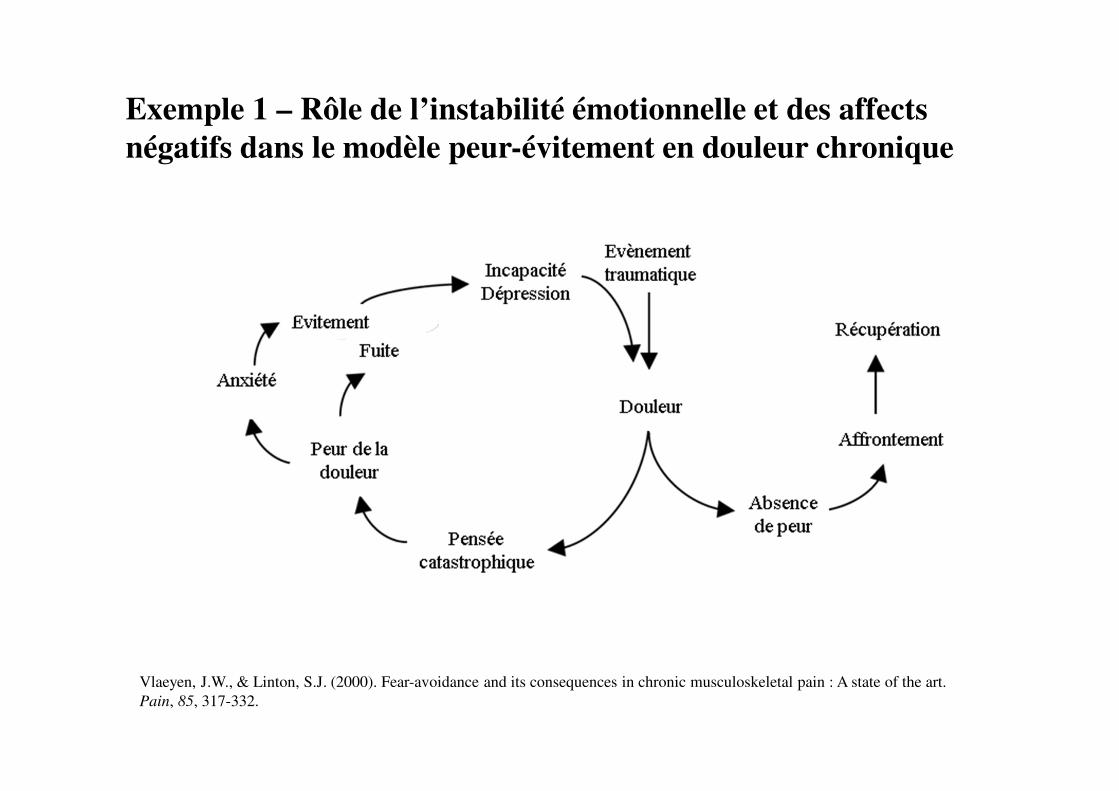
Wong et al. (2015). The fear-avoidance model of chronic pain: Assessing the role of neuroticism and negative affect in pain
catastrophizing using SEM. International Journal of Behavioral Medicine, 22(1), 118-132.
N=401 patients souffrant de douleurs musculo-squelettiques [âge: 43.66 (E.T.=9.68)]
Exemple 1 – Rôle de l’instabilité émotionnelle et des affects
négatifs dans le modèle peur-évitement en douleur chronique

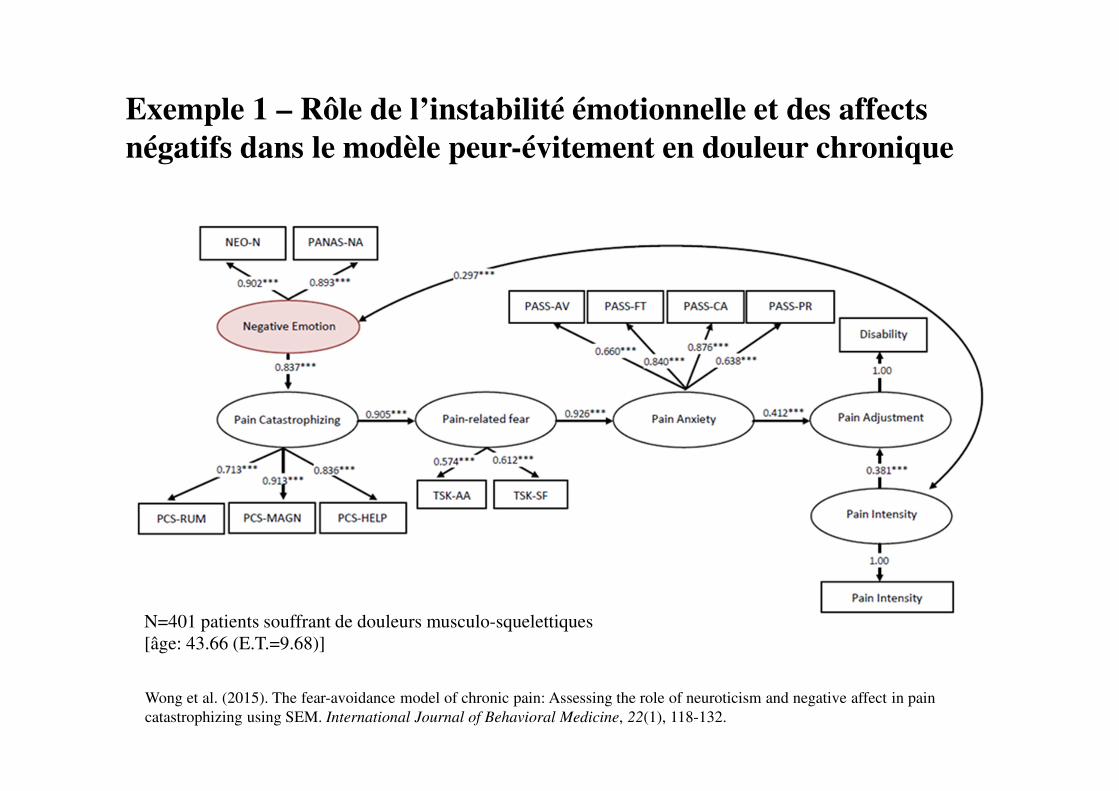
Exemple 2 – Rôle des perceptions de compétences par autrui
sur les performances scolaires
Hypothèse générale :
la perception par autrui (les parents, les enseignants) des
compétences scolaires des jeunes enfants est un médiateur de la
relation entre 1) ce que l’on connaît d’eux et de leur environnement,
2) leurs performances scolaires.
→ Recherche de prédicteurs possibles des perceptions de compétences par les
parents et les enseignants :
• caractéristiques de l’enfant : efficience intellectuelle (composante
fluide), problèmes de comportement évalués par les parents et les
enseignants ;
• caractéristiques de la famille : niveau d’étude et statut socio-économique
des parents, passé d’immigration).
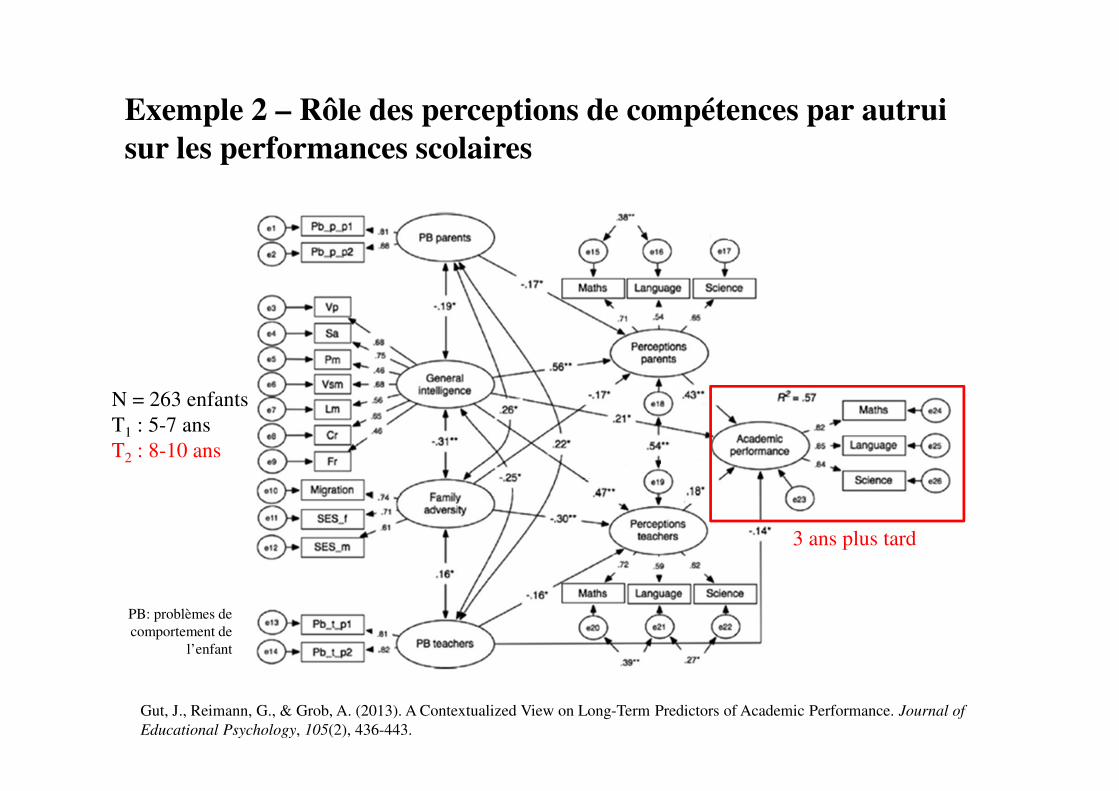
Exemple 2 – Rôle des perceptions de compétences par autrui
sur les performances scolaires
Gut, J., Reimann, G., & Grob, A. (2013). A Contextualized View on Long-Term Predictors of Academic Performance. Journal of
Educational Psychology, 105(2), 436-443.
N = 263 enfants
T1 : 5-7 ans
T2 : 8-10 ans
PB: problèmes de
comportement de
l’enfant
3 ans plus tard

Une approche trop complexe, souvent peu étayée au plan
théorique, très coûteuse à mettre en œuvre, non probante…

Origine et développement des modèles
d’équations structurelles (SEM)

Première moitié du 20ème siècle :
les origines
Psychométrie : l’analyse en facteurs communs
La recherche « exploratoire » de causes communes de variation.
Un modèle statistique qui relie l’espérance des observables à une structure
latente (un ou plusieurs « facteurs ») via une fonction de régression linéaire.
• Pearson (1901) : moindres carrés orthogonaux ;
• Spearman (1904) : modèle à deux facteurs ;
• Hotelling (1933) : analyse en composantes principales ;
• Thurstone (1935) : analyse multifactorielle, principes (qualitatifs) de structure simple
et rotation des axes factoriels ;
• Lawley (1940) : application de la méthode du maximum de vraisemblance à
l’estimation des saturations ;
• Carroll (1953) : critère de rotation analytique des axes factoriels ;
• Tucker (1955) : distinction entre analyse factorielle « exploratoire » (EFA) et analyse
factorielle « confirmatoire » (CFA).

Biométrie : les pistes causales
Approche déductive : calcul des corrélations entre variables en fonction
de relations causales spécifiées a priori.
La méthode des coefficients de parcours (Wright, 1921, 1934).
Wright, S. (1921). Correlation and Causation. Jounal of Agricultural Research, 20, 557-585.
Première moitié du 20ème siècle :
les origines

Econométrie : les équations simultanées
Approche inductive : utilisation de systèmes d’équations linéaires mettant
en relation des variables exogènes et des variables endogènes.
Extension logique de l’analyse de régression à des prédicteurs aléatoires et à des
données temporellement non homogènes.
• Frisch (1929, 1934, Prix Nobel 1969) : analyse de confluence ;
• Tinbergen (1939, Prix Nobel 1969) : test de « l’influence quantitative des facteurs
suggérés par une théorie » ;
• ReiersØl (1941) : méthode des variables instrumentales ;
• Haavelmo (1943 – Prix Nobel 1989) : approche probabiliste des modèles
économiques, problème de l’identification ;
• Koopmans (1945 – Prix Nobel 1975) : estimation de relations économiques
simultanées ;
• Theil (1953) : méthode des doubles moindres carrés (2SLS).
→ Débat Tinbergen-Keynes (autour des années 40) sur la méthode économétrique et le passage de
la modélisation statistique à la généralisation inductive.
Première moitié du 20ème siècle :
les origines

Années 60-70 :
synthèses et intégration
L’intégration de l’analyse factorielle, des équations simultanées
et des pistes causales
Synthèse pistes causales-équations simultanées :
• Les « modèles causaux » en sociologie quantitative (Blalock, 1964; Boudon, 1965;
Duncan, 1966; Heise, 1968) ; illustrations en psychologie (Werts & Linn, 1970).
Synthèse économétrie-psychométrie :
• Bock & Bargman (1966) : analyse des structures de covariance (ACOVS) ;
• Jöreskog (1969) : modèle général d’analyse factorielle confirmatoire (CFA) et
estimation des paramètres par maximum de vraisemblance (ML).
• Goldberger (1971) : traitement des variables non observées ;
• Jöreskog, Keesling et Wiley (début des années 70) : modèle d’équations linéaires
simultanées en variables latentes (Jöreskog, 1973 ; LISREL : Linear Structural Relations) ;
• Wold (1974) : analyse de parcours avec variables latentes (PLS-PM : Partial Least Squares
Path Modeling).

L’émergence et le développement de
deux approches des SEM
L’approche LISREL (début des années 70)
• Une approche « confirmatoire » : un modèle de connaissance orienté vers le
mécanisme de génération des données.
• Modèle de mesure : analyse factorielle (en facteurs communs).
• Principe : estimer les valeurs des paramètres de la population pour lesquelles
la matrice de variance-covariance impliquée par le modèle spécifié est la plus
proche possible de la matrice de variance-covariance observée.
• Procédure d'ajustement : minimiser l’écart entre les valeurs observées des
paramètres et les valeurs calculées à l'aide d’une fonction de perte (moindres
carrés, maximum de vraisemblance, etc.).
→ Logiciels : LISREL, EQS, AMOS, Mplus, Lavaan, OpenMx, etc.

L’approche PLS (fin des années 70)
• Approche « prévisionnelle » : un modèle de comportement orienté vers la
réalisation des prévisions.
• Modèle de mesure : analyse en composantes principales.
• Principe : maximiser la variance expliquée des variables endogènes, i.e., la
précision des prévisions (R2).
• Procédure d’estimation :
1. Des variables latentes : par itération entre l’estimation externe
(combinaison linéaire des indicateurs des variables latentes) et l’estimation
interne (en considérant les corrélations entre variables latentes) ;
2. Des équations structurelles : à l’aide de régressions linéaires (moindres
carrés ordinaires) entre estimations des variables latentes.
→ PLS-Graph, SmartPLS, XLSTAT-PLS, etc.
L’émergence et le développement de
deux approches des SEM

L’évolution des SEM (modèle LISREL)
Les développements statistiques des SEM (modèle LISREL)
1ère génération :
• SEM sous hypothèse de normalité multivariée des données, analyse multi-groupes,
analyses longitudinales, données manquantes, etc.
2nde génération :
• développement de méthodes d’estimation pour données ordinales, nominales, discrètes,
limitées (modèles linéaires généralisés à effets fixes et aléatoires) ;
• intégration des modèles multi-niveaux ;
• intégration des modèles à mélange de distributions (classes latentes), etc.
3ème génération :
• Approche bayésienne des SEM ;
• SEM et graphes cycliques orientés : inférence causale:
• Méta-analyses avec les SEM, etc.

L’utilisation des SEM en psychologie
L’épistémologie des SEM
La représentation de phénomènes complexes
• La simplicité, l’économie d’une recherche renvoient à son aspect pragmatique, pas à
son aspect épistémique.
L’effacement de la rupture entre description et explication
• La description formalisée d’une structure qui explicite les relations fonctionnelles
entre des variables observées et hypothétiques.
Le passage d’une causalité déterministe à une causalité probabiliste
• A chaque valeur d’une variable indépendante est associée une et une seule distribution
de probabilité de l’ensemble des distributions de probabilité de la variable aléatoire
dépendante.
La testabilité d’hypothèses non isolées
• Les hypothèses structurales sont testées au sein d’un système de variables, en accord
avec la thèse de Duhem-Quine (les données empiriques qui contredisent une
hypothèse isolée contredisent en fait l’hypothèse jointe à tout un ensemble
d’hypothèses admises).
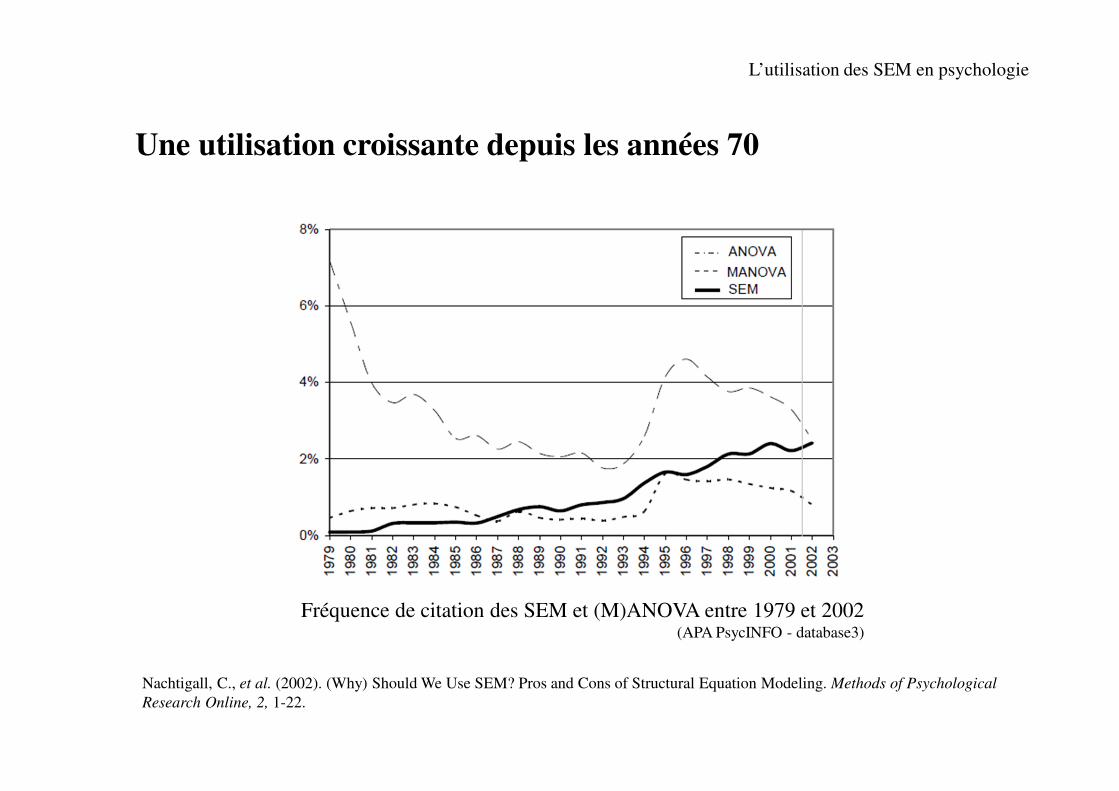
Nachtigall, C., et al. (2002). (Why) Should We Use SEM? Pros and Cons of Structural Equation Modeling. Methods of Psychological
Research Online, 2, 1-22.
Une utilisation croissante depuis les années 70
Fréquence de citation des SEM et (M)ANOVA entre 1979 et 2002 (APA PsycINFO - database3)
L’utilisation des SEM en psychologie

Les SEM sont aujourd’hui utilisés dans de nombreux domaines
de recherche en psychologie
Psychologie différentielle
Psychologie de la santé
Psychologie du développement
Psychologie de l’éducation
Psychologie du travail
Psychologie sociale
Psychologie clinique
Neuropsychologie
Psychologie cognitive
Titre de la revue # articles
Personality and Individual differences 278
Health Psychology 135
Child development 100
Journal of Counseling Psychology 95
Developmental Psychology 91
Journal of Educational Psychology 79
Intelligence 78
Journal of Family Psychology 75
Journal of Organizational Behavior 65
Journal of Applied Psychology 63
Journal of Consulting and Clinical Psychology 60
Psychological Assessment 56
Educational Psychologist 53
Journal of Personality and Social Psychology 52
Journal of Occupational Health Psychology 47
Journal of Abnormal Psychology 45
Development and Psychopathology 43
Developmental Science 43
Psychology and Aging 40
Journal of Occupational and Organizational Psychology 38
Personality and Social Psychology Bulletin 38
Behaviour Research and Therapy 30
Advances in Experimental Social Psychology 24
Neuropsychology Review 24
Leadership Quarterly 22
Current Directions in Psychological Science 20
Personality and Social Psychology Review 20
Personnel Psychology 20
Trends in Cognitive Sciences 18
Depression and Anxiety 16
Neuropsychology 12
Journal of Experimental Psychology : General 8
Journal of Experimental Psychology: Learning, Memory, and Cognition 7
Articles de revues internationales dont le
résumé contient l’expression « Structural
Equation Modeling » (14/08/2015)
L’utilisation des SEM en psychologie

Quelques raisons du succès croissant des SEM dans la
modélisation de données non expérimentales
Un cadre méthodologique très souple qui permet :
• de mesurer des construits « sans erreur », de tester des hypothèses
d’invariance de mesure, etc. ;
• de tester des relations complexes (médiation, modération, médiation
modérée, modération médiatisée) au sein d’un système de variables
observées et latentes ;
• de tester des hypothèses portant sur les coefficients de régression, les
covariances, les variances, les moyennes, etc., dans des comparaisons entre
groupes, entre niveaux, entre moments ;
• de modéliser des données longitudinales, intensives, à processus parallèles,
etc. ;
• de traiter des données manquantes ; etc.
L’utilisation des SEM en psychologie

Principes de mise en œuvre des SEM
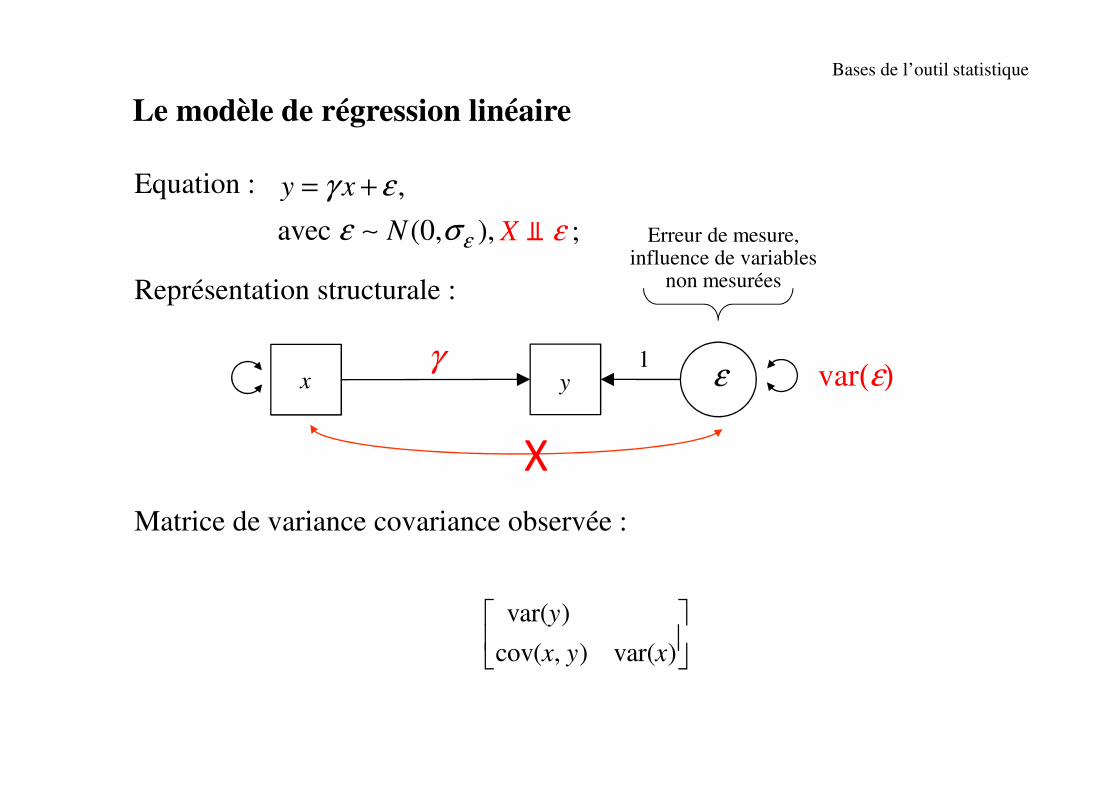
Equation :
X ⫫ ε ;
Représentation structurale :
Matrice de variance covariance observée :
xγ
y ε1
var(ε)
Le modèle de régression linéaire
var( )
cov( , ) var( )
y
x y x
,
avec (0, ),
y x
N ε
γ ε
ε σ
= +
∼
Bases de l’outil statistique
X
Erreur de mesure,influence de variables
non mesurées
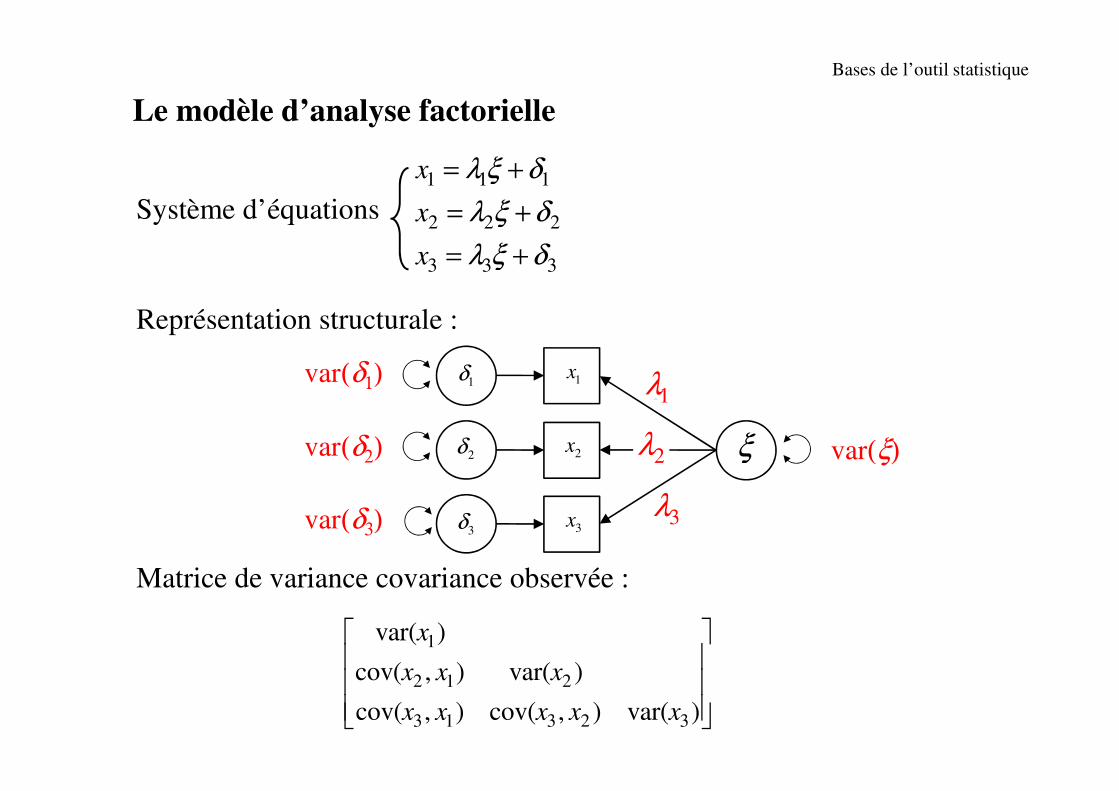
Système d’équations
Représentation structurale :
Matrice de variance covariance observée :
1 1 1
2 2 2
3 3 3
x
x
x
λ ξ δ
λ ξ δ
λ ξ δ
= +
= +
= +
Le modèle d’analyse factorielle
var(δ1) 1x
2x ξ
1 1λ =
2λ
1δ
2δ
3x3δ
3λvar(δ2)
var(δ3)
ξ
3λ
1λ
2λ var(ξ)
1
2 1 2
3 1 3 2 3
var( )
cov( , ) var( )
cov( , ) cov( , ) var( )
x
x x x
x x x x x
Bases de l’outil statistique
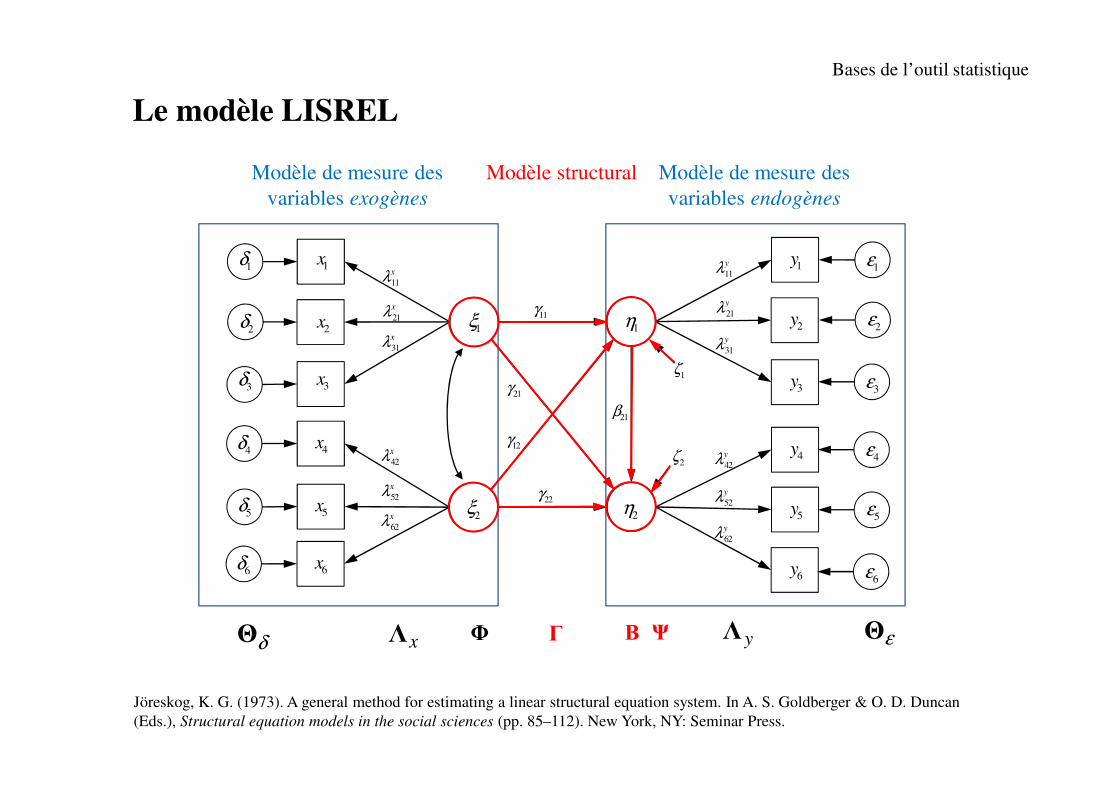
1y
2y
3y
4y
5y
6y
1ε
2ε
3ε
4ε
5ε
6ε
1η
2η
4x
5x
6x
4δ
5δ
6δ
1ξ
2ξ
1δ
2δ
3δ
1x
2x
3x 1ζ
2ζ
11γ
21β
12γ
21γ
22γ
11
xλ
21
xλ
31
xλ
52
xλ
62
xλ
42
xλ
11
yλ
21
yλ
31
yλ
52
yλ
62
yλ
42
yλ
Jöreskog, K. G. (1973). A general method for estimating a linear structural equation system. In A. S. Goldberger & O. D. Duncan
(Eds.), Structural equation models in the social sciences (pp. 85–112). New York, NY: Seminar Press.
δΘ xΛ Φ Β εΘyΛΨΓ
Modèle de mesure des
variables exogènes
Modèle de mesure des
variables endogènes
Modèle structural
Le modèle LISREL
Bases de l’outil statistique

Conditions d’application
Des suppositions qui garantissent l’interprétation des résultats
du modèle
Pouvoir justifier a priori des spécifications du modèle structural :
• le choix des variables exogènes et endogènes ;
• l’exogénéité des variables indépendantes (X→Y et X ⫫ εY) ;
• les contraintes imposées au modèle (par ex., l’absence de relation entre
deux variables) et dont dépendent les estimations ;
• l’orientation des relations : non orientées, récurrentes, non récurrentes ;
• le respect de la condition d’antériorité temporelle si une variable
intermédiaire est distinguée d’un antécédent qui conditionne le
phénomène ;
• le respect de l’hypothèse de perturbations indépendantes les unes des
autres ;
• etc.
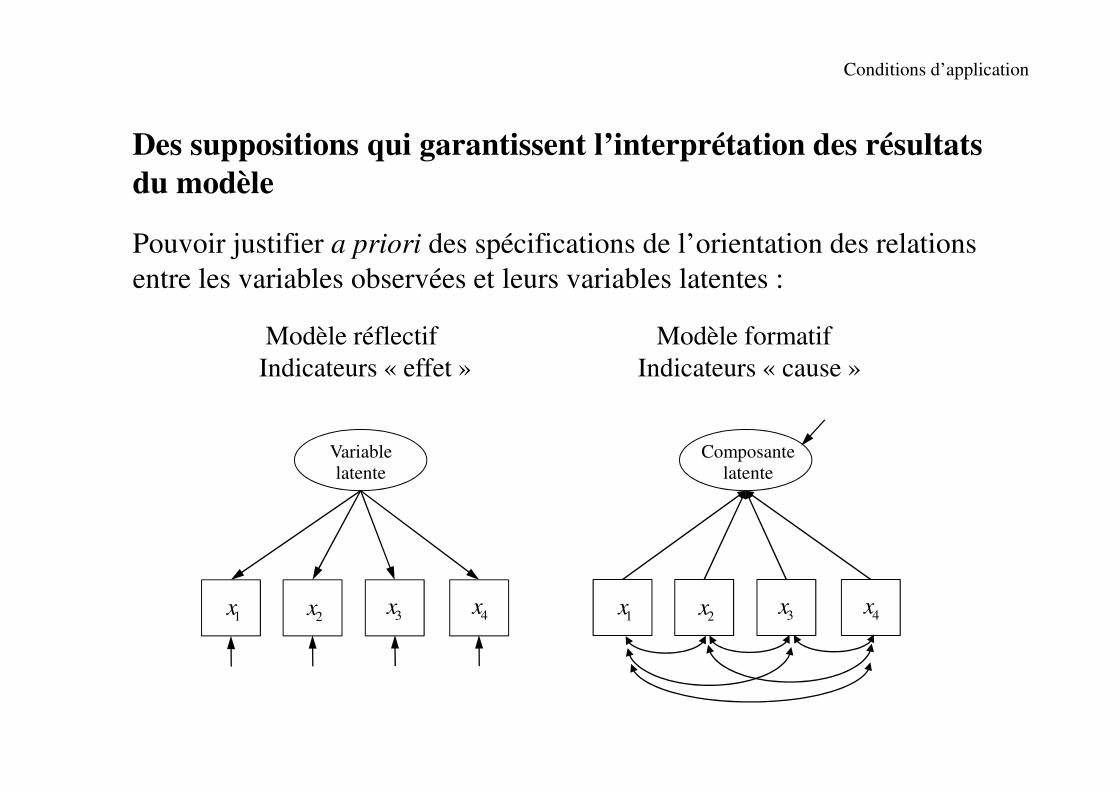
Conditions d’application
Des suppositions qui garantissent l’interprétation des résultats
du modèle
Pouvoir justifier a priori des spécifications de l’orientation des relations
entre les variables observées et leurs variables latentes :
Modèle réflectif Modèle formatif
Indicateurs « effet » Indicateurs « cause »
1x 4x3x2x 1x 4x3x2x
Variable latente
Composante latente
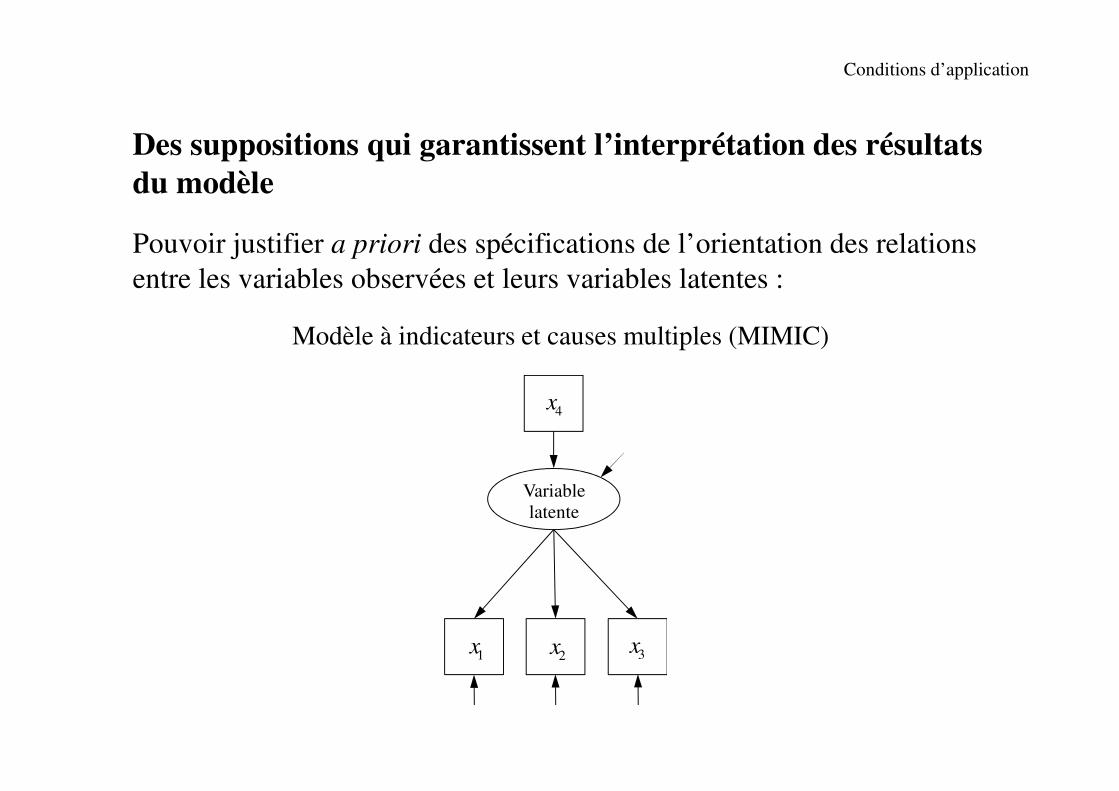
Conditions d’application
Des suppositions qui garantissent l’interprétation des résultats
du modèle
Pouvoir justifier a priori des spécifications de l’orientation des relations
entre les variables observées et leurs variables latentes :
Modèle à indicateurs et causes multiples (MIMIC)
1x
4x
3x2x
Variable latente

Conditions d’application
Des suppositions qui garantissent l’interprétation des résultats
du modèle
Pouvoir justifier du respect de certaines hypothèses statistiques liées aux
données d’observation :
• l’hypothèse de variables exogènes mesurées sans erreur (les perturbations des
variables endogènes latentes proviennent des erreurs de mesure et de certaines
causes non mesurées).
• des hypothèses distributionnelles : par ex., l’hypothèse de normalité
multivariée des variables endogènes pour l’estimateur du maximum de
vraisemblance.
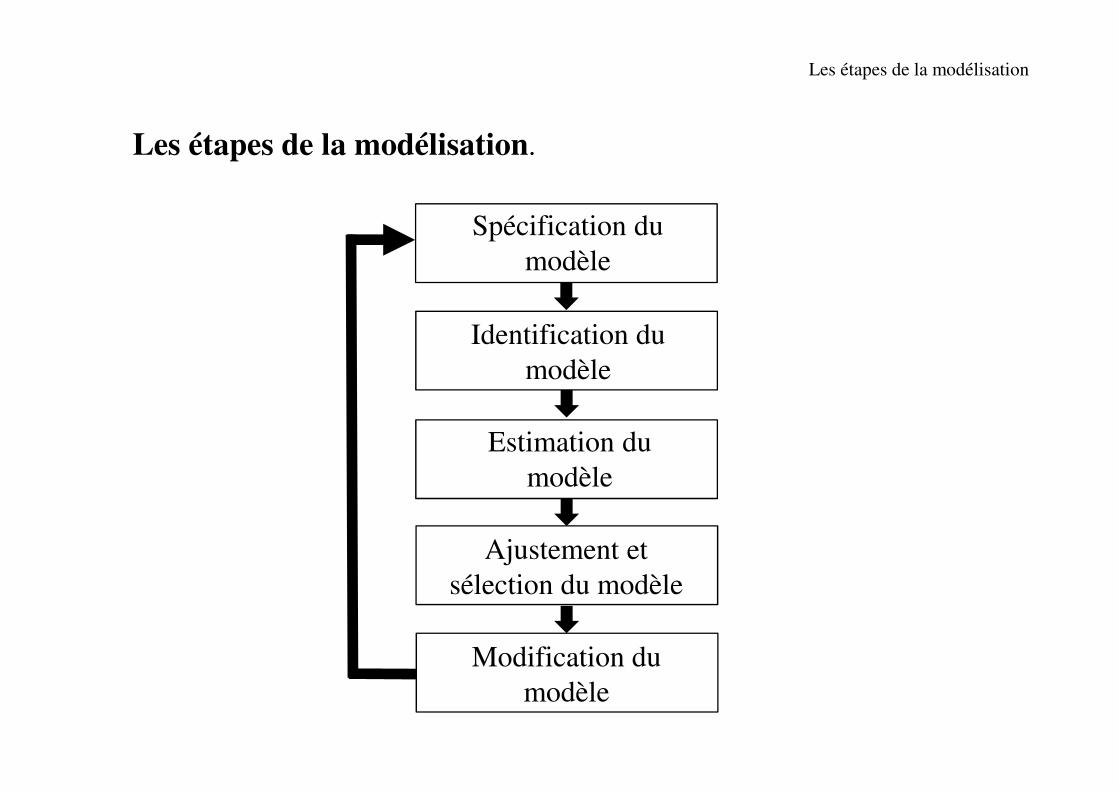
Les étapes de la modélisation
Les étapes de la modélisation.
Description desSpécification du
modèle
Description desIdentification du
modèle
Description des
Description des
Estimation du
modèle
Ajustement et
sélection du modèle
Description desModification du
modèle
Les étapes de la modélisation
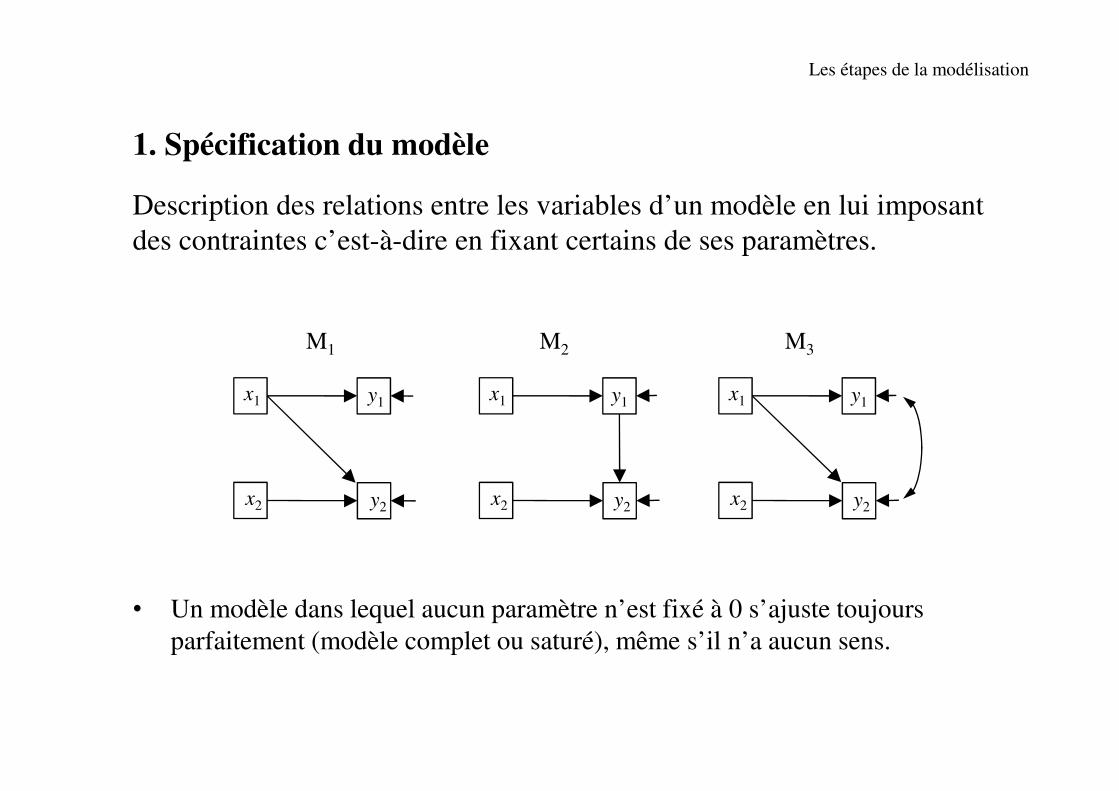
1. Spécification du modèle
Description des relations entre les variables d’un modèle en lui imposant
des contraintes c’est-à-dire en fixant certains de ses paramètres.
• Un modèle dans lequel aucun paramètre n’est fixé à 0 s’ajuste toujours
parfaitement (modèle complet ou saturé), même s’il n’a aucun sens.
x1
y2x2
y1 x1
y2x2
y1 x1
y2x2
y1
M1 M2 M3
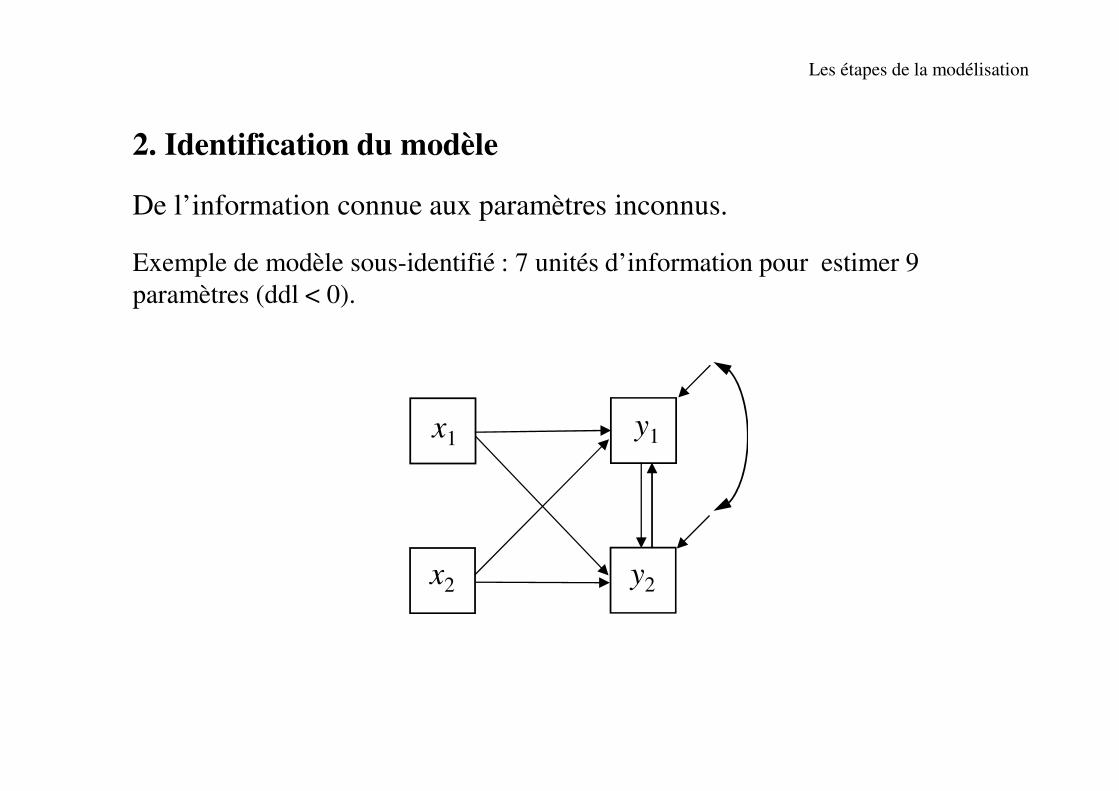
2. Identification du modèle
De l’information connue aux paramètres inconnus.
Exemple de modèle sous-identifié : 7 unités d’information pour estimer 9
paramètres (ddl < 0).
x1
x2
y1
y2
Les étapes de la modélisation
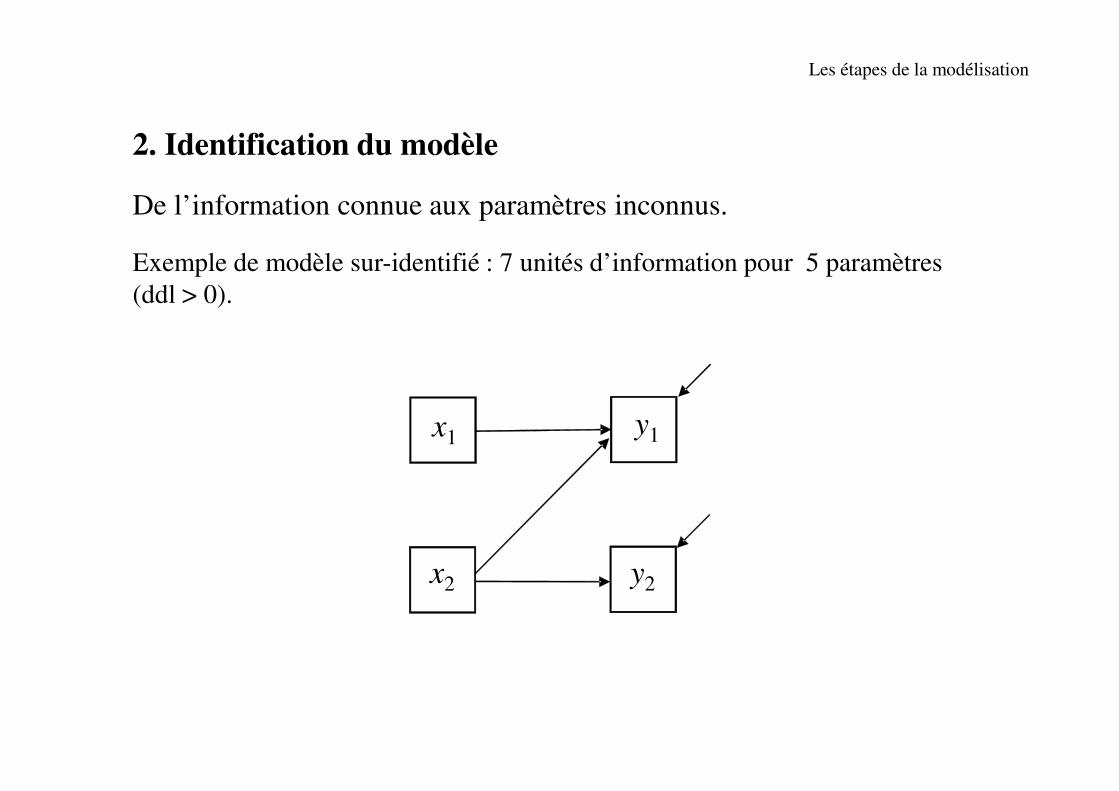
2. Identification du modèle
De l’information connue aux paramètres inconnus.
Exemple de modèle sur-identifié : 7 unités d’information pour 5 paramètres
(ddl > 0).
x1
x2
y1
y2
Les étapes de la modélisation
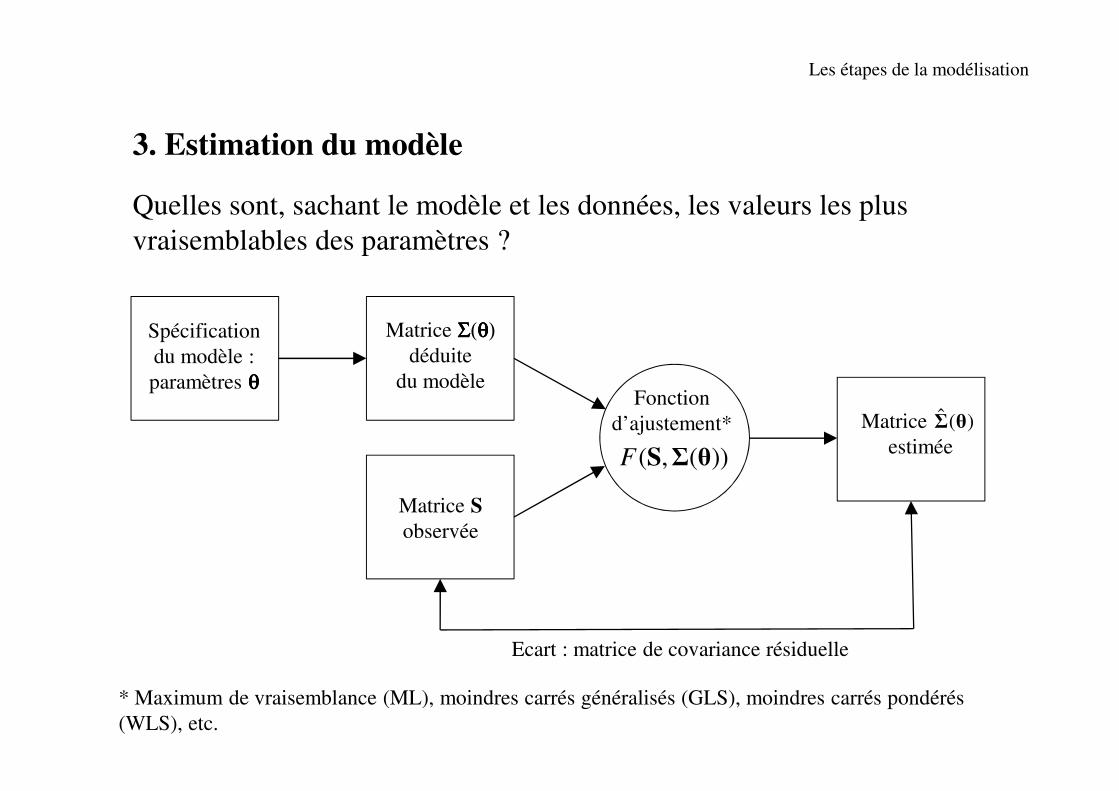
3. Estimation du modèle
Quelles sont, sachant le modèle et les données, les valeurs les plus
vraisemblables des paramètres ?
Spécification
du modèle :
paramètres θθθθ
Matrice ΣΣΣΣ(θθθθ) déduite
du modèle
Matrice S
observée
( , ( ))F S Σ θ
Fonction
d’ajustement* Matrice
δ estimée
Ecart : matrice de covariance résiduelle
ˆ ( )Σ θ
Les étapes de la modélisation
* Maximum de vraisemblance (ML), moindres carrés généralisés (GLS), moindres carrés pondérés
(WLS), etc.

4. Ajustement et sélection du modèle
Le modèle a) s’ajuste-t-il ; b) s’ajuste-t-il mieux que les autres ?
• Indices d’ajustement calculés à partir de la fonction de discordance : χ2 du
modèle, CFI, TLI, RMSEA, etc.
• D’autres prennent en compte les résidus ( ) : GFI, RMR et SRMR.
• Comparaison de modèles emboîtés : test du χ2(LR)
• Comparaison de modèles non emboîtés : AIC, CAIC (consistent AIC), BIC.
Les étapes de la modélisation
ˆ ( )−S Σ θ
2 2 2plus parcimonieux moins parcimonieux
plus parcimonieux moins parcimonieuxddl ddl ddl
χ χ χ∆ = −
∆ = −

5. Modification du modèle
L’ajustement du modèle peut-il être amélioré ?
• Procédure exploratoire basée sur les estimations obtenues sur l’échantillon.
• Les modèles re-spécifiés doivent (en principe) être estimés sur un nouvel
échantillon (validation croisée).
Les étapes de la modélisation

Exemples d’application
des SEM en psychologie

Trois grandes stratégies de modélisation de données non
expérimentales
• Strictement « confirmatoire » : non rejet (plutôt que « validation »)
ou rejet du modèle.
• Développement de modèle : spécifications successives d’un même
modèle avec validation croisée.
• Comparaison de modèles : identification du « meilleur » modèle
parmi tous ceux testés.
Exemples d’application des SEM en psychologie

Analyse factorielle confirmatoire (CFA)
→ Des fonctions exécutives distinctes mais interdépendantes
Mise à jour Flexibilité Inhibition
N=137 [18 ans-30 ans]
Structure factorielle des fonctions exécutives
Miyake, A., et al. (2000). The Unity and Diversity of Executive Functions and Their Contributions to Complex ‘‘Frontal Lobe’’
Tasks : A Latent Variable Analysis. Cognitive Psychology, 41, 49–100.
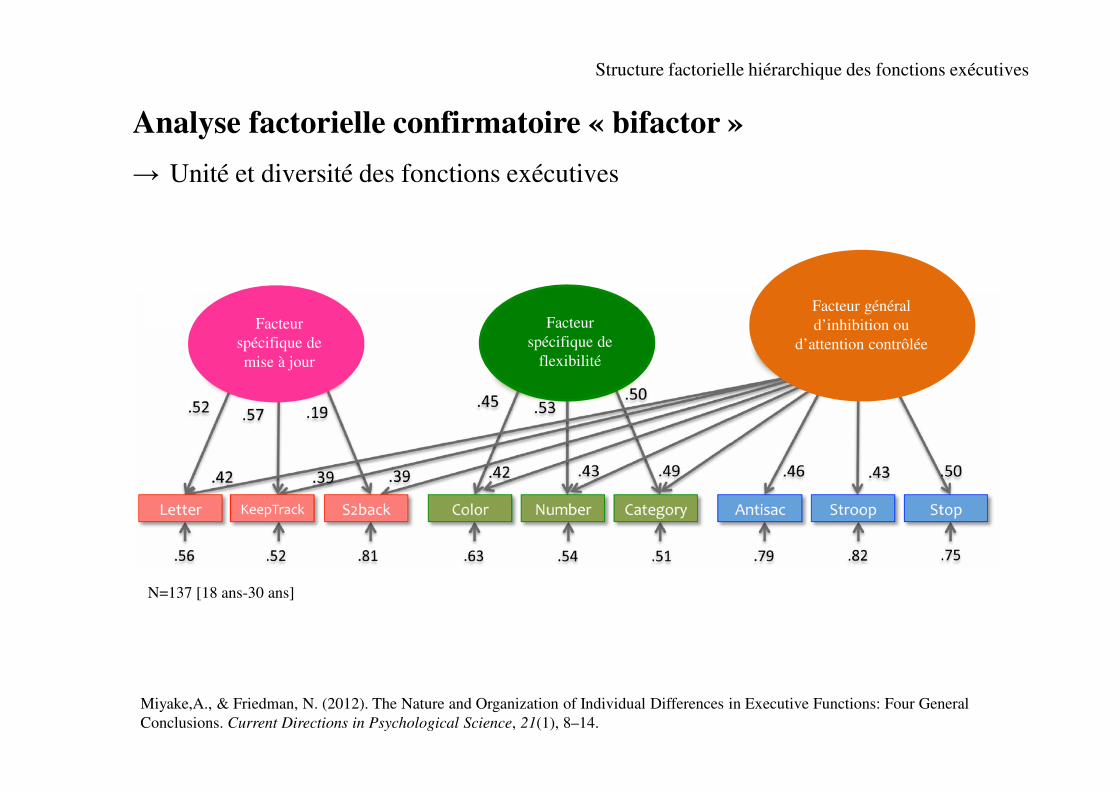
Analyse factorielle confirmatoire « bifactor »
→ Unité et diversité des fonctions exécutives
N=137 [18 ans-30 ans]
Miyake,A., & Friedman, N. (2012). The Nature and Organization of Individual Differences in Executive Functions: Four General
Conclusions. Current Directions in Psychological Science, 21(1), 8–14.
Facteur
spécifique de
mise à jour
Facteur
spécifique de
flexibilité
Facteur général
d’inhibition ou
d’attention contrôlée
Structure factorielle hiérarchique des fonctions exécutives
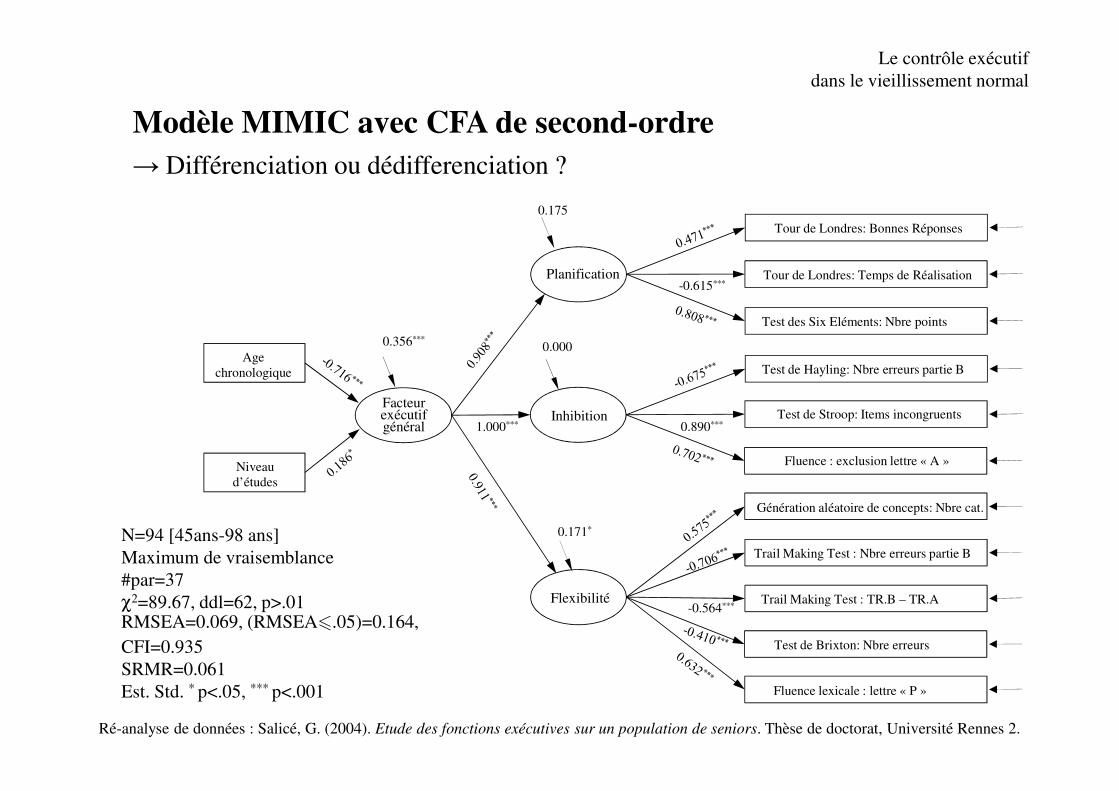
Facteur exécutifgénéral
Planification
Inhibition
Flexibilité
Tour de Londres: Bonnes Réponses
Tour de Londres: Temps de Réalisation
Test des Six Eléments: Nbre points
Test de Hayling: Nbre erreurs partie B
Test de Stroop: Items incongruents
Fluence : exclusion lettre « A »
Génération aléatoire de concepts: Nbre cat.
Trail Making Test : Nbre erreurs partie B
Trail Making Test : TR.B – TR.A
Fluence lexicale : lettre « P »
Test de Brixton: Nbre erreurs
-0.615***
0.890***
-0.564***
1.000***
Agechronologique
Niveau d’études
0.356***
0.175
0.000
0.171*N=94 [45ans-98 ans]
Maximum de vraisemblance
#par=37
χ2=89.67, ddl=62, p>.01RMSEA=0.069, (RMSEA�.05)=0.164,
CFI=0.935
SRMR=0.061
Est. Std. * p<.05, *** p<.001
Le contrôle exécutif
dans le vieillissement normal
Ré-analyse de données : Salicé, G. (2004). Etude des fonctions exécutives sur un population de seniors. Thèse de doctorat, Université Rennes 2.
Modèle MIMIC avec CFA de second-ordre
→ Différenciation ou dédifferenciation ?
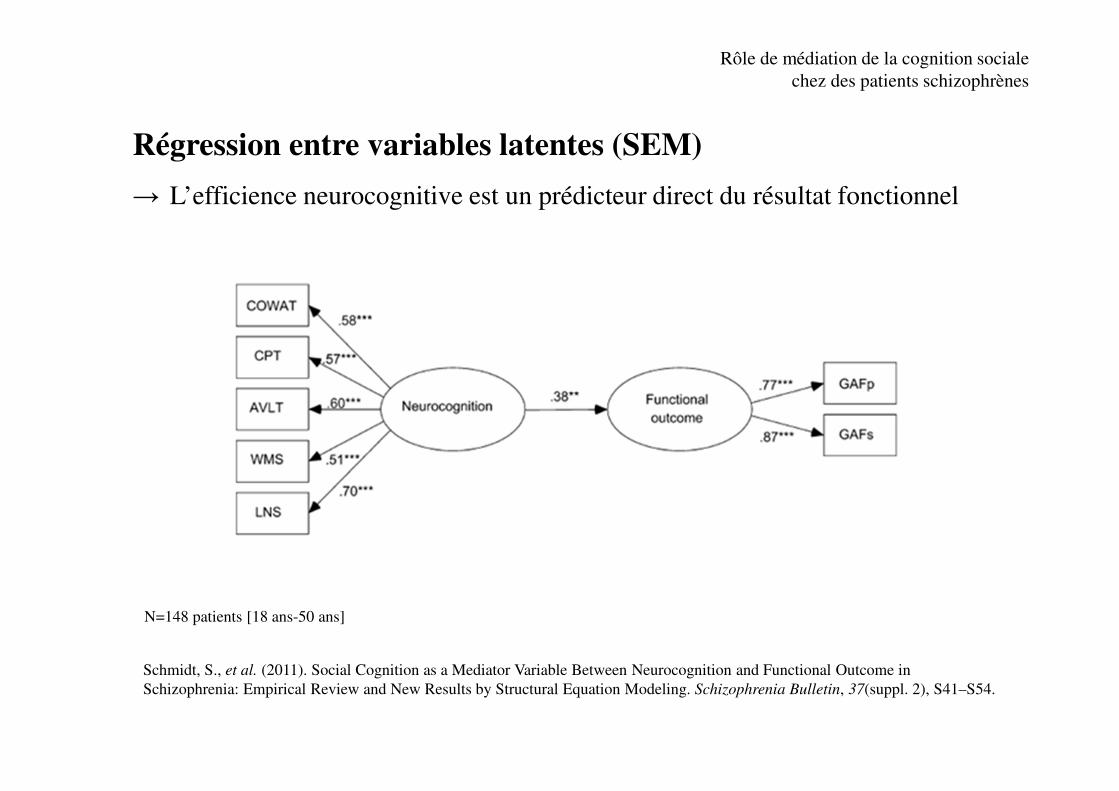
Régression entre variables latentes (SEM)
→ L’efficience neurocognitive est un prédicteur direct du résultat fonctionnel
Rôle de médiation de la cognition sociale
chez des patients schizophrènes
N=148 patients [18 ans-50 ans]
Schmidt, S., et al. (2011). Social Cognition as a Mediator Variable Between Neurocognition and Functional Outcome in
Schizophrenia: Empirical Review and New Results by Structural Equation Modeling. Schizophrenia Bulletin, 37(suppl. 2), S41–S54.
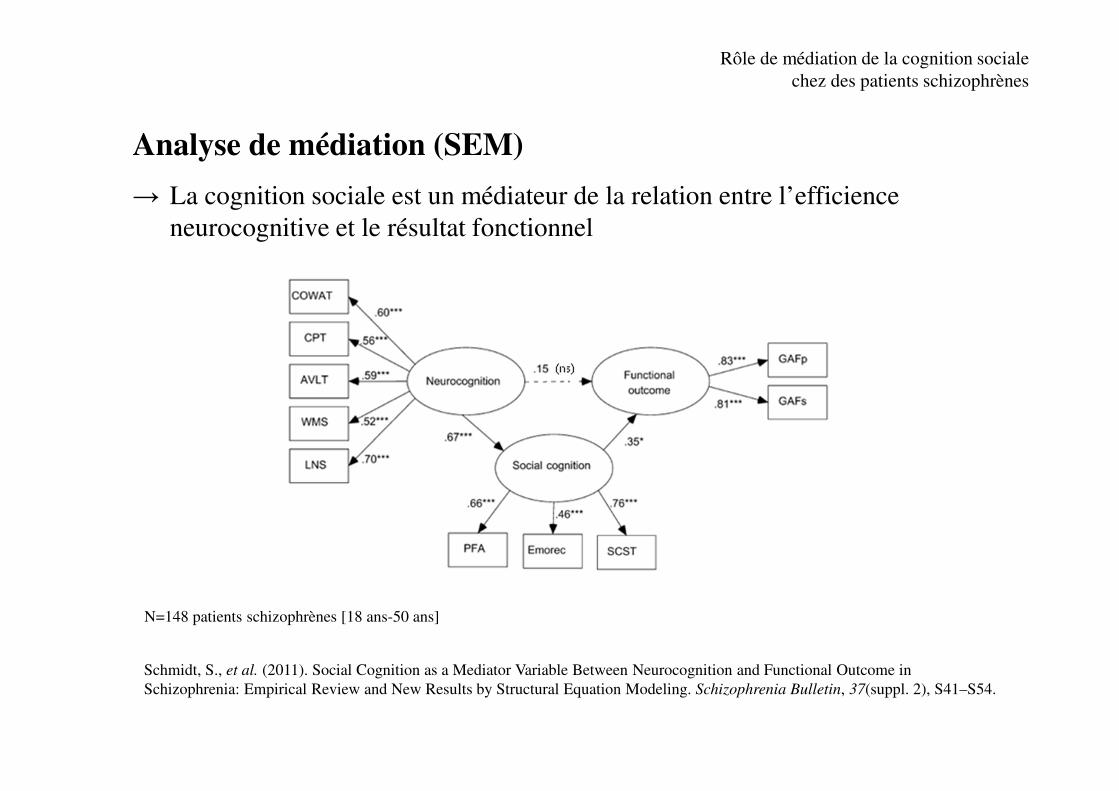
Analyse de médiation (SEM)
→ La cognition sociale est un médiateur de la relation entre l’efficience
neurocognitive et le résultat fonctionnel
N=148 patients schizophrènes [18 ans-50 ans]
Schmidt, S., et al. (2011). Social Cognition as a Mediator Variable Between Neurocognition and Functional Outcome in
Schizophrenia: Empirical Review and New Results by Structural Equation Modeling. Schizophrenia Bulletin, 37(suppl. 2), S41–S54.
Rôle de médiation de la cognition sociale
chez des patients schizophrènes
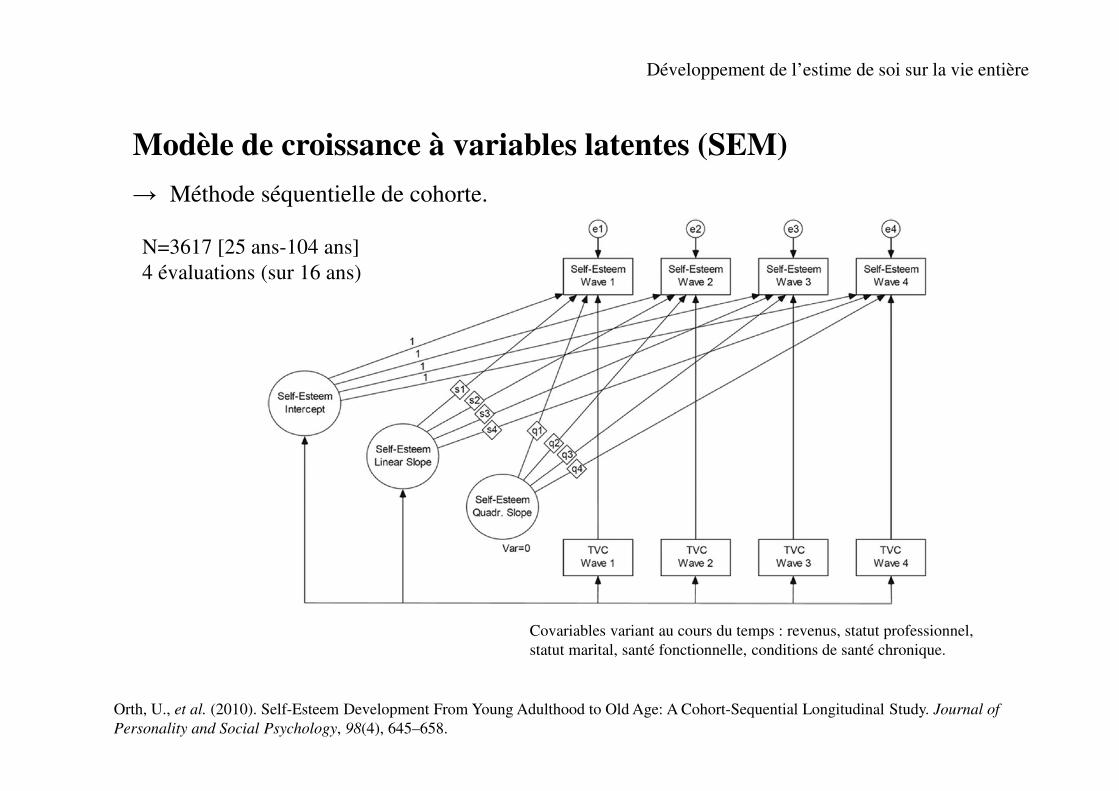
Modèle de croissance à variables latentes (SEM)
→ Méthode séquentielle de cohorte.
Développement de l’estime de soi sur la vie entière
Orth, U., et al. (2010). Self-Esteem Development From Young Adulthood to Old Age: A Cohort-Sequential Longitudinal Study. Journal of
Personality and Social Psychology, 98(4), 645–658.
N=3617 [25 ans-104 ans]
4 évaluations (sur 16 ans)
Covariables variant au cours du temps : revenus, statut professionnel,
statut marital, santé fonctionnelle, conditions de santé chronique.
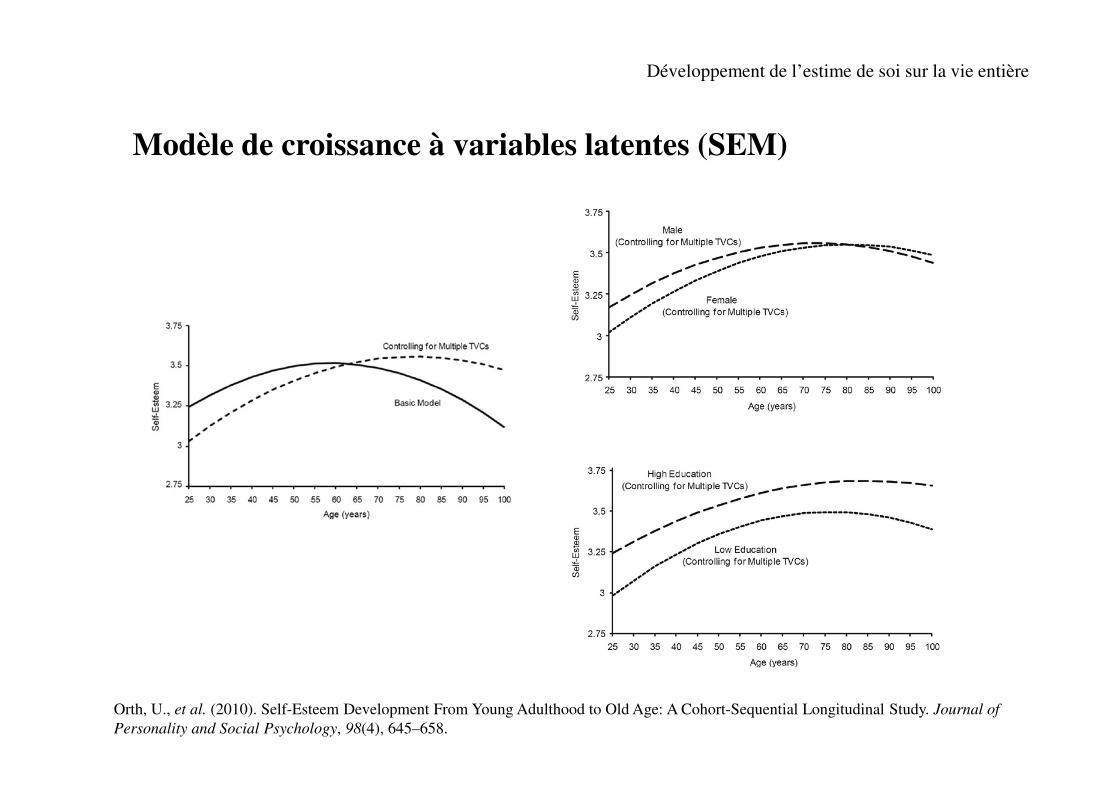
Orth, U., et al. (2010). Self-Esteem Development From Young Adulthood to Old Age: A Cohort-Sequential Longitudinal Study. Journal of
Personality and Social Psychology, 98(4), 645–658.
Modèle de croissance à variables latentes (SEM)
Développement de l’estime de soi sur la vie entière

Précautions d’emploi
des SEM

Les SEM ont été l’objet de vives critiques
• Ling (1982) : « des méthodes de pseudo-magie noire » sous-tendues par des
lacunes statistiques et logiques ;
• Baumrind (1983) : « le fantasme de la justification par n’importe quel système
statistique des inférences causales tirées de données corrélationnelles » ;
• Cliff (1983) : « tout semble se passer comme si les SEM conduisaient à
abandonner tout esprit critique normal » ;
• Freedman (1987) : « personne ne prête beaucoup d'attention aux hypothèses et
la technologie tend à submerger le sens commun ». Menaces à la validité de
l’approche :
- l’erreur de mesure des variables indépendantes dans l’analyse de parcours,
- la non linéarité des relations entre variables exogènes et variables endogènes,
- les variables omises (hypothèse de clôture).
Précautions d’emploi des SEM

Le plus important commence avant !
• Le passage d’une théorie substantielle (psychologique) à un modèle testable
empiriquement.
• Le respect de l’hypothèse de clôture (chaque variable non incluse dans le
système affecte au plus une variable du système).
• La plausibilité des suppositions (non testables) qui garantissent l’interprétation
des SEM employés comme outils d’analyse causale : un ajustement
« satisfaisant » du modèle ne permet pas en soi d’établir un lien de causalité.
• La recherche d’hypothèses alternatives : des effets statistiques conformes aux
attendus accroissent d’autant plus la crédibilité du modèle que celui-ci a été
mis en compétition avec d’autres modèles.
• Le choix du plan d’expérience (les SEM ne peuvent pas compenser les erreurs
méthodologiques).
Précautions d’emploi des SEM

Garder présent à l’esprit que :
• La logique est d’imposer des contraintes au modèle (i.e., de fixer des
paramètres) plutôt que d’estimer (i.e., de libérer) tous ses paramètres.
• Les erreurs de spécification d’un modèle contribuent à biaiser les estimations
et leurs erreurs-type.
• L’importance des variances et des covariances résiduelles libérées pour
améliorer l’ajustement d’un modèle ne doit pas être sous-estimée (paradoxe :
des unités d’information sans signification théorique contribuent à l’ajustement
du modèle!).
• Il est préférable de se focaliser sur des mesures de taille d’effet, d’intervalle de
confiance (ou de crédibilité) plutôt que sur les seuls indices d’ajustement (la
part de variance des endogènes peut être très faible dans un modèle s’ajustant
bien).
• Le jugement de l’ajustement d’un modèle complexe s’accompagne toujours
d’une certaine subjectivité…
Précautions d’emploi des SEM

Quelques FAQ, parmi de très nombreuses autres…
• Taille de l’échantillon ?
• SEM à partir d’une matrice de corrélation ?
• Normalité des variables endogènes ?
• Identification d’un modèle factoriel ?
• Choix de l’estimateur.
• …
Précautions d’emploi des SEM

Niveau débutant
Hoyle, R.H. (2011). Structural Equation Modeling for Social and Personality Psychology. Sage.
Raykov, T., & Marcoulides, G.A. (2006). A First Course in Structural Equation Modeling. New York :
Psychology Press.
Schumacker, R.E., & Lomax, R.G. (2010). A Beginner's Guide to Structural Equation Modeling: Third
Edition. New York: Routledge.
Niveau intermédiaire/avancé
Bartholomew, D.J., Knott, M., & Moustaki, I. (2011). Latent Variable Models and Factor Analysis: A
Unified Approach. Wiley.
Bollen, K. (1989). Structural Equations with Latent Variables. Wiley.
Hancock, G.R. & Mueller, R.O. (Ed.) (2006). Structural Equation Modeling: A second course.
Greenwich : IAP.
Hoyle, R.H. (Ed.) (2012). Handbook of Structural Equation Modeling. New York: The Guilford Press.
Kaplan, D. (Ed.) (2009). Structural Equation Modeling: Foundations and Extensions. London : Sage.
Kline, R.B. (2011). Principles and Practice of Structural Equation Modeling. The Guilford Press.
Skrondal, A., & Rabe-Hesketh, S. (Eds.) (2005). Generalized Latent Variable Modeling: Multilevel,
Longitudinal, and Structural Equation Models. Chapman et Hall/CRC.
Niveau avancé/très avancé
Lee, S.-Y. (Ed.) (2007). Handbook of Latent Variable and Related Models. Oxford: Elsevier.
Lee, S.-Y. (2007). Structural Equation Modeling: A Bayesian Approach. Wiley.
Song, X.-Y., & Lee, S.-Y. (2012). Basic and Advanced Bayesian Structural Equation Modeling. Wiley.
Références





![ASTHME DE L’ENFANT ME DE L · Asthme de l’enfant : définition et épidémiologie Une atteinte inflammatoire chronique et multifactorielle[1] L’asthme est une atteinte inflammatoire](https://img.pdfslide.fr/doc/110x75/60b4661c1b99690cc75d22b6/asthme-de-laenfant-me-de-l-asthme-de-laenfant-dfinition-et-pidmiologie.jpg)