Embed Size (px)
Citation preview

Introduction au Data-Mining
Gilles Gasso
INSA Rouen -Département ASILaboratoire LITIS 1
13 septembre 2016
1. Ce cours est librement inspiré du cours DM de Alain Rakotomamonjy
Gilles Gasso Introduction au Data-Mining 1 / 30

Data-Mining : introduction
Data-mining ≡ Fouille de données
Regroupe un ensemble de techniques et d’outils de la Statistique,l’Informatique et la Science de l’information
A évolué vers le data scienceMachine Learning, Data-Mining
Big Data (explosion des données)
Formalismes de stockage et de traitementdistribués des données (NoSQL, Hadoop,MapReduce, Spark ...)
Gilles Gasso Introduction au Data-Mining 2 / 30

Data-Mining : définition
Définition 1
Le data-mining est un processus de découverte de règle, relations,corrélations et/ou dépendances à travers une grande quantité dedonnées, grâce à des méthodes statistiques, mathématiques et dereconnaissances de formes.
Définition 2Le data-mining est un processus d’extractions automatiqued’informations predictives à partir de grandes bases de données.
Gilles Gasso Introduction au Data-Mining 3 / 30

Data-Mining : les raisons du développement
DonnéesBig Data : augmentation sans cesse de données générées
Twitter : 50M de tweets /jour (=7 téraoctets)Facebook : 10 téraoctets /jourYoutube : 50h de vidéos uploadées /minute2.9 million de mail /seconde
Puissance de calculLoi de MooreCalcul massivementdistribué
Création de valeur ajoutéeIntérêt : du produit aux clients.Extraction de connaissances des bigdata
Gilles Gasso Introduction au Data-Mining 4 / 30

Exemples d’applications
Entreprise et Relation Clients : création de profils clients, ciblage declients potentiels et nouveaux marchés
Finances : minimisation de risques financiers
Bioinformatique : analyse du génome, mise au point de médicaments...Internet : spam, e-commerce, détection d’intrusion, recherched’informations ...
Sécurité
1
1
1
1 1
1
1
1
1
1
1
Y
? 1
1
Gilles Gasso Introduction au Data-Mining 5 / 30

Exemples d’applications : E-commerceTargeting
Stocker les séquences de clicks des visiteurs, analyser lescaractéristiques des acheteursFaire du ”targeting” lors de la visite d’un client potentiel
1
1
1
1 1
1
1
1
1
1
1
Y
? 1
1
Systèmes de recommandationOpportunité : les clients notent les produits ! Comment tirer profit deces données pour proposer des produits à un autre client ?Solutions : technique dit de filtrage collaboratif pour regrouper lesclients ayant les mêmes “goûts”.
Gilles Gasso Introduction au Data-Mining 6 / 30

Exemples d’applications : Analyse des risques
Détection de fraudes pour les assurancesAnalyse des déclarations des assurés par un expert afin d’identifier lescas de fraudes.Applications de méthodes statistiques pour identifier les déclarationsfortement corrélées à la fraude.
Prêt BancaireObjectif des banques : réduire le risque des prêts bancaires.Créer un modèle à partir de caractérisques des clients pour discriminerles clients à risque des autres.
Gilles Gasso Introduction au Data-Mining 7 / 30

Exemples d’applications : Commerce
Opinion miningExemple : analyser l’opinion des usagers sur les produits d’uneentreprise à travers les commentaires sur les réseaux sociaux et lesblogs
Gilles Gasso Introduction au Data-Mining 8 / 30
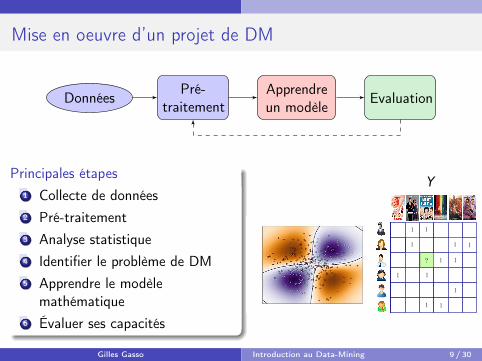
Mise en oeuvre d’un projet de DM
DonnéesPré-
traitementApprendreun modèle
Evaluation
Principales étapes1 Collecte de données2 Pré-traitement3 Analyse statistique4 Identifier le problème de DM5 Apprendre le modèle
mathématique6 Évaluer ses capacités
1
1
1
1 1
1
1
1
1
1
1
Y
? 1
1
Gilles Gasso Introduction au Data-Mining 9 / 30

Ensemble de données
Données d’un problème de DMLes informations sont des exemples avec des attributsOn dispose généralement d’un ensemble de N données
AttributsUn attribut est un descripteur d’une entité. On l’appelle égalementvariable, ou caractéristique
ExempleC’est une entité caractérisant un objet ; il est constitué d’attributs.Synonymes : point, vecteur (souvent dans Rd)
Gilles Gasso Introduction au Data-Mining 10 / 30
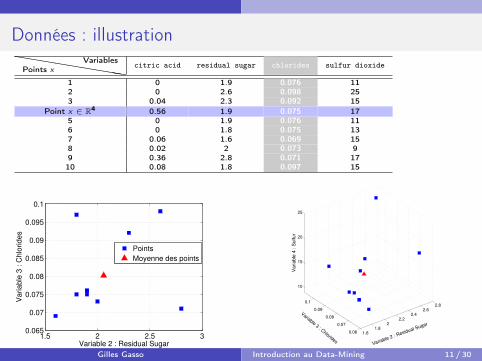
Données : illustrationhhhhhhhhhPoints x
Variables citric acid residual sugar chlorides sulfur dioxide
1 0 1.9 0.076 112 0 2.6 0.098 253 0.04 2.3 0.092 15
Point x ∈ R4 0.56 1.9 0.075 175 0 1.9 0.076 116 0 1.8 0.075 137 0.06 1.6 0.069 158 0.02 2 0.073 99 0.36 2.8 0.071 1710 0.08 1.8 0.097 15
1.5 2 2.5 30.065
0.07
0.075
0.08
0.085
0.09
0.095
0.1
Variable 2 : Residual Sugar
Variable
3 : C
hlo
rides
Points
Moyenne des points
1.61.8
22.2
2.42.6
2.8
0.06
0.07
0.08
0.09
0.1
10
15
20
25
Variable 2 : Residual Sugar
Variable 3 : Chlorides
Variable
4 : S
ulfur
Gilles Gasso Introduction au Data-Mining 11 / 30

Type de données
Capteurs → variables quantitatives, qualitatives,ordinales
Texte → Chaîne de caractèresParole → Séries temporellesImages → données 2DVideos → données 2D + temps
Réseaux → GraphesFlux → Logs, coupons. . .
Etiquettes → information d’évaluation
Big Data (volume, vélocité, variété)
Flot "continu" de données→ Pre-traitement des données (nettoyage,normalisation, codage . . .)→ Représentation : des données aux vecteurs
Typesnumérique continue : la variable prend ses valeurs dans Rnumérique discrète : la valeur de la variable appartient à Z ou N (parexemple : l’age de patients)catégorie : avec ou sans relation d’ordre ( {rouge, vert, bleu}).Chaînes de caractères (par exemple : un texte)Arbre : (par exemple Page XML)Données structurées : graphe, enregistrement
Gilles Gasso Introduction au Data-Mining 12 / 30

Données et Métriques
Les algorithmes nécessitent une notion de similarité dans l’espace X desdonnées. La similarité est traduite par la notion de distance.
distance euclidienne : x , z ∈ Rd , on ad(x , z) = ‖x − z‖2 =√∑d
j=1(xj − zj)2 =√
(x − z)>(x − z)
distance de manhattand(x , z) = ‖x − z‖1 =
∑dj=1 |(xj − zj)|
distance de mahalanobisd(x , z) =
√(x − z)>Σ−1(x − z)
Σ ∈ Rd×d : matrice carrée définie positive
−1 0 1
−1
0
1
EuclidienManhattanMahalanobis
Gilles Gasso Introduction au Data-Mining 13 / 30
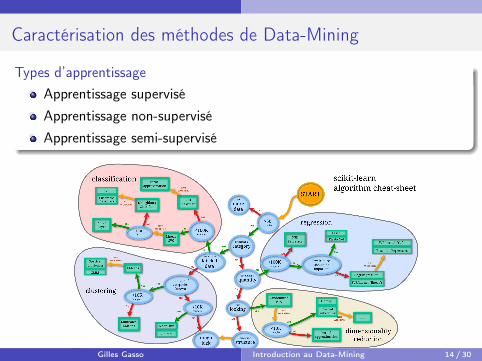
Caractérisation des méthodes de Data-Mining
Types d’apprentissageApprentissage superviséApprentissage non-superviséApprentissage semi-supervisé
Gilles Gasso Introduction au Data-Mining 14 / 30

Caractérisation des méthodes : apprentissage supervisé
Objectif
A partir des données {(xi , yi ) ∈ X × Y, i = · · · ,N}, estimer lesdépendances entre X et Y.
On parle d’apprentissage supervisé car les yi permettent de guider leprocessus d’estimation.
ExemplesEstimer les liens entre habitudes alimentaires et risque d’infarctus. xi :d attributs concernant le régime d’un patient, yi sa catégorie (risque,pas risque).
Applications : détection de fraude, diagnostic médical ...
Techniquesk-plus proches voisins, SVM, régression logistique, arbre de décision ...
Gilles Gasso Introduction au Data-Mining 15 / 30

Caractérisation des méthodes : Apprentissage non-supervisé
Objectifs
Seules les données {xi ∈ X , i = · · · ,N} sont disponibles. On chercheà décrire comment les données sont organisées et en extraire dessous-ensemble homogènes.
ExemplesCatégoriser les clients d’un supermarché. xi représente un individu(adresse, âge, habitudes de courses ...)
Applications : identification de segments de marchés, catégorisation dedocuments similaires, segmentation d’images biomédicales ...
TechniquesClassification hiérarchique, Carte de Kohonen, K-means, extractions derègles ...
Gilles Gasso Introduction au Data-Mining 16 / 30

Caractérisation des méthodes : apprentissage semi-supervisé
ObjectifsObjectifs : parmi les données, seulement un petit nombre ont un labeli.e {(x1, y1), · · · , (xn, yn), xn+1, · · · ,N}. L’objectif est le même quepour l’apprentissage supervisé mais on aimerait tirer profit des donnéessans étiquette.
ExemplesExemple : pour la discrimination de pages Web, le nombre ’exemplespeut être très grand mais leur associer un label (ou étiquette) estcoûteux.
TechniquesMéthodes bayésiennes, SVM ...
Gilles Gasso Introduction au Data-Mining 17 / 30

Apprentissage supervisé : les concepts
Soit deux ensembles X et Y munis d’une loi de probabilité jointep(X ,Y ).
Objectifs : On cherche une fonction f : X → Y qui à X associe f (X )qui permet d’estimer la valeur y associée à x . f appartient à un espaceH appelé espace d’hypothèses.
Exemple de H : ensemble des fonctions polynomiales
Gilles Gasso Introduction au Data-Mining 18 / 30

Apprentissage supervisé : les concepts
On introduit une notion de coût L(Y , f (X )) qui permet d’évaluer lapertinence de la prédiction de f , et de pénaliser les erreurs.
L’objectif est donc de choisir la fonction f qui minimise
R(f ) = EX ,Y [L(Y , f (X ))]
où R est appelé le risque moyen ou erreur de généralisation. Il estégalement noté EPE (f ) pour expected prediction error
Gilles Gasso Introduction au Data-Mining 19 / 30

Apprentissage supervisé : les concepts
Exemples de fonction coût et de risque moyen associé.Coût quadratique (moindres carrés)
L(Y , f (X )) = (Y − f (X ))2
R(f ) = E [(Y − f (X ))2] =
∫(y − f (x))2p(x , y)dxdy
Coût `1 (moindres valeurs absolues)
L(Y , f (X )) = |Y − f (X )|
R(f ) = E [|Y − f (X ))|] =
∫|y − f (x)|p(x , y)dxdy
Gilles Gasso Introduction au Data-Mining 20 / 30
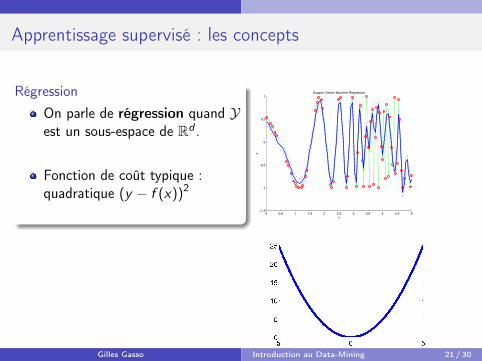
Apprentissage supervisé : les concepts
RégressionOn parle de régression quand Yest un sous-espace de Rd .
Fonction de coût typique :quadratique (y − f (x))2
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5−1.5
−1
−0.5
0
0.5
1Support Vector Machine Regression
x
y
Gilles Gasso Introduction au Data-Mining 21 / 30
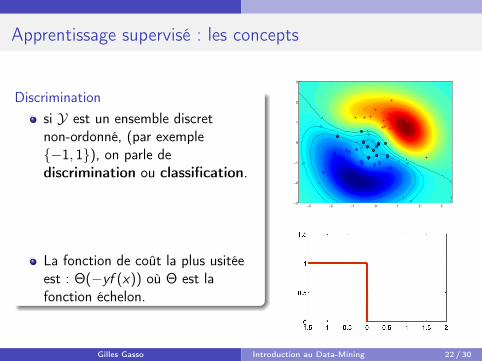
Apprentissage supervisé : les concepts
Discriminationsi Y est un ensemble discretnon-ordonné, (par exemple{−1, 1}), on parle dediscrimination ou classification.
La fonction de coût la plus usitéeest : Θ(−yf (x)) où Θ est lafonction échelon.
−3 −2 −1 0 1 2 3−3
−2
−1
0
1
2
3
−1
−1
−1
−1
−1
−1
0
0
0
0
0
1
1
1
1
1
Gilles Gasso Introduction au Data-Mining 22 / 30

Apprentissage supervisé : les concepts
En pratique, on a un ensemble de données {(xi , yi ) ∈ X × Y}Ni=1appelé ensemble d’apprentissage obtenu par échantillonnageindépendant de p(X ,Y ) que l’on ne connaît pas.
On cherche une fonction f , appartenant à H qui minimise le risqueempirique :
Remp(f ) =1N
N∑i=1
L(yi , f (xi ))
Le risque empirique ne permet pas d’évaluer la pertinence d’un modèlecar il est possible de choisir f de sorte que le risque empirique soit nulmais que l’erreur en généralisation soit élevée. On parle alors desur-apprentissage
Gilles Gasso Introduction au Data-Mining 23 / 30
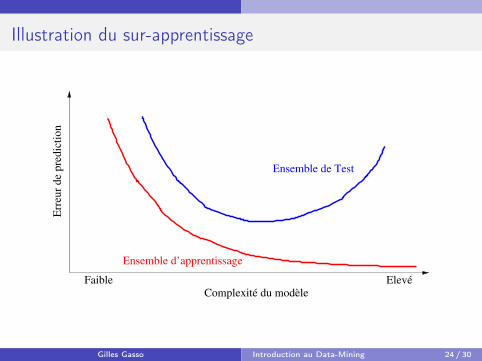
Illustration du sur-apprentissageE
rreu
r d
e p
red
icti
on
Ensemble de Test
Ensemble d’apprentissage
Faible ElevéComplexité du modèle
Gilles Gasso Introduction au Data-Mining 24 / 30

Sélection de modèles
ProblématiqueOn cherche une fonction f qui minimise un risque empirique donné.On suppose que f appartient à une classe de fonctions paramétréespar α. Comment choisir α pour que f minimise le risque empirique etgénéralise bien ?
Exemple : On cherche un polynôme de degré α qui minimise un risqueRemp(fα) =
∑Ni=1(yi − fα(xi ))2.
Objectifs :1 proposer une méthode d’estimation d’un modèle afin de choisir
(approximativement) le meilleur modèle appartenant à l’espacehypothèses.
2 une fois le modèle choisi, calculer son erreur de généralisation.
Gilles Gasso Introduction au Data-Mining 25 / 30

Sélection de modèles : approche classiqueCas idéal : les données DN abondent (N est très grand)
Validation Apprentissage {X app ,Y app }
Données disponibles
Test {X test ,Y test }{X val ,Y val}
1 Découper aléatoirement DN = Dapp ∪ Dval ∪ Dtest
2 Apprendre chaque modèle possible sur Dapp
3 Evaluer sa performance en généralisation sur Dval
Rval = 1Nval
∑i∈Dval
L(yi , f (xi ))
4 Sélectionner le modèle qui donne la meilleure performance sur Dval
5 Tester le modèle retenu sur Dtest
RemarqueDtest n’est utilisé qu’une seule fois !
Gilles Gasso Introduction au Data-Mining 26 / 30

Sélection de modèles : Validation Croisée
Cas moins favorable : les données DN sont modestes (N est petit)
Estimation de l’erreur de généralisation par rééchantillonnage.
Principe
1 Séparer les N données en K ensembles de part égales.
2 Pour chaque k = 1, · · · ,K , apprendre un modèle en utilisant les K − 1autres ensemble de données et évaluer le modèle sur la k-ième partie.
3 Moyenner les K estimations de l’erreur obtenues pour avoir l’erreur devalidation croisée.
K=2K=1 K=4 K=5
APP APP TEST APP APP
K=3
Gilles Gasso Introduction au Data-Mining 27 / 30

Sélection de modèles : Validation Croisée (2)
Détails :
RCV =1K
K∑k=1
1Nk
Nk∑i=1
L(yki , f−k(xki ))
où f −k est le modèle f appris sur l’ensemble des données sauf lak-ième partie.
Propriétés : Si K = N, CV est approximativement un estimateur sansbiais de l’erreur en généralisation. L’inconvénient est qu’il fautapprendre N − 1 modèles.
typiquement, on choisit K = 5 ou K = 10 pour un bon compromisentre le biais et la variance de l’estimateur.
Gilles Gasso Introduction au Data-Mining 28 / 30

Conclusions
Pour bien mener un projet de DMIdentifier et énoncer clairement les besoins.
Créer ou obtenir des données représentatives du problème
Identifier le contexte de l’apprentissage
Analyser et réduire la dimension des données
Choisir un algorithme et/ou un espace d’hypothèses.
Choisir un modèle en appliquant l’algorithme aux données prétraitées.
Valider les performances de la méthode.
Gilles Gasso Introduction au Data-Mining 29 / 30
Au final ...
Les voies du Machine Learning et du traitement des données c’est ...
Gilles Gasso Introduction au Data-Mining 30 / 30





























