Embed Size (px)
Citation preview

La modélisation des connaissances1
Sommaire
Sommaire .......................................................................................................................................................................... 1
Introduction ..................................................................................................................................................................... 2
1. De l’information aux connaissances ............................................................................................................... 2
1.1 Modèle mental et représentations ....................................................................................................................... 3
1.2 Syntaxe et sémantique ........................................................................................................................................ 3
1.3 Un langage formel : les propositions .............................................................................................................. 5
2. Le langage graphique de modélisation par objets typés (MOT) ....................................................... 7
2.1 La grammaire et la sémantique du langage MOT ....................................................................................... 7
2.2 Des exemples de modèles MOT...................................................................................................................... 10
2.3 Typologie des modèles MOT ........................................................................................................................... 14
3. Les outils de modélisation : du semi-formel au formel ...................................................................... 15
3.1 Les fonctionnalités de base de G-MOT ......................................................................................................... 15
3.2 Méthode de modélisation ................................................................................................................................ 16
4. Scénarios et ontologies pour la gestion des connaissances ............................................................. 18
4.1 L’éditeur de scénarios de G-MOT .................................................................................................................. 18
4.2 L’éditeur d’ontologies de G-MOT ................................................................................................................... 20
Conclusion...................................................................................................................................................................... 22
1 Ce texte est une adaptation de certaines sections des premiers chapitres du livre de Paquette, G. (2002). Modélisation des
connaissances et des compétences. Québec, Canada : PUQ.

2
Introduction
Le vaste mouvement irréversible qui nous conduit vers une société et une économie du savoir met en évidence l’importance des connaissances et des compétences. Pour gérer les connaissances et les compétences, pour les acquérir, pour concevoir des environnements de travail et de formation, pour construire les processus par lesquels une organisation devient apprenante, axée sur le savoir, il faut représenter les connaissances d’une façon structurée, visuelle et transmissible, il faut modéliser les connaissances.
C'est justement l'objet de ce texte : identifier et structurer les connaissances en une représentation schématique pour les rendre visibles, manipulables, compréhensibles, communicables entre les humains et entre les humains et les ordinateurs. C’est aussi le but poursuivi par le web 3.0, le web sémantique.
1. De l’information aux connaissances
En informatique, les premiers systèmes traitaient uniquement les données numériques. Ensuite, une seconde vague de systèmes s’est intéressée aux banques d’informations et de documents. Au cours des trois dernières décennies, une nouvelle vague de systèmes informatiques en sont arrivés à traiter des connaissances de plus haut niveau. Les systèmes à base de connaissances2 peuvent représenter et traiter des principes et des règles de décisions, des taxonomies, des théories, des processus et des méthodes mémorisées dans l’ordinateur. En un mot, ils sont capables d’aider l’utilisateur à accomplir des tâches de façon plus intelligente. Ce niveau « cognitif »3 est encore trop peu répandu dans les systèmes d’information et dans la pratique des individus et des organisations.
Il importe, d’entrée de jeu, d’établir une distinction claire entre les concepts d’information et de connaissance. Par « information », nous entendons toutes les données externes aux personnes, communiquées oralement ou médiatisées dans des matériels sur divers supports numériques, imprimés ou analogiques. Par « connaissance » nous entendons le résultat de toute construction mentale effectuée par un individu à partir d’informations ou d’autres stimuli. Les connaissances sont donc internes aux personnes, les informations, externes. L’apprentissage par un individu consiste à transformer les informations qu’il obtient par différents moyens en connaissances.
La représentation des connaissances est un moyen indispensable pour dépasser la gestion des informations et entreprendre celle des connaissances. La représentation des connaissances est au cœur de deux processus inverses et complémentaires :
d’abord l’extraction des connaissances que possèdent certaines personnes expertes dans leur domaine, ou que d’autres personnes médiatisent dans des documents, de façon à les rendre largement disponibles (sous forme d’informations) pour le travail et la formation d’autres personnes;
2 Voir Paquette G. et Roy, L. (1990). Systèmes à base de connaissances. Montréal, Canada : Télé-université du Québec.
3 Pour reprendre l’expression the knowledge level, proposée par Allen Newell : Newell, A. (1982). The knowledge level. Artificial
intelligence, 18(1), 87-127.

3
inversement, l’acquisition de connaissances et de compétences nouvelles, c’est-à-dire la transformation des informations en connaissances par des personnes, au moyen d'activités formelles ou informelles d’apprentissage utilisant une variété de formes et de supports.
Pour échanger, transmettre ou traiter des connaissances, il est nécessaire de pouvoir les représenter sur un support externe à notre cerveau, sous une forme transmissible ou traitable. Avant de définir plus précisément ce qu’est un langage et un système de représentation, examinons d’abord un exemple.
1.1 Modèle mental et représentations
Dans le manuel d’accompagnement d’un récepteur de télévision, on trouve les conseils suivants : s’il n’y a pas d’image, mais que vous entendiez le son, vérifiez le réglage d’intensité de l’écran; si l’image apparaît sans qu’il y ait de son, vérifiez le contrôle du volume ou celui de la sourdine (mute). S’il n’y a ni image ni son, vérifiez la prise de secteur ou l’interrupteur principal.
Ce texte transmet un certain nombre de connaissances utiles à la solution de problèmes mineurs, dans la mesure où le lecteur comprend le sens de l’information contenue dans le texte. Une représentation alternative de ces mêmes connaissances peut être fournie sous forme d’image. Cette seconde représentation ne contient aucun mot de la langue française et repose exclusivement sur l’interprétation que l’on peut donner à des dessins. Un ensemble de connaissances admettra en général plusieurs types de représentations qui pourront servir à des fins différentes, comme le texte d’accompagnement ou les pictogrammes.
La compréhension d’un texte ou d’un pictogramme par un être humain passe par une représentation mentale de la situation, c’est-à-dire un ensemble d’idées que l’on se forme sur la situation. Plusieurs hypothèses sont avancées dans les sciences cognitives sur la forme de cette représentation mentale, mais il est facile d’en vérifier l’existence par un simple exercice : sans consulter ni le texte, ni les dessins, essayez de transmettre à quelqu’un les mêmes connaissances. En général, vous n’utiliserez ni les mêmes mots, ni les mêmes dessins, mais les connaissances communes aux différentes formes d’expression resteront les mêmes. La connaissance qu’un récepteur de télévision ne produit pas de son (un énoncé factuel) peut être exprimée par une variété d’informations de forme différente.
Représenter symboliquement un certain nombre de connaissances, c’est définir un ensemble d’expressions et faire correspondre à chaque connaissance une ou plusieurs expressions, ainsi qu’à chaque expression une ou plusieurs connaissances. Dans l’exemple précédent, les expressions étaient des phrases de la langue française ou des dessins.
1.2 Syntaxe et sémantique
Pour établir un système de représentation des connaissances intéressant pour la gestion des connaissances, nous aurons besoin de spécifier des conventions et des règles qui décrivent un langage symbolique. L’élaboration d’un système de représentation (un langage) comporte notamment les étapes suivantes.
1. La définition d’une grammaire ou syntaxe décrivant l’ensemble des expressions acceptables obtenue en combinant les symboles de base d’un lexique.

4
Dans le cas de la langue française, le lexique est constitué des lettres de l’alphabet, des signes de ponctuation et des mots acceptés par un dictionnaire officiel. Dans le cas du langage musical, il s’agit de la portée et des symboles représentant les clefs, les notes, les silences, etc.
Dans le cas de la langue française, la grammaire décrit comment composer l’ensemble des phrases du langage. Si nous voulons décrire la structure moléculaire de certains composés chimiques, l’ensemble des expressions acceptables consisterait en une suite de symboles chimiques avec des indices numériques comme H2O ou NaCl. Dans le cas du langage musical, des règles de grammaire stipulent que chaque portée doit comporter une clef, une subdivision des temps, un respect de la subdivision en fonction de la valeur des notes et des silences, etc.
2. La définition d’une sémantique est une méthode pour donner un sens aux expressions de la grammaire, ce qui revient à les associer à une représentation mentale intelligible et, inversement, une méthode pour associer une ou plusieurs expressions de la grammaire à des connaissances faisant partie du modèle mental de la personne qui s’exprime à l’aide du langage.
Figure 1 Des opérations inverses : représenter et interpréter.
Étant donné une connaissance que nous possédons, nous devons disposer de méthodes pour la traduire à l’aide des expressions du langage. C’est ce qu’on appelle représenter ou modéliser. Cette traduction implique également une série de choix : Quel est le niveau de détails souhaitable? Quels sont les facteurs importants?
Comme il est indiqué sur la figure 1, l’opération inverse de la représentation est l’interprétation, soit la capacité de se représenter mentalement les faits ou les connaissances suggérés par une expression du langage.
Modèle mental
Représentation
en français
Représentation
graphique
Représentation
dans un autre
langage
Représenter
Représenter
Représenter
Interpréter
InterpréterInterpréter

5
1.3 Un langage formel : les propositions
Nous allons maintenant illustrer ce qui précède en élaborant un langage formel qui porte le nom de logique propositionnelle. Ce système permettra de représenter certains aspects de situations qui impliquent des raisonnements élémentaires, mais aussi de faire des requêtes dans une base de données.
Tableau 1 Deux représentations d’énoncés simples.
Langue naturelle Langage schématique
S’il n’y a pas d’image, mais que vous entendiez le son, vérifiez le réglage d’intensité de l’écran.
si non IMAGE et SON
alors RÉGLAGE_INTENSITE
Si l’image apparaît sans qu’il y ait de son, vérifiez le contrôle du volume
ou celui de la sourdine.
si IMAGE et non SON
alors VOLUME ou SOURDINE
S’il n’y a ni image ni son, vérifiez la prise de secteur ou l’interrupteur principal.
si non IMAGE et non SON
alors PRISE_SECTEUR ou
INTERRUPTEUR
Mon appareil n’a ni son ni image. La prise de secteur fonctionne pourtant bien. Où est le problème?
non SON et non IMAGE
et non PRISE_SECTEUR
Le tableau 1 reprend les phrases concernant les difficultés de réception de la télévision. Il est facile de voir que les nouvelles expressions de la deuxième colonne traduisent l’essentiel de la situation par rapport au problème posé. Les « détails » comme les articles, les adjectifs ou les verbes (entendre, apparaître, vérifier) sont disparus. La structure française du texte a été tellement simplifiée que les nouvelles expressions ne sont plus acceptables au sens de la grammaire française, mais elles véhiculent l’essentiel de l’information qui nous intéresse.
La grammaire de la logique propositionnelle est constituée d’un lexique simple et de quelques règles qui permettent de combiner les termes du lexique et de définir les expressions correctes du langage.
Le lexique de la logique propositionnelle se compose de deux types de symboles : soit les propositions élémentaires qui sont des suites d’une ou de plusieurs lettres majuscules telles que IMAGE, SON, ou PRISE_SECTEUR et les connecteurs logiques non, et, ou, si…alors.
Les règles de grammaire stipulent le rôle de ces quatre connecteurs, qui consiste à lier les propositions entre elles de façon à former des propositions plus complexes.
Le connecteur non peut être placé devant toute proposition simple ou composée entourée de parenthèses (comme le signe – devant un nombre).
Les connecteurs et, ou et si…alors peuvent être placés entre deux propositions simples ou entre deux propositions composées entourées de parenthèses.

6
La sémantique de la logique propositionnelle consiste à interpréter chaque proposition élémentaire comme vraie ou fausse dans un contexte donné. Par ailleurs, les connecteurs ont un sens très précis qui est proche, mais non identique, au sens des mots correspondants de la langue française. Le connecteur si…alors exprime l’idée de conséquence. On appelle antécédent ou prémisse la première proposition qui y figure et conséquent ou conclusion la seconde. Elle est vérifiée si la conclusion est vraie dès que l’antécédent l’est. Une proposition contenant le connecteur ou est vérifiée si au moins une des deux propositions l’est. Une proposition contenant le connecteur et sera vérifiée si chacune des deux propositions l’est. Une proposition de la forme non sera vérifiée si la proposition qui suit le « non » est fausse.
Le caractère dépouillé et très structuré du langage propositionnel facilite certaines formes de raisonnement élémentaires basé sur les règles d’inférence suivantes :
R1 : De (A) et de (Si A alors B), on peut déduire B (Si nous savons que deux expressions telles que « A » et « si A alors B » sont vraies, peu importe la signification accordée aux symboles A et B, on peut déduire que B est vrai).
R2 : De (non A) et de (A ou B), on peut déduire B (D’une façon analogue, si nous savons que deux expressions telles que « Non A » et «A ou B » sont vraies, peu importe la signification accordée aux symboles A et B, on peut déduire que B est vrai.)
Ce langage et ces règles d’inférence permettent de clarifier certains raisonnements. Reprenons les expressions du tableau 1 suivantes et appliquons les règles d’inférence présentées plus haut.
(1) si non (IMAGE et SON) alors RÉGLAGE_INTENSITE
(2) si (IMAGE et non SON) alors VOLUME ou SOURDINE
(3) si (non IMAGE et non SON) alors (PRISE_SECTEUR ou INTERRUPTEUR)
(4) non IMAGE et non SON
(5) non PRISE_SECTEUR
L’application de la règle R1 aux propositions (3) et (4) nous permet de déduire :
(6) PRISE_SECTEUR ou INTERRUPTEUR (au moins l’une des deux est la cause)
Puis l’application de la règle R2 à cette dernière proposition et à (5) nous permet de déduire qu’entre ces deux hypothèses, c’est l’interrupteur qui est défectueux.
Malgré sa simplicité, le langage propositionnel permet de démêler des situations beaucoup plus complexes que ce petit exemple, grâce à sa schématisation des structures de propositions et à la précision de ses règles de grammaire et d’interprétation. On retrouve ce type de langage à la base des systèmes experts : les propositions telles que (1), (2) et (3) constituant une base de connaissances et les faits énoncés en (4) et (5) constituant une base de faits.
Dans un système expert, les règles de déduction telles que R1 et R2 constituent ce qu’on appelle le « moteur d’inférence ». Avec un même moteur d’inférence, on peut en principe traiter des bases de connaissances dans des domaines très différents, pour autant qu’on puisse les représenter adéquatement dans un langage formel semblable à celui présenté ici.
7
2. Le langage graphique de modélisation par objets typés (MOT)
Le langage de représentation de modélisation par objets typés (MOT) est un langage général qui permet de construire une variété de modèles.
Comme tout langage, MOT se caractérise par sa grammaire et sa sémantique. Comme MOT est un langage graphique, sa grammaire sert à définir les règles d’utilisation des symboles graphiques qui composent l’alphabet ou le lexique du langage. Sa sémantique est la définition du sens, de l’interprétation donnée aux symboles.
2.1 La grammaire et la sémantique du langage MOT
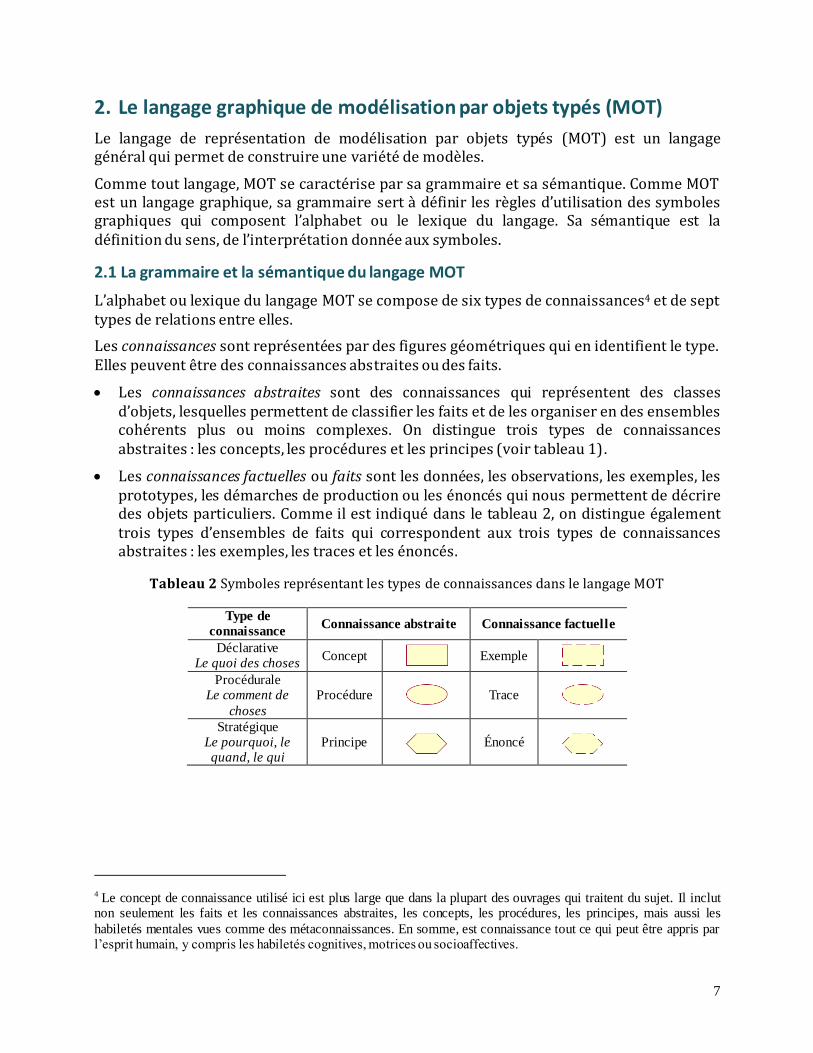
L’alphabet ou lexique du langage MOT se compose de six types de connaissances4 et de sept types de relations entre elles.
Les connaissances sont représentées par des figures géométriques qui en identifient le type. Elles peuvent être des connaissances abstraites ou des faits.
Les connaissances abstraites sont des connaissances qui représentent des classes d’objets, lesquelles permettent de classifier les faits et de les organiser en des ensembles cohérents plus ou moins complexes. On distingue trois types de connaissances abstraites : les concepts, les procédures et les principes (voir tableau 1).
Les connaissances factuelles ou faits sont les données, les observations, les exemples, les prototypes, les démarches de production ou les énoncés qui nous permettent de décrire des objets particuliers. Comme il est indiqué dans le tableau 2, on distingue également trois types d’ensembles de faits qui correspondent aux trois types de connaissances abstraites : les exemples, les traces et les énoncés.
Tableau 2 Symboles représentant les types de connaissances dans le langage MOT
Type de
connaissance Connaissance abstraite Connaissance factuelle
Déclarative Le quoi des choses
Concept Exemple
Procédurale Le comment de
choses
Procédure Trace
Stratégique Le pourquoi, le quand, le qui
Principe Énoncé
4 Le concept de connaissance utilisé ici est plus large que dans la plupart des ouvrages qui traitent du sujet. Il inclut
non seulement les faits et les connaissances abstraites, les concepts, les procédures, les principes, mais aussi les
habiletés mentales vues comme des métaconnaissances. En somme, est connaissance tout ce qui peut être appris par l’esprit humain, y compris les habiletés cognitives, motrices ou socioaffectives.

8
Du point de vue de la sémantique, les concepts ou connaissances conceptuelles décrivent la nature des objets d’un domaine (le quoi); ils représentent une classe d’objets définis par leurs propriétés communes, chaque objet de la classe se distinguant des autres par les « valeurs » que prennent ses propriétés.
Les procédures ou connaissances procédurales décrivent des ensembles d’opérations qui permettent d’agir sur les objets (le comment); elles s’intéressent aux combinaisons d’actions qui s’appliquent dans plusieurs cas, chaque cas se distinguant des autres par les objets auxquels les actions peuvent s’appliquer et les résultats des transformations qu’on leur fait subir.
Les principes ou connaissances stratégiques sont des énoncés qui permettent de décrire les propriétés des objets, d’établir des liens de cause à effet entre des objets (le pourquoi), ou de déterminer dans quelles conditions appliquer une procédure (le quand); les principes prennent le plus souvent la forme « Si telle condition Alors, telle condition ou telle action ».
Aux trois types de connaissances abstraites correspondent trois types de faits :
− Les exemples sont obtenus en spécifiant les valeurs de chacun des attributs d’un concept; Il en résulte un ensemble de faits qui décrivent un objet concret bien précis.
− Les traces sont obtenues en spécifiant les variables de chacune des actions qui composent une procédure, obtenant un ensemble d’actions particulières, une trace d’exécution.
− Les énoncés sont obtenus en spécifiant les variables d’un principe, obtenant ainsi un lien de cause à effet entre les propriétés d’objets particuliers ou entre des propriétés d’un objet particulier et une action précise à effectuer.
Les relations entre les connaissances sont représentées par des liens orientés (flèches) munis d’une lettre désignant le type de la relation. Les relations entre les connaissances appartiennent à sept types dont voici la sémantique.
Le lien d’instanciation (I) relie une connaissance abstraite à un fait obtenu en donnant des valeurs à tous les attributs (variables) qui définissent la connaissance abstraite. Chaque connaissance abstraite, concept, procédure ou principe « s’instancient » ainsi à un ensemble de faits, appelé respectivement exemple, trace ou énoncé.
Exemple : « Les voitures Renault » a pour instance « La-voiture-de-Jean ».
Le lien de composition (C) relie une connaissance à l’une de ses composantes ou de ses parties constitutives5. On peut spécifier ainsi les attributs d’un objet comme des composantes d’une connaissance en reliant celle-ci à chacun de ses attributs par un lien de composition « se compose de ».
Exemple : L’ « Automobile » se compose d’une « Carrosserie ».
5 Notons que le lien de composition a un sens plus large que dans d’autres systèmes de représentation où il prend le
sens de « a pour partie » (on lit toujours les liens de l’origine vers la destination). Ici, le lien C peut aussi être utilisé à cette fin comme dans « l’automobile se compose (a comme parties) la carrosserie et la transmission », mais aussi
plus largement pour tout attribut d’un objet, par exemple « l’automobile (le concept) se compose d’une carrosserie, d’un prix, d’une couleur ».

9
Le lien de spécialisation (S) met en relation deux connaissances abstraites de même type dont l’une est « une sorte de », un cas particulier de l’autre. Autrement dit, la seconde est plus générale ou plus abstraite que la première.
Exemple : Une « Décapotable » est une sorte d’« Automobile ».
Le lien de précédence (P) relie deux procédures ou deux principes dont le premier doit être terminé, réalisé ou évalué avant que le second ne le soit.
Exemple : « Faire le plan » précède « Rédiger le texte ».
Le lien intrant-produit (I/P) relie un concept et une procédure. Du concept vers la procédure, on dira que le concept est un intrant de la procédure. De la procédure vers le concept, on dira que la procédure a pour produit le concept, celui-ci représentant généralement la classe d’objets résultant de la procédure.
Exemple : « Le plan » est intrant de « Rédiger le texte ». « Rédiger le texte » a pour produit « le texte ».
Le lien de régulation (R) s’utilise d’un principe vers une autre connaissance abstraite qui peut être un concept, une procédure ou un autre principe. Dans le premier cas, le principe définit le concept par des contraintes à satisfaire (parfois appelées contraintes d’intégrité), ou encore établit une loi ou une relation entre deux ou plusieurs concepts. D’un principe vers une procédure ou un autre principe, le lien de régulation signifie que le principe contrôle de l’extérieur (régit) l’exécution d’une procédure ou la sélection d’autres principes. Si le lien unit une connaissance à un principe qui la régit, il faut lire le lien « est régi par ».
Exemples : « Les règles de disposition sur la page » régissent « le plan ». « Les règles de contrôle du trafic » régissent « Faire décoller un avion ». « Les règles de gestion de projet » régissent « Les principes de design à appliquer ».
Le lien d’application (A) relie un fait à une autre connaissance; ce fait est défini par une connaissance générique définie dans une autre domaine (qualifié de « méta »), et il s’applique à des connaissances d’un domaine d’application.6
Exemple : L’habileté « simuler une procédure » s’applique à la procédure « faire une recherche sur Internet ». Le métaconcept « connaissance acceptée » s’applique à « la théorie de l’évolution ».
6 La relation d’application est la seule dont l’interprétation repose sur une association entre deux domaines de
connaissances. Le premier domaine, celui des métaconnaissances, étudie les connaissances. On y représente notamment les propriétés des connaissances ainsi que les processus de transformation des connaissances (les habiletés). Quand on dit que « simuler une procédure » s’applique à « faire une recherche sur Internet », cela implique que la variable « procédure » du domaine « méta », prend une valeur spécifique dans le domaine d’application, soit la procédure « faire une recherche sur Internet ». Nous avons besoin de ce type de lien pour traiter
adéquatement la notion de compétence. Une compétence est essentiellement une habileté (ou métaconnaissance procédurale) appliquée à une ou plusieurs connaissances d’un domaine.
10
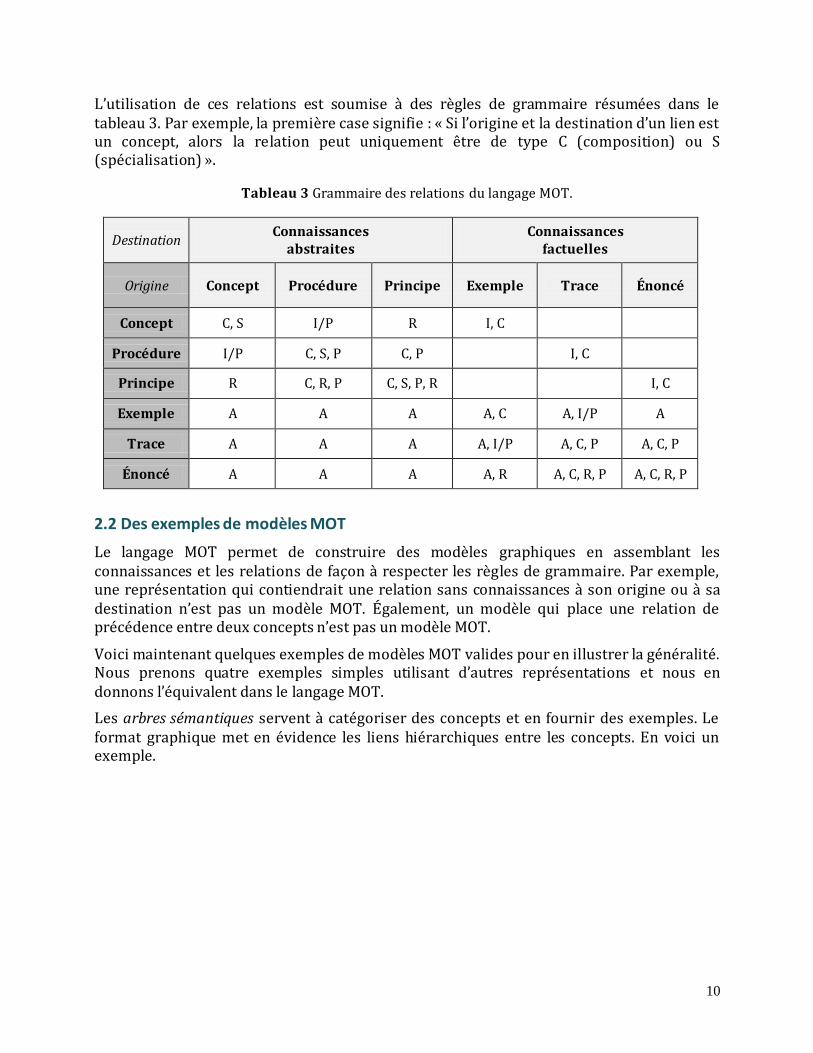
L’utilisation de ces relations est soumise à des règles de grammaire résumées dans le tableau 3. Par exemple, la première case signifie : « Si l’origine et la destination d’un lien est un concept, alors la relation peut uniquement être de type C (composition) ou S (spécialisation) ».
Tableau 3 Grammaire des relations du langage MOT.
Destination Connaissances
abstraites Connaissances
factuelles
Origine Concept Procédure Principe Exemple Trace Énoncé
Concept C, S I/P R I, C
Procédure I/P C, S, P C, P I, C
Principe R C, R, P C, S, P, R I, C
Exemple A A A A, C A, I/P A
Trace A A A A, I/P A, C, P A, C, P
Énoncé A A A A, R A, C, R, P A, C, R, P
2.2 Des exemples de modèles MOT
Le langage MOT permet de construire des modèles graphiques en assemblant les connaissances et les relations de façon à respecter les règles de grammaire. Par exemple, une représentation qui contiendrait une relation sans connaissances à son origine ou à sa destination n’est pas un modèle MOT. Également, un modèle qui place une relation de précédence entre deux concepts n’est pas un modèle MOT.
Voici maintenant quelques exemples de modèles MOT valides pour en illustrer la généralité. Nous prenons quatre exemples simples utilisant d’autres représentations et nous en donnons l’équivalent dans le langage MOT.
Les arbres sémantiques servent à catégoriser des concepts et en fournir des exemples. Le format graphique met en évidence les liens hiérarchiques entre les concepts. En voici un exemple.

11
Figure 2 Un arbre sémantique en histoire de l’art et un modèle MOT correspondant.
Le graphe de gauche de la figure 2 fait ressortir une hiérarchie, de la catégorie la plus générale, «Peintres », jusqu’aux individus représentatifs de certains groupes ou écoles de peinture. Remarquons que ce type de graphe, en tant que langage, laisse plusieurs interprétations possibles, car il ne précise pas la nature du lien qui est de plus non orienté. Dans des domaines moins bien connus ou totalement inconnus du lecteur, la distinction entre les deux types de liens passera probablement inaperçue. Les liens supérieurs indiquent une relation entre des concepteurs, une classe et ses sous-classes (liens S), alors que les liens inférieurs sont des liens d’appartenance d’un individu à une classe ( liens I). Le graphe correspondant en langage MOT fait mieux ressortir ces distinctions importantes.
Les cartes conceptuelles, appelées parfois « réseaux sémantiques », prennent aussi la forme d’un graphe, mais qui n’est pas nécessairement de nature hiérarchique comme le précédent.
Figure 3 Une carte conceptuelle et un modèle MOT sur les changements climatiques.
Dans une carte conceptuelle, les nœuds du graphe représentent les concepts alors que les liens représentent les relations entre concepts. Cette fois, la nature de chaque lien est indiquée par un mot inscrit sur la ligne qui représente graphiquement le lien. La figure 3 présente une carte conceptuelle qui décrit les relations de causalité et d’influence entre différents facteurs des changements climatiques.
Peintres
Peintres de la
Renaissance
Réalistes
Impressionnistes
daVinci Monet
Post-impressionnistes
Surréalistes
Courbet Matisse
Expressionnistes
Cubistes
Modernes
DaliPicasso
Pop
WarholVan Gogh
Changements
climatiques
Pratiques agricoles actuelles
Gaz à effet
de serre
Nouvelles
pratiques agricoles
Fertilisants
Production
du riz
Méthane
Oxyde
nitrique
CFCs
Dioxyde de
carbone
Nouveaux
intrants
Nouvelles
productions
Nouvelles
méthodes
de culture
Contribuent à
causés par nécessitent
impliquent
impliquent
impliquent
impliquent
impliquent
produit
produisent
sorte de
sorte de
sorte de
sorte de
Changements
climatiques
Pratiques agricoles actuelles
Gaz à effet de serre
Nouvelles pratiques agricoles
Fertilisants
Production du riz
Méthane
Oxyde nitrique
CFCs
Dioxyde decarbone
Nouveaux intrants
Nouvelles productions
Nouvelles méthodes de
culture
S
S
S
S
S
S S
S
S
I/P
I/P
I/P
I/P
I/P

12
Remarquons que cette carte conceptuelle utilise des liens non orientés, ce qui peut en compliquer parfois l’interprétation. Ainsi, il faut faire appel à d’autres connaissances de contexte qui n’apparaissent pas sur le graphe pour savoir que les fertilisants produisent des oxydes nitriques et non l’inverse. Il faut aussi établir un mode de lecture de haut en bas et de gauche à droite pour comprendre le graphe. Par ailleurs, le choix des termes attribués aux liens étant laissé à l’utilisateur, leur caractère ambigu peut rendre difficiles la communication et l’interprétation. Ainsi, que veut-on dire exactement par « implique » et comment un facteur contribue-t-il à un autre?
Le graphe correspondant en langage MOT (figure 3, graphe de droite) apporte plusieurs précisions. Il présente les pratiques agricoles, actuelles ou nouvelles comme des procédures, car l’auteur du modèle les considère comme des ensembles d’activités humaines dont certaines sous-classes (liens S), telles que l’usage de fertilisants ou la production de riz, produisent (liens I/P) une augmentation des gaz à effet de serre comme le méthane ou les oxydes nitriques. Il en est de même de nouvelles pratiques agricoles qui peuvent produire une diminution des gaz à effet de serre. Le modèle fait également ressortir des catégories de gaz à effet de serre et le fait que ceux-ci sont des intrants des changements climatiques.
Les ordinogrammes sont un autre type de modèle largement utilisé pour représenter des algorithmes et plus généralement des procédures. La figure 4 présente les grandes lignes d’une méthode qui vise la validation des matériels pédagogiques par les apprenants. Le graphe se compose d’actions et de décisions qui s’enchaînent dans le temps. Il comporte un certain nombre de cycle ou de boucles, par exemple lorsque la validation indique que les besoins sont satisfaits.
La figure 4 présente un modèle correspondant en langage MOT qui comporte la même expressivité, mais avec une signification plus précise en distinguant les tâches (procédures), des décisions et des types liens.
Corrections face aux besoins
Construire un prototype du matériel
Majeures
Construire une autre version
Identifier les besoins
Mettre à l’essai le prototype
Mineures
Mettre à l’essai la version
Besoins satisfaits ?
Diffuser le matériel
Non
Oui
Figure 4 Un exemple d’ordinogramme en langage MOT.
Identifier les
besoins
Constuire un
prototype du
matériel
Mettre à l'essai
le prototype
Construire
version complète
Mettre à
l'essai la
version
Diffuser le matériels
Si correction majeure
Si besoins non
satisfaits
P
P
PP
P
P
Si correction mineure
P
P
Si besoins
satisfaits
P
P P

13
Les arbres de décision, utilisés dans le domaine des systèmes experts, servent à représenter une base de connaissances sous forme de règles. Dans le langage MOT, les règles sont des principes. On retrouve de tels arbres de décision dans de nombreux domaines : le choix d’un véhicule financier à partir de certaines caractéristiques du client, l’identification de plantules de mauvaises herbes, la détermination du statut d’un immigrant selon les lois de citoyenneté et d’immigration, etc. La figure 5 présente un exemple (fictif) visant à déterminer un taux d’imposition progressif pour un contribuable selon son revenu imposable, selon qu’il est marié ou non ou selon qu’il a des enfants ou non.
Identification
du taux
d'imposition
Revenu
imposable
faible
Revenu
imposable
moyen
Revenu
imposable
élevé
Marié MariéMarié CélibataireCélibataireCélibataire
Avec
personnes
à charge
Avec
personnes
à charge
Avec
personnes
à charge
Sans
personnes
à charge
Sans
personnes
à charge
Sans
personnes
à charge
Fixer le
taux à
0%
C C C
P P
P
PP
P P
P P
P P
P P
P P
P P
P
P P
P
Fixer le
taux à
10%
Fixer
le taux
à 15%
Fixer le
taux à
25%
Fixer
le taux
à 30%
Fixer le
taux à
20%
Fixer le
taux à
35%
Fixer le
taux à
50%
Fixer le
taux à
40%
Figure 5 Un arbre de décision pour le calcul de l’impôt en langage MOT.
La base de règles se compose (lien C) de trois groupes de règles selon que le contribuable a un revenu imposable faible moyen ou élevé. Dans chaque groupe on retrouve d’abord une condition selon que le contribuable est marié ou célibataire; puis une autre condition spécifiant si le contribuable a ou non des personnes à charge. Chaque groupe se compose ainsi de trois principes, chacun correspondant aux trois chemins principaux de parcours du graphe. Par exemple, le premier groupe (« revenu imposable faible ») se compose de trois règles qui se lisent ainsi :
Si le revenu imposable est faible et le contribuable est marié avec personnes à charge, alors le taux est de 0 %.
Si le revenu imposable est faible et le contribuable est marié sans personnes à charge, alors le taux est de 10 %.
Si le revenu imposable est faible et le contribuable est célibataire, le taux est de 15 %.
14
2.3 Typologie des modèles MOT
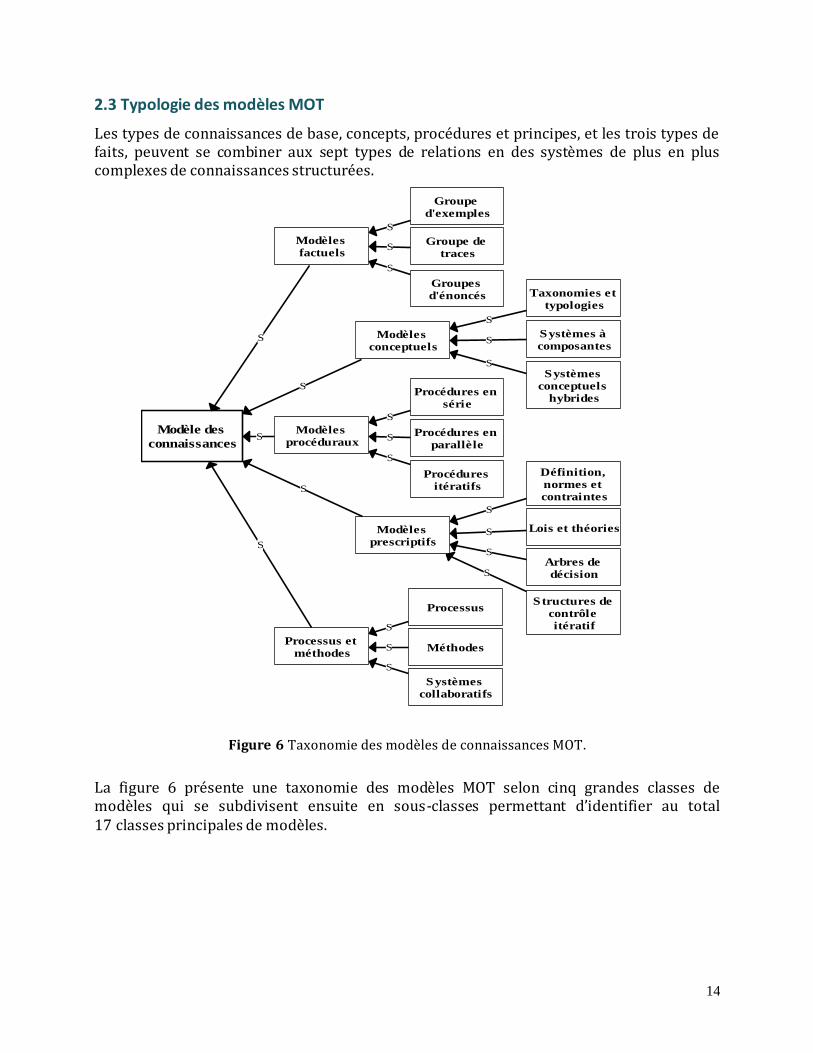
Les types de connaissances de base, concepts, procédures et principes, et les trois types de faits, peuvent se combiner aux sept types de relations en des systèmes de plus en plus complexes de connaissances structurées.
Modèle des
connaissances
Modèles
factuels
Groupe
d'exemples
Groupe de traces
Groupes
d'énoncés
Modèles
conceptuels
Taxonomies et
typologies
Systèmes à
composantes
Systèmes conceptuels
hybrides
Modèles procéduraux
Procédures en
série
Procédures en
parallèle
Procédures
itératifs
Modèles prescriptifs
Définition,
normes et
contraintes
Lois et théories
Arbres de décision
Structures de
contrôle
itératif
Processus et
méthodes
Processus
Méthodes
Systèmes
collaboratifs
S
S
S
S
S
S
S
S
S
S
S
S
S
S
S
S
S
S
S
S
S
Figure 6 Taxonomie des modèles de connaissances MOT.
La figure 6 présente une taxonomie des modèles MOT selon cinq grandes classes de modèles qui se subdivisent ensuite en sous-classes permettant d’identifier au total 17 classes principales de modèles.

15
Le livre Modélisation des connaissances et des compétences7 présente une définition de chacune des 17 sous-classes de modèles et des graphes et des exemples de chacune. Nous examinons plus loin deux classes particulièrement importantes pour la gestion des connaissances :
les scénarios d’activités ou workflow, classe particulière de modèles de type processus et méthodes;
les ontologies, classe particulière de modèles prescriptifs qui permettent de décrire une théorie d’un domaine du savoir par ses concepts et leurs propriétés.
3. Les outils de modélisation : du semi-formel au formel
Ces deux types de modèles ont donné lieu à des extensions apportées au langage MOT, reflétées dans les outils de modélisation. Le langage MOT a évolué à travers trois générations d’outils de modélisation.
L’éditeur de modèle MOT a été rendu disponible en version 2.3 dès 1996. Il est toujours largement utilisé. De 1996 à 1999, l’éditeur de modèle MOTplus a été créé. Il intègre la plupart des fonctionnalités de l’éditeur MOT 2.3 en leur ajoutant notamment deux nouvelles versions : l’éditeur MOT+LD permet de créer des scénarios de travail ou de formation qui peuvent être exportés selon différents formats, notamment un format exécutable dans les systèmes compatibles à la norme IMS-LD, par exemple RELOAD ou TELOS8; l’éditeur MOT+OWL permet de construire totalement graphiquement et d’exporter des ontologies selon le format OWL-DL fondé sur les logiques de description étendant la logique propositionnelle présentée plus haut.
Le multi-éditeur G-MOT a été créé de 2008 à 2012. Il existe en version autonome ou intégrée au système TELOS. Cet outil polyvalent regroupe les principales fonctionnalités de l’éditeur MOTplus. Il est construit sur des bases technologiques plus récentes. Nous ne présentons ici que les principales fonctionnalités. Le lecteur pourra se référer aux guides d’utilisation9 pour la réalisation d’activités de modélisation à l’aide de cet outil.
3.1 Les fonctionnalités de base de G-MOT10
Le multi-éditeur G-MOT offre cinq types d’éditeurs de modèles. L’éditeur de diagrammes informels permet de créer des cartes conceptuelles et d’autres types de modèles informels sans typer les connaissances et les relations. Ces modèles peuvent être utiles dans les premières phases d’analyse, mais ils possèdent une grande ambigüité lors de leur interprétation comme ’indiqué précédemment.
7 Paquette, G. (2002). Modélisation des connaissance et des compétences. Québec, Canada : PUQ.
8 RELOAD est le premier système créé par l’équipe d’OUNL permettant de « jouer » des scénarios d’apprentissage
rédigés selon la norme IMS LD. TELOS est un système dirigé par ontologie, construit par l’équipe du Centre LICEF de la TÉLUQ, qui permet d’exécuter, dans une interface utilisateur web, des scénarios de formation ou de travail.
9 Voir la page Introduction à G-MOT dans la section Ressources du site du cours.
10 Nous conseillons au lecteur de lire cette section en manipulant le logiciel G-MOT à l’aide de son guide
d’utilisation.

16
L’éditeur de modèles MOT permet de construire des modèles comme ceux présentés aux sections précédentes. Ces modèles respectent la syntaxe et la sémantique du langage MOT. Ils sont qualifiés de semi-formels, car leur interprétation est faite sans exiger la précision d’un langage formel interprétable sans ambigüité par un programme informatique. En gestion des connaissances, on les recommande à la fois comme moyen de transfert des connaissances entre experts et novices lors d’activité de co-construction d’un modèle de connaissances, ou encore comme étape préliminaire pour modéliser un processus ou un domaine de connaissances avant leur formalisation sous forme de scénario exécutable ou d’ontologie.
Les éditeurs de modèles de scénario, de graphes RDF/RDFS et de modèles d’ontologies sont au contraire formels, c’est-à-dire interprétables par un agent logiciel. L’éditeur de scénarios permet de créer des modèles de processus multi-acteurs exécutables dans une interface Web, permettant ainsi aux acteurs d’interagir entre eux, de réaliser les tâches dont ils sont responsables, et ce, en utilisant les ressources intrants de ces tâches et en produisant les ressources prévues dans le scénario. On peut ainsi modéliser toutes sortes de processus de gestion des connaissances.
L’éditeur de graphes RDF/RDFS est fondé sur les langages correspondants élaborés par le W3C, l’organisme qui gère le web. Il permet de construire graphiquement des ensembles de triples RDF et d’y ajouter le langage RDFS qui permet de définir des vocabulaires formés de classes et de relations de spécialisation entre elles ou d’instanciation à individus concrets. Ce type de graphe est à la base du web de données liées, qui sera présenté dans un autre texte de ce module et qui fera l’objet des modules 2 et 3 du cours.
L’éditeur d’ontologies peut être vu comme une extension du vocabulaire RDFS. Les ontologies ainsi construites respectent la grammaire du langage d’ontologies OWL-DL. Elles peuvent être traitées par des moteurs d’inférences qui permettront de déduire des faits et de valider la cohérence des composants du modèle. Les ontologies sont au cœur des technologies sémantiques nécessaires à la gestion des connaissances d’un domaine. Elles feront l’objet du module 4 de ce cours.
Le cinq éditeurs de G-MOT ont en commun des capacités d’édition évoluées. On peut modifier la plupart des attributs graphiques d’un objet tels que la couleur, la trame, la fonte, l’alignement, ainsi que la position relative des objets par superposition, alignement, espacement, etc. On peut ainsi documenter une connaissance ou un modèle par un texte, une figure, un tableau ou une page web. On peut aussi documenter un modèle au moyen de commentaires associés aux connaissances ou aux liens et obtenir automatiquement un fichier texte regroupant ces commentaires.
Les modèles élaborés étant difficilement lisibles dans une seule fenêtre, l’éditeur G-MOT permet d’associer des modèles à chacune des connaissances d’un modèle et de déployer le modèle par niveaux au moyen de sous-modèles, et ce, sur autant de niveaux que nécessaire.
3.2 Méthode de modélisation
La présentation faite ici du processus de modélisation se veut la plus générale possible. Elle pourra servir dans une variété d’applications, notamment en réingénierie des processus administratifs, dans la modélisation des processus de gestion des connaissances, dans la

17
construction des scénarios de travail ou de formation, dans l’élaboration d’une ontologie décrivant un domaine de connaissances. Il va de soit qu’il faut spécialiser la méthode selon les types de modèles, ce que nous ferons plus loin pour les scénarios et les ontologies.
La méthode proposée ici a pour but de résoudre des problèmes de modélisation à travers cinq sous-processus principaux. Le résultat est un modèle de connaissances correspondant à des objectifs et à des contraintes fournies initialement au concepteur du modèle.
Le processus de modélisation est orienté au départ par un problème de représentation des connaissances qui est fourni au concepteur ou à l’équipe de conception du modèle. Le but, les données et les contraintes de ce problème déterminent le type de connaissances et le type de liens qui seront utilisés dans le modèle. Le résultat final est un modèle des connaissances qui apporte une solution au problème initial, respectant le but de la modélisation et ses contraintes.
Le processus de modélisation se déploie en cinq sous-processus.
Le premier sous-processus vise à identifier les objets ou entités du modèle. Pour ce faire, on définit les orientations du modèle des connaissances et le type de modèle (choisi par exemple dans la typologie présentée à la figure 6), ces éléments étant eux-mêmes élaborés en fonction des résultats de l’analyse du problème de représentation. Sur cette base, on développe un modèle principal des connaissances. À ce stade initial du développement du modèle, on se préoccupe uniquement d’identifier les faits, les connaissances et leurs principaux liens sur un seul niveau, c’est-à-dire sans sous-modèles descendants.
Le deuxième sous-processus consiste à orienter le développement du modèle en priorisant certaines connaissances qualifiées de principales. Ce sont les connaissances pour lesquels les publics cibles auxquels le modèle est destiné ont un écart de compétence à combler.
Le troisième sous-processus vise à déployer ce modèle principal initial en associant un modèle descendant à chaque connaissance principale, obtenant ainsi des sous-modèles de niveau 2. Puis on fera appel de nouveau au deuxième sous-processus pour identifier les connaissances principales de ces sous-modèles. Celles-ci seront à leur tour développées en leur associant des modèles descendants, donc de niveau 3. On procédera ainsi sur un certain nombre de niveaux jusqu’à ce que le modèle soit jugé satisfaisant en regard du but et des contraintes initiales du projet de modélisation.
Le quatrième sous-processus vise à utiliser le modèle en cours de développement pour décrire les connaissances d’un autre domaine appelé codomaine. Le codomaine peut représenter les chapitres d’un livre, les modules d’un système logiciel ou les unités d’apprentissage d’un cours. Il s’agit ici d’associer à certains objets du codomaine (par exemple une unité d’apprentissage), un sous-ensemble des connaissances du modèle qui en définit le contenu. Cette opération peut être répétée avec plus d’un codomaine.
Le dernier sous-processus consiste à mettre à l’essai le modèle auprès de personnes représentatives des publics cibles. Cette validation portera à la fois sur l’exactitude, la cohérence et la complétude du modèle en regard du but et des contraintes initiales. Elle

18
permettra de réviser le modèle, ses sous-modèles et ses comodèles, de produire un compte rendu des modifications apportées et de documenter le modèle.
4. Scénarios et ontologies pour la gestion des connaissances
Nous allons maintenant nous concentrer sur deux des éditeurs G-MOT qui produisent des modèles formels : les éditeurs de graphes RDF/RDFS, d’ontologies et de scénarios.
4.1 L’éditeur de scénarios de G-MOT
L’éditeur de scénarios G-MOT sert à représenter des scénarios d’activités multi-acteurs. Il a été construit par une analyse, comparative du standard BPMN11 pour les scénarios de d’activités (workflow), la spécification IMS LD12 pour les scénarios d’apprentissage et le langage général MOT. Ce travail a conduit au repérage de 21 situations de contrôle utilisés en génie logiciel pour construire des workflow. Ces situations englobent les conditions de la spécification IMS-LD, niveaux B et C.
Sur la base du langage MOT, l’éditeur de scénarios G-MOT utilise quatre sortes de symboles, présentés à la figure 7, pour représenter les acteurs, les fonctions, les ressources et les conditions, chacun avec des sous-types. Ces symboles ne sont pas en correspondance directe avec les termes d’IMS-LD, mais un outil d’exportation permet de générer un fichier XML conforme à la spécification. Un outil d’exportation vers BPMN n’a pas encore été réalisé, mais la chose serait possible.
Le symbole « Concept » du langage MOT prend une forme différente du rectangle utilisé dans l’éditeur de modèle MOT; il est représenté par un icône « dossier ». Il sert à représenter toutes les sortes de ressources : documents, outils, ressources sémantiques, fonctions (en tant que ressource), et divers types de données : chaîne, entier, collection, etc.
Les symboles « Procédure » du langage MOT représentent les fonctions qui peuvent se décomposer en fonctions plus restreintes sur un certain nombre de niveaux jusqu’aux « Activités » ou « Multi-activités » réalisées par des utilisateurs du scénarios ou des « Opérations » réalisées automatiquement par le système.
11 Object Management Group (2009). Business process modeling notation specification. version 1.2. Récupéré le 7 octobre 2013 de : http://www.omg.org/spec/BPMN/1.2/
12 IMS-LD. (2003). IMS learning design. Information model, best practice and implementation guide, binding document, schemas. Récupéré le 7 octobre 2013 de : http://www.imsglobal.org/learningdesign/index.cfm

19
Figure 7 Les symboles de base de l’éditeur de scénarios G-MOT.
Le symbole « Principe » du langage MOT sert à représenter d’une part les « Acteurs » du scénarios et d’autre part les « Conditions ». Ces deux types de principes MOT sont représentés par des symboles graphiques différents pour mieux les distinguer. Le symbole de type « Acteur » peut représenter des utilisateurs individuels, des groupes ou des agents logiciels. Les symboles de type « Condition » sont aussi des éléments de contrôle insérés dans le modèle pour décider de la suite des activités ou des opérations, soit pour marquer le début ou la fin d’un scénario. Trois types de conditions de « Séparation » servent à créer des options dans le scénario entre les séquences d’activités et les opérations alternatives. Trois types de conditions de « Jonction » servent à décider quand des séquences peuvent fusionner pour la poursuite du scénario. Les « Conditions événementielles » altèrent le déroulement du scénario lorsque divers événements se produisent, par exemple une limite de temps écoulé, une ressource produite ou une action d’un utilisateur.
La figure 8 présente un exemple de scénario qui combine certains de ces symboles. Un acteur appelé « coordinateur » écrit le plan d’un site web lors d’une première activité. Puis, trois autres acteurs « rédacteurs » écrivent en parallèle autant de sections du site web. Ce déroulement en parallèle est indiqué par la condition de séparation. Quand ces activités sont toutes terminées, une condition de jonction permet de passer à l’avant-dernière activité où le coordonnateur assemble les sections à l’aide d’un éditeur web, produisant un site web. Dans la dernière activité précédent la condition de terminaison, le coordonnateur référence le site web par des métadonnées; celles-ci sont des données sémantiques décrivant le contenu du site et les auteurs.

20
Figure 8 Un exemple de scénario d’activités.
Cet exemple montre que l’éditeur de scénarios combine un flux de contrôle et un flux de données. Le flux de contrôle est représenté par les liens de précédence (P) et de réglementation (R) du langage MOT. Les liens P tracent la séquence principale d’exécution entre les conditions, les activités, les opérations et les fonctions qui regroupent ces dernières. Lorsqu’une fonction est décomposée en sous-fonctions, le flux de contrôle « descend » dans la sous-fonction, laquelle doit se terminer avant le contrôle ne « remonte » à la sur-fonction. Les liens R associent un acteur à la source d’un événement où il doit agir avant que le flux de contrôle se poursuive. Cette action peut altérer la suite des activités. Les conditions tiennent compte de ces événements pour fixer la suite des choses.
Les liens MOT intrant/produit (I/P) servent à représenter le flux de données. Un lien I/P entre une ressource et une activité signifie que les données de la ressource vont être utilisées par une opération automatisée ou consultées par un acteur, influençant ainsi sa réalisation de l’activité. Un lien I/P entre une activité et une ressource signifie que cette ressource et ses données sont produites lors de l’activité, ce produit devenant disponible comme intrant dans d’autres activités.
4.2 L’éditeur d’ontologies de G-MOT
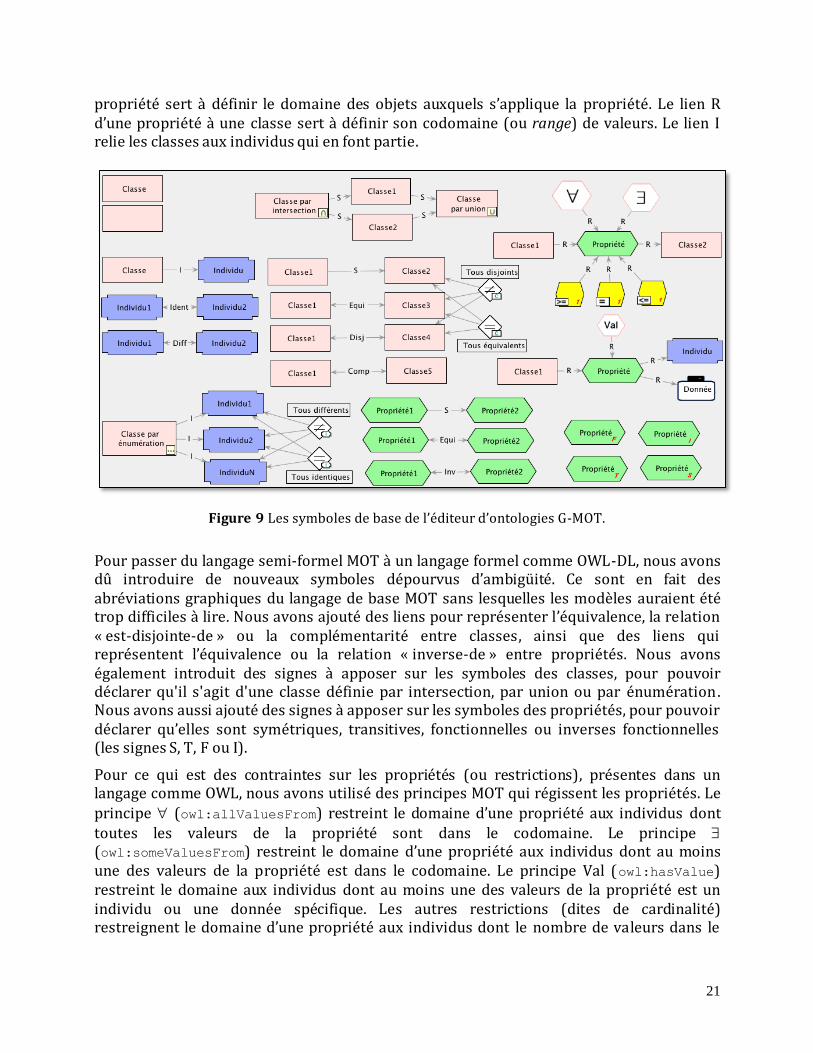
Les ontologies, de même que les graphes RDF/RDFS forment une classe de modèles dont les connaissances sont des propriétés reliant des classes d’objets , elles-mêmes formées d’individus. Elles comportent trois types d’objets MOT comme il est ’illustré sur la figure 9. Les concepts MOT représentent les classes, les principes MOT représentent les propriétés et les exemples MOT représentent des individus. Nous avons également réutilisé certains liens du langage MOT. Le lien S relie des concepts formant une hiérarchie de spécialisation d’un classe à une surclasse ou d’une propriété à une sur-propriété. Le lien R d’une classe à une
21
propriété sert à définir le domaine des objets auxquels s’applique la propriété. Le lien R d’une propriété à une classe sert à définir son codomaine (ou range) de valeurs. Le lien I relie les classes aux individus qui en font partie.
Figure 9 Les symboles de base de l’éditeur d’ontologies G-MOT.
Pour passer du langage semi-formel MOT à un langage formel comme OWL-DL, nous avons dû introduire de nouveaux symboles dépourvus d’ambigüité. Ce sont en fait des abréviations graphiques du langage de base MOT sans lesquelles les modèles auraient été trop difficiles à lire. Nous avons ajouté des liens pour représenter l’équivalence, la relation « est-disjointe-de » ou la complémentarité entre classes, ainsi que des liens qui représentent l’équivalence ou la relation « inverse-de » entre propriétés. Nous avons également introduit des signes à apposer sur les symboles des classes, pour pouvoir déclarer qu'il s'agit d'une classe définie par intersection, par union ou par énumération. Nous avons aussi ajouté des signes à apposer sur les symboles des propriétés, pour pouvoir déclarer qu’elles sont symétriques, transitives, fonctionnelles ou inverses fonctionnelles (les signes S, T, F ou I).
Pour ce qui est des contraintes sur les propriétés (ou restrictions), présentes dans un langage comme OWL, nous avons utilisé des principes MOT qui régissent les propriétés. Le
principe (owl:allValuesFrom) restreint le domaine d’une propriété aux individus dont toutes les valeurs de la propriété sont dans le codomaine. Le principe (owl:someValuesFrom) restreint le domaine d’une propriété aux individus dont au moins une des valeurs de la propriété est dans le codomaine. Le principe Val (owl:hasValue) restreint le domaine aux individus dont au moins une des valeurs de la propriété est un individu ou une donnée spécifique. Les autres restrictions (dites de cardinalité) restreignent le domaine d’une propriété aux individus dont le nombre de valeurs dans le

22
codomaine est égal, plus petit ou plus grand au nombre indiqué sur le symbole graphique. Ces notions seront présentées en détail dans le module 4 du cours.
Figure 10 Un exemple d’ontologie produite avec l’éditeur d’ontologies G-MOT.
La figure 10 présente une ontologie où ces symboles sont utilisés. L’ontologie regroupe des déclarations à propos des carnivores et des herbivores, quant à leur type de nourriture. Le concept de girafe est défini comme mangeant uniquement (symbole ) des feuilles qui sont partie d’une branche, elle-même partie d’un arbre. Ce dernier concept est défini comme une sorte de plante. Au centre de la figure, les herbivores sont définis comme mangeant quelque chose qui est une plante ou (classe union non nommée) ou qui est partie d’une plante. Les carnivores, comme le lion, mangent d’autres animaux. Le lion est défini comment mangeant des herbivores, mais pas uniquement (symbole ) sans quoi on aurait utilisé le symbole . La propriété « mange » est définie comme l’inverse de « est-mangé-par ».
Nous avons présenté à la section précédent un processus cadre de modélisation des connaissances. Lorsqu’il s’agit de construire une ontologie, des processus plus précis ont été proposés dans la littérature tel celui présenté à la figure 10.
Conclusion
La modélisation des connaissances et des compétences, c’est-à-dire l’ingénierie cognitive, est une activité sur laquelle reposeront de plus en plus la plupart des décisions relatives aux systèmes de formation ou de soutien au travail dans toutes leurs dimensions. Des activités de modélisation peuvent se réaliser à divers niveaux et dans divers milieux : celui de l’ensemble d’une organisation ou de plusieurs organisations similaires, par grandes

23
divisions de l’organisation ou par programmes de formation, ou encore au niveau d’un ensemble d’activités de travail et de formation.
L’ingénierie cognitive est donc un instrument essentiel pour aider une organisation à conserver et à faire évoluer son expertise, à maîtriser la masse de ses informations, à transférer des connaissances et des compétences entre ses membres, à produire plus efficacement des biens et des services.
Dans l’approche traditionnelle de gestion des données et des documents, on répond aux besoins d’acquisition de connaissances et de compétences en cherchant quels documents ou données peuvent y répondre, en organisant un système technologique d’accès à l’information et en effectuant une réingénierie des processus utilisant les documents, en parallèle avec les activités de formation.
Dans la gestion des connaissances, on commence plutôt par identifier et structurer les objets de connaissances, puis on construit des processus de création, de traitement et de formation entourant ces objets de connaissances et on organise en conséquence l’infrastructure technologique et administrative de soutien.
Le référencement sémantique sera présenté dans un autre texte. Essentiellement, il consiste à associer des concepts d’un modèle de connaissance semi-formel ou par ontologie aux composantes d’un modèle de scénario : les acteurs, les tâches ou les activités et les ressources utilisées ou produites dans un scénario de gestion des connaissances.
Cette association entre les connaissances procédurales intégrées dans un scénario et les connaissances conceptuelles d’un domaine modélisées sous forme de graphe RDF/RDFS ou d’ontologies permet de décrire les interactions entre savoirs et savoir-faire, deux notions qui sont ici réconciliées. Il s’agit d’un élément central de la gestion des connaissances.





























