Embed Size (px)
Citation preview

Chapitre 2
La Quantification des Signaux
Notes de Cours.
B. Gosselin
2.1 Introduction
La représentation numérique d’un signal implique la quantification de chaque échantillon selon
un nombre fini de valeurs discrètes. L’objectif visé est, soit une transmission, soit un traitement
déterminé (filtrage, analyse spectrale,…) :
• Dans le premier cas, chaque échantillon du signal est quantifié, codé, puis transmis; à la
réception, il est décodé, puis converti en amplitude continue : après interpolation, on souhaite
retrouver l’image la plus fidèle possible du signal original. La statistique du signal doit donc être
préservée : elle va influencer d’une façon essentielle la procédure de quantification.
• Dans le second cas, la loi de quantification est imposée par le système de traitement ; une
contrainte importante pour un système de traitement numérique consiste à commettre des erreurs
de calcul qui soient négligeables vis-à-vis de l’incertitude sur le signal lui-même ; cet objectif doit
être atteint malgré le caractère non - stationnaire de certains signaux, tel le signal vocal par
exemple.
L’erreur qui résulte de la quantification d’un signal déterministe est aussi déterministe ; ses
propriétés peuvent donc, en principe, être établies par une approche déterministe. En réalité, les
signaux tels que, par exemple, le signal vocal, doivent être considérés comme étant aléatoires : la
suite des erreurs de quantification est par conséquent aussi aléatoire, et l’on parle alors de bruit de
quantification. Il est très important d’en connaître les propriétés statistiques, tout au moins celles
des premier et second ordre, c’est-à-dire :

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
2
• la densité de probabilité ( )epe ;
• la moyenne eµ ;
• la variance 2
eσ ;
• la fonction d’autocovariance ( )keeφ ;
• la covariance mutuelle avec le signal ( )kexφ ;
• le rapport signal à bruit RSB.
Considérons un signal ( )tx à temps continu et à bande limitée [ ]BB +− , . Lorsqu’on
l’échantillonne à une fréquence supérieure ou égale à la fréquence de Nyquist Bf e 2= , on obtient,
sans perte d’information, un signal à temps discret ( )nx . On interprétera ce signal comme un
processus aléatoire à temps discret ( )nX . On suppose que ce processus aléatoire possède les
bonnes propriétés habituelles de stationnarité et d’ergodicité. A la sortie du quantificateur, ce
processus devient un processus aléatoire à valeurs discrètes, c’est à dire que ( )XQY = prend ses
valeurs dans un ensemble fini de L éléments.
Une loi de quantification sans mémoire, ou instantanée, est définie par :
• (L+1) niveaux de décision : Lxxx ⋯,, 10 ;
• L valeurs quantifiées : Lyyy ⋯,, 21 .
A toute amplitude X comprise dans l’intervalle [ ]ii xx ,1− , on fait correspondre une valeur quantifiée
iy située dans cet intervalle :
iyY = si [ ]ii xxX ,1−∈ pour Li ,,2,1 ⋯= (2.1)
Les amplitudes extrêmes du signal sont en principe −∞=0x et +∞=Lx ; en fait, le domaine de
variation de x est borné et supposé symétrique par rapport à l’origine. On a donc max0 xx −= et
maxxxL += .
La valeur quantifiée de sortie peut également être représentée au moyen d’un mot,
généralement au format binaire, choisi parmi les L que contient un dictionnaire. Ainsi, par exemple,
lorsque le nombre de valeurs quantifiées est une puissance de 2, soit bL 2= , chaque valeur
quantifiée peut être représentée par un mot de b bits, en codant les indices de référence de ces
valeurs.
La loi de quantification ( )xQ peut affecter deux formes :
• L est pair et 0=x est un niveau de décision (midrise characteristic) ;
• L est impair et 0=y est une valeur de sortie (midthread characteristic) ;

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
3
Ces caractéristiques sont représentées à la figure 2.1, qui illustre également l’erreur de quantification
( ) xxQe −= . La seconde caractéristique, qui assure une valeur quantifiée insensible aux petites
fluctuations éventuelles autour de l’origine, est en général préférée.
La différence entre deux niveaux de quantification successifs est appelée pas de
quantification :
1−−=∆ iii xx (2.2)
Le pas de quantification est en général fonction de l’amplitude du signal (quantification non
uniforme). Le cas le plus simple est celui de la quantification uniforme.
y
xx(2)x(1) x(3)
y(8)
x(7)x(6)x(5)
y(2)
y(3)
y(7)
y(6)
y(1)
e = y - x
x
y
xx(2)x(1) x(3)
y(9)
x(6)x(5)x(4)
y(2)
y(3)
y(8)
y(7)
y(1)
e = y - x
x
Figure 2.1 - Exemples de lois de quantification.
La statistique du bruit de quantification ( )ne est relativement aisée à déterminer lorsque le
signal est aléatoire et de grande amplitude, c’est-à-dire lorsqu’à la fois son écart-type et la différence
entre deux échantillons successifs sont grands vis-à-vis du pas de quantification. Les propriétés qui
correspondent à la quantification d’un bruit blanc continu gaussien de variance finie lorsque le pas de
quantification tend vers zéro sont appelées propriétés asymptotiques. Ces dernières ne sont
toutefois pas valables pour les signaux aléatoires dont l’amplitude est de l’ordre de grandeur du pas
de quantification, et une analyse mathématique précise de la quantification est dans ce cas
indispensable.

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
4
2.2 Quantification Uniforme
Une loi uniforme et symétrique (figure 2.2) est caractérisée par :
• Les niveaux de saturation sx± ;
• Le nombre de niveaux quantifiés L ; on choisi normalement L (ou L+1) = b2 .
Le pas de quantification ∆ vaut alors :L
xs2=∆ , (2.3)
et la valeur quantifiée iy est choisie au milieu de l’intervalle i :2
1 iii
xxy
+= − (2.4)
x(1)-xs
xs
x(2)
x(8)
x(3) x(4)
x(5) x(6) x(7)
y(1)
y(4)
y(6)
y(7)
y(8)
y(9)
y(2)
y(3)
y
x
x
e = y - x
∆ /2
-∆ /2
Figure 2.2 - Loi de Quantification Uniforme.
• Pour2
∆⋅=≤
Lxx s , l’erreur de quantification est comprise entre
2
∆− et
2
∆+ :
2
∆≤⇒≤≤− exxx ss (2.5)
On parle dans ce cas d’erreur (ou de bruit) de granulation.
• Lorsque sxx > , Il y a dépassement ; on parle alors d’erreur (ou de bruit) de saturation ou de
dépassement.

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
5
Erreur de granulation
Soit un signal x, dont la densité de probabilité ( )xpx est Gaussienne, d’écart-type xσ (figure
2.3). L’aire hachurée définit la probabilité pour que les amplitudes de x contribuent à la valeur
quantifiée ky , soit :
22
∆+<≤
∆− kk yxy (2.6)
px
xyk
D
Figure 2.3 - Quantification d’un signal Gaussien.
La densité de probabilité ( )epe de l’erreur de granulation peut être obtenue par la superposition de
telles aires ramenées entre2
∆− et
2
∆+ :
( ) ( ) ( )∑ ∆⋅+=k
kxe erecteypep 2/ (2.7)
où la fonction ( )erect 2/∆ est définie par :
( )ailleurs
rect
,0
,1
=α<τ≤α−=τα
(2.8)
On conçoit aisément que lorsque le rapport ∆
σ x tend vers l’infini, la loi (2.7) tende vers une
répartition de moyenne nulle, et uniforme entre 2
∆− et
2
∆+ (
∆σ x > 3 ou 4 est considéré comme
suffisant en pratique). Si la probabilité de dépassement est négligeable, on a donc :

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
6
( )
∆>
∆≤
∆=
20
2
1
e
e
epe (2.9)
On en déduit que la moyenne du bruit de granulation est nulle, et que sa variance (“ mean
squared error ”) vaut :
( )12
22
2
222 ∆
=∆
==σ ∫∫∆
∆−
∞
∞−
dee
deepe ee (2.10)
t
t
x
y = e - x
-∆ /2
∆ /2
∆
2∆
3∆
4∆
-∆
-2∆
-3∆
0
Figure 2.4 - Quantification avant échantillonnage.
Toujours dans l’hypothèse d’un rapport ∆σx supérieur à 3 ou 4, considérons la figure 2.4. Il
est clair que les opérations d’échantillonnage et de quantification peuvent être permutées ; or cette
figure met en évidence le fait que l’erreur de granulation continue présente un spectre beaucoup plus
étendu que celui du signal. Le signal ( )ne obtenu par l’échantillonnage de ( )te sera donc sujet au
phénomène de recouvrement des spectres ; à la limite, il apparaîtra comme un bruit blanc. En
d’autres termes, pourvu qu’entre deux instants d’échantillonnage successifs, le signal ( )tx traverse
un nombre suffisant de niveaux de décision ( ( )eFFT
éch
éch
max.
.2
11>>= ), on peut admettre que les

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
7
erreurs successives ( )ne ne sont pratiquement pas corrélées ; de même, la corrélation mutuelle
erreur - signal est négligeable.
En résumé, pour un signal aléatoire Gaussien dont l’écart-type est supérieur à quelques pas de
quantification, on peut considérer deux points importants :
• L’erreur de quantification est un bruit blanc de répartition uniforme, de moyenne nulle et dont la
variance est égale à 12
2∆:
( )
∆>
∆≤
∆=
20
2
1
e
e
epe
0=µe (2.11)
( )
≠
=∆=φ
00
012
2
k
kkee
• La corrélation entre l’erreur de granulation et le signal est négligeable :
( ) kkex ∀=φ 0 (2.12)
Ces propriétés restent qualitativement valables pour la quantification d’un signal présentant une
distribution Gamma, ou de Laplace (table 2.1). La distribution Gamma est très proche de la loi de
répartition expérimentale d’un signal de parole. La distribution de Laplace, quant à elle, en est
relativement proche, tout en présentant une expression plus simple à utiliser.
Distorsions dues aux dépassements de capacité
Si la valeur à représenter excède le domaine de représentation admissible, il en résulte des
distorsions. Un dépassement doit donc en principe être évité, mais cela n’est pas possible avec
rigueur pour un signal tel que Gaussien, par exemple. De manière générale, la probabilité de
dépassement vaut, pour un signal symétrique :
( )∫∞
=sx
xD dxxpp 2 (2.13)
On définit le facteur de charge du quantificateur par :
x
sx
σ=Γ (2.14)

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
8
Lois de répartition Expression analytique ( )µx = 0
Uniforme 3/;)(.2/1 22 aerect xa =σ
Gaussienne 1
2
2 22
π σσ
..
/( )
x
xe x−
Laplace 1
2
2
..
. /
σσ
x
xe x−
Gamma 3
8
3 2
πσσ
x
x
xe x.
/( )−
Table 2.1 - Lois de répartition usuelles (signaux à moyenne nulle).
La table 2.2 reprend l’évolution de la probabilité de dépassement en fonction du facteur de charge,
pour un signal Gaussien.
Γ DP
2 0,0455
3 0,0027
4 0,0000634
Table 2.2 - Probabilités de dépassement pour un signal Gaussien.
Lorsque cette probabilité de dépassement n’est pas négligeable, les expressions précédentes
doivent être corrigées. La densité de probabilité du bruit de granulation devient :
( )
∆>
∆≤
∆−
=
20
2
1
e
ep
ep
D
e (2.15)
et la variance : ( )De p−∆
=σ 112
22 (2.16)
Quant à la variance du bruit de dépassement, elle vaut :
( ) ( )∫∞
−=σsx
xsD dxxpxx22 2 (2.17)

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
9
et la variance totale du bruit de quantification est égale à 22
De σ+σ . Il est clair que l’erreur de
dépassement est fortement corrélée avec le signal.
Rapport Signal à Bruit (RSB)
En l’absence de dépassement, le rapport signal à bruit (RSB) est calculé comme suit :
bse
x 222
2 2312
−=∆
=σ (2.18)
Le RSB vaut donc :
( ) Γ−+≈
σ= log2077,402,62
3log10
2
2
2
bx
dBRSBb
s
x (2.19)
Cette loi est représentée à la figure 2.5.
-100 -80 -60 -40 -20 0
0
20
40
60
80
100
-20logG
RSB=10log(sx2/se
2) (dB)
b=16
810
12
14 42
65.8
86
(dB)
Figure 2.5 - RSB pour la quantification uniforme d’un signal Gaussien.
En cas de dépassement, le RSB est dégradé, et devient :
σ+σ
σ=
22
2
log10De
xRSB (2.20)
Cette dégradation du RSB dépend essentiellement de la loi de répartition du signal x (cfr. 2.13,
2.16, 2.17).

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
10
Exemples :
• Dans le cas d’un signal aléatoire à répartition uniforme, le dépassement se manifeste pour
3
1=
σ
s
x
x (une répartition uniforme entre -a et +a implique une variance
3
22 ax =σ ), soit pour
dB77,4log20 −=Γ− .
• Pour un signal sinusoïdal, il y a dépassement à partir de 2
1=
σ
s
x
x ( dB01,3log20 −=Γ− ).
• Pour un signal à répartition Gaussienne, le dépassement se manifeste progressivement.
Ces propriétés sont illustrées à la figure 2.6.
-100 -80 -60 -40 -20 0
0
20
40
60
80
100
-20logG
RSB=10log(sx2/se
2) (dB)
b=16
96.3
77.4
86.0
98.1
1
2
3
4
1: Laplace
Loi de répartition :
2: Gauss
3: Uniforme
4: Sinusoïdale
Figure 2.6 - Dégradation du RSB due à la saturation.
2.3 Quantification Non Uniforme
La figure 2.6 a mis en évidence l’existence d’un maximum du RSB pour un nombre donné de
bits et pour une loi de répartition donnée. Ce maximum est atteint pour une certaine valeur du facteur
de charge ; il est lié à la loi de répartition et à la loi de quantification. Il est légitime de penser qu’une
adaptation de la loi de quantification à la densité de probabilité du signal est susceptible de conduire
à un meilleur RSB. En effet, l’importance de l’erreur de granulation sera réduite pour les amplitudes
du signal les plus probables.

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
11
On supposera le signal borné maxmax xxx +≤≤− , ce qui correspond à la situation concrète
usuelle. Pour un nombre L de niveaux de quantification, la variance du bruit de granulation peut
s’écrire :
( ) ( ) ( )∑ ∫∫=
∞
∞− −
−==σL
i
x
x
xiee
i
i
dxxpyxdeepe1
222
1
(2.21)
Cette variance peut être minimisée par un choix adéquat des niveaux de décision ix et des
niveaux quantifiés iy . Un ensemble de conditions nécessaires est fourni par :
==∂σ∂
−==∂σ∂
Liy
Lix
i
e
i
e
,,2,10
1,,2,10
2
2
⋯
⋯
(2.22)
On peut montrer que ces conditions deviennent suffisantes si ( )xpxln est concave, c’est-à-dire si
( )( )x
x
xpx ∀<∂
∂0
ln2
2
. On peut également montrer que cette condition est vérifiée pour les
distributions de Gauss et de Laplace.
La résolution de (2.22) en tenant compte de (2.21) conduit à :
1,,2,12
1* −=+
= + Liyy
x iii ⋯ (2.23)
Le niveau de décision optimum est donc situé à égale distance des valeurs quantifiées qui
l’entoure.
D’autre part, lorsque les ix sont fixés, on déduit de (2.22) et (2.21) :
( )
( )Li
dxxp
dxxpx
yi
i
i
i
x
x
x
x
x
x
i ,,2,1
1
1*⋯=
⋅
=
∫
∫
−
− (2.24)
La valeur quantifiée optimum coïncide donc avec la valeur moyenne du signal dans l’intervalle
associé: { }iii xxxxEy ≤<= −1
*.
On peut par conséquent concevoir une procédure itérative qui, à partir de la loi uniforme (par
exemple), converge vers la loi optimum par application successive et alternée de (2.23) et (2.24).

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
12
2.4 Quantification Logarithmique
2.4.1 Principe
Une loi de quantification non uniforme peut être conçue comme le résultat d’une compression
des amplitudes du signal, suivie par une quantification uniforme. Vient ensuite une expansion qui
agit en sens opposé à celui de la compression (figure 2.7).
Quantification
uniforme
x u û y
Figure 2.7 - Quantification avec compression et expansion.
Le signal x possède par hypothèse une densité de probabilité symétrique et bornée par maxx−et maxx+ . Après avoir subi une compression définie par la fonction ( )xFu = , telle que
maxmax xu = , il est quantifié uniformément sur L niveaux, avec un pas L
xmax2=∆ (figure 2.8). Les
seuils de décision ix et les pas de quantification i∆ sont ainsi définis.
Aux valeurs quantifiées iu correspondent les niveaux quantifiés de sortie iy après expansion
par la fonction ( )uFy 1−= .
Lorsque 1>>L , on peut linéariser la fonction F dans l’intervalle [ ]ii xx ,1− , et il vient :
( ) ( ) ( )L
xxFxFyF iiii
max1
2=∆=−≈∆⋅′ − (2.25)
En prenant la convention de désigner ( )xF ′ par ( )xg , on obtient :
( ) ( )ii
iyLg
x
yg
max2=
∆=∆ (2.26)

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
13
u=F(x)
x
xmax
umax
ûi
u i
u i-1
D
yixixi-1
Di
Figure 2.8 - Exemple de Loi de Compression.
D’autre part, si le nombre L de niveaux de quantification est élevé, ( )xpx peut être considéré
comme constante dans l’intervalle [ ]ii xx ,1− , et l’on a :
( ) ix Pxp ≈ pour [ ]ii xxx ,1−∈ (2.27)
Dès lors, l’expression (2.21) peut s’écrire : ( )∑ ∫= −
−=σL
i
x
x
iie
i
i
dxyxP1
22
1
(2.28)
D’autre part, pour un intervalle i donné, on a :
( )( )iii yxyguu −+= ˆ (2.29)
Il vient alors :
( )( ) ( )
( )( )∑ ∫∑ ∫
== −−∆∆
⋅−
=⋅−
=σL
i
u
u
i
i
ii
L
i
u
u ii
iie
i
i
i
i
duyg
uuPdu
ygyg
uuP
12
2
12
2
2
11
ˆ1ˆ (2.30)
( )( )∑ ∫
= −∆
⋅−∆=σL
i
u
u
ii
i
ie
i
i
duuuyg
P
1
2
2
2
1
1ˆ (2.31)
Les intégrales qui interviennent dans (2.31) sont relatives à une quantification uniforme, et valent
chacune12
2∆. On obtient ainsi :

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
14
( )∑=
∆∆
=σL
i
i
i
ie
yg
P
12
22
12 (2.32)
Par passage à la limite, on obtient finalement :
( )( )
( )( )∫∫ =
∆=σ
−
maxmax
max 0
22
2
max
2
22
3
2
12
x
x
x
x
xe dx
xg
xp
L
xdx
xg
xp (2.33)
Cette dernière expression doit être minimisée sous la contrainte :
( ) ( )maxmax
0
max
xxFdxxg
x
==∫ (2.34)
On en déduit la loi de compression optimale :
( )( )
( )dxxp
dxxp
xxFx
x
x
x
opt
∫
∫=
max
0
3
0
3
max (2.35)
Les niveaux de décision ix et les valeurs quantifiées iy sont donnés respectivement par :
( )
( )
+==
=
−−
−
2ˆˆ 11
1
iiiii
ii
uuuuFy
uFx
(2.36)
Quant à la variance de l’erreur de granulation, on obtient après calcul :
( ) ( ) b
x
x
x
x
xe dxxpdxxpL
2
3
3
3
0
32
2
min, 212
1
3
2 max
max
max
−
−
⋅
=
=σ ∫∫ (2.37)
Exemple : Soit une source Gaussienne de variance 2
xσ , la variance de l’erreur de
granulation vaut alors : b
xe
222 22
3 −⋅πσ=σ (2.38)
L’expression (2.37), valable lorsque le nombre de niveaux quantifiés est élevé, ne concerne
que l’erreur de granulation. En pratique, la valeur de maxx peut cependant être choisie pour que le
bruit de dépassement soit négligeable.
Ce qui paraît plus génant, c’est que l’expression (2.37) résulte d’une adaptation à la densité
de probabilité du signal, c’est-à-dire aussi à sa variance. Un objectif fréquent en pratique consiste à
assurer un RSB indépendant de la variance du signal dans une gamme d’amplitudes aussi large que

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
15
possible (pour rappel, le signal de parole est non- stationnaire). La solution consiste en principe à
choisir la loi de compression de la forme :
( )x
xgα
= (2.39)
La variance (2.33) devient alors :
( )
2
2
max
0
2
2
max2
min,
3
1
3
2 max
x
x
xe
L
x
dxxpxL
x
σ
α≈
⋅
α=σ ∫
(2.40)
de sorte que le RSB est indépendant de la variance du signal :
( )
α=
2
max
3log10x
LdBRSB (2.41)
La loi de compression (2.39) est cependant inutilisable telle quelle car elle implique une densité
de niveaux quantifiés qui tend vers l’infini lorsque l’amplitude du signal tend vers zéro. Il faut donc
raccorder les deux branches de cette loi ( 0<x et 0>x ) par une droite qui passe par l’origine : ce
sont les deux solutions classiques adoptées pour la transmission téléphonique.
2.4.2 La Loi A
La loi A, en usage en Europe, est représentée à la figure 2.9. Elle est définie par :
( )
( )
( )
≤≤⋅+
⋅+
⋅
≤≤⋅+
⋅
=
11
ln1
ln1
10
ln1
max
max
max
max
x
x
Axsgn
A
x
xA
x
Ax
xxsgn
A
xA
xF (2.42)
Pour des signaux de grande amplitude, le RSB est donné par (2.41), avec A
x
ln1max
+=α , soit :
( )
+=
2
ln13log10
A
LdBRSB (2.43)

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
16
Pour bL 2= , il vient : ( ) ( )AbdBRSB ln1log2077,402,6 +−+= (2.44)
10
127
112
80
64
48
32
16
96
0.875
0.750
0.625
0.500
0.375
0.250
0.125
A=87.56
1/4 1/2
1/16
1/8
1/128 1/64 1/32
Niveau relatif du signal d’entrée
Signal codé Sortie Normalisée
Figure 2.9 - La Loi de Compression A.
Pour des petits signaux, on a : ( )A
Axg
ln1 += (2.45)
soit, d’après (2.33) :
22
max2 ln1
3
1
+⋅
=σ
A
A
L
xe (2.46)
et donc, il vient : ( )
σ⋅
+⋅
=2
max
2
ln13log10
xA
ALdbRSB x (2.47)
et pour bL 2= : ( ) Γ−
+++= log20
ln1log2077,402,6
A
AdBRSB (2.48)
Or, pour une quantification uniforme sur L niveaux avec dépassement négligeable, le RSB est
donné par (2.19). La loi A assure donc pour les petits signaux un RSB supérieur de
+ A
A
ln1log20 .
La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
17
La loi européenne utilise une valeur de A telle que 16ln1
=+ A
A, soit A=87,56. De plus, on a
choisi L=256 (b=8). La représentation des petits signaux correspond alors à une quantification
uniforme sur 4096212 = niveaux !
Pour les grands signaux, la formule (2.44) donne, pour A=87,56 :
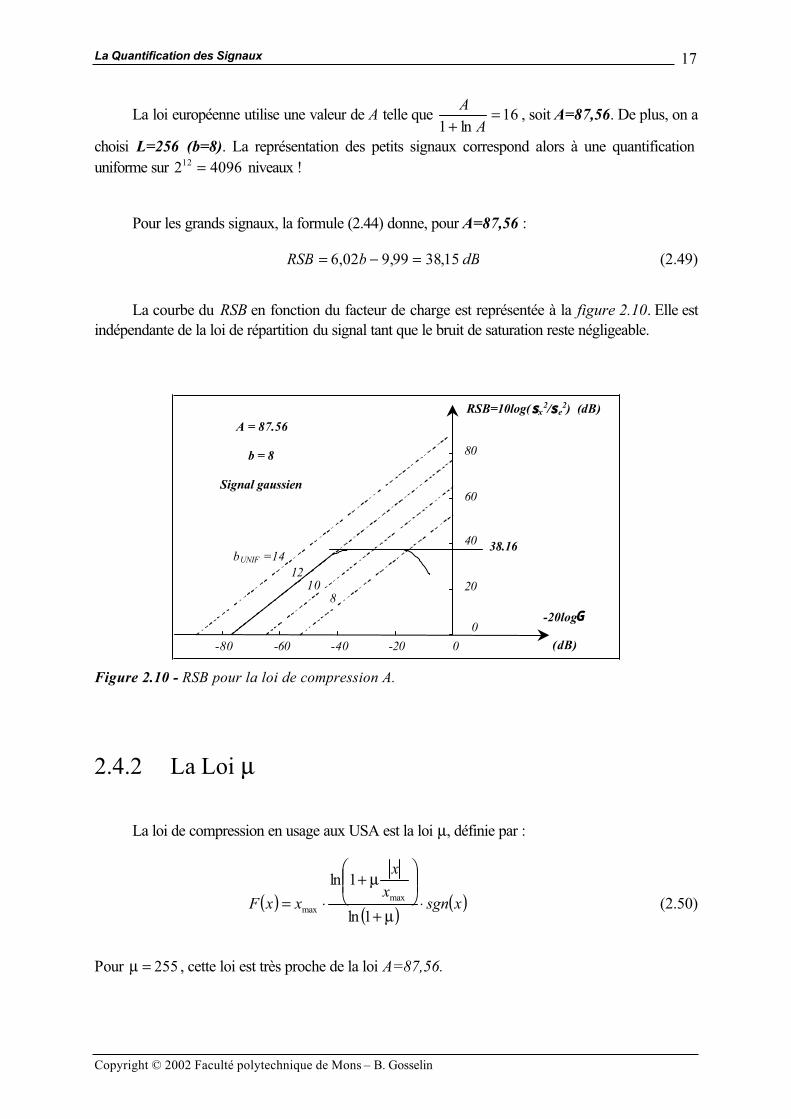
dBbRSB 15,3899,902,6 =−= (2.49)
La courbe du RSB en fonction du facteur de charge est représentée à la figure 2.10. Elle est
indépendante de la loi de répartition du signal tant que le bruit de saturation reste négligeable.
-80 -60 -40 -20 0
0
20
40
60
80
-20logG
RSB=10log(sx2/se
2) (dB)
810
12
bUNIF =1438.16
(dB)
A = 87.56
b = 8
Signal gaussien
Figure 2.10 - RSB pour la loi de compression A.
2.4.2 La Loi µ
La loi de compression en usage aux USA est la loi µ, définie par :
( )( )
( )xsgnx
x
xxF ⋅µ+
µ+
⋅=1ln
1lnmax
max (2.50)
Pour 255=µ , cette loi est très proche de la loi A=87,56.

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
18
2.5 Codage Entropique
2.5.1 Introduction à la Théorie de l’Information
Soit un quantificateur ( )XQY = . La sortie de ce quantificateur prend ses valeurs dans un
ensemble fini de L éléments :
iyY = si [ ]ii xxX ,1−∈ pour Li ,,2,1 ⋯= (2.51)
Chaque sortie iy du quantificateur peut être représentée au moyen d’un mot, le plus souvent
au format binaire, choisi parmi les L que contient un dictionnaire. Par exemple, il est ainsi possible de
coder l’indice i lui-même de la valeur quantifiée iy , ce qui conduit à des mots de code de longueur
identique.
La sortie Y du quantificateur peut être vue comme une source d’information à valeurs
discrètes. Cette source est dite sans mémoire si les sorties du quantificateur sont statistiquement
indépendantes. L’évaluation de l’information qu’apporte la réalisation d’un événement iyY =repose sur les deux principes suivants :
• l’information est dépendante de la probabilité de cet événement (un événement rare apporte
plus d’information) ;
• deux événements indépendants ont une mesure globale d’information égale à la somme des
mesures de chacun d’entre eux ;
Sur ces bases, on définit une mesure de l’information selon :
( ){ }( ) i
i
i PP
ykYpI 22 log1
log −=== (2.52)
et ( ){ } ( ){ }( ) ( ) [ ]jijiji PPPPylYpykYpI 222 logloglog& +−=⋅−=== (2.53)
La quantité d’information qu’apporte, en moyenne, une réalisation de Y, est donnée par l’entropie
d’ordre zéro de la source, soit :
{ } ∑=
−=−=L
i
iiiQ PPPEH1
22 loglog (2.54)
où iP est la probabilité d’occurrence de la sortie iy du quantificateur :
{ } ( )∫−
===i
i
x
x
xii dxxpyYpP
1
(2.55)

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
19
Exemple : entropie d’une variable binaire
Soit un événement Y, prenant la valeur 0, avec une probabilité p0, ou la valeur 1, avec une
probabilité p1=1-p0. L’entropie d’une telle source d’information vaut :
)1(log)1(log 020020 ppppH Q −−−−= (2.56)
Cette entropie est maximale pour p1 = p0 = 1/2, et vaut alors 1 bit. Ceci correspond à une
exploitation optimale du bit utilisé pour coder l’événement, puisque chaque bit émis contient un
maximum d’information.
2.5.2 Codage d’une Source Discrète Sans Mémoire
Le codage entropique repose sur une procédure de codage à longueur variable, qui
assigne des mots de longueur variable aux valeurs possibles iy , de façon telle que les valeurs
hautement probables soient associées à des mots courts du code, et vice - versa. Ceci permet donc
en principe de réduire la longueur moyenne des mots du code.
Définitions :
• Un code instantané est un code tel que chacun des mots du dictionnaire peut être décodé
indépendamment des autres mots, c’est-à-dire dès que le dernier bit du mot considéré est reçu.
• Un code uniquement décodable signifie que, recevant une séquence de mots du code, la
source peut être reconstituée sans ambiguïté.
L’importance de l’entropie QH vient du théorème du codage sans bruit d’une source
discrète sans mémoire :
Pour toute source discrète sans mémoire Y, il existe un code instantané et uniquement
décodable représentant exactement cette source, vérifiant :
1+<≤ QQ HbH (2.57)
où b est le débit moyen, c’est-à-dire la longueur moyenne des mots du code.
Ce théorème signifie que, parmi tous les codes instantanés uniquement décodables, celui qui
minimise la longueur moyenne des mots du code a une longueur moyenne égale à l’entropie de la
source. L’entropie QH apparaît donc comme une limite fondamentale pour représenter sans
distorsion une source d’information.

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
20
Le codage entropique est une technique qui permet de réaliser ce taux de transmission idéal.
Si le codage entropique est parfaitement réalisé, le taux de transmission à la sortie du quantificateur à
L niveaux peut être réduit de :
QHLb −=∆ 2log (2.58)
b∆ représente donc la redondance de la source discrète.
Il est toutefois évident qu’aucune réduction n’est possible si toutes les valeurs iy sont
équiprobables. En effet, on a alors L
Pi
1= , et donc de (2.54), LH Q 2log= .
Taux de transmission moyen :
Soit un mot du code, de ib bits, associé au niveau iy . ib peut être inférieur, égal, ou
supérieur à L2log . La longueur moyenne des mots du code définit également le taux de transmission
moyen, et donc :
∑=
=L
i
iibPb1
bits/échantillon (2.59)
La réduction alors obtenue vaut : bL −2log bits/échantillon (2.60)
Le code optimal est obtenu pour : ii Pb 2log−= (2.61)
Comme ib est entier, le code optimal ne peut être obtenu que si les probabilités satisfont la
contrainte ib
iP −= 2 . Dans tous les autres cas, le taux de transmission moyen b qui résulte du
codage entropique sera légèrement supérieur à QH .
Il peut toutefois s’avérer utile d’appliquer un codage entropique sur des séquences de valeurs,
plutôt que sur des valeurs uniques, afin de se rapprocher le plus possible de QH . L’effet du codage
de séquences est de fournir une meilleure approche de la contrainte ib
iP −= 2 .
2.5.3 Codage d’une Source Discrète Avec Mémoire
Lorsqu’il existe une dépendance statistique entre les échantillons successifs de la source, on
peut chercher à l’exploiter afin de réduire encore le nombre de bits nécessaire pour représenter
exactement la source. Toutefois, le codage entropique devient alors assez complexe, car de longues
séquences doivent être traitées, et les probabilités conjointes connues ou estimées par calcul. En

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
21
pratique, il est possible d’éliminer les redondances linéaires du signal en effectuant un filtrage avant la
quantification, afin d’approximer une source sans mémoire. Les sorties du quantificateur sont alors
non corrélées (linéairement), et le taux de transmission minimum est donc toujours théoriquement
donné par l’entropie d’ordre 0, QH .
La méthode linéaire optimale de décorrélation est l’Analyse en Composantes Principales
(ACP). Cette méthode implique toutefois trop de calculs et s’avère inexploitable en pratique. Deux
solutions sont alors envisageables :
• Prédiction
Cette méthode consiste à coder la différence entre la valeur réelle de l’échantillon et une valeur
prédite. Par exemple, le codage DPCM consiste à coder la différence de valeur entre deux
échantillons consécutifs : ( ) ( ) ( )1−−= txtxtd . La méthode de prédiction est assez efficace pour un
signal de parole, mais s’avère relativement peu adéquate pour un signal d’image.
• Transformation
Cette méthode alternative, souvent employée pour le signal d’image, consiste à décomposer le
signal en blocs, et à appliquer ensuite une transformée sur chacun d’eux. Une transformée très
exploitée en raison de ses performances proches de celles de l’ACP est la Transformée en Cosinus
Discrète (DCT).
2.5.4 L’Algorithme de Huffman
Afin d’éviter un problème inhérent à l’utilisation d’un code de longueur variable, on pourrait
ajouter des séparateurs entre mots du code dans une séquence. Cela n’est cependant pas nécessaire
lorsque le code vérifie la condition dite du préfixe : aucun mot du code ne doit être le préfixe d’un
autre mot du code.
L’algorithme de Huffman permet d’obtenir un tel code, et on peut montrer qu’il est
l’algorithme optimal. Pour aucun autre code uniquement décodable, la longueur moyenne des mots
du code est inférieure. Cet algorithme consiste à construire progressivement un graphe orienté en
forme d’arbre binaire, où chaque branche partant d’un nœud est associée à un symbole 0 ou 1, en
partant des nœuds terminaux. Un mot du code est associé à chaque nœud terminal en prenant
comme mot de code la succession des symboles binaires sur les branches.
Les phases de cet algorithme sont les suivantes :
• Soient les deux listes de départ { }Lyy ⋯1 et { }LPP⋯1 .
• Les deux symboles les moins probables sont sélectionnés, et deux branches dans l’arbre
sont créées et étiquetées par les deux symboles binaires 0 et 1.
• Les deux listes sont réactualisées, en rassemblant les deux symboles utilisés en un nouveau
symbole, et en lui associant comme probabilité la somme des deux probabilités
sélectionnées.
• Les deux étapes précédentes sont répétées tant qu’il reste plus d’un symbole dans la liste.

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
22
Exemple :
Soit une source ne pouvant prendre que six valeurs différentes, avec les probabilités fournies à
la table 2.3 ci-dessous. Un codage direct des indices nécessiterait évidemment 3 bits.
Symbole 1y 2y 3y 4y 5y 6y
Probabilité 0,5 0,15 0,17 0,08 0,06 0,04
Table 2.3 - Probabilités associées aux six événements { }iyY = .
L’entropie de cette source discrète est égale à 2,06 bits. L’algorithme de Huffman fournit
l’arbre binaire représenté à la figure 2.11. La table de codage résultante est reprise à la table 2.4.
La longueur moyenne des mots est égale à 2,1 bits, valeur très voisine de la limite théorique.
0
1
0
1
0
1
0
1
0
1
y1
y2
y3
y4
y5
y6
0,32
0,5
0,18
0,1
0,15
0,5
0,17
0,08
0,06
0,04
Figure 2.11 - Illustration de l’algorithme de Huffman.
Symbole 1y 2y 3y 4y 5y 6y
Code 0 100 101 110 1110 1111
Table 2.4 - Définition du Code.

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
23
2.5.5 Quantification Scalaire avec Contrainte Entropique
Nous avions recherché, à la section 2.3, le quantificateur scalaire qui permettait de minimiser la
distorsion 2
eσ , pour un nombre de niveaux de quantification bL 2= donné, c’est-à-dire en
respectant une contrainte sur le débit de transmission. Nous allons à présent ré-optimiser le
quantificateur, cette fois en vue de rendre possible un codage entropique efficace à sa sortie. Le
problème de la recherche d’un quantificateur optimum consiste alors à minimiser l’entropie QH à la
sortie du quantificateur (et donc le taux de transmission moyen b), étant donné une contrainte 2
eσ sur
la distorsion tolérée pour le signal.
L’entropie QH à la sortie du quantificateur s’exprime :
∑=
−=L
i
iiQ PPH1
2log (2.62)
Sous l’hypothèse que le nombre L de niveaux de quantification est élevé, la densité de
probabilité ( )xpx peut être supposée constante dans l’intervalle [ ]ii xx ,1− . De (2.54), il vient :
( )( ) ( ) iixiiixi ypxxypP ∆=−= −1 (2.63)
Dès lors, l’expression de l’entropie de la sortie du quantificateur peut s’écrire :
( ) ( ) ( )∑∑==
∆∆−∆−=L
i
iiix
L
i
ixiixQ ypypypH1
2
1
2 loglog (2.64)
( ) ( ) ( ) ( )∑∑==
∆∆−∆−=
L
i i
iix
L
i
ixiixQyg
ypypypH1
2
1
2 loglog (2.65)
( ) ( ) ( ) ( ) ( )∑∑∑===
∆+∆∆−∆−=L
i
iiix
L
i
iix
L
i
ixiixQ ygypypypypH1
2
1
2
1
2 logloglog (2.66)
Par passage à la limite, on obtient :
( ) ( ) ( ) ( ) ( )∫∫∫∞
∞−
∞
∞−
∞
∞−
+∆−−= dxxgxpdxxpdxxpxpH xxxxQ 222 logloglog (2.67)
( ) ( ) ( ) ( )∫∫∞
∞−
∞
∞−
+∆−−= dxxgxpdxxpxpH xxxQ 222 logloglog (2.68)
Le premier terme ne dépend que de la source. Il est défini comme étant l’entropie différentielle à
l’entrée du quantificateur :

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
24
( ) ( ){ } ( ) ( )∫∞
∞−
−=−= dxxpxpxpEXh xxx 22 loglog (2.69)
Il vient donc :
( ) ( ) ( )∫∞
∞−
+∆−= dxxgxpXhH xQ 22 loglog (2.70)
Ce résultat fourni l’entropie pour une loi de compression donnée, et caractérisée par ( )xg .
Nous avons vu que, pour un grand nombre de niveaux de quantification, la variance 2
eσ peut
être approximée par :
( )( )∫
−
∆=σ
max
max
2
22
12
x
x
xe dx
xg
xp (2.71)
soit : ( )
∆
=σxg
Ee 2
22 1
12 (2.72)
On montre facilement que, pour une variable aléatoire X, { } { }[ ]22 XEXE ≥ , avec le signe égalité si
et seulement si { }XEX = avec une probabilité égale à 1, c’est-à-dire si X est une constante. Cela
permet d’écrire :
( )
22
2 1
12
∆
≥σxg
Ee (2.73)
avec égalité si la fonction ( )xg est une constante sur tout le support de ( )xpx . En outre, g doit
vérifier les contraintes :
( )( )
==
maxmax
00
xxF
F (2.74)
On en déduit que g = 1.
Cela signifie que le meilleur quantificateur de la source continue ( )nX est tout simplement le
quantificateur uniforme suivi d’un codage entropique (pour autant que le pas de quantification
soit suffisamment petit pour que l’hypothèse de densité de probabilité ( )xpx constante dans un
intervalle i∆ demeure valable).
L’entropie minimisée vaut alors (cfr. Quantification Uniforme) :

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
25
( ) ( ) 2
22 12log2
1logmin eQ XhXhH σ⋅−=∆−= (2.75)
Le terme ∆2log représente donc la perte d’information due à la quantification, et vaut
l’entropie différentielle du quantificateur. En effet :
( ){ } ∆=−= 22 loglog epEH ee , (2.76)
puisque la densité de probabilité ( )epe est considérée comme uniformément répartie entre
∆
+∆
−2
,2
.
Exemples :
Dans le cas d’une source gaussienne de variance 2
xσ , il est aisé de calculer que l’entropie
différentielle ( )Xh vaut :
( ) 2
2 2log2
1xeXh σπ= (2.77)
On obtient alors, pour un taux de transmission b (c’est-à-dire une entropie QH ) donné :
b
xe
e 222 26
−⋅σπ
=σ (2.78)
Dans le cas d’une source Gaussienne, le gain apporté par le quantificateur avec contrainte
entropique, relativement au quantificateur scalaire logarithmique (cfr. (2.38)) est donc de :
91,133
6/
2/3≈=
ππ
ee (2.79)
soit 2,81 dB.
Pour un niveau de bruit toléré 2
eσ , le gain est de :
bits0,46733
log2
12 ≈=∆
eb (2.80)
Dans le cas d’une distribution Gamma (qui, pour rappel, est très proche de la loi de répartition
expérimentale d’un signal de parole), le gain par rapport au quantificateur logarithmique est de 1,7
bits !
Borne Inférieure de Shannon :
Il a été démontré que, lorsqu’on accepte une distorsion moyenne au plus égale à 2
eσ , alors le
plus petit nombre de bits nécessaire pour représenter une source discrète, sans mémoire, de densité
de probabilité ( )xpx quelconque, est donné par la borne inférieure de Shannon :

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
26
( ) ( ) ( )2
2
2 2log2
1ee eXhb σπ−=σ (2.81)
Si l’on veut une distorsion nulle, le codage doit se faire sans perte. On a ( ) QHb =0 , l’entropie
de la source. Plus le niveau de bruit toléré 2
eσ augmente, plus le nombre de bits nécessaires pour
coder le signal diminue. Si l’on accepte une distorsion supérieure ou égale à la puissance de la
source, alors il n’est même plus nécessaire de chercher à la coder. On a ( ) 02 =σeb .
La comparaison de (2.81) avec l’expression (2.75) du taux de transmission minimum du
quantificateur scalaire avec contrainte entropique montre un écart de :
255,06
log2
12 =
π=∆
eb bits (2.82)
Cela signifie que le codage entropique des sorties d’un quantificateur uniforme n’est qu’à
0,255 bit au-dessus de la limite inférieure théorique absolue ! Ce résultat est valable quelque soit la
densité de probabilité ( )xpx du signal.
Pour un débit b fixé, la distorsion obtenue 2
eσ est à 1,53 dB au dessus de la limite théorique.
Cette différence par rapport à la borne inférieure de Shannon est le prix à payer pour avoir la
simplicité d’un codage de symboles élémentaires (source sans mémoire).
Problèmes pratiques du Codage à Longueur Variable
La mise en œuvre du quantificateur scalaire avec contrainte entropique s’avère relativement
délicate en pratique. Les mots du code étant de longueur variable, il se pose des problèmes de
propagation d’erreur : une simple erreur de transmission dans un mot du code peut en effet causer
une perte de synchronisation, ce qui rend impossible la reconstruction correcte de longues séquences
de mots. Il est donc nécessaire d’insérer régulièrement des bits de synchronisation. D’autre part, le
débit global obtenu est variable, puisqu’il dépend de l’information locale contenue dans le signal
(exemple : silence/parole). Si cela ne pose guère de problème pour les systèmes acceptant un débit
variable, tel qu’internet, il est indispensable de rendre fixe le débit pour d’autres systèmes qui, eux,
acceptent les symboles à un taux constant, tels que les GSMs ou les chaînes de télévision
numériques, par exemple. A cette fin, les mots de code de longueur variable doivent être mémorisés
dans un tampon. Sous peine de perte d’information, il est évidemment nécessaire d’éviter un
dépassement de la capacité de cette mémoire tampon. En pratique, le quantificateur est alors
contrôlé par la mémoire tampon elle-même, qui, via un système logique, va permettre une adaptation
du pas de quantification, par exemple (cfr. quantification adaptative). Une alternative consiste à
rendre fixe la longueur des mots du code, en considérant des séquences de symboles de longueur
différentes. Ceci est illustré à la table 2.5, pour le codage de trois symboles élémentaires A, B, et C,
où B est le plus probable.

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
27
Source Code
BBB 000
BBA 001
BBC 010
BA 011
BC 100
A 101
C 110
Table 2.5 - Codage de séquences de longueur variable.
Enfin, il reste les problèmes liés à la statistique du signal. D’une part, un code est établi pour
une densité de probabilité donnée, et n’est donc optimal que pour cette dernière. A titre d’exemple,
le codage d’Huffman exploité pour la transmission de fax ou le codage JPEG a été dans les deux cas
calculé sur un ensemble d’images types, et n’est donc pas optimal pour un signal particulier. D’autre
part, la mémorisation du dictionnaire des valeurs au niveau du récepteur, nécessaire pour procéder
au décodage, peut restreindre les possibilités d’une implémentation matérielle. Une solution
commune à ces deux problèmes consiste à transmettre alors une information sur la statistique du
signal, afin de pouvoir reconstruire (recalculer) le code. On parle alors de Codage à Longueur
Variable Adaptatif Calculé : à une suite de N valeurs x(k), on associe :
- un préfixe, qui détermine la distribution de probabilité ;
- un suffixe, qui consiste en un codage à longueur variable qui peut être recalculé étant donné
le préfixe ;
Un exemple de tel code est le code ATRL, qui peut être utilisé pour la transmission d’un
signal binaire pour lequel la probabilité p0 d’avoir le symbole élémentaire « 0 » est assez élevée (p0
>> p1 = 1- p0). On applique alors un codage entropique sur des séquences de symboles, de
longueur maximum de 2m symboles, où m est à déterminer en fonction de p0. La règle de codage est
la suivante :
• Pour une séquence de 2m symboles « 0 » consécutifs, on émet le code « 0 » ;
• Dans les autres cas (un symbole « 1 » est rencontré), on émet le code « 1 », suivi d’un
nombre de m bits qui représente le nombre de symboles « 0 » consécutifs rencontré avant
ce symbole « 1 ». Un exemple de code est donné à la table 2.6.
Séquence d’entrée Code émis
0000 0
1 100
01 101
001 110
0001 111
Table 2.6 - Exemple de code ATRL, pour m=2.
On peut montrer qu’un tel code est optimal pour un choix de m tel que : ( ) m
p−
= 2
0 2/1 .

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
28
2.6 Quantification Adaptative
Une solution séduisante à priori pour la quantification d’un signal non stationnaire consiste à
utiliser une loi adaptative. En effet, une quantification logarithmique est invariante, et, quoique très
utile pour la quantification de signaux non stationnaires comme la parole avec un nombre de bits
suffisant (typiquement 8), le codage de la parole avec moins de bits par échantillon nécessite une
quantification adaptative.
Il s’agit en général de l’adaptation à la variance à court - terme du signal, d’une loi de
quantification conçue pour une certaine répartition moyenne des amplitudes. Deux types de
réalisations équivalentes sont possibles :
• Le quantificateur est fixe, il est adapté à un signal de variance unité et il est précédé par un
amplificateur à gain variable (figure 2.12) ;
Quantificateurx y
(1) (2)
(1)
(2)
adaptation progressive
adaptation rétrograde
Estimation de
x y( )
2 2σ σ
i i,opt u= 1;δ σδ=
oux y
σ σ
Figure 2.12 - Adaptation d’un quantificateur fixe.
• Les pas de quantification sont rendus proportionnels à la variance du signal (figure 2.13) ;
Quantificateurx y
(1) (2)
(1)
(2)
adaptation progressive
adaptation rétrograde
Estimation de
x y( )
2 2σ σ
i optδ σ δ= .
Figure 2.13 - Adaptation du pas de quantification.

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
29
L’adaptation est dite progressive (Adaptative Quantization with Forward estimation ou
AQF) lorsque l’estimation de la variance est faite sur le signal original x. Dans ce cas, il faut
transmettre, en plus du signal quantifié, une information sur la variance estimée 2ˆ xσ . Cette information
est toutefois transmise à une cadence plus faible que celle utilisée pour les échantillons (une fois par
tranche d’échantillons).
On peut aussi songer à une adaptation rétrograde (Adaptative Quantization with
Backward estimation ou AQB) : la variance est alors estimée sur le signal quantifié y. Ceci permet
de ne pas transmettre d’information sur la variance, qui peut en effet être estimée à la réception après
décodage du signal. Comme y est soumis au bruit de quantification, il est clair que cette procédure
est plus grossière que l’adaptation progressive, sauf lorsque le nombre de niveaux quantifiés est
assez élevé.
Le problème essentiel, pour la quantification adaptative, est celui de l’estimation de la variance 2
xσ . L’écart - type peut être estimé sur un bloc de N échantillons par les formules suivantes :
AQF : ( ) ∑−
=+=σ
1
0
21ˆ
N
i
inx xN
n (2.83)
AQB : ( ) ∑=
−=σN
i
inx yN
n1
21ˆ (2.84)
La période d’apprentissage N est choisie en fonction du délai d'encodage toléré, des
contraintes sur le débit global (AQF), et de la stationnarité du signal. Dans le cas de la parole
échantillonnée à 8 kHz, une valeur de N=128 est une bonne estimation.
Les estimateurs (2.83) et (2.84) demandent la mémorisation de N échantillons avant
quantification, ce qui implique un délai. Une autre procédure consiste à affecter les échantillons
passés d’un poids qui décroît avec leur âge. Par exemple, dans le cas d'une AQB, cela donne :
( ) ( ) 101ˆ1
212 <α<⋅αα−=σ ∑∞
=−
−
i
in
i
x yn (2.85)
Le coefficient ( )α−1 est un coefficient de normalisation qui rend la somme des poids égale à
l’unité. L’équation (2.85) peut être écrite sous la forme :
( ) ( ) ( ) 2
1
22 11ˆˆ −⋅α−+−σ⋅α=σ nxx ynn (2.86)
Lorsque α est voisin de 1, les poids varient peu pour i élevé (signal stationnaire). Par contre,
lorsque α est proche de 0, l’estimateur suit plus fidèlement l’évolution des quelques échantillons
précédents (signal non stationnaire).

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
30
Le paramètre α détermine la constante de temps d’adaptation (laquelle est, par définition,
le temps nécessaire pour que ( )nxσ̂ décroisse d’un facteur e
1 de sa valeur initiale lorsque y
devient une séquence de zéros). On calcule aisément que, si eF désigne la fréquence
d’échantillonnage, la constante de temps du problème vaut :
( )α⋅=τ
/1ln
12
eF (2.87)
La figure 2.14 présente l’effet de la valeur de α sur la vitesse d’adaptation, dans le cas d’un
signal de parole échantillonné à 8 kHz. La valeur de 0,9 cause des changements rapides de 2ˆ xσ qui
suit les maxima locaux du signal avec une constante de temps de 2,2 ms. Cette sorte d’adaptation
est appelée instantanée. La valeur de 0,99 produit des changements lents de 2ˆ xσ qui ne suit pas les
pics locaux du signal mais seulement l’enveloppe, avec une constante de temps de 25 ms. Cette
sorte d’adaptation est appelée syllabique.
Figure 2.14 - Estimation de la variance d’un signal de parole.

La Quantification des Signaux
Copyright © 2002 Faculté polytechnique de Mons – B. Gosselin
31
Références :
1. Jayant N. S. & Noll P., “ Digital Coding of Waveforms ”, Prentice-Hall Ed., 1984.
2. Leich H., “ Le Codage de la Parole ”, Notes de Cours, Faculté Polytechnique de Mons, 1996.
3. Moreau N., “ Techniques de Compression des Signaux ”, Ed. Masson, 1995.
4. Boite R., Hasler M., Dedieu H., «Effets non linéaires dans les filtres numériques », Presses
polytechniques et universitaires romandes, 1997.





























