Embed Size (px)
Citation preview

Version 3.0a, Januar 2012 Seite 1
Haute école spécialisée bernoise Technique et informatique
Section d’Electricité et systèmes de communication
Laboratoire d’Informatique technique
Les microcontrôleurs dans les systèmes embarqués Ce manuscrit traite les thèmes suivants :
Systèmes embarqué Méthodes de design Sécurité et fiabilité des systèmes à microprocesseur Connexions aux composants périphériques Communication avec les autres systèmes à microprocesseur
2012 BFH-TI / FUE1
Dernière modification: Janvier 2011
Auteur: Elham Firouzi
Version: 3.1e

Microcontroller in Embedded Systems Table des matières
Version 3.0a, Januar 2012 Seite 2
Table de matières
1 Introduction ........................................................................................................................................ 5 1.1 Structure du manuscrit .............................................................................................................. 5 1.2 Domaine d’application des microcontrôleurs ............................................................................ 5 1.3 Les caractéristiques des microcontrôleurs ............................................................................... 6 1.4 Les langages de Programmation .............................................................................................. 7
1.4.1 C ........................................................................................................................................ 7 1.4.2 C++ .................................................................................................................................... 7 1.4.3 Assembler .......................................................................................................................... 7 1.4.4 Java ................................................................................................................................... 7
1.5 Environnements et outils de développement ........................................................................... 7 1.5.1 Simulateur .......................................................................................................................... 7 1.5.2 Moniteur ROM.................................................................................................................... 8 1.5.3 Interface JTAG ................................................................................................................... 8 1.5.4 Emulateur ........................................................................................................................... 8 1.5.5 Programmation et test direct de ROM / Flash ................................................................... 8
2 Généralité .......................................................................................................................................... 9 2.1 Les systèmes embarqués ......................................................................................................... 9 2.2 Les systèmes temps réels ........................................................................................................ 9 2.3 Le processus technique .......................................................................................................... 10 2.4 Les systèmes de communication industriels .......................................................................... 11
2.4.1 La structures des systèmes de production industrielle .................................................... 11 2.4.2 Les critères pour la communication ................................................................................. 12
3 Méthodes de conception ................................................................................................................. 13 3.1 Déroulement cyclique ............................................................................................................. 13 3.2 Déroulement quasi-parallèle et évènementielle ...................................................................... 13 3.3 Déroulement quasi-parallèle avec RTOS ............................................................................... 14 3.4 State-Event ............................................................................................................................. 14
3.4.1 Introduction ...................................................................................................................... 14 3.4.2 Conception ....................................................................................................................... 14 3.4.3 Implémentation de diagrammes d’états ........................................................................... 16
4 Sécurité des systèmes .................................................................................................................... 19 4.1 Introduction ............................................................................................................................. 19
4.1.1 Hardware ......................................................................................................................... 19 4.1.2 Software ........................................................................................................................... 19
4.2 Le langage de Programmation C ............................................................................................ 19 4.2.1 MISRA-C .......................................................................................................................... 20 4.2.2 Analyse de code statique ................................................................................................. 20
4.3 Murphy et le langage de Programmation C ............................................................................ 21 4.3.1 Dépassement de capacité dans les tableaux .................................................................. 21 4.3.2 Dépassement de capacité dans la pile (anglais : stack) ................................................. 21 4.3.3 Pointeur NULL ................................................................................................................. 22 4.3.4 Les interruptions .............................................................................................................. 22 4.3.5 Allocation de mémoire dynamique .................................................................................. 22 4.3.6 Les conditions de courses ............................................................................................... 23 4.3.7 Code réentrant ................................................................................................................. 23 4.3.8 Programmation défensive ................................................................................................ 24 4.3.9 assert() ............................................................................................................................. 24

Microcontroller in Embedded Systems Table des matières
Version 3.0a, Januar 2012 Seite 3
4.3.10 Optimisation du code C ................................................................................................... 24 4.4 Sécurité au niveau du système ............................................................................................... 25
4.4.1 La conception................................................................................................................... 25 4.4.2 Spécification et exécutions des testes ............................................................................. 26 4.4.3 La documentation ............................................................................................................ 27 4.4.4 Reviews ........................................................................................................................... 27
4.5 Watchdog ................................................................................................................................ 27 4.5.1 Introduction ...................................................................................................................... 27 4.5.2 Le externe ........................................................................................................................ 27 4.5.3 Le watchdog interne ........................................................................................................ 28 4.5.4 Fonctionnement du watchdog .......................................................................................... 28 4.5.5 Démarrage du watchdog ................................................................................................. 29 4.5.6 Rafraichissement du watchdog ........................................................................................ 29
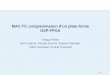
5 Connexion de la périphérie ............................................................................................................. 30 5.1 Bus d’adresse / de données ................................................................................................... 30 5.2 Port d’entrée et de sortie numérique ...................................................................................... 30 5.3 RS232 ..................................................................................................................................... 31 5.4 SPI .......................................................................................................................................... 32 5.5 I2C ........................................................................................................................................... 34
5.5.1 Aperçu .............................................................................................................................. 34 5.5.2 Protocole .......................................................................................................................... 34 5.5.3 Implémentation ................................................................................................................ 36
5.6 Timer ....................................................................................................................................... 36 5.6.1 Introduction ...................................................................................................................... 36 5.6.2 Timer/Counter .................................................................................................................. 37 5.6.3 Timer avec recharge automatique ................................................................................... 37 5.6.4 Unité comparateur ........................................................................................................... 37 5.6.5 Entité de capture .............................................................................................................. 38
5.7 CAN ......................................................................................................................................... 39 A Introduction pour le LM3S9B92 .......................................................................................................... 40
A.1 La famille Cortex-M3 ................................................................................................................... 40 A.2 Le microcontrôleur LM3S9B92 .................................................................................................... 42
A.2.1 Diagramme de blocs ............................................................................................................. 42 A.2.2 Les interruptions ................................................................................................................... 44 A.2.3 GPIOs ................................................................................................................................... 47 A.2.4 Le watchdog .......................................................................................................................... 48 A.2.5 PWM ..................................................................................................................................... 50 A.2.6 CAN ...................................................................................................................................... 51
B CAN ..................................................................................................................................................... 54 B.1 Introduction .................................................................................................................................. 54 B.2 Propriétés .................................................................................................................................... 54 B.3 Couche de transmission des bits (OSI Layer 1) .......................................................................... 55
B.3.1 Topologie Bus ....................................................................................................................... 55 B.3.2 Taux de transmission des données ...................................................................................... 55 B.3.3 Niveaux du signal.................................................................................................................. 55 B.3.4 Bit-Timing .............................................................................................................................. 56 B.3.5 Bit Stuffing ............................................................................................................................. 56
B.4 Méthodes d’accèssibilité au bus (OSI Layer 2a / MAC) .............................................................. 56 B.5 Protocole CAN (OSI Layer 2b / LLC) .......................................................................................... 57
B.5.1 Data Frame ........................................................................................................................... 57

Microcontroller in Embedded Systems Table des matières
Version 3.0a, Januar 2012 Seite 4
B.5.2 Reconnaissance d’erreurs .................................................................................................... 58 B.5.3 Filtrage des messages .......................................................................................................... 59
B.6 Application (OSI Layer 7) ............................................................................................................ 59 C Référence ........................................................................................................................................... 60 Index ....................................................................................................................................................... 61

Microcontroller in Embedded Systems Chapitre 1 : Introduction
Version 3.0a, Januar 2012 Seite 5
1 Introduction
1.1 Structure du manuscrit Le premier chapitre de ce manuscrit traite les domaines d’application des microcontrôleurs embarqués, leurs caractéristiques typiques et les outils de développement des logiciels. Le second chapitre fournit d'importantes notions de base, qui sont essentiels à la compréhension de ce module. Le chapitre trois traite un des aspects les plus important du développement de logiciel embarqués : la conception (design). Le quatrième chapitre se concentre sur la sécurité et la fiabilité des systèmes à microprocesseur. En effet, les erreurs logicielles dans les systèmes embarqués peuvent générer de sérieux problèmes. Le cinquième chapitre traite de la communication dans son ensemble. Il montre, d’une part, comment les composants périphériques peuvent être connectés à un microcontrôleur embarqué et, d’autre part, comment les systèmes peuvent communiquer les uns avec les autres. L'annexe A présente le microcontrôleur LM3S9B92 de Texas Instruments comme représentant typique de la famille de microcontrôleur 32 bits Cortex-M3. L'annexe B contient une brève introduction au bus CAN.
Les deux thèmes suivants sont explicitement exclus de ce manuscrit : RTOS (Real systèmes d'exploitation temps) et le serveur Web intégré (connexion Internet de l'équipement et la machinerie). Bien que ces derniers appartiennent au monde des microcontrôleurs et des systèmes embarqués, ils sont enseignés dans des autres modules du cursus d’enseignement de la Haute école.
1.2 Domaine d’application des microcontrôleurs Le choix du microcontrôleur 8-bit, 16 bits ou 32 bits dépend de la complexité de l’application embarquée. La notion de systèmes embarqués est traitée plus en détail au chapitre 2. Ces derniers sont essentiellement constitués d’une partie matérielle (Hardware) et d’une partie logicielle (Software). Leurs domaines d’applications sont les suivants :
Système de communication:
Les microcontrôleurs 8 bits sont souvent utilisés pour les téléphones portables simples et la téléphonie fixe alors que les microcontrôleurs 32 bits se retrouvent plutôt dans les Smartphones et les PDA.
Les processeurs 8-bits ou 32 bits sont utilisés pour le raccordement des capteurs et actionneurs aux systèmes de bus en fonction de la complexité du bus et de l'application.
Technique médicinale:
Les instruments de mesure (par exemple mesure de la glycémie), les organes artificiels, etc. Selon la complexité application de microcontrôleurs 8 bits, 16 bits ou 32 bits.
Les technologies de la sécurité:
Les systèmes pour gérer la sécurité dans les moyes de transport (par exemple : les passages à niveau), dans les bâtiments (par exemple: alarme incendie, effractions) etc. Les microcontrôleurs 8 bits sont utilisés en particulier dans les appareils périphériques alors les microcontrôleurs 32 bits assument les tâches de contrôle et de gestion.
Mécatronique et automation industrielle :
Installation pour la production de biens, pour la logistique, etc. Les microcontrôleurs 8 bits sont utilisés en particulier pour les capteurs et actionneurs alors que les microcontrôleurs 32 bits assument les tâches de

Microcontroller in Embedded Systems Chapitre 1 : Introduction
Version 3.0a, Januar 2012 Seite 6
contrôle et de gestion.
Moyens de transport:
Autos, avions, vélo électrique etc.
Electronique de consommation:
Appareil hifi, TV, vidéo, beamer, télécommande etc.
Application basse consommations :
Les appareils à piles, tels que ceux développés par la HESB pour la station ornithologique suisse, qui permettent d’enregistre des données spatiales et télémétriques. Le choix des microcontrôleurs se limite principalement à 8 bits en raison de la faible consommation d'énergie et de la petite taille. Toutefois, ce dernier peut être remplacé par un microcontrôleur de 16 voire 32 bits lorsque la puissance de calcul n'est pas suffisante.
1.3 Les caractéristiques des microcontrôleurs La tendance actuellement est de s’éloigner de plus en plus des microcontrôleurs 8 bits afin de s’approcher de plus en plus des microcontrôleurs 32 bits. Les processeurs 8 bits sont utilisés dans les applications qui ont pour critères principaux la consommation et le coût. Les processeurs 16 bits sont relativement peu rependus. Il existe néanmoins quelques exemples comme le MSP430 de TI. Le prix des processeurs 32 bits actuels, comme le Cortex-M3, est devenu tellement intéressant, que ces derniers remplacent de plus en plus les processeurs 8 bits. Les processeurs 32 bits les moins chers coûtent environ un euros.
Les microcontrôleurs 8 bits présentes les avantages suivants faces au microcontrôleur 32 bits :
Faible consommation
Bas coûts
Dimension réduite
Les microcontrôleurs 32 bits présentes les avantages suivants faces au microcontrôleur 8 bits :
Puissance et vitesse de calcul supérieures
Convient pour l'utilisation d'un système d'exploitation. En effet les performances de la CPU et la taille de la mémoire sont suffisantes.
Espace d’adressage plus grand
Taille de mémoire requise pour les microcontrôleurs dans les systèmes embarqués :
La taille de la mémoire programme s’étend typiquement de quelques kilos octets à quelques centaines de kilo octets. Cette règle est valable pour les microcontrôleurs 8 et 32 bits.
La taille de la mémoire pour les données s’étend de quelques centaines d’octets à quelques centaines de kilo octets.
Le portage d’un système d’exploitation embarqué comme celui de Linux ou de Windows CE augmente considérablement l’exigence concernant la mémoire programme ou de données à quelques Méga Octets.

Microcontroller in Embedded Systems Chapitre 1 : Introduction
Version 3.0a, Januar 2012 Seite 7
1.4 Les langages de Programmation
1.4.1 C Le langage de programmation C est la référence pour programmer les microcontrôleurs avec des exigences temps réel (voir chapitre 2). En effet, ce dernier présente l'avantage d’être un langage de programmation orienté matériel. Le code machine généré par le compilateur est presque optimal en ce qui concerne d’une part la taille de la mémoire requise et d’autre part la vitesse d'exécution du programme. Par conséquence, environ 65% des applications embarquées sont programmées en C. Toutefois, le langage C présente également des inconvénients, qui seront traité dans la section 4.3 de ce manuscrit.
1.4.2 C++ C ++ nécessite plus de ressources (utilisation de la mémoire, la puissance du processeur) que C (environ 20%). Cela dépend essentiellement comment le programme a été défini en C++. Est-ce que ce dernier utilise le polymorphisme ou non. Le « C ++ embarqué » est une version plus dépouillée du C++.
C++ présente les avantages de la programmation orientée objet. C qui est particulièrement intéressant pour les applications plus complexes. Environ 25% des applications embarquées sont programmés en C++.
1.4.3 Assembler Les applications programmées uniquement en assembleur sont relativement rares. Par contre, l’assembleur est souvent combiné avec du C ou du C++. Ce langage est principalement utilisé pour optimiser individuellement les fonctions. Comme par exemple pour les drivers (accès direct au Hardware) ou les algorithmes qui nécessitent des calculs intensifs. Moins de 10% de tous les applications embarquées sont programmées (du moins partiellement) en l’assembleur.
1.4.4 Java Java est aujourd'hui rarement utilisée pour programmer les applications embarquées (moins de 3%). Java n’est pas adéquate pour les applications temps réels. En effet, de langage est interprété (lent) et le comportement temporel du « récupérateur de place » (anglais : Garbage-Collection) n’est pas reproductible.
1.5 Environnements et outils de développement Les outils CASE, les éditeurs, les compilateurs / les compilateurs croisés (anglais : cross compiler) et les relieurs (anglais : linker) sont utilisés pour développer les logiciels. Ces outils ont été décrits et appliqués dans les modules d'informatique de base. Cette section s’intéresse en particulier sur les différentes possibilités de débogage qui existent dans le domaine embarqué. Les variantes suivantes sont mises à disposition en fonction de des environnements de développement et des types de microcontrôleurs :
1) Simulator
2) ROM-Monitor
3) Background Debug Mode
4) Emulateur
5) Programmation et test direct sur ROM / Flash
1.5.1 Simulateur Le simulateur permet de tester le code sans que la partie matérielle ne soit disponible. Le comportement du microcontrôleur et des composants de stockage RAM / ROM est simulé sur le PC. La plupart des simulateurs permettent également de commander le comportement des pins d'entrée et de sortie de façon limitée.
Les simulateurs sont souvent utilisés dans de la phase de démarrage du développement, jusqu'à ce que les prototypes de la partie matérielle sont disponibles. Ces derniers permettent également de tester les performances des algorithmes.

Microcontroller in Embedded Systems Chapitre 1 : Introduction
Version 3.0a, Januar 2012 Seite 8
1.5.2 Moniteur ROM Le moniteur ROM (anglais : ROM-Monitor) est la méthode plus simple pour tester une application embarquée. Un programme moniteur (anglais : Rom-Monitor) est exécuté pour cela sur la partie matérielle. Ce dernier communique avec l’environnement de développement et assure les tâches suivantes :
Téléchargement du code à partir de l’environnement de développement dans la RAM
Insertion des points d’arrêts (anglais : break points)
Exécution du code pas à pas
Affichage du contenu des variables
Le désavantage du moniteur ROM réside dans le temps de calcul de la CPU et les ressources matérielles supplémentaires (mémoire, interface sériel), qui sont nécessaires à l’exécution de ce dernier. Toutefois, le moniteur ROM est souvent utilisé à cause de son prix.
1.5.3 Interface JTAG Certains microcontrôleurs possèdent une interface JTAG intégré pour déboguer (ARM par exemple / XScale). La communication entre le PC et la platine de test est assurée par un wiggler. Ce dernier est connecté d’une part au port USB du PC (ou une autre interface comme par exemple : RS232) et d’autre part à l’interface JTAG du microcontrôleur.
Le débogage avec l’interface JTAG ne nécessite pas de puissance de calcul supplémentaire. Ce qui constitue incontestablement un avantage. Néanmoins, les désavantages de cette interface sont d’une part l’augmentation du prix du microcontrôleur (plus de silicium) et d’autre part la nécessité de travailler avec un wiggler. En ce qui concerne les fonctionnalités mis à disposition, l’interface JTAG se comporte comme le moniteur ROM.
1.5.4 Emulateur Le microcontrôleur est remplacé par un émulateur, qui permet de simuler ce dernier. L'émulateur est souvent réalisé avec des versions spéciales des microcontrôleurs, appelées puces bond out. Les émulateurs sont chers mais ils permettent de réaliser un débogage temps réel sans restriction.
1.5.5 Programmation et test direct de ROM / Flash Les ingénieurs en génie logiciel, qui n’ont pas de ressources pour l’installation d’un environnement de test, sont à plaindre. Ces derniers n’ont pas d’autre choix que de télécharger et de tester le code à partir de la Flash. Les tests alors effectués la fonction « printf () » afin d’afficher le comportement de l’application sur un terminal.
Les testes effectués de cette manière nécessite en générale beaucoup plus de temps. Par conséquent, même dans des petits projets, un environnement de développement avec un moniteur ROM ou une interface est rapidement rentabilisé.

Microcontroller in Embedded Systems Chapitre 2 : Généralité
Version 3.0a, Januar 2012 Seite 9
2 Généralité Ce chapitre introduit des notions de bases pour les systèmes embarqués.
2.1 Les systèmes embarqués La littérature fournit pour la notion de « système embarqué » les définitions suivantes :
Laplante :
« A software system that is completely encapsulated. »
Douglass :
« ... the computational system exists inside a larger system to achieve its overall responsibility »
Les systèmes embarqués (en anglais « embedded systems ») sont composés d’une partie matérielle (en anglais « hardware ») et d’une partie logicielle (en anglais « software »). Ils sont intégrés ou embarqués dans un produit. Ces produits sont par exemple un robot, une auto, une téléphone portable, un agenda électronique, une machine à café etc. Le système embarqué sont en générale responsable pour du contrôle, du traitement du signal et de la surveillance des différents composants du produit ou du produit dans son ensemble. La fonctionnalité d'un système embarqué se limite à l’exécution d’une ou quelques tâches dédiées.
2.2 Les systèmes temps réels La littérature fournit pour la notion de « système temps réel » da définition suivante :
Laplante:
« A real-time system is a system that must satisfy explicit (bounded) response-time constraints or risk severe consequences, including failures. A failed system is a system which cannot satisfy one or more of the requirements laid out in the formal system specification. »
Un système temps réel doit toujours livrer des réponses correctes dans des délais prédéfinis. Le dépassement de ces délais se traduit par un dysfonctionnement du système. Par conséquent, dans un système temps-réel, non seulement le résultat mais aussi l'instant auquel ce dernier est livré sont déterminant. Remarque : la définition n’abord pas le délai en sois. Selon les types de spécification, ce dernier peut correspondre à quelques microsecondes, millisecondes voire secondes. Il est seulement important que le résultat soit fourni à la limite de temps défini!
Contraintes temps réel mou/dur
Dans les systèmes temps réel, on distingue souvent entre les contraintes temps réel mou et temps réel dur.
On parle de contrainte temps réel mou (souple) lorsque le système respect souvent la spécification temporelles mais pas toujours. Dans ce cas le comportement temporel n'est pas toujours prévisible. Les conséquences de la non-conformité sont ennuyeuses mais pas graves. Exemple: La diffusion d’un film sur un appareil portatif qui s’effectue de façon « saccadé ».
On parle de contrainte temps réel dur lorsque le système respect toujours les spécifications temporelles. Le système présente alors un comportement temporel déterministique. L’automation industrielle et les applications liées à la sécurité constituent les domaines typiques pour les systèmes temps réels dur (ex. airbag).
Réalisation des contraintes temps réel
Les conditions suivantes doivent être remplies afin de pouvoir respecter les temps de réponse requis :
1) Un design épuré et réfléchi qui prend en compte les exigences temps réel.
2) Des basses latences d’interruption. Cela nécessite que :
a. Les interruptions ne doivent être désactivées que très brièvement
b. Les routines de service d’interruption doivent être aussi courtes que possible
3) Un code compact et rapide. Cela affecte également le choix du langage de programmation (C-Code, également C++ en fonction de la CPU, éventuelles optimisations des points critiques en assembleur).
4) Des testes approfondis qui tiennent compte de touts les situations et conditions possibles. La capacité temps réel est très difficile à démontrer !

Microcontroller in Embedded Systems Chapitre 2 : Généralité
Version 3.0a, Januar 2012 Seite 10
2.3 Le processus technique Le « processus technique » a été décrit dans le module « Conception et développement de logiciel » (2ème semestre). Ce terme apparaît principalement dans le cadre d’automation industriel. Voici une brève synthèse :
Définirons du "processus" selon DIN 6620:
Un processus est une transformation/transport de matière/énergie/information.
L’état du processus techniques peuvent être mesuré, contrôlé et gérer par des moyens techniques.
La figure suivante montre l'interface entre un système embarqué et un processus technique. Selon les applications, le système embarqué peut être équipé avec une interface d’utilisateur ou d’une connexion à d'autres systèmes :
Processus technique
Actuateur
Senseur
Ordinateur temps réels
Interface utilisa-teur
Figure 1 : Interface entre l’ordinateur temps réel et le processus technique
Le processus technique est la source et la destination des données techniques. Le système embarqué lit l’état du processus à l’aide des senseurs et il influence cet état à l’aide des actuateurs. Du point de vue du système embarqué
Exemple de senseur :
Interrupteur mécanique, inductive ou optique
Convertisseur A/D
Sonde de température, sonde de pression
Exemple d’actuateur :
Soupape
Moteur
Ecran, LED
Relais
Convertisseur D/A
La figure suivante montre en détail les transferts de données entre l’ordinateur temps réels et le processus technique ;

Microcontroller in Embedded Systems Chapitre 2 : Généralité
Version 3.0a, Januar 2012 Seite 11
Evénement discret
Valeurs de dérangement
Sortie du processus
Entrée du processus
Paramètres caractéristiques
Données d’entrée
Valeurs de mesure
Valeurs de contrôle
Données de sortie
Ordinateur temps réels
Processus technique
Evénement
Contre réactions
Analyse du processus Algorithme de contrôle
Figure 2 : Transfert de données entre un ordinateur temps réels et le processus technique
Le processus technique possède des entrées et des sorties, qui peuvent être soit de l’information ou du matériel. Les contre réactions ou les valeurs de dérangement influencent également le processus technique. Des paramètres caractéristiques peuvent être transmis au processus technique.
L’ordinateur temps réels analyse le processus technique en lisant les valeurs de mesure à des instants précis, qui sont définis par les occurrences des événements. Les algorithmes de contrôle permettent alors de définir des valeurs de contrôle afin d’assurer le fonctionnement correct du processus technique.
2.4 Les systèmes de communication industriels
2.4.1 La structures des systèmes de production industrielle Des systèmes industriels sont souvent organisés de manière hiérarchique. Dans la figure suivante, nous trouvons un exemple simple et très général:
PC industriel
SPS
PCInternet
SPS
Niveau de commande
Niveau de contrôle
Niveau processus
I/O I/O I/O I/O I/O
I/O I/O I/O I/O
I/O I/O I/O
Ethernet ou bus de champ
Bus de champ, Bus senseurs / acteurs
Firewall
Figure 3 : La hiérarchie dan un système industriel

Microcontroller in Embedded Systems Chapitre 2 : Généralité
Version 3.0a, Januar 2012 Seite 12
Un système industriel consiste en plusieurs calculateurs et/ou systèmes imbriqués sur différent niveaux hiérarchiques. En plus il y a un, ou plusieurs systèmes de communication pour échanger les données.
Le système représenté à la Figure 3 a été partagé en trois niveaux, qui possèdent les tâches suivantes:
Niveau de commande:
Ce niveau est responsable de l’analyse des données systèmes (Coordination et planification), qui est essentiellement réalisée avec des microprocesseurs 32 et 64 bits.
Niveau de contrôle:
Les différents processus techniques sont contrôlés ou gérés (système asservi) à ce niveau. On se sert de microcontrôleurs 32 bits ou de microprocesseur.
Niveau processus: Sur ce niveau ou y trouve les capteurs qui lisent les données processus ainsi que les acteurs, qui influencent directement le processus. Des microcontrôleurs 8 bits sont utilisés principalement à ce niveau. Toutefois, des microcontrôleurs 32 bits sont de plus en plus utilisés à ce niveau. En effet les prix de ce type de processeur ont fortement diminué alors que les exigences pour la communication entre les différents nœuds ont augmenté.
Suivant la complexité du système on a également plus que trois niveaux. Souvent ce sont:
Niveau de contrôle d’entreprise
Niveau de finition
Niveau d’installation
Niveau cellulaire
Niveau de champ
Niveau processus
2.4.2 Les critères pour la communication Les critères pour la transmission de l‘information dans un système de production industriel, comme celui décrit au chapitre 2.4.1 peuvent varier considérablement. En effet ces derniers dépendent d’une part de l’application et d’autre part du niveau hiérarchique. Les principaux critères sont les suivants :
Capacité temps réel pour les niveaux processus et contrôle
Taux de transfert
Standards industriel / dégrée d’utilisation
Fonctionnalité
Tolérance erreurs / fiabilité / immunité contre des perturbations
Économie (Optimisation des couts) Les deux critères les plus importants sont la capacité temps réel et le taux de transfert. Ces derniers sont illustrés graphiquement à l‘aide de pyramide de communication :
Steuerungseben
Leitebene
Bit, Byte
ms
Prozessebene
Reaktions-Zeit
Daten-Menge
kByte sec
Figure 4 : La pyramide de communication
Le chapitre 5 aborde certains systèmes de communication plus en détails.

Microcontroller in Embedded Systems Chapitre 3 : Méthodes de conception
Version 3.0a, Januar 2012 Seite 13
3 Méthodes de conception La fonctionnalité d’un système peut être toujours décomposée en sous-fonctions (modularisation). Il existe plusieurs stratégies pour exécuter ces sous-fonctions (ex. : déroulement cyclique, RTOS etc.). Les différentes approches sont discutées dans les sections suivantes. Il est crucial d’analyser le déroulement du programme durant la phase de conception afin de pouvoir définir une structure adéquat pour ce dernier.
3.1 Déroulement cyclique Toutes les fonctions du programme sont exécutées l’une après l’autre dans l’approche cyclique. Lorsque la dernière fonction du cycle à été exécutée, le programme continue avec l’exécution de la première fonction de ce dernier. L'intervalle de temps nécessaire pour exécuter un cycle entier dépend essentiellement du temps requis pour exécuter ses différentes fonctions.
Applikations-Funktion 1
Applikations-Funktion 2
Applikations-Funktion 3
Applikations-Funktion 4
Applikations-Funktion n-1
Applikations-Funktion n
Figure 5 : Représentation schématique du déroulement cyclique
La programmation de l’approche cyclique est relativement simple. Les fonctions sont appelées l’une après l’autre dans la boucle principale de la fonction main(). Les évènements (par exemple, l’actionnement d’un commutateur ou la réception de données via l'interface série) sont scrutés périodiquement dans cette boucle (anglais : polling). Néanmoins, les spécifications pour les applications embarquées exigent souvent, que les évènements doivent être traités dans un délai très court. Ce qui n’est pas forcément possible avec l’approche cyclique décrite ici.
3.2 Déroulement quasi-parallèle et évènementielle Les événements peuvent interrompre le processus cyclique en déclenchant une interruption. La routine de service d'interruption (abréviation en anglais : ISR) est ainsi appelée en temps réel pour traiter l'événement. Le déroulement du programme devient ainsi quasi-parallèle et évènementielle.
Applikations-Funktion 1
Applikations-Funktion 2
Applikations-Funktion 3
Applikations-Funktion 4
Applikations-Funktion n-1
Applikations-Funktion n
ISR
globale Variable
Figure 6 : Déroulement quasi parallèle avec des évènements

Microcontroller in Embedded Systems Chapitre 3 : Méthodes de conception
Version 3.0a, Januar 2012 Seite 14
Cette approche est souvent utilisée dans les systèmes embarqués. En effet, les interruptions sont relativement faciles à programmer. Les critères temps réel du système sont ainsi bien remplis. Néanmoins il subsiste le problème de la communication entre l’ISR et les fonctions de la boucle principale. En effet, cette communication nécessite le recours aux des variables globales. Il est important d’exclure les accès mutuels à ce genre de variable de sorte qu’une partie du programme n’y puisse accéder à un instant donné. Cela signifie, qu’une fonction de la boucle principale doit verrouiller l'interruption (dont la routine de service pourrait également accéder à cette variable) durant l’accès à cette variable. Pour des applications plus complexes, qui nécessitent plusieurs interruptions et variables globales, cela peut conduire à des interdépendances dissimulées et entraîner des crashs du système. Des exemples pour ce genre de problème, qui peuvent engendrer des conditions dites de course, sont fournis à la Section 4.3.6.
3.3 Déroulement quasi-parallèle avec RTOS Les applications embarqués plus complexes sont souvent réalisées avec des systèmes d'exploitation temps réel (abréviation anglaise : RTOS). Bien que ces systèmes nécessitent plus de ressources que l’approche quasi-parallèle et évènementielle, ils offrent néanmoins des outils supplémentaires pour résoudre les problèmes décrits dans la section précédente. Les RTOS ne sont pas traités dans ce manuscrit. Le lecteur intéressé peut se référer ici au module « Systèmes d'exploitation temps-réel », qui est également dispensé à la HESB.
3.4 State-Event
3.4.1 Introduction Le comportement de la plupart des systèmes techniques peut être décrit avec des machines d'état (anglais : State Machine). Les machines d’état ont été traitées dans les modules « Systèmes électroniques numériques » et « Développement de logiciel orienté fonction en C » (cours d’informatique du premier semestre). Ce chapitre traite la conception d’une machine d'état à l’aide de diagramme d’état et sa programmation en C. Les exemples illustratifs se basent sur une connexion téléphonique simplifiée.
Les systèmes techniques possèdent ont un nombre fini d'états, dans lequel ils peuvent se trouver à un instant donné. Ils réagissent à des événements qui peuvent se produire durant leur fonctionnement. En fonction de l'état actuel du système, ces événements peuvent déclencher des activités et éventuellement générer un changement d’état de ce dernier.
Définition :
Un état (State) est une disposition, dans laquelle le système entre durant une période limitée. Différentes activités (anglais : Activity) peuvent être exécutées au sein d'un état. Exemples d’état : « Sonnerie », « Conversation » etc.
Un événement (anglais : Event) est une influence extérieure sur le système ou un changement dans le système. Un événement est de courte durée (quantité de temps négligeable) et a toujours un impact sur le système. Exemples d'événements: « combiné est décroché », « numéro est sélectionné » etc.
Une transition décrit le passage d'un état à un autre. Une transition est toujours déclenchée par un événement. Exemples de transitions : Le décrochement du combiné (évènement) change l’état du system de « Téléphone libre » à « Saisir le numéro ».
Une action est exécutée au cours d'une transition. La transition « Téléphone libre » à « Saisir le numéro » augmente la tonalité.
3.4.2 Conception
3.4.2.1 Tableau d’états Les tableaux d’état constituent un moyen simple mais pas très compréhensifs les états d’un système. Tous les états, événements, actions et les transitions sont définis sous forme texte dans un tableau. Les tableaux d'état permettent de décrire entièrement le comportement d’un système.

Microcontroller in Embedded Systems Chapitre 3 : Méthodes de conception
Version 3.0a, Januar 2012 Seite 15
Etat actuel Evènement Action Nouvel état
Téléphone libre Combiné est décroché Activer la tonalité bip Saisir le numéro
Saisir le numéro Combiné est raccroché Pause Téléphone libre
Chiffre est sélectionné Transmettre le chiffre Saisir le numéro
Numéro libre est sélectionné
Activer la tonalité d’appel Sonnerie
Numéro occupé est sélectionné
Activer la tonalité occupée Occupé
Sonnerie Combiné est décroché Pause Téléphone libre
Correspondant s’annonce - Conversation
Occupé Combiné est raccroché Pause Téléphone libre
Conversation Combiné est raccroché Pause Téléphone libre
Tableau 1 : Tableau d’état pour le déroulement d’une communication au téléphone
3.4.2.2 Diagramme d’états Les diagrammes d’état permettent de représenter les différents états et transitions du système sous forme graphique. Par conséquent ces derniers sont beaucoup plus compréhensifs que les tableaux d’état. Il existe différentes approches pour la représentation graphique. Ce manuscrit se base sur le standard UML (V2.0), avec lequel deux états et une transition seront représenté de la manière suivante :
Figure 7 : Diagramme d’états simplifié selon le standard UML (V2.0)
Les états sont représentés par des rectangles arrondis qui contient leur nom. Les activités, qui sont exécutées par dans un état donné, sont indiquées en dessous de son nom.
Les transitions sont indiquées par des flèches entre les états. Une transition est exécutée lorsqu’un événement se produit et que la condition requise se réalise. Une action peut être également définie pour les transitions.
La définition des actions, des conditions et des activités est en option.
Notre exemple d’appel téléphonique peut être représenté de la manière suivante avec un diagramme d'état :
Figure 8 : Diagramme d’états pour le déroulement d’une communication au téléphone

Microcontroller in Embedded Systems Chapitre 3 : Méthodes de conception
Version 3.0a, Januar 2012 Seite 16
Les diagrammes d'état peuvent également être imbriqués l’un dans l’autre. Ceci est particulièrement utile quand, comme ci-dessus, les mêmes événements (Combiné est raccroché) permettent d’accéder à partir de plusieurs états à un seul état (Téléphone libre). La représentation peut être ainsi simplifiée.
Figure 9 : Diagramme d’états emboîté pour le déroulement d’une communication au téléphone
3.4.3 Implémentation de diagrammes d’états Il existe plusieurs approches pour implémenter les diagrammes d’états. Deux d’entre eux sont brièvement abordé dans ce chapitre. Si vous définissez un projet en C++, vous avez la possibilité d’utilisé les modèles de conception d’états (anglais : State Design Pattern). Ces derniers ne sont pas abordés dans ce manuscrit.
3.4.3.1 Instructions switch emboîtées Une bonne approche et couramment utilisé pour programmer les machines d'état est l'imbrication des deux structures switch. La structure externe permet de gérer les états possibles alors que la structure interne est responsable du traitement des différents évènements. Le code C se présente ainsi de la manière suivante :
switch(state){ case STATE_1: switch(event){ case EVENT_1: action_1(); state = STATE_V; break; case EVENT_2: action_2(); state = STATE_W; break; … } break; case STATE_2: switch(event){ case EVENT_3: action_3(); state = STATE_X; break; case EVENT_4: action_4(); state = STATE_Y;

Microcontroller in Embedded Systems Chapitre 3 : Méthodes de conception
Version 3.0a, Januar 2012 Seite 17
break; … } break; … }
3.4.3.2 Les tableaux Une manière élégante est de stocker toutes les actions et les états suivants dans un tableau à deux dimensions. Le tableau a la structure suivante :
E1 E2 … En E1 … En: Evènement
A1/Sv … … … S1 S1 … Sn: Etat
… … … … S2 A1 … An: Action
… … … … … Sv: Etat suivante
… … … … Sn
Ce tableau contient pour chaque combinaison possible d’événements et d’états une structure. Cette structure quant à elle contient une information concernant l’action à exécuter et l’état suivant. Le code C se présente en général comme suit :
// typedef pour State et Event typedef enum {S1, S2, S3} StateType; typedef enum {E1, E2, E3, E4, E5, E6, E7, E8, E9} EventType; /* Déclaration d’un élément du tableau d’états, qui contient l’action à exécuter et l’état suivant */ typedef struct tab { int(*action)(void*); StateType nextState; }TabElement; // Déclaration de toutes les actions int Action1(void* para); int Action2(void* para); int Action3(void* para); ... // La définition du tableau d’états TabElement stateTable[3][3] = { // E1 E2 E3 { {Action1,S2},{Action2,S2},{Action3,S3} }, // S1 { {Action4,S1},{Action5,S3},{Action6,S3} }, // S2 { {Action7,S1},{Action8,S2},{Action9,S3} }, // S3 }; // La définition des actions int Action1(void* para){ ... return(0); } int Action2(void* para){ ... return(0); }

Microcontroller in Embedded Systems Chapitre 3 : Méthodes de conception
Version 3.0a, Januar 2012 Seite 18
int Action3(void* para){ ... return(0); } ... void main(void){ int para = 0; // Evénement et état de départ EventType event = E1; StateType state = S1; while(1){ // Code à exécuter à chaque événement (*(stateTable[state][event]).action)(¶); // Exécuter l’action state = (stateTable[state][event]).nextState; /* Lire le prochain état */ } }

Microcontroller in Embedded Systems Chapitre 4 : Sécurité des systèmes
Version 3.0a, Januar 2012 Seite 19
4 Sécurité des systèmes
4.1 Introduction Les exigences de qualité pour les systèmes embarqués sont très élevées. Ces exigences concerne le « cycle de vie » complet du produit : depuis la planification en passant par le développement jusqu’à la formation des clients. Voici quelques commentaires concernant la partie matérielle (software) et la partie logicielle (hardware).
4.1.1 Hardware La qualité du de la partie matérielle (anglais : hardware) peut être déterminée statistiquement. Les probabilités de défaillance (MTTF Mean Time To Fail, ou MTBF, Mean Time Between Failure) des composants sont en générale connue. Cela permet de définir la probabilité de défaillance du système en entier ou le temps nécessaire pour que celui-ci atteigne un état jugé comme étant dangereux.
La qualité de la partie matérielle peut être augmentée grâce à la redondance. La notion de «fail-safe mécanismes » est également utilisée dans ce genre de système. La redondance vise principalement à réaliser des systèmes (hardware et software) sures et fiables. Ces notions sont souvent utilisées mais ils n’ont pas les mêmes significations. Les systèmes sures sont destinés à protéger les hommes. Quant aux systèmes fiables, ils doivent uniquement réduire leur probabilité de défaillance afin de réduire les coûts. Ce qui ne signifie pas nécessairement plus de sécurité. Les options suivantes peuvent être envisagées en fonction des champs d’application :
Surveillance de la partie logicielle à l’aide d’un Watchdog (voir chapitre Fehler! Verweisquelle konnte nicht gefunden werden.).
Surveillance de la partie matérielle (horloge et alimentation) par des composants supplémentaires.
Surveillance de la partie matérielle par la partie logicielle (CRC, Test de la RAM etc.).
Partie matérielle redondante (dédoublement de d’entrée/sorite, deux processeurs en parallèle ou trois avec une stratégie de décision majoritaire).
Partie logicielle redondante (des programmes différents sont exécutés sur des processeurs différents).
4.1.2 Software Le développement du logiciel peut être amélioré qualitativement par des mesures appropriées. Contrairement aux logiciels bureautiques, où les utilisateurs se sont résignés aux problèmes de logiciels (le nom du système d'exploitation a été délibérément omis ici), la fiabilité des logiciels embarqués doit être très élevée. Ces exigences sont encore plus importantes pour les applications liées à la sécurité. Le développement de logiciels de bonnes qualités n'est possible qu’avec plusieurs mesures:
Des ingénieurs bien formés et qualifiés qui ont une bonne connaissance des pièges courants.
Révision des spécifications, de la conception et du code.
Une conception du logiciel de haute qualité.
Code de haute qualité grâce à l'utilisation des normes et des directives SW.
Mécanismes de détection d'erreur dans le logiciel.
Utilisation des outils d'analyse de code statique.
Des tests approfondis durant la phase de développement.
Tests du système complet avant et pendant la mise en service.
Une documentation complète, compréhensible et actuelle.
4.2 Le langage de Programmation C Un critère (mais pas le seul) pour la qualité des logiciels est le langage de programmation. Le langage C, qui est le plus couramment utilisé dans les systèmes embarqués, n’est malheureusement pas sure au niveau des types et présente également de nombreux autres pièges. Par exemple, les pointeurs en C ont été déjà inquiétés de nombreux experts en sécurité (et également les programmeurs). Toutefois, tout n’est pas perdu, si en tant que programmeur, vous êtes conscient du problème. En effet, il faut prendre les précautions nécessaires durant la programmation. Par exemple, il est fortement recommandé de toujours n’utiliser qu’un sous-ensemble du langage de programmation C. Cette recommandation est valable, non seulement pour des systèmes de sécurité

Microcontroller in Embedded Systems Chapitre 4 : Sécurité des systèmes
Version 3.0a, Januar 2012 Seite 20
mais, pour tous les programmes d’utilité générale. Une listes exhaustive de tells recommandation est fournit par l’association MISRA-C [MISRA-C]. Certains d'entre eux sont décrits dans la section suivante.
La question qui pourrait être posée ici est la suivante : pourquoi faut-il utiliser le langage C pour programmer les systèmes embarqués, alors que cette dernière est lacunaire. Pour cela, il ya deux raisons importantes:
Premièrement ; il n’existe dans domaine de la programmation des microcontrôleurs (presque) pas d’alternative. Il faut donc composer avec cela.
Deuxièmement ; il est plus opportun d’utiliser un langage de programmation que l’on connaît (en particulier ses faiblesse), pour lequel il existe de bon compilateur, qu’un langage qui n’est pas répondu et pour lequel il n’existe que des mauvais outils de développement.
4.2.1 MISRA-C L’association MISRA-C (Motor Industry Software Reliability Association) définit les directives pour l’utilisation du langage de programmation C dans l’industrie automobile, qui prévalent également dans d'autres secteurs de l’industrie. Le titre officiel est « Guidelines for the use of the C langage in critical systems ». www.misra.org.uk.
MISRA-C 122 définit règles « nécessaire » et 20 règles « consultatifs ». La figure ci-dessous illustre deux de ces règles. Toutes les règles doivent être respectées pour pouvoir être conforme aux directives MISRA.
Figure 10 : Exemples de règle MISRA-C
4.2.2 Analyse de code statique Les compilateurs C sont en général très tolérants (ou conviviale) durant la compilation. Ils « ferment plusieurs fois sur les deux yeux » pour que le code puisse être compilé et ainsi exécuter le plus rapidement. Mais cela peut s’avérer fatal durant le fonctionnement ! Ce qui est bien entendu beaucoup moins conviviale et en termes de qualité très fâcheux. Il existe différents outils (vérificateur de syntaxe) sur le marché, qui permettent d’effectuer

Microcontroller in Embedded Systems Chapitre 4 : Sécurité des systèmes
Version 3.0a, Januar 2012 Seite 21
des analyses statique du code afin de fournir des messages d’erreurs, des avertissements ou des informations générales sur le code.
Une bonne approche est de faire contrôler votre code à l’aide d'un vérificateur de syntaxe. Les nombreuses réclamations fournies par ce dernier vont peut être vous étonner. Ne soyez toutefois pas frustré mais au montrez vous contraire reconnaissant : en effet la phase de teste sera d’autant plus facile. Les analyses du code à l’aide d’un vérificateur de syntaxe devrait commencer au début - et non à la fin - de la phase de programmation afin d’éviter un flot trop important d'avertissements.
Le logiciel « PC-Lint » de Gimpel est disponible à la HESB pour ce type de vérification. Il existe cependant d'autres produits sur le marché. De tels outils permettent également d’examiner si les règles de MISRA-C sont respectées (pas forcément toutes les règles, mais la plupart, qui sont spécifiées par le fabricant).
4.3 Murphy et le langage de Programmation C Ce chapitre répertorie quelques problèmes typiques, qui peuvent survenir avec le langage de programmation C. Ces indications ne sont pas exhaustives. Elles illustrent cependant quelques-uns des principaux problèmes du langage de programmation C.
4.3.1 Dépassement de capacité dans les tableaux En C, vous pouvez accéder un tableau en dehors de ses limites, sans que vous puissiez vous en rendre compte (ou juste avant un crash du système). Considérez par exemple le code suivant, qui est syntaxiquement correct (c.à.d. que le compilateur va probablement le compiler sans avertissements):
char array[10]; char counter = 0; … for (counter = 0; counter <= 10; counter++){ array[counter] = 0; }
Dans le code ci-dessus vous dépassez les limite du tableau « array » lorsque « counter = 10 ». Quelle est la conséquence de cela ? Dans le pire de cas, le relieur (anglais : linker) réserve de l’espace mémoire pour la variable counter directement à la suite du tableau array. Dans ce cas l’instruction « array[counter] = 0 » efface systématiquement le contenu de la variable counter. La boucle for devient ainsi une boucle infini. A cet égard, il se peut que vous ayez de la chance et que vous trouviez cette erreur durant les premières phases de test. Dans d'autres cas, l’indentification du problème peut s’avérer beaucoup plus chère.
Il existe deux approches pour résoudre ce problème:
Vous apportez une attention particulière aux limites du tableau pendant le codage. Vous pouvez également contrôler l'index du tableau avant d'accéder à ce dernier. Vous pouvez également démontrer que n’avez pas dépassé les limites du tableau à l’aide de tests approfondis. Malheureusement, une certaine incertitude demeure toujours.
Ajoutez un élément supplémentaire au tableau, que vous initialiserez avec une valeur spécifique (par ex. 0x55). Testez à présent le système et contrôler ensuite si la valeur de ce dernier élément n’a pas été modifiée.
4.3.2 Dépassement de capacité dans la pile (anglais : stack) Ce problème est identique à celui lié aux dépassements de capacité dans les tableaux. Lorsque vous dépassez les limites de votre pile (trop d’appels de fonctions imbriqués ou trop de variables locales), vous risquez d’accéder aux segments de la RAM qui contiennent des variables. Les choses peuvent encore se gâter lorsque le programme est exécuté à partir d’un RAM. En effet, dans ce cas, vous risquez sur écrire par dessus le code.
Les erreurs, qui résultent de ce genre de dépassement, vont se manifester à un instant donné (en fonction des objets su récrits et de l’utilisation de ces derniers). Ce qui rend la recherche de telles erreurs encore plus difficiles.
Comment un débordement de la pile peut-il être déterminé :

Microcontroller in Embedded Systems Chapitre 4 : Sécurité des systèmes
Version 3.0a, Januar 2012 Seite 22
Initialiser votre pile au démarrage du système avec des valeurs spécifiques, comme par exemple 0x55. Après un test exhaustive du système, vous pouvez alors déterminer le part de la pile qui a été utilisée par votre programme (la limite se situe à l’endroit où les valeurs spécifiques d’initialisation 0x55 ont été sur écrites).
Quelles sont les solutions pour résoudre ces problèmes :
Agrandissement de la taille de la pile. Des nombreux environnements de développement permettent de définir la taille de la pile à l’aide d’options pour le relieur (anglais : linker).
Réduction de la taille des variables locales dans vos fonctions.
Evitez les appels de fonction récursive!
4.3.3 Pointeur NULL
Un pointeur, qui n’est pas initialisé, adresse la case mémoire NULL (ou même quelque part ailleurs). Une allocation de mémoire pour construire une liste dynamique, qui échoue par manque de mémoire disponible, retourne également l’adresse NULL. Le premier cas est une erreur de programmation classique. Le deuxième cas n'est pas une erreur, mais il peut se produire à n’importe quel instant.
Quelles sont les solutions pour résoudre ces problèmes :
Il faut comparer la valeur de chaque pointeur avec l’adresse NULL avant de l’utiliser! Cette vérification peut se réaliser soit avec : if(pointer != NULL), ou avec : assert(pointer != NULL).
4.3.4 Les interruptions Un microcontrôleur possède de nombreux vecteurs d'interruption, qui sont rassemblés dans son tableau des vecteurs d’interruption. Normalement seul une partie de ces vecteurs est utilisée par votre programme (Timer, interface série et peut-être encore deux ou trois ports IRQ) alors que la grande partie restante ne l’est pas. Que se passe-t-il alors lorsqu’apparaît une interruption, qui n’a pas été prévue et n’est par conséquent pas traitée (comme par exemple la division par zéro) ? Dans ce cas, le contrôleur va accéder au tableau des vecteurs d’interruption afin de charger l’instruction correspondant à cette interruption. Ce vecteur peut contenir avec de la chance la valeur zéro. Le programme fait ainsi un saut à l’adresse NULL, ce qui correspond en général à une réinitialisation du system (anglais : reset). Toutefois ce vecteur peut également contenir une valeur différente de zéro. Le programme fait dans ce second cas un saut à une adresse inconnue, qui engendrera probablement un crash du système.
Quelles sont les solutions pour résoudre ce problème :
Il faut toujours initialiser tous les vecteurs d'interruption. Si vous n'utilisez pas une interruption donnée, implémentez pour cette dernière une routine traitement d’interruption (anglais : ISR) par défaut. Dans cette routine de service, vous pouvez soit afficher un message d'erreur ou implémenter une boucle infinie pour le débogage.
4.3.5 Allocation de mémoire dynamique La mémoire est allouée dynamiquement dans les programmes afin de générer des listes. Cela marche bien tant que la mémoire disponible est suffisante. Des problèmes apparaissent inévitablement lorsque la mémoire requise n’est plus disponible. En d’autre terme, le programme n’a plus de ressource en mémoire. Un autre problème est la fragmentation de la mémoire qui peut survenir avec l’allocation de la mémoire dynamique.
Quelles sont les solutions pour résoudre ce problème :
Essayez de définir les structures de données autant que possible de façon statique.
Assurez-vous que la mémoire, qui a été allouée dynamiquement, soit également de nouveau libérée. Vous devez vous en occupé vous-même en C et en C++.
Testez le système également en termes de ressources en mémoire : Exécutez votre programme durant des heures ou des jours et regardez ensuite si l’espace mémoire disponible reste constant.

Microcontroller in Embedded Systems Chapitre 4 : Sécurité des systèmes
Version 3.0a, Januar 2012 Seite 23
4.3.6 Les conditions de courses Les conditions de course (anglais : race condition) signifient les situations de courses. Lorsque les conditions de course sont remplies, les résultats du programme dépendent du comportement temporel de ce dernier. Les situations de course surviennent lorsqu’il y a une interaction asynchrone entre la partie matérielle (hardware) et la partie logicielle (software). C’est le cas par exemple avec les Timers ou les convertisseurs A/D. Dans ces cas, les conditions de course se produisent lorsque nous les données sont lues systématiquement par le logiciel, alors ils ont changé de manière asynchrone par le hardware.
Exemple Timer : Le code suivant génère des conditions de courses (référence : [Firmware_Handbook]): unsigned int timer_hi; interrupt timer(){ ++timer_hi } unsigned long read_timer(void){ unsigned int low, high; low = read_word(timer_register); high = timer_hi; return (((unsigned long)high)<<16 + (unsigned long)low); }
Le code ci-dessus est erroné. En effet, admettons que l’on commence par lire la valeur du registre « timer_register ». Ce registre contient une information sur la partie fractionnaire du temps qui s’écoule. Supposons qu’ensuite se produit un dépassement de capacité engendrant l’incrémentation de la variable « timer_hi ». Cette variable contient une information sur la partie entière du temps. La combinaison de ces deux variables conduits ainsi à une information erronée sur le temps.
Le problème peut être résolu à l’aide d’approches différentes:
Considération du problème dans la phase de conception (anglais : design)
Désactiver systématiquement les interruptions durant les accès au matériel (anglais : hardware)
Utilisation des « registres de capture » (anglais : Capture-Register)
Attention : les conditions de course sont souvent à l’origine d'erreurs logicielles, qui sont très difficiles à localiser (exemple Timer de ci-dessus)!
4.3.7 Code réentrant Les applications embarqués sont toujours programmées à l’aide d’interruptions ou parfois également avec des systèmes d'exploitation temps réel. Cela signifie qu'une fonction peut être interrompue à tout instant par une interruption ou par une autre tâche (anglais : task). Le chaos est assuré à partir du moment, où les différentes parties du programme accèdent sans précautions spécifiques aux mêmes ressources (interfaces matérielles, variables globales). Par conséquent, les fonctions doivent être programmé afin qu’elles soient réentrantes. C'est-à-dire que :
Les variables globales ne doivent être accessibles que de façon exclusive (« atomique »).
Il ne faut pas appeler les fonctions non réentrantes (attention avec les fonctions des libraires standards.
Les interfaces matérielles (anglais : hardware interfaces) ne doivent être accessibles que de façon exclusive.
La meilleure façon d'obtenir l'accès exclusif, c’est de désactiver les interruptions durant l’accès. Toutefois, cela implique une augmentation des temps de latence pour le traitement des interruptions. Par conséquent, les accès doivent être aussi courts que possibles
Dans ce contexte la règle importante à respecter est la suivante :
"Share the code, not the data"!

Microcontroller in Embedded Systems Chapitre 4 : Sécurité des systèmes
Version 3.0a, Januar 2012 Seite 24
4.3.8 Programmation défensive La programmation défensive signifie que l’on considère toutes les éventualités : arguments transmis aux fonctions non plausibles, transmission de données erronées, séquences temporelles pas prévues, etc.). Lorsque vous programmez de façon défensive, ce qui est particulièrement recommandée pour des systèmes ou la sécurité est essentielle, vérifiez tout auparavant. Cela signifie en particulier que :
La gamme de valeur des arguments transmis aux fonctions doit être contrôlée au début des ces dernières.
Les transmissions de données doivent être vérifiées systématiquement (Check sum).
La plausibilité des résultats doit être vérifiée.
La programmation défensive permet d’augmenter la sécurité du système. Cela n’est cependant pas gratuit. En effet cette approche nécessite plus de code et, par conséquence, plus de puissance de calcul, plus de capacité de stockage et plus de développement.
4.3.9 assert()
assert() est une macro de la bibliothèque standard. assert() permet d’évaluer de façon très simple et efficace divers conditions durant l’exécution du programme : assert(expression);
Lorsque la condition évaluée s’avère comme étant fausse (valeur nulle), la macro assert livre un message d’erreur à travers le canal stderr. Ce message a typiquement la forme suivante :
Assertion failed: expression, file filename, line nnn
La macro assert sera ignorée lorsque la macro NDEBUG est définie avant l’inclusion de la bibliothèque standard <assert.h>.
Les exemples d’application de la macro assert() sont les tests de pointeur (pointeur non nul) ou de gamme de valeurs pour les paramètres etc.
4.3.10 Optimisation du code C Les compilateurs C essayent de générer un code objet le plus optimisé que possible. Cela signifie que ce dernier doit être à la fois aussi rapide et compact que possible. Le résultat du compilateur peut également être influencé de façon significative par la manière dont le code C est défini :
1. Essayez d’éviter autant que possible les variables globales. Définissez plutôt les variables locales à l’intérieur des fonctions. Le compilateur peut ainsi stocker ces dernières dans des registres locales - plutôt que de les placer dans la mémoire externe (RAM). Ce qui diminue le temps d’accès aux variables. Essayez également de réduire autant que possible le nombre de variables locales. En effet, le nombre des registres est limité et les variables, qui ne peuvent pas être stockées dans des registres, sont placées sur les piles. Cependant, si vous avez toujours besoin de nombreuses variables locales, essayez d’utiliser ces dernières de façon limitée à l’intérieur de la fonction. Ainsi, le compilateur peut attribuer un seul registre aux divers variables durant l'exécution de la fonction.
2. Evitez les opérations de prises d’adresse avec les variables locales. En effet, cela empêche le compilateur de les stocker dans des registres.
3. L’assembleur en ligne ne devrait être utilisé qu’en dernier recours. En effet, le compilateur n’a pas de droit d’optimiser le code C autour de ces derniers. Utilisez plutôt les sous-routines en assembleur.
4. Evitez de définir des fonctions avec des listes des paramètres variables (comme printf). En effet, l’appel de ces fonctions nécessite en générale plus de ressources systèmes.
5. Remplacez les fonctions très courtes (1 à 3 lignes de code) par des macros ou des fonctions en ligne. Les ressources systèmes nécessaires à l’appel des fonctions peuvent ainsi être réduites au maximum. En effet, le compilateur copie littéralement les lignes de code des fonctions en ligne aux endroits appropriés dans le programme. Ce qui d’une part augmente considérablement la vitesse d’exécution du programme et d’autre part - surtout avec les fonctions très courtes - réduit le nombre d’instructions assembleur.
6. La transmission des arguments aux fonctions devrait être réalisée à l’aide de paramètres au lieu de variables globales. En effet, dans le premier cas, le compilateur utilise les registres pour transmettre les arguments. Cette procédure est beaucoup plus rapide que l'accès systématique aux variables globales,

Microcontroller in Embedded Systems Chapitre 4 : Sécurité des systèmes
Version 3.0a, Januar 2012 Seite 25
qui sont stockées dans la mémoire externe (RAM). Les premiers arguments sont en général transmis avec des registres et les suivants avec la pile (anglais : stack). Par conséquent, il faut faire également attention au nombre d’arguments, qui vont être transmis à la fonction.
7. Si vous souhaitez transmettre des structures de données comme paramètre à des fonctions, transmettez ces dernières avec des pointeurs constants (avec le mot clé « const »). Le compilateur déposerait autrement la structure entièrement sur la pile.
8. Utilisez le mot-clé « volatile » pour indiquer au compilateur, que la variable ne peut pas être stockée dans un registre. Cette dernières sera ainsi toujours déposée dans la mémoire externe (RAM). Cette définition est même indispensable pour les variables qui permettent d’accéder à la partie matérielle (anglais : hardware) comme par exemple le « Timer ».
9. Essayez les différents niveaux d'optimisation du compilateur. Le niveau le plus haut ne génère ici pas forcément le code le plus rapide ou le plus compact.
10. Utilisez pour la définition des variables toujours le type de données le plus adéquat en fonction de la taille de la CPU (8, 16 ou 32 bits). Autrement, le compilateur doit effectuer une voire plusieurs opérations cast. Les opérations arithmétiques avec le type char sont en principe très efficaces sur les microcontrôleurs 8 bits. Avec ces derniers, les opérations 16 ou 32 bits nécessitent des fonctions de la bibliothèque standard, ce qui n'est pas efficace. Un microcontrôleur 8 bits est en générale dépassé avec les calculs à virgule flottante. Les fonctions de la bibliothèque standard sont alors très complexes et leur temps d'exécution très longs.
11. Les microcontrôleurs 32 bits possèdent souvent des contraintes d'alignement pour les adresses des variables (voir le cours du troisième semestre de l'informatique « Développement de logiciels orienté matériel »). Essayez de déclarer systématiquement les membres 32 bits en premier, les membres 16 bits en second et les membres 8 bits à la fin dans les structures de données. Cela empêche le compilateur de devoir insérer des espaces libres ("padding") entre les différents types de membres. Ce qui a tendance à augmenter la taille de la structure de données.
12. Ne définissez pas de code «intelligent », qui n’est pas compréhensible pour votre collègue (et pour vous après quelques jours). Le compilateur ne comprend pas ce code et ne peut donc l'optimiser. Définissez votre code plutôt de façon « simple et continue ». « Write simple and understandable code »!
13. Définissez une structure « switch » au lieu d'un tableau de saut (anglais : Jump-Table). En effet, le compilateur va générer un tableau de saut optimal pour le microcontrôleur sélectionné pour cette instruction. Le code reste ainsi parfaitement portable.
4.4 Sécurité au niveau du système Les parties matérielles et les logicielles ne sont pas uniquement critique pour la sécurité du système. En effet cette dernière dépend du cycle de vie complet du produit, depuis sa spécification jusqu'à la formation des clients. Les paragraphes suivants traitent quelques points, qui concernent surtout la phase de développement
4.4.1 La conception Comment est-ce que les améliorations peuvent-elles être intégrées sans problèmes ? La structure finale d’un programme dépend de plusieurs critères. Le critère le plus important est celui de la mise en œuvre des spécifications. Toutefois, la conception peut également être influencée par le programmeur lui même. Les expériences et les compétences de ce dernier jouent ici un rôle majeur. C'est un peu la discipline reine de l’ingénieur logiciel, la suite n’est plus que du codage et des tests. Les erreurs de conception sont en général très problématiques. La correction de ces derniers nécessite souvent beaucoup d’efforts. En effet, une grande partie du code doit être modifiée et les testés doivent être effectués à nouveau.
La conception a un impact majeur sur la qualité du code. Cette phase doit inclure les éléments suivants:
La modularisation de votre système en fichier / classes / tâches
La description des interfaces de ces modules
La communication entre ces modules
Le comportement temporel des différents modules et de l'ensemble du système
Les interfaces au processus technique et à l'utilisateur

Microcontroller in Embedded Systems Chapitre 4 : Sécurité des systèmes
Version 3.0a, Januar 2012 Seite 26
4.4.2 Spécification et exécutions des testes Les tests ne devraient pas être simplement réalisés à la fin du projet avec la devise : démarrer le système – ce dernier fonctionne – donc tout est bon. Les testes doivent plutôt être spécifiés durant la conception du système. Cette spécification doit contenir les types, les procédures et les paramètres des tests. Elle peut être obtenue à partir des spécifications du système. La rédaction des spécifications de test devrait être réalisée de préférence durant la phase de conception du système ou, dans tous les cas, avant la phase de codage.
Des tests sont particulièrement importants pour les systèmes embarqués. Les erreurs, qui ne sont pas trouvées durant la phase des tests, sont très coûteuses voire même dangereuses. Dans ces cas, vous devez rappeler les systèmes vendus (en effet, vous ne pouvez pas envoyez simplement une mise à jour du logicielle) ou installer une nouvelle version du logicielle chez le client. La règle d’or dit stipule que si vous avez programmé durant un mois, vous devriez également tester durant un mois !
Les tests sont toujours réalisés sur plusieurs niveaux : ils sont effectués individuellement sur les fonctions au niveau des modules ; puis sur les différentes parties du système et finalement sur le système dans son ensemble dans un environnement réel. Les ingénieurs logiciel sont en général beaucoup trop indulgents face aux à leur propre code. Mais est-ce que ces derniers souhaitent-ils vraiment que quelqu'un d'autre trouve les erreurs à leur place ? Les grandes entreprises emploient des ingénieurs de test : ces derniers se réjouissent toujours lorsqu’ils trouvent des nouvelles erreurs. Mais, il est en général beaucoup plus agréable de trouver ses erreurs soi-même. Par conséquent : essayez de vraiment torturer votre logiciel et d’aller à ses limites. Ici vous serez certainement beaucoup plus créatif ou plutôt plus destructif qu’une personne tierce.
Des nombreux ouvrages ont été publiés sur les modèles et les procédures de tests. Voici quelques points clés en bref :
Vérifier en particulier les interfaces pour les utilisateurs et pour le processus technique (les capteurs, les convertisseurs, les interfaces utilisateurs d’entrée et de sortie, etc.). Vous ne pouvez surement pas tester toutes les combinaisons possibles d’interfaces utilisateurs. Mais quelques types de clavier devraient par exemple être possibles.
Vérifier en profondeur les interfaces de communication. Si vous avez par exemple une interface sérielle ; alors bombardez votre système avec des demandes, envoyez lui également des protocoles non définis, etc.
Vérifier le comportement de votre système même en cas de surcharge.
Une bonne approche est de travailler avec deux versions de code : une version pour un fonctionnement standard et une version pour le débogage. Cette dernière contient du code supplémentaire pour exécuter les tests. Cela peut être défini en C avec une macro de la manière suivante :
#define _DEBUG ... statement; ... #ifdef _DEBUG // additional testing and error messages output
#endif
Vous pouvez commuter entre les versions en commentant l’instruction « #define _DEBUG». Le code pour les deux versions est ainsi défini dans les mêmes fichiers.
Il existe de nombreuses normes et directives pour effectuer des tests logiciels, dont les plus recommandées sont les suivantes :
IEEE 829, Standard for Software Test Documentation
IEEE 1008, Standard for Software Unit Testing
IEEE 1012, Standard for Software Verification and Validation

Microcontroller in Embedded Systems Chapitre 4 : Sécurité des systèmes
Version 3.0a, Januar 2012 Seite 27
4.4.3 La documentation Une bonne documentation permet de s'assurer que :
Les changements ou les améliorations peuvent être effectués sans erreurs.
Toutes les erreurs peuvent être localisées plus facilement.
Vos collègues puissent être intégrés dans le développement logiciel, sans que ces derniers ne vous posent continuellement des questions (et sans que ces derniers ne vous dérangent).
Les tests peuvent être répétés ou complétés.
La documentation est votre carte de visite. Si, par manque de temps ou de ressources, vous renoncer à définir une documentation , vous le regretterez plus tard (par exemple, lorsque vous devez remettre à jours votre code). Si, par manque de temps ou de ressources, vos supérieurs exigent une documentation réduite, alors défendez-vous dans votre propre intérêt.
Une bonne documentation constitue un autre avantage à ne pas sous-estimé. Si une erreur de votre logiciel a causé des dommages à des biens ou des personnes, vous vous trouverez en tant que développeur sans bonne documentation en manques de preuve. Aujourd'hui, les erreurs logicielles ne peuvent pas être exclues. Mais une bonne conception, un bon rapport et des tests bien documentés peuvent prouver que vous avez fait tout votre possible pour éviter les erreurs.
La forme de la documentation est secondaire. L’important est que tout y est décrit. Cela commence par la conception, en incluant les différentes variantes et leur évaluation. Cette dernière est suivie par la description du code et sans oublier par la description compréhensible des tests.
4.4.4 Reviews Effectuez régulièrement des réexamens (reviews) durant le développement du projet. Cela s'applique aux spécifications (en incluant également les spécifications de test), la conception et le code.
Les réexamens du code ne sont pas effectués dans de nombreuses entreprises « par manque de temps ». C'est très dommage. En effet, le temps investi dans les réexamens est gagné par la suite durant le débogage. Certaines erreurs typiques, telles que les conditions de course, ne peuvent être isolées par les développeurs expérimentés que durant les phases de réexamens. Un autre avantage des réexamens est l’échange de connaissances entre les développeurs.
4.5 Watchdog
4.5.1 Introduction La tâche du Watchdog (français : horloge de surveillance) est de réinitialiser un microcontrôleur (c. à d. de ramener le système à un état défini) à partir d'un état indéfini. Cet état est souvent le résultat d’un comportement erroné du programme, comme par exemple une boucle infinie. Dans le langage courant on appelle cela un plantage informatique (anglais : system crash).
L’utilisation d'un watchdog est fortement recommandée pour tous les systèmes (même avec des applications très simples). Par conséquent, de nombreux microcontrôleurs contiennent un interne.
4.5.2 Le externe Les watchdogs externes peuvent exécuter - en complément des applications de surveillance du processeur - les tâches suivantes :
1) Surveillance de l’alimentation du système
2) Surveillance de l’horloge du système

Microcontroller in Embedded Systems Chapitre 4 : Sécurité des systèmes
Version 3.0a, Januar 2012 Seite 28
Les courtes interruptions d’alimentation sont en générale très dangereuses pour les systèmes à microprocesseur. En effet, ces dernières peuvent faire entrer le processeur dans des états non définis. Les watchdogs externes surveillent également l’alimentation et génèrent un reset en cas de problème. Cette fonctionnalité peut également être reprise par le module reset.
Les watchdogs externes possèdent en générale leur propre base de temps. Ce qui leur permet de surveiller également l’horloge du système.
Le circuit de watchdog externe est être réalisé typiquement de la manière suivante :
CPU
Refresh
Reset
Watchdog
Reset-Logic
out out
Zeitbasis 1
Zeitbasis 2 Reset Taste
Figure 11 : Le watchdog externe
4.5.3 Le watchdog interne Un watchdog interne (c. à d. intégré dans un microcontrôleur) génère également un reset en cas d'erreurs. Un tel reset ne se distingue en général pas de celui, qui est généré de façon externe.
Selon la famille des microcontrôleurs, il existe des watchdogs internes qui possèdent leur propre base de temps. Cette dernière est en général produite à l’aide d’un circuit RC.
4.5.4 Fonctionnement du watchdog Le cœur du watchdog est un registre compteur, qui est remis à zéro périodiquement par le logiciel. Un disfonctionnement dans cette procédure de rafraîchissement engendre un dépassement de capacité du compteur et déclenche une réinitialisation du système.
La figure suivante illustre la structure de base d’un watchdog :
Refresh from software
Watch-dog timer
Reload Register
Reset
Figure 12 : Fonctionnement du watchdog

Microcontroller in Embedded Systems Chapitre 4 : Sécurité des systèmes
Version 3.0a, Januar 2012 Seite 29
4.5.5 Démarrage du watchdog Le démarrage du watchdog s’effectue de deux manières :
De façon hardware après le reset. Cela présente l'avantage que le processus de contrôle du microcontrôleur débute à son démarrage.
De façon software en fixant la valeur des bits de contrôle appropriés. Cela devrait être réalisé le plus tôt possible dans le code (c.-à-d. avant l'initialisation du système).
4.5.6 Rafraichissement du watchdog Le rafraichissement du watchdog s’effectue également de façon logiciel en fixant la valeur des indicateurs (anglais : flag) appropriés. Dans ce contexte, il est très important que les opérations de rafraichissement ne soient pas éparpillées au hasard dans le code. En effet, il plutôt recommandé d’effectuer ces opérations une seule fois par cycle d’exécution du programme, comme par exemple à la fin de la boucle principale de main().
La procédure de rafraichissement peut être combiné avec des clés afin d’augmenter encore plus la sécurité du système. La combinaison des clés avec un watchdog permet de réaliser les fonctionnalités suivantes :
Pour contrôler comportement temporel d'un programme.
Pour vérifier si les fonctions les plus importantes ont effectivement été exécutées.
La procédure est la suivante : Une ou plusieurs clés sont nécessaires. Les clés sont des variables communs, qui permettent de contrôler le déroulement du programme. Une valeur spécifique est attribuée à une clé dans toutes les fonctions importantes du système. Si votre programme comporte de nombreux points à contrôler, vous pouvez également utiliser une seule variable clé. Dans ce cas vous pouvez systématiquement changer la valeur de votre clé à l’aide d'un polynôme de CRC. A la fin d'un cycle d’exécution du programme, la valeur de la clé vous assurera systématiquement que toutes les fonctions importantes ont été appelées dans un ordre adéquat. En effet, si cette dernière est correcte, vous pouvez effacer son contenu et rafraichir le watchdog. Toutefois, si la clé est erronée, cela signifie que le programme s’est comporté de façon erronée. Dans ce cas, le watchdog ne se doit pas être rafraichi afin d’engendrer le redémarrage du système avec un reset.
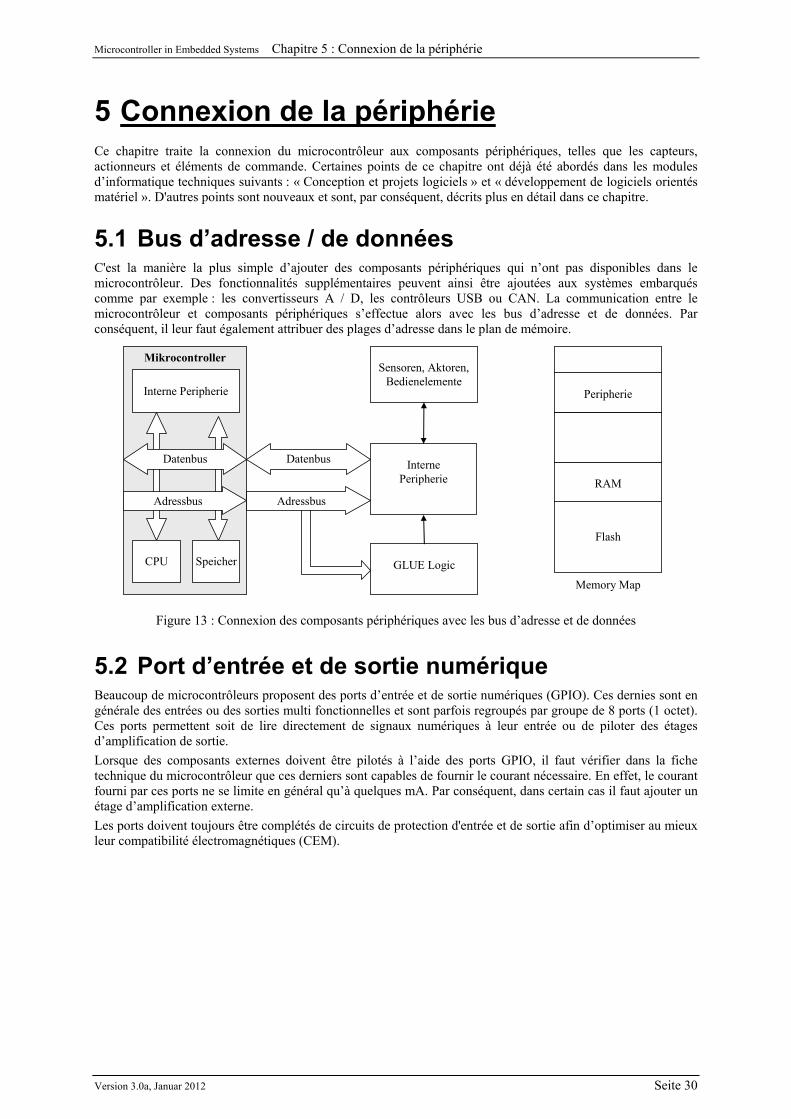
Microcontroller in Embedded Systems Chapitre 5 : Connexion de la périphérie
Version 3.0a, Januar 2012 Seite 30
5 Connexion de la périphérie Ce chapitre traite la connexion du microcontrôleur aux composants périphériques, telles que les capteurs, actionneurs et éléments de commande. Certaines points de ce chapitre ont déjà été abordés dans les modules d’informatique techniques suivants : « Conception et projets logiciels » et « développement de logiciels orientés matériel ». D'autres points sont nouveaux et sont, par conséquent, décrits plus en détail dans ce chapitre.
5.1 Bus d’adresse / de données C'est la manière la plus simple d’ajouter des composants périphériques qui n’ont pas disponibles dans le microcontrôleur. Des fonctionnalités supplémentaires peuvent ainsi être ajoutées aux systèmes embarqués comme par exemple : les convertisseurs A / D, les contrôleurs USB ou CAN. La communication entre le microcontrôleur et composants périphériques s’effectue alors avec les bus d’adresse et de données. Par conséquent, il leur faut également attribuer des plages d’adresse dans le plan de mémoire.
Mikrocontroller
Adressbus
Datenbus
CPU
Speicher
Interne Peripherie
Interne
Peripherie
Datenbus
Sensoren, Aktoren,
Bedienelemente
GLUE Logic
Adressbus
Flash
RAM
Peripherie
Memory Map
Figure 13 : Connexion des composants périphériques avec les bus d’adresse et de données
5.2 Port d’entrée et de sortie numérique Beaucoup de microcontrôleurs proposent des ports d’entrée et de sortie numériques (GPIO). Ces dernies sont en générale des entrées ou des sorties multi fonctionnelles et sont parfois regroupés par groupe de 8 ports (1 octet). Ces ports permettent soit de lire directement de signaux numériques à leur entrée ou de piloter des étages d’amplification de sortie.
Lorsque des composants externes doivent être pilotés à l’aide des ports GPIO, il faut vérifier dans la fiche technique du microcontrôleur que ces derniers sont capables de fournir le courant nécessaire. En effet, le courant fourni par ces ports ne se limite en général qu’à quelques mA. Par conséquent, dans certain cas il faut ajouter un étage d’amplification externe.
Les ports doivent toujours être complétés de circuits de protection d'entrée et de sortie afin d’optimiser au mieux leur compatibilité électromagnétiques (CEM).

Microcontroller in Embedded Systems Chapitre 5 : Connexion de la périphérie
Version 3.0a, Januar 2012 Seite 31
Mikrocontroller
P1.0 P1.1 P1.2
…
Motor
Motortreiber
Endschalter
Eingangs-Schutzschaltung
Figure 14 : Utilisation de ports d’entrée et de sortie numériques
L’accès aux ports est relativement simple en C :
Les différents pins d’un port peuvent être mis à 1 ou à 0 de façon individuelle avec des opérations logiques binaires ET ou OU. Par exemple: P1 |= 0x01; mets le pin P1.0 à 1. Remarque : cette opération lit d’abord l’état actuel du port P1 avant de mettre le pin P1.0 à 1.
Certains microcontrôleurs permettent de programmer les pins des ports bit par bit. Ce genre d’opérations peuvent être réalisées soit à l’aide d’instruction Assembleur (ces instructions sont alors également soutenue par les compilateurs C : P1_0 = 1; met par exemple le pin P1.0 à 1) ou elles sont soutenues directement par le hardware (ex. bit-banding avec ARM).
5.3 RS232 L’interface RS232 est très répandue dans le domaine embarqué. Cette interface permet par exemple de gérer des affichages LCD ou des lignes de commande (Command Line Interface). La plupart des microcontrôleurs possèdent déjà une interface RS232. Toutefois, les tensions de sortie de ces dernières correspondent au niveau TTL. Par conséquent, un convertisseur de tension externe doit être ajouté au système.
Les interfaces RS232 sont accessibles à l’aide de registres.
Les tampons de transmission et de réception contiennent systématiquement 1 octet. Les deux tampons possèdent souvent la même adresse, car il n’est possible que d’écrire dans le tampon de transmission et de lire à partir du tampon de réception.
Les registres de contrôle, qui permettent de définir les modes de fonctionnement (la fréquence de transmission (baud rate), le format des données, le bit de parité etc.) et les interruptions.
Les interfaces RS232 soutiennent différents modes de fonctionnement. Par exemple ils peuvent fonctionner soit en mode synchrone ou en mode asynchrone. La fréquence de transmission est souvent définie avec un Timer standard. Certaine interface RS232 possèdent toutefois leur propre générateur de fréquence. Le Timer peut ainsi être utilisé pour d’autres applications.
Le schéma bloc de l’interface RS232 est typiquement le suivant :
Microcontroller in Embedded Systems Chapitre 5 : Connexion de la périphérie
Version 3.0a, Januar 2012 Seite 32
Inte
rnal
Bus
Transmitter
Transmit FIFO
Transmit Shifter
Transmit Holding Register
Receiver
Receive FIFO
Receive Shifter
Receive Holding Register
Baudrate Generator
Control Unit
TxD
RxD
Figure 15 : Schéma bloc d’un module RS232
5.4 SPI L’interface SPI (Serial Peripheral Interface) est un bus sériel à haut débit, destiné à la communication entre le microcontrôleur et la périphérie. Ce dernier est souvent utilisé pour la communication avec des extensions d’entrée et de sortie, des affichages LCD ainsi que des convertisseurs A/D et D/A. Il peut également être utilisé pour la communication entre microcontrôleurs.
La figure suivante illustre le principe de fonctionnement du SPI :

Microcontroller in Embedded Systems Chapitre 5 : Connexion de la périphérie
Version 3.0a, Januar 2012 Seite 33
Teilnhmer 1
7 0
Taktgenerator Daten-Input parallel
Daten-Output parallel
Teilnhmer n
7 0
Daten-Input parallel
Daten-Output parallel
Figure 16 : Principe d’une connexion SPI
L’interface SPI est toujours utilisée en mode maître esclave. Le maître est alors responsable de la génération de la fréquence d’horloge. Le SPI peut travailler de façon duplexe à l’aide de deux lignes de transmission : MOSI (Master Out Slave In) et MISO (Master In Slave Out). Les esclaves peuvent être connectés soit de façon parallèle (c’est à dire que toutes les sorties des esclaves sont rassemblée et connectées à l’entré MISO du maître) ou de façon sérielle (la sortie d’un esclave est connectée à l’entrée du prochain esclave et la sortie du dernier esclave est connecté à l’entrée MISO du maître).
Le microcontrôleur écrit les données à transmettre dans un tampon de transmission. Ces dernières sont sérialisées à l’aide d’un registre à décalage (comme une transmission RS232). Les données reçues sont également converties à l’aide d’un registre à décalage. Le microcontrôleur peut alors lire ces données de façon parallèle dans le tampon de réception. Du fait que les interfaces SPI ont une bande passante relativement élevé, les tampons de transmission et de réception contiennent souvent plusieurs octets.
SPI Slave 1 SPI Slave 2
SPI des Masters
Receive-FIFO Transmit-FIFO
Schieberegister Takt Slave Selekt
MOSI
MISO
SCK
Schieberegister
Daten
Schieberegister
Daten
Figure 17 : SPI avec maître et 2 esclaves

Microcontroller in Embedded Systems Chapitre 5 : Connexion de la périphérie
Version 3.0a, Januar 2012 Seite 34
5.5 I2C
5.5.1 Aperçu Le bus I2C (Inter Integrated Circuit) a été développé par l’entreprise Philips. Ce bus est utilisé pour connecter les composants périphériques comme l’EEPROM, les affichages LCD ou RTC (Real Time Clock) au microcontrôleur.
Le bus I2C est composé de deux fils, ce qui réduit la partie hardware de façon drastique. Ce bus comprend une ligne d’horloge SCL (Serial Clock) et une ligne de donnée SDA (Serial Data). La communication est par conséquent synchrone. Son mode d’utilisation est souvent du type maître et esclave. Cependant, il soutient également le mode multi-maître.
La Figure suivante illustre une application typique avec le bus I2C :
Figure 18 : Application avec un bus I2C.
Source : Philips, The I2C-Bus Specification, V2.1, Jan 2000
5.5.2 Protocole Le protocole du bus est défini de la manière suivante :
Figure 19: Le maître (émetteur) adresse l’esclave (récepteur) avec une adresse 7 bit et envoie 2 octets de
données.
Source : Philips, The I2C-Bus Specification, V2.1, Jan 2000
Le transfert de données entre le maître et l’esclave s’effectue de la manière suivante :
1. Le maître démarre le transfert des données en envoyant le bit de démarrage. Tous les esclaves entrent ainsi dans un état passif d’écoute.
2. Le maître envoie ensuite l’adresse de l’esclave, avec lequel il aimerait communiquer. Cette adresse est composée de 7 bits.
3. Le maître envoi le bit R/W, qui fixe le sens de la communication : Ecriture depuis le maître à l’esclave ou lecture depuis l’esclave au maître
4. Le protocole I2C exige des confirmations (acknowledge) après chaque transmission d’un octet. L’esclave accrédite avec le premier bit de confirmation, qu’il est prêt pour la communication.
5. Le transfert de données a lieu entre le maître et l’esclave. Un bit de confirmation est également échangé ici
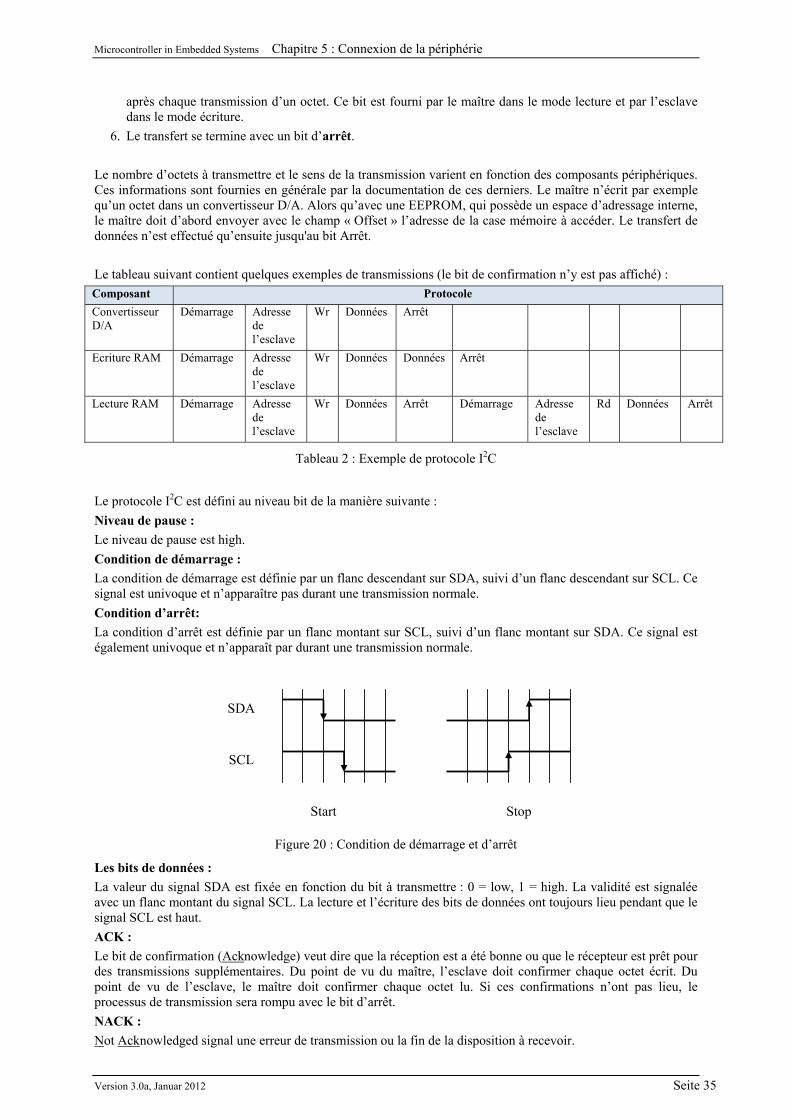
Microcontroller in Embedded Systems Chapitre 5 : Connexion de la périphérie
Version 3.0a, Januar 2012 Seite 35
après chaque transmission d’un octet. Ce bit est fourni par le maître dans le mode lecture et par l’esclave dans le mode écriture.
6. Le transfert se termine avec un bit d’arrêt.
Le nombre d’octets à transmettre et le sens de la transmission varient en fonction des composants périphériques. Ces informations sont fournies en générale par la documentation de ces derniers. Le maître n’écrit par exemple qu’un octet dans un convertisseur D/A. Alors qu’avec une EEPROM, qui possède un espace d’adressage interne, le maître doit d’abord envoyer avec le champ « Offset » l’adresse de la case mémoire à accéder. Le transfert de données n’est effectué qu’ensuite jusqu'au bit Arrêt.
Le tableau suivant contient quelques exemples de transmissions (le bit de confirmation n’y est pas affiché) :
Composant Protocole
Convertisseur D/A
Démarrage Adresse de l’esclave
Wr Données Arrêt
Ecriture RAM Démarrage Adresse de l’esclave
Wr Données Données Arrêt
Lecture RAM Démarrage Adresse de l’esclave
Wr Données Arrêt Démarrage Adresse de l’esclave
Rd Données Arrêt
Tableau 2 : Exemple de protocole I2C
Le protocole I2C est défini au niveau bit de la manière suivante :
Niveau de pause :
Le niveau de pause est high.
Condition de démarrage :
La condition de démarrage est définie par un flanc descendant sur SDA, suivi d’un flanc descendant sur SCL. Ce signal est univoque et n’apparaître pas durant une transmission normale.
Condition d’arrêt:
La condition d’arrêt est définie par un flanc montant sur SCL, suivi d’un flanc montant sur SDA. Ce signal est également univoque et n’apparaît par durant une transmission normale.
SDA
SCL
Start Stop
Figure 20 : Condition de démarrage et d’arrêt
Les bits de données :
La valeur du signal SDA est fixée en fonction du bit à transmettre : 0 = low, 1 = high. La validité est signalée avec un flanc montant du signal SCL. La lecture et l’écriture des bits de données ont toujours lieu pendant que le signal SCL est haut.
ACK :
Le bit de confirmation (Acknowledge) veut dire que la réception est a été bonne ou que le récepteur est prêt pour des transmissions supplémentaires. Du point de vu du maître, l’esclave doit confirmer chaque octet écrit. Du point de vu de l’esclave, le maître doit confirmer chaque octet lu. Si ces confirmations n’ont pas lieu, le processus de transmission sera rompu avec le bit d’arrêt.
NACK :
Not Acknowledged signal une erreur de transmission ou la fin de la disposition à recevoir.

Microcontroller in Embedded Systems Chapitre 5 : Connexion de la périphérie
Version 3.0a, Januar 2012 Seite 36
0 0 0 1 1 1 1 1 SDA
SCL
Start Slave-Adressse R/W Stop ACK
Figure 21: Transmission au niveau bit
Dans Figure 21, le maître envoi en premier la condition de démarrage, ensuite il envoi l’adresse de l’esclave (1001011) et pour finir le bit R/W. L’esclave doit signaler sa présence avec le bit de confirmation. Il est important que le maître maintienne le SDA à un état haut impédance durant cette phase. Les données peuvent être transmises après le bit de confirmation (cela n’est pas montré dans la Figure). La communication est interrompue avec le bit d’arrêt.
Admettons que l’on veut connecter un émetteur à plusieurs participants avec un bus I2C. Dans ce cas tous les participants doivent se mettent dans un état à haute impédance. Certain microcontrôleur peuvent configurer leurs sorties en tri state. Si cela n’est pas possible, il faut configurer les pins SCL et SDA en entrée.
5.5.3 Implémentation Certain microcontrôleur possède une interface I2C intégrée. La programmation du composant périphérique se réalise alors avec des registres.
Toutefois, dans certain cas, la réalisation de l’interface I2C ne peur s’effectuer qu’à l’aide de deux ports d’entrée/sortie numériques et du code. Cette réalisation peut néanmoins varier selon le type de contrôleur. Dans ce cas on commence idéalement par la définition les ports SDA et SCL ainsi que l’énumération des différents codes d’erreurs de la manière suivante : #define SDA P4_2 #define SCL P4_1 typedef enum {I2C_OK, I2C_ACK_ERROR, I2C_BUS_ERROR} I2C_Error;
Les fonctions I2C_Init(), I2C_Start(), I2C_Stop(), I2C_Write() et I2C_Read() sont alors implémentées par la suite.
Ces fonction doivent pourvoir accéder aux ports SCA et SCL. Il est également recommander de retourner des messages d’erreurs en cas de problème.
Exemple de code pour la fonction I2C_Start():
I2C_Error I2C_Start(void) { I2C_Error error = I2C_OK; SDA = 1; // Initial state SCL = 1; if (!SDA||!SCL){ // Test the bus levels
error = I2C_BUS_ERROR; } else {
SDA=0; // Start condition ... // Insert eventually a delay SCL=0;
} return(error); }
5.6 Timer
5.6.1 Introduction La plupart des microcontrôleurs possèdent aujourd’hui un ou plusieurs « Timer/Counter » (français : minuterie/compteur) intégrés. Des fonctionnalités supplémentaires, comme par exemple celle de « Compare/Capture », permettent d’élargir encore plus les applications de ces contrôleurs. Ce chapitre donne un aperçu général sur ce sujet.
Les applications du Timer/Counter sont les suivantes :

Microcontroller in Embedded Systems Chapitre 5 : Connexion de la périphérie
Version 3.0a, Januar 2012 Seite 37
Génération de fréquence d’horloge (ex. débit en Baud pour la communication sérielle)
Compteur d’événements externes
Génération de signaux PWM (ou convertisseur D/A)
Mesure du temps
5.6.2 Timer/Counter En générale des registres de 8 ou 16 bits sont utilisés dans les modules Timer/Counter. Dans le mode Timer, ces registres sont incrémentés périodiquement à l’aide de l’horloge interne du système. Dans le mode Counter, cette incrémentation s’effectue en fonction de signaux externes.
Counter
Timer
Oszillator
externer Eingang
Timer / Counter Register
Overflow Flag
Mode
Figure 22: Timer/Counter Mode
Lorsqu’il y dépassement de capacité (c'est-à-dire au passage de 0xFFFF à 0x0000 avec un registre de 16 bits), le drapeau (flag) d’overflow est mis à un. Ce dernier peut être observé à l’aide d’une boucle software (polling) ou il peut générer une interruption.
Remarque : le contenu du registre Timer est décrémenté avec certain contrôleur.
5.6.3 Timer avec recharge automatique L’option « d’auto rechargement » (anglais: auto reload) du Timer permet de générer une fréquence d’horloge avec une périodicité prédéfinie.
Le mode d’auto rechargement permet d’initialiser également le registre du Timer avec une valeur prédéfinie. Cette dernière est stockée dans le « registre de rechargement » (anglais: reload register). Ce mécanisme permet de générer des fréquences d’horloge de périodicité variable.
Reload
Oszillator TimerRegister
OverflowFlag
ReloadRegister
Figure 23: Timer dans le mode auto chargement
5.6.4 Unité comparateur L’unité comparateur (anglais : Compare Unit) permet de comparer la valeur du registre compteur (Timer Register) avec celle du registre comparateur (anglais : Comparator Register).

Microcontroller in Embedded Systems Chapitre 5 : Connexion de la périphérie
Version 3.0a, Januar 2012 Seite 38
Comparator
Register
OverflowFlag
Port Latch
Comparator
Timer Register
Port
S
R
Figure 24: Unité comparateur
L’unité comparatrice permet ainsi de générer des signaux PWM sans demander de la puissance de calcul du CPU. Le signal de sortie du comparateur et l’indicateur de dépassement (anglais : overflow flag) commutent un port de sortie numérique. Le latch est réinitialisé lorsqu’il y a dépassement de capacité du registre compteur. Ce qui met le port au niveau logique 0. Ce même latch est mis à un lorsque le compteur du Timer atteint la valeur du registre comparateur. Ce qui met le port au niveau logique 1. Ce mécanisme est illustré dans la figure suivante :
t
Timer Register
max
Reload
Compare Value erreicht
Port Output
t
Figure 25: Comportement du port de sortie dans le mode Compare
La Figure 25 se base sur un compteur qui compter vers le haut en mode Count-Up. Une variante ici est un compteur qui compte vers le bas en mode Count-Down. La valeur du registre compteur est alors comparée avec la valeur nulle. A chaque passage par zéro, le registre compteur est alors initialisé avec une valeur de rechargement prédéfinie.
5.6.5 Entité de capture En mode capture, un signal de déclenchement (anglais : trigger) provoque un transfert de la valeur du registre compteur (Timer Register) dans le registre de capture (Capture Register). Le signal de déclenchement peut être fourni soit par la partie logicielle (SW trigger) ou par la partie matérielle (HW trigger).
SW trigger TimerRegister
Overflow Flag
CaptureRegister
Externer HW trigger
Figure 26: Entité de capture

Microcontroller in Embedded Systems Chapitre 5 : Connexion de la périphérie
Version 3.0a, Januar 2012 Seite 39
5.7 CAN L’interface CAN est enseignée au 5ème semestre dans le module de base « Informatique technique ». Le manuscrit qui traite cette interface se trouve également dans l’annexe B de ce document.

Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 40
A Introduction pour le LM3S9B92 Les microcontrôleurs LM3S9B92 utilisés durant ce module se basent sur le noyau Cortex-M3 d'ARM. Par conséquence, les paragraphes suivants traitent d'abord le noyau Cortex-M3 et en suite le microcontrôleur LM3S9B92.
A.1 La famille Cortex-M3 La famille des Cortex-M3 est largement utilisée dans l'industrie. Les raisons en sont principalement les suivantes:
Des performances 32 bits pour le prix d'un microcontrôleur 8 bits.
De nombreux fabricants de semi-conducteur proposent de nombreux dérivés pour ces microcontrôleurs (ces derniers sont tous basés sur ce noyau).
Pratiquement tous les dérivés peuvent être programmés avec les mêmes environnements de développement.
Une fois que vous avez développé un projet avec un microcontrôleur de cette famille, vous êtes en mesure de travailler relativement facilement avec un autre membre de la famille.
Le cœur Cortex-M3 est basé sur l'architecture ARMv7-M et est structuré de façon hiérarchique. Le noyau contiens la CPU (appelé CM3Core) avec des composants périphériques supplémentaires tels que le contrôleur d'interruptions, les unités de protection de la mémoire et les circuits de débogage.
Le cœur Cortex-M3 a les propriétés suivantes:
Processeur 32 bits avec des registres 32 bits et une interface mémoire.
Une architecture de Harvard : il possède deux bus différents pour accéder à la mémoire contenant les instructions du programme et à la mémoire contenant les données. Ce qui augmente les performances du système. En effet les accès aux instructions et aux données du programme peuvent être exécutés en parallèle (c.à.d. d. en même temps).
Un pipeline de trois étages (fetch, decode, execute) avec une prédiction spéculative pour les instructions de branchement.
Jeu d’instruction Thumb-2 : Mélange d’instructions 16 et 32 bits pour une performance optimale avec les exigences minimales en ressource mémoire (code compact).
Accès bit à certaines zones de la mémoire (bit-banding, bit-band regions), ce qui permet la modification d'un bit sans les cycles de lecture/écriture standards.
Support hardware des opérations de multiplications et de divisions 32-bits.
Contrôleur d'interruptions vectorielles imbriqué (Nested Vectored Interrupt Controller : NVIC) avec tableau de vecteurs et huit niveaux de priorité d'interruption. Les opérations de sauvegarde sur la pile (sauvegarde des registres avec les exceptions) sont réalisées de façon hardware.
Unité de protection de la mémoire (Memory Protection Unit : MPU) pour la protection des zones mémoires (applications RTOS).
Support de débogage
La Figure 27 à la page suivante illustre le diagramme de bloc du noyau Cortex-M3. L'architecture Harvard, avec ses deux bus différents pour le code et les données, y est facilement reconnaissable.
Les composants périphériques du Cortex-M3 sont accessibles à travers le plan de mémoire. Le bus d'adresse de 32 bits permet d’adresser un domaine de 4 giga octets. Le plan de mémoire est pré-subdivisé avec des zones de mémoire fixes, qui sont réservées pour le code (code de l'espace), les données (espace mémoire), les composants périphériques internes et la mémoire externe.
La Figure 28 à la page suivante illustre le plan de mémoire du noyau Cortex-M3.
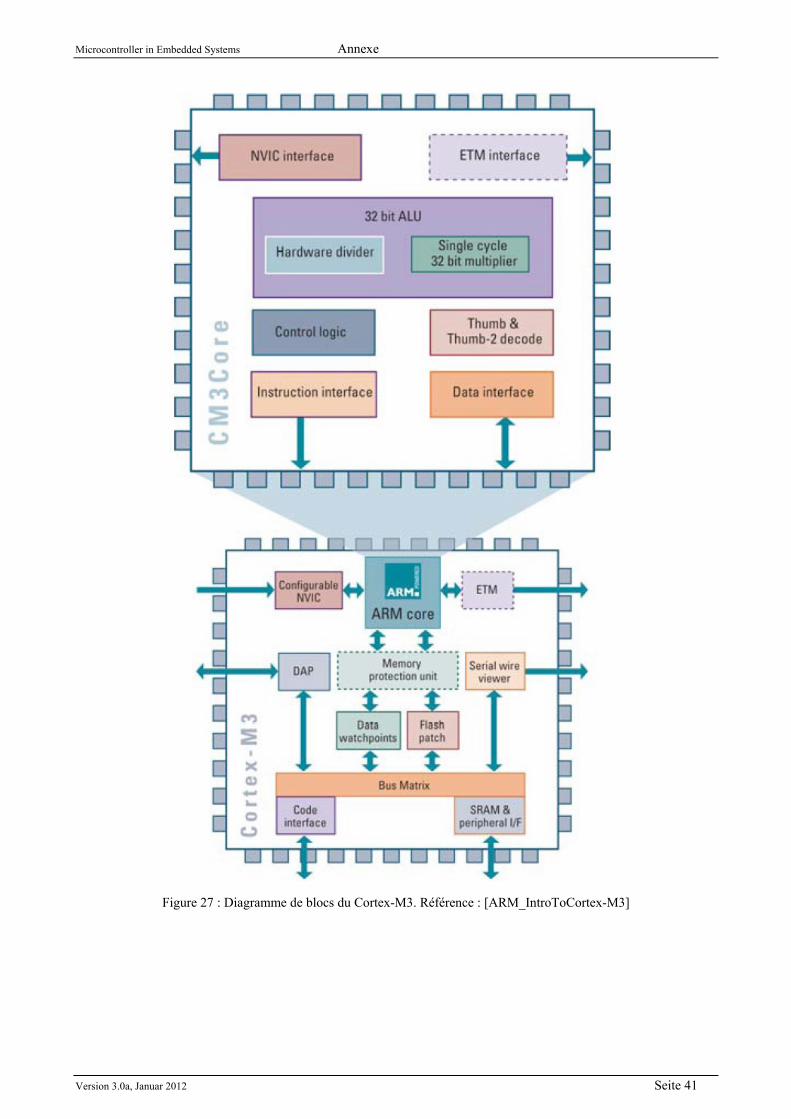
Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 41
Figure 27 : Diagramme de blocs du Cortex-M3. Référence : [ARM_IntroToCortex-M3]

Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 42
Figure 28 : Plan de mémoire du Cortex-M3. Référence : [ARM_IntroToCortex-M3]
A.2 Le microcontrôleur LM3S9B92
A.2.1 Diagramme de blocs Le microcontrôleur « LM3S9B92 » de la famille Stellaris de Texas Instruments complète le noyau Cortex-M3 avec de la mémoire interne et divers modules périphériques :
Les mémoires SRAM de 96 kilo octets et Flash de 256 kilo octets
Les interfaces séries (UART, SPI, Ethernet, CAN, I2C)
Commande du moteur (PWM)
Timer, Watchdog, GPIO, DMA
Deux convertisseurs A/D de 10 bits et trois comparateurs analogiques

Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 43
Figure 29 : Diagramme de blocs du LM3S9B92. Référence : [TI_LM3S9B92Brief]
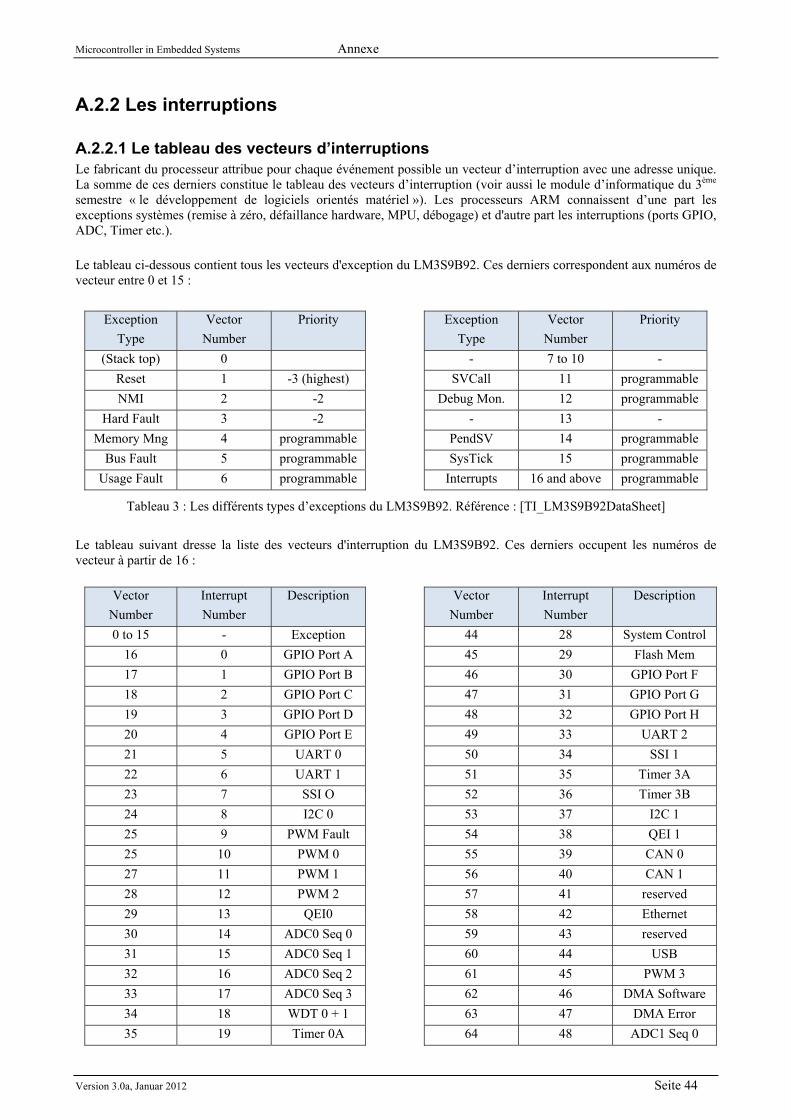
Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 44
A.2.2 Les interruptions
A.2.2.1 Le tableau des vecteurs d’interruptions Le fabricant du processeur attribue pour chaque événement possible un vecteur d’interruption avec une adresse unique. La somme de ces derniers constitue le tableau des vecteurs d’interruption (voir aussi le module d’informatique du 3ème semestre « le développement de logiciels orientés matériel »). Les processeurs ARM connaissent d’une part les exceptions systèmes (remise à zéro, défaillance hardware, MPU, débogage) et d'autre part les interruptions (ports GPIO, ADC, Timer etc.).
Le tableau ci-dessous contient tous les vecteurs d'exception du LM3S9B92. Ces derniers correspondent aux numéros de vecteur entre 0 et 15 :
Exception
Type
Vector
Number
Priority Exception
Type
Vector
Number
Priority
(Stack top) 0 - 7 to 10 -
Reset 1 -3 (highest) SVCall 11 programmable
NMI 2 -2 Debug Mon. 12 programmable
Hard Fault 3 -2 - 13 -
Memory Mng 4 programmable PendSV 14 programmable
Bus Fault 5 programmable SysTick 15 programmable
Usage Fault 6 programmable Interrupts 16 and above programmable
Tableau 3 : Les différents types d’exceptions du LM3S9B92. Référence : [TI_LM3S9B92DataSheet]
Le tableau suivant dresse la liste des vecteurs d'interruption du LM3S9B92. Ces derniers occupent les numéros de vecteur à partir de 16 :
Vector
Number
Interrupt
Number
Description Vector
Number
Interrupt
Number
Description
0 to 15 - Exception 44 28 System Control
16 0 GPIO Port A 45 29 Flash Mem
17 1 GPIO Port B 46 30 GPIO Port F
18 2 GPIO Port C 47 31 GPIO Port G
19 3 GPIO Port D 48 32 GPIO Port H
20 4 GPIO Port E 49 33 UART 2
21 5 UART 0 50 34 SSI 1
22 6 UART 1 51 35 Timer 3A
23 7 SSI O 52 36 Timer 3B
24 8 I2C 0 53 37 I2C 1
25 9 PWM Fault 54 38 QEI 1
25 10 PWM 0 55 39 CAN 0
27 11 PWM 1 56 40 CAN 1
28 12 PWM 2 57 41 reserved
29 13 QEI0 58 42 Ethernet
30 14 ADC0 Seq 0 59 43 reserved
31 15 ADC0 Seq 1 60 44 USB
32 16 ADC0 Seq 2 61 45 PWM 3
33 17 ADC0 Seq 3 62 46 DMA Software
34 18 WDT 0 + 1 63 47 DMA Error
35 19 Timer 0A 64 48 ADC1 Seq 0

Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 45
36 20 Timer 0B 65 49 ADC1 Seq 1
37 21 Timer 1A 66 50 ADC1 Seq 2
38 22 Timer 1B 67 51 ADC1 Seq 3
39 23 Timer 2A 68 52 I2S 0
40 24 Timer 2B 69 53 EPI
41 25 Analog C0 70 54 GPIO Port J
42 26 Analog C1 71 55 reserved
43 27 Analog C2
Tableau 4 : Les différents types d’interruption du LM3S9B92. Référence : [TI_LM3S9B92DataSheet]
A.2.2.2 Masquage et priorités Les problèmes suivants doivent être considérés lorsque plusieurs interruptions apparaissent simultanément :
a) Quelle l'interruption doit être desservie en premier lorsque plusieurs sources lancent simultanément leur requête ?
b) Les interruptions peuvent-elles être interrompues par d'autres interruptions ?
c) Les interruptions peuvent-elles être désactivées ?
Les interruptions peuvent être masquées et priorisées indépendamment l’une de l’autre dans la plupart des processeurs. L'utilisateur peut ainsi définir d’une part les interruptions autorisées et d’autre part leur priorité (voir aussi le module informatique du 3ème semestre « le développement de logiciels orientés matériel »).
L’activation et la désactivation des sources d’interruption se réalisent dans le LM3S9B92 avec la mise à 1 ou à 0 des bits correspondant dans les registres de masquage des interruptions. Une mise à 1 entraine un transfert de l'interruption en question vers le NVIC (activé). Une mise à 0 signifie que l'interruption est désactivée. En outre il faut encore activer le NVIC pour l'interruption en question (registre NVIC_ENx). La figure suivante illustre les registres, qui sont nécessaires pour déclencher une interruption à l'aide d'un bouton poussoir (Button 1). Ce dernier qui est relié au pin 0 du port J dans le module GPIO :
PORT J
J0
Button 1
GPIO_PORTJ_IM_R
NVIC CPU
NVIC_EN1_R
#54
Figure 30 : Les registres de masquage d’interruptions
Cela peut être programmé en C de la manière suivante : // // Enable button 1 interrupt, falling edge // GPIO_PORTJ_IS_R = 0; // GPIO Interrupt Sense: detect edges GPIO_PORTJ_IBE_R = 0; // GPIO Interrupt both edges disabled GPIO_PORTJ_IEV_R = 0; // GPIO Interrupt Event, falling edges GPIO_PORTJ_IM_R = 0x01; // Enable Interrupt button 1, interrupt sent to NVIC // // Enable NVIC for Port J (button 1) interrupt // NVIC_EN1_R |= NVIC_EN1_INT54;

Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 46
La mise à zéro des registres GPIO_PORTJ_IS (Interrupt Sense), GPIO_PORTJ_IBE (Interrupt Both Edges) et GPIO_PORTJ_IEV (Interrupt Event) du port J permet de générer les interruptions aux flans descendant de ce dernier. Pour plus d'informations, voir [TI_LM3S9B92DataSheet]. Les priorités peuvent être définies de façon logicielle pour chaque type d’interruption à l’aide des registres de priorité d'interruption. Les valeurs possibles sont 0-255 (0 étant la priorité la plus élevée, 255 est la priorité la plus basse). Lorsqu’aucune priorité n’est définie de façon logiciel, alors c’est le numéro de priorité hardware, qui correspond au numéro de priorité, qui sera considéré (voir Tableau 4). Ici aussi, un numéro inférieur correspond à une priorité supérieure. Pour plus d'informations, voir [ARM_M3RefManual].
A.2.2.3 Programmation des interruptions en C Lorsqu’une interruption a lieu, les registres du processeur et l’adresse de retours sont sauvegardés de façon matérielle dans les processeurs de la famille Cortex-M3. Ce qui simplifie le traitement des interruptions. En effet, dans ce cas, la routine de service d'interruption (ISR) ne diffère plus d'une autre fonction. Il suffit d'entrer l’adresse de la routine de service dans le tableau des vecteurs d’interruption. Cette dernière se trouve dans le fichier de démarrage (startup_css.c) :
Exemple de tableau de vecteurs d’interruption pour de port J du module GPIO :
//****************************************************************************** // // The vector table. Note that the proper constructs must be placed on this to // ensure that it ends up at physical address 0x0000.0000 or at the start of // the program if located at a start address other than 0. // //****************************************************************************** #pragma DATA_SECTION(g_pfnVectors, ".intvecs") void (* const g_pfnVectors[])(void) = { (void (*)(void))((unsigned long)&__STACK_TOP), // The initial stack pointer ResetISR, // The reset handler NmiSR, // The NMI handler FaultISR, // The hard fault handler IntDefaultHandler, // The MPU fault handler ... IntDefaultHandler, // ADC1 Sequence 3 IntDefaultHandler, // I2S0 IntDefaultHandler, // External Bus Interface 0 ButtonISR // GPIO Port J, buttons };
Il est important que le tableau des vecteurs d’interruption contienne une entrée (vecteur) pour chaque type d’interruption. Un traiteur d’interruption par défaut peut être défini pour les interruptions que ne demandent pas de traitement spécifique (voir également la section 4.3.4).
Exemple de routine de service d’interruption pour le port J du module GPIO : //***************************************************************************** // ISR called if button 1 (Port J) is pressed, // checks which button is pressed and resets interrupt source. //***************************************************************************** void ButtonISR(void){ if((GPIO_PORTJ_MIS_R & 0x01) > 0){ GPIO_PORTJ_ICR_R = 0x01; // clear interrupt button 1 ... } }
La tâche principale de la routine de service d’interruptions est de désactiver la source d’interruption. Ceci peut être réalisé avec les registres d'effacement des interruptions (Interrupt Clear Register) qui sont spécifiques à chaque source d’interruption (dans l’exemple ci-dessus avec le registre GPIO_PORTJ_ICR_R). Une mise à 1 du bit correspondant à la source de l'interruption permet de désactiver cette dernière. En outre, le registre d’état des interruptions masquées

Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 47
(Masked Interrupt Status Registers : MISR) permet d’isoler le pin qui a lancé l’interruption (dans l’exemple ci-dessus avec le registre GPIO_PORTJ_MIS_R).
A.2.3 GPIOs Le LM3S9B92 contient 65 pins d’utilité générale programmables (General Purpose Input/Output : GPIO). Ces pins sont multifonctionnels. Ce qui signifie qu'ils peuvent être utilisés soit comme pin d’entré/sorti numérique standard ou spécifique à un composant périphérique. Par exemple, le pin A0 (pin 0 du port A) peut être utilisé à choix comme GPOI, I2C1_SCL, UART0_Rx ou UART1_Rx. Les 65 pins GPIO sont repartis en 9 ports différents : du port A au port J. Chacun de ces ports a un ensemble de registres qui servent d’interface entre la partie matérielle et la partie logicielle. Figure 31 fournit une vue d'ensemble de ces registres. Ces derniers sont identiques pour chaque port (A ... J).
Figure 31: Diagramme de block du module GPIO. Référence : [TI_LM3S9B92DataSheet]
Une description détaillée de ces registres est fournie dans le chapitre 9 de la documentation pour le processeur LM3S9B92 [TI_LM3S9B92DataSheet]. Cependant peu de registres sont en général nécessaires pour configurer un pin comme entrée/sortie numérique (GPIO). Ces derniers sont fournis dans le tableau suivant :
Nom documentaire du registre
Nom logiciel du registre Brève description du registre
GPIODATA GPIO_PORTx_DATA_R Le registre de données GPIO contient la valeur du port. Ce dernier peut être lu ou écrit.
GPIODIR GPIO_PORTx_DIR_R Le registre de direction GPIO définit le sens du port (entré ou sorti). Ce dernier peut être programmé de façon binaire.
GPIOAFSEL GPIO_PORTx_AFSEL_R Le registre de sélection des fonctions alternatives (GPIO Alternate Function Select) définit la fonctionnalité d’un port.
GPIODEN GPIO_PORTx_DEN_R Le registre d’activation numérique (GPIO Digital Enable) définit si un port doit être utilisé de façon analogique ou numérique.
Tableau 5 : Les principaux registres du module GPIO

Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 48
Les registres GPIO du Tableau 5 sont définis dans le fichier « lm3s9b92.h ». Si vous incluez ce fichier dans votre projet, vous pouvez ensuite utiliser ces registres dans votre programme.
Le port J doit encore être configuré correctement pour notre exemple d’interruption touche de la section A.2.2.2. Cela peut être réalisé en C de la manière suivante : // // Enable GPIO Port J for the buttons: // Set the direction as input. // enable the GPIO pin for digital function. // Enable internal Pull-Up resistors. // GPIO_PORTJ_DIR_R &= ~(0xFF); // 0 is input GPIO_PORTJ_DEN_R |= 0xFF; // 1 is digital GPIO_PORTJ_PUR_R |= 0xFF; // enable intern pull-up resistors
Les bits du registre GPIO pull-up pour le port J (GPIO_PORTJ_PUR_R) sont également mis à 1 dans l’exemple de ci-dessus. Une résistance de rappel vers le haute (pull-up) est ainsi commutée à chaque pin du port J.
Chaque port peut être activé ou désactivé séparément afin d'économiser la consommation d'énergie. Par conséquent, le port J doit également être activé durant la phase d’initialisation. Cela peut être défini en C de la manière suivante : //
// Enable GPIO Port J (buttons)
//
SYSCTL_RCGC2_R |= SYSCTL_RCGC2_GPIOJ;
A.2.4 Le watchdog Le watchdog de l'LM3S9B92 présente les caractéristiques suivantes :
1) Deux watchdogs différents avec des horloges distinctes (horloge système et horloge watchdog)
2) Le watchdog génère un reset ou un NMI (Non Maskable Interrupt)
3) Compteur décrémental de 32 bits
4) L'accès au watchdog peut être bloqué à l’aide de registre de verrouillage (Lock-Register). Ce qui empêche les écritures accidentelles dans les registres du watchdog.
Le schéma bloc du watchdog est illustré dans la figure ci-dessous :

Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 49
Figure 32 : Diagramme de bloc du watchdog du LM3S9B92. Référence [TI_LM3S9B92DataSheet]
Une description détaillée de ces registres est fournie dans le chapitre 12 de la documentation pour le processeur LM3S9B92 [TI_LM3S9B92DataSheet]. Cependant seuls les registres suivants sont en général nécessaires pour la programmation :
Nom documentaire du registre
Nom logiciel du registre Brève description du registre
WDTLOAD WATCHDOG0_LOAD_R Lorsqu’une valeur est écrite dans ce registre, elle est ensuite copiée dans le registre compteur du watchdog.
Cela permet de réinitialiser le watchdog.
WDTCTL WATCHDOG0_CTL_R Le registre de control du watchdog.
Ce registre permet d’activer le watchdog et de définir si ce dernier doit être en mesure de pouvoir générer un reset.
Le watchdog génère au premier délai d’expiration (timeout) une interruption et au second (lorsque ce dernier est configuré ainsi) un reset.
WDTTEST WATCHDOG0_TEST_R Le bit « STALL » permet de définir si le watchdog doit être également stoppé lorsque le programme est arrêté à un certain point durant le débogage (par exemple à un break point).
Tableau 6 : Les principaux registres du module watchdog
Les registres watchdog du Tableau 6 sont définis dans le fichier « lm3s9b92.h ». Si vous incluez ce fichier dans votre projet, vous pouvez ensuite utiliser ces registres dans votre programme.
La démarche nécessaire pour initialiser le watchdog est décrite dans la section 12.3 de la documentation pour le processeur LM3S9B92 [TI_LM3S9B92DataSheet].
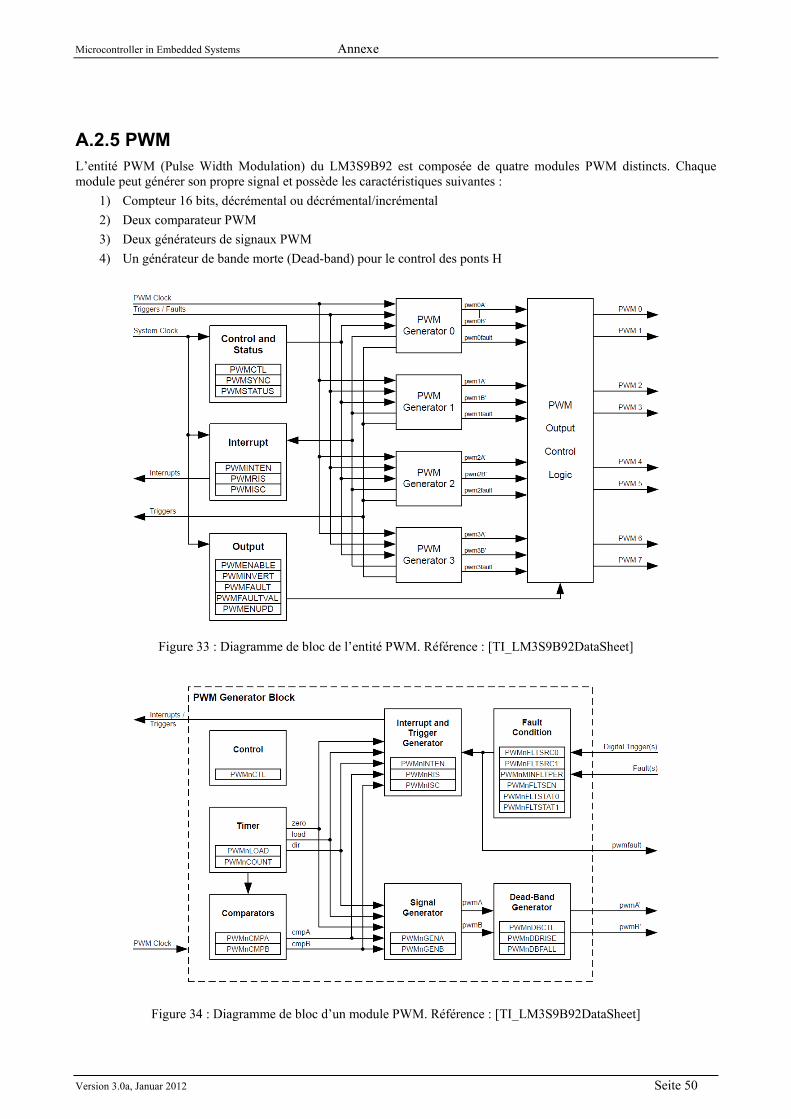
Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 50
A.2.5 PWM L’entité PWM (Pulse Width Modulation) du LM3S9B92 est composée de quatre modules PWM distincts. Chaque module peut générer son propre signal et possède les caractéristiques suivantes :
1) Compteur 16 bits, décrémental ou décrémental/incrémental
2) Deux comparateur PWM
3) Deux générateurs de signaux PWM
4) Un générateur de bande morte (Dead-band) pour le control des ponts H
Figure 33 : Diagramme de bloc de l’entité PWM. Référence : [TI_LM3S9B92DataSheet]
Figure 34 : Diagramme de bloc d’un module PWM. Référence : [TI_LM3S9B92DataSheet]

Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 51
Les modules PWM du LM3S9B92 se distinguent par leur deux comparateurs, qui génèrent en interne les signaux de contrôle cmpA et cmpB. La connexion de ces deux générateurs de signaux PWM avec le générateur de bande morte permet de contrôler également les ponts H.
Une description détaillée des registres PWM est fournie dans le chapitre 22 de la documentation du processeur LM3S9B92 [TI_LM3S9B92DataSheet]. En général, seuls les registres suivants sont nécessaires pour initialiser les modules PWM (exemple : PWM0) :
Nom documentaire du registre
Nom logiciel du registre Brève description du registre
PWMCTL PWM_CTL_R PWM Master Control Register
PWMENABLE PWM_ENABLE_R Output Enable Register
PWM0CTL PWM_0_CTL_R Control Register for PWM0
PWM0LOAD PWM_0_LOAD_R Load-Register PWM0
PWM0CMPA PWM_0_CMPA_R Compare A PWM0
PWM0CMPB PWM_0_CMPB_R Compare B PWM0
PWM0GENA PWM_0_GENA_R PWM0 Generator A Control Register
PWM0GENB PWM_0_GENB_R PWM0 Generator B Control Register
Tableau 7 : Les principaux registres du module PWM
La procédure d’initialisation du PWM est décrite dans la section 22.4 de la documentation pour le processeur LM3S9B92 [TI_LM3S9B92DataSheet]. Ici il faut également faire attention à ne pas oublier l’activation de l’horloge destiné au module PWM et les différents pins GPIO.
A.2.6 CAN Le processeur LM3S9B92 contient deux contrôleurs CAN internes, qui gèrent les messages CAN et permettent de soulager ainsi la CPU. Chaque contrôleur CAN assure les fonctionnalités suivantes :
Envoi des messages CAN
Réception des messages CAN
Arbitrage du bus CAN
Reconnaissance des erreurs
Renvoi à nouveau le message CAN en cas d’erreurs
Génération de signaux d’interruption (interface pour la CPU)
Les contrôleurs CAN-Controller présentent en autre les propriétés suivantes :
1) Les protocoles soutenus : 2.0A et 2.0B
2) Fréquence de transmission de messages CAN : jusqu’à 1 méga bit/s
3) Tampons FIFO pour l’envoi et la réception de plusieurs messages CAN

Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 52
Figure 35 : diagramme de blocs des contrôleurs CAN
Une description détaillée des registres CAN est fournie dans le chapitre 18 de la documentation pour le processeur LM3S9B92 [TI_LM3S9B92DataSheet]. Ce chapitre décrit également les processus d’initialisation du contrôleur CAN et des objets CAN, qui servent à transmettre ou à recevoir des messages CAN.
En général, seuls les registres suivants sont nécessaires pour initialiser les modules CAN (exemple : CAN0) :
Nom documentaire du registre
Nom logiciel du registre Brève description du registre
CANCTL CAN0_CTL_R CAN Control Register
CANBIT CAN0_BIT_R CAN Control Register
CANBRPE CAN0_BRPE_R Baud rate Prescaler Extension
CANIF1CRQ CAN0_IF1CRQ_R CAN IF1 Command Request
CANIF1CMSK CAN0_IF1CMSK_R CAN IF1 Command Mask
CANIF1MSK1 CAN0_IF1MSK1_R CAN IF1 Mask 1
CANIF1MSK2 CAN0_IF1MSK2_R CAN IF1 Mask 2
CANIF1ARB1 CAN0_IF1ARB1_R CAN IF1 Arbitration 1
CANIF1ARB2 CAN0_IF1ARB2_R CAN IF1 Arbitration 2
CANIF1MCTL CAN0_IF1MCTL_R CAN IF1 Message Control
CANIF1DA1
CANIF1DA2
CANIF1DB1
CANIF1DB2
CAN0_IF1DA1_R
CAN0_IF1DA2_R
CAN0_IF1DB1_R
CAN0_IF1DB2_R
CAN0_IF1DA1_R
CAN0_IF1DA2_R
CAN0_IF1DB1_R
CAN0_IF1DB2_R

Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 53
Tableau 8 : Les principaux registres du module CAN
Les registres CAN du Tableau 8 sont définis dans le fichier « lm3s9b92.h ». Si vous incluez ce fichier dans votre projet, vous pouvez ensuite utiliser ces registres dans votre programme.

Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 54
B CAN
B.1 Introduction CAN (Controller Area Network) à été développé en 1981 par la maison Robert Bosch et Intel. Il a été prévu pour l’industrie automobile uniquement. Actuellement, CAN s’est également établi dans l’automation industrielle.
Grace au grand nombre de chips CAN produits, l’accès au bus CAN est devenu relativement bon marché. On peut les trouver aussi bien comme éléments périphériques externes sur des systèmes à microprocesseurs ou comme modules internes à un microcontrôleur.
L’organisation d'utilisateurs CiA (CAN in Automation) a défini plusieurs standards pour son application dans le domaine de « l‘automation industrielle ». Ce qui a conduit à une grande acceptante du bus CAN. Le site suivant peut être consulté à titre d’information : www.can-cia.org .
Avec quelques restrictions, CAN peut être utilisé pour des applications temps réel. Les temps de réactions sont garantis pour des messages avec un ID de haute priorité (voir chapitre B.4) ou dans le service single Master/Slave (à lieu de Multimaster).
B.2 Propriétés Le bus CAN a les propriétés suivantes:
Nombre de nœuds CAN par bus 30
Longueur du bus 40m bis 5000m suivant le taux de transmission
Topologie Bus
Bus management Système Multi-Master, mais il peut également être utilisé dans le service Master/Slave avec du polling.
Méthode accès au bus CSMA/CA. Arbitrage par priorité (ID) par bit. Sans pertes :
(L’émetteur continue sans répétions de son télégramme).
Standards CAN 2.0A (11 bit ID)
CAN 2.0B (29 bit ID)
Codage Codage NRZ, Bitstuffing avec une largeur de 5
Taux de transmission max. 1 Mbit/s
Bytes de données par télégramme max. 8
Sécurité de transmission haute (Distance Hamming de 6)
Câble Deux lignes pour les données et identificateurs
Tableau 9 : Propriétés du bus CAN

Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 55
B.3 Couche de transmission des bits (OSI Layer 1)
B.3.1 Topologie Bus CAN est un bus sériel. L’impédance des lignes est typiquement 120. Le bus est terminé des deux côtés par une impédance de 120. La figure ci-dessous montre la topologie du bus d’un réseau CAN :
CAN-L
CAN-H
CAN Node 1
CAN Node 2
120
120
Figure 36 : Le réseau CAN
Pour la réalisation d’un nœud CAN il y deux possibilités de bases:
1) Microcontrôleur avec un contrôleur CAN intégré et un Bus-Transceiver externe, qui produit les niveaux bus demandés.
2) Microprocesseur avec un contrôleur CAN externe ainsi que un Bus-Transceiver externe également (comparez chapitre Fehler! Verweisquelle konnte nicht gefunden werden.).
B.3.2 Taux de transmission des données Dans les spécifications CAN on distingue entre CAN High-Speed (Taux de transmission 125kBit/s bis 1Mbit/s) et CAN Low-Speed (Taux de transmission jusqu’à 125kBit/s). La longueur maximale du bus dépend du taux de transmission. La table suivante montre les relations entre le taux de transmission et la longueur du bus:
Taux de transmission (Baud) [kBit/s]
Longueur maximale du réseau [m]
1000 25
500 100
250 250
125 500
50 1000
20 2500
10 5000
Tableau 10 : Longueur maximale du réseau en fonction du taux de transmission suivant CANopen
B.3.3 Niveaux du signal Les données sont transmises de manière différentielle par une ligne à deux câbles. Ainsi on peut fortement réduire les perturbations par le rayonnement électromagnétique. Sur le bus on a défini les niveaux signaux suivants :
dominant (logical level low)
récessive (logical lève High)
Un signal dominante peut sur écrire un signal récessive.

Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 56
B.3.4 Bit-Timing Un Bit dans le télégramme CAN est formé de quatre segments. Chaque segment consiste en un certain nombre de quanta temps (Time-Quanta):
Figure 37 : Bit-Timing
Le bit est composé de ces éléments sans que ca soit visible de extérieur. On ne voit donc pas ces composants en examinant les lignes avec un oscilloscope.
Le segment de synchronisation (SYNC_SEG) a la longueur d’ 1 quantum de temps. On s'en sert pour la synchronisation des divers nœuds du bus.
Le segment de propagation (PROP_SEG) est programmable. Ceci dans la gamme de 1, 2,... 8 quanta temps. On s’en sert pour la compensation du retard du signal dans le réseau CAN.
Le segment de phase 1 (PHASE_SEG1) est programmable. Ceci dans la gamme de 1,2, ... 8 quanta temps. On s’en sert pour la compensation des erreurs de flancs.
Le segment de Phase 2 (PHASE_SEG2) a souvent la même longueur que le segment PHASE_SEG1 plus le temps pour le traitement de l’information qui dure 2 quanta temps au maximum (aussi 70%/30%). On s’en sert également pour la compensation des erreurs de flancs montants.
La programmation du point de scrutation (Sample Point) permet l’optimisation du comportement temps du bit: Un point de scrutation proche de la fin du bit permet une grande expansion du bus. Un point de scrutation plus tôt permet des flancs montants plus plats. @@@
En initialisant les registres Bit-Timing on défini le taux de transmission (Baud rate) ainsi que le point de scrutation à l’intérieur du bit pour chaque nœud du contrôleur CAN. Ces registres s’appellent souvent BTR0 et BTR1. C’est idéal, si chaque nœud d’un bus défini le même point de scrutation. Dans ce but, des organisations comme CANopen recommandent des valeurs pour ces registres Bit-Timing. Ils peuvent être repris sans calculs supplémentaires.
B.3.5 Bit Stuffing Le protocole CAN se sert du codage NRZ (Non-Return-to-Zero). Ca permet un taux de transmission maximale. Avec ce codage NRZ le niveau de tension reste constante en cas de plusieurs bit de la même valeur pendent la transmission.
Pour que le récepteur puisse tout de même se synchroniser, on produit un flanc de synchronisation suivant la méthode « Bit-stuffing » Ca signifie que dans notre cas on rajoute un bit de valeur complémentaire dans la chaîne de bits au bout de 5 bits de la même valeur. Ce Stuff-Bit sera éliminé automatiquement par le récepteur. Bit Stuffing se produit dans le « Data Frame » (voir chapitre 0) à partir du SOF jusqu'à et y compris du CRC.
B.4 Méthodes d’accessibilité au bus (OSI Layer 2a / MAC) Pour le CAN on se sert de l méthode CSMA/CA pour l’accès au bus. Avant qu’un nœud puisse émettre des données, il teste si le bus est déjà occupé. Il peut commencer à émettre, si le bus est libre. S’il y en a plusieurs nœuds qui veulent émettre en même temps, il y a un arbitrage du bus qui se produit. Ca se fait par l’ID de l’émetteur. C’est le message avec l’ID le plus petite qui a une priorité supérieure. Il peut envoyer son message sans qu’elle soit détruite par un autre message (pas de répétitions). Ca se fait comme suit:
Chaque émetteur teste l'état du bus après avoir envoyé un bit (dominante ou récessive). Si un nœud donne un signal récessif sur le bus et si ensuite il relit un bit dominant, il se retire du bus. C’est-à-dire il va de nouveau dans l’état récepteur. Cette procédure d’arbitrage est montrée dans la figure suivante :
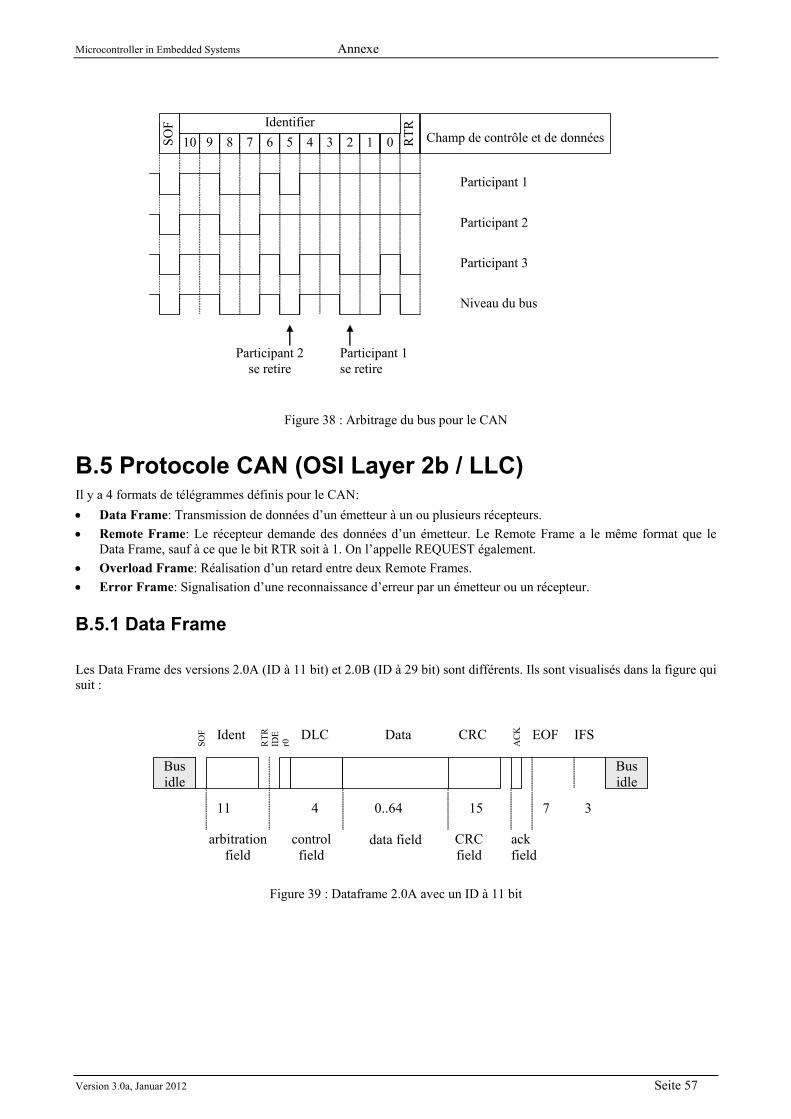
Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 57
SO
F
10 9 8 7 6 5 4 3 2 1 0 RT
R
Champ de contrôle et de données
Participant 1
Participant 2
Participant 3
Niveau du bus
Participant 2 se retire
Participant 1 se retire
Identifier
Figure 38 : Arbitrage du bus pour le CAN
B.5 Protocole CAN (OSI Layer 2b / LLC) Il y a 4 formats de télégrammes définis pour le CAN:
Data Frame: Transmission de données d’un émetteur à un ou plusieurs récepteurs.
Remote Frame: Le récepteur demande des données d’un émetteur. Le Remote Frame a le même format que le Data Frame, sauf à ce que le bit RTR soit à 1. On l’appelle REQUEST également.
Overload Frame: Réalisation d’un retard entre deux Remote Frames.
Error Frame: Signalisation d’une reconnaissance d’erreur par un émetteur ou un récepteur.
B.5.1 Data Frame
Les Data Frame des versions 2.0A (ID à 11 bit) et 2.0B (ID à 29 bit) sont différents. Ils sont visualisés dans la figure qui suit :
SOF Ident
RT
R
IDE
r0
DLC Data CRC
arbitration field
control field
data field CRC field
ack field
AC
K
EOF IFS
11 0..64 15 7 3 4
Bus idle
Bus idle
Figure 39 : Dataframe 2.0A avec un ID à 11 bit

Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 58
SO
F Ident
SR
R
IDE
r0 DLC Data CRC
arbitration field
control field
data field CRC field
ack field
AC
K
EOF IFS
11 0..64 15 7 3 4
ext. Ident
RT
R
18
r1
Bus idle
Bus idle
Figure 40 : Dataframe 2.0B avec un ID à 29 bit
SOF Start of Frame, Startbit 1 bit dominante pour démarrer la transmission. Toutes les autre nœuds (récepteurs) se synchronisent sur le flanc tombant des se bit de démarrage.
EOF End of Frame, 7 bits récessives
IFS Inter Frame Space, 3 bits récessives au moins entre deux frames.
Ident Identifier, 11 Bit (2.0A) ou 29 Bit (2.0B). L’arbitrage du bus suivant le chapitre 0 se base sur cet identificateur. Le bit le plus haut de l’identificateur est transmis comme premier ; le bit de la valeur le plus basse comme dernier.
RTR Remote Transmission Request (Demande d’un message)
0 Data Frame
1 Remote Frame
SRR Substitute Remote Request
IDE Identifier Extension Bit
0 CAN 2.0A
1 CAN 2.0B
r0, r1 Champ de contrôle, réservé pour le CAN étendu (extended CAN).
DLC Data Length Code (Nombre de bytes de données)
Data bytes de données, 0 à 8 Bytes
CRC Cyclic Redundancy Check (Checksum): 15 bit du polynôme de génération ainsi qu’un bit récessive pour terminer le CRC
ACK 1 bit ACK-Slot et 1 bit ACK-limitation. L’émetteur transmet un bit récessives dans le slot ACK-Slot. Les nœuds ayant reçu des données sans erreur le sur-écrivent avec un bit dominante.
B.5.2 Reconnaissance d’erreurs Les mécanismes suivants sont prévus pour la reconnaissance d’erreurs:
Bit-Monitoring: Chaque nœud surveille le bus pendent l’émission. Un signal récessive ne peut être sur-écrite que pendent la phase d’arbitrage (ID) et dans le slot ACK.
Surveillance du format du télégramme: Quelque bits ont des états définis de manière fixe (p.ex. des bits de limitation récessives)
CRC-Check Polynôme de teste x15 + x14 + x10 + x8 + x7 + x4 + x3 +1
Quittance de réception: Si un nœud reçoit un message correctement, il sur-écrit le bit récessif dans le slot ACK avec un bit dominante. Ainsi l’émetteur sait, que le message état correcte, puisque il avait été reçu par au moins un des autres nœuds.
Bit-Stuffing: Ce sont 5 bits de suite au maximum, qui peuvent avoir la même valeur.
Error-Frame: Des qu’un nœud reconnait une erreur, il émet 6 bit dominantes de suite. Ceci viole la règle du Bit-Stuffing et les autres nœuds reconnaissent également une erreur.

Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 59
B.5.3 Filtrage des messages CAN ne travaille pas orienté participant mais orienté message. Suite à ca, l’ID dans le télégramme CAN n’est pas une adresse du nœud / participant mais une identification d’un message. L’émetteur ne sait pas, quels sont les autres nœuds qui vont traiter ce message. Le message est envoyé comme message „broad-casting“ sur le bus et chaque nœud doit vérifier lui-même, si ce message est important pour lui ou non. Dans ce but ils y existent des filtres d’acceptantes dans chaque nœud. Un filtre d’acceptante (filtre étant transparent que pour certains ID’s) a une taille/largeur de 11 bit (CAN 2.0A) ou de 29 bit (CAN 2.0B) et il peut être programmé par bit.
Exemple:
Un senseur change son état et il donne cet événement comme message CAN sur le bus. Le senseur ne sait pas, quels sont les autres nœuds, qui vont traiter cet événement.
Une valve intelligente aille ouverte son masque d’acceptante pour cet ID et s’informe à la suite de ce changement d’état du senseur. Suite a ca (ou éventuellement l’état d’autres senseurs) il va modifier ses sorties.
B.6 Application (OSI Layer 7) En CAN on a défini les couches 1 et 2 (Layer 1 et 2) dans le modèle ISO/OSI. En plus de ces couches ils y existent des normes internationales (ISO DIS 11898 et ISO DIS 11519-1). C’est également CiA qui recommande des prises, câbles etc. (CiA DS 102-1). Les couches plus hautes ne sont pas définies par CAN. Aujourd’hui il y a beaucoup de systèmes propriétaire. C’est-à-dire il y a beaucoup de maisons, qui développent leur propre protocoles d’applications en dessus de ces couche ISO/OSI (layer 7 avec l’intégration supplémentaire des couches 3 à 6). Ca a comme désavantage, que les nœuds bus, les senseurs et les acteurs de différentes maisons ne sont pas compatible entre eux.
Dans le but d’avoir également un protocole unifié sur le niveau « couche application », il y a une organisation utilisateurs CiA qui a défini leur couche 7 supplémentaire sous le nom CANopen. Mais il y encore d’autres protocoles couche 7 qui existent et qui ont eu du succès dans centaines domaines p.ex. DeviceNet.
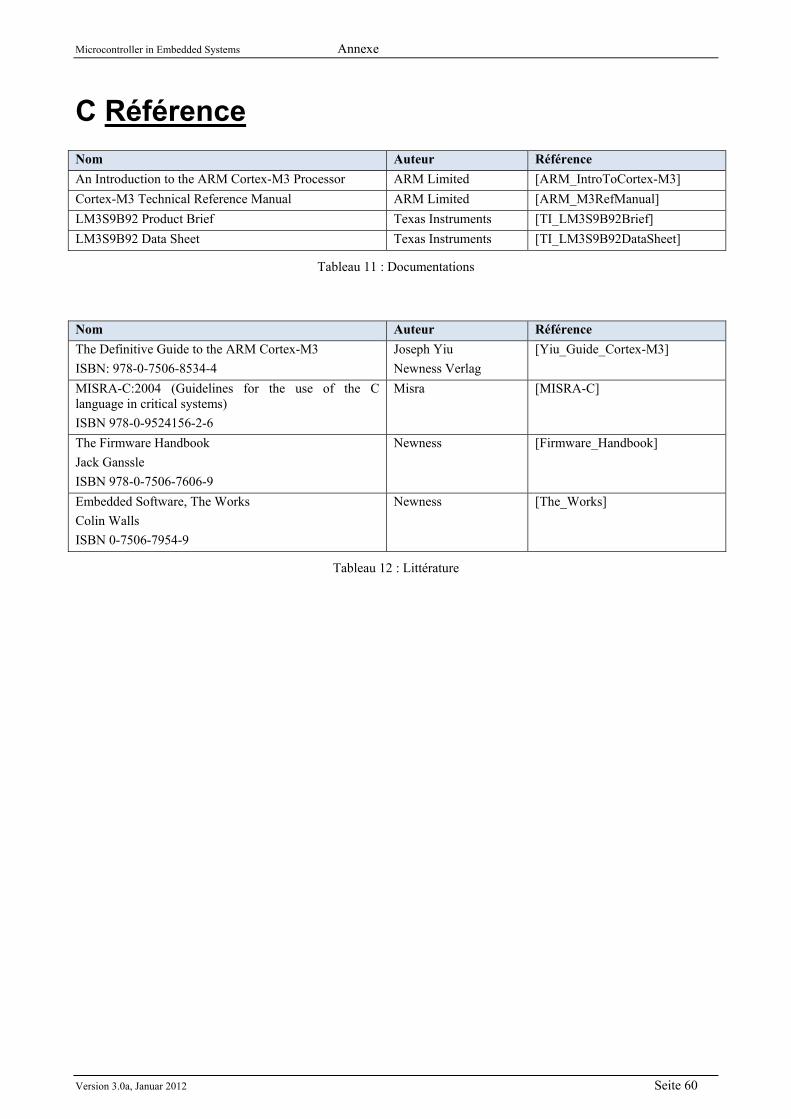
Microcontroller in Embedded Systems Annexe
Version 3.0a, Januar 2012 Seite 60
C Référence
Nom Auteur Référence
An Introduction to the ARM Cortex-M3 Processor ARM Limited [ARM_IntroToCortex-M3]
Cortex-M3 Technical Reference Manual ARM Limited [ARM_M3RefManual]
LM3S9B92 Product Brief Texas Instruments [TI_LM3S9B92Brief]
LM3S9B92 Data Sheet Texas Instruments [TI_LM3S9B92DataSheet]
Tableau 11 : Documentations
Nom Auteur Référence
The Definitive Guide to the ARM Cortex-M3
ISBN: 978-0-7506-8534-4
Joseph Yiu
Newness Verlag
[Yiu_Guide_Cortex-M3]
MISRA-C:2004 (Guidelines for the use of the C language in critical systems)
ISBN 978-0-9524156-2-6
Misra [MISRA-C]
The Firmware Handbook
Jack Ganssle
ISBN 978-0-7506-7606-9
Newness [Firmware_Handbook]
Embedded Software, The Works
Colin Walls
ISBN 0-7506-7954-9
Newness [The_Works]
Tableau 12 : Littérature