Embed Size (px)
Citation preview
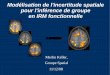
Modélisation de l'incertitude spatialepour l'inférence de groupe
en IRM fonctionnelle
Merlin Keller,
Groupe Spatial
11/12/08

Plan
I. L'imagerie par résonance magnétique fonctionnelle (IRMf)
II. L'inférence de groupe en IRMf
III. Modélisation de l'incertitude spatiale
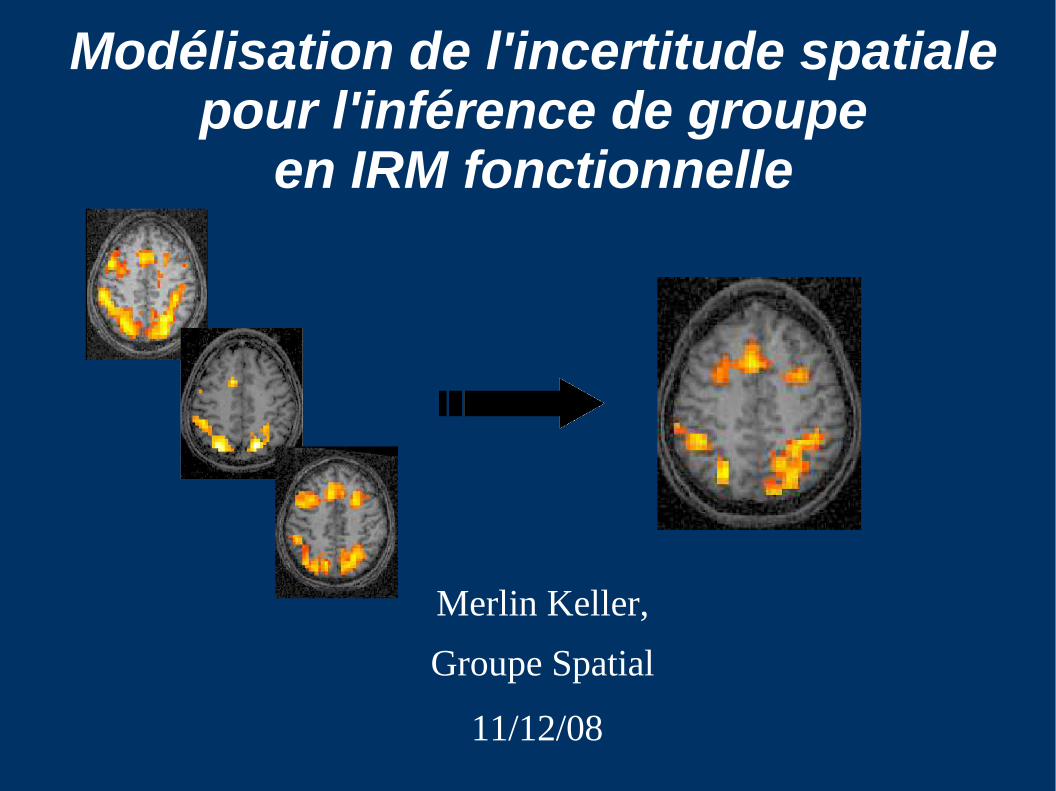
Une expérience d'IRM fonctionnelle
● Acquisition d'une séquence d'images 3D de l'activité cérébrale
● Activité mesurée indirectement par son effet sur le réseau vasculaire ( effet BOLD )
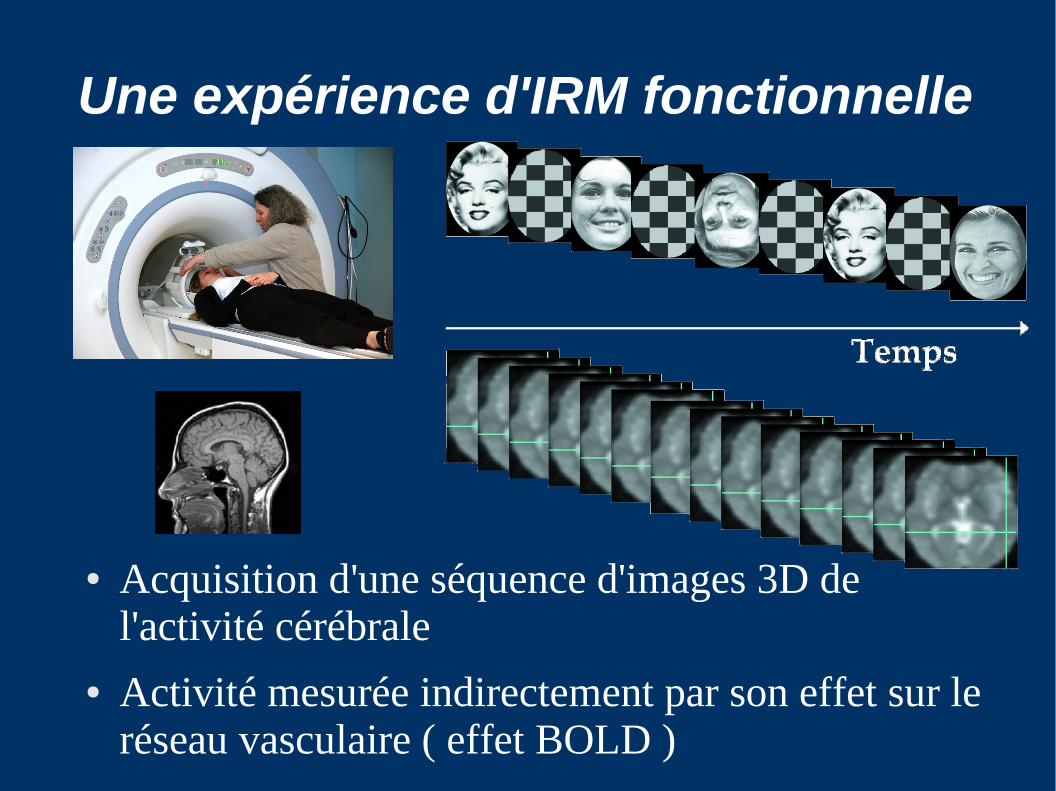
Décours temporel en un voxel
En rouge : Temps d'occurrence (onsets) des stimuli
● On suppose que chaque stimulus induit localement un effet BOLD
● Comment modéliser la relation entre les deux?
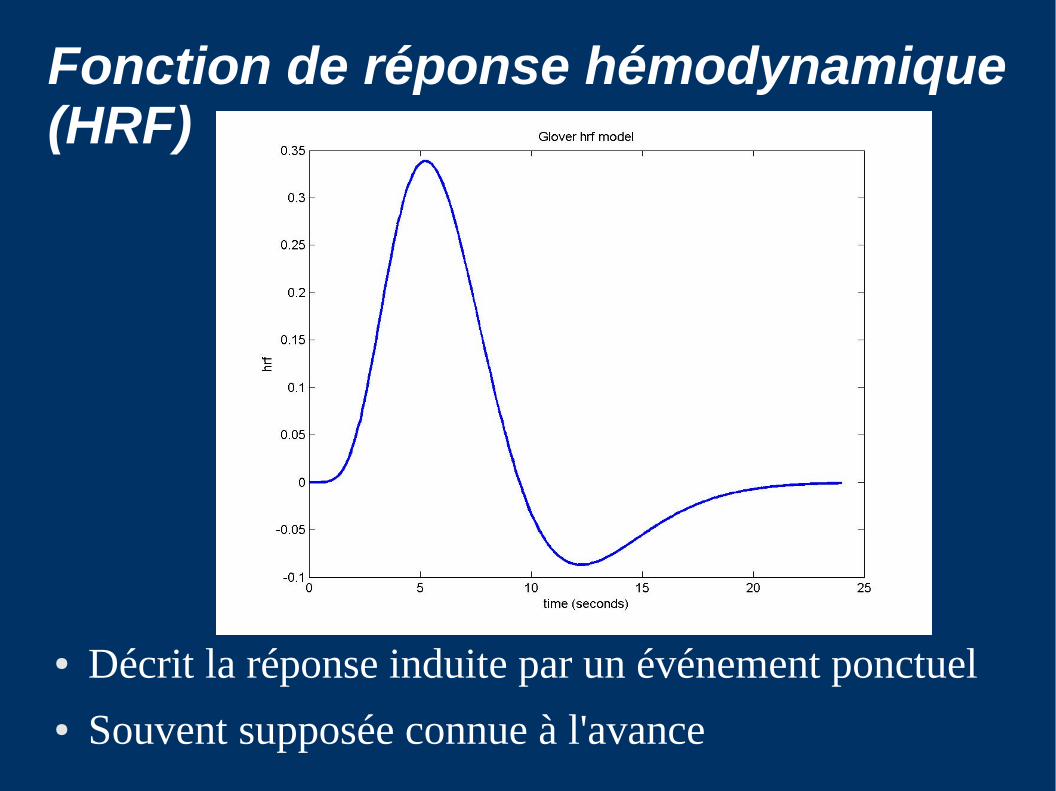
Fonction de réponse hémodynamique (HRF)
● Décrit la réponse induite par un événement ponctuel● Souvent supposée connue à l'avance
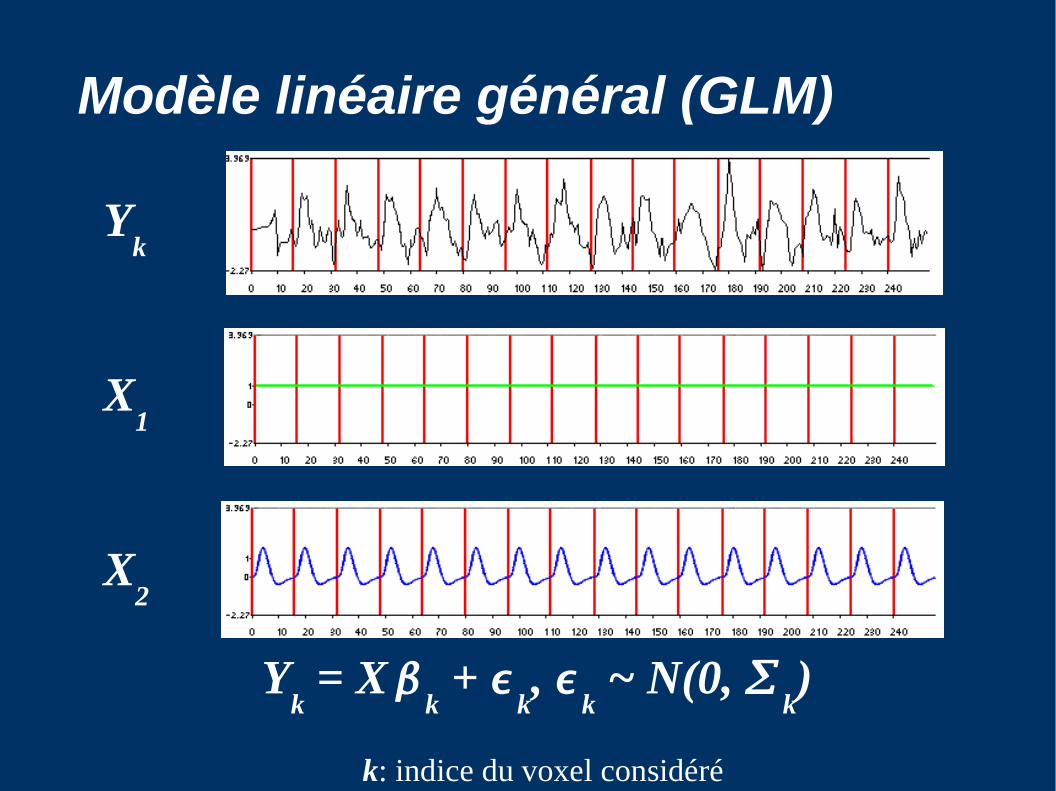
Modèle linéaire général (GLM)
Yk = X
k +
k,
k ~ N(0,
k)
k: indice du voxel considéré
Yk
X1
X2

Modèle linéaire général (GLM)
On a implicitement supposé que les réponses aux différents événements :● sont identiques ( Stationnarité ) ● s'additionnent ( Linéarité )Régresseurs additionnels :● Conditions expérimentales multiples● Facteurs de nuisance
Yk = X
k +
k,
k ~ N(0,
k)
Yk

Contraste d'intérêt
● On s'intéresse à l'effet BOLD c'k au voxel k, en
réponse à un contraste de conditions expérimentales c.● Exemples : Stimulation – Repos, Condition 1 –
Condition 2, etc.● Le voxel k est dit :
– actif ( pour le contraste c ) si : c'k > 0
– inactif si : c'k = 0
– déactivé si : c'k ≤ 0

Test sur un contraste
● Q : Le voxel est-il actif ?
➔ Test de Student de H0: c'
k = 0 contre H
1: c'
k > 0
– Tk =
– Sous H0 : T
k ~ t
N-p
( N = nombre de scans, p = rg(X) )
– On rejette H0 au niveau si T
k > t
1-,N-p
kc'
Var c kc'
k k
k
k
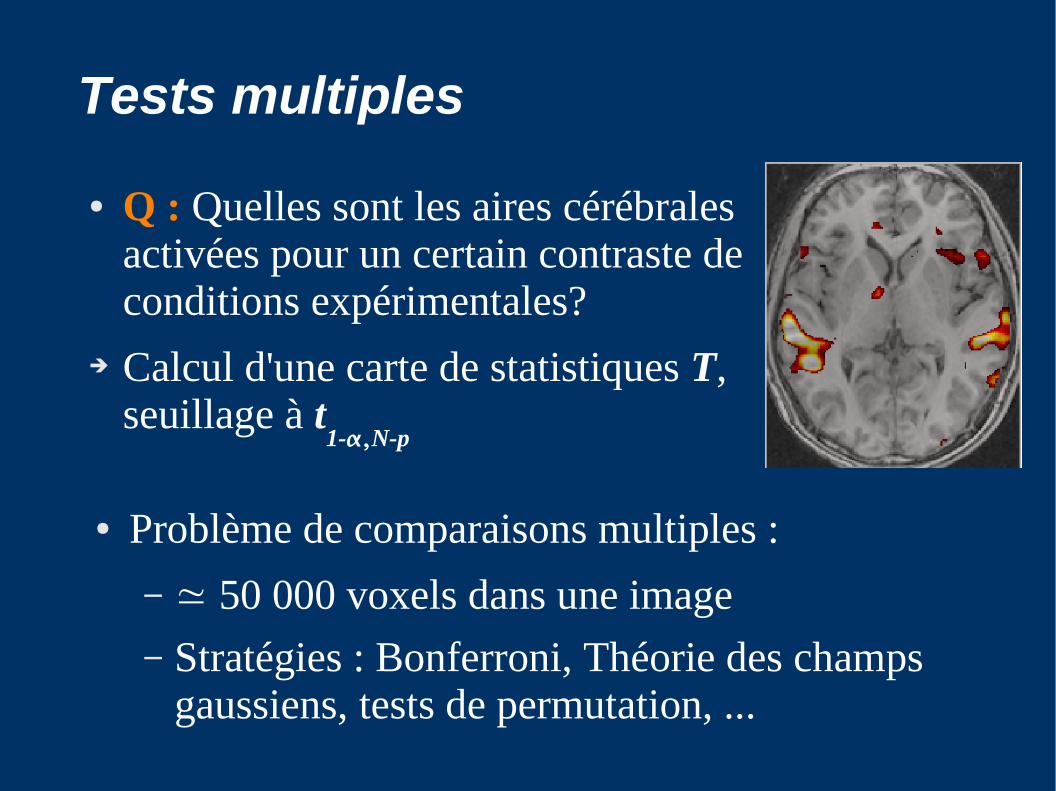
Tests multiples
● Q : Quelles sont les aires cérébrales activées pour un certain contraste de conditions expérimentales?
➔ Calcul d'une carte de statistiques T, seuillage à t
1-,N-p
● Problème de comparaisons multiples :
– ≃ 50 000 voxels dans une image– Stratégies : Bonferroni, Théorie des champs
gaussiens, tests de permutation, ...

L'inférence de groupe en IRMf
● But : Généraliser les résultats individuels à la population d'intérêt
● Exemple : n sujets on participé à une expérience d'IRMf, et leur données ont été traitées séparément
Quel est la carte d'activation moyenne de la population parente?
?
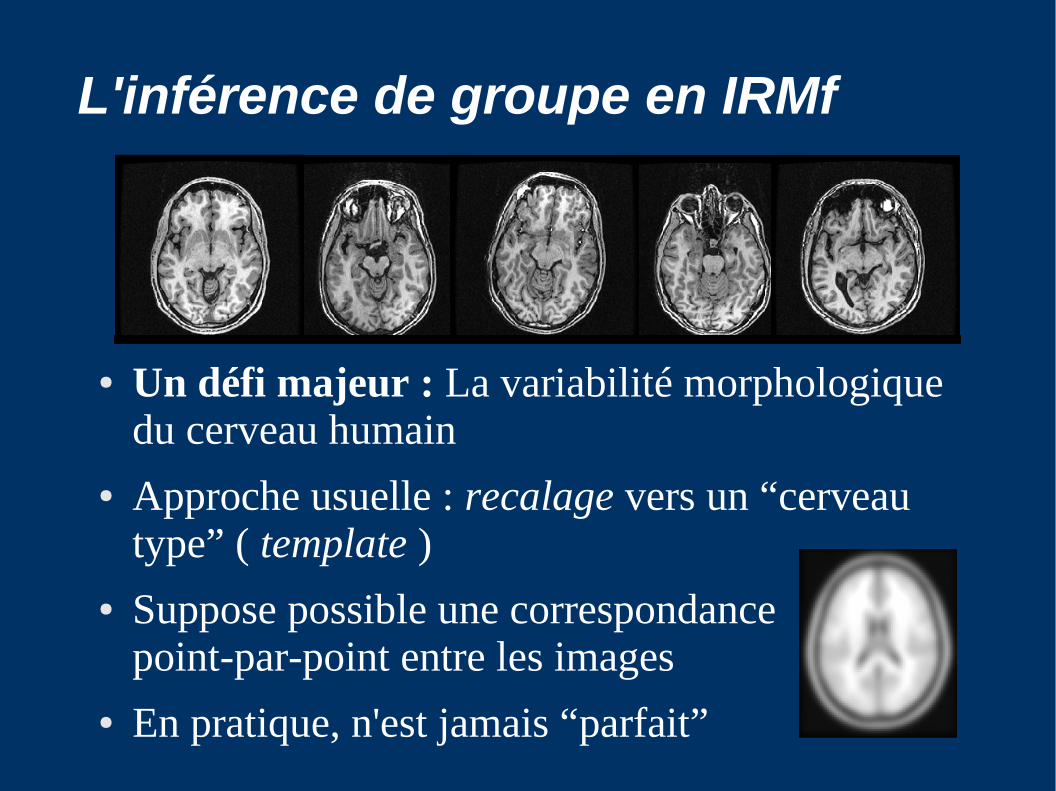
L'inférence de groupe en IRMf
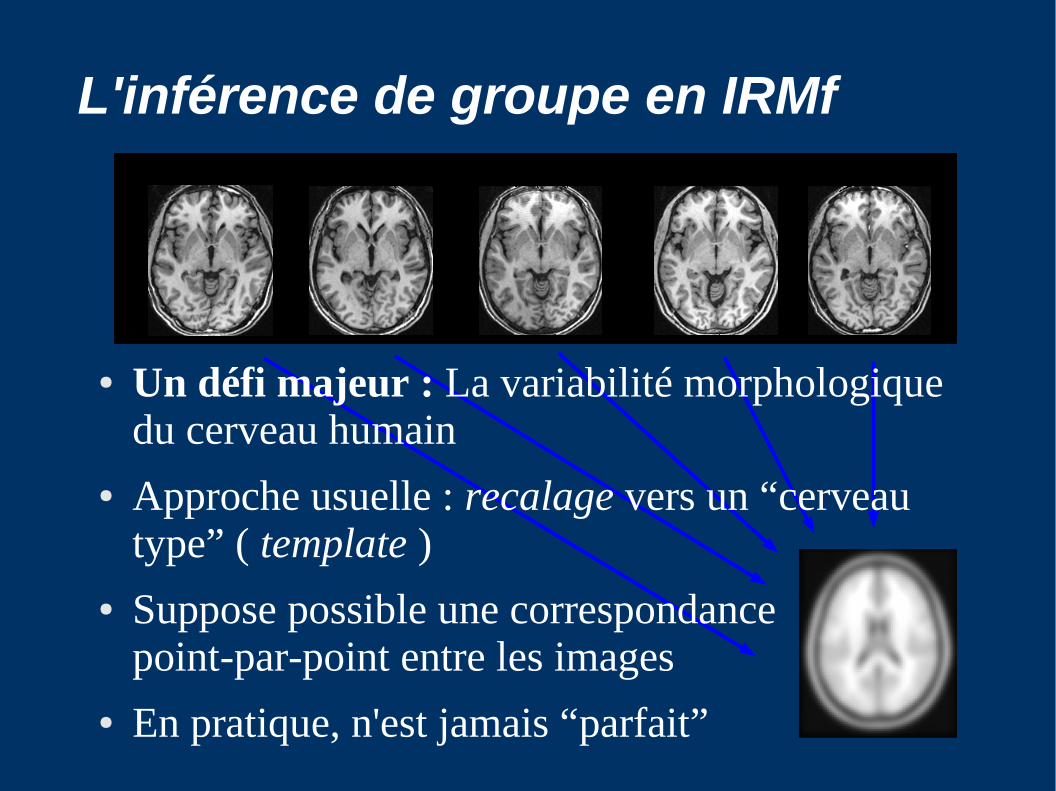
● Un défi majeur : La variabilité morphologique du cerveau humain
● Approche usuelle : recalage vers un “cerveau type” ( template )
● Suppose possible une correspondance point-par-point entre les images
● En pratique, n'est jamais “parfait”
L'inférence de groupe en IRMf
● Un défi majeur : La variabilité morphologique du cerveau humain
● Approche usuelle : recalage vers un “cerveau type” ( template )
● Suppose possible une correspondance point-par-point entre les images
● En pratique, n'est jamais “parfait”

Approche voxel-based (massivement univariée)
Principe : Après recalage, ou normalisation, vers un template, comparaison des images séparément en chaque voxel
● Approche standard (SPM, FSL)● Suppose les images parfaitement réalignées (en
pratique, lissage spatiale préalable des données)● Alternatives : Comparaison des images à un plus
haut niveau ( Thirion et al. (2007b), Xu et al. (2007), Tucholka et al. (2008), ... )

Résumé de l'approche voxel-based
a) Calcul d'une carte statistique pour tester en chaque voxel la présence d'un effet BOLD moyen positif
b) Calibration de la carte statistique pour détecter les régions activées
➔ Nécessite un modèle de la distribution des effets BOLD à travers les sujets
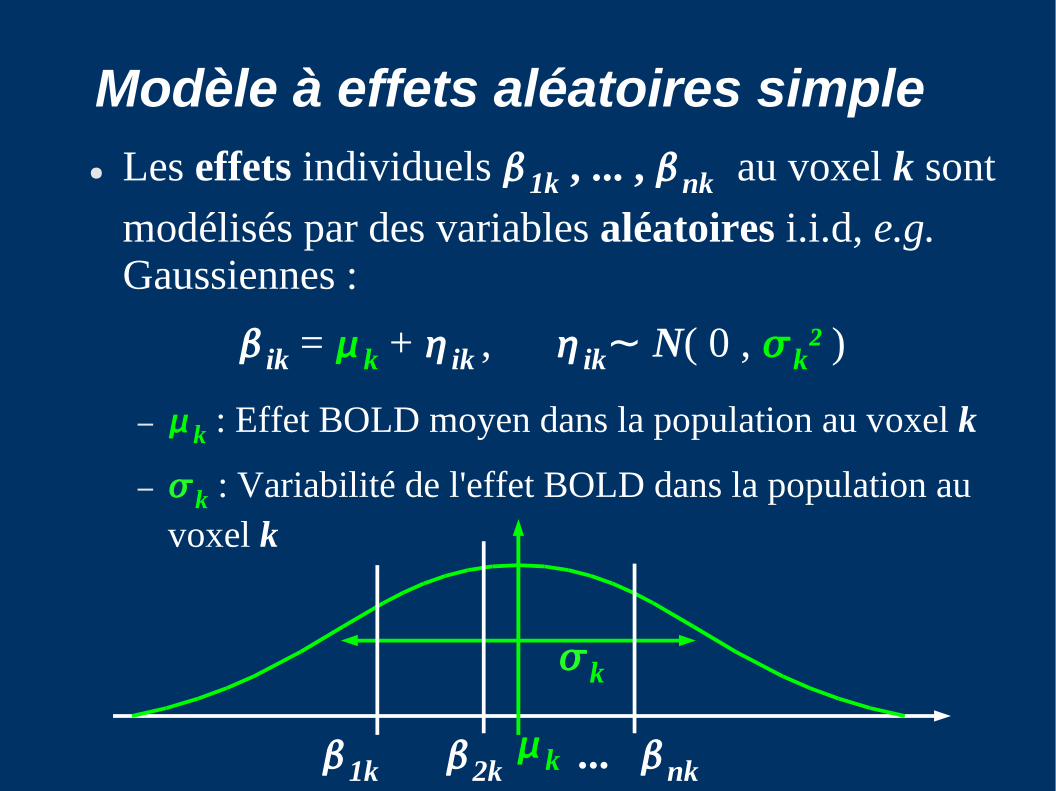
Modèle à effets aléatoires simple● Les effets individuels 1k , ... , nk
au voxel k sont
modélisés par des variables aléatoires i.i.d, e.g. Gaussiennes :
ik = k + ik , ik⁓ N( 0 , k² )
– k : Effet BOLD moyen dans la population au voxel k
– k : Variabilité de l'effet BOLD dans la population au voxel k
k 2k
k
1k nk...

Test sur l'effet moyen
● L'effet BOLD moyen est-il positif pour le voxel k?
➔ Test de Student de H0 :
k ≤ 0 contre H
1 :
k > 0
– Tk =
– Sous H0 : T
k ~ t
n-1
– On rejette H0 au niveau si T
k > t
1-,n-1
k
std( )k
k k
k
k

● Avantages :– Rend la détection d'activation simple à mettre en
oeuvre
– Approche de référence ( logiciel SPM )
● Limites : Suppose– les effets BOLD directement observés :
néglige les erreurs d'estimation
– les images parfaitement recalées : néglige les erreurs de normalisation spatiale
Modèle à effets aléatoires simple

Modèle intra-sujet
● ik effet BOLD (inconnu) du sujet i au voxel k
● ik estimé de ik (par GLM). Si le nombre de scans acquis N est assez grand :
ik = ik + ik , ik ⁓ N(0 , sik²), sik
supposé connu
ik ik
sik
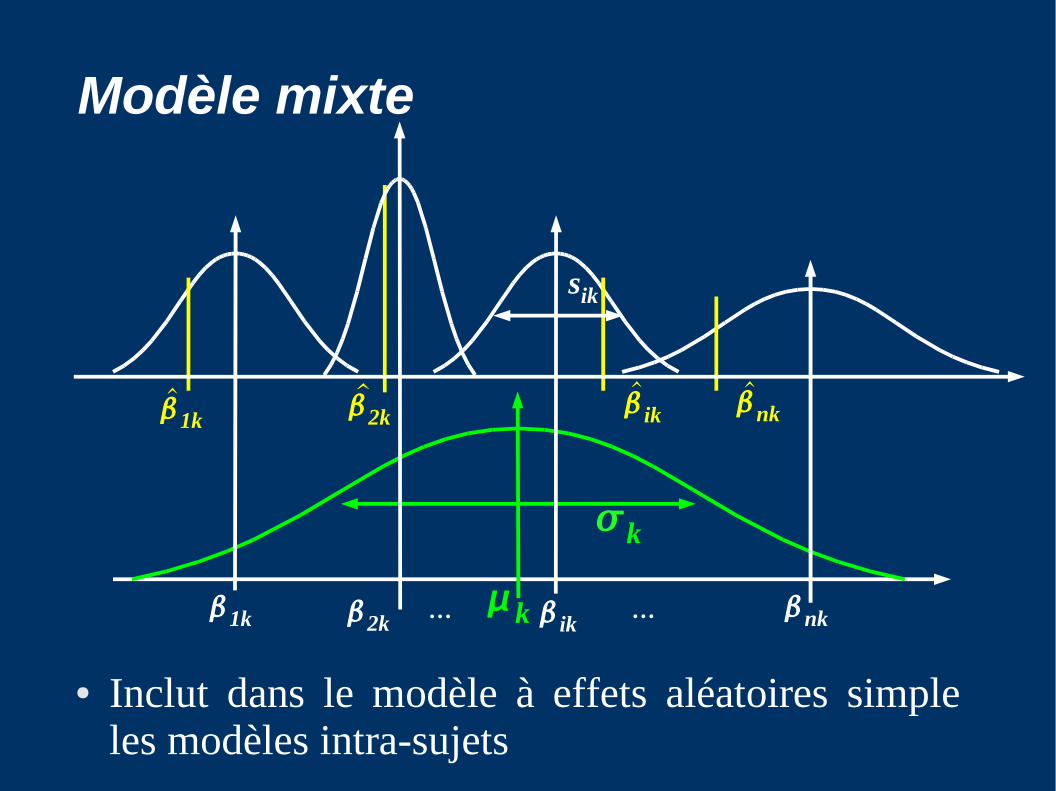
Modèle mixte
● Inclut dans le modèle à effets aléatoires simple les modèles intra-sujets
1k 2k iknk......
sik
1k 2k
ik nk
k
k

Modèle mixte
● S'écrit sous forme d'un modèle hiérarchique :
ik = ik + ik , ik ⁓ N(0 , sik²)
ik = k + ik , ik⁓ N(0 , k²)
● Ou de manière équivalente :
ik = k + ik , ik
⁓ N(0 , k² + sik²)
● Si s1k² = ... = snk², on retrouve le modèle précédent

Test sur l'effet moyen● But : Tester H
0 :
k ≤ 0 contre H
1 :
k > 0
● Statistique de décision : Le rapport des vraisemblances maximales
( L(k,
k²) : vraisemblance
du modèle mixte )
– Pas d'expression explicite : Calcul par algorithme EM
– Loi sous H0 inconnue : Calibration par un test de
permutation
sup L(k,
k²)
k≤0
sup L(k,
k²)
k>0
R =
k k
k
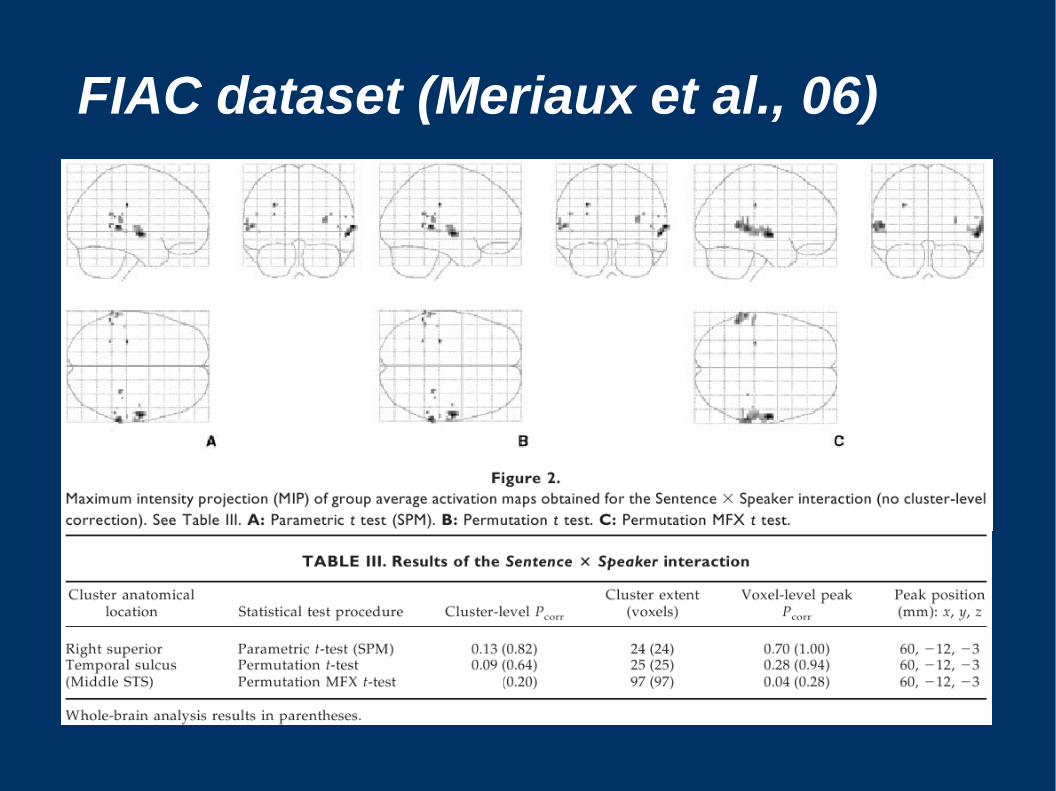
FIAC dataset (Meriaux et al., 06)

Localizer dataset (Keller et al., 08)
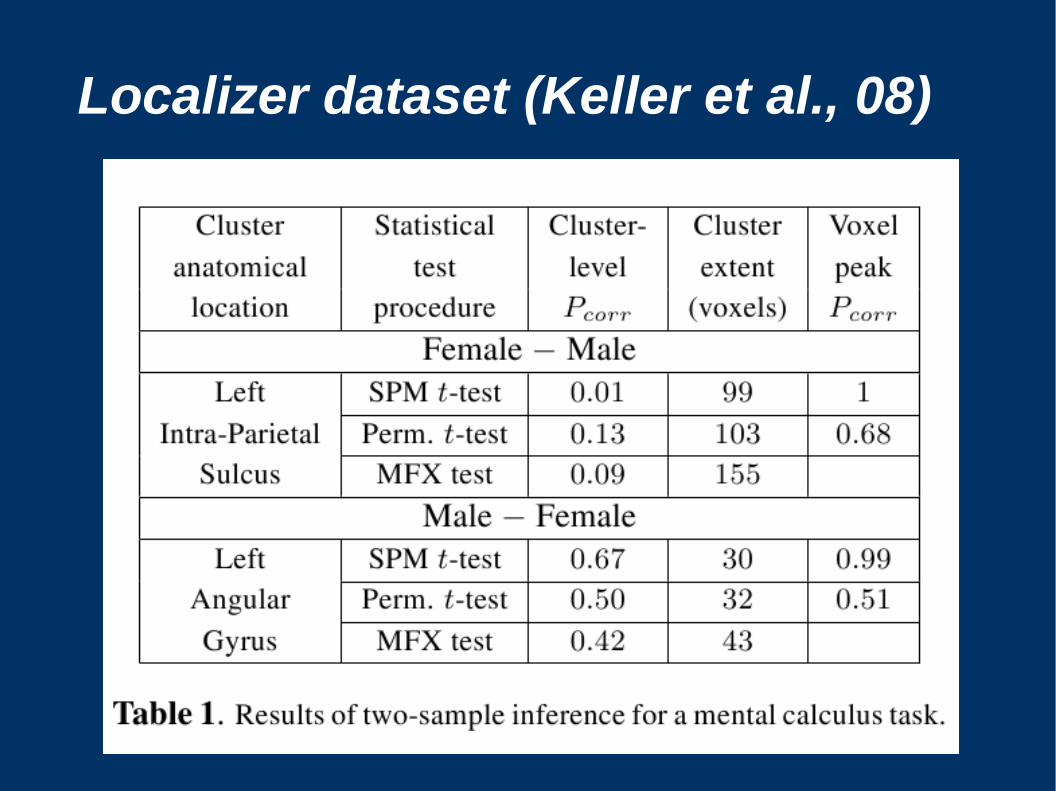
Localizer dataset (Keller et al., 08)

Modèle mixte
● Avantages :– Prends en compte les erreurs d'estimation individuelles
– Permet un gain en sensibilité pour la détection d'activations (Meriaux06, Keller08a) par rapport à l'approche standard
● Limites :– Suppose toujours les images parfaitement recalées :
néglige les erreurs de normalisation spatiale.
Q : Peut-on inclure les erreurs de normalisation spatiale dans le modèle mixte?

Prise en compte de l'incertitude spatiale
● On ne suppose plus les images parfaitement recalées
– vl ∈ ℝ3 voxel de l'espace standard
– uil ∈ ℝ3 erreur de recalage du sujet i au voxel l (inconnue)
– vk = vl + uil voxel déplacé (uil discrétisé)
● Modèle inter-sujet :
i(vl) = (vl + uil) + il , il
⁓ N(0 , ²)
– i(vl) = il effet du sujet i au voxel l
– (vl + uil) = (vk) = k effet moyen au voxel k
vluil
vk

Modélisation du champ de déplacement● ui = (uil)1≤l≤p champ de déplacement du sujet i,
défini par :
– V' = (vk , ... , vk ) points de contrôle (voxels)
– K(l, k ) = K(∥vl – vk ∥) noyau d'interpolation
– wi = (wij)1≤j≤m paramètres de déplacement du champ i
● l = 1, ... , p : uil = ∑ K(l, kj) wij
(cf. Allassonière et al., 07)
● wi champ de Markov Gaussien (GMRF) sur V' :
p(wi) ∝ exp - ∑∥wij∥² - h ∑ wijt wij'
1 m
j=1
m
j=1
m
j ~ j'
12²
m m

Modèle complet
i = i + i ; i
⁓ N(0, Si²)
i = (V + ui) + i ; i ⁓ N(0, ²Ip)
ui = K wi ; wi ⁓ N(0, Q-1)
avec :
– Si² = diag(sil², 1≤l≤p )
– Q matrice de précision des wi : Q( j, j ) = -2 ; Q( j, j' ) = h 1{ j ~ j' }
● Vraisemblance complète :
f( , , w | , ²) = f( | ) p( | w, , ²) p(w)

Inférence Bayésienne
● But : Soit ( , ²) une loi a priori, déterminer :
( , ² | ) = ( , w , , ² | ) d dw
∝ f( , , w | , ²) ( , ²) d dw● Pas d'expression analytique...● Solution : Échantillonner ( , w , , ² | )
➔ ( t, w t , t, (²)t )1≤t≤B
➔ ( t, (²)t )1≤t≤B échantillon de ( , ² | )
∫∫

= min 1,
Échantillonnage a posteriori● Échantillonneur de Gibbs :
– Blocs : , w , ( , ²) – Tirages successifs dans ( |...), (w |...), ( , ² |...)
● Pb : (w | ...) ∝ p( | w, , ²) p(w) difficile à simuler● Metropolis-Hastings 'naïf' : w' tirée dans p(w), acceptée
avec probabilité
– Fruste (tirage dans l'a priori)
– Faible taux d'acceptation observé ( < 0.1 en moyenne)
– Semble difficile à améliorer en pratique
p( | w', , ²)p( | w, , ²)
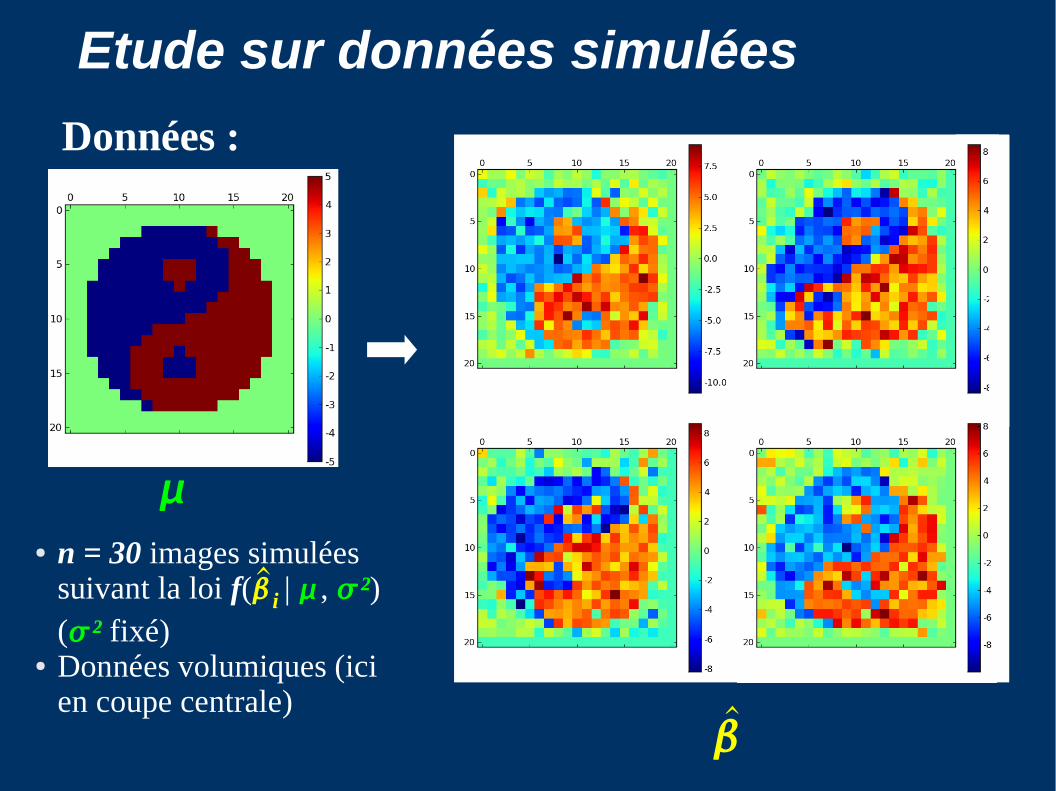
Etude sur données simulées
Données :
● n = 30 images simulées suivant la loi f( i | , ²) (² fixé)
● Données volumiques (ici en coupe centrale)
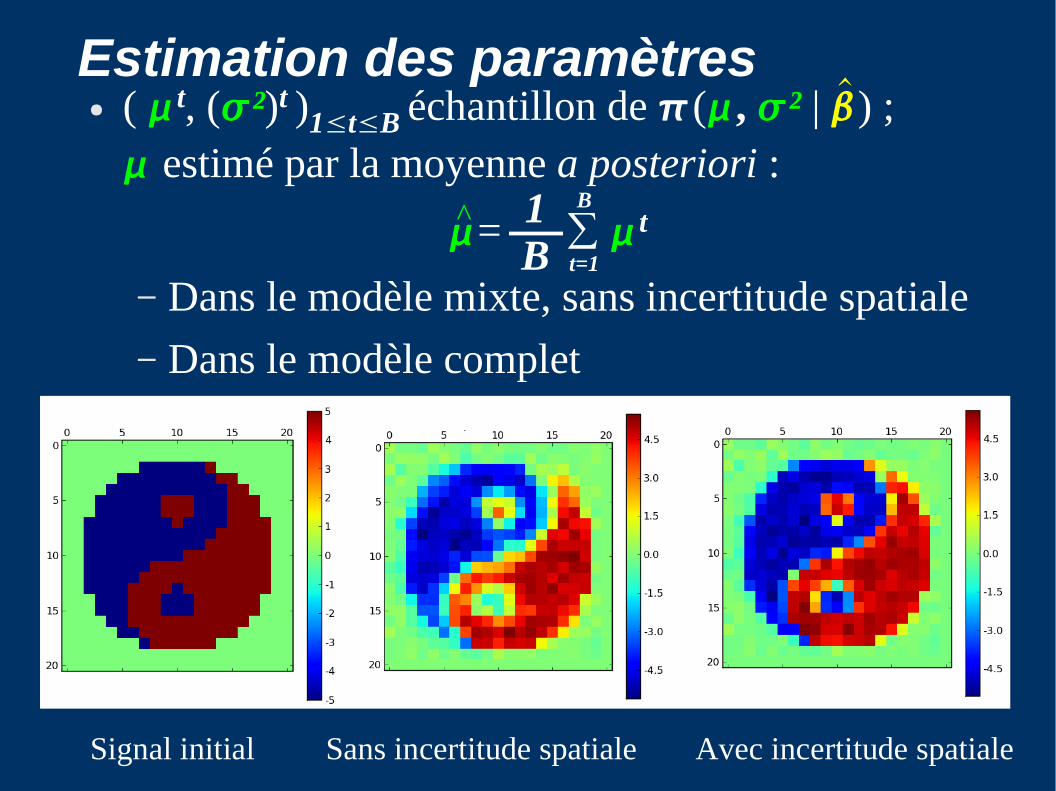
Estimation des paramètres● ( t, (²)t )1≤t≤B échantillon de ( , ² | ) ; estimé par la moyenne a posteriori :
= ∑ t
– Dans le modèle mixte, sans incertitude spatiale– Dans le modèle complet
t=1
B1B
^
Signal initial Sans incertitude spatiale Avec incertitude spatiale
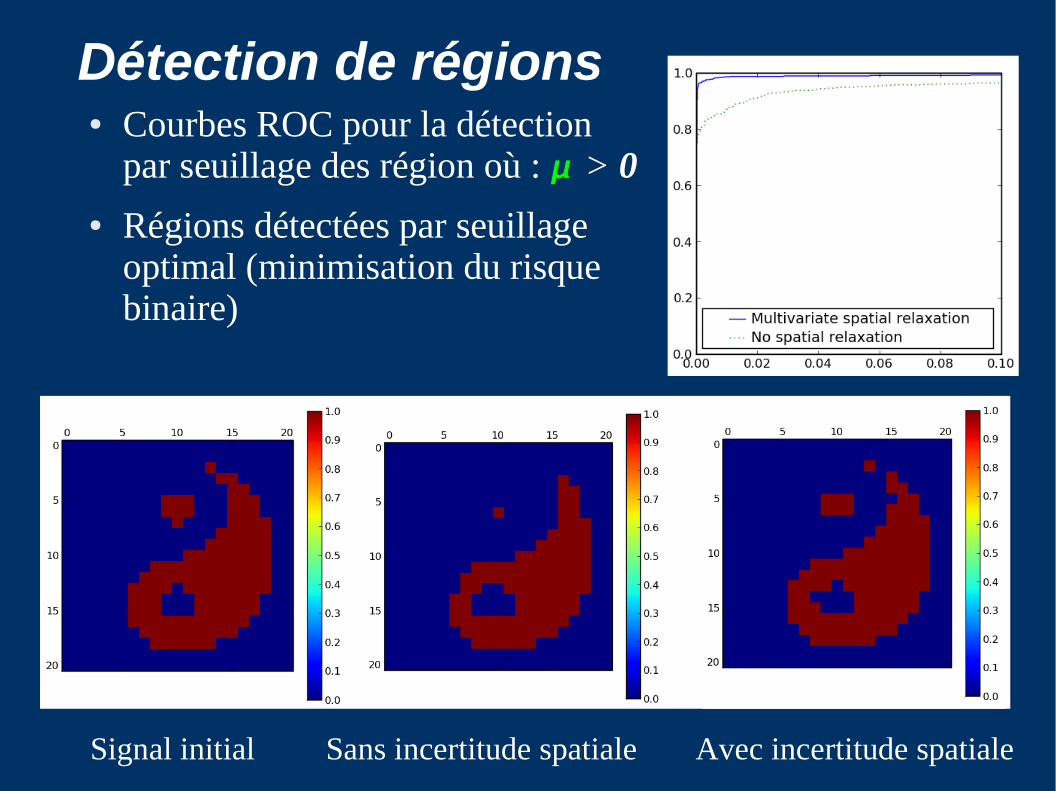
Détection de régions● Courbes ROC pour la détection
par seuillage des région où : > 0
● Régions détectées par seuillage optimal (minimisation du risque binaire)
Signal initial Sans incertitude spatiale Avec incertitude spatiale

Perspectives
● Méthode :– Améliorer l'échantillonnage des champs de déplacement
– Estimation du paramètre d'incertitude spatiale ² ● Applications :
– Détection des aires cérébrales impliquées dans une tâche donnée par sélection Bayésienne de modèle
– Application aux images anatomiques : Évaluation de l'incertitude de recalage

Bibliography (1/2)
● Allassonière et al. (2007) Toward a coherent statistical framework for dense deformable template estimation.
● Keller et al. (2008) A mixed-effect statistic for two-sample group analysis in fMRI. ISBI'08
● Keller et al. (2008) Dealing with spatial normalization errors in fMRI group inference using hierarchical modeling. Statistica Sinica, 18, 4, 1357-1374
● Meriaux et al. (2006) Combined permutation test and mixed-effect model for group average analysis in fMRI. Hum. Brain Mapping 27, 402-410
● Thirion et al. (2007) High level group analysis of fMRI data based on Dirichlet process mixture models. NeuroImage 35, 105-120
● Tucholka et al. (2008) Probabilistic Anatomo-Functional Parcellation of the Cortex : How many regions?

Bibliography (2/2)
● Xu et al. (2007) Bayesian spatial modeling of fMRI data : a multiple subject analysis. Tech. rep., University of Michigan, department of Biostatistics