Embed Size (px)
Citation preview

ORSTOM - Laboratoire d'Hydrologie
Rapport de stage
CHANGEMENT D'ECHELLE
ET
PERTE D'INFORMATION
François LAURENT
1995

Tables des matières
1. AGREGAnON 3
1.1 ECHELLE ET MODELISATION HYDROLOGIQUE 31.2 CONSEQUENCES DE L'AGREGATION SUR LES DONNEES 4
2. INDICES STRUCTURAUX, AGREGAnON ET PERTE D'INFORMATION 6
2.1 TRAVAUX DE GOODCHILD 62.2 TRAVAUX DE TURNER, O'NEILL, GARDNER ET MILNE 62.3 TRAVAUX DE VIEUXETFARAJALLA 7
3. PROGRAMME R.LE SOUS GRASS 4.1 9
4. ETUDE DE L'EVOLUTION DE DONNEES SPATIALES 15
4.1 DONNEES CONTINUES: MNT 154.1.1 MErnODOLOGIE 154.1.2 APTITIIDE DES INDICES STRUCTURAUX A REPRESENTER UNE TYPOLOGIE DE RELIEF 164.1.3 VARIATION DES INDICES STRUCTURAUX EN FONCTION DE L'AGREGATION 164.1.4 IMPAcT DE L'AGREGATION SUR UN CALCUL DE PENTE 214.1.5 IMPACT DE L'AGREGATION SUR UN MODELE HYDROLOGIQUE: SENSIBILITE DE L'INDICETOPOGRAPHIQUE A LA RESOLUTION DU MNT 23
4.2 DONNEES DISCRETES : CARTE D'OCCUPATION DU SOL 294.2.1 AGREGATION EFFECTIJEE A PARTIR DE LA RESOLUTION INTIlALE 294.2.2 AGREGATION EFFECTIJEE A PARTIR DU NIVEAU D'AGREGATION PRECEDENT 354.2.3 ESTIMATION DE LA PERTE D'INFORMATION POUR UN CALCUL D'EVAPOTRANSPIRATIONMAXIMALE 354.2.4 AGREGATION ET PROCESSUS LOCALISES 38
5. CONCLUSION 40
6. BIBLIOGRAPHIE 41
ANNEXES
2

1. Agrégation
L'agrégation est le passage à une résolution plus grossière. La résolution est définie comme lataille du plus petit objet pouvant être discerné sur une carte.
L'agrégation est utilisée pour traduire à une même échelle des informations provenant de sourcesdifférentes et pour offrir une vue plus générale des phénomènes. Néanmoins, l'agrégation altère les donnéespuisqu'une information dont la diversité était représentée par n unités se retrouve représentée par n/m unités(m étant un entier positif). Ainsi, l'agrégation produit un lissage des données et les valeurs d'attributsreprésentées par des éléments de surface réduite tendent à disparaître.
Définition des termes :- discrétisations spatiales :
pixel ou maille : unité élémentaire de discrétisation de l'espace de forme carrée ou rectangulaire, la valeur del'attribut est constante sur toute cette surface.patche : unité spatiale caractérisée par un ensemble de pixels adjacents ayant la même valeur d'attribut.groupe ou zone : unité spatiale caractérisée par un ensemble de pixels ayant la même valeur d'attribut maisn'étant pas forcément adjacents.patterns : formes structurales localisant les éléments les uns par rapport aux autres- qualité des données :exactitude (accuracy en anglais) : relation entre une mesure et la réalité qu'elle se propose de représenter,précision: degré de détail dans le stockage ou dans la manipulation de la mesure lors des calculs,résolution: quelle est la taille du plus petit objet pouvant être discerné dans une carte,échelle: notion intimement liée à la résolution puisqu'il y a une limite physique au dessin d'un objet surune carte. Cette limite est jugée en général à 0,5 mm ce qui correspond à 12,5 m pour une carte au1I25000ème par exemple.
1.1 Echelle et modélisation hydrologique
Dans un article de 1989, Beven a mis en garde les hydrologues contre les illusions entraînées par ledéveloppement des modèles à base physique. En effet, 1'hétérogénéité du monde réel ne peut êtrequ'estimée, la réalité physique des équations n'est valable qu'en laboratoire et le passage au terrain souffrede la grande variabilité spatiale des données. Le problème est de savoir si les équations physiques mesuréesen laboratoire sont valables à l'échelle de la maille de discrétisation et de transférer l'information contenuedans une mesure ponctuelle à l'échelle d'une maille de plusieurs centaines ou milliers de m2
•
Beven (1989) souligne que les études sur les effets de la variabilité spatiale ont révélé qu'il n'estpas possible de définir une valeur de paramètre consistante à différentes échelles spatiales. Une seule valeurde paramètre ne peut pas représenter les hétérogénéités des réponses (surfaces de ruissellement de quelquesm2 au sein d'une surface d'infiltration de 10 000 m2
, par exemple). Les équations validées ponctuellementne peuvent pas être utilisées à l'échelle des mailles, il est nécessaire de trouver des équations qui tiennentcompte de ces hétérogénéités.
Pour Beven (1989), les futurs développements des modèles à base physique doivent intégrer lesbesoins:- d'une théorie de globalisation des processus inférieurs à l'échelle de la maille,- d'une plus forte correspondance en terme d'échelle entre les prédictions et les mesures,- d'une meilleure estimation de l'incertitude dans les prédictions.
3
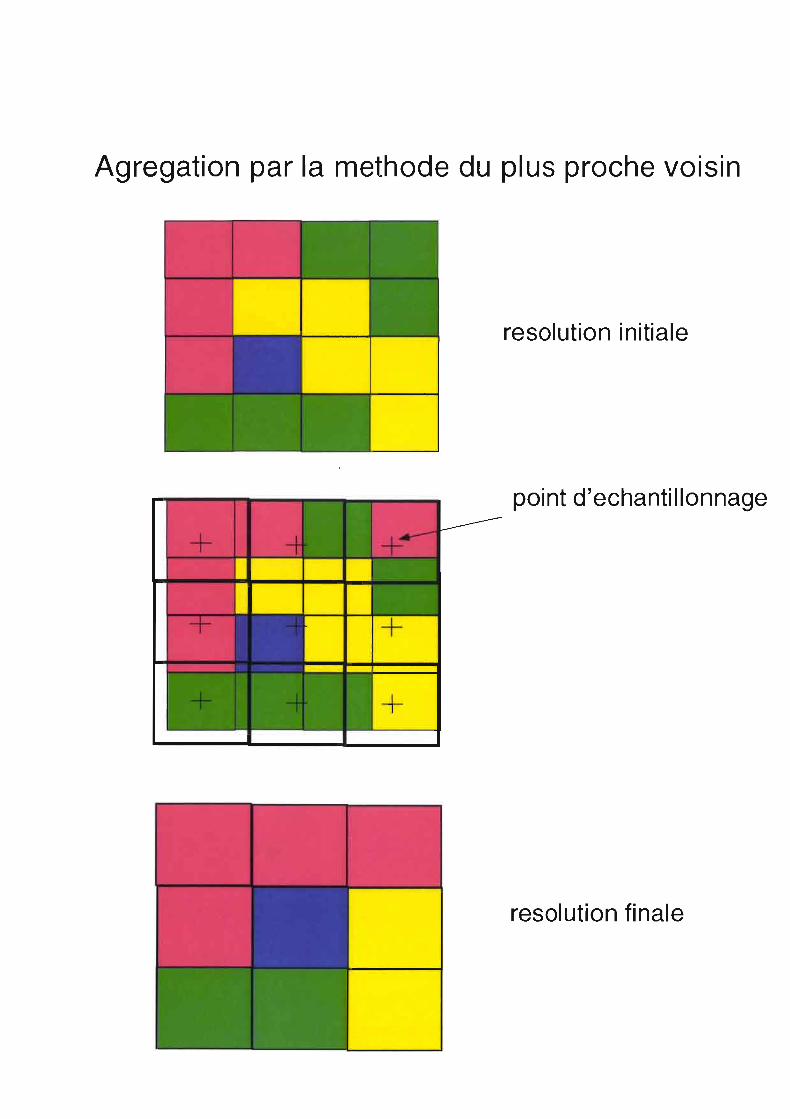
Agregation par la methode du plus proche voisin
1... ;,r;~. - ..:>• ,1 • , 1. >......... -
- 1__-
1 1-.
--Iii
resolution initiale
point d'echantillonnage
resolution finale

Des problèmes similaires surviennent lors du passage d'une maille fine à une maille plus grossière.Comment les processus représentés à l'échelle d'une maille de 50 mètres de côté sont-ils altérés à une maillede 200 mètres ou de 1 kilomètre?
Nous allons étudier les effets des changements d'échelle (ou de résolution) sur la qualité des donnéesen terme de représentativité des proportions initiales et en terme de respect des structures spatiales. Nousillustrerons les problèmes posés par l'agrégation dans des modèles hydrologiques.
1.2 Conséquences de l'Agrégation sur les données
L'agrégation se traduit par une altération de la proportion de chaque valeur d'attribut et par une modificationde la structure spatiale.
L'amplitude de cette altération dépend de 4 facteurs (Turner et al., 1989) :- l'amplitude de la variation d'échelle,- la proportion initiale des éléments Pk(1),- la contagion initiale des éléments C(1) : plus elle est élevée, moins les éléments minoritaires disparaîtrontrapidement,-le mode d'agrégation: par le plus proche voisin (le plus répandu), par moyenne, par majorité.
Tout d'abord, rappelons qu'il est impossible de « remonter» une échelle c'est-à-dire de passer d'un niveaugrossier à un niveau fin. Seul le processus inverse va donc être étudié.
Détermination analytique ou expérimentale?
La détermination analytique de l'évolution des Pk, en connaissant la résolution initiale, est difficile car ellenécessite la construction d'une matrice des adjacences Pij (probabilité pour que l'élément i soit à côté del'élément j) et l'utilisation d'équations dont la complexité augmente en fonction du nombre de mailles agrégées(Turner et al., 1989). Il est beaucoup plus facile et fiable de tester expérimentalement le résultat d'uneagrégation avec le SIG: l'évolution de chaque Pk est ainsi disponible pour une agrégation donnée (passaged'une maille de 50 mètres à une maille de 100 mètres, par exemple).
Variation des Pk et hydrologie
Lorsque la surface relative occupée par des éléments géographiques (Pk) intervient dans un modèle, il estsouhaitable d'étudier la sensibilité de ce modèle aux incertitudes de mesure de ces surfaces. Avec l'hypothèseque l'erreur de mesure croît en fonction de la taille des mailles (hypothèse à nuancer depuis les travaux deMande1brot sur les fractales), les variations des proportions des éléments cartographiques générées parl'agrégation se traduiront pour une dégradation des résultats du modèle.Ceci est le cas lorsqu'il n'y a pas prise en compte des « patterns» ou formes structurales localisant leséléments les uns par rapport aux autres. Ces modèles utilisent des valeurs moyennes de paramètres commepar exemple une altitude moyenne ou résument la distribution spatiale par une distribution statistique sanstenir compte du pattern (théorie du continuum de Wood et al. (1988) pour définir des RepresentativeElementary Area) comme par exemple dans un modèle d'évapotranspiration global où le calcul est effectué àl'aide d'une somme des évapotranspirations de chaque type d'occupation du sol pondérée par sa surfacerelative:
fi
A=""k·*S·~ 1 1
i=lki : poids du facteur iSi : surface relative du facteur i
4

alors, on peut mesurer l'erreur sur A, due au changement d'échelle.Par exemple, dans le cas des mares dans le Sahel qui sont des zones privilégiées de réalimentation desnappes, la réalimentation calculée à l'échelle d'une région va être sous-estimée d'un certain facteur dû à lasous-estimation des Si.
Lorsque la localisation des données a une importance dans la modélisation, l'altération des résultats nepourra pas être simplement calculée à partir des variations de Pk. La disparition de certaines surfaces à lasuite d'une agrégation va avoir des effets beaucoup plus importants sur les résultats du modèle et ces effetssont difficilement quantifiables.* sur des données discrètes : certains patches vont disparaîtrePar exemple, considérant les risques de pollution des cours d'eau à partir de versants en habitat dispersé, sicertaines zones d'habitat disparaissent parce qu'elles sont petites et/ou parce qu'elles sont dispersées, lacartographie des risques de pollution des cours d'eau va être totalement bouleversée.* sur des données continues, il s'opère un "lissage" c'est-à-dire une disparition des valeurs extrêmes.C'est par exemple le cas du calcul de pente ou des chemins d'écoulement avec un Modèle Numérique deTerrain (MNT), l'altération du modèle provoquée par l'agrégation pourra par contre est suivie à l'aided'indices d'entropie (Vieux (1992».
Les modifications de Pk et des indices de structure permettent d'estimer l'adéquation de l'échelle desdonnées au problème posé.
Variabilité spatiale des conséquences de l'agrégation
La variation de la structure dans l'espace est souvent contrôlée par des phénomènes d'étendue plus régionale.Les structures décamétriques ou hectométriques ne sont pas homogènes dans l'espace car il existe descontraintes plus larges d'ordre kilométrique. Ceci est par exemple la cas dans un paysage contrôlé par lagéologie ou la topographie : un paysage de bocage sur une géologie argileuse fait place à un openfield enplaine alluviale ou à des forêts en altitude.
Il est donc important de ne pas mesurer l'évolution des Pk ou de la structure globalement mais de définir deszones d'échantillonnage représentatives de chaque type de structure. Tout le problème est d'arriver àdélimiter ces zones. Les contraintes sur une donnée peuvent être assez évidentes comme dans le cas de lavégétation avec la topographie mais d'autres relations sont plus difficiles à déterminer. L'entropie peut êtreutilisée pour signaler l'existence de macro-structures comme nous l'illustrerons pour les donnéesd'occupation du sol ou la topographie.
5
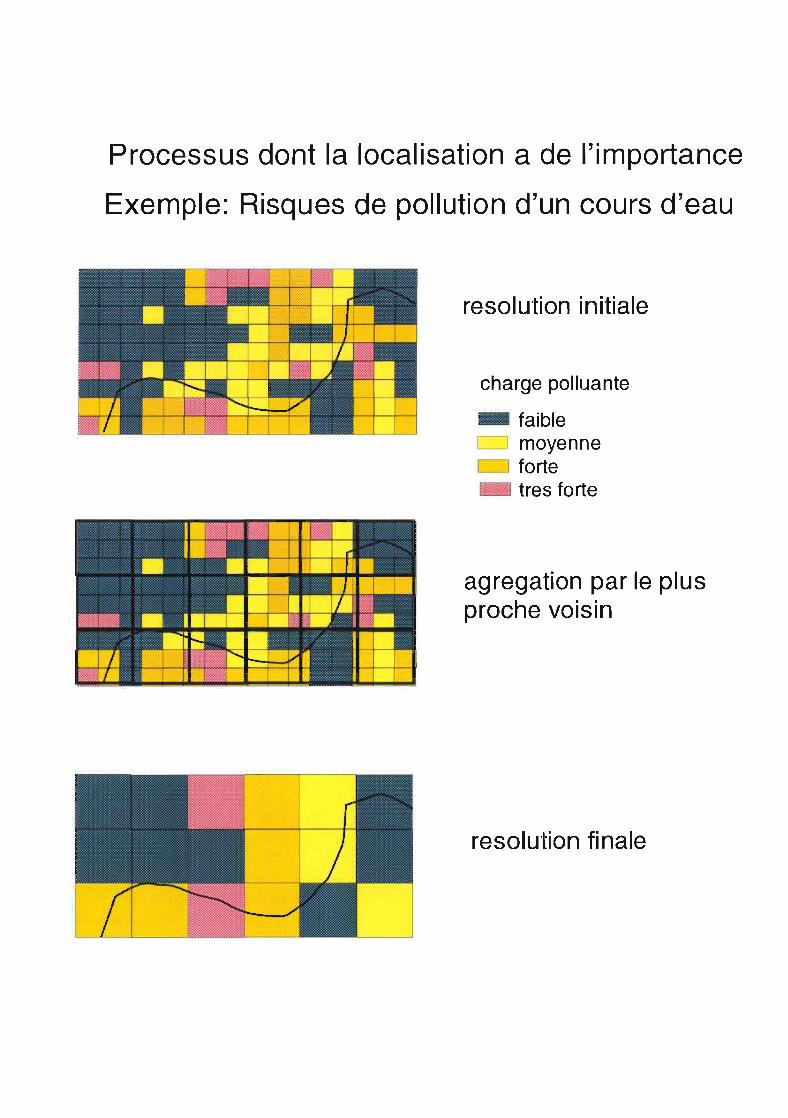
Processus dont la localisation a de l'importance
Exemple: Risques de pollution d'un cours d'eau
resolution initiale
charge polluante
.. faiblec::::J moyenne
fortetres forte
agregation par le plusproche voisin
resolution fi nale
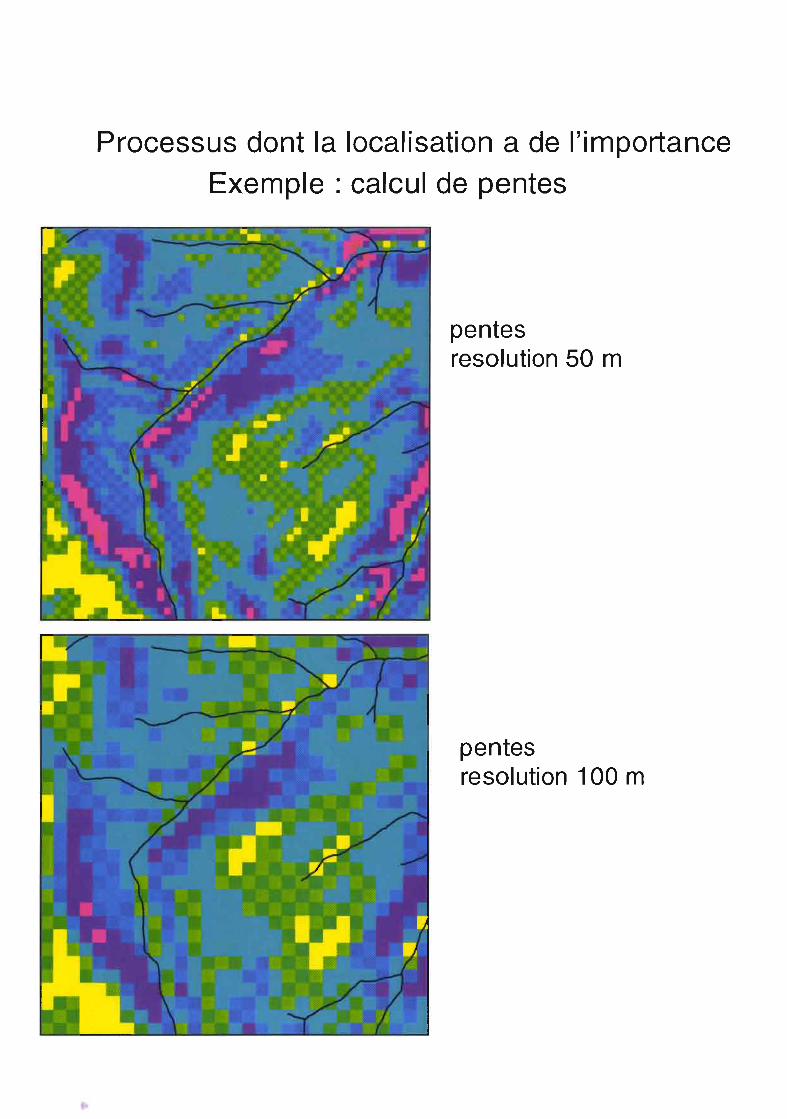
Processus dont la localisation a de l'importance
Exemple: calcul de pentes
pentesresolution 50 m
pentesresolution 100 m

2. Indices structuraux, agrégation et perte d'information
De nombreux indices structuraux peuvent être calculés dans r./e sous GRASS 4.1. Parmi eux, certains ontété utilisés dans la littérature pour quantifier les pertes d'information lors de l'agrégation.
2.1 Travaux de GoodchildGoodchild (1980, 1993) s'est intéressé à la perte d'information lors de la transformation d'une
carte vecteur en raster. Il a étudié deux formes de paysage géographique: une forme qu'il nomme A et quicorrespond à un paysage ramassé en un petit nombre de patches, une forme qu'il nomme B représentant unpaysage très morcelé en une multitude de petits patches. Goodchild trouve qu'une surface réelle estexprimée dans 95 % des cas avec une incertitude telle que (en % de surface totale):- pour le cas A :
1.03*(k*nY/2*(S*Dy3/4
avec: k indice de forme des patches : k =périmètre / (3.54 * ..Jsurface)n nombre de patches sur la surfaceS est la surface estiméeD est la densité de pixels par unité de surface
- pour le cas B :1.96(1 - S/SoY/2 (S/D)1/2
avec: So surface totale présentant les patches éparpillés.Ainsi, un affinement de la taille des maille produira une amélioration plus rapide dans le cas A que
dans le cas B.
2.2 Travaux de Turner, O'Neill, Gardner et MilneTurner et al. (1989) utilisent trois indices structuraux pour estimer la perte d'information liée à l'agrégation:
* indice de diversité de Shannon H', défini par Shannon et Weaver (1964) :
fi
H '=- LPi *log(Pi)i
avec Pi fraction de la surface occupée par l'attribut im nombre de valeurs de l'attribut dans la zone d'échantillonnage
plus cet indice est élevé, plus le paysage est diversifié
* indice de dominance: D = log(m)-H'compare l'indice H' à une valeur maximale de diversité se réalisant lorsque tous les types sont présentsavec une proportion égaleD est élevée quand le paysage est dominé par un type et elle est faible lorsque que de nombreux typessont représentés en proportion similaire, cependant D=O pour un paysage complètement homogène.
* indice de contagion C : exprime au contraire le degré d'agrégation, en comparant une mesured'entropie à une entropie maximale théorique :
fi fi
C =2 * log(m) - L L Pij *log(Pij)i=l j=l
avec: Pij probabilité d'adjacence de i avec jle terme 2 * log(m) indique une valeur maximale lorsque toutes les adjacences possibles entre types seproduisent à une probabilité similaire. C tend donc vers 0 pour un paysage aléatoire sans agrégats oupatches.
6

Pour Turner et al. (1989), « le taux avec lequel des types de couverture rares décroissent avec l'agrégationdépend de leur arrangement spatial )) : si un type de couverture rare est organisé en patches compacts, il neva pas disparaître au cours de l'agrégation ou alors plus lentement qu'un type rare éparpillé. Un indice decontagion élevé réduit la vitesse de disparition des éléments minoritaires par agrégation.
Ces auteurs ont aussi étudié l'effet de l'agrégation sur les indices de paysage précédents:* l'indice de Shannon présente une régression linéaire avec le logarithme de la taille des pixels(coefficient de corrélation r2 > 0.9)* contagion et dominance présentent des relations plus complexes avec le logarithme de la taille despixels : ils sont sensibles au nombre de types présents et leur évolution, au fur et à mesure del'agrégation, montre des seuils lorsqu'un type disparaît. Ils augmentent entre chaque perte de typemais diminuent globalement.
2.3 Travaux de Vieux et FarajallaVieux et Farajalla (1994, 1995) utilisent la dimension fractale pour déterminer si la représentation
spatiale des données peut enrichir un modèle (en précisant à quelle résolution) ou si la moyenne suffit.Comme le soulignent ces auteurs, « l'important dans un modèle distribué est qu'il saisisse la variabilitéspatiale essentielle de chaque paramètre affectant le processus hydrologique)) et non d'affiner au maximumla résolution ce qui gaspille de la mémoire et augmente les temps de calcul. Le problème est donc dedéterminer la résolution minimale qui permette de représenter la variabilité spatiale (Farajalla et Vieux,1995).
La dimension fractale D définie par Mandelbrot (1982) exprime le niveau de variation présent à touteéchelle dans une donnée (Burrough, 1986). D est compris entre 1 et 2 pour des objets linéaires, 2 et 3 pourdes objets surfaciques.
Burrough (1986) remarque que la dimension fractale de la topographie augmente avec l'altitude, etexplique cela par la sédimentation qui domine en plaine et qui empâte le paysage comparativement à lamontagne où les processus d'érosion dominent.
La dimension fractale est obtenue à partir de l'indice d'entropie. En fait, l'indice d'entropie 1qu'utilisent Vieux et Farajalla correspond dans r.le ou chez Turner et al. (1989) à l'indice de diversité H' ouindice de Shannon.
fi
1= H'= - LPi *log(pj}1
L'entropie est nulle pour une surface plane, elle est maximale pour une surface où toutes les valeursont la même probabilité d'occurrence par exemple en topographie pour une surface très variable ou pour unesurface avec une pente constante (Vieux, 1993).
En 1994, Farajalla et Vieux ont introduit une autre mesure de l'entropie: SVM (Spatial VariabilityMeasure). SVM normalise l'entropie de Shannon par le logarithme du nombre de pixels N :
SVM = 1- 1log(N)
Ceci permet d'éliminer dans le calcul de l'entropie en fonction de la résolution, la part due à la variation dunombre de mailles. En effet, 10g(N) représente la variabilité maximale (nombre de valeurs différentes =nombre de pixels), donc 10g(N) > 1. Cependant, à un niveau de résolution identique, une zone avec uneentropie élevée présente une SVM inférieure à une zone à entropie faible, ce qui n'est pas cohérent. Nousn'utilisons donc pas cet indice, nous préférerons le coefficient de Hurst.
Le taux avec lequel l'indice d'entropie 1 change au fur et à mesure de l'agrégation est une mesure dela variation de l'adjacence de valeurs similaires, ce taux est nommé H, coefficient de Hurst (Vieux etFarajalla, 1994).
7
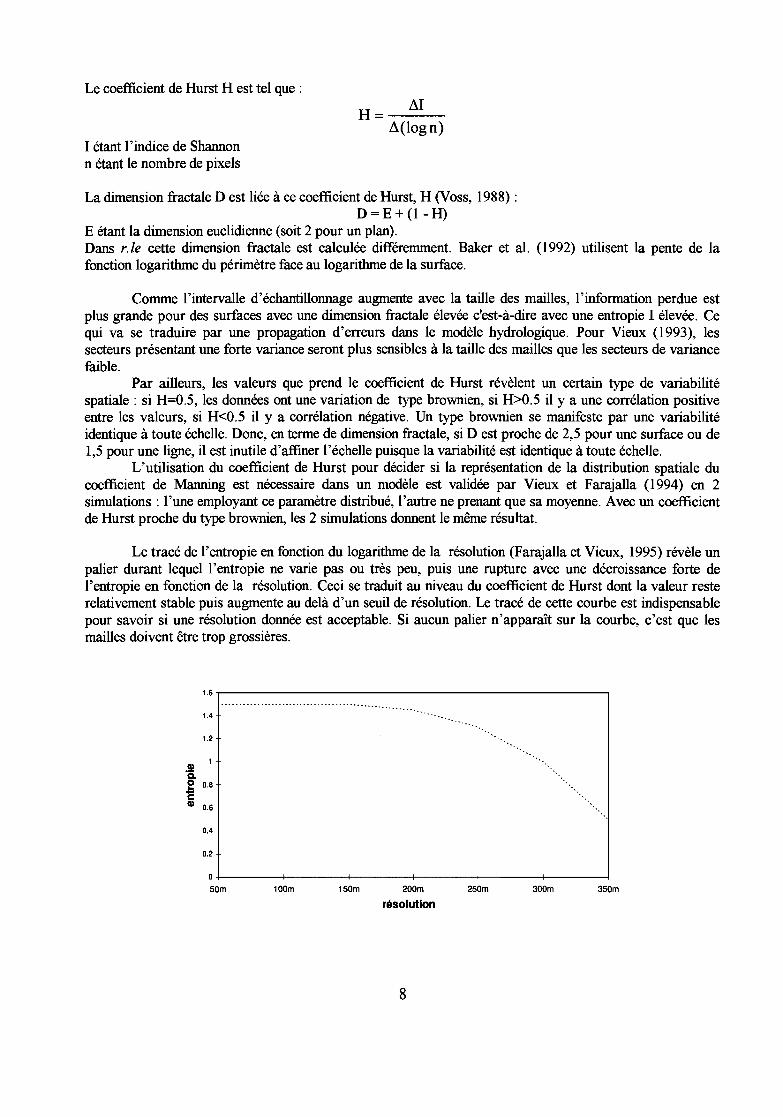
Le coefficient de Hurst H est tel que :
H= ~I~(logn)
1étant l'indice de Shannonn étant le nombre de pixels
La dimension fractale D est liée à ce coefficient de Hurst, H (Voss, 1988) :D=E+(1-H)
E étant la dimension euclidienne (soit 2 pour un plan).Dans r./e cette dimension fractale est calculée différemment. Baker et al. (1992) utilisent la pente de lafonction logarithme du périmètre face au logarithme de la surface.
Comme l'intervalle d'échantillonnage augmente avec la taille des mailles, l'information perdue estplus grande pour des surfaces avec une dimension fractale élevée c'est-à-dire avec une entropie 1 élevée. Cequi va se traduire par une propagation d'erreurs dans le modèle hydrologique. Pour Vieux (1993), lessecteurs présentant une forte variance seront plus sensibles à la taille des mailles que les secteurs de variancefaible.
Par ailleurs, les valeurs que prend le coefficient de Hurst révèlent un certain type de variabilitéspatiale: si H=O.5, les données ont une variation de type brownien, si H>O.5 il y a une corrélation positiveentre les valeurs, si H<O.5 il y a corrélation négative. Un type brownien se manifeste par une variabilitéidentique à toute échelle. Donc, en terme de dimension fractale, si D est proche de 2,5 pour une surface ou de1,5 pour une ligne, il est inutile d'affiner l'échelle puisque la variabilité est identique à toute échelle.
L'utilisation du coefficient de Hurst pour décider si la représentation de la distribution spatiale ducoefficient de Manning est nécessaire dans un modèle est validée par Vieux et Farajalla (1994) en 2simulations: l'une employant ce paramètre distribué, l'autre ne prenant que sa moyenne. Avec un coefficientde Hurst proche du type brownien, les 2 simulations donnent le même résultat.
Le tracé de l'entropie en fonction du logarithme de la résolution (Farajalla et Vieux, 1995) révèle unpalier durant lequel l'entropie ne varie pas ou très peu, puis une rupture avec une décroissance forte del'entropie en fonction de la résolution. Ceci se traduit au niveau du coefficient de Hurst dont la valeur resterelativement stable puis augmente au delà d'un seuil de résolution. Le tracé de cette courbe est indispensablepour savoir si une résolution donnée est acceptable. Si aucun palier n'apparaît sur la courbe, c'est que lesmailles doivent être trop grossières.
1.6,---------------------------,
1.4
1.2
~Q,,g 0.8
Cal 0.6
0.4
0.2
3S0m300m2S0m1S0m 200m
résolution100m
O+----+-----t-----t-----I-----+----~
SOm
8
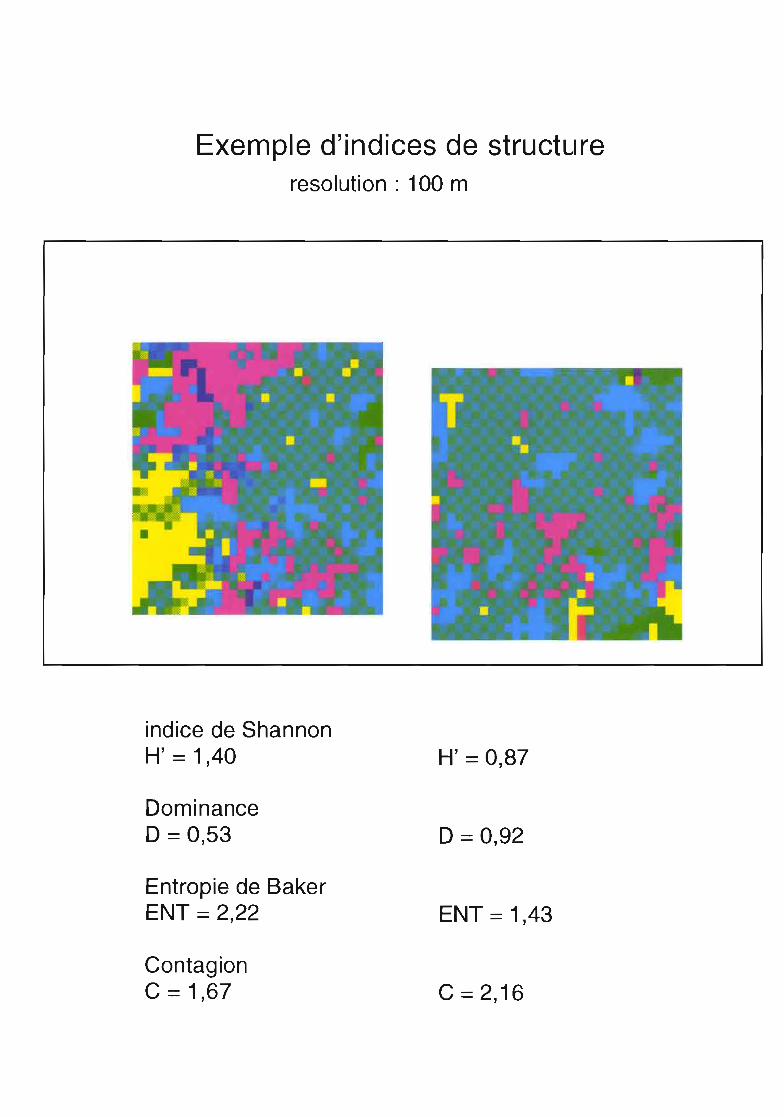
Exemple d'indices de structureresolution : 100 m
indice de ShannonH' = 1,40
DorTlinance0=0,53
Entropie de BakerENT = 2,22
ContagionC = 1,67
H' =0,87
0=0,92
ENT = 1,43
C =2,16

3. Programme r.Ie sous GRASS 4.1
Baker et Cai (1992) ont conçu le programme d'analyse spatiale r./e (raster landscape ecological) sur la basedu SIG GRASS afin de calculer des indices de structure ou de fonne à partir de données géographiques etafin de réaliser ces analyses à différentes échelles ou niveaux d'agrégation.Ce programme est dédié à l'analyse du paysage pour des problématiques écologiques mais il peut très bienêtre utilisé pour d'autres domaines comme l'hydrologie.
Ce programme contient un certain nombre de sous-programmes :- de.setup : fixe la cadre d'échantillonnage,- de.show: contrôle l'échantillonnage,- de.trace : trace les limites des patches identifiés,- de.dist : mesure des distances entre les patches,- de.patch : mesure sur les attributs, la fonne, la taille, le périmètre des patches,- de.pixel : texture des pixels.
r.le.setup4 stratégies d'échantillonnage :- sur toute la surface,- sur la surface discrétisée en régions,- sur des surfaces de taille prédétenninée servant de zones d'échantillonnage,- sur une fenêtre mobile de balayage.
r.le.distIl y a plusieurs façons de mesurer la distance entre patches :
- selon si l'on restreint ou non la recherche à certains groupes,- selon si l'on considère tous les patches voisins ou seulement le plus voisin,- selon si l'on mesure du centre vers le centre, du centre vers la limite, de la limite vers le centre...
En sortie, le programme écrit un fichier table lisible sous le répertoire r.le.out et portant le préfixe de l'optionutilisée (par exemple, nl-4.out pour les mesures de distance).
r.le.patch- mesures des attributs sur toute la zone d'échantillonnage ou par patche ou par groupe: moyenne ou écarttype. Utilisable seulement avec données ratios ou intervalles.Mais aussi: surface couverte par chaque groupe, densité par groupe (nombre de patches rapporté à lasurface de chaque groupe) et densité totale (nombre de patches rapporté à la surface de la zoned'échantillonnage).- taille : moyenne de la taille des patches dans la zone d'étude : surface de la zone / nombre de patchesécart-type de cette taille; variante: calcul par groupe sur la zone d'échantillonnage;calcul du nombre de patches par classe de taille et calcul du nombre de patches par classe de taille et pargroupe.Une option pennet de prendre en compte en plus la largeur affectée par la limite des patches de façon àobtenir la taille moyenne ou l'écart-type de la taille des "cores" et des surfaces affectées par les limites despatches sur toute la zone d'échantillonnage ou par groupe ainsi que le nombre de patches par classe de taille(en prenant ou non en compte le groupe).- fonne des patches :
. indice périmètre / aire : pennet de quantifier la fonne plus ou moins digitée des patches,
. indice périmètre / aire corrigé:0.282 *périmètre / (aire)1I2
idem que le précédent mais échelonne les valeurs de 1.0 pour un cercle, à 1.1 pour un carré et à l'infinipour une fonne très longue et étroite, en effet pour un cercle :0.282 * 2 * PI *R / (PI * RZ)1I2 =0.282 * 2 *PI1I2 = 1.0
9

· cercle englobant RCC: cet indice compare l'aire du patche à l'aire du plus petit cercle pouvantl'englober:
RCC = 2 * (aire / PI)l/2 / (axe long)pour un cercle: RCC = 2 * (PI * R2 / PI)l/2 / 2R = 1.0cet indice de compacité de la forme varie de 0.0 à 1.0, un carré par exemple a une valeur égale à 0.79· en option: moyenne et écart-type des mesures sur toute la zone ou par groupe, nombre de patches parintervalle de valeur d'indice de forme (en prenant ou non en compte le groupe).
- dimension fractale : d = 2 * savec s : pente de la droite de régression de [log(périmètre) / log(surface)]- périmètre: somme, moyenne ou écart-type des périmètres des patches (par groupe ou non).
Domaine d'application des fonctions "patches" : un patche n'a de réalité que si les données sont discrètes, cesfonctions ne peuvent pas être employées avec des continues à moins de les discrétiser.
r.le.pixel- diversité :· richesse = (n - 1) avec n : nombre de valeurs différentes d'attributs,· indice de Shannon H', combine richesse et fréquence :
m
H'= - LPi *ln(Pi)
avec Pi fraction de la surface occupée par l'attribut im nombre de valeurs de l'attribut dans la zone d'échantillonnage
· indice de dominance: D = In(m)-H'compare l'indice H' à une valeur maximale théorique· inverse de l'indice de Simpson (liS) : S étant la probabilité de rencontrer 2 pixels avec une mêmevaleur d'attribut en prenant 2 pixels au hasard :
ID
S = LPi 2
i=l- texture : mesure quantitative de l'adjacence d'attributs similaires dans une matrice de m*m avec commeentrée le nombre d'occurrences que la valeur i soit à côté de la valeur j.
· ENT entropie : exprime la dispersion des valeurs dans l'espace :m m
ENT =- L LPij *ln(p~.i)i=lj=l
· C contagion: exprime au contraire le degré d'agrégation, en comparant une mesure d'entropie à uneentropie maximale théorique :
C = 2 * In(m) - ENT· ASM second moment angulaire: proportionnel à l'homogénéité:
m m
ASM=LLP/i=lj=l
· IDM moment différentiel inverse :m m
IDM = LL[l/(1+(i+ j)2]* Piji=l j=l
· CON contraste: exprime l'amplitude de la différence de valeur entre les voisinsm m
CON =L L[(i - j)2 *Py']i=lj=l
10

- juxtaposition : opération effectuée par la fenêtre mobile, quand on affecte un certain poids à certaineslimites (par exemple, on considère que la limite forêt / terre labourable est plus importante que la limite forêt/ lande)
8
Iqn *Wij
J = .=.n=......:1'-:8=-----
Iqnn=1
avec: qn facteur lié à la position du pixel voisin: 1 pour diagonal et 2 pour orthogonalWij poids entre attribut ll\ et tn.;, compris entre -1 et 1
- edges (= arêtes ou limites) : somme, écart-type des limites entre patches de la zone d'échantillonnage maissans duplication contrairement à la mesure du périmètre. Une variante effectue ce calcul par type endéfinissant une matrice m*m dans un fichier r.1e.para/edge où seules les relations auxquelles on s'intéresseont une valeur non nulle. Ainsi, on peut faire la somme des frontières entre un attribut 1 et un attribut 2 surune zone d'échantillonnage.
Problème avec les sorties cartographiquesGRASS ne supporte que des cartes raster en format integer et non en réels ce qui pose des problèmes
avec certaines fonctions. Pour surmonter ce problème, les auteurs multiplient le résultat par 10, 100 ou 1000.
r.Ie.tracePour tracer les cartes résultats sur toute l'étendue : limites des patches, de leurs attributs, périmètres etformes, et pour les sauver dans un fichier.
Utilisation pratique de r.le
r.Ie.setup
Taper dans le shell de GRASS: r.le.setup.Il ouvre alors un menu dans la fenêtre graphique.
Définition des zones d'échantillonnageC'est dans ces zones définies lors de cette étape que les calculs ultérieurs seront effectués : diversité,dominance, entropie...Dans ce menu, plusieurs options existent pour la définition des zones d'échantillonnage (sampling area).
Il Ya trois types de méthode d'analyse (classification de Tom1in, 1992) :- analyse globale : les traitements sont rapportés à la carte dans son ensemble, ainsi la somme des longueursdes limites ou la moyenne des surfaces sera celle dé toute la carte.- analyse zonale : les valeurs sont calculées à partir des valeurs des mailles d'une carte thématique comprisesdans toute une zone. Les zones sont définies à l'aide de la fonction sampling area. Par exemple, on peutcalculer la somme des valeurs attributaires d'une carte dans chaque zone d'échantillonnage.- analyse focale : traitement par voisinage à l'aide d'une fenêtre mobile de taille définie par l'utilisateur. Lafenêtre se déplace sur toute la couverture cartographique, chaquemailleesttraitéel.uneaprèsl.autre.lavaleur qu'elle prend dépend d'un voisinage plus ou moins étendu (cette valeur peut être la moyenne, la sommedes voisines...). Cette fonction est appelée par Moving Window. Il faut souligner que l'analyse par fenêtremobile est très lente (dans GRASS), elle est donc à utiliser avec parcimonie et si possible à tester enappliquant auparavant un masque de façon à réduire le nombre de mailles analysées.
11

"'"/
" ~"'II. rs;;:
/ 1"'"
de dimeJ,sjQo 3.13
L'analyse zonale peut être effectuée selon différentes modalités dans r.1e, par définition des zonesd'échantillonnage (sampling units) de forme rectangulaire:- tout d'abord la taille, la forme et le nombre des zones d'échantillonnage peuvent être définies soit à la sourissoit au clavier,- si elles sont définies au clavier, elles peuvent être distribuées: au hasard sans chevauchement, de façoncontiguë (rectangles côte à côte et adjacents), de façon non contiguë (rectangles côte à côte mais séparés parune marge), de façon stratifiée (un certain nombre de strates est défini par l'utilisateur, ces strates sontensuite constituées au hasard afin de couvrir toute la carte et une zone d'échantillonnage est placée danschaque strate), centrées sur des sites définis dans une autre couverture cartographique.Il faut remarquer que les zones d'échantillonnage peuvent être placées en dehors de la carte sur des surfacesentièrement en nodata.- si elles sont définies à la souris cela permet de mieux saisir des zones typiques de paysage (zone de plateau,zone de collines disséquées, zones de plaine...).
Il est possible de définir différentes échelles (scale) avec l'analyse zonale. On peut connaître un indice dansune zone rectangulaire d'une certaine taille et la variation de cet indice lorsque la taille augmente. L'intérêt estd'évaluer la dépendance de l'indice vis-à-vis de l'échelle. En pratique, dans la procédure r.le.setup / units area,il est nécessaire de définir explicitement la taille des zones aux différentes échelles.
Par ailleurs, un bouton du menu permet de définir préalablement un cadre d'échantillonnage (SamplingFrame). Les unités d'échantillonnage choisies ultérieurement ne seront prises que dans ce cadre. Ceci peutservir à surmonter l'inconvénient des zones d'échantillonnage en no data ou de cantonner son analyse dans unsecteur géographique déterminé.
Définition des groupes et des classesA partir d'une série de valeurs en entrée, on peut définir une nouvelle valeur résumant cette diversité.Apparemment, ce qui distingue les groupes des classes est que les premiers peuvent être définis à partir devaleurs disjointes alors que les classes ne le peuvent pas. Les groupes paraissent donc mieux adaptés à desvaleurs nominales et les classes à des valeurs cardinales ou ordinales. Par exemple, des catégories de solspourront être regroupées à l'aide de la fonction "groupes" (les sols 1, 6 et 7 formeront le groupe l, les sols 2,3 et 8 formeront le groupe 2), une carte d'élévation nécessitera une classification à l'aide de la fonction"classes" (toutes les valeurs d'altitude de 400 à 499 m donneront la classe 1, les valeurs de 500 à 599donneront la classe 2...).
12

1
2 2
3 3
~2 244
35
3fi
~6 6
Redl1ssificl)tion de valeursnominales
par une fonction "GROUPE"
Redassi fic l) tion de valeursordinales ou cardjnales
par une fonction "CLASSE"
Définition des couleursUn menu supplémentaire permet de modifier la palette de couleurs utilisée.
r.Ie.distPour le principe général se reporter à ce qui a été écrit plus haut et pour le détail des commandes se reporterà la documentation fournie par GRASS.Le mode d'échantillonnage est spécifié comme argument de chaque fonction en précisant sam=u par exemplesi on utilise des zones d'échantillonnage rectangulaires.Il faut souligner que les patches sont redécoupés par la zone d'échantillonnage. Quand une distance parexemple est mesurée entre 2 patches, elle l'est non pas entre leur centre de gravité tel qu'il est définit sur toutel'étendue de la carte mais seulement sur le centre de gravité du patche redécoupé à l'intérieur de la zoned'échantillonnage.Les mesures sont faites en pixels.
fichiers résultats contenus dans le répertoire de.out :exemple: fichier lia 1-4" :1 1 2.68 1.33nO d'échelle nO de la zone moyenne sur les écart type sur les
d'échantillonnage pixels pixels
5.50moyenne sur lespatches
2.22écart type sur lespatches
Les zones d'échantillonnage sont numérotées séquentiellement ligne par ligne en partant du coin hautà gauche.
On peut obtenir la carte des zones d'échantillonnage en sortie en spécifiant l'argument -u dans la lignede commande. Ceci peut être utile dans les analyses de changement d'échelle comme nous le verrons plusloin.
3° Analyse des patches r.Ie.patchPour le principe général se reporter à ce qui a été écrit plus haut et pour le détail des commandes se reporterà la documentation fournie par GRASS.
4° Analyse de texture et de diversité r.Ie.pixelAttention: lorsque une unité est prédominante, les fonctions de diversité ne marchent pas. Ainsi, nous avonspu observer que sur une zone où apparaît 3 entités différentes mais dont l'une forme 99% de la superficie, lesfonctions de diversité ne tiennent compte que d'une seule unité: richness=l, H'=O, D=O, lIS=1.
13

Inconvénient avec de.pixel : le fichier contenant la matrice des cooccurrences (GLCM) des attributs quicontient comme entrées les probabilité Pij et qui sert de calcul à chaque indice n'est pas disponible. Cettematrice pourrait pourtant servir à d'autres calculs que ceux des indices fournis par de.pixel.
14
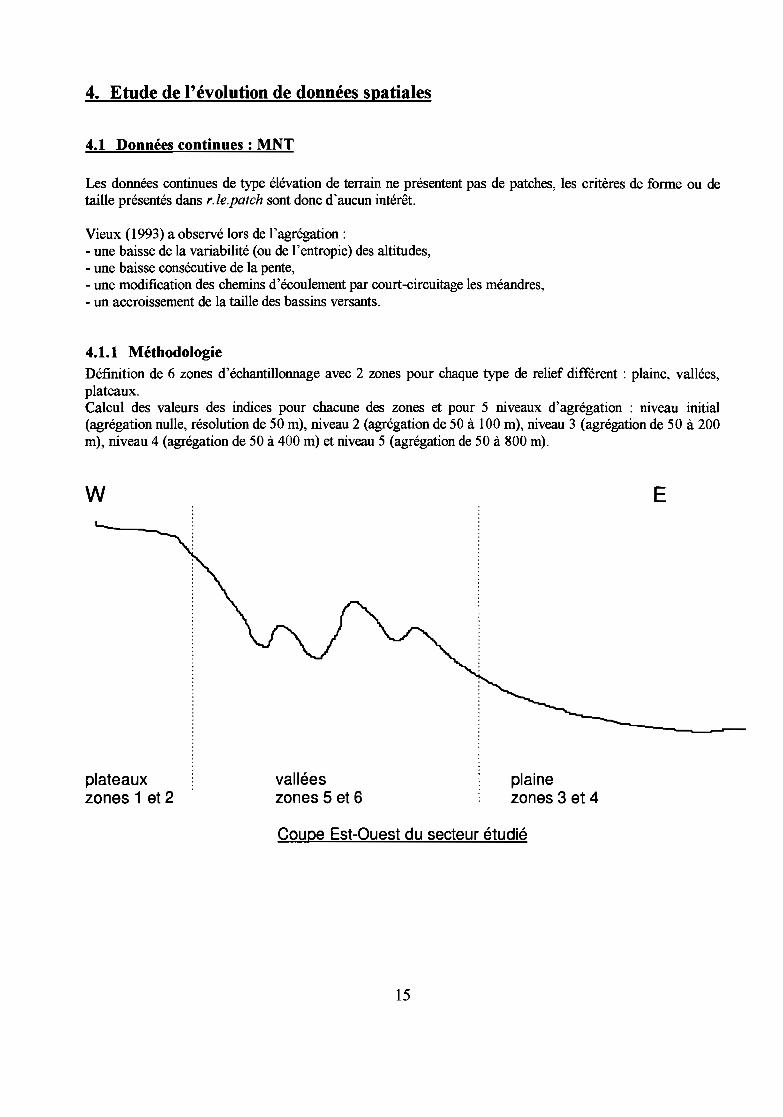
4. Etude de l'évolution de données spatiales
4.1 Données continues: MNT
Les données continues de type élévation de terrain ne présentent pas de patches, les critères de forme ou detaille présentés dans r.le.patch sont donc d'aucun intérêt.
Vieux (1993) a observé lors de l'agrégation:- une baisse de la variabilité (ou de l'entropie) des altitudes,- une baisse consécutive de la pente,- une modification des chemins d'écoulement par court-circuitage les méandres,- un accroissement de la taille des bassins versants.
4.1.1 MéthodologieDéfinition de 6 zones d'échantillonnage avec 2 zones pour chaque type de relief différent: plaine, vallées,plateaux.Calcul des valeurs des indices pour chacune des zones et pour 5 niveaux d'agrégation: niveau initial(agrégation nulle, résolution de 50 m), niveau 2 (agrégation de 50 à 100 m), niveau 3 (agrégation de 50 à 200m), niveau 4 (agrégation de 50 à 400 m) et niveau 5 (agrégation de 50 à 800 m).
w E
plateauxzones 1 et 2
valléeszones 5 et 6
plainezones 3 et 4
Coupe Est-Ouest du secteur étudié
15

4.1.2 Aptitude des indices structuraux à représenter une typologie de reliefL'indice de Shannon (H') individualise les types de relief observés :
5,5 < H' < 6 pour le relief disséqué de vallées,4,5 < H' < 5,5 pour le relief de plateaux sommitaux,H' ~ 3,5 pour la plaine
L'indice ENT produit un résultat similaireL'indice de contagion C ne pennet aucune individualisation entre types de relief.La dominance D est bien adaptée pour révéler les types de relief: 0,286 < D < 0,512 pour la plaine et lesplateaux, 0,146 < D < 0,226 pour les vallées.L'indice de contraste (CON) signe très bien les types de relief:
150 < CON < 210 pour les vallées45 < CON < 100 pour les plateauxCON < 10 pour la plaine
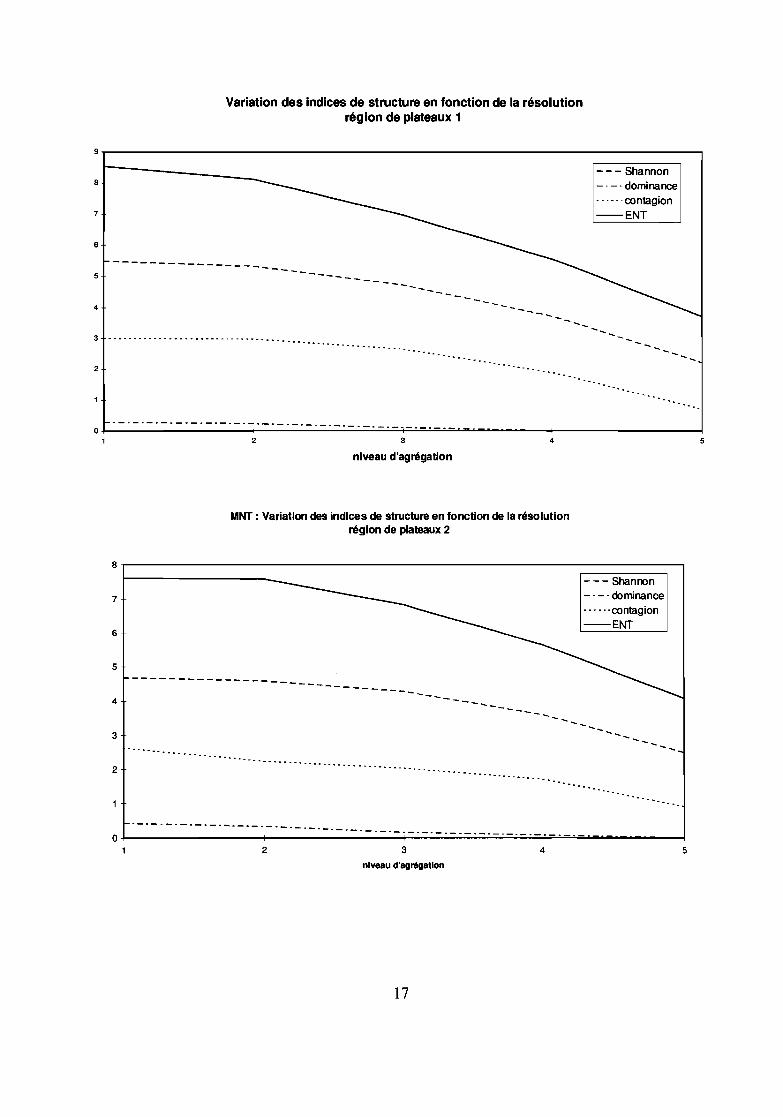
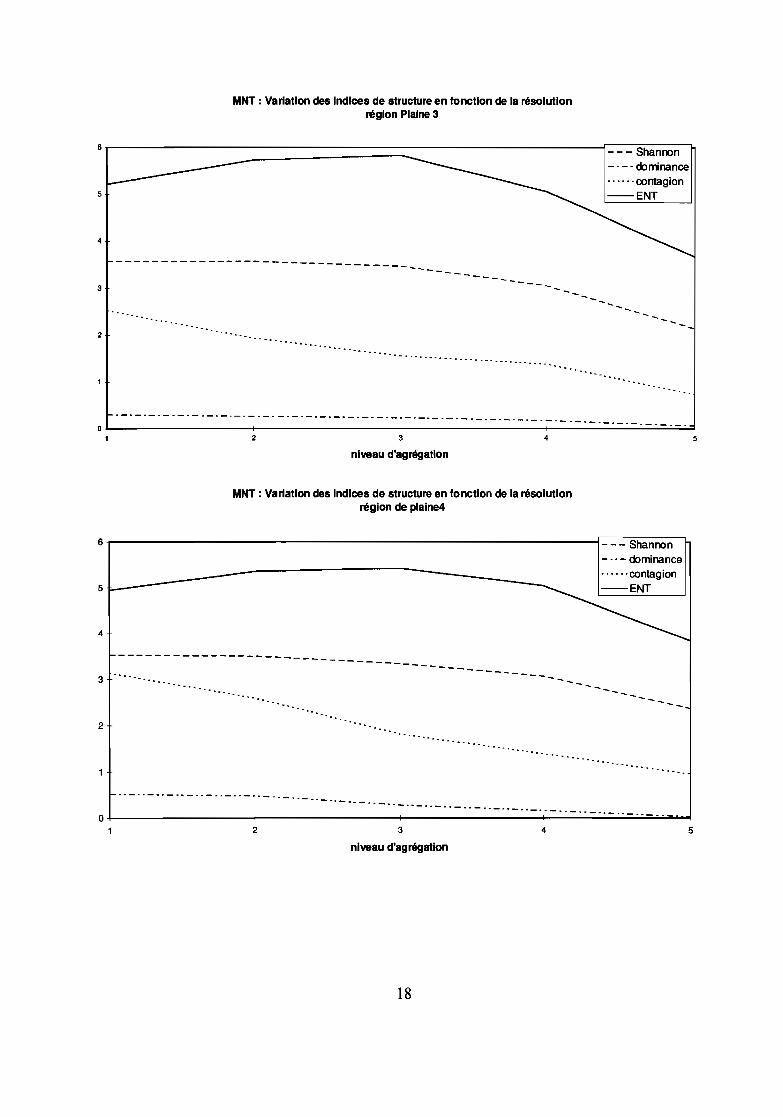
4.1.3 Variation des indices structuraux en fonction de l'agrégationL'agrégation à partir d'un niveau fin vers des niveaux plus ou moins grossiers conduit à une altération duMNT. Mais cette altération est variable selon la morphologie du terrain :
- si le terrain est accidenté (région de vallées), la variation des indices structuraux révèle une augmentation dela monotonie (baisse de la richesse, de l'indice de Shannon, de la dominance, de la contagion, de l'entropie) :les valeurs extrêmes disparaissent ; l'évolution sur les 2 unités d'échantillonnage observées marque unaccroissement pratiquement linéaire du coefficient de Hurst au cours de l'agrégation.
- en plaine, l'évolution est différente:* l'entropie ENT (de Baker) et l'entropie de Shannon (H' ou 1, nommée diversité de Shannon pour Baker)augmentent ou présentent une relative stabilité de 50 à 100 m et de 50 à 200 m voire de 50 à 400 m puisrégressent.Le coefficient de Hurst est faible pour des agrégations jusqu'à 400 m puis augmente légèrement.* contagion et dominance régressent de part leur sensibilité au nombre de valeurs différentes.
- la région de plateaux, présente une régression des indices d'entropie dès le premier niveau d'agrégationmais avec un palier relativement bien marqué pour une agrégation de 50 à 100 m contrairement à la région devallées. L'étude du coefficient de Hurst présente des résultats différents pour les 2 zones d'échantillonnage deplateau: la zone 2 donne une courbe de fonne similaire à celle de la plaine avec un coefficient un peu plusélévé, la zone 1 s'approche des zones de vallées: accroissement linéaire avec une pente semblable à celle deszones de vallées. Les plateaux présentent un comportement intennédiaire entre la plaine et les vallées car lerelief est un peu plus variable qu'en plaine comme l'indique l'entropie initiale (indice de Shannon de 4,5 à 5,5contrairement à la plaine où il est de 3,5).
L'observation des résultats indique que l'existence d'un palier sur la courbe de l'entropie ou ducoefficient de Burst, en fonction de l'agrégation varie selon le type de relief: plus le reliefest plat, plus lepalier est marqué, ce palier n'apparaît pas pour les secteurs où l'entropie initiale est forte.
ConséquenceIl est plus utile d'augmenter la résolution en région accidentée qu'en plaine. Car la résolution de
50m ne représente apparemment pas bien la diversité du terrain (l'entropie ne montre pas de palier entre 50 et100m) dans le secteur de vallées. En plaine, à l'inverse, une résolution de 200 m serait pratiquementacceptable.
16
Variation des indices de structure en fonction de la résolutionrég ion de plateaux 1
9 .......-----------------------------------------.....,
8
7
6
5
4
---------------- --------- ------------
--- Shannon- -- - dominance.. ····contagion--ENT
--......... __ _--- .. ..........
2
"00 o,.
". ".
-_._--.-._----.-._--.- .. - .. _---4 5
niveau d'agrégation
MNT : Variation des Indices de structure en fonction de la résolutionrégion de plateaux 2
8 .......----------------------------------------.
7
6
5
4
3
------------ ------
.........
---- ---
---Shannon-" -" dominance.... "contagion--ENT
----------- -- ------ --- --2
'"
--._-_.-._.-._.-.-.-._-- -- .. -.-.-543
niveau d'agrégation
2
0-1----------+----------"--+'-_.-_"-~.-~"~-..;.o~-..;..=-..;."=-.;..'-=-:."-:':"0=_..:.o=_:..:.o=_:..:.o-=_:..:.•.-... ~
1
17
MNT : Variation des Indices de structure en fonction de la résolutionrégion Plaine 3
4
5
6.,.----------------------------------r:::-=-=-=--=-cS;-.;h:::-a::nno=n:-"h_. _. dominance...... contagion--ENT
3
-------------------- ------------ --- --- --- --- ---
2 ......... ...........
".
543
niveau d'agrégation
2
---------_._-- .. _------._------._-------_.-._ .. _-_ .. - .. _.--------- .. -.- .. -._----.-._--o_---------_----------+------------+--------....;:::..:..=~
1
MNT : Variation des Indices de structure en fonction de la résolutionrégion de plaine4
-5 ___
4
6 -r----------------------------------r:::-::-=c:Si;'ha~n;;-;no~n:l
- .. - dominance.... "contagion
~3
------------------- ------------ ------ ---- -------....... .. ....
".'" ". ".
--- --- -----2 ". ". " .
.. -_ .. -- .. _... - -.- ... _.. - ... - - .. -".- ... -
543
niveau d'agrégation
2
.... - .. _.. - .. - ... - ... - .. _... - ... - ... - ... -0+------------+-----------+----------+----·._-_._..,;;-....;,...;.,.-=....:...':'=':":":::..0..0-1
1
18
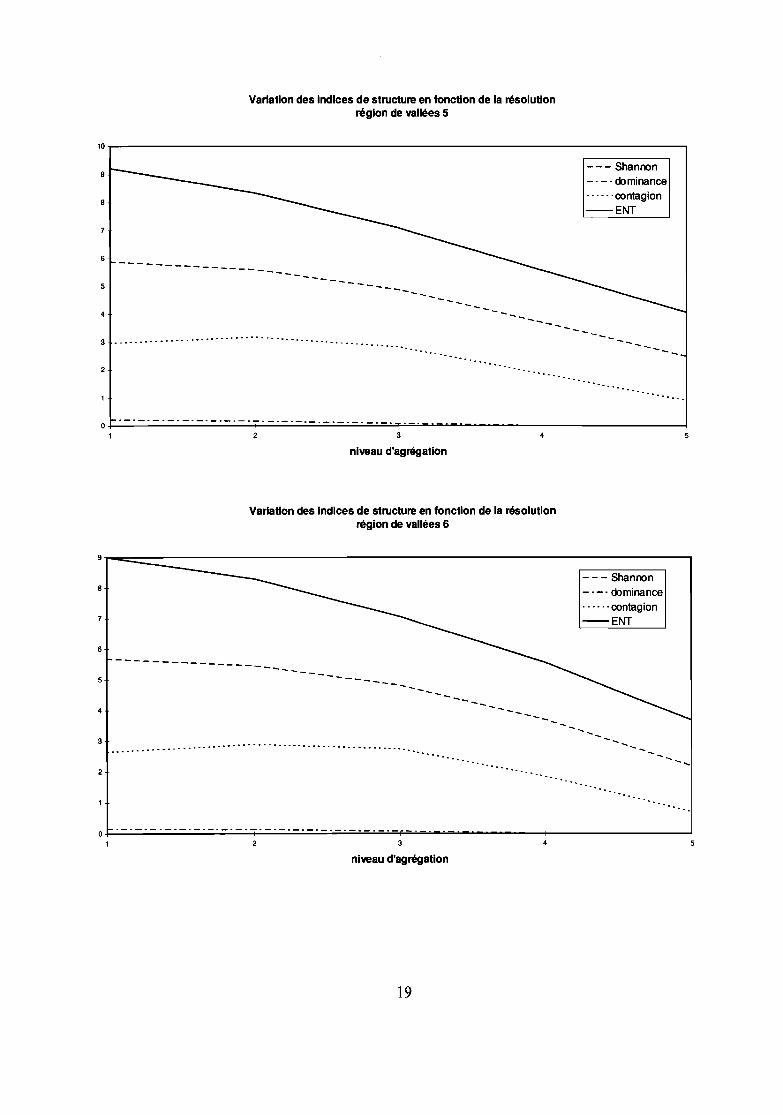
Variation des indices de structure en fonction de la résolutionrégion de vallées 5
10 .......--------------------------------------------,
6 ---------- ------------ --- ------ --- -- --
--- Shannon_. _. dominance
..... -contagion
--ENT
-----3 ~ - .. " - - "" .. -- --
3
niveau d'agrégation
0+-'---'---'---'----------.---.---.------,...;;...-;;;.;.,--;;;;";";;;;-":'-;;;;-":'-;;;;-;':''::-;':',-=-::';';.:-:..:.:'-:..:.:''f-'-'::..:......._~~~-----;----------~
1
Variation des Indices de structure en fonction de la résolutionrégion de vallées 6
------ ---- --- --- --- --- -- -- ------
-- - Shannon- . -. dominance.... ··contagion--ENT
3 ....... - ... .... -...
2
-'. ' .. ".". ".
43
niveau d'agrégation
o -l=--:''':-:'';''':-:'';-:'';-:'':'''-::...:..=-:..:.• ..:-;.:•..:-;.:•..:-:.:.:.:-:.;.;.:-+-:-:.-:..:..'-:..:..'=-":"=-":"'::-;':-'::-;':',-=-::';':.,:-:..:.:'-:..:.:'-=-i'-"-::..:..-="-.....~~-----_---------____
1
19
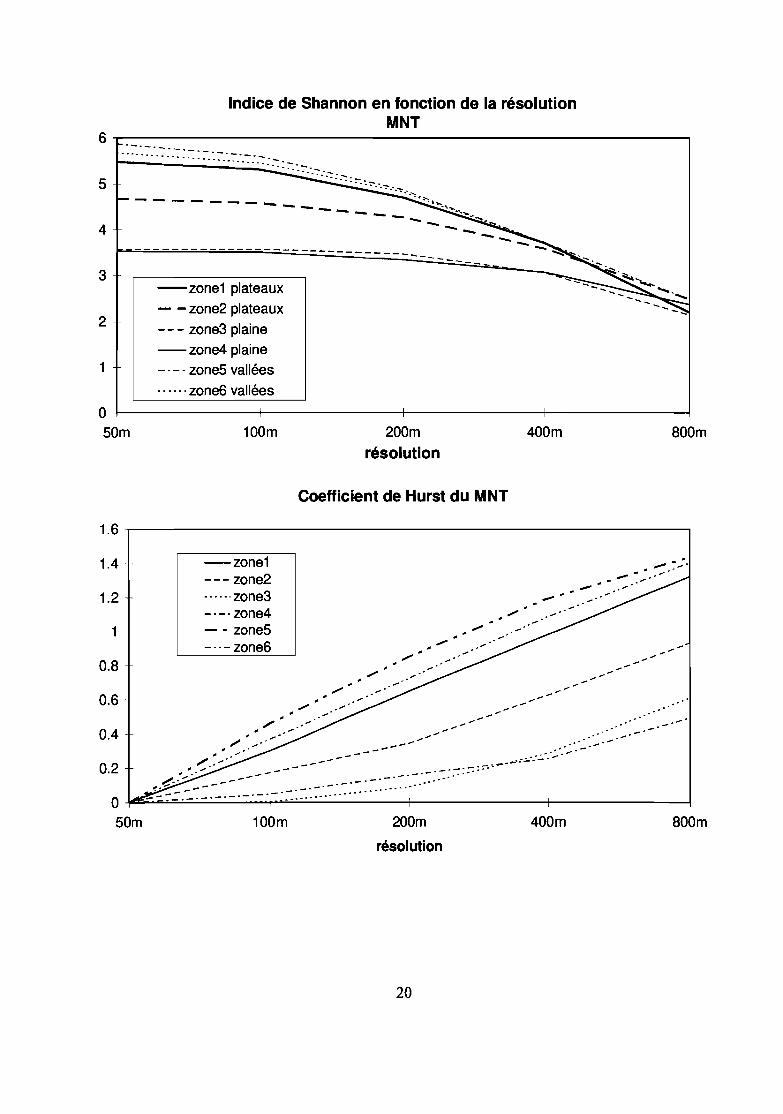
Indice de Shannon en fonction de la résolutionMNT
6...----------------------------------,
--zone1 plateaux
- - zone2 plateaux
- - - zone3 plaine
--zone4 plaine
- . - . zoneS vallées
...... zone6 vallées
~~~~ .... _..~:.-: ....-:.-
------------------------------ ---- ---
4
2
1
3
S
800m400m200m
résolution100m
0+-----------1--------+--------t-------~
SOm
Coefficient de Hurst du MNT
1.6 -r--------------------------------,
800m
. ....
".,... -;.."",.. .. ; ......... ~ ~--
400m200m
résolution
..........
..........
..........
.... ............
............-- -_ ....
-----.. -..-.-_.-.-.- ..
100m
--zone1--- zone2······zone3-·-·zone4- - zoneS_.. - zone6
o ~-............:~;;.;;""..---+---.:..:..:..;;-..-..-..-----+--------+-------~
SOm
1
0.2
0.6
0.4
1.4
0.8
1.2
20
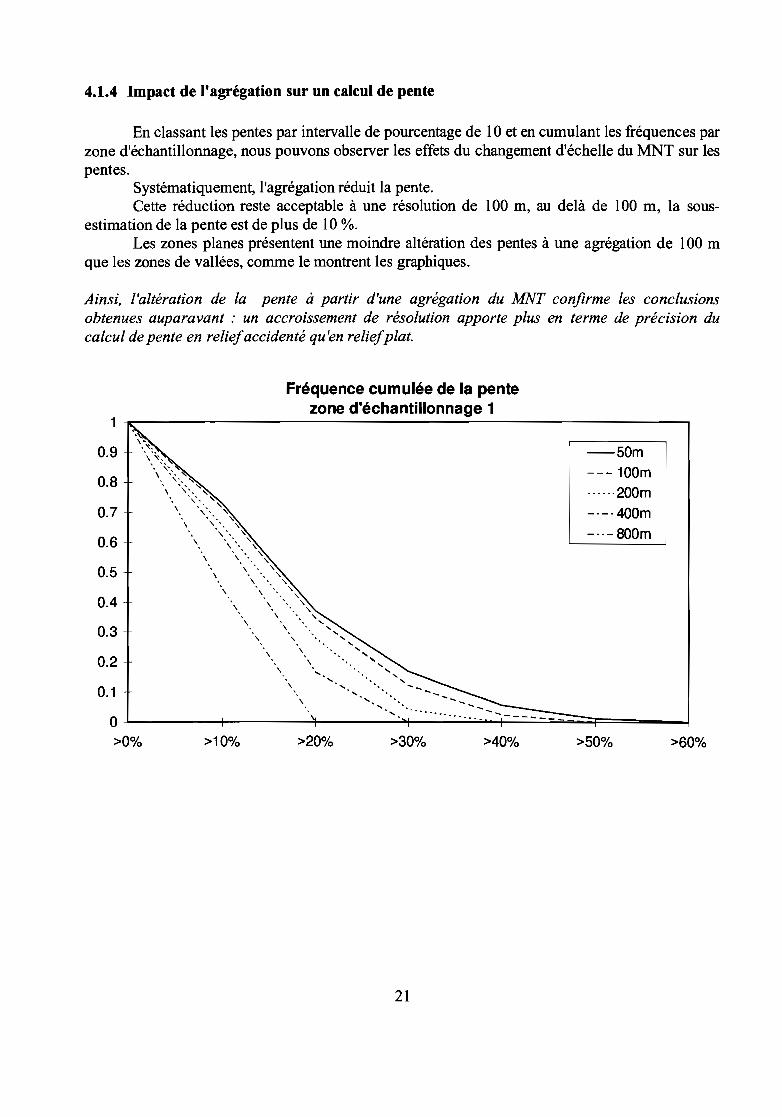
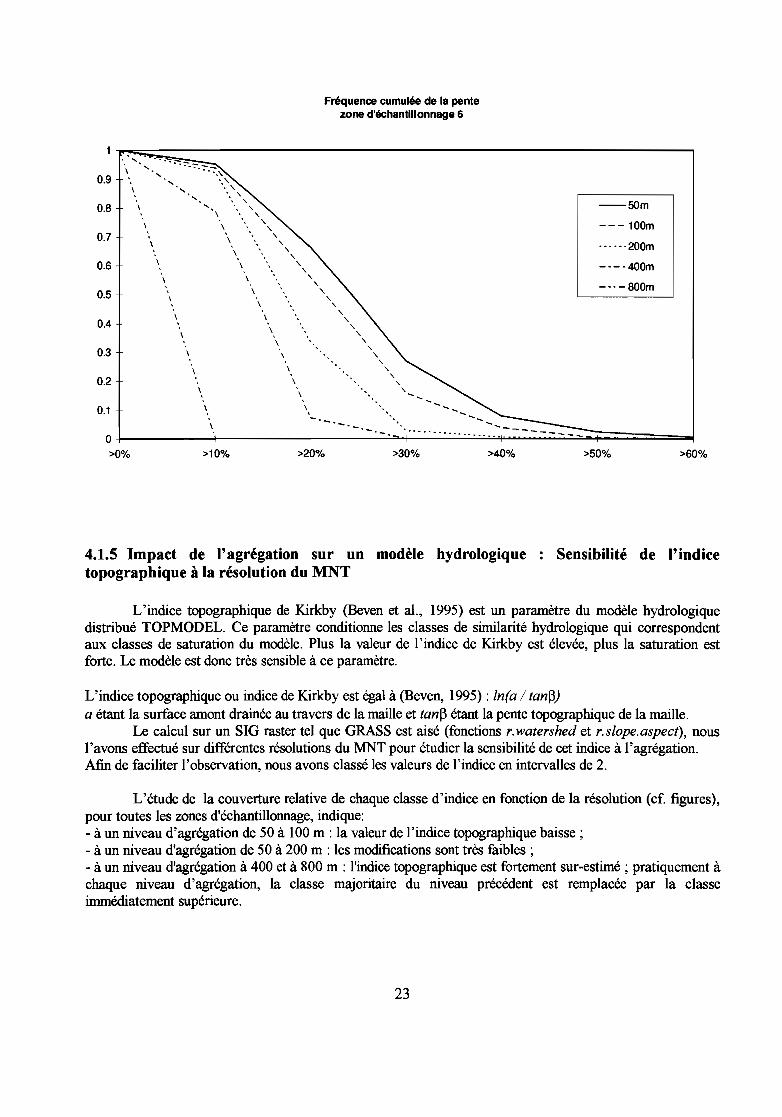
4.1.4 Impact de l'agrégation sur un calcul de pente
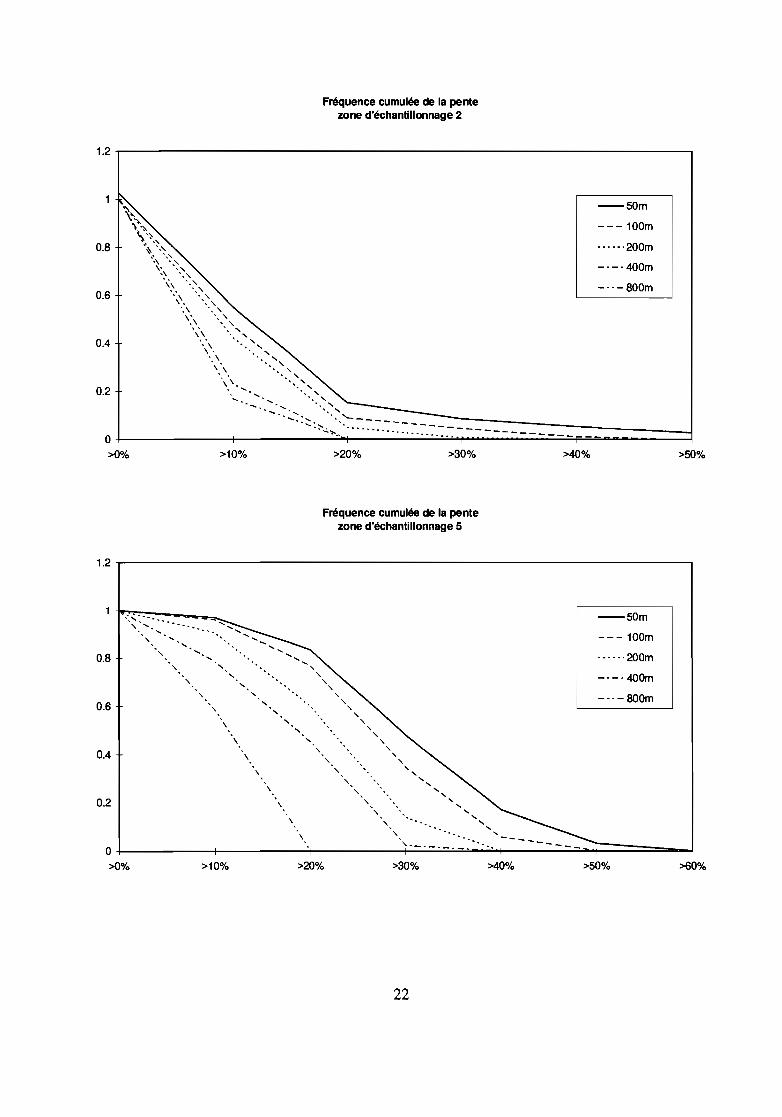
En classant les pentes par intervalle de pourcentage de 10 et en cumulant les fréquences parzone d'échantillonnage, nous pouvons observer les effets du changement d'échelle du MNT sur lespentes.
Systématiquement, l'agrégation réduit la pente.Cette réduction reste acceptable à une résolution de 100 m, au delà de 100 m, la sous
estimation de la pente est de plus de 10 %.Les zones planes présentent une moindre altération des pentes à une agrégation de 100 m
que les zones de vallées, comme le montrent les graphiques.
Ainsi, l'altération de la pente à partir d'une agrégation du MNT confirme les conclusionsobtenues auparavant : un accroissement de résolution apporte plus en terme de précision ducalcul de pente en reliefaccidenté qu'en reliefplat.
>60%
-SOm--- 100m
······200m-·--400m
----BOOm
>SO%>40%>30%>20%
1
0.9
0.8
0.7
0.6
O.S
0.4
0.3
0.2
0.1
0>0% >10%
Fréquence cumulée de la pentezone d'échantillonnage 1
21
Fréquence cumulée de la pentezone d'échantillonnage 2
1.2..,.--------------------------------------,
>50%
--SOm
--- 100m
···· .. 200m
-'-'400m
-··-800m
>40%>30%>20%>10%
~
\'\.,,~
\'~\'~"
" '"., "" '"" '"'" ',''. ','
\'. ',~,'.' " ," "., '"~ .. .........'.'. ", "., '.,,. '.,
"'. ". ", , ". ,, . . ,"'. ", ".. ....... .. .. , .....
'. ,....... .. .. ',
........... ....:------......... :>....:.~ .• ................... -
o+--------+-------""""'1-----.-.-.';.:..""..'"'+.......~~-----'=_F_=:.=.I .....----~
>0%
0.2
0.4
0.8
0.6
Fréquence cumulée de la pentezone d'échantillonnage 5
1.2 -.-----------------------------------------,
>60%
--SOm
--- 100m
······200m
_._. 400m
-··-BOOm
>50%>20%>10%
,, , ,, ,, , ,, ,
, , ,, , ,, ,, , ,, .,, , ,,
,
"
,....~:::: .., ...,
. ---o+------+-------4-----'~.~-:..:.:.-=-.:...=-:...:..=-.....: .~:....,--..:..:.=-=.===;:======-l>0%
0.4
0.2
0.8
0.6
22
Fréquence cumulée de la pentezone d'échantillonnage 6
>60%
--SOm
--- 100m
······200m
-'-'400m
--·-BOOm
>50%>40%>30%>10%
\
\
\
",\ '-"',
o-1------+------+---:..:.'..:..:':...:...:....:~.'':':'-':'':':--':..:...:'.:..:..:....:..::...:...:...:..~:.:.:.=..::...;;:..::..;;;;:::;:====~>0%
0.4
0.5
0.3
\ '" ....-::-: :-::-.:-."':".,0.9' ' , .,
\ , "",.... \.,\ '." ,\ . ,.. ,
\ .. ,,\ ,
\ "\ "
\ '\ .. " ,
\ ,,\ ,
\ "\ '. "
\ ,,\ ,
\ '.',\ "
\
0.2
0.6
0.7
O.B
0.1
4.1.5 Impact de l'agrégation sur un modèle hydrologiquetopographique à la résolution du MNT
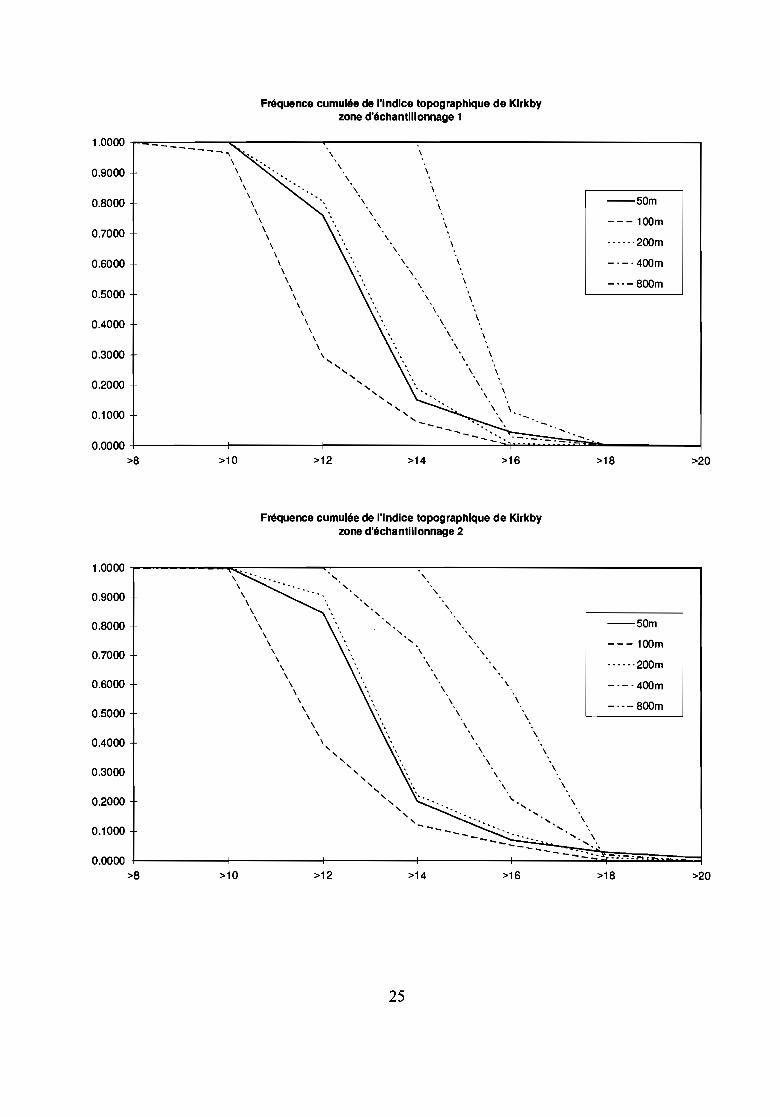
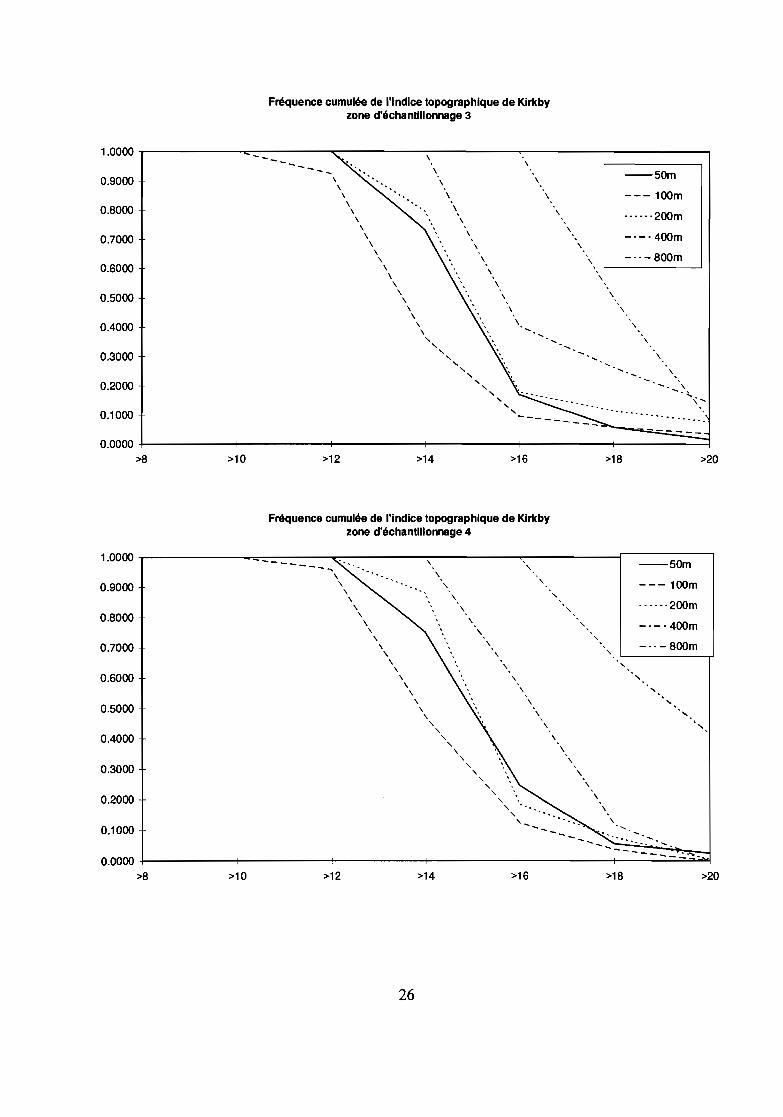
Sensibilité de l'indice
L'indice topographique de Kirkby (Beven et al., 1995) est un paramètre du modèle hydrologiquedistribué TOPMODEL. Ce paramètre conditionne les classes de similarité hydrologique qui correspondentaux classes de saturation du modèle. Plus la valeur de l'indice de Kirkby est élevée, plus la saturation estforte. Le modèle est donc très sensible à ce paramètre.
L'indice topographique ou indice de Kirkby est égal à (Beven, 1995) : ln(a / tanp)a étant la surface amont drainée au travers de la maille et tanp étant la pente topographique de la maille.
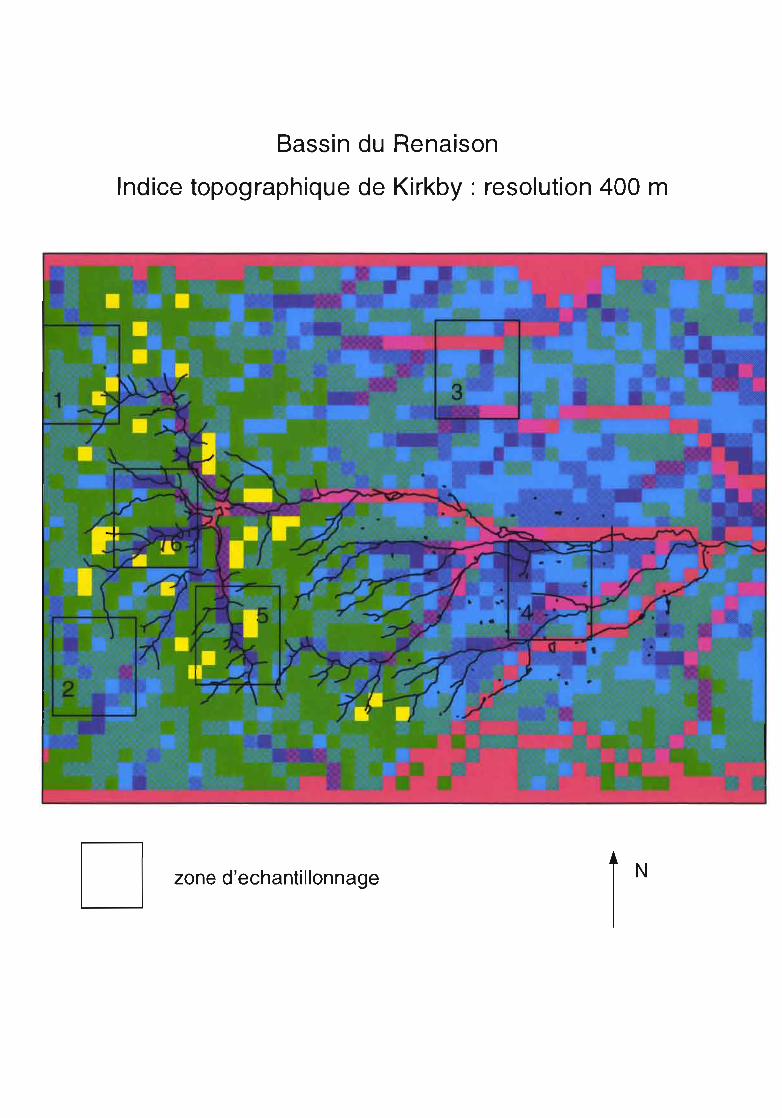
Le calcul sur un SIG raster tel que GRASS est aisé (fonctions r.watershed et r.slope.aspect), nousl'avons effectué sur différentes résolutions du MNT pour étudier la sensibilité de cet indice à l'agrégation.Afin de faciliter l'observation, nous avons classé les valeurs de l'indice en intervalles de 2.
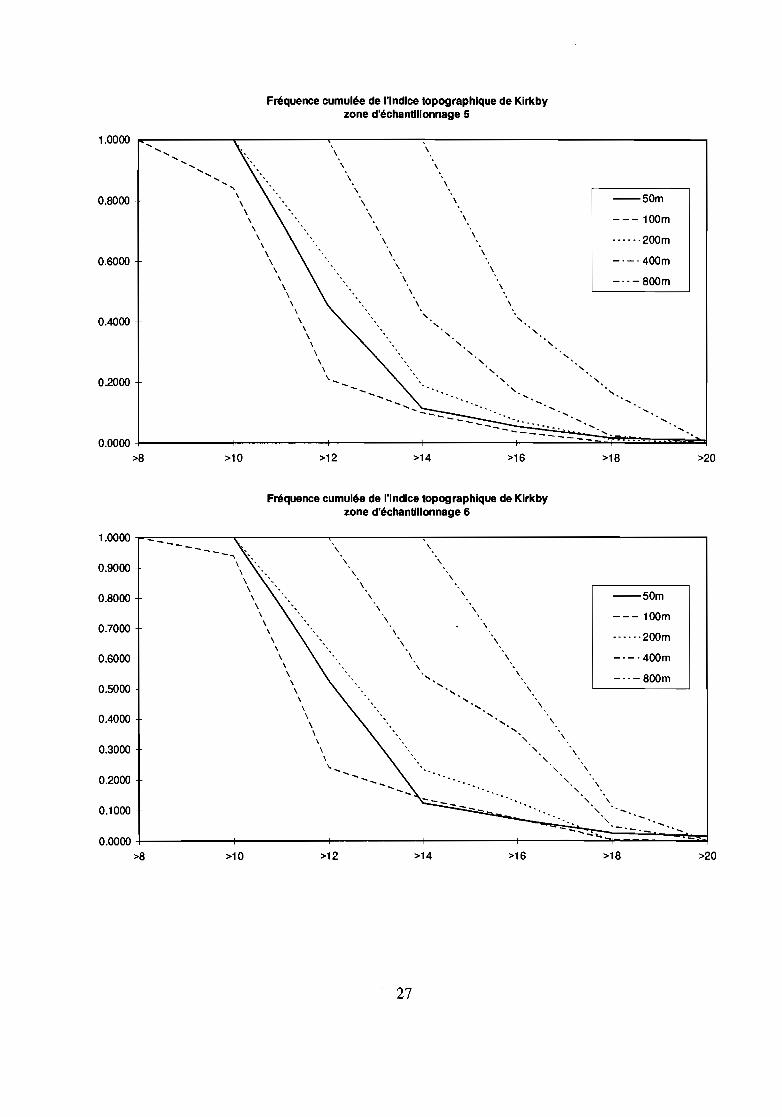
L'étude de la couverture relative de chaque classe d'indice en fonction de la résolution (cf. figures),pour toutes les zones d'échantillonnage, indique:- à un niveau d'agrégation de 50 à 100 m : la valeur de l'indice topographique baisse;- à un niveau d'agrégation de 50 à 200 m : les modifications sont très faibles;- à un niveau d'agrégation à 400 et à 800 m : l'indice topographique est fortement sur-estimé ; pratiquement àchaque niveau d'agrégation, la classe majoritaire du niveau précédent est remplacée par la classeimmédiatement supérieure.
23
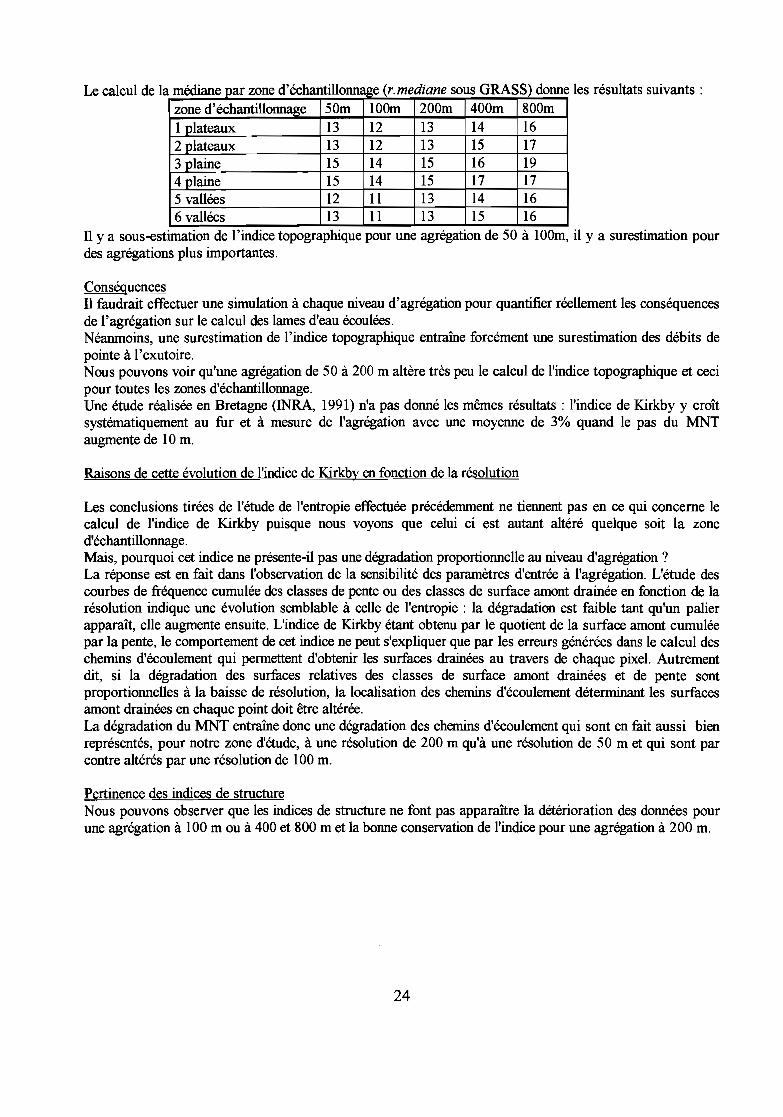
Le calcul de la médiane par zone d'échantillonn Ige (r.mediane sous GRASS) donnezone d'échantillonnage 50m lOOm 200m 400m 800m
1 plateaux 13 12 13 14 162 plateaux 13 12 13 15 173 plaine 15 14 15 16 194 plaine 15 14 15 17 175 vallées 12 11 13 14 166 vallées 13 Il 13 15 16
les résultats suivants :
TI Ya SOUS-estImatIOn de l'mdice topographique pour une agrégatIOn de 50 à 100m, il y a surestimation pourdes agrégations plus importantes.
ConséquencesIl faudrait effectuer une simulation à chaque niveau d'agrégation pour quantifier réellement les conséquencesde l'agrégation sur le calcul des lames d'eau écoulées.Néanmoins, une surestimation de l'indice topographique entraîne forcément une surestimation des débits depointe à l'exutoire.Nous pouvons voir qu'une agrégation de 50 à 200 m altère très peu le calcul de l'indice topographique et cecipour toutes les zones d'échantillonnage.Une étude réalisée en Bretagne (INRA, 1991) n'a pas donné les mêmes résultats : l'indice de Kirkby y croîtsystématiquement au fur et à mesure de l'agrégation avec une moyenne de 3% quand le pas du MNTaugmente de 10 m.
Raisons de cette évolution de l'indice de Kirkby en fonction de la résolution
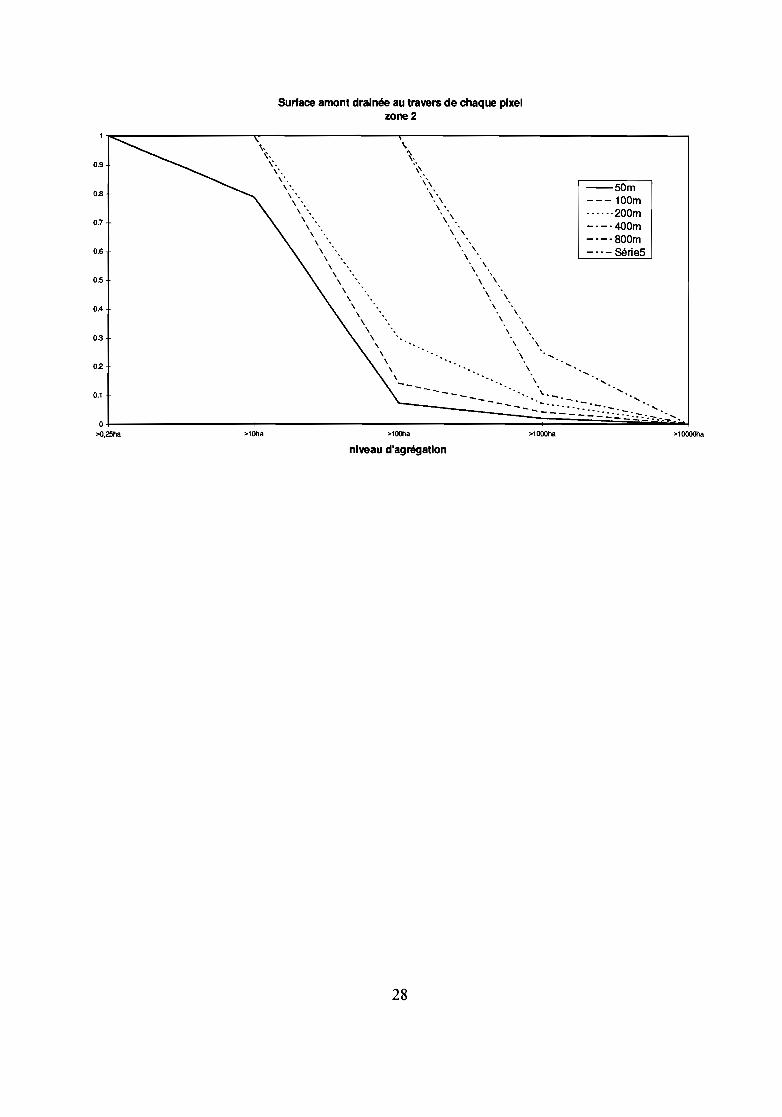
Les conclusions tirées de l'étude de l'entropie effectuée précédemment ne tiennent pas en ce qui concerne lecalcul de l'indice de Kirkby puisque nous voyons que celui ci est autant altéré quelque soit la zoned'échantillonnage.Mais, pourquoi cet indice ne présente-il pas une dégradation proportionnelle au niveau d'agrégation?La réponse est en fait dans l'observation de la sensibilité des paramètres d'entrée à l'agrégation. L'étude descourbes de fréquence cumulée des classes de pente ou des classes de surface amont drainée en fonction de larésolution indique une évolution semblable à celle de l'entropie: la dégradation est faible tant qu'un palierapparaît, elle augmente ensuite. L'indice de Kirkby étant obtenu par le quotient de la surface amont cumuléepar la pente, le comportement de cet indice ne peut s'expliquer que par les erreurs générées dans le calcul deschemins d'écoulement qui permettent d'obtenir les surfaces drainées au travers de chaque pixel. Autrementdit, si la dégradation des surfaces relatives des classes de surface amont drainées et de pente sontproportionnelles à la baisse de résolution, la localisation des chemins d'écoulement détenninant les surfacesamont drainées en chaque point doit être altérée.La dégradation du MNT entraîne donc une dégradation des chemins d'écoulement qui sont en fait aussi bienreprésentés, pour notre zone d'étude, à une résolution de 200 m qu'à une résolution de 50 m et qui sont parcontre altérés par une résolution de 100 m.
Pertinence des indices de structureNous pouvons observer que les indices de structure ne font pas apparaître la détérioration des données pourune agrégation à 100 m ou à 400 et 800 m et la bonne conservation de l'indice pour une agrégation à 200 m.
24
Fréquence cumulée de l'Indice topographique de Kirkbyzone d'échantillonnage 1
--SOm
--- 100m
--····2oom
-'--400m
-"-8oom
\
\
'\
'\
'\
'\
'\
'\
'\
'\
'\
'\
'\
'\
'\
\
\
\
\
\
\
\\ \
'- \'\
0.7000
0.8000
0.4000
0.2000
0.6000
0.3000
0.5000
0.1000
0.9000
1.0000 ..,....r:_::-_=_---~-----.....-------;--------------------,-----"\
\\
\\
\\\
\\\\
\\\\
\\\\
\\\\
\
" """"""""" ""
>20>18>16>14>12>100.0000 +--------i------+-----+-------=:...::...=t.........~.-;.;::O":"'::::::E:Ii_;_----~
>8
Fréquence cumulée de l'indice topographique de Kirkbyzone d'échantillonnage 2
1.0000 1""""-----~;__----.....-------~----------------__,
--SOm
--- 100m
······200m
-'-'400m
_ .. - 800m
\
\
'\
'\
'\'.
'\
'\'.
'\
'\
'\
\
\
\
\
\
\
\
\
\
\
\
\
\,
,,,,
"'.
'\\
\\
\\
\\
\'\
\\
\\
\\
\\
\\
\ , , ,, ,, ,", , ,, ,---0.1000
0.5000
0.9000
0.7000
0.2000
0.6000
0.3000
0.4000
0.8000
>10 >12 >14 >16 >18 >20
25
Fréquence cumulée de l'Indice topographique de Kirkbyzone d'échantillonnage 3
\-. \-.,.... ., .....
\
-----
\
,
--SOm
--- 100m
· .. ···2oom
-'-' 400m
-"- 800m
\'.
,,
,.. '----------'\
\
,,
,,
,,,,,,,,,,,,\
\\
\ ,,,,... ... ... ... ... ... ... ... ... ... ... ... ...
-----0.9000
0.6000
0.4000
1.0000 -r------........=::-:-----"""""l::--------:',--------.--------------,,,
\
\ ,,,,
\ ,,\
'.0.5000
0.8000
0.3000
0.2000
0.1000
0.7000
>20>18>16>14>12>100.0000 +-------I------+------+-------I------+---------....:t
>8
Fréquence cumulée de l'indice topographique de Kirkbyzone d'échantillonnage 4
......
"
......
...
-.. .... -
...,
,",, ...."
--
, ,\
\
\
\
\
\
\.
\
\ ,,
\ ,\
\.
\ ,,
\\
\\
\\
\\
\\
\\
\\
\\
\\
\ ,...,,,,,,,
... ... ... ... "., .,0.1000
0.2000
0.4000
0.5000
0.3000
0.8000
0.7000
1.0000 ..-------........--=--------_-_-"'r:"'"-----""':',-----........------....,-~~-=-=5-=-Om-----,_..... ,\ "
, ---1oom
······2oom
_.-. 400m
_ .. - 800m
0.9000
0.6000
>18 >20>16>14>12>10
---0.0000 +-------+-------+-------+-------+-------+---------.;.,-;;;..:..:."".::::="~
>8
26
Fréquence cumulée de l'Indice topographique de Kirkbyzone d'échantillonnage 5
--SOm
--- 100m
······200m
_._. 400m
_.'- 800m
........ ....
.... ........ ........
.... ........ ....
.... ....
--- ---->16 >18 >20
........
>14
\
\
'.
\
\
\
\
\
\
\
\
\
\
\
>12>10
0.2000
0.4000
0.6000
1.0000 ,...-....-----r--------.------~----------------...,........ .... .... .... ........
........"\
\\
\\
\\
\\
\\
\\\
\\
\\
\\\
\\,
0.8000
Fréquence cumulée de l'Indice topographique de Klrkbyzone d'échantillonnage 6
1.0000 --- --- \ \-",
0.9000 \ \ \
\ \\ \
\ \
0.8000 \ \ \ --SOm\ \ \
\\ --- 100m
0.7000 \ \\ \
\ \ ······200m\
\
0.6000 \ \ \ -'-'400m\ \\ ... \ _ .. - 800m
\0.5000 \ ... \
\ ...\ ... \
0.4000 \ ...\ ... \
\ ...\ "- \
0.3000 \ "- \\ "-
\,"- \--0.2000 -- "- \
"-"- \
0.1000 "-"- '---- '-. -'-
0.0000...: ...
>8 >10 >12 >14 >16 >18 >20
27
Surface amont drainée au travers de chaque pixelzone 2
>10000ha
......
--SOm--- 100m······200m-·-·400m-'--800m_.,- Série5
>1000ha
\.~,
\\'~\,,'.
. \\ '
, ---\ .\ \
\ ', \\ '.
"'."---.\ \
\ ..\ ..
\ '.,\ \
\ "
\
\
\',\,
\'.\',\'.
\ "\ "
\ '\\
\ '\ '.
\ "
\ '.\ "
\ "\
\ "\
\ "\
\\
\\
\\
\\
\
>1Oha
--- ~""- .. \."- ..--- ....... - -"-.-oL-- -----========--~---~.:.·..:.:.:~:.::....::~·.:.~?~~;.·~...>O.25ha
0.1
0.6
0.7
0.8
0.4
0.9
0.2
0.5
0.3
niveau d'agrégation
28

Bassin du Renaison: Indice topographique de Kirkby
resolution : 50 m
N
Bassin du Renaison
Indice topographique de Kirkby : resolution 100 m
D zone d'echantillonnage
Bassin du Renaison
Indice topographique de Kirkby : resolution 200 m
D zone d'echantillonnage
Bassin du Renaison
Indice topographique de Kirkby : resolution 400 m
D zone d'echantillonnage

4.2 Données discrètes: carte d'occupation du sol
Nous étudions l'évolution de plusieurs paramètres sur une carte d'occupation du sol en fonction del'agrégation. La résolution initiale est de 100m, on agrège à 200, puis 400 et 800m.Les mesures sont faites par région d'échantillonnage de 9 km2 correspondant à différents types de paysage.Nous testons 2 méthodes d'agrégation : l'une à partir des données initiales pour tous les niveauxd'agrégation, l'autre à partir des données agrégées du niveau précédent.
Sensibilité de l'agrégation et de la structure à la classificationSoulignons, avant tout, que les indices d'entropie représentent les patches issus d'une classification. Si cetteclassification change alors les indices seront totalement modifiés. Il s'agit donc de définir une classificationpertinente pour l'objectif considéré: par exemple, dans un objectif calcul d'évapotranspiration maximale ouréelle, la distinction feuillus - conifères aura sa raison d'être, mais s'il s'agissait de processus de pollution,cette distinction non seulement serait superflue mais elle déformerait fortement les calculs d'indices commeaussi le changement d'échelle.
4.2.1 Agrégation effectuée à partir de la résolution initiale
Comparaison des indices structuraux et des proportions des différentes zones d'échantillonnage à larésolution initiale
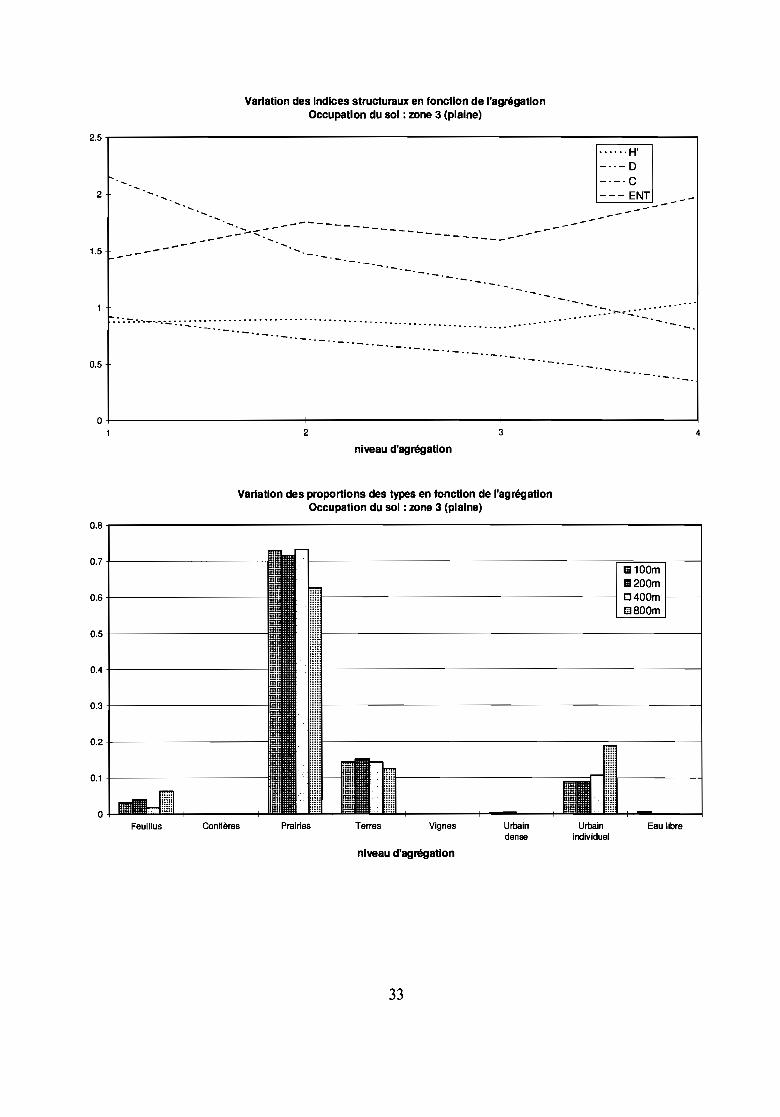
- indice de Shannon H' et indice d'entropie ENTLes zones d'échantillonnage 1 et 2 (montagne) présentent une entropie inférieure, H' = 0,85 et ENT = 1,25, àcelle de la zone 4 (coteaux) : H' = 1,4 et ENT = 2,2. La zone 3 de plaine a relativement une très faibleentropie H' = 0,85 et ENT = 1,4. Ces 2 indices traduisent bien l'impression visuelle de diversité et demorcellement qui est plus forte en montagne et sur les coteaux qu'en plaine.
- indice de contagion C : C = 2,2 en plaine et 1,3 < C < 1,7 en montagne et coteaux, ici aussi les 2 ensemblesde paysage sont bien représentés mais la distinction à l'intérieur de l'ensemble plus diversifié entre lamontagne et le coteau n'est plus visible.
- indice de dominance D : il est plus fort en plaine (D = 0,9) que sur les autres secteurs (0,4 < D < 0,6): celatraduit bien en plaine la dominance du type prairie sur les autres.
- le Second Moment Angulaire (ASM) traduit aussi ces différences de paysage : il est 3 fois plus élevé enplaine qu'en montagne ou coteaux.
-l'IDM a peu de signification, il présente des valeurs proches
-le contraste CON n'a pas d'intérêt puisque nous manipulons des valeurs nominales.
Evolution des indices de structure et des proportions surfaciques des types en fonction de l'agrégation
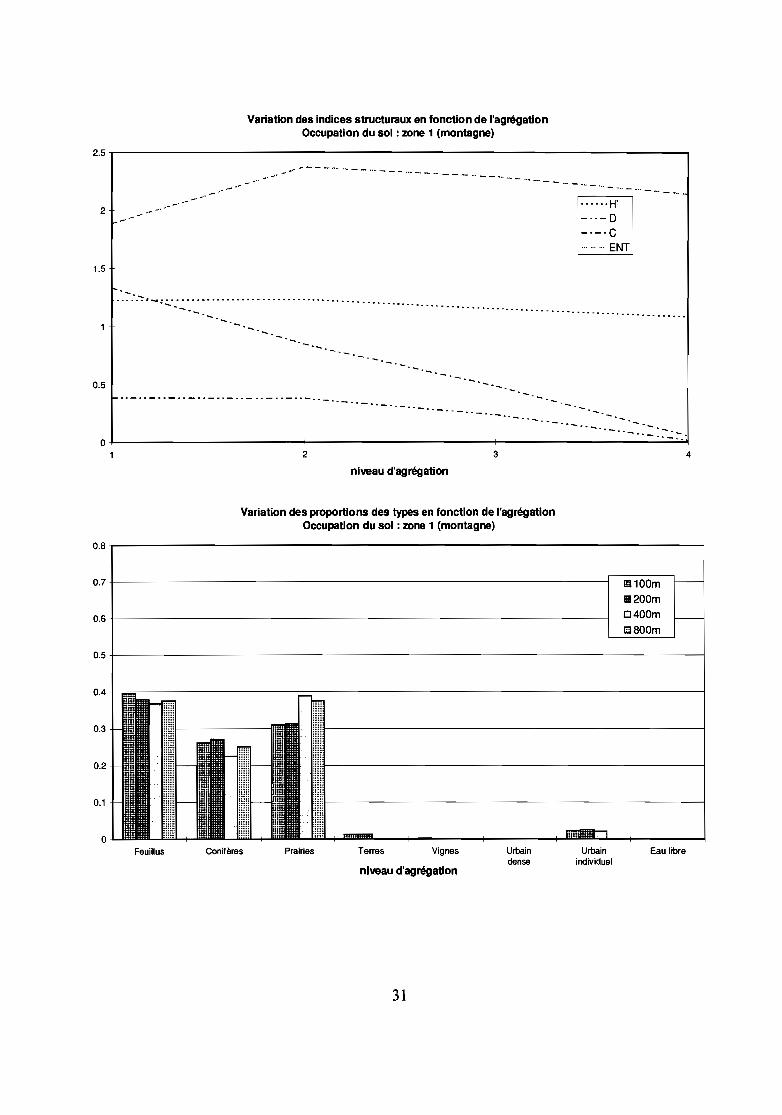
Zone d'échantillonnage 1Paysage de montagne diversifié.L'évolution des types lors de la première agrégation est peu marquée. L'altération est plus forte au cours del'agrégation de 100 à 400 m où la prairie augmente largement aux dépens des conifères, des terres et desfeuillus.Entropie ENT et H' sont faiblement altérées par l'agrégation sur cette zone, ENT augmente même pour uneagrégation de 100 à 200 m. Pour des agrégations à 400 et 800 m, ces 2 indices baissent lentement.
29

Contagion C et Dominance D baissent de façon pratiquement linéaire, elles sont en effet inversementproportionnelles aux 2 indices précédents et régressent en fonction du nombre de types présents.Le coefficient de Hurst traduit mieux la perte d'information en fonction de la résolution: il augmentebrutalement pour une agrégation à 400 ou 800 m, alors qu'il reste faible pour une agrégation à 200m.
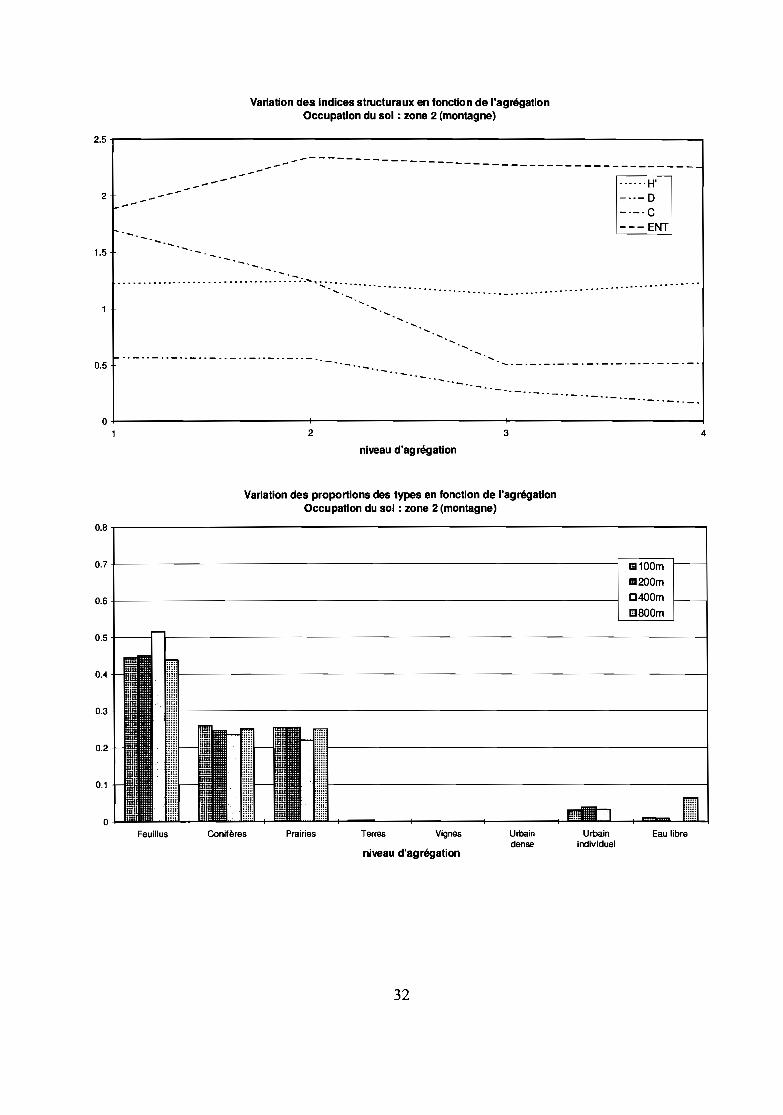
Zone d'échantillonnage 2Paysage de montagne diversifié.Les 3 types majoritaires sont particulièrement stables au cours de l'agrégation. Les type urbain individuelultra-minoritaire n'évolue pas lors des 2 premières agrégations et disparaît brutalement à la troisième (de 100à 800m). L'eau libre qui tend à disparaître pour les 2 premiers niveaux d'agrégation, augmente pour uneagrégation de 100 à 800 m, ceci traduit l'aspect aléatoire de l'échantillonnage lors du changement d'échellepar la méthode du plus proche voisin: il suffit que le point d'échantillonnage «tombe» sur la seule maille detype donné pour que la maille d'agrégation prenne cette valeur.L'indice d'entropie H' varie peu à chaque niveau, ENT augmente fortement au déput puis se stabilise. Laforte augmentation initiale ne correspond pas à une modification sensible des proportions des types.Les indices de contagion C et de dominance D baissent en rapport avec l'augmentation des indices d'entropieet parce qu'ils sont sensibles au nombre de types présents et traduisent la disparition de types pourtant trèsminoritaires.Le coefficient de Hurst traduit bien l'évolution des types: pour une agrégation à 200, il est faible ce quicorrespond à une forte stabilité des proportions, pour une agrégation à 400 m, il est plus élevé ce quicorrespond à une modification des proportions. L'agrégation à 800 m ne se traduit pas par une variation ducoefficient de Hurst qui est pratiquement nul, en effet les types majoritaires restent proches de leur valeurinitiale mais l'eau libre supplante l'urbain individuel: l'entropie ne baisse pas puisqu'il s'agit ici d'un typeminoritaire remplacé par un autre type minoritaire.
Zone d'échantillonnage 3Paysage dominé par les prairies d'élevage avec quelques villages et terres cultivées.Les types évoluent très peu lors d'une agrégation de 100 à 200 et de 100 à 400 m. Par contre, l'agrégation de100 à 800 m conduit à une régression du type prairie très majoritaire au profit du type urbain (couvrantinitialement 9 % de la zone) et des feuillus.Les indices d'entropie augmentent de 100 à 200 m, ils présentent une augmentation similaire de 100 à 400m(palier entre 200 et 400m), puis ils croissent pour une agrégation à 800 m. L'augmentation de H' et ENTpour une agrégation à 800 m peut s'expliquer par la croissance de types minoritaires (feuillus, urbainindividuel) aux dépens des types majoritaires donc par une plus grande diversité et variabilité du paysage.Contagion C et dominance D régressent en fonction du niveau d'agrégation de part la disparition de typesultra-minoritaires (eau libre, urbain dense). Ils sont sensibles au nombre de types mais pas à leur proportion.Le coefficient de Hurst décrit bien les évolutions des types puisque sa valeur absolue est élevée pour uneagrégation à 800 m alors que le type prairies régresse au profit des autres. Une valeur négative du coefficientde Hurst indique un accroissement d'entropie ce qui est aussi une dégradation des données initiales.
Zone d'échantillonnage 4Paysage de transition entre la plaine et la montagne, formé de forêts, prairies, terres labourables, vignobles etvillages.La sensibilité à l'agrégation dépend des types: les prairies majoritaires régressent fortement au profit desconifères, tandis que feuillus, terres labourables et urbain individuel évoluent peu. Les patches minoritaires etdispersés tels que les vignes et l'eau libre disparaissent.Les indices d'entropie ENT et H' augmentent faiblement en fonction du niveau d'agrégation.Cet D baissent avec un seuil entre l'agrégation à 200 et l'agrégation à 400 m sans que cela corresponde àune évolution dans la proportion des types.Le coefficient de Hurst est pertinent pour quantifier l'évolution des types : il est très faible pour l'agrégationde 100 à 200 m lors de laquelle les proportions évoluent très peu, puis sa valeur absolue augmente ce quicorrespond à une évolution plus marquée des proportions.
30
Variation des indices structuraux en fonction de l'agrégationOccupation du sol: zone 1 (montagne)
2.5,--------------------------------------------,
2 ..... ..-0.
...... --- ... _-- ..
g..... H._ .. - D
_·-·C.......... ENTI
1.5
'-.- - _ -::..:.: --- -. - _ ...........................................
-'-0.5 '-. -'-.. _.. _... _.. _.... _... - -- - -. _.. _.. -."--. - .. -.
432o-!---------------+----------------+---------------....;.;.."-'I.
1
niveau d'agrégation
Variation des proportions des types en fonction de l'agrégationOccupation du sol: zone 1 (montagne)
niveau d'agrégation
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0Feuillus Conifères Prairies Terres Vignes Urbain
denseUrbain
individuel
11!1100m11200mD400mliJaOOm
Eau libre
31
Vartation des Indices structuraux en fonction de l'agrégationOccupation du sol: zone 2 (montagne)
2.5 -r-----------------------------------------,
.................................. - . -- ~ - ..
--------------------------------------------
[L~:~~.~'---'C--- ENT
2
1.5
----0_. -0- --.
--
-'- -'- --'--- _ ..
. ..............
.... .....
0.5 '-. a_o..
432o-l--------------+--------------+--------------~
1
niveau d'agrégation
Variation des proportions des types en fonction de l'agrégationOccupation du sol: zone 2 (montagne)
niveau d'agrégation
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0Feuillus Conifères Prairies Terres Vignes Urbain
denseUrbain
individuel
ElI100m111200mD400mDSOOm
Eau libre
32
Variation des Indices structuraux en fonction de l'agrégationOccupation du sol : zone 3 (plaine)
2.5 -r--------------------------------------------,
2[[
..... H'
-··-0_·_-c--- ENT --
-'- --.-1.5
---------'-,------------------- ---- -------
--------
'-. -'- '- ........... ...""":: :::-"':... .. -.. : : ':'"" _ ...:.: -..,: :::::~ ~ - .. - - -.. .. .. .. .. .. .. .. .. .. .. .. .. -.. -.. -
""- ..
0.5
432O+-------------+--------------+------------~
1
niveau d'agrégation
Variation des proportions des types en fonction de l'agrégationOccupation du sol: mne 3 (plaine)
Eau libre
1lI100m111200mC400mIJSOOm
Urbainindividuel
Urbaindense
Vignes
:::::.
:::::
:::::----------------===::fït-------1
TerresPrairiesConifères
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0Feuillus
niveau d'agrégation
33
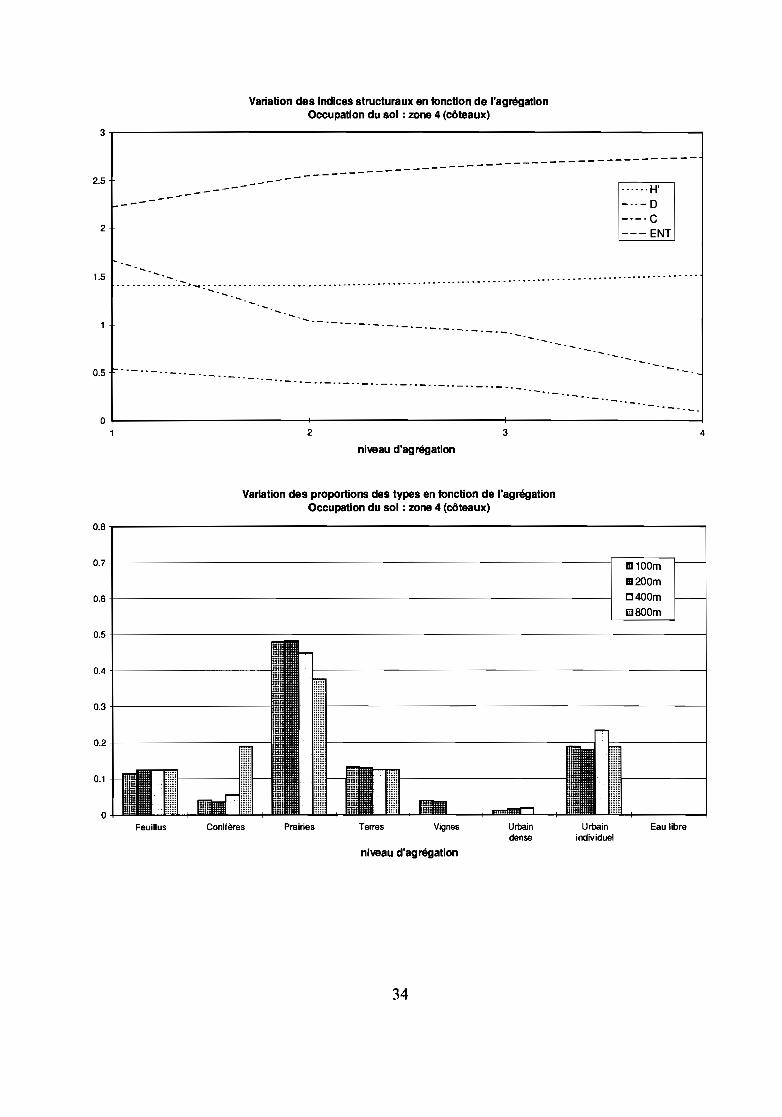
Variation des Indices structuraux en fonction de l'agrégationOccupation du sol: zone 4 (côteaux)
3,.---------------------------------------,---------------------------
2.5
2
1----------
---------------
[!..... H'
---- 0--_oC
--- ENT
'-1.5 --- ------~ ~- ".'"':./'- - . - -- - - ..--
-.-._-- --.-.-.- --.-.- .. - -' '-. '-.-'-
0.5 ,," .• - .. - .. - . - - .. __ . _ .. _ . __.. - .. -_ .. --. ---. ----".-" --. -- .. - ... -" .. - ..
-".-
432o-l-------------l--------------+------------~
1
niveau d'agrégation
Variation des proportions des types en fonction de l'agrégationOccupation du sol : zone 4 (côteaux)
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0Feuillus Conifères Prairies Terres Vignes Urbain
denseUrbain
individuel
ElI100m
11200m
D400m
IJSOOm
Eau libre
niveau d'agrégation
34
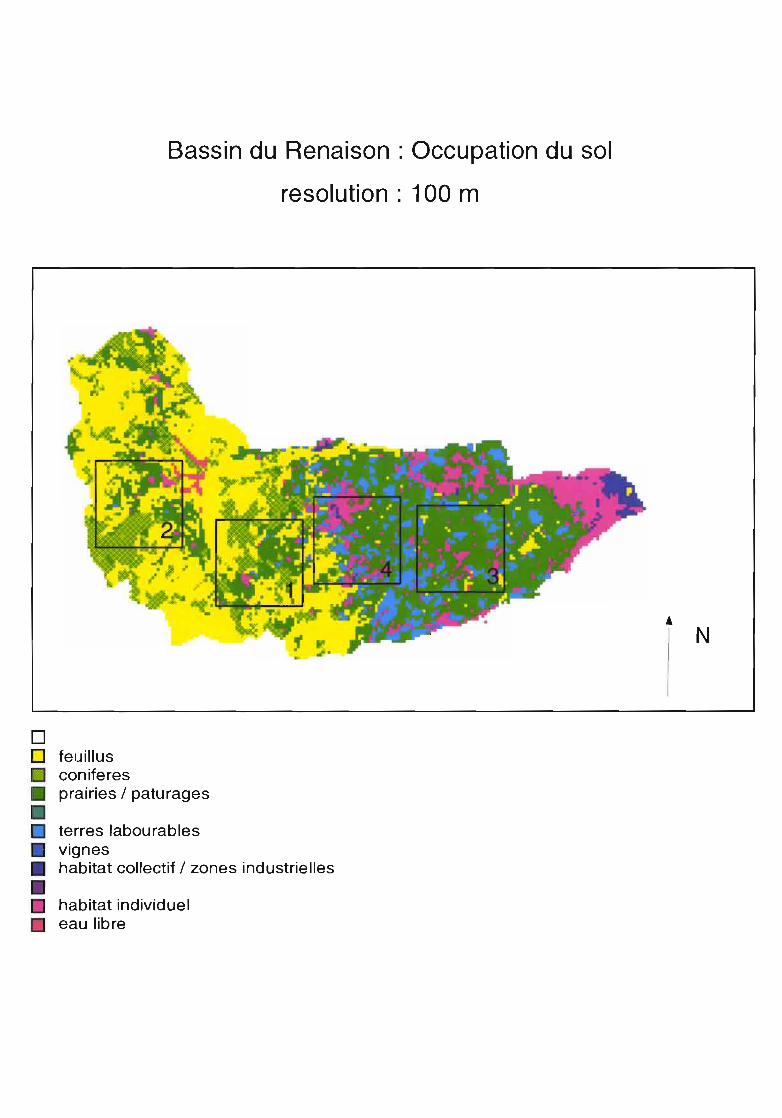
Bassin du Renaison : Occupation du sol
resolution : 100 m
oo feuillus
coniferesprairies / paturages
terres labourablesvigneshabitat collectif / zones industrielles
habitat individueleau libre
N
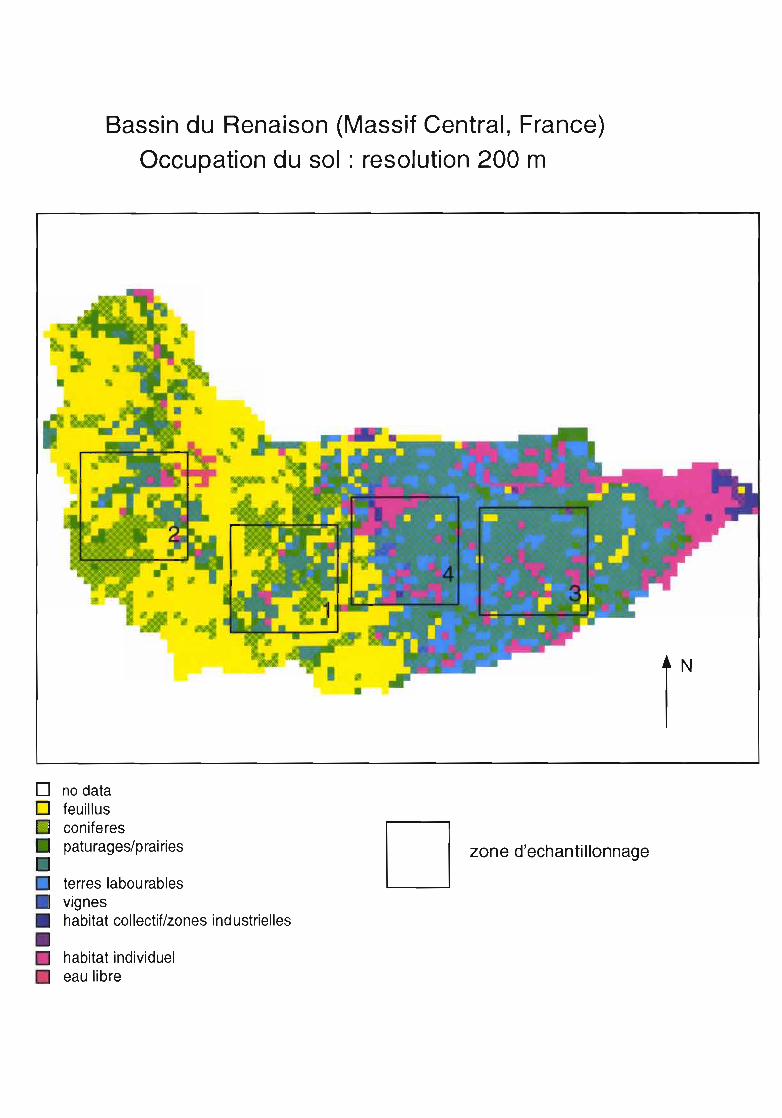
Bassin du Renaison (Massif Central, France)
Occupation du sol : resolution 200 m
o no datao feuillus
coniferespaturages/prai ries
terres labou rablesvignes
• habitat collectif/zones industrielles
D zone d'echantillonnage
habitat individueleau libre
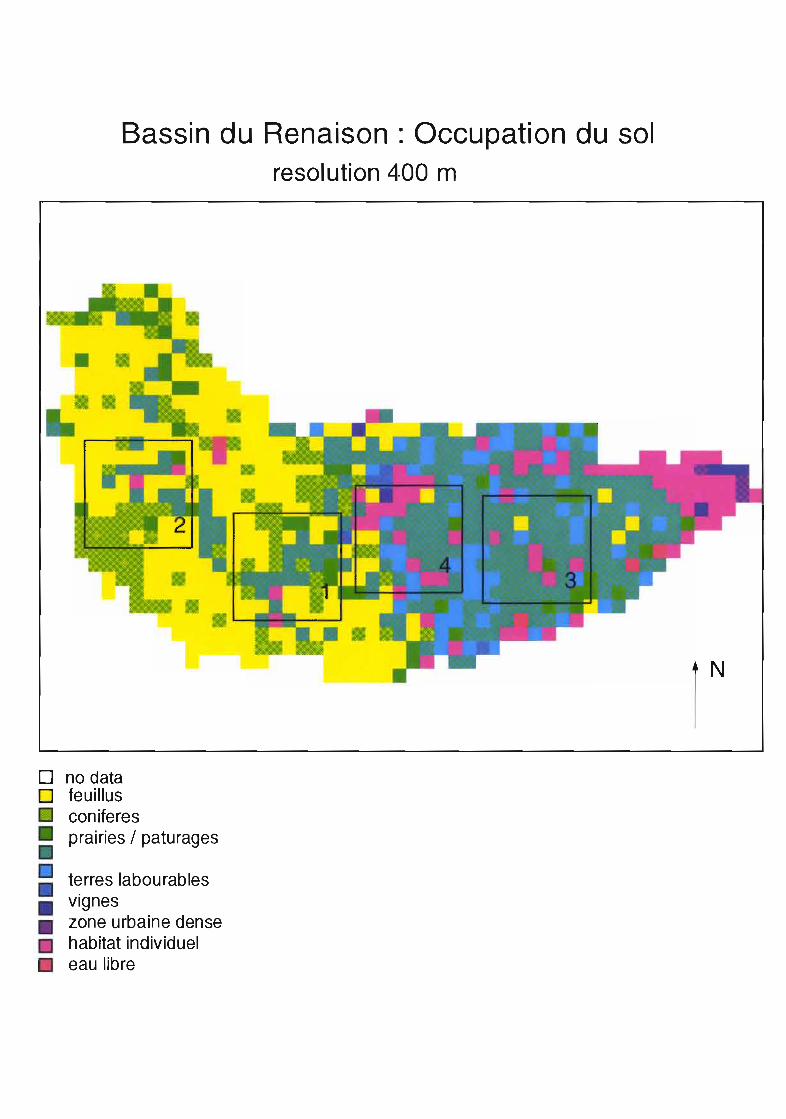
Bassin du Renaison: Occupation du solresolution 400 m
o no datao feuillus
coniferesprairies / paturages
• terres labourables• vignes• zone urbaine dense
habitat individueleau libre
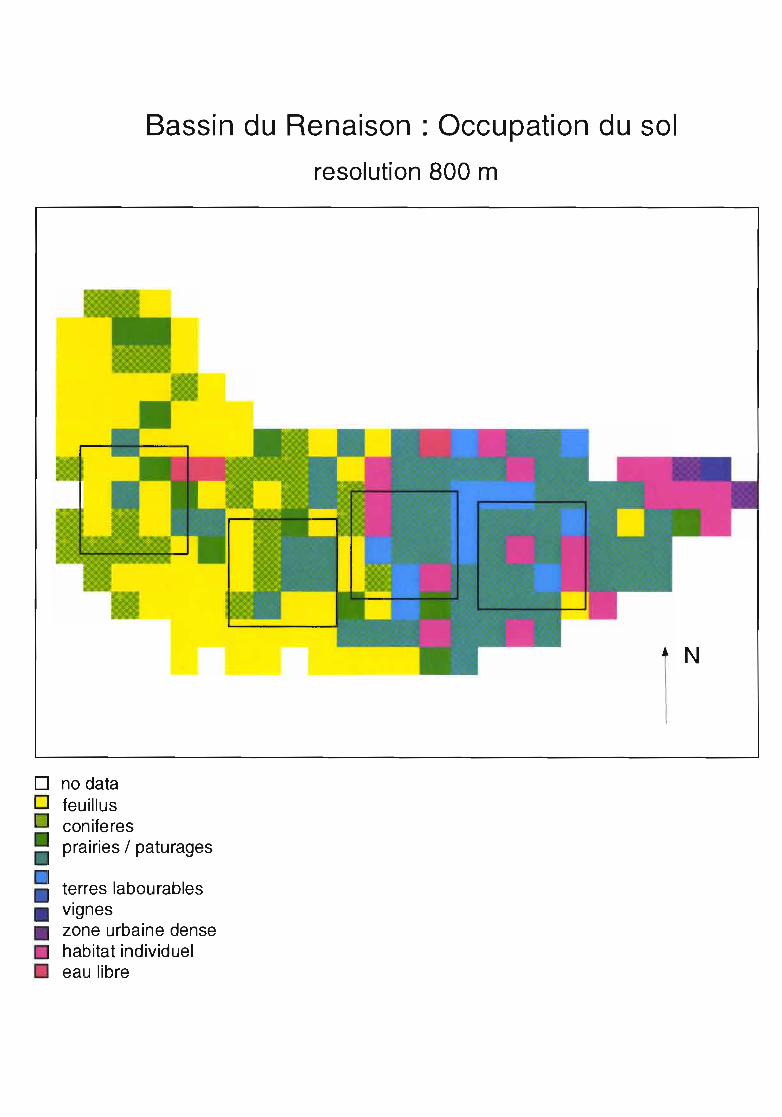
Bassin du Renaison: Occupation du sol
resolution 800 m
o no datao feuillus
coniferesprairies / paturages
terres labourablesvigneszone urbaine densehabitat individueleau libre
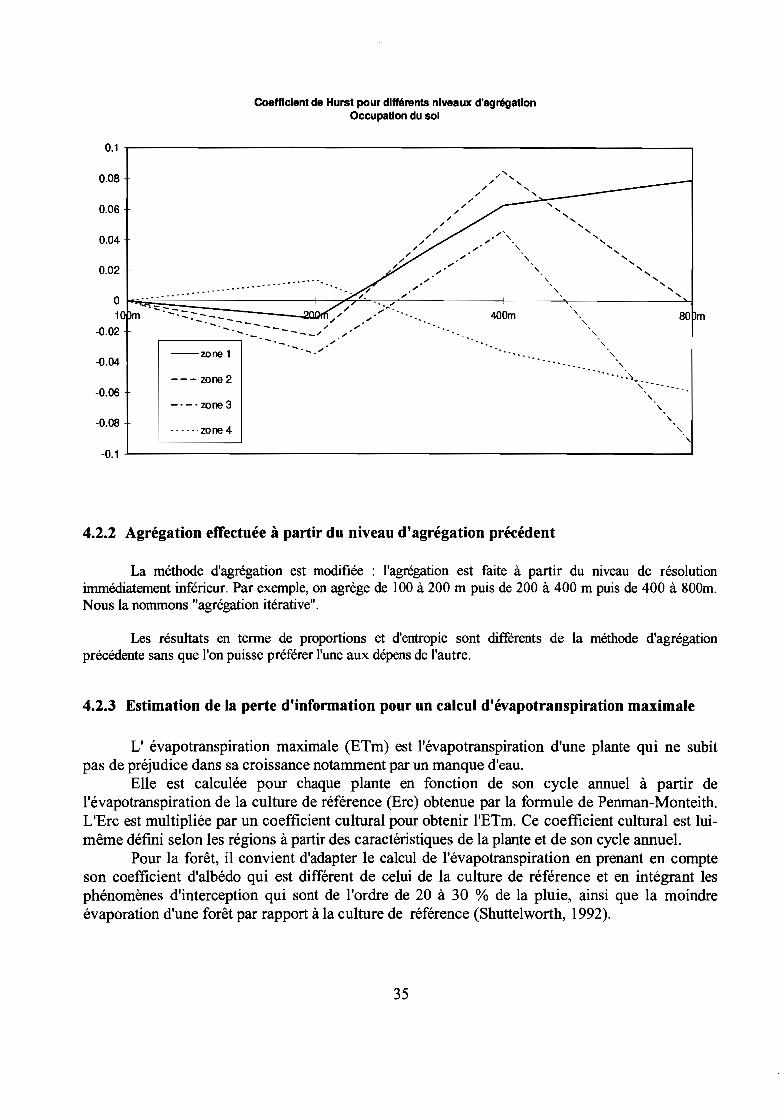
Coefficient de Hurst pour différents niveaux d'agrégationOccupation du sol
0.1 -r-----------------------------------,
".;"-"- " "
_. _. zone 3
--- zone 2
--zone 1
0.04
0.06
0.02
-0.06
"""""""""""""""\ ""
"\ "; "
ot:-~.~-~-~~==:~====~;;(~'-T-'~.:-;::.~;(.:-~---~;~-~~-----~;l10bm -.--::::-_--- ; 400m"\ 80 m--- "\-0.02 -. ; " "\
"\
"\
"\
......: , ."\
-0.04
0.08
-0.08······zone4 "\
"\-0.1 .1..- ----1
4.2.2 Agrégation effectuée à partir du niveau d'agrégation précédent
La méthode d'agrégation est modifiée : l'agrégation est faite à partir du niveau de résolutionimmédiatement inférieur. Par exemple, on agrège de 100 à 200 m puis de 200 à 400 m puis de 400 à SOOm.Nous la nommons "agrégation itérative".
Les résultats en terme de proportions et d'entropie sont différents de la méthode d'agrégationprécédente sans que l'on puisse préférer l'une aux dépens de l'autre.
4.2.3 Estimation de la perte d'information pour un calcul d'évapotranspiration maximale
L' évapotranspiration maximale (ETm) est l'évapotranspiration d'une plante qui ne subitpas de préjudice dans sa croissance notamment par un manque d'eau.
Elle est calculée pour chaque plante en fonction de son cycle annuel à partir del'évapotranspiration de la culture de référence (Erc) obtenue par la fonnule de Penman-Monteith.L'Erc est multipliée par un coefficient cultural pour obtenir l'ETm. Ce coefficient cultural est luimême défini selon les régions à partir des caractéristiques de la plante et de son cycle annuel.
Pour la forêt, il convient d'adapter le calcul de l'évapotranspiration en prenant en compteson coefficient d'albédo qui est différent de celui de la culture de référence et en intégrant lesphénomènes d'interception qui sont de l'ordre de 20 à 30 % de la pluie, ainsi que la moindreévaporation d'une forêt par rapport à la culture de référence (Shuttelworth, 1992).
35
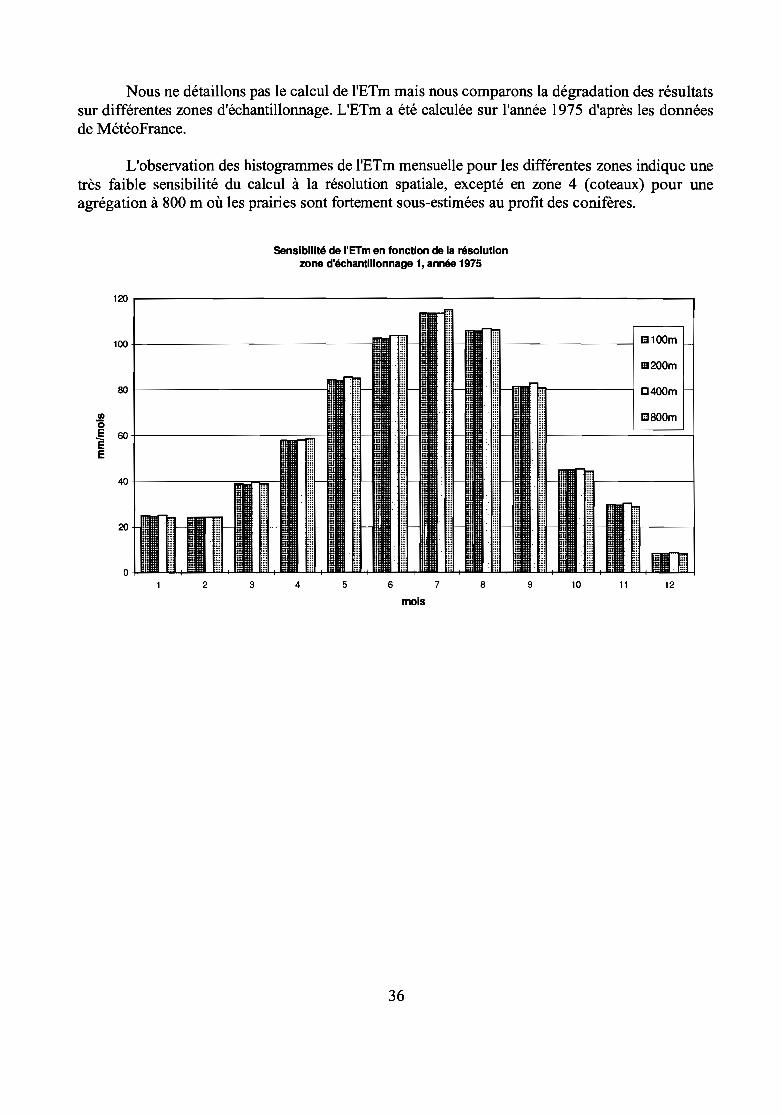
Nous ne détaillons pas le calcul de l'ETm mais nous comparons la dégradation des résultatssur différentes zones d'échantillonnage. L'ETm a été calculée sur l'année 1975 d'après les donnéesde MétéoFrance.
L'observation des histogrammes de l'ETm mensuelle pour les différentes zones indique unetrès faible sensibilité du calcul à la résolution spatiale, excepté en zone 4 (coteaux) pour uneagrégation à 800 m où les prairies sont fortement sous-estimées au profit des conifères.
sensibilité de l'ETm en fonction de la résolutionzone d'échantillonnage 1, année 1975
120 -.-------------------------------------'1
100 +--------------------i!
12
1liI800m
111200m
11
rn-----------1 D4QOm
1-----------1 1liI100m
" :::!!l
·HH
II! ::::
il. miÜi
Iii::::......
Iii :::
1::::
....::::::"
"::
8 9 10765432
40 +---------==-=---1ii
80+---------------\
III'0~ 60E
mois
36
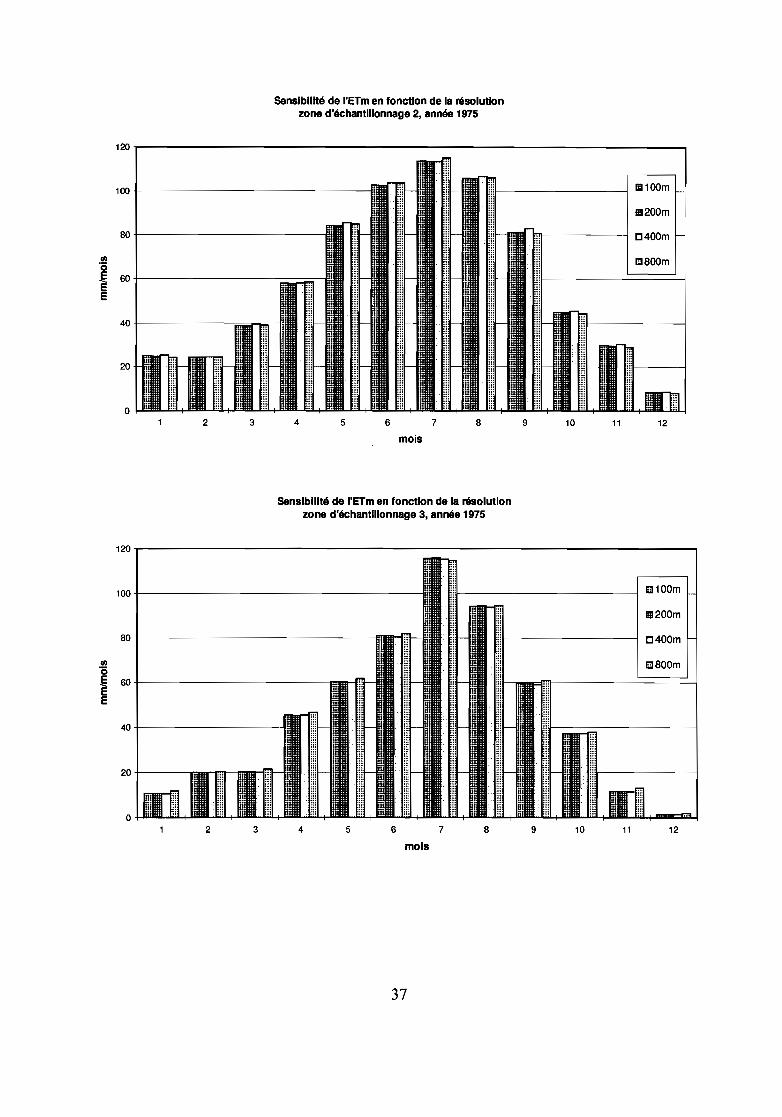
sensibilité de "ETm en fonction de la résolutionzone d'échantillonnage 2, année 1975
5 6 7
i~ :,:li ..
~;......
t:!...
......
"~ m
~~ '1
TIl ...iil :::
lb :::
:1'
.....
F"..
...
8 9 10 11
1!!1100m
11200m
[J400m
IllISOOm
12
mois
sensibilité de l'ETm en fonction de la résolutionzone d'échantillonnage 3, année 1975
[J400m
CSOOm
1lD200m
1llI100m
i~
1
.../-------------1
::::. ::::
::::
....
::::::
120
100
80
fil'0
~ 60
E
40
20
02 3 4 5 6 7 8 9 10 11 12
mols
37
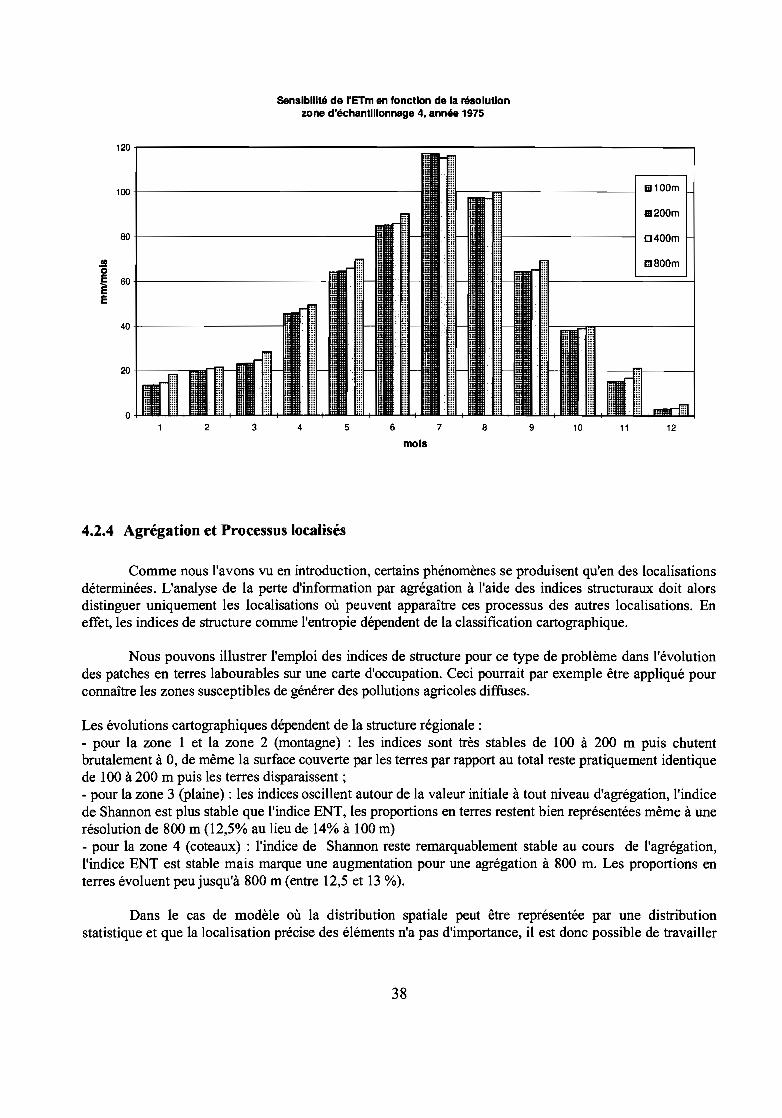
Sensibilité de l'ETm en fonction de la résolutionzone d'échantillonnage 4, année 1975
4.2.4 Agrégation et Processus localisés
Comme nous l'avons vu en introduction, certains phénomènes se produisent qu'en des localisationsdéterminées. L'analyse de la perte d'information par agrégation à l'aide des indices structuraux doit alorsdistinguer uniquement les localisations où peuvent apparaître ces processus des autres localisations. Eneffet, les indices de structure comme l'entropie dépendent de la classification cartographique.
Nous pouvons illustrer l'emploi des indices de structure pour ce type de problème dans l'évolutiondes patches en terres labourables sur une carte d'occupation. Ceci pourrait par exemple être appliqué pourconnaître les zones susceptibles de générer des pollutions agricoles diffuses.
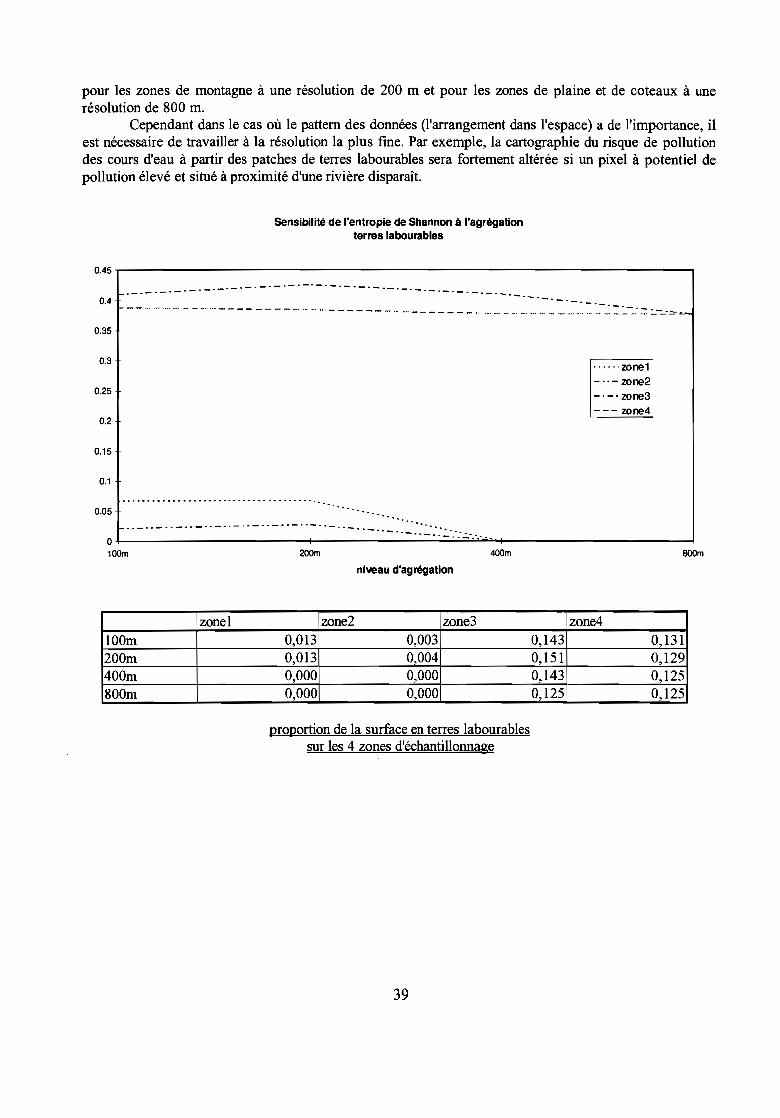
Les évolutions cartographiques dépendent de la structure régionale:- pour la zone 1 et la zone 2 (montagne) : les indices sont très stables de 100 à 200 m puis chutentbrutalement à 0, de même la surface couverte par les terres par rapport au total reste pratiquement identiquede 100 à 200 m puis les terres disparaissent ;- pour la zone 3 (plaine) : les indices oscillent autour de la valeur initiale à tout niveau d'agrégation, l'indicede Shannon est plus stable que l'indice ENT, les proportions en terres restent bien représentées même à unerésolution de 800 m (12,5% au lieu de 14% à 100 m)- pour la zone 4 (coteaux) : l'indice de Shannon reste remarquablement stable au cours de l'agrégation,l'indice ENT est stable mais marque une augmentation pour une agrégation à 800 m. Les proportions enterres évoluent peu jusqu'à 800 m (entre 12,5 et 13 %).
Dans le cas de modèle où la distribution spatiale peut être représentée par une distributionstatistique et que la localisation précise des éléments n'a pas d'importance, il est donc possible de travailler
38
pour les zones de montagne à une résolution de 200 m et pour les zones de plaine et de coteaux à unerésolution de 800 m.
Cependant dans le cas où le pattern des données (l'arrangement dans l'espace) a de l'importance, ilest nécessaire de travailler à la résolution la plus fme. Par exemple, la cartographie du risque de pollutiondes cours d'eau à partir des patches de terres labourables sera fortement altérée si un pixel à potentiel depollution élevé et situé à proximité d'une rivière disparaît.
sensibilité de "entropie de Shannon à l'agrégationterres labourables
0.45...--------------------------------------,
0.4 ..................... ----- - -- - -.. -.. "" -- -- -- , ------ - ------ - - -- ------=:..-:.....=-
0.35
0.3
0.25
0.2
..... 'zone1
- .. - zone2-._. zone3
--- zone4
0.15
0.1
BOOm200m
... - ... - .. _... -_ .. _.. - ._- ---_.- ."-- ".-"._~ .. - .. :_:_-_.~ .
o-l------------+---------.......;;;.:..:.=:...:..,;;.~-----------~l00m
0.05
niveau d'agrégation
zone1 zone2 zone3 zone4100m 0,013 0,003 0,143 0,131200m 0,013 0,004 0,151 0,129400m 0,000 0,000 0,143 0,125SOOm 0,000 0,000 0,125 0,125
proportion de la surface en terres labourablessur les 4 zones d'échantillonnage
39
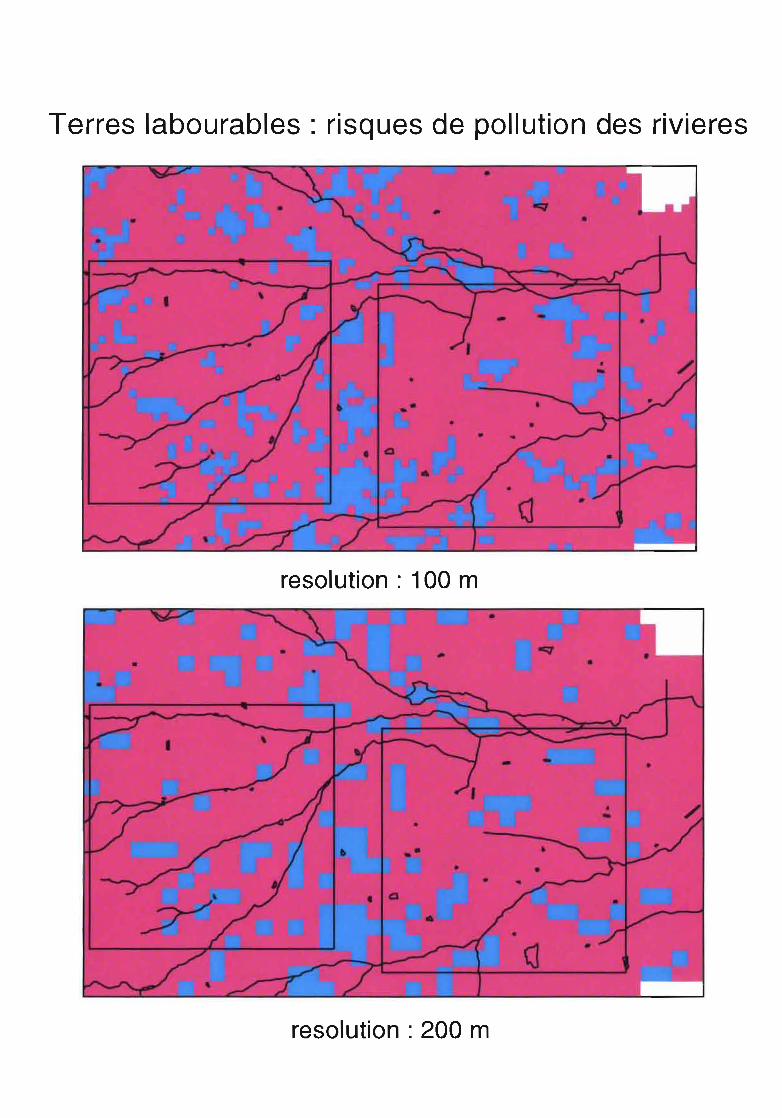
Terres labourables: risques de pollution des rivieres
resolution : 100 m
resolution : 200 m

5. Conclusion
L'intérêt des différents indices de structure spatiale a pu être évalué au cours de cette analyse. Il en ressortque:- les indices d'entropie H' et ENT donnent des résultats similaires:
*pour l'occupation du sol : ils augmentent en fonction de l'agrégation traduisant ainsi un maintient dela diversité et une plus grande dispersion des patches,*pour le MNT : ils baissent ce qui exprime une baisse de la richesse en information.
- les indices de dominance D et de contagion C : leur intérêt est limité car ils sont sensibles au nombre detypes présents.- le coefficient de Hurst paraît l'élément le plus pertinent pour quantifier l'altération de la structure(adjacence) et des proportions des types.
L'étude de l'entropie directement par l'indice de Shannon ou indirectement par le coefficient de Hurstpermet de quantifier la perte d'information au cours de l'agrégation en terme de structure mais aussi en termede proportions.
De plus, la forme de la courbe de l'indice de Shannon en fonction de la résolution, permet de savoir sila résolution la plus fine utilisée exprime correctement la variabilité spatiale des données. En effet, si unpalier n'apparait pas pour des résolutions fines, cette résolution mérite d'être augmentée.
Mais, l'étude de l'entropie ne permet pas de résoudre les problèmes liés à la localisation exacte desdonnées. Donc, pour un modèle distribué, seule l'analyse de sensibilité peut exprimer la perte d'informationliée ni aux changements de proportion, ni à la structure spatiale mais à la localisation précise des données.
40

6. Bibliographie
BAKER W. et CAl Y., 1992 : The rJe programs for mu1tiscale ana1ysis of 1andscape structure using theGRASS geographical information system. Landscape Eco10gy vol.7, nos 4: 291-302.
BEVEN K, 1989 : Changing ideas in hydro10gy. The cas ofphysically-based mode1s. J. Hydrol. 105 : 157172.
BEVEN K, LAMB R., QUINN P., ROMANOWlCZ R ET FREER J., 1994: TOPMODEL. In ComputerMode1s ofWatershed Hydro10gy, V.P. Singh (ed.), Water Resources Publications.
BURROUGH P.A., 1986 : Principles of Geographical Information Systems for Land ResourcesAssessment. Oxford University, Monographs on soil and resources survey, n012. Oxford UK :Charendon Press.
INRA, 1991 : Analyse spatiale de 20 bassins versants bretons par morphométrie à partir des modèlesnumériques de terrain. Mérot P. et Ezzahar B., Rapport de contrat n030 91 02 et n030 91 25 D.
GOODCHlLD M., 1980 : Fractals and accuracy of geographical measures. Math. Geol. 12 : 85-98.
GOODCHlLD M. et MARK D., 1987 : The fractal nature of geographic phenomena. Ann. AAG, 77(2) :265-278.
GOODCHlLD M., 1993 : Data Mode1s and Data Quality : Prob1ems and Prospects. In EnvironmentalModelling with GIS, Oxford University Press: 94-103.
MANDELBROT B.B., 1982: The fractal geometry of nature. Freeman, New York.
SHANNON C. et WEAVER W., 1964 : The mathematical theory of communication. University of IllinoisPress, Urbana,1 Il.
TURNER M., O'NEILL R, GARDNER R et MILNE B., 1989 : Effects of changing spatial sca1e on theanalysis oflandscape data. Landscape Eco10gy vol.3, nos 3-4 : 153-162.
VIEUX B., 1993 : DEM aggregation and smoothing effetcs on surface runoff modelling. Am. Soc. Civ.Eng., J. Comput. Civ. Engin., Spec. Issue Geogr. Information Anal., 7 : 310-338.
VIEUX B. et FARAJALLA N., 1994 : Capturing the essential spatial variability in distributed hydrologicalmodelling: hydraulic roughness. Hydrol. Process., 8 : 221-236.
VIEUX B. et FARAJALLA N., 1995 : Capturing the essential spatial variability in distributed hydrologicalmodelling: infiltration parameters. Hydrol. Process., 9 : 55-68.
VOSS R., 1988: The Science of fractale images. Springer-Verlag, New-York: 21-47.
WOOD E., SIVALIPAN M. et BEVEN K, 1990 : Sirnilarity and scale in catchrnent storm response. Rev.Geophys., 28: 1-18.
41

ANNEXE: Utilisation de GRASS 4.1 pour a2réger des mailles
Plusieurs méthodes d'agrégation sont possibles dans les SIG:- plus proche voisin : la valeur de la maille initiale la plus proche du centre de la nouvelle maille grossière estaffectée à cette nouvelle maille.- moyenne : la valeur affectée à la nouvelle maille est égale à la moyenne des valeurs des mailles initialesqu'elle contient.La méthode du plus proche voisin est la plus répandue, c'est cette méthode qui est employée dans GRASSpar la fonction r. resamp/e.
Définir les fenêtres d'échantillonnage dans r./e.setup suivant la méthode définie plus haut. Attention à définirdes groupes (quitte à créer un groupe par type) dans ce programme car sinon la surface relative couverte parchaque type ne pourra pas être calculée ultérieurement.
Calculer la valeur des indices avec r./e.patch ou r./e.pixe/ dans les fenêtres d'échantillonnage. Mais penser àdéfinir une carte raster de ces zones d'échantillonnage grâce à l'argument -u dans r./e.patch ou r./e.pixe/. Eneffet, les valeurs de ces indices ou de ces mesures à une échelle différente devra être faite dans les mêmeszones. Ces fenêtres d'échantillonnage pourront être alors être rappelées en définissant dans r./e.patch our./e.pixe/ non pas des unités (argument sam=u) mais en appelant une région (sam=r reg=<nom du raster».
Redéfinir la région dans le menu des gestion (MapManagement) en changeant la résolution et l'exécuterpourqu'elle soit active.
Puis, 2 moyens se présentent pour agréger :- r. resamp/e :on définit le nouveau fichier raster à partir de l'ancien,- r.mapca/c :
newraster = o/drasterCalcul d'un nouveau fichier raster dans la région définie.
Attention : si une carte de résolution plus grossière a déjà été calculée dans une session antérieure, redéfinirtout de même la région correspondant à cette résolution sinon r./e.patch ou r./e.pixe/ donneront des résultatsfaux.
ANNEXE : Etapes de calcul de l'indice de Kirkby
1- définition des zones d'échantillonnage dans r./e.setup2- création d'un grid des zones d'échantillonnage avec l'option -u dans une fonction r./e.patch ou r./e.pixe/les autres calculs se feront non pas en appelant des « units areas» mais des régions égales au gridprécédemment calculé (avantage: les units area dépendent de la résolution, il faut les redéfinir pour chaqueniveau d'agrégation et cela entraîne des erreurs)3- modifY current region pour définir la résolution courante4- r. watershed pour obtenir le grid d'accumulation à la résolution n : accumn
5- r.s/ope.aspect pour obtenir le grid de pente à la résolution n : slope"6- r.mapca/c> kirkn = /og(accumn *surfacen *100/ s/open , 2.71828)avec surface", : surface unitaire d'un pixel7- r./e.patch map=kirk sam=r reg=echantmnt att=a5echantmnt étant le grid des unités d'échantillonage
42

ANNEXE : Méthode d'agrégation pour conserver l'information liée à unprocessus localisé sous GRASS 4.1
Lorsque certains processus importants se produisent sur de petites surfaces, il faut conserver cetteinformation lors de l'agrégation. Par exemple, l'alimentation des nappes souterraines au Sahel se fait engrande partie par les mares, il est important de conserver cette information à résolution grossière même si lataille des mailles est supérieure à la taille des mares. Une solution est de calculer un nouvel attribut pour lesgrandes mailles : la somme des surfaces en mares, on perd en tout cas l'information sur la localisation précisedu processus.
Tout d'abord, signalons qu'il existe une fonction d'agrégation automatique dans GRASS 4.1. Cettefonction est r.resample. Après avoir redéfini la région (g.region) c'est-à-dire l'étendue et la résolution detravail, cette fonction r.resample permet de changer la résolution d'une carte initiale. Elle utilise la méthode"nearest neighbor", la valeur d'une nouvelle maille est égale à celle de la maille initiale la plus proche ducentre de cette nouvelle maille. Mais l'agrégation simple est inadaptée à notre problème puisqu'elle conduit àéliminer les éléments minoritaires (Turner, 1989).
Cependant cette fonction peut être testée pour vérifier l'erreur produite par une agrégation "aveugle"en comparant la somme des surfaces de l'attribut clef sur cette nouvelle carte avec celle de la carte d'origine.
Pour obtenir la surface d'un élément minoritaire dans une maille grossière, il faut utiliser la fonctionde r.lepatch : calcul de surface totale couverte par chaque attribut. Il est possible de représenter les maillesgrossières par des "sampling units" de forme rectangulaire. Le calcul est alors effectué pour chaque"sampling unit" et les résultats sont écrits dans un tableau et donnent la surface couverte par chaque unité dela carte d'origine dans chaque "sampling unit".
Il est nécessaire auparavant d'avoir défini les "sampling units" dans r.le.setup avec l'option claviersystematic contiguous et en précisant une taille des sampling units égale à celle des mailles grossières et uneorigine (coin haut-gauche) identique.
Le problème est de rapporter ces informations alphanumériques à des entités spatiales (les maillesgrossières). Ceci est fait en spécifiant l'option -u dans la commande de r.le.patch : une carte formée des"units areas" est alors créée. Mais cette carte possède comme attribut un simple numéro d'ordre commençantpar la haut gauche et défilant de gauche à droite et de haut en bas.
Cette carte des mailles grossières peut être mise à jour par les valeurs de la somme des surfacescalculée dans les tableaux. Pour l'instant nous n'avons pas trouver d'autres méthode que la méthode manuelleà l'aide d'une fonction r.rec/ass sur la carte des mailles grossières: les données lues dans le fichier table sontrecopiées comme nouvelles valeurs de la carte des mailles avec la fonction r. rec/ass.
Cette approche manuelle n'est possible qu'avec un nombre de mailles restreint.
AlternativesCalcul par une fonction zonale: les zones étant les mailles grossières. Les auteurs de GRASS remplacent leterme zone par le terme région.Les fonctions de type zonal sont assez peu développées dans GRASS 4.1 (par rapport à GRIDd'ARC/INfO):r.average : calcul de la moyenne des valeur d'une carte A pour chaque région d'une carte B. Cette fonctionn'est utilisable que pour des données numériques cardinales ou ordinales et non pas pour des donnéesnominales. Quel serait le sens d'une moyenne entre l'attribut 1 et 5, si 1 signifie savane arborée et si 5 signifieétendue d'eau?r.median : calcul de la médiane des valeur d'une carte A pour chaque région d'une carte B.r. mode: calcul de la valeur la plus fréquente d'une carte A pour chaque région d'une carte B.Ces fonctions sont inadaptées à notre problème, puisque nous cherchons à faire apparaître des élémentsminoritaires. Il aurait fallu utilisé une fonction zonale de somme des surfaces minoritaires.
43






![Cours – « L'eau, ressource essentielle » [CA v1.6]aubel.free.fr/GEO/monde/COURS_L_eau_ressource... · International d'Hydrologie). 5/9 (src) = Livre 2nd Hatier p. 94 carte 1](https://img.pdfslide.fr/doc/110x75/5b9a071309d3f2c3468c7513/cours-leau-ressource-essentielle-ca-v16aubelfreefrgeomondecoursleauressource.jpg)






















