Embed Size (px)
Citation preview

LMW : Architecture des équipements
Antoine FRABOULET
– p. 1
Plan• Introduction aux network processors• Architecture des routeurs• Commutation• Quelques network processors
– p. 2

Processeur réseau
• Un processeur réseau (network processor) est uncomposant programmable dédié au traitement des paquetssur un réseau.
• Il est généralement composé d’un processeurprogrammable, souvent spécialisé ainsi que de circuitsdédiés au traitement des paquets.
• Il peut être constitué de diverses technologies:◦ ASIC: Application Specific Integrated circuit◦ ASIP: Application Specific Instruction Processor◦ Co-processeur◦ FPGA: Field Programmable Gate Array◦ GPP: General Purpose Processor
– p. 3
Que fait un processeur réseau?• On peut identifier quelques traitements clefs:
◦ Pattern matching (identification de motifs):identification de bit particuliers dans les champs d’unpaquet.
◦ Lookup (recherche par clef): action de recherched’une donnée dans une table indéxée par une clef.
◦ Calculs: checksum, encryption, decryption...◦ Manipulation de données: fragmentation IP,
re-assemblage, TTL...◦ Gestion de file d’attente: ordonnancement, stockages
avant routage◦ Contrôle: mise à jour des table de routage, analyses
statistiques...
– p. 4

Problèmes dans les réseaux• Les réseaux sont de plus en plus rapides
◦ multiplications des débits• Les réseaux sont de plus en plus étendus
◦ multiplications du nombre de connexions• La gestion du flux dans ces réseaux impose d’avoir des
équipement performants d’interconnexion
– p. 5
Problèmes dans les réseaux
Enjeux : la convergence voix/données• les données représentent une grande partie du trafic• la téléphonie (mobile) génère un trafic de plus en plus
important (VoIP : Voice over IP)
– p. 6

Problèmes dans les réseaux
Utilisation du GSM
GSM
12kb/s
appareil mobile
téléphone station de base 100 mobiles
5 Mb/s 10 stationsde base
50Mb/s
– p. 7
Problèmes dans les réseaux
Mise en place de la convergence
station de base
de base
50Gb/s
1Mb/s
500 mobiles
500 Mb/s100 stations
UMTSvoix données
– p. 8

Interventions des processeurs réseaux• Principalement aux niveaux
◦ . . .◦ 5 : session◦ 4 : transport, contrôle de flux◦ 3 : routage◦ 2 : liaison◦ 1 : physique
– p. 9
Plan• Introduction aux network processors• Architecture des routeurs• Commutation• Quelques network processors
– p. 10
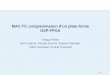
Conception de routeurs
• Ensemble de ports d’entrées/sorties• Aiguillage entre les entrées et les sorties• Gestion de la congestion
– p. 11
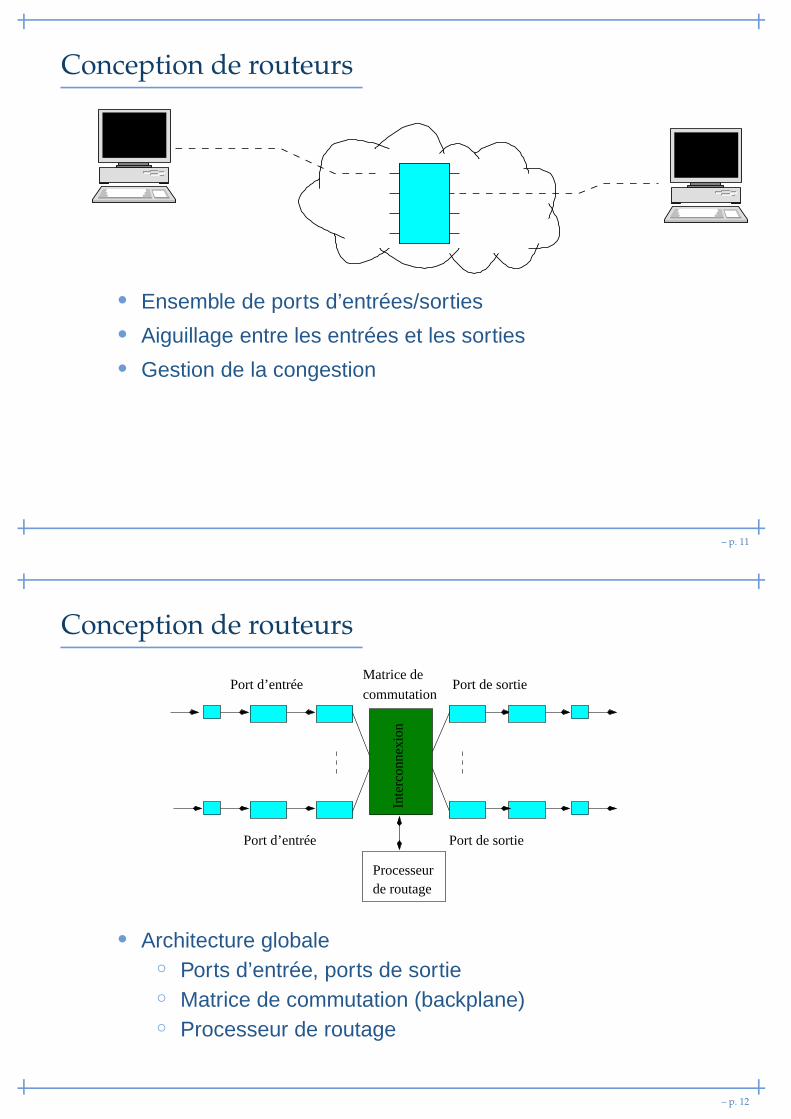
Conception de routeurs
Port de sortie
Port d’entrée
Port d’entrée
Port de sortiecommutation
Matrice de
Processeur de routage
Inte
rcon
nexi
on
• Architecture globale◦ Ports d’entrée, ports de sortie◦ Matrice de commutation (backplane)◦ Processeur de routage
– p. 12

Architecture
processeur de routageconfiguration / routage dynamique
réplication des tables en local
CPU
Inte
rcon
nexi
on
• Le processeur de routage traite les paquets à destinationdu routeur◦ configuration - maintenance◦ services dynamique (routage)
– p. 13
Architecture• La table de routage est recopiée dans chaque port
d’entrée pour avoir un accès rapide et parallèle (pas demémoire partagée)
• Les ports sont autonomes• Lorsqu’un port reçoit un paquet à destination du routeur il
l’envoit au processeur principal qui recalcule les tables etles redistribue
– p. 14

Ports d’entrée
Terminaison de liaisonde donnée (protocole,désencapsulation)
Terminaison de ligne
Consultation,acheminementmise en attente
Matrice decommutation
• interface avec le médium physique• Terminaison de liaison• réachemninement grâce à une table, mise en attente dans
une file d’attente.
– p. 15
Matrice de commutation
Entrées Sorties
Inte
rcon
nexi
on
• Trois types de commutations:◦ mémoire partagée (PC, routeurs bas de gamme)◦ Bus partagé (milieu de gamme)◦ Crossbar point à point (haut de gamme)
– p. 16

Speedup global du routeur
C CB RSRE
Inte
rcon
nexi
on
• C : débit d’entrée/sortie• RE : débit d’entrée de
l’interconnexion• RS : débit de sortie de
l’interconnexion• B : débit interne de
l’interconnexion
• rapport (speedup)bus/liaison B/C
• speedup entrée/liaisonRE /C
• speedup sortie/liaisonRS /C
– p. 17
Où se fait la mise en attente?
File d’attente en sortie
Inte
rcon
nexi
on
• algorithme simple: un seul point de congestion
⇒ nécessite une accélération de sortie de N égale aunombre d’entrées.
– p. 18

File d’attente en entrée
Inte
rcon
nexi
on
• stockage des paquets en entrée si contention en sortie• possibilité d’utiliser l’algorithme de “backpressure”
⇒ efficacité limité à cause des contentions en sortie
⇒ fonctionne bien en pratique
– p. 19
File d’attente en entrée et en sortie
Inte
rcon
nexi
on
• utilisation efficace avec un speedup limité
⇒ algorithmes complexes (plusieurs points de congestion)
⇒ nécessité d’avoir un contrôle de flux
– p. 20

Architecture des routeurs haut débit• Combinaison file en entrée, file en sortie
◦ CE /CS ≤ 2• Interface d’entrée : commutation, routage, classification• Interface de sortie : ordonnancement• Interconnexion :
◦ réseau commuté◦ B = NxC
• L’interconnexion permet de connecter simultanémentplusieurs paires d’entrée / sortie
• Les paquets sont fragmentés en cellules de petites taillesdans l’interconnect pour éviter les contentions
– p. 21
Éviter le blocage en tête de ligne
E1
E3
E2
S1
S2
S3
• la sortie est calculée dans l’interface d’entrée• les interfaces maintiennent une file virtuelle par sortie
– p. 22

Interface de sortie
flux 1
flux 2
flux 3clas
sif.
ordo
nnan
c.
• l’interface de sortie peut lisser le trafic avec unclassificateur et un ordonnanceur
⇒ voir le cours de QoS (délai, bande passante, pertes)
– p. 23
Mémorisation dans les réseaux• Le partage de lien par multiplexage statistique est efficace• La commutation/routage de paquets nécessite des
mémoires• Il faut éviter la perte de paquets
⇒ Utiliser de grosses mémoires
⇒ Les mémoires sont peu chères
– p. 24

Observations
Routeur
• Plus les buffers sont gros, moins il y a de pertes• Si le buffer n’est jamais vide, l’interface de sortie est tout le
temps active.
– p. 25
Théorie des files d’attente
1p
X
P [X > k]
• On peut trouver la taille d’un buffer pour un taux de pertedonné
• Les pertes diminuent avec l’augmentation de la taille• Grand = mieux
⇒ voir le cours de PBS
– p. 26

Taille des buffers• 1Gb de mémoire peut contenir 500k paquets et ne coûte
quasiment rien
⇒ On peut faire des buffers de grande taille
• Les utilisateurs n’aiment pas les buffers• Les opérateurs non plus• Idem pour les concepteurs• En fait ce n’est pas sûr que l’on en ait besoin
– p. 27
Débits importants: exemple• réseau à 10Gb/s
◦ 250ms de mémoire◦ 300Mo de mémoire◦ manipulation d’un paquet de 40 octets toutes les 32ns
• Mémoire utilisée◦ SRAM : 80 modules, 1kW, 2000$◦ DRAM : 4 modules, trop lent
• Réseaux à 40Gb/s ?
– p. 28

Taille de buffers• Utilisation de TCP : contrôle de bout en bout• Les pertes sont prévues dans le protocole
◦ Fenêtre de congestion◦ algorithme du slow start
• Les pertes ne sont pas graves• Le débit est une meilleur métrique
– p. 29
Taille des buffers
source destinationrouteur C
2T
• Règle habituelle : B = 2T ∗ C
• B est la taille de la mémoire (en bits),• C est la capacité du lien (en bit/s),• 2T est le temps d’aller-retour
– p. 30

Taille des buffers• Les routeurs gérant de nombreux flux peuvent en fait
diminuer la taille des buffers
• B =2T∗C√
N
• Cette diminution peut être effectuée car les flux TCP sontdésynchronisés
• réseaux 40Gb/s◦ règle habituelle : 10Gbits◦ nouvelle mesure : 50Mbits
– p. 31
Vue du constructeur de routers• Haut débit• Sécurité• Cryptographie, pare-feux, authentification• Flexibilité
◦ Passage à l’échelle◦ Adaptabilité aux standards (ATM, UMTS, IPv6)◦ Possibilité d’ ajouter de fonctionnalités
• Basse consommation• Coût financier réduit
– p. 32

Plan• Introduction aux network processors• Architecture des routeurs• Commutation et routage rapide• Quelques network processors
– p. 33
Ethernet : commutation• Passage d’un bus à de la commutation de niveau 2• Réduction des domaines de collisions• Les ports d’entrées ont accès à une table de
correspondance adresse MAC <-> port de sortie◦ Possibilité d’avoir des VLAN (filtrage dans la table :
802.1Q)◦ Possibilité de faire de la priorisation (802.1P)
• Rapidité de traitement, pas de modification de la trame• commutateur bas de gamme 8 ports : temps de
commutation de 11µs. Au maximum 90900 trames parseconde.
– p. 34

Niveau 3 : routage / commutation• Les routeurs reprennent la même architecture• Les ports d’entrées ont accès à une table de
correspondance préfixes adresses IP <-> port de sortie◦ Calculée par le routage◦ Possibilité d’avoir des VLAN par adresse IP◦ Possibilité d’avoir de la priorisation
• Commutation de niveau 3 : modification de la trame à lavolée◦ Les réseaux d’entrée et de sortie doivent être de
même nature◦ Adresses MAC (source et destination)◦ Recalcul du checksum (très long)
• Commutation de niveau 3 : reconstruction de trame◦ Cas pour lequel les réseaux de niveau 2 sont différents
– p. 35
Niveau 3 : routage / commutation• Problème du routage
◦ Identifier l’interface de destination en fonction del’adresse destination IP
◦ Les tables de commutations ne stockent que lacorrespondance entre préfixes d’adresses IP et portde sortie
◦ Le choix de la route doit donc trouver le port de sortieayant le préfixe de correspondance le plus long
– p. 36

Table de commutation
12.82.xxx.xxx
128.16.120.xxx3
1
212.82.100.xxx
12.82.100.101
128.16.120.111
1
2
– p. 37
Table de commutation• La structure de données utilisée pour représentée la table
de correspondance est cruciale• Une implémentation naïve fonctionne en O(m × N) où m
est la longueur du préfixe (32 pour IP), et N le nombred’entrée dans la table.
? Quelle est cette représentation ?
– p. 38

Algorithme de lookup• CIDR: préfixe réseau de taille quelconque.• La table de routage peut agréger des adresses de réseaux.• Exemple: réseaux 208.12.16/24 jusqu’à 208.12.31/24 chez
le même provider. Ils sont agrégés par 208.12.16/20.208.12.21/24
208.12.16/20
0 232
− 1
• Exception: 208.12.21/24 passe chez un autre provider.• Deux solutions: repasser en 24 bits de préfixes (16 entrées
au lieu d’une), stocker l’exception (2 entrées au lieu d’une)
– p. 39
Algorithme: binary trie• Recherche, pour une adresse à router, du plus grand
préfixe présent dans la table.• Chaque étage correspond à un bit.
a
b
c e
d
f g h i
Préfixes
a 0*b 01000*c O11*d 1*e 100* f 1100*g 1101*h 1110*i 1111*
0 1
1
10
0
0
0
0
1
0 1
0 1 0 1
– p. 40

Algorithme: path compressed trie• On compresse les chemins inutiles, les nœuds sont
étiquetés avec le bit à consulter.• Arrivé aux feuilles on compare le préfixe à l’adresse et on
remonte éventuellement.
a d
f g h i
Préfixes
a 0*b 01000*c O11*d 1*e 100* f 1100*g 1101*h 1110*i 1111*
0 1
1 0 1
0 1
0 1 0 1
cb
0
3
1
e
2
3
4 4
– p. 41
Algorithme récents pour routage haut débit• minimiser le nombre de lectures dans la table• minimiser la taille de la structure
⇒ Utiliser une structure hiérarchique à trois niveaux
– p. 42

Table de commutation• Premier niveau : couvre tous les préfixes sur 16 bits
◦ Utilisation d’un bit par préfixe (présent / non présent)◦ Mémoire utilisée 216 = 64Kb = 8Ko
◦ On stocke un pointeur vers le niveau suivant si lepréfixe est valide (densité)
• Deuxième niveau, troisième niveau . . .• Les structures sont optimisés pour être rapides en lecture• Le construction de la structure est plus délicate
◦ Les tables de routages ne changent pas souvent
– p. 43
Exemple: niveau 1 (vecteur de bit)• Premier niveau tous les préfixes jusqu’à la profondeur 16
• 1 bit par préfixe (216 = 8KB)
⇒ Utiliser une structure hiérarchique à trois niveaux
1 1 1 1 1 1 1 110 0 0 0 0 0 0
0 1 1532 14
Routing table
pointer array
level 2 chunk
????
– p. 44

Classification• Le problème de lookup peut être vu comme un cas simple
du problème de classification de paquet.• Pour un paquet, on cherche à identifier:
◦ L’adresse destination◦ L’adresse source◦ Les protocoles de différents niveau
• On déduit une action pour chaque paquet.• Ces traitement interviennent surtout dans les niveaux 4 et
5.
– p. 45
Exemple de table de classification
Règle Dest. Addr/Mask Src. Addr/Mask App. Transp. Action
prot. prot. Action
R1 152.163.190.69/ 152.163.80.11/ * * Refuser
255.255.255.255 255.255.255.255
R2 152.163.3.0/ 152.163.200.157/ = www UDP Refuser
255.255.255.0 255.255.255.255
R5 152.198.4/ 152.163.160.0/ >1023 TCP Accepter
255.255.255.255 255.255.252.0
R6 0.0.0.0/ 0.0.0.0/ * * Accepter
0.0.0.0 0.0.0.0
– p. 46

Plan• Introduction aux network processors• Architecture des routeurs• Commutation et routage rapide• Quelques network processors
– p. 47
Quelques network processors• Principaux constructeurs:
◦ Intel IXP◦ IBM◦ Motorola◦ . . .
– p. 48
Intel et IBM• Intel IXP
◦ architecture à espace d’adressage partagé◦ processeur généraliste embarqué : Strong ARM,◦ 6 processeurs programmables de traitement des
paquets◦ nombreux coprocesseurs matériels (gestionnaire de
sémaphores, classification, recherche associative, etc)• IBM PowerNP
◦ architecture à espace d’adressage partagé◦ Processeur généraliste embarqué : PowerPC,◦ 16 processeurs RISC quadri-contexte pour traitement
des paquets coprocesseurs matériels pour lesfonctions de dispatch des paquets et ordonnancementdes threads
– p. 49
Cisco 2600
www.cisco.com
– p. 50

Cisco 7200
www.cisco.com
– p. 51
Cisco 12000
www.cisco.com – p. 52

Niveaux 4, 5, . . .
• Plus on remonte dans les niveaux, plus le traitement àfournir dans l’interface d’entrée est important
• Les performances des routeurs varient grandement si l’onactive des services de haut niveau◦ filtrage d’adresses IP◦ filtrage de port UDP ou TCP◦ filtrage de contenu de requête◦ . . .
• Unité de mesure : MPPS Millions de paquets par secondes
– p. 53
ExtremeNetwork BlackDiamond
www.extremenetworks.com
• BlackDiamond 6800◦ jusqu’à 1400 ports 100Mb/s◦ backplane de commutation 768Gb/s◦ 192 MPPS◦ interventions niveaux 2,3,4 et applicatif
• BlackDiamond 12000◦ 48 ports 10Gb/s Ethernet ou 480 ports Gb/s◦ 1.6Tb/s en commutation◦ 1,2 millions de routes IPv4/IPv6◦ . . .
– p. 54


![Cours de Compilation, Master 1, 2004-2005 - CITI …perso.citi.insa-lyon.fr/trisset/cours/compilStudent.pdf · 2013-08-23 · sity : ”Engineering a Compiler” [CT03]. Il est aussi](https://img.pdfslide.fr/doc/110x75/5b96968709d3f2501c8b679f/cours-de-compilation-master-1-2004-2005-citi-persocitiinsa-lyonfrtrissetcours.jpg)