Embed Size (px)
Citation preview

Université Louis Pasteurde Strasbourg
Département d'informatiqueLSIIT, URA CNRS 1871
Thèse
Numéro d'ordre :1868Année 1994
présentée en vue de l'obtention dugrade de Docteur
de l'Université Louis Pasteur de Strasbourgspécialité Informatique
par
Pierre FERN/QUE
Un Modèlepour l'Administration
des Dépendances entre Services Applicatifsdes Réseaux Informatiques Hétérogènes
Soutenue le 20 septembre 1994 devantla commission d'examen:
Richard CASTANET: Rapporteur externeJean-François DUFOURD: Président
Jean-Jacques PANS/OT: Directeur de thèsePierre ROLIN : Rapporteur externe
André SCHAFF : Examinateur


à François
qUl,
du haut de ses dix-huit mois,son cerveau meurtri,
et son côté désormais si lourd,
m'a simplement révélé le poidsque j'accorde à chaque chose,
et que rien n'est plus merveilleuxque de savourer la minute
présente.


Je remercieles personnes qui m'ont assisté
dans mon travail.
ParticulièrementJean-Jacques Pansiot
et les membres du jury,Gérard Toninato
et bien évidemmentFrançois, Jérémie & Sonia Fernique.
Chacun d'eux, à sa manièrem'a amplement aidé, supporté.


Résumé
Nous présentons, dans notre thèse, un modèle théorique de description des services applicatifs
dans les réseaux informatiques hétérogènes, permettant de traiter les problèmes liés aux
dépendances de ces services entre-eux. La problématique peut être illustrée par ces deux
questions. Quels sont les éléments d'un réseau nécessaires au fonctionnement d'un service
applicatif? Quel est l'impact occasionné par la déficience d'un élément? Le problème sous
jacent prend toute son ampleur pour des réseaux de moyenne ou grande taille sur lesquels les
services réseaux mettent enjeu une série de dépendances particulièrement complexes à établir
et à gérer. Après une étude bibliographique décrivant l'état de l'art dans ce secteur de
recherche, nous exposons notre modèle. Nous proposons une définition d'un service réseau
sous la forme d'applications multivoques qui décrivent les contraintes de fonctionnement du
dit service. Ceci nous permet de construire le graphe global des dépendances appréhendées.
Fiabilité des services, impact des ordinateurs, calcul de coOts, estimation de la charge, sécurité
du réseau, autant de résultats obtenus par notre modélisation. L'implantation d'un prototype
logiciel basé sur de tels concepts nous permet de vérifier la faisabilité de notre modèle. Cette
maquette a été testée avec succès sur un des réseaux de campus de l'Université de Strasbourg.
Mots clés
Réseaux informatiques hétérogènes - Administration de réseaux - Modélisation - Services
applicatifs - Graphes de dépendances - Couche Application.
Administration des applicatifs réseau:( vii


Abstract
In this dissertation, we present a theoretical model which can describe the application services
in heterogeneous computer networks, with particular emphasis on the complex
interdependencies among the various services. The problems the model is meant to handle can
be illustrated with two fundamental questions. Which elements in the network are necessary
for a given application service to operate? What is the overaU impact of the failure of a given
part of the network likely to be? This type of problem can be of real magnitude with medium
and large scale networks, in which the services involve a whole series of interdependencies
particularly difficult to delineate and manage. We begin with a review of the literature to
present the state of the art in the field, and then develop our mode!. We give a network service
definition based on multivocal applications which describing the constraints of its functioning.
By this modelisation, we construct an overaU graph of the various dependencies under study.
The diagnoses in case of failure as weU as the assessment of the reliability of the services, of
the impact of each computer station, of the workload and of security can aU be handled by our
mode!. The implementation of a prototype program based on the above theoretical framework
has aUowed us to demonstrate the feazability of our model within a network management
system, since the prototype has been successfully tested on one the campus networks of the
University of Strasbourg.
Key words
Heterogeneous computer network - Networks management - Modelisation - Application
services - Dependencies graph - Application layer.
Administration des applicatIfs réseaux ix


Tabledes
chapitres
Administration des applicatifs réseau.''; xi


Table des chapitres
Introduction
Partie 1.Administration de réseaux:l'état de l'art
1.Le contexte général de l'administration de réseaux2.L'état de l'art en administration de réseaux3.Administration des dépendances de services applicatifs
Partie 1/.Un modèlepour l'administrationdes applications réseaux
4.Hypothèses et finalité du modèle5.Description formelle du modèle6.Du modèle théorique au modèle informatiquel.Résultats de la modélisation
Partie III.Validation du modèle par implantation
8.Contexte de la maquette9.La maquette ADSAR : implantation, utilisation et évaluation
Conclusion
Annexes
Références et Index
Administratio1l des applicatifs réseau.t xiii


Introduction
AdmÙÛstratioll des applicatifs réseau.Y 1


Celte dernière décennie voit l'informatique totalement transformée par l'avènement des
réseaux informatiques. Il y a encore quelques années, l'ordinateur pouvait être considéré au
singulier : sorte de "potentat" entouré de ses terminaux et périphériques. Désormais, le
matériel informatique est distribué, réparti, et il lui faut nécessairement coopérer; c'est
l'incontournable réseau informatique, colonne vertébrale des systèmes informatiques
modernes.
La croissance de ces réseaux est particulièrement rapide. Il est maintenant courant d'avoir des
réseaux informatiques de plusieurs centaines, voire de milliers d'ordinateurs. Leur étendue
géographique ne fait que s'accroître: réseaux régionaux, nationaux et même internationaux.
Dans un tel contexte, la tâche qui consiste à administrer de tels réseaux devient
particulièrement cruciale, voire vitale pour une entreprise, une organisation, un pays.
L'homme système des années quatre-vingt a été supplanté par l'administrateur réseau
J'ordinateur se remplace désormais en quelques heures, ce n'est pas le cas pour le réseau.
Nous observons, d'une part, que la complexité des réseaux informatiques s'accroît. Elle est
due principalement à l'avancée très rapide des technologies dans ce domaine. Variété des
supports telles la fibre optique, la paire métallique, variété des protocoles tels TCPIIP, IPX,
OSl, X25, variété d'équipements tels les répéteurs, les amplificateurs: autant d'éléments
continuellement améliorés, perfectionnés et qui vont devoir coopérer.
Nous constatons, d'autre part, que l'administration de grands réseaux nécessite une somme
importante d'informations: Quels sont les ordinateurs ? Qui les utilise ? Comment sont-ils
interconnectés? Par quels protocoles?
L'administration de tels réseaux hétérogènes requiert désormais un niveau élevé de
compétences et une base informative importante.
C'est dans ce domaine de l'administration des réseaux informatiques que se situent nos
travaux. Nous focalisons notre étude sur l'administration des dépendances entre applications
réseaux.
Administration des applicatifs réseaux 3

Introduction
Nous avons ainsi élaboré un modèle pour l'administration des dépendances entre services
applicatifs des réseaux informatiques hétérogènes, ceci afin de pouvoir développer des outils
logiciels qui assisteraient l'administrateur réseau dans sa tâche.
Nous appuyant sur les travaux de standardisation et de normalisation effectués par les
organismes tels l'ISO et le CCnT, ainsi que les travaux autour de la famille de protocoles
TCP/IP, nous élargissons leur champ d'application.
L'idée de base est de pouvoir répondre aux deux questions essentielles dans notre secteur de
recherche:
Quels sont les éléments réseaux nécessaires
à l'établissement d'un service applicatif?
Quel est l'impact occasionné par l'état d'un élément du réseau,
sur l'ensemble des services applicatifs?
Ces deux questions peuvent être illustrées par les deux exemples suivants: Pourquoi ne puis
je pas imprimer? L'imprimante est hors-service, qui en pâtit?
Lorsqu'il s'agit de réseaux informatiques réduits à quelques machines, les réponses sont
généralement simples et immédiates. En revanche, le problème sous-jacent prend toute son
ampleur dès qu'il s'agit de réseaux de taille importante, et ceci d'autant plus s'ils mettent en
œuvre des technologies hétérogènes. En effet, tout service réseau va s'appuyer de manière
récursive sur d'autres services réseaux, tels des montages de disques distants, des accès aux
annuaires, des vérifications d'identités, mettant ainsi en jeu une série de dépendances
particulièrement complexes à établir et à gérer. Diagnostics de pannes, modification de
l'architecture, calcul des coûts, estimation de la charge, sécurité du réseau, autant de domaines
qui se basent justement sur la connaissance la plus exhaustive possible de ces
interdépendances; les fonctions de l'administrateur réseau en sont indissociables.
Notre travail dans ce domaine spécifique nous a conduit à définir un modèle théorique, qui
décrit les éléments et leurs interactions nécessaires au fonctionnement des services applicatifs
réseaux. C'est l'objet de cette thèse.
Nous avons structuré notre exposé en trois parties complémentaires.
La première partie de cette thèse présente Hl'état de l'art" de notre domaine de recherche. Pour
une présentation complète, il nous est apparu nécessaire de définir au préalable ce qu'est
l'administration de réseaux informatiques. Ainsi, dans. le premier chapitre, nous précisons le
rôle d'une telle administration, les fonctionnalités que l'on peut en attendre et le cadre de son
4 Administration des applicatifs réseaui:

Introduction
application. Nous présentons, dans un deuxième chapitre, les travaux actuels dans ce domaine.
Nous exposons les différentes voies de recherche ; nous soulignons, entre autres, le rôle
spécifique de la normalisation et des standards. Nous tentons de présenter une synthèse des
divers progrès dans ce contexte. Enfin, l'objet de notre troisième chapitre est la présentation de
notre secteur particulier de recherche. L'administration des dépendances entre services
applicatifs est un domaine relativement récent. Nous présentons les travaux actuels
directement attenants à notre sujet de thèse.
Après avoir présenté le domaine de l'administration de réseau tel qu'il se présente à l'heure
actuelle, nous exposons dans la deuxième partie de notre thèse le modèle de données que nous
avons élaboré pour l'administration des applications réseaux. Cette partie s'articule en quatre
chapitres. Le premier chapitre situe les hypothèses de notre modèle et sa finalité. Dans les
deux chapitres suivants, nous spécifions le modèle lui-même. Nous en proposons, tout
d'abord, une définition théoriqne qui s'appuie sur un formalisme mathématique. Puis, dans un
denxième temps, nous présentons le modèle sous une forme "pratique" qui prend en compte
les spécificités techniques de l'informatique. Nous regroupons dans le dernier chapitre les
résultats que l'on obtient grâce à une telle modélisation.
Dans la dernière partie de notre thèse, nous décrivons la réalisation d'une maquette logicielle
qui implante notre modèle. Celle-ci a été réalisée afin de valider les principes énoncés. En
effet, nous démontrons la faisabilité d'un outil s'appuyant sur de tels concepts. Dans un
premier chapitre, nous présentons le contexte de l'expérimentation et les choix techniques
retenus. Le second chapitre a pour objet d'exposer les détails de l'implantation et les
fonctionnalités de la maquette. Nous terminons par une évaluation des résultats obtenus par un
tel prototype.
Administration des applicatifs réseaux 5


Partie l
Administration de~reseaux:
l'état de l'art
Administration des applicatifs réseall.,( 7


Comme l'automobile du début de ce siècle a engendré les réseaux autoroutiers, l'essor et la
banalisation des ordinateurs de ces quinze dernières années s'accompagnent d'un
développement étonnant des réseaux informatiques, à la fois en complexité et en nombre. Il
est désormais commun de trouver des établissements, entreprises, organismes
gouvernementaux, utilisant plusieurs milliers d'ordinateurs interconnectés entre-eux. Cette
multiplication des réseaux informatiques repose principalement sur deux paramètres: la
baisse des coOts de production du matériel électronique et le plafonnement des puissances de
traitement. L'exemple le plus typique est sans doute la réorganisation actuelle des
infrastructures informatiques bancaires. La solution qui consiste à risquer l'investissement de
sommes colossales dans un ordinateur central dont les capacités de stockage et de traitement
seront inévitablement limitées va être écartée. La tendance actuelle est à la décentralisation de
l'informatique: c'est l'ère des stations de travail, des "fermes(a).. et des micro-ordinateurs
reliés par l'incontournable réseau informatique. Dans ces nouvelles conditions, les personnes
responsables de la maintenance et du développement de telles architectures informatiques
voient leur rôle se complexifier considérablement. Il leur faut l'aide de modèles et d'outils
d'administration, de gestion de réseaux.
Or dans le monde effervescent de l'informatique, de nombreux équipements de divers
constructeurs vont se trouver côte à côte sur un même réseau, voire plusieurs réseaux
interconnectés. En effet, le jeu de la concurrence a entraîné le développement parallèle de
plusieurs types d'ordinateurs et de protocoles réseaux généralement incompatibles entre eux.
Ils devront cependant pouvoir à terme, non seulement échanger de l'information, mais de plus
être administrés de manière cohérente. Cette interopérabilité inévitable pour la fonction
d'administration nécessite la définition de modèles de données, de standards et de normes dès
lors qu'il s'agit de réseaux informatiques hétérogènes.
Ces différents travaux qui forment le domaine de l'administration de réseaux sont exposés
dans cette partie de notre thèse. Notre présentation s'appuie sur les trois composantes qui
(a) Le terme de "ferme" est la traduction française, encore peu usité, de elus/ers d'ordinateurs. Il s'agit de
regroupements d'ordinateurs coopérant étroitement.
Administration des applicatifs réseaux 9

I.
participent à tout système d'administration, à savoir: le modèle de l'Ùiformation, les
mécanismes mis en œuvre pour véhiculer ces données et l'analyse qui en est faite. Nous allons
comparer les solutions proposées, leurs différentes approches, en soulignant les avantages et
inconvénients de chacune d'elles. Nous terminons cette première partie en présentant plus
particulièrement les problèmes et travaux liés au domaine spécifique de l'administration des
dépendances des applications réseaux, sujet de notre thèse.
Cependant, avant cet "état de l'art", il nous semble nécessaire de situer dans un premier
chapitre le contexte général de l'administration de réseaux. Quels en sont le but et l'objet?
10 Administration des applicatifs réseaux
. 1

Le contexte général de l'adrninistration de réseaux
1. Le contexte général del'administration de réseaux
1.1
L'administration des applicatifs dans les réseaux informatiques est un domaine qu'il est
nécessaire de situer. Son contexte est vaste et met en jeu plusieurs notions. Dans le présent
chapitre, nous allons tout d'abord repréciser ce que l'on peut entendre par administration de
réseaux afin de cerner les deux points fondamentaux: l'objet et la finalité de l'administration
de réseaux. Ceci nons amène à traiter les problèmes soulevés par l'hétérogénéité des réseaux
et des matériels informatiques pour la mise en œuvre d'une telle administration.
1.1. Administration de réseaux
1.1.1. Une définition de l'administration de réseaux
Une définition globale de ce qu'est l'administration appliquée à un réseau informatique
pourrait être inspirée de celle qui est proposée par M-P. Gervais [GER 89] dans la thèse de
doctorat:
L'administration de réseaux est l'ensemble des moyens mis en Œuvre pour assurer la
meilleure qualité de service aux utilisateurs du-dit réseau, pour minimaliser les coûts induits
et pour permettre l'évolution des jonctionnalités offertes.
Il s'agit d'une définition bien générale qui va prendre tout son relief si l'on répond à la
question suivante: Qu'est-ce qui est à administrer?
1.1.2. Les éléments à administrer
Un réseau informatique est bâti sur trois types d'entités à administrer. Nous les désignons par
le terme "d'objets" dans la suite de cette thèse. Il s'agit du matériel, du logiciel, et des
utilisateurs. Précisons ce que l'on entend par chacune de ces trois classes:
Administration des applicatifs réseau.x 11

1.1
1.1.2.1. Le matériel
Le contexte général de ['administration de réseaux
Nous entendons par matériel(a) tout élément physique nécessaire au fonctionnement d'un
réseau informatique. Il s'agit bien évidemment des composantes des ordinateurs eux-mêmes
(microprocesseurs, mémoires, disques, etc) mais également des câbles et éléments purement
réseaux (fibres optiques, connecteurs, cartes électroniques des éléments de réamplification des
signaux réseaux, etc) et enfin des éléments que l'on dit périphériques, des composantes d'une
imprimante à ceux d'une table traçante (moteurs, rouages mécaniques, etc). Sont inclus
également dans la notion de matérielles consommables, c'est-à-dire les ressources utilisées
(ramettes de papier de l'imprimante, cartouches magnétique de stockage, etc).
1.1.2.2. Le logiciel
Le logiciel décrit tout programme informatique nécessaire au fonctionnement d'un système
informatique. Ces programmes peuvent être mémorisés de diverses façons, généralement sur
supports magnétiqnes, mais également "câblés", c'est-à-dire que les fonctionnalités du
programme sont réalisées par une carte électronique et non un ordinateur à part entière(b).
1.1.2.3. Les utilisateurs
La classe des utilisateurs est généralement omise lorsque l'on évoque les réseaux
informatiques. C'est pourtant l'élément primordial. Il s'agit simplement des personnes
physiques utilisatrices du réseau informatique.
"L'objet" de l'administration étant posé, il nous faut décrire la finalité de l'administration et
répondre à la question suivante: Pourquoi administrer 1II1 réseau informatique?
1.1.3. Les fonctionnalités de l'administration
La littérature sur le sujet (articles de recherche, normes, standards, etc) délimite le plus
souvent en cinq aires fonctionnelles ce que l'on peut attendre d'une administration de
réseaux: la gestion de la configuration, des anomalies, des pelformances, des informations
comptables et de la sécurité.
(a) Le terme généralement utilisé pour décrire le matériel informatique est "hardware" mais il se restreint auxéléments qui composent un ordinateur et non un réseau d'ordinateurs.
(b) Le logiciel au sein des éléments actifs d'un réseau (tel un régénérateur de trames réseaux) se restreint
rarement à la notion de programmes d'ordinateur. La notion de logiciel est ici plus large que la notion de
"software" habituellement retenue.
12 Administration des applicatifs réseau.),'

Le contexte général de l'administration de réseaux
1.1.3.1. La gestion de la configuration
1.1
Gérer ou administrer la configuration d'un réseau informatique consiste à établir l'inventaire
de tous les éléments nécessaires au réseau informatique. Identification, localisation
géographique, interaction, autant de composantes de la gestion de la configuration. Où se
trouve tel ordinateur? Quel système d'exploitation lui est nécessaire pour fonctionner?
Quelles sont les interfaces réseaux dont il dispose? Quels utilisateurs y ont accès?
L'administration de la configuration nécessite l'établissement d'un inventaire le plus complet
possible des objets à administrer, il s'agit en quelque sorte de la base de travail pour toutes les
autres aires fonctionnelles.
1.1.3.2. La gestion des anomalies
Gérer les anomalies va consister à détecter, isoler et corriger les états de dysfonctionnement
du réseau. Les anomalies sont divisées en deux classes:
-les pannes persistantes,
-les pannes passagères - plus difficiles à traiter car difficiles à repérer et à reproduire.
La gestion des anomalies est la fonction d'administration minimale. Sans elle, le réseau ne
peut fonctionner correctement à court ou moyen terme.
1.1.3.3. La gestion des performances
Gérer les pelformances d'un réseau informatique nécessite de définir des paramètres pour
mesurer certains aspects de la qualité de service. Les quatre indicateurs les plus courants sont:
-le temps de réponse, c'est-à-dire le délai qui s'écoule entre l'émission d'une requête et
l'arrivée de sa réponse,
-le débit, c'est-à-dire la quantité d'information qui peut s'écouler sur un réseau dans un
temps donné,
-le taux d'erreur, c'est-à-dire la proportion des erreurs en fonction de la taille du message,
-la disponibilité, c'est-à-dire l'état du réseau: est-il en service ou hors service ?
Le calcul de ces indicateurs se base généralement sur des échantillons de mesures faites sur
une période donnée, c'est pourquoi la gestion de la performance nécessite souvent la gestion
d'un historique des états du réseau. Il est, par exemple, nécessaire de conserver l'évolution du
débit d'une ligne donnée afin d'en déterminer une moyenne, un maximum, etc.
Certains articles tentent de définir des paramètres plus globaux qui permettent d'apprécier plus
facilement la qualité de service obtenue et de ne pas s'en tenir aux données "brutes". Par
Administration des applicatifs réseaux 13

1.1 Le contexte général de l'administration de réseaux
exemple A. Leinwand [LEI 93] tente de calculer le taux d'utilisation des medium/a) pour
établir des règles de gestion de la congestion(b). Il peut s'agir également d'estimer la
disponibilité moyenne d'un équipement.
Les paramètres de gestion de la performance sont particulièrement importants dans le milieu
industriel car ils permettent d'apprécier directement l'efficacité et la productivité.
1.1.3.4. La gestion des informations comptables
La gestion des informations comptables consiste à déterminer le coût d'utilisation des divers
éléments réseaux, et à établir un système de facturation par utilisateur, en fonction des
éléments utilisés. Différentes politiques de facturation peuvent être retenues. Les plus
courantes sont la facturation en fonction du débit ou du temps et l'abonnement.
Dans le cas de services réseaux offerts à plusieurs utilisateurs, il s'agira d'établir les personnes
qui devront supporter les coûts induits. Par exemple, dans le cas des réseaux téléphoniques,
c'est l'appelant qui paye.
1.1.3.5. La gestion de la sécurité
Particulièrement sensible est la gestion de la sécurité d'un réseau. Il s'agit de répondre aux
deux questions suivantes: "Qui a accès ?A quoi ?". Pour ce faire, on distingue deux grands
volets dans la gestion de la sécurité:
-la sécurité externe,
-la sécurité interne.
La sécurité externe
La sécurité externe regroupe tous les moyens mis en œuvre pour contrôler l'accès physique
des personnes aux différents éléments qui composent le réseau. Elle regroupe la notion de
gestion des locaux, des clés, des badges, etc.
La sécurité interne
On entend par sécurité interne la gestion des accès aux éléments du réseau par l'utilisation du
réseau informatique lui-même. On parlera alors de gestion des accès aux ressources. Elle met
en œuvre un certain nombre de mécanismes dont les plus courants sont: le codage ou
chiffrement, l'authentification des personnes et le contrôle d'accès.
(a) Le terme de médium est utilisé en réseau informatique pour décrire le suppmt physique de transm.ission del'information, typiquement un câble électrique.
(b) L'incapacité d'un réseau à assurer un débit suffisant pour écouler les informations est appelé phénomène
de congestion.
14 Administration des applicatifs réseaux

Le contexte général de l'administration de réseaux 1.1
Les aires fonctionnelles de l'administration forment un découpage qui permet de regrouper
des problèmes similaires entre eux. Il est pourtant difficile de cloisonner ces domaines; ils ont
d'importantes plages communes. Par exemple, la gestion des performances utilise
sensiblement les mêmes paramètres que la gestion des anomalies. De la même manière, la
localisation d'une erreur dans la gestion des anomalies nécessite la connaissance de la
configuration du réseau.
Certains auteurs, tel K. Terplan, préfèrent classer les fonctions d'administration par rapport à
leur impact temporel. C'est ce que nous abordons dans le point snivant.
1.1.4. Les niveaux d'administration
Définir un problème d'administration en estimant qu'il relève d'nne méthode à court, moyen
on long terme permet de définir trois niveaux d'administration. C'est une des méthodes de
classification retenue par K. Terplan [TER 92] dans son ouvrage "Communications NetIVorks
Management". Il distingue: l'administration opérationnelle, tactique et stratégique.
1.1.4.1. L'administration opérationnelle
Tous les problèmes concernant l'administration au jour le jour relèvent du court terme. Il
s'agit principalement de maintenir une configuration donnée en état de fonctionner. Nons
padons alors d'administration ou de contrôle opérationnel. Il met en jeu un certain nombre
d'activités telles la surveillance du bon fonctionnement, la détermination et l'isolation des
incidents et pannes, et la correction.
Un exemple de problème relevant du contrôle opérationnel peut être un dysfonctionnement
d'un amplificateur de signal qu'il s'agit de localiser et réparer.
1.1.4.2. L'administration tactique
Ce qui relève du moyen terme relève de l'administration tactique. Il s'agit par exemple de
définir les meilleurs paramètres de configuration pour obtenir la meilleure qualité de service.
Un exemple typique est de déterminer les ordinateurs qui ont la charge de "serveurs de
nom,,(a) pour le réseau. Ce peut être également le choix de connexion d'une nouvelle machine
en fonction du degré de maillage du réseau informatique. Bref, l'administration tactique
consiste à adapter la configuration sans modification majeure du réseau.
(a) Un ordinateur "serveur de noms" doit gérer un annuaire pour le réseau. Il doit pouvoir répondre aux
interrogations de concordances entre nom de mac/tine et adresse réseau.
Administration des applicatifs réseaux 1S

1.1
1.1.4.3. L'administration stratégique
Le contexte général de l'administration de réseaux
L'administration stratégique doit définir le plan d'extension du réseau à long terme. Elle doit
déterminer les besoins des utilisateurs et choisir, en fonction des moyens disponibles, les
technologies adéquates.
L'administration stratégique d'un réseau informatique est difficile. En effet, la vitesse
d'obsolescence des matériels informatiques et de leur techonologie n'offre une vue d'avenir
que sur deux ou trois ans pour un renouvellement moyen du matériel tous les quatre à
cinq ans.
Le découpage en trois niveaux d'administration, opérationnelle, tactique et stratégique, reflète
relativement correctement les classes de métiers en réseau informatique: techniciens,
ingénieurs/experts et décideurs.
Comme nous l'évoquions dans l'introduction de ce chapitre, l'administration de réseaux doit
"composer" avec la diversité des constructeurs. Nous allons présenter, dans le paragraphe
suivant, en quoi consiste l'hétérogénéité de l'informatique et de ses réseaux.
1.2. Réseaux hétérogènes, standards et normes
1.2.1. Réseaux hétérogènes: une description
La diversité des constructeurs informatiques et l'essor technologique qui composent le
domaine des réseaux informatiques entrainent une hétérogénéité des solutions infomatiques
proposées. Cette hétérogénéité peut être considérée sur trois plans complémentaires:
- hétérogénéité des matériels et des logiciels,
- hétérogénéité architecturale,
- hétérogénéité des données.
Détaillons chacun de ces axes.
1.2.1.1. Hétérogénéité des matériels et des logiciels
Concurrence et coopération sont deux notions généralement antinomiques. C'est pourtant
entre ces deux notions qu'oscillent continuellement les matériels et services proposés par les
différents constructeurs informatiques. La finalité d'un réseau informatique est bien entendu
de pouvoir faire dialoguer les ordinateurs entre eux, il s'agit d'intel'Opérabilité entre machines.
Ce bon sens n'est en fait qu'un vœu pieux par le fait de la concurrence entre constructeurs,
chacun essayant de s'approprier la plus grande part du marché.
16 Administration des applicatifs réseaux

Le contexte général de l'administration de réseaux 1.1
Ainsi, chaque constructeur propose souvent sa propre solution aussi bien au niveau du
matériel qui compose les ordinateurs et les réseaux qu'au niveau des solutions logicielles:
systèmes d'exploitation, protocoles de communication, etc.
1.2.1.2. Hétérogénéité architecturale
Les réseaux informatiques ont des étendues diverses. Il peut s'agir de réseaux entendus sur
une pièce, un étage, un immeuble; nous parlons de réseaux locaux. Ce peut être des réseaux
de campus ou urbains, il s'agit alors de réseaux métropolitains. On parle de réseaux longues
distances pour les réseaux nationaux et internationaux('). Or les technologies retenues pour
ces divers types de réseaux sont très différentes, car les fonctions visées et les contraintes ne
sont pas les mêmes. Vitesse de transfert, qualité et confidentialité des transmissions, débit
minimal assuré, coOt financier faible, autant d'exemples de paramètres généralement
incompatibles qui génèrent cette hétérogénéité architecturale.
1.2.1.3. Hétérogénéité des données
Nous venons d'évoquer les divers types de réseaux en fonction de leurs étendues
géographiques. Les réseaux informatiques se distinguent également par le type de données
qu'ils ont à véhiculer. Voix, images, textes, données informatiques, autant de problèmes
particuliers qu'il va falloir résoudre par un protocole particulier. Faut-il garantir la fidélité
parfaite d'une transmission de séquences d'images au détriment du débit? Peut-on supporter
une dérive entre la voix et l'image d'une séquence vidéo? La variété des problèmes liés au
type de données véhiculées entraîne nécessairement une hétérogénéité des solutions
informatiques utilisées.
L'hétérogénéité est la contrainte incontournable de l'informatique; elle se retrouve à tous les
niveaux. Cependant le poids commercial ou la taille du secteur d'implantation va permettre de
dégager des solutions plus largement reconnues, c'est ce que l'on nomme les standards de fait.
1.2.2. Standards de fait
En fonction de la taille du parc des machines dépendant de tel ou tel constructeur, le type de
réseau associé peut devenir un standard de fait. Le meilleur exemple est celui du protocole
SNA développé par la firme IBM. Un grand nombre de constructeurs ont choisi de s'y rallier
contraints et forcés de ne plus faire "cavalier seul" par le jeu de la concurrence, quitte même à
ne plus développer leur propre type de réseau. Un standard de fait est une forme de
(a) Les sigles anglo-américains équivalents à ces architectures sont respectivement LAN (Local Area
Network), MAN (Metropolit.n Are. Network) et WAN (Wide Are. Network).
Administration des applicatifs réseau.t 17

1.1 Le contexte général de l'administration de réseaux
"coopération" entre ordinateurs de constructeurs différents. Ces standards ont en général un
tronc commun et, malheureusement, des extensions propres à chaque constructeur. La
"coopération" est en fait limitée au "tronc conuuun".
Un deuxième exemple plus récent que SNA est l'impact de plus en plus grand de la solution
réseau proposée par le constructeur Novel1 dans le domaine des micro-ordinateurs de type
compatible PC. La part de marché est tel1e que les constructeurs de stations de travail sous
Unix développent désormais des passerel1es 10giciel1es afin de pouvoir s'implanter dans de
tels réseaux.
1.2.3. Normes et organismes de normalisation
Une deuxième forme que peut revêtir la "coopération" repose sur l'effort des organismes
internationaux de normalisation. Contrairement au standard de fait, l'idée est de définir a
priori un protocole, d'en publier les spécifications afin que chaque constructeur puisse
l'implanter dans son propre matériel.
En matière de réseaux informatiques, deux organismes internationaux de normalisation sont
incontournable!'>: l'ISO (International Standardization Organization) et le CCnT (Comité
ConsultatifInternational pour la Télégraphie et la Téléphonie). Ils se sont attelés à définir une
architecture de communication normalisée, le modèle de référence OSI (Open System
Information) [ISO 7498], et les protocoles et services correspondants.
Les réseaux normalisés semblent être la solution. Cependant, le travail de normalisation est un
processus à long terme, car il nécessite l'unanimité des différents organismes parties
prenantes. Les constructeurs optant pour les protocoles OSI vont nécessairement devoir gérer
un retard pour toute avancée technologique. Ainsi, contrairement à ce que l'on pourrait
imaginer, certains constructeurs préfèrent garder leur propre solution réseau ou les solutions
issues d'un standard de fait plutôt que d'opter pour un protocole normalisé.
1.3. Hétérogénéité et administration
Une telle variété de solutions informatiques ne permet pas la mise en place d'une solution
simple et unique au problème de l'administration de ces réseaux. En nous appuyant sur
l'article de D. Seret et Tie Liao [SER 93], nous distinguons quatre classes de solutions:
-l'administration mise en place par les utilisateurs,
-l'administration proposée par les constructeurs,
-l'administration qui s'impose comme standard,
-l'administration normalisée.
Nous allons développer ces quatre points dans les paragraphes suivants.
18 Administration des applicatifs réseaux

Le contexte général de l'administration de réseaux
1.3.1. L'administration mise en place par les utilisateurs
1.1
Un administrateur de réseau qui ne trouve pas de solution globale à son problème
d'administration va devoir développer sa propre méthodologie. Celle-ci aura l'avantage de
s'appliquer parfaitement à son cahier des charges.
Deux inconvénients majeurs sont alors à dépasser: le coût financier et temporel de
développement, les contraintes techniques(a).
D'autre part, la pérénnité d'une telle solution "maison" est sérieusement remise en cause par
l'essor rapide des matériels informatiques. L'administration utilisateur ne peut se justifier que
s'il n'existe pas d'autres solutions.
Nous détaillons dans le chapitre suivant la solution utilisateur mise en place par l'entreprise
Alcatel Business System [MAU 93] pour l'administration de son réseau de gestion de la
production sur la plate-forme de production de Strasbourg. Il s'agit typiquement d'une
solution utilisateur développée dn fait de la carence des solutions existantes dans le cas
particulier de la gestion des ressources d'un réseau.
1.3.2. L'administration proposée par les constructeurs
Depuis trois à cinq ans, l'administration de réseaux étant devenne un enjen financier
conséquent, les constructeurs proposent leur propre solntion. Elle est généralement restreinte à
leur propre type de matériel et de logiciel. Nous parlons alors d'administration propriétaire.
Les outils d'administration sont très récents, et alors qu'il n'en existait que quelques uns il y a
encore trois ans, ces deux dernières années ont vu un certain nombre de solutions couvrir le
marché. Nous donnons en annexe une liste des outils d'administration sur plate-forme Unix
disponibles en janvier 1994. Nous citons cinq d'entre eux, parmi les plus courants: Netview
(IBM), SunNet Manager (Sun), Openview (Hewlett Packard), DECmcc (DEC) et NMF (Bull).
Les solutions propriétaires sont généralement performantes et très riches en fonctionnalités.
Elles sont généralement restreintes - totalement ou en partie - au type de matériel dn
constructeur ce qui rend difficile ['utilisation d'une telle solution dans un environnement
hétérogène.
(a) L'utilisateur n'a pas accès à tous les paramètres de son réseau, soit par impossibilité technique, soit par
confidentialité technique. Comment pourra-t-il par exemple savoir le débit d'une carte réseau si le
constmcteur de la-dite carte n'a pas prévu une telle fonctionnalité?
Administration des applicatifs réseaux 19

1.1 Le contexte général de l'administration de réseaux
1.3.3. U administration pal' les standards
De manière assez récente, les restrictions des solutions propriétaires au type de matériel du
constructeur a tendance à diminuer, notamment pour certains produits tel Openview. Le
logiciel d'administration s'appuie dès lors sur certains standards d'administration.
Tout comme certaines solutions réseaux s'imposent au marché, certains protocoles et modèles
d'administration deviennent des standards de fait. Ainsi, dans le cadre des réseaux TCPIIP se
sont développés SNMP (Simple Network Management Protocol) [RFC 1I55] et le modèle
associé. L'administration via SNMP est décrite en détail dans le chapitre suivant
(paragraphes 2.3.1. et 2.4.1).
Ces solutions ont l'avantage d'être relativement globales dans le cas de réseaux hétérogènes et
leur pérennité est assurée par les constructeurs eux-mêmes. Le reproche le plus courant qui
leur est fait repose sur le constat qu'il s'agit de solutions un peu simplistes, qui ne décrivent
qu'une petite part des problèmes soulevés par l'administration de réseaux.
Cependant, même dans le cas de l'administration par SNMP, il ne s'agit, somme toute, que
d'un standard pour les réseaux TCPIIP. On ne peut alors parler de réelle solution globale pour
peu que l'on ait d'autres types de réseaux à gérer.
1.3.4. Uadministration normalisée
Il n'existe, à l'heure actuelle, aucun standard d'administration suffisamment générique pour
tout type de réseaux et ordinateurs. L'avancée la plus importante dans l'optique d'une solution
globale repose encore une fois sur les modèles et protocoles préconisées par les organismes de
normalisation.
Ainsi, l'ISO et le CClTT, dans leur modèle de réseau OSl, proposent des méthodes
d'administration très complètes. L'administration via le modèle OSI est vue dans le chapitre
suivant (paragraphes 2.3.2 et 2.4.1). D'autre part, les réseaux de télécommunications
fortement normalisés préconisent également des modèles d'administration. Ainsi le CCITI
propose TMN (Telecommunication Management Network) et INCM (Intelligent Network
Conceptual Model) pour normaliser ses modèles d'administration. Les actes du congrès
d'octobre 1992 sur les réseaux intelligents [GAI 92] donnent une idée assez complète de ces
travaux et notamment l'article de R. Kung [KUN 92]. Nous ne décrivons pas ces modèles
clans notre thèse car il s'applique principalement à cles architectures de réseaux de
télécommunication, ce qui n'entre pas dans le cadre cie nos travaux.
La solution de la normalisation est certainement la plus "avenante". Elle est globale et offre
généralement de très larges fonctionnalités. Cependant, le facteur temporel reste crucial dans
le choix d'un constructeur d'adopter une telle solution pour son matériel, car la normalisation
prend du temps et il reste encore beaucoup d'éléments non définis. C'est pourquoi les
20 AdmÙlistratioll des applicatifs réseatL\·

Le colltexte général de /'administratÎoll de réseaux 1.1
constructeurs n'implantent que rarement les éléments nécessaires à l'administration suivant
les normes, ce qui rend cette solution "globale" plutôt restreinte. Certains auteurs [ECK 92]
vont jusqu'à mettre en doute l'implantation réelle d'une telle solution normalisée.
Nous venons, dans le présent chapitre, de resituer le contexte général de l'administration de
réseaux. Nous avons vu qu'il s'agit d'un domaine en pleine croissance, à plusieurs angles
d'approche suivant les fonctionnalités attendues et le type des objets à administrer. Nous
avons présenté les difficultés à appréhender les problèmes d'administration du fait de
l'hétérogénéité des solutions informatiques actuelles.
Nous allons, dans le chapitre suivant, exposer le plus précisément possible l'état de l'art dans
ce domaine: ce qui est fait et ce qui reste à faire.
Administration des applicatifs réseaux 21

1.2 L'état de l'art ell administration de réseaux
2. L'état de l'art enadministration de réseaux
L'administration de réseaux est, comme nous l'avons dit, en pleine croissance, en pleine
mutation. Nous nous efforçons dans le présent chapitre de fixer l'état de l'art actuel dans ce
domaine, sur le plan tant de la recherche, des normes et standards que des propositions des
constructeurs.
Plutôt que de passer en revue chaque modèle, nous présentons les composantes d'une
architecture générale d'administration en détaillant pour chacune d'elles les diverses solutions
proposées et/ou implantées. Nous comparons ces solutions en tentant de mettre en exergue
leurs avantages et leurs inconvénients respectifs. Nous soulevons certaines carences actuelles
dans le domaine de l'administration des réseaux. Cependant, avant cela, il nous faut sitner
précisément le cadre des travaux dans le domaine de l'administration.
2.1. Cadre des travaux d'administration de réseaux
Comme nous l'avons exposé brièvement dans le chapitre précédent, quatre composantes
travaillent de manière prépondérante sur la gestion de résean. Les utilisateurs finaux, les
constructeurs informatiques, les organismes de normalisation et les laboratoires de
recherche: tons sont acteurs dans l'élaboration des concepts et des outils de ce domaine. Les
interactions sont continuelles. Ainsi la recherche en administration se fait en étroite
collaboration avec les organismes de normalisation. De même, les associations et consortiums
d'utilisateurs ont un poids important sur les futures nonnes et les nouveaux outils. Nous allons
présenter, brièvement les composantes structurées de l'administration de réseaux
2.1.1. Les organismes de normalisation
L'administration de réseaux, de par sa nature, est un domaine où la normalisation a un rôle
particulièrement prépondérant, et il n'est pas étonnant de trouver de nombreux organismes
nationaux et internationaux travaillant sur la gestion de réseau. Les principaux sont L'ISO,
l'IEC (International Electrotechnical Committee) et le CCITI, déjà cités précédemment.
22 Administration des applicatifs réseaux

L'état de l'art en administration de réseaux
2.1.1.1. L'ISO
1.2
L'ISO (International Standardization Organization) a été créée en 1946. Elle regroupe les
organismes internationaux de normalisation de 90 pays. Elle publie des normes couvrant tous
les domaines. Le Tec!lIlical Comittee 97 (Comité Technique) chargé des technologies de
l'information est commun à la !EC. La référence habituelle à leurs travaux est ISOIIEC JTCI
(Joint Technical Committee 1). Le domaine particulier de l'administration repose sur deux
SubComittees (Sous-comités) : SCI6 et SC21 et plus particulièrement sur les Working Groups
(Groupes de travail) SC2IWGI, SC21WG4 et SC2IWG6. Ces groupes de travail ont été
formés dans le milieu des années quatre-vingt. L'article de Y. Kobayashi [KOB 89] présente
les divers groupes de travaux de l'ISO dans le domaine de l'administration de réseaux.
L'ensemble des travaux de ces groupes de normalisation s'intègre directement dans le modèle
générique de réseau défini également par l'ISO: le modèle OSI (Open System Information).
Le modèle OSI est défini par la norme ISO 7498 "Open Systems 1nterconnection - Basic
reference model for Open Systems interconnection". M. Rose présente de manière assez
pédagogique le modèle OSI dans son ouvrage, "The Open Book" [ROS 89]. Le lecteur
trouvera une description plus récente et plus détaillée dans le livre "Gestion de réseaux
Concepts et outils" publié par le CNET (Centre National des Etudes en Télécommunication)
[CNE 92].
Dans le modèle OSI, l'administration de réseaux en particulier est définie dans la quatrième
partie de la norme ISO 7498 "OS1 management Framework". Elle a été publiée en 1988. Elle
réalise la description des différents protocoles, objets et structures qu'il est nécessaire de
mettre en place pour pouvoir décrire et collecter toutes les données pertinentes à
l'administration de réseaux.
D'autre part, les travaux des groupes de normalisation cités ci-dessus ont donné lieu à la
publication d'une série de normes (courant 1991 et 1992) : ISO 10040, ISO 9595, ISO 9596 et
ISO 10164, ISO 10165 dont nous préciserons le contenu dans la suite de cette première partie.
2.1.1.2. Le CClTT
Le CCITT (Comité Consultatif International Télégraphique et Téléphonique) est un
organisme de standardisation international dépendant de l'UIT (Union International des
Télécommunications). Sa principale action est l'édition de recommandations principalement
en téléphonie.
Dans le domaine de l'administration de réseaux, le CCITT développe deux branches.
Historiquement, l'administration des réseaux téléphoniques préconisée par le CCITT repose
sur le modèle TMN (Telecommunications Management Network). Il s'applique aux réseaux
Administration des applicatifs réseaux 23

1.2 L'état de ['art ell administration de réseaux
téléphoniques publics et en particulier au RNIS. 11 a été décrit dans la recommandation M.3ü
[CCITT M3Ü]. Ce modèle est décrit de manière assez complète dans l'ouvrage de D.Gaïti et
G. Pujolle "L'intelligence dans les réseaux" [GAI 93], le lecteur trouvera cependant en
annexe une courte description de TMN. D'autre part, du fait du fort rapprochement des
technologies utilisées dans les réseaux téléphoniques et dans les réseaux informatiques, le
CCITT participe pleinement aux travaux de normalisation issus de l'ISO et co-publie les
normes proposées.
2,1.2. Les associations d'utilisateurs et de constructeurs
De manière complémentaire aux organismes de normalisation, les associations d'utilisateurs
et les consortiums de constructeurs participent pleinement au domaine de l'administration.
Les principaux sont l'OSIINM Forum (OSIINetwork Management Forum), l'OSF (Open
Software Foundation) et l'IAB (Internet Advisory Board).
2.1.2.1. OSINMIFORUM
UOSI NMIFORUM (Network Management Forum) est une association internationale
exclusivement consacrée à la gestion de réseaux. Fondée en 1988, elle dénombre plus de cent
organisations partisipantes (ATI, British Telecom, Franc~ Telecom, NTI, Bull, DEC, IBM,
Siemens, etc). Elle ~'applique principalement à définir dè~ règles d'implantations minimales
du modèle d'administration OSI et tente d'accélérer la disponibilité des produits de gestion de
réseau s'appuyant sur les normes OSI.
2.1.2.2. L'OSF
L' OSF (Open Software Foundation) est une association créée en 1988 qui regroupe différents
contructeurs et fournisseurs informatiques. Les neuf fondateurs sont IBM, Bull, HP, DEC,
Apollo, Hitachi, Nixdorf, Philips et Siemens. Le principe de base est de retenir les meilleurs
logiciels (ou parties des logiciels) des membres de l'association et éventuellement de
demander à des organismes choisis des développements complémentaires. Ainsi a été lancé,
fin 1992, OSF/DCE (Distributed Computing Envil'Onment) dont le concept de base repose sur
la coopération entre les machines. En extension à DCE, dans le domaine de l'administration
de réseaux, l'OSF préconise le DME (Distributed Management Environment) qui est le
gestionnaire des systèmes à administrer. Il est annoncé pour fin 1994, début 95.
2.1.2.3. UIAB
L'IAB (Internet Advisory Board) est une structure qui fédéralise différents groupes de travail
dans le domaine des réseaux. Uun d'entre eux, l'IETF (Internet Engeniering Task Force) est
24 Administration des applicatifs réseaux

L'état de l'art en administration de réseaux 1.2
plus spécialement chargé de tout ce qui à trait à la famille de protocoles TCP/IP. Les
participants à ces groupes de travail sont issus de centres universitaires, d'entreprises,
d'organismes gouvernementaux, etc.
L'Internet - réseau international basé principalement sur TCP/IP - est le domaine d'application
privilégié de ces groupes. L'essor extrèmement rapide de ce réseau fédérateur, décrit entre
autres par M. Lotter [RFC 1296], en fait un élément incontournable du domaine des réseaux.
Les publications faites par l'IAB sont éditées et diffusées sous la forme de RFC (Request For
Comments). Les bases de l'Internet et des protocoles associés (IP, TCP, UDP, ICMP) sont
ainsi décrits dans les documents suivants: RFC 760, RFC 761 et RFC 768.
Le cadre de travail étant présenté, nous allons décrire ce que peut être une architecture
générale d'administration de réseaux.
2.2. Architecture générale d'un système d'administration
L'administration réseau repose sur quatre problèmes imbriqués. Tout d'abord, il s'agit de
recenser les objets qui composent un réseau, ce que l'on peut appeler: la configuration. Le
deuxième problème est l'observation de l'évolution des états et des interactions de ces objets.
Et enfin, il est nécessaire de définir l'analyse à effectuer sur les données obtenues et les
actions à opérer pour une meilleure qualité de service.
Pour définir une architecture suffisamment générique d'un système d'administration de
réseaux qui réponde aux problèmes soulevés ci-dessus, nous reprenons la présentation de W.
Stallings dans son ouvrage "SNMp, SNMPv2 and CMIP" [STA 93] qui distingue trois
composantes essentielles:
- L'information d'administration: Comment peut-on définir l'information nécessaire à
l'administration?
- Les mécanismes mis en jeu: Quelles méthodes sont utilisées pour recueillir ces données et
les stocker?
- Les applications d'administration: Quelles analyses et quels traitements opérer sur les
informations afin d'obtenir des résultats pertinents et exploitables?
Ainsi, suivant ces trois axes, nous allons présenter et comparer les solutions actuelles ou en
cours d'élaboration pour définir un système d'administration de réseaux. Nous détaillerons
principalement les deux solutions les plus connues: SNMP et OS!. Nous indiquerons
quelques solutions particulières, leurs avantages et inconvénients. Le troisième axe concernant
les traitements et analyses effectués sur les données d'administration sera traité dans le
chapitre suivant en s'intéressant plus précisémment aux problèmes liés à l'analyse des
dépendances entre applications réseaux.
Administratioll des applicatifs réseaux 25

1.2 L'état de l'art en administration de réseaux
2.3. L'information d'administration
Toute administration repose sur des données à traiter. Nous avons indiqué au paragraphe
1.1.2 - page 11, que dans le domaine des réseaux, ces données concernaient soit du matériel,
soit du logiciel, ou encore des utilisateurs. Un système d'administration de réseaux doit, en
premier lieu, permettre de nommer chaque objet de façon unique afin de les distinguer. Il doit
d'autre part définir un moyen de description de ces objets (sous-composantes, emplacement
géographique, etc). Cette description doit englober l'évolution dans le temps de l'état des
objets (le port untel a tel débit instantané, tel ordinateur a actuellement telle charge de calcul,
etc). Enfin il est nécessaire d'établir les relations qui existent entre les objets (tel logiciel est
mémorisé sur tel disque magnétique, tel câble est connecté à telle interface, etc),
2.3.1. L'information sous SNMP
L'administration par SNMP s'applique, avant tout, au réseau TCP/IP dont le lecteur trouvera
une description complète dans les ouvrages de D.E. Corner et D.L. Stevens "Internetworking
with TCPIIP" [CaM 88], [CaM 91] et [CaM93].
2.3.1.1. Dénomination et description des objets sous SNMP
L'administration pour les réseaux TCPIIP repose sur des concepts simples définis dans les
documents RFC 1155 et 1156. Ces concepts sont décrits dans ce qui est appelé le SMI
(Structure of Management Information) qui comporte deux principes:
- La dénomination des objets: Elle repose sur la définition d'un arbre comprenant tous les
objets à administrer. Le nom d'un objet est construit en fonction du chemin qu'il est
nécessaire de parcourir depuis la racine de l'arbre jusqu'à l'objet(a). Un exemple est donné
ci-dessous.
- La description des objets: Elle est faite au moyen d'attributs élémentaires(b) eux-mêmes
inscrits dans l'arbre de dénomination juste "en dessous" de l'objet décrit. En fait, il n'y a
pas de distinction entre objet et attribut d'objet.
(a) Il est nécessaire de faire la distinction entre classe d'objets et instance d'objets. L'arbre de nommagerepère de manière absolue les classes d'objets. Nous verrons que lorsqu'il est implanté, il concerne lesinstances des objets et des composantes de l'équipement sur lequel il est localisé.(b) Les types des attributs ne peuvent être que des entiers, des chaînes de caractères et des séquences d'entiersou de chaînes de caractères.
26 Administration des applicatifs réseaux

L'état de l'art en administration de réseaux 1.2
Le SMI définit un ensemble de règles de description formelle de cet arbre et des données qu'il
mémorisera). Pour ce faire, le SMI utilise ASN.l (Abstract Syntax Notation One) [ISO 8824]
[ISO 8825] qui est un langage de description formelle de données.
L'arbre de dénomination et de description des objets à administrer ne se restreint pas
uniquement à l'administration des réseaux TCPIIP, Il s'inscrit dans la structure arborescente
d'identification des objets ISO/CCITI. La racine de cet arbre comporte ainsi trois nœuds: Iso,
ccitt etjoint-iso-ccitt(b). Le chemin à parcourir pour arriver aux objets d'administration des
réseaux TCPIIP est root.iso.org.dod.internet.lIlglllt.lIlib. Ce sous-arbre est appelé MIB TCP/IP
(Management Information Base) .
Le schéma 1 trace la portion de l'arborescence décrite par le SMI pour atteindre la sous
arborescence concernant la MIB TCP/IP.
root
joint-iso-ccitt(3)
~
private(4)
~
Ccill(2)
~
iso(l)
~... org(3) ...
~... dod(6) ...
~... internet(l) ...
-----r ~:-----directory(l) mgmt(2) experimental(3)
~ ~
ManagementInformation
Base
Schéma 1: MIR SNMP au sein de l'arbre de dénomination iso-edit
(a) Les spécifications du SMI initial ont été complétées dans la nouvelle version du SMI publié dans le
RFC 1442 en avril 1993.
(b) L'arbre décrit par le SMI est prévu pour répertorier des objets quelque soit le cadre d'utilisation; nous
verrons qu'il est également utilisé dans l'administration ISO.
Administration des applicatifs réseau.x 27

1.2 L'état de l'art en administration de réseaux
2.3.1.2. MIE, MIE-II, extensions de MIE et MIE privées
La MIE TCP/IP a été décrite initialement dans les documents RFC 1155 et RFC 1156. Elle
comprenait huit branches, qui se subdivisent pour décrire l'ensemble des objets et des
composantes dans le domaine des réseaux Tep/IP, Chaque branche est communément appelée
groupe:
- system: concerne les informations générales sur l'objet: le numéro de série, une
description de la fonctionnalité, le temps qui s'est écoulé depuis la dernière ré
initialisation, etc.
- intelfaee : décrit les informations générales sur les interfaces(a) réseaux de l'objet: nombre
d'interfaces, informations sur chacune d'elles (état courant, vitesse de transfert,
statistiques sur la quantité d'informations ayant transité, etc),
- at: (address-translation) décrit une table de correspondance entre l'adresse physique de
l'objet et l'adresse réseau de niveau de protocole plus élevëb) et ceci pour chaque
interface.
- ip : se rapporte à tout ce qui relève de l'implantation et des opérations de la couche IP
(Internet Protocol). Les informations concernent principalement les tables de routages(c) et
les statistiques de trafic.
- iemp : s'applique aux informations relevant de la couche ICMP (Internet Control Message
Protocol). Il s'agit principalement de compteurs décrivant le nombre de messages de ce
type échangés,
- tep: concerne les informations de la couche TCP (Transmission Control Protocol),
- udp : concerne les informations de la couche UDP (User Datagram Protocol)
- egp : décrit les informations relevant du protocol EOP (External Oateway Protocol) qui
permet l'échange des tables de routages entre routeurid) appartenant à des domaines de
routage différents,
Le schéma 2, ci-après, illustre les huit groupes initiaux de la MIE,
(a) Dans ce contexte, une Inte1face réseau est l'équipement informatique, généralement une carte
électronique, qui gère les communications vers ou en provenance d'un câble réseau (ou médium).
(h) Il s'agit le plus souvent de la correspondance entre des adresses ethemet et des adresses in/eruels mais ilpeut également s'agir d'adresses physiques X,121 dans le cas d'un réseau X.25.
(c) Les tables de routages permettent d'aiguiller les paquets de données à transmettre sur l'interface adéquateen fonction de l'adresse de destination.
(d) Un rouleur est un matériel informatique actif - typiquement un ordinateur dédié à cette tâche - qui permet
d'aiguiller les flux de données circulant sur le réseau en fonction de la destination de chaque paquet de
données.
28 Administration des applicatifs réseallX

L'état de l'art en administration de réseaux 1.2
root(l)
iso(l)
1
1
ecitt(2) joint-iso-ccitt(3)
egp(8)udp(7)tep(6)
mib(l)
__---~1~~=====~=====--_syslem(l) interfaees(2) at(3) ip(4) iemp(S)
Schéma 2 : Structure arborescente de la MIll pour TCP/IP
Prenons l'exemple d'un objet décrit par la MIE. Il s'agit de connaître le fabricant d'un objet,
par exemple un routeur. La référence à un tel attribut aura, par exemple, comme identifiant
root.iso.org.dod.internet.mgmt.mib.system.sysDescr. Une numérotation des nœuds de l'arbre
en fonction de la profondeur permet une dénomination plus maniable, à savoir 1.3.6.1.2.1.1.1.
Nota: Le SMI indique que la dénomination des objets doit se terminer par ".0" lorsque cet
objet est localisé sur une machine. Il ne s'agit pourtant pas d'une instance de l'objet car la
machine elle-même n'est pas à préciser. Deux objets "localisés"pourront donc avoir
exactement la même dénomination sur deux équipements différents.
MIB-II
La définition de la MIE ne peut décrire que les éléments existants. Or les innovations
techniques en matière d'éléments informatiques précèdent inévitablement leurs
standardisations. Ainsi une deuxième définition de la MIE, appelée MIE-II est venue
remplacer et compléter la MIE initiale. Elle est décrite dans le RFC 1213 publié en 1991. Elle
ajoute deux groupes supplémentaires(a) :
- transmission: permet de décrire les détails techniques du médium(b).
- snmp : concerne les informations qui relèvent de l'implantation de la couche SNMP
elle-même.
La définition de la MIE-II en 1991 ne suffit cependant pas à décrire celtains domaines de
l'administration TCPIIP. De nombreux auteurs, tels M. Rose [ROS 94] et
W. Stalling [STA 93], soulignent la carence de la MIE au niveau des couches réseaux les plus
(a) La MIll-II complète également certains éléments des groupes déjà définis dans la MIll initiale.
notamment le groupe ip.
(b) Cf. note a - page 14.
Administration des applicatifs réseaux 29

1.2 L'état de l'art en administration de réseaux
élevées (en référence au modèle hiérarchique OSI). Ainsi aucun groupe ne décrit les
informations concernant les ressources telles les imprimantes, les disques, et les protocoles
associés. De même, aucune définition n'est donnée pour décrire les logiciels dont un
ordinateur dispose, etc. Ainsi de nouvelles extensions de la MIE, mais cette fois-ci par
domaine, sont en cours de définition. De nouvelles extensions ont été publiées: la "RMON
MIE", la "Host Ressource MIE" et la "Network Services Monitorig MIE". La RMON MIE
permet de décrire des paramètres de sondes SNMP dédiées à la surveillance du trafic. Nous
détaillons les deux autres MIE citées dans le chapitre suivant car elles concernent directement
le sujet de cette thèse.
MIE privées
Le SMI a prévu, de manière complémentaire aux spécifications de la MIE standard et de ses
extensions, une branche de l'arbre repérée par le nœud private ne comportant qu'un unique
fils: ellie/prise.
Cette portion de l'arbre permet aux constructeurs de matériel informatique de spécifier leur
propre MIE qui définit les paramètres propres aux matériels et non définis dans la MIE
standard: ce que l'on appelle une MIE privée. Chaque entreprise pouna être référencée sous
le nœud ente/prise et définir, à partir de là, sa propre MIE. La description de cette MIE privée
doit être publiée dans le langage ASN.l afin d'être utilisable par tous.
Le schéma 3, ci-dessous, indique l'emplacement des MIE privées dans l'arborescence SMI.
root
iso(l)
~org(3)
~... dod(6) ...
~internet(l)
ccitt(2)
~
joint-iso-ccitt(3)
~
private(4)
1
enterprise(l)
~MIBprivées ---------------------'1
experimental(3)
~
mgmt(2)
1mib(l)
~
directory(l )
~
Schéma 3 : MIE privées dans le SMI
30 Administration des applicatifs réseaux

L'état de l'art en administration de réseaux 1.2
Comme nous venons de le décrire, les concepts de l'administration SNMP sont relativement
simples pour décire les données d'administration. Nous relevons la simplicité des types
d'attributs, l'architecture arborescente souple permettant des ajouts de définitions aisés, et une
méthode de dénomination des objets homogènes.
Les choix de la normalisation ISO sont différents comme nous allons le présenter maintenant.
2,3,2, L'information d'administration ISO
L'ISO a défini sa SMI (Structure of Management Information) tout comme l'a fait la
communauté Internet pour SNMP. Celle-ci est décrite dans le document de normalisation
ISO 10165. Une présentation plus abordable en est faite dans l'ouvrage de C. Lecerf et D.
Chomel: "Les normes de Gestion de Réseall à l'ISO" [LEC 93].
2.3.2.1. Modèle orienté objet
L'information d'administration des réseaux dans le modèle OSI fait partie d'un modèle
d'information complexe qui s'appuie sur un modèle orienté objet. Le concept repose sur la
définition de classes d'objets spécifiant la vue abstraite des entités réseaux administrables.
Chaque objet est muni de propriétés: les attributs et les méthodes. U attribut décrit des
valeurs associées à l'objet, la méthode est une opération que l'objet peut subir ou engendrer. Il
s'agit de l'approche classique des modèles orientés objets qui est reconnue pour ses propriétés
d'évolutivité et le caractère "réutilisable" de ces objets.
Les classes d'objets d'administration OSI rassemblent des éléments ayant les mêmes
propriétés, c'est-à-dire les mêmes attributs et méthodes. Dans le contexte OSl, ces groupes de
propriétés sont appelés paquetage (package). La norme OSI subdivise un paquetage en quatre
composantes:
-les opérations de gestion que l'objet peut effectuer à la demande,
-les notifications que l'objet génère de son propre chef en fonction d'occurrence
d'évènements spécifiques (on peut les assimiler à des "messages d'alerte").
--la description du comportement de l'objet: cette composante permet de spécifier la
sémantique des opérations, des notifications et des attributs, les dépendances entre valeurs
d'attributs, les préconditions et postconditions des méthodes, les invariants des objets, etc.
Les spécifications du comportement sont généralement décrites en langage naturel(a).
-l'ensemble des attributs associés à l'objet. Un attribut est d'un type donné qui est défini par
l'ensemble des valeurs qu'il peut prendre et par les opérations de comparaison qui peuvent
lui être appliquées.
(a) Certaines spécifications utiliseront des langages formels tels LOTOS ou ESTELLE.
Administration des applicatifs réseau.x 31

1.2 L'étarde l'art en administratioll de réseaux
Les concepts sur les classes sont ceux retenus habituellement dans les modèles objets :
- héritage (multiple): les propriétés d'une classe sont déduites des propriétés d'une ou
plusieurs autres classes définissant ainsi des sous-classes et des super-classes.
- spécialisation: une sous-classe hérite des propriétés d'une autre classe, mais en ajoute des
extensions propres.
- généralisation: création d'une super-classe regroupant des propriétés de sous-classes.
- allomorphisme : propriété de similitude entre membres de classes différentes qui autorise
l'utilisation d'un objet d'une classe comme s'il faisait partie d'une autre classe.
2.3.2.2. Dénomination des objets gérés
La distinction entre noms de classes d'objets et noms d'instances d'objets est plus claire que
dans le modèle SNMP.
Dénomination des classes des objets
Pour ce qui est de la dénomination des classes d'objets, l'ISO utilise l'arbre d'identification
défini conjointement par le eCIIT et l'ISO elle-même (tout comme pour l'administration sous
SNMP).
Nous présentons dans le schéma 4la branche OIW (OSI Implementers Workshop) repérée par
le nom root.iso.org.oiw et sous laquelle est définie un certain nombre de classes d'objets
d'administration OSI(a).
root
iso(l)
~.n org(3) .n
~
/ ~---==-m~~subtree
ccitt(2)
~
joint-=iso-ccitt(3)
~ms
Schéma 4 : Arbre de dénomination des classes d'objets d'amillis/ration ISO
(a) Le tenue MIB est souvent utilisé pour décrire l'arbre de nommage des classes de la même manière quepour l'administration SNMP.
32 Administration des applicalljs réseaux

L'élal de l'art en administration de réseaux 1.2
Nota: Tout objet normalisé doit être inventorié dans l'arbre de dénomination ISO/CCITT à
partir du nœud joint-iso-ccitt.ms(a). Ceci permet d'éviter les doublons et d'établir une
nomenclature exhaustive.
Dénomination des instances d'obiets
La dénomination des instances des objets est totalement indépendante des noms de classes.
Elle est également construite sur une architecture arborescente de la manière suivante. Une
instance d'objet est nommée par rapport à une instance d'objet supérieur auquel il est
subordonné. Cette relation est appelée lien de nommage. Le nom d'un objet peut être donné
relativement à l'objet auquel il est subordonné, on parle alors de RDN (Relative Distinguished
Name) ou de manière absolue, par rapport à la racine de l'arbre de nommage. Il s'agit alors de
GDN (Global Distinguished Name). Ce GDN est constitué de la concaténation de tous les
RDN utilisés depuis l'objet en haut de la hiérarchie jusqu'à l'objet désigné. Un RDN est
simplement un attribut particulier ayant une valeur qui distingue de manière unique les objets
subordonnés à un même objet supérieur, afin de lever toute ambiguïté.
2.3.2.3. La description des objets
L'ISO a défini un langage et une syntaxe de spécification pour décrire les objets. Celui-ci est
décrit dans la quatrième partie de la norme ISO 10165 "GDMO: Guidelinesfor the Definition
of Managed Objects". GDMO reprend d'une part la syntaxe du langage de description
formelle ASN.l et permet d'y associer des clauses comportementales en langage naturel. Il
s'agit en quelque sorte de "formulaires" de spécification.
L'exemple ci-dessous présente le "formulaire" de définition d'une nouvelle classe.
<class-label> l~AGED aBJECT CLASS
[DERIVED FROH<class-label>[,class-label>]*;
J[CHARACTERIZED BY
<package-label> {, <package-label>] *;J[CONDITIONAL PACKAGES
<package-label> PRESENT IF <condition-definition>[,<package-label> PRESENT IF <condition-definition>]*;]
JREGISTERED AS <Object-identifier>;
supporting productionscondition-definiton --> delimited-string
(a) ms est l'abbréviation pour management specification.
Administration des applicatifs réseaux 33

1.2
Les obiets d'administration définis par l'ISO
L'état de l'art en administration de réseaux
L'ISO a défini des ensembles de classes d'objets qui lui permettent de réaliser les fonctions
d'administration qu'il préconise dans ses différentes normes. Ainsi nous retrouvons dans
l'arbre de dénomination ISO/CCITT les nœuds suivants:
-management specification (ms) : déjà signalé précédemment, il établit une nomenclature de
tous les objets d'administration OSI,
- systems-management information overview (smo) : utilisé pour les objets de la norme
ISO 10040,
- comfllon-management information protocol (cmip) : utilisé pour les objets de la norme
ISO 9596,
- systems-management functions (function) : utilisé pour les objets de la norme ISO 10164,
- structure ofmanagement information (smi) : utilisé pour les objets de la norme ISO 10165.
En plus des objets prédéfinis, l'ISO a prédéfini certains attributs courants qu'il distingue en
deux groupes, les attributs génériques et les attributs spécifiques.
Les attributs génériques
L'ISO a prédéfini un ensemble d'attributs génériques qui se répartissent en deux familles:
- counter: il s'agit d'un type relativement simple puisqu'il s'agit d'entiers positifs qui
permettent de compter des occurrences d'évènements (nombre de paquets de données
transmis sur une interface, nombre d'erreurs de transmission, etc). On distingue les
compteurs positionlJables, en lecture seule, et les compteurs qui désignent des seuils pour
les opérations de notification.
-gauge: ce type d'attribut permet de décrire des variations instantanées telles le nombre de
connexions courantes, le débit courant d'une ligne, etc. Les valeurs mémorisées peuvent
croître et décroître. Il s'agit d'attribut en lecture seule mémorisant des valeurs entières,
positives.
Les attributs spécifiques
L'ISO a également défini des attributs pour décrire les informations particulières nécessaires
aux objets décrits dans les branches ms, smo, cmip, function et smi (citées ci-dessus). Il s'agit
des attributs spécifiques. La norme en définit un grand nombre; nous en citons quelques uns:
System ID (nom de l'instance de la classe système), Attribute list (liste d'identificateurs
d'attributs et de leur valeur associée), Event time (date de génération d'un évènement), etc
34 Administration des applicatifs réseaux

L'état de l'art en administration de réseaux 1.2
De la même manière que pour la spécification d'attributs, l'ISO a prédéfini des paquetages
complets, réutilisables. Ainsi, l'ISO propose tout un éventail d'objets, d'attributs et de
méthodes pour décrire les entités à administrer et leur comportement.
2.3.3. Autres modèles d'informations
Nous trouvons peu d'autres modèles de données pour l'administration réseau dans la
littérature académique. Ceci s'explique certaiuement par l'hégémonie du modèle OSI pour ce
qui est de la théorie et du modèle SNMP pour ce qui est de la pratique. Nous citons cependant
le travail de J. Filipiak, A. Lombardo et S. Palazzo [FIL 93], qui choisissent une approche
totalement différente. Ils définissent les objets par leurs coordonnées dans l'espace des
ressources: "F-space". Cet espace est muni de trois dimensions: l'axe F qui concerne les
fonctionnalités, l'axe S qui décrit les différents services et enfin l'axe D qui décrit le niveau
d'importance. Cette méthode de dénomination des ressources est totalement originale et prend
quelque peu à contre-pied les approches plus traditionnelles.
D'autre part, les outils d'administration de réseaux utilisent parfois leur propre modèle de
données mais celui-ci n'est que rarement publié. C'est par exemple le cas pour l'outil
"Sysloacf' édité par Cerg Plus qui offre certaines fonctionnalités nouvelles dans le domaine
qui nous intéresse tout particulièrement, à savoir la gestion des ressources et de leurs
interdépendances.
Après avoir présenté les modèles de description des données d'administration les plus
courants, notamment SNMP et OSl, nous allons maintenant en souligner les avantages et
inconvénients respectifs et en soulever les carences.
2.3.4. Evaluation des modèles d'informations
Les deux modèles de données les plus courants sont très différents. L'ISO préconise un
modèle très complet par le biais d'une approche orientée objet qui offre un avantage certain
par la réutilisation possible des objets spécifiées. Il faut noter, cependant que contrairement à
ce que l'on pouvait penser, cette approche n'a pas empéché une certaine "boulimie" de
définition de classes et sous-classes d'objets (chacun rajoutant ses attributs et ses méthodes
propres). En pratique, l'administration par le modèle OSI n'est que peu utilisée principalement
à cause de la faible implantation de ce type de réseau.
En revanche, le modèle SNMP est très simple; trop simple pour certains. Les objets sont en
fait définis par de simples variables: facilement implantables et interogeables. La plupart des
constructeurs de matériels informatiques implantent la MIB SNMP dans leurs équipements et
Administratioll des applicatifs réseaux 3S

1.2 L'état de l'art en administraaOIl de réseaux
développent généralement leurs propres MIE. SNMP est pour l'instant le modèle
d'administration roi.
Par contre, comme nous l'illustrerons dans le chapitre suivant (paragraphe 3.2.1.4 - page 63)
une des carences profondes de SNMP et de l'administration OSI est la difficulté de décrire les
relations entre les objets. Tant que le modèle ne sert qu'à décrire des objets relativement
simples, les relations ne sont pas particulièrement utiles. Par contre dès qu'il s'agit de décrire
des objets plus complexes (une application réseau par exemple), le problème devient entier.
Nous avons présenté les modèles d'informations d'administration de réseaux. En reprenant
notre architecture générale d'un système d'administration, nous allons maintenant aborder le
deuxième point, c'est-à-dire les mécanismes mis en œuvre pour réaliser les fonctions
d'administration.
2.4. Les mécanismes mis en œuvre pour l'administration
Un système d'administration de réseaux requiert la mise-en-œuvre d'un ensemble de
mécanismes logiciels et/ou matériels. Quel que soit le modèle utilisé pour spécifier les
données d'administration, il est nécessaire de les collecter, de les mémoriser et de les
exploiter. L'architecture habituellement mise en place comporte ainsi les éléments suivants:
-les agents - également appelés sondes,
-les cana/Ix et protocoles de transfert de l'information,
-les plates-formes d'administration, également appelées intégrateurs(a).
2.4.1. Les agents d'administration
Les agents sont localisés sur chaque élément réseau à administrer. Ils ont pour rôle d'observer
les éléments de l'entité réseau qu'ils surveillent et d'en construire une vue abstraite suivant le
modèle d'informations qui est retenu. Ils tiennent à disposition ces données pour les requêtes
issues d'un logiciel d'administration.
2.4.1.1. Les agents SNMP
Nous avons décrit le modèle des données d'administration SNMP au paragraphe 2.3.1
page 26. L'agent SNMP a la charge de répondre aux requêtes en associant à un nom d'objet
de MIE la valeur associée qu'il observe. La manière dont sont réellement stockées les
(a) Nous gardons le terme de plate10rme d'administration plutôt que d'utiliser le mot intégrateur. Ce terme,
bien qu'évitant une périphrase un peu lourde, n'est que très peu utilisé. La littérature anglo-saxonne utilise
souvent le terme de manager.
36 Administration des applicatifs réseaux

L'état de l'art en administration de réseaux 1.2
informations n'est pas spécifiée. Un agent SNMP supporte généralement la MIB-II standard et
éventuellement une extension de MIB propriétaire. Par exemple, un routeur fabriqué par la
société Cisco dispose souvent d'un agent SNMP qui est apte à répondre aux requêtes
concernant des objets de la MIE-II et de la MIB Cisco associée au routeur en question.
2.4.1.2. Les agents OSI
L'ISO a prévu dès la conception de son modèle de réseau OSI d'intégrer des mécanismes
d'administration. Ceux-ci sont présentés dans la quatrième partie de la norme ISO 7498
"Management FramelVork",
Les agents OSI sont en fait des applications de la couche 7 OSI dédiées à l'administration, Il
s'agit d'entités d'application réalisant les services d'administration appelés: SMASE (System
Management Application Service Entity). Ces entités s'intègrent dans une application
gestionnaire nommée SMAP (System Management Application Processus) qui a pour rôle de
gérer les objets OSI d'administration, vue abstraite des équipements et ressources gérés par
l'agent.
Nous représentons dans le schéma 5 les différentes composantes d'un agent OSI :
Requêtesd'interrogationspour l'agent ~-r---ji~\
SMAP
objetsgérés
gère
Application
Présentation
Session
Transport1--------------1
Réseau
Liaison
Physique
Schéma 5 : Composantes d'un agent OS/
Administration des applicatifs réseau;'\: 37

1.2
2.4.1.3. Comparaison entre agents SNMP et agents OSI
L'état de l'art en administration de réseaux
Les agents SNMP et OSI sont relativement similaires sur le concept. En effet, tout deux sont
localisés sur l'équipement dont ils ont la surveillance. Leur rôle est identique; ils offrent tous
les deux une "vue abstraite" de l'équipement. On peut cependant noter une différence quant à
l'élaboration "historique" de ces agents. En effet, l'agent SNMP peut être considéré comme
"une pièce ajoutée" non prévue initialement (d'ailleurs, bon nombre de constructeurs
proposent deux versions de leurs matériels, l'une administrable par SNMP, l'autre non). Nous,
verrons, au paragraphe 2.4.2.1, que l'agent SNMP bénéficie d'un protocole dédié - non prévu
lors de la conception de la famille des protocoles TCP/IP. En revanche, l'agent OSI a été
élaboré d'entrée de jeu; il est considéré comme une application à part entière, qui peut
fonctionner sans le recours du protocole dédié CMIP (cf. 2.4.2.2).
2.4.1.4. Autres solutions
Bien que les agents SNMP et OSI soient largement reconnus et utilisés, certains constructeurs
développent parfois leurs propres agellts pour des besoins spécifiques. Il s'agit alors de
solutions purement propriétaires(a) qui ne rentrent pas dans le cadre de réseaux hétérogènes.
Par exemple, la plate-forme d'administration SUIlllet Mallagel; que nous présentons dans la
suite de ce chapitre, nécessite l'implantation d'un certain nombre d'agents propriétaires tels
traffic (observation du trafic réseau de l'équipement) ou encore layers (statistiques sur les
protocoles de la famille TCP/IP).
Une solution encore plus radicale est d'éviter le recours à l'agellt d'administration. Ainsi,
certains systèmes d'administration tentent d'interroger directement le système d'exploitatioll
de l'équipement à surveiller. Cette méthode est fortement restrictive, car elle ne concerne que
les paramètres qui peuvent être effectivement fournis par le système d'exploitation. De plus,
elle s'appuie implicitement sur la caratéristique mliititâche du-dit système d'exploitation.
Nous avons présenté les différents agents d'administration. Nous présentons maintenant les
mécanismes mis en œuvre pour interroger ces agellts afin de véhiculer l'information de
gestion qu'ils ont observée.
(a) Le terme de propriétaire est utilisé en réseau informatique pour signifier qu'il s'agit d'une solution
dépendant du matériel et du logiciel, définie par le constructeur: le propriétaire.
38 Administration des applicatifs réseaw:

L'état de l'art en administration de réseaux
2.4.2. Les canaux et protocoles d'administration
1.2
L'information de gestion doit pouvoir être véhiculée. Il s'agit ainsi de spécifier le protocole
qui définit les règles de codage et de transmission des données et le canal utilisé pour la
transmission.
Pour ce qui est du canal de transmission, il peut être de deux types. Il peut être le réseau
administré lui-même, soit un réseau parallèle dédié aux informations d'administration(a). On
parle alors de gestion dans la bande ou hors bande.
Quant aux protocoles, nous allons comparer les deux approches classiques:
- SNMP et SNMPv2 pour l'administration sous TCPIIP,
- CMIP et les services associés CMIS pour le modèle OS!.
2.4.2.1. Le protocole SNMP
Le protocole utilisé pour dialoguer avec les agents est appelé SNMP (Simple Network
Management Protocol). C'est ce terme qui a donné son nom au modèle d'administration sous
TCPIIP. Une première version a été publiée en 1988 dans le RFC 1157. En 1993, une seconde
version appelée SNMPv2 [RFC 1442] est venue compléter le protocoleinitial.
Il s'agit d'un protocole relativement simple de questions/réponses en mode asynchrone. Il
dispose de quatre primitives:
- GetRequest : interrogation simple d'une donnée de l'agent,
- GetNextRequest : poursuite d'une demande simple (dans le cas de données stockées en
tableaux, par exemple),
- SetRequest: assignation d'une valeur pour une donnée de l'agent,
- Trap : notification exceptionnelle par l'agent d'un événement particulier.
SNMPv2 modifie ce protocole assez élémentaire en y ajoutant un mécanisme
d'authentification des requêtes plus complet(b) que dans la version initiale. D'autre part
SNMPv2 introduit la notion de dialogue entre plates-formes d'administration et ajoute la
primitive GetBulk pour l'échange d'informations plus volumineuses qu'une simple variable
SNMP par exemple une table (ceci pour réduire l'utilisation excessive de la bande passante
dans le cas de transfert de données composées). Il y a lieu de souligner que SNMPv2 est
(a) Les réseaux parallèles d'administration sont utilisés par exemple dans les réseaux dits "intelligents",
spécifiés par le ccrTI dans son architecture INCM (intelligent Network Conceptual Madel)
(b) La version initiale de SNMP ne comportait qu'un système d'authentification "tout ou rien" en fonction
d'un nom de communauté reconnu ou non. SNMPv2 utilise la notion d'origine des requêtes et module les
droits sur les données (interdit, lecture seule, lecture/écriture). De plus un dispositif de chiffrement des
requêtes SNMP devient possible.
Administration des applicatifs réseau:",. 39

1.2 L'état de l'art en administratioll de réseaux
incompatible avec la version 1 et n'est pas encore, à l'heure actuelle, couramment implanté
dans des éqnipements.
2.4.2.2. CMIP et les services associés CMIS
Comme l'agent SMAP n'est rien d'autre qu'une application du modèle OSI, il peut utiliser
tous les services ISO courants: TP, MHS, FfAM, X500, etc (voir 3.1.2.2 - page 53).
Cependant des services spécifiques à la manipulation de données d'administration ont été
définis: CMIS (Connnon Management Information Service). CMIS est détaillé dans la norme
[ISO 9595-2]. Celle-ci définit les opérations élémentaires pour véhiculer les informations
d'administration d'un site à un autre. Elle va définir les opérations suivantes:
- M-GE'T consu1tation d'un objet,
- M-SET mise-à-jour,
- M-CREA'TE création,
- M-DELETE destruction,
- M-EVENT-REPORT gestion des événements,
- M-AC'TION génération d'actions.
Pour réaliser les opérations du CMIS, l'ISO définit le protocole CMIP (Common Management
Information Protocol) dans sa norme [ISO 9596-2]. La structure des données véhiculées est
définie, tout comme pour le protocole SNMP, dans le langage de description ASN.1. Il s'agit
d'nn protocole connecté très complet comportant des fonctions de détermination et de filtrage
pour sélectionner les objets traités, un système d'horodatage des requêtes, etc. Il est basé sur
le principe habituel de questions/réponses.
2.4.2.3. Comparaison des protocoles SNMP et OSI
Comme nous l'avons présenté, les protocoles et agents d'administration normalisés par l'ISO
s'articulent de manière identique à toutes applications du modèle OS!. Il n'y a par conséquent
pas de mécanisme parallèle pour l'administration. Certains auteurs critiquent cette mise en
œuvre en soulevant l'argument que l'administration de réseau n'est pas une application
comme une autre. Son rôle spécifique nécessite des mécanismes particuliers. Un exemple
généralement cité est le cas d'un écroulement des performances du réseau; les systèmes
d'administration osr s'écroulent en même temps et ne peuvent remplir leur rôle de
gestionnaire. Contrairement à CMIP, l'approche SNMP repose sur un protocole non-connecté,
ce qui évite certains blocages décrits dans l'exemple précédent.
D'autre part, la richesse de description des objets fournie par le modèle des informations OSI
filtrés et véhiculés par le protocole CMIP donne un bénéfice théorique important à l'approche
40 Administration des applicatifs réseau.."'·

L'état de l'art en administration de réseaux 1.2
OSI. Cependant, cet apport théorique entraîne une complexité à l'utilisation. En pratique, c'est
souvent l'approche relativement simpliste de SNMP avec ses quatre primitives qui a la
préférence des constructeurs.
2.4.2.4. Les protocoles à publications
Dans les deux protocoles classiques d'administration de réseau, SNMP et CMIP, les
opérations se basent essentiellement sur le principe de questions/réponses. Une autre approche
est fondée sur le mode de la publication. Le concept est profondément différent: l'agent
plutôt que de répondre aux interrogations de l'application d'administration va au contraire
publier (ou diffuser) systématiquement ses observations(al.
Des travaux dans ce sens ont été publiés récemment par B. Oki, M.Pfuegl, A. Siegel et
D. Skeen [OKI 93]. Il s'agit de la définition et de l'implantation d'un système de publication
de l'information d'administration appelé "The Information Bus". Ils montrent que cette
solution est généralement préférable tant que le volume des données d'administration n'est
pas prohibitif pour la bande passante du réseau administré. Le principal argument est la
facilité d'qjout et de retrait d'équipements. En effet, le système à publication systématique
évite de devoir nécessairement mettre à jour l'application d'administrateur pour prendre en
compte la modification de configuration.
Ce même choix de diffusion de l'information d'administration a été retenu par certains
constructeurs de petits réseaux informatiques. L'exemple le plus typique est celui du protocole
AppleTalk de la firme Apple [KaS 92]. Contrairement au modèle OSI ou aux réseaux bâtis au
dessus du protocole TCPIIP, AppleTalk a été conçu comme un protocole réseau orienté
Utilisateur & Application. Ainsi tout est mis en place pour pouvoir connaître très facilement
les divers éléments du réseau: ressources, utilisateurs, services, etc. Pour cela chaque
équipement du réseau AppleTalk diffuse les informations de gestion dont il dispose. Ainsi il
suffit simplement de connecter un nouvel ordinateur pour qu'il soit immédiatement pris en
compte par les applications d'administration.
Ce principe de protocole à publication bien qu'ayant l'avantage de la simplicité d'utilisation
ne peut malheureusement pas être implanté dès qu'il s'agit de réseaux de taille conséquente.
En effet, pour publier l'information, les agents ne connaissent pas a priori les destinataires de
leurs données, ce qui nécessite l'utilisation de système de diffusion à la cantonade (broadcast)
(al CMIP et SNMP disposent chacun d'une primitive d'alerte mais on ne peut parler de protocole
d'administration par publication, car cette primitive n'est pas destinée à la diffusion des informationsd'administration courante.
Administratioll des applicatifs réseaux 41

1.2 L'état de l'art en administration de réseaux
ou de diffusion sélective (multicast(a)). Ces deux solutions, principalement la première, sont
génératrices d'un trafic réseau important. En effet, toute information d'administration est
transmise à tous les (ou un sous-groupe des) autres équipements. D'autre part, en
fonctionnement normal, on peut estimer que les informations d'administration vont être peu
nombreuses car les équipements ne changent pas profondément d'état. Par contre, s'il survient
un problème sur le réseau, par exemple une coupure de câble, tous les équipements observant
l'incident vont simultanément diffuser cette information. Le système d'administration est mis
à mal au moment où on en aurait le plus besoin. Pour illustrer la difficulté d'implantation
d'une telle solution, le fait suivant est révélateur: AppleTalk était initialement prévu pour des
petits réseaux comportant quelques dizaines d'équipements. L'essor de ce type de réseau a du
s'accompagner d'une modification profonde du protocole, rebaptisé AppleTalk Phase Il,
justement pour "endiguer" les problèmes de saturation du réseau dus à la publication
intempestive des données d'administration(b).
Concrètement, la solution de protocole d'administration basé sur le principe de la publication
ne sera retenu que pour des services d'administration restreints véhiculant très peu de
données.
7.4.2.5. Quelques autres protocoles utilisés pour l'administration
Les protocoles SNMP et CMIP utilisés pour l'administration réseau sont dédiés à des agents
d'administration particuliers. Ces agents se basent sur un modèle d'information standard et
normalisé. Un problème se pose dans le cas où la plate-forme d'administration recherche une
information d'administration non-spécifiée dans le modèle de données, un objet non défini
dans la MIE par exemple.
Une solution peut être le recours à un protocole propriétaire, utilisé conjointement avec des
agents propriétaires (cf. 2.4.1.4). Ainsi, le protocole dédié aux RPC (Remote Procedure Cali)
[RFC 1057] [ISO 11578] est un bon exemple de protocole propriétaire employé en
administration de réseaux. Il s'agit en fait d'exécutions de procédures à distance. Ceci
nécessite par conséquent des processus dédiés s'exécutant sur les machines à observer(c).
C'est une des solutions retenues pour la plate-forme d'administration SunNet Manager.
(a) Les protocoles de niveau réseau supportant le mode nmlticast sont encore peu courants. La seule versionréellement implantée à l'heure actuelle et l'IP multicast.
(b) L'exemple de AppleTalk n'est pas isolé: les réseaux Naveil reposent exactement sur le même principe dediffusion et se retrouvent actuellement confrontés au même problème de restructuration profonde du
protocole IPX utilisé.
(c) Dans ce contexte, ce processus est appelé daemoll.
42 Administration des applicatifs résealLr

L'état de l'art en administration de réseaux 1.2
Une deuxième solution repose sur l'utilisation de langages de commandes à distance non
spécifiquement dédiés à l'administration, mais qui vont permettre de récupérer l'information
souhaitée en interrogeant directement le système d'exploitation du matériel distant
(cf. 2.4.1.4). Ces langages sont généralement des dérivés de shell scriptta). Le langage de
commande à distance le plus simple est sans doute RSH (Remote Shell) qui permet d'exécuter
un shell script Unix sur un ordinateur distant. Cette solution a l'avantage d'être très facile à
mettre en œuvre. Ces performances sont par contre mauvaises; l'exécution de shell script
surcharge considérablement la machine interrogée (la plupart des instructions sont réalisées
par des processus Unix indépendants. L'utilisation de boucles un tant soit peu complexes
génère, dans ces conditions, une "avalanche" de processus).
Le langage PERL [WALL 93] est une alternative à RSH. Il dispose d'une syntaxe plus
complète, fortement inspirée du langage C. Il allie les avantages d'un langage de
programmation courant et la souplesse d'un interpréteur de commandes. Ainsi, la version
dédiée aux systèmes Unix dispose des procédures systèmes de "bas niveaux" tels les
manipulations de fichiers et de répertoires. Elle inclus également des opérations de "hauts
niveaux" telles la manipulation des expressions régulièrestb). D'autre part, ce langage offre de
bonnes performances, car il est basé sur un principe de compilation qui précéde chaque
exécution. Il s'agit d'une forme originale de péréquation entre interpréteur et compilateur.
Enfin, il existe de véritables langages dédiés aux opérations distantes. Scotty en est un bon
exemple. Il est employé dans l'application d'administration de réseau INED que nous
présentons au paragraphe 2.4.3.3. Réalisé par J. SchonwaIder et H. Langendorfer, scotty est un
fait un interpréteur TeLtc) tOUS 90] dédié à l'administration de réseaux [SCH 93]. Un
exemple de programme est donné au paragraphe de présentation de INED.
Comme nous l'avons vu, les langages de commandes à distance se justifient lorsque les
moyens traditionnels de recherche de l'information d'administration ne suffisent plus.
Généralement, la mise en place de telles solutions est rapide et aisée (pas d'implantation
ta) Un shell script est un programme en langage relativement "rudimentaire", interprété. Il s'agit simplement
d'un enchaînement de commandes d'exploitation. munÎ de variables de type élémentaire (chaînes de
caractères) et agrémenté des classiques procédures de contrôle: boucles, sauts conditionnels et
inconditionels.Ch) Les expressions régulières sous UnÎx relèvent des méthodes de m.anipulation des chaînes de caractères, en
vue de substitutions complexes. Elles sont utilisées dans certaines commandes Unix telles awk, sed, grep, etc.te) Définit pa, J.K. Ousterhou~ TeL est un langage de commandes comparable à PERL ou au shell Unix. Les
programmes en TeL peuvent être aisément inclus au sein d'applications plus complexes comme dans le cas
deINED.
Administration des applicatifs réseaux 43

1.2 L'état de l'art en administration de réseaux
d'agent, langage évolué). Malheureusement, elles s'appuient sur l'hypothèse que les systèmes
d'exploitation des équipements interrogés sont connus à l'avance. Donnons un exemple: la
recherche par le langage PERL du nom d'un ordinateur va nécessiter des requêtes totalement
différentes si la machine interrogée tourne sous Unix ou s'il s'agit d'un micro-ordinateur sous
le système 7 de Apple. Il n'est pas évident non plus que tout type d'ordinateur puisse
répondre: un compatible IBM sous MS-DOS pour l'exemple précédent.
2.4.3. Les plates-formes d'administration
Le troisième composant qui entre en jeu dans un système d'administration est la plate10rme
d'administration. C'est le "cœur" du système d'administration. Il s'agit du ou des
programmes qui vont permettre de stocker et d'analyser les données d'administration. Cette
plate-forme comporte généralement un système de mémorisation de l'information telle une
base de données. Elle comporte également une intelface de visualisation des analyses pour
l'utilisateur privilégié, à savoir l'administrateur réseau. La finalité de la plate10rme
d'administration est d'analyser les données observées pour obtenir des paramètres
qualificatifs et quantificatifs de gestion de réseau suivant les aires fonctionnelles présentées
dans le premier chapitre (cf. 1.1.3 - page 12).
Il n'existe pas actuellement de norme ou de standard pour définir une plate-forme
d'administration. L'OSI expose bien les cinq aires fonctionnelles, mais ne spécifie pas la
manière de les implanter. De la même façon, le modèle SNMP ne décrit absolument pas
comment exploiter les informations d'administration recueillies. Nous allons, par conséquent,
nous baser en partie sur l'article de Dupuy, Sengupta, Wolfson et Yemini [DUP 91] publié
sous le titre de "NEFMATE: A NetIVork Management Environment" et sur la présentation de
l'administration de réseaux de P. Rolin [ROL 91] dans la quatrième édition de son ouvrage
"Réseaux locaux: nonnes et protocoles", pour présenter les différents composants
nécessaires au fonctionnement d'une plate10rme d'administration. Nous considérons les trois
angles d'approche suivants: stockage, analyse et présentation de l'information
d'administration.
2.4.3.1. Stockage de l'information
A priori, on pourrait remettre en question la nécessité d'un moyen de stockage de
l'information sur la plate10rme d'administration elle-même. En effet, les données
d'administration sont, en quelque sorte, déjà mémorisées sur les équipements à gérer sous la
forme de MIE ou d'objets OS!. Une base de données sur la plate-forme ferait, en quelque
sorte, "double emploi". Plusieurs auteurs [BAP 91] [VAL 91] soulignent la limitation d'un tel
44 Administration des applicatifs réseaux

L'état de l'art en administration de réseaux 1.2
point de vue pour des raisons évidentes de performances (chaque analyse ne peut relancer
systématiquement des requêtes aux agents concernés) et de gestion de l'historique (Les calculs
statistiques nécessitent la connaissance de l'évolution des états et non l'état courant
uniquement).
La solution qui est généralement retenue est intermédiaire. Une partie des informations
d'administration dont la durée de vie(a) est longue (supérieure à l'heure) va être mémorisée
dans une base de données propre à la plate-forme d'administration. Il s'agit, par exemple, des
données de configurations: nombre d'interfaces d'un routeur, types de protocoles supportés,
etc. Par contre, d'autres informations à durée de vie courte vont être à chaque fois
redemandées à l'agent dépositaire. Ce sera par exemple le nombre de messages en attente pour·
un logiciel de gestion de courrier électronique. L'article "Design of the MANDATE MIE"
[HAR 93] définit clairement les différents moyens de mémorisation de l'information en
fontion de son type. Il distingue notamment les "Sensor Datas" et les "Structural Datas" qui
reprennent le même concept de durée de vie.
Le principe d'une base de données propre à la plate-forme d'administration ne signifie pas
pour autant que la base doive être centralisée. Il est tout à fait envisageable et parfois
préférable que cette base soit distribuée, par exemple dans le cas de plusieurs plates-formes
coopérantes. Cette solution permet une meilleure sécurité des informations (moins de risques
de destruction) et surtout des performances accrues, car chaque plate-forme a son propre
domaine d'administration (plus petite base et interrogation des agents facilitée).
Le choix de la méthode de stockage reste entier. Certaines solutions s'appuient SUl' des bases
de données orientées objets pour garder une homogénéité d'approche avec le modèle osr ,d'autres préfèrent les performances des bases de données relationnelles plus classiques.
D'autres enfin, comme les auteurs de l'article cité ci-dessus [HAR 93], préconisent le
développement de bases de données dédiées à l'administration en soulignant les limitations
des systèmes classiques tels Ingres ou Oracle. Ils estiment que les niveaux de tolérance aux
pannes et de temps de réponse ne peuvent suffire pour des applications d'administration de
réseau.
2.4.3.2. Analyse de l'information
La plate-forme d'administration qui dispose des données d'administration stockées dans sa
base de données va devoir effectuer des calculs SUI' ceux-ci afin de fournir une analyse
pertinente sur l'état du réseau surveillé. 01', à l'heure actuelle, le constat est étonnant: les
(a) La durée de vie d'une informations d'administration est la plage de temps où la donnée est significative et
utilisable. Cette durée de vie est bien évidemment fonction de la périodicité de modification de l'information
en question, et de l'utilisation qui en est faite.
Administration des applicatifs réseaux 45

1.2 L'état de ['art en administration de réseaux
platesjormes d'administration ont tendance à fournir une pléthore d'informations disparates
(alarmes en tout genre, jauges d'interfaces, compteurs de trames, etc) mais beaucoup plus
rarement une vue globale de la qualité de service du réseau. Un exemple particulièrement
révélateur de cet état de fait est l'interface d'exploitation statistique de la plate-forme
d'administration SunNet manager: "the Grapher". Alors qu'il s'agit d'un produit de référence
(sans doute le plus diffusé après Openview), aucune fonctionnalité de traitement global n'est
offerte à l' administrateur (calcul de moyenne, débit moyen par jour/mois ou année, ou plus
prosaïquement, changement d'échelle sur un graphique) et aucune évolution n'a été faite entre
les différentes versions du logiciel. Or, à notre sens, une platejorme d'administration ne peut
se restreindre à l'unique rôle d'interrogateur d'agents.
Nous exposerons largement dans le chapitre suivant ce qui est fait pour l'analyse des
paramètres concernant la gestion des applications réseaux.
2,4,3,3. Interface
L'interface d'une plate-forme d'administration dépend, bien évidenunent, des fonctionnalités
attendues. Est-elle plus particulièrement dédiée à l'analyse des performances? à la gestion de
la configuration? à la détection de pannes?
Les plates-formes actuelles offrent ainsi une série de vues plus ou moins complètes.
Nous trouvons généralement une visualisation de la configuration du réseau. Ainsi il devient
possible de voir en un coup d' œil la localisation des ordinateurs en fonction de leur adresse
réseau. Il faut souligner cependant que cette visualisation se restreint généralement à une vue
logique et non pas à une vue physique. En effet, le maillage physique (câbles, répéteurs,etc)
n'est que très rarement indiqué (impossible sous OpenView, fastidieux et difficile à mettre en
œuvre sous SunNet manager).
La présentation des fonctionnalités touchant aux performances reprend la plupart du temps les
histogrammes, courbes, etc, habituels dans la présentation de données numériques. Les
systèmes de rapport d'alarme s'appuient sur un gestionnaire de notification, etc.
Les intelfaces des plates-formes d'administration se heurtent généralement au problème de la
quantité d'information à visualiser. OpenView en est un bon exemple: dépassé le demi-millier
d'équipements, la représentation à l'écran devient totalement illisible (pléthore d'icônes
minuscules).
Pour ce qui est des travaux plus universitaire nous citons une interface assez complète qui
montrent bien la différence de visualisation suivant les fonctionnalités d'administration
attendues: INED.
46 Administration des applicatifs réseaux

L'état de ['art en administration de réseaux 1.2
INED : lm éditellr réseau
A. Schonwalder et H. Langendorfer (SCH 93] [SCH 93a] ont développé un éditeur graphique,
appelé INED, pour décrire les équipements réseaux. Cet éditeur est couplé à un module
d'interrogation via le langage TCL et son extension scotly. Chaque équipement est représenté
par une icône graphique qui peut être liée au moyen d'arcs à d'autres équipements. Les
liaisons sont à définir par l'administrateur. Il peut s'agir de différents types de relations:
machines sur un même médium, dépendant d'une même administration, etc. D'autre part,
l'éditeur INED permet de visualiser des groupes d'équipements.
000III
SRIllCOOI SIllllOOl MIl)))
II"---II_---<D....IlliOOI
~_ ~,,~ 1----\~ l~I'.Ml1>W..1<b>M rl Iv-b> 6t
'G<Qnt.-bl1;.;:---------I-__~
Schéma 6: L'illterface INED
La simplicité d'utilisation de INED est remarquable. On peut cependant lui reprocher sa forte
orientation sur les réseaux TCP/IP et l'impossiblité de le coupler avec le modèle SNMP. La
fonctionnalité essentielle représentée par INED est l'architecture globale des ordinateurs qui
composent un réseau.
2.4.4. Un exemple de plate-forme d'administration: Sunnet Manager
Nous terminons la présentation des mécanismes utilisés en administration de réseaux en
décrivant une plate-forme d'administration et les agents associés: SlInnet Manager de la
société Sun [SUN 92].
Adminislratioll des applicatifs réseau:,. 47

1.2 L'état de ['art en administration de réseaux
Sunnet est l'une des plates-formes les plus diffusées. Elle est à comparer à Openview de
Hewlett-Packard. Il s'agit d'une plate-forme d'administration fortement orientée vers la
gestion du matériel Sun. Cependant, ses caractéristiques de développement<a) en font un
support de base pour un certain nombre d'applications d'autres constructeurs et/ou utilisateurs
(tel Optivity de Synoptics pour la gestion des répéteurs de cette firme) Celles-ci viennent alors
se "greffer" sur Sunnet Manager.
2.4.4.1. Architecture générale de Sunnet
L'architecture de Sunnet suit les principes généraux décrits précédemment. Dans le schéma 7
ci-dessous, nous illustrons la structure générale de l'outil. L'élément principal est la plate
forme d'administration elle-même (appelée "management station"). Elle a la charge de tenir à
jonr une base de données centralisée qui décrit les caractéristiques et l'état du réseau à gérer.
Pour ce faire, elle dialogue avec une série "d'agents" localisés snr les machines à surveiller. Le
protocole employé entre la plate-forme et les agents est celui des RPC (Remote Procedure
Cali) que nous avons déjà évoqué précédemment (cf. 2.4.2.5)..
Managementstation
autres protocoles...I---- ...~ d'administration
Schéma 7,' Architecture générale de SlIImet Manager
<a) SlIImet dispose d'un langage de description qui permet à l'utiliseur de définir ses propres objets à
administrer. De même, la disponibilité de bibliothèques de programmation offre la possibilité de développer
ses propres agents.
48 AdministratioIJ des applicatifs réseaux

L'état de l'art en administration de réseaux
2.4.4.2. Les agents Sunnet
1.2
Les agents Sunnet d'observation du réseau sont de deux catégories. Les plus courants sont les
agents propriétaires Sun qui surveillent et transmettent certains paramètres spécifiques de la
machine sur laquelle ils sont localisés. Ces agents ne peuvent s'exécuter que sur des machines
du constructeur Sun. Nous donnons dans le tableau ci-dessous quelques agents propriétaires
en exemple:
Nom Fonction de J'agent
diskinfo Informations sur les disques iocaux
traffie Statistiques sur l'interface Ethernet
hostmem Statistiques sur l'utiiisation du processeur
iostat Statistiques sur les entrées/sorties
iproutes informations sur les tabies de routage IP
layers Statistiques sur les différentes protocoles iP, UDP, TCP et ICMP
rpcnfs Statistiques sur les requêtes RPC et NFS
Tableau 1 : Exemples d'agents propriétaires SUIlllet
Une seconde catégorie d'agents permet d'étendre les possibilités de Sunnet Manager à des
objets non Sun. Il s'agit des "proxy agents". Ceux-ci vont assurer la transition entre les
éléments non propriétaires et la plate-forme Sun (cf. schéma 7). L'exemple le plus typique est
le "proxy agent SNMP" qui va se charger de lancer les requêtes SNMP et de transmettre les
résultats à la plate-forme au moyen du protocole RPC.
Nota: La société Sun encourage les autres constructeurs à développer le "proxy agent" adapté
à leur matériel et à leur protocole d'administration propre.
2.4.4.3. La base de données SlIIlIlet
La base de donnée de Sunnet Manager a été développée "sur mesure,,(a). Elle est centralisée
sur la machine qui accueille la plate-forme d'administration. Son principe est fortement
"orienté objet".
La mise à jour de la base se fait par trois méthodes complémentaires. Tout d'abord, un module
appelé "discover" permet d'acquérir un certain nombre d'informations concernant les
ordinateurs qui se trouvent sur le réseau à administrer (types et noms des machines,
caractéristiques réseaux telles l'adresse IP et les possibilités SNMP, etc). Ce processus est
(a) Il serait question qu'une version future abandonne le principe d'une base de donnée propriétaire pourretenir un SGBD plus classique tels ORACLE, INGRES, SYBASE,....
Administration des applicatifs réseaux 49

1.2 L'état de l'art en administration de réseaux
assez lent (plusieurs heures pour un réseau de deux à trois cents machines) et relativement peu
performant dès qu'il s'agit d'ordinateur non Sun. Une deuxième méthode de mise àjour de la
base consiste à utiliser l'éditeur graphique. Souple et commode, il permet de définir plusieurs
vues logiques du réseau, de regrouper des machines au sein d'une même groupe, de décrire le
câblage sous-jacent, etc).
Enfin, la troisième méthode d'acquisition des données repose sur les informations issues des
agents d'observation. Nous en détaillons les possiblités dans le paragraphe suivant.
2.4.4.4. Méthodes d'inten'ogation des agents
Sunnet Manager propose deux modes de "dialogues" avec les agents. Le premier mode est
nommé "data reporting". Ceci signifie que pour les agents désignés, la plate-forme va
périodiquement générer des demandes de rapports. Il s'agit d'un principe de "pol/ing". Par
exemple, il est possible de demander à un agent "traffic" le nombre de trames ethernet
transmises sur l'ordinateur sur lequel il est implanté, et ceci toutes les demi-heures. Le second
mode d'interaction avec les agents est nommé "event reporting". Il s'agit d'un principe de
gestion d'alarmes. Sunnet indique, aux agents concernés, les conditions pour lesquelles ils
doivent générer une alarme de leur propre initiative. Par exemple, l'administrateur va spécifier
à l'agent de surveillance des disques (diskinfo) de prévenir dès que le taux d'occupation est
supérieur à 90%.
2.4.4.5. Exploitation et génération de résultats
Sunnet Manager dispose de trois outils complémentaires pour son exploitation. Tout d'abord,
Sunnet dispose d'une inteiface graphique conviviale et très pratique pour visualiser la
configuration du réseau. Nous en donnons une illustration dans le schéma 8 ci-dessous.
D'autre part, deux outils d'analyse des informations permettent à l'administrateur, soit de
parcourir aisément les rapports de données et d'alarme via le "brolVser", soit de générer des
graphiques (histogrammes et courbes) de visualisation des valeurs observées via le "grapher".
2.4.4.6. Outils de développement de Sunnet
Sunnet Manager offre des possbilités de développements d'applications d'administration
propres à l'utilisateur. Pour cela, il fournit avec le logiciel des bibliothèques de programmation
qui permettent d'écrire des agents spécifiques.
50 Administration des applicatifs réseaux
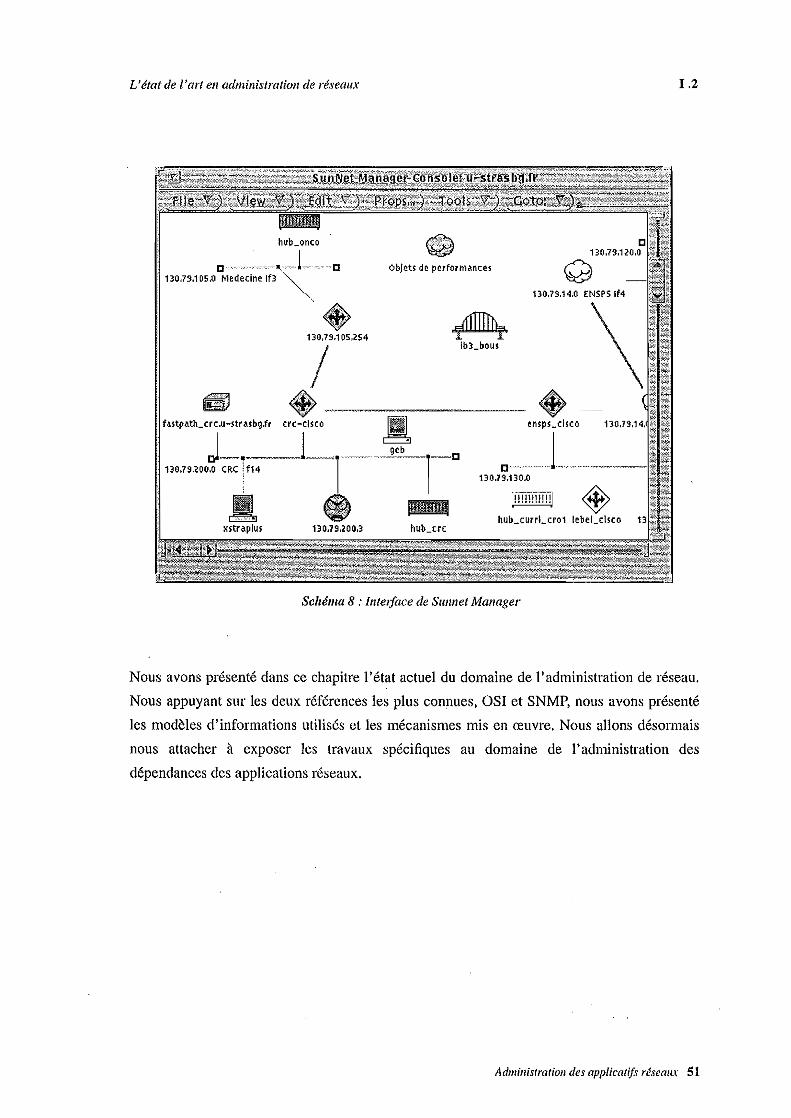
L'état de l'art en administration de réseaux
hub_onco
c--· C'W_"_ -_.>~=,_~.._"_~_~,,l,__ ._c'__=_ - [J
130.79.105,0 Medecine If3'~,Objets de performances
130.79.130,0
!!!!!I!11!!
lJ130.79,120.0
G
1.2
Schéma 8 " Inte/face de Sunnet Manager
Nous avons présenté dans ce chapitre l'état actuel du domaine de l'administration de réseau.
Nous appuyant sur les deux références les plus connues, OSI et SNMP, nous avons présenté
les modèles d'informations utilisés et les mécanismes mis en œuvre. Nous allons désormais
nous attacher à exposer les travaux spécifiques au domaine de l'administration des
dépendances des applications réseaux.
Administration des applicatifs réseaux 51

I.3 Administration des dépendances de sen/ices applicatifs
3. Administration desdépendances de servicesapplicatifs
Administrer les objets qui composent un réseau informatique (matériel, logiciel et utilisateurs)
est, comme nous l'avons vu, la base de l'administration réseau. Et ces dernières années ont vu
se développer des modèles et des outils pour effectuer cette tâche. Nous disposons ainsi des
éléments de base pour réaliser les fonctionnalités d'administration. Cependant, nous avons
souligné qu'à l'heure actuelle, la plupart des plates-formes d'administration se contentent trop
souvent de fournir les données brutes plutôt que de les analyser afin de donner des résultats
offrant une meilleure idée de la qualité de service.
Le sujet de cette thèse est justement de tenter d'administrer, non pas seulement les briques qui
composent les réseaux informatiques mais les services qui en découlent.
Définissons tout d'abord ce qu'est un service réseau et plus précisément un service applicatif
réseau.
3.1. Contexte général de l'administration des dépendances
entre services applicatifs
3.1.1. Service réseau: une définition
Pour la définition d'un service réseau, nous gardons l'approche du modèle client-serveur
communément admise. Celle-ci met en jeu trois composantes:
- un fournisseur de ressources que l'on nomme le servelll;
- un consommateur de ressources également appelé client,
- un ensemble de moyens pour faire dialoguer le serveur et le client.
Un service réseau est l'interaction entre deux entités: le client et le servew: Le serveur met à
disposition du client les ressources qu'il gère. Les deux entités c01llll1llniquent au moyen d'III!
réseau informatique.
52 Administration des applicatifs réseau.'t

Administration des dépendances de sen/ices applicatifs 1.3
Cette approche par décomposition binaire en client et serveur permet de décrire la plupart des
services réseaux existants. Donnons un exemple d'un service réseau qui se décrit typiquement
par le modèle client-serveur. Soient une base de données centralisée sur un ordinateur A et un
programme d'interrogation de cette base localisé sur un ordinateur B ; A joue le rôle de
serveur, B le rôle de client. Les éléments nécessaires à leurs interactions sont les protocoles de
communications adéquats et le matériel nécessaire à l'interconnexion des deux ordinateurs.
Le modèle client-serveur s'applique à une grande majorité de services réseaux, et à des
niveaux d'abstraction divers. En effet, il peut aussi bien s'agir de la lecture d'une variable
mémorisée sur un autre ordinateur, c'est-à-dire d'une ressource relativement élémentaire, que
du transfert d'un fichier d'une machine à une autre.
Pour les réseaux informatiques, le niveau de fonctionnalité le plus haut est l'application. Dès
lors, qu'entend-t-on par service applicatif réseau ?
3.1.2. Application réseau: une définition
Pour définir l'application informatique, nous reprenons la division en niveaux proposée par
l'organisme de normalisation ISO.
3.1.2.1. Les concepts généraux
La couche application est le dernier niveau du modèle OSr. Elle a comme rôle de fournir les
seryices aux tâches applicatives de l'utilisateur.
Le principe est basé sur un empilement d'entités fonctionnelles de complexité croissante. Une
entité fonctionnelle utilise les services de l'entité sous-jacente et fournit elle-même ses
services à l'entité fonctionnelle de niveau plus élevé. Le niveau le plus hant de cette hiérarchie
est appelé couche application. C'est ce que nous illustrons dans le schéma 9 ci-après.
Un service applicatif réseau ou application réseau est un service qui met en coopération une
entité client et une entité serveur du niveau application.
Nous allons décrire dans le point suivant les différentes applications réseaux les plus
courantes.
3.1.2.2. Description des applications réseaux
Les applications réseaux peuvent être classées en cinq grandes catégories:
-l'accès à des périphériques distants,
- l'accès à des données distantes,
-l'émulation de terminaux virtuels,
Admi1listration des applicatifs réseaux 53

1.3 Adm11listratioll des dépendances de seJ1'ices applicatIfs
ProgrammeApplicatif
1 Présentation
1 Session
1 Transport
1 Réseau
1 Liaison
1 Physique 1
ProgrammeApplicatif
W/ZlTLT//UUT/D///L.OTL.OT//T~LTL.OTU/UDJsupport physique
Schéma 9 : Utilisation de la couche application par les programmes des utilisateurs
-le courrier électronique,
-les exécutions déportées.
L'accès à des périphériques distants
Le service d'accès à des périphériques distants regroupe les applications permettant la mise à
disposition de périphériques qui ne sont pas localisés sur l'ordinateur de l'utilisateur. Il peut
s'agir par exemple d'une imprimante pilotée par un ordinateur central sur laquelle un
utilisateur muni de son micro-ordinateur veut pouvoir imprimer. Remarquons que le terme
périphérique n'a pas des contours très bien définis, mais dans ce contexte-ci il s'agit de
matériel disjoint de l'ordinateur lui-mêmeta). Typiquement, il s'agit des éléments tels un
scanner, une imprimante, un modem, une table traçante, etc.
Les applications les plus courantes utilisées dans ce type de services sont par exemple les
gestionnaires d'imprimantes LPILPD [BAC 92] pour le système Unix.
ta) La disjonction n'est pas toujours très claire à poser dans le cas d'un support de stockage tel un disque
magnétique, voire un lecteur optique.
54 Administration des applicatifs réseaux

Administration des dépendances de sen'ices appiicatifs
L'accès à des données distantes
1.3
La catégorie des services formés par les accès à des données distantes se scinde en trois
groupes prédominants: le transfert de fichiers, l'accès à des systèmes de fichiers distants et
l'accès à des bases de données distantes.
Sans entrer dans l'architecture des systèmes informatiques, ces trois groupes relèvent de deux
niveaux d'abstraction totalement différents.
Dans le cas du transfert de fichiers, les moyens mis en œuvre sont relativement mdimentaires
dans le sens où l'utilisateur doit lancer une application dédiée à ce transfert. Ce transfert
concerne l'ensemble de la ressource (en l'occurrence: le fichier) et ne peut être ajusté à un
sous-élément de la ressource.
Dans les deux autres cas: l'accès à des systèmes de fichiers et l'accès à des bases de données
distantes, l'accès aux données est assez fin dans le sens où l'utilisateur dispose d'une panoplie
de requêtes d'interrogation de sous-éléments de la ressource. Il lui est ainsi possible d'accéder
à une portion de fichier, de lire simplement un attribut d'un objet de la base de données, etc(a).
D'autre part, l'application utilisée pour de tels services est généralement inscrite dans un
programme informatique de fonctionnalités plus large. Pour le montage de systèmes de
fichiers, cette application est en fait le système d'exploitation lui-même.
Dans le cas des transferts de fichiers, les applications les plus courantes sont FTP (File
Transfer Protocole) [RFC 959], RCP (Remote CoPy) sous Unix-TCPIIP. Pour ce qui est des
montages de disques distants, les deux grands standards sont NFS [RFC 1094] (Network File
System) et RFS (Remote File Sharing) [RIF 86] pour le monde TCPIIP. Dans le cas de la
micro-informatique, tout dépend du type de système utilisé. Nous trouverons Appleshare
[KaS 92] pour les systèmes Macintosh de Apple, net use pour les systèmes NoveU.
L'application FTAM dans le modèle OSI (décrit dans la norme ISO 8571) permet à la fois
l'accès à des disques distants et le transfert des fichiers.
Les différents systèmes de base de données ont généralement leur propre application
d'interrogation. L'ISO préconise RDA (Remote Database Access) normalisé ISO 9579. Nous
citons également un standard regroupant un sous-ensemble de fonctionnalité, il a été
standardisé sous le nom de SQL (Simple Query Language) et la plupart des systèmes de bases
de données le reconnaissent.
(a) Les moyens mis en œuvre dans le cas d'accès à des sous-éléments de la ressource sont plus complexes carils nécessitent généralement la gestion des accès concurrents entre plusieurs clients (systèmes de verrous et
sémaphores par exemple).
Administration des applicatifs réseaux S5

1.3
L'émulation des terminaux virtuels
Administration des dépendances de services applicatifs
Les applications d'émulation de terminaux virtuels sont certainement les plus utilisées. Elles
consistent à donner les fonctionnalités d'nn terminal passifa) à un ordinateur afin qu'il puisse
se connecter à un autre ordinateur. L'intérêt d'une telle fonctionnalité est importante, car le
coût financier d'un terminal passif est souvent élevé, et l'utilisation d'un micro-ordinateur
fournissant les mêmes services en plus de ses fonctionnalités habituelles offre une alternative
non négligeable. Il s'agit par exemple de l'application Telnet [RFC 854] disponible sur la
majorité des ordinateurs, ou encore VT (Virtnal Terminal) pour le modèle OSI (décrit par la
norme ISO 9040 et 9041).
Le courrier électronique
Le service de courrier électronique est sans doute le plus implanté, car le premier disponible
historiquement. Il regroupe les applications permettant le transfert de lettres par le réseau
informatique entre utilisateurs. Il en existe de nombreuses applications, suivant le type de
réseau. La recommandation X400 du CCITT (normalisée ISO 9579 sous l'appellation MHS
Message Handling System) décrit les différents protocoles et architectures nécessaires à une
telle application. Dans le monde TCP/IP , il s'agit des applications basées sur le protocole
SMTP (Simple Mail Transfert Protocol) [RFC 821], dont il existe diverses implantations
suivant le type de machine. D'autre part, il existe un certain nombres d'autres implantations
propriétaires, MSMail, CCmail, etc.
Les exécutions déportées.
Le service d'exécutions déportées (ou distantes) est très proche du service d'émulation à ceci
près qu'il se restreint simplement à l'exécution d'un programme (ou d'une partie de
programme) se trouvant sur un autre ordinateur. Les résultats sont transférés sur l'ordinateur
de l'utilisateur. Rentrent entre autres dans cette catégorie, les RPC déjà cité, RSH, Rexec pour
les réseaux TCP/IP. Pour le modèle OSl, nous avons RO (Remote Operation) normalisé
ISO 9072.
3.1.2.3. Les applications réseaux pour un ordinateur standard
Concrètement, il est intéressant de connaître les applications réseaux courantes d'un
ordinateur. Pour fixer les idées, un ordinateur en réseau de type station de travail peut assurer
(a) La définition d'un terminal passif a beaucoup évolué du fait de la complexification du-dit terminal de
moins en moins "passif', La différence entre terminaux et ordinateurs n'est pas toujours aussi évidente qu'ilpeut y paraître à première vue. Nous gardons l'approche traditionnelle de la définition des terminaux tels uneVT100, une VT200, Terminal X, etc.
56 Administration des applicatifs réseaw:
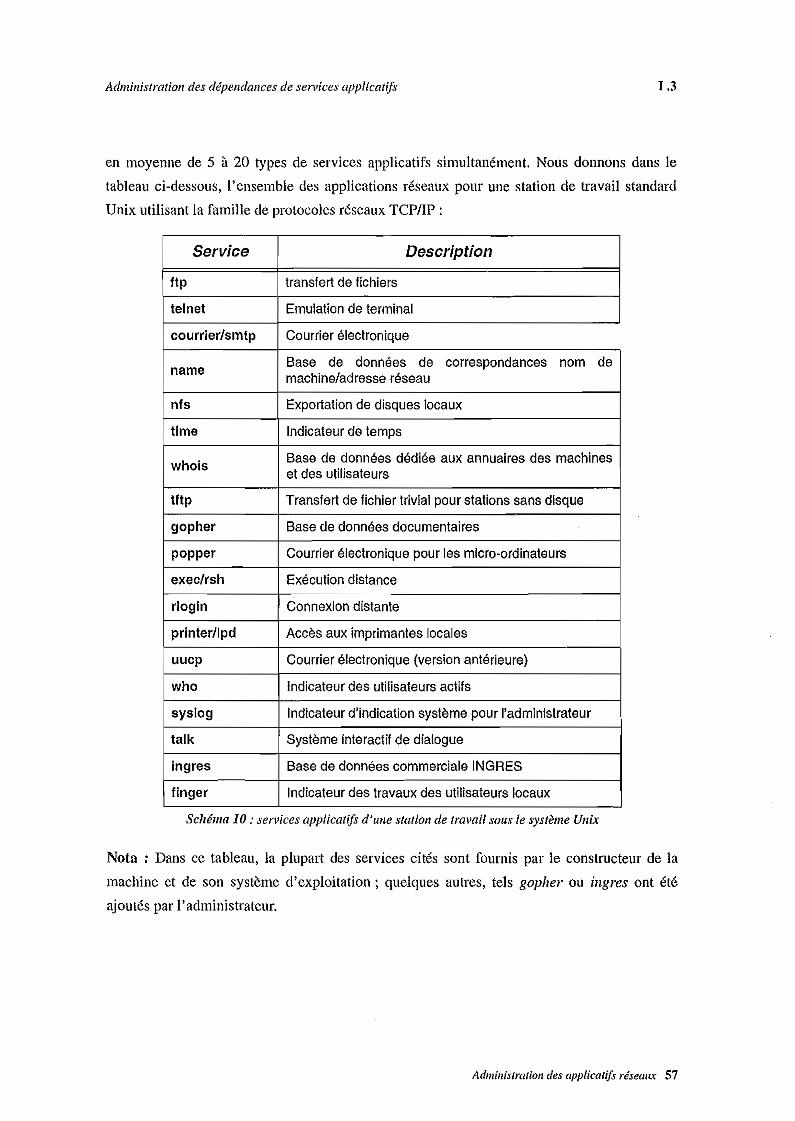
Administration des dépendances de services applicatifs 1.3
en moyenne de 5 à 20 types de services applicatifs simultanément. Nous donnons dans le
tableau ci-dessous, l'ensemble des applications réseaux pour une station de travail standard
Unix utilisant la famille de protocoles réseaux TCPIIP :
Service Description
ftp transfert de fichiers
telnet Emulation de terminal
courrierlsmtp Courrier électronique
Base de données de correspondances nom dename
machine/adresse réseau
nls Exportation de disques locaux
lime Indicateur de temps
whoisBase de données dédiée aux annuaires des machineset des utilisateurs
tltp Transfert de fichier trivial pour stations sans disque
gopher Base de données documentaires
popper Courrier électronique pour les micro-ordinateurs
exec/rsh Exécution distance
rlogln Connexion distante
printer/lpd Accès aux imprimantes locales
uucp Courrier électronique (version antérieure)
who indicateur des utilisateurs actifs
syslog Indicateur d'indication système pour l'administrateur
talk Système interactif de dialogue
ingres Base de données commerciale INGRES
linger Indicateur des travaux des utilisateurs locaux
Schéma 10 : services applicatifs d'une station de travail sous le système Unix
Nota : Dans ce tableau, la plupart des services cités sont fournis par le constructeur de la
machine et de son système d'exploitation; quelques autres, tels gopher ou Ingres ont été
ajoutés par l'administrateur.
Administration des applicatifs réseaux 57

1.3 Administration des dépendances de services applicatifs
Lorsqu'il s'agit de micro-ordinateurs, les applications réseaux sont sensiblement les mêmes,
souvent moins nombreuses et généralement "noyées,,(a) dans le système; il est donc plus
difficile de les nommer.
Nous avons présenté ce qu'était un service applicatif réseau et décrit les principales classes de
ces applications. Voyons maintenant ce que l'on entend par dépendance entre services
applicatifs.
3.1.3. Dépendances entre applications réseaux
Le modèle client-serveur qui nous permet de décrire les services applicatifs réseau ne met pas
en évidence un problème bien connu de l'administration de réseaux: les dépendances des
services entre eux. Exposons tout d'abord un exemple courant.
Exemple de dépendances
Un utilisateur désire lire son courrier depuis le terminal X de son bureau. Or un tel terminal a
besoin, entres autres, des services d'un serveur de noms(b), d'un serveur de codes(c), d'un
serveur de fontes(d) et ceci simplement pour fonctionner. D'autre part, la boîte aux lettres de
l'utilisateur doit être accessible, ce qui signifie que l'ordinateur, sur lequel celle-ci est stockée
doit lui-même fonctionner correctement et rendre accessible cette boîte aux lettres. Serveurs
de noms, montages de disques, autant de services éventuellement nécessaires à la diffusion de
la boîte aux lettres demandée.
Nota: L'exemple présenté ci-dessus n'est pas un cas spécifiques de services particulièrement
dépendants, il est tout à fait commun dans un système informatique de type réparti(e).
Deux facteurs tendent à accroître le niveau de dépendances des services applicatifs. Il s'agit
tout d'abord de la banalisation des montages de disques distants, que ce soit dans les réseaux
de micro-ordinateurs ou dans les réseaux de stations de travail. D'autre part, la volonté
croissante d'interopérabilité entre services réseaux de constructeurs différents entraîne la mise
en œuvre de nombreuses passerelles qui augmentent encore ces dépendances.
(a) Un cas typique est celui du système 7 des micro-ordinateurs macintosh, où l'ensemble des fonctionnalités
réseaux est inclus dans le système d'exploitation de manière indivisible.
(h) Cf. note a - page 15.
(c) Les terminaux X doivent généralement "télécharger" leur système d'exploitation et l'application "serveurX" depuis un mini-ordinateur.(d) Une/onte est la description typographique d'un alphabet particulier.
(e) En opposition au système informatique centralisé (un ordinateur unique au milieu de consoles passives)
où la notion de service applicatif réseau n'as pas réellement de sens.
58 Administration des applicatifs réseaux

Administration des dépendances de sen'ices applicatifs 1.3
Après avoir posé le contexte des dépendances de services applicatifs réseaux, nous allons
présenter les différents travaux qui traitent de leur administration, les modèles définis, les
mécanismes utilisés.
3.2. L'état de l'art de l'administration des dépendances
entre services réseaux
L'administration des services réseaux est un domaine de recherche relativement récent et peu
de publications traitent directement du sujet, notamment dans le contexte de réseaux
hétérogènes. Cet état de fait s'explique principalement par la nécessité qu'il y avait de définir
au préalable les moyens élémentaires d'administration tels SNMP où OSI et de bénéficier
d'une réelle implantation de tels mécanismes au sein des matériels informatiques. Jusqu'en
1993 environ, il s'agissait principalement de gestion propriétaire de configuration, comme par
exemple la base de données d'administration "Moira" du projet Athena du MIT dont nous
rappelons les concepts ci-dessous. Cependant, ces deux dernières années voient désormais la
définition de modèles et de mécanismes pour l'administration des services réseaux. Nous
allons présenter ces différents travaux.
3.2.1. Mécanismes existants
Avant d'exposer les travaux les plus récents, il nous semble intéressant de situer les outils et
concepts précurseurs d'un tel domaine. Nous présentons ainsi la partie administration des
ressources du projet Athena.
3.2.1.1. Une première expérience d'administration des services réseaux: "Moira" du projet
Athena
Le projet Athena a débuté en 1983 au sein du "Massachussets Institute of Technology" en
collaboration étroite avec les firmes DEC et IBM. L'idée de base est de concevoir et
d'implanter les mécanismes qui permettent l'administration d'un grand réseau de campus
(supérieur au millier de stations) afin que tout utilisateur puisse travailler sur n'importe quelle
station comme s'il s'agissait de son propre ordinateur. Ce projet a été à l'origine de la création
de plusieurs applications désormais renommées: l'interface X-windows, le système
d'authentification Kerberos, l'annuaire Hesiod, etc.
Les services réseaux gérés de manière globale dans le projet sont les suivants: la gestion des
annuaires, des fichiers, des impressions, du courrier, des échanges de messages, de
l'authentification des personnes et des configurations logicielles.
Administration des applicatifs réseaux S9

1.3 Administration des dépendances de services applicatifs
Nous ne détaillons pas , cependant, tout le projet Athena (présenté dans l'ouvrage de
G.A. Champine "A Madel for Distributed Campus Computing" [CHA 90)), nous nous
intéressons plus particulièrement à la base de données d'administration utilisée dans le projet
appelé "Moira", aux concepts qu'elle met en œuvre.
Moira: une base de données d'administration des services réseaux
Pour administrer les services réseaux offerts dans le projet Athena, il a été nécessaire de
définir une base de données pour mémoriser les informations nécessaires à une telle gestion.
Les concepts de "Moira", la base de données en question sont les suivants:
- une base de données centralisée,
- des informations sur les disques, sur les configurations matérielles et logicielles, sur les
utilisateurs (comptes de travail, boîtes aux lettres, listes d'accès,etc) et ceci pour
l'ensemble des ordinateurs du réseau,
- des mécanismes de mise en conformité des équipements afin que leur configuration soit
identique à celle décrite dans la base.
Dans le projet Athéna, l'idée principale est de regrouper toutes les informations
d'administration au sein d'une même base de données. Il ne s'agit pas tant de décrire les
configurations qui "pré-existent" sur les ordinateurs, mais bien d'être à l'origine de ces
configurations. Prenons un exemple: la modification de la configuration logicielle d'un
ordinateur ne se fait pas sur l'ordinateur lui-même mais bien sur la base "Moira". C'est la base
elle-même qui va indiquer à l'ordinateur son changement de configuration.
Notons que "Moira" n'est pas l'unique base de données d'administration que comporte le
système Athena. "Hesiod", par exemple, gère l'annuaire des correspondances entre nom
d'ordinateur et adresse réseau. Cependant, c'est bien "Moira" qui est à l'origine des données
et qui délègue à Hésiod le travail de gestion (Hésiod dispose de mécanismes de duplication de
données permettant une résolution plus rapide des requêtes qui lui sont adressées).
Ce principe d'une base de données, "origine" des informations d'administration est à l'opposé
des méthodes d'administration plus récentes; il suppose une gestion uniforme et centralisée
des configurations. Le principe de l'administration SNMP et OS1 consiste à observer les
configurations des équipements. Ainsi, la base d'administration n'est plus "origine" mais
simple "vue" de l'information.
Voyons maintenant les travaux plus récents qui peuvent être utilisés pour l'administration de
services applicatifs.
60 Administration des applicatifs résemL'·

Administration des dépendances de sell'ices applicatifs
3.2.1.2. L'administration des applications sous SNMP
1.3
Pour ce qui est de l'administration SNMP, deux spécifications de MIE ont été publié fin 1993
- début 1994 qui offrent pour la première fois un standard pour l'interrogation des
équipements quant à lenr configuration au niveau applicatif. Nous en donnons une description.
Host Resources MIB
Le RFC 1514, publié en septembre 1993, décrit une extension de MIE: la
"Host Resources MIB", qui permet l'administration SNMP des divers objets considérés
comme ressources d'un ordinateur. L'article de S. Wa1dbusser [WAL 93] en donne une
description plus informelle et plus abordable que les définitions ASN.1 du RFC.
La "Host Resources MIB" définit six groupes:
- system group: permet de décrire un certain nombre de paramètres de configuration de la
machine: nombre d'utilisateurs, description des objets nécessaires au démarrage de
l'ordinateur dans le cas de machines sans disque ou de terminaux X, etc.
- storage group: définit les paramètres décrivant les snpports d'enregistrement de la
machine: disques, mémoire vive, etc.
- devices group: concerne les périphériques connectés: imprimantes, scanners, etc(a).
- running software group: décrit les informations générales concernant les logiciels· actifs,
c'est-à-dire en cours d'exécution.
- running software peiformance group: complète le groupe précédent en décrivant les
informations relevant des pe/formances des logiciels actifs.
- installed software group: décrit l'ensemble des logiciels installés, actifs ou non.
Comme nous pouvons le remarquer, l'orientation de cette MIE est axée principalement sur les
supports de mémorisation (disques magnétiques, bandes, etc) et sur les logiciels en place. En
revanche, nous relevons la pauvreté de la description des ressources utilisateurs (comptes,
répertoires de travails, etc) ; seul le nombre d'utilisateurs est définie dans cette MIE.
Network services monitoring MIB
Les travaux les plus récents d'extension des objets administrables via SNMP tendent à
pouvoir gérer des objets de plus en plus complexes. En janvier 1994, S. Kille et W.G. Chair
co-publient le RFC 1565, première spécification d'une MIE d'administration des applications
réseaux. Ce document met en garde les lecteurs sur la difficulté de définir une MIE commune
pour tous les types d'applications réseaux. Ainsi, le RFC s'applique plus spécifiquement aux
deux applications choisies comme exemples: les programmes de traitement des messages du
(a) La MIB-II décrit déjà partiellement un certain nombre de paramètres propres aux périphériques réseaux
qui ne sont pas repris dans la "Host Resources MIB",
Administration des applicatifs réseaux 61

1.3 Administration des dépendances de services applicatifs
courrier électronique ou MTA (Message Transfer Agent) et les programmes de l'annuaire
x,SOO(a) (DSA : Directory Service Agent).
Pour décrire les informations d'administration des applications réseaux, la MIE définit trois
classes de données:
- une table de tous les services réseaux administrables,
- des paramètres généraux à propos de chaque service (numéro de version, date
d'initialisation, etc),
- des informations sur l'état de chaque application (nombre de connexions courantes, taille
des files d'attentes, etc).
Il faut noter que la "Network services monitoring MIB" permet d'administrer non pas
seulement les applications issues des réseaux TCPIIP, mais également celles des réseaux OS!.
Ces publications permettront à moyen terme un réel développement des outils
d'administration des applications réseaux, mais il est nécessaire d'attendre au moins encore
une année (voire deux) pour trouver les premiers équipements implantant de tels MIE.
3.2.1.3. L'administration des applications dans le modèle OSI
La normalisation est un travail de longue haleine. Comme le soulignent certains auteurs (M.
Rose dans "The Open Book" [ROS 89], C. Lecerf et D. Chomel dans "Les normes de gestion
de réseaux à ['ISO" [LEC 93]), autant les spécifications d'objets d'administration pour les
couches les plus basses du modèle OSI (couche physique, liaison, réseau et transport) sont
nombreuses (presque à l'excès), autant tout reste à faire pour les couches les plus hautes. La
norme ISO N14ü4 en cours d'élaboration (2WD(b)) doit permettre la gestion des logiciels de
communication (configuration et contrôle de l'utilisation). Cette norme introduit deux classes
d'objets pour décrire un logiciel:
- Software managed object class : il s'agit de la classe d'objets qui décrit les logiciels en tant
que fichiers,
- Program descriptor object class : il s'agit de la classe d'objets qui décrit les logiciels en
tant que programmes en cours d'exécution.
Voici les principaux attributs communs à ces classes: le nom, le numéro de version, l'adresse
de stockage dans la mémoire, la relation de dépendance avec des matériels ou des logiciels, les
paramètres de lancement, les droits d'accès, etc.
Les opérations sur ces classes sont entre autres: la lecture de la configuration (enquire), la
suspension de l'activité du logiciel (suspend), l'arrêt du logiciel (hait), etc.
(a) X500 est une norme conjointe du CCITf [X500j et de "ISO [ISO 9594]. Elle décrit la structure logique
de la base d'informations pour un annuaire généralisé.(b) Les normes ISO suivent un cycle d'élaboration avant leur version définitive. Le sigle 2WD signifie qu'il
s'agit de la deuxième version préliminaire.
62 Administration des applicatifs réseaux

Administration des dépendances de services applicatifs
3.2.1.4. Travaux d'extension du modèle osr et SNMP pour l'administration des services
applicatifs réseaux
1.3
Un des aspects qu'il est nécessaire de souligner, aussi bien dans la gestion d'applications par
le modèle osr que pal' le modèle SNMP, est la difficulté à décrire les relations entre les objets
administrés dans de tels modèles. Or l'administration des services réseaux, et encore plus de
leurs interdépendances, nécessite de gérer les relations entre les objets: les relations entre
clients et serveurs, entre ressources et ordinateurs, entre utilisateurs et ordinateurs, etc. Dans le
modèle osr, une relation est spécifiée par un attribut sur les deux objets liés, ce qui soulève les
problèmes de cohérence entre les attributs des objets liés et la difficulté d'exprimer des
relations multiples. Plusieurs auteurs soulignent cette carence [CLEM 93], [BAP 93], [Sm 93]
et proposent plusieurs extensions au modèle. La solution la plus courante, proposée entre
autres par A. Clemm dans son article "Incorporating Relationships into OSI Management
Information ", repose sur la spécification d'objets de relation ayant ses propres attributs et ses
propres méthodes. Une extension à la norme d'administration osr [rSO N139ü]est en cours
d'élaboration pour traiter le problème des relations entre objets.
Pour SNMP, il n'existe, tout simplement, pas de moyen simple de spécifier les relations.
L'administration des services réseaux pose un deuxième problème qui consiste à repérer
chaque instance d'objet de manière unique et à la localiser sur le bon équipement. Le modèle
osr se base sur l'utilisation de DN (Distinguished Names) pour nommer chaque objet
(présenté au paragraphe 2.3.2.2 - page 32). Mais certains auteurs dont M. Sylor dans son
article "Junction Objets - A solution to a problem in naming and locating OSI managed
objects", soulignent que cette recommandation ne suffit pas pour lever toutes les ambiguïtés
sur le repérage de l'instance de l'objet en question. Il propose l'utilisation conjointe du
système d'annuaire normalisé "The Directory,,(a) avec l'administration OSr. L'idée essentielle
est de répertorier les objets à administrer dans l'annuaire, car celui-ci dispose de mécanismes
plus adaptés pour le repérage des équipements. Il ne s'agit pas tant d'utiliser l'annuaire
comme une base de données pour l'administration osr, mais pour résoudre le problème de la
localisation des objets gérés.
Conune nous le soulignions pour l'administration des applications sous SNMP, la définition
des objets liés à l'administration des services réseaux applicatifs n'apparaît que depuis un ou
deux ans, et les travaux pour étendre les modèles d'information à certains problèmes, dont
ceux liés à l'administration de réseaux, sont encore en cours d'élaboration. Il faudra attendre
encore quelque temps pour trouver des implantations de tels systèmes. C'est pourquoi les
<a) Plus géuéralement connu sous l'appellation de la norme CCrIT qui le décrit: X500.
Administration des applicatifs résealO: 63

1.3 Administration des dépendances de services applicatifs
solutions constructeurs et utilisateurs restent pour l'instant, l'unique possibilité pour un tel
domaine d'administration. Ainsi pour tenter d'offrir la vue la plus complète possible de l'état
de l'art de l'administration des services applicatifs réseaux, nous présentons deux solutions
non-standards. Tout d'abord, nous exposons le système de gestion de configuration proposé
par le constructeur informatique Sun; nous décrivons ensuite la solution développée par
Alcatel Business Systems pour la gestion des indisponibilités de ses applications
informatiques.
3.2.1.5. Un modèle constructeur: NIS
La société Sun, face à l'absence de solution globale pour le stockage des informations de
configuration des stations de travail a choisi de développer et commercialiser son propre
système: le NIS(a) (Network Information Service). Ce système d'informations est largement
implanté par les autres constructeurs concurrents sur le parc des machines basées sur le
système Unix. La structure de NIS est décrite dans l'article de D.K. Hess, DR Safford et
U.W. Pooch: UA Unix Protocol Security Sttldy: NetIV01* Information Service" [HES 90]. Le
détail complet du système NIS est spécifié dans le document de référence [SUN 91] fourni par
le constructeur Sun.
NIS a été mis en place afin qu'un parc de machines puisse partager les mêmes fichiers de
configuration. Il s'agit notamment des fichiers concernant les adresses des autres machines,
une partie de leur configuration et des paramètres propres aux utilisateurs.
Description de NIS
NIS est construit sur une architecture de bases de données dupliquées. Un serveur maître,
responsable des informations qu'il détient, met à jour cycliquement une série de serveurs
esclaves par duplication de ses données. Le modèle d'intel1'ogation est basé sur les notions
habituelles de clients/serveurs, à cela près qu'en l'occurrence il ne s'agit pas d'un unique
serveur, mais de serveurs dupliqués.
(a) Le NIS était appelé "Yellow Pages" dans les versions antérieures et rebaptisé NIS suite à un procès entre
Sun et British Telecom pour usurpation du nom de l'annuaire anglais des télécommunications.
64 Administration des applicatifs réseaux

Administration des dépendances de se/l'ices applicatifs 1.3
Clients NIS
Schéma 11 .. Structure des NIS
NIS gère divers types d'objets dont nous donnons les principaux:
-les utilisateurs, leur mot de passe et divers autres paramètres (passwd),
-les groupes d'utilisateurs (group),
-les protocoles acceptés par les machines (protocols, services),
-les machines (hosts).
Nota: Il faut cependant noter que le mécanisme qu'offre NIS ne se restreint pas aux types
d'objets cités. Il est tout à fait envisageable d'utiliser NIS pour partager d'autres types de
données tels des tables de logiciels, etc. La seconde version des NIS, rebaptisée NISPLUS et
diffusée avec le nouveau système d'exploitation Solaris 2.x de Sun, ajoute par exemple des
informations sur les montages de disques distants.
Nous voyons que NIS permet une certaine forme d'administration des applications réseaux,
car il manipule des données concernant les configurations et les utilisateurs. C'est sans doute
la forme d'administration la plus employée actuellement(a). Cependant, comme nous J'avons
présenté dans le premier chapitre de cette première partie, l'administration des services
réseaux ne consiste pas uniquement en J'administration des configurations logicielles et
matérielles. Il est intéressant de pouvoir décrire l'interaction du réseau sur les applications.
(a) Cette forte implantation s'explique principalement par l'importance du parc des stations de travail
utilisant NIS et par les liens entre NIS et NFS.
Administration des applicatifs réseau.'C 6S

1.3 Administration des dépendances de services applicatifs
Nous présentons un deuxième système, mais cette fois-ci développé par un utilisateur de
l'informatique: Alcatel Business Systems, qui intègre la notion d'interdépendance entre
applications réseaux.
3.2.2. Une solution utilisateur précurseur
Le centre de production de Strasbourg du groupe Alcatel Business Systems est en train
d'élaborer une solution d'administration des services réseaux [MAU 93] sous la direction de
P. Potters. Ce projet a débuté en 1991 et s'inscrit dans un projet plus large de suivi des projets
informatiques. Il s'agit de quantifier la disponibilité des ressources à la fois matérielles et
applicatives du Centre d'Informatique de la firme. L'idée repose sur la nécessité de pouvoir
mesurer les taux de service des utilisateurs afin de leur refacturer les coOts, et sur l'intérêt de
pouvoir évaluer les temps d'indisponibilité des services réseaux et d'en déduire les manques à
gagner.
Quatre problèmes ont du être surmontés:
- spécifier une définition de l'indisponibilité,
- définir les données qui permettent le calcul de l'indisponibilité,
- établir un système de nommage des ressources et des équipements,
- donner un modèle des dépendances entre les divers équipements.
Les solutions retenues sont toutes propriétaires et ne s'appuient sur aucune norme ou standard
d'administration de réseaux.
3.2.2.1, Le modèle de données
L'idée est de définir deux classes de données élémentaires: les indisponiblités planifiables et
celles qui ne le sont pas. On compte dans les indisponibilités planifiables les installations de
nouvelles versions de logiciels ou de systèmes d'exploitation, les ajouts de matériel
périphérique tel un disque, les sauvegardes régulières, les restructurations des données
système (défragmentation des disques, modification des arborescences des systèmes de
fichiers, etc). Il s'agit des opérations de maintenance qui nécessitent l'arrêt de j'ordinateur ou
son utilisation exclusive par l'administrateur. D'autre part, les indisponibilités non planifiables
sont les pannes (électriques, mécaniques, etc), non prévisibles bien évidemment.
De ces deux classes sont définis ce qu'ils appellent des "atomes d'indisponibilité brute"
associés à chaque ressource, chaque applicatif, chaque équipement. Un système assez simple
de dénomination est établi pour distinguer chaque élément (chaîne de caractères unique).
Chaque "atome d'indisponibilité" est muni d'une date et heure de début et de fin dans le but de
pouvoir obtenir des données d'indisponibilité en fonction du temps.
66 Administration des applicatifs réseaux

Administration des dépendances de selvices applicatifs 1.3
En fonction de la configuration matérielle et logicielle, des règles de "propagation des
indisponibilités" sont définies dans un langage défini pour la cause. Dans le tableau suivant,
nous donnons quelques unes de ces règles:
CENTREINFO -> CLUSTERl + CLUSTER 2 + CLUSTER_DEVT+ CLUSTER_SII1U + CLUSTER_EVAL + NESTOR + SUNCIS
[COUPURE;CLUSTER1] -> CLUSTERl
[CLUSTER1] -> RANSES + MERLIN + DAPHNE + GASTON + PLUTON
[INGRESV6;CLUSTER1] -> [INGRESV6;RANSESJ + [INGRESV6;MERLIN]+ [INGRESV6;PLUTON] + [INGRESV6;GASTON]
Celles-ci sont à lire de la façon suivante: "CLUSTERI -> RAMSES + MERLIN + ..." signifie
qu'une indisponibilité sur le Cluster de Vax nommé par "CLUSTERI" engendre
l'indisponibilité des équipements (ici des ordinateurs) nommés "RAMSES", "MERLIN", etc.
La notation "[INGRESV6;RAMSES]" doit permettre de savoir sur quels ordinateurs sont
installés les logiciels.
3.2.2.2. Les mécanismes mis en œuvre
Le système de gestion de la disponiblité des services réseau en cours d'élaboration repose sur
une base de données centrale appelée SAR (System Availability Reporting), qui est implantée
sous le gestionnaire Oracle. La description des règles de "propagation des indisponibilités" est
donnée dans un simple fichier texte et la signalisation des incidents utilise la voie prévue dans
l'entreprise à cet effet (notification téléphonique avec quantification de l'importance de la
panne en fonction des inconvénients visibles qui en découlent). Ces incidents viennent
s'ajouter aux indisponibilités planifiées et sont directement insérés dans la base de données par
les outils Oracle. Un moteur de propagation basé sur le principe du "moteur d'inférences" des
systèmes experts a été développé sur mesure. Il permet d'analyser les données de la base SAR
concernant les indisponibilités.
3.2.2.3. Les résultats obtenus
Six types de rapports sont produits par le système de calcul des indisponibilités qui décrivent
des points de vues complémentaires:
- Le rapport d'exceptions: il décrit les indisponibilités et les taux de services anormaux
(c'est-à-dire non prévus à l'avance).
- Le rapport global: il indique les taux d'utilisation en fonction du temps.
- Les rapports de configuration pour certains éléments critiques: il s'agit de la description
des règles de propagation qui concernent directement ces éléments.
Administration des applicatifs réseau.},; 67

1.3 Administration des dépendances de services applicatifs
- Les rapports de domaine: ils regroupent les informations qui concernent un domaine
particulier de l'entreprise.
- Les rapports d'éléments: ils synthétisent les informations d'utilisation et d'indisponibilité
d'un élément donné.
- Les rapports financiers globaux ou spécifiques: ils établissent le coût d'un service, d'un
équipement.
3.2.2.4. Evaluation du modèle
Ce système d'administration des services réseaux en vue de calculer les indisponibilités qui
en découlent est précurseur en la matière et relativement limité. En effet le modèle proposé par
Alcatel Business Systems repose sur une hypothèse qui nous semble fragile, à savoir que la
configuration matérielle et logicielle, qui donne lieu à l'élaboration des règles de propagation
des indisponibilités, est donnée "à la main" par l'administrateur réseau. Pour peu que celui-ci
oublie par exemple que tel logiciel se trouve sur tel disque, les règles ne décrivent plus les
dépendances réelles et les résultats calculés n'ont plus de sens. D'autre part, la notion
d'utilisateur des ressources n'est pas réellement définie, il s'agit plutôt des groupes
d'utilisateurs de chaque machine. Les rapports de domaine seront, par exemple, impossibles à
produire s'ils reposent sur des groupes d'utilisateurs qui ne travaillent pas nécessairement sur
une même machine. Enfin, le langage développé pour décrire les règles de propagation nous
semble pauvre et mal adapté à la description de l'ensemble des cas qui peuvent se présenter.
Ce modèle souligne cependant l'importance que peut revêtir l'administration des applications
et des ressources, et la carence actuelle dans ce domaine. L'investissement qu'Alcatel
Business Systems concède à ce secteur est, à notre sens, un argument significatif.
Nous proposons dans la deuxième partie de notre thèse un modèle qui s'approche quelque peu
de celui-ci. La finalité en est la même, nous essayons cependant de traiter de manière plus
générale les éléments qui entrent en jeu dans l'administration des dépendances entre services
réseaux applicatifs.
68 Administration des applicatifs réseaux

Administration des dépendances de services applicatifs
Conclusion
1
Nous l'avons vu, l'administration de réseaux est un domaine qui met à contribution différents
acteurs : laboratoires de recherche, organismes de normalisation, mais aussi constructeurs et
utilisateurs finaux. C'est pourquoi présenter un "état de l'art" a nécessité d'aborder le
problème sous différents angles d'approche. Après avoir reprécisé le rôle et la finalité de
l'administration, il a été nécessaire de faire un large tour d'horizon pour décrire l'ensemble
des travaux dans ce secteur. Nous avons choisi pour cela de présenter l'architecture générale
d'un système d'administration, et pour chacune de ses composantes d'exposer les différents
travaux actuels. Nous avons ainsi mis en exergue l'importance des deux grands modèles que
sont l'administration OS1 et l'administration SNMP. Nous avons relevé leurs différences
théoriques et leur cadre d'application respectif. Nous avons souligné l'hégémonie d'un
modèle SNMP relativement simpliste, en opposition avec un modèle OS1 définissant une
administration plus complète, mais encore peu implantée. En marge de ces deux modèles,
nous avons présenté des travaux parallèles: certaines méthodes d'interrogation non standard,
et les protocoles d'administration à publication.
Le cadre de travail ayant été posé, nous nous sommes attaché à décrire notre secteur spécifique
de recherche, à savoir l'administration des dépendances entre applicatifs réseaux. Après avoir
précisé ce que nous entendions par "applications réseaux", nous avons relevé le caractère
récent de ce domaine et avons exposé les développements prometteurs - des modèles SNMP,
OS1 et autres - qui appréhendent la gestion des applications et de leurs interdépendances. Il
s'agit d'une part des extensions du modèle d'administration OS1 pour prendre en compte les
"relations" entre les objets, et d'autre part, des spécifications de nouvelles MIE SNMP pour la
description des éléments qui entrent en jeu dans l'administration des dépendances réseaux.
Nous avons également présenté certains projets et travaux moins récents, mais attenants à
notre sujet de thèse: Moira du projet Athéna, et le système des NIS. La présentation de cet
"état de l'art" s'est achevée sur l'exposé d'un modèle précurseur d'administration des
ressources. Celui-ci a des finalités similaires à celles du modèle que nous allons présenter dans
la deuxième partie de notre thèse.
Administration des applicatifs réseau.," 69


Partie II
Un modèlepour l'administration
des applications'"reseaux
Administratioli des applicatifs réseaux 71


Comme nous le présentions dans le chapitre précédent, un des domaines de l'administration
encore peu exploité est, entre autres, tout ce qui concerne la gestion des services applicatifs, et
principalement dans un contexte de réseaux hétérogènes.
Le sujet de notre thèse est d'élaborer un modèle de données dans ce domaine particulier, de
montrer les résultats que l'on peut en tirer et d'en souligner la validité en réalisant son
implantation. Dans cette deuxième partie, nous exposons les deux premiers points - le modèle
de données et les résultats déduits - et présentons, dans la dernière partie de la thèse,
l'implantation du modèle en question en vue de sa validation.
Trois aspects vont être traités. En premier lieu, nous présentons notre modèle de données sous
un angle formel grâce au formalisme mathématique des ensembles et des applications
multivoques. Nous modélisons ainsi les éléments du réseau, leurs relations, ... bref, tout ce qui
nous est apparu nécessaire à la description des services applicatifs d'un réseau informatique
hétérogène. Ce modèle, dans sa description formelle, a été présenté auparavant au Colloque
Francophone de l'Ingénierie des Protocoles [FER 93].
Dans un deuxième temps, nous nous attachons à décrire les concepts informatiques de mise en
œuvre d'un tel modèle à savoir les principes d'acquisition des données, de leur mémorisation
et de leur exploitation, nous détaillons certains algorithmes qui nous ont été nécessaires. Nous
exposons également le diagramme de la base de données relationnelle qui nous permet de
"plonger" notre modèle formel dans un modèle "informatique".
Enfin, nous terminons cette deuxième partie en exposant les résultats que l'on obtient d'un tel
modèle. Nous reprenons pour cela les cinq aires fonctionnelles définies par l'ISO et exposons
pour chacune d'elles, un ou plusieurs résultats relevant du domaine en question. Les deux
résultats les plus importants sont l'estimation de la fiabilité d'lIIl se/vice réseau et la mesure
de l'impact d'un ordinateur ou d'un équipement sur l'ensemble des services réseaux. Nous
exposons également une méthode de recherche des aberrations de configurations concernant
les applications dans certains cas d'interblocages, une analyse de la sécurité des ressources,
Administration des applicatifs réseaux 73

II.
une proposition de règle de répartition des cOLÎts engendrés par l'exploitation d'un réseau et
enfin une méthode d'évaluation des périodes de charges des ordinateurs.
Cependant, avant d'exposer notre modèle et ses résultats, il nous semble nécessaire de préciser
le plus finement possible la finalité de ce modèle et, également, d'en définir le contex'e
d'application. Nous commençons donc cette deuxième partie en donnant le cadre d'utilisation
du modèle et, notamment, nous posons les hypothèses de travail incontournable dans toute
modélisation pour garder une complexité "raisonnable" et exploitable,
74 Administration des applicatifs réseQlL\·

Hypothèses et finalité du modèle
4. Hypothèses et finalité du
modèle
4.1. Finalité du modèle
n.4
Nous avons abordé l'élaboration de notre modèle de façon assez pragmatique en partant des
problèmes courants de gestion des services réseaux rencontrés par l'administrateur ou les
utilisateurs d'un réseau. Nous classons ceux-.ci en deux catégories complémentaires: les
problèmes de dépendances et les problèmes d'impacts. Comme nous le disions en
introduction de cette thèse, la tendance actuelle à une architecture décentralisée et
l'hétérogénéité des réseaux engendrent des phénomènes de dépendances entre applicatifs
réseaux de plus en plus difficiles à administrer. Ce.ci est d'autant plus net si le réseau est de
taille importante. L'exemple- présenté à la page 58 - des conditions nécessaires à la
consultation du courrier électronique à partir d'un terminal X illustre bien l'importance des
dépendances mises en jeu même pour un service réseau courant.
Nous définissons et illustrons les deux catégories de problèmes de gestion des services
réseaux: dépendances et impacts.
La gestion des problèmes de dépendances consiste à établir, contrôler et mesurer les éléments
réseaux nécessaires à l'établissement d'un service applicatif.
?•
Probtèmede ta dépendanceau réseau
Schéma 12 : lIIustration des problèmes de dépendances des services réseaux
Administratioll des applicatifs réseau.t: 75

II.4 Hypothèses et finalité du modèle
La gestion des problèmes d'impacts relève de la mesure de l'importance qu'a sur l'ensemble
des services applicatifs l'état d'llll élément du réseau.
Problème de l'impactsur le réseau
Schéma 13 : IlIuslration des problèmes d'impacts sur les services réseaux
Ainsi, la finalité du modèle de données, que nous présentons formellement dans le chapitre
suivant, est la description - au moyen d'un graphe particulier - des objets et des dépendances
inter-objets qui sont nécessaires au fonctionnement des services applicatifs d'un réseau
informatique hétérogène. C'est ce graphe qui est le véritable base de nos travaux, car nous le
spécifions de telle sorte qu'il modélise toutes les informations nécessaires à une gestion aisée
des applications réseaux; il peut être exploité dans les différents domaines habituels de
l'administration de réseaux (gestion de la configuration, des anomalies, des performances, des
informations comptables et de la sécurité - cf. 1.1.3 - page 12).
De ce graphe, nous déduisons un certain nombre de résultats spécifiques, que nous exposons
dans le dernier chapitre de celle deuxième partie (chapitre 7 - page 132). Nous proposons
ainsi:
- une méthode de calcul de la fiabilité des services réseaux,
- une méthode de calcul de l'impact des équipements sur l'ensemble des services réseaux,
- une méthode de localisation des configurations d'interblocages,
- une évaluation de la charge des ordinateurs,
- une méthode d'aide à la recherche des causes de dysfonctionnements.
- une méthode de calcul de la sécurité des ressources,
- une évaluation des coats financiers des services,
Nous exposons dans le paragraphe suivant le contexte d'application du modèle que nous
définissons: Quels types de réseaux peuvent être décrits par le modèle présenté?
76 Administration des applicatifs réseafLl:

Hypothèses et finalité du modèle
4.2. Contexte d'application du modèle
Il.4
Le contexte d'application du modèle que nous définissons est celui de réseaux de tailles
moyennes comme peuvent l'être les réseaux d'interconnexions de sous-réseaux locaux. Il
s'agit typiquement de réseaux d'entreprise ou de campus qui utilisent les technologies
désormais courantes Ethernet, TokenRing, etc. Il n'y a pas de réel intérêt à appliquer notre
modèle à un réseau de trop petite taille (un segment Ethernet par exemple), qui ne nécessite
pas réellement d'administration des services réseaux car ils sont relativement peu nombreux.
Par contre, notre modèle peut s'appliquer à un réseau de forte étendue géographique.
Cependant, il faut noter que les facteurs qui engendrent les dépendances entre services
applicatifs réseaux (principalement les montages de disques distants et les passerelles
logicielles) sont peu utilisés dans ce cas. D'autre part, le nombre de services et d'applications
gérés doit rester dans des limites exploitables, comme nous le soulignons dans le paragraphe
suivant traitant des hypothèses de travail.
La validation du modèle a été réalisée, quant à elle, sur le réseau de campus de l'Université
des Sciences Humaines de Strasbourg dont une description est donnée dans la troisième partie
de notre thèse. Il s'agit d'un réseau réparti sur deux sites géographiques comportant un peu
moins de deux cents nœuds (ordinateurs, équipements réseaux) et qui utilise principalement
deux familles de protocoles: TCPIIP et AppleTalk.
Polir élaborer notre modèle, il nous a fallu poser certaines hypothèses de travail que nous
allons présenter dans le paragraphe suivant.
4.3. Hypothèses de travail
Comme nous l'avons énoncé, le but affiché est de décrire le plus finement possible les
relations entre les objets qui participent au fonctionnement des services réseaux applicatifs.
Cependant, une des difficultés immédiates est de conserver un modèle dont la quantité de
données garde des proportions raisonnables(a). Il s'agit donc, nécessairement, d'une certaine
forme de péréquation entre précision et exploitation. Nous avons donc posé un certain nombre
d'hypothèses qui, tout en étant réductrices, conservent les propriétés du modèle que nous
voulons gérer.
(a) En informatique. on peut assimiler la périphrase "proportions raisonnables" à la notion de quantité dedonnées exploitables par un ordinateur.
Administration des applicatifs réseaux: 77

II.4 Hypothèses et finalité du modèle
Nous partons de l'observation suivante: la majorité des problèmes d'administration des
services réseaux applicatifs ne relèvent pas de la gestion des protocoles sous-jacents. Nous
pouvons étayer ce constat par l'étude du système d'administration du projet Athena
[CHA 90] (cf. 3.2.1.1 - page 59) ; alors qu'il permet la gestion de l'ensemble des applications,
aucune référence au type et aux informations des protocoles sous-jacents n'est nécessaire(a).
Ainsi, la nature des objets que nous modélisons est déduites d'une part du constat que nous
venons d'énoncer, et d'autre part de l'étude faite sur trois ans d'exploitation du réseau de
campus de l'Université des Sciences Humaines de Strasbourg. Nous soulignons qu'il s'agit de
problèmes d'exploitation et non de mise en œuvre de nouveaux services.
Le tableau ci-dessous montre que les problèmes les plus courants qui affectent les services
applicatifs sont avant tout planifiables car ils concernent la maintenance pour plus des trois
quarts d'entre-eux (79%). D'autre part, les pannes et incidents, par nature imprévisibles, sont
dûs pour la moitié (49%) à des erreurs de configurations (paramètres réseaux ou logiciels).
Enfin nous soulignons le niveau de fiabilité des cartes électroniques des équipements
informatiques actuels.
Nota: Dans le tableau ci-dessous la colonne de droite indique le nombre d'occurences sur une
période de deux ans. Les lignes concernant les problèmes planifiables sont grisées.
Pannes d'électricité 12
Coupures volontaires d'électricité 4
Systèmes d'alimentation hors service 4
ii:lSystèmes pédphériques (disques, imprimantes) hors service 7
ii: Cartes électroniques hors service (CPU, cartes graphiques ou d'entrées!1l!:! sorties, bancs mémoires, etc)
~ Ecrans ou claviers hors service 4
Ruptures ou déconnexions des médiums 15
ReS(ructurations ou maintenance du réseau 6
Equipements réseaux hors service (répéteurs, transceivers, etc) 3
(a) A l'exception des adresses réseaux des ordinateurs.
78 Administration des applicatifs réseaux

Hypothèses et finalité du modèle U.4
Systèmes de stockage saturés 12
Erreurs de configuration réseau (adresses réseaux, masques, routeurs pardéfaut, etc)
30
Erreurs de configuration des protocoles (tables de routages, filtres, etc) 4
25Erreurs de configuration logicielle (droits d'accès, exportations ouimportations de données mal déclarées, etc)
Mises-à-jour des logiciels et systèmes d'exploitation (nécessitant l'arrêt de 1 .
l'ordinateur) 1
Restructuration des données et des disques (nécessitant le fonctionnement 1 .
en mode de maintenance de l'ordinateur) 1
Sau~'eg,'rde:s eot' ' . . le L •• .A.· 1-. .A~~:~'H:«5v. . l;5U'Uv" 1
Thbleau 2 : Répartition des problèmes affectalll les services applicatifs
Pour couvrir plus de 90% des problèmes liés à l'exploitation courante des applications
réseaux, il nous faut modéliser les objets suivants:
- les ressources (disques, périphériques, etc),
- les ordinateurs,
-les logiciels réseaux.
Nous appréhendons plus de 98% des problèmes si nous ajoutons à notre modèle:
- les utilisateurs,
-les équipements réseaux (médiums, répéteurs, etc).
De cette étude nous posons notre première hypothèse de travail :
L'administration des objets suivants: ordinateurs, ressources,
logiciels réseaux, utilisateurs et équipemellts réseaux suffit à
gérer la grande majorité des problèmes de l'administration des
services applicatifs réseaux. Par conséquent, notre modèle ne
s'appuie pas sur la définition et la gestion
des protocoles sous-jacents.
Notre deuxième hypothèse de travail repose sur les travaux de F. Schneider [SCH 83], L.
Lamport, S. Robert et P. Marshall [LAM 82] pour écarter les problèmes de fonctionnements
dégradés. Il s'agit des cas où un élément présente des dysfonctionnements partiels ou
passagers qui n'empêchent pas la réalisation du service mais en dégradent la qualité. Il s'agit
des cas de pannes certainement les plus difficiles à isoler et à repérer, mais dont la fréquence
Administration des applicatifs résemü: 79

II.4 Hypothèses et finalité du modèle
est relativement peu élevée et les conséquences de moindre importance, comme le soulignent
les auteurs précités. Nous ne traitons, dans notre modèle, que des cas francs :
Un objet modélisé ne peut avoir que deux états
defonctionnement: "en service" ou "hors service".
D'autre part, notre modèle s'attache à définir les services réseaux qui peuvent se décrire sous
le mode client-serveur (notion que nous avons présentée au paragraphe 3.1.1 - page 52). Les
services de ce type forment la grande majorité des services applicatifs réseaux actuels. Notons,
cependant, que certains services réseaux récents tels TooITalk(a) ou les systèmes de disques
miroirs(b) utilisent un modèle plus complexe du type client-mu/tiserveurs. Son principe repose
sur le fait qu'il ne s'agit plus d'une simple relation binaire (un client est "servi" par un serveur,
non désigné au préalable, d'un groupe de serveurs donnés). Ceci pose la troisième hypothèse
de notre modèle:
Les services réseaux élémentaires décrits dans notre modèle
doivent pouvoir être définis sous forme de relations binaires de
type client-servetll:
La quatrième hypothèse peut paraître évidente. Nous supposons que si tous les objets
nécessaires à· un service réseau - fonctionnent correctement, alors le service fonctionne
également. Ceci définit notre quatrième hypothèse:
Notre modélisation s'applique à des réseaux dont la
configuration est correcte.
Enfin, nous reprenons la même hypothèse de travail que celle utilisée dans le modèle de calcul
des indisponiblités développé par Alcatel Business Systems (cf. 3.2.2 - page 66) quant à la
gestion temporelle. Les services réseaux traités reposent sur des informations de configuration
à durée de vie(c) longue (supérieure à la journée). Cette hypothèse n'est pas particulièrement
(a) ToolTalk est un système d'appels de procédures dépo11ées basés surIes RPC (Remole Procedure Cali) qui
autorise plusieurs serveurs simultanés. Il est développé par la société Sun.
(b) Le principe des disques miroirs consiste à dupliquer l'information stockée afin d'éviter les pertes
accidentelles.
(e) Cf. note a - page 45.
80 Administration des applicatifs réseau:<

Hypothèses et finalité du modèle n.4
réductrice car elle englobe la grande majorité des services réseaux applicatifs. D'autre part,
l'utilisation d'un service réseau est planifiable dans le temps et peut être muni de fenêtres de
validité. Celles-ci délimitent les plages horaires pendant lesquelles le service réseau doit être
assuré car susceptible d'être utilisé. Cette hypothèse n'est pas nécessaire au modèle mais
permet d'étendre de manière significative ses résultats.
Le modèle est défini pour gérer des services réseaux dont
l'évolution de la configuration est lente (de l'ordre de la
joumée) et qui peuvent être planifiables.
Ces cinq hypothèses vont nous permettre de définir un modèle dont la quantité de données
reste exploitable et qui conserve, cependant, les propriétés que nous voulons traiter.
4.4. Présentation informelle du modèle
Nous avons posé les hypothèses de travail, nous présentons maintenant de manière informelle
les concepts de notre modèle avant de le définir formellement dans le chapitre suivant. L'idée
clé est de considérer qu'un service applicatif réseau peut être modélisé sans tenir compte du
contenu des messages échangés entre les serveurs et les clients pour un service réseau. Suivant
cette approche, nous allons poser les trois définitions des entités suivantes:
- Le service réseau élémentaire: il s'agit de la "brique" de base du modèle. Il décrit les
objets et les relations qui entrent en jeu pour l'établissement d'un service réseau le plus
simple.
- Le service réseau: il permet de regrouper des ensembles de services réseaux élémentaires.
- Le service réseau en cascade: il permet de modéliser les dépendances entre les services
réseaux élémentaires.
La dernière définition est le cœur de notre modèle. Elle permet de modéliser la notion
fondamentale qui est - comme nous allons le voir en détail par la suite - le fait qu'une
ressource ne se trouve pas nécessairement sur l'ordinateur prévu, mais peut être déléguée à un
ordinateur tiers. Le cas typique traité est le fait qu'un logiciel participant à un service réseau
est localisé sur un support magnétique (c'est-à-dire que le logiciel peut être considéré, en
quelque sorte, comme une ressource au même titre qu'un périphérique) . Or le logiciel peut
être sur un disque local, mais également sur un disque déporté rendu accessible par un autre
service réseau (montage de disque distant par NFS par exemple). La problèmatique prend, dès
lors, toute son ampleur.
Administration des applicatifs réseaux 81

II.4 Hypothèses et finalité du modèle
Ces trois définitions nous permettent de construire le graphe global de dépendances déduit des
services réseaux que l'on désire modéliser. C'est de ce graphe particulier que nous déduisons
l'ensemble des résultats précédemment cités.
Avant de présenter formellement le modèle, gardons à l'esprit le schéma ci-dessous qui
illustre intuitivement le concept de base de notre modélisation: tout service peut être décrit
par un couple (nœud client, nœud serveur) :
Noeud client Noeud serveur
Schéma 14 : Illustration intuitive du cOf/cept de base du modèle
82 Administration des applicatifs réseaux

Description formelle du modèle
5. Description formelle du
modèle
ILS
Notre modèle se décompose en trois volets:
-la modélisation des services réseaux à proprement parler, sous forme d'association nœud
client - nœud serveur,
- la modélisation des équipements réseaux nécessaires à l'association des nœuds clients avec
les nœuds serveurs,
- l'augmentation du modèle en fonction du temps.
Pour décrire le modèle de données, nous adoptons une notation ensembliste classique en
mathématiques. Elle al' avantage de la concision dans la définition des graphes que nous
allons manipuler. Il s'agit du même formalisme qu'utilisent M. Gondran et M, Minoux dans
leur ouvrage sur l'étude des graphes "Graphes et algorithmes" [GON 85]. Par souci de
facilité de lecture, nous présentons notre modèle en le "complexifiant" peu à peu, pour prendre
en compte les différents concepts qui entrent en jeu dans la définition des services applicatifs.
Nous n'indiquons pas, dans la description formelle du modèle présentée ici, les moyens
d'acquisition des informations. Notre propos est de poser les bases logiques des relations et
objets nécessaires à l'établissement d'un service réseau, les méthodes d'observation de ces
objets étant traitées dans le chapitre suivant "Du modèle théorique au modèle informatique".
Nota : Les exemples proposés sont issus principalement du système d'exploitation Unix
(station de travail), mais également du Système 6 & 7 (Macintosh) et de MS/DOS
(Compatible PC).
Administration des applicatifs réseau.t: 83

fi .5 Descriptioll formelle du modèle
5.1. Modélisation des services réseaux
5.1.1. Les objets
Pour décrire les objets qui participent à un service réseau, nous définissons quatre ensembles
finis :
- U: l'ensemble des utilisateurs,
- M : l'ensemble des machines,
- R : l'ensemble des ressources,
- P : l'ensemble des instances de programmes.
Un utilisateur est un identificateur unique d'une personne physique, par exemple le nom ou un
numéro d'identification (cet identificateur sera le même pour tout le parc de machines à
administrer).
Une machine est l'outil, en l'occurrence l'ordinateur, dont se servent un ou plusieurs
utilisateurs.
Une ressource est un objet physique que la machine sait piloter, par exemple, une imprimante,
un disque, bref un périphérique au sens le plus large.
Enfin, l'instance de programme est le complément indispensable à la machine pour réaliser
une action. Nous parlons d'instance de programme car il s'agit de chaque programme
mémorisé sur chaque machinera). Nous ne nous intéressons qu'aux instances de programmes
qui effectuentdes actions dans le domaine des services applicatifs réseaux, par exemple nfsd,
lpr, AppleShare, etc (voir le paragraphe 3.1.2.3 - page 56 pour la description des applications
réseaux d'une station de travail).
Nota : Pour faciliter la lecture, nous utiliserons dans la suite de notre thèse le terme
"programme" à la place de la périphrase "instance de programme". Il s'agira toujours
d'instance sauf mention contraire.
(a) Nous distinguons par la suite les instances de programmes stockées sur disques et les instances de
programmes en cours J'exécution (appelées processus ou daemon dans Je monde Unix).
84 Administration des applicatifs réseau..,.

Descriptionforlllelle du'modèle
5.1.2. Les applications de base
5.1.2.1. Les ressources d'une machine
ILS
Nous définissons une application r qui décrit les ressources gérées par une machine de
manière locale:
r: M~R (Eq.l)
Il s'agit d'une application multivoque c'est-à-dire que l'image d'un élément de M est un sous
ensemble de R et non un élément unique.
Cette application décrit la configuration de la machine (disques, périphériques, mais
également les comptes utilisateurs, les boîtes aux lettres, etc).
5.1.2.2. Programmes d'une machine
Nous définissons une application multivoque 1qui décrit les programmes d'une machine:
1: M~P (Eq.2)
Cette application représente le catalogue des programmes applications réseaux de la
machine. Il s'agit, en quelque sorte, de la configuration logicielle de l'ordinateur.
Nous insistons sur le fait qu'il s'agit d'associer les ordinateurs avec des instances de
programmes.
5.1.2.3. Programmes clients et programmes serveurs
Nous distinguons deux sous-ensembles des programmes, les programmes clients et les
programmes serveurs. Ces deux sous-ensembles ne sont pas nécessairement disjoints
(cf. 5.1.5.). Nous notons donc:
Pc Ensemble des programmes clients
Ps Ensemble des programmes serveurs
P=PsuPc(Eq.3)
Nous définissons l'application multivoque a qui définit les programmes clients dont le
protocole est "compréhensible" par un programme serveur:
(Eq.4)
Administration des applicatifs résemu: 85

ILS Descriptioll formelle du modèle
Cette application s'appuie sur la première hypothèse de notre modèle: elle nous permet
d'associer les programmes clients et serveurs sans décrire les protocoles internes utilisés. Le
terme de "compréhensible" signifie que le serveur est conçu pour comprendre les requêtes des
clients qui lui sont associées. Par exemple le programme serveur Popper destiné à la gestion
des boîtes aux lettres peut être interrogé par les programmes clients Eudora, PC_Eudora,
POPmail, Minuet, etc.
5.1.2.4. Ressources gérées par un programme serveur
Nous définissons l'application multivoque g qui décrit les ressources que sait gérer un
programme serveur:
(Eq.5)
Cette application indique, par exemple, que le programme serveur postmaster sait gérer les
bases de données de type POSTGRES, ou autre exemple, que le programme serveur lpd gère
les imprimantes et non pas les boîtes aux lettres.
5.1.2.5. Utilisateurs d'un programme client
Nous définissons une application multivoque ue qui décrit les utilisateurs autorisés d'un
progranune client:
(Eq.6)
Cette application détermine les utilisateurs qui ont le droit d'exécuter le programme client.
Dans le cas d'un système mono-utilisateur, tel un micro-ordinateur, tous les utilisateurs sont
autorisés puisque il n'y a pas de notion de droit d'exécution sur ce type d'équipement.
5.1.2.6. Utilisateurs d'un programme serveur
Nous définissons une application multivoque Us qui décrit les droits d'utilisation des
programmes serveurs. Il est nécessaire de préciser ce que l'on entend par "droits
d'utilisation". Nous nous posons la question: de quels éléments dépendent-ils? La réponse
n'est pas aussi directe qu'il y paraît. Alors qu'un progrannne client doit être lancé par
l'utilisateur (par exemple telnet sous Unix), un programme serveur s'exécute en tâche defond
sur la machine serveur (par exemple telnetd sous Unix). L'utilisateur n'a donc pas à exécuter
le programme. En revanche, il doit être reconnu et autorisé à l'utiliser. Ce droit dépend
généralement de l'identité de l'utilisateur du programme serveur. Bien qu'étant le cas le plus
86 Administration des applicatifs réseaux

Descriptiollformel/e du modèle 11.5
fréquent, il existe des services réseaux qui définissent les droits d'utilisation du programme
serveur non seulement en fonction de l'identité de l'utilisateur, mais également en fonction de
la machine cliente. Par exemple, sous Unix, l'application rshd (sur la machine serveur) vérifie
dans le fichier .l'hast les couples (utilisateur, machine cliente) qui ont le droit d'utiliser le shell
local. Enfin, on pourrait imaginer la notion de droits d'utilisalion en fonction du programme
client lui-même. Ne connaissant aucun exemple réel basé sur ce dernier cas, nous ne retenons
que les deux premiers principes; nous spécifions l'application multivoque Us afin qu'elle
définisse les couples (utilisateur local, machine cliente) autorisés à utiliser un programme
serveur.
(Eq.7)
5.1.2.7. Le réseau physique
Enfin nous définissons l'application multivoque n qui décrit l'existence de liens réseaux entre
machines:
n:M~M (Eq.8)
Cette application est détaillée dans le deuxième volet de notre modèle concernant la
description des équipements réseaux nécessaires à l'établissement d'un service.
5.1.3. Définition des services réseaux élémentaires
Nous avons défini les objets et les relations qui existent entre ces objets afin de pouvoir poser
les conditions nécessaires et suffisantes à l'établissement d'un service réseau que nous
appelons élémentaire. Pour cela, nous définissons, tout d'abord, les ensembles de Cet S que
nous nommons nœuds de services clients (resp. serveurs). Ils sont définis comme suit :
C = UxMxP
S = UxMxPxR
Ensemble des nœuds de services clients
Ensemble des nœuds de services serveurs
(Eq.9)
Administratioll des applicatifs réseaux 87

II.5 Descriptionformel/e dit modèle
Nous définissons, d'autre part, f: C ---7 S une application multivoque ayant les propriétés
suivantes:
Soit (x, y) E CxS décomposé en x= (xu,xM'xp)
et Y= (YU'YM'YP'YR)
Alors: y E f(x) ssi les conditions ci-dessous sont vérifiées:
i) xME Il (YM) YM E Il (xM)
ii) XpE Pc YpE Ps xp E a (Yp)
iii) XpE 1(xM) Yp E 1(YM)
iv) XUE uc(xp) (Yu'xM) E Us (Yp )
v) YR E g(yp)
vi) YR E r(YM)
(Eq.10)
L'ensemble des services réseaux élémentaires ç est, dès lors, défini de la façon suivante:
ç = {(X,Y)E CXSI YEf(x)}
5.1.3.1. Détail des conditions d'un service réseau élémentaire
(Eq.11)
i) Spécifie que les deux machines en question peuvent accéder mutuellement l'une
à l'autre.
ii) Spécifie que le programme serveur comprend le protocole du programme client.
iii) Spécifie que les programmes se trouvent effectivement sur les machines en
question.
iv) Spécifie, d'une part, que dans le noeud de service client, l'utilisateur peut
exécuter le programme client. D'autre part, que le couple (utilisateur du serveur
1machine cliente) est autorisé à utiliser le programme serveur.
v) Spécifie que les programmes serveurs accèdent à la ressource demandée.
vi) Spécifie qne la ressource demandée est gérée par la machine serveur.
Nota: Dans la grande majorité des cas, l'utilisateur de la machine cliente (xu) est identique à
celui indiqué pour la machine serveur (Yu)' Cependant, certains services autorisent le
"changement d'identité", c'est-à-dire que l'identité de la personne qni exécute le programme
client n'est pas la même que celle indiquée pour l'utilisation du programme serveur. Un
88 Administration des applicatifs réseaux

Descriptioll formelle du modèle 11.5
exemple courant est le service d'exécution à distance du système Unix (rsh) qui permet, grâce
à un paramètre de spécifier l'identité de l'utilisateur distant.
5.1.3.2. Exemple de service réseau élémentaire
Soit un utilisateur désirant consulter sa boîte aux lettres. Nous pouvons représenter ce service
réseau élémentaire par le graphique suivant:
(utilisateur, machine_client,eudora)
f t(utilisateur,machine_serveur,popper,/var/spool/bal)
eudora: programme client de consultation de courrierpopper.' programme serveur dialoguant avec eudora
utilisateur: identificateur de l'utilisateur/var/spool/bal: botte aux lettres de l'utilisateur
Schéma 1S : Graphe d'un sell'ÎCe réseau élémentaire
5.1.4. Définition des services réseaux - dénomination de ces services
Nous avons défini, au paragraphe 5.1.3., des services demandant une seule ressource. Il est
pourtant courant qu'un service fasse appel à plusieurs ressources simultanément. Ainsi, nous
introduisons un système de dénomination des services réseaux qui nous permet d'effectuer les
regroupements des services réseaux élémentaires qui sont simultanément nécessaires pour le
fonctionnement des services nommés en question(a).
5.1.4.1. Définition de l'application de dénomination
Soit r l'ensemble des noms de services. Nous définissons l'ensemble des services réseaux çcomme un sous-ensemble du produit r x ç. Les éléments de r x ç qui sont des services
réseaux sont ceux qui sont associés à une application multivoque q, appelée application de
dénomination:
q: r ---7 ç (Eq.12)
Autrement dit, un service réseau est un couple (y, q (y)) où y est un nom de service et
q (y) un ensemble de services élémentaires.
(a) Ce regroupement aurait pu être spécifié au moyen d'ensembles de services réseaux élémentaires. Nousgardons cependant la définition par applications multivoques dans l'idée de pouvoir construire aisément legraphe global de dépendances présenté dans le chapitre suivant.
Administration des applicatifs réseau..,,· 89

11.5
Nous posons la contrainte suivante sur l'application q :
\f (x',y') E q (y) et \f (x",y") E q (y)
Descriptionfonnelle du modèle
, (' , ') , (1 • 1 1)avec x = x v' X M' X P et y = y V' YM' YP' YR
(Eq.13)
1:équation 13 spécifie que tous les services réseaux élémentaires qui participent à un service
réseau doivent nécessairement dépendre de la même machine cliente (XM)'
Dès lors, nous définissons l'application univoque m qui décrit la machine cliente associée à
chaque nom de service.
m: r ---7 M
Soit(x, y) E q (y) alors III (y) =xM
avec x= (xv' xM' xp) et Y= (yv' YM' Yp' YR)
(Eq.14)
5.1.4.2. Exemple de service réseau par dénomination
Un utilisateur dispose du service d'impression suivant: Il peut imprimer les documents d'un
disque magnétique donné sur une imprimante donnée. 1:imprimante et le disque ne sont pas
localisés sur l'ordinateur de l'utilisateur. 1:application q nous décrit les deux services réseaux
élémentaires nécessaires à ce service: accès au disque, accès à l'imprimante.
Nous avons les éléments suivants:
- ImpressiOlunl_laserIl : nom du service réseau,
- klein : identificateur de l'utilisateur,
-Ill, : noms de machines,
- PCNFS.EXE: programme client d'accès à un disque distant,
-nfsd: programme serveur de mise à disposition d'un disque,
- /dev/sdOh : identification du disque distant,
-LPR.EXE: programme client d'accès à une imprimante distante,
-lpd: programme serveur de mise à disposition d'une imprimante,
-laserIl : nom de l'imprimante.
90 Administration des applicatifs réseaux

Description formelle du modèle
Ce qui nous permet de poser les applications suivantes:
Impressionjnl_laserll
q ((klein, ml' PCNFS.EXE) -4 (klein, m2, nfsd, /dev/sdOh»)
-----::> (klein, m]> LPR.EXE) J; (klein, m3, lpd, laserll)
Nous en déduisons que:
Le schéma 16 trace une représentation graphique associé à ce service
ILS
(Eq.1S)
(Eq.16)
(klein,ml,PCNFS.EXE]
f +(klein,m2,nfsd,ldev/sdOh
Schéma 16 : Graphe d'un service réseau par dénomination
5.1.5. Définition des services réseaux en cascade
Nous avons défini, au paragraphe 5.1.3., des services dont la ressource est directement gérée
par la machine serveur.
Or certaines ressources qu'une machine exploite sont elles-mêmes issues d'un service réseau.
Nous parlons alors de services réseaux en cascade.
5.1.5.1. Application de transition
Pour spécifier les services en cascade, il est nécessaire d'introduire une application
multivoque de transition h définie par:
[h:S--'Jï
--(Eq.17)
Administration des applicatifs réseaux 91

ILS Description formelle du modèle
h associe à un élément de S (nœuds serveurs) zéro, un ou plusieurs services réseaux par leurs
dénominations.
Nous posons la contrainte suivante sur l'application h :
Soit Y E S
alors h (y) = 0
ou bien \:Iy E h (y) on a m (y) = YM
avec y= (Yu' YM' Yp' YR)(Eq.18)
L'équation 18 spécifie que la transition pour un nœud serveur donné (y) n'est possible qu'avec
des noms de services (y) dont la machine cliente (m (y) ) est la même que la machine du
nœud serveur (yM ).
L'application h est généralement définie par des fichiers de configurations (par exemple, pour
les impressions sous Unix, le fichier letc/printcap).
5.1.5.2. Définition d'un service réseau en cascade
Un service réseau en cascade est défini de la même façon qu'un service réseau en modifiant
la condition vi) de l'application multivoquef:
Soit (x, y) E CxS décomposé en x= (xU,xM,xp)
et y= (Yu'YM'Yp'YR)
Alors: y E f(x) ssi les conditions i) à v) de l'eq. 10 sont vérifiées,ainsi que la condition vi) ci-dessous:
vi) Ona YR E r(YM)
ou bien \:Iz E h (y) , \:Iw E q (z), (z, w) E S(Eq.19)
La condition vi) de l'équation 19 spécifie que la ressource est directement gérée par la
machine serveur, ou bien elle est rendue accessible à cette machine par un ou plusieurs
services réseaux en cascade.
Nota : La concision d'expression de cette condition ne reflète aucunement la difficulté
d'implantation d'un algorithme qui la vérifie, comme nous allons le voir dans la partie
suivante.
92 Administration des applicatifs réseaux

Descriptionformelle du modèle
5.1.5.3. Exemple de service réseau en cascade
IL5
Supposons que dans l'exemple précédent, l'imprimante en question ne soit pas gérée par la
machine serveur m3, mais par une autre machine m4, et que de plus, elle ait besoin d'un accès
à un serveur de noms.
Nous avons les éléments suivants:
-lmpression_ml_laserII,Acces_laseII: noms du service réseau,
- klein : identificateur de l'utilisateur,
-mi: noms de machines,
- PCNFS.EXE: programme client d'accès à un disque distant,
- nfsd : programme serveur de mise à disposition d'un disque,
- /dev/sdOh : identification du disque distant,
- LPR.EXE : programme client d'accès à une imprimante distante,
-lpd : programme serveur de mise à disposition d'une imprimante,
-laserll: nom de l'imprimante,
- gethostbyname : nom du programme client d'accès au serveur de noms,
- named : nom du programme serveur de noms,
-/etc/namebd: nom de la ressource annuaire du serveur de twms.
Ce qui nous permet de poser les applications suivantes:
ImpressiOlunLlaserII fq ((klein, ml' PCNFS.EXE) ~ (klein, m2, nfsd, /dev/sdOh) J
-----7 (klein, lit l' LPR.EXE) J (klein, m3, lpd, laserII)
Acces_laserlI fq ( (klein, m3, lpr) --'7 (klein, m4, lpd, laserII) J
-----7 (klein, m3, gethostbyname) ~ (klein, /Il y named,/etc/named)
Il(klein, m3' lpd, laserII) ---7 Acces_laserII
(Eq.20)
Nous pouvons illustrer les applications détaillées ci-dessus par le graphe du schéma 17.
5.1.6. Les programmes comme ressources
Pour des raisons de clarté de la présentation du modèle, nous avons, jusqu'à présent, séparé la
notion de programmes de celle des ressources. Or il faut souligner que l'ensemble des
programmes P est inclus dans l'ensemble des ressources R. En effet, les programmes sont
mémorisés sur un support physique, généralement des disques magnétiques, c'est-à-dire une
Administration des applicatifs réseaux 93

n.s Descriptiolljormelle du modèle
Impression_m Claserl/
~ ~-------- -----(klein,mt,PCNFS.EXE)
f t(klein,m2,nfsd,ldevlsdOh)
(klein,m t,LPR.EXE)
t(klein,m3,lpd,laserl/)
(klein,m3,lpr)
f t(klein,m,plpd,laserl/)
(kleln,ma,gethostbyname)t f
(klein,ms,named,letclnamebd)
Schéma 17 : Graphe d'un service réseau en cascade
ressource. Au même titre que n'importe quelle ressource, les programmes peuvent être rendus
accessibles au moyen d'un service réseau, il s'agit typiquement d'un montage de disques
distants. C'est pourquoi, la condition iii) des propriétés de l'application! de définition d'un
service réseau spécifiant l'utilisation d'un programme client ou serveur est modifiée comme
suit:
Soit (x, y) E CxS décomposé en x= (xU,xM,xp)
et y= (Yu'YM'Yp'YR)
Alors: y E tex) ssi les conditions il, iî), iv), v) de l'eq. 10et la condition vi) de l'Eq. 19 sont vérifiées,ainsi que la condition iii) ci-dessous:
iii) On a xp E r (xM )
ou bien :3 (x', y') E S tel que xM = x'M et xp = Y'R
Ona YpE r(YM)
ou bien :3 (x", y") E S tel que YM = x"M et Yp = Y"R
(Eq.21)
94 Administration des applicatifs réSeatLt

Descriptiolljormelle du modèle ILS
La condition iii) de l'équation 21 ci-dessus spécifie que le programme client (respectivement
serveur) est localisé sur la machine cliente (resp. serveur), ou bien le programme client (resp.
serveur) est une ressource issue d'un service réseau.
Remarquons que l'application 1 décrivant les programmes des ordinateurs n'est plus
nécessaire à la définition iii) car nous avons la propriété suivante:
\/mEM l(m)ç;r(m)
(Eq.22)
D'autre part, le fait que l'ensemble des programmes soit inclus dans l'ensemble des ressources
entraîne également la modification de l'application de transition h précédemment définie. En
effet, les nœuds serveurs ne sont plus les seuls éléments origines de l'application, mais
également les nœuds clients. Ainsi, l'application h est complétée comme suit:
h:Suc-)r
5.1.7. Définition générale d'un service réseau
(Eq.23)
En fonction des contraintes énoncées ci-dessus, nous pouvons récapituler la définition d'un
service réseau applicatif comme suit:
L'ensemble des services réseaux é, est un sous-ensemble du produit C X S. Les éléments de
C XS qui sont des services réseaux sont ceux qui sont associés à une application multivoque
f' C -) S décrite par l'équation 24 ci-dessous.
Nota: Les explications concernant les propriétés i), ii) iv) et v) ont été données pour
l'équation 10. Quant aux conditions iii) et vi), elles ont été détaillées aux équations 19 et 21.
5.2. Modélisation du réseau physique
De par sa définition, le modèle présenté ne prend en compte que les objets suivants:
machines, utilisateurs, programmes, ressources.
Il est intéressant de prendre également en compte les éléments du réseau physique qui
permettent l'établissement des services. Nous allons par conséquent, définir le graphe du
réseau physique et nous spécifions les conditions de l'application d'existence de lien réseau
(Eq. 8) précédemment définie.
Administration des applicatifs réseaux 9S

II .5 Descriptioll formelle du modèle
Soit (x, y) E CxS décomposé en x= (xu,xM'xp)
et y= (Yu'YM'YP'YR)
y E f(x) ssi les conditions ci-dessous sont vérifiées:
iii) On a xp E r (xM )
oubien 3 (x',y') E S tel que xM = x'M et xp = Y'R
On a YpE r(YM)
ou bien 3 (x", y") E S tel que YM = x"M et Yp = Y"R
iv) XUE uc(xp) (Yu'xM) E Us (Yp)
v) YRE g(yp)
vi) On a YR E r (YM)
ou bien 't/z E h (y) , 't/w E q (z), (z, w) E S
5.2.1. Graphe du réseau physique
5.2.1.1. Les équipements réseaux
(Eq.24)
Nous définissons l'ensemble Q des équipements réseaux comme tout élément appartenant à
une des familles des éléments suivants:
- médiums: câbles (fibres optiques, coaxiaux, paires métalliques, etc), espace de transport
(espace supportant tout type de transport sur principe ondulatoire, par exemple les ondes
hertziennes),
- entités de regénération et de partage du signal: amplificateurs, répéteurs, etc.,
- entités de branchement: prises et cordons de raccordement.
5.2.1.2. Les équipements
Nous définissons l'ensemble des équipements E comme l'union de l'ensemble des machines
M, et des équipements réseaux Q.
E=QuM
Il s'agit en fait de tous les éléments nécessaires à la liaison entre machines.
96 Administration des applicatifs réseau.x
(Eq.25)

Descriptionformelle du modèle
5.2.1.3. L'ensemble des connexions
ILS
Nous définissons l'ensemble A des connexions inter-équipements. A est inclus dans
l'ensemble des couples non-ordonnés pris dans E tel que:
«el' e2) E A) {=} «el' e2) est une connexion) (Eq.26)
La connexion entre deux équipements est le fait d'être branché l'un à l'autre au moyen d'une
prise, voire d'une soudure.
Nota: Suivant la finesse que l'on recherche dans la définition du graphe physique du réseau, il
y aura lieu éventuellement de distinguer les cartes de circuits imprimés d'un équipement
global comme étant chacune d'elles un équipement réseau.
5.2.1.4. Graphe du réseau physique
L'ensemble E des équipements et A des connexions entre équipements définissent le graphe du
réseau physique noté Gr, où E forme l'ensemble des sommets du graphe, A l'ensemble des
arêtes. Il s'agit d'un graphe pour lequel il existe au plus une seule arête entre deux
équipements.
Nota: Nous posons l'hypothèse que le réseau physique supporte des communications dans les
deux sens simultanément, c'est pourquoi nous travaillons sur un graphe non-orienté. Il est
inutile d'utiliser un graphe orienté pour traiter, par exemple, le cas de fibres optiques qui sont
uni-directionnelles, car il est bien clair qu'au niveau applicatif, une panne de câble même dans
un unique sens met hors-service toute application utilisant ce canal, du fait des protocoles
sous-jacents qui utilisent toujours un système de question-réponse (pour les acquittements par
exemple).
Exemple de graphe réseau
Nous voulons modéliser le réseau physique de trois machines reliées par un réseau de type
Ethernet comme nous le décrit le schéma 18 ci-dessous.
Nota : Les dénominations des équipements réseaux sont simplement mnémoniques dans
l'exemple présenté ici. Il serait nécessaire d'établir une nomenclature complète dans le cas
d'une implantation réelle.
Administration des applicatifs réseaux 97

n.s
Prise vampire~ Prise vampire ~
Descriptionformelle du modèle
Ethernet 10B5
r- DropAUI~ DropAUI
Schéma 18 : Il/ustration d'une portion de réseau Ethanet
Nous pouvons répérer les divers équipements réseaux et leurs connexions, Nous obtenons
ainsi les ensembles E et A suivants:
E = {Mac1,Mac2,PC,Drop1,Drop2, Vamp1, Vamp2,10b5,lOb2,Répétew}
A = {(Mac1,Drop1), (Drop1, Vampl),
(Vainp1,10b5),(lObS, Vamp2),(Vamp2,Drop2),
(Drop2,Répéteur), (Répéteur,1Ob2),(1Ob2,Mac2),(1Ob2,PC)}
Le graphe du réseau physique Gr sera celui décrit ci-dessous au schéma 19.
Nous allons utiliser les graphes ainsi définis pour compléter la définition de l'application
multivoque n donnant les liens réseaux dans le modèle.
5.2.2. Définition de J'application n
5.2.2.1. Rappel
Nous avons défini le réseau physique par une application multivoque n définie par:
Il: M ---7 M
Cette application décrit J'existence de liens réseaux entre les machines.
98 Administratioll des applicatifs réseaux

Descriptioll formelle du modèle
Mael1
Dropl1
Vampl1
lObS1
Vamp21
Drop21
Répéteur1
lOb2----Mae2 PC
Schéma 19 : Exemple de graphe de réseau physique
5.2.2.2. Contrainte sur l'application n
II.S
Pour tenir compte des équipements réseaux permettant la liaison entre machines, nous posons
la contrainte suivante sur l'application n :
(
/Ill E Msoit
/112 E Mon a:
(Eq.27)
Remarquons que suivant l'hypothèse précédente - sur l'approche non-orientée du graphe du
réseau physique (page 97) - nous avons la propriété suivante:
on a:
(Eq.28)
5.2.3. Hypothèses sur le réseau physique
Pour modéliser les éléments qui constituent le réseau physique, nous avons posé
implicitement des hypothèses de travail que nous allons détailler.
5.2.3.1. Hypothèse sur les réseaux multi-protocoles
Il faut noter avec attention que la manière de procéder pour étendre le modèle aux éléments
réseaux repose sur une hypothèse assez forte: tout protocole du modèle est supporté par le
Administratioll des applicatifs réseaux 99

11.5 Descriptioll formelle du modèle
réseau physique. C'est généralement le cas lorsqu'il s'agit d'un réseau de type Ethernet, ça ne
l'est plus lorsqu'il s'agit de méthodes propriétaires telle LocalTalk pour le réseau AppleTalk.
Nous connaissons la capacité d'une instance de programmes clients à dialoguer avec une
instance de programmes serveurs grâce à la définition de l'application multivoque a (Eq.4). La
connaissance du réseau physique ne donne qu'une condition nécessaire à l'établissement des
services, et non pas une condition suffisante quant à l'existence d'un réseau physique
supportant le protocole entre les programmes clients et serveurs. La direction à suivre serait le
typage des éléments réseaux par les protocoles supportés et la modification en conséquence de
l'application multivoque a.
5.3. Modèle temporisé
Jusqu'à présent le modèle formel décrit les services réseaux de manière statique: sans
commencement, ni fin. Nous allons augmenter le modèle pour tenir compte de la notion
temporelle des services décrits.
5.3.1. Fenêtres temporelles
L'extension du modèle au concept temporel que nous utilisons reprend une méthode classique
de définitions d'intervalles basés sur un repère temporda).
Le principe est de munir chaque service réseau d'une fenêtre temporelle décrite par une date
de début et Une date de fin. Cette fenêtre temporelle ne signifie pas que le service réseau
s'exécute pendant tout l'intervalle décrit, mais qu'il est susceptible d'être exécuté dans cette
période. Prenons deux exemples qui illustrent les deux cas les plus opposés. Supposons la
mise en place d'un service de sauvegarde des disques de l'ensemble des ordinateurs du réseau
modélisëb). La fenêtre temporelle de ce service est parfaitement connue à l'avance - par
exemple de 2h à 4h du matin. D'un autre côté, imaginons un service d'impression, lafenêtre
temporelle de ce type de service va être beaucoup moins bien définie. Suivant le contexte, ce
pourra être de 8h à 18h, voire en continu.
Nota : Soulignons qu'il Y a généralement plusieures fenêtres temporelles pour un service
réseau. Dans la majorité des cas, c'est une définition de fenêtres périodiques qui sera spécifiée
(sauvegardes automatiques, impressions aux heures ouvrables, etc).
(a) Cette méthode est utilisée, par exemple, pour les réseaux de Pétri temporisés qui manipulent également
des graphes dont on associe aux sommets des intervalles de temps.
(b) Remarquons qu'il s'agit typiquement d'une application réseau qui met en jeu des services en cascade
particulièrement complexes.
100 Administration des applicatifs réseaux

Descriptiol! formelle du modèle
5.3.1.1. Définition des fenêtres temporelles d'un service
ILS
Plutôt que de gérer des suites d'intervalles, les fenêtres temporelles sont décrites par une
fonction booléenne qui définit si à tel moment, tel service est dans une de ses fenêtres
temporelles ou non.
Ainsi, nous définissons une fonction tir ayant pour antécédents un nom de service réseau et
une valeur du temps t appartenant à T ( un entier décrivant le nombre de secondes écoulées
depuis une origine fixe) et pour image les valeurs booléennes VRAI ou FAUX.
tir: r X T -7 (VRAI,FAUX)
La signification d'une telle fonction est la suivante:
(tir (x, t) = VRAI) ~ (x est susceptible d'être demandé au temps t)
5.3.1.2. Exemple de règle de tir
(Eq.29)
(Eq.30)
Soit à définir la fonction de tir des fenêtres temporelles décrites comme suit: "Monsieur
Dupont désire pouvoir consulter sa boîte aux lettres de 9HOO à 17H00 tous les jours ouvrables
de la semaine". Nous avons la fonction de tir suivante:
(OS; (t/86400) %7 S; 4
tir (Courrier Dupont, t) =- 9 S; (1/3600) %24 S; 17
(Eq.31)
Nota: L'opération notée "%" désigne le "modulo". Ainsi, la première condition de la fonction
de tir ci-dessus spécifie qu'il s'agit d'un jour ouvrable (86.400 étant le nombre de secondes
par jour, (t/86400)%7 donne le numéro du jour de la semaine au temps t), la deuxième
condition indique la fenêtre horaire de ces jours ouvrables (3.600 étant le nombre de secondes
par heure, (t/3600)%24 donne l'heure du jour au temps I)(a).
Nous verrons au chapitre 7 comment les résultats de la modélisation tirent partie de
l'élargissement du modèle au réseau physique et au concept temporel décrit précédemment.
5.4. Graphes associés au modèle
Nous allons décrire plusieurs représentations par graphes de notre modèle, qui nous
permettront de traiter les problèmes de dépendances des services réseaux.
(a) Nous supposons que l'origine du repère temporel est défini, comme SOtlS Unix, à une certaine date
conventionnelle, par exemple le 1 janvier 1970 à 00 heure.
Administration des applicatifs réseau.x 101

II.5 Descrip/iotlformel/e dumodèle
5.4.1. Graphe global de dépendances des services réseaux
Nous proposons une représentation sous forme d'un graphe orienté, pour décrire l'ensemble
des dépendances entre services réseaux. Les sommets sont pris dans les ensembles C (nœud
client), S (nœud serveur) et r (nom de service), et les arcs sont définis par les applications!
(service réseau élémentaire), q (dénomination) et h (transition). Nous l'appelons graphe
global de dépendances. Comme il s'agit de I-graphe(al, nous reprenons la méthode de
définition des l-graphes donnée par M. Gondran et M. Minoux [GON 85]. Ainsi, le graphe
global de dépendances est défini par les équations 32, 33 et 34 :
Gg
est le graphe global de dépendances associé au modèle:
Gg
= (sg, Ag )avec sg ç eus u r ensemble des sommets
et Ag application multivoque de sg dans sg décrivant les arcs.(Eq.32)
Nota: Nous rappelons que dans ce formalisme de définition d'un graphe orienté, pour tout
sommet x appartenant à sg, Ag (x) est l'ensemble des sommets adjacents à x (dans le sens
des arcs).
- L'application multivoque Ag de description des arcs se déduit des applications/, q et h de
la façon suivante:
i) "Iy E r (c'est-à-dire un nom de service)
ona: Ag (y) = {x 1 (x,y) E q (y)}
ii) "Ix E C (c'est-à-dire un nœud client)
ona: Ag(x) =!(x) uh(x)
iii)"Iy E S (c'est-à-dire un nœud serveur)
ana: Ag (y) = h (y)(Eq.33)
- L'ensemble des sommets sg est inclus dans l'union des ensembles des noms de services,
des nœuds clients et des nœuds serveurs. Il est défini comme l'union des sommets
(al Un l-graphe a la propriété suivante: les sommets pris dellx à deux ont au plus un arc entre eux.
102 Administratioll des applicatifs réseaux

Deseriptiollformelle du modèle ILS
successeurs et des sommets prédécesseurs d'un arc. Ce qui peut s'exprimer sous la forme
suivante:
g g gS = SSlIee V Spréd
8avec Ssucc = U Ag (x)
XE cusur
(Eq.34)
Nota: L'équation 34, ci-dessus, restreint donc l'ensemble des sommets du graphe global de
dépendances aux éléments de C v S v r qui ne sont pas isolés. Cette restriction n'est pas
indispensable du point de vue théorique.
Le graphe global de dépendances décrit la totalité des interactions entre les divers objets
modélisés.
Exemple d'un graphe global de dépendances
Nous proposons un exemple de graphe global de dépendances. Cependant, afin de ne pas
alourdir notre exemple, nous le restreignons à trois services (a): deux services d'impression et
un service d'accès au courrier.
Les services d'impression- Un utilisateur (klein) veut pouvoir imprimer, à partir du PC
(pel), les fichiers de son répertoire de travail habituel (monza:/homelklein). L'imprimante
visée (laserII), ainsi que le fichier, ne se trouvent pas sur le PC. De plus, l'imprimante n'est
pas directement gérée par la machine indiquée par l'utilisateur (monaco), mais par une
machine tierce (Imola), ce qui nécessite l'accès à un serveur de noms (Isis). Ce service est
nommé Impression-pel_laserII.
D'autre part, un deuxième utilisateur (hector), demande l'accès à la même imprimante, mais à
partir du compatible PC de son bureau (pc2). Il ne dispose que d'un disque local.
Le service d'accès au courrier - Un utilisateur (Dupont) cherche à consulter sa boîte aux
lettres (/mai//dupont) à partir de son Macintosh (mac1). Sa boîte aux lettres se trouve sur une
machine distante (monza), et c'est grâce aux programmes eudora et popper qu'il lui est
possible d'y accéder. Le logiciel eudora a besoin des services du serveur de noms tournant sur
une tierce machine (isis). Nous nommons ce service: Courriet,-dupont. Nous obtenons le
graphe global de dépendances représenté par le ~chéma 20.
(a) Les trois services présentés sont réels, ils sont tirés de l'implantation du modèle (voir dernière partie).
Administration des applicatifs réseau."" 103
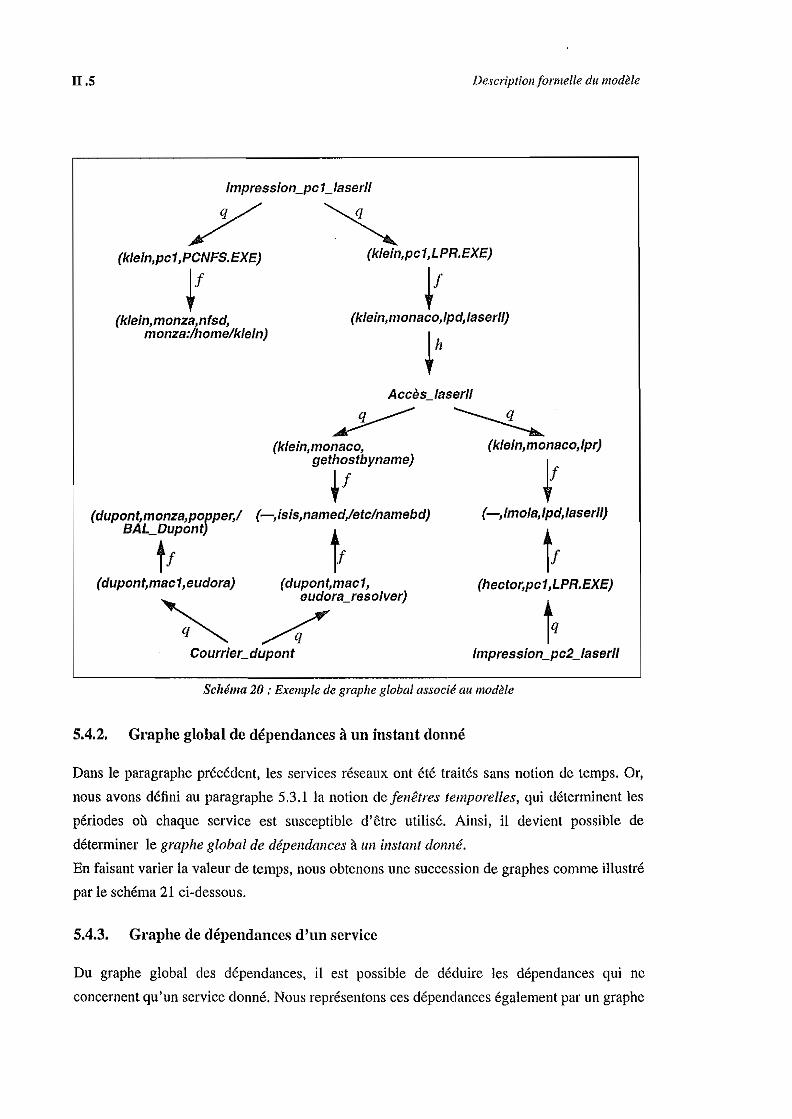
11.5 Descriptiollformelle du modèle
Impression_pcClaserll
/(kleln,pc1, PCNFS.EXE)
~f(klein,monza,nfsd,
monza:lhomelklein)
~(klein,pc1,LPR.EXE)
~f(klein,monaco,lpd,laserll)
~h
~ ~(klein,monaco, (klein,monaco,lpr)
gethostbyname) rtJ(dupont,monza,popper,1 (-,isis,named,letclnamebd) (-,imola,lpd,laserll)
BAL_Dupont)
tf tftf(dupont,mac1,eudora) (dupont,mac1, (hector,pc1,LPR.EXE)
~eudoraJesolver)
tq/Courrier_dupont Impresslon_pc2_'aserll
Schéma 20 : Exemple de graphe global associé au modèle
5.4.2. Gl'aphe global de dépendances à un instant donné
Dans le paragraphe précédent, les services réseaux ont été traités sans notion de temps. Or,
nous avons défini au paragraphe 5.3.1 la notion de fenêtres temporelles, qui déterminent les
périodes où chaque service est susceptible d'être utilisé. Ainsi, il devient possible de
déterminer le graphe global de dépendances à tin instant donné.
En faisant varier la valeur de temps, nous obtenons une succession de graphes comme illustré
par le schéma 21 ci-dessous.
5.4.3. Graphe de dépendances d'un service
Du graphe global des dépendances, il est possible de déduire les dépendances qui ne
concernent qu'un service donné. Nous représentons ces dépendances également par un graphe
104 Administration des applicatifs réseaux

Descriptioll [ormelie du modèie
Temps
Schéma 21 : Evoiutioll dalls le temps des graphes globaux
ILS
orienté que nous nommons, simplement, graphe de dépendances associé au nom de service en
question. Il répond à la définition des équations 35 et 36 :
Soit yE r un nom de service réseau,
alors Gy est son graphe de dépendances associé défini par:
Gy = (SyA) avec Sr'~' Cu sur ensemble des sommets
et A y application multivoque de Sy dans Sy décrivant les arcs.
(Eq.35)
- Ay et Sy se déduisent de G8 de la façon suivante:
(Eq.36)
Le graphe de dépendances permet de représenter aisément tous les "objets" nécessaires au
fonctionnement du dit service.
Exemple de graphes de dépendances
Pour illustrer notre définition, nous reprenons, dans le schéma 20, l'exemple précédent de
graphe global de dépendances et nous en déduisons le graphe de dépendances associé au
service Impression-pc1_laserII (repéré au moyen de la forme grisée en claire), et celui associé
au service Courriel,--dupont (forme grisée en foncé).
Administration des applicatifs réseaux lOS
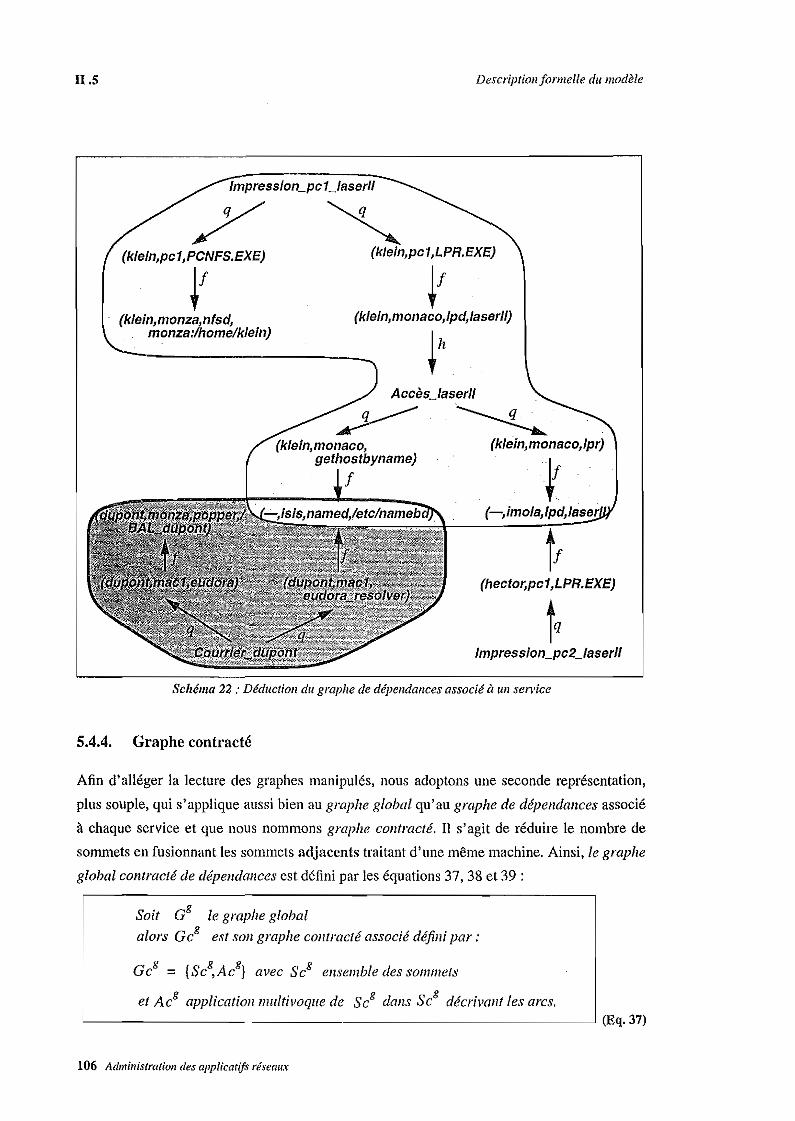
ILS Description formelle du modèle
7(kleln,pc1,PCNFS.EXE)
V(klein,monza,nfsd,
monza:/home/klein)
~(klein,pc1,LPR.EXE)
+1(klein,monaco,lpd,laserll)
+h
f(-,imola,lpd,laser
(hector,pc1,LPR.EXE)
Impression_pc2_laserll
Accès_laserll
~(klein,monaco,lpr)
~(klein,monaco,
gethostbyname)
1
Schéma 22 : Déduction du graphe de dépendances associé à un service
5.4.4. Graphe contracté
Afin d'alléger la lecture des graphes manipulés, nous adoptons une seconde représentation,
plus souple, qui s'applique aussi bien au graphe global qu'au graphe de dépendances associé
à chaque service et que nous nommons graphe contracté. Il s'agit de réduire le nombre de
sommets en fusionnant les sommets adjacents traitant d'une même machine. Ainsi, le graphe
global contracté de dépendances est défini par les équations 37. 38 et 39 :
Soit Gg
alors Gcg
le graphe global
est son graphe contracté associé défini par:
Gcg
= {Scg,Aéj avec Scg
ensemble des sommets
et Aé applicationlt1ultivoque de Scg
dans Scg
décrivant les arcs.'---- -' (Eq.37)
106 Administration des applicatifs réseaux

Description formelle du modèle
- sé se déduit de Gg de la manière suivante:
Scg est une partition de sg
définie par l'application c : sg ~ Scg
telle que \;jx E sg et \;jy E sg
on a: y E Ag (x) et mach (x) = mach (y) =:0 c (x) = c (y)
ILS
avec mach (x) =xMpour tout XE C et décomposé en x = (x U' xM' xp)
mach(x) = xMPour tout XE Setdécomposéenx= (xu,xM'xp,xR )
mach (x) = m (x) pour tout x E rL- -' (Eq.38)
L'équation 38 définit que deux sommets du graphe global de dépendances sont dans la même
classe de la partition s'ils sont adjacents et s'ils concernent tout deux la même machine. Cette
condition nécessaire suffit à décrire la partition.
- Aé se déduit de Gg de la manière suivante:
\;jX E Scg
et \;jy E sé
(3y E Yet 3x E X J
On a " Y E Aé (X) <=>tels que y E Ag (x)
L- ----' (Eq.39)
L'équation 39 définit qu'une classe Yest adjacente à une classe X si et seulement il existe au
moins un élément de la classe y adjacent à au moins un élément de la classe X par le graphe
global de dépendances.
Nota: Nous notons qu'il ne s'agit pas à proprement parler d'une "contraction" mais d'une
nouvelle définition de graphe ;Ies arcs au sein d'une même classe de la partition ne donnent
pas lieu à des boucles.
Exemvle de gravhe contracté de dépendances
Pour illustrer la méthode de contraction des graphes, nous reprenons l'exemple d'un
utilisateur désireux de consulter sa boîte aux lettres électronique à partir de son terminal X
(voir paragraphe 3.1.3 - page 58). Le graphe de dépendances de ce service est donné par le
schéma 23. Comme nous le voyons, trois services réseaux sont nécessaires, dénommés
mailtooCbilboJel1lique, Bilbo_Ok et Montage_monzaJmail. Ils décrivent respectivement les
objets nécessaires au fonctionnement:
Administration des applicatifs réseau..x 107
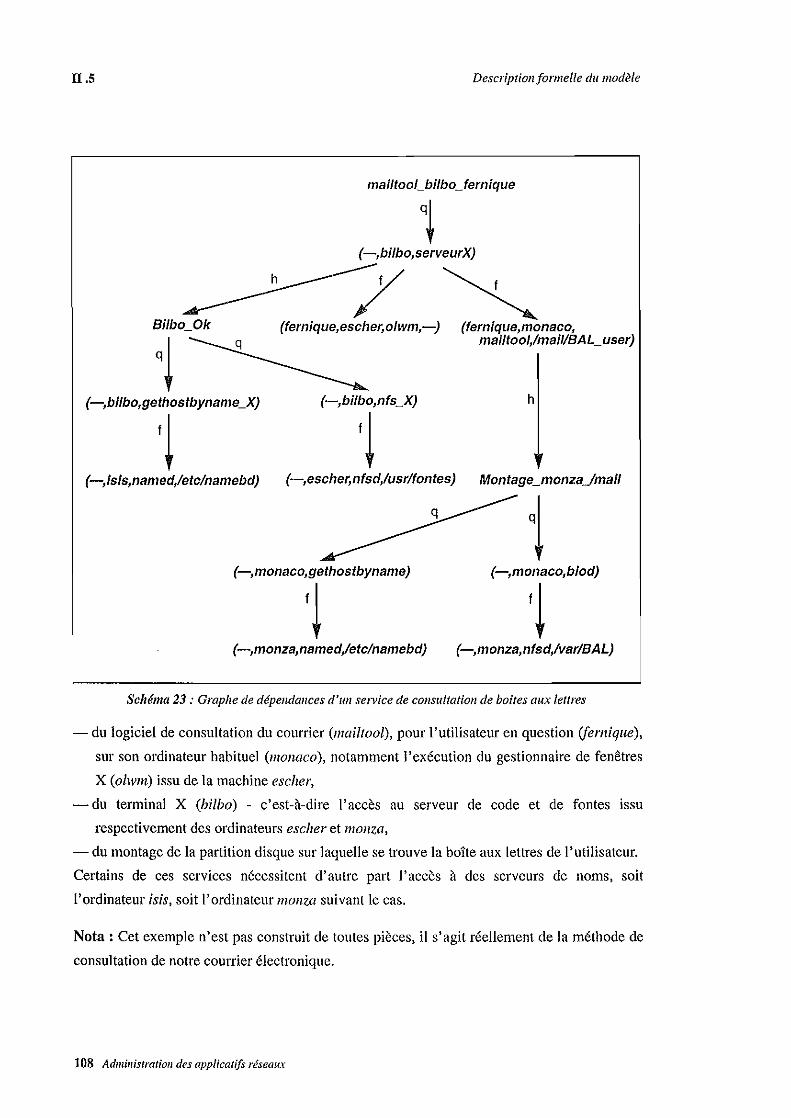
11.5 Descriptionforme/le du modèle
mailtooCbilbo_fernique
h
i(-,monaco,biod)
ft
Montage_monza.Jma/l(-,escher,nfsd,lusr/fontes)
1(-,bilbo,serveurX)
/~(fernique,escher,olwm,-) (fernique,monaco,
mailtool,/maii/BAL_user)
(-,monaco,gethostbyname)
f!
(-,isls,named,letc/namebd)
(-,monza,named,letc/namebd) (-,monza,nfsd,lvar/BAL)
Schéma 23: Graphe de dépendances d'un selvice de consultation de boites aux lettres
- du logiciel de consultation du courrier (mailfool), pour l'utilisateur en question (jernique),
sur son ordinateur habituel (monaco), notamment l'exécution du gestionnaire de fenêtres
X (olwm) issu de la machine escher,
- du terminal X (bilbo) - c'est-à-dire l'accès au serveur de code et de fontes issu
respectivement des ordinateurs escher et monza,
- du montage de la partition disque sur laquelle se trouve la boîte aux lettres de l'utilisateur.
Certains de ces services nécessitent d'autre part l'accès à des serveurs de noms, soit
l'ordinateur isis, soit l'ordinateur monza suivant le cas.
Nota: Cet exemple n'est pas construit de toutes pièces, il s'agit réellement de la méthode de
consultation de notre courrier électronique.
108 Administration des applicatifs réseaux
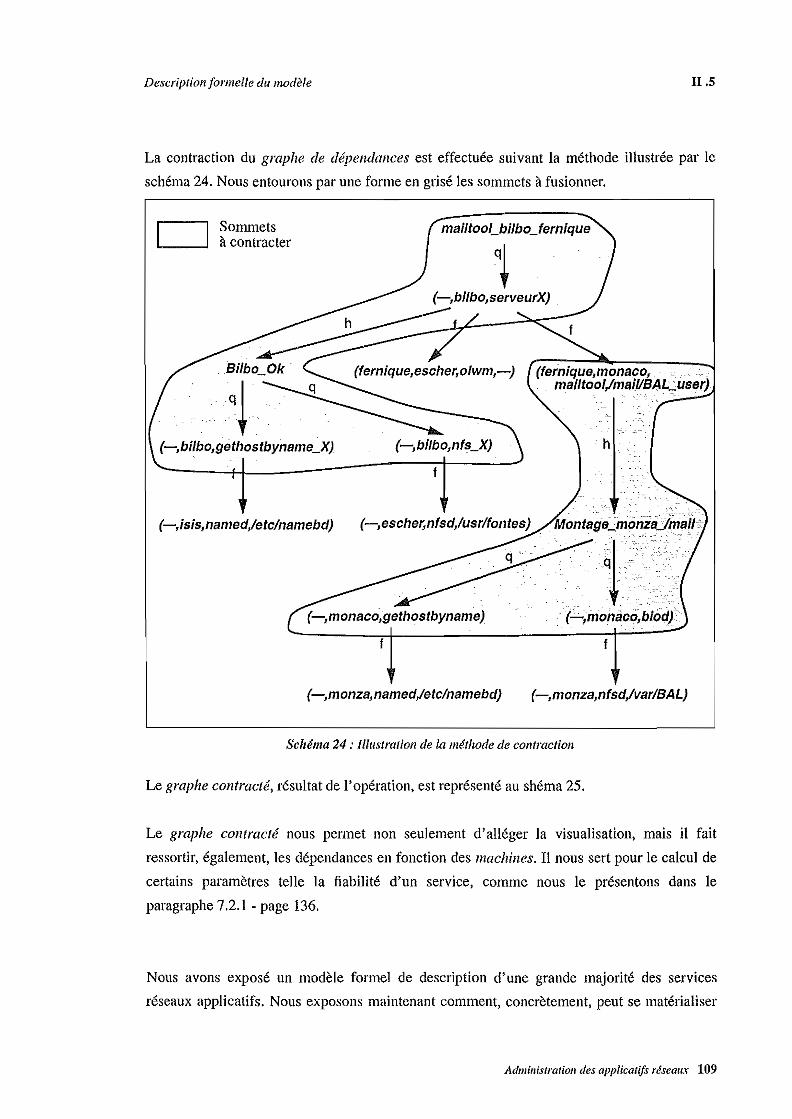
Descriptioll formelle du modèle ILS
La contraction du graphe de dépendances est effectuée suivant la méthode illustrée par le
schéma 24. Nous entourons par une forme en grisé les sommets à fusionner.
r--l SommetsL-J à contracter
q~(-,bilbo,gethostbyname_X)
(-,/s/s,named,letclnamebd)
maiitooLbilbo-'ernlque
1(-,bilbo,serveurX)
(-,bilbo,nfsj)
(-,monza,named,letclnamebd) (-,monza,nfsd,lvarIBAL)
Schéma 24 " Illustratioll de la méthode de cOlltractioll
Le graphe contracté, résultat de l'opération, est représenté au shéma 25.
Le graphe contracté nous permet non seulement d'alléger la visualisation, mais il fait
ressortir, également, les dépendances en fonction des machines. Il nous sert pour le calcul de
certains paramètres telle la fiabilité d'un service, comme nous le présentons dans le
paragraphe 7.2.1 - page 136.
Nous avons exposé un modèle formel de description d'une grande majorité des services
réseaux applicatifs. Nous exposons maintenant comment, concrètement, peut se matérialiser
Admitlistratioll des applicatifs réseaux 109
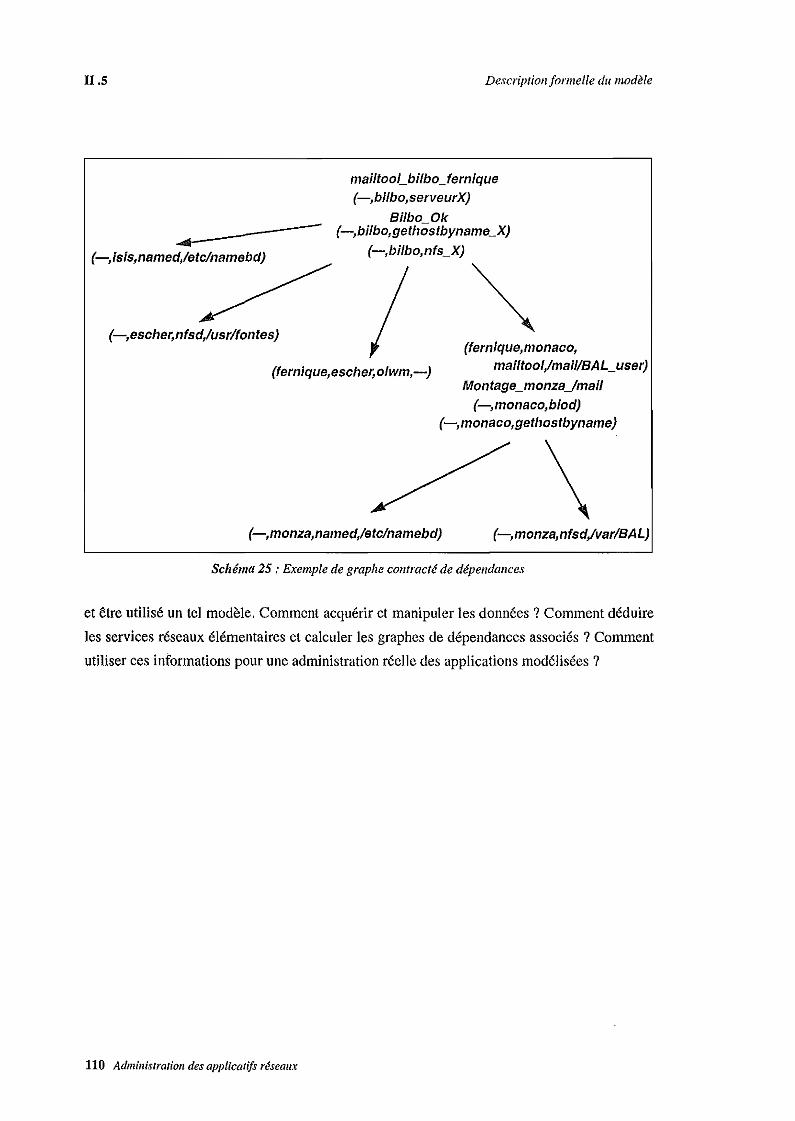
(fernique,escher,oJwm,-)
ILS
.....(-,isis,named,letc/namebd)
(-,escher,nfsd,lusr/fontes)
Description formelle du modèle
mailtooCbi/boJernique(-,bi/bo,serveurX)
Bi/bo_Ok(-,bi/bo,gethostbyname_X)
(-,bi/bo,nfs_X)
~(fernique,monaco,
maiitoollmaiIlBAL_user)Montage_monzajmaiJ
(-,monaco,biod)(-,monaco,gethostbyname)
\(-,monza,named,letc/namebd) (-,monza,nfsd,lvar/BAL)
Schéma 25 " Exemple de graphe contracté de dépendances
et être utilisé un tel modèle. Comment acquérir et manipuler les données? Comment déduire
les services réseaux élémentaires et calculer les graphes de dépendances associés? Comment
utiliser ces informations pour une administration réelle des applications modélisées?
110 Administration des applicatl1s réseaux

Du modèle théorique au modèle Înformatique
6. Du modèle théorique aumodèle informatique
n.6
Nous avons défini, dans le chapitre précédent, un modèle théorique de description des services
applicatifs réseaux. Il nous apparaît nécessaire, dès à présent, de poser certains principes de
mise en œuvre. En effet, le modèle, pour être implanté, doit répondre à certaines spécificités
propres à l'informatique. La .limitation du volume des ensembles est un exemple de telles
contraintes dont il faut tenir compte. Nous proposons donc lUI modèle informatique déduit de
notre modèle théorique.
Comme nous l'évoquions précédemment, l'évaluation du volume des données est un point
incontournable que nous allons traiter en premier lieu. Nous allons dégager des ordres de
grandeur des ensembles manipulés. Ces estimations vont nous permettre de poser certains
principes de mise en œuvre :
-la détermination des services à modéliser,
-la méthode de mémorisation des données décrivant les objets et leurs relations,
-la définition des mécanismes d'acquisition des données d'administration,
-la description des méthodes de déduction des services réseaux et du graphe de leurs
dépendances.
Notons que nous ne décrivons pas, dans ce chapitre, une implantation effective du modèle,
mais uniquement ses principes de mise en œuvre. Le prototype logiciel se basant sur ces
concepts est détaillé dans la troisième partie de notre thèse.
6.1. Evaluation de la quantité d'informations manipulées
Dans notre modèle théorique, nous avons quatre ensembles d'objets à manipuler, à savoir: les
machines, les ressources, les programmes (instances de programmes) et les utilisateurs. Nous
avons également à utiliser un graphe global de dépendances.
Nous allons tenter d'estimer leur taille. Pour cela, nous nous référons aux données réelles
obtenues par la réalisation du prototype implanté sur le réseau informatique de l'Université
des Sciences Humaines de Strasbourg - qui nous a permis de valider le modèle et qui est décrit
Administration des applicatifs réseaux 111

II.6 Du modèle théorique au modèle informatique
dans la dernière partie de cette thèse. De ces chiffres, nous pourrons dégager des ordres de
grandeur pour les différents éléments.
6,1.1. Nombre d'éléments du modèle dans un cils réel
Les informations que nous avons du manipuler lors de l'expérimentation réelle de notre
modèle sont tirées d'un réseau de taille moyenne. Sa description est faite au paragraphe 8.2
page 161. Dans ce cadre, nous nous sommes attachés à surveiller les familles(a) de services
réseaux décrits ci-dessous pour les protocoles TCPIIP et AppleTalk :
-le courrier électronique,
-les impressions,
-les montages de disques distants,
-les accès aux comptes.
Le réseau de test dispose d'un peu plus de ISO machines, les trois-quarts d'entre elles étant des
ordinateurs mono-utilisateur (PC ou Macintosh). En fonction des services réseaux à surveiller,
le nombre des ressources correspondantes avoisine 650. Le tableau 3, ci-dessous, en donne la
répartition exacte.
Ressource Nombre
Disques 20 (en serveur)
Imprimantes 20
Boîtes aux lettres 300
Comptes 300
Tableau 3 : Evaluation dUllombre de ressources
Les utilisateurs du réseau d'expérimentation sont au nombre de 300 environ. Quant aux
instances de programmes, nous en recensons environ 400, décrites dans le tableau 4, ci
dessous.
Programme Nombred'instances
nfsd 10
nfs - PCNFS.EXE 30
CAP60 1
(a) Nous parlons de familles de services réseaux pour désigner l'ensemble des services réseaux de
fonctionnalités similaires (cf. pour exemple la liste qui suit).
112 Administration des applicatifs réseau.'<
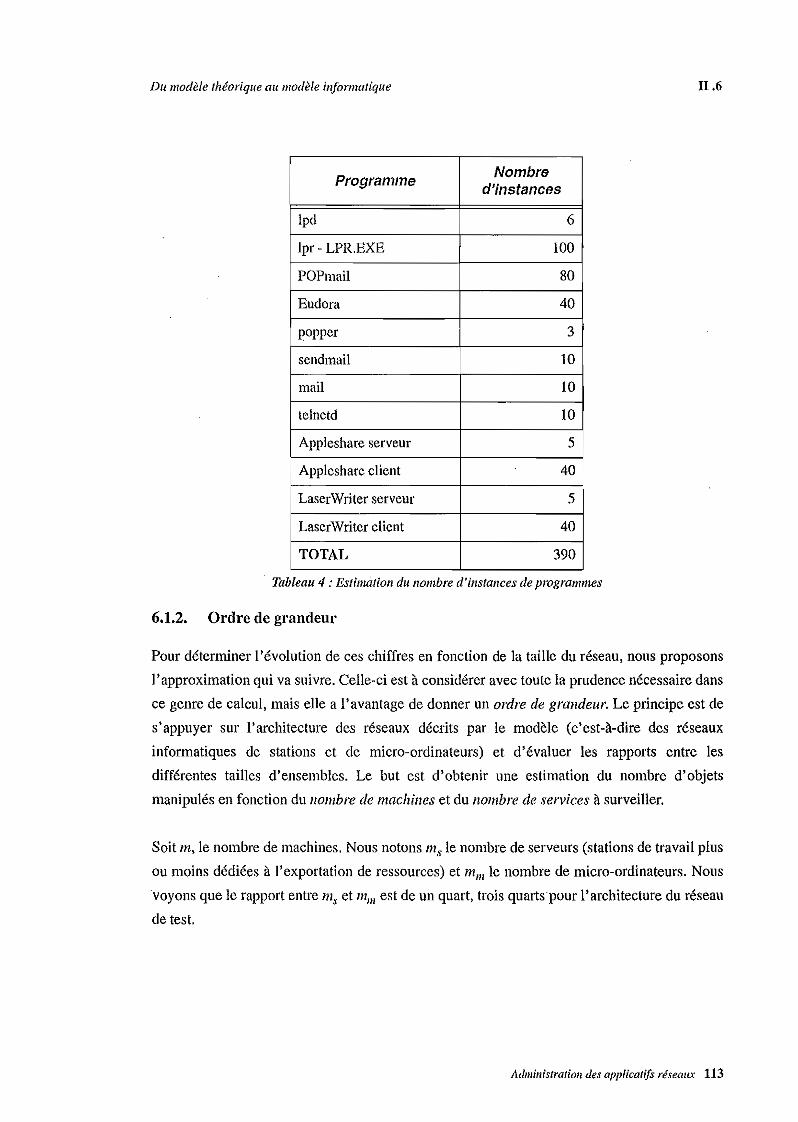
Du modèle théorique au modèle Informatique
ProgrammeNombre
d'instances
lpd 6
lpr - LPR.EXE 100
POPmail 80
Eudora 40
popper 3
sendmail 10
mail 10
telnetd 10
Appleshare serveur 5
Appleshare client 40
LaserWriter serveur 5
LaserWriter client 40
TOTAL 390
. Tableau 4 : Estimation du nombre d'instances de programmes
6.1.2. Ordre de grandeur
11.6
Pour déterminer l'évolution de ces chiffres en fonction de la taille du réseau, nous proposons
l'approximation qui va suivre. Celle-ci est à considérer avec toute la prudence nécessaire dans
ce genre de calcul, mais elle a l'avantage de donner un ordre de grandeur. Le principe est de
s'appuyer sur l'architecture des réseaux décrits par le modèle (c'est-à-dire des réseaux
informatiques de stations et de micro-ordinateurs) et d'évaluer les rapports entre les
différentes tailles d'ensembles. Le but est d'obtenir une estimation du nombre d'objets
manipulés en fonction du nombre de machines et du nombre de services à surveiller.
Soit m, le nombre de machines. Nous notons ms le nombre de serveurs (stations de travail plus
ou moins dédiées à l'exportation de ressources) et mm le nombre de micro-ordinateurs. Nous
voyons que le rapport entre ms et mm est de un quart, trois quarts pour l'architecture du réseau
de test.
Administration des applicatifs réseaux 113

II.6 Du modèle théorique au modèle informatique
Soit u le nombre d'utilisateurs. Une estimation raisonnable est de compter un utilisateur par
micro-ordinateur et une moyenne de cinq utilisateurs par serveur. Nous obtenons l'évaluation
suivante: u ~ mm + Sms ,c'est-à-dire:
u~2m (Eq.40)
Soit s le nombre de familles de services à surveiller. Dans le tableau 4 précédent, nous
pouvons voir que certains services mettent en jeu des ressources qui dépendent des serveurs,
Ss (disques, imprimantes, ...). D'autres services utilisent, par contre, des ressources fonction
des utilisateurs, Su (comptes, boîtes-aux-Iettres, ...). Nous posons l'hypothèse que ces deux
types de services se répartissent moitié-moitié.
Soit r le nombre de ressources. Nous en évaluons leur nombre de la façon suivante. Chaque
service dépendant des utilisateurs (su) met en jeu une seule ressource (compte, boîte-aux
lettres, ...). Par contre, les services associés aux serveurs (ss) utilisent une moyenne de trois
périphériques (disques, imprimantes,...). Ceci nous permet d'estimer r ~ Su + 3ssm s ' c'est-à
dire:
3r~ -sm
2(Eq.41)
Enfin, soitp le nombre d'instances de programmes. Nous proposons la règle suivante: tous les
micro-ordinateurs sont clients pour l'ensemble des services; les serveurs, quant à eux, sont à
la fois clients et serveurs pour tous les services. Nous obtenons ainsi p ~ ~smm + 2sms ' c'est
à-dire:
3p ~ -sm
2(Eq.42)
Ceci nous permet d'estimer que, pour un réseau qui reprend une architecture similaire au
réseau de test, le nombre d'objets manipulés peut être estimé en fonction du nombre de
machines et de services à surveiller par la formule suivante m + u + r +p, c'est-à-dire:
Nombre objets ~ 3sm (Eq.43)
D'une manière ou d'une autre, même si l'architecture du réseau à modéliser n'est pas
exactement celle décrite par notre évaluation, l'estimateur est linéaire en fonction du nombre
de machines et linéaire en fonction du nombre de services. Or, nous pouvons estimer que ces
deux variables sont indépendantes(a). Ainsi nous concluons que la taille de la base de données,
nécessaires à la mémorisation et à la manipulation des éléments, garde des proportions
exploitables, même pour des réseaux informatiques importants.
114 Administration des applicatifs réseau.t

Du modèle théorique au modèle informatique II .6
Nous procédons de la même manière pour donner une estimation du nombre de services
élémentaires (se). Ainsi, nous pourrons obtenir un ordre de grandeur du graphe global de
dépendances à manipuler.
En s'appuyant sur l'hypothèse précédente, qu'un micro-ordinateur est utilisé par un utilisateur
et qu'il réalise tous les services fournis par les serveurs, nous estimons le nombre de services
élémentaires engendrés par les micro-ordinateurs par sem'" mmsms'
De la même manière, en supposant qu'un serveur a en moyenne cinq utilisateurs et réalise tous
les services fournis par les serveurs, nous pouvons évaluer le nombre de services élémentaires
engendrés par les serveurs par ses'" 5mssms'
Ainsi le nombre de services élémentaires peut être estimé par la formule suivante:
Nombre services élémentaires'" 3sm (Eq.44)
Du calcul précédent, nous pouvons majorer la taille du graphe global de dépendances. Nous
estimons, tout d'abord, que pour tous les services élémentaires, chaque nœud client est
associé, pour la plus grande majorité des cas, à un unique nœud serveur. D'autre part, le
nombre de noms de services est au plus égal au nombre de services élémentaires. Ainsi,
sachant que l'ensemble des sommets du graphe global de dépendances est constitué des
nœuds clients, des nœuds serveurs et des noms de services, nous pouvons estimer que la taille
de cet ensemble est, au plus, égale à trois fois le nombre de services élémentaires.
(Eq.45)
En s'appuyant toujours sur les mêmes hypothèses, le nombre d'arcs de ce graphe est du même
ordre de grandeur (un unique arc issu de chaque nœud client et de chaque nom de service).
Comme pour le nombre d'objets de base, la taille du graphe global de dépendance est linéaire
en fonction du nombre de machines et linéaire en fonction du nombre de services.
Pour le réseau de test, le graphe manipulé était d'un peu plus de 3.000 nœuds (la majoration
déduite de l'équation 45 nous donnait 5.400). On peut extrapoler qu'un réseau d'un millier de
machines et de 10 services à surveiller engendrera un graphe de dépendances ne dépassant pas
(a) Le nombre de classes de services à surveiller dépend uniquement de la volonté de l'administrateur. On
pourrait cependant noter que plus un réseau informatique est important, plus son utilisation est variée. Enconséquent, le nombre de classes de services serait en partie fonction du nombre de machines. Même dans
celle hypothèse, il faut garder à l'esprit qu'il s'agit d'un facteur multiplicatif de faible grandeur que l'on peut
raisonnablement majorer par 10, voire 20 suivant la finesse de l'administration désirée (cf. 3.1.2.2).
Administration des applicatifs réseau.t 115

n.6 Du modèle théorique au modèle informatique
les 100.000 nœuds. Or, il suffit de moins de 2 méga-octets d'occupation mémoire pour stocker
un tel graphe (avec une moyenne de 16 octets pOUl' chaque sommet).
En comparant à d'autres applications, en biologie pal' exemple. où pour la modélisation des
molécules les graphes manipulés dépassent le million de sommets, nous pouvons conclure que
notre modèle peut être exploité sur des réseaux informatiques de taille relativement
importante.
6.2. Les services modélisés.
Nous avons proposé, au paragraphe précédent, des estimateurs du volume de données en
fonction du nombre de machines et du nombre de services. La connaissance du premier
paramètre ne pose pas de difficultés particulières; elle est directement donnée par la taille du
réseau à modéliser. En revanche, le nombre de familles de services réseaux est plus difficile à
cerner. L'approche la plus naturelle de l'utilisation du modèle est la possibilité de déterminer
automatiquement la liste exhaustive de tous les services applicatifs d'un réseau informatique
donné en fonction des objets et des applications multivoques qui décrivent leurs inter
dépendances. Cependant, la restriction à un sous-ensemble de familles de services applicatifs
que l'on désire administrer nous semble une approche plus raisonnable. Il nous semble, en
effet, inutile et illusoire de vouloir modéliser la totalité des services. L'inutilité d'une telle
approche est illustrée, par exemple, par la commande ping de test de connectivité de réseau,
ou encore rperfermeter d'interrogation de la charge CPU d'une machine distante - quel intérêt
y a-t-il à vouloir administrer de telles applications?
De ce constat, nous posons notre premier principe de mise en œuvre. Le modèle informatique
ne modélise que certaines familles de services réseaux. C'est l'administrateur qui les définit en
fonction du contexte applicatif du réseau à modéliser (cf. les choix posés pour le prototype
paragraphe 8.1.3 - page 160).
6.3. Principe de mise en œuvre pour la mémorisation des données
L'utilisation de notre modèle théorique implique la mémorisation des données manipulées au
sein d'un ordinateur. Il existe, à l'heure actuelle. plusieurs principes de stockage des données
en vue de leur manipulation aisée. Le plus couramment utilisé est très certainement la base de
données. Ce système prend en compte les spécificités techniques des mémoires propres aux
ordinateurs (vitesses et capacités de la mémoire vive et de la mémoire de masse).
116 Administration des applicatifs réseaux

Du modèle théorique au modèle informatique
6.3.1. Type de la base de donnée
11.6
La première question à se poser concerne le type du système gestionnaire de base de données
(SGBD) à choisir. Le modèle s'exprime-t-il plus facilement dans une base de données orientée
objet (comme pour le modèle OSI) ou dans une base de données plus conventionnelle sur un
modèle relationnel?
Dans notre modèle, il s'agit, avant tout, de pouvoir manipuler aisément les relations entre les
objets. Par contre, les objets modélisés n'ont pas d'attributs particuliers et de méthodes où la
notion d'héritage peut se justifier réellement. C'est pourquoi, malgré l'attrait actuel sur les
modèles orientés objets, nous suivons le même raisonnement que J. Harista , M. Bail, N.
Roussopoulos , J. Baras , A. Datta [HAR 93] et nous optons donc pour un SGBn relationnel
qui se prête mieux, comme son nom l'indique, au problème d'associations d'objets.
6.3.2. Schéma de la base de données des objets et des relations
L'organisation des données - définies dans le modèle théorique - doit pouvoir être décrite dans
le contexte d'un SGBn relationnel. C'est ce que nous traitons dans les paragraphes suivants.
6.3.2.1. Représentation des objets
Chaque ensemble de base du modèle (machine, ressource, etc) peut être représenté par une
table de la base de données relationnelle. Ainsi, chaque élément d'un des ensembles est défini
par un ll-upletCa) réduit à sa plus simple expression:
-un index,
-la dénomination de l'élément.
L'index est donné par le gestionnaire de la base de données afin qu'il soit unique pour toute la
base(b). Par contre, pour la méthode de dénomination des éléments, la solution la plus
intéressante est de reprendre le système de dénomination, soit de l'OSI, soit de SNMP
(cf 2.3.2.2 - page 32) afin de lever toute ambiguïté de redondances.
Dans l'optique d'une utilisation du modèle en tant qu'outil d'administration, le n-uplet devra
être augmenté avec tout attribut associé au type d'objet administré comme le spécifient et le
spécifieront les travaux OSI ou SNMP sur ces d'objets. La "Host Resource MIB", la "Network
services mOllitoring MIB" sont certainement les travaux les plus récents pour définir les
attributs associés au type d'objet que nous utilisons (présentés dans la première partie à la
page 61).
(a) Un synonyme de n-uplet peut être le terme enregistrement dans le vocabulaire des bases de donnéesrelationnelles.(b) C'est le principe même de la base de donnée relationnelle.
Administration des applicatifs réseaux 117

n.6
6.3.2.2. Représentation des relations entre objets
Du modèle théorique au modèle Informatique
Les relations qui associent les objets sont définies par les applications multivoques dans le
modèle formel. Nous les rappelons brièvement:
Ressources d'une machine r: M ~ R
Programmes d'une machine 1: M ~ P
Liens progr. clients / progr. serveurs a: P s~ Pc
Ressources gérées par un programme g: Ps~ R
Utilisateurs d'un programme clien!.. UC" Pc~ U
Utilisateurs d'un programme serveur us:Ps~ U xM
Liens machine / machine 11: M ~ M
Schéma 26 : Récapitulation des applications de base du modèle
Deux solutions sont envisageables pour associer les objets. Il est possible d'inclure
directement dans les n-uplets des tables d'objets un ou plusieurs champs pour mémoriser
l'index de l'objet associé. Une autre solution consiste à utiliser une table tierce uniquement
composée de n-uplets réduits à un couple composé des index et des objets associés deux à
deux. La première méthode est plus performante en terme de vitesse mais a l'inconvénient
majeur de nécessiter la connaissance préalable du nombre de relations associées à chaque
objet, et de ne plus pouvoir l'augmenter par la suite. Le grand nombre de relations générées
par notre modèle nous pousse à opter pour la deuxième solution, et nous l'appliquons
systématiquement pour toutes les relations à représenter(a). Enfin, seule la deuxième solution
permet d'associer des attributs aux relations elles-mêmes dans l'hypothèse d'une utilisation
dans un outil d'administration plus général.
Nota: Remarquons que la deuxième solution nous "offre" également la représentation des
applications réciproques, ce qui pourra être utile dans l'implantation des algorithmes associés
au modèle.
Exemple de modélisation
Soit à modéliser l'application multivoque décrivant les programmes des machines.
1: M~P ]'--------
(a) Il Ya lieu de noter que le passage de la seconde solution à la première est automatisée sur la plupart des
gestionnaires de base de données tel ORACLE, INGRES, etc (lorsque le cas s'y prête).
118 Administration des applicatifs réseaux
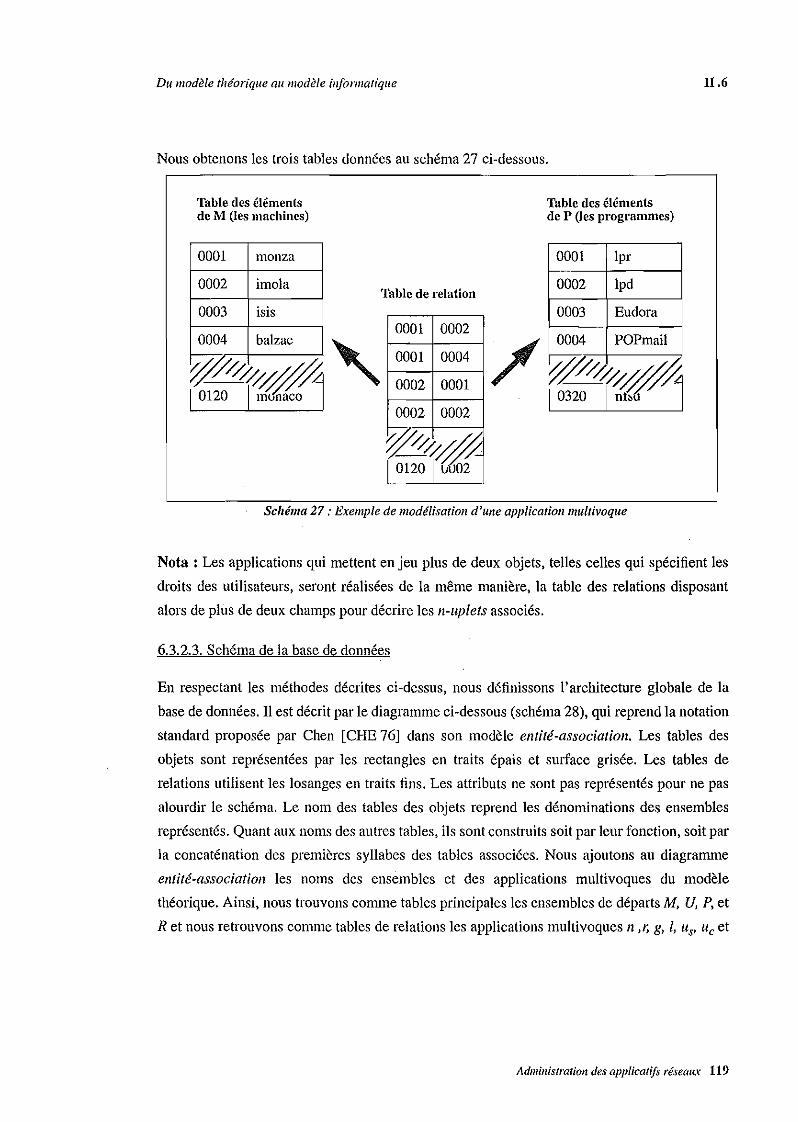
Du modèle théorique au modèle informatique
Nous obtenons les trois tables données au schéma 27 ci-dessous.
II.6
Table des élémentsde M (les machines)
0001 monza
0002 imola
0003 isis
0004 balzac
Table de relation
0001 0002
0001 0004
0002 0001
0002 0002
~~Î0120 Yu 02
Table des élémentsde P (les programmes)
0001 lpr
0002 Ipd
0003 Eudora
0004 POPmail
Schéma 27 : Exemple de modélisation d'Ilne applicationmllltivoqlle
Nota: Les applications qui mettent en jeu plus de deux objets, telles celles qui spécifient les
droits des utilisateurs, seront réalisées de la même manière, la table des relations disposant
alors de plus de deux champs pour décrire les n-uplets associés.
6.3.2.3. Schéma de la base de données
En respectant les méthodes décrites ci-dessus, nous définissons l'architecture globale de la
base de données. Il est décrit par le diagramme ci-dessous (schéma 28), qui reprend la notation
standard proposée par Chen [CHE 76] dans son modèle entité-association. Les tables des
objets sont représentées par les rectangles en traits épais et surface grisée. Les tables de
relations utilisent les losanges en traits fins. Les attributs ne sont pas représentés pour ne pas
alourdir le schéma. Le nom des tables des objets reprend les dénominations des ensembles
représentés. Quant aux noms des autres tables, ils sont construits soit par leur fonction, soit par
la concaténation des premières syllabes des tables associées. Nous ajoutons au diagramme
entité-association les noms des ensembles et des applications multivoques du modèle
théorique. Ainsi, nous trouvons comme tables principales les ensembles de départs M, U, P, et
R et nous retrouvons comme tables de relations les applications multivoques n ,1; g, l, lis, lIc et
Administration des applicatifs réseau.x 119
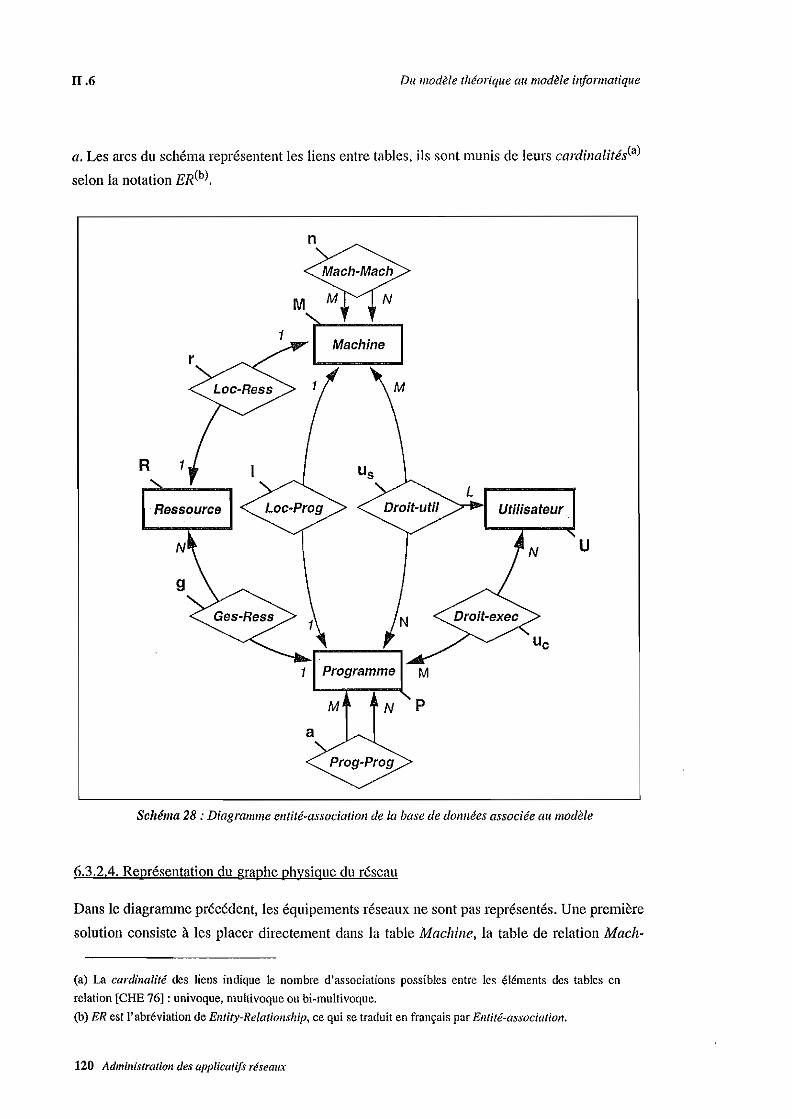
n.6 Du modèle théorique au modèle informatique
a. Les arcs du schéma représentent les liens entre tables, ils sont munis de leurs cardinalitéia)
selon la notation ER(b).
n
Mach·Mach
R
r
1
Ressource
9
M M N
1 l Machine 1
1 Programme M
M N P
a
Prag·Prag
Utilisateur
u
Schéma 28: Diagramme entité-association de la base de données associée au modèle
6.3.2.4. Représentation du graphe physique du réseau
Dans le diagramme précédent, les équipements réseaux ne sont pas représentés, Une première
solution consiste à les placer directement dans la table Machine, la table de relation Mach·
(a) La cardinalité des liens indique le nombre d'associations possibles entre les éléments des tables en
relation [CHE 76] : univoque, multivoque ou bi-multivoque.
(b) ER est l'abréviation de Entity-Relationship, ce qui se traduit en français par Entité-association.
120 Administration des applicatifs réseau:\"

Du modèle théorique au modèle illformatique 11.6
Mach donnant les couples des équipements réseaux interconnectés deux-à-deux. Cependant
dans le cas d'ajouts d'attributs propres à chaque objet, il est préférable de dédier une table aux
équipements, ce qui complète le diagramme précédent de la façon illustrée par le schéma 29.
A
Equip-Equip
E M N
Equipement
Schéma 29 : Extrait du diagramme pour la représentatioll du réseau physique
Comme nous le soulignions ci-dessus, les attributs associés ne sont pas représentés sur les
deux diagrammes précédents, car ils dépendent de choix spécifiques d'implantation en vue de
fonctionnalités particulières d'administration. Nous proposons dans la troisième partie de
cette thèse un schéma de base de données utilisant certains attributs particuliers tels, par
exemple, le type d'ordinateur, le lieu géographique, le responsable administratif, les
paramètres réseaux, la capacité de chaque disque, bref, toutes descriptions utiles.
Nous avons décrit le schéma de la base de données nécessaire à la mémorisation des
informations utilisées par notre modèle. Nous présentons maintenant les principes
d'acquisition de ces données: Quels moyens sont envisageables? Comment peut s'effectuer
la remise à jour des données? etc.
Administration des applicatifs réseau.."!: 121

fi .6 Du modèle théorique au modèle informatique
6.4. Acquisition des données d'administration
6.4.1. Principes d'acquisition
Le principe d'acquisition des données dépend de l'utilisation du modèle. Une première
approche est d'utiliser les informations du modèle comme origine des données des
équipements à administrer, reprenant ainsi le concept de Moira dans le projet Athena du MIT
(présenté au paragraphe 3.2.1.1 - page 59) ou de NIS (présenté au paragraphe 3.2.1.5
page 64). Dans cette optique, la description des utilisateurs, par exemple, est indiquée "à la
main" dans la base de données, le système d'administration se chargent de la diffusion de cette
information sur les différentes machines concernées.
Ce principe est certainement le plus intéressant du point de vue de l'administrateur. En effet,
cette méthode bénéficie de tous les avantages de la gestion centralisée: cohérence des données
dans leurs formes et dans leur contenu, performance des calculs (tout est sur place), etc.
Cependant, même si le principe est intéressant, il ne peut être le seul retenu. En effet, certaines
informations, notamment de description des états des équipements ne peuvent être définies a
priori dans la base d'administration: elles ne peuvent être qu'observées. Il est par conséquent
nécessaire d'utiliser deux principes complémentaires de mise à jour des informations
d'administration, à la fois directement dans la base de gestion, et également par sondes ou
agents d'observation des états des équipements. C'est une des solutions habituellement
retenues, par exemple par les logiciels d'administration comme SunNet Manager.
Le problème repose sur la limite entre les informations déduites du réseau et celles qni sont
déclarées directement par l'administrateur. Notre modèle s'applique à des réseaux
hétérogènes, il est donc difficile d'utiliser la base d'informations comme origine essentielle
des données de configuration. Nons optons, an contraire, pour la réutilisation des informations
pré-existantes sur le résean, tant que faire se peut.
6.4.2. Les informations pré·existantes sur le réseau
6.4.2.1. Principe d'acquisition des données pré-existantes
Nous avons présenté - au chapitre 2 - plusieurs principes pour "interroger le réseau" en vne de
sa gestion. Nous l'avons dit, les deux principales solutions sont l'administration préconisée
par l'ISO et celle basée sur le protocole SNMP (cf. 2.4.1 et 2.4.2). Malheureusement, il
n'existe pas à l'heure actuelle d'implantation d'agents SNMP ou OSI qui nous permettent
d'acquérir toutes les informations nécessaires à notre administration des services réseaux
comme pourra le faire, par exemple, la "Host Resoul'ces MIE" (présentée à la page 61).
122 Administration des applicatifs réseaux

Du modèle théorique au modèle informatique II.6
Cependant, les listes des machines, des utilisateurs, des applicatifs, des ressources sont
pourtant définies. Il s'agit d'éléments connus et répertoriés sur certains équipements du
réseau. Qu'il s'agisse de fichiers de configuration ou de tables distribuées, il est possible de
récupérer ces données par des méthodes moins standards, au moyen de langages
d'interrogation à distance par exemple (cf. 2.4.2.5).
Dans la troisième partie de notre thèse traitant de l'implantation d'un prototype, nous
détaillons un principe d'acquisition des données basé sur le langage de commandes à distances
RSH. Nous verrons que la mise en œuvre d'une telle méthode d'interrogation tient de "l'expert
systèmelréseau"(cf. 8.3.2). En effet, il est nécessaire de connaître parfaitement les systèmes
d'exploitation (Unix, VMS, MSDOS, ...) et les protocoles (Appletalk, TCPIIP, IPX,
DECNET, ...) des ordinateurs du réseau à modéliser.
6.4.2.2. Principe de mise à jour des données pré-existantes
Les données acquises par interrogation et mémorisées dans la base de données doiyent être
nécessairement en adéquation avec les données réelles du réseau modélisé. Or ces dernières
sont susceptibles d'évoluer dans le temps. Dès lors, comment gérer les mises àjour de la base
de données?
Le modèle théorique s'appuie sur plusieurs hypothèses (cf 4.3). L'une d'elles spécifie que les
informations manipulées ont une durée de vie relativement longue, au minimum de l'ordre de
la journée (cf. page 81). La mise à jour des données peut donc se baser sur un principe
d'interrogations cycliques des éléments (quotidiennement ou bi-quotidiennement) pour
recenser les modifications de configuration: les disques démontés, les ajouts d'utilisateurs, les
modifications des logiciels, etc. La méthode la plus raisonnable est de choisir une période de
faible activité des machines interrogées. Ces périodes peuvent être elles-mêmes déduites des
résultats de la modélisation (cf 7.2.3 - page 143).
6.4.2.3. Informations issues d'autres bases de configuration
L'acquisition des informations d'administration ne se restreint pas nécessairement à
l'interrogation des machines elles-mêmes. En effet, les informations peuvent être également
acquises par interrogation de bases d'informations tierces. Il s'agit, par exemple, d'annuaires
tels DNS (Domain Name Server) (a), X500 (cf. note a - page 62) ou encore NIS (cf 3.2.1.5
page 64) dans le cas où ils sont implantés sur le réseau administré. Il s'agit, dès lors, de
disposer des interfaces de communications avec de telles bases d'informations. Dans le cas de
(a) Le DNS est un système d'annuaire distribué contenant en particulier des correspondances entre noms et
adresses réseaux des ordinateurs sous le protocole TCPIIP [RFC 1033].
Administration des applicatifs réseaux 123

II .6 Du modèle théorique au modèle informatique
l'annuaire DNS par exemple, il est nécessaire d'utiliser un outil logiciel implantant le
"resolver',(a) .
Nous avons illustré sur le schéma 30 les tables de la base de données qui sont susceptibles
d'être renseignées - à l'heure actuelle - par interrogation d'informations pré-existantes sur le
réseau. Elles sont hachurées en traits obliques.
6.4.3. Les données déclarées
Certaines informations ne peuvent être acquise par interrogation du réseau. Il s'agit de
données non mémorisées, ou encore de données pour lesquelles il n'existe aucun moyen
(même non-standard) d'acquisition. Dès lors, une part des informations nécessaires à notre
modèle doit être donnée "à la main" en utilisant les commandes adéquates de la base de
données. C'est ce que nous nommons les données déclarées. A moyen terme, les données
déclarées pourraient disparaître avec les progrès effectués dans le domaine de l'administration
de réseaux.
6.4.3.1. Principe d'acquisition des données déclarées
Parmi toutes les données manipulées par le modèle, deux types d'informations doivent être
nécessairement définis "à la main" car il n'existe - à notre connaissance - aucune méthode
pour les acquérir. Il s'agit:
- des informations concernant le réseau physique,
- des descriptions de certaines fonctionnalités des programmes.
Nota: Les tables qui concernent ces informations sont représentées au schéma 30 par les
rectangles et losanges non-hachurés.
Description du réseau physique
Il n'existe pas à l'heure actuelle de méthode d'interrogation pour connaître les éléments qui
composent un réseau informatique, leurs connexions, etc, notllnment lorsque l'on désire une
description assez fine qui fait référence aux équipements passifs (médiums, répéteurs, etc). Il
est donc incontournable de définir les composantes du réseau (table Equipement, Mach-Equip
et Equip-Equip) à la main.
Description des fonctionnalités des programmes
Un deuxième type d'informations non-déductibles du réseau lui-même concerne les
fonctionnalités des programmes. Pour notre modèle, il nous faut alors indiquer manuellement
(a) Dans la description du DNS, le resolverest l'entité interrogatrice de la base d'informations.
124 Administratiol! des applicatifs réseaux
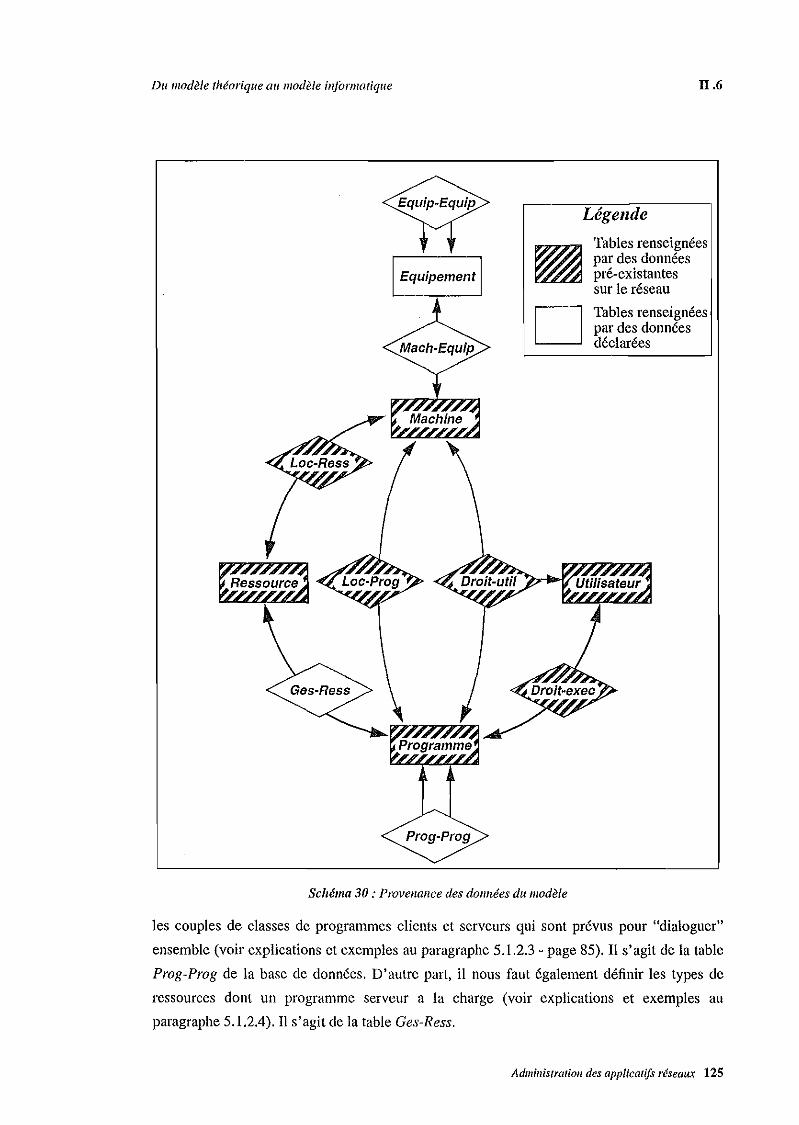
Du modèle théorique au modèle informatique
Equip-Equip'
II .6
Légende
Ges-Ress
Equipement
Programme
Prog-Prog
Tables renseignéespar des donnéespré-existantessur le réseau
Tables renseignéespar des donnéesdéclarées
Schéma 30 : Provenance des données du modèle
les couples de classes de programmes clients et serveurs qui sont prévus pour "dialoguer"
ensemble (voir explications et exemples au paragraphe 5.1.2.3 - page 85). Il s'agit de la table
Prog-Prog de la base de données. D'autre part, il nous faut également définir les types de
ressources dont un programme serveur a la charge (voir explications et exemples au
paragraphe 5.1.2.4). Il s'agit de la table Ges-Ress.
Administration des applicatifs réseaux 125

II.6
6.4.3.2. Principe de mise à jour des données déclarées
Du modèle théorique au modèle informatique
Pour les données déclarées, la mise à jour des informations concernant les progranunes ne
pose pas de problèmes particuliers car il n'y a pas de modifications, mais uniquement des
ajouts. En effet, il s'agit d'indiquer des relations fonctionnelles des classes de programmes.
Celles-ci sont définies une fois pour toutes au développement de ces logiciels. Par contre, pour
ce qui est de la définition des données du réseau physique, il est crucial pour la validité du
modèle, qu'il y ait parfaite adéquation entre le réseau décrit et le réseau réel. Nous retrouvons
une pareille contrainte sur les logiciels d'administration de réseaux du marché (SunNet
Manager, OpenView et outils similaires).
Après avoir exposé les méthodes d'acquisition et de mise à jour des données, nous présentons
les méthodes de définition des services réseaux, et de génération du graphe de leurs
dépendances.
6.5. Recherche des services réseaux et de leurs dépendances
L'établissement des services réseaux dépend à la fois de données déduites et d'informations
déclarées. Pour ce qui est des services réseallx élémentaires, nous présentons un algorithme de
déduction automatique basée sur les données mémorisées dans la base. Pour les applications
de dénominations et de transitions nous montrons comment il est possible d'allier
l'algorithme de recherche automatique des services élémentaires au moyen d'un langage
simple de description de leurs dépendances.
6.5.1. Déduction des services réseaux élémentaires
Les services réseaux élémentaires ont été définis au paragraphe 5.1.3. De cette définition, nous
pouvons déduire un algorithme de recherche automatique de ces services. Il s'agit de vérifier
une à une les six conditions de l'application f pour tout couple (nœud client, nœud serveur),
c'est-à-dire, quels que soient (x, y) de l'ensemble ç. Ceci revient à effectuer des produits
cartésiens en série sur les composantes de x (c'est-à-dire xu. xM et xp) et de y (c'est-à-dire Yu,
126 Administration des applicatifs réseaux

Du modèle théorique au modèle illformatique II .6
YM> YP et YR) et d'éliminer les couples (x, y) non-valides. Cette première approche nous
donne l'algorithme suivant:
pour tout Xu appartenant à Upour tout xM appartenant à M
pour tout xp appartenant à Ppour tout Yu appartenant à U
pour tout YM appartenant à Mpour tout Yp appartenant à Ps
pour tout et YR appartenant à Rsi XM app à Il(YM) et YM app à Il(XM) et
xp app à a(yp) et xp app à r(xM) et Yp app à r(YM) etXu app u,(xp) et (YU,xM) app à usCYp) etYR app g(yp) et YR app à r(YM)
alors (xU,xM,XP)->(YU,YM,Y/lYR) est Uli service élémentaire
Cette première approche brutale nous donne un algorithme dont la complexité est en O(n7), ce
qui ne le rend pas réellement exploitable, pour peu que les ensembles considérés aient une
cardinalité élevée. Cependant, en y regardant de plus près, nous pouvons réduire
considérablement le nombre d'itérations en posant chaque test de sélection dès que possible
dans le déroulement de l'algorithme. Cette méthode est payante car elle repose sur l'hypothèse
qu'il y a relativement peu de services élémentaires par rapport au nombre total de n-uplets
possibles, et qu'il est inutile de continuer à traiter des n-uplets dont une des conditions de
validations n'est pas remplie. Ainsi, cette deuxième approche nous donne une proposition
d'algorithme de recherche des services élémentaires qui peut être la suivante:
pour tout YM appartenant à Mpour tout YR de R tel que YR appat1ient à r(YM)
pour Yp de P tel que YR appartient à g(yp) et Yp appartient à I(YM)pour tout xM appartenant à Il(YM)
pour tout xp appartenant à l(x~t! et xp appartenant à a(yp)pour tout Xu appartenant à u,(xp)
pour tout Yu de U tel que (YU,xM) appartient à ulYp)on a (XU,XAfoXp)->(YU,)'M.Y/lYR) service élémentaire
Nous voyons, dans l'algorithme ci-dessus, que l'ordre des boucles imbriquées n'est pas
quelconque. Pour une performance optimale, il est nécessaire de placer les itérations utilisant
les tests de sélections qui écartent le plus de n-uplets le plus "extérieurement" possible, afin
d'éviter d'entrer inutilement dans les boucles imbriquées. Or cet ordre des boucles est
variable. Il dépend du nombre respectif d'éléments de chaque ensemble traité. Il dépend
également de l'ordre d'instanciation des variables pour les conditions de validation. Nous
proposons ainsi une troisième approche: l'algorithme "adaptatif'. Il s'agit de définir - de
manière générique - les paramètres qui régissent les sept boucles de l'algorithme précédent.
Ainsi la boucle d'indice n est décrite par:
Administration des applicatifs réseaux 127

Il.6 Du modèle théorique au modèle informatique
-l'ensemble qu'elle doit balayer: E(n),
-les conditions de validation de la boucle: C(n),
-la variable de "balayage" de la boucle: i(n).
Prenons comme exemple la deuxième boucle de l'algorithme précédent, à savoir:
pour tout YR de R tel que YR appartient à rIYM)
Les paramètres génériques de la boucle d'indice 2 sont les suivants:
- E(2) décrit l'ensemble R,
- i(2) décrit la variable YR'
- C(2) décrit la condition "YR doit appartenir à r(YM)'"
Soit V la liste des variables déjà instanciées, nous proposons l'algorithme "adaptatif' suivant:
Algo_Adaptatifsoit V liste videProcédure_Bouclee Procédure_Choix_Boucle( V»
Procédure_Bouclee n : indice de la boucle courante)pour tout iln) appartenant à Eln) et dont iln) et V vérifient les conditions Cln)répéter
si Vet iln) définissent toutes les variables alors ils décrivent un service élémentairesinon s' il reste une boucle non encore parcourue
alors Procédure_Bouclee Procédure_Choix_Boucle( I\il"» )
Procédure_Choix_Boucle( liste des variables instanciées)Retourner l'indice de la boucle i non encore parcourue
dont toutes les variables nécessaires à ses conditions Cli) sont instanciéeset dont le cardinal de E(i) est le plus petit
Utilisation des outils du gestionnaire de la base de données
Après avoir présenté les algorithmes de recherche des services réseaux élémentaires, nous
soulignons les possibilités d'utilisation des outils du SGBD qui permet la mémorisation des
informations. En effet, notre modèle s'appuyant sur une base de données relationnelle, les
produits cartésiens et tests de sélections exposés précédemment peuvent être réalisés par le
gestionnaire de base de données sous forme de jointures et de projections successives sur les
tables adéquates. Cette méthode a bien évidemment l'avantage de déléguer le traitement du
problème à un outil prévu pour ces types d'opérations. Cependant, il faut garder à l'esprit que
les gestionnaires de bases de données n'optimisent que les opérations de projections, et
généralement pas l'ordre de traitement de séries de jointures couplées à des projections,
comme pour la méthode présentée ci-dessus. Il est nécessaire d'expliciter, dans le langage
128 Administration des applicatifs réseaux

Du modèle théorique au modèle informatique II.6
spécifique du gestionnaire de la base de données, les opérations à effectuer, ce qui fige l'ordre
des boucles.
Lors de l'implantation d'un prototype de notre modèle, il nous a été possible de comparer les
deux méthodes. Sur le SGBD relationnel (INGRES domaine public(a» utilisé, les
performances sont particulièrement décevantes par rapport à celles de l'algorithme adaptatif
présenté ci-dessus (plus de dix fois plus lent en moyenne sur notre jeu d'essai).
6.5.2. Dénomination des services réseaux élémentaires et fonction de transition
L'opération qui consiste à regrouper les services élémentaires au moyen de l'application de
dénomination ne peut être déduite automatiquement, car cette opération dépend en partie
d'informations déclarées. Il en va de même pour l'applications de transition qui nous permet
de définir les services en cascade et par conséquent de construire le graphe global de
dépendances.
La méthode que nous proposons repose sur la définition d'un langage simple de description
des dénominations et des transitions: suites de règles de réécriture qui permettent de décrire
les dépendances. Certaines de ces règles sont déduites de données pré-existantes sur le réseau,
d'autres doivent être déclarées par l'administrateur.
Syntaxe dl/langage de description des règles de dénomination et de transition
La syntaxe de ce langage s'inspire directement de l'exemple (Eq.20) présenté
paragraphe 5.1.5 pour définir un service réseau en cascade.
Nous donnons une grammaire qui décrit ce langage. Son vocabulaire non-terminal est
composé des symboles P, D, T, F, C, S, r et l'axiome de la grammaire est P. Son vocabulaire
terminal est composé des symboles suivants y, =, {, J, (, J, Yu, YMo YF YR' xu, xM' xl" Les
règles de dérivation de cette grammaire sont les suivantes:
P--7DIT
D --7 DDIDTly = {F}
T--7 TTITDIS = {f} IC = {f}r --7 rflyF--7FFIC = S
S --7 (Yu' YM' Yp, YR)
C --7 (xu' xM' x p )(Eq.46)
(a) La version de INGRES dll domaine public a été rebaptisée POSTGRES à partir de t987 (voir présentation
de POSTGRES dans la troisième partie de la thèse - paragraphe 8.3.1 - page 165).
Administration des applicatifs réseaux 129

11.6 Du modèle théorique au modèle informatique
Nota : Pour les symboles non-terminaux. nous avons choisi la sémantique suivante:
D : dénomination, T: transition, F : service élémentaire, C : nœud client, r :nom de service,
et S : nœud serveur.
Exemple de règle de dénomination - déclarée
Prenons pour exemple une règle déclarée par l'administrateur pour dénommer (et par
conséquent regrouper) les services élémentaires nécessaires aux impressions d'une salle
d'ordinateurs:
Impr_Sallel = {(SU, $M, PCNFS.EXE) = {(SU, monza, nfsd, /dev/sdOh »(SU, $M, LPR.EXE) = ({SU, monaco, lpd, laserII)}
Les variables précédées du caractère "$" vont être celles à instancier en fonction des services
élémentaires déduits par l'algorithme présenté au paragraphe 6.5.1. Les éléments déjà définis
dans la règle soulignent tout l'intérêt d'un tel algorithme "adaptatif' ; certaines variables sont
déjà instanciées ce qui va accélérer d'autant le traitement.
Nota: Il serait nécessaire d'ajouter à ce langage de description une sémantique permettant de
vérifier certaines conditions sur les éléments. Dans notre exemple, il serait nécessaire de
vérifier que la machine cliente décrite par la variable $M est bien localisée dans la salle
d'ordinateurs en question.
Exemple de règle de dénomination - déduite du réseau
En fonction du type de machines, certaines règles peuvent être déduites directement de la
configuration.
Nous donnons en exemple une règle qui peut être aisément déduite du fichier lete/printcap et
lete/I'esolv.confpour une machine Unix; elle indique les services élémentaires mis en œuvre
pour l'accès à une imprimante donnée:
Accès_Laser!I = {
(SU, monaco, lpr) = {(SU, imola, lpd, laserII )}($U, monaco, gethostbyname) = {(-, isis, named, /etc/namebd)}
De la même manière que nous décrivons les regroupements de services élémentaires, nous
décrivons les transitions. Elles sont déduites des informations pré-existantes sur le réseau, ou
bien déclarées par l'administrateur.
130 Administration des applicatifs réSealLl:

Du modèle théorique au modèle informatique
Exemple de règle de transition - déduite du réseau
II .6
En reprenant l'exemple précédent, en fonction des mêmes fichiers de configuration, il est
possible de déduire la règle de transition suivante:
($u,monaco, Ipd, laserII) = {Accès_Laser!I
6.5.3. Construction du graphe global de dépendances
Le langage spécifiant les dénominations et les transitions - allié à l'algorithme adaptatif de
déduction des services élémentaires - permet de construire le graphe global de dépendances.
En effet, les informations qui décrivent le réseau permettent de générer (grâce au langage
décrit ci-dessus) une suite de règles instanciées qui n'est rien d'autre que la description du
graphe global de dépendances en fonction de la sémantique suivante:
- tout facteur d'un mot du langage de la forme (xu, xM' xp) est un nœud client, appartenant àsg ,
- tout facteur d'un mot du langage de la forme (yu, YM> YI' YR) est un nœud serveur,
appartenant à sg ,- tout facteur d'un mot du langage réduit au symbole 'Y est un nom de service, appartenant à
sg,- tout facteur d'un mot du langage x ={yz... } signifie que yz... est successeur de x, c'est-à
dire que les éléments y, z, ... appartiennent à Ag (x) .
Après avoir évalué le volume des données nécessaires à notre modélisation, nous en avons
décrit les principes de mise en œuvre, à savoir: l'application non-exhaustive, les moyens
d'acquisitions et de mémorisations des données, et les méthodes de génération du graphe
global de dépendances. Ce sont ces concepts qui sont retenus dans le prototype logiciel décrit
dans la dernière partie de notre thèse.
Dans le chapitre suivant, nous allons exposer les résultats que nous pouvons obtenir d'une
telle modélisation.
Administration des applicatifs réseau.t 131

II.7 Résultats de la lI1odélisqtioll
78 Résultats de la modélisation
Nous allons exposer plusieurs résultats qui découlent de notre modélisation. Nous détaillons
des exemples d'exploitations de notre modèle pour mettre en relief ses divers domaines
d'application. Afin de donner une vue assez complète des possibilités offertes, nous classons
nos résutats suivant les cinq aires fonctionnelles définies par l'ISO dans le cadre de
l'administration de réseau.
Les résultats présentés se basent sur l'exploitation du graphe global de dépendances ou sur le
graphe de dépendances associé à chaque service. Ils exploitent les notions d'impacts et de
dépendances des objets les uns par rapport aux autres.
7.1. Gestion de la configuration
La première aire fonctionnelle proposée par l'ISO est la gestion de la configuration. Nous
présentons deux résultats de notre modèle dans ce domaine:
-la connaissance des relations entre les éléments qui entrent enjeu dans l'établissement des
services applicatifs,
-le repérage de configurations applicatives aberrantes: les interdépendances cycliques.
7.1.1. Connaissance des configurations
Le modèle présenté dans les deux chapitres précédents nécessite, dans un premier temps,
l'acquisition et la mémorisation d'un certain nombre d'informations de configuration, afin de
pouvoir générer, dans un deuxième temps, le graphe global de dépendances. Cette
connaissance préalable de données n'est pas à proprement parler un "résultat" , mais couplée à
un outil de manipulation de l'information, tel un gestionnaire de base de données, elle offre
des réponses immédiates à bon nombre de questions qu'un administrateur de réseau est amené
à se poser. Celui-ci dispose d'une base d'informations qui lui permet de connaître la
localisation des comptes utilisateurs, les ordinateurs serveurs et clients des montages disques,
les machines de gestion des périphériques dédiés, etc.
En fait, il s'agit de l'exploitation "courante" de la base de données constituée pour le modèle.
Projections, sélections, jointures, autant d'opérations sur le SGBD, qui, appliquées à la base
132 Administration des applicatifs réseaux

Résultats de la modélisation II.7
d'informations du modèle, permettent de résoudre un certain nombre de problèmes courants
d'administration.
Nota: Nous trouvons également ce type de résultat dans certains outils existant de gestion de
réseau, mais généralement limités à quelques types d'ordinateurs. Par exemple, SI/nnet
Manager offre la connaissance des disques gérés par les ordinateurs fabriqués par Sun.
Ne s'agissant pas de résultats particulièrement originaux, et puisqu'il s'agit d'une simple
utilisation de base de données, nous ne nous étendons pas sur cet aspect de l'exploitation de
notre modèle. Nous présentons simplement dans la troisième partie de la thèse les méthodes
d'interrogation de la base de données pour ce type de problèmes. Un deuxième résultat plus
original dans la gestion de la configuration est présenté dans le paragraphe suivant. Nous
exposons la manière d'utiliser notre modèle afin de repérer certains types de configurations
aberrantes: les interdépendances cycliques.
7.1,2, Repérage des interdépendances cycliques
Un cas relativement fréquent de configurations applicatives aberrantes est celui où deux
services réseaux dépendent réciproquement l'un de l'autre pour fonctionner. Nous appelons ce
type de situation interdépendance cyclique.
7.1.2.1. Exemple d'interdépendance cyclique
L'exemple le plus typique d'interdépendance cyclique est le montage croisé de disques. De
quoi s'agit-il? Le cas le plus simple est celui où deux ordinateurs serveurs "exportent" chacun
un certain nombre de leurs partitions-disques. Ces deux ordinateurs sont également
"importateurs" de certaines partitions-disques qui proviennent de l'autre ordinateur. Le
schéma 31 illustre le cas d'un ordinateur serveur (machine B) qui exporte les partitions
disques nécessaires à une station de travail (machine A) fonctionnant sans disque système (1
export et/home). Pour des raisons de convenances personnelles, l'utilisateur de ce deuxième
ordinateur veut gérer localement son propre disque de données (ldev/sdJ). Cependant, il désire
également que certaines de ces données soient accessibles à travers le serveur pour les autres
utilisateurs. Cette situation est parfaitement possible et ne pose aucun problème ni de mise en
œuvre, ni d'utilisation en fonctionnement "normal". Le problème prendra toute son
importance dans le cas de redémarrage simultané des deux ordinateurs (suite à un
rétablissement de l'électricité par exemple). Les deux ordinateurs vont chacun attendre
indéfiniment le rétablissement du fonctionnement normal de l'autre ordinateur: c'est
l'inter!Jlocage.
Administration des applicatIfs réseaux 133

II .7 Résu.ltats de la modélisation
montage des partitions lexport et fllOmesur des répertoires de même nom
Ordinateur B
1
Ordinateur Amontage de la partition/dev/sdlsur le répertoire Ihomc/etudiant
Schéma 31 : fnte/dépendance cyclique dans le cas de maillages de disques
Nota : L'interdépendance cyclique dans le cas de montage de disques est si typique que
certains fournisseurs de ce service réseau, tel Sun par son service NFS (Network File System),
offre une option d'attente sur montage (option "background" de NFS) afin d'éviter les
interblocages. Il s'agit alors d'une possibilité de fonctionnement en mode dégradé du service.
Ce type de situation d'interblocages peut se repérer "à la main" dans le cas de deux
ordinateurs. Cela devient nettement plus aléatoire lorsque plus de deux machines entrent en
jeu. Or les cas d'interdépendances cycliques sont parfaitement repérables grace à notre
modèle de données, comme nous le présentons dans le paragraphe suivant.
7.1.2.2. Cycle dans les graphes de dépendances
Le graphe de dépendances Gy, d'un service y, est défini par l'ensemble de ses sommets Sy et
par l'application multivoque Ay décrivant les arcs (voir définition en 5.4.1). Cette application
a été définie à partir des trois applications multivoques f, q et il prenant leurs valeurs dans les
ensembles suivants:
f: C ---7 Sq: ï ---7 C X S
h: Cu S ---7 ï(Eq.47)
Il y a par conséquent possibilité de cycles dans les graphes de dépendances (par les éléments
de l'ensemble ï).
134 Administration des applicatifs réseaux

Résultats de la modélisation
Nous avons la propriété suivante:
IL7
Soit 'Y E l
3x E Sy tel que 3 Circuitc, (x, x) <=;> 'Y en interdépendance cyclique(Eq.48)
Un cycle dans un graphe de dépendances est la mise en évidence d'une situation
d'interdépendance cyclique susceptible d'engendrer un interblocage. En effet, un cycle dans
un graphe de dépendances signifie que le fonctionnement de chaque service du cycle dépend
de son propre joncfiOllllement préalable. Il est bien clair que de tels services sont impossibles
à établir. Il s'agit typiquement d'une erreur de configuration des applications.
Nota : Dans la suite de la présentation des résultats, nous supposons que tous les cas
d'interdépendances cycliques ont été repérés par la méthode ci-dessus, et corrigés, afin que la
configuration des applications modélisées soit correcte. Par conséquent, la suite des résultats
présentés est obtenue à partir de graphes de dépendances acycliques.
7.2. Gestion des anomalies et des performances
L'ISO délimite deux aires fonctionnelles distinctes pour la gestion des anomalies d'une part et
la gestion des performances d'autre part. Ces deux domaines sont pourtant étroitement liés;
nous préférons les traiter dans un même paragraphe pour une meilleure clarté de notre exposé.
En effet, les résultats qui vont être présentés mettent en œuvre certaines méthodes similaires.
Nous allons développer quatre résultats quant à l'utilisation de notre modèle dans ces
domaines. Il s'agit tout d'abord d'offrir une méthode de calcul de la fiabilité des services
réseaux, ceci pour répondre au type de questions suivantes: Pourquoi tel utilisateur à partir
de son ordinateur habituel ne parvient que rarement à imprimer sur telle imprimante?
Pourquoi ce terminal Xfonctionne mal par rapport à cet autre terminal qui, lui, ne pose aucun
problème? Il peut également s'agir de questions plus générales du genre: Quelle est la
qualité de service d'un réseau applicatifdans sa globalité? Est-elle meilleure que celle de cet
autre réseau? Dans un deuxième temps, nous exposons une méthode originale de mesure de
l'impact de chaque machine sur l'ensemble des services réseaux. L'idée est de pouvoir
répondre à la question suivante: Quels sont les ordinateurs du réseau qui sont "sensibles" ?A
quels moment? Pourquoi? Ce dernier résultat va être utilisé, par la suite, pour évaluer la
charge des ordinateurs, soit de manière globale, soit en fonction du temps. Enfin, nous
terminons l'exposé des résultats concernant les domaines de la gestion des anomalies et des
performances, par la présentation de l'utilisation du modèle pour effectuer des diagnostics en
cas de dysfonctionnement de services réseaux. Il s'agit de pouvoir répondre à la question
Administration des applicatifs réseau.'< 135

IL7 Résultats de la modélisation
suivante: Quels équipements doivent être suspectés dans IlIl cas de dysfonctionnement de
services réseaux?
7.2.1. Fiabilité d'un service réseau
Pour obtenir des paramètres mesurant la fiabilité de service, nous nous appuyons sur les
méthodes présentées, entre autres, dans l'ouvrage "Téléinformatique - Transport et traitement
de l'information dans les réseaux et systèmes téléinformatiques et télématiques" [MAC 87] de
C. Macchi et co-auteurs. en les appliquant aux graphes de dépendances générés selon notre
modèle. Ces méthodes ont été également décrites dans les ouvrages traitant des problèmes de
calculs de disponibilité d'équipements, approfondis dans [KAU 75] et [POL 69]. Le problème
est de pouvoir quantifier la fiabilité d'un service afin d'estimer sa qualité, et de pouvoir la
comparer: Qu'est-ce qu'un "bon" service? Qu'est-ce qu'un "mauvais" service?
7.2.1.1. Définition de la fiabilité d'un service
Nous définissons lafiabilité d'un service comme la disponiblité moyenne du dit service. Celte
disponibilité peut être quantifiée par l'estimation de la probabilité de fonctionnement du
service en question. Par exemple, un service, qui a une probabilité de fonctionnement de
0,988, a une indisponibilité moyenne de 2h par mois (dans le cas où l'on ne considère que les
heures ouvrables du mois - soit environ 160 heures).
7.2.1.2. Calcul de la fiabilité d'un service
Méthode utilisée
Selon la méthode exposée par Macchi, il s'agit d'estimer la probabilité de fonctionnement
d'un équipement enfonction des éléments sous-}acents. Dans le cas où tous les éléments sous
jacents sont strictement nécessaires, le produit des probabilités de fonctionnement de ceux-ci
nous donne la probabilité de fonctionnement de l'équipement. Macchi souligne que celte
méthode s'appuie sur l'hypothèse qu'il s'agit de probabilités indépendantes, hypothèse dont
nous débaltons par la suite.
Utilisation des graphes contractés de dépendances
Pour appliquer cette méthode au calcul de la fiabilité d'un service, nous utilisons le graphe de
dépendances du service en question. En effet, ce graphe a été défini pour modéliser l'ensemble
des objets (machines, utilisateurs, programmes et ressources) strictement nécessaires au
fonctionnement du service sous forme de nœuds clients et nœuds serveurs. Ainsi, pour
calculer la fiabilité d'un service réseau, nous pondérons les sommets du graphe de
136 Administratioll des applicatifs réseaux

Résultats de la modélisatioll II .7
dépendances associé au service, par la probabilité de fonctionnement de chaque nœud. La
probabilité de fonctionnement du service en question est obtenue par produit des probabilités
de chaque nœud du graphe:
P [Service y correct] = II P [x correct]XE Sy
(Eq.49)
Ce résultat s'appuie sur l'hypothèse que la probabilité de fonctionnement d'un nœud est
indépendante de la probabilité de fonctionnement des autres nœuds. Nous voyons dans le
paragraphe suivant que cette hypothèse est relativement réaliste si l'on se restreint à la
probabilité de fonctionnement des machines et des ressources.
Nota: Dans le cas particulier de pannes de secteur, il sera nécessaire d'effectuer des calculs
plus complexes, par regroupement en catégories d'éléments à probabilité de fonctionnement
indépendante. Nous renvoyons le lecteur aux ouvrages présentés précédemment.
Probabilité de fonctionnement des nœuds clients et serveurs
Le problème reste de pouvoir estimer la probabilité de fonctionnement de chaque nœud du
graphe de dépendances. Une approche raisonnable est de considérer uniquement les
probabilités de fonctionnement des machines et des ressources (vu comme des équipements
physiques - disques, imprimantes, etc). En effet, il existe bien sOr des possiblités de
programmes bogués, mais on peut poser l'hypothèse que la probabilité de fonctionnement des
programmes (sur un ordinateur fiable) a un impact négligeable par rapport aux probabilités de
fonctionnement des équipements.
Calcul de la probabilité de fonctionnement d'une machine, d'une ressource
La probabilité de fonctionnement d'une machine peut être calculée de plusieurs manières,
nous en proposons deux:
- calcul par produit sur les diverses composantes de la machine,
- calcul empirique en fonction du taux de fonctionnement.
Le calcul de la probabilité de fonctionnement d'un matériel électronique peut être estimé par
le produit des probabilités de fonctionnement de ses diverses sous-composantes (mémoires,
microprocesseur, cartes d'extension...). La finesse des résultats sera fonction de la définition la
plus exhaustive des composantes. Cette méthode a l'avantage de donner un résultat a priori,
sans aucune simulation, ni essai.
La deuxième méthode semblera peut être plus brutale, mais donne en fait de meilleurs
résultats. Il s'agit simplement de calculer sur une période de temps donnée (un mois, une
semaine), le temps où la machine a effectivement fonctionné, et le temps où elle a été hors-
Administration des applicatifs réseau.t 137

n.7 Résultats de la modélisation
(klein,monza,nfsd,monza:/home/klein)
service. Un simple quotient entre ces deux valeurs nous donnera une très bonne estimation de
la probabilité de fonctionnement de la machine en question. Notons que cette deuxième
méthode a l'avantage d'inclure des paramètres tels le degré de suivi de la machine: rapidité de
dépannage, temps d'immobilisation pour les modifications logicielles de la machine, etcta). Il
s'agit en fait de la disponibilité de la machine.
Exemple de calcul de fiabilité d'llll service
Nous présentons ci-dessous un exemple de calcul defiabilité pour le service d'impression dont
nous nous sommes servi pour illustrer la méthode de construction du graphe global de
dépendances (cf. 5.4.1). Le schéma 32 reprend le graphe contracté de dépendances du service
fn\ Impression_pc1_laserllI!Y ->(klein,pc1,PCNFS.EXE)
-> (klein,pc1,LPR.EXE)
/ ~@(klein,monaco,lpd,laserll)-> Accès_Iaserll
-> (klein,monaco,lpr)-> (klein,monaco,gethostbyname)
/ \®(-,lmola,lpd,laserll) (-,isis,named,letc/namebd)
Schéma 32: Exemple de calclIl de la fiabilité d'lIl1 sen'ice
en question, en y adjoignant les probabilités de fonctionnement de chaque nœud, spécifiées
dans le tableau 5 ci-dessous. Pour notre exemple, nous nous sommes restreints à la probabilité
de fonctionnement des ordinateurs et de l'imprimante, les disques ont été estimés fiables.
Nœuds Indisponibilité moyenne Probabilité defonctionnement
pc! 2 heures par semaine Pl =0,9500
mailza 2 heures par mois P2 =0,9875
monaco 1 heure par mois P3 =0.9938
(a) Suivant le résultat escompté. il peut être intéressant de prendre en compte certains types d'arrêt de lamachine plutôt que d'autres.
138 Administration des applicatifs réseaux

Résultats de la modélisatloll
Nœuds Indisponibilité moyenneProbabilité de
fonctionnement
imola 1 heure par semaineP4 = 0,9141
Laser II 30 minutes par jour
isis 30 minutes par mois Ps = 0,9969
Tableau 5 : Exemple de calcul de laftabilité des services
11,7
Le calcul de la fiabilité du service d'impression est donné ci-dessous. Nous remarquons
immédiatement la fiabilité relativement faible due aux nombreux intermédiaires.
L'indisponibilité du service Impressiotl--pc1_LaserII est estimée à environ 1 heure 15 par jour,
ce qui peut sembler élevé même pour une moyenne.
5
P [Impression_pcl_laserII correct] = II Pi = 0,8443
i ~ 1
(Eq.50)
L'exemple cité est réel. Nous avons pu ainsi mesurer que la fiabilité calculée corrobore assez
fidèlement notre observation directe de l'indisponibililé de ce service. Il est bien clair que
l'estimation des probabilités de fonctionnement des éléments sous-jacents doit être la plus
fidèle possible pour avoir un résultat cohérent(a).
7.2.1.3. Estimation de la qualité d'un réseau
Pouvoir estimer la "qualité d'llll réseau" est un des soucis constant de l'administrateur.
Sachant l'importance vitale que peut prendre le réseau informatique au sein d'une entreprise
où un simple arrêt de quelques heures peut se chiffrer à plusieurs dizaines de milliers de
francs - on peut comprendre l'intérêt d'un tel estimateur. Il s'agit, cependant, d'une notion
vague et à multiples facettes. Parle-t-on de qualité du débit global, du nombre d'utilisateurs
satisfaits, du cumul des temps d'indisponibilités des ordinateurs? Bref, de nombreux
paramètres sont envisageables.
En nous basant sur les calculs de fiabilité pour chaque service, présentés au paragraphe
précédent, nous proposons une méthode pour estimer une certaine forme de "qualité globale"
du réseau modélisé, à savoir la "qualité de service". Nous calculons pour cela la moyenne(b)
(a) Par contre, dans l'exploitation du prototype logiciel présenté dans la troisième partie de la thèse, lesfiabilités calculées nous paraissent légèrement minorées par rapport à la réalité. Ceci est dO, en partie, à uneapproximation, sur une période trop courte, des indisponibilités moyennes des ordinateurs et des ressources(voir paragraphe 9.4 - page 200).
(b) Le calcul de cette moyenne peut être, éventuellement, pondérée en fonction de l'importance accordée à
chaque type de service (les services vitaux pour l'entreprise, etc).
Administration des applicatifs réseau.t 139

11.7 Résultats de la modélisation
des fiabilités pour l'ensemble des services afin d'obtenir une valeur reflétant la disponibilité
globale des services du réseau à évaluer.
Qualité du réseau
l P [Service y correct]_ YErnSg
- card( [' il sg )(Eq.51)
Cet estimateur est à prendre avec les précautions d'usage sur ce type de calcul aussi global,
mais il permet d'opérer une certaine forme de classement des réseaux et d'en évaluer leurs
évolutions.
7.2.2. Impact d'un ordinateur
Dans le cas d'une infrastructure informatique centralisée autour de ce que l'on nonune un
"mainframe", c'est-à-dire un "gros ordinateur central", le problème de l'impact de la machine
en question ne se pose pas réellement. Si l'ordinateur tombe en panne, plus rien ne fonctionne.
Avec une petite note d'humour, nous pouvons dire que cela a l'avantage de simplifier les
explications aux utilisateurs mécontents. Dans les réseaux actuels où la station de travail est
reine, il est beaucoup plus difficile d'estimer, a priori, les dégâts occasionnés par l'atTêt d'une
ou de plusieurs de ces stations.
C'est pourquoi, il est tout à fait vital qu'il soit possible de quantifier l'impact d'une machine
sur l'ensemble des services réseaux et de pouvoir répondre précisément à des questions du
genre: Quel est le moment le plus judicieux pour rajouter un disque à tel serveur? Qui
faudra-t-il prévenir?
Nota: A l'heure actuelle et à notre connaissance, l'impact n'est jamais mesuré, et les seules
précautions consistent à effectuer les al1'êts de machines aux heures susceptibles de ne gêner
que le minimum de personnes (avec toutes les surprises que l'on peut imaginer), et à prévenir
le plus de monde possible (en espérant n'omettre personne).
Une autre application directe de la mesure de l'impact est de justifier les contrats de
maintenance des ordinateurs. Pouvoir répondre à la question: "quel contrat de maintenance
pour quelle machine? (intervention sous les quatre heures, dans la semaine...)" n'est pas aussi
simple qu'il peut y paraître. Notons que le coût des contrats établis par les revendeurs est
uniquement fonction de la machine, et non pas de la finalité que l'utilisateur lui assigne. A
quoi sert de payer des dizaines de milliers de francs par an, sachant que les machines
couvertes ont un impact très faible sur les services réseaux?
140 Administration des applicatifs réseaux

Résultats de la modélisatioll II .7
Nous présentons dans les paragraphes suivants, une méthode de calcul de l'impact de chaque
machine sur l'ensemble des services réseaux, et nous proposons une normalisation de ces
valeurs afin d'en faire des estimateurs comparables.
7.2.2.1. Définition de l'impact d'une machine
En première approche, nous définissons l'impact d'une machine comme le nombre de services
réseaux strictement dépendants du fonctionnement de la machine en question. Nous notons
cet impact lmi pour la machine mi'
Méthode de calcul de l'impact
Pour calculer l'impact d'une machine, nous travaillons par pondération du graphe global des
dépendances, sous sa forme contractée, présenté au paragraphe 5.4.2. Il s'agit de parcourir le
graphe dans le sens descendant, en pondérant chaque nœud par le nombre de services qu'il
aura fallu traverser pour arriver jusqu'à chaque nœud. Dans le cas où le nœud courant a déjà
été traité, il y aura sommation avec l'ancienne valeur.
Exemple de calCltI de l'impact
Pour illustrer la méthode de calcul de l'impact, nous reprenons l'exemple donné lors de la
définition du graphe global de dépendances. Le schéma 33 ci-dessous indique les pondérations
opérées sur un tel graphe. Nous avons opéré trois parcours complets dans le sens des arcs à
partir des trois services modélisés: Impression...JJCClaserII, Accès_laserII et Courrier
(typographie grasse sur le schéma).
7.2.2.2. Définition de l'impact réduit d'une machine
L'impact réduit d'une machille est défini comme le rapport de l'impact d'une machille sur le
nombre total de services. Nous le notons IRmi pour la machine mi'
Il s'agit d'une valeur comprise entre 0 et 1. Une machine d'impact réduit égal à 1 est
nécessaire au bon fonctionnement de la totalité des services du réseau modélisé. Une machine
d'impact réduit nul n'a aucune incidence sur les services du réseau.
Calcul de l'imvact réduit des machines
Pour obtenir l'impact réduit pour chaque machine, il suffit d'effectuer le quotient de chaque
impact sur le nombre total de services. Pour l'exemple précédent, card (s) = 3 ,ce qui
nous donne les résultats suivants:
Administration des applicatifs réseaux 141
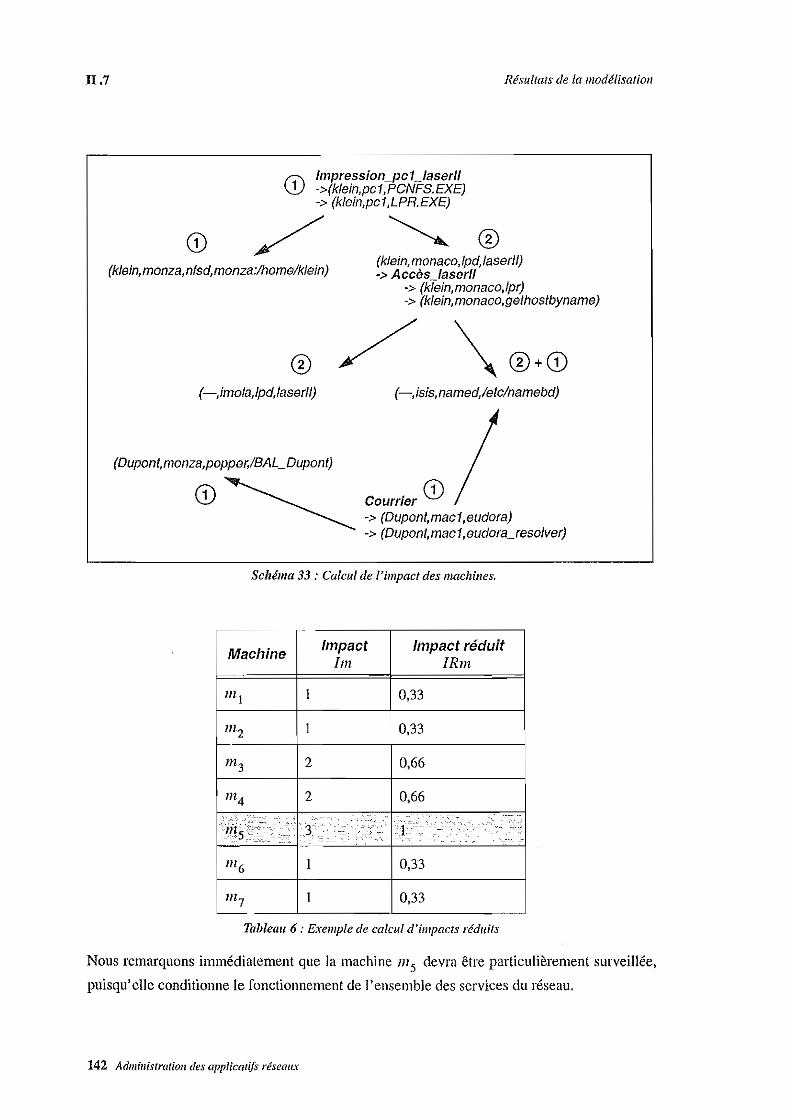
11.7 Résultats de la modélisation
t.\ Impression_pc1_laserllo ->(kleln,pc1,PCNFSEXE)-> (klein,pc1,LPR.EXE)
CD / ~ ®(kleln,monaco,lpd,laserll)
(klein,monza,nlsd,monza:lhome/kleln) _> Accès laserll-> (kTein,monaco,lpr)-> (kleln,monaco,gelhoslbyname)
®(-,imola,lpd,laserll)
(Dupont,monza,popper,/BAL_Dupont)
CD
(-,isis,named,lelclnamebd)
Courrier CD-> (Dupont,mac1,eudora)-> (Dupont,mac1,eudorajesolver)
Schéma 33: Catcul de l'impact des machines.
MachineImpact Impact réduit
J/Il JR/Il
/Ill 1 0,33
/Il2 1 0,33
/Il 3 2 0,66
/Il4 2 0,66
1 0,33
Tableau 6: Exemple de calcul d'impacts réduits
Nous remarquons immédiatement que la machine /Il 5 devra être particulièrement surveillée,
puisqu'elle conditionne le fonctionnement de l'ensemble des services du réseau.
142 Administration des applicatifs réseaux

Résultats de la modélisatioll
Poids variables des serl'ice~
11.7
Dans le calcul présenté précédemment, nous avons supposé que tous les services avaient la
même importance. Il est bien entendu plus réaliste d'affecter des coefficients à chaque service,
afin que le calcul de l'impact en dépende.
Notons que, dans ce cas-là, le calcul de l'impact réduit sera obtenu par quotient sur la
sommation des coefficients de chaque service, et non plus simplement sur le nombre de
services.
Reprenons l'exemple précédent en supposant que le service Courrier a un coefficient de 4 par
rapport aux autres services n'ayant qu'un coefficient 1. Le diviseur pour le calcul de l'impact
réduit sera alors de 6 et nous obtenons le résultat suivant:
MachineImpact Impact réduit
J/Il JR/Il
/Il) 0,17
/Il2 1 0,17
/Il 3 2 0,33
/Il4 2 0,33
4 0,67
Tableau 7: Exemple de calcul d'impacts réduits elljonction de selvices pondérés
7.2,3. Charge des machines
Dans une optique similaire à celle développée dans le rapport de Maurin [MAU 93] sur les
travaux d'Alcate! Strasbourg, nous proposons une méthode d'estimation de la charge des
machines. Nous tentons de répondre aux questions suivantes: Quels sont les ordinateurs
particulièrement sollicités? Par qui? Pourquoi? Et à quel/es périodes?
Nous avons proposé, au paragraphe précédent, une méthode de calcul de l'impact d'un
ordinateur sur l'ensemble des services. La valeur obtenue (dans le cas 011 elle n'est pas
réduite) représente le nombre de services que la machine doit supporter. Si l'on considère le
graphe global de dépendances, parcouru dans le sens inverse des arcs à partir de la machine
concernée, nous retrouvons tous les noms de services, mais également tous les utilisateurs qui
demandent leur réalisation. Or on peut, raisonnablement, estimer la charge engendrée en
Administration des applicatifs réseaux 143

11.7 Résultats de la modélisation
fonction du nombre de programmes qui s'exécutent simultanément sur la machine. Dans notre
modélisation, il s'agit donc de recenser les programmes qui permettent d'assurer la réalisation
de tous les services demandés, c'est-à-dire les nœuds clients et les nœuds serveurs concernant
cette machine.
Si nous parvenons à évaluer la charge moyenne de chaque type de programmes, nous
obtenons, par cumul, un paramètre global pour la charge de chaque machine. Une méthode
assez simple, pour estimer cette charge moyenne, est de reprendre les résultats des outils
d'analyses statistiques, disponibles sur la grande majorité des systèmes d'exploitation. Ainsi,
pour SlmOS(a), la commande "sa" permet d'obtenir une liste des programmes classés en
fonction de leur charge(b) respective.
Le résultat de calcul de charge prend tout son intérêt dès lors que les services élémentaires
sont munis de fenêtres temporelles, comme nous l'avons défini au paragraphe 5.3.1
page 100, car il devient possible de calculer l'évolution de la charge des machines en fonction
du temps. C'est exactement le résultat escompté dans les travaux cités précédemment.
7.2.4. Diagnostic de pannes
S'il est un domaine qui nécessite de fréquents et délicats diagnostics, c'est bien
l'administration de réseau. En effet, dans sa dimension "opérationnelle", la rapidité d'isolation
des causes des pannes est un atout majeur pour garantir la qualité du réseau. Car c'est
généralement la recherche de la cause, plus que la réparation elle-même, qui pose le plus de
problèmes.
Notre travail a consisté à établir la modélisation des dépendances qui entrent en jeu dans le
fonctionnement des services réseaux. Nous avons déjà montré au paragraphe 7.2.2 qu'il nous
était possible de connaître l'impact d'une machine sur l'ensemble des services. Or établir un
diagnostic, n'est-ce pas justement la démarche inverse, à savoir: en fonction des services en
"dérangement", déterminer le (oules éléments) susceptible d'engendrer de tels effets?
Nous proposons le procédé suivant: en fonction du graphe global contracté de dépendances,
et en testant un à un les services réseaux, nous opérons des recoupements successifs afin
d'écarter ou de retenir les sommets du graphe susceptibles d'être nùs en cause. Afin de réduire
le plus rapidement possible le nombre des sommets suspectés, nous proposons le procédé de
(a) SmIO. est le système d'exploitation Unix de Sun.
(b) La valeur, utilisée par la commande "sa ~lC', est le produit de l'espace mémoire nécessaire par le tauxd'occupation du processeur.
144 Administration des applicatifs réseaux

Résultats de la modélisation
recherche suivant:
IL7
Initialisation
1) Nous définissons un ensemble Sp des sommets suspectés, qui comporte au démarrage
tous les sommets du graphe global contracté de dépendances.
2) Nous associons à chacun des éléments de l'ensemble Sp un compteur initialisé à zéro.
3) Pour tout service y signalé défectueux, nous augmentons d'une unité les compteurs
des sommets du graphe contracté de dépendances associé à y ,à savoir SCy compris
dans Sp.
Boucle de réduction des sommets suspects
4) Nous sélectionnons le prochain service y à tester en choisissant celui dont la somme
des compteurs associés aux sommets SCy n Sp (sommets encore suspects de son
propre graphe contracté de dépendances) est la plus proche de la demi-somme des
compteurs associés aux sommets de Sp (principe de dychotomie)
5) Si le service testé s'avère fonctionner, les sommets dépendants sont ôtés de
l'ensemble des sommets suspects, par contre, s'il est également hors-service, nous
ajoutons une unité à tous les sommets SCy n Sp. Dans le cas extrème où il s'agit
d'un singleton(a), ce nœud est nécessairement défecteux.
Arrêt du procédé de recherche
6) La recherche s'arrête au plus tard lorsque tous les services ont été testés. Il est bien
clair que ce procédé ne doit pas être utilisé jusqu'à cette limite. Il offre simplement
une méthode d'aide au diagnostic qui précise de plus en plus le champ
d'investigations.
Nous avons présenté quatre résultats de notre modèle dans le domaine de la gestion des
anomalies et des performances: l'estimation de la fiabilité des services, la mesure de l'impact
d'une machine sur l'ensemble des services réseaux, une utilisation de cet impact pour une
obtention de la charge des ordinateurs et enfin une méthode d'aide aux diagnostics de pannes.
Nous présentons dans le paragraphe suivant nos résultats dans le domaine de la gestion de la
sécurité.
(a) Un singleton est un ensemble réduit à un unique élément.
Admillistralion des applicatifs réseaw: 145

II .7 Résultats de la modélisation
7.3. Gestion de la sécurité
La gestion de la sécurité en informatique comporte deux grands volets complémentaires. Il
s'agit, d'une part, de la composante "préventive" de la sécurité, à savoir la gestion des accès.
Ceci consiste à définir et mettre en œuvre les moyens pour répondre à la question suivante:
Qui a accès? A quoi? Et comment? La deuxième composante de la sécurité informatique est
plus "currative", il s'agit de la mise en œuvre, de la gestion et de l'exploitation des "traces" ou
"audit". Ceci regroupe tous les moyens utilisés pour connaître a posteriori les agissements des
utilisateurs, autorisés ou non, afin de pouvoir surveiller les délits d'accès, les usurpations
d'identités, etc, bref, repérer le "coupable" et le moyen qu'il a utilisé.
Nous exposons dans ce paragraphe un résultat d'exploitation de notre modèle qui concerne le
premier volet présenté ci-dessus: l'administration des accès et plus spécialement des accès
aux ressources. Ainsi, nous définissons des estimateurs de la sécurité d'une ressource, et
présentons leurs méthodes de calculs.
7.3.1. Sécurité d'une ressource
Nous commençons par rappeler ce qu'est une ressource dans notre modèle. Les exemples les
plus simples sont une imprimante, un scanner, etc. La gestion des accès à ce type de
ressources n'est pas le point le plus important de notre exposé. Bien plus intéressantes sont les
ressources telles un disque, le contenu d'un disque et, entre autres, les programmes qu'il
contient. Or, entre tous, un programme particulier est sensible à tout point de vue:
l'intelpréteur de commandes (tel un sheU sous Unix). Cette dernière ressource a une
importance cruciale en sécurité, car si une personne, autorisée ou non, parvient à en disposer
sur une machine, il possède bien plus qu'un simple accès à un programme quelconque, il a
véritablement l'accès à la machine et aux autres programmes dont celle-ci dispose(aJ• C'est ce
type de programmes qu'il faut particulièrement surveiller, puisque c'est grâce à eux qu'un
utilisateur peut accéder à une machine.
Nota: Il faut noter que l'accès à un programme tel un intel]Jréteur de commandes se traduit
dans notre modèle par une fonction de transition h, qui renvoie à tous les services réseaux
autorisés pour l'utilisateur de cet interpréteur.
(a) Avec, cependant. comme restriction d'accès, les droits liés à l'identité de l'utilisateur pour lequel la
personne s'est fait passer (à juste titre ou non). L'interpréteur de commande s'exécutant sous l'identité de
l'administrateur de ['ordinateur est, bien évidemment, particulièrement sensible.
146 Administration des applicatifs réseau.'\:

Résultats de la modélisatioll II .7
Les estimateurs que nous utilisons pour définir la sécurité d'une ressource reposent sur la
connaissance exhaustive de tous les utilisateurs qui ont accès à la ressource en question. Des
paramètres comme le nombre d'utilisateurs, les moyens utilisés pour accéder à la ressource (la
longueur du chemin, le nombre de changements d'identité utilisés ...) nous permettent de
préciser assez finement la sécurité des ressources.
7.3.2. Calcul de la sécurité d'une ressource
Pour le calcul des estimateurs de la sécurité d'une ressource, nous utilisons le graphe global
de dépendances. Le principe repose sur la contraction des sommets concernant la ressource
en question, comme nous le montre le schéma de l'exemple ci-dessous. Le parcours du graphe
ainsi obtenu à partir du sommet - résultat de la contraction, nous donne non seulement les
personnes qui y ont accès, mais également les moyens utilisés, programmes, machines,
changement d'identité, etc. Ce parcours s'effectue dans le sens contraire des arcs.
Exemple de calcul d'estimateurs de sécurité
Notre exemple de calcul d'estimateurs sur la sécurité d'une ressource concerne l'accès à un
interpréteur de commandes (sheU) sous l'identité de l'utilisateur Dupont, sur un ordinateur
donné (m2)' Pour la clarté de l'exposé (et du graphe), le nombre de services du graphe est
réduit à deux.
Le schéma 34, ci-dessous, représente le graphe global de dépendances sur lequel a été effectué
la contraction adéquate des sommets pour la ressource sheU en question.
Rlogin_Durant-> (Durant, mt, nslookup)-> (Durant, mt, rlogin)
(Dupont, m2, rlogind,shell)(Dupont, m2, telnetd, she/I)
(-, m5, named, /etc/named.t)
/Rsh Merlin~->(lIferlin, m4, rsh)
(Hector, m3, rshd, shell)-> Telnet Hector
-> (Hector, m3, telnet)
Schéma 34 " Exemple de graphe de la sécurité d'ulle ressource
Administration des applicatifs réseaux 147
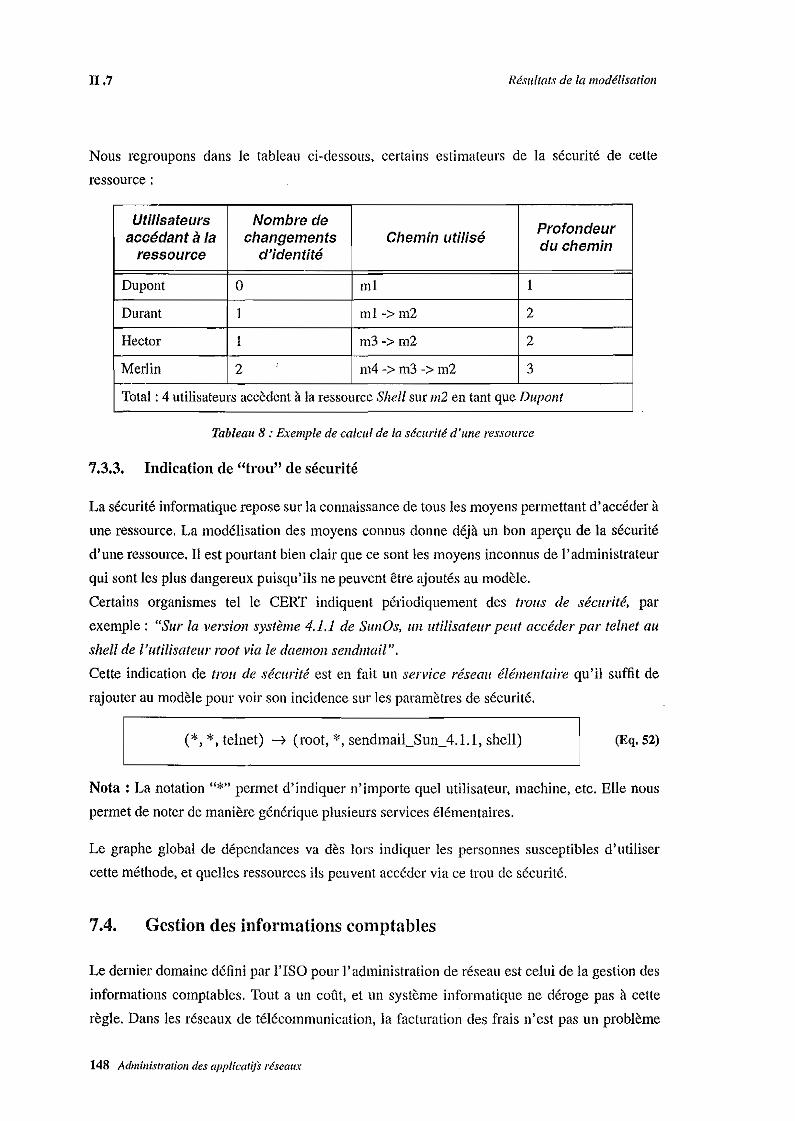
11.7 Résultats de la modélisatiou
Nous regroupons dans le tableau ci-dessous, certains estimateurs de la sécurité de cette
ressource :
Utilisateurs Nombre de Profondeuraccédant à la changements Chemin utilisé du chemin
ressource d'identité
Dupont 0 ml 1
Durant 1 ml->m2 2
Hector 1 m3 -> m2 2
Merlin 2,
m4-> m3 -> m2 3
Total: 4 utilisateurs accèdent à la ressource Shell sur 11I2 en tant que Dupont
l'ableall 8 : Exemple de calcul de la sécurité d'une ressource
7.3.3. Indication de "trou" de sécurité
La sécurité informatique repose sur la connaissance de tous les moyens permettant d'accéder à
une ressource. La modélisation des moyens connus donne déjà un bon aperçu de la sécurité
d'une ressource. Il est pourtant bien clair que ce sont les moyens inconnus de l'administrateur
qui sont les plus dangereux puisqu'ils ne peuvent être ajoutés au modèle.
Certains organismes tel le CERT indiquent périodiquement des trous de sécurité, par
exemple: "Sur la version système 4.1.1 de SunOs, un utilisateur peut accéder par telnet au
shell de l'utilisateur root via le daelllon sendmail".
Cette indication de trou de sécurité est en fait un service réseau élémentaire qu'il suffit de
rajouter au modèle pour voir son incidence sur les paramètres de sécurité.
(*, *, telnet) ---7 (root, *, sendmaiCSun_4. 1. 1, shell) (Eq.52)
Nota: La notation "*,, permet d'indiquer n'importe quel utilisateur, machine, etc. Elle nous
permet de noter de manière générique plusieurs services élémentaires.
Le graphe global de dépendances va dès lors indiquer les personnes susceptibles d'utiliser
cette méthode, et quelles ressources ils peuvent accéder via ce trou de sécurité.
7.4. Gestion des informations comptables
Le dernier domaine défini par l'ISO pour l'administration de réseau est celui de la gestion des
informations comptables. Tout a un coût, et un système informatique ne déroge pas à cette
règle. Dans les réseaux de télécommunication, la facturation des frais n'est pas un problème
148 Administration des applicatifs réseaux

Résultats de la modélisation 11.7
trivial. Il s'agit tout d'abord de définir une politique de facturation, que ce soit en fonction du
débit, de la quantité de données échangés, par abonnement, etc. Il est également nécessaire de
mettre en place les moyens de mesures. Ces derniers s'apparentent, quelque peu, à ceux
utilisés en gestion de la sécurité: c'est-à-dire la mémorisation et la gestion de l'historique des
activités des utilisateurs. Tant qu'il s'agit de facturation de services élémentaires, par exemple
entre un appelé et un appelant, des solutions, relativement simple dans leur principe, peuvent
être mise en œuvre. Il peut s'agir, par exemple, du système de facturation au volume des
réseaux TRANSPAC. De même, ce peut être, dans le cas des réseaux téléphoniques par
exemple, un principe de facturation pour l'usager appelalll en fonction de la durée et de la
distance de la "communication".
Par contre, dans le cas de services informatiques plus complexes, il n'y a plus de notion
d'appelant et d'appelé, ni même de "communication" mais plutôt de machines coopérantes.
De plus, il n'y a qu'exceptionnellement des possibilités techniques de mesure des débits ou
des temps pour un utilisateur donné puisque dans la plupart des protocoles de transmission
utilisés, les paquets de données circulant sur le réseau n'indiquent pas l'utilisateur mais
uniquement la machine initiatrice ou réceptrice. La facturation pour les réseaux informatiques
n'est pas un sujet facile contrairement à ce que l'on pourrait penser en première approche, et la
preuve en est que les organismes de télécommunications proposent des solutions basées sur un
principe d'abonnements par période de temps plutôt que de s'aventurer dans une facturation
plus fine (à la durée ou au volume). C'est le cas, par exemple, du raccordement au réseau
français de la recherche RENATER.
7.4.1. Répartition des frais réels
Notre propos n'est pas de présenter une solution globale de facturation des services réseaux,
nous exposons, plutôt, une méthode de répartition des frais réels des services réseaux. Elle est
relativement facile à mettre en œuvre si le réseau informatique en question a été décrit suivant
notre modèle. Une méthode similaire [MAU 93], mais sur un modèle plus simple, a été
développé dans le cadre du projet de gestion des ressources de Alcatel Business Systems
(présenté au paragraphe 3.2.2 - page 66).
704.1.1. Principe de la répartition des frais
Un système de facturation sans bénéfice repose toujours sur le même principe: la répartition
des coOts sur les usagers (ou groupes d'usagers). Il s'agit par conséquent d'établir les deux
points suivants: d'une part le montant global des frais, d'autre part la règle de répartition de
cette enveloppe.
Administration des applicatifs réseaux 149

IL7 Résultats de la modélisation
Le calcul du total des frais est relativement simple, tout dépend de ce que l'on veut faire entrer
dans l'enveloppe: amortissement des équipements, coûts des logiciels, des consommables
(papier, électricité, etc), salaires des techniciens et ingénieurs, coût de la recherche et du
développement, etc.
Autant le premier point ne pose pas réellement de problèmes théoriques, autant il va être
difficile d'établir la règle de répartition des coûts sur les usagers. En effet, comme nous le
soulignions en introduction, bon nombre de protocoles de réseaux informatiques (par
exemple: TCP/IP, DECNET, AppleTalk, IPX) ne permettent pas de mesm:er l'utilisation
propre à chaque utilisateur car les trames de données véhiculées ne disposent pas de cette
information mais uniquement l'adresse réseau de la machine émettrice et de la machine
réceptrice. Or un serveur informatique peut être utilisé par plusieurs centaines d'utilisateurs.
Dans l'état actuel, il est très difficile d'établir une règle de répartition des coûts sur les
utilisateurs en fonction de la durée et/ou du volume transmis pour les protocoles réseaux tels
TCP/IP, AppleTalk, IPX, etc. Dès lors, comment procéder? En fonction du nombres de
machines raccordées? En fonction du nombre d'utilisateurs déclarés? Nous proposons une
solution intermédiaire qui se base sur le coût réel de chaque service réseau.
7.4.1.2. Une méthode de répartion en fonction des services offerts
Connaissant le montant global des frais, nous reprenons l'idée stipulée dans le rapport de
C. Maurin [MAU 93] qui propose une répartition de ces coûts en fonction des services offerts
aux utilisateurs. Or les graphes de notre modèle permettent justement d'établir assez finement
les équipements et machines nécessaires au fonctionnement de chaque service. Nous
rappelons que dans notre modèle, tous les services sont associés à leurs utilisateurs, ce qui
permet d'imputer les frais aux personnes elles-mêmes.
Nous exposons donc la méthode de calcul suivante:
Nous calculons les coûts d'amortissement, maintenance et/ou fonctionnement de chaque
nœud du graphe global contracté du réseau modélisé. Ainsi pour un nœud mi est associé un
coût ci' Pour répartir la part des frais concernant chaque service réseau nous reprenons les
résultats obtenus lors du calcul de l'impact des machines (voir paragraphe 7.2.2 - page 140).
Le coût d'un service y, noté Cr' est obtenu en effectuant la sommation des coûts de chaque
nœuds nécessaires au fonctionnement du service en question, chacun de ces coûts étant
préalablement divisé par l'impact non-rédltit (Jm) de la machine du nœud en question.
(Eq.53)
150 Administration des applicatifs réseaux

Résultats de la modélisation II .7
7.4.1.3. Exemple de calcul de coût
Pour illustrer cette méthode de calcul de la répartition des frais réel, nous reprenons l'exemple
du graphe utilisé pour la mesure de l'impact de chaque machine (voir 7.2.2).
Impressio/cpc1_laserlJ->(klein,pc1,PCNFS.EXE)-> (klein,pc1,LPR.EXE)
/ ~(klein,monaco,lpd,laserlJ)-> Accès_laserIJ
-> (klein,monaco,lpr)-> (klein,monaco,gethostbyname)
(klein,monza,nfsd,monza:/home/klein)
(-,imola,lpd,laserll)
/\
Courrier-> (Dupont,mac1,eudora)-> (Dupont,mac1,eudoraJesolver)
Schéma 35 : Calcul des coOts des services réseaux.
Nous déduisons du graphe représenté par le schéma 35 la répartition par service réseau,
récapitulée dans le tableau ci-dessous:
Services Coût
Impression_pcl_laserIIc 3 c4 Cs
l2500Fcl + C2 + 2" + 2" + '3 =
Accès_LaserIIC3 C4 Cs
SOOOF-+-+- =223
--
Courrier CslOOOOFc 6 + c7 + '3 =
Tableau 9 .. Exerup/e de répartition des conts globaux sur les sen'ices
Administration des applicatifs réseau:( 151

n.7
Prise en compte des frais liés à la maintenance du réseau
Résultats de la modélisation
Il est possible, avec l'extension du modèle aux équipements du réseau physique, de prendre en
compte dans la répartition des coûts, les frais dûs à la mise en place et à la maintenance du
réseau lui-même (câbles, prises, équipements actifs tels les répétcurs ...).
7.4.1.4. Calcul des frais imputés à l'utilisateur
Notre modèle est bâti sur la notion de service réseau. Comme nous le rappelions
précédemment, ces services sont nominatifs, c'est-à-dire qu'ils dépendent de la personne qui
les utilise.
Ainsi, pour calculer le coût engendré par chaque utilisateur, il suffit de sommer les coûts
calculés pour chacun de ses services comme nous l'avons décrit dans le paragraphe précédent.
152 Administration des applicatifs réseau.\"

Résultats de la modélisation
Conclusion
II
Dans cette deuxième partie, nous avons présenté le point central de notre thèse: un modèle de
données pour la description des services applicatifs réseaux. Il nous a fallu, pour cela, définir
les éléments - et leurs interdépendances - nécessaires au fonctionnement des services
applicatifs.
Ainsi, après avoir précisé la finalité d'un tel modèle et présenté ses hypothèses d'application,
nous avons proposé nne définition du service réseau applicatif. Celle-ci a été décrite sous la
forme d'une application multivoque régie par une série de contraintes. De là, il nous a été
possible de définir un graphe global associé au réseau modélisé, qui décrit toutes les
dépendances mises en jeu.
De ce modèle "théorique", nous avons présenté les points importants pour passer à un modèle
"informatique". Nous prenons ainsi en compte les spécifités techniques de ce domaine. Nous
avons proposé un schéma de base de données pour la mémorisation des informations. Nous
avons également présenté les méthodes d'acquisition de telles informations. La présentation
du modèle "informatique" s'est achevée par l'exposé des moyens et algorithmes nécessaires à
la déduction des services réseaux et de leurs dépendances.
Nons avons ensuite présenté les résultats que nous obtenons d'une telle modélisation; ils ont
trait à tous les domaines de l'administration de réseaux. Les deux principaux résultats sont, à
notre sens, le calcul de la fiabilité d'un service résean et l'impact d'Ime machine sur
l'ensemble des services modélisés.
Il nous reste à démontrer la "faisabilité" d'une plate-forme d'administration basée sur de tels
concepts. C'est l'objet de la dernière partie de notre thèse; nous présentons la maquette
logicielle ADSAR qui implante notre modèle en vue de sa validation.
Administration des applicatifs réseaux 153


Partie III
Validation du modèlepar implantation
Administration des applicatifs réseaux 155


La mise en œuvre d'un logiciel d'administration de réseaux n'est pas une tâche facile, ni
rapide. Ce type d'outil nécessite toujours des développements pointus dans plusieurs
domaines informatiques distincts. Ainsi, il met en jeu, entre autres, des manipulations de base
de données volumineuses, une adéquation indispensable à la normalisation en cours, des
représentations graphiques complexes, bref, c'est le type de logiciel "touche à tout" qui
engendre un volume de développements inexorablement important. Si nous prenons
l'exemple de Openview développé conjointement par Hewlett Packard et Motorola-codex, il
aura fallu plus de 50 années/hommes de recherche et de développement(a) pour sortir la
première version expérimentale. De plus, plutôt que de poursuivre les extensions de son
propre logiciel d'administration de réseaux SNA (Netview) pour l'administration SNMP, IBM
a préféré racheter le code source et les droits d'exploitation de OpenView, commercialisé sous
l'appellation Netview 6000(b). Il s'agit strictement du même moteur logiciel dans le cas de
OpenView et Netview 6000.
Cependant, malgré la difficulté de la tâche, il nous est apparu indispensable d'implanter
réellement le modèle présenté dans notre thèse afin d'en démontrer la faisabilité et l'intérêt de
ses résultats. Nous exposons ainsi, dans cette dernière partie, une maquette logicielle qui
implante une grande majorité des concepts énoncés. Ce prototype, de par sa nature, ne peut
pas, raisonnablement, se restreindre à un réseau informatique miniature, voire simulé, sans
perdre tout son intérêt de validation, car le modèle prend tout son sens lorsqu'il s'applique à
un réseau informatique suffisamment complexe pour mettre en œuvre des dépendances
logicielles nombreuses. Nous avons donc développé une maquette "grandeur nature"
appliquée à un réseau informatique universitaire réel: celui de l'Université des Sciences
Humaines de Strasbourg.
(a) Le monde informatique.
(b) Netview et Netview 6000 n'ont strictement fien de commun si ce n'est IBM" La similitude des noms est
due aux impératifs commerciaux.
Administration des applicatifs réseaux 157

m.
Notre exposé est divisé en trois volets. Nous présentons, tout d'abord, le contexte
d'implantation de la maquette. Nous voyons ainsi, entre autres, les concepts du modèle qui
ont été effectivement programmés, les choix techniques d'implantation et le cadre de
fonctionnement de la maquette. Nous détaillons, ensuite, le prototype logiciel lui-même:
comment il se présente à l'utilisateur et les fonctionnalités dont il dispose. Enfin, nous
terminons cette troisième partie par une évaluation de l'implantation effectuée; nous
comparons notamment les résultats obtenus avec la réalité observée expérimentalement, afin
de justifier la pertinence des résultats.
Il fallait un nom à ce prototype, nous avons opté pour "A.D.S.A.R". Il s'agit du sigle construit
à partir de la périphrase suivante: Administration des Dépendances entre Services Applicatifs
Réseaux.
La maquette ADSAR est issue d'une version préliminaire nommée CQFD. Cette dernière
gérait les données nécessaires à son fonctionnement, au moyen d'un système de gestion de
bases de données développé "sur mesure". Tout comme le prototype ADSAR, CQFD
manipulait les graphes de dépendances, mais ne calculait pas pour autant des résultats tels
ceux présentés au chapitre 7 (fiabilité d'un service, impact d'un ordinateur, etc). Ainsi, la
volonté de s'appuyer sur un gestionnaire de base de données non ad hoc et le manque de
souplesse dans la version préliminaire nous ont poussé à redévelopper un second prototype
plus complet: ADSAR.
158 Administration des applicatifs réseaux

Contexte de la maquette
8. Contexte de la maquette
III.8
"ADSAR" n'est, en aucun cas, un outil d'administration de réseaux, au sens d'un "produit
fini". Même si un soin particulier a été porté aux fonctionnalités et à la qualité de l'interface, il
s'agit bien d'une maquette logicielle destinée à valider les concepts de notre modèle
théorique. Ce prototype a été réalisé dans un contexte donné. Ainsi, des choix ont été faits sur
les concepts qu'il implante, il est réalisé pour un site de test donné, il a mis en œuvre des choix
techniques qui ont été pris en fonction de la finalité de validation et d'expérimentation et non
pas en vue de la production d'un logiciel "clé-en-main". C'est tout ce contexte de mise en
œuvre que nous présentons dans ce chapitre.
8.1. Le modèle implanté
Ne disposant malheureusement pas de 50 années/hommes de développement, l'implantation
de la maquette logicielle, en vue de la validation du modèle, a nécessité des choix
d'implantation. Ceux-ci ont porté, tout d'abord, sur les concepts du modèle effectivement
implantés, également sur les services réseaux retenus, et enfin sur les types d'ordinateurs et de
protocoles gérés. Nos choix ont été dictés dans le but de réaliser l'implantation des éléments
indispensables au modèle dans l'optique de réaliser le calcul des résultats les plus
intéressants. C'est ce que nous présentons dans les paragraphes qui suivent.
8,1.1. Les concepts théoriques implantés
Une certaine forme de péréquation entre les concepts énoncés et ceux programmés
effectivement a été nécessaire. Il nous a fallu réaliser l'implantation d'un modèle minimal qui
garde cependant tout son intérêt. Ainsi, la modélisation des services réseaux a été totalement
implantée sans y adjoindre, toutefois, la description du réseau physique (cf. 5.2.1 - page 96)
qui ne semble pas poser de problèmes pratiques ardus et qui, par contre alourdit les graphes
générés. De même, la description des fenêtres temporelles (cf. 5.3.1 - page 100) a été
volontairement laissée de côté, car elle nécessite un apport important de données dites
"déclarées", ce qui imposerait une enquête assez précise sur les besoins des utilisateurs et
groupes d'utilisateurs. Une dernière restriction du modèle a été retenue, il s'agit de la
description des droits d'utilisation des programmes. Dans une première approche, nous
appliquons la règle simplificatrice suivante: "toute personne qui dispose d'un compte sur une
Administration des applicatifs réseaux 159

m.8 Contexte de la maquette
machine de type Unix peut utiliser tous les programmes (pour les services réseaux) de cette
machine",
En revanche, les informations strictement nécessaires à la réalisation du modèle ont été
augmentées de données supplémentaires dans les cas où celles-ci n'engendraient pas de
difficulté particulière ou de surcoût de développement. Par exemple - et comme nous allons le
voir dans le diagramme de la base de données (ef. 9.1.1.1) - les n-uplets utilisés pour décrire
les ordinateurs ne comportent pas uniquement un nom de machine et un identificateur, mais
également des informations annexes telles que certains paramètres de configuration (adresse et
masque de réseau, système d'exploitation, type de processeur, etc), de localisation
(emplacement géographique, dépendance administrative, etc), et autres indications
pertinentes. Il en est de même pour les autres tables de la base de données, à savoir celle des
utilisateurs, des ressources et des programmes.
8.1.2. Les types d'ordinateurs et de protocoles supportés
Pour la réalisation de la maquette, tous les types d'ordinateurs présents sur le réseau de test ont
été pris en compte. Il s'agit de matériels tout à fait courant: des stations Unix, des compatibles
PC et des Macintosh. Le choix des protocoles réseaux reconnus a été plus restrictif. En effet,
certains protocoles spécifiques des compatibles PC, tels IPX pour les réseaux NOVELL et
LanManager pour les réseaux Microsoft, ont été écartés au bénéfice des protocoles TCP/IP et
AppleTalk qui sont utilisés dans plus de 90% des services du réseau de test. En effet, IPX et
LanManager se restreignent à trois petits "îlots" de faible importance.
8.1.3. Les services réseaux modélisés
Le choix des familles de services réseaux modélisés ne s'est pas réellement posé, car la
maquette développée est suffisamment souple pour permettre d'adjoindre, par la suite, de
nonveaux services sans aueune difficulté. Dans l'état actuel, nous nons sommes
principalement attaché à prendre en compte, avant tout, les services de montages de disques
puisqu'ils engendrent d'importantes dépendances, mais aussi les services d'impressions, et
enfin certains services de courrier électronique. D'autre part, nous avons ajouté quelques
services sous forme d'exemples spécifiques, pour certains cas particuliers. Ainsi, ont été
décrits les services nécessaires au!onctionnement d'un terminal X, ou encore d'un compatible
PC bien particulier car dédié au "flashage(a)" d'image de synthèse (voir le paragraphe suivant
pour la présentation du réseau de test).
(a) Le "flashage" est un terme spécifique au domaine de l'imagerie informatique. Il recouvre les moyens mis
en œuvre afin de convertir le codage d'une image digitale sous forme analogique, en vue de son utilisation enbandes vidéo (Bétacam, VHS, etc) ou de photogmphies.
160 Administration des applicatifs réseaux

Contexte de la maquette
8.1.4. Les résultats implantés
III .8
Nous avons présenté un certain nombre de résultats théoriques dans le dernier chapitre de la
deuxième partie de notre thèse. La liste ci-dessous indique les résultats qui ont été
effectivement réalisés dans le prototype ADSAR. Nous avons implanté:
-la connaissance de la configuration du réseau au niveau applicatif (cf. 7.1.1)
-le repérage des inter-dépendances cycliques (cf. 7.1.2)
-le calcul de la fiabilité de chaque service (cf. 7.2.1)
-l'estimation de la qualité de service globale du réseau (cf. 7.2.1.3)
-le calcul de l'impact de chaque ordinateur (cf. 7.2.2)
Ces résultats comportent la grande majorité des algorithmes de manipulation des graphes ct de
la base de données.
Après avoir précisé les concepts effectivement implantés, nous présentons le cadre
d'exécution de la maquette, à savoir le réseau informatique qui nous a permis de valider le
modèle.
8.2. Cadre de l'expérimentation
Nous ne pouvons décrire l'implantation développée pour la concrétisation du modèle sans
présenter, même succinctement, l'infrastructure du réseau sur lequel les tests ont été effectués.
Il s'agit du réseau de l'Université des Sciences Humaines de Strasbourg baptisé Vivaldi. C'est
un réseau de taille moyenne, hétérogène au niveau des machines et des protocoles. Il fait partie
intégrante du réseau inter-universitaire OSIRIS qui assure les liaisons informatiques sur les
campus universitaires de Strasbourg.
8.2.1. L'infrastructure et la technologie du réseau de test
Le réseau Vivaldi est réparti sur deux sites géographiques distants de quelques kilomètres. Il
comporte cinq bâtiments reliés par des câbles Ethemet(a) de technologie la base 5(b). La
liaison entre les deux sites géographiques est assurée par de la fibre optique. La couverture du
réseau au sein des bâtiments est réalisée également par des câbles Ethernet mais de
(a) Le terme Ethemet regroupe les spécifications technologiques et protocolaires d'un type de réseau,
développé à l'origine par XefOX puis normalisé sous l'appelation ISO 802.3, qui est désormais une des
références incontournables des réseaux informatiques actuels. Ethernet sUppOlte des protocoles réseaux de
niveau plus élevé tels ceux cités précédemment (IPX, TCPIIP, LanManager, DECnet, AppleTalk, etc)
(b) Ethemet supporte principalement 3 types de technologie pour son médium de transmission: le câble
coaxial épais (10 base 5), le câble coaxial fin (10 base 2) et la paire torsadée (10 base T).
Administratioll des applicatifs réseaux 161

m.8 Contexte de la maquette
technologie 10 base 2(a), cette fois-ci. L'ensemble représente un peu plus de 800 points de
connexion potentielle (prises réseaux).
Le réseau Vivaldi utilise principalement la technologie Ethanet sur l'ensemble de sa surface.
Il fait cohabiter sur ses câbles les protocoles TCP/IP, AppleTalk, IPX et LanManager. Il faut
noter, cependant, que certaines sections du réseau utilisent uniquement une technologie
LocaITalk(b), et non Ethanet, pour supporter le protocole Appletalk. Il s'agit, notamment, des
liaisons nécessaires à l'accès à certaines imprimantes Apple LaserWriter.
8.2.2. Le parc des machines
Le parc représente un peu moins de cent cinquante machines (courant juin 1994). Il s'agit de
micro-ordinateurs (50% de PC - 25% de Macintosh) et mini-ordinateurs (20%) et de quelques
terminaux X et imprimantes directement connectés sur le réseau (5%).
8.2.3. Les utilisateurs
Les utilisateurs du réseau informatique de l'Université des Sciences Humaines de Strasbourg
se répartissent en trois classes distinctes, courantes dans ce type de structure universitaire:
-les étudiants (en filière informatique & hors filière informatique),
-les enseignants/chercheurs,
- et les personnels d'administration et de gestion.
L'ensemble représente un peu plus de trois cents utilisateurs, dont une centaine réguliers
(accès à une machine au moins une fois par jour ouvrable).
8.2.4. Les services fournis
Le réseau Vivaldi étant à vocation universitaire, nous retrouvons les types de services réseaux
nécessaires à un tel environnement. Il s'agit principalement des services suivants:
-la messagerie (accès libre aux étudiants, accès par machines dédiées pour les enseignants/
chercheurs et les personnels d'administration),
-l'impression par groupes d'usagers,
-les montages de disques par équipe de recherche (tous protocoles),
(a) La technologie JO base 2 utilisée dans le réseau Vivaldi n'utilise pas les classiques "prises en T" peu
pratiques pour du câblage de bâtiments, mais un système de prises par "clapet" qui autorise J'utilisation d'uncordon de descente entre la prise murale et l'ordinateur. Ce cordon n'cst en fait qu'une boucle du câble
coaxial au sein d'un même enrobage plastique. Il s'agit d'une simple dérivation du bus 10 base 2.
(b) Le protocole AppleTalk suppOlte trois types de technologies sous-jacentes qui se dérivent en EtherTalk
(au-dessus de Ethernet), TokellTalk (au-dessus d'un anneau à jeton) et LocalTalk (pour la technologie
propriétaire Apple).
162 Administration des applicatifs réseaux

Contexte de la maquette III ,8
-l'émulation de terminaux en interne et en externe,
-la consultation de la base de données des bibliothèques de l'université via le logiciel
Gopher et WAIS(a),
-les transferts de fichiers (tous protocoles).
Certains services sont spécifiques au site. Citons, entre autres, la manipulation d'images de
synthèse pour la génération de films en Bétacam(bl, qui engendre un trafic réseau
particulièrement intense.
8.2,5. Les caractéristiques particulières du réseau Vivaldi
Le réseau Vivaldi a subi un développement essentiel et des restructurations importantes ces
trois dernières années. Un des points majeurs de ses caractéristiques actuelles est la présence
de cinq serveurs Unix distingués en fonction de leur cadre d'utilisation (administratif,
recherche ou enseignement) et de leurs fonctionnalités propres (services d'impressions, de
courrier, de montages de disques, etc). Ces cinq serveut's gèl'ent la majeure partie des
ressources partagées (disques, périphériques, etc)(c).
Une passerelle CAP (Columbia AppleTalk Package) implantée sur l'un des serveurs permet
d'assurer certaines interactions entre la composante AppleTalk-Macintosh et la composante
TCPIIP-Unix du réseau. Ainsi, imprimantes et disques sont, en partie, partagés entre les deux
composantes.
Pratiquement la moitié des compatibles PC dispose du logiciel PC-NFS qui leur permet
d'accéder aux disques et aux imprimantes gérés par deux des serveurs cités précédemment. La
totalité des PC dispose de tous lcs utilitaircs réseaux les plus courants dans le monde
universitaire(d) (Paquettages NèsA, CUTCP, POPmai!, GOPHER, WinQvtNET, etc)
Une composante particulière du réseau Vivaldi est le sous-réseau de stations Silicon et de
matériel spécifique à la génération et à la manipulation d'images de synthèse (4 Silicon,
1 Getris, 8 PC dédiés, 1 Macintosh et quelques autres équipements - caméra, Bétacam,
f1asheuse, etc ).
(a) Les outils logiciels Caplter et \VAIS permettent le stockage, l'indexation et la diffusion de documents
informatisés de tout type (textes, images, sons). Très en vogue cette dernière année au sein du réseau Internet,
ils permettent aux utilisateurs non-aveltÎs de rechercher des données informatiques sans se soucier ni de leur
stmcture, ni de leur localisation.
(b) Bétacam est une norme technologique pour la cinématographie professionnelle.
(c) L'ancien serveur principal a du "éclater" ses services sur deux autres serveurs plus petits pour des raisons
de surcharge d'exploitation (fin 93 - début 94).
(d) Le réseau international Internet pemet d'acquérir gracieusement bon nombres de logiciels réseaux
extrêmement intéressants dans le cadre universitaire. et entre autres, la plupart des logiciels réseaux les plus
courants.
Administration des applicatifs réseau.'t 163

m .8 Contexte de la maquette
8.2.6. Le choix de l'ordinateur d'accueil de la plate-forme d'administration
L'ordinateur choisi pour implanter la maquette ADSAR devait nécessairement être
suffisamment puissant pour assurer à la fois le stockage des données et la manipulation des
graphes issus du modèle. Nous avons bénéficié de la possibilité d'implanter le prototype sur le
serveur le plus puissant du réseau, à savoir un SUN 4 - 390, disposant de 10 Go de mémoire de
masse et de 32 Mo de mémoire centrale. Bien que ce matériel soit désormais un peu obsolète,
les performances de ce type de machine ont largement suffi au développement et à l'utilisation
de la maquette.
8.2.7. Avantages et inconvénients du site de test
L'opportunité de pouvoir à la fois disposer d'un ordinateur suffisamment puissant pour
implanter notre prototype logiciel, localisé dans un réseau dont les dépendances entre services
applicatifs sont nombreuses, complexes et variées, nous est apparu particulièrement
intéressante pour valider notre modèle. La diversité des services, des protocoles et des types
d'ordinateurs nous a permis de réaliser une maquette suffisamment complète pour vérifier la
pertinence du modèle proposé. Le réseau Vivaldi est certainement un très bon exemple du type
de réseaux pour lequel notre modèle a été pensé.
En revanche, l'obligation de faire cohabiter la maquette ADSAR avec les autres applications
du serveur fut un inconvénient notable. En effet, il ne s'agissait pas d'une machine dédiée à la
recherche; elle ne pouvait en aucun cas subir d'arrêts intempestifs.
Après avoir présenté le réseau de test Vivaldi, nous exposons, dans le paragraphe qui suit, les
choix globaux que nous avons dO poser pour implanter notre maquette ADSAR.
8.3. Les choix de l'implantation
Pour permettre une présentation claire et complète de la maquette logicielle que nous avons
réalisée, et avant d'entrer dans les détails de l'implantation, nous exposons les choix
techniques généraux que nous avons retenus. Ceux-ci concernent, tout d'abord, le
gestionnaire de base de données. Il existe plusieurs SGBD relationnels; lequel choisir? Nous
exposons ensuite les méthodes d'acquisition des données qui ont été utilisées. Puis, nous
présentons le système de gestion des graphes qui est exploité. Nous terminons par la
présentation des choix globaux de la maquette ADSAR : le langage de programmation et les
bibliothèques sous-jacentes. Nous exposons l'implantation dans le détail dans le chapitre
suivant, au paragraphe 9.1 - page 178.
164 Administration des applicatifs réseaux

Confexte de la maquette
8.3.1. La base de données
III .8
Pour réaliser l'implantation de notre modèle, nous devions nous appuyer sur un système de
gestion de base de données relationnelles. Plusieurs choix s'offraient à nous dont, entre autres,
les SGBD bien connus tels ORACLE, INGRES, SYBASE, PARADOX, etc. Les critères qui
nous ont permis d'arrêter notre choix ont été les suivants:
- un SGBD tournant sur un ordinateur de système d'exploitation Unix,
- dont les capacités de stockage et la puissance de travail se placent parmi les meilleurs,
- qui dispose, à la fois, d'un langage d'interrogation facile à acquérir et à utiliser (SQL par
exemple),
- mais également d'une interface de programmation avec le langage C
- et dont la disponibilité serait la plus courte possible et la mise en œuvre aisée.
Nous avons ainsi retenu la version de INGRES restée dans le domaine de la recherche
universitaire, rebaptisée POSTGRES (POST inGRES) pour se démarquer de la version
commerciale. POSTGRES est développé par l'équipe(a) de M. Stonebraker, C. Ghosh et
C. Mosher de l'Université de Californie-Berkeley, sponsorisée par les organismes de
recherche suivants: la Defense Advanced Research Projects Agency (DARPA), le Army
Research Office (ARO) et la National Science Fotlndation (NSF). Ces principales
caractéristiques ont été largement publiées [STO 76], [STO 81], [STO 83a], [STO 83b] et
[POS2 88]. Il s'agit d'un SGBD qui supporte les fonctionnalités courantes de ce type de bases
de données. Il implante, d'autre part, certaines possibilités particulières issues de la recherche
dans ce domaine [STO 85] et [STO 86], comme par exemple les règles et contraintes par
réécriture, l'héritage des définitions de tables, les opérations génériques, etc. Cependant, nous
n'utilisons pas ces extensions spécifiques, afin de garder une certaine indépendance
d'implantation vis-à-vis du SGBD qui nous permet de réaliser notre prototype logiciel.
Le fait d'avoir choisi POSTGRES, plutôt qu'un autre SGBD, repose principalement sur sa
disponibilité immédiate(b) et sa gratuitëc).
La version utilisée pour l'implantation de la maquette ADSAR est la 4.0.1 qui, bien qu'étant
quelque peu ancienne (1988), a l'avantage certain d'être suffisamment fiable. Selon
M. Stonebraker, ses performances sont sensiblement comparables à celles de lNGRES(d).
(a) Par ordre alphabétique: James Bell, Jennifer Caetta, Jolly Chen, Ron Choi, Jeffrey Goh, Joey Hellerstein,
\Vei Hong, Allant Jhingran, Greg Kemmîtz, Case Larsen, Jeff Meredith, Michael Oison, Lay-Peng Ong,
Spyros Potaminianos, Sunita Sarawagi et Cimarron Taylor.
(b) paSTGRES est disponible sur le réseau Internet par simple transfert FTP anonyme à partir de
l'Université de Californie - Computer Science Division, 521 Evans Hall, University of california - Berkeley,
CA 94720.
(c) paSTGRES est diponible gracieusement pour les universités.
(d) Selon les programmes de tests de performances Wisconsin benchmark.
Administration des applicatifs réseaux 165

m.8 Contexte de la maquette
Le système de gestion de base de données POSTGRES peut être interfacé avec le langage
normalisé d'interrogation de base de données SQL. Nous avons, cependant, préféré utiliser
pour nos développements le langage POSTQUEL [KUN 84] [POS4 88], également
disponible, et mieux référencé dans la documentation de POSTGRES. Ce langage
POSTQUEL peut être utilisé, soit à partir d'un petit interpréteur de commandes nommé
I/Ionilor, soit directement à partir d'un source en langage C, grâce à la bibliothèque libpq
[POSS 88]. Ces deux applications sont fournies avec le paquettage de POSTGRES.
Nous avons opté pour le SGBD POSTGRES. Il nous a fallu, également, choisir les méthodes
d'acquisition des informations d'administration nécessaires au modèle. C'est ce que nous
exposons dans le paragraphe suivant.
8.3.2. U acquisition des données
Comme nous l'avons indiqué dans la partie théorique (cf. paragraphe 6.4.1), deux sortes
d'informations vont être exploitées par le modèle: les informations "pré-existantes" sur le
réseau et celles "déclarées".
8.3.2.1. Méthodes pour l'acquisition des données pré-existantes
Ne disposant pas, à l'heure actuelle, d'agents SNMP ou osr sur le site de test, qui nous
permettent de récupérer les données qui nous sont nécessaires, il nous a fallu utiliser des
moyens moins standards, basés sur les langages de commande à distance (cf. 2.4.2.5).
Nous présentons, ci-dessous, les méthodes d'acquisition des informations d'administration
que nous utilisons dans notre prototype pour les trois grandes familles d'ordinateurs présents
sur le site de test, à savoir: les machines sous le système d'exploitation Unix(a) et réseau TCP!
IF, les micro-ordinateurs Macintosh en réseau Appletalk, et les compatibles PC.
Informations isslles des machines Unix salis TCPIIP
Les ordinateurs sous Unix ont la réputation d'être des systèmes dits "ouverts". En effet, ils se
basent sur un système d'exploitation non-propriétaire qui offre de nombreuses possibilités de
coopérations entre machines. D'autre part, ces spécifications ont été très largement publiées et
sont par conséquent largement connues (citons entre autres [BOUR 82], [COL 94], etc). C'est
certainement le type d'ordinateurs qui est le plus facilement "interrogeable" par des moyens
autres que SNMP ou OS!. Dans notre cas, nous avons opté pour le langage de commande à
(a) Nous détaillons les méthodes d'acquisition pour le système Unix Berkeley. Pour les systèmes Unix AT&T
Version V, une simple correspondance de noms de fichiers doit être opérée.
166 Administration des applicatifs réseaux

Contexte de la maquette m.8
distance définie pour les "remote shell scripts" : RSH (décrit, entre autres, dans [RIF 93]). Il
reprend la syntaxe des interpréteurs de commandes Unix.
La plupart des données de configuration des machines Unix se trouvent regroupées dans un
certain nombre de fichiers [BAC 92]. Il s'agit principalement des suivants:
- lete/hosts liste des machines TCPIIP,
- lete/passlVd liste des utilisateurs de la machine,
- lete/printcap liste des imprimantes gérées,
-/ete/lI1tab liste des partitions-disques montées,
-/ete/exports liste des partitions-disques exportées.
Ces fichiers sont organisés comme des tables de tH/piets associés à la machine qui les
mémorise. L'interrogation de ces fichiers nous permet, en fonction de leur origine, de mettre à
jour une partie des tables de la base de données. Donnons un exemple: le fichier lete/mtab
nous permet de compléter la table Ressource de la base de données et d'associer ainsi les
partitions-disques à l'ordinateur qui les gère (tables Machine et Mach-Ress). C'est ce qui est
illustré au shéma 36.
~..-..
Ordinateur"Pluton"
Fichier /etc/mtab1 4.2 1 1lusr 4.2 1 2lusers 4.2 1 3
Illtel'rogatiollpar sheU script
010 pluton 001 Idev/rsdOa002 Idev/rsdOg003 Idev/sdOla
010 001010 002010 003
Plate-formed'administration
Schéma 36 .' Exemple d'acquisition de données
Généralement, une simple copie des fichiers de configuration ne peut suffire. Il a été
nécessaire d'effectuer certains traitements à distance afin de recouper ou d'ordonner les
données recueillies. Nous illustrons cela pal' les deux exemples qui suivent.
Administration des applicatifs réseaux 167

m.8 Contexte de la maquette
Exemple 1 - L'extrait.de code ci-dessous permet d'effectuer un traitement de filtrage et de
mise enfoi"me des données issues du fichier pré-citéletclmtab. En effet, il s'agit de ne prendre
en compte que les données nécessaires à la modélisation ..
# Interrogation des disques montes locauxHOST=\hostname'grep fA/dey' /etc/mtab \
1 awk '{ printf ("append ressdsq (nom=\" 1 $HOST' _%s\", dev::::\ "%s\",host=\" 1 $HOST' \", classe=\ "disque\". mp=\ "%s\ ") \n", $1, $1, $2) '}
Sans pour autant entrer dans les détails du code, nous donnons une courte description des
conunandes mises en œuvre:
- hostname : commande unix qui retourne le nom de l'ordinateur sur lequel s'exécute le
"shell script".
- gi"ep 'A/dev' letclmtab : commande unix pour filtrer les lignes qui commence par "/dev".
Nous écartons ainsi les informations concernant les disques distants.
- awk : commande unix de filtre et de mise en forme qui permet de ne conserver que les
paramètres pertinents pour chaque ligne traitée.
Exemple 2 - Le deuxième exemple, que nous donnons ci-dessous au schéma 37, illustre de
manière plus convaincante le type de traitement qu'il est nécessaire d'effectuer. Il s'agit du
code qui permet de recenser les programmes serveurs actifs d'un ordinateur unix.
# Interrogations des programmes serveurs actifsservice="shell exec talk smtp ftp telnet login printer pop"# Recuperation des numeros de ports utilisesserv='netstat -an \
1 awk '/'[tcp;udpl/ ( print $4 )' \1 awk -F"." , ( printf("%s\n",$NF) )' \1 a\·,k 'lift $1<1024 && $1!~"*" ) print $1)"
# Recherche des noms de services correspondantsfor i in $serv; do
nom='grep "[ ;]$i/" < fete/services 1 awk '{ print $1 l"~
for k in $service; doif [ "$nom" = "$k n
thenHp='grep "..... ${k}[ ]" /etc/inetd.conf 1 awk '{ print $6 }"if [ -il "$HP" li then
DEV='df $MP 1 awk '{ print $1 } 1 1 grep -v ' ..... Filesystem"echo "append prog (nom=\"${HOST)_$k\", host=\"$HOST\" ,
classe=\"serveur\", dir=\"$HP\" , disq=\"$DEV\")"fi
fidone
done
Schéma 37 "Extrait de code pOUffa recherche des programmes sell'eurs actif'!
168 Administration des applicatifs réseau.l'

Contexte de la maquelte m.8
Nous ne détaillons pas cette portion de "shell script" quelque peu ardue, nous n'en donnons
que le principe de fonctionnement. Il s'agit d'effectuer une série de recoupements afin de
déterminer le nom des programmes serveurs actifs ainsi que les partitions disques sur
lesquelles ils sont localisés.
En appliquant des traitements similaires, notre prototype va acquérir les informations
suivantes nécessaires à la constitution de sa base de données: listes des utilisateurs, des
machines - listes des programmes serveurs actifs et des programmes clients - listes des boîtes
aux lettres et des comptes - liste des périphériques gérés (imprimantes et partitions disques).
Les données nécessaires à l'établissement des fonctions de transitions qui nous permettent de
modéliser les services réseaux en cascade (cf. 5.1.5.1 - page 91) sont également récupérées,
soit dans des fichiers, soit par exécution de petits programmes. Il s'agit principalement de:
- /etc/printcap renvoi sur d'autres imprimantes,
-/etc/fstab renvoi sur d'autres serveurs disques,
-/etc/.rhosts modification des droits d'accès à un compte,
- /etc/sendmail.cf renvoi à d'autres serveurs de messagerie,
-/etc/resolv.cOlif liste des serveurs de noms.
Nota: Un extrait plus complet du "shell script" d'acquisition des données sur les machines
Unix est donné en annexe.
Informations isslles des machines Macintosh SOIIS AvpleTalk
L'acquisition des données pour l'administration des services réseaux, pour les ordinateurs
Macintosh sous le protocole AppleTalk, est un peu plus délicate. En effet, ce type de uùcro
ordinateur n'étant pas réellement muititâche, il n'est pas possible d'interroger le système
d'exploitation comme nous le faisons pour les machines sous Unix. Une preuùère solution
envisagée pour la maquette ADSAR - était d'exploiter la MIE SNMP [RFC 1243] développée
par Apple pour ces machines. Il s'agit d'une MIE propriétaire(a) tout à fait particulière, très
complète, qui nous aurait permis de récupérer les données nécessaires à notre modèle. C'est
pourtant une autre solution qui a du être retenue. En effet, l'adjonction d'un agent SNMP sur
tous les Macintosh du réseau de test n'était pas envisageable en raison du coOt d'une telle
opération. D'autre part, il faut noter que l'implantation d'une telle MlB est très "gourmande"
en place mémoire, ce qui limite considérablement son emploi pour de tels micro-ordinateurs.
Une deuxième solution plus souple, mais moins standard, a donc été choisie. Il s'agit de
(al Bien qu'étant implantée sur un Macintosh utilisant traditionnellement le protocole AppleTalk, cette MlB
utilise un agent SNMP intcrrogeable par Tep/IP, ce qui nécessite l'adjonction d'un tel protocole aux
machines en question.
Administration des applicatifs résealn- 169

m.8 Contexte de la maquette
l'utilisation d'une passerelle logicielle CAP60(a) localisée sur une des machines Unix. CAP60
est un logiciel qui permet de mettre en œuvre, sur une machine Unix, le protocole AppleTalk.
Il est ainsi possible d'effectuer la recherche de ressources, de programmes, etc, du réseau
AppleTalk, au moyen de primitives disponibles par CAP60. Il s'agit, dès lors, de simples
commandes Unix. Par exemple, la liste des machines Apple est directement obtenue par les
commandes CAP60lUnix getzones et atlooks.
Procéder au moyen d'une passerelle telle CAP60 a permis de nous ramener à la même
méthode d'acquisition des données que pour les systèmes Unix.
Nota: Celte méthode s'appuie sur le fait que AppleTalk est un protocole à publication - une
machine sur le réseau connaît en permanence l'état des autres ordinateurs (cf 2.4.2.4
page 41). Cependant, il faut souligner que certaines informations pointues ne peuvent être
récupérées par ce biais, par exemple, les programmes clients d'un Macintosh. Ces données
doivent être nécessairement déclarées (cf. 8.3.2.2).
b.lformations issues des machines compatibles PC
Le parc des ordinateurs compatibles PC sous MSDOS pose un problème plus difficile. Nous
n'avons pas trouvé de solution souple pour notre maquette. En effet, ce type de machine, bien
que très répandu, ne dispose pas à l'heure actuelle d'une MIE d'un niveau comparable à la
MIE Apple et ne permet donc pas de récupérer les informations nécessaires à notre modèle.
D'autre part, les protocoles réseaux utilisés sur les PC sont nombreux. Nous trouvons, entre
autres, IPX développé par Novell, Lau Mannager proposé par Microsoft et plusieurs
implantations de TCPIIP. Or à chaque protocole correspond une solution propre. De plus, il
faut souligner que ce type de micro-ordinateur ne permet pas, tout comme les Macintosh,
d'intenogations aisées (à distance) des paramètres de son système d'exploitation
(généralement MSDOS).Les données concernant les compatibles PC sont donc déclarées sur
le prototype ADSAR.
Nota: Il y a lieu de noter que ce type de micro-ordinateurs est la plupart du temps uniquement
client de quelques services réseaux. Ceci réduit de manière non-négligeable les informations à
déclarer.
8.3.2.;LM~thodes pour l'acquisition dcs données déclarées
Toutes les informations impossibles à acquérir par "remote shell" vont être considérées
comme des données "à déclarer". Pour cela, nous avons choisi de les spécifier par de simples
(a) CAP60 est un logiciel développé par l'UI/iversité de Coll/mbia (V.S). EtherShare est le produit
commercial équivalent.
170 Administration des applicatifs réseaux

Contexte de la maquette 1II.8
fichiers mis à jour "à la main" et directement lus par le système de gestion de la base de
données au moment de la génération de la base et dans le cas de modifications ultérieures. Il
reste cependant possible d'ajouter directement à la base de données certaines informations
supplémentaires au moyen des procédures POSTGRES prévues à cet effet. Le fait d'utiliser
des fichiers, plutôt que de mettre à jour directement la base, permet la régénération aisée de la
base, ce qui est appréciable dans le cas d'un prototype.
Après avoir présenté les méthodes d'acquisition des données, nous exposons les moyens mis
en œuvre, dans notre prototype ADSAR, pour la manipulation des graphes de dépendances du
modèle.
8.3.3. La génération des graphes et le calcul des résultats
Notre modèle utilise des graphes construits à partir des définitions du modèle. Dans le cadre
de l'implantation de la maquette ADSAR, quel système de gestion de graphes adopter?
Contrairement aux systèmes de gestion de base de données que l'on peut acquérir en tant que
"produit fini", les gestionnaires de graphes ne se trouvent pas facilement, pas plus dans le
monde universitaire que dans le secteur commercial. D'autre part, la méthode d'implantation
de tels systèmes a une importance déterminante sur les performances des traitements. Par
exemple, un graphe muni de nombreux sommets et de relativement peu d'arcs (comme ceux
que nous manipulons dans notre modèle) ne doit absolument pas être implanté de la même
façon qu'un graphe muni de très nombreux arcs, comme le souligne très justement
M. Gondran dans son ouvrage sur les graphes [GON 85]. Nous avons donc développé notre
propre système de gestion de graphes. Celui-ci a été écrit en langage C, il implante les notions
suivantes:
- Les graphes manipulés peuvent être orientés ou non.
- Les sommets et les arcs peuvent être valués ou non. Ces valuations sont de tailles
mémoires quelconques.
- L'exploitation des graphes est faite directement en mémoire vive. La gestion de la mémoire
nécessaire aux structures de données est dynamique. Il n'y a donc pas de réservation "à
l'avance". La taille des graphes est théoriquement limitée par la place mémoire virtuelle
disponible pour un processus de l'utilisateur(al.
(al La taille de la mémoire virtuelle disponible pour un utilisateur sur un système Unix est généralement liée
à la taille de la zone "swap" de l'ordinateur. Pour peu que la machine dispose de suffisamment de place
disque, la taille des graphes manipulés peut être très importante. Pour l'implantation de la maquette, nous
avons "retaillé" à 128 Mo la zone de "swap" de la machine supportant la plate-forme d'administration. C'est
une méthode courante pour les logiciels gourmands en mémoire (comme par exemple Softlmage de Silicon,
dont la taille de "swap" préconisée est de 256 Mo).
Administration des applicatifs réseaux 171

III.8 Contexte de la maquette
La méthode choisie pour implanter les graphes a été conçue afin d'optimiser la place mémoire
nécessaire, tout en conservant de bonnes performances de traitements. La spécification de la
bibliothèque glph, développée pour la gestion des graphes, est donnée en annexe. Nous
présentons, cependant, l'architecture générale de la structure de données utilisée.
Chaque graphe comporte un tableau contigu à évolution dynamique (voir paragraphe suivant)
de l'ensemble de ses sommets. Ce qui garantit un accès direct à chaque sommet, par simple
calcul sur l'indice indiqué. A chaque sommet est associé un tableau contigu - à évolution
dynamique - des indices des sommets adjacents classés par ordre croissant. Ceci permet une
recherche rapide par dichotomie d'un sommet adjacent indiqué. La valuation des arcs et des
sommets se fait au moyen d'allocations dynamiques, avec mémorisation de la taille et de
l'adresse de la zone mémoire allouée.
Le schéma 38, ci-dessous, illustre les structures mises en œuvre pour l'implantation des
graphes. Seuls un sommet et un arc sont annotés, les parties en grisé représentent un n-ième
sommet ou arc.
Les tableallx contigus à évoitltion dynamique ont été également développés pour les "besoins
de la cause". Ils sont décrits en annexe, dans la présentation de la bibliothèque nommée tbd.
Leur principe de fonctionnement repose sur la fonction real/oc() du langage C. Un tableau est
alloué par tranches de taille fixetaJ, afin d'éviter les ré-allocations à chaque insertion ou
suppression d'éléments. Contrairement à une simple allocation classique, la fonction real/oc()
assure le déplacement des données dans le cas où l'extension de la zone ne pourrait être
assurée de manière contiguëtb).
Nous terminons ce chapitre en exposant les choix généraux concernant la plate-forme
d'administration elle-même. Comment a-t-elle été réalisée?
8.3.4. La plate·forme d'administration
La plate-forme d'administration que nous avons développée se décompose en deux entités
fonctionnelles distinctes. Il s'agit d'un côté du gestionnaire de la base de données, à savoir le
programme POSTGRES appliqué à la base de données d'administration nommée BDadsar. De
(a) A t'exception de la première tranche qui est de très petite taille.. Ce procédé permet d'éviter le gaspillage
de mémoire dans les cas de tableaux ne possédant que quelques éléments (pour notre maquette, il s'agit par
exemple des tableaux associés à chaque sommet qui décrivent les sommets adjacents).
(b) S'appuyant généralement sur des primitives matérielles de recopies de zones mémoires, disponibles sur la
plupart des stations, la fonction realloc() permet de manipuler des stl1lctures de données dont les propriétés
de contiguïté sont remarquables, et dont les performances de traitement n'ont rien à envier à des structures
chaînées.
172 Administration des applicatifs réseaux
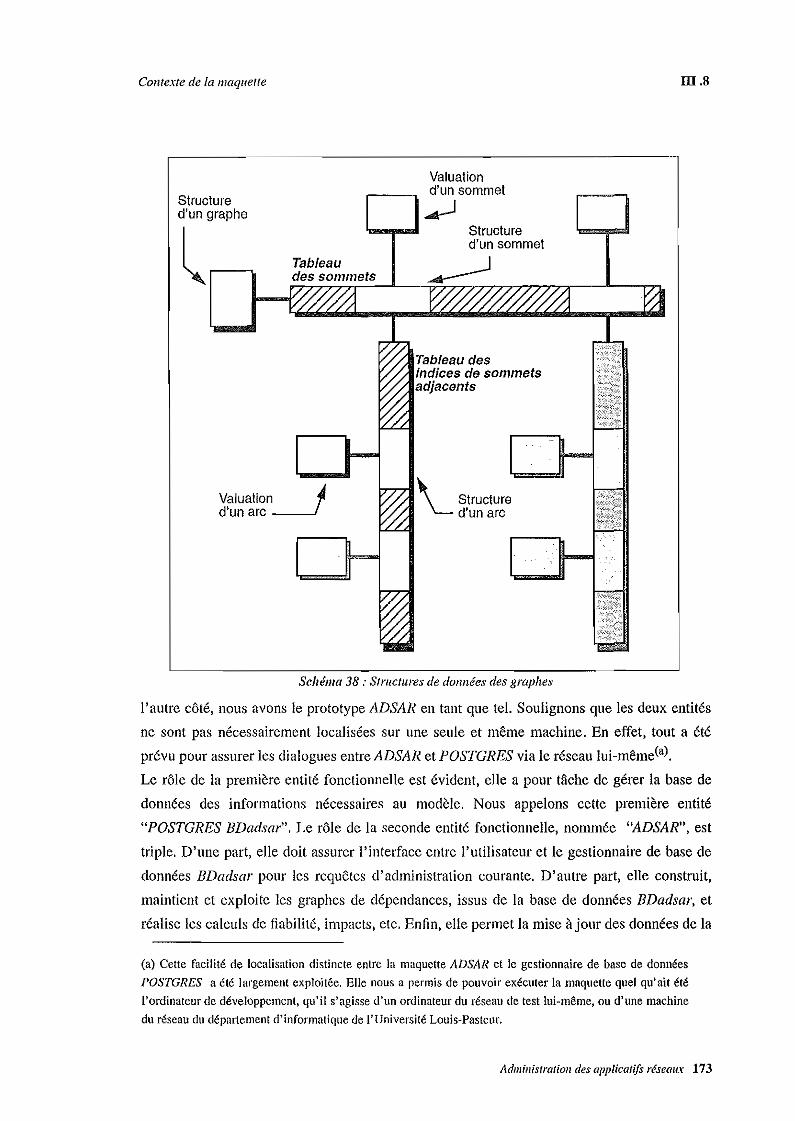
Contexte de la maquette m.8
Valuation Jd'un arc ---.J.
Structured'un sommet
Valuationd'un sommet
.....-J
\ StructureL d'un arc
Tableau desindices de sommetsadjacents
Tableaudes sommets
Structured'un graphe
l...----..
Schéma 38 : Structures de données des graphes
l'autre côté, nous avons le prototype ADSAR en tant que tei. Soulignons que les deux entités
ne sont pas nécessairement localisées sur une seule et même machine. En effet, tout a été
prévu pour assurer les dialogues entre ADSAR et POSTGRES via le réseau lui-même(al.
Le rôle de la première entité fonctionnelle est évident, elle a pour tâche de gérer la base de
données des informations nécessaires au modèle. Nous appelons cette première entité
"POSTGRES BDadsar". Le rôle de la seconde entité fonctionnelle, nommée "ADSAR", est
triple. D'une part, elle doit assurer l'interface entre l'utilisateur et le gestionnaire de base de
données BDadsar pour les requêtes d'administration courante. D'autre part, elle construit,
maintient et exploite les graphes de dépendances, issus de la base de données BDadsar, et
réalise les calculs de fiabilité, impacts, etc. Enfin, elle permet la mise à jour des données de la
(al Cette facilité de localisation distincte entre la maquette ADSAR et le gestionnaire de base de données
POSTGRES a été largement exploitée. Elle nous a permis de pouvoir exécuter la maquette quel qu'ait été
l'ordinateur de développement, qu'il s'agisse d'un ordinateur du réseau de test lui-même, ou d'une machinedu réseau du département d'informatique de l'Université Louis-Pasteur.
Administration des applicatifs réseaux 173
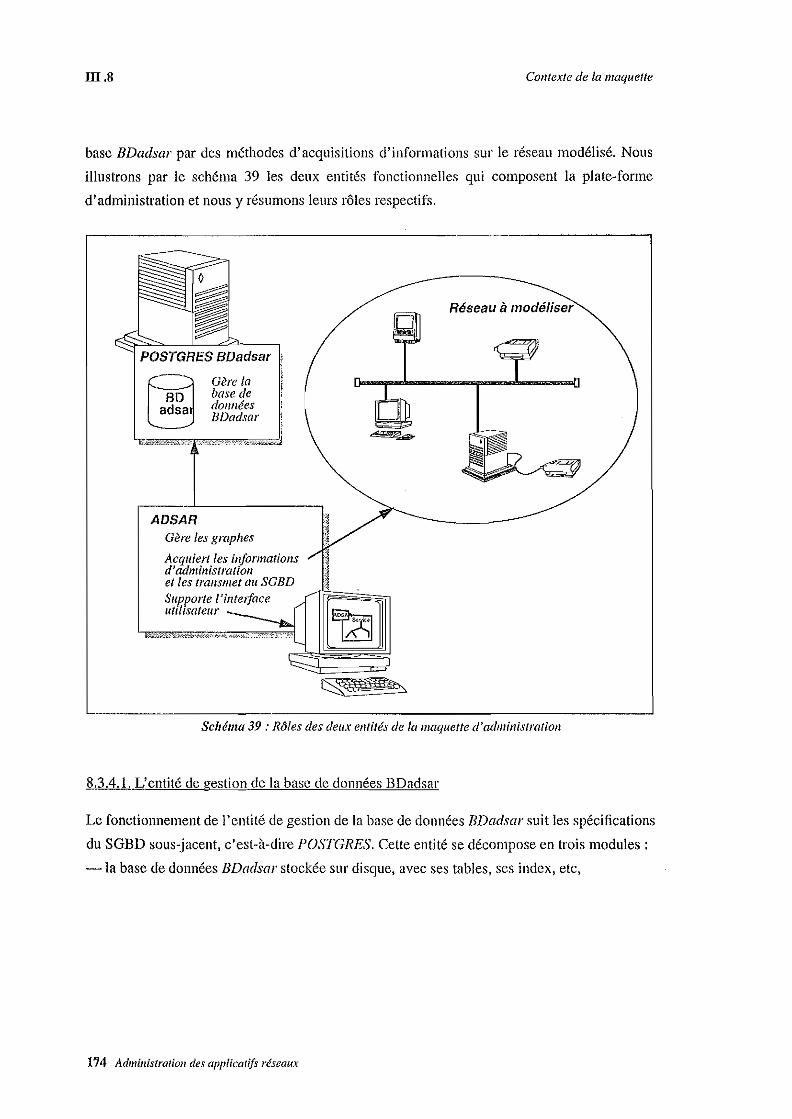
m.8 COlltexle de la maquette
base BDadsar par des méthodes d'acquisitions d'informations sur le réseau modélisé. Nous
illustrons par le schéma 39 les deux entités fonctionnelles qui composent la plate-forme
d'administration et nous y résumons leurs rôles respectifs.
,----------------------------------,------
Réseau à modéliser
Gère labase dedonnéesBDadsar
hili1~
POSTGRES BDadsar
ADSARGère les graphes
Acquiert les informationsd'aâministratiollet les transmet au SGBDSURporte l'intelfaceutIlIsateur
Schéma 39 : Rôles des deux emités de la maquette d'administration
8.3.4.1. L'entité de gestion de la base de données BDadsar
Le fonctionnement de l'entité de gestion de la base de données BDadsar suit les spécifications
du SGED sous-jacent, c'est-à-dire POSTGRES. Cette entité se décompose en trois modules:
-la base de données BDadsar stockée sur disque, avec ses tables, ses index, etc,
174 Administration des applicatifs réseau.),'

Contexte de la maquette m.8
- un ou plusieurs processus Unix, appelés pastgres d'exploitation de la base, qui assurent la
réalisation des requêtes. Ces processus ont la charge de gérer les conflits d'accès à la
base(aJ,
- et enfin, un processus Unix, appelé pastlllaster, qui assure la gestion des accès
d'interrogation via le langage POSTQUEL. Ces interrogations peuvent provenir soit d'un
moniteur POSTQUEL, soit de programmes utilisateurs s'appuyant sur la bibliothèque C
d'interfaçage à ce langage, à savoir libpq. Dans les deux cas, les moniteurs et les
programmes utilisateurs peuvent être soit locaux, soit déportés sur d'autres machines.
8.3.4.2. L'entité fonctionnelle ADSAR
L'entité fonctionnelleADSAR se décompose également en modules. Nous avons, tout d'abord,
un "moteur central", sous forme d'un processus Unix, qui assure les fonctionnalités
principales, à savoir:
-la construction et l'exploitation des graphes,
-l'interfaçage pour réaliser les requêtes de l'utilisateur dans un contexte graphique aisé
(requêtes d'interrogation de la base "emballées" dans des "boîtes à boutons" et des "menus
déroulants,,(bJ).
L'interface utilisateur de ce premier module s'appuie sur la bibliothèque graphique Xl1R4(c)
[DUM 90] et Xview(d) [HEL 90]. La manipulation des graphes est assurée par la librairie grph
présentée au paragraphe précédent. Tous les développements ont été réalisés en langage Cee).
Le deuxième module, nommé explorer, assure l'acquisition des informations nécessaires à la
modélisation du réseau. En fonction des données recueillies, il en demande la mise à jour à
l'entité fonctionnelle de gestion de la base de données BDadsar. Ce module est réalisé sous la
forme d'un ou plusieurs processus Unix, s'exécutant en "tâche de fond" avec une priorité
relativement faible, afin de ne pas surcharger inutilement les machines. Ces processus
d'exploration sont gérés par le module principal, que nous avons appelé "moteur central". Il
(a) POSTGRES utilise les sémaphores IPe pour résoudre les conflits d'accès aux champs de bases dedonnées. Ceux-ci doivent donc être disponibles sur la machine qui implante l'entité de gestion de la base dedonnées BDadsar.
(b) Les "boîtes à boutons" et "menus déroulants" sont des termes décrivant des méthodes courantes mises en
œuvre par les interfaces d'utilisation des logiciels graphiques [HEL 90].
(c) La bibliothèque XIl est le standard par "excellence" des interfaces graphiques sur stations Unix. Elle aété développée par le MIT dans le cadre du projet Athéna.(d) La bihliothèque Xview s'appuie cn partie sur XlI, mais utilise une approche objet pour ledéveloppement d'interfaces graphiques.
(e) Les logiciels d'aide au développement d'interfaces graphiques, tels DevGuide de Sun, n'ont pu être
utilisés du fait de la complexité des affichages des graphes, qui o'est pas gérée par ce type d'outils.
Administration des applicatifs réseau.\" 175

m,8 Conte.l:te de la maquette
en assure la création et la modification de priorités, en fonction de la charge de la machine et
des impératifs du logiciel. Il gère leur suppression éventuelle, Ce deuxième module a été
également écrit en langage C.
Le schéma 40, ci-dessous, représente les différents modules qUI composent l'entité
fonctionnelle ADSAR..
Dialoguent avec l'entité fonctionnellePOSTGRES BDadsar Scrutent le réseau à modéliser au moyen
de "remote shells"
l 'b ~bd1 pq - ---grph
moteurcentral
libpq
Explorer
libpq
Explorer
•-......... "
-------- .rr-::::~-"';'; __ L'IIl 1 1Il 1 1.... " , ,II. .. 1, ,1 Explorer'"'--- --_ ..
,••
Xii Xview
Gère l'illteljaced'wilisatiol/
Pilote (lal/cemel/t, destructiol/, etc)
ADSAR
Schéma 40: Les modules de l'elltitéjol/ctiol/I/elle ADSAR
Nous terminons la présentation des choix globaux qui ont été faits pour l'implantation du
prototype en vue de la validation de notre modèle en présentant, par le schéma 41, l'ensemble
de l'architecture de la maquette ADSAR. Nous y avons représenté les différentes composantes
fonctionnelles et les modules qui ont été détaillés précédemment.
Après avoir présenté, de manière générale, les choix techniques pour la réalisation de la
maquette ADSAR, nous entrons, au chapitre suivant, dans la description précise de son
implantation et de son utilisation.
176 Administration des applicatifs réseaux
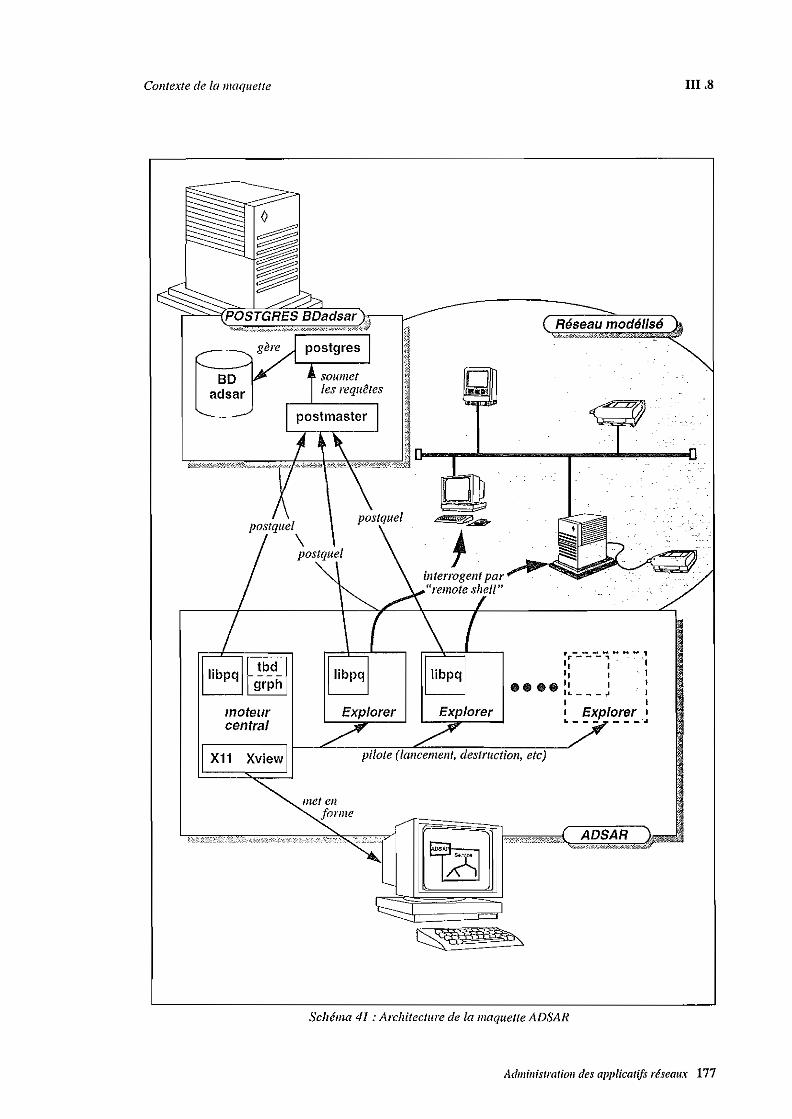
CoJltexte de la maquette 1II.8
POSTGRES BDadsar Réseau modélisé
gère postgres
pilote (lancement, destruction, etc)
r - - - - ..- .. -'.-.."r---'Il 1
" ,.... " ,IL ,J, ,, Explorer'10_·_- . .l
Explorer
IibpqIibpq
soumetles requêtes
postquel\postquel
moteurcentral
X11 Xview
BDadsar
l'b ~bd1 pq u_grph
met enforme
I~jADSAR
Schéma 41 : Architecture de la maquette ADSAR
Administration des applicatifs réseaux 177

m.9 La maquel1e ADSAR : implantation, utilisation et évaluation
9@ La maquette ADSAR :
inlplantation, utilisation et évaluation
Nons présentons, dans ce chapitre, les détails concrets de l'implantation de notre maquette
ADSAR et les fonctionnalités offertes à l'utilisateur. Nous terminons par une évaluation de la
maquette tant du point de vue technique que de ses résultats.
9.1. L'implantation de la maqnette ADSAR
Nous présentons les détails de l'implantation d'ADSAR en deux volets. Nous décrivons, tout
d'abord, la base BDadsar. Quelle est sa structure générale? Comment est définie chaque
table? Comment est-elle générée par le prototype? Nous poursuivons, dans un deuxième
temps, par la présentation de certains détails techniques d'implantation des différents modules
de l'entité fonctionnelle ADSAR.
9.1.1. Implantation et génération de la base de données BDadsar
Pour pouvoir mémoriser et manipuler les données nécessaires à l'élaboration de notre modèle,
nous avons défini une base de données selon le diagramme théorique que nous avons exposé
dans la deuxième partie (voir 6.3.2 - page 117). Nous présentons la structure des tables, le
diagramme effectivement implanté et la méthode de génération de la base par la maqnette
ADSAR.
9.1.1.1. Tables de la base de données
Afin d'alléger la lecture, nous ne décrivons que deux des tables de la base, le reste étant
donnés en annexe. 11 s'agit de la table de base décrivant les machines, et de la table de relation
décrivant la localisation de chaque ressource.
Les tableaux de présentation sont construits de la façon suivante: pour chaque champ sont
spécifiés son identificateur, c'est-à-dire le nom de manipulation du champ, son type de
données (au format POSTGRES - voir annexe) et une courte description de son rôle. De plus,
un qllalifialll ("indispensable" ou "additionnel") caractérise chacun d'eux.
178 Administration des applicatifs réseaux
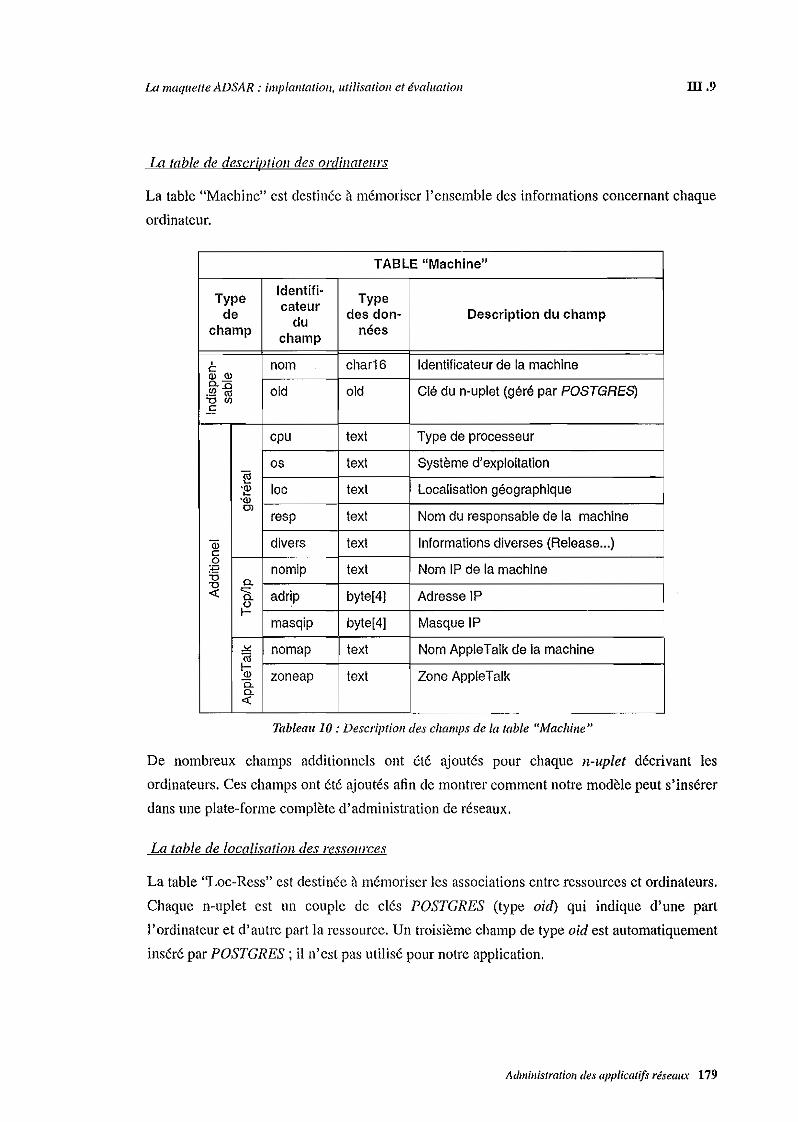
La maquette ADSAR : i111plalllatioll. utilisation et évaluation
La table de description des ordinateurs
m.9
La table "Machine" est destinée à mémoriser l'ensemble des informations concernant chaque
ordinateur.
TABLE "Machine"
TypeIdentifi-
Typecateur
dedu
des don- Description du champchamp
champnées
C nom char16 Identificateur de la machineOl <Il0.-.!:Q~ oid oid Cié du n-uplet (géré par POSTGRES)"0 enc
cpu texl Type de processeur
os text Système d'exploitation~'Ol loc texl Localisation géographique~
'OlCl
Nom du responsable de laresp text machine
ID divers text Informations diverses (Release...)c.9
nomip texl Nom IP de la machine:g"0 0.<>: "" adrip byle[4] Adresse IP0.
~masqip byle[4] Masque IP
"" nomap text Nom AppleTalk de la machine(ij1-Ol zoneap texl Zone AppleTalk0.0.
<>:
Tableau 10 : Description des champs de la table "Machine"
De nombreux champs additionnels ont été ajoutés pour chaque n-uplet décrivant les
ordinateurs. Ces champs ont été ajoutés afin de montrer comment notre modèle peut s'insérer
dans une plate-forme complète d'administration de réseaux.
La table de localisation des ressources
La table "Loc-Ress" est destinée à mémoriser les associations entre ressources et ordinateurs.
Chaque n-uplet est un couple de clés POSTGRES (type oicf) qui indique d'une part
l'ordinateur et d'autre part la ressource. Un troisième champ de type oid est automatiquement
inséré par POSTGRES ; il n'est pas utilisé pour notre application.
Administratioll des applicatifs réseau,\.' 179

III.9 La maquette ADSAR .' implafltation, utilisation et évaluation
-_.~~._-------------_ ..~_.-
TABLE "Loc-Ress"1-----
TypeIdentifi-
Typecaleur
dedu
des don- Description du champchamp
champnées
, mach oid Identificateur de l'ordinateurcCl> Cl>0.- ress oid Identificateur de la ressource",.0.- '""0'"E oid oid Clé du n-uplet (gérée par POSTGRES)
Tableallll : Description des champs de la table "Loc-Ress"
9.1.1.2. Diagramme de la base de données de la maquette
Comme nous l'avons indiqué en introduction, le schéma de la base de donnée a été simplifié
par rapport à celui spécifié dans le modèle (paragraphe 6.3.2) afin de ne pas alourdir
l'implantation. Le diagramme utilisé est illustré par le schéma 42 ci-dessous.
9.1.1.3. Génération de la base de données par le prototype ADSAR
La génération des tables sous le SGBD POSTGRES peut-être effectuée de différentes façons.
Nous avons opté pour l'utilisation d'un programme POSTQUEL qui est, nous le rappelons, un
des langages de manipulation des données sous POSTGRES. Nous donnons, ci-dessous,
l'exemple du programme de création de la table "Utilisateur".
create Utilisateurnom=char16,org=text,adr=text,divers=text
)
define index ind_util_l on utilisateur using btree (nom char16_ops)
Schéma 43 : Symaxe POSTQUEL de création de la table décrivant les lIIi/isatellrs
Nota: Les champs qui sont utilisés fréquemment pour des spécifications de requêtes, tel le
champ "nom" sont munis d'un index afin d'accélérer le traitement des recherches.
L'ensemble des instructions de création de tables et de génération d'index ont été regroupées
dans un fichier nommé createdb.pq. Ce "programme POSTQUEL" peut être exécuté soit sous
le moniteur fourni avec POSTGRES, soit directement sous le prototype logiciel ADSAR. Nous
avons programmé la maquette afin qu'elle puisse assurer l'exécution des fichiers
d'instructions POSTQUEL de la même manière que le moniteur. Ceci a été développé grâce
aux procédures de la biliothèque libpq d'interfaçage à POSTGRES.
180 Administration des applicatifs réseau."(
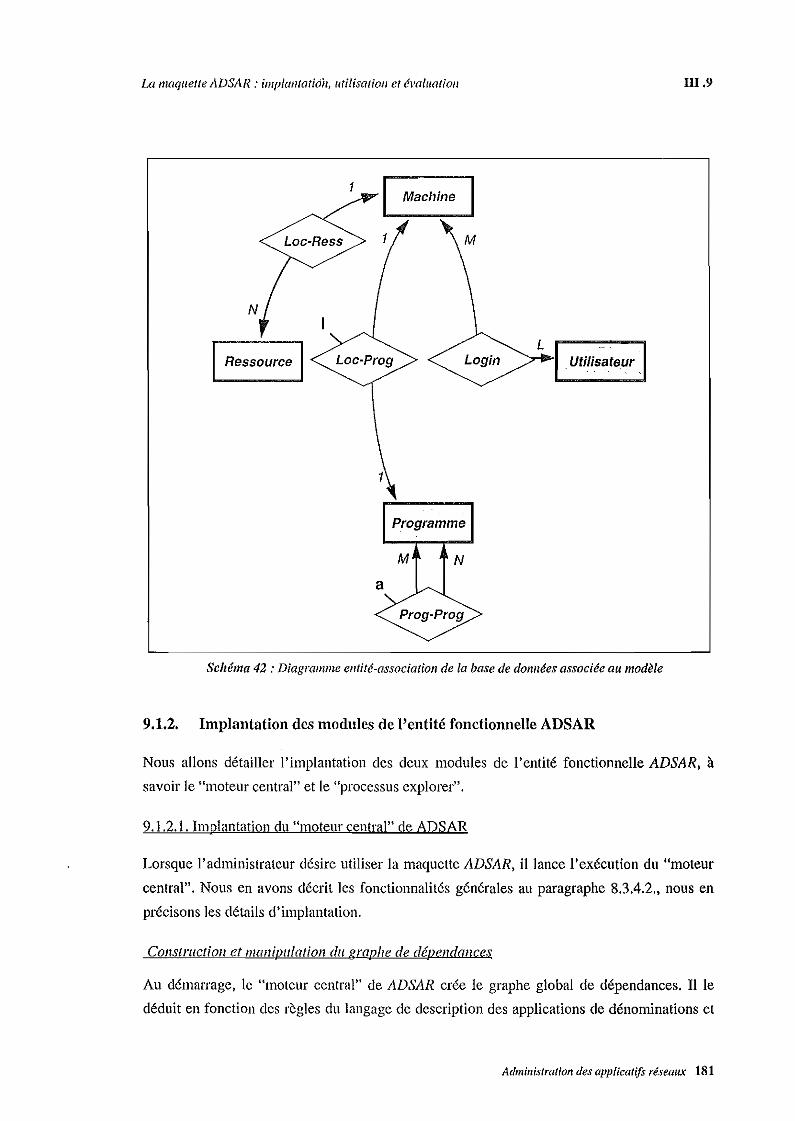
La maquette ADSAR : implamatidil. utilisation et évaluation m.9
1
Loc-Ress
N
Machine
LRessource Loc-Prog Login Utilisateur
Programme
M N
a
Prog-Prog
Schéma 42 : Diagramme entité-association de ia base de données associée au modèle
9.1.2. Implantation des modules de l'entité fonctionnelle AD8AR
Nous allons détailler l'implantation des deux modules de l'entité fonctionnelle ADSAR, à
savoir le "moteur central" et le "processus explorer".
9.1.2.1. Implantation du "moteur central" de ADSAR
Lorsque l'administrateur désire utiliser la maquette ADSAR, il lance l'exécution du "moteur
central". Nous en avons décrit les fonctionnalités générales au paragraphe 8.3.4.2.• nous en
précisons les détails d'implantation.
Construction et maniuulation du graphe de dépendances
Au démarrage, le "moteur central" de ADSAR crée le graphe global de dépendances. Il le
déduit en fonction des règles du langage de description des applications de dénominations et
Administration des applicatifs réseaux 181

m.9 Ln maquette ADSAR : implantation, utilisation et évaluation
de transitions (cf. 6.5.3 - page 131). Ce graphe ne sera plus modifié tant que ADSAR n'est pas
relancé.
Nota: Les règles de description sont placées directement dans le code source. Ceci évite, dans
le cas d'un tel prototype, de développer un compilateur dédié à cette tâche. En effet, le
langage C permet de décrire les règles de réécriture de manière similaire.
Le "moteur central" implante les algorithmes de manipulation des graphes pour :
_. générer le graphe global de dépendances, et vérifier son caractère acyclique,
- extraire un graphe de dépendances associé à un service particulier et le visualiser dans une
fenêtre, soit sous une forme "brute" (fidèle à la définition), soit sous une forme fortement
contractée qui ne décrit que les dépendances entre machines,
- calculer les résultats (fiabilité d'un service, impact d'une machine, etc).
Tous ces algorithmes ont été écrits au moyen de la bibliothèque de programmation grph
(cf. 8.3.3 - page 171).
Manipulation de la base de donnée
La deuxième fonction du "moteur central" est d'établir une interface afin que l'utilisateur
puisse interroger la base de données BDadsar. Pour ce faire, le "moteur central" implante un
interpréteur de commandes du langage POSTQUEL. Celui-ci permet de soumettre à la base de
données POSTGRES des requêtes utilisateurs et d'en restituer les réponses sous la forme de
fenêtres graphiques.
Nota: Sur le même principe, et comme nous l'avons décrit précédemment (cf. 9.1.1.3), le
"moteur central" permet la régénération complète de la base bdadsar.
Gestion des modules explorer
Au moyen des possibilités Unix de communications inter-processus, le "moteur central" gère
les modules "explorer" d'acquisition des données. Grâce à la bibliothèque C de gestion des
signaux, il règle la priorité des différents processus d'exploration en cours d'exécution. Par la
même méthode, il en assure au besoin la destruction.
Implalltatioll de l'algorithme adaptatif
Dans l'état actuel, la maquette ADSAR ne permet pas de construire le graphe global de
dépendances en fonction de tous les services possibles, mais uniquement en fonction d'un
groupe de service désigné. Une extension du "moteur central" implante cependant
l'algorithme adaptatif (décrit au paragraphe 6.5.1" page 126) afin de déduire
automatiquement tous les services élémentaires.
182 Administration des applicatifs réseaux

La maquette ADSAR : implantation. utilisation et évaluation
9.1.2.2. Implantation du module d'acquisition des données
III.9
Nous avons présenté, au paragraphe 8.3.4.2, les fonctionnalités du module explorer
d'acquisition des informations nécessaires au modèle. Nous en détaillons ici l'implantation.
Génération des processus explorer
Le module explorer assure sa fonction sous la forme d'autant de processus Unix que
nécessaire pour scruter le réseau modélisé. Ces processus sont les "fils", au sens Unix du
terme, du module principal d'ADSAR que nous avons appelé "moteur central". Le nombre
maximum de processus explorer, en exécution simultanée, est géré par le processus père. Il en
est de même pour leur prioritëa).
Principe de fonctionnement
Le principe de fonctionnement du module explorer repose essentiellement sur la notion de
"tubes Unix". Ceux-ci nous permettent l'exécution de shell scripts, locaux ou distants, dont
les résultats vont être utilisés directement par le module explorer. Ainsi, en langage C, c'est au
moyen de la procédure popen()(b) que nous nous assurons le concours de ce genre de "tubes".
Le court extrait de pseudo-code source C, ci-dessous, illustre la méthode employée.
/* DECLARATION DES VARIABLES */p : indentificateur du Dtube"s : tableau de 256 caractères
/* OUVERTURE DU "TUBE" */p=popen("commande Unix", ... )i
/* LECTURE DU "TUBE" */tant que lecture_tube(p)->s non terminéerépéter
Traitement (8) i
fin/ * FERNETURE DU l' TUBE 1. * /
pclose (p) ;
Schéma 44 : Méthode de lancement des commandes d'acquisition
(al Dans la version actuelle d'ADSAR, les processus explorer doivent nécessairement être localisés sur la
même machine que le "moteur central ADSAR", car toutes les communications sont assurées par des signaux
Unix et non pas au moyen de RPC ou de tout autre mécanisme similaire.(b) La procédure de bibliothèque popenO lance, en tâche de fond, un interpréteur de commandes (shell) qui
assure l'exécution de la commande Unix passée en paramètre. Cette procédure, bien qu'extrêmenent pratique.s'appuie uniquement sur le "Boume Shell", et ne permet pas l'utilisation du "e-sheH" ni du "Kom-shell".
Administration des applicatifs réseaux 183

m.9
_Le "shell" d'exploration
La maquelte ADSAR .' implantation, utilisation et évaluation
La commande exécutée à travers le "tube" est, dans notre cas, bien particulière. Il s'agit d'un
"remote shell script" pour lequel l'exécution distante doit avoir lieu sur l'ordinateur par le
processus explorer.
Une première solution, employée dans la version préliminaire CQFD dont nous avons parlée
en introduction, consiste à passer en paramètre le shell script d'exploration lui-même (comme
indiqué dans le cadre ci-dessous). Cette méthode implique alors que l'utilisateur initiateur du
"remote shell" (c'est-à-dire l'utilisateur dc CQFD) dispose de droits particuliers d'accès à la
machine à explore/a). Ceci engendre de réels problèmes de sécurité puisque, potentiellement,
tout utilisateur de CQFD va disposer d'un compte sur toutes les machines surveillées. Une
deuxième solution, plus rigoureuse, est employée dans la version ADSAR. Elle consiste à créer
un compte spécifique sur chaque machine à surveiller dont l'interpréteur de commandes
habituel (csh ou autres) est remplacé par le "shell script d'exploration" lui-même. Cette
méthode est directement inspirée de la commande nvho Unix, qui utilise le même principe
pour le système V d'AT&T. Elle permet de limiter strictement les possiblités d'utilisation du
compte en question. Nous indiquons, dans le cadre ci-dessous, la définition particulière dans le
fichier /etc/passwd du système Unix, pour le compte dédié à l'exploration.
explorer: :999:999:Compte d_exploration:/usr/explorer:/usr/explorer/explorer
Dans notre implantation ADSAR, les processus explorer sont lancés périodiquement pour
scruter les cinq serveurs prédominants du réseau de test. La période peut être modifiée; elle
est fixée, par défaut, à une semaine. D'autre part, il est possible de lancer volontairement un
processus explorer en direction de n'importe quelle autre machine sur laquelle aura été
préalablement installé le compte dédié à l'exploration. C'cst ce qui est préconisé au moment
de la génération de la base de données; l'exploration périodique est réservée aux machines
susceptibles d'évoluer le plus rapidement.
Le principe de fonctionnement des "shells d'exploration" a été présenté au paragraphe 8.3.2.1
Au delà de la fonction d'acquistion des données, ils ont un rôle de mise en forme syntaxique.
En effet, les processus explorer doivent comprendre les résultats des "shells d'exploration" et
générer les requêtes de mise à jour correspondantes. Ces dernières sont traitées par l'entité
fonctionnelle de gestion de la base de données BDadsar (cf. shéma 39). Pour ne pas alourdir
(a) II s'agit de mettre en place une dérogation d'accès au moyen du fichier Unix de configuration prévu à ceterrel : .rhosts.
184 Administration des applicatifs réseaux

La maquelle ADSAR : implallfatioll, utilisation et évaluation m.9
inutilement le prototype, nous avons choisi comme syntaxe un sous-ensemble du langage
POSTQUEL. Ceci facilite la formulation des requêtes au niveau du processus explom; car lui
même utilise POSTQUEL pour dialoguer avec l'entité fonctionnelle de gestion de la base
BDadsar.
Soulignons que le "shell d'exploration" doit prendre en compte la spécificité de la machine à
explorer, car de nombreuses différences persistent entre systèmes Unix selon le constructeur
de la machine. Et même pour deux systèmes d'exploitation Unix certifiés "système V
conforme AT&T", nous trouvons de subtiles différences dont il faut tenir compte(a).
Nous terminons la description des modules fonctionnels en présentant deux problèmes
rencontrés et en exposant les solutions retenues.
9.1.2.3. Problèmes d'implantation
Problème lié à la duplication des informations
Un des problèmes que les processus explorer doivent résoudre est la mise à jour de données
déjà notifiées dans la base BDadsar, afin d'éviter leur duplication. Le système de gestion de
base de données POSTGRES ne sait pas gérer les clauses "uniques,,(b) associées à certains
champs d'un n-uplet, et qui en définissent les conditions d'unicité. Il est donc nécessaire de
s'assurer avant tout ajout d'un n-uplet que l'objet qu'il décrit n'est pas déjà recensé dans la
base. Pour cela, le processus explorer est obligé d'effectuer une lecture préalable, et suivant le
cas, d'effectuer soit une mise à jour, soit un ajout. Techniquement, ce problème n'est pas
compliqué à résoudre, mais la solution entraîne un surcoût important de traitements.
Problème lié à l'aima de n-liplets dans les tables de relations
Un deuxième problème a du être résolu. Il s'agit des cas de mises àjour des tables de relations
qui, nous le rappelons, mémorisent les associations entre objets des tables principales, par
exemple les utilisateurs d'un ordinateur. Ces tables de relations ne spécifient pas le "nom" des
objets associés mais uniquement leur index POSTGRES. Or le "shell d'exploration" ne peut
connaître ces index, il ne peut qu'indiquer les "noms" des objets en association. La solution
repose sur le processus explorer qui va assurer, pour chaque insertion ou mise à jour de table
(a) Un des exemples, qui nous a donné un peu de fil à retordre, a été, entre autre, la différence d'affichage de
la commande lpstat, d'analyse des états des imprimantes, entre le systèrne Unix SUIIOS et lrlx pour Silicon
(utilisation de tabulations à la place d'espaces)
(b) La clause "unique", également nppelée "key" dans certains SGBD, est une des évolutions récente
apportée dans ce domaine. La version 4.0.1 de POSTGRES en décrit la syntaxe, mais ne l'implante
malheureusement pas.
Administration des applicatifs réseaux 185

m.9 La maquette ADSAR : i11lplaJ1lation, tlfiUsatioll et évaluation
de relations, la substitution des "noms" des objets par l'index qui leur est associé dans la base
de données BDadsarta).
Après avoir décrit les détails techniques de l'implantation des différents modules
fonctionnelles de la maquette, et présenté le schéma de la base de données, nous exposons les
fonctionnalités de la maquette logicielle ADSAR.
9.2. Fonctionnalités de la maquette ADSAR
Nous présentons et commentons dans ce paragraphe une série de "copies d'écrans" qui
illustrent les possibilités offertes à l'utilisateur de ADSAR. Les résultats d'exploitation et les
caractéristiques de leur obtention sont traités dans le paragraphe suivant.
Nota: Nous rappelons qu'ADSAR n'a pas la prétention d'être un logiciel d'administration
"clé en main", mais un prototype destiné à vérifier que le modèle est exploitable. Ainsi,
certains "menus" destinés à exécuter des portions du programme en cours de développement
ne sont pas détaillés.
9.2.1. Lancement du prototype
Pour pouvoir exécuter le programme ADSAR, il est nécessaire, au préalable, de s'assurer du
bon fonctionnement du gestionnaire de base de données POSTGRES. Il s'agit notamment de
lancer le module postmaster, qui doit gérer les requêtes de mise à jour. Par défaut, ADSAR
recherche localement le gestionnaire de base de données. Cependant. le nom d'une machine
distante et un numéro de port spécifiquetb) peuvent lui-être indiqués en paramètre, dans le cas
où les deux entités fonctionnelles ne sont pas situées sur une même machine.
Le logiciel, au démarrage, vérifie l'existence de la base de données BDadsar, et en cas
d'échec, en demande la création au SGBD POSTGRES. Par défaut, les processus
d'exploration automatique sont relancés. Enfin, l'écran d'accueil d'ADSAR s'affiche
(schéma 45), et offre à l'utilisateur ses différentes fonctionnalités sous forme de "boutons" :
Exploitation de la base, Analyse des dépendances et Importation des données.
(a) Une solution plus élégante, utilisant des règles de réécriture automatique. a du être abandonnée. En effet,
POSTGRES est légèrement bogué. et ne supporte pas plus de 1024 caractères pour l'ensemble des
spécifications des règles de réécriture.
(h) Les communications entre le SGDD et l'entité fonctionnelle ADSAR utilisent le protocole TCPflP. Le
numéro de port et l'adresse réseau permettent de spécifier, de manière non-équivoque, les entités de pait et
d'autre.
186 Administration des applicatifs réseaux

La maquette ADSAR " implantation, utilisation et évaluation
Schéma 45: Ecran d'accl/eil d'ADSAR
9.2.2. Génération et exploitation courante de la base BDadsar
9.2.2.1. Régénération de la base
m.9
La première fonctionnalité offerte à l'utilisateur est la possibilité de régénérer la base de
données BDadsar. Le "sous-menu" adéquat entraîne, après confirmation, la suppression totale
de la base de données existante et la reconstruction des tables et des index d'une nouvelle base
BDadsar. Après une telle opération, il est recommandé de réinitialiser les périodes des
processus d'exploration automatique, et au besoin, de lancer des processus d'exploration vers
les machines que l'on veut scruter.
Schéma 46: Menl/ de "exploitation de la base de données
9.2.2.2. Exploitation courante de la base
Une interface d'interrogation de la base BDadsar est disponible par le "sous-menu":
Exploilation - Interrogation. Celle-ci se présente sous la forme d'une fenêtre destinée à
afficher les résultats de requêtes POSTQUEL. Pour interroger la base BDadsar, deux solutions
sont offertes. Il est possible de choisir une requête pré-programmée exécutable par un simple
"clic-menu", ou encore d'éditer ma/lIIel/ement, dans une fenêtre de texte, la requête
POSTQUEL.
Administratioli des applicatifs réseaw: 187

m.9 La maquette ADSAR : implantation, utilisation et évaluation
En fonction de la réponse à une interrogation, la liste des n-uplets correspondants s'affiche
dans la fenêtre des résultats. Seule la valeur des champs "nom" est indiquée dans cette liste.
Un bouton Détail permet d'afficher la valeur de chaque champ d'un n-uplet donné. Le
schéma 47 illustre un exemple d'exploitation courante de la base BDadsar. La liste affichée
correspond à la requêtc de recherche de tous les ordinateurs de type compatibles PC et dout
l'adresse réseau commence par 130.79.140. Le détail du n-uplet concernant la machine
gauguin est affiché en sur-impression.
Schéma 47 .' Exemple d'interrogation de la base de données
Nota : Les requêtes pré-programmées peuvent être facilement ajoutées au programme, au
moyen d'un simple fichier décrivant les correspondances entre chaque sous-menu et la requête
POSTQUEL associée.
188 Administralioll des applicatif<; réseaux

La maquette ADSAR : implantation, utilisation et évaluation
9.2.2.3. L'analyse des services réseaux
m.9
Le deuxième volet d'utilisation d'ADSAR est l'exploitation des graphes de dépendances pour
l'administration des services réseaux. C'est le principal travail dans la réalisation de la
maquette. Nous avons choisi d'implanter deux approches complémentaires. Nous
construisons et exploitons les graphes de dépendances pour une série de services réseaux
déterminés. Cette fonctionnalité est disponible par le "sous-menu" : Analyse - Les services à
surveiller. Nous avons également implanté l'algorithme de recherche de tous les services
élémentaires possibles ("sous-menu" : Analyse - Tous les services possibles).
Analyse des services à surveiller
L'interface pour l'analyse des services offre deux approches. La première est basée sur des
visualisation de graphes. La deuxième s'appuie sur des représentations sous forme de tables.
Schéma 48 : Meflu de l'analyse des services à slI/veiller
La maquette ADSAR permet de représenter le graphe de dépendances d'un service réseau. La
spécification du nom du service désiré est facilitée par la méthode des caractères
génériqueial . La première visualisation, appelée graphe brut, affiche le graphe de
dépendances dans son expression la plus simple: les noms de service, les nœuds clients et les
nœuds serveurs. Pour éviter la représentation de graphes illisibles du fait des croisements des
arcs, nous dupliquons les sommets, si nécessaire. Nous donnons, dans le schéma 49, le graphe
de dépendances d'un service d'impression, sur une imprimante nommée patinette, pour un
compatible PC : balzac.
Comme nous l'avons dit en introduction, un des résultats théoriques implanté est le calcul de
la fiabilité d'un service réseau. Le "bouton" Calcul, de la fenêtre de visualisation des graphes,
permet d'obtenir la probabilité de fonctionnement du service, le nombre de machines
(a) Les caractères génériques ou ''jokers'', tels "*" ou "7", permettent de spécifier certaines formes
d'abréviations des mots. Cette méthode est plus souple que la simple "troncature" habituellement utilisée en
base de données.
Administration des applicatifs réseaux 189

m.9
t
t
t
t
t
La maquette ADSAR : implantation, utilisation et évaluation
~,ba~ac,PCNFS_baèaq
t
t
Schéma 49 : Exemple de visualisation du graphe de dépendances d'un selvice
nécessaires, et une approximation du temps d'indisponibilité mensuelle. Le schéma 50 nous
donne les résultats de ces calculs pour le service d'impression de l'exemple précédent.
Schéma 50: Exemple de calcul de la fiabilité d'un selvice
Nous offrons une deuxième possibilité de visualisation du graphe de dépendances d'un service
donné, en ne prenant en compte que les ordinateurs. Il s'agit d'une extension de la méthode de
contraction des graphes de dépendances (présentée au paragraphe 5.4.4.) olt seuls les noms
des machines sont affichés. Cette représentation permet de souligner, de manière évidente, les
dépendances entre ordinateurs. Le schéma 51 illustre ce type de visualisation.
190 Administration des applicatifs réseaux

La maquette ADSAR : impla1lfatioll, utilisation et évaluation III.9
Schéma 51 : Graphe de dépendances d'lin service rédllil allx ordinalellrs
La représentation sous forme de graphes n'est pas toujours la plus indiquée. L'exploitation du
modèle est parfois plus aisée en utilisant des tables. Nous avons ainsi implanté une méthode
de recherche des éléments qui composent les graphes (noms de service, utilisateurs, machines,
programmes et ressources), afin de pouvoir les sélectionner facilement. Par exemple, le
schéma 52 représente toutes les ressources (masque de recherche: "*") spécifiées dans les
graphes de dépendances.
En faisant défiler cette liste (lorsqu'elle visualise des machines), il est possible d'en
sélectionner un élément et de lancer, en ce qui le concerne, un calcul d'impacts. En exemple,
le schéma 52 nous donne ainsi l'impact réel de l'ordinateur nommé spa: 61 services sont
dépendants de son fonctionnement. Ce schéma nous donne également l'impact réduit calculé
sous forme de pourcentage.
Schéma 53: Exemple de calclli de l'impacl d'lm Oldinalellr
Administration des applicatifs réseaux 191

m.9 La maquette ADSAR : implantation, utilisation et évaluation
Schéma 52 " Liste des ressol/rces dal/s le graphe global
9.2.2.4. Recherche de tous les services réseaux
En extension à l'exploitation des services réseaux à surveiller, nous avons implanté
l'algorithme de recherche de tous les services réseaux possibles, et non plus seulement d'un
sous··groupe désigné.
Schéma 54 : At/elllt de l'analyse des services possibles
Nous proposons ainsi, dans la maquette ADSAR, une utilisation de recherche des services, en
fonction d'une ou plusieurs composantes spécifiées. Le schéma 55 montre, par exemple, tous
les services élémentaires concernant l'utilisateur ferniqlle depuis la machine cliente ba/zac
(compatible pC).
192 Administration des applicatifs réseaux

La maquette ADSAR : implantation, utilisation et évaluation III .9
Schéma 55 : Exemple de recherche de selvices élémentaires
9.2.3. Acquisition des données
L'acquisition des données, nous le répétons, est assurée par des processus explorer
indépendants. Ceux-ci sont lancés soit automatiquement au démarrage du logiciel, soit à la
main au moyen d'un menu (schéma 56). La liste des ordinateurs pouvant être interrogés par
explorer est décrite par un fichier de configuration afin de faciliter les remises à jour.
Schéma 56 : Menu de lancement manuel des sondes
Nous venons d'exposer les fonctionnalités de la maquette ADSAR. Dans le paragraphe
suivant, nous préscntons les résultats numériques obtenus lors de nos tests.
Administration des applicatifs réseau.'t 193

III.9 La maquette ADSAR: i11lplaHlatioll. utilisation el évaluation
9.3. Résultats d'exploitation et caractéristiques de leur
obtention
Le but de la réalisation de la maquette fut avant tout de démontrer la faisabilité du modèle.
Cependant, cette maquette a été testée sur un réseau réel, ce qui nous a permis d'obtenir
certaines valeurs pour les résultats théoriques ayant été implantés. Nous présentons dans ce
paragraphe ces résultats numériques. Nous allons exposer également en fin de paragraphe les
conditions de leur obtention: temps de calcul, occupation mémoire, etc.
9.3.1. Résultats des calculs de la fiabilité des services
Ne pouvant donner la liste exhaustive de toutes les mesures de fiabilité (environ 600 services
élémentaires modélisés), nous présentons certains services relativement significatifs.
Les tableaux ci-dessous comportent trois mesures: la fiabilité sous la forme d'une mesure de
probabilité de fonctionnement, le nombre d'Oidinateurs nécessaires au service et enfin le
ealcul de l'indisponibilité mensuelle correspondante.
Il faut noter que ces calculs se basent sur une estimation du fonctionnement moyen des
ordinateurs, sur une période d'un an au plus(a). Elle prend en compte les arrêts dus aux pannes
et à la maintenance (sauvegardes, installations de nouveaux logiciels, ajouts de périphériques,
tests et essais, etc).
9.3.1.1. Services d'impressions
Le tableau ci-dessous indique les valeurs· numériques de fiabilité pour trois services
d'impression relativement illustratifs :
Nom du service Fiabilité Ordinateurs Indisponibiliténécessaires mensuelle
_.1 impr_stendhaLpirouette 0,9693 4 4h17mn
-2 impr_stendhaLcamionnette 0,9363 4 8h57mn
3 impr_cezanne_Fiordiiigi 0,9831 2 2h22mn
l'ableau12 : Fiabilités de certains services d'impression
Mesure 1 - La première mesure concerne un compatible PC (stendhal) en libre accès pour
les étudiants. L'imprimante visée (pirouette) est connectée à une station Sun - sans disque
important son système d'un autre serveur Unix (monza). L'accès à un servcur de noms est
(a) Certains services ayant été mis en place plus récemment, l'estimation de leur fonctionnement moyen a dO
être évaluée sur une période plus courte.
194 Administration des applicatifs réseaux

La maquette ADSAR : implantation. utilisation et évaluation III .9
nécessaire. L'indisponibilité moyenne de 4hl7mn mensuelle reste une valeur raisonnable,
sachant que ce service utilise un des plus gros serveurs du réseau de test dont la disponibilité
plafonne à 0,9875 (nombreux arrêts pour la maintenance et la sauvegarde des disques).
Mesure 2 - Le deuxième exemple est plus complexe. Il s'agit cette fois-ci d'une imprimante
gérée par un Macintosh (cezalllle). Une passerelle CAP60 - localisée sur une station Unix
tierce - assure la conversion du protocole d'impression sous TCP/IP en celui de AppleTalk.
Nous voyons que la fiabilité est nettement moins bonne (0,9343). Cela s'explique
principalement par l'utilisation de la passerelle, mais également par le mauvais suivi du
Macintosh en question.
Mesure 3 - Enfin, la dernière mesure concerne le même Macintosh (cezalllle), pour une
impression sur imprimante LaserWriter (Fiordiligi). Les dépendances sont réduites; la
fiabilité s'avère assez bonne (0,9831) pour ce type de service.
9.3.1.2. Services d'importation de disÇjues
Dans le contexte du réseau de test, les mesures de "montages" de disques distants s'appuient
soit sur le protocole NFS pour TCP/IP, soit sur AppleShare pour AppleTalk. Nous présentons
les mesures suivantes:
Nbre IndisponibilitéNom du service Fiabilité d'ordinateurs
nécessaires mensuelle
1 NFS_imola_monza-lusr 0,9831 2 2h22mn
2 NFS_nardo_spa-ldisq1 0,9604 3 5h32mn
3 NFS_daILmonza-lusr/local 0,9831 2 3h28mn
4 AS_cezanne_monza_CCASH 0,9711 2 4h02mn
Tableau 13 : Fiabilités de certains seJ1lices de montages de disques
Mesure i - La première mesure concerne un montage de disque entre une station Sun sans
disque (imola) et un autre serveur Unix (mollza).
Mesure 2 - En deuxième ligne, c'est un service d'importation de disque un peu particulier
qui est calculé. Il met en jeu trois stations Unix. La partition (jdisqi) - montée sur une station
Silicon (nardo) - est gérée par une station Sun (spa) dont le disque système est lui-même
importé depuis une tierce machine (mollza). Il y a lieu de noter la différence de fiabilité avec la
première mesure (0,9604 par rapport à 0,9831). Celle-ci est due principalement au fait que la
sation Silicon dispose de ses propres disques (la maintenance de ces disques locaux abaisse le
taux moyen de disponibilité de cette station).
Admillislration des applicatifs réseaux 195
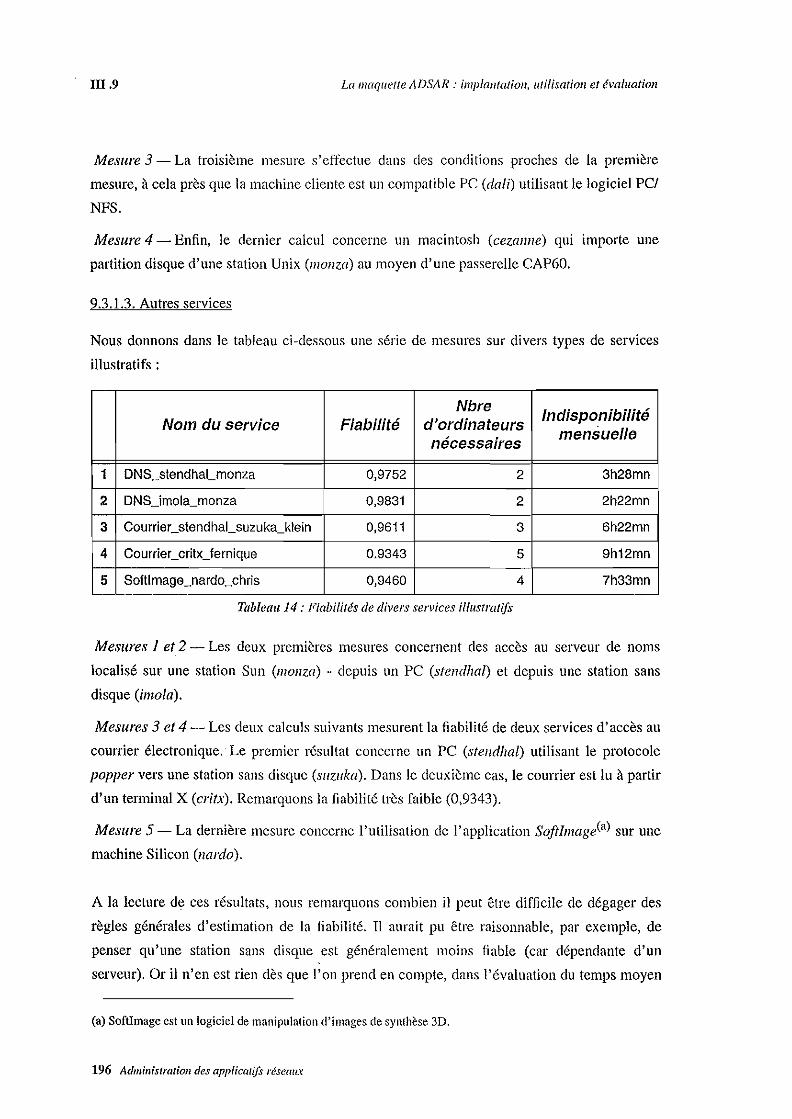
111.9 La maquette ADSAR : implantation, utilisation et évaluation
Mesure 3 - La troisième mesure s'effectue dans des conditions proches de la première
mesure, à cela près que la machine cliente est un compatible PC (dali) utilisant le logiciel PCI
NFS.
Mesure 4 - Enfin, le dernier calcul concerne un macintosh (cezanne) qui importe une
partition disque d'une station Unix (lIlonza) au moyen d'une passerelle CAPGO.
9.3.1.3. Autres services
Nous donnons dans le tableau ci-dessous une série de mesures sur divers types de services
illustratifs :
NbreIndisponibilité
Nom du service Fiabilité d'ordinateursnécessaires
mensuelle
1 ONS_stendhaLmonza 0,9752 2 3h28mn
2 ONS_imola_monza 0,9831 2 2h22mn
3 Courrier_stendhaLsuzuka_klein 0,9611 3 6h22mn
4 Courrier_crilx_fernique 0.9343 5 9h12mn
5 Softlmage_nardo_chris 0,9460 4 7h33mn
Tableall14 : Fiabilités de divers services illllstratifs
Mesures 1 et 2 - Les deux premières mesures concernent des accès au serveur de noms
localisé sur une station Sun (lIlonza) - depuis un PC (stendhal) et depuis une station sans
disque (imola).
Mesures 3 et 4 - Les deux calculs suivants mesurent la fiabilité de deux services d'accès au
courrier électronique. Le premier résultat concerne un PC (stendhal) utilisant le protocole
popper vers une station sans disque (sIIZllka). Dans le deuxième cas, le courrier est lu à partir
d'un terminal X (critx). Remarquons la fiabilité très faible (0,9343).
Mesure 5 - La dernière mesure concerne l'utilisation de l'application So!tIlIlage(a) sur une
machine Silicon (nardo).
A la lecture de ces résultats, nous remarquons combien il peut être difficile de dégager des
règles générales d'estimation de la fiabilité. Il aurait pu être raisonnable, par exemple, de
penser qu'une station sans disque est généralement moins fiable (car dépendante d'un
serveur). Or il n'en est rien dès que l'on prend en compte, dans l'évaluation du temps moyen
(a) Softlmage est un logiciel de manipulation d'images de synthèse 3D.
196 Administration des applicatifs réseaux
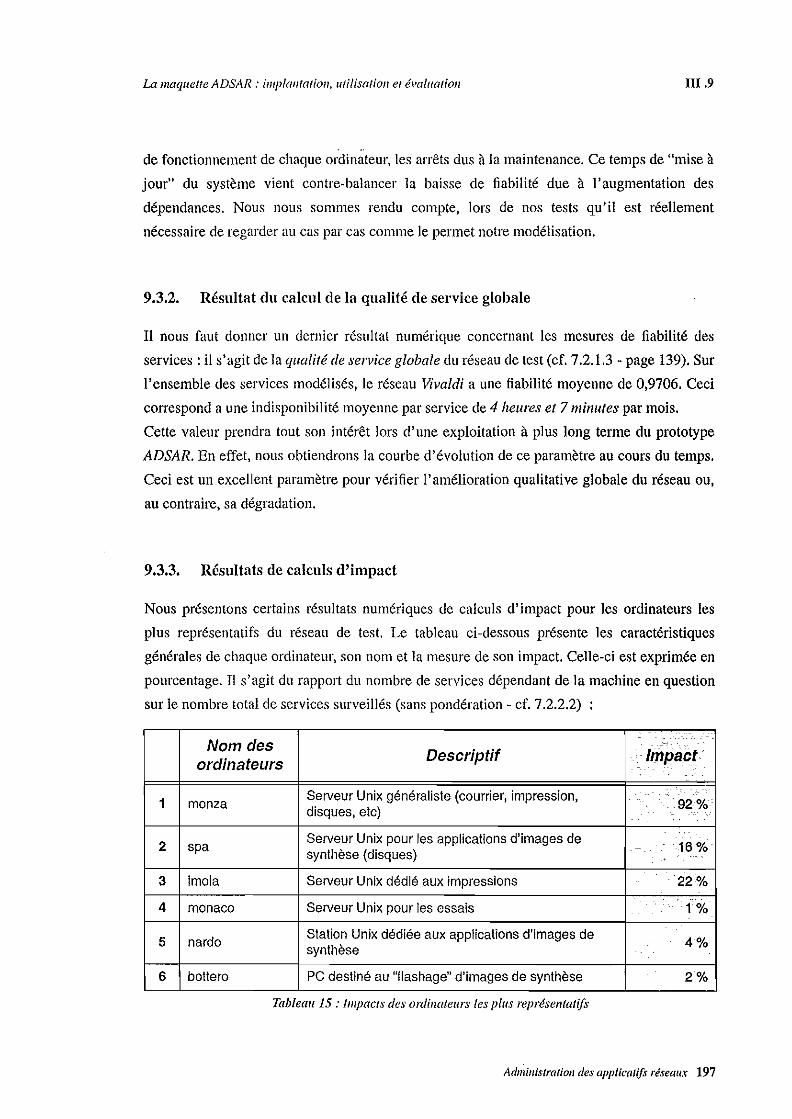
La maquette ADSAR : implantation, utilisation et évaluation 1II.9
de fonctionnement de chaque ordinateur, les arrêts dus à la maintenance. Ce temps de "mise à
jour" du système vient contre-balancer la baisse de fiabilité due à l'augmentation des
dépendances. Nous nous sommes rendu compte, lors de nos tests qu'il est réellement
nécessaire de regarder au cas par cas comme le permet notre modélisation.
9.3.2. Résultat du calcul de la qualité de service globale
Il nous faut donner un dernier résultat numérique concernant les mesures de fiabilité des
services: il s'agit de la qualité de service globale du réseau de test (cf. 7.2.1.3 - page 139). Sur
l'ensemble des services modélisés, le réseau Vivaldi a une fiabilité moyenne de 0,9706. Ceci
correspond a une indisponibilité moyenne par service de 4 heures et 7 minutes par mois.
Cette valeur prendra tout son intérêt lors d'une exploitation à plus long terme du prototype
ADSAR. En effet, nous obtiendrons la courbe d'évolution de ce paramètre au cours du temps.
Ceci est un excellent paramètre pour vérifier l'amélioration qualitative globale du réseau ou,
au contraire, sa dégradation.
9.3.3. Résultats de calculs d'impact
Nous présentons certains résultats numériques de calculs d'impact pour les ordinateurs les
plus représentatifs du réseau de test. Le tableau ci-dessous présente les caractéristiques
générales de chaque ordinateur, son nom et la mesure de son impact. Celle-ci est exprimée en
pourcentage. Il s'agit du rapport du nombre de services dépendant de la machine en question
sur le nombre total de services surveillés (sans pondération - cf. 7.2.2.2) :
Nom desDescriptif
·······...(>iordinateurs 1.····· 'T
li .....••• >
1 monzaServeur Unix généraliste (courrier, impression, ·····················.·"X·;,)idisques, etc)
1 .•••,,"'r~ii
2 spaServeur Unix pour les applications d'images de 16·0;0synthèse (disques)
3 imola Serveur Unix dédié aux impressions 22~"
4 monaco Serveur Unix pour les essais1 ····if%
5 nardoStation Unix dédiée aux applications d'images de < 1%synthèse
6 bottero PC destiné au "f1ashage" d'images de synthèse /2%
Tableau 15 : Impacts des ordinateurs les plus représentatifs
Administration des applicatifs réseaux 197
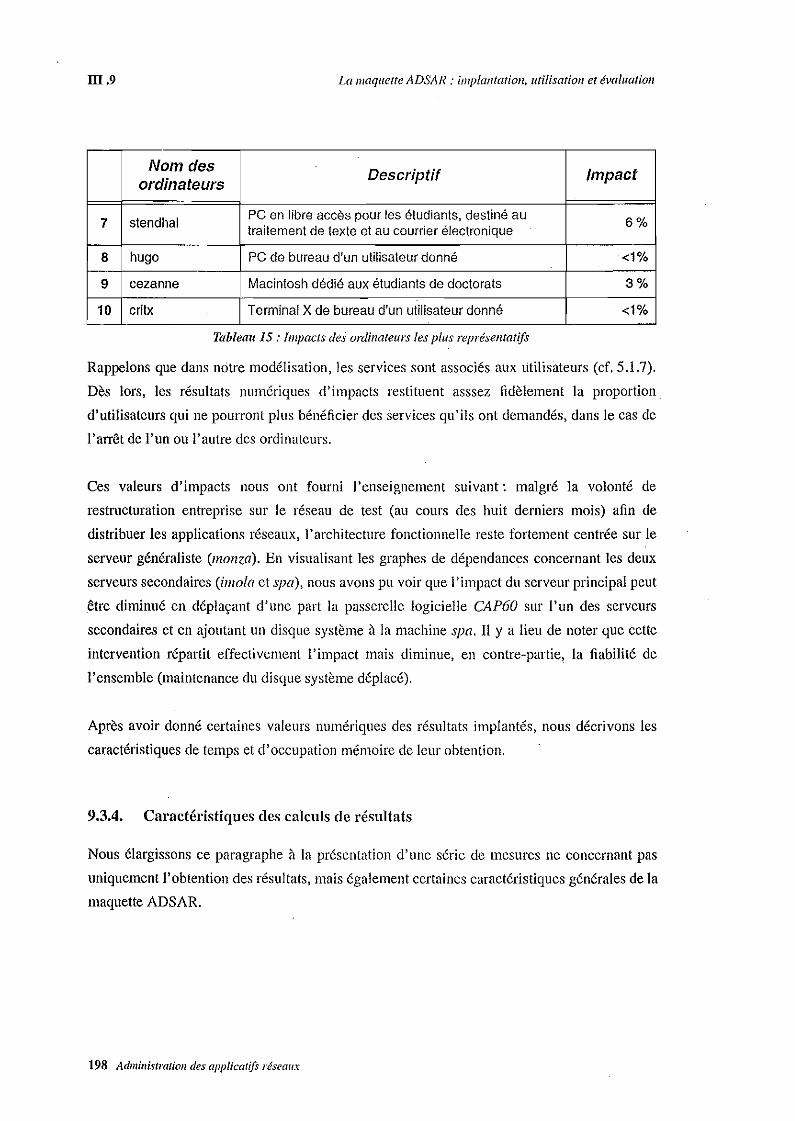
m.9 La maquette ADSAR : implantation, utilisation et évaluation
Nom des.
ordinateursDescriptif Impact
7 stendhal PC en libre accès pour les étudiants, destiné au 6%traitement de texte et au courrier électronique
8 hugo PC de bureau d'un utilisateur donné <1%
9 cezanne Macintosh dédié aux étudiants de doctorats 3%
10 critx Terminal Xde bureau d'un utilisateur donné <1%
Tableau 15 : Impacts des ordinateurs les plus représentatifs
Rappelons que dans notre modélisation, les services sont associés aux utilisateurs (cf. 5.1.7).
Dès lors, les résultats numériques d'impacts restituent asssez fidèlement la proportion
d'utilisateurs qui ne pourront plus bénéficier des services qu'ils ont demandés, dans le cas de
l'arrêt de l'un ou l'autre des ordinateurs.
Ces valeurs d'impacts nous ont fourni l'enseignement suivant: malgré la volonté de
restructuration entreprise sur le réseau de test (au cours des huit derniers mois) afin de
distribuer les applications réseaux, l'architecture fonctionnelle reste fortement centrée sur le
serveur généraliste (monza). En visualisant les graphes de dépendances concernant les deux
serveurs secondaires (Imola et spa), nous avons pu voir que l'impact du serveur principal peut
être diminué en déplaçant d'une part la passerelle logicielle CAP60 sur l'un des serveurs
secondaires et en ajoutant un disque système à la machine spa. Il y a lieu de noter que cette
intervention répartit effectivement l'impact mais diminue, en contre-partie, la fiabilité de
l'ensemble (maintenance du disque système déplacé).
Après avoir donné certaines valeurs numériques des résultats implantés, nous décrivons les
caractéristiques de temps et d'occupation mémoire de leur obtention.
9.3.4. Caractéristiques des calculs de résultats
Nous élargissons ce paragraphe à la présentation d'une série dc mesures ne concernant pas
uniquement l'obtention des résultats, mais également certaines caractéristiques générales de la
maquette ADSAR.
198 Administration des applicatifs réseaux
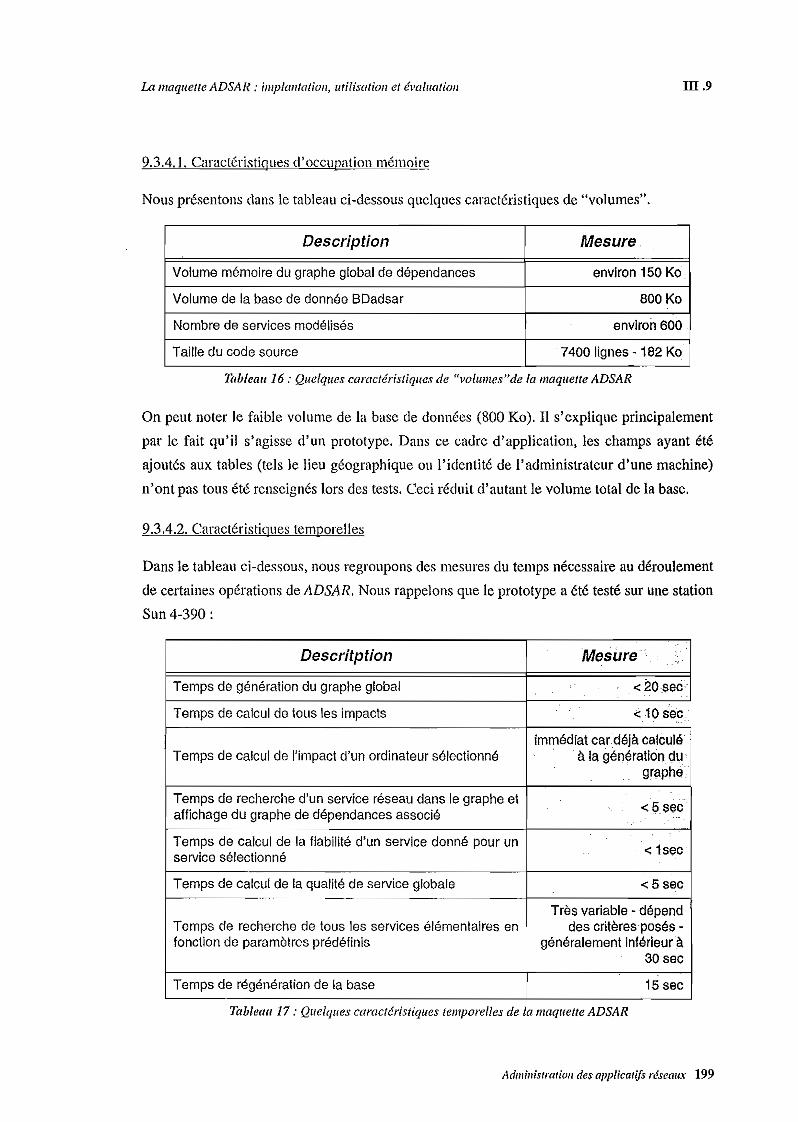
La maquette ADSAR : implantatioll, utilisation et évaluatioll
9.3.4.1. Caractéristiques d'occupation mémoire
Nous présentons dans le tableau ci-dessous quelques caractéristiques de "volumes".
III .9
Description Mesure
Volume mémoire du graphe giobal de dépendances environ 150 Ko
Volume de la base de donnée BDadsar 800Ko
Nombre de services modélisés environ 600
Taille du code source 7400 lignes -1.82 Ko
Tableau 16 : Quelques caractéristiques de "volumes"de la maquette ADSAR
On peut noter le faible volume de la base de données (800 Ko). Il s'explique principalement
par le fait qu'il s'agisse d'un prototype. Dans ce eadre d'application, les ehamps ayant été
ajoutés aux tables (tels le lieu géographique ou l'identité de l'administrateur d'une machine)
n'ont pas tous été renseignés lors des tests. Ceci réduit d'autant le volume total de la base.
9.3.4.2. Caractéristiques temporelles
Dans le tableau ci-dessous, nous regroupons des mesures du temps nécessaire au déroulement
de certaines opérations de ADSAR. Nous rappelons que le prototype a été testé sur une station
Sun 4-390:
M"""~(3.•.. <
Descritption .;
Temps de génération du graphe global :20$$ç:
Temps de calcul de tous les impacts <10âeq
immédiat cardéjàcalculéTemps de calcul de l'impact d'un ordinateur sélectionné . à lagénératlonYclQ
grElphe
Temps de recherche d'un service réseau dans le graphe et;$eC
affichage du graphe de dépendances associé ...... .....
Temps de calcul de la fiabilité d'un service donné pour untsElcservice sélectionné
Temps de calcul de la qualité de service globale ... <5 sec
Très variable- dépendTemps de recherche de tous les services élémentaires en des critères posés-fonction de paramètres prédéfinis généralement inférieur à
30 sec
Temps de régénération de la base 15sec
Tableau 17 : Quelques caractéristiques temporelles de la maquette ADSAR
Administration des applicatifs réSeaflX 199

III .9 La maquette AD5AR .' implalllatioll, lltilisatioll et évaluation
Descritption Mesure
Temps d'acquisition des données déclarées (sous forme 2 mnde fichiers)
Temps d'acquisition des données pré-existantes sur une 20 mnstation Unix (SLC)
1libleall 17 : Quelques caractéristiques temporelles de la maquette ADSAR
Notons tout d'abord la vitesse de génération du graphe global de dépendances. Ce temps court
permet de justifier la régénération du graphe à chaque démarrage (ceci est comparable à un
éditeur de texte qui charge en mémoire le document, et travaille par la suite en mémoire vive).
Une deuxième valeur à souligner est la rapidité de calcul des résultats de fiabilités et
d'impacts. Ceci s'explique principalement par l'utilisation d'un graphe totalement en
mémoire vive. En revanche, nous relevons le temps très long d'acquistion des données (20 mn
pour une station) principalement dû à la lenteur d'interprétation des "remote shells scripts".
9.4. Evaluation de la maquette et retour d'expérience
Nous terminons cette troisième partie par l'évaluation de la maquette ADSAR. Nous
répondons aux questions suivantes: Les choix d'implantation ont-ils été judicieux? Les
résultats obtenus sont-ils pertinents? Dans quelle mesure?
9.4.1. Evaluation des choix techniques
Deux critères principanx avaient été définis pour les choix techniqnes concernant
l'implantation de notre modèlc. Sachant que le travail de développement serait nécessairement
lourd, les solutions dont la rapidité de mise en œuvre était la meilleure ont été retenues. Par
ailleurs, le prototype initial CQFD ct la maquetteADSAR qui a suivi ont nécessité une certaine
forme de "tâtonnement" dans le développement: essais. retours en arrière, changements de
méthodes. La souplesse des moyens techniques a donc été absolument nécessaire. Nous
présentons succinctement, dans les paragraphes suivants, une courte évaluation de différents
choix techniques que nous avons retenus pour l'implantation du modèle.
9.4.1.1. Méthode d'acquisition
La méthode d'acquisition des informations est l'exemple le plus Oagrant d'un choix technique
qui ne se justifie que par la rapidité de mise en œuvre et la souplesse de réalisation. En effet, la
méthode des "remote shell scripts" a d'importants inconvénients, qui se sont révélés au cours
de l'implantation.
200 Administration des applicatifs réseaux

La maquette AD5AR " implamtllioJl, lI1ilisatio1l el é\'aluatioll m.9
Le principal problème rencontré est la dépendance inhérente des "shell scripts" au type de
système d'exploitation, voire à la version même du système. Notre choix s'était posé sur
l'interrogation des machines sous Unix. Or même avec cette restriction importante, le nombre
de "variétés" de Unix s'est révélé être un inconvénient majeur pour le développement d'un ou
de plusieurs "shell scripts" d'acquisition de données. D'autre part, la pérennité de cette
méthode est extrêmement faible. Chaque nouvelle version de système d'exploitation remet en
cause le fonctionnement de la méthode d'acquisition.
D'autre part, la charge infligée à la machine interrogée est particulièrement lourde
(cf. tableau 17). En effet, cette méthode génère une succession importante de petits processus
de mise en forme, de troncature et d'analyse des fichiers, qui entraînent une surcharge
difficilement justifiable pour le traitement fourni.
En conclusion, il nous apparaît que tant que l'implantation d'agents d'acquisition pour
l'administration des applicatifs réseaux n'est pas réalisée sur les machines (agents basés sur
CMIP, SNMP, RPC ou tout système similaire), une plate-forme d'administration de telles
applications ne pourra être qu'un "pis-aller", une solution transitoire. Et ceci d'autant plus s'il
s'agit d'un réseau hétérogène.
9.4.1.2. Manipulation des graphes
Pour ce qui est des choix retenus concernant la manipulation et l'exploitation des graphes, les
résultats obtenus ont été tout à fait satisfaisants (cf. 9.3.4.2). Le développement d'un
gestionnaire de graphes dédié à notre application nous a permis de prendre en compte les
problèmes liés à la place mémoire ou au temps de traitement. L'idée de travailler directement
en mémoire pal' allocations dynamiques s'est avérée pertinente. La taille des graphes, déduits
de la modélisation du réseau de test, est restée dans des proportions parfaitement exploitables.
Nous notons cependant l'importance de disposer d'une "bonne" implantation des librairies
d'allocations (malloc(), l'ealloc(), jl'ee()... ), qui prend en compte les spécificités techniques de
la machine à laquelle elle est destinée.
9.4.1.3. Base de données
Comme nous l'avons déjà dit, le choix de s'appuyer sur un gestionnaire de base de données
existant n'a été décidé que pour la deuxième version de la maquette. Bien que nécessitant une
réécriture importante du code, cette décision s'est avérée très intéressante sur plusieurs plans.
Tout d'abord, du point de vue théorique, nous avons pu montrer que le choix d'une base de
données relationnelles convenait bien à notre modèle. D'un point de vue plus pratique, le
modèle a pu être testé en vraic grandeur, car la puissance de la base de données nous a permis
de manipuler des quantités de données importantes. D'autre part, la disponibilité d'outils de
Admin;slratioll des applicatifs réseaux 201

DI.9 La maquette AD5AR : implantation, utilisation et évaluation
lecture et de mise à jour manuelle de la base a permis une très grande souplesse de mise en
œuvre. Nous pensons notamment il la facilité d'exploitation sous le monilellr fourni avec le
paquetage du SGBD. Enfin, la possibilité d'avoir des accès simultanés à la base nous a permis
d'implanter les modules parallèles (explorer, molellr cenlral, voire monilellr), qui sont très
souples dans leur utilisation.
Quant au choix de POSTGRES, une importante carence nous a fortement handicapé.
L'impossibilité de préciser la clause "unique" sur un champ ou un ensemble de champs d'un
n-uplel, afin d'en caractériser son unicité, nécessite de conditionner toute nouvelle écriture sur
la base à une lecture préalable (cf. 9.1.2.3). Or, le type d'opérations engendrées par une
application telle une plate-forme d'administration justifie, nous semble-t-il, le choix d'un
SGBD implantant cette fonctionnalité.
9.4.1.4. Interface utilisateur
Il est toujours souhaitable de développer un programme dont la présentation est agréable.
Cependant, le soin apporté à l'interface-utilisateur a certainement été trop poussé pour le type
de maquette que nous avons développée. A notre décharge, nous notons simplement qu'il
aurait été, sans doute, regrettable de ne pouvoir visualiser les graphes de dépendances.
9.4.2. Evaluation des résultats d'exploitation
Nous avons présenté au paragraphe 9.3 certains résultats d'exploitation de notre prototype sur
le réseau de test. Nous en présentons dans ce paragraphe une évaluation dans le contexte du
réseau de test. Nous répondons à la question suivante: A qnoi cela nOlis a-I-il servi?
9.4.2.1. Gestion de la configuration
La possibilité de regrouper dans une base de donnée centrale les informations décrivant la
configuration des applications du réseaux de test est un avantage indiscutable. D'autant plus,
si l'opération est faite plus ou moins automatiquement. Dans l'état actuel, la maquette ADSAR
offre une telle fonctionnalité en se basant sur des "shells scripts" d'acquisition d'informations.
Malgré les inconvénients d'une telle méthode (cf. 9.4.1.1), les résultats sont tout à fait
exploitables. Dans l'éventualité d'une exploitation ultérieure du prototype, il serait cependant
nécessaire de s'assurer à chaque installation d'un nouveau système (par exemple SunOS 6.0)
que le "shell d'acqllisilion" fonctionne correctement, et de le modifier si besoin. D'autre part,
il pourrait être judicieux de compléter les champs non encore renseignés dans la base de
donnée (lieu géographique de chaque machine....).
202 Administration des applicatifs réseallx

La maquette ADSAN : implafllafioll, utilisation et é\'aluatioll III.9
Le deuxième résultat implanté concernant la gestion de la configuration a été le repérage des
inter-dépendances cycliqucs. Cette opération s'effectue uniquement au moment de la
génération du graphe global de dépendances, afin de signaler les cycles. Il serait intéressant de
réaliser une interface utilisateur plus sophistiquée dans l'optique d'une utilisation à plus long
terme de la maquette. En effet, dans l'état actuel, le logiciel signale simplement les éléments
cycliques et demande une correction immédiate afin de pouvoir être relancé.
9.4.2.2. Calcul de la fiabilité
Pour ce qui est du calcul de la fiabilité, les résultats obtenus nous ont surpris. En effet, bien
que difficile à vérifier expérimentalement, la fiabilité de certains services nous a semblé sous
évaluée. Pour ne citer qu'un exemple, nous avons obtenu une indisponibilité moyenne de
six heures par mois sur des services de courrier électronique (fiabilité de 0,9611). Après
enquête, une valeur de trois heures par mois semble être plus proche de la réalité (fiabilité de
0,980). Pourquoi ce décalage? Nous avançons trois hypothèses non exclusives. Tout d'abord,
le temps moyen de fonctionnement de chaque machine aurait dû être mesuré sur une période
d'au moins un an pour avoir des chiffres sur lesquels s'appuyer. Ceci n'a pas été le cas pour
certaines machines, mises en place récenunent, ou qui simplement n'ont pas été suffisamment
suivies pour en déterminer précisémment la disponibilité. Une deuxième hypothèse repose sur
la condition d'indépendance des probabilités de fonctionnement. Nous avions cité un cas de
dépendance de probabilité - les coupures d'électricité - et en avions tenu compte dans les
estimateurs. Cependant, après utilisation de la maquette, un deuxième facteur de dépendance
semble devoir être pris en compte. Les administrateurs réseaux ont tendance à regrouper les
interventions qui nécessitent un arrêt d'une partie du réseau. Ils travaillent par exemple sur
toute une salle de PC, pour les systèmes desquels ils assurent les remises à jour en une après
midi. Les probabilités d'indisponibilité des machines de cette salle ne peuvent être, dès lors,
considérées comme indépendantes.
Cependant, les valeurs obtenues peuvent être considérées comme des majorants. Nous
disposons d'une excellente échelle d'ordre de grandeur pour évaluer et classer les services.
9.4.2.3. Calcul de la qualité de service
On peut s'étonner d'une valcur de 0,9706 pour la qualité de service globale du réseau de test
(cf. 9.3.2). En effet, une indisponibilité moyenne de 4 heures sur l'ensemble des services peut
sembler relativement élevée. Il faut cependant garder à l'esprit que ce résultat se base sur
l'estimation du taux de fonctionnement de chaque machine. Or celui-ci a été évalué en prenant
en compte les temps nécessaires à l'administration elle-même (sauvegarde, modifications de
configurations, etc). Une enquête plus précise permettrait de distinguer les temps d'arrêts dus
Administration des applicatifs réseau"y 203

m.9 La maquette ADSAR : ÎlJlplaJltatiulI, lltiUsatiol1 et évaluation
aux évènements "accidentels" (pannes d'électricité. disques hors service. etc) et les temps
d'arrêts de maintenance du réseau. Nous obtiendrions ainsi deux valeurs complémentaires de
la mesure de la qualité de service globale, qui permettraicnt une analyse plus fine.
9.4.2.4. Calcul de l'impact
La mesure de l'impact de chaque machine a donné cles résultats auxquels nous ne nous
attendions pas, ou peu. Bien évidemment, nous avions une idée assez claire des machines
particulièrement sensibles. Mais la maquette nous a apporté bien plus. Nous disposons d'une
liste des machines classées par ordre d'impact dans le réseau. C'est un clocument précieux sur
plusieurs points. Il permet, tout d'abord, de justifier les contrats de maintenallce des machines
(cf. 7.2.2). Il serait raisonnable de moduler la rapidité de dépannage (sous 4h, dans la journée,
dans la semaine, etc) en fonction du pourcentage cI'impact des machines en question. Pour le
réseau de test et dans l'état actuel de la configuraiton, les machines mOllza, spa et imola
doivent bénéficier d'un bon contrat de maintenance (cf. tableau 15). D'autre part, cette liste
permet d'établir sans conteste le degré de centralisation des applications réseaux. Ainsi, si l'on
veut assurer un fonctionnement moyen régulier de l'ensemble des services du réseau, il est
nécessaire de vérifier que l'impact cie chaque machine ne dépasse pas un certain seuil - par
exemple 25%). Dès lors, sous l'hypothèse que les causes des pannes sont indépendantes, on
pourra vérifier que jamais plus du quart des services réseaux n'est en panne simultanément..
C'est l'approche entreprise actuellement sur le réseau Vivaldi afin de supprimer le rôle
prépondérant du serveur mOllza.
Pour terminer cette évaluation de notre maquette, nous pourrions dire que l'ensemble des
résultats fournis nous a été déjà réellement utile, dans le cadre du réseau Vivaldi. ADSAR a
permis de poser et de justifier dcs choix cI'administration tactiques et stratégiques alors même
qu'il ne s'agit que d'un prototype.
204 Administration des applicatifs réseaux

La maquette ADSAR : implantation, utilisation et évalu(lfioll
Conclusion
III
Nous avons préscnté, dans cette dernière partie, une réalisation logicielle concrète en vue de
vérifier la validité de notre modèle théorique. Nous avons exposé, tout d'abord, les choix
techniques généraux pour l'implantation d'une telle maquette. Les langages et les
bibliothèques de programmation, le gestionnaire dc base de données, le gestionnaire de
graphes, ct cnfin l'architccture du logiciel, ont été successivement présentés. Il nous a fallu,
également, décrire succinctemcnt lc cadre de l'expérimentation, c'cst-à-dire le réseau
universitaire utilisé pour les tests. Par la suitc, nous avons détaillé l'implantation en elle
même: le diagramme de la base de données ainsi que le détail de ses tables, les méthodes
d'acquisition des informations nécessaires à la modélisation, et enfin, les moyens mis en
œuvre pour obtenir des résultats, exposés dans la deuxième partie de notre thèse. Quelques
exemples tirés dc la maquette implantée ont pcrmis d'illustrer les fonctionnalités d'un tel
prototype. Nous avons présenté certains résultats numériques propres au site de test et nous
avons précisé les caractéristiques de leur obtention. Pour terminer, nous avons tenté d'évaluer
notre travail d'implantation. Ainsi, nous avons soupesé chaque choix techniqne, mais
principalement, nous nous sommes attachés à évaluer les résultats obtenus.
En conclusion, nous constatons, tout d'abord, que cette expérience a nécessité un
développement lourd et relativement "tâtonnant". Mesurer la "taille" d'un programme n'est
jamais très facile; cependant - pour ne citer qu'un seul chiffre - 11.500 lignes de
développemcnt dc code ont été nécessaires pour obtenir une maquette logicielle
satisfaisante(a). D'autre part, l'apprcntissage du fonctionnement du gestionnaire de base de
données POSTGRES et du langage associé POSTQUEL, l'utilisation des bibliothèques de
programmation et de celles dcs interfaces graphiqucs ont été un investissement important. Le
résultat: une maqucttc baptisée ADSAR qui nous a permis de démontrer une certaine forme de
validité du modèle proposé.
Pouvions-nous faire l'économic d'un tel développemcnt? Il nous semble que pour une
modélisation tcllc quc nous la proposons dans notre thèse, c'est ccrtainement l'argument sur la
(a) La maquette ADSAR a nécessité 7400 lignes, le prototype initial CQFD comprenait 5000 lignes
supplémentaires pour la gestion de sa base de données.
Admillistration des applicatifs réseaux 205

ID La IJwql{ette AD5AR : implalltation, utilisation et é~lalliation
faisabilité qui doit être, avant tout, développé. A notre sens, un modèle non exploitable dans
ce domaine n'aurait que peu d'intérêt. Or, ayant été implanté dans des conditions réelles, notre
prototype montre que des plates-formes d'administration, qui s'appuieraient sur les concepts
exposés, peuvent être réalisées et exploitées.
Peut-on dire qu'il s'agisse d'une véritable plate-forme d'administration? Evidemment non!
Nous le redisons: les choix techniques retenus pour l'implantation de notre maquette, sur le
plan de la rapidité et de la souplesse de mise en œuvre, ne peuvent être les bases d'un logiciel
d'administration destiné à une exploitation réelle. ADSAR n'est qu'un prototype dont la
réalisation nous est apparue incontournable pour notre sujet de thèse.
206 Administration des applicatifs réseaux

Conclusion
Administration des applicatifs réseaux 207


Nous avons présenté dans cette thèse un modèle théorique pour l'administration des services
applicatifs au sein d'un réseau informatique hétérogène, et ceci en vue d'appréhender les
problèmes de dépendances qui régissent de tels services. Nous avons, d'une part, situé cette
étude dans le contexte actuel des travaux sur l'administration des réseaux informatiques. Nous
avons, d'autre part, montré la faisabilité des idées avancées, par la réalisation du logiciel
implantant les concepts décrits dans notre modèle.
Résultats et contributions
Quatre types de résultats, qui représentent des contributions nouvelles et personnelles au
domaine de l'administration de réseaux, nous paraissent devoir être soulignés:
- L'approche originale
- La méthodologie employée
- L'implantation réalisée
- La pertinence des résultats obtenus
Avvroche originale
L'administration de réseaux, indispensable pour la gestion des réseaux informatiques de taille
conséquente, repose principalement sur les concepts de dénomination et de description des
divers éléments mis en œuvre. Elle définit également les méthodes pour connaître les états de
ces divers éléments.
Cette méthode suffira, sans doute, lorsqu'il s'agit d'administration des couches les plus basses
des protocoles réseaux. Par contre, il nous apparaît que la gestion des applications réseaux
nécessite la connaissance des interdépendances entre les divers éléments. Il n'est plus possible
de considérer uniquement les états des éléments, mais il devient nécessaire d'appréhender les
relations qui les associent.
Administration des applicatifs réseaux 209

Conclusion
Cette approche plus globale nous a permis de définir un modèle de données basé sur la
définition d'un service réseau élémentaire.
Méthodologie emplovée
La méthode employée pour décrire ce modèle de données a été appuyée sur des définitions
mathématiques d'applications multivoques. Cette manière de procéder nous a permis de
définir, dans un formalisme très générique, les relations de dépendances et d'appartenances
des divers éléments composant notre modèle.
Nous soulignons, en particulier, la facilité d'expression de la définition d'un service réseau
élémentaire et généralisé. Elle nous permet d'exprimer les dépendances modélisées sous la
forme d'un graphe global.
Parallèlement au modèle théorique, nous avons décrit les même concepts sous la forme d'un
modèle "informatique" tenant compte des spécificités techniques de ce domaine.
Implantation réalisée
L'implantation, facilitée par la méthodologie employée, nous a permis de démontrer la
faisabilité des idées présentées dans le modèle abstrait. Nous avons ainsi pu réaliser un
logiciel prototype, qui a été testé avec succès sur un réseau informatique réel de taille
moyenne.
La réalisation de cette maquette nous a permis de démontrer que la taille des graphes
manipulés restait parfaitement exploitable. Ce logiciel prototype nous a permis, non
seulement, de confirmer ou infirmer certains choix d'implémentation initialement retenus,
mais bien plus, d'évaluer les résultats obtenus en fonction de la réalité observée.
Pertinence des résultats
Nous soulignons tout particulièrement la vaste gamme des problèmes qui peuvent trouver une
solution lorsqu'ils sont abordés dans l'optique de notre modèle. Nous les résumons dans ces
trois mots: validation, impact, dépendance.
Ainsi, nous citerons tout d'abord l'originalité de la méthode pour rechercher les phénomènes
d'interblocages applicatifs en fonction des propriétés de cycles sur les graphes de
dépendances déduits du modèle. Elle nous donne une solution efficace au problème suivant:
"La configuration du réseau, projetée pour l'ajout de tel ou tel service, est-elle correcte? A-t
elle une incidence sur les autres services initialement offerts à l'utilisateur?"
Nous rappelons, ensuite, les divers résultats concernants les calculs d'impacts.
210 Administration des applicatifs réseau.>:

Conclusion
Tout d'abord, nous avons exposé une méthode de calculs d'impacts en cas de
dysfonctionnement d'un élément réseau sur la globalité des services fournis. Nous répondons
ainsi au type de questions suivant : "Quels vont être les utilisateurs dérangés par
l'indisponibilité de tel ou tel ordinateur ?". Nous avons ainsi proposé une méthode de calcul
de paramètres quantificatifs afin de déterminer les ordinateurs les plus sensibles.
Dans la même optique de calcul d'impacts, nous soulignons la facilité de mise en œuvre de la
méthode de calcul de charge d'une machine en fonction des services réseaux qui lui sont
démandés.
Enfin, nous avons proposé une exploitation du modèle en vue de déterminer la sécurité des
ressources du réseau, par exemple: "Qui a accès à ce compte-machine? Comment y arrive
t-il ?".
Les autres résultats de la modélisation relèvent de la dépendance entre éléments.
Nous avons ainsi pu établir une méthode de calcul de la fiabilité d'nn service réseau. Il s'agit
de répondre à la question suivante: "Dans une configuration réseau donnée, quelle est la
disponibilité de tel ou tel service ?". De là, nous avons déduit nn paramètre de mesure globale
de la "qualité de service" d'un réseau.
Nous avons également proposé une méthode d'aide aux diagnostics. Elle décrit un moyen
rapide pour localiser un ou plusieurs éléments défectueux, en fonction de l'observation de
l'état des services réseaux. Le principe est illustré par la question suivante: "Quel est le
prochain service réseau qu'il faut tester pour trouver le plus rapidement la panne ?".
Nous proposons enfin une méthode de calcul des cOlÎts réels des divers services réseaux, afin
de pouvoir répartir les frais en fonction des utilisateurs, ce qui répond à la question
incontournable: "Comment répartir les frais dus au réseau informatique ?".
Extensions et perspectives
Nous proposons de continuer notre étude dans deux directions complémentaires. Il nous
semble nécessaire d'étendre notre modèle afin d'y inclure les notions de protocoles. En effet,
le modèle à l'heure actuelle pose l'hypothèse que le réseau physique sous-jacent supporte tous
les protocoles utilisés, ce qui est quasiment le cas pour les réseaux de type Ethernet.
Cependant, hors de cette hypothèse, il sera nécessaire de spécifier les protocoles supportés par
les diverses composantes du réseau physique. Dans cette perspective nous nous
rapprocherions des travaux de P. Françon [FRA 92] concernant la modélisation des
protocoles. Il faudra vérifier avec soin que la tame du modèle est encore exploitable.
Administration des applicatifs réseau.'.; 211

Conclusion
Une deuxième voie de recherche serait d'étendre not!:e modèle afin qu'i! prenne en compte les
services de type "client-lIlultiserveur", c'est-à-dire qu'il n'y a plus un unique serveur désigné
pour un service réseau, mais plusieurs serveurs susceptibles de rendre le service. Le choix
effectif du serveur peut être fonction de la disponibilité de chacun des serveurs parallèles, ou
encore, de caractéristiques des messages véhiculés. Décrire ce type de services signifierait que
le modèle ne gèrerait pas uniquement les conditions nécessaires de dépendances, mais
également les conditions suffisantes. Ceci élargirait sans aucun doute le champ d'application
de notre modèle.
D'autre part, l'expérimentation, effectuée grâce à la maquette ADSAR, gagnerait à être
prolongée. En effet, l'étude de l'évolution de certains résultats numériques permettrait de se
faire une idée plus objective quant à l'utilisation à moyen terme de ces indicateurs.
Enfin, l'évolution future des solutions standards et/ou normalisées pour l'administration des
applications réseaux nous permettra vraisemblablement d'appliquer et d'implanter notre
modèle dans un contexte cohérent, fiable et largement reconnu.
212 Administration des applicatifs résemo:

Annexes
Administration des applicatifs réseaux A·l

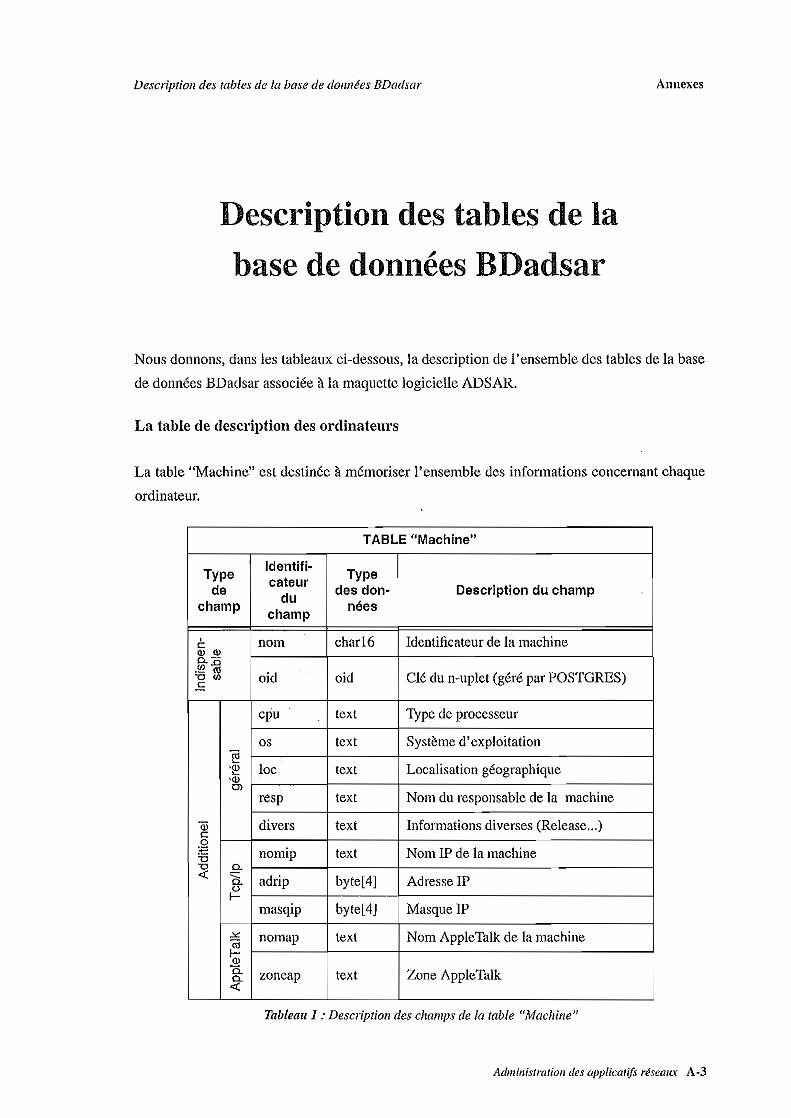
Descriptioll des tabies de la base de dOllllées BDadsar
Description des tables de la
base de données BDadsar
Annexes
Nous donnons, dans les tableaux ci-dessous, la description de l'ensemble des tables de la base
de données BDadsar associée à la maquette logicielle ADSAR.
La table de description des ordinateurs
La table "Machine" est destinée à mémoriser l'ensemble des informations concernant chaque
ordinateur.
TABLE "Machine"
TypeIdenti!i-
Typecateur
de dudes don- Description du champ
champ champ nées
, nom chari6 Identificateur de la machinec., .,0.-.~~
oid Clé du n-uplet (géré par paSTORES)"0'"oS
\~pu/ text Type de processeur
os text Système d'exploitation~.., loc text Localisation géographique~..,0)
resp text Nom du responsable de la machine
ID divers text Informations diverses (Release...)c0:e nomip text Nom IP de la machine"0"0 0.« 'ii adrip byte[4] Adresse IP
~masqip byte[4] Masque IP
"" nomap text Nom AppleTalk de la machine(ij
tmCi. zoneap text Zone AppleTalk0.«
Tableau 1 : Description des champs de ia table "Machine"
Administration des applicatifs réseau..... A·3
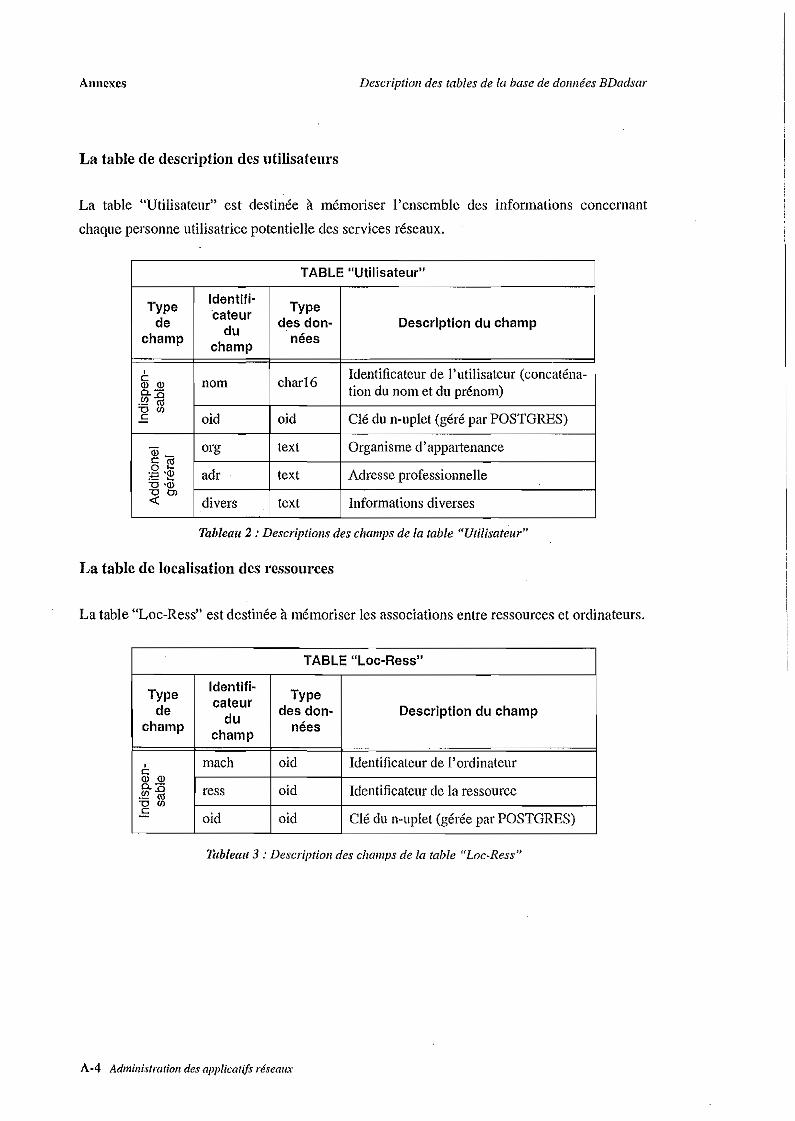
Annexes
La table de description des utilisateurs
Description des tables de la base de dOJlnées BDadsar
La table "Utilisateur" est destinée à mémoriser l'ensemble des informations concernant
chaque personne utilisatrice potentielle des services réseaux.
TABLE "Utilisateur"
Type Identifi- Typecateur
de du des don- Description du champchamp champ nées
, Identificateur de l'utilisateur (concaténa-c nom char16<Il <Il tion du nom et du prénom)0.-(/).0._ <Il'O(/)E oid oid Clé du n-uplet (géré par paSTORES)
0>_ org text Organisme d'appartenanceC <Ilo ~
adr Adresse professionnelle~'(1) text.- ~'0 'Q)'O0l« divers text Informations diverses
Tableau 2 " Descriptions des champs de la table "Utilisateur"
La table de localisation des ressources
La table "Loc-Ress" est destinée à mémoriser les associations entre ressources et ordinateurs.
TABLE "Loc-Ress"
Type Identifi· Typecateur
dedu
des don· Description du champchamp
champ nées
, mach oid Identificateur de l'ordinateurC<Il <Ilg-:o ress oid Identificateur de la ressource.- <Il'O(/)E oid oid Clé du n·uplet (gérée par paSTORES)
Tableau 3 " Description des champs de la table "Loc-Ress"
A·4 Administration des applicatifs réseaux
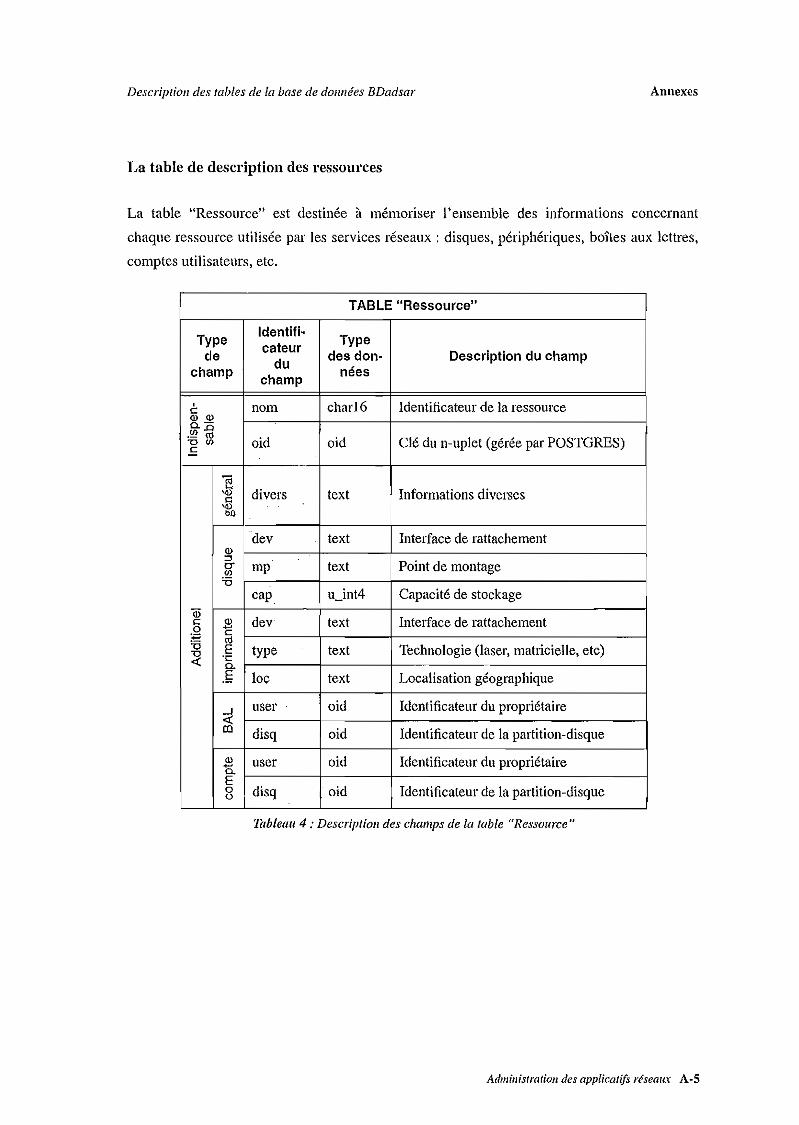
Description des tables de la base de dOllnées BDadsar
La table de description des ressources
Annexes
La table "Ressource" est destinée à mémoriser l'ensemble des informations concernant
chaque ressource utilisée par les services réseaux: disques, périphériques, boîtes aux lettres,
comptes utilisateurs, etc.
TABLE "Ressource"
TypeIdentl!i-
Typecateur
dedu
des don- Description du champchamp champ nées
C nom charl6 Identificateur de la ressource<Il <Il0.-.~ ~
oid oid Clé du n-uplet (gérée par POSTORES)'0 V>5
]Informations diverses." text
oÉÎbl)
1···· text Interface de rattachement<Il;j
n\P Point de montage0' textV>'6
iêap u_int4 Capacité de stockagea;
Interface de rattachementc <Il text0 -c:e ro'0 E type text Technologie (laser, matticielle, etc)'0<>: 'C
0.
.ê text Localisation géographique
....J user oid Identificateur du propriétaire<>:OJ disq oid Identificateur de la partition-disque
J!l oid Identificateur du propriétaire0.E0 disq oid Identificateur de la partition-disque0
Tableau 4 : Description des champs de la table "Ressource"
Administration des applicatifs réseaux A~S
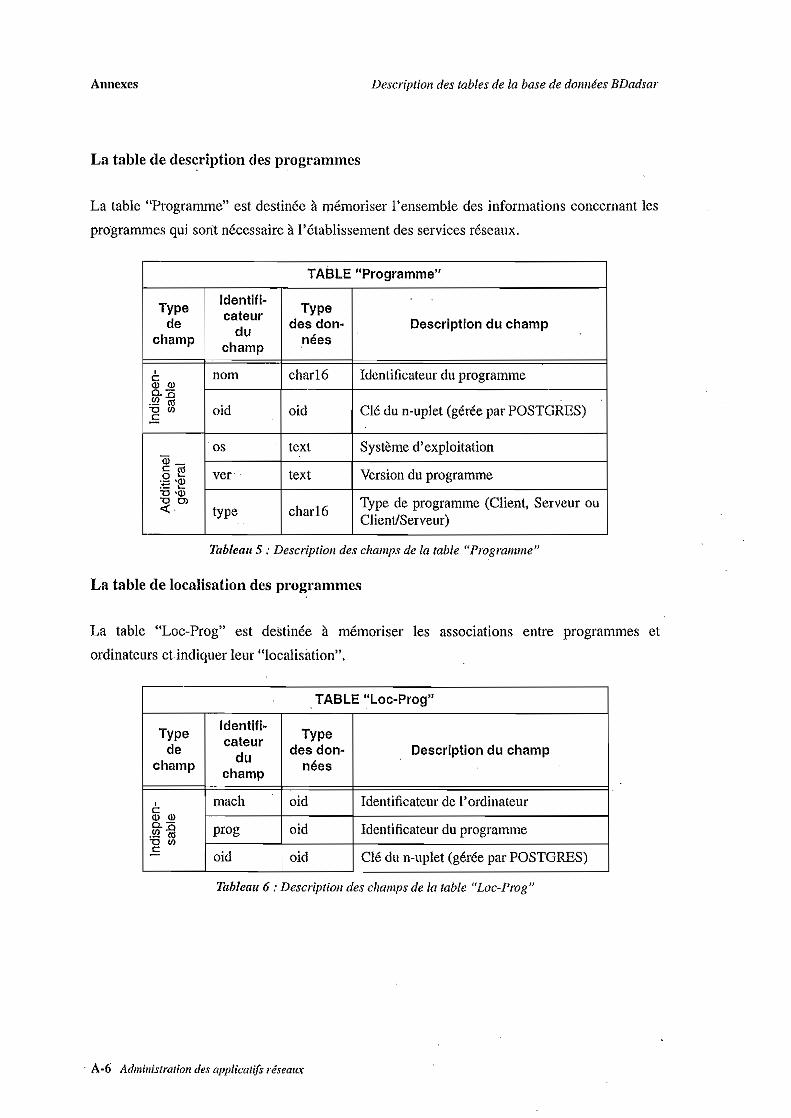
Annexes
La table de description des programmes
Description des tables de la base de données BDadsar
La table "Programme" est destinée à mémoriser l'ensemble des informations concernant les
programmes qui sorit nécessaire à l'établissement des services réseaux.
TABLE "Programme"
TypeIdentifi-
Typecateurdedu des don- Description du champ
champchamp nées
C: nom char16 Identificateur du programmeID ID0.-",.0._ eu
oid oid Clé du n-uplet (gérée par POSTORES)"0'"oS
text Système d'exploitationID-e eu text Version du programmeo ~
;e'~"O-ID"00> Type de programme (Client, Serveur ou« type charl6
Client/Serveur)
Tableau 5 : Description des champs de la table IIProgranune"
La table de localisation des programmes
La table "Loc-Prog" est destinée à mémoriser les associations entre programmes et
ordinateurs et indiquer leur "localisation".
TABLE "Loc-Prog"
Type Identifi-Typecateurde
dudes don- Description du champ
champchamp nées
mach.
oid Identificateur de ['ordinateur,eID Ol~:o prog oid Identificateur du programme:am
oS oid oid Clé du n-uplet (gérée par POSTORES)
Tableau 6 "Description des champs de la table "Loc-Prog"
. A·6 Administration des applicatifs réseaux
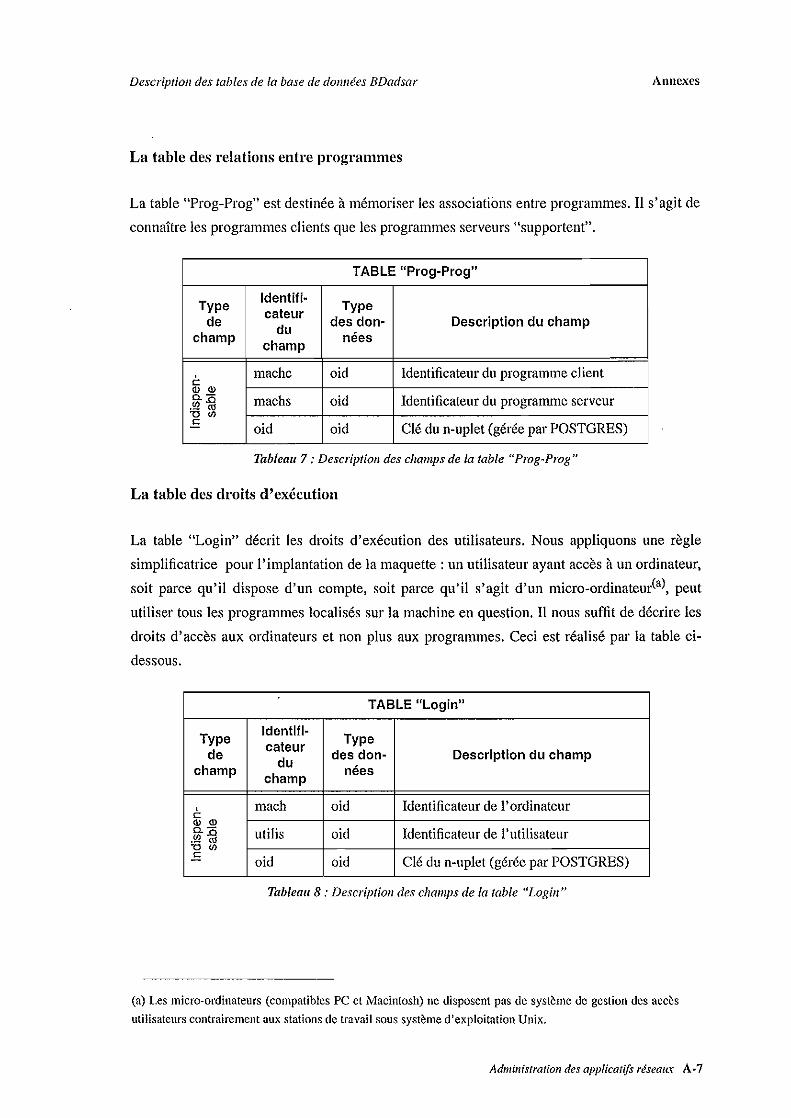
Descriptioll des tables de la base de dOllllées BDadsar
La table des relations entre programmes
Annexes
La table "Prog-Prog" est destinée à mémoriser les associations entre programmes. Il s'agit de
connaître les programmes clients que les programmes serveurs "supportent".
TABLE "Prog-Prog"
Type Identifi- Typecateurde du des don- Description du champ
champ champ nées
C:.machc oid Identificateur du programme client
<Il <Ilg-:o machs oid Identificateur du programme serveur.- '"'0 '".5 oid oid Clé du n-uplet (gérée par POSTORES)
Tableau 7: Descriptioll des champs de la table "Prag-Prag"
La table des droits d'exécution
La table "Login" décrit les droits d'exécution des utilisateurs. Nous appliquons une règle
simplificatrice pour l'implantation de la maquette: un utilisateur ayant accès à un ordinateur,
soit parce qu'il dispose d'un compte, soit parce qu'il s'agit d'un micro-ordinateur(a), peut
utiliser tous les programmes localisés sur la machine en question. Il nous suffit de décrire les
droits d'accès aux ordinateurs et non plus aux programmes. Ceci est réalisé par la table ci
dessous.
TABLE "Login"
Type Identifi- Typecateurde du des don- Description du champ
champ champ nées
, mach oid Identificateur de l'ordinateurc<Il <Il0.- utilis oid Identificateur de l'utilisateur",.0.- '"'0'".5 oid oid Clé du n-uplet (gérée par POSTORES)
Tableau 8 : Descriptioll des champs de la table "Logifl"
(a) Les micro-ordinateurs (compatibles PC et Macintosh) ne disposent pas de système de gestion des accès
utilisateurs contrairement aux stations de travail sous système d'exploitation Unix.
Administration des applicatifs réseau..r A·7

Annexes Primitives et structures d'implalltatioll des tableauxdYllamiqlles et des graphes
Primitives et structures
d'implantation des tableaux
dynamiques et des graphes
/* indice du dernier element *//* Taille du tableau dynamique *//* Pointeur sur le tableau *//* Taille des elements *//* Taille des buffers d'allocation */
Les tableaux dynamiques: bibliothèque tbd
La librairie tbd offre les structures de données ainsi que les procédures de manipulation de
tableaux dynamiques. L'implémentation effectuée permet un accès direct au moyen d'un
index car elle utilise un tableau de pointeurs contigus plutôt que le chaînage traditionnel des
listes. La taille des objets du tableau est définie par l'utilisateur. Des objets de tailles
différentes ne peuvent être enregistrés dans le même tbd sans passer par le truchement d'une
nouvelle indexation (tbd de pointeurs sur des objets de tailles variables).
La variation dynamique de la taille du tbd se fait par la fonction real/oc() du langage C, c'est
elle qui permet de conserver la contiguïté du tbd.
La structure de données
Un tbd se manipule au moyen d'un pointeur sur la structure suivante:
/* Type de tableau dynamique */typedef struct Stbd {int n;long m;char *pt;int size;int sizebuf;
}*tbd, tbds;
A-S Administration des applicatifs réseaux

Primitives et structures d'implantation des tableauxdynamiques et des graphes
Schéma de la stl'llctllre
Annexes
'tbd
le·' 1tbds
m tjs multiple de sizebuf
..n
-------lon-1: On ~01 1 02 )1 1
m~
'pt size
size
sizebu!
Schéma 1 .' Structure d'un tableau dynamique (tbd)
Les primitives de manivulation
• tbd tbdopen(size,sizebuf): ".,,"" Ouverture.
• tbdclose(tbd) : """"""""."""""" Fermeture.
• tbdclr(tbd) : "."""""""""""""""Libération du buffer (comme après un tbdopen).
• tbdins(tbd,ind) :""""""""""""'" Insertion d'une place libre à partir de l'indice
ind.
• tbdinsn(tbd,ind,size) ;""."""""." Insertion de size places à partir de ind.
• tbddel(tbd,ind) :""""""""""""". Suppression d'une place sur l'indice ind.
• tbddeln(tbd,ind,size) : .,,""""""" Suppresion de size places à partir de l'indice
ind.
• tbdset(tbd,ind,void *obj) : "."."."Insertion de l'élément d'adresse ob} à l'indice
ind.
• tbdcp(tbd d,s) : """",,""",,""""" Copie d'un tbd sur un autre.
• int tbdadj(tbd,void *x) ; "."".,,"" Adjonction d'un objet à la fin d'un tbd.
• tbdtrvas(tbd s,tbd d) :."""".""""Recopie des éléments d'un tbd dans un autre
(sans vérification de redondance).
• void *tbdget(void *x,tbd,ind): ". Récupération dans l'objet x de l'objet stocké à
l'indice ind avec retour de l'adresse effective.
si x==NULL pas de recopie.
Administration des applicatifs réseau.x Am 9

Annexes Primitives et structures d'implantation des tableauxdynamiques et des graphes
• tbdn(tbd) : Retourne le nombre d'éléments.
• tbdmem(tbd) : Retourne l'occupation mémoire.
• int tbdind(tbd,void*x) : Retourne l'indice du premier objet similaire à x
dans tbd, -1 sinon.
• int tbdin(tbd,void *x) : Retourne 1 si x se trouve dans le tbd, 0 sinon.
Les graphes orientés valués: bibliothèque grph
Le paquetage grph fournit des outils puissants de manipulation de graphes dont voici quelques
caractéristiques:
- Taille du graphe dynamique
- Graphe orienté ou non
- Valuation des sommet ou non
- Valuation des arcs (resp. arêtes) ou non
- Multi-arcs (resp. arêtes) entre mêmes sommets
- Tailles variables des objets de valuations
La structure des données a été définie afin d'optimiser la place mémoire et les traitements pour
des graphes relativement creux (c'est-à-dire que le nombre d'arcs est du même ordre de
grandeur que le nombre de sommets). Elle assure de bonnes performances de recherche au
moyen d'algorithmes dichotomiques (voir ci-dessous).
Les structures de données
Un glph se manipule au moyen d'un pointeur sur la structure suivante:
t* Type d'un grph *ttypedef struct Sgrph {
iut ns; t*int na; t*int sizesom; t*int sizearc; t*int opt; t*tbd s; t*
}*grph,grphs;
La structure d'un sommet est la suivante:
Nbre de sommets */Nbre d'arcs */Taille structure des sommets */Taille structure des arcs */VAL_ARC 1 VAL_Sml 1 NON_ORr * ttbd des sommets */
tbd 0; t*
char *v; t*int sv; t*
}Tgsom;
/* Typetypedefint
dlun sonunet */struct Sgsom (
d; /* delta: Nombre d'arc dont lesommet est l'origine */
omega : tbd des arcs dont lesommet est l'origine */
Valeur associee (optionnel) */Nbre d'octets pointes (opt) */
A-IO .Administratioll des applicatifs réseaux

Primitives et structures d'implantation des tableauxdynamiques et des graphes
La structure d'un arc (resp. arête) est la suivante:
Annexes
/* Typetypedefintcharint}Tarci
d'un arc */struct Sarc {
i;*Vi
sv;
/* Indice du sommet d'arrivee *//* pointeur sur valeur (opt) */
/* Nbre d'octets pointes (opt) */
Une occurence de g/ph est un pointeur sur une structure. Cette structure décrit le graphe, c'est
à-dire le nombre de sommets, le nombre d'arcs (resp. arêtes), le type de graphe (sommet
valué, arc valué, graphe orienté). Cette structure enregistre également un tableau dynamique
(tbd) qui décrit chaque sommet du graphe. Le numéro de rang d'un sommet dans le tbd
représente le numéro (ou indice) du sommet.
Chaque sommet est lui-même décrit par une structure dont la taille est variable suivant le type
de graphe (sommet valué ou non). Cette structure décrit le nombre de sommets adjacents au
sommet, un pointeur (optionnel) sur la valuation du sommet ainsi que la taille mémoire
utilisée pour cette valuation. Elle enregistre également un tbd décrivant chaque arc issu du
sommet.
Un arc est également décrit par une structure dont la taille dépend du type de graphe (arc valué
ou non). La structure d'un arc mémorise l'indice du sommet visé, un pointeur (optionnel) sur
la valuation de l'arc ainsi que la taille mémoire utilisée pour cette valuation. Pour une
recherche rapide des indices des sommets voisins, l'ordre des arcs dans le tbd est trié par
indice des sommets visés. La recherche pourra donc se faire de manière dichotomique.
Il faut noter qu'un graphe non-orienté sera implanté comme un graphe orienté dont chaque
arête donne lieu à une paire d'arcs de sens imposé. En cas de valuation des arêtes, les
pointeurs de la paire d'arcs désigneront une plage mémoire unique.
Administration des applicatifs réseaux A·ll
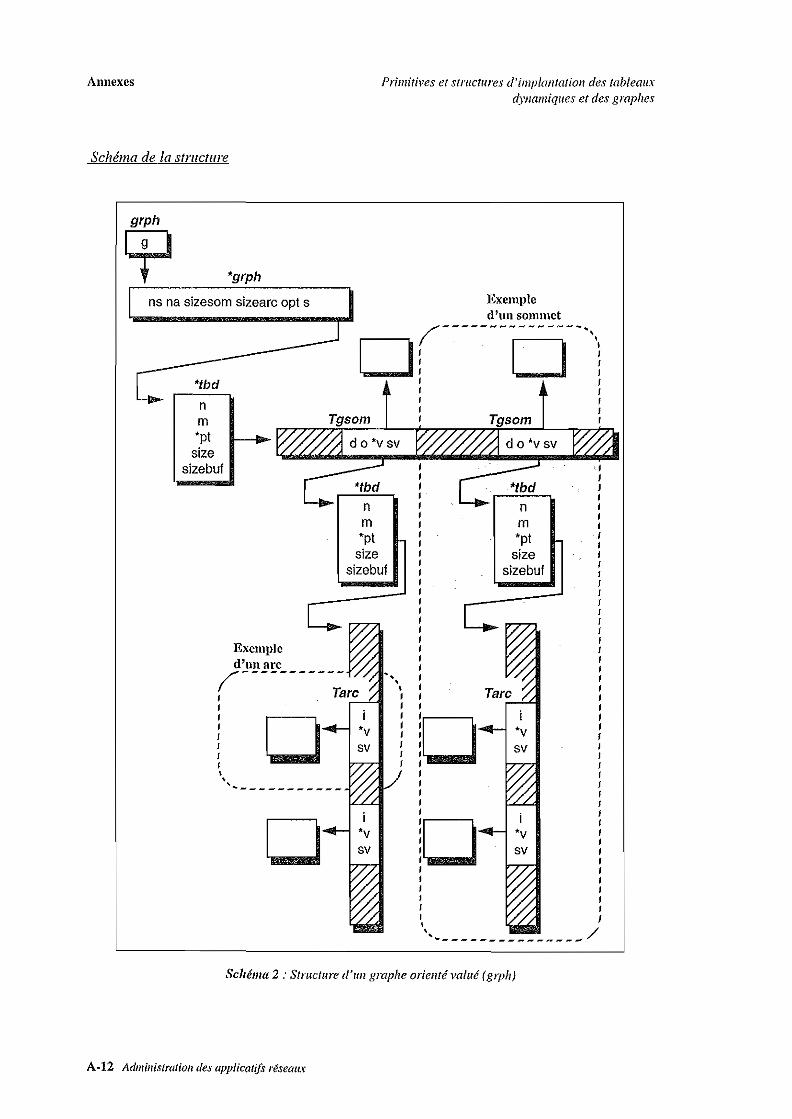
Annexes Primitives et structures d'implantation des tableauxdynamiques et des graphes
Schéma de la structure
'tbd
do 'v sv
nm*ptsize
sizebuf
,1111111111111111111111,11
!O11111
1011111 1, J
\.. /... _--------------
-,,,,,,,1111
Exempted'un sommet
;"---------------'"0:0 l
, 1, 1, 1, 1, 1
*tbd
do 'v sv
nm'pl
sizesizebuf
oo
'grph
Exempled'un arc;"-----------
Tare1111111,•" ... _----------
ns na sizesom sizearc opl s
G nm'pt
sizesizebuf
grphcp
Schéma 2 : Structure d'un graphe orielllé valué (grphJ
A·12 Administration des applicatifs réseaux

Primitives et structures d'implantation des tableauxdynamiques et des graphes
Les primitives de manivulation
Annexes
• grph grphopen(int opt) : Ouverture.
• grphclose(grph g): Fermeture.
• grphclr(grph g) : Libération de la mémoire.
• grphadjs(grph g, int inds) : Adjonction d'un sommet.
• grphadja(grph g, int indd, int inda) : Adjonction d'un arc(arête).
• grphseta(grph g, int indd,inda, void *obj, int size) : Valuation d'un arc (premier
trouvé).
• grphsetan(grph g, int indd,inda,nrg, void *obj, int size) : Valuation d'un arc (de
rang nrg).
• grphmake(char *s) : Constructeur rapide de graphe.
Exemple: grphmake(g, "1-2,3,8 2-2,3);
• void *grphgets(void *x, grph g, int ind) : Récupération d'une valeur d'un
sommet.
Dans la zone pointée par "x" sera recopiée la
valeur
du sommet, par contre le pointeur retourné par
la
procédure sera l'adresse de la valeur elle-même.
L'allocation de la zône mémoire pointée pas "x"
est à la charge du programmeur.
• void *grphgeta(void *obj, grph g ,int indd, inda) : Récupération d'une valeur sur
un arc (premier trouvé). Même remarque pour
"ob)" que pour "x" dans glphgets.
• void *grphgetan(void *obj, grph g, int indd,inda,nrg) : Récupération d'une valeur
sur un arc (rang=nrg). Même remarque pour
"ob)" que pour "x" dans glphgets.
• grphns(grph g) : Retourne le nombre de sommets.
• grphna(grph g): Retourne le nombre d'arcs.
• grphd(grph g,int ind) : Retourne le delta d'un sommet.
(càd le nombre de sommets adjacents).
• .grphss(grph g, int inds,inda) : .... Retourne l'indice du sommet pointe par l'arc
donné
par (inds,inda).
Administration des applicatifs réseaux A·13

Annexes Primitives et structures d'impla11lation des tableauxdynamiques et des graphes
o grphconnexe(tbd *t, grph g, int ind) : Remplit un tbd. de la composante fortement
connexe qui contient le sommet d'indice illd. La
création du tbd est à la charge du programmeur.
o grphoriente(grph g) : Graphe orienté.
o grphsornv(grph g) : Sommets valués.
o grpharcv(grph g) : Arcs (arêtes) valués.
o grphexs(grph g, int ind) : Existence d'un sommet.
o gl'phexa(grph g, int indd,inda) : Existence d'un arc (premier trouvé).
o grphexan(grph g, int indd,inda,nrg) : Existence d'un arc de rang Ilrg.
o grphsave(char *path,grph g) : Sauvegarde du grph dans le fichier path.
o grphload(grph g, char *path): Lecture d'un glph à partir d'un fichier.
A·14 Administration des applicatifs réseaux

Extrait du shell script d'acquisition d 'informations
Extrait du shen script
d'acquisition d'informations
Annexes
Nous donnons ci-dessous le début du "shen script" d'acquisition des données des machines
Unix. Celui-ci est exécuté par les modules "explorel" de la maquette ADSAR.
monza# more explorer#! /bin/sh
# Explorer Version 1.2# Recuperation des donnees propres a un systeme# Auteur P.Fernique# Date : 16/2/94#
# Initialisation des variables globalesHOST::::' hostname'REP=$HOME/exp1orer
# Recuperation d'infos generales sur le systeme courantif [ -f /etc/motd Jthen
head -1 /etc/motd 1 awk '{ printf("append host (nom=\"'$HOST'\",\divers=\Il%s\Il)\nH,$O) }'
fi
# Recuperation des utilisateurs ayant un loginawk -F: '{ printf("append user (nom=\"%s\", divers=\"%s\")\n",$1,$S) ri \
letc/passwd
# Recuperation des disques montes localementgrep In/dev' letc/mtab \
1 awk '{ printf("append ressdsq (nom=\lll$HOST'_%s\", dev=\"%s\Il,\host=\ H' $HOST' \", classe=\ "disque\", mp=\ "%s\") \n", $1, $1, $2) '}
# Recuperation des imprimantes locales1pstat -s 1 grep /dev \
1 awk 1 { printf (Happend ressimp (nom=\ I/%s\", dev=\ "%s\ Il 1 host=\ H'$HOST 1 \", \
classe=\ II imprimante\ H) \n" ,$3, $5) '}
Administration des applicatifs réseaux A·15

Annexes Extrait du shell script d'acquisition d'informations
# Recuperation des comptes locauxfor i in 'cat /etc/passwd 1 sed "si /_/g"'do
nom='echo $i 1 ai'lk -F: 1 { print $1 }.,mp=' echo $i 1 awk -F,' { print $6 }"if [ -d $mp Jthen
dev='df $mp 1 grep Idevl 1 awk '{ print $1 }"eeho "append resscpt (nom=\ "$ {HOST}_cpt_$norn\" , host=\D$HOST\D,\
user=\"${nom}\", classe=' "compte\" , rep=\"$mp\", disq=\"$dev\")"fi
done
# Recuperation des boites aux lettres localesif [ -d Ivarlspool/mail J
thenDEV='df Ivarlspool/mail 1 grep Idev 1 awk '{ print $1 l"~
if [ -n "$DEV" Jthen
awk -F; 1 { printf ("append ressbal (nom=\ U • $HOST' _bal_%s\ n, \
host=\ n' $HOST' \", user=\ "%s\ n 1 classe=\ "bal \ A, \
disq=\"'$DEV'\")\n",$l,$l) }' \/etc/passwd
fifi
# Recuperation des programmes serveursservice="shell exec talk smtp ftp telnet printer pop"# Recuperation des numeros de ports utilisesserv=~netstat -an \
1 awk 'l'[tcp;udpll { print $4 }' \1 awk -F",' , ( printf{"%s\n",$NF) }' \1 awk 'lift $1<1024 && $1!="*" ) print $1}"
# Recherche des noms correspondantsfor i in $serv; do
nom=~grep M{ ;]$i/" < Jete/services 1 awk '{ print $1 }l~
for k in $service; doif { "$nom" = "$k"then
Hp='grep "${k} [ 1" letc/inetd.conf 1 awk '{ print $6 }"if ( -n 1'$Mpn ); then
DEV='df $HP 1 awk '{ print $1 J' 1 grep -v "Filesystem"echo "append prog (nom=\ "${HOSTl-$k\ " , host=\ "$HOST\ " , \
classe=\"serveur\", dir=\"$Mp\lI J disq=\"$DEV\") Il
fifi
donedone
( ... )
A·16 Administration des applicatifs réseaux
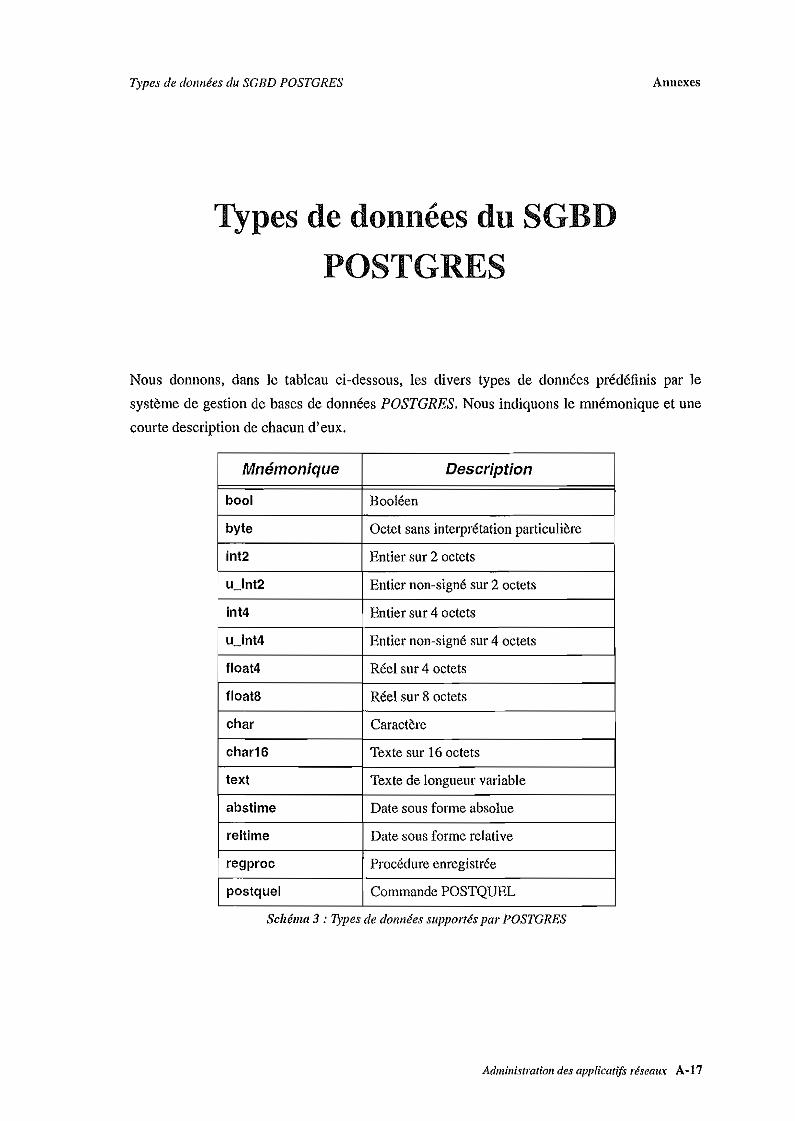
Types de dOl/l/ées du SCBD POSTCRES
Types de données du SGBD
POSTGRES
Annexes
Nous donnons, dans le tableau ci-dessous, les divers types de données prédéfinis par le
système de gestion de bases de données POSTGRES. Nous indiquons le mnémonique et une
courte description de chacun d'eux.
Mnémonique Description
bool Booléen
byte Octet sans interprétation particulière
Int2 Entier sur 2 octets
u_int2 Entier non-signé sur 2 octets
int4 Entier sur 4 octets
u_int4 Entier non-signé sur 4 octets
float4 Réel sur 4 octets
floatB Réel sur 8 octets
char Caractère
char16 Texte sur 16 octets
text Texte de longueur variable
abstime Date sous forme absolue
reltime Date sous forme relative
regproc Procédure enregistrée
postquel Commande POSTQUEL
Schéma 3 : Types de donl/ées supportés par POSTCRES
Administration des applicatifs réseaux A-17
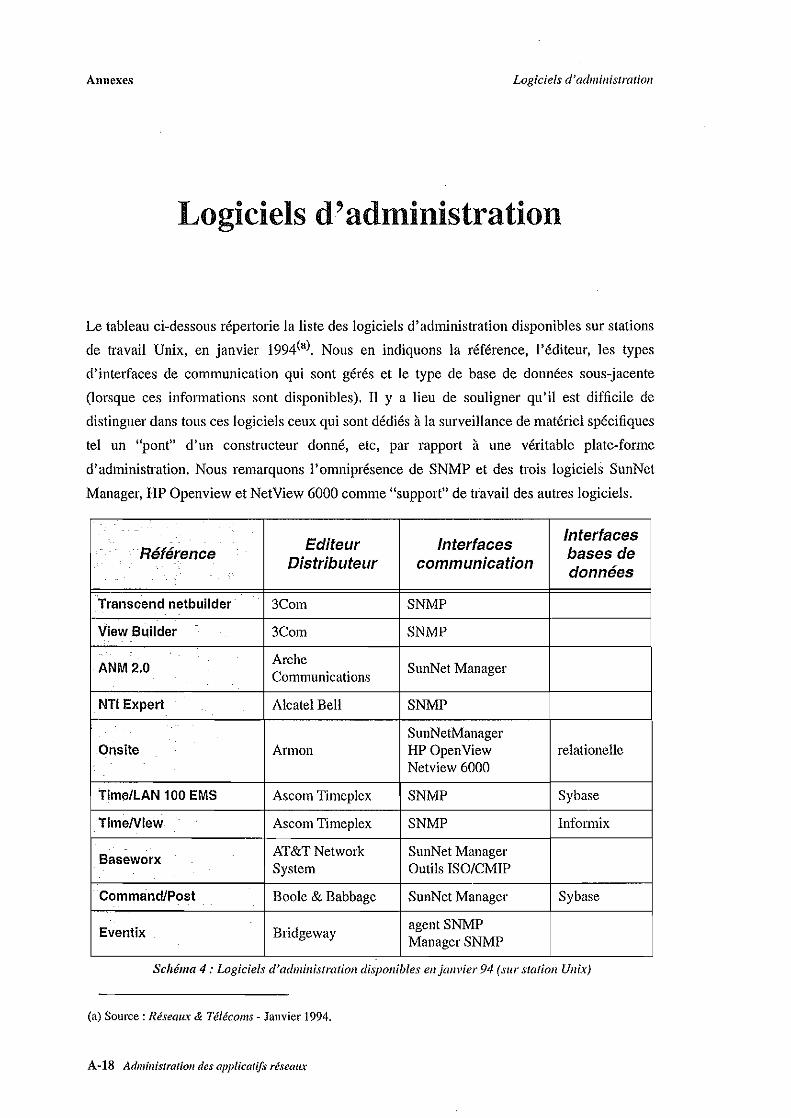
Annexes Logiciels d'administration
Logiciels d'administration
Le tableau ci-dessous répertorie la liste des logiciels d'administration disponibles sur stations
de travail Unix, en janvier 1994(a). Nous en indiquons la référence, l'éditeur, les types
d'interfaces de communication qui sont gérés et le type de base de données sous-jacente
(lorsque ces informations sont disponibles). Il y a lieu de souligner qu'il est difficile de
distinguer dans tous ces logiciels ceux qui sont dédiés à la surveillance de matériel spécifiques
tel un "pont" d'un constructeur donné, etc, par rapport à une véritable plate-forme
d'administration. Nous remarquons l'omniprésence de SNMP et des trois logiciels SunNet
Manager, HP Openview et NetView 6000 comme "support" de travail des autres logiciels .
...Editeur Interfaces
Interfaces"< ••.< "'"'' Distributeur communication
bases de
•••• ••••• \) . données
Transcend Ilélbuilder 3Com SNMP
View."""",,· . 3Com SNMP
•••••••• • ••• ArcheCommunications
SunNet Manager....
Alcatel Bell SNMP'o"AI''''''....
SunNetManager•••• Armon HP OpenView relationelle
Netview 6000
Time/LAN100 EMS Ascom Timeplex SNMP Sybase
TiméNiew Ascom Timeplex SNMP Informix
....... AT&TNetwork SunNet Manager'h System Outils ISO/CMIP
1 ...CommandlPosl Boole & Babbage SunNet Manager Sybase
Evenlix Bridgewayagent SNMPManager SNMP
Schéma 4: Logiciels d'administration disponibles enjallvier 94 (sur station Unix)
(a) Source: Réseaux & lëlécollls - Janvier 1994.
A-18 Administration des applicatifs réseaux
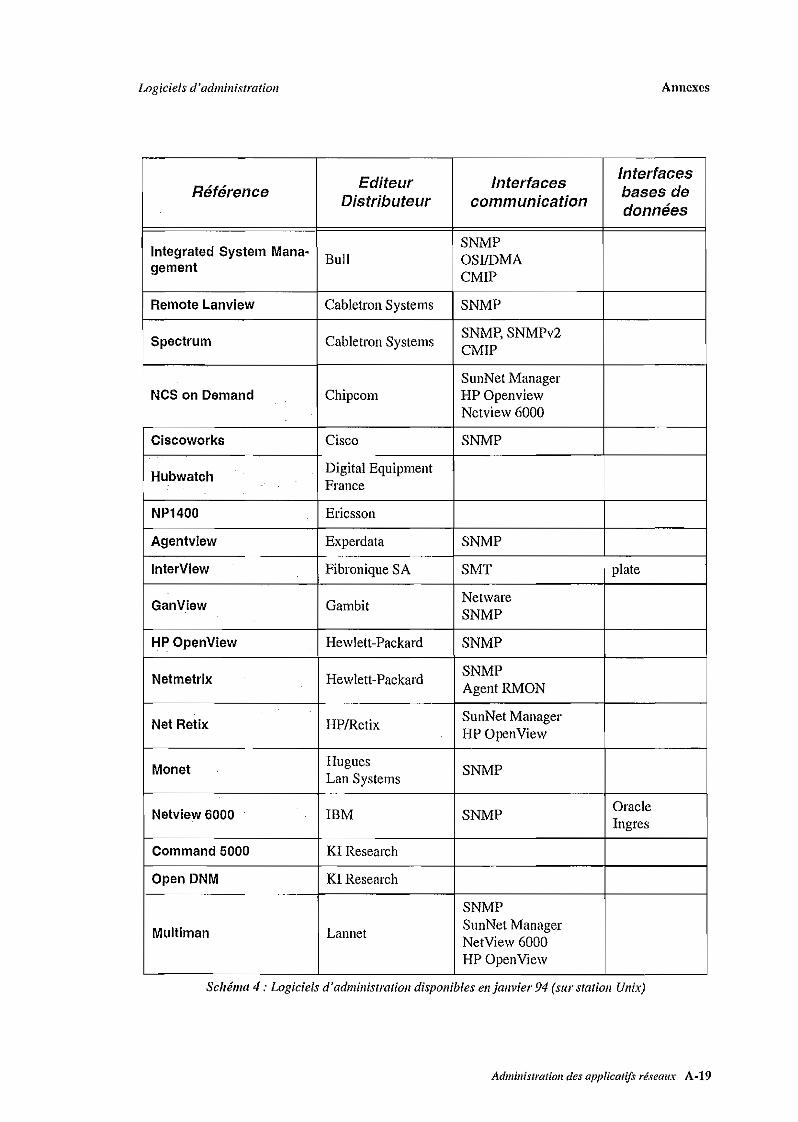
Logiciels d'administration Annexes
Editeur InterfacesInterfaces
Référence bases deDistributeur communication données
Integrated System Mana-SNMP
Bull OSIIDMAgement
CMIP
Remote Lanview Cabletron Systems SNMP
Spectrum Cabletron SystemsSNMP, SNMPv2CMIP
SunNet ManagerNCS on Demand Chipcom HPOpenview
Netview 6000
Ciscoworks Cisco SNMP...
Digital Equipment..." France
. .
NP.1400 Ericsson
Agentview Experdata SNMP
InterVieW Fibronique SA SMT plate
GanView GambitNetwareSNMP
HPOpenView Hewlett-Packard SNMP
Netmetrix Hewlett-PackardSNMPAgentRMON
.
SunNet ManagerNet ReUx HP/Retix
HPOpenView
MonetHugues
SNMPLan Systems
Netview 6000 IBM SNMPOracleIngres
Command 5000 KI Research
Open DNM KI Research
SNMP
Multiman LannetSunNet ManagerNetView 6000HPOpenView
Schéma 4 : Logiciels d'administratioll disponibles en janvier 94 (SUI" stalion Unix)
Administration des applicatifs réseaux A·19
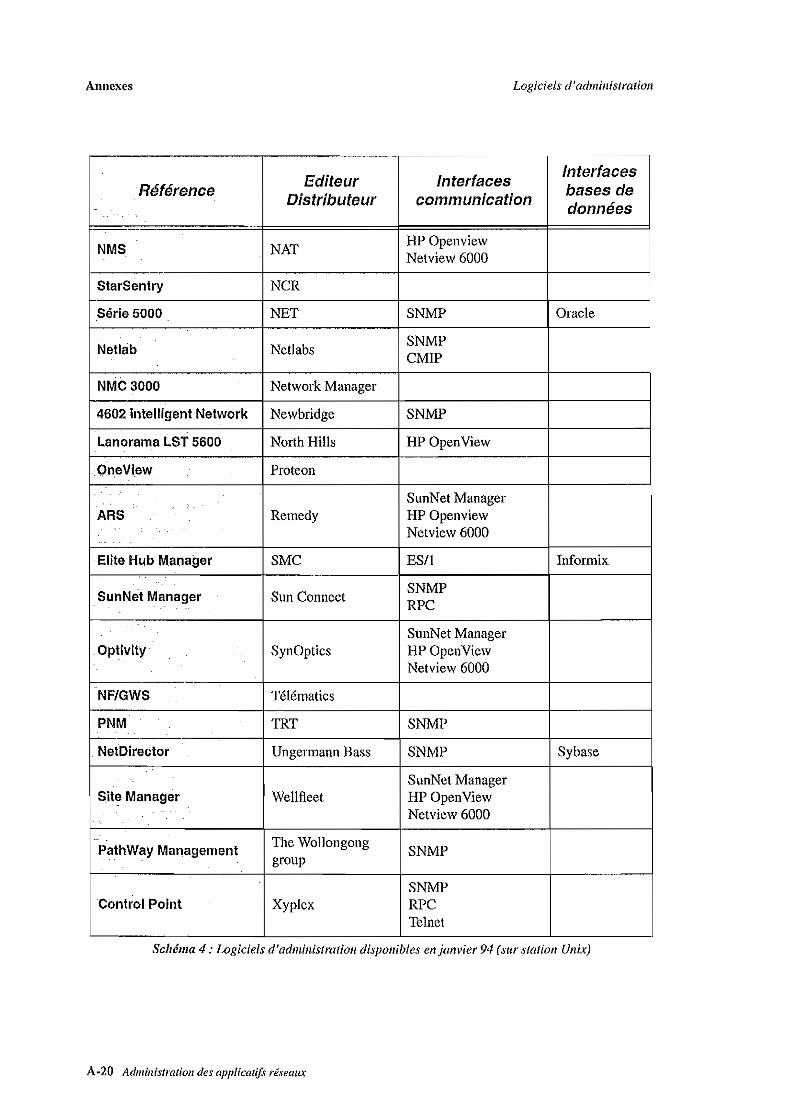
Annexes Logiciels d'administration
Editeur InterfacesInterfaces
• ""'v' vUVv Distributeur communicationbases de
"
données
NMS NATHPOpenviewNetview 6000
StarS!lntry NCR
Série 5000 NET SNMP Oracle
NetlabsSNMP
"., CMIP
NMC3000 Network Manager
4602 lntellig!lnt N!ltwork Newbridge SNMP
LahorarnaLST5600 North Hills HPOpenView
QneVi!lw Proteon
SunNet ManagerRemedy HP Openview
,.... Netview 6000
EUt!l SMC ESII Informix....
SNMP,........~. Sun ConnectRPC
SunNet Manager.... -, SynOptics HPOpenView
Netview 6000
NF/GWS Télématics
TRT SNMP
N!ltOirector Ungermann Bass SNMP Sybase
SunNet Manager, ...n ••"",,,, Wellfleet HPOpenView
Netview 6000
PathWayManagement The WollongongSNMP
group
SNMPControl Point Xyplex RPC
Telnet
Schéma 4: Logiciels d'administration disponibles en janvier 94 (sur station Unix)
A~20 Administration des applicatifs réseaux

Références et Index

Référellces bibliographiques Références et Index
Références bibliographiques
[BAC 92] C. BAC & D. BOUILLET - "Administrer des systèmes Unix en réseall" - Edition
Duno - 1992
[BAP 93] S. BAPAT - "Richer Modeling Semantics for Management Information" - IFIP
Transaction C : Communication Systems - Integrated Network Management III - San
fransisco - 18-23 Avril- pages 15-28.
[BOU 82] S. BOURNE - "The Unix System" - Ed. Addison-Wesley Publishing Company
1982.
[BEN 93] C. BENZ, M. LEISCHNER - "A Righ Level Specification Technique for Modeling
Networks and their Environments ineluding Semantic Aspects" - IFIP Transaction C :
Communication Systems - Integrated Network Management III - San fransisco - 18
23 Avril- pages 29-44.
[CHE 76] CHEN P.P-S - "The Entity-Relationship Model- To\Vard a Unified Vie\V ofData" ,
ACM Trans. Database Syst - 1 - p19 - 1976.
[CCITT M30] CCITT recommendation M.30 "Principles for Telecommunications
Management Network, version 5" - 1992.
[CHA 90] G.A. CHAMPINE - "MIT Project Athena - A model for Distributed Campus
Computing" - Digital Press - 1990.
[CLEM 93] A. CLEMM - "Incorporating Relationships into OSI Management Illformation"
2nd IEEE Network Management and Control Workshop - Tarrytown - 21-23 Sept
1993.
[COL 94] J.P. ARMPACH, P. COLIN et F. OSTRE-WAERZEGGERS - "UNIX, Initiation et
utilisation" - Ed. InterEditions - 1994.
[COM 88] D.E. COMER - "Intemet\Vorking \Vith TCP/IP - Volume 1 - Principles, Protocols
and Architecture" - Prentice-Hall International Editions - 1988.
[COM 91] D.E. COMER, D.L. STEVENS - "Intemetworking \Vith TCP/IP Volume II
Design, implémentation, and intemals" - Prentice-Hall International Editions - 1991.
Administration des applicatifs réseaux B~ 2

Références et Index Références bibliographiques
[COM 93] D.E. COMER, DL STEVENS - "Intel'lletlVorking lVith TCP/IP Volume III
Client-server programming and applications" - Prentice-Hall International Editions
1993.
[CNE 92] CNET - "Gestion de réseaux - Concepts et Outils" - Masson - 1992.
[DUM 90] R. DUMEUR, J-A. LE BORGNE & M. BASSINI, "PratiX, Utiliser et
programmer X" - Edition C2V - 1990.
[ECK 92] W. Eckerson, E. MESSMER - "Is OSI Dead" - Network World - 1992.
[FER 93] P. FERNIQUE - "Un modèle pour l'administration des services applicatifs en
réseaux hétérogènes" - Acte du CFIP'93 - page 239 à 253 - 1993.
[FIL 93] J. FILIPIAK, A. LOMBARDO, S. PALAZZO - "Design of Network Management
Architecturesfor Heterogeneous Networks Using abject OrientedApproach" - IFIP
Transaction C : Communication Systems - Integrated Network Management III- San
fransisco - 18-23 Avril- pages 59-72.
[FRA 92] P. FRANÇON - "Configuration de Réseaux hétérogènes: Modèlisation par Objets
et Outil de Validation" - Thèse de Doctorat de l'Université Louis Pasteur de
Strasbourg - 1992.
[GAI 92] D. GAiTI, G. PUJOLLE - "De nouvelles architectures pour les communications
Réseaux intelligents - Service - Architecture et Outils" - Actes du Congrès - Paris - 13
au 15 oct. 1992.
[GAI 93] D. GAITI, G. PUJOLLE - "L'intelligence dans les Réseaux" - Eyrolles - 1993.
[GER 89] M-P. GERVAIS - "Modèle architectural pour la distribution et l'interconnexion
d'administrations de réseaux hétérogènes" - Thèse de Doctorat de l'Université Pierre
et Marie Curie - 1989.
[GON 85] M. Gondran, M. Minoux, "Graphes et algorithmes", Collection de la Direction des
Etudes et Recherches d'Electricité de France, Edition Eyroles, 1985.
[HAR 93] J. HARISTA, M. BALL, N. ROUSSOPOULOS, J. BARAS, A. DATTA - "Design
ofthe MANDATE MIE" -lF1P Transaction C: Communication Systems - Integrated
Network Management III - San fransisco - 18-23 Avril - pages 85-96.
[HEL 90] D. HELLER - "XvielV Programming Manual, an OPEN LOOK Toolkit for Xll"
dans "The Definitive Guides to the X WindolVs System - Volume 7" - O'Reilly &
Associates -1990.
Il .. 3 Administration des applicatifs réseau.'t

Références bibliographiques Références et Index
[HES 90] D.K. Hess, D.R. Safford, U.w. Pooch : "A Unix Protocol Secl/rity Stl/dy : Network
Information Service" - 1990.
[HON 93] J-w. HONG, M-A BAUER, F-M BENNET - "Integration ofThe Directory Service
in the Network Management Framework" - IFIP Transaction C : Communication
Systems - Integrated Network Management III - San fransisco - 18-23 Avril - pages
149-160.
[ISO N1387] ISO / IEC JTC 1 / SC 21 WG 4 N1387 - "Management Domain Management
FI/nction" - Décembre 1991.
[ISO N1389] ISO / IEC JTC 1/ SC 21 WG 4 N1389 - "Management Knowledge Management
FI/nction" - Novembre 1991.
[ISO N1390] ISO / IEC JTC 1 / SC 21 WG 4 N1390 - "General Relationship Model"
Novembre 1991.
[ISO N1404] ISO / IEC JTC 1 / SC 21 WG 4 N1390 - "OSI Software Management" - Janvier
1991.
[ISO 1002] ISOIIEC 1002 - "Information processing System - Open Systems Interconnection
-Message HandLing System".
[ISO 7498] ISOIIEC 7498 - "Information processing - Open Systems Interconnection - Basic
reference modelfor Open Systems Interconnection" - 1989.
[ISO 7498.4] ISOIIEC 7498-4- "Information Processing Systems - Open Systems
Interconnection - Basic Reference Model- Part 4: Management Framework" - 1989.
[ISO 8571] ISOIIEC 8571 - "Information processing System - Open Systems Interconnection
-File Transfert Access Management".
[ISO 8649] ISOIIEC 8649 - "Information processing System - Open Systems Interconnection
Association Control Service Element".
[ISO 8824] ISOIIEC 8824 - "Information processing System - Open Systems Illterconnection
- Specification ofAbstract Syntax Notation One (ASN.J)" - 1986.
[ISO 8825] ISO/IEC 8825 - "Information processing System - Open Systems Interconneetion
- Specification ofBasic Encoding RI/les for Abstract Syntax Notation One (ASN.J)"
1986.
[ISO 9072] ISOIIEC 9072 - "Information processing System - Open Systems Interconnection
-Remote Operatin Service Element".
Administration des applicat{fs réseaux B· 4

Références et Index Références bibliographiques
[ISO 9545] ISO/IEC 9545 - "Information processing System - Open Systems Interconnection
- Application Layer Structure" - 1987
[ISO 9579] ISO/IEC 9579 - "Information processing System - Open Systems Interconnection
-Remote Data Access".
[ISO 9594] ISO/IEC 9594 - "The Directory" - co-publié sous l'appellation CCITT X.500
1990.
[ISO 9595·2] ISO / IEC JTC 1 / SC2l IS 9595-2, "Information processing System - Open
Systems Interconnection - Management Information Protocol Definition - Part 2 :
Common Management Information Service" - co-publié sous l'appellation CCITT
X.71O - Janvier 1991.
[ISO 9596·2] ISO / IEC JTC 1 / SC21 IS 9596-2, "Information processing System - Open
Systems Interconnection - Management biformation Protocol Definition - Part 2 :
Common Management Information Protocol" - co-publié sous l'appellation CCITT
X.712 - Janvier 1991.
[ISO 9804] ISO/IEC 9804 - "biformation processing System - Open Systems Interconnection
-Commitment, Concurrency and Recovery".
[ISO 10040] ISO / IEC JTC 1 / SC21 IS 10040, "biformation Technology - Open Systems
Interconnection - Systems Management Overview" - co-publié sous l'appellation
CCITI X.701 - Janvier 1992
[ISO 10164·1] ISO / IEC JTC 1 / SC21 IS 10164-1, "Infonnation Teclmology - Open Systems
Interconnection - Systems management - Part 1 : Object Management Function" - co
publié sous l'appellation CCITI X.730 - Octobre 1991.
[ISO 10164-2] ISO / IEC JTC 1 / SC21 IS 10164-2, "biformation Technology - Open Systems
Interconnection - Systems management - Part 2 : State Management Function" - co
publié sous l'appellation CCITI X.73l - Octobre 1991.
[ISO 10164-3] ISO / IEC JTC 1 / SC2l IS 10164-3, "biformation Technology - Open Systems
Interconnection - Systems management - Part 3 : Attributes for Representing
Relationships" - co-publié sous l'appellation CCITT X.732 - Janvier 1992.
[ISO 10165.1] ISO / IEC JTC 1/ SC21 IS 10165-1, "biformation Teclmology - Open Systems
Interconnection - Structure of Management Information - Part 1 : Management
Information Madel" - co-publié sous l'appellation CCITI x.no -Janvier 1992.
B~ 5 Administration des applicatifs réseaux

Références bibliographiques Références el Index
[ISO 10165-2] ISO / IEC JTC 1/ SC2l IS 10165-2, "Information Technology - Open Systems
Interconnection - Structure of Management Information - Part 2: Definition of
Management Information" - co-publié sous l'appellation CCITI X.721 - Janvier
1992.
[ISO 10165-4] ISO / IEC JTC 1/ SC2l IS 10165-4, "Information Technology - Open Systems
Interconnection - Structure ofManagement Information - Part 4: Guidelines for the
Definition ofManaged Objects" - co-publié sous l'appellation CCITT X.722 - Janvier
1992.
[ISO 11183-1] ISO/IECJTC 1 /SC2l DISP 11183-1, "InformationprocessingSystem- Open
Systems Interconnection - ??? - Part 1 : Specification of ACSE, Presentation and
Session Protocole for the use by ROSE and CMISE" - Octobre 1990.
[ISO 11183-2] ISO IIEC JTC 1/ SC2l DISP 11183-2, "Information processing System - Open
Systems Interconnection - ??? - Part 2 : Entranced Management Communications"
Octobre 1990.
[ISO 11183-3] ISO / IEC JTC 1 / SC2l DISP 11183-3, "Information processing System - Open
Systems Interconnection - ??? - Part 3 : Basic Management Communications"
Octobre 1990.
[ISO 11578] ISO / IEC CD 11578, "RPC: Remote Procedure CalI Protocol" - 1992.
[KOn 89] Y. KOBAYASHI - "Standardization issues in integrated Management" -Integrated
Network Management 1 - Proceedings of the IFIP TC 6IWG 6.6 Symposium on
Integrad Network management - Boston, MA, USA, 16-17 Mai 1989.
[KAU 75] A. KAUFMANN, GROUCHKO, CRUON - "Modèles mathématiques pour l'étude
de la fiabilité des systèmes" - Masson - 1975
[KOS 92] D. KOSIUR - "Réseaux Macilltosh -le livre MacWorld" - Editions Sybex - 1992.
[KUN 84] R. KUNG - "Heuristic Search in Database Design" - SpringerVerlag, 1985.
[KUN 92] R. KUNG - "L'état du Réseau Intelligent" - Actes du Congrès sur les nouvelles
architectures pour les communications - Paris - 1992.
[LAM 82] L. LAMPORT, S. ROBERT, P. MARSHALL - "The Byzantine Generais Problem"
- ACM Transactions on Progamming Languages and Systems Vol 4 - Numéro 3
1982.
[LEC 93] C. LECERF - D. CHOMEL - "Les nonnes de gestion de réseau à l'ISO" - Cnet &
Enst - Ed Masson - 1993.
Administration des applicatifs réseaux B~ 6

Références ct Index Références bibliographiques
[LEI 93] A. LEINWAND - "Accomplishing Pe/formance Management lVith SNMP" - Proc.
INET - 1993.
[MAC 87] C. MACCHI - "Téléinformatique - Transport et traitement de l'information dans
les réseaux et systèmes téléinformatiques et télématiques, Chapitre i4 : Disponibilité
d'un système téléinformatique" - page 724 à 744 - Bordas - 1987.
[MAU 93] C. MAURIN - "Rapports de disponibilité matérielle et applicative" - Alcatel
Business Systems - 1993.
[MAN 90] K. MANNING, D. SPENCER - "Model Based Network Management" - Roke
Manor Research Ltd - 1990
[NEU 93] B. NEUMAIR - "Modelling Resourcesfor integrated Pe/formance Management"
IFIP Transaction C : Communication Systems - Integrated Network Management III
- San fransisco - 18-23 Avril- pages 109-122.
[OKI 93] B. OKI, M. PFUEGL, A. SIEGEL, D. SKEEN - "The information Bus - An
architecture for Extensive Distributed Systems" - Operating Systems Review - ACM
Press - Vol 27, Numéro 5 - Décembre 1993.
tOUS 90] J.K. OUSTERHOUT - "TCL: An Embeddable Command Language"- Proc. Winter
USEN1X Conference - pages 133-146 - 1990.
[POL 69] A.M. POLOVKO - "Fundamentals ofreliability theory" - Academie Press - 1969
[POS2 88] "POSTGRES reference manllal - Section 2 : information on the illteractill between
POSTGRES and the operating system UNiX" - University of California - 1988.
[POS4 88] "POSTGRES reference manllal - Section 4 : POSTQUEL - description of the
general syntax ofPOSTQUEL" - University of California - 1988.
[POSS 88] "POSTGRES reference manual - Section 5 : LIBPQ - programmer's interface to
POSTGRES" - University of California - 1988.
[RFC 760] J. POSTEL - "internet Protocol" - Request for comments 760 - Network
Information Center, SRI International - 1980.
[RFC 761] J. POSTEL - "Transmissioll Control Protocol" - Request for comments 761
Network Information Center, SRI International - 1980.
[RFC 768] J. POSTEL - "User Datagram Protocol" - Request for comments 768 - Network
Information Center, SRI International - 1980.
B- 7 Administration des applicatifs résemo:

Références bibliographiques Références et Index
[RFC 821] J. POSTEL - "Simple Mail I)'ansfer Protocol" - Request for comments 821
Network Information Center, SRI International - 1982.
[RFC 854] J. POSTEL, J.K. REYNOLDS - "Telnet Protocol specification" - Request for
comments 854 - Network Information Center, SRI International - 1983.
[RFC 959] J.POSTEL, J.K. REYNOLDS - "File Transfert Protocol" - Request for comments
959 - Network Information Center, SRI International - 1985.
[RFC 1033] "Domain Names - Concepts and facilities" - Request for comments 1033
Network Information Center, SRI International.
[RFC 1052] V. Cerf - "IAB Recommendations for the Development of Intemet Management
Standards" - Request for comments 1052 - 1988.
[RFC 1057] Sun Microsystems, Inc., - "RPC .' Remote Procedure Call Protocol specification .'
version 2" - Request for comments 1057 - 1988.
[RFC 1094] Sun Microsystems, Inc., - "NFS.' Nehvork File System Protocol specification"
Request for comments 1094 - 1988.
[RFC 1094] M. ROSE, Mc. CLOGHRIE - "Structure & Identification of Management
Information fol' TCPIIP-Based Intemets" - Request for comments 1155 - Network
Information Center, SRI International - 1988.
[RFC 1156] "Management Information Base fol' NehVork Management of TCPIIP-based
Intemets" - Request for comments 1156 - Network Information Center, SRI
International - 1988
[RFC 1157] "A Simple Network Management Protocol (SNMP)" - Request for comments
1157 - Network Information Center, SRI Internationa1- 1989.
[RFC 1158] M. ROSE - "Management Information Basefor NehVork Management ofTCPIIP
based intemets - MIB IF' - Request for comments 1158 - Network Information Center,
SRI Internationa1- 1990.
[RFC 1213] K. McCLOGHRIE, M. ROSE - "Management Information Base fol' NehVork
Management of TCP/IP-based intemets.' MIB-II" - Request for comments 1213,
Hughes LAN Systems, Performance Systems International - 1991.
[RFC 1243] S. WALDBUSSER - "AppleTalk Management Information Base" - Request for
comments 1243 - Carnegie Mellon University - 1991.
[RFC 1296] M. LüTTER - "Internet Growth" - Request for comments 1296 - 1992.
AdminÎstration des applicatifs réseaux B· 8

Références et Index Références bibliographiques
[RFC 1442] J. CASE, K. McCLOGHRIE, M. ROSE, S. WALDBUSSER, "Structure of
Management Information for version 2 ofthe Simple NetworkManagemelll Protocol
(SNMPv2)" - Reguest for comments 1442 - Network Information Center, SRI
International - 1993.
[RFC 1514] P. GRILLO, S. WALDBUSSER - "Host Resources MIB" - Reguest for comments
1514 - Sept 1993.
[RFC 1565] S. KILLE, WG. CHAIR - "NellVork Services Monitoring MIB" - Reguest for
comments 1565 - 1994.
[RIF 86] A.P. RIFKIN - "Remote File Sharing : Architecture Overview" - Conférence Usenix
- 1986.
[RIF 93] J.M. RIFFLET - "La programmation sous UNIX" - Ed. Ediscience international
3ème édition - 1993.
[ROL 91] P. ROLIN - "Réseaux locaux - Normes et protocoles" - Ed. Hermès - 4ème édition
- 1991.
[ROS 89] M. ROSE - "The Open Book : A Practical Perspective on Open Systems
interconnection", Prentice-Hall, 1989
[ROS 94] M. ROSE - "The Simple Book: An introduction to Internet Management", Prentice
Hall - 2nd ed. - 1994.
[SER 93] D. SERET, T. LIAO - "La gestion des réseaux d'elllreprise" - Réseaux et
informatigue répartie - Ed. Hermes - Volume 3 - numéro 4 - 1993.
[SCH 83] F. SCHNEIDER - "Fail-Stop Processors" - Digest ofPapers from Spring CompCon
- IEEE Computer Society International Conference - 1983.
[SCH 93] J. SCHONWALDER, H. LANGENDORFER - "Administration oflarge distributed
UNIX !ANs with BONES" - Proc. World Conference On Tools and Techniques for
System Administration, Networking, and Security, Arlington (Virginia) -Avril 1993.
[SCH 93a] J. SCHONWALDER, H. LANGENDORFER - "An application Independent
NellVork EditaI''' - Institute for Operating Systems and Computer Networks - 1993.
[sm 93] M. SIBILLA, D. MARQUIE, Y. RAYNAUD - "Management Information Base;
Guidelines leadig from generic specification of managed abject relationships ta
consistent implemelllation" - 4th. annual Int. Workshop on Distributed Systems,
Operations and Management (DSOM'93), Long Branch NJ., US - 5 et 6 Octobre
1993.
B· 9 Administration des applicatifs réseaux

Références bibliographiques Références et Index
[STA 93] W. STALLINGS - "SNMp, SNMPv2, and CMIP - The practical Guide ta NetlVork
Management Standards" - Ed. Addison-Wesley Publishing Company, Inc - 1993.
[STE 91] H. STERN - "Managing NFS and NIS" - O'Reilly & Associates - 1991.
[STO 76] M. Stonebraker - "The Design and Implementation of INGRES" - ACM-TODS,
1976.
[STO 81] M. Stonebraker - "Operating System Support for Databas Management" - CACM,
1981.
[STO 83a] M. Stonebraker - "Pelformance Analysis of a Distributed Data Base System"
Proc. 3th Symposium on Reliability in Distributed Software and Data Base Systems,
Clearwater, Fla, 1983.
[STO 83b] M. Stonebraker - "Document Processing in a Relalional Daabase System" - ACM
TOOIS, 1983.
[STO 85] M. Stonebraker - "Triggers and Inference in Data Base systems" - Proc. Islamoora
Conference on Expert Data Bases, Islamoora, Fla, 1985.
[STO 86] M. Stonebraker - "Ine/usion ofNew Types in Relational Data Base Systems" - Proc.
Second International Conference on Data BAse Engineering, Los Angeles, Ca, 1986.
[SUN 91] "The Network Information Service" - SunOs Reference Manual- Sun Corporation
1991.
[SUN 92] SunConnect - "Sunnet Manager 2.0 - Usas Guide Reference and Programmer's
Guide" - 1992.
[SYL 93] M. SYLOR - "Junction Objets - A solution ta a problem innaming and locating OSI
managed abjects" - Integrated Network Management III - Noth-Holland - 1993.
[TER 92] K. TERPLAN - "Communications NetlVorks Management" - Ed. Prentice-Hall
1992.
[VAL 91] R. VALTA - "Design concepts for a Global Network Management Database"
Integrated Network Management II - 1991.
[WAL 93] S. WALDBUSSER - "A look at the Host Resources MIE" - The Simple Times, Vol
2, No 3, mai/juin 1993 ou Connexions, Vol 17, No 11, no 1993.
[WALL 93] L. WALL, R.L. SCHWARTZ - "Programming PERL" - O'Reilly & Associates,
Inc - 1993.
Administration des applicatifs réseaux B· 10

Références et Index
Liste des figures
Administration de réseaux:J'état de J'art
Liste des figures
Partie 1
Fig. 1 : MIE SNMP au sein de l'arbre de dénomination iso-ccil! 27Fig. 2 : Structure arborescente de la MIE pour TCPIIP 29Fig. 3 : MIE privées dans le SMI 30Fig.4 : Arbre de dénomination des classes d'objets d'aministration ISO 32Fig. 5 : Composantes d'un agent OS1. 37Fig.6 : L'interface INED 47Fig. 7 : Architecture générale de Sunnet Manager 48Fig. 8 : Interface de Sunnet Manager 51Fig. 9 : Utilisation de la couche application par les programmes des utilisateurs 54Fig. 10 : services applicatifs d'une station de travail sous le système Unix 57Fig. 11 : Structure des NIS 65
Un modèlepour J'administrationdes applications réseaux Partie Il
Fig. 12 : Illustration des problèmes de dépendances des services réseaux 75Fig. 13 : Illustration des problèmes d'impacts sur les services réseaux 76Fig. 14 : Illustration intuitive du concept de base du modèle 82Fig. 15 : Graphe d'un service réseau élémentaire 89Fig. 16 : Graphe d'un service réseau par dénomination 91Fig. 17 : Graphe d'un service réseau en cascade 94Fig. 18 : Illustration d'une portion de réseau Ethernet 98Fig. 19 : Exemple de graphe de réseau physique 99Fig. 20 : Exemple de graphe global associé au modèle 104Fig.21 : Evolution dans le temps des graphes globaux 105Fig. 22 : Déduction du graphe de dépendances associé à un service 106Fig. 23 : Graphe de dépendances d'un service de consultation de boites aux lettres 108Fig. 24 : Illustration de la méthode de contraction 109Fig. 25 : Exemple de graphe contracté de dépendances 110Fig. 26 : Récapitulation des applications de base du modèle 118Fig. 27 : Exemple de modélisation d'une application multivoque 119Fig.28 : Diagramme entité-association de la base de données associée au modèle 120Fig.29 : Extrait du diagramme pour la représentation du réseau physique 121Fig. 30 : Provenance des données du modèle 125
c- 1 Administratioll des applicatifs réseaux

Liste des figures Références et Index
Fig. 31 : Interdépendance cyclique dans le cas de montages de disques 134:Fig.32 : Exemple de calcul de la fiabilité d'un service 138Fig.33 : Calcul de l'impact des machines 142Fig.34 : Exemple de graphe de la sécurité d'une ressource 147Fig.35 : Calcul des coûts des services réseaux 151 .
Validation du modèle par implantation Partie III
Fig.36 : Exemple d'acquisition de données 167Fig. 37 : Extrait de code pour la recherche des programmes serveurs actifs 168Fig. 38 : Structures de données des graphes 173Fig. 39 : Rôles des deux entités de la maquette d'administration 174Fig. 40 : Les modules de l'entité fonctionnelle ADSAR 176Fig. 41 : Architecture de la maquette ADSAR 177Fig. 43 : Syntaxe POSTQUEL de création de la table décrivant les utilisateurs 180Fig. 42 : Diagramme entité-association de la base de données associée au modèle 181Fig. 44 : Méthode de lancement des commandes d'acquisition 183Fig. 45 : Ecran d'accueil d' ADSAR 187Fig.46 : Menu de l'exploitation de la base de données 187Fig. 47 : Exemple d'interrogation de la base de données 188Fig. 48 : Menu de l'analyse des services à surveiller 189Fig.49 : Exemple de visualisation du graphe de dépendances d'un service 190Fig.50 : Exemple de calcul de la fiabilité d'un service 190Fig.51 : Graphe de dépendances d'un service réduit aux ordinateurs 191Fig.53 : Exemple de calcul de l'impact d'un ordinateur 191Fig. 52 : Liste des ressources dans le graphe global 192Fig. 54 : Menu de l'analyse des services possibles 192Fig. 55 : Exemple de recherche de services élémentaires 193Fig. 56 : Menu de lancement manuel des sondes 193
Annexes
Fig. 1 : Structure d'un tableau dynamique(tbd) A-9Fig. 2 : Structure d'un graphe orienté valué (grph) A-12Fig. 3 : Types de données supportés pal' POSTGRES A-17Fig. 4 : Logiciels d'administration disponibles en janvier 94 (sur station Unix) A-18
Administration des applicatifs réseaux C- 2
)
!\
\
\

Références et Index
Liste des tableaux
Administration de réseaux:l'état de l'art
Liste des tableaux
Partie 1
Tab. 1 : Exemples d'agents propriétaires Sunnet.. 49
Un modèlepour l'administrationdes applications réseaux Partie /1
Tab. 2 : Répartition des problèmes affectant les services applicatifs 79Tab. 3 : Evaluation du nombre de ressources 112Tab.4 : Estimation du nombre d'instances de programmes 113Tab.5 : Exemple de calcul de la fiabilité des services 139Tab.6 : Exemple de calcul d'impacts réduits 142Tab.7 : Exemple de calcul d'impacts réduits en fonction de services pondérés 143Tab.8 : Exemple de calcul de la sécurité d'une ressource 148Tab.9 : Exemple de répartition des coûts globaux sur les services 151
Validation du modèle par implantation Partie /1/
Tab. 10 : Description des champs de la table "Machine" 179Tab.ll : Description des champs de la table "Loc-Ress" 180Tab.12 : Fiabilités de certains services d'impression 194Tab.13 : Fiabilités de certains services de montages de disques 195Tab. 14 : Fiabilités de divers services illustratifs 196Tab. 15 : Impacts des ordinateurs les plus représentatifs 197Tab. 16 : Quelques caractéristiques de "volumes"de la maquette ADSAR 199Tab. 17 : Quelques caractéristiques temporelles de la maquette ADSAR 199
Annexes
Tab.l : Description des champs de la table "Machine" A-3Tab.2 : Descriptions des champs de la table "Utilisateur" A-4Tab.3 : Description des champs de la table "Loc-Ress" A-4Tab.4 : Description des champs de la table "Ressource" A-5
1). 1 Administration des applicatifs réseaux

Liste des tableaux Références et Index
Tab. 5 : Description des champs de la table "Programme" A-6Tab.6 : Description des champs de la table "Loc-Prog" A-6Tab.7 : Description des champs de la table "Prog-Prog" A-7Tab.8 : Description des champs de la table "Login" : A-7
AdmÙÛstralioll des applicatifs réseaux D~ 2
Références et Index Glossaire des abréviations
Glossaire des abréviations
- ADSAR Administration des Dépendances entre Services ApplicatifsRéseaux
- ANSI American National Standards Institute-ARO Army Research Office- ASN.l Abstract Syntax Notation One- AUI.. Attachment Unit Interface- CAP Columbia Appletalk Package- ccnT Comité Consultatif International pour la Télégraphie et la
Téléphonie- CERT Computer Emergency Response Team- CMIS Common Management Information Service- CMIP Common Management Information Protocol- CNET.. Centre National des Etudes en Télécommunication- CPU Control Process Unit- DARPA Defense Advanced Research Projects Agency- DIS Draft Internet Standard- DCE Distributed Computing Environment- DME Distributed Management Environment- DN Distinguished Names- DNS Domain Name Server- DP Draf Proposais- DSA Directory Service Agent- EGP External Gateway Protocol- ER Entity Relationship- FTAM File Tranfer Acces and Management- FTP File Transfer Protocol- GDM0 Guidelines for the Definition of Managed abjects- GDN Global Distinguished Name-IAB .Internet Advisory Board-ICMP Internet Control Message Protocol-1EC. .International Electrotechnical Committee- IETF .Internet Engeneering Task Force-INCM Intelligent Network Conceptual Model-IP .Internet Protocol-IPX Internet Protocol eXchange-ISO .International Standardization Organization- JTC Joint Technical Commiltee- LAN Local Area Network- MAN Metropolitan Area Network- MHS Message Handling System-- MIB Management Information Base- MSDOS MicroSoft Disk Operating System
EM 1 Administration des applicatifs réseaux

Glossaire des abréviations Références et Index
- MTA Message Transfer Agent- NCSA National Center for Supercomputing Applications- NIS Network Information Service- NFS Network File System- NSF National Science Foundation- OIW OSI Implementers Workshop- OSF Open Software Foundation- OS!.. Open System Information- OSI NMIFORUM Open System Information / Network Management Forum- PC Personal Computer- RCP Remote CoPy- RFC Request For Comments- RFS Remote File Sharing- RDA Remote Data Access- RDN Relative Distinguished Name- RENATER Réseau NAtional de Télécommunication pour l'Enseignement et
la Recherche- RMON MlB Remote Monitoring Management Information Base- RNIS Réseau Numérique à Intégration de Services- RO Remote Opération- RPC Remote Procedure Cali- RSH Remote SHeli- SAR System Availability Reporting- SC SubComittee- SGBD Système de Gestion de Base de Données- SMAP System Management Application Process- SMI Structure of Management Information- SMTP Simple Mail Transfer Protocol- SNMP Simple Network Management Protocol- SQL Simple Quety Language- TCP Transmission Control Protocol- TCPIIP Transmission Control Protocol / Internet Protocol- TMN Telecommunication Management Network- TP Transaction Processing- UDP User Datagram Protocol- UIT.. Union Internationale des Télécommunications- VT Virtual Terminal- WAIS Wide Area Internet Space- WAN Wide Area Network- WD Working Draft- WG Working Group
Administration des applicatifs réseaux E· 2

Références et Index
Table des matières
Partie /.
Administration de réseaux:l'état de l'art
1. Le contexte général del'administration de réseaux
Table des matières
1.1. Administration de réseaux 111.1.1. Une définition de l'administration de réseaux 111.1.2. Les éléments à administrer 11
• Le matériel 12• Le logiciel 12• Les utilisateurs 12
1.1.3. Les fonctionnalités de l'administration 12- La gestion de la configuration 13- La gestion des anomalies 13- La gestion des performances 13• La gestion des informations comptables 14- La gestion de la sécurité 14
1.1.4. Les niveaux d'administration 15• L'administration opérationnelle 15- L'administration tactique 15- L'administration stratégique 16
1.2. Réseaux hétérogènes, standards et normes 161.2.1. Réseaux hétérogènes: une description 16
- Hétérogénéité des matériels et des logiciels 16- Hétérogénéité architecturale 17• Hétérogénéité des données 17
1.2.2. Standards de fait 171.2.3. Normes et organismes de normalisation 18
1.3. Hétérogénéité et administration 181.3.1. L'administration mise en place par les utilisateurs 191.3.2. L'administration proposée par les constructeurs 191.3.3. L'administration par les standards 201.3.4. L'administration normalisée 20
F~ 1 Administration des applicatifs réseaux

Table des matières
2. L'état de l'art en administration deréseaux
Références et Index
2.1. Cadre des travaux d'administration de réseaux 222.1.1. Les organismes de normalisation 22
- L'ISO 23- Le CCITT 23
2.1.2. Les associations d'utilisateurs et de constructeurs 24- OSI NM/FORUM 24- L'OSF 24- L'IAB 24
2.2. Architecture générale d'un système d'administration 252.3. L'information d'administration 26
2.3.1. L'information sous SNMP 26- Dénomination et description des objets sous SNMP 26- MIB, MIB-II, extensions de MIB et MIB privées 28
2.3.2. L'information d'administration ISO 31- Modèle orienté objet 31- Dénomination des objets gérés 32- La description des objets 33
2.3.3. Autres modèles d'informations 352.3.4. Evaluation des modèles d'informations 35
2.4. Les mécanismes mis en œuvre pour l'administration 362.4.1. Les agents d'administration 36
- Les agents SNMP 36- Les agents OSI 3'1- Comparaison entre agents SNMP et agents OSI 38- Autres solutions 38
2.4.2. Les canaux et protocoles d'administration : 39- Le protocole SNMP : 39- CMIP et les services associés CMIS 40- Comparaison des protocoles SNMP et OSI 40- Les protocoles à publications 41- Quelques autres protocoles utilisés pour l'administration 42
2.4.3. Les plates-formes d'administration 44- Stockage de l'information 44- Analyse de l'information 45- Interface 46
2.4.4. Un exemple de plate-forme d'administration: Sunnet Manager 47- Architecture générale de Sunnet 48- Les agents Sunnet 49- La base de données Sunnet 49- Méthodes d'interrogation des agents 50- Exploitation et génération de résultats 50- Outils de développement de Sunnet.. 50
Administration des applicatifs réseaux F· 2

Références et Indcx
3. Administration des dépendances deservices applicatifs
Table des matières
3.1. Contexte général de l'administration des dépendances entre services applicatifs 523.1.1. Service réseau: une définition 523.1.2. Application réseau: une définition 53
- Les concepts généraux 53- Description des applications réseaux 53- Les applications réseaux pour un ordinateur standard 56
3.1.3. Dépendances entre applications réseaux 583.2. L'état de l'art de l'administration des dépendances entre services réseaux 59
3.2.1. Mécanismes existants 59- Une première expérience d'administration des services réseaux: "Moira" du pro-
jet Athena 59- L'administration des applications sous SNMP 61- L'administration des applications dans le modèle OSI 62- Travaux d'extension du modèle OSI et SNMP pour l'administration des services
applicatifs réseaux 63- Un modèle constructeur: NIS 64
3.2.2. Une solution utilisateur précurseur 66- Le modèle de données 66- Les mécanismes mis en œuvre 67- Les résultats obtenus 67- Evaluation du modèle 68
Partie Il.
Un modèlepour l'administrationdes applications réseaux
4. Hypothèses et finalité du modèle
4.1. Finalité du modèle 754.2. Contexte d'application du modèle 774.3. Hypothèses de travail 774.4. Présentation informelle du modèle 81
5. Description formelle du modèle
5.1. Modélisation des services réseaux 845.1.1. Les objets 84
F ~ 3 Administration des applicatifs réseaux

Table des matières Références et Index
5.1.2. Les applications de base 85- Les ressources d'une machine 85- Programmes d'une machine 85- Programmes clients et programmes serveurs 85- Ressources gérées par un programme serveur 86- Utilisateurs d'un programme c1ienl.. 86- Utilisateurs d'un programme serveur 86- Le réseau physique 87
5.1.3. Définition des services réseaux élémentaires 87- Détail des conditions d'un service réseau élémentaire 88- Exemple de service réseau élémentaire 89
5.1.4. Définition des services réseaux - dénomination de ces services 89- Définition de l'application de dénomination 89- Exemple de service réseau par dénomination 90
5.1.5. Définition des services réseaux en cascade 91- Application de transition 91- Définition d'un service réseau en cascade 92- Exemple de service réseau en cascade 93
5.1.6. Les programmes comme ressources 935.1.7. Définition générale d'un service réseau 95
5.2. Modélisation du réseau physique 955.2.1. Graphe du réseau physique 96
- Les équipements réseaux 96- Les équipements 96- L'ensemble des connexions 97- Graphe du réseau physique 97
5.2.2. Définition de l'application n 98- Rappel 98- Contrainte sur l'application n 99
5.2.3. Hypothèses sur le réseau physique 99- Hypothèse sur les réseaux multi-protocoles 99
5.3. Modèle temporisé 1005.3.1. Fenêtres temporelles 100
- Définition des fenêtres temporelles d'un service 101- Exemple de règle de tir 101
5.4. Graphes associés au modèle 1015.4.1. Graphe global de dépendances des services réseaux 1025.4.2. Graphe global de dépendances à un instant donné 1045.4.3. Graphe de dépendances d'un service 1045.4.4. Graphe contracté 106
6. Du modèle théorique au modèleinformatique
6.1. Evaluation de la quantité d'informations manipulées 1116.1.1. Nombre d'éléments du modèle dans un cas réel 1126.1.2. Ordre de grandeur 113
6.2. Les services modélisés 1166.3. Principe de mise en œuvre pour la mémorisation des données 116
Administration des applicatifs réseau.:r F· 4

Références et Index Table des matières
6.3.1. Type de la base de donnée 1176.3.2. Schéma de la base de données des objets et des relations 117
• Représentation des objets 117· Représentation des relations entre objets 118· Schéma de la base de données 119· Représentation du graphe physique du réseau 120
6.4. Acquisition des données d'administration 1226.4.1. Principes d'acquisition 1226.4.2. Les informations pré·existantes sur le réseau 122
· Principe d'acquisition des données pré·existantes 122• Principe de mise à jour des données pré·existantes 123• Informations issues d'autres bases de configuration 123
6.4.3. Les données déclarées 124• Principe d'acquisition des données déclarées 124· Principe de mise à jour des données déclarées 126
6.5. Recherche des services réseaux et de leurs dépendances 1266.5.1. Déduction des services réseaux élémentaires 1266.5.2. Dénomination des services réseaux élémentaires et fonction de transition 1296.5.3. Construction du graphe global de dépendances 131
7. Résultats de la modélisation
7.1. Gestion de la configuration 1327.1.1. Connaissance des configurations 1327.1.2. Repérage des interdépendances cycliques 133
- Exemple d'interdépendance cyclique 133· Cycle dans les graphes de dépendances 134
7.2. Gestion des anomalies et des performances 1357.2.1. Fiabilité d'un service réseau 136
- Définition de la fiabilité d'un service 136- Calcul de la fiabilité d'un service 136- Estimation de la qualité d'un réseau 139
7.2.2. Impact d'un ordinateur 140_Définition de l'impact d'une machine 141- Définition de l'impact réduit d'une machine 141
7.2.3. Charge des machines 1437.2.4. Diagnostic de pannes 144
7.3. Gestion de la sécurité 1467.3.1. Sécurité d'une ressource 1467.3.2. Calcul de la sécurité d'une ressource 1477.3.3. Indication de "trou" de sécurité 148
7.4. Gestion des informations comptables 1487.4.1. Répartition des frais réels 149
· Principe de la répartition des frais 149• Une méthode de répartion en fonction des services offerts 150• Exemple de calcul de coût.. 151· Calcul des frais imputés à l'utilisateur 152
F· 5 Administratioli des applicatifs réseaux

Table des matières
Partie III.
Références et Index
Validation du modèle par implantation
8. Contexte de la maquette
8.1. Le modèle implanté 1598.1.1. Les concepts théoriques implantés 1598.1.2. Les types d'ordinateurs et de protocoles supportés 1608.1.3. Les services réseaux modélisés 1608.1.4. Les résultats implantés 161
8.2. Cadre de l'expérimentation 1618.2.1. L'infrastructure et la technologie du réseau de test 1618.2.2. Le parc des machines 1628.2.3. Les utilisateurs 1628.2.4. Les services fournis 1628.2.5. Les caractéristiques particulières du réseau Vivaldi 1638.2.6. Le choix de l'ordinateur d'accueil de la plate-forme d'administration 1648.2.7. Avantages et inconvénients du site de tes\.. 164
8.3. Les choix de l'implantation 1648.3.1. La base de données 1658.3.2. L'acquisition des données 166
- Méthodes pour l'acquisition des données pré-existantes 166- Méthodes pour l'acquisition des données déclarées 170
8.3.3. La génération des graphes et le calcul des résultats 1718.3.4. La plate-forme d'administration 172
- L'entité de gestion de la base de données BDadsar 174- L'entité fonctionnelle AD8AR 175
9. La maquette ADSAR : implantation,utilisation et évaluation
9.1. L'implantation de la maquette AD8AR 1789.1.1. Implantation et génération de la base de données BDadsar 178
- Tables de la base de données 178- Diagramme de la base de données de la maquette 180- Génération de la base de données par le prototype AD8AR 180
9.1.2. Implantation des modules de l'entité fonctionnelle AD8AR 181- Implantation du "moteur central" de AD8AR 181- Implantation du module d'acquisition des données 183- Problèmes d'implantation 185
9.2. Fonctionnaiités de la maquette AD8AR 1869.2.1. Lancement du prototype 1869.2.2. Génération et exploitation courante de la base BDadsar 187
- Régénération de la base 187- Exploitation courante de la base 187
Administratioll des applicatifs réseaw,: F.. 6

Références et Index Table des matières
• L'analyse des services réseaux 189• Recherche de tous les services réseaux 192
9.2.3. Acquisition des données 1939.3. Résultats d'exploitation et caractéristiques de leur obtention 194
9.3.1. Résultats des calculs de la fiabilité des services 194• Services d'impressions 194· Services d'importation de disques 195· Autres services 196
9.3.2. Résultat du calcul de la qualité de service globale 1979.3.3. Résultats de calculs d'impact.. 1979.3.4. Caractéristiques des calculs de résultats 198
• Caractéristiques d'occupation mémoire 199• Caractéristiques temporelles 199
9.4. Evaluation de la maquette et retour d'expérience 2009.4.1. Evaluation des choix techniques 200
· Méthode d'acquisition 200· Manipulation des graphes 201• Base de données 201• Interface utilisateur 202
9.4.2. Evaluation des résultats d'exploitation 202- Gestion de la configuration 202• Calcul de la fiabilité 203- Calcul de la qualité de service 203- Calcul de l'impact 204
Annexes
- Description des tables de la base de données BDadsar A-3- La table de description des ordinateurs A-3- La table de description des utilisateurs A-4• La table de localisation des ressources A-4• La table de description des ressources A-5- La table de description des programmes A-6- La table de localisation des programmes A-6• La table des relations entre programmes A·7- La table des droits d'exécution A-7
- Primitives et structures d'implantation des tableaux dynamiques et des graphes A-8- Les tableaux dynamiques: bibliothèque tbd A·8• Les graphes orientés valués: bibliothèque grph A-10
FR 7 Administration des applicatifs réseaux

Table des matières Références el Index
- Extrait du shell script d'acquisition d'informations A-15- Types de données du SGSD POSTGRES .A-17- Logiciels d'administration A-18- Références bibliographiques 8·2_ Liste des figures C-1- Liste des tableaux 0-1_ Glossaire des abréviations E.1- Table des matières F-1
Administratioll des applicatifs réseaux F~ 8