Embed Size (px)
Citation preview

UNIVERSITÉ DU QUÉBEC À MONTRÉAL
ÉCOLE DES SCIENCES DE LA GESTION
VALIDATION DE LA PERFORMANCE D’UN MODÈLE DE NOTATION
COMPORTEMENTALE DE CARTES DE CRÉDIT
.
RAPPORT DE STAGE
PRÉSENTÉ
COMME EXIGENCE PARTIELLE
DE LA MAÎTRISE EN FINANCE APPLIQUÉE
PAR: ENYONAM ADOSSI
DIRECTEUR DE STAGE : JEAN-PIERRE GUEYIE
AOÛT 2014

REMERCIEMENTS
Je tiens à remercier dans un premier temps, mon directeur de stage Mr Jean-Pierre
Gueyie pour ses conseils et sa disponibilité qui m’ont permis de mener à bien ce
projet de fin de maîtrise tout au long de la session.
J’aimerais aussi exprimer ma gratitude et adresser mes remerciements à toute l’équipe
de la direction de modélisation Crédit et celle de Validation en Modélisation à
Desjardins pour leur confiance et le soutien qu’ils ont pu me prodiguer au cours de
ces derniers mois. Ces personnes m’ont permis de vivre une expérience enrichissante
durant la réalisation de ce travail.
Enfin, le plus grand merci à mes chers parents, mon mari pour leur amour
inconditionnel, leur patience et soutien tout au long de ces années d’études. Sans eux,
je n’aurai probablement pas trouvé la force pour y parvenir. Merci à vous tous qui de
près ou de loin avez contribué à ma réussite.


i
TABLE DES MATIÈRES LISTE DES TABLEAUX ............................................................................................. ii
LISTE DES FIGURES ................................................................................................. iii
LISTE DES ÉQUATIONS .......................................................................................... iv
LISTE DES ABRÉVIATIONS ..................................................................................... v
INTRODUCTION ........................................................................................................ 1
CHAPITRE I ................................................................................................................. 3
REVUE DE LA LITTÉRATURE ................................................................................. 3
1.1 Définition du credit scoring ........................................................................ 3
1.2 Historique des techniques de modélisation de la notation de crédit ........... 4
1.3 Importance de la réglementation............................................................... 10
1.4 Méthodes d’évaluation de la performance d’un modèle de notation ........ 11
CHAPITRE II ............................................................................................................. 18
DONNÉES ET MÉTHODOLOGIE ........................................................................... 18
2.1. Définition du défaut .................................................................................. 18
2.2. Description et traitement des données d’analyse ...................................... 19
2.3. Méthodologie ............................................................................................ 26
CHAPITRE III ............................................................................................................ 36
DISCUSSION DES RÉSULTATS ............................................................................. 36
3.1. Analyse des taux de défaut selon les strates d’engagement...................... 36
3.2. Analyse des taux de défaut selon les niveaux de risque ........................... 38
3.3. Écart entre les taux de défaut observés et les probabilités de défaut prédites ................................................................................................................. 39
3.4. Fiabilité : évaluation quantitative de la performance du modèle BHV .... 43
CONCLUSIONS ET AVENUES DE RECHERCHE ................................................ 50
BIBLIOGRAPHIE ...................................................................................................... 53

ii
LISTE DES TABLEAUX
Tableau 1 – Matrice de confusion ............................................................................... 12
Tableau 2 – Échelle d’efficacité d’un modèle donné par L’AUC .............................. 16
Tableau 3 – Échelle d’efficacité d’un modèle donné par la statistique K-S ............... 17
Tableau 4 – Date d’observation et période de performance par image ...................... 21
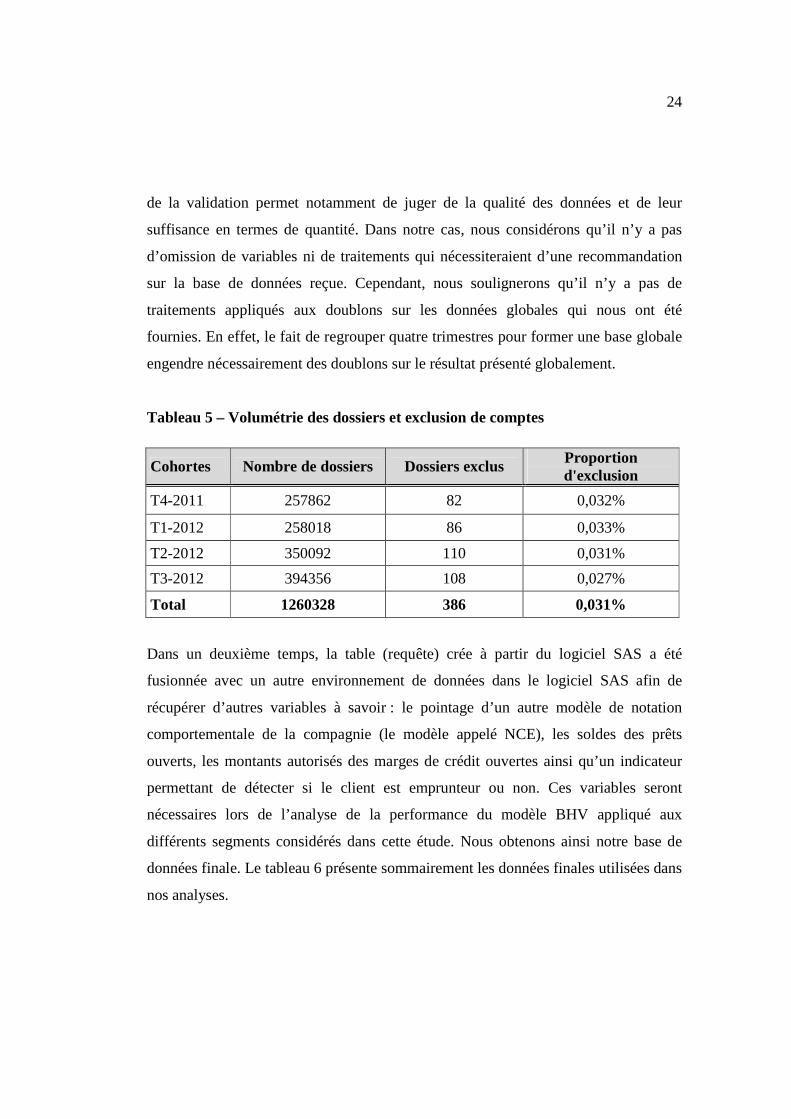
Tableau 5 – Volumétrie des dossiers et exclusion de comptes ................................... 24
Tableau 6 – Base de données finale ............................................................................ 25
Tableau 7 – Grille de pointage du modèle BHV ......................................................... 30
Tableau 8 – Grille de pointage du modèle NCE- Entreprise agricole......................... 34
Tableau 9 – Grille de pointage du modèle NCE- Entreprise commerciale/industriel. 34
Tableau 10 – Distribution des clients selon les strates d’engagement ........................ 37
Tableau 11 – Taux de défaut par niveau de risque...................................................... 39
Tableau 12 – Écart entre probabilités de défaut prédites et taux de défaut observés
pour tous les segments d’engagement. ........................................................................ 40
Tableau 13 – Écart entre probabilités de défaut prédites et taux de défaut observés
pour les moins de 500 000 et 500 000 à 2 500 000 ..................................................... 41
Tableau 14 – MSE par niveau de risque pour chaque segment d’engagement ........... 42
Tableau 15 – MSE par niveau de risque pour les 2 grands segments ......................... 42
Tableau 16 – Performance AUROC et KS pour le modèle BHV sur différents
segments de montants d’engagement .......................................................................... 44
Tableau 17 – Performance pour les modèles le BHV et NCE sur tous les segments
d’engagements............................................................................................................. 45

iii
LISTE DES FIGURES
Figure 1 – Exemple de la courbe ROC ....................................................................... 14
Figure 2 – Fenêtre de performance ............................................................................. 20
Figure 3 – Évolution du taux de défaut des dossiers BHV sur la période d’observation
..................................................................................................................................... 21
Figure 4 – Cadre de manipulation des données .......................................................... 23
Figure 5 – Évolution du taux de défaut par segment d’engagements ......................... 36
Figure 6 – Distribution des dossiers selon les segments d’engagements .................... 37
Figure 7 – Courbe AUROC sur 12 mois- Modèles BHV et NCE sur engagements de
250 000 ou moins ........................................................................................................ 46
Figure 8 – Courbe AUROC sur 12 mois- Modèle BHV et NCE sur engagements de
250 000 à 750 000 ....................................................................................................... 47
Figure 9 – Courbe AUROC sur 12 mois- Modèle BHV et NCE sur engagements de
750 000 à 1 750 000 .................................................................................................... 48
Figure 10 – Courbe AUROC sur 12 mois- Modèle BHV et NCE sur engagements de
1 750 000 à 2 500 000 ................................................................................................. 49

iv
LISTE DES ÉQUATIONS
Équation 1 – Fonction de distribution du pointage ..................................................... 13
Équation 2 – Fonction «Accuracy» (AC) ................................................................... 13
Équation 3 – Sensibilité et spécificité de l’AUC ........................................................ 15
Équation 4 – AUC ....................................................................................................... 15
Équation 5 – Le test de Kolmogorov-Smirnov (KS) .................................................. 17
Équation 6 – Montant d’engagement par type de produit ........................................... 28
Équation 7 – Limite SCD total (3 produits SCD) ....................................................... 28
Équation 8 – Engagement total pour NdC non valide et NdC valide sans score NCE29
Équation 9 – Engagement total pour NdC valide et score NCE disponible................ 29
Équation 10 – Calibrage des pointages ....................................................................... 31
Équation 11 – Calibrage des pointages ....................................................................... 31
Équation 12 – PD prédite pour un compte .................................................................. 32
Équation 13 – PD prédite pour un niveau de risque donné ......................................... 32
Équation 14 – Calcul du MSE par niveau de risque ................................................... 40

v
LISTE DES ABRÉVIATIONS
AIRB Advanced Internal Rating-Based
AMF Autorité des Marchés Financiers
AR Accuracy Ratio
AUC Area Under Curve
AUROC Area Under Receiver Operating Characteristic
BHV Modèle de notation comportementale des cartes de crédits
BSIF Bureau du Surintendant des Institutions Financières
CAP Cumulative Accuracy Profiles
FICO Fair Isaac Corporation
KS Kolmogorov-Smirnov
MSE Mean Square Error
NCE Modèle de Notation Comportementale pour Entreprises dans le Réseau
NI Notation Interne
PD Probabilité de Défaut
ROC Receiver Operating Characteristic
SCD Service de Carte Desjardins
SPID Strategic Portfolio IDentification (Regroupement de comptes)
TD Taux de Défaut

1
INTRODUCTION
Le risque de crédit, qui est l’un des plus importants lorsqu’on parle de risques
financiers, a pris de l’ampleur au cours des dernières années. Il faut dire que
l’instabilité des marchés financiers et de certaines institutions financières a favorisé
une plus grande prise en compte (évaluation et gestion) de ce risque. La mise en place
dans les années 2000 des accords de Bâle II permet aux institutions financières qui
répondent à certaines exigences de pouvoir développer à l’interne leurs propres
modèles de notation de crédit tout en respectant les normes préétablies. Un des
éléments importants dans le processus de gestion des modèles de crédit est l’étape de
validation du modèle.
Dans cette logique, notre projet s’inscrit dans le cadre de la validation du modèle de
notation comportementale utilisé par une institution financière de la place pour la
gestion du risque de crédit des cartes de crédit. Le modèle comportemental BHV
évalue le risque des détenteurs particuliers et entreprises des Services des Cartes
Desjardins. Il est utilisé lors de prises de décisions d’octroi, d’augmentation de
limites ou encore lors de la mise en place de stratégies de délinquance.
L’objectif de notre analyse dans ce projet est d’évaluer la possibilité d’utiliser ce
modèle sur un échantillon autre que celui pour lequel il a été initialement développé.
En effet, nous validerons dans ce projet la performance du modèle BHV suite à un
ajustement du périmètre d’utilisation.
Notre étude s’articule autour de trois grandes parties divisées en chapitre. Le chapitre
1 couvre la revue de littérature qui permet de comprendre les modèles de notation de
crédit, souvent appelés «credit scoring models» ou encore «behavior scoring
models», les différentes techniques de modélisation ainsi que l’importance de la
réglementation dans le processus de développement et de validation des modèles de

2
notation. Par ailleurs, nous présenterons les outils de mesure de performance que
nous utiliserons dans notre analyse de fiabilité du modèle. Dans le chapitre 2, nous
procéderons à la description de nos données ainsi que de la méthodologie suivie.
Enfin, dans le chapitre 3 nous discuterons des différents résultats obtenus.
Tous nos calculs et analyses ont été faits et obtenus avec les procédures des logiciels
SQL, SAS1, MS Excel et Visio.
1 Statistical Analysis System, est un langage propriétaire de programmation, utilisé généralement dans la statistique ou encore dans l’industrie du risque de crédit.

3
CHAPITRE I
REVUE DE LA LITTÉRATURE
Au cours des dernières années, les modèles de notation de crédit ont fait l’objet de
plusieurs études. Cependant, très peu d’articles ont été consacrés à l’évaluation de la
performance des modèles de notation comportementale.2 Dans cette section, nous
aborderons quatre points qui nous permettrons d’avoir une meilleure compréhension
de la notation de crédit (credit scoring) et de la notation comportementale (behavior
scoring), des différentes techniques développées dans la littérature, du rôle de la
réglementation dans le processus de développement et de validation, et finalement
des différents outils permettant d’évaluer la performance d’un modèle de notation de
crédit.
1.1 Définition du credit scoring
Bien que la définition donnée au credit scoring puisse être différente d’un auteur à un
autre, cette méthode est considérée par la plupart comme étant une technique de
gestion de risque, qui permet de prédire la probabilité de défaut, un des paramètres
très importants dans le calcul du capital réglementaire de Bâle. C’est donc un outil de
gestion de risque de crédit qui permet d’évaluer le niveau de risque de chaque client
ou d’une institution financière.
Selon Thomas [1] la notation de crédit est essentiellement un moyen de reconnaître
les différents groupes dans une population quand on ne peut observer les
2 La notation comportementale est encore appelée «behavior scoring».

4
caractéristiques qui les séparent mais seulement celles qui les lient. Il soulève la
nuance entre la notation de crédit et la notation comportementale. Alors que la
notation de crédit permet de prendre la décision d’accorder ou de ne pas accorder un
prêt, la notation comportementale permet de gérer le comportement de prêt des clients
existants. Il assure en quelque sorte un suivi de leurs cotes de risque.
Schreiner [2] définit la notation de crédit comme étant l’utilisation de la connaissance
de la performance et des caractéristiques de prêts passés pour prédire la performance
des prêts futurs. Il utilise une technique qui attribue des scores aux emprunteurs
comme un moyen d'évaluer la performance de leurs futurs prêts. Caire et Kossman
[3] considèrent que la notation de crédit n’approuve ni ne rejette une application de
crédit mais permet de prédire la perte telle que définie par l’institution financière.
1.2 Historique des techniques de modélisation de la notation de crédit
On constate à travers la littérature que l’objectif et l’élément important d’un système
de notation se résume à déterminer le meilleur outil de classification ou encore de
discrimination.
Avant même qu’Anderson [4] ne présente la notation de crédit comme étant un
recours aux modèles statistiques en vue de transformer des données qualitatives et
quantitatives en indicateurs numériques, plusieurs auteurs ont proposé différentes
techniques de modélisation. Le pionner à avoir introduit le concept est David Durand
[5]. Il a utilisé l’approche de classification développée par Fisher en 1936 [24] pour
examiner différents dossiers de «bon et mauvais» prêts. Son étude publiée par The
National Bureau of Economic Research, s’est basée sur un vaste échantillon composé
de 7200 clients de 37 institutions financières. À l’aide de l’analyse discriminante

5
(technique statistique visant à expliquer ou identifier décrire, expliquer et prédire
l’appartenance à des groupes prédéfinis (modalité de bons ou mauvais) d’un
ensemble d’observations (demandeurs de crédit) à partir d’une série de variables
prédictives (revenus, âge etc..), l’auteur a pu identifier des facteurs de risque de crédit
dans le financement de la consommation. De plus, il est important de noter qu’il n’a
pas fait usage d’informations comportementales.
Quelques années plus tard, Myers et Forgy [6] ont construit des cartes de pointage à
partir de données d’une seule institution financière en utilisant plusieurs approches
techniques. De l’analyse discriminante à la régression multiple en passant par la
régression simple. Les auteurs étaient à la recherche d’une carte avec un meilleur
pouvoir prédictif. C’est ainsi qu’ils ont incorporé un nouvel élément dans leur
processus, l’échantillon de validation.
Dans une plus récente étude empirique, Kao & al [7], propose un modèle bayésien à
variable latente de classification et d’arbre de régression pour notation de crédit et
comportementale. Cette approche permet de répondre à trois principaux défis
auxquels font face des banques émettrices de carte de crédit : prévision plus précise
du type de demandeur, détermination du niveau de limite basée sur l’utilisation et le
comportement de remboursement des clients actuels, et l’amélioration du processus
de décision d’octroi de crédit. La technique permet de conclure que les variables
démographiques généralement utilisées par les banques ont un pouvoir explicatif très
faible. En outre, ce modèle très différent du modèle de notation binaire classique
permet d’obtenir un taux de performance de près de 92% comparativement aux
modèles paramétriques présentés par Altman et Saunders [18] à savoir l’analyse
discriminante, la régression logistique qui vise à prédire une variable binaire (tel que
le défaut qui prend la valeur 0 ou 1) à partir de variables explicatives, régression
adaptée multivariée ainsi que les modèles non paramétriques, le réseau de neurones

6
(utilisée généralement lorsque la relation entre la variables dépendante et
indépendantes ne sont pas linéaire) [29]. L’approche a aussi le taux de mauvaise
classification le plus bas. L’ensemble des notions conceptuelles et statistiques
concernant la méthodologie des modèles de notation de crédit sont décrites plus
amplement dans [28] par Kiefer et al.
Ogler fut l’un des quelques auteurs à avoir développé des modèles de notation pour
évaluer les prêts commerciaux dans la littérature [8] . FICO, encore connu sous le
nom de Fair & Isaac Corporation est le leader pour développer ces modèles internes
depuis l’apparition de leur première carte de pointage qui avait permis de réduire les
mauvais comptes de 50% dans les années 60. La plupart des modèles de notation
comportementale externes tel que celui étudié dans le présent document ont été
développés par FICO.
Il est important de soulever que la plus part des modèles de notation de crédit sont
généralement développés, en utilisant des échantillons constitués uniquement de
demandeurs dont les applications ont été acceptées en excluant donc les
caractéristiques de ceux refusés. Un échantillon non représentatif est donc utilisé,
créant ainsi un problème de biais de sélection. On parle souvent de ‘’biais de rejet’’.
Cette façon de procéder, pourrait selon certains auteurs conduire à l’obtention de
paramètres biaisés et donc pourrait aussi impacter la performance du modèle de
notation. Banasik et al se sont penchés sur ce sujet. En effet, dans leur article [25], les
auteurs ont analysé la capacité prédictive (accuracy) des modèles de notation de
crédit basés uniquement sur des applications acceptées et ont vérifié s’il y aurait un
gain ou amélioration de la performance en utilisant des techniques économétriques de
sélections. Pour pallier au biais de rejet, la méthodologie généralement utilisée est
l’inférence des rejets, connue sous ‘’reject inference’’. Il s’agit d’intégrer les dossiers
refusés dans le bassin des applications utilisées pour le développement du modèle de

7
notation afin d’avoir une population plus représentative de la réalité. Il existe un
ensemble de techniques, notamment la repondération «re weighting» ou encore
l’augmentation, l’extrapolation des paramètres obtenus par les dossiers acceptés sur
les rejetés, l’ajout d’informations supplémentaires du bureau de crédit et bien
d’autres. Siddiqi [16] décrit chacune de ces techniques ainsi que les différentes
étapes de leurs méthodologies. La méthode d’augmentation par exemple, consiste à
ajuster le poids du modèle d’acceptation initialement basé sur l’ensemble des
acceptés et refusés par une estimation de la probabilité d’acceptation (celle d’être
inclus dans la population connue). Ceci est fait de façon à ce que les informations des
demandeurs approuvés sont utilisées pour déterminer le nouveau modèle en
pondérant chaque accepté par un poids inverse de la probabilité afin d’être plus
représentatif de la population totale. Une autre méthode est la reclassification. Elle
consiste à appliquer le modèle de notation construit à partir des dossiers acceptés sur
ceux refusés afin de déterminer les «bons refusés». Par la suite, les bons sont rajoutés
à l’échantillon de bons acceptés et un nouveau modèle est construit sur l’ensemble du
nouvel échantillon «bons refusés» et «bons acceptés». Dans l’article [25], Banasik et
al ont utilisé la régression logistique pour construire deux types de modèles à savoir,
un modèle composé de toutes les applications (refusées et acceptées) et un autre
composé que d’applications acceptées. Par ailleurs, ils ont analysé la prédiction de la
performance en se basant sur la courbe ROC et le pourcentage de tous les cas
correctement classifiés. De plus, les approches telle que celle du «weight of
evidence3» pour transformer les variables explicatives, celle de variables binaires
ainsi que celle du modèle probit bivarié4 ont été utilisées afin de pouvoir comparer la
prédiction de la performance sur les deux types de modèles. Les résultats obtenus,
démontrent que la valeur ajoutée en incorporant le comportement des applications
3 Approche qui permet de remplacer la variable prédictive par le «weight of evidence» correspondant. Le calcul du weight of evidence est décrit par Siddiqi dans [16] . 4 C’est un modèle à deux équations utilisé lorsque deux variables qualitatives dichotomiques doivent être expliquées simultanément. Il permet donc de dériver la probabilité de deux événements simultanés.

8
rejetées dans le modèle de notation est très modeste basé sur le seuil fixé par les
données utilisées. L’approche de repondération utilisée par Banasik et al dans [26]
démontre aussi qu’empiriquement, la performance du modèle n’est pas améliorée.
Dans une étude plus récente, Barakova et al [27] ont utilisé une toute autre approche
basée sur l’utilisation de données supplémentaires du bureau de crédit pour un
échantillon de cartes de crédit pour un modèle de notation de crédit. Ils ont pu
montrer que l’impact sur le pouvoir discriminant du modèle est certes minime, mais
le fait de juste considérer les dossiers acceptés dans le système de notation, sous-
estime le risque de délinquance des clients. De plus, la validation de ces systèmes de
notation tend à une sous-estimation de la détérioration de la performance du système
de notation.
Un autre aspect souvent omis dans les modèles de notation de crédit développés par
les institutions financières est l’horizon de défaut. Autrement dit, le moment de
l’évènement défaut (ou encore le temps de survie du client) n’est aucunement
considéré dans des modèles de notation de crédit utilisés par les institutions
financières. Mavri et al [30] ont proposé un modèle dynamique en deux étapes,
permettant non seulement d’estimer le risque de demandeurs de cartes de crédit mais
aussi la probabilité de défaut sur un temps prédéfini. Le modèle prend donc en
compte la variabilité des différentes variables associées à la modélisation d’un
modèle de notation de crédit. En se basant sur 350 données, les auteurs déterminent
dans un premier temps, à l’aide d’une régression logistique les variables significatives
permettant de dériver le niveau de risque (probabilité) et ainsi classer les clients en
«bons» ou «mauvais» emprunteurs5. Par la suite, ils appliquent l’analyse de survie
(Kaplan-Meyer) sur le groupe des bons demandeurs. Cette analyse représente un
ensemble de techniques statistiques d'analyse de données, où la variable de résultat
5 La mesure de performance ROC a été utilisé pour mesurer l’adéquation de la classification des bons et mauvais.

9
est le temps jusqu'à ce qu’un événement se produise dans ce cas, le défaut. L’analyse
a permis de démontrer qu’en moyenne, le temps de survie des demandeurs approuvés
est de 15,1 années. Cet élément est pertinent dans la mesure où, elle permet
d’incorporer une information supplémentaire favorisant une meilleure gestion de
crédit des institutions financières notamment dans le cas des cartes de crédit.
.
Rappelons que l’objectif principal de ce rapport est de mesurer la validité d’un
modèle de notation de crédit, et donc de s’assurer que le modèle de crédit est adéquat
sur périmètre sur lequel il sera évalué. Dans son article ‘’How good is your credit-
scoring model?’’ [31], Fensterstock confirme que la partie la plus importante de
l’évaluation de la performance d’un système de notation est la validation ou
revalidation des modèles existants, tel que nous nous proposons de réaliser pour le
modèle BHV. En effet, l’auteur s’est proposé de répondre à la question, en reportant
les résultats de l’enquête prévisionnelle de la fondation ‘’Equipment Leasing and
Finance’’ et en y incorporant des recommandations destinées à l’industrie de crédit.
Fensterstock soulève dans un premier temps, l’impact que pourrait engendrer
l’utilisation d’un modèle sur une population autre que celle pour laquelle, elle aurait
été développée. On constate que plus de 20% des répondants prennent ce risque en
évaluant des segments avec des modèles de notation de crédit qui ne leurs sont pas
destinés. Ce risque est d’autant plus élevé, si aucune validation n’est effectuée au
préalable sur le modèle afin de connaître la performance, les limites et risques de ce
dernier. De plus, il est recommandé que les compagnies utilisent des données récentes
dans leurs modèles afin d’optimiser les résultats. Par ailleurs, il est recommandé voire
nécessaire que la validation des modèles se fasse sur une base régulière6 afin de
prendre en compte les variations dans le cycle économique, détecter des lacunes liées
6 Généralement chaque année pour les modèles réglementaires. Fensterstock propose entre 18 et 24 mois [31].

10
au système et enfin, permettre une meilleure gestion des décisions de crédit. Les
institutions financières devraient implémenter un système d’évaluation de la
performance pour s’assurer de l’adéquation des paramètres estimés par les modèles.
Un système d’évaluation adéquat selon Fensterstock, devrait adresser deux types
d’exigence à savoir le ‘’front-end’’ (il permet à l’institution de mesurer l'évolution de
la population au moment de l’application du client en donnant un signal sur la
détérioration de la performance du modèle) et le ‘’back end’’ (il fournit une mesure
de la qualité du portefeuille). Les résultats et recommandations de cet article,
corroborent les exigences prévues par les instances règlementaires.
1.3 Importance de la réglementation
Les modèles de notation de crédit sont autorisés par la réglementation, notamment
Bâle II, à jouer un rôle dans l’estimation des paramètres de risque aussi longtemps
qu’un certain jugement humain non capté par le modèle est pris en compte pour
attribuer la note finale à l’emprunteur. En effet, en vue de minimiser les risques
financiers dans le système bancaire, le Comité de Bâle a créé un cadre réglementaire
concernant les fonds propres. En plus d’exiger un montant minimal de fonds propres,
le Comité de Bâle cherche à «récompenser» les institutions financières ayant les
meilleures pratiques en matière de mesure et contrôle du risque de crédit. Par le biais
de la méthode notation interne (NI) avancée, le Comité de Bâle offre ainsi la
possibilité d’utiliser des outils de gestion de risque tel que le modèle BHV pour
déterminer les probabilités de défaut des comptes du portefeuille, paramètres
importants dans le calcul des fonds propres et du capital économique. Par ailleurs, il
est requis par l’AMF, ainsi que par le BSIF, que l’institution procède à la validation
réglementaire de ces modèles et à celle de la définition de défaut utilisée pour
construire les différents scores et indicateurs de risques, afin de s’assurer qu’elles

11
s’alignent sur celles exigées par les autorités [9] . La banque devra donc vérifier la
calibration du modèle ainsi que son pouvoir discriminant. Tel que l’indique l’autorité
dans ses lignes directrices: ‘’Au titre des normes minimales à respecter pour être
autorisées par l’Autorité à utiliser l’approche NI, les entités financières devront faire
la démonstration de la validité de leurs systèmes de notation’’.
1.4 Méthodes d’évaluation de la performance d’un modèle de notation
Avant l’implantation ou l’utilisation opérationnelle d’un modèle de risque de crédit, il
est très important d’évaluer sa capacité à distinguer les bons emprunteurs (non-
défaillants) des mauvais (défaillants). Cette capacité encore appelée pouvoir
discriminant s’inscrit dans la procédure de la validation et permet de s’assurer de la
fiabilité du modèle. Elle peut être mesurée à l’aide de tests de performance. Il existe
plusieurs indicateurs statistiques que l’on peut nommer: la courbe de caractéristiques
d'efficacité (ROC), le Profil de Précision Cumulatif (CAP) et son indice le ratio de
précision (AR), le graphique des gains (Gains Chart), l’entropie conditionnelle, la
divergence de Kullback-Leibler, ainsi que le Score de Brier. Tel que le préconisent
les accords de Bâle II dans leur document de travail, nous appliquerons la méthode
ROC, son indice AUC7 ainsi que l’indice KS sur notre échantillon d’analyse, pour
l’évaluation du pouvoir de discrimination de notre modèle BHV.
7 Il représente l’aire sous la courbe ROC que nous présenterons plus bas.

12
1.4.1 «L’accuracy» (AC)
Chaque emprunteur peut être caractérisé par deux variables aléatoires :
• le pointage (score) dénoté S attribué à chaque emprunteur
• la variable binaire de Bernoulli dénotée B qui nous donne l’état de
l’emprunteur : B = � 1,sil�emprunteurfaitdéfaut�d�0, sil�emprunteurnefaitpasdéfaut�nd�
Nous avons donc quatre possibilités d’états selon les prédictions et les défauts réels.
Ces états sont définis par la matrice de confusion représentée dans le tableau 1.
Tableau 1 – Matrice de confusion
Défauts Non-Défauts
Défauts prédits (sous le seuil S) Les vrais défauts (vrais positifs) (TP)
Les faux défauts (faux positifs) (FP) erreur de type II
Non Défauts prédits (au-dessus du seuil S)
Les faux non défauts (faux négatifs) (FN) erreur de type I
Les vrais non défauts (vrais négatifs) (TN)
Nd Nnd où Nd et Nnd représentent respectivement les nombres de défauts et non défauts
totaux.
Tel que l’indiquent Tasche [19] et Hong [20] , les fonctions de distribution
conditionnelle du score S pour une valeur de B sont respectivement �� et ���. Nous
pouvons donc écrire l’équation suivante qui représente la fonction de distribution du
pointage S :

13
Équation 1 – Fonction de distribution du pointage
���� = ������ + �1 − ��������, où � représente la probabilité de défaut � = P[B = d].
La statistique « accuracy » est obtenue selon [20] tel que suit :
Équation 2 – Fonction «Accuracy» (AC)
AC = ������ + �1 − ��[1 − ������] = 2������ − ���� + �1 − ��.
À partir des informations ci-haut, nous pouvons déterminer la statistique AUC ainsi
que la courbe ROC dans la sous-section suivante.
1.4.2 La courbe ROC et l’aire sous la courbe (AUROC)
La courbe ROC est un outil visuel qui peut être facile à tracer si nous disposons de
deux échantillons représentatifs de scores pour des emprunteurs solvables (non
défaut) et non solvables (en défauts). Cette courbe représente le taux de vrais défauts
(vrais positifs), ceux qui sont prédits correctement en fonction du taux des fausses
alarmes, la probabilité de classer une entreprise non défaut par exemple. Le taux des
vrais défauts est encore connu sous le nom de la sensibilité de la courbe ROC et est
représenté sur l’axe des ordonnés du graphique du ROC. Par ailleurs, les non défauts
prédits correctement (vrais négatifs) représentent l’élément de la courbe ROC nommé
spécificité.
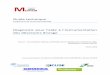
14
L’approche de la courbe ROC fut développée initialement pour détecter des signaux
électriques associés aux radars pendant la Seconde Guerre mondiale [11]. Elle a été
largement utilisée aussi en médecine.
Sobehart et Keenan [12] et [13] ont montré dans leur étude comment mesurer
précisément le défaut en utilisant la courbe ROC et ses indices. Les auteurs ont
présenté l’approche mathématique de la courbe ROC et de l’aire sous cette courbe. Ils
ont pu démontrer que l’espace se situant sous cette courbe est un indicateur de la
qualité d’un modèle de prédiction.
Le principe de construction de cette courbe est donné par Stein pour Moody’s KMV
[14]. La figure 1 illustre un exemple de la courbe ROC.
Figure 1 – Exemple de la courbe ROC
0
0,2
0,4
0,6
0,8
1
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1
Sen
sibi
lité
1-Spécificité
Courbe ROC
Modèle de notation
Modèle parfait
Modèle aleatoire

15
Cette figure montre clairement qu’un modèle parfait n’enregistrera que des
déplacements verticaux, jusqu’à l’identification de tous les emprunteurs en défaut. Le
modèle aléatoire, quant à lui, est équivalent à déterminer l’état de défaut en tirant une
pièce de monnaie à pile ou face.
Équation 3 – Sensibilité et spécificité de l’AUC
'(��� = )*�+�,� et 1 − '���� = -*�+�
,�� ,
où :
� ./��� représente les entreprises en défaut, prédites correctement avec 01 le
nombre total de défauts;
� �/��� représente les fausses alarmes, les non-défauts classés incorrectement
défauts et 021 le nombre total de non-défauts;
� � est la valeur de seuil du pointage donné.
Équation 4 – AUC
345 = 6 '([1 − '����]171 − '����89: , et 345 ∈ [0.5, 1].
où :
� '( représente la sensibilité, le taux des entreprises réellement en défaut (les
vrais positifs);
� 1 − '� = 1- spécificité représente, le taux des entreprises non défaut (les faux
négatifs).

16
Le meilleur modèle de notation, celui qui possède un pouvoir discriminant
appréciable, se rapprochera le plus de l’AUC maximale égale à 1. Cette aire
correspond à la probabilité de distinguer un positif d’un négatif. Une valeur d’AUC
de 0.5 représente le modèle aléatoire tandis que celle égale à 1 représente le modèle
parfait.
Dans le cadre d’une saine gestion de risque de crédit notamment pour les modèles de
notation, les institutions financières dont la nôtre, adoptent l’échelle de l’indice AUC
défini par Hosmer et Lemeshow [15] tel que le montre le tableau 2.
Tableau 2 – Échelle d’efficacité d’un modèle donné par L’AUC
AUC Appréciation de la qualité du modèle
[0.5 , 0.7[ Non concluant
[0.7 , 0.9[ Bien
[0.9 , 1.0[ Excellent
Notons que cet indice de mesure du pouvoir discriminant des modèles de notation reste un indicateur subjectif. Bien d’institutions suggèrent de considérer aussi les éléments stratégiques et opérationnels dans la prise de décision.
De plus, l’inconvénient de cette mesure est qu’elle ne tient pas compte de coûts liés à
la mauvaise classification [21]. Hand soulève cette problématique dans plusieurs de
ces études notamment [21] et propose des pistes de solutions qui seront repris par
bien d’autres auteurs.

17
1.4.3 La statistique de Kolmogorov-Smirnov
En statistique, le test de Kolmogorov-Smirnov (KS-test) permet de déterminer si deux
échantillons suivent une loi identique. Dans le cadre d’un modèle de notation, on
utilise cet indicateur non paramétrique pour mesurer la distance maximale entre les
distributions cumulatives des scores des comptes en défaut et les non défauts. Plus la
distance de séparation est grande, meilleure est la capacité prédictive ou
discriminante des pointages entre les deux groupes. Il se calcule selon l’équation 5.
Équation 5 – Le test de Kolmogorov-Smirnov (KS)
<' = Max | M(x)-B(x) |; > ∈ [L, H], où B(x) et M(x) représentent les fonctions de distributions cumulatives empiriques des
«bons» et «mauvais» emprunteurs respectivement. L et H quant à eux, représentent
un seuil minimum et maximum d’un pointage donné [23] .
Son échelle d’efficacité (donné par [17]) est presque similaire à celle de l’AUROC et
son interprétation, tout comme celle de l’AUROC, doit tenir compte aussi des besoins
d’affaires de l’institution financière.
Tableau 3 – Échelle d’efficacité d’un modèle donné par la statistique K-S
KS (en %) Appréciation de la qualité du modèle
[0 , 20] Non concluant ]20 , 40] Moyen ]40 , 50] Bien ]50 , 60] Très bien ]60 , ...] Excellent

18
CHAPITRE II
DONNÉES ET MÉTHODOLOGIE
À travers cette section, nous décrirons dans un premier temps, les données utilisées
dans ce projet et présenterons les principaux processus de manipulation de données
ainsi que la définition du défaut utilisée dans ce modèle. Plus tard, nous aborderons
les différentes étapes de la méthodologie utilisée dans le cadre de l’application du
modèle BHV sur différents segments de montants d’engagements.
2.1. Définition du défaut
Au cours de l’évaluation d’un modèle de risque de crédit, un des critères très
importants à valider est la définition du défaut. En effet, celle-ci doit être similaire
pour tous les paramètres et conforme à celle des autorités réglementaires (AMF,
BSIF, Bâle). Il est important de souligner que ce modèle avait été initialement conçu
par FICO en 2009 et implanté en 2010. L’institution financière n’a pas fait de
nouveau développement mais un simple recalibrage8 en 2013 à l’interne pour
s’assurer de la robustesse du modèle BHV. Par ailleurs pour cette analyse, la
définition du défaut considérée s’aligne avec celle utilisée lors du développement et
en vigueur dans les opérations de la compagnie. En effet, un compte est considéré
comme «mauvais» ou encore «en défaut», lorsque sur une période de 12 mois, l’un
des évènements suivants se matérialise :
8 Réajuster les paramètres du modèle existant afin de rétablir la qualité de prévision à travers l’augmentation des pointages (scores).

19
� Un retard de 90 jours et plus sur au moins une carte ou un compte, même
si les autres cartes sont à jours;
� Une radiation;
� Une faillite. Cette définition est en conformité avec les paragraphes 452 et 453 de l'Accord de
Bâle II. Cependant, une modification a été apportée aux comptes qualifiés de bons
afin d’être en accord avec les stratégies et définitions opérationnelles. En effet, les
comptes indéterminés9 qui étaient exclus lors de la conception du modèle, sont
considérés comme «bons» lors de la validation. Ceci dit, cette approche avait été
utilisée lors du recalibrage du modèle BHV et est conforme à celle utilisée dans
d’autres projets de l’institution.
2.2. Description et traitement des données d’analyse
Pour réaliser ce projet de validation, nous avons reçu une base de données interne
constituée de données de suivi du modèle récemment calibré10. Cette base est
constituée de 1 260 328 dossiers de clients qui représentent quatre cohortes
mensuelles distinctes à savoir les images de Décembre 2011, Mars 2012, Juin 2012 et
finalement Septembre 2012. Le choix de ces groupes se justifie par le fait que l’on
voulait avoir des données récentes avec des performances de 12 mois tel que le
montrent le tableau 4 et la figure 2. Il s’agit d’observer le client à une date X et
d’évaluer 12 mois (1 an) plus tard si ce dernier à fait défaut ou pas (si un des
évènements de défauts présentés plus haut s’est réalisé) et utiliser la mesure de
performance AUROC pour évaluer si le modèle a bien prédit les défauts 12 mois
9 Comptes ayant plus de 5 retards d’un (1) jour ou des retards de 89 jours et moins. 10 Pour des raisons de confidentialité, certaines données de la base ont été légèrement modifiées

20
après l’observation. Chaque image est composée de comptes d’entreprises détentrices
de cartes de crédit et ayant des scores (ou encore pointages) valides. De plus, les
comptes inactifs11 ont été au préalable exclus en amont. Pour chacune des 1 260 328
observations, nous disposons de 30 variables mais n’en énumérons que quelques-
unes:
� Le numéro de la carte de crédit;
� FIID : les 6 premiers chiffres de la carte;
� Le SPID auquel le compte est associé;
� La date d’observation;
� L’indicateur défaut BHV;
� Le pointage comportemental brut BHV : c’est-à-dire le score non calibré
ou non aligné;
� Le pointage comportemental NCE;
� Les soldes et limites de carte et prêts.
Figure 2 – Fenêtre de performance
Fenêtre de performance
12 mois Date d’observation défaut ou non-défaut
11 Comptes qui se caractérisent par une absence d’activité ou encore présence d’un plan de paiement différé non échu. Leur pointage n’est pas significatif (inférieur à 100).
21
Tableau 4 – Date d’observation et période de performance par image
Cohortes Dates d'observation Périodes de performance
T4-2011 01 Décembre 2011 du 02 Décembre 2011 au 01 Décembre 2012
T1-2012 01 Mars 2012 du 02 Mars 2012 au 01 Mars 2013
T2-2012 01 Juin 2012 du 02 Juin 2012 au 02 Juin 2013
T3-2012 01 Septembre 2012 du 02 Septembre 2012 au 02 Septembre 2013
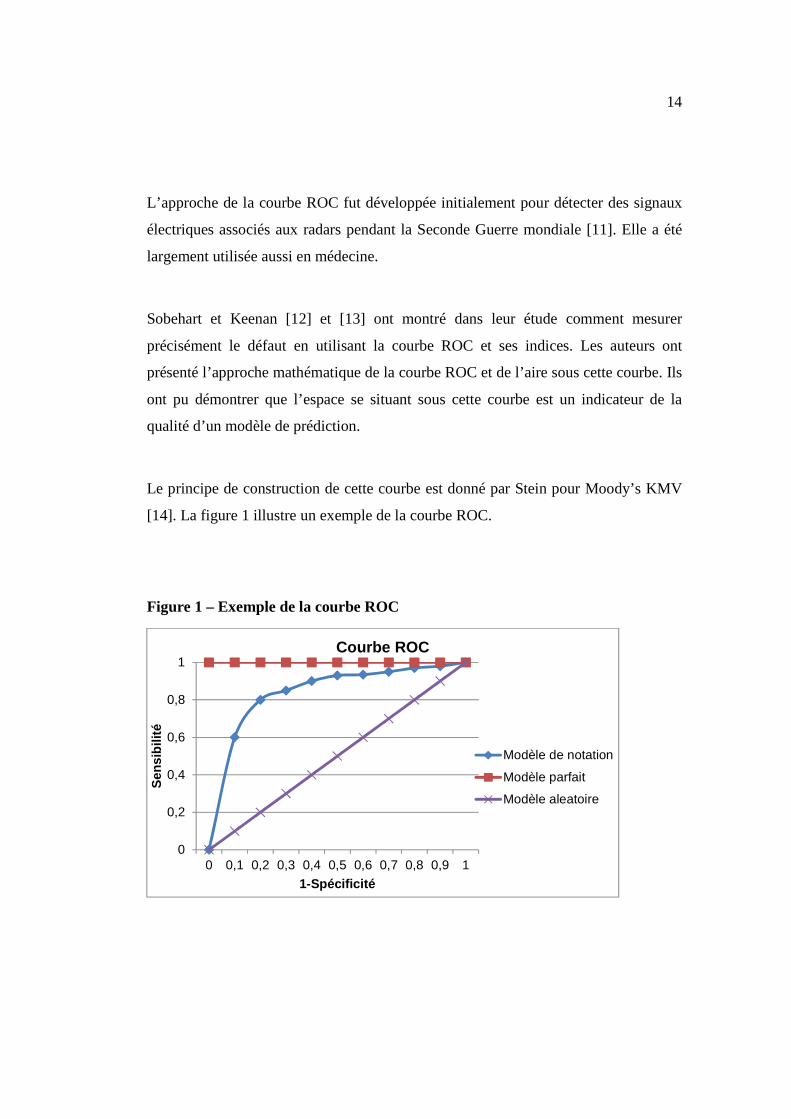
Figure 3 – Évolution du taux de défaut des dossiers BHV sur la période
d’observation
Par la suite, cette base a subi plusieurs traitements avant que l’on obtienne la base
finale d’analyse. La figure 4 nous montre le cadre de tous les traitements. Pour
chaque image, la base principale a été fusionnée avec une des tables de
l’environnement de données interne à la coopérative. Cette fusion permet de
0,75%
0,80%
0,85%
0,90%
0,95%
1,00%
T4-2011 T1-2012 T2-2012 T3-2012
Évolution du taux de défauts Décembre 2011 à Septembre-2012
Taux dedéfautsobservés

22
récupérer la variable ‘’numéro de compte’’12. En outre, lors de cette fusion, seuls les
comptes considérés opérationnels ou potentiellement opérationnels sont conservés.
Ce filtre permet d’exclure 0,03 % de dossiers. Le tableau 4 nous permet de voir le
détail des comptes et exclusions pour chaque trimestre. Il est important d’avoir cette
volumétrie car ceci nous permet de noter la quantité d’éléments qui ne feront pas
partie de l’analyse. Certaines exclusions ou filtres peuvent avoir de gros impacts dans
l’analyse de la performance.
12 Cette variable est unique à chaque client.
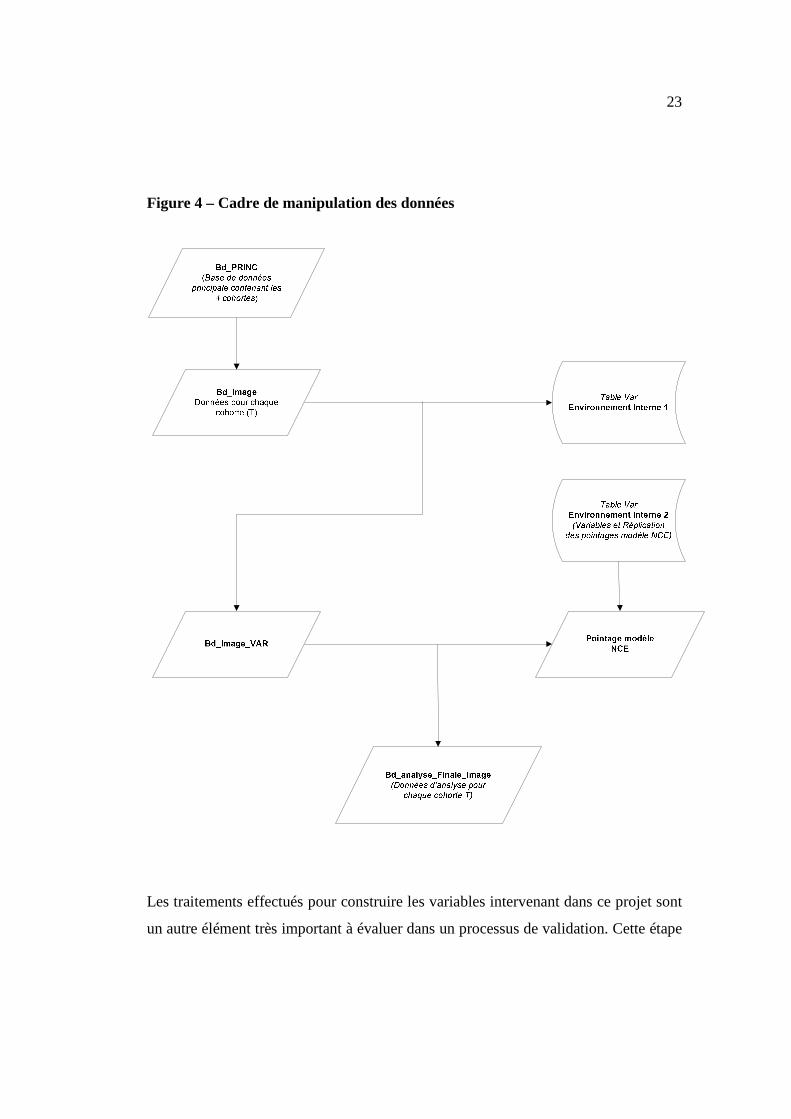
23
Figure 4 – Cadre de manipulation des données
Les traitements effectués pour construire les variables intervenant dans ce projet sont
un autre élément très important à évaluer dans un processus de validation. Cette étape
24
de la validation permet notamment de juger de la qualité des données et de leur
suffisance en termes de quantité. Dans notre cas, nous considérons qu’il n’y a pas
d’omission de variables ni de traitements qui nécessiteraient d’une recommandation
sur la base de données reçue. Cependant, nous soulignerons qu’il n’y a pas de
traitements appliqués aux doublons sur les données globales qui nous ont été
fournies. En effet, le fait de regrouper quatre trimestres pour former une base globale
engendre nécessairement des doublons sur le résultat présenté globalement.
Tableau 5 – Volumétrie des dossiers et exclusion de comptes
Cohortes Nombre de dossiers Dossiers exclus Proportion d'exclusion
T4-2011 257862 82 0,032%
T1-2012 258018 86 0,033%
T2-2012 350092 110 0,031%
T3-2012 394356 108 0,027%
Total 1260328 386 0,031%
Dans un deuxième temps, la table (requête) crée à partir du logiciel SAS a été
fusionnée avec un autre environnement de données dans le logiciel SAS afin de
récupérer d’autres variables à savoir : le pointage d’un autre modèle de notation
comportementale de la compagnie (le modèle appelé NCE), les soldes des prêts
ouverts, les montants autorisés des marges de crédit ouvertes ainsi qu’un indicateur
permettant de détecter si le client est emprunteur ou non. Ces variables seront
nécessaires lors de l’analyse de la performance du modèle BHV appliqué aux
différents segments considérés dans cette étude. Nous obtenons ainsi notre base de
données finale. Le tableau 6 présente sommairement les données finales utilisées dans
nos analyses.
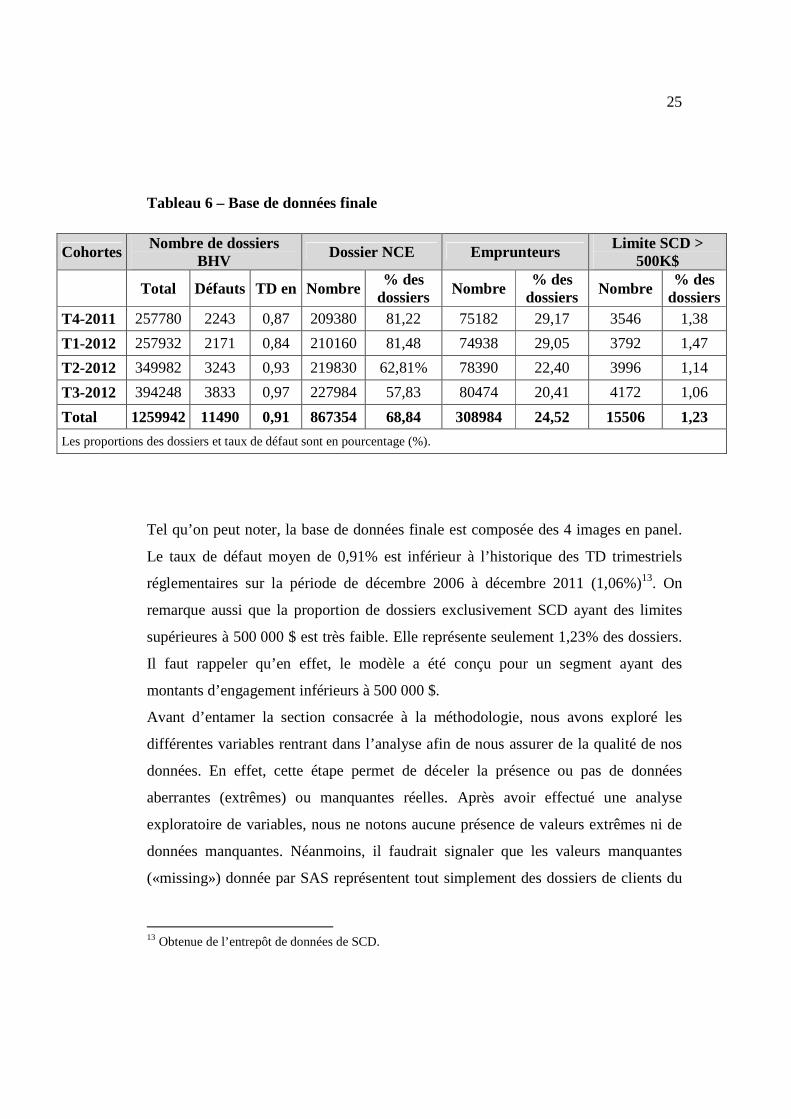
25
Tableau 6 – Base de données finale
Cohortes Nombre de dossiers BHV Dossier NCE Emprunteurs Limite SCD >
500K$
Total Défauts TD en Nombre % des
dossiers Nombre % des
dossiers Nombre % des
dossiers T4-2011 257780 2243 0,87 209380 81,22 75182 29,17 3546 1,38
T1-2012 257932 2171 0,84 210160 81,48 74938 29,05 3792 1,47
T2-2012 349982 3243 0,93 219830 62,81% 78390 22,40 3996 1,14
T3-2012 394248 3833 0,97 227984 57,83 80474 20,41 4172 1,06
Total 1259942 11490 0,91 867354 68,84 308984 24,52 15506 1,23
Les proportions des dossiers et taux de défaut sont en pourcentage (%).
Tel qu’on peut noter, la base de données finale est composée des 4 images en panel.
Le taux de défaut moyen de 0,91% est inférieur à l’historique des TD trimestriels
réglementaires sur la période de décembre 2006 à décembre 2011 (1,06%)13. On
remarque aussi que la proportion de dossiers exclusivement SCD ayant des limites
supérieures à 500 000 $ est très faible. Elle représente seulement 1,23% des dossiers.
Il faut rappeler qu’en effet, le modèle a été conçu pour un segment ayant des
montants d’engagement inférieurs à 500 000 $.
Avant d’entamer la section consacrée à la méthodologie, nous avons exploré les
différentes variables rentrant dans l’analyse afin de nous assurer de la qualité de nos
données. En effet, cette étape permet de déceler la présence ou pas de données
aberrantes (extrêmes) ou manquantes réelles. Après avoir effectué une analyse
exploratoire de variables, nous ne notons aucune présence de valeurs extrêmes ni de
données manquantes. Néanmoins, il faudrait signaler que les valeurs manquantes
(«missing») donnée par SAS représentent tout simplement des dossiers de clients du
13 Obtenue de l’entrepôt de données de SCD.

26
SCD qui n’ont pas de lien au niveau du réseau des caisses. En d’autres mots, des
entreprises détenant des cartes mais pas de prêts au niveau du réseau.
2.3. Méthodologie
Dans cette section, nous présenterons les objectifs, les différentes hypothèses, les
critères de succès et les différentes étapes de la méthodologie adoptée.
2.3.1 Objectifs et hypothèses
Rappelons que l’objectif de ce projet est d’analyser la performance du modèle BHV
sur un tout autre périmètre que celui pour lequel il a été développé à l’origine. Afin de
justifier l’utilisation de ce modèle sur des montants d’engagement pouvant aller
jusqu’à 2 500 000$, le modèle BHV actuel devrait afficher un pouvoir discriminant
qualifié de «bien» ou «mieux» basé sur l’appréciation de l’institution financière. De
plus, il devrait être plus performant qu’un modèle alternatif existant dans l’institution.
Plusieurs hypothèses ont été considérées. L’hypothèse usuelle de représentativité des
données actuelles pour prédire le futur est l’hypothèse centrale à ce projet. Nous
jugeons cette hypothèse adéquate considérant les données d’analyse utilisées. Par
ailleurs, nous utiliserons le critère de performance AUROC pour comparer la
performance du modèle BHV et d’un modèle de référence. La macro «roc.sas»14
permet de calculer l’AUROC des deux modèles et calcule, pour chaque paire, la
statistique T qui permet de tester la significativité de l’écart entre ces deux AUROC
potentiellement corrélées ([22] p.281). Cette statistique T, asymptotiquement non
14 http://support.sas.com/kb/25/017.html

27
biaisée (consistent), est basée sur l’hypothèse nulle d’égalité des deux AUROC
comparées. Elle est distribuée asymptotiquement selon une distribution χ2 à un degré
de liberté :
.
De plus, la comparaison de deux modèles suppose aussi que les scores de ces
modèles sont dérivés du même identifiant défaut si aucun autre identifiant n’est
choisi.
Dans la validation d’un modèle de risque financier, il faut soulever l’impact potentiel
sur l’adéquation des résultats du modèle dans le cas où les hypothèses s’avéraient
fausses. Ainsi, dans la mesure où l’on relâcherait l’hypothèse que les pointages du
modèle de référence (‘’benchmark’’) le NCE sont associés à un même identifiant
défaut que le modèle à valider le BHV, le pouvoir discriminant de ces deux modèles
serait affecté puisque la performance d’un modèle est reliée à l’identifiant choisi.
L’objectif de notre projet étant de valider la performance du score NCE sur la
population BHV, nous éliminerons cette problématique.
2.3.2 L’AUROC : la mesure de performance par ‘’excellence’’.
Tel que décrite à la section 1.4, l’AUROC (l’aire sous la courbe ROC) est une mesure
utilisée dans l’industrie du risque de crédit lorsqu’il vient à la validation de la
performance des modèles de notation de crédit. La section 1.4.2 de cette étude,
présente en détail la méthodologie, les différentes étapes de détermination de
l’AUROC ainsi que son interprétation dans la prise de décision.

28
2.3.3 Calcul du montant d’engagement
Le montant d’engagement doit être déterminé car la base de données finale ne
contient que les montants pour chaque produit du SCD et les autres produits de prêts
dans tout le réseau. Sachant qu’un même client peut avoir plusieurs cartes ou comptes
de prêts, nous avons calculé les montants pour chacune des observations. De plus, il
existe trois types de numéro de compte (NdC) dans la base de données. Le montant
d’engagement est donc calculé selon le type de numéro de compte. Lorsque le NdC
n’est pas valide ou est valide mais les dossiers du SCD n’ont pu être appariés avec
ceux du réseau (le modèle NCE), l’engagement total est calculé selon l’équation 8 ci-
dessous. Lorsque le NdC est valide et l’entreprise détient des produits du réseau (des
prêts), le montant d’engagement est calculé selon l’équation 9 ci-après. Ainsi, ces
différentes équations nous permettent de dériver le montant d’engagement à utiliser
dans l’analyse de la performance du modèle comportemental.
Équation 6 – Montant d’engagement par type de produit
AB2C_E2FGHI�_JKL_M = ma x O'BP1(GHI�QRST ; UVWVC(GHI�QRSTX, où Soldeprod_SCD_k et Limiteprod_SCD_k représentent respectivement le solde et la limite
du produit k (accordD, VISA et autres).
Équation 7 – Limite SCD total (3 produits SCD)
UVWVC('5Y = Z AB2C_E2FGHI�_JKL_M.[
M\9
La limite SCD ou encore le montant d’engagement total du Service des Cartes est
donc la somme des trois produits SCD disponibles.

29
Équation 8 – Engagement total pour NdC non valide et NdC valide sans score NCE
E2F_.BC = UVWVC('5Y.
Équation 9 – Engagement total pour NdC valide et score NCE disponible
E2F)I] = UVWVC('5Y + Z AB2C_/^êCH`+�
M\9+ Z AB2C_A5H`+
[
M\9.
Dans l’équation 9, les montants des prêts et marges de crédits ouverts dans le réseau
sont rajoutés au montant d’engagement SCD. Le but de cet ajout, est de pouvoir
obtenir le montant supérieur à 500 000$ pour valider l’application du modèle sur un
segment supérieur. En effet, tel que mentionné dans la section de données, seulement
1 % de comptes SCD de notre base de données ont une limite supérieure à 500 000$.
Une fois les montants d’engagement calculés, ces derniers sont divisés en quatre
strates à savoir 250 000$ ou moins, 250 000$ à 750 000$, 750 000$ à 1 750 000$, et
finalement 1 750 000$ à 2 500 000$ pour avoir une analyse plus granulaire de la
performance et de l’évolution du défaut dans chaque strate.
2.3.4 Strate de risque du modèle BHV et probabilité de défaut
Le modèle comportemental de carte de crédit BHV comme tous les modèles de
notation, dispose d’une échelle de scores (pointages). À chaque client-entreprise, on
affecte un pointage déterminé par le modèle initial. Ce score est une variable présente
dans notre base de données. Nous pouvons donc segmenter notre échantillon
d’analyse par strates de risque c’est à dire que chaque échelle de pointage
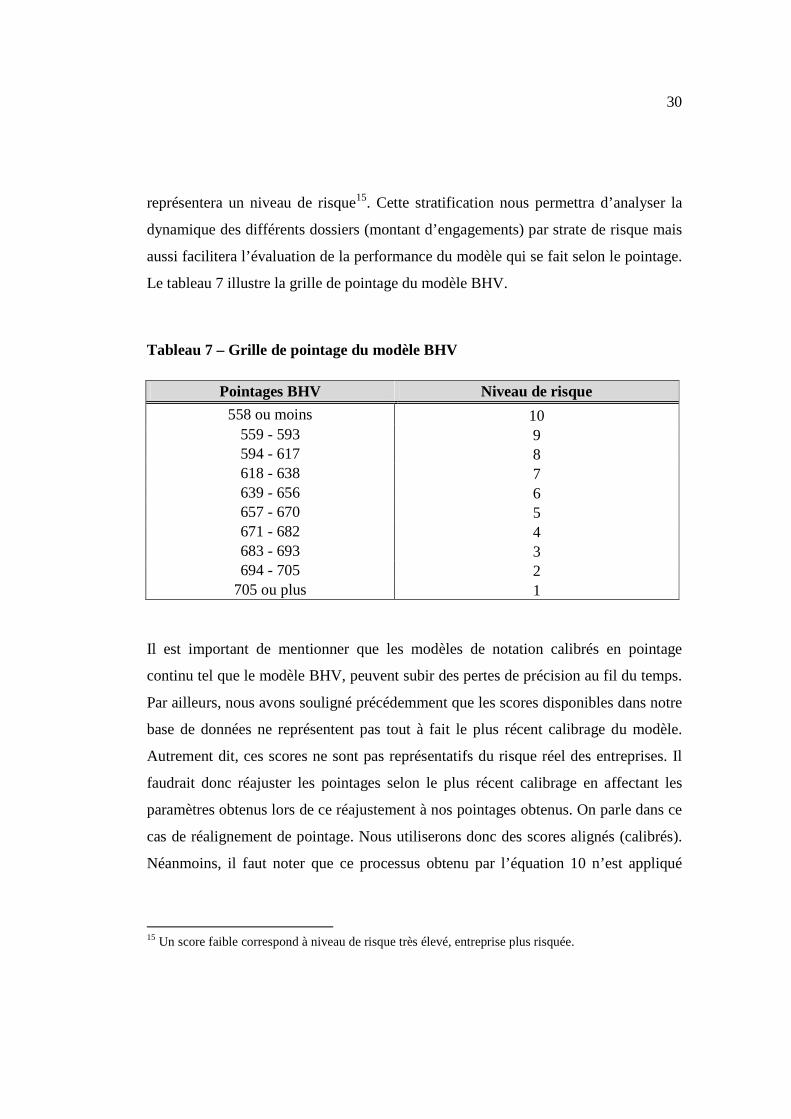
30
représentera un niveau de risque15. Cette stratification nous permettra d’analyser la
dynamique des différents dossiers (montant d’engagements) par strate de risque mais
aussi facilitera l’évaluation de la performance du modèle qui se fait selon le pointage.
Le tableau 7 illustre la grille de pointage du modèle BHV.
Tableau 7 – Grille de pointage du modèle BHV
Pointages BHV Niveau de risque
558 ou moins 10 559 - 593 9 594 - 617 8 618 - 638 7 639 - 656 6 657 - 670 5 671 - 682 4 683 - 693 3 694 - 705 2
705 ou plus 1
Il est important de mentionner que les modèles de notation calibrés en pointage
continu tel que le modèle BHV, peuvent subir des pertes de précision au fil du temps.
Par ailleurs, nous avons souligné précédemment que les scores disponibles dans notre
base de données ne représentent pas tout à fait le plus récent calibrage du modèle.
Autrement dit, ces scores ne sont pas représentatifs du risque réel des entreprises. Il
faudrait donc réajuster les pointages selon le plus récent calibrage en affectant les
paramètres obtenus lors de ce réajustement à nos pointages obtenus. On parle dans ce
cas de réalignement de pointage. Nous utiliserons donc des scores alignés (calibrés).
Néanmoins, il faut noter que ce processus obtenu par l’équation 10 n’est appliqué
15 Un score faible correspond à niveau de risque très élevé, entreprise plus risquée.

31
qu’à certains groupes de comptes. Les autres groupes non affectés conservent leurs
scores initiaux tels que donnés par la base de données principale.
Équation 10 – Calibrage des pointages
'aB^(bV2cP =∝ +e ∗ 'aB^(g� + h,
où α et β respectivement 150.647 et 0,769 sont des paramètres d’ajustement obtenus
lors du processus de calibrage le plus récent. 'aB^(g� représente le pointage
disponible dans notre base de données et 'aB^(bV2cP représente le pointage final que
nous considèrerons dans l’évaluation de la performance.
Une fois les pointages obtenus, nous pouvons calculer les taux de défauts de chaque
strate de montant d’engagement et de chaque strate de pointage. L’indicateur de
défaut (badBHV) présent dans la base de données prend les valeurs discrètes 1
(défaut) ou 0 (pas de défaut). Le taux de défaut réellement observé sur nos différents
segments est calculé afin d’être comparé avec la probabilité de défaut prédite. Alors
que le taux de défaut observé est calculé simplement en faisant le rapport entre le
nombre de défauts et nombre total de dossiers (défauts/Nb dossiers), la probabilité
prédite est obtenue par une méthode proposée par Siddiqi [16] (équation 11). Selon
l’auteur, la relation entre la chance («odds») en d’autres mots, la probabilité d’être en
défaut et le pointage, est une relation de transformation linéaire donnée ci bas :
Équation 11 – Calibrage des pointages
/BV2CcF(gij = kbb�(C + �caCB^ ∗ l n�B11�� (1),
/BV2CcF(gij + �1B = kbb�(C + �caCB^ ∗ l n�2 ∗ B11�� (2).

32
Selon Siddiqi, le �1B représente le point pour doubler la chance («point to double the
odds»). En faisant des transformations avec l’équation 11 (2), le modélisateur peut
déterminer les paramètres kbb�(Cet�caCB^ pour une «odds» et un score fixé et
obtenir les trois équations ci bas :
�1B = �caCB^ ∗ l n�2 ∗ B11�� �caCB^ = �1B/ln�2�
kbb�(C = /BV2CcF(gij − {�caCB^ ∗ l n�B11��}. De la même façon, nous pouvons en déduire «l’odd» qui nous permettra de calculer
les PD prédites selon l’équation suivante :
B11�o = (>� p/BV2CcF(gij − kbb�(C�caCB^ q.
Équation 12 – PD prédite pour un compte
/Yo = 11 + B11�o
.
Ainsi, nous déduisons la PD d'une strate de risque du modèle BHV ayant N comptes à
l'aide de l'équation suivante :
Équation 13 – PD prédite pour un niveau de risque donné
/Y+]Hr]`_stu = 10Z/Yo
,
o\9.

33
2.3.5 Réplication des pointages du modèle comparatif NCE
Dans l’évaluation de la performance d’un modèle, il est judicieux d’avoir un modèle
comparable (modèle de référence) ou encore un «benchmark» comme un critère
d’évaluation. En effet, en comparant le modèle analysé avec cette référence, l’analyse
permettrait d’avoir une meilleure évaluation quant au caractère discriminant du
modèle choisi par rapport à l’étalon choisi.
C’est dans cette optique que le modèle de notation comportementale pour entreprises
du réseau (NCE) a été choisi comme référence. Ce modèle avait été conçu aussi par
une firme externe en 2009, et a subi quelques améliorations à l’interne de l’institution
depuis sa conception. Les pointages de ce modèle sont répliqués et extraits par un
programme SAS qui permet de se connecter à l’environnement interne 2 tel
qu’illustré à la figure 4. Il faut noter que pour ce modèle, il existe deux types de
pointages représentant les deux secteurs principaux des clients-entreprises (agricole et
commercial/industriel). Il est important de préciser que le choix de ces deux secteurs
est fait suivant des règles d’affaires préétablies par des équipes de stratégies de
l’institution financière. En effet, pour tous ses portefeuilles de crédit pour entreprises,
la coopérative regroupe ses prêts suivant ces deux groupes selon le type d’activité
ainsi que les risques associés à ces dernières. On constate que les entreprises à
l’intérieur de chacune des deux groupes, ont des types de risques similaires. On peut
noter selon les tableaux 8 et 9 que les strates du niveau de risque sont différentes non
seulement au sein du même modèle (NCE) mais aussi par rapport au modèle du SCD.
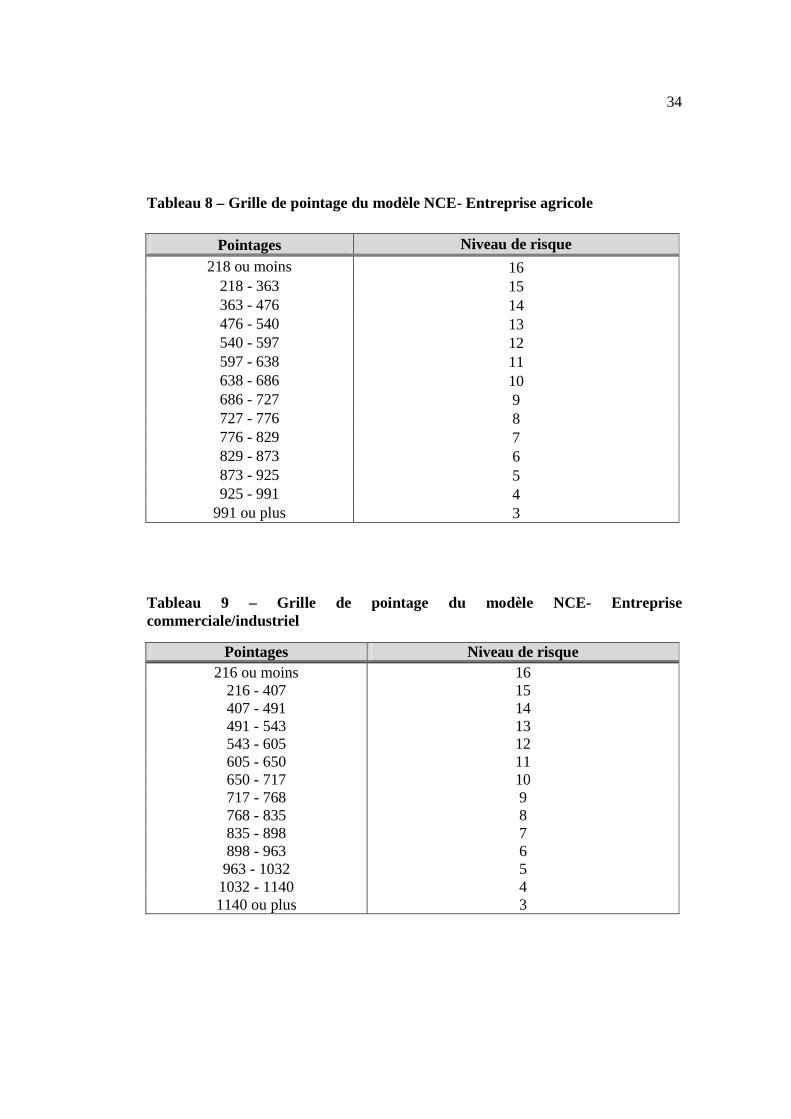
34
Tableau 8 – Grille de pointage du modèle NCE- Entreprise agricole
Pointages Niveau de risque 218 ou moins 16
218 - 363 15 363 - 476 14 476 - 540 13 540 - 597 12 597 - 638 11 638 - 686 10 686 - 727 9 727 - 776 8 776 - 829 7 829 - 873 6 873 - 925 5 925 - 991 4
991 ou plus 3
Tableau 9 – Grille de pointage du modèle NCE- Entreprise commerciale/industriel
Pointages Niveau de risque 216 ou moins 16
216 - 407 15 407 - 491 14 491 - 543 13 543 - 605 12 605 - 650 11 650 - 717 10 717 - 768 9 768 - 835 8 835 - 898 7 898 - 963 6 963 - 1032 5 1032 - 1140 4 1140 ou plus 3

35
2.3.6 Évaluation de la performance des différents segments
Le but principal des étapes précédentes de la méthodologie est de pouvoir récupérer
les scores des différents modèles pour les différentes strates d’engagements afin de
valider la performance selon les deux indicateurs présentés (AUROC et KS).
Nous avons procédé à la validation du pouvoir discriminant du modèle selon
l’engagement pour chaque image traitée en appliquant les mesures AUROC et KS sur
nos différents segments. Les deux mesures seront validées aussi bien au niveau du
modèle BHV que du modèle NCE. La p-value obtenue nous permettra de conclure
sur la différence significative du modèle «behavior» par rapport au modèle
benchmark.
36
CHAPITRE III
DISCUSSION DES RÉSULTATS
3.1. Analyse des taux de défaut selon les strates d’engagement
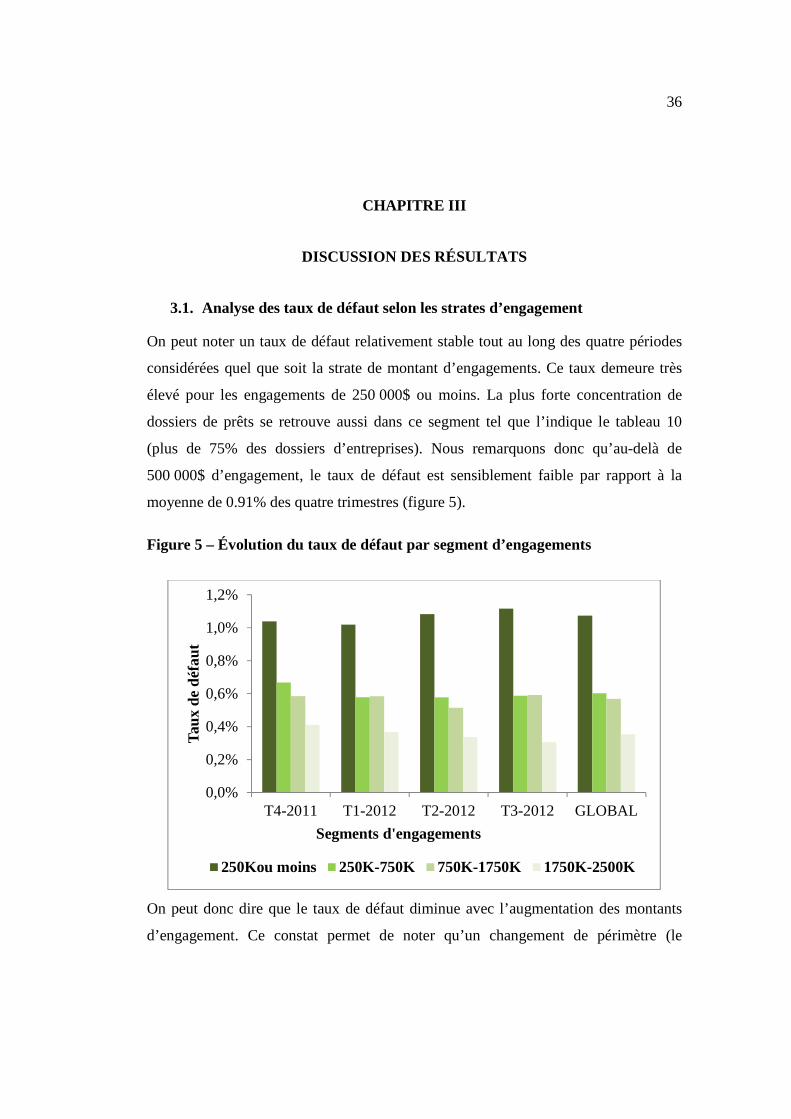
On peut noter un taux de défaut relativement stable tout au long des quatre périodes
considérées quel que soit la strate de montant d’engagements. Ce taux demeure très
élevé pour les engagements de 250 000$ ou moins. La plus forte concentration de
dossiers de prêts se retrouve aussi dans ce segment tel que l’indique le tableau 10
(plus de 75% des dossiers d’entreprises). Nous remarquons donc qu’au-delà de
500 000$ d’engagement, le taux de défaut est sensiblement faible par rapport à la
moyenne de 0.91% des quatre trimestres (figure 5).
Figure 5 – Évolution du taux de défaut par segment d’engagements
On peut donc dire que le taux de défaut diminue avec l’augmentation des montants
d’engagement. Ce constat permet de noter qu’un changement de périmètre (le
0,0%
0,2%
0,4%
0,6%
0,8%
1,0%
1,2%
T4-2011 T1-2012 T2-2012 T3-2012 GLOBAL
Taux
de
défa
ut
Segments d'engagements
250Kou moins 250K-750K 750K-1750K 1750K-2500K
37
passage de montant d’engagement de 500 000$ à des montants pouvant aller à
2 500 000$) ne devrait donc pas avoir un impact négatif sur le taux de défauts du
segment entreprise des cartes de crédit.
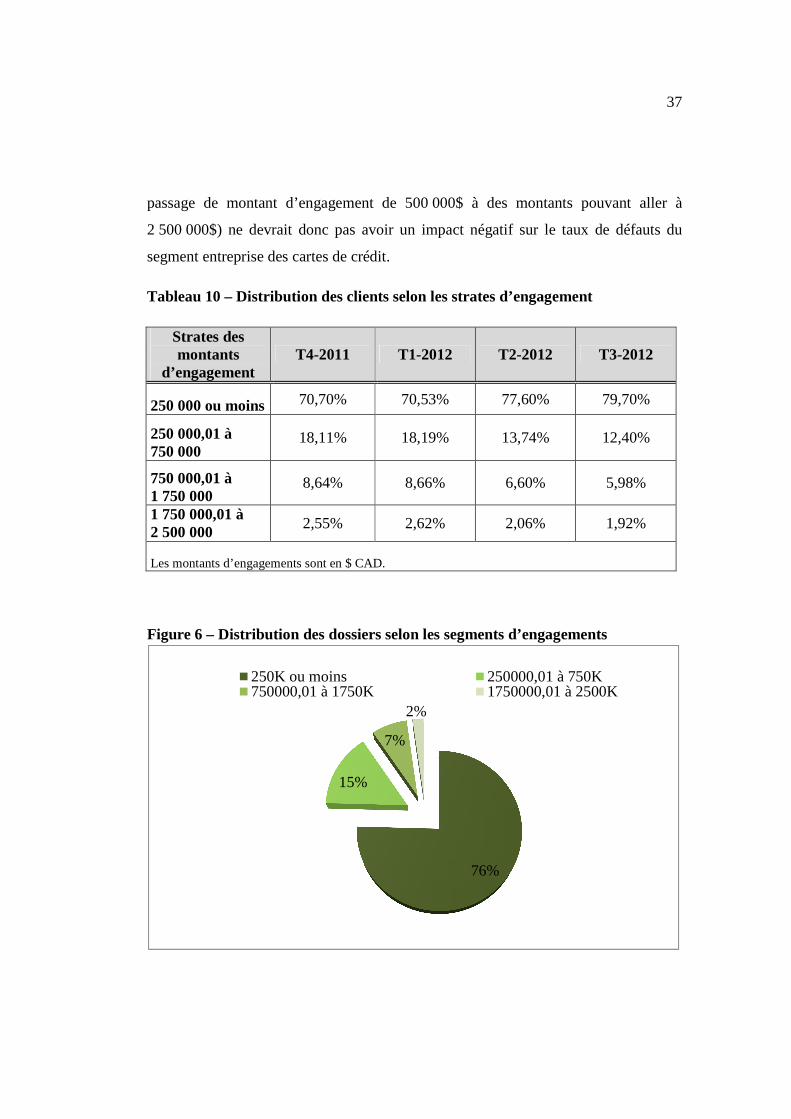
Tableau 10 – Distribution des clients selon les strates d’engagement
Strates des montants
d’engagement T4-2011 T1-2012 T2-2012 T3-2012
250 000 ou moins 70,70% 70,53% 77,60% 79,70%
250 000,01 à 750 000
18,11% 18,19% 13,74% 12,40%
750 000,01 à 1 750 000
8,64% 8,66% 6,60% 5,98%
1 750 000,01 à 2 500 000 2,55% 2,62% 2,06% 1,92%
Les montants d’engagements sont en $ CAD.
Figure 6 – Distribution des dossiers selon les segments d’engagements
76%
15%
7%
2%
250K ou moins 250000,01 à 750K750000,01 à 1750K 1750000,01 à 2500K

38
3.2. Analyse des taux de défaut selon les niveaux de risque
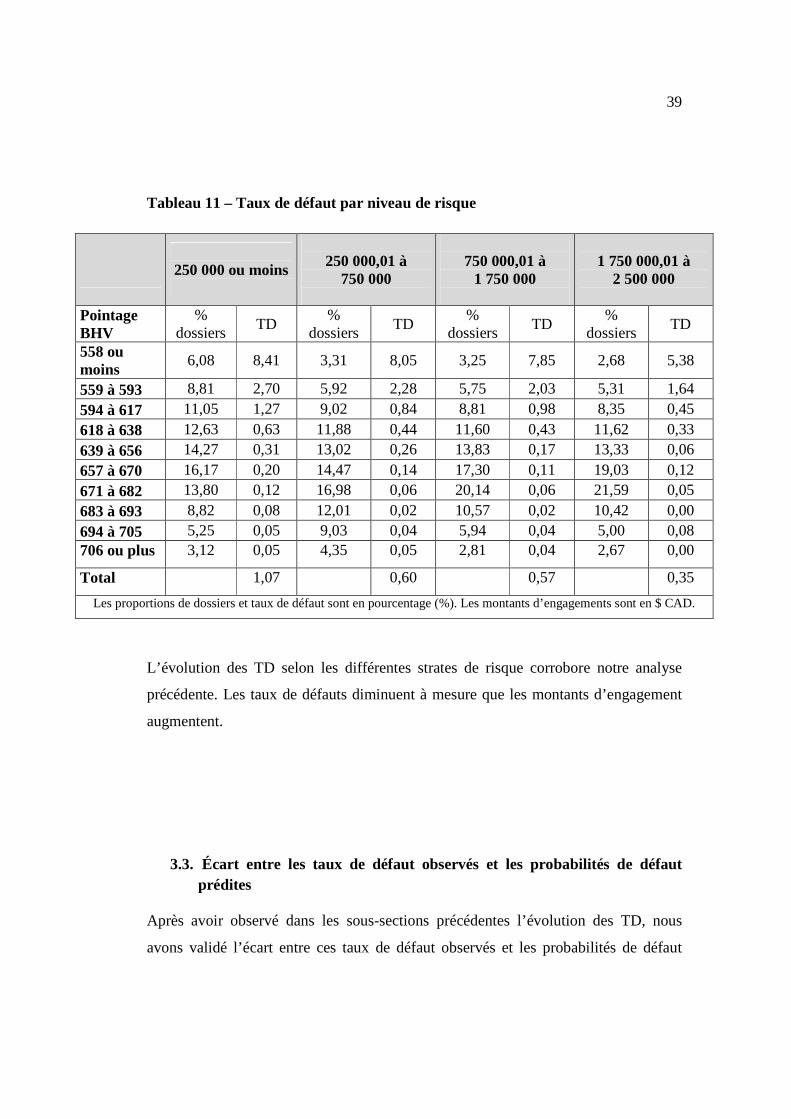
L’assignation de pointage ou encore de score à chaque client nous permet d’analyser
le comportement de groupes clients pour chaque niveau de risque du modèle BHV.
Rappelons qu’un score faible est synonyme d’un niveau de risque élevé. Il n’est donc
pas étonnant de constater un fort taux de défaut pour la plus faible strate, celle de 558
ou moins. Les entreprises détenant un faible score sont celles ayant une probabilité de
défaut plus élevée par rapport à l’institution financière. Par ailleurs, lorsque l’on
combine le pointage et le montant d’engagement, on réalise que les taux de défaut
même s’ils diminuent avec l’augmentation du montant d’engagement, restent tout de
même très élevés pour des niveaux de pointage bas. Dans le tableau 11, nous
illustrons les taux de défauts selon les montants d’engagement et les niveaux de
risque. Les pointages moyens regroupent près de 50% des dossiers mais les TD sont
relativement bas (moins de 1%).
39
Tableau 11 – Taux de défaut par niveau de risque
250 000 ou moins
250 000,01 à
750 000
750 000,01 à
1 750 000
1 750 000,01 à
2 500 000
Pointage BHV
% dossiers
TD %
dossiers TD
% dossiers
TD %
dossiers TD
558 ou moins
6,08 8,41 3,31 8,05 3,25 7,85 2,68 5,38
559 à 593 8,81 2,70 5,92 2,28 5,75 2,03 5,31 1,64 594 à 617 11,05 1,27 9,02 0,84 8,81 0,98 8,35 0,45 618 à 638 12,63 0,63 11,88 0,44 11,60 0,43 11,62 0,33 639 à 656 14,27 0,31 13,02 0,26 13,83 0,17 13,33 0,06 657 à 670 16,17 0,20 14,47 0,14 17,30 0,11 19,03 0,12 671 à 682 13,80 0,12 16,98 0,06 20,14 0,06 21,59 0,05 683 à 693 8,82 0,08 12,01 0,02 10,57 0,02 10,42 0,00 694 à 705 5,25 0,05 9,03 0,04 5,94 0,04 5,00 0,08 706 ou plus 3,12 0,05 4,35 0,05 2,81 0,04 2,67 0,00
Total
1,07
0,60
0,57
0,35
Les proportions de dossiers et taux de défaut sont en pourcentage (%). Les montants d’engagements sont en $ CAD.
L’évolution des TD selon les différentes strates de risque corrobore notre analyse
précédente. Les taux de défauts diminuent à mesure que les montants d’engagement
augmentent.
3.3. Écart entre les taux de défaut observés et les probabilités de défaut prédites
Après avoir observé dans les sous-sections précédentes l’évolution des TD, nous
avons validé l’écart entre ces taux de défaut observés et les probabilités de défaut
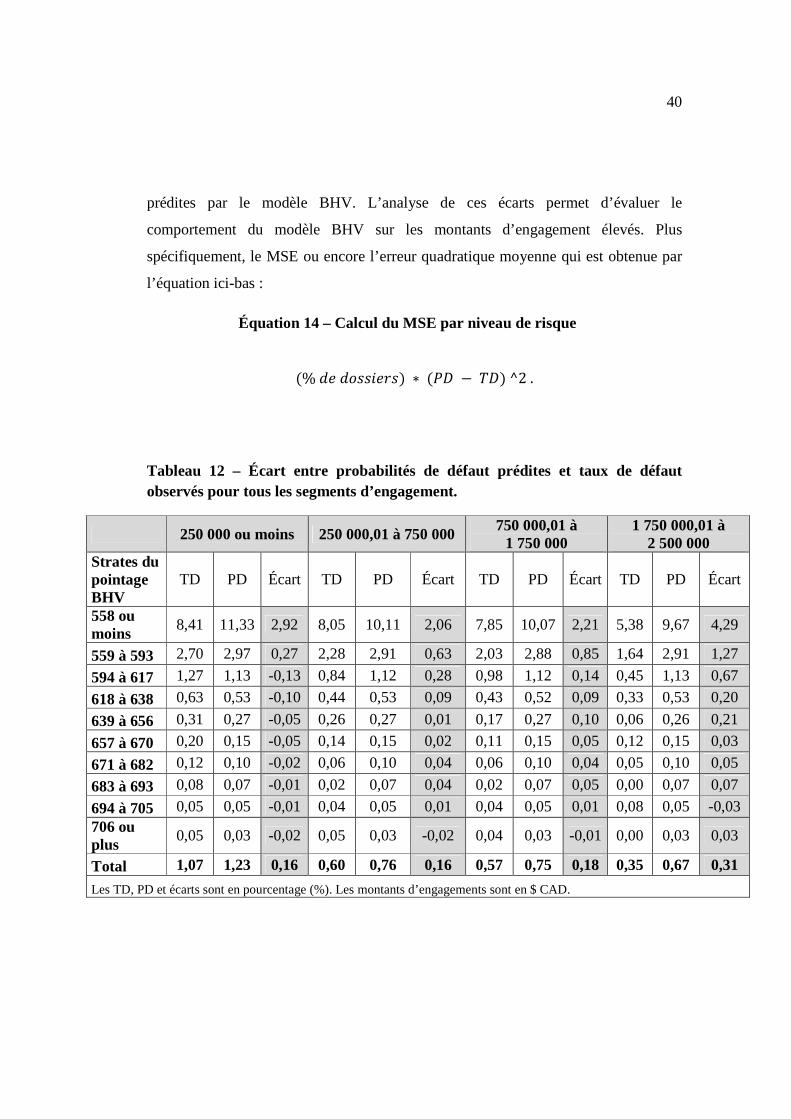
40
prédites par le modèle BHV. L’analyse de ces écarts permet d’évaluer le
comportement du modèle BHV sur les montants d’engagement élevés. Plus
spécifiquement, le MSE ou encore l’erreur quadratique moyenne qui est obtenue par
l’équation ici-bas :
Équation 14 – Calcul du MSE par niveau de risque
�%1(1B��V(^�� ∗ �/Y − .Y�^2.
Tableau 12 – Écart entre probabilités de défaut prédites et taux de défaut observés pour tous les segments d’engagement.
250 000 ou moins 250 000,01 à 750 000 750 000,01 à 1 750 000
1 750 000,01 à 2 500 000
Strates du pointage BHV
TD PD Écart TD PD Écart TD PD Écart TD PD Écart
558 ou moins
8,41 11,33 2,92 8,05 10,11 2,06 7,85 10,07 2,21 5,38 9,67 4,29
559 à 593 2,70 2,97 0,27 2,28 2,91 0,63 2,03 2,88 0,85 1,64 2,91 1,27
594 à 617 1,27 1,13 -0,13 0,84 1,12 0,28 0,98 1,12 0,14 0,45 1,13 0,67
618 à 638 0,63 0,53 -0,10 0,44 0,53 0,09 0,43 0,52 0,09 0,33 0,53 0,20
639 à 656 0,31 0,27 -0,05 0,26 0,27 0,01 0,17 0,27 0,10 0,06 0,26 0,21
657 à 670 0,20 0,15 -0,05 0,14 0,15 0,02 0,11 0,15 0,05 0,12 0,15 0,03
671 à 682 0,12 0,10 -0,02 0,06 0,10 0,04 0,06 0,10 0,04 0,05 0,10 0,05
683 à 693 0,08 0,07 -0,01 0,02 0,07 0,04 0,02 0,07 0,05 0,00 0,07 0,07
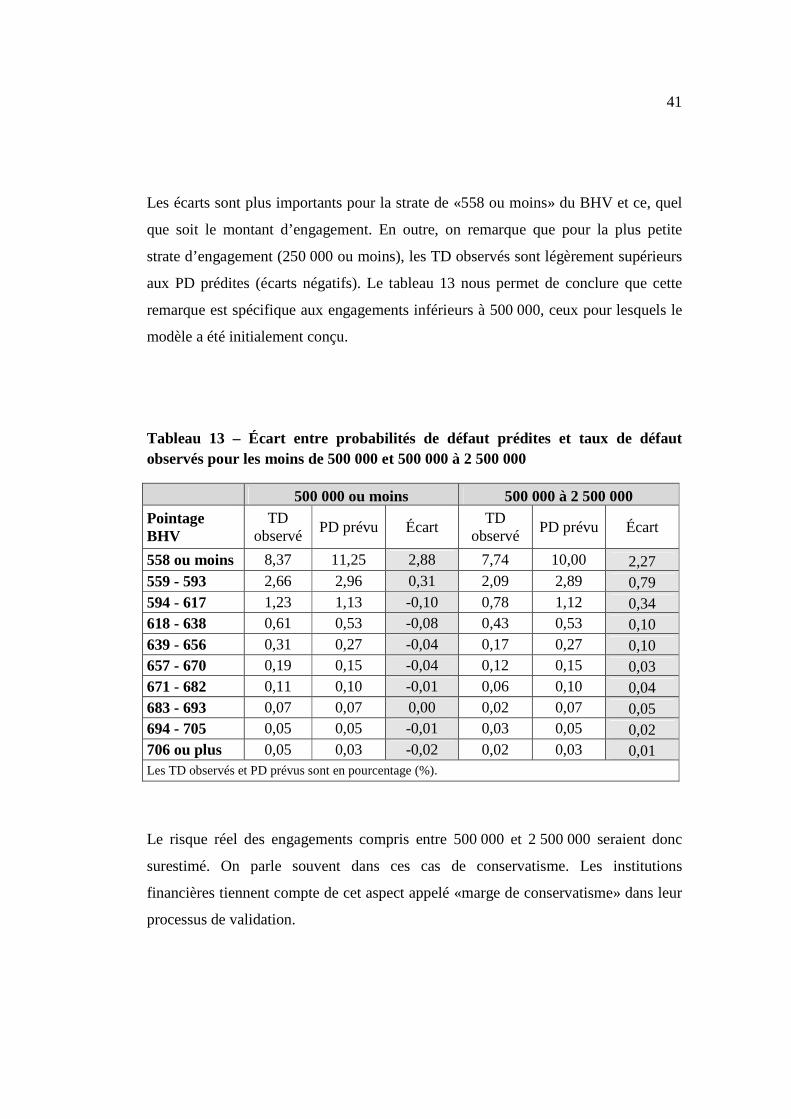
694 à 705 0,05 0,05 -0,01 0,04 0,05 0,01 0,04 0,05 0,01 0,08 0,05 -0,03 706 ou plus
0,05 0,03 -0,02 0,05 0,03 -0,02 0,04 0,03 -0,01 0,00 0,03 0,03
Total 1,07 1,23 0,16 0,60 0,76 0,16 0,57 0,75 0,18 0,35 0,67 0,31
Les TD, PD et écarts sont en pourcentage (%). Les montants d’engagements sont en $ CAD.
41
Les écarts sont plus importants pour la strate de «558 ou moins» du BHV et ce, quel
que soit le montant d’engagement. En outre, on remarque que pour la plus petite
strate d’engagement (250 000 ou moins), les TD observés sont légèrement supérieurs
aux PD prédites (écarts négatifs). Le tableau 13 nous permet de conclure que cette
remarque est spécifique aux engagements inférieurs à 500 000, ceux pour lesquels le
modèle a été initialement conçu.
Tableau 13 – Écart entre probabilités de défaut prédites et taux de défaut observés pour les moins de 500 000 et 500 000 à 2 500 000
500 000 ou moins 500 000 à 2 500 000 Pointage BHV
TD observé
PD prévu Écart TD
observé PD prévu Écart
558 ou moins 8,37 11,25 2,88 7,74 10,00 2,27 559 - 593 2,66 2,96 0,31 2,09 2,89 0,79 594 - 617 1,23 1,13 -0,10 0,78 1,12 0,34 618 - 638 0,61 0,53 -0,08 0,43 0,53 0,10 639 - 656 0,31 0,27 -0,04 0,17 0,27 0,10 657 - 670 0,19 0,15 -0,04 0,12 0,15 0,03 671 - 682 0,11 0,10 -0,01 0,06 0,10 0,04 683 - 693 0,07 0,07 0,00 0,02 0,07 0,05 694 - 705 0,05 0,05 -0,01 0,03 0,05 0,02 706 ou plus 0,05 0,03 -0,02 0,02 0,03 0,01 Les TD observés et PD prévus sont en pourcentage (%).
Le risque réel des engagements compris entre 500 000 et 2 500 000 seraient donc
surestimé. On parle souvent dans ces cas de conservatisme. Les institutions
financières tiennent compte de cet aspect appelé «marge de conservatisme» dans leur
processus de validation.
42
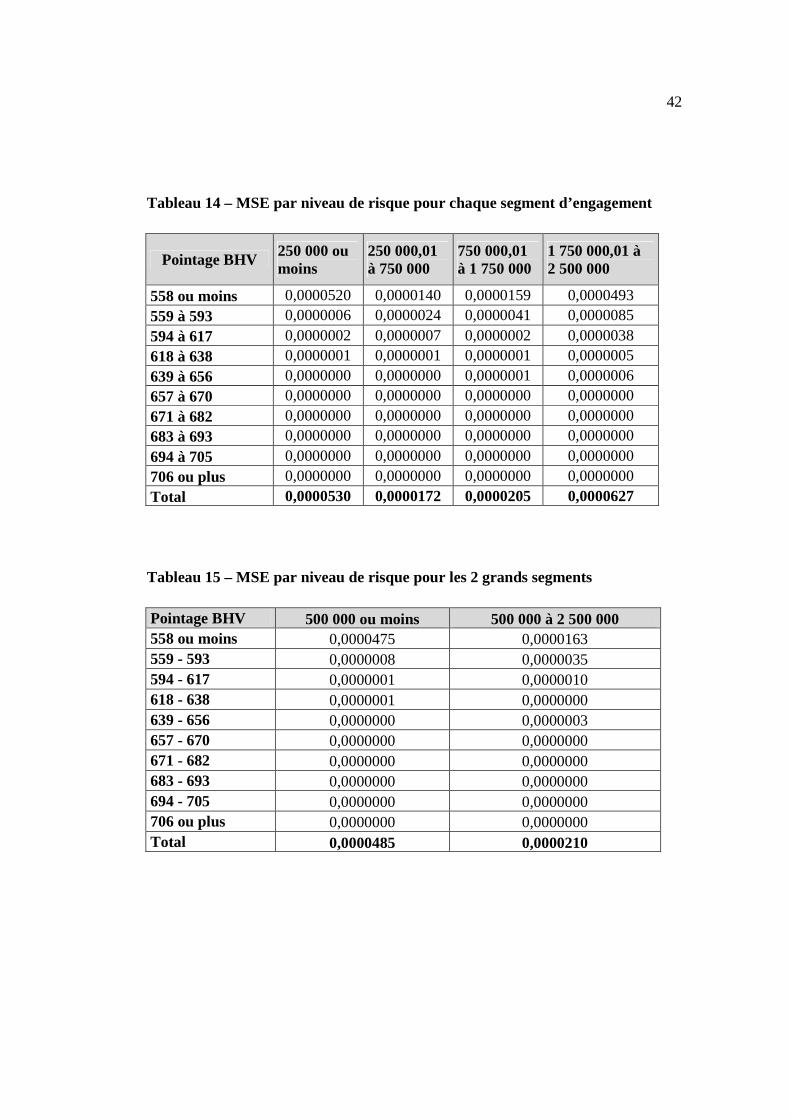
Tableau 14 – MSE par niveau de risque pour chaque segment d’engagement
Pointage BHV 250 000 ou moins
250 000,01 à 750 000
750 000,01 à 1 750 000
1 750 000,01 à 2 500 000
558 ou moins 0,0000520 0,0000140 0,0000159 0,0000493 559 à 593 0,0000006 0,0000024 0,0000041 0,0000085 594 à 617 0,0000002 0,0000007 0,0000002 0,0000038 618 à 638 0,0000001 0,0000001 0,0000001 0,0000005 639 à 656 0,0000000 0,0000000 0,0000001 0,0000006 657 à 670 0,0000000 0,0000000 0,0000000 0,0000000 671 à 682 0,0000000 0,0000000 0,0000000 0,0000000 683 à 693 0,0000000 0,0000000 0,0000000 0,0000000 694 à 705 0,0000000 0,0000000 0,0000000 0,0000000 706 ou plus 0,0000000 0,0000000 0,0000000 0,0000000 Total 0,0000530 0,0000172 0,0000205 0,0000627
Tableau 15 – MSE par niveau de risque pour les 2 grands segments
Pointage BHV 500 000 ou moins 500 000 à 2 500 000 558 ou moins 0,0000475 0,0000163 559 - 593 0,0000008 0,0000035 594 - 617 0,0000001 0,0000010 618 - 638 0,0000001 0,0000000 639 - 656 0,0000000 0,0000003 657 - 670 0,0000000 0,0000000 671 - 682 0,0000000 0,0000000 683 - 693 0,0000000 0,0000000 694 - 705 0,0000000 0,0000000 706 ou plus 0,0000000 0,0000000 Total 0,0000485 0,0000210

43
Certes nous remarquons selon les résultats des tableaux 14 et 15 que les erreurs
quadratiques moyennes sont très faibles mais on note aussi que lorsque l’on regroupe
les montants d’engagements en seulement 2 sous strates, le MSE peut être un
mauvais indicateur. En effet, le tableau 15 semble montrer que le modèle BHV sur le
montant d’engagement inférieur à 500 000$ aurait un MSE supérieur que celui des
engagements compris entre 500 000$ et 2 500 000. Le tableau 14 nous illustre de
manière granulaire que l’erreur sur les PD prédites donnée par le MSE sur les
engagements compris entre 1 750 000$ et 2 500 000$ est légèrement supérieure à
celle de 250 000 et moins et nettement plus élevée que celles des deux strates
intermédiaires d’engagements. Ce constat permet de dire qu’en validation de modèle,
il est important d’évaluer chaque strate de données, d’effectuer des analyses sur
différents segments avant de conclure sur la performance d’un modèle.
3.4. Fiabilité : évaluation quantitative de la performance du modèle BHV
Dans cette dernière section, nous présenterons les résultats sur le pouvoir
discriminant du modèle sur les différents montants d’engagement et ceux obtenus en
le comparant au modèle de référence.
Les deux critères présentés dans la revue de littérature le KS et l’AUROC, sont ceux
retenus pour l’évaluation du pouvoir discriminant de notre modèle BHV sur les
différents montants d’engagement.
Les résultats obtenus aussi bien en AUROC qu’en KS montrent une bonne
adéquation de la performance du modèle sur les différents périmètres. On peut noter
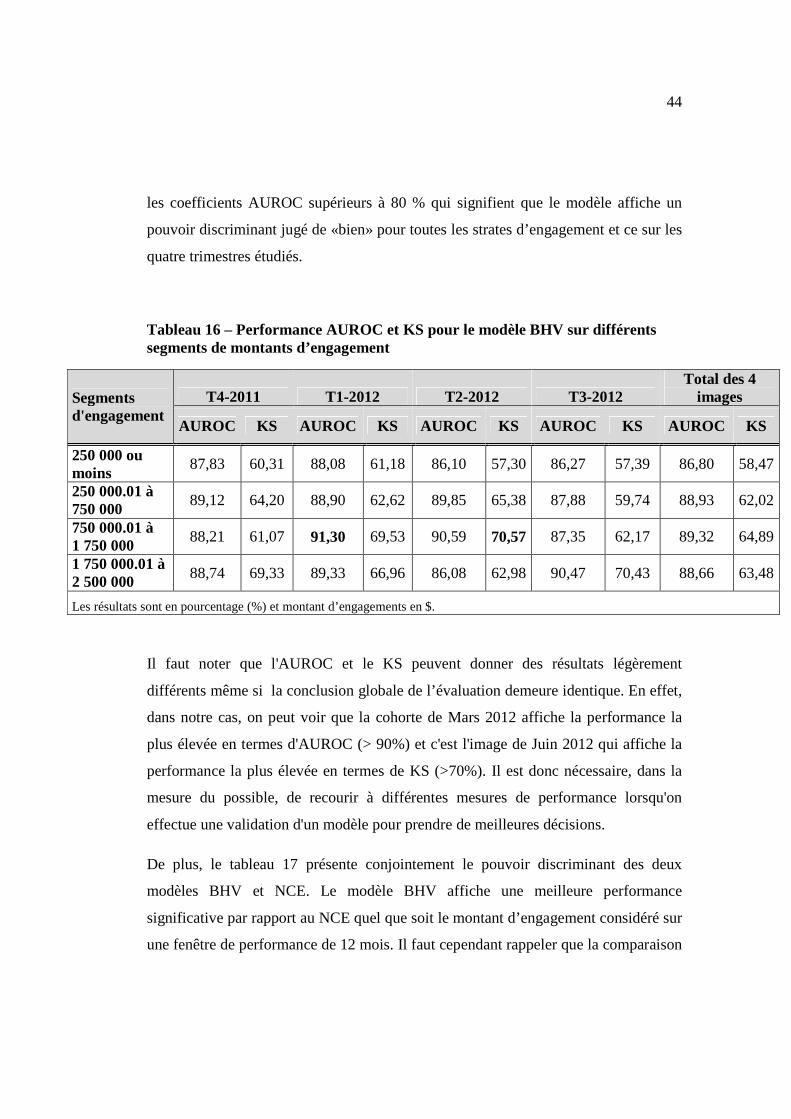
44
les coefficients AUROC supérieurs à 80 % qui signifient que le modèle affiche un
pouvoir discriminant jugé de «bien» pour toutes les strates d’engagement et ce sur les
quatre trimestres étudiés.
Tableau 16 – Performance AUROC et KS pour le modèle BHV sur différents segments de montants d’engagement
Segments d'engagement
T4-2011 T1-2012 T2-2012 T3-2012 Total des 4
images
AUROC KS AUROC KS AUROC KS AUROC KS AUROC KS
250 000 ou moins
87,83 60,31 88,08 61,18 86,10 57,30 86,27 57,39 86,80 58,47
250 000.01 à 750 000
89,12 64,20 88,90 62,62 89,85 65,38 87,88 59,74 88,93 62,02
750 000.01 à 1 750 000
88,21 61,07 91,30 69,53 90,59 70,57 87,35 62,17 89,32 64,89
1 750 000.01 à 2 500 000 88,74 69,33 89,33 66,96 86,08 62,98 90,47 70,43 88,66 63,48
Les résultats sont en pourcentage (%) et montant d’engagements en $.
Il faut noter que l'AUROC et le KS peuvent donner des résultats légèrement
différents même si la conclusion globale de l’évaluation demeure identique. En effet,
dans notre cas, on peut voir que la cohorte de Mars 2012 affiche la performance la
plus élevée en termes d'AUROC (> 90%) et c'est l'image de Juin 2012 qui affiche la
performance la plus élevée en termes de KS (>70%). Il est donc nécessaire, dans la
mesure du possible, de recourir à différentes mesures de performance lorsqu'on
effectue une validation d'un modèle pour prendre de meilleures décisions.
De plus, le tableau 17 présente conjointement le pouvoir discriminant des deux
modèles BHV et NCE. Le modèle BHV affiche une meilleure performance
significative par rapport au NCE quel que soit le montant d’engagement considéré sur
une fenêtre de performance de 12 mois. Il faut cependant rappeler que la comparaison
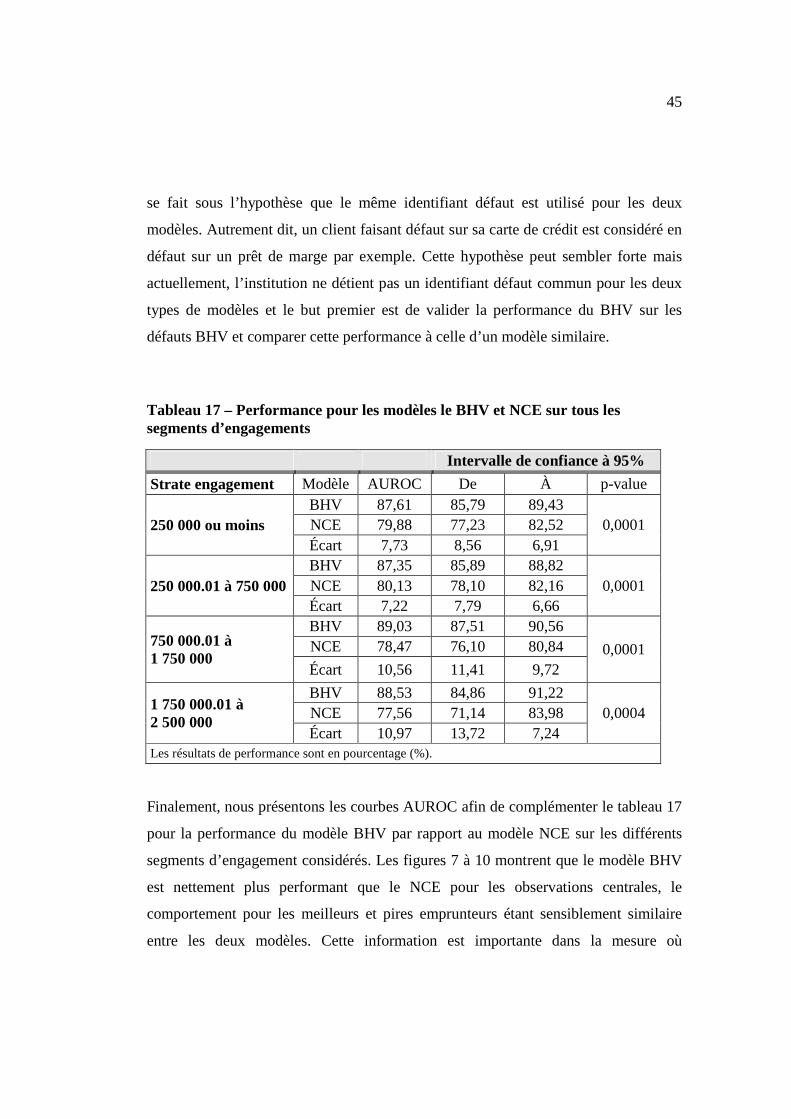
45
se fait sous l’hypothèse que le même identifiant défaut est utilisé pour les deux
modèles. Autrement dit, un client faisant défaut sur sa carte de crédit est considéré en
défaut sur un prêt de marge par exemple. Cette hypothèse peut sembler forte mais
actuellement, l’institution ne détient pas un identifiant défaut commun pour les deux
types de modèles et le but premier est de valider la performance du BHV sur les
défauts BHV et comparer cette performance à celle d’un modèle similaire.
Tableau 17 – Performance pour les modèles le BHV et NCE sur tous les segments d’engagements
Intervalle de confiance à 95%
Strate engagement Modèle AUROC De À p-value
250 000 ou moins BHV 87,61 85,79 89,43
0,0001 NCE 79,88 77,23 82,52 Écart 7,73 8,56 6,91
250 000.01 à 750 000 BHV 87,35 85,89 88,82
0,0001 NCE 80,13 78,10 82,16 Écart 7,22 7,79 6,66
750 000.01 à 1 750 000
BHV 89,03 87,51 90,56
0,0001 NCE 78,47 76,10 80,84
Écart 10,56 11,41 9,72
1 750 000.01 à 2 500 000
BHV 88,53 84,86 91,22 0,0004 NCE 77,56 71,14 83,98
Écart 10,97 13,72 7,24 Les résultats de performance sont en pourcentage (%).
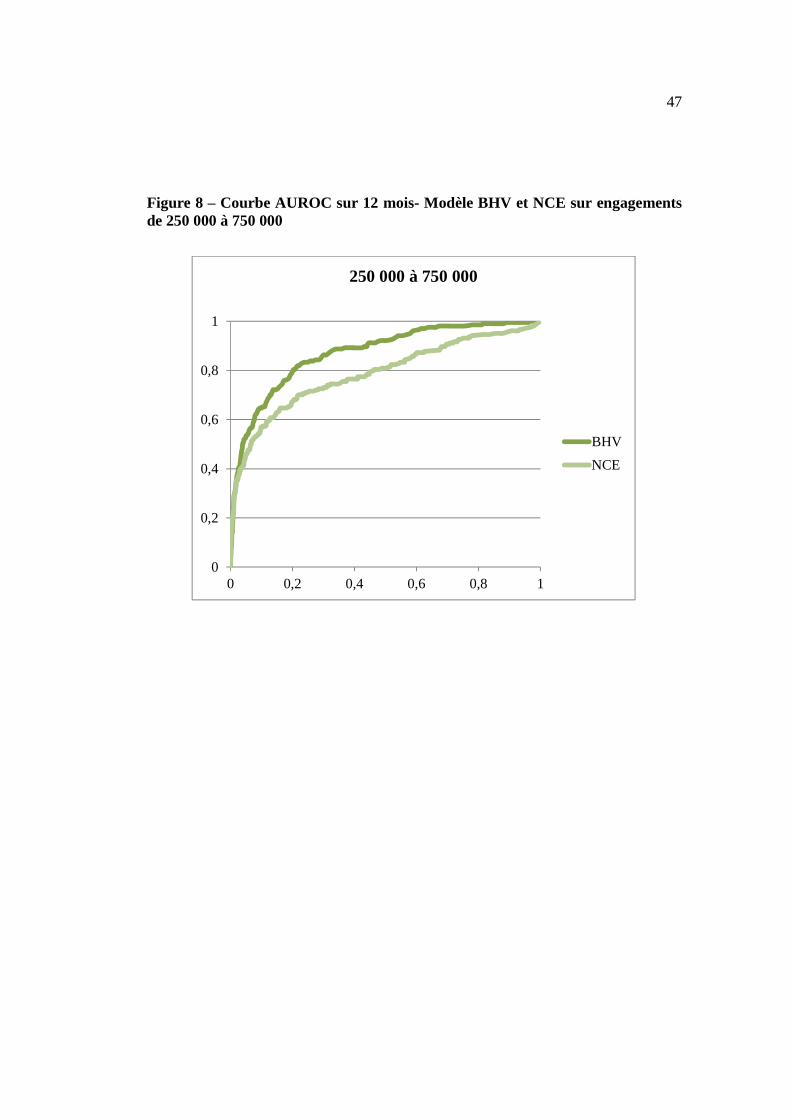
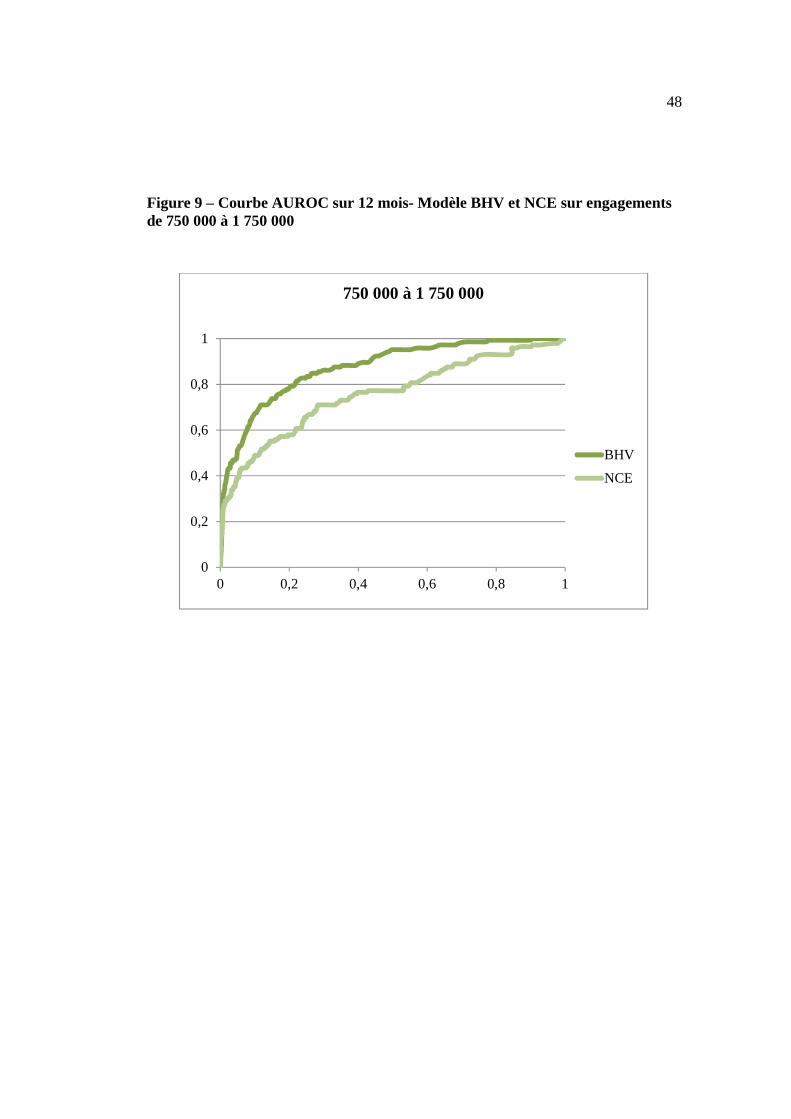
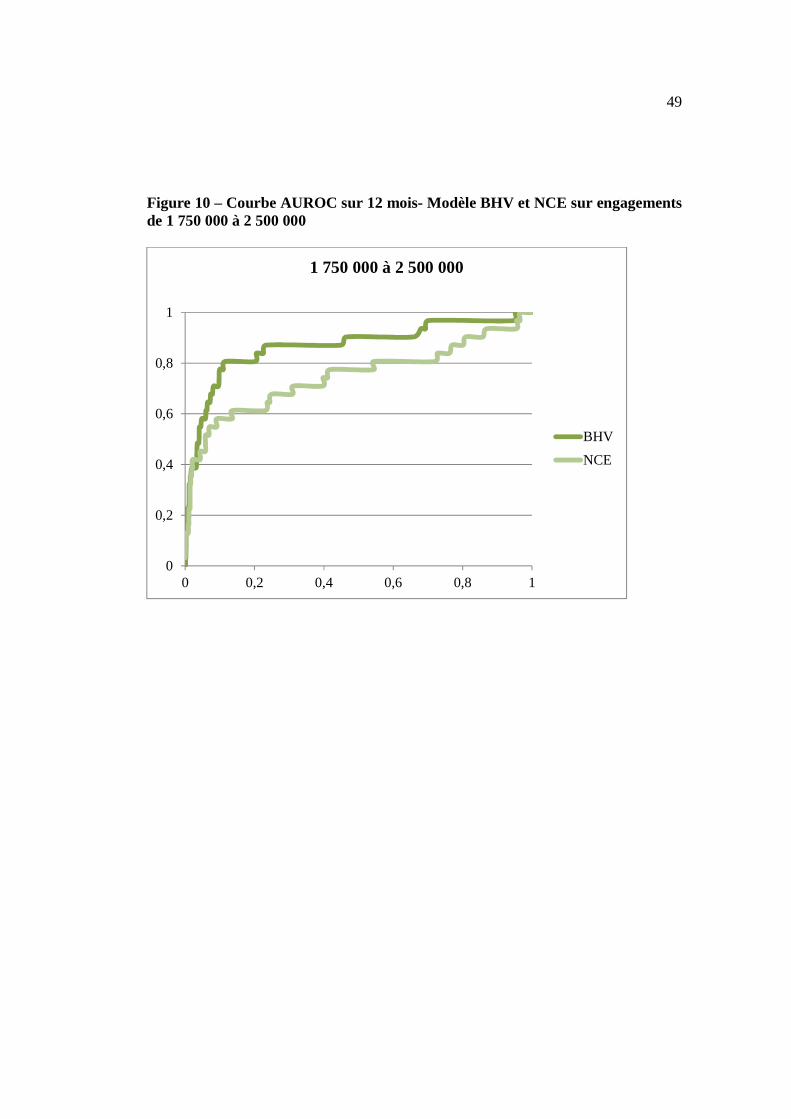
Finalement, nous présentons les courbes AUROC afin de complémenter le tableau 17
pour la performance du modèle BHV par rapport au modèle NCE sur les différents
segments d’engagement considérés. Les figures 7 à 10 montrent que le modèle BHV
est nettement plus performant que le NCE pour les observations centrales, le
comportement pour les meilleurs et pires emprunteurs étant sensiblement similaire
entre les deux modèles. Cette information est importante dans la mesure où
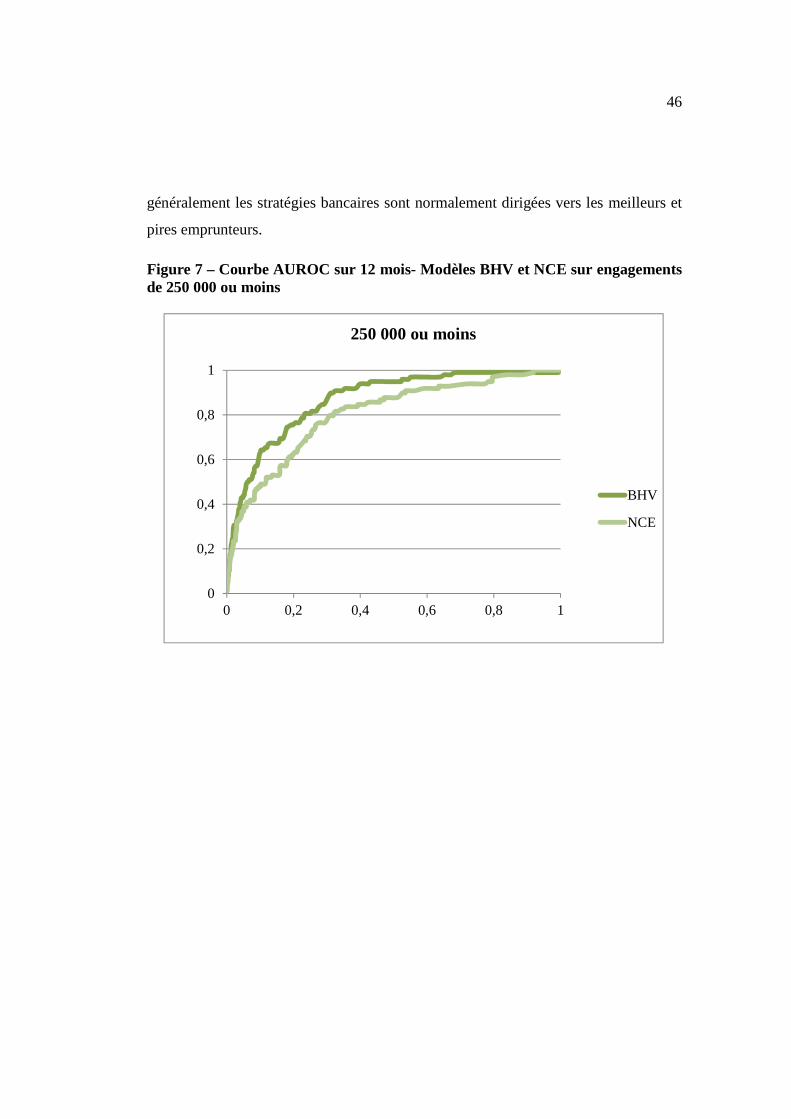
46
généralement les stratégies bancaires sont normalement dirigées vers les meilleurs et
pires emprunteurs.
Figure 7 – Courbe AUROC sur 12 mois- Modèles BHV et NCE sur engagements de 250 000 ou moins
0
0,2
0,4
0,6
0,8
1
0 0,2 0,4 0,6 0,8 1
250 000 ou moins
BHV
NCE
47
Figure 8 – Courbe AUROC sur 12 mois- Modèle BHV et NCE sur engagements de 250 000 à 750 000
0
0,2
0,4
0,6
0,8
1
0 0,2 0,4 0,6 0,8 1
250 000 à 750 000
BHV
NCE
48
Figure 9 – Courbe AUROC sur 12 mois- Modèle BHV et NCE sur engagements de 750 000 à 1 750 000
0
0,2
0,4
0,6
0,8
1
0 0,2 0,4 0,6 0,8 1
750 000 à 1 750 000
BHV
NCE
49
Figure 10 – Courbe AUROC sur 12 mois- Modèle BHV et NCE sur engagements de 1 750 000 à 2 500 000
0
0,2
0,4
0,6
0,8
1
0 0,2 0,4 0,6 0,8 1
1 750 000 à 2 500 000
BHV
NCE

50
CONCLUSIONS ET AVENUES DE RECHERCHE
Le risque de crédit est l’un des risques les plus importants pour les institutions
financières. De ce fait, il devient important pour elles non seulement de mettre en
place des modèles qui permettent de le quantifier, mais surtout de s’assurer de la
performance de ces modèles. Ce dernier rôle dans la gestion du risque financier
s’insère dans ce que l’on appelle l’étape de validation de modèle.
À travers ce projet, nous avons étudié l’utilisation du modèle de notation de crédit
(encore appelé «credit scoring») sur une population différente de celle du
développement du modèle. Il s’agit de montrer que le modèle comportemental BHV
conçu initialement par une firme externe pour permettre de mieux discriminer les
bons emprunteurs des mauvais pourrait être utilisé pour des montants d’engagement
supérieurs et ce, tout en maintenant un bon pouvoir discriminant. Le modèle attribue
différents pointages (scores) à chacun des emprunteurs afin de représenter son niveau
de risque pour l’institution.
Dans un premier temps, nous avons dans notre méthodologie déterminé les montants
d’engagements pour chaque client-entreprise, et stratifié ces derniers afin d’avoir non
seulement une vue granulaire du comportement du modèle BHV sur chaque strate de
montant d’engagement, mais aussi sur chaque strate de niveau de risque associé à ce
montant d’engagement. Ainsi, nous avons pu constater l’évolution du taux de défaut à
l’intérieur de chaque segment d’engagement. Ces TD diminuent avec l’augmentation
du montant d’engagement pour les niveaux de pointage faibles, et se stabilisent pour
les niveaux moyens et élevés. Par la suite, les TD sont comparés à la PD prédite afin
de montrer le degré de conservatisme de l’institution dans la gestion du risque pour
chaque strate d’engagement. Nous remarquons que les écarts entre les TD observés et

51
les PD prédites sont moins importants pour les niveaux de pointage moyen et élevé
du modèle BHV.
La dernière étape et non la moindre, nous a permis d’analyser la fiabilité du modèle
sur chaque strate de montant d’engagement. Dans ce processus de validation de la
performance, nous avons fait usage des deux outils les plus utilisés dans l’analyse du
pouvoir discriminant d’un modèle de notation à savoir l’AUROC et le KS. Les
coefficients AUROC et KS élevés nous ont montré que le pouvoir discriminant du
modèle BHV demeure adéquat quel que soit le montant d’engagement considéré
selon l’appréciation adoptée par l’institution. D’autre part, le modèle BHV affiche
une performance supérieure à celle du modèle de référence.
Nous comprenons donc que dans l’éventualité d’une utilisation du modèle BHV sur
des montants d’engagement allant jusqu’à 2 500 000$, la performance du modèle ne
devrait aucunement être affectée.
Néanmoins, il faut noter qu’une hypothèse utilisée pour permettre la comparaison
entre les deux modèles pourrait en réalité être fausse et dans ce cas, la performance
des deux modèles serait affectée. On pourrait donc pour faire suite à ce projet, faire
une analyse plus complète. Dans un premier temps, en déterminant un identifiant
défaut unique qui regroupe tous les produits de prêts et donc prendrait en compte
équitablement les deux modèles BHV et NCE dans l’analyse comparative de
performance.
En outre, une autre contribution future pourrait être l’utilisation des statistiques de
performance qui tiendraient compte du coût de mauvaise classification, ce que ne font
ni le KS, ni l’AUROC. Hand [21] dans son article, a élaboré une approche alternative
à l’AUROC. Cette dernière permettrait de tenir compte du coût de mauvaise
classification dans les méthodes d’évaluation. L’approche de Hand même si elle a été
proposée dans ses écrits de 2009 et 2010, reste d’actualité d’autant plus que depuis sa

52
proposition, nous n’avons pas trouvé de travaux empiriques qui auraient essayé de
l’implémenter. Quelques auteurs ont repris l’étude de Hand sans apporter de plus-
value. Par ailleurs, en septembre 2012, Anagnostopoulos et al16 ont proposé la
‘’mesure H’’ (hmesure) [32] qui met en pratique l’article de Hand. Cette mesure
pourrait être une piste de solution à cette critique de l’AUROC tant soulevée mais
jamais abordée sur les modèles de notation de crédit.
Enfin, dans la mesure où le modèle BHV serait appliqué aux segments supérieurs à
500 000$, nous recommanderons une validation du processus de cette implantation
afin de s’assurer d’une part que l’hypothèse de représentativité est bel et bien
maintenue, mais aussi que le modèle est adéquatement déployé dans l’environnement
opérationnel.
16 http://cran.r-project.org/web/packages/hmeasure/vignettes/hmeasure.pdf, consulté le 30 Juillet 2014.

BIBLIOGRAPHIE
[1] Thomas, L.C. (2000). A survey of credit and behavioural scoring: forecasting financial risk of lending to consumers. International Journal of Forecasting, 16, 149-172. [2] Schreiner, M. (2000). Credit scoring for microfinance: Can it work? Journal of Microfinance, 2 (2), 105–118.
[3] Caire, D. et Kossmann, R. (2003). Credit scoring: Is it right for your bank? Bannock Consulting.
[4] Anderson, R. (2007). The credit scoring toolkit, Oxford University press, p 6.
[5] Durand, D. (1941). Risk elements in consumer instalment financing, NBER.
[6] Myers, J.H. et Forgy, E.W. (1963). The development of numerical credit evaluation systems. Journal of the American Statistical Association, 58 (303), 799-806.
[7] Kao, L.J., Chiu, C.C. et Chiu, F.Y. (2012). A Bayesian latent variable model with classification and regression tree approach for behavior and credit scoring. Knowledge-Based System, 36, 245-252.
[8] Ogler, Y. (1970). A credit scoring model for commercial loan, Journal of Money, Credit & Banking, 2 (4), 435-445.
[9] Autorité des Marchés Financiers (2013), Ligne directrice sur les normes relatives à la suffisance du capital de base, Coopératives des services financiers.
[10] Bank for International Settlements (2005). Studies on the validation of internal rating systems. Working Paper 14.
[11] Peterson, W.W., Birdsall, T.G., et Fox, W. (1954). The theory of signal detectability. Transactions IRE Profession Group on Information Theory, Vol. 4 (4), 171- 212.
[12] Sobehart, J.R. et Keenan, S.C. (2001). Measuring default accurately. Credit Risk Special Report, Risk 14, 31–33.
[13] Sobehart, J.R., and Keenan, S.C. (2007). Understanding performance measures for validating default risk models: a review of performance metrics. Journal of Risk Model Validation, 1 (2), 61–79.

[14] Stein, R.M. (2007). Benchmarking default prediction models: pitfalls and remedies in model validation. Journal of Risk Model Validation, 1, 77–113.
[15] Hosmer, D.W., and Lemeshow, S. (2000). Assessing the fit of the model. Applied Logistic Regression, chap 5, John Wiley & Sons Second Edition.
[16] Siddiqi, N. (2006). Credit risk scorecards: developing and implementing intelligent credit scoring, John Wiley & Sons, New Jersey.
[17] Mays, E. (2001). Handbook of credit scoring, The Glenlake Publishing Company Ltd.
[18] Altman, E.I. et Saunders, A. (1998). Credit risk measurement: Developments over the last 20 years. Journal of Banking and Finance, 21, 1721-1742.
[19] Tasche, D. (2006). Validation of internal rating systems and PD estimates, arXiv: physics/0606071. [20] Hong, C.S. (2009). Optimal threshold from ROC and CAP curves. Communications in Statistics - Simulation and Computation, 38(10), 2060-2072. [21] Hand, D.J. (2009). Measuring classifier performance: A coherent alternative to the area under the ROC curve. Machine Learning, 77, 103–123.
[22] Engelmann, B. et Rauhmeier, R. (2006). Estimation, validation, and stress testing, The Basel II Risk Parameters, p 281.
[23] Rezáč M. et Rezáč F. (2011), How to measure the quality of credit scoring models. Finance a úvěr-Czech Journal of Economics and Finance, 61(5), 486-507.
[24] Fisher, R. A (1936), The use of multiple measurements in taxonomic problems. Annals of Eugenics, 7, 179-188.
[25] Banasik, A J, Crook, J et Thomas, L (2003). Sample selection bias in credit scoring model. Journal of the Operational Research Society, 54, 822-832.
[26] Crook, J, Banasik, A J (2004). Does reject inference really improve the performance of application scoring models. Journal of Banking and Finance, 28, 857-874.
[27] Barakova, I, Glennon, D, Palvia, A (2013). Sample selection bias in acquisition Credit Scoring Models: an evaluation of the supplemental-data approach. Journal of credit risk, 9(3), 77-117.

[28] Glennon, D., Larson, C.E., Kiefer, N.M. et Choi, H. (2008). Development and validation of credit-scoring models, Journal of Credit Risk, 4, 1-61.
[29] West D. (2000). Neural network credit scoring models, Computers and Operations Research, 27, 1131-1152.
[30] Mavri M., Angelis, V., Ioannou, G., Gaki, E. et Koufodontis, I (2008). A two-stage dynamic credit scoring model, based on customers’ profile and time horizon, Journal of Financial Services Marketing, 13 (1), 17-27.
[31] Fensterstock A. (2010). How good is your credit-scoring model? Journal of Equipment Lease Financing, 28 (1), 1D-13D.
[32] Anagnostopoulos, C., Hand D.J., Adams, N.M (2012). Measuring classification performance: the hmeasure package, http://cran.r-project.org/web/packages/hmeasure/vignettes/hmeasure.pdf, consulté le 30 Juillet 2014.