Embed Size (px)
Citation preview

!LIF5 : Algorithmique et programmation procédurale
Fascicule de travaux dirigés et de travaux pratiques
Carole Knibbe et Samir Akkouche ! Université Lyon 1
Notes :
! LIF5 : Algorithmique et programmation procédurale
! Page 2
Table des matières
Travaux dirigés .............................................................................................................. 3 Types primitifs ......................................................................................................................................................... 4 Vie et mort des variables en mémoire ............................................................................................................ 10 Algorithmes, invariants de boucle et complexité .......................................................................................... 22 Algorithmes sur les fichiers ................................................................................................................................ 32 Exercices de synthèse - préparation au CC mi-parcours ........................................................................... 37 Tableaux dynamiques ........................................................................................................................................... 41 Listes chaînées ....................................................................................................................................................... 43 Arbres binaires ...................................................................................................................................................... 45 Piles et files ............................................................................................................................................................. 46
Travaux pratiques ....................................................................................................... 48 TP1 (A) : Premiers pas sous Linux ................................................................................................................... 49 TP1 (B) : Types primitifs ..................................................................................................................................... 53 TP2 : Vie et mort des variables en mémoire, pointeurs ............................................................................. 57 TP3 : Tableaux, structures, algorithmes de tri internes .............................................................................. 59 TP4 : Fichiers, complexité, algorithme de tri externe ................................................................................. 61 TP additionnel (à faire chez soi, pour les plus motivés !) : Traitement d'images ................................... 63 TP5 : Tableau dynamique .................................................................................................................................... 68 TP6 : Liste (doublement) chaînée ..................................................................................................................... 71 TP7 : Arbre binaire de recherche ..................................................................................................................... 73 TP8 : TP de synthèse ........................................................................................................................................... 75 Annexe 1 : Commandes Linux usuelles ........................................................................................................... 77 Annexe 2 : Fonctionnement de scanf ............................................................................................................... 78

! LIF5 : Algorithmique et programmation procédurale
! Page 3
Travaux dirigés
Notes :
! LIF5 : Algorithmique et programmation procédurale
! Page 4
Types primitifs
Exercice 1 * : Codage des entiers naturels
a) Quel est le plus grand entier naturel que l’on puisse exprimer dans une base B si l’on dispose de L positions ? En conséquence, peut-on représenter le nombre d'électrons dans l'univers (soit un nombre de l’ordre de 1078) dans un entier naturel codé sur 32 bits ?
b) Convertissez en binaire le nombre 23810 en utilisant le principe des divisions successives. Déduisez-en sa représentation hexadécimale en regroupant les bits par paquets de quatre. Peut-on aussi utiliser une méthode de regroupement pour passer de l’écriture binaire de 238 à son écriture décimale ?
c) Réalisez l’addition binaire de 238 et de 32 après avoir représenté ces nombres en binaire pur sur 8 bits (unsigned char). Que constatez-vous ? Comment éviter ce problème ici ?
d) Question à faire chez soi : Convertissez 238 en base 16 en utilisant la méthode des divisions successives (divisions par 16). Vérifiez que vous obtenez bien la même représentation qu’en regroupant les bits du codage binaire par paquets de quatre.
Exercice 2 * : Codage des entiers relatifs
a) Quelle est la représentation de -3 et +10 en « binaire - complément à 2 » sur 8 bits (signed char) ?
b) Additionnez à présent les deux nombres (en binaire). Le résultat est-il correct ? Aurait-on obtenu un résultat correct en additionnant les représentations en « signe-valeur absolue » des deux nombres ?
Exercice 3 ** : Codage des réels
a) Convertir 9 et 5/32 au format IEEE 754 simple précision. Donnez les résultats en écriture binaire et en écriture hexadécimale. Additionnez ces deux nombres.
b) Pour le format IEEE simple précision, quel est l’écart entre deux nombres machines successifs ? En conséquence, combien y a-t-il de chiffres décimaux significatifs dans un nombre codé dans ce format ? A votre avis, écrire float pi=3.14159265358979 a-t-il un sens ?
Exercice 4 * : Opérateurs et conversions implicites en C
Etant données les définitions ci-dessous,
char monChar1 = ’a’, monChar2 = 97;
int monInt = 1;
long monLong = 1L;
float monFloat = 1.0f;
double monDouble = 1.0;
donner le type et la valeur de chacune des expressions suivantes :
a) monChar1 + monChar2

! LIF5 : Algorithmique et programmation procédurale
! Page 5
b) monChar1 + 1
c) monChar1 + 1.0
d) monChar1 + 1.0f
e) monFloat + monFloat
f) monChar1 + monInt + monLong
g) monChar1 + monInt + monLong + monFloat + monDouble
h) monChar1 = monChar1 + monInt + monLong + monFloat + monDouble
i) monChar1 == monChar2
j) monChar1 = monChar2 + monInt + monLong + monFloat + monDouble, monFloat = 2
Exercice 5 *** : Algorithmique sur des entiers relatifs
On dispose, dans le langage algorithmique, d’un type booleen pouvant prendre les valeurs {vrai, faux} et sur lequel on peut effectuer des opérations de comparaison (opérateur =), d’affectation (opérateur ←) et de négation (fonction non(b: booleen): booleen). On définit alors le type « Entier64 » comme suit :
type Entier64 = tableau[1..64] de booleens
Un Entier64 permet de coder un entier compris entre -263 et 263 - 1, de façon identique au codage dans un signed char, un short ou un int, mais sur plus de bits.
a) Ecrire la fonction addition(e1: Entier 64, e2: Entier64): Entier64 qui retourne la somme de 2 Entier64. On utilisera uniquement les opérations de comparaison, d’affectation et de négation de booléens. On pourra recourir à une variable interne pour la gestion de la retenue. Remarque : on bénéficie toujours du type entier « normal », qui permet de gérer des entiers qui restent relativement petits, comme l’indice d’un tableau.
b) Ecrire une procédure incremente(e: Entier64) qui ajoute 1 un Entier64, en utilisant la fonction d’addition. On supposera que l’on a déjà écrit la procédure d’affectation entre Entier64 :
Procédure affecte(e: Entier64, val: Entier64) Précondition : val doit appartenir à l’intervalle -263 .. 263-1 Postcondition : e+ = val Paramètre en donnée-résultat : e Paramètre en donnée : val
Questions à faire chez soi :
c) Supposons que l’on ait déjà écrit les sous-programmes suivants, en plus des précédents :
Procédure initialiseZero(e: Entier64) Précondition : aucune Postcondition : e+ = 0 Paramètre en donnée-résultat : e Procédure decremente(e: Entier64)
! LIF5 : Algorithmique et programmation procédurale
! Page 6
Précondition : l’entier e-1 doit appartenir à l’intervalle -263 .. 263−1 Postcondition : e+ = e- - 1 Paramètre en donnée-résultat : e Fonction estSuperieur(e1: Entier64, e2: Entier64) : booleen Précondition : e1 et e2 appartiennent à l’intervalle -263 .. 263−1 Résultat : retourne vrai si e1 > e2, faux sinon Paramètres en mode donnée : e1, e2
Proposez alors une fonction de calcul du produit de 2 Entier64 qui ne fasse intervenir que des opérations d’addition et de décrémentation d’Entier64, en plus des opérations de comparaison et d’affectation d’Entier64. On utilisera 4 variables internes de type Entier64 : zeroE64, res, nb_ajouts_restants et qte_ajoutee. On écrira l’algorithme pour le cas où e1 et e2 sont positifs, puis on expliquera comment procéder dans le cas plus général (sans écrire l’algorithme).
d) Améliorez l’algorithme précédent en supposant que l’on dispose aussi des sous-programmes suivants (Indice : posez la multiplication en binaire) :
Procédure multiplieParDeux(e: Entier64) Précondition : e et 2*e doivent appartenir à l’intervalle -263 .. 263−1 Postcondition : e+ = 2*e- Paramètre en donnée-résultat : e Procédure diviseParDeux(e: Entier64) Précondition : e et e/2 doivent appartenir à l’intervalle -263 .. 263−1 Postcondition : e+ = e-/2 (attention, c’est une division entière) Paramètre en donnée-résultat : e Fonction estImpair(e: Entier64) : booleen Précondition : e appartient à l’intervalle -263 .. 263−1 Résultat : retourne vrai si e est impair faux sinon Paramètres en mode donnée : e
e) Comparez les deux méthodes de multiplication en estimant le nombre d’opérations à effectuer : • nombre de tours de boucle • pour chaque tour, les nombres maximum de comparaisons, d’additions, d’affectations et de
décrémentations, de tests de parité, de divisions par 2 et de multiplications par 2. Quelle méthode vous semble la plus efficace ? Pourquoi ?
Exercice 6 **
Votre patron découvre Internet et les réseaux. Il est très inquiet vis à vis des codages et transmissions de données. Il vous pose quelques questions tous azimuts : Pourquoi les données sont-elles codées sous forme binaire ? Qu'est-ce que le codage ASCII et le codage binaire ? Comment coder des nombres de la manière la plus efficace ? Est-ce qu'il est plus rapide de transmettre des données (des listes de petits nombres entiers, précise-t-il, entre environ 200 pour les plus petits et environ 1000 pour les plus gros nombres) sous forme ASCII ou sous forme binaire ? Est-ce qu'il n'y a pas un moyen d'avoir un codage pour les nombres qui ressemble au codage ASCII (du décimal codé en binaire) ? Qu'est-ce qui sera le plus « court » lors des

! LIF5 : Algorithmique et programmation procédurale
! Page 7
sauvegardes sur disque parmi tous ces codages ? Répondez de façon simple et en au maximum une demi-page à chacune de ces questions.
Exercice 7 *
Soit la suite : 01101111 01001111 00110000 00110010 11011101 11101111 11001110 11100100. Interpréter le sens des trois premiers éléments de cette suite en considérant qu’il s’agit de :
a) une suite de code ASCII
b) des entiers codés en binaire pur sur un octet
c) des entiers codés en binaire complément à deux sur un octet
d) des entiers codés en binaire complément à deux sur deux octets
e) des entiers codés en binaire excédent à 127 sur 1 octet
Exercice 8 *
Soit la suite d’octets suivante : 11100000 01001111 00110000 00110010
a) Réécrivez cette suite en hexadécimal.
b) Interprétez le sens de cette suite en considérant qu’il s’agit:
• d’une suite de codes ASCII,
• d’entiers codés en binaire pur sur un octet,
• d’entiers codés en binaire complément à deux sur un octet,
• d’entiers codés en binaire complément à deux sur deux octets,
• d’un réel au format IEEE 754 simple précision.
Exercice 9 *
Donnez la traduction à laquelle correspond le mot 0x4c494635 (4 octets), selon qu’on le lit comme :
a) un entier naturel,
b) un entier relatif représenté en complément à 2,
c) un nombre représenté en virgule flottante simple précision suivant la norme IEEE 754,
d) une suite de caractères ASCII
Exercice 10 *
! LIF5 : Algorithmique et programmation procédurale
! Page 8
Traduire en binaire les 5 informations suivantes : « Bon », 0, 20, 10.5, -2. Pour chacune, précisez le codage employé, donnez son principe et justifiez votre choix.
Exercice 11 *
a) Donner, en binaire, puis en hexadécimal, le codage ASCII du mot : « Lyon »
b) Donner un moyen de passer du code ASCII d'une lettre en majuscule à celui de la même lettre en minuscule et inversement
c) Donner un moyen de passer du code ASCII d'un chiffre à la valeur de ce chiffre et inversement.
d) Idem pour un nombre.
Exercice 12 *
Compléter (sans calculatrice) la table suivante :
nombre base 2 base 8 base 10 base 16 001011012 _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ 000378 _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ 55510 _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ A216 _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
Exercice 13 *
Indiquer, parmi les combinaisons suivantes, celles qui correspondent à des nombres hexadécimaux : BED, CAB, DEAD, DECADE, ACCEDED, BAG, DAD.
Exercice 14 **
Lorsqu’on somme 2 bits, à quelles opérations logiques binaires correspondent respectivement la somme (valeur que l’on écrirait sous le trait de l’addition si on la posait à la main) et la retenue ?
! LIF5 : Algorithmique et programmation procédurale
! Page 9
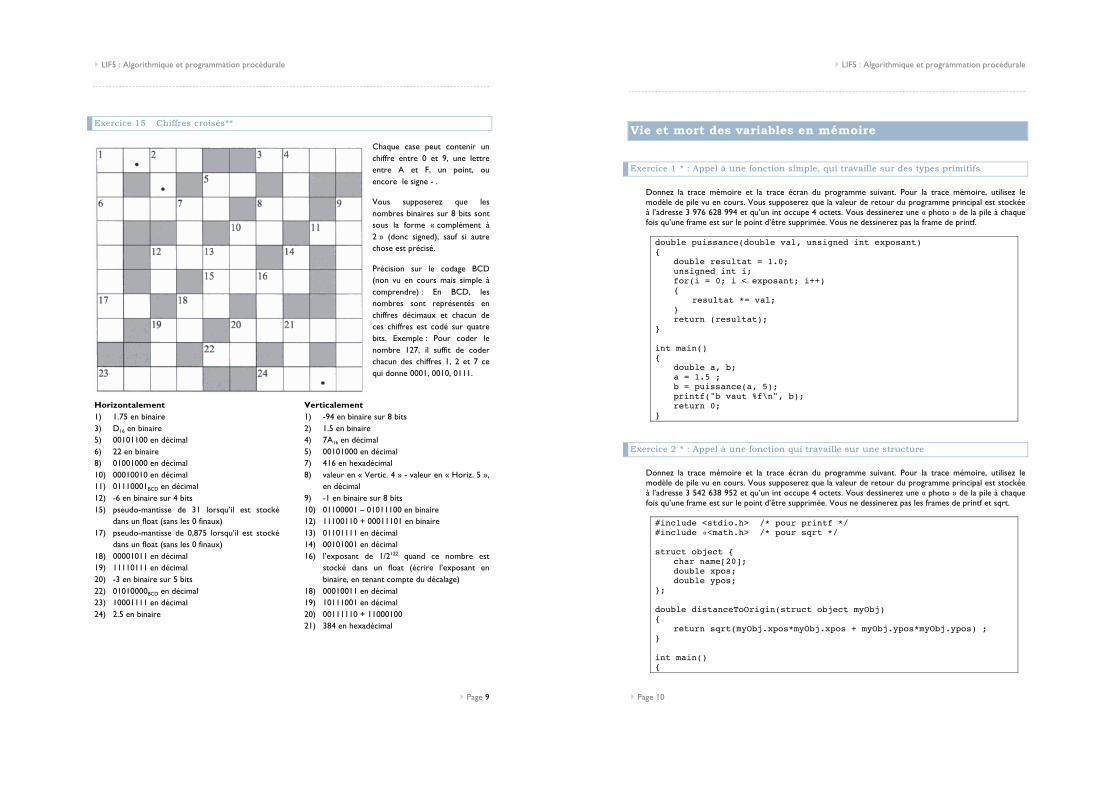
Exercice 15 Chiffres croisés**
Chaque case peut contenir un chiffre entre 0 et 9, une lettre entre A et F, un point, ou encore le signe - .
Vous supposerez que les nombres binaires sur 8 bits sont sous la forme « complément à 2 » (donc signed), sauf si autre chose est précisé.
Précision sur le codage BCD (non vu en cours mais simple à comprendre) : En BCD, les nombres sont représentés en chiffres décimaux et chacun de ces chiffres est codé sur quatre bits. Exemple : Pour coder le nombre 127, il suffit de coder chacun des chiffres 1, 2 et 7 ce qui donne 0001, 0010, 0111.
Horizontalement 1) 1.75 en binaire 3) D16 en binaire 5) 00101100 en décimal 6) 22 en binaire 8) 01001000 en décimal 10) 00010010 en décimal 11) 01110001BCD en décimal 12) -6 en binaire sur 4 bits 15) pseudo-mantisse de 31 lorsqu’il est stocké
dans un float (sans les 0 finaux) 17) pseudo-mantisse de 0,875 lorsqu’il est stocké
dans un float (sans les 0 finaux) 18) 00001011 en décimal 19) 11110111 en décimal 20) -3 en binaire sur 5 bits 22) 01010000BCD en décimal 23) 10001111 en décimal 24) 2.5 en binaire
Verticalement 1) -94 en binaire sur 8 bits 2) 1.5 en binaire 4) 7A16 en décimal 5) 00101000 en décimal 7) 416 en hexadécimal 8) valeur en « Vertic. 4 » - valeur en « Horiz. 5 »,
en décimal 9) -1 en binaire sur 8 bits 10) 01100001 – 01011100 en binaire 12) 11100110 + 00011101 en binaire 13) 01101111 en décimal 14) 00101001 en décimal 16) l’exposant de 1/2122 quand ce nombre est
stocké dans un float (écrire l’exposant en binaire, en tenant compte du décalage)
18) 00010011 en décimal 19) 10111001 en décimal 20) 00111110 + 11000100 21) 384 en hexadécimal
! LIF5 : Algorithmique et programmation procédurale
! Page 10
Vie et mort des variables en mémoire
Exercice 1 * : Appel à une fonction simple, qui travaille sur des types primitifs
Donnez la trace mémoire et la trace écran du programme suivant. Pour la trace mémoire, utilisez le modèle de pile vu en cours. Vous supposerez que la valeur de retour du programme principal est stockée à l’adresse 3 976 628 994 et qu’un int occupe 4 octets. Vous dessinerez une « photo » de la pile à chaque fois qu’une frame est sur le point d’être supprimée. Vous ne dessinerez pas la frame de printf.
double puissance(double val, unsigned int exposant) { double resultat = 1.0; unsigned int i; for(i = 0; i < exposant; i++) { resultat *= val; } return (resultat); } int main() { double a, b; a = 1.5 ; b = puissance(a, 5); printf("b vaut %f\n", b); return 0; }
Exercice 2 * : Appel à une fonction qui travaille sur une structure
Donnez la trace mémoire et la trace écran du programme suivant. Pour la trace mémoire, utilisez le modèle de pile vu en cours. Vous supposerez que la valeur de retour du programme principal est stockée à l’adresse 3 542 638 952 et qu’un int occupe 4 octets. Vous dessinerez une « photo » de la pile à chaque fois qu’une frame est sur le point d’être supprimée. Vous ne dessinerez pas les frames de printf et sqrt.
#include <stdio.h> /* pour printf */ #include «<math.h> /* pour sqrt */ struct object { char name[20]; double xpos; double ypos; }; double distanceToOrigin(struct object myObj) { return sqrt(myObj.xpos*myObj.xpos + myObj.ypos*myObj.ypos) ; } int main() {

! LIF5 : Algorithmique et programmation procédurale
! Page 11
struct object player1 = {"Andrew", 5.0, 8.0}; double dist ; dist = distanceToOrigin(player1); printf("Player %s is at distance %f from the origin.\n", \ player1.name, dist); return 0; }
Exercice 3 ** : Appel à une fonction qui travaille sur un tableau
a) Donnez la trace mémoire et la trace écran du programme suivant, en supposant que l’utilisateur s’appelle Leonard. Pour la trace mémoire, utilisez le modèle de pile vu en cours. Vous supposerez que la valeur de retour du programme principal est stockée à l’adresse 3 976 628 994 et qu’un int occupe 4 octets. Vous dessinerez une « photo » de la pile à chaque fois qu’une frame est sur le point d’être supprimée. Vous ne dessinerez pas les frames de printf et scanf.
int longueurChaine(const char chaine[]) { int i = 0; while (chaine[i] != ‘\0’) { i++; } return i; } int main() { char prenom[30]; int longueur; printf("Entrez votre prénom : "); scanf("%29s", prenom); longueur = longueurChaine(prenom); printf("\n Votre prénom est composé de %d lettres.\n", longueur); return 0; }
b) Expliquez à quoi sert le mot-clé const dans l’entête de la fonction longueur.
c) Expliquez à quoi sert le « 29 » dans le code de format du scanf.
Exercice 4 *** : Appel à une fonction récursive
a) Donnez la trace mémoire et la trace écran du programme suivant. Pour la trace mémoire, utilisez le modèle de pile vu en cours. Vous supposerez que la valeur de retour du programme principal est stockée à l’adresse 3 965 281 684 et qu’un int occupe 4 octets. Vous dessinerez une « photo » de la pile à chaque fois qu’une frame est sur le point d’être supprimée. Vous ne dessinerez pas les frames des appels à printf.
#include <stdio.h> /* Calcul d’un coefficient binomial a l’aide du triangle de Pascal */ int comb(int n, int p) { int tmp1, tmp2;
! LIF5 : Algorithmique et programmation procédurale
! Page 12
printf("Calcul du nb de combinaisons de %d elts parmi %d\n", p, n); if ((p==0) || (n==p)) { return 1; } tmp1 = comb(n-1, p-1); /* premier appel recursif */ tmp2 = comb(n-1, p); /* second appel recursif */ return tmp1 + tmp2; } int main() { int c; c = comb(4, 3); printf("c vaut %d\n", c); return 0; }
Exercice 5 ** : Appel à une procédure qui doit échanger deux valeurs
a) Un étudiant a écrit le code suivant pour une procédure qui échange les valeurs de deux variables. Ce code est erroné : pour savoir pourquoi, dessinez la trace mémoire du programme suivant selon le modèle de pile vu en cours (vous supposerez que la valeur de retour du programme principal est stockée à l’adresse 3 965 281 684 et qu’un int occupe 4 octets). Vous ne dessinerez pas les frames des appels à printf.
#include <stdio.h> void echange(int a, int b) { int temp; temp = a; a = b; b = temp; printf("Dans la procédure echange: "); printf("a = %d, b = %d\n", a, b); } int main() { int a, b; a = 5; b = 7; printf("Dans le main: a = %d, b = %d\n", a, b); echange(a, b); printf("De retour dans le main: "); printf("a = %d, b = %d\n", a, b); return 0; }

! LIF5 : Algorithmique et programmation procédurale
! Page 13
b) Corrigez ce code.
Exercice 6 ** : Appel à une procédure qui doit multiplier une valeur par deux
a) Un étudiant a écrit le code suivant pour une procédure qui multiplie un entier par deux. Ce code est erroné : pour savoir pourquoi, dessinez la trace mémoire du programme suivant selon le modèle de pile vu en cours (vous supposerez que la valeur de retour du programme principal est stockée à l’adresse 3 965 281 684 et qu’un int occupe 4 octets). Vous ne dessinerez pas les frames des appels à printf.
#include <stdio.h> void multiplierParDeux(int x) { x *= 2; printf ("Dans la procédure, après multiplication x = %d\n",x); } int main(void) { int number = 10; printf ("Dans main, au départ number = %d\n",number); multiplierParDeux(number); printf("Dans main, après exécution de la procédure number %d\n", number); return 0; }
b) Corrigez ce code.
Exercice 7 ** : Appel à une procédure avec effet de bord
Soit le programme C suivant :
void proc(int * ad, int j)
/* Précondition : ad adresse valide non nulle Postcondition : à votre avis? */ { *ad = (*ad + j)*3; /* dessiner l’etat de la memoire */ } int main()
{ double a = 0.001, b = 0.003; double c, *pa, *pb; int i=0; /* dessiner l’etat de la memoire */ pa = &a; *pa *= 2; pb = &b;
! LIF5 : Algorithmique et programmation procédurale
! Page 14
c = 3*(*pb - *pa); /* dessiner l’etat de la memoire */ proc(&i,4); /* dessiner l’etat de la memoire */ return 0; }
a) En utilisant le modèle de pile vu en cours, dessinez l’état de la mémoire à chaque fois que c’est indiqué en commentaire. Vous supposerez que les variables sont stockées à partir de l’adresse 0xbffff3a0 (note : bffff3a0 en base 16 = 3 221 222 304 en base 10). Veillez à faire des dessins distincts mais cohérents entre eux.
b) Qu’en déduisez-vous au sujet du mode de passage de i lorsqu’il est passé en paramètre à proc ?
Exercice 8 ** : Pointeurs et allocation dynamique de mémoire
#include <stdio.h> /* entrées-sorties avec printf et scanf */ #include <stdlib.h> /* malloc, free, exit */ int main() { int e = 10; double r = 3.14; int * p1; double * p2; int i; p1 = (int*) malloc (5*sizeof(int)); if(p1 == NULL) { printf("Allocation ratee \n"); exit(1); } p2 = (double*) malloc (sizeof(double)); if(p2 == NULL) { printf("Allocation ratee \n"); exit(1); } for(i=0 ; i < 5 ; i++) {p1[i] = e-i;} *p2 = r; (*p1)*=5; *p2=p1[3]*2.0; e = 25; r = -8.3; free(p1); free(p2); return 0; }
a) Expliquez ce que signifie l’instruction p1 = (int*) malloc (5*sizeof(int));
b) Proposez une autre façon d’écrire l’instruction (*p1)*=5;
c) Faites la trace mémoire de ce programme, en supposant que la valeur de retour du main est stockée à l’adresse 0xD4986C36 (soit 3 566 758 966 en base 10).
Exercice 9 ** : Procédure récursive sur un tableau (CC mi-parcours avril 2010)

! LIF5 : Algorithmique et programmation procédurale
! Page 15
Considérons le programme C suivant :
#include <stdio.h> #include <stdlib.h> void mystere(double t[], int a, int b) { double aux; if (a < b) { aux = t[a]; t[a] = t[b]; t[b] = aux; mystere(t, a+1, b-1); } else { /* DESSIN 2 : etat de la memoire quand on passe dans ce else */ } } int main() { double * monTab; int n, i; printf("Combien d'elements souhaitez vous saisir ?\n"); scanf("%d", &n); monTab = (double *) malloc(n*sizeof(double)); for(i = 0; i < n; i++) { printf("Saisir l'element %d:\n", i); scanf("%lf", monTab + i); } /* DESSIN 1 : etat de la memoire a ce moment */ mystere(monTab, 0, n-1); printf("Tableau apres traitement :\n"); for(i = 0; i < n; i++) {printf("Elt %d = %f\n", i, monTab[i]);} free(monTab); return 0; }
a) Que fait la procédure mystere ? Autrement dit, si vous deviez lui donner un nom plus explicite, lequel choisiriez-vous ?
b) Dessinez l’état de la pile et du tas aux deux moments indiqués en commentaires (on vous demande pour chaque dessin une « photo » de la pile entière et de tout ce qu’il y a dans le tas). Vous utiliserez le modèle théorique de pile vu en cours et en TD. Vous supposerez que la valeur de retour du main est stockée à l’adresse 3 987 546 988, et que l’utilisateur tape successivement les valeurs 4, 9.0, 10.0, 11.0, 12.0.
! LIF5 : Algorithmique et programmation procédurale
! Page 16
Exercice 10 ** : Pointeurs et tableaux en C, arithmétique des pointeurs
int monTab[] = {-25, -6, 8, 15, 38, 50, 72, 81, 98};
int * p = monTab;
Quelles valeurs ou adresses fournissent les expressions suivantes ?
a) *p+2
b) *(p+2)
c) p+2
d) &p
e) &monTab[4] - 3
f) monTab+3
g) &monTab[7] - p
h) *(p+8) - monTab[7]
Exercice 11 ** : Pointeurs et tableaux de structures
Le but de cet exercice est de dessiner la trace mémoire (pile et tas) du programme suivant. Pour des raisons de clarté, il vous est demandé de faire 5 dessins distincts, à différents moments de l’exécution du programme, indiqués en commentaires. Chaque dessin devra représenter toutes des données du programme actuellement présentes dans la pile et le tas (les différents dessins pourront donc être partiellement redondants). Vous supposerez que la valeur de retour du « main » se trouve à l’adresse 3 556 894 980. Vous ne dessinerez pas les frames des appels à printf.
#include <stdio.h> #include <stdlib.h> struct sPoint { double x; double y; }; typedef struct sPoint Point; void initialiserPoint(Point * p, double abs, double ord) { (*p).x = abs; (*p).y = ord; /* DESSIN 3 : etat de la memoire juste avant la sortie de procedure */ } void initialiserTableauDePoints(Point tab[], int nb)

! LIF5 : Algorithmique et programmation procédurale
! Page 17
{ int i; for(i = 0; i < nb; i++) { tab[i].x = i; tab[i].y = i*i; } /* DESSIN 1 : etat de la memoire juste avant la sortie de procedure */ } double distanceDeManhattan(Point p1, Point p2) { double tmpx, tmpy; tmpx = p2.x - p1.x; if (tmpx < 0) {tmpx = -tmpx;} tmpy = p2.y - p1.y; if (tmpy < 0) {tmpy = -tmpy;} /* DESSINS 2 et 4 : etat de la memoire juste avant le return */ return (tmpx + tmpy); } int main() { Point lesPoints[5]; double dist = 0.0; initialiserTableauDePoints(lesPoints, 5); dist = distanceDeManhattan(lesPoints[0], lesPoints[4]); printf("La distance de Manhattan entre le 1er et le dernier point est %f\n", dist); Point * nouveauPt = (Point *) malloc(sizeof(Point)); initialiserPoint(nouveauPt, 1.5, -2.0); dist = distanceDeManhattan(lesPoints[0], *nouveauPt); printf("La distance de Manhattan entre le 1er et le nouveau point est %f\n", dist); free(nouveauPt); /* DESSIN 5 : etat de la memoire juste apres le free */ return 0; }
Exercice 12 Pointeurs et tableaux de structures (bis) (CC mi-parcours octobre 2010)
#include <stdio.h> #include <stdlib.h> #define TAILLETAB 3 struct date { int jour; int mois; int annee; };
! LIF5 : Algorithmique et programmation procédurale
! Page 18
char estAnterieure(struct date d1, struct date d2) { char res; if (d1.annee < d2.annee) { res = 1; } else { if (d1.annee > d2.annee) { res = 0; } else { if (d1.mois < d2.mois) { res = 1; } else { if (d1.mois > d2.mois) { res = 0; } else { if (d1.jour < d2.jour) { res = 1; } else { res = 0; } } } } } /* Dessiner l’état de la mémoire à chaque fois que l’on passe ici */ return res; } void chercherLaPlusAncienne(const struct date TabDates[], struct date * d, int * pos) { int i; *d = TabDates[0]; *pos = 0; for(i = 1; i < TAILLETAB; i++) { if (estAnterieure(TabDates[i], *d)==1) { *d = TabDates[i]; *pos = i; } } } int main() { struct date mesDates[TAILLETAB]; int p; struct date * oldest; mesDates[0].jour = 17; mesDates[0].mois = 9; mesDates[0].annee = 1982; mesDates[1].jour = 29; mesDates[1].mois = 11; mesDates[1].annee = 1955;

! LIF5 : Algorithmique et programmation procédurale
! Page 19
mesDates[2].jour = 17; mesDates[2].mois = 11; mesDates[2].annee = 1955; oldest = (struct date *) malloc(sizeof(struct date)); chercherLaPlusAncienne(mesDates, oldest, &p); printf("La date la plus ancienne est le %d/%d/%d.\n", (*oldest).jour, (*oldest).mois, (*oldest).annee); printf("Elle est situee a la position %d dans le tableau.\n", p); /* Dessiner l’état de la mémoire à ce moment */ free(oldest); return 0; }
Dessinez l’état de la pile et du tas aux moments indiqués en commentaires (on vous demande pour chaque dessin une « photo » de la pile entière et de tout ce qu’il y a dans le tas). Vous utiliserez le modèle théorique de pile vu en cours et en TD. Vous supposerez que la valeur de retour du main est stockée à l’adresse 3 987 546 988.
Exercice 13 *** : Tableaux de structures, et fonction récursive
#include <stdio.h> #include <math.h> struct point { double x; double y; }; typedef struct point sPoint; double dist(sPoint p1, sPoint p2) { return sqrt((p1.x - p2.x)*(p1.x - p2.x) + (p1.y - p2.y)*(p1.y - p2.y)); } double longueurchemin(const sPoint * chemin, int nb) /* Preconditions : chemin est un tableau contenant au moins nb points, avec nb avec superieur ou egal a 2 Resultat : calcule la longueur du chemin de points */ { double res; double d1, d2; if (nb==2) res = dist(chemin[1], chemin[0]); else { d1 = dist(chemin[nb-1], chemin[nb-2]);
! LIF5 : Algorithmique et programmation procédurale
! Page 20
d2 = longueurchemin(chemin, nb-1); res = d1 + d2; } return res; } int main() { double perimetre; sPoint cheminTriangle[4]; cheminTriangle[0].x = 0.0 ; cheminTriangle[0].y = 0.0 ; cheminTriangle[1].x = 3.0 ; cheminTriangle[1].y = 0.0 ; cheminTriangle[2].x = 3.0 ; cheminTriangle[2].y = 1.0 ; cheminTriangle[3].x = cheminTriangle[0].x ; cheminTriangle[3].y = cheminTriangle[0].y ; perimetre = longueurchemin(cheminTriangle, 4); printf("Le perimetre du triangle vaut %f\n", perimetre); return 0; }
a) Combien d’octets une variable de type sPoint occupe-t-elle en mémoire (sur une machine où un int occupe 4 octets et un double 8) ?
b) Combien d’octets occupe le tableau cheminTriangle ?
c) La fonction longueurchemin est-elle récursive ? Même question pour la fonction dist.
d) A quoi sert le mot-clé const dans l’entête de la fonction longueurchemin ?
e) Dessinez l’évolution de la pile lors de l’exécution de ce programme, en utilisant le modèle théorique de pile vu en cours et en TD.
f) Combien de fois la fonction longueurchemin est-elle appelée ? Même question pour la fonction dist.
g) Que pensez-vous de l’implantation récursive de longueurchemin, en termes de ressources mémoire ?
h) Quelle valeur obtenez-vous pour la variable perimetre ? Indication : √10 ≈ 3,162.
Exercice 14 *** : Appel à une procédure qui modifie un pointeur
Soit le programme C suivant :

! LIF5 : Algorithmique et programmation procédurale
! Page 21
#include <stdlib.h>
double deux_fois(const double * i) {return 2*(*i);} double * allouer_en_initialisant(double val) { double *p = (double*) malloc(sizeof(double)); *p = val; return p; } void liberer_en_mettant_a_zero(double ** pa) {free(*pa); *pa = 0x0;} int main()
{ double e = 3.1; double k; double * p1; double tab[4]; double * p2; double **pp2; k = deux_fois(&e); p1 = allouer_en_initialisant(-8.0); for(p2=tab; p2 < tab+4; p2++) { *p2 = (*p1) + k; } p2 = &e; liberer_en_mettant_a_zero(&p1); pp2 = &p2; return 0; }
a) Pour chaque apparition du caractère ‘*’, indiquez s’il s’agit d’une déclaration de pointeur, de l’opérateur de déréférencement d’un pointeur, ou bien de l’opérateur de multiplication.
b) Faîtes la trace mémoire de ce programme, en supposant que la valeur de retour du main est située à l’adresse 3 678 556 960.
c) Pourquoi passe-t-on un « pointeur sur pointeur » (double **, c’est-à-dire adresse d’une adresse de double) à la procédure liberer_en_mettant_a_zero ?
! LIF5 : Algorithmique et programmation procédurale
! Page 22
Algorithmes, invariants de boucle et complexité
Exercice 1 * : Algorithme de cryptage d’une chaîne de caractères
Considérons un algorithme de cryptage de chaînes de caractères qui consiste à « additionner » les caractères du texte à crypter avec ceux d’une clé de chiffrement. Par exemple, le cryptage de la chaîne « Cherchez au pied de l’arbre » avec la clé « indice » peut s’illustrer ainsi :
• on place la clé en regard du texte à crypter, en répétant la clé autant de fois que nécessaire pour couvrir le texte, et en ignorant les caractères qui ne sont pas des lettres (ils seront laissés inchangés par l’algorithme de cryptage) :
C h e r c h e z a u p i e d d e l ‘ a r b r e i n d i c e i n d i c e i n d i c ‘ e i n d i
• on remplace chaque lettre de la clé par sa position dans l’alphabet (0 pour ‘a’, 1 pour ‘b’…),
C h e r c h e z a u p i e d d e l ‘ a r b r e 8 13 3 8 2 4 8 13 3 8 2 4 8 13 3 8 2 ‘ 4 8 13 3 8
• on remplace chaque lettre du texte à crypter par la lettre située d positions plus loin dans l’alphabet, où d est le nombre indiqué par la clé (si on dépasse z, on reboucle sur a, b etc) :
C h e r c h e z a u p i e d d e l ‘ a r b r e K u h z e l m m d c r m m q g m n ‘ e z o u m
a) Si x est le code ASCII d’une lettre à crypter et y le code ASCII de la lettre de la clé située en regard, quelle formule permet de calculer le code ASCII résultant ? On supposera pour cette question que les deux lettres sont des minuscules. Indice : que vaut y – ‘a’ ?
b) Ecrire en langage algorithmique la procédure de cryptage, dont voici l’entête :
Procédure crypter (texte : tableau de caractères, cle : tableau de caractères, result : tableau de caractères) Préconditions : texte contient un ou plusieurs caractères suivis d’un ‘\0’. cle contient une ou plusieurs lettres minuscules suivies d’un ‘\0’. Postcondition : result contient la version cryptée de texte jusqu’au ‘\0’ exclu, puis un ‘\0’. Seules les lettres (majuscules ou minuscules) non accentuées sont cryptées, les autres caractères sont recopiés tels quels. Les éventuels caractères situés derrière le ‘\0’ sont ignorés. Paramètres en mode donnée : texte, cle Paramètre en mode résultat : result
c) Supposons que l’on veuille crypter, avec une clé de longueur k, une chaine constituée exclusivement de L minuscules, avec L > k. Comptez le nombre d’opérations de chaque type (affectations d’entiers, comparaison de caractères, etc.) pour évaluer la complexité en temps de cet algorithme de cryptage. Qui de L ou de k influence le plus le temps d’exécution ? Ce temps sera-t-il plus long ou plus court avec une plus longue clé ?
d) Quel serait le prototype de la procédure en C ?

! LIF5 : Algorithmique et programmation procédurale
! Page 23
Exercice 2 * : Tri mystère
Voici le début de la trace d’un algorithme de tri :
10 56 -2 52 -8 41 13 -8 56 -2 52 10 41 13 -8 -2 56 52 10 41 13 -8 -2 10 52 56 41 13
a) De quel algorithme s’agit-il ? Pourquoi ?
b) Complétez le tableau ci-dessus en indiquant les étapes suivantes, jusqu’à ce que le tableau soit complètement trié.
c) Si le tableau est de taille n, quelle est la complexité de cet algorithme en fonction de n ? Justifiez (brièvement) votre réponse.
Exercice 3 ** : Analyse de la complexité d’un algorithme (CC mi-parcours oct. 2010)
On considère le pseudo-code suivant, comportant deux « tant que » imbriqués. On cherche à mesurer la complexité de cette imbrication en fonction de n. Pour cela, on utilise la variable « compteur », qui est incrémentée à chaque passage dans le « tant que » interne.
Variables : n : entier compteur : entier i, j : entiers Début Afficher(« Quelle est la valeur de n ? ») SaisirAuClavier(n) compteur ← 0 i ← 1 Tant que (i < n) Faire j ← i + 1 Tant que (j ≤ n) Faire compteur ← compteur + 1 j ← j + 1 Fin tantque i ← i * 2 Fin tantque Afficher(compteur) Fin
a) Quelle est la valeur finale du compteur dans le cas où n = 16 ?
b) Considérons le cas particulier où n est une puissance de 2 : on suppose que n = 2p avec p connu. Quelle est la valeur finale du compteur en fonction de p ? Justifiez votre réponse.
! LIF5 : Algorithmique et programmation procédurale
! Page 24
c) Réexprimez le résultat précédent en fonction de n.
Exercice 4 ** : Tri à bulles (CC mi-parcours novembre 2009)
Le tri à bulles est un algorithme de tri qui s’appuie sur des permutations répétées d’éléments contigus qui ne sont pas dans le bon ordre.
Procédure tri_bulles(tab : tableau [1..n] de réels) Précondition : tab est un tableau contenant n réels Postcondition : les éléments de tab sont triés dans l’ordre croissant Paramètre en mode donnée : aucun Paramètre en mode donnée-résultat : tab Variables locales : i, j : entiers, e : réel Début 1 i ! 1 2 Tant que i <= n-1 Faire 3 j! n 4 Tant que j >= i+1 Faire 5 Si tab[j] < tab[j-1] Alors 6 {on permute les deux éléments} 7 e ! tab[j-1] 8 tab[j-1] ! tab[j] 9 tab[j] ! e 10 Fin Si 11 j ! j-1 12 Fin Tant que 13 i ! i + 1 14 Fin Tant que Fin tri_bulles
a) Soit le tableau suivant : {53.8, 26.1, 2.5, 13.6, 8.8, 4.0}. Donnez les premiers états intermédiaires par lesquels passe ce tableau lorsqu’on lui applique la procédure tri_bulles.
b) Complétez la phrase suivante de sorte à ce qu’elle corresponde à l’invariant de boucle du Tant que interne (boucle sur j, lignes 4 à 12 de l’algorithme).
« Lorsqu’on vient de décrémenter j (ligne 11), le ______________________ du sous-tableau
tab[ ______... ______] se trouve en position _________. De plus, si j>1, les éléments du sous-
tableau tab[_______..._______] occupent les mêmes positions qu’avant le démarrage de la boucle
sur j. »
c) Déduisez-en la propriété que présente le tableau lorsqu’on a terminé cette boucle interne, c’est-à-dire lorsqu’on arrive sur la ligne 13.

! LIF5 : Algorithmique et programmation procédurale
! Page 25
d) En utilisant la propriété précédente, on peut montrer l’invariant de boucle du Tant que externe (boucle sur i) est le suivant : « Juste avant d’incrémenter i (ligne 13) : tab est trié entre les indices 1 et i, et tous les éléments restants sont supérieurs ou égaux à tab[i] ». Donnez la première étape de cette démonstration (initialisation). Les étapes de conservation et de terminaison ne sont pas demandées.
e) Calculez le nombre total d’affectations de réels réalisées par la procédure tri_bulles lors du tri complet d’un tableau de n réels, dans le cas le plus défavorable.
Exercice 5 ** : Tri par insertion
Le tri par insertion est l’algorithme utilisé par la plupart des joueurs lorsqu’ils trient leur « main » de cartes à jouer. Le principe consiste à prendre le premier élément du sous-tableau non trié et à l’insérer à sa place dans la partie triée du tableau.
a) Dérouler le tri par insertion du tableau {5.1, 2.4, 4.9, 6.8, 1.1, 3.0}.
b) Ecrire en langage algorithmique le corps de la procédure de tri par insertion, par ordre croissant, d’un tableau de réels :
Procédure tri_par_insertion (tab : tableau [1..n] de réels) Précondition : tab[1], tab[2], … tab[n] initialisés Postcondition : tab[1] ≤ tab[2] ≤ … ≤ tab[n] Paramètres en mode donnée : aucun Paramètre en mode donnée-résultat : tab
c) Donner l’invariant de boucle correspondant à cet algorithme, en démontrant qu’il vérifie bien les 3 propriétés d’un invariant de boucle : initialisation, conservation, terminaison.
d) Evaluer le nombre de comparaisons de réels et le nombre d’affectations de réels pour un tableau de taille n, dans le cas le plus défavorable (tableau trié dans l’ordre décroissant). Cet algorithme est-il meilleur que le tri par sélection (ou tri du minimum), vu en cours magistral ?
Exercice 6 * : Stabilité d’un algorithme de tri (CC mi-parcours mars 2012)
Considérons la liste de noms-prénoms suivante : Doe, Phil Doe, Jane Doe, Fred Jones, Bill Jones, Jane Smith, Mary Smith, Fred Smith, Jane
Elle est pour l’instant triée dans l’ordre alphabétique des noms de famille. Mais on veut la trier dans l’ordre alphabétique des prénoms, à l’aide du tri ci-dessous.
Procédure tri (tab : tableau [1..n] de Personnes)
! LIF5 : Algorithmique et programmation procédurale
! Page 26
Précondition : tab[1], tab[2], … tab[n] initialisés Postcondition : tab[1] ≤ tab[2] ≤ … ≤ tab[n] Paramètres en mode donnée : aucun Paramètre en mode donnée-résultat : tab Variables locales : i, j : entiers elt_a_placer : Personne Début Pour i allant de 2 à n par pas de 1 Faire elt_a_placer ← tab[i] j ← i – 1 Tant que (j > 0) et que (elt_a_placer.prenom est strictement avant tab[j].prenom dans l’alphabet) Faire tab[j+1] ← tab[j] j ← j – 1 FinTantQue tab[j+1] ← elt_a_placer FinPour Fin tri_par_insertion
a) De quel algorithme de tri s’agit-il ?
b) Quelle liste obtient-on au final avec ce tri ?
c) Un algorithme de tri est dit « stable » s’il préserve toujours l’ordre initial des ex-aequos. Dans notre exemple, l’algorithme est stable si les personnes avec le même prénom (qui vont être groupées ensemble lors du tri par prénom) restent dans l’ordre alphabétique des noms de famille. L’algorithme de tri par insertion est-il stable ? (La preuve n’est pas demandée).
d) Combien de comparaisons de prénoms ferait-on avec cet algorithme s’il était appelé sur un tableau de taille n qui serait déjà dans le bon ordre (c’est-à-dire, ici, déjà trié dans l’ordre alphabétique des prénoms) ?
Exercice 7 *** : Calcul d’un polynôme en un point (CC mi-parcours avril 2010)
Soit un polynôme P tel que
€
P(x) = akxk
k= 0
n
∑ .
On veut écrire la fonction qui retourne la valeur de
€
P(x) pour une valeur de x passée en paramètre, les coefficients du polynôme étant également passés en paramètre dans un tableau. Pour cela, une méthode efficace est la méthode de Horner, qui utilise la réécriture suivante de P(x) :
€
P(x) = ... anx + an−1( )x + an−2( )x + ...( ) + a1( )x + a0
! LIF5 : Algorithmique et programmation procédurale
! Page 27
La méthode consiste donc à multiplier le coefficient de plus haut degré par x et à lui ajouter le coefficient suivant. On multiplie alors le nombre obtenu par x et on lui ajoute le troisième coefficient, etc, jusqu’à avoir ajouté le coefficient constant.
Exemple : calcul de
€
4x 3 − 7x 2 + 3x − 5 = ((4x – 7)x + 3)x – 5 pour x = 2
• première étape : 4*2 – 7 = 1 • deuxième étape : 1*2 + 3 = 5 • troisième étape : 5*2 – 5 = 5
Voici le code C de la fonction qui calcule P(x) selon cette méthode :
/* Précondition : coef contient les (n+1) coefficients du polynôme, ainsi coef[0] contient a0, coef[1] contient a1, etc. Résultat : retourne P(x), la valeur du polynôme au point x */ double valeur_polynome (double x, double coef[], int n)
{
1 double y = 0; 2 int k = n; 3 while(k >= 0) 4 { 5 y = coef[k] + x*y; 6 k = k - 1; 7 } 8 return y; }
a) Combien de fois passe-t-on par les lignes 5 et 6 si le polynôme est de degré n ?
b) Complétez le tableau suivant en fonction de n, le degré du polynôme. Vous prendrez bien sûr en compte le nombre de fois que l’on passe sur chaque ligne lors de l’exécution complète de la fonction.
Ligne Nombre
d’affectations Nombre d’additions ou
de soustractions Nombre de
multiplications Nombre de
comparaisons 1 1 0 0 0
2 1 0 0 0
3
5
6
Total
c) Déduisez-en le temps d’exécution T(n) de la fonction en microsecondes, en supposant qu’une affectation prend taff microsecondes, une addition ou une soustraction tadd microsecondes, une multiplication tmult microsecondes, et une comparaison tcomp microsecondes.
d) De quelle fonction mathématique de n ce temps d’exécution T(n) est-il « grand O » ?
! LIF5 : Algorithmique et programmation procédurale
! Page 28
e) Complétez l’invariant de boucle de l’algorithme de Horner : « Au début de chaque itération de la boucle While (juste avant d’exécuter la ligne 5), on sait que (complétez les pointillés) :
€
y = a....................xi
i= 0
n−(k+1)
∑ » .
f) A l’aide la propriété de terminaison de cet invariant, montrez que l’algorithme de Horner permet bien d’obtenir la valeur du polynôme au point x.
g) Ecrivez en langage C la version « naïve » de la fonction valeur_polynome, qui calcule P(x) selon la
formule
€
P(x) = akxk
k= 0
n
∑ , c’est-à-dire en calculant pour chaque terme la puissance de x via autant de
multiplications que nécessaire (on n’utilisera donc pas la fonction pow())
h) Combien de multiplications fait-on dans cette version naïve, si le polynôme est de degré n ?
Exercice 8 ** : Traitement d’image (CC mi-parcours oct. 2012)
Un filtrage est un traitement qui s'applique globalement à toute l'image. Un algorithme de filtrage calcule la nouvelle valeur du pixel en tenant compte des valeurs des pixels voisins. On considère ici un voisinage carré, centré sur le pixel que l’on calcule. Ce carré peut avoir différentes tailles : 3x3 (rayon 1), 5x5 (rayon 2), 7x7 (rayon 3), etc. Dans cet exercice, on considère le filtre « flou moyenneur », qui attribue au pixel la moyenne des valeurs dans le voisinage (sauf pour les pixels en bordure, qui eux deviennent noirs, pour simplifier l’algorithme).
Image originale Après un filtre « flou moyenneur » de rayon 3 (voisinage 7x7)
Dans tout l’exercice, nous utiliserons le langage algorithmique. Nous supposerons que l’image est en niveaux de gris (chaque pixel est donc caractérisable par un seul entier) et que l’image est stockée dans une matrice (tableau 2D) d’entiers. Une image sera par exemple déclarée de la façon suivante :
monImage : tableau [1..HAUTEUR][1..LARGEUR] d’entiers
On peut accéder au niveau de gris du pixel situé sur la ligne i et la colonne j en utilisant deux fois l’opérateur crochets : monImage[i][j]. Rappel : dans le langage algorithmique, les lignes et de colonnes sont numérotées à partir de 1.

! LIF5 : Algorithmique et programmation procédurale
! Page 29
a) Ecrire la procédure flouNaif qui prend en paramètre une image de départ (mode donnée), une image d’arrivée (mode résultat) et le rayon r du voisinage (entier, mode donnée). Pour chaque pixel de l’image (sauf ceux des bords), cette procédure parcourt les (2r + 1)2 voisins pour calculer la moyenne du niveau de gris dans le voisinage. La procédure ne fera pas d’allocation mémoire, on suppose que les deux images passées en paramètres ont déjà été allouées en mémoire avant l’appel. Vous pourrez appeler la procédure suivante sans en donner le code :
Procédure mettrePixelsDuBordEnNoir (monImage : tableau [1..HAUTEUR][1..LARGEUR] d’entiers, epaisseurBord : entier) Paramètres en mode donnée : epaisseurBord Paramètres en mode donnée-résultat : monImage Préconditions : epaisseurBord > 0, monImage a déjà été allouée en mémoire Postconditions : le niveau de gris des pixels du bord de l’image sont mis à 0. On appelle bord de l’image les lignes de pixels allant de 1 à epaisseurBord (bordure du bas), les colonnes allant de 1 à epaisseurBord (bordure de gauche), les colonnes allant de LARGEUR – epaisseurBord + 1 à LARGEUR (bordure de droite), les lignes allant de HAUTEUR – epaisseurBord + 1 à HAUTEUR (bordure du haut). Les autres pixels sont inchangés.
b) Si l’image est de dimensions H x L et que le rayon du filtre est r, combien d’additions de niveaux de gris effectue-t-on avec cet algorithme naïf ? Répondez en fonction de L, H et r, puis faîtes l’application numérique pour r = 3, H = 200 et L = 400.
c) On peut optimiser cet algorithme en remarquant que la somme des niveaux du voisinage carré peut se décomposer comme la somme des sommes des colonnes. Quand on déplace la fenêtre d’un vers la droite, il suffit d’ajouter la somme de la nouvelle colonne et de retrancher la somme de la colonne la plus à gauche :
Les sommes des colonnes peuvent être mises à jour efficacement quand on change de ligne, en retranchant le pixel du bas de la colonne et en ajoutant le pixel juste au-dessus de la colonne :
Voici la version optimisée du filtrage en langage algorithmique :
Procédure flouOptim (imageOrig: tableau [1..HAUTEUR][1..LARGEUR] d’entiers, imageFloue : tableau [1..HAUTEUR][1..LARGEUR] d’entiers, r : entier) Paramètres en mode donnée : imageOrig, r Paramètres en mode résultat : imageFloue Préconditions : r > 0, imageOrig et imageFloue ont déjà été allouées en mémoire
+ - Exemple avec un voisinage 5x5 (r = 2) :
Pour calculer la somme relative au pixel noir, on part de la somme calculée pour le pixel précédent (zone grisée), on retire la colonne
+
-
! LIF5 : Algorithmique et programmation procédurale
! Page 30
Postconditions : A l’exception des pixels situés sur les bords de l’image, chaque pixel de imageFloue a son niveau de gris qui correspond à la moyenne des niveaux de gris de ses voisins, le voisinage étant un carré de largeur 2r+1 centré sur le pixel. Les pixels situés sur les bords, pour lesquels le voisinage n’est pas complet, sont noirs. Variables locales :
lig, col, somme, nbvoisins, largeurVoisinage : entiers sommeColonne : tableau [1..LARGEUR] d’entiers
Début mettrePixelsDuBordEnNoir(imageFloue, r)
nbvoisins ! (2*r+1)*(2*r+1) largeurVoisinage ! 2*r + 1
{On initialise la somme des colonnes}
Pour col allant de 1 à LARGEUR par pas de 1 Faire sommeColonne[col] ! 0 Pour lig allant de 1 à largeurVoisinage par pas de 1 Faire sommeColonne[col] ! sommeColonne[col] + imageOrig[lig][col] FinPour FinPour Pour lig allant de (r+1) à (HAUTEUR-r) par pas de 1 Faire
{On traite séparément le premier pixel à flouter de la ligne, pour initialiser la somme intercolonnes} somme ! 0 Pour col allant de 1 à largeurVoisinage par pas de 1 Faire somme ! somme + sommeColonne[col] FinPour imageFloue[lig][r + 1] ! somme / nbvoisins {Pour les autres pixels de la ligne, la somme intercolonnes est mise à jour de façon incrémentale} Pour col allant de (r+2) à (LARGEUR-r) par pas de 1 Faire somme ! somme – sommeColonne[col – r - 1] + sommeColonne[col+r] imageFloue[lig][col] ! somme / nbvoisins FinPour Si (lig < HAUTEUR – r) {On prépare les sommes des colonnes pour la ligne suivante, de façon incrémentale (on ne le fait pas si on vient de traiter la dernière ligne)} Pour col allant de 1 à LARGEUR par pas de 1 Faire sommeColonne[col] ! sommeColonne[col] – imageOrig[lig-r][col] + imageOrig[lig+r+1][col] FinPour FinSi

! LIF5 : Algorithmique et programmation procédurale
! Page 31
FinPour
Fin flouOptim
d) Si l’image est de dimensions H x L et que le rayon du filtre est r, combien d’additions de niveaux de gris effectue-t-on avec cet algorithme optimisé ? Dans votre comptage, considérez qu’une soustraction de niveaux de gris compte pour une addition. Répondez en fonction de L, H et r, puis faîtes l’application numérique pour r = 3, H = 200 et L = 400.
e) On décide d’implémenter cet algorithme optimisé en C en stockant les images sous forme de matrices (tableaux 2D) d’unsigned char. Peut-on utiliser aussi le type unsigned char pour les éléments du tableau sommeColonne ? Justifiez votre réponse.
! LIF5 : Algorithmique et programmation procédurale
! Page 32
Algorithmes sur les fichiers
Exercice 1 ** : Fusion de deux monotonies sur fichiers (CC mi-parcours nov. 2009)
On dispose de deux fichiers contenant chacun une séquence triée de réels. En d’autres termes, chacun des deux fichiers contient une monotonie et une seule – il s’agit donc d’un problème plus simple que celui du tri fusion sur fichiers. On veut écrire une procédure qui fusionne ces deux monotonies et écrit la monotonie résultante dans un troisième fichier. Cette procédure prend comme seuls paramètres les noms des deux fichiers d’entrée (nomfic1 et nomfic2) et le nom du fichier de sortie (nomficSortie).
Préconditions : • nomfic1 et nomfic2 sont des fichiers binaires qui contiennent chacun une séquence triée (monotonie)
de nombres au format IEEE 754 double précision. Si l’un de ces fichiers ne peut pas être ouvert (par exemple parce qu’il n’existe pas), alors le programme se termine avec un code d’échec.
• Les deux séquences peuvent être de longueur différente, mais elles sont au moins de longueur 1 : autrement dit, chaque fichier contient au moins un élément.
Postconditions : • Un nouveau fichier binaire nommé nomficSortie est créé (s’il existait déjà, son contenu est écrasé). Ce
fichier contient une monotonie correspondant à la fusion des deux monotonies contenues dans nomfic1 et nomfic2. Si ce fichier ne peut pas être créé (par exemple à cause d’un problème de droits insuffisants dans le répertoire courant), le programme se termine avec un code d’échec.
• Les contenus des fichiers nomfic1 et nomfic2 sont inchangés.
Donnez le code C de cette procédure. Vous utiliserez les variables locales suivantes (à vous d’en préciser le type) : e1, e2, fic1, fic2, ficSortie, succeslect1, succeslect2. Vous pouvez en ajouter d’autres si nécessaire.
On rappelle l’ordre des paramètres pour les sous-programmes suivants, à vous de déterminer lequel ou lesquels doivent être utilisés ici :
• fscanf(pointeur sur le flot, chaîne de format, adresse variable 1, adresse variable 2...) • fprintf(pointeur sur le flot, chaîne de format, valeur variable 1, valeur variable 2...) • fread(adresse 1er bloc, taille d’un bloc, nombre de blocs, pointeur sur le flot) • fwrite(adresse 1er bloc, taille d’un bloc, nombre de blocs, pointeur sur le flot)
Exercice 2 *** : Tri fusion sur fichiers
On considère le fichier non trié contenant la séquence d’éléments suivante :
65 5 89 56 7 15 28 2 98 33
a) Donnez le contenu des 3 fichiers (appelés A, B et X dans les diapositives de cours) intervenant dans le tri fusion du fichier ci-dessus, après chaque étape d’éclatement et chaque étape de fusion.
b) Combien de comparaisons d’éléments effectue-t-on au pire lorsqu’on fusionne une monotonie de longueur La avec une autre monotonie de longueur Lb ?

! LIF5 : Algorithmique et programmation procédurale
! Page 33
c) Combien de comparaisons d’éléments effectue-t-on au pire lorsqu’on trie par fusion un fichier de n éléments, dans le cas particulier où n est une puissance de 2 (n=2p) ?
d) Ecrire en langage algorithmique la procédure de tri par fusion d’un fichier, en supposant que vous disposez déjà des procédures « eclatement » et « fusion » (voir les entêtes ci-dessous). La procédure de tri doit appeler les procédures « eclatement » et « fusion » jusqu’à ce que le fichier soit complètement trié.
Procédure eclatement(nomFicX : chaîne de caractères, lg : entier, nomFicA : chaîne de caractères, nomFicB : chaîne de caractères) Précondition : le fichier appelé nomFicX contient des monotonies de longueur lg, sauf peut-être la dernière qui peut être plus courte Postcondition : Les monotonies de nomFicX sont réparties (1 sur 2) dans des fichiers appelés nomFicA et nomFicB : : la première monotonie est copiée dans le fichier A, la seconde dans le fichier B, la troisième dans le A, etc. Si ces fichiers existaient déjà, leur contenu est écrasé. Le fichier A peut recueillir une monotonie de plus le fichier B, et cette dernière monotonie peut être de longueur inférieure à lg. Si au contraire ficA et ficB recueillent le même nombre de monotonies, la dernière monotonie écrite dans ficB peut être de longueur inférieure à lg. Paramètres en mode donnée : nomFicX, nomFicA, nomFicB, lg {Les chaînes de caractères contenant les noms des fichiers ne vont pas être affectées par la procédure, d’où le passage en mode donnée, mais bien sûr, les fichiers désignés par nomFicA et nomFicB vont être affectés, comme cela est précisé dans les post-conditions.} Procédure fusion(nomFicA : chaîne de caractères, nomFicB : chaîne de caractères, lg : entier, nomFicX : chaîne de caractères, nbMonoDansX : entier Préconditions : les fichiers appelés nomFicA et nomFicB contiennent des monotonies de longueur lg. FicA peut contenir une monotonie de plus (éventuellement incomplète) que FicB. Si au contraire FicA et FicB contiennent le même nombre de monotonies, alors la dernière monotonie de FicB peut être incomplète. Postconditions : le fichier appelé nomFicX contient nbMonoApres monotonies de longueur 2*lg, la dernière pouvant être plus courte. Ces monotonies résultent de la fusion 2 à 2 des monotonies de FicA et de FicB. Si FicX existait déjà, son ancien contenu est écrasé. Paramètres en mode donnée : nomFicX, nomFicA, nomFicB, lg Paramètre en mode résultat : nbMonoDansX
e) Donnez le code de la procédure d’éclatement en langage C.
Exercice 3 *** : Compression RLE (CC mi-parcours avril 2011)
Soit un fichier binaire de n octets pouvant contenir des séquences répétitives d’un même octet. Par exemple, en décodant chaque octet comme un « unsigned char » :
{12, 6, 6, 6, 6, 6, 1, 3, 8, 8, 10, 2, 53, 53, 53, 53, 53, 6, 6, 6, 13}
Une première technique de compression consiste à écrire pour chaque octet le nombre de répétitions supplémentaires. On pourrait donc remplacer {53, 53, 53, 53, 53} par {53, 4}, ce qui signifie : l’octet 53, suivi d’encore 4 fois l’octet 53. Le problème de cette première idée est que la séquence {53, 53, 53, 53, 53} va bien être compressée, mais qu’au contraire, toutes les séquences non répétitives vont être dilatées : par exemple, {10} serait réécrit en {10, 0}.
! LIF5 : Algorithmique et programmation procédurale
! Page 34
Une meilleure idée consiste à ne transformer une séquence que si un octet est immédiatement répété au moins une fois. Ainsi, {53, 53, 53, 53, 53} serait réécrite en {53, 53, 3}, {10} serait inchangée et {8, 8} serait réécrite en {8, 8, 0}. La séquence entière donnée en exemple serait donc réécrite de la façon suivante : {12, 6, 6, 3, 1, 3, 8, 8, 0, 10, 2, 53, 53, 3, 6, 6, 1, 13}. Lors de la décompression, c’est le fait d’avoir deux octets identiques à la suite qui indique que l’octet suivant est un nombre d’occurrences supplémentaires et non un octet du fichier de départ. C’est à cette seconde idée que vous allez vous intéresser dans tout cet exercice. Il s’agit de la compression dite « RLE » (Run Length Encoding). Notez que bien que ce second algorithme soit la plupart du temps meilleur que le premier, il n’est pas parfait pour autant : il existe tout de même des cas pour lesquels il dilate au lieu de compresser.
a) Supposons que le fichier d’entrée contient 10 octets. Donnez un exemple de contenu de fichier qui donnerait la plus petite taille possible pour le fichier de sortie, puis un exemple de contenu qui donnerait la plus grande taille possible en sortie.
Considérons la procédure C suivante, qui compresse un fichier binaire selon l’algorithme RLE.
void compresser(const char * nomFichierEntree, const char * nomFichierSortie) 1 { 2 FILE *entree, *sortie; 3 unsigned char octet_courant, octet_prec, nb_occ = 1, nb_occ_suppl = 0; 4 5 entree = fopen(nomFichierEntree, "rb"); if (entree == NULL) {exit(EXIT_FAILURE);} 6 sortie = fopen(nomFichierSortie, "wb"); if (sortie == NULL) {exit(EXIT_FAILURE);} 7 8 if( fread(&octet_prec, 1, 1, entree) != 1 ) 9 { 10 /* Fichier d'entree vide, on laisse le fichier de sortie vide */ 11 fclose(entree); 12 fclose(sortie); 13 return; 14 } 15 fwrite(&octet_prec, 1, 1, sortie); /* on recopie le 1er octet */ 16 17 while (fread(&octet_courant, 1, 1, entree) == 1) 18 { 19 if (octet_courant != octet_prec) 20 { 21 if (nb_occ > 1) 22 { 23 nb_occ_suppl = nb_occ - 2; 24 fwrite(&octet_prec, 1, 1, sortie); 25 fwrite(&nb_occ_suppl, 1, 1, sortie); 26 nb_occ = 1; 27 } 28 fwrite(&octet_courant, 1, 1, sortie); 29 octet_prec = octet_courant; 30 } 31 else 32 { 33 nb_occ ++; 34 nb_occ_suppl = nb_occ - 2; 35 if (nb_occ == 255) 36 { 37 fwrite(&octet_prec, 1, 1, sortie); 38 fwrite(&nb_occ_suppl, 1, 1, sortie); 39 nb_occ = 1; 40 octet_prec += 5; /* modification arbitraire de octet_prec, 41

! LIF5 : Algorithmique et programmation procédurale
! Page 35
pour etre dans le bon cas a l'iteration suivante */ 42 } 43 } 44 } 45 46 if (nb_occ > 1) /* si le fichier se termine par une séquence répétitive */ 47 { 48 nb_occ_suppl = nb_occ - 2; 49 fwrite(&octet_prec, 1, 1, sortie); 50 fwrite(&nb_occ_suppl, 1, 1, sortie); 51 } 52 fclose(entree); 53 fclose(sortie); 54 }55
b) Considérons un fichier d’entrée contenant n octets avec n pair et non nul, et dont le contenu correspondrait au cas le pire en termes de taux de compression (voir la question a). Combien fait-on d’opérations de chaque type lors de l’exécution de la procédure compresser ? Pour simplifier, vous supposerez que la valeur de retour de fread est de type unsigned char (elle est en réalité de type size_t, un type dont la taille dépend de la machine). Vous supposerez aussi qu’un appel à fread ne compte pas en plus pour une affectation d’unsigned char.
• Nombre d’affectations d’unsigned char :
• Nombre d’additions d’unsigned char :
• Nombre de soustractions d’unsigned char
• Nombre de comparaisons d’unsigned char :
• Nombre d’affectations de pointeurs :
• Nombre de comparaisons de pointeurs :
• Nombre d’appels à fopen :
• Nombre d’appels à fclose :
• Nombre d’appels à fread :
• Nombre d’appels à fwrite :
c) A quoi servent les lignes 36 à 43 ?
d) Considérons le « main » suivant. Il comporte une faille de sécurité. Indiquez où, expliquez de quelle faille il s’agit (quel est le risque) et comment la corriger.
#include <stdio.h> #include <stdlib.h> void compresser(const char * nomFichierEntree, const char * nomFichierSortie); int main() { char nomGrosFichier[50]; printf("Tapez le nom du fichier à compresser (45 caracteres max, pas d’espace) :\n"); scanf("%s", nomGrosFichier); compresser(nomGrosFichier, "compression.bin");
! LIF5 : Algorithmique et programmation procédurale
! Page 36
return 0; }
e) Donnez le code C de la procédure de décompression, dont l’entête est la suivante :
void decompresser(const char * nomFichierEntree, const char * nomFichierSortie); /* Préconditions : nomFichierEntree est le nom d’un fichier binaire compressé selon l’algorithme RLE. Postconditions : un nouveau fichier nommé comme spécifié dans la chaîne nomFichierSortie est créé, son contenu correspond à la décompression du fichier d’entrée. */

! LIF5 : Algorithmique et programmation procédurale
! Page 37
Exercices de synthèse - préparation au CC mi-parcours
Exercice 1 ** : Codage en base 5 (CC mi-parcours avril 2008)
On souhaite écrire une procédure prenant en paramètre donnée un entier naturel et en paramètre résultat une chaîne de caractères. La procédure remplit la chaîne de caractères avec la décomposition en base 5 de l’entier passé en paramètre. Donnez le prototype et les conditions d’utilisation de cette procédure, ainsi que le code correspondant (le tout en langage C). Attention, l’une des difficultés de cet exercice est la précondition…
Exercice 2 ** : Débogage (CC mi-parcours octobre 2008)
Le fichier source suivant contient plusieurs « bugs » que vous allez devoir localiser.
#include <stdio.h> #include <stdlib.h> #include "ESrobustes.h" double moyenne(double tab[]) { int i; double moy = 0.0; for(i = 0; i < nb; i++) {moy += tab[i];} return moy/nb; } int main() { char prenom[20]; double * lesNombres; int i, nb; printf("Entrez votre prenom :\n"); scanf("%s", prenom); printf("Bonjour, %s !\n", prenom); do { printf("Entrez le nombre d'elements du tableau \n"); printf("(ce nombre doit etre un entier superieur ou egal a 1) \n"); initialisation_robuste_entier(&nb); } while (nb < 1); lesNombres = (double *) malloc(nb*sizeof(double)); printf("Saisissez les %d valeurs :\n", nb); for(i=0;i<nb;i++) {initialisation_robuste_flottant(&lesNombres[i]);} printf("La moyenne des valeurs est %f\n", moyenne(lesNombres)); double x = 0.0; while(x != 1.0) { printf("%f\n", x); x += 0.05; }
! LIF5 : Algorithmique et programmation procédurale
! Page 38
printf("Au revoir, %s !\n", prenom); return 0; }
a) Ce code ne compile pas. Expliquez pourquoi et indiquez la ou les modifications qu’il faut apporter au code pour qu’il compile. Indication : cette erreur ne se situe PAS dans les appels à initialisation_robuste_entier et initialisation_robuste_flottant (procédures fournies par le module ESrobustes, dont vous n’avez pas à vous soucier ici).
b) Ce code comporte une faille de sécurité. Expliquez pourquoi et indiquez la ou les modifications qu’il faut apporter au code pour corriger cette faille.
c) Ce code comporte une fuite de mémoire. Expliquez pourquoi et indiquez la ou les modifications qu’il faut apporter au code pour corriger cette fuite. (1 point)
d) Ce code tourne en boucle infinie. Expliquez pourquoi et indiquez la ou les modifications qu’il faut apporter au code pour éviter ce problème. (2 points)
Exercice 3 Trace mémoire avec procédure récursive (CC mi-parcours nov. 2009)
Considérons le programme C suivant :
#include <stdio.h> #include <stdlib.h> void mystere(unsigned int i, unsigned int nbr, char t[]) { unsigned int reste; if (nbr != 0) { reste = nbr % 16; if (reste <= 9) {t[i] = reste + '0';} else {t[i] = reste - 10 + 'a';} mystere(i-1, nbr / 16, t); } else { /* Dessin 1 = etat de la memoire quand on rentre dans ce else */ } } int main() { char monTab[9]; char * c = 0x0;

! LIF5 : Algorithmique et programmation procédurale
! Page 39
unsigned int k; unsigned int monNombre = 455; for(k = 0; k < 8; k++) {monTab[k] = '0';} monTab[k] = '\0'; mystere(7, monNombre, monTab); printf("%s\n", monTab); c = (char *) malloc(9*sizeof(char)); for(k = 0; k < 9; k++) {*(c + k) = monTab[k];} /* Dessin 2 = etat de la memoire a ce moment */ free(c); return 0; }
a) Dessinez l’état de la pile et du tas aux deux moments indiqués en commentaires (on vous demande pour chaque dessin une « photo » de la pile entière et de tout ce qu’il y a dans le tas). Vous utiliserez le modèle théorique de pile vu en cours et en TD. Vous supposerez que la valeur de retour du main est stockée à l’adresse 3 987 546 988.
b) Indiquez ce qu’affiche le printf du main lorsqu’on exécute ce programme précis.
c) Que fait la procédure mystere ? Autrement dit, si vous deviez lui donner un nom plus explicite, lequel choisiriez-vous ?
d) Si les unsigned int sont codés sur 32 bits, risque-t-on un « buffer overflow » lorsqu’on remplit monTab (tableau de 9 char) avec la procédure mystère ?
Exercice 4 ** : Trace mémoire, tri et invariant de boucle (CC mi-parcours avril 2011)
#include <stdio.h> #include <stdlib.h> struct snbcomplexe { double a; double b; }; typedef struct snbcomplexe nbcomplexe; char estSuperieurEnModule(const nbcomplexe * x, const nbcomplexe * y) { double mx, my; mx = (*x).a*(*x).a + (*x).b*(*x).b; my = (*y).a*(*y).a + (*y).b*(*y).b; /* question 3 : Dessinez l’état de la mémoire à chaque fois que l’on passe ici */ if (mx > my) return 1;
! LIF5 : Algorithmique et programmation procédurale
! Page 40
else return 0; } void tri(nbcomplexe * t, int n) { int i, j; nbcomplexe z; char rescomp; for(j = 1; j < n; j++) { /* question 2 : Indiquez quel est l’invariant de boucle à ce moment */ z = t[j]; i = j - 1; rescomp = estSuperieurEnModule(&(t[i]), &z); while ((i >= 0) && (rescomp==1)) { t[i+1] = t[i]; i--; if (i >= 0) rescomp=estSuperieurEnModule(&(t[i]), &z); } t[i+1] = z; } } int main() { int s = 3; nbcomplexe * mesNb = NULL; mesNb = (nbcomplexe *) malloc(s*sizeof(nbcomplexe)); mesNb[0].a = 2.0; mesNb[0].b = 4.0; mesNb[1].a = 0.0; mesNb[1].b = 1.0; mesNb[2].a = 1.0; mesNb[2].b = 2.0; (*(mesNb + 1)).b = 0.0; tri(mesNb, s); free(mesNb); return 0; }
a) De quel algorithme de tri s’agit-il ?
b) Quel est son invariant de boucle ? Vous utiliserez les notations du code ci-dessus (j, n…) et vous considérerez que le tableau est indexé de 0 à n-1.
c) Dessinez l’état de la pile et du tas aux moments indiqués en commentaires (on vous demande pour chaque dessin une « photo » de la pile entière et de tout ce qu’il y a dans le tas). Vous utiliserez le modèle théorique de pile vu en cours et en TD. Vous supposerez que la valeur de retour du main est stockée à l’adresse 3 987 546 988.

! LIF5 : Algorithmique et programmation procédurale
! Page 41
Tableaux dynamiques
Exercice 1 *: Rappels
a) Quelle est la spécificité d’un tableau dynamique ?
b) Déclarez en C la structure de données utilisée pour l’implémentation d’un tableau dynamique.
c) Ecrire en C une procédure initialiserTabDyn avec deux paramètres, qui initialise un tableau dynamique d’une taille donnée.
Exercice 2 ** : Dynamique des données en mémoire
Expliquez pourquoi la précondition de la procédure initialiserTabDyn est nécessaire. Pour illustrer votre propos, voici un exemple de programme principal qui ne respecte pas cette précondition : faîtes un schéma de ce qu’il se passe en mémoire lorsqu’on l’exécute. Pour faire ce schéma, vous pouvez supposer que les Elements sont simplement des réels.
Importer module TableauDynamique module Element Début monTab : TableauDynamique monElem : Element i : entier initialiserTabDyn(monTab) initialiserElem(monElem, 17.3) Pour i allant de 1 à 5 par pas de 1 ajouterElementTabDyn(monTab, monElem) Fin Pour initialiserTabDyn(monTab) {travail demandé = photo de la mémoire à ce moment du programme} testamentTabDyn(monTab) Fin
Exercice 3 ** : Crible d’Eratosthène et décomposition en facteurs premiers
a) On se propose de calculer tous les nombres premiers plus petits qu’un entier N donné. La méthode consiste à calculer pas à pas ces nombres en utilisant la règle suivante : Si un entier K n’est divisible par aucun nombre premier plus petit que K alors il est lui-même premier. Quelles sont les structures de données qu’on peut utiliser pour résoudre ce problème ? Quelle est la plus efficace ?
b) Ecrire en C la procédure eratosthene qui calcule les nombres premiers plus petits que N passé en paramètre.
! LIF5 : Algorithmique et programmation procédurale
! Page 42
c) Ecrivez en C la procédure decompose, qui détermine les nombres premiers entrant dans la décomposition d’un entier N.
d) On veut écrire un fichier Makefile pour mettre au point un module appelé NombresPremiers qui fournit les procédures eratosthene et decompose, et un exécutable qui permet de tester ce module. Commencez par lister les dépendances de chaque fichier .o et de l'exécutable, puis écrivez le Makefile.
Exercice 4 *** : Complexité de l'extension et notion de coût amorti
En cours, nous avons fait le choix de doubler la capacité du tableau à chaque fois qu’une extension s’avère nécessaire. Aurait-on eu la même performance si l’on avait choisi d’augmenter la capacité du tableau de 10 alvéoles au lieu de la doubler ?
Exercice 5 ** : Recherche dichotomique dans un tableau initialement trié.
a) Ecrire en C la fonction qui renvoie l’indice, de l’élément e passé en paramètre, dans un tableau trié lui aussi passé en paramètre. Cette recherche se fera de façon dichotomique.
b) Quel est le coût d’une telle recherche ?
Exercice 6 **: Suppression d’un élément dans un tableau dynamique.
On veut maintenant libérer de la place lorsqu’on en a de trop. En effet, lorsqu’on supprime un ou plusieurs éléments dans un tableau, la taille utilisée peut devenir très petite par rapport à la taille réservée. Dans ce cas on va libérer « un peu » de place pour n’utiliser que ce qu’il faut.
a) Réfléchissez à la méthode à employer.
b) Ecrivez la procédure supprimeElement qui tient compte de la réduction de la capacité d’un tableau dynamique.
Exercice 7 Procédure de recopie
a) Que se passe-t-il lorsqu’on fait a = b quand a et b sont deux tableaux dynamiques ? et testamentTabDyn(a) ensuite?
b) Ecrire en C une procédure recopieTableau qui recopie un tableau bien initialisé b dans un autre tableau bien initialisé a.

! LIF5 : Algorithmique et programmation procédurale
! Page 43
Listes chaînées On supposera dans tout ce TD que les listes sont simplement chaînées.
Exercice 1 * : Dynamique des données en mémoire
Considérons le main et l’état de la mémoire correspondant :
int main() { Liste l; initialiserListe(&l); ajouterEn......(&l,8); ajouterEn......(&l,5); /* Etat de la mémoire dessiné à ce moment */ ...................... /* Instruction à rajouter*/ ...................... /* Instruction à rajouter*/ testamentListe(&l); return 0 ; }
a) Utilisez la représentation graphique présentée en cours pour décrire la liste créée par ce main.
b) Complétez les pointillés de l’appel ajouterEn....(&l,8).
c) Rajoutez dans le main l’instruction qui permet :
• d’afficher l’information contenue dans la première cellule.
• d’afficher l’information contenue dans la deuxième cellule.
Exercice 2 * : Affichage d'une liste
Ecrivez la procédure afficher qui affiche dans l’ordre le contenu d’une liste l.
Pile Tas
vrmain 3-962-837-636l.adPremiere 87242 3-962-837-632
0 872625 87258
87258 872468 87242
! LIF5 : Algorithmique et programmation procédurale
! Page 44
Exercice 3 * : Création d'une liste à partir d'un tableau
Écrivez une procédure creerListeDepuisTableau qui, à partir d’un tableau d’éléments, crée une liste contenant les mêmes éléments dans le même ordre. Donnez un exemple d’appel de cette procédure.
Exercice 4 ** : Inversion d'une liste
Ecrire en C une procédure qui inverse l'ordre des éléments d'une liste chaînée, sans faire de free ni de malloc.
Exercice 5 ** : Fusion de deux listes
Ecrire en C une procédure qui fusionne deux listes triées. Le résultat de la fusion sera stocké dans une troisième liste, triée elle aussi. Les deux listes de départ sont inchangées.
Exercice 6 ** : Tri d'une liste chaînée par insertion
Ecrire en C une procédure qui trie une liste chaînée en utilisant l'algorithme de tri par insertion.
Exercice 7 ** : Suppression des occurrences d'un élément
a) Ecrire une procédure qui supprime la première occurrence d’un élément e d’une liste l.
b) Ecrire une procédure qui supprime toutes les occurrences d’un élément e dans une liste l.

! LIF5 : Algorithmique et programmation procédurale
! Page 45
Arbres binaires
Exercice 1 **: Hauteur d'un arbre binaire
Ecrire en langage C la fonction qui détermine la hauteur d’un arbre binaire.
Exercice 2 **: Egalité de deux arbres binaires
Ecrire en langage algorithmique une fonction qui teste l’égalité de deux arbres binaires.
Exercice 3 *: Dessiner des arbres binaires de recherche
Dessiner des ABR de hauteur 2, 3, 4, 5 et 6 pour le même ensemble de clés {1, 4, 5, 10, 16, 17, 21}.
Exercice 4 *** : Tester si un arbre binaire est un arbre binaire de recherche
Ecrire en langage C une fonction qui renvoie vrai si un arbre binaire passé en paramètre est un arbre binaire de recherche et faux sinon.
Exercice 5 *** : Suppression dans un ABR
Ecrire en langage algorithmique la procédure de suppression d’un élément dans un arbre binaire de recherche.
! LIF5 : Algorithmique et programmation procédurale
! Page 46
Piles et files
Exercice 1 * : Fonctionnement de base d'une pile et d'une file
Dans cet exercice, on suppose que les éléments sont des caractères. Donner l’état de la pile ou de la file ainsi que les valeurs des autres variables après l’exécution des instructions suivantes :
Exercice 2 ** : Inversion d'une File en utilisant une Pile
Le but de cet exercice est d’écrire (en langage algorithmique) une procédure qui inverse une file d'entiers qui lui est passée en paramètre. On demande de ne pas utiliser de tableau ou de liste de travail pour effectuer l'inversion, mais d'utiliser plutôt une pile. Il existe en effet une méthode très simple pour inverser une file en utilisant une pile.
Exercice 3 ** : Validité du parenthésage d'une expression
Un problème fréquent pour les compilateurs et les traitements de textes est de déterminer si les parenthèses d’une chaîne de caractères sont balancées et proprement incluses les unes dans les autres. On désire donc écrire une fonction qui teste la validité du parenthésage d’une expression :
– on considère que les expressions suivantes sont valides : "()", "[([bonjour+]essai)7plus- ];"
– alors que les suivantes ne le sont pas : "(", ")(", "4(essai]".
Notre but est donc d’évaluer la validité d’une expression en ne considérant que ses parenthèses et ses crochets. On suppose que l’expression à tester est dans une chaîne de caractères, dont on peut
Début p : Pile s : Element v : booléen initialiserPile(p) empilerPile(p, ‘a’) empilerPile(p, ‘k’) empilerPile(p, ‘z’) dépilerPile(p) empilerPile(p, ‘m’) s <- consulterSommetPile(p) v <- estVidePile(p) testamentPile(p) Fin
Début f : File t : Element v : booléen initialiserFile(f) enfilerFile(f, ‘a’) enfilerFile(f, ‘k’) enfilerFile(f, ‘z’) défilerFile(f) enfilerFile(f, ‘m’) t <- premierDeLaFile (f) v <- estVideFile(f) testamentFile(f) Fin

! LIF5 : Algorithmique et programmation procédurale
! Page 47
ignorer tous les caractères autres que ‘(’, ‘[’, ’]’ et ‘)’. Écrire en langage algorithmique la fonction valide(ch : chaîne de caractères) : booléen qui renvoie vrai si l’expression passée en paramètre est valide, faux sinon.
Exercice 4 ** : Parcours préfixé itératif d'un arbre binaire
Ecrire en langage C la procédure itérative du parcours préfixé dans un arbre binaire.
Exercice 5 ** : Recherche itérative dans un arbre binaire quelconque
Ecrire en langage C une fonction itérative qui cherche un élément dans un arbre binaire quelconque. Comparez le coût de cette recherche avec celui de la recherche dans un ABR.
! LIF5 : Algorithmique et programmation procédurale
! Page 48
Travaux pratiques
Notes :

! LIF5 : Algorithmique et programmation procédurale
! Page 49
TP1 (A) : Premiers pas sous Linux
Exercice 1 Connexion sous Linux et configuration de Firefox
Redémarrez l’ordinateur sous Linux (Ubuntu). Connectez-vous avec les mêmes login / mot de passe que sous Windows. Lancez le navigateur Firefox (menu Applications / Internet). Configurez la taille de son cache à 2 Mo pour qu’il ne sature pas votre espace disque personnel (menu Edition / Préférences, icône Avancé, onglet Réseau).
Exercice 2 Familiarisation avec le système de fichiers Linux
Pour utiliser au mieux son compte Linux, il est nécessaire de connaître quelques notions basiques sur le système de fichiers Linux. La racine du système de fichier (l’équivalent du « C :\ » d’un Windows non partitionné) est le répertoire « / ». Voici un schéma des principaux répertoires que contient ce dossier racine.
/
bin (exécutables très utilisés en ligne de commande : cp, mv, rm, cat,
dev (canaux de communication avec les périphériques [disques, carte son...])
home
a
b
p052345 (répertoire personnel de Barra Aurélie)
p060896 (répertoire personnel de Butan Simon)
c
lib (librairies et modules du noyau Linux)
usr (sorte d’équivalent du dossier « Program Files » de Windows)
bin (fichiers exécutables accessibles aux utilisateurs : mozilla, nautilus, …)
etc (fichiers de configuration du système)
include (fichiers d’entête [.h] inclus par les programmes C)
media
cdrom usbdisk
boot (fichiers de démarrage et noyau vmlinuz)
tmp (fichiers temporaires)
var (données variables de la machine : files d’impression, traces de connexion http…)
lib (librairies utilisées par les programmes) src (code source des programmes)
A l’UCBL, stockage physique sur un serveur distant
! LIF5 : Algorithmique et programmation procédurale
! Page 50
A l’université, les répertoires des utilisateurs ne sont pas stockés physiquement sur les machines des salles de TP, mais sur un serveur auquel les machines de TP accèdent par le réseau (même principe que pour votre lecteur W: sous Windows). Mais cela est transparent pour l’utilisateur, qui accède toujours à son répertoire personnel en allant dans :
/home/[1e lettre du nom de famille]/[n°d’étudiant]
Cela permet d’avoir accès à ses données même si l’on change de poste de travail.
Regardez le contenu (peut-être vide) de votre compte utilisateur de deux façons :
• avec le gestionnaire de fichiers Nautilus (menu Applications / Dossier personnel) • en ligne de commande :
! ouvrez un terminal (menu Applications) ! vérifiez que vous êtes dans votre répertoire personnel en tapant pwd (cela signifie « print
working directory ») ! demandez le listing du contenu du répertoire en tapant ls -a
Dans cette UE, nous allons privilégier l’utilisation de la ligne de commande. Voir l’annexe en fin de ce sujet pour les commandes Linux de base et des précisions sur la notion de chemin sous Linux.
Exercice 3 Création d’une arborescence LIF5 dans votre répertoire personnel
Vous allez créer l’arborescence suivante dans votre répertoire personnel, en n’utilisant que la ligne de commande.
Pour cela, allez dans le terminal, puis :
• vérifiez que vous êtes dans votre répertoire personnel en tapant pwd. Si vous n’y êtes pas, retournez-y en tapant cd (cela signifie « change directory », et si l’on ne précise pas de répertoire de destination, on va par défaut dans le répertoire personnel).
• créez le répertoire LIF5-automne2013 en tapant la commande suivante (respectez bien l’espace après mkdir, mais n’en mettez pas dans le nom du répertoire) : mkdir LIF5-automne2013
• vérifiez que ce nouveau répertoire apparaît dans le répertoire courant, en tapant ls • allez dans le répertoire créé en tapant cd LIF5-automne2013 • créez le répertoire TP1 en tapant mkdir TP1
Vérifiez que vous retrouvez bien les dossiers créés en explorant votre dossier personnel en mode graphique.
p052345
LIF5-automne2013
TP1

! LIF5 : Algorithmique et programmation procédurale
! Page 51
Exercice 4 Programmer sans environnement de développement
En LIF1, vous avez programmé en C/C++ à l’aide de Dev-C++, qui est un « environnement de développement intégré » regroupant un éditeur de texte, un compilateur, des outils automatiques de fabrication, et un débogueur. Il en existe d’autres, par exemple CodeBlocks. Cependant, il n’est pas indispensable d’utiliser ce genre d’environnement intégré pour programmer : on peut aussi utiliser un éditeur de texte et lancer la compilation et l’exécution en ligne de commande, depuis le terminal. C’est ce que nous allons faire dans cette UE. Cela vous permettra, par la suite, de mieux comprendre ce que fait un environnement de développement lorsque vous cliquez sur « Compiler », par exemple. Cela vous permettra aussi de mieux comprendre les mystérieux fichiers « Makefile » utilisés par ces environnements, car vous en aurez fait vous-même (mais nous verrons cela plus tard…).
Nous allons utiliser l’éditeur de texte « gedit ». Pour cela, allez dans le terminal, puis :
• Vérifiez que vous êtes dans le répertoire TP1 en tapant pwd. Si vous n’y êtes pas, retournez-y en tapant cd ~/LIF5-automne2013/TP1 (~ désigne votre répertoire personnel).
• Lancez gedit en tapant gedit hello.c & . Comme le fichier hello.c n’existe pas encore, gedit crée un fichier vide que vous allez pouvoir remplir.
• Tapez le code suivant dans gedit :
#include <stdio.h> int main() { printf("Hello world !\n"); return 0; }
• Sauvegardez vos modifications.
Nous allons maintenant compiler ce code à l’aide de gcc. Il s’agit du principal compilateur C libre. Pour compiler, retournez dans le terminal (sans fermer gedit) et tapez :
gcc –g -Wall -ansi -pedantic -o hello.out hello.c
Tapez man gcc pour comprendre ce que signifient les différents éléments de cette commande et compléter le tableau suivant (aide : une fois la documentation affichée, tapez /mot pour rechercher un mot, n pour passer à l’occurrence suivante, q pour sortir).
gcc
-g
-Wall
-ansi et –pedantic
-o hello.out
hello.c
! LIF5 : Algorithmique et programmation procédurale
! Page 52
Exécutez le programme en tapant ./hello.out dans le terminal.
Toujours dans le terminal, appuyez plusieurs fois sur la flèche en haut du clavier. Que se passe-t-il ? A quoi cela peut-il servir ?

! LIF5 : Algorithmique et programmation procédurale
! Page 53
TP1 (B) : Types primitifs
Exercice 1 Découverte de printf
En LIF1, vous avez utilisé la librairie C++ « iostream » pour gérer les saisies au clavier et les affichages à l’écran. Dans cette UE, vous allez découvrir et utiliser une autre librairie, la librairie « stdio », qui est une librairie C. La première fonction à connaître dans cette librairie est la fonction « printf », qui est la fonction d’affichage sur la sortie standard du processus (en général l’écran, pour nous). Exemple :
#include <stdio.h> int main() { double a = 18.159; int i = 3; printf(“Le réel vaut %f et l’entier vaut %d \n”, a, i); return 0; }
Quelques explications :
• le premier paramètre est une chaîne de caractères appelée « chaîne de format », contenant à la fois des libellés (“Le réel vaut ”, “ et l’entier vaut ”, “ \n”) et des codes de format (%f et %d ici). Il y a ensuite autant de paramètres supplémentaires que de codes de format.
• printf convertit ses paramètres en caractères affichables selon les codes de format demandés, construit la chaîne à afficher en remplaçant les codes de format par les valeurs converties, et affiche le résultat sur la sortie standard.
Code de format
Conversion en…
Ecriture
%d int base 10 signée %ld long int base 10 signée %u unsigned int base 10 non signée %lu unsigned long base 10 non signée %o unsigned int base 8 (octale) non signée %lo unsigned long base 8 (octale) non signée %x unsigned int base 16 (hexadécimale) non signée %lx unsigned long base 16 (hexadécimale) non signée %f ou %.nf double décimale virgule fixe (taille auto ou n chiffres après la virgule) %lf ou %.nlf long double décimale virgule fixe (taille auto ou n chiffres après la virgule) %e double décimale notation exponentielle %le long double décimale notation exponentielle %g double décimale, représentation la plus courte parmi %f et %e %lg long double décimale, représentation la plus courte parmi %lf et %le %c unsigned char caractère %s char* chaîne de caractères
! LIF5 : Algorithmique et programmation procédurale
! Page 54
• printf retourne ensuite le nombre de caractères écrits, ou un nombre négatif en cas d’erreur (dans l’exemple ci-dessous, cette valeur de retour n’a pas été utilisée).
Dans gedit, ouvrez un nouveau fichier que vous appellerez exo_printf.c.Vous avez à présent deux fichiers ouverts dans gedit : hello.c et exo_printf.c. Lorsqu’on travaille sur plusieurs fichiers en même temps, il est nettement préférable d’ouvrir une seule fenêtre gedit et d’utiliser les onglets, plutôt que d’ouvrir plusieurs fenêtres gedit.
Dans le fichier exo_printf.c, écrire un petit programme qui crée et initialise des variables de différents types (char, short, unsigned short, int, unsigned int, float, double, ...), puis affiche leur contenu en utilisant printf et les codes de format appropriés. Compilez et exécutez votre programme (nommez l’exécutable exo_printf.out), et vérifiez ses résultats. Testez au passage les effets des caractères spéciaux \n, \t, \b, \a, \" et \\.
Modifiez à présent votre programme pour pouvoir répondre aux questions suivantes : que se passe-t-il si…
… on affiche un « unsigned char » initialisé à ‘A’ avec le code %u au lieu de %c ?
… on affiche un signed int avec le code %u : obtient-on sa valeur absolue ? Qu’obtient-on ?
… on affiche un « unsigned int » proche de 232 avec le code %d : quelle valeur obtient-on ?
A-t-on le problème précédent avec un « unsigned char » proche de 28 ou un « unsigned short » proche de 216 ? Pourquoi ?
… on affiche un float avec le code %d : obtient-on un arrondi du réel ?
Exercice 2 Entiers et caractères
Considérons le programme suivant.
#include <stdio.h> int main() { unsigned char v; v = 0; while (v <= 255) { printf("%u %c\n", v, v);

! LIF5 : Algorithmique et programmation procédurale
! Page 55
v++; } return 0; }
a) A votre avis, qu’est-il censé faire ?
b) Tapez ce code dans un nouveau fichier que vous appelerez exo_entiers.c. Compilez-le et exécutez-le. Que se passe-t-il ? Comment l’expliquez-vous ?
Exercice 3 Nombres à virgule flottante
Tapez le code suivant dans un nouveau fichier que vous appellerez exo_reels.c.
#include <stdio.h> int main() { float pi = 3.14159265; float tmp1 = pi + 5e9; float tmp2 = tmp1 – 5e9; if (pi == tmp2) { printf("pi = pi, tout va bien !\n"); } else { printf("pi != pi, oups...\n"); } return 0; }
a) Compilez et exécutez ce programme. Quel affichage obtenez-vous ? Essayez de localiser le ou les problèmes en ajoutant des printf pour voir les résultats des calculs intermédiaires avec au moins 10 chiffres après la virgule (code de format : %.10f).
b) Proposez à présent une explication, en utilisant l’indication suivante : 3,14159265 est codé en interne sous la forme 1,10010010000111111011011 . 21, c’est-à-dire avec un exposant qui vaut 1.
c) Comment résoudre ce problème ici ? Quelle conclusion en tirez-vous sur l’addition de flottants sur un ordinateur ?
Exercice 4 Affichage binaire
Le but de cet exercice est d’écrire un programme qui affiche un entier naturel de type « unsigned int » (initialisé à une valeur valide de votre choix) en base 2, en utilisant les opérateurs de manipulation bit à bit. L’affichage commencera, bien sûr, par les bits de poids fort. Exemples :
0 " Le nombre 0 s’écrit en binaire : 00000000000000000000000000000000 9 " Le nombre 9 s’écrit en binaire : 00000000000000000000000000001001 812 " Le nombre 812 s’écrit en binaire : 00000000000000000000001100101100
! LIF5 : Algorithmique et programmation procédurale
! Page 56
Procédons par étapes.
a) Sur combien de bits est codé un unsigned int sur votre machine ? Pour le vérifier, ouvrez un nouveau fichier nommé affichage_binaire.c dans gedit et tapez-y le code suivant :
#include <stdio.h> #include <limits.h> /* pour CHAR_BIT */ int main() { unsigned int nbbits = sizeof(unsigned int)*CHAR_BIT; /* sizeof renvoie la taille en bytes au sens C/C++ (1 byte =
quantité de mémoire nécessaire pour stocker un caractère). CHAR_BIT est une constante definie dans le fichier limits.h, elle donne le nombre de bits pour stocker un char. C’est très souvent 8 bits, mais cela peut être plus sur certaines architectures. */
printf("Un unsigned int est code sur %u bits.\n", nbbits); return 0; }
b) Soit a un « unsigned int » intialisé à une valeur valide. Soit valbit un « unsigned int » également. On veut que valbit vaille 0 si le bit de poids faible de a vaut 0, ou 1 si le bit de poids faible de a vaut 1. Quelle instruction faut-il utiliser ? Indication : il faut utiliser l’opérateur & (« et » bit à bit) et une constante.
c) On veut maintenant que valbit prenne la valeur du bit i de a (le bit de poids faible étant le bit 0, et le bit de poids fort étant le bit nbbits-1). Quelle instruction faut-il utiliser ? Indication : il faut utiliser les opérateurs de décalage (<< et >>) en plus de l’opérateur &.
d) Vous pouvez à présent compléter le « main » de votre fichier pour qu’il affiche un « unsigned int » a en base 2 : il faut effectuer l’instruction précédente pour i allant de nbbits-1 à 0, en affichant la valeur de valbit à chaque fois. Attention de ne pas tomber dans une boucle infinie. Testez votre programme pour différentes valeurs, dont zéro.

! LIF5 : Algorithmique et programmation procédurale
! Page 57
TP2 : Vie et mort des variables en mémoire, pointeurs
Exercice 1 Modèle de pile : passage d’un tableau en paramètre
Choisissez dans la partie TD de ce fascicule un code C dont vous avez fait la trace mémoire, et dans lequel un tableau est passé en paramètre d’un sous-programme. Tapez ce code dans un fichier et ajoutez des « printf » pour visualiser les adresses mémoires des paramètres et des variables locales des différents sous-programmes.
Aide : pour afficher l’adresse d’une variable, vous pouvez utiliser le code de format « %p », mais dans ce cas, l’adresse sera affichée en hexadécimal. Pour la voir en base 10, vous pouvez l’afficher comme un unsigned long : printf("Adresse de monFloat : %lu\n", (unsigned long) &monFloat); Vous pouvez aussi demander la taille en octets occupée par une variable ou un paramètre avec l’opérateur sizeof : printf("Taille occupée par monTab : %lu\n", sizeof(monTab));
Comparez ensuite l’évolution théorique de la pile avec ce qui se passe en réalité :
a) Dans quel ordre sont empilés les éléments d’un tableau ? La case 0 a-t-elle l’adresse la plus haute ou la plus basse ?
b) Dans quel ordre sont empilés les paramètres d’une fonction ou d’une procédure ?
c) Les variables locales d’un même sous-programme sont-elles, comme en TD, dans l’ordre dans lequel elles étaient déclarées dans le code ?
d) Lorsque l’un des paramètres d’un sous-programme est un tableau, combien d’octets ce paramètre occupe-t-il dans la frame du sous-programme ? Le tableau est-il recopié dans cette frame ?
e) Quel écart observez-vous entre l’adresse la plus haute et l’adresse la plus basse, parmi les adresses affichées ? Cet écart correspond-il à l’écart théorique (celui de votre trace « papier ») ? Demandez à votre encadrant d’où vient cette différence.
Exercice 2 Modèle de pile : appels récursifs, visualisation des frames avec gdb
a) Tapez le programme de l’Exercice 4 page 11 (appel à une fonction récursive) dans un fichier. Compilez-le et exécutez-le pour vérifier que tout fonctionne bien.
b) Puis recompilez-le en ajoutant à gcc l’option –g (cette option ajoute à l’exécutable des informations de débogage), et lancez le débugger GDB avec la commande gdb nomDeVotreExecutable. Placez un point d’arrêt sur la ligne 9 en tapant break 9 . gdb vous informe que ce breakpoint est le numéro 1, on pourrait en mettre d’autres si on le souhaitait. Lancez ensuite l’exécution du programme en tapant run. L’exécution va s’arrêter lorsqu'on va entrer dans le if.
c) Demandez à gdb la liste des « frames » actives en mémoire à ce moment en tapant backtrace. Combien de frames voyez-vous pour comb ? Que se passe-t-il donc quand une fonction s’appelle elle-même : réutilise-t-on la même frame ou en empile-t-on une nouvelle à chaque appel ?
d) Gdb identifie les frames par des numéros (frame #0, frame #1, etc…). Sélectionner la frame 0 pour l’examiner, en tapant select-frame 0. Demandez ensuite à gdb quels sont les paramètres de cette frame et quels sont les valeurs courantes de ses variables locales en tapant info args puis info locals. Pourquoi les valeurs de tmp1 et tmp2 sont-elles étranges ?
! LIF5 : Algorithmique et programmation procédurale
! Page 58
e) Recommencez pour une autre frame. Les valeurs des paramètres sont-elles les mêmes pour des frames différentes d’une même fonction ?
Exercice 3 Saisie « robuste » d’un flottant au clavier
Au cours du TP précédent, vous avez manipulé la fonction printf, qui permet l’affichage à l’écran. Vous allez maintenant découvrir sa sœur : la fonction scanf, qui permet de récupérer des informations saisies au clavier. L’objectif final de cet exercice est d’écrire un sous-programme C de saisie « robuste » d’un nombre à virgule flottante, en utilisant scanf. Procédons par étapes.
a) Pour utiliser scanf, il faut avoir compris la notion d’adresse mémoire : lisez l’annexe sur le fonctionnement de scanf (Annexe 2 : Fonctionnement de scanf, page 78).
b) Voici l’entête du sous-programme à produire en langage algorithmique :
Procédure initialisation_robuste_flottant(r : réel) Précondition : aucune Postcondition : r contient un nombre à virgule flottante lu sur l’entree standard Paramètres en mode donnée : aucun
Vous allez implanter cette procédure en langage C. Elle utilisera scanf. Créez un fichier saisieRobusteFlottant.c et définissez une première version de la procédure initialisation_robuste_flottant. En cas de caractère invalide ou de fin de fichier, la procédure affichera un message d’erreur à l’écran et provoquera l’arrêt du programme. Utilisez pour cela l’instruction exit(EXIT_FAILURE); (avec #include <stdlib.h> en début de fichier). Ecrivez également un programme principal (main) qui appelle cette procédure pour initialiser une variable et qui affiche ensuite la valeur de cette variable avec deux chiffres après la virgule. Compilez et testez votre programme.
c) Modifiez la procédure pour qu’en cas de caractère invalide, elle demande à l’utilisateur de recommencer sa saisie au lieu de provoquer l’arrêt du programme. La saisie devra être recommencée jusqu’à ce que le scanf réussisse. Attention à la gestion du tampon…
Exercice 4 Allocation dynamique de mémoire
Ecrivez dans un nouveau fichier un « main » qui demande à l’utilisateur de taper la taille qu’il souhaite pour son tableau, alloue un tableau de réels de la taille demandée, et demande à l’utilisateur les valeurs des réels à stocker dans le tableau. Pour la lecture des saisies clavier, vous pourrez utiliser directement scanf, ou bien (mieux) des procédures plus robustes inspirées de l’exercice Saisie « robuste » d’un flottant au clavier, page 58. Le programme affichera ensuite le tableau et se terminera proprement, c’est-à-dire en libérant la mémoire allouée dynamiquement.

! LIF5 : Algorithmique et programmation procédurale
! Page 59
TP3 : Tableaux, structures, algorithmes de tri internes
Dans ce TP, nous allons écrire un programme qui va trier des tableaux de dates.
Exercice 1 * : Définition du type date
a) Définissez le type date à l'aide d'une struct, en réfléchissant au type primitif le plus approprié pour chaque champ.
b) Créez un main qui affiche la taille en octets d'une date.
Exercice 2 * : Comparaison de deux dates
Ajoutez dans votre programme une fonction estAnterieure qui prend deux dates en paramètres et retourne 1 si la première date est strictement antérieure à la seconde, et 0 sinon. Testez votre fonction dans plusieurs cas.
Exercice 3 Création d'un tableau de dates aléatoires
a) Dans le main, allouez un tableau de dates dont la taille sera saisie par l'utilisateur.
b) Définissez une procédure remplirAvecDesDatesAleatoires qui prend un tableau de dates et sa taille en paramètres, et qui le remplit avec des dates aléatoires comprises entre le 01/01/1900 et le 31/12/2013. Pour simplifier, vous considérerez que le mois de février a toujours 28 jours.
Aide : pour le tirage de nombres aléatoires, vous pouvez vous inspirer du petit programme suivant :
#include <stdio.h> #include <stdlib.h> #include <sys/time.h> int main() { int i, alea; int min = 1, max = 5; /* Initialisation du générateur, à ne faire qu’une fois dans le programme. En l’initialisant avec l’heure à laquelle l’exécution est lancée, on aura des valeurs différentes à chaque exécution, ce qui est souhaitable ! */ srand((unsigned) time(NULL)); /* Tirage de 20 entiers aléatoires compris entre min et max inclus */ for (i = 0; i <20; i++) { alea = min + rand()%(max - min + 1); printf("%d\n", alea); } return 0; }
! LIF5 : Algorithmique et programmation procédurale
! Page 60
c) Testez votre procédure. N'oubliez pas de libérer la mémoire allouée dynamiquement quand vous n'en avez plus besoin.
Exercice 4 Tri du tableau
a) ** Définissez une procédure triParSelection qui prend en paramètres un tableau de dates et sa taille, et qui le trie de la date la plus ancienne à la date la plus récente, en utilisant l'algorithme de tri par sélection. Testez votre procédure.
b) ** Même question avec le tri par insertion.
c) *** Même question avec le tri par fusion. NB: En cours magistral et en TD, vous avez vu le principe général du tri par fusion. Vous avez également vu comment il était utilisé pour faire du tri externe, c’est-à-dire pour trier de très gros fichiers sans charger toutes les données en mémoire. L’implantation du tri externe étant un peu délicate, vous allez, dans cet exercice, implanter le tri interne par fusion : comme pour le tri par sélection ou par insertion, les données du fichier sont entièrement chargées dans un tableau, puis on trie le tableau en fusionnant des monotonies de taille 1, puis de taille 2, puis de taille 4, etc.
! LIF5 : Algorithmique et programmation procédurale
! Page 61
TP4 : Fichiers, complexité, algorithme de tri externe
Le but de ce TP est de comparer les temps d’exécution de différents algorithmes de tri, lorsqu’on les fait tourner sur des volumes de données relativement grands. Les données à trier seront ici des dates, stockées dans un fichier. Récupérez sur le site de l'UE les fichiers random.txt, sorted.txt et reverse.txt.
Exercice 1 ** : Lire un fichier texte
Ouvrez les fichiers txt pour en comprendre la structure, puis fermez-les. Modifiez ensuite le fichier c que vous avez créé au TP précédent pour qu'au lieu de remplir le tableau de dates avec des dates aléatoires, le programme remplisse le tableau avec les dates contenues dans le fichier. Ensuite le programme triera le tableau avec l'algorithme de votre choix et l'affichera à l'écran. Attention, votre programme devra s'adapter automatiquement (= sans qu'il y ait besoin de recompiler) au nombre de dates contenues dans le fichier.
Exercice 2 * : Ecrire un fichier texte
Ajoutez dans votre programme une procédure qui écrit un tableau de dates dans un fichier txt, en respectant le format des fichiers fournis sur le site de l'UE. Testez votre procédure en l'appelant sur le tableau après le tri.
Exercice 3 * : Mesurer les temps d'exécution des algorithmes de tri simples
Testez le comportement du tri par sélection et du tri par insertion en exécutant votre programme sur les trois fichiers txt fournis. Notez à chaque fois le temps d’exécution pour compléter le tableau suivant (pour l’instant, laissez la dernière colonne vide). Aide : utilisez la commande time de Linux pour exécuter le programme (exemple: time ./tp4.out ).
Fichier à trier Tri par sélection Tri par insertion Tri par fusion interne
random.txt
sorted.txt
reverse.txt
Lequel des trois algorithmes est le plus performant sur un fichier aléatoire ? Même question pour un fichier déjà trié ? un fichier trié dans l'ordre inverse ?
Exercice 4 *** : Implanter le tri par fusion externe
Les algorithmes de tri interne ne sont pas adaptés pour de très gros volumes de données. Dans ce cas, il est préférable d’utiliser des algorithmes de tri externe, qui ne chargent pas l’ensemble des données en mémoire, et
! LIF5 : Algorithmique et programmation procédurale
! Page 62
qui accèdent séquentiellement aux données. Dans cet exercice, vous allez implanter le tri externe par fusion, tel que vous l’avez vu en CM et en TD : contrairement à ce que vous avez fait pour les autres algorithmes, vous n'allez par charger l’ensemble du fichier dans un tableau. La ligne d'entête du fichier devient donc inutile. Codez les procédures eclatement (vue en TD) et fusion, et triParFusion (vue en TD). Testez votre programme sur un petit fichier, puis sur le fichier random-pourTriExterne.txt fourni sur le site de l'UE, et remplissez la dernière colonne de l’exercice précédent.

! LIF5 : Algorithmique et programmation procédurale
! Page 63
TP additionnel (à faire chez soi, pour les plus motivés !) : Traitement d'images
Exercice 1 * : Utiliser fwrite pour créer un fichier BMP
Récupérez le fichier creerBMPmystere.c sur le site de l’UE. Dans ce code, on définit un tableau statique de 48x48=2304 pixels. Chaque case du tableau correspond à un pixel de l'image et contient ainsi les valeurs RGB de ce pixel. Les premières cases de tab contiennent la ligne de pixels tout en bas de l'image. Les cases suivantes contiennent les pixels de la ligne juste au-dessus (2e ligne en partant du bas), etc, jusqu'a la ligne du haut de l'image.
Complétez le main pour créer un fichier BMP qui contiendra ces pixels. Suivez pour cela les indications données en commentaires. Une fois votre programme terminé, exécutez-le et vérifiez qu’un fichier BMP a été créé dans votre répertoire courant. Ouvrez ce fichier pour découvrir l’image !
Rappel : Bitmap, connu aussi sous son abréviation BMP, est un format d'image matricielle ouvert développé par Microsoft et IBM. C’est l’un des formats d’images les plus simples à développer et à utiliser pour programmer. Il est lisible par quasiment tous les visualiseurs et éditeurs d'images. Le fichier se découpe en 2 zones :
• L’en-tête du fichier : on y trouve notamment la largeur et la hauteur de l’image, en nombre de pixels. • Les données relatives à l’image : les pixels de l'image sont codés ligne par ligne, en partant de la ligne
inférieure de l’image. Si l'image est codée en 24 bits (ce qui sera le cas pour tout ce TP), chaque pixel est codé par trois octets (trois unsigned char) codant successivement les niveaux de bleu, vert et rouge. Chacun de ces trois niveaux est compris entre 0 et 255. Exemples de pixels :
(0, 0, 0) " noir (255, 255, 255) " blanc (255, 0, 0) " rouge (0, 255, 0) " vert (0, 0, 255) " bleu (255, 192, 203) " une nuance possible de rose
Exercice 2 * : Conversion d’une image en niveaux de gris
Vous allez maintenant programmer le passage d’une image en niveaux de gris. Les procédures de lecture et d’écriture de fichier vous sont fournies, de sorte à ce que vous vous concentriez sur les calculs des valeurs RGB des pixels. Dans le codage RGB, si l’on fixe les trois octets à la même valeur (par exemple 125, 125, 125), on obtient une nuance de gris. La conversion d’une image en niveaux de gris consiste à calculer pour chaque pixel la moyenne de ses trois niveaux R, G, B : dans l’image convertie, le pixel aura ses trois niveaux R, G, B égaux à cette moyenne.
a) Récupérez les fichiers traitement-images.c et grey_wolf.bmp sur le site de l’UE. Le fichier traitement-images.c contient deux procédures utiles pour lire un fichier BMP : lireEntete et remplirTableauPixelsDepuisFichier. Lisez attentivement les entêtes de ces procédures, puis complétez le « main » pour récupérer la largeur et la hauteur de l’image originale (grey_wolf.bmp), allouer un tableau 1D de taille suffisante pour contenir tous les pixels, et remplir ce tableau à partir du fichier. Vérifiez que votre code ne contient pas d’erreur de compilation ni d’exécution.
! LIF5 : Algorithmique et programmation procédurale
! Page 64
b) Pour une image de largeur L et de hauteur H, quelle instruction faudrait-il écrire pour afficher les niveaux R, G, B du pixel qui se trouve à la ligne 2 (en partant du bas), et à la colonne 8 (en supposant que lignes et colonnes sont numérotées à partir de 0) ?
c) Ecrivez au-dessus du main la procédure traitementNiveauxDeGris, qui prend en paramètres un tableau de pixels correspondant à l’image originale (mode donnée), un tableau de pixels assez grand pour contenir l’image convertie (mode résultat, la procédure va remplir ce tableau), ainsi que la largeur et la hauteur de l’image (mode donnée). Veillez à indiquer les pré- et post-conditions en commentaires.
d) Complétez le main pour qu’il appelle correctement cette procédure, puis écrive le tableau de pixels résultant dans un fichier au format BMP que vous appellerez « grayscale.bmp » (utilisez pour cela les procédures ecrireEntete et ecrirePixelsDansFichier). Vérifiez que votre code ne contient pas d’erreur de compilation ni d’exécution. Vérifiez que l’image produite correspond au résultat attendu. Votre main doit se terminer proprement et donc libérer la mémoire allouée dynamiquement.
Exercice 3 * : Conversion d’une image en « sépia »
En photographie, le Sépia est une qualité de tirage qui ressemble au noir et blanc, mais avec des variations de brun, et non de gris.
Image originale en couleurs Image après un traitement sépia
Pour réaliser ce traitement sur une image numérique, on modifie la couleur de chaque pixel selon le calcul suivant :
• on calcule la moyenne m des trois valeurs R, G, B du pixel, • on calcule les nouvelles valeurs selon les formules suivantes, où p est un entier qui détermine l’intensité
du traitement sépia : R = m – 2p, G = m – p, B = m + 3p • si l’une quelconque de ces 3 valeurs est négative, on la ramène à 0, • si l’une quelconque de ces 3 valeurs excède 255, on la ramène à 255.
a) Est-il pertinent d’utiliser une variable de type « unsigned char » pour stocker le niveau brut ? Pourquoi ? Quel type suggérez-vous ?
b) Dans le fichier traitement-images.c, écrivez au-dessus du main la procédure traitementSepia, qui prend en paramètres un tableau de pixels correspondant à l’image originale (mode donnée), un tableau de pixels assez grand pour contenir l’image convertie (mode résultat), ainsi que la largeur, la hauteur de l’image et la profondeur p du traitement (mode donnée). Cette procédure remplit le second tableau

! LIF5 : Algorithmique et programmation procédurale
! Page 65
de pixels selon l’algorithme décrit ci-dessus. Veillez à indiquer les pré- et post-conditions en commentaires.
c) Complétez le main pour qu’il appelle correctement cette procédure (avec p = 5), puis écrive le tableau de pixels résultant dans un fichier au format BMP que vous appellerez « sepia.bmp » (utilisez pour cela la procédure ecrireFichier). Vérifiez que votre code ne contient pas d’erreur de compilation ni d’exécution. Vérifiez que l’image produite correspond au résultat attendu.
Exercice 4 ** : Embossage d’une image en niveaux de gris
En haut à gauche : image originale, en couleurs En haut à droite : image en niveaux de gris Ci-contre : image en niveaux de gris après traitement par un filtre d’embossage, donnant une impression de relief.
Le filtre d’embossage donne l’illusion optique que certains objets de l’image sont plus ou moins près du fond, ce qui crée un effet de relief. Cet effet est obtenu de la façon suivante :
• on part d’une image en niveaux de gris, • pour chaque pixel de l’image de sortie (sauf ceux en bordure de l’image), on calcule le niveau de gris
en tenant compte du niveau de ce pixel et de 2 de ses voisins dans l’image originale, selon le calcul suivant :
Niveau brut pour le pixel central = 2*niveau du pixel voisin nord-est - niveau de ce pixel - niveau du pixel voisin sud-ouest + 128 Si ce niveau brut excède 255, on met le pixel à 255. S’il est négatif, on met le pixel à zéro.
• ce calcul n’est pas réalisable pour les pixels en bordure de l’image, on les mettra donc en noir.
2 -1
-1
! LIF5 : Algorithmique et programmation procédurale
! Page 66
a) Est-il pertinent d’utiliser une variable de type « unsigned char » pour stocker le niveau brut ? Pourquoi ? Quel type suggérez-vous ?
b) Ecrivez au-dessus du main la procédure traitementEmbossage, qui prend en paramètres un tableau de pixels correspondant à une image en niveaux de gris (mode donnée), un tableau de pixels assez grand pour contenir l’image embossée (mode résultat), ainsi que la largeur et la hauteur de l’image (mode donnée). Cette procédure remplit le second tableau de pixels selon l’algorithme décrit ci-dessus. Veillez à indiquer les pré- et post-conditions en commentaires.
c) Complétez le main pour qu’il appelle correctement cette procédure, puis écrive le tableau de pixels résultant dans un fichier au format BMP que vous appellerez « embossage.bmp ». Vérifiez que votre code ne contient pas d’erreur de compilation ni d’exécution. Vérifiez que l’image produite correspond au résultat attendu. Votre main doit se terminer proprement et donc libérer la mémoire éventuellement allouée dynamiquement.
Exercice 5 *** : Dissimulation d’une image dans une autre (stéganographie)
Si la cryptographie est l’art du secret, la stéganographie est l’art de la dissimulation : il s’agit de faire passer inaperçu un message dans un autre message et non de rendre un message inintelligible à autre que qui-de-droit. Si on utilise le coffre-fort pour symboliser la cryptographie, la stéganographie revient à enterrer son argent dans son jardin.
Dans cet exercice, vous allez programmer la dissimulation d’une image dans une autre (les deux images étant de même taille). La technique de base --- dite LSB pour Least Significant Bits --- consiste à modifier les bits de poids faible des pixels codant l’image apparente. On les remplace par les bits de poids fort de l’image à cacher. Modifier les bits de poids faible de l’image apparente ne produit pas de changement visible à l’œil nu car cela ne modifie que très légèrement les niveaux RGB des pixels. Mais si le destinataire de l’image sait qu’elle en contient une autre, il pourra extraire ces bits de poids faible et reconstruire l’image cachée, ou tout du moins une version approchée de cette image cachée.
Image d’origine (gargouille.bmp) Image à cacher (F15.bmp)

! LIF5 : Algorithmique et programmation procédurale
! Page 67
Image modifiée pour inclure les 3 bits de Image obtenue lorsqu’on extrait les 3 bits de poids fort de F15.bmp à la place des 3 bits poids faible de l’image ci-contre de poids faible initiaux (verif-extraction.bmp) (verif-dissimulation.bmp)
Exemple pour un entrelacement 5bits/3bits (remplacement des 3 bits de poids faible pour chaque niveau R, G, B du pixel) :
Pixel dans gargouille.bmp = 00000000-00001111-11010110
Pixel dans F15.bmp = 11101001-00101101-00101000
Pixel entrelacé dans dissimulation.bmp = 00000111-00001001-11010001
Pixel pseudoreconstruit dans extraction.bmp= 11100000-00100000-00100000
Une partie de l’information de F15.bmp est perdue puisqu’on ne garde que les 3 bits de poids fort de chaque niveau R, G, B, d’où la qualité dégradée de l’image reconstruite. On pourrait améliorer la qualité de l’image reconstruite en faisant un entrelacement 4bits/4bits, mais elle commencerait à être devinable à l’œil nu dans l’image apparente. Vous allez donc programmer ici un entrelacement 5bits/3bits. Pour vous aider, les procédures getIemeBit, setIemeBit1 et setIemeBit0 vous sont fournies. Vous n’avez donc pas à manipuler vous même les opérateurs bit à bit. Notez bien que pour les procédures setIemeBit, le premier paramètre est passé en mode donnée-résultat.
a) Récupérez sur le site de l’UE les fichiers gargouille.bmp et F15.bmp.
b) Ecrivez au-dessus du main la procédure dissimulation, qui prend en paramètres deux tableau de pixels en mode donnée (les deux images originales), un tableau de pixels assez grand pour contenir l’image entrelacée (mode résultat), ainsi que la largeur et la hauteur de l’image (mode donnée). Cette procédure remplit le troisième tableau de pixels à partir des deux premiers, selon l’algorithme décrit ci-dessus. Veillez à indiquer les pré- et post-conditions en commentaires.
c) Complétez le main pour qu’il appelle correctement cette procédure, puis écrive le tableau de pixels résultant dans un fichier au format BMP que vous appellerez « dissimulation.bmp ». Vérifiez que votre code ne contient pas d’erreur de compilation ni d’exécution. Vérifiez que l’image produite correspond au résultat attendu. Votre main doit se terminer proprement et donc libérer la mémoire éventuellement allouée dynamiquement.
d) Ecrivez la procédure extraction, qui prend en paramètre donnée un tableau de pixels d’une image entrelacée, et en paramètre résultat un tableau de pixels suffisamment grand pour contenir l’image cachée. La procédure prend aussi en paramètre donnée la largeur et la hauteur de l’image. Appelez cette procédure depuis le main pour la tester.
! LIF5 : Algorithmique et programmation procédurale
! Page 68
TP5 : Tableau dynamique
Dans ce TP, vous allez implanter en C un module TableauDynamique qui devrait être utilisable par d’autres. Dans cette implantation, les cases du tableau seront numérotées à partir de 0. Vous allez créer votre module sous forme de type de données abstrait, c’est-à-dire avec l’interface (fichier .h) séparée de l’implantation (fichier .c). Ce sera aussi l’occasion pour vous d’écrire votre premier Makefile et de vous entraîner à bien valider vos procédures et fonctions au fur et à mesure.
Exercice 1 Initialisation et testament, première compilation multi-fichiers
a) Le type TableauDynamique doit permettre de stocker des éléments de type « ElementTD ». Vous trouverez les fichiers ElementTD.h, ElementTD.c et TableauDynamique.h sur le site de l’UE. Dans votre répertoire LIF5, créez un sous-répertoire TP5 et enregistrez les fichiers dedans.
b) Examinez le contenu du fichier TableauDynamique.h : il contient les prototypes (= déclarations) des fonctions et procédures promis par le module.
c) Créez un nouveau fichier « TableauDynamique.c », destiné à contenir l’implantation de votre module. Dans ce fichier, commencez par indiquer que vous allez utiliser les types et sous-programmes déclarés dans les fichiers TableauDynamique.h et ElementTD.h, grâce à la directive de précompilation #include. Ecrivez ensuite la définition de la procédure d’initialisation à une case vide, et celle de la procédure de testament, en respectant bien les prototypes déclarés dans le .h. Enregistrez votre fichier mais ne le fermez pas.
d) Créez un nouveau fichier « main.c » et écrivez un main qui appelle les procédure que vous venez d’écrire, afin de tester si elle fonctionne bien. Enregistrez votre fichier mais ne le fermez pas.
e) Compilez votre programme en tapant successivement les commandes suivantes (ne passez pas à la commande 2 tant que vous avez des erreurs sur la commande 1, etc) :
gcc -c –Wall –ansi –pedantic TableauDynamique.c gcc -c –Wall –ansi –pedantic ElementTD.c gcc -c –Wall –ansi –pedantic main.c gcc TableauDynamique.o main.o ElementTD.o -o monprog.out
Notez bien l’option –c dans les 3 premières commandes : elle indique à gcc de s’arrêter à l’étape de traduction de votre code en langage binaire, sans essayer de créer un exécutable. C’est la 4e commande qui crée l’exécutable en éditant les liens entre les 3 fichiers .o et avec les bibliothèques.
Exercice 2 Création d’un fichier Makefile et utilisation de la commande make
Créez un nouveau fichier Makefile, qui permettra de compiler automatiquement, en tapant simplement make au lieu des 4 commandes précédentes. Inspirez vous de l’exemple vu en cours magistral.
Exercice 3 Implantation des fonctionnalités de base du module
Définissez dans TableauDynamique.c les fonctionnalités ci-dessous, en respectant les prototypes déclarés dans le .h. Remarque importante : Testez au fur et à mesure que vous ajoutez une fonctionnalité : appelez-la dans le

! LIF5 : Algorithmique et programmation procédurale
! Page 69
main, enregistrez tous vos fichiers, recompilez en utilisant simplement la commande make et exécutez le programme.
a) ajout d’un élément en fin de tableau,
b) accès à l’élément de la case i,
c) modification de l’élément de la case i,
d) affichage du tableau,
e) suppression d'un élément.
Exercice 4 Expérimenter la complexité du remplissage du tableau
a) Le but de cet exercice est de vérifier le que le coût amorti d’un ajout dans un TableauDynamique est de l’ordre de 3 affectations. Pour cela, vous allez comparer le temps T1 (en secondes) nécessaire pour faire n ajouts dans un TableauDynamique, avec le temps T0 nécessaire pour faire n ajouts dans un tableau « simple », qui ne change pas de taille au fur et à mesure des ajouts (ce tableau simple doit donc être déjà de taille n au départ). Prenez n = 500000 pour cette question.
Aide : Pour mesurer le temps d'exécution, vous pouvez utiliser la commande time dans le terminal (time ./monprog.out) ou vous inspirer du code ci-dessous.
#include <time.h> int main() { clock_t heureDebut, heureFin; double temps; heureDebut = clock(); /* bout de code à mesurer ici */ heureFin = clock(); temps = ((double)(heureFin - heureDebut))/CLOCKS_PER_SEC; printf("Temps d'exécution : %f secondes\n", temps); return 0; }
b) Mesurez les deux temps d'exécution pour n allant de 1 000 000 à 20 000 000 par pas de 100 000. En utilisant un tableur, tracez les deux courbes T0(n) et T1(n). Retrouvez-vous bien un coût 3 fois plus important pour le remplissage du tableau extensible comparé au tableau simple ?
c) Listez les avantages et inconvénients d'un TableauDynamique (extensible en fonction des besoins) comparé à un tableau simple (dont la taille ne change pas).
Exercice 5 Fonctionnalités plus avancées
a) Testez dans votre main ce qu’il se passe lorsqu’on fait a = b quand a et b sont deux tableaux dynamiques, et testamentTabDyn(&a) ensuite. Expliquez. Implantez alors la procédure affecterTabDyn qui recopie un tableau bien initialisé b dans un autre tableau bien initialisé a. Le contenu précédent de a est libéré.
b) Implantez la procédure d'insertion d'un élément en i-ème position.
! LIF5 : Algorithmique et programmation procédurale
! Page 70
c) Implantez la procédure de tri d’un tableau dynamique. Vous pouvez commencer par un tri par sélection, puis, si vous avez le temps, opter par un tri par fusion interne (voir TP4).
d) Implantez la procédure de recherche d’un élément dans un tableau trié. Vous pouvez commencer par une recherche linéaire, puis, si vous avez le temps, opter pour une recherche dichotomique.

! LIF5 : Algorithmique et programmation procédurale
! Page 71
TP6 : Liste (doublement) chaînée Commencez par créer un répertoire TP6 à l’intérieur de votre répertoire LIF5, en utilisant les lignes de commandes vues au TP1 (cd, mkdir, ls…). L’objectif de ce TP est d’écrire une nouvelle implantation de liste chaînée, différente de celle vue en cours, mais ayant la même interface (mêmes services proposés aux utilisateurs du module). L’implantation que vous allez écrire est celle d’une liste doublement chaînée, dans laquelle :
• chaque cellule contient un pointeur sur la cellule suivante et un pointeur sur la cellule précédente, • la structure Liste contient un pointeur sur la première cellule et un pointeur sur la dernière cellule.
Ainsi, il est possible de parcourir la liste dans les deux sens, et d'ajouter un élément en queue de liste en temps constant.
Exercice 1 Initialisation et Makefile
a) Récupérez sur le site de l’UE les fichiers ElementL.h, ElementL.c et Liste.h. Enregistrez-les dans votre répertoire TP6. Toujours dans ce répertoire, créez avec gedit un nouveau fichier que vous appellerez ListeDC.c. Ecrivez-y les #include requis, puis le code de la procédure d’initialisation d’une liste doublement chaînée (uniquement cette procédure-ci pour l’instant !). Enregistrez le fichier mais ne le fermez pas, vous y reviendrez plus tard.
b) Créez un nouveau fichier main.c, et écrivez-y un programme principal minimal, qui teste la procédure d’initialisation.
c) Créez un fichier Makefile et écrivez-y les lignes nécessaires pour compiler votre programme : « link » entre les trois .o, et construction de chaque .o. Inspirez-vous de ce que vous avez fait lors du TP précédent. Dans la console, compilez votre code (make), exécutez-le et corrigez-le si nécessaire.
Exercice 2 Implantation des fonctionnalités de base du module
Définissez dans ListeDC.c les fonctionnalités ci-dessous, en respectant les prototypes déclarés dans le .h. Remarque importante : Testez au fur et à mesure que vous ajoutez une fonctionnalité : appelez-la dans le main, enregistrez tous vos fichiers, recompilez en utilisant simplement la commande make et exécutez le programme.
a) ajout d’un élément en tête de liste,
b) ajout d’un élément en queue de liste,
c) test si une liste est vide,
d) accès au i-ème élément,
e) modification du i-ème élément,
f) affichage de la liste (de droite à gauche, et de gauche à droite),
g) suppression de l'élément de tête,
h) suppression de tous les éléments,
i) testament.
! LIF5 : Algorithmique et programmation procédurale
! Page 72
Exercice 3 Fonctionnalités plus avancées
a) Testez dans votre main ce qu’il se passe lorsqu’on fait a = b quand a et b sont deux listes chaînées, et testamentListe(&a) ensuite. Expliquez. Implantez alors la procédure affecterListe qui recopie une liste bien initialisée b dans une autre liste bien initialisée a. Le contenu précédent de a est libéré.
b) Implantez la procédure d'insertion d'un élément en i-ème position.
c) Implantez la procédure de tri d'une liste chaînée, en utilisant l'algorithme de tri par insertion.
d) Implantez la procédure de recherche d’un élément dans une liste quelconque.

! LIF5 : Algorithmique et programmation procédurale
! Page 73
TP7 : Arbre binaire de recherche
Objectifs
• Etre capable d’implanter les services fondamentaux offerts par un module Arbre Binaire de Recherche. • Etre capable de mesurer la performance d’un arbre binaire de recherche. • Comprendre l’influence de la hauteur de l’arbre sur la performance.
Scénario
Vous travaillez pour un réseau interbancaire qui émet des cartes de paiement. Lorsqu’un client veut effectuer un paiement dans une boutique, le terminal de paiement émet une requête auprès du réseau interbancaire pour déterminer si la transaction peut être approuvée ou non : il s’agit de retrouver le numéro de carte dans la liste des cartes existantes, et de vérifier si la banque s’oppose ou non à la transaction. Le serveur du réseau interbancaire reçoit ainsi des centaines de milliers de requêtes par minute et elles doivent donc être traitées le plus rapidement possible. De plus, la base de données est dynamique : à chaque minute, des numéros de carte peuvent être créés ou supprimés. Récemment, le serveur s’est avéré incapable de répondre à toutes les requêtes aux heures de pointe et des transactions ont échoué. Votre travail est d’implanter une nouvelle structure de données présentant de meilleures performances, c’est-à-dire capable d’insérer, de supprimer ou de retrouver très rapidement un numéro de carte. Dans ce cadre, vous décidez d’implanter un arbre binaire de recherche permettant de stocker des entiers, et de vérifier ses performances en simulant des opérations aléatoires d’insertion et de recherche.
Travail demandé
a) Récupérez sur le site de LIF5 les fichiers ElementA.h, ElementA.c et Arbre.h. Créez un nouveau fichier main.c et écrivez-y un « main() » vide pour l’instant. Créez également le Makefile qui permettra de compiler tout votre programme.
b) Créez le fichier arbre.c en y plaçant les définitions des fonctions et procédures suivantes :
• initialiserArbre • insererElementArbre • afficherArbreParcoursInfixe • rechercherElementArbre • testamentArbre
Remarque : Pour certains de ces sous-programmes, vous devrez utiliser une fonction ou procédure auxiliaire travaillant sur un sous-arbre, et prenant donc comme paramètre supplémentaire l’adresse du nœud dans lequel le sous-arbre est enraciné. Ces sous-programmes auxiliaires restent internes au module Arbre : ils n’apparaissent donc pas dans le .h, et sont précédés du mot-clé static dans le .c.
c) Codez ensuite les procédures hauteurArbre et profondeurMoyenneArbre.
d) Dans le fichier main.c, complétez le main() pour qu’il insère dans un arbre binaire de recherche 255 entiers aléatoires compris entre 1 et 100000, puis qu’il calcule la hauteur maximale de l’arbre et sa profondeur moyenne. Le programme devra bien entendu se terminer proprement, c’est-à-dire en
! LIF5 : Algorithmique et programmation procédurale
! Page 74
vidant l’arbre. Testez que tout fonctionne bien, en utilisant notamment la procédure d’affichage d’arbre qui vous est fournie. Vérifiez que vous n’obtenez pas le même arbre si vous exécutez deux fois le programme.
Aide : pour le tirage de nombres aléatoires, vous pouvez vous inspirer du petit programme suivant :
#include <stdio.h> #include <stdlib.h> #include <sys/time.h> #define VALEUR_MAX 100000 int main() { int alea1, alea2; /* Initialisation du générateur, à ne faire qu’une fois dans le programme. En l’initialisant avec l’heure à laquelle l’exécution est lancée, on aura des valeurs différentes à chaque exécution, ce qui est souhaitable ! */ srand((unsigned) time(NULL)); /* Tirage de deux nombres aléatoires compris entre 0 et VALEUR_MAX incluse */ alea1 = rand()%(VALEUR_MAX + 1); alea2 = rand()%(VALEUR_MAX + 1); printf("%d %d\n", alea1, alea2); return 0; }
e) Complétez le main pour qu’il recherche 100 nombres aléatoires entre 0 et 100000 dans l’arbre (bien évidemment, parmi ces 100 nombres, certains seront effectivement présents dans l’arbre et d’autres non). En plus de la hauteur maximale et de la profondeur moyenne de l’arbre, le main devra afficher le nombre moyen de nœuds visités par opération de recherche.
f) Modifiez le main pour qu’il répète 60 fois le processus complet de création d’arbre + recherche de 100 éléments. Vous devez obtenir comme affichage 60 lignes, avec sur chaque ligne la hauteur maximale et le nombre moyen de nœuds visités par opération de recherche (n’affichez plus les arbres eux-mêmes, donc). Quelle relation constatez-vous entre les deux quantités ?
Epilogue
Ce TP devrait vous avoir convaincu de l’intérêt d'équilibrer les arbres. Les algorithmes d’équilibrage sont au programme de LIF9.

! LIF5 : Algorithmique et programmation procédurale
! Page 75
TP8 : TP de synthèse
Objectifs
• Faire fonctionner ensemble différentes structures de données dynamiques dans un même programme • Savoir écrire un Makefile avec plus d’unités de compilation • Mettre en œuvre la notion d’abstraction
Travail demandé
Le but de ce TP est de compléter le module Arbre réalisé lors du TP7 en le dotant de procédures de parcours itératives, qui vont utiliser des Piles ou des Files pour stocker les adresses des nœuds en attente de traitement. Dans ce TP, vous allez donc écrire un module Pile (basé sur le module TableauDynamique du TP5), et un module File (basé sur le module Liste du TP6).
[Si vous n’aviez pas fini la question b) du TP7] Terminez la question b) du TP7, de sorte à obtenir un module Arbre avec toutes les fonctionnalités de base, et correctement testé.
Exercice 1 Parcours en largeur (version itérative utilisant une File)
a) [Si vous n’aviez pas fini l'exercice 2 du TP6] Terminez l'exercice 2 du TP6, de sorte à obtenir un module Liste avec toutes les fonctionnalités de base, et correctement testé.
b) Dans votre répertoire LIF5, créez un répertoire TP8. Placez-y les fichiers ElementL.h et ElementL.c que vous trouverez sur le site de l'UE dans le répertoire tp8/. Observez le contenu de ces fichiers : au lieu de stocker des entiers dans Listes, nous allons stocker des adresses (type "adresse générique" void*).
c) Copiez dans votre répertoire TP8 vos fichiers Liste.h et ListeDC.c du TP6, et Arbre.h, Arbre.c, ElementA.h, ElementA.c et main.c du TP7.
d) Toujours dans votre répertoire TP8, ajoutez le fichier File.h qui se trouve sur le site de l’UE. Ouvrez-le : vous verrez que le type File est simplement défini comme étant une Liste, mais sur laquelle seules certaines opérations sont possibles : enfiler, défiler, etc. Créez un nouveau fichier File.c et écrivez le code des fonctions et procédures annoncées dans File.h. Indication : chacun de ces sous-programmes s’écrit en une ligne. Vérifiez que votre code est syntaxiquement correct en tapant : gcc –c –Wall –ansi –pedantic File.c.
C’est un exemple d’abstraction et d’encapsulation : la « sur-couche » File, par dessus le module Liste, permet à l’utilisateur du module File de la voir comme une boîte noire, simple à utiliser, qui ne propose que les services permis sur une File. L’utilisateur du module File n’a pas à savoir si elle est implantée « en interne » sous forme d’une liste chaînée ou d’un tableau dynamique ou autre. Idéalement, il ne voit que les services proposés dans le fichier file.h et ne risque pas d’effectuer des opérations illégales sur une File, comme une insertion en plein milieu par exemple.
! LIF5 : Algorithmique et programmation procédurale
! Page 76
e) Dans Arbre.h, ajoutez la déclaration d’une procédure d’affichage en largeur. Dans Arbre.c, écrivez la définition de cette procédure. Ce code utilisera bien sûr une variable locale de type File. Vous devrez donc ajouter un #include "File.h" au début du fichier Arbre.c. Vérifiez que votre code est syntaxiquement correct en tapant : gcc –c –Wall –ansi –pedantic Arbre.c.
f) Modifiez le main() pour qu’il l’affiche deux fois un arbre rempli : d’abord en utilisant la procédure d’affichage dans l’ordre croissant (parcours infixe), puis en utilisant votre parcours en largeur.
g) Placez dans votre répertoire TP8 une copie du Makefile de votre TP7 et complétez-le pour prendre en compte les deux unités de compilation supplémentaires (Liste et File). Attention à bien mettre à jour la liste des .h dans les listes de dépendances : on rappelle que pour une ligne commençant par ‘fic.o:’, il faut indiquer le fichier .c correspondant et tous les .h inclus dans ce .c (et seulement ceux-là). Compilez et testez votre programme, corrigez-le jusqu’à ce qu’il fonctionne.
Exercice 2 Parcours postfixe (version itérative utilisant deux Piles)
a) [Si vous n’aviez pas fini l'exercice 3 du TP5] Terminez l'exercice 3 du TP5, de sorte à obtenir un module TableauDynamique avec toutes les fonctionnalités de base, et correctement testé. Copiez dans votre répertoire TP8 vos fichiers TableauDynamique.h et TableauDynamique.c du TP5.
b) Placez dans votre répertoire TP8 les fichiers ElementTD.h et ElementTD.c que vous trouverez sur le site de l'UE dans le répertoire tp8/. Toujours dans votre répertoire TP8, ajoutez le fichier Pile.h qui se trouve sur le site de l’UE. Ouvrez-le : vous verrez que le type Pile est simplement défini comme étant un TableauDynamique, mais sur laquelle seules certaines opérations sont possibles : empiler, dépiler, etc. Créez un nouveau fichier pile.c et écrivez le code des fonctions et procédures annoncées dans Pile.h. Indication : chacun de ces sous-programmes s’écrit en une ligne.
c) Dans Arbre.h, ajoutez la déclaration d’une procédure itérative d’affichage postfixe. Dans Arbre.c, écrivez la définition de cette procédure avec l’algorithme suivant, qui utilise deux piles d’adresses de nœuds, qu’on appellera pileA et pileB :
• on place la racine dans la pileB, • tant qu’on n’a pas épuisé la pileB, on déplace le sommet de la pileB vers la pileA, et on empile
son fils gauche (s’il existe) puis son fils droit (s’il existe) dans la pileB, finTantQue • une fois la pileB vide, on dépile la pileA jusqu’à la vider, en affichant au fur et à mesure les
éléments contenus dans les nœuds.
d) Modifiez le main() pour qu’il l’affiche deux fois un arbre rempli : d’abord en utilisant la procédure d’affichage dans l’ordre croissant (parcours infixe), puis en utilisant votre parcours postfixe.
e) Complétez votre Makefile pour prendre en compte les deux unités de compilation supplémentaires (TableauDynamique et Pile). Attention à bien mettre à jour la liste des .h dans les listes de dépendances : on rappelle que pour une ligne commençant par ‘fic.o:’, il faut indiquer le fichier .c correspondant et tous les .h inclus dans ce .c (et seulement ceux-là). Compilez et testez votre programme, corrigez-le jusqu’à ce qu’il fonctionne.
! LIF5 : Algorithmique et programmation procédurale
! Page 77
Annexe 1 : Commandes Linux usuelles
Action Commande Obtenir de l’aide sur une commande man commande Chercher les commandes relatives à un mot-clé man –k motcle Obtenir des informations sur l’utilisateur courant who am i Lister le contenu du répertoire courant ls
ls –a (affiche aussi les fichiers cachés) ls –al (affichage d’étaillé)
Lister le contenu d’un répertoire autre que le répertoire courant
ls cheminrepertoire ls –a cheminrepertoire ls –al cheminrepertoire
Changer de répertoire cd cheminrepertoire Aller au répertoire père cd .. Aller à la racine de son répertoire personnel cd
cd ~ Afficher le chemin du répertoire courant pwd (print working directory) Créer un répertoire mkdir cheminrepertoire Visualiser le contenu d’un fichier texte more cheminfichier
(entree = ligne suivante ; espace = page suivante ; q = quitter)
Editer un fichier texte gedit cheminfichier & Faire une copie d’un fichier cp cheminsource chemincible Déplacer ou renommer un fichier mv cheminsource chemincible Supprimer un fichier rm cheminfichier Supprimer un répertoire et tout son contenu rm –r cheminrepertoire
Notion de chemin
Le chemin permet de savoir où se trouve un fichier ou un répertoire dans l'arborescence. Deux types de chemins sont utilisés sous Linux :
• les chemins absolus : ils indiquent tout le chemin d'accès à partir de la racine du système (/) • les chemins relatifs : ils indiquent le chemin à partir du point où l'on est dans l'arborescence (répertoire
courant). Le chemin relatif permettant d'accéder au répertoire père du noeud courant est ..
Exemples :
• /home/b/p012456/LIF5-automne2008/TP1 est le chemin absolu du répertoire TP1. • /home/b/p012456/LIF5-automne2008/TP2 est le chemin absolu du répertoire TP2. • /home/b/p012456/LIF5-automne2008/TP1/hello.c est le chemin absolu du fichier hello.c. • Si on est dans le répertoire LIF5-automne2008, alors le chemin relatif d'accès au répertoire TP1 est
simplement TP1 (ou ./TP1). • Si on est dans le répertoire TP1, alors :
o le chemin relatif d'accès au répertoire LIF5-automne2008 est .. o le chemin relatif d'accès au répertoire TP2 est ../TP2 o le chemin relatif d'accès au fichier hello.C est hello.c (ou ./hello.c)
Lorsque vous vous connectez, vous êtes placé dans votre répertoire personnel (par exemple /home/b/p012456).
! LIF5 : Algorithmique et programmation procédurale
! Page 78
Annexe 2 : Fonctionnement de scanf
La fonction scanf, fournie par la bibliothèque stdio, permet de récupérer les informations de l’entrée standard (il s’agira pour nous des informations saisies au clavier). Pour utiliser scanf, il faut avoir compris la notion d’adresse mémoire. Exemple :
#include <stdio.h> int main() { double a; int i ; int valretour; printf(“Donnez un nombre réel, puis un entier : \n“) ; valretour = scanf(“%lf %d“, &a, &i); if (valretour == 2) {printf(“Vous avez donné les valeurs %f et %d\n”, a, i);} else {printf(“Caractère invalide ou fin de saisie\n”);} return 0; }
Quelques explications :
• scanf lit une suite de caractères sur l’entrée standard et effectue les opérations de formatage indiquées dans la chaîne de format (1er paramètre). Les autres paramètres indiquent les emplacements mémoire (adresses) où scanf doit placer les informations formatées.
Type de la variable
Code de conversion Remarques
char unsigned char signed char
%c Contrairement à ce qui se passe pour printf, on ne peut pas lire un caractère par son code numérique
signed short int %hd unsigned short int
%hu
(signed) int %d unsigned int %u (signed) long %ld unsigned long %lu float %f, %e ou %g double %lf, %le ou %lg void * %p char *
%s ou %ns - Ignore les éventuels espaces initiaux - S’arrête au premier caractère « blanc » rencontré - Attention de bien disposer de la place nécessaire à l’adresse correspondante (contrôle possible : si n est précisé, au plus n caractères sont lus) - Un ‘\0’ de fin est ajouté
%nc - Lit exactement n caractères - Ne supprime pas les espaces initiaux - Un espace n’interrompt pas l’analyse - Le ‘\0’ n’est pas ajouté, il faut le faire manuellement

! LIF5 : Algorithmique et programmation procédurale
! Page 79
• scanf retourne le nombre de valeurs lues convenablement, ou bien la valeur spéciale EOF (généralement -1, en tout cas toujours négative) si l’utilisateur a tapé une combinaison de touches qui est interprétée comme une fin de fichier (CTRL+D sous Unix).
• L’utilisateur peut modifier les informations en cours de frappe (par retour arrière) car scanf attend une « validation » (retour chariot) avant de tenter effectivement de formater les données tapées. Ce mécanisme fait intervenir en interne un emplacement mémoire appelé « tampon » (buffer) dans lequel sont rangées provisoirement les informations tapées avant qu’elles ne soient effectivement exploitées par scanf. Différents cas peuvent se présenter lorsque l’utilisateur valide sa ligne :
o le tampon contient exactement le nombre voulu de données (ici un réel et un entier) : tout se passe bien, scanf convertit les informations de façon appropriée et les place dans les emplacements désignés et le programme continue son cours.
o le tampon contient plus de données qu’attendu (ex. un réel et trois entiers) : comme précédemment, mais les données supplémentaires restent disponibles pour un (éventuel) prochain appel à scanf.
o le tampon ne contient pas toutes les informations voulues au moment de la validation (ex. seulement un réel) : scanf exploite les données tapées puis attend que l’utilisateur complète sa saisie en tapant une nouvelle ligne. Le programme reste « bloqué » sur le scanf tant que toutes les informations n’ont pas été saisies.
• Pour exploiter les informations du tampon, scanf utilise un indicateur de position appelé « pointeur de tampon » qui pointe sur le premier caractère non encore pris en compte. Tous les codes de format numériques (%d, %u, %f, %lf…) ainsi que le code %s provoquent l’avancement de ce pointeur sur le premier caractère qui n’est ni un espace ni une fin de ligne : les espaces et les retours chariot qui précèdent éventuellement l’information sont ignorés. En revanche, le code %c (caractère) prélève directement le caractère désigné par le pointeur, même s’il s’agit d’un espace ou d’un retour chariot.
• Lorsque scanf lit une information de type caractère (%c) ou chaîne de caractère (%s), tout caractère est acceptable. En revanche, pour les informations numériques, seuls certains caractères sont valides. Par exemple, pour le code %d, une lettre ne conviendra pas. Lorsque le pointeur de tampon pointe sur un caractère invalide pour le code de format spécifié, deux situations peuvent se présenter :
o on dispose, avant le caractère invalide, d’autres caractères (autres que des espaces) qui permettent de « fabriquer » effectivement une valeur (par exemple, l’utilisateur a tapé « 456ty » pour un %d). Dans ce cas, la valeur 456 est stockée à l’emplacement désigné et le pointeur de tampon reste sur le ‘t’.
o on ne dispose d’aucun caractère permettant de fabriquer une valeur (par exemple, frappe de « abc » pour un %d). Dans ce cas, scanf n’affecte aucune valeur à l’emplacement désigné et interrompt son traitement sans tenir compte des éventuels codes de format suivants et donc des autres informations à lire. On parle d’arrêt prématuré de scanf. Pour savoir si ce problème s’est produit, il faut examiner la valeur de retour de scanf. Remarque importante : le tampon n’est pas vidé, et le pointeur de tampon reste positionné sur le caractère invalide.





























