Embed Size (px)
Citation preview

CER
N-T
HES
IS-2
014-
144
27/0
8/20
14
Institut Supérieur d’Informatique
de Modélisation et de leurs Applications
Organisation Européenne
pour la Recherche Nucléaire
Campus des Cézeaux
BP 125 – 63173 Aubière Cedex, FRANCE
CERN
CH-1211 Genève 23, SUISSE
Rapport d’ingénieur
Stage de 2ème
année
Filière Systèmes d’information et aide à la décision
Mise à jour de l’infrastructure de l’expérience LHCb
Présenté par: Driss El MAJDOUBI
Responsables CERN: Christophe HAEN, Loïc BRARDA
Responsable ISIMA : Emmanuel MESNARD
Date de soutenance : 27-08-2014
Durée du stage : 5 mois
g

i
Remerciements
Je tiens tout d’abord à remercier mes tuteurs au CERN, Christophe HAEN et Loïc BRARDA,
pour leur grande disponibilité, leur soutien technique et la confiance qu’ils m’ont attribuée
tout au long du stage.
Je remercie également tous les membres de l’équipe LHCb Online pour m’avoir accueilli et
pour avoir porté un intérêt à mon travail.
Par la même occasion, je tiens à remercier M. Emmanuel MESNARD mon tuteur de l‘ISIMA
pour son encadrement judicieux.
Un grand merci à toutes les personnes de bonne volonté, ayant contribuées de près ou de loin
à la réalisation de ce projet.
Que les membres de jury trouvent également ici, l’expression de ma haute reconnaissance
pour avoir accepté de juger mon travail.

ii
Table des figures et illustrations
Figure 1: Tunnel LHC [Haen 2013] ................................................................................................. 3
Figure 2: Fonctionnement du LHC [Haen 2013] .............................................................................. 4
Figure 3: Quark B .......................................................................................................................... 5
Figure 4: détecteur LHCb .............................................................................................................. 6
Figure 5: Représentation de la structure du réseau LHCb Online .................................................... 7
Figure 6: Principe de fonctionnement de la supervision ............................................................... 10
Figure 7: Infrastructure de supervision Icinga 1.x [Haen, Bonaccorsi et Neufeld 2011] .................. 12
Figure 8: Extrait de l'arbre logique de configuration Icinga 1.x [Haen, Bonaccorsi et Neufeld 2011] 13
Figure 9: Planning prévisionnel du stage ..................................................................................... 16
Figure 10: Logo Icinga 2 .............................................................................................................. 17
Figure 11: Architecture de Icinga 2 .............................................................................................. 19
Figure 12: La supervision distribuée basée sur la fonctionnalité cluster ........................................ 20
Figure 13: Schéma réseau de l'atelier .......................................................................................... 25
Figure 14: Digramme d'héritage des "Templates" des hôtes ........................................................ 26
Figure 15: Diagramme des "Host Group" fonctionnels ................................................................. 28
Figure 16: Digramme des "Host Group" logique ........................................................................... 29
Figure 17: Digramme des services ............................................................................................... 30
Figure 18: Diagramme des dépendances ..................................................................................... 32
Figure 19: Mécanisme d'exécution des plugins ............................................................................ 33
Figure 20: Page d'authentification Icinga-web ............................................................................. 34
Figure 21: Interface des états des hôtes ...................................................................................... 35
Figure 22: Interface des états des services ................................................................................... 36
Figure 23: Interface des groupes des hôtes .................................................................................. 37
Figure 24: Dépendance du switch_ux .......................................................................................... 38
Figure 25: Logo Puppet ............................................................................................................... 39
Figure 26: Architecture client/serveur de Puppet ........................................................................ 40
Figure 27: Fonctionnement de Puppet ........................................................................................ 42
Figure 28: Extrait du diagramme des "Templates" ....................................................................... 46
Figure 29: Fonctionnement du NRPE ........................................................................................... 48
Figure 30: Fonctionnement des vérifications directes .................................................................. 48
Figure 31: Fonctionnement des vérifications indirectes ............................................................... 49
Figure 32: Extrait des hôtes en état "UP" ..................................................................................... 52

iii
Figure 33: Extrait des hôtes en état "DOWN" .............................................................................. 52
Figure 34: Extrait des différents états des services ....................................................................... 53
Figure 35: Graphe des statistiques .............................................................................................. 54
Figure 36: Extrait des groupes "hostgroup" ................................................................................. 54
Figure 37: Processus de configuration Puppet-Foreman ............................................................... 57
Figure 38: Interface web Foreman ............................................................................................... 58
Figure 39: Extrait des facts sur Foreman ...................................................................................... 59

iv
Résumé
Le présent document constitue le fruit de mon travail dans le cadre du stage de deuxième
année, réalisé au sein de l’Organisation Européenne pour la Recherche Nucléaire (CERN).
L’objectif du stage est d’élaborer et de mettre en place une nouvelle infrastructure de
supervision de l’expérience LHCb en utilisant l’outil Icinga 2 et de l’intégrer autant que
possible à Puppet le nouveau système de gestion de configuration des serveurs.
Durant mon stage, j’avais pour mission dans une première étape de dialoguer avec les
membres de l’équipe LHCb Online afin d’avoir une vue globale du fonctionnement du
système. Ensuite, j’étais amené à bien comprendre les concepts de base d’Icinga 2 ainsi que
ceux du Puppet avant de passer à la mise en place de la solution complète de supervision.
Mots clés : Supervision, Icinga 2, Puppet, LHCb Online, Gestion de configuration.

v
Abstract
This document is the result of my work during the second year internship, realized within the
European Organization for Nuclear Research (CERN).
The goal of this internship is to design and setup a new monitoring infrastructure based on
Icinga 2 tool and integrate it as much as possible to a new configuration management tool,
Puppet.
During this internship, the first step of my mission was to interact with members of the LHCb
Online team to have an overview of the system. Then I had to understand the basic concepts
of Icinga 2 as well as those of Puppet before proceeding to the implementation of the
complete monitoring solution.
Keywords: monitoring, configuration management, Icinga2, Puppet, LHCb Online.

vi
Tables des matières
Remerciements ............................................................................................................................. i
Table des figures et illustrations ................................................................................................... ii
Résumé ........................................................................................................................................iv
Abstract ....................................................................................................................................... v
Tables des matières ......................................................................................................................vi
Lexique / Liste des abréviations .................................................................................................. viii
Introduction ................................................................................................................................. 1
1. Présentation du cadre du stage ............................................................................................. 2
1.1 Présentation générale ................................................................................................................................... 2
1.1.1 CERN (Organisation Européenne pour la Recherche Nucléaire)................................................. 2
1.1.2 LHC (Large Hadron Collider) .......................................................................................................... 2
1.1.3 Présentation de l’expérience LHCb ................................................................................................ 4
1.1.4 Système LHCb Online ...................................................................................................................... 6
1.1.5 L’équipe LHCb Online ...................................................................................................................... 9
1.2 Analyse de l’existant ..................................................................................................................................... 9
1.2.1 La supervision .................................................................................................................................. 9
1.2.2 Etude du système de supervision actuel ..................................................................................... 10
1.2.3 Solution proposée .................................................................................................................... 14
1.3 Cahier des charges ...................................................................................................................................... 15
1.4 Planification prévisionnelle ...................................................................................................................... 16
2. Etude et tests des outils choisis ............................................................................................... 17
2.1 Icinga 2: solution de supervision des réseaux .......................................................................................... 17
2.1.1 Icinga2: définition ............................................................................................................................ 17
2.1.2 Icinga 2: spécificités techniques [Icinga2 2014]. ........................................................................... 18
2.2 Les étapes d’installation de Icinga 2 et ses interfaces web...................................................................... 21

vii
2.2.1 Installation de Icinga 2 ..................................................................................................................... 21
2.2.2 Installation du module DB IDO (Database Icinga Data Output) ................................................... 21
2.2.3 Installation des interfaces graphiques ........................................................................................... 22
2.2.4 Les fichiers de configuration de base ............................................................................................. 22
2.3 Atelier de tests ............................................................................................................................................ 23
2.3.1 Schéma réseau de l’atelier ............................................................................................................... 23
2.3.2 Conception de la configuration de l’atelier de test ........................................................................ 25
2.3.3 Implémentation de la configuration et résultats des tests ........................................................... 33
2.4 Puppet : solution de gestion des configurations ...................................................................................... 38
2.4.1 Puppet : définition ............................................................................................................................ 38
2.4.2 Fonctionnement et caractéristiques de Puppet ............................................................................. 39
2.4.3 Exemple d’utilisation : Installation de Icinga 2 par Puppet .......................................................... 42
3. Mise en œuvre de la solution complète de supervision sur le système LHCb Online .................. 45
3.1 Présentation du système à superviser ...................................................................................................... 45
3.2 Conception de la configuration du système de supervision .................................................................... 45
3.3 Implémentation de la configuration .......................................................................................................... 47
3.3.1 Agent NRPE (Nagios Remote Plugin Executor) ............................................................................. 47
3.3.2 NAN (Nagios Notifications Daemon) .............................................................................................. 50
3.3.3 Résultats de supervision du système LHCb Online ....................................................................... 51
3.3.4 Discussion des résultats .................................................................................................................. 55
3.4 Automatisation de la configuration par Puppet ....................................................................................... 56
3.4.1 Analyse du problème ....................................................................................................................... 56
3.4.2 Solution proposée ............................................................................................................................ 56
Conclusion ................................................................................................................................. 62
Références bibliographiques ......................................................................................................... ix
Webographie ............................................................................................................................... ix
Annexe A .................................................................................................................................... xii
Annexe B ................................................................................................................................... xiii
viii
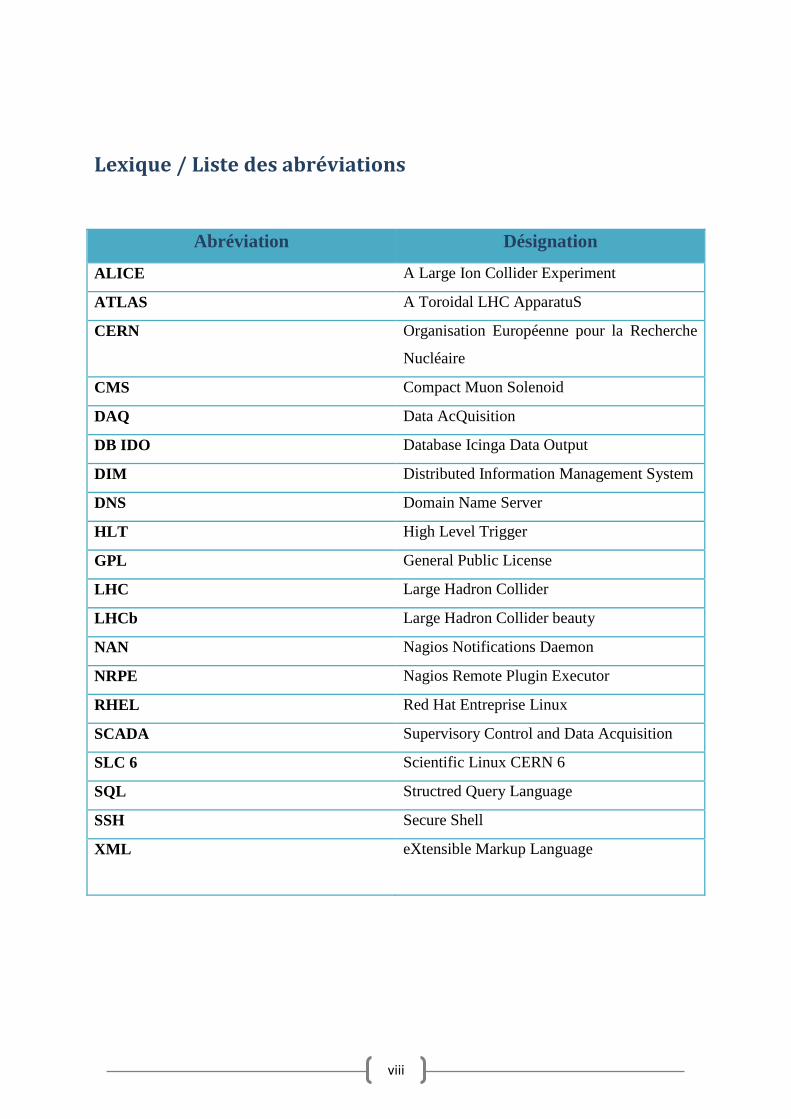
Lexique / Liste des abréviations
Abréviation Désignation
ALICE A Large Ion Collider Experiment
ATLAS A Toroidal LHC ApparatuS
CERN Organisation Européenne pour la Recherche
Nucléaire
CMS Compact Muon Solenoid
DAQ Data AcQuisition
DB IDO Database Icinga Data Output
DIM Distributed Information Management System
DNS Domain Name Server
HLT High Level Trigger
GPL General Public License
LHC Large Hadron Collider
LHCb Large Hadron Collider beauty
NAN Nagios Notifications Daemon
NRPE Nagios Remote Plugin Executor
RHEL Red Hat Entreprise Linux
SCADA Supervisory Control and Data Acquisition
SLC 6 Scientific Linux CERN 6
SQL Structred Query Language
SSH Secure Shell
XML eXtensible Markup Language

1
Introduction
Dans le cadre du stage de ma deuxième année d’études à l’ISIMA, j’ai effectué un stage de 5
mois au sein de l’Organisation Européenne pour la Recherche Nucléaire CERN. Ma mission
durant la période du stage était de mettre en place un système de supervision et de
surveillance de l’infrastructure informatique de l’expérience LHCb.
En effet, l’infrastructure de l’expérience LHCb est constituée de plus de 2000 serveurs et 200
équipements réseaux, gérés par une équipe relativement restreinte d’experts. Mettre en place
un système de supervision capable de réagir dans les minutes qui suivent à un incident sur
l’infrastructure est un réel défi, mais est nécessaire. LHCb utilisait une installation
particulièrement complexe de Icinga 1.8 pour la supervision du fonctionnement et la gestion
des alarmes.
Ainsi, ce stage s’inscrivait dans le cadre de la phase d’amélioration de l’expérience LHCb en
particulier celle de l’infrastructure informatique. Cette évolution concernait le système de
gestion de configuration des serveurs en utilisant Puppet, ainsi que l’infrastructure de
supervision basée sur Icinga 2. Le but du stage était donc d’élaborer et de mettre en place une
nouvelle infrastructure Icinga 2 et de l’intégrer autant que possible à Puppet.
Ce rapport se propose de découvrir les spécifications de ce stage à travers une
présentation générale du contexte du stage, une analyse détaillée du problème ainsi
qu’une présentation des différentes phases permettant la réalisation du travail demandé.

2
1. Présentation du cadre du stage
Ce chapitre se focalise sur la présentation de l’organisme d’accueil et l’étude détaillée de
l’existant où on cernera la problématique de mon sujet et on présentera la solution
adoptée pour ce dernier.
1.1 Présentation générale
1.1.1 CERN (Organisation Européenne pour la Recherche Nucléaire)
En 1952, un ensemble de 11 gouvernements européens décident de créer un Conseil Européen
pour la Recherche Nucléaire (CERN) dans le petit village de Meyrin dans le canton de
Genève, près de la frontière franco-suisse.
Le 29 septembre 1954, la convention du CERN est ratifiée par 12 États européens, le CERN
est officiellement créé et se nomme maintenant Organisation Européenne pour la Recherche
Nucléaire.
Aujourd’hui, le CERN emploie environ 2500 personnes. Le personnel scientifique et
technique du laboratoire conçoit et construit les accélérateurs de particules et assure leur bon
fonctionnement. Il contribue également à la préparation et à la mise en œuvre des expériences
scientifiques complexes, ainsi qu’à l’analyse et à l’interprétation des résultats.
Environ 8000 scientifiques visiteurs, soit la moitié des physiciens des particules du monde,
viennent au CERN pour faire des recherches. 580 universités et 85 nationalités sont
représentées [CERN_homepage 2014].
1.1.2 LHC (Large Hadron Collider)
Le Grand Collisionneur de Hadrons au CERN (Figure 1) est un gigantesque instrument
scientifique situé près de Genève, sur la frontière franco-suisse, à environ 100 mètres sous
terre. C’est un accélérateur de particules d’environ 27 kilomètres de circonférence, avec
lequel les physiciens étudient les plus petites particules connues : les composants
fondamentaux de la matière [LHC 2007].

3
Figure 1: Tunnel LHC [Haen 2013]
Deux faisceaux de particules (Figure 2) subatomiques de la famille des « hadrons » (des
protons ou des ions de plomb) circulent en sens inverse à l’intérieur de l’accélérateur
circulaire, emmagasinant de l’énergie à chaque tour. En faisant entrer en collision frontale les
deux faisceaux à une vitesse proche de celle de la lumière et à de très hautes énergies dans le
cœur des principales expériences connues par leurs acronymes : ALICE, ATLAS, CMS et
LHCb, le LHC recrée les conditions qui existaient juste après le Big Bang. Des équipes de
physiciens du monde entier analyseront les particules issues de ces collisions en utilisant des
détecteurs spéciaux. Les détecteurs peuvent observer jusqu’à 600 millions de collisions par
seconde, avec les expériences qui trient les données pour analyser des événements
extrêmement rares comme la création de l’amplement recherché boson de Higgs [Haen
2013].

4
Figure 2: Fonctionnement du LHC [Haen 2013]
1.1.3 Présentation de l’expérience LHCb
L’expérience LHCb cherche à comprendre pourquoi nous vivons dans un univers qui semble
être constitué entièrement de matière, sans aucune présence d’antimatière.
L’acronyme LHCb signifie Large Hadron Collider beauty. Ce dernier mot « beauty » vient du
nom de la particule que ce détecteur se propose d’étudier, le méson B.
L’univers est en apparence formé uniquement de matière, de particules. Les physiciens
pensent que lors du Bing Bang, la matière et l’antimatière ont été créées dans des proportions
égales mais ils ne savent pas expliquer ce que serait devenue l’antimatière.
La collision entre deux protons permet de produire de nombreuses particules. Les
scientifiques du LHCb prévoient de détecter des mésons B et d’observer leur désintégration.
En effet un méson est composé d’un nombre égal de quark et d’antiquark (les quarks étant les
particules élémentaires qui composent la matière). Ainsi, en comprenant comment, lors de la
décomposition d’un méson, la matière l’emporte sur l’antimatière, ils pourront expliquer par
extension pourquoi l’univers n’est composé que de matière [LHCb 2007].
5
Figure 3: Quark B
LHCb utilise une série de sous-détecteurs alignés le long du faisceau afin de traquer
principalement les particules à petits angles. Le premier sous-détecteur est installé près du
point de collision ; les autres se suivent sur une longueur de 20 m.
Une grande variété de types de quarks sera créée par le LHC avant de se désintégrer
rapidement pour former d’autres particules. Pour intercepter les quarks b, la collaboration
LHCb a mis au point des trajectographes mobiles, installés au plus près de la trajectoire des
faisceaux.
Tous ces détecteurs envoient les données sur un réseau Ethernet chargé de les prétraiter
(filtrer les événements) et de les stocker pour ensuite permettre aux physiciens de les
analyser, c’est le système LHCb Online.

6
Figure 4: détecteur LHCb
Le détecteur LHCb (Figure 4) a les caractéristiques suivantes :
Dimensions : 21 mètres de long, 13 mètres de large et 10 mètres de haut.
Poids : 5600 tonnes.
Configuration : spectromètre à petits angles avec détecteurs planaires.
1.1.4 Système LHCb Online
Le système LHCb Online se charge des aspects informatiques, de contrôle et de
synchronisation de l’expérience. Il fournit également l’infrastructure nécessaire au traitement
des données reçues du détecteur. Ainsi, Le réseau LHCb se devise en deux réseaux de
fonctionnement différent. Le premier est appelé Le réseau de donnée (DAQ) qui a pour but
de transporter les données acquises par les détecteurs au disque de stockage. Le second est
un système de contrôle qui a pour rôle le contrôle de tous les équipements dans le réseau
(Figure 5).
L’expérience LHCb est actuellement équipée de plus d’une centaine d’équipements réseau
(Figure 5) répartis dans les différents secteurs, que ce soit aussi bien dans la partie SX (au-

7
dessus du sol) qu’UX (en dessous du sol). Ces équipements produisent un travail constant
tous les jours et leur fonctionnement en continue est primordial.
Figure 5: Représentation de la structure du réseau LHCb Online
Le système d’acquisition (DAQ)
Le système DAQ (Data AcQuisition) s’étend de l’électronique qui interface les sous-
détecteurs de l’expérience LHCb jusqu’au système de stockage des données potentiellement
intéressantes [LHCb Collaboration 2001]. Tout au long de ce système, les données sont
sélectionnées par différents mécanismes pour ne conserver que ce qui est potentiellement
pertinent et intéressant pour l’expérience. On différencie ainsi LHCb Online, qui regroupe
donc le traitement effectué au cours de l’acquisition, de LHCb Offline, qui regroupe donc le
traitement effectué sur les données stockées.
Le LHC produit des collisions, ou événements, à une fréquence de 40 Mhz. Seulement les
collisions intéressantes ne seront que de l’ordre de 10 MHz, mais seulement 1% de ces

8
collisions produiront des paires de quark et d’antiquark Beauty. Au final, la fréquence
intéressante sera de 15 Hz. Dans ce sens, le LHCb a mis au point conjointement au système
DAQ, un système de sélection des données, le Trigger System. Ce système de sélection est
aussi bien basé sur de l’électronique que sur du logiciel. Ses différents niveaux de sélection
permettent de déterminer quels sont les événements à conserver. La première sélection
s’effectue au niveau de L0 trigger. Après L0, les données sont envoyées vers les cartes
TELL1. [LHCb Collaboration 2001].
Ces cartes mettent les données en mémoire tampon, puis elles les transfèrent via un réseau IP
assez complexe vers les ordinateurs (nœuds) qui appliqueront ensuite des algorithmes de
sélections pour encore réduire la fréquence d’événements intéressants et donc réduire la taille
des données à mémoriser. Cette ferme de calcul correspond au HLT (High Level Trigger)
[LHCb Collaboration 2001]..
N.B : il existe 6 fermes de calcul chaque ferme contient un nombre précis de sous-
fermes, chaque sous-ferme comporte un nombre important de nœuds (ordinateurs sans
disque). Le nœud hlta0101 veut dire le nœud numéro 1 de la sous ferme a01 de la ferme
a de la grande ferme hlt.
Le système de contrôle: ECS (Experiment System Control)
Avec plus de 500 000 composants, le détecteur LHCb est un système d’une grande
complexité. La configuration de tous ses composants devient rapidement une opération
fastidieuse, d’autre part il n’est pas toujours possible de se déplacer sur le lieu où se trouve le
matériel, celui-ci pouvant de plus se trouver dans une zone soumise aux radiations.
L’objectif principal du système de contrôle est la configuration et la supervision de
l’infrastructure du détecteur. Ce système de contrôle est basé sur un système SCADA
(Supervisory Control and Data Acquisition) appelé WinCC Open Architecture. Ce logiciel
qui a été développé par la société allemande « Siemens » permet de récupérer des données à
partir du matériel afin de surveiller et contrôler son fonctionnement ainsi que de le configurer
à distance. Tous les modules contrôlables doivent donc être représentés dans WinCC
[LHCb Collaboration 2001].
Le système WinCC est dépendant de plusieurs autres systèmes tels que le storage, le réseau,
DNS (Domain Name Server), par conséquent, il est nécessaire de superviser l’infrastructure

9
réseau de l’expérience à bas niveau d’où l’intérêt de mettre en place un système de
supervision.
1.1.5 L’équipe LHCb Online
Mon stage se situait au sein de l’équipe LHCb Online, qui est l’une des composantes de
l’expérience LHCb. Composée d’ingénieurs, d’administrateurs systèmes et de physiciens, sa
mission principale est l’administration de l’infrastructure matérielle et logicielle du système
LHCb Online décrit dans la section 1.1.4.
Administrativement, cette équipe est rattachée au département PH: département de la
physique qui est l’un de nombreux départements du CERN (Voir Annexe A).
1.2 Analyse de l’existant
1.2.1 La supervision
La supervision est l’ensemble d’outils logiciels et/ou matériels permettant de mesurer à un
instant donné l’état d’un système (Figure 6). Ainsi, la supervision s’impose dans la plupart
des entreprises possédant un parc informatique conséquent.
La supervision est la surveillance du bon fonctionnement des éléments suivants :
Serveurs : CPU, mémoire, processus, fichiers de journalisation, place disque,
services.
Matériels : Disques, cartes Raid, cartes réseau, température, alimentation, onduleurs,
batteries.
Réseaux : Bande passante, protocoles, éléments actifs, commutateurs, routeurs, pare-
feux, accès externes, bornes wifi, etc.
Vue globale du système.
Détection des pannes.
Indicateurs sur la performance de l’architecture du système
Niveau de supervision (actif ou passif).
Remontées d’alertes (disponibilité des services).
Actions de correction.

10
Il existe deux grandes familles de solutions de supervision :
Les logiciels propriétaires : HP Open View, Tivoli d’IBM, Ciscoworks, etc.
Les logiciels libres : Nagios, Icinga, Zabbix, MRTG, Centreon, etc.
Figure 6: Principe de fonctionnement de la supervision
1.2.2 Etude du système de supervision actuel
Dans l’optique de superviser le grand réseau LHCb Online, une infrastructure distribuée
basée sur un outil appelé Icinga 1.x était mise en place [Haen, Bonaccorsi et Neufeld 2011].
Nagios, Icinga et autres outils de supervision permettent à la fois de superviser des « hosts »
(serveurs, switchs, etc) ainsi que des « services » (logiciels, ressources, etc) en utilisant des
petits programmes exécutables appelés « plugins ». Un plugin est chargé de réaliser les
vérifications et de fournir par la suite au moteur un code de retour par exemple :
0 = tout va bien (OK)
1 = avertissement (WARNING)

11
2 = alerte (CRITICAL)
3 = inconnu (UNKNOWN)
Il peut également retourner des courts messages descriptifs ainsi que des informations de
performances.
le nombre de vérifications pouvant éventuellement être exécuté est de l’ordre de dizaine de
milliers de vérifications dans un intervalle de temps de quelques minutes. Par conséquent, une
infrastructure très large telle que celle du LHCb ne peut pas être supervisée par une seule
instance du logiciel de supervision sans pour autant provoquer des délais de latence. La
latence désigne en fait la différence entre le temps d’exécution prévus et le temps d’exécution
réel de la vérification. Ainsi, l’exécution de telles vérifications nécessite sans nul doute d’être
distribuée ou encore parallélisée.
Dans ce sens, la solution appliquée pour la supervision du système LHCb consistait à la mise
en place d’une seule instance centrale Icinga 1.x qui délègue l’exécution des vérifications à
d’autres serveurs appelés « workers » [Haen, Bonaccorsi et Neufeld 2011]. En effet, un
module appelé « mod-german » intercepte les vérifications déclenchées par l’instance Icinga
et les place dans des files d’attente, permettant ainsi aux serveurs distants « workers » de les
exécuter et de retourner les résultats de ces vérifications (Figure 7).
La solution qui vient d’être décrite est adoptée depuis plus de deux ans dans l’environnement
LHCb Online. Cette architecture a donné des résultats généralement positifs plus
particulièrement en terme de performance. En effet, grâce au module « mod-gearman »
l’instance Icinga peut exécuter approximativement 40 000 vérifications dans un intervalle de
cinq minutes sans délais de latence [Haen, Bonaccorsi et Neufeld 2011]..

12
Figure 7: Infrastructure de supervision Icinga 1.x [Haen, Bonaccorsi et Neufeld 2011]
Par ailleurs, réécrire la même configuration Icinga pour les différentes machines (hosts) de
l’expérience serait sans nul doute couteux sur plusieurs plans (temps, performance…).
Afin d’éviter ce problème Icinga offre deux concepts :
Héritage : une machine (host) peut hériter la configuration d’une autre machines
exactement de la même façon que le principe de la programmation orientée objet.
L’héritage s’occupe seulement des paramètres de supervision et non pas par exemple
des services appliqués à la machine parent (parent host).
HostGroup : qui désigne un ensemble de machines (hosts). Une machine peut être
membre de plusieurs groupes et un groupe peut être membre d’un autre groupe.
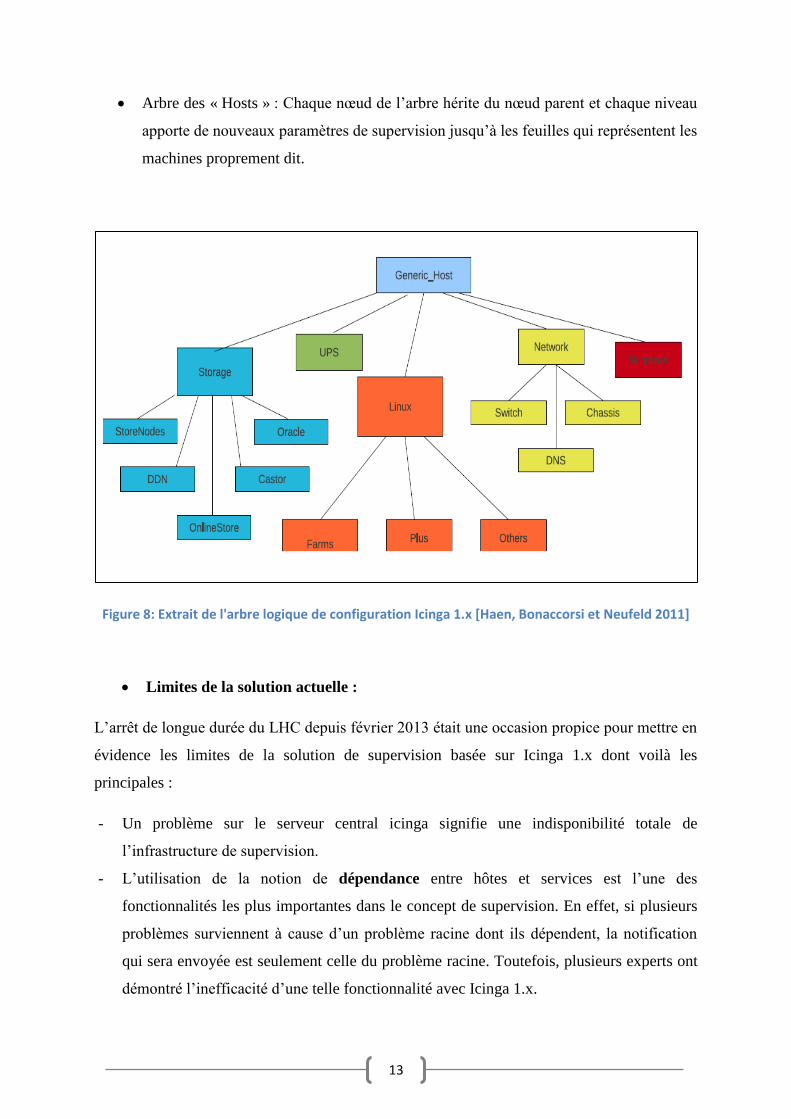
Ainsi, la définition exacte des rôles de chaque machine a permis l’élaboration d’un arbre
logique implémenté par la suite sous deux formes : (Figure 8)
Arbre des « HostGroups » : la vérification d’un service est toujours appliquée à un
« HostGroup » et jamais à un « host » unique.
13
Arbre des « Hosts » : Chaque nœud de l’arbre hérite du nœud parent et chaque niveau
apporte de nouveaux paramètres de supervision jusqu’à les feuilles qui représentent les
machines proprement dit.
Figure 8: Extrait de l'arbre logique de configuration Icinga 1.x [Haen, Bonaccorsi et Neufeld 2011]
Limites de la solution actuelle :
L’arrêt de longue durée du LHC depuis février 2013 était une occasion propice pour mettre en
évidence les limites de la solution de supervision basée sur Icinga 1.x dont voilà les
principales :
- Un problème sur le serveur central icinga signifie une indisponibilité totale de
l’infrastructure de supervision.
- L’utilisation de la notion de dépendance entre hôtes et services est l’une des
fonctionnalités les plus importantes dans le concept de supervision. En effet, si plusieurs
problèmes surviennent à cause d’un problème racine dont ils dépendent, la notification
qui sera envoyée est seulement celle du problème racine. Toutefois, plusieurs experts ont
démontré l’inefficacité d’une telle fonctionnalité avec Icinga 1.x.

14
- En cas de défaillance ou d’indisponibilité d’une grande portion de l’environnement,
Icinga 1.x nécessite une durée importante pour pouvoir détecter ce genre de pannes, par
conséquent les délais de latence sont énormes.
- Icinga 1.x offre une configuration très statique : une vérification configurée dans Icinga
1.x ne peut pas récupérer des valeurs en temps d’exécution (les derniers résultats ou
encore les sorties d’autres vérifications). De même, la configuration ne peut pas être
modifiée en temps d’exécution, ainsi un redémarrage de l’installation est nécessaire.
- Le redémarrage de l’installation entraîne une analyse complète de la configuration après
modification ce qui pourrait être très longue : 60 000 services sont analysés dans environ
25 secondes, tandis qu’environ 8 minutes est nécessaire pour analyser 200 000 services.
1.2.3 Solution proposée
Afin de remédier aux différents problèmes cités précédemment un benchmark très détaillé des
différentes alternatives a fait l’objet d’un article publié en 2013 par l’équipe LHCb Online à
l’occasion d’une conférence à San Francisco, USA :
[Haen, Bonaccorsi et Neufeld 2013].
L’article en question a mis en évidence la possibilité d’adopter deux solutions potentielles à
savoir : Icinga2 et Shinken.
Finalement, le choix était sur Icinga2 un outil récemment en version stable, simple à installer,
logique à configurer et surtout facile à étendre.
Icinga2 se distingue notamment par ses performances : une même instance a déjà réussi à
effectuer 1 million de vérifications actives par minutes afin de surveiller 60000 hôtes, indique
le site icinga.org [Icinga2 2014].
Signalons aussi la simplification de l’installation: les fonctionnalités habituellement
nécessaires sont fournies de base avec Icinga2, l’utilisateur n’ayant qu’à les activer grâce à
des commandes.

15
En outre, il est maintenant facile d’étendre la solution grâce à la présence de plusieurs back-
offices et à la prise en charge native des livestatus et de graphite pour la représentation
graphique des performances en temps réel.
Le sujet proposé dans ce stage, est donc, de concevoir et d’installer un système complet de
supervision basée sur Icinga2 et de l’intégrer autant que possible à Puppet l’outil utilisé pour
la configuration des serveurs du système LHCb Online.
Pour bien cerner l’ensemble du travail demandé, il convient de définir les besoins et les
contraintes dans un cahier des charges.
1.3 Cahier des charges
La mission du stage consiste à concevoir et installer un nouveau système de supervision de
l’infrastructure de l’expérience LHCb. Le travail final sera déployé sur l’un des serveurs du
réseau.
La solution recommandée est l’outil open-source Icinga2. Une documentation approfondie de
cette solution, ainsi qu’une série de tests, seront nécessaires avant le déploiement du travail.
Le travail réalisé doit à la fin assurer les fonctionnalités suivantes :
Superviser les différents équipements du réseau LHCb Online.
Superviser les différents services réseaux.
Superviser les ressources systèmes (CPU, charge mémoire)
Gérer d’une façon optimale les alertes et les notifications.
Automatiser l’installation de Icinga2 en utilisant Puppet.
Pouvoir installer plusieurs instances de l’interface graphique dans des serveurs
différents de celui qui comporte Icinga2 core.
Automatiser l’ajout des éléments du réseau au système de supervision en utilisant
Puppet (l’ajout de nouveaux nœuds, des fermes….).

16
1.4 Planification prévisionnelle
L’analyse du cahier des charges a aidé à prévoir le déroulement du projet dans le temps en
adoptant le planning cité dans la figure ci-dessous :
Figure 9: Planning prévisionnel du stage
Compréhension générale du sujet et planification : c’est la toute première étape. Elle
consiste à bien comprendre le travail demandé. Elle permet également de définir le bon
chemin à suivre pour réaliser les différentes tâches du projet.
Documentation et compréhension des outils : il s’agit de faire des recherches approfondies
sur le sujet. Une documentation initiale, pour découvrir et appréhender les différents points
clés du sujet, et une autre en parallèle, pour résoudre d’éventuels problèmes qui peuvent
survenir au cours de la réalisation.
Réalisation : cette partie se divisera en deux sous parties. La première concernera la mise en
place d’un atelier de tests basé sur la virtualisation, tandis qu’une deuxième présentera le
déploiement de la solution complète sur le système de production.
N.B : voir le planning réel en Annexes : Annexe B.

17
2. Etude et tests des outils choisis
Ce chapitre décrit la première partie de la réalisation du projet. Il s’agit d’une
réalisation à base de la virtualisation et d’un atelier personnalisé pour les tests. Ainsi, ce
chapitre présente l’installation et la configuration de l’outil de supervision Icinga 2, la
mise en place de l’atelier proprement dit, ainsi que la mise en œuvre de Puppet dans un
exemple d’utilisation.
2.1 Icinga 2: solution de supervision des réseaux
2.1.1 Icinga2: définition
Icinga 2 est un logiciel de supervision libre et sous license GPL (General Public License
Version 2). Destiné à informer les informaticiens des problèmes éventuels du réseau, générer
des indicateurs de la performance ainsi que superviser des environnements larges et
complexes.
Cette version de la solution de surveillance des réseaux développée en parallèle de la branche
1.x d’Icinga, a pour objectif de combiner ce qui a fait le succès de la branche 1.x tout en
corrigeant les défauts issus de Nagios, dont Icinga est un fork [Icinga2_doc 2014].
Figure 10: Logo Icinga 2

18
2.1.2 Icinga 2: spécificités techniques [Icinga2 2014].
Cette nouvelle mouture actuellement en version stable a les caractéristiques suivantes :
Construit à partir de zero, Icinga 2 est basé sur le langage C++ et utilise des
bibliothèques Boost.
Multi-plate-forme, Icinga 2 fonctionne sous les plates-formes *NIX (les systèmes
d’exploitation implémentant le standard POSIX), actuelles et anciennes, ainsi que
Windows.
Contrairement à ses prédécesseurs Icinga 2 a une architecture modulaire et flexible
(Figure 11). En effet, Icinga 2 est livré avec toutes les fonctionnalités modernes de
supervision (IDO, Livestatus, data writers,…), il suffit d’exécuter la commande
« icinga-enable-feature » ou « icinga-disable-feature » afin d’activer les
fonctionnalités voulues. Par exemple, une fois le module Perfdata est activé, Icinga 2
simplifie davantage l’intégration de l’outil PNP4NAGIOS permettant d’extraire les
données de performance remontées.
Icinga 2 est compatible avec Icinga 1.x et avec Nagios à travers une couche de
compatibilité. Cette nouvelle version intègre en effet des couches de compatibilité
permettant d’utiliser la solution tant avec des interfaces utilisateurs classiques qu’avec
des interfaces web (Figure 11).

19
Figure 11: Architecture de Icinga 2
.
Afin de gérer la répartition de charge des tâches de supervision telles que les
vérifications, notifications, ainsi que les mises à jour de la base de données, Icinga 2
utilise la fonctionnalité « cluster » permettant d’une part une supervision distribuée et
d’autre part une meilleure disponibilité. En effet, les instances du cluster désignent un
« maître » chargé d’écrire dans la base de données DB IDO (Database Icinga Data
Output) et de gérer la supervision de tous les nœuds. Si le master tombe en panne, une
autre instance est automatiquement élue pour ce rôle. De plus, chaque instance a un
identifiant unique permettant d’éviter les éventuels conflits afférents à la base de
données (Figure 12). Par ailleurs, en cas de basculement automatique « failover » les
instances du cluster sont conçues de façon à reproduire en temps réel la configuration
ainsi que les états des programmes assurant ainsi une intégrité complète des données.
En outre, toutes les communications réseau entres ces instances sont assurées par des
certificats SSL x509 (Figure 12).

20
Figure 12: La supervision distribuée basée sur la fonctionnalité cluster
Icinga 2 est conçu pour être rapide. Grace à sa conception multithread, il peut
exécuter des milliers de vérifications en une seconde sans aucun problème au niveau
du processeur. Contrairement à Icinga 1.x, le processus responsable de recharger une
nouvelle configuration tourne d’une façon asynchrone. Dans ce sens, si le processus
fils est entrain de valider la configuration le processus parent continue les vérifications
et les autres tâches de supervision, deux cas de figures se présentent :
Si la configuration est valide : le processus fils envoie le signal « STOP »
au processus parent, ce dernier avant d’être terminé enregistre son état
courant dans un fichier appelé icinga 2.state. Ensuite, le processus fils lit le
fichier de l’état et synchronise tout l’historique des données avant de
devenir le nouveau leader de la session.
Si la configuration n’est pas valide : le processus fils se termine, le
processus parent continue avec l’ancien état de configuration (ce qui est
essentiel pour assurer la synchronisation en cas du mode cluster).

21
La configuration de Icinga est simplifiée dans cette version 2 grâce à l’utilisation d’un
nouveau format basé objet et fondé sur les templates (plus de détails sur la
configuration et les notions de dépendance, notifications seront vus ultérieurement).
2.2 Les étapes d’installation de Icinga 2 et ses interfaces web
2.2.1 Installation de Icinga 2
La première étape du processus est celle de l’installation d’Icinga 2 proprement dit. La
meilleure façon de faire ceci consiste à utiliser un dépôt officiel (RPM ou Debian) selon le
type du système d’exploitation (distribution) utilisé. Dans notre cas, le système utilisé est
SLC 6 (Scientific Linux CERN 6) qui n’est d’autre qu’une distribution Linux Open Source,
codéveloppée par Fermi National Accelerator Laboratory et par le CERN et basée sur Red
Hat Entreprise Linux (RHEL). La majorité des fonctionnalités de Icinga 2 sont disponibles
dans les paquets du dépôt : [Icinga2_epel 2014].
L’installation par défaut permet d’activer trois fonctionnalités nécessaires pour une
installation de base de Icinga 2 :
La fonctionnalité « checker » : pour exécuter les vérifications.
La fonctionnalité « notification » : pour l’envoi des notifications.
La fonctionnalité « mainlog » : pour écrire dans le fichier icinga2.log.
2.2.2 Installation du module DB IDO (Database Icinga Data Output)
Le module DB IDO de Icinga 2 a pour rôle d’exporter la configuration à la base de données.
La base de données IDO est utilisé par plusieurs projets tels que Icinga Web 1.x et Icinga
Web 2.
Dans notre cas la base de données utilisée est de type MySQL, une installation du paquet
icinga2-ido-mysql est donc nécessaire avant de créer la base de données proprement dit.
Après la création de la base de données vient l’étape d’activation du module IDO Mysql en
utilisant : icinga-enable-feature ido-mysql.

22
2.2.3 Installation des interfaces graphiques
Icinga 2 est compatible avec les interfaces graphiques d’Icinga 1.x en utilisant quelques
fonctionnalités supplémentaires. Ces interfaces sont Icinga Classic UI et Icinga Web. En
outre, une interface graphique propre à la version 2 de Icinga est en cours de développement.
Pour faire les tests le choix était sur l’interface graphique Icinga Web, son installation passe
par les étapes suivantes :
L’installation du paquet icinga-web ou icinga-web-mysql
La création d’une base de données icinga-web.
L’activation du module ido-mysql.
L’édition du fichier databases.xml pour déclarer la base de données icinga-web.
L’édition du fichier access.xml afin de permettre à Icinga Web d’envoyer des
commandes.
Vérification de l’interface web en utilisant l’URL suivant : [Icinga-web-URL 2014].
2.2.4 Les fichiers de configuration de base
Une fois l’installation est effectuée, plusieurs fichiers de configuration sont créés :
icinga2.conf :
Il s’agit du fichier principal de configuration d’Icinga 2. Il contient notamment la liste
des autres fichiers de configuration utilisés, ainsi que l’ensemble des directives
globales de fonctionnement de Icinga 2, comme la directive « include » ou encore
« include_recursive » permettant d’inclure les fichiers de configuration.
(ex : include_recursive "conf.d").
constants.conf :
Il s’agit d’un fichier de déclaration utilisé par les autres fichiers de configuration de
Icinga 2. Il permet de définir des constantes globales pour une utilisation simplifiée
dans les autres fichiers de configuration.
(ex : const PluginDir = " /usr/lib/nagios/plugins ").
zones.conf :
Ce fichier est utilisé pour configurer les objets « Endpoint » et « Zone » nécessaires
dans le cas de l’utilisation de plusieurs instances Icinga 2.

23
conf.d :
Même si en théorie, il est possible de définir tous les objets de configuration dans le
fichier principale icinga2.conf, il est vivement recommandé de créer des répertoires et
fichiers séparés dans le dossier conf.d. Tous ces fichiers doivent obligatoirement avoir
l’extension « .conf ».
2.3 Atelier de tests
2.3.1 Schéma réseau de l’atelier
Pour tester les différentes fonctionnalités qu’offre Icinga 2 en terme de supervision, j’ai pensé
à mettre en place un petit atelier qui regroupe presque les différents équipements réseau du
système LHCb Online (Figure 13). En effet, le système LHCb Online est composé de
plusieurs fermes de calculs ainsi qu’un ensemble de composants réseau permettant de relier
ces fermes. Dans ce sens, le schéma réseau de l’atelier présente les éléments suivants :
Un système de données physiques : à travers lequel transitent les données de
collisions, il est composé d’un ensemble d’équipements (nœuds de calcul, Switch,
Stores…).
Un système de contrôle : à travers lequel transitent les données autres que les
données de collisions notamment :
Les données des systèmes d’exploitation qui proviennent des serveurs
« NFS ».
Les données des utilisateurs (fichiers, homedir, groupdir…) qui proviennent du
« storage ».
Les données de contrôle proprement dit qui proviennent des contrôleurs.
Les données provenant de l’instance Icinga 2.
Une ferme de calcul X composé de :
Nœuds X : sont des serveurs de calcul permettant de trier les événements qui
proviennent du détecteur.
Switch-dt-X : il s’agit d’un switch permettant de faire acheminer les données
de collisions.
Switch-ctrl-X : il s’agit d’un switch permettant de faire acheminer les données
de contrôle.

24
NFS-X : est un serveur NFS (Network File System) permettant aux nœuds de
calcul d’accéder à des données du système d’exploitation.
Contrôleur X : est un serveur hébergé soit sur une machine virtuelle fournit par
l’hyperviseur soit sur une machine réelle. Ce serveur a pour rôle de données
des directives et des ordres de configuration aux nœuds.
Storage : est un grand serveur NFS permettant à tous les composants du réseau
d’accéder aux fichiers des utilisateurs, il se compose de deux parties :
Une petite partie pour stocker les fichiers des utilisateurs.
Une grande partie pour stocker temporairement les données physiques de
l’expérience avant de les envoyées au système LHCb Offline.
Store XYZ : est un serveur permettant également de stocker des données physiques de
l’expérience.
Switch-UX : est un grand commutateur permettant de relier les différents équipements
réseau du système.
Hyperviseur : est un logiciel installé directement sur la couche matérielle du serveur,
permettant la gestion des systèmes d’exploitation invités.
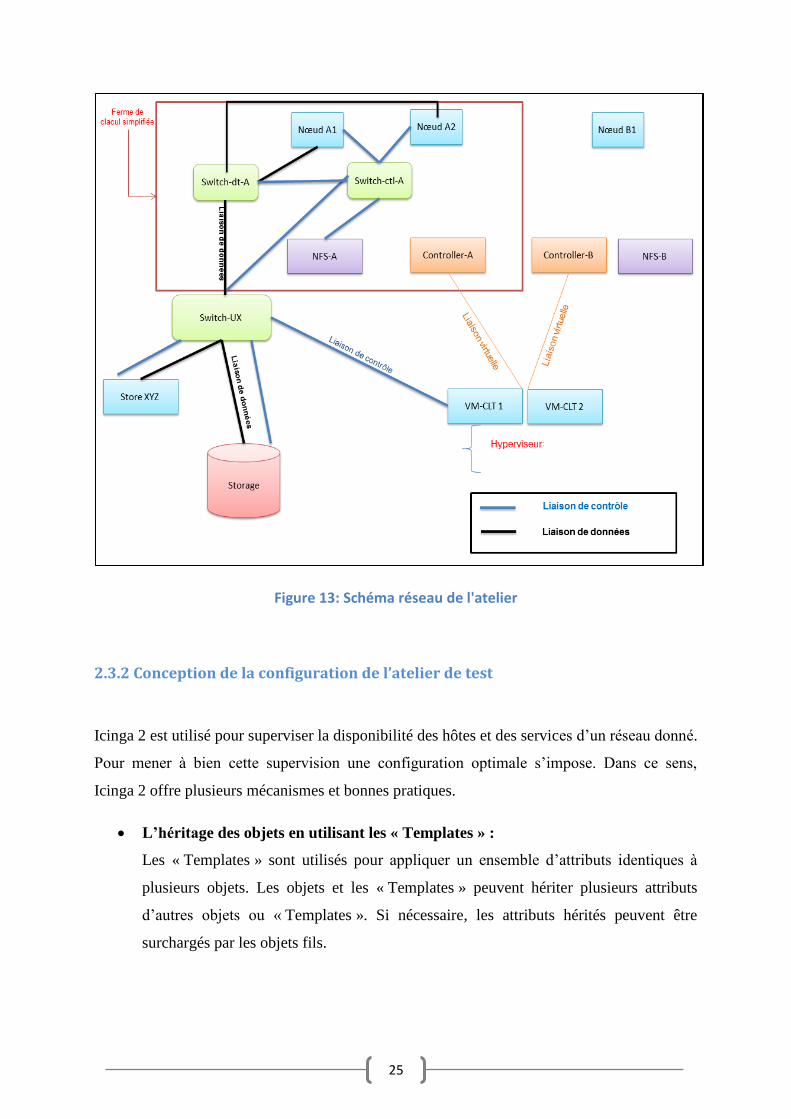
25
Figure 13: Schéma réseau de l'atelier
2.3.2 Conception de la configuration de l’atelier de test
Icinga 2 est utilisé pour superviser la disponibilité des hôtes et des services d’un réseau donné.
Pour mener à bien cette supervision une configuration optimale s’impose. Dans ce sens,
Icinga 2 offre plusieurs mécanismes et bonnes pratiques.
L’héritage des objets en utilisant les « Templates » :
Les « Templates » sont utilisés pour appliquer un ensemble d’attributs identiques à
plusieurs objets. Les objets et les « Templates » peuvent hériter plusieurs attributs
d’autres objets ou « Templates ». Si nécessaire, les attributs hérités peuvent être
surchargés par les objets fils.
26
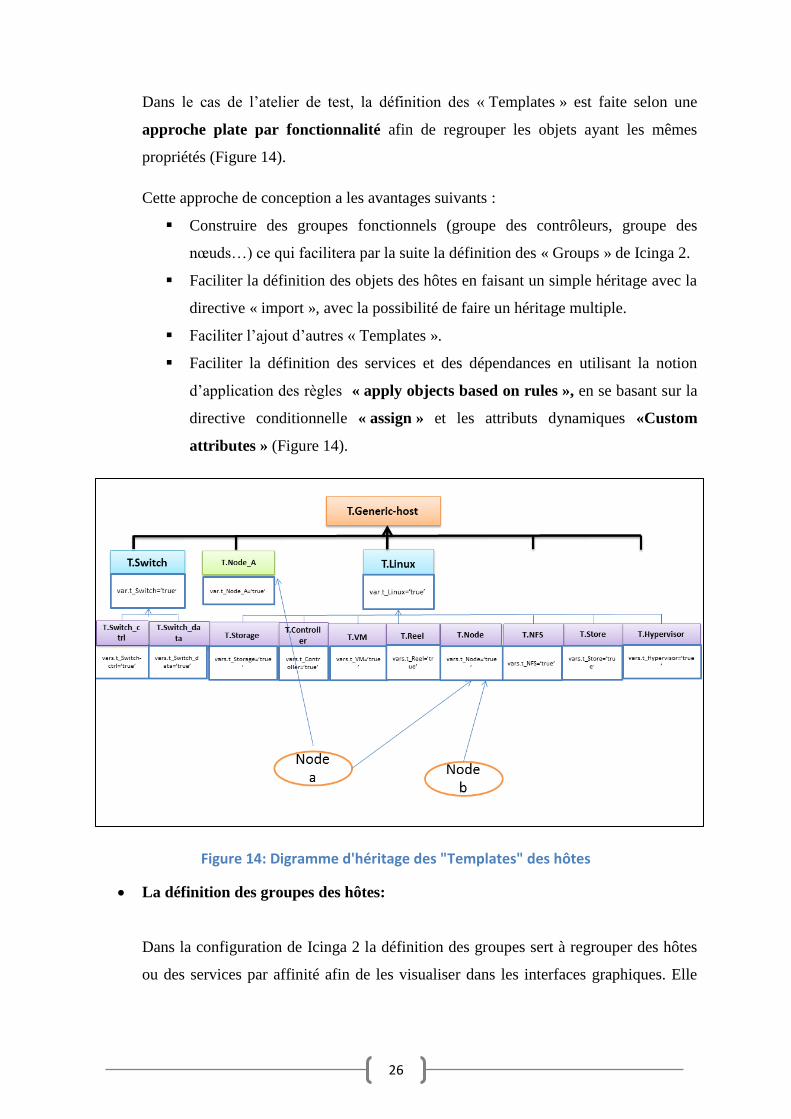
Dans le cas de l’atelier de test, la définition des « Templates » est faite selon une
approche plate par fonctionnalité afin de regrouper les objets ayant les mêmes
propriétés (Figure 14).
Cette approche de conception a les avantages suivants :
Construire des groupes fonctionnels (groupe des contrôleurs, groupe des
nœuds…) ce qui facilitera par la suite la définition des « Groups » de Icinga 2.
Faciliter la définition des objets des hôtes en faisant un simple héritage avec la
directive « import », avec la possibilité de faire un héritage multiple.
Faciliter l’ajout d’autres « Templates ».
Faciliter la définition des services et des dépendances en utilisant la notion
d’application des règles « apply objects based on rules », en se basant sur la
directive conditionnelle « assign » et les attributs dynamiques «Custom
attributes » (Figure 14).
Figure 14: Digramme d'héritage des "Templates" des hôtes
La définition des groupes des hôtes:
Dans la configuration de Icinga 2 la définition des groupes sert à regrouper des hôtes
ou des services par affinité afin de les visualiser dans les interfaces graphiques. Elle

27
sert également à permettre de déployer massivement des services prédéfinis ou encore
des règles de dépendances en fonction du type, rôle de l’hôte.
Dans le cas de l’atelier du test, deux types de groupes ont été créés :
Les groupes fonctionnels : il s’agit d’un ensemble de hôtes qui ont le même
rôle au sein du réseau (groupe des contrôleurs, groupe des switches...), ce qui
permettra de visualiser les états des hôtes par groupe fonctionnel (Figure 15).
La définition de ces groupes est faite en utilisant la notion d’application des
règles « Group assign rules » avec des conditions sur les attributs « custom
attributes » déjà crées dans les « Templates » exemple :
Object HostGroup "Nodes" {
Display_name = " HG.Nodes"
Assign where host.vars.t_Node
}
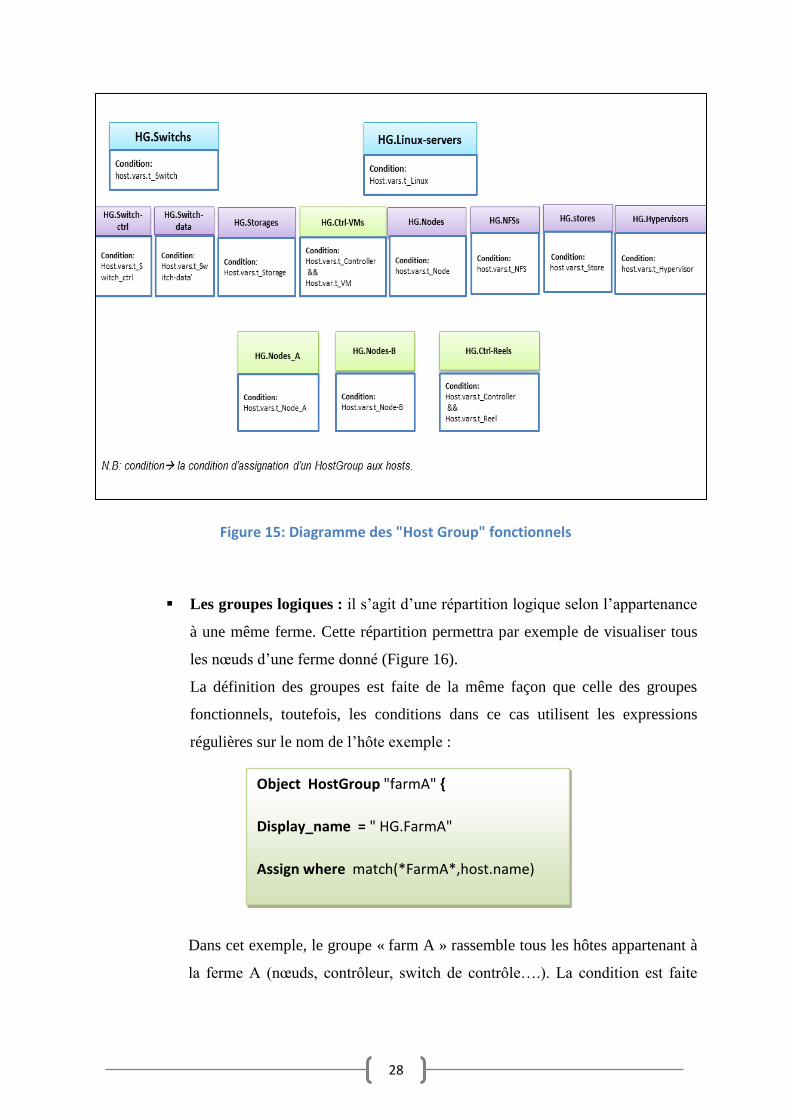
28
Figure 15: Diagramme des "Host Group" fonctionnels
Les groupes logiques : il s’agit d’une répartition logique selon l’appartenance
à une même ferme. Cette répartition permettra par exemple de visualiser tous
les nœuds d’une ferme donné (Figure 16).
La définition des groupes est faite de la même façon que celle des groupes
fonctionnels, toutefois, les conditions dans ce cas utilisent les expressions
régulières sur le nom de l’hôte exemple :
Dans cet exemple, le groupe « farm A » rassemble tous les hôtes appartenant à
la ferme A (nœuds, contrôleur, switch de contrôle….). La condition est faite
Object HostGroup "farmA" {
Display_name = " HG.FarmA"
Assign where match(*FarmA*,host.name)
}

29
sur le nom du hôte du faite que tous les hôtes d’une ferme donnée X
contiennent l’expression « ferme X ».
Figure 16: Digramme des "Host Group" logique
La définition des services :
La définition d’un service identifie une ressource sur un hôte. Le terme « service » est
très générique. Il peut s’appliquer à un processus (SSH, HTTP, SMTP…) ou bien tout
autre type de mesures associé à l’hôte (temps de réponse à un ping, nombre
d’utilisateurs connectés, usage de CPU).
Dans notre cas, la définition des services est faite selon la notion « Apply services to
hosts » qui consiste à appliquer un service à un ensemble de hôtes en utilisant une
seule règle de définition. La condition d’application du service porte encore une fois
sur les attributs « custom attributes » déjà créés dans les « Templates » (Figure 17).

30
Figure 17: Digramme des services
Exemple d’utilisation :
L’exemple ci-dessous illustre la définition et l’application d’un service « NFS-sce » sur tous
les hôtes de type NFS. La directive « check_command » est utilisée pour spécifier le nom de
la commande que Icinga 2 exécutera pour déterminer l’état du service.
La définition des dépendances d’hôtes et de services :
Les dépendances d’hôtes et de services sont une fonctionnalité avancée qui permet de
contrôler le comportement des hôtes et des services selon l’état d’un ou plusieurs
autres hôtes ou services.
Icinga 2 offre la possibilité de définir trois types de dépendances :
Host-to-Host : entre deux hôtes.
apply Service "NFS-sce" {
import “generic-service”
check_command = " check_NFS"
Assign where host.vars.t_NFS

31
Service-to-Service : entre deux services.
Service-to-Host ou Host-to-Service : entre un service et un hôte.
Les dépendances permettent de limiter d’une part les vérifications d’hôtes ou de
services et d’autre part l’envoi des notifications en cas de l’échec de la dépendance.
Une dépendance est considérée avoir échoué si l’état courant d’un hôte ou d’un service
(parent) correspond à une des options d’échec (CRITICAL, DOWN…).
Avant qu’Icinga 2 n’exécute un contrôle ou n’envoie des notifications concernant un
service ou un hôte, il vérifiera si le service ou l’hôte comporte des dépendances. Si ce
n’est le cas, le contrôle est exécuté ou la notification est envoyée comme en temps
normal, si le service ou l’hôte a bien une ou plusieurs dépendances, Icinga 2 vérifiera
chacune de la manière suivante :
1. Icinga 2 récupère l’état courant du service ou de l’hôte dont il dépend.
2. Icinga 2 compare l’état courant du service ou de l’hôte dont il dépend aux
options d’échec.
3. Si l’état courant correspond à une des options d’échec, Icinga 2 sortira de la
boucle de vérification des dépendances.
4. Si non, Icinga 2 continuera avec la prochaine dépendance.
Ce cycle continue jusqu’à ce que toutes les dépendances du service aient été vérifiées,
ou jusqu’à ce qu’une dépendance échoue.
Compte tenu des spécificités du réseau de l’atelier de test, plusieurs dépendances ont
été identifiées (Figure 18).
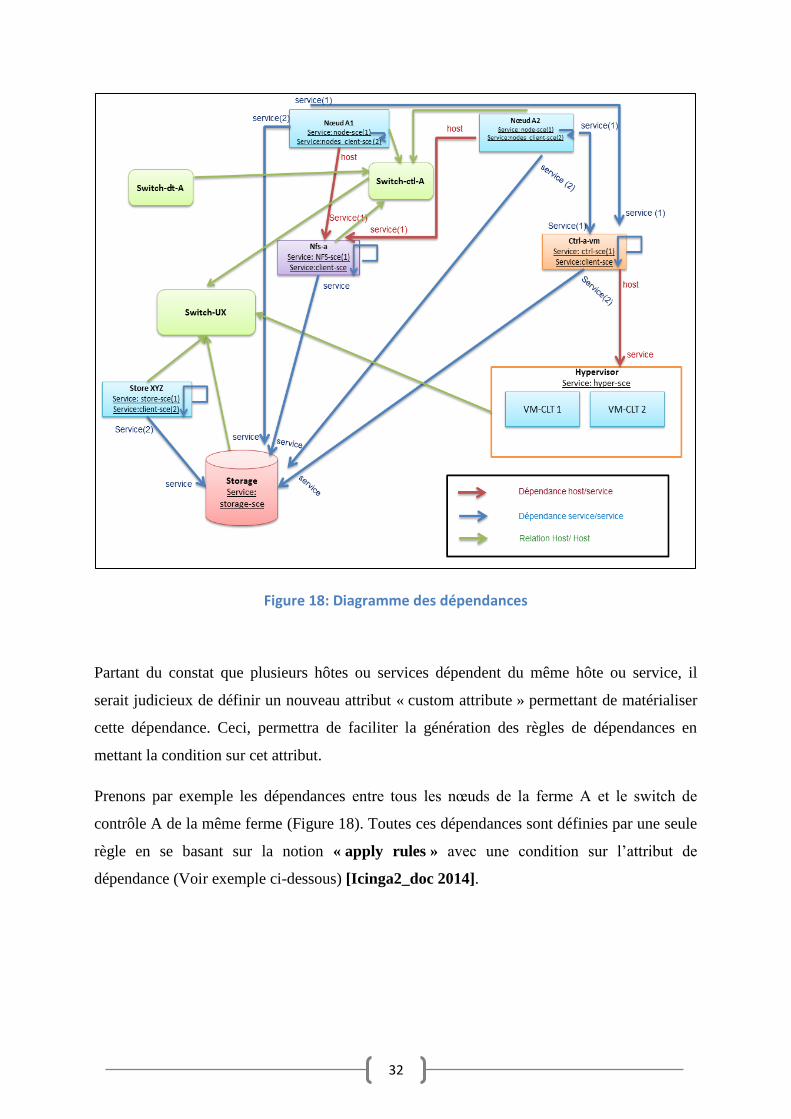
32
Figure 18: Diagramme des dépendances
Partant du constat que plusieurs hôtes ou services dépendent du même hôte ou service, il
serait judicieux de définir un nouveau attribut « custom attribute » permettant de matérialiser
cette dépendance. Ceci, permettra de faciliter la génération des règles de dépendances en
mettant la condition sur cet attribut.
Prenons par exemple les dépendances entre tous les nœuds de la ferme A et le switch de
contrôle A de la même ferme (Figure 18). Toutes ces dépendances sont définies par une seule
règle en se basant sur la notion « apply rules » avec une condition sur l’attribut de
dépendance (Voir exemple ci-dessous) [Icinga2_doc 2014].

33
2.3.3 Implémentation de la configuration et résultats des tests
A la différence de beaucoup d’autres outils de supervision, Icinga 2 ne dispose pas de
mécanisme interne pour vérifier l’état d’un service, d’un hôte, etc. A la place, il utilise des
programmes externes appelés plugins. Icinga 2 exécutera un plugin dès qu’il a besoin de tester
un service ou un hôte qui est supervisé. Les plugins font ce qu’il faut pour exécuter le contrôle
et ensuite envoient simplement le résultat à Icinga 2. Icinga 2 analysera le résultat reçu pour
déterminer le statut des hôtes ou services sur le réseau. Les plugins sont des programmes bien
séparés d’Icinga 2, ils peuvent contrôler une ressource ou un service local ou distant selon
l’architecture de la Figure 19.
Figure 19: Mécanisme d'exécution des plugins
apply Dependancy "nodes-switch-ctrl" to Host {
parent_host_name = "switch-ctrl-a"
disable_checks = true
disable_notifications = true
Assign where host.vars.Dep_network = = "switch-ctrl-a"
}
34
Afin d’implémenter la configuration de l’atelier de tests, un seul script Shell est utilisé pour
simuler l’exécution des différents plugins. Ce script consiste à chercher dans un fichier le nom
d’un service ou d’un hôte du réseau, s’il trouve le nom il retourne l’état « CRITICAL » ou
« DOWN » selon qu’il s’agit d’un service ou d’un hôte, le cas échéant, il retourne l’état
« OK » ou « UP ».
Ainsi, ayant fait toute la configuration nécessaire au bon fonctionnement de Icinga 2, le
système de supervision commence à récupérer des informations, signaler des problèmes et
envoyer des informations. Les figures suivantes donnent une idée sur les résultats des tests
visualisés sur l’interface Icinga-web.
Au démarrage de l’interface web, une page d’authentification apparaît permettant de faire
entrer le login et le mot de passe (Figure 20).
Figure 20: Page d'authentification Icinga-web
Une fois que l’authentification est faite avec succès, l’écran principal apparaît contenant les
différents menus proposés. En appuyant sur l’onglet « HostSatus », les différents états des
hôtes sont visualisés avec les éléments de description associés (Last check, Duration,
35
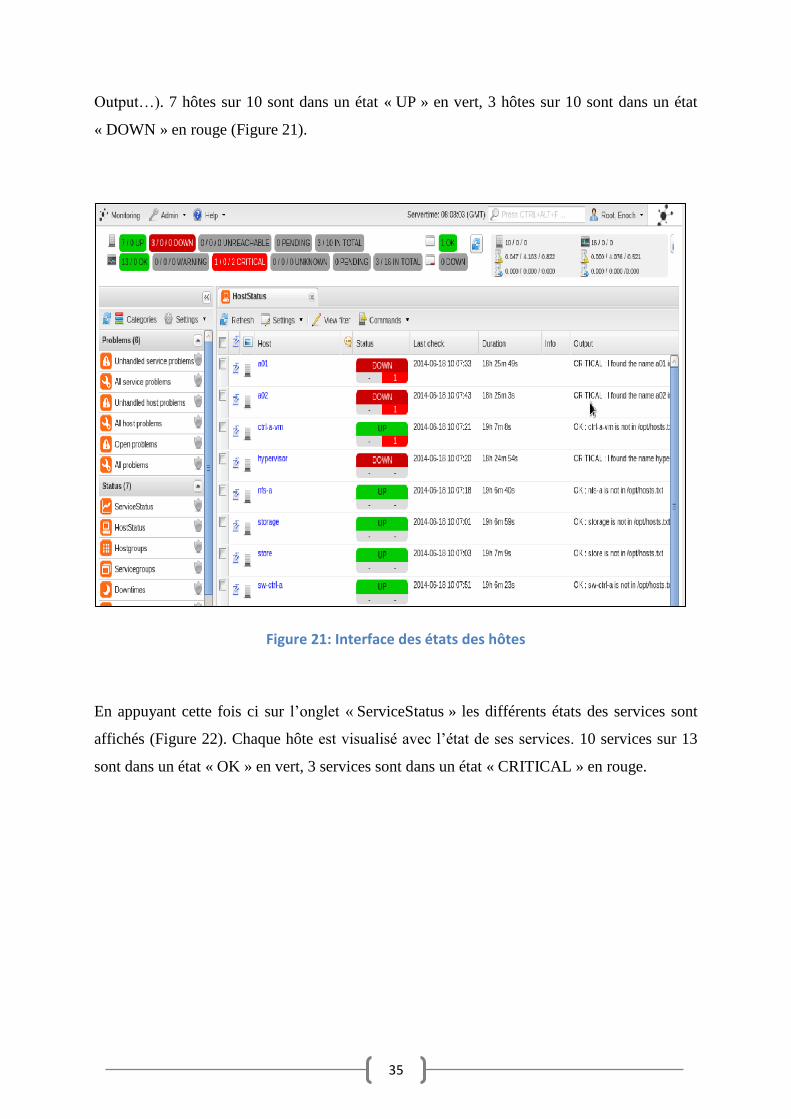
Output…). 7 hôtes sur 10 sont dans un état « UP » en vert, 3 hôtes sur 10 sont dans un état
« DOWN » en rouge (Figure 21).
Figure 21: Interface des états des hôtes
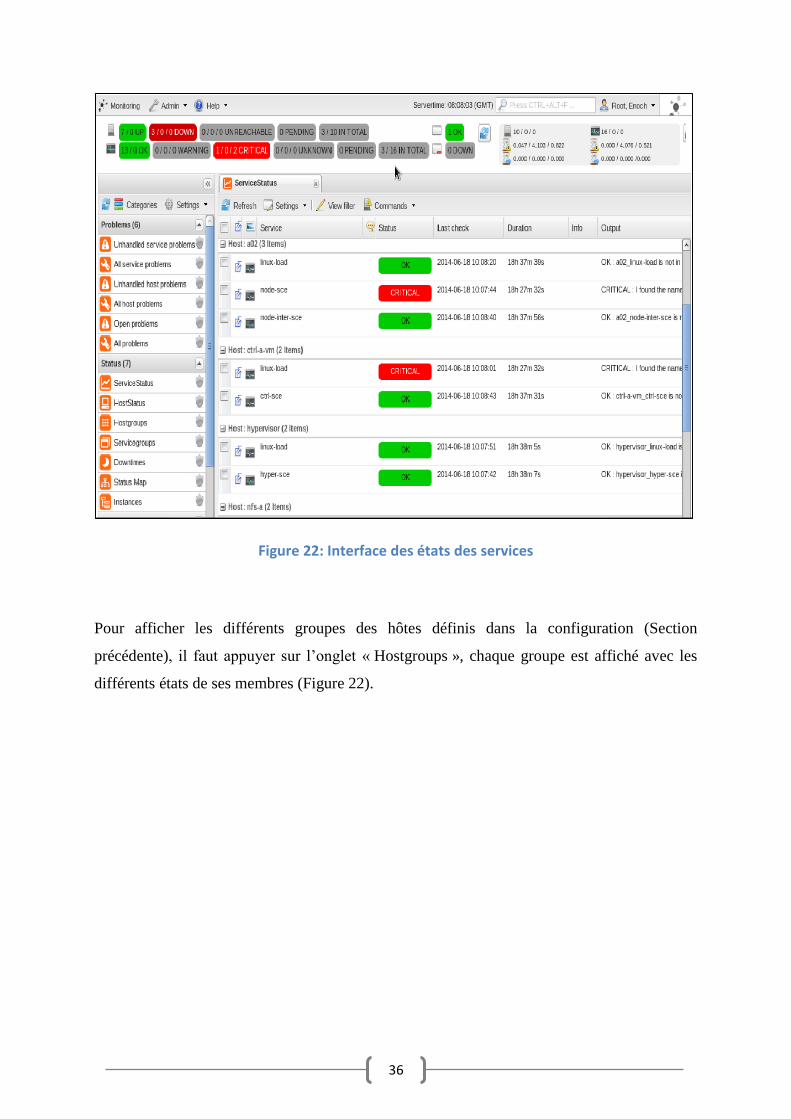
En appuyant cette fois ci sur l’onglet « ServiceStatus » les différents états des services sont
affichés (Figure 22). Chaque hôte est visualisé avec l’état de ses services. 10 services sur 13
sont dans un état « OK » en vert, 3 services sont dans un état « CRITICAL » en rouge.
36
Figure 22: Interface des états des services
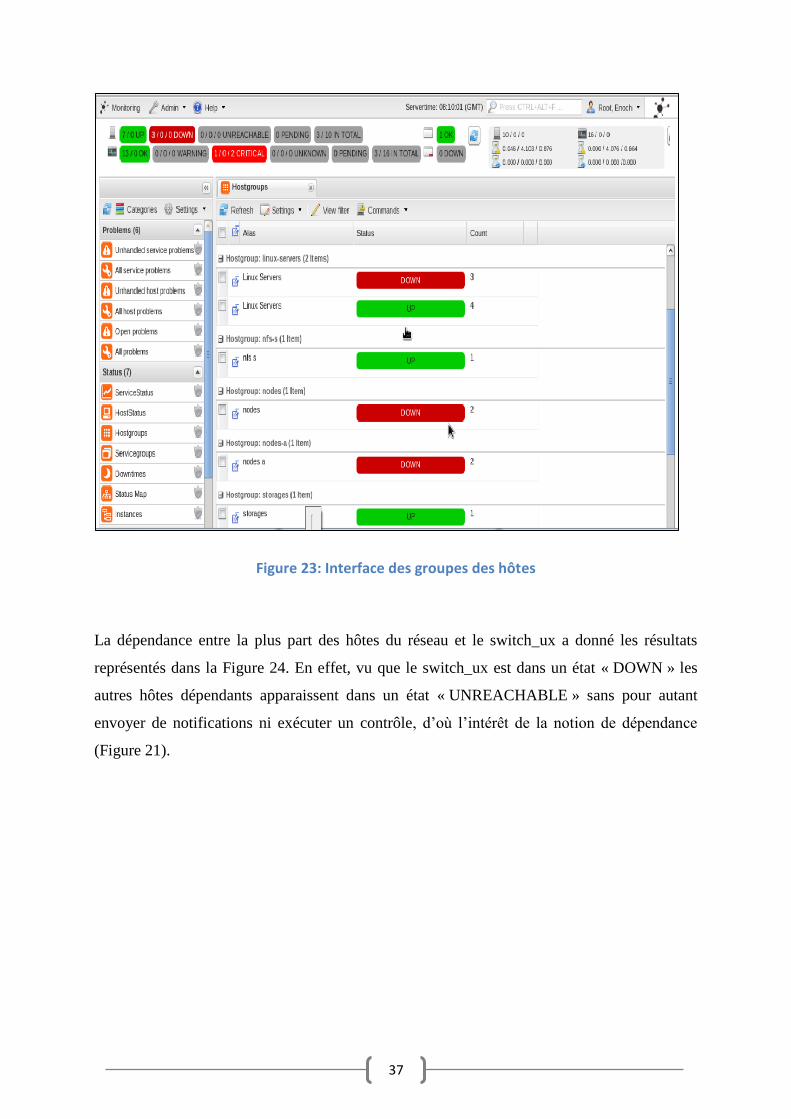
Pour afficher les différents groupes des hôtes définis dans la configuration (Section
précédente), il faut appuyer sur l’onglet « Hostgroups », chaque groupe est affiché avec les
différents états de ses membres (Figure 22).
37
Figure 23: Interface des groupes des hôtes
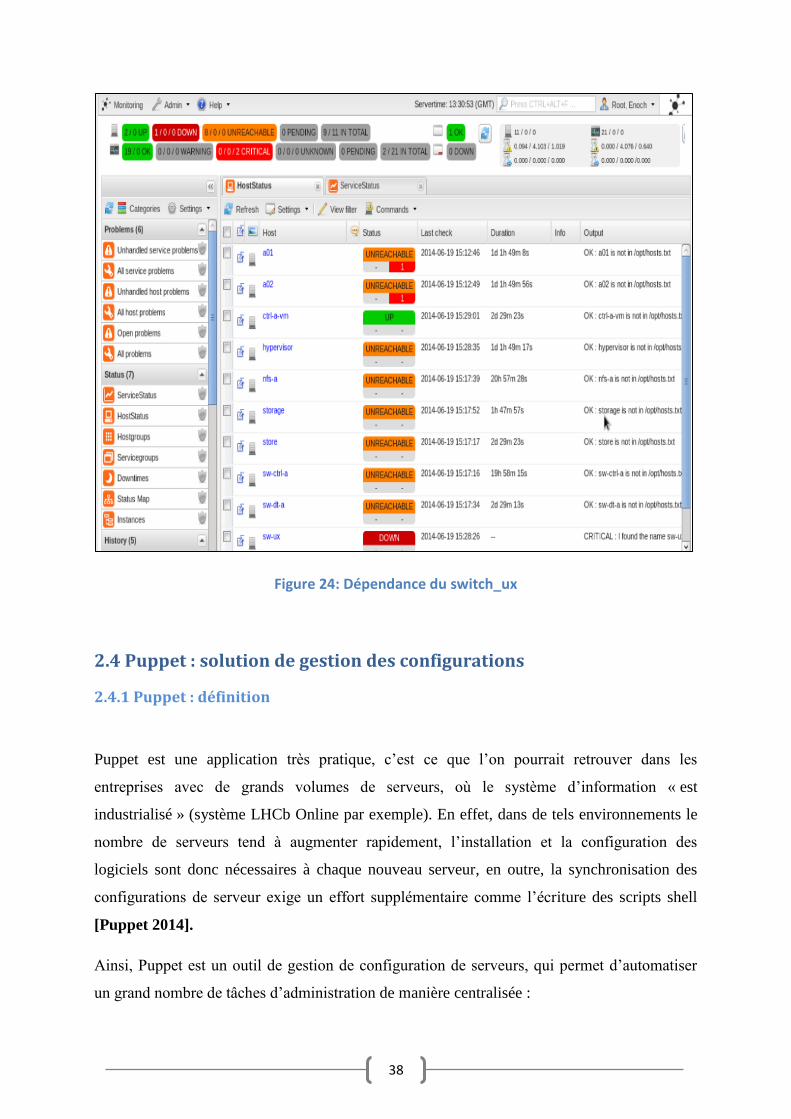
La dépendance entre la plus part des hôtes du réseau et le switch_ux a donné les résultats
représentés dans la Figure 24. En effet, vu que le switch_ux est dans un état « DOWN » les
autres hôtes dépendants apparaissent dans un état « UNREACHABLE » sans pour autant
envoyer de notifications ni exécuter un contrôle, d’où l’intérêt de la notion de dépendance
(Figure 21).
38
Figure 24: Dépendance du switch_ux
2.4 Puppet : solution de gestion des configurations
2.4.1 Puppet : définition
Puppet est une application très pratique, c’est ce que l’on pourrait retrouver dans les
entreprises avec de grands volumes de serveurs, où le système d’information « est
industrialisé » (système LHCb Online par exemple). En effet, dans de tels environnements le
nombre de serveurs tend à augmenter rapidement, l’installation et la configuration des
logiciels sont donc nécessaires à chaque nouveau serveur, en outre, la synchronisation des
configurations de serveur exige un effort supplémentaire comme l’écriture des scripts shell
[Puppet 2014].
Ainsi, Puppet est un outil de gestion de configuration de serveurs, qui permet d’automatiser
un grand nombre de tâches d’administration de manière centralisée :

39
Configurer de façon homogène un ensemble se serveurs,
Contrôler et corriger tout écart de configuration,
Faire du déploiement rapide de serveurs,
Augmenter le niveau de sécurité : déploiement rapide de patchs, mise à jour de
paquets, alerte si une configuration est modifiée…
Figure 25: Logo Puppet
2.4.2 Fonctionnement et caractéristiques de Puppet
Puppet est un outil qui permet de mettre à jour de façon automatisée et selon un scénario
prédéfini un ensemble de serveurs clients selon une architecture client /serveur. Sur chaque
machine un client va être installé et c’est lui qui va contacter le PuppetMaster par le biais de
communication HTTPS (Figure 26).

40
Figure 26: Architecture client/serveur de Puppet
Pour assurer son bon fonctionnement, Puppet dispose des éléments suivants [Puppet_doc
2014] :
Langage déclaratif :
L’idée est de définir un certain nombre de ressources et leurs relations afin d’amener
le serveur client dans l’état désiré. Si l’état du serveur diffère de l’état désiré, Puppet
réalisera les actions nécessaires pour y remédier. Pour cela, Puppet dispose d’un
langage déclaratif dont le modèle est implémenté comme un graphe orienté acyclique :
il faut définir les relations et les dépendances entre les ressources pour obtenir l’ordre
d’exécution recherché (contrairement à un langage procédural ou l’ordre d’exécution
serait implicite).
Exemple : si mon logiciel à installer dans le serveur client a besoin d’un fichier de
configuration « File » dans le répertoire « Directory », je vais devoir clairement
écrire :
Mon programme a besoin d’un fichier de configuration nommé « File ».
Mon fichier de configuration « File » doit être stocké dans le répertoire
« Directory » qui doit donc être présent.
Couche d’abstraction des ressources :
Puppet utilise une couche d’abstraction des ressources (RAL) : le client Puppet saura
automatiquement faire une installation d’un paquet indépendamment du système
d’exploitation.
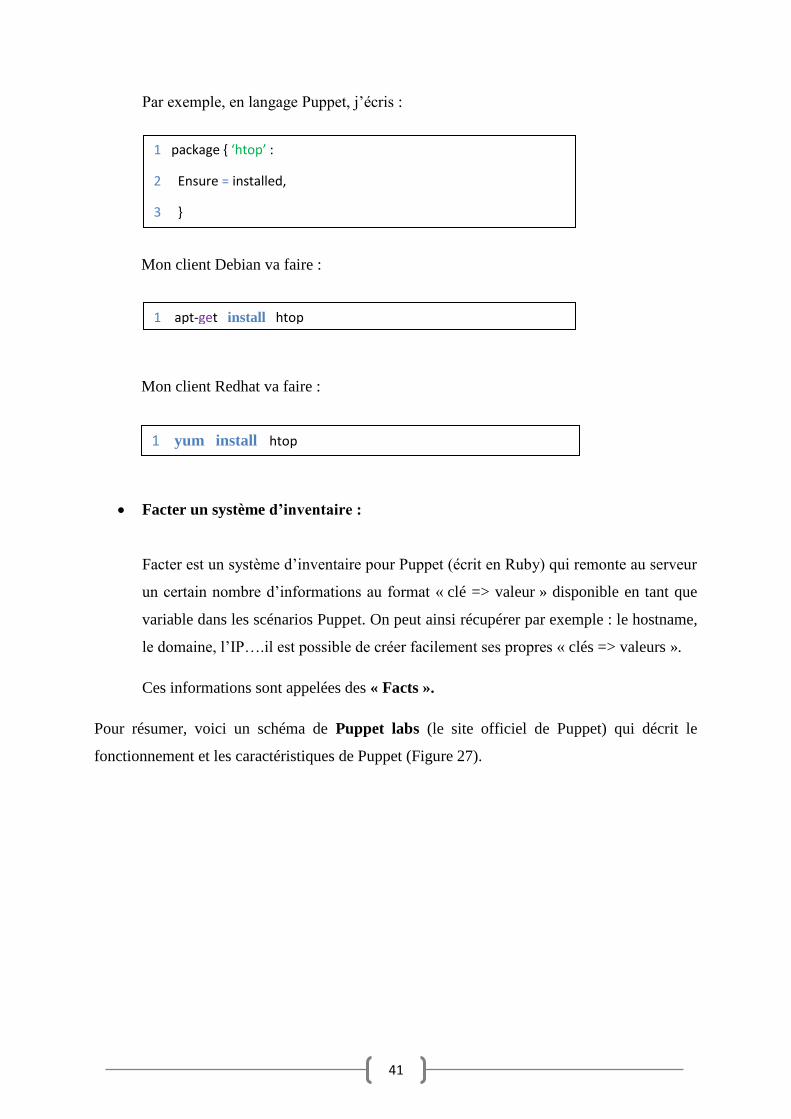
41
Par exemple, en langage Puppet, j’écris :
Mon client Debian va faire :
Mon client Redhat va faire :
Facter un système d’inventaire :
Facter est un système d’inventaire pour Puppet (écrit en Ruby) qui remonte au serveur
un certain nombre d’informations au format « clé => valeur » disponible en tant que
variable dans les scénarios Puppet. On peut ainsi récupérer par exemple : le hostname,
le domaine, l’IP….il est possible de créer facilement ses propres « clés => valeurs ».
Ces informations sont appelées des « Facts ».
Pour résumer, voici un schéma de Puppet labs (le site officiel de Puppet) qui décrit le
fonctionnement et les caractéristiques de Puppet (Figure 27).
1 package { ‘htop’ :
2 Ensure = installed,
3 }
1 apt-get install htop
1 yum install htop

42
Figure 27: Fonctionnement de Puppet
2.4.3 Exemple d’utilisation : Installation de Icinga 2 par Puppet
Installation de Puppet :
Dans l’objectif de tester les fonctionnalités de Puppet, une installation de l’outil sur
des machines virtuelles SLC 6 a été réalisée selon les étapes suivantes :
1) Au niveau du serveur master :
Installer Puppet Master : cette installation nécessite l’ajout du dépôt Puppet
Labs qui contient les différents packages de Puppet.
Configurer Puppet Master pour qu’il s’exécute au démarrage.
S’assurer que le port 8140 est ouvert et qu’il est en état « listening »
Signer les certificats des nœuds clients pour que la communication soit
autorisée.
2) Au niveau des serveurs clients:
Ajouter le dépôt Puppet Labs.
Installer Puppet Client.

43
Editer le fichier « /etc/hosts » afin d’associer les adresses IP du master et du
client avec leurs noms de domaine.
Configurer Puppet agent pour qu’il s’exécute au démarrage.
Installation d’Icinga 2 par Puppet :
L’installation d’Icinga 2 par Puppet est faite selon les mêmes étapes d’installation
manuelle (voir la section 2.2). Dans Puppet, chaque étape d’installation correspond à la
définition d’un ensemble de ressources (paquets, fichiers, commandes…) qui peuvent être
regroupées dans des classes (qui supportent l’héritage) qu’il sera ensuite possible
d’associer à des nodes. Dans notre cas, toutes les classes définies ont été regroupées dans
un seul module appelé « icinga2 ».
L’ensemble des classes sont écrites en un langage propre à Puppet (langage déclaratif) et
compilées par la suite par le serveur master pour former un « catalogue ». Ce dernier est
téléchargé en local par le client Puppet (ce qui permettra au client de continuer à
fonctionner si la connexion au serveur n’est plus possible).
Le module d’installation « icinga2 » est composé d’une seule classe « icinga2 » qui
comporte à son tour les sous-classes suivantes :
icinga2 :: rpm-snapshot : cette sous-classe a pour rôle de configurer tous les
dépôts d’installation de Icinga 2.
icinga2 :: doc : cette sous-classe a pour rôle d’installer le package qui fournit la
documentation de Icinga 2.
icinga2 :: nagios-plugins : cette sous-classe permet d’installer les plugins nagios
nécessaire pour les vérification des hôtes et des services.
icinga2 :: feature : cette sous-classe permet d’ajouter des fonctionnalités de
Icinga 2 comme ido-mysql par exemple.
icinga2 :: apache : cette sous-classe a pour but d’installer « apache » nécessaire
pour l’interface web.
icinga2 :: php : cette sous-classe a pour but d’installer « php » nécessaire pour
l’interface web.
Icinga2 :: mysql : cette sous-classe a pour but d’installer le mysql-server et de
s’assurer que le service mysql est démarré.

44
Icinga2 :: web : c’est la sous-classe permettant d’installer le package icinga-web
et toutes les fonctionnalités relatives à l’interface web.
Icinga2 :: core : c’est la sous-classe d’installation d’icinga 2 proprement dit qui
fait appel à la majorité des sous-classes déjà cités.

45
3. Mise en œuvre de la solution complète de supervision sur
le système LHCb Online
Ce chapitre décrit la deuxième et la dernière partie de la réalisation du projet. Il s’agit
du déploiement de la solution complète sur le système de production LHCb Online. Il
présente d’une part la solution de supervision du système par Icinga 2, d’autre part
l’automatisation de cette supervision en utilisant l’outil Puppet.
3.1 Présentation du système à superviser
Le système à superviser est le système LHCb Online décrit en détails dans la section 1.1.4 du
premier chapitre. Il s’agit d’une infrastructure hétérogène composée de plus de 2000 serveurs
et 200 équipements réseau.
3.2 Conception de la configuration du système de supervision
La conception adoptée pour le système de production est la même que celle de l’atelier de test
appliquée à un échelon plus grand (section 2.3.2). Il s’agit d’une conception plate basée sur
les « Templates » chaque template désigne une fonctionnalité ou un type de machine.
La Figure 28 présente un extrait du diagramme des « Templates » du système de supervision
réel. Tous les « Templates » (types de machines) héritent d’un « Template » générique appelé
« tpl-host » qui comprend des attributs génériques valables pour tous les types d’hôtes
notamment :
max_check_attempts : désigne le nombre de fois qu’un hôte est vérifié avant de
passer à l’état « HARD », par défaut cet attribut est à 3.
check_interval : cet attribut est utilisé pour les vérifications lorsque le hôte est en état
« HARD », par défaut c’est 5 minutes.
retry_interval : cet attribut est utilisé pour les vérifications lorsque le hôte est en état
« SOFT », par défaut c’est 1 minute.
N.B : « HARD » : l’état de l’hôte ou du service n’a pas changé.
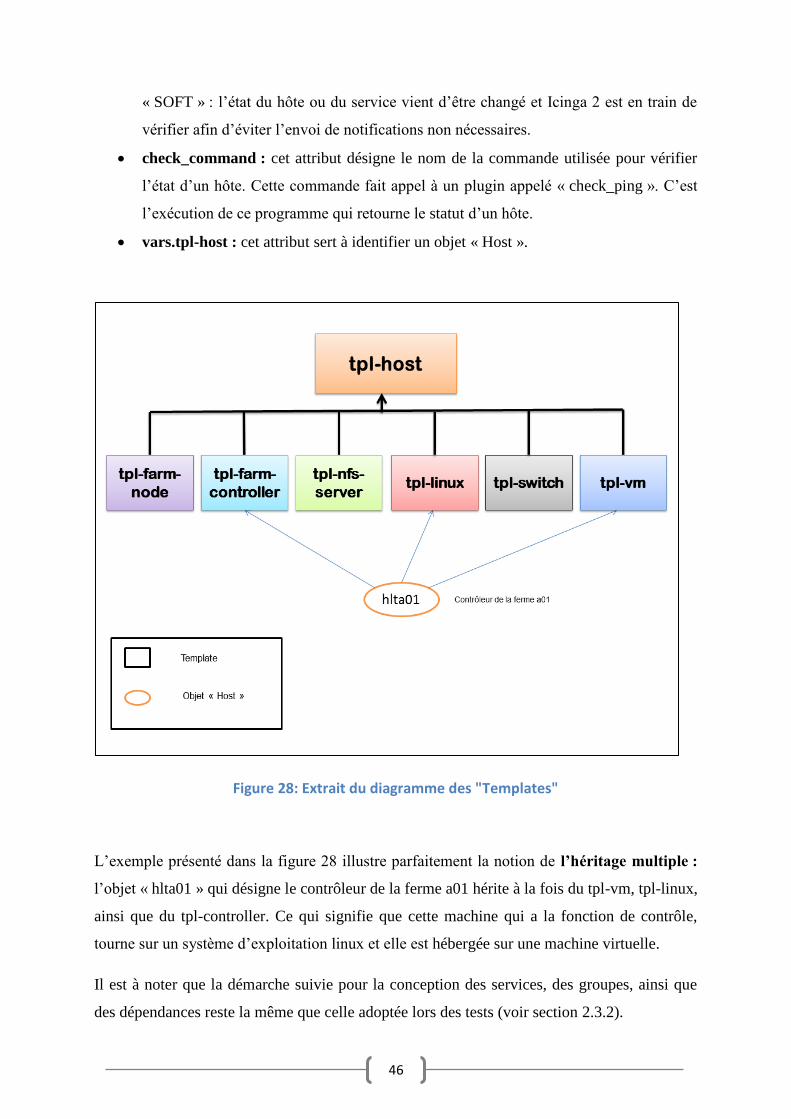
46
« SOFT » : l’état du hôte ou du service vient d’être changé et Icinga 2 est en train de
vérifier afin d’éviter l’envoi de notifications non nécessaires.
check_command : cet attribut désigne le nom de la commande utilisée pour vérifier
l’état d’un hôte. Cette commande fait appel à un plugin appelé « check_ping ». C’est
l’exécution de ce programme qui retourne le statut d’un hôte.
vars.tpl-host : cet attribut sert à identifier un objet « Host ».
Figure 28: Extrait du diagramme des "Templates"
L’exemple présenté dans la figure 28 illustre parfaitement la notion de l’héritage multiple :
l’objet « hlta01 » qui désigne le contrôleur de la ferme a01 hérite à la fois du tpl-vm, tpl-linux,
ainsi que du tpl-controller. Ce qui signifie que cette machine qui a la fonction de contrôle,
tourne sur un système d’exploitation linux et elle est hébergée sur une machine virtuelle.
Il est à noter que la démarche suivie pour la conception des services, des groupes, ainsi que
des dépendances reste la même que celle adoptée lors des tests (voir section 2.3.2).

47
3.3 Implémentation de la configuration
Afin de garantir la mise en place d’une solution complète, qui répond aux besoins déjà fixés,
plusieurs outils complémentaires ont été ajoutés à Icinga 2.
3.3.1 Agent NRPE (Nagios Remote Plugin Executor)
Définition
Si il est possible pour le serveur Icinga 2 de vérifier par exemple qu’un port est toujours en
écoute sur une machine distante en utilisant les plugins (voir section 2.3.3), il est plus difficile
de connaître la charge de la machine ou encore la mémoire utilisée. D’où l’intérêt de faire
appel à des petits programmes appelés agents de supervision.
NRPE est parmi ces agents de supervision qui permet de récupérer les informations à
distance. Son principe de fonctionnement est simple : il suffit d’installer le démon sur la
machine distante et de l’interroger à partir du serveur Nagios.
N.B : il est possible d’exécuter des plugins sur des machines à distance sans utiliser NRPE. Il
existe un plugin appelé « check_by_ssh » qui permet d’exécuter des commandes à distance en
utilisant SSH (Secure Shell). Certes, l’utilisation de SSH est plus sécurisée que NRPE,
toutefois elle provoque des niveaux très élevés de charge CPU surtout avec des milliers de
machines à superviser (cas du LHCb Online).
Principe de fonctionnement [NRPE 2013]
Le fonctionnement est simple : plutôt que d’appeler directement une commande
particulière depuis Icinga 2, le plugin « check_nrpe » sur le serveur Icinga 2 initie une
connexion vers l’agent NRPE de l’hôte cible en lui demandant d’exécuter une
vérification. L’agent NRPE retourne le résultat au serveur Icinga 2 (Figure 29) .
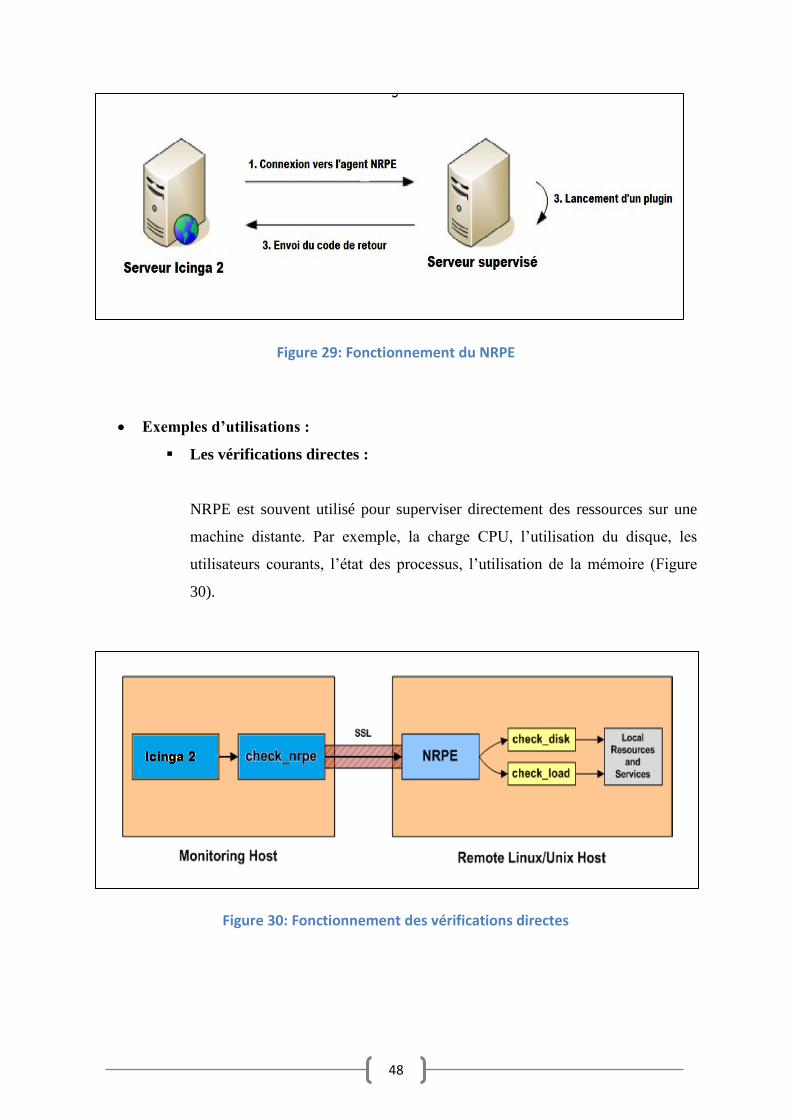
48
Figure 29: Fonctionnement du NRPE
Exemples d’utilisations :
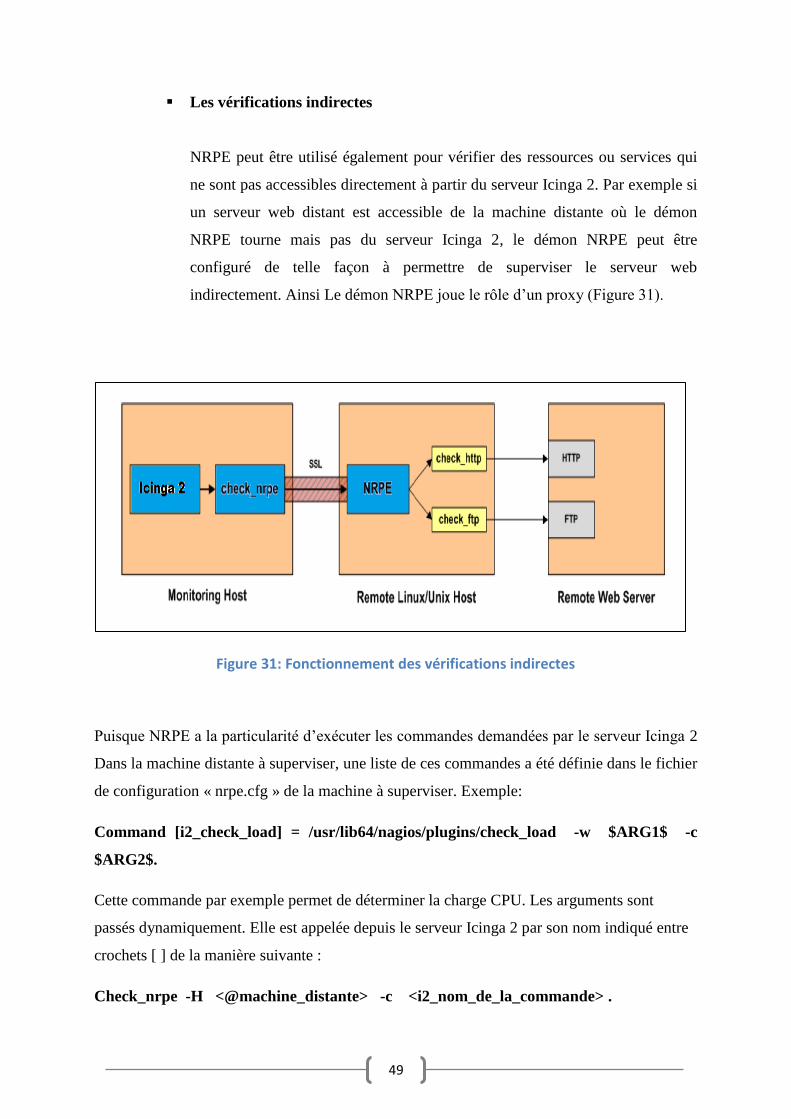
Les vérifications directes :
NRPE est souvent utilisé pour superviser directement des ressources sur une
machine distante. Par exemple, la charge CPU, l’utilisation du disque, les
utilisateurs courants, l’état des processus, l’utilisation de la mémoire (Figure
30).
Figure 30: Fonctionnement des vérifications directes
49
Les vérifications indirectes
NRPE peut être utilisé également pour vérifier des ressources ou services qui
ne sont pas accessibles directement à partir du serveur Icinga 2. Par exemple si
un serveur web distant est accessible de la machine distante où le démon
NRPE tourne mais pas du serveur Icinga 2, le démon NRPE peut être
configuré de telle façon à permettre de superviser le serveur web
indirectement. Ainsi Le démon NRPE joue le rôle d’un proxy (Figure 31).
Figure 31: Fonctionnement des vérifications indirectes
Puisque NRPE a la particularité d’exécuter les commandes demandées par le serveur Icinga 2
Dans la machine distante à superviser, une liste de ces commandes a été définie dans le fichier
de configuration « nrpe.cfg » de la machine à superviser. Exemple:
Command [i2_check_load] = /usr/lib64/nagios/plugins/check_load -w $ARG1$ -c
$ARG2$.
Cette commande par exemple permet de déterminer la charge CPU. Les arguments sont
passés dynamiquement. Elle est appelée depuis le serveur Icinga 2 par son nom indiqué entre
crochets [ ] de la manière suivante :
Check_nrpe -H <@machine_distante> -c <i2_nom_de_la_commande> .

50
3.3.2 NAN (Nagios Notifications Daemon)
Notifications et alertes
La solution de supervision doit faire gagner du temps à l’administrateur et lui
permettre d’intervenir en temps opportun. Pour cela, Icinga 2 génère des notifications
et des alertes en cas de problèmes et les envoie au superviseur par différents
méthodes : e-mails, sms, twitter, etc.
Pour envoyer les notifications aux utilisateurs, Icinga 2 se base sur des mécanismes
externes tels que les scripts Shell. Ainsi, la définition d’une notification nécessite un
ou plusieurs utilisateurs (et /ou des groupes d’utilisateurs) qui vont être notifiés en cas
de problèmes.
Dans notre cas, l’utilisateur « Chris » dans l’exemple ci-dessous appartenant à un
groupe d’utilisateur « Icinga2admins » sera notifié seulement dans le cas des états
« WARNING » et « CRITICAL » et recevra uniquement les notifications de type
« Problem » et «Recovery ».
Utilisation de NAN [Nicodemus 2005]
NAN est utilisé pour limiter le nombre de notifications que Icinga 2 pourrait envoyer,
ceci est réalisé en concaténant plusieurs notifications pour n’en envoyer qu’une seule
chaque x seconds.
Lorsqu’il reçoit une notification de Icinga 2 NAN utilise trois arguments :
Méthode de notification : page, service_email, host_email, etc.
object User "Chris" {
display_name = "egroup"
states = [ OK, Warning, Critical ]
types = [ Problem, Recovery ]
groups = [ "icinga2admins"]
email = "[email protected]"
pager = ""
= "

51
Adresse de destination : numéro de téléphone, adresse email, etc.
Type de notification : PROBLEM, AKNOWLEDGEMENT et RECOVERY.
Le contenu du mail.
L’exemple ci-dessous illustre l’utilisation de NAN (la commmande nanc) dans la
définition de l’objet « NotificationCommand » :
Installation de NAN
L’installation de NAN a été réalisée en utilisant Puppet. Un module Puppet dédié
permet l’installation de l’outil NAN sur le serveur de supervision après l’installation
d’Icinga 2.
3.3.3 Résultats de supervision du système LHCb Online
Ayant ajouté les outils complémentaires nécessaires au bon fonctionnement de la supervision
par Icinga 2, l’interface web (icinga-web) a permis d’afficher les résultats suivants :
L’interface web de Icinga permet de visualiser les hôtes selon les résultats des vérifications.
La Figure 32 présente un extrait des machines ayant un état « UP ». 1471 hôtes sont en état
« UP » .
object NotificationCommand "aggregated-mail-notification" {
import "plugin-notification-command"
command = "/usr/bin/printf \"%b\" $mail_content$ | /usr/local/nan/nanc -t
$notification.type$ -m $notification_method$ -d $user.email$"
}
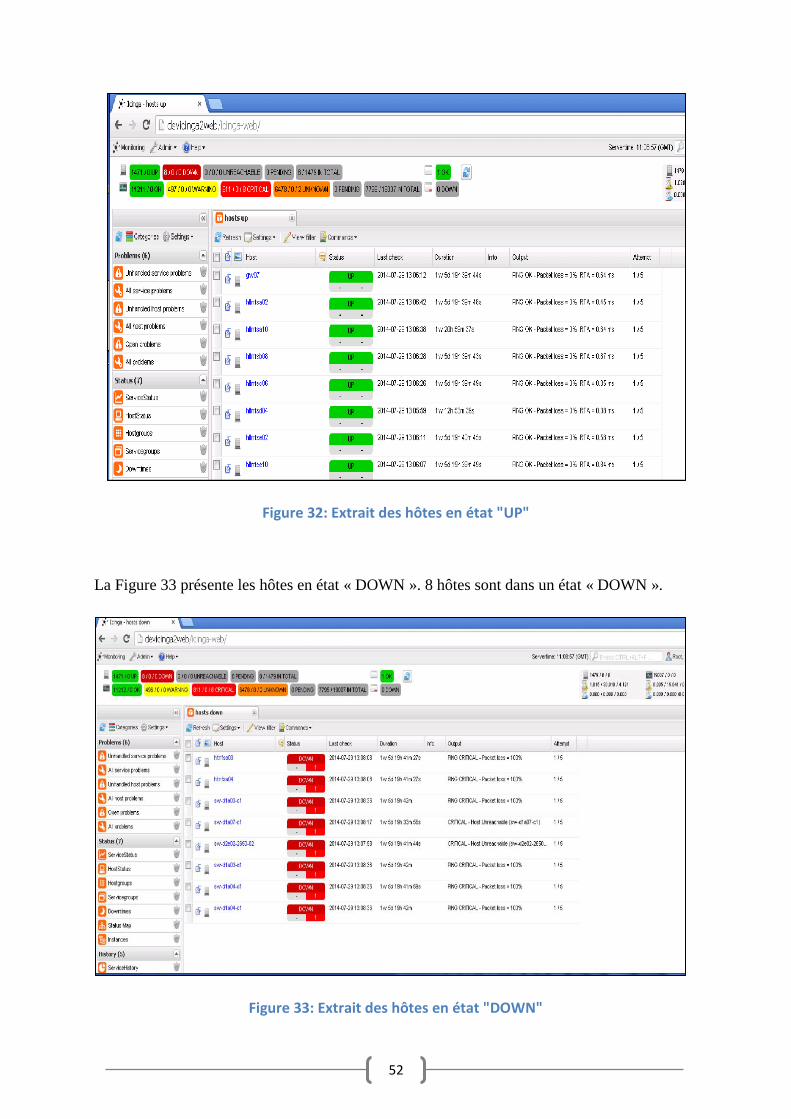
52
Figure 32: Extrait des hôtes en état "UP"
La Figure 33 présente les hôtes en état « DOWN ». 8 hôtes sont dans un état « DOWN ».
Figure 33: Extrait des hôtes en état "DOWN"

53
Icinga 2 permet également de vérifier l’état des services. La figure 34 présente un extrait des
services du système LHCb Online avec leurs états (OK, WARNING, CRITICAL,
UNKNOWN). 1211 services sont en état « OK », 498 en état « WARNING », 810 en état
« CRITICAL » et 6478 en état « UNKNOWN ».
Figure 34: Extrait des différents états des services
L’interface web offre la possibilité d’avoir des statistiques sur les vérifications sous forme de
graphes, la figure 35 présente deux graphes un pour l’état des hôtes et un autre pour l’état des
services.
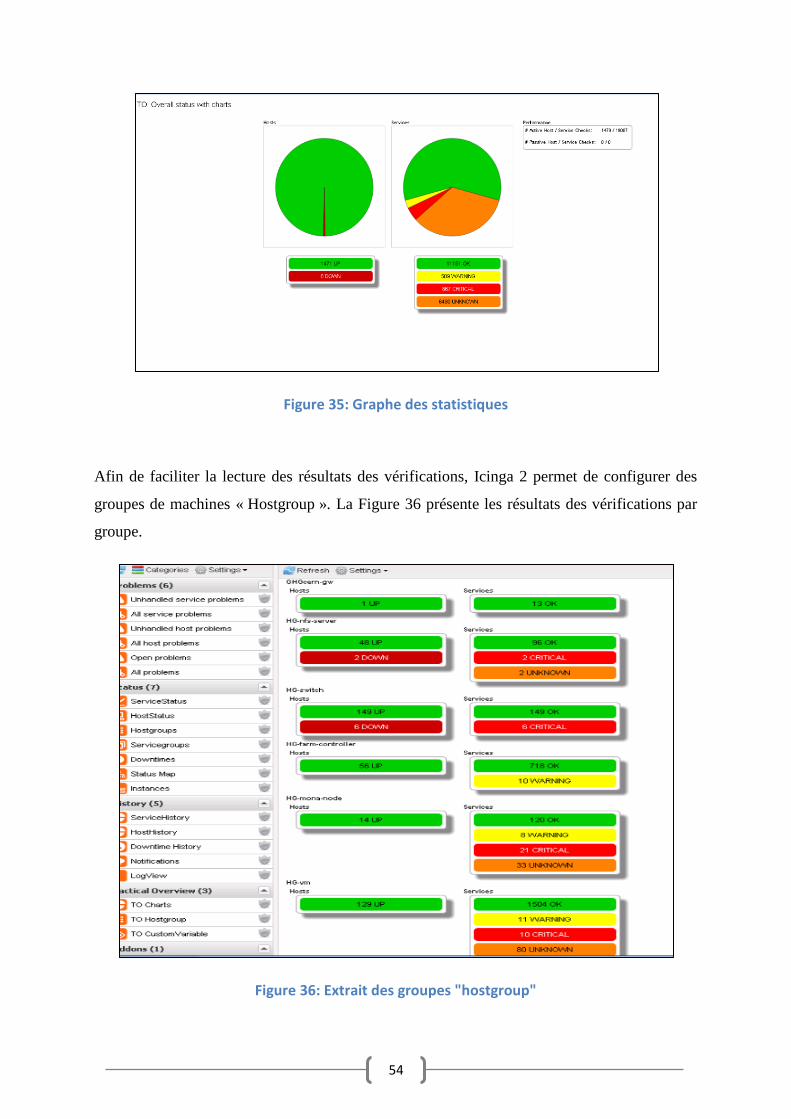
54
Figure 35: Graphe des statistiques
Afin de faciliter la lecture des résultats des vérifications, Icinga 2 permet de configurer des
groupes de machines « Hostgroup ». La Figure 36 présente les résultats des vérifications par
groupe.
Figure 36: Extrait des groupes "hostgroup"

55
3.3.4 Discussion des résultats
Si les résultats de supervision du système LHCb Online illustrent parfaitement les avantages
de l’outil Icinga 2, il n’en reste pas moins que certains problèmes persistent encore.
En effet, la solution de supervision basée sur Icinga 2 a permis de pallier les limites de la
solution actuelle (basée sur Icinga 1.x) :
1) Les résultats obtenus ont démontré les bonnes performances de Icinga 2 : l’instance
Icinga 2 a réussi à effectuer 30 000 vérifications actives dans moins d’une minute afin
de surveiller plus de 1500 hôtes. De plus, les délais de latences ne sont plus énormes.
2) L’utilisation de la notion de dépendance surtout celle relative au réseau (dépendance
par rapport aux switchs) a permis de diminuer davantage le nombre de notifications
envoyées.
3) Il est maintenant facile d’étendre la solution grâce à une configuration dynamique et
flexible.
4) La configuration Icinga 2 grâce à l’utilisation des « Templates » et d’autres
mécanismes a facilité la communication avec des outils d’automatisation de
configurations tel que Puppet (la dernière section traitera ce point).
Toutefois, pendant les tests de la configuration, quelques problèmes ont été soulevés plusieurs
fois :
1) Selon la documentation officielle de Icinga 2, il existe une dépendance implicite entre
un hôte et ses services, toutefois les résultats obtenus ont démontrés le contraire :
même si un hôte est « DOWN » les vérifications de ses services seront exécutés. Ce
problème a été soumis aux développeurs de Icinga 2 pour d’éventuelles solutions.
2) Dans certains cas, une vérification de l’état d’un service donne l’état « PENDING » ce
qui signifie en attente. Ce comportement est étrange du fait que le même service
tourne sur plusieurs machines et il est correctement vérifié. Ce bug a été également
soumis aux développeurs icinga 2.

56
3.4 Automatisation de la configuration par Puppet
3.4.1 Analyse du problème
Dans une infrastructure à grande échelle comme celle du LHCb Online, le nombre de serveurs
à superviser tend à augmenter rapidement. La configuration du serveur Icinga 2 est donc
nécessaire à chaque nouveau nœud ajouté. En outre, l’hétérogénéité et la complexité de
l’infrastructure à superviser exige un effort considérable comme l’écriture des scripts Shell.
Ainsi, concevoir et implémenter une solution permettant d’automatiser la génération de la
configuration du serveur de supervision constitue sans nul doute un apport considérable en
terme de temps et de performance.
Scénario escompté : Dès qu’un serveur ou plusieurs (le cas de l’ajout d’une ferme) sont
ajoutés au système à superviser, mettre à jour dynamiquement les fichiers de
configuration du serveur Icinga 2.
3.4.2 Solution proposée
La solution retenue consiste à utiliser l’outil Puppet (voir la section 2.4) ainsi qu’un outil
appelé Foreman permettant entre autres la gestion de la configuration des serveurs en
collectant les « facts » (informations des nœuds : OS, IP adresse….) et les rapports générés
par puppet [Foreman 2014].
La Figure 37 présente les principales étapes du processus de génération de la configuration du
serveur Icinga 2 à savoir :
1) Demande de configuration du client au serveur Puppet master et envoi des « facts »
en même temps. Dans ce cas, le serveur Icinga 2 est également un agent de Puppet.
2) Stockage des « facts » au niveau de la base de données du serveur Foreman.
3) En fonction des informations de chaque agent, les ressources sont interprétées et
compilées. Envoi de la configuration compilée à chaque client. du fait que la
configuration du serveur Icinga 2 utilise les « facts » des autres agents, il est
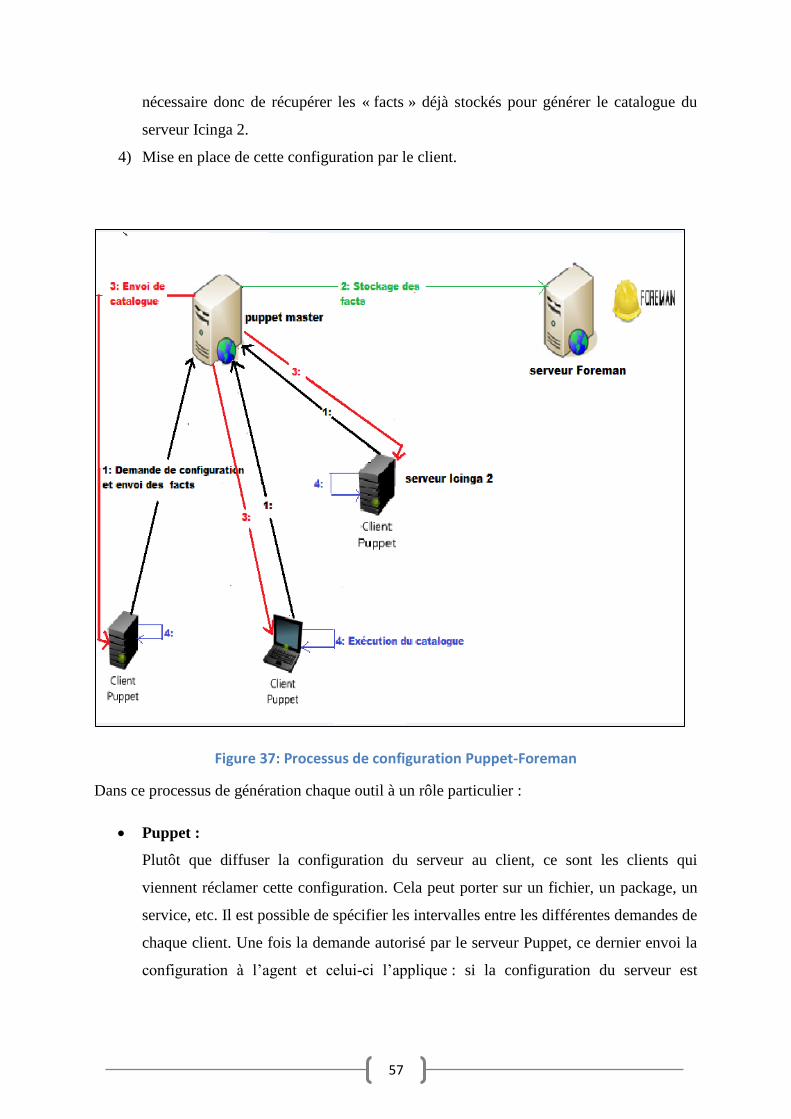
57
nécessaire donc de récupérer les « facts » déjà stockés pour générer le catalogue du
serveur Icinga 2.
4) Mise en place de cette configuration par le client.
Figure 37: Processus de configuration Puppet-Foreman
Dans ce processus de génération chaque outil à un rôle particulier :
Puppet :
Plutôt que diffuser la configuration du serveur au client, ce sont les clients qui
viennent réclamer cette configuration. Cela peut porter sur un fichier, un package, un
service, etc. Il est possible de spécifier les intervalles entre les différentes demandes de
chaque client. Une fois la demande autorisé par le serveur Puppet, ce dernier envoi la
configuration à l’agent et celui-ci l’applique : si la configuration du serveur est

58
identique à celle du client, aucune action n’est effectué (exemple : un logiciel déjà
installé sur le client ne sera pas réinstallé).
Utilisation des facts : le package Facter est un outil d’inventaire système : il
retourne des « facts » : des variables globales de chaque agent Puppet telle que
son adresse IP, son hostname, son OS et sa version etc. Ces « facts » sont
utilisés par Puppet master afin de servir de variables nécessaires à la génération
des catalogues (configuration compilée). En plus des facts par défaut, Il est
possible d’ajouter d’autres types d’informations au facter.
Agent Icinga 2 : le serveur Icinga 2 est un agent de Puppet, toutefois sa
configuration est particulière, car elle consiste à générer des fichiers contenant
les informations des autres agents (hostname, adresse IP..) qu’il supervise.
D’où l’intérêt de faire appel à un autre outil appelé Foreman.
Foreman : [Foreman 2014]
Foreman est un projet open source qui aide les administrateurs systèmes à gérer les
serveurs tout au long de leur cycle de vie, de la configuration à la supervision. En
utilisant Puppet et Foreman ensemble, il est facile d’automatiser les tâches répétitives
d’administration, de déployer des applications et de gérer de manière proactive les
changements. En outre, Foreman fournit des facilités d’interaction notamment une
interface web (Figure 38) ainsi qu’une API (Application Programming Interface)
Restful permettant de construire une logique métier sur une base solide .
Figure 38: Interface web Foreman

59
Parmi les fonctionnalités offertes par Foreman est celle de pouvoir ajouter les hôtes et
leurs facts dans la base de données Foreman [Foreman 2014], La figure 39 illustre
cette possibilité.
Figure 39: Extrait des facts sur Foreman
Afin de récupérer les facts depuis foreman , il existe une fonction appelée foreman( )
dont le rôle est de faire une requête vers l’API Foreman ce dernier une fois il la reçoit ,
il retourne le résultat sous forme de flux JSON (Javascript Object Notation).
Génération d’un fichier de configuration Icinga 2 :
Un fichier de configuration Icinga 2 est un fichier permettant de définir un objet
« host » ainsi que ses dépendances si elles existent. Ce fichier peut être décomposé en
plusieurs fragments, chaque fragment vient du fait que le hôte en question a une
fonctionnalité ou une caractéristique particulière. Exemple : le fichier de définition du
hôte « hlta0208 » est la concaténation des fragments suivants :

60
Header_fragment : chaque hôte quel que soit son type doit inclure ce fragment
dans son fichier de configuration.
Farmnode_Fragment : ce hôte inclus ce fragment car il est de type
« Farmnode, » c’est-à-dire qu’il est un nœud d’une ferme.
Linux_Fragment : ce hôte tourne sur un système d’exploitation linux.
Footer_Fragment : chaque hôte quel que soit son type doit inclure ce fragment
dans son fichier de configuration.
Dependancy_Fragment : ce hôte comporte une dépendance.
N.B : La génération de ce genre de fichiers par puppet nécessite en plus du fact
« hostname », l’ajout d’un fact qui comporte la liste des types de la machine en
question : i2_type.
Les facts sont récupérés sous forme d’une structure de données comme suit :
object Host "hlta0208" {
address = "hlta0208"
import "tpl-farm-node"
vars.dep_farm_nfs = "hltnfsa02"
vars.dep_network = "sw-d1a02-c1"
import "tpl-linux"
}
apply Dependency "dep-mountpoint-hlta0208" to Service {
parent_host_name = "hlta0208"
parent_service_name = "mountpoint"
disable_checks = true
disable_notifications = true
assign where host.name == "hlta0208" && service.name !=
"mountpoint"
}
Header_Fragment
Farmnode_Fragment
Linux_Fragment
Footer_Fragment
Dependancy_Fragment

61
Une fois que Puppet récupère cette structure, il procède à la concaténation des
fragments selon la valeur du fact « i2_type ».
Cas particulier : Les machines qui ne sont pas des agents Puppet :
Pour les machines qui ne peuvent pas être des agents Puppet : par exemple les
« switchs », la solution retenue est d’écrire leurs informations (équivalent des facts en
Puppet) dans un fichier YAML (format de fichiers), et d’utiliser une fonction Puppet
appelée Hiera( ) permettant de récupérer ces données .
"hlta0208.lbdaq.cern.ch"=>
{
"facts"=> {
"i2_type"=> ["linux", "Farmnode"]
"hostname"=>"hlta0208"
}
}

62
Conclusion
Mon projet s’inscrit dans le cadre de la phase d’amélioration de l’infrastructure informatique
de l’expérience LHCb, une des quatre expériences du grand accélérateur des particules LHC.
Mon travail consistait à mettre en place une nouvelle infrastructure de supervision basée sur
les outils Icinga 2 et Puppet.
Afin de réaliser les objectifs estimés du projet, j’ai, dans un premier temps effectué l’analyse
des besoins des membres de l’équipe LHCb Online via l’organisation hebdomadaire des
réunions. Au cours de ces rencontres et des différents échanges avec l’équipe j’ai pu
comprendre le fonctionnement complexe du système LHCb Online. Ensuite, j’étais amené à
bien maîtriser les concepts de base de l’outil de supervision Icinga 2 ainsi que ceux de l’outil
de gestion de la configuration des serveurs Puppet.
Dans l’optique de tester les fonctionnalités qu’offrent les deux outils, une réalisation à base de
la virtualisation et d’un atelier personnalisé de tests s’est avérée nécessaire. Icinga 2 est
conçu pour superviser la disponibilité d’un réseau donné, cette supervision est basée
essentiellement sur la définition de plusieurs fichiers de configuration, d’où était l’intérêt de
choisir une conception adaptée aux contraintes du système LHCb Online.
En outre, l’automatisation de la configuration du serveur Icinga 2 en utilisant Puppet était un
réel défi, dans ce sens, un système de génération des fichiers de configuration Icinga 2 a été
mis en place résolvant ainsi l’une des problématiques majeures de la supervision des
infrastructures informatiques de grande taille.
Les principales difficultés techniques ont porté sur deux points, le premier concerne l’outil de
supervision Icinga 2 récemment en version stable, ce qui a entrainé certains problèmes plus
particulièrement le manque de documentation et d’experience utilisateur tandis que le second
point concerne l’utilisation de l’outil Puppet. L’apprentissage et la maîtrise du langage
spécifique à Puppet n’est pas aisé surtout avec des besoins très pointus en terme de rapidité et
de performance.
Mon projet s’est achevé en août 2014. Plusieurs améliorations pourraient être envisageables
notamment l’utilisation de l’interface web Icinga 2 en cours de développement, l’usage de
l’agent icinga 2 (au lieu de NRPE) pour l’exécution des vérifications à distance, le
renforcement des aspects de sécurité des communications au sein du système de supervision,
ainsi que l’utilisation de la nouvelle fonctionnalité « cluster » afin d’assurer en permanence la
disponibilité de l’infrastructure de supervision.

ix
Références bibliographiques
[CERN 2014], CERN, Rapport annuel 2013, Genève, Suisse, 2014.
[Haen 2013], Christophe Haen, OPhronsis a diagnosis and recovery tool for system administrators, Thèse de doctorat, Université Blaise Pascal-Clermont II, 24 octobre 2013.
[Haen, Bonaccorsi et Neufeld 2011], C.Haen, E.Bonaccorsi, N.Neufeld, Distributed monitoring system based on Icinga, In Proceedings of WEPMU035 ICALEPCS 2011, Grenoble, France, 2011.
[LHCb Collaboration 2001], LHCb Collaboration, TDR LHCb Online System Data Acquisition & Experiment Control, Technical Design Report, CERN/LHCC 2001-040 LHCb TDR 7, 19 décembre 2001.
Webographie
[CERN_homepage 2014], About CERN, 2014, [Ressource électronique], [Réf. du 30
juin 2014 à 23:26]. Disponible sur : http://home.web.cern.ch/about
[Haen, Bonaccorsi et Neufeld 2013], C.Haen, E.Bonaccorsi, N.Neufeld, Evolution of
the monitoring in the LHCb Online System [Ressource électronique], 2013, USA. Disponible sur : http://accelconf.web.cern.ch/AccelConf/ICALEPCS2013/papers/thcoba01.pdf.
[Icinga2 2014], Icinga2, Icinga2 redesigns Open Source Monitoring, 2014, [En ligne], Disponible sur : https://www.icinga.org/icinga/icinga-2/
[Icinga2_doc 2014], Icinga2, Icinga2 documentation, 2014, [En ligne], Disponible sur : http://docs.icinga.org/icinga2/latest/doc/module/icinga2/toc
[Icinga2_epel 2014], Icinga2, Icinga EPEL Repository, 2014, [En ligne], Disponible sur : http://packages.icinga.org/epel/

x
[Icinga-web-URL 2014], Icinga, Icinga-web URL, 2014, [En ligne],
Disponible sur : http://localhost/icinga-web
[Puppet 2014], Icinga2, C’est quoi Puppet ?, 2014, [En ligne], Disponible sur : http://doc.ubuntu-fr.org/puppet
[LHC 2007], Large Hadron Collider, 2007, [Ressource électronique], [Réf. du 12 mai
2014 à 08:48]. Disponible sur : http://fr.wikipedia.org/wiki/Large_Hadron_Collider
[LHCb 2007], Large Hadron Collider beauty experiment, 2007, [Ressource électronique], [Réf. du 15 mars 2013 à 16:49]. Disponible sur : http://fr.wikipedia.org/wiki/LHCb
[Puppet_doc 2014], Icinga2, learning Puppet, 2014, [En ligne], Disponible sur : https://docs.puppetlabs.com/learning/introduction.html
[NRPE 2013], Icinga2, Protocole NRPE, 2013, [En ligne], Disponible sur : http://wiki.monitoring-fr.org/nagios/addons/nrpe
[Nicodemus 2005], Nicodemus, PNAN-Nagios Notification Daemon, 2005, Dernière date de modification : 12-10-2010, [En ligne], Disponible sur : https://www.monitoringexchange.org/inventory/Utilities/AddOn-
Projects/Notifications/NAN---Nagios-Notification-Daemon
[Foreman 2014], Foreman, Foreman 1.5 Manual, 2014, [En ligne], Disponible sur :
http://theforeman.org/manuals/1.5/index.html

xi
Annexes
xii
Annexe A
Organigramme du CERN :[CERN 2014]
xiii
Annexe B
Planning réel :





























