Embed Size (px)
Citation preview

Vers une architecture de micro services
Tuteur entreprise : Damien FATREZ

1
Tuteur universitaire : Philippe MARQUET
Corentin Bernard
21 Juin 2019
Table des matières
Novastream 2
L’entreprise 2
Les produits 2
Les spécificités 3
Les problèmes de l’architecture monolithique 4
Objectif : diviser pour simplifier 5
Un cas concret : les statistiques 6
Mise en œuvre de la refonte 8
Une architecture 100% AWS 8
Encore plus de services 10
Gérer les droits d’accès 10
Tracer les erreurs 10
Le problème du démarrage des Lambdas 11
Faire évoluer l’architecture 12
Mutualiser les clients 12
Identifier et sécuriser 12
Simplifier et fiabiliser 13
Déploiements automatisés 14
Une infrastructure codifiée 14
Déploiement client 15
Retour d’expérience 15
Sur le projet 15
Sur l’alternance 15
Références 16

2
Novastream
L’entreprise
J’ai commencé mon alternance chez Novastream en août 2017 après mon stage de licence. Elle est
située dans la zone d’activités Les Prés à Villeneuve d’Ascq.
Créé en 2007, Novastream propose des solutions de stockage et de diffusion de contenu vidéo pour
d’autres entreprises, majoritairement des grands comptes.
L'entreprise s'est spécialisée dans le développement et l'intégration de plateforme vidéo à usage privé
et sécurisé, autrement dit des "Youtube interne d'entreprise".
En 12 ans, Novastream a su s’imposer sur son marché grâce à l’intérêt grandissant des entreprises pour
la vidéo, et grâce à sa facilité d’adaptation face aux besoins spécifiques de chacun de ses clients.
A ce jour, l'entreprise compte environ 40 clients grands comptes et diffuse chaque année environ 130
millions de vidéos par an.
Les produits
Le produit principal de Novastream est un CMS Vidéo1 appelé communément le Manager. Le Manager
est composé de plusieurs modules de base permettant de centraliser, d’enrichir et de diffuser
simplement des vidéos. On retrouve par exemple la fiche vidéo permettant d’associer des
métadonnées au média, un système de playlists pour agréger des vidéos ou encore un menu de sous
titrage automatique du contenu, avec traduction en plusieurs langues.
L'autre activité de Novastream consiste à produire des chaînes vidéo d'entreprise. Il s'agit d'une
application web dédiée à une entreprise pour lui permettre de diffuser ses contenus vidéo, que ce soit
pour de la communication interne, de la formation ou du marketing.
Enfin, Novastream propose également l’intégration de la solution de son partenaire américain
Brightcove, leader mondial des solutions vidéo pour entreprises. Ce partenariat permet à Novastream
de répondre aux clients qui ont des besoins considérables en matière de quantité de contenus, de
bande passante, etc.
1 CMS pour Content Management System, ou Système de Gestion de Contenu en français.
3
Les spécificités
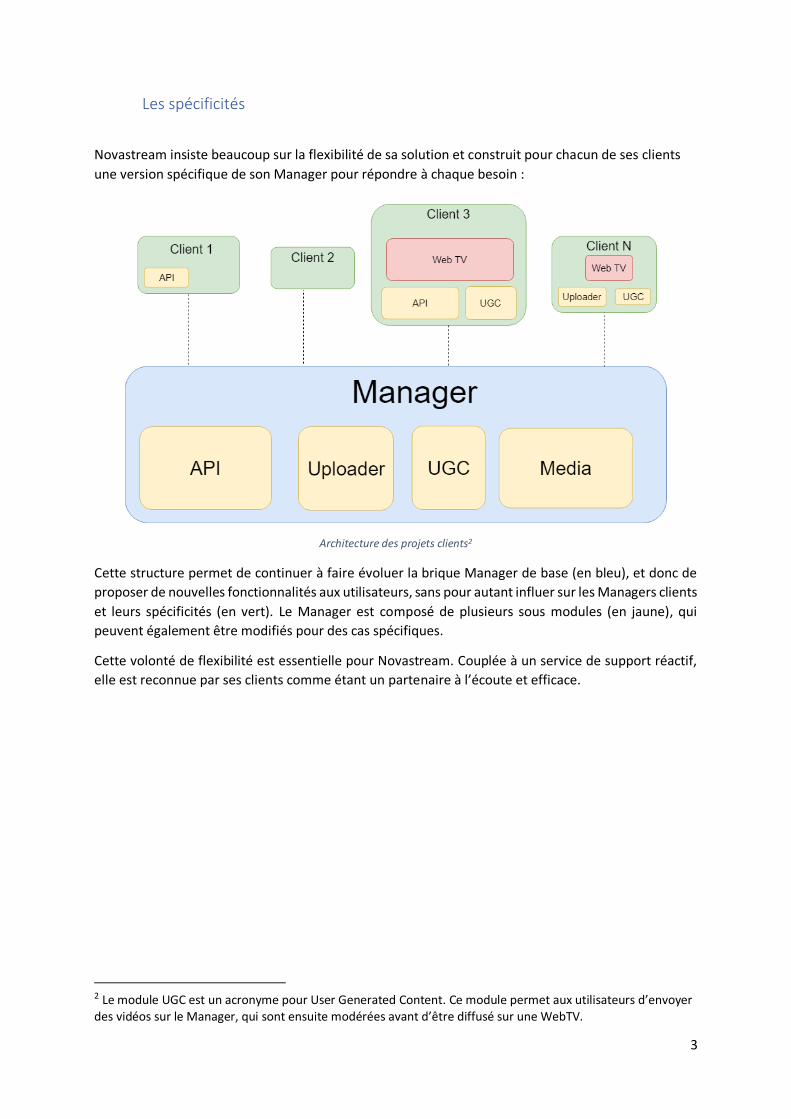
Novastream insiste beaucoup sur la flexibilité de sa solution et construit pour chacun de ses clients
une version spécifique de son Manager pour répondre à chaque besoin :
Architecture des projets clients2
Cette structure permet de continuer à faire évoluer la brique Manager de base (en bleu), et donc de
proposer de nouvelles fonctionnalités aux utilisateurs, sans pour autant influer sur les Managers clients
et leurs spécificités (en vert). Le Manager est composé de plusieurs sous modules (en jaune), qui
peuvent également être modifiés pour des cas spécifiques.
Cette volonté de flexibilité est essentielle pour Novastream. Couplée à un service de support réactif,
elle est reconnue par ses clients comme étant un partenaire à l’écoute et efficace.
2 Le module UGC est un acronyme pour User Generated Content. Ce module permet aux utilisateurs d’envoyer des vidéos sur le Manager, qui sont ensuite modérées avant d’être diffusé sur une WebTV.

4
Les problèmes de l’architecture monolithique
L’architecture présentée ci-dessus n’est cependant pas sans défaut, et certains problèmes
s’accumulent depuis plusieurs années, devenant de plus en plus impactants.
Le Manager est un projet monolithique avec une base de code conséquent. Cela rend l’intégration plus
complexe, car il faut redéployer l’intégralité du projet, peu importe la taille du changement. Certains
changements ont des impacts sur d’autres parties de l'application car il existe des dépendances entre
ses parties. Il est aussi plus difficile de gérer la montée en charge de cette solution. Enfin, ce monolithe
impose aux nouveaux membres de l’équipe de comprendre son fonctionnement en intégralité avant
de pouvoir commencer à travailler dessus.
Exemple :
On souhaite mettre en place un module de suivi de la consommation des commandes de sous-titres,
pour permettre aux utilisateurs du Manager de consulter le budget consacré, le nombre de
commandes passées et le statut des différentes commandes. Ce module générique ne s’affiche que
chez les clients qui ont souscrit à l’offre incluant des sous-titres. Le module étant désactivé par défaut,
il a fallu lors du déploiement mettre à jour manuellement les droits de chacun des utilisateurs
concernés pour leur donner accès à ce nouveau module.

5
Objectif : diviser pour simplifier
Afin de faciliter la maintenance de ce projet ainsi que de réduire les dépendances entre les modules,
nous nous sommes fixés comme objectif de découper certaines parties du projet en modules
indépendants et autonomes, sous forme de micro-services.
L’entreprise souhaite déployer certains de ces modules en Serverless afin de réduire les coûts en
matière de budget et de maintenance d’infrastructure. Novastream mise particulièrement sur AWS car
ils proposent une gamme de service plus adaptés à nos besoins que leurs concurrents, comme
Microsoft Azure ou Google Cloud Platform.
Détacher ces briques du Manager permettrait pour une personne extérieure de comprendre plus
rapidement le fonctionnement de chacun des modules. De plus cela permettra de faire évoluer chaque
partie indépendamment et de versionner chacun des modules plutôt qu’un ensemble.
Le premier module concerné par cette refonte est le module statistique, car c’est un module qui génère
une forte attente de la part des clients. En effet, plusieurs enquêtes effectuées en début d’année par
nos soins démontrent que le besoin le plus remonté est celui d’une visualisation globale de l’utilisation
de la plateforme, ce que ne permet pas la version actuelle du module.
Réponses d'une partie d’un questionnaire client
6
Un cas concret : les statistiques
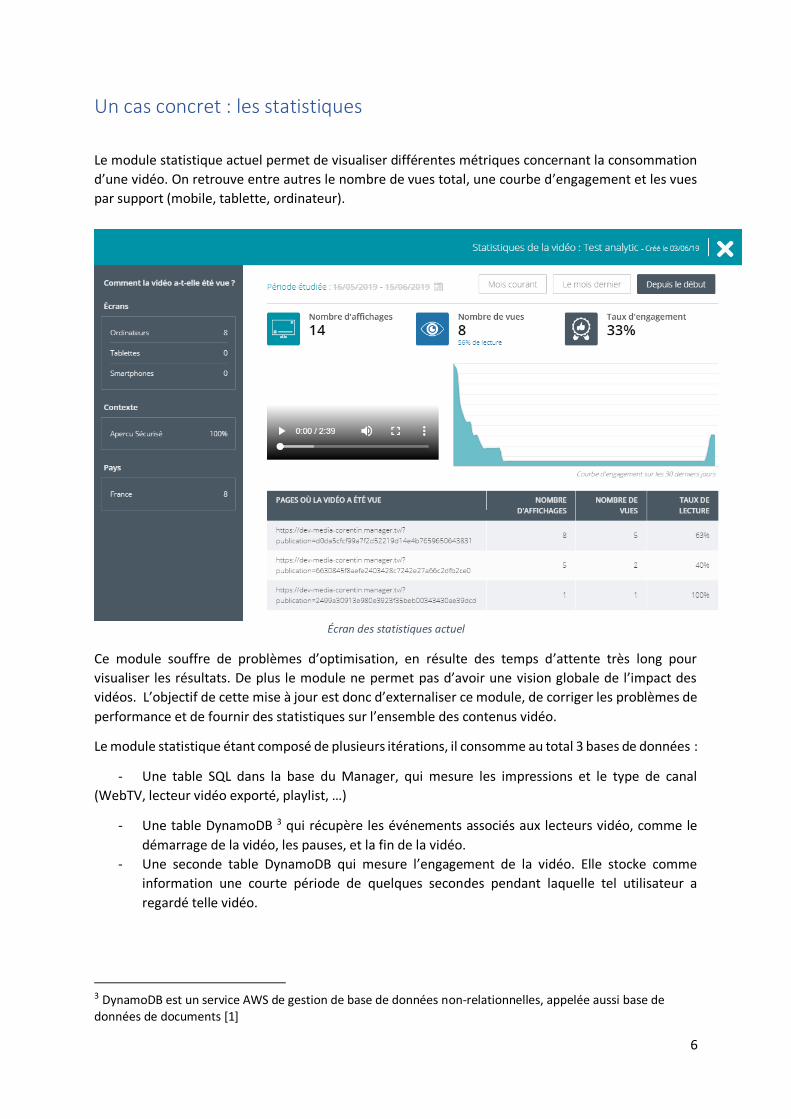
Le module statistique actuel permet de visualiser différentes métriques concernant la consommation
d’une vidéo. On retrouve entre autres le nombre de vues total, une courbe d’engagement et les vues
par support (mobile, tablette, ordinateur).
Écran des statistiques actuel
Ce module souffre de problèmes d’optimisation, en résulte des temps d’attente très long pour
visualiser les résultats. De plus le module ne permet pas d’avoir une vision globale de l’impact des
vidéos. L’objectif de cette mise à jour est donc d’externaliser ce module, de corriger les problèmes de
performance et de fournir des statistiques sur l’ensemble des contenus vidéo.
Le module statistique étant composé de plusieurs itérations, il consomme au total 3 bases de données :
- Une table SQL dans la base du Manager, qui mesure les impressions et le type de canal
(WebTV, lecteur vidéo exporté, playlist, …)
- Une table DynamoDB 3 qui récupère les événements associés aux lecteurs vidéo, comme le
démarrage de la vidéo, les pauses, et la fin de la vidéo.
- Une seconde table DynamoDB qui mesure l’engagement de la vidéo. Elle stocke comme
information une courte période de quelques secondes pendant laquelle tel utilisateur a
regardé telle vidéo.
3 DynamoDB est un service AWS de gestion de base de données non-relationnelles, appelée aussi base de données de documents [1]
7
Le service DynamoDB ne permet pas de récupérer des données filtrées, c’est donc le serveur qui
calcule les statistiques affichées dans la fenêtre montrée précédemment, d’où les temps de traitement
importants. Une solution serait de déplacer les instances sur des machines plus puissantes, mais le
coût financier de cette opération est trop élevé par rapport à la valeur ajoutée.
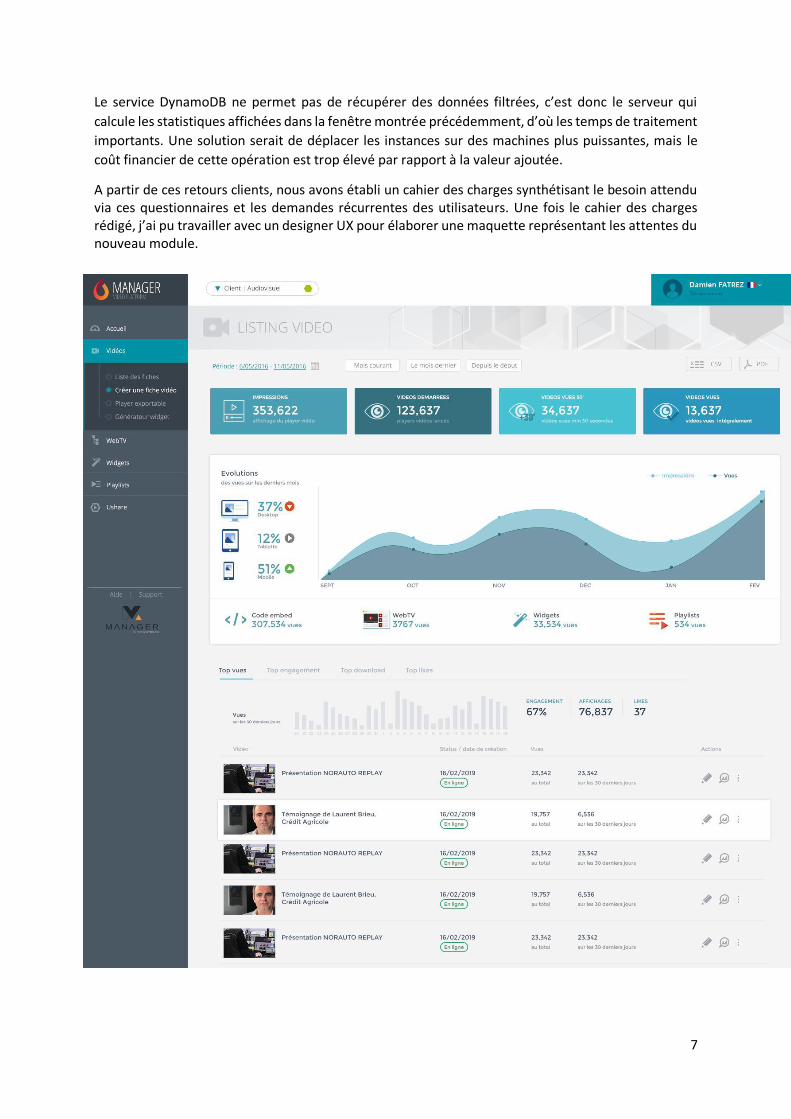
A partir de ces retours clients, nous avons établi un cahier des charges synthétisant le besoin attendu via ces questionnaires et les demandes récurrentes des utilisateurs. Une fois le cahier des charges rédigé, j’ai pu travailler avec un designer UX pour élaborer une maquette représentant les attentes du nouveau module.
Charte graphique du nouveau module
8
Mise en œuvre de la refonte
Une architecture 100% AWS
Comme vue précédemment, Novastream a choisi AWS comme principal fournisseur de solutions cloud.
Il y a 3 ans, ce choix s’était imposé pour la gestion des instances des clients ainsi que le stockage des
bases de données. Aujourd’hui Novastream maintient ce choix et souhaite investir encore plus dans
les services Amazon, notamment dans les solutions Serverless [2], qui nous intéresse beaucoup pour
ce module.
AWS propose également un service managé de stockage et d’analyse de données : Elasticsearch [3].
Ce service stocke les informations sur une base de données orientée document et fournit une interface
RESTful pour analyser ces données.
Cette solution est parfaitement adaptée à notre besoin d’analyse et de stockage de données. Elle nous
facilite également la migration de nos données car ces dernières sont stockées au format JSON dans
les bases DynamoDB, le format de prédilection d’Elasticsearch.
Pour faciliter la compréhension du fonctionnement d’Elasticsearch, sont listées ci-dessous les termes
utilisés dans un système de base de données classique et leurs équivalents dans Elasticsearch :
Base relationnelle Elasticsearch
Table Index
Ligne Document
Colonne Champ
Base Cluster
Pour concevoir une première version de l’architecture, nous avons listé les problématiques que le
nouveau module aurait à satisfaire :
- Pouvoir gérer les gros volumes de données entrantes, par exemple lors de campagnes
d’emailing,
- Fournir des résultats dans un temps raisonnable (moins de quelques secondes),
- Sécuriser l’accès aux données
Le point d’entrée de cette architecture est l’API Gateway [4]. Ce service définit des routes API au format
REST qui peuvent être appelées par les utilisateurs pour déclencher d’autres services. Dans notre cas,

9
lorsque notre lecteur vidéo envoi des données, celles-ci arrivent dans une file d’attente de message,
en attendant d’être traitée, via le service SQS (Simple Queue Message) [5].
Les messages sont traités par des Lambdas [6], des fonctions qui sont exécutées à la volée et qui ne
nécessitent pas de serveur pour être fonctionnelles. Les Lambdas Message Filter et POST parsed data
vérifient la validité du message et de la donnée, et l’enregistre dans l’index approprié dans le moteur
Elasticsearch. D’autres Lambdas permettent d’effectuer des requêtes vers l’Elasticsearch et de
retourner les statistiques voulues.
Le moteur Elasticsearch est placé dans un VPC (Virtual Private Cloud) [7], un réseau privé et dédié dans
AWS. Ce réseau rend l’Elasticsearch inaccessible depuis l’Internet et donc protège l’accès aux données,
mais impose quelques contraintes. En effet, cela signifie aussi que les Lambdas doivent être exécutées
dans le même réseau que celui d’Elasticsearch.
La taille du réseau étant limitée, cela réduit le nombre maximum d’appel en concurrence des fonctions
Lambdas et donc le nombre de messages que l’on peut traiter en même temps. C’est pourquoi nous
avons choisi de placer une file d’attente de message entre la réception des données via l’API Gateway
et les fonctions Lambdas qui traitent ces données.
Première version de l'architecture

10
Encore plus de services
Lors de la conception de la première version, j’ai dû faire face à de nouvelles problématiques. En
premier lieu, j’ai passé beaucoup de temps à me documenter sur tous les services utilisés, et j’ai dû
utiliser plus de services que prévus, notamment pour la gestion des logs et des autorisations.
Gérer les droits d’accès Pour que les différents services puissent interagir entre eux, j’ai créé des stratégies d’accès en utilisant
le service IAM (Identity and Access Management) [8]. Les stratégies d’accès sont des documents JSON
qui servent à autoriser l’accès à certaines ressources d’un service, et sont rattachés à un rôle. Ce rôle
est ensuite associé au service voulu, par exemple une fonction Lambda.
Exemple de stratégie d'accès
La stratégie ci-dessus autorise certaines actions sur toutes les ressources Elasticsearch. Cette stratégie
est associée aux fonctions Lambdas qui interrogent l’Elasticsearch, et permettent par exemple de
récupérer le nom du ou des domaines grâce à la ligne huit.
Au total, trois rôles ont été créés pour les trois types de Lambdas : celle qui lit les messages dans la file
d’attente de message, celles qui envoient des données dans l’Elasticsearch, et celles qui lisent les
données.
Tracer les erreurs Pour récupérer les informations sur les erreurs éventuelles générées par les Lambdas, j’ai mis en place
le service CloudWatch [9], qui intercepte les fonctions ayant échouées, et les messages de logs s’ils
existent. J’ai également configuré le service X-Ray [10] qui récupère des informations sur l’exécution
des fonctions, pour trouver des éventuels problèmes de performances.

11
Le problème du démarrage des Lambdas
Lors du développement des fonctions Lambdas qui récupèrent les données depuis Elasticsearch, je suis
tombé sur un problème majeur : le démarrage à froid.
Lorsqu’une fonction Lambda s’exécute pour la première fois depuis un moment, celle-ci s’initialise sur
un réseau disponible, et reste ‘active’ pendant quelques minutes au cas où la fonction doit être
exécutée à nouveau, pour gagner en performances. Cette phase d’initialisation est entièrement gérée
par AWS, et n’est censée durer que quelques millisecondes.
Or, dans notre cas, j’ai pu constater que ce démarrage à froid prenait jusqu’à 20 secondes, car la
Lambda doit s’initialiser dans notre VPC, le même réseau que l’Elasticsearch. Cette initialisation prend
beaucoup plus de temps pour la Lambda car elle doit créer une Interface Réseau Elastic (ENI), une carte
réseau virtuel pour communiquer avec le VPC.
Différences entre le démarrage d’une Lambda classique et une Lambda dans un VPC [11]
Amazon est au courant du problème et a annoncé en décembre 2018 [12] qu’ils concevaient une
nouvelle architecture pour réduire le temps de démarrage à froid. En attendant cette évolution, nous
avons mis en place une solution temporaire qui consiste à appeler les lambdas régulièrement pour les
garder dans un état actif. Nous avons pour cela réutilisé le service CloudWatch, qui permet aussi
d’appeler régulièrement d’autres services. Grâce à cette solution on peut obtenir les statistiques en
moins de trois secondes.
Une autre solution possible aurait été de sortir l’Elasticsearch de son réseau privé et de sécuriser les
accès en utilisant le service IAM évoqué précédemment, mais malgré tout cela expose l’Elasticsearch
à l’internet et donc à de potentielles failles de sécurité. C’est pourquoi nous avons choisi d’écarter
cette solution.

12
Faire évoluer l’architecture
Mutualiser les clients Après avoir prouvé que l’architecture était viable, nous nous sommes posé la question du déploiement
client. Faut-il plutôt déployer une architecture pour chaque client ou plutôt maintenir une seule
instance mutualisée pour tous nos clients ?
En comparant les coûts d’une instance à l’utilisation du module statistique actuel, nous avons choisi
de construire une instance mutualisée, plus économique et suffisamment performante pour gérer tous
nos clients.
Identifier et sécuriser Ce choix implique de devoir identifier tous les clients sur l’API Gateway, et de sécuriser les accès pour
qu’un client ne puisse pas accéder aux données d’un autre. Pour cela j’ai mis en place deux niveaux de
sécurité :
Le premier est une clé API chiffrée de vingt caractères. Cette clé unique permet d’identifier le client
lors de ses requêtes et donc d’interroger et d’envoyer les données dans les bons indexes de
l’Elasticsearch. Cette clé permet uniquement d’envoyer des données vers l’API Gateway, et n’est pas
suffisante pour récupérer des statistiques.
Le second niveau d’identification est un JSON Web Token (ou JWT) [13] qui contient des informations
supplémentaires sur le client. Ce token est généré dans le Manager de sorte que seuls ses utilisateurs
puissent l’utiliser. Couplé à la clé API vu précédemment, il permet d’effectuer les requêtes retournant
des statistiques.
Une fonction Lambda a été ajouté en entrée de l’API Gateway pour vérifier la validité du JWT, tandis
que la clé API est entièrement gérée par AWS.

13
Nouvelle version de l'architecture
Simplifier et fiabiliser
Après la sécurisation de l’architecture nous avons cherché à l’optimiser et à la fiabiliser pour s’assurer
qu’aucune donnée ne soit perdue. Pour cela nous avons ajouté une file d’attente de lettres mortes
(Dead queue dans le schéma ci-dessus) qui récupère les messages qui sortent en erreur de la fonction
Message Filter. Cela permet de récupérer les messages en erreur et d’appliquer des correctifs si
nécessaires avant de les renvoyer manuellement dans la file. Cela permet aussi en cas de problème
avec l’instance Elasticsearch de stocker temporairement les données pour les traiter plus tard.
Les fonctions Lambda ont aussi été simplifié grâce à un système de codage en couche qui permet de
grouper les éléments communs entre différentes fonctions, comme la connexion à l’Elasticsearch, les
librairies externes utilisées, ou encore les variables d’environnement communes.

14
Déploiements automatisés
Une infrastructure codifiée
Une fois l’architecture finalisée, j’ai utilisé le service CloudFormation [14] pour la versionner et la déployer de la manière la plus simple possible. CloudFormation permet de stocker dans un fichier au format JSON les détails d’une architecture AWS. Cela inclut les différents services et les connexions entre eux, les stratégies d’accès et des variables de configuration. Ce fichier permet à AWS de déployer l’ensemble de l’architecture, ou de mettre à jour une instance existante s’il y a des différences. Ainsi nous n’avons qu’un fichier à versionner pour maintenir l’ensemble de l’infrastructure.
Lors du déploiement, le fichier indique l’emplacement du code à récupérer pour les fonctions Lambdas4, ce qui permet de toujours récupérer la dernière version. Il est également possible de passer des paramètres pour configurer un déploiement pour du développement ou de la production.
On peut distinguer dans la vue d’ensemble ci-dessus la brique API Gateway en orange sur la gauche,
les stratégies d’accès en bleue sur la droite et les rôles en vert. Le réseau privé est représenté sur la
droite, avec l’Elasticsearch au milieu en vert également. On retrouve également dans le VPC les
fonctions Lambda en orange. Les flèches noires représentent soit des liaisons de type événement
déclencheur, soit des dépendances.
Ce schéma démontre qu’il existe malgré tout des complexités dans l’architecture, dans le sens où il y
a beaucoup de liaisons entre les différents éléments.
Déploiement client
4 Le code des différentes fonctions est placé dans un bucket S3 [15], un système de stockage et de distribution de fichiers
Vue d'ensemble de l'architecture dans CloudFormation

15
Le déploiement du nouveau module statistique est prévu pour les clients courant Juillet. Le module est
d’abord uniquement accessible par l’équipe Novastream pour surveiller la qualité des statistiques
récupérées. Les scripts présents dans les lecteurs vidéo ont été mis à jour pour alimenter à la fois
l’ancien module et le nouveau. Cela nous permettra de détecter en interne des éventuelles différences
et d’appliquer des correctifs si nécessaire. Une fois cette étape terminée nous activerons le module
pour tous les clients.
Retour d’expérience
Sur le projet
Cette première expérience de transition vers du micro-service fût enrichissante pour moi comme pour
l’entreprise. Le nouveau module peut fonctionner de manière totalement autonome, et est
complètement indépendant du Manager.
Nous avons également pu constater l’efficacité de l’architecture Serverless, et confronter les nouvelles
problématiques qu’elle relève. La logique en matière de code est grandement simplifiée mais en
contrepartie la complexité architecturale augmente, comme le démontre le schéma page précédente.
Enfin, le nouveau module est beaucoup plus performant que l’ancien, et permet de manipuler plus
facilement les données pour obtenir de nouvelles métriques. La suite logique est de migrer l’ancien
affichage (figure page 5) pour appeler le nouveau module statistique. Une fois cette étape terminée,
nous pourrons retirer définitivement l’ancien module du Manager.
Sur l’alternance
Le projet présenté dans ce mémoire est le projet le plus conséquent que j’ai pu faire depuis mon
arrivée chez Novastream il y a deux ans. J’ai acquis énormément d’expérience durant ces deux années,
et je ne regrette absolument pas le choix de l’alternance. En plus du contenu de la formation, j’ai pu
continuer à étoffer mon bagage technique, que j’estime être essentiel pour les projets futurs.
Je tiens à adresser mes remerciements à toute l’équipe de Novastream pour leur accompagnement et
pour la confiance qu’ils m’ont accordée, ainsi qu’aux enseignants et intervenants de la formation pour
toutes les connaissances qu’ils m’ont partagées.

16
Références
[1] DynamoDB https://aws.amazon.com/fr/dynamodb/
[2] Définition du Serverless https://fr.wikipedia.org/wiki/Informatique_sans_serveur
[3] Elasticsearch https://www.elastic.co/fr/products/elasticsearch
[4] API Gateway https://aws.amazon.com/fr/api-gateway/
[5] Simple Queue Message https://aws.amazon.com/fr/sqs/
[6] Fonctions Lambda https://aws.amazon.com/fr/lambda/
[7] Virtual Private Cloud https://aws.amazon.com/fr/vpc/
[8] Identity and Access Management https://aws.amazon.com/fr/iam/
[9] CloudWatch https://aws.amazon.com/fr/cloudwatch/
[10] X-Ray https://aws.amazon.com/fr/xray/
[11] How to manage Lambda VPC cold starts and deal with that killer latency. https://www.freecodecamp.org/news/lambda-vpc-cold-starts-a-latency-killer-5408323278dd/
[12] AWS Lambda in a VPC Will Soon be Much Faster. https://www.nuweba.com/AWS-Lambda-in-a-VPC-will-soon-be-faster
[13] JSON Web Token https://jwt.io/
[14] CloudFormation https://aws.amazon.com/fr/cloudformation/
[15] S3 https://aws.amazon.com/fr/s3/







![Entrées Sorties - [Cedric]cedric.cnam.fr/~farinone/IAGL/EntSort.pdf · Les entrées/sorties Le langage Java VIII-2 JMF Introduction Java possède une grosse bibliothèque de classes](https://img.pdfslide.fr/doc/110x75/5aab9fa37f8b9a8d678c0c75/entres-sorties-cedric-farinoneiaglentsortpdfles-entressorties-le-langage.jpg)













![AIQL: Enabling Efficient Attack Investigation from System ...pmittal/publications/aiql-atc18.pdfSplunk [23], and ElasticSearch [10] are ineffective in ex-pressing event relationships](https://img.pdfslide.fr/doc/110x75/5ec7e65e9b761d7a4112aa81/aiql-enabling-eficient-attack-investigation-from-system-pmittalpublicationsaiql-atc18pdf.jpg)







