
La recherche fulltext :
D’ES à PG
23 juin 2015
- Louise Grandjonc : dev. python - django à Novapost
- PeopleDoc : dématerialisation de document RH (fiches de paye, factures, contrats etc.)
- Pourquoi et comment sommes nous passés d’une recherche fulltext utilisant ES à PG?
Introduction
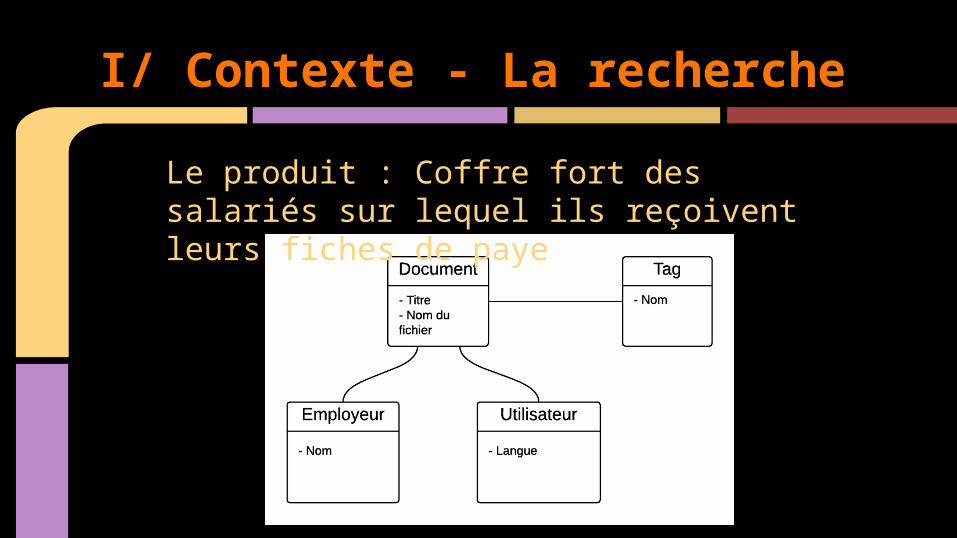
I/ Contexte - La recherche
Le produit : Coffre fort des salariés sur lequel ils reçoivent leurs fiches de paye
- Historiquement : recherche fulltext avec ES
- Développement d’un nouveau coffre fort… Pas de remise en cause.
I / Contexte

Côté déploiement…- Une machine avec ES à configurer- 7 millions de documents migrés pas
encore indexés- Les distributions arrivent- Indexation à la main… C’est le chaos
II / Les problèmes arrivent

Côté dev…- Manque de connaissance d’ES Fuzzy sur la
recherche- Indexation en anglais uniquement (pas d’utilisation
de stopwords pour les autres langues)
… La recherche est mal faite, des documents manquent, les utilisateurs se plaignent...
II / Les problèmes arrivent

On en conclu :- Processus trop chaotique côté
déploiement- Développement mal fait par manque de
connaissanceMais en fait… On a vraiment besoin d’ES?
II/ Les problèmes arrivent
Pourquoi alors ?- Postgresql déjà utilisé- Simplification du déploiement- Un spécialiste à la maison- Meilleure documentation pour les devs
Comment alors...
III/ PG à la rescousse
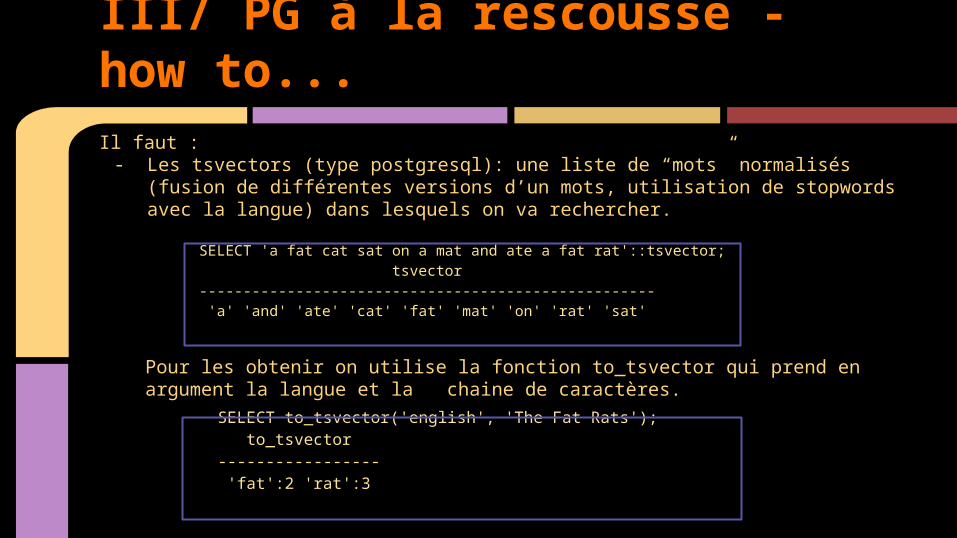
Il faut : - Les tsvectors (type postgresql): une liste de “mots” normalisés (fusion de différentes
versions d’un mots, utilisation de stopwords avec la langue) dans lesquels on va rechercher.
III/ PG à la rescousse - how to...
SELECT 'a fat cat sat on a mat and ate a fat rat'::tsvector; tsvector---------------------------------------------------- 'a' 'and' 'ate' 'cat' 'fat' 'mat' 'on' 'rat' 'sat'
SELECT to_tsvector('english', 'The Fat Rats'); to_tsvector ----------------- 'fat':2 'rat':3
Pour les obtenir on utilise la fonction to_tsvector qui prend en argument la langue et la chaine de caractères.
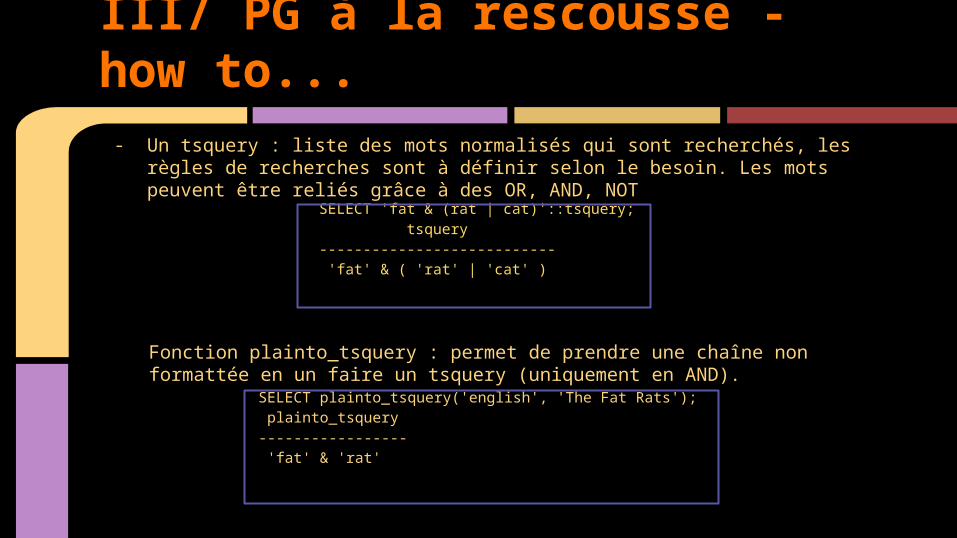
- Un tsquery : liste des mots normalisés qui sont recherchés, les règles de recherches sont à définir selon le besoin. Les mots peuvent être reliés grâce à des OR, AND, NOT
III/ PG à la rescousse - how to...
SELECT 'fat & (rat | cat)'::tsquery; tsquery --------------------------- 'fat' & ( 'rat' | 'cat' )
Fonction plainto_tsquery : permet de prendre une chaîne non formattée en un faire un tsquery (uniquement en AND).
SELECT plainto_tsquery('english', 'The Fat Rats'); plainto_tsquery ----------------- 'fat' & 'rat'
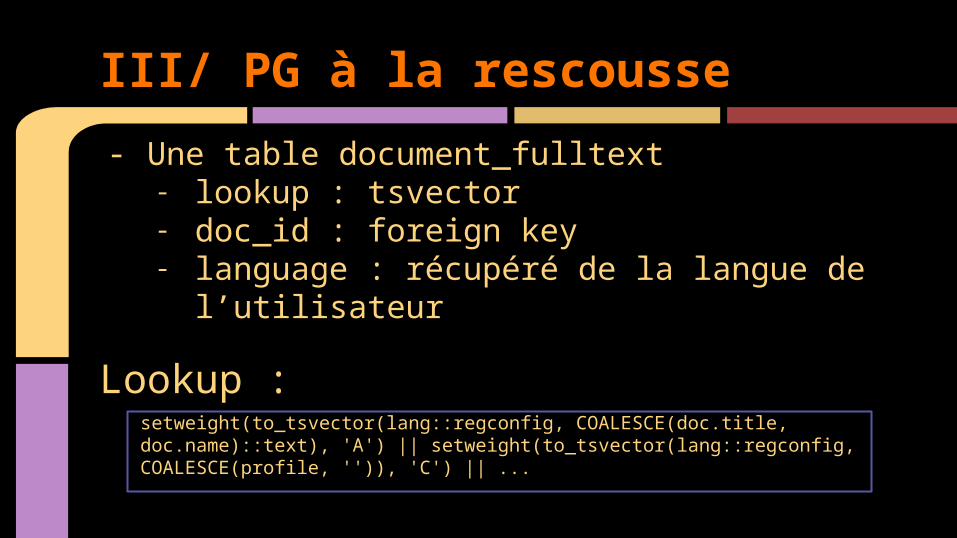
- Une table document_fulltext- lookup : tsvector- doc_id : foreign key- language : récupéré de la langue de l’utilisateur
Lookup :
III/ PG à la rescousse
setweight(to_tsvector(lang::regconfig, COALESCE(doc.title, doc.name)::text), 'A') || setweight(to_tsvector(lang::regconfig, COALESCE(profile, '')), 'C') || ...
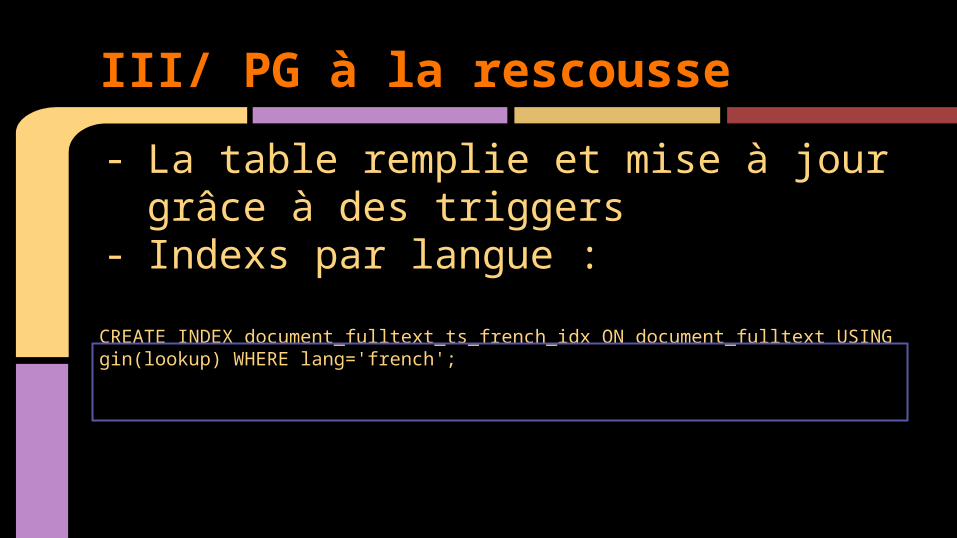
- La table remplie et mise à jour grâce à des triggers
- Indexs par langue :
CREATE INDEX document_fulltext_ts_french_idx ON document_fulltext USING gin(lookup) WHERE lang='french';
III/ PG à la rescousse
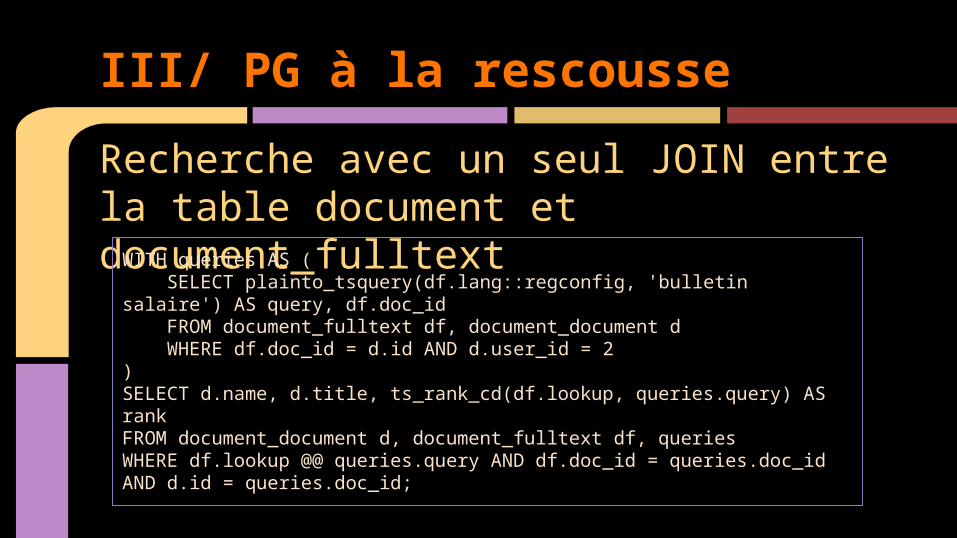
Recherche avec un seul JOIN entre la table document et document_fulltext
III/ PG à la rescousse
WITH queries AS ( SELECT plainto_tsquery(df.lang::regconfig, 'bulletin salaire') AS query, df.doc_id FROM document_fulltext df, document_document d WHERE df.doc_id = d.id AND d.user_id = 2)SELECT d.name, d.title, ts_rank_cd(df.lookup, queries.query) AS rankFROM document_document d, document_fulltext df, queriesWHERE df.lookup @@ queries.query AND df.doc_id = queries.doc_id AND d.id = queries.doc_id;
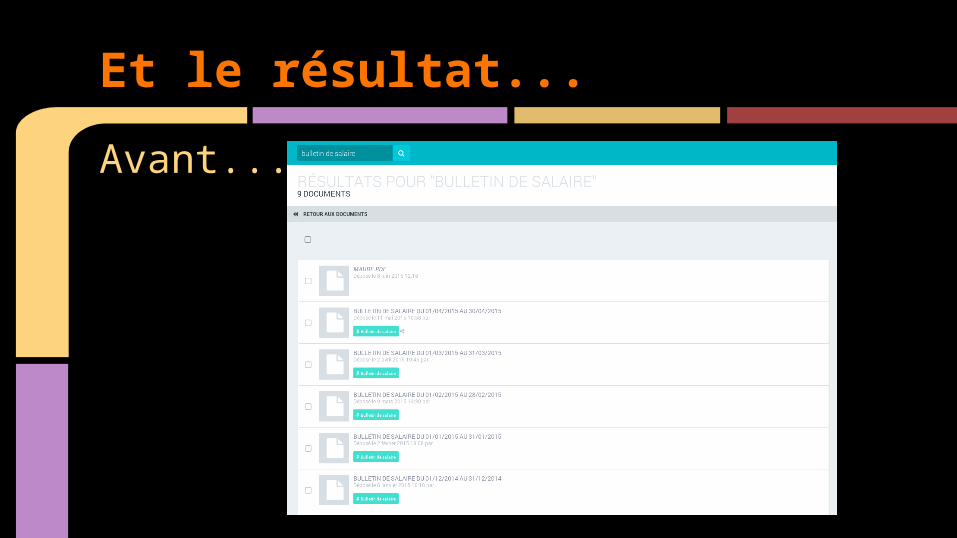
Avant...
Et le résultat...
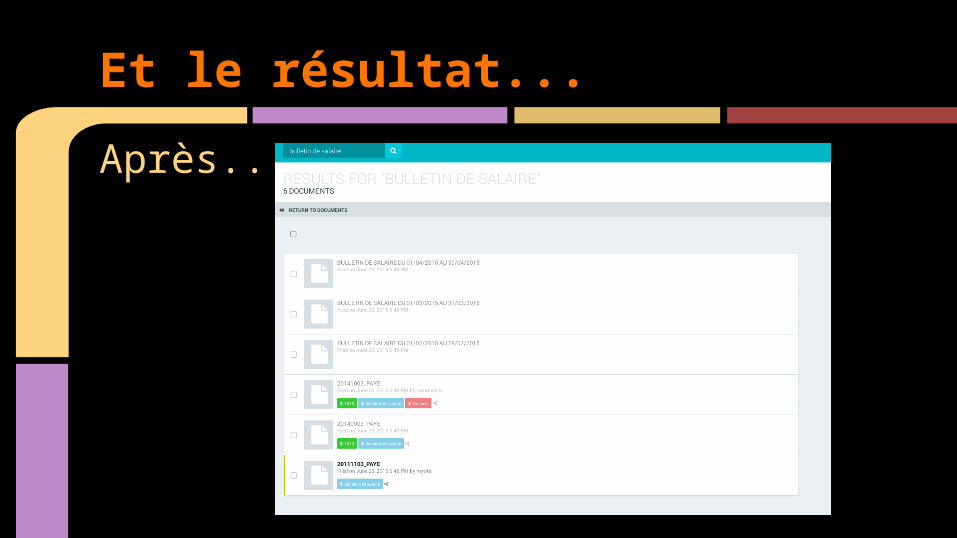
Après...
Et le résultat...

- Initialisation de la table simple et rapide via un script
- Plus de tâches d’indexation à gérer grâce aux triggers
- Développement simple grâce à la collaboration DBA/dev.
Conclusion

Des questions ?
Recommended


















![[Laws] Meetup - AWS Lambda](https://img.pdfslide.fr/doc/110x75/58ef2b011a28ab50758b45f1/laws-meetup-aws-lambda.jpg)