
Importation de données depuis une
source Ascii
Université des Sciences et Techniques de Franche Comté
Rapport de stage 2010
BONVALOT Vincent Licence professionnelle : Conception Orientée Objet d’Applications Multi-Tiers
Entreprise Digital Surf
16 rue Lavoisier
25000 Besançon
Tuteur de stage Professeur Encadrant
Jérémie BLANC Bruno TATIBOUËT

Page 2
Importation de données depuis une source Ascii
Remerciements
Dans un premier temps ma reconnaissance s’adresse à Jérémie BLANC, Respon-
sable des Développements Expérimentaux de Digital Surf. Sa patience, son amabilité et
le soutien technique qu’il m’a apporté ont rendu ce stage d’autant plus intéressant.
Plus généralement, je tiens { remercier l’ensemble des salariés de l’entreprise pour leur
amabilité et l’accueil agréable qu’ils m’ont réservé.
Pour terminer, merci à Bruno TATIBOUËT pour m’avoir suivi durant ce stage et pour avoir fait l’effort de se déplacer sur mon lieu de travail.

Page 3
Importation de données depuis une source Ascii
Sommaire Introduction ..................................................................................................................................... 4
1. Présentation de L’entreprise ..................................................................................................... 5
1.1 Digital Surf ......................................................................................................................... 5
1.2 Le logiciel Mountains ....................................................................................................... 6
2. Présentation du stage.............................................................................................................. 10
2.1 Présentation du sujet ...................................................................................................... 10
2.2 Les types de formats de fichiers ...................................................................................... 10
2.3 Les outils de développement .......................................................................................... 17
2.4 Calendrier du stage ......................................................................................................... 18
3. Analyse de l’existant ................................................................................................................ 19
4. Le Travail réalisé ..................................................................................................................... 22
4.1 Le parseur de fichier ........................................................................................................ 22
4.1.1 Les fichiers au format colonnes de coordonnées ................................................... 22
4.1.2 Les fichiers au format matrice de points ................................................................ 23
4.1.3 Les paramètres nécessaires au parseur ................................................................... 24
4.1.4 L’extraction des paramètres contenus dans l’entête .............................................. 25
4.2 L’interface utilisateur ......................................................................................................26
4.2.1 Écran des réglages généraux....................................................................................26
4.2.2 Écran des réglages concernant l’entête ................................................................... 30
4.3 Le système de sauvegarde/chargement de configurations ............................................ 31
4.4 La génération de l’étudiable / interprétation des données ............................................ 33
5. Analyse critique de la solution développée............................................................................ 35
5.1 Les avantages ................................................................................................................... 35
5.2 Les inconvénients ............................................................................................................ 35
5.3 Une solution alternative .................................................................................................. 36
Conclusion technique ..................................................................................................................... 38
Conclusion générale ....................................................................................................................... 39

Page 4
Importation de données depuis une source Ascii
Introduction
Dans le cadre de ma formation en troisième année de licence professionnelle,
j’ai été amené { effectuer un stage dans une entreprise de mon choix. Mes recherches
m’ont mené jusqu’{ l’entreprise Digital Surf, dont le siège social se situe { Besançon. Le
stage s’est déroulé sous la tutelle de Jérémie BLANC, au sein de l’unité Mountains Sur-
face Analysis de l’entreprise.
Digital Surf est spécialisée dans la métrologie de surfaces. Son activité est
double car elle consiste { fournir { ses clients non seulement des moyens d’acquérir
des données { partir de l’environnement, mais également des solutions pour les traiter
et les étudier.
Mon objectif était en quelque sorte médian à ces deux activités dans le sens ou
j’ai du développer un outil qui permette d’acquérir des données, mais qui serait utilisé
dans le logiciel d’analyse que développe l’entreprise.
Digital Surf travaille avec divers clients, qui disposent chacun de leurs propres
normes en ce qui concerne l’export de données acquises pendant les mesures. Cette
diversité pose un problème, car elle oblige le logiciel d’analyse Mountains { s’adapter {
chaque nouveau format de fichier. Mon but était de proposer une solution générique,
pour permettre d’importer facilement les mesures dans le logiciel, en prenant en
compte les différences de chaque format.
Pour présenter au mieux mon expérience de ces derniers mois, je commencerai
par décrire en détail la structure qui m’a accueilli. Je présenterai ensuite le sujet de
mon stage, la solution actuellement en place et devant être améliorée, puis la façon
dont j’ai abordé et réalisé ma tâche. La dernière partie sera consacrée aux conclusions
que je tire de cette expérience, et { ce qu’elle m’a apporté.

Page 5
Importation de données depuis une source Ascii
1. Présentation de L’entreprise
1.1 Digital Surf
La société a été co-créée en 1989 par Christophe MIGNOT (actuel directeur) et
s’est depuis imposée comme leader mondial dans le domaine de la métrologie de sur-
face { l’échelle micro et nanométrique. Son implantation à Besançon, centre européen
des microtechniques lui a permis de bénéficier des compétences locales. Les solutions
que l’entreprise propose sont utilisées dans le monde entier, principalement dans les
laboratoires de recherche et l’industrie, dans des domaines très variés tels que
l’automobile, la cosmétique, la métallurgie ou encore les semi-conducteurs.
L’entreprise est organisée autour de deux domaines d’activité complémentaires
qui sont : le scanning (Volcanyon Scanning Solutions) et l’analyse (Mountains Surface
Analysis).
Volcanyon Scanning Solutions :
Le terme scanning est utilisé pour désigner les technologies permettant
d’acquérir des données { partir de supports physiques, grâce { un balayage.
Volcanyon est une suite d’outils qui permet de gérer le processus
d’acquisition des données. Cela est réalisé grâce { la technologie de capteur Nobis
(capteur confocal chromatique à haute résolution), et aux contrôleurs permettant de le
piloter. Aujourd’hui, cette activité tend { disparaître, car plus assez rentable.
Mountains Surface Analysis :
L’entreprise développe le logiciel Mountains, qui fourni une large gamme
d’outils d’analyse et de traitement de surfaces. Mountains permet de traiter
aussi bien des étudiables 2D (profils) que 3D (surfaces). C’est dans cette
équipe que j’ai été intégré pour réaliser mon stage.

Page 6
Importation de données depuis une source Ascii
L’équipe de DigitalSurf est donc compétente dans l’ensemble du processus acquisi-
tion/traitement de données de métrologie de surface. Les ingénieurs de l’entreprise
conçoivent eux même les cartes d’acquisition permettant d’utiliser les capteurs, le logi-
ciel pour les piloter, ainsi que l’application post-traitement.
L’entreprise est également très { l’écoute de toutes les innovations dans le domaine de
la métrologie, afin de s’y adapter facilement et d’anticiper les besoins de ses clients.
Elle travaille aujourd’hui avec de grands groupes à renommée mondiale tel que Taylor
Hobson.
Figure 1 : Processus d'analyse métrologique grâce aux composants Digital Surf
1.2 Le logiciel Mountains
Il a été primordial pour moi de bien comprendre le principe de fonctionnement du lo-
giciel afin de voir la place que mon outil allait y occuper.
Le logiciel permet l’étude et la manipulation de toute surface numérisée. Le terme utili-
sé par Digital Surf pour désigner une mesure importée, manipulée dans Mountains est « étu-
diable ». Ce terme est générique et désigne aussi bien des profils (2D) que des surfaces (3D).
Page 7
Importation de données depuis une source Ascii
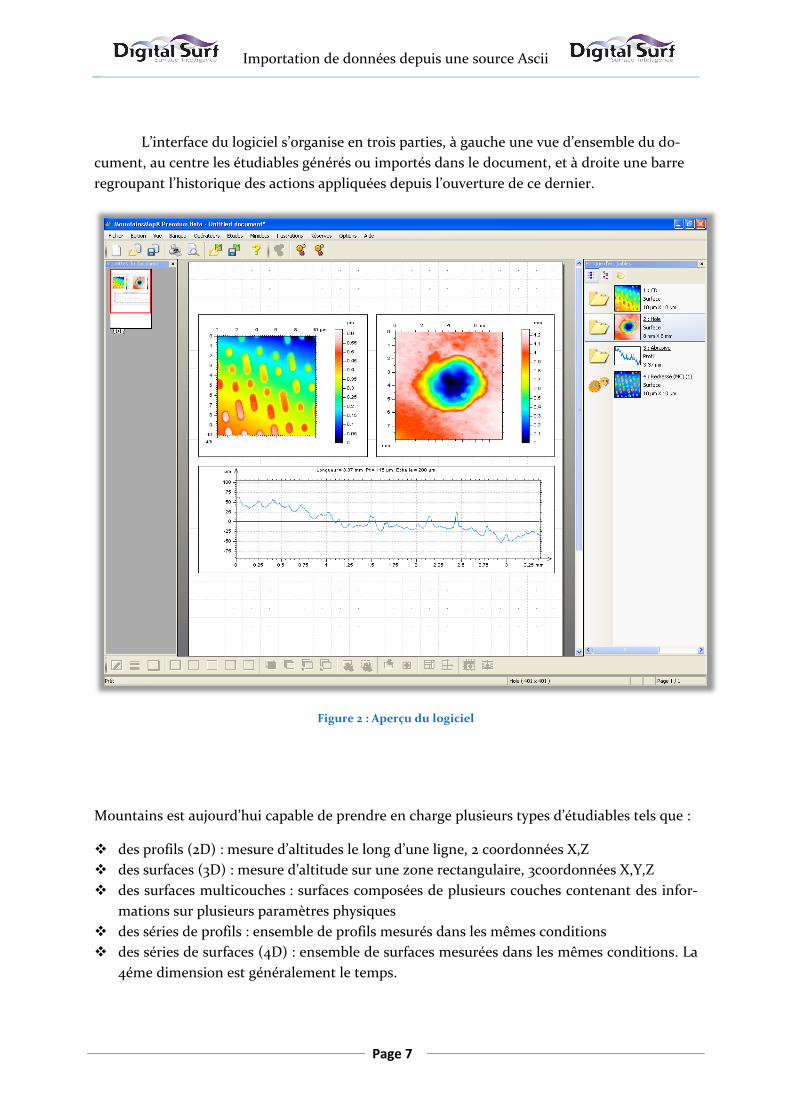
L’interface du logiciel s’organise en trois parties, { gauche une vue d’ensemble du do-
cument, au centre les étudiables générés ou importés dans le document, et à droite une barre
regroupant l’historique des actions appliquées depuis l’ouverture de ce dernier.
Figure 2 : Aperçu du logiciel
Mountains est aujourd’hui capable de prendre en charge plusieurs types d’étudiables tels que :
des profils (2D) : mesure d’altitudes le long d’une ligne, 2 coordonnées X,Z
des surfaces (3D) : mesure d’altitude sur une zone rectangulaire, 3coordonnées X,Y,Z
des surfaces multicouches : surfaces composées de plusieurs couches contenant des infor-
mations sur plusieurs paramètres physiques
des séries de profils : ensemble de profils mesurés dans les mêmes conditions
des séries de surfaces (4D) : ensemble de surfaces mesurées dans les mêmes conditions. La
4éme dimension est généralement le temps.

Page 8
Importation de données depuis une source Ascii
Les outils d’analyse présents dans le logiciel se divisent en deux catégories : les opérateurs
et les études.
La première regroupe les outils de transformation. Ils prennent un étudiable en entrée,
et en produisent un nouveau transformé via un algorithme mathématique. L’étudiable
d’origine est conservé afin de pouvoir le réutiliser, et le comparer à celui qui a été produit. Les
opérateurs permettent entre autre de redresser une surface, de corriger des points non mesu-
rés, de détecter les contours des formes etc.
Figure 3 : Aperçu de la fenêtre « opérateur de redressement »
Nous avons ci-dessus un aperçu de la boite de dialogue donnant accès à la fonction de
redressement d’une surface. L’étudiable d’origine est situé au centre de la fenêtre, et le dégradé
de couleur de l’image (symbolisant les altitudes des points) indique bien que la surface n’a pas
été mesurée exactement { l’horizontale.
En bas { gauche, on peut voir l’étudiable qui sera généré en sortie de cet opérateur. On re-
marque que les altitudes des points ont été modifiées, donnant donc un étudiable « redressé ».
Page 9
Importation de données depuis une source Ascii
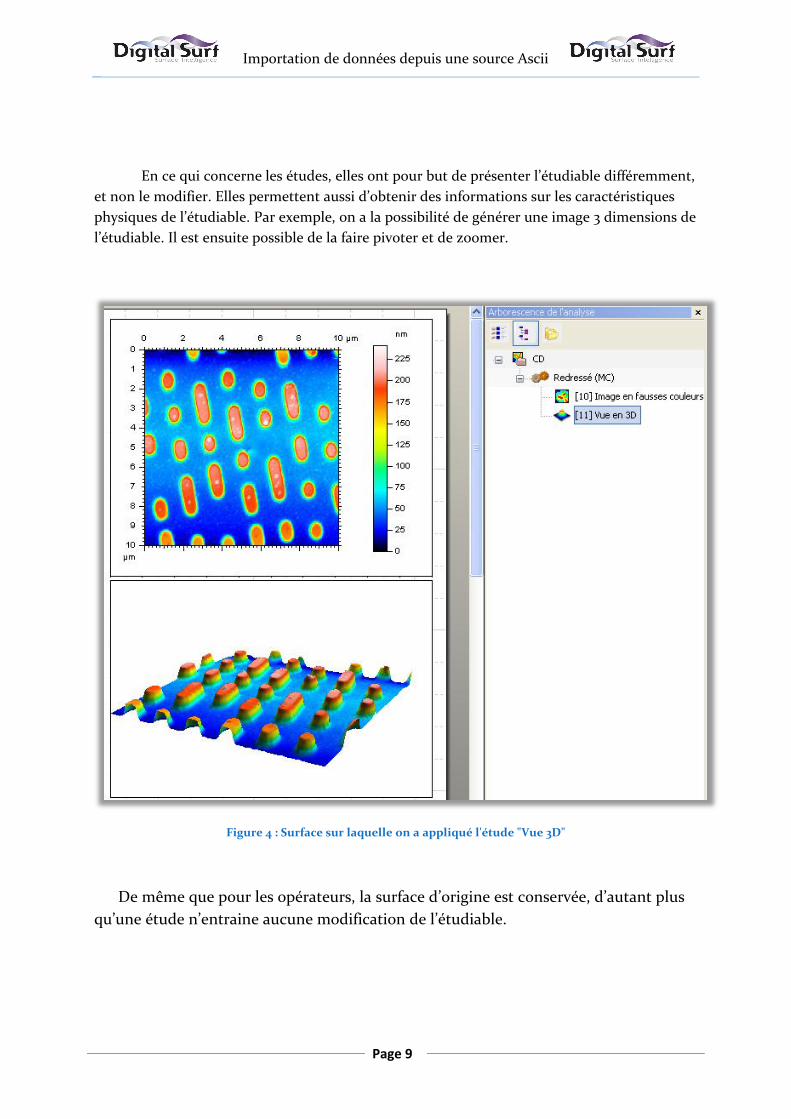
En ce qui concerne les études, elles ont pour but de présenter l’étudiable différemment,
et non le modifier. Elles permettent aussi d’obtenir des informations sur les caractéristiques
physiques de l’étudiable. Par exemple, on a la possibilité de générer une image 3 dimensions de
l’étudiable. Il est ensuite possible de la faire pivoter et de zoomer.
Figure 4 : Surface sur laquelle on a appliqué l'étude "Vue 3D"
De même que pour les opérateurs, la surface d’origine est conservée, d’autant plus
qu’une étude n’entraine aucune modification de l’étudiable.

Page 10
Importation de données depuis une source Ascii
2. Présentation du stage
2.1 Présentation du sujet
Digital Surf reçoit souvent de ses futurs clients des exemples de fichiers de mesures que
ces derniers voudraient voir importés dans Mountains, afin de se faire une idée du logiciel. Ces
mesures sont stockées dans des fichiers au format texte. Le problème auquel est confrontée
l’entreprise vient de la disposition des données dans le fichier en question. En effet, aucune
norme n’impose aux entreprises disposant d’appareils de mesures d’organiser leurs exports de
données d’une façon précise.
Digital Surf doit donc s’adapter { la façon de faire de chacun de ses clients, afin de
prouver son efficacité et d’avoir la possibilité de travailler avec eux.
Le logiciel manipule actuellement plus de quatre-vingt formats de fichiers différents,
mais il reste difficile de lui en faire importer certains dont l’organisation des données se trouve
être atypique. La majorité du temps, une modification rapide du fichier de mesure permettait
au logiciel d’en extraire les informations, mais ce n’était pas toujours le cas.
Le but du stage était donc de proposer une solution capable d’importer un grand
nombre de types de fichiers de données, et disposant d’une interface utilisateur la plus intui-
tive possible. Le tout devait être réalisé sans aucune modification du fichier de mesures source.
Il s’agissait en somme de créer un parseur* de fichiers, dont le comportement serait
fonction des réglages de l’utilisateur, renseignés par celui ci via une interface de contrôle.
Un des objectifs principaux était aussi de pouvoir conserver une configuration pour un format
de fichier donné, afin de pouvoir l’importer très facilement par la suite, sans reconfigurer le
parseur*. L’étudiable ainsi calculé devait ensuite être importé dans le logiciel, afin d’être traité
comme tout étudiable aujourd’hui compatible avec Mountains.
2.2 Les types de formats de fichiers
Voici les principaux formats de fichiers devant être pris en charge par l’application. Pour
chacun d’eux, il faut prendre en compte qu’ils peuvent débuter ou non par un entête, donnant
des informations sur le contenu du fichier ; les tailles des axes, les unités de la mesure… Le con-
tenu de cet entête est tout { fait aléatoire d’un fichier à un autre.

Page 11
Importation de données depuis une source Ascii
Les profils Z,
Ces fichiers se présentent sous forme d’une colonne de coordonnées Z. Le nombre de
lignes dans le fichier permet donc de déterminer la taille, ainsi que le nombre de points de
l’axe X.
Figure 5 : Exemple de fichier « profil Z »
Dans l’exemple ci-dessus, on remarque que le fichier dispose d’un entête de trois lignes.
Comme rien de textuel n’apparaît, on peut supposer que le nombre « 3999 » indique le nombre
de points du profil. Quant aux deux autres chiffres (4.00 et 1), il est difficile de connaître leur
utilité.
Pour importer les points de ce fichier, il faudra le lire ligne par ligne, et à chaque fois récu-
pérer le nombre qui s’y trouve. « 3999 » est le nombre total de points, et donc le nombre de
points sur l’axe X.

Page 12
Importation de données depuis une source Ascii
Les profils XZ
Ces fichiers contiennent généralement deux colonnes de coordonnées disposées côte à
côte. Dans le cas standard, la colonne de gauche contiendra les points de l’axe X, et celle de
droite ceux de l’axe Z. Cela étant, rien ne garanti que la situation inverse ne pourrait pas se
produire. D’autre part, certains fichiers disposent les points X et Z en une seule colonne, en
alternant les deux coordonnées d’une ligne sur l’autre.
Figure 6 : Exemple de fichier « profil XZ »
Le fichier ci-dessus contient deux colonnes de coordonnées côte à côte. La première
ligne est l’entête et semble nous indiquer que la colonne de gauche correspond aux coor-
données X, et la colonne de droits aux Z.
Pour extraire les points de ce fichier, il faudra le lire ligne par ligne, pour chacune
d’elles détecter les deux coordonnées présentes et les stocker.

Page 13
Importation de données depuis une source Ascii
Les surfaces XYZ (disposition colonnes)
Ces fichiers contiennent généralement trois colonnes de coordonnées côte à côte, dont
l’ordre d’apparition est aléatoire. On peut donc se trouver face à plusieurs configurations :
XYZ, ZYX, ZXY, etc.
Dans d’autres cas, d’autres mesures peuvent être présentes dans le fichier, ce qui se mani-
feste par l’ajout d’une ou plusieurs colonnes au milieu, { gauche ou { droite des coordon-
nées.
Figure 7 : Exemple de fichier « surface XYZ » (disposition colonnes)
Le fichier ci-dessus contient trois colonnes de coordonnées, et la deuxième ligne
d’entête nous indique qu’elles correspondent de gauche { droite { X Y Z. Ici, on remarque
que l’entête spécifie également l’unité de chaque axe. Cette information n’a pas d’intérêt en
ce qui concerne l’extraction des points, en revanche Moutains en aura l’utilité.
Ce type de fichier sera importé de la même manière que le précédent, à ceci près que
l’on va extraire cette fois ci pas deux mais trois coordonnées de chaque ligne.

Page 14
Importation de données depuis une source Ascii
Les surfaces XYZ (disposition matrice)
Ces fichiers contiennent les points tels qu’ils sont situés dans l’espace. La matrice contient
généralement une première ligne complète représentant les coordonnées en X. En dessous
de celle-ci, une deuxième ligne contient les points en Y, et la fin de fichier contient tous les
points en Z, tels qu’ils sont répartis dans l’espace. Par exemple, si la ligne des X et celle des
Y contiennent chacune 100 points, la fin du fichier sera composée de 100 lignes de 100
points, correspondantes aux coordonnées Z.
Dans ce type de fichier, c’est le nombre de points par ligne, et le nombre de lignes qui ren-
seignent respectivement la taille en X et en Y de l’étudiable.
Figure 8 : Exemple de fichier « surface XYZ » (disposition matrice)
Le fichier ci-dessus dispose d’un entête très limitée, mais on remarque que les deux
premières lignes de points sont très différentes au niveau des valeurs que les autres. On
suppose donc qu’elles correspondent aux coordonnées X et Y. Les autres lignes contien-
nent les coordonnées Z.

Page 15
Importation de données depuis une source Ascii
L’importation de ce type de fichier nécessite de connaître les bornes (les numéros de
lignes) qui délimitent le début et la fin de chaque coordonnée. Sachant cela, il suffit ensuite
de lire le fichier ligne par ligne et suivant que la ligne courante se trouve dans les bornes
des X, des Y, ou des Z, on stocke les points comme il faut.
Les surfaces Z
Ces fichiers ont une disposition semblable aux précédent, mais ne comportent pas de
ligne de points X et Y. On a donc seulement la présence des coordonnées Z. Comme le
stockage des points est réalisé sous forme de matrice, on est capable de déterminer la taille
de chaque axe, et de replacer les coordonnées Z dans l’espace.
Figure 9 : Exemple de fichier « surface Z »

Page 16
Importation de données depuis une source Ascii
Les nuages de points
Ces fichiers ont un contenu très similaire à celui des surfaces XYZ (disposition colonnes).
La principale différence se situe au niveau des valeurs des coordonnées, qui, n’étant pas ré-
gulières rendent difficile l’importation de ce type d’étudiable. De plus, en l’absence
d’entête, le résultat est très souvent différent de l’original car on est obligé d’émettre des
suppositions quant à la taille de chaque axe.
Figure 10 : Exemple de fichier « nuage de points »
Ci-dessus, un cas plutôt atypique, mais assez fréquemment rencontré. Dans ce fichier,
on trouve six colonnes de nombres, et pas d’entête. On devine facilement que les trois coor-
données X, Y et Z sont présentes dans les colonnes 2, 3 et 4, mais on en est réduit à supposer
qu’elles sont données dans cet ordre et pas autrement. De plus, aucune des trois colonnes ne
contient de valeurs totalement constantes (contrairement { ce que l’on peut voir sur la figure

Page 17
Importation de données depuis une source Ascii
7), ce qui prouve qu’on est bien en présence d’un nuage de point : les coordonnées Z ne sont
pas réparties régulièrement dans l’espace.
2.3 Les outils de développement
L’entreprise Digital Surf développe son logiciel Mountains exclusivement grâce au lan-
gage C++. Elle utilise comme environnement de développement l’outil Visual Studio 2008, ain-
si que les bibliothèques MFC (Microsoft Foundation Class).
Le C++ apporte au logiciel une très bonne vitesse d’exécution, ce qui est primordial
dans le cas de Moutains. En effet, un logiciel de traitement d’image 2D et 3D est amené { réali-
ser de lourds calculs, et le fait d’attendre trop longtemps les résultats n’enchanterait aucun
utilisateur. Le C++ permet également un développement « objet », vivement conseillé pour
structurer un projet conséquent tel que Mountains.
Quant à Visual Studio 2008, cet outil est en premier lieu conçu pour développer en
C++, il est donc tout indiqué afin de tirer le meilleur parti de ce langage. Cet environnement de
développement permet un codage rapide et un débogage précis grâce à toutes les fonctionnali-
tés dont il dispose.
L’entreprise a choisi de développer son logiciel entièrement avec les MFC. Ces biblio-
thèques encapsulent l’API Win32* utilisée par Microsoft dans ses systèmes d’exploitation. Le
premier inconvénient des MFC réside dans leur utilisation qui reste très bas niveau (très tech-
nique). En effet, il n’y a pas de réelle abstraction des fonctions brutes Win32, ce qui rend cet
outil assez contraignant à utiliser de prime abord. En outre, les fonctions de base étant très
accessibles au développeur, elles lui permettent de réaliser très précisément ce dont il a envie,
et de manière optimisée puisqu’il fait fi d’une couche d’encapsulation dont il n’aurait pas for-
cément besoin et qui aurait donc tendance à ralentir le programme. Autre désagrément,
l’utilisation des MFC dans toute l’application la rend impossible { porter sur un autre système
d’exploitation que Windows. Mais ceci n’étant en aucun cas l’objectif de Digital Surf, cela ne
pose pas de réel problème.
Pour finir, il m’a été demandé d’encapsuler mon programme dans un contrôle ActiveX.
Ce système { l’avantage de s’intégrer facilement dans une application, sans entraîner de modi-
fication importante dans son code. Son utilisation était donc tout indiquée pour pouvoir tester
la fonctionnalité à développer sans devoir modifier Mountains.
Page 18
Importation de données depuis une source Ascii
2.4 Calendrier du stage
Voici chronologiquement les différentes phases de réalisation du stage.
Semaine 1 Prise en main des outils : Visual Studio, les MFC Documentation sur les Contrôles ActiveX
Semaine 2 Étude des techniques de parsing via divers essais. Codage de fonctions outils pour le parsing.
Semaines 3, 4 Étude des solutions de parsing du header. Réflexion sur l’interface graphique utilisateur.
Semaines 5,6
Implémentation de l’interface graphique dé-finitive. Création du système de sauve-garde/chargement de configurations.
Semaines 8, 9, 10
Implémentation du système de prévisualisa-tion de l’étudiable. Mise en place de fonctions concernant l’ergonomie de l’application.
Semaines 11, 12, 13, 14, 15 Correction de bugs. Finitions diverses. Rédaction du rapport de stage.
Page 19
Importation de données depuis une source Ascii
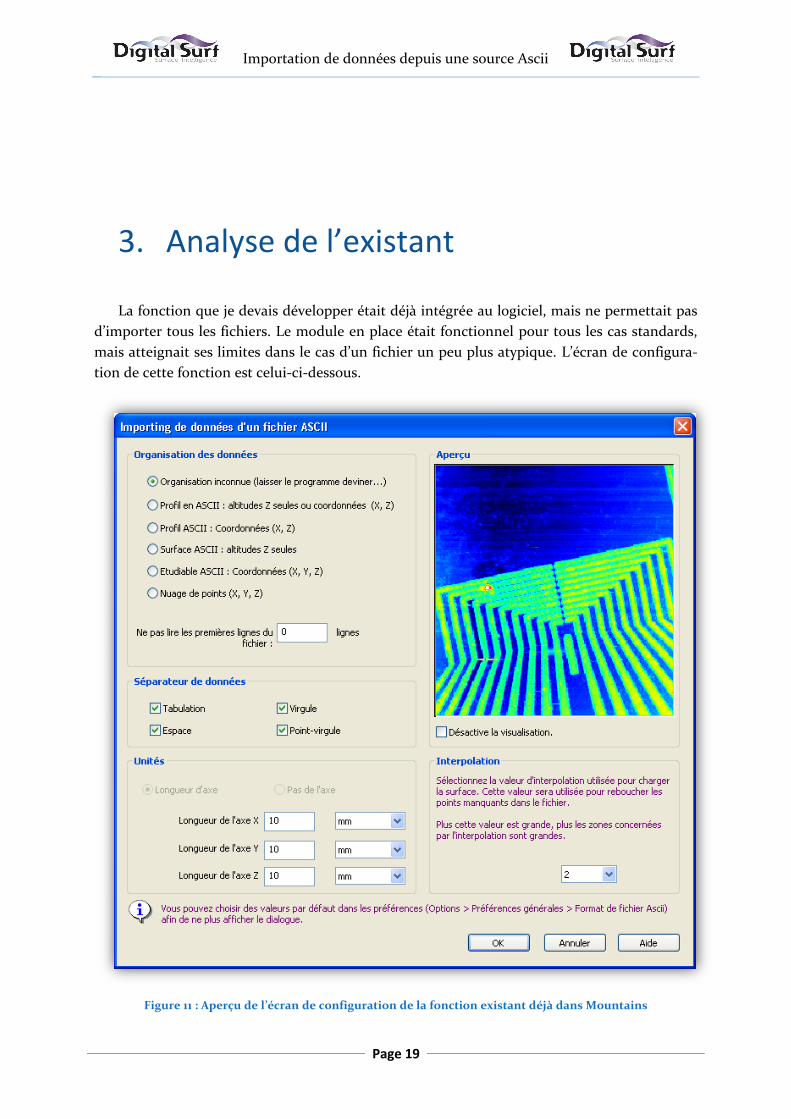
3. Analyse de l’existant
La fonction que je devais développer était déjà intégrée au logiciel, mais ne permettait pas
d’importer tous les fichiers. Le module en place était fonctionnel pour tous les cas standards,
mais atteignait ses limites dans le cas d’un fichier un peu plus atypique. L’écran de configura-
tion de cette fonction est celui-ci-dessous.
Figure 11 : Aperçu de l’écran de configuration de la fonction existant déjà dans Mountains

Page 20
Importation de données depuis une source Ascii
On remarque que l’interface comprend très peu de réglages. Parmi eux, l’utilisateur a la
possibilité de choisir le type d’étudiable { importer, le nombre de lignes { ignorer en début de
fichier, le caractère séparateur des données, l’unité de chaque axe, et la valeur de
l’interpolation des points non mesurés. Ces paramètres seront repris et détaillés dans la section
suivante.
Avantages de cette solution :
Simple à utiliser.
Présence d’un mode de détection automatique de l’étudiable { charger.
Prévisualisation en temps réel.
Inconvénients :
Aucun réglage concernant les éventuels entêtes de fichiers.
Caractères séparateurs proposés fixes (on ne peut pas en spécifier un personnalisé).
Travail en aveugle (on ne voit pas le fichier que l’on veut importer).
Impossibilité d’importer des étudiables dont le fichier source aurait une disposition
atypique.

Page 21
Importation de données depuis une source Ascii

Page 22
Importation de données depuis une source Ascii
4. Le Travail réalisé
L’application développée devait s’utiliser dans Mountains comme un opérateur. Il a
donc été décidé de l’encapsuler dans un contrôle ActiveX afin de faciliter son intégration
dans le logiciel.
4.1 Le parseur de fichier
La première étape du développement consistait à penser et implémenter un parseur* de
fichier assez souple pour permettre d’extraire les informations d’un maximum de fichiers, aussi
différents qu’ils soient les uns des autres.
Je disposais de multiples fichiers d’exemples, qui m’ont permis de noter leurs simili-
tudes, par rapport au type d’étudiable qu’ils contenaient.
Au niveau de la méthode pour parser* ces fichiers, il était avantageux pour moi de les
lire ligne par ligne. En effet de cette façon je pouvais récupérer un bloc d’informations « cohé-
rent ». J’entends par l{ qu’une ligne contient souvent les coordonnées qui caractérisent un
point de l’étudiable et un seul. En traitant les fichiers ligne par ligne, je pouvais donc extraire
les points individuellement dans la majorité des fichiers.
J’ai fini par distinguer deux types de fichiers principaux dont la méthode d’extraction
des données se devait d’être différente à cause de la façon dont ils stockent les points.
4.1.1 Les fichiers au format colonnes de coordonnées
Ces fichiers contiennent dans le cas standard trois colonnes de coordonnées, qui sont
dans tous les cas de tailles identiques. Si un fichier contient 150 lignes, la colonne des X
s’étendra sur 150 lignes, comme celle des Y et celle des Z.
Cela soulève d’ores et déj{ une question car le nombre de points dans une surface est donné
par le produit :
En effet, à chaque point correspond une abscisse et une ordonnée. Mais dans les fichiers de
type colonnes de coordonnées, on trouve autant de lignes de coordonnées X que Y que Z.
Cela est du à la façon dont les capteurs mesurent les surfaces. Ils parcourent les objets de façon
linéaire, en mesurant pour chaque abscisse toutes les ordonnées, ou l’inverse. Pour une surface
carrée mesurant 3 points de coté, on aurait donc :

Page 23
Importation de données depuis une source Ascii
Figure 12 : Répartition des points dans un fichier de type colonnes de coordonnées
4.1.2 Les fichiers au format matrice de points
Ces fichiers contiennent les points tels qu’ils sont disposés dans l’espace. Un fichier décrivant
une surface XYZ contiendra comme première ligne les coordonnées X et comme deuxième les
coordonnées Y. A la suite on trouvera toutes les coordonnées Z, disposées en matrice. Voila ce
que donnerait un fichier représentant un étudiable carré de coté 4 :
Figure 13 : Répartition des points dans un fichier de type matrice de points
Les couples (X, Y) sont donnés { titre d’explication mais ne seraient bien sûr pas présents dans
un fichier normal.
Dans ce type de fichier, on peut facilement déduire le nombre de points sur l’axe X : donné par
le nombre de points présents dans une ligne de la matrice, et le nombre de points en Y : donné
par le nombre de lignes de la matrice.

Page 24
Importation de données depuis une source Ascii
4.1.3 Les paramètres nécessaires au parseur
Au vu de tous les cas pouvant se présenter, le parseur doit être fonction de plusieurs para-
mètres afin d’être le plus polyvalent et efficace possible. Ces paramètres sont renseignés par
l’utilisateur via l’interface d’importation des données ASCII et sont différents suivant le type de
fichier à importer.
Les voici donc séparés en trois catégories : les réglages communs à tous les types de fi-
chiers, les réglages concernant les fichiers dont l’organisation est de type colonnes de coor-
données, et les réglages concernant les fichiers dont l’organisation est de type matrice de
points.
Les paramètres communs aux deux types de fichier
Type d’étudiable (Profil Z, Surface Z, Surface XYZ etc.) : ce paramètre est nécessaire
pour déterminer si l’on doit rechercher une deux ou trois coordonnées dans le fichier.
Nombre de lignes sur lesquelles s’étend l’entête du fichier : le parseur en lui-même a
pour seul objectif de classer les coordonnées dans un, deux ou trois tableaux de points.
Certains fichiers contenant un entête, ce paramètre permet de l’ignorer.
Chaine dans le fichier représentant un point non mesuré par le capteur : pour des rai-
sons quelconques les capteurs ne mesurent pas toujours tous les points de la surface
qu’ils analysent. Dans le fichier d’export, il est mis à la place de ces données man-
quantes un « marqueur », désignant un point non mesuré, mais néanmoins existant. Ce
marqueur est généralement une suite de caractères quelconques, mais il peut très bien
s’agir d’une valeur numérique.
Séparateurs de données : les points peuvent êtres stockés de manière très différente
d’un fichier source { l’autre, et le seul moyen de les délimiter est le séparateur utilisé
entre chacun d’eux. Ce paramètre est donc le caractère utilisé pour ce faire.
Pour les fichiers dont la disposition est de type colonnes de coordonnées
Numéro de la colonne représentant les coordonnées X (si elles existent) : chaque co-
lonne dans le fichier représente une coordonnée, ou une donnée quelconque. Il est
donc nécessaire de déterminer (de gauche à droite) le numéro de la colonne représen-
tant les coordonnées X. C’est le rôle de ce paramètre.
Numéro de la colonne représentant les coordonnées Y (si elles existent) : même chose
que précédemment.
Numéro de la colonne représentant les coordonnées Z : même chose que précédem-
ment.

Page 25
Importation de données depuis une source Ascii
Le fichier stocke t’il les points les uns en dessous des autres ? : les fichiers contenant
des profils XZ peuvent parfois stocker les points en une seule colonne, alternant les
coordonnées X et Z. Ce paramètre sert donc à spécifier cela, car la méthode pour par-
ser* le fichier est dans ce cas différente du cas général.
Pour les fichiers dont la disposition est de type matrice de points :
Voici la méthode utilisée pour parser* ce type de fichier, et qui justifie l’utilisation des pa-
ramètres suivants.
Le fichier est lu ligne par ligne. Le numéro de la ligne courante est connu à chaque instant.
Si l’on se trouve entre la ligne de début des points X et la ligne de fin des points X, on dé-
coupe la ligne courante selon les séparateurs renseignés par l’utilisateur, et on ajoute les
points dans le tableau contenant les coordonnées en X.
Si l’on se trouve entre la ligne de début des points Y et la ligne de fin des points Y, on dé-
coupe la ligne courante selon les séparateurs renseignés par l’utilisateur, et on ajoute les
points dans le tableau contenant les coordonnées en Y.
Même chose pour les coordonnées Z.
Numéro de ligne de début des coordonnées X (si elles existent)
Numéro de ligne de début des coordonnées Y (si elles existent)
Numéro de ligne de début des coordonnées Z.
Numéro de ligne de fin des coordonnées X (si elles existent)
Numéro de ligne de fin des coordonnées Y (si elles existent)
Numéro de ligne de fin des coordonnées Z.
4.1.4 L’extraction des paramètres contenus dans l’entête
Certains fichiers disposent d’un entête contenu dans ses premières lignes, qui dispense
des informations quant { la nature de l’étudiable qu’il contient. Ces entêtes peuvent avoir des
formats très variés, contenir de nombreuses informations ou non, s’étaler sur un grand nombre
de lignes ou non. Ils contiennent généralement tout ou partie des informations citées ci-
dessous.
Le nombre de points chaque axe X et/ou Y et/ou Z
La taille (en valeur) de chaque axe X et/ou Y
L’unité sur chaque axe X et/ou Y et/ou Z
Le pas sur chaque axe X et/ou Y
Informations diverses, le plus souvent inutiles { l’importation des données
Page 26
Importation de données depuis une source Ascii
L’extraction de ces paramètres est réalisée directement via l’interface graphique présentée ci-
dessous.
4.2 L’interface utilisateur
Pour être utilisé dans le logiciel, le parseur devait disposer de sa propre interface, pour
permettre { l’utilisateur de le configurer. L’objectif était de créer un parseur performant, et
donc dépendant d’un certain nombre de réglages, mais sans pour autant imposer { l’utilisateur
une configuration très fastidieuse, qui aurait eu pour conséquence d’amoindrir la productivité
de l’outil.
4.2.1 Écran des réglages généraux
Voici ci-dessous la première fenêtre que l’utilisateur voit apparaître lorsqu’il active la fonction-
nalité d’import de fichiers ASCII.
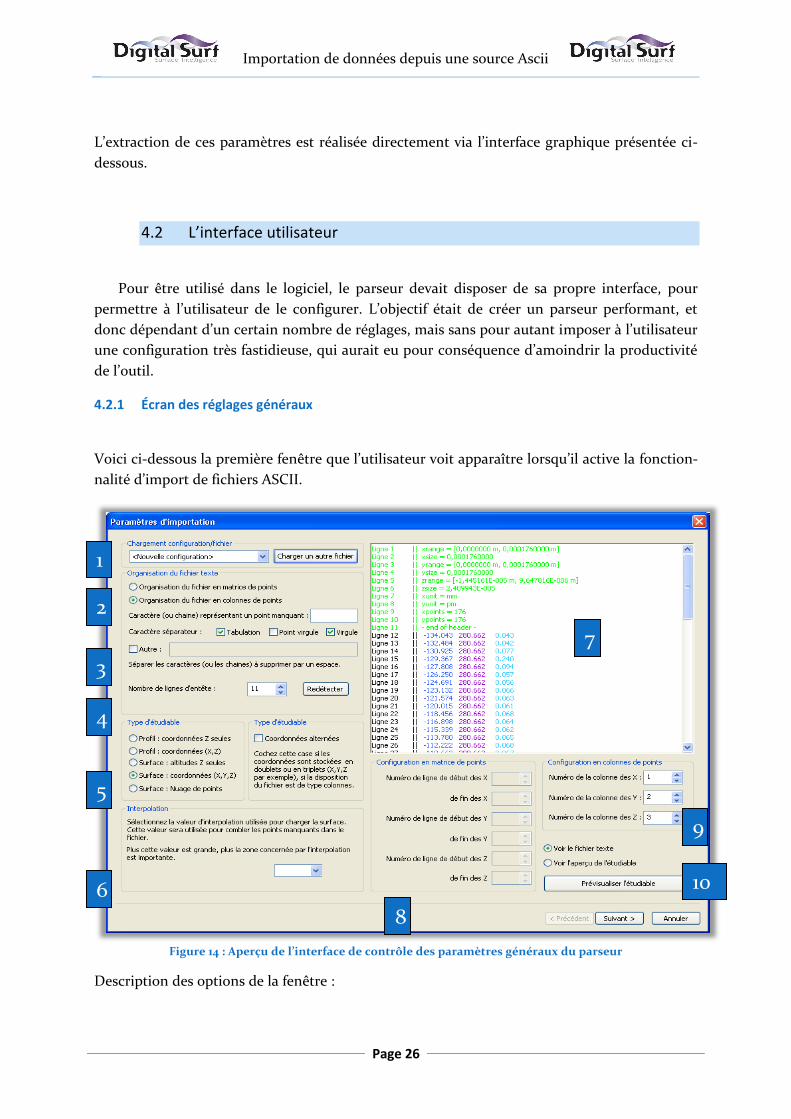
Figure 14 : Aperçu de l’interface de contrôle des paramètres généraux du parseur
Description des options de la fenêtre :
1
2
3
4
5
6
8
9
7
10

Page 27
Importation de données depuis une source Ascii
1 : Réglages donnant accès au chargement rapide d’une configuration précédemment
enregistrée.
2 : Options permettant de définir l’organisation du fichier texte (fichier de type co-
lonnes de coordonnées ou de type matrice de points).
3 : Options permettant de définir le/les caractère(s) séparant deux points dans le fi-
chier. Le champ « Autre » permet de spécifier des caractères non standards.
4 : Réglage permettant de définir le nombre de lignes d’entêtes du fichier. Ce champ est
calculé automatiquement, mais le réglage manuel est possible.
5 : Réglages permettant de sélectionner le type d’étudiable. Ce champ est préconfiguré
automatiquement.
6 : Valeur d’interpolation, utilisée pour combler les points non mesurés grâces au va-
leurs des points appartenant à son voisinage.
7 : Cadre donnant accès à la visualisation du fichier source, ou la prévisualisation de
l’étudiable calculé en fonction des réglages.
8 : Réglages concernant les fichiers dont la disposition des données est de type matrice
de points.
9 : Réglages concernant les fichiers dont la disposition des données est de type co-
lonnes de coordonnées.
10 : Options permettant de sélectionner ce que l’on veut voir affiché : le fichier texte, ou
la prévisualisation de l’étudiable.
Dans cette fenêtre une option permet { l’utilisateur de passer de la visualisation du fichier à
la prévisualisation de l’étudiable tel qu’il serait calculé avec les réglages courants.
Afin d’aider l’utilisateur à mieux visualiser ses actions, la visualisation du fichier texte utilise un
système de couleurs pour mettre en évidence :
Le nombre de lignes d’entête spécifié.
Les colonnes de coordonnées ou les lignes de points (suivant le type d’étudiable
matrice ou colonnes) grâce à une couleur associée à chaque coordonnée.
L’affichage de ces couleurs est réalisé en temps réel et s’actualise dès que l’utilisateur modifie
un réglage dans la boite de dialogue. L’utilisation de threads* permet de ne pas figer la fenêtre
pendant le calcul de la prévisualisation de l’étudiable d’une part, et l’affichage des couleurs
d’autre part.
Afin de faciliter l’utilisation de l’outil et de le rendre plus dynamique, la majorité des réglages
sont calculés automatiquement en fonction du fichier à importer.
L’organisation des points dans le fichier (matrice de points ou colonnes de coor-
données).

Page 28
Importation de données depuis une source Ascii
Figure 15 : Réglage « organisation du fichier texte »
Pour déterminer l’organisation du fichier texte, le programme analyse la ligne qui suit
la dernière ligne d’entête. Il faut donc déj{ que le nombre de lignes d’entête ait été calculé
avant de lancer cette détection. Ensuite, le nombre de caractères de la ligne est trouvé, et s’il
dépasse une certaine valeur, on en déduit que l’organisation du fichier est de type matrice de
points. En effet, ce type de fichier contient des lignes bien plus grandes que dans le cas d’une
configuration de type colonnes de coordonnées.
Les caractères séparateurs de données.
Figure 16 : Réglages « caractères séparateurs »
Pour trouver le ou les caractères qui séparent les coordonnées dans le fichier, le pro-
gramme parcourt simplement les lignes qui suivent celles de l’entête, et coche donc les cases
correspondantes aux caractères trouvés. Il faut cependant ne pas détecter un mauvais carac-
tère. En effet dans certains fichiers la virgule est utilisée comme symbole décimal (à la place du
point dans le cas standard). A ce moment là, il ne faut pas la cocher systématiquement, mais
justement lever l’indétermination quant { son rôle dans le fichier. Pour se faire, le programme
regarde si des points sont également présents dans les lignes. Si des points et des virgules sont
trouvés, on suppose donc que le caractère décimal est le point et que la virgule est un sépara-
teur de données. Si on trouve uniquement des virgules, on ne coche pas la case dans l’interface.
Le nombre de lignes d’entête.
Figure 17 : Réglage « nombre de lignes d’entête »

Page 29
Importation de données depuis une source Ascii
Ce réglage est important et doit être déterminé avec précision car il est utilisé pour
mener à bien toutes les autres détections automatiques.
La détection du nombre de lignes d’entête se base sur le principe suivant. Le pro-
gramme compte pour chaque ligne le nombre de caractères « lettre », et le nombre de carac-
tères « chiffres » qu’elle contient. Il établi ensuite un rapport entre le nombre de chiffres et le
nombre de lettres de la ligne. Si ce rapport n’excède pas un certain seuil, on considère que la
ligne fait partie de l’entête.
Il est aussi nécessaire que cette détection possède une « sécurité ». En effet, si on prend
comme un entête de quinze lignes, il se peut très bien que la que la quatrième ligne (par
exemple) ne contienne que des chiffres. Le programme calculerait donc un rapport indiquant
que la ligne ne contient pas de lettres, et on aurait un faux positif. Pour parer à cela, si le pro-
gramme détecte qu’une ligne semble ne pas faire partie de l’entête, il continue tout de même {
analyser les lignes suivantes. Si la tendance reste la même, alors il considère que la détection
n’est pas un faux positif, et que le bon nombre de lignes d’entête a été trouvé.
Le type de l’étudiable.
Figure 18 : Réglage « type d’étudiable »
Cette détection se base non seulement sur le nombre de lignes d’entête, mais égale-
ment sur les caractères séparateurs trouvés. Le principe est le suivant : la ligne qui suit la der-
nière ligne d’entête est nettoyée de ses caractères séparateurs, afin de pouvoir compter le
nombre de coordonnées qui s’y trouvent. Si le nombre de coordonnées est égal { :
un, on en déduit que l’étudiable est un profil Z.
deux, on en déduit que le type d’étudiable est un profil XZ.
trois ou plus, on en déduit que le type d’étudiable est une surface XYZ, une sur-
face Z ou un nuage de points.
Page 30
Importation de données depuis une source Ascii
Il n’est en revanche pas possible de trancher entre l’une ou l’autre des possibilités dans le troi-
sième cas. Dans cette situation on sélectionne l’option la plus courante, c'est-à-dire les sur-
faces Z.
Ainsi, les étudiables basés sur un fichier de données assez standard ne demandent au-
cune configuration de la part de l’utilisateur. Quant aux autres, ils ne demandent souvent que
peu de réglages supplémentaires. Le bouton « suivant » de la fenêtre donne accès l’interface
permettant de découper l’entête du fichier.
4.2.2 Écran des réglages concernant l’entête
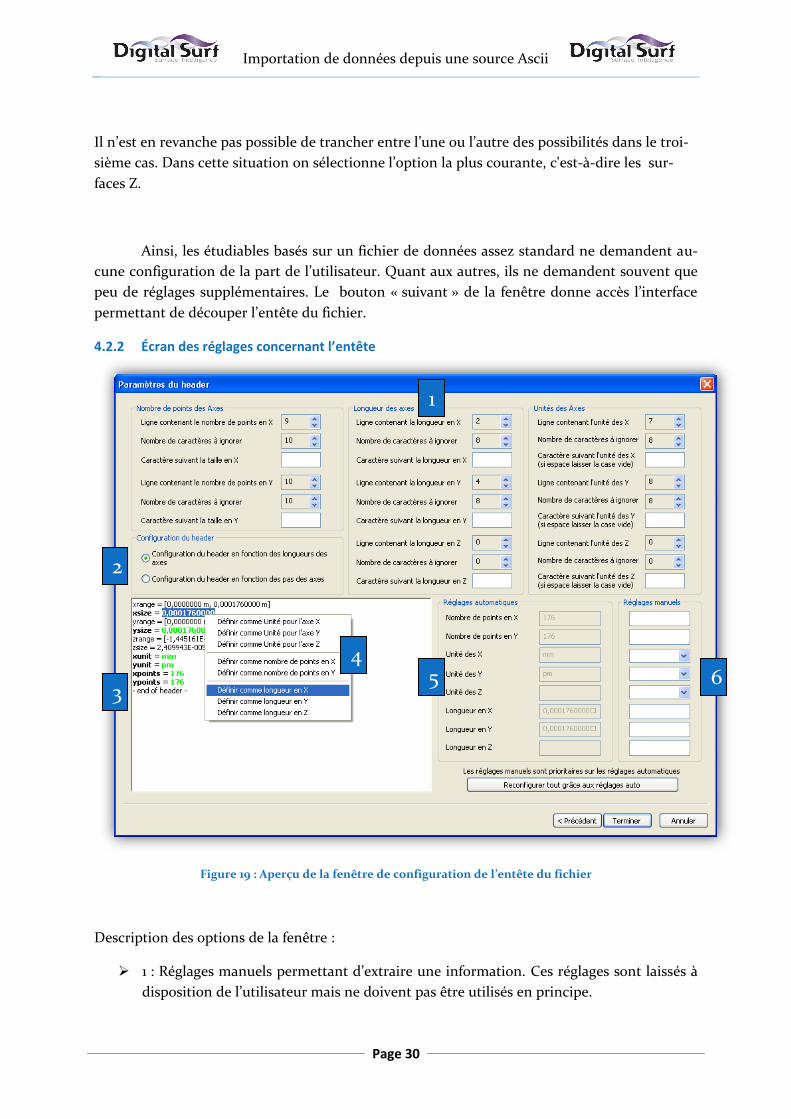
Figure 19 : Aperçu de la fenêtre de configuration de l’entête du fichier
Description des options de la fenêtre :
1 : Réglages manuels permettant d’extraire une information. Ces réglages sont laissés à
disposition de l’utilisateur mais ne doivent pas être utilisés en principe.
1
2
3
4 5 6

Page 31
Importation de données depuis une source Ascii
2 : Options de sélection du type de configuration de l’entête. Pour générer un étudiable
on a besoin du pas ou de la longueur de chaque axe X et Y mais pas des deux. On choisi
donc la grandeur en fonction de laquelle l’étudiable sera calculé. Quand cette option
est modifiée, la fenêtre et le menu contextuel se reconfigurent afin de faire corres-
pondre les textes affichés à la configuration choisie.
3 : Espace de visualisation de l’entête du fichier. Il se base sur la configuration de la fe-
nêtre précédente pour afficher le nombre de lignes d’entête qui y a été configuré.
4 : Menu contextuel permettant l’extraction d’informations. C’est le moyen de configu-
ration à privilégier par rapport aux réglages manuels.
5 : Zone d’affichage des grandeurs sélectionnées dans l’entête via le menu contextuel ou
les réglages manuels.
6 : Zone d’affichage des réglages personnalisés. L’utilisateur a la possibilité de définir
des réglages arbitraires, ne se trouvant pas dans l’entête. Ces réglages sont prioritaires
par rapport aux réglages sélectionnés avec l’interface.
Tout comme la fenêtre précédente, cette boite de dialogue dispose d’un système de visualisa-
tion en couleurs des réglages de l’utilisateur. Chaque ligne de l’entête contenant une informa-
tion est mise en gras, et l’information qu’elle contient est surlignée en vert. Tout cela est éga-
lement réalisé en temps réel, sans figer la fenêtre.
4.3 Le système de sauvegarde/chargement de configurations
L’application possède un système pour enregistrer ou charger des configurations étant déj{ été
faites pour une importation de fichier antérieure.
Figure 20 : Aperçu de l’interface de sauvegarde/chargement de configuration
L’interface se trouve en haut { gauche de la première fenêtre de configuration, et affiche via
une liste déroulante les configurations précédemment enregistrées. Si l’on sélectionne le texte
« <Nouvelle configuration> » le programme proposera d’enregistrer la configuration lors de
l’appui sur le bouton « terminer » de la deuxième fenêtre. Sinon, la configuration sélectionnée
est chargée automatiquement.
Les configurations enregistrées sont stockées dans un fichier .xml.

Page 32
Importation de données depuis une source Ascii
Figure 21 : Exemple de fichier de configuration XML
Dans l’image ci-dessus on retrouve les réglages de l’interface stockés entre des balises
portant leur nom. Le caractère qui permet de séparer deux données dans les fichiers de confi-
guration est « ^ ». L’écriture et la lecture du fichier sont réalisées grâce à la bibliothèque
MSXML (Microsoft XML). Le programme l’utilise via une couche supplémentaire implémentée
par les développeurs de Digital Surf. Elle rend l’utilisation de cet outil plus facile qu’elle ne l’est
{ l’état brut.

Page 33
Importation de données depuis une source Ascii
4.4 La génération de l’étudiable / interprétation des données
Que ce soit pour la prévisualisation ou l’importation dans Mountains, il est nécessaire de cal-
culer l’étudiable grâce aux données extraites du fichier source.
Figure 22 : Fichier source Figure 23 : Étudiable produit
Le calcul de l’étudiable nécessite d’avoir un minimum d’informations le concernant :
Le nombre de points sur l’axe X/Y : ces paramètres sont nécessaires pour déterminer la
taille de l’étudiable. S’ils ne sont pas précisés, le parseur peut dans certains cas le dé-
duire ou les calculer automatiquement.
Soit le pas en X/Y : le pas est l’écart de distance entre deux coordonnées en X par
exemple. Il détermine l’intervalle selon lequel les données on été acquises. Son but
premier est de pouvoir remettre les valeurs présentes dans le fichier « { l’échelle ».
Soit la taille en X/Y : la taille d’un axe se calcule facilement de la façon suivante :
On peut ensuite facilement déduire un pas de cette valeur, en la divisant par le nombre
de points sur l’axe.
Pourquoi a-t’on besoin du nombre de points sur chaque axe ?
Tout simplement pour pouvoir déterminer la taille de l’étudiable stocké dans le fichier source.

Page 34
Importation de données depuis une source Ascii
Pourquoi a-t’on besoin du pas sur chaque axe ?
Au moment de générer l’étudiable, il va falloir reconstruire une matrice de points. Chaque
coordonnée Z aura alors une abscisse entière, allant de 0 à N, de 1 en 1, ou N représente le
nombre de points sur l’axe X. Il en va de même pour les ordonnées.
Les nouvelles abscisses/ordonnées n’auront donc plus rien en commun avec celles spécifiées
dans le fichier. En revanche, en spécifiant le pas sur chaque axe, on pourra remettre l’étudiable
{ l’échelle.
Si les informations son manquantes, le programme peut dans beaucoup de cas les déduire du
fichier.
Concernant le nombre de points sur chaque axe, il est très facile de le trouver { partir d’un
étudiable dont l’organisation des données est de type matrice, comme expliqué dans la section
4.1.2.
Pour un étudiable dont l’organisation des données est de type colonnes de coordonnées, la
technique employée est différente. Comme expliqué dans la section 4.1.1, les coordonnées dans
ces fichiers sont données en fonction d’un axe de référence.
Par exemple : si l’axe de référence d’un étudiable dans le fichier est X et que l’on note N le
nombre de points en X, on aura alors un changement de valeur toutes les N lignes du fichier
source dans la colonne des coordonnées X. Ainsi, en détectant ces « sauts » on peut calculer le
nombre de points sur cet axe. Le nombre de points en Z étant le nombre total de lignes de
points dans le fichier, et connaissant le nombre de points sur l’axe X, il est ensuite aisé de dé-
duire le nombre de points sur l’axe Y :
Le programme utilise les bibliothèques développées par Digital Surf pour générer l’étudiable de
sortie. Elles permettent de faire abstraction de certaines tâches dont il faudrait s’acquitter en
utilisant des moyens conventionnels. Par exemple, la création de l’image est totalement en-
capsulée par une fonction très simple d’utilisation.

Page 35
Importation de données depuis une source Ascii
5. Analyse critique de la solution déve-
loppée
5.1 Les avantages
La solution mise en place a pour premier avantage d’être fonctionnelle et de remplir
son rôle. En effet pendant les tests elle a su extraire les données de tous les exemples de fi-
chiers récalcitrants que Digital Surf avait mis à ma disposition.
Ensuite, même si la disposition des éléments dans les différentes fenêtres est discutable
au niveau de l’apparence, l’interface reste pratique à utiliser. En effet, les différents moyens
pour mettre en relation les réglages de l’utilisateur et l’aperçu du fichier / de l’étudiable appor-
tent une dimension visuelle de l’ensemble et au final permettent un gain de temps.
Le fait que la majorité des réglages soient détectés automatiquement augmente aussi la
praticité de l’outil. Dans la majorité des cas, les fichiers à importer ne contiennent pas d’entête,
et la disposition de leurs données n’est pas si spécifique que ça. Il suffit donc à ce moment la de
quelques cliques pour voir l’étudiable importé dans le logiciel.
Pour finir, le système de sauvegarde/chargement de configurations fait aussi gagner à
l’utilisateur un temps précieux dans le cas de fichiers dont la configuration du parseur nécessi-
terait d’être très spécifique.
5.2 Les inconvénients
On peut mettre en évidence les problèmes suivants.
Tout d’abord, même s’ils ne sont pas tous { utiliser couramment, on trouve une multi-
tude de réglages sur les deux écrans qui composent l’application. Cela entraîne une surcharge
de l’interface, même si on gagne évidemment en flexibilité au niveau du parseur.
Ensuite, le fonctionnement interne du parseur n’est pas le même suivant les types de
fichiers que l’on veut importer. Tel qu’il est implémenté actuellement, deux algorithmes sont
utilisés : un pour les fichiers dont la disposition des données est de type matrice, et l’autre pour
les fichiers de type colonnes de coordonnées. Cela a pour inconvénient premier d’augmenter la
quantité de code nécessaire pour arriver au même résultat. De plus, l’utilisateur doit s’acquitter
de réglages différents pour traiter l’un ou l’autre des deux types de fichiers. Cela implique qu’il

Page 36
Importation de données depuis une source Ascii
doit être capable de différencier les deux, on perd donc en transparence et en confort
d’utilisation.
5.3 Une solution alternative
Il était possible d’implémenter le parseur d’une façon différente, en changeant son
fonctionnement. La solution aurait été de se baser sur un système d’expressions régulières*.
Ainsi, on aurait demandé { l’utilisateur de rentrer le schéma selon lequel découper le fichier et
en extraire les données.
Cela étant, comme pour la solution mise en place actuellement, il aurait surement été
nécessaire de faire une distinction pour chacun des deux types de fichiers. En effet, il aurait été
difficile de découper de la même manière un fichier dont l’organisation des données est de
type colonnes de coordonnées et un fichier dont l’organisation est de type matrice de points.
Si l’on prend par exemple un fichier de type colonnes de coordonnées, dont les trois co-
lonnes X Y Z sont rangées dans cet ordre de gauche à droite, et où le caractère séparateur est
l’espace.
Pour importer ce type de fichier il suffit de régler les trois champs placés dans le cadre « confi-
guration en colonnes de coordonnées » de la première fenêtre de configuration respectivement
avec les valeurs « 1 », « 2 » et « 3 ».
Avec un système d’expressions régulières*, on aurait pu imaginer une syntaxe comme :
Le parseur aurait traité le fichier comme il le fait actuellement. De plus, il aurait fallu encapsu-
ler cette syntaxe dans une interface graphique pour privilégier le confort de l’utilisateur.
Maintenant, si l’on prend l’exemple d’un fichier dont l’organisation est de type matrice de
points, contenant trois coordonnées X, Y et Z. Dans le cas standard, les coordonnées X se trou-
veraient sur la première ligne, les coordonnées Y sur la deuxièmes, et les coordonnées Z en
dessous.
Via le système développé, il faudrait configurer dans la première fenêtre de l’application les six
champs dans le cadre « configuration en matrice de points », afin de délimiter le début et la fin
de chaque coordonnée dans le fichier.
Maintenant si l’on avait utilisé un système d’expressions régulières*, on aurait par exemple
écrit :
Cette expression répond à la syntaxe : NomDeLaCoordonnée{LigneDébut,LigneFin,Séparateur}

Page 37
Importation de données depuis une source Ascii
Comme pour l’exemple précédent, le fichier aurait été traité de la même manière qu’il l’est déj{
par le parseur.
En définitive, cette solution bien que réalisable n’est pas certifiée plus avantageuse que
l’actuelle. En effet, même en explorant plusieurs pistes je n’ai pu qu’arriver à la conclusion que
le parseur se servirait des mêmes paramètres que ceux dont il a besoin actuellement, pour arri-
ver { extraire les données du fichier. C’est { cause de cela que je me permets de dire qu’il n’est
pas évident que le système des expressions régulières* soit plus performant que la solution
développée. N’ayant pas approfondi complètement cette idée, je ne peux cependant pas me
montrer affirmatif.

Page 38
Importation de données depuis une source Ascii
Conclusion technique
Ce stage m’a permis d’enrichir nettement mes connaissances, dans le domaine informa-
tique évidemment mais pas seulement.
Premièrement, j’ai renforcé et acquis des notions en C++. Je pense plus particulière-
ment à la manière de travailler et de gérer la mémoire grâce à ce langage. De plus, le C++ étant
un langage objet, j’ai également pu apprendre de nouvelles subtilités sur ce concept.
D’autre part, j’ai découvert la plateforme de développement Visual Studio que j’avais
très peu utilisée auparavant, et qui se révèle être un bon outil, contrairement aux préjugés que
je pouvais avoir à son sujet. Cette plateforme étant très prisée par les développeurs de diffé-
rents langages, le fait de l’avoir pratiquée ne peut être que bénéfique. En effet, je serai sure-
ment amené à la réutiliser par la suite.
Pour en finir avec la partie informatique, le fait d’avoir développé une application ex-
clusivement { l’aide des MFC m’a permis de me faire une idée plus précise du fonctionnement
de l’API Windows, et de la manière dont ses fonctions s’articulent entre elles. De plus, son ma-
niement via le langage C++ était totalement nouveau pour moi.
Travailler à Digital Surf m’a également permis d’acquérir des connaissances en image-
rie. Le logiciel Mountains servant principalement à manipuler et analyser des surfaces, et ma
mission étant directement en relation avec cela, j’ai dû me rappeler et apprendre quelques
concepts sur la façon de générer, lire ou encore modifier une image. Je considère comme un
plus important d’avoir acquis des connaissances autres que dans le domaine informatique
pendant ce stage.

Page 39
Importation de données depuis une source Ascii
Conclusion générale
Durant cette période de trois mois et demi, j’ai réalisé l’objectif qui m’était fixé
dans le cadre de mon sujet de stage, à savoir l’implémentation d’un module permettant
d’importer dans le logiciel Mountains des fichiers de mesures venant des clients de
l’entreprise Digital Surf. Certains formats de fichiers n’étant pas pris en charge native-
ment dans le logiciel, il était nécessaire de proposer une solution qui permette de tra-
vailler avec ces mesures.
Mon travail s’organisait donc en plusieurs étapes. Tout d’abord, une phase de
recherche nécessaire pour regrouper les informations dont j’avais besoin pour mener {
bien ce projet. Il fallait ensuite réfléchir à son implémentation et conceptualiser la so-
lution finale. Il restait pour finir à implémenter informatiquement la fonction.
Ce stage m’a également permis d’acquérir des méthodes de travail et
d’apprendre { m’organiser dans la création d’un projet. J’ai dû travailler en autonomie
et donc faire face à toutes sortes de problèmes et y trouver des solutions. Les méthodes
de développement des ingénieurs de Digital Surf, que j’ai dû respecter également,
m’ont permis de prendre de bonnes habitudes en matière de programmation.
Ce stage m’a aussi permis de mieux maitriser le langage C++ ainsi que la plate-
forme de développement Visual Studio. J’ai appris à programmer avec les MFC, biblio-
thèques que je n’avais jamais utilisées auparavant. J’ai aussi eu l’occasion d’acquérir des
connaissances dans le domaine de l’imagerie, car ma mission y était directement liée.
Enfin, je suis très satisfait d’avoir effectué mon stage au sein d’une entreprise
telle que Digital Surf pour plusieurs raisons. D’une part parce que son secteur d’activité
propose des métiers intéressants, d’autre part car j’ai apprécié le cadre dans lequel j’ai
travaillé et les personnes que je côtoyais chaque jour.
Finalement cette expérience a confirmé que mon orientation professionnelle
était la bonne, même si je n’avais pas de doute à ce sujet.

Page 40
Importation de données depuis une source Ascii
Lexique
API Win32 : (Application Programming Interface) est le nom donné par Microsoft à l'Interface
de programmation sur les systèmes d'exploitation Microsoft Windows. Elle est conçue pour
les langages de programmation C et C++ et est la manière la plus directe pour une application
d'interagir avec le système d'exploitation Windows.
Expression régulière : c’est en informatique une chaîne de caractères que l’on appelle parfois
un motif et qui décrit un ensemble de chaînes de caractères possibles selon une syntaxe pré-
cise. Les expressions régulières* sont aujourd’hui utilisées par les informaticiens dans l’édition
et le contrôle de texte.
Parser : Terme venant de l’anglais, et qui traduit l’action d’analyser, découper et extraire des
informations d’une source de données.
Parseur : L'analyse syntaxique consiste à mettre en évidence la structure d'un texte, générale-
ment un programme informatique ou du texte écrit dans une langue naturelle. Un analyseur
syntaxique (parser, en anglais) est un programme informatique qui réalise cette tâche. Cette
opération suppose une formalisation du texte, qui est vu le plus souvent comme un élément
d'un langage formel, défini par un ensemble de règles de syntaxe formant une grammaire for-
melle.
Thread : ou fil (d'exécution) ou tâche, est similaire à un processus car tous deux représentent
l'exécution d'un ensemble d'instructions du langage machine d'un processeur. Du point de vue
de l'utilisateur ces exécutions semblent se dérouler en parallèle, ce qui permet d’exécuter deux
actions simultanément.
Page 41
Importation de données depuis une source Ascii
Table des figures
Figure 1 : Processus d'analyse métrologique grâce aux composants Digital Surf .......................... 6
Figure 2 : Aperçu du logiciel ............................................................................................................. 7
Figure 3 : Aperçu de la fenêtre « opérateur de redressement » ..................................................... 8
Figure 4 : Surface sur laquelle on a appliqué l'étude "Vue 3D" ...................................................... 9
Figure 5 : Exemple de fichier « profil Z » ........................................................................................ 11
Figure 6 : Exemple de fichier « profil XZ » .................................................................................... 12
Figure 7 : Exemple de fichier « surface XYZ » (disposition colonnes) .......................................... 13
Figure 8 : Exemple de fichier « surface XYZ » (disposition matrice) ........................................... 14
Figure 9 : Exemple de fichier « surface Z » .................................................................................... 15
Figure 10 : Exemple de fichier « nuage de points » ....................................................................... 16
Figure 11 : Aperçu de l’écran de configuration de la fonction existant déj{ dans Mountains ...... 19
Figure 12 : Répartition des points dans un fichier de type colonnes de coordonnées ................. 23
Figure 13 : Répartition des points dans un fichier de type matrice de points .............................. 23
Figure 14 : Aperçu de l’interface de contrôle des paramètres généraux du parseur ....................26
Figure 15 : Réglage « organisation du fichier texte » .....................................................................28
Figure 16 : Réglages « caractères séparateurs » .............................................................................28
Figure 17 : Réglage « nombre de lignes d’entête » .........................................................................28
Figure 18 : Réglage « type d’étudiable » .........................................................................................29
Figure 19 : Aperçu de la fenêtre de configuration de l’entête du fichier ...................................... 30
Figure 20 : Aperçu de l’interface de sauvegarde/chargement de configuration .......................... 31
Figure 21 : Exemple de fichier de configuration XML ................................................................... 32
Figure 22 : Fichier source.. .............................................................................................................. 33
Figure 23 : Étudiable produit …………………………………………………………………….…………………………….33

Page 42
Importation de données depuis une source Ascii
Mots clefs
Développement – Étude de solution - Informatique – Langage C++ - Métrologie des surfaces – Format ASCII – Parseur – Import de données.
BONVALOT Vincent Rapport de stage 2010
Résumé
Dans le cadre de ma formation en troisième année de licence professionnelle, j’ai été amené { effectuer un
stage dans une entreprise de mon choix. Mes recherches m’ont mené jusqu’{ l’entreprise Digital Surf, leader mon-
dial dans le domaine de la métrologie de surfaces. La durée du stage était de trois mois et demi, pendant lesquels
j’ai été intégré { l’unité Mountains Surface Analysis, chargée du développement du logiciel de métrologie Moun-
tains.
Ma mission a été de prendre part au développement du logiciel, en conceptualisant et mettant en œuvre
une solution qui puisse permettre { l’entreprise d’importer dans son produit les exports de données de ses clients.
Mon travail a pour but de servir de base aux ingénieurs de l’équipe de développement, qui le reprendront par la
suite pour l’améliorer et l’intégrer définitivement dans le logiciel.
Le développement a été réalisé grâce { la plateforme Visual Studio 2008, en langage C++ et { l’aide des Mi-
crosoft Foundation Class(MFC). Le produit fini est un contrôle ActiveX, facile à intégrer dans Moutains, et permet-
tant aisément le transfert de données de l’un { l’autre.
As part of the third year training for a professional license, I was required to do an apprenticeship in a
company of my choice. My research led me to the company Digital Surf, world leader in surface metrology soft-
ware. The training period was three and a half months, during which I was incorporated into the Mountains Sur-
face Analysis Unit, responsible for the development of Mountains Surface Analysis Software.
My mission was to take part in developing the software, conception and implementation of a solution that
would enable the company to import into its product the data files of its customers. My work is intended to serve
as a basis for engineers of the development team, who will resume it thereafter to improve and integrate it perma-
nently into the software.
The development has been achieved through the platform Visual Studio 2008, using C + + programming
language, and helped by the Microsoft Foundation Class (MFC). The finished product is an ActiveX control, easy to
integrate in Mountains and which will enable easy data sharing from each other.
Recommended

















