
1
Master Biologie Intégrative 2017-2018
Biostatistiques avancées
Responsable du cours : Yves Desdevises
Corrigé
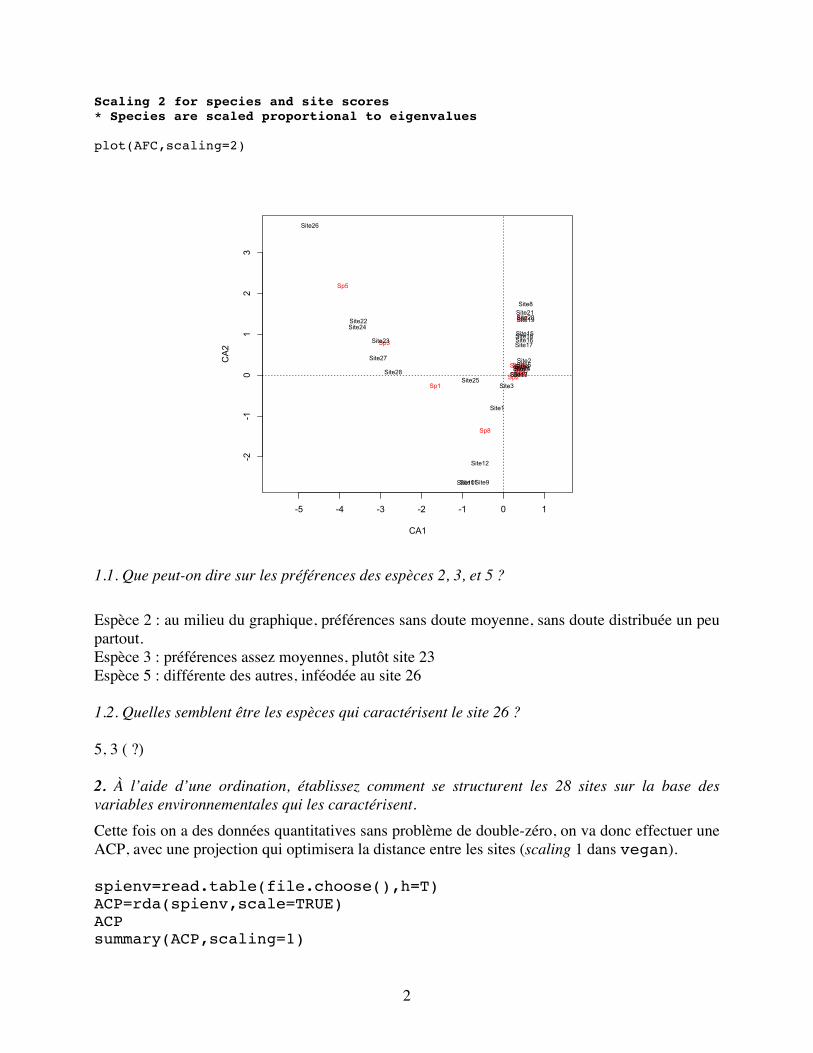
Des biologistes ont étudié les araignées Lycosidae des Pays-Bas (van der Aart & Smeenk-Enserink 1975), afin de comprendre comment les communautés d’espèces se répartissent dans un environnement de dunes sableuses. Les individus appartenant à 12 espèces ont été dénombrés à 28 sites (Spiders_spe.txt). Plusieurs variables environnementales ont été relevées à ces mêmes sites (Spiders_env.txt) : % d’humidité, réflectance de la lumière par le sol, densité de 2 plantes dunaires (Calamagrostis et Corynephorus). Exercice 1 1. Réalisez une ordination appropriée pour comprendre comment se structurent les communautés d’araignées des 28 sites. La nature des données implique de faire une AFC (quoique qu’une ACP pourrait être utilisée avec certaines transformations des données). On choisira la projection qui optimise la projection des espèces (colonnes), soit le scaling de type 2 avec vegan. library(vegan) Le chargement a nécessité le package : permute Le chargement a nécessité le package : lattice This is vegan 2.4-0 spisp=read.table(file.choose(),h=T) AFC=cca(spisp) AFC summary(AFC,scaling=2) Importance of components: CA1 CA2 CA3 CA4 CA5 CA6 CA7 CA8 Eigenvalue 0.7005 0.4214 0.3490 0.18855 0.07979 0.05377 0.04553 0.03057 Proportion Explained 0.3643 0.2191 0.1815 0.09805 0.04149 0.02796 0.02368 0.01590 Cumulative Proportion 0.3643 0.5834 0.7649 0.86298 0.90447 0.93243 0.95611 0.97201 Le plan formé par les 2 premiers axes explique 58 % de la variation des données. CA9 CA10 CA11 Eigenvalue 0.02419 0.01962 0.01002 Proportion Explained 0.01258 0.01020 0.00521 Cumulative Proportion 0.98459 0.99479 1.00000
Travaux Dirigés no 6
2
Scaling 2 for species and site scores * Species are scaled proportional to eigenvalues plot(AFC,scaling=2)
-5 -4 -3 -2 -1 0 1
-2-1
01
23
CA1
CA2
Sp1Sp2
Sp3
Sp4
Sp5
Sp6
Sp7
Sp8
Sp9Sp10Sp11Sp12
Site1
Site2
Site3
Site4Site5Site6Site7
Site8
Site9Site10Site11
Site12
Site13Site14
Site15Site16Site17Site18
Site19Site20Site21
Site22
Site23
Site24
Site25
Site26
Site27
Site28
1.1. Que peut-on dire sur les préférences des espèces 2, 3, et 5 ? Espèce 2 : au milieu du graphique, préférences sans doute moyenne, sans doute distribuée un peu partout. Espèce 3 : préférences assez moyennes, plutôt site 23 Espèce 5 : différente des autres, inféodée au site 26 1.2. Quelles semblent être les espèces qui caractérisent le site 26 ? 5, 3 ( ?) 2. À l’aide d’une ordination, établissez comment se structurent les 28 sites sur la base des variables environnementales qui les caractérisent. Cette fois on a des données quantitatives sans problème de double-zéro, on va donc effectuer une ACP, avec une projection qui optimisera la distance entre les sites (scaling 1 dans vegan). spienv=read.table(file.choose(),h=T) ACP=rda(spienv,scale=TRUE) ACP summary(ACP,scaling=1)
3
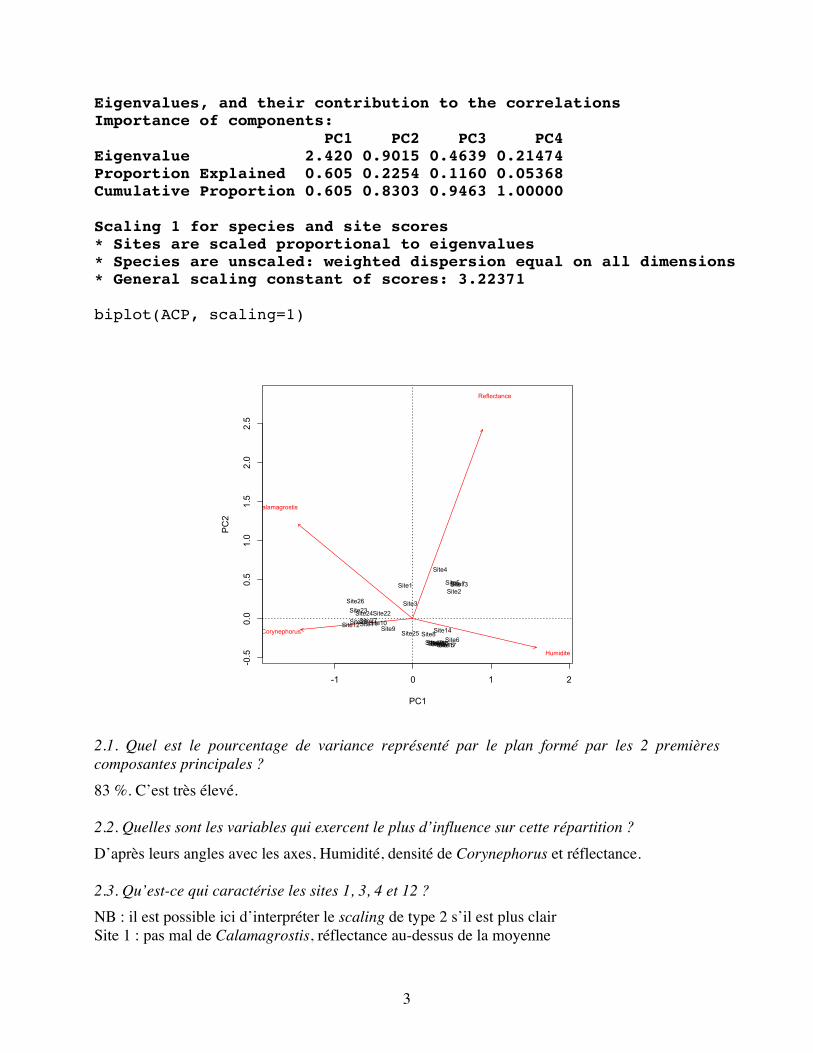
Eigenvalues, and their contribution to the correlations Importance of components: PC1 PC2 PC3 PC4 Eigenvalue 2.420 0.9015 0.4639 0.21474 Proportion Explained 0.605 0.2254 0.1160 0.05368 Cumulative Proportion 0.605 0.8303 0.9463 1.00000 Scaling 1 for species and site scores * Sites are scaled proportional to eigenvalues * Species are unscaled: weighted dispersion equal on all dimensions * General scaling constant of scores: 3.22371 biplot(ACP, scaling=1)
-1 0 1 2
-0.5
0.0
0.5
1.0
1.5
2.0
2.5
PC1
PC2
Humidite
Reflectance
Calamagrostis
Corynephorus
Site1Site2
Site3
Site4
Site5
Site6
Site7
Site8Site9
Site10Site11Site12
Site13
Site14
Site15Site16Site17Site18Site19Site20Site21
Site22Site23Site24
Site25
Site26
Site27Site28
2.1. Quel est le pourcentage de variance représenté par le plan formé par les 2 premières composantes principales ? 83 %. C’est très élevé. 2.2. Quelles sont les variables qui exercent le plus d’influence sur cette répartition ? D’après leurs angles avec les axes, Humidité, densité de Corynephorus et réflectance. 2.3. Qu’est-ce qui caractérise les sites 1, 3, 4 et 12 ? NB : il est possible ici d’interpréter le scaling de type 2 s’il est plus clair Site 1 : pas mal de Calamagrostis, réflectance au-dessus de la moyenne
4
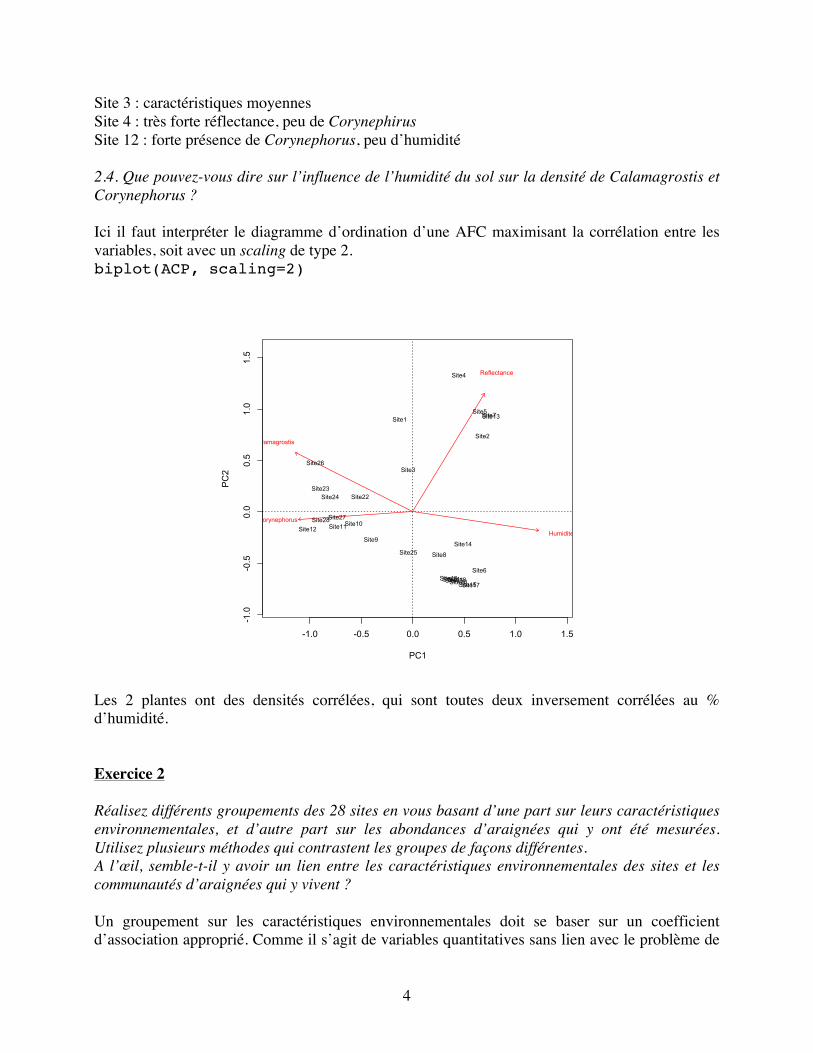
Site 3 : caractéristiques moyennes Site 4 : très forte réflectance, peu de Corynephirus Site 12 : forte présence de Corynephorus, peu d’humidité 2.4. Que pouvez-vous dire sur l’influence de l’humidité du sol sur la densité de Calamagrostis et Corynephorus ? Ici il faut interpréter le diagramme d’ordination d’une AFC maximisant la corrélation entre les variables, soit avec un scaling de type 2. biplot(ACP, scaling=2)
-1.0 -0.5 0.0 0.5 1.0 1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
PC1
PC2
Humidite
Reflectance
Calamagrostis
Corynephorus
Site1
Site2
Site3
Site4
Site5
Site6
Site7
Site8
Site9
Site10Site11Site12
Site13
Site14
Site15Site16
Site17Site18Site19Site20Site21
Site22Site23
Site24
Site25
Site26
Site27Site28
Les 2 plantes ont des densités corrélées, qui sont toutes deux inversement corrélées au % d’humidité. Exercice 2 Réalisez différents groupements des 28 sites en vous basant d’une part sur leurs caractéristiques environnementales, et d’autre part sur les abondances d’araignées qui y ont été mesurées. Utilisez plusieurs méthodes qui contrastent les groupes de façons différentes. A l’œil, semble-t-il y avoir un lien entre les caractéristiques environnementales des sites et les communautés d’araignées qui y vivent ? Un groupement sur les caractéristiques environnementales doit se baser sur un coefficient d’association approprié. Comme il s’agit de variables quantitatives sans lien avec le problème de

5
la double absence, une distance Euclidienne peut être utilisée, en ayant pris soin de standardiser les données auparavant : spienv=read.table(file.choose(),h=T) spienvst=decostand(spienv,method="standardize") D1=vegdist(spienvst,method="euclidean") On peut ensuite réaliser des groupements avec différentes approches : liens simples, complets, ou basé sur l’association moyenne (les 2 premiers sont illustrés ci-dessous) : plot(hclust(D1,method="single"))
Site13
Site4
Site7
Site2
Site5
Site25
Site8
Site14
Site18
Site20
Site16
Site19
Site21
Site6
Site15
Site17
Site12
Site26
Site23
Site24
Site27
Site9
Site10Site11
Site28
Site22
Site1
Site3
0.0
0.5
1.0
1.5
Cluster Dendrogram
hclust (*, "single")D1
Height
plot(hclust(D1,method="complete"))
Site13
Site4
Site7
Site2
Site5Site8
Site25
Site6
Site15
Site17 Site14
Site18
Site20
Site16
Site19
Site21
Site1
Site3Site22
Site26
Site12
Site9
Site10
Site11
Site28
Site27
Site23
Site24
01
23
45
Cluster Dendrogram
hclust (*, "complete")D1
Height

6
Pour les données d’abondances, c’est l’indice de dissimilarité de Bray-Curtis, puis les mêmes méthodes agglomératives de groupement : D14=vegdist(spisp,method="bray") plot(hclust(D14,method="single"))
Site8
Site16
Site17
Site15
Site18 Site21
Site19
Site20
Site26
Site25
Site27
Site23
Site28
Site22
Site24 Site9
Site10
Site11
Site12Site1
Site3
Site2
Site6
Site5
Site7
Site13
Site4
Site14
0.0
0.1
0.2
0.3
0.4
0.5
0.6
Cluster Dendrogram
hclust (*, "single")D14
Height
plot(hclust(D14,method="complete"))
Site4
Site14 Site5
Site7
Site13
Site1
Site3Site2
Site6
Site8
Site21
Site19
Site20
Site16
Site17
Site15
Site18 Site11
Site12 Site9
Site10
Site26
Site25
Site27
Site23
Site28
Site22
Site240.0
0.2
0.4
0.6
0.8
1.0
Cluster Dendrogram
hclust (*, "complete")D14
Height
Il n’est pas facile de détecter un lien entre les communautés d’espèces d’araignées et les caractéristiques environnementales des sites où elles vivent, mais les topologies des arbres semblent parfois grouper les mêmes sites.

7
Exercice 3 Testez statistiquement si les communautés d’araignées sont liées aux variables environnementales des 28 sites où elles ont été échantillonnées. Il suffit de comparer les matrices de distances D1 et D14 à l’aide d’un test de Mantel : mantel(D1,D14) Mantel statistic based on Pearson's product-moment correlation Call: mantel(xdis = D1, ydis = D14) Mantel statistic r: 0.6603 Significance: 0.001 Upper quantiles of permutations (null model): 90% 95% 97.5% 99% 0.0717 0.0986 0.1214 0.1463 Permutation: free Number of permutations: 999 On rejette largement l’hypothèse nulle d’absence de lien. Exercice 4 Réalisez un dendrogramme des 21 vis du tableau vis.txt en utilisant une procédure de groupement appropriée. Ces données sont binaires, il faut donc utiliser un indice approprié. Ce ne sont pas des données de présence-absence, mais simplement d’identification de deux états. On peut donc utiliser un indice de simple concordance : vis=read.table(file.choose(),header=T) Dbin=dist(vis,method="binary") Le groupement peut ensuite être effectué, à l’aide ici de la méthode UPGMA : plot(hclust(Dbin,method="average"))
Vis18
Vis19
Vis20
Vis21
Vis14
Vis16
Vis17
Vis13
Vis15
Vis2
Vis4
Vis10
Vis11
Vis8
Vis9
Vis1
Vis6
Vis7
Vis3
Vis5
Vis12
0.0
0.2
0.4
0.6
0.8
Cluster Dendrogram
hclust (*, "average")Dbin
Height
Recommended

















