Embed Size (px)
DESCRIPTION
Citation preview

République Tunisienne
Ministère d’Enseignement SupérieurMinistère d’Enseignement Supérieur,
Université de Sfax
ECOLE NATIONALE D’INGENIEURS DE SFAX

ENIS ENIS 2011/20122011/2012
C DSPC DSP2011/20122011/2012
Cours DSPCours DSP3è é GE ISI EEI3ème année GE ISI-EEI
Nouri MASMOUDINouri MASMOUDIProfesseur à l’ENISResponsable de l’Équipe Circuits et Systèmes L b t i d’Él t i t d T h l i d l’I f tiLaboratoire d’Électronique et des Technologies de l’Information

Plan du coursa du cou s
Chapitre I : Introduction aux DSP
Chapitre II : Architectures des DSP
Chapitre III : Architecture interne du TMS320 C64X
ÉChapitre IV : Étude pratique du pipeline pour le TMS320 C64X
Chapitre V : Techniques d’optimisationChapitre V : Techniques d optimisation
ENIS 2011-2012 Cours DSP 3
ENISENIS 2011/201
Chapitre I :
Introduction aux DSP’s
Plan Ch suivant

SommaireBesoins et contraintes en traitement numérique du signal
Applications typiques
Algorithmes typiques
Présentation des DSPProcesseurs actuelsProcesseurs actuels
Exemples des DSP
Comparaison avec les processeurs généralistesp p g
Représentation des nombresTypes de donnéesTypes de données
Virgule fixe
Virgule flottant
ENIS 2011-2012 Cours DSP Chapitre 1 5
Virgule flottant

Définition d’un DSPDSP = Digital Signal Processor
Processeur de traitement Numérique du Signal
U DSP i li d iUn DSP est un type particulier de microprocesseur.Il intègre un ensemble de fonctions spéciales destinées à le
rendre particulièrement performant dans le domaine du traitementnumérique du signal (TNS).
Il se présente généralement sous la forme d’un microcontrôleurintégrant, selon les marques et les gammes des constructeurs, dela mémoire, des timers, des ports série synchrones rapides, descontrôleurs DMA, des ports d’E/S divers.
Cours DSP Chapitre 1 6ENIS 2011-2012
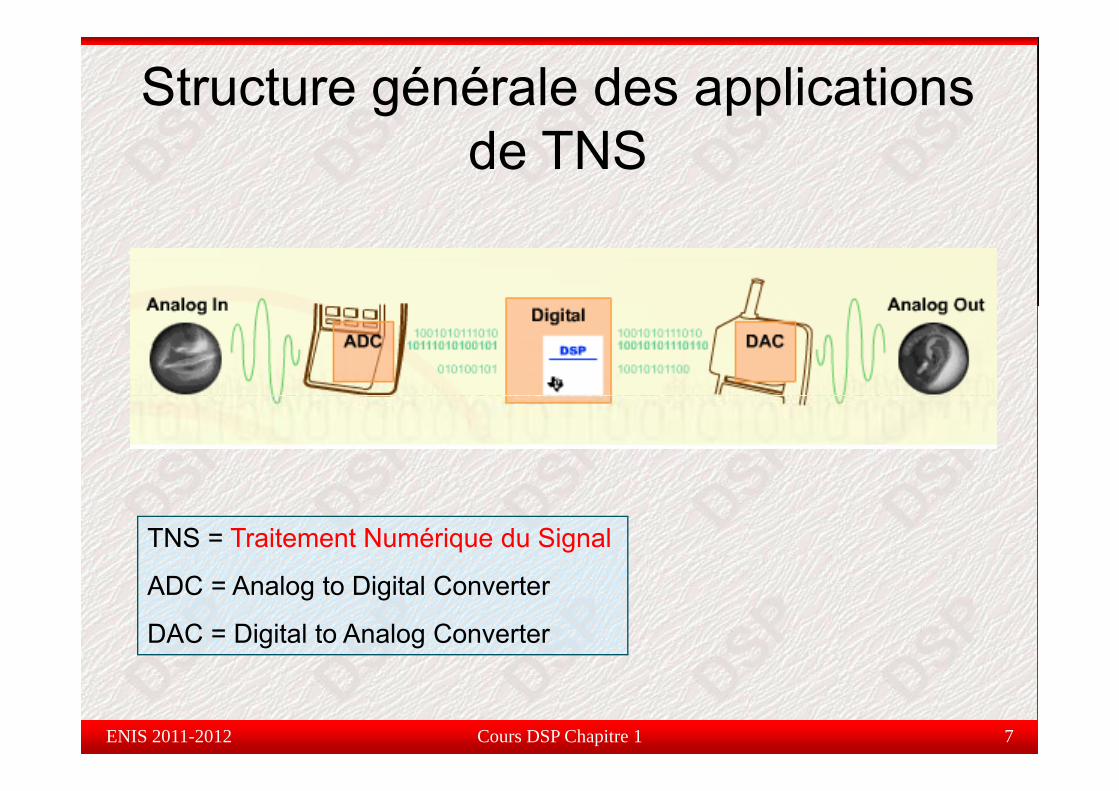
Structure générale des applications de TNS
TNS = Traitement Numérique du Signal
ADC = Analog to Digital Converter
DAC = Digital to Analog Converter
ENIS 2011-2012 Cours DSP Chapitre 1 7

Pourquoi le TNS ?q
Les principaux avantages du calcul numérique / au calcul analogique :p p g q g q
Grande résistance aux bruitsvariations des tensions d’alimentationa a o s des e s o s d a e a o
variations de la température
interférences électromagnétiques (EMI)g q ( )
Indépendance par rapport aux tolérances de fabrication
Précision arbitrairePrécision arbitraire
Stabilité dans le temps
Stockage des données sans dégradationStockage des données sans dégradation
Programmation flexible et développement rapide
Contrôle absolu des données lors du traitement
Cours DSP Chapitre 1 8
Contrôle absolu des données lors du traitement
ENIS 2011-2012

Applications des DSPpp
Communications Image / vidéoCommunicationsFilaire (DSL, cable)Sans fil (cellulaires, télé i i é i di
Image / vidéoCompression/CodageComposition
télévision numérique, radio numérique)Modem
Traitement
CryptageMilitaire
I i dAudioMixage et éditionEffets
Imagerie : radar, sonar…CryptographieGuidage de missilesEffets
Suppression de bruitAnnuleur d’echo
gNavigation
Cours DSP Chapitre 1 9ENIS 2011-2012

Applications des DSPpp
Biomédical AutomatisationBiomédicalEquipements de monitoring
Signaux biophysiquesElectroEncéphaloGramme (EEG)
AutomatisationCommande de machinesContrôle de moteursRobotsElectroEncéphaloGramme (EEG)
ElectroCardioGramme (ECG)Radiographie
Robots
InstrumentationAnalyseurs de spectre Electronique Automobile
Contrôle du moteurGénérations de fonctionsAnalyseurs de régimes transitoires
Contrôle du moteurAssistance au freinageAide à la navigationCommandes vocales
Cours DSP Chapitre 1 10ENIS 2011-2012
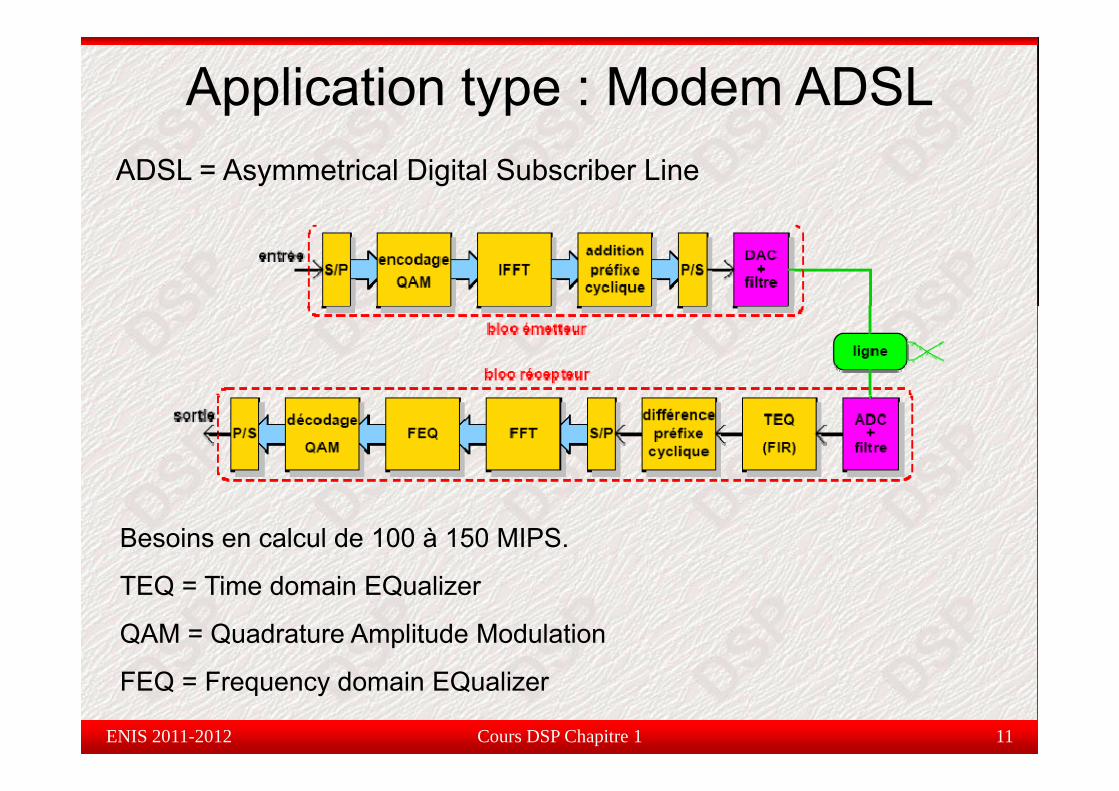
Application type : Modem ADSLADSL = Asymmetrical Digital Subscriber Line
Besoins en calcul de 100 à 150 MIPS.
TEQ = Time domain EQualizer
QAM = Quadrature Amplitude Modulation
Cours DSP Chapitre 1 11
FEQ = Frequency domain EQualizer
ENIS 2011-2012
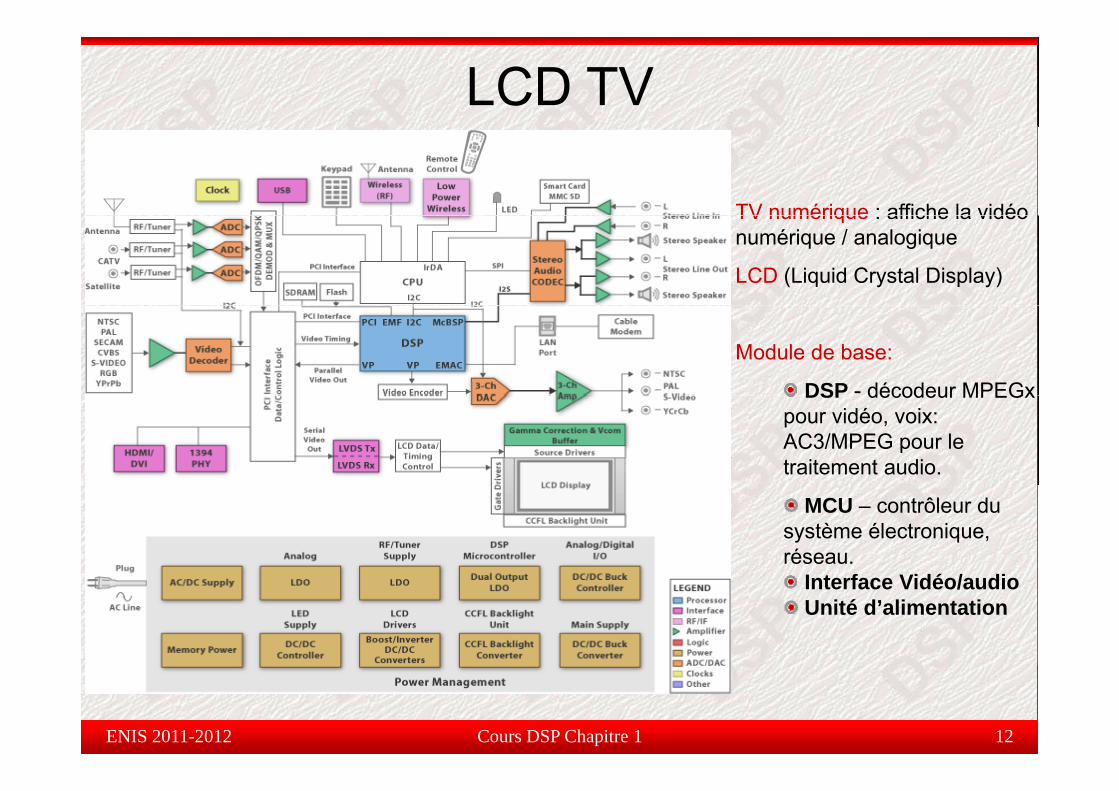
LCD TV
TV numérique : affiche la vidéoTV numérique : affiche la vidéo numérique / analogique
LCD (Liquid Crystal Display)
Module de base:
DSP - décodeur MPEGxDSP décodeur MPEGx pour vidéo, voix: AC3/MPEG pour le traitement audio.
MCU – contrôleur du système électronique, réseau.
I t f Vidé / diInterface Vidéo/audioUnité d’alimentation
Cours DSP Chapitre 1 12ENIS 2011-2012
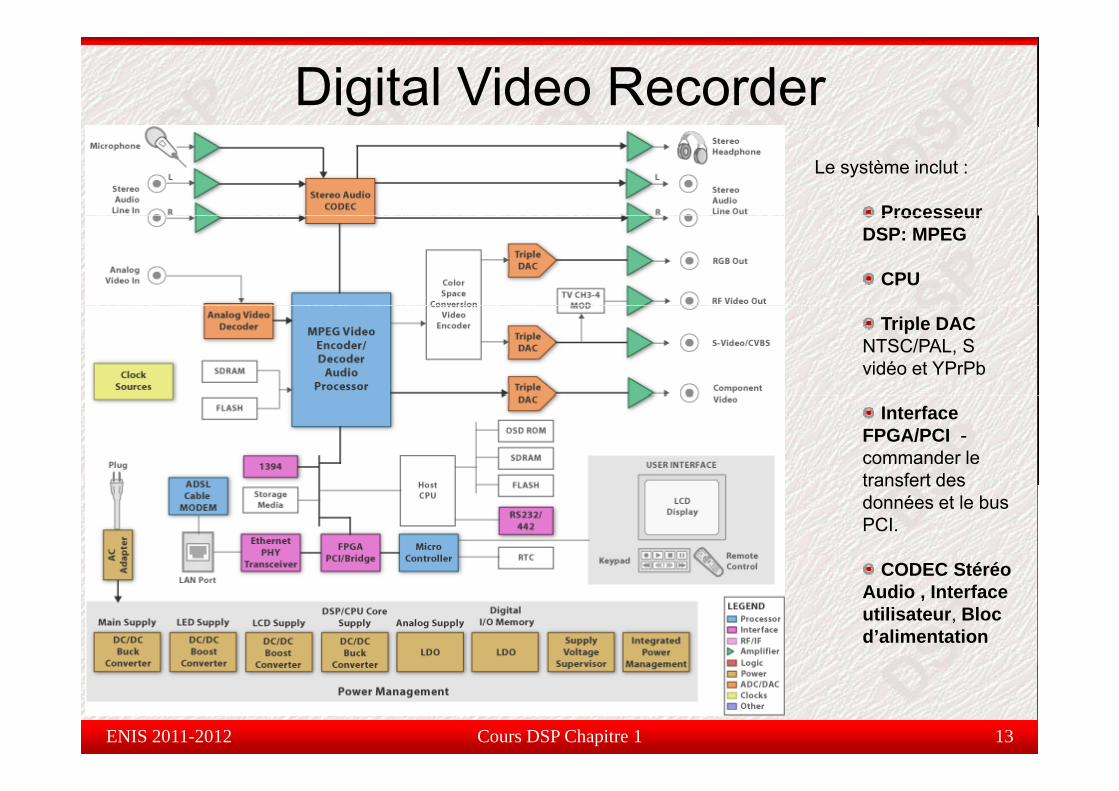
Digital Video RecorderLe système inclut :
ProcesseurProcesseur DSP: MPEG
CPU
Triple DACNTSC/PAL, S vidéo et YPrPb
Interface FPGA/PCI -commander le transfert destransfert des données et le bus PCI.
CODEC StéréoCODEC Stéréo Audio , Interface utilisateur, Bloc d’alimentation
Cours DSP Chapitre 1 13ENIS 2011-2012
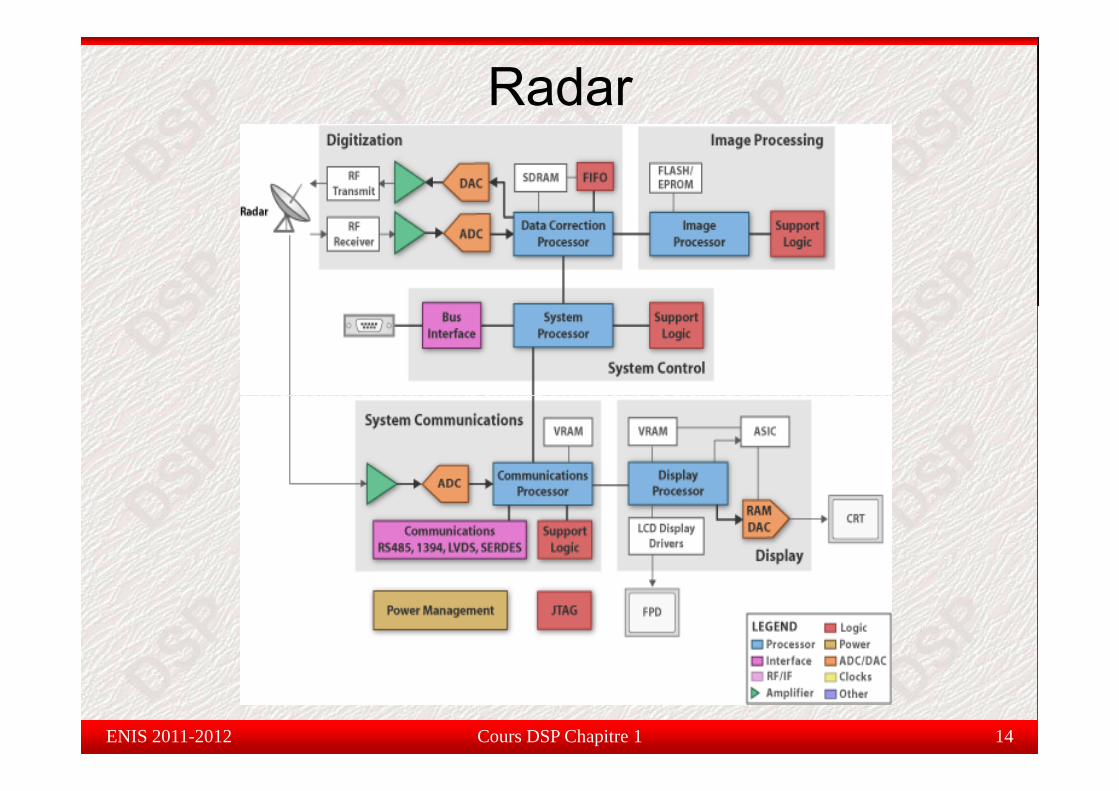
Radar
Cours DSP Chapitre 1 14ENIS 2011-2012
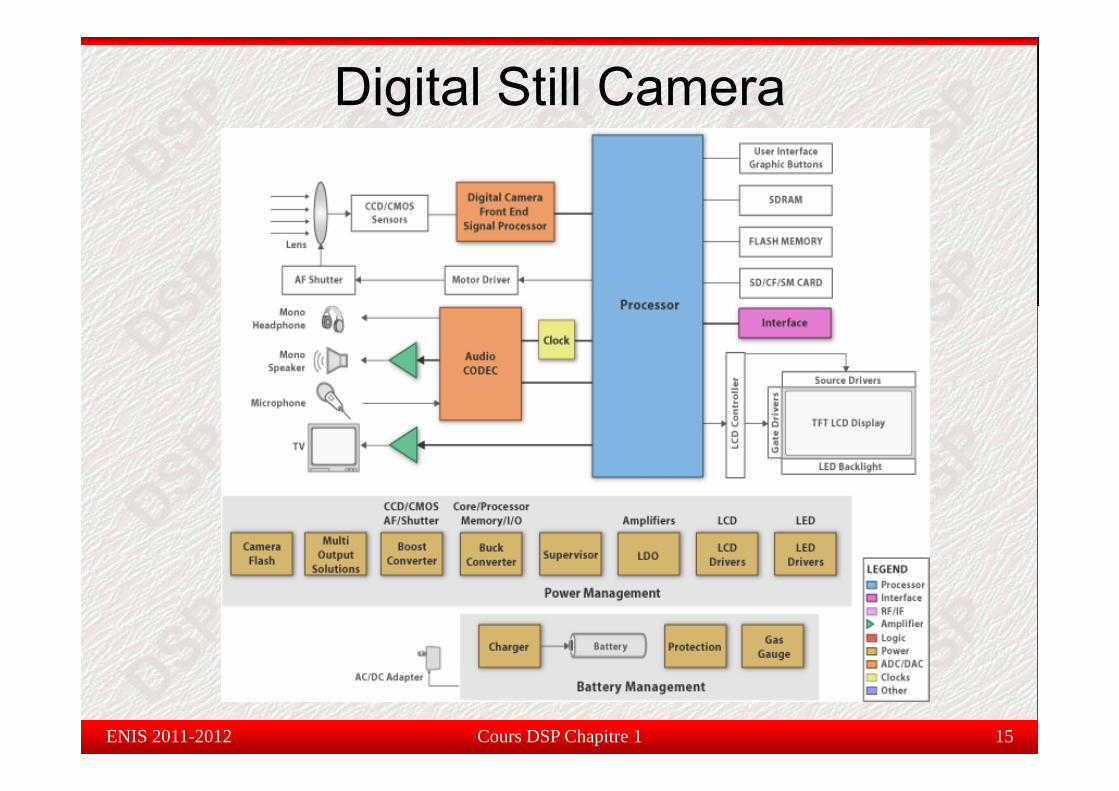
Digital Still Camera
Cours DSP Chapitre 1 15ENIS 2011-2012

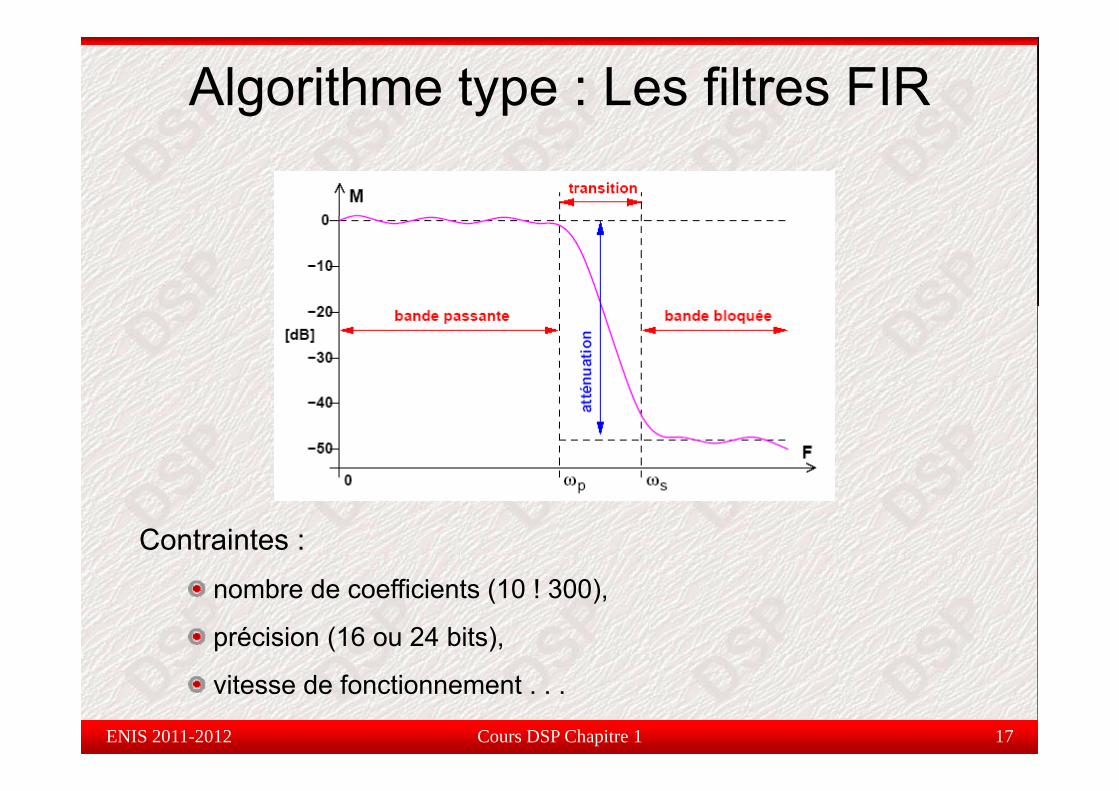
Algorithme type : Les filtres FIR
Pour un filtre à réponse impulsionnelle finie (Finite ImpulseResponse) de taille N (nombre de coefficients), on doit effectuerun calcul du type :
Cours DSP Chapitre 1 16ENIS 2011-2012
Algorithme type : Les filtres FIR
Contraintes : nombre de coefficients (10 ! 300),
précision (16 ou 24 bits),
Cours DSP Chapitre 1 17
vitesse de fonctionnement . . .
ENIS 2011-2012

Profils d’utilisation du DSP
Embarqué Haute performanceEmbarquéFaible coût unitaireFaible consommation : part importante de la
Haute performancePuissance : Calcul intensifParallélisme
Multiplication des unités deimportante de la consommation pour la mémoireArchitecture limitée au strict
Multiplication des unités de calcul internesInterfaces multi-DSP
Interface avec un ordinateurArchitecture limitée au strict nécessaireTemps réel
Interface avec un ordinateur hôte
Non prioritaires :Performance
Non prioritaires :Coût élevéUtilisation mémoirePerformance
Facilité de programmationUt sat o é o eConsommation
Cours DSP Chapitre 1 18ENIS 2011-2012

Caractéristiques classiques des DSPDSP
Ch i d d é i é t it t d i lChemin de données organisé pour traitement du signal
Jeu d’instructions spécialisép
Plusieurs bancs mémoire et plusieurs bus
Modes d’adressage spécialisés
Contrôle d’exécution spécialiséContrôle d exécution spécialisé
Périphériques spéciaux pour le traitement du signal
Augmentation du parallélisme
Cours DSP Chapitre 1 19ENIS 2011-2012

Caractéristiques classiques des DSPDSP
Augmentation du parallélisme
CalculsUnités de calcul en parallèle
Mémoire à accès multiplesLecture/Écriture de plusieurs données simultanémentp
PipelineDécoupage des instructions de façon à les exécuter àDécoupage des instructions de façon à les exécuter à intervalles plus rapprochés
Cours DSP Chapitre 1 20ENIS 2011-2012

Traitement en Temps RéelLes processeurs DSP doivent accomplir des tâches en
Traitement en Temps RéelLes processeurs DSP doivent accomplir des tâches en temps réel, ainsi comment définissons-nous le temps réel ?
La définition du temps réel dépend de l’application.
Example: un filtre FIR de 100 échantillons est exécuté en temps réel si le DSP peut effectuer et accomplir l'opération suivante entre deux échantillons :
( ) ( ) ( )∑=
−=99
0k
knxkany
Cours DSP Chapitre 1 21
=0k
ENIS 2011-2012

Traitement en Temps RéelTraitement en Temps Réel
Temps Temps d’ tt td’ tt tTemps de TraitementTemps de Traitement d’attented’attente
nn n+1n+1Temps d’échantillonTemps d’échantillon
nn n+1n+1
Nous pouvons dire que nous avons unep qapplication en temps réel si :
ENIS 2010-2011 Cours DSP Chapitre 1 22
• Temps d'attente ≥ 0

Spécificités des DSP
Algorithme classique de TNS : Filtre RIF
Spécificités des DSP
Algorithme classique de TNS : Filtre RIF
∑−
−=1
)()()(N
inxiany
Pour chaque a(i) x(n-i) :
∑=0
)()()(i
inxiany
Pour chaque a(i) x(n-i) :
Recherche de l’instruction
Recherche du coefficients a(i)
Recherche de la donnée x(n-i)
3 accès à la mémoire
Recherche de la donnée x(n i)
Multiplication a(i) x(n-i)2 accès à l’unité
ENIS 2010-2011 Cours DSP Chapitre 1 23
Accumulation a(i-1) x(n-i-1) + a(i) x(n-i)de calcul

Spécificités des DSPSpécificités des DSP
Obj tifObjectifs :
Réduire les accès mémoire
Augmenter les accès mémoire simultanés
Réduire le temps passé pour faire des calculs
Instruction MAC(multiplication-accumulation)
ENIS 2010-2011 Cours DSP Chapitre 1 24
( p )en 1 seul cycle d’instruction
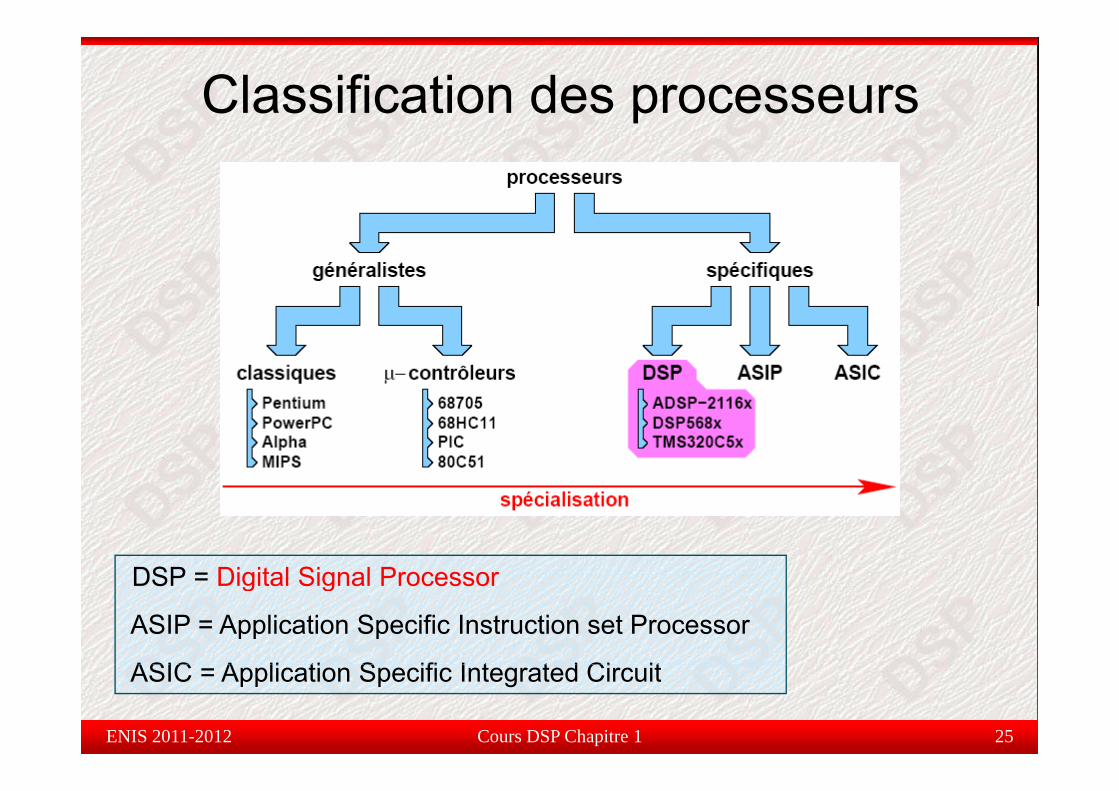
Classification des processeurs
DSP = Digital Signal ProcessorDSP = Digital Signal Processor
ASIP = Application Specific Instruction set Processor
ASIC A li ti S ifi I t t d Ci it
Cours DSP Chapitre 1 25
ASIC = Application Specific Integrated Circuit
ENIS 2011-2012

Quel processeur utiliser pour le TNS
µ-contrôleurs : pas assez performants
ASIC : beaucoup trop coûteux, mise en oeuvre complexe etlongueg
ASIP : beaucoup trop coûteux complexe et surtout spécifiqueASIP : beaucoup trop coûteux, complexe et surtout spécifique
Processeurs généralistes (GPP) : pas temps réel, trop coûteux,consomment trop d’énergie, difficilement embarquables
Cours DSP Chapitre 1 26ENIS 2011-2012
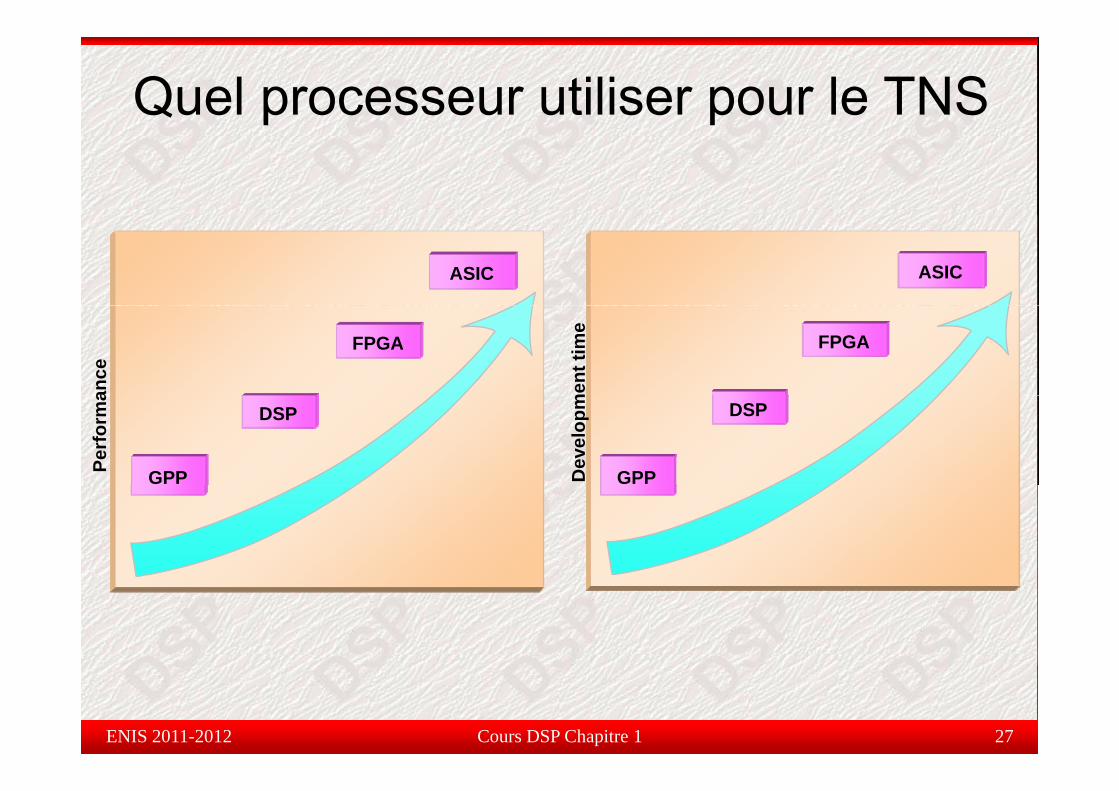
Quel processeur utiliser pour le TNS
ASIC ASIC
ance
FPGA
men
t tim
e
FPGA
Perf
orm
a
GPP
DSP
Dev
elop
m
GPP
DSP
Cours DSP Chapitre 1 27ENIS 2011-2012
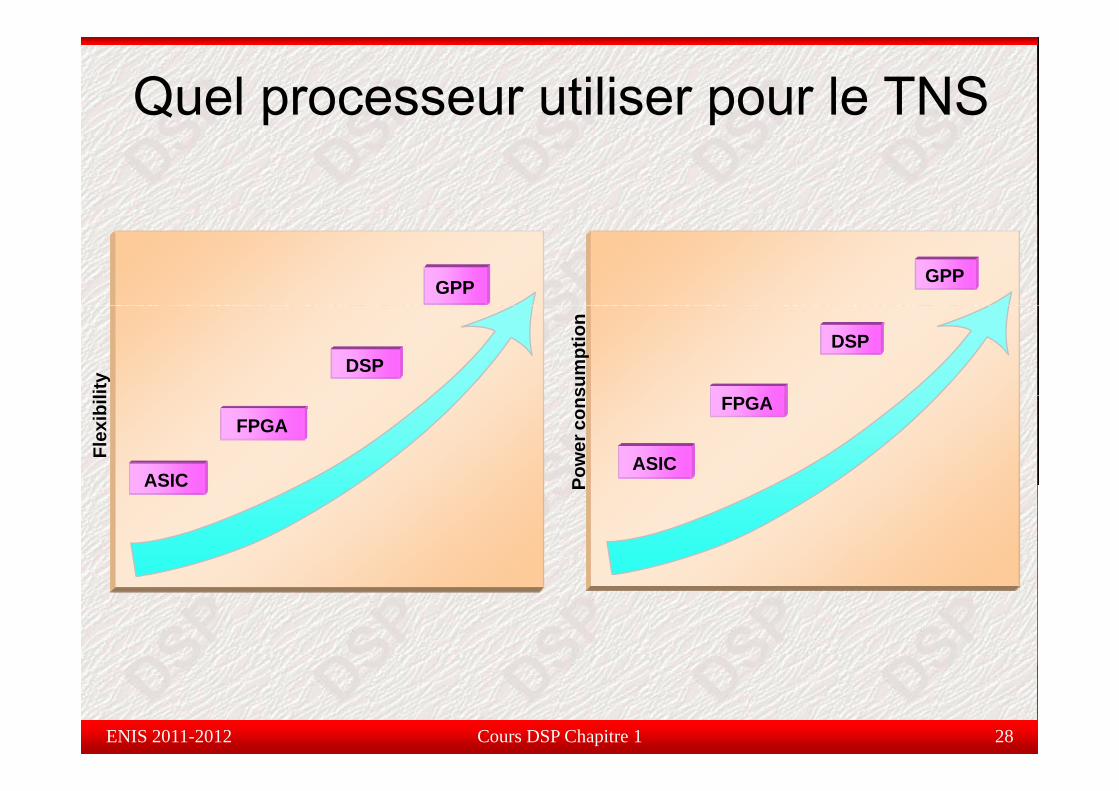
Quel processeur utiliser pour le TNS
GPP GPP
lity
sum
ptio
n
DSPDSP
Flex
ibil
Pow
erco
ns
ASIC
FPGA
ASIC
FPGA
PASIC
Cours DSP Chapitre 1 28ENIS 2011-2012

General Purpose DSP / DSP in ASICGeneral Purpose DSP / DSP in ASIC• Circuit intégré à application Spécifique
(ASICs) est conçu à base des fonctions en semi-conducteurs.
• Les avantages et les inconvénients d’utiliser les ASICs sont énumérés ci-dessous :les ASICs sont énumérés ci dessous :AdvantagesAdvantages
S iS i ééll ééInconvInconvéénients nients
CC ûûtt ééll éé•• Sortie Sortie éélevlevéé•• Faible surface en siliciumFaible surface en silicium•• Faible consommation de Faible consommation de
•• CoCoûût t éélevlevéé•• Moins de flexibilitMoins de flexibilitéé•• Temps de dTemps de dééveloppement est veloppement est
puissancepuissance•• FiabilitFiabilitéé amamééliorliorééee•• RRééduction du bruit duction du bruit
éélevlevéé
Cours DSP Chapitre 1 29
•• Faible coFaible coûût du systt du systèème globalme global
ENIS 2011-2012

Hardware / Microcode multiplicationHardware / Microcode multiplication• Les processeurs DSP sont optimisés pour
effectuer des opérations de multiplication et d'addition.
• Multiplication et addition sont exécutées matériellement pendant un seul cycle. p yExemple: Multiplication 4-bit (non-signé).
HardwareHardware MicrocodeMicrocodeHardwareHardware MicrocodeMicrocode
10111011x 1110x 1110
10111011x 1110x 1110
1001101010011010 00000000 Cycle 1Cycle 1
10111011x 1110x 1110
10111011x 1110x 1110
1001101010011010 00000000 Cycle 1Cycle 11001101010011010 000000001011.1011.1011..1011..1011...1011...
Cycle 1Cycle 1Cycle 2Cycle 2Cycle 3Cycle 3Cycle 4Cycle 4
1001101010011010 000000001011.1011.1011..1011..1011...1011...
Cycle 1Cycle 1Cycle 2Cycle 2Cycle 3Cycle 3Cycle 4Cycle 4
Cours DSP Chapitre 1 30
1011...1011...
1001101010011010
Cycle 4Cycle 4
Cycle 5Cycle 5
1011...1011...
1001101010011010
Cycle 4Cycle 4
Cycle 5Cycle 5
ENIS 2011-2012

Paramètres à considérerParamètres à considérerParameter TMS320C6211
(@150MHz)TMS320C6711
(@150MHz)Parameter TMS320C6211
(@150MHz)TMS320C6711
(@150MHz)Arithmetic formatExtended floating pointExtended Arithmetic
32-bitN/A
40-bit
32-bit64-bit40-bit
@ @Arithmetic formatExtended floating pointExtended Arithmetic
32-bitN/A
40-bit
32-bit64-bit40-bit
@ @
Extended ArithmeticPerformance (peak)Number of hardware multipliers
40-bit1200MIPS
2 (16 x 16-bit) with 32-bit result
40-bit1200MFLOPS
2 (32 x 32-bit) with 32 or 64-bit result
Extended ArithmeticPerformance (peak)Number of hardware multipliers
40-bit1200MIPS
2 (16 x 16-bit) with 32-bit result
40-bit1200MFLOPS
2 (32 x 32-bit) with 32 or 64-bit result
Number of registersInternal L1 program memory cacheI t l L1 d t h
bit result32
32K32K
or 64 bit result32
32K32K
Number of registersInternal L1 program memory cacheI t l L1 d t h
bit result32
32K32K
or 64 bit result32
32K32KInternal L1 data memory cache
Internal L2 cache32K512K
32K512K
Internal L1 data memory cacheInternal L2 cache
32K512K
32K512K
C6711 Datasheet: C6711 Datasheet: \\LinksLinks\\TMS320C6711.pdfTMS320C6711.pdf
Cours DSP Chapitre 1 31
ppC6211 Datasheet: C6211 Datasheet: \\LinksLinks\\TMS320C6211.pdfTMS320C6211.pdf
ENIS 2011-2012
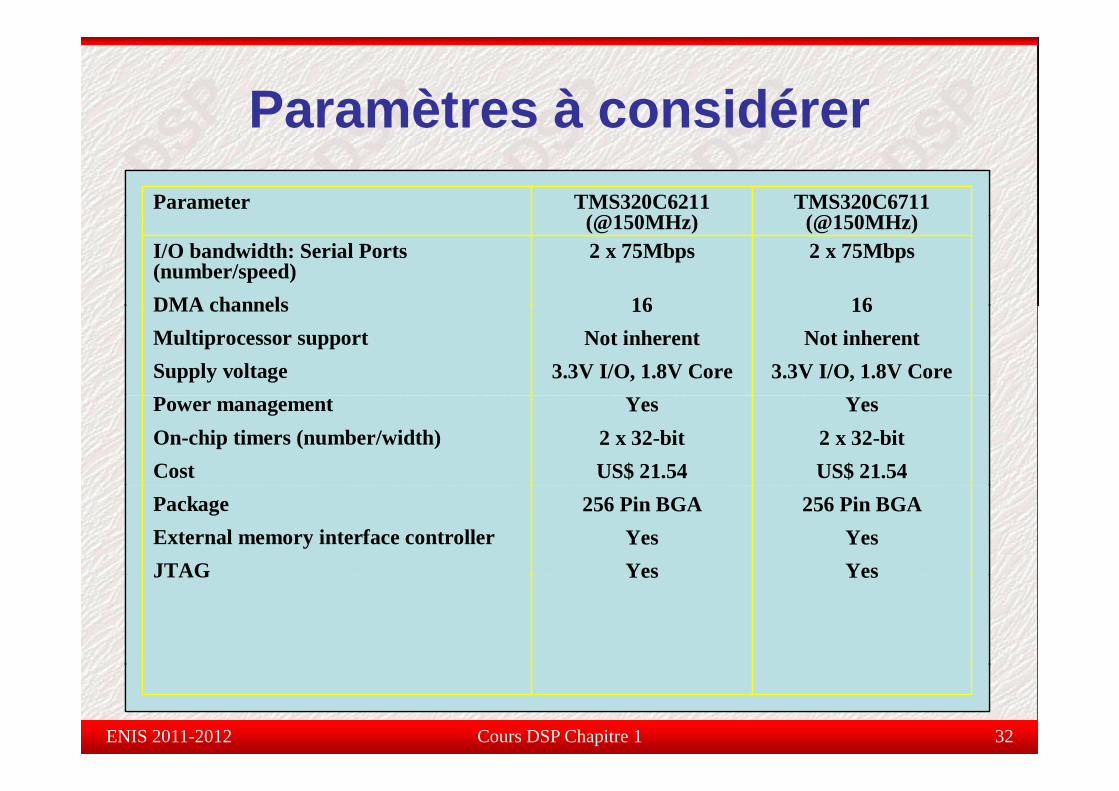
Paramètres à considérerParamètres à considérerParameter TMS320C6211
(@150MH )TMS320C6711
(@150MH )Parameter TMS320C6211
(@150MH )TMS320C6711
(@150MH )I/O bandwidth: Serial Ports (number/speed)DMA channels
2 x 75Mbps
16
2 x 75Mbps
16
(@150MHz) (@150MHz)I/O bandwidth: Serial Ports (number/speed)DMA channels
2 x 75Mbps
16
2 x 75Mbps
16
(@150MHz) (@150MHz)
DMA channelsMultiprocessor supportSupply voltage
16Not inherent
3.3V I/O, 1.8V Core
16Not inherent
3.3V I/O, 1.8V Core
DMA channelsMultiprocessor supportSupply voltage
16Not inherent
3.3V I/O, 1.8V Core
16Not inherent
3.3V I/O, 1.8V CorePower managementOn-chip timers (number/width)Cost
Yes2 x 32-bitUS$ 21.54
Yes2 x 32-bitUS$ 21.54
Power managementOn-chip timers (number/width)Cost
Yes2 x 32-bitUS$ 21.54
Yes2 x 32-bitUS$ 21.54
PackageExternal memory interface controllerJTAG
256 Pin BGAYesYes
256 Pin BGAYesYes
PackageExternal memory interface controllerJTAG
256 Pin BGAYesYes
256 Pin BGAYesYesJTAG Yes YesJTAG Yes Yes
Cours DSP Chapitre 1 32ENIS 2011-2012

Algorithmes typiques du DSPLa somme des produits (SOP) est l’élément clé dans la plupart des algorithmes:
Algorithm Equation
∑M
Finite Impulse Response Filter ∑=
−=k
k knxany0
)()(
Infinite Impulse Response Filter ∑∑ +=NM
knybknxany )()()(Infinite Impulse Response Filter ∑∑==
−+−=k
kk
k knybknxany10
)()()(
Convolution ∑ −=N
knhkxny )()()( Co vo u o ∑=k
y0
)()()(
Discrete Fourier Transform ∑−
−=1
])/2(exp[)()(N
nkNjnxkX π =0n
Discrete Cosine Transform ( ) ( )∑−
=⎥⎦⎤
⎢⎣⎡ +=
1
0
122
cos).().(N
x
xuN
xfucuF π
Cours DSP Chapitre 1 33
= ⎦⎣0x
ENIS 2011-2012

DSP à i l fl tt t / FiDSP à virgule flottante / Fixe
• Applications qui exigent:
– À haute précision.– dynamique large.– Rapport signal/bruit élevé.Rapport signal/bruit élevé.– Facilité d'utilisation.
Ayez besoin d'un processeur de
Cours DSP Chapitre 1 34
virgule flottante.ENIS 2011-2012

DSP à virgule flottante / FixeDSP à virgule flottante / Fixe
• C’est l’application qui définie la plateforme àutiliser dans le but d’obtenir les performances poptimums à faible prix.
• Pour un but éducatif, utiliser un DSP à virgule flottante (6711 ou 6713) qui peut supporter lesflottante (6711 ou 6713) qui peut supporter les opérations à virgule flottante et fixe.
Cours DSP Chapitre 1 35ENIS 2011-2012

DSP à virgule flottante / Fixe
• Inconvénient des processeurs à virgule• Inconvénient des processeurs à virgule flottante:
– Consommation de puissance plus élevéConsommation de puissance plus élevé– Peut être plus coûteux.
P t êt i id l DSP à– Peut être moins rapide que le DSP àvirgule fixe et de taille plus importante.
Cours DSP Chapitre 1 36ENIS 2011-2012
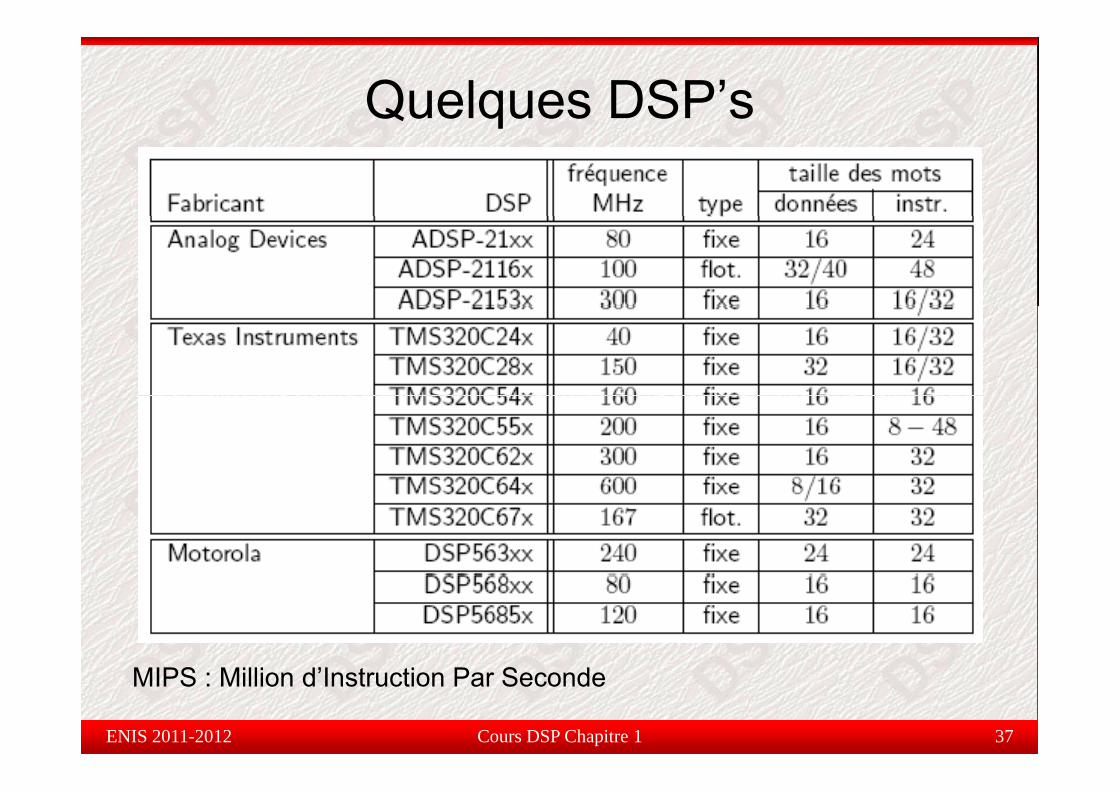
Quelques DSP’sq
Cours DSP Chapitre 1 37
MIPS : Million d’Instruction Par Seconde
ENIS 2011-2012
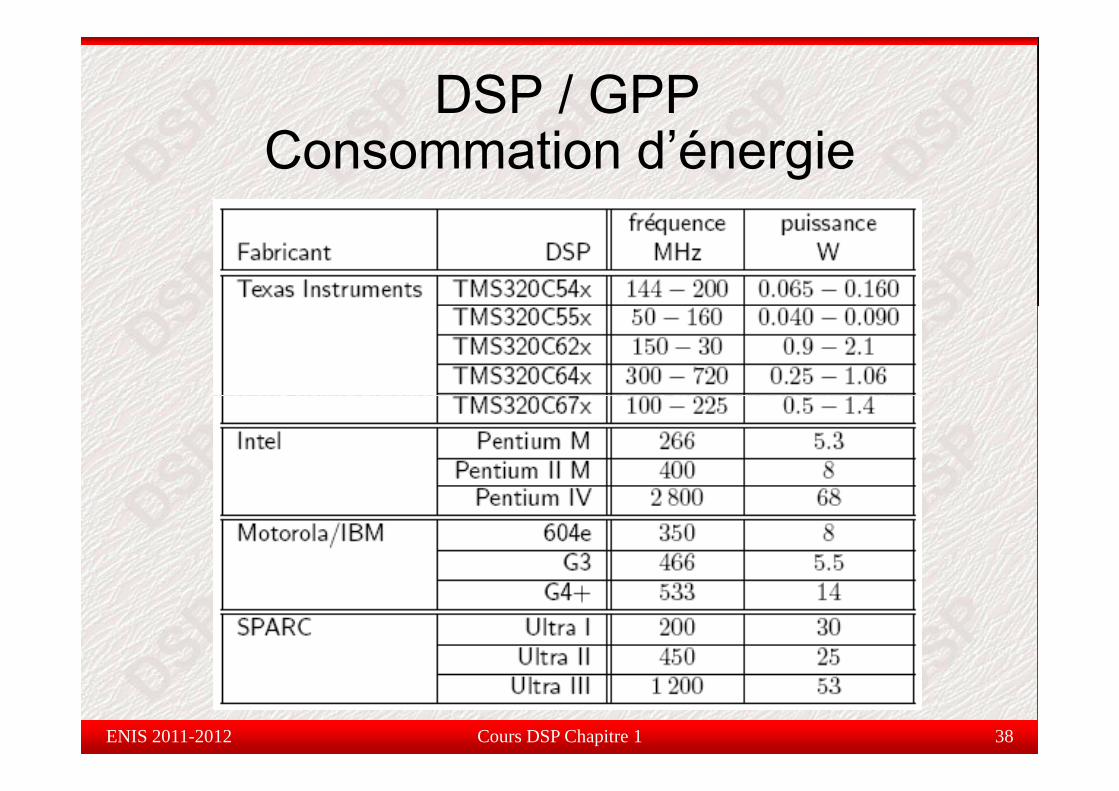
DSP / GPP Consommation d’énergie
Cours DSP Chapitre 1 38ENIS 2011-2012

Représentation des nombres
Les DSP à virgule fixeLes DSP à virgule fixeLes données sont représentées comme étant des nombres fractionnaires à
virgule fixe, (exemple -1.0 à +1.0), ou comme des entiers classiques.g ( p ) qLa représentation de ces nombres fractionnaires s’appuie la méthode du
«complément à deux».P t f il t l’ dditi bi i d b itif t é tifPermet facilement l’addition binaire de nombres positifs et négatifs.
Les DSP à virgule flottantegLes données sont représentées en utilisant une mantisse et un exposant.La représentation de ces nombres s’effectue selon la formule suivante :
tn = mantisse x 2exposant
Généralement, la mantisse est un nombre fractionnaire (-1.0 à +1.0), etl’exposant est un entier indiquant la place de la virgule en base 2.
Cours DSP Chapitre 1 39
e posa es u e e d qua a p ace de a gu e e base
ENIS 2011-2012

Représentation des nombres
Cours DSP Chapitre 1 40ENIS 2011-2012

Représentation des nombresVirgule fixe
Cours DSP Chapitre 1 41ENIS 2011-2012

Représentation des nombresVirgule flottante
Cours DSP Chapitre 1 42ENIS 2011-2012

Représentation des nombresVirgule flottante
Cours DSP Chapitre 1 43ENIS 2011-2012

Texas Instruments’ TMS320 familyy• Les différents familles et sous families
existent pour soutenir différents marchésexistent pour soutenir différents marchés
C2000C2000 C5000C5000 C6000C6000C2000C2000 C5000C5000 C6000C6000C2000C2000C2000C2000 C5000C5000C5000C5000 C6000C6000
Lowest CostLowest Cost EfficiencyEfficiency PerformancePerformance &&Lowest CostLowest Cost EfficiencyEfficiencyLowest CostLowest CostLowest CostLowest CostLowest CostLowest Cost EfficiencyEfficiencyEfficiencyEfficiency PerformancePerformance &&PerformancePerformance &&Lowest CostLowest CostControl SystemsControl Systems
Motor ControlMotor Control
EfficiencyEfficiencyBest MIPS perBest MIPS per
Watt / Dollar / SizeWatt / Dollar / Size Multi Channel andMulti Channel and
PerformancePerformance &&Best Best EaseEase--ofof--UseUse
Lowest CostLowest CostControl SystemsControl Systems
Motor ControlMotor Control
EfficiencyEfficiencyBest MIPS perBest MIPS per
Watt / Dollar / SizeWatt / Dollar / Size
Lowest CostLowest CostControl SystemsControl Systems
Motor ControlMotor Control
Lowest CostLowest CostControl SystemsControl Systems
Motor ControlMotor Control
Lowest CostLowest CostControl SystemsControl Systems
Motor ControlMotor Control
EfficiencyEfficiencyBest MIPS perBest MIPS per
Watt / Dollar / SizeWatt / Dollar / Size
EfficiencyEfficiencyBest MIPS perBest MIPS per
Watt / Dollar / SizeWatt / Dollar / Size Multi Channel andMulti Channel and
PerformancePerformance &&Best Best EaseEase--ofof--UseUse
Multi Channel andMulti Channel and
PerformancePerformance &&Best Best EaseEase--ofof--UseUse
StorageStorageDigital Ctrl SystemsDigital Ctrl Systems
Wireless phonesWireless phonesInternet audio playersInternet audio playersDigital still cameras Digital still cameras
Multi Channel and Multi Channel and Multi Function App'sMulti Function App'sComm InfrastructureComm InfrastructureWi l BWi l B t tit ti
StorageStorageDigital Ctrl SystemsDigital Ctrl Systems
Wireless phonesWireless phonesInternet audio playersInternet audio playersDigital still cameras Digital still cameras
StorageStorageDigital Ctrl SystemsDigital Ctrl SystemsStorageStorageDigital Ctrl SystemsDigital Ctrl SystemsStorageStorageDigital Ctrl SystemsDigital Ctrl Systems
Wireless phonesWireless phonesInternet audio playersInternet audio playersDigital still cameras Digital still cameras
Wireless phonesWireless phonesInternet audio playersInternet audio playersDigital still cameras Digital still cameras
Multi Channel and Multi Channel and Multi Function App'sMulti Function App'sComm InfrastructureComm InfrastructureWi l BWi l B t tit ti
Multi Channel and Multi Channel and Multi Function App'sMulti Function App'sComm InfrastructureComm InfrastructureWi l BWi l B t tit tiDigital still cameras Digital still cameras
ModemsModemsTelephonyTelephonyVoIPVoIP
Wireless BaseWireless Base--stationsstationsDSLDSLImagingImaging
Digital still cameras Digital still cameras ModemsModemsTelephonyTelephonyVoIPVoIP
Digital still cameras Digital still cameras ModemsModemsTelephonyTelephonyVoIPVoIP
Digital still cameras Digital still cameras ModemsModemsTelephonyTelephonyVoIPVoIP
Wireless BaseWireless Base--stationsstationsDSLDSLImagingImaging
Wireless BaseWireless Base--stationsstationsDSLDSLImagingImaging
Cours DSP Chapitre 1 44
VoIPVoIP MultiMulti--media Serversmedia ServersVideoVideo
VoIPVoIPVoIPVoIPVoIPVoIP MultiMulti--media Serversmedia ServersVideoVideoMultiMulti--media Serversmedia ServersVideoVideo
ENIS 2011-2012
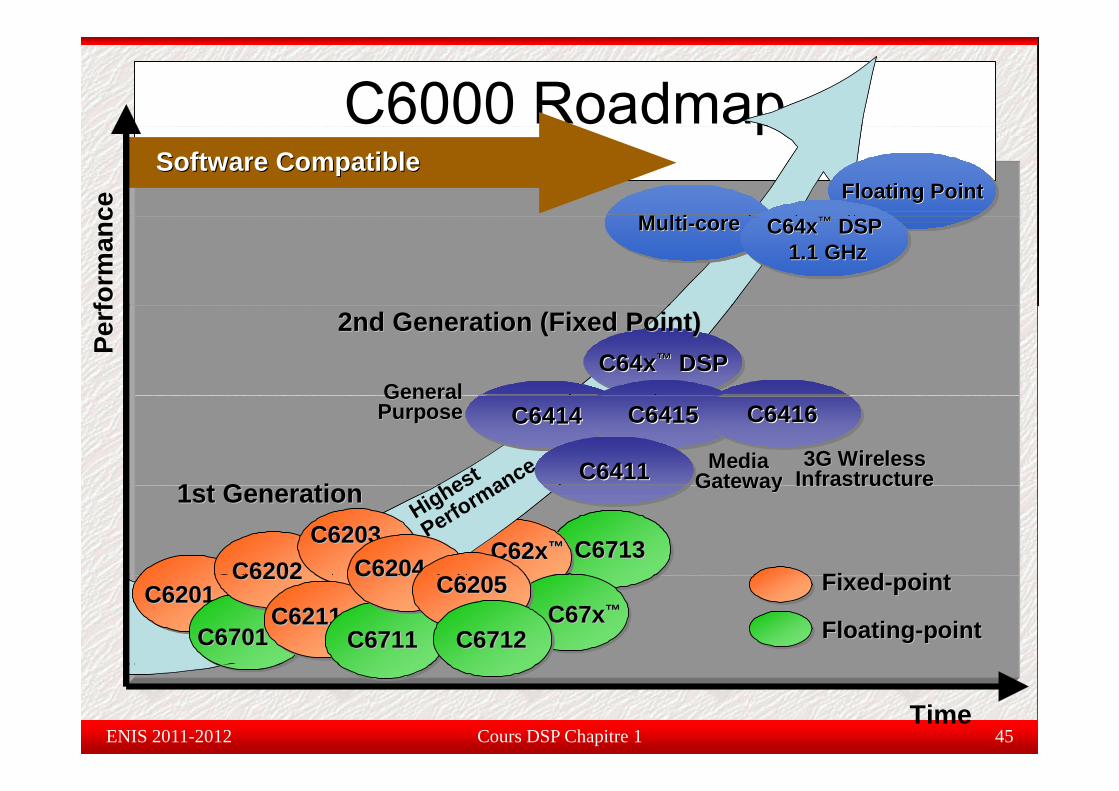
C6000 Roadmappce
Software CompatibleSoftware CompatibleFloating PointFloating PointFloating Point
M ltiM ltiFloating PointFloating PointFloating Point
M ltiM lti
form
anc Multi-coreMultiMulti--corecore C64x™ DSP
1.1 GHzC64xC64x™™ DSPDSP
1.1 GHz1.1 GHzMulti-coreMultiMulti--corecore C64x™ DSP
1.1 GHzC64xC64x™™ DSPDSP
1.1 GHz1.1 GHz
Perf
C64x™ DSPC64xC64x™™ DSPDSP2nd Generation (Fixed Point)2nd Generation (Fixed Point)
GeneralGeneral
hest ancehest ance
General General PurposePurpose C6414C6414C6414 C6415C6415C6415 C6416C6416C6416
MediaMediaGatewayGateway
3G Wireless 3G Wireless InfrastructureInfrastructure1 t G ti1 t G ti
C6411C6411C6411
C6713C6713C6713C6713C62xC62x™™C62xC62x™™
Highes
Performan
Highes
Performan GatewayGateway InfrastructureInfrastructure
C6202C6202C6203C6203
C6204C6204
1st Generation1st Generation
Fi dFi d i ti tC6201C6201
C6701C6701
C6202C6202
C6211C6211C6711C6711
C6204C6204C6205C6205
C6712C6712C67xC67x™™
FixedFixed--pointpoint
FloatingFloating--pointpoint
Cours DSP Chapitre 1 45Time
ENIS 2011-2012

Plus d’informationInternetInternet
Website:Website: www.ti.comwww.ti.comdspvillage.comdspvillage.com
FTPFTP ft //ft ti / b/t 320bbft //ft ti / b/t 320bbFTP:FTP: ftp://ftp.ti.com/pub/tms320bbsftp://ftp.ti.com/pub/tms320bbs
FAQ:FAQ: http://wwwhttp://www--k.ext.ti.com/sc/technical_support/knowledgebase.htm k.ext.ti.com/sc/technical_support/knowledgebase.htm
D i i f tiD i i f ti TI & METI & ME
USA USA -- Product Information Center ( PIC )Product Information Center ( PIC )
Device informationDevice information TI & METI & MEApplication notesApplication notes News and eventsNews and events
Technical documentationTechnical documentation TrainingTraining
Phone:Phone: 972972--644644--55805580Email:Email: [email protected]@ti.com
( )( )
Information and support for Information and support for allall TI Semiconductor products/toolsTI Semiconductor products/toolsSubmit suggestions and errata for tools, silicon and documentsSubmit suggestions and errata for tools, silicon and documents
Software Registration/Upgrades:Software Registration/Upgrades: 972972--293293--50505050H d R i /U dH d R i /U d 281281 274274 22852285
Other ResourcesOther Resources
Cours DSP Chapitre 1 46ENIS 2011-2012
Hardware Repair/Upgrades:Hardware Repair/Upgrades: 281281--274274--22852285Enroll in Technical Training:Enroll in Technical Training: www.ti.com/sc/trainingwww.ti.com/sc/training
(choose (choose Design WorkshopsDesign Workshops))
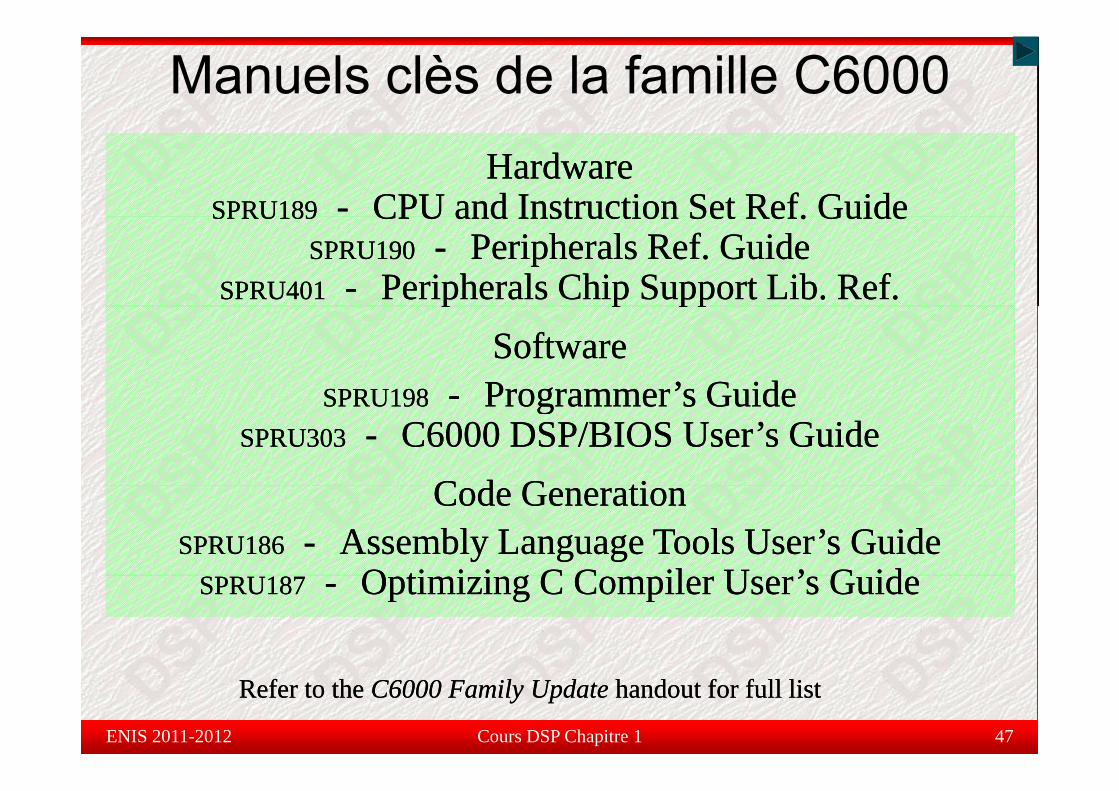
Manuels clès de la famille C6000HardwareHardware
SPRU189SPRU189 -- CPU and Instruction Set Ref. GuideCPU and Instruction Set Ref. GuideSPRU189SPRU189 CPU and Instruction Set Ref. GuideCPU and Instruction Set Ref. GuideSPRU190SPRU190 -- Peripherals Ref. GuidePeripherals Ref. Guide
SPRU401SPRU401 -- Peripherals Chip Support Lib. Ref.Peripherals Chip Support Lib. Ref.p p ppp p ppSoftwareSoftware
SPRU198SPRU198 Programmer’s GuideProgrammer’s GuideSPRU198SPRU198 -- Programmer s GuideProgrammer s GuideSPRU303SPRU303 -- C6000 DSP/BIOS User’s GuideC6000 DSP/BIOS User’s Guide
C d G tiC d G tiCode GenerationCode GenerationSPRU186SPRU186 -- Assembly Language Tools User’s GuideAssembly Language Tools User’s Guide
O ti i i C C il U ’ G idO ti i i C C il U ’ G idSPRU187SPRU187 -- Optimizing C Compiler User’s GuideOptimizing C Compiler User’s Guide
Cours DSP Chapitre 1 47ENIS 2011-2012
Refer to the Refer to the C6000 Family UpdateC6000 Family Update handout for full listhandout for full list

Literature sud les DSP
“A Simple Approach to Digital Signal Processing”“A Simple Approach to Digital Signal Processing”by Craig by Craig MarvenMarven and Gillian Ewers; and Gillian Ewers; ISBN 0ISBN 0--47114711--52435243--99y gy g
“DSP Primer (Primer Series)”“DSP Primer (Primer Series)”by C. Britton by C. Britton RorabaughRorabaugh; ; ISBN 0ISBN 0--07050705--40044004--77
“A DSP Primer : With Applications to Digital Audio“A DSP Primer : With Applications to Digital Audioand Computer Music” by Ken Steiglitz; ISBN 0-8053-1684-1
“DSP First : A Multimedia Approach”
Cours DSP Chapitre 1 48ENIS 2011-2012
James H. McClellan, Ronald W. Schafer, Mark A. Yoder;ISBN 0-1324-3171-8

Literature sud les DSP
“Digital Signal Processing Implementation “Digital Signal Processing Implementation g g g pg g g pusing the TMS320C6000TM DSP Platform”using the TMS320C6000TM DSP Platform”
by Naim Dahnoun; ISBN 0201by Naim Dahnoun; ISBN 0201--6191661916--44
“C6x“C6x--Based Digital Signal Processing”Based Digital Signal Processing”by Nasser Kehtarnavaz and Burc Simsek;by Nasser Kehtarnavaz and Burc Simsek;
ISBN 0ISBN 0--1313--088310088310--77
Cours DSP Chapitre 1 49ENIS 2011-2012

Programmation des DSPIl est relativement facile d'écrire un programme pour un DSP, grâce aux
compilateurs C interfacés avec le DSP.La façon d'écrire le programme C a une influence significative sur
l'efficacité du code généré.Il existe une phase d'adaptation du code C à un code DSP, permettantp p p
au compilateur de tirer le meilleur parti de l'architecture de calcul.
Cours DSP Chapitre 1 50ENIS 2011-2012

Programmation des DSP de TICode Composer Studio (CCS) : Le logiciel de pilotage de la carte DSP
est un logiciel très performant comportant un ensemble complet d'outils deest un logiciel très performant comportant un ensemble complet d outils dedéveloppement d'applications sur DSP.
Il t i d' t t d' éli l dIl permet aussi d'augmenter et d'améliorer le processus dedéveloppement pour les programmeurs qui cherchent à créer et tester entemps réel des applications de traitement de signal.
Il met en disposition des outils pour configurer, construire, exécuter,suivre et analyser des programmes.y p g
Cours DSP Chapitre 1 51ENIS 2011-2012
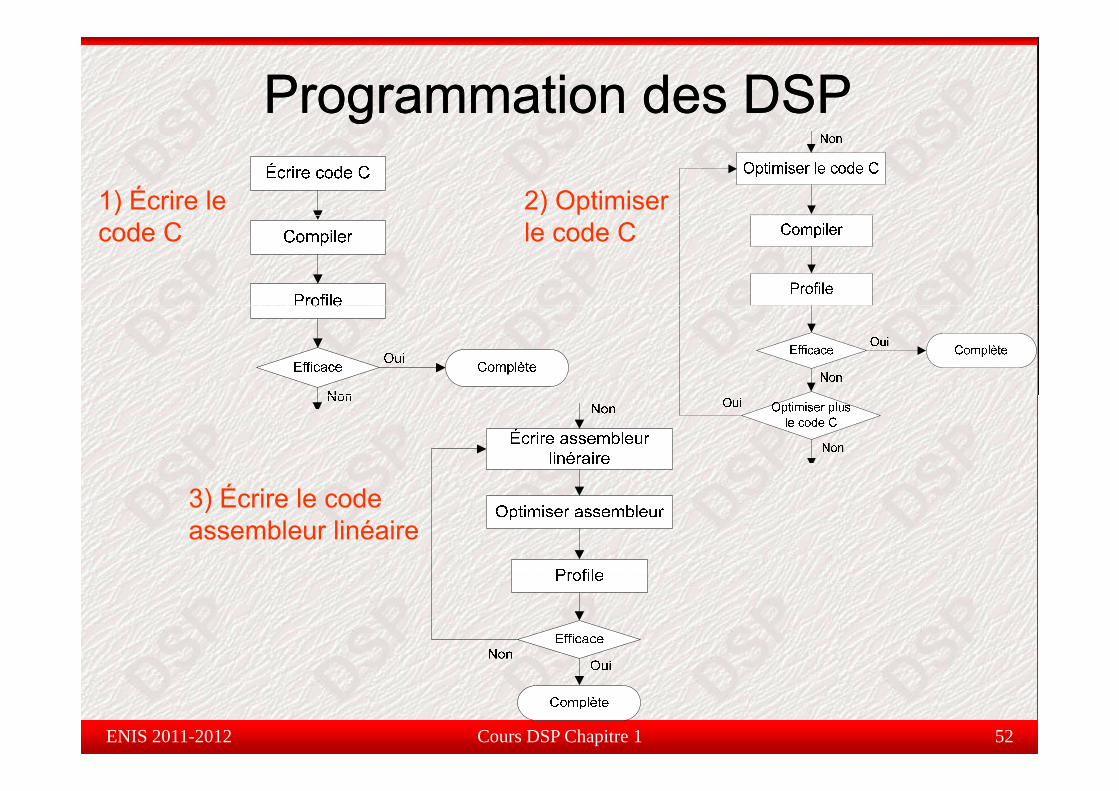
Programmation des DSPProgrammation des DSP
1) Écrire le 2) Optimiser code C le code C
É3) Écrire le code assembleur linéaire
Cours DSP Chapitre 1 52ENIS 2011-2012
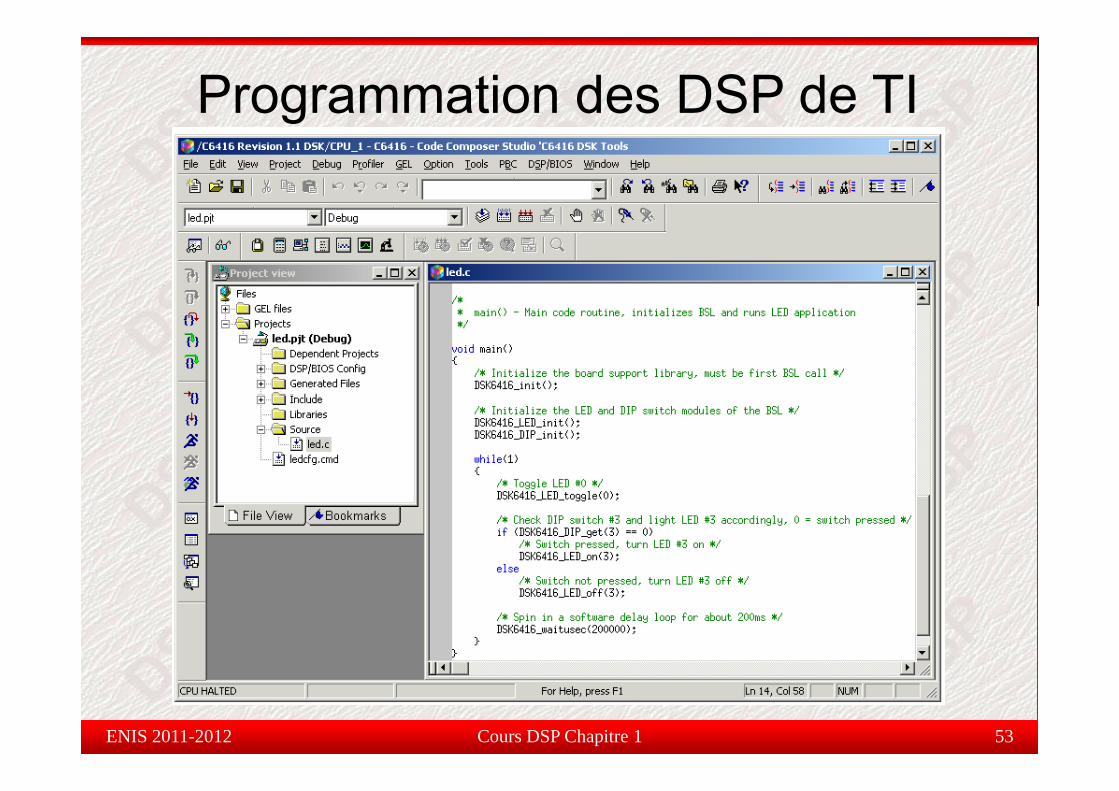
Programmation des DSP de TI
Cours DSP Chapitre 1 53ENIS 2011-2012

ENISENIS 2011/2012
Chapitre II :
Architectures des DSP’s
Plan Ch suivantCh précédent

SommaireTypes de structures mémoireyp
Les caches dans les DSP
Évolution des DSP
SIMD (DSP16xxx, ADSP-2116x, …)
Superscalaire (LSI401Z, …)
VLIW (TMS320 C6x)
DSP conventionnels multicoreDSP conventionnels multicore
Processeurs hybrides ARM+DSP
Cours DSP Chapitre 2 55ENIS 2011-2012

Perspective historique1970 1971: Intel 4004
1972: Intel 8008
1980
1972: Intel 80081974: 1er microcontrôleur : TMS 1000
1er ordinateur personnel (8008)1979: 1er DSP single-chip : Bell Labs Mac 4
1980 Intel 80861980: 1er DSP autonome : NEC µPD77101981: IBM PC (8088)1982: Intel 80286
1990
1982: Intel 802861983: 1er succès commercial pour un DSP : TMS 320 C101985: Intel 3861986: MIPS -> R2000, premier microprocesseur RISC commercial
2000
p p1989: Intel 486 (utilisation d’un pipeline)1993: Intel Pentium, PowerPC 6011996: 1er DSP VLIW : TMS 320 C62xx1999 P ti III1999: Pentium III 2000: Pentium 4
Cours DSP Chapitre 2 56ENIS 2011-2012

Historique des Processeurs
1e génération 79-… 4e génération 92-…1e génération 79 …• Architecture Harvard• Multiplieur cablé
4 génération 92 …Image et vidéoProcesseurs faible
2e génération 85-…Parallélisme
consommation
• Parallélisme• Bus multiples• Mémoire sur la puce
5e génération 97-…VLIW
3e génération 88-… HybridesMulticore• Virgule flottante MulticoreDSP + RISC
Cours DSP Chapitre 2 57ENIS 2011-2012
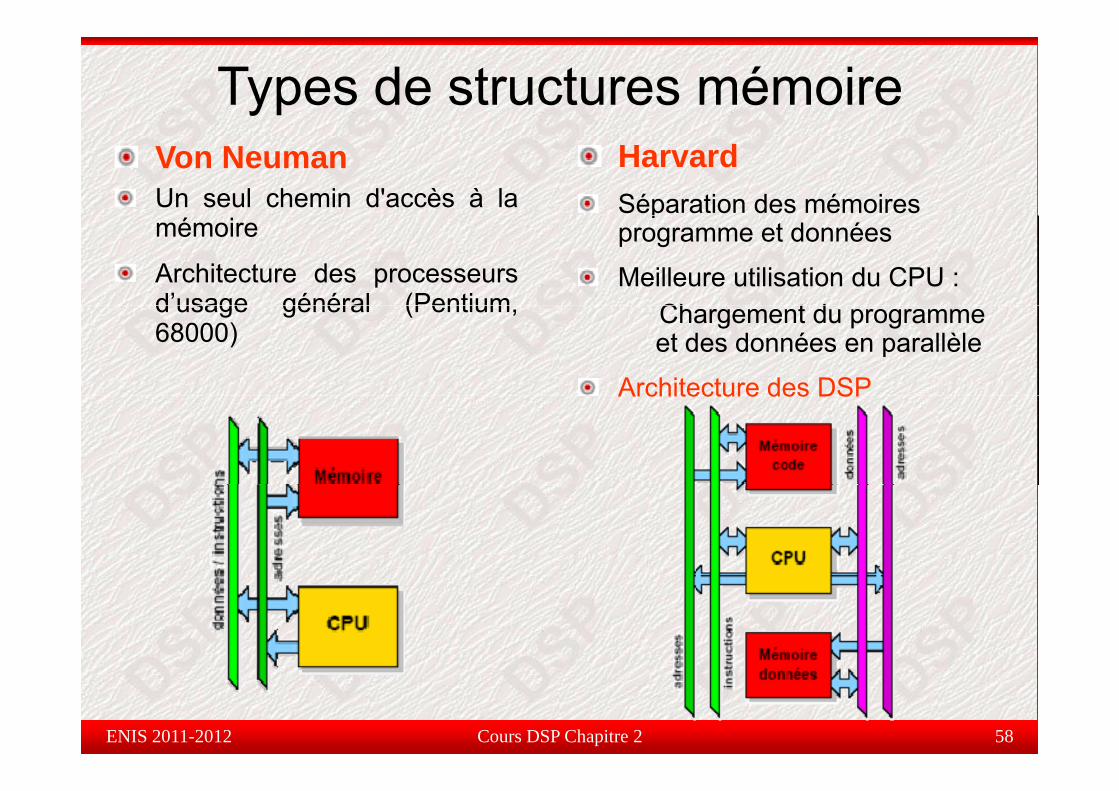
Types de structures mémoireHarvardSéparation des mémoires
Von NeumanUn seul chemin d'accès à la p
programme et données
Meilleure utilisation du CPU :Ch t d
mémoire
Architecture des processeursd’usage général (Pentium Chargement du programme
et des données en parallèle
Architecture des DSP
d usage général (Pentium,68000)
Architecture des DSP
Cours DSP Chapitre 2 58ENIS 2011-2012

Les types de structures mémoire
Principales différences :Principales différences :
Bande passante (accès instruction et donnée simultanés ou non)p ( )
Mémoires (coût, surface)
Contrôle plus ou moins complexe
Cours DSP Chapitre 2 59ENIS 2011-2012
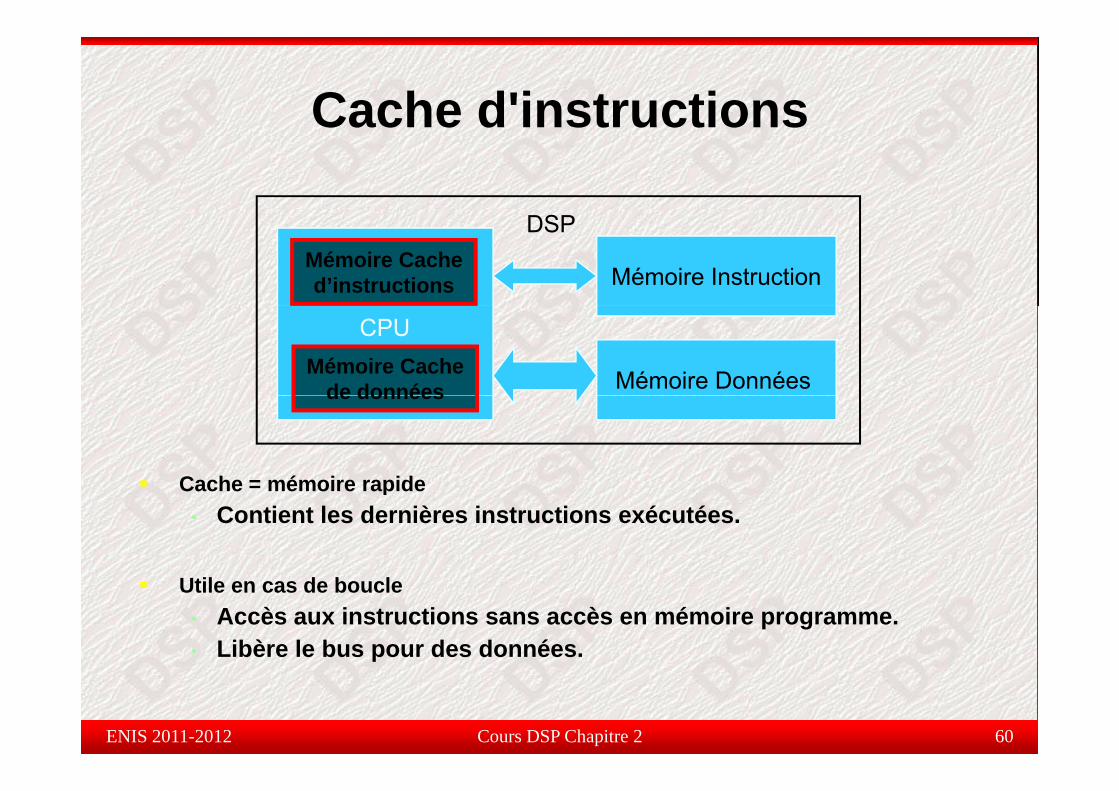
Cache d'instructionsCache d instructions
DSPDSP
Mémoire InstructionMémoire Cached’instructions
Mémoire Données
CPUMémoire Cache
de donnéesde données
Cache = mémoire rapideCache = mémoire rapide• Contient les dernières instructions exécutées.
Utile en cas de boucle• Accès aux instructions sans accès en mémoire programme.• Libère le bus pour des données.
Cours DSP Chapitre 2 60ENIS 2011-2012
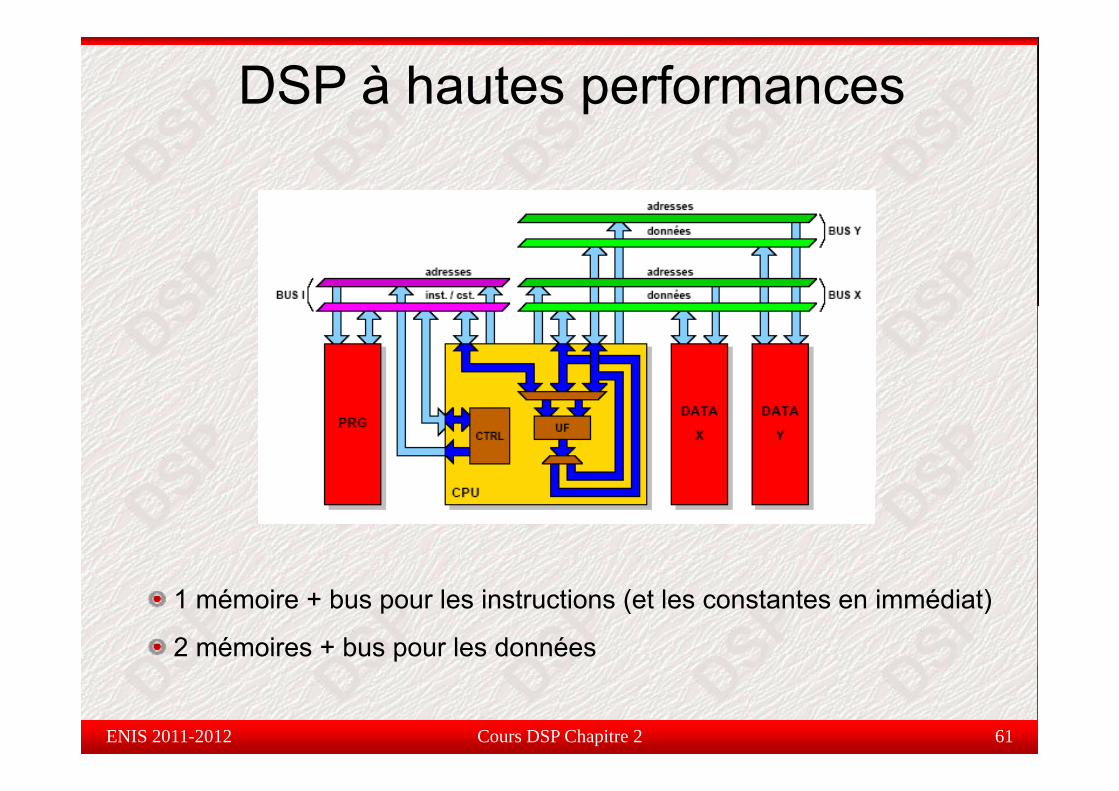
DSP à hautes performances
1 mémoire + bus pour les instructions (et les constantes en immédiat)
2 mémoires + bus pour les données
Cours DSP Chapitre 2 61ENIS 2011-2012

Évolution “hautes performances” des DSP
Comment accélérer les programmes ?
PARALLELISME
Solutions courantes :
SIMD : DSP16xxx, ADSP-2116xSIMD : DSP16xxx, ADSP 2116x
Superscalaire : LSI401Z
VLIW : TMS320 C6xVLIW : TMS320 C6x
Approches combinées : VLIW + SIMD : TigerSHARC
Cours DSP Chapitre 2 62ENIS 2011-2012

DSP SIMDSIMD = Single Instruction Multiple DataD t d SIMDDeux types de SIMD
Unités parallèlesUnités parallèlesEffectuent la même opération sur des données différentesExemple : ADSP-2116x
Partage de l’unité de traitementPartage un mot de donnée en sous-motsEffectue les calculs sur les sous motsEffectue les calculs sur les sous-motsExemple : instructions MMX du Pentium
D d ff dDemande un effort du programmeurEfficace pour des algorithmes parallèles
Cours DSP Chapitre 2 63ENIS 2011-2012
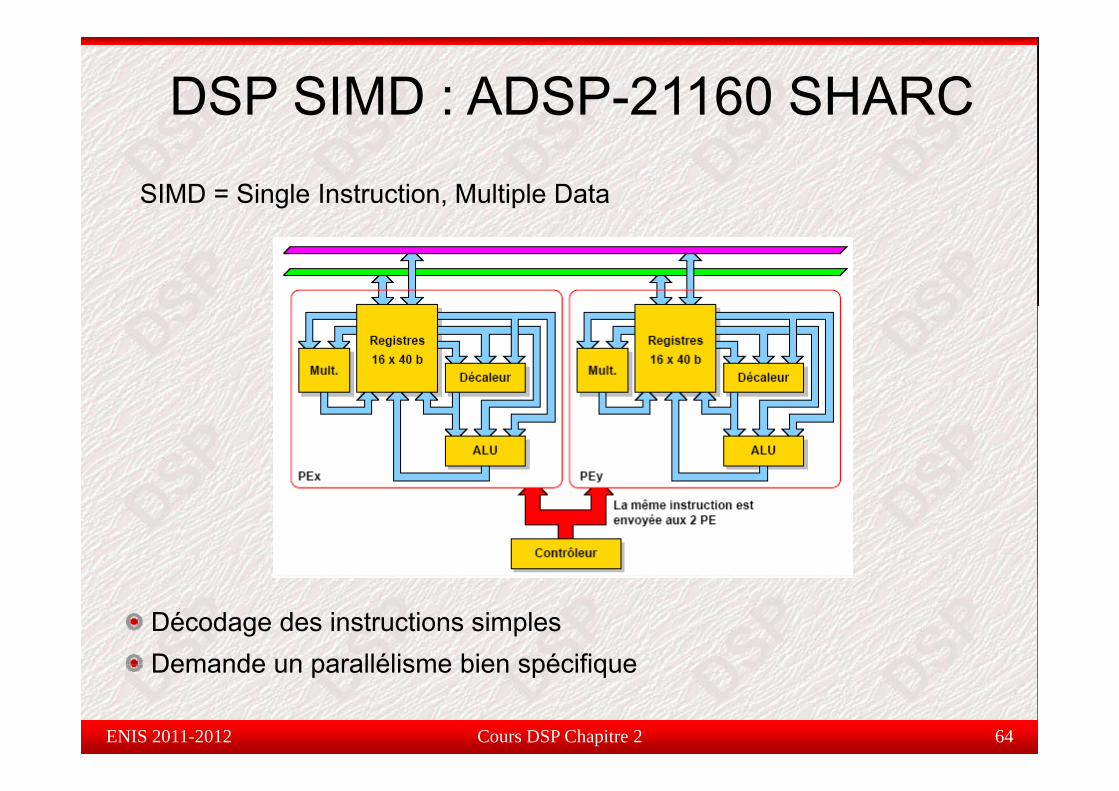
DSP SIMD : ADSP-21160 SHARCSIMD = Single Instruction, Multiple Data
Décodage des instructions simplesDemande un parallélisme bien spécifique
Cours DSP Chapitre 2 64
Demande un parallélisme bien spécifique
ENIS 2011-2012
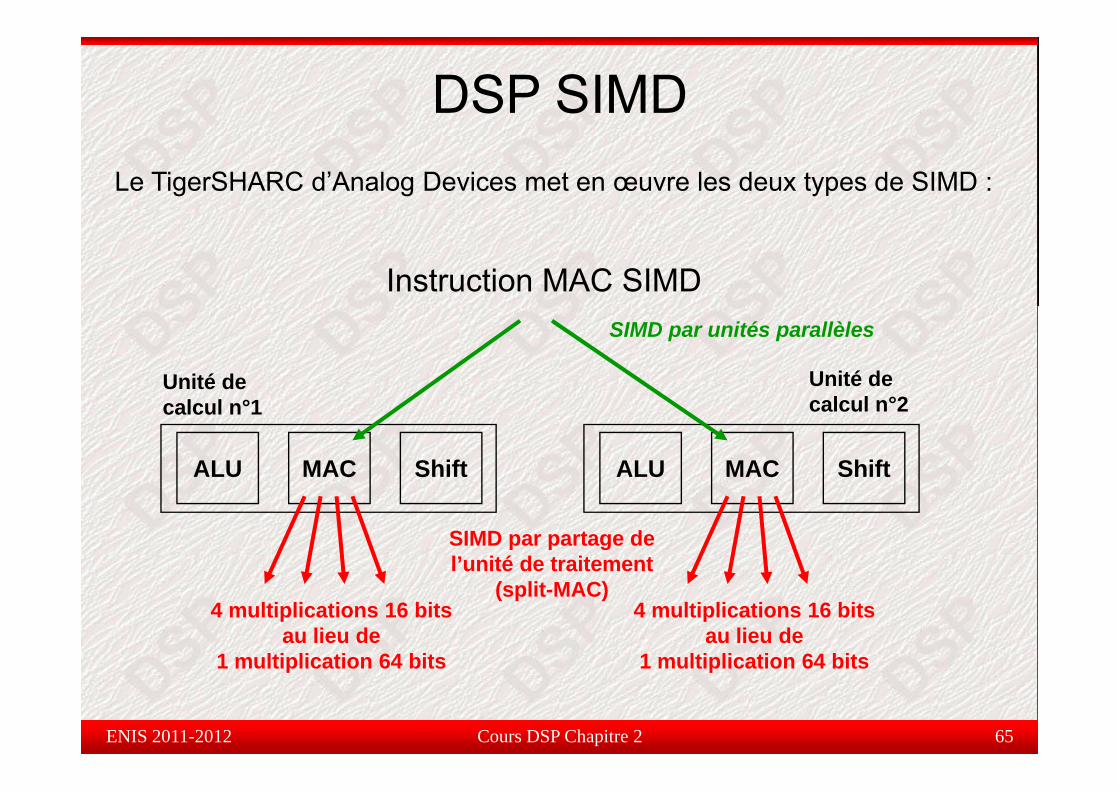
DSP SIMDLe TigerSHARC d’Analog Devices met en œuvre les deux types de SIMD :
Instruction MAC SIMD
Unité de Unité de
SIMD par unités parallèles
MACALU Shift MACALU Shift
calcul n°1 calcul n°2
SIMD par partage de l’unité de traitement
4 multiplications 16 bitsau lieu de
1 multiplication 64 bits
4 multiplications 16 bitsau lieu de
1 multiplication 64 bits
(split-MAC)
Cours DSP Chapitre 2 65
1 multiplication 64 bits 1 multiplication 64 bits
ENIS 2011-2012
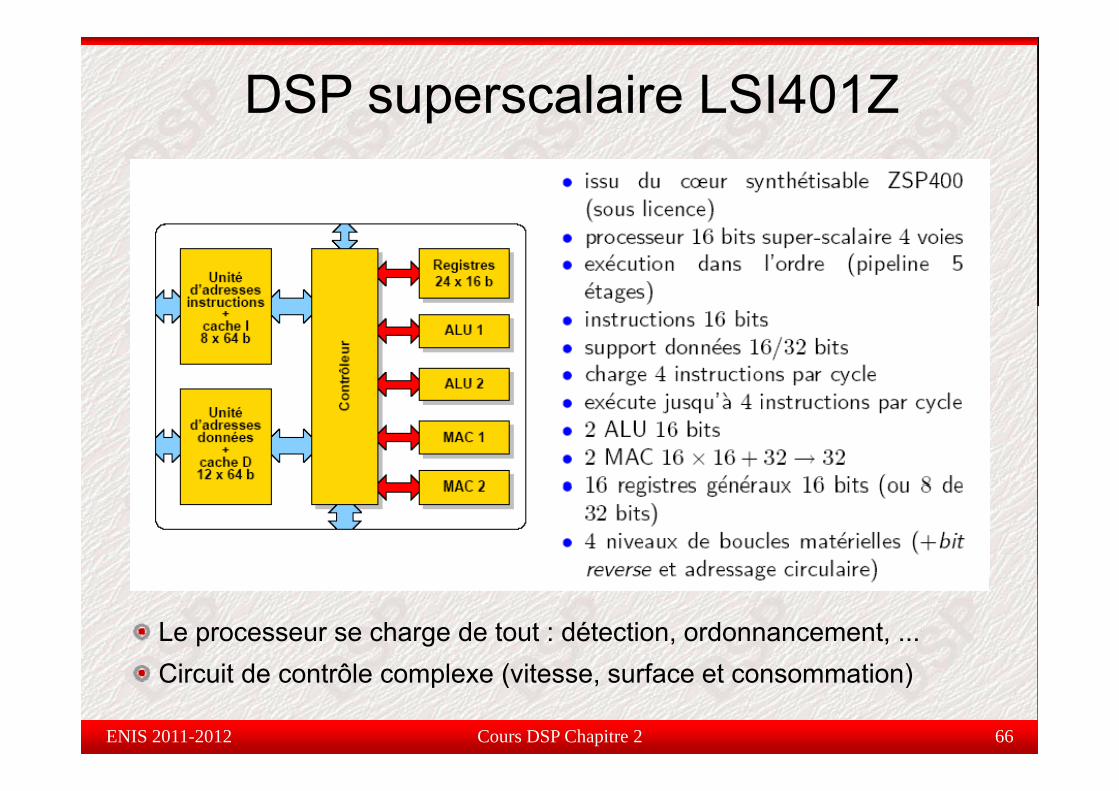
DSP superscalaire LSI401Z
Le processeur se charge de tout : détection, ordonnancement, ...Ci it d t ôl l ( it f t ti )
Cours DSP Chapitre 2 66
Circuit de contrôle complexe (vitesse, surface et consommation)
ENIS 2011-2012
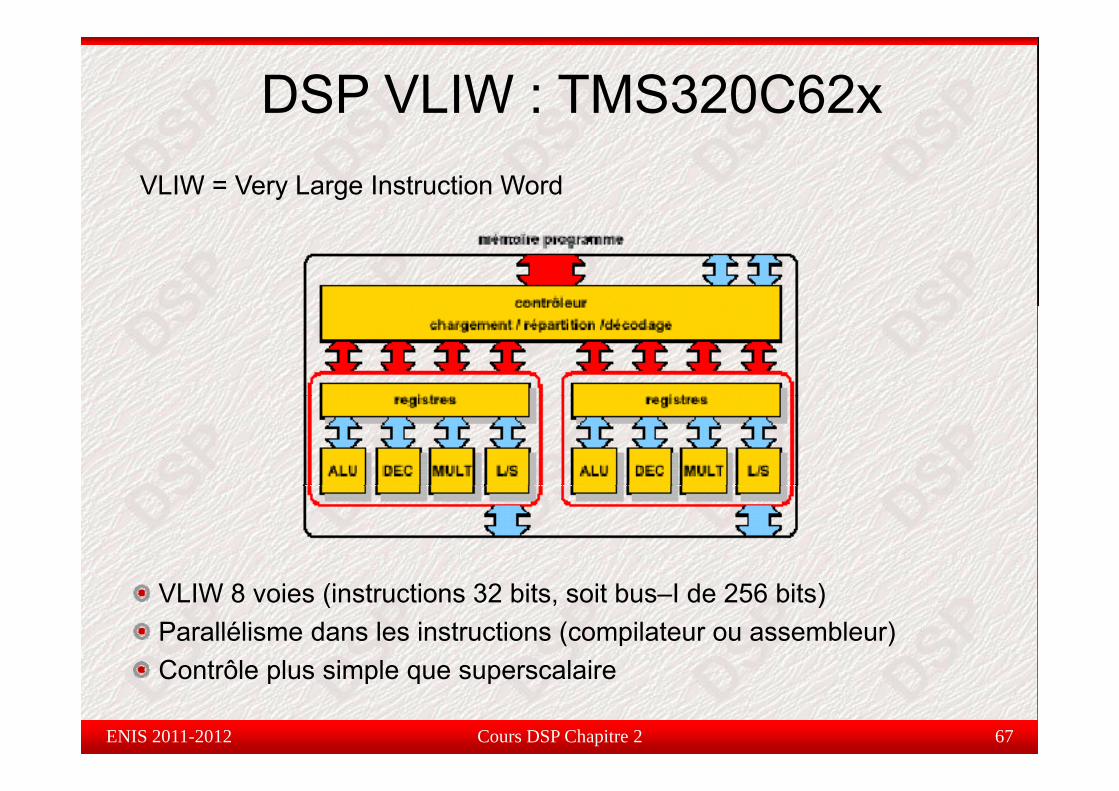
DSP VLIW : TMS320C62xVLIW = Very Large Instruction Word
VLIW 8 voies (instructions 32 bits, soit bus–I de 256 bits)Parallélisme dans les instructions (compilateur ou assembleur)Contrôle pl s simple q e s perscalaire
Cours DSP Chapitre 2 67
Contrôle plus simple que superscalaire
ENIS 2011-2012
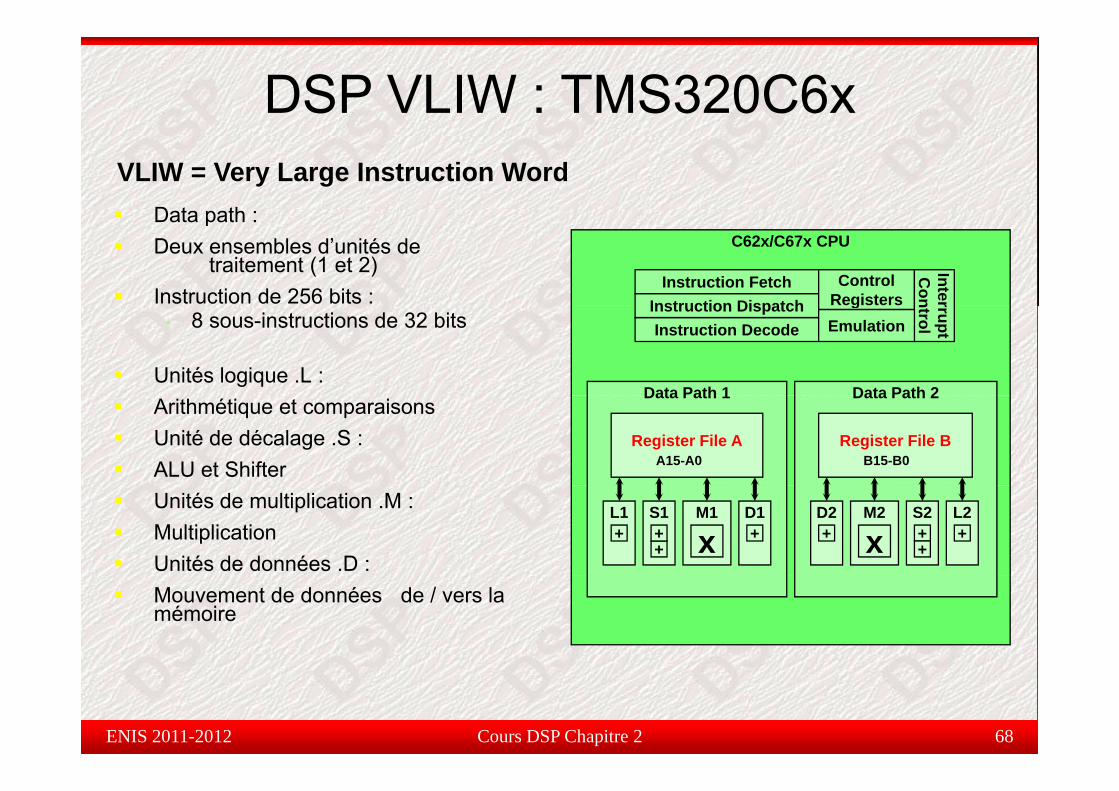
DSP VLIW : TMS320C6xVLIW = Very Large Instruction Word
Data path :Data path :Deux ensembles d’unités de
traitement (1 et 2)Instruction de 256 bits :
C62x/C67x CPU
Instruction DispatchInstruction Fetch Control
Registers
InterC
on
• 8 sous-instructions de 32 bits
Unités logique .L :Data Path 2Data Path 1
Instruction DecodeInstruction Dispatch g rrupt
ntrolEmulation
Arithmétique et comparaisonsUnité de décalage .S :ALU et Shifter
Data Path 2Data Path 1
Register File AA15-A0
Register File BB15-B0
Unités de multiplication .M :MultiplicationUnités de données .D :
L1 M2D2 S2 L2S1
++ +
++x+
M1
xD1++
Mouvement de données de / vers la mémoire
Cours DSP Chapitre 2 68ENIS 2011-2012
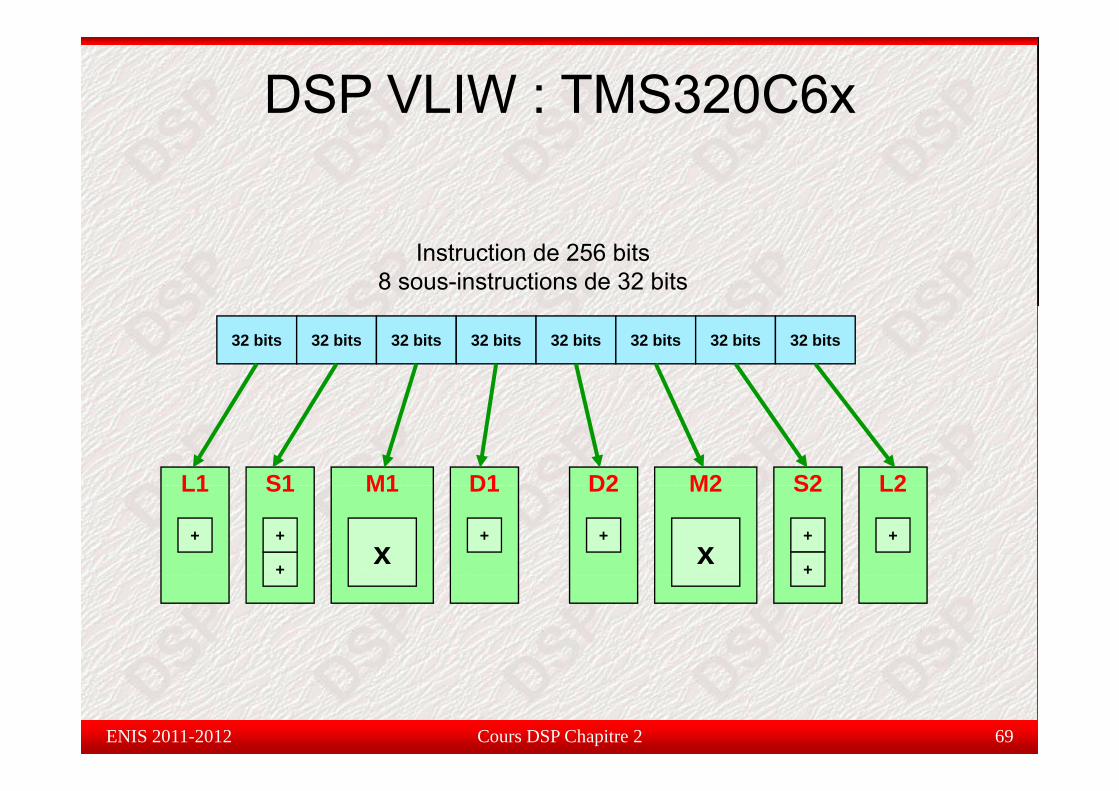
DSP VLIW : TMS320C6x
Instruction de 256 bits8 sous-instructions de 32 bits
32 bits 32 bits 32 bits 32 bits 32 bits 32 bits 32 bits 32 bits
L1 M2D2 S2 L2S1 M1 D1L1 M2D2 S2 L2S1
+
+ +
+
+x
+
M1
x
D1
++
Cours DSP Chapitre 2 69ENIS 2011-2012
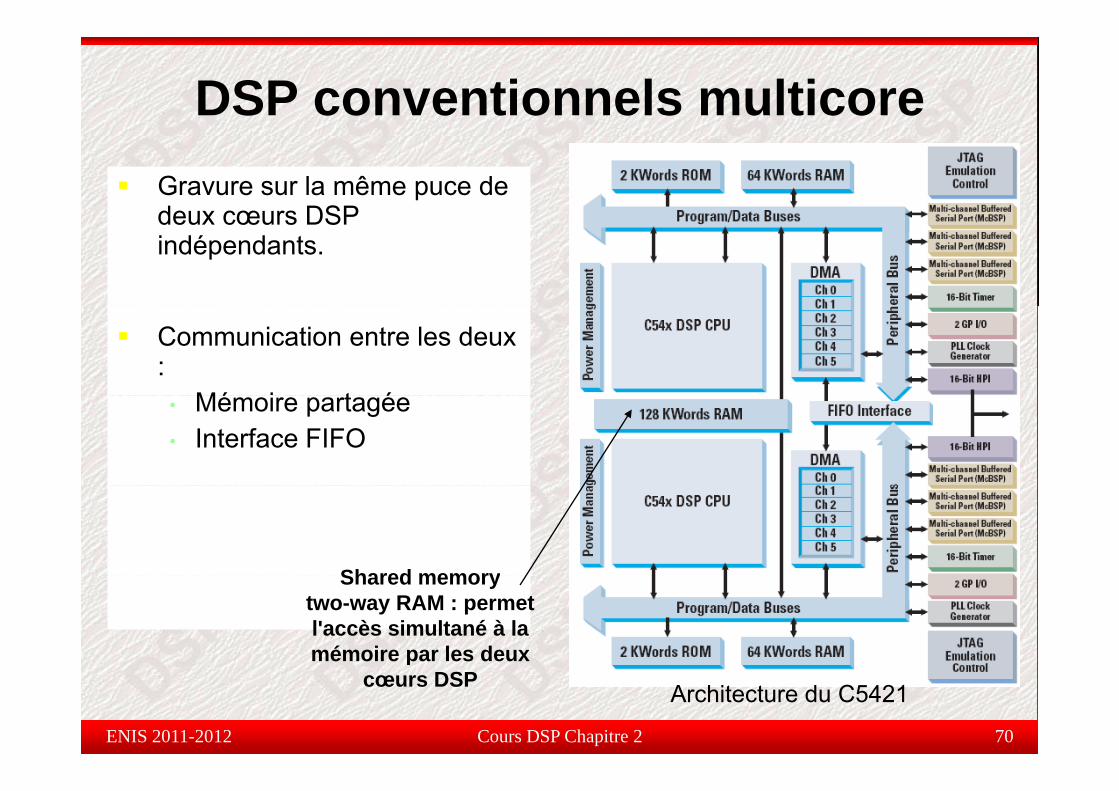
DSP conventionnels multicoreGravure sur la même puce de deux cœurs DSPdeux cœurs DSP indépendants.
Communication entre les deux :
Mé i t é• Mémoire partagée• Interface FIFO
Shared memoryShared memorytwo-way RAM : permet l'accès simultané à la mémoire par les deux
Cours DSP Chapitre 2 70
Architecture du C5421
pcœurs DSP
ENIS 2011-2012
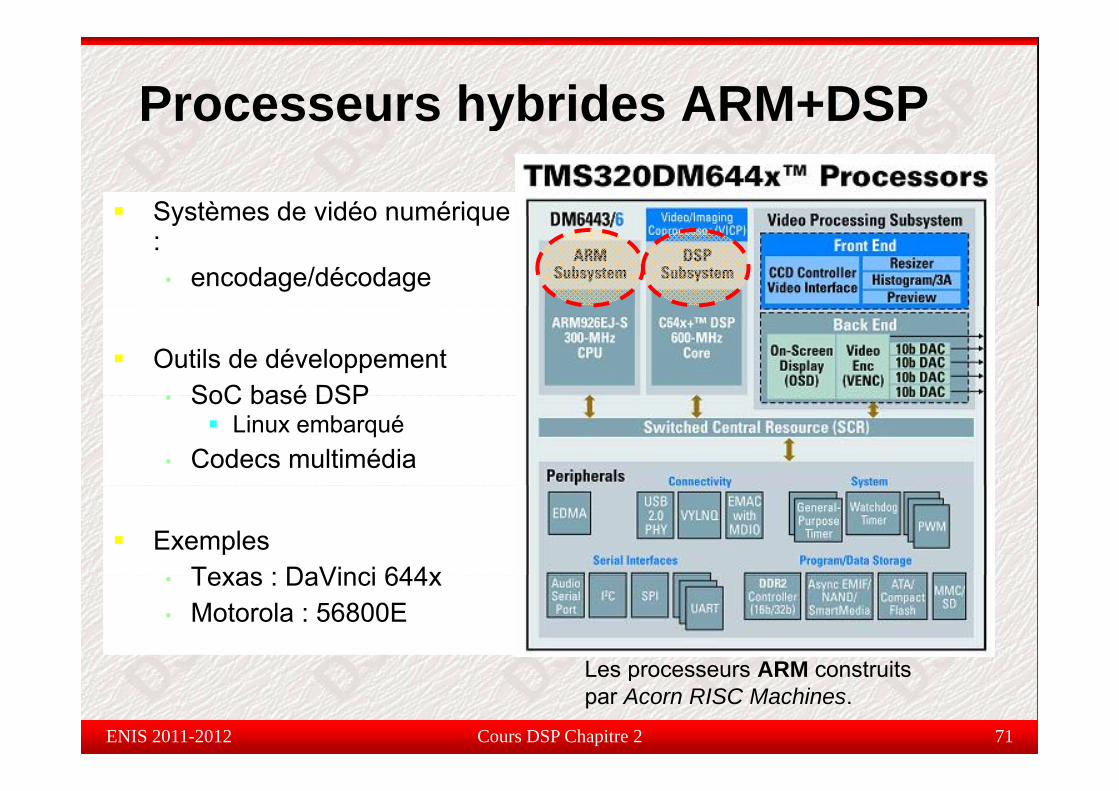
Processeurs hybrides ARM+DSPy
Systèmes de vidéo numériqueSystèmes de vidéo numérique :
• encodage/décodage
Outils de développement• SoC basé DSP• SoC basé DSP
Linux embarqué• Codecs multimédia
ExemplesTexas : DaVinci 644x• Texas : DaVinci 644x
• Motorola : 56800E
Les processe rs ARM constr its
Cours DSP Chapitre 2 71
Les processeurs ARM construits par Acorn RISC Machines.
ENIS 2011-2012

Modes d’adressage standards⇒Le mode d'adressage général:
♣ registre: l'opérande est un registre du CPU. ♣ immédiat court: l'opérande est une valeur immédiate à 16 bits.♣ direct: l'opérande est le contenu d'une adresse de 24 bits.♣ direct: l opérande est le contenu d une adresse de 24 bits.♣ indirect: un registre auxiliaire indique l'adresse de l'opérande.
⇒ Le mode d'adressage à trois opérandes:⇒ Le mode d adressage à trois opérandes:♣ registre (identique).♣ indirect (identique).
⇒ Le mode d'adressage parallèle:♣ registre: l'opérande est un registre à précision étendue.♣ indirect (identique).
Cours DSP Chapitre 2 72ENIS 2011-2012

Modes d’adressage standards
⇒ Le mode d'adressage immédiat long:♣ l'opérande est une valeur immédiate à 24 bits.
⇒Le mode d'adressage à branchement conditionnel:i t (id ti )♣ registre (identique)..
♣ relatif au PC: un déplacement signé sur 16 bits est ajouté au PC.
Cours DSP Chapitre 2 73ENIS 2011-2012

Modes d’adressage standards
Les modes d’adressage ont une grande importance pour garantir la hauteperformance (moins d’instructions) Mais ceci augmente la complexitéperformance (moins d instructions). Mais, ceci augmente la complexitéarchitecturale des DSP (décodage plus complexe, surface de circuit plusimportante).
Instruction typique : OP SRC1, SRC2, DEST
Opération DestinationSource 2
Les DSP possèdent des instructions à usage général et des instructions
p DestinationSource 1 Source 2
Les DSP possèdent des instructions à usage général et des instructionsarithmétiques intensives qui sont particulièrement convenables pour letraitement du signal et les autres applications numériques intensives.
Cinq groupes pour le mode d'adressage sont fournies, six types
Cours DSP Chapitre 2 74
d'adressage peuvent être utilisés dans chaque groupe:
ENIS 2011-2012

Les caches dans les DSP
L’accès à une mémoire externe, ou des mémoires internes degrande taille, est coûteuse en terme temps et/ou énergie.
Solution : Intégrer des mémoires cachesDi i l t fi é i t / CPUDiminuer le trafic mémoire externe / CPUModes d’adressage spécifiques (circulaire)Optimisation du codeOptimisation du code
Les mémoires caches sont caractérisées par :Coût élevé.Petites tailles (32 instructions à 2 K instructions).Cache instruction et cache données.Configurables par l’utilisateur
Ces caractéristiques particulières sont indispensables pour garantirles bonnes performances pour le traitement en temps réel
Cours DSP Chapitre 2 75
les bonnes performances pour le traitement en temps réel.
ENIS 2011-2012
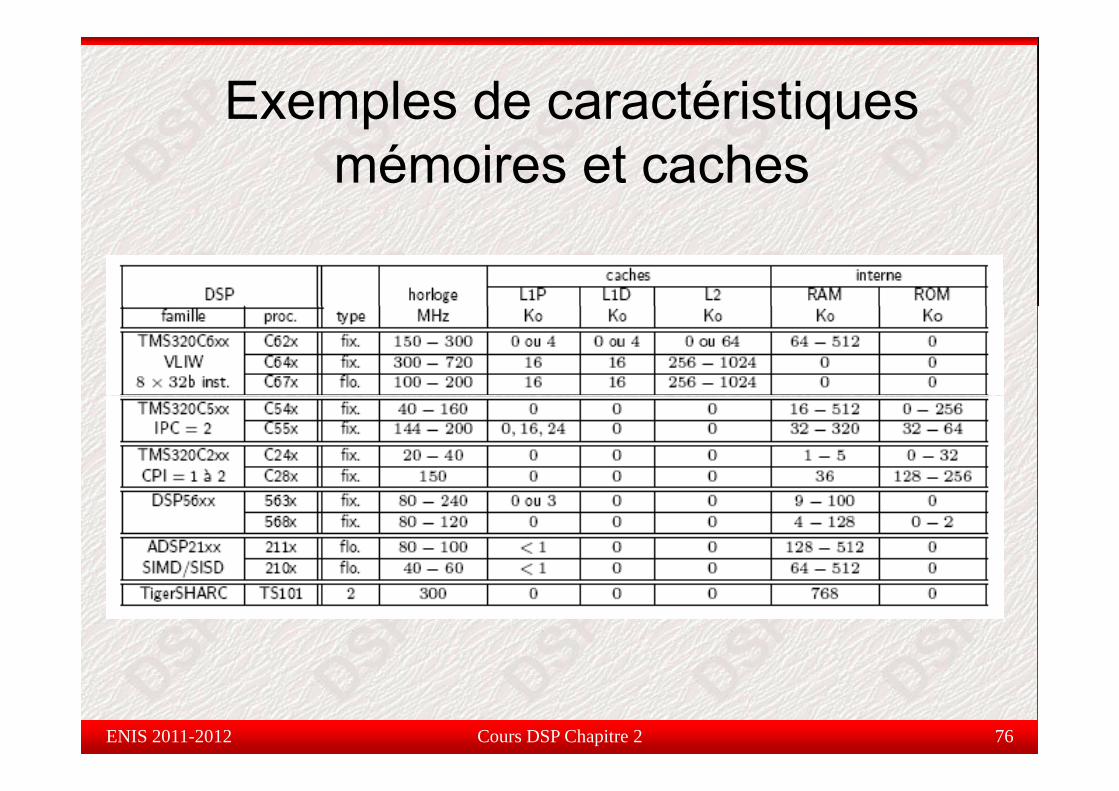
Exemples de caractéristiques p qmémoires et caches
Cours DSP Chapitre 2 76ENIS 2011-2012

ENISENIS 2011/2012
Chapitre III :
Architecture Interne du TMS320 C64x
Plan Ch suivantCh précédent

SommaireSo a e
Unités fonctionnellesUnités fonctionnellesRegistresP t d f t h t d’ é tiPaquet de fetch et d’exécutionStructure d’une instructionPi liPipelineMémoire cacheJ d’i iJeu d’instructionDifférents modes d’adressagesSyntaxe des instructionsContraintes
Cours DSP Chapitre 3 78ENIS 2011-2012

Unités fonctionnellesU tés o ct o e esDeux chemins de données : A et B
Chaque chemin contient 4 unités de traitement :Chaque chemin contient 4 unités de traitement : (.M) : Multiplication
( L) : Opération logique et arithmétique(.L) : Opération logique et arithmétique
(.S) : Branchement et manipulation binaire
( D) : Chargement et stockage des données(.D) : Chargement et stockage des données
64 registres de 32 bits (A0 à A31) et (B0 à B31)
2 chemins croisés (1x et 2x) (cross path)2 chemins croisés (1x et 2x) (cross path)
Chemin de données A Chemin de données B
.L1 .S1 .M1 .D1 .L2 .S2 .M2 .D2
Registre A0 à A31 Registre B0 à B31
Cours DSP Chapitre 3 79
Chemin croisé
ENIS 2011-2012

Registreseg st es
Registres A0, A1, A2, B0, B1 et B2 peuvent êtres utilisés comme desregistres à condition.
Registres A4 à A7 et B4 à B7 : pointeur pour le mode d’adressageRegistres A4 à A7 et B4 à B7 : pointeur pour le mode d adressagecirculaire.
Registres A0 à A9 et B0 à B9 : registre temporaireRegistres A0 à A9 et B0 à B9 : registre temporaire.Registre A10 à A31 et B10 à B31 : mémorisés et puis restaurés à
chaque appel à un sous programme.On peut former 32 registres de 40 ou 64 bits en utilisant les paires de
registres A0:A1, A2:A3, ……et B30:B31.Il existe d’autres registres de contrôles, d’interruptions, de modes,
etc.
Cours DSP Chapitre 3 80ENIS 2011-2012

Paquet de Fetch et d’ExécutionVELOCI TI : architecture élaborée par TI basée sur la structure VLIW
aquet de etc et d écut op
(Very Long Instruction Word)
I t ti 4 t t 32 bitInstruction : 4 octets = 32 bits
PE : paquet exécutable: groupe d’instructions exécutables en //PE : paquet exécutable: groupe d instructions exécutables en //pendant un seul cycle
PF : paquet Fetch formé de 8 instructions
peut contenir 1 PE (si toutes les 8 Insts en //) ou 8 PE (pasd’insts en // )
Le LSB d’une instruction (p-bit) indique si la prochaine instructionappartiennent au même PE (si 1) ou non (si 0).
Cours DSP Chapitre 3 81
appartiennent au même PE (si 1) ou non (si 0).
ENIS 2011-2012

Paquet de Fetch et d’ExécutionExemple 1 :
aquet de etc et d écut op
Instruction A
Instruction B
Un PF avec 3 PEs le LSB (p-bit) de chaque Intr
Instruction C
31 0 31 0 31 0 31 0 31 0 31 0 31 0 31 0
A B C D E F G H1 0 1 1 0 1 1 0
Instruction D
Instruction E
A B C D E F G H
Instruction FNoté que si un branchement aura lieu à l’adresse del’inst D, D et E seront exécutés dans un cycle et F, Get H dans le cycle suivant Les instructions A B et C
Instruction G
Instruction H
et H dans le cycle suivant. Les instructions A, B et Cseront ignorés
Cours DSP Chapitre 3 82ENIS 2011-2012

Paquet de Fetch et d’Exécutionaquet de etc et d écut oExemple 2:
Cours DSP Chapitre 3 83ENIS 2011-2012

Paquet de Fetch et d’Exécutionaquet de etc et d écut oExemple 3:
Exemple 4:
Cours DSP Chapitre 3 84ENIS 2011-2012
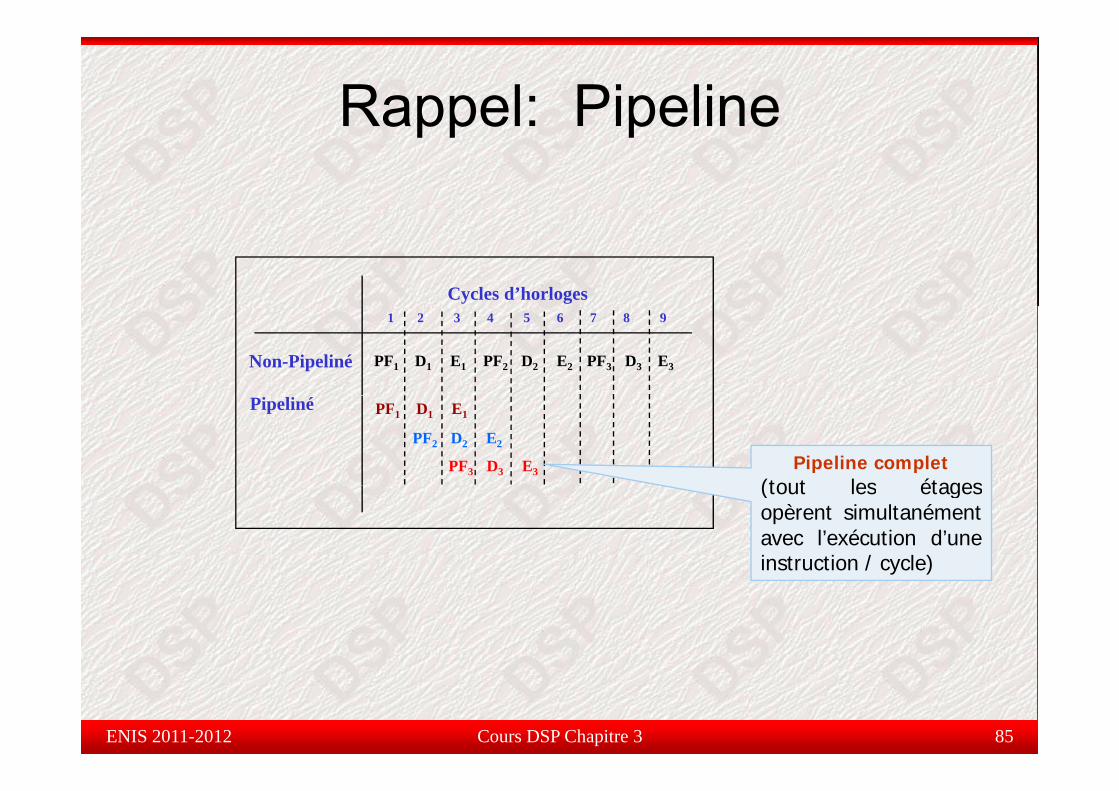
Rappel: Pipeline appe pe e
Cycles d’horloges
Non-Pipeliné
1 2 3 4 5 6 7 8 9
PF1 D1 E1 PF2 D2 E2 PF3 D3 E3
Pipeliné PF1 D1 E1
PF2 D2 E2
PF3 D3 E3 Pipeline complet (tout les étages(tout les étagesopèrent simultanémentavec l’exécution d’uneinstruction / cycle)
Cours DSP Chapitre 3 85ENIS 2011-2012
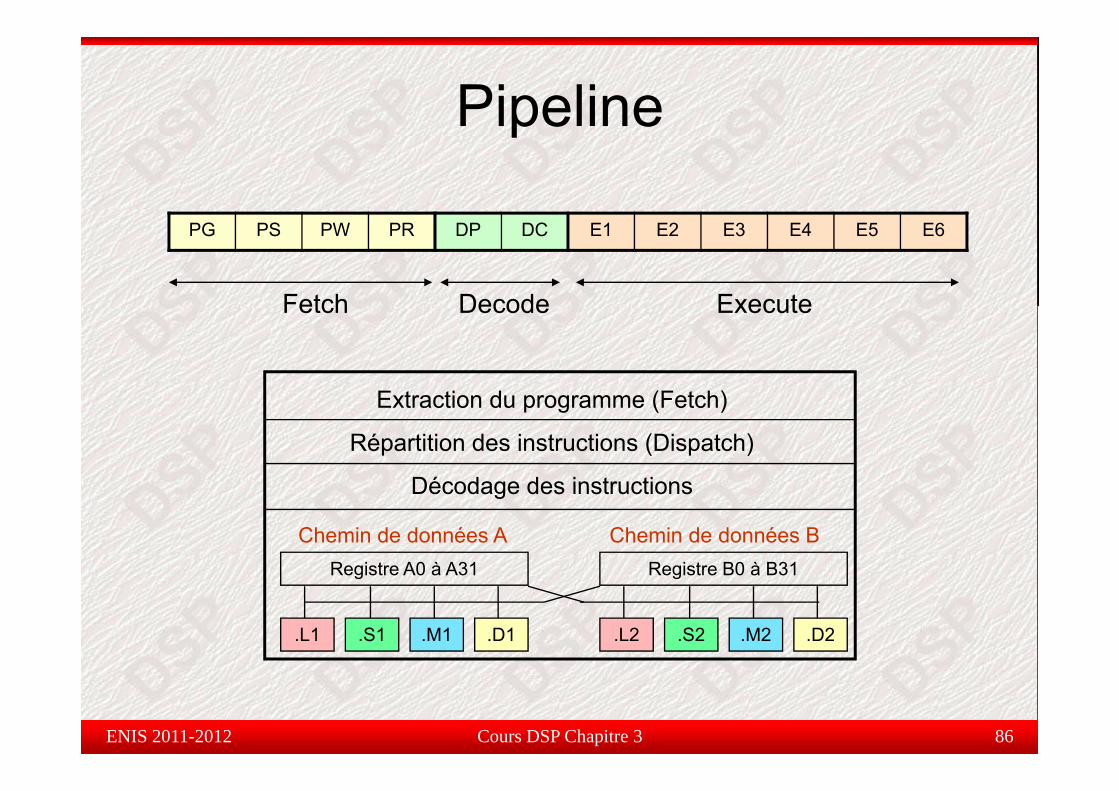
Pipelinepe e
PG PS PW PR DP DC E1 E2 E3 E4 E5 E6
Fetch Decode Execute
Extraction du programme (Fetch)
Fetch Decode Execute
Extraction du programme (Fetch)
Répartition des instructions (Dispatch)
Décodage des instructions
Registre A0 à A31 Registre B0 à B31
Chemin de données A Chemin de données B
Décodage des instructions
.L1 .S1 .M1 .D1 .L2 .S2 .M2 .D2
Registre A0 à A31 Registre B0 à B31
Cours DSP Chapitre 3 86ENIS 2011-2012
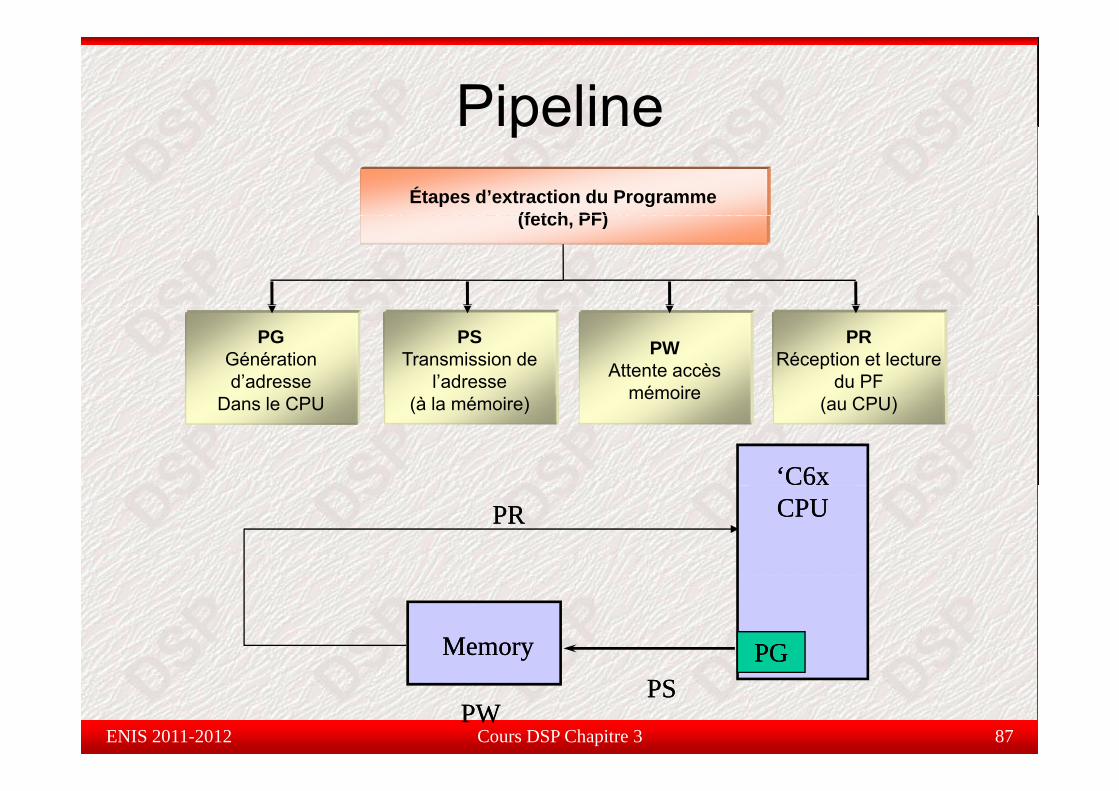
Pipelinepe eÉtapes d’extraction du Programme
(fetch PF)(fetch, PF)
PGGénération d’adresse
PSTransmission de
l’adresse
PWAttente accès
mémoire
PRRéception et lecture
du PFDans le CPU (à la mémoire) mémoire (au CPU)
‘C6x‘C6xCPUCPUPRPR
MemoryMemory PGPG
Cours DSP Chapitre 3 87ENIS 2011-2012PWPW
PSPS
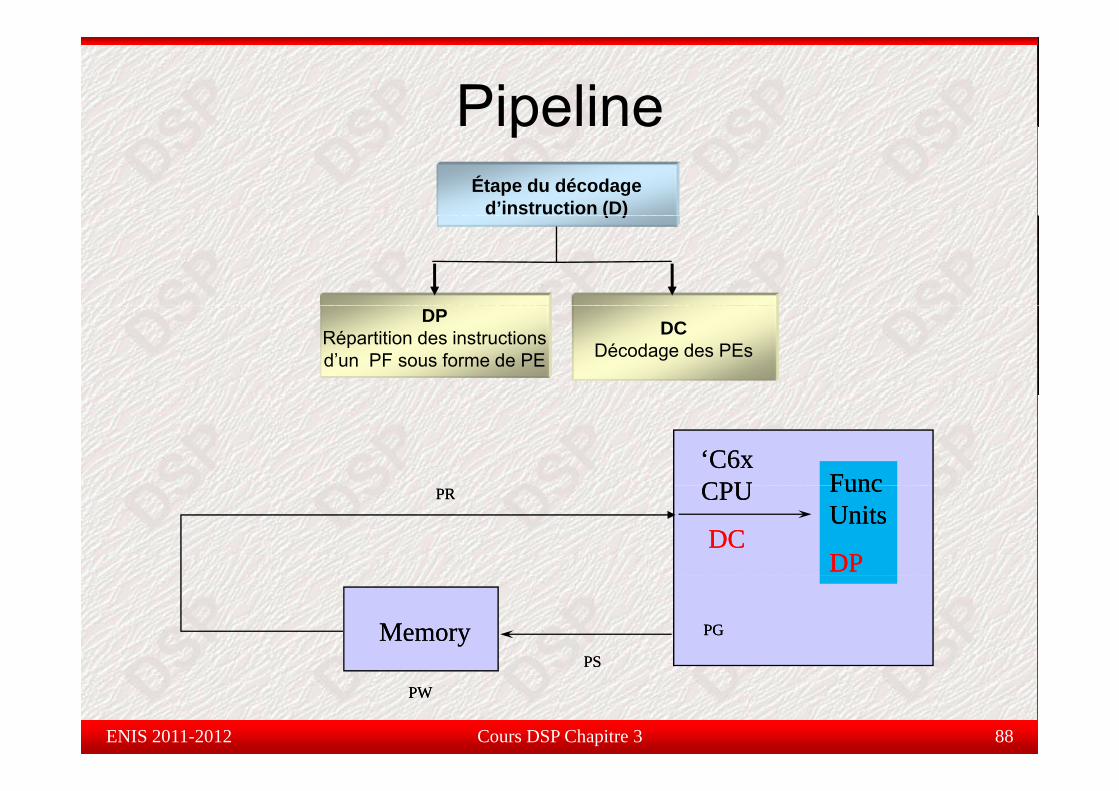
Pipelinepe eÉtape du décodage
d’instruction (D)( )
DPRépartition des instructions d’un PF sous forme de PE
DCDécodage des PEs
‘C6x ‘C6x CPUCPU FuncFuncPRPR CPUCPU
DCDC
FuncFuncUnitsUnits
DPDP
PGPGMemoryMemoryPSPS
Cours DSP Chapitre 3 88ENIS 2011-2012
PWPW
PSPS
Pipelinepe e
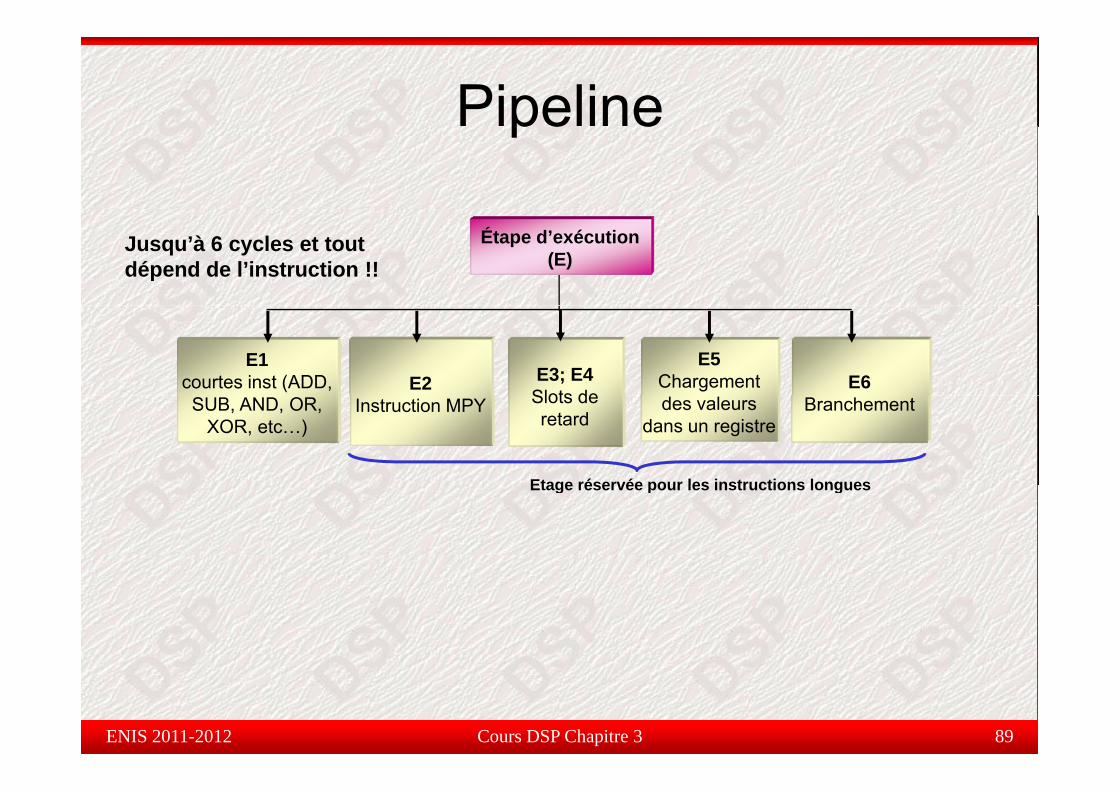
Jusqu’à 6 cycles et tout dépend de l’instruction !!
Étape d’exécution(E)
E1courtes inst (ADD, E2 E3; E4
Slots deE6
E5Chargement
SUB, AND, OR, XOR, etc…)
Instruction MPY Slots de retard
Branchementdes valeurs dans un registre
Etage réservée pour les instructions longuesEtage réservée pour les instructions longues
Cours DSP Chapitre 3 89ENIS 2011-2012
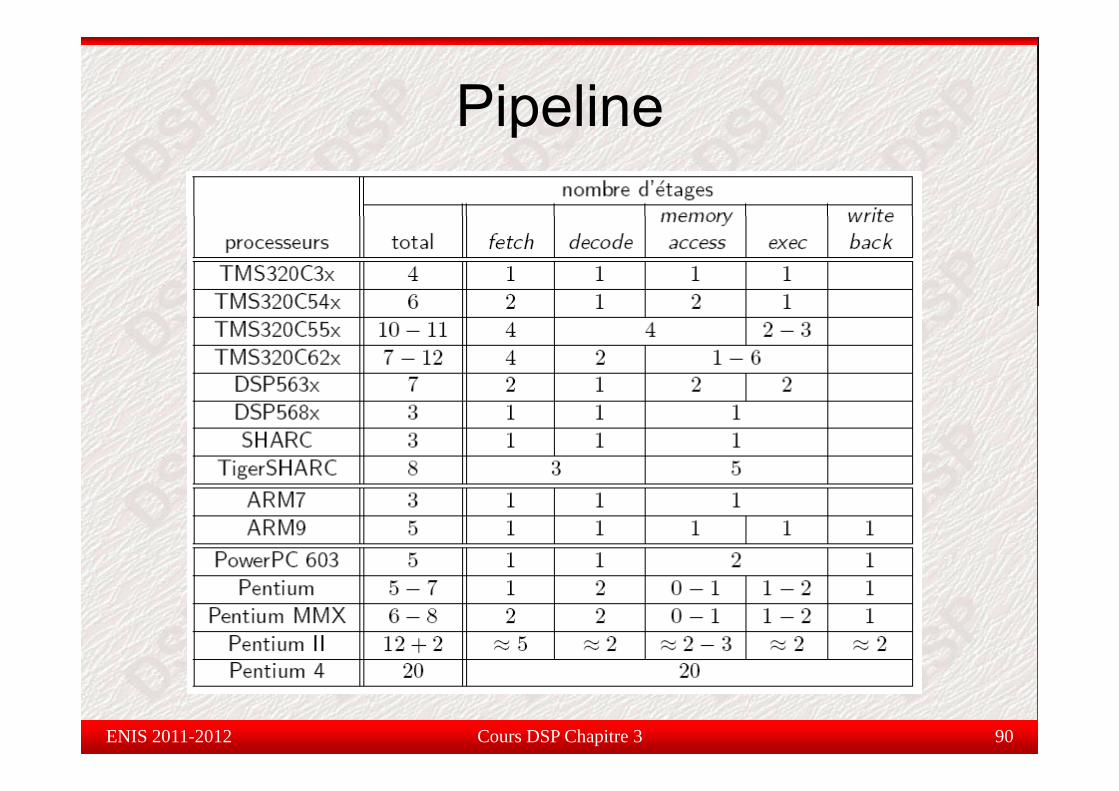
Pipelinepe e
Cours DSP Chapitre 3 90ENIS 2011-2012

Pipelinepe e
Pour compléter le sujet du pipeline, on va voir à travers un exemple la manière dont un DSP
exécute des instructions en // et pipelinées.
Considérons les 3 exemples suivants :
) Sé i b) P llèl P ti ll ) P llèl t t l
B .S1MVK .S1
B .S1|| MVK .S2
a) Série b) Parallèle Partielle
B .S1|| MVK .S2
c) Parallèle totale
ADD .L1ADD .L1MPY .M1MPY .M1LDW .D1
ADD .L1|| ADD .L2|| MPY .M1
MPY M1
|||| ADD .L1|| ADD .L2|| MPY .M1|| MPY .M2|| LDW D1LDW .D1
LDB .D1MPY .M1
|| LDW .D1|| LDB .D2
|| LDW .D1|| LDB .D2
Cours DSP Chapitre 3 91ENIS 2011-2012

Pipelinepe eExécution en Série (1er exemple)
Une seule INSTRUCTION par Cycle entre dans le pipeline En arrivant à l’étape DP (Decode)Une seule INSTRUCTION par Cycle entre dans le pipeline En arrivant à l étape DP (Decode),
Cycle =
PF Decode Execute Donea) SériePR DP DC E1 E2 E3 E4 E5 E6 √
B .S1MVK .S1ADD L1
a) Série
ADD .L1ADD .L1MPY .M1MPY .M1LDW .D1LDB D1LDB .D1
Cours DSP Chapitre 3 92ENIS 2011-2012

Pipelinepe eExécution en Série (1er exemple)
Une seule INSTRUCTION par Cycle entre dans le pipeline En arrivant à l’étape DP (Decode)Une seule INSTRUCTION par Cycle entre dans le pipeline En arrivant à l étape DP (Decode),
Cycle =
PF Decode Execute Donea) SériePR DP DC E1 E2 E3 E4 E5 E6 √
B .S1MVK .S1ADD L1
a) Série
ADD .L1ADD .L1MPY .M1MPY .M1LDW .D1LDB D1LDB .D1
Cours DSP Chapitre 3 93ENIS 2011-2012

Pipelinepe eExécution en Série (1er exemple)
Une seule INSTRUCTION par Cycle entre dans le pipeline En arrivant à l’étape DP (Decode)Une seule INSTRUCTION par Cycle entre dans le pipeline En arrivant à l étape DP (Decode),
Cycle =
PF Decode Execute Donea) SériePR DP DC E1 E2 E3 E4 E5 E6 √
B .S1MVK .S1ADD L1
a) Série
ADD .L1ADD .L1MPY .M1MPY .M1LDW .D1LDB D1LDB .D1
Cours DSP Chapitre 3 94ENIS 2011-2012

PipelineExécution en // partielle (2eme exemple)
pe e
Comment écrire des instructions en //? On utilise le symbole “||” :
B .S1|| MVK .S2
ADD .L1|| ADD .L2|||| MPY .M1
MPY .M1|| LDW .D1|| LDB D2
Cours DSP Chapitre 3 95
|| LDB .D2
ENIS 2011-2012

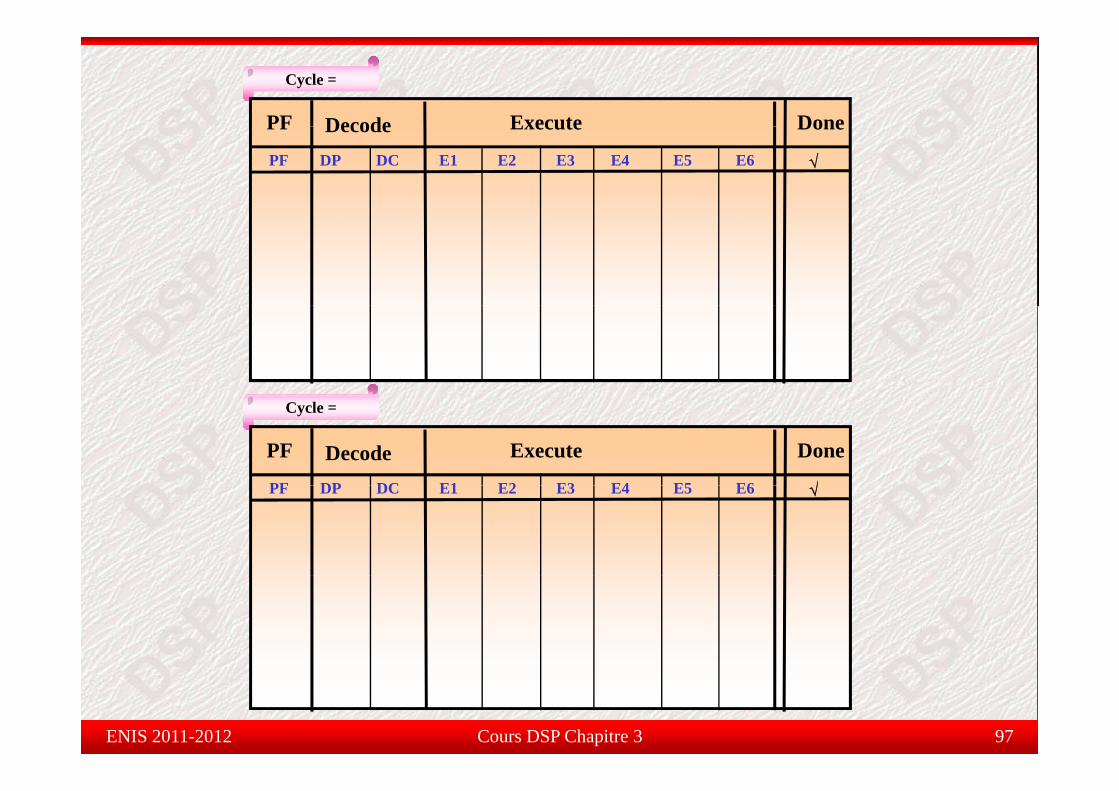
PipelineExécution en // partielle (2eme exemple)
pe e
Comment écrire des instructions en //? On utilise le symbole “||” :
Cycle =
PF D d Execute Done
PF DP DC E1 E2 E3 E4 E5 E6
PF Decode Execute Done
√B .S1|| MVK .S2
A 1Paquets Paquets d’exécutiond’exécution
ADD .L1|| ADD .L2|| MPY .M1
MPY .M1|| LDW .D1|| LDB .D2
Cours DSP Chapitre 3 96ENIS 2011-2012
Cycle =
PF Decode Execute Done
PF DP DC E1 E2 E3 E4 E5 E6
PF Decode Execute Done
√
Cycle =
PF DP DC E1 E2 E3 E4 E5 E6
PF Decode Execute Done
√PF DP DC E1 E2 E3 E4 E5 E6 √
Cours DSP Chapitre 3 97ENIS 2011-2012
Cycle =
PF Decode Execute Done
PF DP DC E1 E2 E3 E4 E5 E6
PF Decode Execute Done
√
Cycle =
PF DP DC E1 E2 E3 E4 E5 E6
PF Decode Execute Done
√PF DP DC E1 E2 E3 E4 E5 E6 √
Cours DSP Chapitre 3 98ENIS 2011-2012

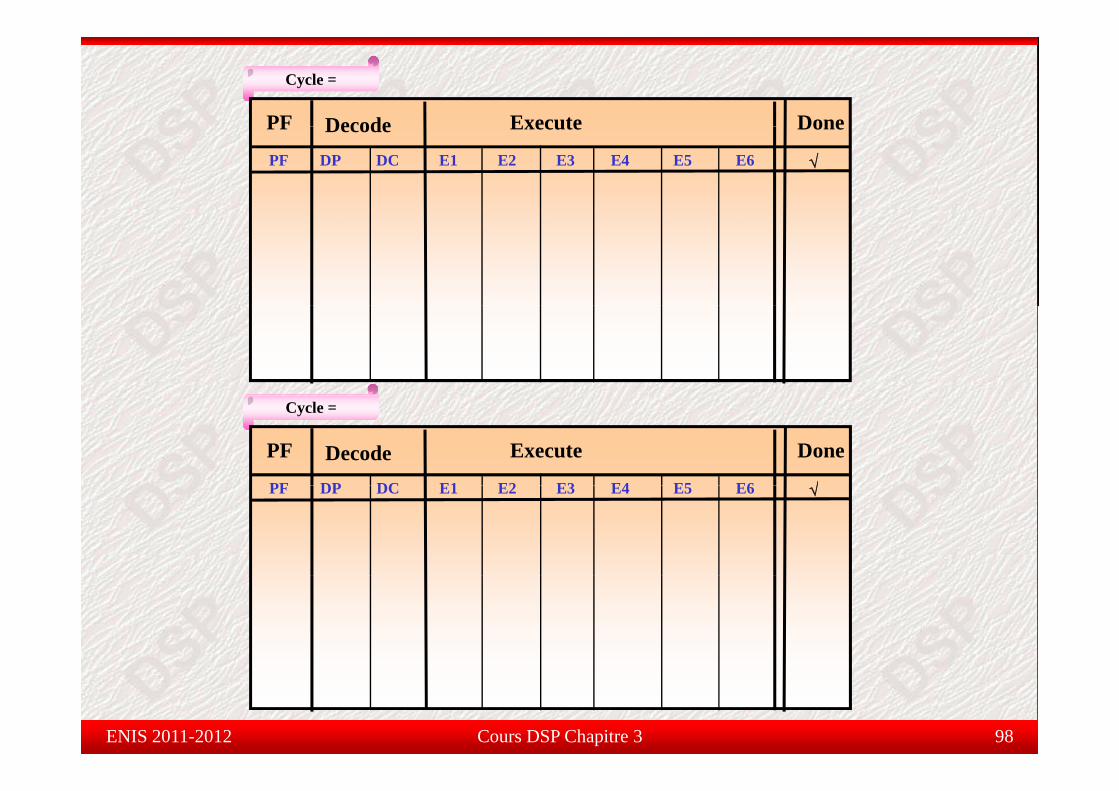
Pipelinepe eExécution en // totale
On a déjà vu un PF contenant 8 instructions en série ou 3 PEs en utilisant le parallélisme. Il est
possible que toutes les instructions soient en //. On aura donc un seul PE.possible que toutes les instructions soient en //. On aura donc un seul PE.
B .S1
Parallèle totale
|| MVK .S2|| ADD .L1|| ADD .L2|| MPY .M1|| MPY M2|| MPY .M2|| LDW .D1|| LDB .D2
Cours DSP Chapitre 3 99ENIS 2011-2012

Pipelinepe e
Cycle =
PF Decode Execute Done
PF DP DC E1 E2 E3 E4 E5 E6
PF Decode Execute Done
√
Cours DSP Chapitre 3 100

Cycle =
PF Decode Execute Done
PF DP DC E1 E2 E3 E4 E5 E6
Decode
√
C lCycle =
PF DP DC E1 E2 E3 E4 E5 E6
PF Decode Execute Done
√PF DP DC E1 E2 E3 E4 E5 E6 √
Cours DSP Chapitre 3 101ENIS 2011-2012
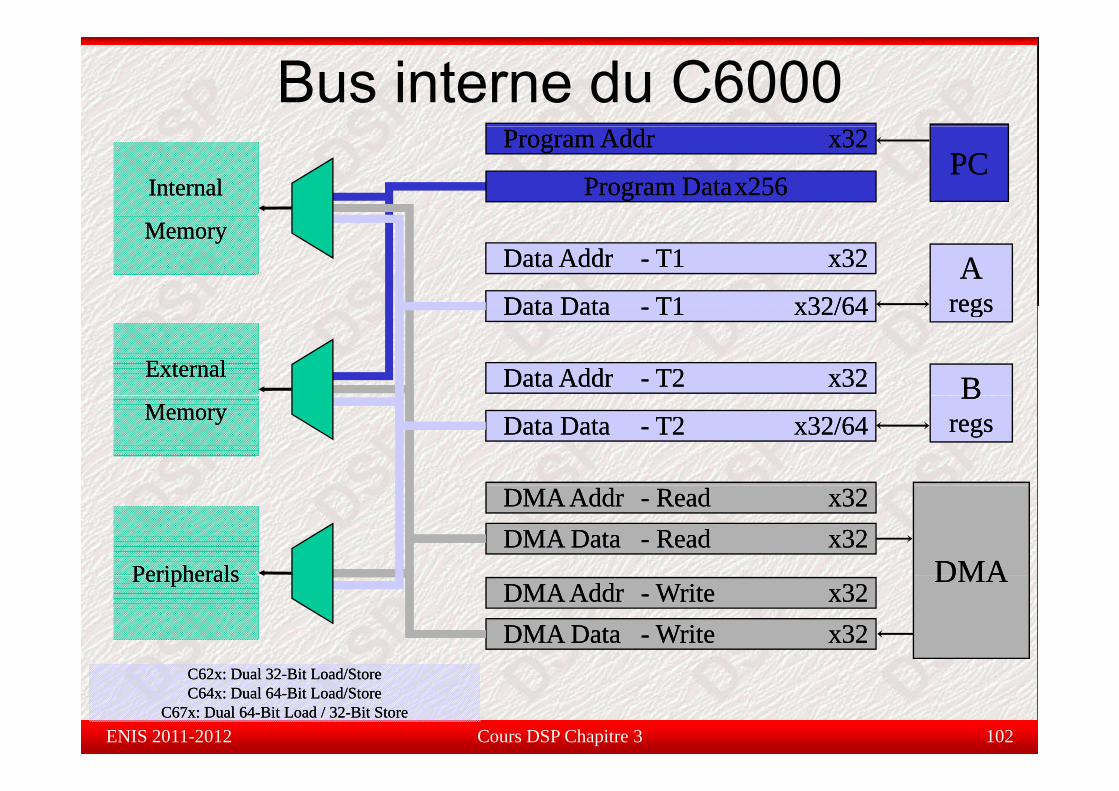
Bus interne du C6000PCPC
Program AddrProgram Addr x32x32
Program DataProgram Datax256x256InternalInternal
AAregsregs
Data AddrData Addr -- T1T1 x32x32
Data DataData Data T1T1 x32/64x32/64
MemoryMemory
regsregs
BB
Data DataData Data -- T1T1 x32/64x32/64
Data AddrData Addr -- T2T2 x32x32ExternalExternalBB
regsregsData DataData Data -- T2T2 x32/64x32/64MemoryMemory
DMADMA
DMA AddrDMA Addr -- ReadRead x32x32DMA DataDMA Data -- ReadRead x32x32
PeripheralsPeripherals DMADMADMA AddrDMA Addr -- WriteWrite x32x32DMA DataDMA Data -- WriteWrite x32x32
PeripheralsPeripherals
Cours DSP Chapitre 3 102ENIS 2011-2012
C62x: Dual 32C62x: Dual 32--Bit Load/StoreBit Load/StoreC64x: Dual 64C64x: Dual 64--Bit Load/StoreBit Load/Store
C67x: Dual 64C67x: Dual 64--Bit Load / 32Bit Load / 32--Bit StoreBit Store
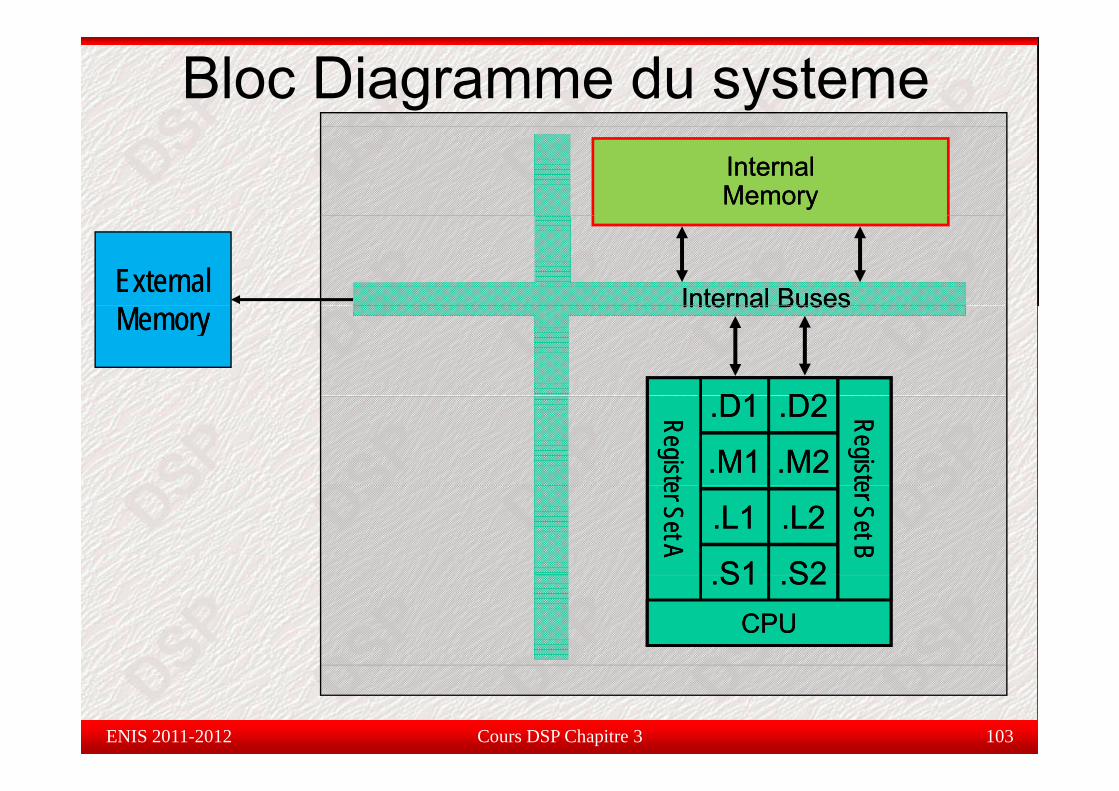
Bloc Diagramme du systemeInternalInternalMemoryMemory
ExternalExternal Internal BusesInternal BusesMemoryMemory
D1D1 D2D2
Internal BusesInternal Buses
.D1.D1
.M1.M1
.D2.D2
.M2.M2
RegisteRegiste
RegisteRegiste
.L1.L1
S1S1
.L2.L2
S2S2
er Set Ber Set B
er Set Aer Set A
.S1.S1 .S2.S2CPUCPU
Cours DSP Chapitre 3 103ENIS 2011-2012

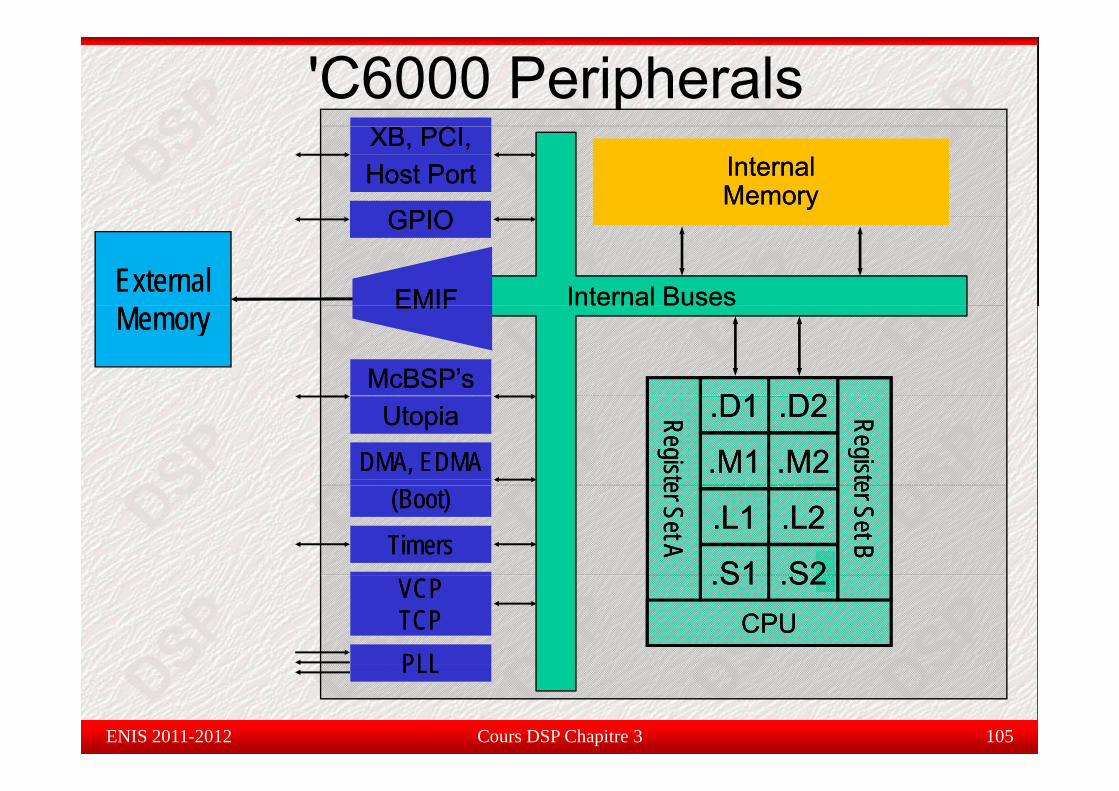
Contrôleurs d’accès mémoireDMA : Contrôleur du transfert des données entre les plages
Co t ô eu s d accès é o e
d’adresse de la mémoire sans l’interférence du CPU. Formé par 4canaux programmables et un cinquième auxiliaire.
EDMA : même chose que le DMA mais avec 16 canauxprogrammable et une RAM pour la mémorisation de plusieurs
fi ti d t f t j téconfigurations pour des transferts projeté.
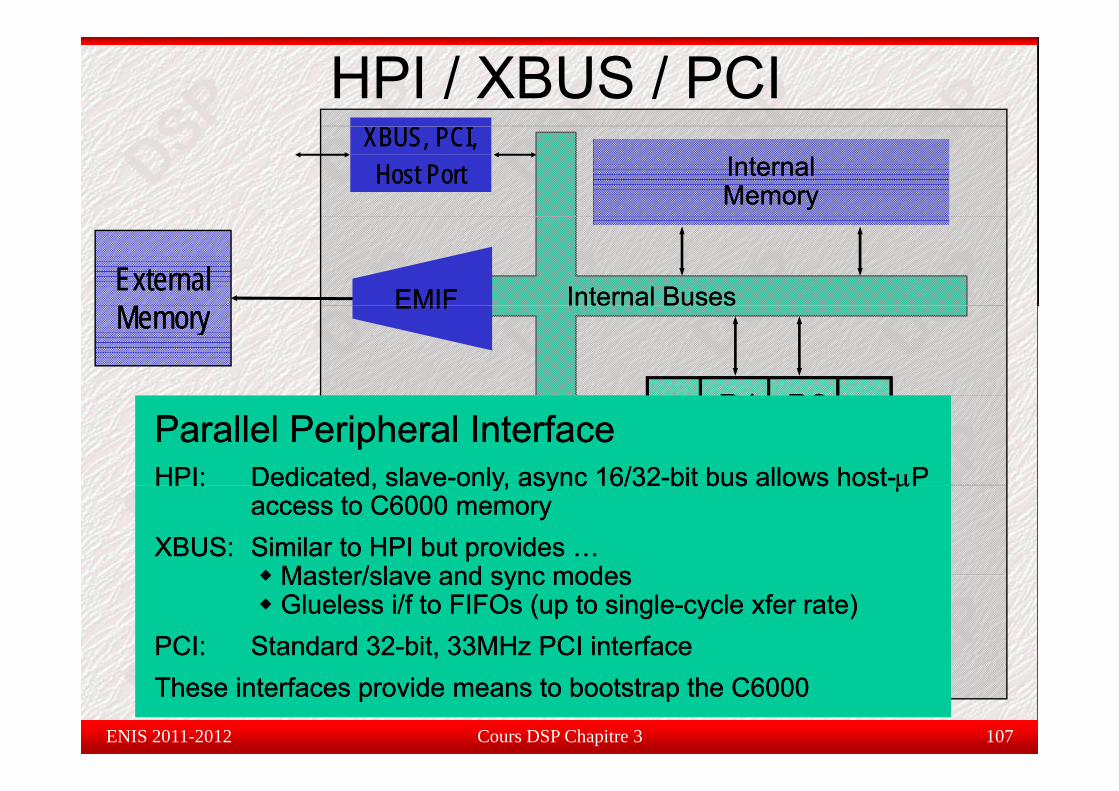
HPI : interface parallèle du processeur host permettant l’accès directHPI : interface parallèle du processeur host permettant l accès directà l’espace mémoire du CPU pour échanger le contenu des registresd’état.
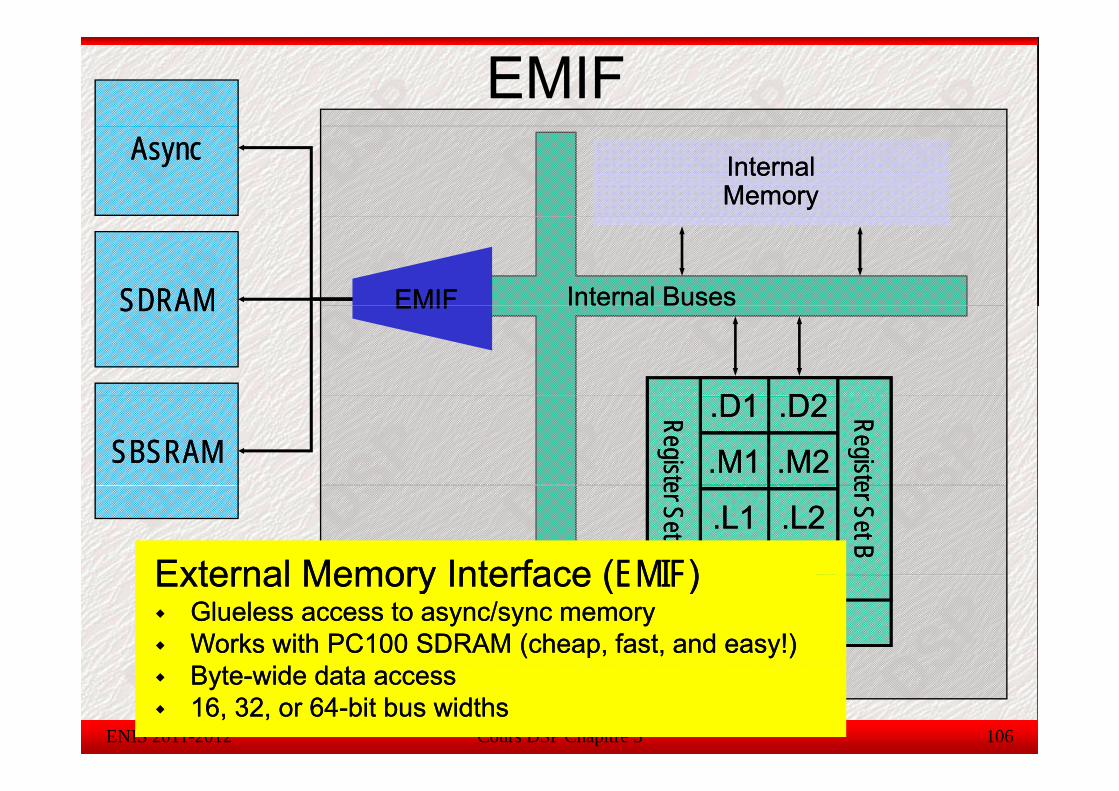
EMIF : remplace le HPI. Il permet l’échange asynchrone d’informationentre non seulement le CPU et le Processeur host mais aussi avec
Cours DSP Chapitre 3 104
l’extérieur à travers les ports d’E/S .
ENIS 2011-2012
'C6000 Peripherals InternalInternalMemoryMemory
GPIOGPIO
XB, PCI,XB, PCI,Host PortHost Port
ExternalExternal Internal BusesInternal Buses
GPIOGPIO
EMIFEMIFMemoryMemory
D1D1 D2D2
e a usese a uses
McBSP’sMcBSP’s
EMIFEMIF
.D1.D1
.M1.M1
.D2.D2
.M2.M2
RegisteRegiste
RegisteRegiste
UtopiaUtopia
DMA, EDMADMA, EDMA
.L1.L1
S1S1
.L2.L2
S2S2
er Set Ber Set B
er Set Aer Set A
(Boot)(Boot)TimersTimers
.S1.S1 .S2.S2CPUCPU
VCPVCPTCPTCPPLLPLL
Cours DSP Chapitre 3 105ENIS 2011-2012
PLLPLL
EMIFInternalInternalMemoryMemory
AsyncAsync
Internal BusesInternal BusesSDRAMSDRAM EMIFEMIF
D1D1 D2D2
e a usese a usesSDRAMSDRAM EMIFEMIF
.D1.D1
.M1.M1
.D2.D2
.M2.M2
RegisteRegiste
RegisteRegisteSBSRAMSBSRAM
.L1.L1
S1S1
.L2.L2
S2S2
er Set Ber Set B
er Set Aer Set A
External Memory Interface (External Memory Interface (EMIFEMIF))External Memory Interface (External Memory Interface (EMIFEMIF)) .S1.S1 .S2.S2CPUCPU
External Memory Interface (External Memory Interface (EMIFEMIF))GluelessGlueless access to access to asyncasync/sync memory/sync memoryWorks with PC100 SDRAM (cheap, fast, and easy!)Works with PC100 SDRAM (cheap, fast, and easy!)
External Memory Interface (External Memory Interface (EMIFEMIF))GluelessGlueless access to access to asyncasync/sync memory/sync memoryWorks with PC100 SDRAM (cheap, fast, and easy!)Works with PC100 SDRAM (cheap, fast, and easy!)
Cours DSP Chapitre 3 106ENIS 2011-2012
ByteByte--wide data accesswide data access16, 32, or 6416, 32, or 64--bit bus widthsbit bus widthsByteByte--wide data accesswide data access16, 32, or 6416, 32, or 64--bit bus widthsbit bus widths
HPI / XBUS / PCIInternalInternalMemoryMemory
XBUS, PCI,XBUS, PCI,Host PortHost Port
ExternalExternalMM
Internal BusesInternal BusesEMIFEMIFMemoryMemory
D1D1 D2D2
e a usese a usesEMIFEMIF
.D1.D1
.M1.M1
.D2.D2
.M2.M2
RegisteRegiste
RegisteRegiste
Parallel Peripheral InterfaceParallel Peripheral InterfaceHPI:HPI: Dedicated, slaveDedicated, slave--only, async 16/32only, async 16/32--bit bus allows hostbit bus allows host--μμPPParallel Peripheral InterfaceParallel Peripheral InterfaceHPI:HPI: Dedicated, slaveDedicated, slave--only, async 16/32only, async 16/32--bit bus allows hostbit bus allows host--μμPP
.L1.L1
S1S1
.L2.L2
S2S2
er Set Ber Set B
er Set Aer Set A
HPI:HPI: Dedicated, slaveDedicated, slave only, async 16/32only, async 16/32 bit bus allows hostbit bus allows host μμP P access to C6000 memoryaccess to C6000 memory
XBUS:XBUS: Similar to HPI but provides …Similar to HPI but provides …Master/slave and sync modesMaster/slave and sync modes
HPI:HPI: Dedicated, slaveDedicated, slave only, async 16/32only, async 16/32 bit bus allows hostbit bus allows host μμP P access to C6000 memoryaccess to C6000 memory
XBUS:XBUS: Similar to HPI but provides …Similar to HPI but provides …Master/slave and sync modesMaster/slave and sync modes .S1.S1 .S2.S2
CPUCPU
Master/slave and sync modesMaster/slave and sync modesGlueless i/f to FIFOs (up to singleGlueless i/f to FIFOs (up to single--cycle xfer rate)cycle xfer rate)
PCI:PCI: Standard 32Standard 32--bit, 33MHz PCI interfacebit, 33MHz PCI interface
Master/slave and sync modesMaster/slave and sync modesGlueless i/f to FIFOs (up to singleGlueless i/f to FIFOs (up to single--cycle xfer rate)cycle xfer rate)
PCI:PCI: Standard 32Standard 32--bit, 33MHz PCI interfacebit, 33MHz PCI interface
Cours DSP Chapitre 3 107ENIS 2011-2012
These interfaces provide means to bootstrap the C6000These interfaces provide means to bootstrap the C6000These interfaces provide means to bootstrap the C6000These interfaces provide means to bootstrap the C6000
GPIOInternalInternalMemoryMemory
GPIOGPIO
XB, PCI,XB, PCI,Host PortHost Port
ExternalExternalMM
Internal BusesInternal Buses
GPIOGPIO
EMIFEMIFMemoryMemory
D1D1 D2D2
e a usese a usesEMIFEMIF
.D1.D1
.M1.M1
.D2.D2
.M2.M2
RegisteRegiste
RegisteRegiste
.L1.L1
S1S1
.L2.L2
S2S2
er Set Ber Set B
er Set Aer Set A
.S1.S1 .S2.S2CPUCPU
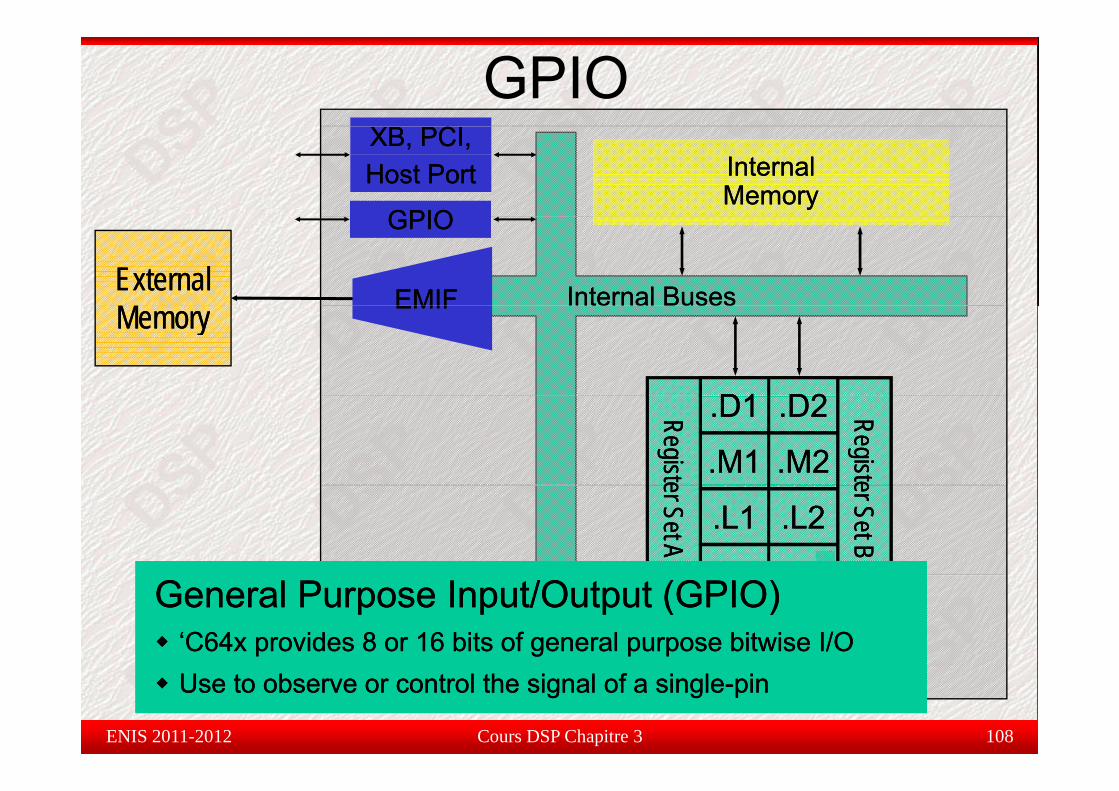
General Purpose General Purpose Input/OutputInput/Output (GPIO)(GPIO)‘C64x provides 8 or 16 bits of general purpose bitwise I/O‘C64x provides 8 or 16 bits of general purpose bitwise I/O
General Purpose General Purpose Input/OutputInput/Output (GPIO)(GPIO)‘C64x provides 8 or 16 bits of general purpose bitwise I/O‘C64x provides 8 or 16 bits of general purpose bitwise I/O
Cours DSP Chapitre 3 108ENIS 2011-2012
Use to observe or control the signal of a singleUse to observe or control the signal of a single--pinpinUse to observe or control the signal of a singleUse to observe or control the signal of a single--pinpin
InternalInternalMemoryMemory
GPIOGPIO
XB, PCI,XB, PCI,Host PortHost Port
ExternalExternal Internal BusesInternal Buses
GPIOGPIO
EMIFEMIFMemoryMemory
D1D1 D2D2
e a usese a uses
McBSP’sMcBSP’s
EMIFEMIF
.D1.D1
.M1.M1
.D2.D2
.M2.M2
RegisteRegiste
RegisteRegiste
UtopiaUtopia
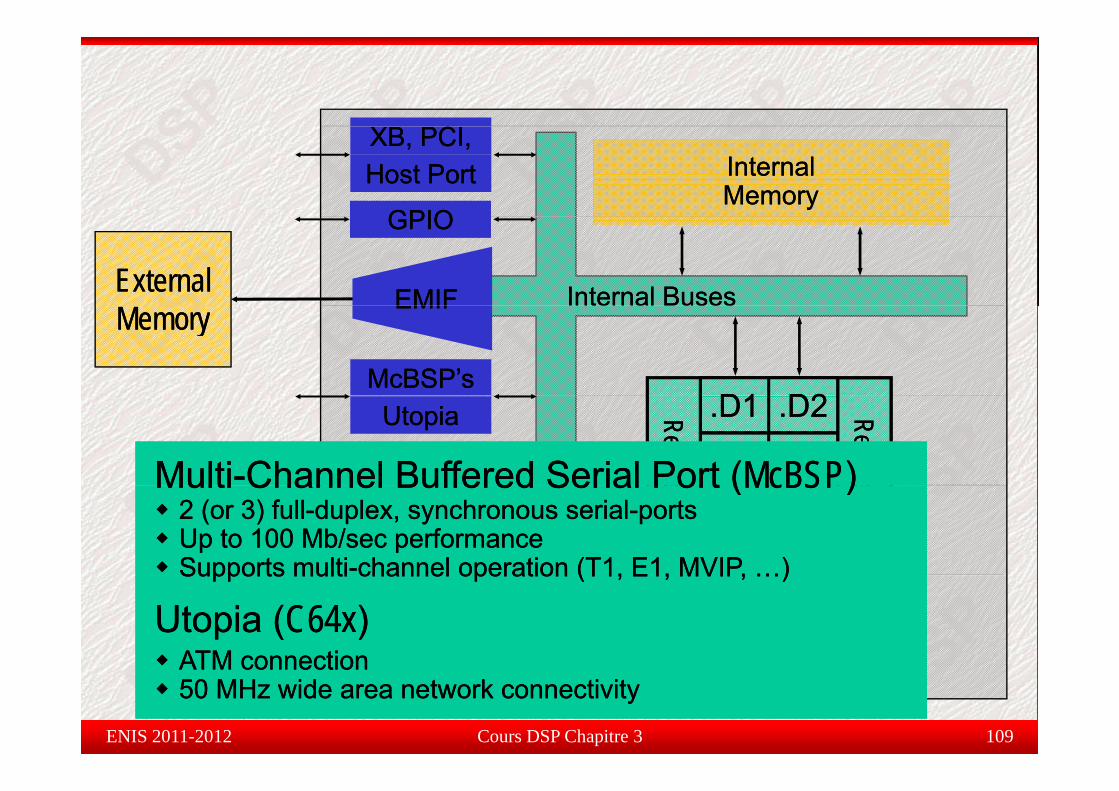
MultiMulti--Channel Buffered Serial Port (Channel Buffered Serial Port (McBSPMcBSP))MultiMulti--Channel Buffered Serial Port (Channel Buffered Serial Port (McBSPMcBSP)).L1.L1
S1S1
.L2.L2
S2S2
er Set Ber Set B
er Set Aer Set A
MultiMulti Channel Buffered Serial Port (Channel Buffered Serial Port (McBSPMcBSP))2 (or 3) f2 (or 3) fullull--duplex, synchronous serialduplex, synchronous serial--portsportsUp to 100 Mb/sec performanceUp to 100 Mb/sec performanceSSupportsupports multimulti--channel operation (T1, E1, MVIP, …)channel operation (T1, E1, MVIP, …)
MultiMulti Channel Buffered Serial Port (Channel Buffered Serial Port (McBSPMcBSP))2 (or 3) f2 (or 3) fullull--duplex, synchronous serialduplex, synchronous serial--portsportsUp to 100 Mb/sec performanceUp to 100 Mb/sec performanceSSupportsupports multimulti--channel operation (T1, E1, MVIP, …)channel operation (T1, E1, MVIP, …).S1.S1 .S2.S2
CPUCPU
SSupportsupports multimulti channel operation (T1, E1, MVIP, …)channel operation (T1, E1, MVIP, …)
Utopia (Utopia (C64xC64x))ATM connectionATM connection
SSupportsupports multimulti channel operation (T1, E1, MVIP, …)channel operation (T1, E1, MVIP, …)
Utopia (Utopia (C64xC64x))ATM connectionATM connection
Cours DSP Chapitre 3 109ENIS 2011-2012
ATM connectionATM connection50 MHz wide area network connectivity50 MHz wide area network connectivityATM connectionATM connection50 MHz wide area network connectivity50 MHz wide area network connectivity
DMA / EDMAInternalInternalMemoryMemory
GPIOGPIO
XB, PCI,XB, PCI,Host PortHost Port
ExternalExternal Internal BusesInternal Buses
GPIOGPIO
EMIFEMIFMemoryMemory
D1D1 D2D2
e a usese a uses
McBSP’sMcBSP’s
EMIFEMIF
.D1.D1
.M1.M1
.D2.D2
.M2.M2
RegisteRegiste
RegisteRegiste
UtopiaUtopia
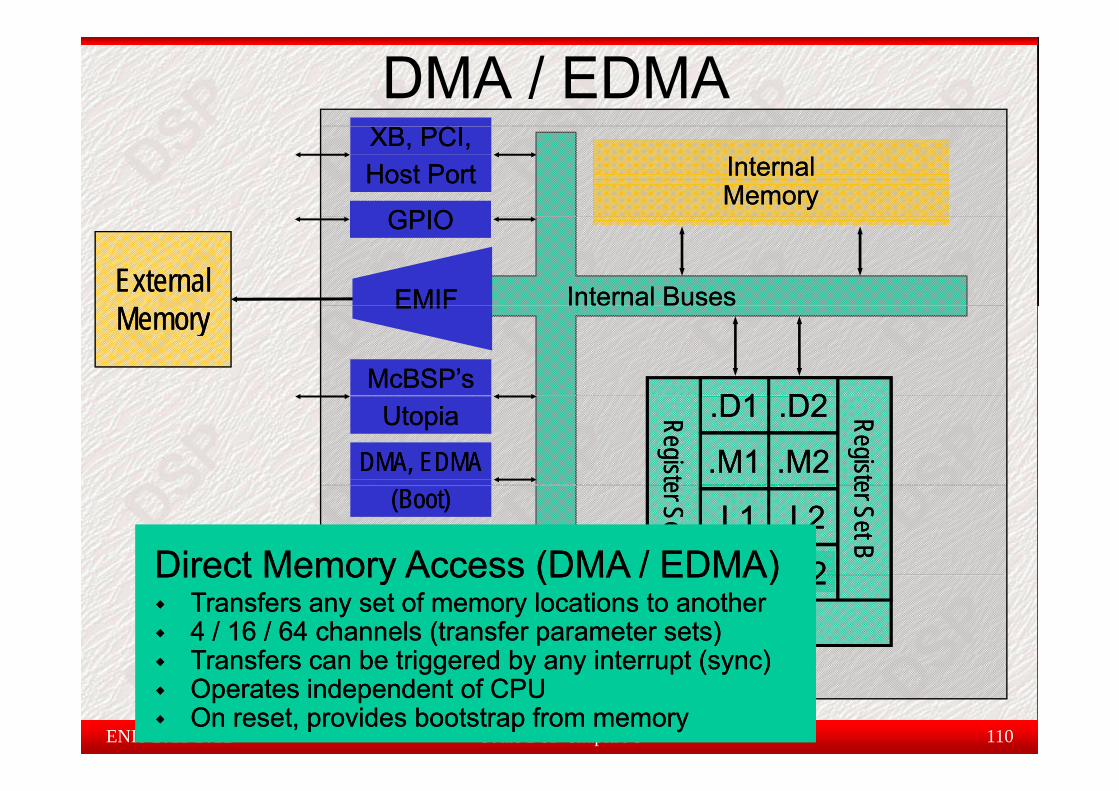
DMA, EDMADMA, EDMA
.L1.L1
S1S1
.L2.L2
S2S2
er Set Ber Set B
er Set Aer Set A
(Boot)(Boot)
Direct Memory Access (DMA / EDMA)Direct Memory Access (DMA / EDMA)Direct Memory Access (DMA / EDMA)Direct Memory Access (DMA / EDMA).S1.S1 .S2.S2CPUCPU
Direct Memory Access (DMA / EDMA) Direct Memory Access (DMA / EDMA) Transfers any set of memory locations to anotherTransfers any set of memory locations to another4 / 16 / 64 channels (transfer parameter sets)4 / 16 / 64 channels (transfer parameter sets)Transfers can be triggered by any interrupt (sync)Transfers can be triggered by any interrupt (sync)
Direct Memory Access (DMA / EDMA) Direct Memory Access (DMA / EDMA) Transfers any set of memory locations to anotherTransfers any set of memory locations to another4 / 16 / 64 channels (transfer parameter sets)4 / 16 / 64 channels (transfer parameter sets)Transfers can be triggered by any interrupt (sync)Transfers can be triggered by any interrupt (sync)
Cours DSP Chapitre 3 110ENIS 2011-2012
Transfers can be triggered by any interrupt (sync)Transfers can be triggered by any interrupt (sync)Operates independent of CPUOperates independent of CPUOn reset, provides bootstrap from memoryOn reset, provides bootstrap from memory
Transfers can be triggered by any interrupt (sync)Transfers can be triggered by any interrupt (sync)Operates independent of CPUOperates independent of CPUOn reset, provides bootstrap from memoryOn reset, provides bootstrap from memory
Timer/CounterInternalInternalMemoryMemory
GPIOGPIO
XB, PCI,XB, PCI,Host PortHost Port
ExternalExternal Internal BusesInternal Buses
GPIOGPIO
EMIFEMIFMemoryMemory
D1D1 D2D2
e a usese a uses
McBSP’sMcBSP’s
EMIFEMIF
.D1.D1
.M1.M1
.D2.D2
.M2.M2
RegisteRegiste
RegisteRegiste
UtopiaUtopia
DMA, EDMADMA, EDMA
.L1.L1
S1S1
.L2.L2
S2S2
er Set Ber Set B
er Set Aer Set A
(Boot)(Boot)TimersTimers
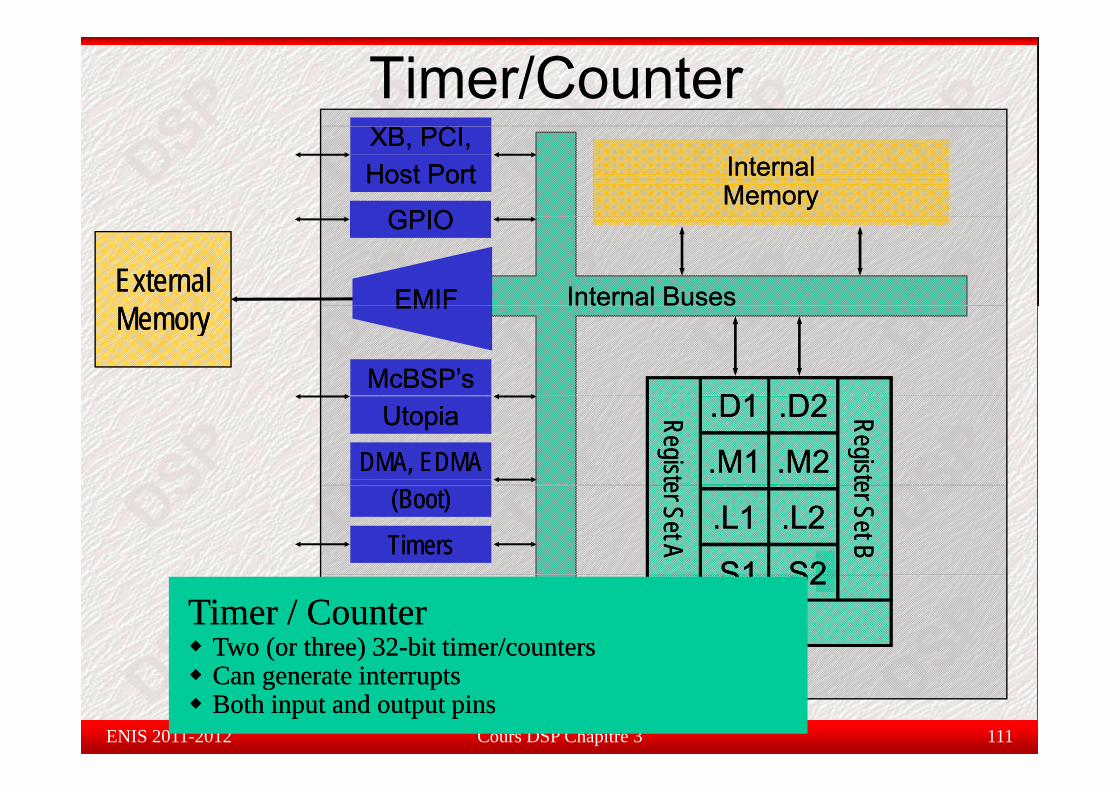
.S1.S1 .S2.S2CPUCPUTimer / CounterTimer / Counter
Two (or three) 32Two (or three) 32--bit timer/countersbit timer/countersTimer / CounterTimer / Counter
Two (or three) 32Two (or three) 32--bit timer/countersbit timer/counters
Cours DSP Chapitre 3 111ENIS 2011-2012
Can generate interruptsCan generate interruptsBoth iBoth input and output pinsnput and output pinsCan generate interruptsCan generate interruptsBoth iBoth input and output pinsnput and output pins
Phase Locked Loop (PLL)InternalInternalMemoryMemory
GPIOGPIO
XB, PCI,XB, PCI,Host PortHost Port
ExternalExternal Internal BusesInternal Buses
GPIOGPIO
EMIFEMIFMemoryMemory
D1D1 D2D2
RRRR
e a usese a uses
McBSP’sMcBSP’s
EMIFEMIF
IIII .D1.D1
.M1.M1
.D2.D2
.M2.M2
Register SeRegister Se
Register SeRegister Se
UtopiaUtopia
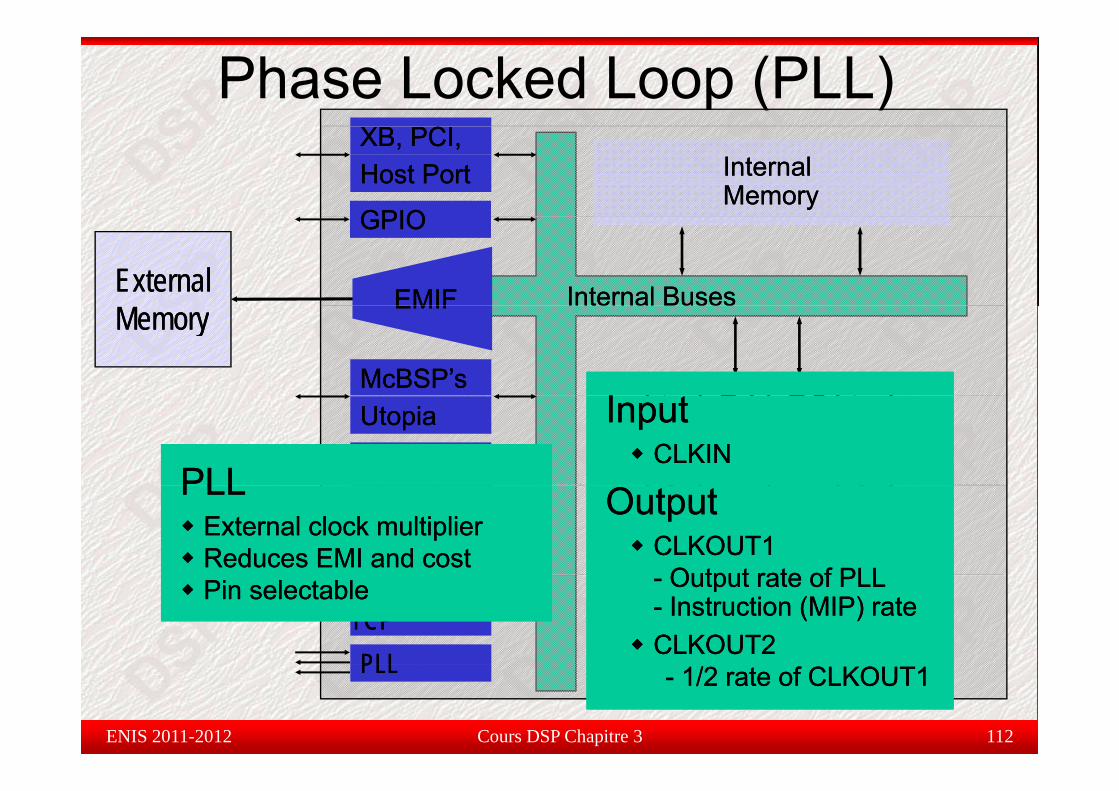
DMA, EDMADMA, EDMAPLLPLLPLLPLL
InputInputCLKINCLKIN
InputInputCLKINCLKIN
.L1.L1
S1S1
.L2.L2
S2S2
et Bet B
et Aet A(Boot)(Boot)
TimersTimers
PLLPLLExternal clock multiplierExternal clock multiplierReduces EMI and costReduces EMI and cost
PLLPLLExternal clock multiplierExternal clock multiplierReduces EMI and costReduces EMI and cost
OutputOutputCLKOUT1CLKOUT1
Output rate of PLLOutput rate of PLL
OutputOutputCLKOUT1CLKOUT1
Output rate of PLLOutput rate of PLL.S1.S1 .S2.S2CPUCPU
VCPVCPTCPTCPPLLPLL
Pin selectablePin selectablePin selectablePin selectable -- Output rate of PLLOutput rate of PLL-- Instruction (MIP) rateInstruction (MIP) rateCLKOUT2CLKOUT2
-- Output rate of PLLOutput rate of PLL-- Instruction (MIP) rateInstruction (MIP) rateCLKOUT2CLKOUT2
Cours DSP Chapitre 3 112ENIS 2011-2012
PLLPLL -- 1/2 rate of CLKOUT11/2 rate of CLKOUT1-- 1/2 rate of CLKOUT11/2 rate of CLKOUT1
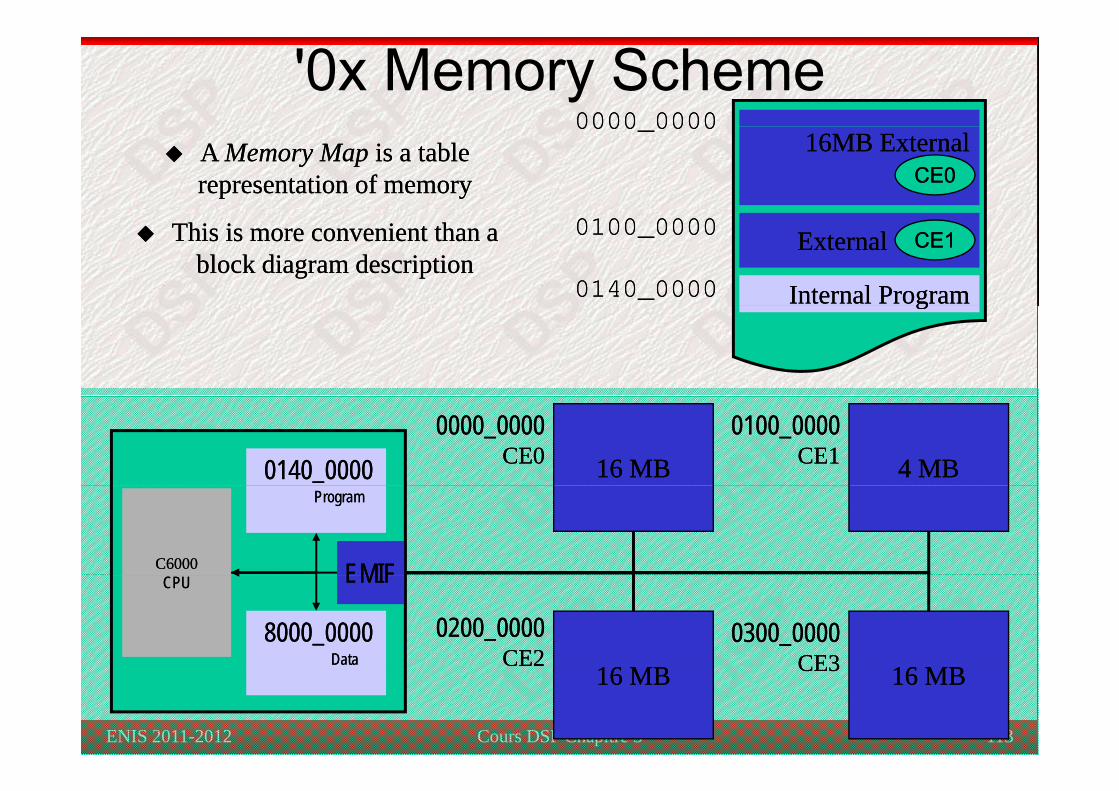
'0x Memory Scheme0000 00000000 00000000_00000000_0000
16MB External16MB External((CE0CE0))CE0CE0
A A Memory MapMemory Map is a table is a table representation of memoryrepresentation of memory
External (External (CE1CE1))
Internal ProgramInternal Program
0100_00000100_0000
0140_00000140_0000
CE1CE1This is more convenient than a This is more convenient than a block diagram descriptionblock diagram description
gg
16 MB16 MB0000_00000000_0000
CE0CE0 4 MB4 MB0100_00000100_0000
CE1CE10140_00000140_0000
C6000C6000
ProgramProgram
EMIFEMIF
0200_00000200_0000CE2CE2
0300_00000300_0000CE3CE3
CPUCPU EMIFEMIF
8000_00008000_0000DataData
Cours DSP Chapitre 3 113ENIS 2011-2012
16 MB16 MBCE2CE2
16 MB16 MBCE3CE3
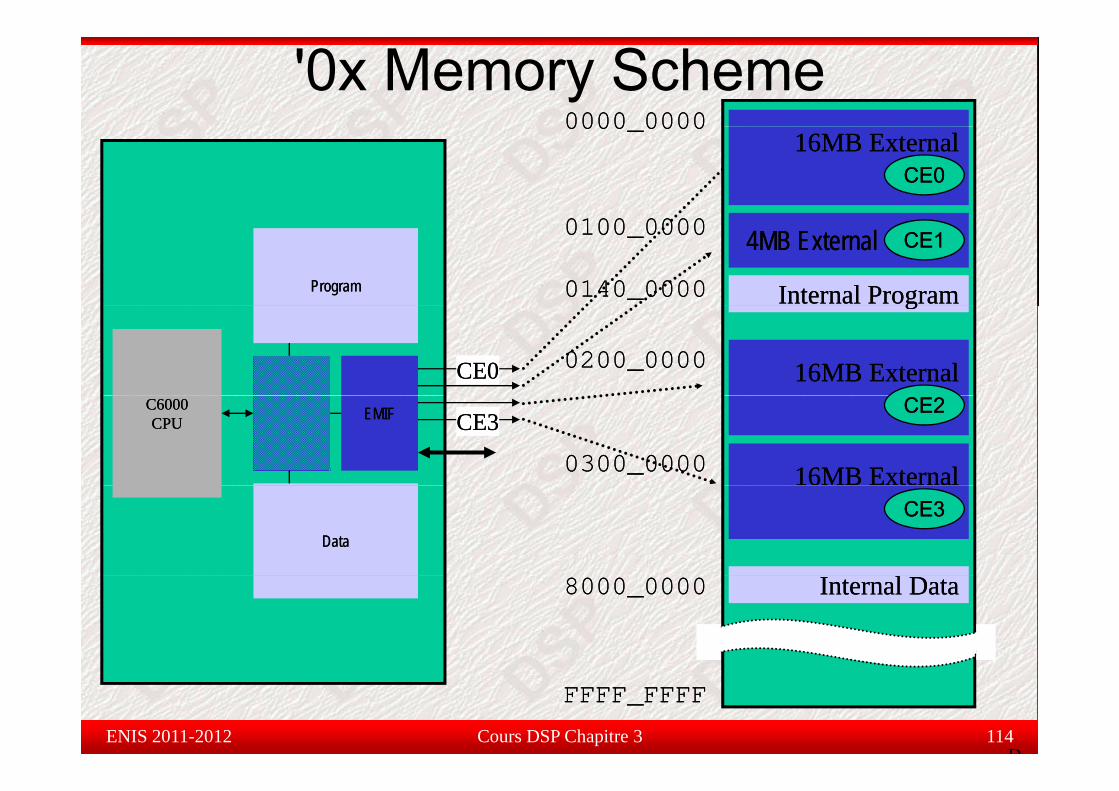
'0x Memory Scheme0000 00000000 00000000_00000000_0000
16MB External16MB External((CE0CE0))CE0CE0
ProgramProgram Internal ProgramInternal Program
0100_00000100_0000
0140_00000140_0000
4MB External 4MB External ((CE1CE1))CE1CE1
CE0CE0
gg
16MB External16MB External((CE0CE0))
0200_00000200_0000
C6000C6000CPUCPU EMIFEMIF CE3CE3
((CE0CE0))CE2CE2
16MB External16MB External0300_00000300_0000
DataData
((CE0CE0))CE3CE3
Internal DataInternal Data8000_00008000_0000
Cours DSP Chapitre 3 114ENIS 2011-2012D
FFFF_FFFFFFFF_FFFF
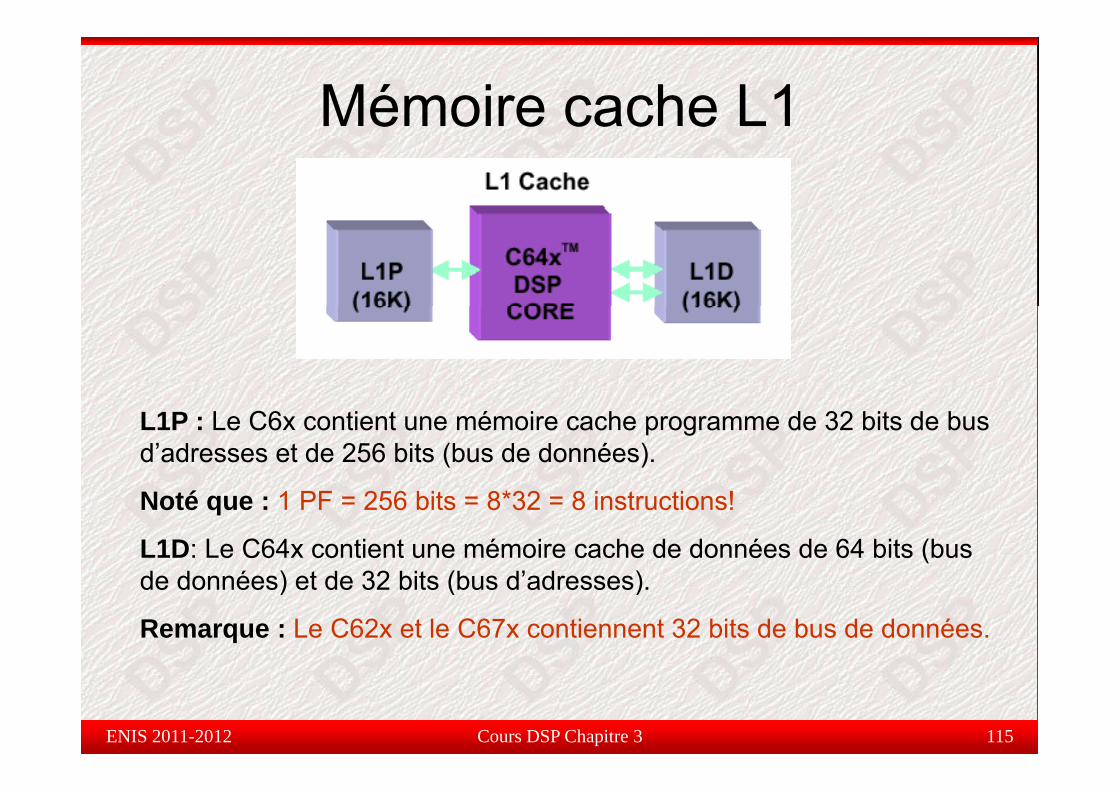
Mémoire cache L1é o e cac e
L1P : Le C6x contient une mémoire cache programme de 32 bits de bus d’adresses et de 256 bits (bus de données).
Noté que : 1 PF = 256 bits = 8*32 = 8 instructions!
L1D: Le C64x contient une mémoire cache de données de 64 bits (bus d d é ) t d 32 bit (b d’ d )de données) et de 32 bits (bus d’adresses).
Remarque : Le C62x et le C67x contiennent 32 bits de bus de données.
Cours DSP Chapitre 3 115ENIS 2011-2012
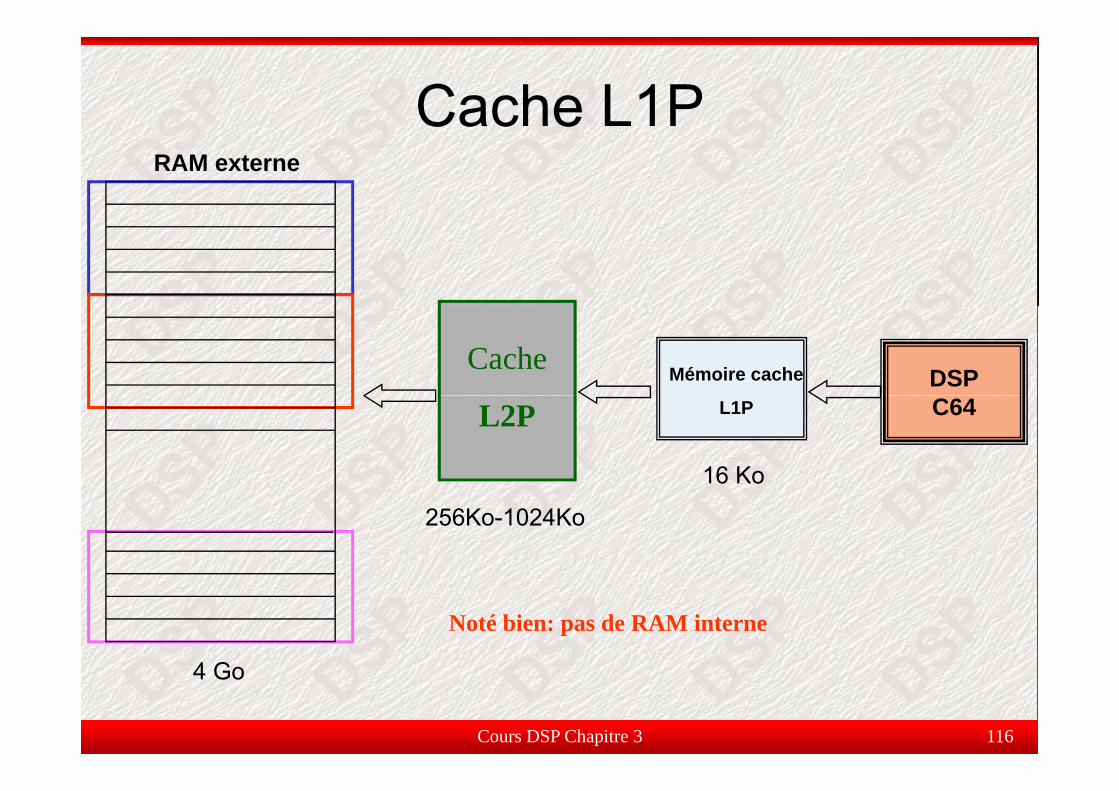
Cache L1PCac eRAM externe
DSPCache Mémoire cache
C64L2P
16 Ko
L1P
256Ko-1024Ko
4 G
Noté bien: pas de RAM interne
Cours DSP Chapitre 3 116
4 Go

Cache L1PCac e31 14 13 5 4 0
Tag Set Index Offset
TAG (18 bits) : il contient les MSB de l’adresse. Stocké dansune mémoire tampon pour indiquer la présence de la plaged’ d dé i é d l hd’adresse désirée dans la cache ou non.
Set Index (9 bits) : un set est une collection de ligne de trame.Set Index (9 bits) : un set est une collection de ligne de trame.Dans un système d’adressage direct, chaque set contient uneseule ligne.
Offset (5 bits) : détermine l’offset dans une ligne et permet parconséquent l’adressage par octet dans un PF.
Cours DSP Chapitre 3 117
q g p
ENIS 2011-2012
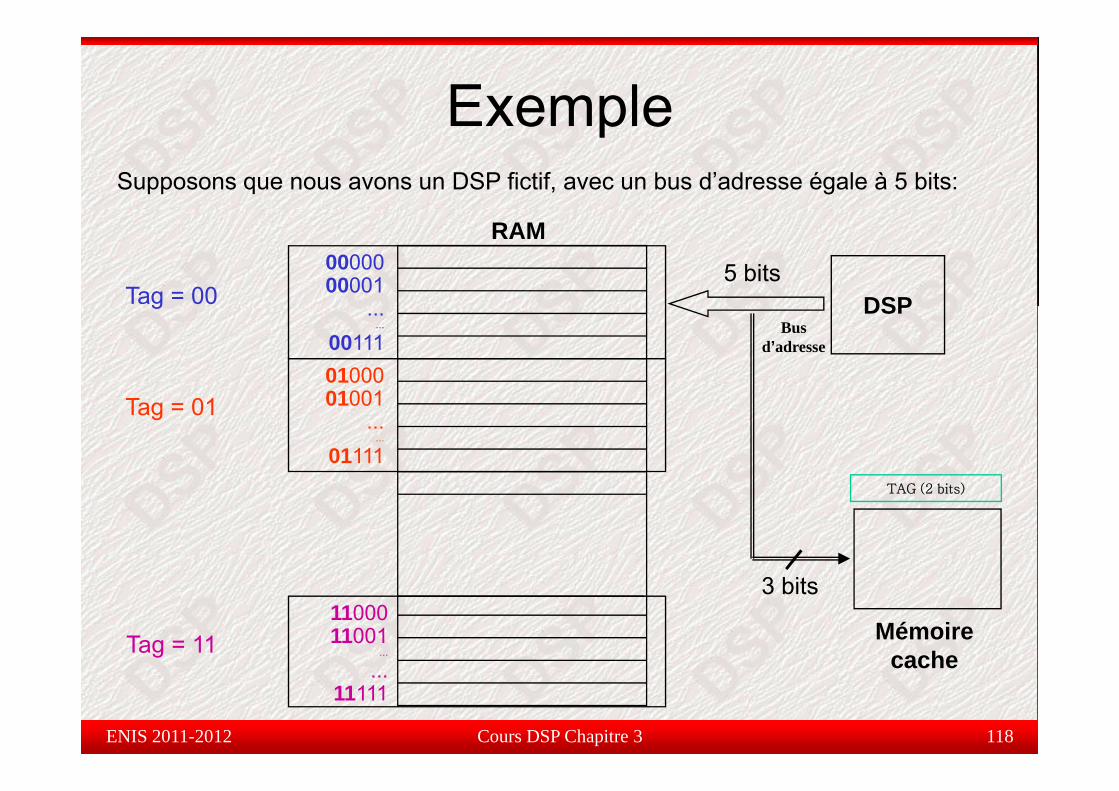
ExempleSupposons que nous avons un DSP fictif, avec un bus d’adresse égale à 5 bits:
e p e
DSP
RAM0000000001 5 bits
Tag = 00 DSP......
001110100001001
gBus
d’adresse
01001...
...
01111
Tag = 01
TAG (2 bit )TAG (2 bits)
Mémoire cache
1100011001
...
3 bits
Tag = 11
Cours DSP Chapitre 3 118
cache...11111
ENIS 2011-2012

Cache L1PCac e
offsetSet/Cache ligne
31 3 2 1 031 3 2 1 0
31 3 2 1 0………
012
8bits
31 3 2 1 0
31 3 2 1 031 3 2 1 0
31 3 2 1 031 3 2 1 0
………
……
345…
511
D l C64Dans le C64x,L1P = 16 Ko = …. * …octets pour un mode d’adressage direct.
Cours DSP Chapitre 3 119ENIS 2011-2012
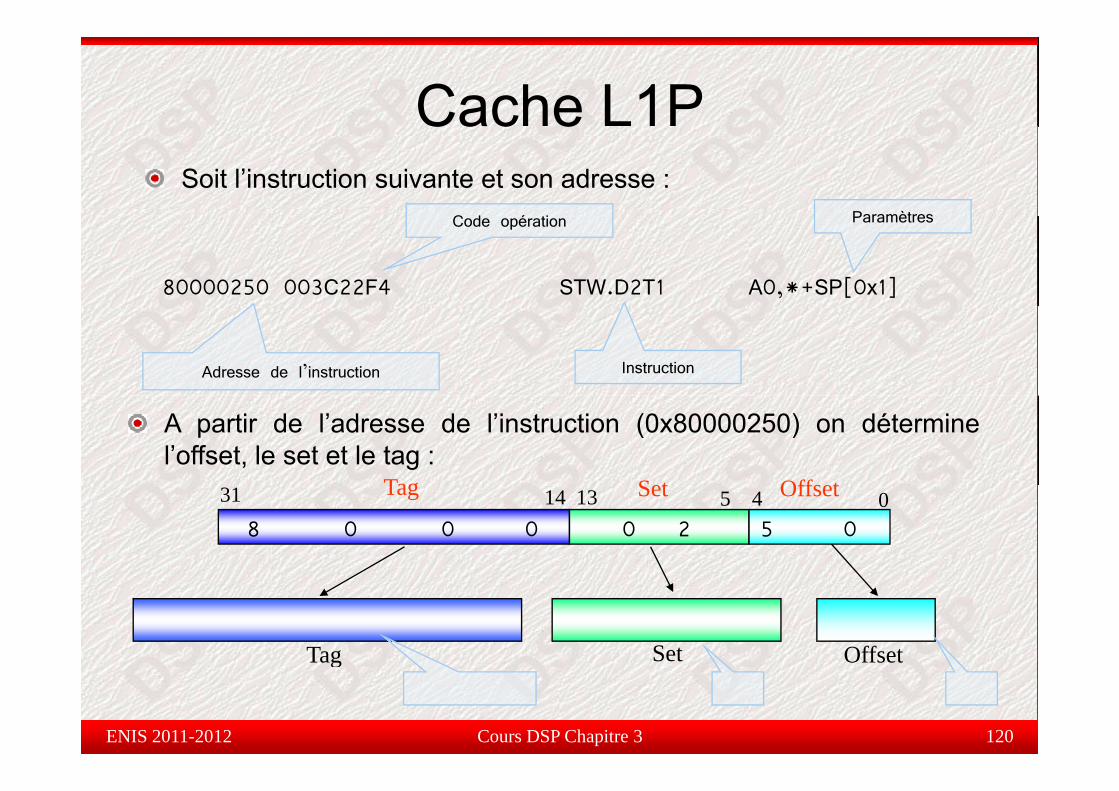
Cache L1PSoit l’instruction suivante et son adresse :
C d é i Paramètres
Cac e
80000250 003C22F4 STW.D2T1 A0,*+SP[0x1]
Code opération Paramètres
Adresse de l’instruction Instruction
A partir de l’adresse de l’instruction (0x80000250) on déterminel’offset, le set et le tag :
Tag Set Offset31 14 13 5 4 08 0 0 0 0 2 5 0
Tag Set Offset
Tag Set Offset
Cours DSP Chapitre 3 120
g
ENIS 2011-2012

Cache L1DCac eTag Set Index Offset
31 13 12 2 1Group
6 5 0Tag Set Index OffsetGroup
TAG (19 bits) : il contient les MSB de l’adresse. Stocké dans unemémoire tampon pour indiquer la présence de la plage d’adressedésirée dans le cache ou non (miss / hit).
Set Index (7 bits) : un ensemble est une collection de ligne detrame. Dans un système d’adressage associatives par ensembled d bl h bl ti t d lide deux blocs, chaque ensemble contient deux ligne.
Group (4 bits) : sélectionne le mot dans un ensemble qui contientGroup (4 bits) : sélectionne le mot dans un ensemble qui contientles données désirées.
Cours DSP Chapitre 3 121
Offset (2 bits) : détermine l’offset d’un mot dans l’adresse.
ENIS 2011-2012

Cache L1DCac eLigne cache (2 per set)Set Groupe
2
Ligne cache (2 per set)
15 3 2 1 015 3 1 0…0
32bits
Groupe
2…15 3 2 1 0
15 3 2 1 015 3 2 1 0
15 3 2 1 015 3 2 1 0
15 3 2 1 0
………
……1
2…
15 3 2 1 015 3 2 1 0……127
Dans le C64x L1D = 16 Ko = * * * 2 octets pour un modeDans le C64x, L1D = 16 Ko = … … .. 2 octets pour un moded’adressage associative par ensemble de 2 blocs.
Il y’a 128 ensembles contenant chacun 2 lignes cache.
Chaque ligne est formée de 64 octets
Cours DSP Chapitre 3 122
Chaque ligne est formée de 64 octets.
ENIS 2011-2012
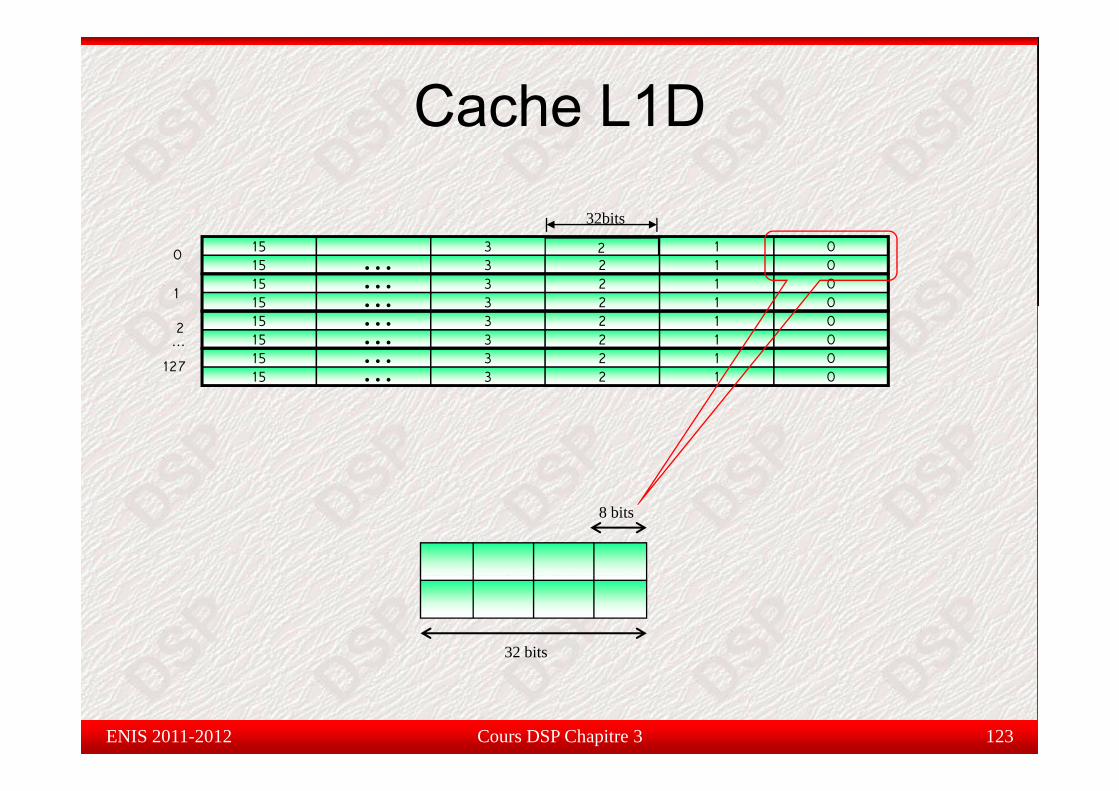
Cache L1D
32bit
Cac e
215 3 2 1 015 3 1 0
15 3 2 1 015 3 2 1 0
………
0
1
32bits
15 3 2 1 0
15 3 2 1 015 3 2 1 0
15 3 2 1 015 3 2 1 0
………
……2
127
…
8 bits
32 bits
Cours DSP Chapitre 3 123ENIS 2011-2012
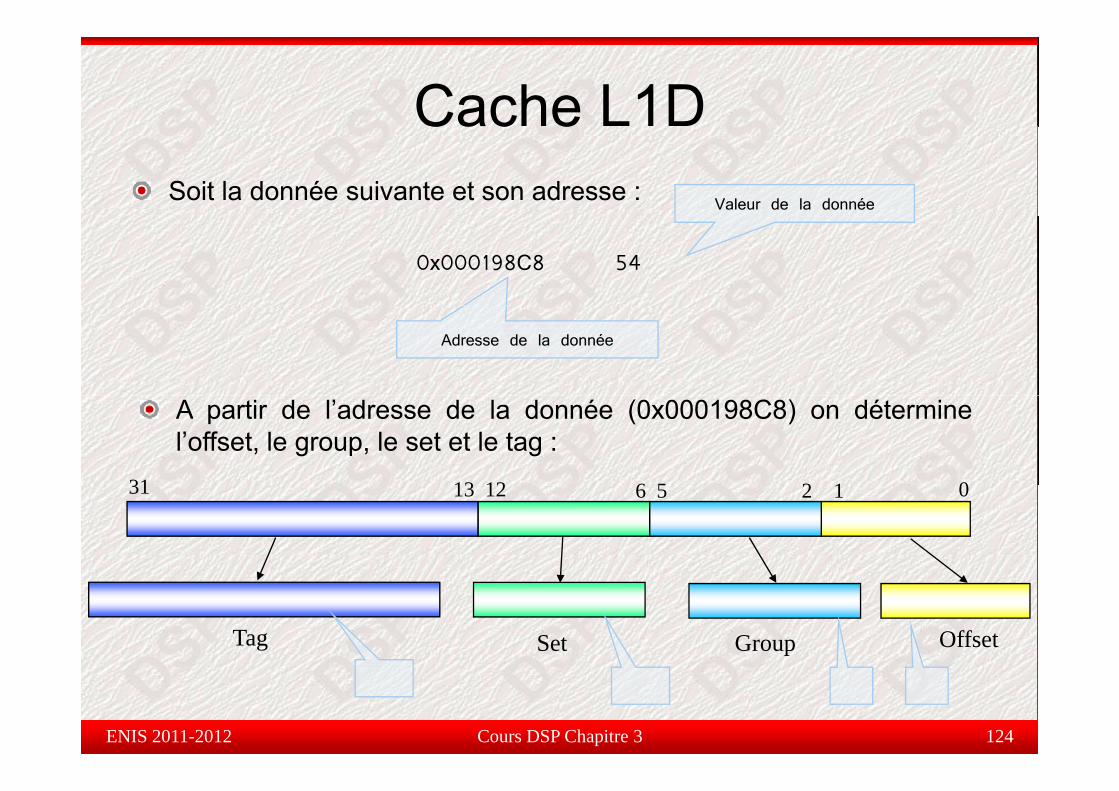
Cache L1DSoit la donnée suivante et son adresse : Valeur de la donnée
Cac e
0x000198C8 54
Adresse de la donnée
A partir de l’adresse de la donnée (0x000198C8) on déterminel’offset, le group, le set et le tag :
31 13 12 2 16 5 031 13 12 2 16 5 0
Tag Set Group Offset
Cours DSP Chapitre 3 124ENIS 2011-2012
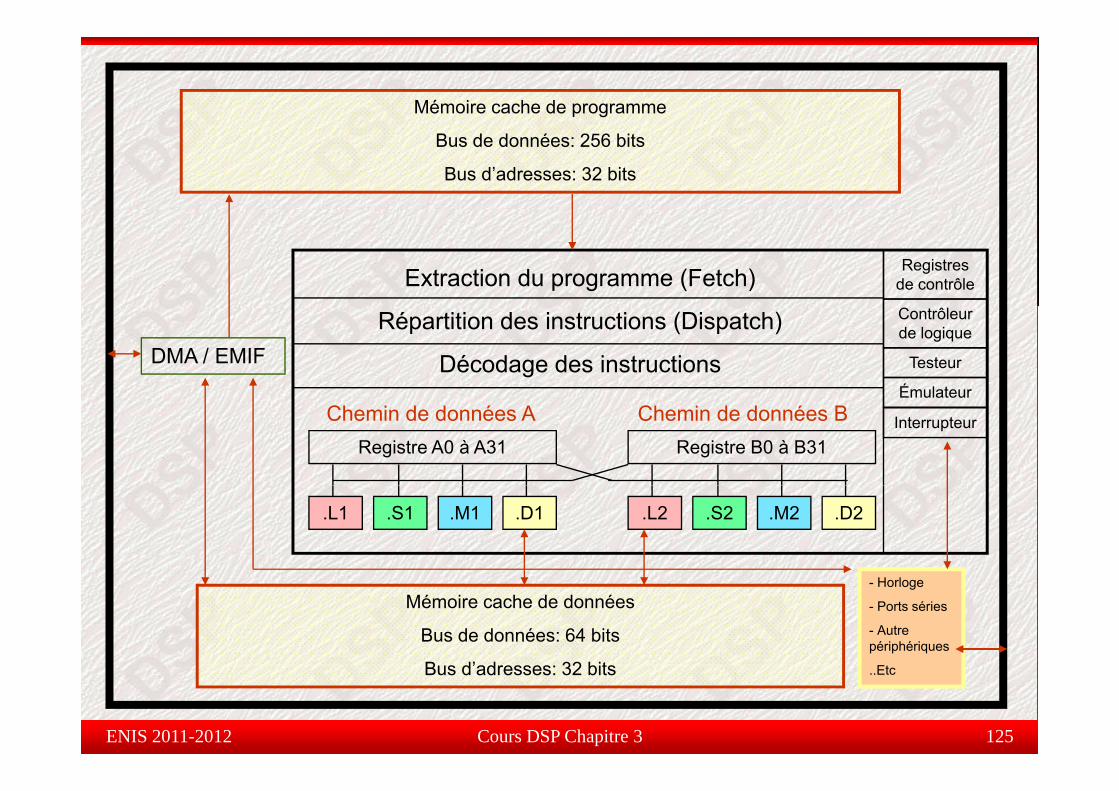
Mémoire cache de programme
Bus de données: 256 bits
Bus d’adresses: 32 bits
Registres de contrôleExtraction du programme (Fetch)
DMA / EMIF
Contrôleur de logique
Testeur
Émulateur
Répartition des instructions (Dispatch)
Décodage des instructionsÉmulateur
InterrupteurRegistre A0 à A31 Registre B0 à B31
Chemin de données A Chemin de données B
.L1 .S1 .M1 .D1 .L2 .S2 .M2 .D2
Mémoire cache de données
Bus de données: 64 bits
B d’ d 32 bit
- Horloge
- Ports séries
- Autre périphériques
Cours DSP Chapitre 3 125
Bus d’adresses: 32 bits ..Etc
ENIS 2011-2012

C6416 DSK
Cours DSP Chapitre 3 126ENIS 2011-2012

C64X
C6211/C6711 C64x DM64x
L2: 64K L2 1 MB L2: 256KB---642
150, 166 MHz 500, 600, 720 MHz; 1GHz
500, 600 MHz; 400MHz (640)
L1: 4K L1D & 4K L1P L1: 16K L1D &16K L1P L1: 16K L1D &16K L1P
L2: 64K L2: 1 MB128KB---641,
640
32-bit EMIF 64-bit EMIF, 16-bit EMIF 64-bit EMIF---642
16-channel EDMA 64-channel EDMA 64-channel EDMA
No Video port No video portDM642: 3 video ports
DM641: 2 video ports
DM640 1 id
32-bit EMIF---641, 640
No Ethernet MAC No Ethernet MAC Ethernet MAC
DM640: 1 video port
Cours DSP Chapitre 3 127ENIS 2011-2012
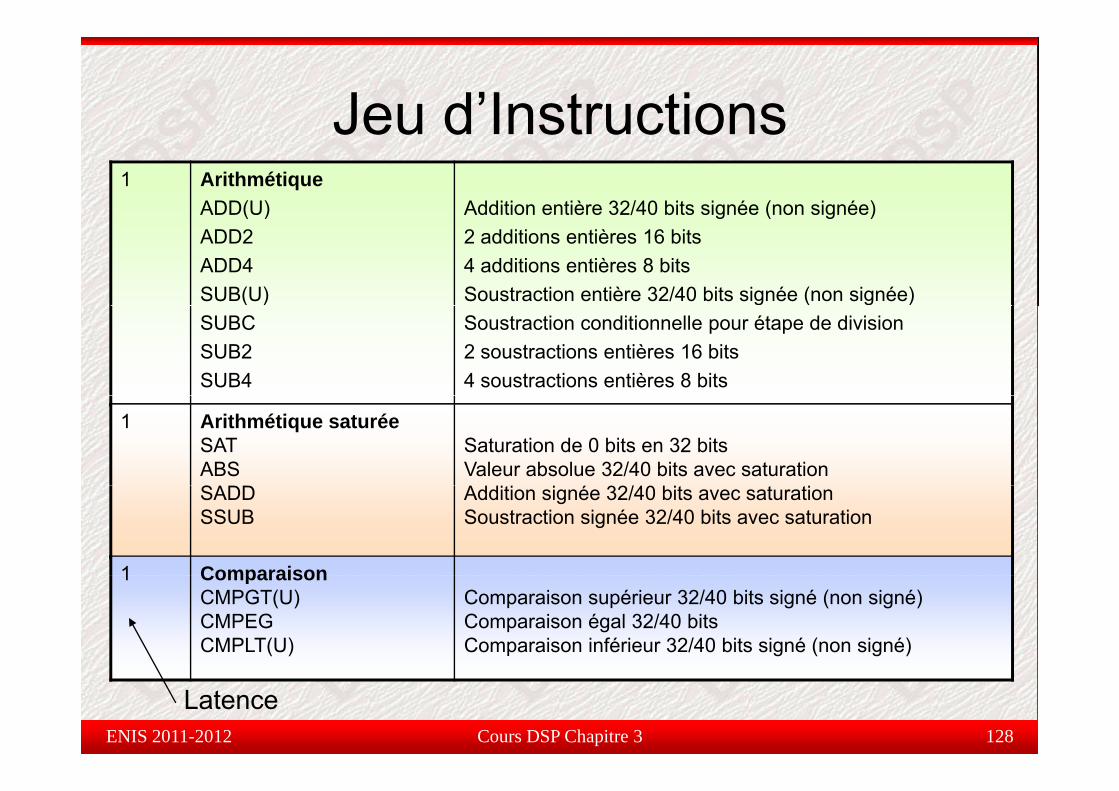
Jeu d’Instructions1 Arithmétique
ADD(U) Addition entière 32/40 bits signée (non signée)
Jeu d Instructions( )
ADD2ADD4SUB(U)
g ( g )2 additions entières 16 bits4 additions entières 8 bitsSoustraction entière 32/40 bits signée (non signée)
SUBCSUB2SUB4
Soustraction conditionnelle pour étape de division2 soustractions entières 16 bits4 soustractions entières 8 bits
1 Arithmétique saturéeSATABSS
Saturation de 0 bits en 32 bitsValeur absolue 32/40 bits avec saturation
/SADDSSUB
Addition signée 32/40 bits avec saturationSoustraction signée 32/40 bits avec saturation
1 Comparaison1 ComparaisonCMPGT(U)CMPEGCMPLT(U)
Comparaison supérieur 32/40 bits signé (non signé)Comparaison égal 32/40 bits Comparaison inférieur 32/40 bits signé (non signé)
Cours DSP Chapitre 3 128
LatenceENIS 2011-2012
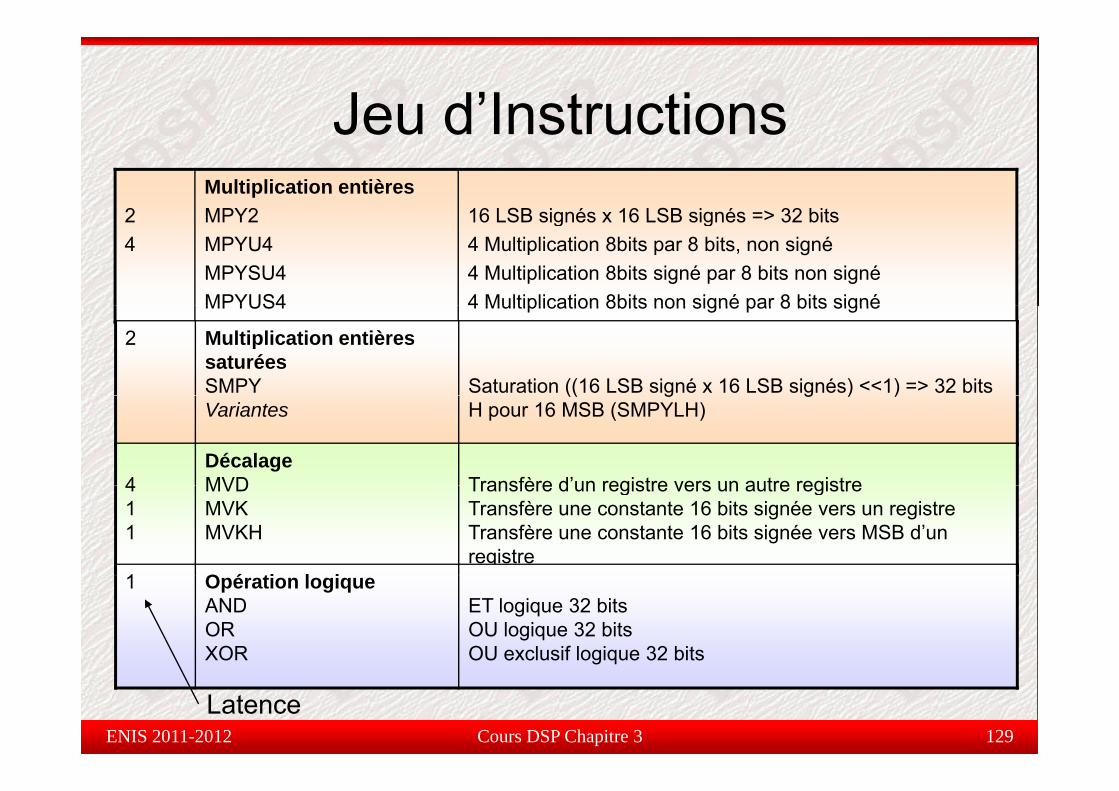
Jeu d’InstructionsJeu d Instructions2
Multiplication entièresMPY2 16 LSB signés x 16 LSB signés => 32 bits2
4MPY2MPYU4MPYSU4MPYUS4
16 LSB signés x 16 LSB signés => 32 bits4 Multiplication 8bits par 8 bits, non signé4 Multiplication 8bits signé par 8 bits non signé4 Multiplication 8bits non signé par 8 bits signéMPYUS4 4 Multiplication 8bits non signé par 8 bits signé
2 Multiplication entières saturéesSMPY Saturation ((16 LSB signé x 16 LSB signés) <<1) => 32 bitsVariantes
(( g g ) )H pour 16 MSB (SMPYLH)
4DécalageMVD Transfère d’un registre vers un autre registre4
11
MVDMVKMVKH
Transfère d un registre vers un autre registreTransfère une constante 16 bits signée vers un registre Transfère une constante 16 bits signée vers MSB d’un registre
1 O é ti l i1 Opération logiqueANDORXOR
ET logique 32 bitsOU logique 32 bitsOU exclusif logique 32 bits
Cours DSP Chapitre 3 129Latence
ENIS 2011-2012
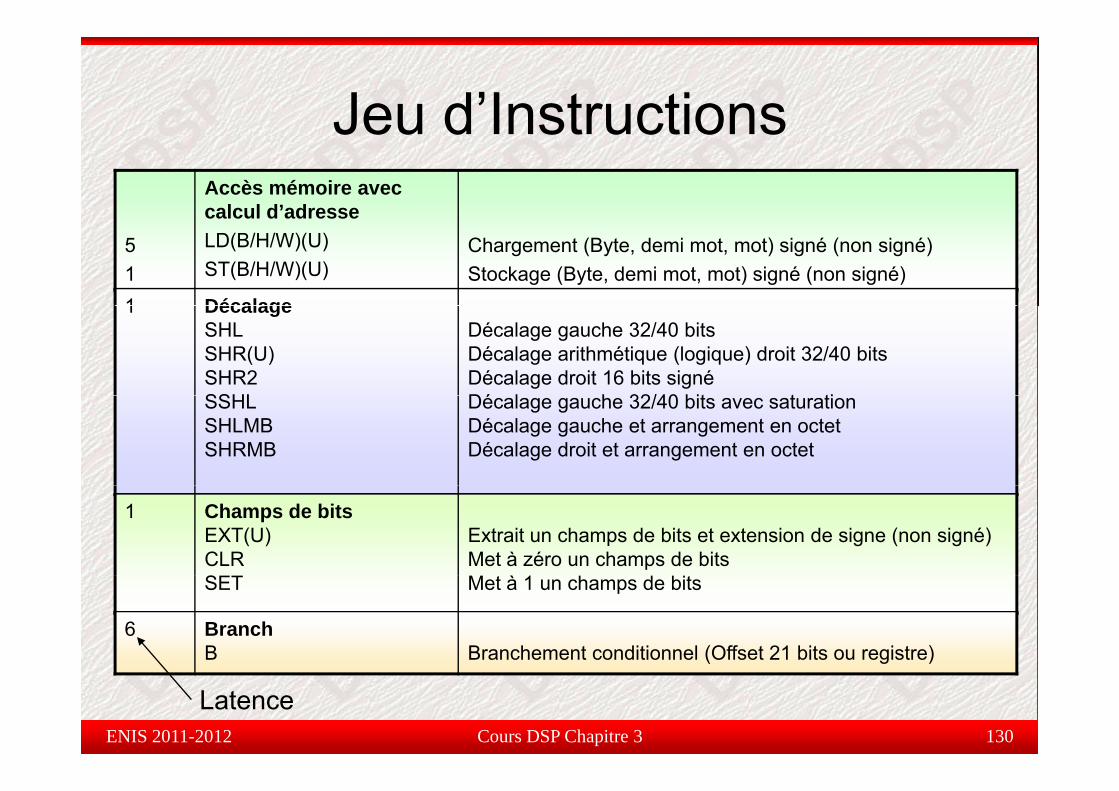
Jeu d’InstructionsJeu d InstructionsAccès mémoire avec calcul d’adresse
51
calcul d adresseLD(B/H/W)(U)ST(B/H/W)(U)
Chargement (Byte, demi mot, mot) signé (non signé)Stockage (Byte, demi mot, mot) signé (non signé)
1 Décalage1 DécalageSHLSHR(U)SHR2SSHL
Décalage gauche 32/40 bitsDécalage arithmétique (logique) droit 32/40 bitsDécalage droit 16 bits signéDé l h 32/40 bit t tiSSHL
SHLMBSHRMB
Décalage gauche 32/40 bits avec saturationDécalage gauche et arrangement en octet Décalage droit et arrangement en octet
1 Champs de bitsEXT(U)CLR
Extrait un champs de bits et extension de signe (non signé)Met à zéro un champs de bits
SET Met à 1 un champs de bits
6 BranchB Branchement conditionnel (Offset 21 bits ou registre)
Cours DSP Chapitre 3 130
LatenceENIS 2011-2012
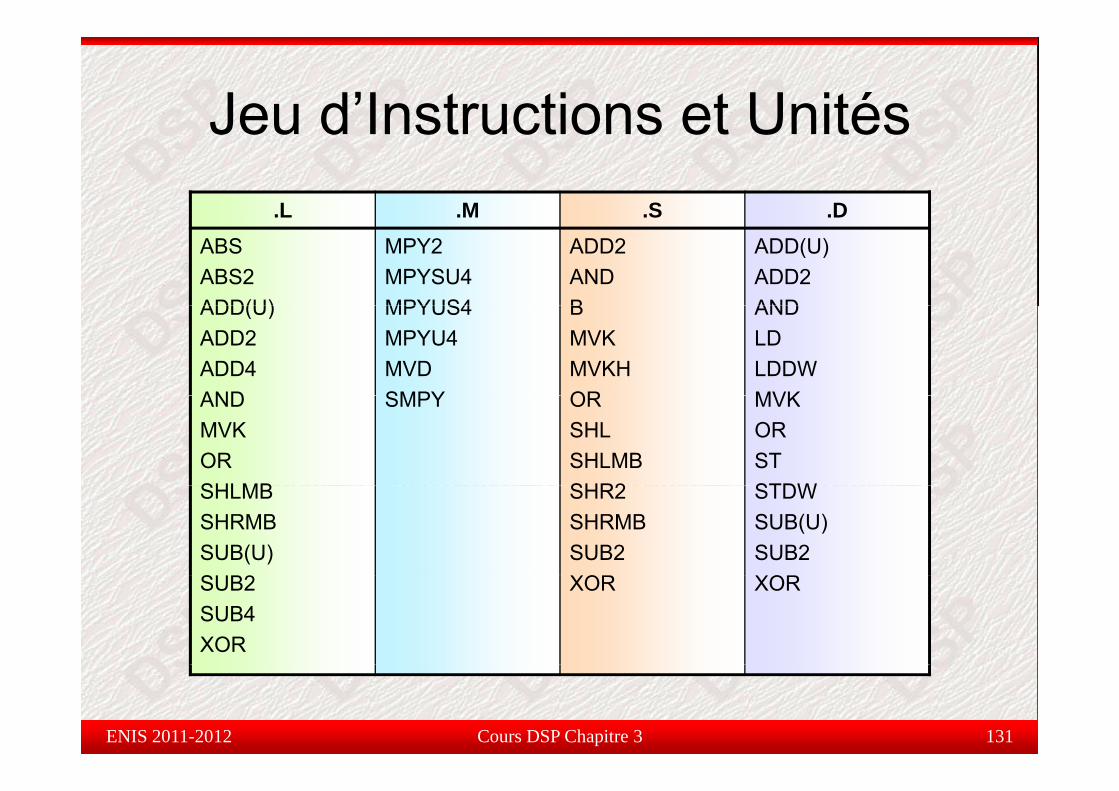
Jeu d’Instructions et UnitésJeu d Instructions et Unités.L .M .S .D.L .M .S .D
ABSABS2ADD(U)
MPY2MPYSU4MPYUS4
ADD2ANDB
ADD(U)ADD2ANDADD(U)
ADD2ADD4AND
MPYUS4MPYU4MVDSMPY
BMVKMVKHOR
ANDLDLDDWMVKAND
MVKORSHLMB
SMPY ORSHLSHLMBSHR2
MVKORSTSTDWSHLMB
SHRMBSUB(U)S
SHR2SHRMBSUB2
O
STDWSUB(U)SUB2
OSUB2SUB4XOR
XOR XOR
Cours DSP Chapitre 3 131ENIS 2011-2012

Modes d’adressagesodes d ad essagesIl existe deux différents modes d’adressages :
- Mode linéaire
- Mode circulaire
L’adressage le plus utilisé est le mode linéaire indirect.
Supposant que R est un registre d’adresse :pp q g*R : Le registre R pointe sur une adresse mémoire.
*R++(d) : Le registre R contient une adresse mémoire en plus il y aura une( ) g p ypost incrémentation c.à.d après une lecture R va s’auto incrémenter par unevaleur (d) qui est 1 par défaut.
*++R(d) : Même chose que le cas précédent mais maintenant une pré++R(d) : Même chose que le cas précédent mais maintenant une préincrémentation.
*+R(d) : L’adresse est pré incrémentée de tel sorte que l’adresse actuelle
Cours DSP Chapitre 3 132
est R+d. Par contre, R ne va pas être modifier.
ENIS 2011-2012

Modes d’adressagesodes d ad essagesMode circulaire :
Utiliser pour créer un tampon circulaire très utilisé.Dans le TSN : algorithmes de filtrage, corrélation ..etc.
Il existe deux tampons circulaire indépendants BK0 et BK1 et 8registres pointeurs : A4-A7 et B4-B7.
Initialiser le registre du mode d’adressage : AMR pour activer le modeInitialiser le registre du mode d adressage : AMR pour activer le moded’adressage circulaire désiré en spécifiant le mode du registre pointeuret la taille du tampon utilisé.
Seulement l’unité D1 peut être utile pour effectuer les opérationsSeulement l’unité D1 peut être utile pour effectuer les opérationsarithmétiques ou logiques.
Cours DSP Chapitre 3 133ENIS 2011-2012

Modes d’adressagesodes d ad essagesRegistre AMR :
réservé BK1 BK0
31 26 25 21 20 16
Mode B7 Mode B6 Mode B5 Mode B4 Mode A7 Mode A6 Mode A5 Mode A4
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
Mode Description00 Adressage linéaire par défaut
Exemple :
Si dé i i t00 Adressage linéaire par défaut01 Adressage circulaire utilisant BK010 Adressage circulaire utilisant BK1
Si on désire avoir un tamponcirculaire de 128 octets dansBK1 pointé par le registre B5,
11 Réservé
BK0 et BK1 : N taille du tampon qui sera 2N+1
AMR doit être initialisé à :
0x00C00800
Cours DSP Chapitre 3 134
BK0 et BK1 : N taille du tampon qui sera 2N+1.
ENIS 2011-2012

Syntaxe des instructionsSy ta e des st uct o sAdd / Soustraction / Multiplication :
ADD .L1 A3, A7, A7 si le résultat est stocké dans B7 on choisie l’unité L2
; A3 + A7 → A7
si le résultat est stocké dans B7, on choisie l unité .L2
SUB .S1 A1, 1, A1 ; A1 – 1 → A1
2 instructions en // :
MPY .M2 A7, B7, B6
|| MPYH M2 A7 B7 A6
; les LSB(A7) * LSB(B7) → B6
; les MSB(A7) * MSB(B7) → A6|| MPYH .M2 A7, B7, A6
Le choix de l’unité de traitement dépend de la destination
M1; les MSB(A7) MSB(B7) → A6
Cours DSP Chapitre 3 135
Le choix de l unité de traitement dépend de la destination.
ENIS 2011-2012

Syntaxe des instructionsSy ta e des st uct o s
Load / Store :Load / Store :
LDH .D2 *B2++, B7 ; charger (B2) → B7, Incrémenter B2
LDH .D1 *A2++, A7 ;LDH: chargement de 16 bits (H: half word)
charger (A2) → A7, Incrémenter A2
LDW: chargement de 32 bits (W: word)
STW .D1 A1, *+A4[20] ;stocké 32 bits de A1 dans une mémoire dont l’adresse est spécifiée par
store A1 → (A4) offset par 20
p pA4 décalée par 20 mots (32 bits) c.à.d. 80 octets.
Noté que le continu de A4 ne va pas changer après le stockage puisque une seule + est utilisée
Cours DSP Chapitre 3 136
une seule + est utilisée
ENIS 2011-2012

Syntaxe des instructionsSy ta e des st uct o sBranchement / Move :
Loop:MVK .S1 x, A4 ;
MVKH S1 x A4 ;
move 16 LSBs de l’adresse x → A4
move 16 MSBs de l’adresse x → A4MVKH .S1 x, A4 ;.
move 16 MSBs de l adresse x → A4
.
.
SUB S1 A1 1 A1; Décrémenter A1SUB .S1 A1, 1, A1;
[A1] B .S2 Loop ;
Décrémenter A1
Branchement à Loop si A1≠0
NOP 5 ;
STW D1 A3 *A7 ;
5 instructions de No-operation
Stocker A3 dans (A7)
Cours DSP Chapitre 3 137
STW .D1 A3, A7 ; Stocker A3 dans (A7)
ENIS 2011-2012

ContraintesCo t a tesContrainte mémoire :
La mémoire interne est arrangée sous forme de banc de mémoirespour permettre le stockage et le chargement simultanément.
Contrainte chemin croisé :
Le code suivant est valide :Le code suivant est valide :
ADD .L1x A1, B1, A0
|| MPY M2 A2 B2 B3|| MPY .M2x A2, B2, B3
Par contre, le code suivant n’est pas valide :
ADD .L1x A1, B1, A0
|| MPY .M1x A2, B2, B3
Cours DSP Chapitre 3 138
|| , ,M2x
ENIS 2011-2012

ContraintesCo t a tes
C i k / hContrainte stockage/chargement :
Les registres adresses utilisés doivent être du même chemin quel’ ité Dl’unité .D :
Le code suivant est valide :
LDW .D1 *A1, A2
|| LDW .D2 *B1, B2|| ,
Par contre le code suivant n’est pas valide :
LDW D1 *A1 A2LDW .D1 *A1, A2
|| LDW .D2 *A3, B2
Cours DSP Chapitre 3 139ENIS 2011-2012

ContraintesCo t a tesEn plus, le chargement et le stockage en // ne peuvent pas être du mêmechemin de registres (les registres A et les registres B)
Exemple :
Le code suivant est valide :
chemin de registres (les registres A et les registres B).
Le code suivant est valide :
LDW .D1 *A0, B1
|| STW D2 A1 *B2|| STW .D2 A1, *B2
De même, le code suivant est valide :
LDW D1 *A0 B1LDW .D1 *A0, B1
|| LDW .D2 *B2, A1
Par contre, le code suivant n’est pas valide :
LDW .D1 *A0, A1
Cours DSP Chapitre 3 140
|| STW .D2 A2, *B2
ENIS 2011-2012

FINFIN
Cours DSP Chapitre 3 141ENIS 2011-2012
ENISENIS 2011/2012
Chapitre IV :
Étude pratique du pipeline pour le TMS320 C64XTMS320 C64X
Plan Ch suivantCh précédent

SommaireSo a e
Pipeline
Exemples :
1èr exemple : Somme des produits
2ème exemple : Sum of Absolute Difference
3ème exemple : Interpolation Bilinéaire3 exemple : Interpolation Bilinéaire
Cours DSP Chapitre 4 143ENIS 2011-2012

Étude de cas : 1er Exempletude de cas e p e
Dans ce qui suit, on va étudier la fonction permettant de calculer lasomme de produits :
Y ∑40
nn
n xaY ∑=
=1
void somme_produit(unsigned char a[40], unsigned char b[40])
{
int x;
int sum=0;
for(x=1; x <= 40; x++)
sum += (a[x] * b[x]);
}
Cours DSP Chapitre 4 144
}
ENIS 2011-2012
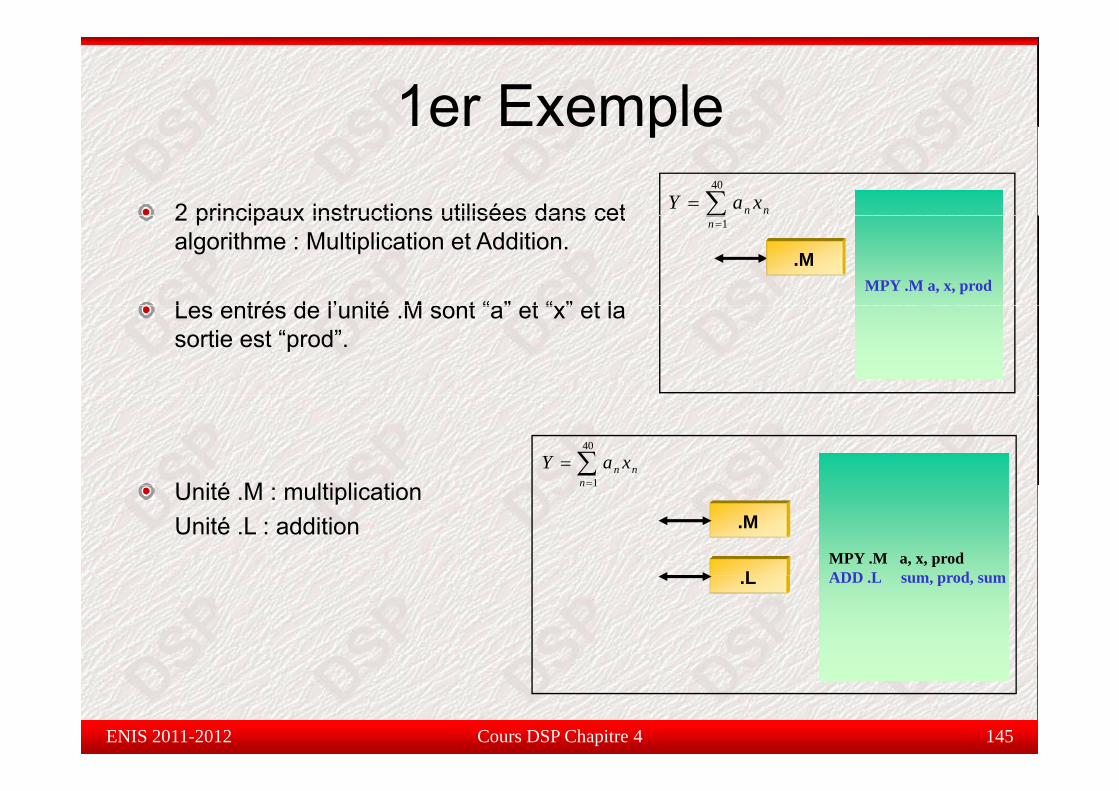
1er Exemple2 principaux instructions utilisées dans cet nn xaY ∑=
40
e e p e2 principaux instructions utilisées dans cetalgorithme : Multiplication et Addition.
Les entrés de l’ nité M sont “a” et “ ” et la
n∑=1
.MMPY .M a, x, prod
Les entrés de l’unité .M sont “a” et “x” et lasortie est “prod”.
nn
n xaY ∑=
=40
1U ité M lti li ti.M
MPY .M a, x, prodADD L s m prod s mL
n 1Unité .M : multiplicationUnité .L : addition
ADD .L sum, prod, sum.L
Cours DSP Chapitre 4 145ENIS 2011-2012

1er ExempleLes variables a, x, prod et Y seront stockés ou? Et comment peut on y
e p e, , p p y
accéder?
Ces variables seront stockés comme suit :Ces variables seront stockés comme suit :
nn
n xaY ∑=
=40
1
MPY .M a, x, prodADD .L sum, prod, sum
n 1
A0
A1
a
x
Register File A
.M
.LMPY .M A0, A1, A3ADD .L A4, A3, A4
A2
prodA3
A4 Y
A15
32-bits
Cours DSP Chapitre 4 146ENIS 2011-2012

1er Exemplee p e
Que faut – il faire apres ?
On a besoin de répéter les instructions MPY/ADD 40 fois. Comment peuton faire ça? A loop of course…
Dans une boucle on a :1. Instruction branch (B) et un nom pour la boucle2. Un compteur (= 40)3 Instruction pour décrémenter le compteur3. Instruction pour décrémenter le compteur4. Un test de branchement on se basant sur la valeur du compteur
Cours DSP Chapitre 4 147ENIS 2011-2012

1er ExempleOn commence par le branchement. L’unité permettant d’effectuer lebranchement est l’unité .S.
e p e
Après, on va créer le compteur avec une valeur égale à 40.
On va utiliser l’instruction MVK (MoVe a Konstant dans un registre). 0nchoisit le registre A2).
nn
n xaY ∑=
=40
1
Register File A
Mloop:
.S MVK .S 40, A2A0
A1
A2
a
x
prodA3
40
.M
.L
MPY .M A0, A1, A3ADD .L A4, A3, A4
B .S loopA15
A4 Y
Cours DSP Chapitre 4 148
B .S loopA15
32-bits
ENIS 2011-2012

1er ExempleDécrémenter le compteur dans la boucle (soustraire 1 de A2).
e p e
L’instruction SUB utilise aussi l’unité .L, comme pour l’ADD.add et sub peut etre fonctionner avec 6 unités.
nn
n xaY ∑=
=40
1
.S MVK .S 40, A2A0
A1
a
x
Register File A
.Mloop:
MPY .M A0, A1, A3ADD .L A4, A3, A4
A2
prodA3
A4 Y
40
.L, ,
B .S loop
SUB .L A2, 1, A2A15
32-bits
Cours DSP Chapitre 4 149ENIS 2011-2012

1er Exemple
L d iè ét t d’ j t l diti b t l l d A2
e p e
La dernière étape est d’ajouter la condition on se basant sur la valeur de A2: si A2>0, branchement.
On va ajouter [A2] avant l’instruction branch.
Si on utilise un registre dans des "[ ]", le CPU exécute l’instruction si laSi on utilise un registre dans des [ ] , le CPU exécute l instruction si lacondition est vrai ou non-nulle. Si la condition est fausse ou nulle,l’instruction ne sera pas exécuter.
Les registres conditionnels sont :pour C62x/C67x : A1, A2, B0, B1 et B2
C64 A0 A1 A2 B0 B1 t B2pour C64x : A0, A1, A2, B0, B1 et B2
ENIS 2010-2011 Cours DSP Chapitre 4 150

1er Exemplee p eHow How do you load a pointer with an address?do you load a pointer with an address?
An address is a constant, so use MVK:An address is a constant, so use MVK:
MVKMVK SS A5A5MVKMVK .S.S a, A5a, A5
How many bits can MVK move?How many bits can MVK move? 1616
How many bits represent a full address?How many bits represent a full address? 3232
yy
MVKL SMVKL S A5A5Solution?Solution?
MVKL .SMVKL .S a, A5a, A5
MVKH .SMVKH .S a, A5a, A5
ENIS 2010-2011 Cours DSP Chapitre 4 151
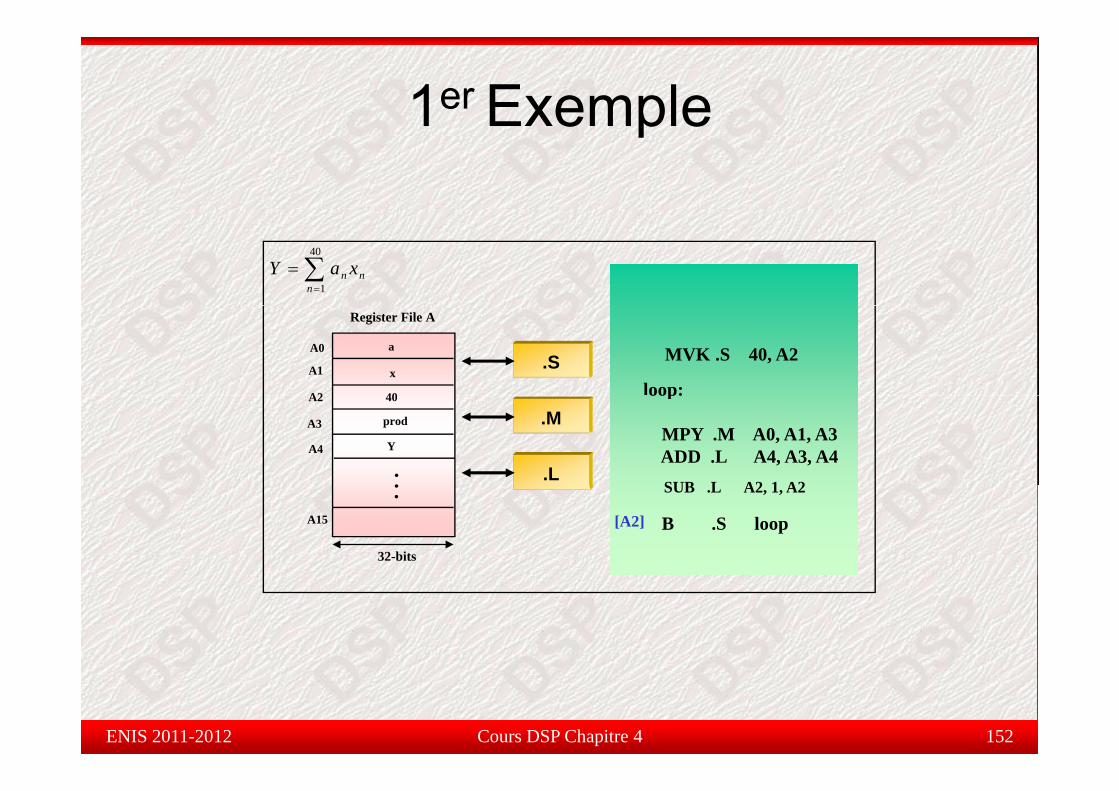
1er Exemplee p e
nn
n xaY ∑=
=40
1
.Sloop:
MVK .S 40, A2A0
A1
A2
a
x
40
Register File A
.M
.L
oop:
MPY .M A0, A1, A3ADD .L A4, A3, A4SUB L A2 1 A2
A2
prodA3
A4 Y
40
B .S loop
SUB .L A2, 1, A2
[A2]A15
32-bits
Cours DSP Chapitre 4 152ENIS 2011-2012

Load/Store OptionspBecause the 'C6000 provides byte addressability, the instruction Because the 'C6000 provides byte addressability, the instruction
set supports several types of load/store instructions:set supports several types of load/store instructions:
LoadLoad instructions:instructions:LDBLDB L d 8L d 8 bit b tbit b t ( h )( h )LDBLDB Load 8Load 8--bit bytebit byte (char)(char)LDHLDH Load 16Load 16--bit halfbit half--word word (short)(short)LDWLDW Load 32Load 32--bit wordbit word ((intint))
LDDWLDDW Load 64Load 64--bit doublebit double--wordword (C67x, C64x) (C67x, C64x) (double)(double)
StoreStore instructions:instructions:STBSTBSTHSTHSTWSTW
If we’reIf we’re mulitplyingmulitplying 1616--bit numbers whichbit numbers which
STDW (C64x)STDW (C64x)
Cours DSP Chapitre 4 153ENIS 2011-2012
If we re If we re mulitplyingmulitplying 1616--bit numbers, which bit numbers, which load instruction should be used?load instruction should be used?

1er ExempleComment charger les variables dans les registres?On va créer un pointeur pour une variable le pointeur contient l’adresse de
e p eOn va créer un pointeur pour une variable. le pointeur contient l adresse dela variable. On stocke le contenue du pointeur dans un registre A.On va utiliser l’instruction load (LD) pour charger les variables “a” et “x“ dansles registres et l’instruction store (ST) pour stocker le résultat Yles registres et l instruction store (ST) pour stocker le résultat Y.
Register File A
• Créer des pointeurs pour:•A5=&a•A6=&x•A7=&Y
• Inst Load/Store.S
A0A1
A2
a
x
prodA3
40
.M
L
Inst Load/Store•LD *A5, A0•LD *A6, A1•ST A4, *A7
A4 YA5 &a[n]A6 &x[n]A7 &Y
*A5: accéder audonnée pointé parl’adresse A5
.L
A15
32-bits
Mémoire
a[40]
x[40]
Y
*A5
*A6
*A7
Cours DSP Chapitre 4 154ENIS 2011-2012
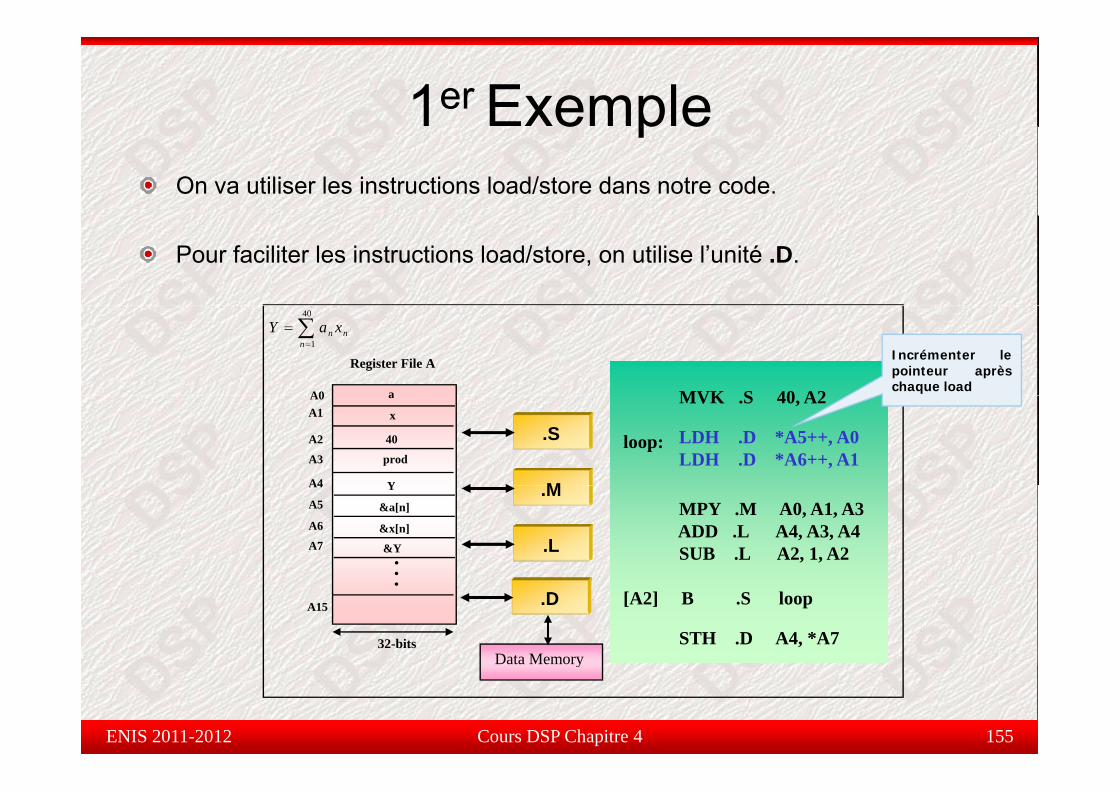
1er ExempleOn va utiliser les instructions load/store dans notre code.
e p e
Pour faciliter les instructions load/store, on utilise l’unité .D.
A0 a
Register File A
MVK S 40 A2
nn
n xaY ∑=
=40
1Incrémenter lepointeur aprèschaque load
M
.S
A0A1
A2
a
x
prodA3
A4 Y
40
MVK .S 40, A2
loop: LDH .D *A5++, A0LDH .D *A6++, A1
.M
.L
A4 YA5 &a[n]A6 &x[n]A7 &Y
MPY .M A0, A1, A3ADD .L A4, A3, A4SUB .L A2, 1, A2
A15
32-bitsData Memory
[A2] B .S loop.D
STH .D A4, *A7
Cours DSP Chapitre 4 155
y
ENIS 2011-2012
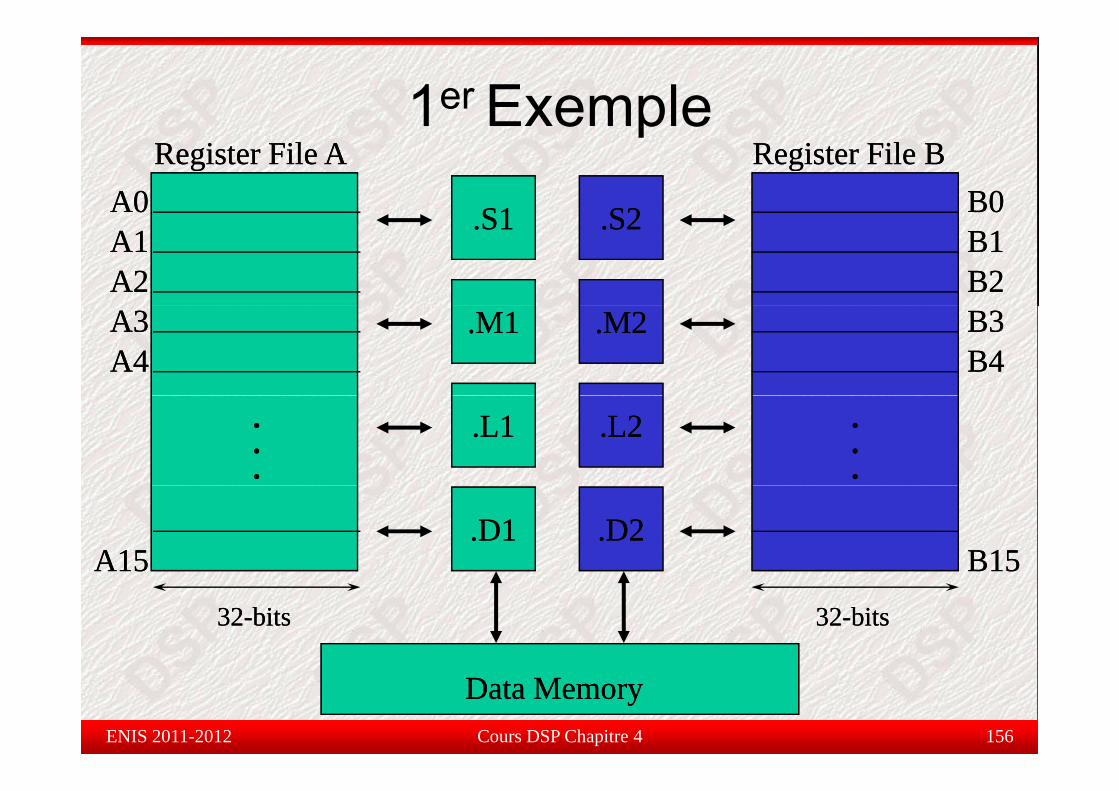
1er Exemplee p e
S1S1 S2S2A0A0Register File ARegister File A
B0B0Register File BRegister File B
.S1.S1 .S2.S2A1A1A2A2
B1B1B2B2
.M1.M1 .M2.M2A3A3A4A4
B3B3B4B4
.L1.L1 .L2.L2............
.D1.D1 .D2.D2A15A15 B15B15
3232--bitsbits 3232--bitsbits
Cours DSP Chapitre 4 156ENIS 2011-2012
Data MemoryData Memory

Utilisant seulement les registres de AUt sa t seu e e t es eg st es de
YY4040∑∑ aa xx**
ll
Y =Y = ∑∑ aann xxnnn = 1n = 1
**
MVKMVK .S1.S1 40, A240, A2 ; A2 = 40, loop count; A2 = 40, loop countloop:loop: LDHLDH .D1.D1 *A5++, A0*A5++, A0 ; A0 = a(n); A0 = a(n)
LDHLDH .D1.D1 *A6++, A1*A6++, A1 ; A1 = x(n); A1 = x(n)MPYMPY .M1.M1 A0, A1, A3A0, A1, A3 ; A3 = a(n) * x(n); A3 = a(n) * x(n)ADDADD .L1.L1 A3, A4, A4A3, A4, A4 ; Y = Y + A3; Y = Y + A3SUBSUB .L1.L1 A2, 1, A2A2, 1, A2 ; decrement loop count; decrement loop count
[A2][A2] BB .S1.S1 looploop ; if A2 ; if A2 ≠≠ 0, branch0, branchSTHSTH .D1.D1 A4, *A7A4, *A7 ; *A7 = Y; *A7 = Y
Cours DSP Chapitre 4 157ENIS 2011-2012Note: Note: Le Le registreregistre A4 A4 doitdoit contenircontenir zerozero..
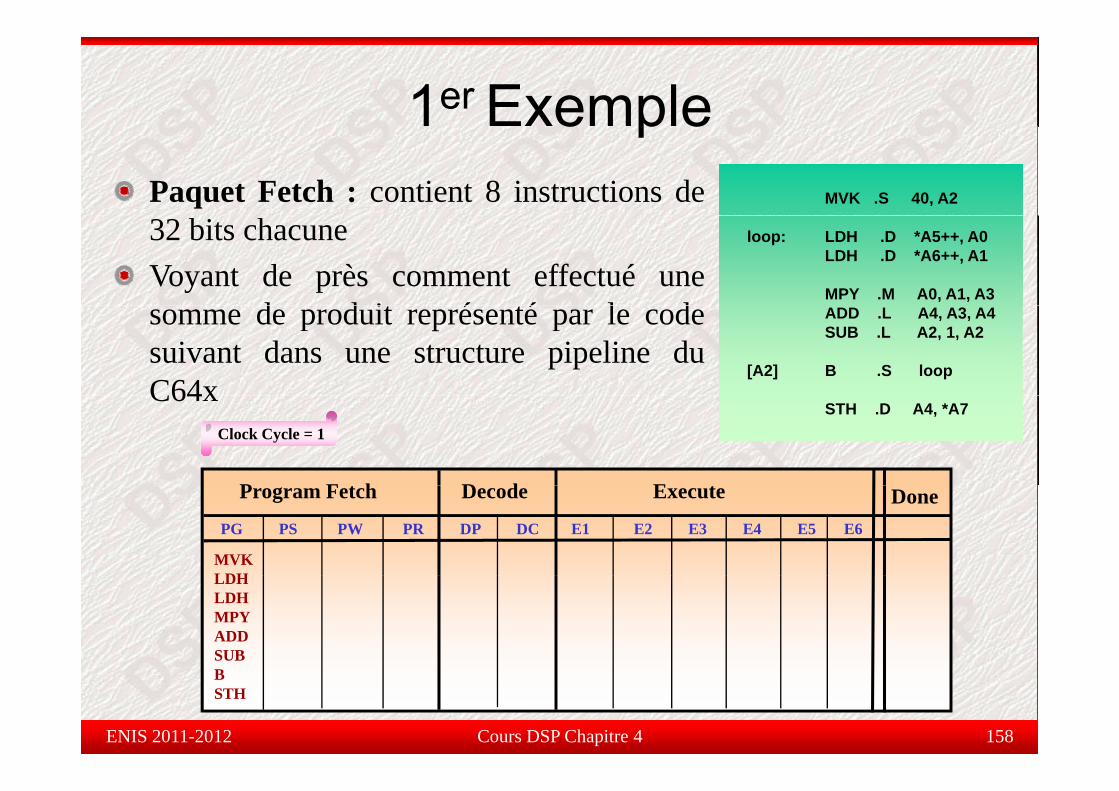
1er Exemplee p ePaquet Fetch : contient 8 instructions de MVK .S 40, A2
32 bits chacuneVoyant de près comment effectué une
d d it é té l d
loop: LDH .D *A5++, A0LDH .D *A6++, A1
MPY .M A0, A1, A3somme de produit représenté par le codesuivant dans une structure pipeline duC64x
ADD .L A4, A3, A4SUB .L A2, 1, A2
[A2] B .S loopC64x
STH .D A4, *A7
P F t h D d E t
Clock Cycle = 1
PG PS PW PR DP DC E1 E2 E3 E4 E5 E6
MVKLDH
Program Fetch Decode Execute Done
LDHLDHMPYADDSUB
Cours DSP Chapitre 4 158
BSTH
ENIS 2011-2012

1er Exemplee p e
Program Fetch Decode Execute Done
Clock Cycle = 4
PG PS PW PR DP DC E1 E2 E3 E4 E5 E6
MVKLDHLDHMPYADDSUBBSTH
FP2FP3FP4
STH
Cours DSP Chapitre 4 159ENIS 2011-2012

1er ExempleClock Cycle =
PF Decode Execute Done
p
PF DP DC E1 E2 E3 E4 E5 E6 √
PF E t D
Clock Cycle =
PF DP DC E1 E2 E3 E4 E5 E6
PF Decode Execute Done
√
Cours DSP Chapitre 4 160ENIS 2011-2012

1er ExempleClock Cycle =
PF Decode Execute Done
p
PF DP DC E1 E2 E3 E4 E5 E6 √
PF E t D
Clock Cycle =
PF DP DC E1 E2 E3 E4 E5 E6
PF Decode Execute Done
√
Cours DSP Chapitre 4 161ENIS 2011-2012

1er Exemplee p eAlors comment résoudre ce problème?
En premier lieu, on va se concentrer sur les instructions MPY/ADD. On doit retarder add par un
cycle pour que la multiplication aura lieu avant que l’addition commence. Utiliser NOP.
Clock Cycle = 11
PF DP DC E1 E2 E3 E4 E5 E6
PF Decode Execute Done
√
MVK
FP5-2
LDHLDH
MVK+
+ + MPY
NOP
SUBBSTH
ADD
Cours DSP Chapitre 4 162
STH
ENIS 2011-2012
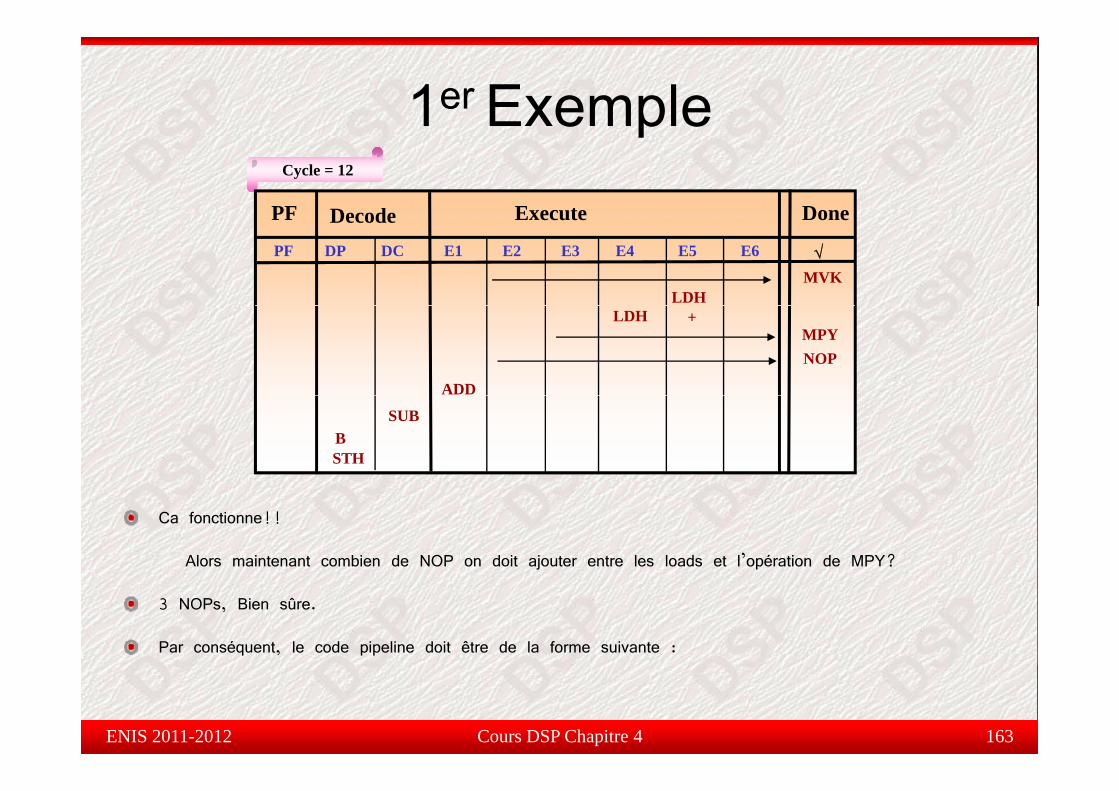
1er Exemplee p eCycle = 12
PF Decode Execute Done
PF DP DC E1 E2 E3 E4 E5 E6
PF Decode Execute Done
√MVK
LDH
ADD
LDH +MPYNOP
STH
SUBB
Ca fonctionne!!
Alors maintenant combien de NOP on doit ajouter entre les loads et l’opération de MPY?
3 NOPs, Bien sûre.
Par conséquent, le code pipeline doit être de la forme suivante :
Cours DSP Chapitre 4 163ENIS 2011-2012

1er Exemplee p eMVK .S 40, A2
loop: LDH .D *A5++, A0LDH .D *A6++, A1NOP 3
Évaluation de ce code en cycles:NOP 3
MPY .M A0, A1, A3NOP ADD .L A4, A3, A4
y
Loop interne:1ère load 52ème load 1MPY 2ADD/SUB 2SUB .L A2, 1, A2
[A2] B .S loopNOP 5STH D A4 *A7
ADD/SUB 2B 6
Total 16*40+2 = 642
STH .D A4, A7
Attendez, est il possible de remplir les retards par des instructions utiles?
Oui, en effet on peut prendre avantage des retards pour réécrire le code intelligemment. il peut être
vu en désordre, mais il nous fourni rapidement le bon résultat !
Cours DSP Chapitre 4 164ENIS 2011-2012
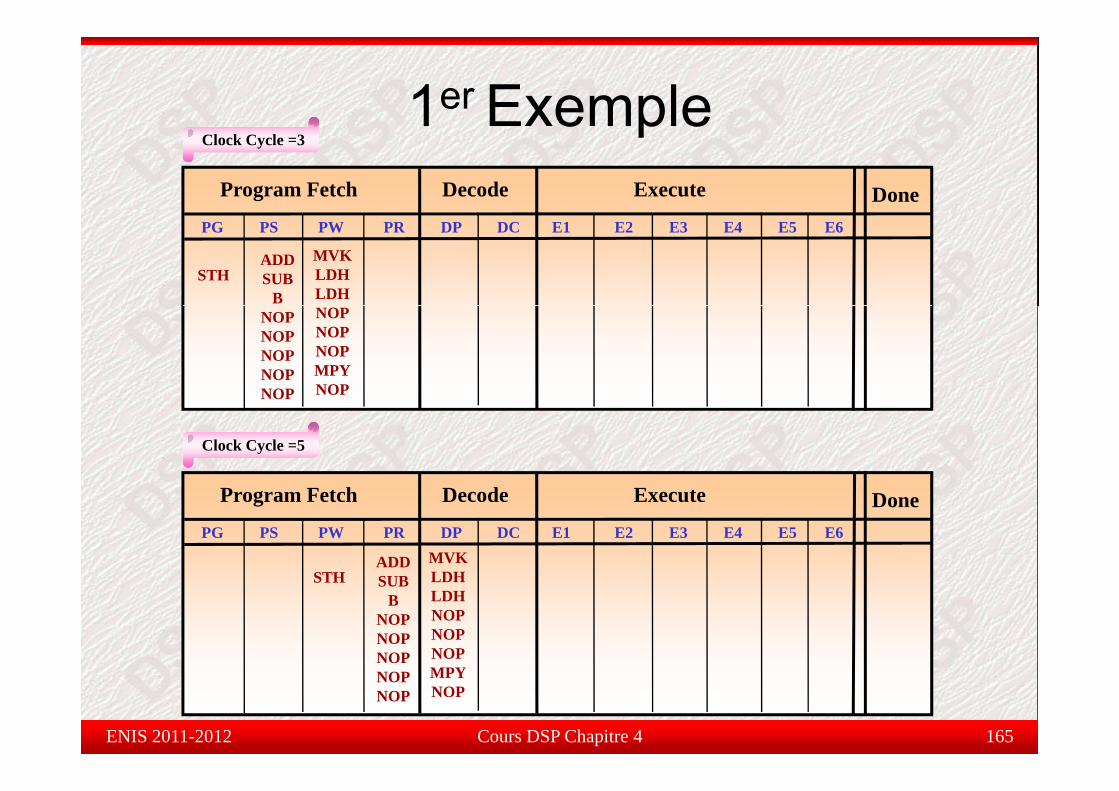
1er Exemplee p eProgram Fetch Decode Execute Done
Clock Cycle =3
PG PS PW PR DP DC E1 E2 E3 E4 E5 E6
MVKLDHLDH
ADDSUB
BSTH
NOPNOPNOPMPYNOP
NOPNOPNOPNOPNOP
Clock Cycle =5
NOP
PG PS PW PR DP DC E1 E2 E3 E4 E5 E6
Program Fetch Decode Execute Done
MVKLDH
ADDSTH LDH
LDHNOPNOPNOP
SUBB
NOPNOPNOP
STH
Cours DSP Chapitre 4 165
MPYNOP
NOPNOP
ENIS 2011-2012
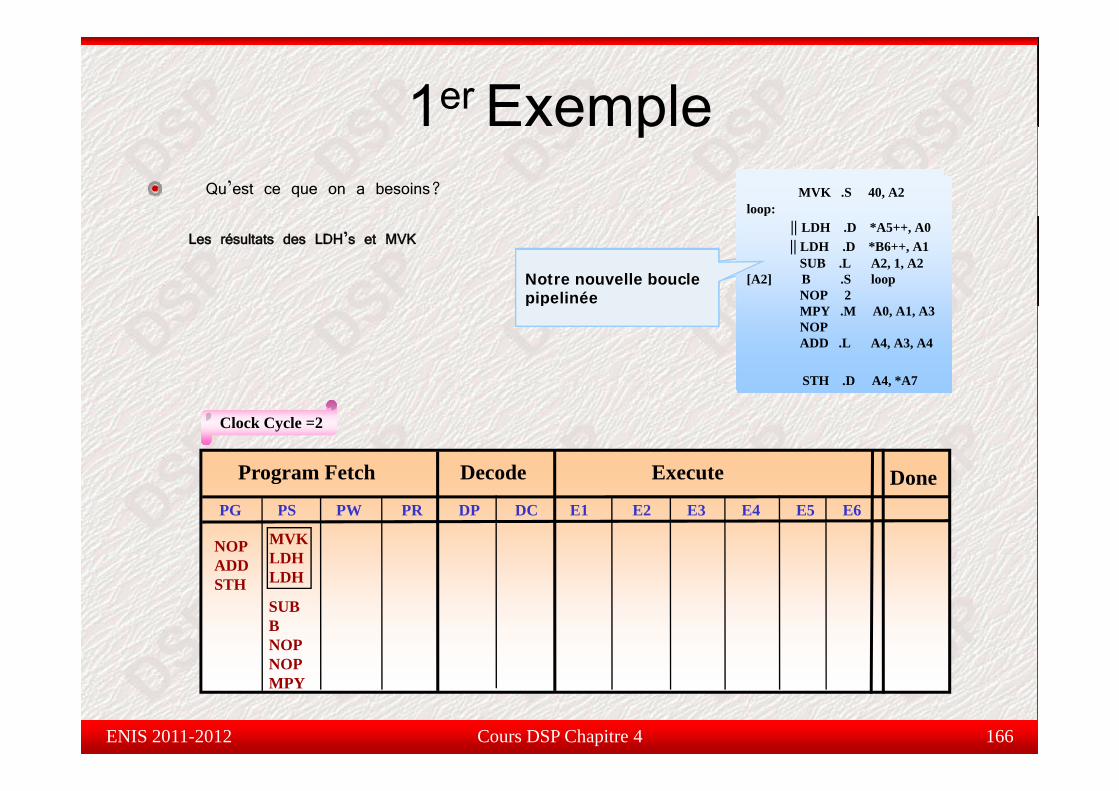
1er Exemplee p eQu’est ce que on a besoins? MVK .S 40, A2
loop:
MVK .S 40, A2loop:
Les résultats des LDH’s et MVKloop:
MPY .M A0, A1, A3ADD .L A4, A3, A4SUB .L A2, 1, A2
LDH .D *A5++, A0LDH .D *B6++, A1
On place le 2ème load sur le chemin B, pour qu’on puisse exécuté les 2 i i //
p|| LDH .D *A5++, A0|| LDH .D *B6++, A1
SUB .L A2, 1, A2[A2] B .S loop
NOP 2Notre nouvelle boucle pipelinée
[A2] B .S loop
STH .D A4, *A7
instructions en // MPY .M A0, A1, A3NOPADD .L A4, A3, A4
STH .D A4, *A7
p p
Program Fetch Decode Execute Done
Clock Cycle =2
PG PS PW PR DP DC E1 E2 E3 E4 E5 E6
MVKLDHLDH
NOPADD
LDH
SUBBNOPNOP
STH
Cours DSP Chapitre 4 166
NOPMPY
ENIS 2011-2012
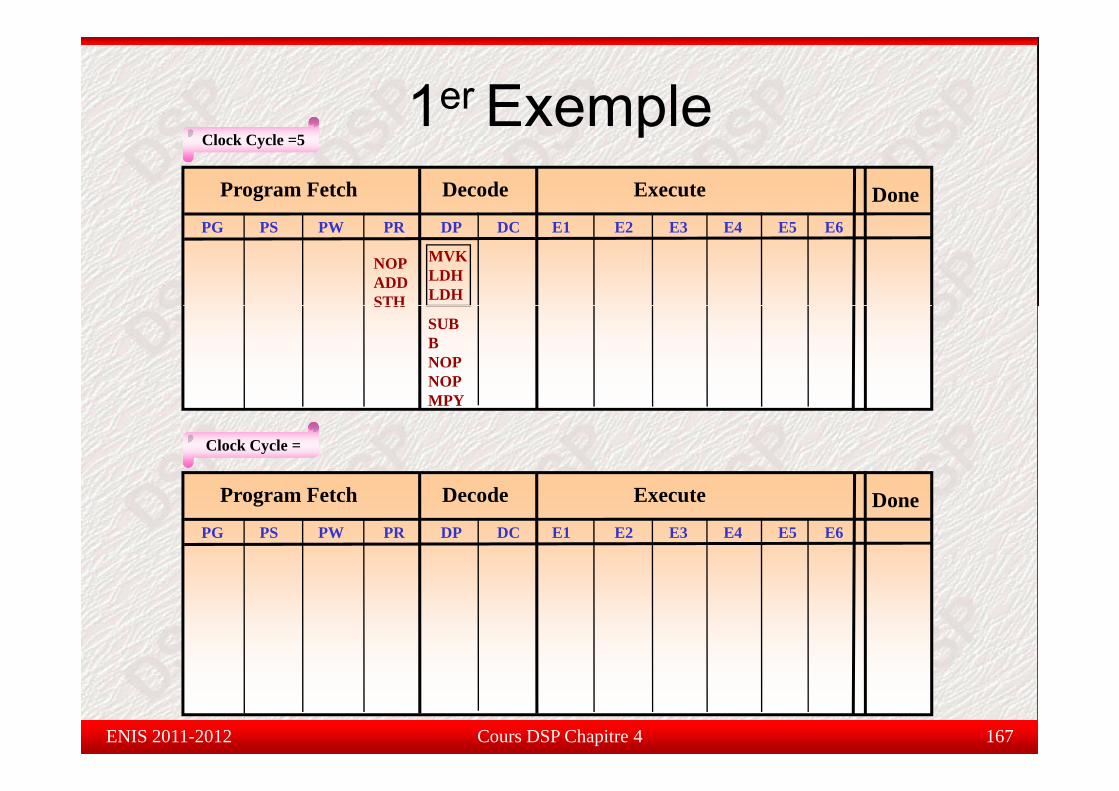
1er Exemplee p eProgram Fetch Decode Execute Done
Clock Cycle =5
PG PS PW PR DP DC E1 E2 E3 E4 E5 E6
MVKLDHLDH
NOPADDSTH
SUBBNOPNOPMPY
STH
Clock Cycle =
MPY
PG PS PW PR DP DC E1 E2 E3 E4 E5 E6
Program Fetch Decode Execute Done
Cours DSP Chapitre 4 167ENIS 2011-2012

FINFIN
Nouri MASMOUDI f à ’ SProfesseur à l’ENIS
Responsable de l’Équipe Circuits et Systèmes Laboratoire d’Électronique et des Technologies de l’Information [email protected] // i i è
ENIS 2010-2011 Cours DSP Chapitre 5 168
http://www.circtuitsystème.tunet.tn





























