Embed Size (px)
Citation preview

Nouveaux outils SEO- vers un seo plus scientifique -
SEOCamp’us 20168 Avril 2016

Qui suis-je ?Dimitri Brunel
8 ans en Agence
Chez l’annonceur à date
Affinité Technique / outils startup
Affinité R&D / outils internes
Nouveau jouet SEO à date : Le langage R
https://www.linkedin.com/in/seoconsultantdimitribrunel

Sommaire
Web Performance
Crawls / Logs / RegEx
TextMining / Outils sémantiques
Moteurs de Recherche internes
API et KPI Dashboard Softwares
Le langage R / Data ScienceLa tendance ?
Une compréhension plus scientifique des moteurs

Web PerformanceUn peu d’historique
Les bons outils
Ce qu’il faudra retenir
TTFB500ms
FEO
(HTTP/2)

Autrefois le focus était sur les “scorings”On s’est tous acharné sur les :
- Scoring Yslow (Yahoo)- Scoring PageSpeed (Google)- Bonnes pratiques à la main- On parlait un peu de cache Varnish
Mais pendant ce temps :
- Les corrélations entre Vitesse et Positions ne sont pas très évidentes
https://webmasters.googleblog.com/2010/04/using-site-speed-in-web-search-ranking.html
Google commence à évangéliser (Avril
2010)
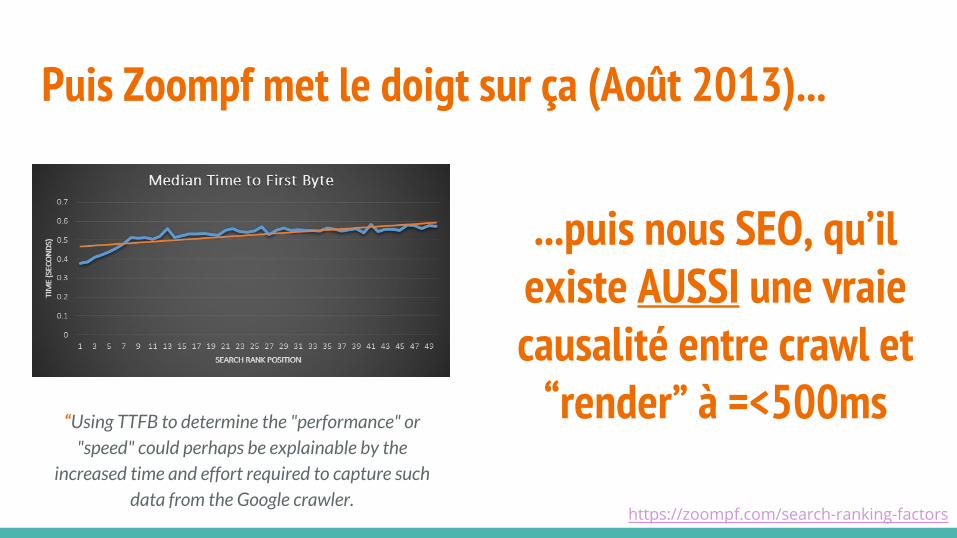
Puis Zoompf met le doigt sur ça (Août 2013)...
“Using TTFB to determine the "performance" or "speed" could perhaps be explainable by the
increased time and effort required to capture such data from the Google crawler.
https://zoompf.com/search-ranking-factors
...puis nous SEO, qu’il existe AUSSI une vraie causalité entre crawl et
“render” à =<500ms

Et qui dit plus de vitesse dit plus de ...- pages explorées- pages découvertes- pages indexées- pages actives- pages re re explorées- grappillage de ranks
+meilleure expérience=plus de conversions
“In 2006, Amazon presented a clear causation between page load time and online customer revenue. Every 100ms delay costs 1% of
sales”
”Kyle Rush from the 2011 Obama campaign site showed through A/B testing that a 3-seconds page time reduction (5>2) improved
onsite donations by 14%, (+ $34 million in election contributions.)”
“Amazon's calculated that a page load slowdown of just one second could cost it $1.6 billion in sales each year”
”Google has calculated that by slowing its search results by just four tenths of a second (40ms!!!) they could lose 8 million searches per day—meaning they'd serve up many millions fewer online adverts”
etc...

Enfin Google a redit “make the web faster”Avec :
- PageSpeed Insight- PageSpeed Modules (Apache / Nginx)- Format WebP (image)- SPDY (pré-HTTP2 par google)- W3C Web Perf Working Group
Les enjeux sont forts.Les objectifs sont ambitieux.Le mobile nous occupe en plus en plus.
Objectifs :=<100ms TTFB
500ms StartRender
Comment booster ?Comment monitorer ?

Petite parenthèse : Google met les moyens…Ce serait dommage de ne pas s’en servir ?
Ferme de serveurs (au dessus / Iowa)Data Center à Hanima (à gauche / Finlande)
https://www.google.com/about/datacenters/efficiency/internal/index.html#servers
Sea Cooling Water

Petite parenthèse bis : Imaginons que …
Vous êtes CEO d’un moteur de rechercheVous avez des crawlers, Des Data centers, etc.
Vous garderiez dans votre index...Des sites très lent ?
Avec des URLs qui tappent dans le vide ?

Pour adresser Web Performance et SEO
4 solutions SaaS

- Optimisation Front (proxy SaaS)- Optimisation Middle (CDN)
- Règles web perf (à la demande)- Réductions Requêtes (HTTP/s)- Réduction Poids (Ko)- Ré-ordonnance (source HTML)
- Pre-fetch HTML intelligent- Cache à trous- Monitoring / Dashboard pour SEO :)
FASTERIZE (TTFB & front-end optimization)
http://www.fasterize.com/fr/services/
métriques / solutions

- Analyses conseil (page / versus)- Rapport journalier- Rapports hebdomadaires
- Alertes (qualité / lenteur / régression)- Dashboard (historique / kpis)- Waterfall (timings)
- Simulation géo-loc / devices / débit 3G- Test transactionnels (beta)- Test staging / cookies / En-tête HTTP
DAREBOOST (analyse / suivi / simulation)
https://www.dareboost.com/fr/features

Mesure l’impact des perf :
- l’acquisition (par medium)- les chemins de conversions- l’animation commercial (alertes)- par device (ex: mobile)
- analyse les pages- propose des solutions A/B- etc
WEBPERF.IO(web performance monitoring)
http://webperf.io/

TAG PERFORMANCE (tags monitoring)
http://fr.slideshare.net/TagCommander/tag-performance-slidesharefr
Situation à date :
- Le nombre de tags croit
- Ils peuvent ralentir les chargements utilisateurs
- GoogleBot peut crawler (abusivement) des ressources externes dont les JS donc aussi des tags...
La vision de TagCommander :
- Mesurer vos tags- Sur vos visiteurs / toutes pages- Sans échantillonage- Brique de “Tag Commander”
Pour identifier les soucis :
- par conteneur, page, ou device- sur le chargement du DOM- entre deux mise en production

http://chimera.labs.oreilly.com/books/1230000000545/ch12.html
Le futur ? HTTP/2Est déjà là (15 ans d’attente...)
Web chiffré, Réduction des latences, et plus encore
SPD
Y (d
ead)
2014

Analyseurs deCrawls et Logs
Un peu d’historiqueLes bons outils
Les RegEx
Ce qu’il faudra retenir
Taux de crawlsTaux de pages actives
Codes HTTP

Un peu d’historique La tendance actuelle ?- Quelques crawlers
(XENU, Link Examiner)- Gros besoins en RAM- Peu de solutions SaaS- Des analyses incomplètes- Peu d’informations en sortie- Des graph à refaire- Les limites de Excel (sans
power pivot + langage DAX)
(je force un peu le trait mais à peine…)
- Startups et levées de fonds- QUE des solutions SaaS- Critères en expansions- Dataset “XXL” / Délégation- Explorateurs d’URLs- Dashboards typé “Bootstrap”- Possibilités “custom”
Et aussi :
- Des APIs (= nouveaux usages)- Tests de papiers de recherche

Y a t’il encore de la place pour eux ?
Peuvent-ils crawler de grosse structure ? (ex: 150K URLs)
Oui et Oui ! et sont très bien pour des actions “one shot”
Software à l’ancienne ?

- Gratuit ! (pour l’instant)- 150.000 URLs crawlables- 2GB de RAM suffisent- Analyse les basiques- Crawl l’AJAX- Crawls parallélisables- Intégration SearchConsole- Intégration BingWT- Intégration YandexWT (en cours)
Sinon vous avez un MAC ?Dont’ panic ! (slide suivante)
Visual Seo Studio (desktop - win)
http://visual-seo.com/SEO-Software-Features/Development-Status

- Peu couteux !- Crawl l’AJAX- Accept-Language Header- Extraction par patterns- Template d’exports- Simulation de snippets- Support Robots.txt- Intégration Google Analytics- Intégration Search Console- NoMatch GA et GSC- Amélioration en continue
Screaming Frog (desktop - win/mac)
https://www.screamingfrog.co.uk/seo-spider-5-0/

Vous avez 10 marques ? 15 boutiques ?
Des gros catalogues ? Des milliers de produits ?
Ou xxx langues / régions ?
Quoi de plus “scalable” ?

Matures
Robustes
API REST “url centric”
Améliorations en continue
Solutions SaaS

BOTIFY ANALYTICS (crawls + Google Analytics)
https://www.botify.com/support/videos/https://developers.botify.com/api/
- Intégration GA- Main HTML Tags- Load Time Performance- Liens internes / sortant- Exploreur d’URLs (dataset)- Calcul du PageRank interne- Catégorisations et Filtres- Comparaison de crawls- Virtual Robots- Custom HTTP Headers- Planification, Plugin Chrome
BOTIFY LOG ANALYSER (crawls + logs)
https://www.botify.com/log-analyzer/
- Les features des CRAWLSplus
- Suivi bots moteurs majeurs- Catégorisation transversales- Codes HTTP, Pages orphelines- Lost / Recovered URLs- Taux de crawls (hits)- Taux de pages actives (visits)- Fenêtre de crawls- Rapports journaliers- et bien d’autre features encore
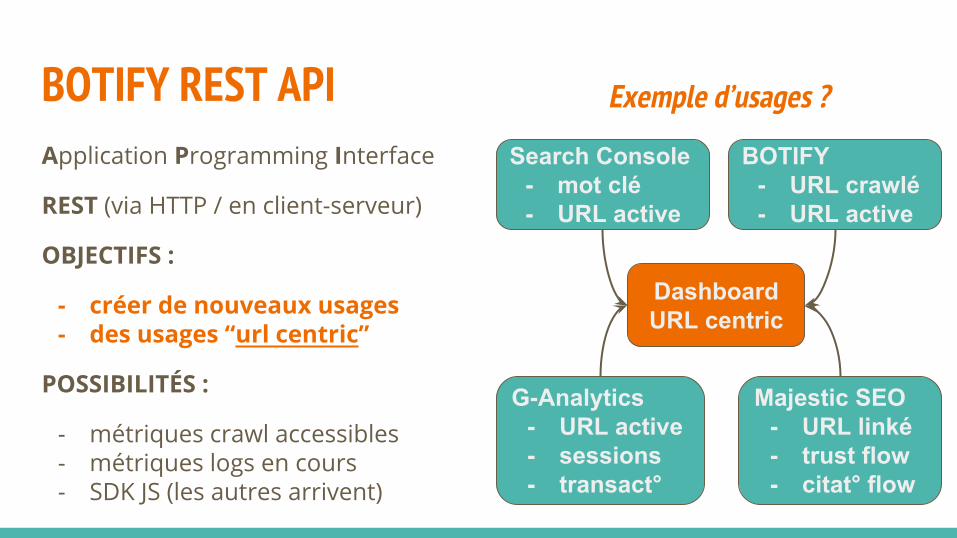
BOTIFY REST APIApplication Programming Interface
REST (via HTTP / en client-serveur)
OBJECTIFS :
- créer de nouveaux usages- des usages “url centric”
POSSIBILITÉS :
- métriques crawl accessibles- métriques logs en cours- SDK JS (les autres arrivent)
Exemple d’usages ?
Dashboard URL centric
Search Console- mot clé- URL active
G-Analytics- URL active- sessions- transact°
BOTIFY- URL crawlé- URL active
Majestic SEO- URL linké- trust flow- citat° flow

DEEPCRAWL (crawls)
https://www.deepcrawl.com/case-studies/
- Crawl types (5 types différents)- Crawl parrallélisables- API disponible à la demande- Custom extraction (regex)- DeepRank (≈PageRank)- Détection “Duplicate” Avancé- Intégration GA- Custom robots- Custom filters / limits
- Deepcrawl V2 arrive bientôt

ONCRAWL (crawls)
http://fr.oncrawl.com/knowledge-base/
- Editorial Insights=> words count, schema=> OG, twitter cards=> extraction de n-grams
- Duplicate content=> par similarité (simhash)=> par tags par clusters
- Architecture (Inlinks, Outlinks, flux de page rank)
- Performance (load, weight, etc)
ONCRAWL ADVANCED PLATFORM (crawls + logs)
http://www.slideshare.net/Cogniteev/seo-breakfast-toulouse-analyse-de-logs
- Open Source ! https://github.com/cogniteev/oncrawl-elkou
- Hosted Version : chez Cogniteev
- Suivi des bots courants- Analyse croisé (crawls + logs)- Nb. et Taux de crawls / Pages actives- Nb. et Taux de pages orphelines- Catégorisations et Distribution- Graph historisés, Fenêtre de crawls
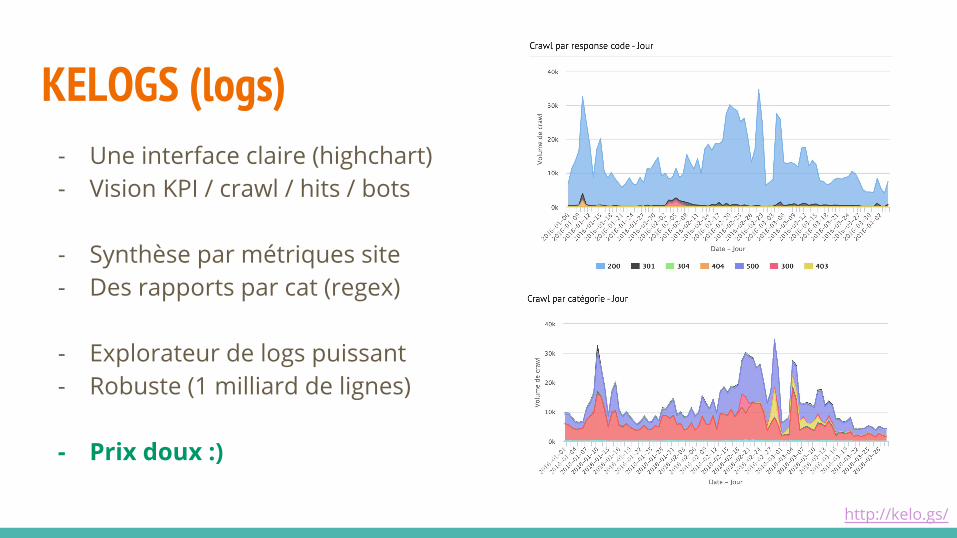
KELOGS (logs)
http://kelo.gs/
- Une interface claire (highchart)- Vision KPI / crawl / hits / bots
- Synthèse par métriques site- Des rapports par cat (regex)
- Explorateur de logs puissant- Robuste (1 milliard de lignes)
- Prix doux :)
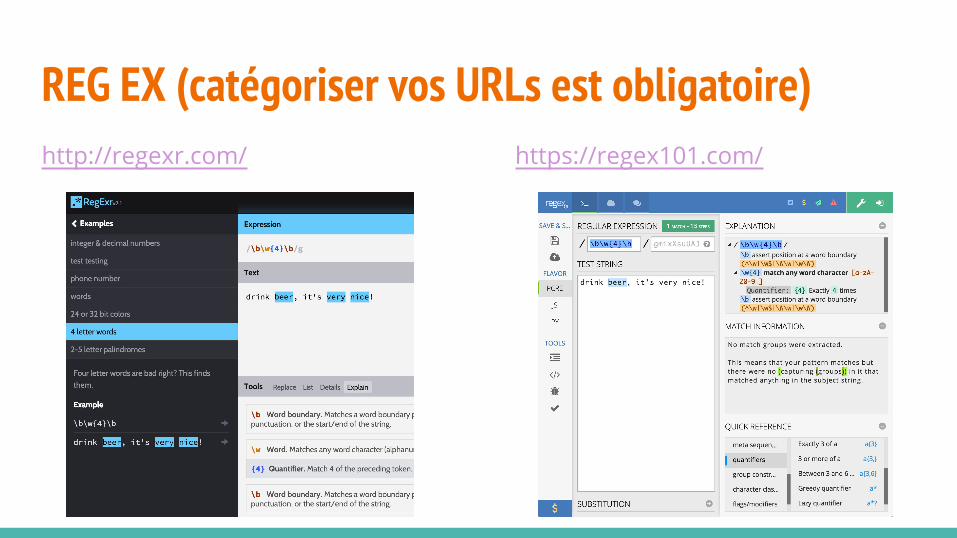
REG EX (catégoriser vos URLs est obligatoire)http://regexr.com/ https://regex101.com/

TextMining etOutils Sémantiques
Un peu d’historiqueLa fouille de texteSituation à date ?
Ce qu’il faudra retenir
Quantification sémantiqueScore sémantiqueAffiné sémantiqueCocon sémantique
Word EmbeddingMots en relations
Fichier de vocabulaire

TextMining / DataMiningPouvait déjà servir en SEO ...
Un peu d’historique SEOQuelques tentatives sur :
- Analyse de texte ou URLs- Fréquence de mots- Densité selon tag, pertinence- Paires de mots, proximité
Quelques outils :
- Textalyser- Alyse- et Rapidminner (2006) !

« Extraction de connaissances » dans les textes
Désigné sous l'anglicisme “text mining“
Les disciplines impliquées : linguistique informatique,l'ingénierie du langage (TAL), l'apprentissage artificiel et les statistiques
Fouille de texte ?

Rapidminer : “Text Processing”Traitement de texte :
- création de corpus (n doc => BDD)- tokenisation (découpe éléments)- stopwords (suppression)- stemming (racine des mots)- lemmatisation (mot simplifié)- n-grams (séquences contiguës)
=> table de fréquences des mots
Via du TextMining, puis applications d’algo, on peut simuler les documents

Rapidminer : “Association Rules with text”Apprentissage Règles Associations(=trouver relations ayant un intérêt)
- en explorant un corpus- en traitant les textes- en créant des “vecteurs” - en trouvant les items fréquents
(algo FP-Growth. Il en existe des tas => APriori, Eclat, GUHA…)
- trouver ces règles d’association- et visualiser ces règles
{onion, potatoes} => burger{data, mining} => rapidminer
https://en.wikipedia.org/wiki/Association_rule_learning#Definition
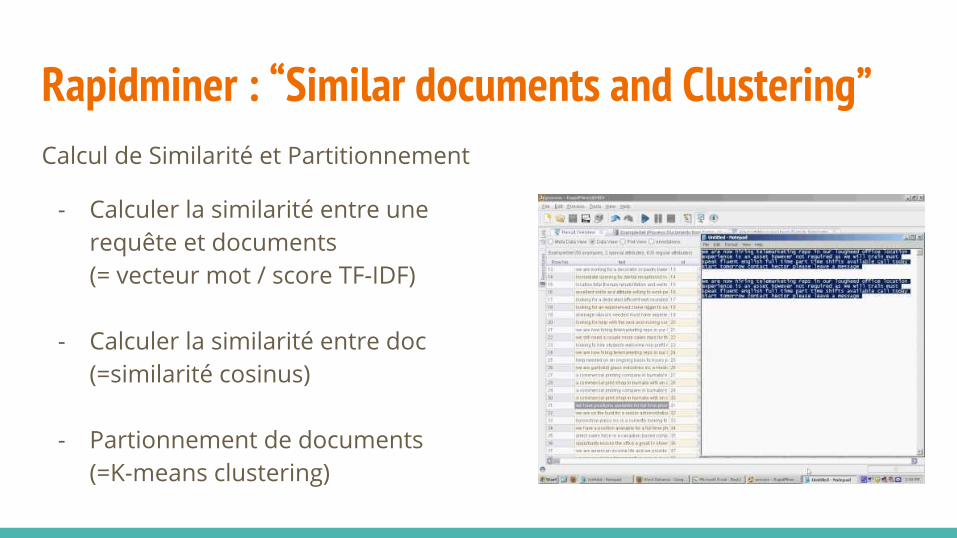
Rapidminer : “Similar documents and Clustering”Calcul de Similarité et Partitionnement
- Calculer la similarité entre une requête et documents(= vecteur mot / score TF-IDF)
- Calculer la similarité entre doc (=similarité cosinus)
- Partionnement de documents(=K-means clustering)

RapidMiner a évolué
et en parallèle
Des outils de “quantification sémantique” pour nous SEO !
Situation à date ? (2016)
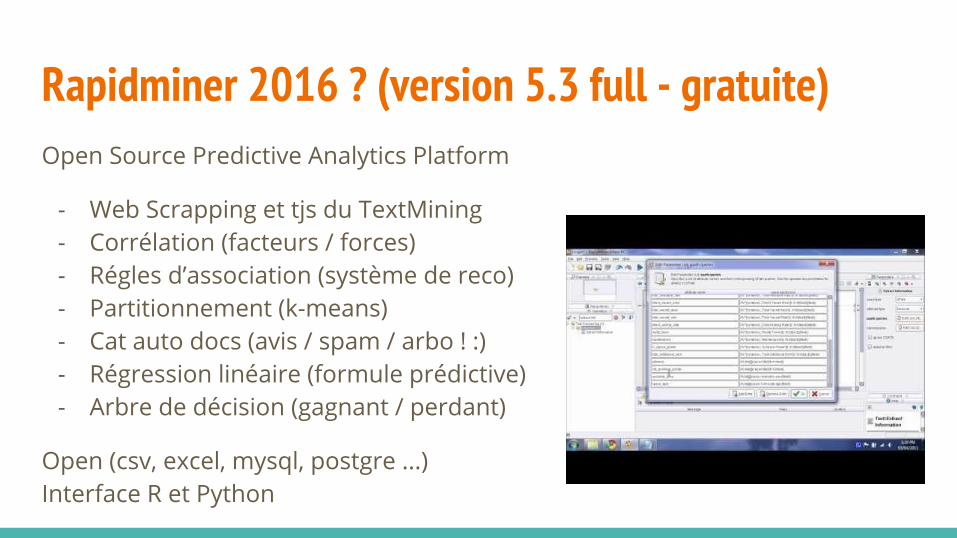
Rapidminer 2016 ? (version 5.3 full - gratuite)Open Source Predictive Analytics Platform
- Web Scrapping et tjs du TextMining- Corrélation (facteurs / forces)- Régles d’association (système de reco)- Partitionnement (k-means)- Cat auto docs (avis / spam / arbo ! :) - Régression linéaire (formule prédictive)- Arbre de décision (gagnant / perdant)
Open (csv, excel, mysql, postgre ...)Interface R et Python

1.FR (score sémantique)L’idée ? Trouver des relations entre termes, et regrouper (=créer champs sémantiques)
Comment ? Un corpus (millier de pages), un apprentissage (créer la BDD des champs)
L’app ? Audit les textes, donne des scorings (vs concurrents), trouve des mots proches
Pour action ? Sculpter les champs lexicaux=> affiner / ajouter (termes absents)=> suppression (hors sujet, diluants)=> contrôler avec le scoring (0 à 100%)

VISIBLIS V2 (affinité sémantique et cocon)L’idée initiale ? Un corpus de 17 millions de doc. Des algo de traitement du langage.
Pourquoi Visiblis V2 est très très fort ?
- analyse (TAL) de structure en silo- n-grams (avec synapsie par ex)- visualisation des liens internes- visualisation des clusters sémantiques- corpus visiblis / corpus perso- API V2 en dev / à venir- Analyse sémantique TOP10 à venir https://fr.wikipedia.org/wiki/Synapsie
https://en.wikipedia.org/wiki/N-gram
n-gram= séquence contiguë n-items
{paire = AGC, GCT, CTT}{lettre = to_, o_b, _be,}
{mot = to be, be or, or not}
synapsie= liaison par joncteurs (ex: de, à)
{pomme de terre}

Autres modèles vectoriels :TF-IDF, BM25, BOW
VISIBLIS V2 (Outils > Affinité Sémantique)C’est quoi ? La similarité entre une requête=> et un document (vecteur G.Salton)=> et une cooccurrence (n-gram) du corpus
TitrAlyser : mesure l’affinité requête > titre, suggère des opti, simule l’affichage
TextAlyser : mesure l’affinité requête > phrases, suggère des opti d’affinité
WebAlyser : fait la synthèse (requête > url), par affinité titre et contenus, diagnostique et re suggère des coocurrences
https://fr.wikipedia.org/wiki/Synapsiehttps://fr.wikipedia.org/wiki/Formation_des_mots
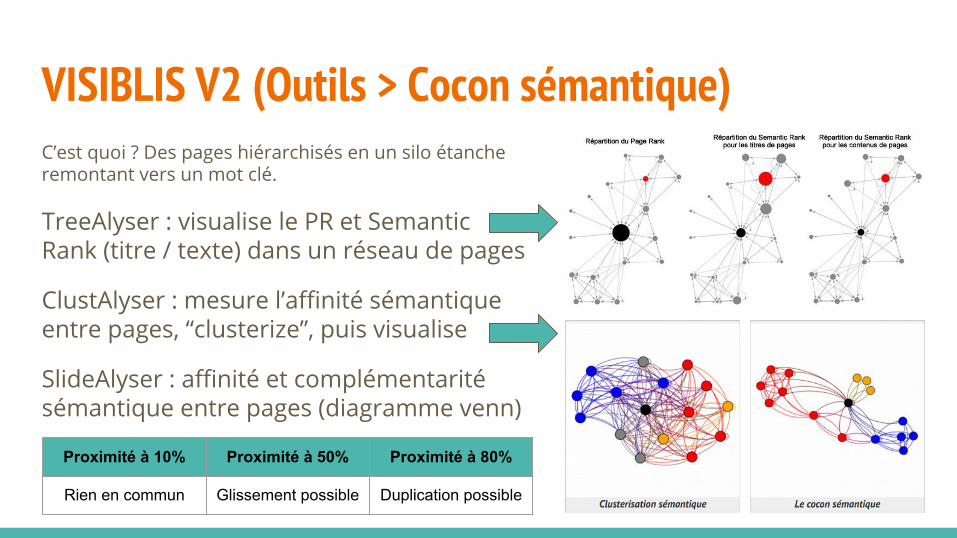
VISIBLIS V2 (Outils > Cocon sémantique)C’est quoi ? Des pages hiérarchisés en un silo étanche remontant vers un mot clé.
TreeAlyser : visualise le PR et Semantic Rank (titre / texte) dans un réseau de pages
ClustAlyser : mesure l’affinité sémantique entre pages, “clusterize”, puis visualise
SlideAlyser : affinité et complémentarité sémantique entre pages (diagramme venn)
Proximité à 10% Proximité à 50% Proximité à 80%
Rien en commun Glissement possible Duplication possible

COCON.SE (des cocons moins con)Des outils pour visualiser des pages bien organisés en silo (cocon, wordpress, etc.)
- Maillages sous une forme lisible- Vision crawler (1er lien suivi)- Vision hiérarchisé (selon arborescence)- Colorisation topologique (pages / liens)- Diamètres apparenté au PageRank- Éventails (liens intra-silo / fuites)
Simuler la structure permet de pousser les pages utiles, et supprimer les liens inutiles
http://cocon.se/visualisation/visu-cmap

Si l’on avait eu plus de temps pour discuter :Alternative en Text Mining / Data Mining :
- KNIME https://en.wikipedia.org/wiki/KNIME(merci à Aurélien Berrut http://www.htitipi.com/ )
Traitement du langage et Analyse du sentiment :
- INBENDA https://www.inbenta.com/fr/solutions(merci à la personne qui m’en a parlé après la conf)

Natural Langage Processing
et
Learning Machine
Aller encore plus loin ?
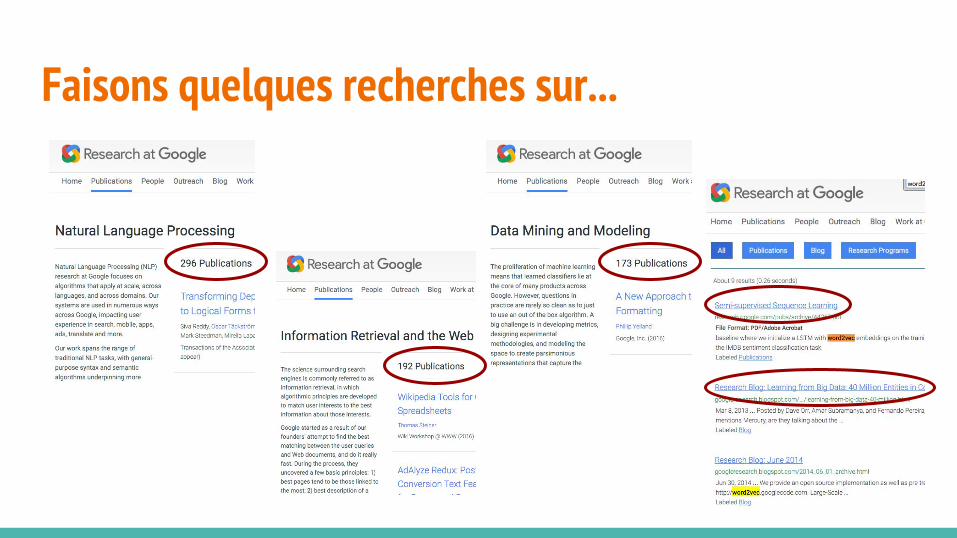
Faisons quelques recherches sur...

WORD2VEC ?D’abord un papier de recherche en 2013 :
- Efficient Estimation of Word Representations in Vector Space, by Tomas Mikolov, Kai Chen, Greg S. Corrado, Jeffrey Dean [ICLR Workshop 2013]
Puis une version (pas la vraie en fait) open-source :
- https://code.google.com/archive/p/word2vec/
Enfin de gros Dataset rendus accessibles :
- FREEBASE a pré-entraîné WORD2VEC- GoogleNews a été rendu public et a aussi pré-entraîné WORD2VEC

WORD2VEC, c’est quoi ?Nouvelle approche simple et rapide pour entraîner des “machine learning” à faire du “word embedding” = représentations vectorielles (nombre) des mots par rapport aux autres mots voisins un large corpus.
Word2Vec s'entraîne à reconnaître :=> d’un contexte des mots => Sac de mots=> des mots un contexte => Skip-gram
DeepLearning4J obtient des résultats plus précis sur de gros dataset via skip-gram
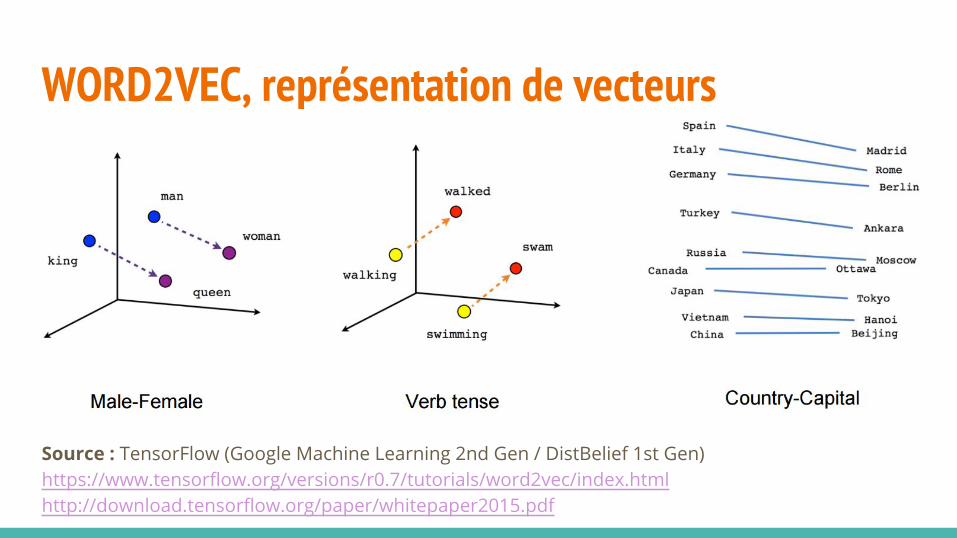
WORD2VEC, représentation de vecteurs
Source : TensorFlow (Google Machine Learning 2nd Gen / DistBelief 1st Gen)https://www.tensorflow.org/versions/r0.7/tutorials/word2vec/index.htmlhttp://download.tensorflow.org/paper/whitepaper2015.pdf

WORD2VEC, concrètement ça fait quoi ?Les vecteurs capturent avec une forte régularité, la sémantique et la syntaxe des mots du corpus.
Au final, Word2Vec renvoie des distances cosinus entre les mots en relation.
Les vecteurs ont certaines propriétés comme la correspondance entre langues
FranceWord Cosine distance
spain 0.678515
belgium 0.665923
netherlands 0.652428
italy 0.633130
switzerland 0.622323
luxembourg 0.610033
portugal 0.577154
russia 0.571507
germany 0.563291
catalonia 0.534176

WORD2VEC, concrètement ça fait quoi ?Les vecteurs ont des propriétés linguistiques aussi ! Des calculs simples permettent de résoudre analogies, antinomies, etc :
- vector('Paris') - vector('France') + vector('Italy') =
vector('Rome')
Les modèles peuvent être entraînés sur d’énorme dataset (100 millards de mots)
L’entrainement peut être pré-processé (mots vers phrases) et partitionnés sur les vecteurs hauts (=K-means => fichiers de vocabulaire).
san_franciscoWord Cosine distance
los_angeles 0.666175
golden_gate 0.571522
oakland 0.557521
california 0.554623
san_diego 0.534939
pasadena 0.519115
seattle 0.512098
taiko 0.507570
Vocabulary fileacceptance 412 argue 412 argues 412 arguing
412 argument 412 arguments 412 belief 412
believe 412 challenge 412 claim 412

WORD2VEC, librairies et applications ?Comment jouer avec ?
- en Java => DeepLearning4JS- en Python => Gensim- en R => wordVectors
Quatre applications connus avec Word2Vec?
- Traduction de langues- Analyse du sentiment- Reconnaissance d’entités nommées- Semantic-role labeling
Pourquoi donc ne pas essayerd’utiliser ceci
en SEO !?

WORD2VEC, quelles utilisations pour nous SEO ?- Suggérer des mots clés, des analogies (vecteurs proches)- Sortir des fichiers de vocabulaire (vecteurs partitionnés)- Itérer par langue simplement (vecteurs très proches)
- Interroger Word2Vec sur des entités nommées (entraînement freebase)- Dérouler un graph de connaissance ensuite
- Calculer la similarité entre mot ⇔ documents (index inversé)- Calculer la similarité entre syntagmes, phrases, docs (doc2vec + gensim)
http://stackoverflow.com/a/31417164- Entraîner l’outil sur des DataSet perso => qualité du corpus indispensable

Moteurs de recherche interne
Rapport avec le SEO ?Moteur indexé
Moteur non indexé
Ce qu’il faudra retenir
Moteur non indexéMilliseconds matter
Indexation SEO

Pourquoi vous s'intéresser à la recherche interne ?- Recherche Interne / SEO reposent sur de même briques du TAL (ex TF-IDF)
- Vous captez de nouvelles recherches (mots clés)- Vous devriez mailler / indexer certaines de ces recherches- Vous voulez récupérer / garder vos visiteurs seo mobiles / desktop
- Vous ne voulez pas qu’un collègue indexe 1M de page de recherche...
- Votre moteur à facettes est fermé sur des requêtes marques / génériques=> la recherche interne peut aider temporairement (mode pansement)

MOTEURS indexés et MOTEURS non indexésMoteur indexé(ex: elastic search)
- basé sur du crawl de docs- basé sur des index (lucène)
- scalable (architecture adaptable)
- possède la recherche à facettes
- quasi temps réel (latence faible)
Moteur non indexé(ex: json et attributs)
- zéro crawl = pas d’index de docs- seemless indexing
Seemless Indexing ?
- index JSON- on the fly (MAJ temps réèl)- attributs (détection auto)- reindexing (modif de conf)

Moteur Indexé(exemple)

SWIFTTYPE / moteur indexé- site search- mobile- real-time analytics
- custom result ranking- autocomplete- facetted search- synonyms- spellcheck- weights- real-time indexing

Moteur non Indexé(exemple)

ALGOLIA (milliseconds matter) / non indexéOut of the box :
Seamless indexing : vous poussez un JSON, c’est prêt !Intuitive ranking : vous réglez VOTRE moteur de recherche (TAL / Business)API REST, 13 clients : Ruby, Rails, Python, PHP, JS, Java, Android, ...
Lighting-fast back-end : répond entre 6ms et 9msDistributed Search Network (DSN) : 30 data centers / 14 régionsMAI 2015 : 18,3 M$ de levée de fonds chez Accel Partners !

ALGOLIA (milliseconds matters) / aspects saillantsInstant Search :c’est un package UX “all-in-one” avec
- widget slider (prix)- widger search (auto complete)- widget grid (tuiles de produits)- widget filter (facettes
Au final c’est un moteur à facettes ultra complet, qui s'intègre en 2J, et que vous pouvez indexer (au choix) avec votre dev full-stack interne
https://community.algolia.com/instantsearch.js/

ALGOLIA (milliseconds matters) / aspects saillantsIntuitive Ranking :Agit sur la pertinence via des curseurs
DISPLAY- attribut : catégories, rayons- attribut : facettes x y z
RANKING- attribut : état du catalogue produits
BUSINESS- attribut : prix, ventes, geoloc, etc

API &KPIs dashboard
softwaresLa multiplication des API
Les bon outils
Ce qu’il faudra retenir
API RESTPrototype R
Solutions SaaS

(Application Programming Interface)
API

Situation à date et REST ?Google fait des API pour tout :
- Search Console- Google Analytics- Google Trends - Google Chart- ...
Chaque startup se doit de créer son API REST !
SEOtools pour Excel intègre les plus spécifiques au SEO
API REST (representational state
transfer). A la mode, car très pratique à utiliser :
- via des URI- via HTTP- via des VERBES (get, …)- via des JETONS (token)- via des XML ou JSON

CATALISIO > API Google Search Console V3Résout le “not provided” via :
- données par PAGE- dimension par MOT CLÉS- dimension par DEVICES- dimension par X ou Y DATA- A haut volume (récolte tout)
L’outil étant “URL centric” :
- volume de recherche sont alignés- trafic et conversions sont alignés
Connecteurs GA / eulerian / adwords
Des “dashboard” clairsDes “score cards” par KPIs
https://www.catalisio.com/fonctionnalites/

CATALISIO > API Google Search Console V3Vision apporte une vision ROI-ste :
- estimer l’acquisition Ranks / CTR- estimer l’acquisition Mots / €€
Mais aussi insciter des “pour actions” :
- activer potentiels sous-exploités- activer potentiels à conquérir
Catalisio connecte tout. Vous pouvez vous recentrer sur votre plan d’action.
Vision par Mots ClésSuggestions d'Opportunités
https://www.catalisio.com/fonctionnalites/
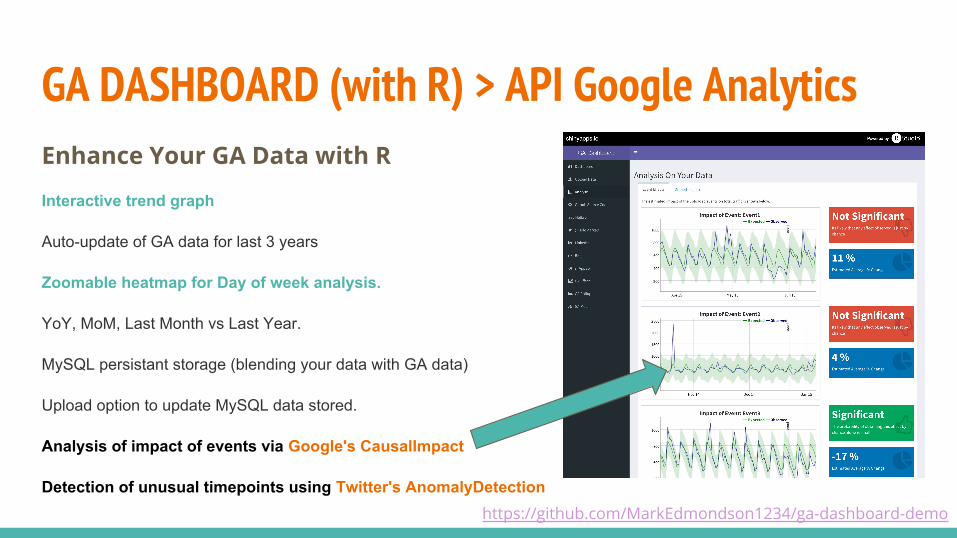
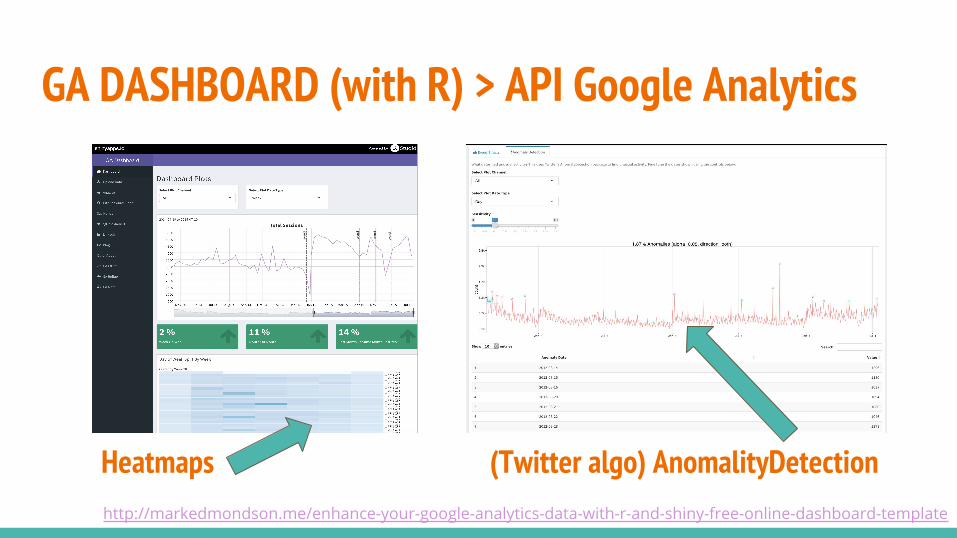
GA DASHBOARD (with R) > API Google AnalyticsEnhance Your GA Data with R
Interactive trend graph
Auto-update of GA data for last 3 years
Zoomable heatmap for Day of week analysis.
YoY, MoM, Last Month vs Last Year.
MySQL persistant storage (blending your data with GA data)
Upload option to update MySQL data stored.
Analysis of impact of events via Google's CausalImpact
Detection of unusual timepoints using Twitter's AnomalyDetectionhttps://github.com/MarkEdmondson1234/ga-dashboard-demo
GA DASHBOARD (with R) > API Google Analytics
http://markedmondson.me/enhance-your-google-analytics-data-with-r-and-shiny-free-online-dashboard-template
Heatmaps (Twitter algo) AnomalityDetection

TextMining (for Google Sheets) > API dandelionLe plus utile pour nous SEO :
- extraction d’entités nommées (nom, lieux, concept, etc)
- analyse du sentiment (positif, négatif, neutre)
Autred fonctionnalités via l’API :
- similarité de texte (BOW, langues, etc)
- classification de texte (modèle de taxons ou personnalisable)
https://dandelion.eu/

Plugin et WebApp se multiplient à tour de brasExemplesAPI Search Gonsole :
- searchConsoleR (R package)- SearchAnalytics (GoogleSheets)- SuperMetrics (GoogleSheets)- SEOtools (Excel)
ExemplesAPI Google Analytics :
- googleAuthR (R package)- GA Dashboard (R Shiny App)- GA Effect (R Shiny App)- GA Rollup (R Shiny App)- GA Meta (R Shiny App)- Analytics Canvas (GoogleSheets)- SuperMetrics (GoogleSheets)- SEOtools (Excel)

(Software as a Service)
DASHBOARD SaaS

KLIPFOLIOCreate dashboards using datafrom 100s of services
- alexa- adobe analytics- google analytics- google adwords- search console- MOZ- Searchmetrics- etc...
https://www.klipfolio.com/integrations
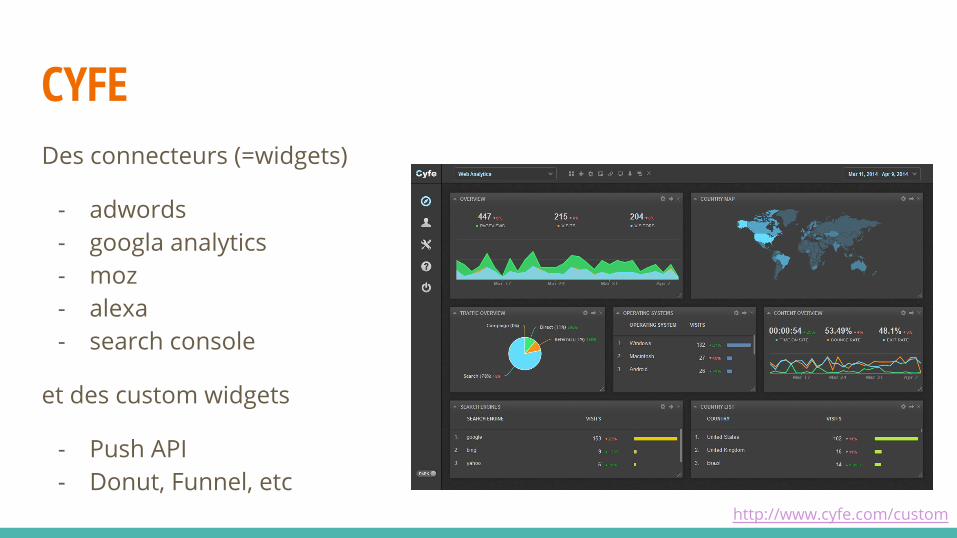
CYFEDes connecteurs (=widgets)
- adwords- googla analytics- moz- alexa- search console
et des custom widgets
- Push API- Donut, Funnel, etc
http://www.cyfe.com/custom
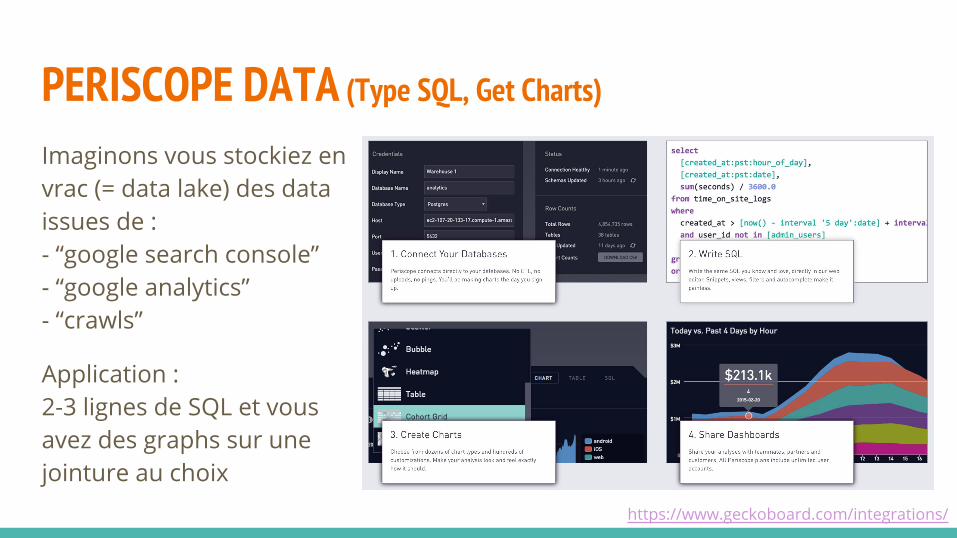
PERISCOPE DATA (Type SQL, Get Charts)
Imaginons vous stockiez en vrac (= data lake) des data issues de :- “google search console”- “google analytics”- “crawls”
Application :2-3 lignes de SQL et vous avez des graphs sur une jointure au choix
https://www.geckoboard.com/integrations/

Le langageR
Pourquoi c’est bien ?
Après avoir parlé des API......que faire avec R en SEO ?
Ce qu’il faudra retenir
RstudioR + Shiny + SEO
ALGO

Introduction sur RLe langage d’analyse statistique
- Utilisé par tous les chercheurs- +2 millions users et ça augmente - votre ami le Data Scientist l’utilise
Open source, il y a des “packages” sur TOUT :
- collecter / visualiser de la data (ggplot2)- interroger des “machine learning” (word2vec, glove)- lancer des “deep learning framework” (Tensorflow, MXNet)- appliquer des tas d’algo (BM25, Apriori, K-means, C4.5, CausualImpact)- déployer des web app sans aligner une ligne de CSS et de JS (seriously)
2015 2014

D’être un expert en math
D’être un expert en algorithmes
D’être un expert en programmation
exemples ?
Avec pas besoin...

Mark Edmondson (Data Insight Dev / IIH Nordic)A créé des interface R (API Google) et contribué à de nombres de packages :
- googleAuthR (interface R pour OAuth 2)- googleAnalyticsR_public (interface R pour GA)- dygraphs : lib R pour diagramme avec tracé des zone de confiance- ggraph : add-on R pour le librairie de dataviz ggplot2
Puis des applications R avec Shiny Dashboard proche et utilisable en SEO :
- searchConsoleR (APP search console)- GoogleTrendsDashboard (APP google trends)- GA Dashboard (APP google analytics console)- GA Effect (implémentation de CasualImpact (structures bayésiennes))
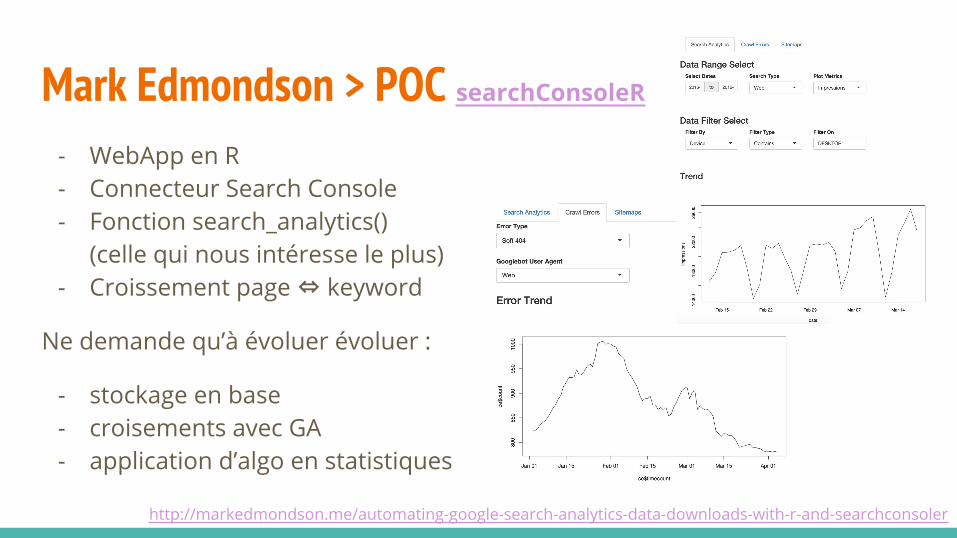
Mark Edmondson > POC searchConsoleR
- WebApp en R- Connecteur Search Console- Fonction search_analytics()
(celle qui nous intéresse le plus)- Croissement page ⇔ keyword
Ne demande qu’à évoluer évoluer :
- stockage en base- croisements avec GA- application d’algo en statistiques
http://markedmondson.me/automating-google-search-analytics-data-downloads-with-r-and-searchconsoler
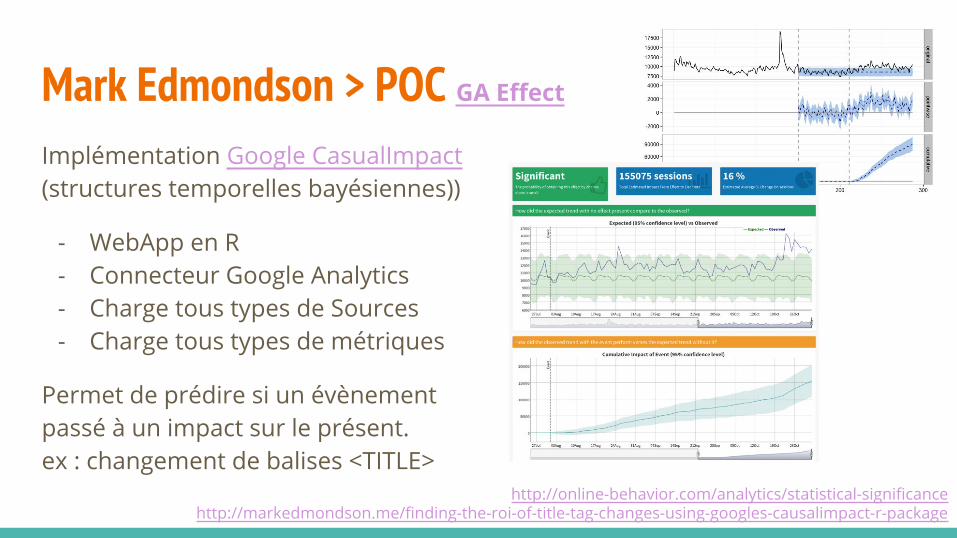
Mark Edmondson > POC GA Effect
Implémentation Google CasualImpact(structures temporelles bayésiennes))
- WebApp en R- Connecteur Google Analytics- Charge tous types de Sources- Charge tous types de métriques
Permet de prédire si un évènement passé à un impact sur le présent.ex : changement de balises <TITLE>
http://online-behavior.com/analytics/statistical-significancehttp://markedmondson.me/finding-the-roi-of-title-tag-changes-using-googles-causalimpact-r-package
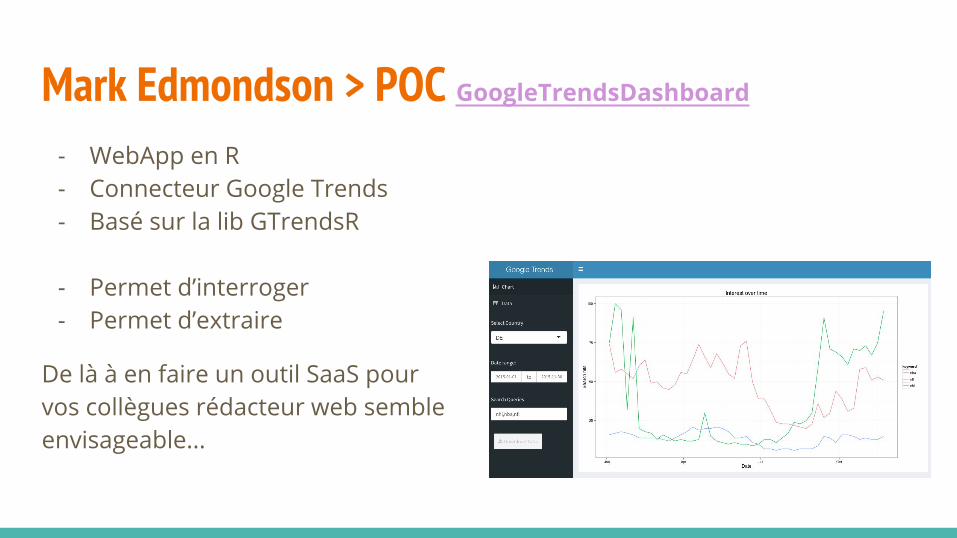
Mark Edmondson > POC GoogleTrendsDashboard - WebApp en R- Connecteur Google Trends- Basé sur la lib GTrendsR
- Permet d’interroger- Permet d’extraire
De là à en faire un outil SaaS pour vos collègues rédacteur web semble envisageable...

Débuter avec R1/ Installer un IDE : Rstudio
2/ Installer les packages utiles
- Shiny web app framework- Shiny Dashboard- htmlwidget- ggplot2- readr
3/ Déployer votre Web App SEO :
- Shiny App IO

R > d’autres “packages” à connaîtregTrendR : interface R pour récupérer / afficher des informations GG Trends.
googleVis : interface R pour utiliser Google Chart API
DiagrammeR : lib R pour diagrammes sous Rstudio très simplement
CasualImpact : prédire le présent avec les structures temporelles bayésiennes
AnomalyDetection : trending topics / marronniers / points sous-jacents
et les packages en fouille de textes comme Aylien

Pour chaque problème ...
Le mot de la fin ?
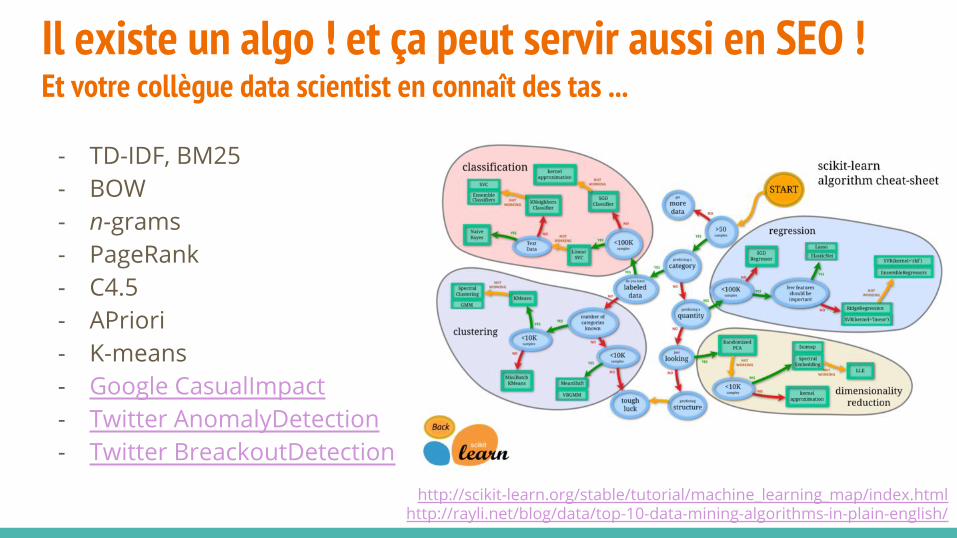
Il existe un algo ! et ça peut servir aussi en SEO !Et votre collègue data scientist en connaît des tas ...
- TD-IDF, BM25- BOW- n-grams- PageRank- C4.5- APriori- K-means- Google CasualImpact- Twitter AnomalyDetection- Twitter BreackoutDetection
http://scikit-learn.org/stable/tutorial/machine_learning_map/index.htmlhttp://rayli.net/blog/data/top-10-data-mining-algorithms-in-plain-english/

Questions ?
MERCI





























