Embed Size (px)
Citation preview

Laboratoire ERICUniversité Lumière Lyon 2
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire de l’équipe ADVANSE - Laboratoire d'Informatique, de Robotique et de Microélectronique de Montpellier
23 janvier 2015
Adrien Guille, PhDLaboratoire ERIC, Université Lumière Lyon 2
Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
Contexte
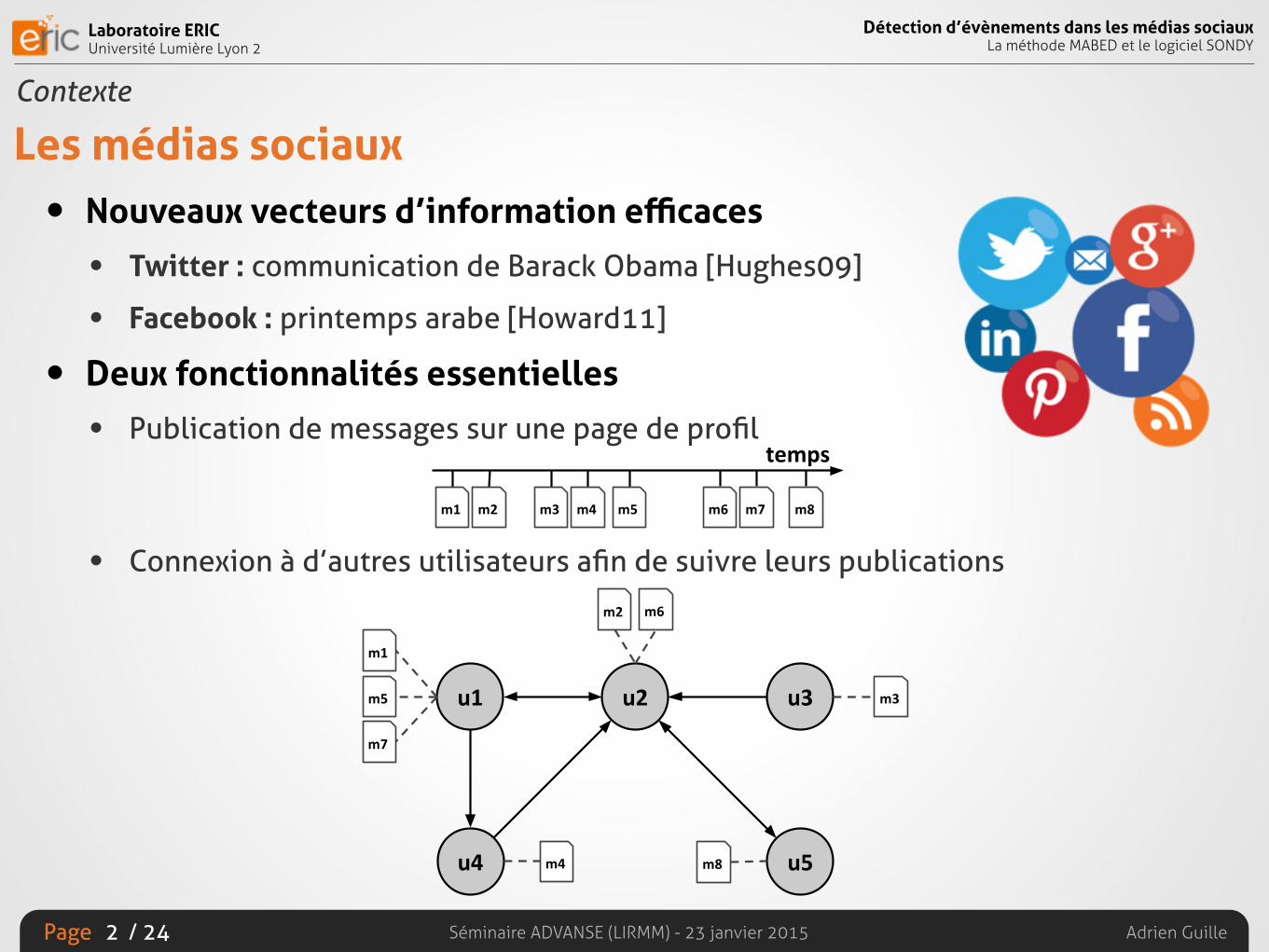
Les médias sociaux• Nouveaux vecteurs d’information efficaces
• Twitter : communication de Barack Obama [Hughes09]
• Facebook : printemps arabe [Howard11]
• Deux fonctionnalités essentielles
• Publication de messages sur une page de profil
• Connexion à d’autres utilisateurs afin de suivre leurs publications
2
�
Į ș
ȕ ࢥ
ȕ
ȕ Ȗ
��
�
Į ș
ȕ ࢥ
ȕ
ȕ Ȗ
��

Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
Introduction• Détecter les évènements significatifs dans les médias sociaux
• Évènement : «quelque chose» qui se produit à un moment donné [Aggarwal12]
• Évènement significatif : potentiellement traité par les médias traditionnels [McMinn13]
• Utile pour l’analyse journalistique, la veille d’information, etc.
• Tâche complexe
• Messages liés aux évènements noyés par des messages sans rapport, i.e. bruit
• On suppose que les thématiques saillantes signalent les évènements [Kleinberg02]
3
�
Į ș
ȕ ࢥ
ȕ
ȕ Ȗ
��

Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
État de l’art• Idée commune : détecter les thématiques saillantes
• Pondération statistique des termes
• Peaky Topics [Shamma11], Trending Score [Benhardus13]
• Possible ambiguité, manque de contexte
• Modélisation probabiliste des thématiques latentes
• On-line LDA [Lau12], ET-LDA [Yuheng12]
• Passage à l’échelle difficile [Aiello13]
• Classification non supervisée des termes
• EDCoW [Weng11], TwEvent [Li12], ET [Parikh13]
• Descriptions des évènements bruités
4
Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
Synthèse de l’état de l’art et proposition• Limitations des méthodes existantes
• Supposent que tous les évènements ont une même durée
• Paramètre fixé manuellement [Romero11]
• Considèrent uniquement l’aspect textuel des messages
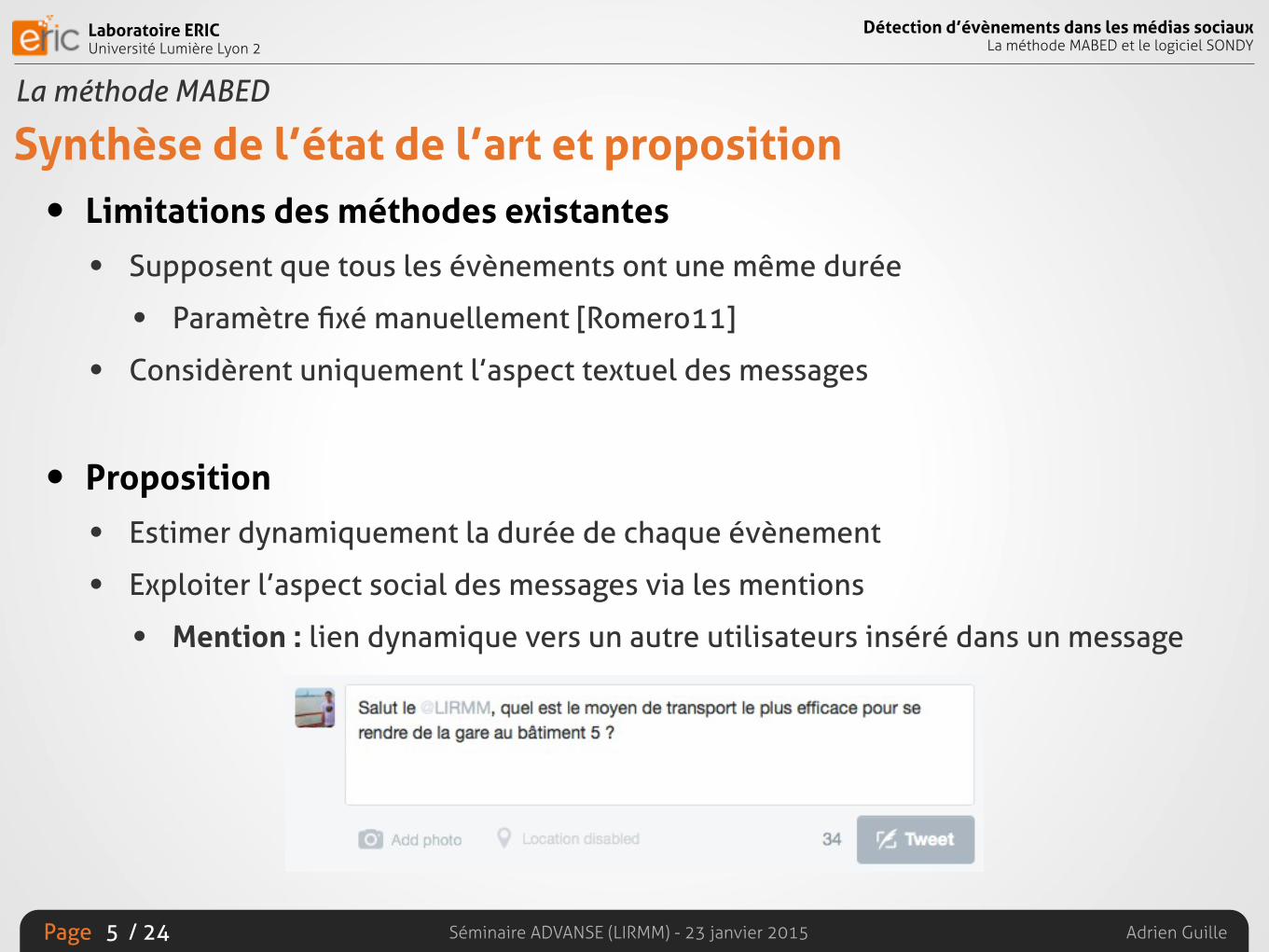
• Proposition
• Estimer dynamiquement la durée de chaque évènement
• Exploiter l’aspect social des messages via les mentions
• Mention : lien dynamique vers un autre utilisateurs inséré dans un message
5
Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
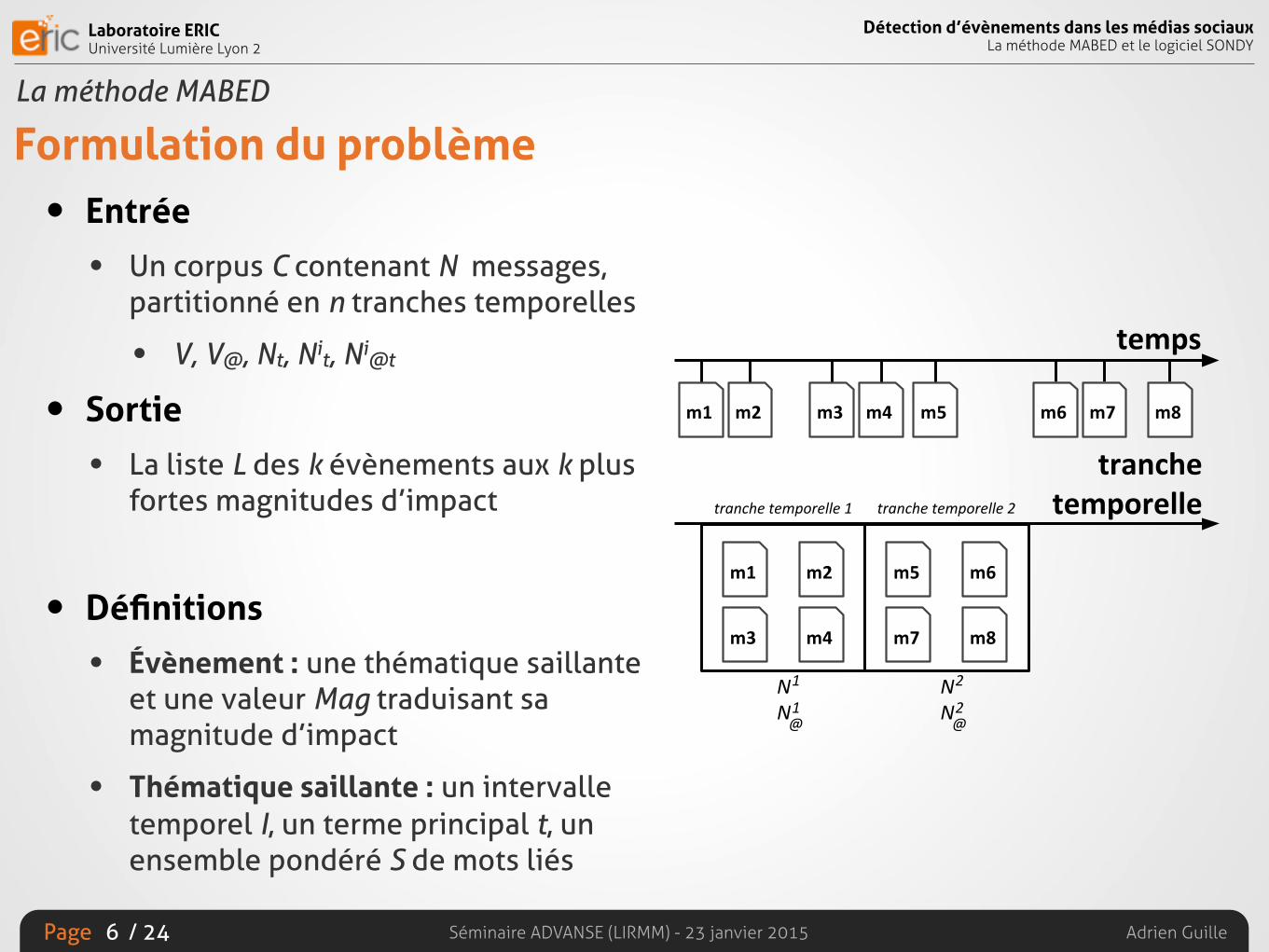
Formulation du problème• Entrée
• Un corpus C contenant N messages, partitionné en n tranches temporelles
• V, V@, Nt, Nit, Ni@t
• Sortie
• La liste L des k évènements aux k plus fortes magnitudes d’impact
• Définitions
• Évènement : une thématique saillante et une valeur Mag traduisant sa magnitude d’impact
• Thématique saillante : un intervalle temporel I, un terme principal t, un ensemble pondéré S de mots liés
6
�
Į ș
ȕ ࢥ
ȕ
ȕ Ȗ
��

Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
Vue d’ensemble de la méthode proposée• MABED
• Mention-Anomaly-Based Event Detection
• Processus en deux phases
• Phase 1
• Analyser la fréquence de création de mentions associée à chaque mot du vocabulaire V@ pour détecter les évènements (Mag,I,t,Ø)
• Phase 2
• Sélectionner les mots liés à chaque évènement
• Générer la liste des k évènements
7
���
������
���
���
���
���
���

Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
Méthode proposée : phase 1• Mesurer l’anomalie
• Par rapport à la fréquence de création de mentions à la tranche temporelle i
• Pour chaque mot t
• Mesurer la magnitude d’impact
• En fonction de la mesure d’anomalie
• Pour un évènement décrit par :
• Un mot principal t
• Un intervalle temporel I = [a;b]
8
Détecter les évènements
tranche temporelle, puis nous montrons comment mesurer la magnitude d’impactd’un mot pour une séquence contiguë de longueur quelconque de tranches tempo-relles. Enfin, nous expliquons comment identifier les intervalles qui maximisent lamagnitude d’impact pour tous les mots de V@.
Calcul de l’anomalie en un point. Avant de formuler la mesure d’anomalie, nousdéfinissons le nombre espéré de messages contenant le mot t et au moins une mentionpour chaque tranche temporelle i 2 [1; n], en supposant que ce mot ne soit lié àaucun évènement. Pour cela, nous supposons que le nombre de tels messages à la ième
tranche temporelle, N i@t , suit un modèle génératif probabiliste. Ainsi il est possible de
calculer la probabilité P(N i@t) d’observer N i
@t . Pour un corpus suffisamment grand, ilsemble raisonnable de modéliser ce type de probabilité avec une loi binomiale (Funget al., 2005). Par conséquent nous pouvons écrire :
P(N i@t) =✓
N i
N i@t
◆p
N i@t
@t (1� p@t)Ni�N i
@t ,
où p@t est la probabilité qu’un message contienne le mot t et au moins une men-tion, quelle que soit la tranche temporelle. Comme le nombre de messages N i estgrand dans le contexte des médias sociaux, nous pouvons raisonnablement supposerque P(N i
@t) peut être approximée par une loi normale, c’est-à-dire :
P(N i@t)⇠N (N i p@t , N i p@t(1� p@t)).
Il en découle que la quantité espérée de messages contenant le mot t et au moinsune mention à la ième tranche temporelle est :
E[t|i] = N i p@t , où p@t = N@t/N .
Enfin, nous définissons l’anomalie dans la fréquence de création de mentions liéeau mot t à la ième tranche temporelle comme suit :
anomalie(t, i) = N i@t � E[t|i].
Avec cette formulation, l’anomalie est positive uniquement lorsque la fréquenceobservée de création de mentions est strictement supérieure à l’espérance. Les mots
59
Détecter les évènements
tranche temporelle, puis nous montrons comment mesurer la magnitude d’impactd’un mot pour une séquence contiguë de longueur quelconque de tranches tempo-relles. Enfin, nous expliquons comment identifier les intervalles qui maximisent lamagnitude d’impact pour tous les mots de V@.
Calcul de l’anomalie en un point. Avant de formuler la mesure d’anomalie, nousdéfinissons le nombre espéré de messages contenant le mot t et au moins une mentionpour chaque tranche temporelle i 2 [1; n], en supposant que ce mot ne soit lié àaucun évènement. Pour cela, nous supposons que le nombre de tels messages à la ième
tranche temporelle, N i@t , suit un modèle génératif probabiliste. Ainsi il est possible de
calculer la probabilité P(N i@t) d’observer N i
@t . Pour un corpus suffisamment grand, ilsemble raisonnable de modéliser ce type de probabilité avec une loi binomiale (Funget al., 2005). Par conséquent nous pouvons écrire :
P(N i@t) =✓
N i
N i@t
◆p
N i@t
@t (1� p@t)Ni�N i
@t ,
où p@t est la probabilité qu’un message contienne le mot t et au moins une men-tion, quelle que soit la tranche temporelle. Comme le nombre de messages N i estgrand dans le contexte des médias sociaux, nous pouvons raisonnablement supposerque P(N i
@t) peut être approximée par une loi normale, c’est-à-dire :
P(N i@t)⇠N (N i p@t , N i p@t(1� p@t)).
Il en découle que la quantité espérée de messages contenant le mot t et au moinsune mention à la ième tranche temporelle est :
E[t|i] = N i p@t , où p@t = N@t/N .
Enfin, nous définissons l’anomalie dans la fréquence de création de mentions liéeau mot t à la ième tranche temporelle comme suit :
anomalie(t, i) = N i@t � E[t|i].
Avec cette formulation, l’anomalie est positive uniquement lorsque la fréquenceobservée de création de mentions est strictement supérieure à l’espérance. Les mots
59
Détecter les évènements
tranche temporelle, puis nous montrons comment mesurer la magnitude d’impactd’un mot pour une séquence contiguë de longueur quelconque de tranches tempo-relles. Enfin, nous expliquons comment identifier les intervalles qui maximisent lamagnitude d’impact pour tous les mots de V@.
Calcul de l’anomalie en un point. Avant de formuler la mesure d’anomalie, nousdéfinissons le nombre espéré de messages contenant le mot t et au moins une mentionpour chaque tranche temporelle i 2 [1; n], en supposant que ce mot ne soit lié àaucun évènement. Pour cela, nous supposons que le nombre de tels messages à la ième
tranche temporelle, N i@t , suit un modèle génératif probabiliste. Ainsi il est possible de
calculer la probabilité P(N i@t) d’observer N i
@t . Pour un corpus suffisamment grand, ilsemble raisonnable de modéliser ce type de probabilité avec une loi binomiale (Funget al., 2005). Par conséquent nous pouvons écrire :
P(N i@t) =✓
N i
N i@t
◆p
N i@t
@t (1� p@t)Ni�N i
@t ,
où p@t est la probabilité qu’un message contienne le mot t et au moins une men-tion, quelle que soit la tranche temporelle. Comme le nombre de messages N i estgrand dans le contexte des médias sociaux, nous pouvons raisonnablement supposerque P(N i
@t) peut être approximée par une loi normale, c’est-à-dire :
P(N i@t)⇠N (N i p@t , N i p@t(1� p@t)).
Il en découle que la quantité espérée de messages contenant le mot t et au moinsune mention à la ième tranche temporelle est :
E[t|i] = N i p@t , où p@t = N@t/N .
Enfin, nous définissons l’anomalie dans la fréquence de création de mentions liéeau mot t à la ième tranche temporelle comme suit :
anomalie(t, i) = N i@t � E[t|i].
Avec cette formulation, l’anomalie est positive uniquement lorsque la fréquenceobservée de création de mentions est strictement supérieure à l’espérance. Les mots
59
³�X<GP<NQ
< D
�¥X<GP<NQ¦
��Þ�§<�D¨
X<GP<NQNQ[<[EK
ÃÁÁÈ
< D
X<GP<NQ��Z<jgQEI�GIh�E]]EEkgI[EIh
<����������������������������D���
���
"X<GP<NQ
"NQ[<[EK
q
!<O��
"
E<Zd<O[I
NQ[<[EKh<gX]vs
Q
Q
Q
!<O¥�¦
h<gX]vs
E<dQj<Y
!Ç
Q[pQjK
q
- ++
3.3. Méthode proposée
liés à des évènements et spécifiques à une période temporelle particulière auronttendance à avoir des valeurs d’anomalie positives élevées durant cette période. Aucontraire, les mots récurrents (i.e. triviaux) qui ne sont pas liés à un évènement aurontdes valeurs d’anomalie qui divergeront peu par rapport à l’espérance. Par ailleurs,contrairement à des approches plus sophistiquées comme par exemple la modélisationdes fréquences à l’aide de mixtures gaussiennes, cette formulation passe facilement àl’échelle et s’adapte donc facilement à la taille du vocabulaire.
Calcul de la magnitude d’impact. La magnitude d’impact, Mag, d’un évènementassocié à l’intervalle I = [a; b] et au mot principal t est donnée par la formule ci-dessous. Elle correspond à l’aire algébrique sous la fonction d’anomalie sur l’intervalle[a; b].
Mag(t, I) =
bZ
a
anomalie(t, i)di
=bX
i=a
anomalie(t, i)
L’aire algébrique est obtenue en intégrant la fonction discrète d’anomalie, ce quirevient dans ce cas à une somme.
Identification des évènements. Pour chaque mot t 2 V@, nous cherchons à iden-tifier l’intervalle qui maximise la magnitude d’impact, c’est-à-dire :
I = argmaxI
Mag(t, I).
Or, nous avons montré précédemment que la magnitude d’impact d’un évènementdécrit par le mot principal t et l’intervalle I = [a; b] correspond à la somme de l’ano-malie sur cet intervalle. Par conséquent, cela revient à résoudre un problème du type« Sous-séquence contiguë de somme maximale » (SSCSM), un type de problème cou-rant en fouille de flots de données (Lappas et al., 2009), qui trouve également desapplications dans divers domaines tels que la bio-informatique (Fan et al., 2003) oula fouille de règles d’associations (Fukuda et al., 1996). En d’autres termes, pour un
60
3.3. Méthode proposée
liés à des évènements et spécifiques à une période temporelle particulière auronttendance à avoir des valeurs d’anomalie positives élevées durant cette période. Aucontraire, les mots récurrents (i.e. triviaux) qui ne sont pas liés à un évènement aurontdes valeurs d’anomalie qui divergeront peu par rapport à l’espérance. Par ailleurs,contrairement à des approches plus sophistiquées comme par exemple la modélisationdes fréquences à l’aide de mixtures gaussiennes, cette formulation passe facilement àl’échelle et s’adapte donc facilement à la taille du vocabulaire.
Calcul de la magnitude d’impact. La magnitude d’impact, Mag, d’un évènementassocié à l’intervalle I = [a; b] et au mot principal t est donnée par la formule ci-dessous. Elle correspond à l’aire algébrique sous la fonction d’anomalie sur l’intervalle[a; b].
Mag(t, I) =
bZ
a
anomalie(t, i)di
=bX
i=a
anomalie(t, i)
L’aire algébrique est obtenue en intégrant la fonction discrète d’anomalie, ce quirevient dans ce cas à une somme.
Identification des évènements. Pour chaque mot t 2 V@, nous cherchons à iden-tifier l’intervalle qui maximise la magnitude d’impact, c’est-à-dire :
I = argmaxI
Mag(t, I).
Or, nous avons montré précédemment que la magnitude d’impact d’un évènementdécrit par le mot principal t et l’intervalle I = [a; b] correspond à la somme de l’ano-malie sur cet intervalle. Par conséquent, cela revient à résoudre un problème du type« Sous-séquence contiguë de somme maximale » (SSCSM), un type de problème cou-rant en fouille de flots de données (Lappas et al., 2009), qui trouve également desapplications dans divers domaines tels que la bio-informatique (Fan et al., 2003) oula fouille de règles d’associations (Fukuda et al., 1996). En d’autres termes, pour un
60

Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
Méthode proposée : phase 1• Détecter les évènements
• Pour tous les mots du vocabulaire V@
• Identifier l’intervalle I tel que :
• Résoudre un problème du type «Sous-Séquence Contiguë de Somme Maximale» :
• À la fin de la phase I
• Une liste L’ d’évènements (|L’| = V@), chacun décrit par :
• Un mot principal t
• Un intervalle temporel I
• Sa magnitude d’impact Mag
9
³�X<GP<NQ
< D
�¥X<GP<NQ¦
��Þ�§<�D¨
X<GP<NQNQ[<[EK
ÃÁÁÈ
< D
X<GP<NQ��Z<jgQEI�GIh�E]]EEkgI[EIh
<����������������������������D���
���
"X<GP<NQ
"NQ[<[EK
q
!<O��
"
E<Zd<O[I
NQ[<[EKh<gX]vs
Q
Q
Q
!<O¥�¦
h<gX]vs
E<dQj<Y
!Ç
Q[pQjK
q
- ++
3.3. Méthode proposée
liés à des évènements et spécifiques à une période temporelle particulière auronttendance à avoir des valeurs d’anomalie positives élevées durant cette période. Aucontraire, les mots récurrents (i.e. triviaux) qui ne sont pas liés à un évènement aurontdes valeurs d’anomalie qui divergeront peu par rapport à l’espérance. Par ailleurs,contrairement à des approches plus sophistiquées comme par exemple la modélisationdes fréquences à l’aide de mixtures gaussiennes, cette formulation passe facilement àl’échelle et s’adapte donc facilement à la taille du vocabulaire.
Calcul de la magnitude d’impact. La magnitude d’impact, Mag, d’un évènementassocié à l’intervalle I = [a; b] et au mot principal t est donnée par la formule ci-dessous. Elle correspond à l’aire algébrique sous la fonction d’anomalie sur l’intervalle[a; b].
Mag(t, I) =
bZ
a
anomalie(t, i)di
=bX
i=a
anomalie(t, i)
L’aire algébrique est obtenue en intégrant la fonction discrète d’anomalie, ce quirevient dans ce cas à une somme.
Identification des évènements. Pour chaque mot t 2 V@, nous cherchons à iden-tifier l’intervalle qui maximise la magnitude d’impact, c’est-à-dire :
I = argmaxI
Mag(t, I).
Or, nous avons montré précédemment que la magnitude d’impact d’un évènementdécrit par le mot principal t et l’intervalle I = [a; b] correspond à la somme de l’ano-malie sur cet intervalle. Par conséquent, cela revient à résoudre un problème du type« Sous-séquence contiguë de somme maximale » (SSCSM), un type de problème cou-rant en fouille de flots de données (Lappas et al., 2009), qui trouve également desapplications dans divers domaines tels que la bio-informatique (Fan et al., 2003) oula fouille de règles d’associations (Fukuda et al., 1996). En d’autres termes, pour un
60
Détecter les évènements
FIGURE 3.7 – Identification d’un évènement lié au mot « kadhafi ». L’aire algébriquesous la fonction d’anomalie correspond aux zones grisées.
tifier l’intervalle qui maximise la magnitude d’impact, c’est-à-dire :
I = argmaxI
Mag(t, I)
Or, nous avons montré précédemment que la magnitude d’impact d’un évènementdécrit par le mot principal t et l’intervalle I = [a; b] correspond à la somme de l’ano-malie sur cet intervalle. Par conséquent, cela revient à résoudre un problème du type« Sous-séquence contiguë de somme maximale » (SSCSM), un type de problème cou-rant en fouille de flots de données (Lappas et al., 2009), qui trouve également desapplications dans divers domaines tels que la bio-informatique (Fan et al., 2003) oula fouille de règles d’associations (Fukuda et al., 1996). En d’autres termes, pour unmot t, nous cherchons à identifier l’intervalle I = [a; b] tel que :
Mag(t, I) =max{bX
i=a
anomalie(t, i)|1∂ a ∂ b ∂ n}
Cette formulation permet à l’anomalie d’être négative en certains points de l’in-tervalle, si et seulement si cela permet d’étendre l’intervalle tout en augmentant lamagnitude. C’est une propriété intéressante, puisque cela permet d’éviter la fragmen-tation de longs évènements s’étendant sur plusieurs jours et dont l’anomalie associéedevient négative par exemple la nuit, du fait du faible niveau d’activité nocturne sur
63

Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
Méthode proposée : phase 2• Identifier les mots décrivant au mieux les évènements
• Identification des mots candidats (parmi V) selon la cooccurrence
• Sélection selon l’intensité de la corrélation entre leur fréquence absolue
• Mesurée selon le coefficient ne supposant pas la stationnarité [Erdem12]
• Comparée à un seuil θ
10
³�X<GP<NQ
< D
�¥X<GP<NQ¦
��Þ�§<�D¨
X<GP<NQNQ[<[EK
ÃÁÁÈ
< D
X<GP<NQ��Z<jgQEI�GIh�E]]EEkgI[EIh
<����������������������������D���
���
"X<GP<NQ
"NQ[<[EK
q
!<O��
"
E<Zd<O[I
NQ[<[EK
Q
Q
Q
!<O¥�¦
h<gX]vs
E<dQj<Y
!Ç
Q[pQjK
q
³�X<GP<NQ
< D
�¥X<GP<NQ¦
��Þ�§<�D¨
X<GP<NQNQ[<[EK
ÃÁÁÈ
< D
X<GP<NQ��Z<jgQEI�GIh�E]]EEkgI[EIh
<����������������������������D���
���
"X<GP<NQ
"NQ[<[EK
q
!<O��
"
E<Zd<O[I
NQ[<[EK
Q
Q
Q
!<O¥�¦
h<gX]vs
E<dQj<Y
!Ç
Q[pQjK
q
Détecter les évènements
conçu pour analyser des données boursières, réputées non-stationnaires – possèdedeux propriétés intéressantes pour notre application : (i) il est non-paramétrique et(ii) il ne requiert pas d’hypothèse de stationnarité contrairement, par exemple, aucoefficient de Pearson. Ce coefficient prend en compte le décalage temporel afin decapturer au mieux la direction de la co-variation des deux séries temporelles au fildu temps. Par souci de concision, nous ne donnons ici que la formule permettantd’approximer ce coefficient, étant donnés les mots t, t 0q et l’intervalle temporel I =[a; b] :
⇢Ot,t 0q =
bX
i=a+1
At,t 0q
(b� a� 1)AtAt 0q,
où At,t 0q = (Nit � N i�1
t )(N it 0q� N i�1
t 0q)
A2t =
Pbi=a+1(N
it � N i�1
t )2
b� a� 1
A2t 0q=
Pbi=a+1(N
it 0q� N i�1
t 0q)2
b� a� 1Cela correspond quasiment à l’auto-corrélation du premier ordre des séries tempo-
relles N it et N i
t 0q. Erdem et al. (2012) fournissent la preuve que ⇢O satisfait la condition
|⇢O| ∂ 1 en utilisant l’inégalité de Cauchy-Schwartz. Enfin, nous définissons le poidsdu mot t 0q comme une fonction affine de ⇢O afin de se conformer à notre définitionde thématique saillante, i.e. 0∂ wq ∂ 1 :
wq =⇢Ot,t 0q + 1
2
Parce que la dynamique temporelle des mots toujours très fréquents est moinsimpactée par un évènement particulier, cette formulation – d’une certaine manièrecomme tf · idf – diminue le poids des mots généralement fréquents dans le flux demessages et augmente le poids des mots qui le sont moins, i.e. les mots plus spéci-fiques.
Sélection des mots les plus pertinents. L’ensemble final des mots retenus pourdécrire un évènement est l’ensemble S, tel que 8t 0q 2 S, wq > ✓ . Les paramètres p et ✓
65
Détecter les évènements
conçu pour analyser des données boursières, réputées non-stationnaires – possèdedeux propriétés intéressantes pour notre application : (i) il est non-paramétrique et(ii) il ne requiert pas d’hypothèse de stationnarité contrairement, par exemple, aucoefficient de Pearson. Ce coefficient prend en compte le décalage temporel afin decapturer au mieux la direction de la co-variation des deux séries temporelles au fildu temps. Par souci de concision, nous ne donnons ici que la formule permettantd’approximer ce coefficient, étant donnés les mots t, t 0q et l’intervalle temporel I =[a; b] :
⇢Ot,t 0q =
bX
i=a+1
At,t 0q
(b� a� 1)AtAt 0q,
où At,t 0q = (Nit � N i�1
t )(N it 0q� N i�1
t 0q)
A2t =
Pbi=a+1(N
it � N i�1
t )2
b� a� 1
A2t 0q=
Pbi=a+1(N
it 0q� N i�1
t 0q)2
b� a� 1Cela correspond quasiment à l’auto-corrélation du premier ordre des séries tempo-
relles N it et N i
t 0q. Erdem et al. (2012) fournissent la preuve que ⇢O satisfait la condition
|⇢O| ∂ 1 en utilisant l’inégalité de Cauchy-Schwartz. Enfin, nous définissons le poidsdu mot t 0q comme une fonction affine de ⇢O afin de se conformer à notre définitionde thématique saillante, i.e. 0∂ wq ∂ 1 :
wq =⇢Ot,t 0q + 1
2
Parce que la dynamique temporelle des mots toujours très fréquents est moinsimpactée par un évènement particulier, cette formulation – d’une certaine manièrecomme tf · idf – diminue le poids des mots généralement fréquents dans le flux demessages et augmente le poids des mots qui le sont moins, i.e. les mots plus spéci-fiques.
Sélection des mots les plus pertinents. L’ensemble final des mots retenus pourdécrire un évènement est l’ensemble S, tel que 8t 0q 2 S, wq > ✓ . Les paramètres p et ✓
65
Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
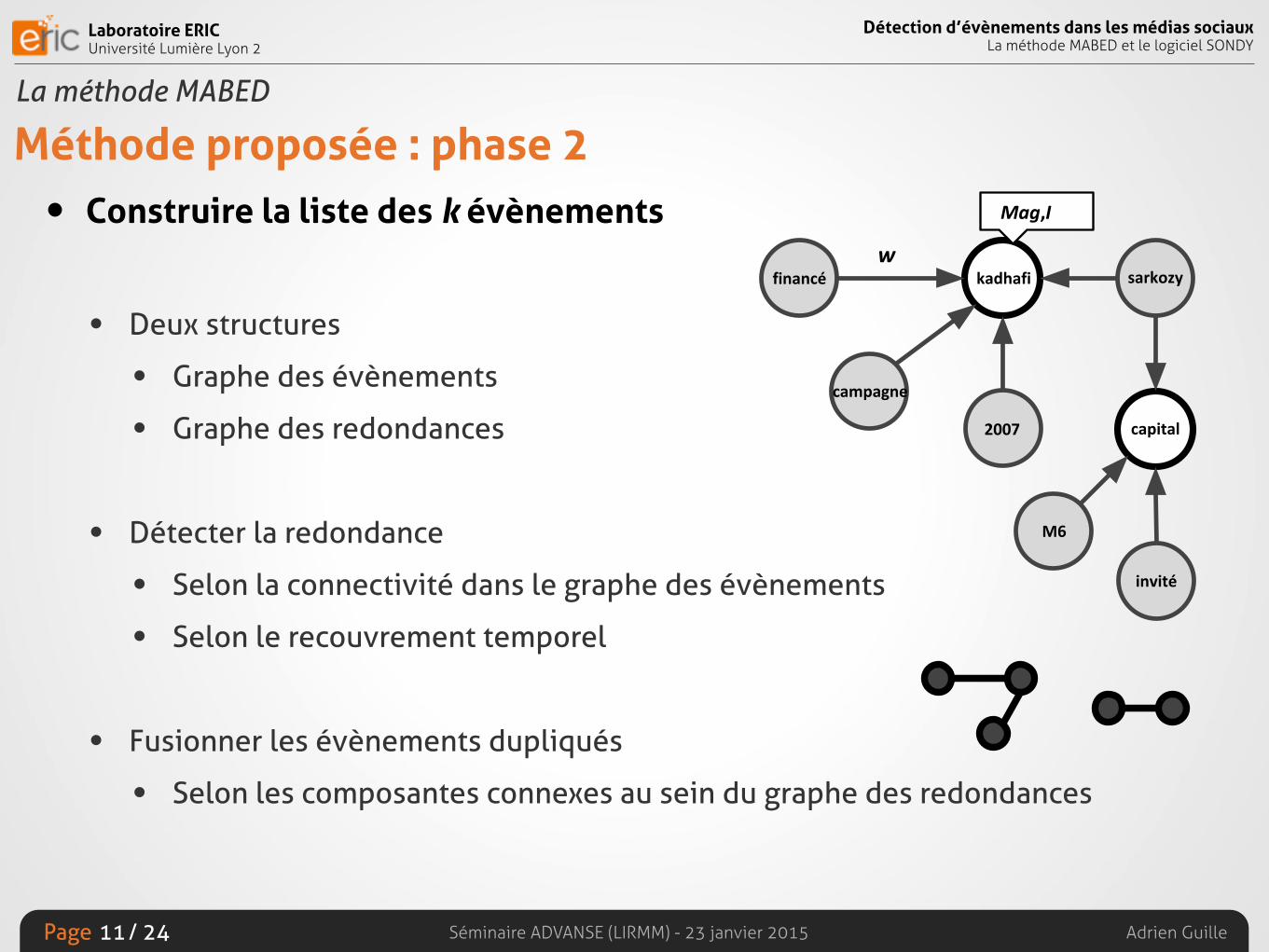
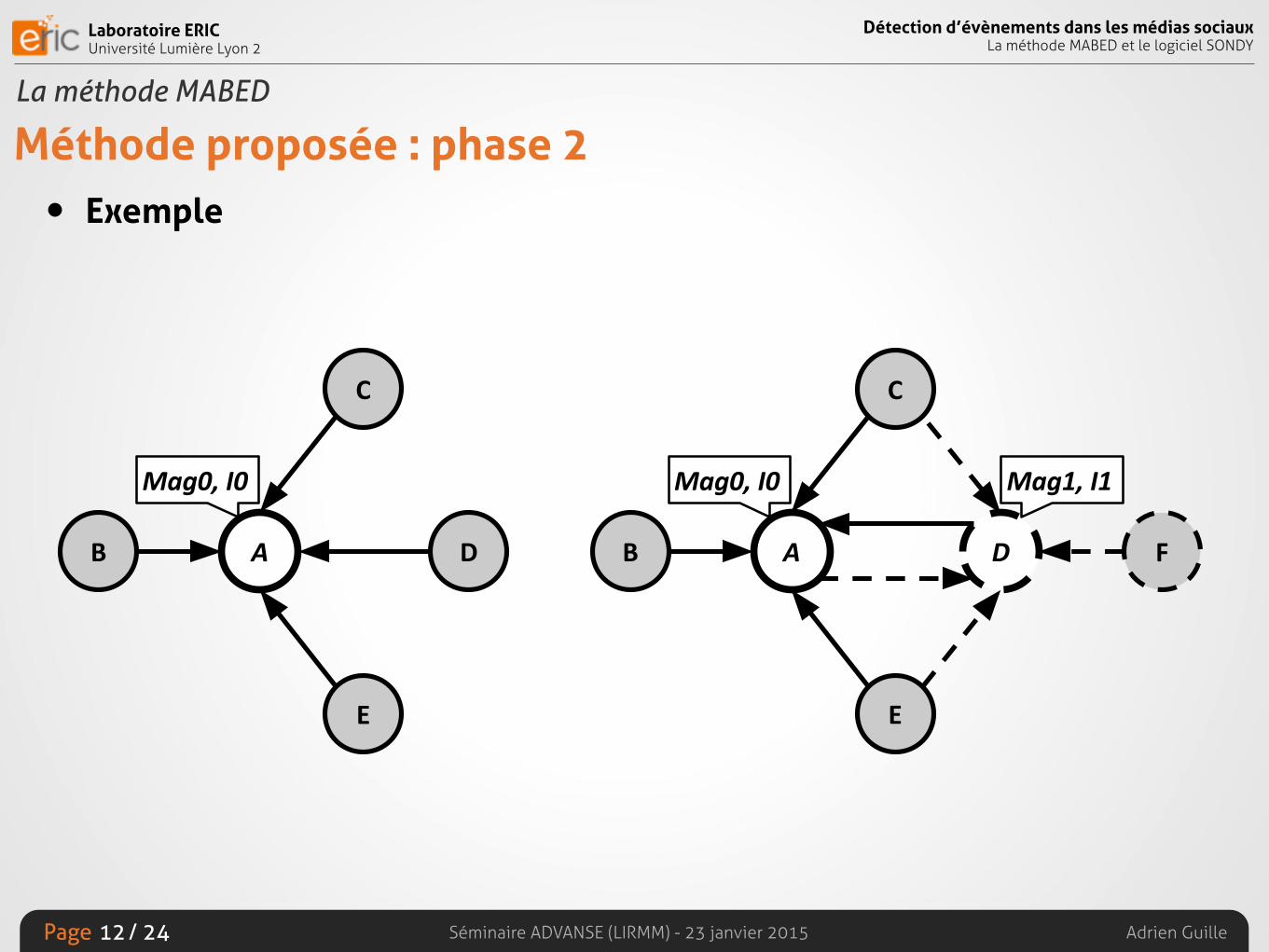
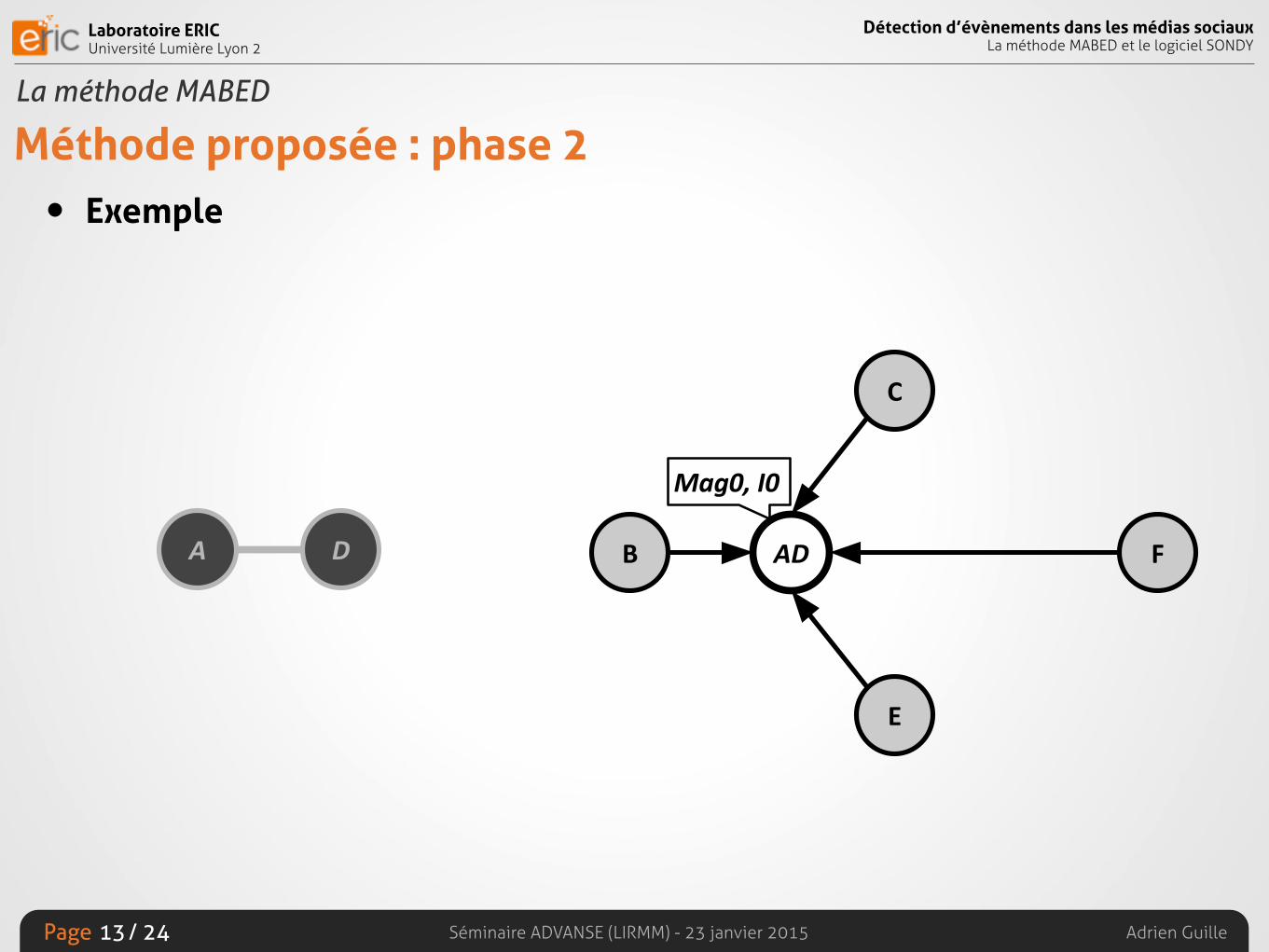
Méthode proposée : phase 2• Construire la liste des k évènements
• Deux structures
• Graphe des évènements
• Graphe des redondances
• Détecter la redondance
• Selon la connectivité dans le graphe des évènements
• Selon le recouvrement temporel
• Fusionner les évènements dupliqués
• Selon les composantes connexes au sein du graphe des redondances
11
³�X<GP<NQ
< D
�¥X<GP<NQ¦
��Þ�§<�D¨
X<GP<NQNQ[<[EK
ÃÁÁÈ
< D
X<GP<NQ��Z<jgQEI�GIh�E]]EEkgI[EIh
<����������������������������D���
���
"X<GP<NQ
"NQ[<[EK
q
!<O��
"
E<Zd<O[I
NQ[<[EK
Q
Q
Q
!<O¥�¦
h<gX]vs
E<dQj<Y
!Ç
Q[pQjK
q
���
������
���
���
���
���
���
Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
Méthode proposée : phase 2• Exemple
12
� � �
�
�
!<O¿���¿ !<OÀ���À
� � �
�
!<O¿���¿
� �� �
�
!<O¿���¿
� �
� � �
�
�
!<O¿���¿ !<OÀ���À
� � �
�
!<O¿���¿
� �� �
�
!<O¿���¿
� �
Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
Méthode proposée : phase 2• Exemple
13
� � �
�
�
!<O¿���¿ !<OÀ���À
� � �
�
!<O¿���¿
� �� �
�
!<O¿���¿
� � �
�
�
!<O¿���¿ !<OÀ���À
� � �
�
!<O¿���¿
� �� �
�
!<O¿���¿
� �

Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
Expérimentations : protocole• Corpus
• Cen : 1,5·106 tweets publiés nov. 2009 [Yang11]
• Cfr : 2·106 tweets publiés en mar. 2012 contenant des mots-clés [ANR ImagiWeb]
• Méthodes comparées
• Trending Score (TS2, TS3) [Benhardus13] et ET [Parikh13]
• α-MABED
• Choix des paramètres
• (α)-MABED : tranches temporelles de 30 minutes, p=10, θ=0.7, σ=0.5
• Trending Score et ET : tranches temporelles de 24 heures
• Métriques d’évaluation
• Évaluation de la significativité des évènements par des juges humains
• Précision, rappel et F-mesure
• DERate [Li12]
• Temps de calcul
14

Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
Expérimentations : évaluation quantitative• Observations
• Gain moyen concernant la F-mesure de 17,2% par rapport à α-MABED
• Gain plus important pour le corpus le plus bruité, Cen
15
3.4. Expérimentations
Corpus : CenMéthode Précision F-mesure DERate Temps de calcul
MABED 0,775 0,682 0,193 96s↵-MABED 0,625 0,571 0,160 126s
ET 0,575 0,575 0 3480sTS2 0,600 0,514 0,250 80sTS3 0,375 0,281 0,4 82s
Corpus : C f rMéthode Précision F-mesure DERate Temps de calcul
MABED 0,825 0,825 0 88s↵-MABED 0,725 0,712 0,025 113s
ET 0,700 0.674 0,071 4620sTS2 0,725 0,671 0,138 69sTS3 0,700 0,616 0,214 74s
TABLE 3.4 – Performances des cinq méthodes sur les deux corpus.
compte le comportement des utilisateurs des médias sociaux en matière de créationde mentions permet une détection plus robuste des évènements à partir d’un flux detweets bruité. Le DERate révèle que MABED n’a dédoublé aucun évènement signifi-catif parmi ceux détectés dans C f r , mais que – en dépit de la gestion explicite de laredondance par le troisième composant – 6 (DERate = 0, 193) des 31 (P = 0,775)évènements significatifs détectés dans Cen sont redondants. Ce DERate reste toutefoisinférieur à celui mesuré pour les méthodes TS2 ou TS3, et MABED obtient néanmoinsle meilleur rappel sur ce corpus.
Explication de la performance de MABED. Il apparaît que les évènements signi-ficatifs détectés par les méthodes de référence sont un sous-ensemble de ceux détectéspar MABED. L’analyse plus approfondie des résultats d’↵-MABED, TS2 et TS3 révèleque la plupart des évènements jugés non-significatifs sont aisément assimilables à duspam. La non-détection de ces évènements non-significatifs par MABED suggère quela prise en compte des mentions limite la sensibilité au spam, ce qui expliquerait enpartie l’amélioration plus importante de la F-mesure de MABED sur Cen que C f r parrapport aux méthodes de référence. En ce qui concerne ET, nous remarquons quela longueur moyenne des descriptions des évènements est de 17,25 bigrammes (i.e.plus de 30 mots). Nous constatons que les descriptions des évènements détectés parcette méthode à base de classification non supervisée sont bruitées. Les descriptions
72
3.4. Expérimentations
Corpus : CenMéthode Précision F-mesure DERate Temps de calcul
MABED 0,775 0,682 0,193 96s↵-MABED 0,625 0,571 0,160 126s
ET 0,575 0,575 0 3480sTS2 0,600 0,514 0,250 80sTS3 0,375 0,281 0,4 82s
Corpus : C f rMéthode Précision F-mesure DERate Temps de calcul
MABED 0,825 0,825 0 88s↵-MABED 0,725 0,712 0,025 113s
ET 0,700 0.674 0,071 4620sTS2 0,725 0,671 0,138 69sTS3 0,700 0,616 0,214 74s
TABLE 3.4 – Performances des cinq méthodes sur les deux corpus.
compte le comportement des utilisateurs des médias sociaux en matière de créationde mentions permet une détection plus robuste des évènements à partir d’un flux detweets bruité. Le DERate révèle que MABED n’a dédoublé aucun évènement signifi-catif parmi ceux détectés dans C f r , mais que – en dépit de la gestion explicite de laredondance par le troisième composant – 6 (DERate = 0, 193) des 31 (P = 0,775)évènements significatifs détectés dans Cen sont redondants. Ce DERate reste toutefoisinférieur à celui mesuré pour les méthodes TS2 ou TS3, et MABED obtient néanmoinsle meilleur rappel sur ce corpus.
Explication de la performance de MABED. Il apparaît que les évènements signi-ficatifs détectés par les méthodes de référence sont un sous-ensemble de ceux détectéspar MABED. L’analyse plus approfondie des résultats d’↵-MABED, TS2 et TS3 révèleque la plupart des évènements jugés non-significatifs sont aisément assimilables à duspam. La non-détection de ces évènements non-significatifs par MABED suggère quela prise en compte des mentions limite la sensibilité au spam, ce qui expliquerait enpartie l’amélioration plus importante de la F-mesure de MABED sur Cen que C f r parrapport aux méthodes de référence. En ce qui concerne ET, nous remarquons quela longueur moyenne des descriptions des évènements est de 17,25 bigrammes (i.e.plus de 30 mots). Nous constatons que les descriptions des évènements détectés parcette méthode à base de classification non supervisée sont bruitées. Les descriptions
72
Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
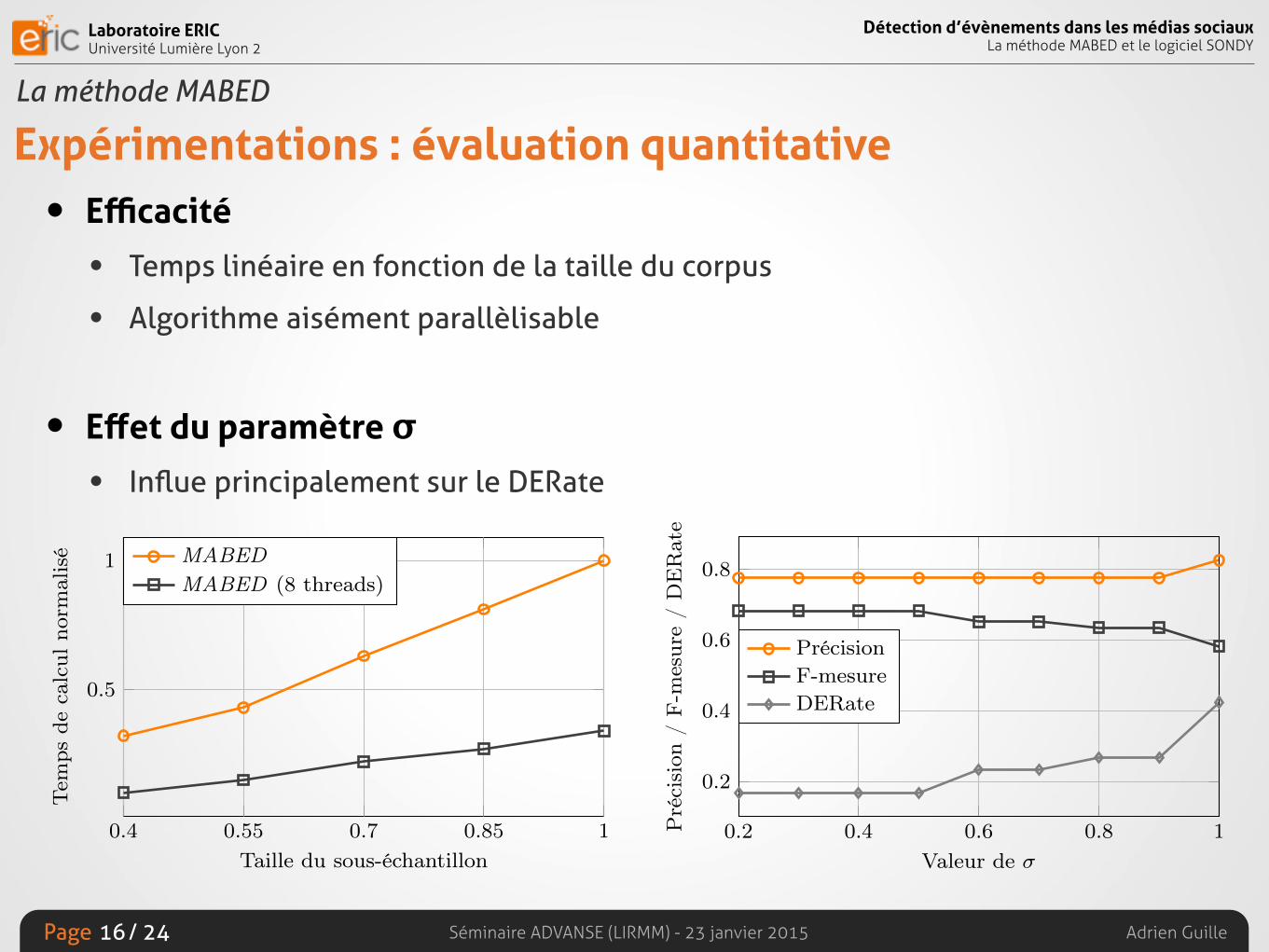
Expérimentations : évaluation quantitative• Efficacité
• Temps linéaire en fonction de la taille du corpus
• Algorithme aisément parallèlisable
• Effet du paramètre σ• Influe principalement sur le DERate
16
Event Detection, Tracking and Visualization in Twitter 9
We also measure the DERate (Li et al, 2012), whichdenotes the percentage of events that are duplicatesamong all significant events detected :
DERate =
# of duplicated events# of detected significant events
4.2 Quantitative Evaluation
Hereafter, we discuss the performance of the fiveconsidered methods, based on the rates assigned bythe annotators. The inter-annotator agreement, mea-sured with Cohen’s Kappa (Landis and Koch, 1977),is ' 0.76, showing a strong agreement. Table 3 (page10) reports the precision, the F-measure defined as theharmonic mean of precision and recall (i.e. 2 · P ·R
P+R), the
DERate and the running-time of each method for bothcorpora.Comparison against baselines We notice that MABEDachieves the best performance on the two corpora, witha precision of 0.775 and F-measure of 0.682 on Cen, anda precision and a F-measure of 0.825 on Cfr. AlthoughET yields a better DERate on Cen, it still achieves lowerprecision and recall than MABED on both corpora. Fur-thermore, we measure an average relative gain of 17.2%over ↵-MABED in the F-measure, which suggests thatconsidering the mentioning behavior of users leads tomore accurate detection of significant events in Twit-ter. Interestingly, we notice that MABED outperformsall baselines in the F-measure with a bigger margin onCen, which contains a lot more noise than Cfr – with upto 50% non-event-related tweets according to the studyconducted by PearAnalytics (2009). This suggests thatconsidering the mentioning behavior of users also leadsto more robust detection of events from noisy Twittercontent. The DERate reveals that none of the signifi-cant events detected in Cfr by MABED were duplicated,whereas 6 of the significant events detected in Cen areduplicates.
We find that the set of events detected by the fourbaseline methods is a sub-set of the events detectedby MABED. Further analysis of the results producedby ↵-MABED, TS2 and TS3 reveals that most of non-significant events they detected are related to spam.The fact that most of these irrelevant events aren’t de-tected by MABED suggest that considering the presenceof mentions in tweets helps filtering away spam. Concer-ning ET, the average event description is 17.25 bigramslong (i.e. more than 30 words). As a consequence, thedescriptions contain some unrelated words. Specifically,irrelevant events are mostly sets of unrelated words thatdon’t make any sense. This is due in part to the factthat clustering-based approaches are prone to aggressi-
0.5
1
0.4 0.55 0.7 0.85 1
Taille du sous-échantillon
Tem
psde
calc
ulno
rmal
isé MABED
MABED (8 threads)
Figure 5 Runtime comparison versus subsample size.
0.2 0.4 0.6 0.8 1
0.2
0.4
0.6
0.8
Valeur de �
Pré
cisi
on/
F-m
esur
e/
DE
Rat
e
PrécisionF-mesureDERate
Figure 6 Precision, F-measure and DERate of MABED onCen for different values of �.
vely grouping terms together, as Valkanas and Guno-pulos (2013) stated in a previous study.Efficiency It appears that MABED and TS have run-ning-times of the same order, whereas ET is orders ofmagnitude slower, which is due to the clustering stepthat requires computing temporal and semantical simi-larity between all bigrams. We also observe that MA-BED runs faster than ↵-MABED. The main reason forthis is that |V
@
| 6 |V |, which speeds up the first phase. Itshould be noted that the running-times given in Table 3don’t include the time required for preparing vocabula-ries and pre-computing term frequencies, which is moreimportant for methods that rely on bigrams or trigrams.We evaluate the scalability of (i) MABED and (ii) a pa-rallelized version of MABED (8 threads), by measuringtheir running-times on random subsamples of both cor-pora, for subsample sizes varying from 40% to 100%.Figure 5 shows the average normalized running--timeversus subsample size. This means that the runtimesmeasured on a corpus are normalized by the longestruntime on this corpus and are then averaged for MA-BED and MABED (8 threads). We notice that runtimesgrow linearly in size of the subsample. Furthermore, wenote that MABED (8 threads) is on average 67% fasterthan MABED.
Event Detection, Tracking and Visualization in Twitter 9
We also measure the DERate (Li et al, 2012), whichdenotes the percentage of events that are duplicatesamong all significant events detected :
DERate =
# of duplicated events# of detected significant events
4.2 Quantitative Evaluation
Hereafter, we discuss the performance of the fiveconsidered methods, based on the rates assigned bythe annotators. The inter-annotator agreement, mea-sured with Cohen’s Kappa (Landis and Koch, 1977),is ' 0.76, showing a strong agreement. Table 3 (page10) reports the precision, the F-measure defined as theharmonic mean of precision and recall (i.e. 2 · P ·R
P+R), the
DERate and the running-time of each method for bothcorpora.Comparison against baselines We notice that MABEDachieves the best performance on the two corpora, witha precision of 0.775 and F-measure of 0.682 on Cen, anda precision and a F-measure of 0.825 on Cfr. AlthoughET yields a better DERate on Cen, it still achieves lowerprecision and recall than MABED on both corpora. Fur-thermore, we measure an average relative gain of 17.2%over ↵-MABED in the F-measure, which suggests thatconsidering the mentioning behavior of users leads tomore accurate detection of significant events in Twit-ter. Interestingly, we notice that MABED outperformsall baselines in the F-measure with a bigger margin onCen, which contains a lot more noise than Cfr – with upto 50% non-event-related tweets according to the studyconducted by PearAnalytics (2009). This suggests thatconsidering the mentioning behavior of users also leadsto more robust detection of events from noisy Twittercontent. The DERate reveals that none of the signifi-cant events detected in Cfr by MABED were duplicated,whereas 6 of the significant events detected in Cen areduplicates.
We find that the set of events detected by the fourbaseline methods is a sub-set of the events detectedby MABED. Further analysis of the results producedby ↵-MABED, TS2 and TS3 reveals that most of non-significant events they detected are related to spam.The fact that most of these irrelevant events aren’t de-tected by MABED suggest that considering the presenceof mentions in tweets helps filtering away spam. Concer-ning ET, the average event description is 17.25 bigramslong (i.e. more than 30 words). As a consequence, thedescriptions contain some unrelated words. Specifically,irrelevant events are mostly sets of unrelated words thatdon’t make any sense. This is due in part to the factthat clustering-based approaches are prone to aggressi-
0.5
1
0.4 0.55 0.7 0.85 1
Taille du sous-échantillon
Tem
psde
calc
ulno
rmal
isé MABED
MABED (8 threads)
Figure 5 Runtime comparison versus subsample size.
0.2 0.4 0.6 0.8 1
0.2
0.4
0.6
0.8
Valeur de �
Pré
cisi
on/
F-m
esur
e/
DE
Rat
ePrécisionF-mesureDERate
Figure 6 Precision, F-measure and DERate of MABED onCen for different values of �.
vely grouping terms together, as Valkanas and Guno-pulos (2013) stated in a previous study.Efficiency It appears that MABED and TS have run-ning-times of the same order, whereas ET is orders ofmagnitude slower, which is due to the clustering stepthat requires computing temporal and semantical simi-larity between all bigrams. We also observe that MA-BED runs faster than ↵-MABED. The main reason forthis is that |V
@
| 6 |V |, which speeds up the first phase. Itshould be noted that the running-times given in Table 3don’t include the time required for preparing vocabula-ries and pre-computing term frequencies, which is moreimportant for methods that rely on bigrams or trigrams.We evaluate the scalability of (i) MABED and (ii) a pa-rallelized version of MABED (8 threads), by measuringtheir running-times on random subsamples of both cor-pora, for subsample sizes varying from 40% to 100%.Figure 5 shows the average normalized running--timeversus subsample size. This means that the runtimesmeasured on a corpus are normalized by the longestruntime on this corpus and are then averaged for MA-BED and MABED (8 threads). We notice that runtimesgrow linearly in size of the subsample. Furthermore, wenote that MABED (8 threads) is on average 67% fasterthan MABED.
Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
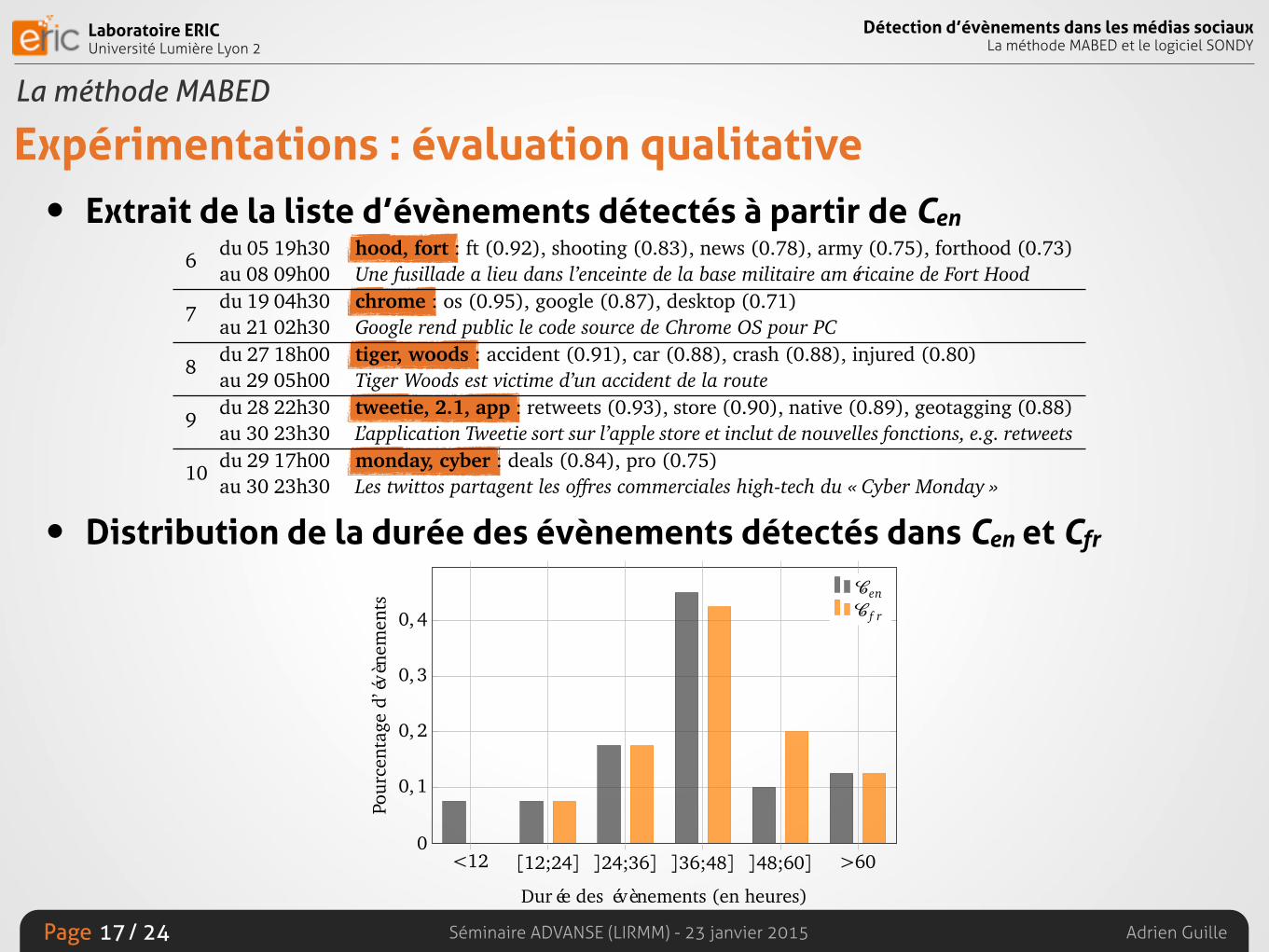
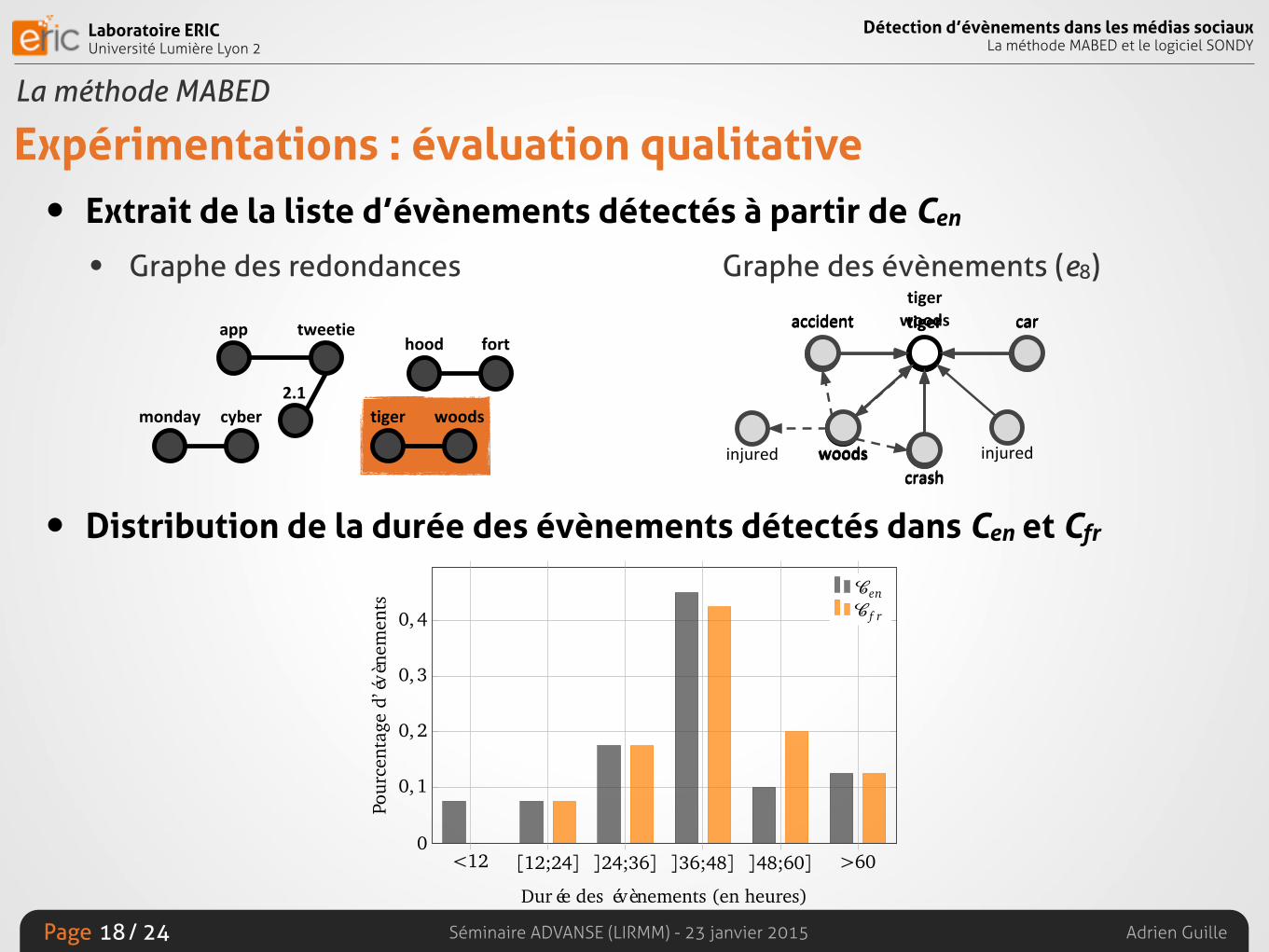
Expérimentations : évaluation qualitative• Extrait de la liste d’évènements détectés à partir de Cen
• Distribution de la durée des évènements détectés dans Cen et Cfr
17
3.4. Expérimentations
# Intervalle Thématique
1 du 25 09h30 thanksgiving, turkey : hope (0.72), happy (0.71)au 28 06h30 Les twittos célèbrent Thanksgiving
2 du 25 09h30 thankful : happy (0.77), thanksgiving (0.71)au 27 09h00 Lié à l’évènement # 1
3 du 10 16h00 veterans : served (0.80), country (0.78), military (0.73), happy (0.72)au 12 08h00 Commémoration du 11 novembre, « Veterans Day »
4 du 26 13h00 black : friday (0.95), amazon (0.75)au 28 10h30 Les twittos discutent des offres proposées par Amazon la veille du « Black Friday »
5 du 07 13h30 hcr, bill, health, house, vote : reform (0.92), passed (0.91), passes (0.88)au 09 04h30 La Chambre des représentants des États-Unis adopte la réforme de santé
6 du 05 19h30 hood, fort : ft (0.92), shooting (0.83), news (0.78), army (0.75), forthood (0.73)au 08 09h00 Une fusillade a lieu dans l’enceinte de la base militaire américaine de Fort Hood
7 du 19 04h30 chrome : os (0.95), google (0.87), desktop (0.71)au 21 02h30 Google rend public le code source de Chrome OS pour PC
8 du 27 18h00 tiger, woods : accident (0.91), car (0.88), crash (0.88), injured (0.80)au 29 05h00 Tiger Woods est victime d’un accident de la route
9 du 28 22h30 tweetie, 2.1, app : retweets (0.93), store (0.90), native (0.89), geotagging (0.88)au 30 23h30 L’application Tweetie sort sur l’apple store et inclut de nouvelles fonctions, e.g. retweets
10 du 29 17h00 monday, cyber : deals (0.84), pro (0.75)au 30 23h30 Les twittos partagent les offres commerciales high-tech du « Cyber Monday »
11 du 10 01h00 linkedin : synced (0.86), updates (0.84), status (0.83), twitter (0.71)au 12 03h00 Linkedin permet à ses utilisateurs de synchroniser leurs statuts avec Twitter
12 du 04 17h00 yankees, series : win (0.84), won (0.84), fans (0.78), phillies (0.73), york (0.72)au 06 05h30 Les Yankees, l’équipe de baseball de New York remporte la World Series face aux Philies
13 du 15 09h00 obama : chinese (0.75), barack (0.72), twitter (0.72), china (0.70)au 17 23h30 Lors d’une visite en Chine, Barack Obama admet n’avoir jamais utilisé Twitter
14 du 25 10h00 holiday : shopping (0.72)au 26 10h00 Les twittos réagissent par rapport au « Black Friday », un jour férié dédié au shopping
15 du 19 21h30 oprah, end : talk (0.81), show (0.79), 2011 (0.73), winfrey (0.71)au 21 16h00 Oprah Winfrey annonce la fin de son talk-show en septembre 2011
16 du 07 11h30 healthcare, reform : house (0.91), bill (0.88), passes (0.83), vote (0.83)au 09 05h00 Lié à l’évènement #5
17 du 11 03h30 facebook : app (0.74), twitter (0.73)au 13 08h30 Pas d’évènement correspondant
18 du 18 14h00 whats : happening (0.76), twitter (0.73)au 21 03h00 Twitter demande maintenant « What’s happening ? » et plus « What are you doing ? »
19 du 20 10h00 cern : lhc (0.86), beam (0.79)au 22 00h00 Les faisceaux de particules circulent à nouveau dans l’accélérateur LHC du CERN
20 du 26 08h00 icom : lisbon (0.99), roundtable (0.98), national (0.88)au 26 15h00 Tenue de la table ronde de l’ICOM à propos des marchés financiers portugais
TABLE 3.5 – Liste des 20 évènements ayant eu le plus fort impact sur les utilisateurs,détectés par MABED à partir du corpus Cen. Les mots principaux sont en gras et lepoids de chaque mot lié est donné entre parenthèses. Les intervalles temporels sontexprimés en temps UTC.
74
Détecter les évènements
5 nov. #6 (13h30) 6 nov. 7 nov.0
max
Temps (CST)A
nom
alie
« hood »« fort »
« shooting »
FIGURE 3.12 – Anomalie mesurée pour les mots « hood », « fort » et « shooting » du 5au 7 novembre à minuit (CST).
0
0, 1
0, 2
0, 3
0, 4
<12 [12;24] ]24;36] ]36;48] ]48;60] >60
Durée des évènements (en heures)
Pour
cent
age
d’év
ènem
ents
CenC f r
FIGURE 3.13 – Distribution de la durée des évènements détectés par MABED.
77
Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
Expérimentations : évaluation qualitative• Extrait de la liste d’évènements détectés à partir de Cen
• Graphe des redondances Graphe des évènements (e8)
• Distribution de la durée des évènements détectés dans Cen et Cfr
18
Détecter les évènements
5 nov. #6 (13h30) 6 nov. 7 nov.0
max
Temps (CST)A
nom
alie
« hood »« fort »
« shooting »
FIGURE 3.12 – Anomalie mesurée pour les mots « hood », « fort » et « shooting » du 5au 7 novembre à minuit (CST).
0
0, 1
0, 2
0, 3
0, 4
<12 [12;24] ]24;36] ]36;48] ]48;60] >60
Durée des évènements (en heures)
Pour
cent
age
d’év
ènem
ents
CenC f r
FIGURE 3.13 – Distribution de la durée des évènements détectés par MABED.
77
³�X<GP<NQ
< D
�¥X<GP<NQ¦
��Þ�§<�D¨
X<GP<NQNQ[<[EK
ÃÁÁÈ
< D
X<GP<NQ��Z<jgQEI�GIh�E]]EEkgI[EIh
<����������������������������D���
���
"X<GP<NQ
"NQ[<[EK
q
!<O��
"
E<Zd<O[I
NQ[<[EK
Q
Q
Q
!<O¥�¦
h<gX]vs
E<dQj<Y
!Ç
Q[pQjK
q
jqIIjQI<dd
Ã�Â
P]]G N]gj
jQOIg q]]GhZ][G<s EsDIg
jQOIg<EEQGI[j
q]]Gh
Eg<hP
E<g
�g<dPI�GIh�gIG][G<[EIh �g<dPI�GIh�KpJ[IZI[jh<p<[j�NkhQ][
jQOIg<EEQGI[j
q]]Gh
Eg<hP
E<g
Q[WkgIG
jQOIgq]]Gh<EEQGI[j
q]]Gh
Eg<hP
E<g
�g<dPI�GIh�KpJ[IZI[jh<dgJh�NkhQ][
Q[WkgIG
³�X<GP<NQ
< D
�¥X<GP<NQ¦
��Þ�§<�D¨
X<GP<NQNQ[<[EK
ÃÁÁÈ
< D
X<GP<NQ��Z<jgQEI�GIh�E]]EEkgI[EIh
<����������������������������D���
���
"X<GP<NQ
"NQ[<[EK
q
!<O��
"
E<Zd<O[I
NQ[<[EK
Q
Q
Q
!<O¥�¦
h<gX]vs
E<dQj<Y
!Ç
Q[pQjK
q
jqIIjQI<dd
Ã�Â
P]]G N]gj
jQOIg q]]GhZ][G<s EsDIg
jQOIg<EEQGI[j
q]]Gh
Eg<hP
E<g
�g<dPI�GIh�gIG][G<[EIh �g<dPI�GIh�KpJ[IZI[jh<p<[j�NkhQ][
jQOIg<EEQGI[j
q]]Gh
Eg<hP
E<g
Q[WkgIG
jQOIgq]]Gh<EEQGI[j
q]]Gh
Eg<hP
E<g
�g<dPI�GIh�KpJ[IZI[jh<dgJh�NkhQ][
Q[WkgIG
³�X<GP<NQ
< D
�¥X<GP<NQ¦
��Þ�§<�D¨
X<GP<NQNQ[<[EK
ÃÁÁÈ
< D
X<GP<NQ��Z<jgQEI�GIh�E]]EEkgI[EIh
<����������������������������D���
���
"X<GP<NQ
"NQ[<[EK
q
!<O��
"
E<Zd<O[I
NQ[<[EK
Q
Q
Q
!<O¥�¦
h<gX]vs
E<dQj<Y
!Ç
Q[pQjK
q
jqIIjQI<dd
Ã�Â
P]]G N]gj
jQOIg q]]GhZ][G<s EsDIg
jQOIg<EEQGI[j
q]]Gh
Eg<hP
E<g
�g<dPI�GIh�gIG][G<[EIh �g<dPI�GIh�KpJ[IZI[jh<p<[j�NkhQ][
jQOIg<EEQGI[j
q]]Gh
Eg<hP
E<g
Q[WkgIG
jQOIgq]]Gh<EEQGI[j
q]]Gh
Eg<hP
E<g
�g<dPI�GIh�KpJ[IZI[jh<dgJh�NkhQ][
Q[WkgIG
³�X<GP<NQ
< D
�¥X<GP<NQ¦
��Þ�§<�D¨
X<GP<NQNQ[<[EK
ÃÁÁÈ
< D
X<GP<NQ��Z<jgQEI�GIh�E]]EEkgI[EIh
<����������������������������D���
���
"X<GP<NQ
"NQ[<[EK
q
!<O��
"
E<Zd<O[I
NQ[<[EK
Q
Q
Q
!<O¥�¦
h<gX]vs
E<dQj<Y
!Ç
Q[pQjK
q
jqIIjQI<dd
Ã�Â
P]]G N]gj
jQOIg q]]GhZ][G<s EsDIg
jQOIg<EEQGI[j
q]]Gh
Eg<hP
E<g
�g<dPI�GIh�gIG][G<[EIh �g<dPI�GIh�KpJ[IZI[jh<p<[j�NkhQ][
jQOIg<EEQGI[j
q]]Gh
Eg<hP
E<g
Q[WkgIG
jQOIgq]]Gh<EEQGI[j
q]]Gh
Eg<hP
E<g
�g<dPI�GIh�KpJ[IZI[jh<dgJh�NkhQ][
Q[WkgIG
Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
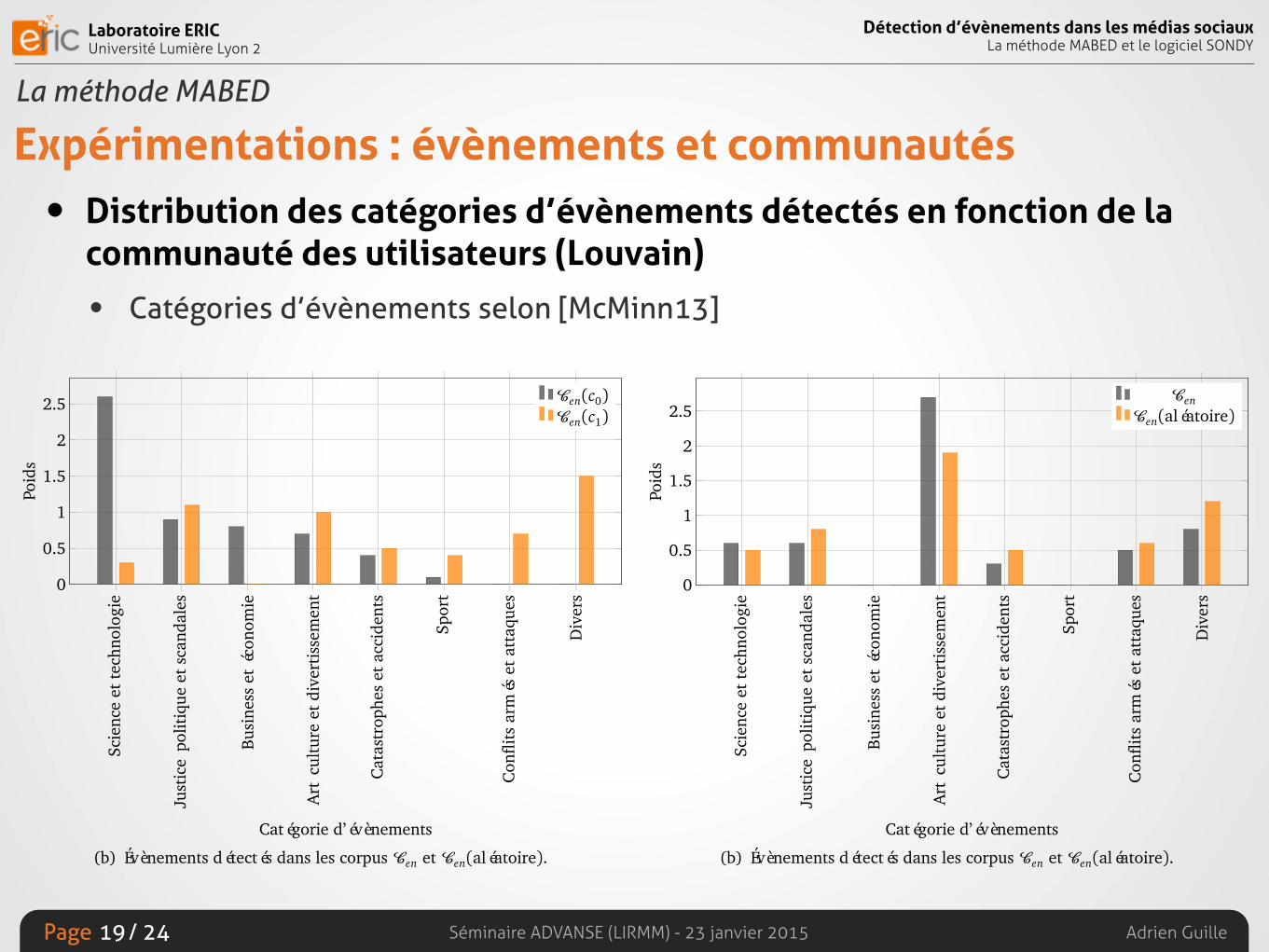
Expérimentations : évènements et communautés• Distribution des catégories d’évènements détectés en fonction de la
communauté des utilisateurs (Louvain)
• Catégories d’évènements selon [McMinn13]
19
Détecter les évènements
0
0.5
1
1.5
2
2.5
Poid
s
Cen(c0)Cen(c1)
(a) Évènements détectés dans les corpus Cen(c0) et Cen(c1).
0
0.5
1
1.5
2
2.5
Div
ers
Con
flits
arm
éset
atta
ques
Spor
t
Cat
astr
ophe
set
acci
dent
s
Art
cultu
reet
dive
rtis
sem
ent
Busi
ness
etéc
onom
ie
Just
ice
polit
ique
etsc
anda
les
Scie
nce
ette
chno
logi
e
Catégorie d’évènements
Poid
s
CenCen(aléatoire)
(b) Évènements détectés dans les corpus Cen et Cen(aléatoire).
FIGURE 3.17 – Distribution du poids des catégories des évènements détectés par MA-BED dans les corpus Cen(c0), Cen(c1), Cen et Cen(aléatoire)
85
Détecter les évènements
0
0.5
1
1.5
2
2.5
Poid
s
Cen(c0)Cen(c1)
(a) Évènements détectés dans les corpus Cen(c0) et Cen(c1).
0
0.5
1
1.5
2
2.5
Div
ers
Con
flits
arm
éset
atta
ques
Spor
t
Cat
astr
ophe
set
acci
dent
s
Art
cultu
reet
dive
rtis
sem
ent
Busi
ness
etéc
onom
ie
Just
ice
polit
ique
etsc
anda
les
Scie
nce
ette
chno
logi
e
Catégorie d’évènements
Poid
s
CenCen(aléatoire)
(b) Évènements détectés dans les corpus Cen et Cen(aléatoire).
FIGURE 3.17 – Distribution du poids des catégories des évènements détectés par MA-BED dans les corpus Cen(c0), Cen(c1), Cen et Cen(aléatoire)
85
Détecter les évènements
0
0.5
1
1.5
2
2.5
Poid
s
Cen(c0)Cen(c1)
(a) Évènements détectés dans les corpus Cen(c0) et Cen(c1).
0
0.5
1
1.5
2
2.5
Div
ers
Con
flits
arm
éset
atta
ques
Spor
t
Cat
astr
ophe
set
acci
dent
s
Art
cultu
reet
dive
rtis
sem
ent
Busi
ness
etéc
onom
ie
Just
ice
polit
ique
etsc
anda
les
Scie
nce
ette
chno
logi
e
Catégorie d’évènements
Poid
s
CenCen(aléatoire)
(b) Évènements détectés dans les corpus Cen et Cen(aléatoire).
FIGURE 3.17 – Distribution du poids des catégories des évènements détectés par MA-BED dans les corpus Cen(c0), Cen(c1), Cen et Cen(aléatoire)
85
Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
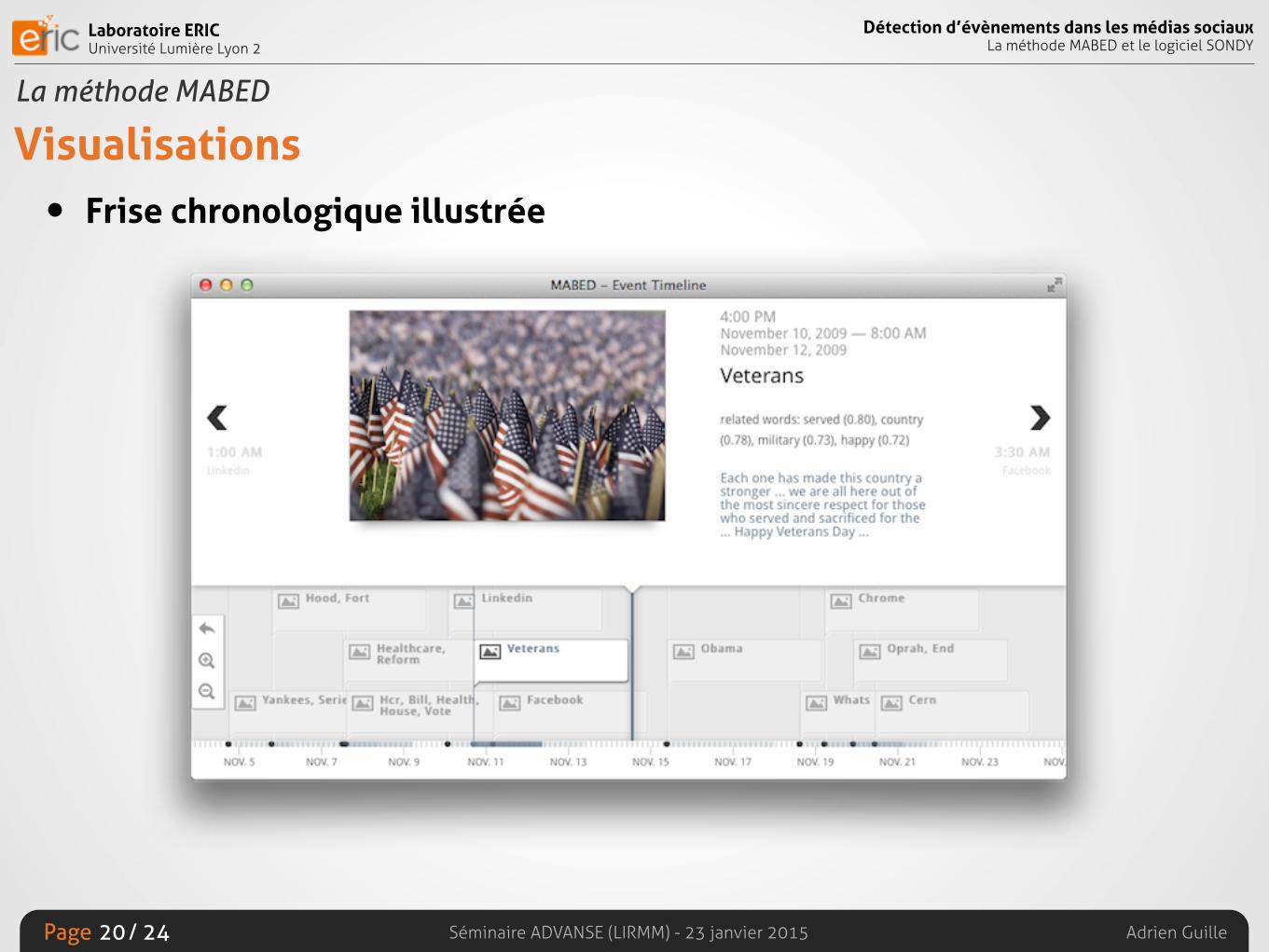
Visualisations• Frise chronologique illustrée
20
Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
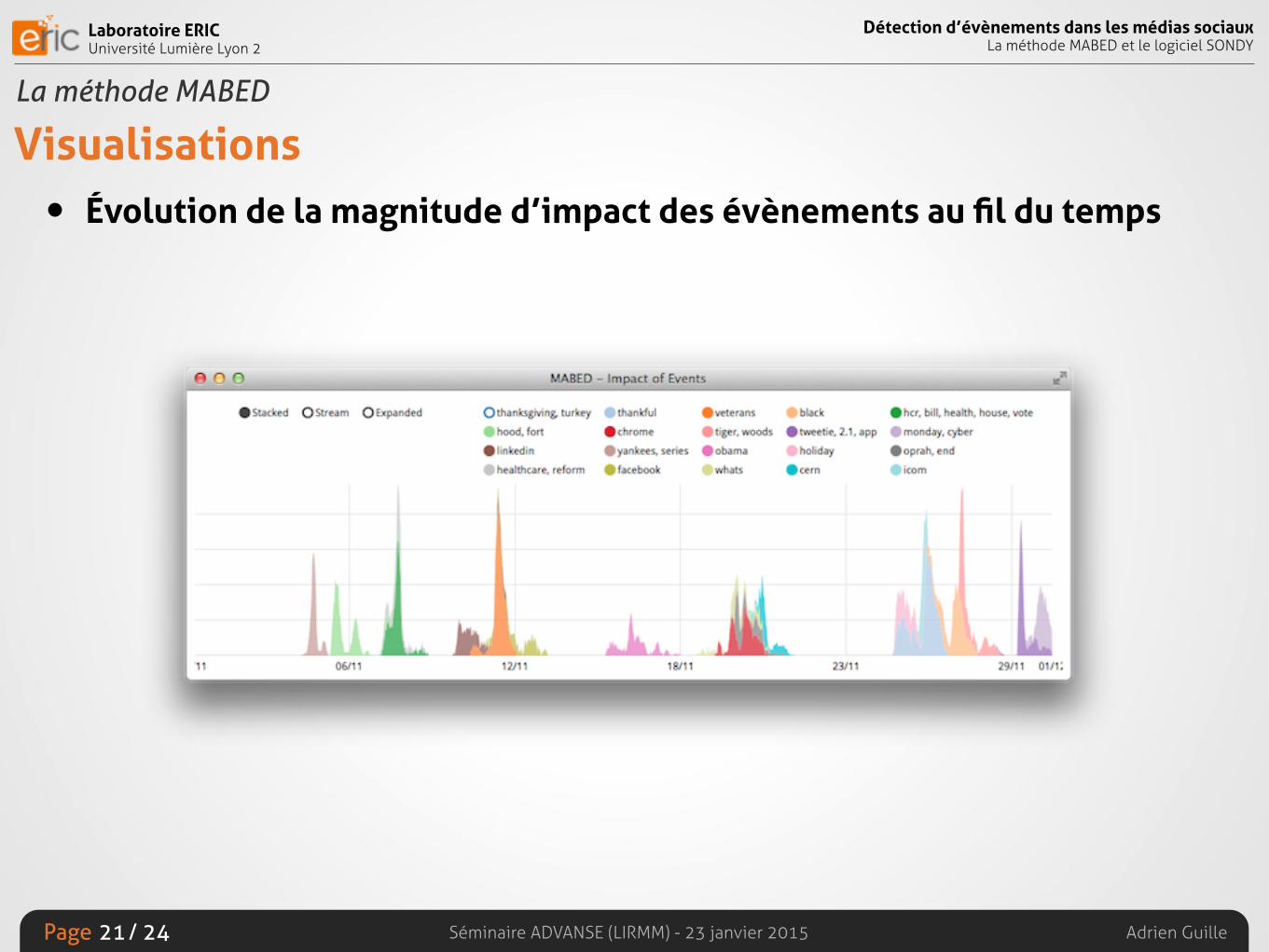
Visualisations• Évolution de la magnitude d’impact des évènements au fil du temps
21
Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
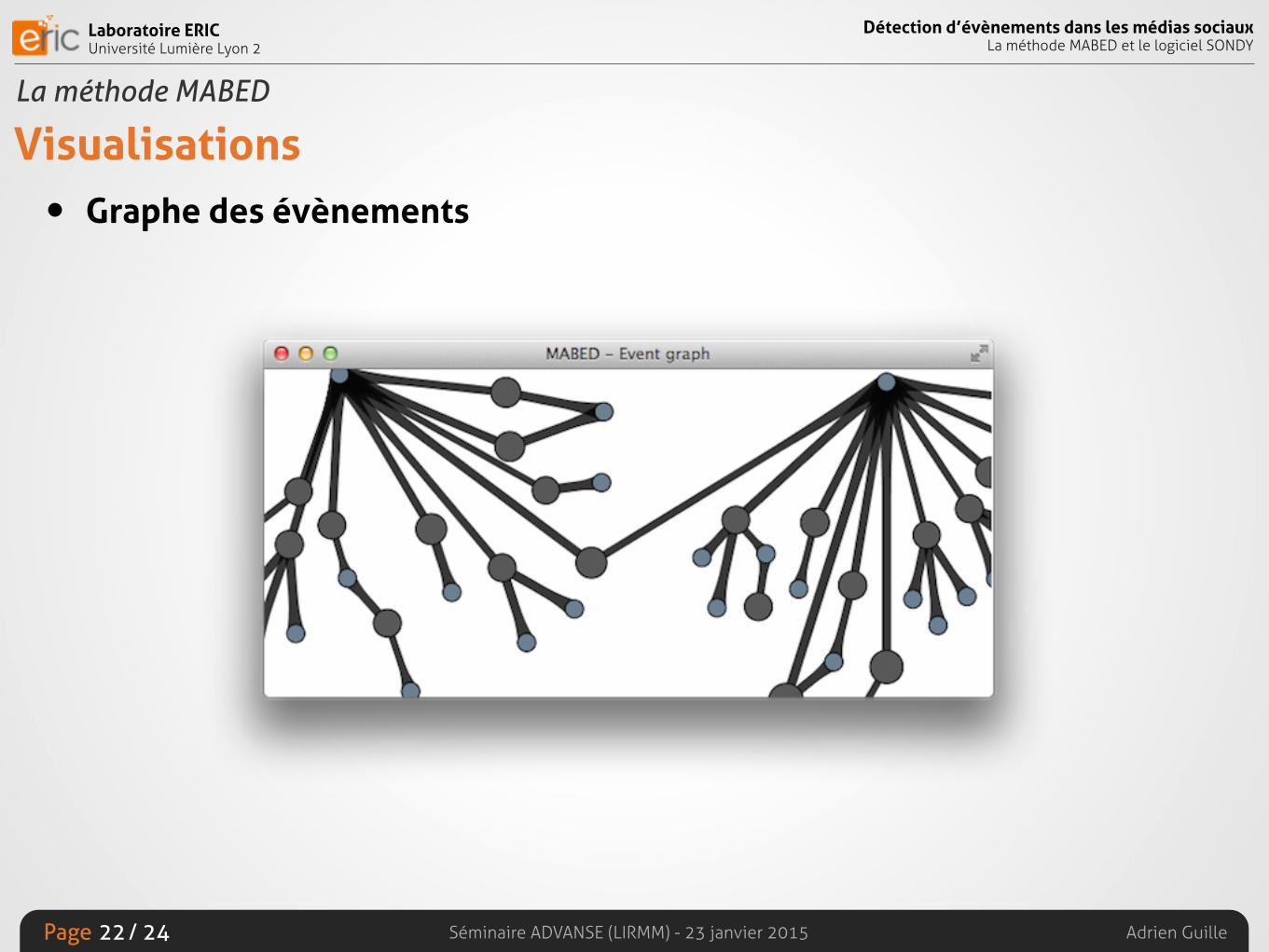
Visualisations• Graphe des évènements
22

Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
La méthode MABED
Conclusion• Proposition d’une nouvelle méthode : MABED
• Prise en compte de l’aspect social du flux de message
• Estimation dynamique de la durée de chaque évènement
• Expérimentations
• Temps d’exécution linéaire en fonction de la taille du corpus
• Meilleure précision en considérant l’aspect social
• Robustesse accrue en présence de bruit
• Mise en lumière du lien entre détection d’évènements et communautés
• Partage du code
• Implémentation centralisée/parallèlisée http://github.com/AdrienGuille/MABED
• Visualisations http://mediamining.univ-lyon2.fr/people/guille/MABED
• Publications liées
• ASONAM 2014, invitation pour la revue SNAM (en cours de relecture)
23
Laboratoire ERICUniversité Lumière Lyon 2
Page
Détection d’évènements dans les médias sociauxLa méthode MABED et le logiciel SONDY
Séminaire ADVANSE (LIRMM) - 23 janvier 2015 Adrien Guille/ 24
Le logiciel SONDY
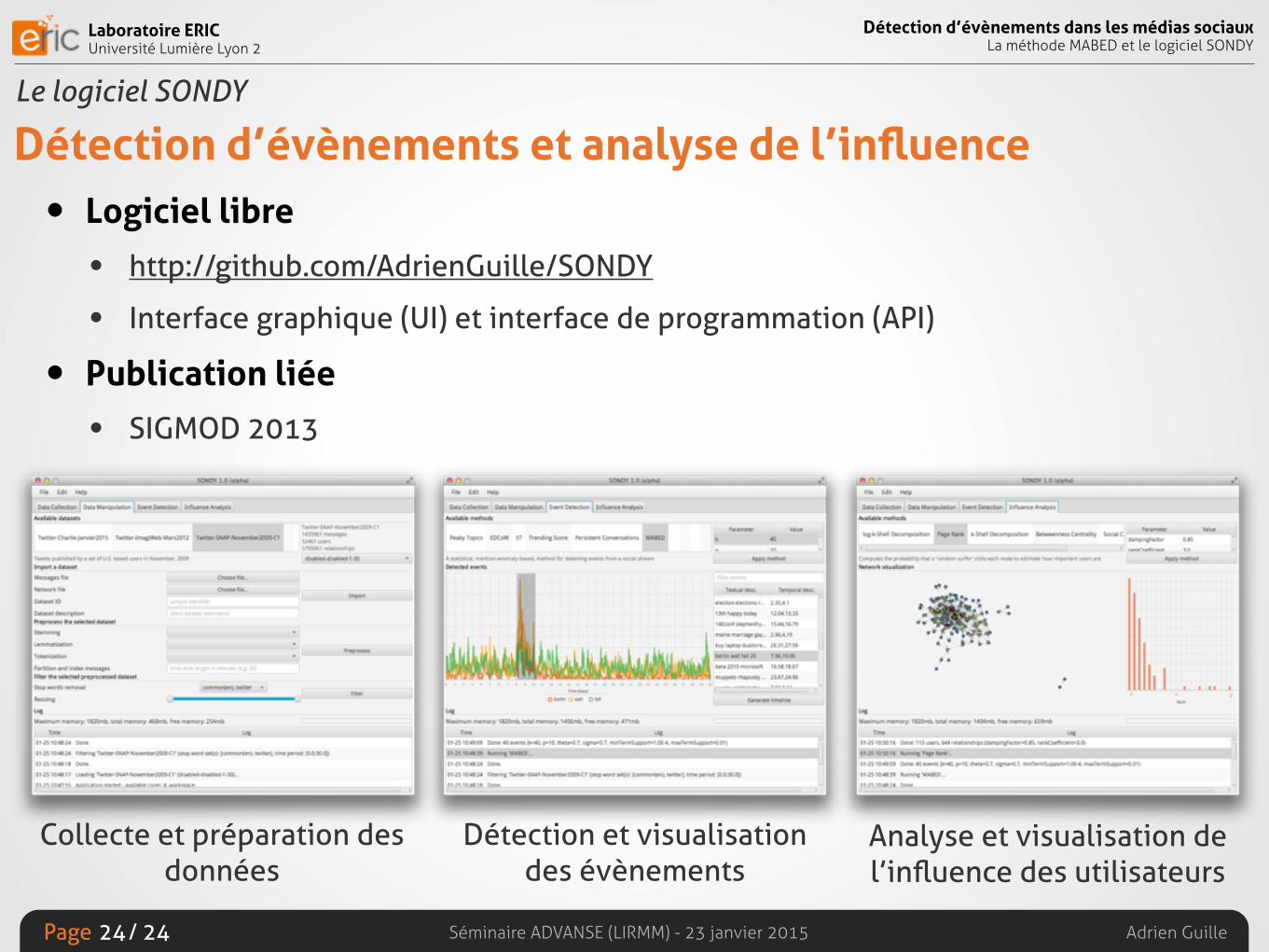
Détection d’évènements et analyse de l’influence• Logiciel libre
• http://github.com/AdrienGuille/SONDY
• Interface graphique (UI) et interface de programmation (API)
• Publication liée
• SIGMOD 2013
24
Collecte et préparation des données
Détection et visualisation des évènements
Analyse et visualisation de l’influence des utilisateurs





























