Embed Size (px)
Citation preview

@hayssams #devoxxml
Machine Learning avec Spark, MLLib et D3.js
Datascientist : Une personne meilleure en statistiques que n’importe quel développeur et meilleure en développement que n’importe quel Statisticien - Josh Wills (Cloudera)
Datascientist : Une personne moins bonne en statistiques que n’importe quel statisticien et moins bonne en développement que n’importe quel développeur
- Will Cukierski (Kaggle)

@hayssams #devoxxml
Machine Learning avec Spark, MLLib et D3.js
Hayssam Saleh blog.ebiznext.com slideshare.net/hayssamsaleh1

@hayssams #devoxxml
• Motivation de l’approche Machine Learning
• Pourquoi Spark / MLLib
• La préparation de l’échantillon de données
• La sélection de l’algorithme MLLib
• La visualisation avec D3.js
Sommaire

@hayssams #devoxxml
Machine Learning
• Branche de l’intelligence artificielle
• Capacité à apprendre sans être explicitement programmé
• Exemple : Distinguer les mails de type spam des autres

@YourTwiDerHandle @YourTwiDerHandle @hayssams #devoxxml
Motivation de l’approche Machine Learning
@hayssams #devoxxml
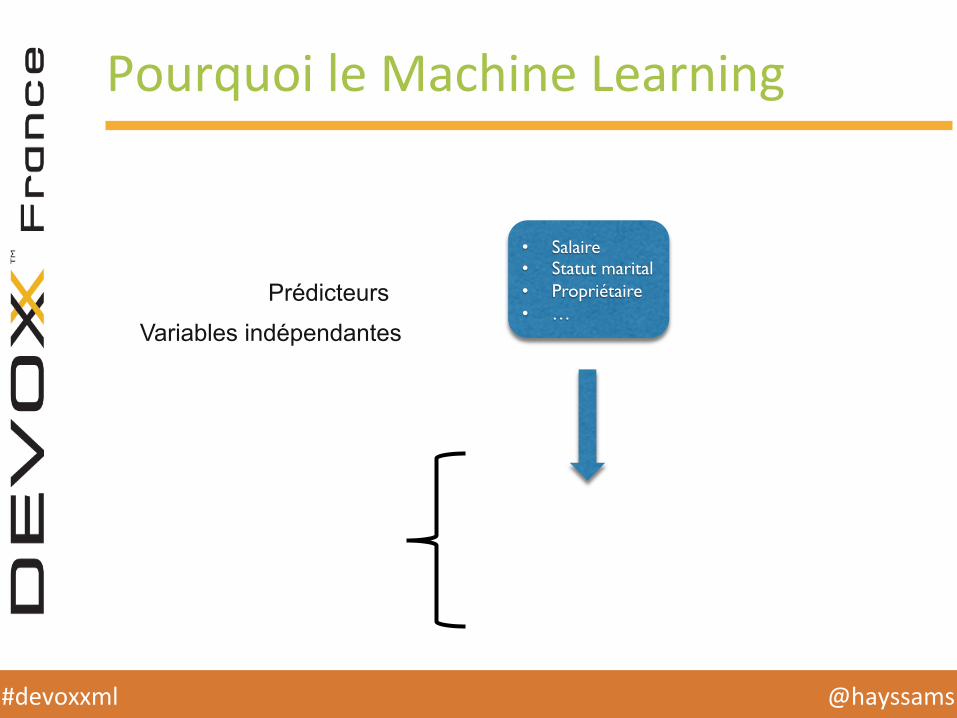
Pourquoi le Machine Learning
• Salaire• Statut marital• Propriétaire• …
Prédicteurs
Variables indépendantes
Réponse / Label
Variable dépendante
@hayssams #devoxxml
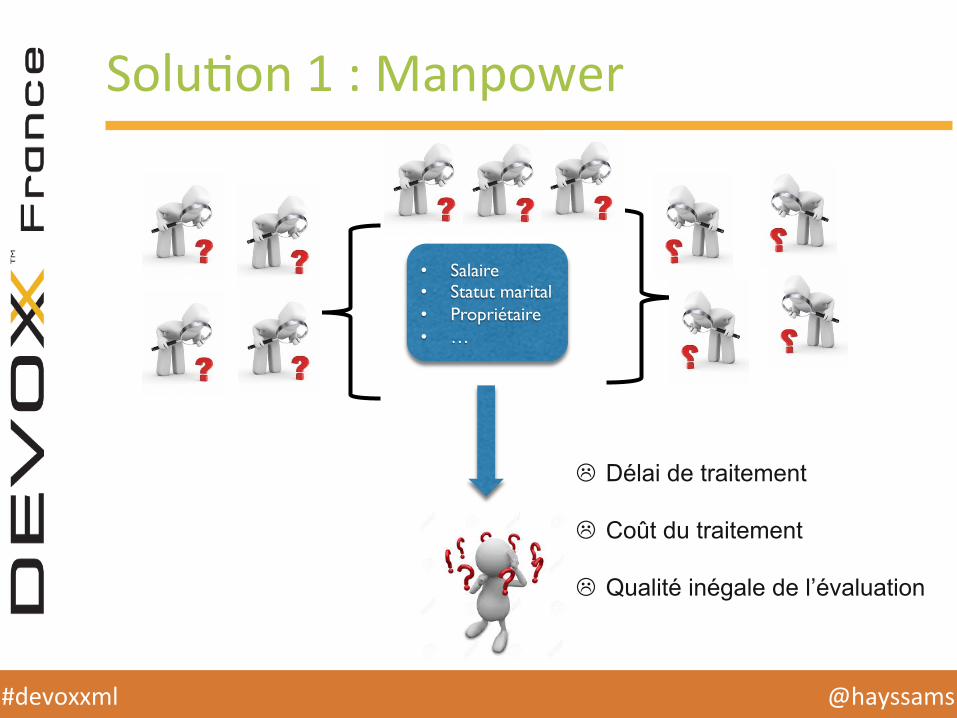
SoluHon 1 : Manpower
• Salaire• Statut marital• Propriétaire• …
L Délai de traitement
L Coût du traitement
L Qualité inégale de l’évaluation
@hayssams #devoxxml
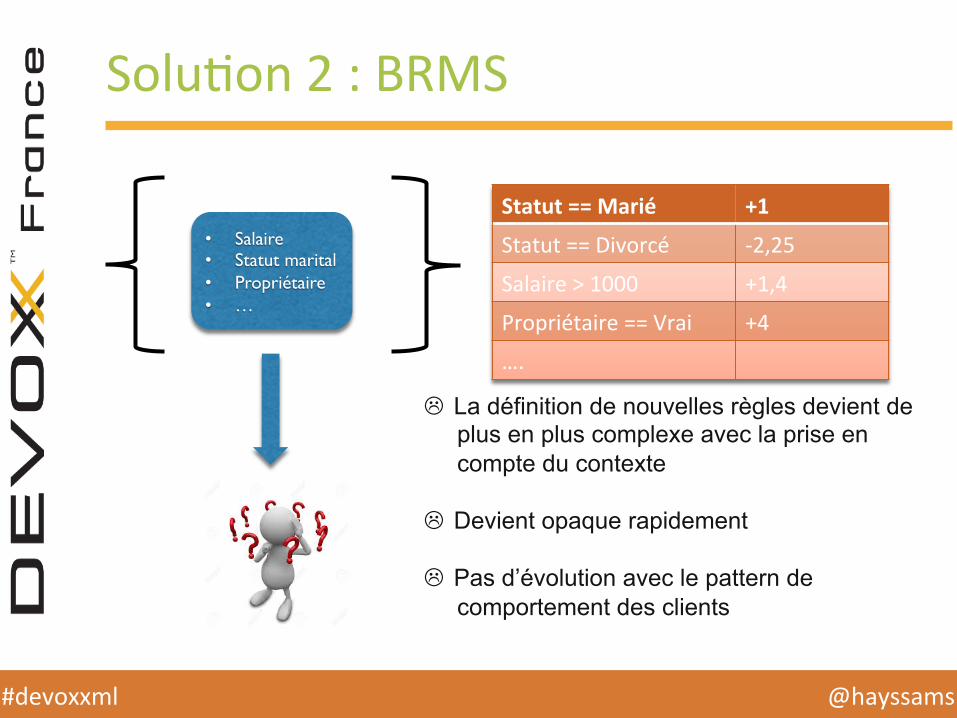
SoluHon 2 : BRMS
• Salaire• Statut marital• Propriétaire• …
L La définition de nouvelles règles devient de plus en plus complexe avec la prise en compte du contexte
L Devient opaque rapidement
L Pas d’évolution avec le pattern de comportement des clients
Statut == Marié +1
Statut == Divorcé -‐2,25
Salaire > 1000 +1,4
Propriétaire == Vrai +4
….
@hayssams #devoxxml
SoluHon 3 : Machine Learning
• Salaire• Statut marital• Propriétaire• …
• Salaire• Statut marital• Propriétaire• …
• Salaire• Statut marital• Propriétaire• …
• Salaire• Statut marital• Propriétaire• …
• Salaire• Statut marita
l• Propriétaire• …• => OK / KO
Historique représentatif +
Prédicteurs significatifs +
Labels
Calcul du meilleur Algorithme de prédiction
J Précision J Autonomie J Performance J Scalabilité

@hayssams #devoxxml
Cas d’uHlisaHon
• Recommandation
• Classification de contenu en groupes prédéfinis
• Regroupement de contenus similaires
• Recherche d’association/patterns dans les actions/comportements
• Identification de topics clefs
• Détection de fraude et d’anomalies
• Ranking

@YourTwiDerHandle @YourTwiDerHandle @hayssams #devoxxml
Pourquoi Spark / MLLib

@hayssams #devoxxml
Spark : DatascienHst DevOps
Analytics d’investigation
Analytics opérationnelle
Echantillon de données
Poste de travail
Requête Ad Hoc offline
Métrique : La précision
Facilité de développement
Données de production
Cluster de serveurs
Sollicitation online continue
Métrique : Le temps de réponse
Performance
Données
Infrastructure
Contexte
Métrique
Langage

@hayssams #devoxxml
Spark : DatascienHst DevOps
Analytics d’investigation
Analytics opérationnelle

@YourTwiDerHandle @YourTwiDerHandle @hayssams #devoxxml
La préparation de l’échantillon de données
@hayssams #devoxxml
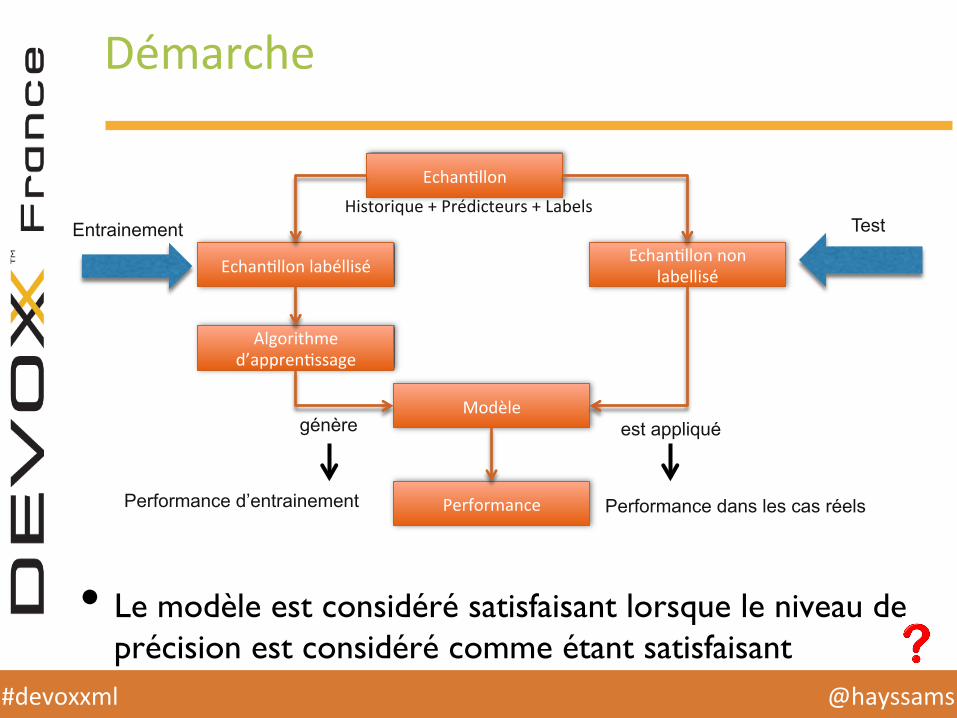
Démarche
• Le modèle est considéré satisfaisant lorsque le niveau de précision est considéré comme étant satisfaisant
EchanHllon
EchanHllon labéllisé EchanHllon non labellisé
Algorithme d’apprenHssage
Modèle
Performance
Entrainement Test
génère est appliqué
Performance d’entrainement Performance dans les cas réels
Historique + Prédicteurs + Labels
@hayssams #devoxxml
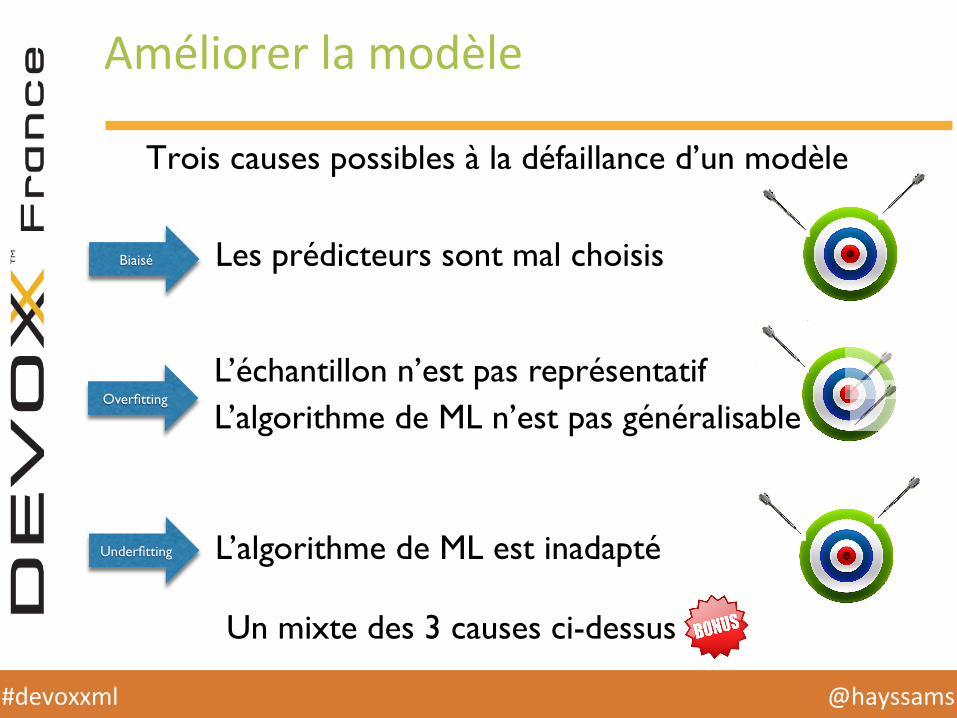
Améliorer la modèle
Trois causes possibles à la défaillance d’un modèle
Overfitting
Biaisé
Underfitting
L’échantillon n’est pas représentatifL’algorithme de ML n’est pas généralisable
Les prédicteurs sont mal choisis
L’algorithme de ML est inadapté
Un mixte des 3 causes ci-dessus
@hayssams #devoxxml
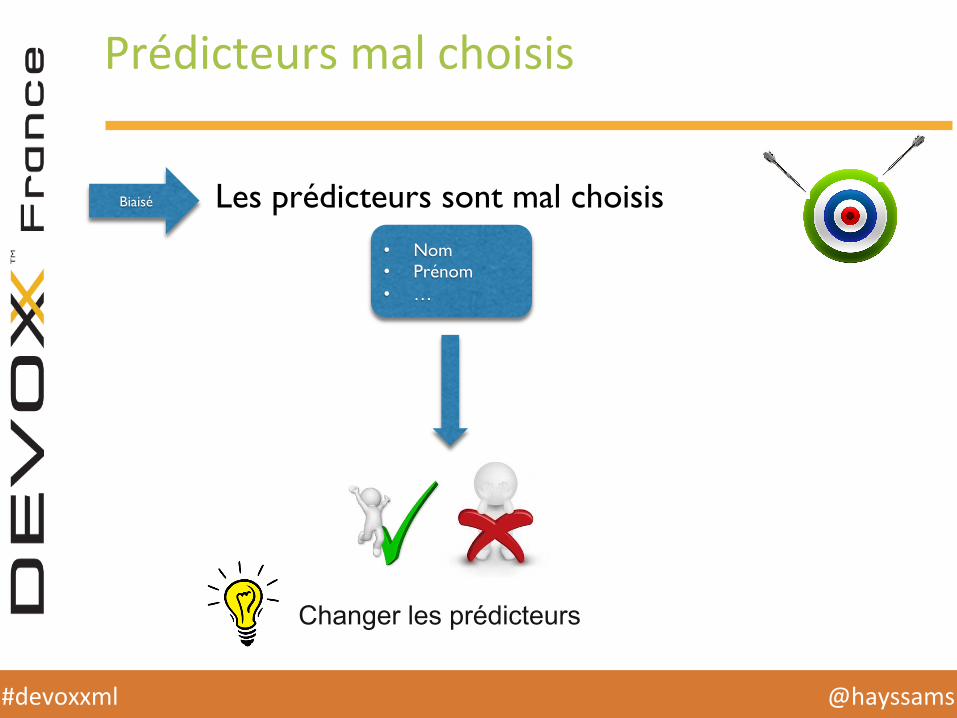
Prédicteurs mal choisis
Biaisé Les prédicteurs sont mal choisis• Nom• Prénom• …
Changer les prédicteurs
@hayssams #devoxxml
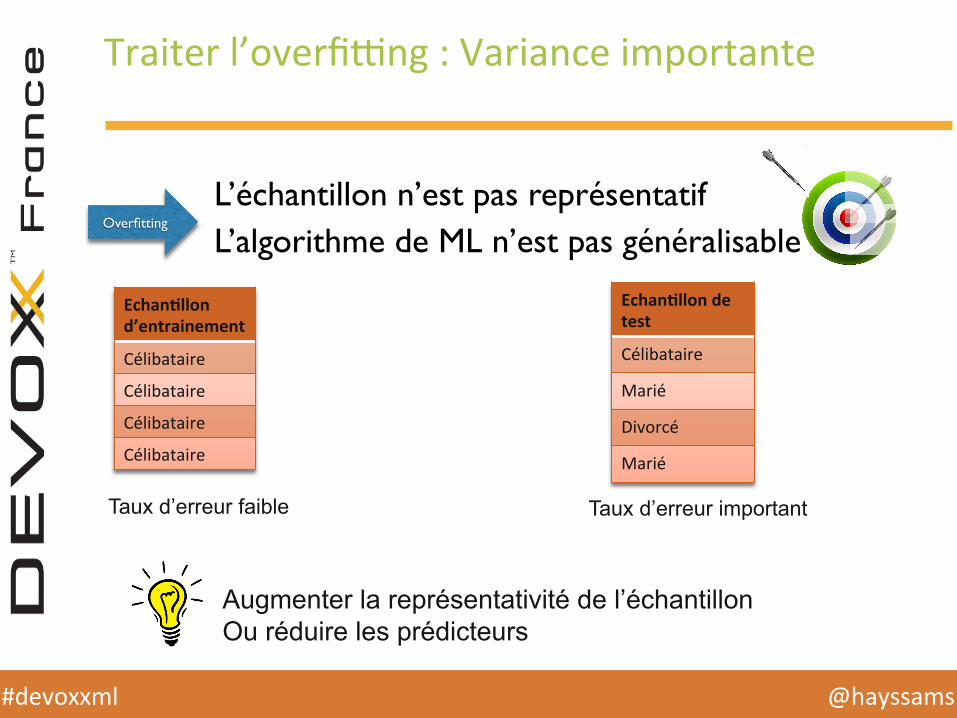
Traiter l’overfi`ng : Variance importante
Overfitting
L’échantillon n’est pas représentatifL’algorithme de ML n’est pas généralisable
Echan1llon d’entrainement
Célibataire
Célibataire
Célibataire
Célibataire
Echan1llon de test
Célibataire
Marié
Divorcé
Marié
Taux d’erreur faible Taux d’erreur important
Augmenter la représentativité de l’échantillon Ou réduire les prédicteurs
@hayssams #devoxxml
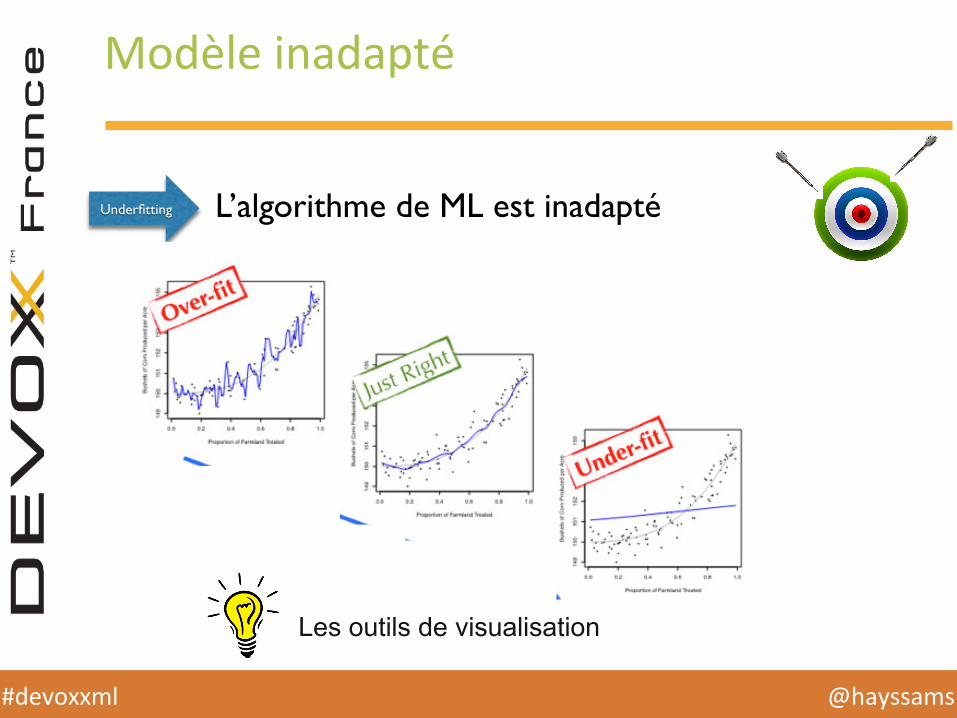
Modèle inadapté
Underfitting L’algorithme de ML est inadapté
Les outils de visualisation

@YourTwiDerHandle @YourTwiDerHandle @hayssams #devoxxml
La sélection de l’algorithme dans MLLib

@hayssams #devoxxml
ClassificaHon : ApprenHssage supervisé
Le résultat est une valeur parmi N sans ordre quelconque et dans un ensemble prédéfini
Exemple : Ce film est-il un film d’horreur ou un film d’actions ou un film romantique ?
Prédire le label de nouvelles données à partir des labels des données existantes

@hayssams #devoxxml
Régression : ApprenHssage supervisé
Le résultat est une valeur dans un ensemble de valeurs continues
Exemple : Quel est le prix prévisionnel de cet appartement dans les 6 prochains mois ?
Prédire le label de nouvelles données à partir des labels des données existantes

@hayssams #devoxxml
Clustering : ApprenHssage non supervisé
Les données en entrée de l’algorithme d’apprentissage ne sont pas labellisées
Grouper les consommateurs en fonction de leur similarité
Prédire le label de données existantes à partir de leurs prédicteurs

@hayssams #devoxxml
CollaboraHve filtering
Prédire l’intérêt d’un utilisateur pour un item

@hayssams #devoxxml
Fréquent PaDern Matching
Extraire les produits les plus souvent achetés ensemble dans le même panier

@YourTwiDerHandle @YourTwiDerHandle @hayssams #devoxxml
Scoring avec le meilleur arbre de décision

@hayssams #devoxxml
Recherche du meilleur arbre Prédire les labels de données futures à partir de labels de données existantes
Salaire Statut Marital Propriétaire OK/KO
100 Célibataire Oui OK
120 Marié Non OK
100 Divorcé Non KO
80 Célibataire Non KO
70 Marié Non KO
100 Célibataire Oui OK
x y
ConHnue Catégorie Binaire Label
x1 x2 x3
@hayssams #devoxxml
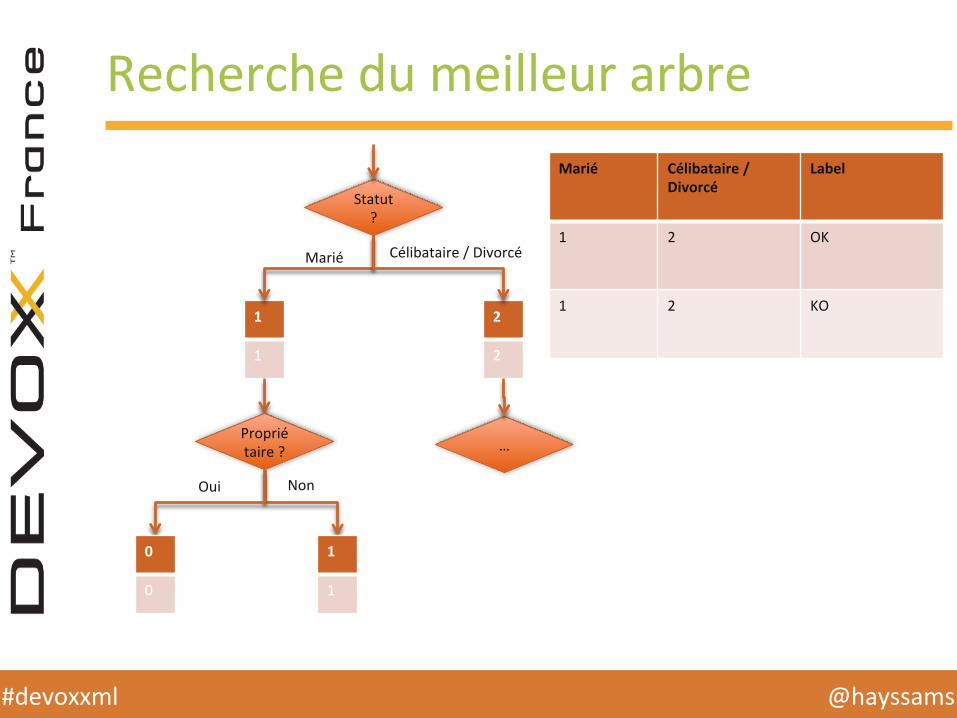
Recherche du meilleur arbre
Statut ?
1
1
2
2
Marié Célibataire / Divorcé
Marié Célibataire / Divorcé
Label
1 2 OK
1 2 KO
Propriétaire ?
Non Oui
1
1
0
0
…
@hayssams #devoxxml
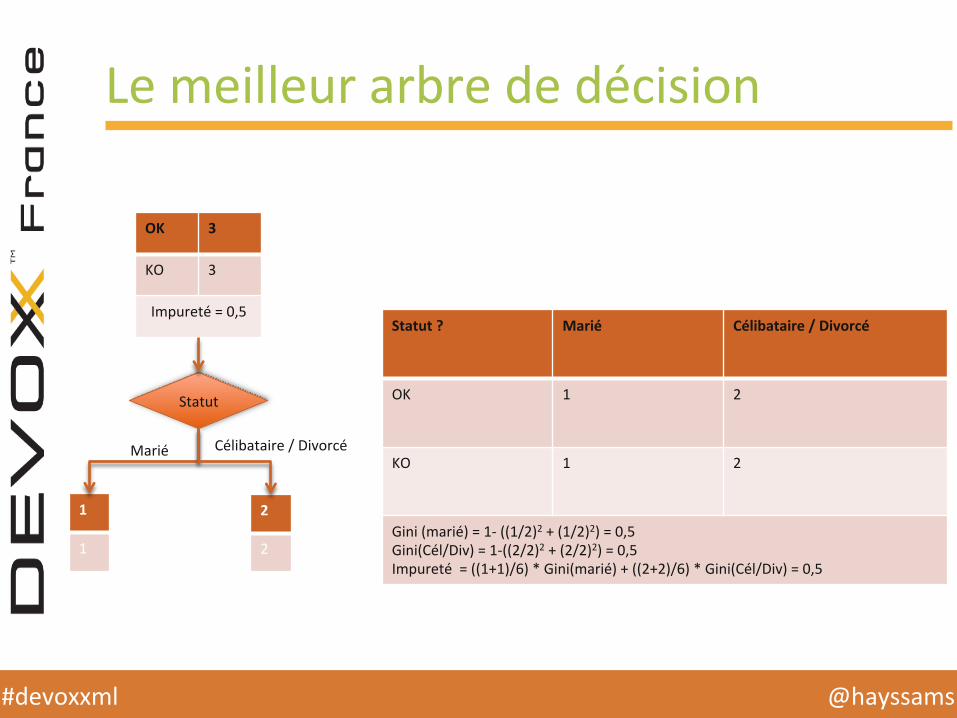
Le meilleur arbre de décision
OK 3
KO 3
Impureté = 0,5
Statut
Statut ? Marié Célibataire / Divorcé
OK 1 2
KO 1 2
Gini (marié) = 1-‐ ((1/2)2 + (1/2)2) = 0,5 Gini(Cél/Div) = 1-‐((2/2)2 + (2/2)2) = 0,5 Impureté = ((1+1)/6) * Gini(marié) + ((2+2)/6) * Gini(Cél/Div) = 0,5
1
1
2
2
Marié Célibataire / Divorcé

@hayssams #devoxxml
Le meilleur arbre de décision

@hayssams #devoxxml
Le meilleur arbre de décision
Propriétaire ? Oui Non
OK 2 1
KO 0 3
Gini (Oui) = 1-‐ ((2/2)2 + (0/2)2) = 0 Gini(Non) = 1-‐((1/4)2 + (3/4)2) = 0,375 Impureté = ((2+0)/6) * Gini(Oui) + ((1+3)/6) * Gini(Non) = 0,25
Marge d’erreur 1 -‐ max(2/2, 0/2) = 0 1 – max(1/4, 3/4) = 0,25
OK 3
KO 3
Impureté = 0,5
Propriétaire
2
0
1
3
Oui Non
UHlisaHon de l’index Gini
@hayssams #devoxxml
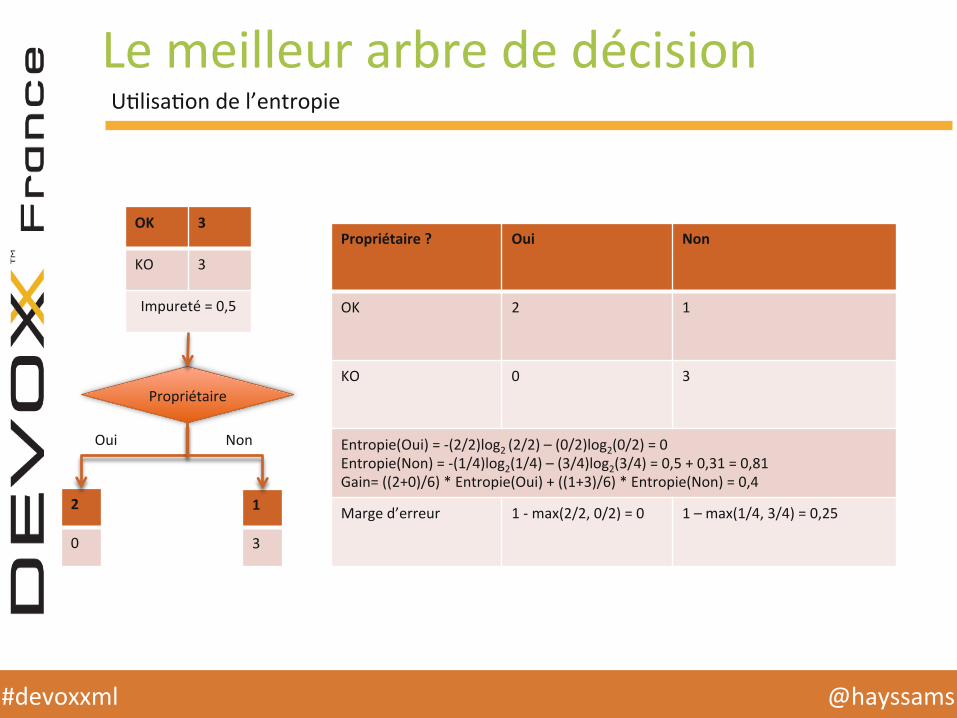
Le meilleur arbre de décision
Propriétaire ? Oui Non
OK 2 1
KO 0 3
Entropie(Oui) = -‐(2/2)log2 (2/2) – (0/2)log2(0/2) = 0 Entropie(Non) = -‐(1/4)log2(1/4) – (3/4)log2(3/4) = 0,5 + 0,31 = 0,81 Gain= ((2+0)/6) * Entropie(Oui) + ((1+3)/6) * Entropie(Non) = 0,4
Marge d’erreur 1 -‐ max(2/2, 0/2) = 0 1 – max(1/4, 3/4) = 0,25
OK 3
KO 3
Impureté = 0,5
Propriétaire
2
0
1
3
Oui Non
UHlisaHon de l’entropie

@hayssams #devoxxml
Le meilleur arbre de décision
Recherche de la meilleure condition de segmentation en s’appuyant sur l’impureté
Qu’est ce que la mesure d’impureté ? Mesure la qualité de la séparation
La segmentation s’arrête lorsque : - Tous les échantillons d’un nœud appartiennent à la même classe - Il n’y a plus de nouveaux attributs
@hayssams #devoxxml
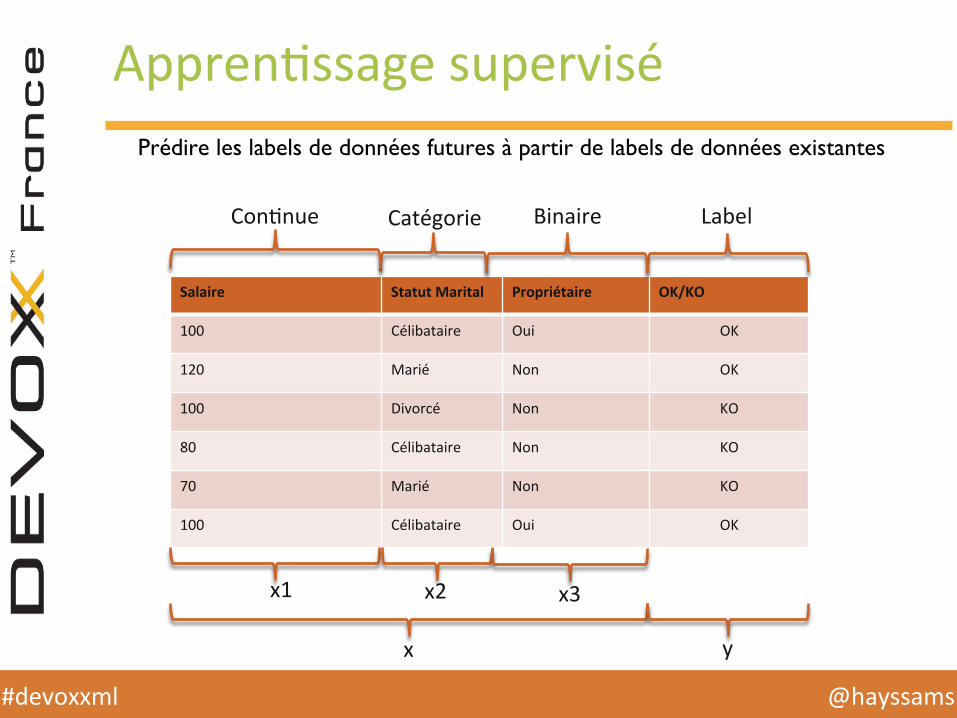
ApprenHssage supervisé Prédire les labels de données futures à partir de labels de données existantes
Salaire Statut Marital Propriétaire OK/KO
100 Célibataire Oui OK
120 Marié Non OK
100 Divorcé Non KO
80 Célibataire Non KO
70 Marié Non KO
100 Célibataire Oui OK
x y
ConHnue Catégorie Binaire Label
x1 x2 x3
@hayssams #devoxxml
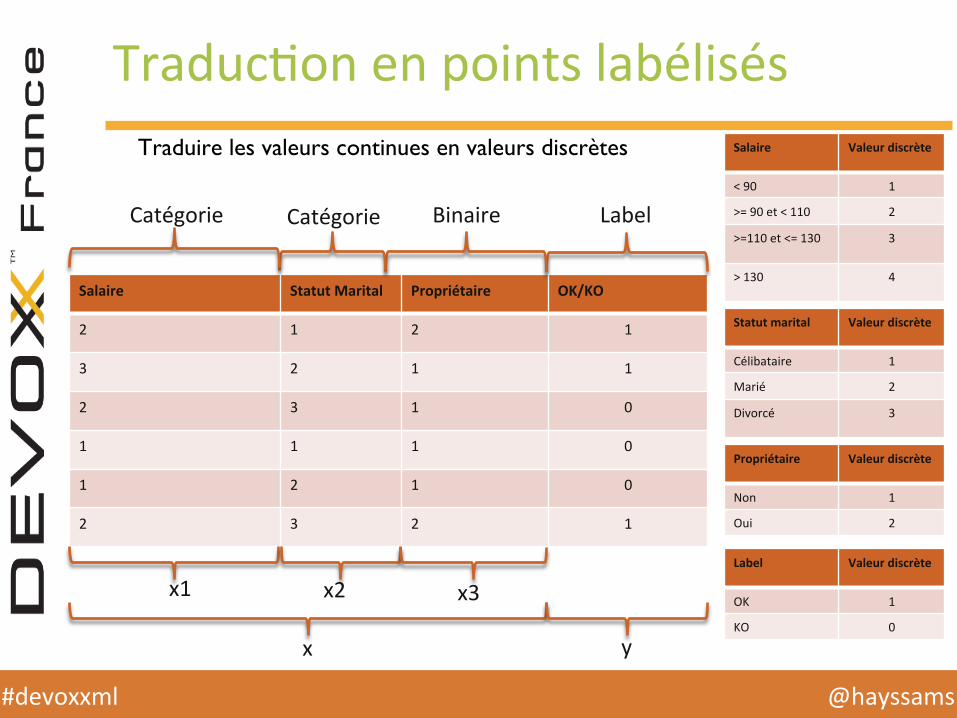
TraducHon en points labélisés Traduire les valeurs continues en valeurs discrètes
Salaire Statut Marital Propriétaire OK/KO
2 1 2 1
3 2 1 1
2 3 1 0
1 1 1 0
1 2 1 0
2 3 2 1
x y
Catégorie Catégorie Binaire Label
x1 x2 x3
Salaire Valeur discrète
< 90 1
>= 90 et < 110 2
>=110 et <= 130 3
> 130 4
Statut marital Valeur discrète
Célibataire 1
Marié 2
Divorcé 3
Propriétaire Valeur discrète
Non 1
Oui 2
Label Valeur discrète
OK 1
KO 0

@hayssams #devoxxml
Etape 1 : Chargement des données
Format du fichier Label,Salaire,Statut Marital,Propriétaire

@hayssams #devoxxml
Etape 2 : Recherche de l’arbre

@hayssams #devoxxml
Etape 3 : EvaluaHon de sa performance

@YourTwiDerHandle @YourTwiDerHandle @hayssams #devoxxml
Visualisation avec D3.js���Librairie statapss���
http://mih5.github.io/statapps/

@hayssams #devoxxml
Choix du diagramme de visualisaHon
Label
Catégorie Numérique
Prédicteur Catégorie Mosaic Plot Density Plot
Numérique BoxPlot ScaDer Plot
Permet de visualiser la force de la relation entre le prédicteur et le label
@hayssams #devoxxml
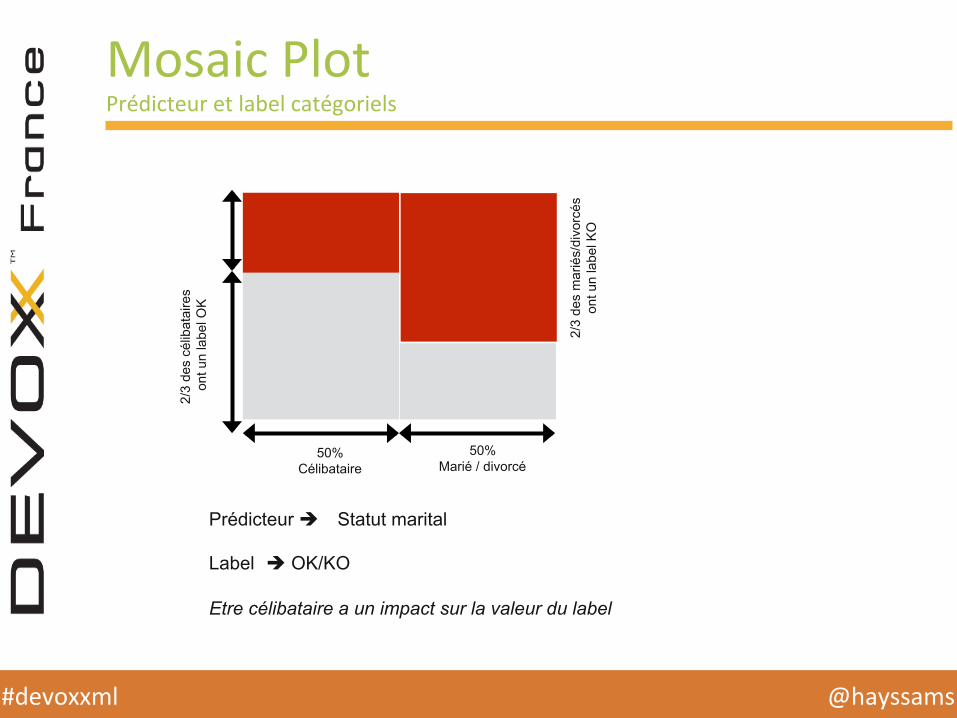
Mosaic Plot Prédicteur et label catégoriels
50% Célibataire
50% Marié / divorcé
2/3
des
célib
atai
res
ont u
n la
bel O
K
2/3
des
mar
iés/
divo
rcés
on
t un
labe
l KO
Prédicteur è Statut marital Label è OK/KO Etre célibataire a un impact sur la valeur du label
@hayssams #devoxxml
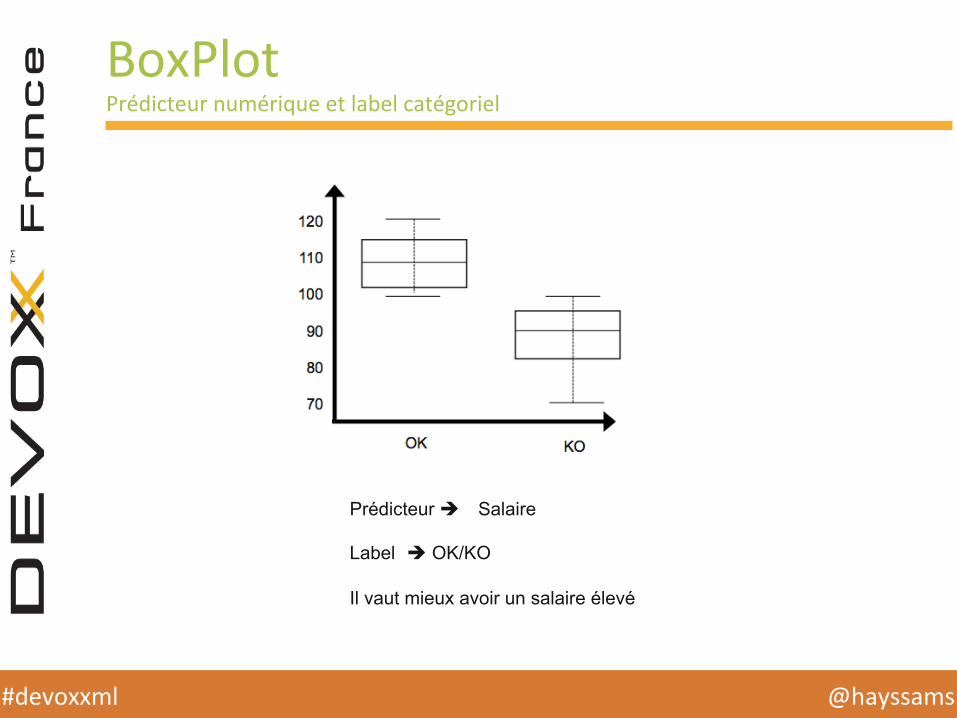
BoxPlot Prédicteur numérique et label catégoriel
Prédicteur è Salaire Label è OK/KO Il vaut mieux avoir un salaire élevé
@hayssams #devoxxml
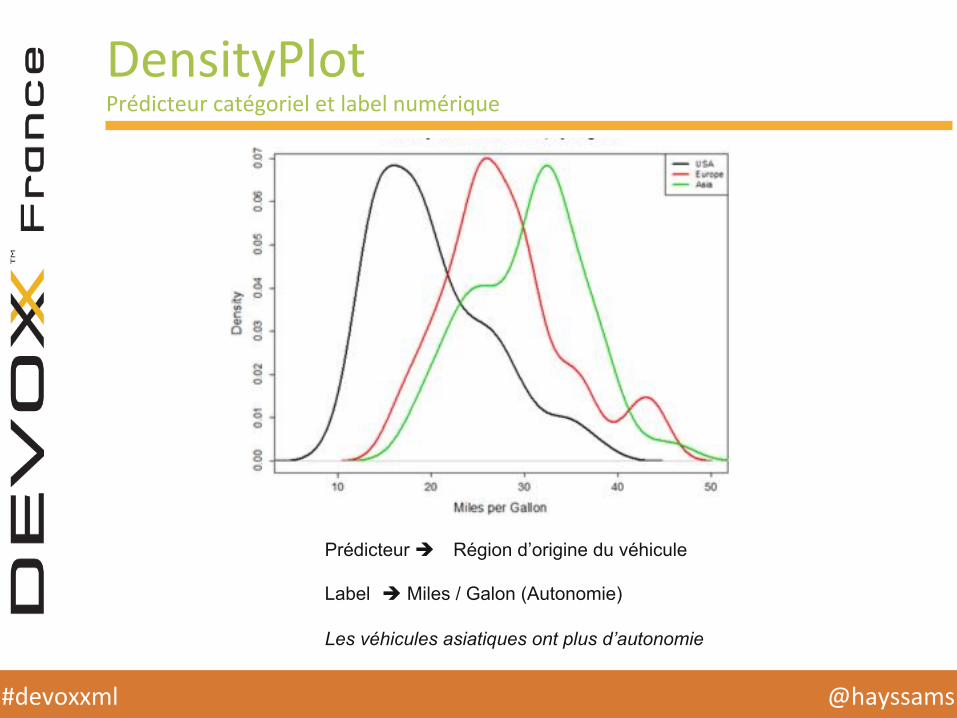
DensityPlot Prédicteur catégoriel et label numérique
Prédicteur è Région d’origine du véhicule Label è Miles / Galon (Autonomie) Les véhicules asiatiques ont plus d’autonomie
@hayssams #devoxxml
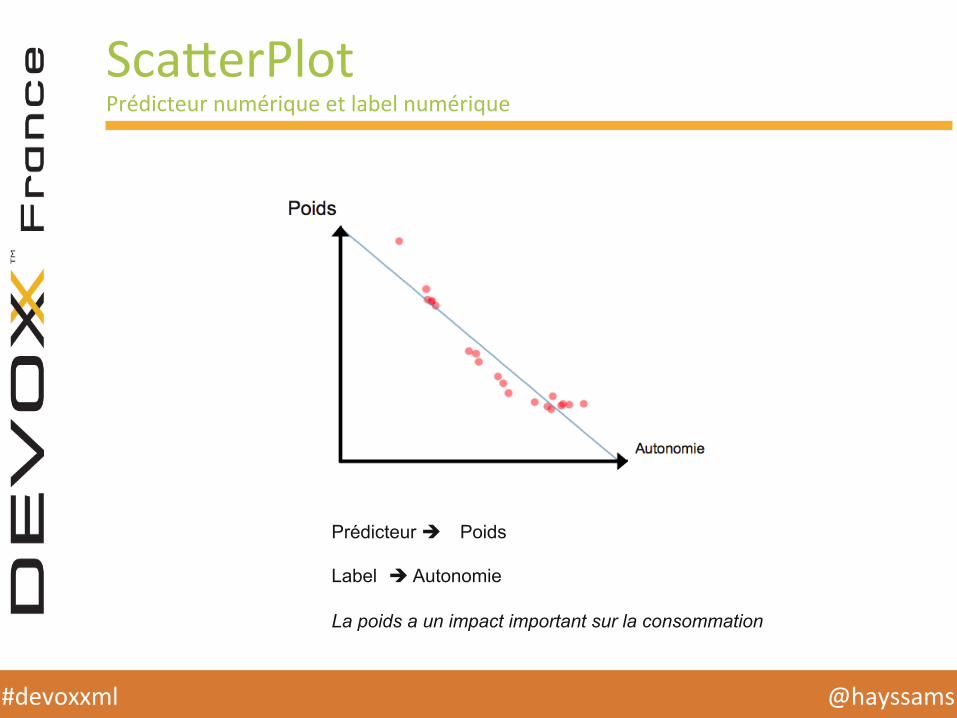
ScaDerPlot Prédicteur numérique et label numérique
Prédicteur è Poids Label è Autonomie La poids a un impact important sur la consommation

@hayssams #devoxxml
• Motivation de l’approche Machine Learning
è Précision, autonomie et performance
• Pourquoi Spark / MLLib è Briser le mur qui sépare le Datascientist du développeur
• La préparation de l’échantillon de données è Qualité des prédicteurs, Adéquation du modèle, Représentativité des échantillons
• La sélection de l’algorithme MLLib è Classification / Régression / Clustering / Collaborative Filtering / Frequent Pattern mining
• La visualisation avec D3.js
è Déterminer la nature du prédicteur et du label pour sélectionner le diagramme correspondant
Conclusion

@YourTwiDerHandle @YourTwiDerHandle @hayssams #devoxxml
Q & A