Embed Size (px)
DESCRIPTION
Information retrieval, search, vertical search, domain-specific search, faceted search, ontology, Description Logics, Medical Search, CLEF, precision-oriented search,
Citation preview

UNIVERSITE DE GENEVE UNIVERSITE JOSEPH FOURIER
Un modele de recherche d’information
oriente precision fonde sur les dimensions
de domaine
THESE
en co-tutelle presentee par
Saıd RADHOUANI
pour l’obtention des titres
Docteur es sciences economiques et sociales (Universite de Geneve)
Mention : Systemes d’Information
Docteur en informatique (Universite Joseph Fourier)
Composition du jury :
Monsieur Mohand BOUGHANEM, Universite de Toulouse
Madame Sylvie CALABRETTO, INSA Lyon
Messieurs Jean-Pierre CHEVALLET, IPAL Singapour, co-directeur de these
Yves CHIARAMELLA, Universite de Grenoble, co-directeur de these
Gilles FALQUET, Universite de Geneve, co-directeur de these
Dimitri KONSTANTAS, Universite de Geneve, president du jury
These No 671
Geneve, 2008

La Faculte des sciences economiques et sociales, sur preavis du jury, a autorise
l’impression de la presente these, sans entendre, par la, emettre aucune opinion sur
les propositions qui s’y trouvent enoncees et qui n’engagent que la responsabilite de
leur auteur.
Geneve, le 18 juillet 2008
Le doyen
Bernard MORARD
Impression d’apres le manuscrit de l’auteur.
c© Saıd Radhouani 2008. Tous droits reserves.
i

Remerciements
C’est un grand plaisir pour moi de remercier toutes les personnes qui ont permis
a ce travail d’etre ce qu’il est.
Je remercie tout d’abord M. Dimitri Konstantas qui m’a fait l’honneur de presider
le jury de cette these.
Je tiens ensuite a remercier Mme Sylvie Calabretto ainsi que M. Mohand Bou-
ghanem pour avoir accepte de rapporter mon travail de these, ainsi que pour l’interet
qu’ils ont manifeste a son egard.
Je tiens a adresser mes plus vifs remerciements a M. Yves Chiaramella de m’avoir
encadre pendant mon travail de these. Il a su me transmettre sa passion pour le do-
maine de la Recherche d’Information et je lui en suis profondement reconnaissant.
Je voudrais egalement remercier M. Jean-Pierre Chevallet d’avoir accepte de co-
diriger mon travail de these malgre les milliers de kilometres qui nous separaient. Sa
patience et ses nombreuses remarques tres pertinentes m’ont ete des plus precieuses
durant ce travail.
Durant ma these, j’ai eu la toute grande chance de connaıtre et de travailler avec
M. Gilles Falquet, un directeur de these exceptionnel tant pour ses competences
scientifiques que pour ses qualites humaines. Sans sa patience, sa disponibilite et son
appui de tous les instants, cette these n’aurait probablement jamais vu le jour. Je
lui en suis donc tres profondement reconnaissant.
Je remercie les membres du laboratoire IPAL-I2R, en particulier Dr. Joo-Hwee
Lim, pour leurs conseils et leurs soutiens tout au long de mon stage a Singapour.
Je remercie aussi les membres de l’equipe MRIM pour leurs remarques et leurs
questions pertinentes lors des reunions de travail.
Un grand merci a tous les membres du groupe ISI pour les moments agreables
ii

que l’on a toujours partages : les moments sympathiques passes a “La Petite Italie”,
les pauses the, les branches Cailler, les ecoles de printemps, et tellement d’autres
choses dont je ne peux faire la liste. Merci tout particulierement a Claire-Lise pour
sa disponibilite, son ecoute, et son soutien permanent. Merci a Jean-Pierre pour les
corrections multiples de mon manuscrit, et les discussions sur l’histoire et la physique
(dont les fameux trous noirs). Un grand merci a Jacques pour ses conseils et sa colla-
boration qui m’ont ete d’une grande utilite pendant mon travail et me seront d’une
grande utilite dans toute ma vie. Merci a Mathieu pour les longues discussions que
l’on a eues sur la logique descriptive. Merci aussi a Claudine, Gabriela, Jean-Claude,
Kaveh, Luka, Mustapha et Patrick pour toutes sortes de raisons qu’il serait trop long
d’enumerer ici.
Je remercie egalement Evelyne Kohl, Marie-France Culebras et Celine Marleix-
Bardeau pour leur soutien administratif, ainsi que Daniel Agulleiro et Nicolas Mayen-
court, Ingenieurs systeme du CUI, pour leur disponibilite permanente.
Je tiens a adresser mes plus sinceres remerciements a toute la famille Falquet en
temoignage de ma profonde reconnaissance pour son hospitalite, son encouragement
et son soutien permanent tout au long de mon sejour a Geneve.
Je remercie mon oncle Mustapha Kouki en reconnaissance de son interminable
encouragement et de ses precieux conseils.
Je remercie egalement mon instituteur M. Othman Bouzidi, a qui je dois tout ce
que je suis.
Je tiens a remercier mon cousin Badra pour son soutien pendant mon sejour en
France.
Mes sinceres remerciements a Jonas pour sa comprehension, son soutien, et sa
patience en partageant mes periodes difficiles.
Je tiens a remercier toute ma famille pour son encouragement constant ; avec une
mention speciale a mes parents en temoignage de ma profonde reconnaissance pour
leur patience et tous les sacrifices qu’ils ont consentis a mon egard. Un grand merci
iii

a Radhouane, Haykel, Marouane et l’adorable Amira pour leur soutien, encourage-
ment, et tellement de merveilleuses choses.
J’adresse mes sinceres remerciements a Takoua qui a su me reconforter et soute-
nir pendant la derniere ligne droite de ma these.
Je remercie enfin tous mes amis (Isaac, Michael, Ramzi, Rim, . . .) et tous ceux
que j’aime et qui m’aiment.
iv

Resume
Nous nous interessons a un contexte de Recherche d’Information (RI) dans des mi-
lieux professionnels, ou les besoins d’information sont formules a travers des requetes
precises. Notre travail consiste a definir un modele de RI capable de resoudre ce type
de requetes.
Notre approche est fondee sur les dimensions de domaine. Celles-ci sont definies a
travers des ressources externes, et utilisees pour produire une representation precise
du contenu semantique des documents et des requetes.
Nous definissons notre modele en utilisant la logique de descripton (LD). Nous
profitons de l’algorithme de calcul de subsomption offert par la LD afin de definir
la fonction de correspondance mettant en œuvre la pertinence systeme. A travers
cet algorithme, la LD offre une capacite de raisonnement qui permet de deduire
des connaissances implicites a partir de celles representees explicitement dans la
ressource externe, et permet ainsi de retrouver des documents pertinents pour une
requete meme s’ils ne partagent pas les memes concepts que cette derniere.
Afin de tester la faisabilite de notre approche, une serie d’experiences a ete ef-
fectuee sur la collection ImageCLEFmed-2005. Ces experiences nous ont permis de
savoir jusqu’a quel point notre modele peut etre applique, et quelles sont les limites
formelles et techniques qui lui sont liees.
Afin d’evaluer l’apport de l’usage des dimensions en termes de performance
de recherche, nous avons mene une deuxieme serie d’experiences sur la collection
ImageCLEFmed-2005. Les resultats obtenus nous ont permis de conclure que la
prise en compte des dimensions est un moyen efficace pour la resolution des requetes
precises.
Mots cles : Recherche d’Information, requetes precises, recherche multi-dimensions
(multi-facettes), dimensions de domaine, ressources externes, indexation semantique,
Logique de description.
v

Abstract
We are interested in a context of Information Retrieval (IR) in professional envi-
ronments, where information needs are expressed through precise queries. Our goal
is to define an IR model capable to solve such queries.
Our approach is based on domain dimensions. These are defined through external
resources, and used to produce a precise representation of the semantic content of
documents and queries.
We define our model using the description logic (DL). We take advantage of the
algorithm for computing subsomption offered by the LD, in order to define the mat-
ching function implementing the system’s relevance. Through this algorithm, the DL
has a capacity of reasoning which can deduce implicit knowledge from those expli-
citly represented in the external resource, and thus find relevant documents for a
query even if they do not share the same concepts with this query.
In order to test the feasibility of our approach, a series of experiments was carried
out on the ImageCLEFmed-2005 collection. These experiences have enabled us to
know the extent to which our model can be applied, and what are the formal and
technical limits associated with it.
In order to evaluate the contribution of the use of dimensions in terms of retrieval
performance, we conducted a second series of experiments on the ImageCLEFmed-
2005 collection. The obtained results have shown that taking into account dimensions
is an effective way to solve precise queries.
Keywords : Information Retrieval, precise queries, multi-dimensional (faceted)
search, domain dimensions, external resources, semantic indexing, Description Logic.
vi

Table des matieres
1 Introduction generale 1
1.1 Preambule . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Modeles de RI bases sur les mots-cles . . . . . . . . . . . . . . . . . . 2
1.3 Modeles de RI bases sur les concepts . . . . . . . . . . . . . . . . . . 4
1.4 Vers un modele de RI base sur les dimensions de domaine . . . . . . . 7
1.5 Problematique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.6 Plan de la these . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2 Ressources externes et dimensions de domaine 15
2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.2 Ressources externes & RI . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.2.1 Credibilite des approches basees sur les ressources externes . . 17
2.2.2 Exemple de ressource externe utilisee en RI : WordNet . . . . 18
2.3 Usage des ressources externes pour la representation des documents . 19
2.3.1 La desambiguısation . . . . . . . . . . . . . . . . . . . . . . . 20
2.3.2 Indexation conceptuelle/semantique . . . . . . . . . . . . . . . 23
2.3.3 Evaluation de la desambiguısation . . . . . . . . . . . . . . . . 33
2.4 Usage des ressources externes pour l’expansion des requetes . . . . . . 39
2.4.1 Expansion de requetes basee sur les relations lexico-semantiques
de WordNet . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
2.4.2 Utilisation de WordNet pour une expansion “guidee” de requetes 43
2.4.3 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
2.5 Dimensions & RI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
2.5.1 Le paradigme de la recherche basee sur les facettes . . . . . . 46
2.5.2 Outils bases sur le paradigme de recherche multi-facettes . . . 48
2.5.3 Fabrication des dimensions/facettes . . . . . . . . . . . . . . . 50
vii

2.5.4 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
2.6 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
3 Un Modele de RI fonde sur les dimensions de domaine 57
3.1 Preambule . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3.2 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
3.3 Specificites du modele . . . . . . . . . . . . . . . . . . . . . . . . . . 61
3.3.1 Exemples typiques de besoins d’information precis . . . . . . . 62
3.3.2 Vers un modele de RI oriente precision . . . . . . . . . . . . . 67
3.4 La logique descriptive . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
3.4.1 Syntaxe et semantique du langage ALCQ . . . . . . . . . . . . 70
3.4.2 Logique Descriptive et Recherche d’Information . . . . . . . . 72
3.5 Modele de RI : notation et definitions . . . . . . . . . . . . . . . . . . 73
3.5.1 Ressource externe . . . . . . . . . . . . . . . . . . . . . . . . . 73
3.5.2 Indexation des documents . . . . . . . . . . . . . . . . . . . . 76
3.5.3 Formulation de la requete . . . . . . . . . . . . . . . . . . . . 77
3.5.4 Correspondance entre la requete et le document . . . . . . . . 77
3.6 Modele de RI oriente precision . . . . . . . . . . . . . . . . . . . . . . 78
3.6.1 Modele de document . . . . . . . . . . . . . . . . . . . . . . . 79
3.6.2 Modele de requete . . . . . . . . . . . . . . . . . . . . . . . . 83
3.6.3 Evaluation des requetes . . . . . . . . . . . . . . . . . . . . . 95
3.7 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
4 Mise en œuvre du modele 99
4.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
4.2 Etapes necessaires pour la mise en œuvre du modele . . . . . . . . . . 100
4.2.1 E1 : Identification des elements de dimension . . . . . . . . . . 100
4.2.2 E2 : Indexation pour la correspondance . . . . . . . . . . . . . 101
4.2.3 E3 : Selection des documents . . . . . . . . . . . . . . . . . . 101
4.2.4 E4 : Indexation pour l’ordonnancement . . . . . . . . . . . . . 102
4.2.5 E5 : Ordonnancement des documents . . . . . . . . . . . . . . 102
4.3 Realisation des etapes necessaires pour la mise en œuvre du modele . 102
4.3.1 Realisation des etapes E2 & E3 . . . . . . . . . . . . . . . . . 103
4.3.2 Realisation des etapes E4 & E5 . . . . . . . . . . . . . . . . . 109
4.4 Experimentations sur la collection CLEF-2005 . . . . . . . . . . . . . 110
viii

4.4.1 Contexte des experimentations . . . . . . . . . . . . . . . . . . 110
4.4.2 Mise en œuvre du modele a base de la logique descriptive sur
la collection ImageCLEFmed-2005 . . . . . . . . . . . . . . . . 114
4.4.3 Definition des elements de dimensions par des mots . . . . . . 120
4.4.4 Definition des elements de dimensions par des concepts . . . . 124
4.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
5 Conclusion 133
5.1 Apport theorique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
5.2 Apport pratique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
5.3 Perspectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
ix

Table des figures
1.1 Objectif et processus de la Recherche d’Information . . . . . . . . . . 3
1.2 Schema global de notre approche . . . . . . . . . . . . . . . . . . . . 12
1.3 Dimensions de domaine stockees dans une ressource externe . . . . . 13
2.1 Denotation d’un concept par un ensemble de termes synonymes dans
differentes langues. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.2 Enonce de la requete 122 de la collection TREC-1 . . . . . . . . . . . 41
2.3 Interface d’acces multi-vues [38][39] . . . . . . . . . . . . . . . . . . . 48
2.4 Interface multi-facettes du systeme Flamenco . . . . . . . . . . . . . . 50
3.1 Correspondance entre une requete et un document representes en lo-
gique descriptive. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
3.2 Representation graphique du modele de document . . . . . . . . . . . 82
3.3 Calcul de la correspondance entre un document doc et une requete q
au niveau de l’indexation pour la correspondance . . . . . . . . . . . 96
3.4 Calcul du RSV entre une requete et un document au niveau de l’in-
dexation pour l’ordonnancement . . . . . . . . . . . . . . . . . . . . . 97
4.1 Representation graphique des etapes necessaires pour la mise en œuvre
du modele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
4.2 Exemple pour la mise en œuvre du modele . . . . . . . . . . . . . . . 103
4.3 Representation graphique du modele de document . . . . . . . . . . . 105
4.4 Representation graphique de la T-Box . . . . . . . . . . . . . . . . . 107
4.5 Calcul de la correspondance entre un document doc et une requete q . 108
4.6 La hierarchie de subsomption fabriquee par le raisonneur Pellet . . . 109
4.7 Calcul du RSV entre une requete et un document au niveau de l’in-
dexation pour l’ordonnancement . . . . . . . . . . . . . . . . . . . . . 110
4.8 Exemple de requete de la collection ImageCLEFmed-2005 . . . . . . . 111
x

4.9 Premier niveau de la structure hierarchique de MeSH . . . . . . . . . 113
4.10 Resultats experimentaux de la prise en compte des elements de di-
mensions definis par des mots . . . . . . . . . . . . . . . . . . . . . . 124
4.11 Variations des performances de notre systeme applique sur trois index
differents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
xi

Liste des tableaux
2.1 Pourcentage des documents corrects retrouves en premiere position [32] 37
3.1 Syntaxe et semantique du langage ALCQ. . . . . . . . . . . . . . . . 71
4.1 Comparaison des resultats de notre approche avec le baseline. . . . . 122
4.2 Comparaison des resultats de notre approche avec le baseline. . . . . 127
4.3 Variations des performances de notre systeme applique sur trois index
differents. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
xii

Chapitre 1
Introduction generale
1.1 Preambule
Depuis l’apparition de l’informatique, les connaissances stockees sur support
numerique n’ont cesse de s’accumuler, et le nombre des documents qui les stockent
s’accroıt tres rapidement. Nous arrivons ainsi a une situation parfaitement contradic-
toire : jamais il n’y a eu autant d’informations disponibles, mais trouver dans cette
accumulation, precisement ce que l’on recherche, devient de plus en plus ardu.
Devant le nombre important de documents disponibles, la recherche sequentielle1
est bien sur tres limitee et l’acces a l’information base sur une requete semble plus
efficace. Ainsi, la Recherche d’Informations (RI) devient davantage cruciale et les
Systemes de Recherche d’Information (SRI) deviennent une aide inestimable pour
rechercher une information.
La RI est un processus qui, a partir d’une requete (expression des besoins en
information d’un utilisateur), permet de retrouver l’ensemble des documents conte-
nant l’information recherchee. La mise en œuvre de ce processus passe par une
specification d’un modele de RI integrant : i) une representation des documents ;
ii) une representation de la requete ; et iii) un appariement entre le document et la
requete. Plusieurs modeles ont ete proposes dans la litterature dont l’objectif com-
mun est de satisfaire au mieux les besoins de l’utilisateur. Chacun de ces modeles se
differencie par sa maniere de representer les documents et la requete, et de les mettre
en correspondance. Ceci depend generalement du contexte de la recherche : la na-
1En explorant manuellement une collection de documents.
1

ture du besoin de l’utilisateur, sa maniere d’exprimer son besoin, ses exigences, les
connaissances qu’il a sur le domaine2 et les documents, etc. Dans la section suivante,
nous detaillons les principes de base de ces modeles et presentons leurs limites.
1.2 Modeles de RI bases sur les mots-cles
L’objectif de la RI est de selectionner les documents qui traitent le mieux pos-
sible du theme de la requete (cf. Figure 1.1). A notre connaissance, il n’y pas de
consensus sur la notion de theme en RI. Dans notre these, nous adoptons la definition
suivante : un theme est une idee, un sujet developpe dans un discours, un ecrit, un
ouvrage3.
Pour atteindre l’objectif precite, les approches existantes4 en RI textuelle s’ap-
puyent sur des methodes purement statistiques basees sur les distributions de mots-
cles, pour calculer la similarite entre la requete et les documents du corpus. La
pertinence d’un document par rapport a une requete est calculee en fonction de
la similarite du vocabulaire et non pas en fonction de la similarite thematique qui
existe entre le document et la requete. En effet, pour qu’un document soit selectionne
par le systeme, il doit partager les memes mots (du moins une partie d’entre eux)
avec la requete. Dans le cas du modele booleen, pour etre selectionne, le document
doit contenir tous les mots (conjonction) ou une partie des mots (disjonction) de la
requete. Dans le modele vectoriel, plus un document partage des mots avec la requete
et dans la meme proportion de poids, plus il est pertinent pour cette requete. En
realite, un document peut etre pertinent meme s’il ne partage pas les memes mots
avec la requete. Par exemple, un document contenant le mot “voiture” peut consti-
tuer une reponse pertinente a une requete contenant le mot “automobile”, meme si
le mot “automobile” n’existe pas dans le document. Salton a souligne ce probleme
ou les auteurs de documents et les utilisateurs des SRI utilisent une grande variete
de mots pour denoter le meme concept [75]. Ce probleme, qualifie de term mismatch
ou word mismatch [25][103], est du au fait que l’analyse purement statistique, sur
laquelle est basee la fonction de correspondance, permet seulement l’extraction des
2Selon le dictionnaire de l’Academie francaise, un domaine est tout ce qu’embrasse un art, une
science, une faculte de l’esprit, etc. (exemples : le domaine de la peinture, de la sculpture, de lapolitique, etc.).
3Definition donnee par le Centre National de Ressources Textuelles et Lexicales.4Basees sur les modeles classiques de RI.
2

descripteurs mais pas leur signification.
Fig. 1.1 – Objectif et processus de la Recherche d’Information
Ainsi, nous observons un fosse entre l’objectif de la RI et la methode qui la realise :
les techniques de RI existantes traitent essentiellement le signifiant, mais tres peu
le signifie. En effet, l’objectif de la RI est de retrouver des documents qui traitent
du theme de la requete, c’est-a-dire, dont le contenu semantique est similaire a
celui de la requete. Mais en pratique, la mise en œuvre des SRI est faite de facon a
ce que ces systemes recherchent les documents partageant les memes mots avec la
requete. Dans ce cas, soit les modeles de RI sous-jacents ignorent le sens des mots
(signifie), soit ils supposent implicitement qu’il y a une correspondance stricte entre
les mots (signifiants) et les sens (signifies). Cette derniere supposition est erronee car
un signifie peut etre exprime par differents signifiants, et un signifiant peut expri-
mer plusieurs signifies differents (selon le contexte). Par exemple, pour une requete
contenant le mot “Java” (langage de programmation), le systeme peut completement
ignorer le sens du mot Java et retourner des documents qui parlent de l’ıle de Java
situee en Indonesie.
Il est clair que les SRI bases sur les modeles de RI classiques ont fait beaucoup de
progres pour representer et comparer la requete et les documents. Nous avons quand
3

meme constate, dans les campagnes d’evaluation (TREC5, NTCIR6, CLEF7, etc.),
que la plupart des systemes semblent avoir atteint leurs limites de performances, bien
que la marge d’amelioration semble encore grande (selon les mesures utilisees pour
l’evaluation). Ceci est une indication que les optimisations de nature essentiellement
statistiques des modeles existants ont atteint leurs limites.
Il nous apparaıt qu’une amelioration supplementaire des performances des SRI
requiert l’utilisation de connaissances externes8 a celles du corpus, notamment grace
a la disponibilite croissante des ressources qui les stockent (dictionnaire, thesaurus,
ontologie, etc.). Un certain nombre de ces ressources ont rencontre beaucoup de
succes dans le domaine de RI, que ce soit dans des domaines specialises (ex. MeSH
et UMLS pour le domaine medical), ou dans un domaine generaliste (ex. WordNet).
Grace a l’apparition de nouvelles ressources dans des domaines de plus en plus divers
(geographie, genomique, droit, etc.), cette tendance ne cesse de s’amplifier.
1.3 Modeles de RI bases sur les concepts
Parmi les travaux de recherche qui ont essaye de surmonter les limites presentees
dans la section precedente, il existe une approche de RI dite “basee-concepts” (Conce-
pt-Based Information Retrieval).
Selon les communautes (Intelligence Artificielle, Philosophie, Linguistique, Scien-
ce de la cognition, etc.), il existe differentes definitions de la notion de concept [31].
De facon generale, un concept est un objet mental (son milieu, c’est l’esprit hu-
main) qui peut etre defini comme une abstraction generalisee a partir de proprietes
communes a des objets concrets (leur milieu, c’est la realite telle qu’on la ren-
contre). En d’autres termes, une conceptualisation est une abstraction qui consiste
a analyser la realite pour en tirer les proprietes pertinentes qui permettent de passer
du particulier au general. Un concept possede une extension et une comprehension.
L’extension est l’ensemble des objets qui possedent les proprietes correspondant au
concept. En d’autres termes, c’est la quantite de realite a laquelle le concept se rap-
5http ://trec.nist.gov/6http ://research.nii.ac.jp/ntcir/7http ://www.clef-campaign.org/8“externes” car non presentes dans les documents a traiter, du moins sous une forme explicite
et complete.
4

porte. Par exemple, le concept “Personne” a une plus grande extension que le concept
“Femme”. La comprehension quant a elle est l’ensemble des proprietes qui donnent
son contenu a un concept (l’ensemble des proprietes qui caracterisent les objets du
concept). Elle varie en fonction inverse de l’extension. Par exemple, le concept “Fem-
me” a une comprehension plus grande que le concept “Personne” (on peut enumerer
plus de proprietes a son sujet).
Un concept est construit par l’etre humain d’une maniere non-ambigue, indepen-
damment des langues, des supports et des formalismes de representation [18]. Meme
s’il est exprime a travers une forme materielle (des mots), le concept n’est pas
materiel.
En considerant cette definition, il est tres difficile pour une machine d’extraire
des concepts a partir d’une source numerique. Cependant, il est possible d’associer
un concept a des elements decrits dans des documents numeriques (textes, images,
etc.). C’est pour cette raison pratique qu’en RI la notion de concept est souvent
liee au sens des mots : un concept correspond a une signification particuliere d’un
mot (ou sequence de mots). De son cote, un terme est une paire (mot ou sequence
de mots, concept). C’est-a-dire, un terme est constitue d’un mot (ou sequence de
mots) qui sert pour denoter un concept dans un domaine particulier. Le mot, quant
a lui, est l’unite du discours oral ou ecrit. Dans des langues comme le francais ou
l’anglais ecrits, le mot est represente par une sequence de lettres entre deux blancs.
Pour alleger l’ecriture, nous utilisons “terme” egalement pour designer le mot ou la
sequence de mots correspondant a un terme.
Une approche de RI basee-concepts se caracterise par la notion d’espace concep-
tuel dans lequel les documents et les requetes sont representes par opposition a l’es-
pace de mots simples utilises dans les modeles classiques [3]. Les travaux presentes
dans le cadre de notre these se situent dans cette classe d’approches.
Nous nous interessons ici a l’amelioration de la precision en RI. A cette fin, nous
etudions l’utilisation des connaissances externes pour identifier les themes au niveau
des documents et la requete. Plus precisement, il s’agit de concevoir des modeles de
representation du contenu semantique des documents et des requetes.
5

L’utilisation des connaissances externes a fait l’objet de plusieurs travaux souvent
orientes vers l’amelioration de la precision (desambiguısation de termes, indexation
conceptuelle), et/ou vers l’amelioration du rappel (expansion de requetes). Dans ce
contexte, elles servent a expliciter le sens des termes dans le corpus en identifiant des
concepts et eventuellement des relations entre ces concepts. Ceci permet au systeme
de prendre en compte la semantique sous-jacente aux termes ; d’abord, au moment
de l’indexation, la ressource externe est utilisee pour extraire des termes faisant
reference aux entites conceptuelles traitees dans les documents ; ensuite, au moment
de l’interrogation (reformulation de requete et correspondance), elle sert a identifier
les concepts des documents denotes par les descripteurs de la requete. Enfin, son
utilisation permet d’avoir des informations supplementaires sur la semantique as-
sociee aux termes issus du contenu (document et requete), et d’aider ainsi le SRI a
interpreter le contenu semantique et a ameliorer les performances de recherche.
Cette classe d’approches presente plusieurs avantages. L’utilisateur peut faire
usage des connaissances presentes dans la ressource externe a partir de laquelle le
corpus a ete indexe. Cela peut l’aider a augmenter sa connaissance par rapport
a l’information qui lui est disponible dans le corpus. L’utilisateur peut egalement
utiliser le vocabulaire controle, present dans la ressource externe et utilise pour la
representation des documents, pour mieux exprimer son besoin. Dans ce cas, la
description du besoin d’information a les memes caracteristiques que celles des do-
cuments.
Nous pouvons dire que le principal avantage des approches basees-concepts est
que l’utilisateur et le systeme arrivent a “parler” le meme langage (celui qui cor-
respond au vocabulaire de la ressource externe utilisee). Cependant, ces approches
considerent les documents et requetes comme des sacs de concepts. Ainsi, les relations
semantiques qui peuvent exister entre les concepts ne sont pas toujours exploitees.
Ceci peut provoquer des problemes comme mentionnes dans la section precedente :
un document est considere pertinent seulement s’il partage les memes concepts de la
requete (requete initiale ou etendue). Par exemple, pour la requete donne-moi les do-
cuments qui parlent du politicien americain qui a eu le prix Nobel de la paix en 2007,
un document pertinent doit contenir le nom Al Gore. Ce document ne peut cepen-
dant pas etre retrouve par un systeme qui n’exploite pas les relations semantiques.
Pour pouvoir resoudre cette requete, un SRI a besoin de connaissances externes pour
6

inferer que Al Gore est un politicien originaire des Etats Unis, etc.
Nous pensons que le principal probleme de ces modeles de RI est qu’ils considerent
peu la structure semantique des documents (requetes) lors de l’interpretation de
leurs contenus [4][58][68][92][96]. Nous sommes convaincus, qu’en plus de decrire les
connaissances du(des) domaine(s) present(s) dans le corpus, les ressources externes
peuvent apporter des information utiles pour l’interpretation des themes developpes
dans les documents de ce corpus. Nos travaux vont actuellement dans ce sens.
1.4 Vers un modele de RI base sur les dimensions
de domaine
Dans notre travail de these, nous nous interessons a un processus de RI dont le
contexte est precise par le domaine d’interet de l’utilisateur.
Nous avons vu precedemment qu’un document qui partage les memes descrip-
teurs (que ce soient des mots ou des concepts) avec la requete n’est pas forcement
pertinent pour cette requete. Ainsi, la question que nous nous sommes posee est :
“Y a-t-il des elements, autres que les descripteurs, qu’un document doit
partager9 avec la requete pour qu’il soit considere pertinent ?”
Dans un processus de RI, l’utilisateur souffre d’un manque d’information, mais a
une idee des lacunes de ses connaissances et donc de son besoin en information. Une
premiere difficulte majeure a laquelle doit faire face un SRI est que le besoin d’infor-
mation est une chose particuliere a l’utilisateur. Comme il est rarement integre dans
le processus de RI, son besoin d’information est souvent mal interprete. Pour pouvoir
satisfaire l’utilisateur, le SRI doit d’abord “comprendre” son besoin d’information.
Une premiere question se pose alors : Q1 “comment aider le SRI a interpreter ce que
l’utilisateur essaye de decrire”. Autrement dit, en plus des descripteurs de la requete,
y a-t-il d’autres elements qui peuvent aider le SRI a avoir plus d’informations sur le
9Ce n’est pas seulement une intersection au sens simpliste du terme : ca pourrait etre uneimplication logique, ou une probabilite, etc.
7

besoin de l’utilisateur ?
Une deuxieme difficulte a laquelle doit faire face un SRI est que l’utilisateur juge
les documents qui lui sont retournes par rapport a l’interpretation de son besoin et
non pas par rapport a l’ensemble des documents du corpus susceptibles de l’interesser
[91]. Une deuxieme question se pose alors : Q2 “comment integrer l’utilisateur lors
du processus d’indexation et du calcul de pertinence des documents ?”
Pour repondre aux questions Q1 et Q2, nous avons choisi d’utiliser les connais-
sances du domaine d’interet de l’utilisateur qui peuvent etre decrites a travers des
ressources externes. Nous avons suppose que ces ressources peuvent : i) nous ren-
seigner sur les besoins de l’utilisateur pendant sa tache de recherche ; et ii) aider le
SRI a interpreter le contenu semantique du document et a calculer la pertinence en
prenant en compte la similarite thematique entre le document et la requete10.
En pratique, nous avons analyse plusieurs requetes extraites de differentes collec-
tions des campagnes d’evaluation des SRI (ex. TREC, CLEF, etc.). A titre d’exemple,
nous presentons ici deux requetes extraites de deux collections de la campagne CLEF-
2005 : la premiere est extraite de la collection multilingue Multi-8, et la deuxieme de
la collection des comptes-rendus medicaux ImageCLEFmed.
Requete 1 : “Donne-moi les documents qui parlent du general francais responsable
de la creation de la zone de securite pendant le conflit des Balkans ?”
Pour un lecteur humain, il est clair que l’on recherche des documents qui parlent
d’une personne : general francais. Un document pertinent, contenant le nom de la
personne en question, ne contient pas forcement les termes “general” et “francais”.
Pour y remedier, une solution possible est de faire une expansion “intelligente” de
la requete pour informer le systeme qu’on est a la recherche d’une personne et pas
seulement des termes “general” et “francais”. Le fait d’identifier l’element personne
dans cette requete n’est pas suffisant pour la resoudre. En effet, cet element ap-
paraıt dans un contexte particulier qui est decrit par d’autres elements. La personne
10Nous verrons dans le chapitre de l’etat de l’art que ces deux hypotheses sont inspirees decertaines idees qui ont ete deja developpees.
8

que l’on cherche a cree une zone de securite. Celle-ci a ete creee dans un lieu
geographique : les Balkans. Enfin, la creation de cette zone a eu lieu suite a un
evenement : conflit des Balkans.
Ainsi, pour interpreter le besoin d’information formule a travers la requete 1, nous
allons supposer qu’il est necessaire d’expliciter11 tous les elements-cles introduits par
l’utilisateur, et de disposer d’un langage de requete expressif pour mieux cerner ce
que l’utilisateur recherche.
Requete 2 : “Show me x-ray images with fractures of femur”
Pour un etre humain, il est clair que l’on cherche des images qui contiennent un
aspect anatomie (le femur) et un aspect pathologie (fracture). Ces deux elements,
qui sont semantiquement relies12, doivent apparaıtre dans une image dont la moda-
lite est rayon-x. Ainsi, une image au rayon-x qui contient “une fracture du crane”
ou “un femur sans fracture” est supposee non pertinente par rapport a cette requete.
De meme pour les images contenant “une fracture du femur” dont la modalite n’est
pas rayon-x.
En observant plusieurs documents (requetes) de differents domaines13, nous avons
remarque une regularite au niveau des elements qui decrivent les themes developpes
dans les documents (requetes) appartenant a un meme domaine. Par exemple, les
themes du domaine de la politique internationale peuvent etre developpes en utili-
sant des elements tels que Personne, Lieu geographique, Epoque, Evenement, etc. En
medecine, un theme peut etre developpe en utilisant des elements tels que Anatomie,
Pathologie, Stade de la maladie, Type de traitement, etc. Ainsi, nous appellerons ces
elements les dimensions de domaine et nous les definissons comme suit :
“Une dimension d’un domaine est un concept utilise pour exprimer des themes
dans ce domaine.”
11Par exemple, en procedant par une expansion “intelligente”.12En medecine, une fracture est une pathologie d’un os tel que le femur.13Medical, politique internationale, astronomie, etc.
9

Le concept associe a la dimension est en pratique general, c’est-a-dire, possede une
vaste extension et une comprehension minimale. Si l’on peut construire une hierarchie
des concepts du domaine, il devrait se trouver pres de la racine de la hierarchie, c’est-
a-dire, il aurait de nombreux sous-concepts et peu ou pas de concepts super-ordonnes.
L’idee sous-jacente a notre approche est qu’un auteur, quand il redige son docu-
ment, s’interesse a un domaine particulier pour developper un theme. Ainsi, il fait
reference a des dimensions de son domaine d’interet pour detailler l’idee exprimee
dans son document. Pour ce faire, il fait reference aux concepts relatifs aux dimen-
sions choisies. Pour denoter ces concepts dans son texte, il utilise des termes de son
domaine d’interet.
Par exemple, pour rediger un compte-rendu medical, un medecin peut faire
reference dans son texte aux dimensions “Pathologie” et “Anatomie”. Ensuite, il
fait reference a des concepts relatifs a ces dimensions, et enfin il utilise des termes
pour denoter ces concepts. Par exemple, il peut utiliser les termes “seins” et “can-
cer”, ou “femur” et “fracture”, etc.
De la meme maniere, un utilisateur s’interesse a un domaine particulier pour
decrire son besoin d’information. Il fait d’abord reference a des dimensions de son
domaine d’interet. Ensuite, il fait reference a des concepts relatifs a ces dimensions.
Enfin, il emploie des termes pour denoter ces concepts dans la requete qui exprime
son besoin d’information.
1.5 Problematique
Nous nous placons dans un contexte de recherche ou l’utilisateur decrit un be-
soin precis. Ce contexte est typiquement celui des milieux professionnels, ou les
utilisateurs ont de bonnes connaissances de leur domaine d’interet, ainsi que des
documents (comptes-rendus, textes de loi, etc.) qu’ils consultent regulierement. Lors
d’une tache de recherche, les professionnels essayent de completer l’information qu’ils
ont deja mais qui est insuffisante. Leurs besoins dans ce cas sont precis et decrits
10

a travers une terminologie specifique a leurs domaines d’interet. Par exemple, un
medecin desirant retrouver un compte-rendu, voudrait pouvoir formuler son besoin
d’information de la maniere suivante :
“Je cherche un compte-rendu sur le type de traitements a effectuer en cas d’un
cancer du sein de stade M0”.
Nous remarquons, a partir de cet exemple, que le medecin connaıt bien la ter-
minologie de son domaine, et par consequent, que la description de son besoin est
tres precise. Nous remarquons egalement qu’il se sert des dimensions de son domaine
pour decrire son besoin : anatomie, pathologie, traitement, stade de la maladie, etc.
Les professionnels sont des utilisateurs qui s’attendent a trouver une reponse
precise et de qualite a leur requete, leur permettant de realiser leur tache profession-
nelle (etablir un diagnostic, rediger un article de presse, se documenter, etc.). Afin
de permettre au systeme de retrouver des documents en meilleure adequation avec
le reel besoin de tels utilisateurs, nous pensons qu’il est necessaire de prendre en
compte les dimensions du domaine d’interet de l’utilisateur. La question principale
que nous posons ainsi est :
“Comment satisfaire, a partir de l’information “brute”14, une requete precise
formulee par un utilisateur qui s’interesse a un domaine particulier ?”
Nous denotons par le qualificateur “precise” une requete qui, au contraire d’une
requete vague, contient une terminologie tres specialisee. Elle presente une complexite
au niveau de sa structure semantique qui peut etre materialisee par un ensemble de
relations semantiques et d’operateurs15. Ce type de requete semble etre adapte a une
indexation relationnelle qui permet de prendre en compte les relations semantiques
lors de la representation du contenu du document a indexer.
L’objectif du travail decrit dans notre these est donc de definir un modele de Re-
cherche d’Information qui soit en adequation avec le contexte particulier dans lequel
14Sac de mots dans les documents textuels, etc.15Booleens, quantificateurs, etc.
11
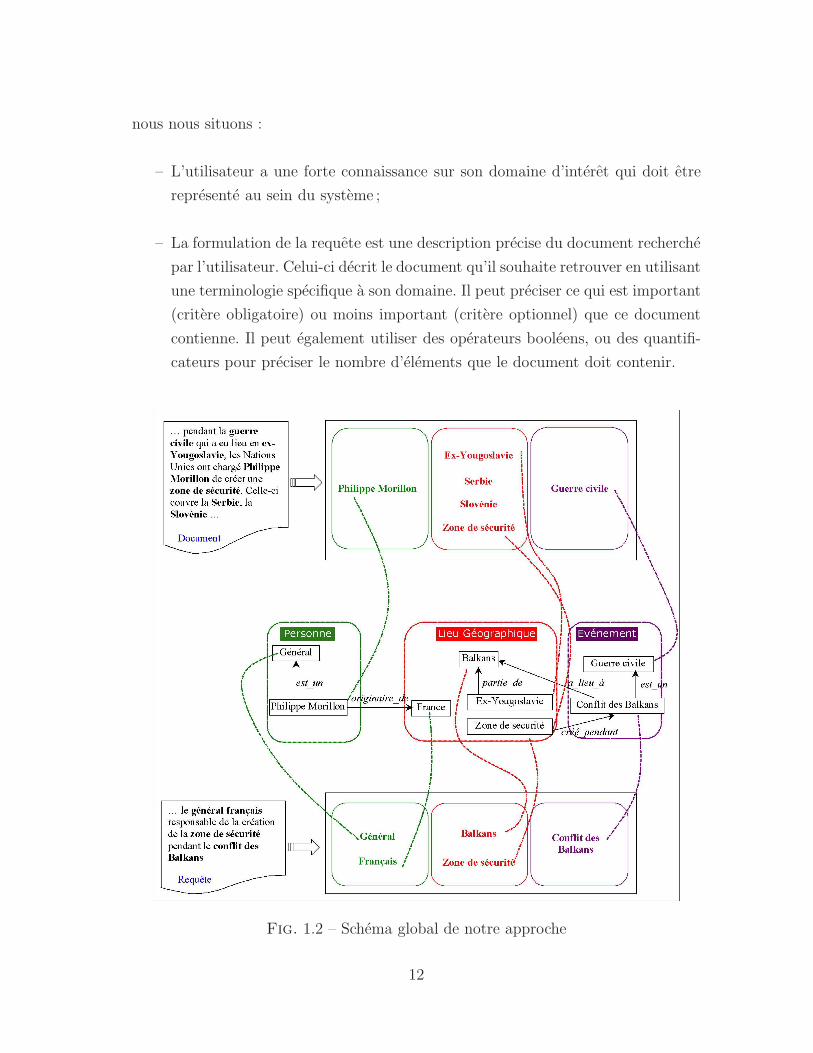
nous nous situons :
– L’utilisateur a une forte connaissance sur son domaine d’interet qui doit etre
represente au sein du systeme ;
– La formulation de la requete est une description precise du document recherche
par l’utilisateur. Celui-ci decrit le document qu’il souhaite retrouver en utilisant
une terminologie specifique a son domaine. Il peut preciser ce qui est important
(critere obligatoire) ou moins important (critere optionnel) que ce document
contienne. Il peut egalement utiliser des operateurs booleens, ou des quantifi-
cateurs pour preciser le nombre d’elements que le document doit contenir.
Fig. 1.2 – Schema global de notre approche
12

Fig. 1.3 – Dimensions de domaine stockees dans une ressource externe
Nous proposons d’utiliser les dimensions de domaine afin de mettre en exergue les
aspects lies aux descriptions semantiques du contenu des documents (requetes), et
d’identifier ainsi les themes qui y sont developpes. A cette fin, un modele de RI fonde
sur les dimensions est propose. En considerant les exigences en termes de precision
du systeme, le langage de document et le langage de requete sur lesquels est
fonde notre modele doivent etre expressifs. Ils permettent d’une part, d’indexer
avec precision le contenu semantique des documents, et d’autre part, d’interpreter le
contenu semantique des requetes precises. Evidemment, notre modele doit permettre
a l’utilisateur d’exprimer son besoin d’information precis a travers une requete.
La mise en œuvre de notre modele necessite d’abord de definir les dimensions de
domaine puis de les reperer au niveau des documents (requetes). Pour reperer ces
dimensions, il faut identifier les concepts qui leur sont associes, et donc les termes
qui les denotent dans les documents (requetes). Ceci peut necessiter une etape de
desambiguısation des sens des termes presents dans les documents (requetes).
Nous avons decide de definir les dimensions a travers une ressource externe16 a
large couverture qui associe un ensemble de termes a un concept. Dans la figure
1.2, nous presentons le schema global de notre approche. Disposant d’un ensemble
16Semantique : ontologie, linguistique : thesaurus, terminologique : dictionnaire terminologique,etc.
13

de dimensions definies a travers une ressource externe (figure 1.3), notre approche
interprete le contenu semantique des documents et des requetes et les mets en cor-
respondance.
1.6 Plan de la these
Apres ce chapitre introductif exposant notre problematique et les idees que nous
defendons, nous consacrons chapitre 2 a l’etat de l’art. Nous passons en revue
les travaux qui utilisent les ressources externes pour la representation du contenu
semantique des documents (requetes) lors du processus de RI. Nous etudions egalement
les travaux qui s’interessent a la notion de dimensions de domaine.
Dans le troisieme chapitre, nous presentons une definition formelle de notre
modele de RI, et nous discutons plus particulierement de maniere approfondie le
modele de documents et le modele de requete. Nous montrons comment, en se basant
sur les dimensions de domaines, notre modele parvient a representer avec precision
le contenu semantique des documents et satisfaire ainsi des requetes precises.
Le quatrieme chapitre decrit les etapes necessaires a la mise en œuvre de notre
modele dans le cadre d’application de documents textuels. Il decrit egalement une
evaluation experimentale, de l’utilisation des dimensions pour la RI, basee sur des
criteres d’evaluation orientes systeme [23] operee sur une collection de la campagne
CLEF.
Le cinquieme chapitre resume les contributions apportees par ce travail au do-
maine de la RI et evoque egalement les perspectives de developpement et d’optimi-
sation du modele propose.
14

Chapitre 2
Ressources externes et dimensions
de domaine
2.1 Introduction
Dans le chapitre precedent, nous avons presente les limites des approches de RI
existantes qui ne prennent pas en compte la semantique des documents (requetes).
Devant ces limites, plusieurs travaux, tentant d’incorporer l’information semantique
dans le processus de RI, sont apparus en se basant sur la disponibilite de ressources
externes telles que les ontologies ou les thesaurus. Dans le cas du processus d’indexa-
tion, nous pouvons principalement identifier l’indexation conceptuelle ou l’indexation
semantique1 [10][58]. Pour ce qui est du processus d’interrogation, l’accent a surtout
porte sur l’expansion de requetes. Les ressources externes peuvent egalement aider
a la formulation du besoin de l’utilisateur a travers une interface graphique. C’est
dans cette derniere direction que Hearts [37] et Hyvonen [38] ont propose d’utiliser
les dimensions de domaines .
Dans le but de comprendre comment les ressources externes ont ete utilisees pour
la prise en compte de la semantique lors du processus de RI, nous presentons, dans
la suite de ce chapitre, les approches les plus representatives dans la litterature.
Ainsi, nous avons etudie des travaux sur l’indexation conceptuelle/semantique, puis
des travaux sur l’expansion de requetes. Avant de conclure ce chapitre avec une
synthese des travaux existants, nous y discutons des travaux qui prennent en compte
1Ces deux terminologies sont utilisees parfois par les chercheurs en RI avec quelques confusions.
15

la notion de dimensions lors du processus de RI. Mais commencons d’abord par
definir quelques notions sur les ressources externes.
2.2 Ressources externes & RI
De facon generale, selon les communautes (Linguistique, Sciences de la cognition,
Intelligence artificielle, Philosophie, etc.), il existe differentes definitions des notions
que nous presentons ici. Dans la suite, nous presentons les definitions telles qu’elles
sont utilisees en Recherche d’Information et telles que nous les utilisons dans notre
approche.
Par ressource externe, nous entendons toute structure externe au corpus conte-
nant des concepts et des termes qui les denotent. Cette ressource peut egalement
contenir des relations entre les differents concepts ; par extension, nous appelons
connaissances externes toutes les informations stockees dans la ressource externe
(concept, termes, relations, definition, etc.).
Nous avons opte pour cette terminologie parce que, dans la communaute de RI,
on utilise les memes notations pour designer des ressources differentes. Par exemple,
par abus de langage, le mot “ontologie” est utilise pour designer des ressources telles
que, les thesaurus, les taxonomies, les hierarchies de concepts, etc. [32][51][62]. Nous
n’allons pas detailler ici les definitions de ces differents types de ressources ; nous
allons seulement decrire, dans la suite du manuscrit, les caracteristiques de celle
dont nous avons besoin pour definir notre modele de RI. Ensuite, en fonction de nos
besoins, nous choisissons la ressource qui nous convient le mieux, quelle que soit sa
nature.
Les concepts correspondent generalement aux nœuds (entrees) d’une ressource
externe. Ces nœuds peuvent contenir des informations supplementaires telles que la
definition du concept, le terme le plus couramment utilise pour le denoter, les termes
synonymes qui le denotent, etc.
Par exemple, dans le meta-thesaurus UMLS2, le concept correspondant au “li-
2http ://www.nlm.nih.gov/research/umls/
16

gament croise anterieur” est identifie par le code “C0630058”, et denote, dans le
domaine medical, par un ensemble de termes dans differentes langues naturelles (cf.
figure 2.1).
Fig. 2.1 – Denotation d’un concept par un ensemble de termes synonymes dansdifferentes langues.
2.2.1 Credibilite des approches basees sur les ressources ex-
ternes
Nous sommes convaincus que les ambitions des approches basees sur les res-
sources externes sont de plus en plus credibles car le spectre d’applications et de
domaines concernes ne cesse de s’elargir, ce qui favorise le developpement de ces
ressources. Parmi celles-ci, nous mentionnons particulierement les ontologies qui de-
viennent de plus en plus utiles dans une large famille de systemes d’information.
Par exemple, elles sont utilisees pour decrire et traiter des ressources multimedias,
permettre l’integration de sources heterogenes d’information, piloter des traitements
automatiques de la langue naturelle, construire des solutions multilingues et inter-
culturelles, etc. Ces utilisations se retrouvent dans de nombreux domaines d’applica-
tion : Recherche d’Information, integration d’informations geographiques, commerce
electronique, enseignement assiste par ordinateur, suivi medical informatise, etc.
Un cadre d’application particulierement prometteur pour le developpement des
systemes a base d’ontologies est celui du Web semantique3 [8][15]. En effet, dans ce
3Il s’agit d’une extension du Web actuel, dans laquelle l’information se voit associee a un sensbien defini, ameliorant la capacite des logiciels a traiter l’information disponible sur le Web.
17

contexte, l’annotation des ressources d’information repose sur des ontologies (elles-
memes disponibles et echangees sur le Web). Grace au Web semantique, l’ontologie
a trouve un formalisme standard a l’echelle mondiale et s’integre dans de plus en
plus d’applications Web, sans meme que les utilisateurs ne le sachent.
De ce fait, de plus en plus d’ontologies de domaines deviennent disponibles : on-
tologie medicale, ontologie de la genetique, ontologie de la geometrie, ontologie pour
le batiment, ontologie de systemes documentaires, ontologie dans le secteur automo-
bile, etc.4
La croissance du nombre d’ontologies sur le Web a meme favorise le developpement
d’outils specialises dans la recherche de ce genre de ressources. A ce sujet, men-
tionnons par exemple swoogle5 (semantic Web search engine) qui est un moteur de
recherche qui permet de retrouver des ressources ontologiques disponibles sur le Web.
Malgre toutes ces realisations, l’expansion du developpement des ontologies est
loin d’etre achevee. Ainsi, les ontologies qui s’appliquaient essentiellement a des
donnees (multimedias) sont desormais utilisees pour decrire des logiciels (ex. les
services Web). Elles commencent egalement a etre utilisees pour decrire l’utilisateur
en specifiant par exemple son contexte d’interaction (les preferences de l’utilisateur :
langue, gouts, droits, etc. ; les caracteristiques de son terminal : mobile, vocal, etc. ; sa
situation geographique : l’etranger, dans une salle avec imprimante, etc. ; l’historique
d’utilisation, etc.).
2.2.2 Exemple de ressource externe utilisee en RI : WordNet
WordNet6 est une base lexicale organisee sous forme hierarchique autour de la
notion de synset (ensemble de synonymes). Un synset regroupe des termes (simples
ou composes) ayant un meme sens dans un contexte donne. Par definition, chaque
synset dans lequel un terme apparaıt represente un sens different de ce terme.
Les synsets sont organises par des relations definies sur eux, qui different selon la
4http ://ontology.buffalo.edu/, http ://www.geneontology.org/, http ://diseaseonto-logy.sourceforge.net/, http ://ontolingua.stanford.edu/, etc.
5http ://swoogle.umbc.edu/ [visite le 08/07/07]6Le choix de presenter WordNet est motive par le fait qu’il est largement utilisee dans la plupart
des approches que nous etudions dans notre travail, et dans la RI d’une maniere generale.
18

categorie grammaticale (Part Of Speech). Les principales relations semantiques is-
sues de WordNet utilisees en RI sont les suivantes : la synonymie, la meronymie7,
et l’hyperonymie8 (is-a). Celle-ci est la plus dominante. Elle organise les synsets
dans un ensemble de hierarchies.
En plus d’etre gratuitement disponible, l’avantage d’utiliser WordNet est qu’il
couvre la majorite de la langue anglaise, ce qui la place souvent en adequation avec
les donnees traitees en RI dans le cas general.
2.3 Usage des ressources externes pour la represe-
ntation des documents
Afin de representer le contenu des textes par des concepts, l’indexation concep-
tuelle se base sur des techniques de desambiguısation qui servent a identifier les
concepts denotes par les termes dans le texte. Dans la section suivante, nous rap-
pelons quelques techniques de desambiguısation capable de realiser cette tache. En-
suite, nous examinons des approches qui utilisent les ressources externes pour la
representation du contenu des documents.
Nous verrons dans la suite de ce chapitre que les performances d’une approche
de RI dependent de plusieurs facteurs. Dans notre cas, elles peuvent dependre de
la qualite de la ressource externe utilisee, de la qualite du desambiguıseur utilise,
du modele de RI sous-jacent, etc. Donc, afin de bien evaluer une approche de RI,
il est interessant d’evaluer l’impact de chacun de ces facteurs sur ses performances.
De cette facon, nous avons la possibilite d’identifier ce qui a bien fonctionne et ce
qui a mal fonctionne lors d’une experimentation de RI. C’est dans cette direction
que nous presentons un ensemble de travaux sur l’utilisation des ressource externe
et l’utilisation de desambiguıseur pour la RI.
7La classe des meronymes contient respectivement les concepts constituant des parties du concept(... is a part of this concept, ... is a member of this concept), ou dont le concept est une partie (thisconcept is a part of ... etc.). Exemple : voiture a pour meronymes porte, moteur.
8La classe des Hyperonymes contient les concepts peres pour la relation de generalisation. Larelation inverse est l’hyponymie (specialisation).
19

2.3.1 La desambiguısation
La desambiguısation automatique des sens des mots est un probleme qui a ete
longuement etudie : Gale, Church et Yarowsky [30] citent par exemple un travail re-
montant a 1950. Dans ce chapitre, nous nous concentrons seulement sur les approches
les plus recentes. Une revue plus detaillee de la desambiguısation est presentee par
Krovetz [47] et Voorhees [27] et plus recemment une autre exposee par Mark San-
derson [79].
Plusieurs travaux ont etudie l’utilite de la desambiguısation pour la RI [32][47][77]
[78][80]. Ces efforts ont clairement montre que la desambiguısation est un probleme
plus subtil que l’on pensait. Une des premieres tentatives d’utiliser un desambiguıseur
avec un systeme de RI a ete faite par Stephen Weiss [100]. En utilisant son desambiguıs-
eur pour resoudre les sens de cinq mots ambigus extraits a la main de la collection
de ADI, Weiss a rapporte une amelioration de seulement 1% des performances de
recherche. Une des recherches les plus approfondies sur l’ambiguıte et la RI a ete
effectuee par Krovetz et Croft [47] qui ont examine manuellement deux collections
test (CACM et TIME) pour etudier l’ampleur de l’ambiguıte lexicale dans ces col-
lections, ainsi que son effet sur la performance de la recherche. Ils ont trouve que ces
collections, meme si elles sont relativement petites et specialisees, contiennent des
mots utilises dans de multiples sens ; ils ont cependant conclu que les performances
de recherche ne sont pas fortement affectees par l’ambiguıte des mots. En effet, les
documents qui partagent plusieurs mots avec la requete tendent a utiliser ces mots
avec les memes sens que ceux de la requete. Les auteurs presument neanmoins que
la desambiguısation des mots est probablement benefique a la recherche quand les
collections contiennent des themes divers, et qu’il y a peu de mots en commun entre
le document et la requete [47].
Selon Mark Sanderson [77], les premiers essais a grande echelle d’application d’un
desambiguıseur a un systeme de RI ont ete realises par Voorhees [95] et Wallis [99].
Voorhees a construit un desambiguıseur de mots base sur WordNet [28][60]. Elle a
applique le desambiguıseur aux collections de CACM, de CISI, de CRAN, de MED et
de TIME. Les tests menes sur ces dernieres collections desambiguısees ont eu comme
consequence paradoxale une baisse dans la performance de la RI. Wallis a employe
un desambiguıseur en tant qu’element d’une experience plus raffinee dans laquelle il
20

a remplace les mots dans une collection de textes par le texte de leurs definitions
issues d’un dictionnaire. Ceci a ete fait de sorte que des mots synonymes (qui ont
des definitions similaires) soient representes par les memes descripteurs, et donc que
les documents contenant ces mots synonymes soient representes par les memes des-
cripteurs. En remplacant un mot par sa definition, un desambiguıseur a ete employe
pour choisir la definition qui represente le mieux le mot. Wallis a realise des essais
sur les collections CACM et TIME, mais n’a trouve aucune amelioration significative
des performances de recherche.
Les resultats de Voorhees et de Wallis sont surprenants car il semble raisonnable
que la performance de RI augmente si l’ambiguıte est resolue. Parmi les problemes
qu’ils ont souleves, nous pouvons citer le manque de fiabilite au niveau de la perfor-
mance de leurs desambiguısations : par exemple, Voorhees a signale des problemes
lors du choix du sens correct de certains des mots dans les requetes. De tels problemes
ne permettent pas d’etablir clairement au juste ce qui a mal fonctionne lors de
l’experience. Pour cette raison, plusieurs travaux sur l’evaluation des desambiguıseurs
ont ete entrepris.
L’evaluation reste un probleme majeur de la recherche dans le domaine de la
desambiguısation car jusqu’a present l’evaluation d’un desambiguıseur necessite une
verification manuelle de ses propositions. Comme c’est un processus tres long, la
plupart des desambiguıseurs ont ete evalues seulement sur une poignee de mots.
Cependant, Yarowsky a presente une technique completement automatique pour
l’evaluation des desambiguıseurs [104] ; elle consiste a introduire, dans une collection
de textes, des mots ambigus crees artificiellement, appeles des “pseudo-mots”. Cette
technique consiste a remplacer toutes les occurrences de deux mots, par exemple
“banane” et “kalashnikov” par un nouveau mot ambigu “banana/kalashnikov”. Le
desambiguıseur est alors applique a chaque occurrence du nouveau mot. L’evaluation
de la precision du desambiguıseur est alors facilitee car on connaıt a l’avance le sens
correct de chaque occurrence des mots. Cependant, comme n’importe quelle simu-
lation, celle-ci a ses limites. La methode choisie pour former des pseudo-mots de
differents mots consiste a faire un choix aleatoire. Par consequent, les divers sens
d’un pseudo-mot sont peu susceptibles d’etre etroitement lies. Cela differe des mots
ambigus reels dont les sens peuvent dans certains cas etre relies d’une facon quel-
conque. La signification de cette difference est peu claire, et donc on ne peut pas
21

affirmer que l’ambiguıte introduite artificiellement correspond exactement a l’am-
biguıte que l’on trouve dans des situations reelles.
Bien que Yarowsky ait invente les pseudo-mots seulement pour l’evaluation des
desambiguıseurs, sa methode semble a priori bien adaptee a l’etude du rapport entre
l’ambiguıte des mots et la RI [77][78]. Pour verifier cette idee, Sanderson a fait
d’abord une premiere experience pour evaluer les performances d’un SRI sur une
collection de test. Ensuite, il a introduit de l’ambiguıte dans la collection en utilisant
des pseudo-mots. Ainsi, il a pu comparer les performances du SRI sur cette collection
accompagnee d’ambiguıte avec les performances du systeme obtenues sur la collection
initiale. De cette maniere, Sanderson peut changer a volonte la quantite d’ambiguıte
dans une collection. Ainsi, par exemple, des niveaux d’ambiguıte qui depassent de
loin ceux des collections test standards peuvent etre etudies. Cependant, l’avantage
principal d’utiliser des pseudo-mots est que la desambiguısation des pseudo-mots
peut etre controlee avec precision par l’experimentateur. Par consequent, les effets
d’un desambiguıseur sur les performances d’un SRI, fonctionnant a des niveaux va-
riables de precision, peuvent egalement etre etudies.
Suite a ces experimentations, Sanderson a montre que l’ambiguıte des mots a des
effets mineurs sur la precision de la recherche, confirmant vraisemblablement que
les strategies d’appariement (matching), entre la requete et le document, effectuent
deja une desambiguısation implicite. C’est a dire, quand un ensemble de mots appa-
raissent simultanement dans un contexte, que la signification appropriee de chacun
peut etre determinee (meme si chacun de ces mots pris individuellement est ambigu).
Nous reprenons l’exemple utilise par Vooheers ou, dans l’ensemble base, bat, glove,
hit , la plupart des mots ont plusieurs sens. Mais pris conjointement, ces mots font
reference au jeu du Baseball. Sanderson estime que, si la desambiguısation automa-
tique des mots est effectuee avec moins de 90% de precision, les resultats sont plus
mauvais que si on ne desambiguısait pas du tout.
Un etat de l’art sur cette question de desambiguısation des mots dans le cadre
de la RI est presente par Sanderson [79]. Les resultats obtenus par differents cher-
cheurs sont parfois contradictoires. A partir de ces experiences, nous pouvons tirer la
conclusion que, pour ameliorer les performances d’un SRI, il est necessaire d’utiliser
un desambiguıseur fonctionnant avec une grande precision.
22

Sanderson [79] et Zernik [106] ont egalement conclu que les dictionnaires ne four-
nissent pas une bonne source de definitions des termes (sens) pour les desambiguıseurs,
parce que leurs distinctions entre les definitions sont trop fines car souvent basees
sur des criteres grammaticaux plutot que semantiques. Heureusement, d’autres res-
sources externes sont devenues de plus en plus disponibles. Ces ressources representent
le sens de termes a travers les concepts qu’ils denotent. En plus, elles offrent des
connaissances en organisant les concepts dans une structure basee sur des relations
semantiques. Ceci offre des capacites non negligeables a la RI, meme si l’utilisa-
tion des concepts exige une etape de desambiguısation des termes qui les denotent
dans le texte. En effet, les connaissances presentes dans la ressource externe peuvent
etres utiles tant pour la desambiguısation que pour la representation du contenu
semantique des textes.
Voyons maintenant les travaux les plus representatifs qui utilisent des ressources
externes, principalement WordNet, pour representer le contenu semantique des textes.
2.3.2 Indexation conceptuelle/semantique
Dans la litterature, l’indexation conceptuelle (ou l’indexation semantique) a ete
presentee comme une solution pour pallier les defauts de l’indexation classique basee
sur des mots simples. Differentes methodes ont ete proposees. Nous pouvons les
repartir en deux categories qui ne sont pas totalement disjointes :
- Celles qui utilisent seulement les connaissances presentes dans le corpus [80][86][106] ;
- Celles qui utilisent les connaissances externes au corpus [64][71][83][88][89][97][98],
utilisent WordNet [60] ; et [45][46][99] utilisent le dictionnaire LDOCE9 [67].
Dans la suite, nous presentons seulement les methodes les plus representatives
qui utilisent les connaissances externes pour la desambiguısation [4][58][95]. Nous
presentons egalement deux approches qui etudient l’impact de la desambiguısation
sur les performances de la RI [32][77].
9The Longman Dictionary of Contemporary English.
23

Utilisation de WordNet pour la desambiguısation des sens de mots
Voorhees a exploite les connaissances codees dans WordNet pour ameliorer les
effets que les synonymes et les homographes ont sur les SRI bases sur les mots. Au
lieu d’utiliser les mots eux-memes, elle a utilise les concepts que ces mots denotent.
Dans cette direction, elle a essaye de voir si les synsets de WordNet peuvent etre
utilises comme des concepts dans un SRI a usage non limite a un domaine particu-
lier. Ainsi, elle a propose une technique pour desambiguıser les mots utilises lors du
processus d’indexation automatique. La technique consiste a selectionner un concept
pour chaque mot ambigu apparaissant dans les textes des documents et des requetes.
Pour ce faire, l’auteur utilise la base WordNet. Ainsi, l’approche proposee consiste
a selectionner un synset de WordNet comme un concept denote par un mot. Dans
WordNet, les synsets sont lies par differentes relations. Voorhees utilise l’ensemble
des synsets correspondants aux noms10 ainsi que les relations suivantes : antonymie,
hyperonymie/hyponymie (is-a) et meronymie/holonomie (part-of ).
La technique de desambiguısation utilisee dans ce travail est basee sur l’idee qu’un
ensemble de mots, apparaissant ensemble dans un contexte, determine la significa-
tion appropriee pour un autre mot, en depit du fait que chaque mot present dans
texte pris individuellement est ambigu (comme montre plus haut dans l’exemple des
mots dont l’ensemble denote le baseball). Pour desambiguıser un mot m, une tech-
nique a ete proposee pour classer les synsets auxquels m appartient. Le classement
est effectue en se basant sur la valeur de cooccurrence calculee entre le contexte du
mot en question et un voisinage contenant les mots du synset dans la hierarchie de
WordNet (Voorhees l’a appele hood).
Pour definir le voisinage d’un synset s donne, Voorhees considere l’ensemble des
synsets et les relations d’Hyponymie dans WordNet comme un ensemble de sommets
et d’arcs diriges d’un graphe. Par la suite, le voisinage de s est le plus large sous-
graphe connexe qui contient s et seulement les descendants d’un ancetre de s, et qui
ne contient aucun synset ayant un descendant qui inclut une autre instance d’un
membre (mot) de s. Le synset le mieux classe est selectionne comme etant le sens
du mot m dans le texte. Il est possible qu’un mot ne corresponde a aucun synset de
WordNet. Dans ce cas, aucun synset n’est selectionne.
10Dans WordNet, il y a quatre categories : les noms, les verbes, les adjectifs et les adverbes.
24

Apres l’etape de desambiguısation, vient l’etape d’indexation qui prend en compte
le sens des mots. Voorhees a utilise le modele vectoriel etendu introduit par Fox [29].
Dans ce modele, chaque vecteur est compose d’un ensemble de sous-vecteurs de
differents types de concept (appeles ctypes)11. Ainsi, un vecteur peut contenir trois
ctypes : les lemmes des mots qui n’apparaissent pas dans WordNet ou qui ne sont
pas des noms, les identificateurs des synsets des noms desambiguıses, et les lemmes
des noms desambiguıses.
Dans le modele vectoriel etendu, la similitude entre un document et une requete
est calculee comme suit :
sim(D, Q) =∑
ctypei
αisimi(Di, Qi) (2.1)
Avec simi, la fonction de similarite pour le ctypei, Di et Qi sont les iemes sous-
vecteurs des vecteurs D et Q, et αi, un nombre reel qui reflete l’importance du ctypei
relativement aux autres ctypes.
Pour evaluer son approche, Voorhees a mene des experimentations sur les col-
lections CACM [75], CISI, Cranfield 1400, MED, et TIME [41]. Elle a compare son
approche avec une approche basee seulement sur les lemmes de tous les mots du texte.
Plusieurs tests ont ete effectues en faisant differentes combinaisons avec les ctypes
et la valeur de α. Les resultats de ces experimentations ont montre paradoxalement
que les performances du SRI diminuent sensiblement dans le cas de l’utilisation des
collections desambiguısees.
Voorhees a pu constater que les requetes courtes sont difficiles a desambiguıser
et que ceci est la cause majeure de la degradation des performances de recherche.
Par consequent, elle a evalue son approche en desambiguısant seulement les mots
dans les documents. En effet, au lieu de selectionner un seul sens pour un mot m
11Ce modele permet la manipulation d’autres types de concepts que ceux qui sont representespar les descripteurs du document : les citations, les cocitations, les donnees bibliographiques, etc.Ainsi, chaque sous-vecteur represente un aspect different des documents de la collection.
25

ambigu appartenant a la requete, elle a ajoute tous les identificateurs des synsets
de m au vecteur de la requete. Les resultats de cette approche ont montre que les
performances du SRI diminuent sensiblement dans la plupart des collections utilisees.
Dans ce travail, la qualite de la desambiguısation n’a pas ete mesuree empi-
riquement. Une evaluation subjective a ete effectuee par l’auteur qui conclut que
l’etiquetage avec les sens tel qu’il est realise n’est pas exact, ce qui est la cause la
plus probable de la degradation des performances. L’auteur mentionne egalement une
grande difficulte a desambiguıser les mots dans des requetes courtes. Enfin, elle pense
que les relations is-a qui definissent une hierarchie generalisation/specialisation ne
sont pas suffisantes pour selectionner correctement le sens exact d’un mot a partir
des sens presents dans WordNet.
Combinaison de donnees lexicales et semantiques pour la representation
des textes
Pour construire une representation semantique de texte, Mihalcea et Moldovan
ajoutent des informations lexicales et semantiques aux documents et aux requetes
durant une phase de pretraitement dans laquelle le texte des requetes et des docu-
ments est desambiguıse. Le processus de desambiguısation se base sur l’information
contextuelle, et sur l’identification des sens des mots a partir de WordNet. Un nou-
veau mot est desambiguıse en tenant compte de sa relation avec les mots du corpus
qui sont deja desambiguıses. Ce processus iteratif leur permet d’identifier dans le
corpus d’origine les mots qui peuvent etre desambiguıses avec une grande precision.
Au lieu d’utiliser un algorithme de desambiguısation complet12 et peu precis, ils
ont opte pour un algorithme semi-complet qui desambiguıse environ 55% des noms
et des verbes mais avec un taux de precision de 92%. La sortie du desambiguıseur
est un texte dont les mots ont la forme suivante : Pos|Stem|POS |Offset.
Ou : Pos est la position du mot dans le texte ; Stem est le lemme du mot ; POS
est la categorie grammaticale du mot, et Offset est l’identifiant du synset de Word-
Net dans lequel ce mot apparaıt. Au cas ou aucun sens ne serait attribue par le
desambiguıseur, ou si le mot ne se trouve pas dans WordNet, le dernier champ reste
12Qui desambiguıse TOUT le texte.
26

vide. Apres l’ajout de ces etiquettes lexicales et semantiques, les documents sont
indexes. L’index est cree en combinant les mots simples (recherche basee mots), et
les etiquettes semantiques (recherche basee sens).
Au moment de l’interrogation, chaque requete est desambiguısee, ensuite elle
est adaptee a un format specifique qui incorpore l’information semantique, comme
trouvee dans l’index, et utilise les operateurs AND et OR.
Leur systeme a ete teste sur la collection Cranfield. Celle-ci contient 1400 docu-
ments du domaine de l’aerodynamique. Parmi les 225 requetes de cette collection,
les auteurs en ont choisi aleatoirement 50 et ont construit pour chacune d’entre elles
trois types de requetes :
1) Une requete contenant seulement les mots selectionnes a partir de la requete
initiale lemmatisee ;
2) Une requete contenant les mots cles de la requete initiale et les synsets qui lui
sont associes ;
3) Une requete contenant les mots cles de la requete initiale, les synsets qui leur
sont associes, et les synsets des hyperonymes des mots cles.
Nous reprenons ici l’exemple presente par les auteurs. Soit la requete suivante :
“Has anyone investigated the effect of surface mass transfer on hypersonic vis-
cous interactions ?”
Apres l’etiquetage lexical et semantique, la requete se presente comme suite :
Has anyone investigated |VB|535831 the effect |NN|7766144
of surface|NN|3447223 mass|NN|3923435 transfer |NN|132095
on hypersonic|JJ viscous|JJ interactions|NN|7840572|
Les auteurs rapportent que la selection des mots-cles (les 55%) a desambiguıser
(par l’algorithme semi-complet) n’est pas simple, et qu’ils utilisent pour cela huit
heuristiques [61]. Pour chaque requete, les trois types de requetes precitees sont
27

formees en utilisant les operateurs booleens AND et OR. Ainsi, pour la requete de
type 2 par exemple, les auteurs obtiennent :
(effect OR 7766144|NN) AND (surface OR 3447223|NN)
AND (mass OR 3923435|NN) AND (transfer OR 132095|NN)
AND (interaction OR 7840572|NN).
Suite a leurs experimentations, les auteurs ont pu constater que la combinaison
des mots-cles avec les synsets ameliore les performances du systeme de RI par rapport
a la recherche basee seulement sur les mots (+16% de rappel et +4% de precision).
Nous pensons que ce resultat est du au fait que la base WordNet ne couvre pas la
totalite du vocabulaire de la collection utilisee. Donc, une combinaison des synsets
avec les mots peut garantir une couverture de tout le vocabulaire en question. Ce
resultat est en accord avec d’autres resultats positifs obtenus par des chercheurs qui
ont fait une indexation combinee de la sorte [4].
En utilisant les hyperonymes, les auteurs ont constate une amelioration de 28%
du rappel mais une baisse de 9% de la precision. Il est probable que l’augmenta-
tion du rappel est du au fait que l’expansion a permis de retrouver des documents
pertinents mais qui ne partagent pas exactement les memes termes avec la requete.
En revanche, la degradation de la precision pourrait etre expliquee par le fait que
l’expansion a ete faite d’une maniere imprudente, ce qui ajoute parfois des concepts
a la requete qui ne sont pas en rapport avec son theme. Par consequent, le contenu
de la requete etendu devient bruite par rapport au contenu original, et les documents
reponses ne sont pas forcement pertinents pour la requete originale. Nous verrons
dans la suite des solutions possibles a ce probleme d’expansion imprudente [4][68].
Le modele DocCore
Baziz considere que le theme developpe dans un document (requete) est decrit
par un ensemble de concepts. Ainsi, au lieu de representer les documents (requetes)
par une liste de mots cles, il propose de les representer par des concepts. Pour ce
faire, il utilise une ressource externe pour extraire, a partir d’un texte, les termes qui
font references aux concepts decrits dans ce texte. Une etape de desambiguısation a
28

ete proposee afin d’associer chaque terme a un seul concept de la ressource externe
utilisee.
Baziz construit pour chaque document de la collection ce qu’il appelle un Reseau
Semantique de Document. Le modele de representation qu’il propose, DocCore, est
base sur un processus automatise faisant appel a une ressource externe pour identifier
les concepts du document et calculer les liens de proximite entre eux. Les arcs entre
les nœuds du reseau semantique sont ponderes en fonction de la proximite semantique
que peuvent avoir les deux nœuds correspondants. Le processus de desambiguısation
propose s’accomplit en trois etapes :
1) Extraction des concepts candidats : l’objectif de cette etape est d’ex-
traire tous les termes du document susceptibles de representer des concepts de la
ressource externe. Ces termes sont extraits en projetant13 le texte sur la ressource
externe. De ce fait, pour un texte donne, seuls les mots ou groupes de mots recon-
nus comme des entrees dans la ressource externe sont conserves. De cette facon, les
termes representant les concepts candidats sont extraits. Concernant la combinaison
des mots, le terme le plus long qui denote un concept est retenu. Une fois ces termes
extraits du document, un poids leur est affecte pour determiner leur importance dans
ce document. Pour cela, Baziz a propose une variante du TF.IDF qui tient compte
de la longueur du terme (en nombre de mots). Cette variante est appelee CF.IDF et
est calculee de la maniere suivante :
cf(T ) = count(T ) +∑
ST∈sub terms(T )
Length(ST )
Length(T ).count(ST ) (2.2)
ou T est un terme compose de n mots, Length(T) represente le nombre de mots
dans T et sub terms(T) le nombre de tous les sous-termes (qui doivent denoter a
leur tour des concepts de la ressource externe) derives de T : sous-termes de n-1
mots, sous-termes de n-2, ... et tous les mots simple de T.
13Faire un appariement entre le texte et les entrees de la ressource externe.
29

Une fois les termes14 importants extraits du document, ils sont utilises pour
construire le reseau semantique de ce document. Comme chaque terme extrait peut
avoir plusieurs sens, des mesures de similarite entre les differents sens des termes sont
calculees en vue de selectionner, pour chaque terme, le meilleur sens correspondant
dans la ressource externe.
2) Calcul de similarite entre concepts candidats : la mesure de similarite
entre deux nœuds represente une valeur condensee resultant de la comparaison de
deux sens possibles pour deux termes (donc deux concepts candidats) en utilisant la
distance entre les positions des deux concepts candidats dans la ressource externe,
ou encore les relations semantiques de celle-ci. Pour ce faire, Baziz emploie quatre
mesures de proximite semantique connues dans la litterature utilisant des structures
de reseaux semantiques ou hierarchiques (Lch [22], Lin [50], Lesk [81] et Resnik [70]).
3) Construction du reseau semantique : la derniere etape de l’approche
concerne la construction du “meilleur” reseau semantique qui represente au mieux
le contenu du document. Pour chaque terme du document, un score C score est
calcule pour chacun des concepts candidats qu’il denote. Le score d’un concept can-
didat est obtenu en sommant les valeurs de similarite qu’il a avec les autres concepts
candidats (correspondant aux differents sens des autres termes du document). Cela
permet, selon l’auteur, de desambiguıser les termes compte tenu du contexte du do-
cument. Les concepts candidats ayant les plus grands scores sont alors selectionnes
pour representer les nœuds du “meilleur” reseau semantique. Les liens (arcs) entre
ces differents nœuds sont etiquetes alors par les valeurs de similarite semantique
deja calculees dans la phase 2. Enfin, les reseaux semantiques des documents sont
construits pour chacune des quatre mesures (Lch, Lin, Lesk et Rensik). Lors de l’in-
dexation, les descripteurs des documents a indexer sont alors les nœuds des reseaux
semantiques.
L’auteur ne precise pas comment il procede pour construire les reseaux semantiqu-
es des requetes. D’apres l’exemple presente, l’auteur ne fait pas de desambiguısation
des termes de la requete, mais detecte seulement le(s) concept(s) denotes par les
termes les plus longs a partir de la requete en utilisant WordNet.
14Denotant les concepts candidats.
30

Etant donne que les requetes sont courtes, il nous semble difficile de construire
un reseau semantique pour chacune d’entre elles. Voorhees, dans sa methode de
desambiguısation, tient compte du contexte d’un mot pour le desambiguıser [95].
Elle a deja souleve le probleme de la desambiguısation des requetes courtes. Elle a
constate qu’il est difficile de desambiguıser les mots des requetes courtes, ainsi elle a
propose de desambiguıser seulement les documents.
Baziz a evalue son approche en utilisant une collection issue du projet Much-
More15 [7]. Cette collection contient 7823 documents qui traitent du domaine medical
et qui contiennent des resumes d’articles extraits de SpringerLink. La collection
contient egalement 25 topics a partir desquels les requetes sont extraites. L’auteur a
utilise WordNet en considerant ses synsets comme des concepts.
Pour les requetes, seule la detection des termes et leur ponderation avec CF.IDF
sont appliquees du fait de leur taille relativement reduite.
Impact de l’indexation conceptuelle : Seuls les concepts (nœuds) des reseaux
semantiques construits sont utilises pour indexer les documents. Ces concepts sont
ponderes en utilisant la variante CF.IDF. Les resultats ont montre que cette methode
ne permet pas d’ameliorer les resultats par rapport la methode classique basee sur
les mots cles. L’auteur justifie ce resultat par le fait que WordNet ne couvre pas
tout le vocabulaire utilise dans la collection (le taux de couverture represente 87%
du vocabulaire des documents et 77% du vocabulaire utilise dans les requetes). Par
consequent, et afin de couvrir la totalite des documents/requetes lors de l’indexation,
Baziz a fait une indexation combinee utilisant les mots cles et les concepts. De ce fait,
les concepts des reseaux semantiques ponderes avec CF.IDF sont ajoutes aux mots
qui sont resultants de l’indexation classique. De cette maniere, les performances du
systeme en precision ont ete ameliorees de 26%.
Impact de la ponderation avec les C scores : Baziz a egalement essaye d’evaluer
l’impact de la ponderation sur les performances de recherche. Ainsi, au lieu d’utiliser
le CF.IDF, il a utilise les C scores correspondant aux quatre mesures de similarite
15http ://muchmore.dfki.de (visite le 15-12-2006).
31

semantique utilisees. Les documents et les requetes sont, dans ce cas, representes a la
fois par des concepts et des mots cles. Lors de l’indexation, si le concept est denote par
un multi-mots, il est pondere par le C score, sinon il est pondere par le TF.IDF. Les
resultats ont montre que cette methode peut ameliorer les performances de recherche.
Tout comme Gonzalo [32], Baziz a propose une expansion de document en utili-
sant les synsets de WordNet. Ainsi, chaque concept du reseau semantique est etendu
par ses synonymes (les termes appartenant au meme synset de WordNet que lui).
Dans ce cas, deux ponderations differentes ont ete testees :
1) Les poids des concepts d’origine et de ceux qui sont issus de l’extension sont
calcules de la meme maniere : les resultats restent globalement meilleurs compares
a l’indexation.
2) Les synonymes ajoutes ont un poids inferieur (multiplie par 0.5) a ceux des
concepts d’origine : les resultats sont meilleurs compares a l’indexation classique, ce
qui est est en accord avec Voorhees [96] ou un facteur α entre 0 et 1 est utilise pour
ponderer les mots ajoutes (il est reporte que la valeur optimale pour α est 0.5). Ceci
paraıt valable aussi pour l’expansion de document [95].
Baziz a pu conclure que les poids utilisant les mesures de similarite donnent
des precisions meilleures que celles obtenues avec CF.IDF. Il a egalement conclu
que, dans sa methode de desambiguısation, le choix de la mesure de similarite a
un impact sur la precision de la selection des concepts adequats. En particulier, la
meilleure mesure, d’apres ses resultats, est celle de Resnik, suivie par les mesures de
Lin, Lch et Lesk.
Discussion
La plupart des travaux rapportes ici ne permettent pas une amelioration signi-
ficative des performances des SRI. Un des facteurs qui influencent les performances
est sans doute la qualite de la ressource externe utilisee, et surtout sa couverture
par rapport au vocabulaire du corpus. Dans son experience, Baziz a rapporte que
WordNet ne couvre pas tout le vocabulaire utilise dans la collection (le taux de cou-
verture represente 87% du vocabulaire des documents et 77% du vocabulaire utilise
32

dans les requetes) [4]. Par consequent, et afin de couvrir la totalite du vocabulaire
des documents/requetes, Baziz a fait une indexation combinee utilisant les mots-cles
et les concepts. C’est le seul moyen qui lui a permis d’avoir des resultats significatifs.
Ces resultats sont confirmes par Mihalcea et Moldovan, et Schutze et Pederson qui
ont constate qu’une indexation par concepts combinee avec une indexation par mots-
cles est plus performante qu’une indexation basee seulement sur les concepts [58][80].
Le deuxieme facteur duquel dependent les performances est la qualite (precision)
du desambiguıseur. Afin de mesurer l’impact de la desambiguısation sur les perfor-
mances de recherche, il faut evaluer le desambiguıseur utilise en termes de precision.
Nous presentons donc dans la suite, les travaux les plus representatifs qui se rap-
portent a ce champ de recherche. Ceci nous permettra de comprendre davantage les
raisons d’echecs des approches basees sur la desambiguısation des termes.
2.3.3 Evaluation de la desambiguısation
L’impact de la desambiguısation des termes sur les performances des SRIs a fait
l’objet de plusieurs travaux de recherche. En voici deux parmi les plus representatifs.
Usage d’une simulation d’ambiguıte a base de pseudo-mots
Sanderson simule l’ambiguıte dans une collection de test en utilisant des pseudo-
mots [104]. Un pseudo-mot de taille n a n sens differents. Afin d’eviter de creer une
ambiguıte au niveau des pseudo-mots eux-memes, un mot ne peut etre membre que
d’un seul pseudo-mot [77][78].
Dans ses experimentations Sanderson a utilise la collection de categorisation
de texte Reuters (creee par Hayes [35] et modifiee par Lewis [49]). La principale
difference entre la collection Reuters et les collections de test de RI est que Reuters
ne dispose pas d’ensemble de requetes avec les documents pertinents correspondants.
Neanmoins, les documents de Reuters sont balises par des codes de sujets assignes
manuellement. Sanderson se sert de ces codes pour utiliser Reuters comme une col-
lection de test. Ainsi, il divise aleatoirement la totalite des documents de Reuters
en deux ensembles egaux : Q (l’ensemble des requetes) et T (l’ensemble des tests).
Ensuite, l’ensemble S est defini comme l’ensemble de tous les codes de sujets qui ont
33

ete assignes a au moins un document dans Q et un document de T. Par consequent,
une recherche peut etre effectuee en selectionnant un des codes de sujets de S.
Par exemple, pour effectuer une recherche pour le code C, Sanderson selectionne
tous les documents dans Q qui sont etiquetes par C. Ensuite, il effectue une reinjection
de pertinence (relevance feedback) en utilisant les documents selectionnes auparavant
pour avoir comme resultat le code C, plus des mots des documents selectionnes. Le
resultat produit constitue une requete. De cette maniere, Sanderson a la possibilite
de varier la taille de la requete en jouant sur le nombre de mots selectionnes. La
requete est utilisee pour effectuer une recherche sur les documents de l’ensemble T.
Les documents qui sont etiquetes par C sont consideres pertinents pour cette requete.
La liste des documents retrouves est examinee pour voir a quel rang apparaissent
les documents etiquetes par C. En fonction de ce rang, des courbes rappel/precision
sont generees.
Sanderson compare les performances du SRI en effectuant d’abord des experiences
sur la collection initiale, ensuite des experiences sur la meme collection en y intro-
duisant de l’ambiguıte a l’aide des pseudo-mots. Ensuite, il etudie l’impact de la
desambiguısation des pseudo-mots, avec un desambiguıseur fonctionnant a differents
taux de precision, sur les performances de la RI.
Suite a ses experimentations, Sanderson a pu conclure que quand le desambiguıseur
fonctionne a un taux d’erreurs de 25%, les performances du SRI sont plus mauvaises
que celles qui sont obtenues en utilisant la collection ambigue. Avec un taux d’erreurs
de 10%, les performances du systeme sont similaires a celles qui sont obtenues sur
la collection ambigue. Il conclut que la desambiguısation peut etre benefique a la RI
quand les requetes sont courtes (un ou deux mots) et si le desambiguıseur ne fait
pas beaucoup d’erreurs (moins de 10%). Ceci confirme la conclusion de Krovetz et
Croft [47] selon qui, l’ambiguıte des mots a des effets mineurs sur la precision de la
recherche.
Le fait que l’ambiguıte des mots pose problemes au SRI seulement quand les
requetes sont courtes confirme vraisemblablement que les strategies de recouvrement
(matching) entre la requete et le document effectuent deja une desambiguısation im-
plicite.
34

Nous pensons que la desambiguısation partielle est une faiblesse des experiences
de Sanderson. Par exemple, sa desambiguısation du mot spring/bank donne le mot
“bank” ; or ce dernier mot peut etre employe dans plus qu’un sens dans le texte de
la collection.
Evaluation de l’impact d’un desambiguıseur base sur WordNet
Gonzalo et ses collegues proposent d’etudier le benefice d’une recherche a par-
tir d’une collection de documents completement desambiguısee [32]. Pour ce faire,
ils ont transforme une partie du corpus SEMCOR en une collection de test de RI.
SEMCOR, un sous-ensemble du corpus Brown, est desambiguıse manuellement avec
des synsets de WordNet. La collection ainsi construite permet d’evaluer un SRI
independamment des outils de desambiguısation. Elle permet egalement d’evaluer
l’impact de la desambiguısation des termes sur les performances des SRI et ce en in-
troduisant volontairement des erreurs de desambiguısation (a differents taux). Ainsi,
les auteurs peuvent determiner jusqu’a quel taux d’erreurs le SRI donne de meilleurs
resultats.
Pour construire la collection test, les auteurs ont pris un ensemble de documents
textuels de SEMCOR. A partir de chaque document, ils ont extrait des fragments de
texte. Chaque fragment contient une portion coherente de texte. En tout, 117 frag-
ments constituent leur collection test avec en moyenne 1331 mots par fragment. Pour
chaque fragment, un resume decrivant le contenu thematique a ete ecrit manuelle-
ment. Afin de desambiguıser les termes des resumes, les auteurs les ont etiquetes
manuellement par des synsets de WordNet. Plus precisement, les auteurs utilisent
les numeros de sens dans WordNet pour etiqueter un terme. Chaque etiquette est
composee de la categorie grammaticale (Part Of Speech ou POS), suivie du fichier
de WordNet auquel appartient le terme, suivie du numero du sens dans ce fichier.
Ainsi, le terme “debate” du fichier 10 de WordNet ayant le sens 1 sera etiquete par
“debate%1 :10 :1 : :”. Dans ce cas, le sens des termes est considere, mais les termes
synonymes ne sont pas encore identifies. Pour ce faire, les auteurs substituent chaque
sens par l’identifiant du synset qui lui est associe. Ainsi, “debate%1 :10 :1 : :” sera
substitue par l’identifiant du synset “argument, debate” (a discussion in which rea-
sons are advanced for and against some proposition or proposal ; “the argument over
35

foreign aid gœs on and on”).
Les resumes ont chacun une taille moyenne de 22 mots. Ils deviennent les requetes
pour la collection. Par consequent, pour chaque requete, il y a exactement une seule
reponse pertinente (le fragment pour lequel le resume a ete ecrit).
Dans leur etude experimentale, les auteurs ont utilise le systeme SMART [74]
avec trois espaces d’indexation differents : les mots initiaux des documents, les mots-
sens (word-senses) correspondant aux termes des documents (c’est a dire, la version
des documents desambiguıses manuellement), et les synsets de WordNet correspon-
dant aux termes des documents. En se basant sur ces trois espaces d’indexation, les
auteurs ont mene 6 experiences :
1. Les documents et les requetes sont representes par des mots simples ;
2. Les documents et les requetes sont representes par ce que les auteurs appellent
les mots-sens (ex. debate et argument seront substitues respectivement par
“debate%1 :10 :1 : :” et “argument%1 :10 :3 : :)” ;
3. Les documents et les requetes sont representes par les synsets de WordNet. En
d’autres termes, les mots-sens equivalents seront representes par un seul synset
(ex. “debate%1 :10 :1 : :” et “argument%1 :10 :3 : :)” seront representes par
l’identifiant n04616654 du synset correspondant) ;
4. Differentes versions de la collection sont produites en introduisant volontairement
des erreurs de desambiguısation a differents taux : 5%,10%,20%,30% et 60% ;
5. Pour completer l’experience precedente, une version de la collection a ete produite
en utilisant tous les sens possibles (dans leurs versions mot-sens et synset) pour
chaque terme. Ceci represente une limite pour la desambiguısation automa-
tique : on ne doit pas desambiguıser si la performance est plus mauvaise que si
l’on considere tous les sens possibles ;
6. Enfin, les auteurs ont produit une version non-desambiguısee pour les requetes
(avec les deux variantes mots-sens et synsets).
Les resultats ainsi obtenus (cf. tableau 2.1) representent la precision pour les
documents retournes en premiere position. Ils montrent que les meilleurs resultats
36

Tab. 2.1 – Pourcentage des documents corrects retrouves en premiere position [32]Experimentation % de documents correct re-
trouves en premiere position
Indexation (Id.) avec les synsets 62.0Id. avec les mots-sens 53.2Id. avec les mots simples 48.0Id. avec les synsets avec 5% detaux d’erreurs
62.0
Id. avec 10% de taux d’erreurs 60.8Id. avec 20% de taux d’erreurs 56.1Id. avec 30% de taux d’erreurs 54.4Id. avec tous les synsets possibles(pas de desambiguısation)
52.6
Id. avec 60% de taux d’erreurs 49.1Id. avec les synsets avec desrequetes non desambiguısees
48.5
Id. avec les mots-Sens avec desrequetes non desambiguısees
40.9
sont obtenus avec l’indexation par synsets ou 62% des documents pertinents ont ete
retrouves en premiere position. Ceci represente une amelioration de 29% par rapport
au resultat obtenu avec l’indexation par des mots simples qui est de 48%.
De son cote, l’indexation par mots-sens a permis de retourner 53.2% de docu-
ments pertinent en premiere position, ameliorant ainsi les performances de 11% (par
rapport aux mots simples).
Les resultats obtenus avec les synsets sont meilleurs que ceux obtenus avec les
mots-sens. Ceci peut etre explique par le fait que la representation par synset est
plus riche vu qu’un synset contient les synonymes d’un mot-sens.
Meme avec une indexation par les synsets et sans desambiguısation manuelle
(chaque terme est represente par tous les synsets possibles qui correspondent a ses
differents sens), les resultats (52.6%) sont superieurs a ceux qui sont obtenus par
la representation par mots simples (48%). Avec une methode aussi simpliste, une
interpretation possible de ce resultat est que la prise en compte des synonymes, qui
sont regroupes dans un synset, a un impact positif dans cette situation de recherche.
37

En analysant l’impact de la desambiguısation sur les performances du SRI, Gon-
zalo et al. ont pu conclure que, dans le cas de l’indexation par des synsets, moins de
10% d’erreurs de desambiguısation n’affecte pas sensiblement les performances. Et
a partir de 10% d’erreurs, les performances commencent a se degrader. Ces conclu-
sions sont en accord avec celles de Sanderson [77]. Neanmoins, l’indexation par des
synsets donne de meilleurs resultats que ceux de l’indexation par mots simples et
ce jusqu’a un taux d’erreurs de 30%. De 30% a 60%, les resultats ne montrent pas
des differences significatives entre l’indexation par synsets et l’indexation par mots
simples. Cette conclusion n’est pas en accord avec celle de Sanderson [77] qui pretend
qu’il vaut mieux desambiguıser avec au moins une precision de 90% pour avoir des
bonnes performances. Selon Gonzalo et al., la principale difference entre leur travail
et celui de Sanderson [77] est le langage d’indexation utilise. Tandis que Gonzalo
et al. utilisent des synsets qui regroupent les synonymes des mots-sens, Sanderson
utilise des pseudo-mots ambigus crees artificiellement (tels que “bank/spring”). Il
n’est pas garanti que ces pseudo-mots se comportent comme de vrais mots ambi-
gus. D’ailleurs, par desambiguısation, Sanderson veut dire selectionner - a partir de
l’exemple - bank ou spring qui restent eux-memes des mots ambigus.
Discussion
Comme note par plusieurs chercheurs ([77], [47]), la principale difficulte pour
ameliorer les performances de recherche est due a l’inefficacite des desambiguıseurs
utilises. En effet, il est judicieux de penser qu’en utilisant un desambiguıseur par-
fait (ayant une precision de 100%), les performances de recherche seront au moins
egales a celles d’une indexation basee sur les mots-cles. Les etudes menees jusqu’a
present ont montre que, pour ameliorer les performances de recherche, l’indexation
ne doit pas etre seulement basee sur les concepts mais egalement sur les mots, et ce
en grande partie a cause des erreurs provoquees par les desambiguıseurs.
Nous pouvons constater, a partir des travaux existants, que la prise en compte du
contenu semantique des documents (requetes) passe seulement par leur representation
par des concepts au lieu de simples mots. En effet, les documents (requetes) dans
ce cas sont consideres comme des sacs de concepts, et les relations semantiques qui
peuvent exister entre ces concepts ne sont pas exploitees. C’est pourquoi les docu-
38

ments traitant du meme theme que celui de la requete ne pourront pas etre retrouves
avec ces approches s’ils ne partagent pas les memes concepts avec cette requete. Pour
resoudre ce probleme, certains travaux ont propose d’utiliser des ressources externes
pour enrichir la representation du contenu des requetes. Ces travaux sont bases sur
l’expansion de requetes et visent a avoir une representation etendue du contenu de
la requete afin d’augmenter les chances de sa correspondance avec les documents qui
lui sont pertinents. Dans la section suivante, nous presentons les travaux les plus
representatifs qui traitent cet aspect.
2.4 Usage des ressources externes pour l’expan-
sion des requetes
Les techniques d’expansion de requetes sont apparues depuis plus de 30 ans [76].
En procedant par une expansion de requetes, on peut augmenter le rappel et/ou la
precision de recherche. Les techniques d’expansion de requetes peuvent etre reparties
en deux categories :
- Expansion basee sur les connaissances presentes dans le corpus : cette technique uti-
lise des donnees statistiques extraites de la collection etudiee (ex. co-occurrences
de termes [65], thesaurus de similarite [68], etc.). Elle peut etre egalement basee
sur l’injection de pertinence [14][33][84][102]. L’etape de desambiguısation des
mots n’est pas indispensable pour que cette technique fonctionne. Cette ap-
proche n’a pas rencontre beaucoup de succes ; ainsi, Peat a pu conclure que les
requetes etendues avec cette methode ne sont pas meilleures que les requetes
d’origine, et que des requetes etendues avec des mots choisis aleatoirement
donnent des resultats parfois meilleurs [65]. Mais avec la disponibilite des res-
sources externes, la methode suivante a vu le jour ;
- Expansion basee sur les ressources externes : [5][7][59][96] utilisent WordNet pour
ajouter des termes qui sont semantiquement lies a ceux presents dans la requete
initiale. Cette technique demande une desambiguısation des mots de la requete
initiale. Elle peut etre utile si la desambiguısation s’avere performante, notam-
ment dans le cas des requetes courtes qui sont difficiles a desambiguıser et qui
39

exigent donc une expansion [47][78].
Ces deux techniques peuvent etre combinees [11][62]. Par exemple, Bodner et
Song utilisent deux sources de connaissances differentes. La premiere reflete les
connaissances specifiques au domaine decrit a travers la collection utilisee. Il s’agit
d’une base de connaissances construite automatiquement en utilisant une methode
statistique. La deuxieme contient des connaissances universelles et est utilisee pour
completer les lacunes de la premiere base. Il s’agit d’une adaptation manuelle de
WordNet [11].
2.4.1 Expansion de requetes basee sur les relations lexico-
semantiques de WordNet
Voorhees examine l’utilite de l’expansion de requete par l’utilisation des rela-
tions lexicales-semantiques dans une grande collection contenant plusieurs domaines.
Elle utilise la collection TREC [34] ou chaque requete contient un ensemble de
champs identifies par des balises speciales. Le champ Narrative fournit une des-
cription detaillee de ce que constitue un document pertinent ; le champ Concepts
contient des mots et des expressions qui sont lies au theme de la requete. Le champ
Description contient une courte description de chaque requete generalement sous la
forme d’une simple phrase ; le champ Topic contient un resume de la requete ; le
dernier champ designe le domaine auquel appartient la requete (cf. figure 2.2).
Elle ajoute un nouveau champ a la requete : une liste de synsets de WordNet,
selectionnes a la main, contenant des mots en rapport avec le sujet de la requete
(Topic). Le but est de selectionner, pour une requete particuliere, les synsets qui ac-
centuent les concepts importants du sujet. Le choix des synsets a ete fait par l’auteur
en se basant sur sa propre comprehension de la requete entiere et sur le fait que les
synsets selectionnes seront utilises pour l’expansion.
Par exemple, concernant la requete 122, le synset drug a plusieurs descendants
dans WordNet a travers la hierarchie is-a (pharmaceutical, stimulants, intoxicants,
sedatives, etc.) mais qui ne sont pas tous relies au concept “cancer fighting”. Dans
ce cas, Voorhees ajoute seulement le synset qui est en relation avec les concepts de
la requete, c.-a-d. le synset pharmaceutical . La liste complete des synsets ajoutes a
40

Fig. 2.2 – Enonce de la requete 122 de la collection TREC-1
la requete 122 est : cancer , skin cancer , and pharmaceutical .
Rien n’a ete ajoute aux requetes dont les concepts n’ont pas des synsets corres-
pondants dans WordNet.
Une fois les requetes etendues par des synsets, le reste du processus est auto-
matique. Les champs de la requete originale sont d’abord indexes par le systeme
SMART [13]. Le processus d’expansion est lance quand le champ de synsets est at-
teint.
Pour un synset donne, il y a un large choix de mots a ajouter a un vecteur de
requete : on peut ajouter au choix seulement les synonymes presents dans le synset,
ou bien tous les descendants presents dans la hierarchie is-a, ou bien tous les syno-
nymes presents dans les synsets qui ont un lien quelconque avec le synset original,
etc. Le processus d’expansion est parametre pour faciliter la comparaison de l’effi-
cacite d’une variete de ces schemas. Tous les synonymes presents dans les synsets
ajoutes a la requete sont utilises lors du processus d’expansion.
Voorhees utilise le modele vectoriel etendu presente par Fox [29]. Chaque vecteur
de requete est compose de sous-vecteurs correspondant a differents types de concepts
(appeles ctypes) ou ctype correspond a une relation lexicale. Un vecteur de requete
41

a potentiellement onze ctypes comme par exemple : un pour les mots originaux de
la requete, un pour les synonymes, un pour chaque type de relation present dans la
categorie des noms de WordNet, etc.
Lors des experimentations, l’efficacite du systeme a ete evaluee en fonction des
types de relations utilises pendant l’expansion et le poids relatif donne a chaque type
de relation (les αi dans la fonction de similarite). Quatre types d’expansion ont ete
effectues :
1. Seulement par les synonymes ;
2. Par synonymes plus tous les descendants dans la hierarchie is-a ;
3. Par synonymes plus les parents plus tous les descendants dans la hierarchie
is-a ;
4. Par synonymes plus tous les synsets lies directement au synset donne. La va-
leur de α du sous-vecteur des mots originaux est plus eleve que celles des α des
autres sous-vecteurs.
Les resultats ont clairement montre qu’aucune des strategies d’expansion n’ameliore
de maniere significative les performances de recherche comparees aux requetes non
etendues. Etant donne que l’expansion de requete telle qu’elle est utilisee ici est
une methode qui sert a ameliorer le rappel, il n’est pas etonnant que les requetes
longues beneficient moins du processus d’expansion que les requetes courtes. Voo-
rhees a mentionne que certaines requetes courtes ont pu beneficier du processus
d’expansion. Supposant que les requetes courtes ont le potentiel d’etre sensiblement
amelioree par l’expansion, Voorhees a essaye de voir si ce potentiel peut etre revele
par un procede completement automatique. Ainsi, elle a propose un algorithme d’ex-
pansion automatique. De nouveau, les resultats n’ont pas ete satisfaisants.
Voorhees signale que les requetes longues sont tres sensibles a l’expansion et
provoquent des resultats negatifs. En effet, si l’expansion n’est pas controlee, elle
devient “agressive” et produit un bruit dans la requete. Dans cette direction, Qiu
et Frei [68] ont revele comment une expansion peut etre utile quand la requete est
etendue en choisissant soigneusement les mots a ajouter. Contrairement aux autres
methodes, leurs requetes sont etendues en ajoutant les mots qui sont similaires au
42

concept de la requete16, plutot que de choisir les mots qui sont similaires aux mots
de la requete. Ils proposent un modele d’expansion de requetes base sur un thesaurus
de similarite construit automatiquement. Ce thesaurus reflete la connaissance du
domaine decrit dans la collection de documents a partir de laquelle il est construit.
Il est represente par une matrice contenant des similarites mot-mot. Le principe de
leur methode peut etre compare a la traduction d’un texte d’une langue naturelle
vers une autre : la consultation des dictionnaires pour un mot ne donne pas souvent
la reponse finale. Au contraire, le traducteur qui connaıt la signification du texte
doit choisir le mot approprie a partir d’une liste entiere de traductions possibles.
Les experimentations qu’ils ont menees sur les collections MED, CACM et NPL
ont donne de bons resultats. Les performances ont ete ameliorees respectivement
de 18.31%, 22.85% et de 29.21%. Dans cette meme idee d’etendre les requetes d’une
maniere “controlee”, Baziz prend en compte le contexte de toute la requete et suppose
que meme si chaque mot dans une requete est individuellement ambigu, l’ensemble
des mots de cette requete pris ensemble contribue a exprimer une meme idee (sens)
[4][6].
2.4.2 Utilisation de WordNet pour une expansion “guidee”
de requetes
La demarche d’expansion de requete suivie par Baziz consiste d’abord a detecter
les termes de la requete qui renvoient a des concepts d’une ressource externe, puis,
de les etendre par des termes representant d’autres concepts proches de ceux de la
requete. Ces termes sont identifies grace aux liens semantiques entre concepts qu’offre
l’ontologie. Baziz rapporte que la desambiguısation s’effectue en meme temps que
l’expansion, en prenant en compte le contexte de la requete et en cherchant a iden-
tifier les concepts correspondant aux plus longs termes que l’on peut former a partir
des mots de la requete [4][6].
Baziz a etudie trois points importants lors du processus d’expansion de requete :
i) L’apport de chaque type de relation semantique ;
ii) L’impact de la ponderation des termes ajoutes ;
16Qui veut dire la requete entiere (selon la propre terminologie des auteurs).
43

iii) La quantite de termes a ajouter.
En etudiant l’usage de differents types de relations semantiques pour l’expansion
de requete, Baziz a propose les trois methodes suivantes :
1) L’expansion aveugle : chaque terme de la requete est etendu en utilisant les
differentes relations semantiques. Le resultat de cette expansion est un ensemble de
concepts candidats (nœuds possibles) relies au terme. Une expansion aveugle consiste
alors a ajouter a la requete initiale tous les concepts possibles pour toutes les rela-
tions.
Une autre maniere de proceder est de faire une selection des concepts qui sont lies
aux termes de la requete initiale. Ainsi, Baziz a propose une technique qui permet de
selectionner le “meilleur” concept a ajouter au moment de l’expansion. En se basant
sur cette technique, il a propose deux methodes d’expansion :
2) L’expansion moderee : ajouter pour chaque terme de la requete, le meilleur
(un seul donc) concept par type de relation. Dans ce cas, le nombre de concepts
ajoutes est egal au nombre de termes dans la requete. Cette approche traduit l’hy-
pothese que l’utilisateur utilise differents termes pour faire allusion a plusieurs concepts
differents dans sa requete.
3) L’expansion prudente : ajouter pour toute la requete, le meilleur (un seul
donc) concept (pour chaque type de relation). Cette approche traduit l’hypothese
que meme si les termes de la requete peuvent decrire individuellement des concepts
differents, ensemble ils contribuent a denoter un seul concept (idee). Cette idee a
ete developpee par Qiu et Frei qui representent le contenu de la requete par un seul
concept qu’ils appellent “concept virtuel” [68]. Cependant Qiu et Frei ne considerent
pas differents types de relations vu qu’ils utilisent un thesaurus de similarite mot-mot.
Ces trois methodes d’expansion ont ete evaluees pour mesurer leurs impacts sur
les performances de recherche. Ainsi, Baziz a utilise la collection CLEF-2001. Il a
egalement utilise WordNet pour la desambiguısation et l’utilisation des relations
semantiques. Les resultats presentes montrent que les trois methodes d’expansion
44

ameliorent les performances de recherche. Les meilleurs resultats ont ete obtenus
avec l’expansion prudente (+55%). Ceci confirme la conclusion tiree par Qiu et Frei,
a savoir qu’une expansion peut etre utile si la requete est etendue en choisissant
soigneusement les mots a ajouter [68].
Baziz a egalement etudie l’impact de la ponderation des termes ajoutes a la
requete. Les resultats obtenus montrent qu’une ponderation uniforme (egale a 1) des
termes d’origine et des termes ajoutes degrade les performances de recherche de plus
de 80%. Baziz a egalement remarque que les performances s’ameliorent sensiblement
des qu’il affecte aux termes ajoutes un poids inferieur a celui des termes d’origine.
Par exemple, en affectant le poids 0.9 aux termes ajoutes, les performances ont aug-
mente de plus de 60%. Tout comme Voorhees [94], Baziz a remarque l’existence d’un
poids optimal a utiliser pour les termes ajoutes (0.5) ce qui a permis d’ameliorer les
performances de 78%. Voorhees a trouve la meme valeur (0.5) mais il ne s’agit pas
du poids des termes ajoutes mais plutot d’un nombre reel qui reflete l’importance de
termes ajoutes relativement aux termes d’origine.
Finalement Baziz a etudie l’impact du type de relation utilisee lors de l’expan-
sion sur les performances de recherche. Ainsi, il a pu conclure que l’apport de la
relation d’holonymie, est le moins important, puis vient celui de sa relation inverse,
la meronymie. La relation d’hyponymie qui exprime la specialisation a un meilleur
apport mais vient derriere sa relation inverse l’hyperonymie. Cette derniere a re-
tourne un resultat superieur a celui de la synonymie.
L’effet de plusieurs expansions successives d’une requete s’est revele negatif sur la
precision du systeme. En etudiant le nombre de termes a ajouter a une requete lors
de l’expansion, Baziz a conclu que le nombre de termes, a retenir dans le processus
d’expansion, doit etre limite pour ne pas engendrer un bruit trop important.
2.4.3 Discussion
Nous avons montre que l’expansion de requete peut etre un moyen efficace pour
avoir une representation riche du contenu de la requete, et ameliorer ainsi la per-
formance du systeme. Le point cle de la reussite de cette methode reside dans le
choix “prudent” des concepts a ajouter a la requete initiale. En effet, une expansion
45

“aveugle” ne fait que degrader les resultats en ajoutant du bruit a la description
de la requete. Malgre l’apport des approches existantes, une limite persiste encore.
En effet, meme apres l’expansion, la requete est toujours consideree comme un sac
de concepts. Ceci ne favorise pas la resolution d’une requete precise qui dispose
d’une structure semantique complexe, et demande ainsi un traitement specifique
pour mettre en exergue tous les aspects lies a son contenu semantique. Nous sommes
convaincus que la prise en compte des dimensions de domaine est une solution pos-
sible pour satisfaire des requetes precises. C’est pourquoi nous etudions, dans la
section suivante, les travaux les plus representatifs qui s’interessent a la notion de
dimensions et qui sont proches de notre problematique.
2.5 Dimensions & RI
A notre connaissance, les travaux qui s’interessent a la notion de dimensions sont
lies principalement aux developpements d’outils de navigation dans des bases de
documents. Ces outils sont bases sur le paradigme de la recherche dite “basee sur
les facettes” (faceted search) [36][54][66][82][105] ou “basee sur les vues” (view-based
search) [52][53]. Dans la litterature, les termes “facette”, “vue”, et “dimension” sont
utilisees pour designer la meme chose. La recherche basee sur les facettes est un
paradigme qui a ete propose a la fin des annees 1920, et qui retrouve un regain
d’interet (durant la conference SIGIR 2006, il a ete organise un atelier17 sur ce
theme). Dans la suite, nous decrivons ce paradigme et nous examinons quelques
travaux qui s’inscrivent dans ce champ de recherche.
2.5.1 Le paradigme de la recherche basee sur les facettes
La recherche multi-facettes est un paradigme base sur la classification a facettes
qui a ete elaboree par le mathematicien et bibliothecaire S. R. Ranganathan. Celui-ci
a propose ce paradigme comme reponse au probleme suivant : “Comment ranger les
livres dans une bibliotheque quand on sait qu’il y en a des grands et des petits, des
livres d’histoire et des romans, des auteurs qui ont ecrit les deux et des collections
reliees qui traitent de tout et que l’on doit y ajouter les dossiers correspondant aux
differents sujets ?”
17SIGIR’2006 Workshop on Faceted Search : http ://facetedsearch.googlepages.com/
46

D’un point de vue editeur, l’idee derriere le paradigme de recherche multi-facettes
est qu’un document, pour etre classe, possede generalement differentes caracteristiques
(facettes), chacune peut etre decrite par une hierarchie de concepts differente [72].
De cette maniere, les resultats de recherche (les documents) peuvent etre organises a
travers des facettes (generalement) orthogonales. Par exemple, dans une bibliotheque
numerique, les resultats peuvent etre groupes par auteur, annee de publication, theme,
etc.
D’un point de vue utilisateur, l’idee est de permettre a l’usager, a travers une
interface graphique, d’avoir plusieurs points d’entree pour explorer une base de do-
cuments. Dans ce cas, les facettes offrent differentes hierarchies (generalement or-
thogonales) que l’utilisateur peut utiliser pour naviguer dans une base. Les facettes
peuvent ainsi etre vues comme une maniere de categoriser le contenu d’une base
de documents pour permettre des interactions utilisateur intuitives. Les hierarchies
decrivant les facettes offrent a l’usager une vue d’ensemble sur le contenu de la
collection, et un moyen pour le guider a formuler son besoin et la requete correspon-
dante. Elles sont donc utilisables pour la navigation, la recherche, et l’organisation
des reponses [53][105].
Generalement ce paradigme marche bien dans le cas ou les documents sont an-
notes (de preference manuellement), la collection est statique et relativement de
petite taille, et son contenu est homogene [42].
Bien que d’une maniere generale la structure d’une facette soit hierarchique, il
peut y avoir des facettes dont la structure est plate. Dans ce cas, la facette est
representee par un ensemble18 de termes sans aucune structure entre eux [21]. Le
contenu des facettes peut correspondre a des proprietes thematiques ou a des pro-
prietes meta-donnees19 des documents [40].
18Generalement de taille reduite19Langue, type du document, date de creation, etc.
47

2.5.2 Outils bases sur le paradigme de recherche multi-facettes
Le systeme du musee de l’Universite d’Helsinki
Les auteurs utilisent le paradigme de recherche multi-facettes pour developper
une interface graphique pour la navigation dans une base de photos. Celles-ci sont
extraites a partir de la base du musee de l’Universite d’Helsinki. Elles contiennent
des personnes, des evenements, des lieux, des objets physiques, etc. Les auteurs pro-
posent d’utiliser une ontologie pour l’annotation des photos et le developpement de
l’interface. L’ontologie est construite manuellement et son contenu est extrait a par-
tir de celui des photos. Elle est constituee d’un ensemble de categories hierarchiques
qui correspondent a des facettes. L’annotation des photos est egalement effectuee
manuellement en utilisant les instances des concepts de l’ontologie.
Fig. 2.3 – Interface d’acces multi-vues [38][39]
A travers l’interface, l’utilisateur peut naviguer dans les facettes de l’ontologie
pour : i) formuler son besoin d’information au cas ou il ne connaıt pas le contenu de
la base ; et ii) formuler la requete correspondante.
L’ontologie est egalement utilisee par le systeme pour “fabriquer” des reponses
plus significatives en proposant a l’utilisateur, non seulement l’image qu’il cherche,
48

mais aussi les images dont le contenu est proche.
Dans la figure 2.3, nous presentons une copie d’ecran de l’interface developpee
par Hyvonen et ses collegues. Du cote gauche de l’ecran, l’utilisateur peut choisir
les facettes ontologiques (ontological view) selon lesquelles il veut explorer la base.
Ceci s’effectue en choisissant des entrees depuis le menu deroulant add more views.
Ces facettes ontologiques sont celles qui ont ete employees pour annoter manuelle-
ment les photos. Elles indiquent a l’utilisateur les termes pertinents lies aux photos.
L’utilisateur peut focaliser son besoin d’information en naviguant dans ces facettes.
En choisissant des entrees des facettes ontologiques, un filtrage de la base se fait,
et les photos correspondantes apparaissent sur la partie droite de l’interface. Dans
la figure 2.3, le choix est Personne=GarlandBinder et Place=Building. Une photo
annotee par ces deux termes est ainsi affichee20. Le systeme recommande egalement
d’autres photos en se basant sur leurs annotations et les definitions ontologiques. A
titre d’exemple, le systeme peut recommander des photos ou le meme GarlandBinder
figure mais pas dans un batiment, ou encore des photos prises dans un batiment mais
decrivant d’autres personnes.
La difficulte principale mentionnee par les auteurs est l’effort supplementaire
necessaire pour la creation de l’ontologie et les annotations detaillees des photos. Ils
ne presentent aucune evaluation, ni au niveau des performances de recherche ni au
niveau de l’utilisabilite de leur interface.
Le systeme Flamenco
Le systeme Flamenco21 propose une interface (cf. figure 2.4) qui permet a la fois
la recherche par mot-cles et la navigation dans une base d’images selon plusieurs
facettes [36][105]. La base d’images gerees par le systeme est annotee manuellement
par des descriptions textuelles. Chaque image est associee manuellement a une ou
plusieurs facettes qui sont elles-memes fabriquees manuellement. Le systeme permet
d’afficher ces facettes (hierarchiques ou plates) en proposant des liens hypertextes
sur lesquels l’utilisateur peut cliquer pour faire une recherche. Chaque fois que l’uti-
lisateur clique sur un lien, un ensemble d’images est propose par le systeme. Lors de
20Le choix de la photo a afficher en premier en cas ou plusieurs photos sont annotees par lesmemes termes n’a pas ete evoque par les auteurs.
21http ://flamenco.berkeley.edu/
49

la recherche par mots-cles, la notion de multi-facettes n’est pas prise en compte, et
le systeme affiche tout simplement les images qui sont annotees par ces mots22.
Fig. 2.4 – Interface multi-facettes du systeme Flamenco
2.5.3 Fabrication des dimensions/facettes
La plupart des travaux existants construisent les facettes manuellement. Une
premiere methode consiste a diviser une ressource existante (ontologie, thesaurus,
etc.) en differentes hierarchies, chacune correspond a une facette. Cette methode a
22Le choix de l’ordre dans lequel les images doivent etre affichees n’est pas discute par les auteurs.
50

ete adoptee par Aussenac-Gilles et Mothe qui ont divise manuellement une onto-
logie de domaine en differentes hierarchies dans le but de developper une interface
d’acces multi-facettes [1]. Une autre methode consiste a fabriquer individuellement
les facettes. Dans ce cas, elles peuvent etre structurees separement ou dans une seule
ontologie [39][52].
En ce qui concerne la construction automatique de facettes, le peu de travaux
qui s’interessent a cet aspect n’ont pas encore conduit a des resultats aboutis mais
proposent seulement quelques idees [101][26][87].
Dakka et ses collegues ont propose un algorithme qui permet d’enrichir automa-
tiquement des facettes existantes [26]. Ils utilisent des techniques de classification
supervisee pour classer des nouveaux termes dans des facettes existantes. Pour ce
faire, ils utilisent une base d’images annotees manuellement. A chaque image est as-
socie un ensemble de mots-cles, chacun appartenant a une des facettes. Pour enrichir
une facette F, les auteurs utilisent WordNet pour extraire les synonymes des mots
utilises pour annoter les images appartenant a F. Ces synonymes seront ajoutes au
vocabulaire de F. Les auteurs utilisent la structure de WordNet pour organiser le vo-
cabulaire de chaque facette “enrichie” autour d’une hierarchie. Pour cela, ils utilisent
des heuristiques pour extraire automatiquement des relations (generique/specifique,
et equivalent) entre les mots du vocabulaire de F.
La limite de cette methode est que l’algorithme utilise est supervise, par conseque-
nt, les facettes doivent etre connues a l’avance, et aucune nouvelle facette ne peut
etre decouverte. Une idee interessante serait de decouvrir automatiquement des nou-
velles facettes, ce qui pourrait passer par trois etapes : i) decouvrir automatique-
ment, et d’une maniere non supervisee, a partir d’une base textuelle, un ensemble de
termes candidats pour le vocabulaire d’une facette ; ii) regrouper automatiquement
les termes qui appartiennent a la meme facette ; iii) construire la structure de chaque
facette.
Pour franchir la premiere etape, Dakka et ses collegues ont propose un algorithme
qui se base sur des connaissances externes [101]. L’idee est que les termes utilises
dans les documents sont specifiques et ne decrivent generalement pas la facette. Par
exemple, dans un article de presse, un journaliste va mentionner “Jacques Chirac”
51

sans dire qu’il s’agit d’un “homme politique” ou qu’il est originaire de “l’Europe”
ou meme de “France”. Ainsi, pour decouvrir des termes generiques qui decrivent
les facettes, les auteurs utilisent des ressources externes23 pour etendre le contenu
des documents. L’idee de base est d’interroger ces ressources et de voir quels termes
co-occurrent souvent avec les termes de la base. L’hypothese est que les termes qui
decrivent les facettes sont des termes rares dans la base de documents mais qui co-
occurrent frequemment dans les ressources externes avec les termes de la base. Le
contenu de chaque document est alors etendu en utilisant certains termes de la res-
source externe, et ces documents etendus sont par la suite utilises pour extraire les
facettes. Finalement, les auteurs font l’hypothese que les termes candidats doivent
etre peu frequents dans les documents originaux, mais frequents dans les documents
etendus. Ce travail est en cours d’elaboration, et les auteurs ne presentent aucune
evaluation experimentale.
Pour franchir la deuxieme et la troisieme etape, Stoica et Hearst proposent de
decouper WordNet en facettes en utilisant la relation d’hyperonymie (is-a) [87].
L’algorithme propose suppose que chaque document de la collection est annote par
une description textuelle. Celle-ci est utilisee pour fabriquer les hierarchies des fa-
cettes. Le processus consiste a selectionner un ensemble de termes (selon certains
criteres statistiques simples) a partir des descriptions textuelles. L’ensemble des
termes selectionnes forme un “noyau d’arbre” (tree core). Ce dernier est enrichi par
des termes extraits de WordNet. Ces termes appartiennent aux chemins d’hyperony-
mie qui existent entre les termes du noyau d’arbre dans WordNet. L’etape suivante
consiste a reduire la taille du noyau d’arbre enrichi. Pour ce faire, les auteurs utilisent
des criteres simples comme un concept pere qui a moins de x fils est elimine. Fina-
lement, ils suppriment les nœuds tres generiques de sorte a produire les hierarchies
desirees. Quelques experiences ont ete effectuees afin d’evaluer l’algorithme propose.
Comme l’algorithme est destine a etre utilise par des architectes d’informations (in-
formation architects), son evaluation a ete effectuee par des utilisateurs de ce type.
85% des 34 participants ont souhaite utiliser l’outil dans leur travail.
23Comme WordNet ou Wikipedia.
52

2.5.4 Discussion
La recherche multi-facettes est un paradigme prometteur pour la resolution des
requetes precises. Toutefois, les approches basees sur ce paradigme ne peuvent fonc-
tionner que dans un cadre limite. En effet, les documents doivent etre annotes de
preference manuellement. Ceci impose donc une limite sur la collection qui doit etre
statique et relativement de petite taille, et dont le contenu doit etre homogene.
Vu que la recherche se fait par navigation, une grande taille de la hierarchie de
concepts peut representer une surcharge cognitive a laquelle l’utilisateur doit faire
face pour choisir les entrees qui l’interessent. Dans ce sens, il y a quelques tentatives
pour afficher dynamiquement les hierarchies de concepts a l’utilisateur, mais il n’y
a pas encore de resultats aboutis [90]. A notre avis, ceci restera un probleme delicat
dans le sens ou les requetes precises contiennent une terminologie tres specifique qui
demande une navigation profonde dans la hierarchie de concepts.
La complexite de la structure semantique des requetes precises represente une
autre difficulte que les interfaces multi-facettes n’arrivent pas a surmonter. En ef-
fet, ce type de requetes peut contenir des operateurs, et/ou mettre en relation
des concepts qu’elles contiennent. Ceci demande un traitement specifique pour in-
terpreter la semantique vehiculee par la structure de la requete.
Les travaux bases sur le paradigme de recherche multi-facettes supposent que les
facettes existent, et que les documents leurs sont associes manuellement. A notre
connaissance, le seul travail qui associe automatiquement des documents a des fa-
cettes est celui de Aussenac-Gilles et Mothe [1].
Tel qu’il est utilise, le paradigme de recherche multi-facettes represente une
maniere de structurer une collection de documents sous forme de “bases de donnees”
ou les facettes correspondent a des attributs. Ainsi, pendant la navigation, l’usa-
ger choisit les attributs qui l’interessent et le systeme lui fournit leurs valeurs. Les
systemes existants n’ont pas ete testes en termes de performance de recherche. A
notre connaissance, la seule evaluation a ete effectuee par Yee et ses collegues qui
ont fait une etude d’utilisabilite d’une interface multi-facettes sur une base d’images
[105]. Leurs resultats ont montre que les utilisateurs preferent utiliser ce type d’in-
53

terface aux interfaces d’interrogation basees sur les mots-cles.
2.6 Conclusion
Nous nous sommes interesses aux travaux qui utilisent les ressources externes
pour prendre en compte la semantique vehiculee par les documents et les requetes.
Ainsi, nous avons pu identifier une classe d’approches qui representent les documents
(requetes) par des concepts au lieu des mots-cles. Ces approches necessitent un pro-
cessus de desambiguısation afin d’associer des concepts aux termes presents dans les
documents (requetes). Les resultats obtenus jusqu’a present ont montre les limites
de ces approches par rapport a celles basees sur les mots-cles. Un premier facteur
qui influe sur les performances d’un SRI base sur les concepts est la precision du
desambiguıseur utilise. Pour cette raison, nous avons examine les travaux les plus
representatifs qui s’interessent a l’evaluation des desambiguıseurs dans le cadre de
la RI. Une telle evaluation permet de savoir avec precision l’impact de la precision
du desambiguıseur sur les performances de recherche. De cette facon, la plupart des
travaux ont pu conclure que l’ambiguıte n’a pas un effet dramatique sur les perfor-
mances de recherche. Au cas ou un desambiguıseur est utilise, il faut qu’il soit tres
precis (≥90%) pour qu’on puisse avoir des bons resultats.
Un deuxieme facteur dont depend les performances de recherche est le degre de
couverture de la ressource externe utilisee par rapport au vocabulaire du corpus. A ce
sujet, les rares travaux qui ont obtenu des resultats positifs, sont ceux qui combinent
l’indexation conceptuelle avec l’indexation a base de mots-cles.
Le troisieme facteur dont depend les performances de recherche est la methode
utilisee pour “interpreter” le contenu semantique du document et du besoin d’infor-
mation. Dans les approches existantes, une fois les concepts extraits, les documents
(requetes) sont considere(e)s comme des sacs de concepts. Par consequent, les rela-
tions semantiques qui peuvent exister entre les differents concepts qu’ils contiennent
ne sont pas exploitees. C’est pourquoi des documents qui ne partagent pas les memes
concepts avec une requete ne pourront pas etre retrouves avec ces approches meme
s’ils sont pertinents pour cette requete. L’expansion de requetes represente une so-
lution possible a ce probleme. Plusieurs travaux se sont interesses a cet aspect, mais
54

rares sont ceux qui ont eu des resultats positifs. Face a ces echecs, des chercheurs ont
propose d’etendre les requetes d’une maniere “prudente”. Dans cette direction Baziz
a obtenu des resultats positifs. Baziz s’est egalement interesse a la representation des
documents par des reseaux semantiques qui mettent en relation les concepts du meme
document. Cependant, ces reseaux sont utilises seulement pour la desambiguısation
et pas durant le processus de RI. Meme s’il a propose une approche d’expansion
prudente qui lui a permis d’ameliorer les resultats, Baziz considere de nouveau la
requete etendue comme un sac de concepts.
Ces resultats nous ont persuades que le fait de passer d’un niveau mot a un niveau
concept n’est pas suffisant pour prendre en compte le contenu semantique des docu-
ments (requetes), et resoudre ainsi des requetes precises. Nous sommes convaincus
que la prise en compte des dimensions de domaine represente un moyen pour at-
teindre ces objectifs. Nous avons donc etudie les principaux travaux qui s’interessent
aux dimensions de domaine en RI.
Les travaux qui s’interessent aux dimensions concernent pour le moment la re-
cherche basee sur le paradigme multi-facette. Les approches basees sur ce type de re-
cherche sont prometteuses, mais leur application reste limitee a petite echelle vu que
tout le processus d’annotation des documents est manuel. La complexite de la struc-
ture des requetes precises represente une difficulte que les interfaces multi-facettes
n’arrivent pas a surmonter. De plus, ce type de requetes contient une terminologie
tres specifique qui demande une navigation profonde dans les hierarchies de concepts
qui definissent les facettes. Ceci represente une lourde surcharge cognitive pour l’uti-
lisateur lors du choix des entrees qui l’interessent.
Pour conclure, nous pouvons constater que, malgre les efforts fournis par de
nombreux chercheurs, la prise en compte du contenu semantique des documents
(requetes) reste encore un probleme largement ouvert. Nous sommes donc persuades
que les approches existantes qui considerent les documents (requetes) comme des
sacs de concepts ne peuvent pas resoudre des requetes precises. Pour notre part,
l’approche que nous avons adoptee consiste a utiliser les dimensions de domaines.
L’utilisation des dimensions en dehors du paradigme multi-facette a pour but d’ex-
pliciter la structure semantique au niveau de la representation des documents et des
requetes. Nous utilisons les dimensions afin d’extraire les elements importants qui
55

contribuent au developpement du theme present dans le document et dans la requete.
En se basant sur ces elements, nous tentons de representer le contenu des documents
(requetes) en mettant en exergue la semantique qu’ils(elles) vehiculent. Dans la suite
du document, nous presentons en details notre contribution et son apport theorique
et pratique par rapport a l’etat de l’art.
56

Chapitre 3
Un Modele de RI fonde sur les
dimensions de domaine
3.1 Preambule
L’objectif de la Recherche d’Information est de selectionner les documents per-
tinents qui traitent du theme de la requete. Pour atteindre cet objectif, l’indexation
joue un role primordial en definissant les descripteurs qui representent les documents
et a partir desquels ils peuvent etre accedes ou analyses. Dans les approches exis-
tantes, les descripteurs utilises sont les mots ou les termes ou les concepts. Comme
nous l’avons presente dans le premier chapitre, ces descripteurs ne sont pas suffisants
pour interpreter le contenu semantique des documents/requetes, et prendre correc-
tement en compte le theme lors de l’interrogation.
Dans notre travail, nous proposons une nouvelle approche qui consiste a utiliser
un nouveau type de descripteurs lors de l’indexation : les dimensions de domaine.
L’interet principal de cette approche est de mettre en exergue les aspects lies aux
descriptions semantiques du contenu du document et de la requete. Nous utilisons
les dimensions comme un moyen pour completer l’information partielle transmise
par le contenu brut1 des documents/requetes. Ceci permet au systeme de produire,
d’une part, une representation precise du contenu semantique des documents, et
d’interpreter, d’autre part, le besoin de l’utilisateur. Ainsi, le jugement de la perti-
nence d’un document pour une requete fait intervenir les aspects lies aux descriptions
1sac de mots, sac de termes, sac de concepts, etc.
57

semantiques du contenu du document et de la requete.
Notre approche concerne l’acces a un corpus ou plusieurs domaines peuvent co-
exister. Selon le dictionnaire de l’Academie francaise, un domaine est tout ce qu’em-
brasse un art, une science, une faculte de l’esprit, etc. (exemples : le domaine de
la peinture, de la sculpture, de la politique, etc.). Nous travaillons uniquement sur
des domaines “connus”, c’est-a-dire qui ont atteint une certaine notoriete et par la
meme une certaine stabilite (par opposition a des domaines “nouveaux” qui corres-
pondent a des theories en cours d’elaboration et dont la terminologie n’est pas fixee).
Pour pouvoir acceder a ce corpus, nous faisons coexister des ressources externes
decrivant chacun de ces domaines. Si plusieurs ecoles de pensees/conceptions s’af-
frontent a l’interieur d’un domaine, nous pensons qu’il est preferable de les traiter
comme des domaines separes : le but n’est pas de forcer un consensus artificiel sur
les definitions des concepts d’un domaine. Le role d’une ressource externe n’est pas
de normaliser un domaine, mais de donner une representation de l’existant.
Chaque domaine present dans le corpus est decrit a travers la ressource externe
par trois types de descripteurs :
- Dimensions : une dimension d’un domaine est un concept general utilise pour
exprimer des themes dans ce domaine. Par exemple, dans le domaine de la Politique
internationale, un theme peut etre developpe par un redacteur en faisant reference
aux dimensions “Lieux geographiques”, “Personne”, “Evenement”, etc. Une meme
dimension peut appartenir a differents domaines a la fois. Par exemple, la dimension
“Lieu geographique” peut etre utilisee pour developper les themes du domaine de la
Politique internationale et du domaine du Sport, etc.
- Concepts : un concept correspond a une signification particuliere d’un mot
(ou sequence de mots). Dans un domaine, chaque dimension contient un ensemble
de concepts. Par exemple, la dimension “Personne” dans le domaine du Sport peut
contenir les concepts Joueur, Arbitre, Entraineur, etc.
- Termes : un terme est constitue d’un mot (ou sequence de mots) qui sert
pour denoter un concept dans un domaine particulier. La signification d’un terme
58

est determinee par les concepts qu’il denote a l’interieur du meme domaine.
3.2 Introduction
Nous proposons ici de definir un modele de RI capable de satisafaire des utilisa-
teurs souhaitant formuler leurs requetes de la maniere suivante :
R1 : “Donne-moi les documents qui parlent du general francais responsable de la
creation de la zone de securite pendant le conflit des Balkans” ;
R2 : “Donne moi des documents qui parlent de Bill Gates et de Steve Jobes et au
moins de deux societes d’informatique” ;
R3 : “Donne-moi des images de type rayon-x contenant une fracture ou une luxa-
tion d’un tibia” ;
R4 : “Donne-moi des images de type rayon-x des fractures de tous les os de la
jambe” ;
R5 : “Donne-moi des images de type rayon-x de femur sans fracture” ;
R6 : “Donne-moi des images de la peau de la main sans aucune pathologie” ;
etc.
Les besoins formules a travers ces requetes sont dits “precis”. En effet, un utilisa-
teur fait reference a des dimensions de son domaine d’interet pour decrire precisement
son besoin d’information en utilisant des concepts et des relations semantiques entre
eux. Par exemple, dans la requete R1 l’utilisateur cherche un element de la dimension
Personne, en particulier, le nom d’une personne P. Celle-ci est decrite a travers deux
dimensions, en utilisant les deux concepts suivants : General qui est un concept de la
dimension Personne, et France qui est un concept de la dimension Lieu geographique.
En effet, la personne recherchee est un General, et originaire de France.
59

Lors de la formulation d’une requete precise, l’utilisateur pourrait souhaiter
decrire davantage son besoin en employant des quantificateurs (au moins deux,
tous, etc.) ou bien des operateurs booleens ET/OU/NON, etc.
En considerant les exigences de l’utilisateur, un langage expressif de requete est
necessaire. Il doit permettre a l’usager d’utiliser des concepts et des dimensions pour
decrire son besoin. Il doit egalement permettre a l’utilisateur d’employer des relations
entre les descripteurs de sa requete. Finalement, l’utilisateur doit pouvoir enrichir la
description de son besoin a travers des operateurs.
Pour interpreter les requetes precises ainsi formulees, un traitement specifique est
necessaire :
- Prise en compte des deux types de descripteurs (concepts et dimensions) pour in-
terpreter le contenu semantique vehicule dans la requete ;
- Prise en compte des relations entre descripteurs de la requete ;
- Prise en compte des operateurs.
Pour pouvoir repondre precisement a ce type de requetes, leurs specificites doivent
etre prises en compte lors de l’indexation des documents. Pour etre retrouve, un do-
cument doit donc etre represente par des concepts et des dimensions, et sa description
doit permettre de satisfaire des requetes qui contiennent des relations semantiques
ainsi que des operateurs.
En se basant sur des ressources externes, nous proposons dans la suite un modele,
fonde sur les dimensions, associant des concepts et des relations semantiques dans la
description du contenu des documents(requetes). Ce modele s’appuie sur un langage
d’indexation expressif permettant une description precise du contenu des documents.
Il s’appuie egalement sur un langage de requete expressif permettant a l’utilisateur
d’exprimer des requetes precises. Les connaissances du domaine sont utilisees lors de
la definition de notre modele tout en garantissant une representation uniforme des
documents, des requetes et de la ressource externe. Ceci a ete effectue en utilisant
60

un formalisme de representation de connaissances adequat : il s’agit de la logique
descriptive.
3.3 Specificites du modele
Usage des dimensions
Les dimensions dans notre modele peuvent etre vues comme une couche descrip-
tive qui permet d’associer a un concept un role particulier lors de la description du
contenu d’un document ou d’une requete. Par exemple, sachant que “Joueur” est un
element de la dimension Personne, meme s’il ne contient pas le terme “joueur”, un do-
cument contenant “Zidane” peut etre retrouve comme reponse a la requete suivante :
R7 : “Donne-moi les documents qui parlent du joueur francais qui a ete elu
meilleur footballeur en 2004”.
Usage des relations
Nous nous interessons aux relations semantiques que l’on peut trouver dans la res-
source externe et qui permettent d’apporter une precision sur une entite ambigue du
document, comme les relations “est un”, ou “partie de”, etc.
Exemple : un document reponse a la requete R7 doit contenir le nom d’une
personne P. P est un “joueur”, et P est originaire de “France”. En utilisant les
relations semantiques presentes dans la ressource externe, nous pouvons selectionner
l’ensemble des joueurs francais. Les documents qui contiennent un des noms de
ces joueurs est un candidat pour repondre a cette requete. Mais pour repondre
entierement et avec precision, il faut prendre en compte les autres informations de
la requete : la date (2004) et la consecration (meilleur footballeur).
Usage des operateurs
Nous nous interessons a une formulation precise du besoin de l’utilisateur. Celui-
ci veut exprimer a travers sa requete un besoin tel que : “donne-moi les images qui
61

decrivent une main sans aucune pathologie”. Il faut donc permettre a l’utilisateur
d’employer un operateur de negation pour exprimer ce genre de besoin.
Dans la section suivante, nous presentons avec detail des exemples typiques de
besoins d’informations precis que nous proposons de satisfaire a travers notre modele
de recherche. L’expression de ces requetes dans notre modele est presentee dans la
section 3.6.2.
3.3.1 Exemples typiques de besoins d’information precis
Le but de cette section est d’analyser ce genre de requete afin de proposer un
modele de recherche adequat. Nous presentons donc un ensemble de requetes en
detaillant leurs specificites et en suggerant des moyens pour les resoudre. Nous men-
tionnons la necessite d’introduire explicitement les dimensions dans la description
des documents et des requetes, ainsi que la necessite d’utiliser les operateurs sur les
dimensions et pas seulement sur les concepts et les termes comme cela a ete deja fait
(ex. dans le modele booleen).
Pour les besoins des exemples, nous supposons que les dimensions suivantes sont
disponibles a travers une ressource externe :
Personne : contenant des politiciens, des sportifs, des celebrites, etc.
Organisation : contenant des entreprises, des organisations internationales, etc.
Lieu geographique : contenant l’ensemble des lieux dans le monde (continent,
pays, villes, etc.) ;
Evenement : contenant des evenements de la vie courante (guerre en Iraq, raz-de-
maree, etc.) ;
Anatomie : contenant les differents membres du corps humain ;
62

Pathologie : contenant l’ensemble des maladies qui peuvent affecter le corps hu-
main ;
Modalite : contenant l’ensemble des types des images medicales.
Voici maintenant quelques exemples de besoins d’information precis.
R8 : “Donne-moi les documents qui parlent de Bill Gates et d’une societe d’infor-
matique”.
L’utilisateur cherche des documents relatifs a un element de la dimension Per-
sonne : Bill Gates et a un element de la dimension Organisation : societe d’infor-
matique. Un document pertinent doit traiter des deux elements de dimensions. Ceci
se traduit par l’operateur booleen de conjonction ET.
R9 : “Donne-moi les documents qui parlent de Steve Jobs ou de Apple, Inc.”.
L’utilisateur cherche des documents relatifs a un element de la dimension Per-
sonne : Steve Jobs ou un element de la dimension Organisation : Apple, Inc. Un
document pertinent doit traiter d’un des deux elements de dimensions. Ceci se tra-
duit par l’operateur booleen de disjonction OU.
R10 : “Donne-moi des images qui montrent un tibia sans aucune pathologie”.
L’utilisateur cherche des images qui contiennent un element de la dimension Ana-
tomie : tibia sans aucun element de la dimension Pathologie : pas de fracture ou
luxation, etc. Un document pertinent doit contenir l’element de la dimension Ana-
tomie et ne doit pas contenir l’element de la dimension Pathologie. Ceci se traduit
par l’operateur booleen de negation NON.
Il est possible qu’un document presente un tibia sans aucune pathologie, mais
montre aussi une autre partie de l’anatomie avec d’autres pathologies que celles qui
63

peuvent affecter le tibia. Dans ce cas, ce document peut etre considere pertinent. Il
faut donc distinguer, au moment de l’interrogation, qu’il faut exclure seulement les
documents qui contiennent des pathologies du tibia. Ceci peut se traduire par une
relation entre les elements de dimensions au moment de la formulation de la requete.
R1 : “Donne-moi les documents qui parlent du general francais responsable de la
creation de la zone de securite pendant le conflit des Balkans”.
Un utilisateur peut preciser a travers sa requete ce dont le document doit obli-
gatoirement parler. Il peut egalement introduire des descripteurs dont le document
reponse ne doit pas obligatoirement parler. Par exemple, a travers la requete R1,
l’utilisateur cherche un element de la dimension Personne, en particulier, le nom
d’un general francais. Donc un document pertinent doit obligatoirement parler du
nom de cette personne. Meme si ce document ne parle pas du conflit ou des Bal-
kans, il peut etre considere pertinent. Donc tandis que l’element de la dimension
Personne est obligatoire, les autres elements de dimensions peuvent etre option-
nels (evenement et lieu geographique). Les operateurs booleens ne sont pas suffisants
pour exprimer ces deux notions. En effet, l’emploi d’un operateur booleen implique
toujours l’utilisation de deux elements. Ceci ne permet donc pas a l’utilisateur d’ex-
primer qu’il y a un seul element qui est obligatoire ou bien un seul element qui est
optionnel. D’une part, l’utilisation du ET implique que les deux elements en ques-
tion sont obligatoires. D’autre part, l’utilisation du OU implique que l’un des deux
elements en question est optionnel, sans preciser lequel. La notion d’obligation n’est
pas nouvelle : certains moteurs de recherche 2 utilisent un tel critere (represente par
le prefixe “+”) afin de fournir une syntaxe plus simple et plus intuitive, permet-
tant ainsi de resoudre la difficulte rencontree par les utilisateurs pour exprimer des
requetes booleennes.
Ces deux types d’expressions de besoins peuvent etre prises en compte en uti-
lisant des operateurs sur les elements de dimensions presents dans la requete. Ces
operateurs peuvent etre : obligatoire ou optionnel. Ils ont ete detailles dans [48][44]
dans un contexte ou l’utilisateur a deja vu les documents et ne se souvient pas exac-
tement de leur contenu. Nous pouvons reprendre ces operateurs afin de donner les
2ex. Google, Altavista, etc.
64

moyens a l’utilisateur de decrire avec precision son besoin d’information.
Il est possible que l’utilisateur n’arrive pas a utiliser les deux operateurs precedents.
Par exemple, imaginons que l’utilisateur puisse considerer que les documents qui
traitent du theme de sa requete sont pertinents, mais en privilegiant ceux qui contien-
nent le nom de la personne d’abord, ensuite ceux qui parlent du conflit, ensuite ceux
qui parlent des Balkans. Dans ce cas, l’expression de ce besoin peut etre mise en
œuvre avec un operateur priorite. Celui-ci permet a l’utilisateur d’avoir plus de flexi-
bilite lors de la definition de son besoin. Ainsi, il peut donner la plus grande priorite
aux documents qui contiennent le nom de la personne recherchee, et une priorite
moins importante aux documents qui contiennent les autres elements de dimensions.
Nous pouvons imaginer un scenario ou l’utilisateur veut donner des poids aux
elements de dimensions de sa requete . La valeur de chaque poids peut etre comprise
entre 0 et 1. 1 etant la valeur la plus elevee qui signifie que l’element de dimension
correspondant est tres importante dans la requete et obligatoire, et 0 signifie que
l’element de dimension correspondant est optionnel. L’expression de ce besoin peut
se faire a travers un operateur jauge. Ainsi, l’utilisateur peut preciser explicitement
les degres d’importance relatifs aux elements de dimensions presents dans sa requete.
Jusqu’a present, nous avons vu des cas ou la requete contient un seul element de
chaque dimension. Il est possible que la requete contienne plusieurs elements de la
meme dimension. La question est donc de savoir quel(s) operateur(s) utiliser entre
les elements d’une meme dimension. Nous essayons de repondre a cette question a
travers les exemples suivants.
R11 : “Donne-moi les documents qui parlent de Bill Gates et Steve Jobs et d’une
societe d’informatique”.
Dans cette requete, il y a deux elements de la dimension Personne : Bill Gates et
Steve Jobs, et un element de la dimension Organisation : societe d’informatique.
Un document pertinent doit parler des DEUX elements de la dimension Personne
presents dans la requete ET d’un element de la dimension Organisation. Dans ce
cas, il faut utiliser l’operateur ET entre les elements de la dimension Personne.
65

R12 : “Donne-moi les images qui montrent une fracture ou une luxation d’un ti-
bia”.
Deux dimensions sont presentes dans cette requete : la dimension Pathologie : frac-
ture, luxation ; la dimension Anatomie : tibia. Une image pertinente doit contenir
une fracture OU une luxation, ET un tibia. Dans ce cas, il suffit d’utiliser l’operateur
OU entre les elements de la dimension Pathologie pour preciser le besoin de l’utili-
sateur.
R13 : “Donne-moi des images qui montrent un tibia sans fracture”.
L’utilisateur cherche des images qui contiennent un element de la dimension Anato-
mie : tibia sans l’element de la dimension Pathologie : fracture. Il est possible qu’un
document contenant un autre element de la dimension Pathologie (ex. luxation) soit
pertinent pour cette requete. Pour bien preciser ce besoin d’information, il faut uti-
liser l’operateur de negation NON sur la pathologie de type fracture seulement et
pas sur tous les elements de la dimension Pathologie.
R2 : “Donne-moi les documents qui parlent de Bill Gates et Steve Jobs et au
moins de deux societes d’informatique”.
Nous remarquons a partir de cette requete que l’utilisateur cherche un document
qui parlent de deux elements de la dimension Personnes : Bill Gates et Steve Jobs,
dont les noms sont connus ET AU MOINS DE DEUX elements de la dimension
Organisation : societe d’informatique, dont les noms sont inconnus. Par consequent,
un document qui parlent des deux personnes avec une seule societe informatique ne
satisfait pas le besoin de l’utilisateur. Il est donc necessaire d’introduire un operateur
quantificateur qui permet a l’utilisateur de preciser a travers sa requete le nombre
d’elements de dimension recherches. L’utilisateur pourra donc preciser qu’il cherche
des documents qui parlent de deux societes d’informatique ou plus.
66

R14 : “Donne-moi les images qui montrent une hanche sans pathologie”.
Nous remarquons que l’utilisateur ne precise pas le nom de l’element de la dimension
Pathologie qu’il cherche. La seule information qu’il fournit est qu’il s’agit d’une
pathologie de la hanche. Dans ce cas, il est possible que les documents pertinents
ne contiennent pas le terme “pathologie” mais contiennent plutot des termes comme
“Fracture” et/ou “Luxation”, etc. Afin que le systeme puisse bien interpreter le
contenu semantique de cette requete, il faut qu’il arrive a inferer que “pathologie”
n’est pas le terme recherche mais plutot une description des elements recherches. Un
moyen possible est de permettre a l’utilisateur de faire explicitement cette precision.
Il peut ainsi specifier qu’un terme de sa requete represente une description d’un
element recherche. On peut aussi fournir a l’utilisateur les moyens pour utiliser des
relations semantiques. Ainsi, il peut preciser que les elements recherches sont des
“pathologies qui affectent la hanche”. Ainsi, lors de la recherche, le systeme ne se
contente pas de rechercher les documents qui contiennent le terme “pathologie”,
mais surtout les documents qui contiennent des types de pathologies qui affectent la
hanche.
3.3.2 Vers un modele de RI oriente precision
Les approches existantes semblent insuffisantes devant les exigences que nous
avons presentees. Elles traitent les documents et les requetes comme des sacs de
concepts lors de l’indexation et sont donc incapables de resoudre des requetes precises.
Le modele booleen represente une solution possible pour prendre en compte les
operateurs booleens, mais il reste toutefois limite devant la complexite de la struc-
ture semantique des requetes precises auxquelles nous nous interessons. Il faut donc
avoir recours a de nouveaux formalismes de representation de connaissances pour
introduire plus de semantique lors de l’indexation. Il faut utiliser une ressource ex-
terne pour representer le contenu semantique des documents et requete. Il serait ainsi
souhaitable d’avoir une representation uniforme des documents, requetes, et de la res-
source externe. Ceci peut etre atteint en utilisant un formalisme de representation
de connaissances commun a ces trois elements. Ce formalisme doit aussi proposer
une operation de comparaison jouant le role de la fonction de correspondance d’un
SRI. Il doit egalement prendre en compte les exigences des utilisateurs en termes
d’operateurs (booleens, quantificateurs, etc.).
67

Plusieurs formalismes ont ete experimentes dans ce sens. Nous notons parti-
culierement les Arborescences Semantiques [9], les Graphes Conceptuels [16][63] et
les Logiques Descriptives [55][56][57].
Le choix du formalisme de representation de connaissances adequat depend evide-
mment de nos besoins. Nous avons opte pour les Logiques Descriptives qui per-
mettent d’exprimer la connaissance d’un domaine particulier et raisonner sur cette
derniere de facon efficace. Ainsi, il est possible que les trois sources de connais-
sances (representation du document, de la requete, et de la ressource externe) soient
representees par le meme formalisme, ce qui assure que toutes ces sources de connais-
sances participent au processus de recherche d’une maniere uniforme. Ce formalisme
dispose par ailleurs d’un niveau d’expressivite assez eleve qui convient tres bien a
la representation precise des documents et des besoins d’informations. Par exemple,
il contient tous les operateurs dont nous avons besoin dans notre modele. Ces rai-
sons font des Logiques Descriptives une solution particulierement appropriee pour la
modelisation dans notre contexte de RI.
Dans la section suivante, nous introduisons les logiques descriptives, puis nous
presentons leurs applications dans notre modele de RI.
3.4 La logique descriptive
La logique descriptive (DL) [2], appelee egalement logique terminologique [12] est
une famille de formalismes de representation de la connaissance basee sur la logique.
Elle est concue pour representer et raisonner sur la connaissance d’un domaine d’ap-
plication d’une maniere structuree. Elle descend des formalismes plus anciens que
sont les reseaux semantiques et les “frames”.
Les notions de base de la DL sont les concepts atomiques et les roles atomiques.
Les concepts sont interpretes comme des sous-ensembles d’individus constituant soit
des entites, soit des elements particuliers du domaine a modeliser. Dans ce deuxieme
cas, ils sont appeles des constantes individuelles. Les roles, quant a eux, representent
des relations binaires entre des concepts, toujours sur le meme domaine. Une majo-
68

rite de DLs permet d’exprimer qu’une constante individuelle est une instance d’un
concept particulier, ou qu’une paire de constantes individuelles est une instance d’un
role donne.
Chaque DL est caracterisee par les constructeurs qu’elle fournit pour former des
concepts et roles complexes a partir des concepts et roles atomiques. D’abord, deux
constructeurs de concepts assez particuliers sont generalement introduits : il s’agit
des constructeurs “Top” et “Bottom”, denotant respectivement, l’ensemble de tous
les individus du domaine de discours et l’ensemble vide. Les deux constructeurs
conjonction (⊓) et disjonction (⊔) sont respectivement l’intersection et l’union de
concepts. Le quantificateur existentiel type (∃R.C ou R est un role et C un concept)
et le quantificateur universel (∀R.C) sont tels que :
- Pour qu’un objet a soit l’instance de l’ensemble ∃R.C, il doit exister un objet b,
qui est une instance de C et qui est lie a a via R ;
- a est une instance de l’ensemble ∀R.C, si tous les objets lies a a via R sont des
instances de C.
Le composant terminologique de la logique descriptive est la T(erminologique)-
Box. Elle est utilisee pour introduire des noms (abreviations) pour les concepts
complexes. Elle permet la declaration des axiomes generaux d’inclusion de concepts
(General Concepts Inclusion (GCI) axiomes). Un GCI est de la forme C ⊑ D ou
C ≡ Dou C et D sont des concepts sans restriction. Une T-Box est donc un en-
semble, qui peut etre vide, de GCI.
Les DL adoptent toutes une semantique reposant sur une interpretation ensem-
bliste des termes. Ce procede est connu sous l’appellation de semantique denotationn-
elle (denotational semantics). Ils introduisent ainsi une interpretation I = (∆I , .I)
qui consiste en un ensemble non vide ∆I appele le domaine de discours de I, et en
une fonction .I qui associe pour chaque nom de concept C un ensemble CI ⊆ ∆I , et
pour chaque nom de role R, une relation binaire RI ⊆ ∆I × ∆I .
Une interpretation I satisfait le GCI C ⊑ D si CI ⊆ DI . I satisfait la T-Box
69

T , si I satisfait tous les GCI dans T . Dans ce cas, I est appele modele de T . Un
concept C est satisfiable par rapport a une T-Box T s’il y a un modele I de T tel
que CI 6= ∅. Ainsi, un algorithme de satisfiabilite (consistance) teste si un concept
donne peut effectivement etre instancie. Un element d ∈ CI est appele une instance
de C.
Le composant assertionnel de la logique descriptive est la A(ssertion)-Box. Celle-
ci contient l’ensemble des assertions. Par exemple, si la T-Box contient le concept
Personne, alors la A-Box peut contenir Jacques qui en est une instance.
Il existe des algorithmes, pour certaines logiques descriptives, pour calculer la
taxonomie de la T-Box : c’est la hierarchie de subsomption de tous les concepts
introduits dans la T-Box. Ils offrent une capacite de raisonnement qui deduit de la
connaissance implicite a partir de celle qui est donnee explicitement dans la T-Box T .
Ainsi, l’algorithme de subsomption determine les relations de sous et super-concepts :
un concept C est subsume par un concept D (C ⊑T D), si chaque instance de C est
aussi une instance de D, c’est-a-dire, si chaque modele I de la T-Box T interprete
C comme un sous ensemble de l’interpretation de D (CI ⊆ DI). Deux concepts sont
dits equivalents s’ils se subsument mutuellement : C ≡ D si C ⊑ D et D ⊑ C.
Il existe plusieurs logiques descriptives, la minimale etant le langageAL (Attribut-
ive Langauge). Ce langage ne remplit pas les exigences de notre modele, a savoir
contenir tous les operateurs booleens, l’operateur de quantification, etc. En fonc-
tion de nos besoins, nous avons choisi un langage DL qui a un pouvoir d’expressivite
superieur a AL. Il s’agit du langage ALCQ (Attributive Language with Complements
and Qualified number restrictions) dont la syntaxe et la semantique sont representees
dans la section suivante.
3.4.1 Syntaxe et semantique du langage ALCQ
Les descriptions de concepts sont formees selon les regles syntaxiques presentees
dans le tableau 3.1. Soient c un concept atomique, r un role atomique et C et D des
descriptions de concepts. L’interpretation de concepts complexes est definie dans le
tableau 3.1.
70

Tab. 3.1 – Syntaxe et semantique du langage ALCQ.Constructeur Syntaxe SemantiqueNom de concept c cI
Top (concept univer-sel)
⊤ ∆I
Negation de conceptsnon necessairementprimitifs
¬C ¬CI = ∆I�CI
Bottom ⊥ ∅Conjonction C ⊓ D CI ∩ DI
Disjonction C ⊔ D CI ∪ DI
Quantificateur univer-selle
∀R.C {d ∈ ∆I |∀ e ∈ ∆I .(RI(d, e) → e ∈ CI)}
Quantificateur exis-tentiel type
∃R.C {d ∈ ∆I |∃ e ∈ ∆I .(RI(d, e), e ∈ CI)}
Restriction de nombrequalifiee
> nR.C {d ∈ ∆I ||{e|RI(d, e), e ∈ CI}| > n}
Restriction de nombrequalifiee
6 nR.C {d ∈ ∆I ||{e|RI(d, e), e ∈ CI}| 6 n}
Voici quelques exemples pouvant etre exprimes en ALCQ :
Soient Personne et F eminin des concepts atomiques. Alors Personne⊓F eminin
(les personnes qui sont feminines) et Personne ⊓ ¬F eminin (les personnes qui ne
sont pas feminines) sont des concepts ALCQ.
Soit a-enfant un role atomique, nous pouvons alors former les concepts :
- Personne ⊓ ∃ a-enfant .⊤ denote les personnes qui ont un enfant ;
- Personne ⊓ ∀ a-enfant .F eminin denote toutes les personnes dont les enfants sont
des filles ;
- Personne ⊓ ∀ a-enfant .⊥ denote les personnes qui n’ont pas d’enfant.
Si Femme ≡ Personne ⊓ F eminin, alors :
- ¬Femme denote les individus qui ne sont pas des femmes ;
71

- Femme ⊓ ∃ a-enfant .P ersonne denote les meres ;
- Femme⊓ > 3a-enfant .P ersonne denote les meres qui ont au moins trois enfants.
3.4.2 Logique Descriptive et Recherche d’Information
L’application de la logique descriptive au domaine de la RI est prometteuse, car
il suffit de considerer le corpus des documents comme un sous-ensemble du domaine
de discours choisi, et y representer les documents et les requetes par des concepts.
Ainsi, chaque document d (requete q) sera represente(e) dans la T-Box T par son
index docI (qI) qui est une expression (concept) ALCQ. docI est une abstraction
(representation) d’un ensemble de documents qui ont le meme contenu. Les docu-
ments physiques representent alors les instances de docI. Conformement a la termi-
nologie des DL, la correspondance entre une requete q et un document doc se calcule
ainsi dans la hierarchie de subsomption : un document doc est pertinent pour une
requete q si le concept docI est subsume par le concept qI : docI ⊑T qI (cf. figure 3.1).
Ainsi, pour repondre a une requete q, le SRI selectionne les documents dont l’index
docI est subsume par le concept qI. Cette idee s’appuie sur le modele logique propose
par Van Rijsbergen qui considere le processus de recherche comme une evaluation
d’une implication logique entre la requete q et chaque document doc du corpus, re-
lativement a un ensemble de connaissances K [93]. Ceci independemment du choix
de formalisme de representation de doc, q et K. Selon la suggestion de Van Rijsber-
gen, seuls doivent etre consideres pertinents, les documents dont on peut deduire la
requete d’une maniere logique. La correspondance revient donc a donner une mesure
d’incertitude PK(doc → q).
Meghini et ses collaborateurs [56] ont propose une DL nommee MIRTL comme un
formalisme adequat pour la conception des SRI bases sur le modele logique. La DL
ainsi proposee a ete utilisee pour la representation des documents selon differentes
caracteristiques : le contenu du document, la structure, le contexte, etc. Nous allons
nous inspirer de ce travail afin de tirer profit des DL dans notre modelisation.
Dans les sections suivantes, nous allons voir comment nous utilisons les DL dans
notre contexte de modelisation d’un modele de RI oriente precision.
72

Fig. 3.1 – Correspondance entre une requete et un document representes en logiquedescriptive.
3.5 Modele de RI : notation et definitions
Nous definissons ici, d’une maniere generale, les composantes de notre modele de
Recherche d’Information.
3.5.1 Ressource externe
Nous presentons ici le modele formel de la ressource externe K decrivant l’en-
semble des connaissances presentes dans le corpus.
Soit C = {c1 . . . cnc} un ensemble de nc concepts atomiques, R = {r1 . . . rnr} un
ensemble de nr roles. Nous appelons S = (C, R) la signature de K. Une fois que la
signature S est fixee, une interpretation I pour S est une paire I = (∆I , .I) ou :
- ∆I est un ensemble non vide ;
- .I est une fonction assignant :
◦ Un sous-ensemble CIi ⊆ ∆I a chaque concept atomique ci ∈ C ;
◦ Une relation RIi ⊆ ∆I × ∆I a chaque role Ri ∈ R ;
73

Dans notre contexte de RI, nous nous interessons a la modelisation du contenu des
documents et non a la modelisation du monde reel. Ainsi, la fonction d’interpretation
.I depend du contenu des documents. C’est-a-dire, l’interpretation d’un concept ne
represente pas des entites du monde reel, mais plutot un ensemble d’instances dans les
documents. Par exemple, l’interpretation de “Berlusconi” n’est pas la personne elle-
meme dans le monde reel, mais plutot ses apparitions dans les documents. Chaque
apparition de “Berlusconi” dans un document different est une instance : “Berlusconi
en tant que president du club Milan AC”, “Berlusconi en tant que Premier ministre
de l’Italie”, etc. Pour cette raison, dans notre modelisation la A-Box est un ensemble
vide, et les documents et les requetes sont representes uniquement par des concepts.
Par exemple, Zidane, qui est en principe une instance du concept Joueur, donnera
lieu au concept Zidane ⊑ Joueur qui sera stocke dans la T-Box. Comme nous le
verrons dans la suite, ceci ne represente aucune contrainte lors de la representation
du contenu des documents et des requetes. Bien au contraire, nous aurons un cadre
unifie ou la requete de l’utilisateur peut faire reference a la fois a des “instances”
(Zidane) et a des “concepts” (joueur). De plus, en RI il n’y a pas un besoin evident
de separer les concepts des instances. Parfois, afin de bien decrire un element, il est
meme necessaire d’utiliser dans la meme phrase des termes qui denotent des concepts
et d’autres denotant des instances. Par exemple, pour chercher des documents qui
parlent de Berlusconi, il est parfois necessaire de preciser le besoin d’information
en utilisant, en plus de l’instance “Berlusconi”, le concept “president du club Milan
AC” ou bien le concept “Premier ministre de l’Italie”.
Etant donne le langage de description ALCQ et une signature S, une ressource
externe K dans ALCQ est un quadruple K = (S, T, A, Dim), tel que T est la T-Box,
A est la A-Box, et Dim est l’ensemble des dimensions.
Pour des contraintes pratiques (l’existence des ressources hierarchiques), nous im-
posons une condition necessaire pour definir une dimension a travers la hierarchie3
de la ressource externe K. Ainsi, une dimension dimi est definie par un concept
rac dimi et tous les concepts qu’il subsume. Formellement une dimension dimi issue
d’une ressource K est definie comme suit :
3Definie par l’ensemble d’axiomes terminologiques de la forme C ⊑ D, ou C et D sont desexpressions ALCQ sur la signature S.
74

dimi = (rac dimi, Ci)
ou :
- rac dimi ∈ C est le concept racine de la hierarchie definissant dimi ;
- Ci = {c ∈ C | c ⊑ rac dimi} est l’ensemble des concepts specifiques a dimi.
Ainsi, Dim = {dimi . . . dimnd} forme l’ensemble des nd dimensions definies a
travers la ressource externe K.
Cette definition est simplifiee car elle correspond seulement a des ressources or-
ganisees autour d’une hierarchie de concepts. La realite peut etre plus complexe,
notamment en organisant les connaissances d’un domaine dans une ressource non
hierarchique. Il peut donc exister des dimensions de domaine qui ne font pas partie
de la categorie des dimensions que nous avons definies.
Dans un cas reel, il est possible qu’il n’y ait pas une sous-hierarchie qui definisse
explicitement la dimension. Dans ce cas, il est possible que la dimension en ques-
tion puisse etre definie a travers plusieurs sous hierarchies de la ressource externe
utilisee. Par consequent, nous pouvons creer manuellement la racine pour regrou-
per toutes ces sous-hierarchies et definir ainsi une dimension. Par exemple, pour
definir les dimensions “Anatomie”, “Pathologie”, et “Modalite” dans le cadre de nos
experimentations dans le domaine de l’imagerie medicale, nous avions le choix entre
les ressources MeSH4 et UMLS5. Supposons que ces deux ressources aient ete decrites
en DL (les entrees sont des concepts, et la structure hierarchique est formee par des
axiomes de subsomption)6. Ainsi, dans la premiere ressource, ces dimensions peuvent
etre definies respectivement a travers les sous hierarchies suivantes : Anatomy [A],
Diseases [C], et Analytical, Diagnostic and Therapeutic Techniques and Equipment
[E]. En revanche, dans la ressource UMLS nous avons du creer manuellement les
4http ://www.nlm.nih.gov/mesh/5http ://www.nlm.nih.gov/research/umls/6En realite, et d’apres nos experiences, il est tres difficile de modeliser UMLS en DL. En effet,
ce meta-thesaurus dispose d’une caracteristique unique qui consiste a avoir plusieurs hierarchiesparalleles et pas forcement compatibles. Pour plus d’informations sur ce sujet, nous invitons lelecteur a lire les travaux de Barry Smith [http ://ontology.buffalo.edu/smith/]
75

racines pour regrouper des sous hierarchies de la ressource et definir ainsi les di-
mensions en question. Par exemple, pour definir la dimension “Pathologie”, nous
avons cree une racine pour regrouper les sous-hierarchies “Disease or Syndrome”,
“Finding”, et “Injury or Poisoning”.
3.5.2 Indexation des documents
Soit Doc = {doci|1 6 i 6 nd} l’ensemble des nd documents presents dans le
corpus. Un document doci peut etre un article de presse, un compte-rendu medical,
une image, etc.
Dans notre cas, une requete represente une description textuelle des documents
recherches.
Vocabulaire d’indexation
Le vocabulaire d’indexation VDoc constitue l’ensemble des descripteurs qui servent
a la description du contenu des documents Doc lors de la phase d’indexation. Chaque
document est represente par les descripteurs presents dans la ressource externe.
VDoc contient donc l’union de l’ensemble des concepts et de l’ensemble des dimen-
sions extraits de la ressource externe K.
VDoc = (V cDoc ∪ V dimDoc)7, avec V cDoc = C, V dimDoc = Dim.
Collection de documents indexes
Chaque document doc ∈ Doc contient un ensemble de concepts docc = {c ∈ C}.
A partir de docc nous pouvons deduire l’ensemble des dimensions docdim = {dim}
presentes dans doc.
7Dans notre modele, il est possible de former un besoin d’information en utilisant uniquementdes dimensions. Pour cette raison, nous separons ici les dimensions et les concepts meme s’ils sontrelies dans la base de connaissances.
76

Chaque concept c ∈ docc a un poids wc,doc qui caracterise son degre d’importance
a decrire le contenu de doc8.
Le contenu semantique d’un document doc sera represente par l’index docI qui
est une expression ALCQ sur le vocabulaire VDoc. La definition formelle de docI est
presentee plus loin dans ce chapitre.
3.5.3 Formulation de la requete
Vocabulaire d’interrogation
Le vocabulaire d’interrogation sert a la formulation des requetes de l’utilisateur.
Celui-ci peut utiliser le vocabulaire present dans la ressource externe K. Il peut
preciser davantage son besoin d’information en ajoutant a sa requete des operateurs
et des relations semantiques entre les descripteurs.
D’une maniere generale, nous definissons le vocabulaire d’interrogation VQ comme
etant le resultat d’une combinaison de dimensions, de concepts, de relations et
d’operateurs. Le contenu semantique d’une requete q est donc representee par qI
qui est une expression ALCQ sur le vocabulaire VQ. La definition formelle de qI est
presentee plus loin dans ce chapitre.
3.5.4 Correspondance entre la requete et le document
Pour repondre a une requete, deux operations sont necessaires :
i. La premiere consiste a selectionner, parmi les documents indexes, ceux qui satis-
font la requete. Cette operation est effectuee a l’aide d’une fonction fSel qui
doit respecter, lors de l’evaluation des documents, les operateurs et les relations
presents dans la requete. Nous verrons plus loin que cette fonction est basee
sur la hierarchie de subsomption. En effet, afin de calculer la correspondance
entre un document et une requete, nous procederons par un premier niveau
d’indexation base sur la logique descriptive : il s’agit de l’indexation pour la
8Dans notre modelisation, les poids ne font pas partie de la DL. Nous les utilisons plus loin lorsde l’ordonnancement des documents pertinents pour une requete.
77

correspondance.
ii. La deuxieme operation est effectuee a l’aide d’une fonction fOrd qui permet d’or-
ganiser l’ensemble des documents selectionnes (par fSel) dans leur ordre de
pertinence par rapport a la requete. La valeur de pertinence d’un document
d par rapport a une requete q est calculee par fOrd en fonction des poids
des descripteurs dans d et q. Afin de mettre en œuvre la fonction fOrd, nous
procederons par un deuxieme niveau d’indexation : l’indexation pour l’or-
donnancement.
Selon Meghini [56], la complexite d’integration des ponderations dans un modele
de RI a base de logique descriptive est tres elevee. Pour cette raison, nous avons
decide de separer ces deux niveaux d’indexation de telle sorte que les ponderations
ne feront pas partie de notre modele a base de logique descriptive.
Les definitions formelles des fonctions fSel et fOrd sont presentees dans la suite
de ce chapitre.
3.6 Modele de RI oriente precision
A partir des notations presentees dans la section precedente, nous introduisons
ici une description de notre modele de Recherche d’Information oriente precision qui
comprend les elements suivants :
- Une ressource externe contenant des dimensions, des concepts, et des relations
semantiques ;
- Les concepts et les dimensions constituent le vocabulaire d’indexation et le voca-
bulaire d’interrogation :
- Le contenu semantique d’un document est decrit par ces descripteurs mis en
relations les uns avec les autres ;
- La requete est representee par ces descripteurs mis en relations les uns avec les
autres. Elle est egalement enrichie avec des operateurs ;
78

- La correspondance entre la requete et les documents est realisee en utilisant les
deux types de descripteurs et en respectant les operateurs qui leur sont associes
dans la requete.
3.6.1 Modele de document
Nous avons montre lors du deuxieme chapitre que les approches qui considerent les
documents (requetes) comme des sacs de concepts ne permettent pas de resoudre des
requetes precises. Dans notre approche, nous proposons d’utiliser les dimensions de
domaine pour mettre en exergue les elements pertinents qui contribuent a la descrip-
tion du contenu semantique des documents et des requetes. Ainsi, nous utilisons les
dimensions, les concepts et les relations pour definir une nouvelle unite d’indexation
qui nous permet de produire une representation precise du contenu des documents et
des requetes tout en considerant les aspects lies a leur semantique. Par consequent,
au lieu de considerer un document qui parle du “president francais Jacques Chirac”
comme un sac de concepts, nous representons son contenu par l’element appartenant
a la dimension “Personne” qui est “Jacques Chirac” et qui est “president” originaire
de “France”. De meme, lors de l’interrogation, l’utilisateur peut decrire son besoin
en identifiant l’element qu’il recherche (ex. le nom d’un joueur : “Zidane”) et/ou en
le decrivant en utilisant un ou plusieurs concepts. De cette maniere, en voulant cher-
cher un element qui correspond a un president francais, l’utilisateur peut preciser
que l’element appartient a la dimension “Personne”, et qu’il est “President” decrit
par le concept “France”9.
L’element de dimension : une nouvelle unite d’indexation
Tout concept specifique a une dimension est susceptible de constituer un element
de cette dimension lorsqu’il est utilise dans un document ou une requete. Un element
d’une dimension dimi est une expression ALCQ qui cherche a correspondre le plus
precisement possible au concept specifique de dimi auquel il est fait reference dans
un document ou une requete. Cette expression est une conjonction dont au moins
un des concepts appartient a dimi. Elle peut contenir d’autres concepts qui servent
a “raffiner” la description de l’element de dimension en question. Formellement, un
9Deux concepts appartenant chacun a une dimension differente : “France” appartient a la di-mension “Lieu geographique”, et “President” appartient a la dimension “Personne”.
79

element de la dimension dimi est une expression ALCQ de la forme suivante :
edimie ≡ cidf 1 ⊓ . . . ⊓ cidf n ⊓ ∃ decrit par.cdes 1 ⊓ . . . ⊓ ∃ decrit par.cdes m
ou :
- les concepts cidfiappartiennent a dimi ;
- les concepts cdes j appartiennent a d’autres dimensions que dimi.
edimie est donc identifie par les concepts cidfi
, et decrit par les concepts cdes j.
decrit par est une relation utilisee uniquement lors de la modelisation pour decrire
un element de dimension. Dans la pratique, elle est remplacee par d’autres relations
concretes (Par ex. President originaire de France, Pathologie affecte Femur, etc.).
Exemple 1
Soit un document qui contient l’element de la dimension “Personne” SteveJobs
et l’element de la dimension “Organisation” Apple, Inc.. Supposons que ces deux
elements de dimensions sont representes respectivement par edimp et edimo. Nous
aurons ainsi :
edimP ≡ Steve Jobs
edimO ≡ Apple, Inc
Exemple 2
Dans un document qui contient le “General francais Philippe Morillon”, l’element
de la dimension “Personne” est identifie par “Philippe Morillon” et “General”, et
decrit par “France”. Supposons que cet element de dimension soit represente par
edimp. Nous aurons ainsi :
edimp ≡ Philippe Morillon ⊓ General ⊓ ∃ originaire de.France
80

Si l’on indexe un document par l’element edimp, cela peut paraıtre redondant
car Philippe Morillon ⊑ General et Philippe Morillon ⊑ ∃ originaire de.France.
Mais ca ne l’est pas car la ressource externe ne contient pas forcement toutes les
connaissances presentes dans les documents (on ne sait pas forcement que Philippe
Morillon est originaire de France). Ceci permettra par exemple de repondre a une
requete dont le contenu est represente par ∃ originaire de.France.
Dans notre modele de document, les elements de dimension sont utilises afin de
produire une representation precise du contenu semantique des documents. Nous
proposons ainsi le role indexe par afin d’associer un element de dimension a un
document. Soit un document doc contenant d dimensions, pour chacune il existe ni
elements de dimension. La representation (l’index) docI du contenu semantique de
doc est une expression ALCQ sur VDoc ∪ {indexe par} representee de la forme sui-
vante :
docI ≡ ∃ indexe par.edim11 ⊓ . . .⊓ ∃ indexe par.edim1
n1 ⊓ . . .⊓ ∃ indexe par.edimi1 ⊓
. . . ⊓ ∃ indexe par.edimini ⊓ . . . ⊓ ∃ indexe par.edimd
1 ⊓ . . . ⊓ ∃ indexe par.edimdnd
Apres le processus d’indexation, toutes les representations docI des documents
doc sont ajoutees a la T-Box. Celle-ci contient alors, en plus des connaissances du
domaine, les index des documents presents dans la collection.
Dans la figure 3.2, nous presentons la representation graphique de notre modele
de document. Le contenu semantique d’un document physique doc est represente par
le concept docI qui est une expression ALCQ. docI est defini par la conjonction d’un
ensemble d’elements de dimensions edim qui sont relies a docI par le role indexe par.
Chaque element de dimension edim est identifie par un concept de la dimension a
laquelle il appartient (⊑ cidf ) ou bien sa racine (⊑ rac dim). edim peut etre decrit
par zeros ou plusieurs concepts (∃ decrit par.cdes). Notons que les documents phy-
siques qui ont le meme contenu sont representes par des concepts (expression ALCQ)
81
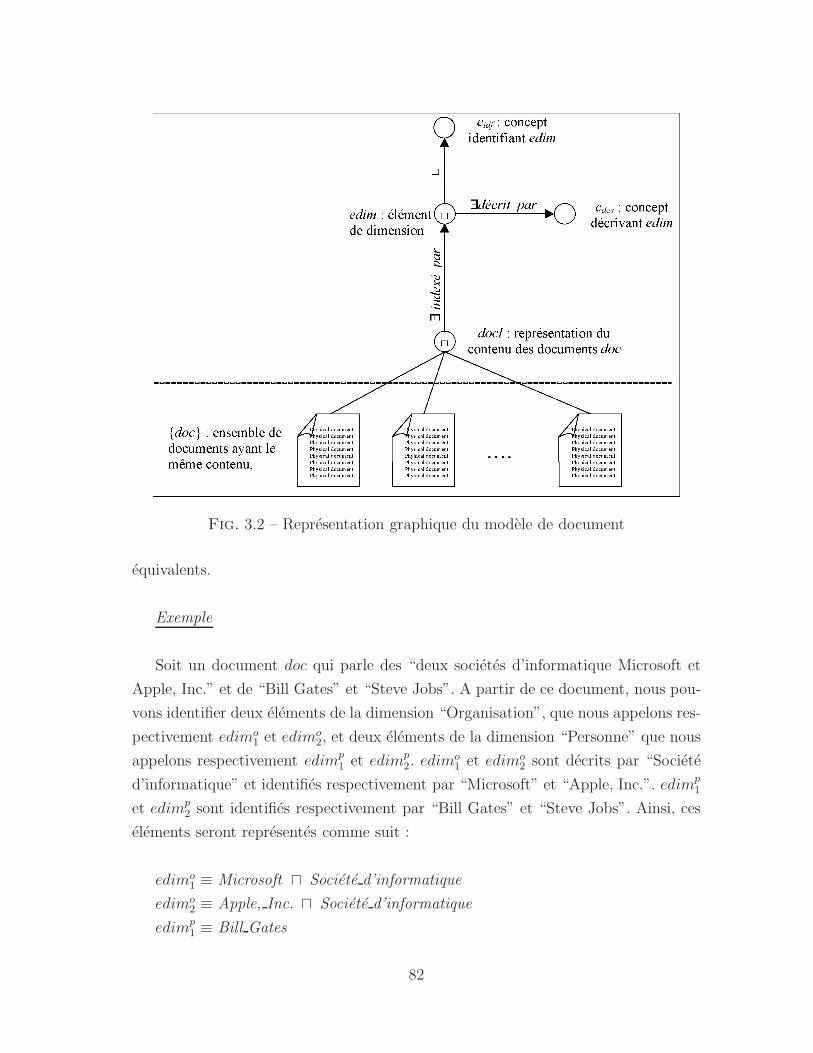
Fig. 3.2 – Representation graphique du modele de document
equivalents.
Exemple
Soit un document doc qui parle des “deux societes d’informatique Microsoft et
Apple, Inc.” et de “Bill Gates” et “Steve Jobs”. A partir de ce document, nous pou-
vons identifier deux elements de la dimension “Organisation”, que nous appelons res-
pectivement edimo1 et edimo
2, et deux elements de la dimension “Personne” que nous
appelons respectivement edimp1 et edim
p2. edimo
1 et edimo2 sont decrits par “Societe
d’informatique” et identifies respectivement par “Microsoft” et “Apple, Inc.”. edimp1
et edimp2 sont identifies respectivement par “Bill Gates” et “Steve Jobs”. Ainsi, ces
elements seront representes comme suit :
edimo1 ≡ Microsoft ⊓ Societe d’informatique
edimo2 ≡ Apple, Inc. ⊓ Societe d’informatique
edimp1 ≡ Bill Gates
82

edimp2 ≡ Steve Jobs
Finalement la representation du contenu semantique du document doc dans la
T-Box est definie comme suit :
docI ≡ ∃ indexe par.edimo1 ⊓ ∃ indexe par.edimo
2 ⊓ ∃ indexe par.edimp1 ⊓
∃ indexe par.edimp2
Chaque element de dimension edimini a un poids wedimi
ni
qui caracterise son
degre d’importance a decrire le contenu du document auquel il appartient10. La
valeur de wedimi
ni
depend des poids des concepts qui l’identifie et des concepts qui le
decrivent. En effet, nous supposons que plus le poids des concepts identifiant edimini
est grand, plus wedimi
ni
est eleve. Nous supposons egalement que plus il y a des
concepts decrivant edimini, plus la valeur de wedimi
ni
est elevee.
3.6.2 Modele de requete
Preambule
Dans les systemes de recherche existants, le mode d’interaction typique avec l’uti-
lisateur est base sur les mots-cles ou sur le processus de requete par l’exemple : dans
le premier cas, l’utilisateur introduit une liste de mots-cles pour decrire son besoin
d’information. A partir de la requete, le systeme essaye d’interpreter le besoin de
l’utilisateur et repondre par un ensemble de documents. Dans le deuxieme cas, un
utilisateur propose une image en entree du systeme qui genere une requete puis pro-
pose en sortie les images qui lui sont les plus ’proches’ ou ’similaires’.
Ces modes d’interaction souffrent du fait que les besoins de l’utilisateur restent
implicites. En effet, le systeme doit utiliser sa connaissance du contenu de la requete
(mots-cles ou image) afin d’extraire l’information explicite et mettre en œuvre les
representations correspondantes. Ce processus peut aboutir a des ambiguıtes et des
resultats de recherche peu satisfaisants lorsque le besoin de l’utilisateur est tres precis.
10Dans notre modelisation, les poids ne font pas partie de la DL. Nous les utilisons plus loin pourl’ordonnancement des documents pertinents pour une requete.
83

Nous proposons ici un modele base sur un langage de requete textuel expressif
dans le sens ou il permet a l’utilisateur d’exprimer des requetes precises en combi-
nant dimensions, concepts et relations de son domaine d’interet. La requete peut etre
enrichie, en cas de besoin, par un ensemble d’operateurs.
Ainsi, l’interaction avec l’utilisateur est directe puisque, contrairement aux syste-
mes existants, l’utilisateur prend en charge le processus de formulation de requete
en traduisant ses besoins au systeme de maniere explicite et precise11.
Nous presentons apres les elements de base de notre modele de correspondance.
Nous decrirons dans un premier temps le langage de requetes puis nous aborderons les
conditions a verifier pour tout couple (q, doc) afin que le document doc soit considere
pertinent pour la requete q selon le processus de correspondance defini pour notre
modele de recherche oriente precision.
Langage de requetes
Dans notre modele de requete, les elements de dimension sont utilises afin de
produire une representation precise du contenu semantique des requetes. Ainsi, la
representation d’une requete q est definie par la combinaison de criteres de selection
sur les elements de dimensions introduit par l’utilisateur pour identifier les docu-
ments recherches. Nous proposons a l’utilisateur d’employer explicitement des re-
lations semantiques afin d’identifier et/ou decrire des elements de dimensions (cf.
section 3.6.1). Formellement, une requete est representee de la meme maniere qu’un
document avec en plus les operateurs qui permettent a l’utilisateur de decrire son
besoin avec precision.
Soit une requete q contenant d dimensions, pour chacune il existe ni elements
de dimension. La representation qI du contenu semantique de q est une expression
ALCQ sur VQ ∪ {indexe par}. Le role indexe par, introduit precedemment, permet
d’associer un element de dimension a une requete.
Chaque element de dimension edimini peut avoir un poids wedimi
ni
qui pondere
11Evidemment, une interface graphique doit etre proposee a l’utilisateur pour qu’il exprime sonbesoin en langue naturel.
84

son degre d’importance pour decrire le contenu de la requete a laquelle il appartient.
La valeur de wedimi
ni
peut etre introduite par l’utilisateur a travers une interface au
cas ou il le souhaite.
Expression de requetes
L’expression de requetes a pour but d’extraire un ensemble de documents juges
pertinents par le systeme. La representation d’une requete q doit donc denoter l’en-
semble des documents qui lui sont pertinents. De cette maniere, nous pourrons
selectionner tous les documents doc tel que docI est subsume par qI.
Relations d’interrogation
Comme dans le modele de document, les relations de subsomption, et decrit par
sont utilisees pour l’interrogation. La difference ici par rapport au modele de docu-
ment est que l’utilisateur doit employer explicitement ces deux relations afin d’iden-
tifier et decrire les elements de dimension dans sa requete. Pour cette raison, nous
fournissons a l’utilisateur ces deux relations lors du processus de formulation de
requetes. L’usage de ces relations peut etre effectue d’une maniere graphique simple
en proposant a l’utilisateur des zones de texte pour les concepts qui servent a iden-
tifier les elements de dimensions, et d’autres zones de texte pour les concepts qui
servent a les decrire.
La relation de subsomption
L’utilisateur emploie la relation de subsomption (est un) pour identifier un element
de dimension dans sa requete.
Exemple
Dans la requete R9, l’utilisateur est a la recherche d’un document qui contient un
element de la dimension “Personne” : “Steve Jobs” ou un element de la dimension
“Organisation” : “Apple, Inc.”. Dans ce cas, les elements des dimensions “Person-
ne” et “Organisation” sont identifies respectivement par les concepts “Steve Jobs”
et “Apple, Inc.”. Supposons que ces deux elements de dimensions soient representes
85

respectivement par edimp et edimo. Nous aurons ainsi :
edimp ≡ Steve Jobs
edimo ≡ Apple, Inc.
Dans le langage ALCQ, la requete R9 se traduit donc par la notation suivante :
R9 ≡ ∃ indexe par.edimp ⊔ ∃ indexe par.edimo
Le systeme interprete cette requete de la maniere suivante : l’utilisateur est a la
recherche d’un document qui contient un element de la dimension “Personne” qui
est “Steve Jobs” ou un element de la dimension “Organisation” qui est “Apple, Inc.”.
La relation decrit par :
Cette relation est employee par l’utilisateur afin de decrire un element de dimen-
sion par un ou plusieurs concepts.
Exemple
R15 : “Donne-moi les documents qui parlent du joueur francais qui a eu un
carton rouge lors de la finale de la coupe du monde FIFA 2006”.
L’utilisateur cherche un document qui contient un element de la dimension “Per-
sonne” : un “Joueur” qui est originaire de “France”. Soit edimp l’element recherche
par l’utilisateur. edimp est decrit par un concept de la dimension “Personne” :
“Joueur”, et un concept de la dimension “Lieu geographique” : “France”. Il est
donc represente comme suit :
edimp ≡ Joueur ⊓ ∃ originaire de.France
La requete R15 se traduit donc par la notation suivante :
86

R15 ≡ ∃ indexe par.edimp
Dans les sections suivantes, nous presentons comment ces relations sont utilisees
par le systeme pour repondre a une requete. Mais avant cela, nous introduisons
maintenant les operateurs que notre systeme fournit a l’utilisateur pour preciser son
besoin.
Operateurs d’interrogation
En fonction des besoins d’information que nous avons presentes au debut de ce
chapitre, nous distinguons trois types d’operateurs : booleens, quantificateurs, jauge.
Nous detaillons chacun d’eux dans les sections suivantes.
Operateurs booleens
Nous distinguons trois operateurs booleens : la conjonction notee ⊓, la disjonc-
tion notee ⊔, et lanegation materialisee par ¬. Nous presentons quelques exemples
de requetes afin de montrer l’utilite de ces operateurs et leur usage dans notre modele.
La conjonction
Exemple
La requete R8 met en œuvre un element de la dimension “Personne : “Bill Ga-
tes” et un element de la dimension “Organisation” : “Societe d’informatique”, par
l’intermediaire d’une conjonction. Nous representons ces deux elements de dimension
respectivement par edimp et edimo.
edimp ≡ Bill Gates
edimo ≡ Societe d′informatique
La requete R8 a donc l’expression suivante dans notre modele :
87

R8 ≡ ∃ indexe par.edimp ⊓ ∃ indexe par.edimo
La disjonction
Exemple
La requete R9 met en œuvre un element de la dimension “Personne” : “Steve
Jobs” et un element de la dimension “Organisation” : “Apple, Inc.”, par l’intermediai-
re d’une disjonction. Nous representons ces deux elements respectivement par edimp
et edimo.
edimp ≡ Steve Jobs
edimo ≡ Societe d′informatique
La requete R9 a donc l’expression suivante dans notre modele :
R9 ≡ ∃ indexe par.edimp ⊔ ∃ indexe par.edimo
La negation
Exemple 1
La requete R10 met en œuvre un element de la dimension “Anatomie” : “Tibia” et
un element de la dimension “Pathologie” : “Pathologie du tibia”, par l’intermediaire
d’une negation. Nous representons ces deux elements respectivement par edima et
edimp.
edima ≡ T ibia
edimp ≡ rac Pathologie ⊓ ∃ affecte.T ibia
88

La requete R10 a donc l’expression suivante dans notre modele :
R10 ≡ ∃ indexe par.edima ⊓ ¬∃ indexe par.edimp
Ceci se traduit par le fait qu’un document pertinent doit contenir un tibia et
aucune pathologie liee a cette partie de l’anatomie. Comme la pathologie dans cette
requete est un element generique, il faut donc identifier tous les types de pathologies
que l’on peut avoir sur un tibia et les utiliser pour repondre a cette requete.
Exemple 2
La requete R13 met en œuvre un element de la dimension “Anatomie” : “Tibia”
et un element de la dimension “Pathologie” : “Fracture”, par l’intermediaire d’une
negation. Nous representons ces deux elements respectivement par edima et edimp.
edima ≡ Tibia
edimp ≡ Fracture
La requete R13 a donc la transcription suivante dans notre modele :
R13 ≡ ∃ indexe par.edima ⊓ ¬∃ indexe par.edimp
Ceci se traduit par le fait qu’un document pertinent doit contenir un tibia sans
fracture. Il est possible qu’une image contenant un tibia avec une luxation puisse
etre consideree comme pertinente par l’utilisateur. Comme la pathologie dans cette
requete est identifiee, l’appariement se fait entre le document et la requete en prenant
en compte seulement la pathologie “fracture” pour eliminer les documents corres-
pondants.
Combinaisons des operateurs booleens
89

Exemple
La requete R12 met en œuvre un element de la dimension “Anatomie” : “Tibia”,
et deux elements de la dimension “Pathologie” : “Fracture” ou “Luxation”, par l’in-
termediaire d’une conjonction. Nous representons ces trois elements respectivement
par edima, edimp1, et edim
p2.
edima ≡ T ibia
edimp1 ≡ Fracture
edimp2 ≡ Luxation
La requete R12 a donc l’expression suivante dans notre modele :
R12 ≡ ∃ indexe par.edima ⊓ (∃ indexe par.edimp1 ⊔ ∃ indexe par.edim
p2)
Operateur quantificateur
L’operateur quantificateur permet a l’utilisateur de preciser le nombre d’elements
de dimensions qu’il aimerait trouver dans le document pertinent. Nous distinguons
trois valeurs possibles a cet operateur : egal materialise par “=”, au moins material-
isee par >, et au plus materialisee par 6. La restriction de nombre “= nR.C” n’est
pas incluse dans le langage ALCQ mais nous pouvons l’exprimer par (> nR.C ⊓ 6
nR.C).
Le cas egal
Exemple
Soit la requete R16 “Donne-moi une image qui contient Zinedine Zidane tout
seul”.
Cette requete contient un element de la dimension “Personne” : “Zinedine Zida-
ne”, avec une restriction de nombre (tout seul). Nous representons cet element par
90

edimp1. Le document pertinent doit contenir un seul element de la dimension per-
sonne. Afin d’exprimer ce besoin d’information, nous avons besoin des deux elements
suivants :
edimp1 ≡ Zinedine Zidane
edimp2 ≡ rac Personne
La requete R16 a donc l’expression suivante dans notre modele :
R16 ≡ ∃ indexe par.edimp1 ⊓ ∃ = 1 indexe par.edim
p2
Les cas au moins et au plus
Exemple
La requete R2 contient deux element de la dimension Personne : Bill Gates et
Steve Jobs, et un element de la dimension Organisation : Societe d’informatique.
Nous representons ces trois elements respectivement par edimp1, edim
p2, et edimo
1.
edimp1 ≡ Bill Gates
edimp2 ≡ Steve Jobs
edimo1 ≡ Societe d’informatique
Nous remarquons que le document recherche doit contenir au moins deux
societe d’informatique. Ceci se traduit dans notre modele par l’operateur quanti-
ficateur > 2.
La requete R2 a donc l’expression suivante dans notre modele :
91

R2 ≡ ∃ indexe par.edimp1 ⊓ ∃ indexe par.edim
p2 ⊓ > 2 indexe par.edimo
1
Le cas “au plus” est idem a ce cas en changeant le symbole “>” par “6”.
Operateur jauge
Cet operateur permet a l’utilisateur de preciser les degres d’importance relatifs
aux elements de dimension de sa requete. Ce degre peut etre materialise par un poids
qui correspond a une valeur reelle appartenant a l’intervalle [0,1]12.
En effet, comme deja discute, il est possible qu’un utilisateur veuille preciser qu’il
y a des elements de dimensions de sa requete qui sont obligatoires et d’autres qui sont
optionnels. En realite, un element de dimension marque comme obligatoire dans
une requete doit absolument apparaıtre dans les documents retrouves, alors qu’un
element de dimension optionnel peut y apparaıtre ou non. Cette notion d’obligation
n’est pas nouvelle : Kefi et ses collaborateurs [48] ont propose d’utiliser les criteres
obligatoire et optionnel dans un contexte ou l’utilisateur a deja vu les documents
et ne se souvient pas exactement de leur contenu. Leur but etait de permettre une
formulation precise mais neanmoins aisee de la requete. Nous nous inspirons ici de
leur travail pour utiliser ces deux criteres.
Ces deux modalites d’expression de besoin peuvent etre prises en compte dans
notre modele en utilisant les poids. Ainsi, un element obligatoire doit avoir un poids
egal a 1, tandis qu’un element optionnel doit avoir un poids egal a 0.
Il est possible que l’utilisateur n’arrive pas a decider quels elements sont obliga-
toires et quels elements sont optionnels. Dans ce cas, nous lui fournissons a travers
notre modele un moyen pour privilegier certains elements a d’autres sans pour autant
preciser ce qui est obligatoire et ce qui est optionnel. Ceci peut etre mis en œuvre
par des valeurs de priorite que l’utilisateur donne a chaque element de dimension de
sa requete.
12Nous rappelons que les poids ne sont pas integre dans notre modele a base de logique descriptive.Ils sont uniquement utilises pour l’ordonnancement des documents pertinents pour une requete.
92

L’element de dimension qui a une priorite i doit apparaıtre dans tous les docu-
ments retrouves, sinon, c’est l’element de dimension qui a une priorite i+1. Avec i
est un entier qui appartient a l’intervalle [2, nd+1], et nd est le nombre d’elements
de dimensions presents dans la requete.
Les documents reponses a une requete sont classes en fonction des priorites des
elements de dimensions qu’ils contiennent. Une classe de documents est creee pour
chaque valeur de priorite. Comme un document peut contenir plusieurs elements de
dimensions qui ont des priorites differentes, il peut appartenir a plusieurs classes a
la fois. Les classes des documents reponses sont presentees a l’utilisateur en fonction
de la valeur de priorite de dimension en question : d’abord, la classe des documents
contenant les elements de dimensions de priorite i, ensuite celle des documents conte-
nant les elements de dimensions de priorite i+1, ainsi de suite. L’ordre d’affichage
des documents au sein d’une meme classe est calcule a l’aide de la fonction d’ordon-
nancement que nous verrons plus loin dans ce manuscrit.
Obligatoire vs optionnel
Exemple
A travers la requete R1, l’utilisateur cherche des documents qui parlent d’une per-
sonne. Donc un document pertinent doit obligatoirement contenir l’element decrivant
cette personne. Meme si ce document ne parle pas du conflit ou des Balkans, il peut
etre considere pertinent.
Soit edimp la representation de l’element de la dimension “Personne” : “General
francais”, edime represente l’element de la dimension “Evenement” : “Conflit des
Balkans”, et ediml1 et ediml
2 representent respectivement les deux elements de la
dimension “Lieu geographique”.
edimp ≡ General ⊓ ∃ originaire de.France
edime ≡ Conflit des Balkans
ediml1 ≡ Balkans
ediml2 ≡ Zone de securite ⊓ ∃ cree pendant.Conflit des Balkans
93

Supposons que l’element de la dimension “Personne” est obligatoire, et les autres
elements sont optionnels. Dans ce cas, la requete R1 a la transcription suivante dans
notre modele :
R1 ≡ ∃ indexe par.edimp
Priorite
Supposons maintenant que l’utilisateur veuille preciser des priorites sur les eleme-
nts de dimension de sa requete. Par exemple, l’element de la dimension “Personne”
est le plus prioritaire, et ceux de la dimension “Lieu geographique” sont les moins
prioritaires.
Formellement, il est relativement complique de definir cet operateur dans le lan-
gage ALCQ que nous avons adopte. Mais techniquement, il est tres simple de l’ap-
pliquer. En effet, il suffit de retourner les documents qui contiennent l’element de
dimension de priorite i, suivis par les documents qui contiennent l’element de dimen-
sion de priorite i + 1, et ainsi de suite.
Afin de specifier les criteres de recherche les plus exigeants dans le processus de
recherche, il est possible qu’une requete combine tous les operateurs proposes dans
notre modele.
Finalement, comme pour les documents (cf. la figure 3.2), la representation qI
du contenu semantique de q est une expression ALCQ. Lors de l’interrogation, l’ex-
pression qI est ajoutee a la T-Box qui contient deja les connaissances du domaine
ainsi que les index des documents de la collection. Il ne reste donc qu’a evaluer la
requete.
94

3.6.3 Evaluation des requetes
Pour evaluer une requete, nous avons besoin d’une fonction qui respecte les
contraintes imposees par l’utilisateur pour la correspondance entre un document
et une requete. Cette fonction est definie au niveau de l’indexation pour la corres-
pondance qui est basee sur la logique descriptive.
Nous avons egalement besoin d’une fonction qui permette d’organiser les docu-
ments dans leur ordre de pertinence par rapport a la requete. cette fonction est
definie au niveau de l’indexation pour l’ordonnancement que nous presentons dans
la suite.
Nous illustrons dans la suite comment ces deux fonctions sont integrees dans
notre modele.
La fonction de correspondance fSel
La fonction de correspondance est basee sur le calcul de la subsomption dans la
T-Box. En effet, en logique descriptive, le processus de RI peut etre vu comme la
tache de retrouver les documents representes par des concepts qui sont subsumes par
le concept representant la requete. Pour deux concepts C1 et C2 appartenant a la
T-Box T , on considere que C1 est subsume par C2 dans T (C1 ⊑T C2) si et seulement
si, pour chaque modele I de T , il est vrai que CI1 ⊆ CI
2 .
Dans la figure 3.3, un document doc et une requete q sont representes respec-
tivement, au niveau de l’indexation pour la correspondance, par docI et qI
dans la T-Box. La correspondance entre doc et q se traduit en logique descriptive
par la subsomption : doc est considere pertinent pour q si docI est subsume par qI
(docI ⊑T qI) (c’est-a-dire, en verifiant que docII ⊆ qII est vrai). Cette verification
prend en compte les documents qui satisfont l’operateur booleen, l’operateur quan-
tificateur, et l’operateur jauge qui sont utilises pour la definition du concept qI
representant la requete.
Finalement, l’ensemble des documents pertinents pour une requete q est defini
comme suit :
95

DPert = {doc ∈ Doc|docI ⊑K qI}
Fig. 3.3 – Calcul de la correspondance entre un document doc et une requete q auniveau de l’indexation pour la correspondance
Afin de proposer a l’utilisateur une liste de documents ordonnes, nous organi-
sation l’ensemble DPert en fonction du degre de pertinence de ses documents par
rapport a la requete. Cette etape est decrite dans la section suivante.
La fonction d’ordonnancement fOrd
La fonction d’ordonnancement fOrd a pour but d’organiser les documents re-
tournes pour une requete. Comme nous l’avons deja mentionne, cette fonction n’est
pas modelisee en DL dans notre modele. Nous n’avons pas encore aborde precisement
ce probleme d’ordonnancement, c’est pourquoi nous n’avons pas defini une fonction
particuliere a cet effet. Il existe plusieurs metriques dont nous pouvons nous inspirer
pour definir une fonction d’ordonnancement.
D’une maniere generale, la fonction fOrd doit calculer une valeur de pertinence,
notee RSV13, d’un document doc par rapport a une requete q en tenant compte des
13Retrieval Status Value.
96

parametres suivants :
- Les poids des elements de dimension dans doc : plus le poids des elements de di-
mension partages par q et doc est grand, plus la valeur de pertinence de doc
est elevee par rapport a q ;
- Les poids des elements de dimension dans q : plus doc contient des elements de
dimension dont le poids est eleve dans q, plus la valeur de pertinence de doc
est grande ;
- Les valeurs de priorite des elements de dimension dans q : un document contenant
un element de dimension dont la valeur de priorite est egale a Π est plus per-
tinent qu’un document contenant un element de dimension dont la valeur de
priorite est egale a Π + 1.
Fig. 3.4 – Calcul du RSV entre une requete et un document au niveau de l’indexationpour l’ordonnancement
Dans nos experimentations (cf. chapitre 4), nous avons utilise le modele vectoriel
pour mettre en œuvre la fonction fOrd. Dans ce cas, comme presente dans la figure
3.4, un document doc et une requete q sont representes respectivement, au niveau de
l’indexation pour l’ordonnancement, par les vecteurs−→doc et −→q . Le RSV entre
doc et q est calcule en appliquant le cosinus sur l’angle forme par les deux vecteurs−→doc et−→q .
97

3.7 Conclusion
En considerant les exigences de l’utilisateur en termes de precision, nous avons
propose un modele de Recherche d’Information capable de resoudre des requetes
precises. En se basant sur des connaissances du domaine representees a travers une
ressource externe, nous avons propose d’utiliser les dimensions de domaine pour
mettre en exergue les elements pertinents qui contribuent a la description du contenu
semantique des documents et des requetes. Ainsi, nous utilisons les dimensions, les
concepts et les relations pour definir une nouvelle unite d’indexation : l’element
de dimension. L’utilisation des elements de dimension nous permet de produire
une representation precise des documents tout en considerant les aspects lies a leur
semantique. Un langage expressif de requete a ete propose afin de permettre a l’usa-
ger d’utiliser des elements de dimensions et des operateurs pour decrire avec precision
son besoin d’information.
Afin de definir notre modele, nous avons choisi un formalisme de representation de
connaissances adequat qui permet la representation precise du contenu semantique
des documents et des requetes : il s’agit de la logique descriptive. Ainsi, nous avons
pu incorporer les connaissances du domaine lors de la definition de notre modele
tout en garantissant une representation uniforme des documents, des requetes et de
la ressource externe. Nous avons montre que ce formalisme dispose d’un niveau d’ex-
pressivite assez eleve qui convient tres bien a la representation precise du contenu
semantique des documents et des requetes. Ce formalisme offre egalement un moyen
pour calculer la correspondance entre un document et une requete mettant en œuvre
la pertinence systeme : il s’agit de l’algorithme de calcul de subsomption.
Dans le chapitre suivant, nous montrons, a travers la mise en œuvre de notre
modele, ses apports significatifs par rapport aux approches existantes. Nous presentons
en particulier, comment le calcul de la subsomption est un moyen efficace pour
resoudre des requetes precises representees dans notre modele. Nous presentons
egalement l’impact positif de l’utilisation des dimensions de domaine sur les per-
formances d’un Systeme de Recherche d’Information.
98

Chapitre 4
Mise en œuvre du modele
4.1 Introduction
La premiere partie de ce chapitre est consacree a la mise en œuvre de notre modele
base sur la logique descriptive. Nous y presentons les etapes necessaires pour cette
mise en œuvre (Section 4.2) et illustrons leur realisation par des exemples concrets
(Section 4.3).
La deuxieme partie quant a elle est consacree aux evaluations experimentales
de l’apport de l’usage des dimensions de domaine. D’abord, nous presentons le
contexte dans lequel nous avons mene nos experiences (Section 4.4.1). Ensuite, nous
exposons les conclusions tirees de l’application de notre modele sur des requetes
de la collection CLEF-2005 (Section 4.4.2). Dans les sections 4.4.3 et 4.4.4, nous
evaluons experimentalement l’apport de l’utilisation des dimensions de domaine pour
la resolution de requetes precises (issues du domaine medical). Les performances
de notre systeme sont ainsi evaluees en termes de precision moyenne. Enfin, nous
concluons ce chapitre par une synthese des resultats obtenus et quelques perspec-
tives (Section 4.5).
99
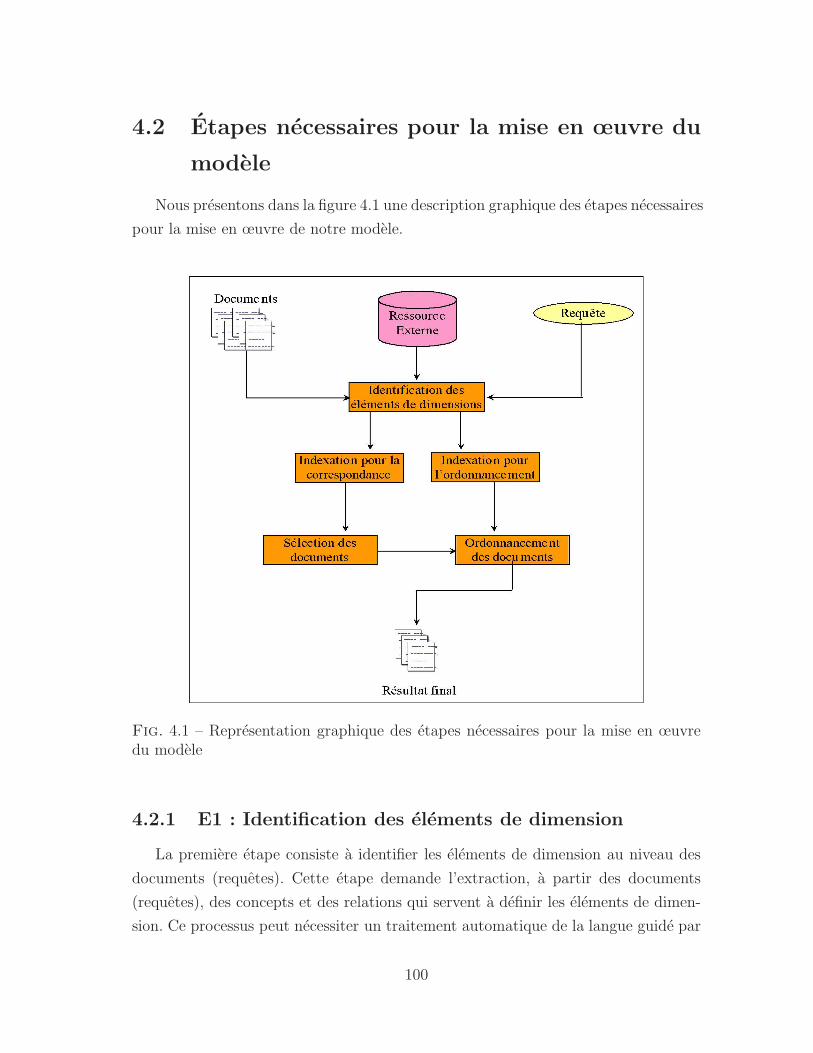
4.2 Etapes necessaires pour la mise en œuvre du
modele
Nous presentons dans la figure 4.1 une description graphique des etapes necessaires
pour la mise en œuvre de notre modele.
Fig. 4.1 – Representation graphique des etapes necessaires pour la mise en œuvredu modele
4.2.1 E1 : Identification des elements de dimension
La premiere etape consiste a identifier les elements de dimension au niveau des
documents (requetes). Cette etape demande l’extraction, a partir des documents
(requetes), des concepts et des relations qui servent a definir les elements de dimen-
sion. Ce processus peut necessiter un traitement automatique de la langue guide par
100

l’utilisation des ressources externes.
Du cote des documents, nous n’avons pas encore propose une methode pour ex-
traire automatiquement les elements de dimensions. Ceci s’inscrit dans le cadre de
nos perspectives a court terme. Dans les experiences que nous presentons ici, nous
avons fait des simplifications pour identifier les elements de dimension. En effet, dans
une premiere experience, nous definissons un element de dimension par un simple mot
(Section 4.4.3). Dans une deuxieme experience, nous le definissons par un concept
(Section 4.4.4).
Du cote des requetes, le probleme d’extraction des elements de dimension ne se
pose pas vu qu’une interface graphique doit etre proposee a l’utilisateur afin qu’il
puisse decrire son besoin en langue naturelle. Il y aura donc des champs de texte
pour decrire explicitement les elements de dimensions.
4.2.2 E2 : Indexation pour la correspondance
Lors de cette etape, nous utilisons la logique descriptive pour modeliser la res-
source externe, les documents, et les requetes en se basant respectivement sur le
modele de connaissances, le modele de document, et le modele de requete que nous
avons defini. Chaque document (requete) est represente(e) par la conjonction (et/ou
la disjonction) d’un ensemble d’elements de dimension. Dans la terminologie de la
logique descriptive, cette etape permet de construire la T-Box.
4.2.3 E3 : Selection des documents
La troisieme etape concerne la resolution des requetes. Une requete peut conte-
nir une combinaison de criteres de selection sur les elements de dimensions definis
par l’utilisateur pour identifier les documents recherches. Il n’y a pas de combinai-
son “ideale” d’operateurs pour former une requete. C’est a l’utilisateur de choisir,
en fonction de ses besoins et de son domaine d’interet, un ou plusieurs operateurs
parmi ceux que nous proposons dans notre modele de requete.
Pour effectuer cette etape, nous utilisons une fonction de selection (fSel) qui nous
permet de selectionner les documents pertinents pour une requete donnee. Cette
101

fonction est basee sur le calcul de la subsumption dans la T-Box construit lors de
l’etape E2.
A la fin de cette etape, les documents pertinents pour une requete sont selectionnes.
En vue de pouvoir les organiser dans leur ordre de pertinence par rapport a la requete,
nous procedons par les deux etapes qui suivent.
4.2.4 E4 : Indexation pour l’ordonnancement
Dans notre modele, un element de dimension peut avoir un poids qui reflete son
degre de representativite dans un document (requete). Cette etape est consacree donc
a la ponderation des elements de dimension au niveau des documents (requetes). A
ce niveau, nous n’avons pas encore propose une methode particuliere, mais nous
envisageons d’utiliser une des metriques existantes. En l’occurrence, cette etape a
ete effectuee, lors de nos experimentations, a l’aide du modele vectoriel.
4.2.5 E5 : Ordonnancement des documents
La cinquieme et derniere etape consiste a organiser, en utilisant la fonction fOrd,
les documents selectionnes (par fSel) dans leur ordre de pertinence par rapport a la
requete en question. Dans notre modele, nous n’avons pas defini une fonction par-
ticuliere a cette fin. Nous nous sommes bornes a utiliser le modele vectoriel pour le
calcul d’une valeur de similarite entre une requete et un document en prenant en
compte les poids des elements de dimensions.
Nous detaillons maintenant la realisation de ces etapes en illustrant par des
exemples concrets.
4.3 Realisation des etapes necessaires pour la mise
en œuvre du modele
Nous reprenons ici l’exemple que nous avons presente dans la problematique (cf.
figure 4.2). Nous montrons comment, en disposant d’une ressource externe, d’un
document, et d’une requete, la T-Box est construite. Par la suite, nous presentons
102

comment le calcul de la hierarchie de subsomption dans la T-Box est utilise pour la
resolution de requetes.
Fig. 4.2 – Exemple pour la mise en œuvre du modele
4.3.1 Realisation des etapes E2 & E3
Il s’agit ici de construire la T-Box contenant les connaissances traitees par notre
systeme. La logique descriptive represente un moyen pour presenter des informations
a l’etre humain. Pour que ces informations soient traitees par des applications, elles
doivent etre representees dans un langage adequat. Dans notre cas, nous avons choisi
d’utiliser le langage OWL1 (Web Ontology Language). Celui-ci a ete propose par le
1http ://www.w3.org/TR/owl-features/
103

consortium W3C2 pour etre utilise par des applications qui doivent traiter des onto-
logies.
Techniquement, la T-Box, contenant la ressource externe K, les representations
docI des documents et qI des requetes, est stockee dans un fichier que nous appelons
T-Box.owl (cf. le contenu de ce fichier dans l’annexe).
Modele de connaissances
Il s’agit ici de traduire une ressource externe, representee en logique descriptive,
en OWL et la stocker dans le fichier T-Box.owl. Dans notre modele, nous supposons
que les ressources externes sont deja representees en logique descriptive. Dans le cas
contraire, nous avons developpe un outil qui permet de representer une ressource
externe existante en logique descriptive et la traduire en format OWL. Nous nous
basons sur des heuristiques tres simples pour effectuer la traduction : les entrees de
la ressource externe sont traduites en concepts, et les relations en roles [43][85].
Pour notre exemple (figure 4.2), voici la description en logique descriptive de la
ressource externe. Sa traduction en OWL est presentee dans l’annexe.
⊤
Personne ⊑ ⊤
General ⊑ Personne
Philippe Morillon ⊑ General
Philippe Morillon ≡ ∃Originaire de.France
Lieu geographique ⊑ ⊤
France ⊑ Lieu geographique
Balkans ⊑ Lieu geographique
Ex-Yougoslavie ⊑ Lieu geographique
Ex-Yougoslavie ≡ ∃Partie de.Balkans
Zone de securite ⊑ Lieu geographique
Serbie ⊑ Ex-Yougoslavie
2http ://www.w3.org/TR/owl-ref/
104

Slovenie ⊑ Ex-Yougoslavie
Zone de securite ≡ ∃Cree pendant.Conflit des Balkans
Evenement ⊑ ⊤
Guerre civile ⊑ Evenement
Conflit des Balkans ⊑ Guerre civile
Conflit des Balkans ≡ ∃A lieu a.Balkans
A ce niveau, le fichier T-Box.owl contient seulement la ressource externe.
Modele de documents
Il s’agit ici d’ajouter, a la T-Box, les representations des documents tout en res-
pectant le modele de documents (cf. figure 4.3). Ainsi, chaque document doc de la
collection est represente, dans le fichier T-Box.owl, par un concept docI qui est une
expression en logique descriptive qui decrit le contenu de doc.
Fig. 4.3 – Representation graphique du modele de document
105

En supposant que les elements de dimension ont ete extraits a partir du docu-
ment presente dans la figure 4.2, leur representation en logique descriptive est de la
maniere suivante :
edim1 ≡ Philippe Morillon
edim2 ≡ Zone de securite ⊓ ∃Cree pendant.Guerre civile
edim3 ≡ Ex-Yougoslavie
edim4 ≡ Serbie
edim5 ≡ Slovenie
Le document de notre exemple est donc represente en logique descriptive par
l’expression suivante :
docI ≡ ∃indexe par.edim1 ⊓ ∃indexe par.edim2 ⊓ ∃indexe par.edim3 ⊓
∃indexe par.edim4 ⊓ ∃indexe par.edim5
Cette expression est ajoutee automatiquement a la T-Box. En effet, nous avons
developpe un outil qui permet de representer un document en logique descriptive et
le traduire en format OWL. Cet outil accepte en entree un ensemble d’elements de
dimensions, et produit en sortie le concept docI et l’ajoute dans le fichier T-Box.owl.
Modele de requetes
Il s’agit ici d’ajouter a la T-Box la representation de la requete en respectant
le modele de requete propose. Ainsi, chaque requete est representee, dans le fichier
T-Box.owl, par un concept qI.
En supposant que les elements de dimensions sont extraits a partir de la requete
de notre exemple (4.2), leur representation en logique descriptive est la suivante :
edim6 ≡ General ⊓ ∃Orginaire de.France
edim7 ≡ Zone de securite ⊓ ∃Cree pendant.Conflit des Balkans
106

De la meme maniere que pour les documents, notre outil permet de representer
une requete en logique descriptive et la traduire automatiquement en format OWL.
La requete de notre exemple est donc representee en logique descriptive par l’ex-
pression suivante :
qI ≡ ∃indexe par.edim6 ⊓ ∃indexe par.edim7
En ajoutant le concept qI au fichier T-Box.owl, la T-Box est construite, et la cor-
respondance entre documents et requetes peut etre effectuee. Nous presentons dans la
figure 4.4 une representation graphique de la T-Box. Les concepts sont presentes dans
l’ordre alphabetique : d’abord le concept docI, ensuite les concepts de la ressource
externe K (contenant les dimensions Evenement, Lieu geographique, et Personne),
enfin le concept qI.
Fig. 4.4 – Representation graphique de la T-Box
107

Correspondance
La correspondance entre le document et la requete se traduit en logique descrip-
tive par la subsomption : le document d est considere pertinent pour la requete q si
docI est subsume par qI (docI ⊑T qI) (cf. figure 4.5). Techniquement, il faut faire
des inferences dans le fichier T-Box.owl et fabriquer la hierarchie de subsomption. Il
existe plusieurs raisonneurs qui permettent d’effectuer cette tache (Racer3, Fact++4,
etc.). Dans nos experimentations, nous avons choisi le raisonneur Pellet5.
Fig. 4.5 – Calcul de la correspondance entre un document doc et une requete q
Le raisonneur prend en entree le fichier T-Box.owl qui est represente graphique-
ment dans la figure 4.4. En faisant des inferences, le raisonneur produit la hierarchie
de subsomption qui est presentee dans la figure 4.6. Dans celle-ci, nous pouvons
constater que le concept docI est plus specifique que le concept qI dans la hierarchie
ainsi fabriquee. Cette information implique que le concept qI subsume le concept
docI, ce qui veut dire que le document doc peut etre considere comme une reponse
pertinente pour la requete q.
A ce niveau, notre systeme arrive a selectionner les documents pertinents pour
une requete. Il ne reste qu’a les classer dans leur ordre de pertinence par rapport a
la requete. Ce processus est decrit dans la section suivante.
3http ://www.racer-systems.com/4http ://owl.man.ac.uk/factplusplus/5http ://pellet.owldl.com/
108

Fig. 4.6 – La hierarchie de subsomption fabriquee par le raisonneur Pellet
4.3.2 Realisation des etapes E4 & E5
Nous avons utilise le modele vectoriel pour mettre en œuvre ces deux etapes.
Comme presente dans la figure 4.7, un document doc et une requete q sont representes
respectivement par les vecteurs−→doc et −→q . Le RSV6 entre doc et q est calcule en ap-
pliquant le cosinus sur l’angle forme par les deux vecteurs−→doc et −→q .
Dans les experiences presentees ici, nous considerons un element de dimension
comme un concept ou un mot. Ainsi, l’application du modele vectoriel est tres simple
car chaque document (requete) est represente(e) par un vecteur de concepts ou mots.
Nous presentons maintenant les experiences menees sur la collection CLEF-2005
qui ont pour but d’evaluer l’apport de l’utilisation des dimensions pour la resolution
des requetes precises.
6Retrieval Status Value.
109

Fig. 4.7 – Calcul du RSV entre une requete et un document au niveau de l’indexationpour l’ordonnancement
4.4 Experimentations sur la collection CLEF-2005
Avant d’exposer nos experiences, nous presentons d’abord le contexte dans lequel
elles ont ete menees.
4.4.1 Contexte des experimentations
Protocole d’evaluation
Nous avons utilise une collection de la campagne d’evaluation CLEF-2005. Elle
a ete utilisee dans la tache de recherche d’images medicales (MedIR) [24] qui fait
partie de la piste ImageCLEF qui concerne la recherche multilingue d’images.
Dans la campagne CLEF, les systemes sont evalues selon l’approche d’evaluation
caracteristique des systemes de Recherche d’Information. Celle-ci est basee sur la
notion de pertinence qui consiste en la quantification de la correspondance d’un do-
cument par rapport a une requete. Elle repose sur une mesure des performances des
systemes basee sur le calcul de deux indicateurs : le rappel et la precision [23]. Un
Systeme de Recherche d’Information de qualite maximise ces deux valeurs, bien que
celles-ci soient generalement antinomiques.
La methode d’evaluation des systemes est faite selon le protocole TREC7. Pour
chaque requete, les 1000 premiers documents sont restitues par le systeme et des
7http ://trec.nist.gov/
110

precisions sont calculees a differents points (5, 10, 15, 30, 100, et 1000 premiers
documents restitues), puis une moyenne Avg Pr de toutes ces precisions est calculee.
Le corpus
Les experimentations sont conduites sur le corpus ImageCLEFmed-2005. Celui-ci
contient 50,026 images avec des annotations en format XML. La majorite des anno-
tations sont en anglais, mais il y a un nombre significatif en francais et en allemand,
avec quelques cas sans aucune annotation.
Le corpus comprend egalement 25 requetes contenant chacune une ou plusieurs
images exemples (positives, negatives). Chaque requete contient trois courtes des-
criptions textuelles respectivement en francais, en anglais, et en allemand.
Dans la figure 4.8, nous presentons un exemple typique d’une requete de la col-
lection ImageCLEFmed-2005 :
Fig. 4.8 – Exemple de requete de la collection ImageCLEFmed-2005
111

Pourquoi la collection ImageCLEFmed ?
Nous pensons que la collection ImageCLEFmed est particulierement pertinente
pour evaluer notre approche. En effet, cette collection contient des requetes qui
expriment des besoins precis de medecins. A travers ces requetes, l’etre humain com-
prend clairement que l’on cherche des images qui contiennent deux elements en rap-
port l’un avec l’autre : i) une partie de l’anatomie du corps humain (ex. femur), ii)
une pathologie liee a cette partie de l’anatomie (ex. fracture), iii) enfin, ces elements
doivent etre decrits dans une image d’une modalite particuliere (ex. x-ray). Ces
trois types d’elements d’informations representent des dimensions du domaine de la
medecine.
Notre defi est de resoudre ces requetes precises Nous proposons ainsi de prendre
en compte les dimensions susmentionnees et montrer que leur utilisation permet d’in-
terpreter avec precision les requetes de la collection ImageCLEFmed, et d’augmenter
ainsi la precision du systeme.
Les ressources externes utilisees
Nous avons utilise deux ressources externes pour definir les dimensions du do-
maine medical. Nous les presentons brievement dans les sections suivantes.
Le thesaurus MeSH
MeSH8 (Medical Subject Headings) est un thesaurus developpe par la “National
Library of Medicine9”. Il se compose d’un ensemble de termes de la medicine fai-
sant reference a des descripteurs organises dans une structure hierarchique. MeSH
contenait 22997 descripteurs classes a la fois dans une structure alphabetique et
hierarchique. Au niveau superieur de la structure hierarchique, on trouve des termes
tres generiques tels que “Anatomy” ou “Diseases”. Des termes plus specifiques tels
que “Femur” et “Cancer” se trouvent a des niveaux plus bas de la hierarchie qui
contient onze niveaux. Nous presentons, dans la figure 4.9, les premiers niveaux de
la hierarchie de MeSH.
8http ://www.nlm.nih.gov/mesh/ [visite le 19-6-2007]9http ://www.nlm.nih.gov/ [visite le 19-6-2007]
112

Fig. 4.9 – Premier niveau de la structure hierarchique de MeSH
Dans notre experience, nous avons utilise la structure hierarchique de MeSH
pour definir les dimensions “Anatomie”, “Pathologie”, et “Modalite”. Celles-ci sont
definies respectivement par les hierarchies suivantes :
- Anatomy [A] ;
- Diseases [C] ;
- Analytical, Diagnostic and Therapeutic Techniques and Equipment [E]
Le meta-thesaurus UMLS
UMLS (Unified Medical Language System) resulte de la fusion de 140 sources de
donnees terminologiques (UMLS knowledge sources) du domaine medical. Il contient
egalement des outils linguistiques destines a faciliter les taches d’acces, de recherche,
d’integration, et d’agregation des informations biomedicales et de sante. Il est com-
pose de trois elements : le Meta-thesaurus, le Semantic Network, et le Specialist Lexi-
con. Le Meta-thesaurus est la partie la plus importante par sa taille et son contenu.
Il regroupe des concepts denotes par des termes differents. Ces termes peuvent
eventuellement provenir de sources differentes. La structure du meta-thesaurus com-
prend les quatre niveaux suivants :
113

- Atome : c’est le plus petit element dans la structure. Il represente les instances
d’une chaıne de caracteres venant de differentes sources ;
- Chaınes : represente les variations de forme d’une chaıne de caracteres. C’est le
regroupement des atomes qui ont la meme forme de chaıne de caracteres ;
- Terme : represente les variations de denotation d’un concept. Ce sont donc les
termes des synonymes qui regroupent un ensemble de chaınes ;
- Concept : represente le sens des termes. C’est le regroupement des synonymes.
UMLS comprend environ 170 types de relations entre les concepts presents dans
le Meta-thesaurus. La relation de synonymie est representee implicitement dans la
structure des concepts. Tous les concepts sont organises en 135 categories, appelees
types semantiques dans le Semantic Network. Cette structure est un ajout a la fusion
des thesaurus. Elle permet de “couvrir” cette fusion d’une classification hierarchique.
C’est precisement cette structure que nous utilisons pour definir les dimensions.
Pour les requetes d’ImagCLEFmed-2005, nous avons utilise les dimensions Ana-
tomie, Pathologie, et Modalite. En analysant manuellement les requetes et UMLS,
nous avons choisi les concepts qui definissent chacune de ces dimensions :
- Anatomie “Anatomical Structure”, “Body System”, “Body Space or Junction”,
“Body Location or Region” ;
- Pathologie “Disease or Syndrome”, “Finding”, “Injury or Poisoning” ;
- Modalite “Diagnostic Procedure”, “Manufactured Object”.
Les concepts de chaque categorie sont organises autour d’une sous-hierarchie
d’UMLS. Donc, pour definir une dimension, nous regroupons les sous-hierarchies qui
correspondent au concept definissant cette dimension.
4.4.2 Mise en œuvre du modele a base de la logique descrip-
tive sur la collection ImageCLEFmed-2005
L’objectif a travers cette experience est de tester la faisabilite de l’application de
notre approche sur des requetes extraites d’une collection reference. Il s’agit princi-
palement de savoir a quel point notre modele peut etre applique et quelles sont les
114

limites techniques et formelles qui lui sont liees.
Nous avons effectue des tests sur quelques requetes choisies en fonction de leur
complexite. Pour chacune de ces requetes, nous construisons une T-Box constituee
de la requete elle-meme, des documents qui lui sont pertinents et d’une partie de
UMLS. Ensuite, nous calculons la correspondance a l’aide du raisonneur Pellet et
comparons le resultat avec la correspondance calculee par un modele de RI classique
(i.e. le modele vectoriel).
Analyses concernant les donnees
La premiere difficulte concerne la selection d’un sous-ensemble de UMLS pour
chacune des requetes etudiees. Techniquement cette tache est assez simple a realiser :
il suffit de selectionner, a partir de UMLS, les hierarchies auxquelles appartiennent
les concepts de la requete et les traduire dans un format OWL. Lors du calcul de la
subsomption, ces hierarchies sont utilisees par le raisonneur Pellet afin de retrouver
les documents pertinents pour la requete en question.
Le probleme majeur a ce niveau est que UMLS contient plusieurs hierarchies pa-
ralleles provenant chacune d’une ressource independante. Ceci represente une diffi-
culte lors de la representation de UMLS en logique descriptive. Une solution possible
est de choisir une seule hierarchie (par exemple, provenant d’une ressource parti-
culiere) et l’utiliser pour le calcul de la subsomption.
Le deuxieme probleme rencontre consiste en l’extraction automatique des elements
de dimension a partir des documents. Cette tache n’est pas facile a realiser. Elle de-
mande une analyse precise de la langue naturelle afin d’extraire les concepts et les
relations qui servent a definir les elements de dimension. Nous avons simplifie le
modele en supposant qu’un element de dimension est defini par un concept. Du cote
de la requete, ce probleme est mineur vu que l’extraction des elements de dimension
se fait tres facilement d’une maniere manuelle.
Le troisieme probleme est lie au contenu des documents de la collection ImageCL-
EFmed-2005. Certains de ces documents contiennent un texte (meta-donnees) qui
ne decrit pas le contenu de l’image associee. En effet, les jugements de pertinence
115

dans la collection ImageCLEFmed-2005 ont ete effectues en se basant sur les images
et non pas sur les textes qui leur sont associes. Ceci represente un handicap lors de
l’evaluation de la fonction de correspondance, surtout quand le systeme ne retrouve
pas les documents pertinents. En effet, dans ce cas, on ne peut pas determiner ce qui
a mal fonctionne lors de l’experience : est-ce que notre fonction de correspondance ne
fonctionne vraiment pas bien, ou bien les documents ne contiennent-ils effectivement
pas de texte decrivant l’image.
Analyses concernant le modele
La fonction de correspondance
Apres moult essais, nous avons conclu que la qualite de la conception de la res-
source externe utilisee a un impact majeur sur la performance de la fonction de
correspondance basee sur le calcul de la subsomption. En effet, plus cette ressource
contient des relations de subsomption (is-a), plus la fonction de correspondance est
capable de retrouver des documents pertinents a une requete meme s’ils ne partagent
pas les memes concepts qu’elle. Par exemple, pour une requete contenant “Tibia”,
la correspondance a base du modele vectoriel n’a pu retrouver que 3 documents per-
tinents alors que notre fonction de correspondance a permis d’en retrouver 12, en
utilisant la relation “Tibia is-a Bone”. En effet, a travers l’algorithme qui calcule
la subsomption, l’utilisation de la Logique Descriptive offre une capacite de raison-
nement qui peut deduire des connaissances implicites a partir de celles qui sont
explicitement definies dans la T-Box, et permet ainsi de retrouver des documents
pertinents pour une requete meme s’ils ne partagent aucun concept avec elle.
Cependant, nous avons rencontre quelques problemes en utilisant la hierarchie de
subsomption. En effet, selon le domaine, la ressource externe peut etre organisee a
travers des hierarchies semantiques differentes. Par exemple, dans le domaine de la
Geographie, la relation part of est probablement une des relations les plus utilisees
dans les hierarchies de concepts. Il en est de meme pour l’anatomie humaine. Par
exemple, si un utilisateur cherche ”fracture in the leg”, il va certainement considerer
un document contenant “fracture of the hip” comme pertinent. Ainsi, le systeme de
recherche doit prendre en compte, lors du calcul de la subsomption, la hierarchie
part of decrivant l’anatomie humaine.
116

Une facon de resoudre ce probleme est d’effectuer une expansion guidee de la
requete telle que propose par Baziz [4]. Il s’agit de specifier les relations a utiliser
lors de l’expansion de requete. Dans l’exemple precedent, une expansion possible
serait de rechercher les documents qui contiennent “Leg” et les membres de l’ana-
tomie qui font partie de “Leg” (Leg ⊔ ∃ part of.Leg). Evidemment, pour que cette
solution marche, il faut etudier le nombre de niveaux dans la hierarchie a utiliser
lors de l’expansion. En l’occurrence, l’expansion doit etre faite d’une facon a pouvoir
ajouter “Hip”, “Femur”, “Tibia”, etc.
Une deuxieme facon de resoudre ce probleme est de “tordre” la relation de sub-
somption et de representer ainsi la hierarchie part of comme une hierarchie de sub-
somption, donc declarer implicitement, par exemple, que Hip is a Leg. Avec cette
approche, nous aurions les elements de dimensions suivants respectivement dans la
requete et le document :
edimq ≡ Fracture ⊓ ∃ affect .Leg
edimd ≡ Fracture ⊓ ∃ affect .Hip
Ayant declare que Hip ⊑ Leg, le raisonneur va correctement inferer que edimd ⊑
edimq. Dans nos experimentations, nous avons implemente cette approche “rapide
et naıve”. Cependant, l’utilisation de la subsomption pour mimer une autre relation
peut conduire, dans certains cas, a des deductions contre-intuitives imprevues. Une
approche plus “sure et propre” consiste a definir des proprietes transitives afin de
representer les differents types de hierarchies qui peuvent exister dans un domaine
donne. Ainsi, les elements de dimension de l’exemple precedent seront presentes
comme suit :
edimq ≡ Fracture ⊓ ∃ affect ∃part of .Leg
edimd ≡ Fracture ⊓ ∃ affect ∃part of .Hip
Si un axiome specifie que part of est transitive, et si la definition de Hip est de
la forme “... ⊓ ∃part of.Leg”, alors le raisonneur peut inferer que edimd ⊑ edimq.
117

Nous pouvons donc conclure que la fonction de correspondance basee sur le calcul
de la subsomption a l’avantage d’etre tres flexible dans le sens ou elle permet d’uti-
liser n’importe quelle relation pour calculer la correspondance entre un document et
une requete. Mais, comme nous le verrons dans la section suivante, le prix a payer
peut survenir au niveau de la fonction d’ordonnancement.
La fonction d’ordonnancement
Avec notre fonction de correspondance, un document peut etre retrouve comme
reponse a une requete meme s’il ne partage pas les memes concepts qu’elle. Dans ce
cas, il n’est pas possible de calculer (a l’aide du modele vectoriel) une valeur de si-
milarite entre un document et une requete qui ne partagent pas les memes concepts.
Par exemple, pour la requete contenant “Tibia” et un document contenant “Bone”,
le modele vectoriel a retourne une valeur de similarite nulle alors que le document
est pertinent pour la requete en question.
Une solution possible a ce probleme consiste a etendre la requete ou le docu-
ment avant de fabriquer leurs vecteurs respectifs et calculer la valeur de similarite
entre eux. En effet, lors du calcul de la subsomption, il est possible de savoir quelles
sont les relations qui ont ete utilisees par le raisonneur pour fabriquer la hierarchie
de subsomption. Ces relations peuvent etre utilisees pour etendre la requete ou ses
documents reponses. Par exemple, pour la requete contenant “Tibia” et le docu-
ment contenant “Bone”, nous pouvons utiliser la relation “is-a” pour etendre soit la
requete par le concept “Bone”, soit le document par le concept “Tibia”.
Suite a ce probleme, deux questions meritent d’etre posees :
1. Est-ce que l’ordonnancement dans un contexte de recherche precise est indis-
pensable ?
2. Est-ce que la notion de pertinence dans un contexte de recherche precise est la
meme que celle qui est utilisee dans la recherche generale ?
Nous pensons que dans une tache de recherche precise, l’utilisateur peut se satis-
118

faire de n’importe quelle reponse pertinente retournee par le systeme. Etant donne
que la fonction de correspondance est censee ne retourner que des documents tres
pertinents, l’ordonnancement devient moins important que dans un cas de recherche
generale (comme sur le Web par exemple). Cependant, on peut penser que la no-
tion de pertinence dans un contexte de recherche precise differe de celle qui est
utilisee dans une recherche generale. Par exemple, pour une requete demandant la
liste des joueurs de l’equipe de Rugby de France, un document contenant les 15
joueurs peut etre considere par l’utilisateur comme plus pertinent qu’un document
contenant seulement quelques joueurs.
Nous pensons qu’avant de proposer une fonction d’ordonnancement, il faut d’abord
definir la notion de pertinence dans un contexte de recherche precise. Il est possible
que la definition de cette notion depende du domaine d’application considere. Pour
cette raison, il semble souhaitable de collaborer avec des utilisateurs d’un domaine
particulier afin de definir leur notion de pertinence et proposer par la suite une fonc-
tion d’ordonnancement.
Consideration des performances en temps de calcul
Il est evident que l’utilisation d’un raisonneur pour mettre en œuvre la fonction
de correspondance conduit a des temps de calcul nettement plus longs que dans le
cas des SRI bases sur un index classique. Neanmoins, plusieurs points peuvent etre
interessants a etudier afin d’ameliorer les performances d’une approche basee sur la
logique descriptive : i) le contenu des documents est generalement represente par une
simple expression logique en utilisant les constructeurs ⊓ et ∃. Ainsi, nous pouvons
imaginer un algorithme de raisonnement plus simple que ceux utilises dans le cas
general ; ii) le contenu de la collection est generalement stable, et peut donc etre
pre-traite afin de minimiser les calculs au moment de l’interrogation. Par exemple,
nous pouvons pre-calculer la hierarchie de subsomption, et une fois la requete posee,
le raisonneur n’a qu’a placer le concept representant la requete au bon endroit de
cette hierarchie. De plus, il est inutile de calculer la subsomption entre les concepts
representant les documents ; iii) en cas ou les requetes sont representees par des ex-
pressions logiques simples ou regulieres, un traitement specifique peut etre applique
afin de faciliter la tache du raisonneur et eviter des calculs inutiles.
119

Apres cette analyse sur la mise en œuvre du modele, nous detaillons maintenant
deux experiences preliminaires dediees a l’evaluation, en terme de performance de
recherche, de l’apport de l’utilisation des dimensions de domaine. Dans chacune
de ces deux experiences, nous avons utilise le systeme d’experimentation X-IOTA
developpe par l’equipe MRIM du laboratoire LIG [17].
4.4.3 Definition des elements de dimensions par des mots
Dans cette nouvelle experience10, nous avons utilise le thesaurus MeSH comme
ressource externe pour la definition des dimensions du domaine medical. Nous avons
egalement utilise les mots pour identifier les elements de dimensions au niveau des
documents/requetes. Le but de cette experience est de montrer comment, en dispo-
sant d’un thesaurus de petite taille et d’un index a base de mots-cles, l’application
de l’usage des dimensions de domaine peut resoudre des requetes precises et depasser
les approches basees sur les modeles existants.
Identification et ponderation des elements de dimensions
Une fois les dimensions definies, nous les utilisons pour identifier les elements
de dimension au niveau des documents (requetes) du corpus ImageCLEFmed. Nous
avons fait une simplification en definissant un element de dimension par un simple
mot. Donc si un mot appartenant a un document (requete) existe dans une des
dimensions definies, alors il sera considere comme un element de cette dimension.
Une fois les elements de dimensions identifies, nous les ponderons en employant le
schema de ponderation LTC du modele vectoriel.
Selection et ordonnancement des documents pertinents pour une requete
Afin de resoudre les requetes du corpus ImageCLEFmed, nous utilisons trois
criteres parmi ceux que nous avons proposes dans notre modele : obligatoire, option-
nel, et priorite.
Rappelons qu’un element de dimension marque comme obligatoire dans une
requete doit absolument apparaıtre dans les documents retrouves, alors qu’un element
de dimension optionnel peut y apparaıtre ou non. Enfin, un element de dimension qui
10Cette experience a ete menee en collaboration avec Dr. J-P. Chevallet et Dr. J-W. Lim [20] [19]
120

a une priorite i doit apparaıtre dans les documents retrouves, sinon, c’est l’element
de dimension qui a une priorite i + 1.
En se basant sur ces trois criteres, nous avons effectue quatre tests afin de pou-
voir interpreter le contenu des requetes. Nous presentons ces tests dans la section
suivante, ainsi que les resultats obtenus.
Notre objectif ici n’est pas d’evaluer la fonction de correspondance, basee sur le
calcul de la subsomption, mais plutot l’apport de l’utilisation des dimensions pour
la resolution de requetes precises. Ainsi, lors du calcul de la correspondance, nous
n’avons pas besoin de faire des inferences dans la ressource externe pour le cal-
cul de la subsomption. La correspondance entre une requete et un document peut
etre effectuee avec un modele booleen classique ou les documents (requetes) sont
represente(e)s comme une conjonction (et/ou disjonction) d’elements de dimension.
Une fois les documents selectionnes, nous utilisons le modele vectoriel pour les
ordonner en fonction de leur pertinence par rapport a la requete en question. Comme
la correspondance a ete effectuee sans aucune inference dans la ressource externe,
chaque document retrouve partage forcement les memes elements de dimension que
la requete. Ainsi, l’application du modele vectoriel pour le calcul d’une valeur de
similarite entre un document et une requete ne pose aucun probleme.
Resultats experimentaux
Nous avons d’abord effectue une indexation classique basee sur le modele vec-
toriel (avec le schema de ponderation LTC) sans prise en compte des dimensions.
Le resultat de cette methode d’indexation classique servira de reference (baseline)
pour evaluer l’apport de l’usage des dimensions de domaine. La precision moyenne
(MAP : Mean Average Precision) obtenu avec le baseline est egale a 0.1725.
Les resultats obtenus sont presentes dans le tableau 4.1, ou les lignes corres-
pondent aux tests, et les valeurs correspondent aux resultats et leur taux de variation
compare au baseline.
Voici les quatre tests effectues lors de nos experiences. Evidemment, ce sont de
121

Tab. 4.1 – Comparaison des resultats de notre approche avec le baseline.Tests MAP Comparaison avec le baseline (%)T1 0.1463 -17.90T2 0.1956 +13.39T3 0.2075 +20.28T4 0.2130 +23.47
simples tests sur des cas particuliers qui n’ont pas de portee generale. Le but ici etant
de montrer comment les operateurs que nous avons proposes peuvent etre utilises
pour mieux preciser un besoin d’information.
T1 : “Un document est considere pertinent s’il contient les trois dimensions presentes
dans la requete”.
Cette requete se traduit par le fait que les elements des dimensions Anatomie,
Pathologie, et Modalite sont obligatoires et doivent donc etre presents dans les do-
cuments pertinents.
Nous nous attendions a ce que ce test ameliore les resultats mais les experiences
demontrent le contraire : une baisse de 17.90%. Apres analyse de la collection, nous
avons remarque que ce resultat est du au fait que les documents de ImageCLEFmed-
2005 ne contiennent pas souvent les termes decrivant la modalite des images. Le fait
que la modalite ne soit pas assez explicitee dans les documents nous paraıt normal
car un compte-rendu decrit une pathologie sur une partie de l’anatomie, et l’informa-
tion sur le type d’image est souvent implicite. Pour cette raison, nous avons propose
le test suivant :
T2 : “Un document est considere pertinent s’il contient au moins une des dimen-
sions de la requete”.
Cette requete se traduit par le fait que les elements des dimensions Anatomie,
Pathologie, et Modalite sont tous optionnels et qu’au moins un d’entre eux doit etre
present dans les documents pertinents.
122

Avec ce test, nous avons obtenu une amelioration du resultat de 13.39%. Dans
ce cas, nous avons suppose que toutes les dimensions ont la meme importance dans
la requete. Cette supposition n’est pas toujours valide. En effet, les termes decrivant
la modalite dans la requete ne sont pas discriminants (ex : une CT 11 peut etre
“une image d’un rein” ou “une image d’un emphyseme”, etc.). De meme, les termes
decrivant la pathologie sont parfois ambigus (ex : une fracture peut etre “une frac-
ture d’un femur” ou “une fracture d’un crane”, etc.). Donc, il nous a semble que
l’anatomie est la dimension la plus importante parce qu’elle est discriminante et non
ambigue. Ceci nous a suggere le test suivant :
T3 : “Un document pertinent doit contenir l’anatomie, sinon la pathologie, sinon la
modalite”.
Avec ce test, nous avons ameliore les performances de recherche de 20.28%.
Comme les termes decrivant la modalite ne sont pas souvent presents dans les
documents, nous avons considere dans notre quatrieme test que les elements des
dimensions Anatomie et Pathologie sont obligatoires, et que les elements de la di-
mension Modalite sont optionnels.
T4 : “Un document est considere pertinent s’il contient les dimensions anatomie et
pathologie”.
Avec ce test, nous avons obtenu une amelioration des performances de recherche
de 23.47%.
Dans la figure 4.10, nous proposons une comparaison graphique des performances
de notre systeme par rapport au baseline.
Nous presentons dans la section suivante la deuxieme experience que nous avons
menee en se basant sur une indexation conceptuelle. Nous revenons a la fin de ce
chapitre aux interpretations de ces resultats et aux conclusions que l’on peut tirer
apres ces experiences.
11Computed Tomography.
123
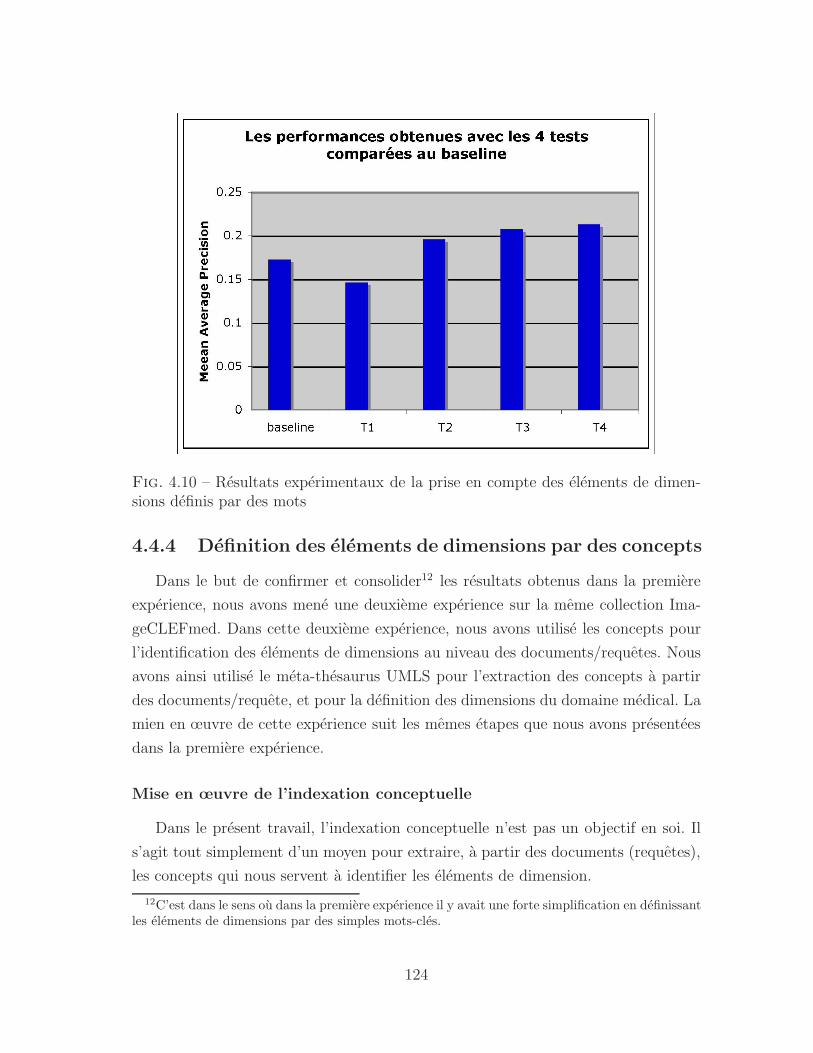
Fig. 4.10 – Resultats experimentaux de la prise en compte des elements de dimen-sions definis par des mots
4.4.4 Definition des elements de dimensions par des concepts
Dans le but de confirmer et consolider12 les resultats obtenus dans la premiere
experience, nous avons mene une deuxieme experience sur la meme collection Ima-
geCLEFmed. Dans cette deuxieme experience, nous avons utilise les concepts pour
l’identification des elements de dimensions au niveau des documents/requetes. Nous
avons ainsi utilise le meta-thesaurus UMLS pour l’extraction des concepts a partir
des documents/requete, et pour la definition des dimensions du domaine medical. La
mien en œuvre de cette experience suit les memes etapes que nous avons presentees
dans la premiere experience.
Mise en œuvre de l’indexation conceptuelle
Dans le present travail, l’indexation conceptuelle n’est pas un objectif en soi. Il
s’agit tout simplement d’un moyen pour extraire, a partir des documents (requetes),
les concepts qui nous servent a identifier les elements de dimension.
12C’est dans le sens ou dans la premiere experience il y avait une forte simplification en definissantles elements de dimensions par des simples mots-cles.
124

Voyons brievement la mise en œuvre de l’indexation conceptuelle que nous avons
utilisee. Une description detaillee avec tous les resultats est disponible dans [73].
L’outil13 que nous avons utilise est adapte aux textes ecrits en anglais. Nous l’avons
egalement utilise pour les textes ecrits en allemand et en francais.
Le principe general de l’extraction des termes et des concepts qu’ils denotent est
base sur l’utilisation des outils de TAL traditionnellement utilises en RI, guides par
les donnees terminologiques de UMLS. Tout d’abord, tous les textes de la collection
sont analyses a l’aide de TreeTagger14 qui fournit comme resultat des mots segmentes,
etiquetes syntaxiquement et lemmatises. Ensuite, une correspondance est faite entre
les (groupes de) mots fournis par TreeTagger et les entrees de UMLS. L’hypothese
sur laquelle se base la mise en œuvre de l’indexation conceptuelle est que seuls les
termes presents dans UMLS et retrouves, avec seulement des variantes lexicales dans
les textes, permettent d’identifier un terme. Cette hypothese est restrictive car il
est possible que les donnees terminologiques dans UMLS ne couvrent pas toutes les
formes textuelles possibles.
La mise en œuvre de l’indexation conceptuelle est une tache difficile. Par exemple,
le meta-thesaurus UMLS ne contient pas toutes les formes textuelles possibles qui
denotent un concept. Ainsi, la correspondance stricte entre le texte des documents
et les entrees de UMLS ne permet pas d’extraire tous les concepts. Cette limite peut
etre contournee en tenant compte de deux types de variations :
i) La variation au niveau de la casse (utiliser les formes en majuscule ou en mi-
nuscule) : selon les resultats, il semble difficile de pouvoir dire quelle methode
effectue la meilleure correspondance entre les (groupe de) mots des textes et
les entrees de UMLS. En tout cas, d’un point de vue RI, la suppression de la
casse est plus simple a mettre en œuvre et semble donc plus interessante.
ii) La variation au niveau lexical (la forme d’origine d’un mot ou sa forme lem-
matisee). A ce niveau il existe un probleme de non-detection des termes qui
13Developpe par Loıc Maisonnasse.14http ://www.ims.uni-stuttgart.de/projekte/corplex/TreeTagger/DecisionTreeTagger.html
125

pourraient denoter des concepts dans le texte. Ce type d’erreur provient de
l’analyse lexicale de TreeTagger qui ne permet pas de retrouver les lemmes de
tous les mots utilises dans le corpus medical. Par exemple, le terme “angio-
grams”, qui est present dans une requete sous la forme au pluriel, ne peut pas
etre associe au concept correspondant car UMLS ne contient que la forme au
singulier (angiogram) et TreeTagger n’est pas capable de retrouver le lemme
correspondant a “angiograms”. En effet, l’analyseur TreeTagger est un ana-
lyseur general et donc non adapte au vocabulaire medical. L’utilisation d’un
analyseur specialise sur le domaine pourrait ameliorer les resultats.
Un autre probleme concerne l’association entre une chaıne de caracteres et les
entrees d’UMLS. Faut-il considerer seulement les termes presents dans le texte et qui
sont les plus longs (contiennent le plus grand nombre de mots), ou bien considerer
tous les termes independamment de leurs tailles ? Dans le premier cas, notamment
considere par Baziz [4], le terme pertinent a extraire de la sequence “Images of right
middle lobe”, est “right middle lobe” et non pas seulement “lobe”.
Les experiences que nous avons effectuees ont montre que la correspondance basee
sur les termes les plus longs donne des resultats inferieurs a ceux qui sont obtenus a
l’aide des mots. Cette baisse de performance s’explique par l’extreme precision des
concepts extraits. En effet, des concepts denotes par “Right middle lobe” ou “Chest
CT” sont trop precis de sorte que leur utilisation a la place de leurs constituants
entraıne une forte baisse du rappel. D’autres problemes tels que la metonymie influe
sur la correspondance entre les concepts.
En extrayant les concepts denotes par tous les termes presents dans le texte, on
obtient une nette amelioration dans les performances du systeme, surpassant ainsi
les resultats obtenus par l’indexation basee sur les mots cles. Cette amelioration est
la consequence d’une augmentation du taux du rappel qui est du a l’extraction de
certains concepts plus generaux.
Dans la presente experimentation, nous n’avons pas traite le probleme de l’am-
biguıte des termes. Nous avons suppose que dans un domaine tres specifique, tel que
la medecine, le taux d’ambiguıte des termes n’est pas eleve. Dans ce cas, l’indexation
126
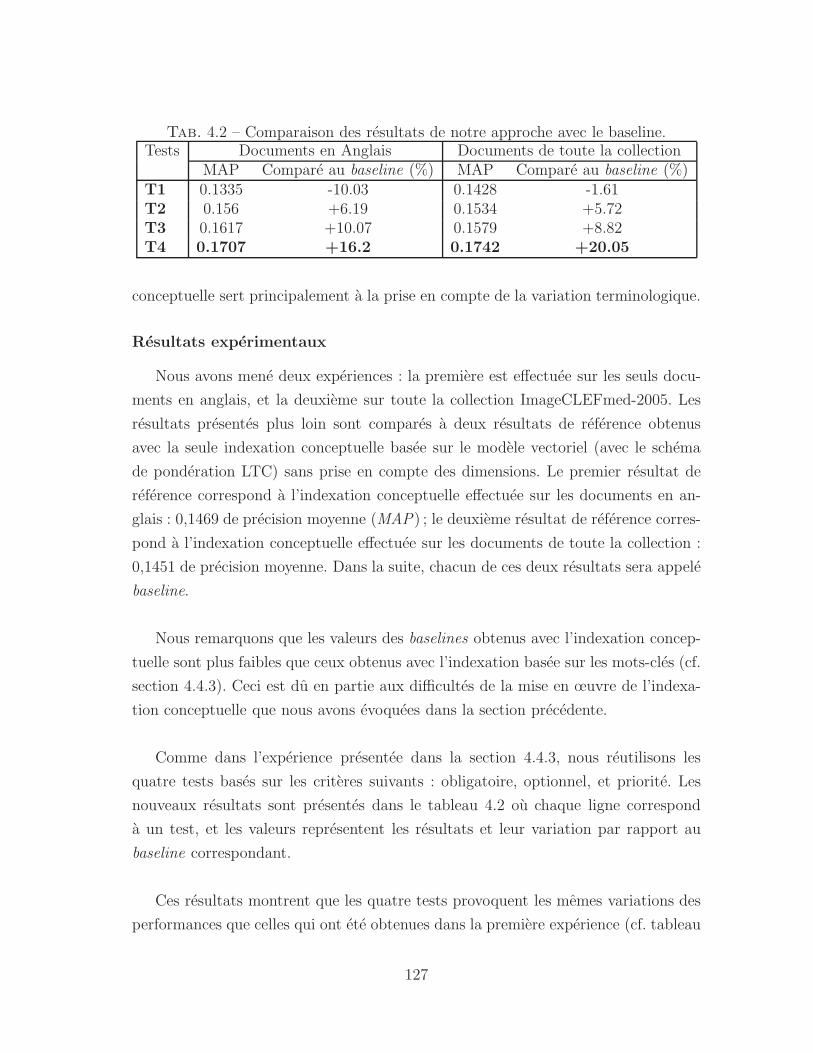
Tab. 4.2 – Comparaison des resultats de notre approche avec le baseline.Tests Documents en Anglais Documents de toute la collection
MAP Compare au baseline (%) MAP Compare au baseline (%)T1 0.1335 -10.03 0.1428 -1.61T2 0.156 +6.19 0.1534 +5.72T3 0.1617 +10.07 0.1579 +8.82T4 0.1707 +16.2 0.1742 +20.05
conceptuelle sert principalement a la prise en compte de la variation terminologique.
Resultats experimentaux
Nous avons mene deux experiences : la premiere est effectuee sur les seuls docu-
ments en anglais, et la deuxieme sur toute la collection ImageCLEFmed-2005. Les
resultats presentes plus loin sont compares a deux resultats de reference obtenus
avec la seule indexation conceptuelle basee sur le modele vectoriel (avec le schema
de ponderation LTC) sans prise en compte des dimensions. Le premier resultat de
reference correspond a l’indexation conceptuelle effectuee sur les documents en an-
glais : 0,1469 de precision moyenne (MAP) ; le deuxieme resultat de reference corres-
pond a l’indexation conceptuelle effectuee sur les documents de toute la collection :
0,1451 de precision moyenne. Dans la suite, chacun de ces deux resultats sera appele
baseline.
Nous remarquons que les valeurs des baselines obtenus avec l’indexation concep-
tuelle sont plus faibles que ceux obtenus avec l’indexation basee sur les mots-cles (cf.
section 4.4.3). Ceci est du en partie aux difficultes de la mise en œuvre de l’indexa-
tion conceptuelle que nous avons evoquees dans la section precedente.
Comme dans l’experience presentee dans la section 4.4.3, nous reutilisons les
quatre tests bases sur les criteres suivants : obligatoire, optionnel, et priorite. Les
nouveaux resultats sont presentes dans le tableau 4.2 ou chaque ligne correspond
a un test, et les valeurs representent les resultats et leur variation par rapport au
baseline correspondant.
Ces resultats montrent que les quatre tests provoquent les memes variations des
performances que celles qui ont ete obtenues dans la premiere experience (cf. tableau
127

Tab. 4.3 – Variations des performances de notre systeme applique sur trois indexdifferents.
Index 1 Index 2 Index 3
T1 -17.90 -10.03 -1.61T2 +13.39 +6.19 +5.72T3 +20.28 +10.07 +8.82T4 +23.47 +16.2 +20.05
4.315). Le test T1 provoque une baisse dans les performances, et tous les autres tests
conduisent a des ameliorations dont les meilleures ont ete obtenues par le test T4 :
+16.2% pour les seuls documents en anglais, et +20.05% pour l’ensemble des docu-
ments de la collection.
Ces resultats confirment les conclusions tirees suite a la premiere experience :
- Les documents de la collection ImageCLEFmed-2005 ne contiennent pas souvent
les concepts decrivant la modalite des images. Ainsi, il suffit de considerer que
les elements de la dimension modalite sont optionnels pour obtenir une forte
amelioration des performances ;
- Les dimensions de domaine n’ont pas toujours la meme importance dans la requete :
les elements de la dimension Anatomie ne sont pas ambigus et il est donc
benefique de leur donner une priorite plus elevee que celles des elements des
autres dimensions. Le fait de mettre des priorites sur les elements de dimen-
sions des requetes conduit dans tous les cas a de nettes ameliorations au niveau
des performances de notre systeme.
La figure 4.11 illustre les variations des performances de notre systeme en effec-
tuant les tests respectivement sur Index1, Index2, et Index3.
15ou Idex1 = Documents de toute la collection (elements de dimensions definis par des mots-cles) ;Index2 = Documents en Anglais (elements de dimensions definis par des concepts), et Index3 =Documents de toute la collection (elements de dimensions definis par des concepts)
128

Fig. 4.11 – Variations des performances de notre systeme applique sur trois indexdifferents
4.5 Conclusion
Dans tout ce quatrieme chapitre, nous avons detaille la mise en œuvre de notre
modele et son application sur des exemples de la collection ImageCLEFmed-2005.
Plus particulierement, nous avons montre comment le calcul de subsomption est
utilise pour mettre en œuvre la fonction de correspondance a base de la logique
descriptive. Ainsi, nous avons pu conclure que la performance de la fonction de cor-
respondance depend principalement de la qualite de la ressource externe utilisee :
plus cette ressource contient de relations de subsomption, plus la fonction de corres-
pondance est capable de retrouver des documents pertinents a une requete, meme
s’ils ne partagent pas les memes concepts qu’elle.
Nous avons montre que la fonction de correspondance est tres flexible dans le sens
ou elle permet d’utiliser n’importe quelle relation pour calculer la correspondance
entre un document et une requete. Il suffit de specifier des proprietes transitives afin
de permettre a un raisonneur d’utiliser n’importe quel type de relation lors du calcul
de la subsomption.
En utilisant les relations lors du calcul de la subsomption, un document peut etre
retrouve comme reponse a une requete meme s’il ne partage pas les memes concepts
avec elle. Ceci pose probleme au niveau de la fonction d’ordonnancement car elle
129

est incapable de calculer une valeur de similarite entre un document et une requete
qui ne partagent pas les memes concepts. Une solution tres simple est d’etendre la
requete ou le document durant le calcul de l’ordonnancement. Jusqu’a present, nous
n’avons pas propose une fonction d’ordonnancement particuliere et nous envisageons
d’etudier ce probleme dans nos futurs travaux. En particulier, nous souhaiterions
definir la notion de pertinence dans un contexte de recherche precise. Ceci devrait
nous permettre de proposer une fonction d’ordonnancement qui soit encore plus en
adequation avec les besoins precis d’utilisateurs professionnels.
Apres la mise en œuvre du modele, nous avons presente deux experiences prelimin-
aires dediees a l’evaluation, en terme de performance de recherche, de l’apport de
l’utilisation des dimensions de domaine :
i) La premiere est basee sur l’usage d’elements de dimensions representes par des
mots-cles. Dans cette experience, nous avons utilise la structure hierarchique du
thesaurus MeSH pour definir les dimensions. Malgre une approche simplifiee
de la definition des elements de dimension, nous avons reussi a depasser les
performances des systemes qui ne prennent pas en compte les dimensions de
domaine. Les resultats obtenus lors de cette experience ont clairement montre
l’avantage de l’usage des dimensions de domaine pour l’interpretation des be-
soins precis (une amelioration de plus de 23% de la precision moyenne). Cette
meme idee nous a permis d’obtenir le meilleur resultat lors de notre participa-
tion16 a la piste de recherche d’images medicales de la campagne d’evaluation
CLEF-2005 [20][19] ;
ii) La deuxieme est basee sur l’usage d’elements de dimensions representes par des
concepts. Dans cette experience, nous avons utilise le meta-thesaurus UMLS
pour la definition des dimensions et la mise en œuvre de l’indexation concep-
tuelle. Les elements de dimensions ont ete representes par les concepts extraits
de ce meta-thesaurus. Bien que la technique d’extraction des concepts, et donc
la reconnaissance des dimensions, ne soit pas totalement fiable, nous avons
reussi a ameliorer les performances de notre systeme de 20%. Les resultats
obtenus lors de cette experience consolident ceux obtenus lors de la premiere
16En collaboration avec Dr. J-P. Chevallet et Dr. J-W. Lim.
130

experience, et confirment l’apport significatif de l’usage des dimensions pour la
resolution des requetes precises.
L’ensemble des resultats obtenus ici nous permet d’affirmer que la prise en compte
des dimensions permet d’augmenter la precision moyenne du SRI. En effet, il s’agit
d’un complement d’information qui permet d’identifier les elements pertinents qui
decrivent le theme detaille dans la requete (document). En identifiant ces elements,
que nous avons appeles elements de dimensions, notre systeme arrive a interpreter
avec plus de precision le contenu de la requete et donc de mieux la resoudre. Nous
avons egalement propose un langage de requete expressif qui permet a l’usager d’uti-
liser des operateurs sur les elements de dimensions de sa requete, et de mieux preciser
son besoin en information. Nos experiences ont montre l’impact positif de l’usage de
ces operateurs17 sur la precision du contenu de la requete, et sur les performances.
Comme notre systeme s’adresse a des utilisateurs professionnels qui connaissaient
bien leur domaine d’interet, il est relativement facile d’utiliser notre langage de
requete pour decrire avec precision les besoins d’information. Dans le cas ou l’uti-
lisateur ne souhaiterait pas utiliser notre langage de requete, et se contente d’un
texte brut pour decrire son besoin, il semble neanmoins que notre systeme soit ca-
pable d’identifier les dimensions et de les prendre en compte lors du processus d’in-
terrogation. Dans cette direction, nous avons mene une experience sur la collection
imageCLEFmed-2005 sans utiliser explicitement les operateurs sur les elements de di-
mensions. La requete est alors toujours consideree comme une conjonction d’elements
de dimensions. Apres la selection des documents pertinents, nous les organisons dans
leur ordre de pertinence en fonction du nombre d’elements de dimensions qu’ils par-
tagent avec la requete en question. Ce processus se fait d’une maniere transparente
sans aucune intervention humaine. Les resultats obtenus lors de cette experience ont
montre une amelioration superieure a 12% dans les performances. Ceci prouve en-
core l’apport significatif de l’usage des dimensions lors du processus de RI meme
sans aucune intervention de l’utilisateur.
Nous pouvons conclure apres les resultats encourageant obtenus ici que la prise
en compte des dimensions de domaine est un moyen efficace pour la resolution des
17les criteres obligatoire, optionnel, et priorite
131

requetes precises. Cependant, nous considerons que les resultats presentes ici ne sont
qu’une premiere etape en vue de valider l’apport de l’usage des dimensions dans
un processus de RI oriente precision. Afin de quantifier l’apport de notre approche,
nous projetons de mettre en œuvre l’integralite de notre modele. La prochaine etape
consiste donc a representer les elements de dimensions tel que nous les avons definis.
C’est-a-dire, a les representer par un ensemble de concepts et des relations. Une fois
les elements de dimension extraits, il reste seulement a appliquer la fonction de cor-
respondance pour evaluer l’integralite de notre approche. Une deuxieme perspective
est de proposer une fonction d’ordonnancement adequate au contexte de recherche
precise. La troisieme perspective est de developper une interface graphique afin que
les utilisateurs puissent tester l’utilisabite de notre systeme.
132

Chapitre 5
Conclusion
Nous nous sommes interesses a un contexte de RI dans des milieux profession-
nels, ou les besoins d’information des utilisateurs sont formules a travers des requetes
precises. L’objectif de notre travail de these a donc ete de definir un modele de RI
capable de resoudre ce type de requetes. Pour ce faire, nous avons opte pour l’uti-
lisation des connaissances du domaine d’interet de l’utilisateur afin de considerer
la semantique vehiculee par les documents et les requetes. Ces connaissances sont
decrites a travers des ressources externes, et leur usage a pour but d’“augmenter”
les connaissances du systeme sur le domaine traite afin qu’il puisse expliciter la
semantique vehiculee par le document, et resoudre ainsi des requetes precises.
Nous nous sommes interesses aux travaux qui utilisent les ressources externes
pour la representation du contenu semantique des documents et des requetes. Ces
travaux concernent principalement l’approche de RI dite “basee-concepts” (Concept-
Based Information Retrieval). L’etude des travaux les plus significatifs situes dans
cette classe d’approches nous a montre leurs limites face aux exigences de l’utilisateur
en termes de precision du systeme. En effet, ces approches considerent les documents
et les requetes comme des sacs de concepts (ponderes), et ne peuvent donc mettre
en exergue les aspects lies aux descriptions semantiques du contenu du document et
de la requete. Pour notre part, l’approche que nous avons adoptee consiste a utiliser
les dimensions de domaine.
133

5.1 Apport theorique
Dans notre approche, nous definissons d’abord les dimensions de domaine a tra-
vers des ressources externes. Il s’agit d’ajouter une structure dans la ressource externe
en creant des concepts definissant les dimensions. Ensuite, nous utilisons les dimen-
sions pour mettre en avant les elements pertinents qui contribuent a la description
du contenu semantique des documents et des requetes. Ainsi, au lieu de considerer
les documents et les requetes comme des sacs de concepts, nous avons propose une
nouvelle unite d’indexation definie par des dimensions, des concepts et des relations
semantiques : il s’agit de l’element de dimension. Nous utilisons cette nouvelle
unite d’indexation afin de produire une representation precise des documents et des
requetes tout en considerant les aspects lies a leur semantique. Ainsi, nous avons
propose un langage de document expressif qui permet une indexation precise du
contenu semantique des documents. Nous avons egalement propose un langage de
requete expressif permettant a l’usager d’utiliser ces elements de dimensions et des
operateurs pour decrire avec precision son besoin d’information. En considerant les
exigences de l’utilisateur en termes de precision, nous avons propose un modele de
Recherche d’Information capable de resoudre des requetes precises.
Pour definir notre modele, nous avons choisi un formalisme de representation de
connaissances disposant d’un niveau d’expressivite assez eleve qui convient tres bien
a la representation precise du contenu semantique des documents et des requetes : il
s’agit de la logique descriptive. Ainsi, nous avons pu incorporer les connaissances du
domaine lors de la definition de notre modele tout en garantissant une representation
uniforme des documents, des requetes et de la ressource externe. Nous avons egalement
profite de l’algorithme de calcul de subsomption offert par la logique descriptive afin
de definir la fonction de correspondance mettant en œuvre la pertinence systeme.
5.2 Apport pratique
Dans le but de tester la faisabilite de notre approche, nous avons effectue une serie
d’experiences sur des requetes de la collection ImageCLEFmed-2005. Ces experiences
nous ont permis de savoir jusqu’a quel point notre modele, base sur la logique des-
criptive, peut etre applique et quelles sont les limites formelles et techniques qui lui
sont liees. Nous avons principalement conclu que la qualite de la conception de la
134

ressource externe, utilisee pour la representation du contenu des documents et des
requetes, a un impact majeur sur les performances de recherche. En effet, la fonc-
tion de correspondance basee sur le calcul de subsomption s’avere souvent benefique
quand la ressource externe est riche en terme de relation de subsomption (is-a). En
effet, c’est surtout a travers l’algorithme de calcul de subsomption que la logique des-
criptive offre une capacite de raisonnement qui permet de deduire des connaissances
implicites a partir de celles representees explicitement dans la T-Box, et permet ainsi
de retrouver des documents pertinents pour une requete meme s’ils ne partagent pas
les memes concepts que cette derniere. Nos experiences ont cependant montre que
la relation de subsomption n’est pas suffisante pour calculer la correspondance entre
un document et une requete. Pour cette raison, nous avons entrepris d’utiliser des
proprietes transitives. Ainsi, nous avons rendu notre fonction de correspondance tres
flexible dans le sens ou elle permet d’utiliser n’importe quel type de relation lors du
calcul de la correspondance entre un document et une requete.
Dans le but d’evaluer l’apport de l’usage des dimensions en terme de performance
de recherche, nous avons mene une deuxieme serie d’experiences sur la collection
ImageCLEFmed-2005. L’ensemble des resultats encourageant obtenus nous a permis
de conclure que la prise en compte des dimensions de domaine est un moyen efficace
pour la resolution des requetes precises.
5.3 Perspectives
Avant de pouvoir utiliser les dimensions de domaine, il faut d’abord les construire.
Dans les experiences presentees dans ce manuscrit, les dimensions ont ete construites
manuellement a travers des ressources externes existantes. Pour nos futures experien-
ces, nous projetons de les construire automatiquement. Nous avons deja commence
l’etude de ce probleme et concu un algorithme preliminaire pour cette construction
[69]. La prochaine etape consiste a evaluer experimentalement cet algorithme. Pour
ce faire, nous allons nous inspirer des travaux de Stoica et Hearst sur la construction
automatique des facettes [87].
Les resultats presentes dans ce manuscrit ne sont qu’une premiere etape en vue
de la validation de l’apport de l’usage des dimensions dans un processus de RI oriente
135

precision. Afin de quantifier plus precisement l’apport de notre approche, nous proje-
tons de mettre en œuvre l’integralite de notre modele. La prochaine etape consistera
donc a identifier automatiquement les elements de dimension au niveau des docu-
ments. Cette etape demande de savoir extraire, a partir des documents, des concepts
et des relations qui servent a definir les elements de dimension. Ce processus peut
necessiter un traitement automatique de la langue, guide par l’utilisation des res-
sources externes. Une fois les elements de dimension extraits, il ne restera plus qu’a
appliquer la fonction de correspondance pour evaluer l’integralite de notre approche.
Une troisieme perspective est de proposer une fonction d’ordonnancement adequ-
ate au contexte de recherche dans les milieux professionnels. Mais avant de proposer
une telle fonction, nous pensons qu’il faut d’abord definir la notion de pertinence
dans ce contexte particulier. Il est possible que la definition de cette notion puisse
dependre du domaine d’application considere. Pour cette raison, il apparaıt sou-
haitable de collaborer avec des utilisateurs d’un domaine particulier afin de definir
leur notion de pertinence et proposer par la suite une fonction d’ordonnancement
adequate.
La fonction d’ordonnancement recherchee devrait s’appuyer sur les ponderations
des elements de dimension afin de permettre le calcul d’une valeur de pertinence
d’un document par rapport a une requete. Une quatrieme perspective concerne donc
l’etude de la possibilite d’integrer les ponderations dans notre modele base sur la lo-
gique descriptive. Ceci semble necessiter l’extension du modele actuel par la logique
floue.
La cinquieme perspective est de developper une interface graphique afin que les
utilisateurs puissent tester l’utilisabite de notre systeme. Cette interface devrait per-
mette a l’utilisateur de tirer pleinement profit de notre modele, en particulier, en
exploitant le langage de requete lors de l’expression de son besoin d’information. Le
developpement de cette interface devrait etre centre sur les utilisateurs afin qu’elle
soit adaptee a leur besoin.
136

Bibliographie
[1] Nathalie Aussenac-Gilles and Josiane Mothe. Ontologies as Background Know-
ledge to Explore Document Collections . In RIAO 2004, Avignon,, pages 129–
142, April 2004.
[2] Franz Baader, Diego Calvanese, Deborah L. McGuinness, Daniele Nardi, and
Peter F. Patel-Schneider, editors. The description logic handbook : theory,
implementation, and applications. Cambridge University Press, New York,
NY, USA, 2003.
[3] Ricardo A. Baeza-Yates and Berthier Ribeiro-Neto. Modern Information Re-
trieval. Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA,
1999.
[4] Mustapha Baziz. Indexation conceptuelle guidee par ontologie pour la recherche
d’information. These de doctorat, Universite Paul Sabatier, Toulouse, France,
decembre 2005.
[5] Mustapha Baziz, Nathalie Aussenac-Gilles, and Mohand Boughanem.
Desambiguisation et Expansion de Requetes dans un SRI, Etude de l’apport
des liens semantiques. Revue des Sciences et Technologies de l’Information
(RSTI) serie ISI, 8(4/2003) :113–136, decembre 2003.
[6] Mustapha Baziz, Mohand Boughanem, and Nathalie Aussenac-Gilles. IRIT
at CLEF 2004 : The English GIRT task . In Carol Peters, Paul Clough,
Julio Gonzalo, and Gareth J. F. Jones, editors, Cross Language Evaluation
Forum CLEF’2004 Workshop , Bath, UK, 15/09/04-17/09/04, pages 283–291.
Lecture Notes in Computer Science LNCS Volume 3491/2005, Springer-Verlag,
September 2004.
[7] Mustapha Baziz, Mohand Boughanem, Nathalie Aussenac-Gilles, and Claude
Chrisment. Semantic cores for representing documents in ir. In SAC’05 :
137

Proceedings of the 2005 ACM symposium on Applied computing, pages 1011–
1017, New York, NY, USA, 2005. ACM.
[8] Tim Berners-Lee, James Hendler, and Ora Lasilla. The semantic web. Scientific
American, May 2001.
[9] Catherine Berrut. Une methode d’indexation fondee sur l’analyse semantique
de documents specialises. Le prototype RIME et son application a un corpus
medical. These de doctorat, Universite Joseph Fourier, Grenoble, France, 1988.
[10] C. Biemann. Semantic indexing with typed terms using rapid annotation. In
Proceedings of the TKE-05-Workshop on Methods and Applications of Seman-
tic Indexing, Copenhagen, 2005.
[11] Richard C. Bodner and Fei Song. Knowledge-based approaches to query ex-
pansion in information retrieval. In AI ’96 : Proceedings of the 11th Bien-
nial Conference of the Canadian Society for Computational Studies of Intelli-
gence on Advances in Artificial Intelligence, pages 146–158, London, UK, 1996.
Springer-Verlag.
[12] R. J. Brachman and J. G. Schmolze. An overview of the kl-one knowledge
representation system. In J. Mylopoulos and M. L. Brodie, editors, Artifi-
cial Intelligence & Databases, pages 207–230. Kaufmann Publishers, INC., San
Mateo, CA, 1989.
[13] Chris Buckley. The smart lab report : The modern smart years (1980-1996).
SIGIR Forum, 31(1), 1997.
[14] Chris Buckley, Gerard Salton, James Allan, and Amit Singhal. Automatic
query expansion using smart : Trec 3. In TREC, pages 0–, 1994.
[15] Jean Charlet, Philippe Laublet, and Chantal Reynaud. Web semantique :
Rapport final. Technical report, Action specifique 32 CNRS / STIC, December
2003.
[16] Jean-Pierre Chevallet. Un Modele Logique de Recherche d’Informations ap-
plique au formalisme des Graphes Conceptuels. Le prototype ELEN et son
experimentation sur un corpus de composants logiciels. PhD thesis, Univer-
site Joseph Fourier, Grenoble, 1992.
[17] Jean-Pierre Chevallet. X-iota : An open xml framework for ir experimentation
application on multiple weighting scheme tests in a bilingual corpus. Lecture
138

Notes in Computer Science (LNCS), AIRS’04 Conference Beijing, 3211 :263–
280, 2004.
[18] Jean-Pierre Chevallet, Joo-Hwee Lim, and Diem Thi Hoang Le. Domain know-
ledge conceptual inter-media indexing : application to multilingual multimedia
medical reports. In CIKM, pages 495–504. ACM, 2007.
[19] Jean-Pierre Chevallet, Joo-Hwee Lim, and Saıd Radhouani. A structured visual
learning approach mixed with ontology dimensions for medical queries. In Ca-
rol Peters, Fredric C. Gey, Julio Gonzalo, Henning Muller, Gareth J. F. Jones,
Michael Kluck, Bernardo Magnini, and Maarten de Rijke, editors, CLEF, vo-
lume 4022 of Lecture Notes in Computer Science, pages 642–651. Springer,
2005.
[20] Jean-Pierre Chevallet, Joo-Hwee Lim, and Saıd Radhouani. Using ontology
dimensions and negative expansion to solve precise queries in clef medical task.
In CLEF Workhop, Working Notes Medical Image Track, Vienna, Austria, 21–
23 September 2005.
[21] Paul-Alexandru Chirita Christian Kohlschutter and Wolfgang Nejdl. Using link
analysis to identify aspects in faceted web search. In ACM SIGIR Workshop
on Faceted Search, Seattle, USA, August 2006.
[22] Martin Chodorow Claudia Leacock and George Miller. Using corpus statis-
tics and wordnet relations for sense identification. computational linguistics.
Computational Linguistics, 24(1) :147–165, 1998.
[23] C. Cleverdon and M. Kean. Factors determining the performance of indexing
systems. Aslib Cranfield Research Project, Cranfield, England, 1968.
[24] Paul Clough and Henning Muller. The clef cross language image retrieval track
2005. In http ://ir.shef.ac.uk/imageclef2005/, visited on November 2005.
[25] Fabio Crestani. Exploiting the similarity of non-matching terms at retrieval
time. Information Retrieval, 2(1) :23–43, 2000.
[26] Wisam Dakka, Panagiotis G. Ipeirotis, and Kenneth R. Wood. Automatic
construction of multifaceted browsing interfaces. In Otthein Herzog, Hans-
Jorg Schek, Norbert Fuhr, Abdur Chowdhury, and Wilfried Teiken, editors,
CIKM, pages 768–775. ACM, 2005.
139

[27] Claudia Leacock Ellen Marie Voorhees and Geoffrey Towell. Learning context
to disambiguate word senses. In the 3rd Computational Learning Theory and
iVatural Learning Systems Conference. MIT Press, 1992.
[28] Christiane Fellbaum, editor. WordNet : an electronic lexical database. Massa-
chusetts : The MIT Press, 1998. p.423.
[29] Edward Alan Fox. Extending the boolean and vector space models of infor-
mation retrieval with p-norm queries and multiple concept types. PhD thesis,
Ithaca, NY, USA, 1983.
[30] William Gale, Kenneth Ward Church, and David Yarowsky. Estimating upper
and lower bounds on the performance of word-sense disambiguation programs.
In Proceedings of the 30th annual meeting on Association for Computational
Linguistics, pages 249–256, Morristown, NJ, USA, 1992. Association for Com-
putational Linguistics.
[31] Joseph A. Goguen. What is a concept ? In Frithjof Dau, Marie-Laure Mugnier,
and Gerd Stumme, editors, Proceedings of the 13th International Conference on
Conceptual Structures (ICCS 2005), volume 3596 of Lecture Notes in Computer
Science, pages 52–77. Springer, 2005.
[32] Julio Gonzalo, Felisa Verdejo, Irina Chugur, and Juan Cigarran. Indexing
with wordnet synsets can improve text retrieval. In Proceedings of the CO-
LING/ACL ’98 Workshop on Usage of WordNet for NLP, pages 38–44, Mon-
treal, Canada, 1998.
[33] Donna Harman. Relevance feedback revisited. In SIGIR ’92 : Proceedings of
the 15th annual international ACM SIGIR conference on Research and deve-
lopment in information retrieval, pages 1–10, New York, NY, USA, 1992. ACM
Press.
[34] Donna Harman. The first text retrieval conference (trec-1), rockville, md, usa,
4-6 november 1992. Inf. Process. Manage., 29(4) :411–414, 1993.
[35] Philip J. Hayes. Intelligent high-volume text processing using shallow, domain-
specific techniques. pages 227–241, 1992.
[36] Marti A. Hearst. Clustering versus faceted categories for information explora-
tion. Commun. ACM, 49(4) :59–61, 2006.
140

[37] Marti A. Hearst. Design recommendations for hierarchical faceted search in-
terfaces. In ACM SIGIR Workshop on Faceted Search, Seattle, USA, August
2006.
[38] Eero Hyvonen, Samppa Saarela, Avril Styrman, and Kim Viljanen. Ontology-
based image retrieval. In WWW (Posters), 2003.
[39] Eero Hyvonen, Avril Styrman, and Samppa Saarela. Ontology-based image
retrieval. In Towards the semantic web and web services, Proceedings of XML
Finland 2002 Conference, pages 15–27, October 21–22 2002.
[40] Haward Jie and Yi Zhang. Personalized faceted query expansion. In ACM
SIGIR Workshop on Faceted Search, Seattle, USA, August 2006.
[41] Karen Sparck Jones and C.J. Keith van Rijsbergen. Progress in documentation.
Journal of Documentation, 32(1) :59–75, 1976.
[42] Uwe Thaden Jorg Diederich and Wolf-Tilo Balke. The semantic growbag de-
monstrator for automatically organizing topic facets. In ACM SIGIR Workshop
on Faceted Search, Seattle, USA, August 2006.
[43] Vipul Kashyap and Alexander Borgida. Representing the umls semantic net-
work using owl : (or ”what’s in a semantic web link ?”). In Dieter Fensel,
Katia P. Sycara, and John Mylopoulos, editors, International Semantic Web
Conference, volume 2870 of Lecture Notes in Computer Science, pages 1–16.
Springer, 2003.
[44] Leila Kefi. Modele general de recherche d’information : Application a la re-
cherche de documents techniques. These de doctorat, Universite Joseph Fou-
rier, Grenoble, France, 2006.
[45] Robert Krovetz. Viewing morphology as an inference process. In Proc. of 16th
Annual International ACM/SIGIR Conference on Research & Development in
Information Retrieval, pages 191–203, 1993.
[46] Robert Krovetz. Homonymy and polysemy in information retrieval. In ACL,
pages 72–79, 1997.
[47] Robert Krovetz and W. Bruce Croft. Lexical ambiguity and information re-
trieval. ACM Transactions on Information Systems, 10(2) :115–141, 1992.
[48] Catherine Berrut Leila Kefi and Eric Gaussier. un modele de ri base sur des
criteres d’obligation et de certitude. In CORIA06 COnference en Recherche
Information, Lyon (France), 15–17 mars 2006.
141

[49] David D Lewis. Representation and learning in information retrieval. Technical
report, Amherst, MA, USA, 1991.
[50] Dekang Lin. An Information-Theoretic Definition of Similarity. In Proceedings
of the 15th International Conference on Machine Learning, pages 296–304.
Morgan Kaufmann, San Francisco, CA, 1998.
[51] Shuang Liu, Fang Liu, Clement Yu, and Weiyi Meng. An effective approach to
document retrieval via utilizing wordnet and recognizing phrases. In SIGIR,
2004.
[52] Eetu Makela, Eero Hyvonen, and Samppa Saarela. Ontogator - a semantic
view-based search engine service for web applications. In International Se-
mantic Web Conference, pages 847–860, 2006.
[53] Eetu Makela, Eero Hyvonen, and Teemu Sidoroff. View-based user interfaces
for information retrieval on the semantic web. In ISWC-2005 Workshop End
User Semantic Web Interaction, November.
[54] Mourad Mechkour. A multifacet formal image model for information retrieval.
In Ian Ruthven, editor, MIRO, Workshops in Computing. BCS, 1995.
[55] Carlo Meghini, Fabrizio Sebastiani, and Umberto Straccia. A model of multi-
media information retrieval. J. ACM, 48(5) :909–970, 2001.
[56] Carlo Meghini, Fabrizio Sebastiani, Umberto Straccia, and Costantino Thanos.
A model of information retrieval based on a terminological logic. In SIGIR
’93 : Proceedings of the 16th annual international ACM SIGIR conference on
Research and development in information retrieval, pages 298–307, New York,
NY, USA, 1993.
[57] Carlo Meghini and Umberto Straccia. A relevance terminological logic for
information retrieval. In Hans-Peter Frei, Donna Harman, Peter Schuble, and
Ross Wilkinson, editors, SIGIR, pages 197–205. ACM, 1996.
[58] Rada Mihalcea and Dan Moldovan. Semantic indexing using wordnet senses. In
Proceedings of the ACL-2000 workshop on Recent advances in natural language
processing and information retrieval, pages 35–45, Morristown, NJ, USA, 2000.
Association for Computational Linguistics.
[59] Rada Mihalcea and Dan I. Moldovan. An iterative approach to word sense di-
sambiguation. In Proceedings of the Thirteenth International Florida Artificial
Intelligence Research Society Conference, pages 219–223. AAAI Press, 2000.
142

[60] George Miller. Wordnet : an on-line lexical database. International Journal of
Lexicography, 4(3), 1990.
[61] Dan I. Moldovan, Sanda M. Harabagiu, Marius Pasca, Rada Mihalcea, Richard
Goodrum, Roxana Girju, and Vasile Rus. Lasso : A tool for surfing the answer
net. In TREC, 1999.
[62] Dan I. Moldovan and Rada Mihalcea. Using wordnet and lexical operators to
improve internet searches. IEEE Internet Computing, 4(1) :34–43, 2000.
[63] Iadh Ounis. Un modele d’indexation relationnel pour les graphes conceptuels
fonde sur une interpretation logique. These de doctorat, Universite Joseph
Fourier, Grenoble, France, 1998.
[64] Ozlem Uzuner, Boris Katz, and Deniz Yuret. Word sense disambiguation for
information retrieval. In AAAI/IAAI, page 985, 1999.
[65] Helen J. Peat and Peter Willett. The limitations of term co-occurrence data
for query expansion in document retrieval systems. JASIS, 42(5) :378–383,
1991.
[66] A Steven Pollitt. The key role of classification and indexing in view-based
searching. In Proceedings of the 63rd International Federation of Library As-
sociations and Institutions General Conference (IFLA’97), 1997.
[67] Paul Procter. Longman Dictionary of Contemporary English. Longman Group,
1978.
[68] Yonggang Qiu and Hans-Peter Frei. Concept based query expansion. In Robert
Korfhage, Edie M. Rasmussen, and Peter Willett, editors, SIGIR, pages 160–
169. ACM, 1993.
[69] Saıd Radhouani. Un algorithme pour la construction automatique de dimen-
sions a partir de resources existantes. Technical report, CUI, University of
Geneva, Switzerland, September 2007.
[70] Philip Resnik. Semantic similarity in a taxonomy : An information-based mea-
sure and its application to problems of ambiguity in natural language. Journal
of Artificial Intelligence Research, 11 :95–130, 1999.
[71] Ray Richardson and Alan F. Smeaton. Using WordNet in a knowledge-based
approach to information retrieval. Technical Report CA-0395, Dublin, Ireland,
1995.
143

[72] Giovanni Maria Sacco. Research results in dynamic taxonomy and faceted
search systems. In DEXA Workshops, pages 201–206. IEEE Computer Society,
2007.
[73] Joo-Hwee Lim Le Thi-Hoang-Diem Saıd Radhouani, Loıc Maisonnasse, , and
Jean-Pierre Chevallet. Une indexation conceptuelle pour un filtrage par di-
mensions, experimentation sur la base medicale imageclefmed avec le meta-
thesaurus umls. In CORIA06 COnference en Recherche d’Information, Lyon
(France), 15–17 mars 2006.
[74] G. Salton. The SMART Retrieval System ;Experiments in Automatic Document
Processing. Prentice-Hall, Inc., Upper Saddle River, NJ, USA, 1971.
[75] Gerard Salton. Some research problems in automatic information retrieval. In
Jennifer J. Kuehn, editor, SIGIR, pages 252–263. ACM, 1983.
[76] Gerard Salton and Michael Lesk. Computer evaluation of indexing and text
processing. J. ACM, 15(1) :8–36, 1968.
[77] Mark Sanderson. Word sense disambiguation and information retrieval. In
Proc. of the 17th ACM/SIGIR Conference, pages 142–150, 1994.
[78] Mark Sanderson. Word Sense Disambiguation and Information Retrieval.
Ph.d. thesis, University of Glasgow, Glasgow G12 8QQ, UK, 1997.
[79] Mark Sanderson. Retrieving with good sense. Information Retrieval, 2(1) :45–
65, 2000.
[80] Hinrich Schutze and Jan O. Pedersen. Information Retrieval Based on Word
Senses. In Fourth Annual Symposium on Document Analysis and Information
Retrieval, 1995.
[81] Satanjeev Banerjee Siddharth Patwardhan and Ted Pedersen. Using measures
of semantic relatedness for word sense disambiguation. In Proceedings of the
Fourth International Conference on Intelligent Text Processing and Computa-
tional Linguistics, pages 241–257, 2003.
[82] Malika Smaıl. Raisonnement a base de cas pour une recherche evolutive d’in-
formation. These de doctorat, Universite de Nancy, Nancy, France, 1994.
[83] Alan F. Smeaton and Ian Quigley. Experiments on using semantic distances
between words in image caption retrieval. In Proc. of 19th International Confe-
rence on Research and Development in Information Retrieval, Zurich, Switzer-
land, 1996.
144

[84] Alan F. Smeaton and C. J. van Rijsbergen. The retrieval effects of query
expansion on a feedback document retrieval system. Comput. J., 26(3) :239–
246, 1983.
[85] Lina Fatima Soualmia, Christine Golbreich, and Stefan Jacques Darmoni. Re-
presenting the mesh in owl : Towards a semi-automatic migration. In Udo
Hahn, editor, KR-MED, volume 102 of CEUR Workshop Proceedings, pages
81–87. CEUR-WS.org, 2004.
[86] J.A. Stein. Alternative methods of indexing legal material : Development of a
conceptual index. In Conference ”Law Via the Internet g7”, Sydney, Australia,
1997.
[87] Emilia Stoica and Marti A. Hearst. Demonstration : Using wordnet to build
hierarchical facet categories. In ACM SIGIR Workshop on Faceted Search,
Seattle, USA, August 2006.
[88] Michael Sussna. Word sense disambiguation for free-text indexing using a
massive semantic network. In Proc. of 2nd International Conference on Infor-
mation and Knowledge Management, Arlington, Virginia, 1993.
[89] Michael John Sussna. Text retrieval using inference in semantic metanetworks.
PhD thesis, University of California at San Diego, La Jolla, CA, USA, 1997.
[90] Daniel Tunkelang. Dynamic category sets : An approach for faceted search. In
ACM SIGIR Workshop on Faceted Search, Seattle, USA, August 2006.
[91] Howard R. Turtle and W. Bruce Croft. Inference networks for document re-
trieval. In Jean-Luc Vidick, editor, SIGIR, pages 1–24. ACM, 1990.
[92] David Vallet, Miriam Fernandez, and Pablo Castells. An ontology-based in-
formation retrieval model. In Asuncion Gomez-Perez and Jerome Euzenat,
editors, ESWC, volume 3532 of Lecture Notes in Computer Science, pages
455–470. Springer, 2005.
[93] C.J. Keith van Rijsbergen. A new theoretical framework for information re-
trieval. In ACM Conference on Research and development in Information
Retrieval, Pisa, pages 194–200, 1986.
[94] Ellen Marie Voorhees. On expanding query vectors with lexically related words.
In TREC, pages 223–232, 1993.
145

[95] Ellen Marie Voorhees. Using wordnet to disambiguate word senses for text
retrieval. In Robert Korfhage, Edie M. Rasmussen, and Peter Willett, editors,
SIGIR, pages 171–180. ACM, 1993.
[96] Ellen Marie Voorhees. Query expansion using lexical-semantic relations. In
SIGIR ’94 : Proceedings of the 17th annual international ACM SIGIR confe-
rence on Research and development in information retrieval, pages 61–69, New
York, NY, USA, 1994. Springer-Verlag New York, Inc.
[97] Ellen Marie Voorhees. Using WordNet for Text Retrieval. In C. Fellbaum,
editor, WordNet : an electronic lexical database. MIT Press, 1998.
[98] Ellen Marie Voorhees. Natural language processing and information retrie-
val. In Maria Teresa Pazienza, editor, SCIE, volume 1714 of Lecture Notes in
Computer Science, pages 32–48. Springer, 1999.
[99] Peter Wallis. Information retrieval based on paraphrase. In the 1st Pacific
Association for Computational Linguistics Conference, 1993.
[100] Stephen F. Weiss. Learning to disambiguate. Information Storage and Retrie-
val, 9(1) :33–41, 1973.
[101] Rishabh Dayal Wisam Dakka and Panagiotis G. Ipeirotis. Automatic discovery
of useful facet terms. In ACM SIGIR Workshop on Faceted Search, Seattle,
USA, August 2006.
[102] Jinxi Xu and W. Bruce Croft. Query expansion using local and global docu-
ment analysis. In Hans-Peter Frei, Donna Harman, Peter Schauble, and Ross
Wilkinson, editors, SIGIR, pages 4–11. ACM, 1996.
[103] Jinxi Xu and W. Bruce Croft. Improving the effectiveness of information
retrieval with local context analysis. ACM Trans. Inf. Syst., 18(1) :79–112,
2000.
[104] David Yarowsky. One sense per collocation. In Proceedings ARPA Human
Language Technology Workshop, pages 266–271, 1993.
[105] Ka-Ping Yee, Kirsten Swearingen, Kevin Li, and Marti Hearst. Faceted meta-
data for image search and browsing. In CHI ’03 : Proceedings of the conference
on Human factors in computing systems, pages 401–408. ACM Press, 2003.
[106] Uri Zernik. Train1 vs. train2 : Tagging word senses in corpus. In Lexical
Acquisition : Exploiting On-Line Resources to Build a Lexicon, pages 91–112.
Lawrence Erlbaum, Hillsdale, NJ, 1991.
146