Embed Size (px)
Citation preview

Data Mining
1 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
TP n°4 : Les Arbres de Décision
Ben harrath arij 4INFINI
Note
Ce TP est à rendre en fin de séance.
Objectifs :
Comprendre l’Apprentissage Supervisé à travers la construction des Arbres de Décisions
I. Construction d'un Arbre de Décision pour un « Jeu de Tennis» avec R Source : http://www.grappa.univ-lille3.fr/~ppreux/ensg/miashs/fouilleDeDonneesI/tp/arbres-de-decision/
Objectif : Construire un Arbre de Décision à partir de données climatiques, afin de
prédire si on pourra jouer au Tennis ou non. 1. Chargement de la bibliothèque :
Pour pouvoir construire des arbres de décision, on va utiliser la bibliothèque « rpart » de l'environnement R. Il faut tout d'abord la rendre accessible. Pour cela, on tape la commande suivante :
2. Importation de données :
On commence par charger le jeu de données « Tennis1.txt ». Pour ce faire, placer cet entrepôt de données
dans un data frame ‘Tennis’ :
library (rpart)
télécharger le package rpart « Partitionnement récursif pour les arbres de classification, régression et
de survie »
téééééééaa
setwd("C:\TP4”)
tennis1<-read.table(file="tennis1.txt", row.names=1, header=T)

Data Mining
2 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
La colonne « jouer » est la variable décisionnelle
3. Construction et Visualisation de l’arbre de décision : i. Les commandes suivantes permettent de construire l'arbre de décision. Tout d'abord, on doit spécifier
quelques paramètres qui précisent comment l'arbre de décision doit être construit. On tape la
commande suivante :
La variable ad.tennis.cnt stocke les paramètres de l'algorithme.
minsplit = 1 signifie que le nombre minimal d'exemples nécessaires à la création d'un nœud est 1. La valeur par défaut
est 20. Comme le jeu de données contient moins de 20 exemples, utiliser la valeur par défaut ne produirait pas d'arbre
du tout, juste une racine !
Le nom utilisé pour cette variable, ad.tennis.cnt suit la convention R : il indique qu'il s'agît d'un arbre de décision (préfixe
ad), pour le jeu de tennis (tennis !) et qu'il s'agît des paramètres de contrôle (cnt) ; des points (.) séparent ces différentes
informations.
On va construire l'arbre de décision en indiquant :
l'attribut qui représente la variable cible à prédire : ‘la classe : Jouer’ les attributs qui doivent être utilisés pour effectuer cette prédiction (pour l'instant, ce seront les 4 autres attributs :
Ciel, Température, HumiditéetVent)
l’entrepôt de données avec lequel on construit l'arbre : Tennis le nom de la variable qui contient les paramètres : control = ad.tennis.cnt
ad.tennis.cnt<- rpart.control (minsplit = 1)
ad.tennis<- rpart (Jouer ~ Ciel+ Température +Humidité + Vent, tennis1, control = ad.tennis.cnt)

Data Mining
3 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
La représentation graphique des Arbres de Décision avec R a deux formes : Représentation Textuelle et
Représentation Graphique.
Concernant le premier type de visualisation, l’arbre est donné sous forme de lignes imbriquées dont chacune
correspondant à une classe séparatrice. R distingue une variable séparatrice majoritaire (nœud feuille) des
classes non majoritaires par le caractère « * »
ii. Afficher le résultat de la construction sous forme de texte:
iii. Afficher le résultat de la construction sous forme graphique :
NB : on utilisera les deux commandes plot et text
La décision commence en testant sur la température il y a 4 non et 0 oui la probabilité de cas non est 1 donc
c’est une décision

Data Mining
4 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
plot(ad.tennis)
text(ad.tennis)
Modalisation des décisions on remarque l’absence de la variable vent car elle n’est pas décisive
plot (ad.tennis, branch=.2, uniform=T, compress=T, margin=.1)
text (ad.tennis, all=T, use.n=T, fancy=T)

Data Mining
5 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
printcp(ad.tennis)
plotcp(ad.tennis)
tracer les résultats de validation croisée et Affiche la table de cp pour objet rpart équipée.
Ici, il semble que l'erreur relative est réduite au minimum pour un arbre de 5 nœuds. Nous reviendrons l'arbre élagué aux
pruneaux et le cp associée à la taille de notre arbre désiré

Data Mining
6 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
4. La prédiction de la classe d'une donnée par un arbre de décision i. La fonction predict() utilise un arbre de décision pour prédire la classe de nouvelles données. Elle prend en
paramètres l'arbre et un data frame qui contient les données dont il faut prédire la classe. Pour prédire la classe
des données du jeu d'exemples (avec lesquels on a construit l'arbre de décision), on tapera la commande :
ii. Utilisez l'arbre pour donner une prédiction pour l’entrepôt de données « Tennis2.txt »
tennis2<-read.table(file="tennis2.txt", row.names=1, header=T)
tennis2
predict(ad.tennis,tennis2)
Nous constatons que la prédiction utiliser à travers le model d’arbre de l’entrepôt tennis 1 a pu prédire les
conditions de jouabilité dans l’entrepôt tennis 2 avec la même erreur distinguable précédemment c’est-à-dire
lorsque l’humidité est élevé, le vent est fort, la température est basse la jouabilité dans la prédiction est supposé
être valide.

Data Mining
7 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
II. Construction d’un modèle de classement à partir d’un arbre de décision
pour les demandes de crédits
Objectif : Construire un Arbre de Décision à partir de données sur des clients d’une
banque afin de prendre une décision concernant l’acceptation ou le refus d’une
demande de crédit.
La décision est décrite par une variable qualitative Decision, ayant trois modalités :
accepted, tolerated, ou refused, ce dernier cas ne sera pas pris en considération lors de
la prise de décision par le modèle construit
1. Chargement de la bibliothèque : Pour pouvoir construire des arbres de décision, on va utiliser la
bibliothèque « rpart » de l'environnement R. Il faut tout d'abord la rendre accessible. Pour cela, on
tape la commande suivante :
2. Importation de données : On commence par charger le jeu de données « ScoreData.xls». Pour ce faire,
placer cet entrepôt de données dans un data frame ‘score’ :
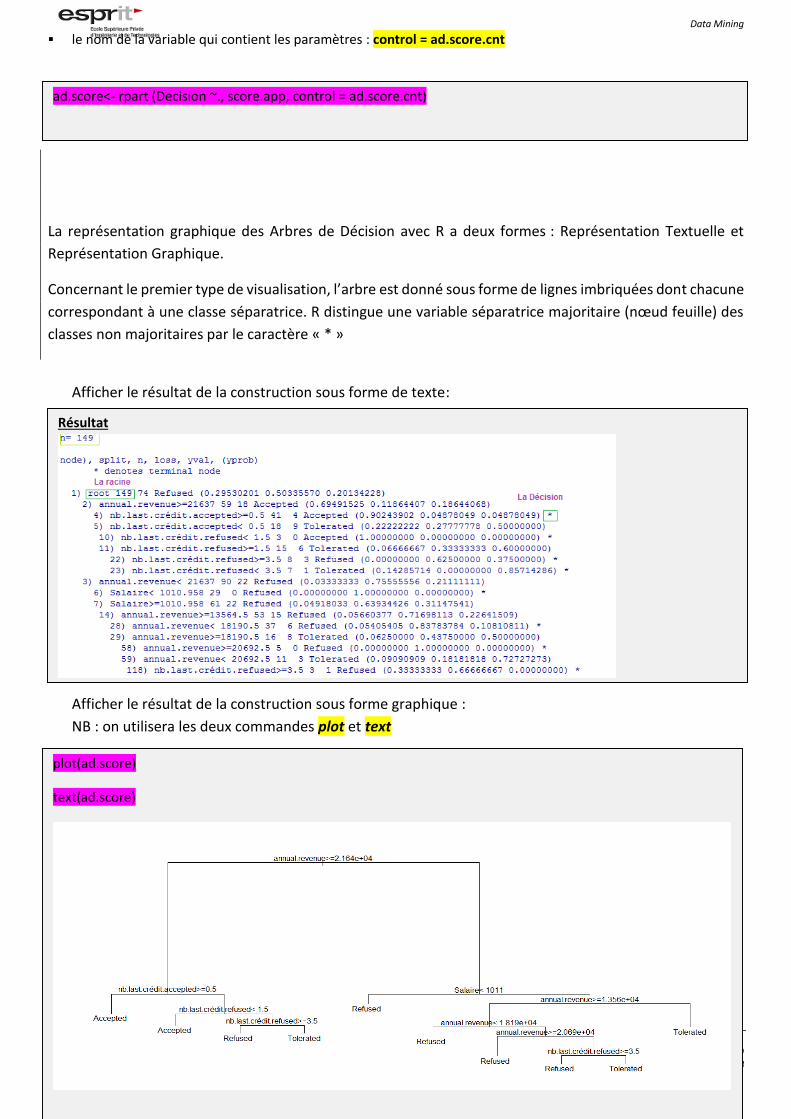
4. Construction de l'arbre de décision : l'attribut qui représente la variable cible à prédire : ‘Decision’ les attributs qui doivent être utilisés pour effectuer cette prédiction (pour l'instant, ce seront tous les autres
attributs : ‘.’)
l’entrepôt de données avec lequel on construit l'arbre : score
#chargement des données : échantillon d’apprentissage
Library(xlsReadWrite)
score.app<-read.xls(file=file.choose(),sheet=1)
ad.score.cnt<- rpart.control (minsplit = 10)
#importation de library
Library(rpart)
Data Mining
8 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
le nom de la variable qui contient les paramètres : control = ad.score.cnt
La représentation graphique des Arbres de Décision avec R a deux formes : Représentation Textuelle et
Représentation Graphique.
Concernant le premier type de visualisation, l’arbre est donné sous forme de lignes imbriquées dont chacune
correspondant à une classe séparatrice. R distingue une variable séparatrice majoritaire (nœud feuille) des
classes non majoritaires par le caractère « * »
Afficher le résultat de la construction sous forme de texte:
Afficher le résultat de la construction sous forme graphique :
NB : on utilisera les deux commandes plot et text
ad.score<- rpart (Decision ~., score.app, control = ad.score.cnt)
Résultat
plot(ad.score)
text(ad.score)

Data Mining
9 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
4
La racine de neud d’erreur est 0.4664
0

Data Mining
10 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
tracer les résultats de validation croisée
Ici, il semble que l'erreur relative est réduite au minimum pour un arbre de 10 nœuds. Nous reviendrons l'arbre élagué aux
pruneaux et le cp associée à la taille de notre arbre désiré
5. Evaluation de l’arbre de décision
i. Prédiction sur le même échantillon
La fonction predict() utilise un arbre de décision pour prédire la classe de nouvelles données. Elle prend en
paramètres l'arbre et un data frame qui contient les données dont il faut prédire la classe. Pour prédire la classe
des données du jeu d'exemples (avec lesquels on a construit l'arbre de décision), on tapera la commande :
#prédiction sur le même échatillon
pred.classe<- predict(ad.score,score.app,type="class")
print(summary(pred.classe))
plot(pred.classe)
Il s’agit de 44 accepted et82 Refused et 23 Torlerated
Data Mining
11 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
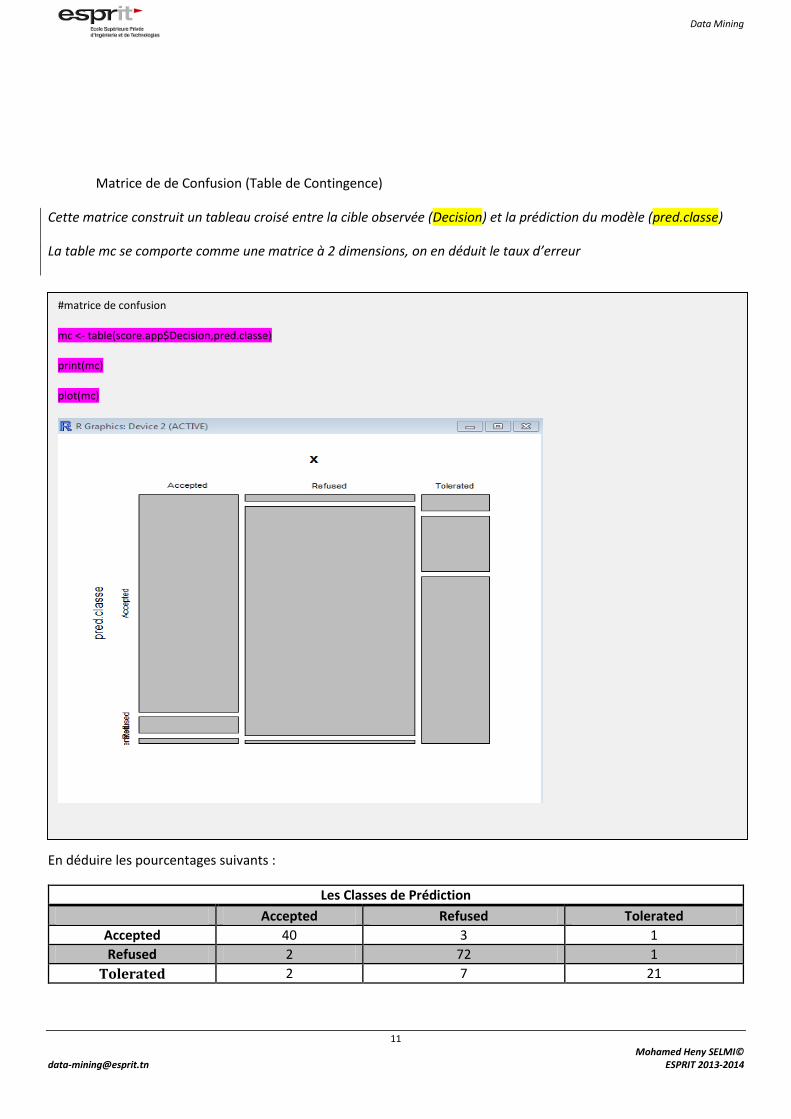
Matrice de de Confusion (Table de Contingence)
Cette matrice construit un tableau croisé entre la cible observée (Decision) et la prédiction du modèle (pred.classe)
La table mc se comporte comme une matrice à 2 dimensions, on en déduit le taux d’erreur
En déduire les pourcentages suivants :
Les Classes de Prédiction
Accepted Refused Tolerated
Accepted 40 3 1
Refused 2 72 1
Tolerated 2 7 21
#matrice de confusion
mc <- table(score.app$Decision,pred.classe)
print(mc)
plot(mc)

Data Mining
12 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
ii. Calcul du taux de l’erreur :
Calculer le taux d’erreur en appliquant la formule suivante :
erreur = Somme des éléments hors diagonale principale / Nombre total des observations.
iii. Utilisez l'arbre pour donner une prédiction pour l’échantillon du test
iv.
6. La prédiction de la classe d'une donnée par un arbre de décision
Prédiction sur un échantillon de test (2ème feuille du fichier ScoreData.xls)
Utilisez l'arbre pour donner une prédiction pour l’échantillon de test
7. Modification des paramètres de construction de l’arbre :
i. Décrire l’utilité de la fonction rpart.control :
#taux d'erreur
TauxErreur<- (mc[2,1]+mc[1,2])/sum(mc)
score<-read.xls(file=file.choose(),sheet=2)
> pred.classe<- predict(ad.score,score,type="class")
Résultat et interprétation
Dans la prédiction de l’échantillon test nous obtenons les différent cas ainsi que la décision prise au niveau de 3
différents résultats : accepté, refusé ou toléré. Ceci décidé à travers l’arbre de décision établi c’est-à-dire :
ad.score.
Il permet donc d’automatiser la prise d’accords, refus ou tolérance de crédit pour les différents clients.
Il permet de contrôler les différents aspects en fonction d’une segmentation de nombre de lignes décrite par le
paramètre minsplit et d’ajuster les modèles.

Data Mining
13 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
ii. En fixant les paramètres suivants, donner le nouvel arbre de décision :
Minsplit = taille minimale pour segmenter = 50 Minbucket = effectif d’admissibilité = 20
8. Utilisation du package « tree » :
Paramètres d’apprentissage : nobs = nombre d’obs. dans l’éch. d’apprentissage ; mincut = effectif d’admissibilité, minsize = taille min. pour segmenter Apprentissage : classe vs. toutes les autres variables du data.frame
control<- rpart.control( minsplit = 50 , minbucket = 20 )
Aad.score<- rpart (Decision ~., score.app, control = control)
print(Aad.score)
library (tree )
cnt<- tree.control(nobs=nrow(score.app), mincut=20, minsize=50) Arb<- tree(Decision ~ ., data=score.app,control=cnt) print(Arb)

Data Mining
14 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
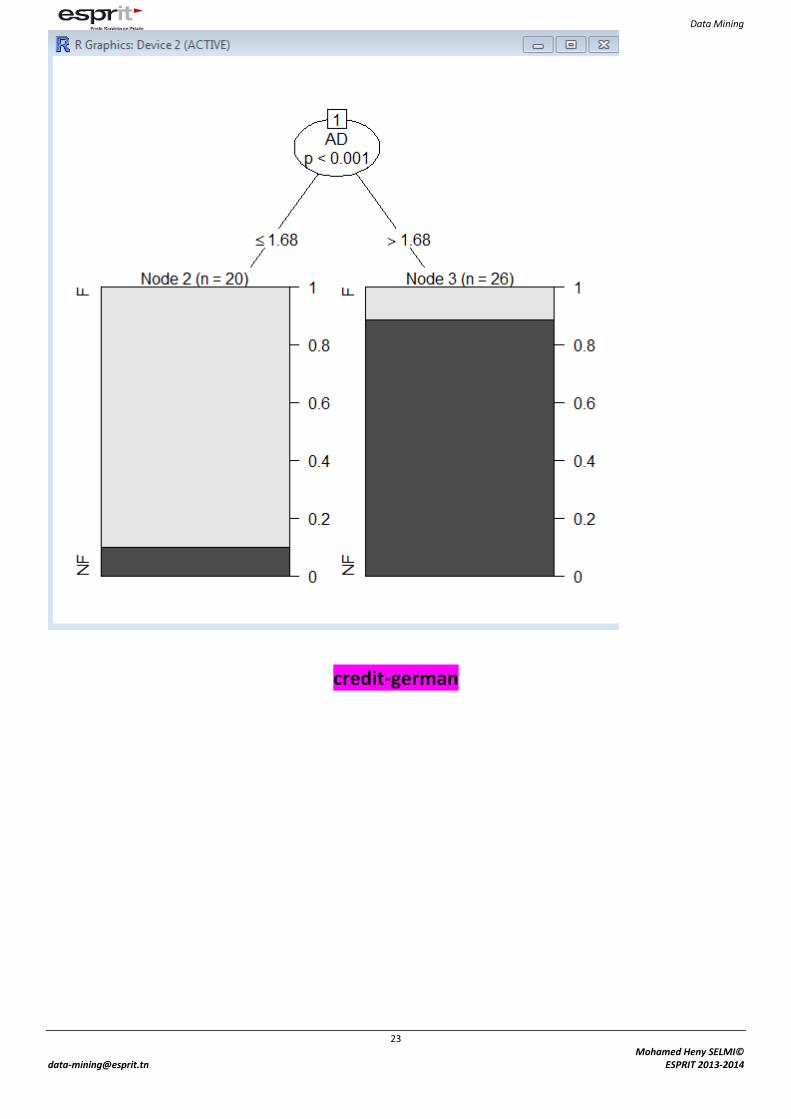
9. Utilisation du package « party » :
Travail demandé : 1. Construire des modèles de prise décision sur les entrepôts de données :
Faillite_entrep
credit-german
2. Donner un rapport sur chaque modèle
library(party)
party <- ctree_control(minsplit=20,minbucket=10)
arbre<- ctree(Decision ~ ., score.app, controls= party) plot(arbre)

Data Mining
15 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
Faillite_entrep
> library (rpart)
> Faillite<-read.table(file="Faillite_entrep.txt", row.names=1, header=T)
Notre variable de décision est ET
ad.Faillite.cnt<- rpart.control (minsplit = 1)
ad.Faillite <- rpart (ET ~., Faillite, control = ad.Faillite.cnt)
On constate que la prise de décision commence si F est 0 donc la probabilité de F est 1
plot (ad.Faillite, branch=.2, uniform=T, compress=T, margin=.1)
text (ad.Faillite, all=T, use.n=T, fancy=T)
Data Mining
16 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
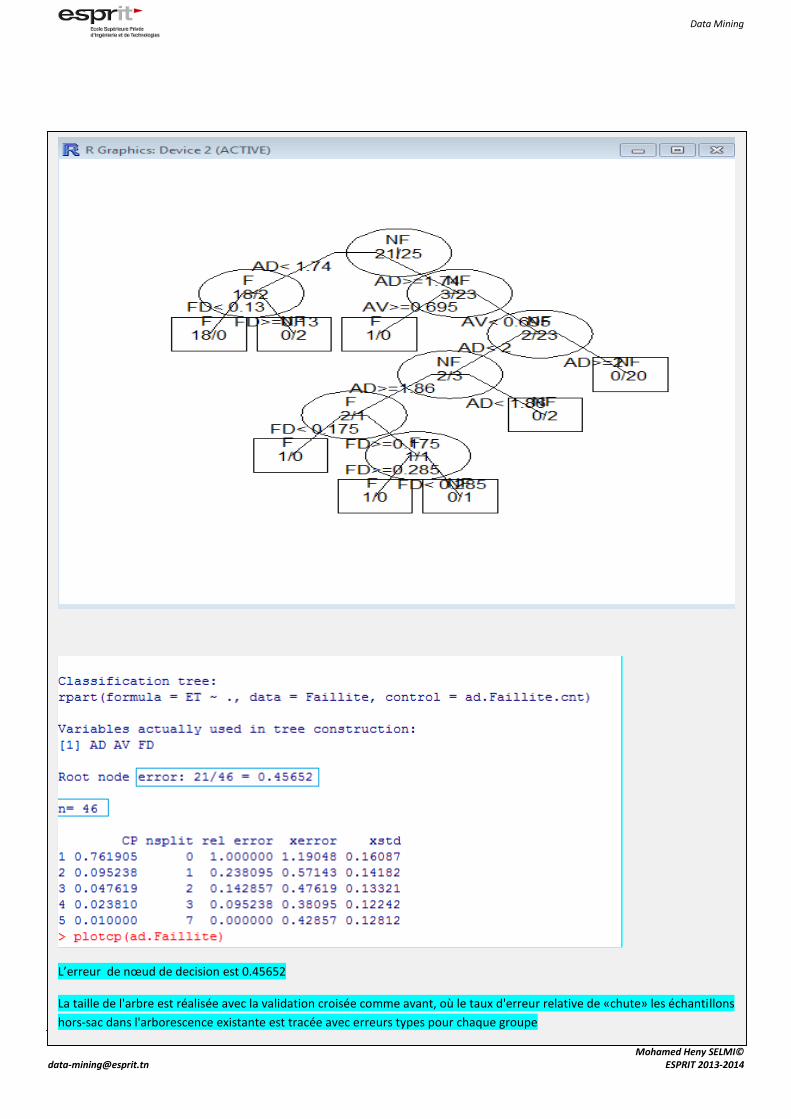
L’erreur de nœud de decision est 0.45652
La taille de l'arbre est réalisée avec la validation croisée comme avant, où le taux d'erreur relative de «chute» les échantillons
hors-sac dans l'arborescence existante est tracée avec erreurs types pour chaque groupe
Data Mining
17 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
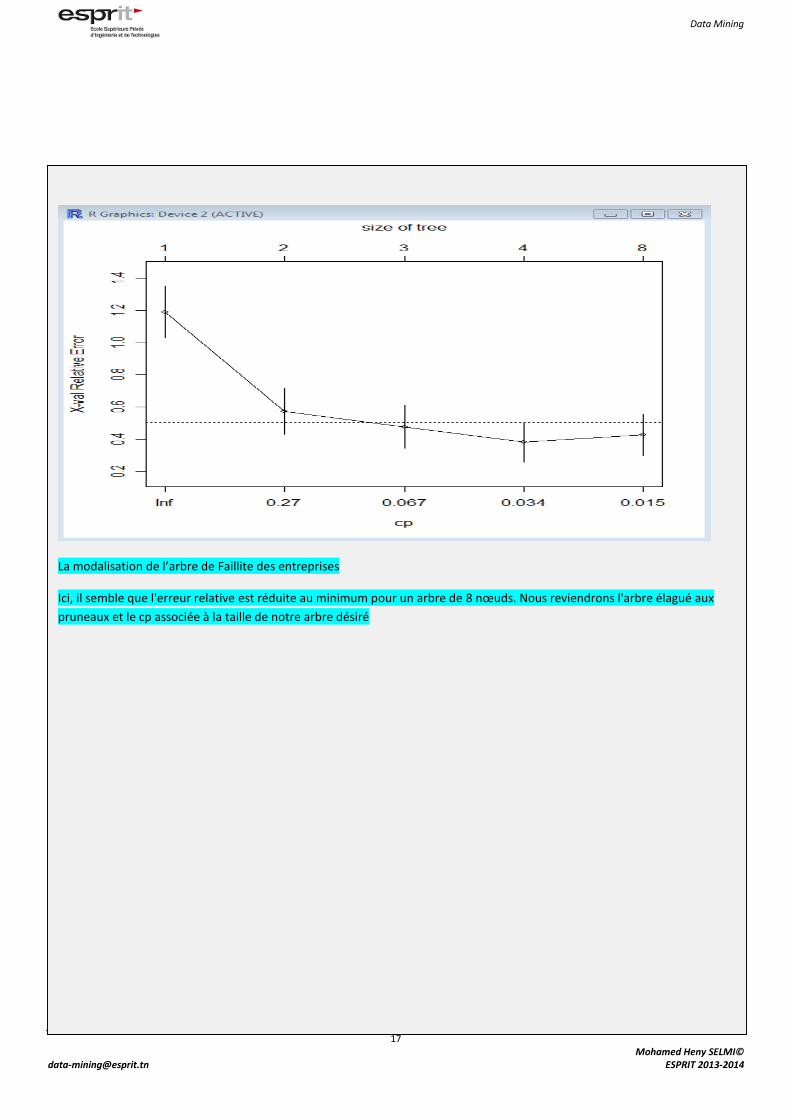
La modalisation de l’arbre de Faillite des entreprises
Ici, il semble que l'erreur relative est réduite au minimum pour un arbre de 8 nœuds. Nous reviendrons l'arbre élagué aux
pruneaux et le cp associée à la taille de notre arbre désiré

Data Mining
18 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
> summary(ad.Faillite)
Call:
rpart(formula = ET ~ ., data = Faillite, control = ad.Faillite.cnt)
n= 46
CP nsplit rel error xerror xstd
1 0.76190476 0 1.0000000 1.1904762 0.1608724
2 0.09523810 1 0.2380952 0.5714286 0.1418182
3 0.04761905 2 0.1428571 0.4761905 0.1332150
4 0.02380952 3 0.0952381 0.3809524 0.1224161
5 0.01000000 7 0.0000000 0.4285714 0.1281221
Node number 1: 46 observations, complexity param=0.7619048
predicted class=NF expected loss=0.4565217
class counts: 21 25
probabilities: 0.457 0.543
left son=2 (20 obs) right son=3 (26 obs)
Primary splits:
AD < 1.74 to the left, improve=13.918390, (0 missing)
FD < 0.075 to the left, improve=12.403230, (0 missing)
RA < 0.035 to the left, improve= 9.782609, (0 missing)
AV < 0.695 to the right, improve= 1.895854, (0 missing)
Surrogate splits:
FD < 0.075 to the left, agree=0.848, adj=0.65, (0 split)
RA < 0.035 to the left, agree=0.848, adj=0.65, (0 split)
AV < 0.265 to the left, agree=0.674, adj=0.25, (0 split)
Node number 2: 20 observations, complexity param=0.0952381
predicted class=F expected loss=0.1
class counts: 18 2
probabilities: 0.900 0.100

Data Mining
19 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
left son=4 (18 obs) right son=5 (2 obs)
Primary splits:
FD < 0.13 to the left, improve=3.6000000, (0 missing)
RA < 0.06 to the left, improve=0.7111111, (0 missing)
AD < 0.585 to the right, improve=0.7111111, (0 missing)
AV < 0.27 to the right, improve=0.6000000, (0 missing)
Node number 3: 26 observations, complexity param=0.04761905
predicted class=NF expected loss=0.1153846
class counts: 3 23
probabilities: 0.115 0.885
left son=6 (1 obs) right son=7 (25 obs)
Primary splits:
AV < 0.695 to the right, improve=1.6276920, (0 missing)
AD < 2.16 to the left, improve=1.5576920, (0 missing)
RA < 0.01 to the left, improve=0.3221851, (0 missing)
FD < 0.155 to the left, improve=0.2326923, (0 missing)
Node number 4: 18 observations
predicted class=F expected loss=0
class counts: 18 0
probabilities: 1.000 0.000
Node number 5: 2 observations
predicted class=NF expected loss=0
class counts: 0 2
probabilities: 0.000 1.000
Node number 6: 1 observations
predicted class=F expected loss=0
class counts: 1 0
probabilities: 1.000 0.000
Node number 7: 25 observations, complexity param=0.02380952

Data Mining
20 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
predicted class=NF expected loss=0.08
class counts: 2 23
probabilities: 0.080 0.920
left son=14 (5 obs) right son=15 (20 obs)
Primary splits:
AD < 2 to the left, improve=1.2800000, (0 missing)
AV < 0.39 to the left, improve=0.4800000, (0 missing)
RA < 0.105 to the right, improve=0.1185965, (0 missing)
FD < 0.145 to the right, improve=0.1010526, (0 missing)
Node number 14: 5 observations, complexity param=0.02380952
predicted class=NF expected loss=0.4
class counts: 2 3
probabilities: 0.400 0.600
left son=28 (3 obs) right son=29 (2 obs)
Primary splits:
AD < 1.86 to the right, improve=1.066667, (0 missing)
FD < 0.16 to the left, improve=0.900000, (0 missing)
RA < 0.055 to the left, improve=0.900000, (0 missing)
AV < 0.285 to the left, improve=0.900000, (0 missing)
Surrogate splits:
RA < 0.075 to the right, agree=0.8, adj=0.5, (0 split)
AV < 0.34 to the left, agree=0.8, adj=0.5, (0 split)
Node number 15: 20 observations
predicted class=NF expected loss=0
class counts: 0 20
probabilities: 0.000 1.000
Node number 28: 3 observations, complexity param=0.02380952
predicted class=F expected loss=0.3333333
class counts: 2 1

Data Mining
21 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
probabilities: 0.667 0.333
left son=56 (1 obs) right son=57 (2 obs)
Primary splits:
FD < 0.175 to the left, improve=0.3333333, (0 missing)
RA < 0.065 to the left, improve=0.3333333, (0 missing)
AD < 1.935 to the left, improve=0.3333333, (0 missing)
AV < 0.285 to the left, improve=0.3333333, (0 missing)
Node number 29: 2 observations
predicted class=NF expected loss=0
class counts: 0 2
probabilities: 0.000 1.000
Node number 56: 1 observations
predicted class=F expected loss=0
class counts: 1 0
probabilities: 1.000 0.000
Node number 57: 2 observations, complexity param=0.02380952
predicted class=F expected loss=0.5
class counts: 1 1
probabilities: 0.500 0.500
left son=114 (1 obs) right son=115 (1 obs)
Primary splits:
FD < 0.285 to the right, improve=1, (0 missing)
RA < 0.095 to the right, improve=1, (0 missing)
AV < 0.34 to the right, improve=1, (0 missing)
Node number 114: 1 observations
predicted class=F expected loss=0
class counts: 1 0
probabilities: 1.000 0.000
Node number 115: 1 observations

Data Mining
22 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
predicted class=NF expected loss=0
class counts: 0 1
probabilities: 0.000 1.000
library (tree )
cnt<- tree.control(nobs=nrow(Faillite,), mincut=20, minsize=50) Arb<- tree(ET ~ ., data= Faillite,,control=cnt) print(Arb)
library(party)
party <- ctree_control(minsplit=20,minbucket=10)
arbre<- ctree(ET ~ ., Faillite,,, controls= party) plot(arbre)

Data Mining
24 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
credit<-read.table(file="credit-german.txt",sep="\t",header=T)
ad. credit. cnt<- rpart.control (minsplit = 1)
ad. credit <- rpart (class ~., credit, control = ad.credit.cnt
plot (ad. credit, branch=.2, uniform=T, compress=T, margin=.1)
text (ad. credit, all=T, use.n=T, fancy=T)
Data Mining
25 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
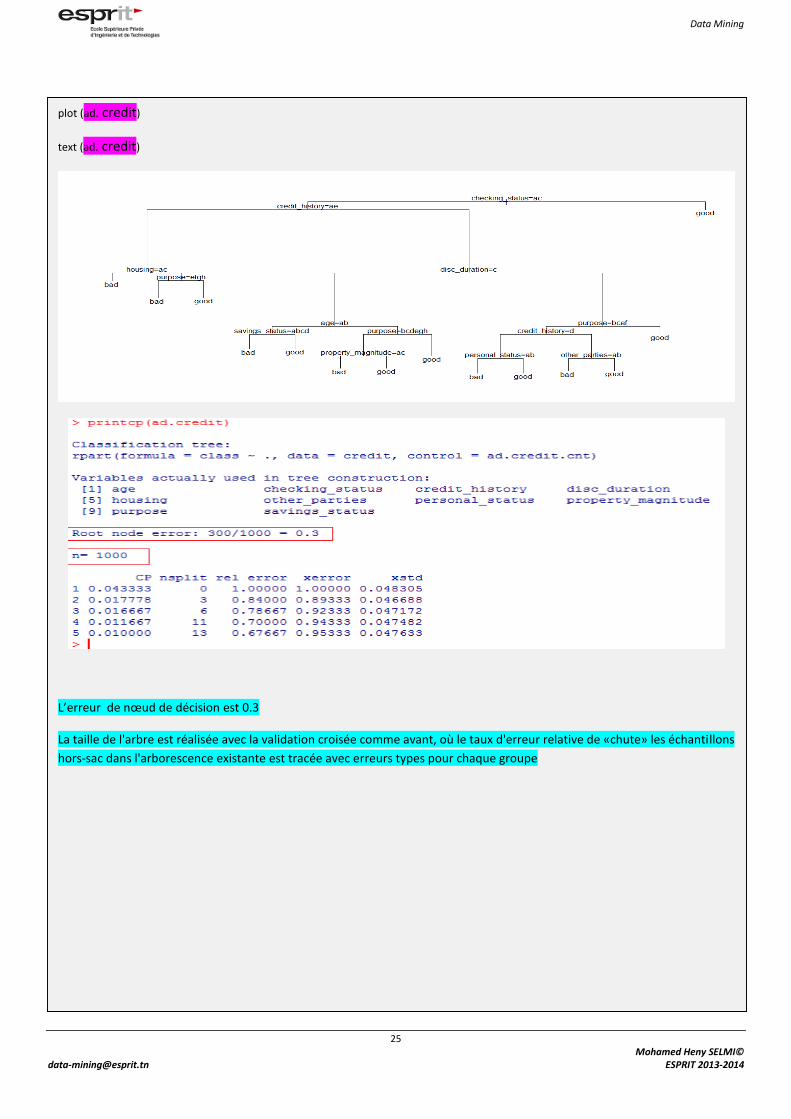
plot (ad. credit)
text (ad. credit)
L’erreur de nœud de décision est 0.3
La taille de l'arbre est réalisée avec la validation croisée comme avant, où le taux d'erreur relative de «chute» les échantillons
hors-sac dans l'arborescence existante est tracée avec erreurs types pour chaque groupe

Data Mining
26 Mohamed Heny SELMI©
[email protected] ESPRIT 2013-2014
Ici, il semble que l'erreur relative est réduite au minimum pour un arbre de 14 nœuds. Nous reviendrons l'arbre élagué aux
pruneaux et le cp associée à la taille de notre arbre désiré
library (tree )
cnt<- tree.control(nobs=nrow(credit), mincut=20, minsize=50) Arb<- tree(class ~ ., data= credit,control=cnt) print(Arb)




![Arbres de décision - GRAPPA -- Page d'accueil · Objectif : inférer un arbre de décision à partir d'exemples. ... C4.5 [Quinlan, 1993], CART; dimension de Vapnik-Chervonenkis?](https://img.pdfslide.fr/doc/110x75/5b9d0eb609d3f2443d8b643f/arbres-de-decision-grappa-page-d-objectif-inferer-un-arbre-de-decision.jpg)


![Data Mining Modèles et Algorithmes - Erick STATTNER · Induction d'un arbre de décision ID3 [Quinlan 1986] a évolué jusqu'aux versions C4.5 et C5.0 principe de base : construire](https://img.pdfslide.fr/doc/110x75/5b9d0eb609d3f2443d8b6432/data-mining-modeles-et-algorithmes-erick-induction-dun-arbre-de-decision.jpg)