Embed Size (px)
Citation preview

L'ADMINISTRATION SOUS UNIX
Jacques PHILIPP
Consultant
10 mai 2023
1

AVANT PROPOS
Nous présentons dans le présent ouvrage les concepts de base d'administration des systèmes fonctionnant sous UNIX.
Ils couvrent les systèmes UNIX d'aujourd'hui, fonctionnant soit dans l'environnement BSD, soit dans l'environnement SYSTEM V.
Nous présentons également quelques outils constructeurs. Ceci dit, leur bonne utilisation est conditionnée par la bonne connaissance des concepts de base.
Les concepts de base système nécessaires à une "bonne administration" sont rappelés dans les chapitre 2 à 5.
Les concepts d'administration de réseau sous UNIX sont présentés dans l'ouvrage "Les réseaux sous Unix", du même auteur, chez le même éditeur. Ils seront complétés très prochainement par un ouvrage complet sur l'administration de systèmes UNIX en réseau.
10 mai 2023
2

TABLE DES MATIERES
1. L'ADMINISTRATEUR UNIX 13
1.1 Rôles 13
1.2 Connaissances techniques 13
1.3 Outils d'administration 141.3.1 Outils de base 141.3.2 Outils standards 141.3.3 Outils constructeurs 14
1.4 UNIX et l'administration 15
1.5 Le carnet de bord 15
2. GESTION DES UTILISATEURS 16
2.1 Généralités 16
2.2 Le fichier /etc/passwd 162.2.1 Nom de l'utilisateur 162.2.2 Mot de passe 162.2.3 Identificateur de l'utilisateur 172.2.4 Identificateur du groupe 172.2.5 Informations diverses 172.2.6 Répertoire de connexion 172.2.7 Commande de connexion 172.2.8 Séparateur des champs 172.2.9 Utilisateurs particuliers 182.2.10 Les privilèges du super-utilisateur 18
2.3 Le fichier /etc/group 18
2.4 SECURITE et classes d'utilisateurs 20
2.5 Gestion des Mots de passe 212.5.1 Stratégie 212.5.2 Le fichier /etc/shadow 222.5.3 Utilisateur synonyme de root 232.5.4 Terminal sécurisé et login root 23
2.6 Principes de Création d'un utilisateur 24
2.7 Principes de Suppression d'un utilisateur 27
2.8 Récapitulation des commandes d'administration 28
3. GESTION DES PROCESSUS 30
3.1 Définitions 303.1.1 Etats et transitions 313.1.2 Statut et transitions 32
3.2 Descripteurs associés a un processus 343.2.1 Identificateur 34
3

3.2.2 Table Proc[] 343.2.3 Structure U 353.2.4 Table TEXT 353.2.5 Conséquences pour l'administrateur 373.2.6 La commande ps 373.2.7 Structure d'un fichier exécutable 383.2.8 Correspondance entre fichier exécutable et processus 403.2.9 Credential 40
3.3 Tables systèmes de gestion des processus 40
3.4 Principes de fonctionnement des appels systèmes 41
3.5 Appels système de création et terminaison de processus 423.5.1 L'appel système fork : présentation externe 423.5.2 L'appel système canonique exec* 433.5.3 Données limites d’exécution d’un processus 433.5.4 L'appel système exit 44
3.6 Synchronisation de processus filiés 443.6.1 Généralités 443.6.2 L'appel système wait 443.6.3 La commande du shell wait 453.6.4 La commande du shell sleep 45
3.7 Signaux 453.7.1 Emission de signaux 463.7.2 Réception de signaux 47
3.8 Contrôle de l'exécution des processus 483.8.1 Modes d'exécution d'un processus 483.8.2 Commande jobs 483.8.3 Commandes de changement d'état 483.8.4 Graphe de changement d'état 493.8.5 Commande nohup 503.8.6 Commande killall 503.8.7 Commande lastcomm 503.8.8 Commandes nice et renice 50
3.9 Exercices 513.9.1 Commande ps 513.9.2 Gestion des modes d'exécution (commandes bg &fg) 513.9.3 Gestion des priorités 52
3.10 récapitulation des Commandes d'administration 52
4. GESTION DE LA MEMOIRE 53
4.1 Historique 53
4

4.2 Gestion de la mémoire centrale 54
4.3 Swap 544.3.1 Stratégie du swapping 544.3.2 Swap out 554.3.3 Swap in 55
4.4 Pagination 55
4.5 Segmentation 56
4.6 Création de processus 57
4.7 Fichiers en mémoire 57
4.8 Généralités sur les IPC SYSTEM V 584.8.1 Mémoire partagée 584.8.2 Messages 594.8.3 Sémaphores 594.8.4 Commandes shell associées 59
4.9 Récapitulation des commandes d'administration 59
5. GESTION DE FICHIERS 60
5.1 Types de fichiers 605.1.1 Fichier ordinaire 605.1.2 Répertoire 605.1.3 Lien matériel et lien symbolique 615.1.4 Création des liens 625.1.5 Fichiers spéciaux 625.1.6 Fichiers standards 645.1.7 Redirection 645.1.8 Tube 665.1.9 Affichage du type d'un fichier 67
5.2 Commandes de gestion des fichiers 675.2.1 Règles de nommage 675.2.2 Caractères spéciaux élémentaires du shell 675.2.3 Chemins d’accès 685.2.4 Informations générales 695.2.5 Copie 695.2.6 Renommage ou déplacement 705.2.7 Suppression 705.2.8 Comparaison 705.2.9 Concaténation 715.2.10 Contenu 715.2.11 L’heure de dernière modification 725.2.12 La commande fuser 72
5

5.2.13 Recherche récursive avec condition et traitement 735.2.14 Recherche d’une chaîne de caractères 745.2.15 Tri d’un fichier texte 755.2.16 Autres commandes 76
5.3 Gestion des répertoires 76
5.4 Exercices 785.4.1 Liens et redirection 785.4.2 Tube 785.4.3 Commandes de base du SGF 785.4.4 Commandes d’affichage 795.4.5 Commandes find, grep et sort 79
6. L'ARBORESCENCE UNIX 81
6.1 Racine (root) 81
6.2 Entrées sous la racine 81
6.3 Commandes publiques 82
6.4 gestion des périphériques 82
6.5 Fichiers temporaires 83
6.6 Bibliothèques 84
6.7 Répertoire /usr 846.7.1 Audit 856.7.2 Répertoire /usr/spool 856.7.3 Sources d'UNIX 856.7.4 Génération du noyau 866.7.5 Autres fichiers du répertoire /usr 86
6.8 Fichiers de démarrage 86
6.9 gestion des utilisateurs 87
6.10 Evolutions avec UNIX SYSTEM V R4 87
7. SÉCURITÉ DANS LA GESTION DES FICHIERS 90
7.1 Attributs de sécurité 90
7.2 Gestion des attributs de propriété 91
7.3 Gestion des attributs de sécurité 917.3.1 La commande chmod 917.3.2 Le bit s 927.3.3 Le bit S 927.3.4 Le bit de collage 937.3.5 Gestion du bit suid 93
7.4 Liste de contrôle d'accès 93
7.5 Masque de sécurité par défaut 95
8. GESTION DES ENTRÉES-SORTIES 96
6

8.1 Volume et systèmes de fichiers 96
8.2 Inode 97
8.3 Structure d'un système de fichiers 988.3.1 Inode et I-list 998.3.2 Super bloc 1008.3.3 Structure des informations dans un répertoire 1018.3.4 Comparaison des types de systèmes de fichiers 102
8.4 Tables systèmes associées au système de gestion de fichiers 1028.4.1 Table des descripteurs des fichiers d'un processus 1028.4.2 Table des fichiers ouverts 1038.4.3 Table des inodes 1048.4.4 Montage des systèmes de fichiers 1068.4.5 Fichiers virtuels et systèmes de fichiers virtuels 107
8.5 Cache disque 1088.5.1 Mécanismes d'adressage 1088.5.2 Mécanismes de base du cache 1098.5.3 Tampons 1108.5.4 Tampons virtuels 1108.5.5 Consistance du cache 110
8.6 Pilotes 1108.6.1 Les deux types de pilote 1118.6.2 Interface avec le noyau 1118.6.3 Tables d'interface bdevsw et cdevsw 1128.6.4 Mise en oeuvre d'un pilote 1138.6.5 Pseudo-pilotes 1148.6.6 Pseudo-périphérique 1158.6.7 Autres pseudo-périphériques 1158.6.8 Applications 1168.6.9 Réalisation d'un pilote 1168.6.10 Intégration d'un pilote 1168.6.11 Evolution des pilotes 1178.6.12 L'exemple du pilote TTY 117
8.7 Généralités sur les streams 1178.7.1 Streams et flots 1188.7.2 Modules 1198.7.3 Message 1208.7.4 Services d'un module 121
8.8 Opérations de bas niveau sur les flots de messages 1218.8.1 Procédures d'écriture des messages 121
7

8.8.2 Ordonnancement et procédures de services 1218.8.3 Contrôle de flux 1228.8.4 Gestion des ressources 1228.8.5 Multiplexage de modules 123
8.9 Fichiers de configuration 123
8.10 Flots et API 124
8.11 Récapitulation des Commandes d'administration 124
9. GESTION DES SYSTEMES DE FICHIERS 125
9.1 Rappels 1259.1.1 Architecture d'un disque 1259.1.2 Gestion mémoire 126
9.2 Partitionnement d'un disque 1269.2.1 Généralités 1269.2.2 Partitionnement SYSTEM V 128
9.3 Création d'un système de fichiers 1299.3.1 Généralités 1299.3.2 SYSTEM V 1299.3.3 BSD 130
9.4 Montage 1319.4.1 La commande /etc/mount 1319.4.2 Options de sécurité de la commande mount 1329.4.3 Table des systèmes de fichiers montés 1339.4.4 Droit d'exécution de la commande mount 1339.4.5 Points de montage 1339.4.6 Stratégie de montage des systèmes de fichiers 1339.4.7 Démontage 133
9.5 Cohérence des systèmes de fichiers 1349.5.1 Généralités sur la commande fsck 1349.5.2 Mode opératoire 1359.5.3 Utilisation de la commande fsck 1369.5.4 Le shell script bcheckrc 136
9.6 Protection, droits d'accès et cryptage 1379.6.1 Classification des fichiers selon leur utilisation 1389.6.2 Accès aux répertoires 1389.6.3 Stratégie de montage des systèmes de fichiers 1389.6.4 Cryptage 139
9.7 Quota d'utilisation des systèmes de fichiers 139
9.8 Gestion des zones de swap 140
9.9 Commandes diverses 141
8

9.9.1 Etat d'occupation des systèmes de fichiers 1419.9.2 Nettoyage et Commande find 1419.9.3 Espace utilisé par une arborescence 1419.9.4 Correspondance inode-fichier 1429.9.5 Label de périphérique 1429.9.6 Fsdb 1439.9.7 Corrections directe d'anomalies 145
9.10 Définitions associées au gestionnaire de volumes Logiques sous AIX 146
9.11 Commandes de gestion des volumes physiques sous AIX 1489.11.1 Création 1489.11.2 Affichage des informations 1489.11.3 Modification des caractéristiques 149
9.12 Commandes de gestion des groupes de volumes physiques sous AIX 1499.12.1 Création 1499.12.2 Affichage des informations 1519.12.3 Modification du status de démarrage 1519.12.4 Ajout de volume physique à un groupe 1519.12.5 Suppression d'un volume physique d'un groupe 1529.12.6 Cohérence de l'association volume physique/volume logique 1529.12.7 Synchronisation des disques miroirs 1529.12.8 Activation/désactivation d'un groupe 1539.12.9 Exportation/importation d'un groupe 1539.12.10 Réorganisation de l'allocation de la partition physique 1549.12.11 Graphe d'état associé à la gestion des groupes de volumes physiques 154
9.13 Commandes de gestion des volumes logiques sous AIX 1559.13.1 Création 1559.13.2 Affichage des informations d'un volume logique 1569.13.3 Modification des caractéristiques d'un volume logique 1579.13.4 Définition et suppression de disques miroirs 1579.13.5 Copie d'un volume logique 1589.13.6 Gestion de la base de données des périphériques 1589.13.7 Graphe d'état associé à la gestion des volumes logiques 158
9.14 Gestion des systèmes de fichiers sous AIX 1599.14.1 Etapes de la création d'une arborescence 1599.14.2 Création d'un système de fichiers 1599.14.3 Modification des caractéristiques d'un système de fichiers 1609.14.4 Affichage des informations d'un système de fichiers 1609.14.5 Montage et démontage d'un système de fichiers sous AIX 160
9.15 Récapitulation des commandes d'administration 161
9

9.15.1 Migration des données d'un disque physique vers un autre 1619.15.2 Graphe d'état d'un volume physique 161
10. SÉCURITÉ DES DONNÉES ET SAUVEGARDES 161
10.1 Généralités sur les sauvegardes 161
10.2 Sauvegarde d'une arborescence 16310.2.1 La commande tar 16310.2.2 La commande cpio 165
10.3 Sauvegarde et restauration de Systèmes de fichiers avec contrôle de label 16710.3.1 Dump (BSD) 16710.3.2 Restore (BSD) 168
10.4 Sauvegarde et réorganisation d'un système de fichiers (SYSTEME V) 170
10.5 Copie physique 171
10.6 Compression 172
10.7 Gestion séquentielle des fichiers sur support magnétique : La commande mt (BSD) 174
10.8 Récapitulation des commandes de Sauvegardes 174
11. DEMARRAGE ET ARRET DU SYSTÈME 175
11.1 Démarrage à froid 175
11.2 Modes mono et multi-utilisateurs 177
11.3 Démarrage BERKELEY 178
11.4 Démarrage SYSTEM V 17811.4.1 Niveaux d'exécution 17811.4.2 Modification du niveau d'exécution courant 17911.4.3 Le fichier inittab 17911.4.4 Réinitialisation du processus init 18011.4.5 Propriétés du répertoire init.d 18011.4.6 Processus à démarrer selon le niveau 18011.4.7 Diagramme récapitulatif des changements de mode d'exécution 182
Généralités sur les processus démons 18211.4.8 Définition 18211.4.9 Schéma de fonctionnement 182
11.5 Démarrage des processus démons 183
11.6 Arrêt du système 18411.6.1 Précautions 18411.6.2 Commande sync et processus démons 18511.6.3 Arrêt depuis le mode mono-utilisateur 18511.6.4 Arrêt depuis le mode multi-utilisateur 18511.6.5 Commande init 186
11.7 Démarrage a chaud 186
11.8 Récapitulation des commandes d'administration 186
10

12. ORDONNANCEMENT DE TRAVAUX 187
12.1 Description des services cron 187
12.2 La commande at 188
12.3 La commande batch 189
12.4 Le répertoire /usr/lib/cron 189
12.5 Le répertoire usr/spool/cron 19012.5.1 Le sous répertoire /usr/spool/cron/crontabs 19012.5.2 Le sous répertoire usr/spool/cron/atjobs 19012.5.3 Structure d'un fichier crontab 190
12.6 Récapitulation des commandes et des fichiers d'administration 191
13. GESTION DES TERMINAUX 192
13.1 Rappels sur le pilote TTY 19213.1.1 Architecture 19213.1.2 Structures de données associées 192
13.2 System V et l'interface termio 19313.2.1 Indicateurs de contrôle 19313.2.2 Caractéristiques physiques de la ligne 19513.2.3 Caractéristiques logiques 197
13.3 Gestion des terminaux avec SystemV R3.2 19813.3.1 Port avec ou sans connexion 19813.3.2 Le processus getty 19813.3.3 Le fichier gettydefs 19913.3.4 Réinitialisation dynamique des ports 200
13.4 Gestion des terminaux avec SystemV R4 20013.4.1 Services SAF 20013.4.2 Service de contrôle d'accès 20013.4.3 Moniteur de ports 20113.4.4 Graphe d'état du service SAC 20113.4.5 Graphe d'état d'un gestionnaire de ports 20113.4.6 Scrutation d'un gestionnaire de ports 20213.4.7 Structure des fichiers d'administration du SAC 20213.4.8 Commandes d'administration associées au SAC 20313.4.9 Structure des fichiers d'administration des ports 20313.4.10 Administration des gestionnaires de ports 20413.4.11 Fichiers de configuration des terminaux 204
13.5 Gestion des terminaux dans l'environnement BSD 20413.5.1 Le processus getty 20413.5.2 Le fichier /etc/gettytab 20513.5.3 BSD 4.2 206
11

13.5.4 BSD 4.3 207
13.6 Le processus login 208
13.7 Types de terminaux 20913.7.1 BSD : la base de données termcap 20913.7.2 SYSTEM V : la base de données terminfo 20913.7.3 Commandes associées à la base de données terminfo 21013.7.4 Correspondance termcap-terminfo 211
13.8 La commande stty 21113.8.1 BSD 21113.8.2 SYSTEM V 211
13.9 Récapitulation des commandes et des fichiers d'administration 213
14. SERVICES D'IMPRESSION 214
14.1 Généralités sur le service d'impression 214
14.2 Le service BSD 21414.2.1 Service 21414.2.2 Commandes d'administration 21414.2.3 Fichier printcap 215
14.3 Le service SYSTEM V 21614.3.1 Classes d'imprimantes 21614.3.2 Commandes associées au service utilisateur 21614.3.3 Commandes d'administration 21714.3.4 Attributs d'une imprimante 21814.3.5 Options de configuration de la commande lpadmin 22014.3.6 Graphe d'état du service d'impression 224
14.4 Récapitulation des commandes et des fichiers d'administration 224
15. SERVICES D'USAGE GÉNÉRAL 225
15.1 Comptabilité 22515.1.1 Architecture du service 22515.1.2 L'utilisateur adm et les répertoires associés 22515.1.3 Initialisation et démarrage du service 22515.1.4 Collecte des informations 22615.1.5 Arrêt, contrôle et suspension du service 22615.1.6 Fichiers de données comptables 22615.1.7 Exploitation des données comptables 22715.1.8 Commandes utilisateurs 22815.1.9 Graphe d'état associé au service comptable 229
15.2 Service profiler 229
15.3 Suivi d'activités 230
15.4 Gestion des messages d'erreur 231
12

15.4.1 Le processus démon errdemon 23115.4.2 Le processus démon syslogd 231
15.5 Gestion des ressources 23315.5.1 Définition des ressources système 23315.5.2 Environnement BSD 23315.5.3 ACL 234
15.6 Autres services 234
15.7 Récapitulation des commandes et des fichiers d'administration 235
16. GENERATION SYSTEME 236
16.1 Généralités 23616.1.1 Génération système 23616.1.2 Génération du noyau 236
16.2 Installation de logiciel 23616.2.1 Ressources 23716.2.2 Installation effective 23716.2.3 Fichiers de configuration 23716.2.4 Test 23716.2.5 Avertissement aux utilisateurs 23816.2.6 Modification d'une installation 238
16.3 Adjonction d'une commande publique 238
16.4 Génération ou Optimisation du noyau 23816.4.1 Généralités 23816.4.2 Distribution 23816.4.3 Principes généraux 23916.4.4 Noyau SYSTEM V 23916.4.5 Optimisation du noyau 240
16.5 Génération système 24016.5.1 Etude préalable 24016.5.2 Premier démarrage 240
16.6 Récapitulation des commandes et des fichiers d'administration 241
17. EXERCICES DIVERS 245
17.1 Gestion des utilisateurs 245
17.2 Attributs de sécurité 245
17.3 Gestion du SGF 24517.3.1 Montage 24517.3.2 Commande fsck et mkfs 246
17.4 Cheval de Troie 246
17.5 Démarrage et arrêt du système 246
17.6 Gestion des périphériques et pseudo-périphériques 246
13

17.7 Sauvegardes 247
17.8 Divers 247
18. INDEX 248
14

1. L'ADMINISTRATEUR UNIX
1.1 RÔLES
L'administrateur d'un système informatique doit assurer les services suivants : mise en place et évolution du système, sur le plan matériel (installation et gestion de périphériques
divers (terminaux, imprimantes,...)), et logiciel,
connaissance des outils et des procédures standards d'administration et d'installation,
définition et/ou utilisation des procédures d'installation,
définition de procédures de nettoyage,
élimination des redondances,
définition et utilisation des procédures de sauvegarde,
mise à jour de la documentation,
mise en place éventuelle de la comptabilité et d'outils d'analyse,
mise en place éventuelle de procédures d'audit et de surveillance du système,
mise en place des services réguliers,
mise en place du suivi des activités,
addition et suppression des utilisateurs,
écoute des besoins et aide aux utilisateurs.
gestion des disques et des systèmes de fichiers,
vérification de leur cohérence,
assurer le suivi du fonctionnement,
assurer l'archivage et les sauvegardes,
assurer le démarrage et l'arrêt du système,
génération système,
installation de logiciels,
génération et l'optimisation du noyau,
mise en place des procédures convenables de sécurité.
1.2 CONNAISSANCES TECHNIQUES
L'administration est une tâche complexe. Elle nécessite de solides compétences techniques sur le matériel et sur le système d'exploitation. Le métier d'administrateur évolue car de plus en plus, il doit gérer un parc constitué de systèmes hétérogènes.
Il doit connaître la philosophie de fonctionnement du système plus que le détail fastidieux de l'ensemble des commandes disponibles.
15

1.3 OUTILS D'ADMINISTRATION
Il existe trois types d'outils d'administration : les outils de base, dépendants du système, les outils standards et les outils constructeurs.
1.3.1Outils de base
Ce sont les commandes, souvent spécifiques à chaque constructeurs, d'installation de logiciels ou de génération système. La philosophie est partout semblable mais les commandes sont différentes, par exemple divvy (SCO), diskpart (SUN), prtvtok (BULL), pour des renseignements sur le partitionnement d'un disque.
1.3.2Outils standards
Ce sont les commandes de base d'administration. Elles sont de plus en plus normalisées et comportent les outils historiques BSD et SV. La tendance étant de plus en plus imposée par ATT, les outils commerciaux sont des noyaux ATT avec des fonctions BSD. Compte tenu de l'accord Unix International et OSF intervenu le 1er Septembre 1993, la norme définie par ATT dans UNIX SVR4.2 s'impose à tous.
1.3.3Outils constructeurs
Ils sont spécifiques à chaque constructeurs et permettent d'exécuter la plupart des tâches usuelles d'administration. Ils ne sont pas normalisés. Leur utilisation devient de plus en plus impératives car ils modifient souvent de nombreux fichiers. Les principaux systèmes constructeurs sont :
SYSADMSH UNIX SCO
SYSADM UNIX Interactive
SYSADM UNIXWARE (différent du précédent)
SAM HP
AIX SMIT
Avantages
Ils masquent les problèmes sous jacents. Ils permettent donc d'assurer le suivi quotidien des tâches d'administration sans avoir forcément les compétences pointues d'un administrateur professionnel. Les commandes sont gérées à partir de menus déroulants.
Inconvénients
En cas de problèmes imprévus, l'utilisateur néophyte risque de ne pas savoir comment le résoudre.
1.4 UNIX ET L'ADMINISTRATION
Le système UNIX est doté de nombreux et solides outils d'administration qui peuvent assurer tous les services précédemment décrits.
16

Des commandes d'administration, des répertoires spécifiques, des processus spécialisés vont assurer toutes ces tâches.
1.5 LE CARNET DE BORD
Les informations contenues dans le carnet de bord sont les suivantes :
Procédures spécifiques à un site donné
Matériel ou logiciel spécifiques nécessitant une procédure particulière de démarrage ou d'arrêt.
Messages d'avertissement à envoyer aux utilisateurs d'un système en réseau lors de l'indisponibilité d'une ressource distribuée telle une base de données.
Gestionnaires locaux de services réguliers d'archivage : utilisation, labelisation, réutilisation des bandes.
Configuration du système
Paramètres spécifiques d'une installation donnée.
Audit système
Enregistrement des modifications de l'installation (matériel et logiciels).
Enregistrement des raisons des arrêts, de la maintenance, ou du passage en mode mono-utilisateur.
Procédures spécifiques à un site donné
Démarrage et arrêt.
Sauvegarde des données.
Procédures d'urgence.
Configuration du système et numéro de série.
Etat du système
Description des modifications du système, en indiquant les auteurs et les causes.
Raisons des démarrages et arrêts des divers services.
Heures et type des sauvegardes.
Erreurs systèmes ou activités inhabituelles du système.
17

2. GESTION DES UTILISATEURS
2.1 GÉNÉRALITÉS
Les opérations de gestion des utilisateurs sont la création et la suppression.
Trois fichiers essentiels : le fichier /etc/passwd contenant la liste de tous les utilisateurs référencés,
le fichier /etc/group contenant la liste des groupes ainsi que leurs membres,
le fichier /etc/shadow, contenant les mots de passe cryptés des utilisateurs.
Pour des raisons élémentaires de sécurité, ces fichiers ne doivent être accessibles en écriture qu'à l'administrateur (et encore).
2.2 LE FICHIER /ETC/PASSWD
Ce fichier comprend, pour chaque utilisateur, une ligne constituée de sept champs séparés par le caractère : dans l'ordre ci-dessous :
nom:mot_de_passe_crypté:UID:GID:information:répertoire_de_login:commande
2.2.1Nom de l'utilisateur
C'est l'identificateur (unique) de l'utilisateur (réponse à l'invitation à se connecter login). Il est recommandé qu'il soit composé d'au plus huit caractères.
2.2.2Mot de passe Sur les versions BSD et avant SYSTEM V R4, on y trouve le mot de passe crypté de l'utilisateur,
enregistré à partir de la commande /bin/passwd soit par l'administrateur, soit par l'utilisateur lui-même. Il est possible d'obliger un utilisateur à mettre ou modifier son mot de passe en écrivant le caractère * dans ce champ. La seule façon de supprimer un mot de passe est de rendre ce champ vide à partir d'un éditeur de textes. Certains systèmes permettent d'interdire la pose d'un mot de passe pour un nom à accès public (tel que invité ou guest) en écrivant le caractère dans ce champ.
A partir d'UNIX SYSTEM V Release 4, ce champ est remplacé par le caractère * pour tout utilisateur et les divers mots de passe sont dans un fichier invisible de tous (par exemple /etc/shadow).
Le mot de passe : a un nombre de caractères compris entre 6 et 8.
doit contenir au moins 2 lettres, 1 chiffre ou caractère spécial.
peut avoir plus de huit caractères. Toutefois, certains appels système ne considèrent que les huit premiers ce qui peut-être source d'erreur.
doit être modifié par l'utilisateur lors de sa première connexion s'il a choisi par l'administrateur à la
18

création.
2.2.3 Identificateur de l'utilisateur
Le champ uid
Le champ uid est un entier représentant le numéro d'identification de l'utilisateur. Il doit être compris entre 100 et 32767.
Il doit en général être unique car deux utilisateurs ayant le même uid ont les mêmes droits d'accès aux fichiers et aux processus actifs sous des noms différents ce qui peut poser des problèmes pour certaines commandes (par exemple la messagerie), qui en recherchant le nom d'un utilisateur à partir du champ uid sélectionnent toujours la première entrée. Si cette règle n'est pas respectée, des fichiers peuvent changer de propriétaires car l'inode ne contient pas le nom du propriétaire mais seulement le champ uid.
2.2.4 Identificateur du groupe
Le champ gid est est un entier représentant le numéro d'identification du groupe, existant, auquel appartient l'utilisateur.
2.2.5 Informations diverses
Le champ information est disponible pour ajouter divers renseignements par exemple le nom patronymique, le numéro de téléphone, etc. Certains utilitaires peuvent exploiter ce champ (pour la comptabilité par exemple).
2.2.6Répertoire de connexion C'est le chemin d'accès absolu du répertoire de connexion de l'utilisateur (home directory).
Il doit être créé s'il est inexistant.
Attention aux erreurs
Si la partition devant contenir le répertoire de l'utilisateur n'est pas montée à la création et que le répertoire est tout de même créé, les risques de dysfonctionnement ultérieurs sont très importants.
2.2.7Commande de connexion
C'est le chemin d'accès absolu du fichiers exécutable lancé lors de la connexion. C'est le plus souvent un des interprètes de commande (shell de Bourne /bin/sh, C-shell /bin/csh, shell réduit /bin/rsh, Korn Shell /bin/ksh ...) qui est aussi l'option par défaut si ce champ est vide. Mais tout autre programme (éditeur, application, commande...) est valide ce qui permet de limiter les droits de l'utilisateur, et provoque une déconnexion automatique à la fin d'exécution du programme.
2.2.8Séparateur des champs
Le caractère : étant le séparateur des champs, son utilisation interdite à d'autres fins.
Exempleroot:wJ5Vex9P7RdLM:0:1:Operator:/:/bin/csh
19

nobody:*:65534:65534::/daemon:*:1:1::/sys:*:2:2::/:/bin/cshbin:*:3:3::/binuucp:*:4:8::/var/spool/uucppublicnews:*:6:6::/var/spool/news:/bin/cshingres:*:7:7::/usr/ingres:/bin/cshaudit:*:9:9::/etc/security/audit:/bin/cshsync::1:1::/:/bin/syncsysdiag:*:0:1:Old System
2.2.9Utilisateurs particuliers
Certains utilisateurs répondent à des fonctions spécifiques. On en distingue trois types : les utilisateurs liés aux fonctions système, dont fait partie au moins le super utilisateur root qui a pour
UID 0 ainsi que les utilisateurs bin, sys, manager ...
les utilisateurs liés à une commande, par exemple uucp, qui exécute le programme uucico et qui permet la gestion des accès externe par le protocole uucp, nuucp qui assure la gestion des comptes accessibles par le protocole uucp, ou encore who qui permet d'obtenir facilement une information donnée,
les utilisateurs publics permettant à n'importe qui de se connecter (par exemple guest) pour accéder à certaines ressources publiques du système.
2.2.10 Les privilèges du super-utilisateur Opération autorisée sur n'importe quel fichier ou processus.
Modification de l'heure du système.
Modification des paramètres du noyau.
Choix du nom de la machine.
Création des systèmes de fichiers.
Montage et démontage des systèmes de fichiers.
Modification des attributs de propriété et de sécurité des fichiers.
Création des mots de passe des utilisateurs.
Arrêt du système.
Beaucoup d'autres.
Outils constructeurs
Les fichiers /etc/passwd et /etc/shadow ne doivent plus être modifiés directement. Il faut de plus en plus souvent utiliser les interfaces d'administration.
2.3 LE FICHIER /ETC/GROUP Un groupe est un ensemble d'utilisateurs disposant de privilèges d'accès sur certains fichiers. Le
groupe auquel appartient un utilisateur détermine donc les privilèges de partages de fichiers, avec une possibilité de contrôle.
Un utilisateur peut faire partie d'au plus 16 groupes.
20

Le fichier /etc/group est constitué, pour chaque groupe déclaré, d'une ligne constituée de quatre champs séparés par le caractère : et dans l'ordre ci-dessous :
nom:mot_de_passe_crypté:gid:membres
Interprétation
nom : nom du groupe sur six caractères maximum.
mot_de_passe : mot de passe crypté pour le groupe, utilisé par les utilisateurs qui désirent changer de groupe (commande shell newgrp) sans y être inscrit. Mais comme il n'y a pas de moyen simple pour mettre ce mot de passe, ce champ est pratiquement toujours vide.
gid : entier représentant le numéro de groupe.
membres : liste des utilisateurs (noms de connexion séparés par une virgule) constituant un groupe. Ils sont autorisés à utiliser la commande newgrp quand ils sont déclarés dans plusieurs groupes. La commande newgrp n'entraîne pas la création d'un processus, contrairement à la commande su qui permet de changer d'identité mais en créant un nouveau shell.
Exemplezero:*:0:who,rwho,finger,philippnobody:*:-2:nobodyother:*:1daemon:*:2:daemonadm:*:3:admbin:*:4:bin,rjekmem:*:5:root,cshroot,daemon,adm,binoperator:*:7:root,cshroot,adm,barratoperateur:*:8:barrat,heasguest:*:9:networkstaff:*:10:root,cshroot,barratuucp:*:66:root,cshroot,daemon,uucp,Uccselc,newsnews:*:70:news,usenetrje:*:14:rjeuser:*:20dfcai:*:21prof:*:22tftp:*:100:tftp+::0
Commande de changement de groupe d'un fichier
BSD
Le seul utilisateur autorisé à utiliser la commande chown est le super-utilisateur.
SYSTEM V Tous les utilisateurs peuvent l'utiliser.
Il existe un paramètre ajustable du noyau permettant d'en restreindre l'usage.
Groupe de connexion par défaut
C'est le groupe other.
21

Choix des numéros de groupe
Il est recommandé que les numéros inférieurs à 100 soient utilisés par les groupes systèmes.
La commande groups
Elle affiche la liste des groupes contenant un utilisateur donné.
Changement du groupe courant
Un utilisateur appartenant à plusieurs groupe peut changer de groupe courant en utilisant la commande newgrp.
2.4 SECURITE ET CLASSES D'UTILISATEURS
Rôle de l'administrateur
Historiquement, le système UNIX a souvent été considéré comme peu sécurisé. Cette mauvaise image est imméritée. Il a toujours été possible de sécuriser un système UNIX en utilisant les outils standards d'administration comme nous allons le voir. Le point essentiel est que la sécurité d'un système dépend essentiellement de l'administrateur. Il doit définir un compromis entre l'ouverture naturelle du système et sa sécurité.
Classes d'utilisateurs
Comme nous l'avons, il est important de définir des groupes d'utilisateurs différents, selon les types de travaux qu'ils effectuent.
Classes d'administrateurs
Sur les versions d'UNIX antérieures à SYSTEM V R4, le super utilisateur a tous les droits ce qui est aujourd'hui considéré comme un privilège exorbitant. Une solution est la définition de classes de privilèges permettant de limiter les droits d'un utilisateur à un type d'application donné. On distingue l'administrateur des mots de passe, celui de la comptabilité...
Il est possible de restreindre l'accès à certaines commandes, par exemple en leur adjoignant un mot de passe. Une autre possibilité est de définir des groupes d'utilisateurs.
Les différents utilisateurs système sont caractérisés de la façon les suivante :
Login uid Fonctionroot 0 accès à l'intégralité du systèmesys 3 propriétaires de certains fichiers systèmesbin 2 propriétaire de la plupart des commandesadm 4 propriétaire de certains fichiers d'administrationuucp 5 propriétaire d'objet et de données spoulées pour uucpnuucp 6 utilisé par des utilisateurs distantsdaemon 1 gestion des processus démons et différéslp 71 propriétaires des objets et des fichiers pour impression.
22

2.5 GESTION DES MOTS DE PASSE
2.5.1Stratégie
Obligation d'utilisation
Il est important d'obliger un utilisateur à avoir un mot de passe.
Le mécanisme dit d'aging, intégré sur toutes les plates-formes actuelles
Choix du mot de passe
Il ne doit pas être trivial. Il faut donc proscrire son propre nom, les prénoms usuels, les numéros de sécurité sociale...Un tel mécanisme est appelé "contrôle de l'obviousnesseté" du mot de passe.
Gestion du mot de passe
Le mot de passe doit être facile à retenir.
Il doit comporter au moins six caractères non triviaux (majuscules, minuscules, chiffres, caractères de contrôle...).
Il doit être changé périodiquement.
Modification du fichier /etc/passwd
Le mot de passe crypté d'un utilisateur, contenu dans le fichier /etc/passwd, accessible à tous en lecture est camouflé dans un fichier caché, par exemple /etc/shadow sous UNIX SYSTEM V Release 4.
Mot de passe non trivial
Il est possible d'obliger les utilisateurs à utiliser un chiffre ou des caractères de contrôle dans les mots de passe.
2.5.2Le fichier /etc/shadow
Mécanisme d'aging
Il est possible d'obliger les utilisateurs à changer de mot de passe de façon périodique. On peut même s'assurer qu'ils n'utilisent pas un ancien mot de passe considéré comme périmé.
Le fichier /etc/shadow, s'il existe, est consulté pour la validation des mots de passe. Il est accessible par le super-utilisateur en lecture seulement .
Les champs du fichier /etc/shadow
login_name,
mot_de_passe_crypté,
date_de_dernière_modification du mot de passe, en jour depuis le 1er Janvier 1970,
intervalle en jour minimum entre deux changements,
nombre maximum de jours de validité,
23

masque d'audit,
chaîne de caractère indiquant si le login est anonyme.
Exempleroot:h0xhfsg9NV3pa:7116:::normal:daemon:NONE:6645:::normal:joe:4v92wsUm2BVMo:7116:7:28:normal:
Mécanisme d'aging
La date du système doit être correcte. Le principe est d'obliger un utilisateur dont le mot de passe n'est plus valide à en indiquer un nouveau.
Le mécanisme peut-être désactivé selon les utilisateurs.
Il n'est pas utilisé si : le nombre de jours entre les changements de mot de passe est nul.
le nombre de jours d'existence du mot de passe est supérieur à celui de sa validité.
si les quatrième et cinquième champs sont vides.
si les opérations d'écriture dans le fichier /etc/shadow sont supprimées.
Masque d'audit
Le masque d'audit indique le type d'événement à surveiller. Le masque usuel permet de connaître l'activité normale d'un utilisateur à savoir les connexions effectives, les tentatives d'utilisation de la commande su, les problèmes d'autorisation sur les fichiers ouverts.
Login anonyme
Le login anonymous est utilisé pour des connexions ouvertes sur le monde extérieur.
2.5.3Utilisateur synonyme de root
Il est possible de définir un utilisateur synonyme de root dans le fichier /etc/passwd en lui donnant l'uid et le gid 0. Chacun des administrateurs ne se connectera pas sous l'uid root mais sous son identificateur propre et avec son mot de passe personnel. Le fichier d'audit /var/adm/sulog permet de savoir qui a fait quoi et quand.
Il faut éviter de travailler sous l'uid root quand cela n'est pas nécessaire car une erreur peut ne pas pardonner (suppression de fichiers par exemple).
2.5.4Terminal sécurisé et login root
Il faut interdire la possibilité pour l'administrateur de se connecter directement (login root) sauf sur la console système.
Poste de travail sécurisé
Un terminal est dit sécurisé si le super utilisateur peut s'y connecter directement. Ce droit est défini, par exemple à partir du mot clé secure dans le fichier ttytab ou du fichier ttys.
24

La console système est le seul terminal depuis lequel la connexion directe en tant que root est autorisée. Elle doit être allumée en permanence car quand un utilisateur exécute la commande /bin/su, un message s'y affiche
Groupe su
Tout candidat au login root doit impérativement utiliser la commande /bin/su, dont l'usage doit être restreint à un groupe d'utilisateurs de la façon suivante :
création d'un groupe su dans le fichier /etc/group contenant la liste du groupe d'utilisateurs autorisés,
attribution du fichier /bin/su au groupe su (commande shell chgrp).
modification éventuelle du propriétaire du fichier à l'aide de la commande chown,
modification des droits d'accès et d'utilisation par la commande chmod.
Nous reviendrons sur toutes ces commandes ultérieurement.
Audit de la commande su
Le fichier /var/adm/sulog peut contenir l'historique des utilisations de la commande su. On peut donc identifier les pirates potentiels car c'est en général le premier moyen utilisé.
Remarque
Par défaut, tout utilisateur détenteur du mot de passe de root peut exécuter la commande su sur n'importe quel poste de travail.
Verrouillage du terminal
Il ne faut jamais laisser l'accès libre à un terminal quand une session de travail est ouverte. Des utilitaires tels xlock permettent un verrou temporaire d'accès contrôlé par mot de passe.
Surveillance des lignes d'accès
Sur UNIX SYSTEM V, il est possible d'ajouter un mots de passe complémentaire nécessaire à tout accès par modem au système (fichier /etc/dialup et /etc/d_passwd).
Limitation de l'accès physique
Une protection élémentaire de l'accès à la machine permet déjà d'offrir un certain niveau de sécurité.
2.6 PRINCIPES DE CRÉATION D'UN UTILISATEUR
La plupart des systèmes offrent un shell-script permettant l'automatisation de cette procédure (adduser, mkuser, defuser...).
La première action nécessaire pour déclarer un utilisateur est d'ajouter une entrée au fichier /etc/passwd en respectant le format décrit ci-dessus.
Pour que cet utilisateur puisse accéder au ressources du système, il est nécessaire de : lui créer un répertoire de connexion (home directory),
25

affecter un ou plusieurs groupes à cet utilisateur,
rendre l'utilisateur propriétaire de son répertoire (commande shell chown) et d'affecter à ce répertoire l'un de ses groupes (commande shell chgrp),
mettre à jour les fichiers utilisés par certains utilitaires (cron, acct, at)...
créer un environnement par défaut à l'utilisateur (fichier .profile, .login ...).
Une procédure automatique de création doit prendre certaines précautions telles : l'accès réservé à l'administrateur (en vérifiant le droit d'écriture dans /etc/passwd),
l'accès exclusif (par un fichier de verrouillage). Certains systèmes offrent une commande vipw permettant d'éditer le fichier /etc/passwd avec l'éditeur vi en accès exclusif,
les contrôles sur l'unicité de l'identité et du champ UID, l'existence du groupe, du répertoire de connexion et du répertoire parent,
divers contrôles sur la validité des arguments (nom incorrect...),
la récupération des signaux d'arrêt afin de supprimer les fichiers temporaires et de maintenir un état cohérent.
Il est possible également de définir des quota d'utilisation sur l'espace alloué et sur le nombre de fichiers ouverts.
Exemple# !/bin/csh## sauvegarde fichier passwdrm /etc/passwd.oldcp /etc/passwd /etc/passwd.oldecho ""echo " paramètres de la zone commentaire pour chaque enregistrement "echo " ------------------------------------------------------------ "echo ""echo " (1) code : Prof "echo " Eleve "echo ""echo " 2) promotion : 1ère année : promotion 1993 "echo " 2ème année : promotion 1992 "echo " 3ème année : promotion 1991 "echo ""echo " (3) NOM Prénoms "echo ""echo " (4) COURS (éventuel) "echo ""echo " (5) date enregistrement (jj-mm-aa) "echo ""echo; echo; echoecho -n " login : "set log=$<grep -s "^${log} :" /etc/passwdif ( $status == 0 ) thenecho; echo " Usager deja existant! _"
26

exec $0endifechoecho " groupe :"echo " etudiants répondez par 1"echo " etudiants2 répondez par 2"echo " prof répondez par 3"echo " dfcai répondez par 4"echo " autré groupe répondez par 5"echo -n " votre reponse :"set rep=$<switch ($rep)case 1set grp = userset chemin = etudiantsbreakswcase 2set grp = userset chemin = etudiants2breakswcase 3set grp = profset chemin = $grpbreakswcase 4set grp = dfcaiset chemin = $grpbreakswcase 5echo -n " entrez le groupe : "set grp=$<grep -s "^${grp} :" /etc/groupif ( $status != 0 ) thenecho; echo " Ce groupe n'existe pas _"exec $0endifecho -n " entrez le chemin d'acces : "set chemin=$<breakswdefaultecho; echo " Ce groupe n'existe pas "exec $0breakswendswechoecho -n " commentaires : "set com=$<set hom = /usr2/$chemin/$logechoecho -n " sh/csh/tcsh : "set she=$<echoecho -n " Procédure en cours "set max=0
27

foreach n ( `cat /etc/passwd|/usr/5bin/cut -f3 -d :` )if ( $max < $n ) then
set max=$nendifendecho -n ". "@ uid = $max + 1set gid=`grep $grp /etc/group | /usr/5bin/cut -f3 -d :`echo "${log} : :${uid} :${gid} :${com} :${hom} :/bin/${she}" >> /etc/passwdecho -n ".. "mkdir $hom#définition de l'environnement par défautforeach j (.suntools .suntools.sta .defaults .login .profile .cshrc .exrc .rootmenu)cp /usr/local/gould/$j $homend#l'utilisateur devient propriétaire de son home directory/etc/chown -R $log $hom/bin/chgrp -R $grp $homecho -n "... "#mise en place des quotaswitch($grp)case useredquota -p guest $logecho " quota installés"breakswcase dfcaiedquota -p guest $logecho " quota installés "breakswdefault : echo " pas de quota installés "endswecho " Operation terminee _"echoecho -n " Autre utilisateur (o/n) "set rep=$<if ( $rep == "o" ) thenexec $0endifecho; echotouch /etc/passwdcd /usr/etc/ypmakeecho# sauvegarderm /etc/passwd.oldcp /etc/passwd /passwd.old
28

2.7 PRINCIPES DE SUPPRESSION D'UN UTILISATEUR
Opérations à effectuer
Cette opération est plus délicate que la précédente, car il y a plus de risques en détruisant qu'en créant. Les opérations à effectuer sont les suivantes : la suppression de l'entrée de l'utilisateur dans le fichier /etc/passwd avec un éditeur,
la suppression de toute référence à cet utilisateur dans le fichier /etc/group ainsi que les divers fichiers liés à la messagerie, aux spoulers et commandes telles que cron, acct, at ...
la suppression de tous les répertoires et fichiers de l'utilisateur.
Risques
Ce dernier point est particulièrement délicat : à priori une destruction en force (rm -rf) du répertoire de connexion permet de résoudre ce problème. Certaines incohérences peuvent alors se produire dans le système : des fichiers d'un autre utilisateur contenus dans ce répertoire sont détruits.
d'éventuels fichiers de l'utilisateur créés en dehors de son répertoire ne sont pas supprimés. La commande shell find permet de les localiser.
si d'autres utilisateurs ont établi des liens symboliques sur des fichiers de cet utilisateur, ces derniers deviennent inaccessibles. Toutefois, le lien symbolique demeure. Les numéros d'inode des fichiers détruits étant réutilisables par le système d'exploitation, les liens symboliques risquent de pointer sur un fichier différent de celui d'origine dès leur réutilisation.
Shells scripts
Un programme en shell peut automatiser tout ou partie de ces tâches, mais il doit être établi et utilisé avec beaucoup de précautions.
Pour tenir compte de la remarque précédente, il serait judicieux d'ajouter dans la procédure une commande de recherche des liens symboliques éventuels sur des fichiers appartenant à l'utilisateur dont le répertoire va être supprimé.
Cas de certains systèmes propriétaires
De plus en plus, certains systèmes UNIX offrent (ou imposent) une interface permettant d'ajouter ou de supprimer un utilisateur (UNIX SCO, AIX V3...). Une base de données interne au système d'exploitation, inaccessible à quiconque, est gérée par cette interface. Il est alors impossible de modifier le fichier /etc/passwd manuellement car le risque de d'incohérence de la base est très important.
Commandes SYSTEM V R4.2
Des commandes d'administration complémentaires ont été introduites :
Gestion des utilisateurs
Ajout useraddModification usermodSuppression userdel
29

Paramètres par défaut defadmCaractéristiques logins, listusers
Gestion des groupes
Ajout groupaddModification groupmodSuppression groupdel
2.8 RÉCAPITULATION DES COMMANDES D'ADMINISTRATIONadduser, useradd, userdel, usermod, usersgroupadd, groupdel, groupmodwho, id , newgrp, chgrp, chmod, chown/etc/passwd, /etc/group, /etc/security.profile, .login, .cshrc, .kshrc, .mwmrc, .xinitrc, .mailrc, .netrc, .exrc
30

31

3. GESTION DES PROCESSUS
3.1 DÉFINITIONS
Processus sous UNIX
L'image d'un processus en mémoire est l'ensemble des instructions et des données exécutables par un ordinateur dont un processus est l'exécution dynamique. Toutes les processus s'exécutent en multiplexage temporel sur le processeur fonctionnant en mode système ou noyau (kernel) ou en mode utilisateur ou usager (user).
Mode système
Un processus en mode système exécute du code du noyau.
Plusieurs processus en mode système peuvent être activables simultanément.
La nécessité d'intégrité du noyau impose des contraintes de changement de contexte très fortes : la préemption d'un processus en mode système par un autre est interdite. C'est la solution adoptée par le système UNIX traditionnel pour résoudre le problème de l'exclusion mutuelle et garantir le franchissement des sections critiques lorsque certaines interruptions sont masquées.
La durée de fonctionnement du mode système est limitée et sa terminaison "normale" se traduit par un retour à l'état originel.
Unix et le temps réel
L'exécution d'un processus en mode système étant non préemptible, la reprise d'un traitement suite à une interruption peut être différée jusqu'à la fin de l'appel système courant. Deux conséquences essentielles :
le traitement résultant d'une interruption étant par nature différé, le système UNIX dans ses implémentations traditionnelles n'a aucune vocation temps réel.
Toute nouvelle fonctionnalité intégrée dans le noyau du système d'exploitation doit être la plus courte possible.
Mode utilisateur
Un processus en mode utilisateur exécute une application dans un mode non privilégié. Il accède aux ressources de la machine (sous contrôle) par l'utilisation d'appels système ce qui lui permet d'exécuter du code du noyau. Le changement de mode d'exécution doit impérativement être réalisé par matériel.
Exemple La création d'un processus utilisateur, en shell se déroule comme suit : le processus système,
l'interprète de commande shell, contrôle ce que l'utilisateur saisit au clavier. Un processus fils, appelé sous-shell, exécutant la commande est alors créé.
Un processus shell peut lancer l'exécution de plusieurs processus en parallèle qui par définition sont
32

ses fils.
Un processus shell s'exécute en général en mode utilisateur avec un niveau de priorité qui baisse selon le temps CPU consommé.
Remarque
Il ne faut pas confondre le mode d'exécution d'un processus (système ou utilisateur), sa priorité d'exécution et ses autorisations d'exécution.
Exemple Un processus démon s'exécute en mode non privilégié, peut-être avec les droits du super utilisateur.
Le processus de pagination s'exécute en mode privilégié avec une priorité fixe très élevée.
Changement de mode d'exécution
Trois situations provoquent le basculement du mode utilisateur au mode système :
un appel système d'un processus utilisateur fait un appel explicite à des services du noyau,
une anomalie (trap) d'exécution du processus utilisateur provoque un déroutement,
une interruption système provoque l'exécution d'un traitement particulier dans le noyau.
Le passage en mode système est réalisé par :
matériel : il y a une commutation de l'espace d'adressage et le noyau dispose d'un ensemble d'instructions privilégiées supplémentaires.
logiciel : il y a une exécution d'un code spécifique.
3.1.1Etats et transitions
Les évolutions des transitions des modes d'exécution des processus sont les suivantes :
Le graphe des transitions des modes d'un processus est un graphe orienté dont les noeuds représentent les états que peut prendre un processus et dont les arcs représentent les événements qui provoquent son changement d'état. Ceux-ci sont définis quand il existe un arc d'un état vers un autre état. Plusieurs transitions sont possibles à partir d'un état donné mais un processus n'en suivra qu'une selon l'événement produit. Au cours de son exécution, l'état d'un processus évolue selon son degré d'avancement ou son mode de fonctionnement.
33

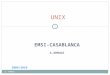
Les différents états sont les suivants :
SIDL le processus en cours de création est dans un état inconsistant.SRUN le processus est activable, en attente de sélection par l'ordonnanceur (le scheduler).SUNPROC le processus est actif et détient la ressource processeur.SSLEEP le processus est en attente d'événement (par exemple une attente de fin d'entrées/sorties).
La primitive d'interruption dont l'exécution sera provoquée par l'événement attendu rendra activable le processus endormi.
SWAIT le processus est activable, en attente de terminaison d'un processus fils.SZOMB le processus est zombie car son exécution est terminé (appel système exit ). Les
ressources attribuées (mémoire, disque, etc..) sont restituées. Il doit, avant de disparaître complètement, transmettre ses variables de gestion interne (état au moment de sa terminaison, temps cpu consommé, temps de résidence, etc.) pour prise en compte au processus père. Il occupe encore un point d'entrée de la table des processus proc qui sera restitué dès la transmission de ces informations.
SSTOP le processus est arrêté ou son exécution est contrôlée par un débogueur.SXBRK le processus est en cours de commutation de contexte.
3.1.2Statut et transitions
Le statut d'un processus est sa localisation dans la mémoire (virtuelle) du système. Il évolue au cours de son existence et peut être l'un des suivants :
SLOAD chargé en mémoire centrale, swappable,SSYS processus crée par le système (swapper ou démon),SLOCK chargé en mémoire centrale avant une opération de swapout,SSWAP chargé en mémoire centrale après une opération de swapin,STRC processus en mode trace (sous contrôle du débogueur),SULOCK chargé en mémoire centrale, non swappable,SPAGE en attente de rechargement de page (mécanisme de paginiation),SWEXIT en cours de terminaison,SPHYSIO opération d'entrée/sortie physique en cours.
Le couple (état, statut), caractérisant un processus à un instant donné, peut être l'un des suivants :
1 le processus s'exécute en mode utilisateur.2 le processus s'exécute en mode système.3 le processus est chargé en mémoire, inactif, prêt devenir actif dès sa sélection par le ordonnanceur.4 le processus est endormi en mémoire.5 le processus est swappé out, prêt à être activé. Il doit être préalablement chargé en mémoire.
34

6 le processus est swappé out, endormi.7 le processus, préempté par le noyau pour permettre à un autre processus de passer en mode système,
passe du mode système au mode usager.8 le processus vient d'être crée et son état est transitoire : il existe mais il n'est ni prêt ni endormi.9 le processus exécute l'appel système exit, passe à l'état SZOMB.
A c tif e n m o deutilisateu r
M ode noyauzom bie
prée m pté
m é m oireinsu ffisan te
end o rm i en w a ke up p rê t enm ém oire m é m oire
e nd o rm i w a ke u p p rê tsw ap pé sw a ppé
en cou rsde c ré a tio n
A p pe l systè m e R eto ur A Sou ouin terrup tio n d 'in terrup tion
ex it
finslee p
1
7
29
8
3
56
4
sw a pou t sw apo ut
sw a pin
G ra p h e d e s tra n sitio n s d 'u n p ro ce ssu s
35

3.2 DESCRIPTEURS ASSOCIÉS A UN PROCESSUS
Un processus est décrit par plusieurs structures de données, présentées ci-dessous.
3.2.1 Identificateur
Un processus a deux identifiants : son pid et un index dans la table (système) proc[].
Le pid (process id) est un nombre entier tel que :
0 £ PID < 32 000
Exemples
L'ordonnanceur (swapper) est souvent le processus 0 et le processus init (l'ancêtre de tous les processus) le processus 1. A l'exception du processus 0, tous les processus sont crées par d'autres processus par l'appel système fork.
3.2.2Table Proc[]
Deux tables systèmes sont utilisées pour la gestion des processus : la table proc, résidente en mémoire centrale, et la structure U, swappable avec le processus.
La table proc[], résidente, contient la liste de tous les processus présents dans le système ainsi que les informations nécessaires au noyau pour en assurer la gestion permanente. Elle est décrite dans le fichier /usr/include/sys/proc.h et contient les vecteurs `'état de l'ensemble des processus en cours d'exécution. Pour chacun d'entre eux, on y trouve son état et son statut, ses temps d'exécution en mode utilisateur et en mode système, son identité (PID), sa priorité pour l'ordonnancement, les signaux reçus, en attente, masqués, son propriétaire, sa localisation en mémoire, sa taille, etc. En voici quelques champs extraits :
Champs et structures utilisées par l'ordonnanceur,
addr adresse de la table des pages,usrpri priorité de l'utilisateur f(cpu, nice),pri priorité courante du processus,cpu durée de dernière utilisation du cpu,stat utilisé par l'appel système stat,time temps de résidence pour l'ordonnancement,nice requête d'ordonnancement de l'utilisateur.
Gestion des signaux reçus
sig signaux suspendus en attente d'émission,sigmask signal masqué,sigignore signaux ignorés,sigcatch signaux captés.

Informations comptables
pgrp nom du processus leader de la session,pid pid du processus,ppid pid du processus père,xstat exit status, utilisé par l'appel système wait,wchan événement attendu par le processus.
3.2.3Structure U
La structure U est l'extension de la table proc contenant les informations swappables du processus nécessaires à son exécution. Un processus en mode utilisateur y a indirectement accès par utilisation de la commande shell ps.
Les informations qu'elle contient sont :
le mode d'exécution (noyau ou utilisateur),
l'état de retour des appels systèmes,
la table des descripteurs,
les informations comptables,
les informations de contrôle des ressources,
la pile d'exécution du processus.
3.2.4Table TEXT
Le code exécutable d'un processus (text segment) n'étant pas modifié en cours d'exécution, plusieurs processus peuvent l'exécuter simultanément. Il est donc séparé des données (structure U + TAS + pile utilisateur).
Les programmes peuvent aussi être réentrants.
Le pointeur de la table proc pointe vers le point d'entrée de la table text où se trouve le nombre de processus résidents ou swappés exécutant le même segment de code, ses adresses en mémoire centrale

et/ou en zone de swap car il est recopié parallèlement en zone swap lors de son chargement en mémoire, et y reste tant qu'un processus est susceptible d'y accéder.
Lorsque le processus est swappé out, la zone mémoire contenant le texte est libérée sans être réécrite sur disque.
La zone U+TAS+PILE est recopiée intégralement en zone de swap. La fonction swap in recharge la zone U+TAS+PILE et texte en mémoire centrale et elle ne libère de la zone de swap que la zone U+TAS+PILE.
Certains programmes très utilisés restent dans la table text et dans la zone de swap, qu'ils soient exécutés ou non grâce au bit de collage (sticky bit).
Lorsqu'un processus s'exécute, le noyau incrémente les compteurs, le charge s'il est présent dans la table des codes et lui alloue une entrée dans la table text, le recopie de la zone de swap et le charge sinon.
Lorsque le processus a terminé son exécution, les compteurs de la table text sont décrémentés. Si le processus est le dernier utilisateur, la mémoire centrale est libérée.
La table text permet la gestion séparée des segments de données et des segments de texte. Elle pointe vers la table vnode, modifiée dès le chargement d'une vnode en mémoire centrale. D'où le schéma précédent utilisé pour la recherche et l'exécution d'un segment de code.
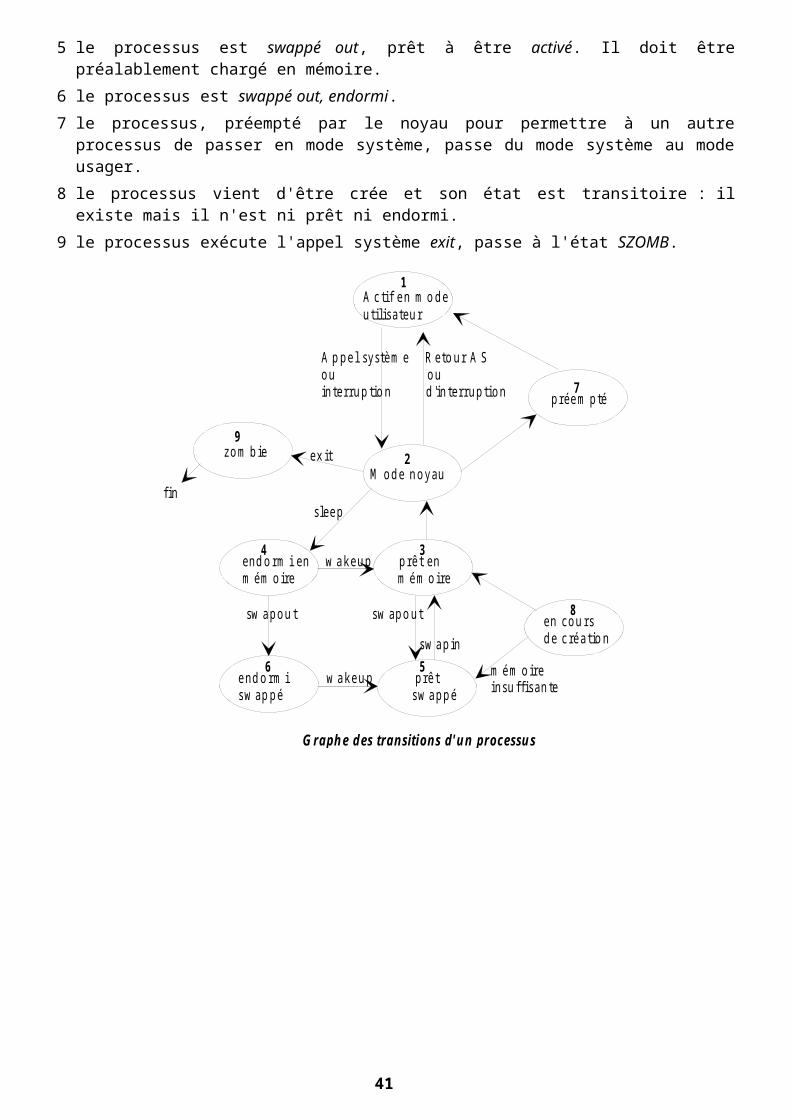
Exemple de partage de fichier par deux processus
Sur le schéma ci-dessous, les deux processus Pi et Pj partagent le même code.
Le drapeau de la structure vnode indique les droits d'accès du fichier par un autre processus et permet l'interdiction des ouvertures en écriture mais pas en lecture.
La copie en zone de swap est réalisée dès le départ de l'exécution.

3.2.5Conséquences pour l'administrateur
Le nombre de processus étant limité, l'administrateur doit adapter le noyau au système matériel. Il peut définir le nombre maximum de processus simultanés, le nombre maximum de processus autorisés par utilisateur de telle sorte qu'un utilisateur ne risque pas de saturer le système.
SYSTEM V
Ces nombres sont les paramètres ajustables (tunable parameters) NPROC et MAXUP, définis dans le fichier config.h. Ils sont accessibles directement ou par une interface d'administration (SMIT sur AIX, sysadm (SCO, INTERACTIVE, BOS....).
BSD
Les formules suivantes sont utilisées.
Nombre maximum de processus 20+8*MAXUSERS
Nombre maximum de segment de texte partageables 36+MAXUSERS
Nombre maximum de fichiers ouverts 69+9*MAXUERS
Taille maximum de la table FILE[] 32+(8/5)*(36+9*MAXUERS)
...
3.2.6La commande ps
La commande ps fournit des informations sur l'état des processus actifs.
Synopsisps [options]
Les options sont différentes sous System V et sous BSD. Les principales sont :
BSD SYSTEM V
a e tous les utilisateurs,l l forme longue,u f sortie orientée utilisateur,x détache les terminaux.
Les informations listées sont, selon les options choisies :
F, indicateur du statut
01 en mémoire centrale,02 processus système,04 entrée-sortie en cours,

10 processus swappé,20 processus en mode trace.
STAT, indicateur d'état
0 inexistant,D swappé,S en sommeil (sleep) depuis moins de 20 secondes,I en sommeil (interrupt) depuis plus de 20 secondes,W en attente de la fin d'un processus fils (wait),R en cours d'exécution (run),Z terminé (zombie),T arrêté (stop).
Autres champs
UID uid du propriétaire du processus,PID pid du processus,PPID pid du processus père,STlME heure de démarrage du processus,PRI priorité (plus ce nombre est élevé, plus la priorité est faible),ADDR adresse en mémoire ou sur disque si le processus est swappé,SZ nombre de blocs en mémoire de l'image du processus,WCHAN événement attendu par le processus quand son état est S ou W, ou <espace>,TTY étiquette logique du terminal associé à l'exécution du processus,TlME temps d'exécution CPU,COMMAND nom de la commande exécutée.
ExempleF S UID PID PPID C PRI NI ADDR1 SZ WCHAN STIME TTY TIME CMD
31 S root 0 0 0 0 20 ded 0 f0219534 Jun 30 ? 0:00 sched
20 S root 1 0 0 39 20 254 36 e0000000 Jun 30 ? 0:00 init
31 S root 2 0 0 0 20 256 0 f00c215c Jun 30 ? 0:00 vhand
31 S root 3 0 0 20 20 258 0 f00b9074 Jun 30 ? 0:00 bdflush
20 S root 449 1 0 28 20 275 48 f01000cc 17:43:41 ? 0:00 -ksh
20 S root 224 1 0 26 20 3e4 88 f01cd8d6 17:43:14 ? 0:00 /etc/cron
3.2.7Structure d'un fichier exécutable
Un processus est décrit par plusieurs structures de données dont les principales sont présentées ci-après.
Un fichier exécutable résulte de la compilation d'un programme source. Son image sur disque est statique et se compose de quatre parties :
- le premier en tête décrit le nombre de sections du fichiers, l'adresse de départ de l'exécution du processus, le nombre magique (magic number) indiquant le type du fichier exécutable (interprété ou compilé),
- l'en-tête de chaque section décrit sa taille et son adresse virtuelle à l'exécution,
- les sections de données, chargées au début de l'exécution du processus,
- les sections contenant la table des symboles.
Cette structure est définie ci-dessous :
struct exec {
long a_magic; nombre magique
unsigned long a_text; taille du text segment
unsigned long a_data; taille des données statiques initialisées
unsigned long a_bss; taille des données dynamiques
unsigned long a_syms; taille de la table des symboles
unsigned a_txbase; base du text segment
};
#define NMAGIC 04100 text segment en lecture seulement
D'où la représentation :
Un fichier exécutable est stripé quand la table des symboles est supprimée (gain de place, sécurité). La commande shell associée est la commande strip.
Les caractéristiques des différents segments sont accessibles avec les commandes suivantes :

- la partie code text avec la commande size,
- la table des symboles avec la commande nm dans l'hypothèse où le fichier exécutable est non "stripé".
Un fichier exécutable est aussi appelé un fichier a.out, son nom par défaut, suite à l'édition de lien.
Il existe plusieurs formats de fichiers exécutables : COFF (Common Object Format), GOFF, XCOFF. La version UNIX SYSTEM V R4 propose la définition du format ELF (Extensible Linking Format) selon les différents type de modules binaires :
- les fichiers objets relogeables, suffixés par .o,
- les fichiers exécutables,
- les fichiers partageables, suffixés par .so (shared object) pour l'édition de liens dynamique.
3.2.8Correspondance entre fichier exécutable et processus
Sous SYSTEM V, un processus se compose de trois segments essentiels : le segment de code, le segment de données, le segment de la pile. Les autres segments peuvent être : la ou les segments de bibliothèques partagées, la ou les segments de mémoire partagée, la ou les segments de fichier(s) attaché(s).
La partie code correspond au segment de code.
Les parties données initialisées et une partie du bss (globales) correspondent au segment de données.
Le segment de pile est créée au chargement par l'empilement des appels de fonctions et l'autre partie du bss (locales).
Les autres segments (mémoire partagée et fichier attaché) sont créées à la demande du processus (sauf les bibliothèques partagées).
3.2.9 Credential
Le propriétaire du processus est en général l'utilisateur qui a lancé le processus. Le groupe associé au processus représente un ensemble d'utilisateurs ayant des droits particuliers. Ils sont représentés par le couple (uid, gid), définis dans le fichier /etc/passwd, qui déterminent les droits d'exécution du processus.
Le propriétaire réel d'un processus en cours d'exécution est l'utilisateur qui a lancé le processus. Le propriétaire effectif est le propriétaire du fichier exécutable qui en a défini les droits d'accès, autorisant, par l'appel système setuid d'autres utilisateurs à l'exécuter. Des définitions similaires existent pour le groupe (rguid, eguid).
Le sextuplet (uid, euid, ruid, guid, sguid, ruid) est la représentation du processus (credential).
3.3 TABLES SYSTÈMES DE GESTION DES PROCESSUS
Deux tables systèmes sont associées à la gestion des processus : la table proc, résidente en mémoire et la structure U, swappable avec le processus. Les versions ultérieures d'UNIX verront probablement la structure U disparaître.

3.4 PRINCIPES DE FONCTIONNEMENT DES APPELS SYSTÈMES
Les mécanismes de base de gestion des processus :
appel système,
matérialisation d'un événement par un signal,
gestion d'un événement par un processus (mécanismes de synchronisation et appels système correspondants) sont présentés dans le présent chapitre.
Programmation objet et appel système
L'appel système est l'unique interface permettant à un processus utilisateur d'accéder aux ressources de la machine en exécutant en mode système une fonction du noyau. Il protège donc la machine vis à vis de la programmation d'application par un mécanisme d'encapsulation. Leur écriture est du domaine du programmeur système.
Utilisation
Du point de vue de l'utilisateur, un appel système est un appel de fonction qui provoque un changement de mode d'exécution par un mécanisme matériel adapté. L'interruption générée par l'appel système est traitée en mode noyau dans le contexte du processus utilisateur appelant par la primitive de bas niveau syscall qui se déroule en trois phases :
Transfert des arguments et changement de contexte
Transfert des arguments d'appel depuis la pile utilisateur vers la pile système ce qui permet au noyau de contrôler la validité de l'appel dans son espace d'adressage propre.
Choix de l'appel et exécution
Détermination de l'appel système et contrôle de la validité des arguments d'appel,
exécution éventuelle de l'appel système.
Fin d'exécution et retour en mode utilisateur
Deux situations :
succès de l'appel : le code de retour de l'appel système est nul et les valeurs sont transférés de la pile système à la pile utilisateur.
échec de l'appel : le code de retour de l'appel système vaut -1 et le champ erreur que l'utilisateur peut tester (variable errno) contient le code de l'erreur détectée.
Un processus revient du mode système avec le contexte du mode utilisateur au moment du changement de mode d'exécution. Le lien le plus direct entre le mode utilisateur et le mode système est la structure U, seule structure présente et stable dans les deux modes. On y stocke le résultat de l'appel système (code de retour) et le champ erreur. Le passage en mode système et le retour en mode utilisateur se déroulent suivant des conventions parfaitement établies. Voici par exemple le déroulement de l'appel système read.
Synopsisint read(int fd, char *buf, unsigned nbyte);
Description

fd est le descripteur de fichier.buf est l'adresse du tampon en mémoire contenant les données à transférer.nbyte est le nombre de bytes à transférer.
3.5 APPELS SYSTÈME DE CRÉATION ET TERMINAISON DE PROCESSUS
Les mécanismes élémentaires de création et de terminaison de processus sont présentés ci-dessous.
3.5.1L'appel système fork : présentation externe
La création d'un processus est réalisée par la duplication (clonage) de son créateur : l'image du processus fils crée est identique à celle de son créateur, le processus père. Les différences sont le pid et quelques champs de la table proc (time, etc.)
Synopsispid_t fork(void);
Le code de retour de l'appel système fork dans le processus père est la valeur du pid du processus fils crée. Dans le processus fils, le code de retour de cet appel système est nul ce qui permet d'écrire la séquence traditionnelle :n=fork();if (n <0) {/* échec de l'appel système fork() */}if (n==0) {/* code du processus fils */}else {/* code du processus père */}
Quand la table proc[] est saturée, l'appel système fork ne peut s'exécuter et il faut attendre la terminaison d'un processus pour le réitérer.
Cette séquence de code a la particularité de permettre l'exécution des deux alternatives par deux processus différents : une dans le processus père et une dans le processus fils. Son effet est le suivant :
le processus père crée un processus fils qui a les mêmes programme, données, descripteurs de fichiers, et système de signaux (concept d'héritage).
le processus fils peut modifier ses données sans que le père en soit affecté. Chacun reprend son exécution au l'instruction de retour de l'appel fork. Pour le processus fils, c'est une illusion puisqu'il n'existait pas avant l'appel.
3.5.2L'appel système canonique exec* Le processus fils n'ayant en général aucune raison d'exécuter le code du père, il est nécessaire de le
modifier après sa création par des primitives de recouvrement (overlay) du code du père par le programme désiré.
La terminaison d'un processus décrémente le nombre de liens associé au code exécutable (text segment) dans la table text[]. Quand ce nombre est nul, le segment de mémoire alloué au text segment est libéré. Le bit de collage (sticky bit) augmente artificiellement le nombre de liens ce qui permet de maintenir le code d'un processus en mémoire même s'il n'est pas en cours d'exécution.
Les appels système de la forme générique exec* permettent le chargement du texte, des données statiques et dynamiques, et de la pile d'un processus. Il en existe plusieurs versions (execl, execv...) dont la forme canonique d'utilisation est la suivante :if ((n = fork()) == 0){ /* processus fils */exec*("/.../application",...);}
Le code de retour de l'appel système fork étant nul dans le processus fils, il est seul à exécuter l'appel système exec*.
Synopsis (forme canonique)exec* (char *path, char *argv[], char *envp[]);
avec :
path le chemin d'accès du fichier exécutable à charger.argv le tableau de pointeurs sur les éventuels arguments.envp les variables de description du contexte d'environnement d'exécution du processus père
transmises à chaque processus fils.
Comme la primitive exec* détruit le programme appelant, il est nécessaire d'enchaîner les appels fork et exec*, d'où la séquence :
code du processus pèreint main().../* création du processus fils */if ((n = fork())==0) exec*(...)
3.5.3Données limites d’exécution d’un processus
Les paramètres limites par défaut sont obtenus par la commande ulimit.
Exempleulimit -acore file size (blocks) 1000000data seg size (kbytes) unlimitedfile size (blocks) unlimitedmax memory size (kbytes) unlimitedstack size (kbytes) 8192

cpu time (seconds) unlimitedmax user processes 256pipe size (512 bytes) 8open files 256virtual memory (kbytes) 2105343
3.5.4L'appel système exit C'est l'appel système de terminaison d'un processus exécuté (explicitement ou implicitement) par tout
processus quand il se termine. Il n'a jamais de retour.
Le noyau peut aussi l'invoquer à la réception d'un signal inattendu. La valeur retournée par la variable status est le numéro du signal correspondant.
Synopsisint exit(short int status);
Description
La variable d'état status est retournée au processus père.
P roc essus p ère Proc ess us fil s
ZO M B IE
p _c pu p id. .. ppidp _tim e p_ cp u... p_tim e p_xs ta t
T ra n sm issio n d es va ria b le s d 'é ta t en tre p ro c essu s p ère /fils
3.6 SYNCHRONISATION DE PROCESSUS FILIÉS
3.6.1Généralités
On distingue deux types de mécanismes de synchronisation :
les primitives de bas niveau du noyau assurent les synchronisations des processus par le système,
les appels systèmes, que nous présentons ci-après, permettent au programmeur de gérer la prise en compte d'événements dans ses applications.
3.6.2L'appel système wait Cet appel système suspend à sa demande l'exécution d'un processus jusqu'à la terminaison d'un
processus fils.
Le processus père appelle l'ordonnanceur avant de s'endormir. En général, il ne reprend son exécution que lorsqu'un processus fils exécute une primitive exit. Le retour de l'appel est immédiat dès qu'un des processus fils s'est achevé avant l'exécution de la primitive wait par les autres processus fils.
Exemple : mécanisme de création d'un shellif ((n = fork()) == 0){/* processus fils */

exec*("/bin/application",...); exit(1);}/* processus père */ while (wait(&status) != pid);
3.6.3La commande du shell wait
La commande wait permet de synchroniser des processus. Le processus l'exécutant attend la fin d'un processus particulier pour poursuivre son exécution.
Synopsiswait [pid]
3.6.4La commande du shell sleep
La commande sleep suspend l'exécution d'un processus pendant une durée définie.
Synopsissleep durée_en_secondes
3.7 SIGNAUX
Un signal est la matérialisation d'un événement matériel (interruption) ou logiciel (déroutement ou exception) notifié au processus pouvant provoquer l'exécution d'une procédure prédéfinie dans le système d'exploitation ou dans le processus lui-même. Par ce mécanisme, le noyau peut communiquer avec les processus utilisateurs en cas d'erreur (violation protection mémoire, erreur d'entrées/sorties, etc.), ou des processus utilisateurs peuvent communiquer entre eux.
Voici la liste des signaux usuels, définie dans le fichier /usr/include/sys/signal.h. A chacun d'eux correspond un nom symbolique (quelquefois précédé des lettres SIG) associé à un nombre :
NOM NUMERO ROLEHUP 1 Signal de fin de session, émis à tous les processus associés à un terminal,
lorsque celui-ci est déconnecté.INT 2 Signal d'interruption d'un processus (Ctrl C en général).QUIT 3* Identique au signal INT avec la génération d'un fichier core.ILL 4* Instruction illégale.TRAP 5* Emis après l'exécution de chaque instruction, quand le processus fonctionne
sous le contrôle d'un débogueur (mode trace).IOT 6* Problème matériel.EMT 7 Emulateur Trap.FPE 8* Erreur d'exécution d'une instruction sur des nombres représentés en virgule
flottante.KILL 9 Meurtre d'un processus dont on est propriétaire.BUS 10* Erreur matérielle sur le bus.SEGV 11* Violation protection mémoire (segmentation ou pagination).SYS 12* Appel système invalide.PIPE 13 Ecriture sur un tube sans lecteur ou erreur sur une prise (BSD seulement).ALRM 14 Signal généré par l'horloge du système, utilisé par les primitives sleep,
alarm, setitimer pour définir des temporisations.

TERM 15 Terminaison normale d'un processus.USR1 16 Signal à la disposition des utilisateurs.USR2 17 Idem USR1.CLD,CHLD 18 Terminaison d'un processus un fils.PWR 19 Coupure de courant.WINCH 20 Modification de la taille d'une fenêtre.URG 21 Information urgente sur une prise (socket).POLL, IO 22 Gestion des Entrée/sortie asynchrones sur un périphérique de type stream.STOP 23 Fin d'un processus.TSTP 24 Arrêt temporaire d'un processus depuis le terminal.CONT 25 Redémarrage d'un processus stoppé.TTIN 26 Lecture d'un terminal en mode background.TOU 27 Ecriture d'un terminal en mode background.XCPU 30 Limite de temps CPU dépassée.XFSZ 31 Limite de taille de fichier atteinte. Les signaux dont le numéro est suivi par * génèrent un fichier image du processus appelé core qui est
une image de la mémoire sur disque du processus ayant provoqué l'émission du signal.
Le signal 9 (KILL), émis par le propriétaire du processus ou par le super-utilisateur, est le seul qu'on ne puisse ni ignorer, ni traiter par une fonction (c'est le meurtre du processus). L'arrivée des signaux TERM et KILL provoquent respectivement une fin normale et une fin catastrophique.
Application : signal de fin d'une session de travail
Selon l'interprète de commandes utilisé, tous les processus actifs d'un utilisateur qui se déconnecte sont tués (signal HUP). Ce choix peut sembler draconien, mais pour assurer la bonne gestion du système, il est nécessaire qu'il ne soit pas une "poubelle".
La commande du shell nohup permet de lancer un travail en mode différé (background), et de se déconnecter avec requête explicite de non prise en compte du signal HUP.
3.7.1Emission de signaux
Appel système kill
L'appel système kill permet l'émission d'un signal vers un processus.
Synopsisint kill(int pid, int signum)
Description
Le signal signum est envoyé au processus (ou au groupe de processus) d'identificateur pid et à tous ses fils.
La commande du shell kill
La commande du shell kill envoie un signal donné à un processus.
Synopsiskill -num_sig pid_du_processus_destinataire

Exemple
La commande :
kill -9 2383
provoque la mort du processus dont le pid est 2383.
3.7.2Réception de signaux
Comportement par défaut des processus à un réception d'un signal donné
signaux non masquables : par exemple le signal KILL. Le processus destinataire ne peut ni ignorer, ni modifier son comportement à réception.
signaux masquable : le processus destinataire peut ignorer ou modifier le comportement par défaut du processus à réception du signal
Application : la commande du shell trap
La commande (interne) du shell trap permet de spécifier le comportement d'un processus à réception d'un signal donné.
Synopsistrap [argument] numéro_de_signal
Les arguments autorisés sont les suivants :
"" signal reçu ignoré,• comportement par défaut du signal à redéfinir,'commande' une commande ou une fonction du shell à exécuter à réception du
signal.

Exempletrap 'rm /tmp/fichier; exit' 2 3
3.8 CONTRÔLE DE L'EXÉCUTION DES PROCESSUS
3.8.1Modes d'exécution d'un processus
Modes d'exécution
Les processus peuvent : s'exécuter en mode interactif ou mode foreground (tâche d'avant plan),
s'exécuter en mode différé ou mode background (tâche d'arrière plan),
être suspendu pour être relancé.
Lancement des processus
En mode interactif : c'est le mode par défaut.
En mode différé : avec l'opérateur &.
3.8.2Commande jobs
Référence aux processus
On peut référencer un processus : à partir du caractère % (numéro relatif de session, obtenu à partir de la commande jobs),
par son numéro (absolu) dans la table des processus (pid) obtenu à partir de la commande ps,
par son nom.
3.8.3Commandes de changement d'état
Changements d'état
Les interprètes de commandes C-Shell et Korn-shell permettent de contrôler les mode d'exécution d'un processus. Les changements d'état d'un processus sont : sa suspension,
sa mise en mode foreground,
sa mise en mode background,
sa terminaison.
Suspension d'un processus
L'arrêt immédiat d'un processus s'exécutant en mode foreground s'effectue par la commande ^Z (CTRL-Z).

Mise en mode interractif
Le passage en mode foreground d'un processus (passage de l'arrière plan en avant plan) s'effectue avec la commande fg (foreground).
Synopsis sur le processus courant fg
à partir du pid de processus fg pid_processus,
à partir du numéro de processus fg %numéro_relatif_processus,
à partir du nom du processus fg %identificateur_du_processus
Mise en mode background
Le passage en mode background d'un processus (passage de l'avant plan en arrière plan) s'effectue : sur le processus courant bg
à partir du numéro de processus bg %numéro_relatif_processus
à partir du nom de processus bg %nom_du_processus
Terminaison d'un processus
S'il en a les privilèges, un utilisateur peut forcer la terminaison d'un processus avec la commande kill.
Synopsiskill [-identificateur_du_signal] pid_du_processus
kill [-identificateur _du_signal] %numéro_du_processus
kill [-identificateur _du_signal] %nom_du_processus
Le signal de meurtre est celui par défaut.
Exempleskill 345
kill -INT 346
kill %1
kill %boucle
3.8.4Graphe de changement d'état
Les changements d'état évoluent selon l'algorithme suivant :

3.8.5Commande nohup La commande nohup permet d'ignorer certaines événements associés à la gestion des terminaux
(coupure de ligne, fin de session).
Elle est utilisée quand on souhaite lancer une commande qui poursuit son exécution après une déconnection.
Elle doit être utilisée sur des processus s’exécutant en mode différé.
Synopsisnohup commande [option(s)][argument(s)] &
3.8.6Commande killall
La commande killall commande termine tous les occurences de la commande lancée par l'utilisateur qui l'exécute.
Synopsiskillall identificateur_commande_à_supprimer
3.8.7Commande lastcomm
La commande lastcomm ne peut être utilisée que si la comptabilité est active. Elle affiche toutes les commandes exécutées, dans leur ordre inverse d'exécution.
Synopsislastcomm [commande]
3.8.8Commandes nice et renice
La commande nice
La commande nice permet de modifier la priorité d'un processus.
Synopsisnice -n commande

Description
Le nombre n positif rend un processus moins prioritaire. Négatif, il le rend plus prioritaire. Dans ce dernier cas, seul l'administrateur peut l'utiliser.
Exemplenice –20 ./boucle&
La commande renice
La commande renice permet de modifier la priorité d'un processus déjà démarré avec les mêmes règles que celles de la commande nice.
Exemplerenice 20 23561
3.9 EXERCICES
3.9.1Commande ps
a) Afficher la liste des processus de la session de travail courante.
b) Afficher la liste de tous les processus actifs.
c) Afficher la liste des processus d’un utilisateur donné.
d) Afficher la liste des processus actifs (option d'affichage avec le maximum de renseignements).
3.9.2Gestion des modes d'exécution (commandes bg &fg)
Exécuter le § a) ou le §a') selon les outils dont vous disposez.
a) Avec l'éditeur de votre choix, écrire le shell script boucle suivant :#!/bin/bash# remplacer éventuellement bash par kshwhile [ vrai ]do:done
Rendre le programme exécutable avec la commande
chmod +x boucle
a') Avec l'éditeur de votre choix, éditer le programme boucle.c suivant :
int main(){for(;;);}
Créer le fichier exécutable boucle par la commande :

make boucle
b) Lancer le shell-script ./boucle en mode interractif (foreground) puis, dans une autre fenêtre, l'identifier à partir de la commande ps.
c) Tuer le processus associé à la commande boucle à partir de la commande kill. Emettre les signaux HUP, QUIT, KILL, BUS.
d) Lancer le shell-script ./boucle puis modifier son mode d'exécution en mode différé à partir des signaux de contrôle ou à partir des commandes fg, bg, jobs.
e) Lancer plusieurs occurences du shell-script ./boucle, certaines précédées de la commande nohup. Se déconnecter et se connecter à nouveau. A partir des commandes ps et grep, rechercher les occurences de la commandes boucle. Conclusion ?
f) Soit le shell script signal :#!/bin/bashtrap "" INT QUITwhile [ vrai ]do:done
Après lancement du shell script signal, interpréter le comportement des signaux INT, QUIT sur le shell script ./signal.
3.9.3Gestion des priorités
a) Modifier les priorités d’exécution d’un processus boucle à partir des commandes nice puis renice.
b) Lancer plusieurs occurences du programme boucle puis, après vérification de sa syntaxe dans le manuel, la commande killall opérant sur ces dernières. Conclusion.
3.10 RÉCAPITULATION DES COMMANDES D'ADMINISTRATION
ps, sar, pstat, prfdc, prfld, prfswap

4. GESTION DE LA MEMOIRE
Le système d'exploitation UNIX utilise toutes les techniques classiques de gestion mémoire : swapping, pagination, segmentation, gestion de la mémoire virtuelle. Le programmeur peut faire des requêtes d'allocation dynamique de mémoire (primitive malloc), définir et utiliser des zones de mémoire partagée par plusieurs processus.
4.1 HISTORIQUE
La version UNIX V7 est basée sur l'architecture du PDP/11, mini-ordinateur 16 bits dont la gestion mémoire est segmentée. L'espace d'adressage virtuel, limité sur cette machine à 64 K-octets, impose une gestion mémoire basée sur le swapping.
L'apparition du Vax 11/780, dont l'espace d'adressage virtuel est sur 32 bits (4 Giga octets), permet de supporter la gestion de la mémoire virtuelle par pagination avec la version d'UNIX 32V. L'opération de swap partiel permet de récupérer de la mémoire quand c'est nécessaire. De plus, les processus peuvent disposer d'un espace d'adressage virtuel linéaire.
Apports de l'Université de Berkeley
Version 3BSD pagination à la demande,
stratégie de positionnement et de remplacement des pages de type LRU,
pré-allocation de l'espace de swap à la création d'un processus.
Version 4.1 BSD regroupement des pages par grappe (cluster) pour accélérer leur chargement et réduire la surcharge
due à la gestion des pages "sales",
stratégie de chargement des pages par anticipation,
les processus peuvent contrôler le remplacement des pages.
Version 4.3BSD le segment de code des programmes ainsi que leur table des pages sont conservés dans un cache après
l'exécution de l'appel système exit,
l'algorithme de remplacement des pages est modifié pour être indépendant de la taille de la mémoire centrale.
Apports de SYSTEM V
La segmentation des programmes et des données est introduite. La pagination des versions d'UNIX BSD est intégrée depuis SYSTEM V release 3.2.

Le mécanisme de la mémoire partagée permet la communication de plusieurs processus actifs par l'intermédiaire d'une zone de mémoire commune.
4.2 GESTION DE LA MÉMOIRE CENTRALE
La mémoire centrale est divisée en deux parties : le noyau et la table proc sont résidants,
le reste de la mémoire centrale est alloué aux processus actifs.
La table système coremap est la structure de données utilisée pour la gestion de la mémoire. C'est une table de structures de gestion des grappes utilisée pour : stocker l'état courant des clusters donc des pages associées,
convertir l'adresse virtuelle en son adresse réelle,
assurer la synchronisation de la gestion des pages,
assurer la gestion des pages disponibles par la création et la gestion d'une liste doublement chaînée de clusters,
définir les limites de l'espace mémoire utilisable par un processus,
définir le nombre maximum de processus.
Tout processus dispose de ses propres tables des pages.
4.3 SWAP
L'opération de swap in est la possibilité pour le noyau de transférer des zones de la mémoire centrale dans l'espace de swap sur le disque. L'opération de swap in est le chargement en mémoire d'un processus swappé out pour la reprise de son exécution. Ces opérations s'effectuent à la demande du processus ou du noyau par le processus système swapper.
4.3.1Stratégie du swapping
Les états du swapper sont les suivants : état IDLE : il n'y a pas de processus à swapper in ou à swapper out,
état swap out,
état swap in.
La zone de swap est gérée par groupement de blocs et sans cache. Elle ne doit pas être structurée en système de fichiers
La stratégie du swapping est définie par la primitive sched : sélection en mémoire centrale du processus le moins prioritaire, si possible endormi pour le swapper
out,
sélection en zone de swap du processus le plus prioritaire dont le statut est non(SLOAD) et l'état SRUN pour le swapper in.

4.3.2Swap out
L'opération de swap out transfère la table des pages, les pages de données et les segments de pile d'un processus en cours de traitement de la mémoire centrale en zone de swap. Le segment de texte reste en mémoire s'il est partagé. Elle se produit dans les cas suivants : duplication d'un processus,
extension de la taille des données ou de la pile d'un processus,
requête du noyau pour charger un processus plus prioritaire,
saturation du mécanisme de pagination,
fragmentation de la table des pages empêchant l'allocation éventuelle de pages,
inactivité d'un processus actif pendant plus de vingt secondes.
4.3.3Swap in
La priorité d'un processus swappé out est recalculée à partir de la durée pendant laquelle il a été swappé out, sa taille, sa valeur nice. Une fois le processus sélectionné, le noyau vérifie qu'il y a suffisamment de mémoire pour charger sa structure U, sa table des pages et les pages constituant son espace vital.
La swap_map est la table de swap associée à un processus. L'allocation d'espace de swap est réalisée par blocs contigus par un algorithme de type First Fit. Lors de sa libération, il est recompacté pour éviter la fragmentation.
L'augmentation de la taille et du nombre des processus nécessite l'augmentation des zones de swap. Il est possible, depuis les versions d'UNIX 4.3 BSD de définir dynamiquement plusieurs zones de swap sur des disques différents (commandes swap, swapon, et swapoff).
La pagination et le swapping de stations de travail sans disque étant réalisés sur une station serveur par l'intermédiaire du réseau, une mémoire centrale importante sur la station serveur minimise la charge du réseau.
4.4 PAGINATION
La pagination est exécuté par le processus pagedaemon (BSD). Différentes tables de pages sont nécessaires. Les tables des pages virtuelles décrivent les pages, en zone de swap ou en mémoire, utilisées par un processus. Les tables du cadre de pages ou encore table des pages inversées décrivent les pages de la mémoire réelle, en assurant la correspondance entre les pages virtuelles et la table du cadre des pages réelles. Sur certains systèmes, un cache associatif (TLB Translation Lookaside Buffer) permet d'accélérer les performances de recherches des pages réelles.
Le principe de localisation est utilisée pour le chargement des clusters par anticipation. Le choix des victimes est déterminé selon un des algorithmes : Démon voleur de pages type Système V R3
Démon voleur de pages type BSD (clock et double clock)
Algorithme de la double chance

Remplacement de page
Le noyau conserve le maximum de pages en mémoire pour qu'elle soit toujours intégralement occupée, par exemple avec des segments de texte inutilisés. L'algorithme de remplacement de pages, de type LRU, est implémenté dans le processus pagedaemon, qui n'est activé que lorsque le nombre de pages disponibles est inférieur à un seuil fixé à l'initialisation du système.
Si le processus pagedaemon provoque un taux de défauts de pages trop élevé, le processus swapper est activé. Les pics en demande de mémoire causés par l'appel système fork sont atténués par l'utilisation de l'appel système vfork. Ceux de l'appel système exec le sont également car les pages du nouveau processus sont chargées au fur et à mesure des besoins.
Le fonctionnement du pagin et celui du pageout sont différents. Les pages à swapper in sont chargées ainsi que les pages voisines (mécanisme d'anticipation). Les pages à swapper out sont groupées en grappes (cluster).
4.5 SEGMENTATION
Le problème est d'établir l'adressage des régions (segments) constituant le processus. L'adressage est réalisé par l'intermédiaire de tables qui font la correspondance entre les adresses effectives (processus) et les adresses virtuelles (noyau).
L'adressage effectif est calculé pour permettre l'extension des régions ou segments (données, pile, etc. ...)
Mais subsiste les problèmes d'adressage des bibliothèques (les bibliothèques partagées ont des adresses fixes) et des fichiers attachés (agrandissement).
Sous SYSTEM V, l'espace d'adressage virtuel d'un processus est divisé en régions, une région étant une zone continue de l'espace d'adressage virtuel. Plusieurs processus peuvent simultanément accéder à une même région pour exécuter le même segment de texte ou partager des données communes.
La table système des régions contient un point d'entrée pour chaque région active du système.
Le texte, les données et la pile d'un processus constituent trois régions distinctes : le segment de texte (text segment),
le segment de donnée (data segment),
la pile (stack segment).
Il y a en outre : les régions associées aux fichiers adressées en mémoire,
les régions de mémoire partagées,
les régions associées aux bibliothèques partagées.
La table des pointeurs sur les régions associées à un processus est la table prégion.Chacune de ses entrées pointe sur une entrée de la table des régions et contient l'adresse virtuelle de base de la région correspondante, ainsi que les droits d'accès associés. Il y a une analogie entre le rôle de la structure FILE pour la table des inodes et celui de la table pregion pour la table des régions.

Le noyau dispose également d'une table des régions dont les entrées sont gérées par l'intermédiaire de deux listes : la liste des entrées disponibles et la liste des entrées actives.
La protection et le partage d'une région de texte entre plusieurs processus exécutant le même code (accès uniquement en lecture) est réalisée par des mécanismes matériels. La fonction xalloc vérifie la présence du texte en mémoire centrale en lisant la table des régions et les pointeurs d'inode. La région est attachée au processus et son compteur de références incrémenté. A chaque modification de la table des régions, le point d'entrée est verrouillé puis libéré quand les compteurs (et/ou pointeurs d'inode) sont correctement initialisé puis incrémentés. Quand le compteur d'inode devient nul, son point d'entrée est libéré. Dans le cas de segment de texte avec bit de collage, le point d'entrée inode est conservé et le compteur de liens est forcé à 1, même après un exit. Un point d'entrée nul indique que le fichier est chargé mais qu'il n'est pas utilisé par un autre processus. Une référence au même fichier est immédiatement satisfaite.
4.6 CRÉATION DE PROCESSUS
Swapping
Dans un environnement de swapping pur, l'appel système fork duplique l'intégralité des ressources consommées par le processus père pour créer le processus fils à savoir les régions privées, les zones données et la pile utilisateur. Comme en général, l'appel fork est suivi de l'exécution d'un appel système exec*, cette duplication est inutile.
4.3 BSD
Les ressources sont dupliquées de la façon suivante :
Ressources du noyau
Allocation des ressources de swap.
Allocation et initialisation de la structure proc associée au processus.
Allocation des tables de pages et des pages associées.
Le processus père est verrouillé en mémoire pendant toute la durée de la création pour éviter un verrou mortel : processus père swappé out alors que l'état du fils est inconsistant.
SYSTEM V
La copie des ressources est évitée par l'utilisation des différentes tables de gestion mémoire.
Une page est partagée par les processus père et fils jusqu'à ce que l'un des deux tente d'y écrire. La page est alors dupliquée à cause de la validation préalable du bit copie sur écriture.
4.7 FICHIERS EN MÉMOIRE
La version UNIX 4.2 BSD permet l'inclusion totale ou partielle d'un fichier dans l'espace adressable d'un processus (appel système mmap). Les entrées/sorties s'exécutent alors directement en mémoire. Ce dernier apport est particulièrement bénéfique pour des stations de travail sans disque.

4.8 GÉNÉRALITÉS SUR LES IPC SYSTEM V
On appelle IPC (interprocess communication) les trois mécanismes de communication et de synchronisation inter processus définis dans la version UNIX SYSTEM V release 2. Ils permettent à des processus quelconques d'échanger des données et de synchroniser leur exécution. Ce sont la mémoire partagée, les messages et les sémaphores.
Propriétés communes des IPC
Chaque type d'IPC est gérée par une table spécifique : il existe donc une table système des zones de mémoire partagées, des queues de messages, ou des tableaux de sémaphores. Le nombre de points d'entrée de chacune de ces tables est limité.
Chaque IPC est décrit par une structure dont les champs en décrivent toutes les propriétés. Chaque point d'entrée des différentes tables des IPC contient les droits d'accès contenant l'uid et le gid du processus créateur, l'uid et le gid du processus propriétaire, un ensemble de drapeaux en lecture, écriture, et exécution similaires à ceux des fichiers, des informations sur l'état de l'IPC telles que le pid du dernier processus à y avoir accédé ainsi que l'heure du dernier accès et de la dernière mise à jour. Les processus créateur et propriétaire peuvent modifier les droits. Le processus créateur est inamovible.
Un appel système de contrôle spécifique à chaque IPC permet au programmeur de faire des requêtes d'état d'une information, ou de supprimer une entrée de la table. Les appels système relatifs aux différents IPC ont une forme d'utilisation voisine. Par exemple :
message mémoire partagée sémaphorecréation msgget shmget semgetcontrôle msgctl shmctl semctl.
Les processus serveur et client d'une même application doivent utiliser un même chemin d'accès (pathname) et un même caractère (id) pour que la clé d'accès obtenue soit unique. Il faut également s'assurer que le chemin d'accès n'est pas détruit en cours d'exécution Le descripteur numérique de l'IPC, obtenu à partir des appels système shmget, msgget, semget et de la clé d'accès est défini de façon unique dans les processus clients et le processus serveur. Il y a une analogie entre les descripteurs numériques de chaque IPC et les descripteurs logiques de fichiers.
4.8.1Mémoire partagée
Plusieurs processus peuvent communiquer directement en lisant ou en écrivant des données dans une région de mémoire partagée, zone commune de leur espace d'adressage virtuel respectif. Une clé d'accès lui est associée à sa création lui permettant d'être ensuite attachée au processus utilisateur et intégrée à son espace d'adressage virtuel. Après utilisation, le processus la détache de son espace d'adressage. Il ne peut la détruire que s'il est le dernier processus à lui être attaché et s'il en a le droit.
La gestion des sections critiques en écriture dans les zones de mémoire partagée doit être faite au niveau applicatif (par utilisation de sémaphores par exemple).
Le mécanisme de mémoire partagé est très performant car il ne nécessite pas la recopie des données partagées entre processus.

4.8.2Messages
Les queues (files) de messages permettent la communication indirecte de processus asynchrones par une gestion de boites à lettres suivant le modèle des lecteurs et des rédacteurs. Quand un processus crée une file de messages, il en définit la clé d'accès dont la connaissance est nécessaire pour l'envoi ou la réception de messages. Chaque message est typé par l'utilisateur de façon à éviter les conflits d'accès.
Un processus ne peut accéder à une file que s'il en possède les droits d'accès, identiques à ceux des fichiers.:
4.8.3Sémaphores
Un processus peut créer un ensemble de sémaphores, accessibles par leur identificateur et une clé d'accès et réaliser les opérations P et V.
4.8.4Commandes shell associées
La commande shell ipcs permet l'affichage de l'ensemble des IPC utilisés par le système à un instant donné. Sans option, on obtient la liste des IPC utilisées à un instant donné.
Les options q (Message Queues), m (Shared Memory), s (Semaphores) permettent l'affichage d'une table particulière.
Les options b,c,p,t,a permettent la consultation de la structure ipc_perm.
La commande shell ipcrm permet la suppression des canaux d'IPC.
4.9 RÉCAPITULATION DES COMMANDES D'ADMINISTRATIONswapper, swap (ordonnanceur)
update, sync (gestion du cache)
pagedaemon, vpage (gestionnaire de page)
ramdisk (disque virtuel en mémoire)
ipcs, ipcrm (gestion des ipc)

5. GESTION DE FICHIERS
5.1 TYPES DE FICHIERS L’utilisateur a une vision uniforme des entrées sorties que celles-ci s’effectuent sur des fichiers, des
périphériques ou des IPC (outils de communications interprocessus). La notion de fichiers est donc très générale puisque qu’un fichier est la représentation abstraite d’un périphérique (par exemple le disque /dev/dk0) ou bien d’une unité logique de stockage (par exemple /home/prof/livre).
La sémantique des appels systèmes d’accès aux fichiers et leurs protections est identique quelque soit leur type.
Un système de fichiers est arborescent et défini récursivement.
On distingue quatre types de fichiers:
5.1.1Fichier ordinaire Un fichier ordinaire (ou encore normal, régulier, banalisé) est constitué d’une suite finie d’octets
sans organisation particulière, et d’un pointeur sur l’octet courant.
Il ne faut pas confondre les fichiers ordinaires et les fichiers standards (définis ci-après).
5.1.2Répertoire Un répertoire assure la correspondance entre un nom logique de fichiers et sa situation géographique
sur le disque.
Il est constitué de fichiers de n’importe quel type.
L’utilisateur perçoit l'arborescence d’UNIX sous la forme d’un arbre où les noeuds sont des répertoires (hiérarchisés) et les feuilles des fichiers ordinaires. Le noeud le plus élevé est appelé racine (root) et notée /. C’est le répertoire à partir duquel l’utilisateur va désigner un fichier par son chemin d’accès (pathname) représenté par un arc orienté.

Un répertoire se distingue des fichiers ordinaires par son type et la structure de ses blocs structurés en entrées de longueur variable jusqu’à 255 caractères depuis les versions 4.2 BSD et SYSTEM V R4), correspondant chacune à un fichier, ou à un sous répertoire.
5.1.3Lien matériel et lien symbolique
Inode
Le descripteur d'un fichier est appelé inode.
Lien matériel
Un lien matériel représente le nombre de chemins d’accès à un fichier donné dans un même système de fichiers. Le fichier est supprimé si ce nombre devient nul.
Le lien matériel est réalisé entre deux fichiers associés à un même inode. C’est un élément d’un répertoire qui fait référence à un fichier. Un même fichier (avec ses caractéristiques propres: taille, protections, etc.) peut comporter plusieurs liens. On ne peut établir de lien matériel sur un fichier d'une autre partition. La seule façon de reconnaître un lien matériel entre deux fichiers est de visualiser leur numéro d’inode et de constater qu’ils sont identiques. Quand deux fichiers pointent sur le même inode, le fait d’en modifier un modifie automatiquement l’autre.
Un inode est accessible par une entrée d’un répertoire qui crée un lien matériel entre le fichier et l’inode le matérialisant. Il peut avoir plusieurs chemin d’accès à un inode dans son système de fichiers donc plusieurs liens matériel sur un même inode. Le concept de lien matériel est fondamental: les inodes ne font pas partie d’un répertoire donné. Ils existent séparément et sont accessibles par les liens matériels. Quand le nombre de liens d’un inode devient nul, l’inode est désallouée.
Un lien matériel définit un deuxième chemin d’accès à un fichier sans en faire de copie effective. Il n'existe qu'une unique occurrence du fichier même si différents chemins d’accès permettent d’y accéder.
Liens symbolique
Il existe un deuxième type de liens: le lien symbolique, d’origine BSD. Un lien symbolique (BSD) définit un chemin d’accès synonyme du chemin d’accès du fichier (ordinaire ou répertoire). C’est une entrée d’un répertoire quelconque de l’arborescence définissant un nouvel inode contenant un nouveau chemin d’accès (absolu ou relatif) d’un inode existant (banalisé ou répertoire) d’un système de fichiers quelconque de l’arborescence. On a la représentation suivante :
Le lien symbolique généralise la notion de lien matériel à un système de fichiers quelconque. Toutefois, contrairement à un lien matériel, le déplacement ou la suppression d’un fichier ne modifie

pas un lien symbolique sur ce fichier qui ne pointera sur rien si le fichier n’est pas remplacé ou qui pointera sur le nouveau fichier dont l’inode est identique au fichier antérieur.
Le lien symbolique sur un répertoire est très utile mais n’est pas symétrique. Un changement de répertoire relatif à un fichier accédé par un lien symbolique peut laisser l’utilisateur perplexe quand à sa position dans l’arborescence.
Le protocole NFS a permis de généraliser la notion de lien symbolique sur des systèmes de fichiers distants ce qui est d’un intérêt considérable pour l’administration de réseaux.
OSF/DCE introduit la notion de lien symbolique avec temporisation: le fichier cible est contrôlé périodiquement et le lien détruit s’il est inexistant.
5.1.4Création des liens
Liens matériel
Synopsisln fichier_origine lien_destination
Liens symboliques
Synopsisln -s fichier_origine lien_destination
Le lien symbolique, entre deux fichiers, s’exécute sur des numéros d’inodes différents et peut associer des fichiers se trouvant sur des systèmes de fichiers différents.
5.1.5Fichiers spéciaux
Un fichier spécial est référencé dans le répertoire /dev ou un de ses sous répertoires. Il matérialise un périphérique qui est dans un des trois modes de fonctionnement suivants : mode c (caractère): tous les périphériques,
mode b (bloc): ce sont les supports magnétiques de stockage (disque, bande, etc.) structurés dont les entrées/sorties sont gérées par le système de gestion des fichiers via le cache,
tubes nommés (nammed pipe).
La représentation par la commande shell ls -l de ces types de fichiers est la suivante:• pour les fichiers ordinaires,d pour les fichiers répertoire,b pour les fichiers spéciaux en mode bloc,c pour les fichiers spéciaux en mode non bloc,
Les autres types de fichiers sont:p pour les fichiers spéciaux tube nommél pour les liens symboliques,s pour les sockets,m pour une entrée partagée.

Entrées/sorties de haut niveau
Les opérations d’entrées/sorties de haut niveau assurent le transfert des données entre le processus utilisateur et le noyau.
Entrées/sorties de bas niveau
Les opérations d’entrées/sorties de bas niveau assurent le transfert des données entre le noyau et le support physique.
Entrées/sorties sur les fichiers ou en mode bloc
Elles assurent la lecture et l’écriture de fichiers d’un système de fichiers avec autorisation de lecture anticipé (read ahead) et d’écriture différée (delayed write) dans le cache. Les transferts sont réalisés au niveau supérieur par les primitives de haut niveau et au niveau inférieur par les pilotes de périphérique en mode bloc. L’accès au périphérique est indépendant de l’application.
Entrées/sorties en mode caractère
L’application gérant elle-même le tampon d’entrées/sorties utilise directement la structure des systèmes de fichiers sur le disque et n’utilise pas le cache. Les données sont transmises aux pilotes de périphérique en mode caractère.
Entrées/sorties en mode cru (mode raw)
L’application gère elle-même les tampons associés et l’opération d’entrée/sortie, usuellement exécutée en mode bloc, n’utilise pas le cache.
5.1.6Fichiers standards
Trois fichiers utilisés pour la saisie et l'affichage, appelés fichiers standards sont ouverts au début de toute session de travail. Ce sont: le fichier standard d’entrée: le clavier, dont le pointeur est stdin et le descripteur 0,
le fichier standard de sortie: l’écran, dont le pointeur est stdout et le descripteur 1,
le fichier standard d’affichage des messages d’erreurs système : l’écran, dont le pointeur est stderr et le descripteur 2.

entrée standardCommande
sortie standard
messages d'erreur standard
L’appellation fichier standard ne signifie pas que les autres fichiers ne sont pas des fichiers "normaux" : cela veut seulement dire qu’ils sont différents des fichiers stdin, stdout, stderr Les fichiers autres que les fichiers standards sont les fichiers ordinaires.
5.1.7Redirection
Définition
La redirection d’un fichier consiste à modifier son descripteur de telle sorte que l’inode cible par défaut soit modifiée.
Redirection des fichiers standards
Il est donc possible de rediriger les trois fichiers standards sur des fichiers (saisie ou résultat) quand on utilise l’interprète de commandes.
Une redirection n’est valable que pour la commande courante.
Redirection de la sortie standard
Le caractère spécial associé à la redirection de la sortie standard est le caractère > suivi du nom de fichier (ordinaire ou spécial) sur lequel on souhaite l’effectuer.
Exemplesls Affiche à l’écran la liste des fichiers du répertoire courant,ls > liste La liste des fichiers du répertoire courant est stockée dans le fichier
liste.ls > /dev/tty12 La liste des fichiers du répertoire courant est redirigée sur le terminal
associé au périphérique /dev/tty12.
Remarque
La redirection de la sortie permet de créer un fichier vide en shell de Bourne ou en Korn shell . Il suffit d’exécuter la commande
cp /dev/null > fic
Ordre d’exécution des opérateurs
Le fichier cible de la redirection est détruit (s’il existe) puis recrée lors de son exécution ce qui provoquer des conséquences inattendues. Soit la commande:
cat f1 f2 > f1
utilisée pour concaténer les fichiers f1 et f2 en appelant f1 le fichier résultat. Le fichier f1 d’origine est détruit puis recréé, identique à f2.

Redirection en mode ajout
Il est possible d’éviter cette destruction en utilisant le symbole >> au lieu du symbole > qui s’exécute selon le principe suivant: si le fichier existe, l’information est ajoutée à sa fin. Il est créé sinon.
Exemplels > liste création du fichier liste,date >> liste ajout de la date courante en fin du fichier liste,cat f2 >> f1 ajout de f2 après f1.
Redirection du fichier standard d'affichage des messages d’erreur
Pour rediriger le fichier standard d'affichage des messages d’erreurs (stderr), les symboles > ou >> doivent être précédés de l’étiquette logique 2.
Exemple
cc pg.c 2> pg.e compilation du fichier pg.c avec redirection des messages d'erreur dans le fichier pg.e
Redirection de l’entrée standard
Le caractère de redirection est le caractère < suivi du nom du fichier à partir duquel on souhaite faire la redirection.
Exemplecrypt cle < clair
le fichier clair (prééxistant) est redirigé sur l’entrée standard. Il est crypté (ou décrypté) et le résultat est affiché à l’écran.
Redirections simultanées
On peut exécuter simultanément des redirections sur les fichiers standards d’entrée et de sortie.
Exemplecrypt cle < clair > code
Le résultat n’est plus affiché sur la sortie standard mais stocké dans le fichier code.
Autre forme de la redirection de l’entrée standard
Une deuxième forme de redirection de l’entrée standard, surtout utilisée dans les shell scripts, est représentée par le symbole <<.
L’entrée est le texte qui suit immédiatement le symbole, encadré par un séparateur (un caractère ou une chaîne de caractère n’apparaissant pas dans le texte, séparé ou non par des caractères d’espacement). Dans l’exemple ci-après, le séparateur est le caractère !. Il doit apparaître après le symbole << et à la fin du texte saisi, au début d’une ligne.
Exempleed fic << ! #appel de l’éditeur sur le fichier fic
On saisit alors des directives d'édition de l'éditeur ed :

/mot/ recherche de la chaîne mot,d suppression de la ligne,w écriture du fichier,q sortie de l’éditeur ed,! fin de la redirection.
Les remarques sur la position du symbole ainsi que sur l’enchaînement et l’ordre des redirections restent valables avec le symbole << .
Exempledebut << EOT ed fic1,4pqEOT
Description
Appel de ed sur le fichier fic avec double redirection (en sortie, le fichier debut contient les 4 premières lignes), EOT est ici le séparateur.
5.1.8Tube
Le principe du tube est de rediriger la sortie standard d’une commande sur l’entrée standard d’une autre. L’opérateur | est associé à son utilisation.
Exemple
La commande ls –l | wc -l affiche le nombre de lignes du résultat de la commande ls –l donc le nombre de fichiers du répertoire courant.
La position du caractère | est stricte car il doit se trouver entre les deux commandes, après les options et les paramètres de la première, séparés ou non par des caractères d’espacement.
Tubes et redirection
On peut enchaîner plusieurs tubes et utiliser simultanément des redirections.
Exemplesls | wc -l > nbfic le résultat apparaît dans le fichier nbficls | tee inter | wc -1 le résultat de ls est transmis à la commande tee qui transmet
son résultat à wc (inter est une copie du résultat de ls).
5.1.9Affichage du type d'un fichier
file
Synopsisfile nom_de_fichier
Description
Affichage du type des informations d'un fichier.
Exemple : file *Types de fichiers:

ascii textarchive random libraryC program textdatacpio archivedirectoryemptyexecutable shell scriptmc68020 executablesymbolic linkroll nroff or eqn input text
5.2 COMMANDES DE GESTION DES FICHIERS
5.2.1Règles de nommage
C’est une chaîne de caractères alphanumériques significatifs et explicites, pouvant être constituée de lettres majuscules, minuscules, chiffres et des caractères spéciaux -, _ etc.
Certains caractères spéciaux sont réservés : (,[,),],{,},/, \,*, ’,’’, ^, $, ‘,).
Pour le système UNIX, les lettres majuscules et minuscules sont considérées comme différentes.
Dans les environnements actuels, la longueur du nom est limitée à 256 caractères.
Les fichiers silencieux
Leur nom commence par un point (.) et ils sont utilisés pour personnaliser l’environnement utilisateur. On visualiser leurs caractéristiques avec la commande ls -a.
Exemple.login .cshrc .profile .logout
5.2.2Caractères spéciaux élémentaires du shell
Les caractères spéciaux permettent de remplacement de caractères explicites par des méta-caractères, dans les éditeurs de textes ou avec les commandes du shell.
Exemple
Les fichiers peuvent être désignés de façon explicite (en indiquant le chemin d’accès absolu ou relatif) où générique si on utilise des caractères spéciaux qui permettent la substitution du nom.
Le caractère spécial *
Il remplace un nombre quelconque de caractères donc toute chaîne de caractères.
Le caractère spécial ?
Il remplace un unique caractère.

Le caractère backslash
Le caractère spécial qui suit le caractère \ (backslash) perd sa signification et est considéré comme un caractère ordinaire par le shell. Ainsi, le caractère \ précédent un caractère CR permet de poursuive l'instruction sur la ligne suivante.
Les crochets
Les crochets [] délimitent un ensemble de caractères et permettent de compléter une chaîne de caractères par une des occurences de la liste.
Exemplenom[abc] noma, nomb ou nomcnom[123] nom1, nom2 ou nom3nom[ab1] noma, nomb ou nom1
Crochet et -
L'expression[f-j] représente un des caractères de l'intervalle (ordre lexicographique) défini entre les deux caractères.
Exemplenom[a-z] nom[0-9]
Crochet et !
L'expression [! représente le début du complément d'un ensemble.
L'expression ] représente la marque de fin de l'ensemble.
5.2.3Chemins d’accès
Chemin d’accès absolu
Le chemin d’accès peut-être absolu chemin d’accès ou relatif chemin d’accès. Les différents répertoires utilisés sont décrits dans l’ordre décroissant de l’arborescence de la gauche vers la droite et séparés par le caractère spécial /.
Le chemin d’accès absolu décrit la chaîne des répertoires depuis la racine (root = /) jusqu’au répertoire courant.
Exemple/home/philipp/f1
Chemin d’accès relatif
Le chemin d’accès est relatif aux fichiers et répertoires du répertoire courant.
Exemplephilipp/f1

Commandes associées
Synopsisbasename fichier affichage du nom relatif du fichier à partir du chemin absolu,dirname fichier affichage du répertoire contenant le fichier.
Répertoires particuliers
Le répertoire courant est noté .Le répertoire père est noté ..
5.2.4 Informations généralesSynopsisls [option] [fichier(s)] [répertoire(s)]
Description
La commande ls sans options affiche le nom des fichiers du répertoire courant.
Optionsa affichage les fichiers silencieux (.mailrc,.profile,...).l affichage (format long) des informations suivantes:
nom,type (fichier ordinaire, répertoire, périphérique, lien, etc.),date de dernière modification,taille (en octets),attributs de sécurité et de propriétés.
R affichage (récursif) du contenu des sous-répertoires.
5.2.5CopieSynopsis
Deux syntaxes:cp [options] fichier_origine fichier_ciblecp [options] fichier_origine(s) répertoire_cible
Description recopie d’un fichier vers un autre fichier, écrasé s’il existe déjà,
recopie des fichiers vers le répertoire cible (prééexistant).
5.2.6Renommage ou déplacementSynopsismv [options] fichier_origine fichier_ciblemv [options] fichier_origine(s) répertoire_cible
Description
Déplacement d’un fichier dans un autre répertoire ou renommage dans le même répertoire. Un fichier cible existant est écrasé sauf avec l’option -l

5.2.7SuppressionSynopsisrm [-option(s)] fichier(s)
Description
Cette commande supprime des fichiers. Ses principales options sont: i demande (interactive) de confirmation avant destruction,
f destruction sans prise en compte des attributs du fichier (forçage),
r destruction de tous les sous-répertoires et de leur contenu (récursif).
5.2.8Comparaison
diff
Synopsisdiff [option(s)] fichier1 fichier2
Description
Affichage des lignes différentes des fichiers textes fichier1 et fichier2. Les options sont: b ignore les caractères d’espacement ou tabulations,
e mise en forme du résultat pour rendre les 2 fichiers identiques
cmp
Synopsiscmp [-l] -[s] fichier1 fichier2
Description
Comparaison des fichiers binaires fichier1 et fichier2 et affichage de l’octet et du numéro de la ligne où se trouve la première différence. L’option -l permet d’afficher la valeur des octets en octal et le numéro de la ligne en décimal.
L’option -s permet de récupérer un code de retour sans affichage (0: fichiers identiques, 1: fichiers différents, 2: erreur d'exécution de la commande).
comm
Synopsiscomm [-123] fichier1 fichier2
Description
Comparaison des fichiers (triés en ASCII) fichier1 et fichier2 et affichage sur 3 colonnes: des lignes différentes dans fichier1 uniquement,
des lignes différentes dans fichier2 uniquement,
des lignes différentes dans fichier1 et dans fichier2.

L’option 123 permet de supprimer l’affichage de la ou des colonnes indiquées.
5.2.9Concaténation
cat
Affichage du contenu ASCII d’un ou plusieurs fichiers sur la sortie standard.
Synopsiscat fichier(s)
La redirection de la sortie standard permet de concaténer plusieurs fichiers.
Attention à la commande:
cat f1 f2 > f1
Selon les implémentations, elle peut provoquer l’écrasement de f1 puis son remplacement par f2.
5.2.10 Contenu
Affichage par page
more [options] nom de fichier
Description
Affichage du contenu d’un fichier page par page. La commande utilise les caractéristiques du terminal définies par la variable d'environnement TERM.
Options affichage ligne par ligne ( < cr > )
affichage par page d’écran (< caractère d’espacement > )
recherche d’une chaîne de caractères dans la suite du fichier (/chaîne < cr > ).
La sortie de la commande s'exécute avec l’un des caractères q ou ^C.
Lignes en tête du fichier
head [options] nom de fichier
Description
Affichage, par défaut, des 10 premières lignes d’un fichier.
Lignes à la fin du fichier
Synopsistail [options] nom de_fichier
Description
Affichage, par défaut, du contenu des 10 dernières lignes d’un fichier. Avec l’option -f, la commande boucle en lecture sur le fichier en attendant que sa taille ne s’accroisse.

Dump d'un fichier
od [options] nom de_fichier
Cette commande permet d’examiner des fichiers contenant des caractères spéciaux non imprimables. Quatre options :
c caractère• octald décimalx hexadécimal.
5.2.11 L’heure de dernière modification
La commande touch est utilisée pour: créer un fichier vide,
changer la date de dernière modification d’un fichier (souvent utilisé pour l’utilitaire make).
Synopsistouch fichier
5.2.12 La commande fuser
La commande fuser affiche la liste des processus utilisant un fichier donné.
Syntaxe
fuser [-v] répertoire
Description
Affiche la liste des fichiers utilisés et les processus correspondants d'un répertoire donné
Exemplefuser –v /home
USER PID ACCESS COMMAND/home user1 881 ..c.. bash
user1 2647 ..c.. startx
5.2.13 Recherche récursive avec condition et traitement
La commande find permet d’écrire des shells scripts de gestion des fichiers dans une arborescence donnée. Elle permet par exemple de connaître, récursivement, la liste des fichiers: d’une taille inférieure ou supérieure à une taille donnée,
inutilisés pendant une certaine période,
appartenant à un utilisateur ou à un groupe donné.
Synopsisfind chemin_rech condition(s)_recherche action

Chemin de recherche
Répertoire à partir duquel s'effectue récursivement la recherche.
Conditions de recherche
Elles sont définies à partir des mots clés suivants :user propriétaire du fichier défini par la variable user,
name nom du fichier,
group groupe donné du fichier,
size taille du fichier (blocs de 512 octets ou caractères),
atime à partir de la date de dernier accès,
ctime à partir de la date de création,
mtime date de dernière modification,
type type du fichier (b (bloc), c (caractère), d (répertoire), p (tube nommé), f (fichier ordinaire),
u nombre de liens matériels,
perm attributs de sécurité (en octal),
cpio sauvegarde par appel de la commande cpio,
newer f fichiers modifiés plus récemment que le fichier f,
depth recherche dans l’arborescence de telle sorte que les entrées d’un répertoire soient prises en compte avant le répertoire lui-même ce qui permet d’écrire des fichiers dans des répertoires sans avoir les droits convenables.
Liste des actions
print affichage des fichiers trouvés,
exec exécution de la commande du shell qui suit et qui doit être terminée par le caractère spécial ; précédé du caractère \. Les accolades {} représentent l’ensemble des fichiers satisfaisant au critère de recherche sur lesquels la commande doit s'exécuter.
Opérateurs logiques et caractères spéciaux de la commande
Les conditions de recherche peuvent être combinées à l’aide des opérateurs logiques:a et logique,
• ou logique,
! non logique,
(...) parenthèses de regroupement de critères qui doivent être précédées du caractère \ (escape sequence) pour les différencier des parenthèses du shell.
Exemples Recherche à partir du répertoire courant du fichier prog.c.

find . -name prog.c -print
Recherche à partir du répertoire courant des fichiers non modifiés depuis plus de 15 jours.
find . -mtime +15 -print
Recherche à partir du répertoire /home des fichiers de l’utilisateur jean.
find /home -user jean -print
Recherche à partir du répertoire courant des fichiers créés ou modifiés plus récemment que le fichier /etc/motd.
find . -newer /etc/motd -print
Recherche à partir du répertoire / des fichiers auquels personne n’a accédé depuis plus de 30 jours avec impression de la liste dans le fichier /tmp/access.
find / -atime +30 -print > /tmp/access
Recherche à partir du répertoire /etc des fichiers d’une taille comprise entre 1000 et 2000 caractères.
find /etc -size +1000c -size -2000c -print
Recherche à partir du répertoire / de tous les fichiers appartenant à l’utilisateur betty et suppression.
Pratique, mais dangereux car la commande rm ne requiert pas de confirmation.
Attention aux caractères d'espacement.
find / -user betty -exec rm -f {} \ ;
Recherche à partir du répertoire /users de tous les fichiers core et des fichiers suffixés par .o auxquels personne n’a accédé depuis plus de 2 jours et suppression.
find /users -type f \(-name core -o -name ‘*.o‘ \)-atime +2 -exec rm {} \ ;
Recherche à partir du répertoire /usr des fichiers ayant le numéro d’inode 4156.
find /usr -inum 4156 -print
5.2.14 Recherche d’une chaîne de caractères
La commande grep recherche toutes les instances d’une chaîne de caractères d’un fichier (texte) et affiche (par défaut) toutes les lignes la contenant.
Synopsis
grep [option(s)] expression fichier(s)
Les principales options sont:v affichage des lignes ne contenant pas l’occurrence recherchée,c affichage du nombre de lignes contenant l’occurrence recherchée,l affichage du nom des fichiers,n affichage pour chaque ligne de son numéro,b affichage pour chaque ligne du numéro du bloc la contenant,s suppression des messages d’erreur,

h pas d’affichage du nom des fichiers,i pas de distinction entre lettres majuscules et minuscules,e exp expression à rechercher.
L’expression à rechercher est une expression régulière au sens de l’éditeur ed. Elle a en particulier la signification suivante avec les caractères spéciaux ci-après :. un caractère quelconque,[...] un ensemble de caractères,[^..] caractères n’appartenant pas à l’ensemble indiqué,[a-e] les caractères compris entre a et e,exp* répétition de l’expression exp n fois (n ³ 0),exp+ idem avec n > 1,exp ?. Idem avec n=0 ou 1,^exp expression exp en début de ligne,exp$ expression exp en fin de ligne,e1 | e2 l'expression e1 ou l’expression e2.
Remarque
Les variantes de la commande grep sont egrep, qui interprète d’autres caractères spéciaux, et fgrep, plus rapide mais qui ne recherche que des chaînes fixes.
5.2.15 Tri d’un fichier texteSynopsissort [-option(s)] [-o f_resultat] [+pos1 [-pos2]].. fichier(s)
Description La commande sort tri des fichiers dans l’ordre lexicographique.
Un champ par défaut est un ensemble de caractères séparés par un caractère d’espacement ou de tabulation.
Les options +posl et -pos2 limitent le tri à un champ précis au lieu de la ligne entière (défaut). Elles sont définies sous le format m,n où m est le nombre de champs à ignorer depuis le début de la ligne et n le nombre de caractères à ignorer depuis le début du champ.
fichier_resulat est un nom de fichier résultat (par défaut stdout).
Les principales options sont:b ignore les caractères d’espacement et tabulations en fin de champ,d tri par ordre alphabétique (lettres, chiffres et caractères d’espacement),f conversion des lettres majuscules en lettres minuscules,i ignore les caractères de contrôle,n tri d'un champ numérique de la forme -n ou n,r inverse l’ordre des comparaisons,tx le caractère x est séparateur de champ au lieu du caractère d’espacement,

c vérification que le fichier est trié,m fusionne les fichiers préalablement triés.
5.2.16 Autres commandes
Cryptage
Synopsiscrypt clef < f1 > fichier2crypt clef < fichier2
Description Création d’un fichier fichier2, version cryptée du fichier fichier1 à partir d’une clé de chiffrement cle,
affichage du fichier fichier2 crypté avec la clé de chiffrement clef.
Gestion des lignes d'un fichier texte
Synopsisuniq [option(s)] f_source [f_cible]
Description
Suppression des lignes identiques du fichier trié f_source, résultat dans f_cible.
Les options sont:u copie des lignes n’ayant qu’une seule occurrence (défaut),d copie une seule occurence des lignes en ayant plusieurs (défaut),c indique le nombre d’occurences d’une ligne,n ignore les n premiers champs des lignes dans la comparaison,+n ignore les n premiers caractères de la ligne ou du champ spécifié.
5.3 GESTION DES RÉPERTOIRES
Dans tout ce qui suit, nous supposons que l'utilisateur détient des droits d'accès "convenables" lui permettant d'exécuter les commandes présentées.
Affichage du chemin courant absolu
pwd
Création de répertoire(s)
Syntaxemkdir repertoire1 [repertoire2...]
Les chemin d’accès peuvent être absolus ou relatifs.
Renommage ou déplacement d’un répertoiremv (BSD)

mvdir (SV)
Syntaxemv nom_répertoire nouveau_nom_du_répertoire
Les chemins d’accès peuvent être absolus ou relatifs.
Le déplacement d’un fichier n’est possible que dans un même système de fichiers.
Suppression de répertoire(s)
Syntaxermdir dir1 [dir2...]
La commande rmdir ne peut supprimer qu’un répertoire vide. La commande rm, utilisée avec l’option -r (récursif) permet de supprimer un répertoire non vide.
Déplacement dans l’arborescence
La commande interne cd (change directory) permet de se déplacer dans les répertoires de l’arborescence.
Synopsiscd [nom_répertoire_cible]cd ~[nom_de_login]
Description
Modification du répertoire courant. La commande cd sans argument ramène l’utilisateur dans son répertoire de travail (home directory).
La commande cd ~ (ksh) est identique au cas précédent.
La commande cd ~ (ksh) avec un nom d’utilisateur en argument, positionne l’utilisateur émetteur de la requête sur le répertoire de travail associé à l’utilisateur correspondant au nom de login.
Nombre de blocs d’une arborescence
La commande du affiche le nombre de blocs utilisé par un répertoire et ses sous-répertoires.
Synopsisdu [-as][répertoire(s)]
Description
Affichage du nombre de blocs (512 octets) d'un répertoire et ses sous-répertoires, par défaut le répertoire courant.
Options• a (all) tous les fichiers y compris les fichiers cachés,• s (summary) chacun des arguments.
Exempledu -a /etc/vtoc
2 /etc/vtoc/m2333k4 /etc/vtoc/m2344k

5.4 EXERCICES
5.4.1Liens et redirection
1°) A partir de l’opérateur de redirection et de la commande ls, créer un fichier liste contenant la liste de tous les fichiers du répertoire courant.
2°) A partir de la commande ln, créer un lien matériel sur le fichier liste appelé liste2.
3°) Avec l’éditeur de votre choix, modifier le fichier liste2 et constater que cette modification est visible dans le fichier liste.
4°) A partir de la commande ls -l, constater l’existence de deux liens matériels.
5°) Supprimer le fichier liste et constater que le contenu du fichier liste2 est toujours accessible.
6°) A partir de la commande ln, créer un lien symbolique sur le fichier liste2 appelé liste3.
7°) Avec l’éditeur de votre choix, modifier le fichier liste2 et constater que cette modification est visible dans le fichier liste3.
8°) A partir de la commande ls -l, constater l’existence du lien symbolique.
9°) Supprimer le fichier liste2 et constater que le fichier liste3 existe toujours mais que son contenu n’est plus accessible.
10°) Recréer un nouveau fichier liste2 et constater qu’il est à nouveau accessible par liste3.
5.4.2Tube
A partir des commandes who et wc, calculer le nombre d'utilisateurs connectés.
who | wc -l
5.4.3Commandes de base du SGF
1°) Rappeler le rôle des commandes pwd, cd, mkdir, cp, ls, mv.
2°) Créer le répertoire tempo dans votre répertoire de travail, puis s’y déplacer. Y copier en une seule commande, le fichier /etc/hosts dont on affichera ensuite la taille et le contenu.
3°) Supprimer le répertoire tempo à partir de la commande rmdir.
4°) Réexécuter le 2° puis déplacer la copie du fichier /etc/hosts dans le répertoire père. Supprimer, en une seule commande différente de la précédente le répertoire tempo.
5°) Déplacez vous dans l’arborescence d’UNIX pour étudier les répertoires /, /etc, /usr, /home et essayer d’y détruire des fichiers au hasard (vous n'êtes pas root!!).
6°) Y a-t-il une différence entre les commandes:

rm *.o et rm * .o
5.4.4Commandes d’affichage
1°) Rappeler les fonctions des commandes clear, tail, head, more, man.
2°) Afficher les 10 premières lignes du fichier /etc/profile ou du fichier /etc/termcap.
3°) Afficher les 10 dernières lignes du fichier /etc/profile ou du fichier /etc/termcap.
4°) A partir des commandes ls, more ou de la commande pg, afficher de façon lisible le contenu détaillé du répertoire /dev.
5.4.5Commandes find, grep et sort
1°) Rechercher dans le répertoire /dev, tous les fichiers qui ne sont ni de type bloc ni de type caractère.
find /dev ! -type b ! -type c -print
2°) Rechercher dans le répertoire /usr/adm les fichiers non modifiés depuis 24 H.
find /usr/adm/ -mtime +l -print
3°) Rechercher dans le répertoire /etc, les fichiers ayant une taille comprise entre 10000 et 20000 octets et afficher leurs attributs.
find /etc -size +10000c -size -20000 -exec ls -l {} \;
4°) Rechercher dans tous les fichiers du répertoire courant ceux qui contiennent la lettre a, puis ceux qui contiennent la lettre a en premier caractère d’une ligne.
grep a *
grep "^a" *
5°) Rechercher, quand c’est possible, dans le fichier /etc/passwd ou dans le fichier /etc/shadow les utilisateurs sans mot de passe
grep "^[:]*::" /etc/passwd
6°) Afficher à l’écran le fichier /etc/passwd trié selon l’ordre lexicographique inverse.
sort -r /etc/passwd
7°) Afficher à l’écran le fichier /etc/passwd trié selon le champ GID.
sort -t: +3n -4 /etc/passwd
8°) Afficher à l’écran le fichier /etc/passwd trié selon le champ GID et en cas d’égalité sur le numéro décroissant du champ UID.
sort -t: +3n -4 +2nr -3 /etc/passwd

6. L'ARBORESCENCE UNIX
Les commandes non résidentes sont organisées en répertoires ayant des rôles bien définis. Tout utilisateur doit donc respecter l'organisation de l'arborescence pour faciliter la portabilité de logiciels. Une des fonctions de l'administrateur d'un système est de veiller à l'existence et à l'accessibilité des répertoires dont les noms sont figés dans le code de telle ou telle commande.
Voici les répertoires standards classiques d'UNIX.
6.1 RACINE (ROOT)
Au sommet de l'arborescence se trouve le répertoire root noté / qui sert de référence aux noms absolus des fichiers.
Il faut distinguer le sens du caractère / selon sa position dans le nom du fichier : à gauche, il représente la racine; ailleurs il sert de séparateur des différents répertoires référencés.
Chaque répertoire créé contient au moins deux entrées symbolisées par . qui représente le répertoire courant et par .. qui représente le répertoire parent. Une particularité du répertoire root est qu'il est le seul répertoire tel que . = ..
6.2 ENTRÉES SOUS LA RACINE
/mnt
Le rattachement par la commande /etc/mount d'un système de gestion de fichiers sur l'arborescence peut se faire sur un répertoire quelconque (les différentes partitions d'un disque sont ainsi montées à l'initialisation). Le répertoire /mnt, en général réservé pour le rattachement de systèmes de fichiers en provenance de supports amovibles externes (cartouches, lecteur de disquettes...). dont l'utilisation est en général temporaire (récupération de fichiers, copies, archivage...).
/lost+found
Chaque système de fichiers doit impérativement contenir le répertoire lost+found dans lequel sont transféré les blocs récupérés lors de l'exécution de la commande fsck, avec comme nom leur numéro d'inode.
/unix
Le fichier /unix (ou /vmunix) est le noyau du système. Les systèmes ayant plusieurs noyaux correspondant à diverses configurations doivent effectuer un lien lors de l'initialisation entre le noyau chargé et l'entrée /unix, pour un fonctionnement correct de certaines commandes telles ps.

6.3 COMMANDES PUBLIQUES
L'exécution d'un commande par l'interprète nécessite la consultation des répertoires dans l'ordre où ils sont définis dans la variable shell PATH.
/bin et /usr/bin
Les deux répertoires contenant le binaire exécutable des commandes publiques sont /bin et /usr/bin. L'utilisation de deux répertoires pour les commandes était liée à l'origine aux caractéristiques des disques : on utilisait un disque d'accès rapide mais de faible capacité pour le répertoire /bin qui contenait les commandes les plus utilisées, avec en particulier celles nécessaires pour la phase d'initialisation (boot). Les autres commandes (le répertoire /usr/bin) étaient stockées sur un disque plus lent. Cette organisation subsiste aujourd'hui : elle permet d'équilibrer les échanges avec les disques et de faciliter la maintenance par la création de systèmes de fichiers gérés séparément.
Il est conseillé à tout utilisateur de créer sous son répertoire de connexion un sous-répertoire bin pour y stocker ses propres commandes (binaires exécutables ou fichiers de commande shell). Il lui suffit alors d'ajouter $HOME/bin à sa variable PATH. L'ordre des répertoires indiqués dans la variable PATH étant significatif (de gauche à droite), cela permet à l'utilisateur de réutiliser le nom des commandes publiques. Cela est néanmoins déconseillé et oblige à donner un nom absolu pour accéder à la commande publique.
/usr/lbin
Ce répertoire contient des fichiers binaire locaux (ATT).
/usr/ucb et /usr/local/bin
Le répertoire /usr/ucb contient les commandes compatibles BSD et le répertoire /usr/local/bin contient des commandes spécifiques à un site. Une des taches de l'administrateur est de veiller à ce que les répertoires de commandes soient accessibles par tous, mais que le droit d'écriture dans ces répertoires et sur les fichiers soit limité au propriétaire (en général bin ou root).
6.4 GESTION DES PÉRIPHÉRIQUES
Le répertoire /dev contient la définition des périphériques. les disques réels(discxy, dxy, pdxy ... ou xy est un numéro),
les disques virtuels (noms variables : noms des partitions et noms logiques),
les bandes magnétiques et les streamers (mtxy, stxy ...),
les terminaux (ttyxy ou un nom spécifique de terminal),
les imprimantes (lpxy ...),
tout autre périphérique (bitmap, traceur ...).
Les fichiers sont de type b (bloc) ou c (caractère) et le champ taille est remplacé par le couple (majeur, mineur).
Les entrées des systèmes de fichiers d'un disque accessible en modes bloc et raw bloc sont définis dans les sous-répertoires dsk et rdsk. Les noms logiques d'une partition dans le répertoire /dev ne sont que des

liens sur les entrées correspondantes des répertoires dsk et rdsk. Sous système V R4, les conventions suivantes sont utilisées :
/dev/[r]dsk/c#d#s#
/dev/[r]mt/c#d#x
Les caractères c,d,s désignent respectivement un contrôleur, un disque, un système de fichiers sur le disque. Le caractère # est le numéro correspondant.
Le caractère d désigne une unité de bande magnétique. Le caractère x représente la densité d'écriture qui peut être h (6250 bpi), m (1600 bpi), l (800 bpi).
Exemples : /dev/dsk/c2d3s5, /dev/rdsk/c1d2s4, /dev/rmt/c2d3h
Entrées particulières du répertoire /dev
tty représente à tout instant le terminal connecté,
null représente un périphérique "poubelle" utilisé pour rediriger la sortie de commandes dont on ne veut pas garder trace ou pour créer des fichiers vides,
mem représente l'image mémoire du programme courant et peut être utilisé avec le débogueur adb,
kmem représente l'image mémoire du noyau. Elle est utilisée par certaines commandes (ps, sar) pour connaître l'état des tables système.
Certains noms logiques "standards" sont des liens matériels sur des périphériques existants, par exemple /dev/lp. Les entrées swap et tmp représentent les zones de swap et les zones temporaires. Les entrées console, syscon, systty représentent la console système.
Les fichiers de définition des périphériques et les fonctions d'entrées/sorties sont compilées et éditées dans une bibliothèque (par exemple la librairie LIB2).
Les pseudo-périphériques sont les entrées /dev/ptyxx.
6.5 FICHIERS TEMPORAIRES
/tmp et /usr/tmp
L'utilisation de certains utilitaires (éditeurs, compilateurs) provoque la création de fichiers temporaires dont le répertoire standard est /tmp (pour les mêmes raisons qu'avec /bin et /usr/bin, certains utilitaires utilisent /usr/tmp), les versions actuelles tendant à éliminer cette particularité).
Le répertoire /tmp doit avoir les droits rwx pour tous les utilisateurs. Il est utilisé par différents utilitaires pour y créer des fichiers temporaires lors d'édition de textes ou de compilation.
Par convention, les noms des fichiers temporaires comportent le plus souvent deux parties : l'une littérale identifiant la fonction assurée, et l'autre numérique garantissant l'unicité du nom (souvent le PID du processus associé).

Les utilitaires créant des fichiers dans le répertoire /tmp doivent normalement les détruire à leur terminaison. Cependant, il peut arriver que des fichiers subsistent. Aussi lors du démarrage du système, le répertoire /tmp est normalement purgé. Il est judicieux de charger le répertoire /tmp en mémoire (ramdisk) ce qui permet une accélération importante des entrées/sorties qui l'utilisent. Attention au gros fichiers qui risquent alors de saturer la mémoire.
6.6 BIBLIOTHÈQUES
Les bibliothèques standards d'UNIX sont stockés dans les répertoires /lib et /usr/lib (l'existence de deux répertoires provient des mêmes considérations historiques que pour /bin et /usr/bin).
Chaque bibliothèque a pour nom libxxx.a où xxx précise sa nature (c pour le langage C, f77 pour fortran ...) et a le suffixe signifiant archive. Sur SYSTEM V R4, l'édition de liens dynamique est possible. Dans ce cas, les bibliothèques concernées sont suffixées par .so (shared objects).
Les sous programmes des bibliothèques sont examinées séquentiellement ce qui pose des problèmes si un sous-programme fait référence à un sous-programme placé avant lui. Il faut alors soit examiner deux fois la bibliothèque, soit la réorganiser pour garantir que toutes les références sont en avant. La répartition des bibliothèques entre /lib et /usr/lib dépend de l'implémentation sur chaque système en fonction des outils disponibles. Il existe des bibliothèques pour les langages (C, PASCAL ...), mathématiques (IMSL, NAG,...), graphiques (PHIGS,...), pour la gestion de terminaux, pour divers utilitaires (yacc, profil ...), pour la génération du noyau. Des commandes spécifiques (ar, ranlib ...) permettent de les gérer.
Ces deux répertoires, à l'origine réservés aux bibliothèques, sont de plus en plus souvent complétés par des fichiers utilisables par tous de façon transparente, regroupés en sous-répertoires s'ils existent en quantité pour une même fonction. On trouve ainsi : les programmes comportant les différentes passes des traducteurs (cpp ...) ainsi que les fichiers
run-time (crto.o...),
les programmes et fichiers associés aux commandes refer, struct, style, uucp, learn ... regroupés en sous répertoires du même nom,
les macros utilisés par les commandes nroff et troff regroupées sous tmac,
les caractéristiques des terminaux pour troff regroupées sous term,
les polices de caractères (fontes) regroupées sous font,
les fichiers associés au service cron regroupés sous cron (ou les fichiers crontab et atrun en version Berkeley),
des fichiers isolés associés aux commandes calendar, lint, spell, units, cref, xref, yacc...
6.7 RÉPERTOIRE /USR
Ce répertoire contient un certain nombre de sous-répertoires fonction de la configuration logicielle du site (on peut considérer que /usr correspond à une "racine locale").
Avec les sous-répertoires bin, lib, tmp déjà cités et des répertoires d'utilisateurs, ce répertoire peut contenir les sous-répertoires suivants :

/usr/man
Contient la documentation en ligne des commandes UNIX accessible par la commande man. Ce répertoire est lui-même composé de sous-répertoires correspondant à la classification de la documentation (en général man1, ... man8 pour les 8 sections dans l'environnement BSD, man.C, man.ADM,... pour les environnements SYSTEM V). Les fichiers ont pour nom cmd.x où cmd est le nom de la commande, x le numéro de section avec parfois un suffixe (m pour maintenance, c pour communication, g pour graphique ...).
Les fichiers contenus dans les divers répertoires associés sont mis en page selon le format nroff. Il est judicieux qu'ils soient stockés préalablement mis en forme ce qui accélère les temps de réponse des requêtes. Dans ce cas, l'usage veut que les noms des répertoires associés au manuel soient cat1, cat2,..., ou cat.C, cat.ADM,...etc. Toutefois, la place occupée par le répertoire man augmente en conséquence. En général, les fichiers associés aux commandes sont compressées.
/usr/games
Contient divers jeux. Ce répertoire (quand il existe) peut être rendu inaccessible à certaines heures.
/usr/include
Contient les fichiers de définition de structures de données (fichiers .h) utilisables par les programmes (ordre # include du pré-processeur C). Un sous-répertoire sys regroupe les fichiers de configuration des tables systèmes du noyau.
6.7.1Audit
/usr/adm
Contient divers fichiers d'audit de l'activité du système tels wtmp (connexions), sulog (appels à su), cronlog (activité du processus cron)... Ces fichiers grossissant rapidement, il faut les purger régulièrement.
6.7.2Répertoire /usr/spool
Le répertoire /usr/spool est réservé au stockage de fichiers temporaires devant subsister en cas d'arrêt du système (impression, communications, courrier ...). Ce sont principalement les sous-répertoires lpd (fichiers de spoule d'impression), uucp (fichiers à transférer par le service uucp), mail (fichiers des boites aux lettres publiques envoyées par mail), cron ou at (services définis dans la crontab ou commandes à exécuter ultérieurement)...
6.7.3Sources d'UNIX
Le répertoire /usr/src contient les fichiers sources regroupés dans les quatre sous-répertoires cmd (pour les commandes), lib (pour les bibliothèques), sys (pour le noyau parfois directement sous /usr/sys) et games (pour les jeux).
Pour les commandes simples, un seul fichier de même nom suffit. Pour les commandes plus complexes (par exemple l'éditeur vi) sont regroupées sous un sous-répertoire du nom de la commande.

6.7.4Génération du noyau
Les fichiers de génération du noyau sources sont réparties dans les cinq répertoires :
/usr/h
Il contient les fichiers de description des variables, des structures de données et des constantes utilisées.
/usr/conf
Il contient les fichiers de configuration du système et d'interfaçage avec la machine (les seuls programmes en assembleur).
/usr/sys
Il contient les fonctions du noyau regroupées par domaine d'activité.
/usr/cmd
Il contient les fichiers sources en C des commandes.
La génération du noyau est obtenue après compilation et édition de liens des fichiers du répertoire conf.
6.7.5Autres fichiers du répertoire /usr
/usr/news
Contient toute information utile pour les utilisateurs.
/usr/old
Contient des logiciels qui ne seront plus supportés dans les versions ultérieures (BSD).
/usr/new
Contient des logiciels qui seront supportés dans les versions ultérieures (BSD).
6.8 FICHIERS DE DÉMARRAGE
Le répertoire /etc comprend les commandes utilisées pour l'administration du système ainsi que les fichiers associés. Les commandes sont des fichiers exécutables fournis avec le noyau UNIX mais aussi des programmes écrits en langage de commandes shell (shell-scripts) écrits ou adaptés par l'administrateur. On trouve les commandes d'initialisation du système (init), d'arrêt (shutdown), de gestion des systèmes de fichiers (fsck, mkfs, mount, etc.), de gestion des périphériques (mknod...), de gestion de divers services (cron, accton ...). Sur UNIX SYSTEM R4, seuls, les fichiers subsistent. Les commandes sont transférées dans le répertoire /usr/etc.
Les fichiers mis en oeuvre par ces commandes sont getty, gettytab, gettydefs, init, inittab, motd, rc*, ttys, mtab ... ou des fichiers de définition d'utilisateurs (passwd et group) et de terminaux (termcap, ttytype ...). Ils n'évoluent guère dans le temps alors que les autres fichiers liés à l'administration (enregistrement de

l'activité) qui grossissent rapidement sont reliés à d'autres répertoires (en général /usr/adm). Ceci permet d'avoir deux partitions distinctes; l'une pour le système incluant /etc, et l'autre pour /usr, monté à l'initialisation sans risque de saturation du disque système.
6.9 GESTION DES UTILISATEURS
A l'origine, le répertoire des utilisateurs est /usr. Compte tenu de ses nombreux rôles, certains administrateurs préfèrent créer le répertoire /users contenant les répertoires de connexion des utilisateurs (home directory) ou /usr2.
6.10 EVOLUTIONS AVEC UNIX SYSTEM V R4
L'organisation physique des fichiers et des répertoires a été modifiée avec les objectifs suivants : le partage doit être facilité dans un environnement réseau,
la séparation des sous-arborescence doit être claire,
l'installation des nouveaux produits doit être facilitée.
L'agencement de la hiérarchie traditionnelle a été conservée pour garantir la compatibilité avec les anciennes versions d'UNIX. Les liens symboliques sur les fichiers déplacés sont utilisés.
L'arborescence est divisée en trois zones : zone privée associée à la machine contenant les fichiers de configuration,
zone dépendante de l'architecture contenant les programmes et les bibliothèques,
zone indépendante de l'architecture contenant les bases de données en format texte (par exemple le manuel).
On distingue alors trois types de répertoires : les répertoires privés, non partageables, de la machine, dépendants de l'architecture matérielle,
utilisés pour décrire sa configuration,
les répertoires publics, partageable entre machines de même architecture, dépendants de l'architecture matérielle, contenant les bibliothèques et les programmes spécifiques,
les répertoires dont le contenu est indépendant de l'architecture matérielle (bases de données ASCII).
Répertoires privés
Ils sont définis dans le répertoire racine. Ce sont les répertoires :
/dev, /etc, /export, /mnt, /home, /opt, /proc, /tmp, /sbin, /var.
Les modifications par rapport à l'arborescence classique sont les suivantes :
/proc : répertoire contenant l'image des processus en cours, accessible par les appels systèmes classiques open, read, write,
/home : répertoire contenant les répertoires de travail (home directory) des utilisateurs,
/export : répertoire contenant les sous-répertoires ainsi que les fichiers systèmes des stations sans disques,

/opt : répertoire dédié aux "packages" optionnels
Le répertoire /var contient l'ensemble des sous répertoires d'administration dont la taille va croître au cours du temps à savoir :
/var/adm : contient les fichiers des messages d'audit et des statistiques associées
/var/mail : contient l'ensemble des boites aux lettres publiques
/var/news : contient les fichiers associés au service des news
/var/preserve : contient les fichiers textes récupérés après un crash
/var/saf : compte rendu du service SAF (Service Access Facility)
/var/tmp : fichiers temporaires
/var/cron : contient les répertoires de chaque utilisateur ayant définis des services cron
/var/uucp : contient les fichiers des services uucp
/var/spool : contient les différents spoules des diverses imprimantes
/var/spool/lp : contient le spoule associé à l'imprimante lp
/var/spool/uucp : contient les fichiers en instance d'émission pour le protocole uucp
/var/spool/uucp/public : contient les fichiers accessibles par uucp.
Répertoires publics
Ce sont les fichiers et répertoires définis dans le répertoire /usr :
/usr/bin : binaires publics, complète le répertoire /bin
/usr/sbin : fichiers accessibles en mode single user, essentiellement lors du démarrage,
/usr/games : jeux disponibles
/usr/include : fichiers définissants les prototypes des appels systèmes ou des fichiers de la bibliothèque C
/usr/ccs : contenant des outils de développement en C
/usr/lib : répertoire des fichiers binaires constitués par les diverses bibliothèques. Les bibliothèques à édition de liens statiques sont suffixées par .a, celles à édition de liens dynamiques sont suffixées par .so (choix par défaut).
/usr/ucb : utilitaires des versions BSD
/usr/ucbinclude : prototypes des utilitaires des fonctions BSD
/usr/ucblib : bibliothèques spécifiques BSD.

Répertoires partageables
/usr/share : fichiers partageables entre différentes machines sur un réseau local
/usr/share/man : pages partageables du manuel
/usr/share/lib : bibliothèques compilées et éditées partageables
/usr/src : fichiers sources
Utilisateurs particuliers
Des utilisateurs particuliers répondent à des fonctions systèmes spécifiques dont on peut distinguer trois types :
-les utilisateurs liés aux fonctions système, dont fait partie au moins l'utilisateur root (le super utilisateur) dont l'identificateur (UID) est ainsi que bin, sys, manager...
-les utilisateurs liés à une commande, par exemple uucp (qui exécute le programme uucico) permettant la communication entre deux sites. D'autres utilisateurs ont le nom d'une commande (who), ce qui permet d'obtenir facilement une information donnée.
-les utilisateurs publics (guest, invite, public ...) permettant de se connecter temporairement sur le site.

7. SÉCURITÉ DANS LA GESTION DES FICHIERS
7.1 ATTRIBUTS DE SÉCURITÉ
Un fichier est caractérisé par ses attributs de propriété ( propriétaire, groupe) et de sécurité (droits d’accès).
Propriétaire
L'utilisateur propriétaire, défini dans le fichier /etc/passwd (le créateur en général) est celui auquel le fichier est rattaché dans le système.
Par définition, c'est l'utilisateur qui va pouvoir modifier les attributs de sécurité et les drapeaux d'accès du fichier.
Son identité est modifiable sur la plupart des implémentations par l’administrateur du système avec la commande chown.
Groupe
Un groupe est un ensemble d’utilisateurs, définis par l’administrateur, avec des droits communs.
Un utilisateur peut appartenir à plusieurs groupes, définis dans le fichier /etc/group.
Le groupe par défaut d'une session est celui qui est défini dans le fichier /etc/passwd.
Le groupe de travail d’un fichier est modifiable par l’utilisateur avec la commande shell chgrp.
Synopsischgrp nouveau_groupe_de_travail
Drapeaux d'accès
Les droits d’accès d'un fichier en définissent les protections par des drapeaux.
Ils sont répartis en trois champs: un pour l'utilisateur propriétaire, un pour le groupe et un pour les autres utilisateurs. Chaque champ contient trois drapeaux d’accès : rwx. Leur signification est variable selon que le fichier est ordinaire ou répertoire.
r w xfichier lecture écriture shell script
suppression fichier exécutablerépertoire listable modification traversable
création
Exemple
Un fichier ordinaire avec les droits rwxr-x—x peut être lu, écrit et exécuté respectivement par le propriétaire, lu et exécuté par les membre de son groupe et seulement exécuté par les autres utilisateurs.
91

Commandes associées
La commande shell ls permet de visualiser les attributs de sécurité d’un fichier.
La commande shell chmod permet de les modifier.
Sur certaines implémentations fantaisistes, la destruction d’un fichier (rm) ne nécessite que le droit d’écriture dans le répertoire où le fichier est enregistré mais pas le droit d’écriture sur le fichier lui-même. Un fichier accessible en lecture seule peut donc être détruit si le répertoire est accessible en écriture. Dans ce cas, la commande shell rm s’exécute avec une requête de confirmation.
En complément des droits rwx, un fichier peut avoir un des trois attributs s, S, t. Ce dernier permet de résoudre le problème posé au paragraphe précédent.
7.2 GESTION DES ATTRIBUTS DE PROPRIÉTÉ
chown
Modification du propriétaire d’un fichier. C'est un acte irréversible pour l'ex propriétaire.
Synopsischown nouveau_propriétaire fichier(s)
Cette commande n’est accessible que par l’utilisateur root sous BSD.
Sous SYSTEM V, le (futur ex) propriétaire du fichier peut également l’utiliser.
chgrp
Modification du groupe d’appartenance d’un fichier part le propriétaire ou l'administrateur.
Synopsischgrp nouveau_groupe fichier(s)
7.3 GESTION DES ATTRIBUTS DE SÉCURITÉ
7.3.1La commande chmodSynopsischmod modif_autorisations_courantes fichier(s)
Cette commande permet de modifier les attributs de sécurité d’un fichier ou d’un répertoire. Elle a deux syntaxes.

Méthode symbolique
UTILISATEURS OPERATEURS PERMISSIONSu propriétaire + ajouter r g groupe - enlever w o autres (others) = assignation x
Exemplechmod go-rx archivchmod g+w progl
Méthode octale
Les droits d'accès d'un fichier sont définis par l'interprétation (par 3) des 9 drapeaux en octal.
LECTURE = 4 ECRlTURE = 2 EXECUTlON = 1644 -rw-r—r-- droits par défaut pour fichier755 drwxr-xr-x droits par défaut pour répertoire
7.3.2Le bit s
Le bit s aussi appelé bit sUID (set user id). S'il est positionné, un utilisateur autre que le propriétaire du fichier est autorisé à emprunter temporairement son identité pour l'exécuter avec les droits du propriétaire. Le propriétaire réel d'un processus en cours d'exécution est l'utilisateur qui a lancé le processus. Le propriétaire effectif est le propriétaire du fichier exécutable qui en a défini les droits d'accès, autorisant, par l'appel système setuid d'autres utilisateurs à les exécuter.
Synopsischmod 4555 fichier
On obtient les droits r-sr-xr-x
Exemple
Le fichier /etc/passwd contient la liste des utilisateurs ainsi que leur mot de passe crypté. Il appartient au super-utilisateur avec les droits rw-r--r--. Pourtant, un utilisateur peut modifier son mot de passe par la commande /bin/passwd qui lui permet d'écrire dans le fichier /bin/passwd alors qu'il n'a pas le droit en écriture. Les droits de cette commande, qui appartient au super-utilisateur, sont rwsr-xr-x.
Tous les fichiers avec le bit s sont des fichiers sensibles car ils peuvent être des failles dans la sécurité du système. Il faut donc éviter d'en créer (shell-scripts).
7.3.3Le bit S
Le bit S est aussi appelé bit SGID. C'est l'équivalent du bit SUID pour le groupe et les fichiers exécutables, comme héritage sur les répertoires et comme descripteur de comportement de verrouillage sur les fichiers de données.
Synopsischmod 2555 fichier
On obtient les droits r-xr-sr-x

7.3.4Le bit de collage
Le bit de collage (sticky bit) a deux utilisations distinctes : une sur les fichiers et une sur les répertoires.
Fichier
Il permet le maintien de l'image du fichier en mémoire à la fin de son exécution. Les plus fréquents sont les éditeurs et les outils de production de logiciels : compilateurs, assembleurs, éditeur de liens....
Répertoire
Appelé bit t, le bit de collage est utilisé sur des répertoires d'accès publics (rwxrwxrwx) avec les versions UNIX 4.3 BSD et UNIX SYSTEM V R4. Il permet d'interdire à un utilisateur de détruire des fichiers dont il n'est pas propriétaire.
Synopsischmod 1555 fichier
On obtient les droits dr-xr-xr-t
7.3.5Gestion du bit suid
Il faut minimiser l'utilisation des programmes suid. Si possible, éviter que leur propriétaire soit le super-utilisateur. De plus en plus, des utilisateurs spécifiques sont crées, par exemple lp ou uucp. Par exemple, la restriction d'un droit d'accès à une base de données n'implique pas l'utilisation d'un programme suid root. Il est plus facile de créer un pseudo utilisateur avec des droits d'accès limités, et de rendre le programme suid avec cet utilisateur.
Les programmes suid ne doivent pas être accessibles en lecture : un pirate pourrait profiter des erreurs de programmation pour l'utiliser à l'insu de l'administrateur.
Si ces programmes utilisent des appels systèmes, il faut impérativement que les chemin d'accès des fichiers soient absolus. Sinon, les propres programmes de l'administrateur risquent de devenir des chevaux de Troie.
7.4 LISTE DE CONTRÔLE D'ACCÈS
Sur les implémentations d'UNIX actuelles, il devient en outre possible de définir des listes de contrôle d'accès (LCA) ou ACL (Access Control List).
La norme POSIX P1006.3 définit les LCA comme un moyen formel d'exprimer des opérations sur des objets, selon l'identité de l'entité émettrice de la requête.
Une LCA est une entrée dans un fichier de la forme :
:type:principal:permissions
Le champ type spécifie l'interprétation du champ principal, par exemple le propriétaire du fichier, un autre utilisateur (local ou distant), un groupe (local ou distant).

Le champ principal est le nom de l'entité à qui appliquer les droits.
Le champ permission est l'ensemble des drapeaux suivants :
les droits classiques RWX
les drapeaux CID, avec les interprétationsC habilité à modifier les ACL,
I droits d'insertion de fichiers dans un répertoire,
D droits de destruction de fichier dans un répertoire.
Exemple 1
root:/etc:RWXCID
Exemple 2 : ACL sur AIX
Sur AIX, la sémantique suivante est utilisée : les ACL comportent les informations suivantes : attributs
permissions de base
permissions étendues.
Attributs
Les attributs indiquent les attributs spéciaux du fichier ou du répertoire (bit s, S, t).
Permissions de base
Les permissions de base décrivent les attributs traditionnels définis par les commandes chmod, chown, etc.
Permissions étendues
Les permissions étendues sont décrites sous la forme d'ACE (Access Control Entry), qui, pour chaque instance décrite, suit le format :
opération type_d'accès [[info_utilisateur] [info_groupe]
Opérations
Trois types d'opérations sont supportés : deny interdit le type d'accès spécifié
permit autorise le type d'accès spécifié
specify définition du type d'accès.
Types d'accès
L'utilisateur ou le groupe auquel s'appliquent les droits décrits est précédé du suffixe u: ou g:.
Une entrée est crée pour chaque utilisateur ou groupe.

Il est possible de combiner plusieurs utilisateurs ou groupes dans une seule entrée.
Exempleattributesbase permissionsowner(philipp): rwxgroup(root): r-xother: r--extended permissions:enableddeny rwx g:staffpermit rwx u:root, g:staffpermit r-x g:sysadm
Commandes associées
aclget affichage d'une ACL,
aclput définition d'une ACL,
acleditmodification d'une ACL.
7.5 MASQUE DE SÉCURITÉ PAR DÉFAUT
La commande umask permet de modifier le masque de création des bits de sécurité utilisé lors de la création des fichiers et des répertoires pour définir leurs attributs par défaut. Il n’agit que sur les bits rwx.
Droits par défaut sur les fichiers ordinaires et les répertoires
Sur les fichiers ordinaires, les droits par défaut sont définis selon la règle:
droits_par_defaut=non(masque) et 666
Sur les répertoires, les droits par défaut sont définis selon la règle:
droits_par_defaut=non(masque)
Droits par défaut usuels
L’exécution de la commande umask indique la valeur par défaut du masque courant, souvent 022.
Exemple
Avec le masque précédent, on obtient:
Fichiers ordinaires rw-r—r—Répertoires rwxr-xr-x
ce qui constitue des droits d’accès raisonnables. Le masque de protection peut-être défini soit par l’administrateur, éventuellement comme paramètre du noyau, soit redéfini par l’utilisateur dans son fichier .profile (ou équivalent).
Il est fondamental pour l'administrateur de définir la variable umask dès que possible (lors de la génération système ou dans le fichier /etc/profile).

8. GESTION DES ENTRÉES-SORTIES
8.1 VOLUME ET SYSTÈMES DE FICHIERS
Le partitionnement d'un disque est une division du disque physique en plusieurs disques logiques appelés système de fichiers (file system). On distingue les unités physiques (disque ou volume) des unités logiques.
Systèmes UNIX classiques (jusqu'à SYSTEM V R3 et BSD 4.3)
Une unité physique contient toujours un ou plusieurs systèmes de fichiers, divisés, en blocs dont la taille peut varier de 512 à 4096 Octets suivant les versions d'UNIX.
Il n'est pas possible de modifier la taille d'un système de fichiers sans effectuer préalablement une sauvegarde.
IBM AIX V3 et OSF/1
La notion de volume logique a été introduite permettant plusieurs améliorations importantes :
-possibilité de définir un système de fichiers unique réparti sur plusieurs disques physiques,
-extension dynamique de la taille des systèmes de fichiers,
-possibilité de faire du mirroring.
Types de systèmes de fichiers
Il existe plusieurs types de systèmes de fichiers suivant les différentes implémentations d'UNIX.
SYSTEM V
C'est le plus classique, basé sur l'implémentation d'UNIX V7, connu sous le type S5. Aucune optimisation des opérations d'entrée/sortie. Les noms de fichiers sont limités à 14 caractères.
BSD
Différents type de systèmes de fichiers ont été successivement définis avec deux objectifs :
-amélioration des performances des opérations d'entrée/sortie,
-amélioration de la gestion de l'espace disque car la granularité du stockage et de l'accès est plus fine (gestion des blocs et des fragments dans les blocs). Les noms de fichiers sont limités à 255 caractères.
Ce sont FFS (Fast File System), UFS (Universal File System)
AFS

Le système de fichier distribué AFS (Andrew File System), est défini à l'Université d'Andrew.
NFS
L'extension de la notion de système de fichiers à une machine distante a été réalisée par SUN avec le protocole NFS (Network File System). Pour tenir compte des différents types de systèmes de fichiers, la notion de système de fichiers virtuel (Virtual File System -VFS) a alors été introduite. L'idée est de rajouter une couche d'interface entre l'application et le système de fichiers.
OSF/1
Définition du type LFS (Local File System).
L'utilisateur a une vision virtuelle (logique) de l'arborescence UNIX différente de l'implémentation physique des systèmes de fichiers par le mécanisme du montage.
8.2 INODE
Le vecteur d'état d'un fichier est son inode, abréviation de index-node, contenant la description du fichier (taille, position sur le disque, ...) ainsi que les informations nécessaires à son utilisation (nom, propriétaire, droits d'accès, protections...). Les inodes sont stockées dans le système de fichiers qui les contient.
La nature et les droits d'accès de l'inode sont définies dans le fichier inode.h :
/* liens matériels, propriétaire */struct icommon{u_short ic_mode; /* attributs et type du fichier */short ic_nlink; /* nombre de liens matériels */short ic_uid; /* identificateur du propriétaire */short ic_gid; /* identificateur du groupe */quad ic_size; /* nombre d'octets du fichier *//* dates */struct timeval ic_atime; /* date de dernier accès */struct timeval ic_mtime; /* date de dernière modification */struct timeval ic_ctime; /* date de dernier changement d'inode *//* modes */#define IFMT 0170000 /* type du fichier */#define IFCHR 0020000 /* caractère spécial */#define IFDIR 0040000 /* répertoire */#define IFBLK 0060000 /* bloc special */#define IFLNK 0120000 /* lien matériel */#define IFSOCK 0140000 /* prise (socket) */#define IFIFO 0010000 /* tube nommé spécial */#define ISUID 04000 /* user id à l'exécution */#define ISGID 02000 /* group id à l'exécution */#define ISVTX 01000 /* sauvegarde du texte swappé *//* droits d'accès en lecture, écriture, exécution */#define IREAD 0400#define IWRITE 0200#define IEXEC 0100

8.3 STRUCTURE D'UN SYSTÈME DE FICHIERS
Compte tenu des différentes implémentations, nous présentons ici les systèmes de fichiers classiques (V7). Nous verrons ensuite les différences d'implémentation.
Organisation générale
Un système de fichiers est composé de quatre unités fonctionnelles organisées en une suite de blocs de taille fixe de 512, 1024, 2048, ou 4096 octets.
ORGANISATION LOGIQUE D'UN SYSTÈME DE FICHIERS
Le bloc 0 est utilisé au chargement et au démarrage du système.
Le bloc 1 est le super bloc contenant la description de l'organisation du système de fichiers et la liste de leurs descripteurs ou inode (un par fichier). Il est utilisé au démarrage. Les blocs suivants contiennent la liste des inodes. Viennent ensuite les données, les blocs de chaînages entre les blocs de données, la liste des blocs libres.
Un volume contenant plusieurs systèmes de fichiers a la forme suivante :
Les différents systèmes de fichiers d'un volume sont connus et gérés par le même pilote.
Le nombre maximum de fichiers d'un système de fichiers est imposée par la taille de la partition du disque et est calculée sa création (commande du SHELL mkfs ou newfs (BSD)), préalablement à son montage. Pour l'augmenter, il est nécessaire de reformater le disque après sauvegarde de l'arborescence complète (commandes du SHELL dump, tar, cpio). Le descripteur des différents systèmes de fichiers du volume est chargé en mémoire par la commande du SHELL mount qui utilise le fichier /etc/fstab pour monter les différents systèmes de fichiers. La commande SHELL umount permet de les démonter. La commande SHELL fsck permet le contrôle de l'état d'un système de fichiers.

8.3.1 Inode et I-list
On appelle inode le descripteur d'un fichier. On y trouve ses attributs (bits d'accès, type du fichier, propriétaire, groupe) et les treize adresses physiques de blocs de données. Le i-number (abréviation de index number) est l'index dans la table des inodes de l'inode du fichier.
La liste des inodes est la i-liste. Par défaut, la première entrée est inutilisée (sauf en cas de chaînage de blocs défectueux) et la seconde entrée contient le descripteur du répertoire racine du système de fichiers et la taille de la i-liste (fixée à sa création). Il suffit de préciser le nombre de blocs total du système de fichiers et le système calcule automatiquement le nombre maximum de points d'entrée de la i-list. Quand un système de fichiers est plein, il faut en créer un autre plus grand et y recopier les fichiers.
Le super bloc contient une liste partielle des descripteurs des inodes libres. Le mécanisme utilisé est similaire à celui de l'allocation des blocs libres.
La première entrée de la i-liste est la racine du système de fichiers correspondant. Il n'y a pas d'espace alloué sur le disque lors de la création d'un fichier dont la taille évolue dynamiquement, suivant les besoins.
La taille d'un répertoire est le produit N * t où :
N est le nombre de fichiers contenus (détruit ou non)
t est la taille standard d'une entrée (par exemple 16)
Soit Tb la taille d'un bloc en octets. Le nombre d'adresses de n octets d'un bloc est de Tb/n. Pour un fichier normal, les blocs de données sont atteints :
-directement pour les 10 (V7) ou 12 (BSD 4.2) premiers blocs ,
-par indirection simple pour les (Tb/n) blocs suivants,
-par indirection double pour les (Tb/n)2 blocs suivants,
-par indirection triple pour les (Tb/n)3 derniers blocs du fichiers (ATT).
Dans les versions ATT, la taille T maximum d'un fichier est calculée par la formule :
T = Tb * (10+(Tb/n)+(Tb/n)2+(Tb/n)3)
soit environ 232 caractères si les blocs ont 1024 octets et les adresses 4 octets.
L'accroissement du temps d'accès (overhead) aux informations du système de fichier est du :
-aux modalités du stockage,
-à la fragmentation possible des fichiers,
-au temps d'accès (indirections multiples) pénalisant fortement l'accès au gros fichiers. L'accès séquentiel peut être accéléré par une lecture anticipée.

La structure d'un inode sur un disque est décrite dans le fichier /usr/include/ino.h.
La taille des blocs peut-être de 8 K-octets sur les versions 4.3 BSD permettant une accélération des flots d'entrée/sortie de 40 à 50 %.
Statistiquement, il a été montré que la taille de la majorité des fichiers est inférieure à 10 K-octets dont une grosse proportion est inférieure à 1 K-octets. Pour éviter une perte de place sur le disque due à une trop grande taille des blocs, ceux-ci sont alloués par fragments de 1 K-octets permettant un bon compromis entre la taille des blocs et la taille moyenne des fichiers.
8.3.2Super bloc
Le super bloc d'un système de fichiers contient la taille des blocs qui le constituent, leur nombre, le nombre des fragments, la localisation et la taille de la liste des inodes, les adresses des blocs sur le disque, la taille des groupes de cylindre et d'autres informations du disque. Il assure la gestion des inodes et des blocs libres. Les principaux champs de la structure filsys sont définis dans le fichier filsys.h./* structure du super bloc */struct filsys {ushort s_isize; /* taille en blocs de la i-list */daddr_t s_fsize; /* taille totale du système de fichiers */short s_nfree; /* nombre d'adresses dans la s_free_liste */daddr_t s_free[NICFREE]; /* liste des blocs libres */short s_ninode; /* nombre d'inodes dans la liste s_inode */ino_t s_inode[NICINOD]; /* liste des inodes libres */char s_flock; /* verrou associé au cache */char s_ilock; /* verrouillage de la i-liste */

char s_fmod; /* drapeau d'état du superbloc modifié */char s_ronly; /* système de fichiers monté en lecture seule */time_t s_time; /* date de dernière mise à jour du super bloc */short s_dinfo[4]; /* information sur le volume */daddr_t s_tfree; /* nombre total de blocs libres*/ino_t s_tinode; /* total total d'inodes libres */char s_fname[6]; /* nom du système de fichiers */long s_magic; /* magic number */long s_type; /* type du système de fichiers */};#define FsMAGIC 0xfd187e20 /* magic number */#define Fs1b 1 /* bloc de 512 octets */#define Fs2b 2 /* bloc de 1024 octets */
Interprétation
La s_freelist est la liste des blocs disponibles du système de fichiers.
La liste partielle des blocs libres est la tête de la file des blocs logiques libres.
Les drapeaux s_free et s_inode permettent le contrôle de collisions éventuelles de plusieurs processus accédant aux listes partielles.
Le drapeau s_fmod est utilisé par la commande shell sync pour le vidage du cache-disque sur le disque.
Le premier facteur d'entrelacement y est défini pour optimiser les performances des entrées/sorties physiques (meilleure gestion des cylindres et des secteurs).
Quand le bloc n est vide, il est transféré dans la liste des blocs disponibles.
Un mécanisme similaire est utilisé lors de la libération des blocs. Si la liste partielle n'est pas pleine, un bloc libre y est inséré. Dans le cas contraire, le bloc libéré devient bloc de chaînage et la liste est déverrouillée.
Lors de la création du système de fichiers, les facteurs d'entrelacement sont optimisés et la liste des blocs libres est chaînée pour réduire les temps d'accès (mise en coïncidence du temps d'accès à deux blocs successifs et optimisation de la période de rotation entre ces deux blocs sur le disque).
8.3.3Structure des informations dans un répertoire
Un répertoire se distingue des fichiers normaux par son type et la structure de ses blocs structurés en entrées de 16 caractères chacun (14 caractères pour le nom, 2 caractères pour le numéro de l'inode dans les anciennes versions SYSTEM V), variable jusqu'à 255 caractères dans les versions 4.2 BSD et SYSTEM V R4), correspondant chacune à un fichier, ou à un sous répertoire. La création d'un répertoire est faite par la commande shell mkdir ou l'appel système mknod. Les entrées sont crées par l'appel système link, et supprimée par l'appel système unlink (seul, le numéro de l'inode est remis à 0).
Dans la version UNIX 4.3 BSD, un répertoire est alloué par unité appelée chunk dont la taille est déterminée de telle sorte que chaque allocation peut être transférée sur disque en une seule opération. Un répertoire est un ensemble de blocs contenant des pointeurs sur des structures de répertoire de longueur variable composées des champs : taille de l'entrée, longueur de son identificateur, pointeur sur l'inode correspondant.

8.3.4Comparaison des types de systèmes de fichiers
Les améliorations apportées dans la version 4.3 BSD sont les suivantes :
-la taille des blocs est de 8 K octets,
-les blocs sont divisés en fragment de 1 K-octets
-il existe douze blocs de données d'accès direct
-il n'existe pas d'indirection triple.
-une partition devient un groupe de cylindres, chacun constitué d'une copie du super bloc, d'un espace pour les inodes, d'une description du groupe de cylindres qui remplace la free-list.
On peut résumer les caractéristiques des différents types de systèmes de fichiers dans le tableau suivant :SYSTEM V BSD 4.3 OSF/DCE
Taille des blocs 512,1024,2048 4K ou 8K
Fragmentation Non Oui Oui
Nombre d'octets de l'adresse 4 4 8
Nombre de blocs d'accès direct 10 12
Indirection simple 1 1 1
Indirection double 1 1 1
Indirection triple 1 0 1
Indirection quadruple 0 0 1
Taille maximale des fichiers 1, 16, 256 G 4 ou 32 G ?
Nombre maximum de caractères 14 255
8.4 TABLES SYSTÈMES ASSOCIÉES AU SYSTÈME DE GESTION DE FICHIERS
Nous allons étudier quelques tables systèmes nécessaires à la gestion des fichiers.
8.4.1Table des descripteurs des fichiers d'un processus
Lors d'une création ou d'une ouverture d'un fichier par un processus, le noyau lui associe un point d'entrée dans la table u_ofile[] définie dans la structure U, table locale associée au processus et permettant en particulier l'identification de l'ensemble de ses fichiers ouverts. L'index dans cette table est la variable entière retournée par l'appel système open.
Exemple : les fichiers standards
Trois fichiers, appelés fichiers standards, sont automatiquement ouverts au début de chaque session de travail. Ce sont :
-le fichier standard d'entrée : le clavier, dont le pointeur est stdin et le descripteur 0,

-le fichier standard de sortie : l'écran, dont le pointeur est stdout et le descripteur 1,
-le fichier standard d'affichage des diagnostics d'erreurs : l'écran, dont le pointeur est stderr et le descripteur 2.
On travaille implicitement avec ces trois fichiers que l'on peut toujours rediriger quand on utilise l'interprète de commande.
Il faut bien voir que l'appellation fichier standard ne signifie pas que les autres fichiers ne sont pas des fichiers "normaux" : cela veut seulement dire qu'ils sont différents des fichiers stdin, stdout, stderr. Les fichiers autres que les fichiers standards sont les fichiers ordinaires.
8.4.2Table des fichiers ouverts
La table file[] est un tableau de structures contenant la liste de tous les fichiers ouverts dans le système à un instant donné. Une entrée y est utilisée à chaque ouverture d'un nouveau fichier par un processus contenant la définition des paramètres d'accès à un fichier : type, mode d'accès. Les structures de données sont définies dans file.h/* définition de la structure file */struct file {struct file *f_next; /* pointeur de chaînage sur la structure suivante ou dans la freelist */int f_flag; /* drapeaux d'accès */short f_type; /* descripteur de type */short f_count; /* compteur des appels open */short f_msgcount; /* références queues de messages *//* opérations sur la structure file */struct fileops {int (*fo_rw)();int (*fo_ioctl)();int (*fo_select)();int (*fo_close)();} *f_ops;caddr_t f_data; /* inode */off_t f_offset; /* déplacement */};/* drapeaux pour l'appel système fcntl */#define FOPEN (-1)#define FREAD 00001 /* habilité en lecture/réception */#define FWRITE 00002 /* habilité en écriture/émission */#define FNDELAY 00004 /* entrée/sortie synchrone */#define FAPPEND 00010 /* mise à jour à chaque écriture */#define FSHLOCK 00200 /* verrou de partage présent */#define FEXLOCK 00400 /* verrou d'exclusion mutuelle *//* mode de création */#define FCREAT 01000 /* création si fichier inexistant */#define FTRUNC 02000 /* troncature à une longueur nulle */#define FEXCL 04000 /* erreur si le fichier existe déjà *//* drapeaux pour l'appel système open */#define O_RDONLY 000 /* ouverture en lecture seulement */#define O_WRONLY 001 /* ouverture en écriture seulement */#define O_RDWR 002 /* ouverture en lecture écriture */

#define O_NDELAY FNDELAY /* ouverture non bloquante asynchrone */#define O_APPEND FAPPEND /* mise à jour à chaque écriture */#define O_CREAT FCREAT /* ouverture avec la création */#define O_TRUNC FTRUNC /* ouverture avec troncature */#define O_EXCL FEXCL /* erreur en création si existence *//* drapeaux de verrou (appel lockf) */#define LOCK_SH 1 /* verrou partagé */#define LOCK_EX 2 /* verrou exclusif */#define LOCK_NB 4 /* non blocage au verrouillage */#define LOCK_UN 8 /* déverrouillage *//* drapeaux des droits d'accès */#define F_OK 0 /* drapeau d'existence */#define X_OK 1 /* exécutable */#define W_OK 2 /* écriture autorisée */#define R_OK 4 /* lecture autorisée *//* appel lseek : définition des déplacements autorisés */#define L_SET 0 /* absolu */#define L_INCR 1 /* par rapport à l'adresse courante */#define L_XTND 2 /* relatif à la fin du fichier */
La variable f_offset est le pointeur de déplacement dans le fichier utilisé à la fois en lecture et en écriture. Lors de la création d'un processus par l'appel système fork, le processus fils héritant des attributs du processus père, une modification du champ f_offset par le processus père est répercutée dans le processus fils et réciproquement. Pour l'éviter, le processus fils utilisant le fichier doit également exécuter l'appel système open pour disposer de son propre pointeur de déplacement.
La variable f_count représente le nombre d'appels système open simultanés sur ce fichier dans un même ou dans plusieurs processus.
Le système d'exploitation UNIX ne gère pas le contrôle des accès concurrents à un fichier. Le seul contrôle existant est celui de l'appel système read. Rien n'interdit à un autre processus de modifier de manière incohérente un fichier dès que l'appel système read est terminé. Ce problème de section critique est relégué au niveau de l'application.
8.4.3Table des inodes
Un système de fichiers contient la liste des inodes du disque logique. La table inode[] contient la liste des fichiers chargés en mémoire permettant l'accès aux blocs de données sur disque.struct inode {
struct vnode i_vnode; /* vnode associée à l'inode */
struct vnode *i_devvp; /* vnode pour e/s mode bloc */
u_long i_flag; /* drapeaux d'état */
dev_t i_dev; /* volume associé à l'inode */
ino_t i_number; /* i_number associée */
int i_diroff; /* dernière entrée du répertoire */
struct fs *i_fs; /* système de fichiers associé */
struct inode *inode; /* pointeur sur la table des inodes */
struct inode *inodeNINODE; /* fin de la table des inodes */

int ninode; /* nombre d'inodes dans la table */
struct dquot *i_dquot; /* quota associés à ce fichier */
}
/* opérations sur les inodes */
extern struct inode *ialloc();
extern struct inode *iget();
/* drapeaux */
#define ILOCKED 0x1 /* inode verrouillé */
#define IUPD 0x2 /* fichier modifié */
#define IACC 0x4 /* heure d'accès à l'inode modifiée */
#define IMOUNT 0x8 /* système de fichiers monté sur l'inode */
#define IWANT 0x10 /* processus en attente de verrouillage */
#define ITEXT 0x20 /* inode exclusivement texte */
#define ICHG 0x40 /* modification de l'inode */
#define ISHLOCK 0x80 /* fichier avec verrou de partage */
#define IEXLOCK 0x100 /* fichier avec verrou exclusif */
#define ILWAIT 0x200 /* processus en attente fichier verrouillé */
#define IREF 0x400 /* inode référencé */
#define IFIR 0x500 /* lecteur (tube nommé) endormi */
#define IFIW 0x600 /* rédacteur endormi (tube nommé) */
Interprétation
Les zones de la structure i_flag indiquent :
-l'accès du fichier par un ou plusieurs processus,
-la modification de l'image du fichier en mémoire pour une réécriture éventuelle sur le disque de l'image à jour du cache disque,
-la modification de la structure de l'inode pour réécrire les informations de gestion sur l'inode disque,
-le montage éventuel du système de fichier,
-si le fichier est en cours d'exécution interdisant ainsi son écriture mais non sa lecture.
Chaque appel de la primitive open incrémente de 1 le champ f_count et chaque appel de la primitive close le décrémente de 1. Le dernier des appels à close le rend nul permettant ainsi la restitution de l'entrée dans la table.
De la même façon, lorqu'un fichier est supprimé (appel système unlink), le compteur ic_nlink du nombre de liens matériels est décrémenté de 1. L'inode correspondante est restituée à la liste des inodes libre quand il devient nul.

Exemple : on suppose que les processus Pi et Pj ont ouvert le même fichier (1). En outre, le processus P j
en a ouvert un deuxième. D'où le schéma d'accès suivant :
La table u_ofile[], locale au processus, est dans la structure U.
La table file[] des fichiers ouverts en mémoire centrale est résidente dans l'espace système.
La table inode[] est la table des inodes actives en mémoire.
Si le fichier recherché est déjà chargé en mémoire centrale, la lecture est immédiate. Dans le cas contraire, la primitive bmap est utilisée pour accéder au fichier sur le disque.
Contraintes d'administration
Il est nécessaire, à la génération système, d'ajuster ces tables pour tenir compte de la charge du système et de son utilisation.
8.4.4Montage des systèmes de fichiers
Mécanisme de base
Le mécanisme du montage permet, à partir des multiples systèmes de fichiers des différents volumes de créer l'arborescence logique. Soit le volume d'étiquette logique /dev/dk0, partitionné en deux systèmes de fichiers /dev/dk0a et /dev/dk0b.
systè m e de fichiers /d ev/d k0a
systè m e de fichiers /d ev/d k0b
Supposons que le système de fichiers /dev/dk0a contienne les fichiers du répertoire / et que le système de fichiers /dev/dk0b contienne ceux du répertoire /usr. La commande shell mount s'utilise de la façon suivante :
mount /dev/dk0a /mount /dev/dk0b /usr

Il est en outre nécessaire de créer avant le montage le répertoire /usr.
Sécurité
Supposons le répertoire /user non vide avant montage. Après montage, tous les fichiers présents avant montage deviennent invisibles et inaccessibles. Ils redeviennent accessibles après démontage.
Gestion des crash
La notion de montage est intéressante pour la gestion d'un crash d'un système de fichiers. Il suffit de démonter (commande shell umount) le système de fichiers malade pour que l'arborescence restante reste valide; sa restauration est alors possible. Cela permet également l'optimisation des temps de recherche par la lecture simultanée de différents systèmes de fichiers.
Tables associées
La liste des partitions à monter au démarrage du système est contenue dans le fichier /etc/fstab. La table des volumes montés (/etc/mtab) évolue dynamiquement et comporte trois champs pour chaque système de fichiers monté :
-le type du périphérique contenant le système de fichiers m_dev permet l'utilisation des appels d'entrées/sorties adaptées au volume,
-le pointeur m_bufp est l'adresse en mémoire centrale du super bloc du système de fichiers monté (bloc libre, inode libre, etc.),
-le pointeur m_inodep de l'inode sur lequel est monté la racine du système de fichiers monté permet l'accès à la racine.
8.4.5Fichiers virtuels et systèmes de fichiers virtuels
Le montage d'un système de fichiers à travers un réseau local généralise le montage local. Il est possible de définir des systèmes de fichiers répartis en utilisant le protocole Network File System défini par SUN.
Un système de fichiers virtuel offre une interface commune aux différents systèmes de fichiers. Par exemple, dans les systèmes UNIX 4.2BSD et UNIX SYSTEM V R4, il est possible d'accéder à des systèmes de fichiers de types différents ou à ceux d'un autre système d'exploitation (par exemple MS/DOS) permettant ainsi de stocker des fichiers sous le format MS/DOS et de disposer d'un serveur MS/DOS, accessibles sous UNIX ou sous MS/DOS ayant le niveau de sécurité d'UNIX.
Un système de fichiers virtuel est constitué de fichiers virtuels.

8.5 CACHE DISQUE
Le cache est une région de la mémoire utilisée pour le chargement des fichiers. Elle permet d'accéder directement à leur contenu. L'avantage est l'accélération des accès disque, l'inconvénient est la non cohérence entre le contenu du cache et le contenu du fichier sur le disque.
8.5.1Mécanismes d'adressage
Lors d'une entrée/sortie, le support physique de l'information et les routines utilisées sont accessibles par l'entier i_dev, dont les huit bits de poids fort représentent le majeur (major) et les huit bits de poids faible le mineur (minor).
i_dev = (majeur, mineur)
Le majeur détermine le type du périphérique utilisé et permet l'identification de l'ensemble des appels système du pilote associé.
Le mineur permet l'identification de l'unité logique sur laquelle le pilote doit opérer, par exemple une partition d'un disque ou un circuit virtuel d'une interface réseau.
Chaque périphérique est décrit par une entrée dans le répertoire /dev qui le déclare par son mineur et son majeur. La commande du shell mknod permet la création dans le répertoire /dev d'un nouveau nom de périphérique associé à un majeur et un mineur. Cette information figure dans la table des inodes après l'exécution de la primitive open sur le périphérique dans le champ entier m_dev qui contient le majeur dans sa partie haute et le mineur dans sa partie basse. Le nombre de bits utilisé pour coder le couple (majeur, mineur) est parfois une limitation (cas d'un pilote gestionnaire d'un grand nombre de disques).
Les différents types d'adressage utilisés pour la gestion des entrées/sorties sont les suivants :
Adressage physique
Ce type d'adressage est dépendant du support physique et se décompose en champs de la forme :
adresse = f(numéro du cylindre, numéro de la tête, numéro du secteur)
Le système de gestion de fichiers utilise le moins possible ce type d'adressage la traduction adresse logique/adresse physique étant réalisée au dernier moment.
Adressage logique
Le disque est divisé en blocs de taille fixe (512, 1024, 4096, 8192 octets) dont le nombre total est déterminé à la création du système de fichiers lors de l'appel de la commande shell mkfs.
On a la relation :
adresse_logique = f(i_dev, numéro de bloc)
Le noyau utilise essentiellement ce type d'adressage la traduction devenant effective lors des appels système du pilote.

Adressage relatif
Lorsqu'un utilisateur utilise un fichier, il précise son nom et le ou les caractères qu'il recherche à partir du début de ce fichier. On a donc :
adresse_rel = f(i_dev, i_number, offset)
La conversion adressage relatif/adressage logique nécessaire aux appels système du pilote est réalisée par l'appel système bmap.
8.5.2Mécanismes de base du cache
Principes
Les lectures et les écritures sur disque sont réalisées par blocs. Une lecture ou une écriture d'un bloc en mémoire centrale n'entraînant pas d'accès en mode bloc sur le disque, la fréquence des accès disques est diminuée si la copie d'un certain nombre de blocs disques y est conservée. Un bloc n'est écrit effectivement sur le disque que lorsque le cache est saturé (write behind). En cas d'incident, le système de fichiers correspondant risque d'être incohérent. Pour tenter d'y remédier, le système d'exploitation exécute périodiquement la commande shell sync qui recopie sur disque les blocs modifiés du cache. L'utilitaire fsck permet, au démarrage du système de rétablir quand c'est nécessaire la cohérence d'un système de fichiers. Toutefois, la durée d'exécution de cet utilitaire étant proportionnelle à la taille du système de fichier, elle n'est pas exécutée systématiquement.
Les performances sont améliorées par anticipation des lectures séquentielles du bloc suivant (primitive breada).
Une opération n'affectant que la copie en mémoire du bloc est une entrée-sortie logique. Une entrée-sortie physique est l'écriture ou la lecture effective du bloc sur le périphérique correspondant.
La table des blocs en mémoire est en zone système et n'est pas swappable.
Avantages
Réduction du nombre des accès disques en profitant de leur géographie. Un même bloc est consultable plusieurs fois.
Amélioration des performances par anticipation des lectures séquentielles sans intervention de l'utilisateur (read ahead).
Mise en commun des blocs d'entrées/sorties.
Désynchronisation de la lecture ou l'écriture logique avec l'opération physique : il est possible de lire ou écrire un seul octet sans pénalisation puisqu'il est lu en mémoire. Une entrée/sortie physique d'un bloc de 512 octets permet jusqu'à 512 accès logiques d'un octet. Du point de vue du processus utilisateur, les opérations d'entrées/sorties sont synchrones. Du point de vue du système d'exploitation, elles peuvent être asynchrones.

8.5.3Tampons
Un tampon (buffer) est une zone de la mémoire centrale contenant un bloc de données lues sur le disque. Le cache disque ou cache est l'ensemble des tampons conservés en mémoire. Il gère la partie de la mémoire utilisée pour les transferts sur disque. Le nombre et la taille des tampons peut être optimisée suivant la mémoire disponible et le type de travaux. Plus le nombre de tampons est élevé, plus la probabilité de présence des données en mémoire est importante. Mais une taille du cache trop importante risque de provoquer davantage de swap puisque l'espace en mémoire centrale est plus réduit. C'est à la génération du noyau que l'on peut définir la taille du cache. Si les processus ont des tailles importantes, il est judicieux que les tampons associés soient importants. La taille du cache peut évoluer dynamiquement depuis UNIX SYSTEM V release 4.
8.5.4Tampons virtuels
Si tous les tampons étaient de taille constantes et si les blocs associés aux fichiers étaient tous de taille fixe, l'allocation d'un tampon serait triviale. Or, nous avons vu que dans l'environnement BSD, les blocs peuvent être de taille variable puisque la granularité est très fine (fragmentation). Pour résoudre ce problème, la taille d'une structure buf est limitée à 8K. Une conséquence est que la probabilité que tous les tampons n'aient pas une taille maximale est très importante. Si un tampon fait une requête d'extension, l'espace nécessaire est "volé" à une autre structure buf.
8.5.5Consistance du cache
Pour résoudre les problèmes associés à la cohérence du cache, les structures de données système sont écrite en mode synchrone et dans le bon ordre : par exemple, un bloc contenant la cible d'un pointeur est mis à jour avant celui contenant le pointeur.
Les données d'un processus utilisateur sont traitées différemment : par défaut, la mise à jour du cache est réalisée toute les trente secondes. Il est également d'ouvrir un fichier avec des opérations d'écriture exécutées en mode synchrone. C'est coûteux en temps CPU.
8.6 PILOTES
Définition
Un pilote est un ensemble de fonctions constituant le niveau logiciel le plus bas du sous système d'entrées/sorties, permettant au noyau de dialoguer avec un périphérique de type donné (disque SMD, pilote de terminal TTY). Il s'interface avec le noyau par des tables dont il doit respecter les normes ce qui se traduit par le respect impératif de la définition d'une liste de fonctions rigoureusement définies car leurs noms, leurs arguments, leurs valeurs de retour leurs structures de données internes sont figées.
Utilisation
Son utilisation ne demande pas la connaissance de l'ensemble du code du noyau. Il faut seulement connaître : les structures de données et les fonctions utilisées par le noyau et le pilote,
les méthodes d'intégration des primitives du pilote dans les tables d'interface avec le noyau.

8.6.1Les deux types de pilote
Il y a deux types de pilotes : pilotes des périphériques fonctionnant en mode bloc et pilotes des périphériques fonctionnant en mode caractère.
Mode caractère
C'est le mode de fonctionnement par défaut de tous les périphériques. Le mot caractère provient du fait que certains périphériques de stockage sont également gérés en mode bloc.
Mode bloc
Un volume fonctionnant en mode bloc est vu par l'administrateur comme un ensemble de blocs à accès aléatoire.
Une entrée/sortie est réalisée à travers les mécanismes internes du cache qui interface une requête d'un processus (exprimée en octets) et une requête vers un périphérique (exprimée dans l'unité de transfert propre au périphérique, un secteur sur un disque par exemple). Ce type d'entrées/sorties peut être optimisé par une bonne gestion du cache. L'ensemble travaille en coopération car la copie d'un bloc d'un disque dans un tampon du cache reste à disposition des autres requêtes d'accès vers le même tampon. De plus, le cache assure la cohérence des informations en gérant les accès concurrents vers une même donnée. Les entrées/sorties dans le cache sont optimisées par anticipation des requêtes de chargement au pilote.
Dans certains cas (commandes de transfert du shell dd, tar, fsck), il ne faut pas utiliser le cache. Le pilote gère en mode caractère un périphérique géré habituellement en mode bloc : c'est la définition de l'interface périphérique en mode raw (raw device interface). Dans ce cas, le contenu du périphérique est vue comme une suite d'octets non structurée et l'organisation du périphérique en système de fichiers est ignorée.
On en déduit les remarques suivantes : une entrée/sortie prend toujours comme unité de référence celle qui est imposée par le périphérique.
une entrée/sortie utilisant le cache se déroule en plusieurs phases si l'information recherchée en est absente : lecture, puis chargement du disque vers le cache, puis transfert du cache vers le domaine de visibilité du processus.
8.6.2 Interface avec le noyau
Le schéma ci-dessous représente l'architecture générale du système d'exploitation et l'interface noyau/pilote.

8.6.3Tables d'interface bdevsw et cdevsw
Le niveau haut d'un pilote (top half) est constitué de fonctions dont l'adresse est définie par une structure bdevsw (mode bloc) ou une structure cdevsw; (mode caractère).struct bdevsw /* mode bloc */{ int (*d_open)(); /* ouverture */int (*d_close)(); /* fermeture */int (*d_strategy)(); /* initialisation ou terminaison */int (*d_dump)(); /* écriture d'un dump mémoire */int (*d_psize)(); /* taille d'une partition */int d_flags;};struct cdevsw /* mode caractère */{ int (*d_open)(); /* ouverture */int (*d_close)(); /* fermeture */int (*d_read)(); /* lecture */int (*d_write)(); /* écriture */int (*d_ioctl)(); /* contrôle */int (*d_stop)(); /* arrêt */int (*d_reset)(); /* réinitialisation */struct tty *d_ttys;int (*d_select)(); /* contrôle */int (*d_mmap)(); /* adressage en mémoire */};
Les tables d'interface bdevsw et cdevsw sont des ensembles de pointeurs sur des fonctions d'un pilote dont le nom générique est xxopen, xxclose, xxread, xxwrite, etc. pour le pilote de nom logique xx.
Exemples de structures bdevsw et cdevswstruct bdevsw bdevsw[] = {/* 0 procédures associées au pilote md */0, 8, DT_DEV, 0, mdopen, mdclose, mdstrategy, mddump, mdprint/* 1 procédures associées au pilote mt */0, 1, DT_DEV, 0, mtopen, mtclose, mtstrategy, nulldev, mtprint,/* 2 procédures associées au pilote nfsd */

0, 1, DT_SW, 0, nulldev, nulldev, nfsdstrategy, nulldev, nfsdprint,};struct cdevsw cdevsw[] = {/* point d'entrée 0 : pilote vide */0, 0, 0, 0, 0, 0, nodev, nodev, nodev, nodev, nodev, nodev, nodev,/* point d'entrée 1 procédures associées au pilote nfs */ 0, 1, DT_SW, 0, 0, 0, nulldev, nulldev, nodev, nodev, nfsdioctl, seltrue , seltrue,/* point d'entrée 2 procédures associées au pilote nm */0, 1, DT_SW, 0, 0, 0, nulldev, nulldev, mmread, mmwrite, nodev, seltrue, seltrue,/* point d'entrée 3 procédures associées au pilote sy */0, 1, DT_SW, 0, 0, 0, syopen, nulldev, syread, sywrite, syioctl, syselect, syunselect,/* point d'entrée 4 procédures associées au pilote sxt */0, 10, DT_SW, 0, 0, 0, sxtopen, sxtclose, sxtread, sxtwrite, sxtioctl, sxtselect, sxtunselect,};
Chaque point d'entrée de la table a le même nombre de pointeurs. Dans la table cdevsw, le nombre de primitives accessibles à partir d'un appel système est le même quel que soit le volume concerné. C'est à la fois une contrainte et une aide : une contrainte car chaque périphérique étant un cas spécifique, son pilote est unique (les fonctionnalités de gestion d'un disque sont différentes de celles d'un terminal), une aide car cela impose une interface conceptuellement identique pour chacun des volumes du système. Les pointeurs de la table cdevsw pointent soit vers une fonction existante, soit vers la fonction nodev qui retourne une erreur au processus appelant, soit vers la primitive nulldev qui provoque l'interruption du processus appelant.
L'accès à un pilote est réalisé par l'intermédiaire du fichier spécial correspondant du répertoire /dev, crée par la commande shell mknod avec les arguments :
mknod name [b | c] majeur mineur
Le majeur est l'index du périphérique dans la table bdevsw ou cdevsw. Il permet l'accès à une ligne donnée. Le mineur est le numéro logique du périphérique.
Exemple
La commande
mknod /dev/dk0a b 10 0
définit le fichier en mode bloc /dev/dk0a dont les fonctions d'accès sont à la dixième ligne de la table bdevsw. Un appel système (read, write, open,...) sur un périphérique défini dans le répertoire /dev est sans
ambiguïté. La position de chaque pointeur dans la structure à une importance capitale. Ainsi, pour chacun des pilotes, le premier pointeur est celui de sa fonction open.
Le niveau bas (bottom half) du pilote est constitué de primitives de bas niveau qui s'interfacent directement avec le contrôleur du périphérique (fonction d'interruption, fonction start (ou init) émettrice d'une requête au contrôleur, etc.).
8.6.4Mise en oeuvre d'un pilote
Si le principe d'interface entre le noyau et les pilotes est identique sur toutes les implémentations de ce système d'exploitation, le détail des champs des structures des tables d'interface bdevsw et cdevsw varie

d'une version à l'autre. Les primitives constituant un pilote peuvent être appelées de trois manières différentes : à partir d'une requête utilisateur : un appel système traverse les différentes couches du noyau et
appelle la primitive du pilote à travers les tables cdevsw ou bdevsw.
à partir d'une interruption issue du contrôleur du périphérique dont la réponse donnée est l'exécution d'une primitive du pilote, absente des tables d'interface.
au démarrage du système : suivant la machine et la version d'UNIX, cette phase utilise différentes fonctions du pilote appelées à partir des tables bdevsw et cdevsw, par exemple les fonctions xxprobe et xxattach sur les stations SUN.
8.6.5Pseudo-pilotes
Il y a trois méthodes d'intégration d'une nouvelle fonction au systèmes : modification du noyau : c'est toujours délicat à mettre en oeuvre,
utilisation de l'architecture des pilotes et intégration au noyau : c'est la notion de pseudo pilote (pseudo driver),
utilisation de l'architecture des pilotes sans modification du noyau : c'est la notion de pseudo périphérique (pseudo device).
La deuxième solution est basée sur l'idée suivante : l'architecture interne du fonctionnement des pilotes permet l'implémentation de fonctions nouvelles d'une manière élégante mais coûteuse en temps CPU permettant de faire évoluer les fonctionnalités du système d'exploitation sans en altérer la portabilité.
Exemple : création d'un pseudo pilote de verrouillage et de déverrouillage d'accès d'un fichier.
La fonction lck_open initialise la ressource.
La fonction lck_read est la primitive de verrouillage et la fonction lck_close celle de déverrouillage.lck_open(){lock = 0;}lck_read(){ while (lock = 1) sleep(&lock); /* accès interdit si la ressource est utilisée */lock = 1; /* entrée en section critique */}lck_write(){lock = 0; /* libération de la ressource */wakeup(&lock,PRIO);} /* réveil des processus en attente */Après intégration de ce pseudo-pilote, on obtient l'accès exclusif à un fichier par la séquence :Processus actiffd = open("/dev/lock", drapeau_d'accès,..) /* création d'un inode */read(fd,...); /* entrée en section critique */write(fd,..); /* déblocage de la ressource et réveil éventuel des
processus endormis */
Un autre processus tentant une lecture sur le même inode lors de la section critique est bloqué.
Exercice : écrire une implémentation des opérations P et V sur des sémaphores binaires.

8.6.6Pseudo-périphérique
Définition
Un pseudo-périphérique est une entrée de l'arborescence de gestion d'un périphérique virtuel. Leur nature et leur nombre dépendent du système local.
Exemple Les pseudo-périphériques les plus courants sont les terminaux virtuels associés aux connexions via un
réseau local ou aux environnements multi-fenêtres.
Un pseudo-terminal est représenté par deux entrées du répertoires /dev : /dev/ptyxy et /dev/ttyxy, ou x est une lettre de l'intervalle [p,t] et y un numéro de l'ensemble [0-9a-f].
Les pseudo-périphériques maîtres (/dev/ptyxy) et esclaves (/dev/ttyxy) coopèrent selon le modèle serveur-client selon le principe suivant : tout ce qui est écrit sur le pseudo-périphérique maître est accessible en lecture par le pseudo-périphérique esclave et inversement ce qui permet à une application lisant et écrivant sur un pseudo-périphérique esclave de travailler comme avec un périphérique réel. Du côté du pseudo-périphérique maître, un processus pourra y lire ou y écrire.
Tout appel système provenant d'un processus utilise le pseudo-périphérique esclave qui retransmet toutes les requêtes vers le pseudo-périphérique maître. Ce dernier appelle un processus (par exemple un démon) qui exécute un ensemble de traitements spécifiques puis appelle le pilote réel associé au périphérique.
Il est possible d'intégrer des fonctionnalités du code d'un pilote dans un processus qui utilise les pilotes ttyxy et ptyxy, suivant le schéma suivant :
sh1 sh2
ttyxy_rea dttyxy_w rite
p tyxy_ readp tyxy_ w rite
dém on
P ilo te C o ntrôleu r
M od e u tilisa teu r
M od enoyau
L'implémentation est immédiate : il n'est pas nécessaire d'intégrer ou de modifier un pilote existant. C'est portable car les pilotes ttyxy et ptyxy sont standards sous UNIX SYSTEM V.
8.6.7Autres pseudo-périphériques L'entrée /dev/tty représente le périphérique associé à un programme en cours d'exécution.
L'entrée /dev/null sert de poubelle car chaque information qui y est redirigée est perdue.
L'entrée /dev/mem est l'image mémoire du programme en cours d'exécution, modifiable par un débogueur (adb, sdb, dbx...).
L'entrée /dev/kmem est l'image mémoire du noyau. Elle doit être protégée par les attributs convenables.

8.6.8Applications
Multi-fenêtrage
Dans le schéma qui suit, chaque processus shell utilise un couple (ttypy/ptypy) propre attaché à sa propre fenêtre. Un processus démon unique traite les différentes requêtes de l'ensemble des couples (ttypy, ptypy) et s'interface avec le pilote du périphérique.
Jeux de caractères étrangers
Traitement, sans modification des pilotes existants, d'un jeu de caractères arabes qui utilisent un déplacement du curseur de la droite vers la gauche.
8.6.9Réalisation d'un pilote Il est nécessaire de disposer des documentations techniques du contrôleur, de l'interface noyau/pilote
et des particularités propres à la machine cible (gestion des signaux sur le bus, mécanisme d'adressage utilisateur et noyau, ...) et de pouvoir accéder sous le contrôle du moniteur de prom aux différents registres du contrôleur.
Il faut ensuite vérifier que l'on peut intégrer un pseudo-pilote. Il suffit de réaliser un pilote dont la fonction xxopen affiche un message à l'écran. La troisième étape consiste à écrire le squelette du futur pilote, sans utiliser le véritable contrôleur car à ce stade, toute erreur dans le code pourrait provoquer à l'exécution un crash du système. Il est préférable d'effectuer ses tests en mode mono-utilisateur car une erreur peut provoquer un verrou mortel (par exemple un processus de priorité ininterruptible endormis at vitam eternam). Lorsque tous ces problèmes sont résolus, le pilote est testé avec le véritable contrôleur. Des outils de surveillance de l'activité du pilote et du contrôleur sont alors nécessaires.
8.6.10 Intégration d'un pilote
L'intégration d'un pilote est dépendante du constructeur. Les primitives du pilote compilées sans erreur dans un même fichier objet sont intégrées au noyau par modification des fichiers suivants :
/usr/sys/conf/conf.c
Il faut définir un point d'entrée dans les tables interfaces et initialiser les nouvelles primitives pilotes aux différents champs de cette structure.

Les fichiers de génération du noyau
Ce sont les fichiers de paramètrage /etc/master et /etc/system sous SYSTEM V, /usr/sys/sun/conf/GENERIC sur les stations SUN ainsi que le fichier /usr/sys/sun/conf/Makefile de création du noyau.
Le répertoire /dev
Les fichiers rc*
Les fichiers de démarrage (rc.boot ou rc.local dans les version BSD, répertoires rc* dans les systèmes ATT), doivent être modifiés si le système intègre les nouvelles primitives du pilote au démarrage.
8.6.11 Evolution des pilotes
Dans les versions classiques d'UNIX, les pilotes de périphériques sont chargés statiquement dans le noyau. Au démarrage, les pilotes nécessaires sont déterminés puis activés.
La configuration dynamique des pilote est prévues à partir d'UNIX SYSTEM VR4.
Pilotes traditionnels
Pour optimiser le noyau, il est judicieux de n'y intégrer que les pilotes nécessaires à la génération. Tout nouvel ajout nécessite une nouvelle compilation.
Chargement dynamique d'un pilote
Elle permet de configurer dynamiquement les pilotes, les systèmes de fichiers, les modules streams et les pilotes associés, les protocoles réseau. Il est alors possible de charger ou de décharger dynamiquement les modules correspondants.Tout pilote chargeable dynamiquement a un point d'entrée de configuration.
La partie basse du pilote (bottom half) doit s'interfacer dynamiquement avec le contrôleur et le gestionnaire d'interruptions.
La partie supérieure du pilote (top half) doit s'interfacer avec le noyau. Les entrées complémentaires dans les tables bdevsw et cdevsw sont réalisées par les primitives cdevsw_add, bdevsw_add.
8.6.12 L'exemple du pilote TTY
Le pilote tty gère les périphériques (terminaux, modem) sur liaison série en mode asynchrone. Nous y reviendrons au chapitre 11.
8.7 GÉNÉRALITÉS SUR LES STREAMS
Les gestionnaires des périphériques utilisent souvent les mêmes fonctions, quelquefois de façon différentes. Les flots d'entrée/sortie ou Streams, ont été introduits par Dennis Ritchie dans la version d'Unix V8 des Bell Labs. Cette approche révolutionnaire va permettre de réimplémenter l'ensemble des mécanismes de communications inter-processus (tubes, tubes nommés, IPC SV R2, sockets) de façon modulaire ce qui permet par exemple de considérer le système de communications BSD comme un empilement de protocoles. Les Streams sont disponibles depuis UNIX SYSTEM V release 3. Ils sont aujourd'hui présents dans pratiquement toutes les implémentations du système.

Objectifs : évolution et ouverture du système d'entrée/sortie
structuration modulaire et en couches dans le noyau,
masquage des couches de niveau inférieur,
souplesse d'utilisation grâce à l'évolution dynamique des différents modules,
transparence des média,
partage possible du code d'un protocole par plusieurs contrôleurs de communication,
portage aisé des applications.
Dans le présent paragraphe sont définis les termes spécifiques associés aux Streams.
8.7.1Streams et flots
Le terme stream est employé également dans la couche socket. Pour éviter toute ambiguïté, dans tout ce qui suit, les Streams de D.Ritchie seront nommés Streams ou flots d'entrées/sortie ou plus simplement flots.
Flot
Un flot est un gestionnaire de périphériques constitué d'une chaîne de procédures de traitement (Stream Module) opérant sur deux flux de données bidirectionnels entre un processus et un pilote dans le noyau dans un mode full duplex (Stream message).
Extrémités
Les deux extrémités d'un flot sont nécessaires. Elles sont définies : du côté processus en mode utilisateur,
du coté pilote en mode noyau.
Flux de données
On distingue le flux des données descendantes, du processus utilisateur vers le pilote et le flux des données montantes, du pilote vers le processus utilisateur. Les variables d'état de chacun des flux ainsi que les files de messages associées sont gérées par une file (Stream Queue). La file des messages montants (upstream queue) est aussi appelée file en lecture (read queue) ou encore messages entrants. La file des messages descendants (downstream queue) est aussi appelée file d'écriture ou encore messages sortants.

8.7.2Modules
Stream Module
Un module stream ou module assure un traitement, éventuellement optionnel sur les flux de données. Il est constitué d'un allocateur de mémoire privé, des deux flux de données, de procédures internes, appelées services stream ou services, lui permettant d'exécuter des opérations sur ces files. Les services sont implémentés sous forme de primitives de bas niveau du noyau. Ils constituent un filtre bidirectionnel. Les deux flux de données étant full-duplex, les opérations de traitement peuvent être simultanées.
Chaque module s'exécute dans son propre contexte d'exécution. Son espace d'adressage est intégré dans celui du noyau.
Module de Tête
Ce module, appelé également Tête du Flot (Stream Head) est l'interface de dialogue entre le processus utilisateur et les autres modules dans le noyau ce qui permet au processus utilisateur d'y transmettre des paramètres.
Module Terminal
Ce module, également appelé Pied du Flot (Stream End) est un pilote-stream (Stream driver) ou un pseudo-pilote (stream).
Un pilote-stream est un pilote adapté pour devenir un module Stream. Même s'il ne fait rien, sa présence est nécessaire pour supporter la chaîne des modules.
Tables systèmes
Tout pilote est accessible par l'une des tables bdevsw ou cdevsw.
Tout module est identifiable par la table système fmodsw accessible à partir de l'appel système ioctl. Elle est compatible avec les tables cdevsw et bdevsw. Les concepts classiques (inode, utilisation des appels système d'entrée/sortie) restent vrais. Un pilote stream a un point d'entrée dans le répertoire /dev puisque c'est un pilote. Un module stream n'en a pas.

Chaîne de modules
Une chaîne de modules ou chaîne est l'ensemble des modules permettant de constituer un flot. Elle se compose d'un module de tête et d'un module terminal au moins. Dans ce cas, la chaîne de modules internes est vide et aucune opération de filtrage n'est réalisée sur les flux de données.
Tous les modules ont une interface standard permettant leur interconnexion. La chaîne des modules permet de constituer deux chemins de données où circulent des messages.
Exemple
Les caractères saisis à partir d'un clavier sont transmis au processus destinataire (par exemple /etc/getty) à partir de files de caractères, traitées par un pilote de type caractère.
Evolution dynamique d'une chaîne
Une chaîne de modules peut évoluer dynamiquement par empilement ou dépilement de module dans le noyau (commande shell lddr, appel système ioctl) grâce à l'édition de lien dynamique. Les modules compilés doivent donc être relogeables. Les pilotes deviennent donc chargeables dynamiquement à partir du moment où ils sont développés en utilisant les notions associées aux flots (par exemple dans AIX/V3).
La prise en compte d'une modification du code d'un module nécessite une compilation du noyau.
Le code de chaque module peut-être réentrant.
8.7.3Message
Un Stream message ou message est l'unité de communication typée entre deux modules, allouée dans l'espace mémoire propre du module.
Blocs de messages
Un message est constitué d'une liste chaînée de blocs de données, chacun étant un descripteur des données auxquelles il permet d'accéder. Tout message est typé (donnée ou contrôle) et contient des informations de contrôle.
Evolution dynamique
L'extension dynamique de la taille des messages entre différents modules est possible, par des algorithmes de gestion de listes chaînées des blocs de message.
Ordonnancement des messages
Toute requête d'allocation de message est soumise à un ordonnanceur local au module.
Le message doit traverser la chaîne des modules pour le traitement complet.
File de message
Une file de messages est une liste chaînée de messages.

8.7.4Services d'un module
Les opérations réalisées par un module sur un flot sont des services. Ils sont optionnels et ne sont pas d'exécution immédiate car ils sont régulés par le contrôle de flux interne du module avec une gestion interne des priorités.
Autonomie du sous-système d'entrées/sorties
Le sous-système d'entrée/sortie devient autonome dans le noyau car il est muni de ses appels système propres, de son allocateur mémoire, de ses gestionnaires de travaux propres (ordonnanceur, multiplexeur).
Exemples d'applications Module permettant à un pilote de clavier de 102 touche de gérer un clavier à 80 touches.
Module additionnel de cryptage de données d'un disque.
Cryptage de donnée et stockage sur deux disques différents.
8.8 OPÉRATIONS DE BAS NIVEAU SUR LES FLOTS DE MESSAGES
Un module est constitué d'un ensemble de primitives de bas niveau permettant d'exécuter des opérations sur les flots de messages.
8.8.1Procédures d'écriture des messages
Les opérations sur une file de messages sont : la transmission du message de la file sortante vers une file entrante du module suivant sans traitement
du message,
la transmission du message de la file sortante vers une file entrante du module suivant avec traitement du message,
la non transmission du message.
Le traitement dépend en général du type du message. Le message, éventuellement modifié, est transmis à une file ayant en général la même direction (montante ou descendante) mais ce n'est pas obligatoire.
Une file contient toujours une procédure d'écriture et peut contenir une procédure de service associée.
8.8.2Ordonnancement et procédures de services
L'ordonnancement dans un module est indépendant de celui du système d'exploitation. Ainsi, il n'est pas possible d'y exécuter les primitives de bas niveau sleep ou wakeup car les contextes d'exécution sont à la fois celui d'un module, dans le noyau, et celui du processus utilisateur appelant.
L'ordonnanceur local traite chacune des files d'attente de requêtes de messages en FIFO, active la procédure de service associée à la queue, qui traite les messages en attente. La durée de l'attente est donc aléatoire. Tous les traitements différés sont traités simultanément.
L'ordonnanceur du module effectue un vol de cycle sur le temps d'exécution résiduel des appels système des autres processus. Il est plus prioritaire que celui des processus utilisateurs et est seulement

interruptible par des traitement sur interruption de haut niveau. Les transfert de messages entre modules s'exécutent très rapidement. Ainsi, le routage interne est très rapide s'il est intégré à un module.
Une procédure de service n'est pas obligatoire. Elle complète la procédure d'écriture par écriture du message dans la file associée à l'ordonnanceur du module.
8.8.3Contrôle de flux
Deux niveaux de contrôle de flux : global, au niveau de l'allocation du message pour la chaîne des modules,
local, dans les module dotées d'une procédure de type "service".
Le contrôle du flux des messages est réalisé par l'utilisation des constantes HIGHWATERMARK et LOWWATERMARK selon l'algorithme suivant :
si le nombre d'informations en attente est supérieur à HIGHWATERMARK alors attendre is
si le nombre d'informations en attente est inférieur à LOWWATERMARK alors redémarrer is
8.8.4Gestion des ressources L'environnement stream assure la gestion des ressources associées à savoir les pointeurs sur les flots
de messages, l'allocation statique et bientôt dynamique des ressources (variables NBLKxx du fichier config.h).
Ces ressources doivent être correctement paramétrés à la génération système faute de quoi le risque de perdre des informations est d'autant plus important que la charge du réseau est plus élevée. La commande netstat -m permet de visualiser l'état d'utilisation des ressources selon le format :
class size inuse totaluse maxuse fail lowpri medpri highpri alloc
Interprétation
class classe de messages de 0 à 9

size taille du message, variable de 4 à 8192 octets
inuse nombre de messages actifs
totaluse nombre total de messages alloués depuis le démarrage du système
maxuse nombre maximum de message simultanés depuis le démarrage du système
fail nombre de messages non pris en compte
lowpri nombre de messages de basse priorité
medpri nombre de messages de priorité moyenne
highpri nombre de messages de haute priorité
alloc nombre maximum de message simultanés alloués dans le fichier config.h.
Le dernier paramètre doit être augmenté quand il y a des messages non traités. C'est un des paramètres importants d'optimisation d'un réseau.
Les performances de l'allocateur de messages sont du même ordre que celles de celui des structures mbufs dans l'environnement BSD.
La primitive de bas niveau freems restitue des blocs streams inutilisés.
Exempleclass size inuse totaluse maxuse fail lowpri medpri highpri alloc
0 4 100 1200 150 18 600 400 200 150
8.8.5Multiplexage de modules
Le multiplexage amont ou aval de files issues de différents modules est possible. L'implémentation est réalisé sous forme de pseudo-pilote. La connexion à un module multiplexeur est réalisée avec l'appel système ioctl, avec l'option I_LINK.
8.9 FICHIERS DE CONFIGURATION
Fichier strconf : fichier descripteur des différents modules streams.

8.10 FLOTS ET API
Le système de communications BSD a été réimplémenté sous SYSTEM V en utilisant les mécanismes des streams.
La couche socket s'appuie donc sur des modules streams, même si l'interface utilisateur n'a pas changée.
La couche TLI offre une interface applicative similaire à celle de la couche socket pour développer des applications dialoguant avec le monde ISO.
8.11 RÉCAPITULATION DES COMMANDES D'ADMINISTRATION
Gestion des fichiers
iostatchmod, chown, chgrp, newgrpls, pwd, cd, mkdir, rmdir, umaskfind

9. GESTION DES SYSTEMES DE FICHIERS
Nous présentons dans le présent chapitre les commandes de création des systèmes de fichiers puis celles d'administration.
9.1 RAPPELS
9.1.1Architecture d'un disque
Plateau (platter)
Plateau circulaire et magnétique utilisé pour le stockage de données sur ordinateur.
Piste (track)
Portion radiale d'un plateau accessible par une tête magnétique.
Secteur (sector)
Subdivision de 512 octets d'une piste.
Cylindre (cylinder)
Ensemble de plusieurs pistes d'un groupe de plateaux ayant la même distance radiale au centre du plateau.
Partition
Ensemble de secteurs de stockage des informations, swappées ou non.
Formatage (de bas niveau) d'un disque
Opération d'écriture d'informations permettant d'adresser et de mettre à jour chaque secteur ainsi que l'identification d'éventuels secteurs défectueux.
126

Géométrie d'un disque
9.1.2Gestion mémoire
Swap
L'intégralité du processus est déplacée depuis et vers la mémoire centrale.
La taille d'une zone de swap doit être en principe de l'ordre de trois à cinq fois celle de la mémoire centrale.
Elle peut être répartie sur plusieurs disques.
Pagination
Une partie d'un processus actif peut-être déplacée depuis et vers la zone de swap s'il manque de l'espace en mémoire centrale.
Stockage des données
Les systèmes de fichiers utilisent des entrées/sorties en mode bloc.
Les données brutes utilisent le mode raw.
9.2 PARTITIONNEMENT D'UN DISQUE
9.2.1Généralités
Chaque disque est divisé en parties disjointes appelées partitions.
127

Avantages du partitionnement
L'arborescence des fichiers peut-être répartie sur plusieurs disques physiques ou logiques.
Les zones de swap n'occupent qu'une partie d'un disque.
Il est possible d'optimiser les performances du système en multipliant les zones de swap, en optimisant la répartition des données et /ou des systèmes de fichiers sur le disque.
Partitionnement d'un disque
C'est la première opération à réaliser sur le disque. La syntaxe de la commande n'est absolument pas normalisée. Ce sont par exemple les commandes format, diskpart (BSD), divvy (UNIX SCO)...
Cette opération est très délicate. Voici quelques règles de base : un système de fichiers doit être d'une taille raisonnable : s'il est trop grand, le temps de recherche
risque d'être long. S'il est trop petit, des problèmes d'installation de logiciels risquent de se poser très rapidement. Il faut particulièrement bien dimensionner les systèmes de fichiers root (racine de l'arborescence) et le système de fichier contenant la zone de swap, situé sur le deuxième système de fichiers du disque système.
les tailles des systèmes de fichiers sont indiquées en octets, cylindres, secteurs....Quelquefois, il est demandé de fournir les chiffres manuellement. Attention au systèmes de fichiers entrelacés.
la taille d'un système de fichier est fixe ce qui empêche toute modification ultérieure sans sauvegarde préalable. Une solution partielle à ce problème a été présentée par IBM dans AIX/V3 avec la notion de volume logique.
Volume physique
C'est un fragment ou la totalité du périphérique réel.
Volume logique
Un volume logique peut être constitué de plusieurs volumes physique de différents périphériques.
Le gestionnaire de volume logique (Logical Volume Manager) utilise une table de correspondance entre un volume logique et un ou plusieurs volumes physiques.
Apports
Le système d'exploitation UNIX ne voit que des volumes logiques.
Les apports sont multiples : disques miroir, disque logique d'une taille "infinie", modification "presque" dynamique de la taille d'un système de fichiers.
Il peut y avoir au plus 255 partitions.
128

9.2.2Partitionnement SYSTEM V
La table du partitionnement du volume (VTOC)
La table VTOC (Virtual Table Of Contents) est la partie du disque contenant les informations du partitionnement.
Partitions les plus courantes
Sur le disque système : 0 partition root.
1 zone de swap.
2 système de fichiers contenant le répertoire /usr.
3 à allouer selon le disque.
Création d'une table VTOC
Elle est crée à partir de la commande mkvtoc.
Synopsis
mkvtoc [options] fichier_spécial_en_mode_raw
Options
p affichage de la table VTOC du disque sur la sortie standard
u partitionnement d'un disque utilisateur
s fichier partitionnement d'un disque à partir de sa description contenue dans un fichier VTOC (recommandée).
Principe d'utilisation
Habituellement, le fichier VTOC est crée à partir d'une redirection de la commande mkvtoc -p sur un disque déjà partitionné. Le fichier résultant est édité manuellement et utilisé comme fichier de données de la commande mkvtoc.
Exemple : mkvtoc /dev/rdsk/c2d3s7
Exemple de fichier VTOC*#ident "Header: hp97548 12.4 1991/05/21 $"* hp97548 on SCSI* Dimensions* 512 bytes/sector* 56 sectors/tracks* 16 tracks/cylinder* 896 user accessible sectors/cylinder* 1447 cylinders1445 user accessibles cylinders** Types
129

* 00 No partition01 Regular Partition02 Boot Block03 Reserved Disk Area04 Firmware (not used on SCED SCSI disk)** Partition Type Start Sector Size in Sectors Block Sz Frag Sz0 1 520576 57176 8182 10241 1 577752 198184 8192 10242 1 775936 518784 8192 10243 1 4480 516096 8192 102412 4 32 4448 0 013 3 1294720 1792 0 014 2 0 16 0 015 3 16 16 0 0
Affichage d'une table VTOC
La commande prtvtoc affiche la table VTOC associée à un disque.
Synopsis
prtvtoc fichier_spécial_en_mode_raw
Exempleprtvtoc /dev/rdsk/c2d3s7
9.3 CRÉATION D'UN SYSTÈME DE FICHIERS
9.3.1Généralités
Mode de création
La création d'un système de fichiers doit être exécutée en mode raw, préalablement à tout montage.
Le répertoire lost+found
Le répertoire lost+found est crée sur chaque système de fichiers pour contenir des fichiers ou les blocs récupérés suite à l'exécution de la commande fsck.
Définition du type du système de fichiers
Compte tenu de la diversité des implémentations, il est judicieux de définir le type du système de fichiers utilisé (S51, AFS, FFS, XFS, LFS...) car il peut y en avoir plusieurs sur le même disque. Attention aux performances selon le choix effectué. Les plus performants sont d'origine BSD.
9.3.2SYSTEM V
La commande mkfs crée un système de fichiers.
130

Synopsis
mkfs [-y|-n][-f type_fs] fspecial blocs [:inodes][gap bloc/cylindre][fs_options]
Description
La commande mkfs crée un système de fichiers sur le fichier spécial fspecial, selon les options choisies par l'utilisateur.
La taille du système de fichiers est déterminée soit par l'argument blocs qui en indique le nombre de blocs de 512 octets, soit par l'argument inode, qui en spécifie le nombre d'inodes.
L'option y (resp n) permet d'écraser, après (resp sans) confirmation un système de fichier existant.
L'option f permet de spécifier le type du système de fichier à créer.
Il est possible d'optimiser la gestion des données en indiquant le nombre de blocs par cylindre du disque.
Il existe des options spécifiques à un type de système de fichiers donné.
9.3.3BSD
La commande mkfs est souvent remplacée par la commande newfs, qui en offre une interface conviviale d'utilisation.
Synopsis
newfs [-nNv][options_de_mkfs] fichier_spécial
Options
n non installation du programme de démarrage (boot) sur la partition.
N affichage des paramètres courants du système de fichiers sans modification.
v Mode verbeux.
Les options transmises à la commande mkfs sont : b taille des blocs en octets
c#cylindre/group nombre de cylindres dans un groupe.
d durée en ms d'une interruption du transfert.
f taille d'un fragment
ibytes/inode densité du nombre.
m pourcentage d'espace réservé aux utilisateurs.
o optimisation
r nombre de révolutions par minutes
s taille du système de fichiers en secteur
t#pistes/cylindre le nombre de pistes par cylindre.
L'option m définit le pourcentage du système de fichiers affecté aux utilisateurs. Sur les systèmes BSD, un système de fichiers complet compte 110 % d'occupation potentielle; 10% pour le système, 100 % pour
131

les utilisateurs. Il est possible de moduler ce chiffre. C'est toutefois peu recommandé car en cas de saturation d'un système de fichiers, le fonctionnement global du système peut se révéler incohérent. De plus, ce chiffre permet une gestion interne des blocs du disque aisée.
9.4 MONTAGE
9.4.1La commande /etc/mount
La commande mount est utilisée pour permettre, à partir des différents systèmes de fichiers, de constituer l'arborescence des fichiers du systèmes. Elle assure le montage d'un système de fichiers dans un répertoire de l'arborescence. Elle est utilisée lors de l'initialisation pour raccorder les disques virtuels, et peut servir à tout instant pour accéder à une information présente sur un support amovible non utilisé en temps normal.
Synopsis
mount [-r][-f[NFS]][rhost:]système_de_fichier repertoire_de_montage
Options
r système de fichiers local monté en lecture seule
f type du système de fichiers monté
NFS : système de fichiers distant d'un type quelconque monté par le protocole NFS d système de fichiers distant monté par le protocole RFS (Remote File Sharing).
132

9.4.2Options de sécurité de la commande mount
Les systèmes de fichiers à monter au démarrage de la station sont définis dans le fichier /etc/vfstab (BSD), ou /etc/default/filesys (SYSTEM V).
Le fichier /etc/fstab
Le format d'une ligne est :
système_de_fichiers point_local_de_montage options, type
Le champ système_de_fichier est le nom complet du système de fichiers.
Le champ point_local_de_montage est le nom du répertoire associé (existant). Le mot clé swap indique une zone de swap.
Le champ type indique le type du système de fichiers. Celui qui est supporté peut être quelconque (AFS, FFS, UFS, 4.2) selon les implémentations.
Pour une zone de swap, il faut utiliser le mot clé ignore.
Il est possible d'accéder à n'importe quel type de système de fichiers par le protocole NFS.
Le champ options indique le type de montage qui peut être rw (read, write) ou ro (lecture seule). Le mot clé complémentaire quota permet de définir des systèmes de fichiers avec quota.
Quoique le fichier /etc/fstab soit utilisé seulement pour le montage des systèmes de fichiers, c'est une bonne pratique que de lister l'ensemble des partitions qui sont utilisées.
Le fichier /etc/fstab est éditable manuellement.
Exemple1 (BSD)/dev/dsk/c2d0s0 / 4.2 rw/dev/dsk/c2d0s1 swap ignore ./dev/dsk/c2d1s0 /usr 4.2 rw/dev/dsk/c2d1s1 swap ignore ./dev/dsk/c2d1s2 /home 4.2 rw/dev/dsk/c2d2s6 /tmp 4.2 rwcactus:/usr3 /unix3 NFS,softantinea:/usr2 /unix2 NFS,soft
Le fichier /etc/mntab (SYSTEM V) ou /etc/mtab (BSD) contient la liste des systèmes de fichiers montés à un instant donné. Son contenu évolue dynamiquement.
Exemple 2 : montage d'une disquette dans l'arborescence.
La disquette doit être préalablement formatée. Le répertoire /mnt est ensuite utilisé de la façon suivante:
/etc/mount /dev/fd0135 /mnt
où le fichier spécial /dev/fd0135 est associé au lecteur de disquettes.
Extension à l'environnement réseau
La commande mount fonctionne dans un environnement réseau. Il est alors possible, grâce au protocole NFS de monter des système de fichiers distants, quelque soit leur type (BSD, SYSTEM V, LSF),...

Autres commandes de montage
La commande /etc/mountall (SYSTEM V) permet de monter l'ensemble des systèmes de fichiers du fichier /etc/vfstab. Son équivalent BSD est la commande mount -a.
9.4.3Table des systèmes de fichiers montés
La liste des systèmes de fichiers montés à un instant donné est accessible dans le fichier /etc/mnttab (ou /etc/mtab).
L'exécution de la commande mount, sans argument, affiche les systèmes de fichiers montés. Le champ System indique si le système de fichier est local ou distant.
ExempleSystem Device name Mount Directory Description[local] /dev/dsk/c2d0s0 /[local] /dev/dsk/c2d0s2 /usr[local] /dev/dsk/c2d1s0 /tmp[local] /dev/dsk/c2d1s2 /home user home directories
9.4.4Droit d'exécution de la commande mount
Un utilisateur ayant le droit d'exécution de la commande /etc/mount pourrait faire des montages de systèmes de fichiers distants. Certaines options permettent même le montage de fichiers avec le bits avec conservation de leurs privilèges. Un utilisateur peu scrupuleux pourrait alors exécuter localement des shell-scripts avec les droits des administrateurs distants.
9.4.5Points de montage
Un montage sur un répertoire non vide cache la sous-arborescence qui réapparaît après démontage. C'est donc un excellent moyen d'avoir des fichiers cachés. C'est aussi une autre raison d'interdire l'utilisation de la commande mount à n'importe quel utilisateur.
9.4.6Stratégie de montage des systèmes de fichiers
Le droit d'écriture ou lecture sur les système de fichiers est déterminé au montage.
En mode lecture, toute écriture est interdite, quels que soient les droits des fichiers ou des répertoires qui y sont contenus. Il faut toujours redémarrer le poste de travail, après avoir modifié la table des systèmes de fichiers, pour pouvoir remonter un fichier en écriture. C'est donc une protection absolue très contraignante. Il convient, au moment de la génération système, de réfléchir soigneusement au type de montage des systèmes de fichiers en fonction des fichiers qui y sont contenus.
9.4.7Démontage La commande umount permet de démonter un système de fichiers de l'arborescence en le rendant
inaccessible aux utilisateurs.
Il est impossible de démonter un système de fichiers en cours d'utilisation. Dans ce cas, le message device busy est envoyé. Il faut donc s'assurer qu'aucun utilisateur ne travaille avant d'essayer un démontage. Par exemple, la commande ps permet de connaître la liste des utilisateurs actifs.
134

Un système de fichiers démonté n'apparaît plus dans l'arborescence.
Remarque
Le système de fichier root ne peut jamais être démonté.
Le système de fichiers associé au répertoire /usr ne peut être démonté qu'en mode mono-utilisateur.
9.5 COHÉRENCE DES SYSTÈMES DE FICHIERS
La cohérence des systèmes de fichiers est essentielle au bon fonctionnement du système. Elle doit être contrôlée périodiquement.
9.5.1Généralités sur la commande fsck
Principe
La commande fsck permet de vérifier la cohérence d'un système de fichiers. Elle doit être exécutée systématiquement au démarrage ou elle est utilisable manuellement, sur un système de fichier démonté, en mode raw.
Il ne faut en aucun cas supprimer son exécution pour "gagner du temps" faute de quoi le système devient rapidement irrécupérable en cas de crash.
Les inconsistances détectées par la commande fsck sont les suivantes : blocs associés à plusieurs inodes dans la liste des blocs libres,
bloc associé par un inode disponible accessible hors du système de fichiers,
nombre de liens matériel incorrect,
contrôles de la taille : nombre de blocs incorrect, taille de répertoire incorrecte
mauvais format d'inode,
blocs perdu,
contrôle de répertoires : fichiers pointant sur un inode non alloué, nombre de blocs alloués supérieur au nombre de blocs disponibles,
mauvais format de la liste de blocs disponibles,
nombre total de bloc libres et compte d'inodes non alloué incorrect.
Durée
Sur les systèmes de fichiers traditionnels, sa durée d'exécution est longue. Sur les nouveaux types de systèmes de fichiers, par exemple Veritas, elle est d'exécution instantanée.
Démarrage
Il est judicieux d'exécuter la commande fsck lors de chaque démarrage du système, même si cette opération peut devenir longue quand la taille des disques est importantes. Sur de nombreux systèmes, elle ne s'exécute au démarrage qu'en cas d'arrêt incorrect (système dirty). Le mécanisme de base est le suivant : création d'un fichier lors de l'arrêt normal du système,
135

vérification au démarrage de la présence de ce dernier, suppression si oui, exécution de la commande fsck sinon.
La liste des systèmes de fichiers à contrôler au démarrage est définie dans le fichier /etc/default/checklist (SYSTEM V), ou /etc/vfstab (BSD).
Exécution manuelle ou automatique
Même dans le cas ou le système est toujours arrêté correctement, sans exécution automatique de la commande fsck, une exécution périodique est fortement recommandée car sinon, les incohérences éventuelles sur les systèmes de fichiers ne sont pas détectées.
9.5.2Mode opératoire
La commande fsck opère en six phases :
Phase d'initialisation de la commande
Cette phase contrôle les options de la commande et contrôle la validité du super bloc par comparaison de la liste des inodes avec la taille du système de fichiers. Si la taille de la liste des inodes est supérieure à celle du système de fichiers, le super bloc doit être modifié. La commande fsck fera une requête pour une adresse alternative (fsck -A bloc).
Phase 1 : contrôle de la taille des blocs et des inodes
Ces contrôles sont effectués pour les types de fichiers, leur taille, le nombre de liens matériels, les adresses des blocs, ainsi que la liste des inodes. La commande fsck -p permet de fixer un nombre de blocs incorrect.
Phase 1B
Quand un bloc dupliqué est trouvé, le système de fichiers est à nouveau analysé pour retrouver l'inode correspondant.
Phase 2 : Contrôle des chemins d'accès et recherche des répertoires non référencés
Les entrées des répertoires pointant sur des inodes défectueuses détectées dans les phases 1 et 1B sont supprimées.
Phase 3 : contrôle de la connectivité des répertoires non référencés
Si l'inode associée à un sous-répertoire d'un répertoire n'existe pas, elle peut être crée, éventuellement dans le répertoire lost+found, par la commande newfs.
Phase 4 : contrôle du nombre de liens matériels
Recherche de fichiers non référencés, du nombre erroné de liens matériels, des blocs défectueux ou dupliqués et du nombre incorrect d'inodes. Les compteurs de contrôle des références permettent la correction de problèmes associés à un nombre de liens matériels incorrect, détectés dans les phases précédentes.
136

Phase 5 : contrôle de la free-liste
Recherche des blocs défectueux, dupliqués, inutilisés ou en nombre incorrect dans la liste des blocs libres. Tout bloc ou fragment doit être alloué ou dans la liste des blocs disponibles.
Phase 6 : reconstruction éventuelle de la free-liste
Quand tout semble correct, la commande fsck affiche les différentes phases et le nombre de fichiers, le nombre de blocs occupés et le nombre de blocs libres. Elle corrige automatiquement certaines erreurs (les fichiers vides non référencés sont détruits ...) et interroge l'opérateur pour les autres (clear pour détruire un fichier à problème, reconnect pour sauvegarder l'information dans le répertoire lost+found du système de fichiers avec comme nom le numéro d'inode ...).
Lorsque qu'un système de fichiers a été modifié , son image dans le cache disque est incorrecte. Le message "Boot UNIX (No Sync!)" est affiché, indiquant qu'il faut réinitialiser le système sans exécution de la commande sync car il y aurait alors recopie de l'information erronée sur le disque.
Cohérence et tolérance de pannes
Un système de fichiers retrouve sa cohérence après l'exécution d'une commande fsck. Toutefois, il peut y avoir une perte d'informations que l'on peut éventuellement récupérer soit depuis une sauvegarde, soit à partir du répertoire lost+found associé au système de fichiers.
9.5.3Utilisation de la commande fsck
Synopsis
fsck [-option(s)] système_de_fichiers_en_mode_raw
Quelques options
y suppose une réponse positive à toutes les questions posées par fsck
n suppose une réponse négative à toutes les questions posées par fsck
q option silencieuse
D contrôle des répertoires (à utiliser après un crash)
f contrôle rapide. La phase 6 est exécutée si nécessaire seulement.
Exemplefsck -y /dev/rroot
9.5.4Le shell script bcheckrc
Le shell script s'exécute au démarrage pour contrôler le système de fichier racine et exécuter la commande fsck en cas d'anomalie évidente (arrêt brutal du système par exemple).
Exemple#! chmod +x ${file}[ -x /instscript ] && exec /instscript# for installation only
137

if [ "$1" != "-a" ]then[ -x /etc/dumpsave ] && /etc/dumpsavefirootfs=/dev/root/etc/fsstat ${rootfs} >/dev/null 2>&1if [ $? -ne 0 ]thendofsck=yesfsckflags="-s -D -b"autoflag=-a if [ "$1" != "-a" ]then
autoflag=echo "
fsstat: root file system needs checking.OK to check the root file system (${rootfs})? (y/n) \c"
whileread reply[ "$reply" ]
docase $reply inn) dofsck=
break;;
y) break;;
*) echo "\n? (y/n) \c";;esac
donefi[ "$dofsck" ] &&/bin/su root -c "/etc/fsck -s -D -b ${autoflag} ${rootfs}"fi[ -f /instscript ] && rm -f /etc/inittab.inst /instscript# post-Upgrade cleanuptrap "" 2# put root into mount table/bin/su root -c "/etc/devnm /" | sed -n '/^\/./p' | grep -v\swap | /etc/setmnt
9.6 PROTECTION, DROITS D'ACCÈS ET CRYPTAGE
On distingue trois niveaux de protection au niveau des droits d'accès :
systèmes de fichiers,
répertoires,
fichiers.
Ils permettent de définir des anneaux de protection de plus en plus fins.
138

9.6.1Classification des fichiers selon leur utilisation
Une classification préliminaire est nécessaire : il faut distinguer les fichiers systèmes privés ou publics, les fichiers utilisateurs...
Une utilisation rigoureuse des attributs rwx assure déjà un premier niveau de protection. Il suffit de choisir rigoureusement l'utilisateur propriétaire, son groupe, ainsi que les droits d'exécution convenables.
Un audit complet du système au moment de la génération peut-être nécessaire si le constructeur est laxiste (ce qui est de plus en plus rare). Que penser d'une commande mkfs avec les droits r-xr-xr-x (exemple vécu) ?
Fichiers d'administration système
Ils ne doivent être accessibles qu'au super-utilisateur et éventuellement aux membres de son groupe. Ils ont au mieux les droits rwxrwx---.
Commandes publiques
Elles doivent bien évidemment être protégées en lecture et en exécution avec les droits rwxrwxr-x
Fichiers utilisateurs
Ils devraient avoir les droits rwxr-x---
Fichiers de configuration de l'environnement de l'administrateur
Ils doivent avoir les droits rwx-----pour empêcher quiconque de les modifier, éventuellement à l'insu de leur propriétaire.
9.6.2Accès aux répertoires
Il faut rappeler que les bits rwx sur un répertoire ont une signification différente des droits sur les fichiers :
le bit r donne l'accès en lecture
le bit w donne le droit d'écriture dans le répertoire ce qui permet éventuellement d'écraser un fichier, même protégé en écriture. C'est aussi un droit de saccage.
le bit x donne le doit de passage.
On peut ainsi autoriser un accès total, ou partiel à un arborescence.
9.6.3Stratégie de montage des systèmes de fichiers
Le droit d'écriture ou lecture sur les système de fichiers est déterminé au montage.
En mode lecture, toute écriture est interdite, quels que soient les droits des fichiers ou des répertoires qui y sont contenus. Il faut toujours redémarrer le poste de travail, après avoir modifié la table des systèmes de fichiers, pour pouvoir remonter un fichier en écriture. C'est donc une protection absolue très
139

contraignante. Il convient, au moment de la génération système, de réfléchir soigneusement au type de montage des systèmes de fichiers en fonction des fichiers qui y sont contenus.
9.6.4Cryptage
La commande crypt permet de crypter, selon une clé personnelle, un fichier. Il est possible de crypter des fichiers, même en utilisant un éditeur standard tel vi ou ed.
9.7QUOTA D'UTILISATION DES SYSTÈMES DE FICHIERS
Le comportement global du système se détériore dès qu'un système de fichier est plein. Il faut donc disposer d'espace disque important (UNIX est gros consommateur) et surveiller souvent l'état des systèmes de fichiers système (dans /var/adm en particulier).
Gestion des quotas utilisateur
L'expérience montre qu'il peut être judicieux d'imposer des quota raisonnables aux utilisateurs.
Sous UNIX, il est possible de définir des quota par utilisateur (place disque en nombre de blocs et nombre maximal de fichiers) sur les version UNIX BSD et SYSTEM V Release 4. Chaque limite est définie par deux paramètres : la limite dure (hard limit) est la limite absolue qu'il est impossible de dépasser,
la limite douce (soft limit), à partir de laquelle des messages sont émis par le noyau pour prévenir l'utilisateur qu'il va atteindre ou dépasser la limite dure.
Un utilisateur peut dépasser sa limite douce en cours de session.
Il est fortement recommandé de les utiliser pour contrôler en permanence l'évolution de l'utilisation des systèmes de fichiers.
Le système de quota s'installe préalablement sur un système de fichiers. Il est donc possible sur un même système de définir des systèmes de fichiers avec ou sans quota.
Cette installation se réalise en cinq étapes.
Modification éventuelle du noyau
Une modification du noyau peut être nécessaire par l'installation de l'option QUOTA sur les versions BSD au moment de la génération du noyau.
Définition des systèmes de fichiers avec quota
Il faut déterminer les systèmes de fichiers sur lesquels l'administrateur souhaite installer des quota par une modification de l'entrée du système de fichiers concerné dans le fichier vfstab (option quota ou noquota).
140

Fichier quota
Il faut créer un fichier quota sur chacun des systèmes de fichiers concernés par exemple par la commande cp /dev/null quota.
Utilisateur avec quota
Le fichier quota est modifié lors de la définition des utilisateurs avec des quota avec la commande edquota.
Démarrage et arrêt du système de gestion des quota
Deux commandes sont disponibles : démarrage des quota (commande quotaon),
arrêt des quota (commande quotaoff).
Contrôle du système de quota
Le contrôle du système de quota est assuré par la commande quotacheck.
Installation permanente
Il faut faire une modification des fichiers de démarrage pour l'initialisation des quota de la façon suivante :#contrôle des quotaecho -n 'checking quotas : ' > /dev/console/etc/quotacheck -a -p > /dev/console 2 > &1echo 'done.' > /dev/console#mise en route des quotas/etc/quotaon -a
9.8 GESTION DES ZONES DE SWAP
Addition d'une zone de swap
La commande swap -a est utilisée dans le fichier /etc/swap. Le nombre indiqué à la fin de la commande indique la longueur de la zone de swap. Le nombre 0 indique la partition entière.
L'ajout d'une zone de swap peut s'effectuer dynamiquement (commande BSD mkfile). Il est recommandé de l'installer sur un autre disque. Pour l'installer, il faut : éventuellement modifier le noyau (selon les implémentations),
créer la zone de swap en utilisant la commande mkfile,
activer la zone en utilisant ma commande swapon. Il est possible de la désactiver en utilisant la commande swapoff
Etat d'une zone de swap
La commande swap -l permet de connaître l'état ainsi que la taille des zones de swap actives.
La commande sar -r affiche les statistiques d'utilisation d'utilisation des zones de swap (espace utilisé
141

et disponible).
Taille d'une zone de swap
Elle est de l'ordre de 200 à 600 Moctets selon la charge et la configuration du système.
9.9 COMMANDES DIVERSES
9.9.1Etat d'occupation des systèmes de fichiers
La commande df permet de connaître l'état d'occupation des systèmes de fichiers en affichant la liste des blocs ou des inodes libres.
Synopsis
df -[t] -[f]-[i]-[v] [système_de_fichiers]
Description
Affichage de l'espace disque disponible sur les systèmes de fichiers montés.
Sans arguments, affichage de l'espace disque disponible sur tous les systèmes de fichiers montés.
Exemple 1df -vi /dev/rootmount Dir Filesystem blocks used free %used iused ifree %iused/ /dev/root 684730 641786 42944 93% 25465 40023 38%
Exemple 2df -t /usr
/ (dev/dsk/c2d0s0): 9610 blocks 12389 i-nodes total: 49896 blocks 13340 i-nodes/usr (dev/dsk/c2d1s0): 25305 blocks 73840 i-nodes total: 328016 blocks 81920 i-nodes
9.9.2Nettoyage et Commande find
UNIX crée de nombreux fichiers temporaires qui sont rarement utilisés et qu'il faut donc purger régulièrement. Ce sont les fichiers crées à la suite d'un "plantage" d'un processus (fichier core), qui, si l'on y prend pas garde, vont rapidement infester l'ensemble des répertoires systèmes et utilisateurs, les fichiers crées dans /tmp ou /usr/tmp par les commandes cc, lint, vi... qui doivent subir le même sort deux ou trois jours après leur création.
La commande find est tout à fait adaptée pour les trouver et les supprimer. Il suffit de la lancer périodiquement (par exemple tous les matins à 4h) à partir de la table des services cron (crontab).
9.9.3Espace utilisé par une arborescence
La commande du affiche l'espace disque utilisé par un répertoire et ses sous-répertoires.
142

Synopsis
du [-as][-nom...]
Description
Indique le nombre de blocs (512 octets) utilisés par un répertoire et ses sous-répertoires.
Par défaut le répertoire courant.
Options a (all) taux d'utilisation pour tous les fichiers y compris les fichiers cachés,
s (summary) taux d'utilisation pour chacun des arguments.
Exempledu -a /etc/vtoc
2 /etc/vtoc/m2333k4 /etc/vtoc/m2344k
9.9.4Correspondance inode-fichier
ff
La commande ff affiche, dans un système de fichiers donné, selon l'ordre croissant de la table des inodes, la liste des fichiers ainsi que leur numéro d'inode respectif.
Synopsis : ff fichier_spécial
Exemple : ff /dev/rroot
ncheck
Cette commande permet d'établir la correspondance entre le numéro d'inode et le nom du fichier.
Synopsis : ncheck fichier_special_en_mode_raw inumber(s)
Exemplencheck /dev/rdsk/c2d0s0 8913 7498
/dev/rdsk/c2d0s0:8913 /command.com7498 /config.sys
9.9.5Label de périphérique
La commande labelit effectue la création d'un label de disque.
Synopsis
labelit fichier_spécial [système_de_fichiers [volume]]
143

Elle associe le fichier spécial contenant le système de fichiers à un volume sur un périphérique externe. Le label peut être utilisé comme identificateur et est constitué de deux parties : le nom du système de fichier : c'est le label primaire, par exemple le point de montage.
le nom de volume : c'est le label secondaire, par exemple le nom du périphérique.
La commande labelit affiche les informations suivantes : fsname premier champ du label (label primaire),
volname deuxième champ du label (label secondaire),
Blocks nombre total de blocs (de 512 octets) du système de fichiers,
Inodes nombre total d'inodes du système de fichiers,
FS units nombre de bytes par unité d'allocation (blocs de 8K par exemple).
Exemplelabelit /dev/rdsk/c2d2s4 home mt0
Current fsname:,home, Current volname:/dev/dsk/c2d2s4, Blocks: 684730, Inodes: 65488FS Units: 1Kb, Date last modified: Mon Sep 6 17:48:49 1993
9.9.6Fsdb
La commande fsdb permet d'examiner un système de fichiers octet par octet, inode par inode, bloc par bloc, et de le corriger après un incident. Elle est d'utilisation interactive.
Utilisateur
Seul, le super utilisateur en détient les privilèges d'utilisation.
Synopsis
fsdb chaîne_de_caractères
La chaîne de caractère représente un fichier spécial ou le nom d'un volume monté.
Format d'une directiveadresse[format d'impression]adresse[opération d'affectation]
Il est judicieux de séparer les différents champs d'une commande par des points.
Directives
q sortie de fsdb,
DEL arrêt d'une impression,
! échappement vers l'interprète de commandes,
0 mode vérification de la commande,
B,W,D sélection du type de données consultées (mode octet, mot, double mot).
144

Format des adresses
nombre[mode] adresse absolue,
[+]|[-]nombre déplacement relatif avant ou arrière,
nombre[i] sélection d'un inode,
nombre[b] sélection d'un bloc,
nombre[d] sélection d'un répertoire.
Exemple40b.d4.p8d
Format d'impression
C'est le dernier argument d'une directive de la forme : i format inode,
d format répertoire,
b,c octet affiché en format octal ou caractère,
o,e format octal ou décimal.
Modification
Toute instruction d'écriture étant immédiatement exécutée, il est nécessaire d'être en mode mono-utilisateur.
Affectation
Les instructions d'affectation autorisées sont : = affectation numérique,
=+ affectation incrémentielle,
=- affectation décrémentielle,
="chaîne_de_caractères" affectation d'une chaîne de caractères.
Modification d'une inode
L'instruction d'affectation est constituée de 4 champs : l'adresse,
le mnémonique du champ à modifier,
l'opérateur =
la valeur.
Mnémoniques autorisés
ln nombre de liens matériels,
at dernier accès,
145

mt dernière modification,
maj le majeur,
min le mineur,
sz la taille en octet,
i# le numéro d'inode,
md les droits d'accès,
a[i] l'adresse en bloc du bloc i.
Exemples12i.ln=4
Visualisation du contenu d'un répertoire
numéro_d'inode.i.fd
Modification du contenu d'un répertoire
Changement du numéro d'inode selon le format
numéro_d'inodei.anuméro_de_blocbdnuméro_d'entrée
Exemple54i.a2b.d18=23
9.9.7Corrections directe d'anomalies
clri
Dans certaine situation, la commande fsck ne fonctionne pas (cas d'une arborescence "infinie"). La commande clri fonctionne dans toutes les situations. Elle permet la destruction physique d'un lien matériel. Pour l'utiliser, il est nécessaire de procéder de la façon suivante : démontage du système de fichier contenant l'inode à supprimer,
utilisation de la commande clri,
contrôle du système de fichier par la commande fsck,
remontage du système de fichiers par la commande mount.
Synopsis
clri système_de_fichier inumber
bdbclk
Cette commande permet de modifier la liste des blocs défectueux d'un disque.
Synopsis
bdbclk option fichier_spécial
146

Les options sont : p affichage de la table des secteurs défectueux,
i vérification et initialisation de la table des secteurs défectueux,
u vérification et mise à jour de la table des secteurs défectueux,
r écriture de la table des secteurs défectueux transmis en argument.
9.10 DÉFINITIONS ASSOCIÉES AU GESTIONNAIRE DE VOLUMES LOGIQUES SOUS AIX
Généralités
Le Gestionnaire de volumes logiques (Logical Volume Manager ou LVM) permet de masquer la structure physique des disques et de les considérer comme des disques logiques.
Avantages
Il est possible de créer des systèmes de fichiers contenus sur plusieurs disques physiques simultanément.
La taille d'un système de fichier peut croître "presque" dynamiquement, selon les besoins.
Il est possible de créer plusieurs disques miroirs.
Le LVM sait récupérer les blocs défectueux d'un disque.
LVM
Le gestionnaire de volume logique est un sous-systèmes de gestion d'entrées/sorties du système d'exploitation qui permet de gérer des volumes logiques au lieu de gérer des disques physiques.
147

Volume physique
Un volume physique est un périphérique (disque), initialisé pour être utilisable par le LVM.
Groupes de volumes physiques
Un groupe de volumes physiques peut regrouper plusieurs volumes physiques. Ainsi, le groupe rootvg (root volume group) contient l'ensemble des volumes physiques nécessaires au démarrage du système.
Partition physique
Une partition physique est une zone d'espace contiguë d'un volume physique. Sa taille fixe (par défaut 4MOctets), peut croître, par puissance de deux, jusqu'à 256 Méga octets. Elle est définie automatiquement au moment de l'ajout au groupe de volumes.
Volume logique
Un groupe de volumes physiques est organisé en volume(s) logique(s) sur le(s)quel(s) il est possible de définir des systèmes de fichiers que l'on peut monter dans l'arborescence.
La commande crfs permet de créer des systèmes de fichiers, d'un type à définir selon les utilisations et les implémentations, sur les disques logiques qu'il est ensuite possible de monter dans l'arborescence par la commande mount.
La cohérence des systèmes de fichiers est vérifiée à partir de la commande fsck.
9.11 COMMANDES DE GESTION DES VOLUMES PHYSIQUES SOUS AIX
9.11.1 Création La commande cfgmgr permet d'ajouter, de configurer, et d'initialiser des périphériques par utilisation
de la base de données associée. Elle peut, dans la plupart des cas, ajouter de nouveaux périphériques, sans intervention externe.
148

Le processus cfgmgr est exécuté lors du démarrage du système en deux phases : la première initialise tous les périphériques strictement nécessaires. La seconde ne s'exécute que si la précédente s'est exécutée correctement pour initialiser le reste des périphériques.
9.11.2 Affichage des informations
La commande lspv affiche les informations caractéristiques d'un volume physique sous la forme suivante : Physical volume le nom du disque physique.
Volume group le groupe de volumes associé.
PVstate
Vgstate
Allocatable
Logical Volumes
States Pps
VG descriptors
l'état du volume physique (inactif, actif, manquant, démonté, supprimé).
l'état du groupe de volumes qui peut être actif, inactif, actif/complet (tous les volumes physiques sont montés), actif/partiel (une partie seulement des volumes physiques est montée.)
les autorisations d'allocation du volume physique.
le nombre de volumes logiques défini dans le disque physique
le nombre de partitions du volume physique non courantes.
le nombre de descripteurs de groupes de volumes sur le disque physique.
PP size la taille d'une partition physique.
Total PPs le nombre total de partitions du volume.
Free PPs le nombre de partitions physiques.
Used PPs le nombre de partitions utilisées du volume.
Free distribution le nombre de partitions disponibles par section.
Used distribution le nombre de partitions utilisées par section.
ExemplePhysical volume hdisk0 Volume group rootvgPV identifier 000007229401c115 VG IDENTIFIER 00002870ddb1c466PVstate activeStale partition 0 Allocatable yesPP size 4 megabyte(s) Logical Volumes 7Total PPs 95 (380 megabytes) VG descriptors 1Free PPs 0 (0 megabytes)Used PPs 95 (380 megabytes)Free distribution 00..00..00..00..00Used distribution 19..19..19..19..19
Des informations additionnelles du volume physique peuvent être affichées avec trois drapeaux, mutuellement exclusifs.
149

Le drapeau -l affiche les informations suivantes : Lvname le nom du volume logique.
Lps
PPs
Distribution
Mount Point
le nombre de partitions logiques du volume logique appartenant au volume physique.
le nombre de partitions physiques du volume logique appartenant au volume physique.
le nombre de partitions physiques du volume logique allouées dans chaque section du volume.
le nom du système de fichiers pour chaque volume logique du disque physique.
Le drapeau -M affiche les champs suivants pour tout volume logique d'un disque physique. PVname le nom du volume physique.
PPnum le numéro de la partition physique.
LVname le nom du volume logique avec cette partition physique est associée.
LPnum le numéro de la partition logique.
Copynum le nombre de disques miroirs.
PPstate si la partition physique n'est pas courante, ce champ contient le mot "stale".
9.11.3 Modification des caractéristiques
La commande chpv permet de modifier l'état d'un disque physique. Les deux variables que l'on peut modifier sont la disponibilité (drapeau -v) suivi du caractère a (available) ou r (removed) et l'allocation additionnelle avec la drapeau -a suivi du caractère y (yes) ou n (no).
Exemplechpv -v a hdisk0chpv -a n hdisk0
9.12 COMMANDES DE GESTION DES GROUPES DE VOLUMES PHYSIQUES SOUS AIX
9.12.1 Création
La commande mkvg crée un groupe de volumes physiques.
Synopsis
mkvg [-opt(s)] volume_physique volumes_physiques_list
Description
Les options suivantes sont valides d MaxPhyVol f
150

i
m MaxPvSize
n
s size
v
y vgname
nombre maximum de volumes physiques du groupe (par défaut 32, maximum 255)
force la création du groupe de volumes sur le volume physique.
lecture du nom du groupe depuis l'entrée standard.
nombre maximum de partitions physiques d'un volume physique (par défaut 1016).
suppression de l'activation automatique du groupe au démarrage du système.
définition de la taille des partitions physiques (par défaut 4 Méga-octets, variable de 1 à 256 Méga octets, avec des puissances de 2 (1, 2, 4, 8, 16, 32, 64, 128, 256), ce qui, combiné, avec l'option m, détermine l'espace maximum de stockage autorisé.
définition du nombre maximum de groupes de volumes.
définition (optionnelle) du nom unique du groupe de volumes, sur 15 caractères au plus.
151

Exemplesmkvg -y PROD disk0 disk1 disk2mkvg -y TEST -d 2 -s 1 disk22
9.12.2 Affichage des informations
La commande lsvg affiche les informations caractéristiques d'un groupe de volumes sous la forme : Volume_group
VGstate
Permissions
MaxLVs
LVs
OpenLVs
TotalPVs
Stale Pvs
Active Pvs
VG identifier
PP size
Total Pps
Free Pps
Alloc Pps
Quorum
VGDS
Auto-on
nom du groupe de volumes.
état du groupe de volumes qui peut être actif, inactif, actif/complet (tous les volumes sont montés), actif/partiel (une partie seulement des volumes est montée).
droits d'accès (lecture seule ou lecture/écriture).
nombre maximum de volumes logiques autorisés dans le groupe.
nombre de volumes logiques du groupe.
nombre de volumes logiques du groupe ouverts.
nombre total de volumes physiques du groupe.
nombre de volumes physiques déjà utilisés dans le groupe.
nombre de volumes physiques actifs du groupe.
identificateur du volume logique.
taille de la partition physique.
nombre total de partitions physiques allouées du volume.
nombre de partitions non allouées du groupe.
nombre de partitions physiques du groupe de volumes alloué au volume logique.
nombre de volumes physiques nécessaire pour une majorité.
nombre de d'aires de descripteurs de groupe de volumes dans le groupe de volumes.
activation automatique au démarrage du système (y(es) ou n(o)).
Des informations additionnelles relativement au groupe de volumes peuvent être affichées avec trois drapeaux, mutuellement exclusifs.
9.12.3 Modification du status de démarrage
La commande chvg modifie le status d'activation d'un groupe de volumes.
9.12.4 Ajout de volume physique à un groupe
La commande extendvg ajoute des volumes physiques à un groupe de volumes physiques.

Synopsis
extendvg [-f] groupe_volumes vol (s)_phys (s)_à_ajouter
L'option f a la même signification celle de la commande mkvg.
Remarque
La totalité de l'espace demandé lors de l'ajout d'un volume n'est pas toujours totalement disponible car elle dépend de la taille et du nombre maximum de partitions physiques. Si l'espace ajouté est supérieur à celui qui est autorisé, l'espace complémentaire est inutilisable donc perdu.
Exempleextendvg TEST disk05
9.12.5 Suppression d'un volume physique d'un groupe
La commande reducevg supprime des volumes physiques d'un groupe, qui disparaît quand chacun des volumes physiques qui le constituait est supprimé.
Cette suppression n'est possible que si aucun volume logique n'est associé au volume physique supprimé. Deux méthodes dans ce cas : utilisation (conseillée) de la commande rmlv), qui garantit la consistance de l'opération,
utilisation (déconseillée) de l'option -d de la commande reducevg, qui ne la garantit pas.
9.12.6 Cohérence de l'association volume physique/volume logique
Quoique le système conserve, en principe, la base de données de gestion des périphériques, certaines inconsistances peuvent apparaître. La commande redefinevg recrée l'association (volume physique, groupe de volumes physiques, volume logique) et remet à jour la base de données.
Il faut toujours indiquer une des options -i (définition explicite du groupe de volumes) ou -d (recherche automatique du groupe de volumes physiques).
Exempleredefinevg -d disk0 rootvg
9.12.7 Synchronisation des disques miroirs
En principe, les copies de la partition physique sont automatiquement synchronisées lors de l'activation d'un groupe de volumes. Si cette synchronisation devient ineffective, par exemple lors d'un problème matériel, la commande syncvg permet d'y remédier, en redéfinissant le niveau de synchronisation des disques et leur(s) miroir(s).
Synopsis
syncvg [-option] volume_à_synchroniser
Le niveau de synchronisation est défini à partir des options de la commande : l synchronisation au niveau du volume logique,

p synchronisation au niveau du volume physique,
v synchronisation au niveau du tout un groupe de volumes.
Exemplesyncvg -v PRODsyncvg -p disk0
9.12.8 Activation/désactivation d'un groupe
La commande varyonvg (resp varyoffvg) active (resp désactive) un groupe de volumes au démarrage ou en cours de session.
Synopsisvaryonvg [-option(s)] groupe_de_volumesvaryoffvg [-option] groupe_de_volumes
Description
Les options de la commande varyonvg sont : p
simpose la présence et la disponibilité de tous les disques physiques avant l'activation du groupe de volumes,
gestion manuelle du groupe de volumes en mode maintenance ce qui permet de modifier le groupe de volumes sans modification du volume logique associé.
La seule option de la commande varyoffvg est s comme précédemment.
9.12.9 Exportation/importation d'un groupe
La commande exportvg exporte la définition d'un groupe de volumes désactivé (commande varyoff). Après son exécution, le groupe de volumes est inutilisable avant d'avoir été (ré)importé soit localement, soit sur un autre site.
Synopsis
exportvg groupe_de_volumes
La commande importvg importe un groupe de volumes exporté par la commande exportvg.
Synopsis
importvg [-f] [-V numéro_vg] [-y nom] volume_physique
Description
-y définition (optionnelle) du nom du groupe de volumes,-V définition explicite du numéro associé au groupe de volumes,volume_physique spécifie un des volumes physiques du groupe, les autres étant automatiquement
identifiés.
Le groupe de volumes importés doit ensuite être activé par la commande varyon.

9.12.10 Réorganisation de l'allocation de la partition physique
Cette commande réorganise les emplacements des partitions physiques allouées à un groupe de volumes. Avant sa réorganisation, le status du groupe doit être modifié (status relocatable) à partir de la commande chlv -r.
Synopsis
reorgvg [-i] groupe_de_volumes [volume_logique]
Description
groupe_de_volumes groupe à réorganiservolume_logique un volume logique spécifié permet une réorganisation similaire à la sienne-i définition interactive du(es) disque(s) physique(s) à réorganiser dans le
groupe.
Exempleecho "disk01 disk02" | reogvg -i PRODUITS shared_info
9.12.11 Graphe d'état associé à la gestion des groupes de volumes physiques

9.13 COMMANDES DE GESTION DES VOLUMES LOGIQUES SOUS AIX
9.13.1 Création
Définition
Un volume logique supporte un unique système de fichiers.
Création
La commande mklv crée un volume logique dans un groupe. Ses caractéristiques sont définies à partir des options de la commande.
La taille maximale d'un volume logique est limitée à 2 Gigabytes. La politique d'allocation par défaut est d'utiliser un nombre minimum de volumes physiques par volume logique.
Si le choix des volumes physiques n'est pas spécifié, le groupe de volumes dans son ensemble est "allouable".
La fonction de disque miroir est possible sur les volumes logiques. Lors de cette opération, le système d'exploitation crée automatiquement une deuxième ou une troisième copie de l'ensemble des données du disque logique. La seule restriction des disques miroirs est que les espaces primaires de dump et de pagination ne sont pas toujours dupliqués sur le miroir.
Synopsis
mklv [option(s)] groupe_de_volumes partitions [volume_physique(s)]
Description groupe_ volumes
partition(s)
volume_physique
groupe associé au volume logique,
nombre de partitions à allouer au disque logique créé,
limite (optionnelle) du nombre de partitions allouées à celle du volume_physique indiqué.
Les options suivantes sont disponibles : a position indique la section du disque physique utilisée pour l'allocation des
partitions. Les indicateurs sont m (middle) par défaut, c (center), e (outer edge), ie (inner edge), im (inner middle).
b bad_blocks c #copies

d schedule drapeau de réallocation des blocs défectueux (par défaut y). L'option n n'est pas recommandée.
nombre de disques miroirs (par défaut 1).
écriture du disque miroir en parallèle (p) par défaut, ou séquentielle (s).
e valeur définition de la politique d'allocation. La valeur par défaut (m), alloue les partitions sur un nombre minimum de disques physiques. La valeur x les alloue sur un nombre maximum de disques physiques.
i nom du volume physique saisi interractivement.
L définition du label du disque logique.
m fichier
r relocation
s y (ou n)
t type
u max
v verify
w consistency
utilisé pour allouer un disque logique sur une partition physique spécifique.
autorisation de reloger le volume logique (y par défaut) lors de l'exécution de la commande reorgvg. L'option n (no) est déconseillée.
définition de la politique d'allocation des partitions physiques sur les disques miroirs. L'option y (défaut) indique que la copie ne réside pas sur le même disque physique.
définition du type du volume logique, par défaut jfs, qui permet une journalisation régulière du système de fichiers. Les autres types sont jfslog (conservation du fichier log), copy (copie miroir), et paging. Il n'est pas possible de faire du mirroring sur les disques logiques de ces deux derniers types.
nombre maximum de volumes physiques à utiliser. Par défaut le nombre total des volumes physiques du groupe.
vérification (y par défaut) de toutes les opérations d'écriture sur le disque.
vérification de la consistance (par défaut y) des disques miroirs. x partition
y LVname
Y prefix
définition du nombre maximum de partitions logiques à associer au volume logique. S'il n'y a pas de disque miroir, il y a correspondance entre les partitions physiques et les partitions logiques.
définition par l'utilisateur du nom du volume logique.
définition par l'utilisateur d'un préfixe auquel le système ajoute un nombre décimal à 2 chiffres.
Exemplemklv -Y donnee_partagees PRODUITS 32mklv -c 2 -e x -a c -y donnee_temporaires PRODUITS 4 disk03 disk04
9.13.2 Affichage des informations d'un volume logique
La commande lslv affiche les caractéristiques d'un volume logique sous la forme suivante :

Logical Volume nom du volume logique
Volume group groupe de volumes associé
LV Identifier Identificateur du volume logique
Permission droits d'accès au volume logique
Vgstate
Lvstateétat du groupe de volumes qui peut être actif, inactif, actif/complete (tous les volumes physiques sont montés), actif/partiel (une partie seulement des volumes physiques est montée).
état du volume logique qui peut être opened/stale (en utilisation, mais pas en mode synchronisé), ou active/partial (quelques volumes physiques sont off line).
Type type du volume logique.
Write verify vérification ou non de l'écriture.
Mirror write consistency
Max Lps consistance du disque miroir ou non (y ou n)
le nombre maximum de partitions allouées dans le volume logique.
PPsize taille de la partition physique.
Copies nombre de disques miroirs.
etc.
9.13.3 Modification des caractéristiques d'un volume logique
La commande chlv modifie les caractéristiques d'un volume logique (politique d'allocation, relogeabilité des secteurs défectueux, ordonnancement, nom du volume logique, droits d'écriture et de lecture, politique de réorganisation, type de volume, etc.). Ses options sont similaires à celle de la commande mklv.
Synopsis
chlv opt opérande [option opérande...] volume_logique
9.13.4 Définition et suppression de disques miroirs
La commande mklvcopy définit ou augmente le nombre de disques miroirs d'un disque logique. Le nouveau nombre n'est effectivement pris en compte qu'après l'exécution d'une des commandes syncvg ou varyonvg, sauf si l'option -k est utilisée.
Toutes les options de la commande mklvcopy sont similaires à celles de la commande mklv.
La commande rmlvcopy diminue ou supprime les disques miroirs.
Synopsis
rmlvcopy volume_logique #copies [volume_physique]
9.13.5 Copie d'un volume logique
La commande cplv copie un volume logique vers un autre (nouveau ou existant). Elle ne vérifie pas la consistance de l'opération. Il faut donc s'assurer préalablement que le volume logique cible contient suffisamment d'espace pour la copie.

Les options de la commande sont : v définition du groupe de volumes cible,
y nom du nouveau volume logique,
Y suffixe du nouveau volume logique,
Si le volume logique est préexistent, il faut utiliser l'option -e.
Exemplecplv -v PROCIBLE -Y info_share info_share
9.13.6 Gestion de la base de données des périphériques
Le LVM doit rester cohérent avec la base de données interne de gestion des périphériques. La commande synclvodm permet de reconstituer une base de données cohérente si nécessaire.
9.13.7 Graphe d'état associé à la gestion des volumes logiques

9.14 GESTION DES SYSTÈMES DE FICHIERS SOUS AIX
9.14.1 Etapes de la création d'une arborescence
9.14.2 Création d'un système de fichiers
La commande AIX de création d'un système de fichiers est crfs. Les règles ci-dessous sont à respecter : un système de fichiers ne peut être créé qu'à partir d'un volume logique.
lors de l'exécution de la commande, un volume logique est créé si nécessaire.
Synopsis
crfs [option argument]
Les options sont les suivantes : a attribut=valeur
Aoption dépendante du type du système de fichiers. Les attributs sont définis dans le fichier /etc/vfs.
montage automatique au démarrage si suivi du caractère y.
d device spécification du disque logique.
g VG groupe de volumes contenant le système de fichiers.
i Logsize taille du journal.
m mp du point de montage du système de fichiers.
n nn système distant pour les systèmes de fichiers nfs.

p définition des attributs du montage (ro ou rw),
t validation éventuelle du système de comptabilité.
u groupe de montage associé.
v type du système de fichiers (jfs, cdrfs, nfs).
Exemplecrfs -v jfs -g PRODUITS -m /usr/local -a size=32768
La taille du système de fichiers est définie en blocs.
9.14.3 Modification des caractéristiques d'un système de fichiers
La commande chfs permet de modifier les caractéristiques d'un système de fichiers préexistent. Ses options sont les mêmes que celles de la commande crfs.
9.14.4 Affichage des informations d'un système de fichiers
Caractéristiques générales
La commande lsfs affiche les caractéristique d'un système de fichiers. Ses options sont : c nombre de colonnes de l'écran d'affichage.
i format d'affichage sous forme de liste.
u mg rapport sur l'ensemble des systèmes de fichiers d'un groupe.
v type rapport sur l'ensemble des systèmes de fichiers d'un type donné.
Exempleslsfslsfs -v jfslsfs /usr/local
La commande traditionnelle d'UNIX df est également disponible.
Dump
La commande dumpfs affiche les informations nécessaires à une étude octet par octet d'un système de fichiers.
9.14.5 Montage et démontage d'un système de fichiers sous AIX
La commande mount permet de monter un systèmes de fichiers conformément aux données contenues dans le fichier /etc/filesystem.
Les commandes de démontage sont umount et unmount, qui ont toutes deux une syntaxe d'utilisation identique.

9.15 RÉCAPITULATION DES COMMANDES D'ADMINISTRATIONfsck, mkfs, newfs, df, labelit, bdblk, clri, mount, mountall, fstab, filesys, checklist, mnttab, fsdb, ncheck, diskpart, divvy, mkvtoc, prtvtok.
9.15.1 Migration des données d'un disque physique vers un autre
La commande migratepv déplace des données d'un volume physique ou logique vers un ou plusieurs autres volumes physiques du groupe.
Les transferts de partitions physiques ne sont possibles que dans un même groupe de volumes physiques.
Exemplemigratepv disk_source disque_ciblemigratepv -l données_communes disk0 disk1 disk2
9.15.2 Graphe d'état d'un volume physique
10. SÉCURITÉ DES DONNÉES ET SAUVEGARDES
Plusieurs types de sauvegardes peuvent être réalisées : sauvegarde complète d'un système de fichiers ou sélective des seuls fichiers modifiés.
10.1 GÉNÉRALITÉS SUR LES SAUVEGARDES
Il existe un grand nombre d'utilitaires de gestion des sauvegardes sous UNIX. Le graphique ci-après compare les fonctionnalités de ceux qui sont les plus fréquemment utilisés à savoir dump, restore, tar, cpio.
Comparaison des principaux utilitaires de sauvegarde

tar cpio dump/restore ddAccessible par les utilisateurs oui oui non ouiPortée de la sauvegarde fichier fichier fichier média
répertoire répertoire SFSystème de fichiers montés oui oui non ouiMulti-volumes oui oui oui non
Quelques considérations élémentaires pour une politique de sauvegardes
Tous les systèmes de fichiers doivent ils être sauvegardés à la même session de sauvegarde ?
Le temps de recherche de la bande contenant la dernière sauvegarde est-il important ?
Quel type de lecteur faut-il utiliser ? lecteurs rapides (6250 bpi), ou supports à grandes capacité (8mm).
Faut-il arrêter le système pour faire les sauvegardes et pendant combien de temps ?
Faut-il conserver les sauvegardes éternellement ?
Il faut des sauvegardes sures.
Quand un disque est endommagé, le seul moyen de garantir une restauration est d'avoir des sauvegardes régulières.
Définir et faire une politique de sauvegardes est probablement la tâche la plus importante d'un administrateur.
Points essentiels à considérer
Nombre de fichiers modifiés chaque jours.
Durée de récupération d'un fichier endommagé.
Type de périphérique disponible.
Coût des bandes magnétiques.
Durée de la sauvegarde.
Durée de conservation.
Gestion des sauvegardes
Il faut toujours étiqueter les bandes de sauvegarde avec : le nom de la sauvegarde,
son type (utilitaire utilisé et options, total, incrémental, niveau de la commande dump si nécessaire).
le numéro de la bande.
la date de la sauvegarde,
la syntaxe complète de la commande utilisée pour la réaliser.
Types de sauvegarde
Il existe deux types de sauvegarde : totale tous les fichiers sont sauvegardés,
163

incrémentale seul les fichiers modifiés ou les nouveaux fichiers sont sauvegardés.
Exempletransactions journalièressauvegarde incrémentale n°331 Déc 1999Bande 1/4/etc/dump /home
Autres opérations sur les supports magnétiques
Liste du contenu.
Rembobinage.
Formatage du média.
Retension de la bande.
Ecrasement du média.
10.2 SAUVEGARDE D'UNE ARBORESCENCE
Les deux commandes les plus utilisées sont tar (tape archive) et cpio.
10.2.1 La commande tar
La commande tar
La commande tar est utilisée pour transférer du logiciel entre différentes machines. Elle copie récursivement un répertoire (en accédant directement aux fichiers alors que la commande dump accède aux inodes) en créant un unique fichier image tar (tarfile). Elle peut créer une bande d'archivage (option c) pouvant être relue avec la commande tar (option x), ou transférer une arborescence (voir l'exemple ci-dessous)). Cette commande semble faire double emploi avec la commande shell cp -R qui permet de transférer récursivement une arborescence. En fait, cette dernière commande transfère, non des liens symboliques quand ils existent, mais les inodes sur lesquels ils pointent. L'intérêt de la commande tar est qu'elle assure la copie des liens symboliques.
Il est possible de stocker séquentiellement plusieurs images tar sur un même média. Dans ce cas, il ne faut pas rembobiner la bande après une écriture (option n). Certains utilitaires permettent de se déplacer sur la bande (par exemple mt sur les environnements BSD).
Synopsis: (simplifiée)
tar action [mod_action] [fichier_tar] [bloc] fichier1 fichier2 ... fichiern
164

Les action disponibles sont c(création), t(liste), x(extraction). Selon l'action spécifiée, le fichier image tar représente la source (action d'extraction) ou la cible (action de création).
Les modificateurs bfv ont la signification suivante : b : définition de la taille des blocs
f : définition du fichier spécial, utilisé en mode raw, associé au périphérique origine ou destinataire du fichier image tar. La lettre désigne l'entrée ou la sortie standard. Il est possible d'imposer ou non le rembobinage de la bande après écriture du fichier
v est l'option verbose.
Exemplestar cvf /dev/ nrst0 . # sauvegarde du répertoire courant sans rembobinage (nrst0)de la bandetar cvf /dev/rst0 . # idem avec rembobinagetar cvf /tmp/norbert ./norbert #sauvegarde du répertoire norbert avec chemin relatiftar tvf /tmp/norbert #contenu du fichier image_tar norbertcdtar xvf /tmp/norbert #restauration du répertoire norbert dans le home directory
Problèmes de sécurité
Attention à certaine options de la commande : une arborescence sauvegardée avec un chemin d'accès absolu de répertoire est restaurée de façon
identique, et risque d'écraser des fichiers de la machine destinataire, sauf dans le cas où l'option A (SYSTEM V) existe. Sinon, il faut utiliser la technique présentée à l'exemple 4. D'une façon générale, il faut éviter d'utiliser la commande tar sous l'identité de root.
une restauration sans précaution peut créer des incohérences (fichiers sans propriétaire) car par défaut, les fichiers sont restaurés avec l'uid et le gid contenu sur la bande, même s'ils n'existent pas sur le système cible.
Il est aussi possible d'utiliser la commande tar dans un réseau local.
Exemples
recopie de l'arborescence depuis nom_repertoire vers le média /dev/ntape
tar cvf /dev/ntape nom_répertoire
affichage du contenu de la bande
tar tvf /dev/ntape
restauration d'une bande sur le répertoire courant (UNIX SCO)
tar Axvf /dev/ntape
copie d'une arborescence d'un répertoire vers un autrecd rep1
tar cvf - . | (cd rep2; tar xvf -)
165

Explication
tar cvf - .
L'image tar du répertoire courant est dirigé sur la sortie standard.
(cd rep2; tar xvf -)
changement de répertoire et utilisation de l'entrée standard comme fichier image tar duquel l'arborescence est extraite vers le répertoire cible (rep2).
10.2.2 La commande cpio
Fonctionnalités
La commande cpio permet la copie et la restauration de fichiers de n'importe quel type y compris les fichiers spéciaux.
De nombreuses options sont possibles avec cette commande (o archivage, i extraction, d création des répertoires...).
Elle est multi-volumes et très performante.
Utilisation
Par défaut, la commande cpio lit ou écrit ses données sur les fichiers standard stdin et stdout. Elle peut donc être utilisée en conjonction avec la commande ls ou la commande find suivi d'un tube.
Synopsis
cpio clé option(s) chemin_d'accès source_ou_cible (selon clé i ou o)
Clés d'utilisation
o
iarchivage sur la sortie standard des fichiers dont les noms sont lus sur l'entrée standard,
extraction sur l'entrée standard de fichiers préalablement sauvegardés par la commande cpio -o. Il est possible de définir des critères de sélection après les options par utilisation des métacaractères du shell.
p copie sur un répertoire des fichiers indiqués sur l'entrée standard.
Options
a sauvegarde avec les dates d'accès des fichiers (clés o et p),
B bloc de 5120 octets au lieu de 512,
d création des sous répertoires si nécessaire (clés o et i),
c écriture ou restauration de fichiers dont l'en tête est en ASCII (clés o et i),
r renommage interactif des fichiers restaurés (clés i et p),
t affichage du contenu de la sauvegarde (clé i),
u copie inconditionnelle (clés i et p),
v affichage de tous les fichiers traités (clés p, o et i),
166

l création de lien matériel au lieu de copie (clé p),
m maintien de la date des fichiers restaurés (clés i et p),
f copie des fichiers ne satisfaisant pas un critère.
Règles d'utilisation
Par défaut, le chemin relatif est stocké sur la bande. Si le chemin absolu est stocké, la restauration s'exécute sous une forme absolue. La solution la plus sure pour faire une sauvegarde est de se déplacer dans le répertoire à sauvegarder et de faire une sauvegarde avec les chemins relatifs.
Un message d'avertissement est affiché pour les sauvegardes multi-volumes.
L'utilisation du caractère spécial du shell "*" est obligatoire pour restaurer un répertoire complet.
Exemple/usr/home/*
Procédure de restauration
Les sauvegardes complètes les plus récentes sont restaurées en premier.
Les sauvegardes incrémentales, si elles existent, sont restaurées ensuite.
Il faut laisser le dernier champ en blanc pour restaurer l'intégralité de la bande et souvent utiliser les caractères spéciaux du shell* et ?.
Exemple 1#sauvegarde de l'arborescence du répertoire courant dans une image find . –name * *.* -print | cpio –ocvB > /tmp/copie#affichage du contenu de la sauvegardecpio –tvf < /tmp/copie#restauration sur le répertoire courantcpio –ivf < /tmp/copie
Exemple 2#sauvegarde du répertoire courantls | cpio -o > /dev/mt0#restauration sur le répertoire courant (relatif)cd /rep; cpio -imBdl < /dev/rmt8#restauration sélectivecd rep; cpio -iBmdlv f1 f2 ...fn < /dev/rmt0#restauration sélectivecpio -icvdumB ./tina/budget < /dev/rmt/tm0
Sauvegarde de fichier ou répertoire avec les commandes find et cpio
Sauvegarde Noms correspondantRépertoire courant et sous répertoires .Fichiers nom_fichier(s)Répertoire différent du répertoire courant chemin absolu du répertoire
Exemples#sauvegarde de rep1 sur rep2cd rep1; find . -depth -print | cpio -pdl rep2
167

#sauvegarde des fichiers modifiés depuis 24 hfind . -mtime -1 -cpio /dev/rmt8find /home/joe -depth -newer time -print | cpio -ocvB > /dev/rmt0
10.3 SAUVEGARDE ET RESTAURATION DE SYSTÈMES DE FICHIERS AVEC CONTRÔLE DE LABEL
10.3.1 Dump (BSD) L'utilitaire dump sauvegarde un système de fichiers complet. Il permet de faire des
sauvegardes de différents types (total, partiel, incrémental...) dont l'utilitaire restore effectue la restauration.
Les commandes dump et restore peuvent être utilisées de façon interactive.
L'utilisation de la commande cpio est plus fréquente sous SYSTEM V.
Règles à respecter lors d'une sauvegarde
Le système de fichiers contenant les données à sauvegarder doit être démonté pour garantir la consistance de l'opération.
Il est judicieux de le contrôler (fsck) préalablement.
Il doit être défini dans le fichier /etc/fstab (BSD) ou /etc/default/filesys (SYSTEM V).
La commande dump considère le répertoire racine du système de fichiers sauvegardé comme la racine de l'arborescence sur la sauvegarde qui est donc relative. La restauration doit donc l'être également.
Synopsis
dump niveau# options système_de_fichiers
Quelques options de la commande /etc/dump u modification du fichiers /etc/dumpdates,
f définition du média cible,
d densité du média cible (par défaut, 1600 bpi).
ExemplesSauvegardes totales#/etc/dump 0uf /dev/rmt/tm0 /usr bande 1/4'#/etc/dump 0ud 6250 /usr densité particulière.
Définitions
Une sauvegarde incrémentale de niveau n contient tous les fichiers modifiés ou créés depuis la sauvegarde (la plus récente) de niveau n-1.
168

Une sauvegarde totale a un niveau 0
Une sauvegarde incrémentale a un niveau de 1 à 9.
Le fichier /etc/dumpdates
Le fichier /etc/dumpdates contient le niveau et la date de la sauvegarde la plus récente des différents systèmes de fichiers. Il n'y a que le plus récent enregistrement d'un niveau de sauvegarde pour un système de fichiers donné. Dans l'Exemple ci-dessous, le système de fichiers wdls2 ne contient pas d'informations critiques qui devraient être sauvegardées plus fréquemment.
Exemple# fichier /etc/dumpdates# à la date du Vendredi 31 Décembre/dev/rdsk/wd1s2 0 Sun Dec 5 23:50:57/dev/rdsk/wd0s0 0 Sun Dec 5 22:45:02/dev/rdsk/wd1s2 1 Sun Dec 26 23:58:55/dev/rdsk/wd0s0 1 Sun Dec 26 22:45:04/dev/rdsk/wd1s2 2 Wed Dec 29 23:16:55/dev/rdsk/wd1s2 3 Fri Dec 29 23:21:30
Exercice
Quel est la périodicité apparente des sauvegardes du système de fichiers root wd0s0 ?
Quel est la périodicité apparente des sauvegardes du système de fichiers wd1s2 ?
Quel est le niveau de la prochaine sauvegarde incrémentale sur le système de fichiers wd1s2, en supposant une sauvegarde quotidienne ?
Quels fichiers seront contenus dans la prochaine sauvegarde du système de fichiers wd1s2 ?
Quels fichiers seront contenus dans la sauvegarde du Dimanche 2 Janvier sur le système de fichiers wd1s2 ?
Cas de sauvegardes multi-volumes
Le moyen le plus efficace pour localiser un fichier est de charger le dernier volume en premier : l'utilitaire peut alors déterminer si un fichier est sur une bande de numéro inférieur.
Si la première est chargée en premier, l'utilitaire va lire l'intégralité de la bande, même si le fichier recherché est sur une autre.
10.3.2 Restore (BSD)
Restaurations partielles (répertoires ou fichiers) ou totale des systèmes de fichiers sauvegardés par l'une des commandes dump ou cpio.
Utilisée interactivement avec des directives .
Les fichiers à extraire de la bande sont ajoutés (directive add) à la liste d'extraction. Ils sont affichés avec une astérisque avec la directive ls. La directive extract effectue l'extraction.
Synopsis
restore [-options] fichier_spécial_source
169

Quelques options
i utilisation interactive,
v mode "verbeux"
Directives interractives de la commande restore
help liste des directives disponibles,
170

lsliste les fichiers du répertoire courant (défaut) ou spécifié sur la bande,
cd changement de répertoire sur la bande,
add ajout d'un fichier ou d'un répertoire sur la liste d'extraction,
delete suppression d'un fichier ou d'un répertoire sur la liste d'extraction,
extract restauration d'un fichier de la liste,
quit sortie de la commande.
Exemple 1
#/etc/restore -iv /dev/rmt/tm0
Exemple 2
/etc/newfs wd1s2
/bin/mkdir /home
/etc/mount /dev/dsk/wd1s2 /home
cd /home
/etc/restore -iv /dev/rmt0
# commencer au niveau 0 et répéter
# pour chaque niveau restauré,
# dans l'ordre inverse de la commande dump
/etc/umount /home
/etc/fsck -p /dev/rdsk/wd1s2
10.4 SAUVEGARDE ET RÉORGANISATION D'UN SYSTÈME DE FICHIERS (SYSTEME V)
La commande dcopy permet de reconstruire un système de fichiers en réorganisant les blocs pour minimiser les déplacements des têtes de lecture. Elle s'exécute en trois passes : réorganisation du système de fichiers,
fixation des numéros d'inodes dans les répertoires,
reconstruction de la liste des blocs libres.
Il est judicieux d'exécuter la commande fsck avant la commande dcopy.
171

Synopsis
dcopy [option(s)] sfentrée sfsortie
Le système de fichiers sfentrée est copié sur le système de fichiers sfsortie avec suppression des entrées inutilisées des répertoires, positionnement physiques des sous-répertoires près du répertoire père, affectation des blocs d'un fichier en fonction des caractéristiques physiques du disque.
Il est judicieux d'utiliser le système de fichiers sfentrée en mode raw et le système de fichiers sfsortie en mode bloc. La commande ne doit s'exécuter que sur deux systèmes de fichiers non montés.
Les principales options sont : d laisse l'ordre des répertoires inchangés. Par défaut, les répertoires sont triés,
F définition du type du système de fichiers cible,
f définition de la taille de sfsortie
ak déplacement des fichiers non accédés depuis k jours après la liste des blocs libres,
v mode verbeux,
sX description des caractéristiques physiques de la cible sous la forme cylindre taille:gap size.
10.5 COPIE PHYSIQUE
La commande dd exécute une copie physique entre deux supports en précisant la taille des blocs transférés. On peut ainsi avec des grands blocs optimiser la place sur une bande en diminuant l'espace résiduel. L'inconvénient de cette commande concerne les blocs défectueux qui peuvent poser des problèmes.
Synopsis dd option=valeur
Optionsif=nom nom du fichier d'entrée, entrée standard par défautof=nom nom du fichier de sortie, sortie standard par défautibs=n nombre d'octets des blocs du fichier d'entréeobs=n nombre d'octets des blocs du fichier de sortiebs=n nombre d'octets des blocs des fichiers d'entrée et de sortiecbs=n taille du tampon de conversionskip=n copie de n fichiers d'entrée avant la terminaisonseek=n saut de n fichiers sur le périphérique de sortie avant écriture effectivecount=n copie de n enregistrements en entrée seulementconv=ascii conversion EBCDIC ASCIIconv=ebcdic conversion ASCII EBCDICconv=lcase conversion en minusculeconv=ucase conversion en majuscule
172

conv=bloc conversion d'enregistrement d'un format variable au format fixeconv=noerror pas d'arrêt du processus en cas d'erreur
Exemple
tar cvfb 20 - . | rsh host_distant dd of=/dev/rmt0 obs=20b
Interprétation
tar cvfb 20 - .
création d'un fichier image tar du répertoire courant, d'une taille de bloc de 20 sur la sortie standard.
rsh host_distant dd of=/dev/rmt0 obs=20b
exécution distante sur la machine host_distant de la commande dd dont les données seront sur la sortie standard et dont le résultat sera sur le périphérique /dev/rmt0 avec une taille de bloc de 20.
La lecture distante de cette bande sera réalisée de la façon suivante :
rsh -n host_distant dd if=/dev/rmt0 bs=20b | tar xvBfb 20 -
10.6 COMPRESSION
Principe
Deux techniques de compression sont utilisées : la compression par code Huffman,
la compression suivant l'algorithme de Lempel-Ziv.
SYSTEM V
Le préfixe des noms des fichiers est limité à 12 caractères. Les utilitaires de compression sont les suivants : pack le fichier compressé est suffixé par .z
unpack décompression
pcat affichage du contenu (ascii) d'un fichier compressé.
Ils utilisent le codage Huffmann et sont peu performants.
BSD
Deux jeux de commandes disponibles :
Commandes utilisant un code Huffman
Ces commandes, disponibles dans le répertoire /usr/old, sont peu performantes. Ce sont :
173

compact (compression),
uncompact (décompression),
cat (visualisation d'un fichier compressé).
Le fichier compressé est suffixé par .C
Commandes utilisant l'algorithme de Lempel-Ziv
Cet algorithme est le plus performant. Les commandes l'utilisant sont : compress compression,
uncompress décompression,
zcat visualisation d'un fichier compressé.
Le fichier compressé est suffixé par .Z. Il n'est pas possible de compresser des répertoires, des liens, des fichiers trop petits (moins de trois blocs).
Application : fichier image_tar compressé. Il est recommandé de compresser les fichier image_tar.
Une solution est de compresser chaque fichier puis d'exécuter la commande tar. Cette méthode n'est pas performante car la compression d'un petit fichier est peu efficace.
L'autre solution est de compresser un fichier image_tar unique selon l'algorithme suivant :
création d'un fichier image_tar puis compression,
recopie de ce fichier sur le périphérique de sauvegarde.
Exempletar cvf - . | compress - cv) > resu.Ztar cvf /dev/ntape resu.Z
La restauration s'effectue de la façon suivante : restauration du fichier image_tar,
décompression et restauration de l'arborescence sur le répertoire courant.
Exempletar xvf /dev/ntape | uncompress -cv | tar xvf -
Fichier .tar
Un fichier image_tar peut contenir d'autres fichiers image_tar. Conventionnellement, ils sont suffixés par .tar.
174

Exempletar cvf /tmp/image1 repertoire1tar cvf /tmp/image2 repertoire2tar cvf image.tar /tmp
10.7 GESTION SÉQUENTIELLE DES FICHIERS SUR SUPPORT MAGNÉTIQUE : LA COMMANDE MT (BSD)
La commande mt permet de se positionner sur fichier séquentiel.
Synopsis
mt [-f fichier] option [compteur]
Options : eof,weof écriture de marques de fin de fichiers sur la bande,
fsf avance de n fichiers,
fsr avance de n enregistrements,
bsf retour de n fichiers,
bsr retour de n enregistrements,
rewind rembobinage de la bande,
offline, rewoffl rembobinage de la bande et mise hors service,
status affichage de l'état de la bande,
retension retension de la bande.
10.8 RÉCAPITULATION DES COMMANDES DE SAUVEGARDEStar, cpio, dd, dump, restore, volcopy, mtpack, unpack, compress, uncompress, zcat
175

11. DEMARRAGE ET ARRET DU SYSTÈME
A la mise sous tension (démarrage à froid) ou après un arrêt du système (démarrage à chaud) débute la phase de démarrage (bootstrap) qui se décompose en quatre phases : le chargement initial du noyau,
le passage en mode mono-utilisateur,
le passage en mode multi-utilisateurs,
le démarrage des services ainsi que l'initialisation des liaisons séries permettant la connexion des utilisateurs.
11.1 DÉMARRAGE À FROID
Moniteur de test
A la mise sous tension, un programme, contenu dans une mémoire morte (ROM), contenant un moniteur de test du matériel et permettant un dialogue limité avec la console système est exécuté.
Périphérique de démarrage
L'opérateur peut définir le périphérique de démarrage (disque, disquette, lecteur de bandes,...) en indiquant son numéro physique. Sur certains systèmes, cette opération est automatique à la mise sous tension, le choix du disque étant réalisé à partir de commutateurs.
Chargement du noyau
Le bloc 0 du périphérique est un programme permettant de charger le noyau Unix et s'appelle en général unix (SYSTEM V) ou vmunix (BSD)).
Une copie de ce bloc est stockée dans un fichier du répertoire /etc (en général boot ou diskboot) pour permettre l'initialisation d'un nouveau disque. Elle n'est pas directement accessible avec les commandes du système de gestion des fichiers et doit être copiée avec une commande (par exemple dd),ou crée par la commande mkfs.
Démarrage
Le noyau exécute les opérations suivantes : reconnaissance de la configuration matérielle (capacité mémoire, contrôleurs installés...) et
initialisations des périphériques,
création du processus 0 (processus sched sur les versions ATT, swapper sur les versions BSD),
création du processus 1 (processus /etc/init).

Processus 0
Le processus 0 ne comporte ni segment de texte, ni segment de données, ni pile utilisateur.
Son code est intégralement en zone système et contient sa structure U.
Il dispose d'une entrée dans la table proc[] et d'une pile système.
Ses fonctions sont les suivantes : Construction des tables systèmes de gestion des entrées/sorties.
Initialisation et chargement des pilotes en mode caractère.
Initialisation et chargement des pilotes en mode bloc.
Initialisation et chargement de la table des volumes montés.
Initialisation de la console système.
Initialisation de la structure U du processus 0.
Calcul de la taille mémoire disponible.
Initialisation des tables de swap et des tables de gestion mémoire.
Algorithme de démarrage
L'algorithme de démarrage du système est le suivant : Chargement du noyau
Initialisation des structures de données du noyau
Montage du système de fichier / (root)
Création de l'environnement du processus sched (SV) ou swapper (BSD) (pid 0)
Création du processus init avec les appels système fork et exec
/* processus init */Allocation des segments mémoireAttachement d'un segment au processus initCopie du code du noyau dans l'espace utilisateurPassage en mode mono-utilisateurExécution du processus /etc/init/* processus sched */Création des processus systèmeAppel du processus 0sleep(événement : il y a quelque chose à faire).

sc h ed (S V )sw a p p e r (B S D )
fo rk
sc h e d in it
sh s h sh
G r ap h e du dém ar ra g e d u sy stè m e
11.2 MODES MONO ET MULTI-UTILISATEURS
Modes d'exécution
Le système a deux modes d'exécution : le mode mono-utilisateur (mode maintenance ou mode single user),
le mode multi-utilisateurs, mode d'exploitation où l'ensemble des services sont lancés.
Mode mono-utilisateur
La première action du processus init est la création d'un processus attaché à la console système : le système fonctionne alors en mode mono-utilisateur et active les fonctions de mise à jour des fichiers de configuration des terminaux, tests du système de fichiers, etc.
Passage en mode multi-utilisateurs
Les shell scripts correspondants ne sont exécutables que par le super-utilisateur ce qui peut poser des problèmes de sécurité si un simple utilisateur doit mettre la machine sous tension. Plusieurs solutions à cette difficulté : un passage automatique en mode multi-utilisateurs (c'est le cas avec UNIX System V si le fichier
/etc/inittab comporte l'entrée initdefault),
un passage automatique en mode multi-utilisateurs avec une temporisation ce qui permet par un code de contrôle de rester en mode mono-utilisateur si nécessaire,
un passage en mode mono-utilisateur avec contrôle impératif du mot de passe de l'administrateur root à la console.
Le passage en mode multi-utilisateurs (lorsqu'il n'est pas automatique) est réalisé suite à l'émission du signal CTRL D, qui réveille le processus init.

11.3 DÉMARRAGE BERKELEY
Le fichier /etc/rc est un shell script pouvant être adapté par l'administrateur en fonction de la configuration du site.
Selon les implémentations, il est constitué des fichiers /etc/rc.boot (démarrage), /etc/rc.local (démarrage des services locaux), /etc/rc.inet (démarrage des services réseaux).
11.4 DÉMARRAGE SYSTEM V
Le processus /etc/init utilise le fichier /etc/inittab dont la fonction essentielle est l'exécution du processus getty pour chaque terminal déclaré avec connexion (SVR3.2).
11.4.1 Niveaux d'exécution
Au démarrage, l'opérateur peut préciser le niveau d'exécution du système ce qui en détermine la configuration. Les niveaux d'exécution suivants sont les plus usuels :
Arrêt et mode moniteur : niveaux 0 et 5
Ils sont la plupart du temps identiques. Quelquefois, le niveau 5 relance les tests matériels pour un redémarrage ultérieur.
Mode mono-utilisateur : niveaux 1, s et S
Les systèmes de fichiers montés ne sont pas démontés quand le niveau s ou S est appelé depuis un mode multi-utilisateurs.
Seuls les processus lancés par le processus init sont tués alors qu'au niveau 1, tous les processus non attachés à la console le sont.
Modes multi-utilisateurs : niveau 2, 3, 4
Tous les processus de la table /etc/inittab spécifiques de ce niveau sont lancés .
Démarrage à chaud : niveau 6
Arrêt et redémarrage du système avec le niveau par défaut (niveau 2 en général).
Exemple 2 niveau normal en mode multi-utilisateurs,
3 montage des systèmes de fichiers accessibles par NFS,
4 nombre de ports activés limités.
La commande who
La commande who -r affiche les informations suivantes : 1 nom_de_l'utilisateur (inutilisé. Seul, le . apparaît).

2-3 niveau courant.
4-6 heure de connexion.
7 niveau courant.
8 pid.
9 niveau précédent.
Exemple d'exécutionrun-level 2 May 7 17:59 2 0 S
Ports démarrés et systèmes de fichiers montés selon le niveau
Niveau Mode Ports d'E/S Systèmes_de_fichiers montés
0 moniteur console aucun1 mono console root2 multi tous décrits (fstab ou checklist)3 selon adaptation ? ?4 selon adaptation ? ?5 moniteur console aucun6 reboot tous décrits (fstab ou checklist)s ou S mono console les systèmes de fichiers restent montés.
11.4.2 Modification du niveau d'exécution courant
On utilise la commande init selon la syntaxe :
init run_level [ q ]
Exempleinit 3
11.4.3 Le fichier inittab
Les champs d'une ligne du fichier /etc/inittab sont :
id:niveau:action:commande
Interprétation
id symbole d'un à quatre caractères de différenciation des lignes.
niveau
action
suite de un ou plusieurs entiers représentant le niveau de lancement du système où la ligne va s'exécuter. Dans le cas d'un changement du niveau courant, les processus qui doivent être supprimés ont un délai de grâce de 5 mn.
mot clef indiquant au processus init le signal provoquant l'exécution de la commande qui suit.

commande nom de la commande à exécuter avec ses arguments.
Les principales actions sont : bootwait action exécutée au démarrage seulement,
initdefault définition du niveau initial par défaut,
off pas d'exécution de la ligne de commande,
once exécution du processus sans attente ni relance,
ondemand analogue à la directive respawn,
powerfail
powerwait
exécution à réception d'un signal powerfail (rupture de la tension d'alimentation),action wait exécutée uniquement à réception du signal powerfail,
respawn
sysinit
wait
création du processus s'il n'existe pas et relance s'il se termine (boucle perpétuelle),
exécution préalable à tout accès à la console,
exécution ultérieure du processus et attente de terminaison avant poursuite.
Exempleconf::bootwait:/etc/conf &>/dev/console 2>&1rc::wait:/etc/rc 1>/dev/console 2>&1pf::powerfail:/etc/powerfail 1>/dev/console 2>&101:2:respawn:/etc/getty -Tvt100 tty01 1920002:2:respawn:/etc/getty -Tvt100 tty01 19200
11.4.4 Réinitialisation du processus init
La commande init q lit le fichier /etc/inittab et réinitialise le niveau d'exécution courant selon les règles suivantes : les actions off, respawn, process et ondemand sont réinitialisées,
les actions wait et once ne sont pas exécutées.
11.4.5 Propriétés du répertoire init.d
Ses fichiers sont : des liens matériel sur les répertoires /etc/rc*.d,
exécutés par le shell script /etc/rc2 depuis le répertoire /etc/rc*.d.
11.4.6 Processus à démarrer selon le niveau
Les shell-scripts Snnxxxx des répertoires rc*.d sont exécutés selon le niveau de démarrage demandé avec la syntaxe :K pour Kill,S pour Start,nn ordre (croissant) de démarrage,xxx action à exécuter

Exemple
Quelques fichiers S* du répertoire /etc/rc2.d S05MOUNTFSYSMontage des systèmes de fichiers.
S10PRESERVE Récupération des dernières sessions d'édition.
S15RMTPFILESNettoyage des répertoires des fichiers temporaires.
S17log Démarrage des processus démons d'audit.
S20bootflagsDéfinition des chaînes de démarrage par défaut.
S21PERFDémarrage du processus démon d'audit des activités.
S22audit
S25savecore
S30autoconfig
Démarrage du processus démon d'audit.
Sauvegarde du fichier core dans le fichier /usr/crash.
Détermine si un nouveau périphérique peut être supporté par le noyau et création de ses points d'entrée dans le répertoire /dev.
S35sysetup Spécifications de configuration du système.
S40addswap Addition de zones de swap.
S51tcp Démarrage des services de l'Internet
S70UUCP Etats et fichiers temporaires associés au service uucp.
S75CRONDémarrage du processus démon /etc/cron.
S80LP Démarrage du spoule d'impression.
Ordre d'exécution
La numérotation des noms des fichiers détermine l'ordre de démarrage ce qui implique que les fichiers lancés antérieurement à un autre niveau sont numérotés de façon cohérente.
Le tri s'effectue selon l'ordre ascii.
Démarrage manuel
Tous les shell-scripts du répertoire peuvent être démarrés ou arrêtés directement selon la syntaxe :
shell_script [start | stop]
Arrêt du système
Les shell-scripts du répertoire rc0.d dont le nom commence par un K sont exécutés à l'arrêt du système selon des conventions identiques.

11.4.7 Diagramme récapitulatif des changements de mode d'exécution
GÉNÉRALITÉS SUR LES PROCESSUS DÉMONS
11.4.8 Définition
Lorsqu'un utilisateur fait une requête de service, celle-ci est prise en charge par un processus actif, fournisseur du service, appelé processus démon (daemon), acronyme de deffered auxiliary execution monitor.
Un processus démon est donc un moniteur auxiliaire à exécution différé. Il s'exécute soit en tant que fournisseur de service, soit à la demande d'autres activités du système (commandes, autres processus démons...)
La plupart des processus démons sont initialisés dans la phase de démarrage.
11.4.9 Schéma de fonctionnement
Trois niveaux : l'administrateur définit préalablement le paramétrage des processus démons,
l'utilisateur fait une requête de service déposée dans une file d'attente puis prise en compte par le processus démon.

10.5.3. Exemples de processus démon Le processus démon /etc/init assure le démarrage du système
Le processus démon /etc/cron gère le service cron.
Le processus démon lpsched prend en charge les requêtes d'impression (SV).
Le processus démon /etc/inetd est le super-démon BSD chargé de prendre en charge les requêtes de service de l'Internet.
11.5 DÉMARRAGE DES PROCESSUS DÉMONS
Les différentes actions qui sont réalisées lors du passage en mode multi-utilisateurs sont : lecture du fichier de configuration de la commande getty sur chaque terminal déclaré avec
connexion (avant SYSTEM V R4), ou de la commande ttymon;
réinitialisation de divers fichiers temporaires nécessaires à l'administration (par exemple le fichier /etc/utmp, contenant la liste des utilisateurs connectés, ou le fichier /etc/mnttab contenant la liste des systèmes de fichiers montés...),
mise à jour éventuelle de la date,
exécution de tests de cohérence des différents systèmes avec la commande fsck. Les noms des systèmes de fichier à monter sont en général enregistrés dans le fichier /etc/fstab, utilisé lors de l'appel de fsck sans argument,
lancement du processus démon gestionnaire du cache update,
montage des différents systèmes de fichiers avec la commande shell mount,
nettoyage des répertoires contenant des fichiers temporaires (/tmp et /usr/tmp) et des fichiers de verrouillage (imprimantes, communications...),
lancement des utilitaires de comptabilité (acct, startup),
lancement du processus démons /etc/cron, gestionnaire du service cron,
lancement du processus démon gestionnaire du spoule d'imprimante,
lancement du logiciel de communication uucp,
lancement d'utilitaires divers (statistiques, performances...),
sauvegarde et la réinitialisation de certains fichiers d'administration, en particulier les fichiers d'audit,

qui enregistrent l'activité du système et qui, grossissant régulièrement, doivent être purgés de temps en temps (par exemple wtmp, cronlog, sulog...) après sauvegarde éventuelle.
L'ordre des opérations est important. Ainsi, il faut monter le système de fichier contenant le répertoire /usr avant d'y monter le système de fichiers contenant le répertoire /usr/spool) ou pour l'effacement de certains fichiers (par exemple le fichier cronlog avant le démarrage des services cron).
Voici un Exemple des pid de processus démons lancés sous SV R3.2.4 :
0 sched1 /etc/init2 vhand3 bdflush96 /etc/logger /dev/error /usr/adm/mes138 /etc/cron143 /usr/lib/lpsched202 cpd204 slink209 strerr215 syslogd217 inetd219 routed -k /unix291 /usr/mmdf/bin/deliver -b308 portmap309 pcnfsd311 rwalld313 rusersd315 nfsclnt 8317 biod 4318 biod 4319 biod 4320 biod 4322 statd324 lckclnt 4326 lockd328 rexd342 pcimapsvr.ip -D0000 -n3 -I127.0.0.1344 pciconsvr.ip -D0000 -L0000 -n3 -I12349 -ksh350 /bin/login o351 /etc/getty tty02 sc_m353 /etc/getty tty03 sc_m354 /etc/getty tty04 sc_m371 /tcb/files/no_luid/sdd403 ps -ealf
11.6 ARRÊT DU SYSTÈME
11.6.1 Précautions
Compte tenu du mécanisme de gestion des entrées/sorties en mode bloc (cache), un arrêt brutal sans précaution risque d'engendrer des incohérences dans les systèmes de fichiers. Il ne faut donc jamais arrêter le système sans utiliser préalablement une procédure d'arrêt.

Diverses commandes d'arrêt sont disponibles : arrêt complet avec ou sans redémarrage en mode mono-utilisateur,
arrêt complet sans redémarrage en mode multi-utilisateur,
arrêt complet avec redémarrage à chaud en mode multi-utilisateur,
arrêt complet avec redémarage à froid en mode multi-utilisateur,
11.6.2 Commande sync et processus démons
La commande sync (exécutée périodiquement par le processus démon update effectue le vidage périodique du cache. Il est donc indispensable que cette commande soit exécutée avant d'arrêter le système. Pour qu'elle soit pleinement efficace, tous les processus actifs doivent être arrêtés avant son exécution. Ainsi, la commande killall stoppe tous les processus actifs sauf celui qui l'exécute.
11.6.3 Arrêt depuis le mode mono-utilisateur
Il suffit d'exécuter la séquencesync;sync;synchaltsys
11.6.4 Arrêt depuis le mode multi-utilisateur
Tous les systèmes UNIX disposent d'une commande d'arrêt en douceur, en général la commande /etc/shutdown qui exécute les actions suivantes : notification à tous les utilisateurs connectés du message d'arrêt imminent (commande wall). Le
message envoyé indique le temps restant avant l'arrêt et est en général renotifié une minute avant l'arrêt effectif,
message d'avertissement aux utilisateurs qui se connectent de l'arrêt prévu par modification temporaire du fichier /etc/motd,
déconnexion forcée des utilisateurs,
destruction de tous les processus actifs (commande killall),
arrêt des processus démons acct, lpsched....
vidage du cache pour une mise à jour du disque (commande sync),
démontage des systèmes de fichiers montés,
retour en mode mono-utilisateur.
Synopsis
shutdown [-y][-gsecs][-iniveau]
Les options ont la signification suivante : y réponse automatique yes à toutes les questions,
g délai de grâce avant le début de la procédure d'arrêt, par défaut 60s,
i niveau d'exécution de démarrage (0,1,s,5,6). Par défaut s.

11.6.5 Commande init
La commande init s (ou init 1) permet de revenir au mode mono-utilisateur.
La commande halt, ou init 5 permet de revenir à un mode moniteur.
Particularité de la commande init 0
Il ne faut pas utiliser la commande init 0 depuis le mode multi-utilisateurs car il n'y aurait alors aucun moyen de prévenir les utilisateurs de l'arrêt imminent du système.
Après une opération de passage en mode mono-utilisateur, l'utilisation du caractère de contrôle CTRL D permet de définir interactivement le niveau d'exécution au démarrage. La question ne sera pas posé dans le cas d'un démarrage en mode moniteur.
11.7 DÉMARRAGE A CHAUD
Versions BSD
La commande fastboot permet de redémarrer, sans vérification des systèmes de fichiers. La commande reboot assure un redémarrage avec vérification complète des système de fichiers.
SYSTEM V
L'utilisation de la commande reboot n'est pas recommandée en mode multi-utilisateurs car elle ne vide pas le cache et peut provoquer des problèmes au démarrage.
11.8 RÉCAPITULATION DES COMMANDES D'ADMINISTRATIONshutdown, halt, fastboot, reboot, powerdowninit, inittab

12. ORDONNANCEMENT DE TRAVAUX
12.1 DESCRIPTION DES SERVICES CRON
L'ensemble des services cron permet d'exécuter un action déterminée à une date fixée. Il crée un processus pour exécuter les commandes arrivées à échéance, puis s'endort pour la durée le séparant du prochain travail.
Il est constitué de trois sous-systèmes : service d'exécution répétitif à heure fixe avec la commande /etc/crontab,
service d'exécution unique à heure fixe avec la commande /etc/at,
service d'exécution différé avec la commande /etc/batch
Le processus démon /etc/cron est le gestionnaire des sous-systèmes précédents.
Le répertoire /usr/lib/cron contient les fichiers d'administration du service (utilisateurs autorisés, historique, restrictions...).
L'historique des travaux effectués est conservé dans le fichier /usr/lib/cron/log.
Les caractéristiques des files d'attente associées sont décrites dans le fichier /usr/lib/cron/queuedefs.
Le répertoire /usr/spool/cron contient les tables des actions à exécuter.

12.2 LA COMMANDE AT
La commande at permet d'exécuter des commandes lues sur l'entrée standard une seule fois à une date et une heure fixée.
Spoule d'attente
Le noyau répond en indiquant le numéro du travail enregistré dans le fichier /usr/spool/cron/atjobs qui contient la description de l'environnement ainsi que les actions à exécuter, mises en forme à partir du fichier .proto.x (où x représente la file).
ACL
L'accès à la commande at est contrôlé par les fichiers at.allow et at.deny dont l'utilisation est similaire à celle de cron.allow et cron.deny.
Notification du résultat
L'utilisateur est averti du résultat et des erreurs par la messagerie électronique, sauf s'il a redirigé la sortie standard d'affichage et celle des messages erreurs.
Synopsisat heure [date] [+ incrément]at -r [job_id]at -l [job_id]at -qheure [date] [+ incrément]
Description
heure est indiquée sous la forme d'un ou de deux chiffres représentant les heures, ou de quatre chiffres représentant les heures et les minutes ou encore sous la forme x:y représentant x heures et y minutes. De plus un suffixe am ou pm peut être ajouté. Les mots clés noon, midnight, now et next sont autorisés.
date est un argument optionnel qui peut être indiqué soit sous la forme le nom du mois (éventuellement abrégé à 3 caractères) suivi du jour et éventuellement de l'année séparée par une virgule, soit sous la forme du jour de la semaine (qui peut aussi être abrégé). Les arguments today ou tomorrow sont autorisés. Si la date n'est pas précisée, le système enregistre la commande pour le jour courant si l'heure indiquée est postérieure à l'heure courante, et pour le lendemain dans le cas contraire. Le noyau procède de façon analogue pour la date si l'année n'est pas précisée. Enfin si la date demandée est antérieure à la date courante, la réponse devient Sorry too late ...
incrément est un argument facultatif composé d'un nombre suivi d'un suffixe parmi minute, hour, today, week, month, year qui sera ajouté à l'heure et/ou à la date indiquée.
La commande at -l indique la liste des travaux en instance ainsi que leur propriétaire, le numéro et la date d'échéance.
La commande at -r num permet de détruire le travail ayant pour numéro num.

La commande at-q permet de choisir la file d'exécution d'un travail. Les files suivantes sont prédéfinies :a file des travaux associés à la commande atb file des travaux associés à la commande batchc file des travaux associés à la commande crontab
Exempleat 16:10pwdCTRL D
12.3 LA COMMANDE BATCH
Cette commande fonctionne de façon similaire à la commande at avec deux différences : les commandes lancées en batch sont insérée dans une file d'attente dédiée et exécutées quand l'activité du système le permet.
La commande at -r numéro permet de détruire un travail lancé par la commande batch.
12.4 LE RÉPERTOIRE /USR/LIB/CRON Ce répertoire appartenant à root doit être en mode r-x pour les autres utilisateurs. Il contient les
fichiers suivants :
Le fichier FIFO est un tube nommé pour la communication entre l'utilisateur et le processus cron.
Le fichier cron.allow contient la liste des utilisateurs ayant le droit d'exécuter la commande crontab (un nom de connexion d'utilisateur par ligne),
Le fichier cron.deny contient la liste des utilisateurs n'ayant pas accès à la commande crontab (un nom de connexion d'utilisateur par ligne).
Un seul de ces deux derniers fichiers est utile à un instant donné. Le principe d'utilisation est le suivant :

si le fichier cron.allow existe, la commande crontab n'accepte des travaux que pour les utilisateurs présents dans ce fichier, les autres recevant le message Sorry ...
si le fichier cron.allow n'existe pas et si le fichier cron.deny existe, la commande crontab n'accepte des travaux que pour les utilisateurs non présents dans ce fichier, les autres recevant le message Sorry ...
si aucun de ces deux fichiers n'existe, seul l'utilisateur root peut utiliser la commande crontab.
Les fichiers at.allow et at.deny ont le même format et jouent le même rôle pour la commande at que les fichiers cron.allow et cron.deny pour la commande crontab.
Le fichier log contient l'historique des actions effectuées par le service cron (trois enregistrements par commande : deux pour l'appel précédés de > et un pour la fin précédé de <). Outre le nom de la commande y figure diverses informations telles le PID du processus, la file de travail associée, la date de lancement ...
Le fichier queuedefs définit les caractéristiques de chaque file de travaux gérée pa4r le service cron. Chaque ligne de ce fichier doit avoir le format suivant :
q.NNj NNn NNw
avec : q est une lettre de l'alphabet précisant la file,
NNj est le nombre maximum de travaux qui peuvent être exécutés à un instant pour la file (par défaut NN=100),
NNn est la valeur de la constante nice pour chaque exécution dans la file,
NNw est le temps d'attente (en secondes) avant d'effectuer un nouvel essai lorsqu'une commande ne peut pas s'exécuter (par défaut 60).
Les champs vides d'une ligne sont initialisés aux valeurs par défaut.
12.5 LE RÉPERTOIRE USR/SPOOL/CRON
Ce répertoire appartient à l'utilisateur root et doit être en mode r-x pour les autres utilisateurs. Il contient les deux sous répertoires crontabs et atjobs.
12.5.1 Le sous répertoire /usr/spool/cron/crontabs
Les fichiers générés par les utilisateurs suite à l'utilisation de la commande crontab y sont enregistrés, chacun accessible par le nom de connexion de l'utilisateur. Par exemple les fichiers crontab des utilisateurs root, adm, news, sys et uucp.
12.5.2 Le sous répertoire usr/spool/cron/atjobs
Y sont enregistrés les travaux lancés à partir des commandes at ou batch. Le nom de chaque fichier est le numéro du travail suivi de .x où x représente la file.
12.5.3 Structure d'un fichier crontab
Les cinq premiers champs sont des entiers précisant dans l'ordre :

la minute (0...59),
l'heure (0...23),
le jour (1...31),
le mois (1...12)
le jour de la semaine (0...6 avec 0 pour dimanche).
Chaque champ peut être donné sous la forme du caractère * représentant toute valeur, ou sous la forme d'une liste d'éléments séparés par une virgule (un élément est soit un nombre, soit de la forme x-y pour représenter tous les nombres de x à y inclus). Si le jour est donné dans les deux champs (jour du mois et jour de la semaine), les deux sont pris en compte.
Le sixième champ contient la commande à exécuter. Tout texte après la fin de ligne ou après le caractère % (interprété comme une fin de ligne) est considéré comme disponible pour l'entrée standard de la commande.
Exemple0 2 * * * /usr/lib/acct/dodisk0 6 * * * find / -name core -exec rm {} \;
Particularités de la version Berkeley 4.2
Les services offerts en version Berkeley BSD 4.2 sont ceux de la V7 d'ATT. Le service cron ne gère pas directement les travaux lancés par la commande at car les commandes batch et crontab n'existent pas.
Le fichier /usr/lib/crontab est l'unique fichier crontab du système. Il est examiné par le processus démon cron chaque fois qu'il exécute une commande, périodiquement (une fois par heure par exemple) où lorsque le processus cron reçoit un signal SIGHUP (qui peut être envoyé lors d'une modification du fichier /usr/lib/crontab). La commande cron enregistre un historique des actions effectuées dans le fichier /usr/adm/cronlog s'il existe.
12.6 RÉCAPITULATION DES COMMANDES ET DES FICHIERS D'ADMINISTRATION
cron, at, batch, cron.allow, cron.deny, at.allow, at.deny

13. GESTION DES TERMINAUX
13.1 RAPPELS SUR LE PILOTE TTY
13.1.1 Architecture
Le pilote TTY est utilisé par les périphériques fonctionnant en mode caractère de type terminaux asynchrones.
Son architecture est représentée sur la figure suivante :
13.1.2 Structures de données associées
Il existe deux modes de fonctionnement des terminaux.
Mode caractère
Les caractères sont transmis individuellement. On distingue : le mode cru (mode raw) : tout caractère saisi est immédiatement transféré sans interprétation des
caractères spéciaux.
le mode cbreak : chaque caractère est transféré après filtrage des caractères spéciaux définis dans la structure TTYCHARS.
Mode ligne
Appelé mode canonique ou mode cooked, c'est le mode usuel de transmission des caractères avec interprétation des caractères spéciaux. Les caractères reçus sont saisis ligne par ligne, une ligne étant une suite de caractères interprétée seulement lorsque le caractère de fin ligne est reconnu. Il est possible dans ce mode de corriger des erreurs de frappe par utilisation de caractères spéciaux : destruction de caractères (erase character),
de mots (word erase character),

de lignes (kill character).
Au cours des transferts, les caractères sont stockés dans trois listes différentes : la rawq contient les caractères saisis en mode raw,
la canonq (canonicalized queue) contient les caractères après filtrage de la rawq,
l'outq stocke les caractères à la sortie du pilote.
Les structures de données utilisées sont : les c_listes, pour les pilotes en mode caractère, utilisées pour décrire une liste de caractères, de
longueur variable, en entrée ou en sortie. Elle est constituée de deux pointeurs sur son premier et son dernier caractère ainsi que le nombre de caractères qu'elle contient. Ces variables sont modifiées quand un caractère est ajouté ou supprimé de la liste. Quand la structure c_liste est pleine, une nouvelle structure c_liste est allouée.
les c_bloc,utilisés par les pilotes fonctionnant en mode bloc.
La discipline de ligne est une couche de logiciel intégrée au noyau utilisée pour décrire le comportement de l'interface et transformer le flot des données en mode raw en mode canonique.
13.2 SYSTEM V ET L'INTERFACE TERMIO
Les caractéristiques des terminaux asynchrones sont : mode asynchrone en full-duplex,
gestion des caractères saisis en mode raw,
saisie ligne par ligne en mode canonique,
gestion des caractères de contrôle.
Les caractères de contrôle des terminaux ainsi que les caractères de paramétrage du pilote associé aux voies asynchrones, sont définis dans le fichier termio.h et constituent l'interface termio, qui est utilisée par la discipline de ligne et la commande stty.
13.2.1 Indicateurs de contrôle
Les drapeaux indicateurs associés aux caractères de contrôle ne peuvent être interprétés qu'en mode canonique.

Indicateurs de correction de saisie
ICANON
Drapeau indicateur du mode saisie de ligne ou mode canonique.
ERASE
Caractère de correction du caractère courant, par défaut #, en général le caractère ^H ou la touche delete.
KILL
Effacement de la ligne, en général l'un des caractères ^X ou ^U.
WERASE
Effacement du mot précédent, en général le caractère ^W.
Caractère de gestion des signaux
ISIG
Drapeau indicateur de la gestion des signaux.
INTR
Prise en compte du signal SIGINT, en général le caractère ^C.
QUIT
Prise en compte du signal SIGQUIT, en général ^D.
SWTCH ou SUSP
Suspension du processus actif en C-shell ou en Korn-shell, en général le caractère ^Z.
Gestion du pool de tampons
NOFLSH
Vidage des files d'attente.

Contrôle de flux
IXON
Contrôle de flux en sortie.
IXOFF
Contrôle de flux en entrée.
STOP
Gestion du protocole XOFF, en général le caractère ^S.
START
Gestion du protocole XON par la caractère ^Q sauf si le drapeau IXANY est positionné (n'importe quel caractère dans ce cas).
EOF
Marque de fin de lecture (^D).
13.2.2 Caractéristiques physiques de la ligne
Les caractéristiques physiques des lignes asynchrones sont définis à partir des indicateurs suivants :
CBAUD
Rapidité de modulation de la ligne en bauds, sous la forme Bn, avec n = 110,300,...,19200
Il est possible d'utiliser une horloge externe à partir des indicateur EXTA et EXTB.
CSIZE
Définition du nombre de bits de la représentation interne des caractères sous la forme CSn, avec n = 5,6,7,ou 8. Les modes usuels sont CS7 et CS8.
ISTRIP
Le huitième bit est ignoré.
CSTOPB
Drapeau de deux bits stop, un seul sinon.

Gestion de la parité
PARODD
Drapeau d'un contrôle de parité impaire. Par défaut, contrôle de parité paire.
INPCK
Drapeau du contrôle de parité en entrée.
IGNPAR
Les caractères lus avec une erreur de contrôle de parité sont ignorés.
PARMRK
Les caractères lus avec une erreur de contrôle de parité sont transmis.
Gestion des délais de retransmission
NLDLY
Délai de passage à la ligne.
CRDLY
Délai de retour en début de ligne.
TABDLY
Délai résultant d'un caractère de tabulation horizontale.
VTDLY
Délai résultant d'une tabulation verticale.
BSDLY
Délai résultant d'un effacement d'un caractère.
FFDLY
Délai résultant d'un saut de page.
OFILL
Délai obtenu par des caractères de bourrage.
IGNBREAK
Touche break désactivée.
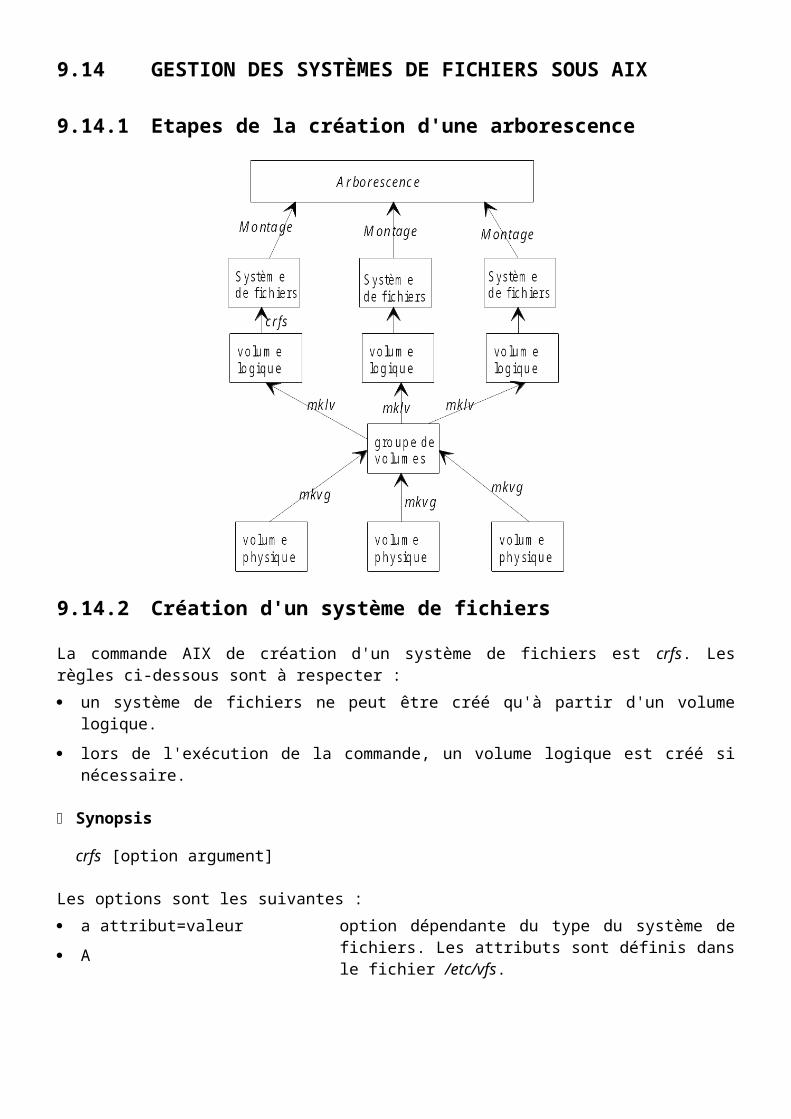
BRKINT
Emission du signal SIGINT, contradictoire avec le drapeau précédent.
CLOCAL
Drapeau de ligne locale. Si absence, la ligne est supposée être reliée à un modem.
HUPCL
Déconnexion de la ligne en fin de processus ou émission du signal SIGHUP aux processus attachés si celle-ci est déconnectée.
13.2.3 Caractéristiques logiques
Les caractéristiques logiques permettent de choisir entre les divers traitements de l'écho, des caractères minuscules ou majuscules, des codes NL et CR, LF.
Flot d'entrée
ICRNL
Conversion du caractère CR en NL
IGNCR
Caractère CR non pris en compte.
INLCR
Caractère NL non pris en compte.
IULCUC
Conversion des lettres minuscules en majuscules en entrée.

Flot de sortie
OPOST
Drapeau nécessaire de traitement des caractères en sortie.
ONLCR
Le caractère NL est transmis sous la forme CR et NL
ONOCR
Le caractère CR est transmis sous la forme NL
OLCUC
Conversion des lettres minuscules en majuscules en sortie.
XCASE
Tout caractère en entrée et en sortie est précédé du caractère \
ECHO
Affichage de chaque caractère frappé.
ECHONL
Affichage du caractère NL.
13.3 GESTION DES TERMINAUX AVEC SYSTEMV R3.2
13.3.1 Port avec ou sans connexion
Un port série est déclaré avec connexion s'il est déclaré dans le fichier /etc/inittab avec l'action respawn (l'action off correspondant à l'absence de connexion).
13.3.2 Le processus getty
Au démarrage du système, il y a la création d'une entité du processus getty associé à chaque port série déclaré avec connexion qui assure les fonctions suivantes : initialisation de la ligne, émission d'un message (contenu dans un des fichiers /etc/logmessage,
/etc/ident, ou /etc/issue...) et d'une invitation à la connexion (message login en général).
attente d'un nom d'utilisateur, lecture jusqu'au caractère de fin de ligne, exécution du processus login avec la réponse comme argument. Une réponse ne comportant que des majuscules provoque une interprétation des lettres minuscules en majuscules précédées du caractère /.

Le processus getty positionne le mode crmod ce qui permet d'utiliser indifféremment les touches Carriage Return et Line Feed comme marque de fin de ligne et en sortie de les afficher dans les deux cas (ce mode n'est pas sélectionné si la réponse se termine par Line Feed).
Synopsis
getty [-t timout] line [speed [type[discipline]]]
Description
t délai de coupure de ligneline périphérique associé dans le répertoire /devspeed rapidité de modulation définie dans le fichier /etc/gettydefstype type du terminal, par défaut none
L'exécution de la commande sans argument affiche les paramètres courants.
13.3.3 Le fichier gettydefs
Les données du processus getty sont lues dans le fichier /etc/gettydefs dont les enregistrements sont constitués de 5 champs séparés par un # selon le format :
label#initial#final#prompt#label_suivant
Label
Champ de différentiation des enregistrements. C'est souvent un nombre entier représentant la rapidité de modulation du terminal.
Initial
Caractéristiques d'initialisation de la ligne au format termio.
Final
Caractéristiques de la ligne après réponse de l'utilisateur au format termio.
Prompt
Chaîne de caractères utilisée comme message d'invitation à la connexion.
Label_suivant
Label de chaînage utilisé lorsque la rapidité de modulation du terminal est inconnue. Il suffit de taper le caractère Break pour indiquer que la rapidité de modulation proposée n'est pas la bonne.
Exemple9600#B9600 HUPCL OPOST CS8 PARENB ONLCR#B9600 CLOCAL SANE ECHOE#login:#4800

13.3.4 Réinitialisation dynamique des ports
L'état d'une ligne est modifiable dynamiquement. Il suffit de modifier le fichier /etc/inittab et d'utiliser la commande init q.
Graphe d'état
13.4 GESTION DES TERMINAUX AVEC SYSTEMV R4
13.4.1 Services SAF
L'ensemble des services de gestion des ports s'appelle le SAF (Service Access Facility).
Tout port physique est associé à un port tty géré par un moniteur de port dont la fonction est le contrôle de son utilisation (acceptation, refus, audit d'utilisation). Il existe deux gestionnaires de ports : le processus démon ttymon, qui remplace le programme getty, pour les connexions locales et le processus listen pour les utilisateurs distants.
Le SAF est constitué des sous-systèmes suivants : le Service de Contrôle d'Accès,
les moniteurs de ports ttymon et listen,
les shell-scripts optionnels de configuration.
L'administration des ports se divise en deux niveaux : le niveau supérieur, assurant l'administration de l'ensemble des moniteurs de ports (gestionnaires de
ports) avec la commande sacadm,
le niveau inférieur, assurant l'administration de chacun des ports avec la commandes pmadm.
13.4.2 Service de contrôle d'accès
Le service de contrôle d'accès (Service Access Controller) est le point de contrôle administratif de tous les gestionnaires de ports, donc de l'ensemble des voies d'accès. Il assure les fonctions suivantes : paramétrage de l'environnent SAC par l'exécution du shell script /etc/saf/sysconfig lors de la
phase de démarrage du système,
initialisation des différents moniteurs de ports par lecture du fichier /etc/saf/sactab,
scrutation périodique des moniteurs de ports pour détection des dysfonctionnements éventuels et redémarrage éventuel,

administration des moniteurs de ports avec les commandes sacadm et pmadm.
13.4.3 Moniteur de ports
Une instance du processus /usr/lib/saf/ttymon assure la gestion : d'un ou plusieurs ports tty,
des disciplines de lignes associées à chaque port tty, des différentes rapidité de modulations de transmission,
des modes des terminaux.
Les valeurs d'initialisation sont dans le fichier commun associé à chaque port tty, maintenu par la commande sttydefs.
Il permet la connexion des utilisateurs (identification et authentification) ou des applications. Normalement, il est configuré pour s'exécuter sous le contrôle du SAC. Il peut être configuré manuellement par utilisation de la commande sacadm.
L'implémentation de la gestion des terminaux a été modifiée pour intégrer les streams.
13.4.4 Graphe d'état du service SAC
13.4.5 Graphe d'état d'un gestionnaire de ports
Tout moniteur de ports est dans un des états :

STARTING démarrage du moniteurENABLED port actif pouvant accepter des connexionsDISABLED port actif ne pouvant accepter de connexions,STOPPING en cours d'arrêtNOTRUNNING gestionnaire de ports arrêtéFAILED gestionnaire de ports incapable de démarrer normalement.
Les transitions des différents états sont résumées dans le graphe suivant :
13.4.6 Scrutation d'un gestionnaire de ports
Le service SAC scrute régulièrement les gestionnaires de ports pour contrôler qu'ils sont dans l'état ENABLED. Il est possible de définir ou de redéfinir l'intervalle de temps de scrutation par la commande sacadm -t ns.
13.4.7 Structure des fichiers d'administration du SAC
Chaque entrée d'un fichier d'administration du SAC est constitué des cinq champs suivants :
PMTAG
unique chaîne de caractères d'au plus 14 caractères d'identification du moniteur de ports.
PMTYPE
type du moniteur (ttymon ou listen).
FLGSx le port est non valide s'il est démarré,d le moniteur de port n'est pas démarré
RCNT
Nombre maximum de tentatives infructueuses de démarrage du gestionnaire de ports.

COMMAND
Commande de démarrage du moniteur de ports.
ExemplePMTAG PMTYPE FLGS RCNT COMMANDttymon1 ttymon d 0 /usr/lib/saf/ttymon #ttymon1ttymon2 ttymon - 0 /usr/lib/saf/ttymon #ports board
13.4.8 Commandes d'administration associées au SAC
Synopsis
/usr/sbin/sacadm -option(s) argument(s)
Description
ajout, démarrage, arrêt, validation ou invalidation, suppression d'un moniteur de ports,
installe ou modifie un shell script de démarrage ou de configuration d'un moniteur de port.
Fichiers associés
/etc/saf/sactab liste des ports à démarrer,/etc/saf/sysconfig gestion de l'environnement SAC.
13.4.9 Structure des fichiers d'administration des ports
Chaque entrée d'un fichier d'administration du gestionnaire de ports est constitué des six champs suivants :
SVCTAG
unique chaîne d'au plus 14 caractères d'identification d'un service.
FLGSx le port est non valideu création d'une entrée pour ce service dans le fichier /var/adm/utmp
ID
Identité de l'utilisateur sous lequel le service est démarré.
SCHEME
Schéma d'authentification utilisé pour le service.
PMSPECIFIC
Exemples d'informations spécifiques pour ce port.
COMMENT

Commentaire associé.
ExemplePMTAG PMTYPE SVCTAGS FLGS ID SCHEME PMSPECIFICttymon3 ttymon 31 ux - /dev/term/31 /usr/bin/shserv 9600 ldterm login:ttymon3 ttymon 32 ux - /dev/term/31 /usr/bin/shserv 9600 ldterm login:
13.4.10 Administration des gestionnaires de ports
La commande pmadm permet d'ajouter, de démarrer, d'invalider un service associé à un port.
13.4.11 Fichiers de configuration des terminaux
Le fichier /etc/ttydefs a un rôle similaire à celui du fichier /etc/gettydefs. Ses enregistrements ont le format suivant :
label:initial:final:autobaud:label_suivant
Label, Initial, Final, Label_suivant
Identiques au cas précédent.
autobaud
Ce champ est soit vide, soit fixé à la valeur A pour indiquer la reconnaissance automatique de la rapidité de modulation.
Exemple de fichier /etc/ttydefs9600:9600 opost onlcr ignpar ixon ixany parenb istrip echo echoe isig cs8 cread:9600 opost onlcr sane ignpar ixon ixany parenb istrip cs7 cread::1200
13.5 GESTION DES TERMINAUX DANS L'ENVIRONNEMENT BSD
Les principes de gestion des terminaux sont similaires à ceux de l'environnement SYSTEM V R3 précédemment décrits. Il y a des variantes dans les noms des fichiers et leurs champs.
13.5.1 Le processus getty
Synopsis
getty [type [ttyxx]]

Description
Le champ type est un index dans le fichier /etc/gettytab permettant d'accéder aux caractéristiques de la ligne.
Le champ tty permet d'initialiser le port /dev/ttyxx correspondant.
13.5.2 Le fichier /etc/gettytab
Son rôle est similaire à celui du fichier /etc/gettydefs des version SYSTEM V. Le format de représentation des données est celui utilisé dans les fichiers /etc/termcap et /etc/printcap. Chaque enregistrement est composé de deux articles : une ligne de label, séparés par le symbole | et plusieurs lignes de caractéristiques physiques séparées par le symboles :.
Format de représentation des données
Les caractéristiques sont définies par des codes de deux caractères et peuvent être de type booléen, entier, ou chaîne de caractères.
Variable booléenne : elle est simplement validée par sa présence.
Variable entière : le code est simplement suivi d'une valeur numérique.
Variable chaîne de caractères
Le code est suivi de la chaîne. Un code ASCII est représenté par le caractère \n où n est le code ascii représenté en octal. Une autre possibilité est le caractère \x, où x=r (return) ou n (new line...).
Il est aussi possible d'utiliser des variable sous la forme %h (nom de machine), ou %t (nom de terminal).
Entrées
On définit le comportement par défaut, le comportement d'une ligne de rapidité de modulation fixe ou variable.
Code de contrôle
Les codes de contrôle utilisés sont similaires à ceux de l'interface termio :er erasekl killqu quitsu suspendwe werasexf xoffxn xone suppression de l'écholm message initial de contrôle.

Définition des modes de contrôle
sp rapidité de modulation en baudis rapidité de modulation en baud en entrée,os rapidité de modulation en baud en sortie,
format de transmissionp8 8 bits sans paritéep 7 bits avec paritéop parité impaireap parité quelconque.
Exempledefault:\ap:lp=\r\n%h login\72 :sp#9600:\:er=\177:kl=^U:in=^C:# entrées à rapidité de modulation constantec:std.300300-baud:\:nd#1:cd#1:sp#300:c:std.300|300-baud:\:nd#1:cd#1:sp#300:f:std.600|600-baud:\:fd#1:sp#1:sp#300:6:std.4800|4800-baud:\:sp#1:sp#4800:ht:3:std.9600|9600-baud:\:sp#9600:nl:# entrées à rapidité de modulation variable# adaptable avec la touche BREAKc:d300|Dial300-:\:nx=d1200:cd#2:sp#300:d:d1200|Dial1200-:\:nx=d110:fd#1:sp#1:sp#1200:
13.5.3 BSD 4.2
Trois fichiers essentiels : /etc/ttys, /etc/ttytype, /etc/securetty.
/etc/ttys
Ce fichier contient une ligne pour chaque port de communication avec : un premier caractère précisant la présence ou l'absence de connexion ( 1 avec connexion, 0 ou - sans
connexion),
un deuxième caractère précisant soit la rapidité de modulation de la ligne (selon un code donné), soit la référence à un enregistrement du fichier /etc/ttytype contenant la rapidité de modulation et divers autres renseignements sur la ligne,
le nom de la ligne telle qu'elle est définie dans le répertoire /dev.
Exemple14console

02ttyh0
/etc/ttytype
Ce fichier associe un type de terminal, décrit dans le fichier /etc/termcap à un port asynchrone pour l'initialisation de la variable shell TERM.
Le fichier est constitué d'une ligne par port selon le format :
type_term ttyxx
ou type_term représente le type du terminal défini dans le fichier /etc/termcap et ttyxx le fichier spécial associé au terminal du répertoire /dev.
/etc/securetty
Un terminal est dit sécurisé (secure) si l'administrateur peut s'y connecter directement sous l'uid root (en général la console système).
Ce fichier contient une ligne par port déclaré secure selon le format :
ttyxx
13.5.4 BSD 4.3
Les fichiers ttys, ttytype, securetty sont regroupés dans le fichier /etc/ttytype, qui contient alors l'ensemble des renseignements nécessaires à l'activation de la ligne. L'option secure définit un poste sécurisé. Son absence, ou l'option unsecure oblige l'administrateur à utiliser la commande /bin/su.
Exempleconsole "/etc/getty e" vt100 on nomodem secure#console systèmetty01 "/etc/getty f" vt100 shared modem #modemtty02 "/etc/getty 2" vt100 nomodem secure#console systèmettyp0 none network #pseudo device
Descriptionon/off possibilité ou impossibilité de connexionshared connexion uucpsecure terminal sécuriséwindow="chaine" utilisé pour l'environnement XWindow.

L'état d'une ligne est modifiable dynamiquement. Il suffit de modifier l'un des fichiers /etc/ttys, /etc/ttytype, /etc/securetty puis d'exécuter la commande kill -1 1.
13.6 LE PROCESSUS LOGIN
Avant SYSTEM V R4
Ce processus recherche le nom de l'utilisateur (login name) dans le fichier /etc/passwd. Si la ligne correspondante contient un mot de passe, le processus login affiche le message Password: , supprime l'écho, attend et lit la réponse, rétablit le mécanisme d'écho, crypte la réponse et la compare au champ correspondant du fichier /etc/passwd. S'il n'y a pas concordance, le message login incorrect, suivi d'une nouvelle invitation à la connexion sont affichés et le processus login attend et lit la réponse et reboucle comme ci-dessus. Si l'utilisateur n'est pas référencé dans le fichier /etc/passwd, le processus login demande un mot de passe et affiche "login incorrect" avant de se terminer, ce qui réveille le processus init.
Avec SYSTEM V R4
Le mot de passe crypté n'apparaît plus dans le fichier /etc/passwd. Il est recherché dans le fichier /etc/shadow, invisible pour l'ensemble des utilisateurs.
Lorsque le nom et le mot de passe sont corrects, le processus login recherche le programme à exécuter (le dernier champ de la ligne du fichier /etc/passwd) qui est en général un interprète de commandes (valeur par défaut si le champ est vide).
Toutes les exécutions depuis le processus init (getty, login, shell) sont réalisées dans le même processus, ce qui nécessite un changement d'identité pour que l'utilisateur puisse prendre son UID et son GID et se positionner dans son répertoire de connexion. En outre, le processus login enregistre la connexion par la mise à jour des fichier utmp et wtmp.
L'interprète de commandes
Le shell de Bourne (ou le Korn Shell dans les environnement POSIX) est invoqué avec un environnement par défaut. Il exécute le fichier /etc/profile (qui affiche en général le message du jour (message off the day) contenu dans le fichier /etc/motd, notifie à l'utilisateur qu'il a du courrier en instance et définit un environnement commun à tous les utilisateurs.
Le C-shell affiche le message contenu dans le fichier /etc/motd et le message éventuel de courrier en instance. Ensuite l'interprète de commandes Shell (resp C-shell) exécute le fichier .profile (resp .login) du répertoire de connexion de l'utilisateur ce qui permet à l'utilisateur de personnaliser son environnement à chaque connexion.
En fin de session (caractère CTRL D), le processus associé à l'interprète de commandes shell se termine (le C-shell exécute alors le fichier .logout) ce qui réveille le processus init qui enregistre la déconnexion (mise à jour des fichiers utmp et wtmp) et recrée un processus de login avec le processus getty.
Le fichier /etc/utmp contient la liste des utilisateurs connectés, alors que le fichier /etc/wtmp enregistre les connexions et les déconnexions ainsi que diverses activités. La commande shell lastcomm exploite ces renseignements.

L'absence des fichiers motd, .profile ne modifie pas le fonctionnement des phases ci-dessus.
13.7 TYPES DE TERMINAUX
La gestion des différents types de terminaux est assurée par les bases de données terminfo (SYSTEM V) ou termcap (BSD) qui contiennent un nombre très important de tables de transcodage correspondants à différents types de terminaux (entre 1000 et 1500).
Le type du terminal est défini, en général au moment de la connexion, par la variable shell TERM qui permet d'accéder à la table de transcodage associée au terminal dans la base de données.
13.7.1 BSD : la base de données termcap
Dans les versions d'UNIX antérieures à SYSTEM V, toutes les caractéristiques des terminaux sont contenues dans l'unique fichier source /etc/termcap, dont la taille peut être très importante. Tout nouveau type de terminal est crée par un simple ajout dans ce fichier. Toute requête de la table de transcodage l'utilise séquentiellement ce qui peut être pénalisant. Une solution est de réduire sa taille par simple extraction des lignes correspondants aux terminaux utilisés sur le site.
Exemple des caractéristiques d'un terminal au format termcapansic:CT:tc=ansi:ln|ansi-nam|ansinam|Ansi standard crt without automargin:\
:al=\E[L:bs:cd=\E[J:ce=\E[K:cl=\E[2J\E[H:cm=\E[%i%d;%dH:co#80:\:dc=\E[P:dl=\E[M:do=\E[B:bt=\E[Z:ei=:ho=\E[H:ic=\E[@:im=:li#25:\:nd=\E[C:pt:so=\E[7m:se=\E[m:us=\E[4m:ue=\E[m:up=\E[A:\:kb=^h:ku=\E[A:kd=\E[B:kl=\E[D:kr=\E[C:eo:sf=\E[S:sr=\E[T:\:GS=\E[12m:GE=\E[10m:GV=\63:GH=D:\:GC=E:GL=\64:GR=C:RT=^J:G1=?:G2=Z:G3=@:G4=Y:G5=;:G6=I:G7=H:G8=<:\:GU=A:GD=B:\:CW=\E[M:NU=\E[N:RF=\E[O:RC=\E[P:\:WL=\E[S:WR=\E[T:CL=\E[U:CR=\E[V:\:HM=\E[H:EN=\E[F:PU=\E[I:PD=\E[G:\:Gc=N:Gd=K:Gh=M:Gl=L:Gu=J:Gv=\072:
13.7.2 SYSTEM V : la base de données terminfo
Fichier source
Chaque fichier source de la base de donnée a le nom du type du terminal qu'il représente (par

exemple vt100). Tous ces fichiers ont un même format standard et sont regroupés dans les sous-répertoires du répertoire /usr/lib/terminfo dont chaque nom est constitué d'un seul caractère (a, b, c ....), qui contiennent les fichiers descripteurs des types de terminaux commençant par ce caractère comme /usr/lib/terminfo/v/vt100.
Cette organisation permet d'optimiser les temps de recherche. Elle permet aussi de diminuer le nombre de fichiers car plusieurs appellations peuvent représenter le même terminal. Par exemple ansi, ou ansic. Dans ce cas, les noms synonymes sont des liens matériels sur le même inode.
Exemple d'un fichier sourceansi|ansic|ansi80x25| Ansi standard console,am, bce, eo, xon,colors#8, cols#80, it#8, lines#25, pairs#64,acsc=0[a1fxgqh2jYk?lZm@nEqDtCu4vAwBx3, bel=^G,blink=\E[5m, bold=\E[1m, cbt=\E[Z, clear=\E[2J\E[H,cr=\r, cub1=\b, cud1=\E[B, cuf1=\E[C,cup=\E[%i%p1%d;%p2%dH, cuu1=\E[A, dch1=\E[P, dl1=\E[M,ed=\E[m\E[J, el=\E[m\E[K, home=\E[H, ht=\t, ich1=\E[@,il1=\E[L, ind=\E[S, invis=\E[8m, kbs=\b, kcbt=\E[Z,kcub1=\E[D, kcud1=\E[B, kcuf1=\E[C, kcuu1=\E[A,kend=\E[F, kf1=\E[M, kf10=\E[V, kf11=\E[W, kf12=\E[X,kf2=\E[N, kf3=\E[O, kf4=\E[P, kf5=\E[Q, kf6=\E[R,kf7=\E[S, kf8=\E[T, kf9=\E[U, khome=\E[H, kich1=\E[L,knp=\E[G, kpp=\E[I, op=\E[37;40m, rev=\E[7m, ri=\E[T,rmacs=\E[10m, rmso=\E[m, rmul=\E[m, setb=\E[4%p1%dm,setf=\E[3%p1%dm, sgr0=\E[10;0m, smacs=\E[12m,smso=\E[7m, smul=\E[4m,
Principe d'utilisation
Tout fichier source au format terminfo doit être "compilé" (commande tic) pour être exploitable.
Fichiers objet
Le fichier objet résultant de la commande de compilation et ses liens matériels sont créés dans le répertoire /usr/lib/terminfo.
Autre organisation
Les sous-répertoires du répertoire /usr/lib/terminfo ne contiennent que les fichiers compilés. L'utilisation de la commande de compilation n'est alors pas nécessaire.
13.7.3 Commandes associées à la base de données terminfo
tic
La commande tic (terminfo compiler) compile un fichier source au format terminfo.
Synopsis
tic fichier_source
infocmp
Cette commande reconstitue sur la sortie standard le fichier source au format terminfo associé à un fichier compilé.

Synopsis
infocmp fichier_compilé
captoinfo
Cette commande convertit un fichier source au format termcap au format terminfo.
13.7.4 Correspondance termcap-terminfo
13.8 LA COMMANDE STTY
La commande stty permet de connaître et de modifier les caractéristiques de la liaison série associée à l'entrée standard. Sa syntaxe est variable selon l'environnement BSD ou l'environnement SYSTEM V.
13.8.1 BSD
Elle reprend aujourd'hui la discipline de la ligne d'UNIX SYSTEM V.
Synopsis
stty option(s)
Description : voir ci-dessous.
Exemplesstty -a #affichage de toutes les optionsstty 2400 even -tabstty new crt -tab ^C kill ^U erase
13.8.2 SYSTEM V
Synopsis
stty [-a][-g] [option(s)]
Description
L'option -a affiche les caractéristiques courantes de la liaison.
L'option -g effectue une mise en forme utilisable comme argument d'une autre commande stty.
Les autres options permettent la définition des modes de contrôle, les modes d'entrée et de sortie, les modes locaux, le contrôle de flux, la gestion des horloges internes des transmissions, la gestion des caractères de contrôle, la gestion de la taille de la fenêtre courante qui sont décrits dans l'interface

termio. Nous les présentons ci-dessous.
Modes de contrôle
parenb validation du contrôle de parité
parodd parité paire,
cs5,cs6,cs7,cs8 caractères représentés sur 5, 6, 7, ou 8 bits,
110 300 600 1200 2400 4800 9600 19200 38400
rapidité de modulation en baud, ispeed 0 110 300 600 1200 2400 4800 9600 19200 38400
rapidité de modulation en baud en entrée, ospeed 0 110 300 600 1200 2400 4800 9600 19200 38400
rapidité de modulation en baud en sortie, hucp arrêt de la connexion,
cstopb (-cstopb) deux ou un bit stop par caractère.
Les modes d'entrée et de sortie
ignbrk ignore le signal de break en entrée,
ixon mise en route du contrôle START/STOP,
ixoff requête d'émission des caractères START/STOP en fin d'émission.
Les modes locaux
icanon utilisation du mode canonique,
echo (-echo) écho validé (invalidé).
La gestion des caractères de contrôle
Les caractère de contrôle choisis doivent être saisis entre ', précédé du caractère ^ (Exemple '^h'). erase c caractère de suppression associé à c (erase '^h'),
kill c caractère kill défini par le caractère c,
quit c caractère quit défini par le caractère c,
start c caractère start défini par le caractère c,
stop c caractère stop défini par le caractère c,
susp c caractère susp défini par le caractère c,
werase c caractère werase défini par le caractère c,
lcase c caractère lcase défini par le caractère à c.
Exempleexécution de la commande stty -aspeed 9600 baud; ispeed 9600 baud; ospeed 9600 baud;line = 0; intr = DEL; quit = ^\; erase = ^H; kill = ^U; eof = ^D; eol = ^M;swtch = ^@;susp <undef>;start = ^Q;stop = ^S;

parenb -parodd cs8 -cstopb -hupcl cread -clocal -loblk -crtsfl -ctsflow -rtsflowignbrk brkint ignpar -parmrk -inpck -istrip inlcr -igncr icrnl -iuclcixon ixany -ixoffisig icanon -xcase echo echoe echok -echonl -noflsh -iexten -tostop -xcludeopost -olcuc onlcr -ocrnl -onocr -onlret -ofill -ofdelisscancode xscancode -cs2scancode
13.9 RÉCAPITULATION DES COMMANDES ET DES FICHIERS D'ADMINISTRATION
getty, gettytab, gettydefs, ttytab, ttydefs, ttys, ttytype, termcap, terminfo, stty, termio, termios

14. SERVICES D'IMPRESSION
14.1 GÉNÉRALITÉS SUR LE SERVICE D'IMPRESSION
Le service d'impression offre à l'utilisateur de nombreux services, similaires, mais très différents d'accès dans les environnements BSD et SYSTEM V.
L'impression peut s'effectuer, localement ou à distance, sur une imprimante particulière, sur une classe (un groupe) d'imprimantes (SYSTEM V) ou toute autre sortie (terminal, fichier...).
14.2 LE SERVICE BSD
Le service d'impression de l'environnement BSD est très simple car il ne comporte que quelques commandes.
14.2.1 Service
Services utilisateur
lpr requête d'impression
lpq état des files d'attente d'impression
lprm suppression d'une requête d'impression en attente
/usr/spool/lpd répertoire associé aux spoules d'impression
/usr/lib/lpd processus démon d'impression
14.2.2 Commandes d'administration
La commande lpc permet d'assurer les tâches d'administration des imprimantes. Elle est interactive et permet de démarrer, d'arrêter le processus démon, de valider ou d'invalider une imprimante, ou de connaître l'état du processus démon ou des imprimantes. Ses directives internes sont : abort arrêt de l'impression en cours,
disable accès au spoule d'impression invalidé,
enable accès au spoule d'impression autorisé,
help aide en ligne,
restart suppression du serveur et recréation,
status état des différents éléments d'impression,
topq mise d'un travail en tête de la file d'impression,
clean suppression d'une file de spoule de fichiers en instance,
exit sortie du mode interactif de lpc,

down requêtes successives stop et disable,
quit sortie du mode interactif de lpc,
start lancement du serveur d'impression,
stop arrêt du serveur à la fin du travail et invalidation,
up requêtes successives restart et enable.
14.2.3 Fichier printcap
Le fichier /etc/printcap permet la description et la définition d'une imprimante. Il se présente sous la forme suivante :
lp|ap|arpa|ucbarpa|LA-180 decwriter III \lp=:rm=gould:rp=lp:sd=/usr/spool/lpd:lf=/usr/adm/lpd-errslp2:lp=:rm=gould:rp=lp2:sd=/usr/spool/spd:lf=/usr/adm/lpd-errs
Interprétation
La première ligne décrit des noms synonymes d'une même imprimante.
Sur la deuxième ligne, les mots clés lp, rm, rp, sd, lf, ont la signification suivante : lp étiquette logique d'accès à l'imprimante,
rm nom de la machine distante (remote machine),
sd spool directory (local),
rp nom de l'imprimante distante (remote printer),
lf fichier des messages d'erreurs (error log file).
La première et la deuxième ligne sont utilisées pour décrire la même imprimante car le caractère \ est le caractère de suite. La première ligne définit les noms logiques d'accès de l'imprimante (lp, ap, etc.) sur le client. La deuxième ligne définit les informations : lp est le type de l'objet LA-180 (line printer)
gould est le nom du serveur (remote machine)
lp est le nom symbolique de l'imprimante utilisée sur le serveur (remote printer)
/usr/spool/lpd est le répertoire d'impression
Le fichier contenant les message d'erreur à l'impression est dans le répertoire /usr/adm/lpd-errs.
Les autres paramètres de configuration d'une imprimante sont indépendants de leur implémentation en réseau.
Remarque
Dans le cas où une station cliente émet des requêtes à une station serveur, le fichier est d'abord stocké dans le spoule local jusqu'à son acceptation sur le spoule distant. Le travail n'est pas imprimé si les ressources distantes sont insuffisantes ce qui peut se produire si le système de fichier distant est saturé. Dans ce cas, la station client émet en permanence des requêtes que la station serveur ne peut satisfaire.

14.3 LE SERVICE SYSTEM V
De nombreuses fonctionnalités ont été ajoutées aux services BSD.
14.3.1 Classes d'imprimantes Un classe d'imprimantes est constituée de plusieurs imprimantes ayant les mêmes caractéristiques.
Une requête d'impression vers une classe est exécutée sur une quelconque des imprimantes de la classe.
Toute classe contient une imprimante au moins.
Il n'est pas obligatoire qu'une imprimante appartienne à une classe donnée.
La notion de classe d'imprimantes n'existe que dans UNIX SYSTEM V.
14.3.2 Commandes associées au service utilisateur
Les commandes publiques d'impression sont dans le répertoire /usr/bin.
Requêtes d'impression
Synopsis
lp [option] fichier
Principales options c création de copie du fichier à imprimer au lieu de lien
ddest impression sur l'imprimante définie
m émission du courrier par mail
nn nombre de copie (par défaut 1)
oo option o disponible dans le fichier modèle de l'imprimante
s suppression du message request id is...
tt impression du titre t
w impression d'un message de fin de l'impression sur la sortie standard.
Annulation d'une requête d'impression
Synopsis
cancel [requête_id][imprimante]
Informations sur l'état des requêtes d'impression.
Synopsis
lpstat [option]

Principales options d nom de l'imprimante par défaut,
r état du processus démon lpsched,
s résumé de l'ensemble des informations,
t affichage de tous les informations d'état.
Déplacement de requêtes d'une file d'impression vers une autre
Cette commande ne s'exécute que si le processus démon lpsched est arrêté.
Deux possibilités : redirection d'une requête simple ou redirection de toutes les requêtes d'une imprimante donnée.
Synopsis
lpmove requête_id nom_imprimante_destinataire
ou
lpmove nom_imprimante_origine nom_imprimante_destinataire
Activation/désactivation d'une imprimante donnée
Synopsis
enable/disable nom_imprimante
14.3.3 Commandes d'administration
Processus démon
Le processus démon ordonnanceur des requêtes d'impression lpsched est lancé au démarrage (par un shell script rc*).
Synopsis
/usr/lib/lpsched
Répertoire des commandes d'administration : /usr/sbin
Les principales commandes d'administration sont présentées ci-après.
lpadmin
Cette commande réalise pratiquement toutes opérations sur les imprimantes ou les classes (création, suppression, modification d'une destination, ajout ou suppression des attributs d'une imprimante dans une classe.
Voici une première présentation simplifiée de sa syntaxe.

Synopsis
lpadmin -p nom_imprimante [option(s)]
lpshut
Arrêt du processus démon lpsched (seule l'impression est arrêtée, les autres services restent accessibles).
Synopsis
lpshut
accept/reject
Autorisation ou interdiction au processus lp d'accepter des requêtes vers une imprimante donnée.
Synopsis
accept/reject nom_imprimante ou nom_classe
Installation ou modification d'un filtre d'impression
Synopsis
lpfilter
Installation ou modification d'un masque d'impression
Synopsis
lpforms
Définition/modification des priorités d'impression des utilisateurs
Synopsis
lpusers -q priorité -liste_d'utilisateurs
Audit
L'activité du processus démon lpsched enregistre son activité dans le fichier /usr/spool/lp/log et utilise parfois le fichier de verrouillage schedlock.
Au lancement du processus démon, le fichier /usr/spool/lp/log devient /usr/spool/oldlog.
Les fichiers temporaires du spoule sont stockés dans le répertoire /usr/spool/lp.
14.3.4 Attributs d'une imprimante
A partir de la commande lpadmin, cinq attributs permettent de caractériser une imprimante :

son nom ou celui de sa classe,
son interface (série ou parallèle),
son type,
le type de fichiers à imprimer,
le pilote associé.
Nom de l'imprimante ou de la classe
Le nom de l'imprimante permet son identification. Il est utilisé par l'administrateur ou l'utilisateur pour la configurer et y accéder. Il n'y a pas de nom pas défaut.
Synopsis
lpadmin -p nom
Interface de l'imprimante
L'interface (série ou parallèle) est définie par le fichier spécial associé à savoir : interfaces séries : fichiers /dev/term/00, /dev/term/01,...
interfaces parallèles : fichiers /dev/lp*.
Type de l'imprimante
Le type de l'imprimante est son nom générique (HPLaserJet 3,...), défini par le constructeur. Les tables de transcodage associées sont définies dans le répertoire /usr/lib/terminfo.
Le type d'une imprimante donnée est accessible par la commande lpadmin.
Synopsis
lpadmin -T type_imprimante
Type de fichiers à imprimer
La plupart des imprimantes peuvent imprimer soit des fichiers de type simple, soit des fichiers du même type que celui de l'imprimante.
Un fichier de type simple ne contient que des caractères ASCII et les caractères de contrôle backspace, tab, linefeed, form feed, carriage return.
Synopsis
lpadmin -I type_fichier

Pilote associé
Trois options de la commande lpadmin permettent d'associer un pilote à une imprimante : e imprimante utilisation de l'interface existante imprimante
i interface utilisation du programme spécifique interface,
m modèle utilisation du modèle d'interface modèle.
Exempleslpadmin -p ps1 -v /dev/term/00 -T PS -I PS -m PSlpadmin -p ps2 -v /dev/lp -T PS-b -I PS -m PS
14.3.5 Options de configuration de la commande lpadmin
La commande lpadmin permet en outre de définir les options suivantes : caractéristiques du port d'impression,
type de l'imprimante
format de mise en page,
jeux de caractères,
avertissement de changement d'une marguerite,
gestion de masque d'impression,
alerte en cas de dysfonctionnement,
redémarrage d'une impression interrompue (service de recovery),
restriction d'accès à certains usagers,
impression éventuelle d'une bannière,
définition des attributs par défaut,
définition de la classe d'impression et de ses instances,
imprimante de destination par défaut.
Caractéristiques du port d'impression
Les caractéristiques par défaut d'un port série sont les suivantes :9600 9600 baudscs8 caractères représentés sur 8 bitscstopb 1 bit stop par caractèreparenb pas de contrôle de paritéixon contrôle de flux par XON/XOFFixany redémarrer la sortie par XON seulementopost le filtrage du flot de données est réalisé selon les paramètres suivants :
-ocuc lettres minuscules non converties en majuscules
onlcr caractère LF transformé en CR+LF
-oncr1 ne transforme pas le caractère LR en LF
-onocr début de ligne en colonne 0

n10 pas d'attente après le caractère CR
cr0 pas d'attente après le caractère CR
tab0 pas d'attente après le caractère de tabulation
bs0 pas d'attente après le caractère backspace
vt0 pas d'attente après le caractère de tabulation verticale,
ff0 pas d'attente après le caractère FF.
Modification des caractéristiques par défaut
Synopsis
lpadmin -p nom_d'imprimante -o "stty='options_de_stty'"
Exemplelpadmin -p nom_d'imprimante -o "stty='parenb parodd cs7'"
Type de l'imprimante
Synopsis
lpadmin -p nom_d'imprimante -T type
Exemplelpadmin -p laser -T 593ibm
Format de mise en page
Les formats de mise en page suivants sont en principe supportés : troff format de mise en page troff
otroff caractères générés dans l'environnement BSD ou avant SV R4
daisy imprimante à marguerite
dmd impression directe d'un écran bit-map
tek4014 impression des images d'un périphérique 4014
tex fichiers au format DVI
plot table à digitaliser tecktronix
raster fichier bitmap au format raster
cif sortie de l'utilitaire BSD cifpbt
poscript support du langage Poscript
pcl support des fichiers au format HP
simple fichier ASCII

Sélection d'un jeu de caractères
Synopsis
lpadmin -p nom_d'imprimante -S jeu_de_caractères
Le champ jeu_de_caractères a le format :
csN=nom_de_la_base_de_données_terminfo
Exemplelpadmin -p laser -S "cs0=french"
Notification en cas de dysfonctionnement
Il est possible d'être alerté en cas de mauvais fonctionnement du service d'impression.
Synopsis
lpadmin -p nom_d'imprimante -A mail -w minutes
Redémarrage d'une impression interrompue
Trois options : continue continuation de l'impression,
beginning redémarrage depuis le début,
wait attente.
Synopsis
lpadmin -p nom_d'imprimante -F option
Restriction d'accès à certains usager
D'une façon similaire aux services cron, il est possible de définir des listes d'utilisateurs autorisés ou non autorisé au service d'impression.
Deux options : allow:liste_d'utilisateurs_autorisés (les autres ne le sont pas),
deny:liste_d'utilisateurs_interdits (les autres sont autorisés).
La liste des utilisateurs peut avoir une des formes : login_name un utilisateur du système local,
nom_système!login_nameun utilisateur d'un système distant,
nom_système!all tous les utilisateurs d'un système distant,
all!login_name un utilisateur donné de tous système,
all tous les utilisateurs locaux,

all!all tous les utilisateurs de tous les systèmes.
Synopsis
lpadmin -p nom_d'imprimante -u option
Mise ou suppression de la bannière d'impression
Deux options : banner impression d'une bannière
nobanner suppression de la bannière
Synopsis
lpadmin -p nom_d'imprimante -o option
Définition des attributs par défaut
Synopsis
lpadmin -o nom_attribut=valeur
Exemplelpadmin -o width=80
Définition de la classe d'impression et de ses instances
Synopsis
lpadmin -p nom_imprimante -c nom_classe
Suppression d'une occurrence d'une classe
Synopsis
lpadmin -p nom_imprimante -r nom_classe
Suppression d'une classe
Synopsis
lpadmin -x nom_classe
Imprimante de destination par défaut
Synopsis
lpadmin -d nom_imprimante ou nom_classe

14.3.6 Graphe d'état du service d'impression
14.4 RÉCAPITULATION DES COMMANDES ET DES FICHIERS D'ADMINISTRATIONSystem V : lp, lpsched; lpstat, lpshut, enable, disable, lpmoveBSD :lpr, lpd, lpc, lprm, lpq/usr/spool/lp

15. SERVICES D'USAGE GÉNÉRAL
15.1 COMPTABILITÉ Ce service permet d'enregistrer les informations relatives à l'utilisation du système (temps de
connexion, temps CPU, comptabilité, utilisation des disques, des imprimantes ...). Il offre également des outils d'exploitation de ces données.
Son utilisation n'est nullement obligatoire. Toutefois, elle donne à l'administrateur un moyen de connaissance du fonctionnement du système ainsi que la possibilité d'optimiser l'utilisation des ressources.
Les fichiers d'exploitation des données comptables grossissant en permanence, il faut les surveiller.
15.1.1 Architecture du service
Le service de comptabilité (accounting) est constitué de shell-scripts de démarrage, d'initialisation, de contrôle, d'arrêt, et d'exploitation des données comptables.
15.1.2 L'utilisateur adm et les répertoires associés
Les processus associés au service comptable s'exécutent sous l'identité de l'utilisateur adm, dont le répertoire de travail est /usr/adm.
Ce sont soit des fichiers exécutables, soit des shell-scripts regroupés dans le répertoire /usr/lib/acct.
Les fichiers de données comptables sont dans le répertoire /usr/lib/adm.
15.1.3 Initialisation et démarrage du service
Les shell-scripts de démarrage (rc*) et d'arrêt du système (shutdown) assurent en général le démarrage et l'arrêt du service.
Le shell script startup
Ce shell script exécute la commande acctwtmp qui enregistre un message indiquant le lancement du service d'accounting dans le fichier wtmp, puis appelle le shell script turnacct.
Le shell script turncacct
Ce shell script, permet d'activer ou de désactiver le service de comptabilité. Lancé avec l'argument on, il initialise le fichier pacct et démarre l'enregistrement des informations comptables. Il lance ensuite le fichier exécutable accton.

15.1.4 Collecte des informations
La commande accton
A chaque terminaison d'un processus, la commande accton ajoute un enregistrement dans le fichier /usr/adm/pacct.
Le fichier pacct
Il contient les enregistrements des données comptables : nom de la commande origine de l'enregistrement, nom de l'utilisateur concerné, du terminal associé, heures de début et de fin de travail, le temps CPU utilisé, l'espace mémoire occupé, le nombre de blocs d'entrées/sorties, le nombre de programmes utilisant le bits s lancés.
15.1.5 Arrêt, contrôle et suspension du service
Le shell script shutacct
Le shell script shutacct exécute la commande acctwtmp pour enregistrer un message indiquant l'arrêt du service de l'accounting, puis appelle le shell script turnacct avec l'argument off.
Le shell script ckpacct
La commande ckpacct est lancée périodiquement pour contrôler qu'il reste suffisamment d'espace sur le disque. Dans le cas contraire, la commande envoie un message sur la console système et appelle le shell script turnacct avec l'argument off.
15.1.6 Fichiers de données comptables Les programmes de création des fichiers des données comptables sont dans le répertoire
/usr/lib/acct. Ils permettent d'enregistrer et de traiter (concaténation, regroupements,...) quotidiennement ou mensuellement les activités des utilisateurs, et d'éditer des états comptables.
Les fichiers de données comptables sont dans les répertoires /usr/adm, /usr/adm/acct, /etc. Ce sont : /etc/wtmp
/etc/utmp
/usr/adm/pacct
historique des sessions, utilisé par les processus init, login, modifié par le shell script acctwtmp,
liste des utilisateurs connectés à un instant donné,
gestion périodique de l'activité des processus,
/usr/adm/acct/nite statistiques relatives à l'activité courante,
/usr/adm/acct/sum total journalier,
/usr/adm/acct/fiscal total mensuel.

15.1.7 Exploitation des données comptables
La commande runacct, généralement lancée par le service cron, assure la comptabilité journalière. Elle est complétée par les commandes chargefees, qui permet la modification manuelle du fichier /usr/adm/pacct, et monacct qui assure la comptabilité mensuelle après mise à jour des fichiers nite, sum et fiscal.
Les commandes d'administration diskusg et acctdisk sont également utilisées.
La commande runacct
La procédure runacct modélise un automate à états finis dont les différents états, enregistrés dans le fichier statefile, sont les suivants :
SETUP copie des fichiers courants en fichiers de travail,
WTMPFIX contrôle de l'intégrité du fichier wtmp avec correction éventuelle des dates,
CONNECT1 enregistrement des connexions selon le format ctmp,
CONNECT2 conversion des fichiers au format ctmp dans le format tacct,
PROCESS conversion de l'activité sur les processus au format tacct,
MERGE fusion des enregistrements relatifs aux connexions et aux processus,
FEES conversion des enregistrements sur les droits et fusion avec les précédents,
DISK fusion des enregistrements sur les disques avec les précédents,
MERGETACCT fusion des totaux journaliers,
CMS calcul des totaux sur les commandes,
USEREXIT réservé pour les actions locales,
CLEANUP purge des fichiers de travail et fin
Utilitaires utilisés par le shell script runacct
Le programme wtmpfix corrige les erreurs éventuelles contenues dans le fichier wtmp.
Le programme accton1 crée un fichier ASCII au format ctmp (une ligne par session) utilisé par la commande accton2 qui le convertit au format interne tacct.
Le programme acctprc1 utilise le fichier au format ctmp pour connaître les utilisateurs et le fichier au format pacctn pour connaître l'activité des différents processus. La commande acctprc2 regroupe ces renseignement par utilisateur.
Le programme acctmerg est ensuite exécuté plusieurs fois pour regrouper l'ensemble des informations précédentes par utilisateur.

Le programme dodisk enregistre l'activité des processus sur les disques dans le répertoire /usr/adm/acct. Le programme acctdisk met à jour les données comptables.
La commande acctcms lit le fichier d'activité des processus, regroupe les enregistrements associés à une même commande, et crée un fichier trié au format cms.
La commande prdaily crée un fichier sum/rprtMMJJ, au format ASCII, qui contient l'historique des commandes utilisées dans la journée, le cumul depuis le début du mois, ainsi que la date de dernière connexions des utilisateurs.
Le shell script monacct
La procédure monacct crée le fichier fiscrptMM dans le répertoire fiscal. Elle utilise les fichiers au format tacct et cms produit par la commande runacct et appelle les commandes pacct et acctcms. Elle réinitialise en outre les fichiers tacct et cms et supprime tous les reports journaliers du répertoire sum.
Autres utilitaires
La commande fwtmp donne une version ASCII éditable du fichier wtmp.
Le shell script prtcmp affiche l'historique des sessions.
Le shell script nulladm crée les fichiers du répertoire /usr/adm/acct avec des droits d'accès convenables.
15.1.8 Commandes utilisateurs
La commande acctcom permet l'affichage des caractéristiques des processus (nom de l'utilisateur, terminal associé, heure de début et de fin de session, le temps CPU, le taux d'occupation de la mémoire) dès que le fichier pacct existe.
La commande lastcomm
La commande lastcomm ne peut être utilisée que si la comptabilité est active. Elle affiche, toutes les commandes exécutées, dans leur ordre inverse d'exécution.
Synopsis
lastcomm [commande]

15.1.9 Graphe d'état associé au service comptable
15.2 SERVICE PROFILER
Le service profiler permet de mesurer le pourcentage d'appels des fonctions du noyau grâce aux commandes prfld, prfstat, prfdc, prfsnap, prfpr.
prfld
Initialisation du service avec la création d'une table contenant les adresses de toutes les fonctions du noyau.
prfstat on (off)
Cette commande autorise ou interdit l'utilisation du service.
prfdc
Cette commande enregistre périodiquement les compteurs dans un fichier.
prfsnap
Cette commande permet une modification des compteurs d'appel des fonctions.

prfpr
Cette commande permet l'édition des résultats.
15.3 SUIVI D'ACTIVITÉS
Le service sar (system activity report) permet d'enregistrer l'activité du système. Il comprend : la commande publique sar pour l'enregistrement et l'édition de différents compteurs,
la commande sadc lancée par le shell script rc* enregistre périodiquement les compteurs dans un fichier,
le shell script sa1 enregistre périodiquement les compteurs dans le fichier /usr/adm/sa/sadd où dd représente le jour. Cette fonction est lancée par le service cron.
le shell script sa2 est une variante de la commande sar qui enregistre ses résultats dans le fichier /usr/adm/sa/sardd où dd représente le jour. Cette fonction est également lancée par le service cron.
Les principales informations sont l'utilisation de l'unité centrale, l'activité des tampons, des disques, des terminaux, des appels système, des zones de swap, des files d'attente...
Synopsis
sar -abcdmnpqruvwy
Les options ont la signification suivante :a opérations d'accès aux fichiers (primitives iget, namei, dirblk),
b activité des tampons,
c activité des appels système,
d activité des périphériques en mode bloc,
m activité des ipc SV R2,
n gestion du cache nommé,
p gestion des pages,
q longueur moyenne des files d'attente des processus actifs et swappés,
r pages inutilisées et blocs disque,
u utilisation du processeur,
v utilisation des tables proc, file, lock,
w gestion du swap et des commutations de contexte (context switching),
y activité des terminaux tty,
A toutes les options précédentes.

15.4 GESTION DES MESSAGES D'ERREUR
15.4.1 Le processus démon errdemon
Ce service d'enregistrement des erreurs système est disponible dans l'environnement SYSTEM V.
Implémentation
Il est implémenté sous la forme du processus démon errdemon, qui utilise le pseudo périphérique /dev/error.
Démarrage
Il est lancé lors du passage en mode multi-utilisateurs.
Fichiers d'audit
Les données sont enregistrées dans un fichier, par défaut /usr/adm/errfile, éditable par la commande errpt.
Arrêt
La commande errstop arrête ce service.
15.4.2 Le processus démon syslogd
Ce service d'enregistrement des erreurs système est issu de l'environnement BSD.
Implémentation
Il est implémenté sous la forme du processus démon syslogd. Les messages d'erreurs sont récupérés à partir : du fichier spécial /dev/log,
d'un socket défini dans le fichier /etc/services pour les messages issus du réseau,
du pseudo-périphérique /dev/klog pour les messages du noyau.
Synopsis
syslogd [-f fichier_de_configuration][-m marque][-d]
Options
f fichier de configuration, par défaut /etc/syslogd.conf
d intervalle entre deux notifications du fichier /usr/adm/messages (défaut 20 mn).

Messages d'erreur
Un message d'erreur est constitué d'une ligne de texte précédée par la priorité du message indiquée par les caractères < et >.
Un message d'information particulier est enregistré par défaut toutes les 20 mn.
Démarrage et pid
Il est lancé lors du passage en mode multi-utilisateurs. Le fichier syslog.pid contient alors l'identificateur du processus démon syslogd.
Fichier syslogd.conf
Le fichier /etc/syslogd.conf décrit les actions à exécuter en fonction de l'origine et de la priorité des messages selon un format reconnu par le préprocesseur m4. Une ligne est stockée selon le format :
sélecteur[;sélecteur...] action
Les champs sélecteurs sont de la forme cause.priorité où cause indique la cause du message d'erreur et priorité son degré d'urgence.
Les champs sélecteur et action doivent être obligatoirement séparés par un caractère de tabulation.
Une action peut être commune à une liste de sélecteurs séparés par un pont virgule.
Le champ cause indique l'un des sélecteurs suivants :cause sélecteur des messages,user processus utilisateurs,kern noyau,mail messagerie,daemon processus démon système,auth service de connexion (login, getty, ...),lpr service d'impression,news service de news,uucp service uucp,cron services cron,locali usage local (i compris entre 0 et 7),mark utilisation interne au processus démon syslogd,
* toute valeur précédente à l'exception de mark.
Tout message d'erreur sans cause définie est de type user par défaut.
Le champ priorité peut prendre une des valeurs suivantes :Priorité Importance_du_messageemerg message urgent (panic) devant être transmis à tous les utilisateurs,

alert message nécessitant une intervention immédiate,crit message critique (erreur matérielle),warning avertissement simple,notice message de simple notification,info message d'information,debug message lié au metteur au point,none message à ne pas répercuter.
Le champ action indique soit : le fichier absolu (local) destinataire du message, ouvert en mode append,
le nom d'un site distant destinataire du message selon la syntaxe @site, pour transmission au processus démon syslogd du site distant,
une liste d'utilisateurs (séparés par une virgule) auxquels le processus démon syslogd notifie les messages s'ils sont connectés,
le caractère * pour que tous les utilisateurs connectés soient destinataire du message.
Les lignes commençant par le caractères # sont ignorées (commentaire).
Exemple# affichage toutes les 20 mn de tous les messages# du noyau et autres erreurs*.err;kern.debug;auth.notice;user.none /dev/console# tous messages d'urgence, tous messages critiques# des services daemon et mail*.emerg;mail,daemon.crit /var/adm/emergency#tous les messages d'erreurs autres, debug noyau, ....*.err,kern.debug;daemon,auth.notice;mail.crit;user.none
/var/adm/messages*.alert;kern.err;daemon.err;user.none operator*.alert;user.none root#notification à tous les utilisateurs connectés*.emerg;user.none *#machine distantemail.debug @loghost
15.5 GESTION DES RESSOURCES
15.5.1 Définition des ressources système
La plupart de ces ressources sont des paramètres de génération du noyau. Il suffit donc de modifier, soit manuellement, soit avec les outils constructeurs les paramètres ajustables du noyau.
15.5.2 Environnement BSD
L'environnement C-shell permet de définir des limites (temps CPU, gestion mémoire, taille maximum des fichiers, taille maximum des fichiers core par utilisateur. Ce sont les options MAXDSIZ, MAXSSIZ,

filesize, coredump de la commande limit, que l'on paramétrer dans le fichier .cshrc de chaque utilisateur.
15.5.3 ACL
Les accès à la plupart des services (services cron, services d'impression, serveurs réseau (ftp, uucp), news, messagerie) peuvent être gérés par des listes de contrôle d'accès (Access Control List) comme cron.allow, cron.deny, ftpusers, etc.
15.6 AUTRES SERVICES
Le processus démon update
Lancé par le shell script rc*, il assure la mise à jour périodique du super bloc.
Le service de l'agenda (calendar)
Lancé tous les jours par le processus démon /etc/cron, la commande /usr/lib/calendar permet d'envoyer à tous les utilisateurs ayant un fichier $HOME/calendar dans leur répertoire de travail un courrier électronique contenant les messages qui y sont enregistrés pour le jour courant et le lendemain. Le fichier $HOME/calendar est constitué de lignes comprenant la date (sous la forme mois jour) ainsi qu'un message à notifier ce jour.
ExempleFeb 28 : conférence UNIX 10 H 45Installation GNU le 3/2Comité de pilotage 16 H Mar 7
Description
Notification le 28 Février (ligne 1), le 2 Mars (ligne 2), le 7 Mars (ligne 3).
La commande crash
Elle permet d'examiner l'image mémoire du système lors d'un "plantage" (tables des processus, des systèmes de fichiers montés, structures des terminaux, paramètres...).
La messagerie
Ce service permet aux utilisateurs d'envoyer du courrier électronique, dans le monde UNIX ou bien dans d'autre mondes Informatiques (DECNET, BITNET, EARN...).
Le service news
Il offre un moyen à l'administrateur de communiquer aux utilisateurs toute information utile pour eux. La commande news exécutée à partir d'un fichier profile permet à chaque utilisateur de connaître à chaque connexion les informations qui ne lui ont pas encore été communiquées.

15.7 RÉCAPITULATION DES COMMANDES ET DES FICHIERS D'ADMINISTRATION
Accounting
acct, acton, acctoff, startup, runacct,monacct, shutacct, turnacct, prdaily, prtacct
Commandes d'audit
sar, psstat, iostat, vmstat, netstat, nfsstat, rpcinfo, users, who, crash, kgmon, timex, idtune
Service profiler
prfld, prfstat
Services d'administration et d'audit/etc/wtmp/etc/utmp/usr/adm/sulog, shutdownlog, syslog/usr/spool/lp/log, /usr/spool/lp/oldlog

16. GENERATION SYSTEME
16.1 GÉNÉRALITÉS
Le terme génération définit soit une génération système, soit la génération du noyau.
16.1.1 Génération système
La génération système peut-être nécessaire pour : mise en service d'un système sur un site avec ses outils,
évolution d'une installation existante,
ajouter de nouveaux services.
Il faut donc connaître les méthodes de génération du système, du noyau, et d'installation de logiciel.
16.1.2 Génération du noyau
Il peut être nécessaire de faire une génération du noyau dans les cas suivants : adaptation du noyau à la configuration locale,
intégration d'un nouveau pilote dans le noyau,
intégration d'un périphérique (écran bit map, imprimante laser, disque, etc.),
modification d'une fonction du noyau.
Il n'est pas nécessaire de modifier le noyau dans les cas suivants : modification d'une commande de base ou ajout d'une commande,
modification des shell-scripts de démarrage,
ajout de nouveaux descripteur de périphériques dans le répertoire /dev,
modification des systèmes de fichiers,
modification des attributs des fichiers.
16.2 INSTALLATION DE LOGICIEL
Les logiciels peuvent être d'origine diverses : logiciels du domaine public, téléchargés ou sur bandes,
logiciels fournis par un distributeur.
La marche à suivre pour installer un logiciel est la suivante : contrôle des ressources systèmes nécessaires,

définition de la machine cible,
copie sur celle-ci des fichiers contenus sur le support de distribution,
installation effective,
mise à jour des fichiers de configuration,
test du produit,
installation de la documentation en ligne,
avertissement des utilisateurs.
16.2.1 Ressources
La notice d'installation doit préciser les ressources nécessaires (espace disque, périphérique particulier, etc.). Il faut vérifier qu'elles sont disponibles avant l'installation du produit.
16.2.2 Installation effective
On distingue deux cas :
Domaine public
Il est judicieux d'avoir une documentation préalable indiquant le format des fichiers sur la bande (tar, cpio, ..., fichiers compressés, fichiers .tar, etc...) faute de quoi on risque de ne pas savoir lire le média,
distribution : le shell script d'installation doit être fourni. Par exemple la commande custom sur UNIX SCO. Dans ce cas, tous les logiciels fournis par SCO l'utilisent et l'installation peut être transparente à l'utilisateur.
Une fois le logiciel transféré sur le disque, lancer la commande d'installation prévue (setup, install, make...). Dans ce dernier cas, il est souvent nécessaire d'adapter le fichier makefile à la configuration locale.
16.2.3 Fichiers de configuration
Cela peut-être les fichiers de démarrage, les services cron, les fichiers d'arrêt, des fichiers contenant la liste des utilisateurs autorisés, des shell-scripts, etc.
16.2.4 Test
Le logiciel doit être testé, éventuellement par les utilisateurs avant d'être recetté. Il faut vérifier la charge induite sur le système, toujours sous-estimée. La mise en place de procédures d'audit peut se justifier.
Il faut également tester le produit sous l'identité d'un utilisateur potentiel du produit, ne fusse que pour vérifier que ses droits d'accès sont convenables.
16.2.5 Avertissement aux utilisateurs
Plusieurs moyens sont disponibles : la modification du message du jour (/etc/motd), la messagerie.

La documentation du logiciel installé peut être intégrée au manuel, ou accessible sous forme d'un fichier texte.
16.2.6 Modification d'une installation
Il faut toujours sauvegarder la version précédente ainsi que les fichiers de données associés.
Les modifications sont ensuite effectuées sur une copie de la version précédente pour permettre aux utilisateurs de continuer à travailler lors de l'installation.
16.3 ADJONCTION D'UNE COMMANDE PUBLIQUE
L'adjonction d'une nouvelle commande ou bibliothèque nécessite les étapes suivantes : installation dans le répertoire approprié (/bin ou /lib, /usr/local/bin,
/usr/local/lib),
rendre le nouvel élément accessible à tous les utilisateurs concernés et l'attribuer à l'utilisateur bin,
insérer la documentation dans le répertoire man à la section correspondante,
stocker les sources dans le répertoire src avec un fichier précisant tous les règles de production (fichier makefile par exemple),
pour une bibliothèque, l'organiser correctement (ranlib).
16.4 GÉNÉRATION OU OPTIMISATION DU NOYAU
16.4.1 Généralités
La génération d'un nouveau noyau peut être réalisée à tout moment. La démarche est relativement standard sur tous les systèmes. Seuls varient les noms des fichiers, et éventuellement les méthodes de modification de ces derniers (par une interface homme-machine impérative (le cas le plus fréquent), ou par une modification manuelle).
16.4.2 Distribution
Il existe trois formes de distribution du système UNIX : la distribution comprenant le fichier exécutable et les fichiers de définition des paramètres systèmes et
ne permettant pas de générer un noyau,
la distribution comprenant les programmes-objet nécessaires à l'édition de liens du noyau permettant de modifier certains paramètres ou certains fichiers et de le régénérer,
la distribution complète avec les fichiers sources à condition d'acquérir la licence d'ATT.
16.4.3 Principes généraux
Le noyau s'adapte à une configuration matérielle donnée, soit par un fichier de configuration, soit avec une interface d'administration.
Les fichiers objets et les fichiers .h nécessaires à la génération du noyau sont fournis avec la distribution.

Le principe de la génération est le suivant : création du fichier de configuration du noyau,
modification par un éditeur,
appel de la commande config (BSD) pour la création des fichiers nécessaires à la configuration,
exécution du fichier Makefile de génération,
transfert du nouveau noyau dans la racine,
démarrage de la station avec son nouveau noyau.
Il faut vérifier que la génération du noyau se déroule sans erreur et impérativement conserver le noyau initial comme noyau de secours.
16.4.4 Noyau SYSTEM V
De nombreux paramètres sont définis dans le fichier config.h. Y figurent en outre les paramètres d'optimisation des ressources streams tels NBLK512.
/* fichier config.h (partiel) *//* Exemples de paramètres ajustables *//* tunables parameters */#define MAXBUF 600#define NCALL 50#define NINODE 600 /* nombre d'inodes en mémoire */#define NFILE 600 /* taille de la table des fichiers */#define NMOUNT 8 /* nombre de systèmes de fichiers montables */#define NPROC 500 /* nombre maximum de processus (table proc) */#define NREGION 1500 /* nombre maximum de segments mémoire */#define NCLIST 120 /* maximum de clist (e/s caractères */#define NOFILES 80 /* maximum de fichiers ouverts par processus */#define ULIMIT 2097152#define NODE "Paris"#define CMASK 22 /* masque de création des fichiers */#define MAXUMEM 4096#define NQUEUE 512 /* queue de messages pour les streams */#define NSTREAM 128#define NSTRPUSH 9 /* maximum de modules streams empilables */#define STRMSGSZ 4096#define STRCTLSZ 1024#define NBLK4096 12 /* max messages stream taille 4096 octets */ #define NBLK2048 52#define NBLK1024 52#define NBLK512 24#define NBLK256 24#define NBLK128 24#define NBLK64 100#define NBLK16 100#define NBLK4 100#define STRLOFRAC 95#define STRMEDFRAC 98/* pamamètres pour les IPC */#define MSGMAP 200#define MSGMAX 2048#define MSGSEG 1024#define SEMMAP 10#define SEMMSL 25#define SEMOPM 10#define SEMUME 10#define SEMVMX 32767#define SEMAEM 16384#define SHMALL 512

#define TIMEZONE 1380#define NSPTTYS 64#define SCSI_NAHA 1
Il est également possible d'intégrer des pilotes de périphérique dans le fichier conf.c.
16.4.5 Optimisation du noyau Le noyau fourni avec la distribution est rarement bien adapté au site. Une fois la station démarrée de
façon apparemment satisfaisante, il est donc judicieux d'améliorer ses performances par une optimisation. Celle-ci peut être réalisée manuellement (version Unix BSD 4.3) ou par l'intermédiaire d'une interface utilisateur (SMIT sur AIX/V3, SYSADMSH sur UNIX SC0,...).
Cette étape est indispensable et ne peut être réalisée que si le système fonctionne avec un nombre d'utilisateurs important ce qui permettra de mettre en évidence les lacunes des paramètres (par exemple NFILE, NPROC, ou NREGION...) par des messages d'erreur explicites sur la console système. Une fois ces paramètres déterminés, il faut redémarrer avec le nouveau noyau et se remettre dans la même situation. De nouvelles anomalies peuvent alors apparaître et pourront être corrigées. Et ainsi de suite jusqu'à ce qu'il n'y ait plus de messages d'erreur.
A ce moment, il faut utiliser les commandes permettant de suivant l'activité du système (sar, pstat, iostat, vmstat, netstat...) qui permettrons peut être d'identifier de nouveaux problèmes (tables systèmes insuffisantes, ressources réseau mal dimensionnées, zone de swap insuffisante, etc.) et régénérer un noyau. Avec un peu d'habitude, le "bon" noyau arrive au troisième ou au quatrième essai.
16.5 GÉNÉRATION SYSTÈME
16.5.1 Etude préalable
Il faut évaluer les tailles des différents logiciels à installer, définir la taille et l'organisation des systèmes de fichiers correspondants, le nom du site.
16.5.2 Premier démarrage
A partir du support de distribution (disquette, CD ROM, cartouche amovible), il faut fournir les informations demandées). Le noyau chargé est en général réduit. Il permet de créer le système de fichiers root et d'y installer un premier noyau.
Le système redémarre alors en chargeant ce noyau et l'installation complète se poursuit après demande à l'administrateur s'il faut installer une partie ou l'ensemble de la distribution.
Une fois les fichiers installés, il faut (de moins en moins) modifier manuellement certains fichiers, à savoir inittab, passwd, group, hosts ...
L'utilisation de l'interface d'administration permet de faire, de façon transparente, toutes ces modifications.
Il faut ensuite installer les logiciels complémentaires (compilateurs, outils spécifiques, restauration de fichiers utilisateurs.
Il faut enfin optimiser le noyau et tester la validité de l'installation.

Exemple de première génération système
Les opérations à effectuer sont les suivantes : démarrage en mode mono-utilisateur à partir de la cartouche (streamer, cdrom...) système,
copie du système sur un disque fixe après l'avoir déclaré (création du répertoire /dev) et éventuellement formaté, et en indiquant la taille du système de fichiers système et de la zone de swap,
redémarrage en mode mono-utilisateur avec le noyau de la distribution,
déclaration des disques physiques et virtuels (partitions) en précisant le nom logique des partitions et la taille des systèmes de fichiers,
création des fichiers associés (mnttab, mountlist, checklist),
déclaration des terminaux (commandes type MAKEDEV ou MAKETTY permettant la création dans le répertoire /dev de toutes les entrées associées à la carte d'interface,
mise à jour des fichiers utilisés à l'initialisation (inittab, rc, motd, profile, issue, gettydefs...),
création des répertoires de montage des systèmes de fichiers,
choix d'un mot de passe pour l'utilisateur root,
passage en mode multi-utilisateurs,
installation des logiciels complémentaires,
installation des services d'administration et mise à jour des fichiers correspondants (crontab, accounting...),
définition des utilisateurs,
diverses actions en fonction du site (par exemple adaptation des fichiers de caractéristiques des terminaux...),
sauvegardes des systèmes de fichiers créés,
tests des différents services offerts (spool, uucp, mail, cron...) et adaptation en fonction des problèmes rencontrés (droits d'accès ...),
mise en oeuvre d'un carnet de bord d'administration.
16.6 RÉCAPITULATION DES COMMANDES ET DES FICHIERS D'ADMINISTRATIONsysadmsh, smit, smile, sam, conf.c, config.h
16.7 COMMANDES PARTICULIÈRES SCO UNIXWARE
Remarque
Le système ScoUnixWare est un système Unix très pur, d'origine SystemV R4. C'est pourquoi il y a très peu de commandes propriétaires qui sont résumées ci-dessous.
Gestion des paquetages
pkgadd addition de paquetage

pkginfo informations relatives aux paquetages installalé
pkgparam informations relatives aux paquetages
pkgcheck contrôle des paquetages installés
pkgrm suppression d'un paquetage installé temporairement
Systèmes de fichiers spécifiques
/stand/boot démarrage
/var fichiers d'installation
/dump images de la mémoire à un instant donné
/var/tmp systèmes de fichiers temporaires d'installation de type memfs (nettoyage automatique au démarrage)
/dev/volprivate volumes privés
La commandes d'administration scoadmin
scoadmin interface graphique d'administration système
Quelques options
scoadmin pnp configuration manager gestionnaire des périphériques PnP
scoadmin video configuration de la carte vidéo, utilise les bases de donée des répertoires moninfoet graphinfo
Commandes d'administration d'usage général
scohelp Aide en ligne, à configurer à partir du moteur config_search
hwconfig affichage de la configuration courante
scosound gestion de la carte son
Variables d'environnement DEDICATED_MEMORY, GENERAL_MEMORY
auditon/auditon activation/désactivation de l'audit
setclk gestion de l'horloge de carte mère
secdefs définition du profil de sécurité du système p 145
psrinfo informations relatives au processeur utilisé
/etc/cleanup nettoyage des fichiers d'audit
Base de données des comptes utilisateur
/etc/passwd, /etc/shadow

/etc/default/passwd, /etc/default/login
/usr/lib/scoadmin/account/Priv/Table autorisations diverses
pwconf création d'un fichier shadow inexistant
ap transfert des comptes utilisation d'une plateforme SCO OpenServer vers SCO UnixWare
Base de données des comptes utilisateur (/etc/security)
./ia/master non lisible, contenant les informations des fichiers /etc/shadow et /etc/passwd
./ia/index non lisible, contenant la liste des comptes utilisateur
./tcb/privs base de donnée des privilèges d'exécution des commandes d'administration
./tfm/users/* répertoire contenant les autorisations de chaque utilisateur
./tfm/roles/* définition des rôles administratifs
Fichiers d'installation (répertoire /info/hardware) et audit
audio.txt périphériques audio
hba.txt adaptateur du bus HBA (Host Bus Adapter)
isdn.txt adaptateur RNIS
mp.txt support du multiprocesseur
nd.txt cartes réseau
xdrivers.txt cartes vidéo
su audit de la commande su
Gestion du noyau
idbuild édition de lien des modules du noyau pour configuration manuelle
/etc/conf/idtune opérations sur le noyau
/etc/dump image mémoire du noyau
/etc/crash étude d'un dump
Démarrage du système interractif
boot

Gestion des utilisateurs
adminuser gestion des privilèges d'un utilisateur donné
defadm définition des valeurs systèmes par défaut
pppsh gestion du mot de passe d'un compte PPP
makeowner allocation de privilèges à un utilisateur donné
Bandes de réparation d'urgence
/sbin/emergency_rec -e ctape(1) taille_bande
Mode monoutilisateur impératif

17. EXERCICES DIVERS
17.1 GESTION DES UTILISATEURS Créer des utilisateurs. On s'attachera à définir leur répertoire de travail, leur groupe(s) de travail, leurs
privilèges d'administration et de programmation.
Essayer de créer un utilisateur synonyme de l'administrateur.
Verrouiller la commande su.
L'utiliser et constater son audit par le système.
17.2 ATTRIBUTS DE SÉCURITÉ
1°) Rappeler les fonctions des commandes chmod, chgrp, umask, basename, file, du, size, od.
2°) Utiliser la commande umask pour définir le masque de création de fichiers 777.
a) Créer un fichier liste à partir de la commande
ls -l > liste
Quels sont ses droits ?
b) Créer un répertoire tempo et constater ses droits. Conclusion.
3°) Refaire la question précédente avec le masque 000. Conclusion.
4°) Aller chez votre voisin et essayer de lui détruire un de ses fichiers ou répertoires. Conclusion ?
5°) Que pensez vous du masque 022 ?
6°) Afficher un dump du fichier .profile.
7°) Quels sont les droits du répertoire /tmp. Essayer d'y détruire un fichier au hasard. Conclusion ?
8°) Supprimer le bit t sur le répertoire /tmp (ou le positionner s'il est absent) et refaire la question précédente. Conclusion.
17.3 GESTION DU SGF
17.3.1 Montage
1°) Analyser le fichier des description des système des fichiers à monter sur votre système. Analyser en détail les attributs de sécurité (ro, rw, bit s, etc.).
246

2°) Vous n'êtes pas root. Essayer de démonter ou de monter des systèmes de fichiers au hasard. Idem si vous êtes root.
17.3.2 Commande fsck et mkfs
1°) Vous n'êtes pas root. Essayer d'utiliser fsck sur un système de fichiers au hasard, avec le système de fichier monté ou démonté.
2°) Idem quand vous êtes root.
3°) Idem avec la commande mkfs (faîtes tout de même attention à votre système…).
17.4 CHEVAL DE TROIE
Essayer de programmer un cheval de Troie avec un (faux) shell script (par exemple su ou mount).
17.5 DÉMARRAGE ET ARRÊT DU SYSTÈME
1°) Quel est le répertoire essentiel utilisé au démarrage du système ?
2°) Analyser le fichier /etc/inittab.
3°) Si possible, sur un terminal en mode texte, tuer le processus de login. Constater qu'il se relance "spontanément".
4°) Visualiser les répertoire et fichiers fichiers de démarrage (rc.*).
5°) Un arrêt et un redémarrage (boot) d'une ou de deux stations seront réalisés en fin de session. Analyser le démarrage à froid puis le démarrage à chaud avec les commande shutdown, init, halt, haltsys.
6°) Modifier le fichier .profile pour y ajouter une fonction logout exécutée automatiquement lors de la déconnexion et effaçant l'écran.
Indication : définir la fonction logout puis utiliser la commande UNIX trap.
17.6 GESTION DES PÉRIPHÉRIQUES ET PSEUDO-PÉRIPHÉRIQUES visualiser les systèmes de fichiers "montés" (commande /etc/mount).
visualiser les fichiers de paramètrages, par exemple /etc/vfstab, /etc/checklist, /etc/ttys, /etc/gettytab et /etc/termcap.
écrire un shell-script utilisant le pseudo-périphérique /dev/tty : ce programme doit afficher une question sur l'écran ("Donner le nom du répertoire ?"), lire la réponse au clavier, puis afficher le résultat de la commande ls dir où dir est la réponse lue. L'objectif est d'utiliser ce programme avec une redirection de la sortie sur un fichier liste tout en conservant sur l'écran l'affichage de la question initiale.
247

17.7 SAUVEGARDES
Commande tar
1°) Effectuer une sauvegarde de votre répertoire sous /tmp.`logname` où `logname` est votre identificateur de connexion.
2°) Restaurer la sauvegarde d'un de vos voisins dans le sous-répertoire tempo (à créer) dans votre répertoire de travail.
3°) A partir de 2 fichiers image_tar, faire un fichier *.tar puis le compresser avec la commande compress (fichier *.tar.Z).
4°) Compresser les 2 fichiers image_tar de la question précédente et fabriquer un fichier *.Z.tar. Comparer sa taille à celui de la question précédente. Conclusion.
Commande cpio
Effectuer une sauvegarde sélective (tous les fichiers plus récents qu'un fichier donné) sous /tmp/nom1 en utilisant la commande UNIX cpio.
Analyser le contenu de la sauvegarde.
Essayer de sauvegarder des fichiers spéciaux (répertoire /dev). Idem avec la commande tar. Conclusion.
17.8 DIVERS
1°) Créer un shell-script qui affiche la liste des utilisateurs connectés, la date, les processus du système et les informations sur la mémoire.
2°) L'exécuter en indiquant le temps d'exécution (commande time) puis en ajoutant en plus le nom de chaque commande avant son exécution.
248

18. INDEX
",68.profile,208/bin,82, 238/bin/passwd,16/bin/su,23, 207/dev,117/dev/error,231/dev/klog,231/dev/kmem,115/dev/log,231/dev/lp,219/dev/mem,115/dev/null,115/dev/term/00,219/dev/term/01,219/dev/tty,115/etc,86, 226/etc/at,187/etc/batch,187/etc/cron,183/etc/crontab,187/etc/d_passwd,24/etc/default/checklist,132, 135/etc/default/filesys,167/etc/dialup,24/etc/dumpdates,167, 168/etc/fstab,98, 132, 135, 167, 179/etc/gettydefs,199, 204, 205/etc/gettytab,205/etc/group,16, 18, 90/etc/inetd,183/etc/init,175, 178, 183/etc/inittab,177, 178/etc/mntab,132/etc/mnttab,183/etc/motd,185, 238/etc/mountall,133/etc/mtab,132/etc/passwd,16, 18, 21, 28, 90/etc/printcap,205, 215/etc/rc,178/etc/saf/sactab,200, 203/etc/saf/sysconfig,200, 203/etc/securetty,206, 207/etc/services,231/etc/shadow,16, 18, 21, 22/etc/syslogd.conf,231/etc/termcap,205, 207, 209/etc/ttydefs,204/etc/ttys,206, 207/etc/ttytype,206, 207/etc/utmp,183, 208, 226/etc/vfs,159/etc/wtmp,208, 226/lib,84, 238/mnt,81/tmp,83, 183
/unix,81/usr,84, 184/usr/adm,85, 226/usr/adm/acct,226, 228/usr/adm/acct/fiscal,226/usr/adm/acct/nite,226/usr/adm/acct/sum,226/usr/adm/cronlog,191/usr/adm/errfile,231/usr/adm/messages,231/usr/adm/pacct,226, 227/usr/adm/sa/sadd,230/usr/adm/sa/sardd,230/usr/bin,82, 216/usr/cmd,86/usr/conf,86/usr/games,85/usr/h,86/usr/include,85/usr/lbin,82/usr/lib,84/usr/lib/acct,225/usr/lib/adm,225/usr/lib/calendar,234/usr/lib/cron,187/usr/lib/cron/queuedefs,187/usr/lib/crontab,191/usr/lib/lpsched,217/usr/lib/saf/ttymon,201/usr/lib/terminfo,210, 219/usr/lib/terminfo/v/vt100,210/usr/local/bin,238/usr/local/lib,238/usr/man,85/usr/new,86/usr/news,86/usr/old,86/usr/sbin/sacadm,203/usr/spool,85, 184/usr/spool/cron,187/usr/spool/cron/atjobs,188/usr/spool/lp,218/usr/spool/lp/log,218/usr/spool/lpd,214/usr/spool/oldlog,218/usr/src,85/usr/sys,86/usr/sys/conf/conf.c,116/usr/sys/sun/conf/Makefile,117/usr/tmp,83, 183/var/adm/utmp,203/vmunix,81accept,218Access Control Entry,94Access Control List,93accounting,225acct,24, 183
249

acctcms,228acctcom,228acctcon1,227acctdisk,227, 228acctmerg,227accton2,227acctprc1,227acctprc2,227acctwtmp,225, 226ACE,94ACL,93acledit,95aclget,95aclput,95Adressage logique,109Adressage physique,108Adressage relatif,109algorithme de Lempel Zev,172Andrew File System,97appel système,31, 41at,24, 188at.allow,188at.deny,188attribut,90backslash,68basename,69batch,191bdevsw_add,117bit de collage,57, 93bit S,92blocs,120bmap,106, 109bootstrap,175breada,109buffer,110c_bloc,193c_liste,193cache,62, 108cache,110cache disque,110calendar,234cancel,216captoinfo,211cat,71, 173cd,77cdevsw_add,117cfgmgr,148chaîne,120chaîne de modules,120chargefees,227chemin d’accès,68chemin d’accès absolu,68chemin d’accès relatif,68chemins de données,120chfs,160chgrp,24, 90, 91chlv,154, 157chmod,23, 91chown,19, 23, 24, 90chpv,149chunk,101chvg,151ckpacct,226classe d'imprimantes,216clri,145cluster,53cmp,70
comm,71Common Object Format,40compact,172compress,173compression,172config,239config.h,37, 239core,46, 233coremap,54cp,69cpio,73, 98, 165, 167cpio,168cplv,158crash,234credential,40crfs,147, 159cron,24, 183, 187cron.allow,189cron.deny,189cronlog,184crontab,191crypt,76custom,237cylinder,125Cylindre,125dcopy,170dd,111, 171defadm,28delayed write,63déroutement,31, 45df,141diff,70dirname,69disable,217discipline de ligne,193diskusg,227dodisk,228downstream queue,118droits d’accès,90du,77, 141dump,98, 167dumpfs,160écran bit map,236édition de liens dynamique,84edquota,140enable,217errdemon,231errpt,231errstop,231espace vital,55etc/fstab,183événement,45exception,45exportvg,153extendvg,151Extensible Linking Format,40Fast File System,96ff,142FFS,96fg,49fichier exécutable,40fichier objet relogeable,40fichier ordinaire,60, 64fichier partageable,40fichier répertoire,60fichier silencieux,67, 69fichier spécial,62
250

fichier standard,64fichier standard d’affichage des diagnostics d’erreurs,64fichier standard d’entrée,64fichier standard d'affichage des diagnostics d'erreurs,103fichier standard de sortie,64, 103fichier standard d'entrée,103fichier virtuel,108fichiers ordinaires,103fichiers standards,102file,118file de messages,120file d'écriture,118file des messages descendants,118file des messages montants,118file en lecture,118file system,96filsys,100find,27, 73, 141fiscal,227flots,117, 118flots d'entrées/sortie,118flux des données descendantes,118flux des données montantes,118fmodsw,119fontes,84fork,104format COFF,40format ELF,40format GOFF,40format XCOFF,40Formatage d'un disque,125fragmentation,55freems,123fsck,98, 109, 111, 134, 136, 145, 147, 167, 170, 183fsdb,143fuser,72fwtmp,228gestion de la mémoire virtuelle,53gestionnaire de volume logique,127Gestionnaire de volumes logiques,146gestionnaires de ports,200getty,183, 198, 199graphe des transitions,31grappe,53groupadd,28groupdel,28groupe,40, 90groupe de volumes physiques,147groupmod,28groups,20halt,186hard limit,139head,71home directory,17, 24i-liste,99image d'un processus,30importvg,153index number,99infocmp,210inode,97, 98, 99interprocess communication,58interruption,31, 45i-number,99ioctl,119, 120IPC,58ipcrm,59ipcs,59
jobs,48kill,46, 49killall,50, 185label de disque,142labelit,142labelit,143LAC,93lastcomm,50, 208, 228lddr,120Le bit s,92lien matériel,97Lien matériel,61lien symbolique,61lien symbolique avec temporisation,62limit,233limite douce,139limite dure,139liste des inodes,99listen,200listes de contrôle d'accès,93listusers,28ln,62Local File System,97Logical Volume Manager,127, 146logins,28lost+found,81, 129, 135lp,216lpadmin,217, 218lpc,214lpfilter,218lpforms,218lpmove,217lpq,214lpr,214lprm,214lpsched,183lpshut,218lpstat,216lpusers,218ls,69, 91lsfs,160lslv,156lspv,148lsvg,151LVM,146magic number,38majeur,82majeur,108make,72man,85masque d'audit,22MAXUP,37mémoire partagée,54, 58message,58, 59, 120messages entrants,118messages sortants,118migratepv,161mineur,82, 108minor,108mkdir,77mkfs,98, 129, 175mklv,155, 157mknod,108mkvg,149mkvtoc,128mode background,48mode bloc,62, 111
251

mode c,62mode canonique,192mode caractère,111, 192mode cbreak,192mode cooked,192mode cru,63, 192mode différé,48mode interactif,48mode ligne,192mode raw,63, 111, 192mode single user,177mode système,30mode utilisateur,30module,119monacct,227moniteur de port,200moniteur de ports,200montage,98more,71motd,208mount,131, 133, 145, 147, 160, 183mt,163, 174mv,77mv,70mvdir,77ncheck,142Network File System,97, 107newfs,98, 130, 135newgrp,20news,234NFS,97nice,50, 51, 190nite,227niveau d'exécution,178nohup,46nombre magique,38NPROC,37nroff,85nulladm,228od,72open,102overhead,99pacct,228pacctn,227pagination,53paramètres ajustables,239Partition,125partition physique,147partitionnement,96pathname,60périphérique virtuel,115pid,34Pied du Flot,119pilote,98, 110pilote-stream,119Piste,125Plateau,125platter,125pmadm,200, 201prdaily,228préemption,30prfdc,229prfld,229prfpr,230prfsnap,229prfstat,229processus démon,182
propriétaire,90propriétaire effectif,40, 92propriétaire réel,40, 92prtcmp,228ps,133pseudo device,114pseudo driver,114pseudo périphérique,114pseudo pilote,114pseudo-périphérique,83, 115pwd,76queuedefs,190quotacheck,140quotaoff,140quotaon,140ranlib,238raw device interface,111rc*,117read ahead,63, 109read queue,118reboot,186reboot,186redefinevg,152reducevg,152région,56reject,218Remote File Sharing,131renice,51répertoire,61, 101répertoire courant,69représentation du processus,40restore,167rm,77rmdir,77rmlv,152rmlvcopy,157runacct,227sa1,230sa2,230sacadm,200, 201sadc,230sar,230sched,54, 175Secteur,125sector,125sémaphore,58Service Access Controller,200Service Access Facility,200service de comptabilité,225service de contrôle d'accès,200service profiler,229services,119, 121services stream,119setuid,40, 92shared objects,84shell chmod,91shutacct,226shutdown,185signal,45sleep,45, 121soft limit,139startup,183statefile,227statut,32stderr,64, 103stdin,64, 103stdout,64, 103
252

sticky bit,93strconf,123Stream driver,119Stream End,119Stream Head,119Stream message,118, 120Stream Module,118Stream Queue,118Streams,117, 118strip,39structure U,35stty,193, 211sttydefs,201su,22sulog,184sum,227superbloc,98, 100swap -a,140swap in,54swap out,55swap_map,55swapoff,140swapon,55, 140swapper,54, 175swapping,53sync,185synclvodm,158syncvg,152syncvg,157syscall,41syslog.pid,232syslogd,231system activity report,230système de fichiers,96, 98système de fichiers virtuel,107table des régions,56table système proc,34table VTOC,128tail,72tampon,110tape archive,163tar,98, 111, 163termcap,209terminfo,209terminfo compiler,210termio,193, 212termio.h,193Tête du Flot,119
text segment,35tic,210touch,72track,125trap,31, 47ttymon,200tube nommé,62tunable parameter,37tunables parameters,239umask,95umount,98, 133uncompact,173uncompress,173uniq,76unités logiques,96unités physiques,96Universal File System,96unmount,160update,183upstream queue,118useradd,28userdel,28usermod,28uucp,183varyoff,153varyoffvg,153varyon,153varyonvg,153, 157VFS,97vipw,24Virtual File System,97Virtual Table Of Contents,128volume,96volume logique,96, 147, 155volume physique,147wait,45wakeup,121wall,185who,18who -r,178write behind,109wtmp,184wtmpfix,227xalloc,57xlock,24zcat,173zombie,32
253