Embed Size (px)
Citation preview

Calculs en SES
1. Calcul de proportions et de répartition
Il s’agit de calculer la part d’une grandeur dans un ensemble donné.
La formule utilisée est :
Le résultat est toujours exprimé en pourcentage.
Lecture : En (date), le (sous-ensemble) représentait (Proportion) de (ensemble donné)
Exemple : Soit le nombre d’habitants par sexe dans une ville A en 1970 et 2012
Hommes Femmes
1970 2500 2700
2012 3200 2900
- Calcul de la part des hommes dans la population totale de la ville A, en 1970 :
Lecture : En 1970, les hommes représentaient 48% de la population de la ville A.
2. Calcul d’écarts et de variations
a) Ecart absolu :
Il s’agit d’opérer une simple soustraction entre deux grandeurs de l’espace (Pays, région,
département…) ou du temps (année, mois, semaine …).
L’écart absolu est exprimé dans la même unité que les valeurs soustraites.
Exemple : la population française est passée de 60 millions d’habitants à 65 millions entre
2000 et 2005. Ainsi, l’écart absolu entre 2000 et 2005 est de 5 millions d’habitants.
La formule générale utilisée est :
Cependant, cette formule ne vaut que lorsqu’on s’intéresse à deux grandeurs temporelles.
Pour des grandeurs liés à l’espace, on soustrait les deux valeurs considérées, en faisant
attention qu’elles soient exprimées dans la même unité.

Lecture : En (date), le (variable considérée) était inférieur / supérieur de (Ecart absolu)
à celui de (grandeur de l’espace / temps)
Exemple :
Hommes Femmes
1970 2500 2700
2012 3200 2900
- Calcul de l’écart absolu entre 1970 et 2012 pour les hommes (mesure
temporelle) EA : 3200 – 2500 = 700 habitants. Lecture : En 2012, le nombre d’hommes dans une ville A était supérieur de 700 habitants à celui de 1970.
- Calcul de l’écart absolu en 1970 entre les hommes et les femmes (mesure dans l’espace)
EA : 2500 – 2700 = - 200 habitants Lecture : En 1970, le nombre d’hommes dans une ville A était inférieur de 200 habitants au nombre de femmes. Remarque : il est possible de calculer des écarts absolus lorsque les données sont exprimées
en %. Dans ce cas, la différence de données exprimées en % donnera un résultat exprimé en
points de %. Ceci vaut aussi lorsqu’on additionne des %. Cependant, la lecture du résultat
reste inchangée.
b) Ecart relatif
L’intérêt que représente l’écart relatif est très important et, à juste titre, bien meilleur que celui
de l’écart absolu. En effet, ce dernier nous permet de savoir simplement quel est l’écart entre
deux grandeurs, exprimé dans la même unité que ces dernières. Autrement dit, nous ne
pouvons admettre, avec cet outil, si l’écart constaté est important ou pas ce qui est un obstacle
statistique lorsque nous comparons deux grandeurs. Il serait judicieux, pour pouvoir faire de
véritables comparaisons, de savoir si l’écart est faible ou élevé, ce que l’écart absolu est
incapable de nous dire. Cependant, l’écart relatif va nous aider à lever cet obstacle. En effet,
contrairement à l’écart absolu, il tient compte d’un élément de base et compare l’écart avec
celui-ci afin de nous informer si, par rapport à la base, l’écart est important ou non. Prenons
un exemple pour illustrer le problème soulevé :
Vous vous souvenez que dans le paragraphe précédent, nous avions dit que « En 2012, le nombre d’hommes dans une ville A était supérieur de 700 habitants à celui de 1970 ». Qui peut dire si cela est élevé ou pas ? Nous n’en savons rien à moins de connaître les données originelles. Un écart de 700 n’est pas de la même importance selon que sa base est de 200 ou de 1 million. Dans le premier cas, l’écart est très important alors que dans le second, il est infinitésimal.

Appelé aussi « Taux de variation » ou « Taux de croissance » (pour des grandeurs
temporelles), il est exprimé en % et se calcule comme suit :
Avec VA : Valeur d’arrivée et VD : valeur de départ (valeur de la base)
Remarque : encore une fois, cette formule est bien appliquée lorsqu’il s’agit de comparer
deux grandeurs temporelles. Cependant, dans le cas de grandeurs dans l’espace, on peut
considérer que VA : valeur de la première grandeur et VD : valeur de la seconde grandeur
mais peu importe le choix que vous faîtes pour VA et VD. La seule différence surgira lors de
l’interprétation du résultat selon que la base est la première ou la seconde grandeur.
Un écart relatif en % peut être positif ou négatif. Mathématiquement, cela se comprend
facilement : si la valeur d’arrivée est inférieure à la valeur de départ, vous conviendrez que
l’écart absolu sera négatif. Sachant que la valeur de départ (dénominateur) est toujours
positive, le quotient total sera alors négatif. Dans ce cas-là, on parlera de diminution de la
grandeur étudiée. Lorsque l’écart est positif, c’est-à-dire que VA > VD, on parlera
d’augmentation de la grandeur étudiée.
Lecture : En (date), le (variable considérée) était inférieur / supérieur de (Ecart relatif) à
celui de (grandeur de l’espace / temps)
Entre (période étudiée), le (variable considérée) a augmenté/diminué de (ER).
Remarque : Lorsque les grandeurs sont déjà exprimées en % (étude portant sur le taux de
croissance du PIB par exemple), la formule peut s’appliquer sans problème : l’écart relatif
sera également exprimé en %. La seule particularité se fera au moment de l’interprétation.
Si par exemple, en étudiant le « taux de croissance du PIB », vous avez constaté une augmentation de 13% entre 2000 et 2005 (nous supposerons que leur taux de croissance respectif est positif), cela ne veut absolument pas dire que le PIB a augmenté de 13% sur la même période. L’objet étudié étant le « taux de croissance », c’est donc ce dernier qui a augmenté de 13%. Autrement dit, en termes de variable PIB, cela signifie que ce dernier a certes augmenté (puisque le taux de croissance est positif), mais le véritable sens du résultat est qu’il a augmenté de plus en plus vite (puisque le taux de croissance a augmenté). Donc, ce n’est pas tant que le PIB a augmenté qui nous intéresse mais c’est avant tout de savoir qu’il a augmenté de plus en plus.
Donc, lorsque votre grandeur porte sur un taux de croissance ou un taux d’évolution, à
supposer qu’il est positif (ici, celui du PIB), si l’écart relatif est positif, on parlera
d’accélération de la variable étudiée (ici, le PIB) et de décélération dans le cas contraire.
Mais, il faut toujours interpréter le résultat obtenu en fonction de la grandeur étudiée.
Dans d’autres cas où la grandeur est exprimée en %, par exemple s’il s’agit de parts (part
moyenne du budget nourriture dans le total du revenu des ménages), le problème exposé ci-
dessus ne se pose pas. Si le résultat est positif, on parlera d’augmentation ou bien de
diminution s’il est négatif.

Illustration de l’écart relatif et interprétation:
Hommes Femmes
1970 2500 2700
2012 3200 2900
- Calcul du taux de variation du nombre d’hommes entre 1970 et 2012 :
ER :
Lecture : en 2012, le nombre d’hommes dans une ville A était supérieur de 28% au nombre d’hommes de 1970.
- Calcul de l’écart relatif en 2012 entre les hommes et les femmes
ER :
Lecture : en 2012, le nombre de femmes dans une ville A était inférieur de 9,38% à celui des hommes. J’aimerais attirer votre attention sur le dernier résultat trouvé. Vous aurez remarqué que la
base choisie est celle des hommes. Sachez que nous aurions pu le faire en prenant pour base
les femmes. Mais, le résultat trouvé aurait été différent. Dans ce cas, nous aurions trouvé un
écart relatif de 10,34% en 2012. Même si la base n’a aucune importance, par contre,
l’interprétation du résultat, elle, est fondamentale. Dans le cas ci-dessus, le nombre de femmes
était inférieur de 9,38% à celui des hommes. Dans le second cas, il faudra dire que le nombre
d’hommes était supérieur de 10,34% à celui des femmes. Vous voyez qu’avec les mêmes
données, nous n’obtenons pas le même résultat, ni la même interprétation. C’est par exemple
de cette manière que les inégalités entre hommes et femmes paraissent si choquantes dans
certains cas.

Pièges à éviter concernant l’interprétation d’un écart relatif en % :
Un taux de variation qui passe de x% à y% (x et y >0), avec y<x, ne signifie pas que la variable a diminué mais qu’elle a augmenté moins vite que précédemment. On parle de décélération. Si y>x, cela signifie que la variable a augmenté plus vite que précédemment. On parlera alors d’accélération.
Un taux de croissance égal à 0% signifie que la variable a cessé de croître : elle n’a ni augmenté, ni diminué, sa valeur est restée la même.
Un taux de variation qui passe de –x% à –y%, avec y<x signifie que le rythme de croissance de la variable continue de diminuer mais plus faiblement qu’auparavant.
Exemple : entre 1970 et 1980, le taux de croissance du nombre de femmes était de -20% et entre 1980 et 1990, il était de -17%. Ceci signifie que le nombre de femmes a continuellement diminué mais moins vite entre 1980 et 1990. Il ne faut pas dire que le nombre de femmes a augmenté de 3% entre 1970 et 1990. Inversement, un taux de variation qui passe de –x% à –y%, avec y>x signifie que le rythme de croissance de la variable continue de diminuer mais plus vite que précédemment.
Les écarts relatifs ne sont pas symétriques : une variation entre T1 et T2 de x% n’implique pas une variation symétrique de –x% entre T2 et T1.
Exemple : En 2001, les exportations françaises sont supérieures de 3% à celles de 2000. Ceci ne signifie pas, qu’en 2000, elles soient inférieures de 3% à celles de 2001. Nous avions rencontré le même problème avec deux grandeurs non temporelles (hommes et femmes) – cf ci-dessus.
c) Coefficient multiplicateur :
Il s’agit du rapport entre deux données que l’on veut comparer. Le CM n’a pas d’unités.
Deux cas se présentent à nous :
Si VA > VD (donc la grandeur a augmenté), le quotient sera supérieur à 1. Donc,
toute augmentation de la grandeur étudiée correspond aux cas où CM > 1.
Si VA < VD (donc la grandeur a diminué), le quotient sera inférieur à 1. Donc, toute
diminution de la grandeur étudiée correspond aux cas où CM < 1.
Si VA = VD (la grandeur reste constante), le quotient sera égal à 1. Donc, toute
stagnation de la grandeur étudiée correspond aux cas où CM = 1.
Remarque : encore une fois, cette formule s’applique essentiellement à une comparaison de
données temporelles. Cependant, de même avec l’écart relatif en %, on peut considérer VA =
valeur de la première grandeur et VD = valeur de la seconde grandeur. Le seul problème se
posera lors de l’interprétation du résultat comme avec l’écart relatif.
Lecture : En (date), le (variable considérée) représentait (CM) fois celui de (grandeur de
l’espace / temps).
Entre (départ) et (arrivée), la variable a été multipliée par (CM)
Remarque : Lorsque les grandeurs sont déjà exprimées en % (étude portant sur le taux de
croissance du PIB par exemple), la formule peut s’appliquer sans problème. Encore une fois,
il faut faire attention aux cas où l’on s’intéresse à des taux de variation.

Si par exemple, en étudiant le « taux de croissance du PIB », vous avez constaté qu’en 2005, il est de 5% et qu’en 2010, il passe à 15% (c’est beau de rêver !), le coefficient multiplicateur sera alors égal à 3. Cela ne signifie pas que le PIB a triplé mais que son taux de variation a triplé. L’objet étudié étant le « taux de croissance », c’est donc ce dernier qui a été multiplié par 3. Autrement dit, en termes de variable PIB, cela signifie que ce dernier a certes augmenté (puisque les taux de croissance sont positifs), mais le véritable sens du résultat est qu’il a augmenté de plus en plus vite (puisque le taux de croissance a triplé). Donc, ce n’est pas tant que le PIB a augmenté qui nous intéresse mais c’est avant tout de savoir qu’il a augmenté de plus en plus.
Donc, lorsque votre grandeur porte sur un taux de croissance ou un taux d’évolution, à
supposer qu’il est positif (ici, celui du PIB), si le coefficient multiplicateur est supérieur à 1,
on parlera d’accélération de la variable étudiée (ici, le PIB) et de décélération dans le cas
contraire. Mais, il faut toujours interpréter le résultat obtenu en fonction de la grandeur
étudiée.
Dans d’autres cas où la grandeur est exprimée en %, par exemple s’il s’agit de parts (part
moyenne du budget nourriture dans le total du revenu des ménages), le problème exposé ci-
dessus ne se pose pas. Si le CM est supérieur à 1, on parlera d’augmentation ou bien de
diminution s’il est inférieur à 1.
Exemple : Hommes Femmes
1970 2500 2700
2012 3200 2900
- Calcul du CM du nombre d’habitants entre 1970 et 2012 :
Lecture : En 2012, le nombre d’habitants dans une ville A représentait 1,17 fois celui de 1970.
- Calcul du CM en 1970 entre le nombre d’hommes et de femmes :
Lecture : en 1970, le nombre d’homme dans une ville A représentait 0,93 fois le nombre de femmes. Relation entre CM et Ecart relatif en % :

Année 2007 2008 2009 2010 2011
Taux de variation 7,10% 5,40% -1,30% 2,30% 4,40%
Année 2007 2008 2009 2010 2011
Coefficient multiplicateur 1,071 1,054 0,987 1,023 1,044
Remarque : le CM est très utile lorsqu’il faut calculer la variation globale (en %) d’une
variable tout en disposant seulement de variations intermédiaires (en %). Autrement dit, nous
connaissons les taux de variation successifs de la variable (PIB par exemple) et nous
aimerions connaître le taux de variation globale de celle-ci. Dans ce cas, il suffit de
transformer les variations en CM, de les multiplier entre eux pour obtenir un CM global, puis
de déterminer la variation globale à partir de ce dernier.
Exemple : Voici l’évolution du PIB en France entre 2007 et 2011 : Il s’agit de calculer le taux de variation globale entre 2007 et 2011 : L’erreur à éviter est d’additionner les taux de variation de chaque année. Vous obtiendrez un résultat sans signification réelle. L’autre erreur serait de ne prendre que les taux de variation de 2007 et 2011 et de calculer un écart relatif. Dans ce cas, nous n’aurions que l’écart relatif du taux de variation entre 2007 et 2011 et non celui de la variable étudiée. La méthode à employer est de transformer les taux de variation en coefficient multiplicateur.
Ensuite, on multiplie les CM entre eux :
Enfin, on transforme ce CM en taux de variation globale :
Lecture : en 2011, le PIB en France était de 19% inférieur à celui de 2007. Remarque :
Si on avait additionné les taux de variation entre eux, on aurait obtenu un écart relatif
de 17,9%. Même s’il n’y a pas une grande différence, le résultat n’a pas tout à fait le
même sens.
De même, si nous n’avions pris que les taux de variation de 2007 (7,1%) et de 2011
(4,4%), nous aurions obtenu un écart relatif de -38%. Cela signifie simplement
qu’entre 2007 et 2011, le taux de variation du PIB a diminué de 38%. Mais nous ne
savons rien sur la variation du PIB lui-même.

Choix de l’indicateur statistique pour la lecture :
Au moment de la lecture d’une donnée, vous avez le choix entre trois outils : Ecart absolu, écart relatif ou coefficient multiplicateur. Ainsi, le choix de l’indicateur ne doit pas être minimisé. Même s’ils peuvent tous être utilisés, certains sont parfois préférables aux autres. On peut davantage se représenter l’importance de la variation selon le choix de l’indicateur.
La lecture de l’écart absolu est très rare, sauf sur demande spécifique. Généralement, lorsqu’il nous est libre de choisir, on privilégiera l’écart relatif ou le CM.
Lorsque l’écart relatif en % est inférieur à 100%, ce qui correspond à un CM inférieur à 2, il faut privilégier la lecture de l’écart relatif exprimé en %. Vous donnerez ainsi plus de sens au résultat.
Lorsque l’écart relatif en % est supérieur à 100%, ce qui correspond à un CM > 2, il faut privilégier la lecture du CM.
Exemple : Le taux de variation du PIB en France est de 150% entre 2000 et 2010. Vous voyez bien que la lecture de ce nombre n’a pas de sens : entre 2000 et 2010, le PIB en France a augmenté de 150%. Par contre, la lecture du CM est beaucoup plus logique et a plus d’impact : en 2010, le PIB en France représentait 2,5 fois celui de 2000.
d) Indice
Il s’agit du dernier indicateur exprimant un écart relatif. Il est calculé à partir du coefficient
multiplicateur ou de l’écart relatif en %. Comme le premier, il n’a pas d’unités.
L’indice, en tant quel tel, n’a pas un grand intérêt scientifique. La seule chose pour laquelle il
est utile est lorsque nous voulons étudier l’évolution d’une variable en référence à une base.
Dans ce cas, on peut facilement repérer la tendance haussière ou baissière d’une grandeur par
rapport à cette base.
Cependant, il est nécessaire de distinguer le cas de grandeurs temporelles et le cas de
grandeurs dans l’espace.
Cas de grandeurs dans l’espace :
Avec Vx : valeur de la première grandeur et Vy : valeur de la seconde grandeur.
Lecture : Habituellement, on ne lit pas directement l’indice. Fondamentalement, sa
lecture directe n’aurait aucun sens. On le transforme soit en écart relatif exprimé en %,
soit en CM. Le choix de l’indicateur suit les mêmes règles qu’auparavant.
Le calcul reste simple lorsque nous avons seulement deux grandeurs dans l’espace à comparer
(par exemple le PIB en France et celui en Allemagne). Lorsque le nombre de grandeurs
augmente, vous comprenez qu’il serait long et sans intérêt de calculer un indice pour toutes
les grandeurs deux à deux (par exemple, 5 grandeurs de l’espace impliqueraient 10 calculs).
Il est alors possible de choisir une grandeur de référence et de comparer toutes les autres à

Pays Allemagne France Pologne Espagne Grèce
PIB (en milliards d'euros) 2240 1800 700 1200 900
Pays Allemagne France Pologne Espagne Grèce
Indice (base 100=France) 124,44 100 38,89 66,67 50
celle-ci. On dira que la grandeur de référence est une « grandeur base 100 » c’est-à-dire que
l’indice de cette dernière est égale à 100 et que tous les autres indices calculés sont déterminés
à partir de cette grandeur de référence. La formule de l’indice devient alors :
Attention : la formule de l’indice ci-dessus ne signifie pas qu’il faut diviser chaque grandeur
par 100 mais bien par la valeur de la grandeur de référence.
Lecture : la lecture de tous les indices s’effectuera par rapport à la grandeur de
référence. Exemple : après étude du PIB en 2010, si la base 100 correspond à la France et qu’en Allemagne, l’indice calculé est de 150, la lecture de ce dernier ne peut se faire qu’en rapport avec celui de la France puisqu’il a été calculé par rapport à ce dernier. Ainsi, après avoir transformé l’indice en écart relatif en %, on dira simplement qu’en Allemagne, le PIB était supérieur de 50% par rapport à celui de la France, en 2010.
Lorsqu’aucun des deux indices à comparer n’est l’indice de base, il est impossible
d’interpréter la valeur et de comparer les deux grandeurs à partir de leurs indices. Il faudra
alors recourir à un calcul d’écart relatif ou de CM ordinaire. N’oubliez pas que l’indice n’est
intéressant qu’en référence à une base 100. Exemple : si en Allemagne, l’indice est de 150 et qu’en Espagne, il est de 120, il est interdit de dire qu’en Allemagne, le PIB est supérieur de 30% à celui de l’Espagne car les deux indices ont été calculés en référence au PIB de la France. On ne peut donc interpréter ces indices que par rapport à ce dernier pays.
Exemple de calcul d’indices : Voici la valeur du PIB en 2005 dans 5 pays :
Nous pouvons, bien entendu, calculer des indices entre deux pays. Calculons l’indice en 2005 entre l’Allemagne et la France :
Lecture : en 2005, le PIB en Allemagne était supérieur de 24,44% à celui de la France. Choisissons maintenant une « grandeur base 100 » : par exemple la France. Ainsi, on va calculer les indices de tous les pays en référence à la France. On dit que l’indice de la France est égal à 100. Toutes les lectures se feront en relation au pays choisi comme référence.
Lecture : en 2005, le PIB de la Pologne était inférieur de 61,11% à celui de la France En 2005, le PIB de la Grèce était inférieur de 50% à celui de la France
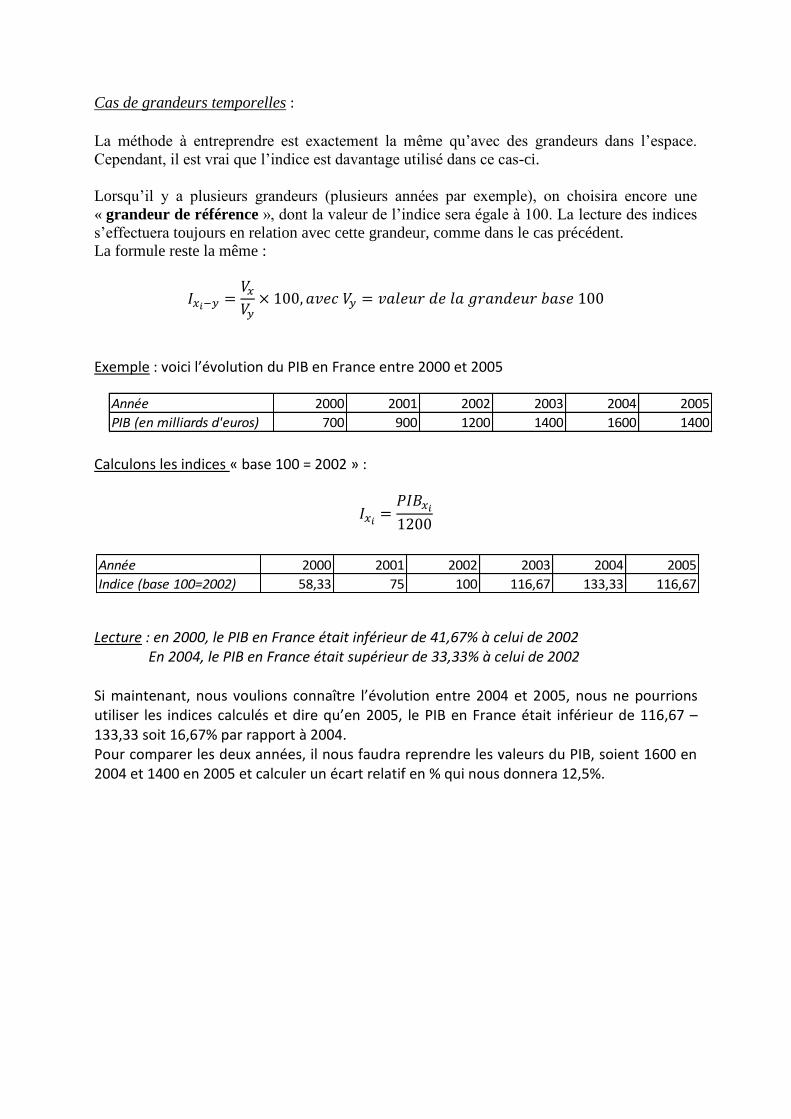
Année 2000 2001 2002 2003 2004 2005
PIB (en milliards d'euros) 700 900 1200 1400 1600 1400
Année 2000 2001 2002 2003 2004 2005
Indice (base 100=2002) 58,33 75 100 116,67 133,33 116,67
Cas de grandeurs temporelles : La méthode à entreprendre est exactement la même qu’avec des grandeurs dans l’espace.
Cependant, il est vrai que l’indice est davantage utilisé dans ce cas-ci.
Lorsqu’il y a plusieurs grandeurs (plusieurs années par exemple), on choisira encore une
« grandeur de référence », dont la valeur de l’indice sera égale à 100. La lecture des indices
s’effectuera toujours en relation avec cette grandeur, comme dans le cas précédent.
La formule reste la même :
Exemple : voici l’évolution du PIB en France entre 2000 et 2005
Calculons les indices « base 100 = 2002 » :
Lecture : en 2000, le PIB en France était inférieur de 41,67% à celui de 2002 En 2004, le PIB en France était supérieur de 33,33% à celui de 2002 Si maintenant, nous voulions connaître l’évolution entre 2004 et 2005, nous ne pourrions utiliser les indices calculés et dire qu’en 2005, le PIB en France était inférieur de 116,67 – 133,33 soit 16,67% par rapport à 2004. Pour comparer les deux années, il nous faudra reprendre les valeurs du PIB, soient 1600 en 2004 et 1400 en 2005 et calculer un écart relatif en % qui nous donnera 12,5%.

Année 2000 2001 2002 2003 2004 2005
PIB (en milliards d'euros) 1200 1300 1400 1500 1600 1550
3. Le Taux de croissance annuel moyen
Appelé souvent TCAM, il s’agit d’un taux qui permet de connaître l’évolution annuelle et
moyenne de la variable étudiée. Autrement dit, il répond à la question : de combien a varié, en
moyenne, chaque année, la variable en question ?
Vous voyez qu’il y a deux choses importantes ici : le terme annuelle et le terme moyenne. Le
premier signifie simplement qu’en utilisant le TCAM, nous connaîtrons uniquement
l’évolution de la variable d’année en année et nous ne pourrons pas la connaître avec d’autres
critères temporels.
De plus, le second critère implique que la variation calculée ne correspond qu’à une valeur
moyenne. Cela veut dire, qu’en réalité, la variable n’évolue pas au même rythme (ce qui est
logique !) mais qu’en moyenne, elle le fera. Dit autrement, pour passer de la valeur d’une
année à celle d’une autre année, il faudra que celle-ci varie à un même taux, celui calculé avec
le TCAM. Exemple : si le PIB augmente, en 2010, de 5% puis, en 2011, de 2% puis, en 2012, diminue de 3%, au lieu d’en rester là, nous pourrons calculer une variation moyenne qui, en restant la même, nous
permettra de passer de la valeur du PIB en 2010 à celle de 2013.
Vous voyez donc que cet indicateur statistique a une double utilité : il nous permet à la fois de
connaître, sur de très longues périodes, l’évolution annuelle d’une variable et en même temps,
de connaître son évolution moyenne, ce qui évite de tenir compte de toutes les fluctuations
plus ou moins importantes de la variable. Grâce au TCAM, on peut en quelque sorte lisser
l’évolution de cette dernière chaque année.
La formule couramment utilisée est :
Ici, le TCAM est obtenu grâce au coefficient multiplicateur global, calculé pour une période
donnée. Lorsqu’on dispose d’un autre type d’écart relatif, il faut d’abord le transformer en
CM puis calculer le TCAM correspondant.
Lecture : Entre (période étudiée), le (variable étudiée) a augmenté/diminué en moyenne,
chaque année, de (TCAM).
Attention : on peut vous donner des écarts relatifs sur plusieurs années consécutives et vous demander de déterminer le TCAM sur toute la période étudiée. Dans ce cas, il vous faut d’abord calculer le CM global, en multipliant les CM successifs, puis déterminer le TCAM qui y est rattaché.
Exemple : a) Voici l’évolution du PIB en France entre 2000 et 2005
- Calcul du TCAM du PIB en France entre 2000 et 2005 :

Année 2007 2008 2009 2010 2011
Coefficient multiplicateur 1,071 1,054 0,987 1,023 1,044
Lecture : entre 2000 et 2005, le PIB en France a augmenté, en moyenne, chaque année, de 4,36%.
b) Reprenons l’exemple de la section précédente avec les CM successifs. Nous avions obtenu comme CM :
Le CM global était égal à 1,19.
Lecture : entre 2007 et 2011, le PIB en France a augmenté en moyenne, chaque année, de 3.54%.
4. Mesurer en valeur et en volume Lorsque l’on compare deux valeurs d’une même variable à deux dates différentes ou entre
deux espaces différents, on utilise, comme on l’a vu précédemment, un écart relatif, qu’il soit
exprimé en % ou qu’il s’agisse du CM ou encore de l’indice.
Cependant, la comparaison dans le temps peut devenir problématique. En effet, toute
évolution d’une variable quelconque dans le temps fait apparaître un effet-quantité (évolution
des quantités étudiées) ainsi qu’un effet-prix (évolution des prix). Or, pour obtenir l’évolution
réelle de la variable étudiée, il faudrait que les prix soient les mêmes aux deux dates en
question, c’est-à-dire que l’effet-prix soit supprimé pour uniquement connaître l’évolution des
quantités. Cela nous donnerait, en quelque sorte, la véritable évolution de cette variable. Pour
cela, il faut DEFLATER la variable en valeur, c’est-à-dire évaluer toutes les quantités au
même prix.
« Déflater » une variable revient donc à exprimer cette variable en volume, c’est-à-dire ne
tenir compte que de l’effet-quantité et annuler l’effet-prix.
Lorsqu’on « déflate », on passe donc d’une variable « en valeur » à une variable exprimée
« en volume ».
ATTENTION : exprimer une variable « en valeur » revient à exprimer la variable « en prix courants ». Exprimer une variable « en volume » revient à l’exprimer « en prix constants ».
La formule, pour passer d’une expression à l’autre, est :

Année 1999 2001 2003 2005
PIB (en milliards d'euros) 1366,5 1497,2 1594,8 1710
Indice des prix (base 100=1995) 98,6 102 106,4 110,2
Année 1999 2001 2003 2005
PIB (en milliards d'euros) 1366,5 1497,2 1594,8 1710
Indice des prix (base 100=1995) 98,6 102 106,4 110,2
PIB en volume 1385,9 1467,8 1498,87 1551,72
Année 1999 2001 2003 2005
PIB (en milliards d'euros) 1366,5 1497,2 1594,8 1710
Indice des prix (base 100=1995) 98,6 102 106,4 110,2
PIB en volume 1385,9 1467,8 1498,87 1551,72
Remarque : L’indice des prix est toujours calculé à partir d’une année de base, comme pour
tout indice. Cela signifie que toute variable exprimée en volume l’est toujours par rapport à
une année de référence. Autrement dit, on déflate, on supprime l’effet-prix par rapport à
l’année de base choisie. Toutes les variables en volume seront donc exprimées au même prix
que cette dernière. Par conséquent, le choix de l’année de référence est fondamental pour
pouvoir faire des comparaisons intéressantes.
Lecture : en (date), le (variable étudiée), en valeur/volume, était de (montant)
Exemple : Voici l’évolution du PIB en France et l’indice des prix entre 1999 et 2005
- Calcul du PIB en volume ou en milliards d’euros constants en 1999 :
En appliquant cette formule pour toutes les années, on obtient : Lecture : en 1999, le PIB, en valeur, était de 1366.5 milliards d’euros, ou, en 1999, le PIB était de 1366.5 milliards d’euros courants. En 1999, le PIB, en volume, était de 1385.9 milliards d’euros, ou, en 1999, le PIB était de 1385.9 milliards d’euros constants. Remarque : lorsqu’il n’y a aucune indication pour préciser s’il s’agit d’une variable en
valeur ou en volume, on considère qu’elle est toujours exprimée « en valeur ».
Il est possible, bien entendu, de mesurer l’évolution de la variable entre des dates
différentes, selon qu’elle soit exprimée en valeur ou en volume. Cependant, le résultat sera
différent selon l’expression utilisée.
Lecture : Entre (période étudiée), le (variable considérée), en valeur/volume a
augmenté/diminué de (ER).
Entre (période étudiée), la valeur / le volume de (variable considérée) a
augmenté/diminué de (ER)
Exemple : Reprenons l’exemple précédent avec l’évolution du PIB entre 1999 et 2005

- Calcul de l’évolution du PIB en valeur entre 1999 et 2005 :
- Calcul de l’évolution du PIB en volume entre 1999 et 2005 :
Remarque : en général, l’évolution en volume sera plus faible que celle en valeur puisque les
grandeurs en € constants ont une caractéristique en moins que celles en € courants (effet-prix).
En annulant cet effet, on annule aussi une partie de l’évolution. Cette remarque est toujours
vraie dans les situations d’inflation, situation largement répandue dans la majorité des
économies mondiales. Par contre, toutes les grandeurs en situation de déflation connaîtront
une variation plus forte en volume qu’en valeur puisque la baisse des prix va faire gonfler
l’importance de l’effet-quantité.

Le calcul statistique
L’étude d’un phénomène économique ou social peut parfois nécessiter l’élaboration d’études
statistiques afin de rendre compte efficacement de ce phénomène. Il est parfois utile d’étudier
l’existence d’inégalités économiques ou sociales, ou bien l’existence d’écarts quantitatifs à
l’intérieur d’un pays ou encore entre différents pays etc…
1) Les caractères statistiques
Toute étude d’une quelconque « population statistique » (ensemble des individus étudiés,
correspondant, en réalité, au total des effectifs) doit se référer à un caractère particulier. En
effet, l’analyse des notes obtenues à un devoir dans une classe de seconde, ne renvoi pas au
même caractère que l’analyse des sports pratiqués par les français. Dans le premier cas, nous
dirons que nous avons affaire à un « caractère quantitatif » (nous pouvons attribuer des
valeurs numériques au caractère, les notes), mais, dans le second cas, nous ne pouvons donner
de valeurs au caractère (ici, les différents sports pratiqués par les français). On parle alors de
« caractère qualitatif ». Les valeurs numériques du caractère sont remplacées par les
différentes qualités que portent ce caractère (ici, le nom des sports pratiqués)
Ces deux caractères ne font pas l’objet des mêmes calculs et des mêmes éléments à analyser.
Cependant, en statistiques, nous utilisons plus souvent le caractère quantitatif, d’autant plus
qu’il recouvre une richesse bien plus grande que le caractère qualitatif, dont l’analyse est
fortement limitée.
C’est pourquoi, nous commencerons par étudier tout ce qui est associé au « caractère
quantitatif ». Ce dernier fait lui-même l’objet d’une subdivision en deux sous-ensembles :
- « Caractère quantitatif discret » : Les valeurs prises par le caractère étudié sont
dénombrables et isolées.
Exemple : Etudions le nombre d’enfants parmi les familles françaises. Bien entendu, les valeurs du caractère (ici, le nombre d’enfants) seront des nombres isolés (0, 1, 2, 3, ….). Nous ne pouvons imaginer une famille avoir 3,4 enfants ……..
- « Caractère quantitatif continu » : Les valeurs prises par le caractère sont
regroupées dans un ensemble d’intervalles de nombres, du type [a ; b [
Exemple : Etudions la taille des feuilles d’un arbre. Il est bien entendu qu’il y a de grandes chances pour que chaque feuille a une taille différente de sa voisine, même avec quelques millimètres de différence. Si nous choisissons d’étudier ce caractère par une analyse discrète, on peut en conclure que chaque dimension (supposons en centimètres) de chaque feuille sera rattachée à un effectif de 1 (1 feuille pour une dimension). Imaginez alors le nombre de valeurs prises par le caractère……. De plus, quel intérêt a-t-on à avoir une infinité de valeurs isolées avec, pour chacune, un effectif de 1 ? Aucune…… Vous comprendrez, alors, qu’il est plus judicieux de regrouper les tailles des feuilles en intervalles pour faciliter l’étude statistique. Par exemple, le premier intervalle sera composé de toutes les feuilles ayant une dimension comprise entre 0 et 5 cm, le second entre 5 et 10 cm etc…..

2) Vocabulaire pour bien commencer
Population (notée N): Ensemble des éléments observés, ce qui
correspond au total des effectifs étudiés. Il répond à la question qui est
étudié ?
Exemple : Ensemble des élèves d’une classe de seconde.
Individu : Un élément isolé de la population Exemple : Un élève
Classe : nom associé à l’intervalle du caractère continu. Exemple : Si le caractère continu correspond aux notes obtenues à un devoir, on peut faire des regroupements de classe : ceux qui ont eu entre 0 et 5 : [0 ; 5[, ceux qui ont eu entre 5 et 10 :[5;10[ etc….
Centre de classe (notée ci) : Milieu de l’intervalle. Il est calculé en
ajoutant les deux bornes de la classe puis en divisant par 2. Exemple : si la classe est [0 ; 5[, le centre de la classe sera de : (0+5)/2 = 2,5.
Effectifs (noté ni): Nombre de fois que l’on retrouve la valeur du
caractère. Exemple : Si le caractère étudié est les « notes obtenues à un devoir », les effectifs correspondront aux nombres d’élèves associés à chaque note du devoir (caractère discret) ou à chaque intervalle de note (caractère continu)
Effectifs cumulés (noté Ni): Ils peuvent être croissants ou décroissants.
Dans le premier cas, il s’agit d’opérer la somme un à un des effectifs en
partant de celui du premier caractère. Dans le second, il s’agit d’opérer la
différence des effectifs un à un en partant de celui du dernier caractère.
Amplitude (noté ai) : Différence entre la borne supérieure de la classe et
la borne inférieure. Exemple : Si une classe correspond à l’intervalle [0 ; 5[, l’amplitude sera égale à : 5-0 = 5
Fréquences simples (noté fi) : Part de chaque effectif dans l’effectif
total. Le calcul est le suivant : fi =
. La somme des fréquences est égale
à 100%. Cet outil a bien plus de sens que celui des effectifs. On peut
affirmer qu’il remplace les effectifs avec un intérêt supplémentaire.
Regardons l’exemple ci-dessous et essayons d’en tirer une conclusion. Exemple : Si 5 élèves ont eu une note de 10/20 (sur un total de 30 élèves), la fréquence associée à cette note sera : 5/30 = 0.17 ou 17%. Ceci signifie que 17% des élèves ont eu une note de 10/20.
Lorsqu’on dit que 5 élèves ont eu une note de 10, c’est un peu comme si on disait que 25
français ont les yeux bleus ou encore que 100 personnes aient été arrêtées par la police
française en 2010. Quel est le problème de ces simples effectifs ? La base sur laquelle ils sont
calculés. Dire que 25 français ont les yeux bleus nous demande de relever une question
importante : Mais sur combien de français ? Car 25 sur 1000 français ne signifie pas la même
chose que 25 sur 1.000.000 de français. Pour répondre à ce problème d’importance de
l’effectif par rapport à l’effectif total, on utilise la fréquence qui nous donne alors une
dimension relative de l’effectif.
Fréquences cumulées (noté Fi) : Ils peuvent être croissants ou
décroissants. Dans le premier cas, il s’agit d’opérer la somme une à une
des fréquences en partant de celle du premier caractère. Dans le second, il
s’agit d’opérer la différence des fréquences une à une en partant de celle
du dernier caractère.

Mode : Il s’agit de la valeur du caractère (ou l’intervalle) ayant l’effectif
le plus grand ou la fréquence la plus grande (Alius et idem). Il se peut
qu’il y ait plusieurs modes si l’effectif ou la fréquence la plus élevée se
retrouvent pour plusieurs valeurs du caractère. Pour un caractère continu,
on parlera de « classe(s) modale(s) »
Etendue : Il s’agit de la différence entre la plus grande valeur du
caractère et la plus petite. Exemple : Si la note minimale est 1/20 et la note maximale est 19/20, l’étendue est égale à : 19-1= 18
3) Les représentations graphiques élémentaires
Il existe, en statistiques descriptives, une multitude de représentations graphiques, dont la
complexité peut varier. Chaque type de caractère possède ses propres représentations
graphiques qui lui sont exclusivement réservées.
Ces représentations sont un moyen facile pour observer les caractéristiques importantes du
caractère étudié. En quelques clins d’œil, nous pouvons en déduire un ensemble de propriétés
sur ce dernier et faire un constat d’ensemble. Cependant, les graphiques ne nous fournissent
qu’une information limitée et non authentique. Nous ne pourrons pas réaliser des études
statistiques complètes avec les seuls graphiques. Il nous faudra toujours opérer des calculs
complémentaires. Ainsi, l’utilisation des représentations graphiques en statistiques nous
permettent de ne faire qu’une étude partielle d’un caractère.
a) Caractère qualitatif : étant donné la pauvreté de ce caractère, les représentations
graphiques se limitent au nombre de trois. Cependant, elles présentent de grands
intérêts, bien supérieurs à la représentation sous forme de tableaux.
Diagramme en bâtons : pour chaque qualité du caractère, nous lui attribuons un bâton
dont la hauteur est proportionnelle à l’effectif.
En abscisse : qualités du caractère
En ordonnée : effectifs (ou
fréquences)

Remarque : l’utilisation des fréquences en ordonnée ne pose aucun problème et n’altère en
rien l’interprétation du caractère.
Tuyaux d’orge : c’est en quelque sorte l’histogramme du caractère qualitatif. Pour chaque
qualité du caractère, nous lui attribuons un rectangle dont la longueur est proportionnelle à
l’effectif (ou fréquence). Il s’agit en fait d’un diagramme en bâtons, dont les bâtons sont
remplacés par des rectangles. Exemple : une étude statistique porte sur la nature des recettes budgétaires de l’Etat français en 2009. Voici le tuyau d’orge que nous pouvons associer au caractère.
Diagramme circulaire : appelé vulgairement fromage, il s’agit du seul graphique dont la
représentation, de forme circulaire, se fait à l’aide de pourcentages ou, plus exactement, de
parts. Chaque modalité reçoit en fait une part du fromage, part qui est proportionnelle à
l’effectif (ou à la fréquence). Le poids de l’effectif détermine donc la plus ou moins grande
part dont bénéficiera la modalité en question.
La construction semble difficile mais est en réalité très simple. De manière littérale, nous
savons que la totalité du cercle (ou du diagramme) représente la population totale (ou effectif
total) dont l’angle vaut 360°. Il suffit alors, à l’aide d’un produit en croix, de calculer l’angle
associé à l’effectif de chaque modalité. Une fois les angles connus, il suffit, avec un
rapporteur, de représenter chaque angle et de tracer un rayon correspondant à celui-ci. On
réitère l’action autant de fois que nécessaire.
Prenons un exemple simple afin de faciliter la compréhension de ce qui vient d’être dit. Supposons une étude statistique portant sur la marque de voitures préféré de 100 français en 2010. Voici, dans un tableau, les résultats de l’enquête :
Marque de voiture
Peugeot Renault Nissan BMW Mercedes Opel Total
Effectifs 10 5 13 20 40 12 100
Etant donné que nous savons que le total des 100 français représente la totalité du cercle, soit
un angle de 360°, comment va-t-on déterminer l’angle associé à la marque Peugeot sachant
que son effectif vaut 10 ?
Posons le produit en croix suivant :
Il suffit alors de poser l’opération :
Ainsi, l’angle associé à la marque Peugeot sera égal à 36°.
En répétant ce produit en croix pour chaque modalité, nous obtenons les résultats suivants :
Marque de voiture
Peugeot Renault Nissan BMW Mercedes Opel Total
Effectifs 10 5 13 20 40 12 100
Angle (en degré)
36 18 46.8 72 144 43.2 360
Nous pouvons facilement vérifier que la somme des angles de chaque modalité est bien égale
à 360°, ce qui sera évidemment toujours vraie.
Une fois les angles connus, nous pouvons tracer un cercle.
Un problème, mineur, apparaît immédiatement : comment représenter les angles de chaque
modalité ? En effet, l’utilisation d’un rapporteur, seul outil apte à nous aider, requiert

l’existence d’une droite (ou d’un segment) comme base pour tracer un angle. Or, sur ce
cercle, il n’en existe aucune.
Il suffit alors, nous-mêmes, et de façon totalement arbitraire, de tracer un rayon du cercle qui
nous servira de base pour utiliser le rapporteur.
On peut alors poser le rapporteur sur cette base et tracer le premier angle associée à la
modalité « Peugeot », soit 36°. Cela nous donnera la première part du fromage, celle, en
l’occurrence, qui préfère la marque Peugeot.
On renouvelle l’opération pour les autres modalités en partant toujours du dernier rayon tracé.
On obtient alors les parts respectives de chaque modalité du caractère.
Voici la forme finale que nous devons obtenir :
Part de la population préférant la
marque Peugeot

Remarque : nous pouvons opter pour le diagramme semi-circulaire. Il a la forme d’un demi-
fromage. Au lieu de prendre pour total 360°, il faut prendre un total de 180°. Les calculs
relatifs aux angles de chaque modalité se font sur le même principe que ceux du diagramme
circulaire, autrement dit, à l’aide d’un produit en croix.
b) Caractère quantitatif discret
Diagramme en bâtons : Il s’agit de tracer des bâtons pour chacune des valeurs du caractère, la
hauteur du bâton représentant l’importance de l’effectif ou de la fréquence. Autrement dit, il
suffit de tracer des segments parallèles à l’axe des ordonnées dont la longueur est
proportionnelle à l’effectif ou à la fréquence.
Remarque : en ordonnée, il est possible d’utiliser les fréquences. Etant donné que ces
dernières ne sont que l’expression relative des effectifs, l’interprétation du graphique ne s’en
trouvera pas modifiée.
En reliant les sommets de chaque bâton, nous obtenons le polygone des effectifs ou des
fréquences.
Diagramme en escalier (ou fonction de répartition) : On associe à chaque valeur du caractère
sa fréquence cumulée qui lui est associée (fréquences cumulées croissantes). Etant donné le
caractère discret de la variable, il n’y a pas de continuité entre chaque fréquence cumulée.
Chaque classe de valeurs a une fréquence cumulée bien définie, différente de la précédente et
de la suivante. C’est pour cela que nous traçons des segments horizontaux entre les valeurs du
caractère car une même fréquence cumulée est supposée valable pour tous les nombres entre
deux valeurs du caractère. Mais, il faut toujours exclure la valeur suivante car pour celle-ci,
une autre fréquence cumulée lui est associée. Cette exclusion est symbolisée par
En abscisse, on place les
valeurs du caractère
En ordonnée, on place les effectifs (ou fréquences)
L’épaisseur du bâton n’a aucune
importance (sauf exagération)

Remarque : pour la dernière valeur du caractère, il faut considérer que son effectif cumulé est
vrai pour toutes les valeurs après celle-là. C’est pour cela que nous traçons un segment
horizontal qui se poursuit bien après la dernière valeur du caractère. Nous aurions pu le
poursuivre jusqu’à l’infini.
Afin de mieux comprendre les raisons du principe de non-continuité entre les valeurs du
caractère, prenons un exemple dont la représentation graphique se trouve ci-dessus.
Exemple : Prenons une étude portant sur le nombre d’enfants de 200 familles de Lille. Voici les résultats de l’enquête :
Nombre d’enfants
0 1 2 3 et + Total
Nombre de familles
25 50 100 25 200
Fréquences simples
0,125 0,25 0,5 0,125 1
Fréquences cumulées
0,125 0,375 0,875 1
Vous remarquerez que chaque fréquence cumulée ne vaut que pour une valeur du caractère et que lorsqu’on passe à la valeur suivante, la fréquence cumulée change. Donc, tout se passe comme si une fréquence cumulée était valable pour tous les nombres compris entre deux valeurs du caractère. Par exemple, la fréquence cumulée égale à 0,375 est valable pour tous les nombres compris entre 1 et 2. C’est pour cette raison qu’on tracera un segment horizontal d’ordonnée 0,375 qui commencera à l’abscisse x=1 jusqu’à l’abscisse x=2 (exclu). Une fois passé exactement
En abscisse :
valeurs du
caractère discret
En ordonnée : Effectifs cumulés croissants

à 2, la fréquence cumulée devient égale à 0,875. Donc, pour la valeur du caractère qui vaut 2, il faut partir de la fréquence cumulée égale à 0,875 jusque 3 (exclu) car en passant exactement à 3, la fréquence cumulée saute et devient égale à 1.
Diagramme en boîte (ou à moustaches) : Il s’agit du seul graphique, pour un caractère discret,
qui permet de représenter, non pas les effectifs (ou fréquences) mais des caractères de
position comme la médiane, le premier quartile etc…. Ces derniers seront explicités en détail
lors de la section suivante.
Le principe est simple : une fois connu les paramètres nécessaires, on trace un rectangle allant
du premier quartile au troisième quartile, coupé perpendiculairement par la médiane. Deux
segments viennent ensuite rejoindre les extrémités du caractère au rectangle. Il est possible de
s’aider d’une échelle graduée pour positionner précisément les valeurs dont on a besoin.
Voici une représentation graphique d’un diagramme en boîte :
Xi
Min Q1 Médiane Q3 Max
: valeur minimale du caractère
: valeur du premier quartile
: valeur du troisième quartile
: valeur maximale du caractère
Ce graphique est amusant mais présente peu d’intérêt. Tout ce que nous pouvons faire avec
celui-ci est d’observer et d’étudier l’écart interquartile. Il s’agit d’une mesure de la dispersion
du caractère autour de la médiane que nous verrons lors de la section f.
Il est aussi pratique, pour un même caractère, lorsque nous voulons comparer des populations
différentes. C’est un moyen simple d’observer les différences caractéristiques entre ces
populations. Nous pouvons par exemple indiquer quelle population possède la valeur de la
médiane la plus élevée, l’écart interquartile le plus important etc….

c) Caractère quantitatif continu
Histogramme : il s’agit de la représentation standard d’un caractère continu. Etant donné que
ce dernier se caractérise par des classes de valeurs, donc par des intervalles, il est donc
intéressant de représenter les effectifs (ou fréquences) sous forme de barres colées les unes
aux autres dont la largeur représente l’amplitude de chaque classe de valeurs.
ATTENTION : Pour le tracer comme ci-dessus, c’est-à-dire avec les ni (ou fi) en ordonnée et
les xi (valeurs du caractère) en abscisse, il est impératif que les amplitudes de classe soient les
mêmes. Autrement dit, la hauteur des rectangles doit être proportionnelle aux effectifs (ou
fréquences) de chaque classe de valeurs. On peut donc, sans problèmes, effectuer des
comparaisons et indiquer quelle classe du caractère a l’effectif (ou fréquence) le plus grand ou
le plus petit. En regardant le graphique ci-dessus, nous constatons sans difficulté que les
amplitudes sont les mêmes, égales à 2, puisque les largeurs des rectangles sont identiques (la
largeur indiquant l’amplitude). On peut donc dire par exemple que c’est la classe [4 ; 6[qui a
le plus grand effectif et la classe [8 ; 10[qui a le plus petit. Dit autrement, nous pouvons
affirmer sans commettre d’erreurs qu’il y a une majorité d’individus dont le caractère vaut
entre 4 et 6.
Si les amplitudes sont différentes, on ne peut étudier l’histogramme efficacement si nous ne
recourons pas au préalable à un changement important de variable. En effet, si les hauteurs ne
sont plus proportionnelles aux effectifs (aux fréquences), toute comparaison et toute étude
deviennent biaisées. On ne peut plus affirmer avec certitude qu’une majorité d’individus est
comprise entre telle et telle valeur du caractère. Dit autrement, ce n’est plus parce qu’une
classe détient l’effectif le plus grand qu’elle concentre la plus grande part relative des
individus.
Pour remédier à ce problème, les hauteurs ne doivent plus être proportionnelles aux effectifs
(ou fréquences) mais aux densités, c’est-à-dire au rapport entre les effectifs et les amplitudes.
On peut parler d’effectif relatif, au sens où il est relatif aux amplitudes.

Cette fois-ci, l’axe des ordonnées est exprimé relativement c’est-à-dire qu’il est exprimé sur
une même base pour toutes les classes de valeurs. Dit autrement, on introduit un critère de
proportionnalité ou de relativité qui est l’amplitude des classes. Tout se passe comme si nous
essayons de connaître, pour chaque classe de valeurs, le nombre d’effectifs pour une
amplitude qui est égale à 1. En effet, diviser les effectifs par les amplitudes revient à exprimer
les premiers pour une seule amplitude. Cela signifie simplement que les effectifs de chaque
classe sont ramenés à une même amplitude qui vaut 1. Comme toutes les classes ont une base
identique, les comparaisons deviennent alors possibles et l’observation n’est donc plus
biaisée.
Mais, pour faciliter la compréhension de ce point, prenons un exemple qui éclaircira, je
l’espère, le raisonnement précédent.
Exemple : Supposons une étude statistique qui s’intéresse au revenu mensuel, en euros, de 200 ménages français. Nous supposerons que cet échantillon est représentatif de la population française. Voici le résultat de l’étude :
Faisons un constat immédiat : n’importe qui affirmerait, sans véritables erreurs, que la majorité des ménages français ont un revenu compris entre 1000€ et 2000€. De même, nous pouvons affirmer que la plus faible part des ménages a un revenu compris entre 500€ et 600€. De plus, nous voyons facilement que les amplitudes de classe sont toutes différentes. Représentons l’histogramme associé à cette étude sans tenir compte de la différence des amplitudes.
L’observation de l’histogramme confirme nos affirmations précédentes : la hauteur du rectangle est la plus élevée pour la classe [1000 ; 2000[et la moins élevée pour la classe [500 ; 600[. A priori, nous aurions donc raison d’affirmer que la majorité de la population étudiée est incluse dans le dernier intervalle de valeurs.
Revenu mensuel
[0 ; 200[ [200 ; 500[ [500 ; 600[ [600 ; 1000[ [1000 ; 2000[ TOTAL
Effectifs 35 50 25 30 60 200
0 200 500 600 1000 2000
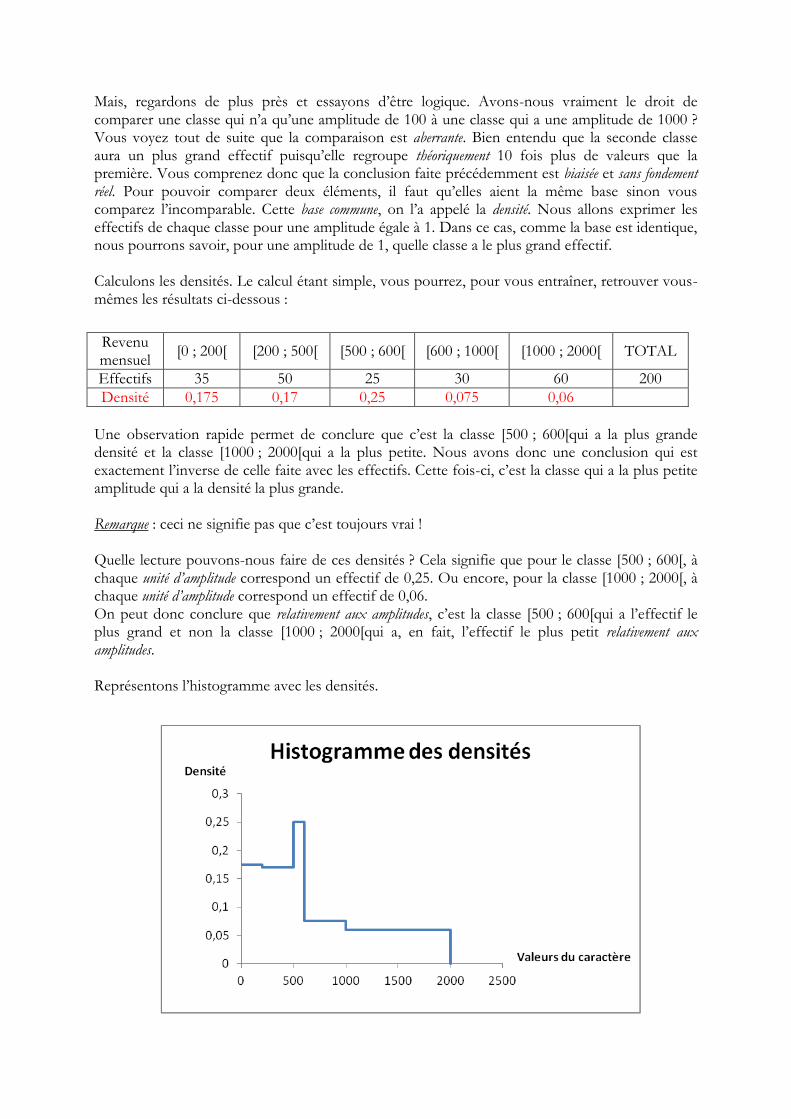
Mais, regardons de plus près et essayons d’être logique. Avons-nous vraiment le droit de comparer une classe qui n’a qu’une amplitude de 100 à une classe qui a une amplitude de 1000 ? Vous voyez tout de suite que la comparaison est aberrante. Bien entendu que la seconde classe aura un plus grand effectif puisqu’elle regroupe théoriquement 10 fois plus de valeurs que la première. Vous comprenez donc que la conclusion faite précédemment est biaisée et sans fondement réel. Pour pouvoir comparer deux éléments, il faut qu’elles aient la même base sinon vous comparez l’incomparable. Cette base commune, on l’a appelé la densité. Nous allons exprimer les effectifs de chaque classe pour une amplitude égale à 1. Dans ce cas, comme la base est identique, nous pourrons savoir, pour une amplitude de 1, quelle classe a le plus grand effectif. Calculons les densités. Le calcul étant simple, vous pourrez, pour vous entraîner, retrouver vous-mêmes les résultats ci-dessous :
Une observation rapide permet de conclure que c’est la classe [500 ; 600[qui a la plus grande densité et la classe [1000 ; 2000[qui a la plus petite. Nous avons donc une conclusion qui est exactement l’inverse de celle faite avec les effectifs. Cette fois-ci, c’est la classe qui a la plus petite amplitude qui a la densité la plus grande. Remarque : ceci ne signifie pas que c’est toujours vrai ! Quelle lecture pouvons-nous faire de ces densités ? Cela signifie que pour le classe [500 ; 600[, à chaque unité d’amplitude correspond un effectif de 0,25. Ou encore, pour la classe [1000 ; 2000[, à chaque unité d’amplitude correspond un effectif de 0,06. On peut donc conclure que relativement aux amplitudes, c’est la classe [500 ; 600[qui a l’effectif le plus grand et non la classe [1000 ; 2000[qui a, en fait, l’effectif le plus petit relativement aux amplitudes. Représentons l’histogramme avec les densités.
Revenu mensuel
[0 ; 200[ [200 ; 500[ [500 ; 600[ [600 ; 1000[ [1000 ; 2000[ TOTAL
Effectifs 35 50 25 30 60 200
Densité 0,175 0,17 0,25 0,075 0,06
L’observation de l’histogramme confirme que la densité (l’effectif relatif aux amplitudes) est la plus élevée pour la classe [500 ; 600[. Je tiens à attirer votre attention sur une erreur à ne pas commettre. A aucun moment, je n’ai affirmé que, pour un revenu mensuel compris entre 500€ et 600€, l’effectif était le plus grand. Tous les statisticiens du monde entier vous diront que c’est pour un revenu mensuel compris entre 1000€ et 2000€ que l’effectif est le plus élevé. Par contre, vous pouvez affirmer que c’est bien la classe [500 ; 600[qui possède l’effectif relatif le plus grand (relatif aux amplitudes).
Remarque : pour ceux qui voudraient un exemple similaire où nous devons introduire un
critère relatif pour pouvoir faire des comparaisons intéressantes, prenez le cas de deux
entreprises A et B, dont la première a réalisé un chiffre d’affaire de 1.000€ et la second de
500€. On peut dire que la première firme a un chiffre d’affaire supérieur à la seconde. Mais, si
nous introduisons un critère relatif, la quantité produite, et qu’on sait que la première a
fabriqué 100 unités et la seconde 20 unités, la conclusion change. Dans ce cas, relativement
aux quantités, c’est la seconde firme qui a réalisé le plus de chiffre d’affaire (25€ par unité)
alors que la première n’a réalisé qu’un chiffre d’affaire de 10€ par unité.
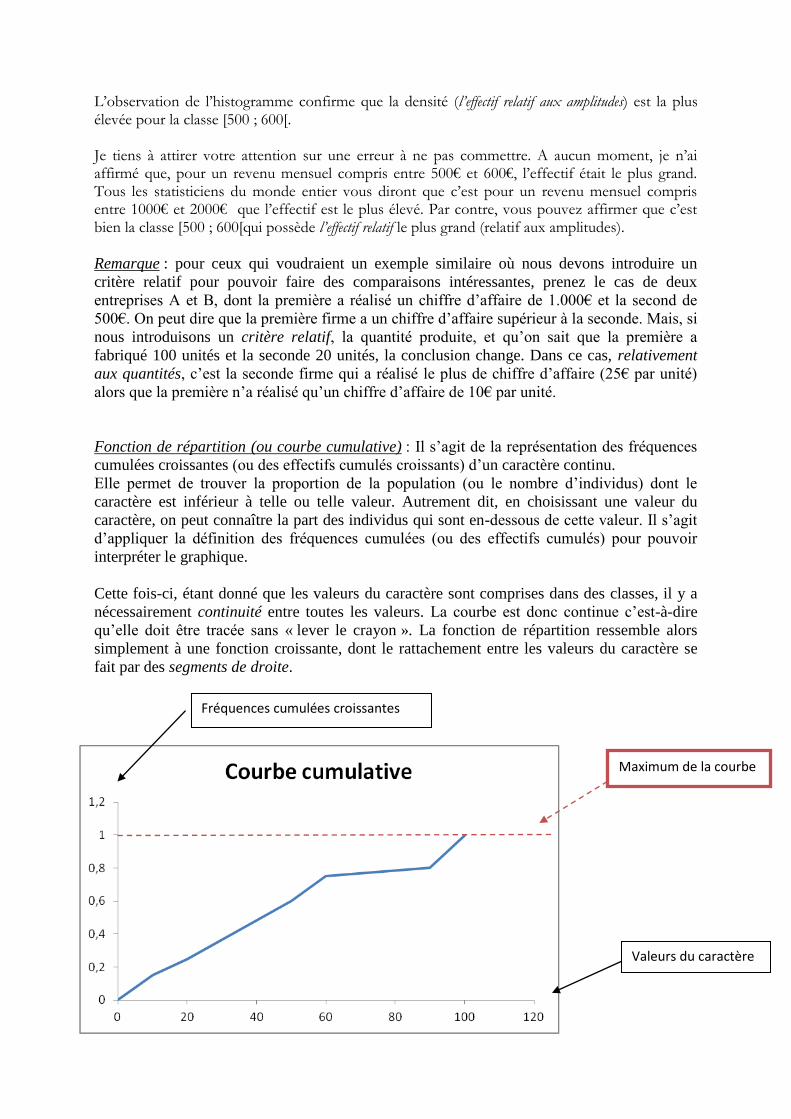
Fonction de répartition (ou courbe cumulative) : Il s’agit de la représentation des fréquences
cumulées croissantes (ou des effectifs cumulés croissants) d’un caractère continu.
Elle permet de trouver la proportion de la population (ou le nombre d’individus) dont le
caractère est inférieur à telle ou telle valeur. Autrement dit, en choisissant une valeur du
caractère, on peut connaître la part des individus qui sont en-dessous de cette valeur. Il s’agit
d’appliquer la définition des fréquences cumulées (ou des effectifs cumulés) pour pouvoir
interpréter le graphique.
Cette fois-ci, étant donné que les valeurs du caractère sont comprises dans des classes, il y a
nécessairement continuité entre toutes les valeurs. La courbe est donc continue c’est-à-dire
qu’elle doit être tracée sans « lever le crayon ». La fonction de répartition ressemble alors
simplement à une fonction croissante, dont le rattachement entre les valeurs du caractère se
fait par des segments de droite.
Valeurs du caractère
Fréquences cumulées croissantes
Maximum de la courbe

Remarques :
Sur l’axe des ordonnés, vous auriez pu mettre les effectifs cumulés croissants, cela
n’aurait absolument rien changé.
La courbe ne peut pas dépasser l’ordonnée de 1 (ou 100%). En effet, nous savons
que pour la dernière valeur du caractère, la fréquence cumulée croissante est égale à
100% puisqu’il y a bien 100% de la population dont le caractère est inférieur à la
dernière valeur.
La représentation par des segments de droite mérite d’être expliquée. Lorsque nous
disposons du tableau de l’étude statistique, tout ce que nous connaissons, c’est
l’importance de l’effectif pour une classe de valeurs et non pour chaque valeur pris
individuellement. Nous savons qu’un ensemble de valeurs regroupe un certain
nombre d’individus. Cependant, nous ne savons rien de la distribution à l’intérieur
de chaque classe de valeurs. Autrement dit, nous ne savons pas comment se distribue
les effectifs pour chaque intervalle. Dans ce cas, les statisticiens ont supposé que
cette distribution serait linéaire c’est-à-dire que pour chaque valeur d’un intervalle,
on lui affecte la même proportion qu’une autre valeur du même intervalle. On dit
encore que la répartition des fréquences est uniforme.
Reprenons la courbe cumulative précédente pour illustrer ce qui vient d’être dit.
Nous observons, pour ne prendre qu’un exemple, qu’entre 20 et 50, la courbe est parfaitement linéaire. Pour la valeur du caractère égale à 20, la fréquence cumulée vaut 25% et pour celle égale à 50, elle vaut 60%. Il y a donc 35% d’individus dont la valeur du caractère est comprise entre 20 et 50. La linéarité de la courbe implique que pour chaque valeur du caractère compris entre 20 et 50, la fréquence qui lui est associée est identique à toutes les autres valeurs. Par exemple, pour chaque unité de la classe [20 ; 50[, étant donné qu’il y a 30 unités, la fréquence sera égale à 0,35/30, soit 1,17%. Chaque valeur d’une classe reçoit la même part de la population cumulée à l’intérieur de cette classe. Peut-être qu’en réalité, la répartition à l’intérieur de la classe est hétérogène mais comme nous n’en savons rien, nous supposons qu’elle est uniforme ou linéaire.
Nous pouvons encore faire d’autres observations intéressantes avec la fonction de répartition
continue :
- L’écart vertical entre chaque segment de droite représente la fréquence simple
associée à chaque classe de valeurs. Pour la calculer, il suffit de soustraire les

Classe fi
[0;10[ 0,15
[10;20[ 0,1
[20;50[ 0,35
[50;60[ 0,15
[60;90[ 0,05
[90;100[ 0,2
1
Xi Fi
0 0
10 0,15
20 0,25
50 0,6
60 0,75
90 0,8
100 1
fréquences cumulées de deux extrémités de chaque intervalle, ces dernières
correspondant aux extrémités des segments de droite. En effet, un segment de
droite représente une classe de valeurs donc les extrémités de celui-ci
représentent les bornes de la classe. En reprenant notre exemple précédent, nous avions affirmé que la fréquence cumulée associée à 20 valait 25% et que celle associée à 50 valait 60%. Cela signifie qu’il y a 25% de la population dont le caractère est inférieur à 20 et que 60% de la population a une valeur inférieur à 50. Nous pouvons donc dire qu’entre 20 et 50, la proportion de la population totale vaut 0,6 – 0,25, soit 0,35. Ce résultat correspond en réalité à la fréquence simple associée à la classe [20 ; 50[. Pour mieux comprendre, représentons la situation sur une droite graduée : 20 50 Comment connaître la fréquence simple associée à l’intervalle 20 – 50 ? Il suffit de prendre les 60% et de retirer le morceau correspondant aux 25%. Il ne restera alors que la partie comprise entre 20 et 50. En appliquant cette règle à chaque intervalle de valeurs, nous pouvons regrouper dans un tableau toutes les fréquences cumulées et ainsi déterminer les fréquences simples de chaque classe du caractère :
Chaque fréquence simple a été calculée par l’écart entre deux fréquences cumulées ce qui signifie par simple soustraction.
Attention : cela ne peut se faire que pour chaque segment de droite. En effet, ces segments
permettent de délimiter les classes de valeurs. Il ne nous est pas permis de créer des
intervalles de manière arbitraire. Le passage d’un segment à un autre est le seul moyen de
reconnaître les intervalles de valeur du caractère étudié dont les bornes se confondent avec les
extrémités des segments.
60%
25%

Graphiquement, nous pouvons reconnaître les fréquences simples de chaque classe de valeurs
par l’écart vertical entre chaque segment de droite.
Vous remarquez que le découpage des fréquences cumulées en fréquences simples s’est fait par segment de droite. Nous n’avons pas choisi nous-mêmes la délimitation des intervalles de valeur car des derniers nous ont été donnés par le passage d’un segment de droite à un autre.

Année 1975 1980 1985 1990 1995 2000 2005
Emplois (en milliers) 21157 21223 21465 22375 22210 23261 24921
Rémunération(en €) 1000 1300 1500 1800 2000 2500 3000 Total
Nombre de salariés 24 52 51 33 13 3 1 177
4) Les critères de position
Exemple :
Soit l’évolution de l’emploi, en France, entre 1975 et 2005
- Calcul de la moyenne des emplois entre 1975 et 2005 :
Lecture : Entre 1975 et 2005, le nombre moyen d’emplois était de 22373000.
Soit la répartition des salariés d’une entreprise A selon la rémunération
mensuelle
- Calcul du salaire moyen :
Lecture : au sein de l’entreprise A, le salaire mensuel moyen est de 1483 euros.
5) La médiane
Définition : Il s’agit de la valeur des xi qui sépare l’effectif global (N) en deux parties égales.
Rémunération(en €) 1000 1300 1500 1800 2000 2500 3000 Total
Nombre de salariés 24 52 51 33 13 3 1 177
Rémunération(en €) 1000 1300 1500 1800 2000 2500 3000 Total
Nombre de salariés (ni) 24 52 51 33 13 3 1 177
ni cumulés 24 76 127 160 173 176 177
Rémunération(en €) [0;1000[ [1000;1300[ [1300;1500[ [1500;1800[ [1800;2000[ [2000;2500[ [2500;3000[ Total
Nombre de salariés (ni) 24 52 51 33 13 3 1 177
ni cumulés 24 76 127 160 173 176 177
e) En cas de variable discrète, il faut ordonner, dans l’ordre croissant, les valeurs
xi, et choisir celle dont l’effectif cumulé croissant correspond à la moitié de
l’effectif total.
Lecture : 50% de (nom de l’effectif) ont un (variable xi) inférieur/supérieur ou égal à
(médiane).
Exemple : Reprenons l’exemple précédent sur la répartition des salariés d’une entreprise A selon le salaire mensuel.
On voit clairement ici que les valeurs xi (rémunération mensuelle) sont déjà ordonnées.
- Calcul de la moitié de l’effectif total :
- Calcul des effectifs cumulés croissants :
- Détermination de la médiane : 88.5 correspond à la valeur xi = 1500€. Lecture :
50% des salariés de l’entreprise A ont une rémunération mensuelle inférieure à 1500€.
Dans le cas d’une variable continue, cette méthode de calcul est insuffisante et imprécise. En
effet, dans notre exemple précédent, si le salaire mensuel était borné inférieurement et
supérieurement, on ne pourrait pas dire, avec précision, que 50% des salariés ont une
rémunération inférieure à 1500€, étant donné qu’à 1500€, l’effectif cumulé est de 127 et non
de 88.5.
Il faut, dans ce cas, recourir à une interpolation linéaire : il s’agit de calculer la médiane de
manière précise, en l’encadrant par les valeurs entre lesquelles elle est comprise.
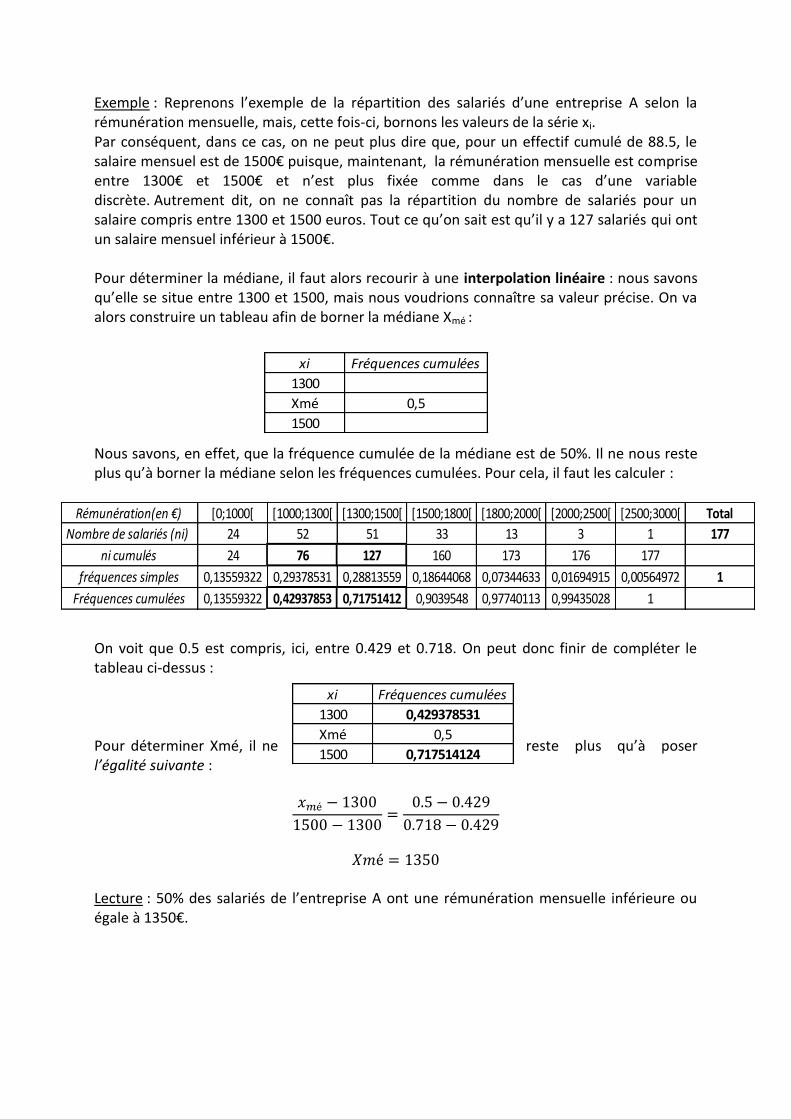
xi Fréquences cumulées
1300
Xmé 0,5
1500
Rémunération(en €) [0;1000[ [1000;1300[ [1300;1500[ [1500;1800[ [1800;2000[ [2000;2500[ [2500;3000[ Total
Nombre de salariés (ni) 24 52 51 33 13 3 1 177
ni cumulés 24 76 127 160 173 176 177
fréquences simples 0,13559322 0,29378531 0,28813559 0,18644068 0,07344633 0,01694915 0,00564972 1
Fréquences cumulées 0,13559322 0,42937853 0,71751412 0,9039548 0,97740113 0,99435028 1
xi Fréquences cumulées
1300 0,429378531
Xmé 0,5
1500 0,717514124
Exemple : Reprenons l’exemple de la répartition des salariés d’une entreprise A selon la rémunération mensuelle, mais, cette fois-ci, bornons les valeurs de la série xi. Par conséquent, dans ce cas, on ne peut plus dire que, pour un effectif cumulé de 88.5, le salaire mensuel est de 1500€ puisque, maintenant, la rémunération mensuelle est comprise entre 1300€ et 1500€ et n’est plus fixée comme dans le cas d’une variable discrète. Autrement dit, on ne connaît pas la répartition du nombre de salariés pour un salaire compris entre 1300 et 1500 euros. Tout ce qu’on sait est qu’il y a 127 salariés qui ont un salaire mensuel inférieur à 1500€. Pour déterminer la médiane, il faut alors recourir à une interpolation linéaire : nous savons qu’elle se situe entre 1300 et 1500, mais nous voudrions connaître sa valeur précise. On va alors construire un tableau afin de borner la médiane Xmé : Nous savons, en effet, que la fréquence cumulée de la médiane est de 50%. Il ne nous reste plus qu’à borner la médiane selon les fréquences cumulées. Pour cela, il faut les calculer :
On voit que 0.5 est compris, ici, entre 0.429 et 0.718. On peut donc finir de compléter le tableau ci-dessus : Pour déterminer Xmé, il ne reste plus qu’à poser l’égalité suivante :
Lecture : 50% des salariés de l’entreprise A ont une rémunération mensuelle inférieure ou égale à 1350€.

Nombre de parts égales Nom du quantile Nombre
100 Centile 99
10 Décile 9
5 Quintile 4
4 Quartile 3
2 Médiane 1
Revenu disponible [0;1000[ [1000;1500[ [1500;2000[ [2000;2500[ [2500;3000[ [3000;5000[ Total
Nombre de ménages (en milliers) 120 200 250 170 60 30 830
Revenu disponible [0;1000[ [1000;1500[ [1500;2000[ [2000;2500[ [2500;3000[ [3000;5000[ Total
Nombre de ménages (en milliers) 120 200 250 170 60 30 830
Fréquences simples 0,14457831 0,24096386 0,30120482 0,20481928 0,07228916 0,03614458 1
Fréquences cumulées 0,14457831 0,38554217 0,68674699 0,89156627 0,96385542 1
6) Les quantiles
Définition : ce sont les valeurs maximales xi de la variable qui partagent la série en « n » parts
égales.
Il en existe plusieurs de noms différents :
L’étude exhaustive de tous les quantiles serait inutile et trop longue. Nous allons alors nous
concentrer sur les 2 plus importants : décile et quartile.
Les déciles : ce sont les valeurs maximales xi qui partagent la série en 10 parts égales c’est-à-
dire en 10 parts de même effectif. On les note « Di ».
Généralement, on calcule le premier décile D1 et le dernier décile D9, surtout lorsqu’on désire
étudier les inégalités économiques. Le calcul des déciles n’apporte aucune utilité en tant que
tel. C’est pour cela qu’habituellement, on compare D1 et D9 afin d’apporter une information
supplémentaire aux simples calculs de déciles.
La méthode de détermination est exactement la même que pour la médiane : une
détermination « directe » si la variable est discrète, ou bien une interpolation linéaire si la
variable est continue.
Lecture : Elle dépend évidemment du décile auquel on s’intéresse.
D1 : 10% de (nom de l’effectif) ont un (variable xi) inférieur ou égal à (D1).
D2 : 20% de (nom de l’effectif) ont un (variable xi) inférieur ou égal à (D2).
…….
…….
D9 : 90% de (nom de l’effectif) ont un (variable xi) inférieur ou égal à (D9).
Remarque : Dire que 10% des effectifs ont une valeur inférieure à D1 revient à dire que 90%
des effectifs ont une valeur supérieure à D1. De même, dire que 90% des effectifs ont une
valeur inférieure à D9 revient à dire que 10% des effectifs ont une valeur supérieure à D9.
Exemple : Soit la répartition des ménages français selon le revenu disponible mensuel, en 2000.
Calcul du premier décile D1 : il faut recourir à une interpolation linéaire.

Xi Fi
0 0
D1 0,1
1000 0,145
On peut construire un tableau en encadrant le premier décile D1 :
En posant une égalité, on peut facilement déterminer la valeur de D1 :
Lecture : En 2000, 10% des ménages français avait un revenu disponible inférieur à 690€ ; ou en 2000, 90% des ménages français avait un revenu disponible supérieur à 690€.
- Calcul du dernier décile D9 : par la même méthode, on finit par trouver :
Lecture : En 2000, 90% des ménages français avait un revenu disponible inférieur à 2556€ ; ou en 2000, 10% des ménages français avait un revenu disponible supérieur à 2556€. Le simple calcul de D1 et D9 n’a pas grande utilité. Cependant, la comparaison des deux valeurs apporte des informations intéressantes. En effet, on peut calculer deux éléments dans ce sens :
Intervalle inter-décile = D9 – D1 = 1866. Lecture : En 2000, les 10% des ménages français les plus aisés avaient un revenu disponible supérieur de 1866€ à celui des 10% des ménages les plus pauvres.
Rapport inter-décile : D9/D1 = 2556/690 = 3.7 Lecture : En 2000, les 10% des ménages français les plus aisés avaient un revenu disponible 3,7 fois supérieur à celui des 10% des ménages les plus pauvres. Remarque : On utilise plus souvent le rapport inter-décile dans la comparaison des déciles,
étant donné son caractère relatif et non absolu comme le premier. Ce rapport est d’ailleurs
très utile dans l’étude des inégalités économiques et sociales.
Les quartiles : ce sont les valeurs maximales xi qui partagent la série en 4 parts égales c’est-
à-dire en 4 parts de même effectif. On les note « Qi ».
Généralement, on calcule le premier quartile Q1 et le troisième quartile Q3.
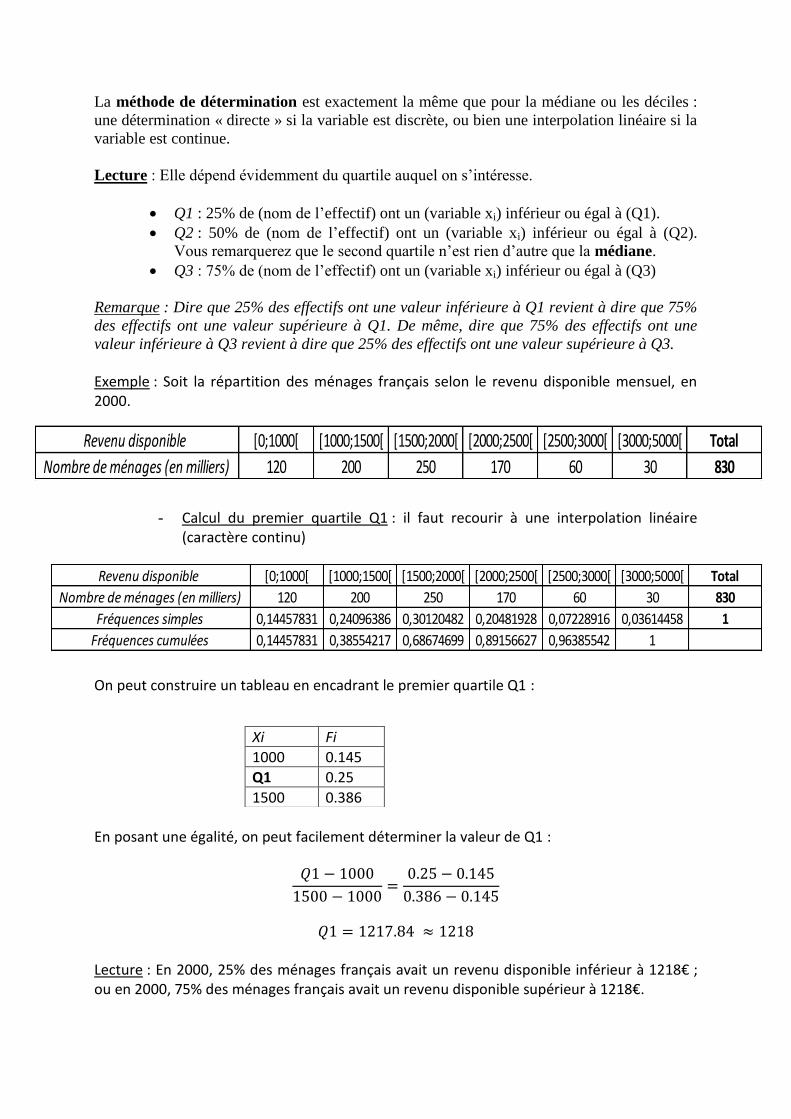
Revenu disponible [0;1000[ [1000;1500[ [1500;2000[ [2000;2500[ [2500;3000[ [3000;5000[ Total
Nombre de ménages (en milliers) 120 200 250 170 60 30 830
Revenu disponible [0;1000[ [1000;1500[ [1500;2000[ [2000;2500[ [2500;3000[ [3000;5000[ Total
Nombre de ménages (en milliers) 120 200 250 170 60 30 830
Fréquences simples 0,14457831 0,24096386 0,30120482 0,20481928 0,07228916 0,03614458 1
Fréquences cumulées 0,14457831 0,38554217 0,68674699 0,89156627 0,96385542 1
La méthode de détermination est exactement la même que pour la médiane ou les déciles :
une détermination « directe » si la variable est discrète, ou bien une interpolation linéaire si la
variable est continue.
Lecture : Elle dépend évidemment du quartile auquel on s’intéresse.
Q1 : 25% de (nom de l’effectif) ont un (variable xi) inférieur ou égal à (Q1).
Q2 : 50% de (nom de l’effectif) ont un (variable xi) inférieur ou égal à (Q2).
Vous remarquerez que le second quartile n’est rien d’autre que la médiane.
Q3 : 75% de (nom de l’effectif) ont un (variable xi) inférieur ou égal à (Q3)
Remarque : Dire que 25% des effectifs ont une valeur inférieure à Q1 revient à dire que 75%
des effectifs ont une valeur supérieure à Q1. De même, dire que 75% des effectifs ont une
valeur inférieure à Q3 revient à dire que 25% des effectifs ont une valeur supérieure à Q3.
Exemple : Soit la répartition des ménages français selon le revenu disponible mensuel, en 2000.
- Calcul du premier quartile Q1 : il faut recourir à une interpolation linéaire
(caractère continu)
On peut construire un tableau en encadrant le premier quartile Q1 :
En posant une égalité, on peut facilement déterminer la valeur de Q1 :
Lecture : En 2000, 25% des ménages français avait un revenu disponible inférieur à 1218€ ; ou en 2000, 75% des ménages français avait un revenu disponible supérieur à 1218€.
Xi Fi
1000 0.145
Q1 0.25
1500 0.386

- Calcul du troisième quartile Q3 : par la même méthode, on finit par trouver :
Lecture : En 2000, 75% des ménages français avait un revenu disponible inférieur à 2154€ ; ou en 2000, 25% des ménages français avait un revenu disponible supérieur à 2154€. Comme pour les déciles, nous pouvons mettre en rapport le premier et le troisième quartile :
Intervalle interquartile : il s’agit de l’intervalle [Q1 ; Q3] Dans notre exemple, l’intervalle est donné par : [1218 ; 2154]
7) La variance et l’écart-type : l’étude de la dispersion
Nous arrivons à ce qui constitue certainement le plus difficile de l’analyse statistique, du
moins pour la plupart des étudiants. En effet, le calcul ainsi que l’interprétation de la variance
n’est pas chose aisée à première vue. Cependant, nous allons voir qu’en réalité, il faut juste un
peu de méthode et une bonne explication.
Commençons par des définitions « conventionnelles » :
- « Variance » : La variance mesure la dispersion de la variable autour de la
moyenne théorique.
- « Ecart-type » : Il s’agit de la racine carrée de la variance.
Voici ce que nous disent la plupart des manuels de statistiques, au moins les manuels de
« professionnels ».
Pour comprendre, plus facilement, la variance et l’écart-type, prenons un exemple concret :
Supposons deux élèves de première année de licence en économie-gestion, ayant passé
leurs examens du premier semestre. Appelons le premier élève X et le second Y. Au vu des résultats, les deux élèves s’aperçoivent que leur moyenne est de 10/20. Les élèves pourraient, à priori, se dire qu’ils ont obtenu, « grosso modo » les mêmes notes aux examens. Mais, il se peut qu’il n’en soit pas ainsi. Après avoir regardé leurs relevés de notes respectifs, les deux élèves confrontent leurs notes. Pour simplifier, on supposera qu’ils ont passé seulement 4 examens : E1, E2, E3 et E4. Chaque examen représente le même coefficient. Voici le tableau récapitulant les notes des deux élèves aux 4 examens :
E1 E2 E3 E4
X 2 3 17 18
Y 8 9 12 11

En regardant ce tableau, les élèves peuvent être surpris des notes obtenues par l’autre : comment quelqu’un ayant eu des 2 et 3/20 peut-il avoir la même moyenne que moi, c’est-à-dire 10/20 ? Regardons de plus près ce tableau : nous sommes d’abord tous d’accord pour dire que ces deux élèves ont eu la même moyenne, c’est-à-dire 10/20. En effet, si nous calculons la moyenne de X et de Y, nous obtenons :
Nous commençons à y voir un peu plus clair. En effet, comparez les notes et vous verrez un phénomène apparaître très simplement : il s’agit d’un « effet de compensation ». Bien sur, X a eu de plus faibles notes à E1 et E2 que Y, mais n’oublions que c’est l’inverse pour E3 et E4. Nous voyons alors que les faibles notes aux deux premiers examens de X (2 et 3/20) ont été largement compensées par les notes élevées aux deux derniers examens (17 et 18/20). Les faibles notes sont compensées par les notes élevées, ce qui, au final, ramène la moyenne au milieu, c’est-à-dire à 10/20. Pour Y, le phénomène est pareil : les notes proches de 10 mais inférieurs à 10 (8 et 9/20) ont été compensées par les notes proches de 10 mais supérieurs à 10 (11 et 12/20), ce qui ramène la moyenne également à 10/20. La compensation fait donc que deux élèves, aux notes très différentes, peuvent obtenir la même moyenne.
Mais, quel rapport avec notre sujet traité ici ?
A ce stade, nous avons compris que la même moyenne peut être obtenue avec des notes très différentes entre les élèves. Si nous regardons ce phénomène par un simple graphique, voici ce que l’on peut dire :
Représentation des notes de X :
2 3 10 17 18
Représentation des notes de Y :
8 9 10 11 12
Je pense que tout le monde, à ce stade, peut faire un constat très simple : nous voyons, en effet, que l’écart entre la moyenne et les notes obtenues est bien plus grand pour X que pour Y, malgré la même moyenne chez les deux. Lorsqu’on parle d’écart entre la moyenne et les notes obtenues, on se réfère directement à ce qu’on appelle la « dispersion de la variable ». La dispersion mesure l’écart moyen entre la moyenne et les valeurs de la variable. Ainsi, dans notre exemple, puisque l’écart est plus grand chez X, on dira que la dispersion de la variable est plus élevée chez

ce dernier. On s’aperçoit que les notes obtenues par Y voyagent autour de la moyenne (sont proches si vous préférez), ce qui constitue une dispersion plus faible. Vous voyez donc qu’une même moyenne peut faire l’objet de dispersions très différentes. La variance et l’écart-type ne font que mesurer cette dispersion de la variable autour de la moyenne, c’est-à-dire l’écart entre la première et les valeurs de la variable. Plus une variable est dispersée et plus sa variance (écart-type) sera élevée.
Méthodes de calcul :
Maintenant que nous comprenons mieux ce qu’est la variance et l’écart-type, nous pouvons
peut-être passer aux méthodes de calcul de ces deux éléments :
Variance =
ou
Ecart-type =
Une question apparaît directement : pourquoi calculer la racine carrée de la variance ?
Reprenons l’exemple précédent : calculons la variance des deux élèves X et Y
Variance de X ou V(X) =
Variance de Y ou V(Y) =
Ouffff ! Les résultats coïncident avec les explications : X a bien une variance (dispersion) plus
élevée que Y. Mais, que signifient 56.5 et 2.5 ?
Simplement que l’écart moyen AU CARRE entre la moyenne et les notes obtenues est de
56.5 pour X et de 2.5 pour Y. Ce qui signifie que la variance mesure l’écart entre la moyenne
et les notes mais cet écart est exprimé au carré c’est-à-dire en unités carrées. Mais quel intérêt
fondamental a-t-on à lire des notes au carré ? Ceci n’a pas grand intérêt et grande
signification…..
C’est pour cette raison que l’on calcule l’écart-type, afin que l’écart soit exprimé dans la
même unité que la variable étudiée, à savoir les notes (tout court…..). L’interprétation et la
lecture des résultats a directement plus de sens, non ??? Je vais vous en convaincre :
Ecart-type de X =
Ecart-type de Y =
Voilà un résultat qui a du sens : l’écart moyen entre la moyenne et les notes obtenues est de
7.52 (/20) pour X et de 1.58 (/20) pour Y
Graphiquement, voici ce qui ceci signifie

Représentation des notes de X : ≈ 7.52 ≈ 7.52
2 3 10 17 18 Représentation des notes de Y :
≈1.58 ≈ 1.58
8 9 10 11 12
En conclusion, pour interpréter la dispersion de la variable, on privilégiera toujours l’écart-
type, dont les unités sont les mêmes que cette dernière.
8) L’indice de Gini et la Courbe de Lorenz : l’étude de la concentration
L’étude de la concentration renvoi directement à l’étude des inégalités. Lorsqu’on parle d’une
variable très concentrée, on ne fait que dire que la répartition de la variable est très
inégalitaire. Ainsi, plus une variable est concentrée, plus il y a d’inégalités. Mais inégalités de
quoi ?
Prenons un exemple pour voir de quoi parle-t-on : supposons que l’on étudie le revenu mensuel de 1400 ménages français en 2010. On supposera que cet échantillon est représentatif de tous les ménages français. Voici la répartition du revenu :
Revenu [400 ; 900[ [900 ; 1300[ [1300 ; 1600[ [1600 ; 2000[ [2000 ; 2500[ Total
Effectifs 200 300 550 260 90 1400
Au premier abord, nous ne pouvons absolument pas dire, ici, que la répartition du revenu est inégalitaire. Ce n’est pas qu’elle ne l’est pas, mais c’est juste, qu’avec ces éléments, nous ne pouvons rien en conclure. En effet, ce n’est pas parce que 550 ménages gagnent entre 1300 et 1600€ et 200 ménages entre 400 et 900€, que nous pouvons conclure que la répartition totale du revenu de la France est inégalitaire. La seule façon de le savoir est d’étudier la part du revenu total que reçoit chaque fraction de la population française, c’est-à-dire la part de la « masse salariale » dont bénéficie chaque fraction des ménages français. Ainsi, si une très petite fraction des ménages reçoit la quasi-totalité du revenu de la France, alors nous pourrons dire que la répartition est inégalitaire. Ce qu’il faut donc calculer, c’est la part de la masse salariale de chaque fraction des ménages français.
Mais avant de calculer la part de la masse salariale, encore faut-il déterminer cette
dernière…..

Masse salariale = Effectifs * Centre de classe
Revenu [400 ; 900[ [900 ; 1300[ [1300 ; 1600[ [1600 ; 2000[ [2000 ; 2500[ Total
Effectifs 200 300 550 260 90 1400
Centre classe
650 1100 1450 1800 2250
Masse salariale
130000 330000 797500 468000 202500 1928000
Nous pouvons alors en déduire la part de la masse salariale pour chaque fraction de revenus.
On les appelle habituellement les « gi ». Il s’agit du même calcul que les fréquences simples
mais, cette fois, en utilisant la masse salariale et non plus les effectifs seuls.
Revenu [400 ; 900[ [900 ; 1300[ [1300 ; 1600[ [1600 ; 2000[ [2000 ; 2500[ Total
Effectifs 200 300 550 260 90 1400
Centre classe
650 1100 1450 1800 2250
Masse salariale
130000 330000 797500 468000 202500 1928000
gi 0.067 0.171 0.414 0.243 0.105 1
Déterminons maintenant la part cumulée de la masse salariale : nous verrons après pourquoi
elle est fondamentale pour comprendre la concentration. On l’appelle « Gi ». Il s’agit du
même calcul que les fréquences cumulées mais, au lieu d’utiliser les fi, on utilise les gi.
Il suffit d’additionner les parts les unes après les autres :
Revenu [400 ; 900[ [900 ; 1300[ [1300 ; 1600[ [1600 ; 2000[ [2000 ; 2500[ Total
gi 0.067 0.171 0.414 0.243 0.105 1
Gi 0.067 0.238 0.652 0.895 1
Fi 0.143 0.357 0.75 0.936 1
Nous en venons au plus intéressant : la comparaison des fréquences cumulées et de la part cumulée de la masse salariale. Voici comment interpréter les valeurs :
- 14.3 % des ménages français reçoivent 6.7% de la masse salariale totale.
- 35.7% des ménages français reçoivent 23.8% de la masse salariale totale.
- …
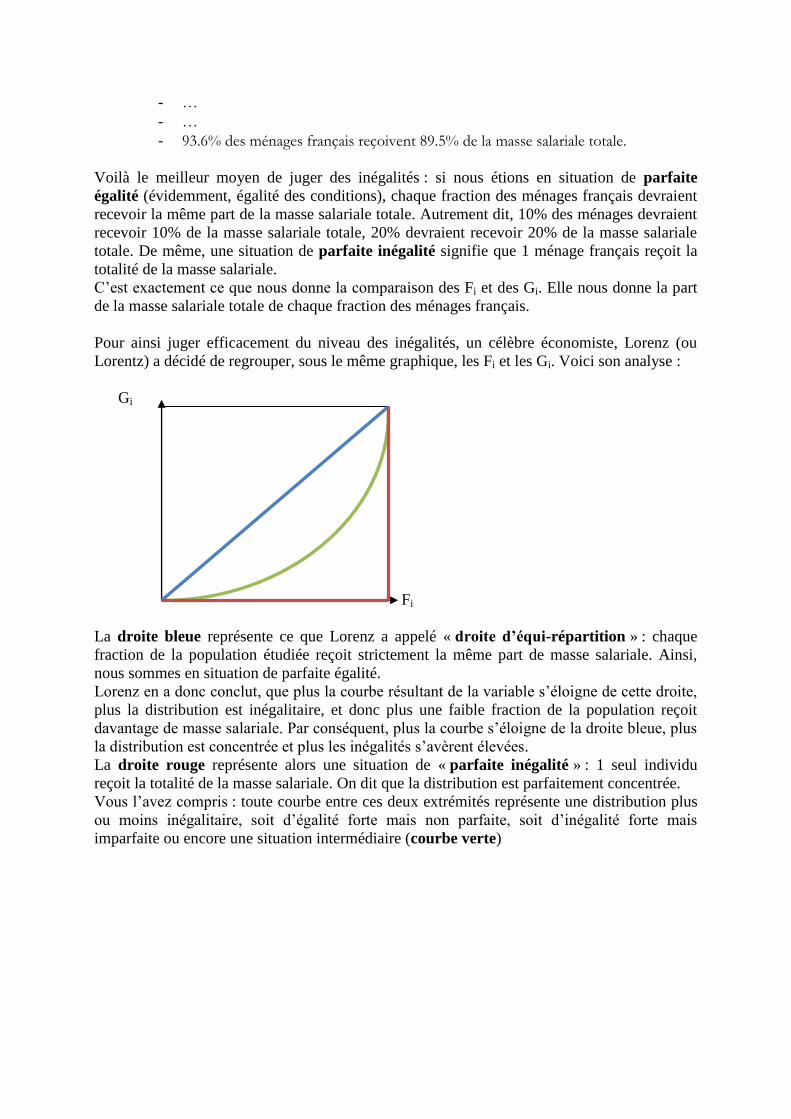
- …
- …
- 93.6% des ménages français reçoivent 89.5% de la masse salariale totale.
Voilà le meilleur moyen de juger des inégalités : si nous étions en situation de parfaite
égalité (évidemment, égalité des conditions), chaque fraction des ménages français devraient
recevoir la même part de la masse salariale totale. Autrement dit, 10% des ménages devraient
recevoir 10% de la masse salariale totale, 20% devraient recevoir 20% de la masse salariale
totale. De même, une situation de parfaite inégalité signifie que 1 ménage français reçoit la
totalité de la masse salariale.
C’est exactement ce que nous donne la comparaison des Fi et des Gi. Elle nous donne la part
de la masse salariale totale de chaque fraction des ménages français.
Pour ainsi juger efficacement du niveau des inégalités, un célèbre économiste, Lorenz (ou
Lorentz) a décidé de regrouper, sous le même graphique, les Fi et les Gi. Voici son analyse :
Gi
Fi
La droite bleue représente ce que Lorenz a appelé « droite d’équi-répartition » : chaque
fraction de la population étudiée reçoit strictement la même part de masse salariale. Ainsi,
nous sommes en situation de parfaite égalité.
Lorenz en a donc conclut, que plus la courbe résultant de la variable s’éloigne de cette droite,
plus la distribution est inégalitaire, et donc plus une faible fraction de la population reçoit
davantage de masse salariale. Par conséquent, plus la courbe s’éloigne de la droite bleue, plus
la distribution est concentrée et plus les inégalités s’avèrent élevées.
La droite rouge représente alors une situation de « parfaite inégalité » : 1 seul individu
reçoit la totalité de la masse salariale. On dit que la distribution est parfaitement concentrée.
Vous l’avez compris : toute courbe entre ces deux extrémités représente une distribution plus
ou moins inégalitaire, soit d’égalité forte mais non parfaite, soit d’inégalité forte mais
imparfaite ou encore une situation intermédiaire (courbe verte)

Reprenons notre exemple et traçons la courbe de Lorenz :
Que peut-on en conclure ? Nous voyons que la droite bleue, notre courbe de concentration, est relativement proche de la droite d’équi-répartition. Ainsi, nous pouvons en conclure que la distribution est faiblement concentrée, donc faiblement inégalitaire. Chaque fraction des ménages français reçoit approximativement la même part de masse salariale.
Indice de Gini :
Gini est un économiste et statisticien qui a tenté de compléter la courbe de Lorenz, la
jugeant insuffisante sur un point : le calcul mathématique de la concentration. En effet, la
courbe de Lorenz n’est qu’une approximation du degré d’inégalités. Mais nous ne pouvons
déterminer précisément ce degré. C’est ce que Gini a tenté de faire. Il pensait que le meilleur
moyen de juger précisément du niveau d’inégalités était de calculer, mathématiquement, la
concentration de la variable. Il a donc établi un indice mathématique, à partir de la courbe de
Lorenz, qui permet de juger efficacement du niveau des inégalités.
La méthode est très simple : le degré d’inégalités correspond à la surface comprise entre la
droite d’équi-répartition et la courbe de Lorenz (surface entre la droite bleue et la courbe
verte).
Cette surface est comprise entre 0 et 1. Un indice proche de 0 signifie une situation de forte
égalité alors qu’un indice proche de 1 correspond à une situation fortement inégalitaire.
Ainsi, l’indice de Gini est beaucoup plus précis que la simple observation de la courbe de
Lorenz.
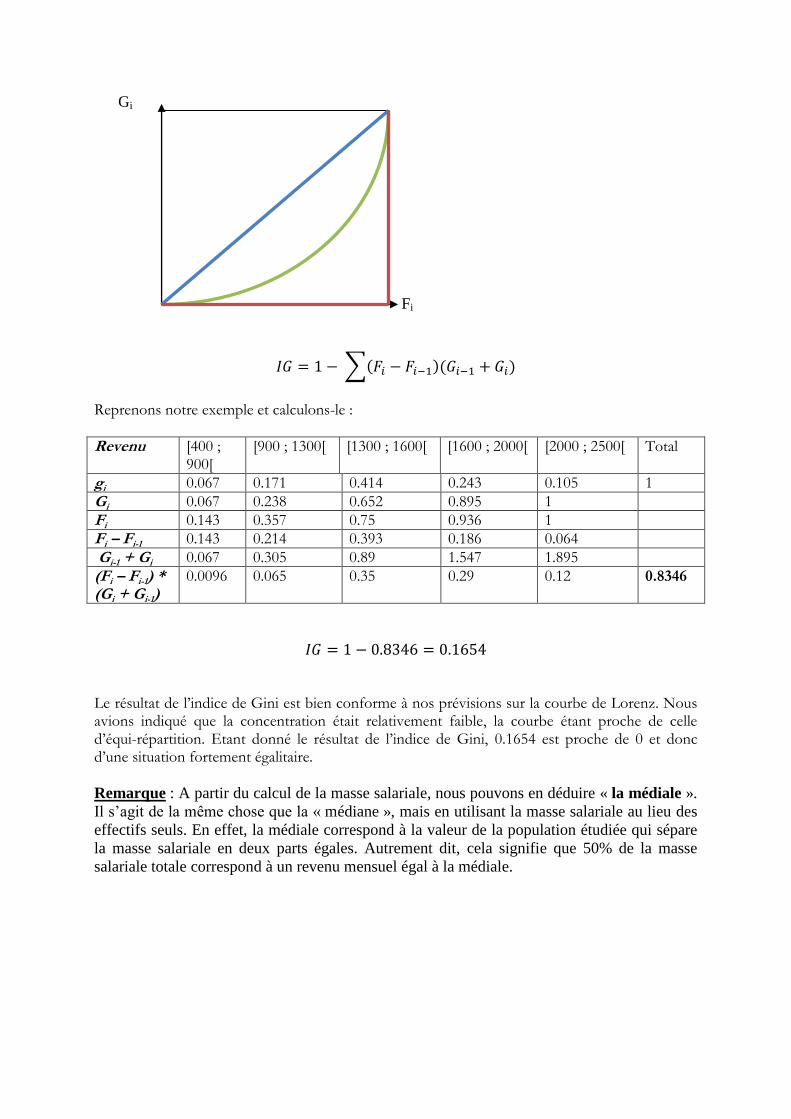
Gi
Fi
Reprenons notre exemple et calculons-le :
Revenu [400 ; 900[
[900 ; 1300[ [1300 ; 1600[ [1600 ; 2000[ [2000 ; 2500[ Total
gi 0.067 0.171 0.414 0.243 0.105 1
Gi 0.067 0.238 0.652 0.895 1
Fi 0.143 0.357 0.75 0.936 1
Fi – Fi-1 0.143 0.214 0.393 0.186 0.064
Gi-1 + Gi 0.067 0.305 0.89 1.547 1.895
(Fi – Fi-1) * (Gi + Gi-1)
0.0096 0.065 0.35 0.29 0.12 0.8346
Le résultat de l’indice de Gini est bien conforme à nos prévisions sur la courbe de Lorenz. Nous avions indiqué que la concentration était relativement faible, la courbe étant proche de celle d’équi-répartition. Etant donné le résultat de l’indice de Gini, 0.1654 est proche de 0 et donc d’une situation fortement égalitaire.
Remarque : A partir du calcul de la masse salariale, nous pouvons en déduire « la médiale ».
Il s’agit de la même chose que la « médiane », mais en utilisant la masse salariale au lieu des
effectifs seuls. En effet, la médiale correspond à la valeur de la population étudiée qui sépare
la masse salariale en deux parts égales. Autrement dit, cela signifie que 50% de la masse
salariale totale correspond à un revenu mensuel égal à la médiale.

Le calcul s’avère le même que celui de n’importe quel quantile : il s’agit de procéder à une
interpolation linéaire. A partir de notre exemple précédent, nous pouvons en déduire :
Xi Gi
1300 0.238
Mél 0.5
1600 0.652
Par une interpolation linéaire, nous pouvons poser :
é
é Interprétation : 50% de la masse salariale totale correspond à un revenu mensuel de 1490 €.