Embed Size (px)
Citation preview

1
Cahier de Mathématiques Appliquées no11
Chaînes de Markov
B. Ycart
Un modèle d’évolution dynamique en temps discret dans lequel on fait dé-pendre l’évolution future de l’état présent et du hasard est une chaîne deMarkov. On en rencontre dans de nombreux domaines d’applications, dessciences de la vie à l’informatique. Ces notes traitent surtout les chaînes àespaces d’états finis, et mettent l’accent sur le traitement algébrique à partirdes matrices de transition. Le matériel présenté reste à un niveau élémen-taire, et se trouve dans la plupart des références classiques, comme les livressuivants.
N. Bouleau Processus stochastiques et applications.Hermann, Paris, 1988.
W. Feller Introduction to probability theory and its applications, Vol. 1.Wiley, London, 1968.
J.G. Kemeny, L. Snell Finite Markov chains.Van Nostrand, Princeton, 1960.
Ce “cahier de mathématiques appliquées” doit beaucoup aux relecturesscrupuleuses de Romain Abraham, au dynamisme de Sylvie Sevestre-Ghalila,au soutien de l’Ecole Supérieure de la Statistique et de l’Analyse de l’Infor-mation de Tunisie, par son directeur Makki Ksouri et son directeur des étudesNacef Elloumi, ainsi qu’à la compétence de Habib Bouchriha, directeur duCentre des Publications Universitaires de la Tunisie.

2 Cahier de Mathématiques Appliquées no 11
Table des matières
1 Modèles markoviens 3
1.1 Définition algorithmique . . . . . . . . . . . . . . . . . . . . . 31.2 Espace d’états fini ou dénombrable . . . . . . . . . . . . . . . 51.3 Informatique . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.4 Génétique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111.5 Planification économique . . . . . . . . . . . . . . . . . . . . . 13
2 Traitement mathématique 14
2.1 Formules récurrentes . . . . . . . . . . . . . . . . . . . . . . . 142.2 Classification des états . . . . . . . . . . . . . . . . . . . . . . 192.3 Mesures stationnaires . . . . . . . . . . . . . . . . . . . . . . 242.4 Comportement asymptotique . . . . . . . . . . . . . . . . . . 292.5 Mesures réversibles . . . . . . . . . . . . . . . . . . . . . . . . 32
3 Modèles sur IN 36
3.1 Le problème de la ruine du joueur . . . . . . . . . . . . . . . 363.2 Un modèle simple de file d’attente . . . . . . . . . . . . . . . 403.3 Le problème de l’extinction du nom . . . . . . . . . . . . . . 44
4 Exercices 48

Chaînes de Markov 3
1 Modèles markoviens
1.1 Définition algorithmique
Une chaîne de Markov est classiquement définie comme une suite de va-riables aléatoires pour laquelle la meilleure prédiction que l’on puisse fairepour l’étape n+1 si on connaît toutes les valeurs antérieures est la mêmeque si on ne connaît que la valeur à l’étape n (le futur et le passé sont indé-pendants conditionnellement au présent). Nous partons ici d’une définitionmoins classique, mais plus proche des applications.
Définition 1.1 Soit E un espace mesurable. Une chaîne de Markov sur Eest une suite de variables aléatoires (Xn) , n∈IN à valeurs dans E telle qu’ilexiste :
1. une suite (Un) , n∈IN de variables aléatoires indépendantes et de mêmeloi, à valeurs dans un espace probabilisé U ,
2. une application mesurable Φ de IN× E × U dans E vérifiant :
∀n ∈ IN , Xn+1 = Φ(n,Xn, Un) .
On distingue plusieurs cas particuliers.• Si l’application Φ ne dépend pas de n, la chaîne est dite homogène.• Si l’application Φ ne dépend pas de x, la chaîne est une suite de va-
riables indépendantes. Si Φ ne dépend ni de n ni de x, ces variablesindépendantes sont de plus identiquement distribuées.
• Si l’application Φ ne dépend pas de u, Φ définit un système itératif.La chaîne est une suite récurrente (déterministe si sa valeur initiale estdéterministe).
Toutes les chaînes de Markov que nous considérons ici sont homogènes. Onpeut toujours passer du cas non homogène au cas homogène en remplaçantXn par le couple (n,Xn).
C’est évidemment aux appels d’un générateur pseudo-aléatoire qu’il fautpenser pour la suite (Un) de la définition 1.1. Nous désignons par Randomun générateur pseudo-aléatoire, qui “retourne des réels au hasard entre 0 et1”. En d’autres termes, nous supposons que tout vecteur constitué d’appelssuccessifs de Random est une réalisation d’un vecteur de variables aléatoiresindépendantes et de même loi, uniforme sur l’intervalle [0, 1].
En pratique une chaîne de Markov est simulée de manière itérative commele dit la définition 1.1. Une initialisation dans E est d’abord choisie (aléatoireou non). Puis chaque nouveau pas est simulé selon une loi de probabilitédépendant du point atteint précédemment. Cette simulation utilise un ouplusieurs appels de Random successifs, qui constituent la variable Un.

4 Cahier de Mathématiques Appliquées no 11
En toute rigueur, les chaînes de Markov au sens de la définition 1.1 de-vraient s’appeler “chaînes de Markov simulables”. Elles vérifient la propriétésuivante, dite “propriété de Markov”.
Proposition 1.2 Soit (Xn), n∈IN une chaîne de Markov.Pour tout n ≥ 0 et pour toute suite d’états i0, . . . , in ∈ E, la loi conditionnellede Xn+1 sachant “X0 = i0, . . . , Xn = in” est égale à la loi conditionnelle deXn+1 sachant “Xn = in”.
Démonstration : Notons IP la loi de probabilité conjointe de X0 et de la suite(Un). D’après la définition 1.1, Un est indépendante de X0, . . . , Xn. Pour toutsous ensemble mesurable B de E, on a :
IP[Xn+1 ∈ B |X0 = i0, . . . , Xn = in]
= IP[Φ(Xn, Un) ∈ B |X0 = i0, . . . , Xn = in]
= IP[Φ(in, Un) ∈ B]
= IP[Xn+1 ∈ B |Xn = in] .
�
Cette propriété d’“oubli du passé” constitue la définition classique des chaînesde Markov. Il est naturel de se demander s’il existe des chaînes de Markov,au sens de la proposition 1.2, qui ne soient pas simulables. Il n’en existe passi E est dénombrable, ou si E est IRd, muni de sa tribu de boréliens. On n’enrencontrera donc jamais en pratique.
Exemple : Marches aléatoires.
Soit (Un), n∈IN une suite de variables aléatoires indépendantes et de mêmeloi sur IRd. La suite de variables aléatoires (Xn), n∈ IN définie par X0 ∈ IRd
et :
∀n , Xn+1 = Xn + Un ,
est une chaîne de Markov. Comme cas particulier, si Un suit la loi normaleNd(0, hId), on obtient une discrétisation du mouvement brownien standardsur IRd (figure 1).
Plus généralement, soit (G, ∗) un groupe topologique quelconque, muni desa tribu des boréliens. Soit π une loi de probabilité sur G, et (Un) une suitede variables aléatoires de même loi π sur G. La suite de variables aléatoiresdéfinie par X0 ∈ G et pour tout n ≥ 0 :
Xn+1 = Xn ∗ Un ,
est une chaîne de Markov sur G, dite “marche aléatoire de pas π”. Les marchesaléatoires sur les groupes constituent un cas particulier important des chaînesde Markov.
Chaînes de Markov 5
-10 -5 0 5 10-10
-5
0
5
10
.
Brownien standard dans le plan
Figure 1 – Mouvement brownien standard dans le plan : trajectoire jusqu’ent = 10.
1.2 Espace d’états fini ou dénombrable
Lorsque E = {i, j, . . .} est un ensemble fini ou dénombrable, la loi dela variable aléatoire Φ(n, i, Un) (définition 1.1) avec laquelle on tire le pasn+1 à partir du pas n, est habituellement notée sous forme matricielle. Si lachaîne est homogène, cette loi ne dépend pas de n. Dans ce cas, on note pijla probabilité de choisir l’état j à partir de l’état i :
pij = IP[Φ(i, Un) = j] = IP[Xn+1 = j |Xn = i] , ∀i, j ∈ E .
Dans la relation ci-dessus, IP désigne encore la loi conjointe de X0 et de lasuite (Un). La probabilité pij porte le nom de “probabilité de transition de ià j”. La matrice :
P = (pij)i,j∈E ,
est la matrice de transition de la chaîne. Dans ce qui suit, la définition usuelledes matrices est étendue au cas dénombrable, les vecteurs indicés par E sontdes vecteurs colonnes. La matrice de transition a des coefficients positifs ounuls, et la somme des éléments d’une même ligne vaut 1. Comme nous le ver-rons dans les exemples des paragraphes suivants, il arrive fréquemment dansles applications que pour un état i donné, le nombre d’états j directementaccessibles depuis i (tels que pij > 0) soit faible. La matrice de transition estalors très creuse (elle contient beaucoup de zéros). Il est plus économique derésumer les probabilités de transitions par le diagramme de transition. C’estun graphe orienté et pondéré, dont l’ensemble des sommets est E. Une arête
6 Cahier de Mathématiques Appliquées no 11
de poids pij va de i à j si pij > 0 (voir par exemple les figures 3, section 2.2et 4, section 2.4).
Exemple : Marche aléatoire symétrique sur un graphe.
Supposons E muni d’une structure de graphe non orienté G = (E,A), où A
-20 -10 0 10 20-20
-10
0
10
20
.
Marche symetrique dans le plan
Figure 2 – Marche aléatoire symétrique dans le plan : 200 pas, partant del’origine.
désigne l’ensemble des arêtes :
A ⊂{
{i, j} , i, j ∈ E}
.
Les sommets j tels que {i, j} ∈ A sont les voisins de i, et on suppose que leurnombre (le degré de i) est borné : on note r le degré maximal.
r = supi∈E
{∣
∣
∣{j ∈ E : {i, j} ∈ A}∣
∣
∣
}
,
où | · | désigne le cardinal d’un ensemble fini. Définissons la matrice de tran-sition P = (pij) par :
pij =1
rsi {i, j} ∈ A ,
= 0 si {i, j} /∈ A ,
les coefficients diagonaux étant tels que la somme des éléments d’une mêmeligne vaut 1. La chaîne de Markov de matrice de transition P s’appelle marchealéatoire symétrique sur le graphe G. Considérons par exemple E = ZZd, muni

Chaînes de Markov 7
de sa structure de réseau habituelle :
A ={
{i, j} ∈ (ZZd)2 , ‖i− j‖ = 1}
,
où ‖ · ‖ désigne la norme euclidienne. La marche aléatoire symétrique sur cegraphe (figure 2) est aussi une marche aléatoire sur le groupe (ZZd,+), dontle pas est la loi uniforme sur l’ensemble des 2d vecteurs de ZZd de norme 1.
Il existe une analogie étroite entre les chaînes de Markov symétriques et lesréseaux électriques. Les états de E sont vus comme les sommets d’un réseau,reliés par des lignes électriques. L’analogue de la probabilité de transition pijest la conductance (inverse de la résistance) de la ligne reliant i à j.
L’algorithme de simulation d’une chaîne de Markov homogène de matricede transition P est le suivant.
n←− 0Initialiser XRépéter
i←− X (état présent)choisir j avec probabilité pijX ←− j (état suivant)n←− n+1
Jusqu’à (arrêt de la simulation)
L’algorithme ci-dessus correspond bien à la définition 1.1, dans la mesure oùles choix successifs sont effectués à l’aide d’appels de Random renouvelés àchaque itération (considérés comme indépendants des précédents). Supposonspar exemple que la loi (pij)j∈E soit simulée par inversion. Notons :• Un le n-ième appel de Random.• Φ l’application de E× [0, 1] dans E qui au couple (i, u) associe l’inverse
de la fonction de répartition de la loi (pij)j∈E , évalué en u.L’algorithme calcule bien Xn+1 = Φ(Xn, Un).
Ceci a une portée plutôt théorique. Il ne faut pas en déduire que c’est forcé-ment par inversion que l’on doit simuler la loi (pij)j∈E . Dans certains cas unautre type de simulation (par exemple par rejet ou décomposition) pourras’avérer plus efficace.
Exemple : Voici une matrice de transition sur E = {a, b, c, d, e}.
P =
a b c d ea 0.2 0.2 0.2 0.2 0.2
b 0 0.2 0.3 0 0.5
c 0.3 0.3 0 0.4 0
d 0 0.3 0.3 0.3 0.1
e 0 1 0 0 0

8 Cahier de Mathématiques Appliquées no 11
L’algorithme ci-après simule une chaîne de Markov de matrice de transitionP . Il n’est pas optimal mais il illustre quelques méthodes standard. Dans lelogiciel Scilab, la fonction grand(n,’markov’,P,x0) retourne une réalisationdes n premiers pas d’une chaîne de Markov de matrice de transition P, partantde l’état initial x0.
Tableau E = [a, b, c, d, e]n←− 0Initialiser XRépéter
i←− X (état présent)Selon i
i = a : j ←− E[Random({1, . . . , 5})]
i = b : Choix ←− RandomSi (Choix < 0.5) alors j ←− e
sinon Si (Choix < 0.8) alors j ←− csinon j ←− b
finSifinSi
i = c : Choix ←− RandomSi (Choix < 0.4) alors j ←− d
sinon j ←− E[Random({1, 2})]finSi
i = d : RépéterTest ←− Vraij ←− E[Random({2, . . . , 5})]Si j = e alors
Si (Random > 1/3) alors Test ←− FauxfinSi
finSiJusqu’à (Test=Vrai)
i = e : j ←− b
finSelonX ←− j (état suivant)n←− n+1
Jusqu’à (arrêt de la simulation)
La loi d’une chaîne de Markov (Xn) est entièrement déterminée par ladonnée de la loi de X0 et de la matrice de transition P , au sens où pour toutn, la loi conjointe de (X0, . . . , Xn) s’exprime en fonction de la loi de X0 etde P .

Chaînes de Markov 9
Proposition 1.3 Soit (Xn) une chaîne de Markov homogène de matrice detransition P . Pour toute suite d’états i0, i1, . . . , in de E, on a :
IP[X0 = i0 et . . . et Xn = in] = IP[X0 = i0] pi0i1 . . . pin−1in .
Démonstration : La formule est vraie pour n = 0. Supposons-la vraie pour n.Si
IP[X0 = i0 et . . . et Xn = in] = 0 ,
alors pour tout in+1,
IP[X0 = i0 et . . . et Xn+1 = in+1] = 0 .
Sinon, on peut conditionner par “X0 = i0 et . . . et Xn = in” :
IP[X0 = i0 et . . . et Xn+1 = in+1]
= IP[Xn+1 = in+1 |X0 = i0 et . . . et Xn = in]IP[X0 = i0 et . . . et Xn = in]
= IP[Xn+1 = in+1 |Xn = in]IP[X0 = i0 et . . . et Xn = in]
= pinin+1IP[X0 = i0 et . . . et Xn = in] .
Le résultat est donc vrai à l’ordre n+ 1. �
Dans les paragraphes suivants, nous décrivons des exemples de chaînes deMarkov, intervenant dans différents types d’applications.
1.3 Informatique
Tout algorithme itératif faisant intervenir une source de nombres aléa-toires simule en fait une chaîne de Markov. Il n’est donc pas étonnant que lesapplications des chaînes de Markov en algorithmique soient nombreuses. Lepremier exemple que nous donnerons concerne la recherche de préfixes dansun fichier binaire.
On recherche un mot binaire donné dans un fichier. Quel sera le coût del’algorithme ? En algorithmique, on donne en général deux réponses à ce typede question : le cas le pire, et le cas le plus favorable. Ici les deux réponses sonttriviales : au mieux on trouvera le mot cherché immédiatement, au pire, on nele trouvera qu’à la fin du fichier. Comme dans de nombreux autres cas, uneanalyse probabiliste donne une réponse plus intéressante, car plus proche dessituations rencontrées en pratique. L’analyse probabiliste d’un algorithmeconsiste à supposer que l’entrée est aléatoire, et à déterminer la loi de lavariable égale au coût de l’algorithme pour cette entrée. Ici, supposons queles bits du fichier soient des variables aléatoires de même loi, uniforme sur{0, 1}. On peut reformuler le problème en termes du jeu de pile ou face. Si onjoue à pile ou face avec une pièce équilibrée, jusqu’à ce qu’apparaisse un motdonné de l’alphabet {P, F}, combien devra-t-on attendre ? Si deux joueurs

10 Cahier de Mathématiques Appliquées no 11
jouent chacun deux mots différents, jusqu’à ce que le premier des deux motsapparaisse, combien de temps le jeu durera-t-il ? Quelle est la probabilité degain de chacun des deux joueurs ? On répond à ces questions en étudiant deschaînes de Markov.
Soit (Un) la suite des tirages (indépendants de loi uniforme sur {0, 1}). SoitA = (ai)1≤i≤l le mot binaire cherché, de longueur l. Pour tout k = 1, . . . , l,on note Ak le mot A tronqué à ses k premières lettres :
∀k = 1, . . . , l , Ak = (ai)1≤i≤k .
Pour tout entier n on définit la variable aléatoire Xn, à valeurs dans {0, . . . , l}comme le nombre de bits parmi les derniers tirages jusqu’au n-ième qui coïn-cident avec le début de A.
Xn = 0 si n = 0 ou ∀k = 1, . . . , l (Un−k+1, . . . , Un) 6= Ak
Xn = k ∈ {1 . . . , l−1} si (Un−k+1, . . . , Un) = Ak
et (Un−k−i, . . . , Un) 6= Ak+i+1 , ∀i = 0, . . . , l−k−1
Xn = l si (Un−l+1, . . . , Un) = Al = A .
Un vérifie facilement que (Xn) est une chaîne de Markov. L’expression desprobabilités de transition pij dépend du mot A (cf. exercice 5). Le tempsd’atteinte du mot cherché est le premier indice n tel que Xn = l. Sa loidépend également du mot A.
Les chaînes de Markov interviennent aussi dans la modélisation du fonc-tionnement des réseaux informatiques. Notre second exemple est un modèlesimple de ressources partagées. Considérons un réseau constitué d’unités, re-présentées par les sommets d’un graphe, qui partagent des ressources, repré-sentées par des arêtes. Une unité ne peut fonctionner que si les unités voisines,avec lesquelles elle partage des ressources, ne fonctionnent pas. Comment faireen sorte que les temps de fonctionnement soient également répartis entre lesunités ? Une des réponses possibles consiste à définir la suite des configura-tions de fonctionnement comme une chaîne de Markov.
Notons S l’ensemble des sommets (unités) et B l’ensemble des arêtes(ressources). Nous identifierons une configuration possible à l’ensemble desunités qui fonctionnent dans cette configuration. Si une unité appartient àun tel ensemble, aucune de ses voisines sur le graphe ne peut y appartenir.En théorie des graphes, un sous-ensemble de sommets qui ne contient pasdeux sommets voisins s’appelle un stable. L’ensemble E des états de notremodèle est donc l’ensemble des stables du graphe (S,B). Une configurationinitiale étant donnée, l’évolution de la chaîne se fait comme suit. A chaqueétape on choisit une unité au hasard. Si elle fonctionne, on la met au repos.Sinon, et si toutes ses voisines sont au repos, on la met en fonctionnement.Remarquons qu’à partir d’une configuration donnée, on ne peut atteindrequ’une configuration différant de la première par une coordonnée au plus.

Chaînes de Markov 11
Chaque ligne de la matrice de transition comporte donc au plus |S| termesnon nuls. Voici l’algorithme, écrit en termes d’ensembles stables.
R←− ∅t←− 0Répéter
choisir x au hasard dans SSi (x ∈ R)
alors R←− R \ {x}sinon
Si (∀y ∈ R , {x, y} /∈ B)alors R←− R ∪ {x}
finSifinSit←− t+ 1
Jusqu’à (arrêt de la simulation)
L’ensemble des stables E est un sous-ensemble de l’ensemble E′ de tous lessous-ensembles de S. E′ est naturellement muni d’une structure de graphe(hypercube), pour laquelle deux sous-ensembles sont voisins s’ils diffèrent enun seul élément. L’algorithme ci-dessus simule la marche aléatoire symétriquesur cet hypercube (à chaque pas on choisit un élément de S au hasard, on lerajoute à l’ensemble courant s’il n’y était pas, on le retranche sinon). Pourobtenir une marche aléatoire symétrique sur l’ensemble des stables, il suffitd’imposer la contrainte que l’on ne peut rajouter un élément x à R que siR ∪ {x} est encore stable.
1.4 Génétique
La transmission des patrimoines génétiques au cours des générations suc-cessives est un exemple standard de chaîne de Markov : le génotype de chaqueindividu ne dépend de ceux de ses ancêtres qu’à travers ses parents.
Le premier modèle de génétique qui ait été introduit est extrêmementrudimentaire. Il s’agit de suivre la répartition d’un gène particulier, noté g,au cours de générations successives, dans une population dont la taille restefixée. Les individus sont supposés n’avoir qu’un seul chromosome, porteur ounon du gène g. Ce chromosome provient d’un parent unique, choisi au hasarddans la génération précédente. Tout se passe comme si les chromosomes dela génération n constituaient un pool de taille N , dans lequel les N chromo-somes de la génération n+ 1 sont tirés au hasard avec remise. Le nombre dechromosomes porteurs du gène g est noté Xn. La suite (Xn) constitue unechaîne de Markov. Les hypothèses de modélisation conduisent à dire que laloi conditionnelle de Xn+1 sachant “Xn = i” est la loi binomiale de para-mètres N et i/N . Remarquons que si Xn = 0 ou Xn = N , alors la chaîne estconstante à partir de la génération n : on dit que ces états sont “absorbants”(cf. section 2.4). Pour tout i, j = 0, . . . , N , la probabilité de transition de i à

12 Cahier de Mathématiques Appliquées no 11
j s’écrit donc :
pij =
(
N
j
)
( i
N
)j(
1−i
N
)N−j
.
Bien évidemment, les hypothèses de ce modèle sont beaucoup trop res-trictives pour être applicables aux populations humaines. D’autres modèlesont été introduits, comme le modèle de Moran. Il considère des générationssuccessives, sans intersections, pour lesquelles le nombre de mâles est fixé àN1 et le nombre de femelles à N2. Le gène d’intérêt est g. Pour chaque indi-vidu, il peut apparaître sur un chromosome paternel, ou sur le chromosomematernel de la même paire. L’état de la population à la n-ième générationest décrit par un vecteur à 6 coordonnées entières :
s = (m0,m1,m2, f0, f1, f2) .
Dans ce vecteur, pour k = 0, 1, 2, mk (respectivement fk) est le nombrede mâles (respectivement de femelles) ayant k copies du gène g dans leurgénotype. Evidemment, quelle que soit la génération n on a :
m0 +m1 +m2 = N1 et f0 + f1 + f2 = N2 . (1.1)
L’espace d’états du modèle est donc le sous-ensemble E de IN6 des i =(m0,m1,m2, f0, f1, f2) vérifiant (1.1). On souhaite définir une chaîne de Mar-kov homogène (Xn) sur E. On doit donc définir les probabilités de transitionpij . Soit i = (m0,m1,m2, f0, f1, f2) un état fixé et supposons-le atteint à lagénération n : Xn = i. Les probabilités des différents états possibles à lagénération n+1 dépendent tout d’abord des fréquences d’apparition du gèneg parmi les mâles et les femelles de la génération n. Ces proportions sontnotées respectivement x(m) et x(f).
x(m) =m1 + 2m2
2N1et x(f) =
f1 + 2f22N2
. (1.2)
Pour constituer la génération suivante, on suppose que les gamètes mâleset femelles sont appariés au hasard, selon le schéma dit “multinomial”. End’autres termes, chacun des N1 mâles et chacune des N2 femelles de la géné-ration n+1 choisit au hasard un gène paternel parmi les 2N1 présents à lagénération n, et un gène maternel parmi les 2N2 possibles. A la conception,les probabilités pour un individu de la génération n+1 d’avoir 0, 1 ou 2 copies
du gène g sont notées P(0)0 , P
(0)1 et P
(0)2 respectivement. Si les proportions
du gène g parmi les mâles et les femelles de la génération n sont x(m) et x(f),le schéma multinomial implique :
P(0)0 = (1− x(m))(1− x(f)) ,
P(0)1 = x(m)(1− x(f)) + (1− x(m))x(f) ,
P(0)2 = x(m)x(f) .
(1.3)

Chaînes de Markov 13
Cependant, du fait de la sélection, on doit pondérer ces probabilités par des
“facteurs de viabilité” w(m)k et w
(f)k . Pour k = 0, 1, 2, w
(m)k (respectivement
w(f)k ) mesure la possibilité pour un mâle (respectivement une femelle) avec k
copies du gène g dans son génotype de transmettre ses gènes à la génération
suivante. Notons P(m)k (respectivement P
(f)k ) les probabilités pour les mâles
(respectivement les femelles) d’atteindre l’âge de reproduction avec k copies
du gène g. Si les probabilités à la conception sont les P(0)k de la formule (1.3),
alors les probabilités à l’âge de reproduction seront, pour k = 0, 1, 2 :
P(m)k =
w(m)k P
(0)k
w(m)0 P
(0)0 + w
(m)1 P
(0)1 + w
(m)2 P
(0)2
,
P(f)k =
w(f)k P
(0)k
w(f)0 P
(0)0 + w
(f)1 P
(0)1 + w
(f)2 P
(0)2
·
(1.4)
Après sélection les génotypes des N1 mâles et des N2 femelles sont suppo-
sés choisis indépendamment avec les probabilités P(m)k et P
(f)k . En d’autres
termes, les lois de probabilité des vecteurs (m0,m1,m2) et (f0, f1, f2) sontmultinomiales, de paramètres respectifs :
(N1, P(m)0 , P
(m)1 , P
(m)2 ) et (N2, P
(f)0 , P
(f)1 , P
(f)2 ) ,
et ces vecteurs sont indépendants.On peut maintenant décrire explicitement les probabilités de transition
pij de la chaîne de Markov homogène sur E.Si i = (m0,m1,m2, f0, f1, f2) et j = (m′
0,m′1,m
′2, f
′0, f
′1, f
′2) sont deux élé-
ments de E, alors la probabilité de transition pij de i vers j est :
N1!
m′0!m
′1!m
′2!
(
P(m)0
)m′
0(
P(m)1
)m′
1(
P(m)2
)m′
2
×
N2!
f ′0!f
′1!f
′2!
(
P(f)0
)f ′
0(
P(f)1
)f ′
1(
P(f)2
)f ′
2
,
(1.5)
où pour k = 0, 1, 2, les probabilités P(m)k = P
(m)k (i) et P
(f)k = P
(f)k (i) sont
déduites de i = (m0,m1,m2, f0, f1, f2) par les formules (1.2), (1.3) et (1.4).
1.5 Planification économique
Un des objectifs de l’utilisation de modèles probabilistes dans les applica-tions est la prédiction en environnement incertain. Etant donnée l’informationdisponible à un instant donné, que peut on prédire pour ce qui va suivre ?Dire d’une suite de décisions qu’elle est une suite de variables aléatoires in-dépendantes revient à dire que l’information apportée par chaque réalisationn’est pas prise en compte par la suite. Les chaînes de Markov, parce qu’elles

14 Cahier de Mathématiques Appliquées no 11
modélisent la prise en compte de l’information présente pour les décisions fu-tures, sont l’outil le plus simple pour la planification économique. Nous nouscontenterons d’illustrer ceci par un modèle de gestion de stock.
On considère un magasin proposant à la vente un article particulier. Lescommandes au fournisseur s’effectuent à la semaine. Les nombres d’articlesdemandés chaque semaine sont vus comme des réalisations de variables aléa-toires indépendantes et de même loi. Cette loi peut être estimée statistique-ment et elle est supposée connue. Pour une semaine donnée, on note pk laprobabilité que k articles soient demandés, et rk = 1 − p0 − · · · − pk la pro-babilité que plus de k articles soient demandés. Le stock maximum d’articlesen magasin est de S. A la fin de chaque semaine, le responsable du stockdécide :• de ne pas commander de nouveaux articles s’il lui en reste au moins s
en stock,• de reconstituer le stock maximum de S articles s’il lui en reste stricte-
ment moins de s.Notons Xn le nombre d’articles restant en stock à la fin de la n-ième semaine.Sous les hypothèses ci-dessus, la suite (Xn) est une chaîne de Markov, àvaleurs dans l’espace d’états {0, . . . , S}. Voici sa matrice de transition pourle cas particulier s = 3, S = 7.
0 1 2 3 4 5 6 70 r6 p6 p5 p4 p3 p2 p1 p01 r6 p6 p5 p4 p3 p2 p1 p02 r6 p6 p5 p4 p3 p2 p1 p03 r2 p2 p1 p0 0 0 0 04 r3 p3 p2 p1 p0 0 0 05 r4 p4 p3 p2 p1 p0 0 06 r5 p5 p4 p3 p2 p1 p0 07 r6 p6 p5 p4 p3 p2 p1 p0
Connaissant les probabilités de vente, les coûts de stockage et les bénéfices devente, l’étude de la chaîne de Markov permettra au gestionnaire de prévoirson bénéfice moyen par semaine et, par exemple, d’optimiser s.
2 Traitement mathématique
2.1 Formules récurrentes
Dans ce paragraphe, nous donnons les techniques de calcul pour un cer-tain nombre de quantités liées aux transitions d’une chaîne de Markov sur unensemble fini ou dénombrable. Ces calculs se font par des algorithmes itéra-tifs, que nous présentons comme des formules récurrentes. On peut aussi lesprésenter sous forme matricielle. La forme matricielle, si elle est en général

Chaînes de Markov 15
beaucoup plus compacte, n’est d’aucune utilité pratique, dans la mesure oùelle ne fait que traduire un algorithme de calcul itératif. Plutôt que de re-tenir des formules matricielles, il est conseillé d’apprendre à voir une chaînede Markov comme un système dynamique aléatoire : c’est un promeneur quisaute d’état en état, et décide du prochain saut en fonction uniquement del’état où il se trouve, en oubliant le chemin suivi pour en arriver là.
Nous commençons par les “probabilités de transition en m pas”.
Définition 2.1 On appelle probabilité de transition de i à j en m pas la
probabilité, notée p(m)ij :
p(m)ij = IP[Xm = j |X0 = i] = IP[Xn+m = j |Xn = i] .
Nous dirons aussi que p(m)ij est la probabilité d’aller de i à j en m pas. Dans la
définition de p(m)ij , on peut comprendre la notation IP[Xm = j |X0 = i] soit
comme une probabilité conditionnelle, soit comme une probabilité relative àla loi de la suite (Un), quand l’initialisation est fixée à X0 = i.
Proposition 2.2 La matrice des probabilité de transition en m pas est lapuissance m-ième de la matrice P :
(
p(m)ij
)
i,j∈E= Pm .
Démonstration : Pour n = 1, on a par définition pij = p(1)ij . Il nous suffit donc
de montrer que pour tout n > 1 :(
p(m)ij
)
i,j∈E=
(
p(m−1)ij
)
i,j∈EP .
Ecrivons pour cela :
p(m)ij = IP[Xm = j |X0 = i]
=∑
k∈E
IP[Xm = j |Xm−1 = k et X0 = i]IP[Xm−1 = k |X0 = i]
=∑
k∈E
IP[Xm = j |Xm−1 = k]IP[Xm−1 = k |X0 = i]
=∑
k∈E
p(m−1)ik pkj .
�
Plus que la formule matricielle, c’est l’interprétation de la formule itérativequ’elle traduit qui est importante. Par exemple, la formule matricielle Pm =P lPm−l se développe comme suit. Pout tout i, j ∈ E :
p(m)ij =
∑
k∈E
p(l)ik p
(m−l)kj . (2.1)

16 Cahier de Mathématiques Appliquées no 11
Cette formule porte le nom de Chapman-Kolmogorov. Il faut la lire commesuit : “aller de i à j en m pas, c’est aller de i à un certain k en l pas, puisde k à j en m−l pas”.
Passons maintenant aux lois marginales des Xn. Rappelons que les vec-teurs indicés par E sont des vecteurs colonnes.
Proposition 2.3 Notons p(m) la loi de Xm :
p(m) = (pi(m))i∈E = (IP[Xm = i])i∈E .
On a, pour tout m ≥ 1 :
p(m) = tPp(m−1) = tPmp(0) .
On peut donc voir l’évolution en loi de la suite (Xn) comme un système itéra-tif linéaire dont tP est la matrice d’évolution. La démonstration de cette pro-position, comme des autres résultats de cette section, est assez élémentaire,en utilisant la formule des probabilités totales. Nous donnons simplement lesformes développées, suivies de leur interprétation.
pi(m) =∑
k∈E
pk(m−1) pki . (2.2)
“Pour être en i au m-ième pas, il faut être en k au (m−1)-ième pas, puispasser de k à i en un pas.”
pi(m) =∑
k∈E
pk(0) p(m)ki . (2.3)
“Pour être en i au m-ième pas, il faut, partant de k, passer de k à i en mpas.”
Nous définissons maintenant les probabilités de premier passage.
Définition 2.4 On appelle probabilité de premier passage de i à j en m pas
et on note f(m)ij la quantité :
f(m)ij = IP[Xm = j etXm−1 6= j . . . etX1 6= j |X0 = i] .
On a bien sûr f(1)ij = p
(1)ij = pij . Nous ne donnerons pas d’expression ma-
tricielle pour les f(m)ij . Nous nous contenterons de deux formules itératives,
suivies de leur interprétation.
f(m)ij =
∑
k 6=j
pik f(m−1)kj . (2.4)

Chaînes de Markov 17
“Pour arriver en j pour la première fois en m pas partant de i, il faut allerde i à k 6= j au premier pas, puis aller de k à j pour la première fois en m−1pas.”
p(m)ij = f
(m)ij +
m−1∑
l=1
f(l)ij p
(m−l)jj . (2.5)
“Pour aller de i à j en m pas, il faut soit y arriver pour la première fois,soit y être arrivé pour la première fois en l pas, puis y être revenu au boutde m−l pas.”
A priori, pour i et j fixés, les probabilités f(m)ij correspondent à des événe-
ments disjoints. Leur somme, que l’on notera fij , est la probabilité d’atteindrej en partant de i. Ces probabilités vérifient :
fij = pij +∑
k 6=j
pik fkj . (2.6)
“Pour arriver en j en partant de i, il faut soit y aller au premier pas, soitaller en k 6= j, puis aller de k à j.”
Il peut se faire que fij soit strictement inférieure à 1. Dans le cas où elleest égale à 1, le nombre de pas nécessaires pour atteindre j en partant de iest une variable aléatoire à valeurs dans IN∗. Son espérance est la somme :
∞∑
m=1
m f(m)ij .
Cette somme peut être infinie. C’est le temps moyen de premier passage de ià j. Il sera noté eij . On étend sa définition à tous les couples (i, j) ∈ E × Een posant eij =∞ si fij < 1.
Proposition 2.5 Pour tout i, j ∈ E, on a :
eij = 1 +∑
k 6=j
pik ekj . (2.7)
L’interprétation de (2.7) est : “pour aller de i à j, il faut effectuer un premiersaut, puis, si ce saut amène en k 6= j, aller de k à j.”
Démonstration : Nous écrivons les formules suivantes sous réserve de conver-gence des séries.
eij =
∞∑
m=1
m f(m)ij
=
∞∑
M=1
∞∑
m=M
f(m)ij .

18 Cahier de Mathématiques Appliquées no 11
Or d’après (2.4) :
∞∑
m=M
f(m)ij =
∑
k 6=j
pik
∞∑
m=M−1
f(m)kj .
On en déduit :
∞∑
M=2
∞∑
m=M
f(m)ij =
∑
k 6=j
pik
∞∑
M=1
∞∑
m=M
f(m)kj ,
soit :
eij −∞∑
m=1
f(m)ij =
∑
k 6=j
pik ekj
Dans le cas où eij est fini, la somme∑∞
m=1 f(m)ij vaut 1, ce qui entraîne (2.7).
Si eij est infini, deux cas sont possibles. Soit fij < 1, alors au moins un des ktels que pik > 0 est tel que fkj < 1, et donc les deux membres de (2.7) sontinfinis. Si fij = 1, alors pour tous les états k tels que pik > 0, on a fkj = 1.Mais nécessairement pour au moins un d’entre eux, on a ekj =∞. �
Exemple : Chaîne à deux états.Sur ce cas particulier, nous mettons en relief des caractéristiques qui restentvraies pour un nombre fini quelconque d’états.
Considérons sur E = {0, 1} la matrice de transition P suivante :
P =
(
1−α αβ 1−β
)
,
où α et β sont deux réels dans l’intervalle [0, 1]. Nous écarterons les deuxcas particuliers où la chaîne est déterministe : α = β = 0 et α = β = 1. Lamatrice P admet pour valeurs propres 1 et (1−α−β), dont la valeur absolueest strictement inférieure à 1. La matrice Pm des probabilités de transitionen m pas s’écrit :
Pm =1
α+ β
(
β αβ α
)
+(1−α−β)m
α+ β
(
α −α−β β
)
Quand m tend vers l’infini, Pm converge vers une matrice dont les deux lignessont égales. Chacune des deux lignes est une loi de probabilité, c’est aussi unvecteur propre de tP associé à la valeur propre 1.Les probabilités de premier passage sont les suivantes, pour m ≥ 2 :
f(m)00 = αβ(1− β)m−2 , f
(m)01 = α(1− α)m−1 ,
f(m)10 = β(1− β)m−1 , f
(m)11 = αβ(1− α)m−2 .
Les expressions de f(m)01 et f
(m)10 donnent les lois des temps de séjour en 0 et
1 respectivement. Ce sont des lois géométriques. Voici les temps moyens de

Chaînes de Markov 19
premier passage, si α et β sont strictement positifs :
e00 = 1 +α
β, e01 =
1
α, e10 =
1
β, e11 = 1 +
β
α,
2.2 Classification des états
Les états d’une chaîne de Markov se classifient en fonction de la possibilitéqu’a la chaîne d’atteindre les uns à partir des autres.
Définition 2.6 Soient i et j deux états de E. On dit que j est accessibledepuis i si et seulement si il existe un entier m ∈ IN∗ et une suite d’étatsk0 = i, k1, . . . , km = j tels que pik1
pk1k2. . . pkm−1j > 0.
En d’autres termes, j est accessible depuis i si il existe un chemin dans lediagramme de transition, partant de i et arrivant en j. Ceci se traduit éga-lement en termes des probabilités de transition en m pas et des probabilitésde premier passage.
Proposition 2.7 L’état j est accessible depuis i si et seulement si il existe
m tel que p(m)ij > 0, ou encore tel que f
(m)ij > 0.
Démonstration : On sait que p(m)ij est le coefficient d’ordre i, j de la matrice
Pm. Son expression développée est :
p(m)ij =
∑
k1,...,km−1∈E
pik1pk1k2
. . . pkm−1j .
Cette somme de termes positifs ou nuls est strictement positive si et seulementsi un de ses termes au moins est non nul. Or le produit pik1
pk1k2. . . pkm−1j est
non nul si et seulement si (ssi) chacun de ses facteurs est strictement positif.Pour les probabilités de premier passage, on déduit le résultat de (2.5). �
Définition 2.8 On dit que deux états i et j communiquent si chacun estaccessible depuis l’autre.
La relation de communication est symétrique et transitive, mais elle n’est pasnécessairement réflexive (quand la chaîne quitte un état i elle peut ne jamaisy revenir).
Définition 2.9 On appelle classe irréductible tout sous ensemble d’états,maximal au sens de l’inclusion, composé d’états qui communiquent deux àdeux.
Si tous les états de E communiquent deux à deux, E tout entier est la seuleclasse irréductible. On dit alors que la chaîne est irréductible. Dans le casgénéral E se partitionne en états isolés dans lesquels on ne revient jamaisune fois qu’on les a quittés, et en classes irréductibles disjointes. Le résultat

20 Cahier de Mathématiques Appliquées no 11
fondamental est que les états d’une même classe irréductible ont des proprié-tés équivalentes vis à vis de la chaîne. Ce que l’on entend par “propriété” d’unétat est précisé dans ce qui suit.
Définition 2.10 L’état i est dit périodique de période k > 1 si tous les
entiers m tels que p(m)ii > 0 sont multiples de k. Un état qui n’admet pas de
période est dit apériodique.
Si i est périodique de période k et communique avec j, on démontre que j estégalement de période k. Les classes irréductibles périodiques constituent uncas particulier que l’on ne rencontre pas dans les applications. Remarquonsque si pii > 0, l’état i, et tous les états avec lequel il communique sontapériodiques. De plus, si une classe irréductible est périodique de périodek pour la chaîne de Markov (Xn), alors la suite (Xnk) , n ∈ IN est encoreune chaîne de Markov, de matrice de transition P k, pour laquelle la classeconsidérée est apériodique.
C’est le temps de premier retour qui permet de distinguer les propriétésdes états.
Définition 2.11 L’état i est dit :• transient si fii < 1,• récurrent nul si fii = 1 et eii =∞,• récurrent positif si fii = 1 et eii <∞.
Les états apériodiques, récurrents positifs sont dits ergodiques. Comme cas
particulier d’état transient, on retrouve les états pour lesquels f(m)ii = p
(m)ii =
0, pour tout m ≥ 1. Ce sont ceux que l’on quitte au premier pas, pour nejamais y revenir. Si un état transient est tel que 0 < fii < 1, le nombrede séjours dans l’état i suit la loi géométrique de paramètre 1−fii. Il estpresque sûrement fini, d’espérance 1/(1−fii). Les états transients sont ceuxdans lesquels on ne passe qu’un nombre fini de fois. Par opposition, on revientdans un état récurrent positif en moyenne tous les eii pas, donc une infinitéde fois. La définition 2.11 a été donnée sous sa forme la plus intuitive, entermes des probabilités de premier retour fii. Elle se traduit en termes des
probabilités de transition en m pas p(m)ii de la façon suivante :
Proposition 2.12 L’état i est :
• transient si la série∑
m p(m)ii converge,
• récurrent nul si la série∑
m p(m)ii diverge mais son terme général p
(m)ii
tend vers 0,
• récurrent positif si p(m)ii ne tend pas vers 0.
En fait, si i est récurrent positif et apériodique (ergodique), nous montrerons
plus loin que p(m)ii tend vers une limite strictement positive.
Démonstration : Nous utilisons la formule (2.5) sous la forme :
p(m)ii = f
(m)ii + f
(m−1)ii pii + · · ·+ f
(1)ii p
(m−1)ii .

Chaînes de Markov 21
En sommant sur m on obtient :
∑
m
p(m)ii = fii
(
1 +∑
m
p(m)ii
)
,
soit :
(1− fii)∑
m
p(m)ii = fii .
Donc la série∑
m p(m)ii converge si et seulement si fii < 1.
Nous admettons que la série définissant eii converge si et seulement si
p(m)ii ne tend pas vers 0. �
Proposition 2.13 Si deux états communiquent, alors ils sont de même na-ture.
Cette proposition permet de qualifier de transiente (respectivement : récur-rente nulle, récurrente positive), toute classe irréductible dont un élément(et donc tous les éléments) sont transients (resp. : récurrents nuls, récurrentspositifs).
Démonstration : Si i et j communiquent, il existe deux instants h et l tels
que p(h)ij > 0 et p
(l)ji > 0. Pour tout m ≥ h+ l, on a :
p(m)ii ≥ p
(h)ij p
(m−h−l)jj p
(l)ji ,
et
p(m)jj ≥ p
(l)ji p
(m−h−l)ii p
(h)ij .
Les deux séries∑
m p(m)ii et
∑
m p(m)jj sont donc de même nature et les conver-
gences vers 0 de leurs termes généraux sont vraies ou fausses simultanément.�
Dans le cas où l’espace d’états est fini, la classification des états se lit immé-diatement sur le graphe de transition.
Proposition 2.14 Soit C ⊂ E une classe irréductible. Si au moins unetransition permet de sortir de C :
∃i ∈ C , ∃j /∈ C , pi,j > 0 ,
alors la classe C est transiente. Si la classe C est finie et si aucune transitionne permet d’en sortir, alors C est récurrente positive.
Démonstration : La formule (2.4), sommée par rapport à m, donne :
fii = pii +∑
k 6=i
pik fki .

22 Cahier de Mathématiques Appliquées no 11
i
c b ga
h
d e
j
f
1/2 1/2 1/3 1/42/3
3/411/3
1/3
1/3
1/4
1/4
1/41/41/3
1/3
1/3
1
1
1
Figure 3 – Diagramme de transition d’une chaîne de Markov. Les classesrécurrentes sont entourées en pointillés.
Or :
1 = pii +∑
k 6=i
pik .
Donc fii = 1 est possible si et seulement si les fki valent 1 également, pour
tous les états k tels que pik = 1. Mais fki = 1 entraîne que f(m)ki > 0 pour
au moins un m, donc i est accessible depuis k, donc i et k communiquent. Siun état i est récurrent, tous les états k tels que pik > 0 sont dans la mêmeclasse. Donc on ne peut pas sortir d’une classe récurrente.
Nous montrerons plus loin que dans une classe irréductible finie dont on nesort pas, pnii tend vers une limite strictement positive, dans le cas apériodique.En particulier tout état d’une telle classe est récurrent positif. �
Nous verrons au paragraphe 3.1 des exemples de chaînes irréductibles tran-sientes ou récurrentes nulles, sur un espace d’états infini.

Chaînes de Markov 23
Exemple : Sur E = {a, b, . . . , j}, considérons la matrice de transition Psuivante :
a b c d e f g h i j
a 1/2 0 1/2 0 0 0 0 0 0 0
b 0 1/3 0 0 0 0 2/3 0 0 0
c 1 0 0 0 0 0 0 0 0 0
d 0 0 0 0 1 0 0 0 0 0
e 0 0 0 1/3 1/3 0 0 0 1/3 0
f 0 0 0 0 0 1 0 0 0 0
g 0 0 0 0 0 0 1/4 0 3/4 0
h 0 0 1/4 1/4 0 0 0 1/4 0 1/4
i 0 1 0 0 0 0 0 0 0 0
j 0 1/3 0 0 1/3 0 0 0 0 1/3
La classification des états se lit clairement sur le diagramme de transition(figure 3). Les classes irréductibles sont les suivantes :
1. {f} : récurrente,
2. {a, c} : récurrente,
3. {b, g, i} : récurrente,
4. {d, e} : transiente,
5. {h} : transiente,
6. {j} : transiente.
On peut souhaiter changer l’ordre des états pour rassembler les classes ir-réductibles. Ceci revient à effectuer un changement de base sur P , dont lamatrice est une matrice de permutation. Par exemple :
f a c b g i d e h j
f 1 0 0 0 0 0 0 0 0 0
a 0 1/2 1/2 0 0 0 0 0 0 0
c 0 1 0 0 0 0 0 0 0 0
b 0 0 0 1/3 2/3 0 0 0 0 0
g 0 0 0 0 1/4 3/4 0 0 0 0
i 0 0 0 1 0 0 0 0 0 0
d 0 0 0 0 0 0 0 1 0 0
e 0 0 0 0 0 1/3 1/3 1/3 0 0
h 0 0 1/4 0 0 0 1/4 0 1/4 1/4
j 0 0 0 1/3 0 0 0 1/3 0 1/3

24 Cahier de Mathématiques Appliquées no 11
Aux classes récurrentes correspondent des blocs diagonaux qui sont eux-mêmes des matrices de transition.
2.3 Mesures stationnaires
Sur l’exemple de la chaîne à deux états, traité au paragraphe 2.1, nousavions constaté que la matrice Pn convergeait à vitesse exponentielle vers unematrice dont toutes les lignes étaient des vecteurs propres de tP , associés à lavaleur propre 1. Ceci est une propriété générale des matrices de transition surun ensemble fini. En effet, si Pn converge, alors sa limite L vérifie LP = L.En d’autres termes, les lignes de L sont les transposées de vecteurs colonnesv vérifiant tPv = v. De plus, comme toutes les lignes de Pn sont des lois deprobabilité, cette propriété se conserve par passage à la limite et v est doncune loi de probabilité. De telles lois sont des mesures stationnaires.
Définition 2.15 On appelle mesure stationnaire d’une chaîne de Markovde matrice de transition P toute loi de probabilité sur E, v = (vi) , i ∈ Evérifiant :
tPv = v .
La formule (2.2) du paragraphe 2.1 montre que la loi p(m) de la chaîne aum-ième pas vérifie :
p(m) = tPp(m−1) = tPmp(0) .
Soit v une mesure stationnaire. Si la loi de X0 est v, alors la loi de Xm
sera également v pour tout m. C’est ce qui justifie le qualificatif de station-naire. Cela signifie que la probabilité de se trouver dans un état donné resteconstante au cours du temps, bien que la chaîne saute constamment d’étaten état. Une mesure stationnaire doit être comprise comme un équilibre dy-namique “en moyenne” pour le modèle.
Nous verrons plus loin qu’une mesure stationnaire ne peut charger queles états récurrents positifs. Le théorème 2.16 ci-dessous a pour conséquenceque toute chaîne irréductible sur un ensemble fini est récurrente positive. Auparagraphe 3.1, nous constaterons sur quelques exemples que la situation estdifférente sur un ensemble infini.
Théorème 2.16 Soit P la matrice d’une chaîne de Markov irréductible etapériodique sur l’ensemble fini E. Il existe une unique mesure stationnaireπ = (πi) , i ∈ E. Elle possède les propriétés suivantes :
1. Pour tout i ∈ E, πi est strictement positif.
2. Pour tout i, j ∈ E, p(m)ij converge vers πj quand m tend vers l’infini.
3. Quelle que soit la loi de X0, la loi de Xm converge vers π quand m tendvers l’infini.

Chaînes de Markov 25
4. Pour toute fonction f de E dans IR :
limM→∞
1
M
M−1∑
m=0
f(Xm) =∑
i∈E
f(i)πi , p.s.
5. Pour tout i ∈ E, le temps moyen de retour en i, eii est égal à 1/πi.
Interprétations : L’existence d’une mesure stationnaire n’est pas un mi-racle. Du fait que la somme des coefficients d’une même ligne vaut 1, toutvecteur constant est vecteur propre de P associé à la valeur propre 1. Donc tPadmet aussi 1 comme valeur propre. Le fait qu’une loi de probabilité puisseêtre vecteur propre associé à 1 est toujours vrai dans le cas fini, pas nécessaire-ment dans le cas infini. Ce qui est particulier au cas irréductible apériodique,c’est que la mesure stationnaire est unique et qu’elle charge tous les étatsavec une probabilité strictement positive. Le fait que la limite quand m tend
vers l’infini de p(m)ii soit non nulle entraîne que i est récurrent positif. Sur un
ensemble fini, une chaîne irréductible et apériodique est ergodique.Le point 2 peut se traduire comme suit :
limm→∞
IP[Xn+m = j |Xn = i] = πj .
Les comportements de la chaîne en deux instants éloignés l’un de l’autre sontà peu près indépendants. Quelle que soit l’information disponible sur le passé,la meilleure prédiction que l’on puisse faire à horizon lointain est la mesurestationnaire.
Le point 3 est une conséquence immédiate de 2. Nous montrerons en faitque la convergence en loi vers la mesure stationnaire se fait à vitesse exponen-tielle. Concrètement, cela signifie que la mesure stationnaire, qui en théorien’est qu’un comportement à l’infini, peut être atteinte en pratique dans lessimulations au bout d’un nombre d’itérations raisonnable. Malheureusementcette vitesse de convergence dépend également de la taille de l’espace d’étatset de la vitesse avec laquelle la chaîne peut le parcourir. Il peut se faire, surdes espaces d’états très gros, que la mesure stationnaire ne puisse jamais êtreobservée à l’échelle de temps des simulations.
Dans 4, il faut comprendre la fonction f comme un coût associé aux vi-sites dans les différents états. Dans l’exemple du paragraphe 1.5 f(k) seraitle bilan d’une semaine terminée avec k articles en magasin. Le membre degauche (1/M)
∑
f(Xm) est le coût moyen observé sur une période de tempsd’amplitude M . Le membre de droite est l’espérance du coût d’une étape enrégime stationnaire. En pratique, si l’espace d’états est très grand, il arriveque l’on ne puisse pas calculer la mesure stationnaire π. On peut néanmoinscalculer une valeur approchée du coût moyen en régime stationnaire en effec-tuant la moyenne des coûts observés sur une seule trajectoire simulée.
Dans le cas particulier où f est la fonction indicatrice de l’état i, lamoyenne (1/M)
∑
m 11i(Xm) est la proportion du temps que la chaîne a passé

26 Cahier de Mathématiques Appliquées no 11
dans l’état i entre 0 et M−1. Le point 4 affirme que sur une longue périodede temps, cette proportion est la probabilité stationnaire πi. Mais si sur unintervalle d’amplitude M il y a eu environ Mπi visites, alors en moyennel’intervalle de temps entre deux visites était de 1/πi. C’est effectivement lavaleur de eii, d’après le point 5.
Démonstration : Elle est basée sur le théorème de Perron-Frobenius, que nousadmettons.
Théorème 2.17 Soit A une matrice carrée finie dont tous les coefficientssont strictement positifs. Alors A a une valeur propre simple α qui est réelle,strictement positive, et supérieure au module de toute autre valeur propre. Acette valeur propre, dite maximale, est associé un vecteur propre dont toutesles coordonnées sont strictement positives.
Le premier pas consiste à montrer qu’une certaine puissance de P est à coeffi-cients strictement positifs. Pour cela montrons d’abord que pour tout i ∈ E,
p(m)ii est non nul à partir d’un certain m. C’est une conséquence de l’apério-
dicité. Observons que l’ensemble des entiers m tels que p(m)ii > 0 contient au
moins deux entiers premiers entre eux, disons u et v. De plus, si p(u)ii > 0 et
p(v)ii > 0, alors pour tout h, k ∈ IN, p
(hu+kv)ii > 0. Tout se ramène donc à mon-
trer que si u et v sont deux entiers premiers entre eux, alors tous les entiersà partir d’un certain rang s’écrivent sous la forme hu + kv, avec h, k ∈ IN.Examinons tout d’abord le cas particulier v = u + 1. Pour tout a > u etb ≤ u, on a :
au+ b = (a− b)u+ b(u+ 1) .
Donc tous les entiers au-delà de u(u+1) s’écrivent bien sous la forme souhai-tée. Montrons maintenant que le cas général se ramène à ce cas particulier.Si u et v sont premiers entre eux, alors il existe deux entiers α et β, l’unpositif et l’autre négatif, tels que αu + βv = 1. Sans perte de généralité,supposons α > 0 et β < 0. Alors αu = −βv + 1, donc αu et −βv sont deuxentiers positifs consécutifs. Tout entier au-delà de (αu)(−βv) s’écrit commecombinaison entière de αu et −βv, donc de u et v.
Pour tout i ∈ E, choisissons un entier m(i) tel que p(m)ii > 0 pour
m ≥ m(i). Pour tout i 6= j ∈ E, choisissons un entier m(i, j) tel que
p(m(i,j))ij > 0 (c’est possible car tous les états communiquent, par définition
de l’irréductibilité). Posons enfin :
m0 = maxi,j∈E
m(i, j) + maxi∈E
m(i) .
Alors pour tout i, j ∈ E,
p(m0)ij ≥ p
(m0−m(i,j))ii p
(m(i,j))ij > 0 .
On peut donc appliquer le théorème de Perron-Frobenius à Pm0 .

Chaînes de Markov 27
Montrons d’abord que la valeur propre maximale α est 1. Soit v = (vi)un vecteur propre de Pm0 associé à α. Pour tout i ∈ E on a :
αvi =∑
p(m0)ij vj ≤
(
maxj∈E
vj
)
∑
j∈E
p(m0)ij = max
j∈Evj .
Donc α ≤ 1. Comme 1 est valeur propre et α maximale, on a nécessairementα = 1. Les autres valeurs propres de Pm0 , donc aussi de P , sont de modulestrictement inférieur à 1. Ecrivons la matrice P sous la forme :
P = C
1 0 . . . 00... B0
C−1 ,
où la matrice de passage C a pour première colonne t(1, . . . , 1). Il est possiblede choisir C de sorte que B soit une matrice triangulaire du type suivant :
B =
λ1 ∗ . . . ∗
0. . .
...... ∗0 . . . 0 λk
,
où λ1, . . . , λk sont les valeurs propres de P différentes de 1, et les coefficientsau-dessus de la diagonale, notés ∗, sont de module inférieur à ǫ, arbitraire.Pour toute matrice carrée A = (aij), indicée par E, notons ‖A‖ la norme :
‖A‖ = maxi∈E
∑
j∈E
|aij | .
Fixons ρ tel que max |λi| < ρ < 1. Il est possible de choisir ǫ et C tels que‖B‖ < 1. Notons alors L la matrice :
L = C
1 0 . . . 00... 00
C−1 .
Comme la norme ‖ · ‖ est une norme d’algèbre, on aura, pour tout n ≥ 1 :
‖Pn − L‖ ≤ ‖C‖‖C−1‖‖B‖n .
Ceci montre que les coefficients de Pn convergent vers ceux de L à vitesseexponentielle.
La matrice L est telle que toutes ses colonnes sont proportionnelles aupremier vecteur colonne de C, qui est constant. Donc toutes les lignes de L

28 Cahier de Mathématiques Appliquées no 11
sont identiques. En raisonnant de même sur tP , on voit que les lignes de Lsont proportionnelles à un vecteur propre de tP , associé à la valeur propre 1.Or les lignes de P , comme de Pn sont des lois de probabilité, propriété qui seconserve par passage à la limite. Comme la valeur propre 1 est simple, tousles vecteurs propres sont proportionnels et il n’y en a qu’un qui soit une loi deprobabilité. C’est la mesure stationnaire π, qui est nécessairement unique, età coefficients strictement positifs, d’après le théorème de Perron-Frobenius.Les points 1 et 2 sont donc démontrés. Le point 3 est conséquence immédiatedu précédent et de la formule p(n) = tPnp(0).
En ce qui concerne le point 4, nous nous contenterons de démontrer quela convergence a lieu en probabilité, et nous admettrons qu’elle est presquesûre. Toute fonction de E dans IR s’écrit comme combinaison linéaire d’indi-catrices :
f =∑
i∈E
f(i)11i .
Il suffit donc de démontrer que pour tout i ∈ E :
limm→∞
1
M
M−1∑
m=0
11i(Xm) = πi .
Nous montrons séparément que l’espérance tend vers πi et que la variancevers 0.
IE[ 1
M
M−1∑
m=0
11i(Xm)]
=1
M
M−1∑
m=0
pi(m) .
Or d’après le point 3, la suite (pi(m)) converge vers πi. Elle converge doncvers la même valeur au sens de Cesaro. Calculons maintenant la variance.
V ar[ 1
M
M−1∑
m=0
11i(Xm)]
=1
M2
M−1∑
m=0
V ar[11i(Xm)]
+2
M2
M−1∑
m=0
M−m∑
l=1
Cov[11i(Xm) , 11i(Xm+l)] .
Or :V ar[11i(Xm)] = pi(m)(1− pi(m)) ,
converge vers πi(1−πi). La somme de ces variances divisée par M2 tend doncvers 0.
Cov[11i(Xm) , 11i(Xm+l)] = pi(m)(
p(l)ii − pi(m+ l)
)
.
Pour m fixé, les suites (p(l)ii ) et (pi(m + l)) tendent vers πi, à vitesse expo-
nentielle. Donc il existe deux constantes K > 0 et ρ < 1 telles que :
M−m∑
l=1
Cov[11i(Xm) , 11i(Xm+l)] ≤ pi(m)K1
1− ρ.

Chaînes de Markov 29
La somme de ces covariances divisée par M2 tend donc vers 0, d’où la conver-gence en probabilité.
Reste à démontrer le point 5. Au vu du point précédent, il est natu-rel que l’intervalle moyen entre deux visites en i soit 1/πi, si la proportionasymptotique de ces visites est πi. Notons T1, T2, . . . les intervalles de tempssuccessifs entre deux visites en i. On démontre que les Ti sont des variablesaléatoires indépendantes et de même loi, d’espérance commune eii. NotonsNM le nombre de visites entre 0 et M − 1. On a :
NM =
M−1∑
m=0
11i(Xm) = inf{n ≥ 1 t.q. T1 + · · ·+ Tn > M} .
La famille de variables aléatoires (NM ) est ce qu’on appelle un processus derenouvellement. Par la loi des grands nombres, on a :
limn→∞
1
n
n∑
l=1
Tl = eii .
Pour M grand, M/NM doit donc être proche de eii. D’autre part nous avonsmontré que NM/M converge vers πi. Ceci impose que πi soit égal à 1/eii.On peut rendre rigoureux ce qui précède, dans le cadre de théorèmes plusgénéraux sur les processus de renouvellement que nous n’expliciterons pas. �
2.4 Comportement asymptotique
L’étude du paragraphe précédent nous permet de décrire complètement lecomportement asymptotique d’une chaîne de Markov de matrice de transitionP quelconque sur un ensemble fini. Comme nous l’avons vu au paragraphe2.2, les états se séparent en classes irréductibles dont certaines sont tran-sientes (celles dont on peut sortir), et les autres récurrentes positives. Parmiles classes récurrentes, certaines peuvent être périodiques. La matrice de tran-sition d’une chaine sur une classe récurrente périodique de période k admetpour valeurs propres 1 et toutes les racines k-ièmes de l’unité. La matrice Pn
ne converge donc pas dans ce cas-là. Nous l’écartons désormais.Les classes irréductibles récurrentes et apériodiques relèvent du théorème
2.16. Si C est une telle classe, la restriction de P à C est une matrice detransition sur C qui est irréductible et apériodique. Il lui correspond doncune mesure stationnaire unique qui charge positivement tous les états de laclasse, et aucun autre.
La proposition suivante montre que les états transients ne jouent aucunrôle dans le comportement asymptotique de la chaîne.
Proposition 2.18 Soit i un état transient. Alors pour tout j ∈ E p(m)ji est
le terme général d’une série convergente. Si v est une mesure stationnaire,alors vi = 0.

30 Cahier de Mathématiques Appliquées no 11
En d’autres termes, si L est la limite de la matrice Pm quand m tend versl’infini, les colonnes de L dont les indices correspondent à des états transientssont nulles.
Démonstration : Pour un état i transient, nous avons déjà montré que p(m)ii est
le terme général d’une série convergente. Si j est récurrent, seuls les élémentsde sa propre classe, qui sont également récurrents, sont accessibles depuis j.
Donc p(m)ji est nul pour tout m. On peut donc supposer désormais que j est
transient. Fixons l ≥ 1. On a :
p(m+l)ii =
∑
j∈E
p(l)ij p
(m)ji .
Ceci entraîne que p(m)ji est le terme général d’une série convergente, pour
tous les j accessibles depuis i. Soit C la classe irréductible de i. Alors lachaîne ne reste qu’un nombre fini de pas dans C. Partant d’une autre classetransiente, la chaîne séjournera dans un nombre fini de classes transientesavant d’atteindre C. Partant de j, la probabilité qu’elle se trouve en i aum-ième pas est inférieure à la probabilité que la chaîne se trouve encore dansla classe de i. Or le nombre de pas total passé dans l’ensemble des classestransientes est presque sûrement fini. Ceci est équivalent à dire que la pro-babilité que la chaîne soit dans une classe transiente en m est le terme générald’une série convergente.
Si v est une mesure stationnaire, elle vérifie, pour tout m ≥ 1 :
vi =∑
j∈E
vjp(m)ji .
On a donc nécessairement vi = 0. �
La proposition suivante décrit les probabilités d’atteinte fij .
Proposition 2.19 Si l’état i est récurrent alors fij vaut 1 pour les états jqui communiquent avec i, 0 pour tous les autres.Si j1, j2 sont deux états de la même classe récurrente, alors pour tout i ∈ E,fij1 = fij2 .
Démonstration : Nous montrons d’abord la première assertion. On ne sort pasd’une classe récurrente. Donc pour tous les états j en dehors de la classe dei, fij = 0. Pour les états de la classe C de i, les fij sont solution du systèmesuivant (équation (2.6)).
fij = pij +∑
k 6=j
pik fkj , ∀j ∈ C .
La seule solution de ce système est fij ≡ 1.Pour la deuxième assertion, soit C une classe récurrente, j1 et j2 deux
éléments de C, et i un état quelconque. Comme fj2j1 = 1, l’équation vérifiée

Chaînes de Markov 31
par fij1 peut s’écrire :
fij1 = pij1 + pij2 +∑
k 6=j1,j2
pikfkj .
Les fij1 et les fij2 sont solution du même système d’équations, ils sont doncégaux. �
Les mesures associées aux différentes classes récurrentes sont linéairementindépendantes, et correspondent à autant de vecteurs propres de tP associésà la valeur propre 1. La multiplicité de la valeur propre 1 est donc égale aunombre de classes récurrentes. Toute mesure stationnaire de P est une com-binaison convexe des mesures stationnaires associées aux différentes classesrécurrentes.
Nous sommes maintenant en mesure de compléter la description de lamatrice L = limm→∞ Pm. Si i est un état récurrent, alors la ligne d’indicei de L est la mesure stationnaire associée à la classe récurrente de i. Cettemesure ne charge que les états de la même classe de i. Il peut se faire que isoit seul dans sa classe récurrente, si pii = 1. Dans ce cas i est dit absorbantet la mesure stationnaire correspondante est la masse de Dirac en i. Si i estun état transient, alors la ligne d’indice i de L est une combinaison convexedes mesures stationnaires πC des différentes classes récurrentes, affectées descoefficients fiC , valeurs communes des fij pour j ∈ C.
Exemple : Voici une matrice de transition P sur {1, 2, . . . , 7} (le diagrammede transition est celui de la figure 4).
1 2 3 4 5 6 7
1 0.2 0.8 0 0 0 0 0
2 0.7 0.3 0 0 0 0 0
3 0 0 0.3 0.5 0.2 0 0
4 0 0 0.6 0 0.4 0 0
5 0 0 0 0.4 0.6 0 0
6 0 0.1 0.1 0.2 0.2 0.3 0.1
7 0.1 0.1 0.1 0 0.1 0.2 0.4
Il y a deux classes récurrentes :
C = {1, 2} et D = {3, 4, 5} .
Leurs mesures stationnaires respectives sont :
πC = t(0.47 , 0.53 , 0 , 0 , 0 , 0 , 0) et πD = t(0 , 0 , 0.26 , 0.30 , 0.43 , 0 , 0) .

32 Cahier de Mathématiques Appliquées no 11
6
3 4
5
21
7
0.2 0.30.3
0.6
0.5
0.6
0.4
0.40.2
0.4 0.3
0.1
0.2
0.1
0.1
0.10.1 0.1
0.1 0.2
0.2
C D
0.8
0.7
Figure 4 – Diagramme de transition d’une chaîne de Markov. Les classesrécurrentes sont entourées en pointillés.
En ce qui concerne les probabilités d’atteinte à partir des deux étatstransients 6 et 7, on trouve :
f6C = 0.2 , f6D = 0.8 , f7C = 0.4 , f7D = 0.6 .
L’ensemble des mesures stationnaires est :
{απC + (1− α)πD , α ∈ [0, 1] }
Selon la loi de X0, chacune de ces mesures stationnaires peut être la limitede la loi de Xn. Supposons en effet que la loi de X0 soit :
p(0) = t(α1 , α2 , α3 , α4 , α5 , α6 , α7) .
Alors la loi de Xn converge quand n tend vers l’infini vers :
(α1 + α2 + 0.2α6 + 0.4α7)πC + (α3 + α4 + α5 + 0.8α6 + 0.6α7)πD .
2.5 Mesures réversibles
La convergence d’une chaîne vers sa mesure stationnaire est souvent uti-lisée dans les applications. C’est même un outil essentiel pour simuler demanière approchée des lois de probabilité sur de grands espaces d’états. Mais

Chaînes de Markov 33
si la taille de l’espace interdit l’énumération des états, elle interdit a fortiorid’écrire le système linéaire reliant les probabilités de transition à une me-sure stationnaire (définition 2.15). La réversibilité est un cas particulier destationnarité, beaucoup plus simple à appréhender algorithmiquement.
Définition 2.20 Soit π = (πi)i∈E une mesure de probabilité sur E. On ditque π est une mesure réversible pour la chaîne de Markov de matrice detransition P , ou que la matrice P est π-réversible, si :
πi pij = πj pji , ∀i, j ∈ E . (2.8)
Observons tout d’abord qu’une mesure réversible est nécessairement station-naire. En effet si on somme par rapport à j l’équation (2.8), on obtient :
πi =∑
j∈E
πj pji , ∀i ∈ E ,
qui est la condition de stationnarité.
Soit (Xt) , t ∈ IN une chaîne de matrice de transition P . Si π est unemesure réversible et si la loi de Xt est π, alors non seulement la loi de Xt+1
est encore π (stationnarité), mais on a :
IP[Xt = i et Xt+1 = j] = IP[Xt = j et Xt+1 = i] .
C’est la raison pour laquelle on parle de mesure réversible. Soit P une matricede transition π-réversible. Soient i et j deux états tels que πi > 0 et πj = 0.Alors pij = 0. Donc la restriction de P à l’ensemble des états i tels queπi > 0 est encore une matrice de transition, qui est réversible par rapport àla restriction de π à son support. Quitte à réduire l’espace d’états, on peutdonc se ramener au cas où la mesure réversible π est strictement positive(πi > 0, ∀i ∈ E). C’est ce que nous supposerons désormais.
Pour donner des exemples de chaînes admettant une mesure réversible, nouscommençons par une observation immédiate, mais qui contient déjà bonnombre d’applications.
Proposition 2.21 Supposons que P soit une matrice de transition symé-trique, alors P admet la loi uniforme sur E comme mesure réversible.
C’est le cas en particulier pour la marche aléatoire symétrique sur E, munid’une structure de graphe non orienté (cf. 1.2).
Des critères pour vérifier si une matrice de transition donnée admet ounon une mesure réversible ont été donnés par Kolmogorov. Nous nous inté-resserons plutôt ici à la construction d’une matrice de transition π-réversible,quand π est une mesure donnée. Voici une méthode générale.

34 Cahier de Mathématiques Appliquées no 11
Proposition 2.22 Soit Q = (qij) une matrice de transition irréductible surE, vérifiant :
qij > 0 =⇒ qji > 0 , ∀i, j ∈ E .
Soit π = (πi)i∈E une loi de probabilité strictement positive sur E. Définissonsla matrice de transition P = (pij) de la façon suivante : pour i 6= j,
pij = qij min
{
πj qjiπi qij
, 1
}
si qij 6= 0 ,
= 0 sinon .
(2.9)
Les coefficients diagonaux sont tels que la somme des éléments d’une mêmeligne vaut 1.La matrice de transition P est π-réversible.
Observons que π peut n’être connue qu’à un coefficient de proportionnalitéprès, puisque la définition des pij ne fait intervenir que les rapports πj/πi.
Démonstration : Soient i 6= j deux états. Supposons sans perte de géneralitéque πj qji < πi qij . Alors pij = πj qji/πi et pji = qji, de sorte que la conditionde réversibilité (2.8) est satisfaite. �
On peut voir la proposition 2.22 comme une extension de la méthode de rejetqui permet de simuler une loi de probabilité quelconque à partir d’une autre.La matrice Q s’appelle matrice de sélection. L’algorithme correspondant portele nom d’algorithme de Metropolis.
Initialiser Xt←− 0Répéter
i←− Xchoisir j avec probabilité qijρ←− (pj ∗ qji)/(pi ∗ qij)Si (ρ ≥ 1) alors
X ←− jsinon
Si (Random < ρ) alorsX ←− j
finSifinSit←− t+1
Jusqu’à (arrêt de la simulation)
Tel qu’il est écrit, cet algorithme n’est évidemment pas optimisé. Dans laplupart des applications, la matrice de transition Q est symétrique, ce quisimplifie le calcul du coefficient d’acceptation ρ (remarquer qu’il vaut mieuxdans ce cas tester si πj < πi avant de faire le calcul de ρ). Très souvent,l’espace des états est naturellement muni d’une structure de graphe déduite

Chaînes de Markov 35
du contexte d’application, et on choisit alors pour Q la matrice de transitionde la marche aléatoire symétrique sur ce graphe.
Exemple : Ensemble des stables d’un graphe.
Nous revenons ici sur le modèle de ressources partagées de 1.3. Les unitéssusceptibles de fonctionner sont les sommets d’un graphe dont les arêtessont les ressources qu’elles partagent. Un sous ensemble d’unités R ne peutfonctionner que si :
∀x, y ∈ R , {x, y} /∈ B ,
c’est à dire si R est stable. Nous avons déjà écrit l’algorithme de simulationde la marche aléatoire symétrique sur l’ensemble E des stables, muni de sastructure héritée de l’hypercube, pour laquelle deux stables sont voisins s’ildiffèrent par un seul sommet. La chaîne de Markov que cet algorithme en-gendre est irréductible et apériodique, et elle admet la loi uniforme sur E pourmesure réversible. En simulant cette chaîne pendant suffisamment longtemps,on est donc capable de simuler la loi uniforme sur l’ensemble des stables, sansavoir besoin de connaître son cardinal, qui grandit exponentiellement avec lenombre d’unités.
Supposons maintenant que l’on veuille simuler la loi de probabilité p = (p(R))sur E telle que la probabilité de tout stable R est donnée par :
pR =1
Zλ|R| ,
où λ est un réel strictement positif, et Z =∑
R∈E λ|R|. Il est inutile de calculerla constante de normalisation Z pour appliquer l’algorithme de Metropolis(proposition 2.22). Pour λ > 1, l’algorithme est le suivant (on le modifieraitde manière évidente pour λ < 1).
R←− ∅t←− 0Répéter
choisir x au hasard dans SSi (x ∈ R)
alorsSi (Random < 1/λ) alors R←− R \ {x}finSi
sinonSi (∀y ∈ R , {x, y} /∈ B)
alors R←− R ∪ {x}finSi
finSit←− t+ 1
Jusqu’à (arrêt de la simulation)

36 Cahier de Mathématiques Appliquées no 11
Supposons que λ soit suffisamment grand (par exemple λ = 10). La loide probabilité p présente la particularité de charger préférentiellement lesconfigurations ou un maximum d’unités sont en fonctionnement : si deuxconfigurations diffèrent par une unité, le rapport de leurs probabilités est 10,en faveur de celle qui a une unité de plus en fonctionnement. Simuler la loide probabilité p pour λ grand est donc une manière approchée d’optimiser lenombre d’unités en fonctionnement dans le problème de ressources partagées.
3 Modèles sur IN
3.1 Le problème de la ruine du joueur
Un joueur joue à un jeu (pile ou face, roulette, . . . ) où il gagne un montantfixe avec probabilité p, et perd le même montant avec probabilité 1−p. Si Un
désigne le bilan de la n-ième partie :
IP[Un = +1] = p , IP[Un = −1] = 1−p .
On suppose que les parties sont indépendantes. Soit Xn la fortune du joueurà l’issue de la n-ième partie. On a :
Xn+1 = Xn + Un+1 .
De sorte que la suite (Xn) est une chaîne de Markov. A priori, Xn prendses valeurs dans l’ensemble ZZ. Cependant des considérations économiquesévidentes conduisent à limiter l’étendue des dégâts. On envisagera plusieurstypes de limitations.
Deux bornes absorbantes : Nous supposerons que le joueur, partant d’unefortune initiale i décide d’arrêter soit s’il est ruiné (Xn = 0), soit s’il aatteint une fortune a > i (son adversaire est ruiné ou lui-même est devenusage). L’ensemble des états est E = {0, . . . , a}. En notant q = 1−p, la matricede transition s’écrit :
P =
1 0 0 . . . 0
q 0 p. . .
...
0. . .
. . .. . .
... 0q 0 p
0 . . . 0 0 1
Les états 0 et a sont absorbants, tous les autres états sont transients (lediagramme de transition est celui de la figure 5).
Nous commençons par calculer la probabilité fi0 avec laquelle le jeu setermine par la ruine du joueur. La probabilité que le jeu se termine par la

Chaînes de Markov 37
i+1i−1 i a−1 a10
q q q
pp p 1
1
Figure 5 – Diagramme de transition pour le jeu de pile ou face avec bornesabsorbantes.
fortune a est fia = 1−fi0. On a évidemment f00 = 1 et fa0 = 0. Pouri = 1, . . . , a−1, les fi0 sont solution de l’équation de récurrence :
fi0 = pfi+1 0 + (1−p)fi−1 0 .
On trouve :
fi0 =
(
1−pp
)a
−(
1−pp
)i
(
1−pp
)a
− 1,
si p 6= 1/2, et fi0 = 1 − i/a si p = 1/2. Le gain du joueur quand la partiese termine est une variable aléatoire G qui prend les valeurs −i et a−i avecprobabilités fi0 et 1−fi0. L’espérance de gain est donc :
IE[G] = a(1− fi0)− i .
Cette espérance a le signe de p − 1/2. Si p = 1/2 (jeu équitable), elle estnulle quelle que soit la fortune initiale. La durée moyenne de la partie est letemps moyen d’atteinte des états 0 ou a, partant de i. Notons-la ei. Les eisont solution de l’équation :
ei = 1 + pei+1 + (1− p)ei−1 ,
avec e0 = ea = 0. On trouve :
ei =i
1− 2p−
a
1− 2p
(
1−pp
)i
− 1(
1−pp
)a
− 1,
si p 6= 1/2 et ei = i(a − i) si p = 1/2. Voici quelques valeurs numériques,

38 Cahier de Mathématiques Appliquées no 11
d’abord pour un jeu équitable, puis défavorable au joueur.
p i a fi0 IE[G] ei
0.5 9 10 0.1 0 90.5 90 100 0.1 0 9000.5 900 1000 0.1 0 900000.5 950 1000 0.05 0 475000.5 8000 10000 0.2 0 1.6 107
0.45 9 10 0.210 −1.1 110.45 90 100 0.866 −76.6 765.60.45 99 100 0.182 −17.2 171.80.4 90 100 0.983 −88.3 441.30.4 99 100 0.333 −32.3 161.7
Comme on le voit, il est préférable de s’abstenir de jouer si le jeu est défavo-rable, et ce même si on se fixe un objectif raisonnable.
Une borne absorbante : Supposons que l’adversaire soit infiniment riche ou lejoueur peu raisonnable. La chaîne de Markov est maintenant définie sur IN,avec un état absorbant, 0 et une classe irréductible transiente formée de tousles autres états. On obtient la probabilité de ruine et la durée moyenne du jeuen faisant tendre a vers l’infini dans les formules précédentes. La probabilitéde ruine fi0 est :
fi0 =
1 si p ≤ 1/2 ,(
1−p
p
)i
si p > 1/2 .
La durée moyenne du jeu est :
ei =
i
1− 2psi p < 1/2 ,
+∞ si p ≥ 1/2 .
Si le jeu est défavorable ou équitable, le joueur est certain de se ruiner. S’ilest strictement défavorable, cette ruine surviendra au bout d’un temps finien moyenne. S’il est équitable, l’espérance du temps de ruine est infinie.
Si le jeu est favorable au joueur, il est possible qu’il se ruine, mais il y aune probabilité strictement positive qu’il devienne infiniment riche.
Une borne réfléchissante : Le joueur joue contre un adversaire infiniment richemais celui-ci, magnanime, l’autorise à continuer le jeu même s’il est ruiné. En
Chaînes de Markov 39
posant q = 1− p, la matrice de transition devient :
P =
q p 0 . . .
q 0 p. . .
0. . .
. . .. . .
...
.
Dans ce cas, tous les états de IN communiquent et la chaîne est irréductible.
0 200 400 600 800 10000
25
50
75
100
.
Xn
n
p=0.45
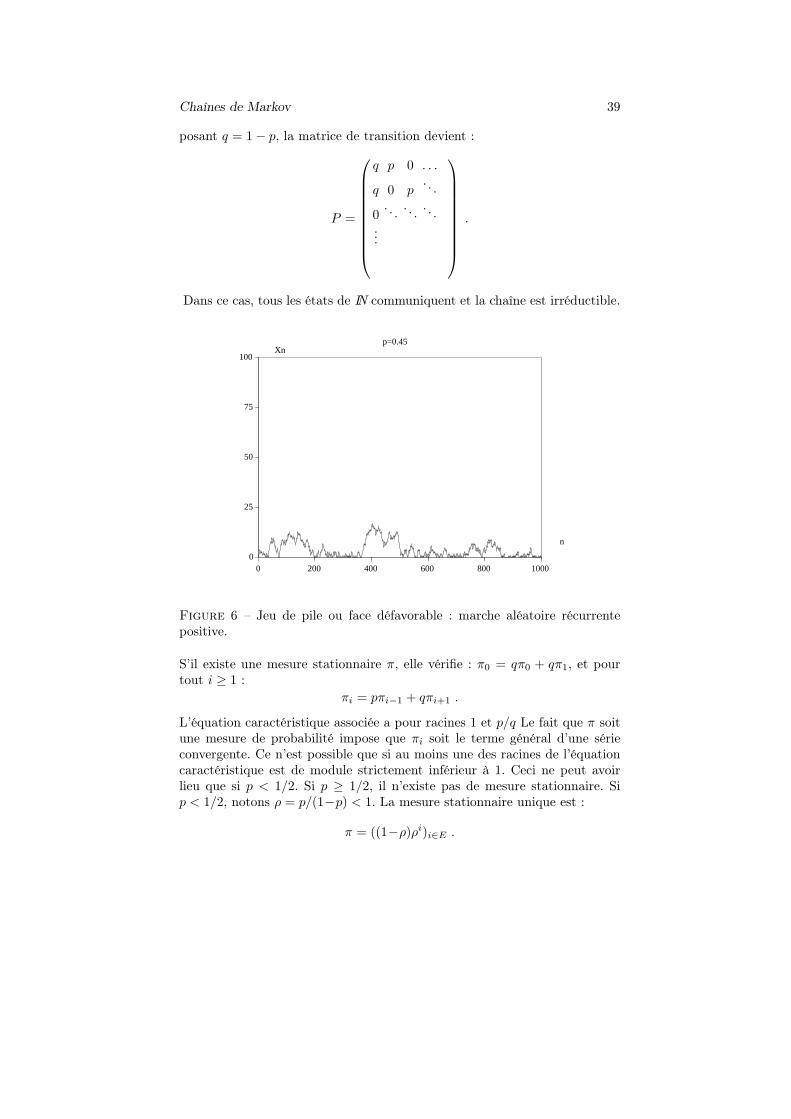
Figure 6 – Jeu de pile ou face défavorable : marche aléatoire récurrentepositive.
S’il existe une mesure stationnaire π, elle vérifie : π0 = qπ0 + qπ1, et pourtout i ≥ 1 :
πi = pπi−1 + qπi+1 .
L’équation caractéristique associée a pour racines 1 et p/q Le fait que π soitune mesure de probabilité impose que πi soit le terme général d’une sérieconvergente. Ce n’est possible que si au moins une des racines de l’équationcaractéristique est de module strictement inférieur à 1. Ceci ne peut avoirlieu que si p < 1/2. Si p ≥ 1/2, il n’existe pas de mesure stationnaire. Sip < 1/2, notons ρ = p/(1−p) < 1. La mesure stationnaire unique est :
π = ((1−ρ)ρi)i∈E .
40 Cahier de Mathématiques Appliquées no 11
0 200 400 600 800 10000
25
50
75
100
.
Xn
n
p=0.5
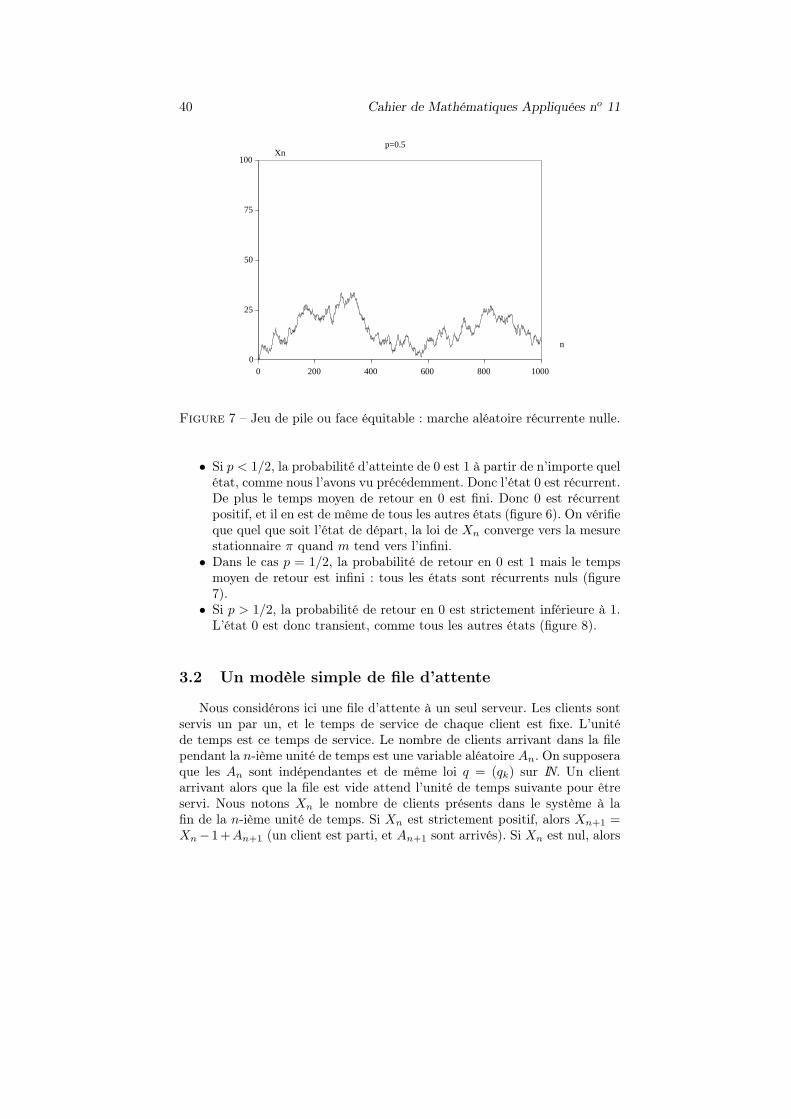
Figure 7 – Jeu de pile ou face équitable : marche aléatoire récurrente nulle.
• Si p < 1/2, la probabilité d’atteinte de 0 est 1 à partir de n’importe quelétat, comme nous l’avons vu précédemment. Donc l’état 0 est récurrent.De plus le temps moyen de retour en 0 est fini. Donc 0 est récurrentpositif, et il en est de même de tous les autres états (figure 6). On vérifieque quel que soit l’état de départ, la loi de Xn converge vers la mesurestationnaire π quand m tend vers l’infini.
• Dans le cas p = 1/2, la probabilité de retour en 0 est 1 mais le tempsmoyen de retour est infini : tous les états sont récurrents nuls (figure7).
• Si p > 1/2, la probabilité de retour en 0 est strictement inférieure à 1.L’état 0 est donc transient, comme tous les autres états (figure 8).
3.2 Un modèle simple de file d’attente
Nous considérons ici une file d’attente à un seul serveur. Les clients sontservis un par un, et le temps de service de chaque client est fixe. L’unitéde temps est ce temps de service. Le nombre de clients arrivant dans la filependant la n-ième unité de temps est une variable aléatoire An. On supposeraque les An sont indépendantes et de même loi q = (qk) sur IN. Un clientarrivant alors que la file est vide attend l’unité de temps suivante pour êtreservi. Nous notons Xn le nombre de clients présents dans le système à lafin de la n-ième unité de temps. Si Xn est strictement positif, alors Xn+1 =Xn−1+An+1 (un client est parti, et An+1 sont arrivés). Si Xn est nul, alors
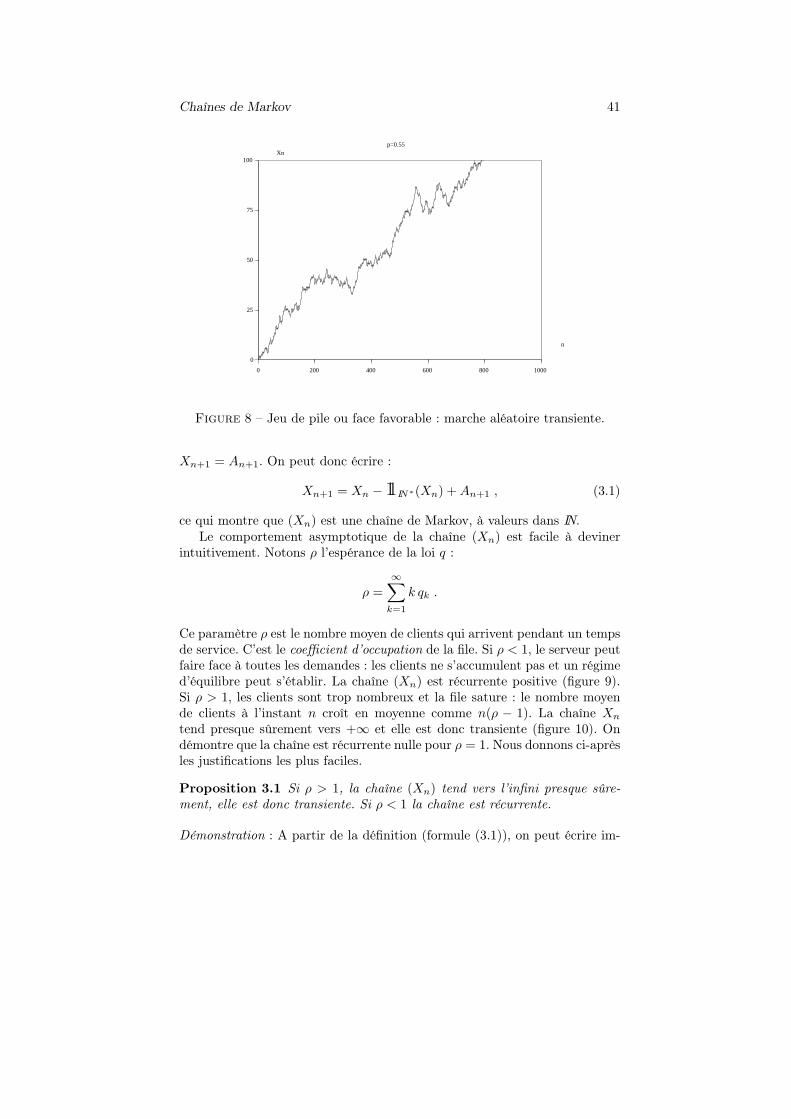
Chaînes de Markov 41
0 200 400 600 800 1000
0
25
50
75
100
.
Xn
n
p=0.55
Figure 8 – Jeu de pile ou face favorable : marche aléatoire transiente.
Xn+1 = An+1. On peut donc écrire :
Xn+1 = Xn − 11IN∗(Xn) +An+1 , (3.1)
ce qui montre que (Xn) est une chaîne de Markov, à valeurs dans IN.Le comportement asymptotique de la chaîne (Xn) est facile à deviner
intuitivement. Notons ρ l’espérance de la loi q :
ρ =
∞∑
k=1
k qk .
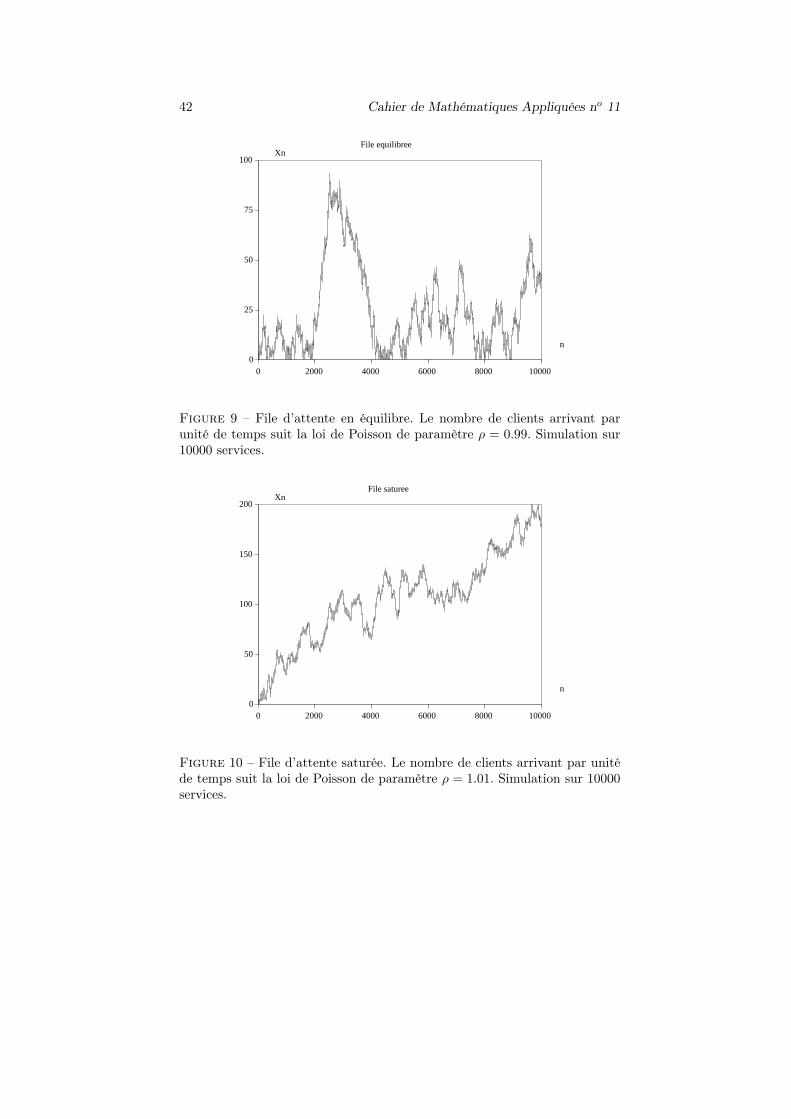
Ce paramètre ρ est le nombre moyen de clients qui arrivent pendant un tempsde service. C’est le coefficient d’occupation de la file. Si ρ < 1, le serveur peutfaire face à toutes les demandes : les clients ne s’accumulent pas et un régimed’équilibre peut s’établir. La chaîne (Xn) est récurrente positive (figure 9).Si ρ > 1, les clients sont trop nombreux et la file sature : le nombre moyende clients à l’instant n croît en moyenne comme n(ρ − 1). La chaîne Xn
tend presque sûrement vers +∞ et elle est donc transiente (figure 10). Ondémontre que la chaîne est récurrente nulle pour ρ = 1. Nous donnons ci-aprèsles justifications les plus faciles.
Proposition 3.1 Si ρ > 1, la chaîne (Xn) tend vers l’infini presque sûre-ment, elle est donc transiente. Si ρ < 1 la chaîne est récurrente.
Démonstration : A partir de la définition (formule (3.1)), on peut écrire im-
42 Cahier de Mathématiques Appliquées no 11
0 2000 4000 6000 8000 100000
25
50
75
100
.
Xn
n
File equilibree
Figure 9 – File d’attente en équilibre. Le nombre de clients arrivant parunité de temps suit la loi de Poisson de paramètre ρ = 0.99. Simulation sur10000 services.
0 2000 4000 6000 8000 100000
50
100
150
200
.
Xn
n
File saturee
Figure 10 – File d’attente saturée. Le nombre de clients arrivant par unitéde temps suit la loi de Poisson de paramètre ρ = 1.01. Simulation sur 10000services.

Chaînes de Markov 43
médiatement :
Xn ≥ −n+
n∑
i=1
An
= n(
− 1 +1
n
n∑
m=1
Am
)
.
D’après la loi forte des grands nombres, 1n
∑nm=1 Am converge presque sûre-
ment vers ρ, d’où le résultat dans le cas ρ > 1.Supposons X0 = i et
∑nm=1 Am < n. On voit aisément à partir de la même
formule (3.1), que parmi X1, . . . , Xn, au moins une des valeurs est égale ài. La probabilité fii de retour en i est donc minorée par IP[
∑nm=1 Am < n].
Pour ρ < 1, cette probabilité tend vers 1 quand n tend vers l’infini, doncfii = 1. �
Dans le cas où un régime d’équilibre s’établit, il est possible de calculerexplicitement la fonction génératrice de la mesure stationnaire.
Proposition 3.2 Notons g la fonction génératrice de la loi q des nombresd’arrivées par unité de temps. La chaîne (Xn) admet une mesure stationnairesi et seulement si le coefficient d’occupation ρ est strictement inférieur à 1.Dans ce cas, la fonction génératrice de cette mesure stationnaire est :
f(z) =(1− ρ)(1− z)g(z)
g(z)− z.
Démonstration : La fonction génératrice de la loi q est définie par :
g(z) =
∞∑
k=0
zk qk .
Le coefficient d’occupation est la dérivée de g en 1 :
ρ =∞∑
k=0
k qk = g′(1) .
A partir de la formule de définition (3.1), il est facile d’écrire les probabilitésde transition de la chaîne. On obtient p0j = qj pour tout j ≥ 0, et pouri > 0, pij = qj−i+1 si j ≥ i−1, pij = 0 sinon. Notons π = (πi) la mesurestationnaire. Si elle existe, elle vérifie le système d’équations suivant :
π0 = π0 q0 + π1 q1π1 = π0 q1 + π1 q1 + π2 q0
...πk = π0 qk + π1 qk + · · ·+ πk+1 q0
...

44 Cahier de Mathématiques Appliquées no 11
La fonction génératrice de π est définie par f(z) =∑
πk zk. Pour la faire
apparaître, on multiplie par zk la k-ième équation du système et on somme :
f(z) = π0g(z) + π1g(z) + · · ·+ πk+1zkg(z)
=g(z)
z
(
π0z − π0 + f(z))
.
On en déduit une expression de f(z) en fonction de π0 et g(z) :
f(z) = π0(1− z)g(z)
g(z)− z.
Pour déterminer la valeur de π0, il faut utiliser le fait que π doit être unemesure de probabilité et que donc f(1) doit être égal à 1. Or z = 1 an-nule le numérateur et le dénominateur de l’expression ci-dessus. Pour leverl’indétermination, on écrit :
g(z) = 1 + (z − 1)ρ+ o(z − 1) .
On en déduit facilement que π0 = 1−ρ. Donc la mesure stationnaire ne peutêtre une loi de probabilité que si ρ < 1. �
Comme cas particulier, supposons que q soit la loi binomiale négativeBN (1, 1
1+ρ ). Sa fonction génératrice est :
g(z) =1
1 + ρ− ρz.
On obtient :
f(z) =1− ρ
1− ρz.
La mesure stationnaire (loi du nombre de clients dans la file à l’équilibre) estdonc la loi BN (1, 1−ρ), d’espérance ρ
1−ρ .
3.3 Le problème de l’extinction du nom
La chaîne que nous étudions ici porte le nom de “processus de Galton-Watson”, du nom des mathématiciens qui l’ont introduite comme modèlede perpétuation des lignées chez les pairs d’Angleterre à la fin du XIXèmesiècle. Les instants successifs sont interprétés comme des générations. Lesindividus sont des “Lords”, qui transmettent leur titre uniquement à leursfils. La variable aléatoire Xn sera comprise comme le nombre d’hommes dela lignée à la n-ième génération. Chaque individu d’une génération donnéecontribue à la génération suivante par un nombre aléatoire d’individus, sadescendance. Toutes les descendances sont supposées indépendantes et demême loi.

Chaînes de Markov 45
Nous commençons par montrer que (Xn) est une chaîne de Markov. Pourcela, donnons-nous une famille (Dnm) , n,m ∈ IN de variables aléatoiresindépendantes et de même loi à valeurs dans IN. La variable Dnm est lenombre de descendants du m-ième individu de la génération n. On a :
Xn+1 =
Xn∑
i=1
Dnm .
On a donc bien défini une chaîne de Markov à valeurs dans IN, pour laquelle0 est un état absorbant. Le problème posé est du même type que celui de laruine du joueur : il faut déterminer la probabilité que la lignée s’éteigne, àsavoir que la chaîne soit absorbée en 0.
Pour tout i = 0, 1, . . ., on note qi la probabilité qu’un individu ait i des-cendants. La fonction génératrice de la descendance d’un individu est notéeg :
g(z) =
∞∑
i=0
zi qi .
Le nombre moyen de descendants d’un individu (supposé fini !) est noté µ.
µ =
∞∑
i=0
i qi = g′(1) .
S’il y a i individus à la n-ième génération (Xn = i), alors Xn+1 sera lasomme des descendances de ces i individus, qui sont des variables aléatoiresindépendantes. La fonction génératrice de la loi conditionnelle de Xn+1 sa-chant Xn = i sera donc le produit des fonctions génératrices des descendancesdes i individus, soit gi. Les probabilités de transition n’ont pas d’expressionsimple, mais :
∞∑
j=0
zj pij = gi(z) .
Théorème 3.3 La probabilité d’extinction pour une lignée de i individus estfi0 = ηi, où η est la plus petite solution de l’équation g(z) = z dans [0, 1].• Si µ ≤ 1, alors η = fi0 = 1 : l’extinction est certaine.• Si µ > 1, l’équation g(z) = z a une unique solution η telle que 0 < η <1. L’extinction est possible (si q0 > 0) mais pas certaine.
Ce que dit ce théorème est intuitivement évident : pour que la lignée ait unechance de perdurer, il faut que chaque individu ait plus d’un descendant enmoyenne.
Démonstration : Commençons par écarter deux cas particuliers triviaux.
1. Si q0 = 0, tout individu a au moins un descendant et la population nepeut pas disparaître.
46 Cahier de Mathématiques Appliquées no 11
0 10
1
.
g(z)
z
Points fixes de g
g sous-critique
g sur-critique
Figure 11 – Fonction génératrice de la descendance.
2. Si q0 + q1 = 1, la population ne peut que rester constante (si q0 = 0)ou diminuer et donc disparaître certainement.
La probabilité qu’une lignée commençant avec i individus disparaisse à la
m-ième génération est la probabilité de premier passage f(m)i0 . Notons F
(M)i0
la somme :
F(M)i0 =
M∑
m=1
f(m)i0 .
C’est la probabilité que chacune des i lignées issues des individus initiauxdisparaisse avant la M -ième génération. Or ces i lignées sont indépendantes,et identiquement distribuées. On a donc :
F(M)i0 =
(
F(M)10
)i
.
Or, f(1)10 = q0 et pour tout m ≥ 2 :
f(m)10 =
∞∑
i=1
qif(m−1)i0 .
En sommant sur m de 1 à M , on obtient :
F(M)10 = q0 +
∞∑
i=1
qi
(
F(M−1)10
)i
= g(F(M−1)10 ) .

Chaînes de Markov 47
La probabilité d’absorption en 0 partant de i, fi0, est la limite de la suite
(F(M)i0 ). Cette suite est croissante et majorée par 1. Elle converge donc. Sa
limite vérifie :fi0 = (f10)
i,
et de plus :f10 = g(f10) .
Comme la suite (F(M)10 ) est croissante, sa limite est la plus petite solution de
l’équation g(z) = z.
La fonction g(z) est convexe dans [0, 1] et croît de g(0) = q0 à g(1) = 1.Deux cas sont possibles.• Cas sous-critique
Si la dérivée de g en 1 est inférieure ou égale à 1, alors g(z) reste audessus de sa tangente en 1. On a donc g(z) − z > 0 pour tout z < 1.Donc 1 est la plus petite solution de l’équation. Dans ce cas fi0 = 1, etl’extinction est certaine.
• Cas sur-critiqueSi la dérivée de g en 1 est strictement supérieure à 1, alors g(z) − zest strictement négatif pour un certain z < 1. Comme g(0) = q0 > 0,l’équation g(z) = z a une solution η strictement comprise entre 0 et 1(voir figure 11).
�
48 Cahier de Mathématiques Appliquées no 11
4 Exercices
Exercice 1 Les matrices suivantes sont des matrices de transition surI = {1, . . . , x}, x = 4, 5 ou 7.
1 0 0 0
0 1/2 1/2 0
0 1/2 1/2 0
1/2 0 0 1/2
0 0 1 0
0 0.4 0.6 0
0.8 0 0.2 0
0.2 0.3 0 0.5
0.8 0 0.2 0
0 0 1 0
1 0 0 0
0.3 0.4 0 0.3
0.2 0.8 0 0
0.6 0.4 0 0
0 0.2 0.3 0.5
0 0 0.5 0.5
0 0 0 0.5 0.5
0 0 0 0.4 0.6
0 0 0 0 1
0.8 0 0.2 0 0
0 1 0 0 0
0.5 0 0 0.5 0
0 0.6 0 0 0.4
0.3 0 0.7 0 0
0 0 1 0 0
0 1 0 0 0
0 0 0.4 0.6 0
0 0.2 0 0.5 0.3
0.5 0 0.5 0 0
0 0 1 0 0
0.3 0 0.5 0 0.2
1/2 0 1/2 0 0
0 1/4 0 3/4 0
0 0 1/3 0 2/3
1/4 1/2 0 1/4 0
1/3 0 1/3 0 1/3
0.2 0.8 0 0 0 0 0
0.7 0.3 0 0 0 0 0
0 0 0.3 0.5 0.2 0 0
0 0 0.6 0 0.4 0 0
0 0 0 0.4 0.6 0 0
0 0.1 0.1 0.2 0.2 0.3 0.1
0.1 0.1 0.1 0 0.1 0.2 0.4
0 0 1/2 1/4 1/4 0 0
0 0 1/3 0 2/3 0 0
0 0 0 0 0 1/3 2/3
0 0 0 0 0 1/2 1/2
0 0 0 0 0 3/4 1/4
1/2 1/2 0 0 0 0 0
1/4 3/4 0 0 0 0 0

Chaînes de Markov 49
0.8 0 0 0 0 0.2 0
0 0 0 0 1 0 0
0.1 0 0.9 0 0 0 0
0 0 0 0.5 0 0 0.5
0 0.3 0 0 0.7 0 0
0 0 1 0 0 0 0
0 0.5 0 0 0 0.5 0
0 0 1 0 0 0 0
0 0.2 0 0 0.4 0.4 0
0.8 0 0 0 0.2 0 0
0 0 0 0 0 1 0
0 0 1 0 0 0 0
0 0 0 0.7 0 0.3 0
0 0 0 0 0 0 1
Pour chacune de ces matrices P :
1. Représenter le diagramme de transitions et classifier les états.
2. Déterminer l’ensemble des mesures stationnaires.
3. Pour tout couple d’états (i, j), calculer la probabilité fij d’atteindre jà partir de i.
4. Si une chaîne de Markov (Xn) , n ∈ IN a pour matrice de transition Pet pour loi initiale α = (αi), déterminer la limite de la loi de Xn quandn tend vers l’infini.
5. Pour n = 10, 20, . . . , 100, calculer numériquement Pn.
6. Pour i ∈ I, simuler 10000 trajectoires de la chaîne de matrice P , par-tant de X0 = i, jusqu’au temps N = 100. Pour n = 10, 20, . . . , 100,tester l’adéquation de la distribution empirique des 10000 trajectoiresau temps t avec la distribution théorique de Xn, calculée numérique-ment à la question précédente.
7. Pour i ∈ I, tirer une trajectoire partant de X0 = i jusqu’au temps N =106 et calculer la proportion empirique du temps passé dans chacundes états. Tester l’adéquation de cette distribution empirique avec lamesure stationnaire de l’une des classes récurrentes de la chaîne.
Exercice 2 Quatre points A,B,C,D sont placés sur un cercle, dans le sensdes aiguilles d’une montre. Le jeu consiste à tourner sur ces quatre points,en partant de A, toujours dans le même sens, d’autant de pas que le nombreindiqué par un dé à 6 faces. On note Xn le point sur lequel on arrive aun-ième lancer de dé (Xn ∈ {A,B,C,D}).
1. Montrer que (Xn) , n ∈ IN est une chaîne de Markov et écrire sa matricede transition P .
2. Pour n = 10, 20, . . . , 100, calculer numériquement Pn.
3. Simuler 10000 trajectoires de la chaîne (Xn), jusqu’au temps N = 100.Pour n = 10, 20, . . . , 100, tester l’adéquation de la distribution empi-rique des 10000 trajectoires au temps t avec la distribution théoriquede Xn, calculée numériquement à la question précédente.
4. Quelle est la limite en loi de Xn quand n tend vers l’infini ?

50 Cahier de Mathématiques Appliquées no 11
5. Simuler 10000 trajectoires de la chaîne (Xn)
6. Simuler une trajectoire jusqu’au temps N = 106 et calculer la propor-tion empirique du temps passé dans chacun des états. Tester l’adéqua-tion de cette distribution empirique avec la mesure stationnaire de lachaîne.
7. On décide de terminer le jeu dès qu’on tombe sur A ou C, la partie étantgagnée si on est tombé sur A, perdue sur C. Quelle est la probabilitéde gagner ?
8. Combien de pas en moyenne aura-t-on effectué quand la partie se ter-minera ?
9. Simuler 10000 trajectoires de la chaîne, arrêtées en A ou C. Calculerla fréquence d’arrêt en A et comparer avec la probabilité de gain. Cal-culer la longueur moyenne des trajectoires et comparer avec le résultatthéorique de la question précédente.
Exercice 3 Deux joueurs A et B jouent au jeu suivant. Chaque joueur lanceune pièce non truquée. Si l’un des deux obtient pile et l’autre face, le jeus’arrête et celui qui a obtenu pile a gagné. Si tous les deux obtiennent pile,la partie est nulle et le jeu s’arrête. Sinon, ils jouent une autre partie.
1. Calculer la probabilité que le jeu s’arrête à la n-ième partie.
2. Calculer la probabilité que A gagne en moins de n parties.
3. Calculer la probabilité que le jeu s’arrête sur une partie nulle.
4. Quelle est la durée moyenne du jeu en nombre de parties ?
5. Simuler 10000 parties, et vérifier expérimentalement les résultats théo-riques des questions précédentes.
Exercice 4 Une souris est lancée dans le labyrinthe suivant. Elle commenceen A où se trouve sa cage. En B il y a un morceau de fromage, en C unchat affamé. La souris parcourt les couloirs en choisissant au hasard parmiles couloirs offerts à chaque nouvelle intersection. Elle met une seconde enmoyenne entre deux intersections.
�������������������������
�������������������������
�������������������������
�������������������������
��������������������
��������������������
������������������������
������������������������
C
D
A BE
F

Chaînes de Markov 51
1. Quelle est la probabilité que la souris se fasse manger le ventre plein ?
2. Quelle est la probabilité que la souris revoit sa chère cage avant de sefaire manger ?
3. Quelle est la probabilité que la souris n’ait pas revu sa cage et se fassemanger le ventre vide ?
4. Combien de temps durera ce jeu cruel ?
5. Simuler 10000 parcours, et vérifier expérimentalement les résultats théo-riques des questions précédentes.
Exercice 5 Le jeu de Penney.Cet exercice développe l’exemple donné en 1.3. Le but est d’étudier les oc-currences de séquences binaires données à l’intérieur d’une suite de tirages depile ou face. Dans ce qui suit (ǫn)n≥1 désigne une suite de tirages de pile ouface, à savoir une suite de variables aléatoires indépendantes identiquementdistribuées, suivant la loi de Bernoulli de paramètre 1/2.
∀n ≥ 1 , P rob[ǫn = 0] = Prob[ǫn = 1] =1
2.
Première partie
On s’intéresse aux occurrences successives d’un “mot” binaire donné.
Soit A = (ai)1≤i≤ℓ un mot binaire de longueur ℓ.
∀i = 1, . . . , ℓ , ai = 0 ou 1 .
Pour tout k = 1, . . . , ℓ, on note Ak le mot A tronqué à ses k premières lettres :
∀k = 1, . . . , ℓ , Ak = (ai)1≤i≤k .
Pour tout entier n on définit la variable aléatoire Xn, à valeurs dans {0, . . . , ℓ}comme le nombre de bits parmi les derniers tirages jusqu’au n-ième qui coïn-cident avec le début de A.
Xn = 0 si n = 0 ou ∀k = 1, . . . , ℓ (ǫn−k+1, . . . , ǫn) 6= Ak
Xn = k ∈ {1 . . . , ℓ−1} si (ǫn−k+1, . . . , ǫn) = Ak
et (ǫn−k−i, . . . , ǫn) 6= Ak+i+1 , ∀i = 0, . . . , ℓ− k − 1
Xn = ℓ si (ǫn−ℓ+1, . . . , ǫn) = Aℓ = A .
1. Montrer que (Xn)n∈IN est une chaîne de Markov.
2. Montrer que la loi de la chaîne (Xn) ne change pas si on remplaceA = (ai)1≤i≤ℓ par A = (1− ai)1≤i≤ℓ.

52 Cahier de Mathématiques Appliquées no 11
3. Expliciter le diagramme et la matrice de transitions de la chaîne (Xn)dans les cas suivants.
a) A = (1, 1, . . . , 1) (ℓ termes égaux à 1).b) A = (1, . . . , 1, 0) (ℓ−1 termes égaux à 1 suivis d’un 0).c) A = (1, 0, 1).d) A = (1, 1, 0, 0).e) A = (1, 0, 1, 1).f) A = (0, 1, 1, 1).
4. Ecrire un algorithme qui prenne en entrée un mot binaire donné commeun tableau de booléens, et qui retourne en sortie la matrice de transitionde la chaîne (Xn).
5. Ecrire un programme de simulation. Ce programme prend en entrée unmot binaire donné comme un tableau de booléens, et un nombre de pasn. Il retourne le tableau des n valeurs prises par la chaîne (Xn), à partirde X0 = 0.
Deuxième partieOn s’intéresse à l’instant de première apparition du mot A = (ai)1≤i≤ℓ à
savoir le premier indice n pour lequel la chaîne (Xn) atteint l’état ℓ.
Pour tout k = 0, . . . , ℓ−1 et pour tout n ≥ 1, on note qk(n) la probabilitéd’atteindre pour la première fois l’état ℓ en exactement n pas, à partir del’état k.
qk(n) = IP[Xm+n = ℓ , Xm+n−1 6= ℓ , . . . , Xm+1 6= ℓ |Xm = k] .
1. Soit P = (pij) la matrice de transition de la chaîne (Xn). Montrer quepour tout k = 0, . . . , ℓ− 1 qk(1) = pkℓ et pour tout n > 1,
qk(n) =
ℓ−1∑
j=0
pkj qj(n− 1) .
2. Pour tout k = 0, . . . , ℓ − 1 montrer que (qk(n))n∈IN est une loi deprobabilité sur IN∗.
On note gk la fonction génératrice de cette loi de probabilité, et mk sonespérance.
gk(z) =
+∞∑
n=1
qk(n) zn ,
mk =
+∞∑
n=1
n qk(n) .
On note G(z) et M les vecteurs :
G(z) = (gk(z))0≤k≤ℓ−1 et M = (mk)0≤k≤ℓ−1 .

Chaînes de Markov 53
On note Pℓ le vecteur formé des ℓ premiers termes de la dernière colonnede P et P ′ la matrice obtenue en ôtant la dernière ligne et la dernièrecolonne de P .
Pℓ = (piℓ)0≤i≤ℓ−1 et P ′ = (pij)0≤i,j≤ℓ−1 .
On note enfin I la matrice identité de dimension ℓ et 11 le vecteur deIRℓ dont toutes les coordonnées valent 1.
3. Montrer que :
G(z) = z(I − zP ′)−1Pℓ et M = (I − P ′)−111 .
4. Soit N la variable aléatoire égale au premier indice d’apparition du motA dans la suite (ǫn). Quelle est la fonction génératrice de la loi de N ?Quelle est son espérance ?
5. Calculer la fonction génératrice de la loi de N pour A = (1, 1) puisA = (1, 0).
6. Calculer l’espérance de N dans les cas suivants :a) A = (1, 1, . . . , 1) (ℓ termes égaux à 1).b) A = (1, . . . , 1, 0) (ℓ−1 termes égaux à 1 suivis d’un 0).c) A = (1, 0, 1).d) A = (1, 1, 0, 0).e) A = (1, 0, 1, 1).f) A = (0, 1, 1, 1).
7. Soit A un mot binaire quelconque. On définit le mot binaire R(A) =(r1, . . . , rℓ), qui compte les auto-recouvrements partiels de A, de la façonsuivante. Pour tout k = 1, . . . , ℓ,
rk = 1 si (a1, . . . , aℓ−k+1) = (ak, . . . , aℓ)= 0 sinon .
On admettra que le temps moyen de première apparition de A est égalà 2 fois la valeur entière de R(A) :
IE[N ] = 2
ℓ∑
k=1
rk2ℓ−k .
a) Vérifier les résultats de la question précédente.b) Calculer le temps moyen de première apparition de :
A = (1, 1, 0, 1, 1, 0, 1, 1, 0) .
8. Vérifier par la simulation les résultats des questions 6 et 7. On donnerapour chacun des temps moyens un intervalle de confiance d’amplitudeinférieure à 0.1, au niveau de confiance 0.99.

54 Cahier de Mathématiques Appliquées no 11
Troisième partie
Le jeu de Penney consiste à faire jouer deux mots binaires A et B l’uncontre l’autre jusqu’à l’instant d’apparition du premier d’entre eux. C’estcelui des deux mots qui apparaît le premier qui gagne. Selon A et B, ilpourrait se faire que l’un des deux ne puisse jamais gagner, ou que les deuxgagnent simultanément. Afin de simplifier les écritures et d’éviter ces casparticuliers, nous supposerons que A et B sont deux mots binaires distinctsde même longueur ℓ. Le but est de calculer la durée moyenne d’une partieainsi que la probabilité que chacun des deux mots a de gagner.
1. La suite de tirages (ǫn) étant fixée, on lui associe les deux chaînes deMarkov (Xn)n∈IN et (Yn)n∈IN où (Xn) est la chaîne associée au motA comme dans la première partie, et (Yn) correspond à B de façonanalogue. Montrer que ((Xn, Yn))n∈IN est une chaîne de Markov sur{0, . . . , ℓ}2. Les variables aléatoires Xn et Yn peuvent-elles être indé-pendantes ?
2. Expliciter le diagramme de transitions de la chaîne ((Xn, Yn)) dans lecas :
A = (1, 1, . . . , 1) ; B = (1, . . . , 1, 0) .
3. Même question pour le cas :
A = (1, 1, . . . , 1) ; B = (0, . . . , 0, 1) .
Pour k et h différents de ℓ, on note qAk,h(n) (respectivement qBk,h(n)) laprobabilité que A (resp. B) gagne au bout de n coups en partant del’état (k, h).
qAk,h(n) = IP[Xm+n = ℓ,Xm+n−1 6= ℓ, . . . , Xm+1 6= ℓ,
Ym+n−1 6= ℓ, . . . , Ym+1 6= ℓ | (Xm, Ym) = (k, h)] .
4. On note mk,h la durée moyenne du jeu en partant de l’état (k, h).
mk,h =
+∞∑
n=1
n (qAk,h(n) + qBk,h(n)) .
Montrer que les mk,h sont solution du système :
∀k, h 6= ℓ , mk,h =
ℓ−1∑
k′=0
ℓ−1∑
h′=0
p(k,h)(k′,h′) mk′,h′ ,
où les p(k,h)(k′,h′) désignent les probabilités de transition de la chaîne{(Xn, Yn) ; n ∈ IN}.

Chaînes de Markov 55
5. On note qAk,h la probabilité que A gagne le jeu en partant de l’état (k, h).
qAk,h =+∞∑
n=1
qAk,h(n) .
Montrer que les qAk,h sont solution du système :
∀k, h 6= ℓ , qAk,h =
ℓ−1∑
k′=0
ℓ−1∑
h′=0
p(k,h)(k′,h′) qAk′,h′ +
ℓ−1∑
h′=0
p(k,h)(ℓ,h′) .
6. Calculer la durée moyenne du jeu et la probabilité que A gagne dansles cas suivants :
a) A = (1, 1) ; B = (1, 0).b) A = (1, 1) ; B = (0, 1).
7. Soient A et B deux mots quelconques. On définit le mot R(A,B) =(r1, . . . , rℓ), qui compte les recouvrements partiels de A par B, de lafaçon suivante. Pour tout k = 1, . . . , ℓ,
rk = 1 si (b1, . . . , bℓ−k+1) = (ak, . . . , aℓ)= 0 sinon .
On note ρ(A), ρ(B), ρ(A,B) et ρ(B,A) les valeurs entières des motsbinaires R(A), R(B), R(A,B) et R(B,A). On admettra la formule don-nant la probabilité que A gagne le jeu de Penney :
qA0,0 =ρ(B)− ρ(B,A)
ρ(B)− ρ(B,A) + ρ(A)− ρ(A,B).
Vérifier les résultats de la question précédente.
8. Calculer la probabilité que A gagne dans les cas suivants :a) A = (1,1,0,1) ; B = (1,0,1,1).b) A = (1,0,1,1) ; B = (0,1,1,1).c) A = (0,1,1,1) ; B = (1,1,0,1).
9. Vérifier par la simulation les résultats de la question précédente. Danschacun des trois cas, on donnera un intervalle de confiance pour laprobabilité de gain de A, d’amplitude inférieure à 0.01. On donneraégalement un intervalle de confiance pour la durée moyenne de chacunedes trois parties. Les niveaux de confiance sont toujours fixés à 0.99.
Exercice 6 Des objets, nommés x, y1, y2, . . . , yN−1, sont rangés dans un ta-bleau de taille N dans lequel on accède de manière séquentielle. A chaqueaccès au tableau, on recherche l’un des N objets, soit x avec probabilité a, soitl’un des N−1 autres, avec probabilité b pour chacun d’eux (a+(N−1)b = 1).Le choix à chaque accès est indépendant des recherches précédentes.

56 Cahier de Mathématiques Appliquées no 11
Les probabilités d’accès a et b sont a priori inconnues, mais on soupçonneque l’objet x est plus fréquemment appelé que les autres. Dans toute la suiteon supposera donc a > b. A chaque accès, on décide de déplacer l’objetchoisi, de manière à ce qu’il soit placé plus près de la tête du tableau s’il estfréquemment appelé. Deux stratégies sont envisagées.
1. Move ahead : Si l’objet choisi est le premier, il n’est pas déplacé. Sinon,il est échangé avec l’objet qui le précédait. On note Xn ∈ {1, . . . , N} lerang de l’objet x dans le tableau à l’issue du n-ième accès.
(a) Montrer que (Xn) , n ∈ IN est une chaîne de Markov homogène.
(b) Ecrire le diagramme de transition et la matrice de transition de lachaîne (Xn).
(c) Soit p = (pi) , i = 1, . . . , N la mesure stationnaire de la chaîne(Xn). Montrer que pour tout i = 2, . . . , N ,
pipi−1
=b
a.
(d) En déduire que la suite des pi est décroissante (on dit que la stra-tégie est auto-arrangeante).
2. Move to front : Si l’objet choisi est le premier, il n’est pas déplacé.Sinon, il est placé en tête, et les objets qui le précédaient sont décalésvers la droite. On note Yn ∈ {1, . . . , N} le rang de l’objet x dans letableau à l’issue du n-ième accès.
(a) Montrer que (Yn) , n ∈ IN est une chaîne de Markov homogène.
(b) Ecrire le diagramme de transition et la matrice de transition de lachaîne (Yn).
(c) Soit q = (qi) , i = 1, . . . , N la mesure stationnaire de la chaîne(Yn). Montrer que pour tout i = 2, . . . , N ,
qiqi−1
=(N − i+ 1)b
a+ (N − i)b.
(d) En déduire que la suite des qi est décroissante.
3. Comparaison :
(a) Montrer que pour tout i = 2, . . . , N ,
pipi−1
<qi
qi−1.
(b) En déduire que p1 > q1.
(c) Laquelle des deux stratégies choisiriez-vous ?

Chaînes de Markov 57
(d) Ecrire un programme de simulation pour les deux stratégies. Leprogramme prend en entrée le nombre d’objets N , la probabilitéa et un nombre d’itérations T . On suppose qu’à l’origine, l’objet xest à la place N . A chaque tirage d’objet effectué, la nouvelle placede x est calculée pour les deux stratégies. Pour N = 1000, a = 0.01et T = 10000, représenter les deux trajectoires des chaînes (Xn)et (Yn). Pour N = 10, a = 0.5 et T = 106, calculer la distribu-tion empirique des places occupées par x pour chacune des deuxstratégies et tester l’adéquation avec la distribution stationnairethéorique.
Exercice 7 On place un rat dans le labyrinthe suivant.
1 2 3
4 5 6
7 8 9
1. A chaque fois qu’il se retrouve dans une des 9 cases, le rat choisitune des portes disponibles au hasard, et indépendamment de ses choixprécédents. Soit Xn le numéro de la n-ième case visitée par le rat.Montrer que (Xn) , n ∈ IN est une chaîne de Markov et représenter sondiagramme de transitions.
2. On considère la partition de l’espace d’états en les trois classes sui-vantes :
a = {1, 3, 7, 9} b = {2, 4, 6, 8} c = {5} .
On note Yn la classe à laquelle appartient Xn. Montrer que (Yn) , n ∈ INest une chaîne de Markov et écrire sa matrice de transition.
3. Déterminer la mesure stationnaire de la chaîne (Yn). En déduire lamesure stationnaire de la chaîne (Xn).
4. Si le rat part de l’un des coins, et franchit une case toutes les secondes,combien de temps mettra-t-il en moyenne à atteindre le fromage qui setrouve au centre ?
5. Simuler 10000 trajectoires de la chaîne (Xn) et vérifier expérimentale-ment les résultats des questions précédentes.
6. Le rat n’est pas si bête : à chaque fois qu’il a passé une porte, il choisitsa prochaine porte au hasard parmi les portes disponibles différentes decelle qu’il vient d’emprunter. A la n-ième porte franchie, on note Zn lecouple formé des numéros de la case de départ et de la case d’arrivée.Montrer que (Zn) , n ∈ IN) est une chaîne de Markov et représenter sondiagramme de transitions.

58 Cahier de Mathématiques Appliquées no 11
7. Sous ces nouvelles hypothèses, montrer que (Xn) n’est pas une chaînede Markov.
8. On définit Tn par :
Tn = (x, y)⇐⇒ Zn ∈ x× y ,
où x et y sont deux éléments quelconques de {a, b, c}. Montrer que(Tn) , n ∈ IN est une chaîne de Markov et représenter son diagrammede transitions.
9. Si le rat part de l’un des coins, et franchit une case toutes les secondes,combien de temps mettra-t-il en moyenne à atteindre le fromage qui setrouve au centre ?
10. Simuler 10000 trajectoires de la chaîne (Zn) et vérifier epérimentale-ment le résultat de la question précédente.
Exercice 8
1. Ecrire un algorithme de simulation approchée par chaîne de Markovpour la loi uniforme sur :
(a) L’ensemble des vecteurs (k1, . . . , kd), à coefficients entiers positifsou nuls, tels que k1 + · · ·+ kd = n (les entiers d et n sont fixés).
(b) La sphère unité de IRd.
(c) L’ensemble des sous ensembles à n éléments d’un ensemble à déléments.
(d) L’ensemble des tables de contingence de taille d, de marges fixées.Une table de contingence A est une matrice d×d à coefficients en-tiers positifs ou nuls, où L = A11 (sommes par lignes) et C = tA11
(sommes par colonnes) sont des vecteurs fixés (tels que t11L =t11C).
(e) L’ensemble des arbres à d sommets.
(f) L’ensemble des graphes connexes à d sommets.
2. Ecrire un algorithme de Metropolis pour la simulation approchée deslois de probabilité suivantes.
(a) La loi sur l’ensemble des vecteurs d’entiers (k1, . . . , kd) de sommen qui est telle que la probabilité d’un vecteur soit proportionnelleà sa première coordonnée.
(b) La loi sur la sphère unité de IRd dont la densité est proportionnelleau carré de la première coordonnée.
(c) La loi sur l’ensemble des sous-ensembles à n éléments de {1, . . . , d},telle que la probabilité d’un sous-ensemble soit proportionnelle àla somme de ses éléments.

Chaînes de Markov 59
(d) La loi sur l’ensemble des tables de contingence de taille d, demarges fixées, telle que la probabilité d’une table de contingencesoit proportionnelle à la somme des éléments de sa diagonale prin-cipale.
(e) La loi sur l’ensemble des arbres à d sommets, telle que la pro-babilité d’un arbre soit proportionnelle à son diamètre (nombremaximum d’arêtes dans un chemin minimal joignant deux som-mets).
(f) La loi sur l’ensemble des graphes connexes à d sommets, telle que laprobabilité d’un graphe connexe soit proportionnelle à son nombred’arêtes.
Exercice 9 Soit F (les filles) et G (les garçons) deux ensembles finis nonvides. On appelle “noce” un ensemble N ⊂ F ×G de couples tel que :
∀f ∈ F , |{g ∈ G ; (f, g) ∈ N}| ≤ 1 et ∀g ∈ G , |{f ∈ F ; (f, g) ∈ N}| ≤ 1 .
(Chaque individu a au plus un conjoint, mais peut rester célibataire.) Onnote E l’ensemble des noces. On note πF et πG les projections canoniques,de sorte que πF (N) est l’ensemble des filles mariées, et πG(N) l’ensemble desgarçons mariés de la noce N .
1. L’algorithme A suivant simule une chaîne de Markov sur E.
N = ∅ ; n←− 0Répéter
choisir f ∈ F avec probabilité 1/|F |choisir g ∈ G avec probabilité 1/|G|Selon ((f, g))
cas ((f, g) ∈ N) (ils sont mariés ensemble)alors N ←− N \ {(f, g)} (divorce)
cas (f /∈ πF (N) et g /∈ πG(N)) (ils sont célibataires)alors N ←− N
⋃
{(f, g)} (mariage)finSelonn←− n+1
Jusqu’à (arrêt de la simulation)
(a) Expliciter les probabilités de transition de cette chaîne. Montrerqu’elle est irréductible et apériodique. Montrer qu’elle admet la loiuniforme sur E comme mesure réversible.
(b) Dans le cas |F | = |G| = 2, l’ensemble E a 7 éléments. Représenterle diagramme de transitions de la chaîne entre ces 7 éléments.
2. L’algorithme B suivant simule une autre chaîne de Markov sur E.
N = ∅ ; n←− 0Répéter

60 Cahier de Mathématiques Appliquées no 11
choisir f ∈ F avec probabilité 1/|F |choisir g ∈ G avec probabilité 1/|G|Selon ((f, g))
cas ((f, g) ∈ N) (ils sont mariésensemble)
alors N ←− N \ {(f, g)}cas (f /∈ πF (N) et g /∈ πG(N)) (ils sont célibataires)
alors N ←− N⋃
{(f, g)}cas ((f, g′) ∈ N et (f ′, g) ∈ N) (ils sont mariés
ailleurs)alors N ←− (N \ {(f, g′), (f ′, g)})
⋃
{(f, g), (f ′, g′)}cas (f /∈ πF (N) et (f ′, g) ∈ N) (elle est libre, pas
lui)alors N ←− (N \ {(f ′, g)})
⋃
{(f, g)}cas (g /∈ πG(N) et (f, g′) ∈ N) (il est libre, pas elle)
alors N ←− (N \ {(f, g′)})⋃
{(f, g)}finSelonn←− n+1
Jusqu’à (arrêt de la simulation)
Reprendre a), b) et c) de la question précédente pour ce nouvel algo-rithme.
3. Ecrire un algorithme qui simule une chaîne de Markov admettant pourmesure réversible la loi de probabilité sur E telle que la probabilitéd’une noce N soit proportionnelle à λ|N |, où λ est un réel supérieur à1 fixé.
4. Chaque individu a ses préférences, qui sont des réels strictement po-sitifs : pf (g) est la préférence de la fille f pour le garçon g, cf est sapréférence pour le célibat. De même qg(f) est la préférence du garçong pour la fille f , et dg sa préférence pour le célibat. (Il peut malheu-reusement arriver que cf > pf (g) ∀g, alors que ∀g , qg(f) > dg).
On définit l’“harmonie” comme la fonction h qui à une noce N associe :
h(N) =∑
(f,g)∈N
(pf (g) + qg(f)) +∑
f /∈πF (N)
cf +∑
g/∈πG(N)
dg .
Le but du jeu est évidemment de trouver une noce dans :
Emax = {N ∈ E t.q. h(N) ≥ h(N ′) , ∀N ′ ∈ E } .
Ecrire un algorithme qui simule une chaîne de Markov admettant pourmesure réversible la loi de probabilité sur E telle que la probabilitéd’une noce N soit proportionnelle à e−
1Th(N), où T est un réel stric-
tement positif fixé. Montrer que quand T décroît vers 0, cette loi deprobabilité converge vers la loi uniforme sur Emax.

Chaînes de Markov 61
Exercice 10 Soit N un entier. On note (XNn , Y N
n )n∈IN la marche aléatoiresur IR × IR, partant de (XN
0 , Y N0 ) = (0, 1), telle que les suites de variables
aléatoires (XNn+1 − XN
n ) et (Y Nn+1 − Y N
n ) soient indépendantes entre elles,formées de variables indépendantes et de même loi :
IP[XNn+1 −XN
n = −1/N ] = IP[XNn+1 −XN
n = 1/N ] = 1/2 ,
IP[Y Nn+1 − Y N
n = −1/N ] = IP[Y Nn+1 − Y N
n = 1/N ] = 1/2 .
A chaque pas la marche choisit au hasard entre les 4 points diagonalementopposés sur les 4 carrés de côté 1/N voisins.
Première partieOn s’intéresse à l’instant de sortie et à l’abscisse de sortie de la marche
aléatoire ainsi définie hors du demi plan supérieur.L’instant de sortie est la variable aléatoire TN définie par :
TN = k ⇐⇒ Y Ni > 0 ∀i < k et Y N
k = 0 .
L’abscisse de sortie UN est l’abscisse de la marche aléatoire à l’instant desortie TN .
TN = k =⇒ UN = XNk .
1. Déterminer la fonction génératrice de TN .
2. En déduire la fonction caractéristique de UN .
3. Montrer que la suite (UN ) converge en loi, quand N tend vers l’infini,vers la loi de Cauchy, de densité :
1
π(1 + x2).
4. Implémenter un algorithme de simulation de la marche aléatoire, demanière à réaliser une étude expérimentale du comportement asymp-totique de TN et UN . Les sorties attendues sont par exemple :– les courbes des intervalles de confiance de niveau 0.99 pour les espé-
rances de TN et UN en fonction de N .– des histogrammes de TN , pour N “assez grand”.– des histogrammes de UN , pour N “assez grand”, superposés avec la
densité de la loi de Cauchy.
5. On modifie la loi des pas de la marche aléatoire qui se déplace mainte-nant verticalement et horizontalement au lieu de se déplacer en diago-nale :
IP[(XNn+1 −XN
n , Y Nn+1 − Y N
n ) = (1/N, 0)] =
IP[(XNn+1 −XN
n , Y Nn+1 − Y N
n ) = (0, 1/N)] =
IP[(XNn+1 −XN
n , Y Nn+1 − Y N
n ) = (−1/N, 0)] =
IP[(XNn+1 −XN
n , Y Nn+1 − Y N
n ) = (0,−1/N)] = 1/4 .

62 Cahier de Mathématiques Appliquées no 11
Qu’est-ce qui change dans l’étude précédente ?
Deuxième partieOn s’intéresse maintenant à l’instant de sortie et à l’abscisse de sortie de
la marche aléatoire hors de la bande de plan IR×]0, 2[.L’instant de sortie est la variable aléatoire TN définie par :
TN = k ⇐⇒ 0 < Y Ni < 2 ∀i < k et Y N
k ∈ {0, 2} .
Soient UN et V N l’abscisse et l’ordonnée de la marche aléatoire à l’instantde sortie TN .
TN = k =⇒ (UN , V N ) = (XNk , Y N
k ) .
1. Montrer que UN et V N sont indépendantes. Quelle est la loi de V N ?Montrer que la loi de UN est symétrique :
∀k ∈ IN IP[UN = k] = IP[UN = −k] .
2. Déterminer la fonction génératrice de TN .
3. En déduire la fonction caractéristique de UN .
4. Montrer que la suite (UN ) converge en loi, quand N tend vers l’infini,vers une loi dont la densité est a/ cosh(bx), où a et b sont des paramètresà calculer.
5. Reprendre les questions 4 et 5 de la première partie.
Exercice 11 Le but de l’exercice est d’étudier le comportement asympto-tique de marches aléatoires sur ZZd.
1. Soit (Un) , n ∈ IN une suite de variables aléatoires indépendantes et demême loi, telles que IP[Un = 1] = p et IP[Un = −1] = 1−p. On définitune marche aléatoire sur ZZ par X0 ∈ ZZ (indépendante de la suite (Un)et pour tout n ≥ 0 :
Xn+1 = Xn + Un .
On note p(n)x,x la probabilité que la chaîne soit en x au n-ième pas, si
elle est partie de x. Montrer que p(n)x,x est nul si n est impair. Pour tout
m ≥ 1, montrer que :
p(2m)x,x =
(
2m
m
)
pm (1− p)m .
Donner un équivalent de p(2m)x,x quand m tend vers l’infini. En déduire
que (Xn) est récurrente nulle pour p = 1/2 et transiente sinon.
2. Pour d ≥ 1, considérons d chaînes de Markov indépendantes
(X(1)n ), . . . , (X(d)
n ) ,

Chaînes de Markov 63
chacune de même loi que la chaîne (Xn) de la question précédente.
Pour n ∈ IN, on note Zn le n-uplet (X(1)n , . . . , X
(d)n ). Montrer que (Zn)
est une chaîne de Markov. Pour z ∈ ZZd. Calculer IP[Zn = z |Z0 = z].Montrer que la chaîne est récurrente nulle si p = 1/2 et d = 1 ou 2,transiente dans tous les autres cas.
3. Pour d = 1, 2, . . . , 10, simuler une trajectoire de la chaîne (Zn) jus-qu’au temps n = 106, partant de Z0 = 0. Représenter la trajectoire desvariables aléatoires ‖Zn‖, où ‖ · ‖ désigne la norme euclidienne.
4. Pour d = 1, 2, . . . , 10, simuler 10000 trajectoires de la chaîne (Zn)jusqu’au temps n = 100, partant de Z0 = 0. Représenter sur unmême graphique un histogramme des réalisations de ‖Zn‖, pour n =10, 20, . . . , 100. Représenter en fonction de n une estimation de IE[‖Zn‖].
Exercice 12 On considère une file d’attente à un seul serveur. Les clientsarrivent un par un, à chaque unité de temps. Pour la n-ième unité de temps,on donne au serveur un quota Dn de clients à servir : si moins de Dn clientssont présents, ils sont tous servis, sinon Dn sont servis. Les Dn sont desvariables aléatoires indépendantes et de même loi q = (qk) sur IN. Le nombrede clients présents dans le système à la n-ième unité de temps est noté Xn.Il est défini par :
Xn+1 = max{0, Xn + 1−Dn} ,
donc (Xn) est une chaîne de Markov. On note ρ le coefficient d’occupationde la file, de sorte que l’espérance de Dn est 1/ρ.
1. Montrer que pour tout n ≥ 1, Xn ≥ X0 + n − (D1 + · · · + Dn). Endéduire que la chaîne est transiente pour ρ > 1.
2. Si X0 = 0, montrer que D1 + · · ·+Dn > n entraîne qu’il existe m ≤ ntel que Xm = 0. En déduire que la chaîne (Xn) est récurrente pourρ < 1.
3. On note g la fonction génératrice de la loi q. On suppose q0 > 0 etρ < 1. Montrer que l’équation g(z) = z admet une solution strictementcomprise entre 0 et 1, que l’on notera η.
4. Pour tout i ∈ IN, on pose πi = (1−η)ηi. Montrer que la mesure π = (πi)(loi BN (1, 1−η)) est stationnaire pour la chaîne (Xn).
5. On suppose que la loi q est la loi BN (1, ρ1+ρ ). Montrer que la mesure
stationnaire est la loi BN (1, 1−ρ).
6. On choisit pour q la loi de Poisson de paramètre 1/ρ. Pour ρ = 0.99puis ρ = 1.01, simuler une trajectoire de la chaîne (Xn) sur 10000 pas.Représenter graphiquement les trajectoires obtenues, et comparer avecles figures 9 et 10. Pour ρ = 0.1, 0.2, . . . , 0.9, calculer numériquement lavaleur de η. Simuler une trajectoire jusqu’au temps 106, et calculer lesfréquences empiriques de chacun des états visités. Tester l’ajustementde cette distribution empirique avec la loi BN (1, 1−η).

Index
algorithmede Metropolis, 34itératif, 3, 9markovien, 3
chaînede Markov, 3récurrente nulle, 39récurrente positive, 41transiente, 39, 41
Chapmann-Kolmogorov, 16classe
irréductible, 19périodique, 20, 29récurrente nulle, 21récurrente positive, 21, 29transiente, 21
classification des états, 19
diagramme de transition, 6, 22
étatabsorbant, 31, 36, 44ergodique, 20périodique, 20récurrent nul, 20, 39récurrent positif, 20transient, 20, 29, 39
file d’attente, 40
Galton-Watson, 44génétique, 11gestion de stock, 14
irréductibleclasse, 19
lois marginales, 16
marche aléatoire, 4sur un groupe, 4symétrique, 6, 11, 33
Markov, 3matrice
de sélection, 34de transition, 5
mesureréversible, 32stationnaire, 23, 43
mouvement brownien, 4, 5
périodiqueétat, 20classe, 20, 29
probabilitéde premier passage, 16, 30de transition, 15, 20
Random, 3récurrent
nul, 20positif, 20
ruine du joueur, 35
simulationd’une chaîne de Markov, 3
simulation d’une chaîne de Markov, 8stables d’un graphe, 10, 34
temps moyende premier passage, 17de premier retour, 20
théorèmede Perron-Frobenius, 25ergodique, 24
transitiondiagramme de, 6matrice de, 5probabilité de, 15
64





























