Embed Size (px)
Citation preview

CONCOURS INTERNE D’INGENIEUR DES SYSTEMES D’INFORMATION ET DE COMMUNICATION
- SESSION 2015 -
Mardi 31 mars 2015
Epreuve n°2
Etude de cas à partir d’un dossier à caractère technique de vingt cinq pages maximum, soumis au choix du candidat, permettant de vérifier les capacités d’analyse et de synthèse du candidat ainsi que son aptitude à dégager les solutions appropriées, portant le thème suivant:
Sujet : RESEAUX ET TELECOMMUNICATION
(Durée : 3 heures – Coefficient 3)
Le dossier documentaire comporte 24 pages.
IMPORTANT
IL EST RAPPELE AUX CANDIDATS QU’AUCUN SIGNE DISTINCTIF NE DOIT APPARAITRE NI SUR LA COPIE NI SUR LES INTERCALAIRES.

SUJET
Dans le cadre d'une croissance externe, une PME française du secteur tertiaire du nord de la
France (Site n°1) a acheté, il y a près d'un an, un concurrent direct, situé en proche banlieue de
Paris (Site n°2). Ces deux entités sont de taille sensiblement équivalente (~1000 personnes sur le
site n°1 et 800 sur le site n°2).
Les deux sites disposent chacun d’un réseau local (LAN) à 1 Gbit/s (« backbone ») et d’une
vingtaine de serveurs pour le site n°1, d’une quinzaine pour le site n°2 (Applications « métier »,
Active Directory, DNS, Antivirus, site Web commerçant, serveurs de fichiers, serveur
d’impressions,..). Ces sites sont interconnectés en VPN-IP via une liaison SDSL à 8 Mbit/s.
Une différence subsiste néanmoins entre les deux sites. Le premier site (Site n°1) possède un
réseau SAN (Storage Area Network) réalisé à base de commutateurs Fiber Channel (FC), qui
permet le stockage de données « métier » conséquentes (~20 To pour une dizaine de disques
montés en Raid) et dont l’investissement a été réalisé dans le courant de l’année 2012.
Le plan d’adressage IP du site n°1 respecte sensiblement un adressage de type classe B
(RFC1597 à partir de l’adresse IP 172.16.16.0) avec un masque de réseau fixé à 20. Quant à
celui du site n°2, il est défini en CIDR (Class Inter Domain Routing) à partir d’un adressage de
type classe C (192.168.0.0/21).
Mandatée par la Direction Générale, la Direction des Systèmes d’Information (DSI) mène
actuellement une réflexion dans le but d’homogénéiser ces deux systèmes d’information,
notamment au niveau applicatif. Celle-ci souhaite mettre en place un seul et unique système
d’information (« Datacenter »), avec comme site principal, le site n°1 (Siège). Le site n°2 serait
alors considéré comme un site distant, qui ne conserverait que ses serveurs locaux de proximité
(fichiers, impressions,..) et son réseau local (LAN) existant.
Le site principal hébergerait ainsi la totalité des applications « métier » et les serveurs associés.
Le projet ne prend pas en compte la téléphonie de l’entreprise, qui évoluera dans un second
temps, vers une solution dite de convergence en IP. Dans la future infrastructure, un VLAN
« spécifique » sera créé pour la mise en œuvre de la téléphonie sur IP.
L’accès aux données de l’entreprise doit être sécurisé à partir du futur réseau d’entreprise, qu’il
soit local ou distant, voire nomade.
Objectifs de ce projet (liste non exhaustive) :
Migrer les serveurs Windows 2003 (fin du support Microsoft le 15 juillet 2015) vers des
serveurs Windows 2012 R2
Remplacer certains serveurs physiques obsolètes par des serveurs « virtualisés »

« Virtualiser » la plupart des serveurs grâce à la technologie « VMWare »
Mettre en place ces serveurs rack dans de nouvelles baies (datacenter)
Sécuriser l’accès aux données « métier » et aux applications « métier »
Gérer l’interconnexion du réseau de stockage SAN actuel avec le nouveau réseau d’entreprise,
ainsi constitué.
Votre mission :
Ingénieur réseau, vous êtes chargé par votre direction (DSI) de concevoir la future infrastructure
réseau à mettre en place (virtualisation des serveurs, SAN, lien d’interconnexion de réseau) et
d'assurer la résilience, la haute disponibilité et la sécurité du nouveau système d'information de
l'entreprise.
Vous devrez rédiger une note à l’intention de votre directeur reprenant les points suivants:
Étudier l’architecture actuelle, les besoins nouveaux à mettre en œuvre et proposer une
solution technique qui vous semble la plus réaliste et la plus performante.
Présenter le schéma d’architecture de votre solution et détailler les mesures à mettre en œuvre
pour assurer la pérennité, la résilience et la sécurité du système d’information.
Proposer un planning du projet décrivant les principales phases de la mise en œuvre de la
solution préconisée.
Dossier documentaire :
Document 1 Synoptiques réseaux actuels et cible (document concepteurs)
Pages 1 à 3
Document 2 Comprendre la différence entre PCA et PRA Pages 4 à 5
Document 3 Focus Datacenter CBRE Pages 6 à 9
Document 4 Interconnexion SAN Orange Pages 10 à 14
Document 5 Quel niveau de redondance pour quels besoins ?
Page 15
Document 6 SAN ou NAS ?Quelle est la différence ? Pages 16 à 19
Document 7 10 Gigabit Ethernet - Indexel Pages 20 à 21
Document 8 FCOE et Ethernet -Indexel Pages 22 à 23
Document 9 FCOE et iSCSI - TechOnApp - NetApp Page 24
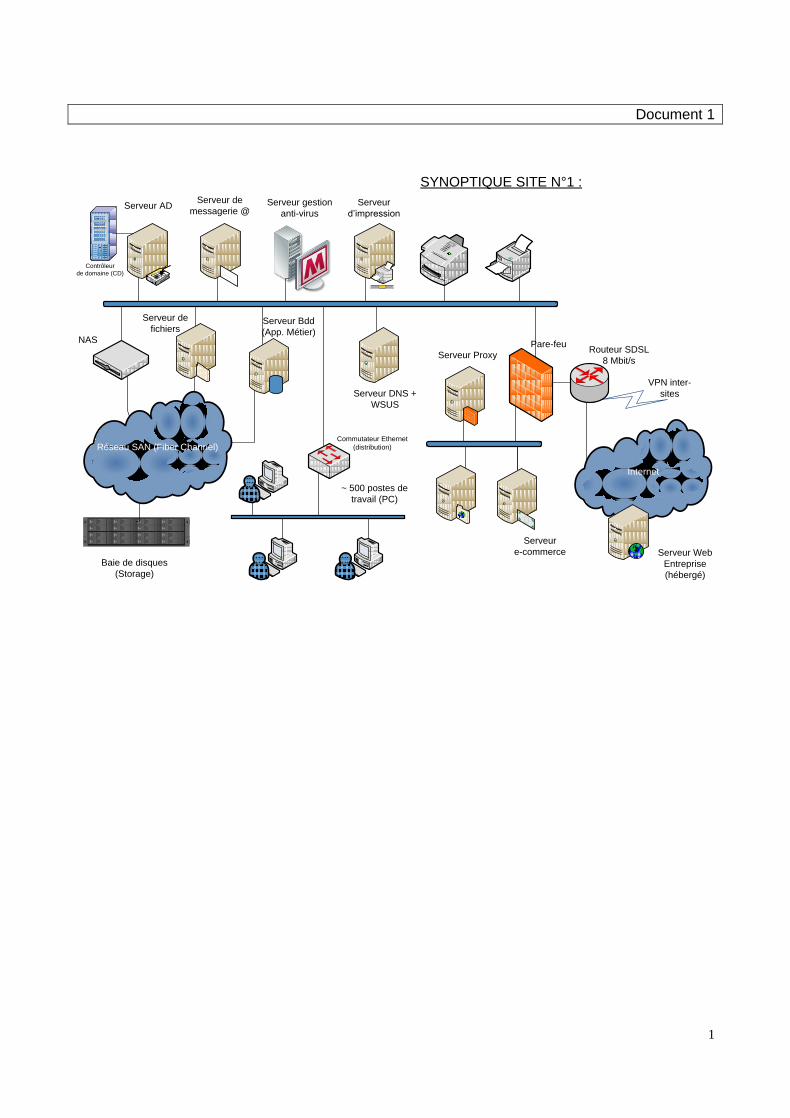
1
Document 1
Serveur de
messagerie @
Serveur Bdd
(App. Métier)
Serveur de
fichiers
Serveur AD
Contrôleur
de domaine (CD)
NAS
Serveur Web
Entreprise
(hébergé)
Baie de disques
(Storage)
Réseau SAN (Fiber Channel)
~ 500 postes de
travail (PC)
Internet
Serveur Proxy
Pare-feu
Commutateur Ethernet
(distribution)
Serveur DNS +
WSUS
Serveur
e-commerce
Routeur SDSL
8 Mbit/s
VPN inter-
sites
SYNOPTIQUE SITE N°1 :
Serveur
d’impression
Serveur gestion
anti-virus
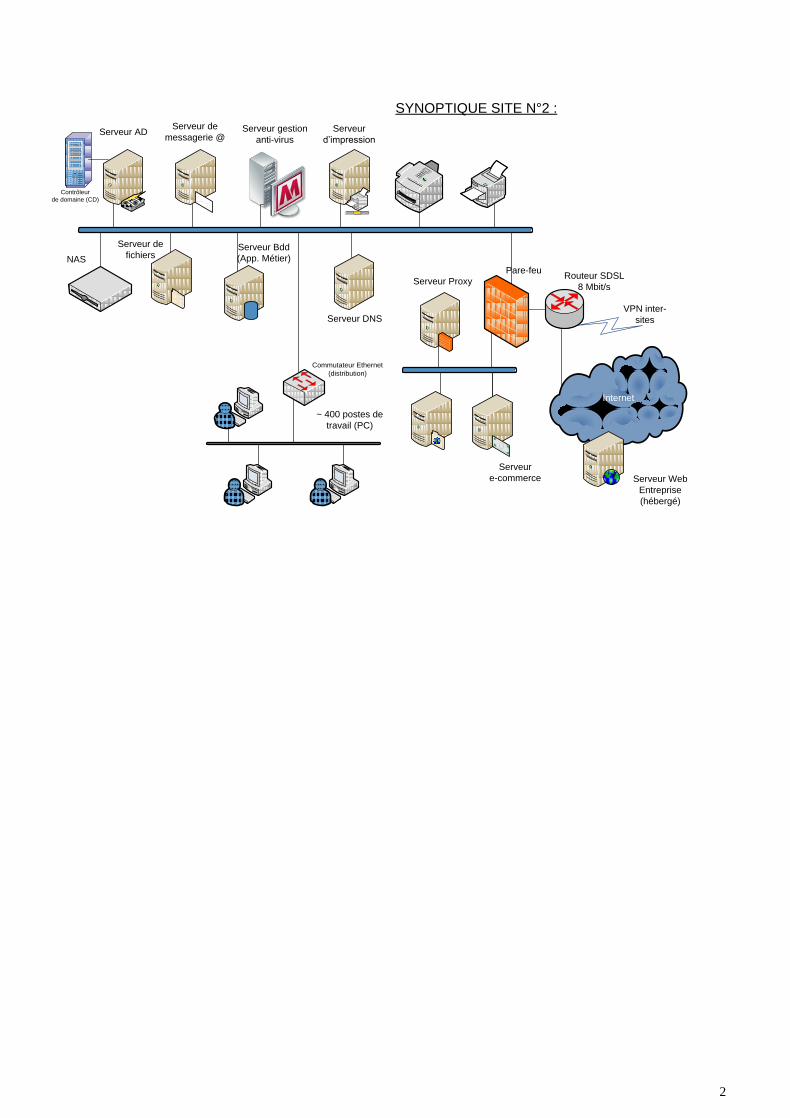
2
Serveur de
messagerie @
Serveur Bdd
(App. Métier)
Serveur de
fichiers
Serveur AD
Contrôleur
de domaine (CD)
NAS
Serveur Web
Entreprise
(hébergé)
~ 400 postes de
travail (PC)
Internet
Serveur Proxy
Pare-feu
Commutateur Ethernet
(distribution)
Serveur DNS
Serveur
e-commerce
Routeur SDSL
8 Mbit/s
VPN inter-
sites
SYNOPTIQUE SITE N°2 :
Serveur
d’impression
Serveur gestion
anti-virus
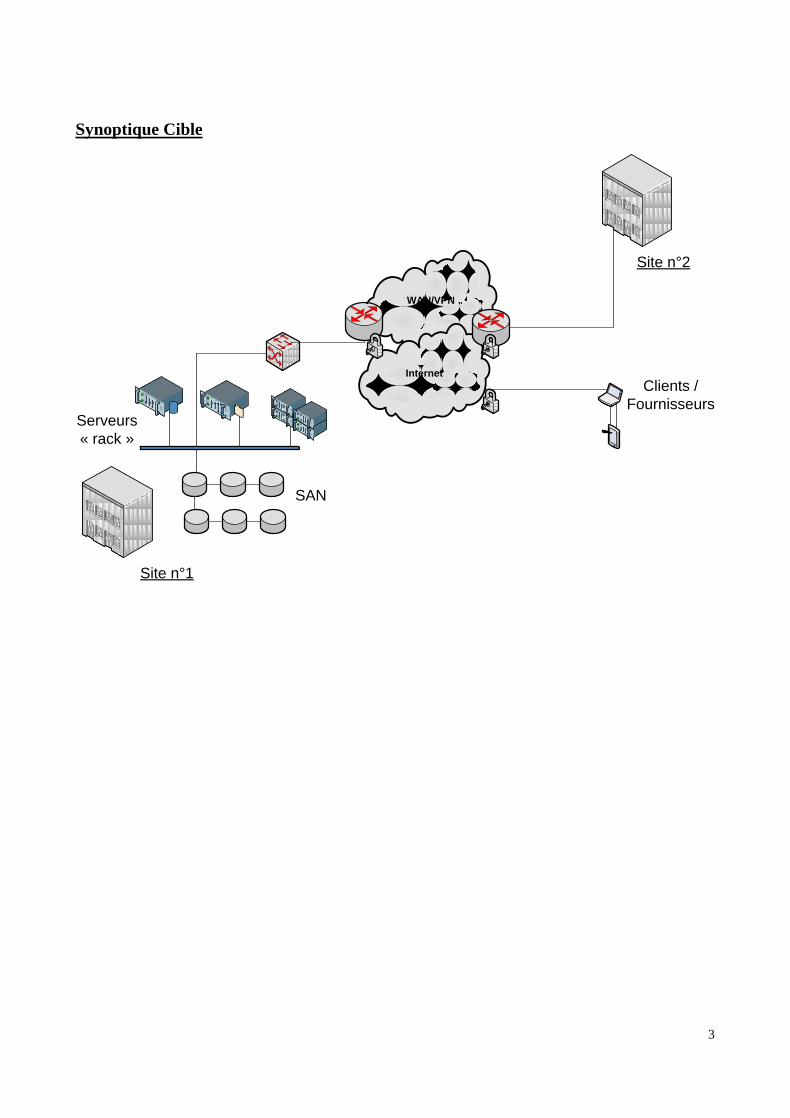
3
Synoptique Cible
WAN/VPN
Site n°1
Site n°2
SAN
Internet
Clients /
FournisseursServeurs
« rack »

4
Document 2 Solution IT PME Leçon n° 15 : comprendre la différence entre PCA et PRA Rares sont aujourd’hui les entreprises qui peuvent se passer de leur informatique à tel point que dans bien des cas l’inaptitude à faire face à un incident informatique peut leur être fatale. Selon une étude du cabinet de conseil américain Eagle Rock, 40% des entreprises ayant subi un arrêt de 72 heures de leurs moyens informatiques et télécoms ne survivent pas à ce désastre C’est la raison pour laquelle de plus en plus de sociétés, de toutes tailles s’attachent à mettre en place un plan de reprise d’activité ou un plan de continuité d’activité. Au fil du temps, la signification de ces deux termes a évolué. Historiquement, le plan de continuité s’attachait à analyser l’impact potentiel d’un désastre ou d’une défaillance sur le métier de l’entreprise et à définir les moyens et procédures à mettre en place pour en limiter les conséquences. Le plan de reprise d’activité s’intéressait quant à lui aux aspects informatiques du PCA. Pour les informaticiens, la terminologie a évolué : de plus en plus le PCA décrit l’ensemble des moyens destinés à assurer la continuité d’activité des applications, c’est-à-dire à garantir la haute disponibilité de ces applications (ce qui implique l’impossibilité d’un arrêt de ces applications même en cas de sinistre sur un site). Le PRA quant à lui décrit l’ensemble des moyens et procédures destiné à assurer une reprise rapide et ordonnée de la production après un arrêt inopiné (lié par exemple à une défaillance technique, ou énergétique, à une erreur humaine ou à un sinistre naturel). La différence entre les deux approches tend donc à se limiter à une différence en matière de temps d’indisponibilité de l’infrastructure et des applications en cas de sinistre.
PCA : objectif haute disponibilité Dans le cadre d’un PCA, l’entreprise veille à définir les architectures, les moyens et les procédures nécessaires pour assurer une haute disponibilité des infrastructures (datacenter, serveurs, réseau, stockage) supportant l’exécution des applications de l’entreprise. L’objectif est d’assurer que quelle que soit la situation, les infrastructures mises en place garantissent aux utilisateurs un service ininterrompu. En général, la mise en œuvre d’un PCA suppose la mise en place d’équipements redondés entre plusieurs datacenters et fonctionnant de façon conjointe de telle sorte qu’en cas de défaillance d’un élément sur le site primaire, le relais soit automatiquement pris par le site secondaire. Typiquement, une telle architecture suppose la mise en place d’un dispositif garantissant la cohérence des données sur les baies de stockage entre le site primaire et le site secondaire, comme la solution VPLEX d’EMC qui assure la réplication transparente des données entre deux sites ainsi que la bascule automatisée des applications d’un datacenter à l’autre en cas de défaillance sur le site primaire. Il est à noter que toutes les applications de l’entreprise ne sont pas forcément concernées par la mise en œuvre d’un PCA, simplement parce que certaines ne sont pas jugées critiques et peuvent tolérer un arrêt, ou une éventuelle perte de données. Cette criticité est à définir avec les métiers de façon à définir quel sera le périmètre du PCA et quelles applications seront concernées par un « simple PRA ». Il convient aussi de dimensionner convenablement les infrastructures pour que la bascule vers le site secondaire n’affecte pas trop les performances. Dans le cas d’une architecture en mode actif/actif, la production est en effet répartie entre les deux datacenters de l’entreprise, ce qui fait qu’un sinistre sur l’un d’entre eux se traduit mécaniquement par une diminution de moitié de la capacité de traitement disponible, donc potentiellement par une dégradation des performances sur l’infrastructure survivante.
PRA : Assurer le redémarrage ordonné en cas de défaillance Pour les entreprises qui n’ont pas les moyens ou le besoin d’un PCA, le PRA est la solution pour assurer un redémarrage ordonné et aussi rapide que possible de l’infrastructure informatique de l’entreprise en cas d’incident. Ce redémarrage s’effectue en général sur un site de secours, propriété de l’entreprise ou fourni par un prestataire tiers. Le PRA définit les architectures, les moyens et les procédures nécessaires à mettre en œuvre pour assurer la protection des applications qu’il couvre. Son objectif est de minimiser l’impact d’un sinistre sur l’activité de l’entreprise. On distingue plusieurs modes de redémarrage : le redémarrage à chaud s’appuie sur une copie synchrone ou asynchrone des données du site principal. Il s’agit de s’appuyer sur le dernier état cohérent connu des données comme base pour les serveurs positionnés sur le site de secours. La réplication des données (qui peut être assurée par une technologie comme RecoverPoint chez EMC) assure un redémarrage rapide des serveurs de secours dans un état aussi proche que possible de celui qui a précédé le sinistre. Le RTO (Recovery Time Objective – le temps nécessaire pour remettre l’application en production – est donc minimal et le RPO (Recovery Point Objective – le temps entre le dernier état cohérent des données et le sinistre) réduit à son minimum, souvent quelques minutes. La situation est un peu différente en cas de secours à froid. Cette situation concerne encore nombre d’entreprises ne disposant pas des moyens financiers et/ou technique pour un PCA ou pour une reprise à chaud. Dans ce cas, le redémarrage après sinistre s’appuie sur les dernières sauvegardes réalisées par l’entreprise. Ces sauvegardes peuvent dans le meilleur des cas être des répliques provenant d’un système de sauvegarde dédupliqué sur disques comme une baie Data Domain ou dans le pire scénario, une simple sauvegarde sur bande.

5
En cas de sinistre, l’entreprise doit donc activer son site de secours, restaurer ex-nihilo ses données depuis leur support de sauvegarde (disque ou bande) et remettre en service ses applications. Il s’agit là de la solution la plus économique pour mettre en place un PRA, mais elle a un prix en matière de RTO et de RPO. Le RTO est au minimum le temps de restauration des données et de mise en service des serveurs, ce qui pour des environnements complexes peut vouloir dire plusieurs heures voire plusieurs jours. La bonne nouvelle est que la banalisation des solutions de sauvegarde sur disque comme Data Domain a largement permis de réduire le RTO (de 17 heures à 2 heures en moyenne selon une étude IDC de 2012). Le RPO dépend de la fréquence des sauvegardes. Dans le pire des cas, il peut atteindre un ou plusieurs jours (notamment pour les applications dont les fenêtres de sauvegarde sont longues et qui ne sont sauvegardées qu’une fois par jour, voire moins). Là encore la sauvegarde sur disques dédupliquée a amélioré la situation en réduisant les fenêtres de sauvegarde (de 11 heures avec une librairie de bandes à 3 heures en moyenne avec systèmes comme Avamar ou Data Domain). Il est à noter que le redémarrage à froid était la règle pour nombre de PME il y a encore 5 ans. Mais la généralisation de la virtualisation et du stockage en réseau a rendu accessible le redémarrage à chaud à un nombre croissant de société. Le PCA n’est pas encore forcément à portée de tous mais il est désormais accessible à nombre de PME de taille intermédiaire. Les progrès accomplis par les baies de stockage, les solutions de sauvegarde sur disque et les technologies de virtualisation devraient le rendre accessible au plus grand nombre au cours des prochaines années.

9
FOCUS « DATACENTER Document 3

7

8

9

10
INTERCONNEXION DE SAN ENTRE DATACENTERS SUR DES RESEAUX ETHERNET de type Carrier Class

11

12

13

14

15
APS-VOXY Quel niveau de redondance pour quels besoins ?
Pour que les applications informatiques sensibles restent opérationnelles en toutes circonstances, on procède au doublement(1) (ou triplement) des composants techniques ou des équipements (alimentation électrique, armoires de refroidissement et de ventilation, moyens de détection d’anmalies, connexions entre équipements …). La conception, l’installation et l’exploitation de systèmes totalement redondants requièrent des compétences étendues et une grande rigueur sans lesquels les investissements et efforts consentis sont, comme dans le cas des sauvegardes, vains. Il ne s’agit pas ici de décrire en détail toutes les solutions techniques disponibles mais de présenter les modèles de redondance (on dit aussi résilience) les plus fréquemment appliqués, en précisant que des modèles distincts peuvent être retenus pour chacune de vos applications, selon leurs objectifs respectifs de disponibilité et les architectures sur lesquelles elles fonctionnent. Modèle 2N+0
Configurations redondantes(2) ou en haute disponibilité(3) en un même lieu (salle, bâtiment ou site) non secourues : fonctionnement en continu 24h/24 et/ou en répartition de charge.
Exige des infrastructures hautement résilientes (alimentation électrique, climatisation, réseaux, moyens de surveillance, fermes de serveurs …) invulnérables aux pannes et n’ayant si possible aucun lien de dépendances entre eux (sinon des travaux sur les infrastructures du site pourraient entraîner des arrêts de production).
En cas d’incident ou pour des travaux de maintenance sur un système, la production est transférée vers un système équivalent(4) après une courte interruption de service (quelques minutes) voire sans arrêt.
Si les architectures techniques le permettent, les systèmes de secours peuvent être maintenu en action et ainsi pouvoir redémarrer sans délais (quelques minutes) et avec des pertes de données minimales.
En cas de sinistre majeur (destruction ou inaccessibilité du site), la reprise d’activité sur un autre site peut réclamer des temps très longs (jusqu’à plusieurs semaines).
Modèle N+N Configurations non redondantes, secourues
sur un site secondaire Les serveurs de secours sont le plus souvent dormants et les données de production sont copiées en léger différé sur des
moyens de stockage du site de secours. En cas de sinistre ou pour des travaux de maintenance sur le site de production, l’activité est transférée sur le site de secours
dans un délai de quelques heures (entre 1 et 24 heures selon les cas) Si les architectures techniques, les liens réseaux et la distance le permettent, les systèmes de secours peuvent être maintenu en
action afin de recevoir en continu les données modifiées sur le site de production, et ainsi pouvoir redémarrer sans délais (quelques minutes) et avec des pertes de données minimales.
Modèle 2N+N
Configurations redondantes ou en haute disponibilité, secourues sur un site secondaire
Les serveurs de secours sont le plus souvent dormants et les données de production sont copiées en léger différé sur des moyens de stockage du site de secours.
En cas d’incident ou pour des travaux de maintenance sur un système, la production est transférée vers un système équivalent du site de production après une courte interruption de service (quelques minutes) voire sans arrêt.
Si les architectures techniques le permettent, les systèmes de secours peuvent être maintenu en action et ainsi pouvoir redémarrer sans délais (quelques minutes) et avec des pertes de données minimales.
En cas de sinistre majeur ou pour des travaux de maintenance sur le site de production, l’activité est transférée sur le site de secours dans un délai de quelques heures (entre 1 et 24 heures selon les cas)
Voir aussi l’article relatif aux RTO et RPO. (1) Remarque : les puristes de la fiabilité considèrent la duplication de moyens comme une mauvaise pratique. En effet, deux composants ou équipements de même fabrication ou employant les mêmes procédés et opérant dans les mêmes conditions ont une probabilité non négligeable de connaître les mêmes défaillances en même temps ou à peu d’intervalle de temps. Ils préfèrent donc choisir des moyens totalement différents capables d’assurer exactement les mêmes fonctions. En informatique cette précaution est rarement prise en raison des coûts très importants qu’entraineraient le choix, la mise en oeuvre, et l’entretien des compétences relatives à deux fois plus de composants et donc de complexité.
(2) La redondance doit être assurée sur la totalité des moyens : énergie, froid, réseau, stockage, etc.
(3) La haute disponibilité requiert des logiciels capables de détecter automatiquement les défaillances et de redémarrer immédiatement la production.
(4) Toutefois, grâce à la virtualisation il n’est plus nécessaire que les matériels serveurs mis en redondance soient parfaitement identiques aux originaux ; des matériels de classe équivalente en performances et en capacités (mémoire, stockage, connectivité …) peuvent désormais accueillir de multiples applications opérant en temps normal sur des matériels très différents.

16
Document 6
SAN ou NAS – Quelle est la différence?
SAN
Le SAN, Storage Area Network, est un réseau à haute disponibilité, dédié au stockage de données et composé de deux éléments principaux :
les commutateurs ou switches dédiés. Le réseau de commutateurs constitue une Fabric.
Un système de stockage généralement constitué de deux processeurs de contrôle (Storage Processor – SP) et de baies de disques (Enclosures)
Tous les composants d’un réseau SAN sont généralement redondés afin d’assurer le maximum de tolérance aux pannes. Ainsi, généralement, on trouve :
2 commutateurs SAN
2 processeurs de contrôle
2 alimentations
2 batteries pour le cache
des grappes de disques en RAID 1, 5, 10 ou 50, …
L’accès à un réseau SAN se fait traditionnellement selon le protocole FC (Fiber Channel), un protocole sans perte (« lossless »), permettant d’atteindre des débits de 2 à 20GB/s. Pour accéder au SAN, un client (Serveur, Bandothèque, Blade Center, …) devra obligatoirement être équipé d’une carte HBA (Host Bus Adapter) spéciale. Une fois connecté, le volume de donnée du SAN est présenté au client comme un nouveau disque dur local (nouvelle lettre qui apparaît dans Windows comme lorsque vous ajoutez une clé USB). C’est ce qui différencie concrètement le SAN du NAS : la façon d’accéder aux données.

17
Afin de rendre le SAN financièrement plus accessible, les fabricants proposent également des configurations basées sur la technologie iSCSI (Internet Small Computer System Interface), en lieu et place du protocole FC. Le protocole iSCSI est encapsulé dans les trames TCP/IP. Il s’intègre alors tout naturellement au réseau Ethernet existant sans investir massivement dans des switchs FC et des cartes HBA très coûteuses. Les clients accèdent au SAN par l’intermédiaire d’un simple pilote iSCSI.
Même si les baies de stockage basées sur du iSCSI n’ont aujourd’hui plus grand chose à envier au FC (au grand dam des fabricants …), une mauvaise implémentation peut rapidement se traduire par une dégradation des performances.
Depuis quelques années (2009), un autre protocole a vu le jour et fait de plus en plus parler de lui. Il s’agit du protocole FCoE (Fiber Channel Over Ethernet). Tout comme la technologie iSCSI, le protocole FCoE fait que la technologie FC s’invite sur le réseau Ethernet, mais avec une très grosse différence. Il n’est pas encapsulé dans des trames TCP/IP. Par contre il nécessite l’acquisition de cartes Ethernet spécifiques (Adaptateurs CNA) et de switchs FCoE très coûteux.
Le SAN propose des fonctionnalités plus ingénieuses les unes que les autres :
Il est possible de cloner un volume de plusieurs térabits en un instant : Le SNAPSHOT
Un volume peut être copié localement ou vers un autre SAN : La COPIE
Un volume peut être répliqué en mode synchrone ou en asynchrone vers une autre baie : La REPLICATION
La possibilité également d‘écrire simultanément sur deux volumes distants de plusieurs dizaines de km et de n’en présenter qu’un au client (grâce à la virtualisation du stockage) : Le GEOCLUSTER ou METROCLUSTER
Les données d’un SAN peuvent être positionnées automatiquement sur des disques performants si elles sont fortement sollicités ou des disques capacitifs à bas coûts si elles sont dormantes : Le TIERING
La possibilité de présenter à un système plus de disque que réellement installé : Le THIN PROVISIONNING
Le SAN permet donc, la mise en œuvre, d’architectures très complexes. Par exemple imaginez une entreprise souhaitant dans le cadre de son plan de reprise d’activité (PRA) que son système d’information soit dupliqué sur un site de secours afin de palier à un sinistre du site principal. Et que pour couronner le tout, cette bascule soit transparente pour l’utilisateur final ! Grâce aux technologies portées par les SAN c’est bel et bien possible, bien que très couteux.
NAS
Le NAS, Network Attached Storage, est en quelque sorte un serveur spécialement configuré pour la gestion d’un espace de stockage à destination de clients hétérogènes.
Directement connecté au réseau Ethernet de l’entreprise, on le trouve sous différentes formes : boitier autonome (« appliance »), serveur pré-packagé ou encore sous la forme de tête NAS (dans ce cas spécifique, le NAS est branché d’un côté sur le réseau Ethernet et de l’autre à un SAN car il ne possède pas de stockage).
.

18
Contrairement au SAN sur lequel seront connectés des serveurs nécessitant de très hautes performances d’accès au système de stockage, le NAS s’adresse à une plus grande palette de clients à travers une panoplie de protocoles:
CIFS (SMB)
NFS
FTP
Ces protocoles ne nécessitent pas l’ajout de matériel additionnel sur les clients. Qu’ils soient sous Windows, Apple, Linux, Unix, AIX, … ils pourront accéder nativement au NAS.
Un NAS se configure et se gère généralement depuis une interface WEB depuis laquelle sera proposée, pour les plus complets, un système de gestion des accès, de gestion de quotas, de sauvegarde automatisée, de réplication, etc…
Le NAS a également trouvé sa place chez les particuliers car il permet de disposer d’un espace de stockage partagé et sécurisé à domicile pour stocker tous vos médias et y accéder depuis n’importe quel PC, « smartphone » ou tablette.
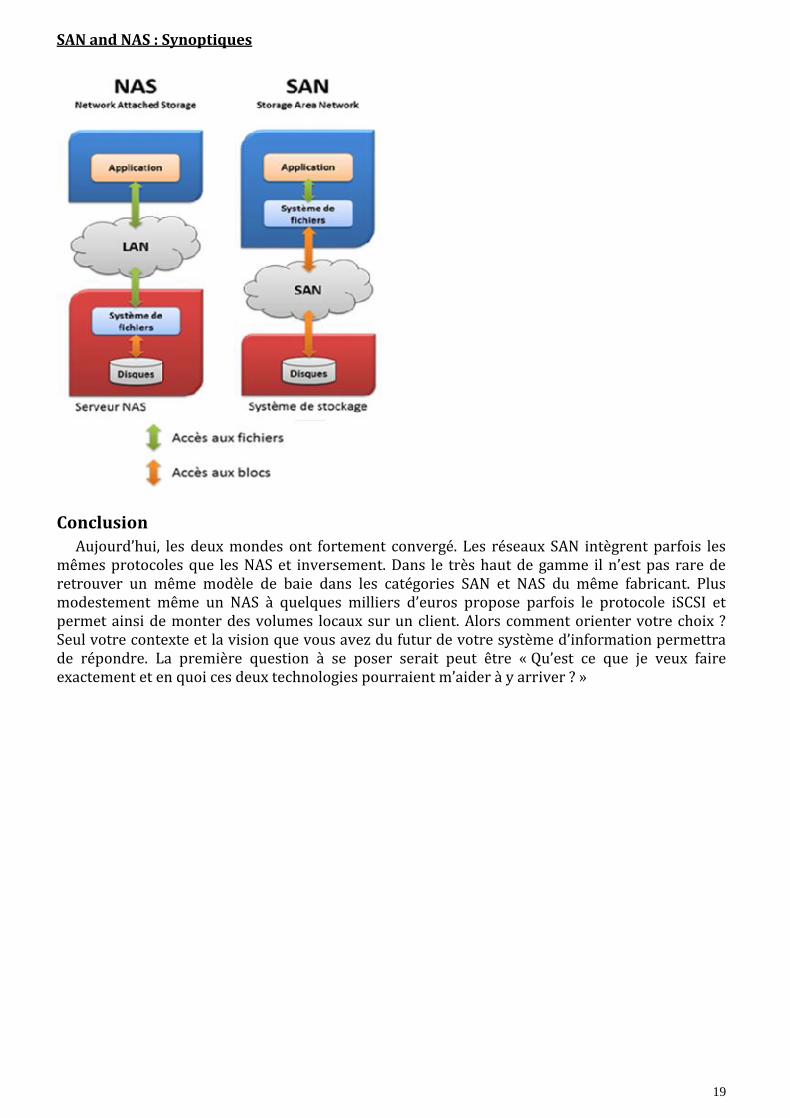
19
SAN and NAS : Synoptiques
Conclusion
Aujourd’hui, les deux mondes ont fortement convergé. Les réseaux SAN intègrent parfois les mêmes protocoles que les NAS et inversement. Dans le très haut de gamme il n’est pas rare de retrouver un même modèle de baie dans les catégories SAN et NAS du même fabricant. Plus modestement même un NAS à quelques milliers d’euros propose parfois le protocole iSCSI et permet ainsi de monter des volumes locaux sur un client. Alors comment orienter votre choix ? Seul votre contexte et la vision que vous avez du futur de votre système d’information permettra de répondre. La première question à se poser serait peut être « Qu’est ce que je veux faire exactement et en quoi ces deux technologies pourraient m’aider à y arriver ? »

20
Document 7

21

22
Document 8

23

24
Document 9





























