Embed Size (px)
Citation preview

Cours de mise à niveau en statistique mathématique
Chapitre 1: Méthodologie statistique
Tabea Rebafka
Septembre 2018
M2 de statistique
Tabea Rebafka M2 Mise à niveau en statistique Méthodologie statistique 1 / 13

Plan
1 Introduction
2 Rappels : Probabilités
3 Modèle statistique et problème d’estimation
Tabea Rebafka M2 Mise à niveau en statistique Méthodologie statistique 2 / 13

La statistique
Objet principal de la statistique
Des données ou des observations x à valeurs dans un espace X .
Souvent : x = (x1, . . . , xn) avec xi 2 R (données univariées) ou xi 2 Rd
(données multivariées).
La statistique est. . .
l’ensemble de méthodes qui permettent
d’analyser ces données,
d’en tirer des conclusions.
Modélisation statistique
L’observation x est considérée comme la réalisation X(!) d’une variable
aléatoire X (par opposition à l’analyse des données).
Tabea Rebafka M2 Mise à niveau en statistique Méthodologie statistique 3 / 13

Rappel : Variable aléatoire I
Tribu
F est une tribu sur l’ensemble ⌦ ssi F est un ensemble de parties de ⌦ tel
que
F n’est pas vide : F 6= ;B 2 F =) Bc 2 F (stable par complémentaire)
Bn 2 F , n 2 N =) [1n=1Bn 2 F (stable par union dénombrable)
Mesure de probabilité
P est une mesure de probabilité sur F ssi
0 P(B) 1 8B 2 FP(⌦) = 1
�-additivité : Pour tout Bn 2 F t.q. Bn \ Bm = ; 8n 6= m
P([1n=1Bn) =
P1n=1 P(Bn).
Tabea Rebafka M2 Mise à niveau en statistique Méthodologie statistique 4 / 13

Rappel : Variable aléatoire II
Espace de probabilité
Soit (⌦,F) est un espace mesurable et P une mesure de probabilité sur F .
Alors (⌦,F ,P) est dit espace de probabilité.
Variable aléatoire
Soit (⌦,F ,P) espace de probabilité. Une variable aléatoire est une
fonction mesurable X : (⌦,F) ! (X ,A), où A est une tribu sur X .
En statistique
Souvent X = Rn
A est la tribu borélienne (tribu engendrée par les ouverts)
En statistique, en général, on identifie (⌦,F) et (X ,A) de sorte que
X devient l’identité.
Tabea Rebafka M2 Mise à niveau en statistique Méthodologie statistique 5 / 13

Rappel : Fonction de répartition I
Loi de probabilité d’une variable aléatoire
La loi de probabilité de X , notée PX , est la mesure image de P par Xdéfinie par
PX (A) = P(X�1(A)), A 2 A.
Fonction de répartition
La fonction de répartition d’une variable aléatoire réelle X est la fonction
F : R ! [0, 1] définie par
F (t) = P(X t) = P({! : X (!) t}), t 2 R.
Théorème
Toute loi de probabilité est entièrement décrite par la fonction de
répartition associée.
Tabea Rebafka M2 Mise à niveau en statistique Méthodologie statistique 6 / 13

Rappel : Fonction de répartition II
Propriétés
Toute fonction de répartition F est
(i) monotone croissante,(ii) continue à droite et(iii) vérifie limt!1 F (t) = 1 et limt!�1 F (t) = 0.
Inversement, toute fonction F avec les propriétés (i)� (iii) est la
fonction de répartition d’une loi de probabilité.
Tabea Rebafka M2 Mise à niveau en statistique Méthodologie statistique 7 / 13

Modèle statistique I
L’observation x est la réalisation d’une v.a. X de loi P inconnue.But : identifier/inférer/estimer P à partir de x.
Modèle statistique
Une famille P de lois de probabilité connues, qui sont des candidats pour
P, est dite modèle statistique. On suppose P 2 P.
Pour définir un modèle P pour PI on utilise des connaissances a priori sur l’origine des données etI on effectue une analyse des données par des outils graphiques de la
statistique descriptive (histogrammes etc.)
Tout modèle est faux. Un modèle n’est qu’une approximation de la
réalité.
Tabea Rebafka M2 Mise à niveau en statistique Méthodologie statistique 8 / 13

Modèle statistique II
On écrit P = {P✓, ✓ 2 ⇥} où ✓ est un paramètre du modèle et ⇥ est
l’ensemble de paramètres.On note ✓0 2 ⇥ la “vraie valeur” du paramètre tel que P = P✓0 .
Le problème d’estimer P devient le problème d’estimer ✓0.
Identifiabilité
Le modèle P est identifiable ssi
8✓, ✓0 2 ⇥,P✓ = P✓0 =) ✓ = ✓0.
Tabea Rebafka M2 Mise à niveau en statistique Méthodologie statistique 9 / 13

Modèle statistique III
Modèle dominé
Le modèle P est dominé ssi il existe une mesure µ sur (X ,A) positive,
�-finie telle que P✓ est absolument continue par rapport à µ (i.e. P✓ ⌧ µ)
pour tout ✓.
µ est �-finie ssi 9An 2 A, n 2 N tels que X = [1n=1An et
µ(An) < 1, 8n 2 N.
P✓ ⌧ µ ssi 8A 2 A, µ(A) = 0 =) P✓(A) = 0.
Tabea Rebafka M2 Mise à niveau en statistique Méthodologie statistique 10 / 13

Modèle statistique IV
(Théorème de Radon-Nikodym) P✓ ⌧ µ équivaut l’existence d’une
densité de P✓ par rapport à µ, notée p✓ =dP✓dµ , définie presque
sûrement, telle que pour toute fonction g P✓-intégrable on a
Z
Xg(x)dP✓ =
Z
Xg(x)
dP✓
dµdµ.
Un modèle dominé P est entièrement décrite par la donnée de la
famille des densités P = {p✓, ✓ 2 ⇥}.Deux cas principaux :
I Cas continu : µ = mesure de Lebesgue. La densité est notée f✓.I Cas discret : µ = mesure de comptage. p✓ est la fonction de masse.
Tabea Rebafka M2 Mise à niveau en statistique Méthodologie statistique 11 / 13

Estimation de paramètre I
Comment estimer ✓0 à partir de l’observation x dans un modèle
P = {P✓, ✓ 2 ⇥} ?
Statistique
On appelle statistique toute fonction borélienne S de l’observation x :
S = S(x).
Exemples :
S(x) = 0 8xSoit x = (x1, . . . , xn). S(x) = 1
n
Pni=1 xi = x .
Estimateur
Une statistique est dit estimateur de ✓0, si elle est censée d’approcher ✓0et si elle ne dépend pas de paramètres inconnus.
Tabea Rebafka M2 Mise à niveau en statistique Méthodologie statistique 12 / 13

Estimation de paramètre II
Il existe différentes méthodes d’estimation selon la taille du modèle P.
Modèle paramétrique
Si ⇥ ⇢ Rd(i. e. ✓ est un vecteur), on dit que le modèle est paramétrique.
Modèle non paramétrique
S’il n’existe pas de paramétrisation de P avec ⇥ ⇢ Rdpour un d < 1,
alors le modèle est dit non paramétrique.
Exemples de modèles non paramétriques :
P = ensemble de toutes les mesures de probabilités sur (R,B(R)).P = ensemble de mesures de probabilités admettant une densité
continue par rapport à la mesure de Lebesgue.
Tabea Rebafka M2 Mise à niveau en statistique Méthodologie statistique 13 / 13

Cours de mise à niveau en statistique mathématique
Chapitre 2: Méthodes classiques d’estimationparamétrique
Tabea Rebafka
Septembre 2018
M2 de statistique
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 1 / 40

Plan
1 Rappels : Moments et espaces Lp
2 Méthode des moments
3 Méthode du maximum de vraisemblance
4 Méthode de Newton-Raphson
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 2 / 40

Cadre : Estimation paramétrique
Soit l’observation x la réalisation d’une v.a. X de loi P✓0 .
Soit P✓0 2 P = {P✓, ✓ 2 ⇥} un modèle statistique paramétrique avec
⇥ ⇢ Rd.
But : estimation du paramètre ✓0 (ou d’une quantité q(✓0) ⇢ Rmqui
dépend da la loi P✓0) à partir de l’observation x.Deux approches d’estimation classiques :
I Méthode des momentsI Méthode du maximum de vraisemblance
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 3 / 40

Rappels : Moments I
Soit X une v.a. réelle de f.d.r. F et de densité p par rapport à une mesure
de référence µ.
Moyenne
La moyenne ou espérance mathématique de X est définie par
E[X ] =
Z 1
�1xdF (x) =
Z
Rxp(x)µ(dx)
=
8>><
>>:
Pk vkP(X = vk) si X est une v.a. discrète à valeurs
dans {vk , k = 1, 2, . . .}R1�1 xf (x)dx si X est une v.a. continue de
densité f
pourvu que E[|X |] =R1�1 |x |dF (x) < 1.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 4 / 40

Rappels : Moments II
Pour toute fonction h mesurable et intégrable on a
E[h(X )] =
Z 1
�1h(x)dF (x) =
⇢ Pk h(vk)P(X = vk) (cas discrète)R1
�1 h(x)f (x)dx (cas continu).
Le moment d’ordre k de X est donné par E[X k ] pour k = 1, 2, . . . .
Le moment centré d’ordre k est donné par E[(X � E[X ])k ].
La variance est le moment centré d’ordre 2 :
Var(X ) = E[(X � E[X ])2].
Ces définitions supposent l’existence des intégrales respectives. Toutes
les lois ne possèdent pas de moments !
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 5 / 40

Rappels : Moments III
Moment empirique
Soient X1, . . . ,Xn des v.a. i.i.d. Le moment empirique d’ordre k est
donné par1n
Pni=1 X
ki .
Les moments empiriques approchent les moments théoriques :
1
n
nX
i=1
Xki ⇡ E[X k
i ],
si E[|Xi |k ] < 1. Plus n est grand, mieux est l’approximation (par la loi des
grands nombres).
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 6 / 40

Espaces Lp I
Espace Lp
L’espace Lp(⌦,F ,P), ou juste espace L
p, est l’ensemble de variables
aléatoires X telles que E[|X |p] < +1.
On définit la norme Lp
de X par
kXkp = E [|X |p]1/p .
En particulier, L1
est l’ensemble des variables aléatoires telles que
E[|X |] < +1, et on dit que X est intégrable.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 7 / 40

Espaces Lp II
L’espace Lp
est un espace vectoriel : pour tout X ,Y 2 Lp
et a 2 R on a
aX 2 Lp,
X + Y 2 Lp.
k·kp définit bien une norme : pour tout X ,Y 2 Lp
et a 2 R on a
kaXkp = |a|kXkp,kXkp = 0 si et seulement si X = 0 presque sûrement,
Inégalité triangulaire : kX + Y kp kXkp + kY kp.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 8 / 40

Espaces Lp III
Les espaces Lp
sont emboîtés :
Théorème
Pour q > p on a Lq ⇢ L
p. En effet,
· · · ⇢ Lp ⇢ L
p�1 ⇢ Lp�2 ⇢ · · · ⇢ L
2 ⇢ L1.
Par conséquent, si E[|X |q] < 1, alors E[|X |p] < 1 pour tout
p = 1, . . . , q.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 9 / 40

L’espace L2 I
Inégalité de Cauchy-Schwarz
Soient X ,Y 2 L2. Alors
|E[XY ]| E[|XY |] E[X 2]1/2E[Y 2]1/2,
avec égalité si et seulement si il existe des constantes a, b telles que a 6= 0
ou b 6= 0 et aX + bY = 0 presque sûrement.
Par conséquent, si X ,Y 2 L2, alors XY 2 L
1.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 10 / 40

L’espace L2 II
Un produit scalaire sur l’espace L2
est défini par
hX ,Y i = E[XY ],
car on a les propriétés suivantes :
Symétrie : hX ,Y i = hY ,X i.Linéarité : haX + bX
0,Y i = ahX ,Y i+ bhX 0,Y i.Caractère défini-positif : hX ,X i � 0. De plus, hX ,X i = 0 si et
seulement X = 0 p.s.
On dit que X et Y sont orthogonal si hX ,Y i = 0 et on écrit X ? Y .
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 11 / 40

L’espace L2 III
Soient E un sous-espace vectoriel de L2
et X 2 L2.
La projection orthogonale de X dans E , notée ⇡E (X ), est la variable
aléatoire ⇡E (X ) 2 E telle que (X � ⇡E (X )) ? Z0pour tout Z
0 2 E .
E
X
Z=⇡E(X )
Z 0
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 12 / 40

L’espace L2 IV
La projection orthogonale ⇡E (X ) de X dans E est caractérisée par un
problème de minimisation.
Théorème
Soient E un sous-espace vectoriel de L2
et X 2 L2. Alors
⇡E (X ) = arg minZ 02E
E[(X � Z0)2].
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 13 / 40

L’espace L2 V
Exercice
Soit X 2 L2. Déterminer la projection orthogonale ⇡E (X ) de X dans
E = {variables aléatoires constantes} = {X = a p.s., a 2 R} ?
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 14 / 40

Méthode des moments I
L’observation x = (x1, . . . , xn) est une réalisation de X = (X1, . . . ,Xn).
Hypothèses
Soient X = (X1, . . . ,Xn) des v.a. i.i.d. réelles de loi P✓0 2 {P✓, ✓ 2 ⇥}.On suppose X1 2 L
d(⌦,F ,P✓) pour tout ✓ 2 ⇥ ⇢ Rd, où d est la
dimension du paramètre ✓(i.e. E✓[|Xi |d ] =
R|x |dF✓(x) < 1 et E✓ est l’espérance sous la loi P✓,
autrement dit lorsque X ⇠ P✓.)
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 15 / 40

Méthode des moments II
Notons les moments µk(✓) = E✓[X ki ] pour k = 1, . . . , d .
Supposons que les fonctions µk sont connues explicitement.
Si les vraies valeurs µ⇤k = µk(✓0), k = 1, . . . , d , étaient disponibles, on
pourrait résoudre le système de d équations
µk(✓) = µ⇤k , k = 1, . . . , d ,
pour trouver la valeur du vecteur ✓0.
Disposant seulement d’un échantillon x = (x1, . . . , xn) de la loi P✓0 , on
remplace les moment inconnus µ⇤k par les moments empiriques
mk = 1n
Pni=1 x
ki .
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 16 / 40

Méthode des moments III
Estimateur par la méthode des moments
Toute statistique ✓MMà valeurs dans ⇥ qui est solution du système de d
équations
µk(✓) = mk , k = 1, . . . , d ,
est dite estimateur par la méthode des moments (EMM) du
paramètre ✓0 dans le modèle {P✓, ✓ 2 ⇥}.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 17 / 40

Méthode des moments IV
Attention
L’EMM peut ne pas avoir d’expression analytique. Il faut alors
appliquer des méthodes numériques pour résoudre le système
d’équations.
L’EMM peut ne pas exister.
L’EMM peut ne pas être unique.
Propriétés
Sous des conditions assez générales, l’EMM est consistant et
asymptotiquement normal.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 18 / 40

Méthode des moments V
Au lieu des d premiers moments, on peut effectuer la même démarche
avec des moments de la forme E✓['k(X )] avec des fonction 'k
intégrables quelconques.
Notons µk(✓) = E✓['k(X )], k = 1, . . . , d .
On cherche la valeur ✓MG 2 ⇥ (si elle existe) qui vérifie
µk(✓MG ) =
1
n
nX
i=1
'k(xi ), k = 1, . . . , d .
On appelle ✓MGl’estimateur par la méthode des moments
généralisée.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 19 / 40

Méthode des moments VI
Exercice : Méthode des moments
Soit (x1, . . . , xn) des réalisations i.i.d. de X .
1 Soit X de loi uniforme sur [0, ✓] avec ✓ > 0. Calculer l’EMM de ✓ en
utilisant le moment d’ordre 1.
2 Soit X de loi uniforme sur [�✓, ✓] avec ✓ 2 R.
I Calculer l’EMM de ✓ en utilisant le moment d’ordre 1.I Calculer l’EMM de ✓ en utilisant le moment d’ordre 2.I Trouver une fonction ' appropriée pour calculer l’estimateur de ✓ par
la méthode des moments généralisés.3 Soit X de loi de Cauchy de densité
fµ(x) =1
⇡((x � µ)2 + 1)x 2 R, µ 2 R.
Calculer l’EMM de µ.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 20 / 40

Méthode du maximum de vraisemblance I
La définition générale de la méthode et l’argumentation de son rôle
fondamental en statistique sont dues à Ronald Fisher (1922).
Hypothèse
{P✓, ✓ 2 ⇥} est un modèle dominé par une mesure µ, et notons p✓ =dP✓dµ
la densité de P✓ par rapport à µ.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 21 / 40

Méthode du maximum de vraisemblance II
Fonction de vraisemblance
La fonction de vraisemblance de x est définie par
✓ 7! L(x; ✓) = p✓(x)
=nY
i=1
p✓(xi ) si x est un échantillon i.i.d.
=
⇢ Qni=1 P✓(Xi = xi ) si i.i.d. et discretQni=1 f✓(xi ) si i.i.d. et continu
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 22 / 40

Méthode du maximum de vraisemblance III
Estimateur du maximum de vraisemblance
Toute statistique ✓MV 2 ⇥ telle que
L(x; ✓MV ) = max✓2⇥
L(x; ✓)
est dite estimateur du maximum de vraisemblance (EMV) du
paramètre ✓0 dans le modèle statistique {P✓, ✓ 2 ⇥}. Autrement dit,
✓MV = arg max✓2⇥
L(x; ✓).
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 23 / 40

Méthode du maximum de vraisemblance IV
Attention
L’EMV peut ne pas exister.
L’EMV peut ne pas être explicite.
L’EMV peut ne pas avoir d’expression analytique, et il faut utiliser des
méthodes numériques d’optimisation pour l’approcher.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 24 / 40

Méthode du maximum de vraisemblance V
Fonction de log-vraisemblance
Si le support des densités x 7! f✓(x) ne dépend pas de ✓ (c’est-à-dire
l’ensemble {x : f✓(x) > 0} est le même pour tout ✓ 2 ⇥), on définit la
fonction de log-vraisemblance `(✓) par
`(✓) = log(L(x; ✓))
=nX
i=1
log(p✓(xi )) si x est un échantillon i.i.d.
=
⇢ Pni=1 log(P✓(Xi = xi )) si i.i.d. et discretPni=1 log(f✓(xi )) si i.i.d. et continu
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 25 / 40

Méthode du maximum de vraisemblance VI
On a
✓MV = arg max✓2⇥
`(✓),
car x 7! log(x) est strictement croissant.
En général, il est plus facile de maximiser la fonction de
log-vraisemblance `(✓) que la fonction de vraisemblance L(x; ✓).
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 26 / 40

Méthode du maximum de vraisemblance VII
Propriétés
Sous des conditions assez faibles, l’EMV est un estimateur consistant.
La loi limite de l’EMV n’est pas toujours la loi normale.
Parfois, l’EMV a des vitesses de convergence plus rapide que n�1/2
.
Sous des conditions de régularité, l’EMV est efficace, c’est-à-dire qu’il
est optimal dans un sens précis.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 27 / 40

Méthode du maximum de vraisemblance VIII
Exercice
Soit (x1, . . . , xn) des réalisations i.i.d. de X .
1 Soit X de loi uniforme sur [0, ✓] avec ✓ > 0. Calculer l’EMV de ✓.
2 Soit X de loi uniforme sur [✓, ✓ + 1] avec ✓ 2 R. Calculer l’EMV de ✓.
3 Soit X de loi de Cauchy de densité
fµ(x) =1
⇡((x � µ)2 + 1)x 2 R, µ 2 R.
Calculer l’EMV de µ.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 28 / 40

Méthode de Newton-Raphson I
Procédure numérique pour trouver un point critique d’une fonction f .
On applique cette méthode à la fonction de log-vraisemblance `(✓)pour trouver l’EMV.
Attention : trouver un point critique n’est pas équivalent à déterminer
le maximum.
Néanmoins, dans de nombreux cas, cette méthode donne des résultats
satisfaisants pour détecter le point maximum d’une fonction.
Hypothèse
Soit f : X ! R où X ⇢ Rdune fonction réelle, deux fois dérivable.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 29 / 40

Méthode de Newton-Raphson II
La méthode repose sur un développement limité afin d’approcher le
gradient rf (x) par un terme linéaire :
rf (x) = rf (⇠) + H(⇠)(x � ⇠) + r(x , ⇠),
où ⇠ 2 X , H(⇠) = r2f (⇠) est la matrice hessienne de f en ⇠ et
r(x , ⇠) est un terme de reste.
Si ⇠ est près de x , le reste r est négligeable comparé au terme linéaire.
Au lieu de résoudre rf (x) = 0, on néglige le terme de reste r pour
résoudre
rf (⇠) + H(⇠)(x � ⇠) = 0
par rapport à x .
La solution est donnée par x = ⇠ � [H(⇠)]�1 rf (⇠).
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 30 / 40

Méthode de Newton-Raphson III
Méthode de Newton-Raphson
On procède itérativement :
On choisit un point initial x(0)
.
A l’itération t 2 {1, 2, . . .} on calcule
x(t) = x
(t�1) �hH(x (t�1))
i�1rf (x (t�1)),
où x(t�1)
est le résultat de l’itération précédente.
On arrête quand un critère de convergence est satisfait.
Pour que l’algorithme soit bien défini, il est nécessaire que l’inverse⇥H(x (t))
⇤�1existe pour tout t.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 31 / 40

Méthode de Newton-Raphson IV
Exemples de critère d’arrêt
Soit " > 0 un seuil fixé.
On arrête dès que kx (t) � x(t�1)k < ".
On arrête dès que krf (x (t))k < ".
Quelque soit le critère d’arrêt, il est possible que la condition soit vérifiée
dans des points qui ne correspondent pas à des zéros de rf (x).
Propriété
En général, il est difficile de garantir que la suite (x (t))t converge.
En revanche, si elle converge, elle converge assez vite (en une dizaine
d’itérations).
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 32 / 40

Interprétation géométrique I
Interprétation géométrique
Le terme rf (⇠) + H(⇠)(x � ⇠) est la tangente à rf (x) au point
x = ⇠.
Au lieu de chercher le point où le gradient rf (x) s’annule, on cherche
donc le zéro de la tangente.
Ce qui est bien plus facile grâce à la linéarité de la tangente.
Les figures suivantes illustrent les cinq premières étapes de la méthode de
Newton-Raphson dans un exemple.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 33 / 40
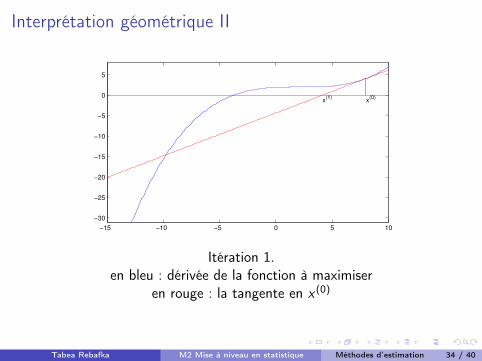
Interprétation géométrique II
−15 −10 −5 0 5 10
−30
−25
−20
−15
−10
−5
0
5
x(0)x(1)
Itération 1.
en bleu : dérivée de la fonction à maximiser
en rouge : la tangente en x(0)
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 34 / 40
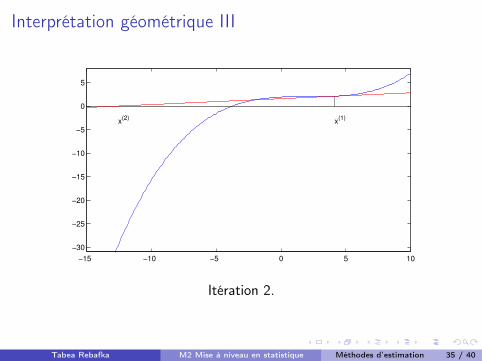
Interprétation géométrique III
−15 −10 −5 0 5 10
−30
−25
−20
−15
−10
−5
0
5
x(1)x(2)
Itération 2.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 35 / 40
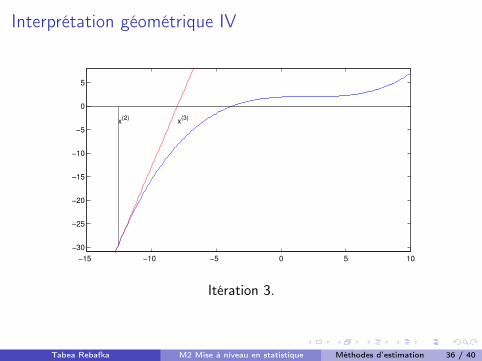
Interprétation géométrique IV
−15 −10 −5 0 5 10
−30
−25
−20
−15
−10
−5
0
5
x(2) x(3)
Itération 3.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 36 / 40
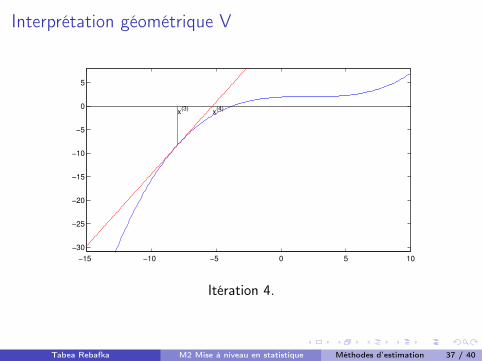
Interprétation géométrique V
−15 −10 −5 0 5 10
−30
−25
−20
−15
−10
−5
0
5
x(3) x(4)
Itération 4.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 37 / 40
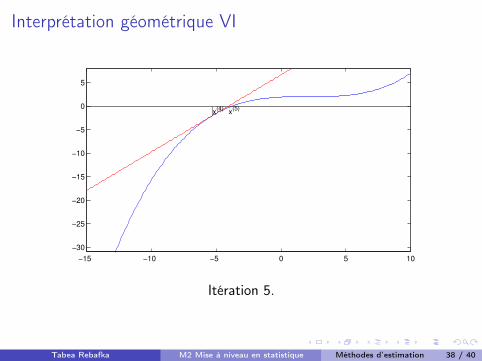
Interprétation géométrique VI
−15 −10 −5 0 5 10
−30
−25
−20
−15
−10
−5
0
5
x(4) x(5)
Itération 5.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 38 / 40

Interprétation géométrique VII
Suite des x(t)
dans l’exemple ci-dessus :
x(0) = 8 rf (x (0)) = 4,07
x(1) = 4,12 rf (x (1)) = 2,08
x(2) = �12,49 rf (x (2)) = �29,61
x(3) = �8,01 rf (x (3)) = �8,28
x(4) = �5,31 rf (x (4)) = �2,02
x(5) = �4,06 rf (x (5)) = �0,32
x(6) = �3,7800 rf (x (6)) = �0,0145
x(7) = �3,7659 rf (x (7)) = �3,48 10
�5
x(8) = �3,7659 rf (x (8)) = �2,02 10
�10
x(9) = �3,7659 rf (x (9)) = 4,44 10
�16
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 39 / 40

Interprétation géométrique VIII
Exercice
Soit (x1, . . . , xn) des réalisations i.i.d. de X de loi de Cauchy de densité
fµ(x) =1
⇡((x � µ)2 + 1)x 2 R, µ 2 R.
Calculer l’EMV de µ.
Tabea Rebafka M2 Mise à niveau en statistique Méthodes d’estimation 40 / 40

Cours de mise à niveau en statistique mathématique
Chapitre 3: Rappel sur les probabilités
Tabea Rebafka
Septembre 2018
M2 de statistique
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 1 / 21

Plan
1 Vecteurs aléatoires
2 Convergence
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 2 / 21

Vecteurs aléatoires IVecteur aléatoireUn vecteur aléatoire dans Rp
est un vecteur X = (X1, . . . ,Xp)T dont
toutes les composantes X1, . . . ,Xp sont des variables aléatoires réelles.
La fonction de répartition est définie par
FX(t) = P(X1 t1, . . . ,Xp tp), t = (t1, . . . , tp)T 2 Rp.
La moyenne est le vecteur des moyennes des variables aléatoires
X1, . . . ,Xp :
E[X] = (E[X1], . . . ,E[Xp])T ,
pourvu que E[|Xj |] < 1 pour tout j .
La fonction caractéristique 'X : Rp ! C est donnée par
'X(t) = Eheit
TXi, pour t 2 Rp.
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 3 / 21

Vecteurs aléatoires II
Dans le cas continu, où la loi de X admet une densité de probabilité fX(·)par rapport à la mesure de Lebesgue sur Rp
:
On a
FX(t) =
Z t1
�1. . .
Z tp
�1fX(u1, . . . , up)dup . . . du1,
pour tout t = (t1, . . . , tp)T 2 Rpet
fX(t) = fX(t1, . . . , tp) =@pFX(t)
@t1 . . . @tp,
pour presque tout t.
Toute densité de probabilité vérifie
fX(t) � 0,
Z 1
�1. . .
Z 1
�1fX(t1, . . . , tp)dt1 . . . dtp = 1.
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 4 / 21

Vecteurs aléatoires III
Soit X = (X1, . . . ,Xk)T (où k < p) un vecteur aléatoire, partie de X.
La densité marginale de X est donnée par
fX(t1, . . . , tk) =
Z 1
�1. . .
Z 1
�1fX(t1, . . . , tk , uk+1 . . . , up)duk+1 . . . dup.
La connaissance de toutes les densités marginales n’est pas suffisante
pour déterminer la loi du vecteur aléatoire X.
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 5 / 21

Indépendance I
IndépendanceSoient X 2 Rp
et Y 2 Rqdeux vecteurs aléatoires. On dit que X est
indépendant de Y (X ?? Y ) si
P(X 2 A,Y 2 B) = P(X 2 A)P(Y 2 B), 8A 2 B(Rp),B 2 B(Rq).
Soient g et h des fonctions boréliennes. Alors
X ?? Y =) g(X) ?? (Y).
Si E|X| < 1,E|Y| < 1, alors
X ?? Y =) E[XY] = E[X]E[Y].
L’inverse est faux.
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 6 / 21

Indépendance II
Caractérisation de l’indépendance par la fonction caractéristique :
X ?? Y () '(X,Y)(t) = 'X(t1)'Y(t2), 8 t = (t1, t2)T 2 Rp+q.
Dans le cas continu où le vecteur aléatoire (X,Y) admet une densité
f(X ,Y ), on a
X ?? Y () f(X ,Y )(x , y) = fX (x)fY (y) 8x , y ,
où fX et fY désignent les densités marginales des vecteurs X et Y.
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 7 / 21

Covariance et corrélation I
La covariance et la corrélation permettent de quantifier le degré de la
relation linéaire entre deux variables aléatoires.
CovarianceSoient X ,Y 2 L2
. La covariance entre X et Y est la valeur
Cov(X ,Y ) = E[(X � E[X ])(Y � E[Y ])]
= E[XY ]� E[X ]E[Y ].
Si Cov(X ,Y ) = 0, on dit que X et Y sont non-corrélées ou
orthogonales et on écrit X ? Y .
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 8 / 21

Covariance et corrélation II
Cov(X ,X ) = Var(X ).
Cov(X ,Y ) = Cov(Y ,X ) (symétrie).
Cov(aX , bY ) = abCov(X ,Y ) pour a, b 2 R.
Cov(X + a,Y + b) = Cov(X ,Y ) pour a, b 2 R.
Var(X + Y ) = Var(X ) + Var(Y ) + 2Cov(X ,Y ).
Si X ?? Y , alors Cov(X ,Y ) = 0. L’inverse est faux.
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 9 / 21

Covariance et corrélation III
CorrélationSoient X ,Y 2 L2
et Var(X ) > 0 et Var(Y ) > 0. La corrélation ou le
coefficient de corrélation entre X et Y est la quantité
⇢X ,Y =Cov(X ,Y )p
Var(X )Var(Y ).
On dit que X et Y sont
positivement correlées si ⇢X ,Y > 0, et
négativement correlées si ⇢X ,Y < 0.
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 10 / 21

Covariance et corrélation IV
Si X ?? Y , alors ⇢X ,Y = 0.
La corrélation est invariante par rapport aux transformations affines :
pour tout a 6= 0, b 6= 0 c , d 2 R,
⇢aX+c,bY+d = signe(ab)⇢X ,Y ,
où signe(u) = 1{u > 0}+ 1{u < 0}.
Proposition�1 ⇢X ,Y 1.
⇢X ,Y = 1 () 9a > 0, b 2 R tels que Y = aX + b p.s..
⇢X ,Y = �1 () 9a < 0, b 2 R tels que Y = aX + b p.s..
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 11 / 21

Covariance et corrélation V
Matrice de covarianceLa matrice de covariance (ou matrice des covariances croisées) des
vecteurs aléatoires X 2 Rpet Y 2 Rq
est définie par
Cov(X,Y) = E[(X � E[X])(Y � E[Y])T ] = (Cov(Xi ,Yj)i ,j .
La matrice de covariance de X est définie par
Var(X) = Cov(X,X).
Cov(X,Y) est une matrice p ⇥ q.
On dit que X est orthogonal à Y (ou X et Y sont non-corrélés)(X ? Y) si Cov(X,Y) = 0 2 Rp⇥q
.
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 12 / 21

Covariance et corrélation VI
Cov(X,Y) = E[XYT ]� E[X]E[YT ].
Cov(X,Y) = Cov(Y,X)T .
Cov(AX + a,BY + b) = ACov(X,Y)BTpour tout A 2 Rm⇥p
,
B 2 Rk⇥q, a 2 Rm
et b 2 Rk.
Si X ?? Y, alors Cov(X,Y) = 0. L’inverse est faux.
Cov(X1 + X2,Y) = Cov(X1,Y) + Cov(X2,Y) avec des vecteurs
aléatoires X1,X2 2 Rp.
Var(X) est une matrice symétrique et semi-définie positive.
Var(AX + b) = AVar(X)ATpour tout A 2 Rq⇥p
et b 2 Rq.
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 13 / 21

Convergence I
Soient X1,X2, . . . et X des vecteurs aléatoires dans Rpdéfinis sur
(⌦,A,P). On note k · k la norme euclidienne.
Convergence en probabilitéLa suite (Xn)n�1 converge en probabilité vers X quand n ! 1(Xn
P! X) ssi
limn!1
P(kXn � Xk > ") = 0, pour tout " > 0.
Convergence presque sûreLa suite (Xn)n�1 converge presque sûrement vers X quand n ! 1(Xn ! X p.s.) ssi
P⇣{! : lim
n!1Xn(!) 6= X(!)}
⌘= 0.
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 14 / 21

Convergence II
Convergence en loiLa suite (Xn)n�1 converge en loi (ou en distribution) vers X quand
n ! 1 (XnL! X) ssi
limn!1
FXn(t) = FX(t),
pour chaque point de continuité t 2 Rpde la fonction de répartition FX(·)
de X.
La convergence en loi est équivalente à la convergence étroite :
Convergence en loi
XnL! X () pour toute fonction h continue et bornée, on a
limn!1
E[h(Xn)] = E[h(X)].
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 15 / 21

Convergence III
Relations entre les modes de convergencecv presque sûre ) cv en probabilité ) cv en loi
Si a 2 Rpest un vecteur déterministe, alors
XnL! a () Xn
P! a.
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 16 / 21

Résultats asymptotiques I
ThéorèmeSoient X ,X1,X2, . . . ,Y ,Y1,Y2, . . . des variables aléatoires.
(i) Si Xn ! X p.s. et Yn ! Y p.s., alors
Xn + Yn ! X + Y p.s. et XnYn ! XY p.s.
(ii) Si XnP! X et Yn
P! Y , alors
Xn + YnP! X + Y et XnYn
P! XY .
(iii) (Théorème de Slutsky) Si XnL! a et Yn
L! Y et a 2 R est une
constante, alors
Xn + YnL! a+ Y et XnYn
L! aY .
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 17 / 21

Résultats asymptotiques II
ThéorèmeSoient X1,X2, . . . des vecteurs aléatoires i.i.d. Notons Xn = 1
n
Pni=1 Xi .
(i) (Loi forte des grands nombres de Kolmogorov) Si E[|X1|] < 1,
alors
Xn ! E[X1] p.s. quand n ! 1.
(ii) (Théorème central limite) Si E[kX1k2] < 1, alors
pn�Xn � E[X1]
� L�! N (0,Var(X1)), quand n ! 1.
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 18 / 21

Résultats asymptotiques III
Théorème de continuitéSoit g : D ⇢ Rp ! Rq
une fonction continue définie sur un sous-ensemble
D de Rpet soient X1,X2, . . . et X des vecteurs aléatoires définis sur
(⌦,A,P) à valeurs dans D. Alors, quand n ! 1,
(i) Xn �! X p.s. =) g(Xn) �! g(X) p.s.,
(ii) XnP�! X =) g(Xn)
P�! g(X),
(iii) XnL�! X =) g(Xn)
L�! g(X).
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 19 / 21

Résultats asymptotiques IV
Méthode deltaSoit g = (g1, . . . , gq)T : D ⇢ Rp ! Rq
une fonction continûment
différentiable. Soient X1,X2, . . . et X des vecteurs aléatoires à valeurs dans
D tels que
rn(Xn �m)L�! X,
où rn ! 1 est une suite réelle et m 2 Rpun vecteur déterministe. Alors
rn (g(Xn)� g(m))L�! rg(m)X, n ! 1,
où rg(t) = (@gi (t)@tj)i ,j .
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 20 / 21

Résultats asymptotiques V
CorollaireSoit g(·) une fonction continûment différentiable. Soient X1,X2, . . . des
variables aléatoires i.i.d. telles que E[X 21 ] < 1 et �2 = Var(X1) > 0. Alors
pn
✓g(Xn)� g(µ)
�
◆L�! g 0(µ)Z , quand n ! 1,
où Xn = 1n
Pni=1 Xi , µ = E[X1] et Z ⇠ N (0, 1).
Tabea Rebafka M2 Mise à niveau en statistique Rappel probabilités 21 / 21

Cours de mise à niveau en statistique mathématique
Chapitre 4: Propriétés des estimateurs
Tabea Rebafka
Septembre 2018
M2 de statistique
Tabea Rebafka M2 Mise à niveau en statistique Propriétés des estimateurs 1 / 20

Plan
1 Consistance
2 Loi limite et vitesse de convergence
3 Risque quadratique
4 Optimalité et modèle régulier
5 Propriétés de l’EMV
Tabea Rebafka M2 Mise à niveau en statistique Propriétés des estimateurs 2 / 20

Introduction
Quand on étudie un estimateur ✓ du paramètre ✓0 dans un modèle P,on veut caractériser la règle générale qui associe une valeur ✓ = ✓(x)à une observation x quelque soit l’observation x (réalisation de P✓0).Il convient alors de considérer la variable aléatoire ✓ = ✓(X) oùX ⇠ P✓0 .Le vrai paramètre ✓0 étant inconnu, il faut étudier le comportement de✓(X) pour X de loi P✓ pour tout ✓ 2 ⇥.Dans ce chapitre : ⇥ ⇢ Rd (cas paramétrique).
Tabea Rebafka M2 Mise à niveau en statistique Propriétés des estimateurs 3 / 20

Consistance I
Soit (✓n)n�1 = (✓n(Xn))n�1 une suite d’estimateurs de ✓0 pour deséchantillons grandissants Xn = (X1, . . . ,Xn).P. ex. la moyenne empirique Xn est bien définie pour tout n � 1
Consistance
Un estimateur ✓n de ✓0 est dit consistant ou convergent ssi
✓nP✓�! ✓ , lorsque n ! 1, pour tout ✓ 2 ⇥ ,
où ✓n = ✓n(Xn) avec Xn ⇠ P✓.
Tabea Rebafka M2 Mise à niveau en statistique Propriétés des estimateurs 4 / 20

Consistance II
La consistance est une propriété assez faible. Cette notion n’est pasassez informative pour nous guider dans le choix d’estimateurs.
Néanmoins, tout estimateur non consistants doit être exclus de touteconsidération.
Tabea Rebafka M2 Mise à niveau en statistique Propriétés des estimateurs 5 / 20

Loi limite et vitesse de convergence I
Loi limite et vitesse de convergence
Soit ✓n un estimateur consistant de ✓0. On appelle G✓0 loi limite del’estimateur ✓n, s’il existe une suite (rn)n�1 déterministe positive telle quern ! 1 et
rn(✓n � ✓0)L�! ⌘ ⇠ G✓0 , pour tout ✓0 2 ⇥ , (1)
lorsque n ! 1. On appelle 1/rn la vitesse de convergence del’estimateur ✓n.
Asymptotiquement normal
Si pn(✓n � ✓0)
L�! N (0,�2✓0) , pour tout ✓0 2 ⇥ ,
où 0 < �2✓0
< 1, alors l’estimateur ✓n est dit asymptotiquement normal.
Tabea Rebafka M2 Mise à niveau en statistique Propriétés des estimateurs 6 / 20

Loi limite et vitesse de convergence II
Dans le contexte de l’estimation paramétrique, la vitesse deconvergence la plus fréquente est 1/rn = n�1/2.On appelle variance limite de ✓n la variance Var(⌘) de la loi limiteG✓0 (si elle existe).Entre deux estimateurs ✓(1) et ✓(2) de ✓0, on préfère celui dont lavitesse de convergence est la plus rapide. Si elles sont identiques, oncompare leurs variances limites, et on préfère l’estimateur avec la pluspetite variance limite.
Tabea Rebafka M2 Mise à niveau en statistique Propriétés des estimateurs 7 / 20

Risque quadratique I
Risque quadratique
On appelle risque quadratique ou erreur quadratique moyenne del’estimateur ✓ au point ✓ 2 ⇥ la quantité
R(✓, ✓) = E✓
hk✓ � ✓k2
i,
où la notation E✓ indique l’espérance sous la loi P✓, i.e. ✓ = ✓(X) avecX ⇠ P✓.
Le risque quadratique est bien défini pour tout estimateur ✓. Il peut, enparticulier, prendre la valeur R(✓, ✓) = +1.
Tabea Rebafka M2 Mise à niveau en statistique Propriétés des estimateurs 8 / 20

Risque quadratique II
Décomposition du risque quadratique
R(✓, ✓) =⇣kE✓[✓]� ✓k
⌘2+ E✓
hk✓ � E✓[✓]k2
i
=: b2(✓, ✓) + �2(✓, ✓) ,
oùle terme b2(✓, ✓) représente la partie déterministe de l’erreurd’estimation (biais au carré) et�2(✓, ✓) mesure la contribution de sa partie stochastique (variance del’estimateur).
Tabea Rebafka M2 Mise à niveau en statistique Propriétés des estimateurs 9 / 20

Risque quadratique III
Théorème
Soit (✓n)n tel que
E✓
hk✓nk2
i< 1 et lim
n!1R(✓, ✓n) = 0, pour tout ✓ 2 ⇥.
Alors ✓n est un estimateur consistant de ✓.
Tabea Rebafka M2 Mise à niveau en statistique Propriétés des estimateurs 10 / 20

Risque quadratique IV
Le risque quadratique est la distance (quadratique moyenne) entrel’estimateur ✓n et ✓ à n fini.Plus la valeur du risque est petite, plus l’estimateur ✓ est performant.Soient ✓(1) et ✓(2) deux estimateurs de ✓ dans le modèle statistique{P✓, ✓ 2 ⇥}. Si
R(✓, ✓(1)) R(✓, ✓(2)) pour tout ✓ 2 ⇥ ,
et si, de plus, il existe ✓0 2 ⇥ tel que l’inégalité est stricte, alors on ditque ✓(1) est plus efficace que ✓(2) (ou meilleur que ✓(2)) et que ✓(2)
est inadmissible.
Tabea Rebafka M2 Mise à niveau en statistique Propriétés des estimateurs 11 / 20

Optimalité et modèle régulier I
Existe-il des estimateurs optimaux ?
Optimalité dans quel sens ?
Tabea Rebafka M2 Mise à niveau en statistique Propriétés des estimateurs 12 / 20

Optimalité et modèle régulier II
Soit P = {p✓, ✓ 2 ⇥} un modèle dominé, où ⇥ est un ouvert de Rd
et p✓ soit une densité par rapport à la mesure dominante µ.Notons X ⇠ P✓ une observation et ✓ = ✓(X) un estimateur de ✓.Notons g(✓) = E✓[✓(X)].
Hypothèses de régularité
(H1) Le support S✓ := {x : p✓(x) > 0} de p✓ ne dépend pas de ✓.(H2) ✓ 7! p✓(x) est dérivable pour µ presque tout x.(H3) @
@✓
Rh(x)p✓(x)dµ =
Rh(x) @
@✓p✓(x)dµ pour h ⌘ 1 et h(x) = ✓(x).(H4) g est dérivable sur ⇥.(H5) I (✓) > 0 pour tout ✓ 2 ⇥ avec
I (✓) = E✓
"@
@✓log p✓(x)
✓@
@✓log p✓(x)
◆T#.
Tabea Rebafka M2 Mise à niveau en statistique Propriétés des estimateurs 13 / 20

Optimalité et modèle régulier III
Théorème de Cramer-Rao ou Inégalité d’information
Sous les hypothèses (H1)–(H5), on a
R(✓, ✓) � (b(✓, ✓))2 +
✓@
@✓g(✓)
◆T
(I (✓))�1✓
@
@✓g(✓)
◆.
I (✓) est l’information de Fisher du modèle P.@@✓ log p✓(x) est le score.
Proposition
Sous les hypothèses (H1)–(H3), l’information de Fisher est égale à lavariance du score, à savoir
I (✓) = Var✓✓
@
@✓log p✓(X)
◆.
Tabea Rebafka M2 Mise à niveau en statistique Propriétés des estimateurs 14 / 20

Optimalité et modèle régulier IV
Proposition
Sous les hypothèses (H1)–(H3), si ✓ 7! p✓(x) est deux fois dérivable, alors
I (✓) = �E✓
@2
@✓@✓Tlog p✓(X)
�.
L’information de Fisher mesure la difficulté d’estimer ✓ dans le modèleP.I (✓) est la quantité d’information sur ✓ apportée par une observationX ⇠ p✓. Plus I (✓) est grand, mieux peut on estimer ✓.
Tabea Rebafka M2 Mise à niveau en statistique Propriétés des estimateurs 15 / 20

Optimalité et modèle régulier V
Divergence de Kullback-Leibler
Soient f et g des densité par rapport à µ. On définit la divergence deKullback-Leibler par
KL(f kg) =Z
logf (x)
g(x)f (x)dµ.
KL(f kg) � 0 pour tout f et g .KL(f kg) = 0 () f = g .En général KL(f kg) 6= KL(gkf ).
Tabea Rebafka M2 Mise à niveau en statistique Propriétés des estimateurs 16 / 20

Optimalité et modèle régulier VI
Au voisinage de ✓0 on a
KL(p✓0kp✓) ⇡12(✓ � ✓0)
T I (✓0)(✓ � ✓0).
I (✓0) correspond à la courbure de la divergence de Kullback-Leibler auvoisinage de ✓0.Plus la courbure est importante, plus il est facile de discriminer entre✓0 et une valeur voisine.
Tabea Rebafka M2 Mise à niveau en statistique Propriétés des estimateurs 17 / 20

Optimalité et modèle régulier VII
Proposition
Soit X = (X1, . . . ,Xn) un échantillon i.i.d. Notons In(✓) l’information deFisher associée à un échantillon X = (X1, . . . ,Xn) i.i.d. de taille n. Alors
In(✓) = nI1(✓).
Dans le cas i.i.d. chaque observation Xi apporte la même quantitéd’information sur le paramètre ✓.
Corollaire
Soit X = (X1, . . . ,Xn) un échantillon i.i.d. Soit ✓n un estimateur sans biaisde ✓. Alors
R(✓, ✓n) �1n(I1(✓))
�1 .
Tabea Rebafka M2 Mise à niveau en statistique Propriétés des estimateurs 18 / 20

Optimalité et modèle régulier VIII
Efficacité
Dans la famille des estimateurs sans biais, on dit qu’un estimateur estoptimal au sens du risque quadratique ou efficace s’il atteint la borne deCramer-Rao, i.e.
R(✓, ✓n) =1n(I1(✓))
�1 .
Tabea Rebafka M2 Mise à niveau en statistique Propriétés des estimateurs 19 / 20

Propriétés de l’EMV
Sous des hypothèses de régularité convenables,
l’EMV est consistant : ✓MVn
P�! ✓ (n ! 1) 8✓ 2 ⇥.l’EMV est asymptotiquement normal :pn(✓MV
n � ✓)L�! N (0,�2
✓) 8✓ 2 ⇥.
Dans le cas i.i.d., la variance limite est donnée par �2✓ = (I1(✓))
�1, eton dit que l’EMV est asymptotiquement efficace.Explication heuristique : Par définition, l’EMV cherche à minimiser uneversion empirique de la divergence de Kullback-Leibler.
Tabea Rebafka M2 Mise à niveau en statistique Propriétés des estimateurs 20 / 20

Cours de mise à niveau en statistique mathématique
Chapitre 5: Intervalle de confiance
Tabea Rebafka
Septembre 2018
M2 de statistique
Tabea Rebafka M2 Mise à niveau en statistique Intervalle de confiance 1 / 17

Plan
1 Définition
2 Quantiles
3 Construction d’intervalles de confiance
Tabea Rebafka M2 Mise à niveau en statistique Intervalle de confiance 2 / 17

Définition IDans ce chapitre le modèle statistique est {P✓, ✓ 2 ⇥} avec ⇥ ⇢ R.
Intervalle de confiance
Soient a(·) et b(·) des fonctions boréliennes à valeurs dans R, telles que
a(x) < b(x) pour tout x. Soit 0 < ↵ < 1. L’intervalle [a(X), b(X)] est dit
intervalle de confiance de niveau 1 � ↵ pour ✓ si
P✓ (a(X) ✓ b(X)) � 1 � ↵, (1)
pour tout ✓ 2 ⇥. On le note IC1�↵(✓).
IC1�↵(✓) est un intervalle de confiance de taille 1 � ↵, si, pour tout
✓ 2 ⇥, on a égalité en (1).
[an(Xn), bn(Xn)] est un intervalle de confiance de niveauasymptotique 1 � ↵, si pour tout ✓ 2 ⇥,
lim infn!1
P✓ (an(Xn) ✓ bn(Xn)) � 1 � ↵.
Tabea Rebafka M2 Mise à niveau en statistique Intervalle de confiance 3 / 17

Définition II
C’est l’intervalle [a(X), b(X)] qui est aléatoire, et non pas le paramètre
✓.
En général, on utilise ↵ = 0,05, et parfois ↵ = 0,01 ou 0,1.
L’intervalle IC1�↵(✓) = (�1,1) convient toujours, mais on cherche
des intervalles courts.On préfère des IC valables pour tout n fini aux intervalles de confiance
asymptotiques.
Si ✓ est un vecteur de dimension d > 1, on cherchera plutôt des
régions de confiance C(X) ⇢ Rdqui contiennent ✓ avec probabilité au
moins 1 � ↵.
Tabea Rebafka M2 Mise à niveau en statistique Intervalle de confiance 4 / 17

Fonction de quantile IFonction de quantile
Soit F : R 7! [0, 1] une fonction de répartition. On appelle fonction dequantile la fonction F�1 :]0, 1[! R définie par
F�1(↵) = inf{t 2 R : F (t) � ↵}, pour ↵ 2]0, 1[.
On appelle quantile q↵ d’ordre ↵, 0 < ↵ < 1, de la loi F la valeur
q↵ = F�1(↵).
Si F : R 7! [0, 1] est une bijection, alors F�1coïncide avec sa fonction
réciproque.
Le quantile d’ordre 1/2, q1/2 est la médiane de F .
Les quantiles d’ordre 1/4 et 3/4 sont dits premier et troisièmequartile, resp.
L’écart interquartile q3/4 � q1/4 est une mesure de la dispersion.
Tabea Rebafka M2 Mise à niveau en statistique Intervalle de confiance 5 / 17

Fonction de quantile II
Proposition
Pour toute fonction de répartition F on a
(i) F�1est croissante.
(ii) F�1est continue à gauche.
(iii) F (F�1(↵)) � ↵ pour ↵ 2]0, 1[.(iv) F�1(F (t)) t pour t 2 R.
Tabea Rebafka M2 Mise à niveau en statistique Intervalle de confiance 6 / 17
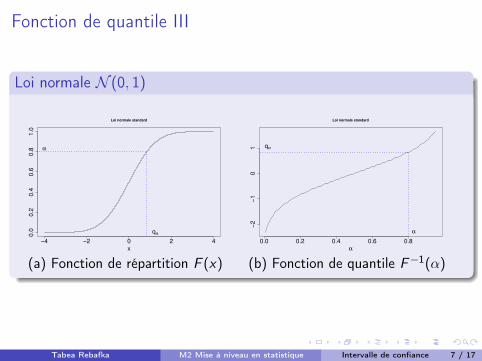
Fonction de quantile III
Loi normale N (0, 1)
−4 −2 0 2 4
0.0
0.2
0.4
0.6
0.8
1.0
Loi normale standard
x
qα
α
0.0 0.2 0.4 0.6 0.8
−2
−1
01
Loi normale standard
α
qα
α
(a) Fonction de répartition F (x) (b) Fonction de quantile F�1(↵)
Tabea Rebafka M2 Mise à niveau en statistique Intervalle de confiance 7 / 17
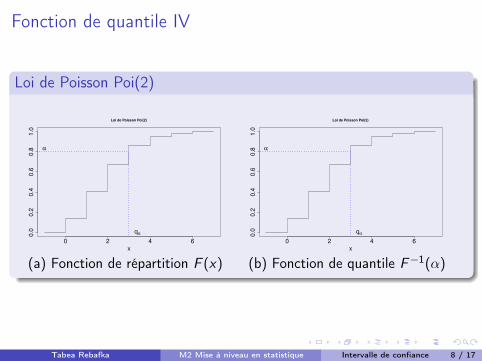
Fonction de quantile IV
Loi de Poisson Poi(2)
0 2 4 6
0.0
0.2
0.4
0.6
0.8
1.0
Loi de Poisson Poi(2)
x
qα
α
0 2 4 6
0.0
0.2
0.4
0.6
0.8
1.0
Loi de Poisson Poi(2)
x
qα
α
(a) Fonction de répartition F (x) (b) Fonction de quantile F�1(↵)
Tabea Rebafka M2 Mise à niveau en statistique Intervalle de confiance 8 / 17
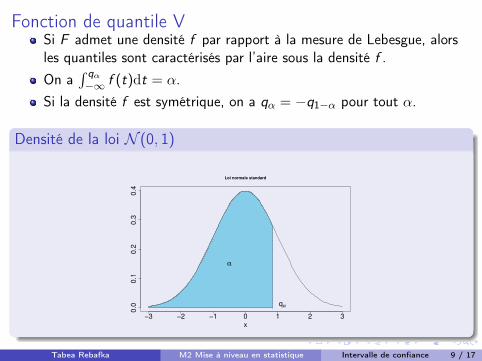
Fonction de quantile VSi F admet une densité f par rapport à la mesure de Lebesgue, alors
les quantiles sont caractérisés par l’aire sous la densité f .
On aR q↵�1 f (t)dt = ↵.
Si la densité f est symétrique, on a q↵ = �q1�↵ pour tout ↵.
Densité de la loi N (0, 1)
−3 −2 −1 0 1 2 3
0.0
0.1
0.2
0.3
0.4
Loi normale standard
x
qα
α
Tabea Rebafka M2 Mise à niveau en statistique Intervalle de confiance 9 / 17

Estimation des quantiles I
Fonction de répartition empirique
La fonction de répartition empirique F (ou Fn) associée à l’échantillon
x = (x1, . . . , xn) est définie par
F (t) =1
n
nX
i=1
1{xi t} =#{i : xi t}
n, t 2 R.
Tabea Rebafka M2 Mise à niveau en statistique Intervalle de confiance 10 / 17

Estimation des quantiles II
F est une fonction croissante en escalier avec des sauts en xi de
hauteur#{j :xj=xi}
n .
F est la fonction de répartition d’une loi discrète : Si Z ⇠ F , alors
P(Z = z) = #{i :xi=z}n pour tout z 2 {x1, . . . , xn}.
F est aussi appelée la loi empirique associée à l’échantillon
(x1, . . . , xn).
Soient X1,X2, . . . des v.a. i.i.d. de loi F . Alors, pour tout t 2 R,
Fn(t) =1
n
nX
i=1
1{Xi t} �! F (t) p.s. (n ! 1)
Tabea Rebafka M2 Mise à niveau en statistique Intervalle de confiance 11 / 17

Estimation des quantiles III
Un estimateur naturel du quantile q↵ de loi F est donné par le quantile
correspondant de la fonction de répartition empirique.
Quantile empirique
Soit F la fonction de répartition empirique associée à (X1, . . . ,Xn). Le
quantile empirique d’ordre ↵ associé à (X1, . . . ,Xn) est défini par
q↵ = F�1(↵), où F�1désigne la fonction de quantile de F .
Tabea Rebafka M2 Mise à niveau en statistique Intervalle de confiance 12 / 17

Estimation des quantiles IV
Statistiques d’ordre
Les statistiques d’ordre x(1), . . . , x(n) associées à (x1, . . . , xn) sont les
valeurs xi classées par ordre croissant telles que
x(j) 2 {x1, . . . , xn}, x(1) x(2) . . . x(n).
Le j-ième plus petit élément x(j) de l’échantillon x s’appelle la j-ièmestatistique d’ordre.
Clairement, x(1) = min{x1, . . . , xn} et x(n) = max{x1, . . . , xn}.
Tabea Rebafka M2 Mise à niveau en statistique Intervalle de confiance 13 / 17

Estimation des quantiles V
Théorème
Le quantile empirique q↵ d’ordre ↵ est donné par
q↵ = x(d↵ne),
où dae désigne le plus petit entier supérieur ou égal à a.
Théorème
Soient X1,X2, . . . des v.a. i.i.d. de loi F . Notons qn↵ le quantile empirique
d’ordre ↵ associé à (X1, . . . ,Xn). Si F est strictement croissant en qF↵ , alors
qn↵P�! qF↵ , lorsque n ! 1.
Tabea Rebafka M2 Mise à niveau en statistique Intervalle de confiance 14 / 17

Construction d’IC par fonction pivotale I
Un procédé assez général pour la construction d’intervalle de confiance
repose sur l’utilisation des fonctions pivotales.
Une fonction ✓ 7! T (✓, ✓) dont la loi ne dépend pas du paramètre ✓(ou d’autres paramètres inconnus du modèle) est dite fonctionpivotale (ou pivot) pour le modèle statistique {P✓, ✓ 2 ⇥}.
Tabea Rebafka M2 Mise à niveau en statistique Intervalle de confiance 15 / 17

Construction d’IC par fonction pivotale IIProcédé
1 On détermine un estimateur ponctuel ✓ de ✓.
2 On détermine la loi de l’estimateur ✓.
3 On cherche une transformation T (✓, ✓) de ✓ dont la loi ne dépend plus
de paramètres inconnus et on détermine cette loi. (T (✓, ✓) est pivotal).
4 Pour �1, �2 2 [0, 1] tels que �2 � �1 = 1 � ↵, on détermine les
quantiles q�1 et q�2 d’ordre �1 et �2 de la loi de T (✓, ✓) tels que
P✓
⇣q�1 T (✓, ✓) q�2
⌘= �2 � �1 = 1 � ↵.
5 En "inversant" T (lorsque c’est possible. . .), on encadre alors ✓ par
deux quantités aléatoires A et B , fonctions uniquement de ✓, q�1 , q�1
et de paramètres connus, telles que
P✓ (A ✓ B) = 1 � ↵.
Tabea Rebafka M2 Mise à niveau en statistique Intervalle de confiance 16 / 17

Construction d’IC par inégalitéDans certains modèles, des inégalités peuvent servir à construire des
intervalles de confiance.
Inégalité de Tchebychev
Soit X 2 L2. Alors, pour tout a > 0,
P(|X | � a) E[X 2]
a2 et P(|X � E[X ]| � a) Var(X )
a2 .
Inégalité de Hoeffding
Soit X1,X2, . . . des variables aléatoires indépendantes, centrées
(E[Xi ] = 0, 8i). S’il existe une constante M > 0 telle que |Xi | < M p.s. 8i ,alors pour tout x > 0,
P(Xn > x) exp
⇢� nx2
2M2
�et P(|Xn| > x) 2 exp
⇢� nx2
2M2
�.
Tabea Rebafka M2 Mise à niveau en statistique Intervalle de confiance 17 / 17

Cours de mise à niveau en statistique mathématique
Chapitre 6: Tests statistiques
Tabea Rebafka
Septembre 2018
M2 de statistique
Tabea Rebafka M2 Mise à niveau en statistique Tests statistiques 1 / 12

Plan
1 Formalisme et vocabulaire
2 Méthodes de construction de tests
Tabea Rebafka M2 Mise à niveau en statistique Tests statistiques 2 / 12

Formalisme et vocabulaire I
On se donne un modèle {P✓, ✓ 2 ⇥} et deux sous-ensembles disjoints
⇥0 et ⇥1 inclus dans ⇥.
Au vu de X de loi P✓ inconnue, on veut décider si ✓ 2 ⇥0 ou pas.
DéfinitionsH0 : ✓ 2 ⇥0 est dit hypothèse nulle.H1 : ✓ 2 ⇥1 est dit hypothèse alternative.L’hypothèse nulle (ou alternative) est dite simple si ⇥0 = {✓0} (ou
⇥1 = {✓1}). Sinon elle est composite ou multiple.Si ⇥1 = {✓ 6= ✓0}, H1 est dite bilatérale.Si ⇥1 = {✓ ✓0} (ou ⇥1 = {✓ � ✓0}), H1 est dite unilatérale.
Tabea Rebafka M2 Mise à niveau en statistique Tests statistiques 3 / 12

Formalisme et vocabulaire II
TestOn appelle test de l’hypothèse H0 contre l’hypothèse H1, toute
fonction mesurable ' : X 7! {0, 1} (où X désigne l’espace des
observations, i.e. X 2 X p.s.).
Lorsque '(X) = 0, on conserve l’hypothèse nulle H0.
Si '(X) = 1, on rejette H0 et on décide/accepte H1.
On appelle région de rejet du test '
R' = {x 2 X : '(x) = 1}.
Un test est entièrement caractérisé par sa région de rejet.
Tabea Rebafka M2 Mise à niveau en statistique Tests statistiques 4 / 12

Formalisme et vocabulaire III
En général, il existe une écriture naturelle de R' en terme d’une
statistique T (X) et d’un ensemble R tels que
R' = {x 2 X : T (X) 2 R}.
Le plus souvent, on a
R' = {x 2 X : T (X) > c} ou R' = {x 2 X : T (X) < c},
pour une constante c 2 R.
On appelle T (X) la statistique de test.
Tabea Rebafka M2 Mise à niveau en statistique Tests statistiques 5 / 12

Formalisme et vocabulaire IV
Quand on décide entre H0 et H1 au vu de X, il y a deux façons de se
tromper, auxquelles on associe une probabilité quantifiant le risque d’erreur.
Risque de première et seconde espèceLe rejet à tort de H0 est dit erreur de première espèce. La
probabilité associée est le risque de première espèce donné par
↵(✓0) = P✓0(T (X) 2 R) 8✓0 2 ⇥0.
Lorsqu’on conserve l’hypothèse nulle H0 alors qu’elle est fausse, c’est
une erreur de seconde espèce. La probabilité associée est le risquede seconde espèce donné par
�(✓1) = P✓1(T (X) /2 R) 8✓1 2 ⇥1.
Tabea Rebafka M2 Mise à niveau en statistique Tests statistiques 6 / 12

Formalisme et vocabulaire V
On définit la taille ↵⇤d’un test comme
↵⇤ = sup✓02⇥0
↵(✓0).
Si ↵⇤est atteinte en ✓⇤ 2 ⇥0, on dit que l’hypothèses ✓ = ✓⇤ est
l’hypothèse la moins favorable.
Niveau du testsSoit ↵ 2]0, 1[. Le test est dit
de niveau ↵ si ↵⇤ ↵.
de niveau exactement ↵ s’il est de taille ↵, i.e. ↵⇤ = ↵.
de niveau asymptotique ↵ si ↵⇤n ! ↵ (n ! 1).
Tabea Rebafka M2 Mise à niveau en statistique Tests statistiques 7 / 12

Formalisme et vocabulaire VI
p-valeurPour tout ↵ 2]0, 1[, soit R↵ = {x 2 X : T (X) 2 R↵} un test de niveau ↵de H0 contre H1. On appelle p-valeur, degré de significativité ou seuilcritique
p(x) = inf{↵ 2]0, 1[: T (x) 2 R↵}.
Ainsi, p(x) est le plus petit seuil ↵ à partir duquel on rejette H0 lorsqu’on
observe x.
Si p(x) est proche de 0 (i.e. p(x) < 0.01), on rejette H0 à tous les
niveaux habituels de ↵ et on dit que le test est en faveur de H1 et le
test est significatif.Si p(x) est grand (i.e. p(x) > 0.1), on ne rejette pas H0. Si, en plus, le
risque maximal de seconde espèce est faible, on peut alors avoir
confiance en H0.
Tabea Rebafka M2 Mise à niveau en statistique Tests statistiques 8 / 12

Formalisme et vocabulaire VII
PuissanceOn appelle fonction puissance du test la fonction
⇡(✓) = P✓(T (X) 2 R), ✓ 2 ⇥.
La restriction de ⇡(✓) à ⇥1 est dite puissance du test.Soit '1 et '2 deux tests de niveau ↵ et de puissances respectives ⇡1et ⇡2. Le test '1 est plus puissant que le test '2 si
⇡1(✓) � ⇡2(✓) 8✓ 2 ⇥1.
Soit '⇤un test de niveau ↵. On dit que '⇤
est uniformément pluspuissant de niveau ↵ (UPP(↵)) lorsque '⇤
est plus puissant que
tout autre test de niveau ↵.
Tabea Rebafka M2 Mise à niveau en statistique Tests statistiques 9 / 12

Construction de tests I
À partir d’un estimateur ou d’une statistique pivotale
Lorsqu’on connaît un estimateur ✓ de ✓, un test naturel consiste à rejeter
H0 lorsque l’estimateur ✓ prend des valeurs près de ⇥1.
À partir d’un intervalle de confianceSoit IC↵ un intervalle de confiance de niveau 1 � ↵ pour ✓. Alors le test
'(x) = 1{⇥0 \ IC↵(x) = ;} = 1{✓0 /2 IC↵(x), 8✓0 2 ⇥0}
est de niveau ↵
Tabea Rebafka M2 Mise à niveau en statistique Tests statistiques 10 / 12

Construction de tests IIUne approche générale et intuitive pour construire des tests repose sur le
rapport des vraisemblances
�(x) =sup✓2⇥1 L(x; ✓)sup✓2⇥0 L(x; ✓)
.
Test du rapport des vraisemblancesOn définit le test du rapport des vraisemblances comme
RRVc = {x 2 X : �(x) > c},
où c 2 R est une constante.
L’idée du test : si �(x) est grand, la vraisemblance L(x; ✓) est grande pour
un ✓ 2 ⇥1 comparé à L(x; ✓) avec ✓ 2 ⇥0, et donc il semble raisonnable de
rejeter H0.
Tabea Rebafka M2 Mise à niveau en statistique Tests statistiques 11 / 12

Construction de tests III
Lemme de Neyman-PearsonSoit ↵ 2]0, 1[. Pour tester deux hypothèses simples
H0 : ✓ = ✓0 contre H1 : ✓ = ✓1,
s’il existe un seuil c⇤
tel que le test du rapport des vraisemblances RRVc⇤ est
exactement de niveau ↵, alors ce test est UPP(↵).
Tabea Rebafka M2 Mise à niveau en statistique Tests statistiques 12 / 12

Cours de mise à niveau en statistique mathématique
Chapitre 7: Modèle linéaire
Tabea Rebafka
Septembre 2018
M2 de statistique
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 1 / 23

Plan
1 Modèle de régression
2 Modèle linéaire
3 Méthodes des moindres carrés
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 2 / 23

Modèle de régression I
Modélisation d’une variable à expliquer (réponse, variable dépendante) en
fonction d’autres facteurs ou variables explicatives X (prédicteurs,
régresseurs, variables indépendantes).
Modèle de régressionSoient
Y1, . . . ,Yn des v.a. réelles (variable à expliquer),
x1, . . . , xn 2 Rpdes vecteurs (variables explicatives),
g : Rp ! R une fonction mesurable inconnue (fonction de régression),
"1, . . . , "n des v.a. centrées et décorrélées.
Le modèle de régression est définit comme
Yi = g(xi ) + "i , pour tout i = 1, . . . , n.
On a E[Yi ] = g(xi ) pour i = 1, . . . , n.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 3 / 23

Modèle de régression II
Problème d’estimationOn observe x1, . . . , xn et des réalisations y1, . . . , yn des Y1, . . . ,Yn
associées. On cherche à estimer la fonction de régression g .
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 4 / 23
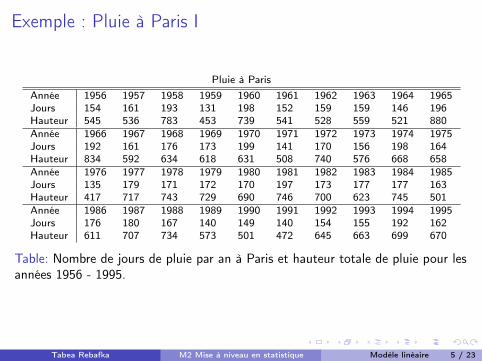
Exemple : Pluie à Paris I
Pluie à Paris
Année 1956 1957 1958 1959 1960 1961 1962 1963 1964 1965
Jours 154 161 193 131 198 152 159 159 146 196
Hauteur 545 536 783 453 739 541 528 559 521 880
Année 1966 1967 1968 1969 1970 1971 1972 1973 1974 1975
Jours 192 161 176 173 199 141 170 156 198 164
Hauteur 834 592 634 618 631 508 740 576 668 658
Année 1976 1977 1978 1979 1980 1981 1982 1983 1984 1985
Jours 135 179 171 172 170 197 173 177 177 163
Hauteur 417 717 743 729 690 746 700 623 745 501
Année 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995
Jours 176 180 167 140 149 140 154 155 192 162
Hauteur 611 707 734 573 501 472 645 663 699 670
Table: Nombre de jours de pluie par an à Paris et hauteur totale de pluie pour lesannées 1956 - 1995.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 5 / 23
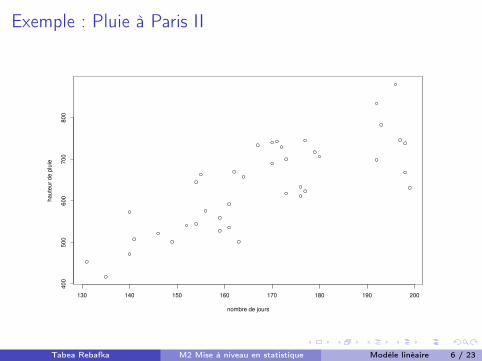
Exemple : Pluie à Paris II
130 140 150 160 170 180 190 200
40
05
00
60
07
00
80
0
nombre de jours
ha
ute
ur
de
plu
ie
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 6 / 23

Exemple : Pluie à Paris III
On dirait qu’il existe des constantes a, b 2 R telles que
yi ⇡ a+ bxi , pour i = 1, . . . , n,
ou
yi = a+ bxi| {z }partie déterministe
+ "i|{z}aléa/erreur (petit)
.
C’est un modèle de régression avec g(x) = a+ bx .
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 7 / 23

Modèle linéaire I
Modèle linéaireLorsque la fonction de régression est linéaire de la forme
g(x) = xT�,
avec � 2 Rp, le modèle de régression associé est dit modèle de
régression linéaire multivariéé ou simplement modèle linéaire.
Estimer g revient à estimer le vecteur de paramètres � 2 Rp.
C’est un problème paramétrique.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 8 / 23

Modèle linéaire II
Forme matricielle du modèle linéaireOn a
Y = X� + ",
où Y = (Y1, . . . ,Yn)T 2 Rn, " = ("1, . . . , "n)T 2 Rn
et
X = (x1, . . . , xn)T =
0
B@x1,1 . . . x1,p...
. . ....
xn,1 . . . xn,p
1
CA 2 Rn⇥p.
L’importance du modèle linéaire s’explique d’une part par sa simplicité et
d’autre part par le fait qu’il couvre une grande variété de modèles.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 9 / 23

Cas particuliers du modèle linéaire I
Régression linéaire simpleOn a xi 2 R, i = 1, . . . , n et on cherche à ajuster une droite :
yi = a+ bxi + "i .
Avec
� =
✓a
b
◆et X =
0
B@1 x1
.
.
....
1 xn
1
CA
on retrouve un modèle linéaire Y = X� + ".
La fonction x 7! a+ bx est dite droite de régression.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 10 / 23

Cas particuliers du modèle linéaire II
Modèle de translationSoit F une loi centrée et de carré intégrable. Soient Yi ⇠ F (·� ✓)i.i.d. pour un paramètre de translation ✓ 2 R inconnu.
P. ex. F = N (0, 1), alors Yi ⇠ N (✓, 1).
Avec
X =
0
B@1
.
.
.
1
1
CA = 1 2 Rnet " =
0
B@"1
.
.
.
"n
1
CA ,
avec "i ⇠ F i.i.d., on a un modèle linéaire donné par
Y =
0
B@Y1
.
.
.
Yn
1
CA = ✓X + ".
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 11 / 23

Cas particuliers du modèle linéaire III
Comparaison des moyennes de m populationsSoit F centrée et de carré intégrable. On observe m échantillons
indépendants Yj ,1, . . . ,Yj ,nj , j = 1, . . . ,m de loi F (·� ✓j) avec
✓j 2 R, j = 1, . . . ,m inconnus.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 12 / 23

Cas particuliers du modèle linéaire IVComparaison des moyennes de m populations (suite)
Avec
X =
0
BBBBBBBBBBBBBB@
1 0 . . . 0
.
.
.
.
.
.
...
.
.
.
1 0 . . . 0
0 1 . . . 0
.
.
.
.
.
.
...
.
.
.
0 1 . . . 0
.
.
. 0 . . ....
0
.
.
. . . . 1
.
.
.
.
.
. . . ....
0 0 . . . 1
1
CCCCCCCCCCCCCCA
0
.
.
.
0
9>=
>;n1
0
.
.
.
0
9>=
>;n2
.
.
.
.
.
.
.
.
.
0
9>>>=
>>>;nm
et " = ("1,1, . . . , "1,n1 , "2,1, . . . , "m,nm)T
avec "i ⇠ F i.i.d.,
� = (✓1, . . . , ✓m)T et Y = (Y1,1, . . . ,Y1,n1 ,Y2,1, . . . ,Ym,nm)T
, le
modèle s’écrit sous la forme d’un modèle linéaire Y = X� + ".
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 13 / 23

Cas particuliers du modèle linéaire V
Régression polynomialeSoient zi 2 R des réalisations d’une variable explicative. On observe
Yi = a1 + a2zi + a3z2
i + · · ·+ apzp�1
i + "i , i = 1, . . . , n.
On retrouve un modèle linéaire Y = X� + " avec � = (a1, . . . , ap)T et
X =
0
B@1 z1 z
2
1· · · z
p�1
1
.
.
....
.
.
....
1 z1 z2n · · · z
p�1n
1
CA .
Remarquons que le modèle linéaire est linéaire en le paramètre �, mais pas
nécessairement en les variables zi .
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 14 / 23

Méthodes des moindres carrés I
La méthode des moindres carrés est la technique d’estimation de
paramètres la plus ancienne.
Initialement proposée par Gauss en 1795 pour l’étude du mouvement
des planètes, elle fut formalisée par Legendre en 1810.
Elle occupe, aujourd’hui encore, une place centrale dans l’arsenal des
méthodes d’estimation : son importance pratique est considérable.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 15 / 23

Méthodes des moindres carrés II
Estimateur des moindres carrésLa méthode des moindres carrés cherche la valeur � 2 Rp
telle que
kY � X�k2 = min�2Rp
kY � X�k2
()nX
i=1
(Yi � xTi �)2 = min
�2Rp
nX
i=1
(Yi � xTi �)2.
On appelle � estimateur des moindres carrés (EMC).
(Yi � xTi �)2
est la distance verticale au carré entre l’observation Yi et
la fonction de régression.
Ce problème de minimisation a toujours une solution �. En revanche,
elle peut ne pas être unique.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 16 / 23

Méthodes des moindres carrés III
ThéorèmeSoit la matrice XTX définie positive. Alors, l’estimateur des moindres
carrés est unique et il s’écrit sous la forme
� = (XTX)�1XTY.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 17 / 23

Méthodes des moindres carrés IV
PropositionLa matrice XTX est toujours semi-définie positive (XTX � 0). De plus,
XTX est définie positive (XTX > 0), si et seulement si le rang de la
matrice X est p.
S’il y a plus de paramètres que d’observations (n < p), alors l’EMC n’est
pas unique.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 18 / 23

Interprétation géométrique I
La méthode des moindres carrés consiste à calculer la projection
orthogonale de Y sur le sous-espace vectoriel engendré par les
colonnes de X.
En effet,
min�2Rp
kY � X�k2 = minv2D
kY � vk2,
où D = {v = X�,� 2 Rp}.On a dim(D) = rang(X).
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 19 / 23

Interprétation géométrique II
ThéorèmeSi XTX > 0, alors la matrice
H = X(XTX)�1XT
est le projecteur orthogonal dans Rnsur le sous-espace D, et rang(H) = p.
Donc, si XTX > 0, la solution unique de minv2D kY � vk2est atteinte en
v = HY = X(XTX)�1XTY = X�.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 20 / 23

Propriétés de l’EMC I
ThéorèmeSoit " = ("1, . . . , "n)T centré (E["] = 0) et de matrice de covariance
Var(") = �2In avec �2 > 0 inconnu.
Si XTX est définie positive, alors l’estimateur des moindres carrés est sans
biais :
E�[�] = �,
et sa matrice de covariance est donnée par
Var✓(�) = �2
⇣XTX
⌘�1
.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 21 / 23

Propriétés de l’EMC II
On appelle " := Y � X� le vecteur des résidus.Dans le modèle Y = X� + ", si � estime bien �, alors " estiment bien
les erreurs ".
Donc, " est un bon candidat pour la construction d’un estimateur de
�2.
On appelle SCR = k"k2 = kY � X�k2la somme des carrés des
résidus.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 22 / 23

Propriétés de l’EMC III
ThéorèmeSous les hypothèses du Théorème précédent, la statistique
�2 =kY � X�k2
n � p=
1
n � p
nX
i=1
(Yi � xTi �)2
est un estimateur sans biais de la variance �2, i.e.
E[�2] = �2.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire 23 / 23

Cours de mise à niveau en statistique mathématique
Chapitre 8: Vecteurs gaussiens
Tabea Rebafka
Septembre 2018
M2 de statistique
Tabea Rebafka M2 Mise à niveau en statistique Vecteurs gaussiens 1 / 16

Plan
1 Définition et propriétés des vecteurs gaussiens
2 Lois dérivées de la loi normale
3 Théorème de Cochran
Tabea Rebafka M2 Mise à niveau en statistique Vecteurs gaussiens 2 / 16

Définition et propriétés des vecteurs gaussiens I
La loi normale N (µ,�2) dans R est la loi de densité
f (x) =1p2⇡�
exp
⇢�(x � µ)2
2�2
�,
où µ 2 R est la moyenne et � > 0 l’écart-type.
La fonction caractéristique de la loi normale N (µ,�2) vaut
�(t) = exp
⇢iµt � �2t2
2
�, t 2 R,
en particulier �(t) = e�t2/2pour la loi normale standard N (0, 1).
Par convention, nous allons inclure les lois dégénérées (lois de Dirac)
dans la famille des lois normales : La v.a. ⇠ suit la loi de Dirac en
µ 2 R si P(⇠ = µ) = 1 et �(t) = eiµt .
Tabea Rebafka M2 Mise à niveau en statistique Vecteurs gaussiens 3 / 16

Définition et propriétés des vecteurs gaussiens II
Vecteur gaussienOn dit que ⇠ = (⇠1, . . . , ⇠p)T suit une loi normale (multivariée)dans Rp
si et seulement si toute combinaison linéaire aT ⇠ suit une loi
normale dans R.
On dit aussi que ⇠ est un vecteur normal dans Rpou bien un
vecteur gaussien dans Rp.
Tabea Rebafka M2 Mise à niveau en statistique Vecteurs gaussiens 4 / 16

Définition et propriétés des vecteurs gaussiens IIIPropositionSoit ⇠ = (⇠1, . . . , ⇠p)T un vecteur aléatoire avec
µ = E[⇠] = (E[⇠1], . . . ,E[⇠p])T et ⌃ = Var(⇠) = (Cov(⇠i , ⇠j))i ,j2{1,...,p},alors ⇠ est un vecteur gaussien si et seulement si sa fonction caractéristique
s’écrit pour tout t 2 Rp,
�⇠(t) = E[eitT ⇠] = exp
⇢itTµ� tT⌃t
2
�.
Par conséquent, toute loi normale dans Rpest entièrement déterminée par
la donnée de sa moyenne et de sa matrice de covariance, comme dans le
cas d’une variable gaussienne réelle. D’où la notation
⇠ ⇠ Np(µ,⌃).
pour un vecteur aléatoire normal ⇠ de moyenne µ et de matrice de
covariance ⌃.
Tabea Rebafka M2 Mise à niveau en statistique Vecteurs gaussiens 5 / 16

Définition et propriétés des vecteurs gaussiens IV
PropositionToute transformation affine d’un vecteur normal est un vecteur normal :
Soient ⇠ ⇠ Np(µ,⌃), B est une matrice déterministe q⇥ p et c 2 Rq, alors
B⇠ + c ⇠ Nq(Bµ+ c ,B⌃BT ).
Tabea Rebafka M2 Mise à niveau en statistique Vecteurs gaussiens 6 / 16

Définition et propriétés des vecteurs gaussiens V
CorollaireTout sous-ensemble de coordonnées d’un vecteur normal est un vecteur
normal : soit ⇠ = (⇠T1 , ⇠T2 )T un vecteur normal dans Rp, où ⇠1 2 Rk
et
⇠2 2 Rp�k, alors ⇠1 et ⇠2 sont des vecteurs normaux.
Tabea Rebafka M2 Mise à niveau en statistique Vecteurs gaussiens 7 / 16

Définition et propriétés des vecteurs gaussiens VI
PropositionSi la matrice de covariance d’un vecteur gaussien se sépare par blocs, alors
les sous-vecteurs correspondants sont mutuellement indépendants : Soit
⇠ = (⇠T1 , . . . , ⇠Tk )T un vecteur gaussien dans Rpavec des sous-vecteurs
⇠j 2 Rmj etPk
j=1 mj = p. Si les matrices de covariance
Cov(⇠j , ⇠l) = E[(⇠j � E[⇠j ])(⇠l � E[⇠l ])T ] = 0, pour tout j 6= l ,
où 0 désigne la matrice nulle, alors les vecteurs ⇠1, . . . , ⇠k sont
mutuellement indépendants.
Tabea Rebafka M2 Mise à niveau en statistique Vecteurs gaussiens 8 / 16

Définition et propriétés des vecteurs gaussiens VII
PropositionSoit ⌃ une matrice de covariance et µ un vecteur dans Rp
. Alors il existe
une matrice déterministe A de taille p ⇥ p telle que pour un vecteur ⌘ de
loi normale standard,
A⌘ + µ ⇠ Np(µ,⌃).
Tabea Rebafka M2 Mise à niveau en statistique Vecteurs gaussiens 9 / 16

Définition et propriétés des vecteurs gaussiens VIII
PropositionSi la matrice de covariance ⌃ est définie positive, ⌃ > 0 (, Det(⌃) > 0),
la loi normale Np(µ,⌃) admet une densité f par rapport à la mesure de
Lebesgue dans Rp, donnée par
f (t) =1
(2⇡)p/2p
Det(⌃)exp
⇢�1
2(t � µ)T⌃�1(t � µ)
�, t 2 Rp.
Tabea Rebafka M2 Mise à niveau en statistique Vecteurs gaussiens 10 / 16

Lois dérivées de la loi normale I
Loi chi-deuxSi ⌘ = (⌘1, . . . , ⌘p)T est un vecteur de loi normale standard Np(0, Ip), alors
la loi de la variable aléatoire Y = k⌘k2 =Pp
i=1 ⌘2i est dite la loi chi-deux
à p degrés de liberté, et on écrit Y ⇠ �2p.
La densité de la loi �2p est
f (y) =1
2p/2�(p)yp/2�1e�y/21{y > 0},
où �(·) est la fonction gamma �(x) =R10 ux�1e�udu, x > 0.
La loi �2p est donc la loi Gamma �(p/2, 1/2).
Pour Y ⇠ �2p, on a E[Y ] = p, Var(Y ) = 2p.
Pour p assez grand, �2p ⇡ N (p, 2p).
Tabea Rebafka M2 Mise à niveau en statistique Vecteurs gaussiens 11 / 16

Lois dérivées de la loi normale II
Loi de Fisher-SnedecorSoit U ⇠ �2
p, V ⇠ �2q, deux v.a. indépendantes. La loi de
Fisher-Snedecor à p et q degrés de liberté est la loi de la variable aléatoire
Y =U/p
V /q.
On écrit alors Y ⇠ Fp,q.
La densité de la loi Fp,q est
f (y) =pp/2qq/2
B(p/2, q/2)
yp/2�1
(q + py)p+q21{y > 0}.
où B(·, ·) est la fonction Beta B(r , s) = �(r)�(s)/�(r + s).
Tabea Rebafka M2 Mise à niveau en statistique Vecteurs gaussiens 12 / 16

Lois dérivées de la loi normale III
On peut montrer que cette densité converge vers une densité de type
�2p quand q ! 1.
Si Y ⇠ Fp,q, alors 1/Y ⇠ Fq,p.
Tabea Rebafka M2 Mise à niveau en statistique Vecteurs gaussiens 13 / 16

Lois dérivées de la loi normale IV
Loi de StudentSoit ⌘ ⇠ N (0, 1), ⇠ ⇠ �2
q deux v.a. indépendantes. La loi de Student à qdegrés de liberté est celle de la variable aléatoire
Y =⌘p⇠/q
.
On écrit alors Y ⇠ tq.
La densité de la loi tq est
f (y) =1
pqB(1/2, q/2)
(1 + y2/q)�(q+1)/2, y 2 R.
La loi de Student est symétrique.
Tabea Rebafka M2 Mise à niveau en statistique Vecteurs gaussiens 14 / 16

Lois dérivées de la loi normale V
Pour q = 1, la loi de Student t1 est la loi de Cauchy.
Si Y ⇠ tq, alors Y 2suit la loi F1,q.
Soit Yq ⇠ tq pour q = 1, 2, . . . . Alors YqL�! N (0, 1) quand q ! 1.
Les queues de tq sont plus lourdes que celles de la loi normale
standard.
Tabea Rebafka M2 Mise à niveau en statistique Vecteurs gaussiens 15 / 16

Théorème de Cochran I
Théorème de CochranSoit Y ⇠ Np(µ,�2In). Soient V1, . . . ,VJ des sous-espaces vectoriels
orthogonaux de Rn(i.e. 8j 6= k 8v 2 Vj\{0}, 8w 2 Vk\{0} on a
vTw = 0). Notons Pj le projecteur orthogonal sur Rndans Vj . Alors,
(i) PjY ⇠ Nn(Pjµ,�2Pj), j = 1, . . . , J,
(ii) les vecteurs aléatoires PjY , j = 1, . . . , J, sont mutuellement
indépendants,
(iii) Avec Nj = dim(Vj) = rangPj ,
kPj(Y � µ)k2
�2 ⇠ �2Nj, j = 1, . . . , J.
Tabea Rebafka M2 Mise à niveau en statistique Vecteurs gaussiens 16 / 16

Cours de mise à niveau en statistique mathématique
Chapitre 9: Modèle linéaire gaussien
Tabea Rebafka
Septembre 2018
M2 de statistique
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 1 / 46

Plan
1 Intervalles de confiance et intervalles de prédiction
2 Tests de significativité
3 Test entre modèles emboîtés
4 Analyse de la variance
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 2 / 46

Estimation dans le modèle linéaire gaussien I
Modèle linéaire gaussienLe modèle de régression linéaire Y = X� + " est dit modèle linéairegaussien si " est un vecteur gaussien de loi Nn(0,�2
In) avec �2 > 0inconnu.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 3 / 46

Estimation dans le modèle linéaire gaussien II
PropositionSoit Y = X� + " avec " ⇠ Nn(0,�2
In). L’estimateur par la méthode desmoindres carrés de � coïncide avec l’estimateur du maximum devraisemblance du paramètre �.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 4 / 46

Estimation dans le modèle linéaire gaussien III
ThéorèmeSoit Y = X� + " avec " ⇠ Nn(0,�2
In) et XTX > 0. Alors, l’estimateurdes moindres carrés � vérifie
(i) � ⇠ Np(�,�2(XTX)�1) ,(ii) � ?? �2 := 1
n�pkY � X�k,
(iii) n�p�2 �2 ⇠ �2
n�p.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 5 / 46

Intervalles de confiance et intervalles de prédiction I
Dans le reste du chapitre, nous considérons le modèle linéaire gaussienY = X� + " avec " ⇠ Nn(0,�2
In), et nous supposons que XTX > 0.
Dans le modèle linéaire, la fonction de régression est
x 2 Rp 7! xT�.
Un estimateur sans biais de cette fonction est donné par
x 2 Rp 7! xT �,
où � désigne l’estimateur des moindres carrés de �.Afin de quantifier l’incertitude de cette estimation, on peut s’intéresserà des intervalles de confiance.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 6 / 46

Intervalles de confiance et intervalles de prédiction II
PropositionSoit x0 2 Rp fixé. Un intervalle de confiance de niveau 1 � ↵ pour xT0 � estdonné par h
xT0 � � �pv0t
1�↵/2n�p , xT0 � + �
pv0t
1�↵/2n�p
i,
où v0 = xT0 (XTX)�1x0.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 7 / 46

Intervalles de confiance et intervalles de prédiction III
Une question différente, et plus importante en pratique, est celle de laprédiction d’une nouvelle observation Y0.
Soit x0 2 Rp fixé (et connu). Notons Y0 = xT0 � + "0 avec"0 ⇠ N (0,�2) et "0 ?? " = ("1, . . . , "n)T .Y0 n’est pas observé (et "0 non plus).Il est naturel d’utiliser comme valeur prédite en x0 ou commeprédiction la valeur de la fonction de régression ajustée aux donnéesen x0, à savoir
Y0 = xT0 �.
Pour quantifier l’incertitude de cette prédiction, on peut calculer unintervalle de prédiction Ipréd de niveau 1 � ↵, i.e.
P(Y0 2 Ipréd) � 1 � ↵.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 8 / 46

Intervalles de confiance et intervalles de prédiction IV
PropositionSoit x0 2 Rp fixé. Un intervalle de prédiction de niveau 1 � ↵ en x0 estdonné par
hxT0 � � �
pv0 + 1t1�↵/2
n�p , xT0 � + �pv0 + 1t1�↵/2
n�p
i,
où v0 = xT0 (XTX)�1x0.
L’intervalle de prédiction est plus large que l’intervalle de confiance pourxT0 �, parce qu’en plus de l’incertitude de l’estimateur xT0 �, il faut tenircompte de la variance de Y0 (i.e. de "0).
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 9 / 46

Test de significativité d’un coefficient I
Lorsque la variable explicative Xk explique effectivement (une partiede) la réponse Y dans le modèle linéaire Y = X� + ", le coefficient �kest non nul.En revanche, si la réponse Y ne dépend pas du tout de la valeur de lavariable explicative Xk , alors �k = 0.Ainsi, pour tester la significativité de la variable Xk , on teste leshypothèses
H0 : �k = 0 contre H1 : �k 6= 0.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 10 / 46

Test de significativité d’un coefficient II
Test de significativité d’un coefficientSoit k 2 {1, . . . , p} fixé. Dans le modèle linéaire gaussien un test de niveauexactement ↵ est donné par la région de rejet
Rk↵ =
n0 /2
h�k � �
pvkt
1�↵2
n�p , �k + �pvkt
1�↵2
n�p
io,
où vk =⇣�
XTX��1
⌘
kk.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 11 / 46

Tests de significativité de plusieurs coefficients I
Le test précédent s’applique à une variable explicative et permetéventuellement la suppression d’une variable.Or, on peut s’interroger sur la pertinence de tout un groupe devariables.Pour faciliter les notations, on va dire qu’on se demande si le modèleavec seulement les p0 premières variables, notamment X1, . . . ,Xp0 , estsuffisant et si on peut supprimer toutes les autres variables.En termes d’hypothèses de test, cela se traduit par
H0 : �p0+1 = · · · = �p = 0contre H1 : 9k 2 {p0, . . . , p} : �k 6= 0.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 12 / 46

Tests de significativité de plusieurs coefficients II
On peut utiliser le test Rk↵ précédent pour k = p0, . . . , p.
Procédure de BonferroniDans le modèle linéaire gaussien, un test de niveau ↵ est obtenu par
R⇤ =p[
k=p0+1
Rk↵
p�p0.
La correction de Bonferroni est aussi appliquée dans d’autres contextesoù il est question de combiner plusieurs tests individuels afin d’effectuer unseul test.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 13 / 46

Tests de significativité de plusieurs coefficients III
Une approche différente consiste à chercher une statistique de test quicompare directement deux modèles.Notons X0 = [X1, . . . ,Xp0 ] 2 Rn⇥p0 etX1 = [Xp0+1, . . . ,Xp] 2 Rn⇥(p�p0) deux sous-matrices de X telles queX = [X0,X1].On réécrit les hypothèses de test :
H0 : Y = X0�0 + " avec �0 2 Rp0
contre H1 : Y = X� + " avec � 2 Rp.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 14 / 46

Tests de significativité de plusieurs coefficients IVLa statistique de test du test de Fisher est donnée par
F =1
p�p0kY � Y0k2
�2 , où �2 =1
n � pkY � Y k2.
Sous H0, 1p�p0
kY � Y0k2 est un estimateur sans biais de �2.
Sous H1, 1p�p0
kY � Y0k2 a tendance à prendre des valeurs plusgrandes.
ThéorèmeSous H0, la statistique de test F est de loi de Fisher à p � p0 et n � p
degrés de liberté. Ainsi
F ⇠ F (p � p0, n � p).
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 15 / 46

Tests de significativité de plusieurs coefficients V
Test de FisherUn test de niveau exactement ↵, appelé test de Fisher, est donné par larégion de rejet
R↵ = {F > f1�↵(p � p0, n � p)} ,
où f�(m, n) dénote le quantile d’ordre � de la loi de Fisher F (m, n).
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 16 / 46

Test entre modèles emboîtés I
Le test de Fisher est un cas particulier du test entre modèles emboîtés.Soient Y ⇠ Nn(µ,�2
I ) un vecteur gaussien et M0 et M1 dessous-espaces vectoriels de Rn tels que M0 ⇢ M1.On veut tester les hypothèses
H0 : E[Y] = µ 2 M0 contre H1 : E[Y] = µ 2 M1.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 17 / 46

Test entre modèles emboîtés II
Notons PM la projection orthogonale dans Rn sur M.Définissons la statistique
F =dim(M?
1 )kPM1Y � PM0Yk2
(dim(M1)� dim(M0))kPM?1Yk2 .
PropositionSous H0,
F ⇠ F (dim(M1)� dim(M0), dim(M?1 )) pour tout µ 2 M0.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 18 / 46

Test entre modèles emboîtés III
Test entre modèles emboîtésUn test de niveau exactement ↵ est donné par la région critique
R =nF > f
1�↵dim(M1)�dim(M0),dim(M?
1 )
o.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 19 / 46

Analyse de la variance à un facteur I
L’analyse de la variance permet d’analyser l’impact d’une variablequalitative (ou catégorielle) sur la réponse.On observe I échantillons
X1,1, . . . ,X1,n1 ⇠ N (µ1,�2)
...
XI ,1, . . . ,XI ,nI ⇠ N (µI ,�2),
avec µi 2 R, i = 1, . . . , I , �2 > 0 et n1, . . . , nI les différentes taillesd’échantillon.On veut tester les hypothèses
H0 : µ1 = · · · = µI contre H1 : 9i , j tels que µi 6= µj .
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 20 / 46

Analyse de la variance à un facteur II
Écriture sous forme de modèle linéaire gaussienLe modèle s’écrit sous la forme X = Aµ+ " avec
X =
0
BBBBBBBBBBB@
X11...
X1n1
X21......
XInI
1
CCCCCCCCCCCA
2 Rn où n =IX
i=1
ni , µ =
0
B@µ1...µI
1
CA 2 RI ,
" ⇠ Nn(0,�2In),
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 21 / 46

Analyse de la variance à un facteur IIIÉcriture sous forme de modèle linéaire gaussien
A =
0
BBBBBBBBBBBBBBBBBB@
1 0 . . . 0...
......
1 0...
0 1. . .
......
......
... 1 0
... 0. . .
...... 1
......
...0 0 1
1
CCCCCCCCCCCCCCCCCCA
=
0
B@
1n1 01n2
. . .0 1nI
1
CA 2 Rn⇥I ,
où 1m = (1, . . . , 1)T 2 Rm.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 22 / 46

Analyse de la variance à un facteur IV
Estimation par moindres carrésL’EMC de µ est unique et donné par
µ = (ATA)�1ATX =
0
B@
1n1
Pn1j=1 X1j...
1nI
PnIj=1 XIj
1
CA =
0
B@X1·...XI ·
1
CA .
L’estimateur sans biais de �2 est
�2 =1
n � IkX � Aµk2 =
1n � I
IX
i=1
niX
j=1
(Xi ,j � Xi ·)2.
On a µ ?? �2.(n � I )�2/�2 ⇠ �2
n�I .
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 23 / 46

Analyse de la variance à un facteur V
Pour utiliser le test entre modèles emboîtés, on réécrit les hypothèsesavec des sous-espaces vectoriels.Notons M0 = Vect(1n) et D =
�A↵,↵ 2 RI
.
On considère alors les hypothèses
H0 : E[X] 2 M0 contre H1 : E[X] 2 D.
D’après le théorème, la statistique
F =dim(D?)kPDX � PM0Xk2
(dim(D)� dim(M0))kPD?Xk2
suit une loi de Fisher sous H0.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 24 / 46

Analyse de la variance à un facteur VI
ThéorèmeNotons
F =(n � I )
PIi=1 ni (Xi · � X··)2
(I � 1)PI
i=1Pni
j=1(Xij � Xi ·)2.
Un test de niveau ↵ pour tester les hypothèses sur l’absence d’effet dû aufacteur est donné par la région de rejet
R =nF > f
1�↵I�1,n�I
o.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 25 / 46

Analyse de la variance à un facteur VII
Troisième écriture du modèleNotons µi = m + ↵i , i = 1, . . . , I , avec m,↵i 2 R.Avec ↵ = (↵1, . . . ,↵I )T , on obtient
X = 1nm + A↵+ " = ~A⇣m
↵
⌘+ ",
où ~A = [1n,A] 2 Rn⇥(I+1).~A n’est pas de rang plein (rang(~A) = I ). Donc, l’EMC de
�m↵
�n’est
pas unique.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 26 / 46

Analyse de la variance à un facteur VIII
Troisième écriture du modèlePour rendre l’EMC unique, on introduit la contrainte
PIi=1 ni↵i = 0.
La contrainte est équivalente à
m =1n
IX
i=1
niµi , ↵i = µi �m, i = 1, . . . , I .
Ainsi, m est la moyenne globale de toute la population et ↵i ladéviation de la moyenne du i-ème groupe de cette moyenne globale.Les hypothèses de test s’écrivent comme
H0 : ↵i = 0, i = 1, . . . , I contre H1 : 9i : ↵i 6= 0.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 27 / 46

Analyse de la variance à un facteur IX
Décomposition de l’espace des observationsOn a
Rn = M0 �MA � D?,
avecM0 = Vect(1n) correspond à l’effet moyen,MA = {A↵,↵ 2 RI ,
PIi=1 ni↵i = 0} correspond à l’effet dû au
facteur etl’espace des résidus D
? avec D = M0 �MA =�A↵,↵ 2 RI
.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 28 / 46

Analyse de la variance à un facteur X
Équation et tableau d’analyse de la varianceSommes des carrés des écarts Degrés de liberté Carrés moyens
SCEtotal = kPM?0
Xk2 =P
i,j (Xij � X··)2 dim(M?0 ) = n � 1 CMEtotal =
SCEtotaln�1
SCEfacteur = kPMAXk2 =
Pi ni (Xi· � X··)2 dim(MA) = I � 1 CMEfacteur =
SCEfacteurI�1
SCEresidu = kPD?Xk2 =P
i,j (Xij � Xi·)2 dim(D?) = n � I CMEresidu =SCEresidu
n�I
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 29 / 46

Analyse de la variance à un facteur XI
Équation de l’analyse de la varianceDans le modèle de l’analyse de la variance à un facteur, les sommes descarrés des écarts vérifient
SCEtotal = SCEfacteur + SCEresidu.
SCEtotal : la variabilité totale dans les données.SCEfacteur : la variabilité due au facteur reflétant l’influence de lastructure en groupes des individus. Elle mesure la déviation desmoyennes par groupe de la moyenne globale.SCEresidu : la variabilité résiduelle, non expliquée par les groupes et quiest purement stochastique.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 30 / 46

Analyse de la variance à deux facteurs I
Dans des applications, on peut s’intéresser à des modèles avec plusd’un facteur.Exemple : la durée de vie des piles et les facteurs qui l’influencentpotentiellement. Les facteurs considérés sont le type de matériau de lapile et la température à laquelle la pile a été utilisée. Nous disposonsd’un jeu de données des durées de vie de 36 piles en fonction de troistype de matériau (1, 2 ou 3) et de trois niveaux de température : bas(-10�C), moyen (20�C) ou élevé (45�C).
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 31 / 46
Analyse de la variance à deux facteurs II
Table: Durées de vie de 36 piles en fonction de la température et du type dematériau. Source : Design and Analysis of Experiments, D. C. Montgomery, 2001.
TempératureMatériau basse (-10�C) moyenne (20�C) élevée (45�C)
1 130 155 74 180 34 40 80 75 20 70 82 582 150 188 159 126 136 122 106 115 25 70 58 453 138 110 168 160 174 120 150 139 96 104 82 60
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 32 / 46

Analyse de la variance à deux facteurs IIIOn considère des variables aléatoires Xijk indépendantes, de loinormale
Xijk ⇠ N (µij ,�2), i = 1, . . . , I , j = 1, . . . , J, k = 1, . . . ,K ,
où K est le nombre d’observations pour chacun des IJ niveaux de(A,B).On peut réécrire le modèle sous la forme
Xijk = m + ↵i + �j + �ij + "ijk , i = 1, . . . , I , j = 1, . . . , J, k = 1, . . . ,K ,
où les erreurs "ijk sont i.i.d. de loi N (0,�2).Pour obtenir l’identifiabilité du modèle on introduit les contraintes
IX
i=1
↵i = 0,JX
j=1
�j = 0,IX
i=1
�ij = 0, 8j ,JX
j=1
�ij = 0, 8i .
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 33 / 46

Analyse de la variance à deux facteurs IV
m est la moyenne globale de toutes les observations, c’est-à-direl’effet moyen et vérifie m = 1
IJ
Pi ,j µij .
Les ↵i décrivent l’effet principal dû au facteur A.
Les �j sont associés à l’effet principal dû au facteur B .
L’effet d’interaction entre les deux facteurs est donné par les �ij .
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 34 / 46

Analyse de la variance à deux facteurs V
Hypothèses pour tester l’absence d’effet principal dû au facteur A :
H0 : ↵i = 0 8i contre H1 : 9i : ↵i 6= 0,
Hypothèses pour tester l’absence d’effet principal dû au facteur B :
H0 : �j = 0 8j contre H1 : 9j : �j 6= 0,
Hypothèses pour tester l’absence d’interaction entre les facteurs :
H0 : �ij = 0 8i , j contre H1 : 9i , j : �ij 6= 0.
Pour déduire des tests de niveau ↵ pour tester ces différentes hypothèses,on considère la décomposition en sous-espaces vectoriels de l’espace desobservations Rn.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 35 / 46

Analyse de la variance à deux facteurs VIModèle sous forme de modèle linéaireLe modèle de l’analyse de la variance à deux facteurs s’écrit comme
X = m1n + A↵+ B� + C� + " = [1n,A,B,C]
0
BB@
m
↵��
1
CCA+ ",
avecn = IJK ,X = (X111, . . . ,X11K ,X121, . . . ,X12K , . . . ,XIJ1, . . . ,XIJK )T 2 Rn,↵ = (↵1, . . . ,↵I )T 2 RI ,� = (�1, . . . ,�J)T 2 RJ ,� = (�11, . . . , �1J , . . . , �I1, . . . , �IJ)T 2 RIJ ," = ("111, . . . , "IJK )T ⇠ Nn(0,�2
In),
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 36 / 46

Analyse de la variance à deux facteurs VII
Modèle sous forme de modèle linéaire
A =
0
BBB@
1JK 01JK
. . .0 1JK
1
CCCA2 Rn⇥I , B =
0
BBBBBBBBBBBBBBBB@
1K 01K
. . .0 1K
...1K 0
1K
. . .0 1K
1
CCCCCCCCCCCCCCCCA
2 Rn⇥J ,
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 37 / 46

Analyse de la variance à deux facteurs VIII
Modèle sous forme de modèle linéaire
C =
0
BBB@
1K 01K
. . .0 1K
1
CCCA2 Rn⇥IJ .
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 38 / 46

Analyse de la variance à deux facteurs IX
Décomposition de l’espace et projections orthogonalesOn a
Rn = M0 �MA �MB �MC � D?,
avec M0 = vect(1n), MA =
(A↵,↵ 2 RI ,
IX
i=1
↵i = 0
),
MB =
8<
:B�,� 2 RJ ,JX
j=1
�j = 0
9=
; ,
MC =
8<
:C�,� 2 RIJ ,IX
i=1
�ij =JX
j=1
�ij = 0 8i , j
9=
; ,
D = M0 �MA �MB �MC .
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 39 / 46

Analyse de la variance à deux facteurs X
Réécriture des hypothèsesHypothèses pour tester l’absence d’effet principal dû au facteur A :
H0 : E[X] 2 M0 �MB �MC contre H1 : E[X] 2 D,
Hypothèses pour tester l’absence d’effet principal dû au facteur B :
H0 : E[X] 2 M0 �MA �MC contre H1 : E[X] 2 D,
Hypothèses pour tester l’absence d’interaction entre les facteurs :
H0 : E[X] 2 M0 �MA �MB contre H1 : E[X] 2 D.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 40 / 46

Analyse de la variance à deux facteurs XI
Les sommes des carrés des écartsSCEtotal = kPM?
0Xk2 (variabilité totale dans les données),
SCEA = kPMAXk2 (variabilité due au facteur A),SCEB = kPMBXk2 (variabilité due au facteur B),SCEinter = kPMCXk2 (variabilité due aux interactions entre lesfacteurs),SCEresidu = kPD?Xk2 (variabilité résiduelle non expliquée par lemodèle).
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 41 / 46

Analyse de la variance à deux facteurs XII
Équation d’analyse de la varianceDans le modèle de l’analyse de la variance à deux facteurs,
SCEtotal = SCEA + SCEB + SCEinter + SCEresidu.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 42 / 46

Analyse de la variance à deux facteurs XIII
Tableau d’analyse de la varianceSommes des carrés des écarts Degrés de liberté Carrés moyensSCEtotal =
Pi,j,k (Xijk � X···)2 dim(M?
0 ) = n � 1 CMEtotal =SCEtotal
n�1SCEA = JK
PIi=1(Xi·· � X···)2 dim(MA) = I � 1 CMEA = SCEA
I�1SCEB = IK
PJj=1(X·j· � X···)2 dim(MB) = J � 1 CMEB = SCEB
J�1SCEinter = dim(MC ) = (I � 1)(J � 1) CMEinter =
SCEinter(I�1)(J�1)
= KP
i,j (Xij· � Xi·· � X·j· + X···)2
SCEresidu =P
i,j,k (Xijk � Xij·)2 dim(D?) = IJ(K � 1) CMEresidu =SCEresiduIJ(K�1)
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 43 / 46

Analyse de la variance à deux facteurs XIV
Test pour l’absence d’effet principal dû au facteur AUn test de niveau ↵ pour l’absence d’effet principal dû au facteur A estdonné par
RA =nFA > f
1�↵I�1,IJ(K�1)
o,
où
FA =dim(D?)kPDX � PM0�MB�MCXk2
(dim(D)� dim(M0 �MB �MC ))kPD?Xk2
=CMEA
CMEresidu
⇠ F (I � 1, IJ(K � 1)) sous H0.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 44 / 46

Analyse de la variance à deux facteurs XV
Test pour l’absence d’effet principal dû au facteur BUn test de niveau ↵ pour l’absence d’effet principal dû au facteur B estdonné par
RB =nFB > f
1�↵J�1,IJ(K�1)
o,
où
FB =dim(D?)kPDX � PM0�MA�MCXk2
(dim(D)� dim(M0 �MA �MC ))kPD?Xk2
=CMEB
CMEresidu
⇠ F (J � 1, IJ(K � 1)) sous H0.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 45 / 46

Analyse de la variance à deux facteurs XVI
Test pour l’absence d’interaction entre les facteursUn test de niveau ↵ pour l’absence d’interaction entre les facteurs estdonné par
Rinter =nFinter > f
1�↵(I�1)(J�1),IJ(K�1)
o,
où
Finter =dim(D?)kPDX � PM0�MA�MBXk2
(dim(D)� dim(M0 �MA �MB))kPD?Xk2
=CMEinter
CMEresidu
⇠ F ((I � 1)(J � 1), IJ(K � 1)) sous H0.
Tabea Rebafka M2 Mise à niveau en statistique Modèle linéaire gaussien 46 / 46

![Nouvelles Acquisitions 2017 - bib.ensmm-annaba.dz Acquisitions_2017 [1].pdf · 519.5 Statistique mathématique 628.4 Technique des ... Des exercices types analysés et commentés](https://img.pdfslide.fr/doc/110x75/5b81604b7f8b9ae47b8c2c42/nouvelles-acquisitions-2017-bibensmm-acquisitions2017-1pdf-5195-statistique.jpg)



























