Embed Size (px)
DESCRIPTION
Étude de marché 53-113-03. COURS 5 Les tableaux croisés, le chi-carré et la corrélation. La nature de la donnée en recherche commerciale. Catégorique Nominale Sexe, langue, marque favorite, etc. Ordinale Attribut préféré, catégorie d’âge, etc. Continue Catégorique - PowerPoint PPT Presentation
Citation preview

Étude de marché53-113-03
COURS 5Les tableaux croisés, le chi-carré
et la corrélation

La nature de la donnée en recherche commerciale
• Catégorique– Nominale
• Sexe, langue, marque favorite, etc.
– Ordinale• Attribut préféré, catégorie d’âge, etc.
• Continue– Catégorique
• Échelles likert ou autres
– Ratio• Salaire, âge, consommation etc

Le croisement entre deux variables (concomitance)
2 variables 2 ou plus
Catégoriques Chi-carré 1-Analyse des correspondance2-Probit
Continues Correlations Régressions
Mixte t-Student ANOVAAnalyse de variance

Les tableaux croisés permettent• De synthétiser l ’information• De faire le lien entre deux variables• De tester l ’indépendance ou la
dépendance entre deux variables• Dans ce dernier cas le test utilisé est celui
du ÷ 2 (chi-carré)

Pour tout tableau croisé il est tentant de trouver des liens entre les deux
variables en cause
Exemple: Si je prend un échantillon de 100 personnes, 50 hommes et 50 femmes et que je
leurs demande s ’ils écoutent l ’émission Fortier . Je trouve les
résultats suivants

Hommes Femmes Total
Écoute 50 0 50
N’écoutepas
0 50 50
Total 50 50 100
Dans cet exemple il semble y avoir un lien entre le sexe et la propension à regarder
Fortier. Le deux variables seront donc dépendantes l ’une de l ’autre
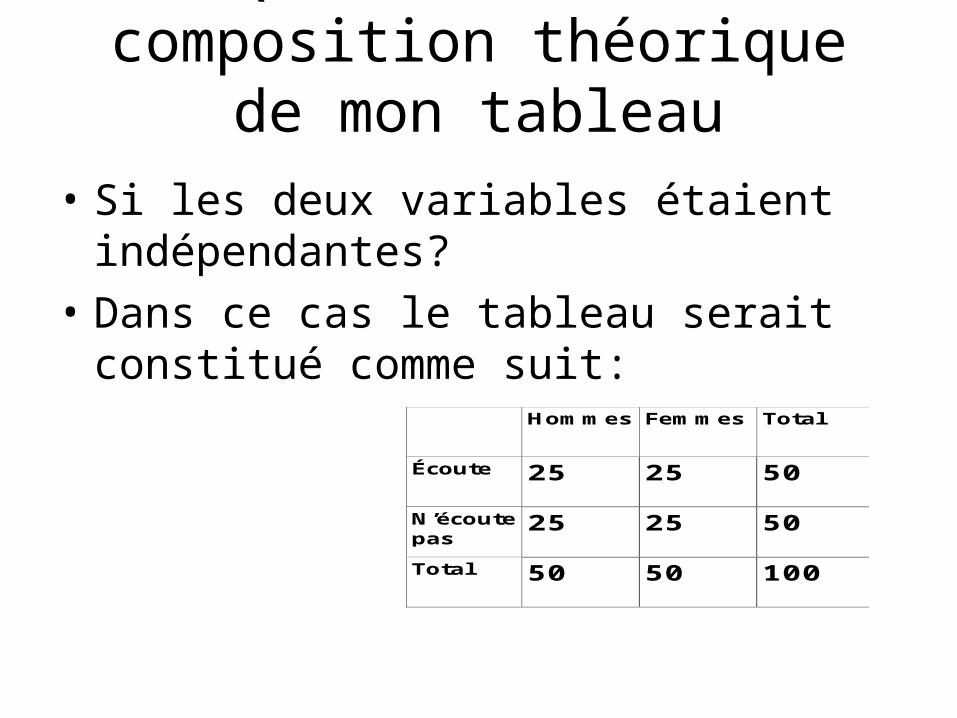
Quel serait la composition théorique de mon tableau
• Si les deux variables étaient indépendantes?
• Dans ce cas le tableau serait constitué comme suit:
Hommes Femmes Total
Écoute 25 25 50
N’écoutepas
25 25 50
Total 50 50 100

• Ce dernier tableau est composé de fréquences théoriques qui sont celles que l ’on aurait si les deux variables étaient parfaitement indépendantes
• Les données, pour chaque cellule, sont trouvées comme suit:

Cellule ij=
((total rangée i X total colonne j)/total)

Tester l ’indépendance entre deux variables revient à tester la différence
entre les cellules observées et les valeurs théoriques. Comme ces dernières sont celles qui seraient obtenues si les deux
variables étaient indépendantes on procédera par calcul de différences entre
les valeurs théorique et les valeurs observées. Plus la somme de ces
différences se rapproche de 0, plus les 2 variables seront dites indépendantes

Le calcul sera alors donné parla formule suivante
Chi-carré = S[(f obs.- f théo)2/ fthéo ]
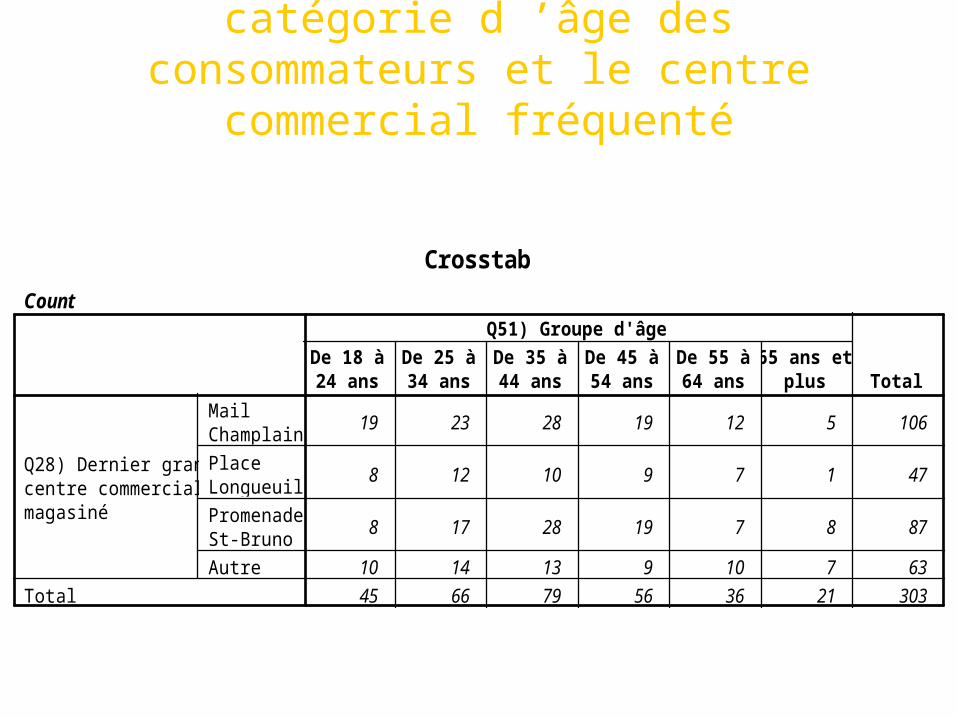
Count
19 23 28 19 12 5 106
8 12 10 9 7 1 47
8 17 28 19 7 8 87
10 14 13 9 10 7 6345 66 79 56 36 21 303
MailChamplainPlaceLongueuilPromenadeSt-BrunoAutre
Q28) Dernier grandcentre commercial amagasiné
Total
De 18 à24 ans
De 25 à34 ans
De 35 à44 ans
De 45 à54 ans
De 55 à64 ans
65 ans etplus
Q51) Groupe d'âge
Total
Crosstab
Liens observés entre la catégorie d ’âge des consommateurs et le centre commercial
fréquenté
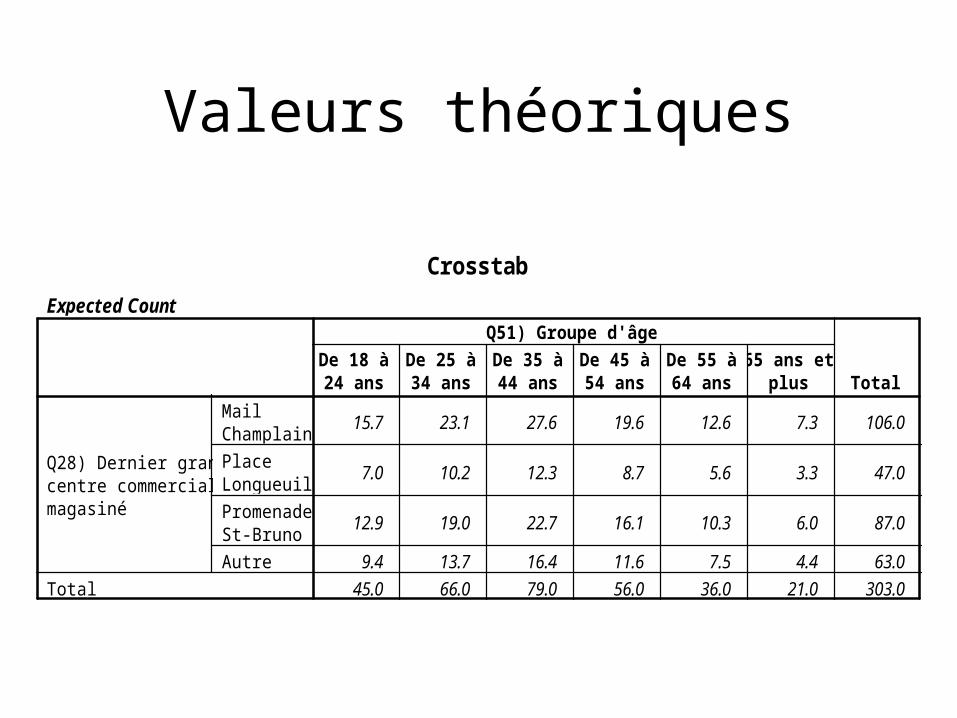
Expected Count
15.7 23.1 27.6 19.6 12.6 7.3 106.0
7.0 10.2 12.3 8.7 5.6 3.3 47.0
12.9 19.0 22.7 16.1 10.3 6.0 87.0
9.4 13.7 16.4 11.6 7.5 4.4 63.045.0 66.0 79.0 56.0 36.0 21.0 303.0
MailChamplainPlaceLongueuilPromenadeSt-BrunoAutre
Q28) Dernier grandcentre commercial amagasiné
Total
De 18 à24 ans
De 25 à34 ans
De 35 à44 ans
De 45 à54 ans
De 55 à64 ans
65 ans etplus
Q51) Groupe d'âge
Total
Crosstab
Valeurs théoriques
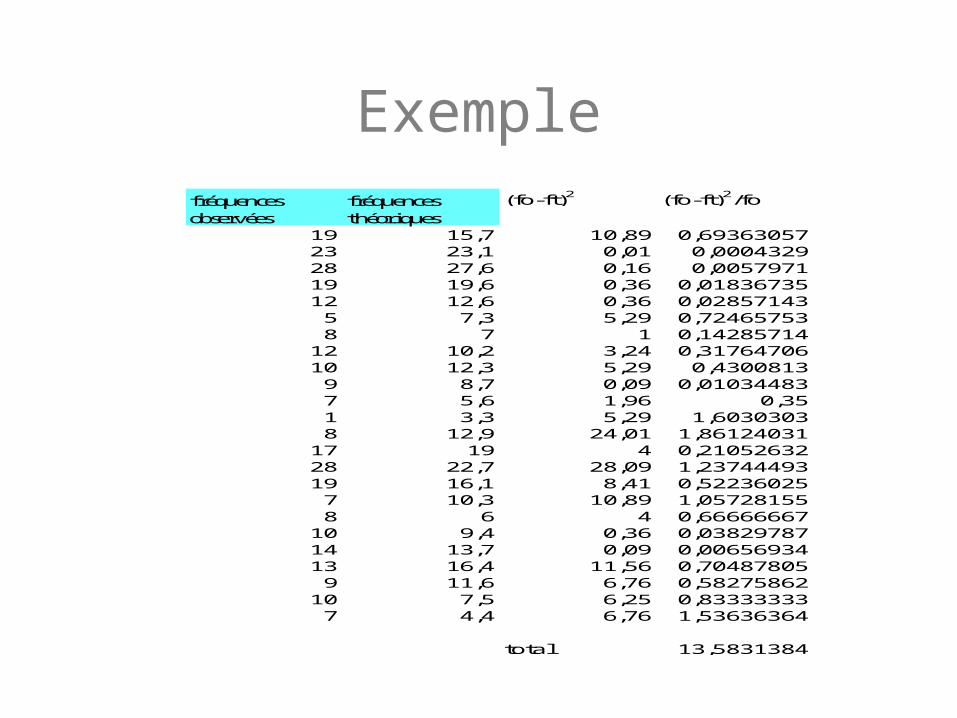
Exemplefréquences fréquences (fo-ft)2 (fo-ft)2/foobservées théoriques
19 15,7 10,89 0,6936305723 23,1 0,01 0,000432928 27,6 0,16 0,005797119 19,6 0,36 0,0183673512 12,6 0,36 0,028571435 7,3 5,29 0,724657538 7 1 0,14285714
12 10,2 3,24 0,3176470610 12,3 5,29 0,43008139 8,7 0,09 0,010344837 5,6 1,96 0,351 3,3 5,29 1,60303038 12,9 24,01 1,86124031
17 19 4 0,2105263228 22,7 28,09 1,2374449319 16,1 8,41 0,522360257 10,3 10,89 1,057281558 6 4 0,66666667
10 9,4 0,36 0,0382978714 13,7 0,09 0,0065693413 16,4 11,56 0,704878059 11,6 6,76 0,58275862
10 7,5 6,25 0,833333337 4,4 6,76 1,53636364
total 13,5831384
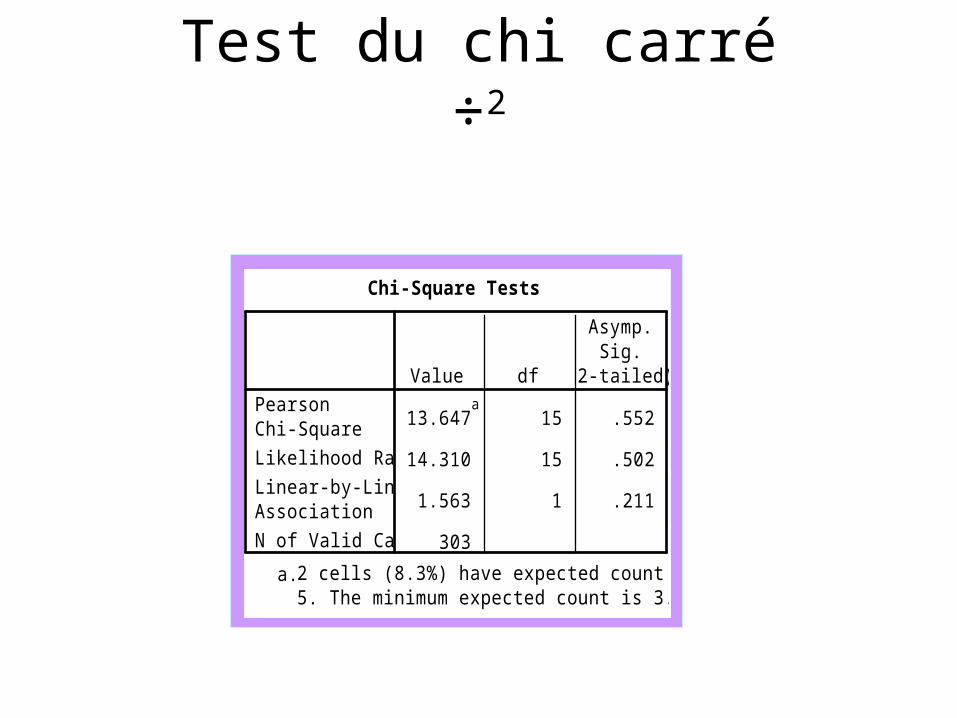
Test du chi carré÷2
13.647a
15 .552
14.310 15 .502
1.563 1 .211
303
PearsonChi-SquareLikelihood RatioLinear-by-LinearAssociationN of Valid Cases
Value df
Asymp.Sig.
(2-tailed)
Chi-Square Tests
2 cells (8.3%) have expected count less than5. The minimum expected count is 3.26.
a.
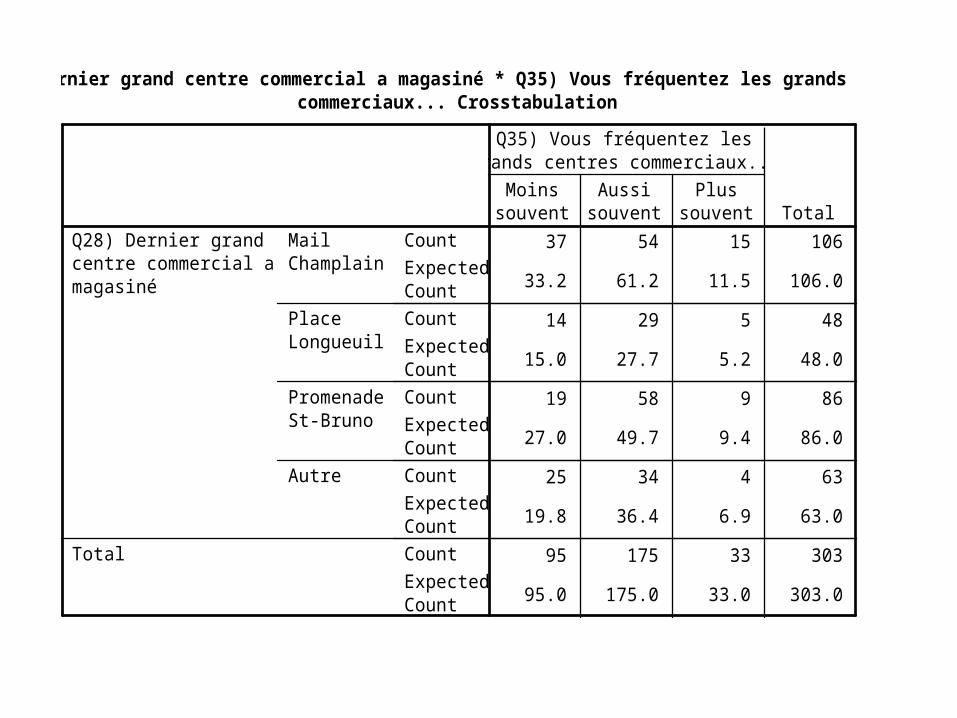
37 54 15 106
33.2 61.2 11.5 106.0
14 29 5 48
15.0 27.7 5.2 48.0
19 58 9 86
27.0 49.7 9.4 86.0
25 34 4 63
19.8 36.4 6.9 63.0
95 175 33 303
95.0 175.0 33.0 303.0
CountExpectedCountCountExpectedCountCountExpectedCountCountExpectedCountCountExpectedCount
MailChamplain
PlaceLongueuil
PromenadeSt-Bruno
Autre
Q28) Dernier grandcentre commercial amagasiné
Total
Moinssouvent
Aussisouvent
Plussouvent
Q35) Vous fréquentez lesgrands centres commerciaux...
Total
Q28) Dernier grand centre commercial a magasiné * Q35) Vous fréquentez les grands centrescommerciaux... Crosstabulation
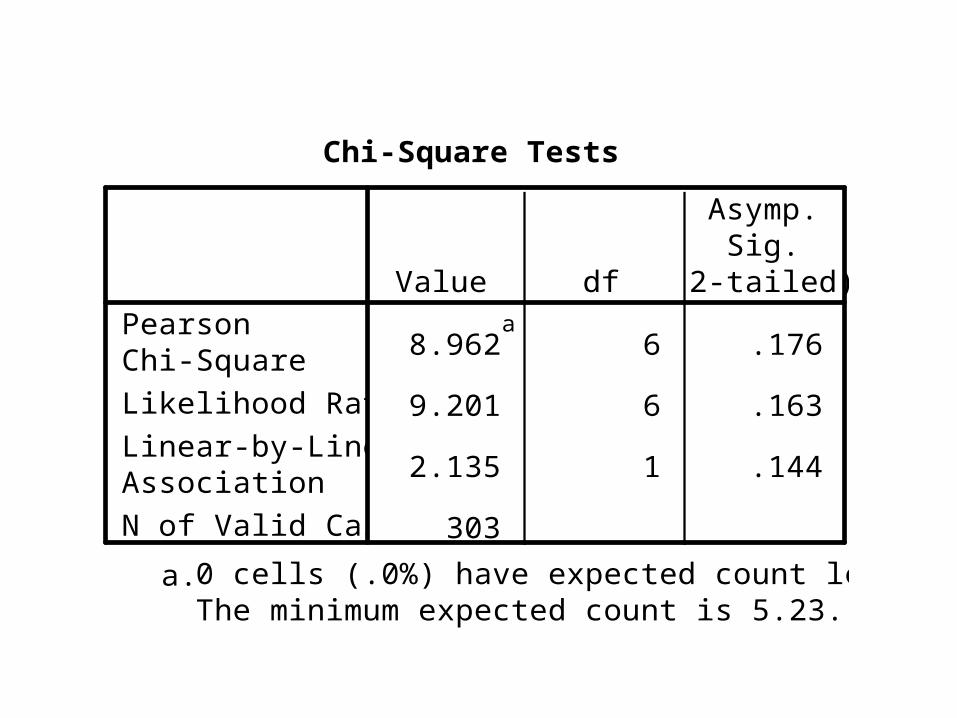
8.962a
6 .176
9.201 6 .163
2.135 1 .144
303
PearsonChi-SquareLikelihood RatioLinear-by-LinearAssociationN of Valid Cases
Value df
Asymp.Sig.
(2-tailed)
Chi-Square Tests
0 cells (.0%) have expected count less than 5.The minimum expected count is 5.23.
a.
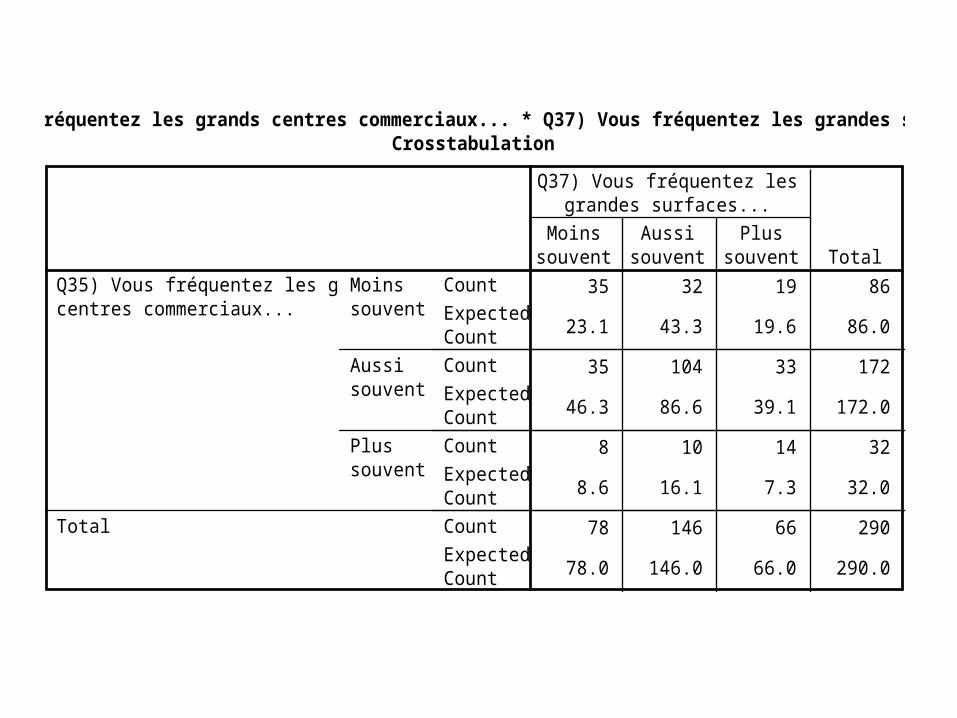
35 32 19 86
23.1 43.3 19.6 86.0
35 104 33 172
46.3 86.6 39.1 172.0
8 10 14 32
8.6 16.1 7.3 32.0
78 146 66 290
78.0 146.0 66.0 290.0
CountExpectedCountCountExpectedCountCountExpectedCountCountExpectedCount
Moinssouvent
Aussisouvent
Plussouvent
Q35) Vous fréquentez les grandscentres commerciaux...
Total
Moinssouvent
Aussisouvent
Plussouvent
Q37) Vous fréquentez lesgrandes surfaces...
Total
Q35) Vous fréquentez les grands centres commerciaux... * Q37) Vous fréquentez les grandes surfaces...Crosstabulation
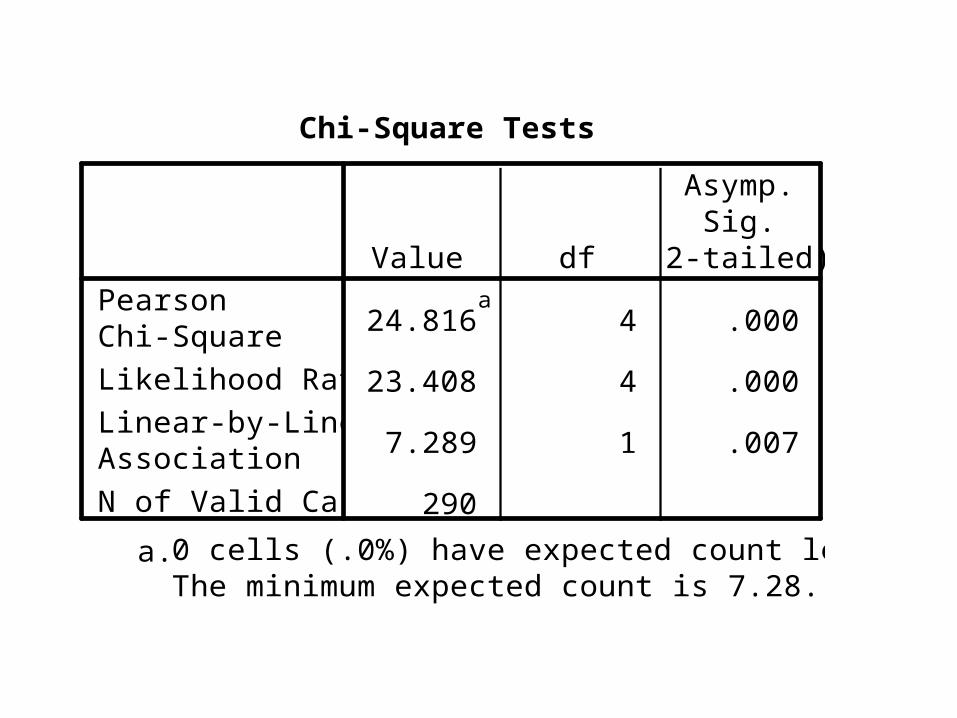
24.816a
4 .000
23.408 4 .000
7.289 1 .007
290
PearsonChi-SquareLikelihood RatioLinear-by-LinearAssociationN of Valid Cases
Value df
Asymp.Sig.
(2-tailed)
Chi-Square Tests
0 cells (.0%) have expected count less than 5.The minimum expected count is 7.28.
a.

Bref rappel sur le t de student• On utilise le t de student afin de tester la
différence entre les moyennes de deux groupes.
• Exemple: consommation hommes= ou ‡ consommation femmes

La corrélation
Sert à tester le lien (dépendance) entre deux variables
continues/quantitative

Dans certains cas le gestionnaire aura besoin de plus d ’information. Afin de se bâtir un tableau de contrôle, il voudra aussi mesurer l ’impact qu ’aura une (ou plusieurs) variable(s) sur une autre. À titre d ’exemple un gestionnaire voudra savoir quel est l ’impact de son investissement publicitaire sur ses ventes. De sa politique de bonus sur la performance de ses employés. C ’est alors qu ’on aura recours à la régression.

Un modèle de régression comporte toujours deux types de variables
• La variable dépendante (Y) qui est généralement constituée par le phénomène que l ’on veut expliquer (ventes, satisfaction, absentéisme etc)
• La ou les variable(s) indépendantes (X; ou X1, X2, X3 etc.) qui, selon le gestionnaire , pourrait(ent) être en mesure d ’expliquer la variation de Y.

• Lorsqu ’un modèle de régression ne comporte qu ’une variable indépendante on dit que c ’est une régression simple qui s ’exprime comme suit
• Y= +x+• Lorsqu ’un modèle comporte plusieurs
variables indépendantes on aura• Y= +1x1+ 2x2 3x3+ 4x4+

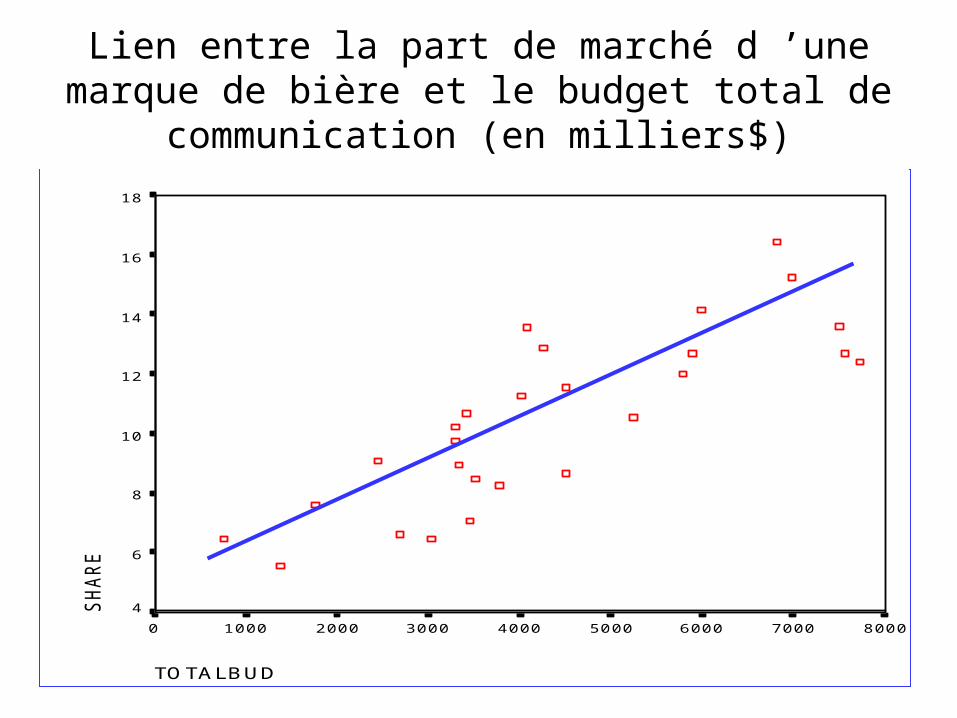
La fonctionY= +x+sera celle qui passera dans un nuage de points liant les Y au
X tout en minimisant la différence entre les Y réels et les Y estimés par la droite de
régression
TOTALBUD
800070006000500040003000200010000
SHAR
E
18
16
14
12
10
8
6
4
Lien entre la part de marché d ’une marque de bière et le budget total de communication (en
milliers$)
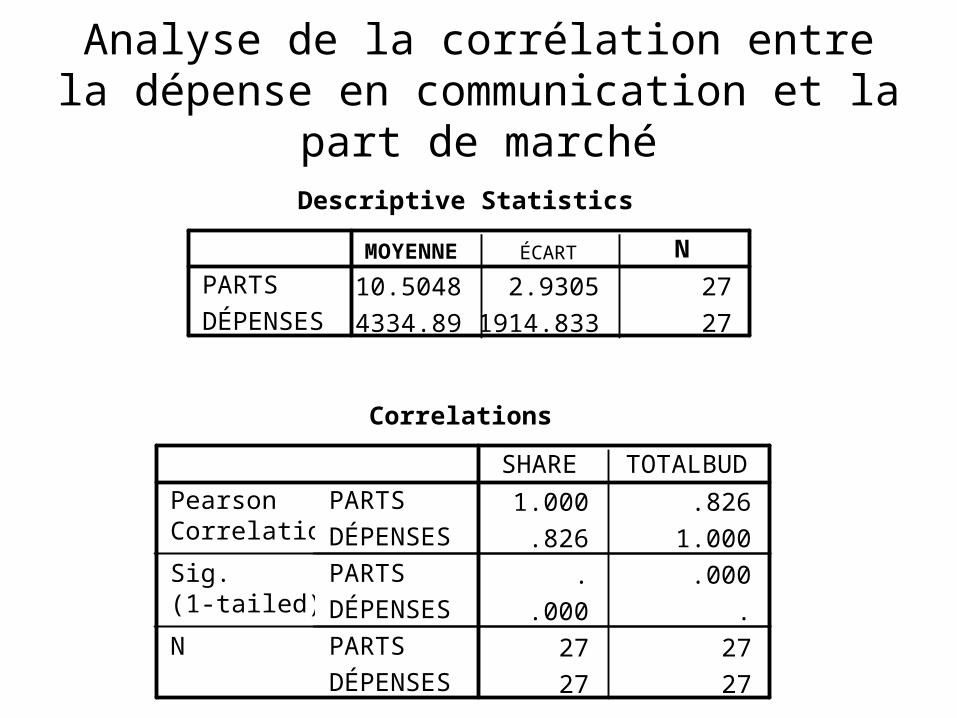
Analyse de la corrélation entre la dépense en communication et la part de marché
10.5048 2.9305 274334.89 1914.833 27
PARTSDÉPENSES
MOYENNE ÉCART N
Descriptive Statistics
1.000 .826.826 1.000
. .000.000 .
27 2727 27
PARTSDÉPENSESPARTSDÉPENSESPARTSDÉPENSES
PearsonCorrelation
Sig.(1-tailed)
N
SHARE TOTALBUD
Correlations
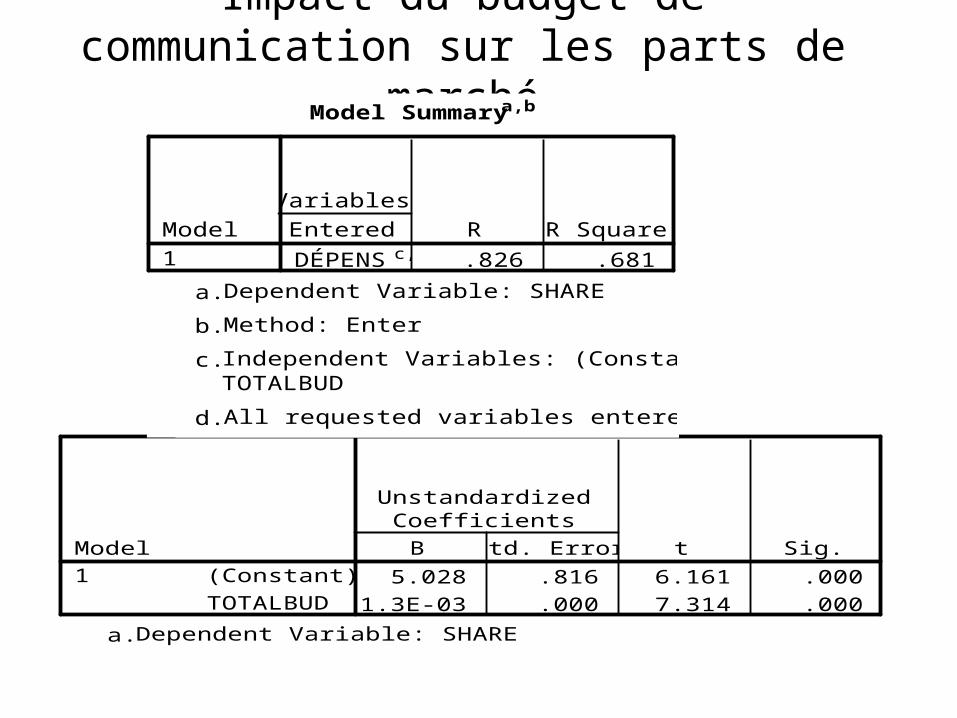
Impact du budget de communication sur les parts de marché
5.028 .816 6.161 .0001.3E-03 .000 7.314 .000
(Constant)TOTALBUD
Model1
B Std. Error
UnstandardizedCoefficients
t Sig.
Coefficientsa
Dependent Variable: SHAREa.
DÉPENSc,d .826 .681Model1
EnteredVariables
R R Square
Model Summarya,b
Dependent Variable: SHAREa.
Method: Enterb.
Independent Variables: (Constant),TOTALBUD
c.
All requested variables entered.d.

Le modèle peut alors s ’exprimer comme suit:
Part de marché (%)=5.028+ .0013(X* milliers
$ en communication)

Autrement dit
• Le modèle prédit une part de marché constante de 5%
• Un accroissement de 1% de P .M. pour chaque 1,000,000$ investit

Impact des trois composantes de la communication sur les parts de marché
10.5048 2.9305 272178.35 975.7836 271001.39 386.6282 271155.15 691.2625 27
SHAREMEDIA$PRODUC$PROMO$
MeanStd.
Deviation N
Descriptive Statistics
1.000 .861** .775**.861** 1.000 .734**.775** .734** 1.000
. .000 .000.000 . .000.000 .000 .
27 27 2727 27 2727 27 27
MEDIA$PRODUC$PROMO$MEDIA$PRODUC$PROMO$MEDIA$PRODUC$PROMO$
PearsonCorrelation
Sig.(2-tailed)
N
MEDIA$ PRODUC$ PROMO$
Correlations
Correlation is significant at the 0.01 level (2-tailed).**.
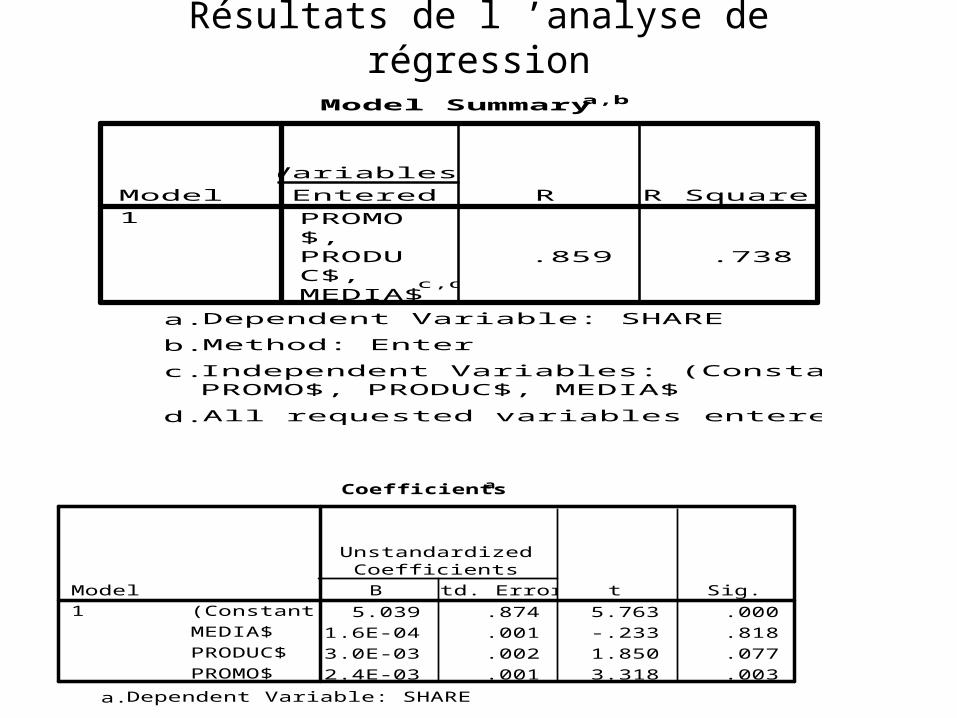
Résultats de l ’analyse de régression
PROMO$,PRODUC$,MEDIA$
c,d
.859 .738
Model1
EnteredVariables
R R Square
Model Summarya,b
Dependent Variable: SHAREa.
Method: Enterb.
Independent Variables: (Constant),PROMO$, PRODUC$, MEDIA$
c.
All requested variables entered.d.
5.039 .874 5.763 .000-1.6E-04 .001 -.233 .8183.0E-03 .002 1.850 .0772.4E-03 .001 3.318 .003
(Constant)MEDIA$PRODUC$PROMO$
Model1
B Std. Error
UnstandardizedCoefficients
t Sig.
Coefficientsa
Dependent Variable: SHAREa.

De une à trois variables
• Le pouvoir explicatif et managerial de trois variables est souvent plus grands que celui d ’une seule
• Mais ce n ’est le cas que si les variables indépendantes ne sont pas corrélées entre elles (D ’où leur nom)
• Autrement le R va augmenter sans que les ne soient significatifs (C ’est le problème dit de la multicollinéarité)

Bref rappel sur le t de student• On utilise le t de student afin de tester la
différence entre les moyennes de deux groupes.
• Exemple: consommation hommes= ou ‡ consommation femmes

Tester cette hypothèse revient à tester s ’il y a un lien entre la
variable sexe(variable catégorique/qualitative) et la
consommation (variable continue/quantitative)

Pour prendre ma décision
• Je puis utiliser un test du t de student qui vise à comparer deux moyennes
• Le test part des hypothèses que– nb magasins hommes=nb femmes– dép. hommes= dépé femmes
• Ceci reviendrait à tester – mag.hommes - mag. Femmes =0– dep.hommes - dep. Femmes = 0

Je chercherai donc à voir
• Si le 0 est inclus dans l ’intervalle de confiance
• OÙ, accessoirement quelle est la probabilité de rejeter les hypothèses (les différences entre hommes et femmes=0) et de me tromper.
• Le tableau suivant nous donne la réponse
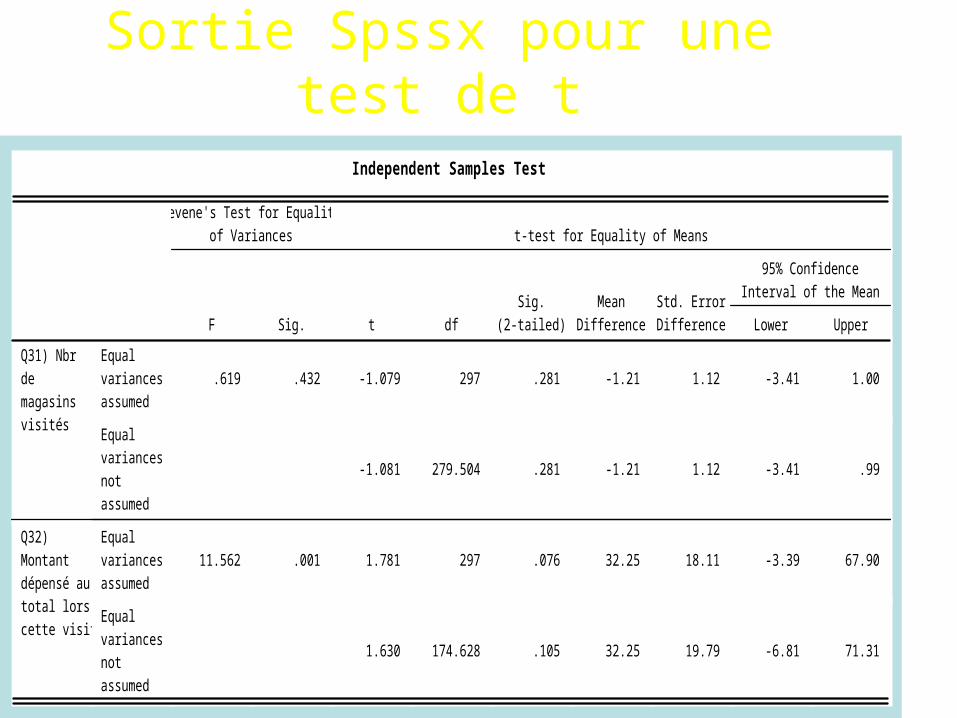
.619 .432 -1.079 297 .281 -1.21 1.12 -3.41 1.00
-1.081 279.504 .281 -1.21 1.12 -3.41 .99
11.562 .001 1.781 297 .076 32.25 18.11 -3.39 67.90
1.630 174.628 .105 32.25 19.79 -6.81 71.31
Equalvariancesassumed
Equalvariancesnotassumed
Equalvariancesassumed
Equalvariancesnotassumed
Q31) Nbrdemagasinsvisités
Q32)Montantdépensé autotal lors decette visite
F Sig.
Levene's Test for Equalityof Variances
t dfSig.
(2-tailed)Mean
DifferenceStd. ErrorDifference Lower Upper
95% ConfidenceInterval of the Mean
t-test for Equality of Means
Independent Samples Test
Sortie Spssx pour une test de t

On peut conclure que
• Je ne puis dire que, de façon statistiquement significative, les femmes visitent plus de magasins que les hommes. L ’intervalle de confiance, de 95%, comprenant le 0.
• Je pourrais cependant dire qu ’à un intervalle de confiance de 72% j ’aurais accepté la différence

On peut conclure que
• Je ne puis dire que, de façon statistiquement significative, les femmes dépensent moins que les hommes. L ’intervalle de confiance, de 95%, comprenant le 0.
• Je pourrais cependant dire qu ’à un intervalle de confiance de 90% j ’aurais accepté la différence
![01 DECEMBRE 2010. CD NR 113 BVA A/T - brainbee.it technews cd 113- page 2 01 decembre 2010. cd nr. 113 ... left/right water regulation valve ... megane ii [2002]](https://img.pdfslide.fr/doc/110x75/5b9d6db509d3f253238c1bd2/01-decembre-2010-cd-nr-113-bva-at-technews-cd-113-page-2-01-decembre-2010.jpg)
![113-113 - [1] Bull. mens. Soc. linn Lyon, 1996, 65 (4) : 113 - 152 Coléoptères de l'Ardèche Deuxième supplément à linventaire de J . Balazuc (1984) Henri-Pierre Aberlenc C/RAD,](https://img.pdfslide.fr/doc/110x75/5f92d20cd372a626571a0751/-113-1-bull-mens-soc-linn-lyon-1996-65-4-113-152-coloptres-de.jpg)



























