Embed Size (px)
DESCRIPTION
(Hitta) Information Binaires
Citation preview

Information binaire
Codes correcteurs
et Compression
Dr HITTA Amara
Guelma University 08-Mai-1945
and
Sci. Res. Center in Welding &
Testing, Draria. Algeria
5.07.2008
1

Page laissee vide
2

TABLE DES MATIERES
Contenu 2
1 Introduction sur les codes binaires 5
1.1 Les corps de Galois . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.2 Les codes binaires en blocs . . . . . . . . . . . . . . . . . . . . . . . 9
1.2.1 Exemples de codes binaires . . . . . . . . . . . . . . . . . . . . 11
1.2.2 Taux de transmission . . . . . . . . . . . . . . . . . . . . . . . 12
1.2.3 Codage des images . . . . . . . . . . . . . . . . . . . . . . . . 13
1.2.4 Compacts Disques . . . . . . . . . . . . . . . . . . . . . . . . 14
1.2.5 Video-Disque . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.2.6 Codes non binaires . . . . . . . . . . . . . . . . . . . . . . . . 15
1.3 Canaux de transmission de l’information . . . . . . . . . . . . . . . . 16
1.4 Decodage par la vraisemblance maximale . . . . . . . . . . . . . . . . 20
3

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
1.5 Codage detecteur et correcteur d’erreurs . . . . . . . . . . . . . . . . 21
2 Codage de source et compression 25
2.1 Entropie et information binaires . . . . . . . . . . . . . . . . . . . . 25
2.1.1 Source Discrete finie . . . . . . . . . . . . . . . . . . . . . . . 26
2.1.2 Information mutuelle . . . . . . . . . . . . . . . . . . . . . . . 30
2.1.3 Capacite d’un canal de transmission . . . . . . . . . . . . . . . 31
2.1.4 Source Continue . . . . . . . . . . . . . . . . . . . . . . . . . . 39
2.2 Codage de source et compression . . . . . . . . . . . . . . . . . . . . 40
2.3 Compression sans perte d’information . . . . . . . . . . . . . . . . . 42
2.3.1 Codage binaire de Shannon-Fano . . . . . . . . . . . . . . . . 48
2.3.2 Codage binaire de Huffman . . . . . . . . . . . . . . . . . . . 50
2.3.3 Codages arithmetique et LZW . . . . . . . . . . . . . . . . . . 52
2.4 Compression avec perte d’information . . . . . . . . . . . . . . . . . 53
2.4.1 JPEG (Joint Photographie Experts Group) . . . . . . . . . . 53
2.4.2 MPEG (Moving Picture Experts Group) . . . . . . . . . . . . 55
2.5 Exercices et solutions . . . . . . . . . . . . . . . . . . . . . . . . . . 56
3 Codes correcteurs lineaires en blocs 63
3.1 Codes lineaires binaires . . . . . . . . . . . . . . . . . . . . . . . . . 63
3.2 Matrice generatrice . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
3.3 Code dual et matrice de controle . . . . . . . . . . . . . . . . . . . . 69
3.4 Codes de Hamming . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
3.5 Codes de Hamming etendu . . . . . . . . . . . . . . . . . . . . . . . 75
3.6 Les Codes de Golay binaires et ternaires . . . . . . . . . . . . . . . . 77
3.7 Codes de Hadamard . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
Mr HITTA Amara4
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
4 Decodage des codes lineaires 81
4.1 Decodage par le syndrome . . . . . . . . . . . . . . . . . . . . . . . . 81
4.1.1 Partition de l’espace . . . . . . . . . . . . . . . . . . . . . . . 82
4.1.2 Algorithme de decodage avec Hr(2) . . . . . . . . . . . . . . . 84
4.1.3 Algorithme de decodage par le syndrome . . . . . . . . . . . . 87
4.2 Decodage a distance minimale . . . . . . . . . . . . . . . . . . . . . 89
4.3 Codes raccourcis, codes demultiplies . . . . . . . . . . . . . . . . . . 96
4.4 Codes de Reed Muller . . . . . . . . . . . . . . . . . . . . . . . . . . 96
4.4.1 Decodage des Codes de Reed Muller . . . . . . . . . . . . . . 99
4.5 Codes de Reed-Solomon . . . . . . . . . . . . . . . . . . . . . . . . . 100
4.6 Codes BCH et leurs algorithmes de decodage . . . . . . . . . . . . . 102
4.6.1 Decodage des codes BCH par l’exemple . . . . . . . . . . . . . 102
4.6.2 Decodage general d’un code BCH . . . . . . . . . . . . . . . . 104
5 Bornes asymptotiques d’un code 109
5.1 Bornes d’un code . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
6 Parametres asymptotiques des codes 119
6.1 Existence de codes et parametres asymptotiques . . . . . . . . . . . 119
6.2 Poids enumerateur et probabilite d’erreurs . . . . . . . . . . . . . . . 121
Mr HITTA Amara5
08-Mai 45 Guelma University

Page laissee vide
6

CHAPITRE
1
INTRODUCTION SUR LES CODES
BINAIRES
De nos jours, l’information represente un enjeu mondiale de taille. Elle tire ses orig-
ines des travaux de Shannon E. (1948) et ceux de Ralph W.L. et Harry Nyquiest
sur la transmission des signaux.
La theorie des codes traite des mecanismes consistant a parer la defaillance physique
sur la transmission des donnees. Un des plus celebres theoremes de Shannon garan-
tit l’ existence de codes pouvant transmettre l’information a des taux (bits/s) ap-
prochant la capacite du canal de communication avec une probabilite d’erreurs ar-
bitrairement petite.
Transmise sous forme a travers des supports de communication ( ligne telephonique,
liaison satellite, onde radio, bande magnetique), l’information peut etre, a ce titre,
perturbee par des sources diverses : erreurs humaines, bruits de fond des appareil-
lages electroniques, qualite mediocre des signaux emis, flou des photographies trans-
7

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
mises, manipulations ou intrusions externes. Le destinataire recevra ainsi un texte
tronque et parfois .
La solution pour la securite de l’information transmise consiste alors en un codage a
son emission et un decodage a sa reception couplee d’un cryptage qui ne laissent
sur le canal de transmission qu’un texte inintelligible et donc inutile pour ceux a qui
elle n’est pas destinee.
Malheureusement, les theoremes de Shannon ne fournissent pas de methodes per-
mettant de construire explicitement des codes aux performances maximales puisque
le but final est de construire des encodeurs et des decodeurs, possedant de bons
parametres, de sorte que le codage et le decodage de l’information soient rapides,
la correction des erreurs soit aisee et le transfert de bits par unite de temps soit
maximal.
Les premiers codes qui ont vus le jour, sous forme algebrique explicite, sont ceux de
R. W. Hamming (1950) de parametres n = 2r − 1 et k = n − r ; ils corrigent une
erreur. J. E. Golay generalisa les codes de Hamming a des codes binaires de longueur
(pr − 1)/(p − 1), p entier premier, et construit deux codes parfaits ; le premier est
le code binaire G2312(2) corrigeant 3 erreurs et le second est le code ternaire G11
6 (2)
corrigeant deux erreurs.
La plus importante des contributions dans ce domaine fut celle de Hocquenghem
(1959), Bose et Ray-Chaudhuri (1960). Leurs codes, baptises BCH, ont de bons
parametres, des algorithmes de decodage efficients et corrigent plusieurs erreurs.
La decouverte de ces codes a ouvert la voie a la recherche des methodes pra-
tiques pour l’implementation des encodeurs et des decodeurs ainsi qu’a la recherche
d’algorithmes de decodage performants ; on cite, entre autres, l’algorithme de Berle-
kamp. En 1960, I. S. Reed et G. Salomon du M.I.T (Massashuts Institute of Tech-
nology) introduisent les codes BCH de longueur p− 1 sur un corps fini de Galois a
p elements.Enfin, recemment des codes aux performances maximales, meilleurs que ceux predits
par la theorie de Shannon et qui depassent asymptotiquement la borne de Var-
shamov, sont proposes par le mathematicien Russe D. . Ils utilisent la geometrie
des courbes algebriques sur les corps finis de Galois. Leurs distances minimales sont
grandes, et se sont reveles tres utiles pour les transmissions tres perturbees, par ex-
Mr HITTA Amara8
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Figure 1.1: Schema general d’un systeme de communication
emple, celles effectuees par satellite. Jusqu’a present, les codes obtenus a partir des
courbes algebriques n’ont pas encore ete utilises, car leurs algorithmes de decodage
n’etaient pas suffisamment effectifs.
1.1 Les corps de Galois
Un corps est un ensemble qui possede des proprietes essentielles qui nous permette
d’effectuer les operations usuelles utilisant la commutativite, l’associativite et la dis-
tribution. Les exemples les plus courants sont: l’ensemble Q des nombres rationnels,
l’ensemble R des nombres reels et l’ensemble C des nombres complexes. L’ensemble
Z des entiers n’est pas un corps car la division de deux entiers non nuls n’est pas
forcement un entier. On s’interesse essentiellement aux corps finis dont les elements
sont un nombre fini de 0 et 1. Pour les obtenir, la methode la plus familliere est
l’arithmetique modulaire sur l’ensemble des entiers relatifs Z. Pour un entier positif
n fixe et a ∈ Z, la division euclidienne de a par n suppose l’existence d’un entier b
et d’un reste r, 0 ≤ r ≤ n, tels que a = nb+ r. On ecrit a ≡ r (mod n). L’ensemble
des restes modulo n est l’ensemble fini Zn = {0, 1, · · · , n− 1}.
Soit p un entier premier.
Definition 1.1.1 (Corps de Galois) Le p-corps de Galois est l’ensemble fini, Zp =
{0, 1, . . . , p− 1}, des restes modulo p.
Mr HITTA Amara9
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
L’arithmetique d’un p-corps finis de Galois, p entier premier, est utile pour le codage
algebrique ceci est du, en particulier, au fait que :
Theoreme 1.1.2 Tout element non nul admet un inverse pour la multiplication.
Preuve : Soit a ∈ Z∗p. Les entiers a et p sont premiers entre eux. Il existe, d’apres le
theoreme de Bezout deux entiers x et y tels que ax+py = 1 donc ax ≡ 1 (mod p).
Ainsi, x est l’inverse de a dans Zp. �
Theoreme 1.1.3 Tout element non nul admet un inverse pour la multiplication.
Definition 1.1.4 (Corps de Galois) Le p-corps de Galois est l’ensemble fini, Zp =
{0, 1, . . . , p− 1}, des restes modulo p.
Exemple 1.1.1 (5-Corps de Galois) Dans le 5-corps de Galois Z5 = {0, 1, 2, 3, 4},l’element 2 admet comme inverse 3 et vice-versa car 2.3 = 3.2 = 6 ≡ 1 modulo 5. Les
elements 1 et 4 sont leurs propres inverses car 1.1 ≡ 1 et 4.4 = 16 ≡ 1 modulo 5. �
Exemple 1.1.2 (11-Corps de Galois) Dans le corps Z11 = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, x},on a modulo 11 : 1.1 ≡ 1, 2.6 ≡ 1, 3.4 ≡ 1, 5.9 ≡ 1, 8.7 ≡ 1, x.x ≡ 1.
D’autre part, 12 ≡ 1, 22 ≡ 4, 32 ≡ 9, 42 ≡ 5, 52 ≡ 3, 62 ≡ 3, 72 ≡ 5, 82 ≡ 9,
92 ≡ 4 et x2 ≡ 1. On peut meme resoudre certaines equations quadratiques. Ainsi,√
1 = ±1 = 1 ou x,√
3 = 5 ou 6. Mais√
2 n’existe pas dans Z11. �
L’ordre d’un corps fini est egal au nombre des elements qu’il contient. On demontre
et nous l’admettons :
• Chaque corps fini est d’ordre pn, puissance d’un certain nombre premier p ou
n est un entier non nul.
• Pour chaque puissance pn d’un nombre premier p, il existe un corps de Galois
unique d’ordre pn note Zpn .
Mr HITTA Amara10
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
• Posons Zq un corps fini d’ordre q = pn. Chaque sous-corps de Zq est d’ordre
pm, pour un entier positif m divisant n. Inversement, si m est un entier positif
diviseur de n, il existe un sous-corps unique de Zq d’ordre pm.
• Si Zq est un corps d’ordre q = pn, p entier premier, la caracteristique de Zq est
p. De plus, le corps Zq contient une copie de Zp comme sous-corps. Le corps
Zq est considere ainsi comme une extension de Zp.
• Le groupe multiplicatif Z∗q du corps fini Zq est cyclique d’ordre q−1 et aq = a,
pour tout a ∈ Zq. Le generateur du groupe cyclique Z∗q est dit element
primitif de Zq.
• Si a, b sont des elements d’un corps fini de caracteristique p, alors (a+ b)pn
=
apn
+ bpn
pour tout n ∈ N∗.
En particulier : Le corps de Galois binaire, Z2 = {0, 1}, possede des proprietes
essentielles et pratiques, a savoir qu’aucune erreur de signe n’est possible et que tout
element est egal a son carre : a2 = a et a = −a pour tout a ∈ Z2. . Les elements 0
et 1 sont dits bits.
1.2 Les codes binaires en blocs
Ce sont des codes dont tous les mots ont la meme longueur, dite longueur du code.
On les rencontre, plus particulierement, lorsqu’il s’agit d’une transmission a travers
un canal sans memoire , c’est-a-dire que les mots envoyes ne dependent pas de
ce qui s’est passe avant leurs transmissions et que la sortie a un instant donne ne
depend statistiquement que de l’entree correspondante.
Definition 1.2.1 (Code binaire) Un code binaire en blocs , note Ckn(2), est
un ensemble de mots, forme par les bits 0 et 1, de longueur n. Leurs nombre est
|Ckn(2)| = 2k. Les k premiers bits sont dits bits d’information. Le poids d’un
mot code est le nombre de bits 1 qui le compose.
Mr HITTA Amara11
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
On peut ainsi ajouter, indifferemment, a chaque mot le bit 0 ou 1 pour que son
poids soit paire. Par ailleurs, on verifie les inegalites
1 ≤ |Ckn(2)| = 2k ≤ 2n.
Lorsque k = n, on obtient le code trivial Zn2 ; Il contient 2n mots de longueur n et
ne corrige aucune erreur.
Le principe general pour la detection des erreurs est le suivant :
• L’emetteur transforme le message initial a l’aide d’une technique qui genere
certaines redondances de l’information au sein du message code.
• Le recepteur verifie, a l’aide de la meme technique, que le message recu est
bien le message envoye grace a ces redondances.
Si le code est bien concu, on peut detecter et corriger l’erreur survenue ; C’est la
vocation principal des codes correcteurs.
Apres detection, il y aurait une auto-correction (Forward Error Correction : FEC)
par des codes par blocs (Hamming ou Reed-Salomon) ou par des codes convolutifs
(Viterbi). Sinon, le recepteur demande a l’emetteur de retransmettre une nouvelle
fois le message code (Automatic Repeat ReQuest : ARQ). Cette requete se presente
sous plusieurs formes :
• Protocole “stop and wait ” attendant une reponse ARQ ou NACK.
• Protocole “go back and N”, N=NACK Seul. Il identifie le bit errone a
partir duquel tout est transmis.
• Protocole NACK selectif qui precise le bit defaillant a transmettre seul.
Le codage ARQ est le plus utilise dans les reseaux notamment les protocoles de
telecommnication, a savoir HDLC, X25 et TCP. Le taux de perte est faible et le
delai de transmission est tolerable. Ces deux methodes peuvent etre combinees.
Mr HITTA Amara12
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
0000 0000 0000 0001 0001 0001 0010 0010 0010 0011 0011 0011
0100 0100 0100 0101 0101 0101 0110 0110 0110 0111 0111 0111
1000 1000 1000 1001 1001 1001 1010 1010 1010 1011 1011 1011
1101 1101 1101 1101 1101 1101 1110 1110 1110 1111 1111 1111
Table 1.1: Code 3-repetition
1.2.1 Exemples de codes binaires
Exemple 1.2.1 (Code de parite C23(2)) Il est forme par les mots code 000, 011,
101 et 110. Il n’y a qu’une erreur a detecter et pas plus, car chaque mot code differe
d’un autre mot code en deux positions. Ce code ne corrige aucune erreur, car si le
mot 010 est recu, l’un des mots 001, 110 ou 011 aurait ete envoye avec une erreur
de transmission. �
Exemple 1.2.2 (Code 2-repetition) Le message code est un double exemplaire
du message initial. Le recepteur s’apercoit qu’il y a eu erreur si les deux exemplaires
ne sont pas identique. �
On utilise aussi les codes ou la redondance est tellement suffisante pour detecter
certaines erreurs survenues lors de la transmission.
Exemple 1.2.3 (Code 3-repetition) C’est un code de longueur 12 ou le message
initial, forme de 4 bits, est repete 3 fois. On obtient les 24 = 16 mots codes suivants :
Avec ce code : Certaines erreurs detectees ne sont pas corrigibles a savoir : une
erreur differente sur au moins deux exemplaires. D’autres sont detectees et mal
corrigees a savoir : une meme erreur sur deux exemplaires simultanement. �
Exemple 1.2.4 (Transmission avec un code de parite C45(2)) La transmission
du message 0101 fait intervenir un codage systematique 01010. Le dernier bit est dit
parite de controle. Il est egal a la somme des autres bits du message. En passant
dans le canal de transmission, une source de bruit lui fait subir des modifications
pour devenir 11010. �
Mr HITTA Amara13
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Figure 1.2: Transmission avec un code de parite C45(2)
1.2.2 Taux de transmission
Definition 1.2.2 (Taux de transmission) Le taux de transmission ou d’
information d’un code binaire Ckn(2) de longueur n qui a |Ckn(2)| = 2k mots,
0 ≤ k ≤ n, est defini par
R[Ckn(2)] =
1
nlog2 |Ck
n(2)| =k
n.
Le nombre r = n − k est dit la redondance du code : Plus la redondance est
grande, plus le codage est precis et efficace.
Ainsi, si chaque mot envoye est un mot code, alors n = k et r = 0 ; il n’y a
rien a corriger dans ce cas de figure. Comme 1 ≤ |Ckn(2)| ≤ 2n, on en deduit que
0 ≤ R[Ckn(2)] ≤ 1. Les travaux de Shannon combines avec ceux du Mathematicien
Sovietique Rom Varshamov et l’americain E. N. Gilbert, ont montre qu’on pouvait
construire des codes ayant un taux de transmission optimal par rapport a la fiabilite
du canal de transmission.
Mr HITTA Amara14
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Exemple 1.2.5 (Codes detecteurs)
• Le code trivial Zn2 = {00, 01, 10, 11} a pour parametres n = k = 2, alors
|Zn2 | = 4 et r = 0. Comme R[Zn
2 ] = 1, ce code ne detecte et ne corrige aucune
erreur.
• Pour le code de parite C23(2) = {000, 011, 101, 110}, on a R[C2
3(2)] = 2/3 et
r = 1. En general, Le code de parite d’ordre n, Cn−1n (2), a pour taux de
transmission (n− 1)/n.
• Le code de repetition C1n(2) a pour taux de transmission a 1/n. �
Les exemples qui suivent montrent que la theorie des codes ne concerne pas que
les transmissions dans le sens des telecommunications mais aussi la sauvegarde des
donnees, les techniques d’archivages, les imperfections sur les surfaces des disques
durs et les interferences des frequences radios avec les receptions des telephones
mobiles.
1.2.3 Codage des images
Le format utilise est le format Bitmap, dit carte de bits. Les points d’une image
sont appeles pixels �picture elements�. Chaque pixel est decrit par un nombre
indiquant sa couleur ; chaque image est, ainsi, representee par une serie de nombre.
Ce codage est simple mais l’inconvenient est que l’image occupe une place memoire
importante car les pixels sont petits et nombreux ...! :
Les photographies, en provenance de la sonde spatiale Mariner 9 a partir de la
planete Mars, etaient divisees en pixels. A chaque pixel etait affecte un niveau de
gris variant entre 1 et 26 = 64 ; chaque pixel etait code par un mot de Z26 . A la
reception, il etait possible de corriger jusqu’a 7 erreurs par pixel, ce qui explique
l’excellente qualite des images recues a l’epoque.
Mr HITTA Amara15
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
1.2.4 Compacts Disques
Une simple rayure sur la surface d’un disque compact, de l’ordre d’un millemetre,
suffit de detruire environ 3300 bits d’information sur la piste ! Il ne s’agit la que
des rayures, et il existe malheureusement bien d’autres sources d’erreurs, a savoir :
les pousieres, le voile du disque, les interferences, ou tout simplement des defauts de
metallisation de la surface.
Pour remedier a cette situation, on utilise les codes de Reed-Solomon : Ils sont
inventes en 1960 par I. S. Reed et G. Solomon au M.I.T. Lincoln Labs. Construits
sur un corps de Galois fini, ils ont ete ensuite utilises par la NASA et l’Agence
Spatiale Europeene. On les rencontre aussi dans les disques audionumeriques (CD)
ou le signal musical est traduit en un code binaire.
Le codage permet de lutter contre l’influence des rayures. Pour les CD audio,
le taux d’une erreur non corrigee par 109 bits lu , passe a 10−13 pour les 109 bits
lu , passe a 10−13 pour les CD-ROM a l’aide du code �Cross-Interleaved Reed-
Solomon Code, C.I.R.C.� ce qui veut dire tout simplement codes croises de
Reed-Solomon avec entrelacement. Ce code utilise dans le systeme du disque
compact permet de corriger 3840 bits effaces, et meme jusqu’a 12288 bits par inter-
polation.
1.2.5 Video-Disque
Il existe, par ailleurs, depuis quelques annees un support de meme nature que le
disque compact, utilise pour le stockage du son et de l’image, le Video-Disque,
VD. Il permet de restituer, en plus de l’image, un son de haute qualite. Le principe
de numerisation de l’image est simple, puisqu’on peut exprimer toutes les couleurs
a partir de trois couleurs : Rouge, Verts et Bleu (RVB).
La couleur C de chaque pixel s’ecrit
C = x.R + y.V + z.B
ou x, y et z designent les intensites (chrominances) respectives des trois couleurs.
Par exemple, une combinaison en proportions identiques du bleu, du rouge et du
Mr HITTA Amara16
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
vert donnera la couleur blanche lorsque les intensites sont a leur maximum, ou gris
lorsque les intensites sont plus faibles et lorsque les intensites sont nulles on a la
couleur noire. En codant sur 8 bits on obtient 28 = 256 intensites. Chaque pixel est
represente par une suite binaire de trois mots de 8 bits.
Pour le stansdard francais PAL, une image video est de 625 lignes, chacune est
formee par des pixels. Cette repesentation permet de supporter 16.777.216 couleurs.
Si l’on considere qu’il y a 400 pixels par ligne, il faut 25× 625× 400××8× 3 = 150
millions bits pour une seconde d’images avec une frequence de 25 images par seconde.
En incluant le son et les differents codages on arrive a une quantite phenomenale
d’information.
Tres prochainement, un nouveau standard de transmission des images video verra
le jour, il sera au format 16×9 (16/9), contrairement au format actuelle 4×3, et en
haute definition, c’est-a-dire 1250 lignes pour 1920 pixels, au lieu de 625 pour 400
points.
Dans l’etat actuel des choses, aucun canal n’a un debit suffisant pour transmettre
le son et l’image en 16/9 et en haute definition. Pour cela, on ne transmet pas les
trois chrominances mais plutot deux chrominances et une luminance (somme
des trois chrominances). La couleur manquante sera reconstituee a partir de ces
trois parametres. Ce qui sera transmis est : le son, la luminance en numerique et
les deux couleurs en analogique.
1.2.6 Codes non binaires
On donne maintenant deux exemples de codes non binaire sur un corps de Galois
Zp ou p est entier premier superieur a 2.
Exemple 1.2.6 (Code de Hamming ternaire) Considerons le corps de Galois
ternaire Z3 = {0, 1, 2} forme par les restes modulo 3. Posons n = 4, le code de
Hamming ternaire est defini par H2(3) = {abcd ∈ Z43 : a+ b = c et b+ c+ d = 0}.
Les premieres bits a et b sont les bits d’information, donc k = 2 et H2(3) = C42(3).
Il a 32 = 9 mots codes, a savoir : 0000, 1012, 2021, 0111, 1120, 2102, 0222, 1201,
2210. �
Mr HITTA Amara17
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Exemple 1.2.7 (Code ISBN) International Standard Book Number, est un code
de longueur 10 sur Z11. A chaque livre est affecte un code a1a2 · · · a9ax tel que la
formule de controle, ci-dessous, soit satisfaite : 1.a1 +2.a2 +3.a3 +4.a4 +5.a5 +6.a6 +
7.a7 +8.a8 +9.a9 +xax ≡ 0 (mod. 11), sachant que x.x ≡ 1 et −x ≡ 1 (mod. 11).
La lettre x est utilisee par les Romains pour designer le nombre 10. Le code ISBN
detecte une erreur : Supposons que ai est change en k ; le terme iai devient ik.
Alors 1.a1 + · · ·+ (i− 1)ai−1 + i(ai− ai + k) + · · ·+xax ≡ i(k− ai) (mod. 11). Mais
i 6= 0 et k − ai 6= 0 donc i(k − ai) 6≡ 0 (mod. 11) car Z11 est un corps. La detection
est realisee puisque l’expression de controle n’est pas satisfaite. Ainsi, dans l’ISBN
2.09.176706.9, les chiffres sont choisis tels que : 2 → la langue francaise, 09 →l’editeur, 176706 → l’identification. Le dernier chiffre est le symbole de controle
puisque∑9
i=1 iai = 207 ≡ 9 (mod. 11). Cet ISBN est bon. �
Contrairement aux codes binaires en bloc ou le codage/decodage d’un bloc depend
uniquement des informations de ce bloc, on defini :
Les codes convolutifs comme etant des codes dont les mots ont des longueurs
differentes. Chaque mot code depend, d’une maniere continue, des mots emis avant
et apres sa transmission.
On les rencontre plus particulierement lorsqu’il s’agit d’une transmission a travers un
canal avec memoire. Le procede du codage convolutif, developpe a partir d’un article
de Peter Elias [1955], repose sur l’idee de transmettre les mots codes determines non
seulement a partir des bits d’information recus de la source mais egalement d’autres
bits recus auparavent. Ces codes presentent la propriete remarquable de pouvoir
etre decode par des algorithmes generaux dont le plus connu est celui propose par
Andrew Viterbi [1967] dans le cadre des techniques de decodage sequentiel.
1.3 Canaux de transmission de l’information
Un canal est un systeme physique permettant la transmission d’une information
entre deux points distants dans le temps ou l’espace. Ainsi, la description d’un canal
necessite
Mr HITTA Amara18
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
• Un alphabet d’entree qui contient les symboles que l’on peut transmettre
a travers ce canal.
• Un alphabet de sortie qui contient les symboles d’entree et probablement
d’autres symboles que l’on peut recevoir a l’autre bout du canal.
• Une fonction probabiliste qui decrit la facon avec laquelle les symboles
d’entree sont transformes par le canal.
Le canal le plus simple est le canal discret sans memoire: C’est la donnee d’une
source (entree) et d’une sortie, discretes finis : X = Xentree = {x1, · · · ,xk} et
Y = Ysortie = {y1, · · · ,yn}. Lorsque xi est envoye, le mot yj sera recu avec une
probabilite conditionnelle :
pij = P{yj recu /xi envoye } telle que∑i,j
pij = 1.
La matrice de passage d’un etat a un autre est de type k × n, a savoir
T =
p11 p12 · · · p1n
......
pk1 pk2 · · · pkn.
Si la somme des termes de chaque ligne et de chaque colonne est egale a 1, on parle
de matrice stochastique ou matrice de transition.
Un canal est dit symetrique si l’ensemble des bits de sortie peut etre partitionne en
sous-ensembles de telle sorte que pour chacun de ces sous-ensembles, la sous-matrice
de passage correspondante est symetrique.
Exemple 1.3.1 (Canal symetrique) Considerons un canal discret de source bi-
naire et de sortie ternaire : X = {0, 1} et Y = {0, 1, 2}. La matrice de transition de
ce canal est
M =
(0.7 0.2 0.1
0.1 0.2 0.7
).
La sortie Y se partitionne en 2 sous-ensembles Y1 = {0, 2} et Y2 = {1} dont les
matrices de passage correspondantes sont symetrique et sont respectivement
M1 =
(0.7 0.1
0.1 0.7
)et M2 =
(0.2
0.2
).
Mr HITTA Amara19
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
11−p //
p
!!
1
0
p
==
1−p//0
Figure 1.3: Canal binaire symetrique
Le canal de transmission est donc symetrique. �
On decrit dans ce qui suit trois types de canaux, suivant que la source et la sortie
sont discretes ou continues
1) Canal Binaire Symetrique a probabilite d’erreurs :
Lorsque la source et la sortie sont binaires,
Xentree = Y sortie = {0, 1},
le canal (X, Y, p) est dit Canal Binaire Symetrique de probabilite d’erreurs p ,
0 ≤ p ≤ 1, et note CBS(p). Le nombre p designe la probabilite lorsque l’un des
bits est altere ou mal recu (le bit 0 est change en 1 et vice-versa). On peut choisir
p < 12, sinon on considere 1 − p. La probabilite de y recu sachant que x transmis,
est
P(y|x) =
p si x 6= y
1− p si x = y.
Ainsi, P(0|0) = P(1|1) = 1− p et P(1|0) = P(0|1) = p.
La transition entre ces deux etats lors de cette transmission est resumee par la
matrice stochastique
T =
(1− p p
p 1− p
).
Si aucune erreur n’est survenue, le canal est dit parfait.
Mr HITTA Amara20
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Un autre canal que nous utiliserons regulierement est le canal d’effacement, dans
lequel les symboles ne sont pas modifies, mais effaces.
2) Canal binaire a effacement :
Lors d’un brouillage sur une ligne telephonique ou d’une interruption breve de lecture
de la piste d’un CD, un bit ou plusieurs sont endomages ou effaces. Soit
Xentree = {0, 1} et Ysortie = {0, 1, ?}
ou ? est un symbole d’effacement qui remplace les bits 0 et 1 avec une probabilite
p, 0 < p < 1. Les probabilites de transition entre les differents etats sont P(0|0) =
P(1|1) = 1− p, P(0|1) = P(1|0) = 0, P(0|?) = P(1|?) = p. Schematiquement, on a
11−p //
p**
1
?
0
p44
1−p//0
Figure 1.4: Canal binaire a effacement
La matrice de transition de ce canal est de type 2× 3 :
TC =
1− p 0 p
0 1− p p
.
Ainsi, le canal de transmission, en recevant le mot x, l’efface avec une probabilite p
ou le transmet intact avec la probabilite 1− p. Dans ce cas, une erreur de canal est
appelee erreur d’effacement.
3) Canal Z :
C’est un canal binaire non symetrique ou Xentree = {0, 1} et Ysortie = {0, 1}. Les
probabilites de transition sont donnees par
P(0|0) = 1, P(0|1) = 0, P(1, 0) = p et P(1, 1) = 1− p.
Mr HITTA Amara21
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
La matrice de transition de ce canal est de type 2× 2 :
TZ =
(1 p
0 1− p
).
Schematiquement, on a
01 //0
1
p
99
1−p//1
Figure 1.5: Canal Z
4) Canal Gaussien :
L’entree est est un intervalle par contre la sortie est l’ensemble R :
Xentree = [−1, 1] et Ysortie = R.
La probabilite de transition est donnee par la loi normale de moyenne x et d’ecart-
type σ :
P(y|x) =1
σ√
2πexp
[−1
2
(y− x
σ
)2].
1.4 Decodage par la vraisemblance maximale
Le decodage par la vraisemblance maximale se fait suivant les principes suivants :
1. Decodage complet : Si y est recu, on decode au mot code x
de facon que la probabilite P(y|x) soit maximale.
Mr HITTA Amara22
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
2. Decodage Incomplet : Si y est recu, le decodage doit se faire a
un mot code telle que la probabilite soit maximale sinon l’erreur
sera detectee sans etre corrigee.
Exemple 1.4.1 Le code ISBN detecte une erreur et ne corrige aucune, le decodage
est incomplet. De meme, le decodage avec le code de parite C23(2) est incomplet. �
Considerons un code binaire de longueur n. Supposons que le mot y est recu sachant
que x est envoye a travers un canal CBS(p). Si y et x different en k positions lors
de cette transmission. L’erreur e survenue admet k bits 1 et les n− k bits restants
sont des 0 :
P(y|x) = pk(1− p)n−k.
Exemple 1.4.2 On utilise le code de Hamming H3(2) = C37(2). Supposons que
y = 0011111 est le mot recu a travers un CBS de probabilite p = 0.1. On prefere
decoder y a 0001111 puisque P(y | 0001111) ' 0, 009414801 > P(y | 1011010) '0, 000000961. �
1.5 Codage detecteur et correcteur d’erreurs
Il s’agit d’ajouter des informations, dites redondantes de types bits de controle, pour
detecter et eventuellement corriger, a la reception, les erreurs provoquees par un
canal bruite. En procedant de cette maniere, on diminue la probabilite d’occurence
des erreurs et on augmente la capacite de correction et de detection du code. Plus
cette probabilite est faible par rapport a celle du canal de transmission, meilleur est
le codage.
Une methode systematique, introduite par R. W. Hamming en 1950, consiste a
ajouter a chaque mot transmis un symbole binaire, dit parite de controle, egal a
la somme de ses bits. Le message x = x1 . . . xn−1 sera code, ainsi, sous la forme
x = x1 . . . xn−1pn ou pn = x1 + x2 + · · ·+ xn−1.
Mr HITTA Amara23
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
• Si pn = 0, le mot emvoye est un mot code. Il n’y a rien a corriger.
• Si pn = 1, le receveur s’apercoit qu’une ou plusieurs erreurs de transmission
sont survenues.
Designons par X la variable aleatoire representant le nombre d’erreurs survenues
lors de la transmission d’un mot de longueur n a travers un CBS de probabilite p.
La variable aleatoire X suit une loi binomiale X ↪→ B(n, p). La probabilite pour que
k erreurs surviennent lors de cette transmission est
P(X = k) = Ckn p
k (1− p)n−k.
Exemple 1.5.1 (Parite de controle) Supposons que XSource = {00, 01, 10, 11}et que la transmission se fait a travers un CBS de probabilite 0, 125. La proba-
bilite pour qu’au moins une erreur survienne est P(X ≥ 1) = C12(0, 125).(0.875) +
C11(0, 125).(0, 125) ≈ 0, 234 < 0, 5. En allongeant chaque mot par sa bit de controle,
les erreurs simples sont facilement detectables. La probabilite d’occurence des er-
reurs doubles parmi les 3 bits est P(X = 2) = C23(0, 125).(0, 125).(0.875) ≈ 0, 041 <
0.234. Que se passe-t-il, lorsqu’il y a plus de bruit, donc plus d’erreurs ?. Pour cela,
soit p = 1/3 > 0, 125, alors P(X ≥ 1) = C12(1/3).(2/3) ≈ 0, 5555 > 0, 5. �
Exemple 1.5.2 (Occurence des erreurs) Supposons qu’on veut transmettre 211 =
2048 mots de longueur n = 11 a travers un CBS de probabilite p = 10−8, et
que les bits sont envoyes a un debit de 107 bits/s. Le nombre de mots transmis
par seconde est 107/11. La probabilite pour qu’une erreur survienne est C111p (1 −
p)10 ' 11.10−8. Le nombre de mots transmis incorrectement chaque seconde est
(11.10−8) × (107/11) = 0, 1 mot. Par consequent, on a une erreur chaque 10 sec-
onde, 6 chaque minute, 360 en une heure et 8640 chaque jour; c’est enorme, n’est-ce
pas ? �
Voyons maintenant, comment on peut minimiser l’occurence des erreurs en al-
longeant chaque mot par sa parite de controle. Dans ce cas, n = 12.
Mr HITTA Amara24
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Exemple 1.5.3 (Minimiser l’oOccurence des erreurs) Seules les erreurs dou-
bles sont indetectables ; la probabilite de leurs occurence est p2 = C212p
2(1 −p)10 ' 66.10−16. Le nombre de mots transmis incorrectement par seconde est
(66.10−16) × (107/12) = 5, 5.10−9. Ce qui correspond a une erreur tous les 2000
jours. �
Mr HITTA Amara25
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Mr HITTA Amara26
08-Mai 45 Guelma University

CHAPITRE
2
CODAGE DE SOURCE ET
COMPRESSION
2.1 Entropie et information binaires
L’outil de base est le concept de l’entropie, introduit par Shannon en 1948 ; elle
est vue comme une mesure mathematique de l’information ou l’incertitude sur
l’information. La quantite d’information d’un message est le nombre de bits
possibles pour obtenir un codage optimal a partir de messages donnes. En pratique,
on s’interesse plutot au cas ou ce message est un texte ecrit, une image de television
ou autre. Pour cela, considerons un message dont le resultat doit etre transmis a
travers un canal quelconque. Ce message est considere comme une variable aleatoire
discrete ou continue qui suit une certaine loi de probabilite.
27

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
2.1.1 Source Discrete finie
Soit X une variable aleatoire discrete prenant les valeurs x1, . . . , xn avec des proba-
bilites d’occurence respectives p1, ..., pn c’est-a-dire
P[X = xi] = pi, i = 1, · · · , n etn∑i=1
pi = 1.
Ainsi :
• Si p1 = 1, alors pi = 0 pour tout i 6= 1, le resultat X = x1 est realise et
n’apporte aucune information.
• Si p1 = 0, 001, la quantite d’information delivree par cet evenement est plus
importante que celle d’avant.
En somme, on cherche a construire une fonction d’une variable aleatoire X de prob-
abilite p, notee I(p), verifiant les hypotheses suivantes :
• I(p) ≥ 0. I(p) est nulle si p = 1 c’est-a-dire que X est un evenement certain.
• I(p) est une fonction decroissante et continue de p.
• I(p1p2) = I(p1) + I(p2) pour deux evenements independants de probabilites p1
et p2.
Dans le cas binaire, la seule fonction qui verifie ces hypotheses est
I(p) = − log2 p = log2(1/p).
Definition 2.1.1 (Entropie) L’ entropie de la variable aleatoire X, notee H(X),
est la quantite d’information moyenne par symbole emis par la source:
H(X) = −n∑i=1
pi log2 pi =n∑i=1
pi log2 (1/pi)
Mr HITTA Amara28
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Par convention, on pose 0× log(1/0) ≡ 0 car limθ→0+
log(1/θ) = 0.
Exemple 2.1.1 (Pile ou face) On jette une piece de monnaie. La variable aleatoire
X, resultat de cette experience, prend les valeurs x1 = pile ou x2 = face. Les deux
evenements sont equiprobables donc p1 = p2 = 0.5 et H(X) = 1. Il n’y a qu’une
seule information. �
Par consequent :
Nous pouvons utiliser, l’information tiree de l’experience de cet exemple, comme
unite de mesure de l’information appelee bit, binary digit, comme l’a deja propose
l’ Organisation Internationale de normalisation (ISO).
La definition de l’entropie necessite les remarques suivantes :
• H(X) depend de la loi de probabilite suivie par X et non des valeurs prises
par X.
• H(X) est l’esperance mathematique de la variable aleatoire I(X) = − log2 P[X].
• La quantite d’information d’un message represente le nombre minimal de bits
necessaires pour coder toutes ces significations possibles.
• Si les n evenements X = xi ont la meme incertitude 1/n alors
H(X) = log2(n) bits.
• L’incertitude d’une variable aleatoire (v.a.), c’est-a-dire son entropie, est max-
imale lorsque sa distribution de probabilite est uniforme c’est-a-dire equipartie.
Son entropie vaut alors le logarithme du cardinal de l’ensemble des valeurs pos-
sibles pour cette v.a..
Mr HITTA Amara29
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Exemple 2.1.2 (Entropie d’un alphabet naturel) Le tableau suivant indique
les probabilites, en pourcentage, d’occurence des 26 lettres de lalphabet anglais :
p(A) = 7.87, p(B) = 1.56, p(C) = 2.68, p(D) = 3.89, p(E) = 12.66, p(F ) = 2.55,
p(G) = 1.87, p(H) = 5.74, p(I) = 7.07, p(J) = 0.10, p(K) = 0.60, p(L) = 3.94,
p(M) = 2.43, p(N) = 7.05, p(O) = 7.76, p(P ) = 1.88, p(Q) = 0.10, p(R) = 5.95,
p(S) = 6.31, p(T ) = 9.78, p(U) = 2.80, p(V ) = 1.02, p(W ) = 2.15, p(X) = 0.16,
p(Y ) = 2.01, p(Z) = 0.07.
L’entropie de l’anglais sera alors d’environ 4.1 bits par lettre. �
Un codage optimal est celui qui minimise le nombre de bits transmis. Chaque
I(pi) = − log2(pi) represente le nombre de bits necessaires pour encoder, d’une facon
optimale, le message X = xi.
Exemple 2.1.3 (Code optimal) Considerons trois messages A, B et C tels que
p(A) = 0.2 et p(B) = p(C) = 0.5 ; on a H(X) = 1, 5. Un codage optimal attribue
un bit a A et 2 bits a B et C. Le message A est code comme 0, par contre les
messages B et C sont codes comme 11 et 10 ; le message ABCA sera code 011100.
Le nombre moyen de bits par message est 6/4 = 1, 5 ; ce code est optimal, car si
le message C est code sous la forme 1, on aura dans ce cas de figure l’embaras du
choix entre CC et B. �
Exemple 2.1.4 (Le jet d’un de) On jette un de. Le resultat de cette experience
est X = 1, 2, · · · , 6. Comme ces evenements sont equiprobables de probabilite 1/6,
alors
H(X) = −6∑i=1
(1
6
)log2
(1
6
)' 2, 5849625 bits.�
Exemple 2.1.5 (Le jet de deux des) On jette deux des. Le resultat sera la vari-
able aleatoire X qui est egale a la somme des deux des. On a 1 facon pour que X = 1,
2 facons pour que X = 3, 3 facons pour que X = 4, 4 facons pour que X = 5, 5
facons pour que X = 6, 6 facons pour que X = 7, 5 facons pour que X = 8, 4 facons
Mr HITTA Amara30
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
pour que X = 9, 3 facons pour que X = 10, 2 facons pour que X = 11 et 1 facon
pour que X = 12. Par consequent, l’entropie de cette exprerience :
H(X) = H
(1
36,
2
36,
3
36,
4
36,
5
36,
6
36,
5
36,
4
36,
3
36,
2
36,
1
36
)= −
(1
36
)log2
(1
36
)− · · · · · · −
(1
36
)log2
(1
36
)= 3, 2744000191929 bits.�
Exemple 2.1.6 (Entropie maximale) Considerons les jeux suivants :
• Loto simple : 6 bons numeros sur les 45, on a n1 = C645 = 8145060 possi-
bilites.
• Quarte : sur les 12 chevaux, il y a n2 = 12.11.10.9 = 11880 resultats possibles.
• Tirer un carre d’as : Il y a une chance sur les n3 = C452 = 270725 cartes.
Le plus incertain est le Loto. Il y a equiprobabilite donc les entropies sont maxi-
males :
H1(Loto) = log n1 ' 23.0 bit,
H2(Quarte) = log n2 ' 13.5 bit,
H3(Poker) = log n3 ' 18.0 bit. �
La fonction d’entropie binaire, a travers un canal binaire symetrique de probabilite
p, est donnee par
H2(p) =
p log2
(1
p
)+ (1− p) log2
(1
1− p
)si p ∈]0, 1[
0 si p = 0 ou 1.
La fonction d’entropie binaire atteint son maximum lorsque p = 0, 5.
Mr HITTA Amara31
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
2.1.2 Information mutuelle
Soit Y une seconde variable aleatoire discrete prenant les valeurs y1, . . . , ym avec des
probabilite d’occurence q1, . . . , qm telles que q1 + . . . + qm = 1. Notons par rij la
probabilite pour que le couple (X, Y ) prenne la valeur (xi, yj)
rij = P{ (X, Y ) |X = xi et Y = yj}.
On a alors
pi =m∑j=1
rij et qj =m∑i=1
rij.
L’entropie du couple (X, Y ) est definie par
H(X, Y ) = −n∑i=1
m∑j=1
rij log2 rij.
Ce qui donne l’inegalite
H(X, Y ) ≤ H(X) +H(Y ).
L’egalite est obtenue si et seulement si les deux variables aleatoires sont independantes.
Les probabilites marginales sont definies par
P(X = xi) ≡m∑j=1
P(X = xi, Yj), P(Y = yi) ≡n∑i=1
P(X = xi, Y = yj),
La probabilite conditionnelle de X sachant Y est
P(X = xi|Y = yj) =P(X = xi, Y = yj)
P(Y = yj)si P(Y = yj) 6= 0.
L’ entropie conditionnelle de la variable aleatoire X sachant Y = yj est donnee par
H(X|Y = yj) = −n∑i=1
P(X = xi|Y = yj) log P(X = xi|Y = yj).
L’entropie conditionnelle de la variable aleatoire X sachant Y sera alors
H(X|Y ) = −m∑j=1
P(Y = yj)
[n∑i=1
P(X = xi|Y = yj) log P(X = xi|Y = yj)
]
= −m∑j=1
n∑i=1
P(X = xi, Y = yj) log P(X = xi|Y = yj).
Mr HITTA Amara32
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
L’entropie du couple (X, Y ), l’entropie conditionnelle et les entropies marginales
sont reliees par la formule
H(X, Y ) = H(X) +H(X|Y ) = H(Y ) +H(Y |X).
La variable Y recue a la sortie du recepteur comporte des differences avec la variable
X dues aux perturbations agissant sur le support de transmission.
La quantite d’information conditionnelle de Y sachant X realisee est I(Y |X) =
− log2[P(Y |X)]. C’est la mesure de l’observation de Y qui n’etait pas deja fournit par
l’observation de X. La formule de Bayes P(X∩Y ) = P(X).P(Y |X) = P(Y ).P(X|Y )
nous donne l’information de la realisation de X et Y : I(X∩Y ) = I(X)+I(Y |X) =
I(Y ) + I(X|Y ). Ainsi, les imperfections du canal de transmission peuvent etre
traduite en termes d’information mutuelle moyenne qu’apporte la variable de sortie
Y (resp. d’entree X) sur la variable d’entree X (resp. de sortie Y ) :
I(X, Y ) = H(X)−H(X|Y ) = H(Y )−H(Y |X) = I(Y,X).
Le terme H(X|Y ) (resp. H(Y |X)), dit ambiguite, est l’incertitude qui reste sur X
(resp. Y ) lorsque Y (resp. X) est connue. L’information mutuelle I(X, Y ) est une
distamce entre X et Y , puisque
• I(X, Y ) ≥ 0.
• I(X, Y ) = 0 si X = Y
• I(X, Y ) = I(Y,X).
• Si Z est une troisieme variable aleatoire alors I(X,Z) + I(Z, Y ) ≤ I(X, Y ).
2.1.3 Capacite d’un canal de transmission
La capacite d’un canal, exprimee en bits, est le maximum des I(X, Y ) suivant
toutes les lois de probabilite possibles sur X
C = max I(X, Y ) = max[H(Y )−H(Y |X)].
Mr HITTA Amara33
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Ainsi :
La capacite d’un canal correspond au maximum d’information
transmise.
Exemple 2.1.7 (Capacite d’un CBS(p)) La capacite de ce canal est atteinte
pour une loi uniforme sur les bits d’entree donc P[X = 0] = P[Y = 1] = 0, 5.
Comme on connait la loi de Y sachant X, on va utiliser I(X, Y ) = H(Y )−H(Y |X).
La probabilite de Y est
P(Y = 0) = (0, 5)× (1− p) + (0, 5)× p = 0, 5 et P(Y = 1) = 0, 5.
Donc H(Y ) = −2× (0, 5)× log2(0, 5) = 1. D’autre part, on a
H(Y |X) = 0, 5×H(Y |X = 0) + 0, 5×H(Y |X = 1).
Comme H(Y |X = 0) = H(Y |X = 1) = H2(p) alors H(Y |X) = H2(p). D’ou
La capacite d’un CBS(p) = 1 - H2(p) .
• Pour p = 0.5, l’entropie binaire est maximale. Donc la capacite est nulle. La
sortie n’apporte aucune information sur la source; X et Y sont independantes.
• Pour p = 0, il n’y a jamais erreur et Y = X. La capacite du canal est
maximum.
• Pour p = 1, il n’y a erreur de transmission. Comme Y = 0 (resp. Y = 1)
correspond X = 1 (resp. X = 0). La capacite du canal est maximum. �
Exemple 2.1.8 (Capacite d’un CBE(p)) La capacite est atteinte pour une loi
uniforme sur l’entree. La loi de probabilite de la v.a. Y est P(Y = 0) = P(Y = 1) =
0, 5(1− p) et P(Y = ε) = p. Ainsi, on a
H(Y ) = − [(1− p) log2(1− p) + p log2 p− (1− p) log2 2]
H(Y |X = 0) = H(Y |X = 1) = −[(1− p) log2(1− p) + p log2 p] = H(X|Y ).
Mr HITTA Amara34
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Ce qui donne
La capacite d’un CBE(p)= 1-p . �
Exemple 2.1.9 (Capacite d’un canal binaire Z(p)) Par definition de la capacite
du canal, on a
C = max I(Y,X) = max[H(Y )−H(Y |X)].
Le maximum est pris sur toutes les lois sur X. Posons P(X = 1) = q alors
necessairement P(X = 0) = 1− q ce qui donne
H(Y |X) = −∑x
P(X = x)∑y
P(Y |X = x) log P(Y |X = x)
= P (X = 0).0 + P(X = 1).H2(p)
= qH2(p).
D’autre part, H(Y ) = H2(P(Y = 1)) = H2(q(1− p)) et alors
C = maxLoi sur X
I(Y,X) = maxq
[H2(q(1− p)− qH2(p)].
Le maximum se trouve en annulant la derivee par rapport a q
dI(X, Y )
dq= (1− p) log
1− (1− p)q(1− p)q
−H2(p) = 0.
Ce qui donne
q =1
(1− p)(
1 + 2H2(p)1−p
)D’ou le maximum :
La capacite de Z(p) est CZ = H2
(1
1 + 2H2(p)1−p
)− H2(p)
(1− p)(
1 + 2H2(p)1−p
) . �
Degageons maintenant les proprietes fondamentales de l’entropie.
Mr HITTA Amara35
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Definition 2.1.2 (Convexite) Une fonction numerique f est dite convexe, sur
un intervalle I =]a, b[, si pour tous x1 et x2 ∈ I et pour 0 ≤ λ ≤ 1, on a
f(λx1 + (1− λ)x2) ≤ λf(x1) + (1− λ)f(x2).
La fonction f est dite strictement convexe si l’egalite est realisee pour λ = 0 et
λ = 1. Une fonction f est concave si −f est convexe.
Definition 2.1.3 (Convexite) Les fonctions log2(1/x), x2, ex et x log x sont stricte-
ment convexes sur l’intervalle ]0,+∞[. �
L’un des importants outils de la theorie de l’information est :
Theoreme 2.1.4 (Inegalite de Jensen) Si f est une fonction continue stricte-
ment convexe sur un intervalle I et sin∑i=1
λi = 1, λi > 0, alors
n∑i=1
λif(xi) ≤ f
(n∑i=1
λixi
), xi ∈ I.
On a l’egalite si x1 = . . . = xn. En general, si X est une variable aleatoire
d’esperance moyenne E(X), alors
E[f(X)] ≥ f(E[X])
Si f est strictement convexe et E[f(X)] = f(E[X]) alors X est une constante de
probabilite 1.
Mr HITTA Amara36
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Preuve : On raisonne par recurrence. Pour n = 1, n = 2 ceci est verifie puisque f
est strictement convexe. Supposons que l’inegalite est verifiee pour n− 1. On a
n∑i=1
λif(xi) = λnf(xn) + (1− λn)n−1∑i=1
λi1− λn
f(xi)
≥ λnf(xn) + (1− λn)f
(n−1∑i=1
λi1− λn
xi
)
≥ f
[λnxn) + (1− λn)
n−1∑i=1
λi1− λn
xi
]
= f
(n∑i=1
λixi
). �
Proposition 2.1.5 Soit X une variable aleatoire discrete prenant les valeurs x1, . . . , xn
avec des probabilites d’occurence p1, . . . , pn, alors
0 ≤ H(X) ≤ log2 n.
Preuve : D’apres l’inegalite de Jensen et le fait que la fonction x 7→ log2(1/x) est
strictement convexe sur l’intervalle ]0,∞[, apres verification, on aura
H(X) =n∑i=1
pi log2
(1
pi
)≤ log2
(n∑i=1
pi1
pi
)= log2 n.
L’egalite est obtenue si pi =1
npour 1 ≤ i ≤ n. �
Soient P et Q deux distributions de probabilites definies sur un meme ensemble AX .
Definition 2.1.6 (Entropie relative) La divergence de Kullback-Leibner de
P par rapport a Q, est
DKL[P ||Q] =∑x
p(x) log (p(x)/q(x))
Mr HITTA Amara37
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
L’information mutuelle peut s’ecrire sous la forme
I(X, Y ) =∑x
∑y
p(x, y) logp(x, y)
p(x)p(y)= DKL[p(X, Y )||p(X)q(Y )].
Proposition 2.1.7 Soient |X| le nombre de valeurs prises par une variable aleatoire
discrete X et U(X) = 1/|X| la distribution uniforme sur ces valeurs. Alors
H(X) = log |X| −DKL[PX ||U ].
Preuve : On a
H(X) = −∑x∈AX
PX(x) logPX(x)
= log |X| −∑x∈AX
[PX(x) log |X|]−∑x∈AX
PX(x) logPX(x)
= log |X| −∑x∈AX
PX(x)[logPX(x) + log |X|]
= log |X| −D[PX ||U ].�
Proposition 2.1.8 (Inegalite de Gibbs) L’entropie relative DKL verifie
DKL[PX ||QX ] ≥ 0 c’est-a-dire∑
x PX(x) log PX(x) ≥∑
x PX(x) log QX(x).
L’egalite est satisfaite si PX = QX .
Preuve. En utilisant l’inegalite de Jensen avec X ≡ Q
Pet f(x) ≡ log
1
x, alors
E [log(1/(Q/P ))] ≥ log(1/E[Q/P ]) = log(1/[∑i
piqi/pi]) = log 1 = 0.
L’egalite est satisfaite lorsque qi/pi est une constante, a savoir 1. �
En general, on a
DKL[P ||Q] 6= DKL[Q||P ]
Mr HITTA Amara38
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
ce qui veut dire que DKL ne peut etre consideree comme une distance au sens
mathematique du terme. Pour cela, considerons P et Q deux densites de distribu-
tions sur {0, 1} et soient p et q la probabilite de 0 respectivement dans les distribu-
tions P et Q c’est-a-dire p(0) = p et q(0) = q. Calculons ces deux expressions.
DKL[P ||Q] = p(0) logp(0)
q(0)+ p(1) log
p(1)
q(1)= p log
p
q+ (1− p) log
1− p1− q
= p log p+ (1− p) log(1− p)− p log q − (1− p) log(1− q)
= −H2(p)− [p log q + (1− p) log(1− q)].
et
DKL[Q||P ] = q(0) logq(0)
p(0)+ q(1) log
q(1)
p(1)= q log
q
p+ (1− q) log
1− q1− p
= q log q + (1− q) log(1− q)− q log p− (1− q) log(1− p)
= −H2(p)− [q log p+ (1− q) log(1− p)].
Si Q est uniforme c’est-a-dire q = 0, 5, alors
DKL[P ||Q] = 1−H2(p) et DKL[Q||P ] = −1− 1
2log(p(1− p))
qui sont differentes pour p 6= 0.5. �
Il existe, par ailleurs, des relations interessantes entre la fonction d’entropie H2(p),
p ∈]0, 1[ et certains cœfficients binomiaux que l’on utilisera ulterieurement lors de
l’etude sur les bornes asymptotiques.
Remarquons que
2−nH2(p) = pnp(1− p)n−np.
Theoreme 2.1.9 Soit 0 ≤ p ≤ 1
2. On a :
pn∑i=0
Cin ≤ 2nH2(p).
Mr HITTA Amara39
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Preuve : On peut ecrire
1 = (p+ (1− p))n ≥∑
0≤i≤pn
Cinp
i(1− p)n−i
≥∑
0≤i≤pn
Cinp
np(1− p)n−np
= 2−nH2(p)∑
0≤i≤pn
Cin.
D’ou le resultat. Pour la deuxieme relation, rappelons la formule de Stirling, a
l’infini :
n! ∼√
2πn(n/e)n.
En effet, la distribution de Poisson de moyenne n s’ecrit
P(r, n) = e−nnr
r!, r ∈ {0, 1, 2, · · · }.
Pour n suffisament grand c’est-a-dire au voisinage n ' r, cette distribution admet
comme approximation la distribution de Gauss de moyenne r et de variance n :
e−nnr
r!' 1√
2πnexp
(−(r − n)2
2λ
).
Posant r = n dans cette formule, on obtient
e−nnn
n!' 1√
2πnc’est-a-dire n! ' nne−n
√2πn. �
Theoreme 2.1.10 Soit 0 ≤ p ≤ 1
2. On a :
H2(p) = limn→∞
1
nlog2
(pn∑i=0
Cni
).
Preuve : Soit m la partie entiere de n m = [n]. Alors m = pn + O(1), lorsque
n→∞. D’apres la formule de Stirling, a l’infini on a :
log2(n!) =1
2log2(2n)− n+ n log2(n) +O(1).
Mr HITTA Amara40
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Par consequent, lorsque n tend vers l’infini, on peut ecrire
n−1 log2
(pn∑i=0
Cin
)≥ n−1 log2C
mn = n−1{n log2 n−m log2m− (n−m) log2(n−m) +O(n)}
= H2(p) +O(1). �
2.1.4 Source Continue
Le message X est considere comme une variable aleatoire continue de probabilite
p(x) verifiant
+∞∫−∞
p(x)dx = 1.
L’entropie de X est l’esperance de la variable aleatoire − log[p(x)] c’est-a-dire
H(X) = −+∞∫−∞
p(x) log[p(x)]dx.
Exemple 2.1.10 (Loi uniforme) Soit X une variable aleatoire continue. Si X
suit la loi uniforme U ([0, a]), alors
p(x) =
1
asi 0 ≤ x ≤ a
0 ailleurs.
Un calcul immediat fournit
H(X) = log a.�
Mr HITTA Amara41
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Exemple 2.1.11 (Loi normale) Si X suit la loi normale centree N (0, 1), sa
densite de probabilite est
p(x) =1
σ√
2πe−(x2/2σ2).
Alors
H(X) = log(σ√
2πe).�
2.2 Codage de source et compression
A l’inverse du codage correcteur et detecteur d’erreurs, le codage qui consiste a
supprimer les redondances peut utiles est dit codage de source ou compression
des donnees, synonyme d’economie et de gain de place important. C’est une
necessite imperative pour reduire l’encombrement des canaux de transmission et
augmenter, par la, la capacite de stockage de l’information.
La compression video fait partie integrante de plusieurs applications multimedia
d’aujourd’hui. Ceratines applications, par exemple les lecteurs DVD, la television
numerique, la television par satellite, la transmission video par l’Internet, la video
conference, la securite video et les cameras numeriques sont limitees par la capacite
memoire ou de bande passante pour la transmission, ce qui stimule la demande pour
des rapports de compression video plus elevee.
Pour illustrer ces situations donnons-en des exemples concrets sur les tailles reelles
des donnees a stocker avant la compression.
Exemple 2.2.1 (Image couleur fixe) Une image est definie par trois composantes,
dites primaires : la luminance Y et deux chrominances U et V. Le nombre de
pixels pour les 576 lignes est de 720 pixels par ligne. Chacune des 3 primaires est
codee sur un octet de 8 bits correspondant a 28 = 256 niveaux de quantification.
On obtient, ainsi, trois structures :
• La structure 4:2:2 : Comporte une luminance Y pour chaque pixel (720×576) et deux chrominances U et V un pixel sur deux (360 × 576). Ce qui
Mr HITTA Amara42
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
donne :
Le nombre de bits dans une image = (bits de luminance) + (bits de chrominance)
= 576× 720× 8 + (576× 360× 8)× 2
' 6, 63× 106 bits ' 0, 83 Moctet.
• Ainsi, une disquette haute densite de 1, 4 Moctets apres formatage, ne peut
contenir qu’une seule image couleur.
• La structure 4:2:0 : Elle comporte un element luminance Y pour chaque
pixel (720× 576) et un element chrominance U ou V un pixel sur deux et en
alternance une ligne sur deux (360× 288). Ce format, base sur une reduction
de la definition verticale pour les informations chrominance peu decelable par
l’œil, favorise la definition horizontale au detriment de la definition verticale.
• La structure 4:1:1. Elle comporte un element luminance pour chaque pixel
(720 × 576) et des elements chrominance tous les quatre pixels (180 × 576).
Ceci implique une reduction de la definition horizontale pour les informations
chrominance. �
Exemple 2.2.2 (Image couleur animee) La frequence image est de 25 Hertz
c’est-a-dire 25 images par seconde. La transmission d’une sequence animee necessite
un debit net de 6, 63 × 106 × 25 ' 166 Mbits/sec. Ce debit ne tient pas compte
des signaux complementaires indispensable a la synchronisation. Ajouter a cela les
signaux de service, on obtient un debit brut de 216 Mbits/sec. Comme le debit max-
imum sur le reseau numerique est de 144 Mbits/sec, la transmission d’une image
couleur animee necessite un codage de source approprie. �
Exemple 2.2.3 (Taille pour un film en couleur) Si on utilise les standards de
Television numerique (4/5) :
• 1 image = 720× 576× 16 = 0, 83 Moctets.
• 25 images par seconde : 1 s = 0, 83× 25 = 20, 75 Moctets/seconde.
• 1 film de 90 minutes = 90× 60× 20, 75 = 114125 Moctets ' 114 Goctets. �
Mr HITTA Amara43
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Ceci dit, on distingue deux types de codage de source :
• Compression sans perte d’information : Quand on decompresse, on peut
reconstruire exactement l’information initiale a patir de l’information com-
primee.
• Compression avec perte d’information : Quand on decompresse, il y
a une perte d’une partie de l’information initiale, mais la perception reste
inchangee dans le cas des images, de filmes ou de musique.
2.3 Compression sans perte d’information
Le plus celebre des codes de compression sans perte d’information est le Code de
Huffman ou l’on suppose que les probabilites d’occurence des mots possibles d’une
source alphabet sont connues. L’algorithme de codage de Huffman produit un code
optimal pour une telle source.
Soit S un alphabet de reference, c’est-a-dire un ensemble de lettres. En general,
S = {0, 1}. En concatenant des lettres de l’alphabet S, on forme des mots dont la
longueur correspond au nombre de lettres utilisees. Notons par S+ l’ensemble des
mots sur S de longueur finie et par Sn l’ensemble des mots de longueur n.
Soit X une variable aleatoire prenant ses valeurs sur un alphabet de reference fini
SX = {a1, a2, · · · , an}. La probabilite pour que X = x ∈ SX sera notee p(x). Un
code binaire Cn(X) est une application : f : SX → {0, 1}+. L’image x = f(x) ∈{0, 1}+, x ∈ SX , est dit mot code. Sa longueur sera notee par `(x). La longueur
moyenne du code Cn(X) est definie par
L[Cn(X)] =∑x∈SX
p(x)`(x).
Le code binaire etendu sur SX , note C+n (X), est une application : f+ : S+
X →{0, 1}+, definie par concatenation
f+(x1x2 · · ·xn) = f(x1)f(x2) · · · f(xn) = x1x2 · · ·xn.
Mr HITTA Amara44
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Exemple 2.3.1 Trouvons tous les decodages possibles du mot code 11001 lorsqu’il
est code a l’aide du code C : a = 1, b = 10 et c = 01. Comme le mot code commence
par 11, le debut du decodage ne peut-etre que la lettre a. Si la deuxıeme lettre du
decodage est a il reste 001 qui ne peut-etre decoder, donc cette eventualite est a
eliminer car le decodage est imcomplet. La deuxieme lettre ne peut-etre, alors, que
la lettre b. le reste se decode a c. Le decodage du mot 11001 est unique, il s’agit de
abc. �
Exemple 2.3.2 Trouvons tous les decodages possibles de 10010110101011010 lorsqu’il
est code a l’aide du code C : a = 10, b = 100, c = 10111 et d = 110110. On procede
comme dans l’exemple precedent. Ce mot peut se decoder de deux manieres, a
savoir : bdcaa ou bdada. �
Un code est dit uniquement dechiffrable, ou a decodage unique ou code
non-ambigu, si tout mot code ne peut etre decoder que d’une seule maniere c’est-
a-direl’application f+ : S+X → {0, 1}+ est injective.
Exemple 2.3.3 (Code uniquement non-ambigu) • Le code {c1 = 0, c2 =
1, c3 = 01} est ambigu car le dernier mot peut-etre interprete comme c3 ou
c1c2.
• Le code {c1 = 0, c2 = 1, c3 = 110} n’est pas uniquement dechiffrable car 110
peut s’ecrire de deux maniere, a savoir c2c2c1 et c3.
• Le code {0, 11, 010} est uniquement dechiffrable. �
Un code prefixe est un code pour lequel aucun mot n’est le debut d’un autre mot.
Tout code prefixe est uniquement dechiffrable.
Exemple 2.3.4 (Code prefixe) Le code {0, 11, 110, 111} n’est pas prefixe car 11
est inclu dans 110 et 111. Le code {0, 10, 110, 111} est un code prefixe. �
Tout code prefixe est dit instantane puisqu’il peut-etre decoder sans faire attention
aux lettres de l’alphabet composant chaque mot.
Mr HITTA Amara45
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Exemple 2.3.5 Posons SX = {a,b, c,d} tel que PX = {1/2, 1/4, 1/8, 1/8}.
• Soit le code C defini par f(a) = 0, f(b) = 10, f(c) = 110, f(d) = 111. On a
H(X) = L[C] = 1.75 bits. Le mot x = acdbac sera code a x = 0110111100110.
Ce code est un code prefixe donc uniquement dechiffrable.
• Soit le code C defini par f(a) = 0, f(b) = 1, f(c) = 00, f(d) = 11. On a
L[C] = 1.25 bits < H(X). Le mot x = acdbac sera code a x = 000111000 qui
se decode a son tour a abcda. Ce code n’est pas a decodage unique.
• Soit le code C3 defini par f(a) = 0, f(b) = 01, f(c) = 011, f(d) = 111. On a
H(X) = L[C] = 1.75 bits. Le mot x = 134213 se code a x = 0011111010011.
Ce code est uniquement dechiffrable mais n’est pas un code prefixe. En rece-
vant 00, le debut de x peut-etre aa, ab ou ac. En recevant le mot 001111,
l’ambiguite reste entiere puisqu’on peut decoder soit a abd... ou a acd.... �
Construction d’un code prefixe : Une maniere tres subtile consiste a utiliser
un arbre dont chaque branche represente une lettre de l’alphabet de reference. Le
chemin permettant de conduire a l’un des mots ne soit pas inclus dans le chemin
menant a l’autre mot.
Un code est dit complet s’il est instantane et si toutes les feuilles de l’arbre, qui
lui est associee, sont des mots code.
Exemple 2.3.6 (Arbre d’un code prefixe) Les codes C1 = {c1 = 0, c2 = 10, c3 =
11} et C2 = {c1 = 00, c2 = 10, c3 = 01, c4 = 11} sont des codes prefixes. De plus, le
deuxieme code est complet. Leurs arbres se presentent comme suit :
•
•
•c3
c1•
c2•
1??
???0
����
�
1????0
����
•
•
•c4
•
•c3c1• c2•
1OOOOOOOOOOO
0ooooooooooo
0��
���1??
??0��
��� 1??
??
Figure 2.1: Arbre d’un code prefixe
Mr HITTA Amara46
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Exemple 2.3.7 Le code {c0 = 0, c1 = 1, c2 = 01} est non instantane. Il es de plus
ambigu, car 01 peut se decoder comme c0c1.
Theoreme 2.3.1 (Inegalite de Kraft) Pour tout code binaire uniquement dechiffrable,
les longueurs `i des mots code verifient :
∑i
2−`i ≤ 1.
Inversement : Etant donne un ensemble de mots de longueurs `i verifiant cette
inegalite, il existe un code prefixe dont les mots codes sont de longueur `i.
Preuve. Elle se fait par recurrence sur la longueur d’un arbre binaire representant
le code instantanee en question :
• On verifie que le theoreme est vrai pour un arbre de longueur 1.
• On suppose, ensuite, qu’il est vrai pour les arbres binaires de longueur 1, 2, · · · , `max
et on montre qu’il l’est pour un arbre de longueur 1 + `max. �
Exemple 2.3.8 Existe-t-il un code binaire instantane dont les mots code ont pour
longueurs : 2, 2, 3, 3, 3, 3, 5, 5 ? D’apres l’inegalite de Kraft-McMillan, ce code existe
si et seulement si∑i
1/2` ≤ 1. Ce qui se traduit, dans ce cas, par
1
4+
1
4+
1
8+
1
8+
1
8+
1
8+
1
32+
1
32= 1.0625 > 1.
Ce code n’existe pas. �
Ainsi, pour obtenir un alphabet optimal il suffit de s’interesser aux codes prefixes.
On remarque, par ailleurs que :
• Comme limk→0
2−k = +∞, cette inegalite implique qu’on ne peut pas prendre
trop de mots code ayant une tres faible longueur.
Mr HITTA Amara47
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
• Dans le cas non binaire, c’est-a-dire, lorsque l’on a un code sur un corps de
Galois Zq ou q > 2, l’inegalite de Kraft-McMillan s’ecrit
∑i
q−`i ≤ 1.
• L’inegalite de Kraft reste vraie lorsque le nombre de mots est infini.
• Dans l’inegalite de Kraft l’alphabet de la source importe peu, seules les longueurs
`i des mots sont prises en compte.
Theoreme 2.3.2 La longueur moyenne d’un code uniquement dechiffrable C d’une
variable aleatoire X verifie
L[C(X)] ≥ H(X).
Preuve : Posons z′ =∑j
2−`j < 1 (inegalite de Kraft), et soit la probabilite implicite
qi ≡ 2−`i/z alors `i = log(1/qi)− log z. L’inegalite de Gibbs s’ecrit∑i
pi log(1/qi) ≤∑i
pi log(1/pi) ou l’egalite est verifiee si qi = pi. Alors
L[C(X)] =∑i
pi`i =∑i
pi log(1/pi)− log z.
(∑i
pi
)≥
∑i
pi log(1/pi)− log z.
≥∑i
pi log(1/pi) = H(X). �
L’efficacite du code C est definie par
η =LminL[C(X)]
=H(X)
L[C(X)].
Le rodandance du code C(X) est la quantite
ρ = 1− η.
Mr HITTA Amara48
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Le cas d’egalite de l’inegalite de Kraft, L[C] = H(X), est atteinte seulement dans le
cas extreme ou pi = 2`i et les longueurs des mots code sont `i = log(1/pi).
Definition 2.3.3 Un code de source C(X) est dit optimal si H(X) = L[C(X)]
c’est-a-direlorsque les longueurs des mots code sont `i = log(1/pi) :
Le code C(X) est optimal ssi H(X) = L[C(X)] c’est-a-dire `i = log(1/pi).
Exemple 2.3.9 Considerons la variable aleatoire X, prenant ses valeurs sur la
source SX , que l’on code a l’aide du code C(X). Ce code est instantane puisqu’aucun
mot n’est prefixe d’un autre.
SX s1 = a s2 = b s3 = c s4 = d
P(SX) 1/2 1/4 1/8 1/8
c1 c2 c3 c4
0 10 110 111
Table 2.1: Code optimal d’une source aleatoire
L’entropie de la source est
U(SX) = 1.75 bits et L[C(X)] = 1/2+2.(1/4)+6.(1/8) = 1.75 = U(SX) bits.
C’est un code est optimal du point de vue de la longueur moyenne. D’autre part,
l’egalite de Kraft est verifiee car (1/21) + (1/22) + (1/23) + (1/24) = 1. Ce code est
complet donc optimal en considerant le nombre de symboles utilises. Remarquons,
par ailleurs, que `i = log(1/pi) pour i = 1, 2, 3, 4. �
Theoreme 2.3.4 (Shannon : Codage de source sans bruit) Soit X une vari-
able aleatoire, il existe un code binaire prefixe C(X) dont la longueur moyenne verifie
H(X) ≤ L[C(X)] ≤ H(X) + 1.
Preuve : Prenons les longueurs des mots code comme etant les parties entieres des
longueurs d’un code optimal c’est-a-dire`i = [log(1/pi)],∑
i pi = 1. Il existe un code
prefixe C(X) telle que l’inegalite de Kraft-McMillan soit satisfaite. Ainsi
L(C(X)) =∑i
pi [log(1/pi)] ≤∑i
pi(log(1/pi) + 1) ≤ H(X) + 1. �
Mr HITTA Amara49
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Ce theoreme donne la meilleure des performances possibles, en termes de longueur
moyenne des mots code, pour encoder la variable aleatoire X qui prend ses valeurs
dans l’alphabet-source S.
Proposition 2.3.5 Soit C(X) un code complet d’une variable aleatoire X prenant
ses valeurs sur une source S, alors
L[C(X)] = H(X) +DKL[PS||PKraft].
ou PKraft designe la distribution de probabilite sur les valeurs de S definie par
PKraft(si) = 2−`i, `i represente la longueur du mot code ci associe a si ∈ S.
Preuve. Comme le code C est complet, alors∑i
PKraft(si) =∑i
2−`i = 1.
Donc PKraft est une distribution de probabilite sur S. D’autre part,
DKL[PS||PKraft] =∑i
PS(si) logPS(si)
PKraft(si)
=∑i
PS(si) logPS(si)−∑i
PS(si) logPKraft(si)
= −H(X)−∑i
PS(si) log 2−`i
= −H(X) +∑i
PS(si)`i
= −H(X) + L[C]. �
Ainsi, la divergence de Kullback-Leibner, entre la distribution de S et la distribution
PKraft definie par les longueurs des mots code, represente le perte en terme de
longueur moyenne du code par rapport a la valeur optimale de l’entropie H(X).
2.3.1 Codage binaire de Shannon-Fano
Le code de Shanonn-Fano est le premier code utilise pour exploiter la redondance
d’une source. L’algorithme de ce codage suit les etapes suivantes :
Mr HITTA Amara50
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
• La classification des differents symboles a coder suivant l’ordre croisant de leur
probabilite les uns en dessus des autres.
• Diviser ses symboles en deux sous-groupes de telle sorte que les probabilites
cumulees de ces deux sous-groupes soient aussi proches que possible l’un de
l’autre.
• On effecte 0 au sous-groupe d’en haut et 1 au sous-groupe d’en bas. Ainsi, les
mots du sous-groupe d’en haut commenceront par 0 et ceux du sous-groupe
d’en bas commenceront par 1.
• On repete les etapes 1 et 2 jusqu’a ce que les derniers sous-groupes ne conti-
ennent qu’un seul element.
Exemple 2.3.10 (Shanonn-Fano) Considerons la source S = {a,b, c,d, e} dont
les frequences d’apparition des symboles sont :
Symboles a b c d e
Probabilites 15/39 7/39 6/39 6/39 5/39
Remarquons que la probabilite cumulee du sous-groupe S1 = {a,b} est presque
S1 Probabilite
a 15/39 0 0
b 7/39 0 1
S2 Probabilite
c 6/39 1 0
d 6/39 1 1 0
e 5/39 1 1 1
Table 2.2: Prob. cumulees des sous-groupes S1 et S2
identique a celle du sous-groupe S2 = {c, d, e}. Le codage de la source S est alors :
a→ 00 b→ 01 c→ 10 d→ 110 e→ 111
Mr HITTA Amara51
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
2.3.2 Codage binaire de Huffman
Son inventeur D. Huffman est parti d’un constat simple : les donnees d’un document
apparaissent selon une frequence irreguliere. Il eut alors l’idee de coder les donnees
qui se repetent souvent avec moins de bits que celles qui apparaissent plus rarement.
L’algorithme de Huffman produit, comme on peut le constater, un code optimal
pour une source-alphabet.
Soit X une variable aleatoire prenant ses valeurs sur une source-alphabet S =
{s1, · · · , sn} telle que P(X = si) = pi, i = 1, · · · , n. Considerons le code binaire
Cn(X) resultant de l’application f : S → {0, 1}+. L’algorithme de codage binaire
de Huffman suit les etapes suivantes :
• La classification des lettres de l’alphabet suivant l’ordre croissant de leur prob-
abilites : en supposant, sans perdre de generalite, que p1 ≥ p2 ≥ · · · ≥ pn−1 ≥pn.
• La combinaison de 2 lettres les moins probables en une seule dont le probabilite
est egale a la somme des probabilites des 2 lettres : Comme les etats X = sn−1
et X = sn sont les moins probables, posons p′n−1 = pn−1 + pn. On reduit ainsi
la source-alphabet S en la nouvelle source-alphabet
S(n−1) = {s1, s2, · · · , sn−2, s(n−1)n−1 }
ou s(n−1)n−1 sera la lettre sn−1 ou sn. Soit X(1) la variable aleatoire prenant ses
valeurs sur S(n−1) telle que
P[X(1) = si] = pi pour i = 1, · · · , n− 2
P[X(1) = s(n−1)n−1 ] = p′n−1 pour i = n− 1.
On definie, ainsi, un encodage de la nouvelle source par
f (n−1) : S(n−1) → {0, 1}+.
• On repete les etapes 1 et 2 jusqu’a ce que la source-alphabet soit reduite a
une source a 2 lettres c’est-a-direS(2) = {x, y}. On defini, enfin, un dernier
encodage par
f (2) : S(2) → {0, 1}+ tel que f (2)(x) = 0 et f (2)(y) = 1.
Mr HITTA Amara52
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
• Par un processus inverse, dit processus d’eclatement, on remonte l’arbre
obtenue en concatenant un 0 ou un 1 aux deux lettres qui resultent d’une
meme lettre jusqu’a epuisement des lettres de la source initiale S.
Exemple 2.3.11 (Codage de Huffman binaire) Soit une source S = {a, b, c}emettant ses lettres avec des probabilites respectives 0.4, 0.3 et 0.3. On combine
les moins probables en la lettre bc de probablite 0.3 + 0.3 = 0.6. On termine, ainsi,
la premiere etape du processus en codant a a 1 et bc a 0. Le code de Huffman est
obtenu, alors, en concatenant les symboles binaires dans le sens inverse : les lettres
b et c resultent de bc, elles seront codees a 00 et 01. Ce qui donne le processus
d’eclatement suivant :
Etape 1
si pi ←↩
a 0.4 1
b 0.3 00
c 0.3 01
Etape 2
s1i p1
i ←↩
bc 0.6 0
a 0.4 1
Le codage de Huffman de la source S est a→ 0, b→ 00 et c→ 01. �
Exemple 2.3.12 Considerons la source S suivante :
si a b c d e
pi 15/39 7/39 6/39 6/39 5/39
Le codage de Huffman se presente en 4 etapes :
Mr HITTA Amara53
08-Mai 45 Guelma University
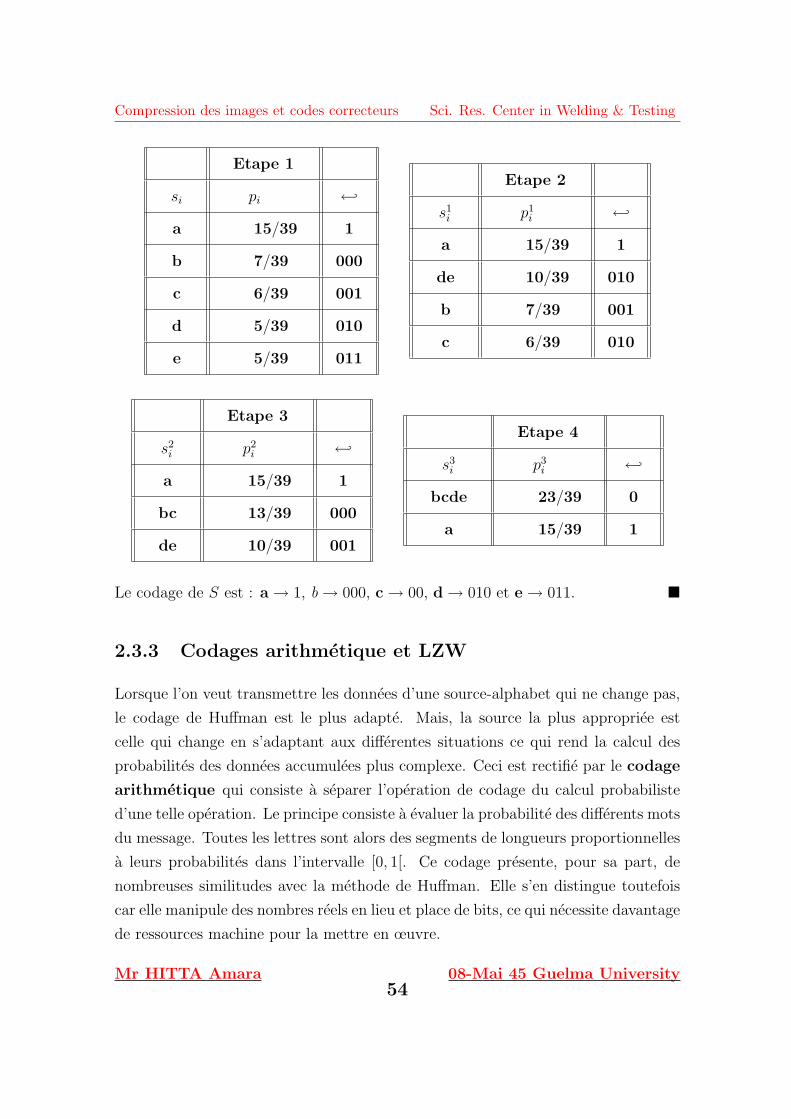
Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Etape 1
si pi ←↩
a 15/39 1
b 7/39 000
c 6/39 001
d 5/39 010
e 5/39 011
Etape 2
s1i p1
i ←↩
a 15/39 1
de 10/39 010
b 7/39 001
c 6/39 010
Etape 3
s2i p2
i ←↩
a 15/39 1
bc 13/39 000
de 10/39 001
Etape 4
s3i p3
i ←↩
bcde 23/39 0
a 15/39 1
Le codage de S est : a→ 1, b→ 000, c→ 00, d→ 010 et e→ 011. �
2.3.3 Codages arithmetique et LZW
Lorsque l’on veut transmettre les donnees d’une source-alphabet qui ne change pas,
le codage de Huffman est le plus adapte. Mais, la source la plus appropriee est
celle qui change en s’adaptant aux differentes situations ce qui rend la calcul des
probabilites des donnees accumulees plus complexe. Ceci est rectifie par le codage
arithmetique qui consiste a separer l’operation de codage du calcul probabiliste
d’une telle operation. Le principe consiste a evaluer la probabilite des differents mots
du message. Toutes les lettres sont alors des segments de longueurs proportionnelles
a leurs probabilites dans l’intervalle [0, 1[. Ce codage presente, pour sa part, de
nombreuses similitudes avec la methode de Huffman. Elle s’en distingue toutefois
car elle manipule des nombres reels en lieu et place de bits, ce qui necessite davantage
de ressources machine pour la mettre en œuvre.
Mr HITTA Amara54
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Notons, enfin, l’existence du code LZW c’est-a-dire Lempel, Ziv, Welch dont
le principe est de chercher si le mot d’un fichier a coder est deja memorise dans un
dictionnaire qui n’est pas stocke dans le fichier compresse et d’envoyer simplement
l’adresse de ce mot.
2.4 Compression avec perte d’information
Propose en 1988, ce codage fait appel a la Transformee en Cosinus Discrete, TCD,
qui s’applique sur un domaine spaciale ou les donnees sont definis en fonction de
leurs positions x et y, pour le transformer en un spectre de frequence definissant
l’apparition de chaque pixel dans un bloc de pixels et inversement, ITCD.
La transformation en Cosinus Discrete s’effectue sur une matrice carree d’ordre n de
valeurs de pixels et donne une matrice de meme taille de cœfficients de frequence.
Le temps de calcul requis pour chaque element dans la TCD depend de la taille de
la matrice. Pour ce faire, on decompose la matrice en blocs de matrices carrees de
taille 8× 8 pour que le calcul de la TCD puissent etre effectue en un laps de temps
raisonnable.
En sortie, La valeur du pixel de cordonnees (0, 0) dans chaque matrice d’ordre 8 est
dit cœfficient continu. Les 64 valeurs transormees de chaque matrice de sortie
sont positionnees de telle sorte que le cœfficient continu soit place en haut a gauche
de ce bloc. Ainsi, la TCD concentre la representation de l’image en haut a gauche.
Les cœfficients en bas a droite de cette matrice contiennent moins d’information
utile.
On peut citer, entre autres, les normes de codage suivantes :
2.4.1 JPEG (Joint Photographie Experts Group)
Concue par le groupe ISO (International Standard Organisation ) et le groupe CEI
(Commissiom Electronic International), cette norme est destinee a la compresssion
des images fixes en couleurs et a niveaux de gris en vue de leurs stockage sur des
supports numeriques.
Mr HITTA Amara55
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Supposons que l’image originale est donnee par la matrice A = (akl)0≤k,l≤n−1 et que
l’image transformee est donnee par la matrice B = (bij)0≤i,j≤n−1. Alors,
bij =2
ncicj
n−1∑i=0
n−1∑i=0
cos
[(2k + 1)
2niπ
]cos
[(2l + 1)
2njπ
]akl
avec c0 = 1/√
2 et ci = 1 si i 6= 0. Il existe une matrice orthogonale P = (pij)
c’est-a-direP−1 = P t telle que
B = P−1AP et pij = cj
√2
ncos
[(2i+ 1)jπ
2n
].
On decoupe l’image en blocs de taille 8 × 8 et on applique a ces blocs la transfor-
mation, pour u, v = 0, · · · , 7,
TCD (u, v) =1
4c(u)c(v)
7∑x=0
7∑y=0
f(x, y) cos
(2x+ 1
16uπ
)cos
(2y + 1
16vπ
),
avec c(0) = 1/√
2 et c(u) = 1 si u 6= 0. La TCD possede une inverse de forme iden-
tique. Bien que la reconstitution exacte des donnees originales puisse etre realisee
en theorie par l’inverse de la TCD, il est souvent impossible de le faire avec une
arithmetique a precision finie. Meme si les erreurs de TCD en aval peuvent etre
tolerees, les erreurs liees a la TCD inverse doivent respecter un minimum de precision
si l’on veut eviter une disparite due a la DCT inverse entre les images reconstituees
et les images originales.
L’amplitude TCD (u, v), lorsque u et v sont faibles, est plus importantes que lorsque
u et v sont grands. On peut ainsi coder les valeurs de TCD (u, v) sur moins de bits
lorsque u et v sont grands et ignorer, eventuellement, les composantes de tres faible
amplitude.
Dans le codeur, la transformee est suivie de la quantification des cœfficients, etape a
laquelle la perte des details video est justifiee par le rapport de compression video :
En effet, l’œil humain est plus sensible aux erreurs de reconstitution liees aux
basses frequences spatiales qu’a celles liees aux hautes frequences. Les changements
lineaires lents de l’intensite ou de la couleur (infomation de basse frequence) sont
Mr HITTA Amara56
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
importants pour l’œil. Les changements rapides dans les hautes frequences peu-
vent souvent etre perceptibles, c’est pourquoi on peut les eliminer. Pour chaque
cœfficient dans la matrice TCD, il faut calculer une valeur quantifiee correspon-
dante en divisant chaque cœfficient de la TCD par un parametre de quantification.
C’est le seul moyen par lequel on peut regir le degre de compression et de reduction
correspondante de la fidelite de l’information video compressee.
On applique ensuite un codage de Huffman. Ce sont ces donnees qui seront trans-
mises; le recepteur calcule alors la transformee inverse de la TCD. On obtient,
ainsi, une qualite acceptable pour un debit de 0.5 bit/pixel et une excellente qualite
pour un debit de 2 bits/pixel alors que dans l’image initiale il fallait un debit de 8
bits/pixel. La compression JPEG se deroule suivant les etapes suivantes :
Image originale→ Calcul TCD→ Quantification→ Compression → Image compressee.
2.4.2 MPEG (Moving Picture Experts Group)
Destinee au codage des images animees en vue de leurs stockage sur les supports
numeriques, cette norme a ete propose en 1990. Il s’agit de reduire le debit de
transmission de quelques dizaines de megabits par seconde ‘ des debits plus faibles,
qui peuvent se reduire a 64000 bits/s ou 44000 bits/s en tenant compte de la remar-
que suivante : dans une sequence d’images, deux images successives se ressemblent
beaucoup et on peut, alors, imaginer de ne coder que la difference entre deux images.
On remarque, de plus, que la difference entre une image et celle qui la precede est
une translation. On opere, alors, comme suit :
On decoupe l’image I(x, y) en blocs de 16. Soit x0 et y0 les coordonnees de
l’origine de l’un de ces blocs dans le plan et on cherche dans l’image precedente
Ip le couple (∆x,∆y) qui minimise∑
x,y≥0 |I(x0+x, y0+y)−Ip(x0+x+∆x, y0+
y + ∆y)|. Une fois trouve le deplacement, on calcul D = I(x0 + x, y0 + y) −Ip(x0 + x+ ∆x, y0 + y + ∆y) qu’on code par une transformee en cosinus dans
le codage JPEG. On transmet le vecteur de deplacement (∆x,∆y) ainsi que
la difference D des images codees. Le recepteur a ainsi toutes les informations
pour reconstruire I(x, y).
Mr HITTA Amara57
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Aux cours des dernieres annees, l’interet pour le multimedia a entraine l’investissement
d’efforts considerables de recherche sur le codage vedio dans les universites et l’industrie,
efforts, qui se sont traduits par l’elaboration de plusieurs normes. Ces normes visent
un vaste eventail d’applications aux exigences variees quant au debit binaire, a la
qualite d’image, a la capacite, a la complexite, a la resilience a l’erreur et au delai
ainsi qu’a l’amelioration des rapports de compression, on cite entre autres :
• MPEG-I (1992) specifie une compression du signal video a un debit de 1.5
Mbits/s.
• MPEG-II (1994) est destine a la compression du signal video a des debits de
10 Mbits/s.
• MPEG-III est destine a la television haute definition a des debits de 30 a 40
Mbits/s.
• MPEG-IV est destine au codage d’images animees a tres faibles debits de 10
Mbits/s.
2.5 Exercices et solutions
Exercice 1.
• Verifiez que 0− 19− 860195− 6 et 0− 19− 853256− 3 sont des ISBN valides.
• Dans une communication, ou l’on utilise un code ASCII 8-bit a parite paire,
les mots recus 11100001, 10000101 et 01100100 s’ont-ils des mots code. Si ce
n’est pas le cas, supposons qu’exactement l’un des 8 bits est errone. Quels
seront les symboles correspondants aux huits mots code resultants de ce mot
recu ? Expliquez pourquoi on peut detecter une seule erreur sans la corrigee.
Solution 1.
• On a respectivement pour les deux ISBN :
Mr HITTA Amara58
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
•
1× 0 +2× 1 + 3× 9 + 4× 8 + 5× 6 + 6× 0 + 7× 1 + 8× 9 + 9× 5 + 10× 6 = 275
1× 0 +2× 1 + 3× 9 + 4× 8 + 5× 5 + 6× 3 + 7× 2 + 8× 5 + 9× 6 + 10× 3 = 242.
• Les deux nombres sont congrus a 0 modulo 11.
Exercice 2.
• Quels sont les mots code du code de repetition de longueur 5 ? Calculer
Perreur sachant que la probabilite qu’un bit soit altere est p = 1/4.
• calculer H2(1/8, 1/8, 3/4); H2(1/3, 2/3); H2(1, 0, 0). Par convention, en base
b, on pose p logb p = 0 pour p = 0.
• Trouver une relation entre Hb(p) et Hc(p).
• Montrer que la fonction d’entropie H2(x) = −x log2 x − (1 − x) log2(1 − x),
0 < x < 1, est symetrique par rapport a la droite verticale x = 1/2 c’est-a-dire
H2[(1/2)− x] = H2[(1/2) + x] pour 0 < x < 1/2.
• Calculer la derivee de la fonction d’entropie, en deduire qu’elle atteint sa valeur
maximale en x = 1/2 sur l’intervalle [0, 1]. En deduire que 0 < H2(p) < 1
lorsque 0 < p < 1.
Solution 1.
• Les mots code sont 00000 et 11111. La probabilite d’erreurs Perreur est la
probabilite d’avoir au moins 3 bit-erreurs. Donc
Perreur =
(5
3
)(1
4
)3(3
4
)2
+
(5
4
)(1
4
)4(3
4
)+
(5
5
)(1
4
)5
= 0.414.
•
H2
(1
8,1
8,3
4
)= −1
8log2
18− 1
8log2
18− 3
4log2
34∼ 1.06 bits.
H2
(1
3,2
3
)= −1
3log2
13− 2
3log2
23∼ 0.918 bits.
H2(1, 0, 0) = −1 log2 1− 0− 0 = 0.
Mr HITTA Amara59
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
• On a
Hb(p) =
(loge c
loge b
).Hc(p)
• On a
H2
(1
2+ x
)= −
(12
+ x)
log2
(12
+ x)−(1−
(12
+ x))
log2
(1−
(12
+ x))
= −(1−
(12− x))
log2
(1−
(12− x))−(
12− x)
log2
(12− x)
= H2
(12− x)
Ce qui montre que le graphe de H2(x) est symetrique par rapport a la verticale
x = 1/2.
• Comme log2 x = c loge x ou c = 1/ loge 2, on obtient H2(x) = cx loge x −
c(1 − x) loge x. Pour 0 < x < 1, on a H ′2()x = c loge
(1− xx
). D’autre
part H ′2(x) = 0 au point x = 1/2. La fonction H2 atteint son maximum
H2(1/2) = 1. Ainsi, pour 0 < p < 1/2 on a 0 < H2(p) < 1.
Exercice 2.
Soit X une variable aleatoire discrete pouvant prendre n valeurs differentes et soit
Y une variable aleatoire discrete de facon uniforme sur m valeurs distinctes. On ne
fera aucune hypothese particuliere sur X.
• Quelle est l’incertitude maximale possible pour X ? JJustifiez votre reponse.
• Que vaut l’entropie de Y ?
• Dans le cas ou n = m, classez par ordre croissant (c’est-a-dire≤) les grandeurs
suivantes :
H(Y ), 0, H(X), H(X) +H(Y ), H(X, Y ), H(X|Y ),
ou H designe l’entropie d’une variable aleatoire. Justifiez chacune des etapes
de votre classement. Explicitez les cas d’egalite, c-a-d. donnez pour chaque
inegalite les cas ou elle devient une egalite.
• On considere le cas ou n = 3, m = 4 et ou la distribution jointe P(X = xi, Y =
yi) est donnee par
Mr HITTA Amara60
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
P(X, Y ) y1 y2 y3 y4
x1 1/24 1/12 1/6 1/24
x2 1/6 1/8 1/24 1/6
x3 1/24 1/24 1/24 1/24
Verifiez que Y est bien uniformement distribuee. Calculez I(X, Y ). Donnez
le resultat sous la forme I(X, Y ) = 124
(a− b log2 3) ou a et b sont deux entiers
positifs.
Solution 2.
• L’incertitude d’une variable aleatoire, c’est-a-direson entropie, est maximale
lorsque sa distribution est uniforme. Son entropie vaut alors le logarithme du
cardinal de l’ensemble des valeurs possibles pour cette variable aleatoire. Pour
X la valeur maximale de H(X) est donc log(n).
• La variable aleatoire Y est uniformement repartie donc H(Y ) = log(m).
• Le resultat complet est :
0 ≤ H(X|Y ) ≤ H(X) ≤ H(Y ) ≤ H(X, Y ) ≤ H(X) +H(Y )
Les justifications sont les suivantes :
• Une entropie est toujours positive. Il y a egalite si H(X|Y ) = 0 c’est-a-diresi
la connaissance de Y determine X autrement dit si X est une fonction de Y .
• L’entropie conditionnelle est inferieure a l’entropie de la variable conditionnee
c’est-a-direX : la connaissance de Y reduit l’incertitude sur X. Si X et Y
sont independante alors H(X, Y ) = H(X|Y ) = H(X, Y ) +H(X, Y ).
• L’entropie de Y etant maximale, elle est plus grande que celle de X, il y’a
egalite si X est equipartie.
• L’entroipie jointe est inferieure a la somme des entropies. Elle n’est egale a
cette somme que dans le cas d’independance.
Mr HITTA Amara61
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
• La variable Y est equipartie
P(Y = y1) = 124
+ 16
+ 124
= 14
P(Y = y2) = 112
+ 18
+ 124
= 14
P(Y = y3) = 16
+ 124
+ 124
= 14
P(Y = y4) = 124
+ 16
+ 124
= 14.
Le plus simple pour calculer I(X, Y ) est d’utiliser I(X, Y ) = H(Y )−H(Y |X)
puisque H(Y ) est connue. En effet, Y est equipartie sur les 4 valeurs, alors
H(Y ) = log2 4 = 2 bit. Pour calculer H(Y |X) le mieux est de passer par la
formule
H(Y |X) =∑x
P(X = x)H(Y |X = x).
On remarque que H(Y |X = x3) = log2 4 == 2 bit puisque Y |x3 est equipartie
sur les 4 valeurs. Pour H(Y |X = x1) et H(Y |X = x2), on a
H(Y |X = x1) = 2.18
log2 8 + 14
log2 4 + 12
log2 2
= 28.3 + 1
4.2 + 1
2= 7
4.
De meme
H(Y |X = x2) = 2.13
log2 3 + 14
log2 4 + 112
(log2 3 + log2 4)
= 23.3 + 9
12log2 3 = 2
3+ 3
4log2 3.
D’ou
H(Y |X) = 13.74 + 1
2
(23
+ 34
log2 3)
+ 16.2
= 3024
+ 924
log2 3
et
I(X, Y ) = 2− 10
8+
3
8log2 3 =
1
24(8− 9 log2 3).
Exercice 3.
On considere le canal binaire a bruit additif, c-a-d. tel que Y = X + Z ou X
est binaire et Z est une variable aleatoire independante de X definie par
P(Z) =
p si X = 0
1− p si X = a ∈ Z∗.
Mr HITTA Amara62
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
• Calculer la capacite de ce canal en fonction de p dans le cas ou a 6= 1 et
a 6= −1.
• Calculer la capacite du canal pour p = 0.5 dans le cas a = 1 eb t a = −1.
• Dans le cas a = 1 et l’addition binaire (“ou exclusif”), que peut-on dire du
canal ?
• Qu’obtient-on dans le cas d’un canal analogique a seuil, c-a-d. tel que a ∈ R∗
et ou y ≥ 0.5 est toujours decode 1 et y < 0.5 est toujours decode 0 ?
Exercice 4.
• Montrer que la cascade d’un nombre quelconque de canaux binaires symetriques
est encore un canal binaire symetrique.
• Dans le cas particulier ou l’on cascade n fois le meme canal de probabilite de
changement de bits p, quelle relation de recurrence verifie la probabilite Pn
• Soit Qn = 1 − 2Pn. Trouver l’expression de Qn en fonction de p. En deduire
la valeur de Pn en fonction de p et n.
• Que veut la capacite du canal ainsi obtenu, c’est-a-direcanal cascade de n
CBS ? Montrer que cette capacite tend vers 0 pour 0 < p < 1.
Mr HITTA Amara63
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Mr HITTA Amara64
08-Mai 45 Guelma University

CHAPITRE
3
CODES CORRECTEURS LINEAIRES
EN BLOCS
3.1 Codes lineaires binaires
C’est Kiyasu (1953) et Slypian (1950-60) qui ont donne une definition mathematique
plus concise des codes lineaires, en leurs imposant une certaine structure algebrique,
les considerant comme des sous-espaces vectoriels. Cette algebrisation du codage
nous aidera a construire des encodeurs et des decodeurs plus pratiques.
Definition 3.1.1 (Code lineaire) Un code binaire C(2) est dit lineaire s’il est
stable sous l’addition des mots code c’est-a-direx + y ∈ C(2) pour tous x,y ∈ C(2).
Si x est un mot code, le mot somme x + x = 2x = 0 l’est aussi. Ainsi, tout code
binaire lineaire contient le mot 0. En fait, le code C(2) est un Z2-espace vectoriel
65

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
car la multiplication par Z2 stabilise C(2) c’est-a-diresi c ∈ C(2) alors 1.c = c et
0.c = 0.
Exemple 3.1.1 (Codes binaires lineaires) • Designons par Zn2 , n ∈ N∗, l’ensemble
des suites binaires a n termes, c’est-a-dire que Zn2 = {(x1, x2, · · · , xn) : xi ∈
Z2, i = 1, · · · , n}. C’est un Z2-espace vectoriel de dimension n.
• Le code binaire de repetition C(2) = {000, 111} est lineaire.
• Le code binaire C′(2) = {000, 001, 101} n ’est pas lineaire car 001 + 101 = 100
n’est pas un mot code. �
Definition 3.1.2 (Encodeur) Un code binaire lineaire note Ckn(2), 0 ≤ k ≤ n,
est l’espace image d’une application lineaire injective, dite encodeur, E : Zk2 →
Zn2 c’est-a-dire
Ckn(2) = E(Zk2) ⊂ Zn
2 .
Le code binaire lineaire Ckn(2), considere comme un sous-espace vectoriel de Zn2 ,
contient |Ckn(2)| = 2k mots codes :
L’entier n est la longueur du code, k sa dimension et r = n − k sa
redondance.
La description de ce code est facile des que l’on a k mots lineairement independants
c’est-a-direune base.
Exemple 3.1.2 (Code de parite) Le code de parite d’ordre 3, note C23(2), est
l’image de l’encodeur E : Z22 → Z3
2 defini par
E(00) = 000, E(01) = 011, E(10) = 101, E(11) = 110.�
Plus generalement: Le code de parite d’ordre n, note Cn−1n (2), est l’image de
l’encodeur E : Zn−12 → Zn
2 defini par E : x1 . . . xn−1 7→ x1 . . . xn−1pn ou pn =
x1 + x2 + . . .+ xn−1.
Mr HITTA Amara66
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Exemple 3.1.3 (Code de Hamming) Le code de Hamming H3(2) = C47(2)
est l’image de l’encodeur E : Z42 → Z7
2 defini par E(x1x2x3x4) = x1x2x3x4c5c6c7 ou
les bits de controle c5, c6 et c7 sont donnes par :c5 = x2 + x3 + x4
c6 = x1 + x3 + x4
c7 = x1 + x2 + x4.
Les mots de ce code sont au nombre de |H3(2)| = 24 = 16, a savoir
0000000 1110000 1001100 1000011
0101010 1001100 0011001 0010110
1111111 0001111 0110011 0111100
1010101 1011010 1100110 1101001.�
L’usage des codes correcteurs lineaires est tres utile pour les raisons suivantes :
• Au lieu d’etablir la liste des 2k mots code, il suffit d’avoir une base generatrice
de k mots.
• La distance minimale du code est facile a calculer.
• Un codage rapide de l’information pour un minimum d’espace de stockage.
• Des methodes nombreuses et pratiques de recherche des erreurs.
Ces principes de bases etant donnees, nous allons decrire dans les sections qui suivent
deux techniques permettant de corriger les erreurs survenues.
3.2 Matrice generatrice
La premiere description consiste a definir un code par une matrice qui lui est as-
sociee :
Mr HITTA Amara67
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Definition 3.2.1 (Matrice generatrice) La matrice generatrice du code lineaire
Ckn(2), notee G, est la matrice de type k × n dont les lignes forment une famille
generatrice du code.
De ce fait, le code est engendre par les mots lignes de la matrice generatrice. La
matrice generatrice represente un tableau de mots independants du code permettant
de trouver tous les autres mots du code par addition ou par soustraction. Chaque
mot x ∈ Zk2, 0 ≤ k ≤ n, sera code et transmis sous la forme xG :
Ckn(2) = {xG : x ∈ Zk2.
Exemple 3.2.1 (Code binaire de repetition) Note C1n(2), il contient deux mots
de longueur n, a savoir(
0 · · · 0)
et(
1 · · · 1)
. Sa matrice generatrice est la
matrice ligne d’ordre n : G =(
1 · · · 1)
. �
Exemple 3.2.2 (Code de parite C23(2)) Il a pour matrice generatrice
G =
(1 0 1
0 1 1
);
elle est de type 2×3. On remarque, par ailleurs, que le mot du code 110 ∈ C23(2) est
la somme des lignes de la matrice G. Plus generalement : Le code Cn−1n (2) admet
pour matrice generatrice, la matrice de type (n− 1)× n :
G =
1 0 · · · 0 1
0 1. . .
... 1...
. . . . . . 0...
0 · · · 0 1 1
. �
Exemple 3.2.3 (Code de Hamming) Le code de Hamming H3(2) = C47(2) a
pour matrice generatrice du type 4× 7 :
G =
1 0 0 0 0 1 1
0 1 0 0 1 0 1
0 0 1 0 1 1 0
0 0 0 1 1 1 1.
. �
Mr HITTA Amara68
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
D’apres ces exemples, on remarque que la matrice generatrice du code Ckn(2) se
presente sous la forme standard
G =(Ik P
)
ou Ik designe la matrice identite d’ordre k et P une matrice de type k × (n− k).
Definition 3.2.2 (Codes equivalents) Deux codes binaire lineaires en bloc sont
equivalents l’un deux s’obtient a partir de l’autre en effectuant des permutations
fixes sur les colonnes des matrices generatrices.
On montre, par ailleurs, que : Tout code lineaire est equivalent a un code dont la
matrice generatrice se presente sous forme standard en appliquant des permutations
fixes a certaines de ses colonnes ce qui donne un code equivalent.
Exemple 3.2.4 (Code de parite d’ordre 2) Le code C23(2) = {000, 011, 101, 110}
admet deux matrices generatrices, a savoir
G1 =
(0 1 1
1 0 1
)et G2 =
(1 1 0
1 0 1
).
Il est plus interessant d’obtenir la matrice generatrice systematique de ce code
G2 ==
(1 1 0
1 0 1
)−→
(1 1 0
0 1 1
)
−→
(1 0 1
0 1 1
). �
Exemple 3.2.5 (Forme standard) • Code de parite d’ordre n : La ma-
trice generatrice du code de parite Cn−1n (2) s’ecrit sous la forme standard
G =(In−1 P
)
Mr HITTA Amara69
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
ou In−1 est la matrice identite d’ordre n − 1 et P la matrice colonne de type
(n− 1)× 1
In−1 =
1 0 · · · 0 0
0 1. . .
... 0...
. . . . . . 0...
0 · · · 0 0 1
et P =
1
1
1
.
• Code de Hamming H3(2) = C47(2): Sa matrice generatrice s’ecrit sous la
forme standard G =(I4 P
)ou
I4 =
1 0 0 0
0 1 0 0
0 0 1 0
0 0 0 1
et P =
1 1
0 1
1 0
1 1
.�
L’avantage d’avoir la matrice generatrice d’un code Ckn(2) sous sa forme standard
G =(Ik P
)facilite le codage des donnees et l’interpretation facile des mots code
envoyes. Soit x un mot code envoye de longueur k, il sera code sous la forme
c = xG =(xIk xP
)=(x xP
).
Seule la deuxieme multiplication est necessaire :
• Les k bits, bits d’information, initialement envoyes sont sauvegardes.
• Les n − k bits restants, determines par la matrice xP , nous fournissent des
informations utiles pour detecter et corriger les erreurs survenues, c’est les bits
de controle.
Exemple 3.2.6 (Matrice standard et parite de controle) Le code lineaire C35(2)
a pour matrice generatrice G =(I3 P
)telle que
I3 =
1 0 0
0 1 0
0 0 1
P =
0 1
1 1
1 1
.
Mr HITTA Amara70
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Le mot x = x1x2x3 sera code sous la forme xG = x1x2x3(x2 +x3)(x1 +x2 +x3). Les
trois premiers bits sont les bits d’information du mot x. Les bits en position 4 et
5 sont determines en fonction des bits d’information : le bit en position 4, a savoir
x2 + x3, nous renseigne en quoi x1 et x2 different ; par contre le bit en position 5, a
savoir x1 + x2 + x3, est la parite de controle de x. �
3.3 Code dual et matrice de controle
La seconde description consiste a definir le code dual et la matrice de controle.
Pour cela, soient x = (x1, . . . , xn) et y = (y1, . . . , yn) deux vecteurs de Zn2 et W un
sous-espace vectoriel de Zn2 .
Definition 3.3.1 (Orthogonalite) Le produit scalaire de x et y est le reel
(x,y) = x1y1 + . . .+ xnyn.
Si (x,y) = 0, les deux vecteurs sont dits orthogonaux. On notera par W⊥ le
sous-espace vectoriel de Zn2 forme par les vecteurs orthogonaux a ceux de W .
Les mots d’un code binaire lineaire sont interpretes comme etant des vecteurs d’un
sous-espace vectoriel de Zn2 .
Definition 3.3.2 (Code dual) Le code dual de Ckn(2) est le sous-espace de Zn2 ,
note [Ckn(2)]⊥, forme par les vecteurs orthogonaux, a ceux de Ckn(2).
Par consequent,
[Ckn(2)]⊥ = {x ∈ Zn2 | (x, c) = 0, ∀c ∈ Ckn(2)}.
Exemple 3.3.1 (Dualite) Soit S = {0100, 0101} ⊂ Z42. Les mots du code lineaire
engendre par S, sont les combinaisons lineaires de ceux de S, a savoir
{0000, 0100, 0101, 0001} = C24(2) ⊂ Z4
2.
Mr HITTA Amara71
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Trouver le code [C24(2)]⊥ revient a chercher les mots x = x1x2x3x4 ortogonaux a
0100 et 0101. L’equation x.0100 = 0 donne x2 = 0 et l’equation x.0101 = 0 donne
x4 = 0. Ainsi,
[C24(2)]⊥ = {x = x10x30 : x1 etx3 ∈ Z2}
= {x = x1.(1000) + x3.(0010).}
est engendre par l’ensemble S ′ = {1000, 0010}. Donc [C24(2)]⊥ = {0000, 1000, 0010, 1010} ⊂
Z42. �
Comme Ckn(2) et [Ckn(2)]⊥ sont des sous-espaces de dimension finies de Zn2 alors
dim Ckn(2) + dim [Ckn(2)]⊥ = n.
D’ou dim [Ckn(2)]⊥ = n− k. Ainsi,
[Ckn(2)]⊥ = Cn−kn (2).
Si [Ckn(2))]⊥ = Ckn(2), on dit que le code Ckn(2) est auto-dual.
Exemple 3.3.2 (Code auto-dual) On a [C23(2)]⊥ = C1
3(2). Le code dual du code
de repetition C23(2) est le code de parite C1
3(2). Par contre le code C36(2) est auto-dual.
�
Definition 3.3.3 (Matrice de controle) La matrice generatrice H du code dual
[Ckn(F)]⊥ est dite matrice de controle du code Ckn(F).
On en deduit,
Ckn(F) = {x ∈ Fn | xH t = 0}
ou H t designe la matrice transposee de H (c’est-a-direobtenue en echangeant les
lignes en colonnes et vice-versa).
Un code peut-etre defini que par sa matrice de controle.
Mr HITTA Amara72
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Exemple 3.3.3 (Code ISBN) Les mots de ce code verifient dans le corps de Ga-
lois Z11
a1a2 · · · ax ∈ ISBN ⇐⇒ 1a1 + 2a2 + · · ·+ xax = 0.
⇐⇒ (a1, a2, · · · , ax).(1, 2, 3, 4, 5, 6, 7, 8, 9, x)t = 0.
La matrice de controle du code ISBN est la matrice ligneH = (1, 2, 3, 4, 5, 6, 7, 8, 9, x). �
Le code Ckn(F) est le noyau de l’application lineaire
s : Fn → Fn−k ou s(x) = xH t.
Ainsi, la matrice de controle H est de type (n− k)× k et peut s’ecrire sous la forme
standard
H =(−P t In−k
).
Lemme 3.3.4 Soient G et H les matrices du code Ckn(F) alors GH t = 0.
Preuve : En effet,
GH t =(Ik P
)(−PIn−k
)= −P + P = 0.
Exemple 3.3.4 Le code de parite Cn−1n (2) a pour matrice de controleH =
(1 · · · 1
);
c’est la matrice generatrice du code de repetition C1n(2). Donc
Cn−1n (2) = [C1
n(2)]⊥.
En particulier, le code dual de C23(2) qui est le code de repetition C1
3(2) est forme
par les mots 000 et 111. Sa matrice de controle est la matrice ligne H =(
1 1 1)
.
�
Definition 3.3.5 (Codes systematiques) Les codes dont les matrices s’ecrivent
sous des formes standards sont dits codes systematiques.
Mr HITTA Amara73
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Pour les obtenir, il suffit d’ajouter aux bits d’information des bits de controle.
Il devient ainsi plus aise de manipuler un code sous sa forme systematique. Pour
cela, on introduit la notion d’equivalence suivante :
Definition 3.3.6 (Equivalence) Deux codes lineaires sont dits equivalents si l’un
s’obtient a partir de l’autre en appliquant une permutation fixe a tous les mots de
sorte que les parametres - par exemple la distance minimale - ne soient pas affectes
par cette transformation.
On verifie par ailleurs que tout code lineaire est equivalent a un code systematique.
Exemple 3.3.5 Considerons le code lineaire C36(2) dont les matrices sont
G =
1 0 0 1 0 1
0 1 1 1 0 1
1 1 0 1 1 0
et H =
1 1 0 0 0 1
1 1 0 1 1 0
0 1 1 0 1 0
En substituant simultanement a la troisieme ligne de G et H la somme de la premiere
et de la troisieme puis en effectuant la permutation (135426) aux lignes, on obient
les matrices
G′ =
1 0 0 1 0 1
0 1 0 1 1 1
0 0 1 0 1 1
et H ′ =
1 1 0 1 0 0
0 1 1 0 1 0
1 1 1 0 0 1
.
qui sont les matrices du code systematique equivalent a C36(2). �
3.4 Codes de Hamming
Un code binaire de longueur n = 2r − 1, r ≥ 2, et de dimension n− r est dit code
binaire de Hamming, note
Hr(2) = C2r−r−12r−1 (2),
Mr HITTA Amara74
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
si sa matrice de controle Hr est de type r × (2r − 1) dont les colonnes sont les
representations binaires, dans cet ordre, des entiers
1, 2 , 3 , . . . , 2r − 2, 2r − 1.
Ecrite sous cette forme la matrice de Hamming n’est pas standard :
• Si r = 1, n = 21 − 1 = 1. La matrice de controle du code de Hamming H1(2)
est de type 1× 1, a savoir
H1 :=(
1).
• Si r = 2 alors n = 22 − 1 = 3. Le code de Hamming H2(2) = C13(2), code
binaire de repetition. Sa matrice de controle est de type 2× 3, a savoir
H2 :=
(0 1 1
1 0 1
).
Les colonnes de H2 represente les entiers 1, 2, 22 − 1 = 3 en base 2, a savoir :
01→ 1, 10→ 2 et 11→ 3.
• Si r = 3 alors n = 23 − 1 = 7, le code de Hamming H3(2) = C47(2) a pour
matrice de controle
H3 :=
0 0 0 1 1 1 1
0 1 1 0 0 1 1
1 0 1 0 1 0 1
.
Les colonnes de H3 representent, dans cet ordre, les entiers 1, 2, 3, 4, 5, 6, 23 −1 = 7 :
001 → 1, 010→ 2, 011→ 3, 100→ 4,
101 → 5, 110→ 6, 111→ 7.
Mr HITTA Amara75
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
• Si r = 4 alors n = 24 − 1 = 15, le code de Hamming H4(2) = C1115(2) a pour
matrice de controle
H4 :=
0 0 0 0 0 0 0 1 1 1 1 1 1 1 1
0 0 0 1 1 1 1 0 0 0 0 1 1 1 1
1 0 1 0 1 0 1 0 1 0 1 0 1 0 1
.
Les colonnes de H4 represente, dans cet ordre, en base 2, les entiers
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 = 24 − 1.�
Definissons maintenant les codes de Hamming sur un corps fini de galois Zp ou p est
un entier premier.
Pour cela, posons
n =pr − 1
p− 1.
La matrice de controle du code de Hamming, notee Hr, sera de type r × n dont
les colonnes sont les representants dans Zp, dans un certain ordre, des entiers
1, 2, . . . , pr − 2, pr − 1. Le code ainsi obtenu est le code de Hamming de type r
sur le corps fini de Galois Zp :
Hr(p) = Cn−rn (p).
Exemple 3.4.1 (Code de Hamming ternaire) Si p = 3 et r = 3 alors n = 13.
On obtient la matrice de controle du code ternaire de Hamming H3(3) = C1013(3).
Elle est de type 3× 13, a savoir
H =
1 1 1 1 0 0 0 0 0 0 1 0 0
0 0 1 1 0 2 2 2 1 1 0 1 0
1 2 0 1 2 0 1 2 1 2 0 0 1
.
Exemple 3.4.2 (Code de Hamming H2(9)) On a p = 9 et r = 2. Donc n = 10
et l’on verifie que la matrice du code H2(9) est
H =
(0 1 1 1 1 1 1 1 1 1
1 0 1 2 i 1 + i 2 + i 2i 1 + 2i 2 + 2i
).
Mr HITTA Amara76
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
ou i est la racine carree de 2 = −1 dans Z9. �
Le code dual de Hr(p) est dit code simplexe, note
Sr(p) = [Hr(p)]⊥ = Crpr−1(p).
3.5 Codes de Hamming etendu
Il est parfois utile de trouver de nouveaux codes a partir des codes deja connus.
Soit C = Ckn(2) un code lineaire de matrices generatrice et de controle sont respec-
tivement G et H.
Le code C de longuer n + 1 obtenu en ajoutant a chaque mot (x1, . . . , xn) ∈ C, sa
parite cn+1 =∑n
i=1 ci, est dit code etendu de C. Tous les mots du code etendu C
ont ainsi un poids pair. Sa matrice generatrice, qui est de type k × (n+ 1), est
EG =(G C
)ou la colonne C est formee par les parites de controle de chaque ligne de G. La
matrice de controle de C s’obtient par
EH =
(H 0
1 1
)
ou 1 et 0 representent respectivement les matrices colonne et ligne de type (n− 1) :(1 . . . 1
)tet(
0 . . . 0)
. La matrice EH de C est de type (n+ 1)× (n+ 1− k).
Lemme 3.5.1 Sous les hypotheses precedentes, on a EG.(EH)t = 0.
Preuve : En effet, on a GH t = 0. Remarquons que G.1 ajoute les bits 1 dans
chaque ligne de G. Par definition de C, on obtient G.1 + C = 0. Par consequent
EG.(EH)t =(G C
)(H t 1
C 1
)=(GH t G.1 + C
)t= 0.
Mr HITTA Amara77
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Exemple 3.5.1 (Extension) Considerons le code C35(2) ou
G =
1 0 0 1 0
0 1 0 0 1
0 0 1 1 1
et H =
(0 0 1 1 0
0 1 1 0 1
).
Le code obtenu par extension de C35(2) a pour matrices generatrice et de controle
EG =
1 0 0 1 0 0
0 1 0 0 1 0
0 0 1 1 1 1
et EH =
1 0 1 1 0 0
0 1 1 0 1 0
1 1 1 1 1 1
.
C’est le code C36(2). �
Un nouveau code defini a partir du code de Hamming Hr(2) est le code etendu de
Hamming, note H3(2). Il est forme par les mots x1x2 · · ·xnxn+1 tels que x1 + x2 +
· · ·+ xn + xn+1 = 0. Sa matrice de controle devient
EHr =
(Hr 0
1 1
),
ou 0 est la matrice colonne formee par des bits 0 de type r × 1, 1 est la matrice
colonne formee par des bits 1 de type 1 × r. Ce code est de longueur n = 2r et de
dimension k = 2r − 1− r,
Hr(2) = C2r−1−r2r (2).
Ce code peut corriger 1 erreur et peut detecter 2 erreurs; il est utilise surtout pour
le decodage incomplet.
Exemple 3.5.2 (Code de hamming etendu H3(2)) Ce code a pour matrice de
controle
EHr =
0 0 0 1 1 1 1 0
0 1 1 0 0 1 1 0
1 0 1 0 1 0 1 0
1 1 1 1 1 1 1 1
. �
Mr HITTA Amara78
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Pour des raisons pratiques, la parite de controle peut-etre ajoutee au debut de
chaque mot du code de Hamming pour obtenir une autre matrice de controle du
code etendu de Hamming, notee aussi EHr, de la forme
EHr =
(0 Hr
1 1
),
Cette forme sera utile ulterieurement, puisqu’elle peut s’ecrire sous la forme recurrente :
EHm =
(0 1
EHm−1 EHm−1
), EH0 =
(1), EH1 =
(0 1
1 1
)=
(0 1
EH0 EH0
).
3.6 Les Codes de Golay binaires et ternaires
Marcel J. E. Golay s’est interesse a la construction des codes parfaits en generalisant
le code de Hamming H3(2) = C47(2) a des codes de longueurs (pk − 1)/(p − 1) ou
p est un entier premier. Il construit le code binaire G1223(2) corrigeant 3 erreurs a
partir du code de Golay etendu G1324(2) puis le code ternaire G6
11(3) sur le corps Z3.
Il montre ensuite, dans son article lg lg notes on digital coding � publie en 1949,
que le code binaire C7898(2) n’existe pas.
Famille de codes de Golay binaires :
Mr HITTA Amara79
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Definissons tout d’abord le code de Golay etendu G1224(2). Pour cela, considerons la
matrice symetrique de type 12× 12 suivante
B =
1 1 0 1 1 1 0 0 0 1 0 1
1 0 1 1 1 0 0 0 1 0 1 1
0 1 1 1 0 0 0 1 0 1 1 1
1 1 1 0 0 0 1 0 1 1 0 1
1 1 0 0 0 1 0 1 1 0 1 1
1 0 0 0 1 0 1 1 0 1 1 1
0 0 0 1 0 1 1 0 1 1 1 1
0 0 1 0 1 1 0 1 1 1 0 1
0 1 0 1 1 0 1 1 1 0 0 1
1 0 1 1 0 1 1 1 0 0 0 1
0 1 1 0 1 1 1 0 0 0 1 1
1 1 1 1 1 1 1 1 1 1 1 0
Pour retenir la matrice B on l’ecrit sous la forme de blocs matriciels
B :=
(B1 1t
1 0
)
ou 1 est la matrice ligne (1 . . . 1) de longueur 11 et B1 la matrice dont la premiere
ligne est 11011100010 ; les lignes suivantes de B1 sont les decalees circulaires suc-
cessifs vers la gauche de cette premiere ligne. Posons
G =(I12 B
)
la matrice de type 12 × 24 ou I12 represente la matrice unite de type 12 × 12. Le
code lineaire dont la matrice generatrice est G est dit code de Golay binaire etendu.
On le note G1224(2). Sa matrice generatrice G a des proprietes interessantes, a savoir:
• Le code de Golay binaire etendu est auto-dual c’est-a-dire
G1224(2) =
[G12
24(2)]⊥.
Mr HITTA Amara80
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Il suffit de remarquer que les lignes de G sont orthogonales entre elles et que
dim G1224(2) = 12 = 24− 12 = dim
[G12
24(2)]⊥.
• La matrice(B I12
)est une autre matrice generatrice de G12
24(2) car(B I12
)=(−Bt I12
)qui est la matrice generatrice de
[G12
24(2)]⊥
.
• Le nombre de bits 1 dans chaque ligne de G est un multiple de 4, a savoir 8
ou 12. On montre, d’une maniere tres precise, que la distance minimale de ce
code est 8.
• Aucun mot code (combinaison lineaire des lignes de G) de G1224(2) ne contient
4 bits ou moins.
Le code de Golay G1223(2) s’obtient du code G12
24(2) en supprimant la derniere colonne
de G. Sa distance minimale est d = 7
Famille des Codes de Golay Ternaires : Le premier code de Golay ternaire est
G612(3). Sa matrice generatrice est G =
(I6
A
)ou
A =
0 1 1 1 1 1
1 0 1 2 2 1
1 1 0 1 2 2
1 2 1 0 1 2
Sa distance minimale est d = 6. Le deuxieme code de Golay ternaire est G6
12(3). Il
se deduit du premier en supprimant de chaque mot code le dernier bit. Ce qui est
equivalent a la suppression de la derniere colonne de la matrice genaratrice G de
G612(3), donc sa longueur est n = 11 et sa dimension ne peut-etre que k = 6.
Interessons-nous maintenant, a titre indicatif, a une famille de codes non-lineaire
qui ont de bonnes capacite de correction.
Mr HITTA Amara81
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
3.7 Codes de Hadamard
Chaque code de Hadamard, note C(Hn), est associe a une matrice carree Hn d’ordre
n. Ce code a un nombre, relativement petit, de mots codes egal a 2n, mais sa
distance minimale est egale a n/2. Le code de Hadamard C(H32) a ete utilise, en
1972, par la sonde spaciale Mariner pour envoyer des images, de couleurs noire et
blanc, de la planete Mars vers la terre. Ce code a 26 = 64 mots code et peut corriger
jusqu’a 7 erreurs.
Mr HITTA Amara82
08-Mai 45 Guelma University

CHAPITRE
4
DECODAGE DES CODES LINEAIRES
Etudions maintenant un mecanisme simple de correction des erreurs appele : deco-
dage par le syndrome.
4.1 Decodage par le syndrome
Pour cela, considerons le code Ckn(F) dont la matrice de controle est H.
Definition 4.1.1 (Syndrome) Le syndrome de x ∈ Fn est le mot (n− k)-tuple
s(x) = x.H t ∈ Fn−k.
L’application lineaire s est dite application syndrome.
Ainsi, les mots codes verifent : y ∈ Ckn(F) si et seuleument si s(y) = 0. En Medecine,
un syndrome est un tableau bien defini de symptomes qui peut s’observer dans
83

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
plusieurs etats pathologiques differents, mais ne permet pas a lui seul de determiner
la nature de la maladie.
Exemple 4.1.1 Considerons le code C59(2) dont la matrice de controle est
H :=
0 0 0 1 1 0 1 1 0
1 1 0 1 1 0 0 0 0
0 1 1 0 1 0 0 0 0
0 0 0 0 1 1 0 1 1
.
Le syndrome du mot recu y1 = 111101000 est s(y1) = (1111)t qui est la colonne 5 de
H, donc y1 /∈ C59(2). Celui de y2 = 010010010 est s(y2) = (0000)t ; donc y2 ∈ C5
9(2).
�
Si le mot x ∈ Ckn(2) est transmis et y le mot recu, l’erreur e survenue lors de cette
transmission verifie
x = y + e.
Si l’on ajoute y aux deux membres de cette egalite, on obtient e = x + y, alors
s(e) = s(x)+s(y) car s est une application lineaire. Comme s(x) = 0 car x ∈ Ckn(2),
alors
s(y) = s(e).
Par consequent :
le syndrome d’un mot recu est determine par celui de l’erreur commise.
Le syndrome ne depend que de l’erreur (maladie) mais pas du mot recu (le patient).
4.1.1 Partition de l’espace
Une partition de l’espace Zn2 s’impose. Pour cela, considerons la relation d’equivalence
suivante
yRz si et seulement si y− z = x ∈ Crn(2).
Mr HITTA Amara84
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Tous les mots z + x, x ∈ Crn(2), ont le meme syndrome que z car s(x) = 0. Ils
forment une classe d’equivalence pour cette relation, notee Cl(y). En particulier :
Le code Ckn(2) est la classe de syndrome 0 ⇐⇒ Ckn(2) = Cl(0).
Definition 4.1.2 (Chef de la classe) Le Chef de la classe Cl(z) est le mot,
note e, dont le poids est le minimum parmi tous les poids des mots de cette classe.
En general, le chef d’une classe est de poids 1.
L’ensemble de ces classes forment le groupe quotient Zn2/R, c’est le groupe des classes
d’equivalence modulo le code Ckn(2).
Exemple 4.1.2 (Suite code C24(2)) Considerons le code de matrice de generatrice
G =
(1 0 1 1
0 1 0 1
)donc la longueur du code est n = 4 et k = 2 car le code contient
4 mots y compris 0000. Ainsi
C = C24(2) = {0000, 1011, 0101, 1110}.
Les classes et leurs chefs de classes sont au nombre 4:
Classes Chef de classes
classe 0000 0000 1011 0101 1110
classe 1000 1000 0011 1101 0110
classe 0100 0100 1111 0001 1010
classe 0010 0010 1001 0111 1100.
Une classe peut avoir deux chefs de classes : les mots 0100 et 0001 ont la meme
classe. �
La probabilite de decoder correctement un mot recu est justement la probabilite pour
que l’erreur soit l’un des chefs des classes. Considerons un canal binaire symetrique
de probabilite p, la probabilite pour que l’erreur soit un mot de poids i est pi(1−p)n−i.
Mr HITTA Amara85
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Si l’on a ai chefs de classes de poids i, la probabilite totale de correction du code C
est
Pcorr(C) =n∑i=0
aipi(1− p)n−i.
La probabilite totale d’erreurs de ce code est
Perr(C) = 1− Pcorr(C).
Exemple 4.1.3 (Suite code C24(2)) Les chefs de classe sont : 0000, 1000, 0100 et
0010. Ainsi, on a a0 = 1, a1 = 3 et a2 = 0. La probabilite de correction du code
C = C24(2) est
Pcorr(C24(2)) = (1− p)4 + 3p(1− p)3 = (1 + 2p)(1− p)3.�
4.1.2 Algorithme de decodage avec Hr(2)
Remarquons que les lignes de la matrice [Hr]t, transposee de la matrice de controle
Hr, sont les representations binaires dans cet ordre des entiers 1, 2, · · · , 2r−1. Ainsi,
si e = (0, · · · , 0, 1, 0 · · · , 0) ou le bit 1 est la j-eme coordonnee, alors s(e ) = e [Hr]t
sera la j-eme ligne de [Hr]t, qui est la representation binaire de j. L’erreur survenu
sur le mot recu sera corrigee en changeant le bit j.
Algorithme de decodage de Hr(2) :
Pour un mot recu y, calculer s(y).
• Si s(y) = 0, alors y est un mot code.
• Sinon, s(y) sera la representation binaire d’un entier j entre 1 et n = 2r − 1.
Le mot y sera corrige en changeant son j-eme bit (0 en 1 ou vice versa).
Exemple 4.1.4 Le code de Hamming H3(2) = C47(2) a pour matrice de controle
H3 =
1 0 1 1 1 0 0
1 1 0 1 0 1 0
1 1 1 0 0 0 1
.
Mr HITTA Amara86
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Utilisons le decodage par le syndrome pour corriger le mot recu y = 1001100 :
• Son syndrome est s(y) = yH t3 = (101)t ; c’est la colonne 3 de H3.
• Le chef de la classe Cl(y) est c = 0010000 qui est de poids minimal et s’obtient
en placant le bit 1 au rang 3 et 0 ailleurs.
• On decode y, en changeant le bit de la position 3, sous la forme x0 = 1011100. �
Remarquons, par ailleurs, que le mot x1 = 0100100 a le meme syndrome que y
mais ne peut lui former un bon decodage. En fait, y differe avec x0 en un seul bit
et avec x1 en 3 bits, ce qui nous fait dire x1 est loin de y que x0. Si plus d’une
erreur affectent un mot code, la procedure de decodage decrite precedemment ne
fonctionne pas.
Exemple 4.1.5 (Detection d’erreurs) Si x = 0111100 est transmis et que y =
0011101 est recu alors le vecteur s(y) = 101 represente la colonne 3 de H3. Si on
change le bit 3 de x, on obtient une erreur supplementaire. On decode a x′ = 0001101
qui est different de x.
La matrice de controle d’un code binaire de Hamming etendu d’ordre r, est
EHr =
(Hr 0
1 1
).
et
Hr(2) = C2r−r−12r (2).
Le decodage avec Hr(2) se fait ainsi :
Algorithme de decodage avec Hr(2) :
• Calculer le syndome s(y) = (s1, · · · , sr, sr+1).
• Si sr+1 = 1, on a une erreur et s1 · · · sr est la representation de la position de
l’erreur ou le mot 00 · · · 0 represente n+ 1 = 2r.
Mr HITTA Amara87
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
• Si sr+1 = 0, on a un nombre paire d’erreurs a savoir 0 et dans ce cas s1 · · · sr =
0 · · · 0 sinon 2.
Exemple 4.1.6 (Decodage par Hamming etendu H4(2) = C48(2)) La matrice
de controle de ce code est 0 0 0 1 1 1 1 0
0 1 1 0 0 1 1 0
1 0 1 0 1 0 1 0
1 1 1 1 1 1 1 1
.
• Si y = 11011010 alors s(y) = 1011. L’erreur se trouve a la position 5 et le
decodage se fait a 11010010.
• Si y = 10101111 alors s(y) = 1100, on detecte 2 erreurs. �
Dans le cas general, le code Hr(q) a pour parametres
n =qr − 1
q − 1, k =
qr − 1
q − 1− r.
Exemple 4.1.7 (Matrices de controle de H2(5) et H3(3)) Chaque mot non nul
peut-etre multiplier par un nombre pour que la premiere coordonnee soit egale a 1.
• La matrice de controle de H2(5) est
H =
(0 1 1 1 1 1
1 0 1 2 3 4
)
• La matrice de controle de H3(3) est
H =
0 0 0 0 1 1 1 1 1 1 1 1 1
0 1 1 1 0 0 0 1 1 1 2 2 2
1 0 1 2 0 1 2 0 1 2 0 1 2
. �
Le decodage se fait suivant l’algorithme :
Algorithme de decodage de Hr(q) :
Mr HITTA Amara88
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
• Les chefs de classe sont λei = (0, · · · , 0, λ, 0, · · · , 0)
• Les syndromes correspondants sont S(λei) = λH ti ou Hi est la colonne i de la
matrice de controle H.
• En choisissant H telle que la premiere coordonnee de chaque colonne Hi soit
1, alors λ sera la premiere coordonnee non nulle de S(λei).
• Pour decoder un mot recu y, il suffit de trouver λ et i tels que S(y) = λH ti et
decoder y a y− λei.
4.1.3 Algorithme de decodage par le syndrome
Considerons un code Ckn(2) dont la matrice de controle est H.
Algorithme de decodage par le Syndrome :
Soit y le mot recu, on procede comme suit :
• Calculer le syndrome s(y) = yH t.
• Si s(y) = 0, prenons e = 0 et y serait un mot du code Ckn(2) ; sinon :
• Trouver le chef de la classe dont le syndrome est s(y). On localise ensuite
l’unique colonne de H qui est egale a s(y), notee par exemple i ; le bit altere
dans le mot transmis est celui qui se trouve a la position i du mot recu y.
Ce qui represente une bonne estimation du mot envoye avec une probabilite
d’erreur maximale.
Remarque : Un code binaire Ckn(2) requiere |Zn2 |/|Ckn(2)| = 2n−k syndromes et 2n−k
chefs de classes. Pour n et k suffisamment grand, la table de decodage devient, dans
ce cas, penible a etablir, ce qui reduit considerablement l’utilite du decodage par le
syndrome.
Mr HITTA Amara89
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Exemple 4.1.8 Considerons le code C35(2) := {00000, 10100, 01111, 11011} dont la
matrice de controle est
H =
1 0 0 1 1
0 1 0 0 1
0 0 1 0 1.
Si le mot y=01100 est recu, sa classe est
Cl(y) = {01100, 11000, 00011, 11111}.
Elle a pour syndrome s(y) = yH t =
0
1
1
. C’est la somme de 2 colonnes de H.
L’erreur est detectee mais le decodage est imcomplet puisque le syndrome de y peut
s’ecrire de deux manieres, a savoir
s(y) =
1
0
0
+
1
1
1
= c1 + c5 → Colonnes 1 et 5 de H → e = 10001
=
0
1
0
+
0
0
1
= c2 + c3 → Colonnes 2 et 3 de H → e = 01100.
Le mot y sera decode indifferemment sous forme x1 = y + 10001 = 11101 ou
x2 = y + 01100 = 00000. �
Exemple 4.1.9 (Tableau de decodage de Slepian) Considerons le code lineaire
C24(2) = {0000, 1011, 0101, 1110} dont les matrices sont
G =
(1 0 1 1
0 1 0 1
)et H =
(1 0 1 0
1 1 0 1
).
Les chefs des classes dont le poids est minimal, parmi les mots des classes, ne peuvent
etre que : c0 = 0000, c1 = 1000, c2 = 0100, c3 = 0010 et c4 = 0001. En remarquant,
au passage, que Cl(c4) = Cl(c2), le nombre de classes est 22 = 4. Leurs syndromes
sont respectivement
s(c0) =
(0
0
), s(c1) =
(1
1
), s(c2) =
(0
1
), s(c3) =
(1
0
).
Mr HITTA Amara90
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
On obtient le tableau de Slepian suivant
Classes Chefs Syndromes
Cl(c0) = C24(2) 0000 1011 0101 1110 00
Cl(c1) 1000 0011 1101 0110 11
Cl(c2) 0100 1111 0001 1010 01
Cl(c3) 0010 1001 0111 1100 10
Pour decoder un mot recu, il suffit de reperer la colonne du tableau dans laquelle
il se trouve. Le resultat de decodage sera le mot situe en haut de cette colonne.
Supposons que le mot recu est y = 1111 ; son syndrome s(y ) = 01 represente
deuxieme la colonne de H. Le chef de la classe Cl(y) est c2 = 0100. Par consequent,
on decode y a x1 = y + c2 = 1011 ∈ C. Le chef de la Cl(y) peut-etre le mot c4 =
0001. Dans ce cas, le mot y = 1111 se decode a x2 = 1111 + 0001 = 1110 ∈ C24(2).
Ce decodage n’est pas unique donc imcomplet. �
4.2 Decodage a distance minimale
Pour detecter une ou plusieurs erreurs survenues dans un mot recu, on introduit la
notion de proximite (distance) entre les mots d’un code ; une fois l’erreur detectee,
on pourra choisir le mot du code le plus proche de c c’est-a-direa distance minimale
du mot recu.
Definition 4.2.1 (Poids et distance de Hamming) Soient x = x1 . . . xn et y =
y1 . . . yn deux mots de Zn2 .
• Le poids de Hamming d’un mot x, note w(x), est le nombre de bits 1 qu’il
contient.
• La distance de Hamming, notee d(x,y), entre deux mots x et y ∈ Zn2 est le
nombre d’indices i pour lesquels xi 6= yi.
Mr HITTA Amara91
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
En particulier : Le poids d’un mot x est egal a sa distance avec le mot 0 c’est-
a-direw(x) = d(x,0). C’est-a-dire que le poids d’un mot est le nombre de bits 1 qui
le composent.
Proposition 4.2.2 La distance de Hamming est une distance metrique qui verifie
• d(x,y) ≥ 0. L’egalite est verifiee si x = y.
• d(x,y) = d(x,y) pour tous x,y ∈ Zn2 .
• d(x,y) = d(x, z) + d(z,y) pour tous x,y, z ∈ Zn2 .
Preuve : L’inegalite triangulaire provient du fait que changer x en z revient a
changer x en y puis y en z. �
Muni de cette distance discrete, l’espace Zn2 est un espace metrique.
Exemple 4.2.1 (Poids et distance) Soient x = 1010111 et y = 111000 deux
mots de Z72. Alors w(x) = 5 et w(y) = 3 et d(x,y) = 3. �
Soient x, y ∈ Zn2 . Comme le mot x + y a le bit 1 lorsque x et y different et 0 sinon,
alors
d(x,y) = w(x + y).
La distance entre deux mots est egale au poids de leurs somme.
Exemple 4.2.2 Soient x = 1010111 et y = 1111010 ∈ Z72 alors d(x,y) = 4.
Comme x + y = 0101101, le nombre de 1 est 4 = w(x + y). �
Lemme 4.2.3 La distance de Hamming est invariante par translation.
Preuve : Soient x, y et c ∈ Zn2 . En effet,
d(x + c,y + c) = w(x + y + 2c).
Le lemme resulte du fait que 2c = 0. �
Nous allons montrer que le decodage par la vraissemblance maximale et le decodage
a distance minimale sont identiques.
Mr HITTA Amara92
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Theoreme 4.2.4 Pour un canal binaire symetrique de probabilite 0 < p < 1/2, les
deux principes de decodage avec un code de distance minimale d sont identiques.
Preuve : Supposons que x le decodage possible du mot recu y. La probabilite
P(y|x) est pd(y,x)(1 − p)n−d(y,x) puisque x et y different en d(y,x) bits. Puisque
p < 1/2 et p/(1− p) < 1, supposons que z et un mot tel que d(z,y) > d(y,x) alors
P(y|x) ≥ P(y|x).
(p
1− p
)d(z,y)−d(x,y)
= pd(z,y)(1− p)n−d(z,y)
= P(y|z).
La probabilite P(y|x) est une fonction decroissante de la distance d(y,x). Ainsi, la
probabilite, pour que y se decode en x, soit grande revient a chercher le mot x le
plus tres proche de y. �
Le decodage de y consiste a trouver le mot code r tel que le mot y + r ait le poids
le plus petit possible.
Puisque (Zn2 , d) est un espace metrique discret, on peut definir la notion de voisinage
d’un mot de l’espace Zn2 .
Definition 4.2.5 (Boule de Hamming) La boule de Hamming de centre x et de
rayon t est le sous-ensemble ferme de Zn2
B(t; x) = {y ∈ Zn2 | d(x,y) ≤ t}.
Il y a :
• C1n mots distants a x de 1,
• C2n mots distants a x de 2,
• ......
• Ctn mots distants a x de t.
Mr HITTA Amara93
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Ainsi :
Proposition 4.2.6 Le nombre de mots contenus dans la boule B(t; x) est
V2(n, t) = |B(t; x)| = C0n + C1
n + . . .+ Ctn.
y compris le centre.
Exemple 4.2.3 (Interpretation geometrique dans l’espace Z32) • Boule B(1; 000)
: La boule B(1; 000), de centre 000 et de rayon 1, contient V(3, 1) = C30 +C3
1 =
4 mots. Elle est formee par les sommets situes sur les axes, y compris le centre
000
B(1; 000) = {100, 000, 010, 001}.
• Boule B(2; 000) : La boule de centre 000 et de rayon 2, contient les sommets
sauf 111, car d(000, 111) = 3. En fait, elle contient V2(3, 2) = C03 +C1
3 +C23 = 7
mots, a savoir
B(2; 000) = {100, 000, 100, 001, 011, 101, 110}.
• Boule B(1; 100) : La boule, de centre en 100 et de rayon 1, est
B(1; 100) = {100, 000, 110, 101}.
Elle contient V2(3, 1) = C03 + C1
3 = 4 mots.
• Boule B(3; 000) : La boule, de centre en 000 et de rayon 3, est formee par les
8 sommets du cube d’arret 1. Elle contient V2(3, 3) = C03 +C1
3 +C23 +C3
3 = 8
mots. �
Exemple 4.2.4 Les 2n mots du code Zn2 , ont pour images les sommets d’un cube
d’arete 1. La distance de Hamming entre deux sommets du cube est egale au nombre
de cotes qui les joignent. �
Mr HITTA Amara94
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
La capacite de correction d’un code est determinee par la distance minimale entre
les mots distincts de ce code. Pour cela, on definit la distance d’un code C(2), par
d = d(C(2)) = minx,y∈C(2)
{d(x,y) | x 6= y}.
Theoreme 4.2.7 La distance d’un code lineaire est donnee par
d = d(C(2)) = min{w(x), x ∈ C(2)∗}.
Preuve : Posons w(C(2)) = min{w(x), x ∈ C(2)∗}. Il existe deux mots x et
y ∈ C(2) tels que
d(C(2)) = d(x,y) = w(x + y) ≥ w(C(2))
car x + y ∈ C(2). D’autre part, pour un certain x ∈ C(2), on a w(x) = d(x, 0) ≥d(C(2)) car 0 ∈ C(2). �
Le principe de decodage a distance minimale consiste a associer au mot recu y ∈ Zn2
le mot code c ∈ C(2) le plus proche de y de telle sorte que y et c different en un
nombre de bits le plus petit possible.
Exemple 4.2.5 (Decodage par la distance minimale) Considerons le code lineaire
C(2) = {0000, 1010, 0111}. Comme la distance de 0000 a 1010 est 2 et celle de 0111
aux mots 1010 et 0000 est 3, la distance du code C(2) sera 2. Le decodage du mot
recu y = 1001 sera le plus proche, c’est-a-dire le mot dont le distance a y est 2,
parmi ceux du code C(2). On s’apercoit que d(0000,y) = d(1010,y) = 2 ; le mot
1001 peut etre decode comme 0000 ou 1010. �
Definition 4.2.8 (Code de type [n,k,d) ] Un code binaire lineaire de longueur
n, de dimension k et de distance d est dit code de type [n, k, d]; on le notera Ck[n,d](2).
Le theoreme suivant determine la capacite de correction et de detection d’un code
donne.
Mr HITTA Amara95
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Theoreme 4.2.9 Un code lineaire Ck[n,d](2) a la capacite de
• detecter jusqu’a t erreurs si d ≥ t+ 1
• corriger jusqu’a t erreurs si d ≥ 2t+ 1.
Preuve :
• Soit d ≥ t + 1. Supposons qu’un mot code x est transmis et qu’au plus t
erreurs sont survenues. Le mot recu demeure un mot code et les erreurs seront
detectees.
• Soit d ≥ 2t + 1. Supposons que le mot code x est recu, apres tranmission,
sous la forme y ou t erreurs ou plus sont survenues, alors d(x,y) ≤ t. Soit
x′ ∈ Ck[n,d])(2) tel que x′ 6= x alors d(x′,y) ≥ t ; car si d(x′,y) ≤ t, on aura
d(x,x′) ≤ d(x,y) + d(y,x′) ≤ 2t. Ce qui contredit l’hypothese. �
Ainsi :
• Il n’existe aucun mot y a une distance au plus t de deux mots differents d’un
code t-correcteur.
• Toutes les boules centrees en des mots distincts du code et de rayon t sont
disjointes.
• Si le mot recu comporte moins de t erreurs, il demeure dans la boule centree
sur le mot initialement emis.
Les raisons pour lesquelles la distance minimale d’un code represente l’un des parametres
importants sont decrites dans le corollaire suivant :
Corollaire 4.2.10 Le code lineaire binaire Ck[n,d](2) est utilise pour
• • detecter jusqu’a d− 1 erreurs.
Mr HITTA Amara96
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Figure 4.1: Schema general d’un systeme de communication
• • corriger jusqu’a t = [(d − 1)/2] erreurs et pas plus. Le nombre t, partie
entiere de (d − 1)/2, est dit capacite de correction du code. Le code
Ck[n,d](2) est dit t-correcteur.
Preuve : On a les equivalences suivantes
d ≥ s+ 1 ⇐⇒ s ≤ d− 1 et d ≥ 2t+ 1⇐⇒ t ≤ d− 1
2. �
Lemme 4.2.11 Un code lineaire Ck[n,d](2) verifie d ≥ s+ 1 si et seulement si toutes
les s colonnes de sa matrice de controle H sont lineairement independantes.
Preuve : Supposons que s colonnes de la matrice H sont lineairement dependantes,
alors xH t = 0 et w(x) ≤ s pour x ∈ Ck[n,d](2), donc d ≤ s, contradiction. Si s colonnes
de H sont lineairement independantes, il n’existe aucun mot x ∈ Ck[n,d](2) de poids
wh(x) ≤ s. Par consequent d ≥ s+ 1. �
Ce lemme est utile pour trouver la distance minimale d’un code. Il etablit une
relation fondamentale entre la distance minimale d’un code lineaire et l’independance
lineaire des colonnes de la matrice de controle.
Mr HITTA Amara97
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Exemple 4.2.6 (Code de Hamming 1-correcteur) Le rang de la matrice de
controle Hr du code de Hamming Hr(2), r ≥ 2, est 2r − r − 1 par definition.
Comme chaque deux colonnes de Hr sont lineairement independantes puisqu’elles
sont les representations binaires des entiers differents alors d ≥ 2 + 1 = 3 d’apres
le lemme precedent. Si Hr contient deux colonnes, elle contient aussi leurs somme,
donc d = 3. Les codes de Hamming corrigent t =[
3−12
]= 1 erreur et peuvent
detecter jusqu’a d − 1 = 2 erreurs. Le Code de Hamming etendu aura, ainsi, pour
distance minimale 4 et pour longueur 2r. Sa dimension est 2r−r. Il est 1-correcteur
et peut detecter 3 erreurs. Pour r ≥ 2
Hr(2) = C2r−r−1[2r , 3] et Hr(2) = C2r−r
[2r , 4].�
4.3 Codes raccourcis, codes demultiplies
Soit C′ l’ensemble des mots du code lineaire systematique Ckn(2) sur Z2 dont les s
premiers composantes sont nulles, s < k + 1.
Proposition 4.3.1 (Code raccourci) L’ensemble C′′ forme par les mots de C′
dont on elimine les s premieres composantes est un code de dimension n − s et
de longueur k − s, appele code raccourci du code Ckn(2) :
C′′ = Ck−sn−s(2) code racourci de Ckn(2).
4.4 Codes de Reed Muller
En 1954, I.S. Reed et D.E. Muller ont defini une classe de codes binaires lineaires non
cycliques de longueur 2m, m ∈ N∗. Ces codes ont un algorithme de decodage tres
simple qui utilise la transformee de Hadamard. Soient m et r deux entier tels que
0 ≤ r ≤ m, le r-eme code de Reed-Muller, note RM[r,m], a pour parametres :
n = 2m, k = 1 + Cm1 + . . .+ Cm
r et d = 2m−r.
Mr HITTA Amara98
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
On demontrera dans la suite ces affirmations dans le cas ou r = 1.
Les premiers code de Reed-Muller ont une relation directe avec les codes de Ham-
ming. Soit m la redondance du code de Hamming, le code de Reed-Muller
d’ordre 1 est le code dual du code de Hamming etendu
RM[1,m] = [Hm(p)]⊥ = Cm+12m (2).
La matrice generatrice du code RM[1,m] sera la matrice de controle EHm du code
Hm(p). Pour :
• m = 1, RM[1,1] = Z22
• m = 2, RM[1,2] = C34(2) : c’est le code de parite d’ordre 4.
• m = 3, RM[1,3] = C48(2) : c’est le code de Hamming etendu auto-dual.
• m = 5, on obtient le code RM[1,5] = C632(2) utilise pour les transmissions
des photos a partir Mariner 9. Sa matrice generatrice se construit comm
suit : Formons une matrice G0 de type 5 × 31 dont les colonnes sont les
representations binaires des entiers de 1 jusqu’a 31. Ce qui donne
G0 =
1 0 1 · · · 0 1
0 1 1 · · · 1 1
0 0 0 · · · 1 1
0 0 0 · · · 1 1
0 0 0 · · · 1 1
La matrice G sera de type 6× 32 :
G =
0
0
G0...
0
1 1 1 · · · 1
Reste a determiner la distance minimale du code de Reed-Muller d’ordre 1.
Mr HITTA Amara99
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Theoreme 4.4.1 Pour chaque m, la distance minimale de RM[1,m] est 2m−1.
Preuve : D’apres la matrice generatrice EHm, le code RM[1,m] est de longueur
2m et de dimension m + 1. Pour la distance, la recurrence est verifiee pour m = 1
et m = 2. Supposons que :
• C1 = RM[1,m-1] est de distance d1 = 2m−2. Sa matrice generatrice est
G1 = EHm−1.
• C2 le code de repetition de longueur 2m−1 et de distance minimale d2 =
2m−1. Sa matrice generatrice est la matrice ligne de type 1 × 2m−1, G2 =(1 1 · · · 1
).
La matrice generatrice de RM[1,m] s’ecrit alors
EHm =
(0 G2
G1 G1
).
Pour la matrice ligne(0 G2
)qui est un mot code forme par 2m−1 bits 0 et 2m−1
bits 1, son poids est 2m−1 = d2. Le code engendre par les lignes de la sous-matrice(G1 G1
)aura pour distance minimale 2.2m−2 = 2d1. D’ou
dmin(RM[1,m]) = min(2d1, d2) = min(2.2m−2, 2m−1) = 2m−1. �
Theoreme 4.4.2 Le code d’ordre de Reed-Muller RM[1,m] est forme par un seul
mot de poids 0 qui est le mot 0, d’un mot de poids 2m qui estle mot 1 et 2m+1 − 2
mots de poids 2m−1.
Preuve : La derniere ligne de la matrice generatrice EHm est 1. Donc, 0 et 1
sont les seuls mots de poids respectivement 0 et 2m. Comme la distance minimale
de RM[1,m] est 2m−1, il n’existe aucun mot code c de poids entre 0 et 2m−1 et il
n’existe aucun mot code 1+ c de poids entre 0 et 2m−1. Donc, il n’y a aucun mot
code de poids entre 2m−1 et 2m. Ainsi tous les mots code autre que 0 et 1 ont pour
poids 2m−1. �
Mr HITTA Amara100
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Corollaire 4.4.3 Le code dual du code de Hamming binaire de redondance m est
forme par un seul mot de poids 0 et 2m − 1 mots de poids 2m−1.
Preuve : Pour passer de RM[1,m] vers le code de Hamming dual, on prend tous
les mots code commencant par 0 et on elimine leurs positions. Le mot code 1 aura
pour poids 2m−1. Donc, les mots code non nuls de poids 2m−1 seront au nombre
2m+1 − 1. �
Ces codes sont dits codes equidistants, dans la mesure ou les mots codes distincts
sont a distance fixe, 2m−1, l’un de l’autre.
4.4.1 Decodage des Codes de Reed Muller
L’outil fondamental de decodage des codes de Reed-Muller est la transformee de
Hadamard. En evoquant la structure de groupe commutatif G = (Zn2 ,+), n ∈ N∗,
cette transformee n’est autre que la transformee de Fourrier sur ce groupe.
Soit x ∈ Zn2 . Un caractere du groupe additif G est l’application, dite de Walsh,
χx : Zn2 7→ C tel que χx(y) = (−1)<x,y>.
ou < x,y > est le produit scalaire ordinaire entre les mots x et y ∈ G.
La transformation de Hadamard d’une fonction a variable complexe f et son inverse
sont definies par
f(y) =∑
x
f(x)(−1)<x,y>
f(x) =1
2n
∑x
f(y)(−1)<x,y>.
Considerons l’espace {+1,−1} et la transformation suivante
Ψ : Z2 = {0, 1} → {+1,−1} telle que Ψ(0) = +1 et Ψ(1) = −1.
Soit x ∈ Zn2 , son image par Ψ sera notee x∗ = Ψ(x) ∈ {+1,−1}n. Cela consiste
a remplacer, respectivement, les bits 0 et 1 dans x par les nombres reels +1 et −1
pour obtenir le mot x∗.
Mr HITTA Amara101
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Lemme 4.4.4 Si x et y sont deux mots de l’espace Zn2 , alors
x∗.y∗ = n− d(x,y).
ou d est la distance de Hamming. Si x,y ∈ Z2h2 et d(x,y) = h alors x∗.y∗ = 0.
Preuve : . Le produit scalaire de x∗ et y∗ est egal au nombre n moins la nombre
de places ou ils different a savoir d(x,y)+d(y,x) = 2d(x,y). Si n = 2h et d(x,y) =
h = n/2 alors x∗.y∗ = 0. �
Posons RM(1,m)± le code obtenu en remplacant chaque mot code x de RM(1,m)
par x∗. Les mots code de RM(1,m)± sont alors x∗1,x∗2, · · · ,x∗2m+1 .
Lemme 4.4.5 Si x∗ ∈ RM(1,m)± alors −x∗ ∈ RM(1,m)±. De plus, on a
x∗i .x∗j =
2m si x∗i = x∗j
−2m si x∗i = −x∗j
0 si x∗i 6= ±x∗j .
Preuve : Puisque 1 ∈ RM(1,m) alors 1 + x ∈ RM(1,m) et l’on a (1 + x)∗ =
−x∗ ∈ RM(1,m)±. Le reste se deduit du lemme precedent puisque n = 2m. �
4.5 Codes de Reed-Solomon
Soit p un nombre premier et posons q = pm ou m est un entier naturel.
Une autre classe de codes tres connue en theorie du codage est celle des codes de
Reed-Solomon sur un corps fini de Galois ; Ils ont de bons parametres. On les definis
de deux manieres :
• Evaluation des polynomes sur un corps de Galois Zq. En general, on prend
p = 2.
• Codes cycliques : Choisissons un polynome g(x) ∈ Zq[x] de degre n − k,
n et k deux entiers tels que k < n. Le message est considere comme les
Mr HITTA Amara102
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
cœfficients d’un certain polynome M(x) tel que d0M(x) < k ; Il sera code
comme les cœfficients du polynome g(x)M(x). Si g(x) divise le polynome
xn−1, on obtient une famille de codes dits cycliques. En optant pour d’autres
restrictions on obtient les codes BCH, qui contiennent comme sous-famille les
codes de Reed-Solomon.
C’est la premiere approche que nous allons aborder dans ce qui suit.
Soient a1, . . . , an des elements distincts du corps de Galois Zq. Pour k ∈ N, con-
siderons l’espace vectoriel des polynomes de degre inferieur ou egal a k − 1 :
Lk = {f ∈ Zq[x] : d0(f) ≤ k − 1}.
Il est evident que dim(Lk) = k, puisqu’il admet pour base canonique {1, x, x2, · · · , xk−1}.
Definissons l’application evaluation, notee ev : Lk → Znq par ev (f) := [f(a1), . . . , f(an)].
Si k < n, elle est injective. Le code de Reed-Solomon est le sous-espace vecto-
riel de Znq defini par
RS(2) = { ev (f) : f ∈ L{k :k<n}}.
Il est clair que la dimension de ce code est k.
Pour trouver sa distance minimale, considerons un mot code ev(f) dont le poids est
egal a la distance d = d(RS(q)). Alors, f s’annule sur (n−d) elements de l’ensemble
{a1, . . . , an}. Par consequent, n− d ≤ d0(f) ≤ k− 1. Il s’en suit que d ≥ n− k+ 1.
Cette inegalite est en realite une egalite car il existe des polynomes non nuls de degre
k − 1 qui ont k − 1 racines distinctes, a savoir h(x) =∏k−1
i=1 (x− ai) qui correspond
au mot code ev (h) de poids (n− k+ 1), ce qui donne d ≤ n− k+ 1 . Donc, le code
RS(q) est de type [n, k, n− k + 1]. Ainsi,
RS(q) = Ckn,n−k+1(q).�
Mr HITTA Amara103
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Comme ev (xi) = (ai1, ai2, · · · , ain), pour tout 0 ≤ i ≤ k − 1, la matrice generatrice
de Reed-Solomon, ainsi defini, sera
GRS(q) =
1 1 · · · 1
a1 a2 · · · an...
......
...
ak−11 ak−2
2 · · · ak−1n
.
Enfin, Il existe un algorithme de decodage rapide, pour ces codes, utilisant l’algorithme
d’Euclide dans l’anneau Z2[x]
4.6 Codes BCH et leurs algorithmes de decodage
Construisons, maintenant, une autre famille de codes dits Codes BCH : Bose,
Ray-Chaudhuri et Hocquenghem.
Posons GF (q) = {a1, a2, · · · , aq} et
H =
1 1 · · · 1
a1 a2 · · · an
a21 a2
2 · · · a2n
...... · · · ...
ad−21 ad−2
2 · · · ad−2n
Soit C un code sur GF (q) de matrice de controle H, d − 1 ≤ n ≤ q. Le code C a
pour redondance d− 1. Sa dimension est n− (d− 1) = n− d+ 1. Chaque ensemble
de d−1 colonnes de H forme une matrice de Vandermonde de determinant non nul.
Ainsi, les d − 1 colonnes sont lineairement independants. La distance minimale de
C est d, sa dimension est k = n− d+ 1. �
4.6.1 Decodage des codes BCH par l’exemple
Ces codes ont un algorithme de decodage tres subtiles et tres puissants mais difficile
a expliquer. Abordons le tout d’abord sur un exemple simple.
Mr HITTA Amara104
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Exemple 4.6.1 (Code BCH sur GF(11)) Soit C un code, sur le corps de Galois
Z11, defini par la matrice de controle
H =
1 1 1 1 · · · 9 X
1 2 3 4 · · · 9 X
12 22 32 42 · · · 92 X2
13 23 33 43 · · · 93 X3
=
1 1 1 1 1 1 1 1 1 1
1 2 3 4 5 6 7 8 9 X
1 4 9 5 3 3 5 9 4 1
1 8 5 9 4 7 2 6 3 X
.
Ce code a pour longueur 10 et de redondance 4. Sa dimension est alors 6 et sa
distance minimale est 5. Sa capacite de correction est [(5 − 1)/2] = 2-correcteur.
Soit aei + bej les erreurs doubles a corriger par ce code. Si (s1, s2, s3, s4) sont les
syndomes, la correction des erreurs revient a determiner a, b, i et j. Les erreurs se
trouvent en positions i et j. Les colonnes de H concernees par le calcul du syndromes
S(aei + bej) sont(
1 i i2 i3)t
et(
1 j j2 j3)t
. Donc
S(aei + bej) = (a+ b, ai+ bj, ai2 + bj2, ai3 + bj3)
= (s1, s2, s3, s4).
Ce qui donne en eliminant a de ces equations :
b(j − i) = s2 − is1 [1]
b(j − i)j = s 3 − is2 [2]
b(j − i)j2 = s4 − is3 [3].
En comparant le carre de l’equation [3] avec le produit des equations [1] et [2], on
obtient (s3 − is2)2 = (s2 − is1)(s4 − is3). Ce qui represente une equation du second
degre de la forme Pi2 +Qi+R = 0 de racine i et j. Plusieurs cas se presentent :
• S(y) = 0, aucune erreur n’est survenue et y se decode a lui-meme.
• S(y) 6= 0 mais l’equation du second degre est nulle alors P = Q = R = 0 et
s2
s1
=s3
s2
=s4
s3
.
Dans ce cas, il existe une seule erreur : i = s2/s1 et a = s1.
Mr HITTA Amara105
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
• S(y) 6= 0 mais l’equation du second degre Pi2+Qi+R = 0 admet deux racines
distinctes dans Z11. Ces racines seront i et j et on obtient a et b en resolvant
a+ b = s1 et ai+ bj = s2.
• L’equation Pi2+Qi+R = 0, n’admet aucune racine ou admet une seule double
dans Z11. Dans ce cas, le vecteur erreur ne peut-etre celui correspondant a
cette racine double, et l’on au moins le merite d’avoir detecter au moins 3
erreurs.
Exemple 4.6.2 (Decodage BCH) Etant donne le syndrome (s1, s2, s3, s4), on
calcule l’erreur survenue lors de la transmission :
• Si le syndrome est (1, 2, 3, 7), l’equation sera i2 + i+ 6 = 0 qui n’admet pas de
solutions dans Z11.
• Si le syndrome est (2, 1, 6, 3), les cœfficients de l’equation du second degre
seront nuls et i = 1/2 et a = 2. Ce qui donne l’erreur e = 0000020000.
• Si le syndrome est (1, 2, 9, 7), on obtient 9i2 + 7 = 0 c’est-a-dire i2 − 9 = 0 et
i = 3 et j = −3 = 8. D’autre part, a + b = 1 et 3a + 8b = 2. Ce qui donne
5b = X, d’ou b = 2 et a = −1 = X. L’erreur sera alors e = 00X0000200. �
4.6.2 Decodage general d’un code BCH
Supposons que l’on a un code t-correcteur de distance d = 2t + 1 et de matrice
de controle a 2t lignes, le syndome sera un vecteur de la forme (s1, s2, · · · , s2t).
L’idee consiste a determiner les localisations xi des coordonnees de l’erreur et leurs
amplitudes ai telle que l’erreur soit∑t
i=1 aiexi. Ce qui revient a determiner les
amplitudes ai et les localisations xi en fonction des si dans le systeme
a1 + a2 + · · ·+ at = s1
a1x1 + a2x2 + · · ·+ atxt = s2
......
......
...
a1x2t−11 + a2x
2t−12 + · · ·+ atx
2t−1t = s2t.
Mr HITTA Amara106
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Multiplions chaque equation i du systeme par αi−1 ou α est une indeterminee. En
ajoutons les 2 cotes du systeme et egalisant, l’on obtient que les 2t premier termes
de s1 + s2α + s3α2 + · · ·+ s2tα
2t−1 sont les 2t premiers termes de
a1
1− x1α+
a2
1− x2α+ · · ·+ at
1− xtα=A1 + A2α + A3α
2 + · · ·+ Atαt−1
1 +B1α +B2α2 + · · ·+Btαt.
Les cœfficientsAi etBi sont a determiner. En reduisant au meme denominateur com-
mun, on obtient l’identite entre deux series dont les cœfficients sont egaux jusqu’au
terme en α2t−2, a savoir
(s1 + s2α + s3α2 + · · ·+ s2tα
2t−1 + · · · )× (1+ B1 α +B2α2 + · · ·+Btα
t)
= A1 + A2α + A3α2 + · · ·+ Atα
t−1.
Ce qui donne t equations lineaires en B1, B2, · · · , Bt. On factorise ensuite ces termes
pour determiner les localisations x1, · · · , xt. Finalement, en egalisant les cœfficients
des termes 1, α, · · · , αt−1, pour calculer les Ai. On obtient
A1 = s1
A2 = s2 + s1B1
A3 = s3 + s2B1 + s1B2
...
At = st + st−1B1 + · · ·+ s1Bt−1.
Ce qui donne
A1 + A2α + A3α2 + · · ·+ Atα
t−1
1 +B1α +B2α2 + · · ·+Btαt= s1 + s2α + s3α
2 + · · ·+ s2tα2t−1 + · · ·
=a1
1− x1α+
a2
1− x2α+ · · ·+ at
1− xtα.
Comme les termes Ai et Bi sont connus, les valeurs de ai et xi en decoule simplement
en decomposant l’expression a gauche en des fractions simples.
Exemple 4.6.3 (Decodage d’un code BCH sur Z11) Considerons le code dont
les paramtres sont n = 10, k = 4, r = 6, q = 11 et d = 7 et de matrice de controle
Mr HITTA Amara107
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
est
H =
1 1 1 1 · · · 9 X
1 2 3 4 · · · 9 X
12 22 32 42 · · · 92 X2
13 23 33 43 · · · 93 X3
14 24 34 44 · · · 94 X4
15 25 35 45 · · · 95 X5
=
1 1 1 1 1 1 1 1 1 1
1 2 3 4 5 6 7 8 9 X
1 4 9 5 3 3 5 9 4 1
1 8 5 9 4 7 2 6 3 X
1 5 4 3 9 9 3 4 5 1
1 X 1 1 1 X X X 1 X
Supposons que le syndrome d’un mot recu y est s(y) = (, 8, 4, 5, 3, 2) alors on a a
resoudre le systeme
2B3 + 8B2 + 4B1 + 5 = 0
8B3 + 4B2 + 5B1 + 3 = 0
4B3 + 5B2 + 3B1 + 2 = 2.
Ce qui donne B1 = 5, B2 = X et B3 = 8. D’autre part, A1 = 2, A2 = 8 + 2B1 = 7 et
A3 = 4 + 8B1 + 2B2 = 9. Le denominateur est 1 + 5α+Xα2 + 8α3 qui se decompose
comme (1 − 3α)(1 − 5α)(1 − 9α). Les positions des erreurs sont alors 3, 5 et 9.
Finalement, on obtient la factorisation en fractions simples
2 + 7α + 9α2
(1− 3α)(1− 5α)(1− 9α)=
4
1− 3α+
2
1− 5α+
7
1− 9α.
L’erreur est alors e = 0040200070.
• Si s(y) = (5, 6, 0, 3, 7, 5), on a les equations 5B3 +6B2 +3 = 0, 6B3 +3B1 +7 = 0 et
3B2+7B1+5 = 0. En eliminant B3, on obtient 6B2+3B1+X = 2(3B2+7B1+5) = 0.
En choisissant B3 = A3 = 0, on a B2 = 5, B1 = 5. On calcule ensuite A1 = S1 = 5
et A2 = s2 + s1B1 = 9. D’autre part,
5 + 9α(1− α)(1− 5α) =2
1− α+
3
1− 5α.
Ce qui donne l’erreur e = 2000300000. �
Algorithme de decodage des codes BCH :
• Calculer le syndrome s(y) = (s1, s2, · · · , s2t) du mot recu y.
Mr HITTA Amara108
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
• Calculer le rang r, qui est le nombre d’erreur, de la matrices1 s2 s3 · · · st
s2 s3 s4 · · · st+2
... . . ....
st st+1 st+2 · · · s2t−1
• Resoudre, ensuite, le systeme a r equations en B1, · · · , Br :
st+1−rBr + st+2−rBr−1 + · · ·+ stB1 + st+1 = 0
st+2−rBr + st+3−rBr−1 + · · ·+ st+1B1 + st+2 = 0...
stBr + st+1Br−1 + · · ·+ st+r−1B1 + st+r = 0.
• Calculer A1, · · · , Ar suivant les equations
A1 = s1
A2 s2 + s1B1
...
Ar = sr + sr−1B1 + · · ·+ s1Br−1.
• Factoriser le polynome
1 +B1α + · · ·+Brαr = (1− x1α)(1− x2α) · · · (1− xrα),
ou x1, · · · , xr sont les positions des r erreurs. Sinon, conclure qu’il existe plus
de t erreurs.
• Decomposer la fraction rationnelle suivante en fractions simples
A1 + A2α + · · ·+ Arαr−1
(1− x1α)(1− x2α) · · · (1− xrα)=
a1
1− x1α+
a2
1− x2α+ · · ·+ ar
1− xrα,
pour obtenir les amplitudes ai des erreurs en positions xi.
• Decoder y a y−r∑i=1
aiexi.
Mr HITTA Amara109
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Mr HITTA Amara110
08-Mai 45 Guelma University

CHAPITRE
5
BORNES ASYMPTOTIQUES D’UN
CODE
5.1 Bornes d’un code
Posons A2(n, d) la valeur maximale possible |Ck[n,d](2)| = 2k, 1 ≤ k ≤ n, pour n et d
donnes.
Exemple 5.1.1 On a
• Les seuls mots de longueur n, a distance 1 l’un de l’autre, sont les mots de
longueur n qui ont un seul bit 1 et le reste c’est des bits 0 ; ils sont au nombre
n et forment une base de l’espace Zn2 . Donc A2(n, 1) = |Zn
2 | = n.
111

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
• Les seuls mots de longueur n, a distance n l’un de l’autre, sont les mots :
0 · · · 0 et 1 · · · 1 du code de repetition de longueur n. Donc, A2(n, n) = 2 =
|C1n(2)| = 2. �
Soit x = x1x2 · · ·xn un mot du code C(2) = Ck[n,d](2). Deux cas se presentent :
• Si w(x) est paire, la parite de controle de ce mot est 0. On obtient un mot de
longueur n+ 1 de la forme x = x1x2 · · ·xn0 .
• Si w(x) est impaire, la parite de controle de ce mot est 1. On obtient un mot
de de longueur n+ 1 de la forme x = x1x2 · · ·xn1.
Les poids des mots du code ainsi construit C(2) sont pairs. Les distances entre ses
mots le sont aussi car d(x, y) = w(x+ y).
Theoreme 5.1.1 Si d est impaire, alors C(2) = Ck[n+1,d+1](2).
Preuve : La distance minimale du code C(2) est paire entre d et d+ 1. �
Inversement : Supposons que l’on a un code binaire de type [n+ 1, k, d+ 1] ou d est
impaire. Choisissons deux mots de ce code qui sont a une distance d+1. Supprimons
les bits ou ils different ainsi que les bits, dans les memes positions, des autres mots
de ce code. On obtient ainsi, un code binaire de type [n, k, d].
Corollaire 5.1.2 On a A2(n, d) = A2(n+ 1, d+ 1) si d est impair.
Definition 5.1.3 (Code optimal) Un code binaire Ck[n,d](2) est dit optimal si
A2(n, d) = |Ck[n,d](2)|.
Exemple 5.1.2 (Codes optimaux) Soit le code C4[5,3] = {00000, 01101, 10110, 11011}.
La construction precedente nous fournit le code C4[6,4] = {000000, 011010, 101100, 110110}.
Comme A2(5, 3) = 4, d’apres la corollaire, on a A2(6, 6) = 4. Ces deux codes sont
des codes optimaux. �
Mr HITTA Amara112
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Le probleme principal, pour obtenir un bon code Ck[n,d](2) est d’optimiser ses trois
parametres de facon que :
• la longueur n soit assez petite pour que les transmissions soient rapides.
• la dimension k soit assez grande pour transmettre une variete de message.
• la distance d soit assez grande pour corriger plusieurs erreurs.
Notre but est donc de trouver les codes Ck[n,d](2) tels que :
• La distance relative δ[Ck[n,d](2)] =d
nsoit assez grande.
• Le taux d’information R[Ck[n,d](2)] =k
nsoit assez grand.
Ces deux conditions sont assez opposees. Mais, on peut d’ores et deja signaler que
l’on a l’ inegalite suivante :
Theoreme 5.1.4 (Inegalite du singleton)) Les parametres du Ck[n,d](2) verifient
k ≤ n− d+ 1
ou plus precisement
A2(n, d) ≤ 2n−d+1.
Preuve : Les mots d’un code existent avec au moins un bit d’information non
nul et (n − k) bits de controle. Un tel mot ne peut avoir un poids plus grand que
1 + (n− k). Par consequent, le poids du code ne peut depasser 1 + (n− k). �
Definition 5.1.5 (Code MDS) Le code Ck[n,d](2) est dit MDS (Maximum Dis-
tance Separable) lorsque l’egalite du singleton est atteinte, c’est-a-dire
k = n− d+ 1.
Mr HITTA Amara113
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Exemple 5.1.3 (Codes MDS) Un code MDS est de la forme Cn−d+1[n,d] (2). Les
codes suivants : C1[n,n](2), Cn−1
[n,2](2) et Cn[n,1](2) sont MDS.
La determination de tous les codes MDS est un probleme non resolu.
Corollaire 5.1.6 Un code MDS est t-correcteur s’il admet 2t symboles de controle.
Preuve : Pour corriger 2t erreurs, il faut que d = 2t+ 1. Comme le code est MDS,
alors k = n− d+ 1 = n− 2t et n− k = 2t qui est le nombre de bits de controle. �
Remarque. Pour un code Ck(n,d)(2), l’on souhaite que le taux de transmission kn
et
la distance relative dn
soient aussi grand que possible. Mais l’inegalite du singleton
nous donnek
n+d
n≤ 1 +
1
n.
Ce qui montre que l’on ne peut pas augmenter les deux taux ensembles.
Definition 5.1.7 (Codes de Justesen) Une classe de�bons codes� ou�codes
de Justesen� est une famille Cki
[ni,di](2) tels que
limi→∞
(dini
)> 0, lim
i→∞
(kini
)> 0 et lim
i→∞ni =∞.
Les seuls bons codes connus actuellement sont ceux de Justesen et ceux de Katsman,
Tasfasman et Vladut. Ces derniers contiennent les codes geometriques de V. Goppa.
Theoreme 5.1.8 (Borne asymtotique de Hamming) Soit un code binaire t-
correcteur Ck[n,d](2) c’est-a-dired = 2t+ 1, alors
1 + C1n + C2
n + . . . Ctn ≤ 2n−k
ou plus precisement :
A2(n, t) ≤2n
V2(n, t).
Mr HITTA Amara114
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Preuve : Pour trouver tous les mots a une distance t d’un point fixe x, on lui
ajoute simplement tous les mots de poids t ; ils sont au nombre Ctn. Comme les
spheres centrees en des mots de C sont disjointes deux a deux, en se donnant
x ∈ C de longueur n, il existe Ckn mots code qui different avec x en k positions. Par
consesquent, la boule Bt(x) contient V2(n, t) = 1 + C1n + . . . + Ct
n mots. Comme il
y a |Ck(n,d)(2)| = 2k mots du code, il y aurait autant de boules centrees en des mots
de Ck(n,d)(2). Leurs reunion est un sous-ensemble de Zn2 . �
Remarque : Cette borne n’est pas toujours la meilleure. Si t ≤ 14n c’est raisonnable
comme borne. Si t est large, les spheres seront assez grandes.
Exemple 5.1.4 Considerons le code Ck(6,3)(2). Sa distance minimale est 3 = 2t+ 1,
c’est-a-diret = 1. D’apres la borne de Hamming, on a
2k = |Ck(6,3)(2)| ≤ 26
C60 + C6
1
=64
7.
Mais |Ck(6,3)(2)| est une puissance de 2, donc |Ck(6,3)(2)| ≤ 8 et alors 2k ≤ 8, c’est-a-
direk ≤ 3. �
Definition 5.1.9 (Codes parfaits) Un code t-correcteur est dit parfait lorsque la
borne de Hamming est atteinte.
Dans ce cas, L’espace Zn2 tout entier est la reunion disjointe de boules de Hamming
de rayon t centrees sur des mots codes :
Ck[n,d](2) code t-correcteur parfait ⇐⇒ Zn2 =
⋃c∈Ck
[n,d](2)
Bt(c).
Cette situation est ideale puisque un code t-correcteur parfait, peut corrige jusqu’a
t erreurs et ne peut corriger t + 1 erreurs par le decodage de la vraissemblance
maximale.
Exemple 5.1.5 (Code trivial) Si t = 0 alors C0n = 1 = 20 et |C(2)| = 2n. C’est
le code trivial Zn2 . �
Mr HITTA Amara115
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Exemple 5.1.6 (Code parfaits) • Tout code ayant exactement un seul mot
est parfait.
• Les codes de repetition C1[n,n](2) d’ordre n = 2t+1 sont parfaits. Ils contiennent
les mots 0 . . . 0 et 1 . . . 1. L’espace Zn2 sera la reunion disjointes des boules
Bt(0 . . . 0) = {x ∈ Zn2 | w(x) < t} et Bt(1 . . . 1) = {x ∈ Zn
2 | w(x) ≥ t+1}.�
Les codes parfaits sont rares et ceux qui existent sont performants. En 1963, Van
Lint et Tietavairen, ont montre le resultat important suivant : Si un code parfait
de longueur n et de distance d = 2t+ 1, alors
• t = 3 et (n, d) = (23, 7), c’est les parametres du code de Golay, G12(23,7)(2).
• (n, d) = (2r − 1, 3) c’est les parametres des codes de Hamming Hr(2).
Remarque. Dans le cas non binaire, un code Ck(n,d)(p) est parfait sur le corps fini
Zp si
1 + C1n(p− 1) + C2
n(p− 1)2 + . . .+ Ctn(p− 1)t = pn−k.
Exemple 5.1.7 (Compression des donnees) Les codes de Hamming Hr(2) =
C2r−1−r(2r−1,3) sont des codes 1-correcteurs parfaits. En effet, puisque t = 1, alors
2n
Cn0 + Cn
1
=2n
1 + n=
22r−1
2r= 22r−1−r = |Hr(2)|.
La borne de Hamming est atteinte. Par consequent, les spheres de rayon 1 centree
sur les mots code forment une partition de Zn2 c’est-a-dire
Zn2 =
⋃c∈Hr(2)
B1(c).
Les codes de Hamming sont utilises pour la compression des donnees en se perme-
ttant une petite distorsion de l’information. Soit G la matrice generatrice du code
de Hamming Hr(2) = C2r−1−r(2r−1,3) de longueur n = 2r − 1. Chaque mot x ∈ Zn
2 est a
Mr HITTA Amara116
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
une distance 1 d’un seul mot code c ∈ Hr(2). On stock le mot x sous la forme d’un
mot m de longueur k = n − r = 2r − 1 − r qui est l’unique solution de c = mG.
Pour la decompression, le message stocke m est code comme c = mG, qui differe
du mot initial x dans au plus une position. �
Exemple 5.1.8 (Codes de Golay 3-correcteurs parfaits) Les codes de Golay
ont ete decouvert par Golay lui-meme en 1949.
• Considerons le code binaire de Golay G = C12[23,7](2). Il verifie la borne de
Hamming car t = 3, n = 23. Comme k = 12 alors |G | = 212. Ainsi,
212(C230 + C23
1 + C232 + C23
3 ) = 223.
Le code de Golay G3(2) = C12(23,7)(2) derive du code de Golay G = C12
(23,8)(2)
en ajoutant des parites de controle (c’est-a-direextension). Son groupe de
symetrie joue un role important dans la theorie des groupes finis ; c’est le
groupe de Mathieu M24 d’ordre 244823040. Il est considere comme le plus
important des 26 groupes simples sporadiques. L’ATLAS de Conway & Co.
(1980) donne la plupart des construction de ces groupes.
• Le code de Golay ternaire, construit sur le corps Z3, G = C6(11,5)(3) est parfait.
Car t = 2, n = 11, k = 6 et 1 + 22 + 5× 11× 4 = 35.
Dans leur traite de reference sur le codage, MacWilliams et Sloane (1977), con-
siderent que les codes de Golay binaires sont probablement les plus importants pour
des raisons pratiques et theoriques.
Une autre borne, cette fois-ci inferieure, dite de Gilbert-Vershamov merite d’etre
signalee. Sa satisfaction garantie l’existence de code.
Theoreme 5.1.10 Si l’on a l’inegalite
1 + Cn−11 + . . .+ Cn−1
d−2 < 2n−k c’est-a-dire V2(n− 1, d− 2) ≥ 2n
A2(n, d),
il existe un code lineaire Ck(n,d)(2).
Mr HITTA Amara117
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Preuve : On va construire, par recurrence, une matrice H de type (n−k)×n telle
que au moins d − 1 colonnes ne soient pas lineairement independantes. D’apres le
lemme [ ], ceci demontre le theoreme. Les premieres colonnes de H peuvent etre
des vecteurs non nuls de longueurs (n − k). Supposons que nous avons choisi une
sous-matrice Hi de type (n − k) × i de H dont le nombre de colonnes est i telles
que d−1 colonnes d’entre elles ne soient lineairement independants. Il y a au moins
Ni = C1i + . . .+Cd−2
i mots qui sont combinaison lineaire distincts d’au moins (d−2)
colonnes de Hi. Si Ni ≤ 2n−k − 1, on peut ajouter une autre colonne differente de
ces combinaisons lineaires, tout en se gardant que les (d− 1) colonnes de la matrice
Hi+1 de type (n−k)× (i+ 1) soient lineairement independantes. On peut raisonner
de cette maniere jusqu’a ce que 1 + Cn−11 + . . .+ Cn−1
d−2 < 2n−k. �
Exemple 5.1.9 (Existence de code) Considerons le code lineaire de type [n, k, d] =
[9, 2, 5] . D’apres la borne de Gilbert-Varshamov, on a
V(8, 3) = 1 + C81 + C8
2 + C83 = 93 < 2n−k = 27 = 128.
Ce code existe. �
Fixons un reel δ, 0 < δ < 1, et posons
α(δ) := lim supn→∞
[1
nlog2[A2(n, δn)]
].
L’etude des nombres A2(n, d) est considere comme un probleme central en theorie
des codes combinatoires. D’ou l’importance du nombre α(δ). Une estimation de
α(δ) est dite borne asymptotique.
Dans le theoreme 1.22, posons p = λn ou 0 ≤ λ ≤ 1
2, on obtient l’expression de
l’entropie binaire
H2(λ) = limn→∞
1
nlog2[V2(n, λn)].
Mr HITTA Amara118
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
On utilise cette expression pour reecrire les resultats precedents en terme des bornes
asymptotiques
α(δ) ≤
1−H2
(1
2δ
)−→ Borne asymptotique de Hamming
1− δ −→ Borne asymptotique du Singleton.
La meilleure des bornes superieures de α(δ) jusqu’a present est celle de McEliece,
Rodemich, Rumsey et Welch :
α(δ) ≤ min {1 + g(u2)− g(u2 + 2δu+ 2δ) : 0 ≤ u ≤ 1− 2δ}
ou
g(x) = H2
(1−√
1− x2
).
Enfin, la borne asymptotique inferieure de Gilbert-Vershamov
α(δ) ≥ 1−H2(δ), 0 ≤ δ ≤ 1
2.
En recapitulant, on obtient le schema suivant :
Ces dernieres annees, on a vu une proliferation de construction de codes geometriques
encodes et decodes en temps polynomiaux en fonction de leurs longueurs. Leurs per-
formances depassent de loin la borne inferieure de Varshamow-Gilbert. Recemment
et en utilisant les courbes algebriques sur les corps de Galois (p ≥ 49), ont demontre
l’existence de bornes meilleures que celles de Varshamow-Gilbert. Ces codes ont de
plus grands taux d’information avec les memes longueurs et les memes distances
minimales. D’autre part, Calderbank, Hammons, Kummer, Sole et Sloane (1995)
ont montre que les meilleurs codes sont les codes lineaires sur Z4 qui n’est pas un
corps.
Mr HITTA Amara119
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
keepaspectratio
Mr HITTA Amara120
08-Mai 45 Guelma University

CHAPITRE
6
PARAMETRES ASYMPTOTIQUES
DES CODES
6.1 Existence de codes et parametres asymptotiques
Soit canal binaire symetrique de probabilite p ∈]0, 12[.
Un mot du code Ckn,d(2) contient en moyenne np bits d’ou l’idee de considerer la
boule de Hamming B(0;np) de centre 0 et de rayon np. Supposons qu’une erreur
e ∈ B(0;np) soit commise lors d’une transmission. Si cette erreur est la seule de
son syndrome, on peut la corriger en suivant la vraissemblance maximale. Si, en
revanche, plusieurs erreurs correspondent a un meme syndrome, l’incertitude ne peut
etre levee.
On pose alors
ECkn(2) = {e ∈ B(0;np) : s−1(s(e)) 6= {e}}
121

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
ou s est l’application syndrome.
Definition 6.1.1 (Probabilite d’erreurs) Le rapport
eCkn(2) :=
|ECkn(2)|
|B(0;np)|
s’appelle la probabilite d’erreurs du code C(2). Les parametres asymptotiques
de Ckn(2) sont la distance relative et le taux de transmission
δCkn(2) =
d
net RCk
n(2) =k
n.
En presence de perturbations et grace a un decodage approprie, il est possible
d’assurer un debit d’information aussi proche que l’on desire de la capacite du canal
de transmission C(p) avec une probabilite d’erreurs arbitrairement petite, mais qu’en
revanche cette probabilite ne peut etre inferieure a une valeur finie si le debit est
superieur a la capacite du canal.
La demonstration suivante du theoreme de Shannon est longue et sort du cadre de
ce livre.
Theoreme 6.1.2 (Shannon) Soit ε > 0. Fixons p ∈]0, 12[. Il existe un code
lineaire C(2) dont le taux de transmission est tel que RC(2) ≥ C(p)− ε et qui verifie
la contrainte de performance sur la probabilite eC(2) < ε.
Une variante au theoreme de Shannon est le resultat suivant
Theoreme 6.1.3 Soit ε > 0. Fixons p ∈]0, 12[. Il existe un code lineaire C(2) dont
le taux de transmission et la distance relative verifient
RC(2) ≥ β(δC(2))− ε et δC(2) ≥ p.
Mr HITTA Amara122
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Interpretation :
Pour p ∈]0, 12[, il existe un code C(2) avec δC(2) ' p et RC(2) ' C(p).�
Le nombre β(δC(2) est dit la borne inferieure de Varshamov-Gilbert du code
C(2).
6.2 Poids enumerateur et probabilite d’erreurs
Il est parfois utile de connaitre le nombre de mots d’un code dont le poids est
prealablement donne ainsi que la probabilite d’erreurs commises lors d’un decodage
par la vraissemblance maximale. Pour cela, on introduit la notion de poids enumerateur
d’un code.
Soit C(2) un code binaire lineaire.
Definition 6.2.1 (Le poids enumerateur) Le poids enumerateur d’un code bi-
naire lineaire C(2) est le polynome
PC(2)(z) =∑
iwizi
ou wi represente le nombre de mots du code C(2) de poids i.
Exemple 6.2.1 Considerons le code C36(2) de matrice generatrice
G =
1 0 0 0 1 1
0 1 0 1 0 1
0 0 1 1 1 0
.
Ce code contient 4 mots de poids 3 (w3 =) et 3 mots de poids 4 (w4 = 3) (il
suffit de considerer les lignes et leurs combinaisons lineaires possibles). Son poids
enumerateur est le polynome
PC36(2)(z) = 1 + 4z3 + 3z4.�
Mr HITTA Amara123
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Exemple 6.2.2 (code binaire de repetition d’ordre n) Ce code a un seul mot
de poids n (wn = 1). Son poids enumerateur est alors
PC1n(2)(z) = zn.�
Exemple 6.2.3 (Code de parite) Considerons le C23(2) = {000, 011, 101, 110}.
Comme C23(2) a 3 mots de poids 2 (w2 = 3), alors
PC23(2)(z) = 1 + 3z2.�
Son code dual est le code de repetition C13(2) = {000, 111} qui a un mot de poids 3,
alors
PC23(2)(z) = 1 + z3.�
En 1963, F. J. MacWilliams a montre que
Proposition 6.2.2 (Formule F.J. Mac Williams) Le poids enumerateur PC(2)
d’un code binaire C(2) et celui de son code dual, note PC⊥(2), sont lies par la formule
PC⊥(2)(z) =1
|C(2)|(1 + z)n PC(2)
(1− z1 + z
)=
1
|C(2)|
n∑i=0
pi(1− z)i(1 + z)n−i.
Exemple 6.2.4 Le code C35(2) admet 23 = 8 mots codes. Son code dual est le code
[C35]⊥(2) = C2
5(2) qui a 22 = 4 mots codes. La matrice generatrice de C25(2) est la
matrice de controle de C35(2) :
H =
(1 1 0 0 0
1 0 1 1 1
).
Les 4 mots du code C25(2) sont :
00000, 11000, 10111 et 01111.
Mr HITTA Amara124
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Comme le poids enumerateur de C25(2) est PC2
5(2)(z) = 1 + z2 + 2z4 il s’en suit le
poids enumerateur de C35(2), d’apres la formule de Mac-Williams :
PC35(2)(z) =
1
4(1 + z)5 PC2
5(2)
(1− z1 + z
)=
1
4
[(1 + z)5 + (1− z)3(1− z)2 + 2(1 + z)(1− z)4
]= 1 + 3z2 + 3z3 + z5.
Donc le code C35(2) contient 1 mot de poids 0, 3 mots de poids 2, 3 mots de poids 3
et un mot de poids 5. Ce qui fait en tout 8 mots. �
Exemple 6.2.5 (Poids enumerateur du code simplexe) Le poids des mots non
nuls du code simplexe iaa Sr est 2r−1 et sa capacite de correction est
t =
[2r−1 − 1
2
]= 2r−2 − 1.
Son poids enumerateur est
Pc Sr(z) = 1 + (2r − 1)z2r−1
.�
Exemple 6.2.6 (Poids enumerateur du code de Hamming) Par la formule de
Mac-Williams, le poids enumerateur du code de Hamming Hr(2) est
PHr(2)(z) =
1
2r
{(1 + z)n + n(1− z)2r−1
(1 + z)n−2r−1}
=1
n+ 1(1 + z)n +
n
n+ 1(1 + z)
n−12 (1− z)
n+12 .
En particulier, le poids enumerateur du code de Hamming H3(2) est
PH3(2)(z) = 1 + 7z3 + 7z4 + z7.�
Pour evaluer les performances d’un systeme de transmission, il est indispensable de
savoir calculer la probabilite d’erreur i Pre lors d’un decodage quelconque. Le poids
enumerateur P(z) d’un code C(2) est tres utile pour etudier la probabilite Pre(c) de
l’erreur survenue lorsqu’on utilise un decodage par la vraissemblance maximale.
Mr HITTA Amara125
08-Mai 45 Guelma University

Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
Par lineairite, supposons que 0 est le mot transmis. Soit c un mot qui n’est pas dans
C(2) de poids w. Posons Pre(c) la probabilite pour que le mot recu soit plus voisin
a c que de 0 :
Pre(c) =∑i≥[w
2 ]
Ciwp
i(1− p)w−i.
La probabilite Pre pour un decodage incorrect verifie
Pre ≤∑
c∈[C(2)]⊥
Pre(c).
Il s’en suit que ∑i≥[w
2]
Ciwp
i(1− p)w−i ≤ pw/2(1− p)w/2∑i≥[w
2]
Ciw.
≤ pw/2(1− p)w/22w
=(
2√p(1− p)
)w.
Par consequent
Pre ≤∑w>0
aw
([2√p(1− p)
]w)= PC(2)(2
√p(1− p))− 1
ou aw est le nombre de mots du code C(2) de poids w.
Ainsi, on vient de montrer le resultat suivant :
Theoreme 6.2.3 Soit C(2) un code binaire de polynome enumerateur PC(2)(z) utilise
sur un CBS de probabilite p. La probabilite Pre pour decoder incorrectement un mot
par l’algorithme de decodage par la vraissemblance maximale verifie
Pre ≤ PC(2)(γ)− 1
ou γ = 2√p(1− p) est un parametre qui ne depend que des caracteristiques du canal
de transmission.
Exemple 6.2.7 Le code de repetition d’ordre 5, C15(2) = {00000, 11111} a pour
poids enumerateur
PC15(2)(z) = 1 + z5.
Mr HITTA Amara126
08-Mai 45 Guelma University
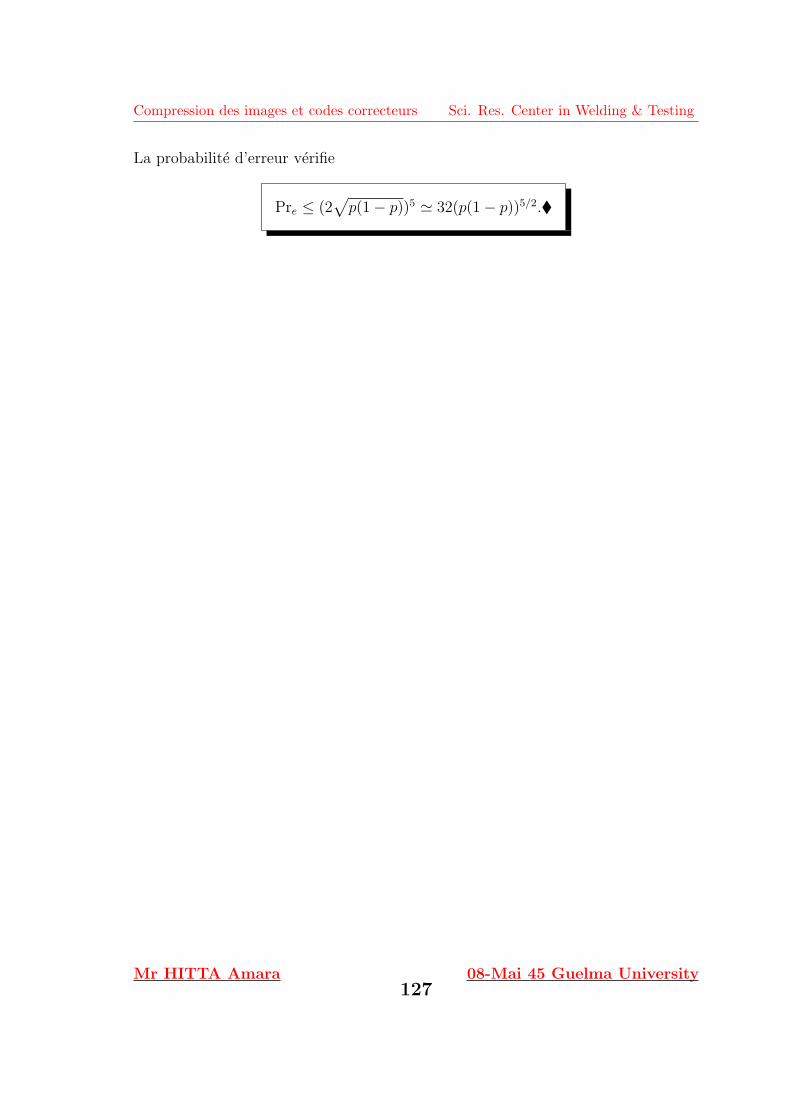
Compression des images et codes correcteurs Sci. Res. Center in Welding & Testing
La probabilite d’erreur verifie
Pre ≤ (2√p(1− p))5 ' 32(p(1− p))5/2.�
Mr HITTA Amara127
08-Mai 45 Guelma University