Embed Size (px)
Citation preview

Université Paris 13/Younès Bennani Traitement Informatique des Données 1
7 Younès BENNANI
ILOG 3
TraitementInformatique desDonnées
Université Paris 13/Younès Bennani Traitement Informatique des Données 2

Université Paris 13/Younès Bennani Traitement Informatique des Données 3
Plan du cours
- Éléments de base
- le neurone
- architectures
- paramètres
- Critères et algorithmes d'apprentissage
- Modèles connexionnistes supervisés
- Perceptron multicouches
- Réseaux à fonctions radiales
- Learning Vector quantization
- Modèles Connexionnistes non supervisés
- Les cartes topologiques de Kohonen
- ART
- Liens avec les statistiques
- Extraction et sélection de caractéristiques
- Fusion de données et de décisions
- Heuristiques pour la généralisation
- régularisation structurelle
- régularisation explicite et pénalisation
- Applications
Université Paris 13/Younès Bennani Traitement Informatique des Données 4
Livres
Neural Networks for Pattern Recognition
Christopher M. Bishop
Clarendon Press - Oxford (1995)
Neural Smithing
Supervised Learning in Feedforward Artificial Neural Networks
Russell D. Reed & Robert J. Marks
Massachusetts Institute of Technology Press (1999)
Pattern Recognition and Neural Networks
B.D. Ripley
Cambridge University Press (1996)
Neural Networks
James A. Freeman & David M. Skapura
Addison-Wesley Publishing Compagny (1991)
Adaptive Pattern Recognition and Neural Networks
Yoh-Han Pao
Addison-Wesley Publishing Compagny (1989)
Neural Networks in Computer Intelligence
LiMin Fu
Massachusetts Institute of Technology Press (1994)
Université Paris 13/Younès Bennani Traitement Informatique des Données 5
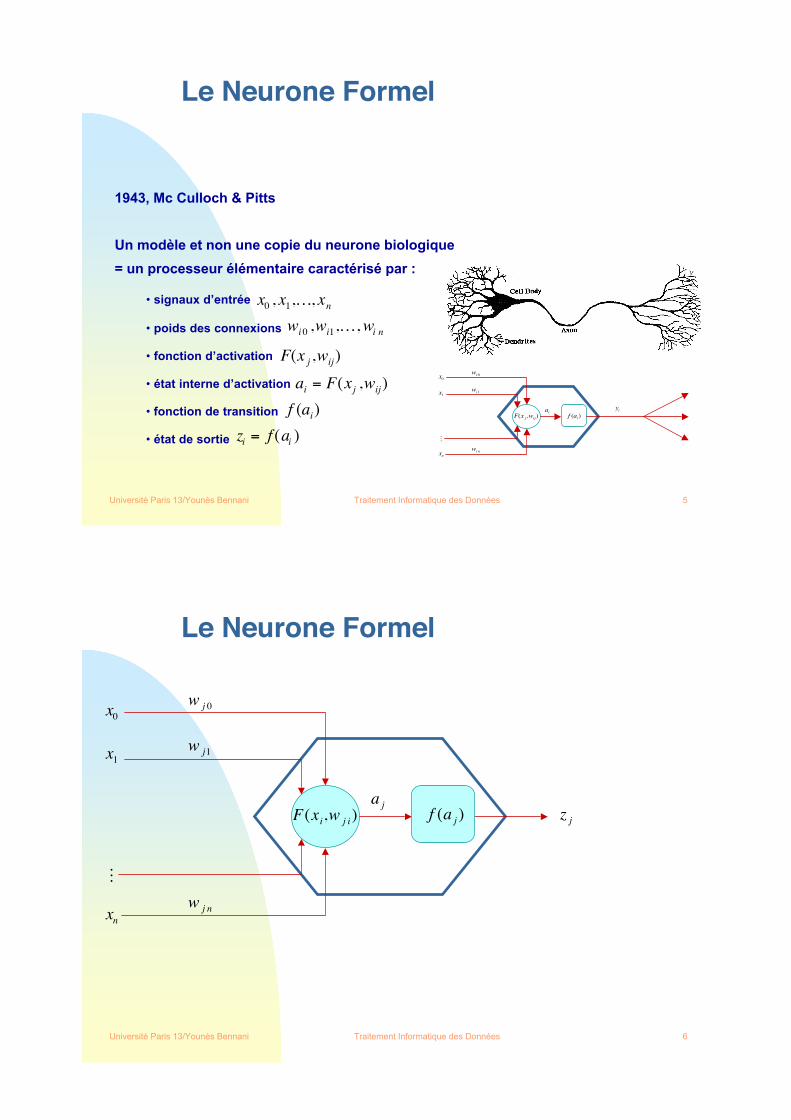
Le Neurone Formel
1943, Mc Culloch & Pitts
Un modèle et non une copie du neurone biologique
= un processeur élémentaire caractérisé par :
• signaux d’entrée
• poids des connexions
• fonction d’activation
• état interne d’activation
• fonction de transition
• état de sortie
x0, x1,K, x
n
wi 0,w
i1,K,w
i n
F(x j ,wij)
ai = F(xj ,wij)
f (ai)
zi = f (ai )
x0
wi 0
ai
yi
x1
xn
M
F(x j ,wij) f (ai)
wi 1
win
Université Paris 13/Younès Bennani Traitement Informatique des Données 6
Le Neurone Formel
x0
!
w j 0
!
z j
x1
xn
M!
F(xi,w j i)
!
f (a j )!
w j1
!
w j n
!
a j
Université Paris 13/Younès Bennani Traitement Informatique des Données 7
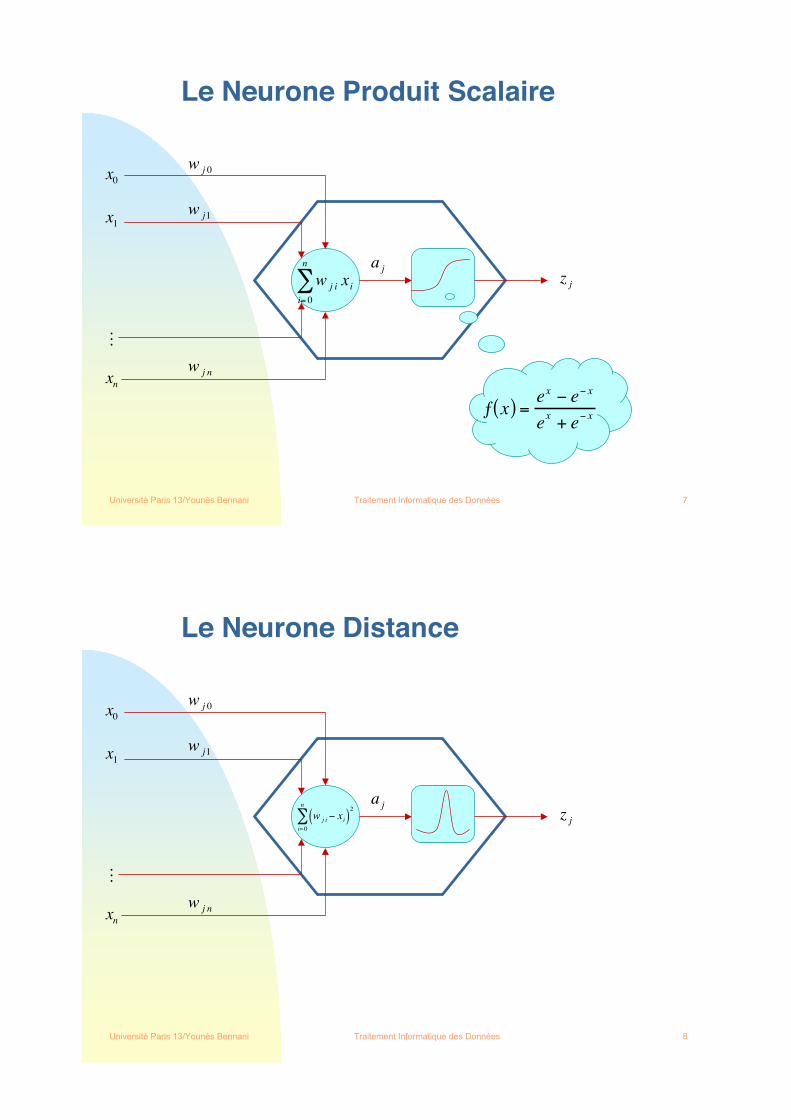
Le Neurone Produit Scalaire
x0
x1
xn
M
!
w j i xii= 0
n
"
ƒ x( ) =ex ! e! x
ex
+ e! x
!
z j
!
a j
!
w j 0
!
w j1
!
w j n
Université Paris 13/Younès Bennani Traitement Informatique des Données 8
Le Neurone Distance
x0
x1
xn
M!
w j i " xi( )2
i= 0
n
#
!
z j
!
a j
!
w j 0
!
w j1
!
w j n

Université Paris 13/Younès Bennani Traitement Informatique des Données 9
Réseau Connexionniste
x0
x1
xn
M
z =! (x,w)
- Architecture massivement parallèles composées d’un grand nombre de simples
composants similaires, utilisés pour l’apprentissage.
- Système basé sur la coopération de plusieurs unités simples (neurones formels).
- Ce sont des unités de traitement qui
reçoivent des données x en entrée et
produisent une sortie y
- Un réseau se caractérise par :
- son architecture
- les fonctions de ses éléments
!
z1
!
zp
M
M
Université Paris 13/Younès Bennani Traitement Informatique des Données 10
Fonctions d’un réseau connexionniste
Le Mode Apprentissage :
Le réseau est modifié en fonction des exemples d ’apprentissage
On peut modifier :
- les poids de ses connexions
- son architecture
- les fonctions de transition des unités
Il existe essentiellement deux sortes d ’algorithmes d ’apprentissage :
- l ’apprentissage supervisé
- l ’apprentissage non supervisé

Université Paris 13/Younès Bennani Traitement Informatique des Données 11
Apprentissage Supervisé
On se donne :
- N exemples étiquetés
- une architecture de réseau
- des poids initiaux
On cherche, au moyen de l’algorithme
d’apprentissage à trouver des poids tels que :
- les exemples sont reconnus :
- on obtient une bonne généralisation :
est une réponse raisonnable pour l’entrée
x
y
DN = x
1, y1( ), x2 ,y2( ),K, x
N,y
N( ){ } xk!"
nyk!"
p
A
w0
w*
yk=! (x
k,w)
y =! (x,w)
x
entrée sortie
! (x,w)
Professeur
z
Sortiedésirée
Sortiecalculée
Université Paris 13/Younès Bennani Traitement Informatique des Données 12
Apprentissage Non Supervisé
On se donne :
- N exemples non étiquetés
- une architecture de réseau
- des poids initiaux
DN= x
1, x
2,K, x
N{ }A
w0
On cherche à trouver des poids tels que :
- les exemples sont correctement regroupés- on obtient une bonne généralisation
w*
! (x,w)x

Université Paris 13/Younès Bennani Traitement Informatique des Données 13
Mode Reconnaissance
Le réseau est utilisé pour traiter des données
- les poids et l ’architecture du réseau sont fixés
- on lui présente un exemple en entrée et le réseau calcule
une sortie qui dépend de l’architecture et des
poids appris.
A
w*
z =! (x,w)
x
La sortie peut être :
- l’étiquette de la classe (identité) Classement/Discrimination
- le N° du cluster Classification/Quantification
- la valeur à prévoir Prévision
- un vecteur du même type que l’entrée Codage/Compaction
Université Paris 13/Younès Bennani Traitement Informatique des Données 14
Utilisation des modèlesconnexionnistes
Grand nombre de mesures + Loi sous-jacente inconnue
Taille
Poids
Danceur de Ballet
Joueur de Rugby
Frontière de décision
Classement
TaillePoids
BalletRugby
x
y
Université Paris 13/Younès Bennani Traitement Informatique des Données 15
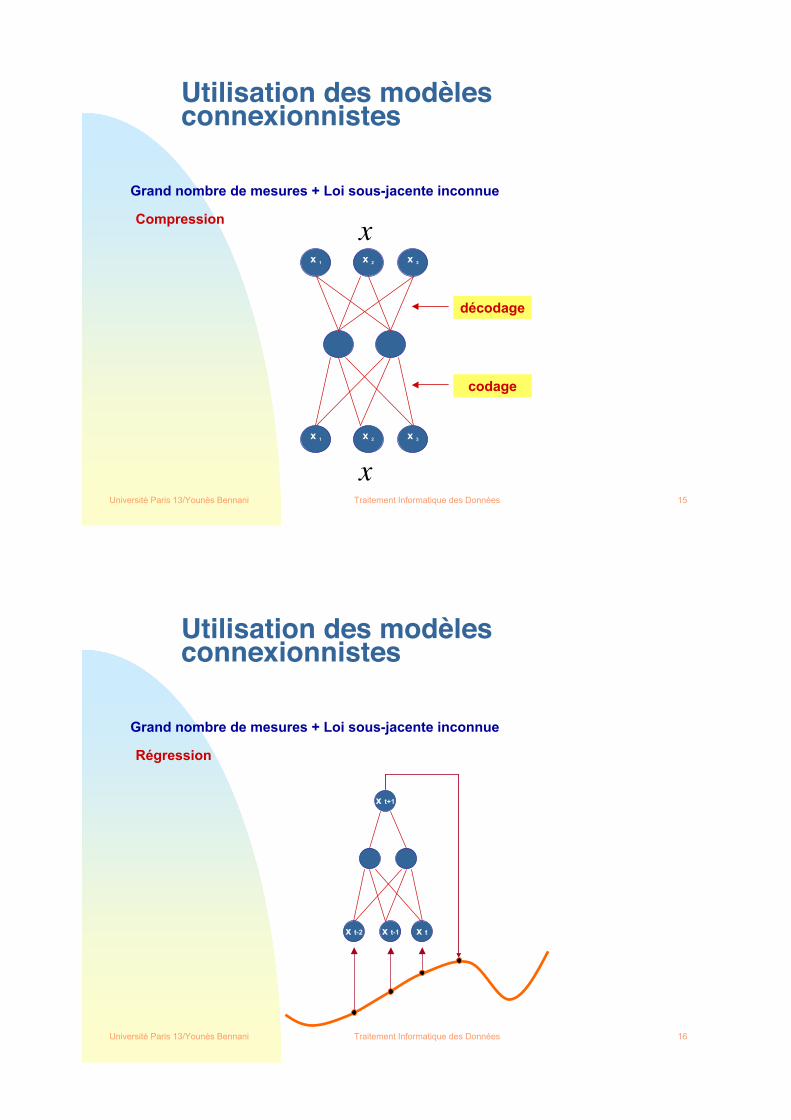
Utilisation des modèlesconnexionnistes
Grand nombre de mesures + Loi sous-jacente inconnue
Compression
décodage
codage
x 1 x 2 x 3
x 1 x 2 x 3
x
x
Université Paris 13/Younès Bennani Traitement Informatique des Données 16
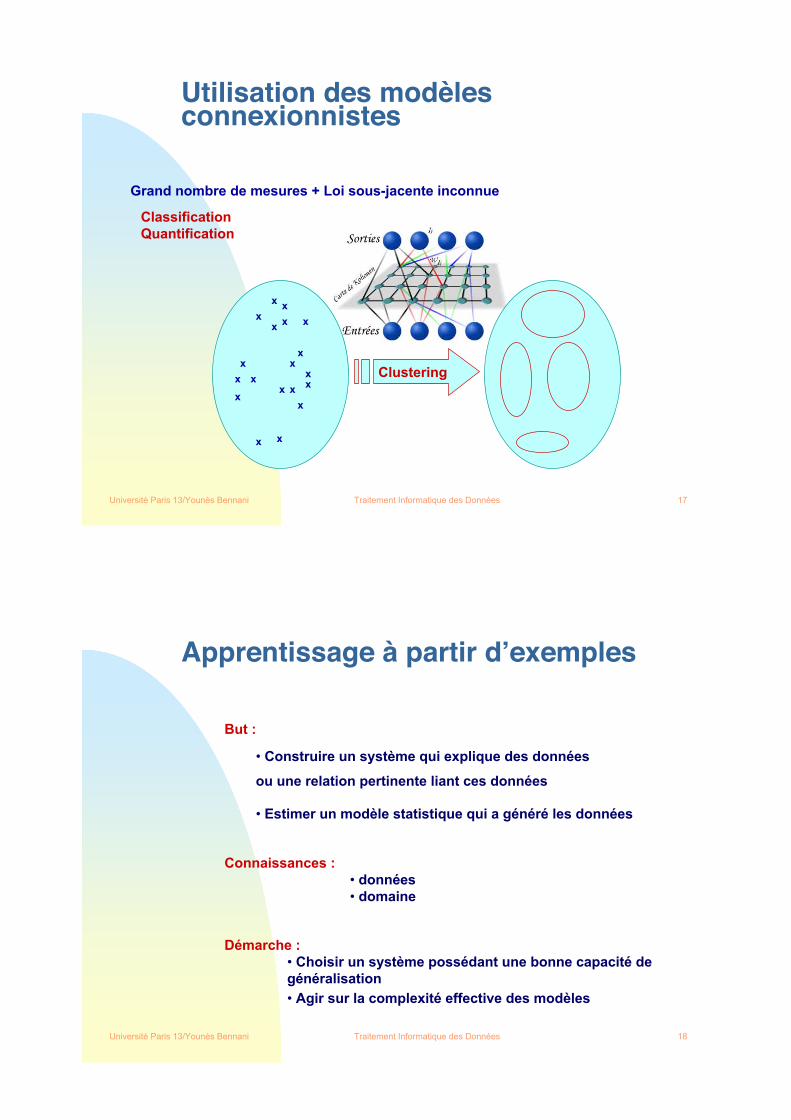
Utilisation des modèlesconnexionnistes
Grand nombre de mesures + Loi sous-jacente inconnue
x t-2 x t-1 x t
x t+1
Régression
Université Paris 13/Younès Bennani Traitement Informatique des Données 17
Utilisation des modèlesconnexionnistes
Grand nombre de mesures + Loi sous-jacente inconnue
ClassificationQuantification
x
x
x
x
x
x
x
x
x
x
x
x
x
x
xxx x
x x
x
x
x
x
x
x
x
x
x
x
x
x
x
xxx x
x
Clustering
Université Paris 13/Younès Bennani Traitement Informatique des Données 18
Apprentissage à partir d’exemples
Connaissances :• données• domaine
But :
• Construire un système qui explique des données
ou une relation pertinente liant ces données
• Estimer un modèle statistique qui a généré les données
Démarche :• Choisir un système possédant une bonne capacité degénéralisation
• Agir sur la complexité effective des modèles

Université Paris 13/Younès Bennani Traitement Informatique des Données 19
Formalisme
D = x1, y1( ), x 2, y2( ), ..., x N , yN( ){ } / p(x, y) = p(x)p(y / x)
Données :
F = ! (x,w) /w "#{ }
Problème :
Trouver dans une famille :
Procédure :
C(w) = L y,! (x,w)[ ] dp(x,y)"Risque théorique(Erreur de généralisation)
! (x,w*) =
! (x ,w )
ArgminC(w)Choix :
Université Paris 13/Younès Bennani Traitement Informatique des Données 20
Formalisme
! (x,w+) =
! (x ,w )
ArgminCemp(w)Choix :
Cemp(w) =1
NL y
k,! (x
k,w)[ ]
k=1
N
"Risque empirique
(Erreur d ’apprentissage)
C(w)
Le risque théorique n’est pas calculable (p(x,y) est inconnue)
On ne peut pas minimiser , on utilise alors un principed’induction.
Le plus courant = minimisation du risque empirique (MRE) :

Université Paris 13/Younès Bennani Traitement Informatique des Données 21
Critères d’Optimalité
Cemp(w) =1
Nyk!" (x
k,w)( )
2
k=1
N
#
Mean Squarred Error :
(MSE)
L ’apprentissage consiste à apprendre une associationentre des vecteurs d ’entrée et des vecteurs de sortie,en minimisant l ’écart entre la sortie désirée et la sortiedu réseau.
Université Paris 13/Younès Bennani Traitement Informatique des Données 22
Critères d’Optimalité
P(D /M)
Maximum Likelihood Estimation :
(MLE)
Il s ’agit du maximum de vraisemblance, utilisé pour lesHMMs par exemple.
Il consiste à estimer la densité de probabilité d ’unedistribution à partir d ’exemples.
Le critère d ’optimalité est de la forme :
Données Modèle

Université Paris 13/Younès Bennani Traitement Informatique des Données 23
Critères d’Optimalité
P(D /M) = P(xk/M)
k
!
Maximum Likelihood Estimation :
(MLE)
Ce critère est non discriminant.
Sous l ’hypothèse d ’indépendance des exemples :
Max P( xk/M)
k
! " Max log P(xk/M)( )" Min
k
# $ log P(xk/M)( )
k
#
Université Paris 13/Younès Bennani Traitement Informatique des Données 24
Critères d’Optimalité
Maximum Mutual Information :
(MMI)
MMI consiste en la maximisation de l ’informationmutuelle entre les données et les différents modèles(classes)
L ’information mutuelle entre un modèle M et unedonnée x est :
logP(M / x)
P(M)= log
P(x /M)
P(Mi)P(x /M
i)
i
!
Ce critère est discriminant.

Université Paris 13/Younès Bennani Traitement Informatique des Données 25
Critères d’Optimalité
Minimum Error :
(ME)
ME consiste à minimiser directement la probabilitéd ’erreur de discrimination.
L ’estimation de cette probabilité se fait d ’une manièreempirique à partir d ’exemples.
Université Paris 13/Younès Bennani Traitement Informatique des Données 26
Algorithmes d’Optimisation
À partir d'une configuration initiale des poids (les paramètres dumodèle), une procédure de gradient modifie les valeurs de cesparamètres par des ajustements successifs qui visent àminimiser le critère d'erreur .
La version la plus simple utilise pour cela les dérivéespremières de , c'est le cas de l'algorithme dit de la plusgrande pente.
La règle d'adaptation :
Cemp(w)
wji(t +1) = wji(t) !1
N"(t)
#Cemp
k(w)
# wji(t)k=1
N
$ wji(t +1) = wji(t) ! "(t)#Cemp
k(w)
#wji(t)
Cemp
k(w) = y
y!" (x
k,w)( )
2
Gradient totalGradient stochastique
Université Paris 13/Younès Bennani Traitement Informatique des Données 27
Systèmes d’ApprentissageSupervisé
Université Paris 13/Younès Bennani Traitement Informatique des Données 28
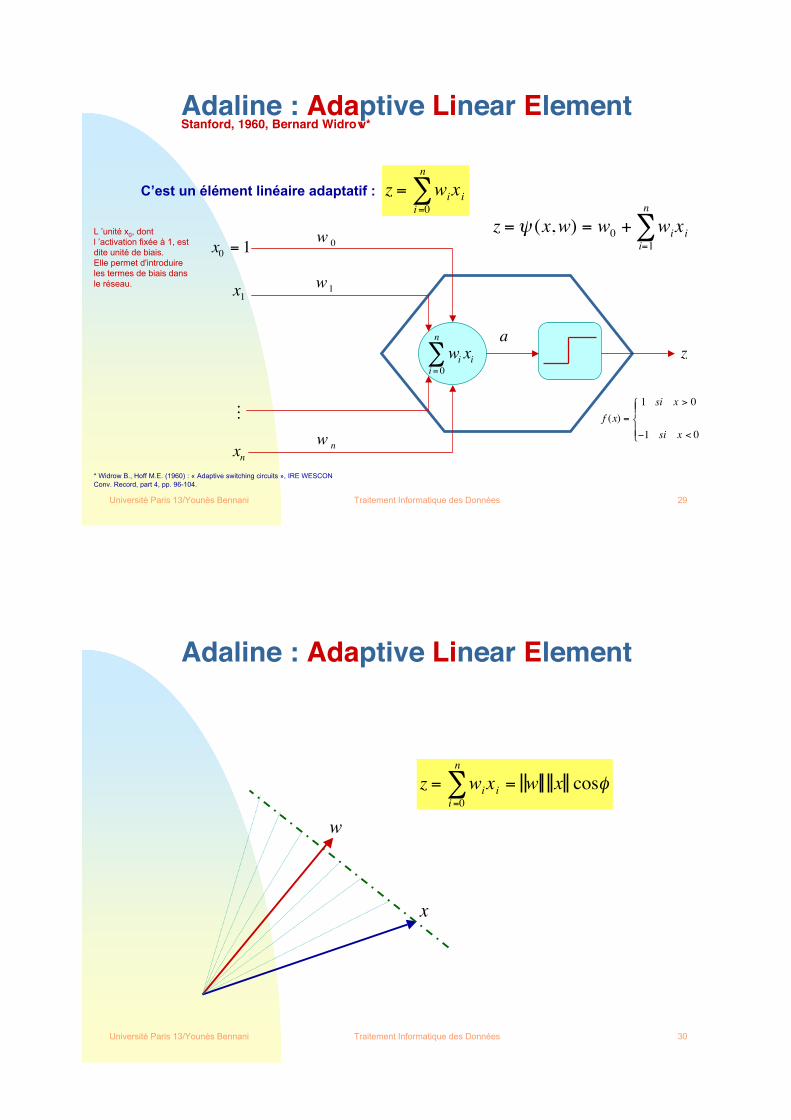
Système d!’Apprentissage Supervisé
Exemples d’apprentissage
Algorithme d ’apprentissage(Méthode d ’optimisation)
Fonctionde coût
Entrée Sortie désirée
EntréeSortie
calculée +- erreur
Adaptationdes poids
x0
x1
xn
z =! (x,w)
!
y
!
x
M
!
z1
!
zp M
Université Paris 13/Younès Bennani Traitement Informatique des Données 29
Adaline : Adaptive Linear ElementStanford, 1960, Bernard Widrow*
x0= 1
w0
a
x1
xn
M
wixi
i= 0
n
!
w1
wn
C’est un élément linéaire adaptatif : z = wixi
i=0
n
!
L ’unité x0, dontl ’activation fixée à 1, estdite unité de biais.Elle permet d'introduireles termes de biais dansle réseau.
* Widrow B., Hoff M.E. (1960) : « Adaptive switching circuits », IRE WESCONConv. Record, part 4, pp. 96-104.
z =! (x,w) = w0+ w
ixi
i=1
n
"
z
f (x) =
1 si x > 0
!1 si x < 0
"
# $
% $
Université Paris 13/Younès Bennani Traitement Informatique des Données 30
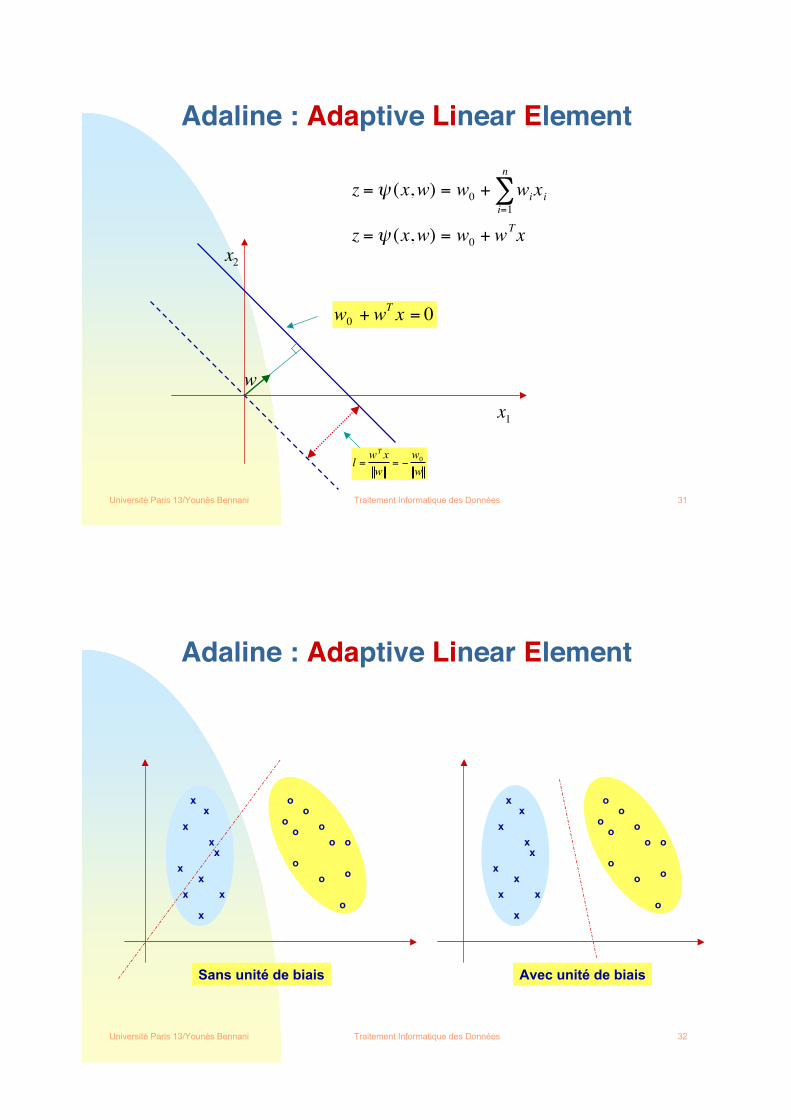
Adaline : Adaptive Linear Element
z = wixi
i=0
n
! = w x cos"
w
x
Université Paris 13/Younès Bennani Traitement Informatique des Données 31
Adaline : Adaptive Linear Element
z =! (x,w) = w0+ w
ixi
i=1
n
"
z =! (x,w) = w0+ w
Tx
w
x2
x1
w0+ w
T
x = 0
l =w
Tx
w= !
w0
w
Université Paris 13/Younès Bennani Traitement Informatique des Données 32
Adaline : Adaptive Linear Element
Sans unité de biais
xx
x
x
x
x
x
x
x
x
oo
o
o
o
o
o
o
o
o
o
xx
x
x
x
x
x
x
x
x
oo
o
o
o
o
o
o
o
o
o
Avec unité de biais
Université Paris 13/Younès Bennani Traitement Informatique des Données 33
Adaline : Adaptive Linear Element
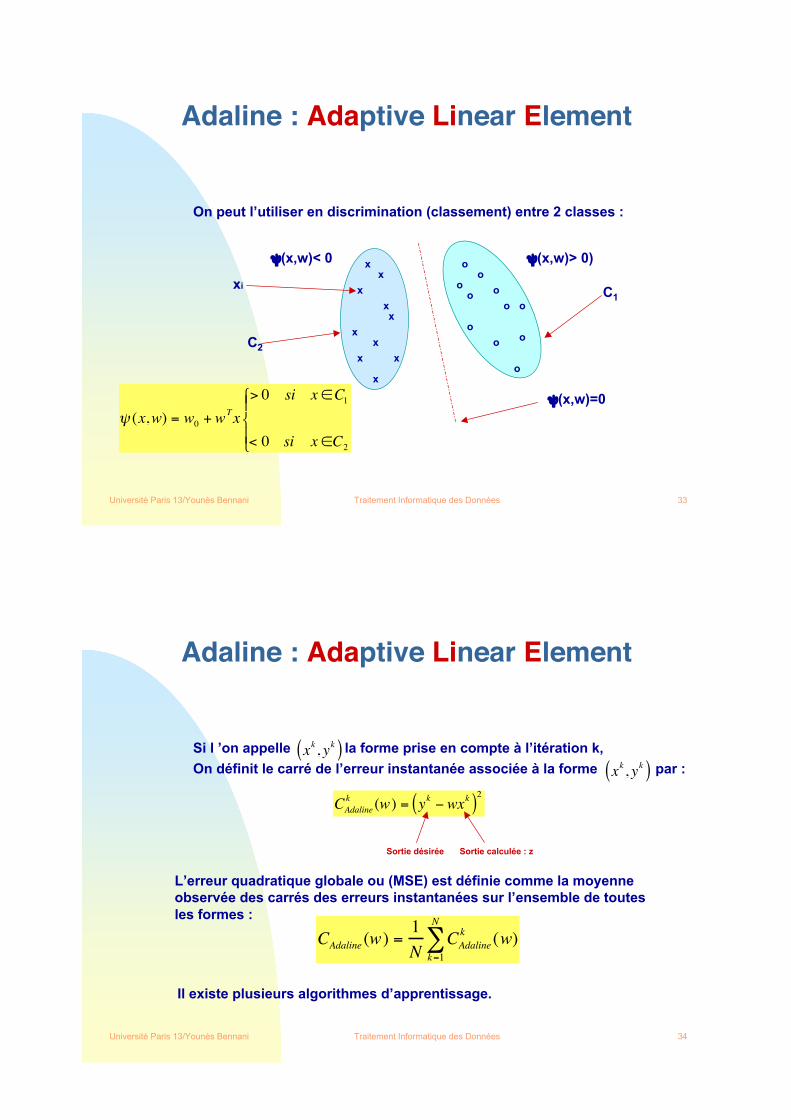
On peut l’utiliser en discrimination (classement) entre 2 classes :
xx
x
x
x
x
x
x
x
x
oo
o
o
o
o
o
o
o
o
o
xi
C2
C1
!(x,w)=0
!(x,w)> 0)!(x,w)< 0
! (x,w) = w0
+ wT
x
> 0 si x "C1
< 0 si x "C2
#
$ %
& %
Université Paris 13/Younès Bennani Traitement Informatique des Données 34
Adaline : Adaptive Linear Element
Si l ’on appelle la forme prise en compte à l’itération k,
On définit le carré de l’erreur instantanée associée à la forme par :
CAdaline
k(w) = y
k! wx
k( )2
xk, y
k( )
Sortie désirée
L’erreur quadratique globale ou (MSE) est définie comme la moyenneobservée des carrés des erreurs instantanées sur l’ensemble de toutesles formes :
xk, y
k( )
Sortie calculée : z
CAdaline
(w) =1
NCAdaline
k(w)
k=1
N
!
Il existe plusieurs algorithmes d’apprentissage.

Université Paris 13/Younès Bennani Traitement Informatique des Données 35
Adaline : Adaptive Linear Element
Techniques de descente de gradient (la plus grande pente) :supposons qu ’à l’instant , les poids de l ’Adaline soient et qu ’on présente la forme ,alors les poids seront modifiés par :
Cette règle est appelée règle du gradient stochastiqueou règle de Widrow-Hoff ou règle du delta de Widrow-Hoffou règle !-LMS (Least Mean Square)
!w CAdaline
k(w)( ) =
"CAdaline
k (w)
"w= #2 y
k# wx
k( )x k
w(t +1) = w(t) !" (t)#wCAdaline
k(w)( )
t
Le pas du gradientLe gradient instantané
w t( )xk, y
k( )
Université Paris 13/Younès Bennani Traitement Informatique des Données 36
Adaline : Adaptive Linear Element
1- Tirer au hasard
2- Présenter une forme
3- Déterminer la valeur de l’écart
4- Calculer une approximation du gradient
5- Adapter les poids
Où est le pas du gradient.
6- Répéter de 2 à 4 jusqu’à l’obtention d’une
valeur acceptable de l’erreur
w0
w t( )
! t( )
ekt( ) = y
k! wx
k( )
!wCAdaline
k(w)( ) = "2ek t( )x k
xk, y
k( )
w(t +1) = w(t) !" (t)#wCAdaline
k(w)( )
Université Paris 13/Younès Bennani Traitement Informatique des Données 37
Adaline : Exemples
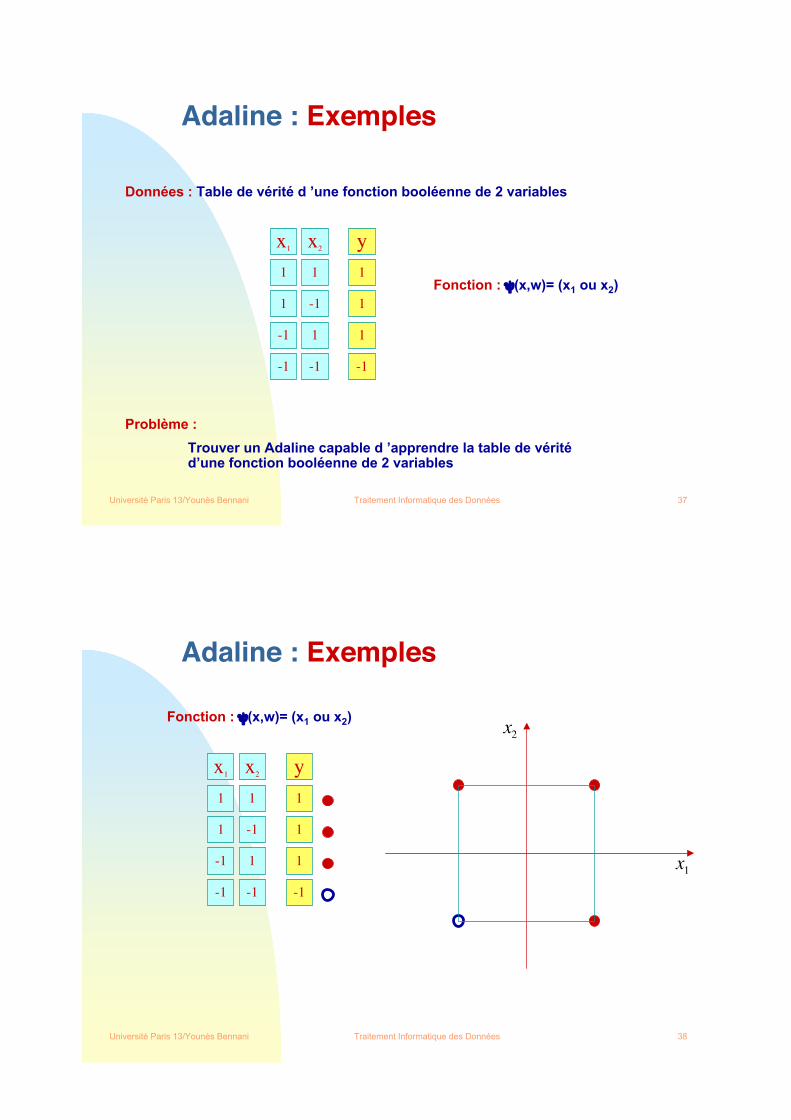
Données : Table de vérité d ’une fonction booléenne de 2 variables
Problème :
Trouver un Adaline capable d ’apprendre la table de véritéd’une fonction booléenne de 2 variables
x1
1
1
x2
1
-1
y
1
1
-1 1 1
-1 -1 -1
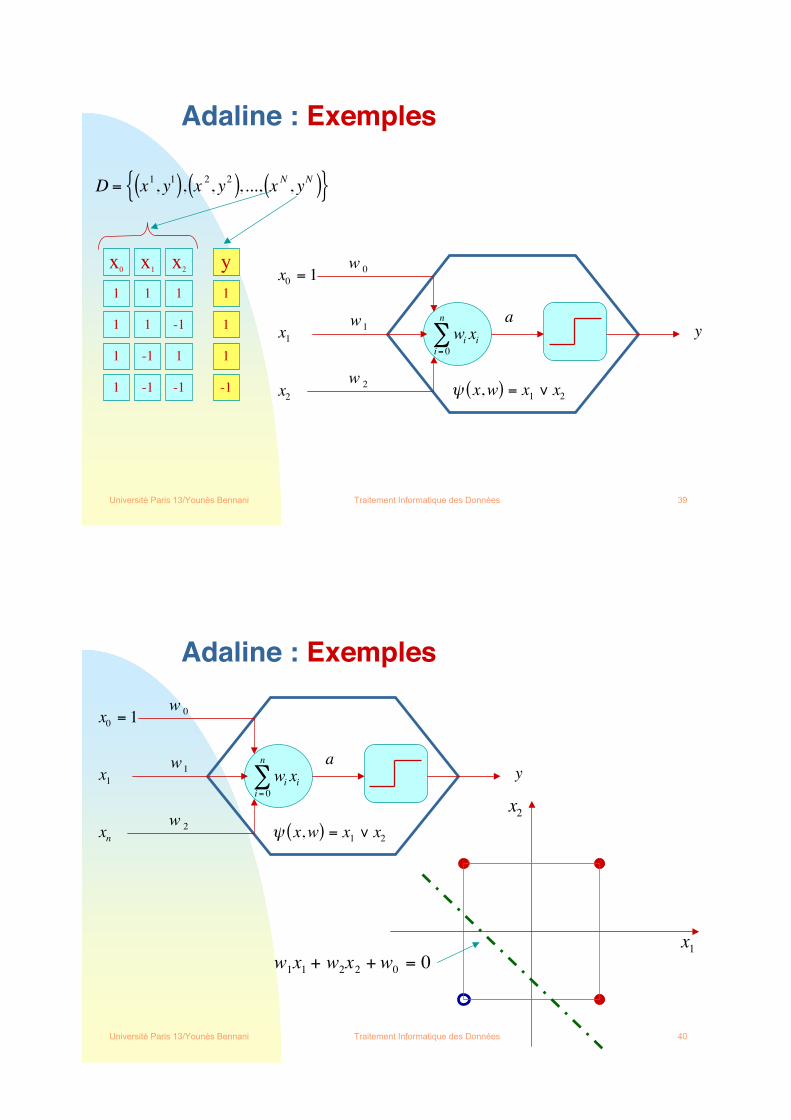
Fonction : !(x,w)= (x1 ou x2)
Université Paris 13/Younès Bennani Traitement Informatique des Données 38
Adaline : Exemples
x1
1
1
x2
1
-1
y
1
1
-1 1 1
-1 -1 -1
Fonction : !(x,w)= (x1 ou x2)x2
x1
Université Paris 13/Younès Bennani Traitement Informatique des Données 39
Adaline : Exemples
D = x1, y1( ), x 2, y2( ), ..., x N , yN( ){ }
x1
1
1
x2
1
-1
y
1
1
x0
1
1
-1 1 11
-1 -1 -11
x0= 1
w0
a
yx1
x2
wixi
i= 0
n
!w1
w2 ! x,w( ) = x
1" x
2
Université Paris 13/Younès Bennani Traitement Informatique des Données 40
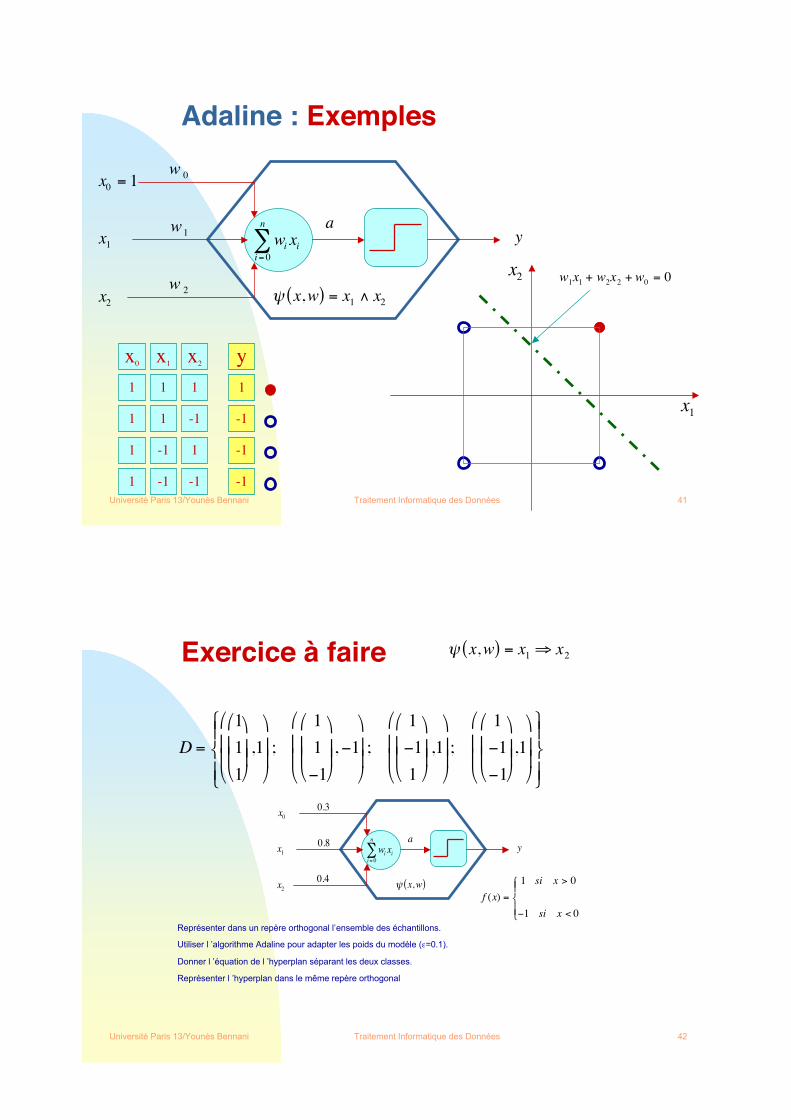
Adaline : Exemples
x0= 1
w0
a
yx1
xn
wixi
i= 0
n
!w1
w2 ! x,w( ) = x
1" x
2
x2
x1
w1x1+ w
2x2+ w
0= 0
Université Paris 13/Younès Bennani Traitement Informatique des Données 41
Adaline : Exemples
x0= 1
w0
a
yx1
x2
wixi
i= 0
n
!w1
w2 ! x,w( ) = x
1" x
2
x2
x1
w1x1+ w
2x2+ w
0= 0
x1
1
1
x2
1
-1
y
1
-1
x0
1
1
-1 1 -11
-1 -1 -11
Université Paris 13/Younès Bennani Traitement Informatique des Données 42
Exercice à faire
x0
0.3
a
yx1
x2
wixi
i= 0
n
!0.8
0.4! x,w( )
D =
1
1
1
!
"
# #
$
%
& & ,1
!
"
# #
$
%
& & ;
1
1
'1
!
"
# #
$
%
& & , '1
!
"
# #
$
%
& & ;
1
'1
1
!
"
# #
$
%
& & ,1
!
"
# #
$
%
& & ;
1
'1
'1
!
"
# #
$
%
& & ,1
!
"
# #
$
%
& &
(
) *
+ *
,
- *
. *
Représenter dans un repère orthogonal l’ensemble des échantillons.
Utiliser l ’algorithme Adaline pour adapter les poids du modèle ("=0.1).
Donner l ’équation de l ’hyperplan séparant les deux classes.
Représenter l ’hyperplan dans le même repère orthogonal
f (x) =
1 si x > 0
!1 si x < 0
"
# $
% $
! x,w( ) = x1" x
2











![06 Data Mining KXEN 2.ppt [Read-Only] - LIPNbennani/tmpc/FDON/06... · Nb de jours entre l’émission de la facture et le paiement Profit : prix d’achat – coût de fabrication](https://img.pdfslide.fr/doc/110x75/5f5b075bdf88c958c265f3e9/06-data-mining-kxen-2ppt-read-only-lipn-bennanitmpcfdon06-nb-de-jours.jpg)