Embed Size (px)
Citation preview

Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 1
Introduction aux méthodes de Fouille de données
(10)
Bernard ESPINASSE Professeur à Aix-Marseille Université (AMU)
Ecole Polytechnique Universitaire de Marseille
Septembre 2009
• Rappel typologies des méthodes de fouille de données • Segmentation par la Méthode des k-moyennes • Méthodes des Règles dʼAssociation • Classification/Prédiction par les Arbres de décision • Classification par la Méthode des k-Plus proches voisins • Classification/Prédiction par les Réseaux de neurones
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 2
PPPlllaaannn 1. Typologies des méthodes de fouille de données 2. Segmentation par la méthode des k-moyennes
! Objet de la segmentation ! Méthode des k-moyennes (k-mean)
3. Méthodes des règles dʼassociation ! Objet de lʼassociation ! Méthode des règles dʼassociation
4. Classification / Prédiction par les Arbres de décision ! Objet de la classification et de la prédiction ! Méthode des arbres de décision
5. Classification par la méthode des k-plus proches voisins ! Méthode des k-plus proches voisins
6. Classification / Prédiction par les réseaux de neurones ! Méthode des Réseaux de Neurones (Perceptron multi-couches) ! Autres méthodes de classification ! Conclusion sur la classification / prédiction
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 3
RRRéééfffééérrreeennnccceeesss bbbiiibbbllliiiooogggrrraaappphhhiiiqqquuueeesss Ouvrages : ! Franco J-M., « Le Data Warehouse et le Data Mining ». Ed. Eyrolles, Paris, 1997.
ISBN 2-212-08956-2. ! Gardarin G., « Internet/intranet et bases de données », Ed. Eyrolles, Paris, 1999, ISBN
2-212-09069-2. ! Han J., Kamber M., « Data Mining: Concepts and Techniques », Morgan Kaufmann
Publishers, 2004. ! Lefébure R., Venturi G., « Le data Mining », Ed. Eyrolles, Paris, 1998. ISBN 2-212-
08981-3. ! Tufféry S., « Data Mining et statistique décisionnelle », Ed. Technip, Paris, 2005, ISBN
2-7108-0867-6. ! …
Cours : ! Cours de A. Rakotomamonjy, INSA Rouen, Lab. PSI, Rouen. ! Cours de G. Gardarin, Univ. de Versailles ! Cours de J. Han et M. Kamber M., Simon Fraser Univ., Vancouver BC, Canada ! Cours de M. Adiba et M.C. Fauvet, Univ. Grenoble ! Cours de R. Gilleron et M. Tommasi, Lab. LIFL., Univ. Charles De Gaulle-Lille 3 ! Cours de R. Rakotomalala, Univ. Lumière Lyon 2, Lab. ERIC Lyon ! Cours du Lab. « Bases de données » de lʼEPFL ! …
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 4
111 ––– TTTyyypppooolllooogggiiieeesss dddeeesss mmméééttthhhooodddeeesss dddeee fffooouuuiiilllllleee dddeee dddooonnnnnnéééeeesss
! Typologie selon objectifs ! Typologie selon le type de modèle obtenu ! Typologie selon le type dʼapprentissage ! Quelques méthodes de fouille de données

Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 5
TTTyyypppooolllooogggiiieee ssseeelllooonnn ooobbbjjjeeeccctttiiifffsss Types dʼobjectifs :
! Classification : ! consiste à examiner les caractéristiques d'un objet et lui attribuer une
classe : • attribuer ou non un prêt à un client • établir un diagnostic
! Prédiction : ! consiste à prédire la valeur future d'un attribut en fonction d'autres
attributs : • prédire la "qualité" d'un client en fonction de son revenu, de son
nombre d'enfant,... ! Association :
! consiste à déterminer les attributs qui sont corrélés : • analyse du panier de la ménagère: ex. poisson et vin blanc
! Segmentation : ! consiste à former des groupes homogènes à l'intérieur d'une population ! tâche souvent faite avant les précédentes pour trouver les groupes sur
lesquels appliquer la classification.
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 6
TTTyyypppooolllooogggiiieee ssseeelllooonnn llleee tttyyypppeee dddeee mmmooodddèèèllleee ooobbbttteeennnuuu Types de modèles obtenus :
! Modèles prédictifs : ! utilisent les données avec des résultats connus pour développer des
modèles permettant de prédire les valeurs d'autres données Ex: modèle permettant de prédire les clients qui ne rembourseront pas leur crédit
! utilisé principalement en classification et prédiction
! Modèles descriptifs : ! proposent des descriptions des données pour aider à la prise de décision ! aident à la construction de modèles prédictifs ! utilisés principalement en segmentation et association
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 7
TTTyyypppooolllooogggiiieee ssseeelllooonnn llleee tttyyypppeee ddd ʼ̓̓aaapppppprrreeennntttiiissssssaaagggeee Types d'apprentissage utilisés dans les méthodes de fouille :
! Apprentissage supervisé - Fouille supervisée : ! processus dans lequel l'apprenant reçoit des exemples d'apprentissage
comprenant à la fois des données d'entrée et de sortie ! les exemples dʼapprentissage sont fournis avec leur classe (valeur de
sortie prédite) ! But : classer correctement un nouvel exemple (généralisation) ! utilisées principalement en classification et prédiction
! Apprentissage non supervisé - Fouille non supervisée : ! processus dans lequel l'apprenant reçoit des exemples d'apprentissage
ne comprenant que des données d'entrée ! pas de notion de classe ! But : regrouper les exemples en « paquets » (clusters) dʼexemples
similaires (on peut ensuite donner un nom à chaque paquet) ! utilisé principalement en association et segmentation
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 8
QQQuuueeelllqqquuueeesss mmméééttthhhooodddeeesss dddeee fffooouuuiiilllllleee dddeee dddooonnnnnnéééeeesss Supervisées Non spervisées
Segmentation ! k moyennes (K-means) ! k plus proches voisins (PPV-
raisonnement à partir de cas) ! Réseaux de neurones avec cartes
de Kohonen ! …
Classification Prédiction
! Arbres de décision ! Réseaux de neurones avec
Perceptron ! (raisonnement à partir de cas) ! Modèles / réseaux bayésiens ! Machines à vecteur supports
(SVM) ! programmation logique inductive ! …
! k plus proches voisins (PPV-raisonnement à partir de cas)
! Règles temporelles ! Recherche de séquences ! Reconnaissance de formes ! …
Prédiction ! Arbres de décision ! Réseaux de neurones avec
Perceptron ! …
! k plus proches voisins (PPV-raisonnement à partir de cas)
! …
Association Règles dʼassociation

Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 9
111 ––– MMMéééttthhhooodddeee dddeee ssseeegggmmmeeennntttaaatttiiiooonnn dddeeesss kkk---mmmoooyyyeeennnnnneeesss (((kkk---mmmeeeaaannn)))
! Objectifs de la segmentation (ou clustering)
! La méthode des K-moyennes
! Problème de mise en œuvre
! Autres méthodes pour la segmentation
! Conclusion sur la Méthode des K-moyennes
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 10
OOObbbjjjeeeccctttiiifffsss dddeee lllaaa ssseeegggmmmeeennntttaaatttiiiooonnn (((ooouuu cccllluuusssttteeerrriiinnnggg))) Face à une grande population (dʼexemples) à étudier, il peut sʼavérer judicieux de commencer par diviser en groupes (clusters) la population, la segmenter la segmentation est une tâche dʼapprentissage NON supervisée car on nʼa rien dʼautre que les exemples (pas de classes) Méthode de segmentation :
! méthode permettant de découvrir les groupes (clusters) d'individus similaires en se basant sur une mesure de similarité (ou distance) pour grouper les données
! on ne connaît pas les classes à priori : elles sont à découvrir automatiquement
! Buts : Maximiser la similarité intra-classes et minimiser la similarité inter-classes.
Méthodes de segmentation par partitionnement : ! Construire k partitions et les corriger jusqu'à obtenir une similarité
satisfaisante ! Méthode des k-moyennes (k-mean) [Mac Queen 67]
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 11
MMMéééttthhhooodddeee dddeeesss KKK---mmmoooyyyeeennnnnneeesss Méthode basée sur une notion de similarité entre enregistrements :
! on considère un espace géométrique muni dʼune distance : 2 points sont similaires sʼils sont proches pour la distance considérée
! on considère un nombre limité de champs dʼenregistrements ! on se place dans lʼespace euclidien de dimension 2, munie de la distance
euclidienne classique
Principe général de lʼalgorithme : ! on a choisi (au hasard) un nombre k de groupes à constituer ! on choisi k enregistrements, soit k points de lʼespace appelés « centres » ! on constitue alors les k groupes initiaux en affectant chacun des
enregistrements dans le groupe correspondant au centre le plus proche ! pour chaque groupe constitué on calcule son nouveau centre (de gravité) en
affectant la moyenne des points du groupe et on réitère le procédé ! critère dʼarrêt : si aucun point nʼa changé de groupe, les groupes sont stables
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 12
MMMéééttthhhooodddeee dddeeesss KKK---mmmoooyyyeeennnnnneeesss Algorithme des K-moyennes ou K-mean (k clusters, n objects):
! choisir aléatoirement k objets comme centres de cluster ! assigner chaque objet au centre le plus proche ! recalculer les k centres ! tant que les k centres ont étéchangés
! réassigner les tuples ! recalculer les k centres
Illustration :
1. cluster initiaux 2. recalcul des centres 3. reconstruction des clusters
par rapport aux nouveaux centres

Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 13
MMMéééttthhhooodddeee dddeeesss KKK---mmmoooyyyeeennnnnneeesss Exemple (Gilleron & Tommasi) :
étape 1 étape 2 étape 3 centre D(2;4) centre D(2;4) centre J(5/3;10/3) centre B(2;2) centre I(27/7;17/7) centre K(24/5;11/5)
points groupe groupe groupe A(1;3) B D J B(2;2) B I J C(2;3) B D J D(2;4) D D J E(4;2) B I K F(5;2) B I K G(6;2) B I K H(7;3) B I K
• Données d'entrée : 8 points A, ..., H de l'espace euclidien de dimension 2 • On choisit k=2 : on cherche à constituer deux groupes dans cet ensemble de 8 points • On tire aléatoirement les 2 centres initiaux : B et D choisis • On répartit les points dans les 2 groupes (nommés B et D) en fonction de leur proximité aux centres B et
D. Géométriquement, il suffit de tracer la médiatrice du segment [BD]. Seul D est affecté au groupe D. • On calcule les nouveaux centres pour l'étape 2, on obtient D et I (26/7;17/7) où les coordonnées de I
sont les moyennes des coordonnées des 7 points autres que D. • On recrée les groupes en fonction de leur proximité aux centres D et I, on remarque que A et C
changent de groupe. • Le procédé est réitéré, la stabilité est obtenue à l'étape 4 car on constate que les groupes ne sont plus
modifiés : les 2 groupes obtenus sont {A, B, C, D} et {E, F, G, H}.
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 14
MMMéééttthhhooodddeee dddeeesss KKK---mmmoooyyyeeennnnnneeesss ::: ppprrrooobbblllèèèmmmeeesss dddeee mmmiiissseee eeennn oooeeeuuuvvvrrreee Mise en œuvre de K-means dans les BD réelles plus complexe : Problème 1 : Proximité/similarité entre les données
! les BD constituées d'enregistrements, les données (des clients, des produits, des ventes) ont peu de rapport avec des points
! nécessité de définir une mesure de proximité/similarité entre ces données (points proches = enregistrements similaires dans la BD).
Si enregistrement avec champs à valeurs continues : ! mesure de similarité = distance euclidienne entre 2 points ! nécessite en général une normalisation des échelles pour les différents
champs : si un champ A prend ses valeurs dans l'intervalle réel [0,1] et un champ B ses valeurs dans [0,100 000], B est privilégié, car 2 enregistrements seront considérés proches si les valeurs pour le champ B sont proches.
Si enregistrements avec champs à valeurs discrètes : ! une mesure de similarité usuelle : étant donné 2 enregistrements x et y, la
similarité est égale au rapport entre le nombre de champs égaux divisé par le nombre total de champs (nombreuses variantes existent).
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 15
MMMéééttthhhooodddeee dddeeesss KKK---mmmoooyyyeeennnnnneeesss ::: ppprrrooobbblllèèèmmmeeesss dddeee mmmiiissseee eeennn oooeeeuuuvvvrrreee Problème 2 : choix initial du nombre de groupes
! Ce nombre est choisi a priori et fourni à l'algorithme ! Il peut avoir été fixé par un expert mais en règle générale, il est inconnu
Sʼil est inconnu :
• on fait fonctionner l'algorithme avec différentes valeurs de k (boucle externe ajoutée à l'algorithme)
• on choisit ensuite une valeur de k telle que, pour les groupes obtenus : ! les distances à l'intérieur du groupe soient petites et ! les distances entre centres des groupes soient grandes.
L'algorithme possède de nombreuses variantes selon :
• la méthode utilisée pour choisir les k premiers centres, • la mesure de similarité choisie, • le choix de la valeur de k et le calcul des distances entre groupes, • la possibilité de pondérer les champs en fonction d'une connaissance
initiale du problème.
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 16
AAAuuutttrrreeesss mmméééttthhhooodddeeesss pppooouuurrr lllaaa ssseeegggmmmeeennntttaaatttiiiooonnn Méthode ascendante, utilisant un algorithme d'agglomération :
• A partir d'un échantillon de m enregistrements, on commence avec m groupes, chacun des groupes est constitué d'un enregistrement :
• On calcule la matrice des distances 2 à 2 entre enregistrements. • On choisit la plus petite valeur dans cette matrice des similarités, elle identifie la
paire de groupes les plus similaires. • On regroupe ces 2 groupes en un seul, on remplace les 2 lignes par une ligne pour
le groupe ainsi créé. • On réitère jusqu'à obtenir un groupe constitué de tous les enregistrements. • On a ainsi construit une suite de partitions de l'échantillon d'entrée où le nombre k
de groupes varie de m à 1. • On choisit ensuite la valeur de k (différentes méthodes possibles)
Méthode ascendante, utilisant des arbres de décision : • On démarre avec un groupe constitué de l'ensemble des enregistrements et on
divise récursivement les groupes en utilisant une fonction de diversité minimisant la distance moyenne dans un groupe et maximise la distance entre groupes.
• On choisit ensuite la valeur de k (différentes méthodes possibles pour ce choix) Méthode par réseaux de neurones (cartes de Kohonen) :
• les cartes de Kohonen (réseaux de neurones auto-organisés) sont bien adaptées à la segmentation

Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 17
CCCooonnncccllluuusssiiiooonnn sssuuurrr lllaaa MMMéééttthhhooodddeee dddeeesss KKK---mmmoooyyyeeennnnnneeesss Apprentissage non supervisé :
! elle réalise une tâche dite « non supervisée », en ne nécessitant pas information sur les données
! elle peut permettre, en segmentation, de découvrir une structure cachée pouvant améliorer les résultats de méthodes d'apprentissage supervisé (classification, estimation, prédiction)
Type de données : ! elle peut s'appliquer à tout type de données (mêmes textuelles), en choisissant une
bonne notion de distance Facile à implanter :
! elle demande peu de transformations sur les données (excepté normalisations de valeurs numériques), pas de champ particulier à identifier, les algorithmes sont faciles à implanter et généralement disponibles dans les environnements de fouille
Performance et sensibilité : ! ses performances (qualité des groupes constitués) dépendent du bon choix d'une
mesure de similarité (délicat quand les données sont de types différents) ! elle est sensible au choix des bons paramètres : choix de k (groupes à constituer)
Interprétation des résultats : ! il est difficile d'interpréter les résultats produits, d'attribuer une signification aux groupes
constitués (vrai pour toutes les méthodes de segmentation).
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 18
333 ––– LLLeeesss RRRèèègggllleeesss dddʼ̓̓aaassssssoooccciiiaaatttiiiooonnn
! Introduction aux règles dʼassociation
! Tableau de co-occurrence
! Notions de support, de confiance et dʼamélioration
! Extraction des règles dʼassociation
! Conclusion sur les règles dʼassociation
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 19
IIInnntttrrroooddduuuccctttiiiooonnn aaauuuxxx rrrèèègggllleeesss ddd ʼ̓̓aaassssssoooccciiiaaatttiiiooonnn (((111))) ! Elles sont principalement utilisées dans le domaine de la distribution, en marketing,
pour « l'analyse du panier de la ménagère » pour : ! rechercher des associations entre produits sur les tickets de caisse,
notamment pour savoir quels produits tendent à être achetés ensemble ! étudier de ce que les clients achètent pour obtenir des informations sur qui
sont les clients et pourquoi ils font certains achats ! Exemple de règles dʼassociation pour lʼanalyse du panier de la ménagère :
! SI un client achète des plantes ALORS il achète du terreau
! SI un client achète du poisson et du citron ALORS il achète du vin blanc
! SI un client achète une télévision, ALORS il achètera un magnétoscope dans un an
! La recherche de règles d'association = méthode non supervisée car on ne dispose en entrée que de la description des achats.
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 20
IIInnntttrrroooddduuuccctttiiiooonnn aaauuuxxx rrrèèègggllleeesss ddd ʼ̓̓aaassssssoooccciiiaaatttiiiooonnn (((222))) ! Domaines dʼutilisation :
! tout domaine où lʼon veut rechercher des groupements potentiels de produits ou de services (services bancaires, services de télécommunications)
! domaine médical : recherche de complications dues à des associations de médicaments
! recherche de fraudes : rechercher des associations inhabituelles ! Intérêt de la méthode :
! la clarté des résultats produits : un ensemble de règles d'association ! ces règles sont en général faciles à interpréter ! elles peuvent être facilement réutilisées dans le SI de l'entreprise
! Limites de la méthode : si elle peut produire des règles intéressantes, elle peut aussi produire des : ! règles triviales (déjà bien connues des intervenants du domaine) ou ! règles inutiles (provenant de particularités de l'ensemble d'apprentissage).

Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 21
RRRèèègggllleeesss ddd ʼ̓̓aaassssssoooccciiiaaatttiiiooonnn ::: uuunnn eeexxxeeemmmpppllleee Exemple (Gilleron & Tommasi) :
! on suppose avoir prédéfini une classification des articles ! les données d'entrée sont constituées d'une liste d'achats ! un achat est lui-même constitué d'une liste d'articles. ! les achats peuvent être de longueur variable (contrairement aux
enregistrements d'une table)
! Soit la liste des achats :
produit A produit B produit C produit D produit E achat 1 X X achat 2 X X X achat 3 X X achat 4 X X X achat 5 X X
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 22
TTTaaabbbllleeeaaauuu dddeee cccooo---oooccccccuuurrreeennnccceee ! Liste des achats :
produit A produit B produit C produit D produit E achat 1 X X achat 2 X X X achat 3 X X achat 4 X X X achat 5 X X
! Pour trouver les associations entre 2 produits, on construit le tableau de co-occurrence montrant combien de fois 2 produits ont été achetés ensemble :
produit A produit B produit C produit D produit E produit A 4 1 1 2 1 produit B 1 2 1 1 0 produit C 1 1 1 0 0 produit D 2 1 0 3 1 produit E 1 0 0 1 2
! permet de déterminer avec quelle fréquence 2 produits se rencontrent dans un même achat : Ex : le produit A apparaît dans 80% des achats, le produit C n'apparaît jamais en même temps que le produit E, les produits A et D apparaissent simultanément dans 40% des achats.
! Ces observations peuvent suggérer une règle de la forme : « SI un client achète le produit A ALORS il achète le produit D ».
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 23
NNNoootttiiiooonnnsss dddeee sssuuuppppppooorrrttt eeettt dddeee cccooonnnfffiiiaaannnccceee (((111))) Une règle n'est pas toujours vraie, aussi on a 2 indicateurs : support et confiance d'une règle « si X alors Y » : ! Support :
! fréquence dʼapparition simultanée des items (articles) qui apparaissent dans la condition et dans le résultat dans la liste des transactions (achats)
! Support (XY) = !XY! / !BD ! avec • !XY!nombre transactions comportant items (articles) X et Y • !BD!nombre transactions (achats) sur lʼensemble de la base Ex: 5% des clients ont acheté X et Y
! Confiance : ! rapport entre le nombre de transactions (achats) où tous les items (articles)
figurants dans la règle apparaissent et le nombre de transaction (achats) où les items (articles) de la partie condition apparaissent (vérifiant lʼimplication X " Y)
! Confiance (X "Y) = !XY! / !X ! ! Confiance (XY) = Support (XY)/Support(X)
Ex: Parmi les clients ayant acheté des X, 90% ont également acheté Y ! Seules les règles ayant une certaine valeur de support et de confiance sont
intéressantes
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 24
NNNoootttiiiooonnnsss dddeee sssuuuppppppooorrrtttsss eeettt dddeee cccooonnnfffiiiaaannnccceee (((222))) ! Considérons les règles relatives à notre exemple :
• si A alors B (règle 1) • si A alors D (règle 2) • si D alors A (règle 3)
! Supports des règles : • A et B apparaissent dans 20% des achats, • A et D apparaissent dans 40% des achats, " support de la règle 1 = support(AB) = 1/5 = 20% " support des règles 2 et 3 = support(AD) support(DA) = 2/5 = 0,4 = 40%
! Confiance des règles : • Considérons les règles 2 et 3, c'est-à-dire les produits A et D. • D apparaît dans 3 achats dans lesquels A apparaît 2 fois. • Par contre, A apparaît dans 4 achats dans lesquels D n'apparaît que 2 fois. • confiance de la règle 3 = support(DA)/support(D) = 0,4/ (3/5) = 0,4/0,6 = 67% • confiance de la règle 2 = support(AD)/support(A) = 0,4/ (4/5) = 0,4/0,8 = 50% " On préfère ainsi la règle 3 (D alors A) à la règle 2 (A alors D)
! On peut généraliser à toutes les combinaisons d'un nombre quelconque d'articles, ainsi pour 3 articles, on cherche à générer des règles de la forme « si X et Y alors Z »
! Mais le support et la confiance ne sont pas toujours suffisants
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 25
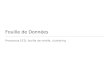
NNNoootttiiiooonnnsss dddeee sssuuuppppppooorrrtttsss eeettt dddeee cccooonnnfffiiiaaannnccceee (((333))) ! En effet, considérons 3 articles A, B et C et leurs fréquences d'apparition :
article(s) A B C A et B A et C B et C A et B et C
fréquence 45% 42,5% 40% 25% 20% 15% 5%
! Si on considère les règles à 3 articles, elles ont le même niveau de support = 5% ! Niveau de confiance des 3 règles est :
Règle confiance
si A et B alors C 0.20
si A et C alors B 0.25
si B et C alors A 0.33
! La règle si B et C alors A possède la plus grande confiance = 0,33 => si B et C apparaissent simultanément dans un achat, alors A y apparaît aussi avec une probabilité estimée de 33%.
! Mais, si on regarde le tableau des fréquences d'apparition des articles, on constate que A apparaît dans 45% des achats => Il vaut mieux prédire A sans autre information que de prédire A lorsque B et C
apparaissent.
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 26
NNNoootttiiiooonnn ddd ʼ̓̓aaammméééllliiiooorrraaatttiiiooonnn ! Aussi on introduit « l'amélioration » permettant de comparer le résultat de la
prédiction en utilisant la règle avec la prédiction sans la règle : amélioration = confiance / fréquence(résultat)
! Une règle est intéressante lorsque l'amélioration est supérieure à 1. ! Dans notre exemple on a :
Règle confiance f(résultat) amélioration
si A et B alors C 0.20 40% 0.50
si A et C alors B 0.25 42.5% 0.59
si B et C alors A 0.33 45% 0.74
! la règle « si A alors B » possède un support de 25%, une confiance de 0.55 et une amélioration de 1.31 => cette règle est la meilleure
! En règle générale, la meilleure règle est celle qui contient le moins d'articles.
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 27
EEExxxtttrrraaaccctttiiiooonnn dddeeesss rrrèèègggllleeesss ddd ʼ̓̓aaassssssoooccciiiaaatttiiiooonnn (((111))) Extraction des règles :
! seules les règles ayant un certain support et une certaine valeur de confiance sont intéressantes :
• valeurs de minconf et minsup doivent être fixées par l'analyste ! La plupart des méthodes pour extraire des règles :
• retiennent les règles dont le support > minsup • et parmi celles-ci retiennent celles dont la confiance > minconf
Génération de règles : ! calcul du support de toutes les règles obtenues par combinaisons dʼitems
possibles de la base ! on ne garde que les règles dont le support est supérieur à un seuil donné =
« ensembles fréquents »
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 28
EEExxxeeemmmpppllleee ddd ʼ̓̓eeexxxtttrrraaaccctttiiiooonnn dddeeesss rrrèèègggllleeesss ddd ʼ̓̓aaassssssoooccciiiaaatttiiiooonnn Exemple (issu du cours EPFL):
Etape 1 : calcul des ensembles fréquents ! calcul du support de toutes les combinaisons dʼitems possibles de la base
! on ne garde que règles dont le support est supérieur à un seuil donné =
ensembles fréquents

Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 29
EEExxxtttrrraaaccctttiiiooonnn dddeeesss rrrèèègggllleeesss ddd ʼ̓̓aaassssssoooccciiiaaatttiiiooonnn (((333))) Etape 2 : recherche des sous-ensembles fréquents Un ensemble de k éléments est appelé « k-ensemble »
Lemme de base: ! Tout k-ensemble fréquent est composé de sous-ensembles fréquents ! ainsi un 3-ensemble fréquent est composé de 2-ensembles et de 1-ensembles
fréquents Procédure:
! 1) on cherche les 1-ensembles fréquents ! 2) on cherche les 2-ensembles fréquents ! ... ! n) on cherche les n-ensembles fréquents ceci jusqu'à ce qu'il n'y ait plus d'ensemble fréquent de taille supérieure
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 30
EEExxxtttrrraaaccctttiiiooonnn dddeeesss rrrèèègggllleeesss ddd ʼ̓̓aaassssssoooccciiiaaatttiiiooonnn (((444)))
Génération d'un k-ensemble fréquent : ! A partir des 1-ensemble fréquents on génère des 2-ensembles fréquents,
! A partir des 2-ensemble fréquents on génère des 3-ensembles fréquents,
! ...
Règle de génération : procédure apriori-gen ! L'algorithme génère un candidat de taille k à partir de 2 candidats de taille k-1
différents par le dernier élément
! on garde ce candidat s'il ne contient pas de k-1 ensemble qui n'est pas fréquent
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 31
EEExxxtttrrraaaccctttiiiooonnn dddeeesss rrrèèègggllleeesss ddd ʼ̓̓aaassssssoooccciiiaaatttiiiooonnn (((555))) Exemple:
! les 2-ensembles fréquents obtenus à partir des 1-ensembles fréquents sont : {1,3,5} et {2,3,5}
! On ne garde que {2,3,5} parce que {1,3,5} comprend le 2-ensemble fréquent {1,5} qui ne fait pas partie des 2-ensembles fréquents => {1,3,5} n'est pas un 3-ensemble fréquent
{1,3} {2,3} {2,5} {3,5}
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 32
EEExxxtttrrraaaccctttiiiooonnn dddeeesss rrrèèègggllleeesss ddd ʼ̓̓aaassssssoooccciiiaaatttiiiooonnn (((666))) Algorithme APriori :
L1 = {frequent1-ensemble} ;
for (k = 2 ; Lk-1 = ! # ; k++) do {
Ck= apriori-gen(Lk-1); // Génération nouveaux candidats
k-ensemble fréquents
for eachtransactions t $ DBdo { //Comptage
Ct= { subset(Ck, t) }; // sous-ensembles de la BD
foreach c $ Ct do c.count++; } comptage support
Lk= { c $ Ck |c.count>= minsup} ;// Filtrer par rapport
au support
}
Answer= {Lk} ;

Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 33
EEExxxtttrrraaaccctttiiiooonnn dddeeesss rrrèèègggllleeesss ddd ʼ̓̓aaassssssoooccciiiaaatttiiiooonnn (((777))) Exemple:
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 34
EEExxxtttrrraaaccctttiiiooonnn dddeeesss rrrèèègggllleeesss ddd ʼ̓̓aaassssssoooccciiiaaatttiiiooonnn (((888))) Génération des règles
! A partir des k-ensembles fréquents: ! pour chaque ensemble fréquent l, générer tous les sous-ensembles s non
vides ! pour chaque sous-ensemble s, si Confiance (s "l –s) > minconf, générer la
règle "s "l –s" Exemple :
! {2,3,5}: sous-ensembles non vides: {2}, {3}, {5}, {2,3}, {2,5}, {3,5} ! Confiance (X "Y) = Support (XY)/Support(X) Règles:
• 2 et 3 " 5 Confiance = 2/2 = 100% • 2 et 5 " 3 Confiance = 2/3 = 66% • 3 et 5 " 2 Confiance = 2/2 = 100% • 2 " 3 et 5 Confiance = 2/3 = 66% • 3 " 2 et 5 Confiance = 2/3 = 66% • 5 " 2 et 3 Confiance = 2/3 = 66% Si seuil = 70% on ne garde que les règles 1 et 3
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 35
EEExxxtttrrraaaccctttiiiooonnn dddeeesss rrrèèègggllleeesss ddd ʼ̓̓aaassssssoooccciiiaaatttiiiooonnn (((888))) Inconvénients de Apriori :
! Beaucoup de candidats : 1041-ensembles vont générer 1072-ensembles ! Plusieurs parcours de la BD (pour calculer les supports) : on doit faire n+1
parcours pour trouver les n-ensembles fréquents ! Les indicateurs de support et confiance sont insuffisants :
• support est symétrique : il ne distingue pas A " B de B " A • confiance favorise les évenements rares :
! confiance (A "B ) = Support (AB)/Support(A) ! si Support(A) est faible, Support(AB) aussi et confiance !
Améliorations de Apriori : ! Algorithme AprioriTID qui garde en mémoire les n°de tuples correspondant à
chaque k-ensemble ! Marquer les tuples qui ne contiennent pas de k-ensembles fréquents pour qu'ils
ne soient pas lus lorsqu'on considère les j-ensembles fréquents (j>k) ! Autres mesures :
• conviction : P(X)*P(non Y)/P(X, nonY) • "lift": Confiance (X " Y)/Support(Y)
Autres algorithmes : ! Apriori partitionné, Algorithme de comptage dynamique, FP-Growth, Close, …
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 36
CCCooonnncccllluuusssiiiooonnn sssuuurrr llleeesss rrrèèègggllleeesss ddd ʼ̓̓aaassssssoooccciiiaaatttiiiooonnn (((111))) • Résultats clairs : les règles d'association sont faciles à interpréter, à utiliser pour
des utilisations concrètes • Apprentissage non supervisé : elles ne nécessitent pas d'autre information
qu'une classification en articles et la donnée d'une liste d'articles pour extraire les règles.
• Achats de taille variable : une des rares méthodes qui prend en entrée des achats qui sont des listes d'articles de taille variable
• Introduction du temps : • possible d'adapter la méthode pour traiter des séries temporelles pour
générer des règles de la forme : « un client ayant acheté le produit A est susceptible d'acheter le produit B dans 2 ans »
• possible d'introduire des « articles virtuels » tels que le jour, la période ou la saison et limiter la forme des règles si on souhaite rechercher des comportements d'achat qui dépendent du temps.
• Simplicité de la méthode : calculs élémentaires (fréquences d'apparition) : • peut être programmée sur tableur pour des problèmes de taille raisonnable • généralement disponible dans la plupart des environnements de fouille

Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 37
CCCooonnncccllluuusssiiiooonnn sssuuurrr llleeesss rrrèèègggllleeesss ddd ʼ̓̓aaassssssoooccciiiaaatttiiiooonnn (((222))) • Coût de la méthode : coûteuse en temps de calcul, le regroupement d'articles et
la méthode du support minimum permettent de diminuer les calculs mais on peut alors éliminer sans le vouloir des règles importantes.
• Le choix des articles : difficile de déterminer le bon niveau d'articles. Les traitements préalables sur les achats peuvent être complexes : par exemple, il peut être difficile de retrouver l'article à partir de son code-barre enregistré sur le ticket de caisse.
• Les articles rares : méthode efficace pour les articles fréquents, pour les articles rares, on peut restreindre la forme des règles choisies ou faire varier le support minimum.
• La qualité des règles : la méthode peut produire des règles triviales ou inutiles. • Les règles triviales sont des règles évidentes (si camembert alors vin rouge)
qui, par conséquent, n'apportent pas d'information. • Les règles inutiles sont des règles difficiles à interpréter qui peuvent provenir
de particularités propres à la liste des achats ayant servie à l'apprentissage.
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 38
444 ––– MMMéééttthhhooodddeeesss dddeee CCClllaaassssssiiifffiiicccaaatttiiiooonnn /// PPPrrrééédddiiiccctttiiiooonnn
! Objet de la classification et de la prédiction
! Méthode des arbres de décision
! Méthode des k-Plus proches voisins
! Méthode des Réseaux de Neurones (Perceptron multi-couches)
! Autres méthodes de classification
! Conclusion sur la classification / prédiction
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 39
OOObbbjjjeeettt dddeee lllaaa ccclllaaassssssiiifffiiicccaaatttiiiooonnn eeettt dddeee lllaaa ppprrrééédddiiiccctttiiiooonnn • La classification : ! consiste à examiner les caractéristiques d'un objet et lui attribuer une
classe, la classe est un champ particulier à valeurs discrètes. ! Exemples :
• attribuer ou non un prêt à un client, • établir un diagnostic, • accepter ou refuser un retrait dans un distributeur, • attribuer un sujet principal à un article de presse, ...
• La prédiction : ! consiste à prédire la valeur future dʼun champ, en général, à partir de
valeurs connues historisées ! tâche proche de la classification, les méthodes de classification peuvent être
utilisées en prédiction. ! Exemples :
• prédire les valeurs futures d'actions, • prédire au vu de leurs actions passées les départs de clients.
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 40
CCClllaaassssssiiifffiiicccaaatttiiiooonnnsss nnnooonnn sssuuupppeeerrrvvviiissséééeee eeettt sssuuupppeeerrrvvviiissséééeee 2 familles de modèles de classification • Classification non supervisée : ! Établir des représentations des données dans des espaces à faible dimensions
pour y lire des typologies dʼindividus ! Nombre de classes initialement inconnu
! Méthodes : • Analyse en composante principales (ACP), …
• Classification supervisée (apprentissage) : ! Obtenir un critère de séparation destiné à prédire lʼappartenance à une classe
! Nombre de classes initialement connu ! Méthodes :
• Analyse discriminante • Régression • k-Plus proches voisins • Arbre de décision " • Réseau de neurones " • …

Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 41
LLLeeesss aaarrrbbbrrreeesss dddeee dddéééccciiisssiiiooonnn Arbre de décision : ! Objectif général :
• A partir dʼun ensemble de valeurs d'attributs (variables prédictives ou variable endogènes)
• il sʼagit de prédire la valeur d'un autre attribut (variable cible ou variable exogène)
! une des méthodes supervisée (apprentissage) les plus connues de classification et de prédiction
! un arbre est équivalent à un ensemble de règles de décision : grande explicabilité du modèle
! un arbre est composé : • de noeuds = classes d'individus de plus en plus fine depuis la racine • dʼarcs = prédicats de partitionnement de la classe source
! arbres binaires : 2 branches partent de chaque nœuds ! arbres n-aire : n branches partent de chaque nœud ! algorithmes dʼapprentissage dʼarbre : ID3 [Quilan 79], CART [Brieman et al.
84], …
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 42
EEExxxeeemmmpppllleee 111 ddd ʼ̓̓aaarrrbbbrrreee dddeee dddéééccciiisssiiiooonnn Il sʼagit de prédire la valeur de lʼattribut risque à partir des valeur des attributs age et type de véhicule (exemple tiré de Gardarin) :
ensemble dʼapprentissage Arbre binaire Règles de déduction associées :
• Si âge < 25 alors élévé • Si âge < 25 et TypeVoiture dans {sportive} alors élevé • Si âge < 25 et TypeVoiture pas dans {sportive} alors faible
TupleId Age Type Voiture Risque 0 23 familiale élevé 1 17 sportive élevé 2 43 sportive élevé 3 68 familiale faible 4 32 utilitaire faible 5 20 familiale élevé
Nœud classes dʼindividus
Oui
Oui
Non
Non élévé
élévé faible
Age < 25
TypeVoiture dans {Sportive}
Nœud attribut
prédicats de partitionnement
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 43
EEExxxeeemmmpppllleee 222 ddd ʼ̓̓aaarrrbbbrrreee dddeee dddéééccciiisssiiiooonnn (((111))) Il sʼagit de prédire si selon la météo (ciel, temp., humidité et vent) on va aller jouer au tennis :
• instance = fonction x qui associe à tout attribut a la valeur v • exemple = paire (x, c) où x est une instance et c la classe à prédire pour cette
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 44
instance

Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 45
EEExxxeeemmmpppllleee 222 ddd ʼ̓̓aaarrrbbbrrreee dddeee dddéééccciiisssiiiooonnn (((222))) Soit lʼinstance :
elle est testée (classée) par son chemin depuis la racine jusquʼà la feuille :
Chaque chemin depuis la racine jusquʼà une feuille est une règle de décision, ici : Si (ciel = soleil) et (humidité = élevée) alors (classe = non)
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 46
PPPrrriiinnnccciiipppeee gggééénnnééérrraaalll dddeee cccooonnnssstttrrruuuccctttiiiooonnn ddd ʼ̓̓uuunnn aaarrrbbbrrreee dddeee dddéééccciiisssiiiooonnn • Arbre est construit en découpant successivement les données en
fonction des variables prédictives selon lʼAlgorithme générique : Segmenter (T) SI (tous les tuples de T appartiennent à la même classe de variable à prédire ou critère d'arrêt) ALORS retourner une feuille; Pour chaque attribut prédictif A évaluer la qualité de découpage selon A Utiliser l'attribut donnant la meilleure découpe pour découper en sous-ensembles T1,...,Tn selon les valeurs de A Pour i = 1..n Segmenter (Ti); Fin
• Problèmes fondamentaux pour construire l'arbre 1. Choix de l'attribut discriminant 2. Affectation d'un label à une feuille 3. Arrêt de segmentation (choix de la profondeur de l'arbre) : si lʼarbre est trop
profond, il est trop complexe et trop adapté à l'ensemble d'apprentissage => pas assez généraliste
4. Choix des bornes de discrétisation : comment découper les valeurs d'un attribut continu, par exemple : 1-25 , 25-50, 50-100 ou 1-50, 50-100 ?
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 47
CCCooonnnssstttrrruuuccctttiiiooonnn ddd ʼ̓̓uuunnn aaarrrbbbrrreee dddeee dddéééccciiisssiiiooonnn 1) Critère de choix de lʼattribut :
! Si y est l'attribut dont la valeur à prédire à partir des valeurs des attributs prédictifs xi : choisir l'attribut dont la valeur a le plus d'influence sur celle de y
! Plusieurs techniques provenant de la théorie de l'information de Shannon : • Ratio du Gain ou de lʼEntropie (algo ID3, C5, …) • indice de Gini (algo CART) • X2
Ratio du gain / entropie ! On parle de gain d'information ou d'entropie (concepts inverses) ! On va chercher à choisir l'attribut qui va induire le gain d'information le plus
élevé (ou dont l'entropie est la plus basse) ! Intuitivement, l'entropie mesure le degré de désordre qui restera si on
découpe selon cet attribut -> entropie la plus basse est la meilleure ! Donc pour chaque attribut candidat, on va calculer son entropie et on choisit
celui qui a l'entropie la plus basse. 2) Affectation d'un label à une feuille : On affecte la modalité la plus fréquente.
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 48
CCCooonnnssstttrrruuuccctttiiiooonnn ddd ʼ̓̓uuunnn aaarrrbbbrrreee dddeee dddéééccciiisssiiiooonnn ::: pppaaarrraaammmèèètttrrreeesss 3) Arrêt de la segmentation : Différentes techniques:
pre-pruning: On arrête l'expansion de l'arbre selon certains critères:
• profondeur maximale • effectif de chaque sous-groupe: on fixe un seuil (souvent empiriquement) • on calcule des mesures comme pour le choix de l'attribut de segmentation
(gain d'information, X2,...) auquel on associe un seuil en dessous duquel la segmentation sera refusée
post-pruning: On laisse l'arbre se construire jusqu'au bout On élague lʼarbre en retirant des sous-arbres :
• à l'aide d'heuristiques ou • grâce à l'intervention d'un expert, • l'arbre est élagué tant que l'erreur de l'arbre élagué reste inférieure à celle
de l'arbre non élagué. • le nœud duquel on a retiré un sous-arbre devient une feuille et porte le label
de la valeur la plus fréquente du sous-arbre

Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 49
CCCooonnnssstttrrruuuccctttiiiooonnn ddd ʼ̓̓uuunnn aaarrrbbbrrreee dddeee dddéééccciiisssiiiooonnn ::: pppaaarrraaammmèèètttrrreeesss 4) Choix des bornes de discrétisation :
• On fixe les valeurs candidates comme les valeurs au milieu de 2 valeurs consécutives :
ex: 35, 45, 52... -> 40, 48.5
• Puis on calcule éventuellement la meilleure valeur parmi celles là grâce à des mesures telles que :
! le gain,
! le X2
! ...
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 50
LLL ʼ̓̓aaalllgggooorrriiittthhhmmmeee IIIDDD333 [[[QQQuuuiiilllaaannn 777999]]] Soit : Classe C : valeur d'attribut à prédire (ex: C1: risque = élevé, C2: risque = faible)
tuples : ensemble des tuples de l'échantillon, liste_attributs: ensemble des attributs
Procédure Générer_arbre_décision Créer un nœud N si tuples est vide alors
• retourner une feuille portant le label "Failure" si tuples sont dans la même classe C alors
• retourner N avec comme label C si liste_attributs = vide alors
• retourner N avec comme label le nom de la classe la plus fréquente dans l'échantillon
Choisir l’attribut a le plus discriminant parmi liste_attributs Affecter le label « a » au nœud N Pour chaque valeur ai de a :
• créer une branche issue du nœud N avec condition a s= ai
• Soit ti l'ensemble des éléments tuples vérifiant cette condition
• Attacher le nœud retourné par Générer_arbre_décision(ti, liste_attributs – a)
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 51
CCCaaalllcccuuulll dddeee lll ʼ̓̓EEEnnntttrrrooopppiiieee Entropie = Quantité d'information nécessaire pour classifier l'exemple • Soit S un ensemble de s tuples • Soit C comprenant m valeurs différentes, définissant Ci classes (i = 1,...,m) • Soit si le nombre de tuples de S appartenant à Ci : • I(s1,...sm) = quantité d'information nécessaire pour classifier l'ensemble des tuples • I(s1,...sm) = - Σ(i=1..m) pi log2(pi)
! pi: probabilité qu'un tuple appartienne à Ci ! pi=si/s
Entropie de l'attribut A = E(A) : • Soit A un attribut candidat possédant v valeurs {a1 ,..., av}. • A permet de partionner l'ensemble S en v sous-ensembles {S1,..., Sv} • Si comprend les tuples ayant la valeur ai pour A • Soit sij le nombre de tuples du sous-ensemble Sj appartenant à Ci
!
E(A) = " (S1 j( j=1..v)# + ...+ Smj ) . I(S1 j ,...,Smj )
Pour chaque valeur de A Probabilité qu'un tuple ait cette
valeur dans ce sous-ensemble Qté d'info nécessaire pour classifier
les tuples ayant cette valeur
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 52
CCCaaalllcccuuulll ddduuu GGGaaaiiinnn Gain (A) = réduction d'entropie (i.e. de désordre) espérée si on utilise A
• On va alors choisir l'attribut ayant le gain le plus élevé
• Données :
! Soit S un ensemble de s tuples
! Soit C comprenant m valeurs différentes définissant Ci classes (i=1,...,m)
! Soit si le nombre de tuples de S appartenant à Ci
! Soit A l'attribut candidat
!
Gain(A) = I(S1,...,Sm ) " E(A)
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 53
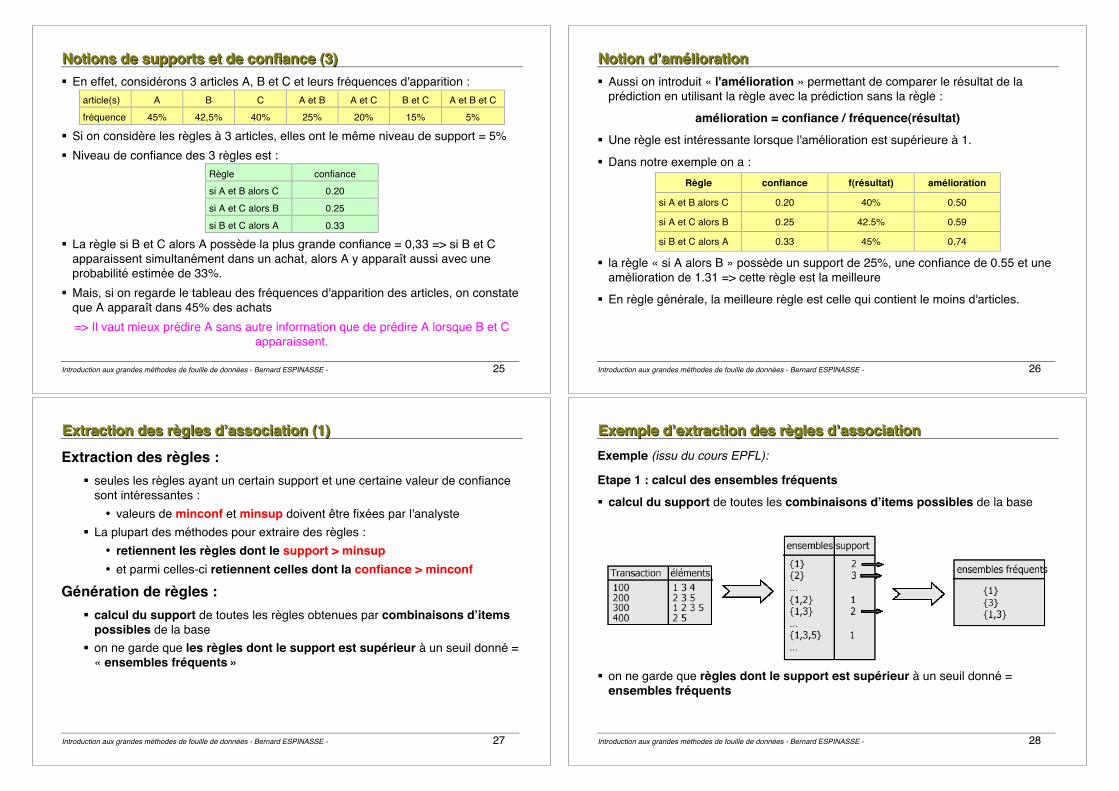
EEExxxeeemmmpppllleee dddeee mmmiiissseee eeennn oooeeeuuuvvvrrreee (((111)))
N° Couleur Contour Point ? Forme 1 vert fin non triangle
2 vert fin oui triangle
3 jaune fin non carré
4 rouge fin non carré
5 rouge plein non carré
6 rouge plein oui triangle
7 vert plein non carré
8 vert fin non triangle
9 jaune plein oui carré
10 rouge plein non carré
11 vert plein oui carré
12 jaune fin oui carré
13 jaune plein non carré
14 rouge fin oui triangle
On veut prédire lʼattribut forme !
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 54
EEExxxeeemmmpppllleee dddeee mmmiiissseee eeennn oooeeeuuuvvvrrreee (((222))) • Entropie de l'attribut Couleur?
! C1: carré ; C2: triangle
!
!
E(A) = " (S1 j( j=1..v)# + ...+ Sij ).I(S1 j ,...,Sij )
• Pour couleur = rouge (i= carré ou triangle?, j=rouge) : ! s11= scarré/rouge= 3 ; s21= striangle/rouge= 2 ! I(s11,s21) = I(3,2) = -3/5 log23/5 - 2/5 log22/5 = 0,971
• Pour couleur = vert : ! s12= scarré/vert= 2 ; s22= striangle/vert= 3 ! I(s12, s22) = I(2,3) = -2/5 log22/5 - 3/5 log23/5 = 0,971
• Pour couleur = jaune : ! s13= scarré/jaune=4 s23= striangle/jaune=0 ! I(s13,s23)=I(4,0)= -4/4 log24/4 - 0/4 log20/4 = 0
• E (couleur) = 5/14 I(s11,s21) + 5/14 I(s12, s22) + 4/14 I(s13,s23) = 0,694 • Gain (couleur) = 0,940 –0,694 = 0,246
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 55
EEExxxeeemmmpppllleee dddeee mmmiiissseee eeennn oooeeeuuuvvvrrreee (((333))) Gain (Couleur) = 0,246 Gain (Contour) = 0,151 Gain (Point?) = 0,048 -> on choisit Couleur
rouge
vert jaune
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 56
EEExxxeeemmmpppllleee dddeee mmmiiissseee eeennn oooeeeuuuvvvrrreee (((444))) Gain (Contour) = 0,971 Gain (point?) = 0,020
rouge
vert jaune
On s'arrête car ce sont tous des carrés (tous les tuples dans la même classe)
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 57
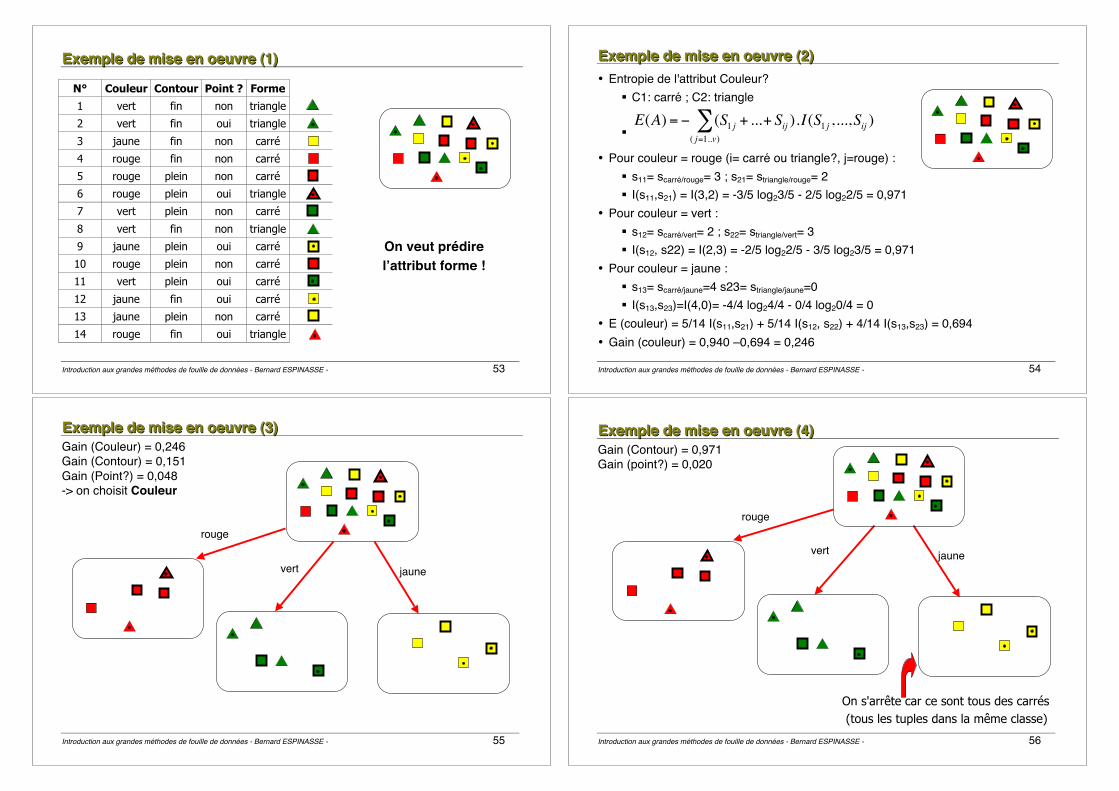
EEExxxeeemmmpppllleee dddeee mmmiiissseee eeennn oooeeeuuuvvvrrreee (((555))) Gain (Contour)=0,020 Gain (point?) =0,971
rouge
vert jaune
plein fin
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 58
EEExxxeeemmmpppllleee dddeee mmmiiissseee eeennn oooeeeuuuvvvrrreee (((666))) rouge
vert jaune
plein fin
point=non point=oui
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 59
EEExxxeeemmmpppllleee dddeee mmmiiissseee eeennn oooeeeuuuvvvrrreee (((777))) Arbre de décision obtenu :
Couleur
Contour Point ? carré
triangle carré triangle carré
vert
fin
rouge jaune
plein oui non
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 60
AAAuuutttrrreeesss aaalllgggooorrriiittthhhmmmeeesss ddd ʼ̓̓aaapppppprrreeennntttiiissssssaaagggeee • Algorithme C5 [Quinlan 93] :
! version plus récente de lʼalgorithme ID3 [Quinlan 79] ! peut prendre en compte des attributs d'arité quelconque. ! fonction entropie, mesurant le degré de mélange (et le gain), a tendance à
privilégier les attributs possédant un grand nombre de valeurs : pour éviter ce biais, une fonction gain d'information est également disponible.
! élagage effectué avec l'ensemble d'apprentissage par une évaluation pessimiste de l'erreur.
• Algorithme CART [Breiman et al., 84] : ! intégré à de nombreux environnements de fouille de données sous de
nombreuses variantes ! fonction mesurant le degré de mélange (et le gain) = fonction de Gini (les
versions diffusées proposent d'autres choix). ! élagage par parcours ascendant de l'arbre : un sous arbre peut être élagué en
comparant l'erreur réelle estimée de l'arbre courant avec l'arbre élagué. ! l'estimation de l'erreur réelle mesurée sur un ensemble test ou par validation
croisée.

Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 61
CCCooonnncccllluuusssiiiooonnn sssuuurrr llleeesss aaarrrbbbrrreeesss dddeee dddéééccciiisssiiiooonnn (((111))) • lisibilité du résultat :
! un arbre de décision est facile à interpréter et constitue la représentation graphique d'un ensemble de règles.
! Si la taille de l'arbre est importante, il est difficile d'appréhender l'arbre dans sa globalité, mais des outils permettent une navigation aisée dans l'arbre
! permet dʼexpliquer comment est classé un exemple par l'arbre, ce qui peut être fait en montrant le chemin de la racine à la feuille pour l'exemple courant.
• tout type de données : ! l'algorithme peut prendre en compte tous les types d'attributs et les valeurs
manquantes ! Il est robuste au bruit.
• sélection des variables : ! l'arbre contient les attributs utiles pour la classification => il peut alors être utilisé comme pré-traitement sélectionnant l'ensemble des variables pertinentes pour ensuite appliquer une autre méthode
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 62
CCCooonnncccllluuusssiiiooonnn sssuuurrr llleeesss aaarrrbbbrrreeesss dddeee dddéééccciiisssiiiooonnn (((222))) • classification efficace : l'attribution d'une classe à un exemple à l'aide d'un arbre
de décision est un processus très efficace (parcours d'un chemin dans un arbre). • outil disponible : les algorithmes de génération d'arbres de décision sont
disponibles dans tous les environnements de fouille de données. • extensions et modifications :
! la méthode peut être adaptée pour résoudre des tâches d'estimation et de prédiction.
! Des améliorations des performances des algorithmes de base sont possibles grâce aux techniques de bagging et de boosting : on génère un ensemble d'arbres qui votent pour attribuer la classe.
• sensible au nombre de classes : les performances tendent à se dégrader lorsque le nombre de classes devient trop important.
• évolutivité dans le temps : l'algorithme n'est pas incrémental, c'est-à-dire, que si les données évoluent avec le temps, il est nécessaire de relancer une phase d'apprentissage sur l'échantillon complet (anciens exemples et nouveaux exemples).
Introduction aux grandes méthodes de fouille de données - Bernard ESPINASSE - 63
444 ––– MMMéééttthhhooodddeee dddeeesss RRRéééssseeeaaauuuxxx dddeee NNNeeeuuurrrooonnneeesss (((pppeeerrrccceeeppptttrrrooonnn mmmuuullltttiii---cccooouuuccchhheeesss)))
! xxx