Embed Size (px)
Citation preview

Article original
L’application des fonctions discriminantesau diagnostic individuel en psychologie>
P. Pichot, J. Perse
Laboratoire de psychologie, clinique des maladies mentales et de l’encéphale, faculté de médecine de Paris, France
1. Introduction
Il est maintenant habituel de désigner par le terme anglaisde « scatter » toute inégalité entre les résultats obtenus par unmême sujet à différents tests mentaux. Les tests utiliséspeuvent être des tests d’efficience ou de personnalité, oubien, comme c’est le cas dans le test de Rorschach, il peuts’agir de notes provenant de différents systèmes de cotationde la même épreuve. Il suffit pour qu’on puisse parler descatter que l’on dispose pour un sujet déterminé de plusieursrésultats numériques et que ces résultats, rapportés à l’échan-tillon de standardisation, ne soient pas égaux entre eux. Onappelle, à la suite de Bijou, « pattern psychométrique »l’énoncé numérique ou verbal des relations existant entredeux ou plusieurs résultats à des tests et concernant le mêmeindividu... Le « pattern psychométrique » est donc un modede formulation du scatter. Ces définitions nous paraissentplus satisfaisantes que celle de Papaport, qui tend à restrein-dre la notion de scatter aux tests d’efficience.
Le problème tel qu’il se pose en psychopathologie, maisaussi en orientation professionnelle, et d’une manière géné-rale en psychologie appliquée, est le suivant : on dispose d’uncritère extérieur qui a permis de classer les sujets en plusieursgroupes, par exemple en psychopathologie, on a constitué ungroupe de schizophrènes, un groupe de maniaques, ungroupe de déprimés, un groupe d’hystériques, etc. Tous lessujets ont été soumis à un certain nombre d’épreuves, parexemple aux dix sub-tests de l’échelle de Wechsler Bellevue.On peut donc définir chaque groupe nosologique par la va-leur moyenne obtenue par l’ensemble des membres dugroupe à chacun des sub-tests, et par la dispersion des résul-tats des membres du groupe autour de cette valeur moyenne.C’est ce que Rorschach avait fait lorsque, dans son « Psycho-diagnostik », il a indiqué les différentes caractéristiques deses groupes de malades mentaux en ce qui concerne le nom-bre total de réponses, le nombre de réponses forme, deréponses couleur, etc. C’est ce que Rapaport a fait pour leWechsler Bellevue et pour d’autres épreuves dans son « Dia-
gnostic Psychological Testing ». Suivant que les différencesentre les résultats moyens des différents groupes sont plus oumoins significatives, elles présentent une valeur diagnostiqueplus ou moins importante. Malheureusement, cette valeur esttrès difficile à préciser quand on considère non plus desrésultats moyens, mais des résultats isolés. En effet, le pro-blème pratique du diagnostic individuel se pose de la façonsuivante : étant donné un individu qu’on a soumis à un certainnombre d’épreuves, quel est, d’après ses résultats à cesépreuves, le groupe auquel il a le plus de chances d’apparte-nir ? La difficulté de la solution tient notamment au fait quel’ensemble des notes doit être considéré non comme uneaddition de variables indépendantes, mais comme une struc-ture intégrée. C’est là un point qui est bien connu en particu-lier des psychologues qui emploient le test de Rorschach ; ilssavent que, par exemple, le nombre de réponses de couleurou de mouvement a un sens très différent suivant le contexte,c’est-à-dire suivant le nombre des autres types de réponses, etque — chaque facteur doit toujours être interprété en fonc-tion de tous les autres.
Jusqu’à présent on a surtout employé pour résoudre ceproblème deux méthodes que nous exposerons très briève-ment. La première peut être appelée méthode impression-niste. Elle consiste par simple inspection (en général de lareprésentation graphique du pattern psychométrique, c’est-à-dire du profil) à décider plus ou moins intuitivement à quelpattern type le pattern obtenu ressemble le plus étroitement,c’est-à-dire à quel groupe le sujet a le plus de chancesd’appartenir. Un simple calcul montre les limites de la mé-thode pour l’échelle de Wechsler, qui comprend 11 tests,chacun noté de 0 à 20, il existe un nombre de patternsthéoriquement possibles représenté par 35 suivi de 13 zéros.Un atlas bien fait devrait donc comprendre ce nombre astro-nomique de profils et indiquer en face de chacun d’eux lediagnostic le plus probable. C’est donc une impossibilitéabsolue.
La deuxième méthode est appelée la méthode des « si-gnes ». Pratiquement tous les travaux consacrés au scatterl’emploient. Elle consiste à. isoler artificiellement dans lepattern certains rapports entre notes ayant une valeur discri-minative. Wechsler, par exemple, écrit : « Un signe est un> Première parution : Revue de Psychologie Appliquée, 1952, 2, 19–34.
Revue européenne de psychologie appliquée 54 (2004) 5–10
www.elsevier.com/locate/
© 2004 Publié par Elsevier SAS.doi:10.1016/j.erap.2004.01.001

score élevé ou bas qui a été trouvé être caractéristique ouassocié avec un type particulier de maladie ou de dysfonc-tionnement mental ». Plus le nombre de signes présents estélevé, plus la probabilité du diagnostic augmente.
La méthode des signes présente de graves inconvénients.D’une part, elle est dans son principe même contraire àl’esprit que nous avons défini du caractère structural et inté-gré du pattern. Elle découpe celui-ci pour pouvoir l’analyser.D’autre part, l’établissement d’une liste complète de signesdiscriminatifs se heurte à l’impossibilité matérielle de passeren revue tous les signes, c’est-à-dire tous les rapports possi-bles entre les résultats, dont le nombre est du même ordre degrandeur que celui que nous avons indiqué plus haut. Enfin,cette méthode ne résout que de façon très imparfaite leproblème du diagnostic individuel, puisque dans la grandemajorité des cas elle ne permet pas d’établir le nombre designes nécessaire et suffisant pour poser, avec une probabilitédonnée, le diagnostic correspondant. Tous les psychologuesfamiliers avec les scatters de l’échelle Wechsler Bellevue ouavec les signes pathologiques du test de Rorschach, parexemple, savent combien ces méthodes se révèlent décevan-tes dans la pratique courante.
Nous nous proposons dans cet article d’exposer commentil est possible de résoudre de façon plus satisfaisante et plusprécise le double problème que nous avons posé, à savoir :
• à partir des données recueillies, comment séparer aumieux les différents groupes constitués sur la base decritères extérieurs (critères nosologiques en psychopa-thologie) ?
• étant donné les différents résultats d’un individu, quelleest la probabilité qu’il appartienne à l’un ou l’autre desgroupes ou en d’autres termes quel est le diagnostic leplus probable ?
2. La discrimination à partir d’une seule variable
Nous commençons par considérer le cas le plus simple quiest celui où l’on ne dispose que d’une seule variable xaffectée à chacun des individus de deux populations A et B.Nous supposerons que les notes x sont centrées et normées etqu’elles se répartissent dans les deux groupes A et B suivantune distribution normale (Fig. 1).
Soient mA et mB les moyennes des notes pour chacun desdeux groupes. Posons : mB – mA = 2�.
Il est clair que la discrimination entre les deux distribu-tions sera d’autant meilleure que la distance 2� sera plus
grande. Ce problème est celui qui se pose par exemple dansl’établissement de tests de développement où l’on cherche àobtenir la meilleure discrimination entre deux populations Aet B constituées par des groupes d’enfants d’âge chronologi-que différent.
La seconde question est la suivante — étant donné unindividu qui obtient une note xi, à quel groupe appartient-il ?On choisira une note discriminante xo et l’on conviendra quetout individu pour lequel on a : x < xo appartient à A et quetout individu pour lequel on a : x > xo appartient à B. Laprécision dépend aussi, bien entendu, de la distance 2�. Pouravoir une égale probabilité d’erreur pour les deux popula-tions, on choisira xo à une égale distance a de mA et de mB. Onvoit que dans ce cas la probabilité d’erreur sera donnée parl’aire de la partie hachurée de la courbe normale réduite, soitP (x > �).
À la limite :P→O quand �→∞P→1⁄2 quand �→0.
ce dernier cas étant celui
où il n’existe aucune différence significative entre les deuxgroupes.
3. La discrimination à partir de plusieurs variables
Si l’on dispose de deux variables x et y affectées à chacundes individus de deux populations A et B, on pourra repré-senter graphiquement l’ensemble des données dans un planavec deux axes de coordonnée rectangulaires, chaque indi-vidu étant figuré par un point d’abscisse x et d’ordonnée y.Dans le cas de distributions normales, on obtiendra deuxnuages de points caractérisés par les ellipses indicatrices deprobabilité (Fig. 2). Les projections sur Ox et sur Oy peuventêtre très largement chevauchantes, c’est-à-dire que ni x, ni yne donnent une bonne discrimination.
Mais il existe des directions projetantes telles que, enprojetant les deux distributions sur la ligne des centres de
Fig. 1.
y
A
B
0 x
OA
OB
Fig. 2.
6 P. Pichot, J. Perse / Revue européenne de psychologie appliquée 54 (2004) 5–10

gravité OAOB parallèlement à l’une de ces directions D, onait une bonne discrimination. Les deux distributions ainsiprojetées sur un seul axe, on est ramené au cas précédent. Leproblème revient à déterminer la direction qui fournit lameilleure discrimination ; nous l’envisagerons plus loin.
Dans le cas de trois variables, on pourra, de même, recou-rir à une représentation graphique dans un espace à troisdimensions et projeter les deux distributions sur un axeparallèlement à un certain plan discriminant, ou encore surun plan parallèlement à un axe discriminant.
La généralisation est évidente. Avec n variables, les nua-ges de points se répartiront suivant des hyperellipsoïdes dansun espace à n dimensions et le problème revient toujours àprojeter tous les points sur la ligne des centres de gravité parexemple, de façon à séparer « au mieux les deux distribu-tions ».
4. Les fonctions discriminantes
La représentation graphique n’étant plus possible dans lecas de n variables, nous traiterons analytiquement le pro-blème dans ce cas général.
Soient : X1, X2, X3 ... Xn les n variables affectées à chacundes N individus de la population A et des N′ individus de lapopulation B.
Soient : ml, m2i, m3 ... mn respectivement les moyennes deces notes dans la population A.
et m′1, m′2, m′3 ... m′n respectivement les moyennes de cesnotes dans la population B. On posera
d1 = m1 – m′1 ; d2 = m2 – m′2 ... dn = mn – m′net nous envisagerons les variables centrées
x1 = X1 – ml ... xn = Xn – mn pour la population A.
x′1 = X′1 – m′1 ... x′n = Xn – mn pour la population B.
Le problème que nous avons exposé revient à déterminerune fonction des différentes variables :
Y = k1x1 + k2x2 + ...+ knxn
telle que la discrimination des notes y entre les deux groupesA et B soit la meilleure possible. Une telle fonction est ditefonction discriminante. En d’autres termes, les coefficients kseront définis par la condition que la distance séparant lesmoyennes des notes y dans les deux populations, évaluée envariables réduites, soit maximum. Appelons D cette distance.On a :
D =�y
N−
�y′
N′
D =�� klx1+k2x2+........+knxn
N−
�� klx1+k2x′2+........+knx′
n
N′
et D = kl dl + k2 d2 + .... + kn dn
Cherchons maintenant à estimer r2D, variance de D. La
variance des y dans la population A s’obtient en divisant par
le nombre de degrés 0 de liberté correspondant à la sommedes carrés qui est :
Ry2 = R (k1x1 + k2x2 + .... + knxn)2
On aura de même dans la population B :
Ry′2 = R (k1x1 + k2x2 + .... + knxn )2
L’estimation de la variance intra des notes y s’obtiendra endivisant par le nombre de degrés de liberté correspondant laquantité :
S = �y2 + �y′2
En développant les carrés ci-dessus et en additionnant, onobtient finalement :
S = �p=1
n
�q=1
n
kpkqSpq
où Spq représente, quand p = q, une somme de carrés étendueaux deux populations, telle que Rx1x2 + Rx′1x′2 ; quand p ≠ q,une somme de produits étendue aux deux populations telleque
� x1x2 + � x′1x′2.
On sait que la variance de D est proportionnelle à la
quantité S, donc rD est proportionnel à �S
Rendre maximum l’expressionD
rD
revient donc, à un fac-
teur constant près, à rendre maximum l’expressionD
�Sou
D
S, ce que l’on obtient en annulant ses dérivés :
2
D
dD
dk−
1
S
dS
dk= 0
ou
dS
dk=
2S
D
dD
dk
En négligeant le terme constant2S
D, on aboutit au système
linéaire suivant :
{k1S11 + k2S12 + ... + knS1n = dl
k1S21 + k2S22 + ... + knS2n = d2
k1Sn1 + k2Sn2 + ... + knSnn = dn
dont la résolution fournit les n coefficient k recherchés.
5. Application à un exemple concret
Pour illustrer la méthode, nous en donnerons une applica-tion dans le cas où deux variables seulement sont utilisées.
7P. Pichot, J. Perse / Revue européenne de psychologie appliquée 54 (2004) 5–10

Dans un travail antérieur avec le Professeur J. Delay et al.,1950, nous avions étudié les différences psychologiques dedeux groupes de sujets présentant un affaiblissement intel-lectuel et entrant dans le cadre des démences de la sénilité,mais se différenciant par l’existence dans un des groupesd’artériosclérose périphérique (déments artériopathiques) etpar l’absence de ce même symptôme dans l’autre groupe(déments séniles). De l’ensemble des tests utilisés, deux sesont avérés avoir un intérêt diagnostique : le test de Vocabu-laire et les Progressive Matrices 38.
Les deux variables X1 et X2 sont donc les notes obtenuespar chaque sujet aux Progressive Matrices 38 et au test deVocabulaire respectivement, les données sont les suivantes
A - Séniles B - ArtériopathiquesN = 25 N′ = 27X1 X2 X1 X2
17 32 18 2114 31 13 1314 33 10 1416 32 13 2012 23 10 715 19 15 2210 17 29 3113 27 18 209 28 18 238 21 15 1910 27 13 1717 31 12 1515 33 10 255 23 5 611 31 16 413 27 19 157 22 16 177 24 14 194 16 5 1410 29 17 2915 35 8 610 26 12 1210 30 20 287 9 12 1712 24 12 23
15 2515 17
m m′ d = m – m′1 11,24 14,07 –2,832 26,00 17,74 +8,26
Le calcul des sommes des carrés et des sommes desproduits est résumé dans le tableau suivant :
Rx21 Rx2
2 Rx1x2
A. 322,560 944,000 359,000B. 619,852 1291,186 556,519
Total 942,412 2235,186 915,519
La matrice des Spq sera donc la suivante :
1 2 1 21 S 11 S12 1 942,412 915,5192 S21 S22 2 2235,186
Le système d’équations linéaires dont les k sont les incon-nues se réduit ici à un système de deux équations à deuxinconnues :
{k1S11 + k2S12 = d1
k1S21 + k2S22 = d2
étant donné que tout système de coefficients proportionnelsaux k ainsi calculés fournira la même discrimination, il sera
commode de poser : k1 = 1 et : k =k2
k1On trouve : k = –,747 (ou –,75 pour ne conserver que deux
décimales).La fonction discriminante :
y = k1 x1 + k2 x2
pourra donc s’écrire à un facteur constant près : y = X1 + k X2
et sera dans le cas présent :
y = X1 − 0.75 X2
Pour déterminer la note discriminante yo, nous commen-cerons par évaluer les moyennes des notes y pour les deuxgroupes :
my = m1 + k m2 = 11,24 – 0,75 × 26,00 = – 8,26
m′y = m′1 + k m′2= 14,07 – 0,75 × 17,74 = + 0,77
En plaçant yo à mi-distance de my et de m′y, on obtient :
yo = − 8,26 +9,03
2= 0,77 −
9,03
2
y0=−3,75
L’estimation de r, racine carrée de la variance intra,donne :
r = �� 827⁄49 � = 4,11
d’où
2r =D
r=
9,03=2,2
4,11et r = 1,1
La probabilité d’erreur de classification sera par consé-quent :
P (y > 1,1) = 13,5 % environ.
En résumé, si l’on considère les distributions des notes dessujets aux Progressive Matrices 38 d’une part (X1) et au testde Vocabulaire d’autre part (X2), on constate (Fig. 3) que cesdistributions ne présentent aucune différence significativepour le premier test et une différence significative pour lesecond. Mais les deux distributions sont si largement chevau-chantes que l’utilisation de ce scatter est de peu de valeurpratique pour le diagnostic individuel. En revanche, l’emploisimultané des deux notes considérées comme constituant un
8 P. Pichot, J. Perse / Revue européenne de psychologie appliquée 54 (2004) 5–10
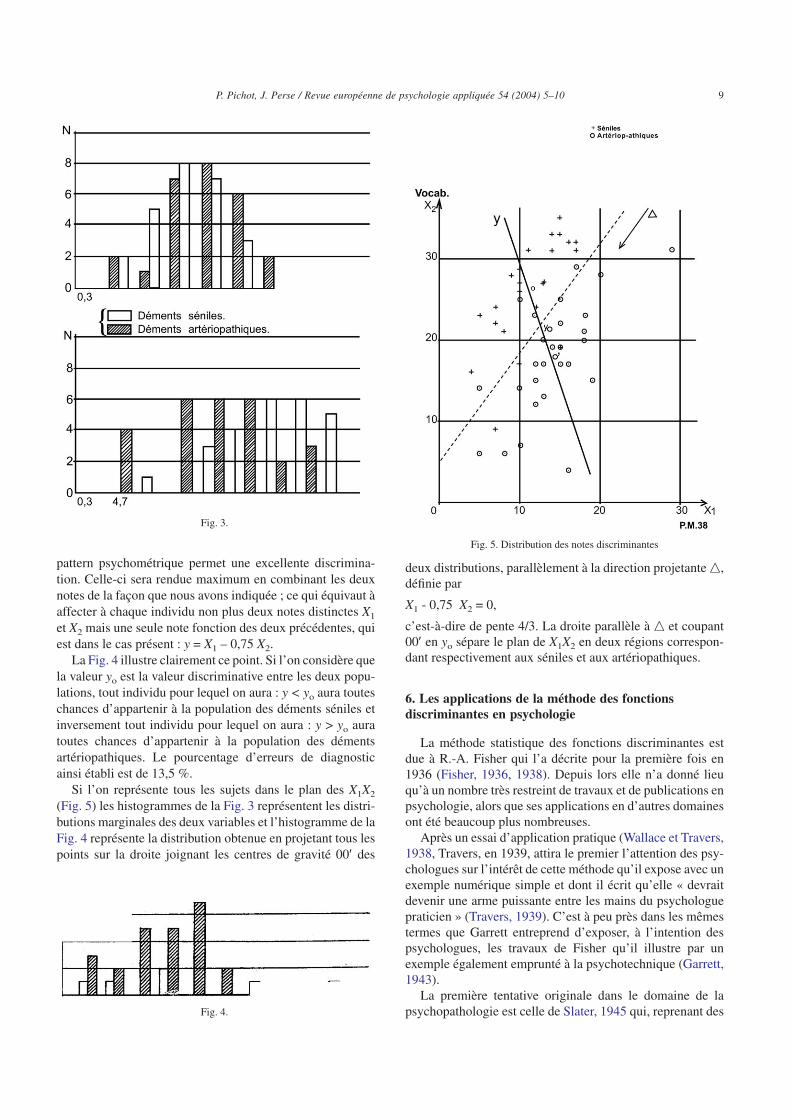
pattern psychométrique permet une excellente discrimina-tion. Celle-ci sera rendue maximum en combinant les deuxnotes de la façon que nous avons indiquée ; ce qui équivaut àaffecter à chaque individu non plus deux notes distinctes X1
et X2 mais une seule note fonction des deux précédentes, quiest dans le cas présent : y = X1 – 0,75 X2.
La Fig. 4 illustre clairement ce point. Si l’on considère quela valeur yo est la valeur discriminative entre les deux popu-lations, tout individu pour lequel on aura : y < yo aura touteschances d’appartenir à la population des déments séniles etinversement tout individu pour lequel on aura : y > yo auratoutes chances d’appartenir à la population des démentsartériopathiques. Le pourcentage d’erreurs de diagnosticainsi établi est de 13,5 %.
Si l’on représente tous les sujets dans le plan des X1X2
(Fig. 5) les histogrammes de la Fig. 3 représentent les distri-butions marginales des deux variables et l’histogramme de laFig. 4 représente la distribution obtenue en projetant tous lespoints sur la droite joignant les centres de gravité 00′ des
deux distributions, parallèlement à la direction projetante n,définie par
X1 - 0,75 X2 = 0,
c’est-à-dire de pente 4/3. La droite parallèle à n et coupant00′ en yo sépare le plan de X1X2 en deux régions correspon-dant respectivement aux séniles et aux artériopathiques.
6. Les applications de la méthode des fonctionsdiscriminantes en psychologie
La méthode statistique des fonctions discriminantes estdue à R.-A. Fisher qui l’a décrite pour la première fois en1936 (Fisher, 1936, 1938). Depuis lors elle n’a donné lieuqu’à un nombre très restreint de travaux et de publications enpsychologie, alors que ses applications en d’autres domainesont été beaucoup plus nombreuses.
Après un essai d’application pratique (Wallace et Travers,1938, Travers, en 1939, attira le premier l’attention des psy-chologues sur l’intérêt de cette méthode qu’il expose avec unexemple numérique simple et dont il écrit qu’elle « devraitdevenir une arme puissante entre les mains du psychologuepraticien » (Travers, 1939). C’est à peu près dans les mêmestermes que Garrett entreprend d’exposer, à l’intention despsychologues, les travaux de Fisher qu’il illustre par unexemple également emprunté à la psychotechnique (Garrett,1943).
La première tentative originale dans le domaine de lapsychopathologie est celle de Slater, 1945 qui, reprenant des
Fig. 3.
Fig. 4.
Fig. 5. Distribution des notes discriminantes
9P. Pichot, J. Perse / Revue européenne de psychologie appliquée 54 (2004) 5–10

données recueillies par Élisabeth Bennett sur des militairesen service dans l’armée anglaise, établit à partir de dixvariables (3 fournies par un « neurotic inventory », 4 par des« annoyances tests » et 3 par le « Pressey X-O ») une fonctiondiscriminante pour le diagnostic d’état névrotique. En s’ap-puyant ensuite sur la double hypothèse :
• qu’un sujet disposé à la névrose répond aux tests de lamême façon qu’un sujet souffrant de névrose et ;
• que la probabilité qu’un sujet névrosé soit admis à l’hô-pital pour y être traité pendant la durée normale de sonservice militaire est de 1 sur 66, il dresse une tabledonnant pour chaque score discriminant la probabilitéque le sujet obtenant ce score soit admis à l’hôpital pourétat névrotique durant son service militaire.
C’est également à partir de données numériques prove-nant de l’armée, mais qui ne sont pas des résultats de testsmentaux, que Rao et Slater, 1949 tentent une étude plusgénérale de la névrose, avec une élaboration statistique beau-coup plus poussée, utilisant des travaux originaux de Rao.
Enfin, Harper a récemment appliqué la méthode des fonc-tions discriminantes à l’étude de la valeur diagnostique desscatters de l’échelle de Wechsler Bellevue. Il utilise 21 varia-bles (10 scores bruts et 8 scatters de l’échelle WechslerBellevue, l’âge chronologique, le niveau éducationnel, lesexe) pour discriminer cinq types de schizophrènes (Harper,1950) se répartissant comme suit : 90 paranoïdes, 29 hébéph-rènes, 45 catatoniques, 35 cas de schizophrénie simple,29 cas de schizophrénie de formes mixtes, auxquels sontajoutés 17 cas de schizophrénie de formes diverses. Il établitles fonctions discriminantes pour comparer chacun de cescinq types à l’ensemble des autres et il calcule les coefficientsde régression multiple correspondants. Ces coefficients serévèlent très significatifs pour la discrimination de chacundes quatre premiers groupes. Mais il est intéressant de noterque l’analyse des résultats montre peu d’accord avec lestravaux antérieurs, en particulier ceux de Rapaport dont ilfaut accepter les conclusions avec la plus grande prudence, etqu’en utilisant seulement trois variables (âge, sexe, QI) aulieu de 21, c’est-à-dire en négligeant complètement la répar-tition des notes au Wechsler Bellevue, on trouve encore descoefficients très significatifs pour la discrimination des troispremiers groupes. L’auteur en conclut légitimement que laméthode des fonctions discriminantes lui paraît une méthoded’avenir mais que l’échelle de Wechsler n’est pas un instru-ment adéquat au diagnostic psychiatrique.
Dans un autre travail (Harper, 1950), il a calculé la fonc-tion discriminante entre le même groupe de 245 schizophrè-
nes et un groupe de 237 sujets normaux, les deux groupesétant convenablement appariés en ce qui concerne l’âge et leQI. Il utilise cette fois dix variables (les 10 scores bruts duWechsler Bellevue). La détermination du score discriminantentre les deux groupes, telle que nous l’avons indiquée,conduit à estimer à 33 % la probabilité d’erreur de diagnosticpar ce procédé. En appliquant dans un deuxième temps laformule à un nouveau groupe de 56 schizophrènes, il cons-tate en effet que 38 d’entre eux sont convenablement dia-gnostiqués alors que les 18 autres (soit 32 %) apparaissentcomme normaux, ce qui coïncide de façon très satisfaisanteavec le pourcentage d’erreur estimé.
Nous n’avons pu donner ici qu’un aperçu très sommaire etincomplet de la méthode des fonctions discriminantes et nousavons dû passer sous silence des développements statistiquesplus récents sur cette question de l’utilisation simultanée devariables multidimensionnelles, en particulier les remarqua-bles travaux de Rao sur le concept de la distance généraliséedû à Hotelling et sur les critères statistiques permettant dedéterminer le groupe auquel un individu appartient. Bien queles applications en aient été jusqu’à maintenant très peunombreuses en psychologie, il est certain qu’il y a là uninstrument remarquablement adapté au problème du dia-gnostic individuel psychométrique et capable d’en renouve-ler entièrement l’abord méthodologique.
Références
Delay, J., Pichot, P., Dursap, R., Perse, J., 1950. L’aphasie latente ; sondiagnostic dans l’artériosclérose cérébrale au moyen d’un test deVocabulaire. Revue. Neur. 83, 180–191.
Fisher, R.-A., 1936. The use of multiple measurements in taxonomy prob-lems. Ann. Eugen 193-6 (7), 179–188.
Fisher, R.-A., 1938. The statistical utilization of multiple measurements.Ann. Eugen 8, 376–386.
1943. Garrett - The discriminant function and its use in psychology. Psy-chometrika 8, 65–79.
Harper Jr, A.-E., 1950a. Discrimination of the types of schizophrenics by theWechsler Bellevue scale. J. Consult. Psychol. 14, 290–296.
Harper Jr, A.-E., 1950b. Discrimination between matched schizophrenicsand normal by the Wechsler Bellevue scale. J. Consult. Psychol. 14,351–357.
Rao, C.-R., Slater, P., 1949. Multivariate analysis applied to differencesbetween neurotic groups. Brit. J. Psychol, Statist. Sect 2, 17–29.
Slater, P., 1945. The psychometric differentiation of neurotic from normalmen. Brit. J. Med. Psychol. 20, 277–279.
Travers, R.-M.-W., 1939. The use of a discriminant function in the treatmentof psychological group differences. Psychomefrika 4, 25–32.
Wallace, N., Travers, R.-M.-W., 1938. A psychometric sociological study ofa group of speciality salesmen. Ann. Eugen. 8, 266–302.
10 P. Pichot, J. Perse / Revue européenne de psychologie appliquée 54 (2004) 5–10




![ANÁLISIS DISCRIMINANTE - Fuenterrebollo · 2013. 5. 3. · (e) El número máximo de funciones discriminantes es el mínimo [número de variables, número de grupos menos 1] –](https://img.pdfslide.fr/doc/110x75/609a21026e352c09d269f222/anlisis-discriminante-fuenterrebollo-2013-5-3-e-el-nmero-mximo-de.jpg)