Embed Size (px)
Citation preview

CRIP – 16/10/2013 1
CRIP - 16/10/2013 – Pierre-Marie Brunet
Le projet Gaïa, le Big Data au service du traitement
de données satellitaires

SO
MM
AIR
E
CRIP – 16/10/2013 2
Le calcul scientifique au CNES
Le BigData au CNES, le cas Gaïa
HPC et BigData computationnel, le temps de la
convergence ?
CRIP – 16/10/2013 3
Le calcul scientifique au CNES
Deux grandes familles de calcul
1) Simulation numérique
Phase « amont » des projets
Type de calcul usuel en HPC, « outil » de la science
expérimentale contemporaine.
champs d’application :
CFD,
Combustion,
Electromagnétisme,
Mécanique spatiale,
CPU intensif
Bande passante mémoire importante
Parallélisme à grain fin (1 job / multiple process)
Tendances : multi échelle, multi physique (couplage de codes)

CRIP – 16/10/2013 4
Le calcul scientifique au CNES
Deux grandes familles de calcul
2) Traitement de données
Phase « aval » des projets
Traitement des données brutes provenant des senseurs satellites en données
intelligibles pour une communauté scientifique :
Terre: Etude du climat (hydrographie, salinité, océan circulation, etc.),
Imagerie (cartographie, etc.), Altimetrie, …
Univers : Cosmologie (matière noire, rayonnement cosmologique, etc.),
Astrométrie (catalogue d’objets)
I/O intensif
Parallélisme gros grain (multiple jobs séquentiels)
Contrainte opérationnelle (temps de restitution borné)
Tendance : augmentation du volume

CRIP – 16/10/2013 5
Le calcul scientifique au CNES
… et une nouvelle classe de problème de traitement
3) Traitement de données orienté « Big Data »
Dataset trop important pour être traité sur la P/F existante
Volume et type d’accès aux données mettant en échec les technologies usuelles
Besoin d’un nouveau paradigme : Map/Reduce
CPU intensif ET I/O intensif

CRIP – 16/10/2013 6
Gaia
Les enjeux : - Produire une cartographie 3D de
notre proche galaxie - Localisation de plus d’un milliard
d’objets avec une précision inégalée
- Détermination des paramètres stellaires/astrophysiques
Le centre de mission : - DPAC = 6 centres de traitement - DPCC (centre de traitement CNES) :
- 3 CU (coordination units) - 10 chaines scientifiques - 60 modules scientifiques - 60 développeurs EU

CRIP – 16/10/2013 7
Gaia
GAIA est un projet à l’échelle du « BigData ».
Une solution dédiée est nécessaire.
Les chiffres: - 3Po de données (1 pile de DVD aussi haute que 4 tours montparnasse) - 290 milliards d’entrée dans la base de données (100 fois plus que la base de données du projet Corot) - Complexité des requêtes d’accès - Plus de 1000 connexions concurrentes à la base

CRIP – 16/10/2013 8
Etude technologique (2011-2012)
Critères d’évaluation
» Performance : ingestion, une requête complexe
» Scalabilité de la solution
» Fiabilité (data safety)
» Impacts sur l’existant (software et hardware)
» Coût global de la solution sur la durée de la mission (jusqu’à 2022)
» Pérennité de la solution
» Utilitaires d’administation/supervision
Analyse de performance
» Jeux de données identiques
» Comparaison avec la solution originelle basée sur PostgreSQL.
» Ecriture/Lecture massive de données (taille objects : petite et moyenne)
» Requêtes complexes
Focus sur un projet Hadoop :
CRIP – 16/10/2013 9
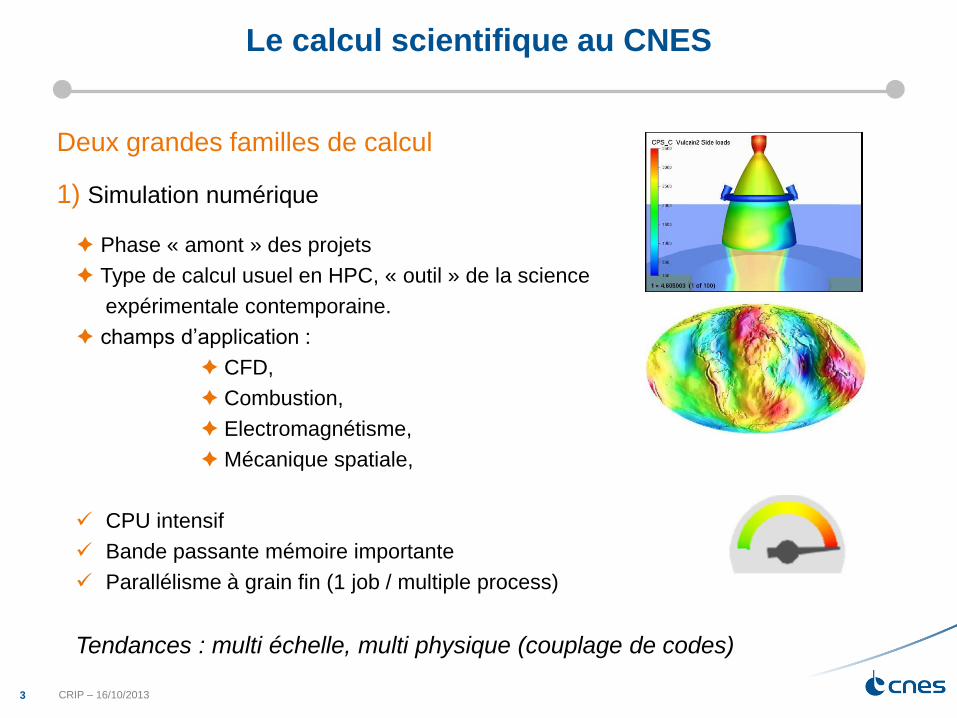
Test de performance
Scalabilité hadoop OK
Focus sur un projet Hadoop : O
bje
cts
/s.
Hadoop Cassandra Caché, PostgreSql, MongoDb
12000
10000
8000
6000
4000
2000
0 1 000 000 10 000 000 100 000 000
Object Number
Hadoop
Caché
PostgreSql
Cassandra
MongoDb

CRIP – 16/10/2013 10
Solution choisie par le DPCC
Migrer sur Hadoop n’a rien changé au niveau des chaînes scientifiques
(Facade pattern)
Quelques impacts sur l’architecture du gestionnaire de workflow
(orchestration)
Focus sur un projet Hadoop :

CRIP – 16/10/2013 11
Solution choisie par le DPCC
Hadoop :
Ordonnanceur de travaux batch : paradigme Map/Reduce (distributed computing,
parallélisme gros grain)
Système de fichiers parallèle HDFS
Principe : Amener le calcul à la donnée
Advantages :
vitesse
flexibilité
scalabilité
écosystème logiciel Hadoop
Focus sur un projet Hadoop :

CRIP – 16/10/2013 12
Cascading
une API Java pour les developpeurs au dessus de la couche Hadoop MapReduce
les process Cascading sont traduites “à la volée” en tâches Map Reduce
(5% d’overhead constaté)
permet des opérations complexes (proches de SQL : join, group,…) sans
penser en MapReduce
Focus sur un projet Hadoop :

CRIP – 16/10/2013 13
Déclinaison matérielle BigData et HPC
DPCC cluster
Specifications hardware :
Masternodes : DELL R620
GlusterFS nodes : DELL R720
Datanodes : DELL C6220
» 12 cœurs
» 48 Go RAM
» Stockage 12To (JBOD)
Réseau Ethernet
» 10Gb interbaie
» 1Gb intrabaie
Configuration globale cible :
» ~ 6500 cores
» ~ 10 TB RAM
» ~ 3PB
» ~ 120 Tflops

CRIP – 16/10/2013 14
Déclinaison matérielle BigData et HPC
HPC cluster
Hardware specifications
Nœuds master : DELL R420
Nœuds de calcul : DELL C6220
» 16 cores
» 64 GB RAM
» Stockage local 0,5 TB (RAID0)
Stockage parallèle : GPFS
» 260 To, 8Go/s
Réseau Infiniband
Configuration actuelle :
» 1700 cores
» 6,5 TB RAM
» 35 Tflops

CRIP – 16/10/2013 15
Déclinaison matérielle BigData et HPC
Convergence des solutions
Comment fusionner les P/F HPC et « BigData computationnel » ?
recherche d’optimisation de coût (acquisition, maintenance, infogérance)
Impact au niveau de l’infrastructure
Densification implique haute consommation des racks
Des solutions arrivent (découplage MR/HDFS)
» Logicielle : Yarn, MR+, Intel Hadoop, LSF, SLURM…
» Matérielle : Lustre, RHS,

CRIP – 16/10/2013 16
Conclusion
Le BigData au CNES : première expérience réussie dans un contexte
orienté calcul.
De nouvelles solutions ont émergé, veille technologique cruciale.
Besoins CNES en continuelle évolution : nouveaux projets identifiés à
l’échelle 10Po.
Convergence des P/F pour optimiser les coûts

CRIP – 16/10/2013
Merci pour votre attention

CRIP – 16/10/2013 18
Annexe1 : To cloud or not to cloud ?
Public cloud, open questions
What kind of hardware
quid of Numercial precision (IEE754 compliance) ?
highly optimized codes ?
Data integrity : duplication across multiple sites ?
Data transfer : feasibility and cost (cost model f°(volume+compute+network)
Intercenter network bottleneck (need of solution such as Aspera… or Fedex!)
Data dissemination (high access rate : geoportail model)
Fixed and well controled actual compute and storage demand.

CRIP – 16/10/2013 19
Annexe1 : To cloud or not to cloud ?
Public cloud
Seems suitable for certain kind of workload
Small to medium data re/processing campaign
(large number of independant sequential jobs)
Pay attention to the transfered volume
Difficult for other ones :
Numerical simulation, parallel, higly optimized
Data volume
Very sensitive codes to the numerical precision
CRIP – 16/10/2013 20
Annexe1 : To cloud or not to cloud ?
Some good examples
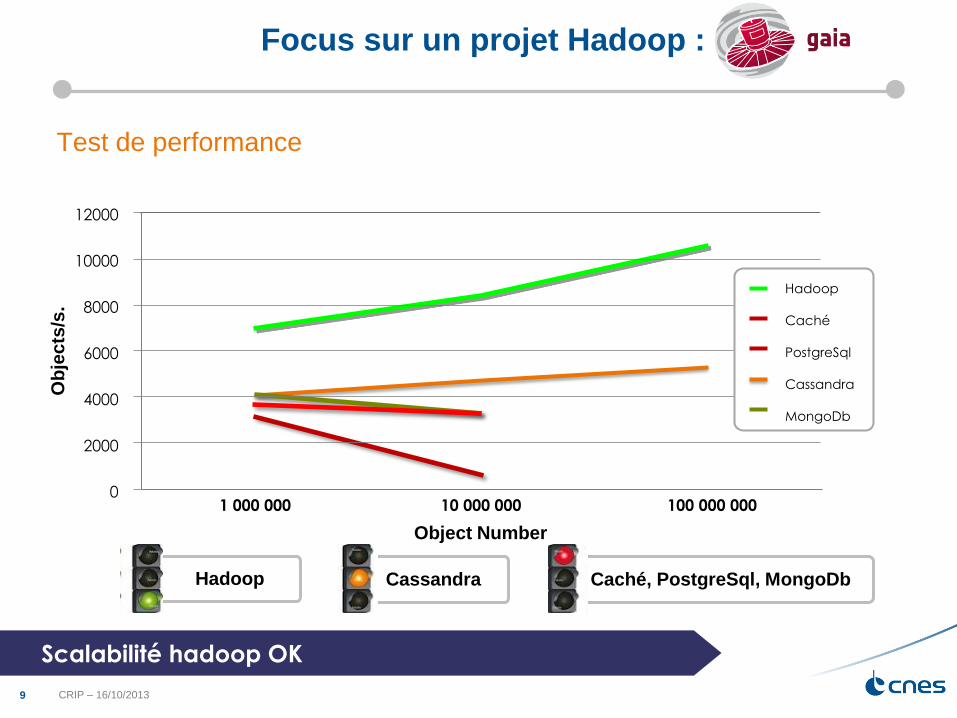
Gaia AGIS peaks (ESA)
Iterative processing – 6 month Data Reduction Cycles
At current estimates AGIS will run 2 weeks every 6 months
Amount of data increases over the 5 year mission
0
500
1000
1500
2000
2500
Hours
Date
AGIS Peak Processing (Hours)
AGIS 6 monthly processing

CRIP – 16/10/2013 21
Annexe1 : To cloud or not to cloud ?
Some good examples
Gaia AGIS peaks (ESA)
Highly distributed usually running on >40 nodes has run on >100 (1400
threads).
Only uses Java no special MPI libraries needed – new languages come
with almost all you need.
Hard part is breaking problem in distributable parts – no language really
helps with that.
Truly portable – can run on laptops desktops, clusters and even Amazon
cloud.

CRIP – 16/10/2013 22
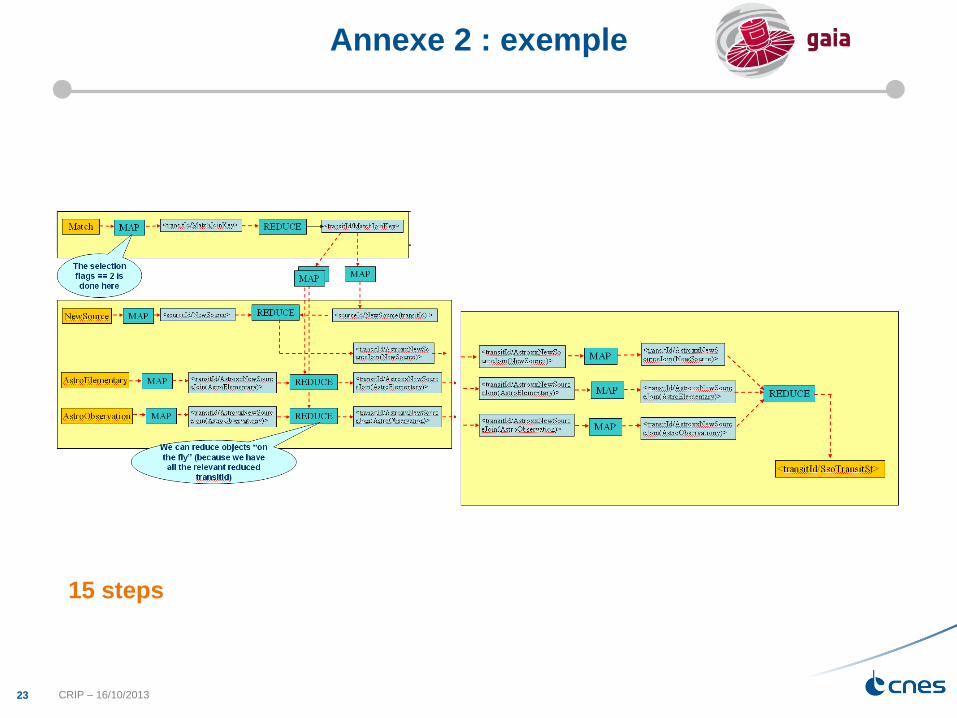
Annexe 2 : exemple
SELECT astroobservation.data as observation,
astroelementary.data as aelementary,
newsource.data as nsource
FROM match
join newsource using (sourceid)
join astroobservation using (transitId)
join astroelementary using (transitid)
WHERE flag =2
CRIP – 16/10/2013 23
Annexe 2 : exemple
15 steps
CRIP – 16/10/2013 24
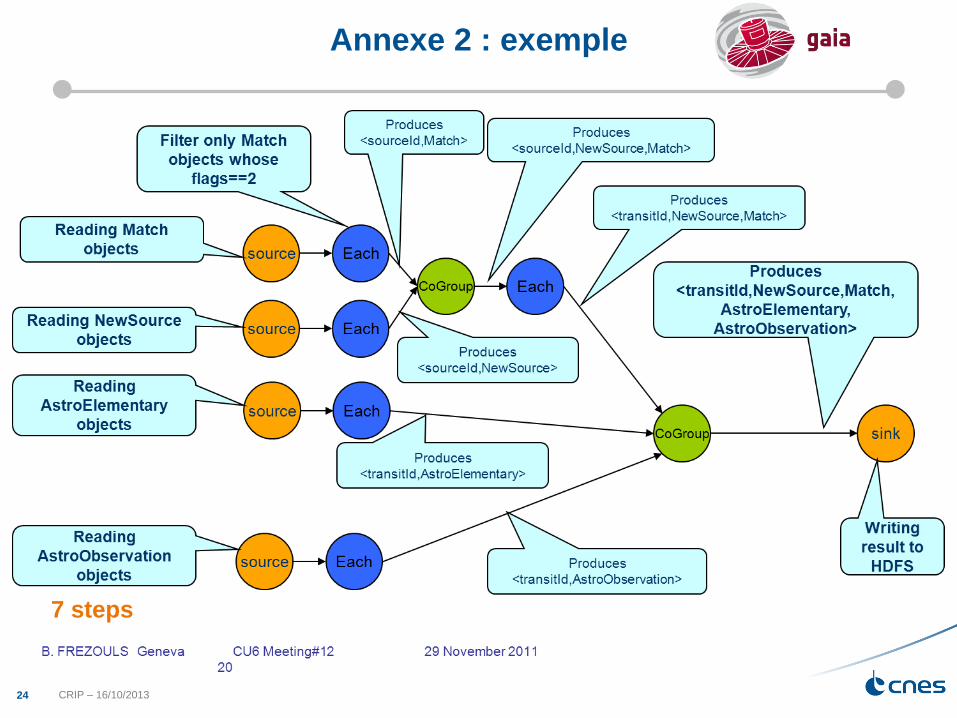
Annexe 2 : exemple
7 steps