Embed Size (px)
Citation preview

© hepia - Tous droits réservés
Métrologie ou l 'ar t de la mesureMétrologie ou l 'ar t de la mesure
Table des matières: 1 Introduction .......................................................................................................................... 2 2 La métrologie... c'est quoi ?[] ............................................................................................... 2
2.1 Qu'est-ce que la métrologie ? ..................................................................................... 2 2.2 Qu'est-ce que mesurer ? ............................................................................................ 2 2.3 Qu'est-ce que la traçabilité ? ...................................................................................... 3 2.4 Qu'est-ce qu'une incertitude de mesure ? .................................................................. 3 2.5 Qu'est-ce que l'accréditation ? ................................................................................... 3 2.6 Livres/articles de référence: ....................................................................................... 4 2.7 Importance de l'incertitude ......................................................................................... 4 2.8 Principes de base ....................................................................................................... 7
3 Calcul de l'incertitude .......................................................................................................... 8 3.1 Deux types d'incertitude: type A et type B .................................................................. 8 3.2 Evaluation de l'incertitude ........................................................................................... 8 3.3 Distribution de mesures indépendantes ................................................................... 17 3.4 Détermination d'une incertitude standard combinée ................................................ 20
4 Méthode des moindres carrés ........................................................................................... 26 4.1 Distribution statistique du !-carré (!2) ..................................................................... 26 4.2 Régression linéaire ................................................................................................... 28 4.3 Affinement de données à l'aide d'une fonction quelconque ..................................... 32
Appendice: l'approche Bayesienne ............................................................................................ 41 4.4 Théorème de Bayes ................................................................................................. 42

GT, Version du 22.06.2011 07:38:00 2
1 Introduction L'objectif de ces quelques pages est de donner aux ingénieurs en technologies industrielles de la haute école du paysage, d'ingénierie et d'architecture de Genève des bases de métrologie leur permettant de savoir:
• à quoi cela sert; • comment effectuer une mesure; • comment calculer les incertitudes de type A et déterminer celles de type B; • comment déterminer un budget d'incertitudes; • comment effectuer un affinement d'une fonction z=f(x, y, t, a1, a2, a3,...); • qu'il existe une approche Bayesienne qui permet d'utiliser les connaissances des
probabilités à priori et à posteriori. Ce n'est qu'à force d'utiliser cette science que les futurs ingénieurs acquerront le niveau d'excellence requis par les normes internationales.
2 La métrologie... c'est quoi ?[1] Avant de débuter ce chapitre important pour un ingénieur, il faut se poser les questions:
– qu'est-ce que la métrologie ? A quoi cela sert ? – qu'est-ce que mesurer ? – qu'est-ce que la traçabilité ? – qu'est-ce qu'une incertitude de mesure ? – qu'est-ce que l'accréditation ?
2.1 Qu'est-ce que la métrologie ? La métrologie est la science de la mesure associée à l'évaluation de son incertitude. Le métrologue s'intéresse à la qualité des mesures et en particulier à deux facteurs. Le premier de ces facteurs est de s'assurer du raccordement de la mesure à des étalons de référence. Le deuxième facteur de la qualité de la mesure est celui du calcul de l'incertitude. Pour évaluer les sources d'incertitude de mesure on utilise communément la méthode dite des 5M; soit que le résultat de mesure peut être altéré par:
1. le Moyen, instrument de mesure; 2. le Milieu, l'environnement dans lequel la mesure est faite; 3. la Méthode utilisée; 4. la Matière ou ses propriétés mécaniques; 5. la Main d'œuvre, c'est à dire la personne qui mesure.
2.2 Qu'est-ce que mesurer ? Mesurer, c'est comparer une grandeur physique inconnue avec une grandeur de même nature prise comme référence, à l'aide d'un instrument. C'est exprimer le résultat de cette comparaison à l'aide d'une valeur numérique, associée à une unité qui rappelle la nature de la référence, et assortie d'une incertitude qui dépend à la fois des qualités de l'expérience effectuée et de la connaissance que l'on a de la référence et de ses conditions d'utilisation. Comparer, c'est mettre en oeuvre un principe de mesure physique, développer des capteurs adaptés à la grandeur concernée, concevoir, construire, caractériser l'instrument optimal, traiter enfin le signal délivré par la chaîne de mesure pour en extraire toute l'information disponible, en s'affranchissant autant que faire se peut des fluctuations indésirables, qui généralement constituent ce qu’on appelle le bruit.
1 Tiré du site http://www.metrodiff.org

GT, Version du 22.06.2011 07:38:00 3
2.3 Qu'est-ce que la traçabilité ? Mesurer a aussi pour finalité d'asseoir les résultats de mesure sur des bases reconnues sans équivoque par plusieurs partenaires, que ce soit à des fins scientifiques, commerciales, ou d'expertise légale. Cela nécessite l'existence de références dont les caractéristiques sont clairement établies. Ce peut être la référence de travail d'un établissement ou d'un laboratoire, périodiquement étalonnée, par comparaison (à nouveau !) à une référence d'incertitude plus faible, c'est-à-dire située à un niveau plus élevé dans ce qu'on appelle la hiérarchie d'une chaîne d'étalonnage. Au sein de cette hiérarchie, les comparaisons sont entreprises selon des méthodes et des procédures de plus en plus élaborées et contraignantes. Le stade ultime de la hiérarchie nationale est la matérialisation dite primaire des unités les plus fondamentales permettant d'accéder à la grandeur. Il n'est plus question alors d'étalonnage, mais de mise en pratique de la définition de l'unité. Seules des intercomparaisons effectuées entre des montages indépendants permettent de préciser l'incertitude, on parle alors d'exactitude de réalisation. L'Office Fédéral de Métrologie (METAS2) est en Suisse le garant de la traçabilité des mesures. Ainsi, les « fournisseurs » de résultats de mesure et leurs « clients » ont besoin d’exprimer ces résultats en utilisant des références reconnues sans équivoque par chacun des acteurs et en exprimant de façon scientifiquement convenue l’incertitude associée. Cet ensemble constitue, pour toutes les grandeurs physiques, le langage (universel ?) de la métrologie.
2.4 Qu'est-ce qu'une incertitude de mesure ? Une valeur mesurée n'est donc pas une valeur certaine: elle est issue de résultats présentant une certaine dispersion, et de plus il existe une certaine méconnaissance de la valeur due à divers facteurs comme: doute sur l'étalonnage du système, problèmes de dérive, conditions de mesure, etc. Une fois prises en compte toutes ces causes qui altère la connaissance de la valeur de la mesurande, on appelle incertitude (et pas erreur !) de mesure le paramètre associé au résultat qui caractérise la dispersion des valeurs numériques. En l'absence d’incertitude, il n'est plus possible, plus pertinent, de comparer entre eux des résultats. Comment savoir, sans connaître l'incertitude, si une grandeur a évolué, si tel procédé de mesure conduit au même résultat, ou si la différence éventuellement observée ne tient qu'à des phénomènes aléatoires mal maîtrisés dont l'origine peut être intrinsèquement liée à la grandeur elle-même3 ? Comment, dans des conditions analogues, comparer un résultat à des valeurs de référence spécifiées par exemple dans une norme, un autre texte réglementaire, un contrat, et donc garantir la conformité du produit ou du système ainsi caractérisé ?
2.5 Qu'est-ce que l'accréditation ? Aujourd'hui, il y a de plus en plus de produits sur le marché. De ce fait, les besoins de protection des consommateurs sont de plus en plus importants. Cette protection est assurée en partie par la certification, l'inspection et les tests réalisés sur les produits et leur mise en oeuvre sous assurance qualité. Les consommateurs ne pouvant pas tester eux-mêmes la qualité, ni la mise en oeuvre des produits qu'ils consomment, ce sont des organismes agrées qui s'en chargent à leur place. Pour qu'un organisme puisse certifier un produit et sa mise en oeuvre, il doit au préalable être accrédité. Les organismes certificateurs de produits sont en général différents de ceux des systèmes d'assurance de la qualité. Ce sont des métiers différents. La certification de produits est importante pour un fabricant de biens de consommation, et la certification de système d'assurance de la qualité est importante pour un sous-traitant.
2 http://www.metas.ch 3 par exemple la mesure d'un comptage radioactif.
GT, Version du 22.06.2011 07:38:00 4
2.6 Livres/articles de référence: Le guide de référence actuel est:
– Guide to the expression of uncertainty in measurement, 1995, International Organization for Standardization, Case postale 56, 1211 Genève 20, Switzerland, ISBN: 92-67-10188-9.
Par la suite nous nous référencierons à ce guide sous le terme GUM. Mais on peut en trouver d'autres, édités par des offices nationaux, et qui sont même disponibles sur internet comme:
– UKAS-M3003: The Expression of Uncertainty and Confidence in Measurement,
United Kingdom Accreditation Service, December 1997, http://www.ukas.com/Library/downloads/publications/M3003 complete.pdf
– NPL-GPG-49: The Assessment of Uncertainty in Radiological Calibration and Testing, National Physical Laboratory, U.K. http://www.npl.co.uk/npl/publications/good_practice/
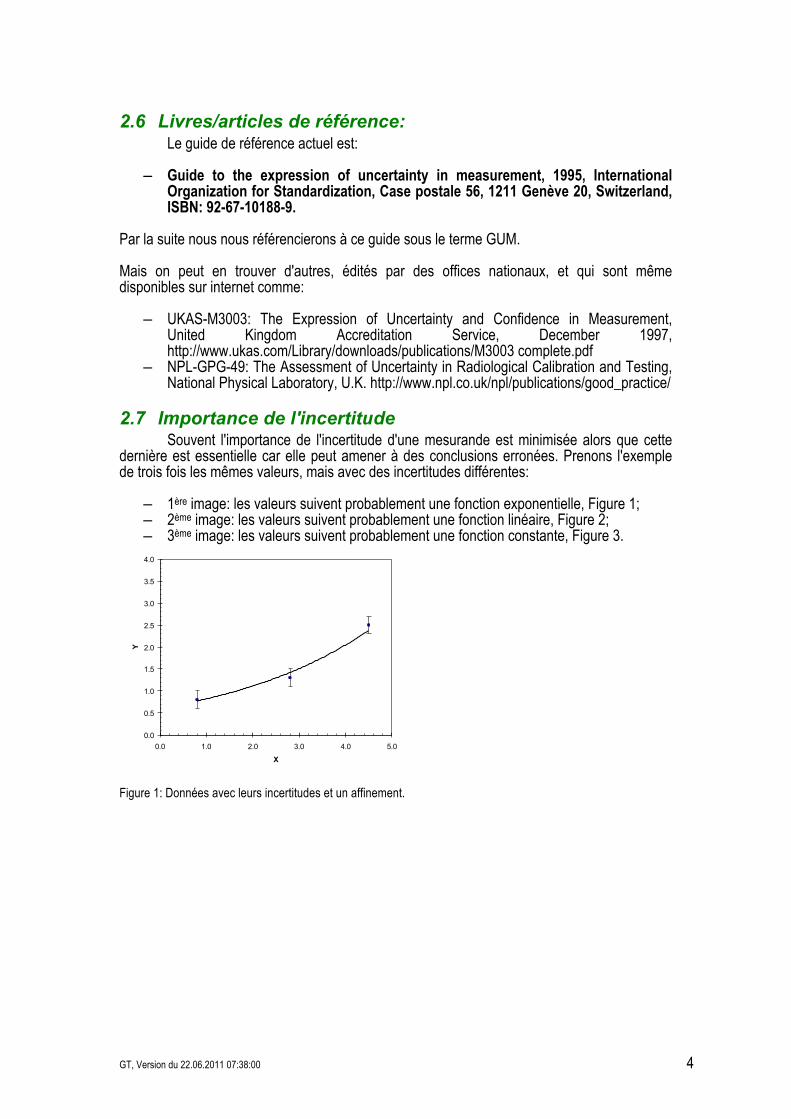
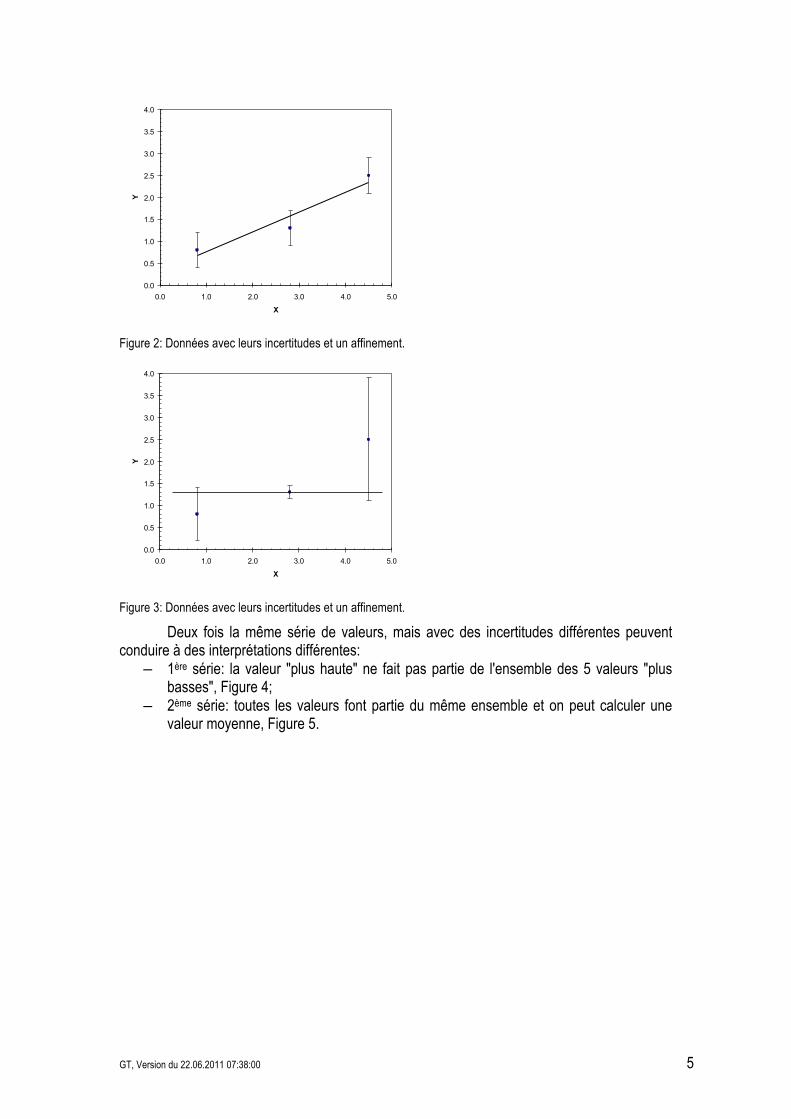
2.7 Importance de l'incertitude Souvent l'importance de l'incertitude d'une mesurande est minimisée alors que cette dernière est essentielle car elle peut amener à des conclusions erronées. Prenons l'exemple de trois fois les mêmes valeurs, mais avec des incertitudes différentes:
– 1ère image: les valeurs suivent probablement une fonction exponentielle, Figure 1; – 2ème image: les valeurs suivent probablement une fonction linéaire, Figure 2; – 3ème image: les valeurs suivent probablement une fonction constante, Figure 3.
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
0.0 1.0 2.0 3.0 4.0 5.0
X
Y
Figure 1: Données avec leurs incertitudes et un affinement.
GT, Version du 22.06.2011 07:38:00 5
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
0.0 1.0 2.0 3.0 4.0 5.0
X
Y
Figure 2: Données avec leurs incertitudes et un affinement.
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
0.0 1.0 2.0 3.0 4.0 5.0
X
Y
Figure 3: Données avec leurs incertitudes et un affinement.
Deux fois la même série de valeurs, mais avec des incertitudes différentes peuvent conduire à des interprétations différentes:
– 1ère série: la valeur "plus haute" ne fait pas partie de l'ensemble des 5 valeurs "plus basses", Figure 4;
– 2ème série: toutes les valeurs font partie du même ensemble et on peut calculer une valeur moyenne, Figure 5.
GT, Version du 22.06.2011 07:38:00 6
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
5.5
6.0
0.0 1.0 2.0 3.0 4.0 5.0 6.0 7.0 8.0
X
Y?
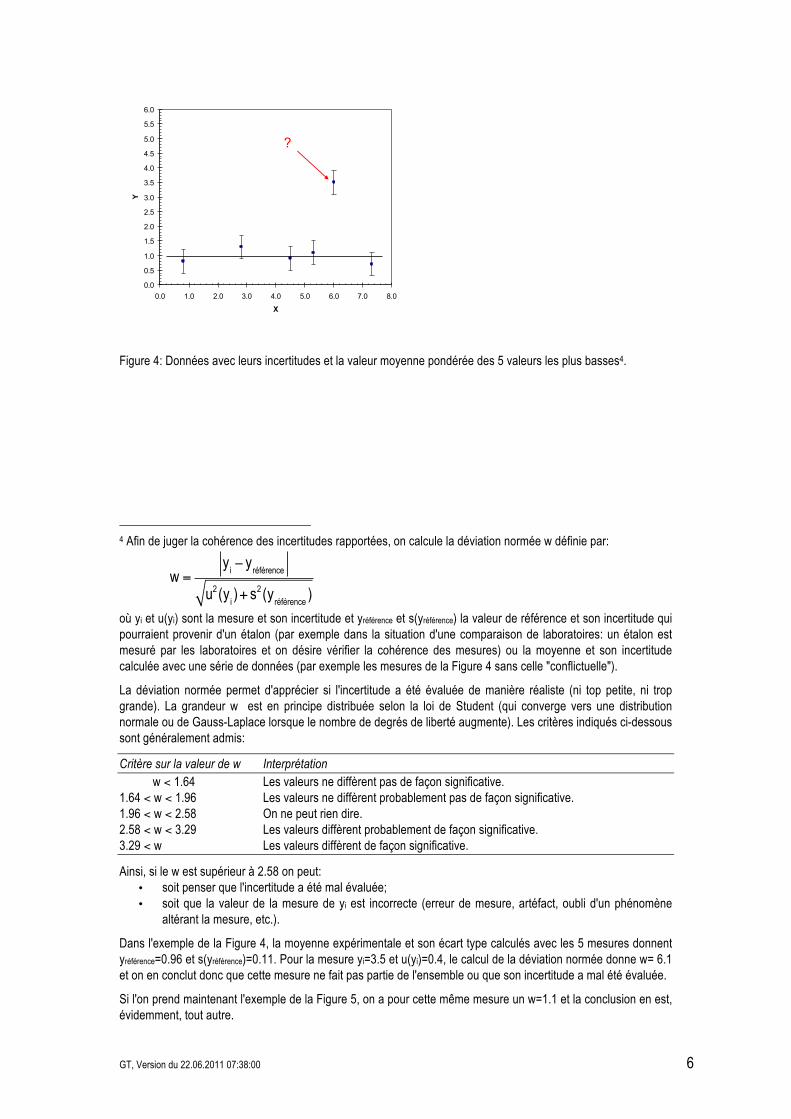
Figure 4: Données avec leurs incertitudes et la valeur moyenne pondérée des 5 valeurs les plus basses4.
4 Afin de juger la cohérence des incertitudes rapportées, on calcule la déviation normée w définie par:
w =y
i! y
référence
u2(yi)+ s2(y
référence)
où yi et u(yi) sont la mesure et son incertitude et yréférence et s(yréférence) la valeur de référence et son incertitude qui pourraient provenir d'un étalon (par exemple dans la situation d'une comparaison de laboratoires: un étalon est mesuré par les laboratoires et on désire vérifier la cohérence des mesures) ou la moyenne et son incertitude calculée avec une série de données (par exemple les mesures de la Figure 4 sans celle "conflictuelle"). La déviation normée permet d'apprécier si l'incertitude a été évaluée de manière réaliste (ni top petite, ni trop grande). La grandeur w est en principe distribuée selon la loi de Student (qui converge vers une distribution normale ou de Gauss-Laplace lorsque le nombre de degrés de liberté augmente). Les critères indiqués ci-dessous sont généralement admis: Critère sur la valeur de w Interprétation w < 1.64 Les valeurs ne diffèrent pas de façon significative. 1.64 < w < 1.96 Les valeurs ne diffèrent probablement pas de façon significative. 1.96 < w < 2.58 On ne peut rien dire. 2.58 < w < 3.29 Les valeurs diffèrent probablement de façon significative. 3.29 < w Les valeurs diffèrent de façon significative. Ainsi, si le w est supérieur à 2.58 on peut:
• soit penser que l'incertitude a été mal évaluée; • soit que la valeur de la mesure de yi est incorrecte (erreur de mesure, artéfact, oubli d'un phénomène
altérant la mesure, etc.). Dans l'exemple de la Figure 4, la moyenne expérimentale et son écart type calculés avec les 5 mesures donnent yréférence=0.96 et s(yréférence)=0.11. Pour la mesure yi=3.5 et u(yi)=0.4, le calcul de la déviation normée donne w= 6.1 et on en conclut donc que cette mesure ne fait pas partie de l'ensemble ou que son incertitude a mal été évaluée. Si l'on prend maintenant l'exemple de la Figure 5, on a pour cette même mesure un w=1.1 et la conclusion en est, évidemment, tout autre.

GT, Version du 22.06.2011 07:38:00 7
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
5.5
6.0
0.0 1.0 2.0 3.0 4.0 5.0 6.0 7.0 8.0
X
Y
Figure 5: Données avec leurs incertitudes et la valeur moyenne pondérée.
2.8 Principes de base Lorsque l'on effectue une mesure c'est pour déterminer une valeur numérique Y d'une mesurande physique. Le résultat obtenu y n'est qu'une estimation de la vraie valeur de la mesurande et de ce fait doit être accompagnée d'une incertitude. Les principes de base sont:
1) utiliser le terme "incertitude" à la place d'"erreur"; 2) pas de résultat sans donner l'incertitude: x ± s(x). En effet, des mesures ne peuvent
être comparées sans avoir d'information sur leur "qualité"; 3) arrondir intelligemment: 28.73 ± 3.88 29 ± 4; 4) pas d'indication de l'incertitude sans donner l'intervalle de confiance soit:
– k=1 ou 1 " un intervalle de confiance de 68.3 %; – k=2 ou 2 " un intervalle de confiance de 95.5 %; – k=3 ou 3 " un intervalle de confiance de 99.7 %;
5) pas d'indication de l'incertitude sans expliquer ce qu'elle veut dire: a. incertitude de comptage et du bruit de fond; b. incertitude d'échantillonnage et préparation de l'échantillon; c. les autres composantes de l'incertitude comme eg.:
– calibration et standards certifiés utilisés; – correction de désintégration; – correction d'autoabsorption et de sommation; – de données nucléaires utilisées; – du programme de calcul pour l'évaluation du spectre; – etc.;
6) la méthode de détermination de l'incertitude doit être universelle et applicable pour tout types de mesures, consistante dans le sens où elle est indépendante des divers groupements des composants qui la constitue et transférable dans le sens où elle peut être directement utilisée comme un composant permettant d'évaluer l'incertitude d'une autre mesure.
7) afin de simplifier l'utilisation de données provenant de différents pays, on utilise le Système International (SI) d'unités;
Pour de plus amples informations, cf le GUM.

GT, Version du 22.06.2011 07:38:00 8
3 Calcul de l'incertitude
3.1 Deux types d'incertitude: type A et type B Selon les recommandations INC-1 (1980), l'incertitude d'une mesure provient de la composition de plusieurs composants qui peuvent être groupés selon deux catégories:
• Type A: incertitudes évaluées selon des méthodes statistiques; • Type B: incertitudes évaluées selon d'autres méthodes.
Les composants i de la composante A sont caractérisés par des variances estimées si2 (où l'écart-type estimé si) et un nombre de degrés de liberté #i. Les composants de la composante B doivent être caractérisés par des quantités ui2 qui peuvent être considérées comme des approximations des variances correspondantes. Les quantités ui2 sont traitées comme des variances et les ui comme les écarts types. L'incertitude combinée est obtenue par une combinaison des variances. L'incertitude finale donnée doit être l'incertitude combinée multipliée par un facteur k entier de sorte à ce que l'intervalle de confiance soit bien indiqué. La valeur du facteur k, appelé facteur d'élargissement, doit toujours être indiquée avec le résultat final[5]. Exemple: m = 25.17 (6) g où m = 25.17 et s(m)=0.06 g où m = (25.17 ± 0.06) g La valeur mesurée m et l'incertitude s(m) qui lui correspond définissent le domaine dans lequel se situe la valeur de la masse avec une probabilité d'environ 95%. Cette incertitude a été estimée conformément aux recommandations internationales (GUM), c'est-à-dire par combinaison quadratique des contributions à l'incertitude et en utilisant un facteur d'élargissement k=2. Remarque: l'incertitude pour un facteur d'élargissement k=1 est équivalente à l'écart type.
3.2 Evaluation de l'incertitude
3.2.1 Modélisation d'une mesure physique En général on désire évaluer une grandeur physique Y, ou mesurande Y, qui est obtenue via la mesure d'autres grandeurs X1, X2, ... selon une relation:
Eq. 1 ,...)X,X(fY 21=
Par exemple la température T déterminée par la mesure de la résistance d'un thermomètre en platine; c'est-à-dire par la mesure de U/i où U et i sont la tension aux bornes du thermomètre et i le courant qui le traverse. Notons que les Xi sont les inputs de la mesurande Y mais sont eux aussi des mesurandes. Ainsi, l'estimation de la mesurande Y, dotée y, est obtenue par la mesure des estimations des mesurandes Xi notées xi.
5 Les recommandations internationales sont de donner l'incertitude pour un facteur d'élargissement k=2.
GT, Version du 22.06.2011 07:38:00 9
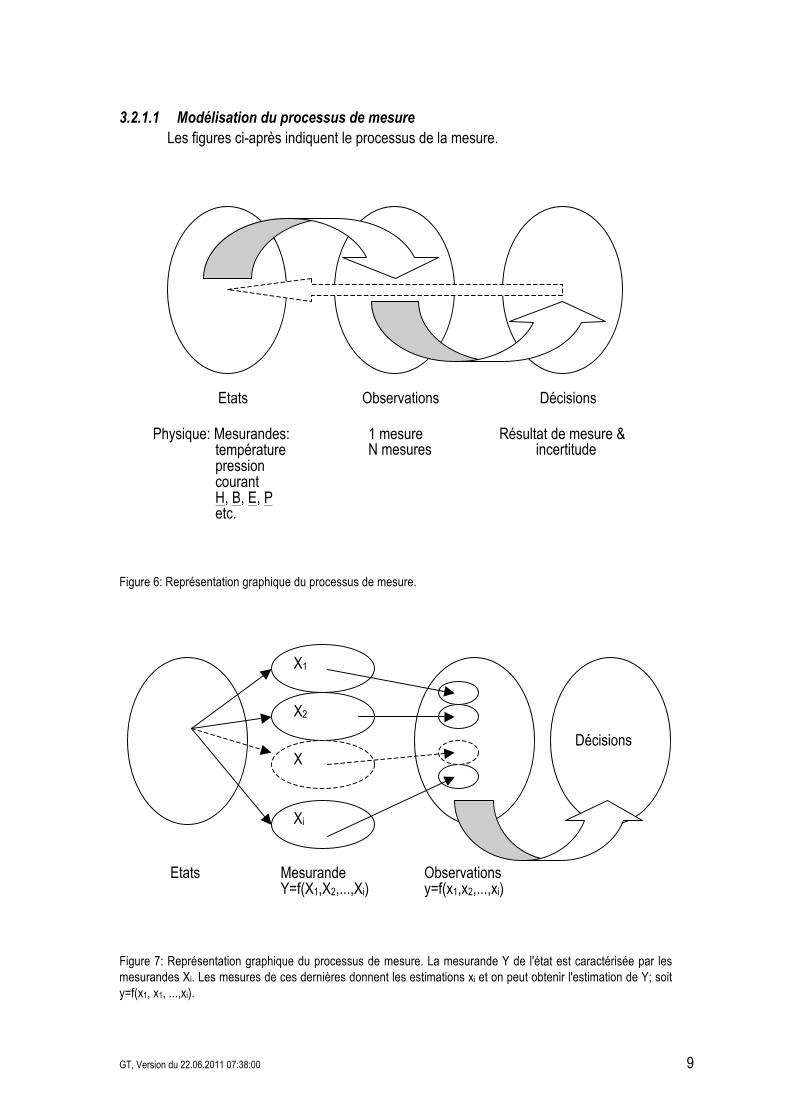
3.2.1.1 Modélisation du processus de mesure Les figures ci-après indiquent le processus de la mesure.
Figure 6: Représentation graphique du processus de mesure.
Figure 7: Représentation graphique du processus de mesure. La mesurande Y de l'état est caractérisée par les mesurandes Xi. Les mesures de ces dernières donnent les estimations xi et on peut obtenir l'estimation de Y; soit y=f(x1, x1, ...,xi).
Mesurande Y=f(X1,X2,...,Xi)
Etats
X1
X2
Xi
X
Observations y=f(x1,x2,...,xi)
Décisions
Etats Observations Décisions
Physique: Mesurandes: température pression courant H, B, E, P etc.
1 mesure M mesures 1 mesure N mesures
Résultat de mesure & incertitude

GT, Version du 22.06.2011 07:38:00 10
3.2.1.2 Evaluation de l'incertitude de type A En général, lorsque l'on effectue une mesure, on effectue plusieurs fois l'expérience. Ce fait de répéter l'expérience permet d'obtenir un ensemble de données qui nous permet de mieux apprécier les mesurandes que l'on cherche à déterminer.
3.2.1.2.1 Estimation de la valeur moyenne expérimentale Dans le cas où l'on a à disposition une série de mesures, on peut estimer la valeur
moyenne expérimentale qexp:
Eq. 2 N
q
q
N
1jj
exp
!==
où les qj ont tous le même poids. Si ce n'est pas le cas, on calcule la moyenne pondérée qui est donnée par:
Eq. 3
!
!
=
== N
1j j2
N
1j j2
j
exp
)q(u1
)q(u
q
q
où les u2(qj) sont les variances des données qj. Remarque: si les variables ne sont pas discrètes on calcule la moyenne (ou espérance mathématique de la variable) via la connaissance de la distribution de probabilité[6]. Pour un nombre de mesure N grand on a qexp $q; q étant la valeur de la mesurande q. C'est-à-dire que la moyenne expérimentale tend vers q si N tend vers l'infini.
qexp est le meilleur estimateur statistique de l'état car son espérance mathématique E(qexp)=q.
De plus comme nous le verrons, s(qexp) est le plus petit écart type de tous
les estimateurs ayant q comme espérance; s(qexp)=%/N1/2.
3.2.1.2.2 Estimation de la variance expérimentale On peut ensuite calculer la variance[7] expérimentale comme (tous les qj ont le même poids): 6 Soit g(x) une fonction de la variable aléatoire x avec une densité de probabilité f(x), on appelle "espérance de g(x)" le nombre:
!"
= dx)x(f)x(g)g(E
La moyenne est simplement l'espérance mathématique de la variable elle-même, nous avons:
µ>==<= !+"
"#
xdx )x(f x)x(E
7 La variance de la variable x est l'espérance mathématique de la fonction:
(x & µ)2 = [x & E(x)]2 que l'on représente de la façon suivante:
V(x)= %2 = E([x & E(x)]2) La variance est donc par définition la moyenne des carrés des écarts. On appelle la déviation standard % ou écart type la racine carrée de la variance.

GT, Version du 22.06.2011 07:38:00 11
Eq. 4 )1N( N
qq N
comme aussiécrit s' qui )1N(
)qq(
)(qs)q(V
2N
1jj
N
1j
2j
N
1j
2
expj
exp2
exp !
""#
$%%&
'!
=!
!
==(((===
où s(qexp) est l'écart type standard expérimental qui tend vers une valeur constante non nulle si N tend vers l'infini. Il représente la fluctuation expérimentale des valeurs mesurées. Remarque: la somme des déviations au carré (qj&qexp)2 se divise par N&1 et non N car le nombre de degré de liberté est diminué de 1 du fait que le nombre de mesure N est contenu dans le calcul de qexp. Les mesures qj fluctuent donc autour de la valeur moyenne q dont on a qu'une estimation par la valeur de qexp.
s(qexp) est un estimateur statistique de l'état type % qui est "mauvais" lorsque N est petit[8].
3.2.1.2.3 Estimation de la variance de la moyenne expérimentale La meilleure estimation de la variance de la moyenne expérimentale est donnée par:
Eq. 5 N
)q(s )q(s)q(V exp
2
exp
2
exp==
Ainsi on a l'écart type standard de la moyenne expérimentale 0 )q(sN
exp !"!
en N&1/2.
La valeur d'une mesurande X peut être obtenue aussi précisément que l'on veut car il suffit de prendre le nombre de mesure adéquat. Si les qj n'ont pas le même poids, on calcule alors la variance de la moyenne expérimentale pondérée comme:
Eq. 6
)q(u1
1 )q(s)q(V N
1j j2
exp
2
exp
!=
==
3.2.1.2.4 Incertitude sur l'incertitude de la moyenne expérimentale Il semble un peut bizarre de parler de l'incertitude sur l'incertitude de la moyenne expérimentale mais cette question prend tout son sens lorsque le nombre de mesures est petit. En effet, dans ce cas, l'écart type expérimental peut être mal estimé. De fait, on devrait calculer les incertitudes selon une approche Bayesienne (Thomas Bayes (1702-1761) découvrit le théorème qui porte son nom; utilisé par Laplace, il sera ensuite très utilisé par les statisticiens). Nous n'allons pas entrer dans ce cours sur cette théorie mais sachons que la correction à apporter à l'incertitude de la moyenne expérimentale est:
Eq. 7 )q(s 3N
1N)q(u
expexpBayesienne .Corr !
!=
qui vaut 1.73 pour N=4, 1.41 pour N=5, 1.29 pour N=6, ..., 1.13 pour N=10. Ce qu'il faut retenir de cela est qu'il faut effectuer cette correction Bayesienne, voir référence[9]. Pour bien estimer la variance expérimentale il faut effectuer au moins une
dizaine de mesures. 8 Le nombre de mesures N doit être suffisamment grand pour pouvoir estimer V(qexp); typiquement supérieur à 10. 9 R. Kacker & A. Jones, Metrologia 40 (2003) 235.
GT, Version du 22.06.2011 07:38:00 12
Pour plus de détail à ce sujet, cf appendice en fin du document.
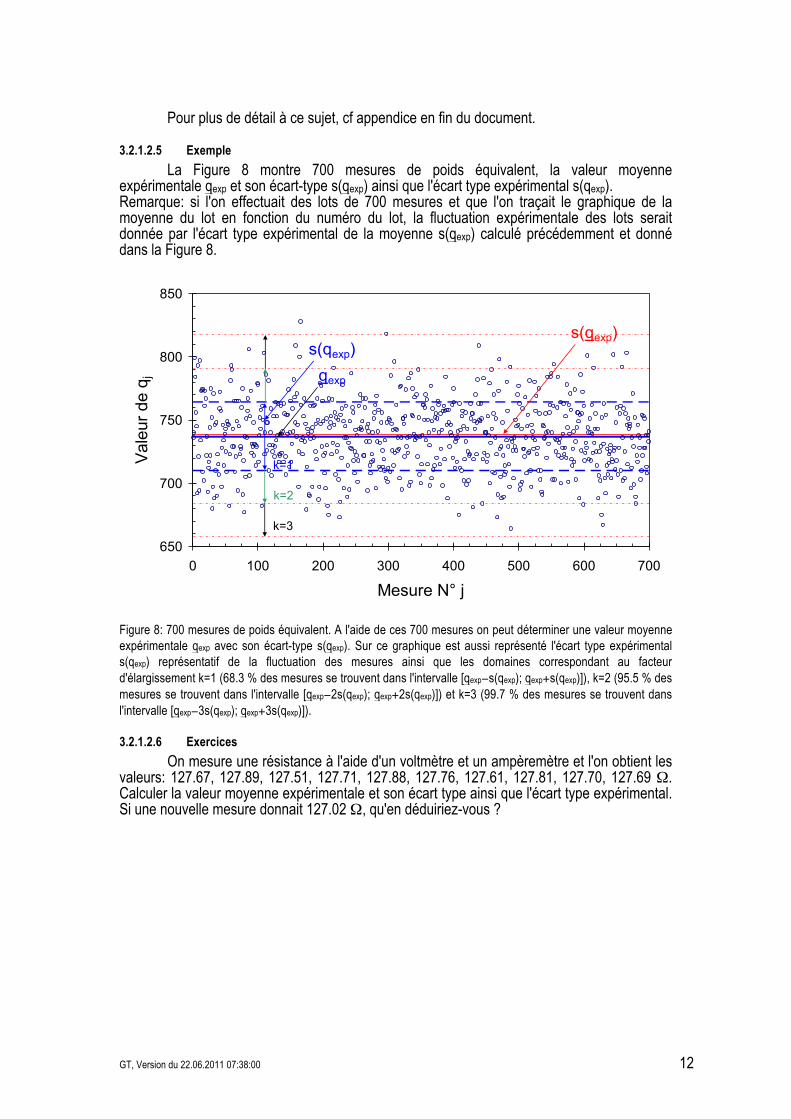
3.2.1.2.5 Exemple La Figure 8 montre 700 mesures de poids équivalent, la valeur moyenne expérimentale qexp et son écart-type s(qexp) ainsi que l'écart type expérimental s(qexp). Remarque: si l'on effectuait des lots de 700 mesures et que l'on traçait le graphique de la moyenne du lot en fonction du numéro du lot, la fluctuation expérimentale des lots serait donnée par l'écart type expérimental de la moyenne s(qexp) calculé précédemment et donné dans la Figure 8.
650
700
750
800
850
0 100 200 300 400 500 600 700
Mesure N° j
Val
eur d
e q j
k=1
k=2
k=3
qexp
s(qexp)s(qexp)
Figure 8: 700 mesures de poids équivalent. A l'aide de ces 700 mesures on peut déterminer une valeur moyenne expérimentale qexp avec son écart-type s(qexp). Sur ce graphique est aussi représenté l'écart type expérimental s(qexp) représentatif de la fluctuation des mesures ainsi que les domaines correspondant au facteur d'élargissement k=1 (68.3 % des mesures se trouvent dans l'intervalle [qexp&s(qexp); qexp+s(qexp)]), k=2 (95.5 % des mesures se trouvent dans l'intervalle [qexp&2s(qexp); qexp+2s(qexp)]) et k=3 (99.7 % des mesures se trouvent dans l'intervalle [qexp&3s(qexp); qexp+3s(qexp)]).
3.2.1.2.6 Exercices On mesure une résistance à l'aide d'un voltmètre et un ampèremètre et l'on obtient les valeurs: 127.67, 127.89, 127.51, 127.71, 127.88, 127.76, 127.61, 127.81, 127.70, 127.69 '. Calculer la valeur moyenne expérimentale et son écart type ainsi que l'écart type expérimental. Si une nouvelle mesure donnait 127.02 ', qu'en déduiriez-vous ?
GT, Version du 22.06.2011 07:38:00 13
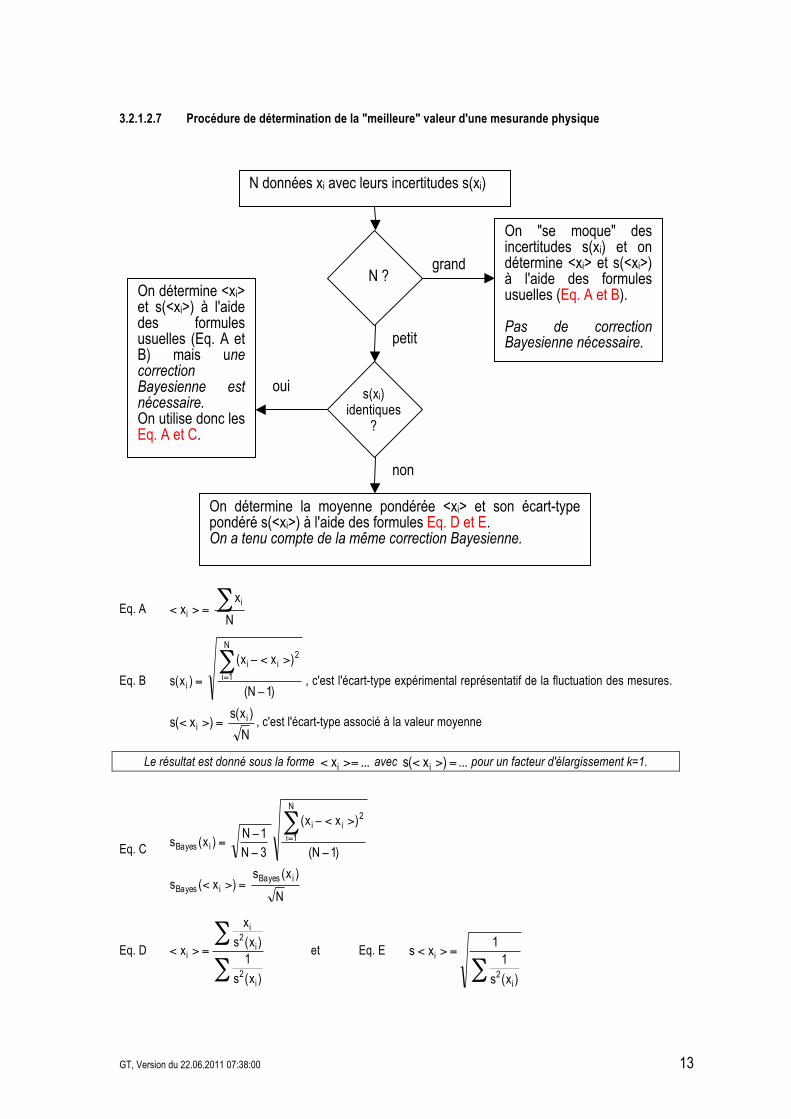
3.2.1.2.7 Procédure de détermination de la "meilleure" valeur d'une mesurande physique
Eq. A N
x x
ii
!=><
Eq. B )1N(
)xx(
)x(s
N
1i
2ii
i !
><!
="= , c'est l'écart-type expérimental représentatif de la fluctuation des mesures.
N
)x(s )x(s i
i =>< , c'est l'écart-type associé à la valeur moyenne
Le résultat est donné sous la forme ...xi >=< avec ... )x(s i =>< pour un facteur d'élargissement k=1.
Eq. C
N
)x(s )x(s
)1N(
)xx(
3N
1N )x(s
iBayesiBayes
N
1i
2ii
iBayes
=><
!
><!
!
!=
"=
Eq. D
!
!=><
)x(s
1)x(s
x
x
i2
i2
i
i et Eq. E
)x(s
11
xs
i2
i
!=><
On "se moque" des incertitudes s(xi) et on détermine <xi> et s(<xi>) à l'aide des formules usuelles (Eq. A et B). Pas de correction Bayesienne nécessaire.
N ? grand
petit
N données xi avec leurs incertitudes s(xi)
On détermine <xi> et s(<xi>) à l'aide des formules usuelles (Eq. A et B) mais une correction Bayesienne est nécessaire. On utilise donc les Eq. A et C.
s(xi) identiques
?
oui
non
On détermine la moyenne pondérée <xi> et son écart-type pondéré s(<xi>) à l'aide des formules Eq. D et E. On a tenu compte de la même correction Bayesienne.

GT, Version du 22.06.2011 07:38:00 14
3.2.1.3 Evaluation de l'incertitude de type B L'estimation de u(q) ne peut pas s'obtenir par une répétition des mesures mais à l'aide d'un jugement scientifique basé sur des toutes les informations disponibles comme par exemple:
• des expériences précédentes; • des données provenant des modes d'emploi des fabricants; • des données obtenues de calibrations et/ou certificats; • des incertitudes sur des données provenant de la littérature; • etc.
Rappel: nous avions vu que l'écart-type s(x) représentait l'intervalle autour de la valeur x (x ± s(x)) où il y a 68.3% de chance que la valeur vraie de la mesurande se trouve. Si l'on donnait l'intervalle pour des facteurs d'élargissement autre que k=1 on avait des intervalles de confiance:
– k=2 ou 2 " un intervalle de confiance de 95.5 %; – k=3 ou 3 " un intervalle de confiance de 99.7 %.
On peut aussi calculer k pour un pourcentage défini et on a:
– pour un intervalle de confiance de 50 % " k=0.676 ou 0.676 ; – pour un intervalle de confiance de 67 % " k=0.977 ou 0.967 ; – pour un intervalle de confiance de 90 % " k=1.645 ou 1.645 ; – pour un intervalle de confiance de 95 % " k=1.960 ou 1.960 ; – pour un intervalle de confiance de 99 % " k=2.576 ou 2.576 .
Ce qui est plus pratique lorsque l'on désire déterminer une incertitude de type B.
3.2.1.3.1 Estimation d'une mesurande - certificat de calibration d'un appareillage Supposons que l'on mesure une tension avec un voltmètre ayant un certificat de calibration indiquant une précision de 10 µV avec un intervalle de confiance de 99%. Alors l'incertitude sur la mesure est de u(U) = 10/2.576 µV =3.9 µV.
3.2.1.3.2 Estimation d'une mesurande - 50-50 Supposons qu'avec les informations se trouvant à notre disposition que:
• il y ait 50% de chance pour que la valeur d'une mesurande se trouve dans l'intervalle entre a& et a+.
Il est alors raisonnable de donner pour valeur de la meilleure estimation de la mesurande (a++a&)/2 et comme écart-type u = [(a+&a&)/2]/0.676.
3.2.1.3.3 Estimation d'une mesurande - 2 sur 3 Supposons qu'avec les informations se trouvant à notre disposition que:
• il y ait 2 chances sur 3 (67%, soit quasiment un facteur d'élargissement k=1) pour que la valeur d'une mesurande se trouve dans l'intervalle entre a& et a+;
Il est alors raisonnable de donner pour valeur de la meilleure estimation de la mesurande (a++a&)/2 et comme écart-type u = [( a+&a&)/2]/0.967 ( [( a+&a&)/2].
3.2.1.3.4 Estimation d'une mesurande - intervalle absolu - probabilité à priori constante Supposons qu'avec les informations se trouvant à notre disposition que:
• la probabilité que la valeur de la mesurande se trouve dans l'intervalle entre a& et a+ soit essentiellement de 100%;
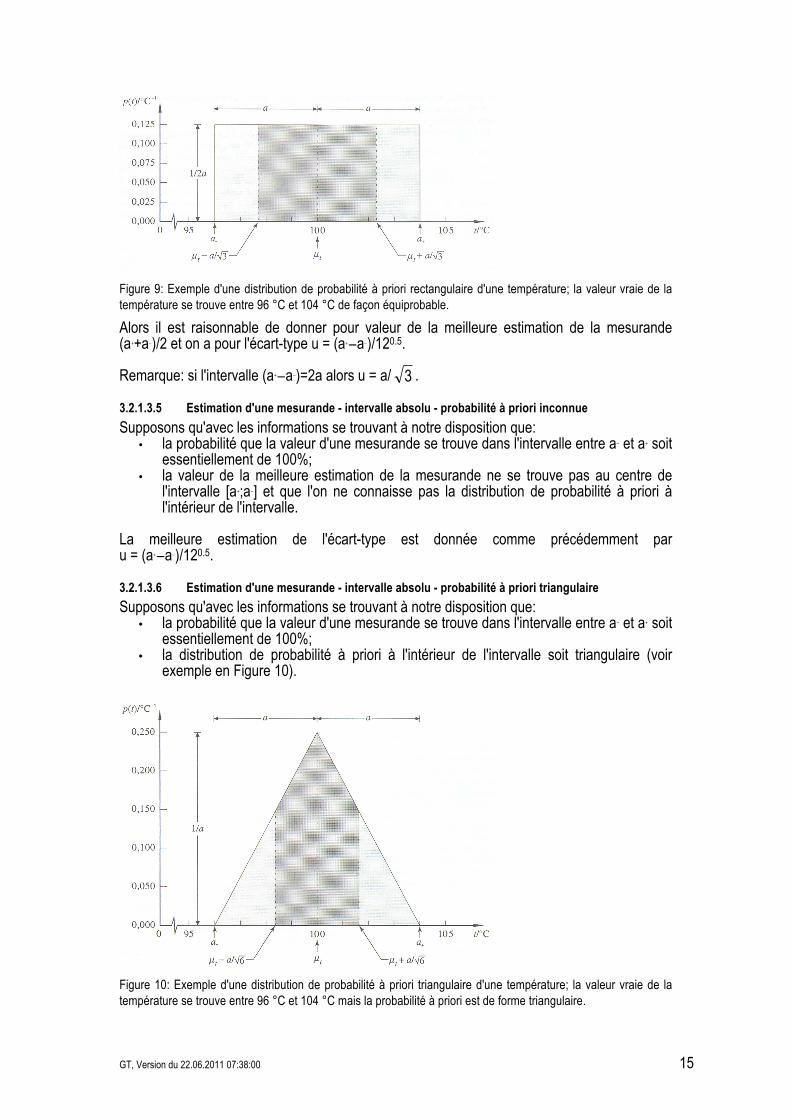
• la distribution de probabilité à priori à l'intérieur de l'intervalle soit constante (voir exemple en Figure 9).
GT, Version du 22.06.2011 07:38:00 15
Figure 9: Exemple d'une distribution de probabilité à priori rectangulaire d'une température; la valeur vraie de la température se trouve entre 96 °C et 104 °C de façon équiprobable.
Alors il est raisonnable de donner pour valeur de la meilleure estimation de la mesurande (a++a&)/2 et on a pour l'écart-type u = (a+&a&)/120.5. Remarque: si l'intervalle (a+&a&)=2a alors u = a/ 3 .
3.2.1.3.5 Estimation d'une mesurande - intervalle absolu - probabilité à priori inconnue Supposons qu'avec les informations se trouvant à notre disposition que:
• la probabilité que la valeur d'une mesurande se trouve dans l'intervalle entre a& et a+ soit essentiellement de 100%;
• la valeur de la meilleure estimation de la mesurande ne se trouve pas au centre de l'intervalle [a+;a&] et que l'on ne connaisse pas la distribution de probabilité à priori à l'intérieur de l'intervalle.
La meilleure estimation de l'écart-type est donnée comme précédemment par u = (a+&a&)/120.5.
3.2.1.3.6 Estimation d'une mesurande - intervalle absolu - probabilité à priori triangulaire Supposons qu'avec les informations se trouvant à notre disposition que:
• la probabilité que la valeur d'une mesurande se trouve dans l'intervalle entre a& et a+ soit essentiellement de 100%;
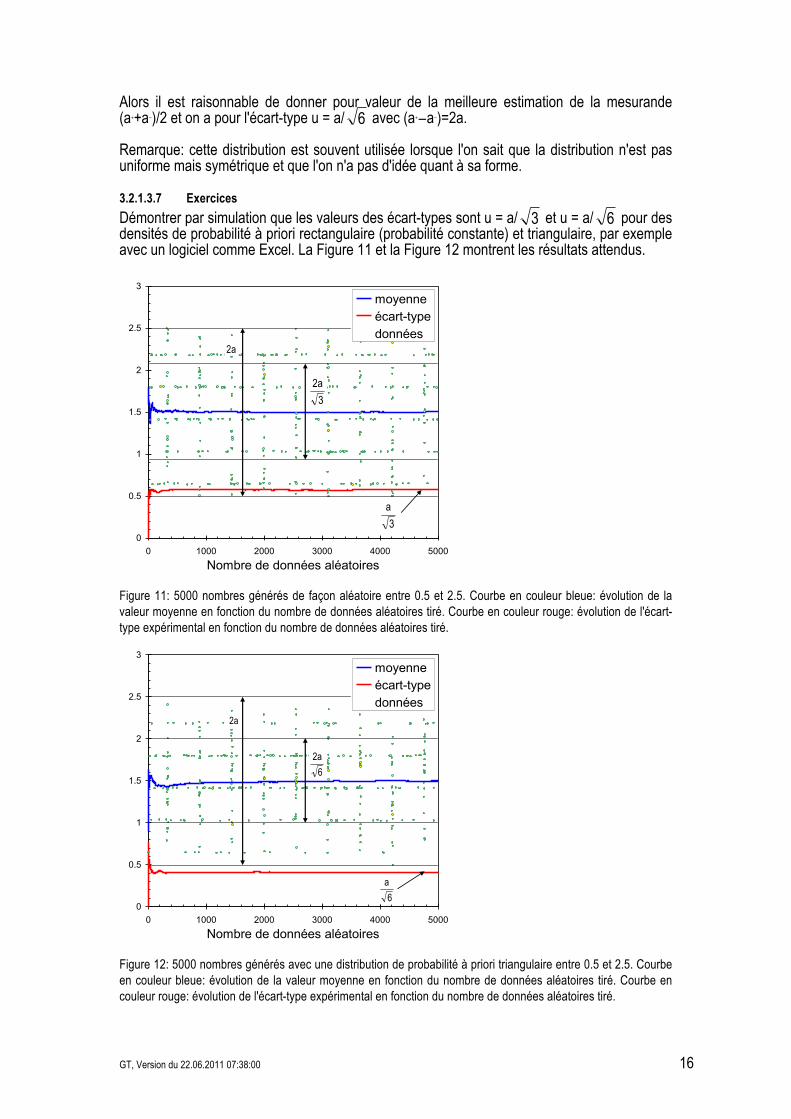
• la distribution de probabilité à priori à l'intérieur de l'intervalle soit triangulaire (voir exemple en Figure 10).
Figure 10: Exemple d'une distribution de probabilité à priori triangulaire d'une température; la valeur vraie de la température se trouve entre 96 °C et 104 °C mais la probabilité à priori est de forme triangulaire.
GT, Version du 22.06.2011 07:38:00 16
Alors il est raisonnable de donner pour valeur de la meilleure estimation de la mesurande (a++a&)/2 et on a pour l'écart-type u = a/ 6 avec (a+&a&)=2a. Remarque: cette distribution est souvent utilisée lorsque l'on sait que la distribution n'est pas uniforme mais symétrique et que l'on n'a pas d'idée quant à sa forme.
3.2.1.3.7 Exercices Démontrer par simulation que les valeurs des écart-types sont u = a/ 3 et u = a/ 6 pour des densités de probabilité à priori rectangulaire (probabilité constante) et triangulaire, par exemple avec un logiciel comme Excel. La Figure 11 et la Figure 12 montrent les résultats attendus.
0
0.5
1
1.5
2
2.5
3
0 1000 2000 3000 4000 5000
Nombre de données aléatoires
moyenneécart-typedonnées
a2
3
a2
3
a
Figure 11: 5000 nombres générés de façon aléatoire entre 0.5 et 2.5. Courbe en couleur bleue: évolution de la valeur moyenne en fonction du nombre de données aléatoires tiré. Courbe en couleur rouge: évolution de l'écart-type expérimental en fonction du nombre de données aléatoires tiré.
0
0.5
1
1.5
2
2.5
3
0 1000 2000 3000 4000 5000
Nombre de données aléatoires
moyenneécart-typedonnées
6
a
6
a2
a2
Figure 12: 5000 nombres générés avec une distribution de probabilité à priori triangulaire entre 0.5 et 2.5. Courbe en couleur bleue: évolution de la valeur moyenne en fonction du nombre de données aléatoires tiré. Courbe en couleur rouge: évolution de l'écart-type expérimental en fonction du nombre de données aléatoires tiré.

GT, Version du 22.06.2011 07:38:00 17
3.2.1.3.8 Exemples (sans tenir compte des distributions de probabilité à priori) a) On mesure une masse de sucre à l'aide d'une balance ménagère dont la graduation
indique les pas de 50 g. Raisonnablement on peut penser que la lecture s'effectue à 10 g près et que la balance peut avoir une erreur de calibration de 10 g. Donc on attribuera à u(m) la valeur de 20 g.
b) On mesure une masse de CuO à l'aide d'une balance de précision. L'indication digitale indique 22.0456 g. Raisonnablement on peut penser que l'incertitude est du même ordre de grandeur que le dernier digit mais quelle valeur ? 0.0001 g, 0.0002 g, 0.0003 g, 0.0005 g ? C'est ici que l'expérience de l'expérimentateur intervient comme par exemple le fait qu'il a déjà mesuré une même masse sur plusieurs jours, en fonction de la température et de la pression ambiante, qu'il "connaît" sa balance, etc. De plus il faut ajouter une incertitude pour la calibration de la balance. Généralement les laboratoires les font étalonner/vérifier une fois par année par un service de maintenance accrédité. Si tel est le cas on peut ajouter une incertitude typique de 0.0002 g.
c) Pour estimer la mesurande vous avez besoin de la masse volumique ) de l'échantillon en cuivre: 1) vous obtenez dans http://www.webelements.com 8920 kg/m3 sans aucune autre
indication. Etant donné que le chiffre contient 4 chiffres significatifs, on peut raisonnablement penser que u()) est de l'ordre du kg/m3 soit par exemple u())=3 kg/m3.
2) Maintenant si vous avez confiance en cette base de donnée car par exemple c'est celle qui est utilisée et mise à jour par les ingénieurs, physiciens, chimistes, etc. du monde entier vous pouvez prendre u())=1 kg/m3.
3) Vous obtenez une valeur dans une table de 8.92(2) g/cm3, valeur donnée avec un facteur d'élargissement k=2. Vous en déduisez que u())=1 g/cm3.
d) Vous devez acheter du papier peint pour tapisser votre appartement et n'avez pas de mètre à disposition. Vous décidez de mesurer le nombre de pas et trouver 15 pas de long et 12 de large. Vous estimez l'incertitude sur un pas comme étant de 0.1 m et déduisez que la longueur L vaut 15.0 m avec u(L)=1.5 m et la largeur M vaut 12.0 m avec u(M)=1.2 m. Quant à la hauteur vous l'estimez à 1.4 m avec une incertitude de 0.2 m.
e) etc.
3.3 Distribution de mesures indépendantes
3.3.1 Distribution normale ou de Gauss-Laplace Lorsque l'on acquièrt des données de mesures indépendantes, ces dernières se distribuent généralement selon une distribution gaussienne (ou de Gauss-Laplace ou encore normale) donnée par une distribution de probabilité:
Eq. 8 2
2)k(21
e2
1)k(P !
µ""
#!= avec: 1dk )k(P =!
+"
"#
où µ la moyenne de la distribution et % l'écart type (ou la déviation standard). En effet, l'espérance mathématique vaut:
µ== !+"
"#
dk )k(P k)r(E (la moyenne)
et la variance:
V(r) = E([r&E(r)]2) = E[(r&µ)2] = %2
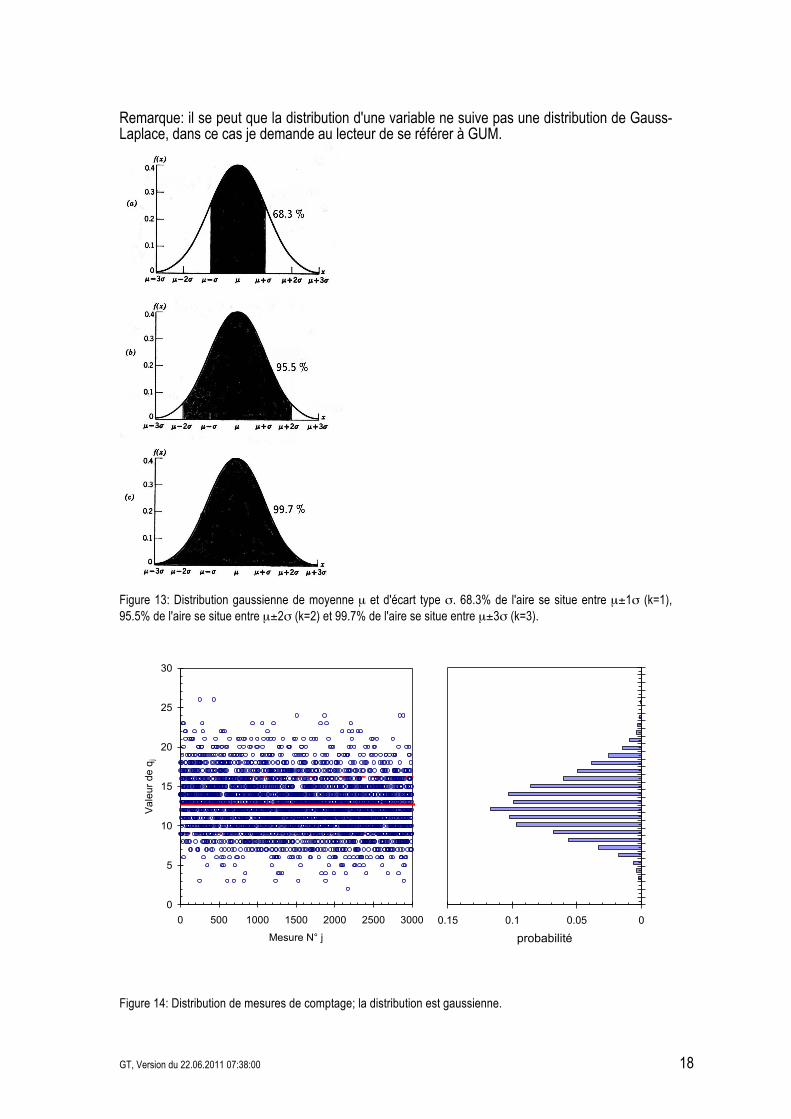
La Figure 13 montre la distribution de probabilité de Gauss-Laplace; dans 68.3% des cas le résultat se trouvera dans l'intervalle µ±%, dans 95.5% dans µ±2% et 99.7% dans µ±3%. La Figure 14 montre l'acquisition de comptage d'un phénomène radioactif. La distribution des valeurs mesurées est une gaussienne de valeur moyenne µ et d'écart type %.
GT, Version du 22.06.2011 07:38:00 18
Remarque: il se peut que la distribution d'une variable ne suive pas une distribution de Gauss-Laplace, dans ce cas je demande au lecteur de se référer à GUM.
Figure 13: Distribution gaussienne de moyenne µ et d'écart type %. 68.3% de l'aire se situe entre µ±1% (k=1), 95.5% de l'aire se situe entre µ±2% (k=2) et 99.7% de l'aire se situe entre µ±3% (k=3).
0
5
10
15
20
25
30
0 500 1000 1500 2000 2500 3000
Mesure N° j
Val
eur d
e q j
00.050.10.15
12345678910111213141516171819202122232425262728293031
probabilité
Figure 14: Distribution de mesures de comptage; la distribution est gaussienne.
GT, Version du 22.06.2011 07:38:00 19
3.3.2 Anecdote[10] Lorsque l’Allemagne eut perdu la guerre en 1945, la situation économique continua à se détériorer rapidement dans le pays. Toute la nourriture resta rationnée, même le pain; cette denrée était limitée à 200 grammes par personne et par jour. Les boulangers étaient par conséquent obligés de se procurer des moules spéciaux pour fabriquer des pains pesant exactement 200 grammes et ils en vendaient un par jour à chaque consommateur. Chaque matin, en se rendant à l’université, un vieux professeur de physique, Herr Pr. Dr. Herbert W., passait chez le boulanger pour prendre sa ration quotidienne. Un jour il lui dit: — Vous êtes un profiteur, vous volez vos clients. Les moules dont vous vous servez sont de 5 pour cent plus
petits qu’ils ne devraient l’être pour faire des pains de 200 grammes, et la farine que vous économisez, vous la vendez au marché noir.
— Mais, Monsieur le Professeur, s’écria le boulanger, personne ne peut donner à tous ses pains exactement le
même poids. Certains sont quelques pour cents plus légers, d’autres quelques pour cent plus lourds. — C’est bien cela, répliqua le professeur, depuis quelques mois, je pèse chaque jour le pain que vous me vendez
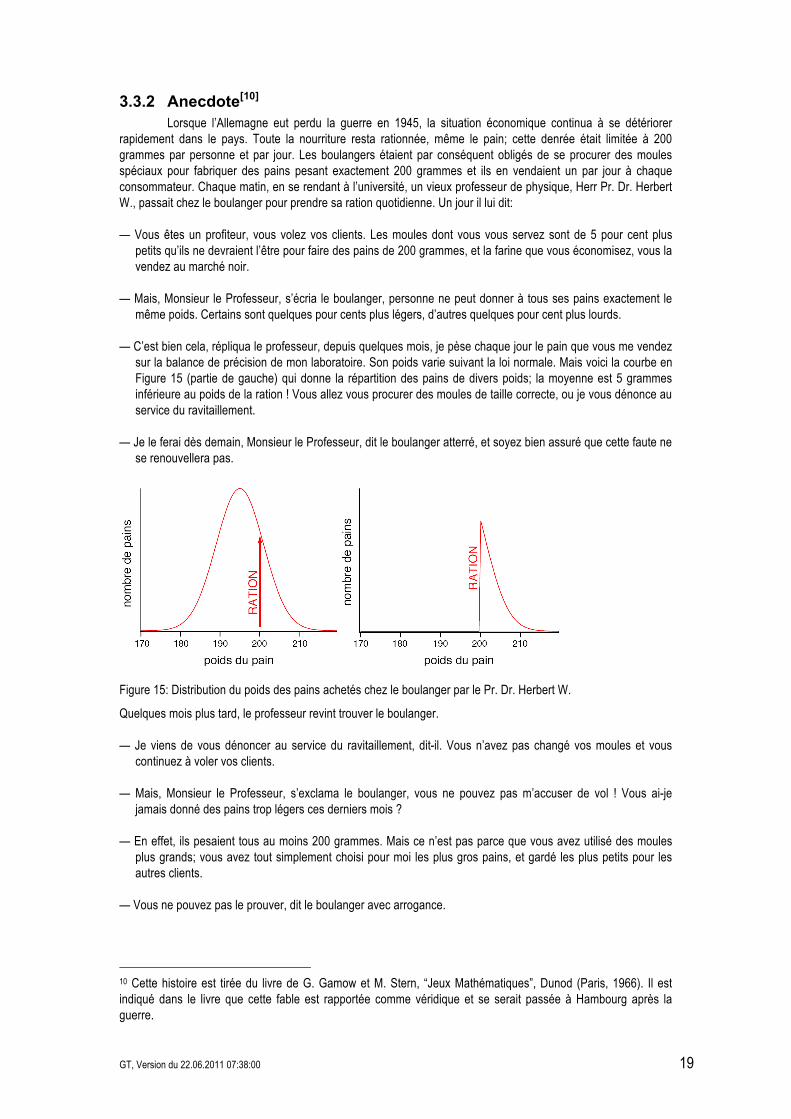
sur la balance de précision de mon laboratoire. Son poids varie suivant la loi normale. Mais voici la courbe en Figure 15 (partie de gauche) qui donne la répartition des pains de divers poids; la moyenne est 5 grammes inférieure au poids de la ration ! Vous allez vous procurer des moules de taille correcte, ou je vous dénonce au service du ravitaillement.
— Je le ferai dès demain, Monsieur le Professeur, dit le boulanger atterré, et soyez bien assuré que cette faute ne
se renouvellera pas.
Figure 15: Distribution du poids des pains achetés chez le boulanger par le Pr. Dr. Herbert W.
Quelques mois plus tard, le professeur revint trouver le boulanger. — Je viens de vous dénoncer au service du ravitaillement, dit-il. Vous n’avez pas changé vos moules et vous
continuez à voler vos clients. — Mais, Monsieur le Professeur, s’exclama le boulanger, vous ne pouvez pas m’accuser de vol ! Vous ai-je
jamais donné des pains trop légers ces derniers mois ? — En effet, ils pesaient tous au moins 200 grammes. Mais ce n’est pas parce que vous avez utilisé des moules
plus grands; vous avez tout simplement choisi pour moi les plus gros pains, et gardé les plus petits pour les autres clients.
— Vous ne pouvez pas le prouver, dit le boulanger avec arrogance.
10 Cette histoire est tirée du livre de G. Gamow et M. Stern, “Jeux Mathématiques”, Dunod (Paris, 1966). Il est indiqué dans le livre que cette fable est rapportée comme véridique et se serait passée à Hambourg après la guerre.

GT, Version du 22.06.2011 07:38:00 20
— Justement si, déclara le professeur. Regardez la distribution statistique que j’ai obtenue en pesant vos pains au cours de ces derniers mois (Figure 15 partie de droite). Au lieu de la distribution normale démontrée par le grand mathématicien Karl Friedrich Gauss, vous avez une courbe qui correspond à des pains trop lourds; elle s’arrête brusquement à gauche, et descend progressivement à droite. Jamais des écarts statistiques autour de la moyenne ne pourraient conduire à une telle distribution, et il est clair que vous avez obtenu cette courbe artificiellement en choisissant des pains qui pesaient plus que le poids minimum autorisé. Cette courbe est tout simplement le pied de la courbe de Gauss (Figure 15 partie de gauche): elle représente la même distribution que celle que j’avais obtenue en pesant mes pains avant notre précédente conversation. Je suis certain que le service du rationnement me croira sur parole. Et, tournant les talons, le Pr. Dr. Herbert W. sortit de la boutique.
On notera qu’en réalité, aucune mesure n’est jamais distribuée exactement suivant la loi gaussienne. Si on répète un grand nombre de fois la mesure d’un paramètre et qu’on trace l’histogramme de ces mesures en fonction de la valeur trouvée, la forme de l’histogramme tend vers une répartition de Gauss lorsqu’on fait tendre le nombre de mesures vers l’infini. Pourquoi cela ? On dit parfois que les expérimentateurs pensent qu’elle a été prouvée par les mathématiciens, puisque sa forme peut être justifiée lorsque les conditions de Borel sont vérifiées, c’est-à-dire lorsqu’il existe des causes d’erreurs multiples d’importance comparable. A l’inverse, les mathématiciens pensent qu’elle est un résultat de l’expérience, puisqu’elle est obtenue dans la quasi-totalité des cas où un expérimentateur soigneux a pris le temps de regrouper un très grand nombre de mesures indépendantes et de poids égaux d’une même grandeur.
3.4 Détermination d'une incertitude standard combinée Supposons que la grandeur de sortie Y=f(X1, X2, ..., Xk) dépende de k valeur Xi. Chaque mesurande Y, X1, X2, ..., Xk est de fait estimée par ses y, x1, x2, ..., xk qui ont pour espérance mathématique les valeurs Y, X1, X2, ..., Xk avec Y=f(X1, X2, ..., Xk). Développons en série de Taylor f autour des espérances mathématiques:
)Xx(xf
Yy ii
k
1i i
!""#
$%%&
'
((
=! )=
où les termes d'ordre supérieur sont négligés. Le carré de l'expression donne:
!!!!"
= +===
""#
#
#
#+"$$
%
&''(
)
#
#=$
$%
&''(
)"$$
%
&''(
)
#
#="
1k
1i
k
1ijjjii
ji
2ii
2k
1i i
2
ii
k
1i i
2 )Xx)(Xx(x
f
x
f2)Xx(
x
f)Xx(
x
f)Yy(
La variance de y, qui est l'espérance mathématique de la relation ci-dessus, c'est-à-dire E[(y&Y)2], conduit à:
Eq. 9 !!!"
= +== #
#
#
#+$$
%
&''(
)
#
#=
1k
1i
k
1ij)x,xcov(
jijiji
i2
2N
1i i
2c
ji
)x,x(r)x(u)x(ux
f
x
f2)x(u
x
f)y(u
!! "!! #$
où r(xi, xj) est coefficient de corrélation de Xi et Xj qui est donné par:
Eq. 10 [ ]
)x(u)x(u
)x,xcov(
)x(u)x(u
)Xx)(XxE)x,x(r
j2
i2
ji
j2
i2
jjiiji =
!!= .
Si les variables sont indépendantes car rij=0 *i,j avec i+j.

GT, Version du 22.06.2011 07:38:00 21
3.4.1 Variables indépendantes L'incertitude standard de y, y étant l'estimation de la mesurande Y, et qui provient du résultat de mesures y=f(x1, x2, ..., xk), est obtenue par la combinaison des incertitudes standards des xi. L'incertitude standard combinée uc(y) de l'estimation y s'obtient à l'aide de la variance combinée uc2(y) donnée, pour des variables xi indépendantes, par l'Eq. 9 simplifiée:
Eq. 11 )x(ux
f)y(u i
2
2k
1i i
2c !
=""#
$%%&
'
(
(=
en se rappelant Eq. 1. Chaque u(xi) est l'incertitude standard de xi qui peut être de type A ou de B. u(y) est l'estimation de l'incertitude standard des valeurs qui peuvent raisonnablement être attribuée à Y. Remarque: cette équation est basée sur un développement en série de Taylor au
premier ordre ce qui signifie que les incertitudes u(xi) doivent être petites. Si des non linéarités de f deviennent importantes, des ordre supérieurs de la série doivent être ajoutés dans l'expression de uc
2(y), Eq. 11, avec le plus important de l'ordre supérieur donné par (pour des distributions des xi symétriques par rapport à leurs moyennes):
Eq. 12 )x(u)x(u xx
f
x
f
xx
f
2
1j
2i
2k
1i
k
1j2ji
3
i
2
ji
2
!!= =
""
#
$
%%
&
'
((
(
(
(+"
"#
$%%&
'
((
(
3.4.2 Variables non indépendantes Si les variables xi sont corrélées, l'expression ne se simplifie pas et reste l'Eq. 9:
Eq. 13 uc2(y)=
!f!x
i
"
#$$
%
&''
i=1
k
(2
u2 (xi)+2
!f!x
i
!f!x
jj=i+1
k
(i=1
k)1
( u(xi) u(x
j) r(x
i,x
j)+ ...
Remarque: dans la littérature Eq. 13 est appelée: "Loi générale de propagation des erreurs". La covariance cov(xi, xj) est une mesure la corrélation entre les deux variables. Elle est donnée par:
Eq. 14 cov(xi,x
j)=E (x
i!Xi )(x j
!Xj )"#
$%= u(x
i) u(x
j) r(x
i,x
j)
Si deux variables aléatoires sont indépendantes leur covariance et leur coefficient de corrélations sont nuls mais l'inverse n'est pas nécessairement vrai. Son estimation se calcule pour deux variables aléatoires x et y selon:
Eq. 15 )1N(
)yy)(xx( )y,x(s
N
1kexpkexpk
!
!!="=

GT, Version du 22.06.2011 07:38:00 22
et, comme pour le cas de la meilleure valeur de l'incertitude de la valeur moyenne, la meilleure estimation de la covariance de la valeur moyenne est donnée par:
Eq. 16 )1N( N
)yy)(xx( )y,x(s
N
1kexpkexpk
expexp !
!!="=
C'est la formule à utiliser pour l'estimation de la covariance dans le calcul de la propagation des incertitudes.
3.4.3 Remarque Souvent l'incertitude est calculée selon:
!=
""#
$%%&
'
(
(=
N
1ii
ic )x(u
x
f)y(u
cette relation n'est pas adéquate et ne doit pas être utilisée. Pour s'en convaincre "avec les mains" prenons l'exemple de deux résistances montées en série tirées d'un lot caractérisé par R et s(R). Choisissons la première R1 et supposons que sa valeur est supérieure à R (de par exemple ,R1). Lorsque l'on prend la seconde R2 on a de fait une chance sur deux pour que sa valeur soit plus petite que R (de par exemple ,R2) et donc "compense" ,R1 ! Dans ce simple exemple on remarque immédiatement que l'incertitude d'une somme n'est pas la somme des incertitudes.
3.4.4 Exemple: somme ou différence de deux mesurandes indépendantes Admettons que la mesurande Y soit égale à la somme ou la soustraction de deux
mesurandes indépendantes X1 et X2. On a Y=f(X1,X2)=X1±X2 et donc:
1x
fet 1
x
f
21
±=!!"
#$$%
&
'
'=!!"
#$$%
&
'
'
et si l'on applique l'Eq. 11, on trouve pour l'incertitude standard combinée uc(y):
)x(u)1()x(u)1()y(u 222
1222
c ±+=
et on a:
Eq. 17 )x(u)x(u)y(u 22
12
c +=
L'incertitude d'une somme de deux variables indépendantes est la racine
carrée de la somme des incertitudes au carré[11].
11 Si X1 et X2 sont caractérisés par une loi normale, leur somme Y= X1+X2 le sera aussi avec une espérance mathématique E(Y) et une variance %2(Y) égales à la somme des espérances E(X1)+E(X2) et à la somme des variances %2(X1)+ %2(X2). Ceci apparaît dans la littérature sous la dénomination de Théorème central limite.

GT, Version du 22.06.2011 07:38:00 23
3.4.5 Exemple: produit de deux mesurandes indépendantes Admettons que la mesurande Y soit égale au produit ou à la division de deux
mesurandes indépendantes X1 et X2. On a Y=f(X1,X2)=X1-X2 et donc:
12
21
xx
fet x
x
f=!!"
#$$%
&
'
'=!!"
#$$%
&
'
'
et si l'on applique l'Eq. 11, on trouve pour l'incertitude standard combinée uc(y): )x(u)x()x(u)x()y(u 2
2211
222
2c +=
et on a après avoir divisé par y:
Eq. 18
2
2
2
2
1
1c
x
)x(u
x
)x(u
y
)y(u!!"
#$$%
&+!!
"
#$$%
&=
L'incertitude relative d'un produit de deux variables indépendantes est la
racine carrée de la somme des incertitudes relatives au carré.
3.4.6 Exemple: produit de deux mesurandes non indépendantes Admettons que l'on détermine la résistance par la mesure simultanée de la différence de potentiel U et du courant i. Les deux mesurandes U et i ne sont évidemment pas indépendantes étant donné que U=Ri. Soit les valeurs mesurées suivantes:
Table 1: Mesures de différences de potentiel et du courant traversant une résistance. Attention: les valeurs de la résistance sont arrondies (données à 4 chiffres significatifs).
N° mesure U (V) i (A) R (') 1 5.007 1.966-10&2 254.7 2 4.994 1.964-10&2 254.3 3 5.005 1.964-10&2 254.8 4 5.002 1.965-10&2 254.6 5 4.997 1.964-10&2 254.4 6 4.993 1.965-10&2 254.1 7 4.990 1.969-10&2 253.4 8 4.999 1.968-10&2 254.0
3.4.6.1 1ère possibilité On calcule R pour chaque mesure et l'on détermine la moyenne (Eq. 2) et l'écart type de la moyenne (Eq. 6). On trouve alors (sans effectuer la correction Bayesienne donnée par Eq. 7): Rexp=254.290 ' et s(Rexp)=0.158 ' Le résultat est donné ici avec trop de chiffres significatifs pour faciliter la comparaison avec votre calcul; de fait on donnerait le résultat: Rexp=254.3 ' et s(Rexp)=0.2 '
3.4.6.2 2ème possibilité On calcule la moyenne des différences de potentiel et son écart type ainsi que la moyenne des courants et son écart type. On a:

GT, Version du 22.06.2011 07:38:00 24
Uexp=4.9984 V et s(Uexp)=0.0021 V iexp =1.9656-10&2 A et s(iexp) =0.0007-10&2 A et on trouve pour R=U/i: R=254.289 ' Pour le calcul de s(R) on obtiendrait la valeur de 0.139 ' si l'on utilisait la formule donnée par Eq. 11 qui, rappelons le, n'est valable que si les variables sont indépendantes. Si maintenant on utilise la formule correcte, soit l'Eq. 13, on a pour R=U/i:
)i,U(r)i(u )U(ui
U
i
1 2)i(u
i
U )U(u
i
1
)i,U(r )i(u )U(ui
R
U
R2)i(u
i
R)U(u
U
R)R(u
22
2
22
2
22
22
2c
!"
#$%
& '!"
#$%
&+!"
#$%
& '+!"
#$%
&=
!"
#$%
&(
(!"
#$%
&(
(+!
"
#$%
&(
(+!
"
#$%
&(
(=
et on obtient pour l'estimateur de la covariance:
(V.A) 10x411.3)1N(
)ii)(UU( )i,U(s 8
N
1kexpkexpk
!= !=!
!!="
et pour l'estimateur de la covariance des deux moyennes (Eq. 16):
(V.A) 10x263.4)1N(N
)ii)(UU( )i,U(s 9
N
1kexpkexpk
expexp!= !=
!
!!="
et un coefficient de corrélation: 296.0 )i,U(r expexp != Finalement, on obtient s(R)=0.158 ' qui est un résultat similaire à celui trouvé par la 1ère méthode. Remarque: nous n'avons pas effectué de corrections Bayesienne dans cet exemple.
3.4.7 Exercices a. On achète des résistances de 100 ' avec une incertitude relative de 5% pour un facteur
d'élargissement k=2. Un étudiant désire avoir une résistance de 1 k' et pour ce faire soude en série 10 résistances. Quelle est l'incertitude de cette dernière ?
b. On construit un thermomètre basé sur la variation de résistance d'un métal (T=f(R)); en particulier une résistance en platine. De sorte à obtenir la valeur de la mesurande R sans modifier la température du thermomètre, on fait une mesure DC à 4 points (deux pour l'entrée et la sortie du courant électrique et deux pour la mesure de la différence de potentielle) avec un courant DC très petit de i=10.0 (2) µA. Une première mesure à l'aide d'un voltmètre digital donne U=22.534 mV. Donner la valeur de R et son incertitude. Lors de l'automation du système de mesure, on décide d'effectuer 7 mesures de U pour diminuer le bruit. Un échantillonnage donne: 22.541, 22.534, 22.536, 22.528, 22.538,

GT, Version du 22.06.2011 07:38:00 25
22.540, 22.531. Donner la valeur de R et son incertitude (n'oubliez pas la correction Bayesienne).
c. On désire connaître la valeur de l'induction magnétique B=µo(H+M), sachant que H=Ni/l avec N le nombre de spires d'une bobine, i le courant qui la traverse et l la longueur de la bobine et que le milieu a une susceptibilité magnétique !; M=!H, donner la valeur de B et son incertitude. N=100, i=2.42(5) A, l=12.5(3) cm, !=0.52(12).
d. Sur un dynamomètre on mesure la force F en plaçant diverses masses m. La table ci-après donne les valeurs mesurées:
m (kg) F (N)
2.014 19.43734 2.095 19.56195 2.075 19.45575 2.100 20.95100 2.083 20.65423 2.021 19.90601 2.001 20.49981 1.914 17.91634 2.026 20.84506 1.939 18.45159
Déterminer la constante de gravité g et son incertitude selon les deux méthodes proposées dans le §3.4.6. Quel est le facteur de corrélation entre m et F ?

GT, Version du 22.06.2011 07:38:00 26
4 Méthode des moindres carrés
4.1 Distribution statistique du !-carré (!2) La distribution statistique du !2 est très importante pour les estimations de paramètres des affinements des fonctions. Cette distribution est définie comme la somme des carrés de N variables réduites Zi indépendantes et distribuées selon une loi normale. On dit que la somme:
Eq. 19 !!==
" ##$
%&&'
(
)
µ*==+
N
1i
2
i
iiN
1i
2i
2 yZ
suit une distribution en 2!" avec # (=N dans ce cas) degrés de liberté sous les conditions:
• les yi sont indépendants; • l'espérance mathématique E(yi)=µi et la variance V(yi)=%i2; • la fonction de probabilité f(yi) est normale[12].
La densité de probabilité de la distribution du !2 est donnée par:
Eq. 20 ( )
2
e22
1
)(f
2
1 22
2
2
!"
##$
%&&'
( )
=)
)*
*!
avec la fonction gamma donnée par ( ) !"
##$=$%0
x1 dx e x
L'espérance mathématique E(!2)=# et la variance V(!2)=2#. Le nombre de degré de liberté # n'est rien d'autre que le nombre de variables indépendantes; soit #=N.
4.1.1 Qu'est-ce que cela veut dire ? Lorsque l'on effectue un affinement, on va utiliser une fonctionnelle f(x) permettant de représenter au mieux les mesures <xi;yi>. De fait, en utilisant la méthode des moindres carrés, on va trouver les paramètres de f qui minimalisent:
Eq. 21 !=
""#
$%%&
' (=
N
1i
2
i
ii2
)y(s
)x(fyQ
où s(yi) est l'incertitude sur la valeur yi. Si le nombre de paramètres libres de l'affinement est M, le nombre de degrés de liberté est diminué d'autant et vaut #=N&M (nombre de mesures moins le nombre de paramètres). Etant donné que Q2 suit une distribution de probabilité du !2 de degré #, on peut calculer quelle est la probabilité que Q2 soit supérieur à une valeur donnée. Mieux, on peut se définir un niveau de confiance . (par exemple 5%) et calculer la valeur critique 2
,!"# [13]. Ainsi:
Eq. 22 hypothèsel' rejette on Q si
hypothèsel' accepte on Q si2
,2
2,
2
!"
!"
#>
#$
L'hypothèse étant que les données puissent être affinées par f. 12 C'est-à-dire que la fonction de probabilité des yi est donnée par:
( )2i
2ix
21
2i
2iii e
2
1),(Normale)y(f !
µ""
#!=!µ$
13 Si la fonction f décrit bien les données, dans (1&.) % des cas le Q2 < 2,!"# .

GT, Version du 22.06.2011 07:38:00 27
ATTENTION: Si 2
,2 Q !"#> il faut se poser la question à savoir si les incertitudes ont bien été
évaluées avant de rejeter l'hypothèse. La Table 2 donne les valeurs critiques de 2
,!"# . Ces dernières sont obtenues en
posant que l'intégrale de la densité de probabilité donnée par l'Eq. 20 dans l'intervalle [0; 2,!"# ]
soit égale à 1&.; soit:
Eq. 23 ( )!!"#"# $
$%
%#
$
$#&
''(
)**+
, $
=$$="%
2,
2
2,
0
2
1 22
0
2 d
2
e22
1
d)(f1
qui est donnée par l'aire blanche de la Figure 16:
Figure 16: Densité de probabilité de la distribution du !2.
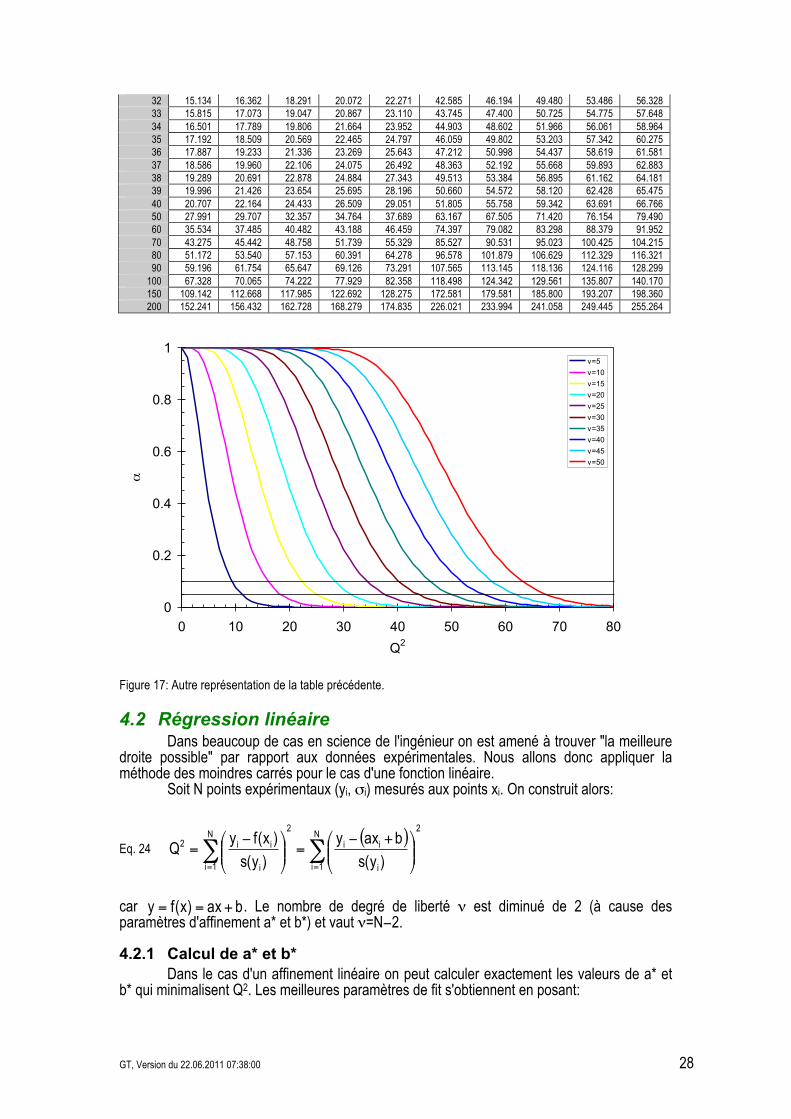
Table 2: Valeurs critiques du !2 pour un affinement de N données à l'aide d'une fonctionnelle ayant M variables indépendantes, soit #=N&M degrés de liberté, et pour un niveau de confiance ..
Valeurs critiques pour la distribution du !2 (Values in the table are critical values of the chi-squared random variable for right hand tails of the indicated areas, alpha).
2,!"#
! ----------------------------------------------------------------- . ----------------------------------------------------------------- ---- # ---- 0.995 0.990 0.975 0.950 0.900 0.100 0.050 0.025 0.010 0.005
1 0.000 0.000 0.001 0.004 0.016 2.706 3.841 5.024 6.635 7.879 2 0.010 0.020 0.051 0.103 0.211 4.605 5.991 7.378 9.210 10.597 3 0.072 0.115 0.216 0.352 0.584 6.251 7.815 9.348 11.345 12.838 4 0.207 0.297 0.484 0.711 1.064 7.779 9.488 11.143 13.277 14.860 5 0.412 0.554 0.831 1.145 1.610 9.236 11.070 12.832 15.086 16.750 6 0.676 0.872 1.237 1.635 2.204 10.645 12.592 14.449 16.812 18.548 7 0.989 1.239 1.690 2.167 2.833 12.017 14.067 16.013 18.475 20.278 8 1.344 1.647 2.180 2.733 3.490 13.362 15.507 17.535 20.090 21.955 9 1.735 2.088 2.700 3.325 4.168 14.684 16.919 19.023 21.666 23.589
10 2.156 2.558 3.247 3.940 4.865 15.987 18.307 20.483 23.209 25.188 11 2.603 3.053 3.816 4.575 5.578 17.275 19.675 21.920 24.725 26.757 12 3.074 3.571 4.404 5.226 6.304 18.549 21.026 23.337 26.217 28.300 13 3.565 4.107 5.009 5.892 7.041 19.812 22.362 24.736 27.688 29.819 14 4.075 4.660 5.629 6.571 7.790 21.064 23.685 26.119 29.141 31.319 15 4.601 5.229 6.262 7.261 8.547 22.307 24.996 27.488 30.578 32.801 16 5.142 5.812 6.908 7.962 9.312 23.542 26.296 28.845 32.000 34.267 17 5.697 6.408 7.564 8.672 10.085 24.769 27.587 30.191 33.409 35.718 18 6.265 7.015 8.231 9.390 10.865 25.989 28.869 31.526 34.805 37.156 19 6.844 7.633 8.907 10.117 11.651 27.204 30.144 32.852 36.191 38.582 20 7.434 8.260 9.591 10.851 12.443 28.412 31.410 34.170 37.566 39.997 21 8.034 8.897 10.283 11.591 13.240 29.615 32.671 35.479 38.932 41.401 22 8.643 9.542 10.982 12.338 14.041 30.813 33.924 36.781 40.289 42.796 23 9.260 10.196 11.689 13.091 14.848 32.007 35.172 38.076 41.638 44.181 24 9.886 10.856 12.401 13.848 15.659 33.196 36.415 39.364 42.980 45.558 25 10.520 11.524 13.120 14.611 16.473 34.382 37.652 40.646 44.314 46.928 26 11.160 12.198 13.844 15.379 17.292 35.563 38.885 41.923 45.642 48.290 27 11.808 12.878 14.573 16.151 18.114 36.741 40.113 43.195 46.963 49.645 28 12.461 13.565 15.308 16.928 18.939 37.916 41.337 44.461 48.278 50.994 29 13.121 14.256 16.047 17.708 19.768 39.087 42.557 45.722 49.588 52.335 30 13.787 14.953 16.791 18.493 20.599 40.256 43.773 46.979 50.892 53.672 31 14.458 15.655 17.539 19.281 21.434 41.422 44.985 48.232 52.191 55.002
GT, Version du 22.06.2011 07:38:00 28
32 15.134 16.362 18.291 20.072 22.271 42.585 46.194 49.480 53.486 56.328 33 15.815 17.073 19.047 20.867 23.110 43.745 47.400 50.725 54.775 57.648 34 16.501 17.789 19.806 21.664 23.952 44.903 48.602 51.966 56.061 58.964 35 17.192 18.509 20.569 22.465 24.797 46.059 49.802 53.203 57.342 60.275 36 17.887 19.233 21.336 23.269 25.643 47.212 50.998 54.437 58.619 61.581 37 18.586 19.960 22.106 24.075 26.492 48.363 52.192 55.668 59.893 62.883 38 19.289 20.691 22.878 24.884 27.343 49.513 53.384 56.895 61.162 64.181 39 19.996 21.426 23.654 25.695 28.196 50.660 54.572 58.120 62.428 65.475 40 20.707 22.164 24.433 26.509 29.051 51.805 55.758 59.342 63.691 66.766 50 27.991 29.707 32.357 34.764 37.689 63.167 67.505 71.420 76.154 79.490 60 35.534 37.485 40.482 43.188 46.459 74.397 79.082 83.298 88.379 91.952 70 43.275 45.442 48.758 51.739 55.329 85.527 90.531 95.023 100.425 104.215 80 51.172 53.540 57.153 60.391 64.278 96.578 101.879 106.629 112.329 116.321 90 59.196 61.754 65.647 69.126 73.291 107.565 113.145 118.136 124.116 128.299
100 67.328 70.065 74.222 77.929 82.358 118.498 124.342 129.561 135.807 140.170 150 109.142 112.668 117.985 122.692 128.275 172.581 179.581 185.800 193.207 198.360 200 152.241 156.432 162.728 168.279 174.835 226.021 233.994 241.058 249.445 255.264
0
0.2
0.4
0.6
0.8
1
0 10 20 30 40 50 60 70 80Q2
!
v=5v=10v=15v=20v=25v=30v=35v=40v=45v=50
Figure 17: Autre représentation de la table précédente.
4.2 Régression linéaire Dans beaucoup de cas en science de l'ingénieur on est amené à trouver "la meilleure droite possible" par rapport aux données expérimentales. Nous allons donc appliquer la méthode des moindres carrés pour le cas d'une fonction linéaire. Soit N points expérimentaux (yi, %i) mesurés aux points xi. On construit alors:
Eq. 24 ( )
!!==
""#
$%%&
' +(=""
#
$%%&
' (=
N
1i
2
i
iiN
1i
2
i
ii2
)y(s
baxy
)y(s
)x(fyQ
car bax)x(fy +== . Le nombre de degré de liberté # est diminué de 2 (à cause des paramètres d'affinement a* et b*) et vaut #=N&2.
4.2.1 Calcul de a* et b* Dans le cas d'un affinement linéaire on peut calculer exactement les valeurs de a* et b* qui minimalisent Q2. Les meilleures paramètres de fit s'obtiennent en posant:

GT, Version du 22.06.2011 07:38:00 29
( )( )( )i
i2
*ii
N
1i*aa
2
x)y(s
bx*ay20
a!
+!==
"
#"$==
( )( )( )1
)y(s
bx*ay20
b i2
*ii
N
1i*bb
2
!+!
=="
#"$==
Si on pose:
!!
!!
!!
==
==
==
==
==
==
N
1i i2
2i
N
1i i2
ii
N
1i i2
2i
N
1i i2
i
N
1i i2
N
1i i2
i
)y(s
yF
)y(s
yxE
)y(s
xD
)y(s
yC
)y(s
1B
)y(s
xA
et que l'on remplace dans les équations précédentes on a:
( )( )2 B*bA*aC0
2 A*bD*aE0
++!=
++!=
et donc:
Eq. 25
2
2
ADB
EADC*b
ADB
CAEB*a
!
!=
!
!=
4.2.1.1 Qualité du fit - Minimisation du !2 La qualité du fit (de l'affinement) est donnée par comparaison de la valeur de Q2 en a=a* et b=b* à celle de la valeur critique 2
,!"# et en utilisant la règle donnée en Eq. 22.
4.2.1.1.1 Coefficient de régression r2 Souvent les logiciels mathématiques donnent une valeur r2 comprise entre [0;1]. De fait ce r2 est appelé coefficient de régression qui mesure le degré de perfectionnement de l'ajustement de la droite de régression. Cette valeur est donnée par (toutes les incertitudes de même poids):
N
yy
N
xx
N
yxyx
r2N
1iiN
1i
2i
2N
1iiN
1i
2i
2N
1ii
N
1iiN
1iii
2
!!!!!
"
#
$$$$$
%
&!"
#$%
&
'
!!!!!
"
#
$$$$$
%
&!"
#$%
&
'
!!!!
"
#
$$$$
%
&
'
=
((
((
(((
=
=
=
=
==
=
et vaut 1 si l'affinement est idéal. Voici quelques exemples graphiques de r2.

GT, Version du 22.06.2011 07:38:00 30
0
5
10
15
20
25
30
35
40
45
0 20 40 60 80 100
x
yr2=1
0
5
10
15
20
25
30
35
40
45
0 20 40 60 80 100
x
y
r2=0.9967
0
5
10
15
20
25
30
35
40
45
0 20 40 60 80 100
x
y
r2=0.9865
0
5
10
15
20
25
30
35
40
45
0 20 40 60 80 100
x
yr2=0.9202
Figure 18: Quelques exemples de données et le r2 correspondant; la fluctuation ajoutée pour l'exemple n'est pas gaussienne.
4.2.1.2 Incertitude sur a* et b* La matrice d'erreur est donnée par:
!!"
#$$%
&
'
'
'=!!
"
#$$%
&'
1112
1222
2122211
1
2221
1211
AA
AA
AAA
1AA
AA
avec:
*b*,a
2
2112
*b*,a2
2
22
*b*,a2
2
11 ba2
1AA
b2
1A
a2
1A
!!
"!==
!
"!=
!
"!=
et on trouve:
Eq. 26
ADB
A*)b*,acov(
ADB
D
AAA
A*)b(
ADB
B
AAA
A*)a(
2
22212211
11222
212211
222
!
!=
!=
!="
!=
!="
GT, Version du 22.06.2011 07:38:00 31
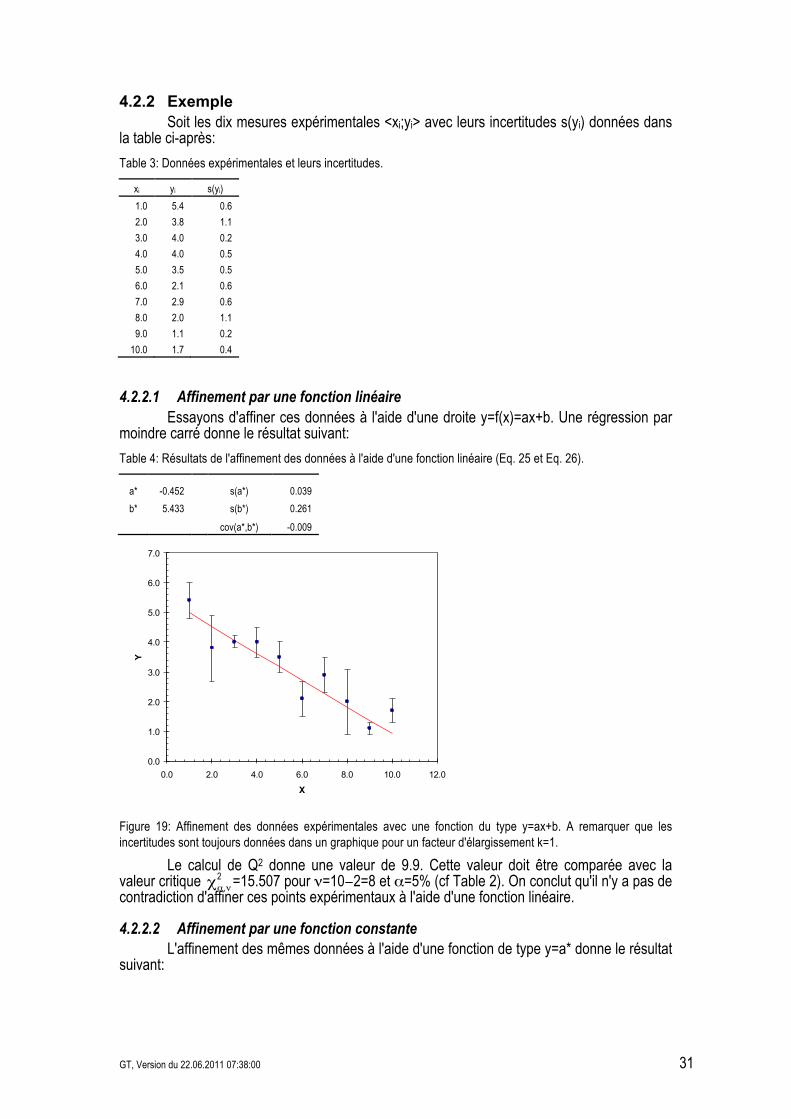
4.2.2 Exemple Soit les dix mesures expérimentales <xi;yi> avec leurs incertitudes s(yi) données dans la table ci-après:
Table 3: Données expérimentales et leurs incertitudes.
xi yi s(yi)
1.0 5.4 0.6
2.0 3.8 1.1
3.0 4.0 0.2
4.0 4.0 0.5
5.0 3.5 0.5
6.0 2.1 0.6
7.0 2.9 0.6
8.0 2.0 1.1
9.0 1.1 0.2
10.0 1.7 0.4
4.2.2.1 Affinement par une fonction linéaire Essayons d'affiner ces données à l'aide d'une droite y=f(x)=ax+b. Une régression par moindre carré donne le résultat suivant:
Table 4: Résultats de l'affinement des données à l'aide d'une fonction linéaire (Eq. 25 et Eq. 26).
a* -0.452
s(a*) 0.039
b* 5.433 s(b*) 0.261
cov(a*,b*) -0.009
0.0
1.0
2.0
3.0
4.0
5.0
6.0
7.0
0.0 2.0 4.0 6.0 8.0 10.0 12.0
X
Y
Figure 19: Affinement des données expérimentales avec une fonction du type y=ax+b. A remarquer que les incertitudes sont toujours données dans un graphique pour un facteur d'élargissement k=1.
Le calcul de Q2 donne une valeur de 9.9. Cette valeur doit être comparée avec la valeur critique 2
,!"# =15.507 pour #=10&2=8 et .=5% (cf Table 2). On conclut qu'il n'y a pas de contradiction d'affiner ces points expérimentaux à l'aide d'une fonction linéaire.
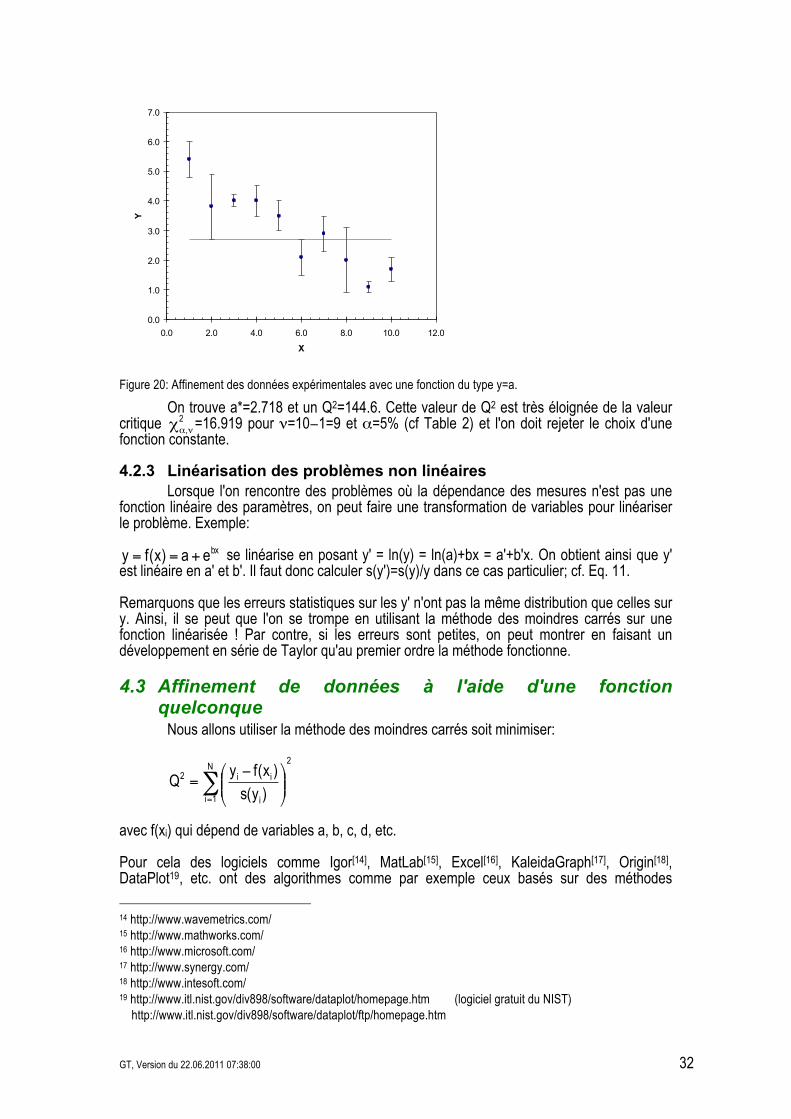
4.2.2.2 Affinement par une fonction constante L'affinement des mêmes données à l'aide d'une fonction de type y=a* donne le résultat suivant:
GT, Version du 22.06.2011 07:38:00 32
0.0
1.0
2.0
3.0
4.0
5.0
6.0
7.0
0.0 2.0 4.0 6.0 8.0 10.0 12.0
X
Y
Figure 20: Affinement des données expérimentales avec une fonction du type y=a.
On trouve a*=2.718 et un Q2=144.6. Cette valeur de Q2 est très éloignée de la valeur critique 2
,!"# =16.919 pour #=10&1=9 et .=5% (cf Table 2) et l'on doit rejeter le choix d'une fonction constante.
4.2.3 Linéarisation des problèmes non linéaires Lorsque l'on rencontre des problèmes où la dépendance des mesures n'est pas une fonction linéaire des paramètres, on peut faire une transformation de variables pour linéariser le problème. Exemple:
bxea)x(fy +== se linéarise en posant y' = ln(y) = ln(a)+bx = a'+b'x. On obtient ainsi que y' est linéaire en a' et b'. Il faut donc calculer s(y')=s(y)/y dans ce cas particulier; cf. Eq. 11. Remarquons que les erreurs statistiques sur les y' n'ont pas la même distribution que celles sur y. Ainsi, il se peut que l'on se trompe en utilisant la méthode des moindres carrés sur une fonction linéarisée ! Par contre, si les erreurs sont petites, on peut montrer en faisant un développement en série de Taylor qu'au premier ordre la méthode fonctionne.
4.3 Affinement de données à l'aide d'une fonction quelconque
Nous allons utiliser la méthode des moindres carrés soit minimiser:
!=
""#
$%%&
' (=
N
1i
2
i
ii2
)y(s
)x(fyQ
avec f(xi) qui dépend de variables a, b, c, d, etc. Pour cela des logiciels comme Igor[14], MatLab[15], Excel[16], KaleidaGraph[17], Origin[18], DataPlot19, etc. ont des algorithmes comme par exemple ceux basés sur des méthodes
14 http://www.wavemetrics.com/ 15 http://www.mathworks.com/ 16 http://www.microsoft.com/ 17 http://www.synergy.com/ 18 http://www.intesoft.com/ 19 http://www.itl.nist.gov/div898/software/dataplot/homepage.htm (logiciel gratuit du NIST) http://www.itl.nist.gov/div898/software/dataplot/ftp/homepage.htm

GT, Version du 22.06.2011 07:38:00 33
Simplex ou Levenberg-Marquardt qui permettent de trouver "facilement" les minima de Q2. Attention, suivant la complexité du problème, les méthodes mathématiques peuvent conduire (souvent d'ailleurs) à "tomber" dans des minima locaux qui ne sont pas ceux de la solution cherchée ! Il faut donc prendre garde de donner aux paramètres de départ des valeurs physiquement proches de celles recherchées.
4.3.1 Exemples à l'aide d'Excel[20] et d'Igor Des exemples de feuilles de calcul Excel et Igor sont donnés à l'adresse internet http://www.eig.unige.ch/nucleaire/pedagogie/polycopies.html
4.3.1.1 Mise en équilibre séculaire d'un élément radioactif avec sa mère Par exemple la mesure de la mise en équilibre séculaire de la fille 90Y du 90Sr lors d'une mesure par scintillation liquide donne le résultat21.
4.3.1.1.1 Equations de la mise en équilibre du Y-90 Le taux de comptage au temps t est donné par:
90Y90Y90Sr90SrBG AAN)t(N !!!! "+"+= !!
90Y
tT
)2ln(
90Sr90Sr90SrBG90Ye1AAN)t(N !
!
!!! "##
$
%
&&
'
(!+"+= !!
où BGN! est le taux de comptage du bruit de fond, ASr-90 l'activité en Sr-90, /Sr-90 et /Y-90 les efficacités de détection d'une mesure par scintillation liquide du Sr-90 et Y-90, respectivement et TY-90 la période radioactive du Y-90. Du fait de la très longue période radioactive du Sr-90, aucune correction de décroissance n'a été effectuée pour ce dernier. Mais la mesure dure un temps tm:
dte1AAN)t,t(Nm
90Y
tt
t
90Y
tT
)2ln(
90Sr90Sr90SrBGm !+
"
"
""" ##
$
%
&&
'
()##
$
%
&&
'
("+)+= "!
( )
!!
"
#
$$
%
&'
!!"
#$$%
&
(+(+(+= ''
'+'
'
''''''
tT
)2ln(tt
T
)2ln(
90Y
90Y90Srm90Y90Srm90Sr90SrmBGm
90Ym
90Y ee
T)2ln(
AtAtAtN)t,t(N !
Si maintenant on pose que les efficacités de détection de Sr-90 et Y-90 sont quasiment égales à 100% (/Sr-90=/Y-90=1) on a:
( )
!!
"
#
$$
%
&'
!!"
#$$%
&++= ''
'+'
'
''
tT
)2ln(tt
T
)2ln(
90Y
90Srm90SrmBGm
90Ym
90Y ee
T)2ln(
AtA2tN)t,t(N !
20 Vérifier dans Tools, Add-Ins que le Solver et les Analysis ToolPak sont bien activés. 21 Voir le fichier d'exemple sur http://www.eig.unige.ch/nucleaire/pedagogie/polycopies.html
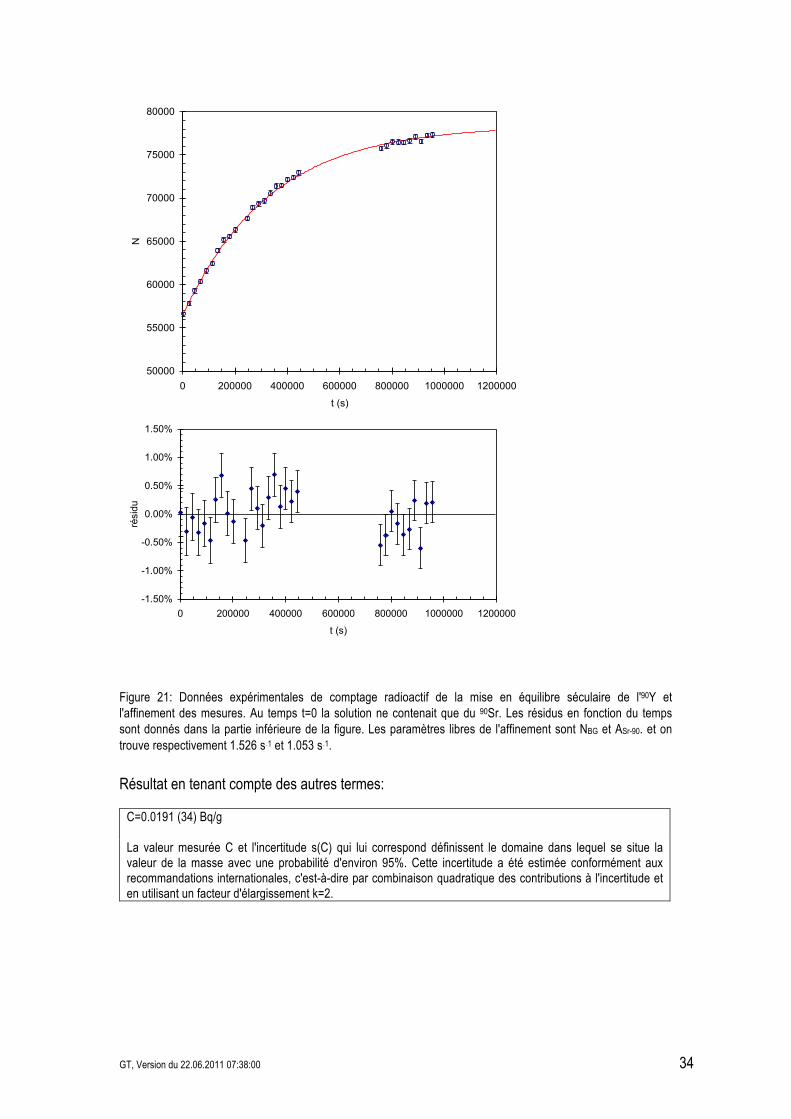
GT, Version du 22.06.2011 07:38:00 34
50000
55000
60000
65000
70000
75000
80000
0 200000 400000 600000 800000 1000000 1200000
t (s)
N
-1.50%
-1.00%
-0.50%
0.00%
0.50%
1.00%
1.50%
0 200000 400000 600000 800000 1000000 1200000
t (s)
rési
du
Figure 21: Données expérimentales de comptage radioactif de la mise en équilibre séculaire de l'90Y et l'affinement des mesures. Au temps t=0 la solution ne contenait que du 90Sr. Les résidus en fonction du temps sont donnés dans la partie inférieure de la figure. Les paramètres libres de l'affinement sont NBG et ASr-90. et on trouve respectivement 1.526 s&1 et 1.053 s&1.
Résultat en tenant compte des autres termes:
C=0.0191 (34) Bq/g La valeur mesurée C et l'incertitude s(C) qui lui correspond définissent le domaine dans lequel se situe la valeur de la masse avec une probabilité d'environ 95%. Cette incertitude a été estimée conformément aux recommandations internationales, c'est-à-dire par combinaison quadratique des contributions à l'incertitude et en utilisant un facteur d'élargissement k=2.
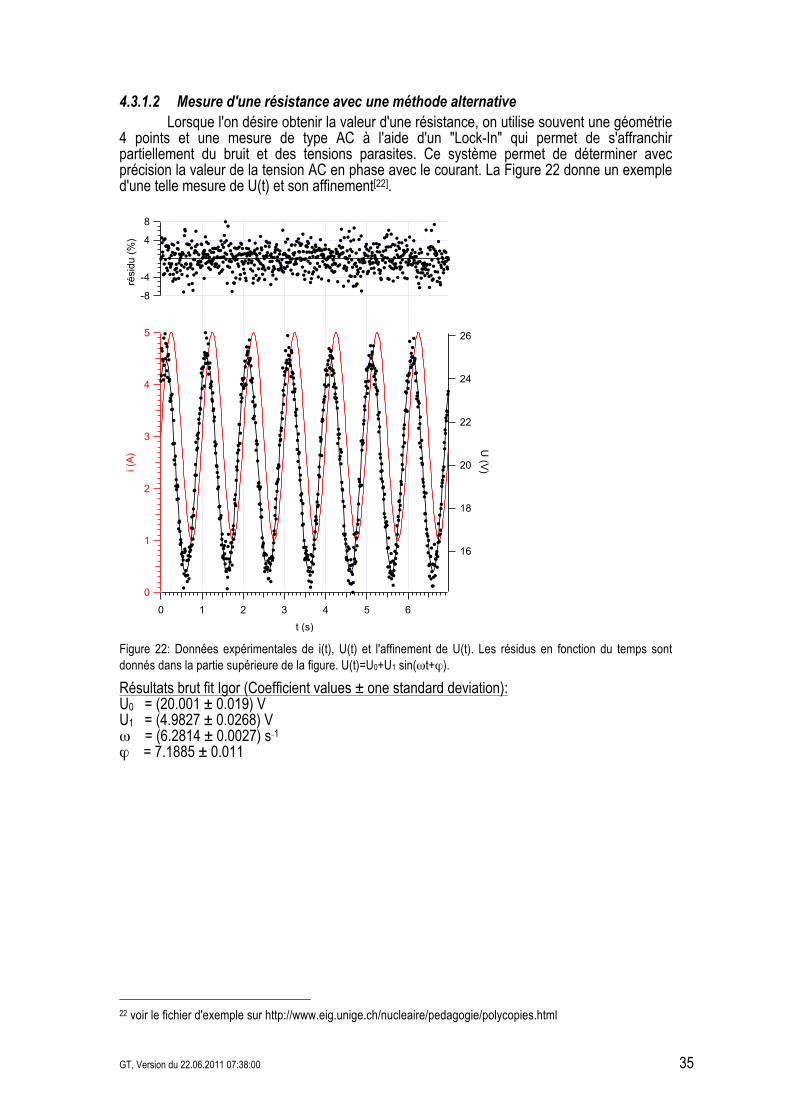
GT, Version du 22.06.2011 07:38:00 35
4.3.1.2 Mesure d'une résistance avec une méthode alternative Lorsque l'on désire obtenir la valeur d'une résistance, on utilise souvent une géométrie 4 points et une mesure de type AC à l'aide d'un "Lock-In" qui permet de s'affranchir partiellement du bruit et des tensions parasites. Ce système permet de déterminer avec précision la valeur de la tension AC en phase avec le courant. La Figure 22 donne un exemple d'une telle mesure de U(t) et son affinement[22].
5
4
3
2
1
0
i (A)
6543210
t (s)
26
24
22
20
18
16
U (V)
-8
-4
4
8
rési
du (%
)
Figure 22: Données expérimentales de i(t), U(t) et l'affinement de U(t). Les résidus en fonction du temps sont donnés dans la partie supérieure de la figure. U(t)=U0+U1 sin(0t+1).
Résultats brut fit Igor (Coefficient values ± one standard deviation): U0 = (20.001 ± 0.019) V U1 = (4.9827 ± 0.0268) V 0 = (6.2814 ± 0.0027) s&1 1 = 7.1885 ± 0.011
22 voir le fichier d'exemple sur http://www.eig.unige.ch/nucleaire/pedagogie/polycopies.html

GT, Version du 22.06.2011 07:38:00 36
4.3.2 Exercices
4.3.2.1 Atténuation d'un faisceau de photons Un faisceau de photons qui traverse un matériau est atténué de façon exponentielle. L'intensité de ce dernier en fonction de l'épaisseur x du matériau est donné par: x
o e I)x(I µ!= où Io est l'intensité initiale du faisceau et µ le coefficient d'atténuation massique qui dépend du matériau. Pour le cuivre, un étudiant a mesuré pendant un temps ,t le nombre d'interaction N produit par les photons dans un détecteur; N est proportionnel à I. Le résultat est donné en Table 5:
Table 5: Données de mesures de l'atténuation d'un faisceau de photons par un écran en cuivre. Remarque: l'incertitude s(N)=N&1/2.
x (cm) N 1.50E-02 4585 3.00E-02 4724 4.50E-02 4566 5.00E-02 4659 6.50E-02 4548 8.00E-02 4610 1.00E-01 4440 1.50E-01 4350 2.00E-01 4375 3.00E-01 4181 4.00E-01 3957 5.00E-01 3720 6.00E-01 3518 7.00E-01 3381 8.00E-01 3316 1.00E+00 2965 1.50E+00 2410 2.00E+00 1920
Figure 23: Schéma de l'installation de mesure de l'atténuation d'un faisceau de photons par un écran d'épaisseur x.
Déterminer le coefficient d'atténuation massique du cuivre en utilisant la formule:
x 1o e NN)x(N µ!+=
Résultats brut fit Igor (Coefficient values ± one standard deviation): N0 = 228.42 ± 353 N1 = 4485.9 ± 340 µ = (0.48637 ± 0.0583) cm&1
Io
x
I(x) détecteur
N(t)
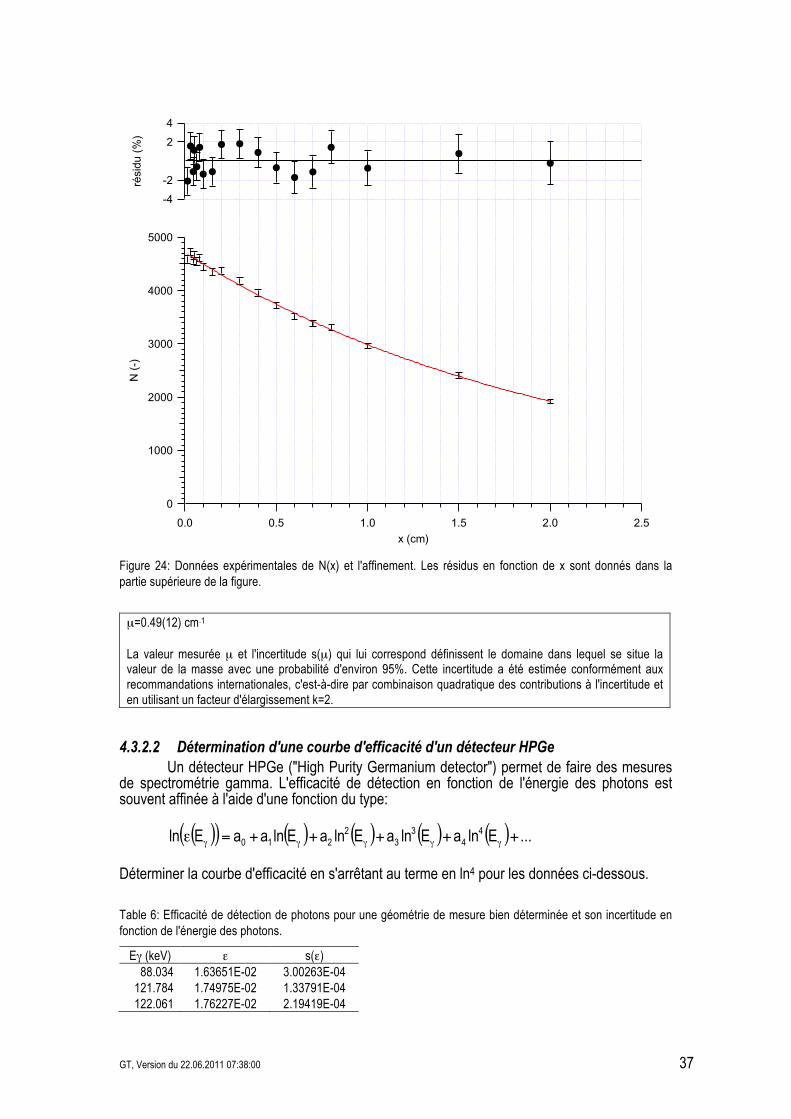
GT, Version du 22.06.2011 07:38:00 37
5000
4000
3000
2000
1000
0
N (-
)
2.52.01.51.00.50.0x (cm)
-4
-2
2
4ré
sidu
(%)
Figure 24: Données expérimentales de N(x) et l'affinement. Les résidus en fonction de x sont donnés dans la partie supérieure de la figure.
µ=0.49(12) cm&1 La valeur mesurée µ et l'incertitude s(µ) qui lui correspond définissent le domaine dans lequel se situe la valeur de la masse avec une probabilité d'environ 95%. Cette incertitude a été estimée conformément aux recommandations internationales, c'est-à-dire par combinaison quadratique des contributions à l'incertitude et en utilisant un facteur d'élargissement k=2.
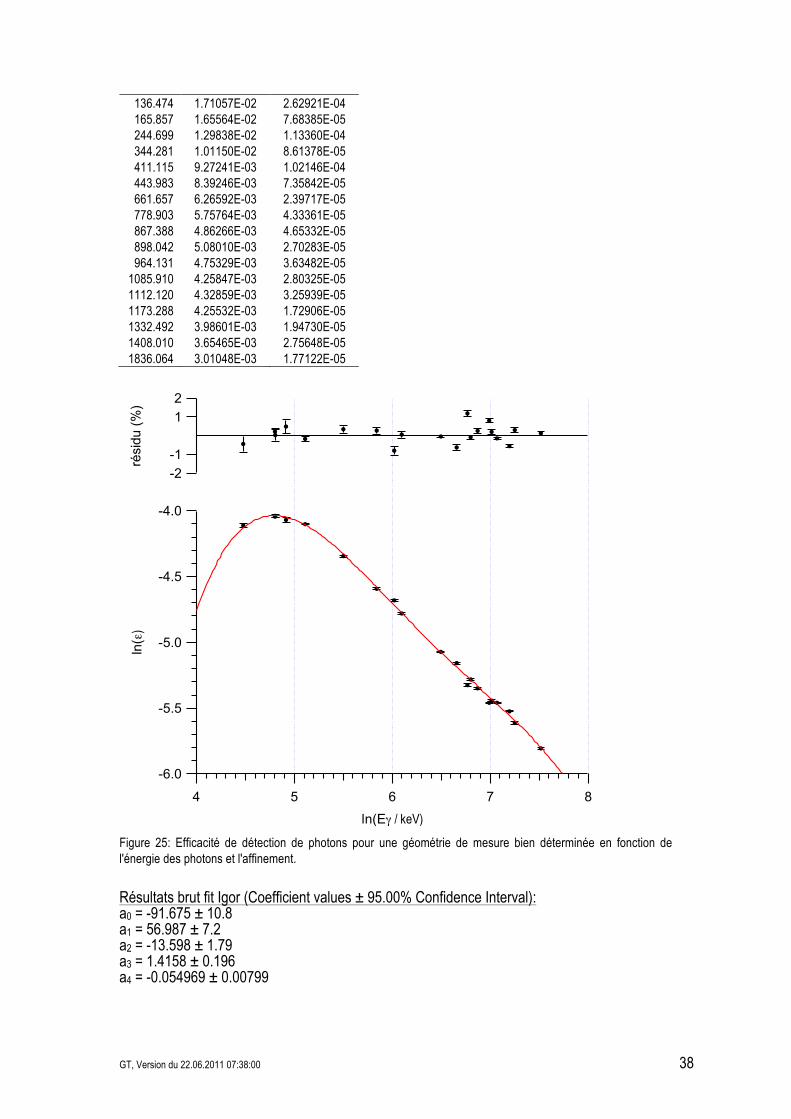
4.3.2.2 Détermination d'une courbe d'efficacité d'un détecteur HPGe Un détecteur HPGe ("High Purity Germanium detector") permet de faire des mesures de spectrométrie gamma. L'efficacité de détection en fonction de l'énergie des photons est souvent affinée à l'aide d'une fonction du type: ( )( ) ( ) ( ) ( ) ( ) ...ElnaElnaElnaElnaaEln 4
43
32
210 +++++=! """"" Déterminer la courbe d'efficacité en s'arrêtant au terme en ln4 pour les données ci-dessous.
Table 6: Efficacité de détection de photons pour une géométrie de mesure bien déterminée et son incertitude en fonction de l'énergie des photons.
E2 (keV) / s(/) 88.034 1.63651E-02 3.00263E-04
121.784 1.74975E-02 1.33791E-04 122.061 1.76227E-02 2.19419E-04
GT, Version du 22.06.2011 07:38:00 38
136.474 1.71057E-02 2.62921E-04 165.857 1.65564E-02 7.68385E-05 244.699 1.29838E-02 1.13360E-04 344.281 1.01150E-02 8.61378E-05 411.115 9.27241E-03 1.02146E-04 443.983 8.39246E-03 7.35842E-05 661.657 6.26592E-03 2.39717E-05 778.903 5.75764E-03 4.33361E-05 867.388 4.86266E-03 4.65332E-05 898.042 5.08010E-03 2.70283E-05 964.131 4.75329E-03 3.63482E-05
1085.910 4.25847E-03 2.80325E-05 1112.120 4.32859E-03 3.25939E-05 1173.288 4.25532E-03 1.72906E-05 1332.492 3.98601E-03 1.94730E-05 1408.010 3.65465E-03 2.75648E-05 1836.064 3.01048E-03 1.77122E-05
-6.0
-5.5
-5.0
-4.5
-4.0
ln(!
)
87654ln(E" / keV)
-2-1
12
rési
du (%
)
Figure 25: Efficacité de détection de photons pour une géométrie de mesure bien déterminée en fonction de l'énergie des photons et l'affinement.
Résultats brut fit Igor (Coefficient values ± 95.00% Confidence Interval): a0 = -91.675 ± 10.8 a1 = 56.987 ± 7.2 a2 = -13.598 ± 1.79 a3 = 1.4158 ± 0.196 a4 = -0.054969 ± 0.00799

GT, Version du 22.06.2011 07:38:00 39
4.4 Ce qu'il faut vérifier ! Un bon affinement est caractérisé par:
1. une valeur de Q2 raisonnable par rapport au nombre de degré de liberté ; 2. un graphique des résidus montrerait qu'ils fluctuent autour de zéro sans montrer une
de quelconque dépendance (un affinement de ces derniers donnerait une droite de pente nulle coupant l'origine, y=0 x + 0)).
Si la condition 1 est remplie mais la 2 par exemple les résidus fluctuent et présentent une dépendance (un affinement de ces derniers donnerait par exemple une droite de pente non nulle). On conclut que la fonctionnelle utilisée dans l'affinement des données expérimentales néglige un terme mineur ou n'est pas adaptée. Si la condition 1 n'est pas remplie mais la 2 l'est alors on peut suspecter que la fonctionnelle utilisée dans l'affinement des données expérimentales est adéquate mais que les incertitudes sont sous estimées. Si la condition 1 n'est pas remplie et la 2 non plus alors on peut suspecter que la fonctionnelle utilisée dans l'affinement des données expérimentales n'est pas adaptée.
4.4.1 Exemple de calcul avec Excel Si je donne c'est exemple c'est que beaucoup d'utilisateurs d'informatique possèdent ce logiciel ! Soit les dix mesures expérimentales <xi;yi> avec leurs incertitudes s(yi) données dans la table ci-après:
Xi Yiexp s(Yi
exp) 1.0 3.2 0.6 2.0 5.3 1.1 3.0 5.5 0.6 4.0 7.2 1.2 5.0 9.5 0.8 6.0 10.2 0.6 7.0 14.5 0.6 8.0 15.6 1.1 9.0 21.0 3.0
10.0 21.2 0.5 Tracer le graphique à l'aide d'Excel (par exemple) avec les incertitudes et effectuer un affinement linéaire et polynomiale de degré 2 selon la méthode du 2! . Quelle est la fonction qui la plus probable ? Rappel sur la procédure :
1. mettre les données xi dans une colonne (par exemple A) ; 2. mettre les données yi dans une autre colonne (par exemple B) ; 3. mettre les incertitudes s(yi) dans une autre colonne (par exemple C). Si il n'y a pas d'incertitude mettre
donner la valeur 1 à chaque s(yi) / toutes les données ont le même poids ; 4. mettre les paramètres libres de la fonction d'affinement dans des cellules comme par exemple :
• f(x)= A e&3t, une fonction décroissante exponentiellement où A et 3 sont les paramètres à déterminer (par exemple la décroissance radioactive) ;
• on mettrait par exemple A en cellule K1 et 3 en cellule K2 et on introduirait une première valeur "de départ" physiquement acceptable. Par exemple A=1000 Bq et 3=3-10&5 s&1 ;
5. on calcule dans une colonne (par exemple D) la valeur de f(xi) ; 6. on calcule dans une colonne (par exemple E) la valeur (yi&f(xi)2/s2(yi)
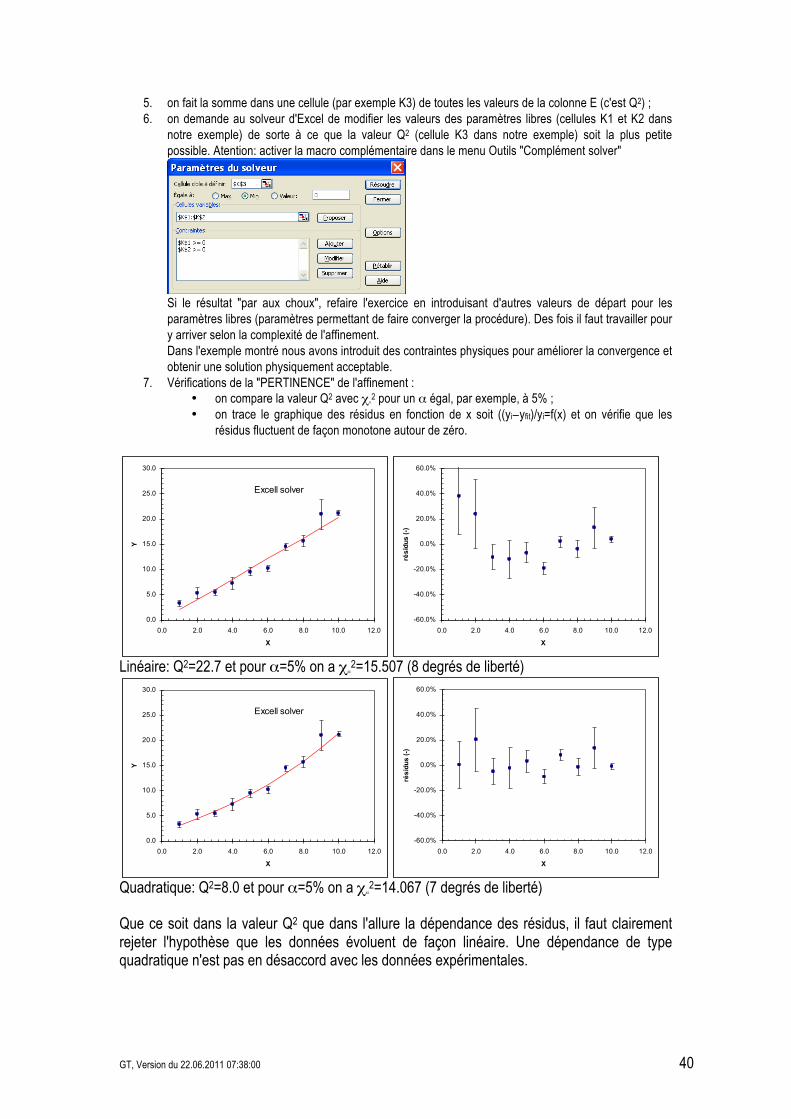
GT, Version du 22.06.2011 07:38:00 40
5. on fait la somme dans une cellule (par exemple K3) de toutes les valeurs de la colonne E (c'est Q2) ; 6. on demande au solveur d'Excel de modifier les valeurs des paramètres libres (cellules K1 et K2 dans
notre exemple) de sorte à ce que la valeur Q2 (cellule K3 dans notre exemple) soit la plus petite possible. Atention: activer la macro complémentaire dans le menu Outils "Complément solver"
Si le résultat "par aux choux", refaire l'exercice en introduisant d'autres valeurs de départ pour les paramètres libres (paramètres permettant de faire converger la procédure). Des fois il faut travailler pour y arriver selon la complexité de l'affinement. Dans l'exemple montré nous avons introduit des contraintes physiques pour améliorer la convergence et obtenir une solution physiquement acceptable.
7. Vérifications de la "PERTINENCE" de l'affinement : • on compare la valeur Q2 avec !.
2 pour un . égal, par exemple, à 5% ; • on trace le graphique des résidus en fonction de x soit ((yi&yfit)/yi=f(x) et on vérifie que les
résidus fluctuent de façon monotone autour de zéro.
0.0
5.0
10.0
15.0
20.0
25.0
30.0
0.0 2.0 4.0 6.0 8.0 10.0 12.0
X
Y
Excell solver
-60.0%
-40.0%
-20.0%
0.0%
20.0%
40.0%
60.0%
0.0 2.0 4.0 6.0 8.0 10.0 12.0
X
rési
dus
(-)
Linéaire: Q2=22.7 et pour .=5% on a !.
2=15.507 (8 degrés de liberté)
0.0
5.0
10.0
15.0
20.0
25.0
30.0
0.0 2.0 4.0 6.0 8.0 10.0 12.0
X
Y
Excell solver
-60.0%
-40.0%
-20.0%
0.0%
20.0%
40.0%
60.0%
0.0 2.0 4.0 6.0 8.0 10.0 12.0
X
rési
dus
(-)
Quadratique: Q2=8.0 et pour .=5% on a !.
2=14.067 (7 degrés de liberté) Que ce soit dans la valeur Q2 que dans l'allure la dépendance des résidus, il faut clairement rejeter l'hypothèse que les données évoluent de façon linéaire. Une dépendance de type quadratique n'est pas en désaccord avec les données expérimentales.

GT, Version du 22.06.2011 07:38:00 41
Appendice: l'approche Bayesienne23 Généralement[24], l'état d'un système est bien défini comme par exemple: le patient a une tumeur, le patient est séropositif, l'échantillon a une masse m, l'échantillon a une température T, etc. Mais, de fait, les observations d'un même état donnent des résultats différents; des radiographies des poumons successives sont différentes, des mesures successives de la masse, de la température donnent des distributions de résultats. La Figure 26 indique ce fait.
Figure 26: Pour un même état 4 l'expérimentateur mesure des valeurs de mesurandes dx dans l'espace des observations. Par définition P(dx|4 ) est la probabilité de mesurer dx étant donné l'état 4 , par exemple la probabilité de mesurer un comptage radioactif N=123 étant donné que l'activité de la source est de 12 kBq.
Mais en fait on procède exactement de façon inverse étant donné que l'on mesure x et on en déduit l'état 4 comme le montre la Figure 27.
Figure 27: Une même observation x peut provenir de différents états 4. Par définition 5 (d4 |x) est la probabilité à posteriori étant donné l'observation x, par exemple la probabilité que le patient soit séropositif si le test est négatif. On peut se convaincre facilement que cette probabilité est différente si le test est effectué en Europe ou, malheureusement, en Afrique.
Si l'on connaît la probabilité à priori 5(d4), par exemple la probabilité de séropositifs dans la population, on peut alors calculer la marginale M(x) correspondant à l'ensemble des observations x comme le montre la Figure 28. M(x) se calcule selon:
23 Tiré de la présentation de François Bochud 2003; http://www.bag.admin.ch/strahlen/ionisant/radio_env/pdf-2003-seminaire/bayes-ok.pdf 24 On peut penser à certains états quantiques où l'expérience modifie l'état.
Etats Observations
x
5(d4|x)
Etats Observations
4
P(dx|4)

GT, Version du 22.06.2011 07:38:00 42
)d()dx(P)x(M !"!= #!
soit la probabilité d'observer dx étant donné l'état 4 intégrée sur tous les états à priori.
Figure 28: La probabilité à priori 5(d4) engendre l'ensemble d'observation M(x).
4.5 Théorème de Bayes Ainsi on a:
Eq. 27 )dx(M
)d()dx(P)xd(
)dx(M)xd()d,dx(P
)d()dx(P)d,dx(P !"!=!"#
$%
$&'
!"=!
!"!=!
qui est le théorème de Bayes qui définit la distribution à posteriori des états, connaissant l'observation x. En mot, la probabilité d'observer dx et que l'état soit d4 est égale à:
• la probabilité de mesurer dx étant donné l'état 4 fois la probabilité à priori des états d4; • la probabilité à posteriori d'avoir l'état d4 étant donné l'observation dx fois la marginale
des observations. Ce théorème donne à l'expérimentateur ce qu'il recherche soit la probabilité d'avoir l'état d" étant donné l'observation dx. Thomas Bayes (1702-1761) découvrit ce théorème. Utilisé par Laplace, puis inutilisé par les statisticiens. Redécouvert par Jeffreys (1938) il est de plus en plus accepté comme base de la théorie de l'inférence.
4.5.1 Exemples
4.5.1.1 Test de cancer du sein Supposons que l'on prenne une mammographie de l'ensemble de la population des femmes entre 40 et 50 ans et que sur ces images, une proportion B présente une information compatible avec la présence d'une tumeur. Si la proportion de femmes réellement atteinte est de A, on a la situation:
Etats Observations
M(x) 5(d4)

GT, Version du 22.06.2011 07:38:00 43
Figure 29: Ensemble C de mammographies, sur cet ensemble une proportion A de personnes présente une tumeur et une proportion B de radiographies sont interprétées comme présentant une tumeur.
Le théorème de Bayes donne:
)B(P
)A(P)AB(P)BA(P
)B(P)BA(P)BA(P
)A(P)AB(P)BA(P=!
"#
"$%
=&
=&
Supposons que la probabilité qu'une femme entre 40 et 50 ans ait un cancer du sein est de P(A)=1%; P(A) est par exemple obtenu à l'aide de nombreuses études dans nos pays occidentaux. Supposons encore que ces mêmes études montrent que le cancer du sein dépisté à l'aide de mammographie est très difficile, principalement lorsque ce dernier est à l'état précoce; on aurait par exemple un P(B|A)=60%. Si l'on sait de plus qu'en moyenne P(B)=10.5% des mammographies sont déclarées positives, alors la probabilité de la présence réelle d'un cancer lors d'un dépistage positif est de P(A|B)=(60%*1%)/10.5%=5.7% ! Remarque: cela ne veut pas dire que les personnes atteintes ne sont pas bien dépistées car elles le sont avec un taux de succès de P(B|A)=60% mais que lorsque le test est positif, il faut des analyses complémentaires car dans beaucoup de cas les patientes ne sont pas atteintes.
4.5.1.2 Test du SIDA Exemple identique que le précédent pour des tests de séropositivité. En Suisse 0.4% des habitants sont séropositifs soit P(A)=0.4%; environ 30'000 personnes. Supposons que les tests présentent un nombre de faux positifs de 0.5% soit P(B|A)=1&0.5%=99.5% (0.5% des tests effectués sur du sang contaminé sont négatifs). Si le nombre de faux négatifs est aussi de 0.5% (0.5% des tests effectués sur du sang non contaminé sont positifs), alors dans le cas d'un dépistage général de la population P(B)=(0.4%*99.5%+99.6%*0.5%)=0.9%[25]. La probabilité réelle de séropositivité d'un patient présentant un test positif est de P(A|B)=(99.5%*0.4%)/0.9%=44.4%. Si maintenant le test est effectué dans une population africaine très fortement touchée par cette épidémie, P(A)=40%, P(B)=(40%*99.5%+60%*0.5%)=40.1%, on a cette fois une probabilité de séropositivité lorsque le test est positif de P(A|B)=(99.5%*40%)/40.1%=99.3% !
25 P(B) serait différent si, par exemple, les tests étaient principalement effectués sur une population à comportements à risques.
A B
A6B
C

GT, Version du 22.06.2011 07:38:00 44
4.5.2 Propositions de modifications du Guide ISO Des propositions de modifications du Guide ISO de l'expression de l'incertitude de mesure sont actuellement proposées par les métrologues; voir e.g.:
• R. Kacker & A. Jones, "On use of Bayesian statistics to make the Guide to the Expression of Uncertainty in Measurement consistent", Metrologia 40 (2003) 235-248[26].
• J.-P. Laedermann, "Théorie Bayesienne appliquée à la mesure de la radioactivité", Thèse de l'Université de Lausanne (2003).
26 Abstract. The International Organization for Standardization (ISO) Guide to the Expression of Uncertainty in Measurement is being increasingly recognized as a de facto international standard. The ISO Guide recommends a standardized way of expressing uncertainty in all kinds of measurements and provides a comprehensive approach for combining information to evaluate that uncertainty. The ISO Guide supports uncertainties evaluated from statistical methods, Type A, and uncertainties determined by other means, Type B. The ISO Guide recommends classical (frequentist) statistics for evaluating the Type A components of uncertainty; but it interprets the combined uncertainty from a Bayesian viewpoint. This is inconsistent. In order to overcome this inconsistency, we suggest that all Type A uncertainties should be evaluated through a Bayesian approach. It turns out that the estimates from a classical statistical analysis are either equal or approximately equal to the corresponding estimates from a Bayesian analysis with non-informative prior probability distributions. So the classical (frequentist) estimates may be used provided they are interpreted from the Bayesian viewpoint. The procedure of the ISO Guide for evaluating the combined uncertainty is to propagate the uncertainties associated with the input quantities. This procedure does not yield a complete specification of the distribution represented by the result of measurement and its associated combined standard uncertainty. So the correct coverage factor for a desired coverage probability of an expanded uncertainty interval cannot always be determined. Nonetheless, the ISO Guide suggests that the coverage factor may be computed by assuming that the distribution represented by the result of measurement and its associated standard uncertainty is a normal distribution or a scaled-and-shifted t-distribution with degrees of freedom determined from the Welch–Satterthwaite formula. This assumption may be unjustified and the coverage factor so determined may be incorrect. A popular convention is to set the coverage factor as 2. When the distribution represented by the result of measurement and its associated standard uncertainty is not completely determined, the 2-standard-uncertainty interval may be interpreted in terms of its minimum coverage probability for an applicable class of probability distributions.





















