Embed Size (px)
Citation preview

Institut Supérieur Cemagref de Clermont-Ferrand d’Informatique de Modélisation et de Campus universitaire des Cézeaux leurs Applications BP50085 24 avenue des Landais Complexe des Cézeaux 63172 Aubière cedex BP 125 63 173 Aubière Cedex
Rapport d’ingénieur Projet de 2ème année
Filière 4
Mise en place d’un protocole d’évaluation de différentes méthodes d’échantillonnage
TOME I
Présenté par : Anthony Ricochon
Nathanaël Le Dantec Responsable ISIMA : Vincent Barra Mardi 24 mars 2009 Chef de projet : Florent Chuffart Durée : 100 heures

Remerciements
Nous souhaitons remercier Florent Chuffart qui nous a propose un sujet de projet et quinous a accueillis au Cemagref de Clermont-Ferrand. Nous tenons egalement a le remercierpour son aide a la realisation du projet et du temps qu’il nous a consacre.
Nous remercions egalement Vincent Barra pour avoir accepte la proposition de sujet deFlorent Chuffart.

Abstract
This report deals with the evaluation of sampling method efficiency. Understanding thebasics of sampling methods is a necessary prerequisite in defining a well-adapted experi-mental protocol in order to compare them with each other. The literature provides us withBenchmark functions that are good candidates to implement the sampling methods. Inorder to compare the efficiency of the different methods, we used the root mean squareerror between the Benchmark function and its polynom.
The project’s aim was to code in Java the process of comparison between the samplingmethods. This process takes at input the sampling method, the problem’s dimension andthe size of the sample. At the end of the process, we have the root mean square error whichis associated with a sampling method. With this programm, it is now possible to obtain theefficiency of several sampling methods for miscellaneous problem dimensions and samplesizes. We focused our study on the comparison between two sampling methods, which arethe regular grid and the Latin Hypercube Sampling (LHS). The study showed thatin 1D, the use of the regular grid is preferable for functions which have the same characte-ristics as the Rastrigin function. On the contrary, in 1D, the use of the LHS is preferablefor functions which have the same characteristics as the Griewank function. Moreover, thestudy showed that the best sampling method in 2D is the regular grid. However, the samplesizes were limited because of the length of calculation. The use of more powerful machineswould be preferable in order to have bigger sample sizes and consequently better comparisons.
Keywords : sampling method, root mean square error, Benchmark function, regular grid,Latin Hypercube Sampling

Resume
Ce rapport porte sur l’etude et l’efficacite de differentes methodes d’echantillonnage.Des lors, il est indispensable de comprendre le principe des differentes methodes d’echan-tillonnage afin de pouvoir determiner un protocole pertinent pour les comparer. Celui-ciconsiste a les appliquer sur des fonctions de Benchmark, connues pour etre de bonnesfonctions de test vis-a-vis de la robustesse des methodes d’echantillonnage. Pour juger del’efficacite de ces methodes, le critere utilise est l’erreur quadratique moyenne entre lesfonctions de Benchmark et un polynome de regression passant par les points de l’echan-tillonnage.
Le projet a donc consiste a coder en Java le processus de comparaison des methodesd’echantillonnage. Celui-ci prend en entree une methode d’echantillonnage, la dimen-sion du probleme et le nombre souhaite de points de l’echantillonnage. En sortie, nous avonsl’erreur quadratique moyenne associee a la methode d’echantillonnage choisie. Unefois ce processus de comparaison code, il est alors possible de determiner l’efficacite de plu-sieurs methodes d’echantillonnage pour plusieurs dimensions du probleme et pour desnombres differents de points pour un echantillon. L’etude s’est alors concentree sur la com-paraison de deux methodes d’echantillonnage, l’une sur une grille reguliere et l’autrepar l’echantillonnage Hypercube Latin (LHS). Celle-ci a revele qu’en dimension 1, l’uti-lisation de la grille reguliere etait preferable pour les fonctions similaires a la fonction deRastrigin alors que l’utilisation du LHS est preferable pour les fonctions similaires a la fonc-tion de Griewank. De plus, cette etude a montre que la grille reguliere etait la meilleuremethode dans le cas de la dimension 2. Cependant, nous avons ete limites dans le choix dela taille des echantillonnages a cause du temps de calcul. Pour une meilleure comparaison desmethodes d’echantillonnage, il faudrait prendre plus de points dans les echantillonnages.Cela pourrait etre effectue avec des machines qui ont une puissance de calcul plus elevee.
Mots cles : methodes d’echantillonnage, erreur quadratique moyenne, fonctions de Bench-mark, grille reguliere, echantillonnage Hypercube Latin

Table des matieres
Introduction 1
1 Analyse du projet 21.1 Les methodes d’echantillonnage . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.1.1 Grille reguliere . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.1.2 Methode d’echantillonnage de l’Hypercube Latin (LHS) . . . . . . . . . 3
1.2 Les fonctions de ”Benchmark” . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.3 L’erreur quadratique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Demarche pour la construction du programme 72.1 Calculs des erreurs quadratiques . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.1 Modification de l’ecriture du polynome de regression . . . . . . . . . . . 82.1.2 Calcul de l’erreur quadratique pour la fonction de Rastrigin . . . . . . . 82.1.3 Calcul de l’erreur quadratique pour la fonction de Griewank . . . . . . . 10
2.2 Demarche informatique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.2.1 Diagramme de classe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.2.2 Enchaınement des processus . . . . . . . . . . . . . . . . . . . . . . . . . 122.2.3 Protocoles de tests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.2.4 Problemes rencontres . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3 Resultats et discussion 153.1 Resultats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.1.1 Observations sur le polynome de regression . . . . . . . . . . . . . . . . 153.1.2 Experience 1 : Evolution de l’erreur en fonction du nombre de points
dans l’echantillon en dimension 1 pour la fonction de Rastrigin . . . . . 163.1.3 Experience 2 : Evolution de l’erreur en fonction de la taille de l’echan-
tillon en dimension 1 pour la fonction de Griewank . . . . . . . . . . . . 183.1.4 Experience 3 : Evolution de l’erreur en fonction du nombre de la taille
de l’echantillon en dimension 2 pour la fonction de Rastrigin . . . . . . 213.1.5 Experience 4 : Evolution de l’erreur en fonction de la taille de l’echan-
tillon en dimension 2 pour la fonction de Griewank . . . . . . . . . . . . 213.2 Discussion des resultats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
Conclusion 23

Introduction
Dans le cadre de notre deuxieme annee d’etude a l’ISIMA, nous avons realise un projetde cent heures reparties sur six mois, entre octobre 2008 et mars 2009, dirige par M. FlorentChuffart, membre du Cemagref de Clermont-Ferrand. Cet institut est specialise dans les tech-nologies de l’information pour les agrosystemes et les mutations des activites, des espaces etdes formes d’organisation dans les territoires ruraux. Le domaine d’application de ce projetconcerne les methodes d’echantillonnage et plus precisement l’efficacite de ces methodes.
L’echantillonnage consiste a transformer un signal analogique (continu) en un signal nu-merique (discret) en capturant des valeurs separees par des intervalles de temps. Un signalanalogique est, par definition, d’une precision infinie en temps et en valeur. L’echantillonnageva discretiser ce signal en un nombre fini de points. Cela implique que seule la valeur presentesur le point de capture est enregistree et tout le reste est perdu. Intuitivement, on se rendcompte qu’il faut bien choisir la methode d’echantillonnage afin de minimiser la perte d’infor-mation. C’est pour cela qu’il est necessaire d’identifier la methode d’echantillonnage la plusefficace pour le probleme que l’on veut traiter. Notre sujet consistait ainsi a evaluer l’efficacitede plusieurs methodes d’echantillonnage et cela en fonction de la dimension dans laquelle leprobleme se situe et en fonction du nombre de points d’echantillonnage que l’on souhaite. M.Chuffart avait implemente differentes methodes d’echantillonnage telles que la grille reguliereou l’Hypercube Latin (LHS : Latin Hypercube Sampling) mais ne savait pas laquelle etait laplus efficace selon les proprietes du probleme. Le projet a alors consiste a mettre en oeuvreun protocole experimental d’evaluation de ces methodes d’echantillonnage.
Pour realiser ce projet, il est necessaire de prendre connaissance des differentes methodesd’echantillonnage qui existent afin de bien comprendre le probleme general. Une fois le prin-cipe des methodes d’echantillonnage assimile, l’etape suivante consiste a prendre connaissancedes fonctions de Benchmark et du critere d’evaluation qui est, en l’occurence, l’erreur quadra-tique moyenne. Des lors, le travail revient a calculer ce critere sur les fonctions de Benchmark.L’elaboration d’un diagramme de classes est alors necessaire afin d’organiser le codage du cal-cul de cette erreur pour diverses methodes d’echantillonnage. Une fois cette etude terminee, ilfaut coder les fonctions de Benchmark et les methodes d’echantillonnage pour determiner leserreurs quadratiques moyennes. Enfin, la derniere etape consiste a exploiter les resultats, asavoir etudier l’evolution de l’erreur quadratique moyenne en fonction du nombre de points del’echantillonnage pour les deux methodes utilisees. Dans ce rapport, nous vous presenterons,dans un premier temps, la phase d’analyse de ce projet. Cette partie contient, notamment,une description des deux methodes d’echantillonnage utilisees, des fonctions de Benchmarket de l’indicateur d’erreur. Dans une seconde partie, nous effectuerons une synthese des cal-culs effectues et de la demarche suivie afin d’elaborer le programme en Java. Enfin, nousindiquerons dans une derniere section les resultats obtenus ainsi que les conclusions qui enresultent.
1

1 Analyse du projet
Dans cette partie, nous vous decrirons la phase d’analyse du projet effectuee en amont de lamise en oeuvre du protocole experimental. Cette phase d’analyse permet de prendre connais-sance du probleme de l’echantillonnage afin de pouvoir construire un protocole experimentalpertinent.
1.1 Les methodes d’echantillonnage
Dans ce paragraphe, nous allons detailler le principe de deux methodes d’echantillonnage.La premiere est basee sur une grille reguliere et la seconde est obtenue a partir de l’HypercubeLatin (LHS).
1.1.1 Grille reguliere
La methode d’echantillonnage basee sur la grille reguliere est la plus intuitive. Celle-ciconsiste a subdiviser les intervalles de chaque dimension en plusieurs sous-intervalles de memetaille. Un exemple de grille reguliere est donnee sur la figure suivante (figure 1).
Figure 1 – Grille reguliere en 2D
On constate qu’avec cette methode d’echantillonnage, on obtient un quadrillage de l’espace2D. On prend comme points d’echantillonnage les points du quadrillage obtenu. De cettemaniere, on obtient plusieurs points qui ont la meme ordonnee ou la meme abscisse. On aainsi des points d’echantillonnage qui sont ”alignes”. Sur la figure precedente, les intervalles enabscisses et en ordonnees ont la meme longueur et ont ete subdivises en un nombre identiquede sous-intervalles. Le quadrillage obtenu est donc carre. Cependant, rien ne nous obligeaita subdiviser les abscisses et les ordonnees en un nombre identique de sous-intervalles. Lequadrillage que l’on obtiendrait alors serait rectangulaire. Ce type d’echantillonnage est utilisedans le cas d’une dimension pour numeriser des documents sonores. Par exemple, un CD audiocontient des donnees musicales echantillonnees a 44,1 kHz (44 100 points d’echantillonnagepar seconde).
2

1.1.2 Methode d’echantillonnage de l’Hypercube Latin (LHS)
La methode d’echantillonnage de l’Hypercube Latin a ete utilisee dans de nombreux mo-deles informatiques depuis 1975. L’echantillonnage de l’Hypercube Latin selectionne n valeursdistinctes pour chacune des k variables X1 X2, ...Xk de la maniere suivante. Le domaine dechaque variable est divise en n intervalles disjoints. La phase suivante consiste a choisir aleatoi-rement dans chaque sous-intervalle une valeur. Les n valeurs obtenues pour X1 sont coupleesaleatoirement avec les n valeurs de X2. Ces n paires sont combinees avec les n valeurs de X3
pour former n triplets, etc. jusqu’a ce que n k-uplets soient formes. Cette construction del’echantillonnage garantit que l’on n’a qu’une valeur dans chaque sous-intervalle de chaquedirection de l’espace.
Nous allons illustrer la construction d’un tel echantillonnage dans le cas de la dimension2 avec 6 points d’echantillonnage. Dans cet exemple, nous avons donc 2 variables X1 et X2.Le domaine de chacune de ces 2 variables est [-3 ; 3]. Comme le nombre de points desire dansl’echantillon est 6, on divise ces 2 intervalles en 6 sous-intervalles. Ceux-ci sont [-3 ; -2], [-2 ;-1], ..., [2 ; 3] dans chaque direction. La phase suivante pour obtenir l’echantillonnage de l’Hy-percube Latin est de selectionner des valeurs specifiques de X1 et X2 dans les 6 intervalles dechacune des dimensions. Ainsi, X1 et X2 possedent maintenant 6 valeurs specifiques. Ensuite,les valeurs selectionnees de X1 et X2 sont aleatoirement couplees afin d’obtenir les 6 coordon-nees des points de l’echantillonnage souhaites. Dans le premier concept de l’Hypercube Latin,les couples etaient concus en utilisant une permutation aleatoire des n premiers entiers. Dansnotre exemple precedent, on considere deux permutations aleatoires des entiers (1, 2, 3, 4, 5,6) comme suit :
Permutation numero 1 : (3, 1, 5, 2, 4, 6)
Permutation numero 2 : (2, 4, 1, 3, 5, 6)
En considerant que les nombres de ces permutations correspondent a des numeros d’intervallespour X1 (permutation 1) et X2 (permutation 2), les couples suivants d’intervalles peuventetre formes :
Point Numero d’intervalle pour X1 Numero d’intervalle pour X2
1 3 22 1 43 5 14 2 35 4 56 6 6
Pour le premier point, les coordonnees sont determinees en selectionnant la valeur specifiquede X1 de l’intervalle 3 ([-1 ; 0]) et en l’associant a la valeur specifique de X2 de l’intervalle2 ([-2 ; -1]). Les coordonnees des autres points sont obtenues de la meme maniere. La figuresuivante (figure 2) montre un exemple d’echantillonnage d’Hypercube Latin.
On constate effectivement sur cet exemple que, grace a cette technique, on obtient un seulpoint dans chaque sous-intervalle de X1 et de X2.
3

Figure 2 – Exemple d’echantillonnage LHS pour 6 points en dimension 2
1.2 Les fonctions de ”Benchmark”
Avec l’essor des calculs, en particulier grace a l’informatique, il est frequent d’utiliserun large ensemble de tests afin de comparer plusieurs algorithmes. Ceci est particulierementvrai lorsque le test concerne des fonctions d’optimisation. Cependant, la mesure de l’efficacited’un algorithme depend de la pertinence du probleme a traiter par cet algorithme. En effet,si l’on compare deux algorithmes de recherche avec toutes les fonctions possibles, alors lesdeux algorithmes seront en moyenne aussi efficaces. Par consequent, essayer de concevoirun ensemble de test parfait ou toutes les fonctions sont presentes, afin de determiner si unalgorithme est meilleur que l’autre pour chaque fonction, est une tache vaine. C’est la raisonpour laquelle, lorsqu’un algorithme est evalue, nous devons plutot regarder pour quels typesde problemes l’algorithme convient. Ainsi, par la suite, le choix de l’algorithme se fera selonle type de probleme que l’on a a traiter. Pour savoir quels algorithmes correspondent a quelstypes de problemes, on utilise un ensemble de tests constitue de fonctions de Benchmarkqui sont utilisees pour divers de problemes. Cet ensemble contient notamment les fonctionsde Ackley, de Rastrigin et de Griewank, mais aussi les fonctions spherique, de Schwefel, deFletcher...
Les fonctions retenues initialement etaient les fonctions de Ackley, de Griewank et deRastrigin. Malheuresement, pour des raisons de problemes d’integration, la fonction de Ackleyn’a pu etre retenue. Ainsi, les fonctions de Benchmark retenues pour evaluer l’efficacite desmethodes d’echantillonnage sont les fonctions de Rastrigin et de Griewank.
La fonction de Rastrigin generalisee (equation 1) est un exemple typique de fonctionnon lineaire ayant de nombreux minima locaux. Cette fonction a d’abord ete proposee parRastrigin comme une fonction a 2 dimensions puis a ete generalisee par Muhlenbein. Cettefonction est assez difficile a etudier du fait du grand nombre de extrema locaux qu’elle possede.La fonction est determinee par les variables externes A et ω, qui controlent respectivementl’amplitude et la modulation en frequences.
4

f(x) = A · n+n∑
i=1
x2i −A · cos(ω · xi) (1)
A = 10 ; ω = 2π ; xi ∈ [−5, 12; 5, 12]
Une representation 3D de la fonction de Rastrigin est donnee sur la figure 3(a) en page 5.
Le probleme de Griewank (equation 2) est un probleme de minimisation. Formellement,ce probleme peut etre resume a trouver un vecteur x = {x1, x2, ..., xn} avec xi ∈ [−600; 600],qui minimise la fonction suivante :
f(x) = 1 +n∑
i=1
x2i
4000−
n∏
i=1
cos
(xi√i
), xi ∈ [−600; 600] (2)
Une representation 3D de la fonction de Griewank est donnee sur la figure 3(b) en page 5.
(a) Fonction de Rastrigin en 3D (b) Fonction de Griewank en 3D
Figure 3 – Fonctions de Rastrigin et de Griewank en dimension 3
1.3 L’erreur quadratique
En mathematiques, la valeur efficace (aussi dite RMS ou Root Mean Square) est unemesure statistique de la magnitude d’une quantite. Elle est tres utile notamment lorsque lesvariations sont positives et negatives, comme par exemple lorsque la fonction est une sinusoıde.Le nom de cette mesure vient du fait qu’elle est egale a la racine carree de la moyenne desvaleurs au carre. Cette valeur peut etre calculee pour des series a valeurs discretes ou pourdes fonctions continues.
Ainsi, l’eRMS de n valeurs x1, x2, ..., xn a la valeur suivante :
xRMS =
√√√√ 1n
n∑
i=1
x2i =
√x2
1 + x22 + ...+ x2
n
n
5

La formule correspondante pour une fonction continue f(t), definie sur un intervalle T1 ≤ t ≤T2, est :
fRMS =
√1
T2 − T1
∫ T2
T1
f2(t) dt
Cette formule peut etre generalisee dans le cas de fonctions a plusieurs variables et on a alorsla definition suivante :
fRMS =
√1|X|
∫
Xf2(t) dt
ou |X| est egal au produit des longueurs de tous les intervalles et t = (t1, ..., tn). Par exemple,|X| est l’aire sur laquelle on integre en 2D ou le volume sur lequel on integre en 3D.
L’erreur quadratique que nous utiliserons par la suite, appelee eRMS , utilise la definitionprecedente, et on a alors :
eRMS =
√1|X|
∫
X[f(t)− r(t)]2 dt
L’erreur quadratique mesure l’erreur commise en approchant f par la fonction r. r est unpolynome de regression et on mesurera alors l’erreur commise en approximant la fonction fpar le polynome r.
6

2 Demarche pour la construction du programme
Afin de programmer le calcul de l’erreur quadratique pour les fonctions de Benchmark,il etait necessaire de calculer celle-ci manuellement. Une fois cette erreur calculee formelle-ment, il restait a etudier la maniere d’implementer ce calcul d’erreur. Cette partie montrela ligne directrice suivie pour le calcul des erreurs quadratiques ainsi que l’etude faite pourl’elaboration du programme.
2.1 Calculs des erreurs quadratiques
Dans cette partie, nous allons decrire le principe suivi pour le calcul des erreurs quadra-tiques des deux fonctions. Ces calculs sont detailles en annexe.
Pour calculer les erreurs quadratiques, nous utiliserons une methode de regression qui seraun polynome de la forme suivante :
r(x) =m∑
i=1
Yi
n∏
l=1
m∏
j=1j 6=i
g(Xi,Xj)=l
xl −Xjl
Xil −Xjl
Xi est le ie vecteur de l’echantillonnage.Xil est la valeur de la le composante du vecteur Xi.g(Xi, Xj) est une fonction qui retourne le premier indice k0 pour lequel Xi,k0 et Xj,k0 different.m est la taille de l’echantillonnage.Yi est la valeur par f du point Xi de l’echantillonnage.L’introduction de la fonction g est necessaire afin d’eviter d’avoir une division par 0. Ainsi, sinous avons les deux points d’echantillonnage (1; 1) et (1; 2) dont les valeurs respectives par fsont Y1 et Y2, le polynome associe serait
P (x) = Y1.x1 − 11− 1
.x2 − 21− 2
+ Y2.x1 − 11− 1
.x2 − 12− 1
et l’on constate que l’on a une division par 0, ce qui est interdit.D’apres la definition de l’erreur quadratique donnee en partie 1.3 en page 5, nous avons
donc a calculer la quantite suivante pour les fonctions de Rastrigin et de Griewank :
eRMS =
√1|X|
∫
X[f(x)− r(x)]2 dx
=
√1|X|
∫
Xf2(x)− 2f(x).r(x) + r2(x) dx
ou r(x) est le polynome de regression decrit dans la partie precedente et f(x) est soit lafonction de Rastrigin, soit la fonction de Griewank.
Pour calculer cette erreur quadratique, nous aurons a calculer les grandeurs suivantes :∫
Xf2(x) dx puis
∫
Xf(x).r(x) dx et enfin
∫
Xr2(x) dx
7

2.1.1 Modification de l’ecriture du polynome de regression
Afin de faciliter les calculs d’integrales, nous avons modifie la forme du polynome deregression. La forme initiale du polynome etait
m∑
i=1
Yi
n∏
l=1
m∏
j=1j 6=i
g(Xi,Xj)=l
xl −Xjl
Xil −Xjl
La nouvelle forme du polynome sera la suivante :
m∑
i=1
Yi.αi
n∏
l=1
x
γill +
γil−1∑
u=0
(−1)γil−u
∑
1≤l1<...<lγil−u≤mlβ 6=i
γil−u∏
t=1g(Xlt
,Xi)=l
Xltl
xul
ou αi =n∏
l=1
m∏
j=1j 6=i
g(Xi,Xj)=l
1Xil −Xjl
Pour le detail des calculs, voir la partie 1 de l’annexe en page i.
2.1.2 Calcul de l’erreur quadratique pour la fonction de Rastrigin
On rappelle que la fonction de Rastrigin est definie de la maniere suivante :
f(x) = A · n+n∑
i=1
x2i −A · cos(ω · xi)
A = 10 ; ω = 2π ; xi ∈ [−5.12; 5.12]
Pour simplifier, on prend X = [−L,L]n, un intervalle symetrique avec L ∈ [0, 5.12]. Ainsi X ⊂ [−5.12, 5.12]n.
On rappelle egalement que pour le calcul de l’eRMS , nous devons calculer les grandeurs sui-vantes : ∫
Xf2(x) dx puis
∫
Xf(x).r(x) dx et enfin
∫
Xr2(x) dx
Or :– Le calcul dans le paragraphe 3.1 en page ii de l’annexe nous donne :
∫
X
f(x)2 dx =
(2L)nA2.n2 + 2n+1.A.n2
(Ln+2
3− A.Ln−1
ω.sin(ω.L)
)
+(2L)n−1.n
[2L5
5− 4A
ω
(L2.sin(ω.L) +
2L
ω.cos(ω.L)− 2
ω2.sin(ω.L)
)+ A2
(L +
1
2ω.sin(2− ω.L)
)]
+(2L)n−2
(n−1∑
i=1
2i
)(2
3L3 − 2A
ω.sin(ω.L)
)2
8

– Le calcul dans le paragraphe 3.2 en page vii de l’annexe nous donne :∫
Xf(x).r(x) dx =
A.nm∑
i=1
Yi.αi
n∏
l=1
Lγil+1 − (−L)γil+1
γil + 1+
E
(γil−1
2
)
∑
q=0(−1)
γil−2q
∑
1≤l1<...<lγil−2q≤mlβ 6=i
γil−2q∏
t=1g(Xlt
,Xi)=l
Xltl
2L2q+1
2q + 1
+m∑
i=1
αi.Yi
n∑
k=1
1− (−1)γik−1
2.c(γik) +
E
(γik−1
2
)
∑
q=0(−1)
γik−2q
∑
1≤l1<...<lγik−2q≤mlβ 6=i
γik−2q∏
t=1g(Xlt
,Xi)=k
Xltk
c(2q)
.
n∏
z=1z 6=k
Lγiz+1 − (−L)γiz+1
γiz + 1+
E
(γiz−1
2
)
∑
v=0(−1)
γiz−2v
∑
1≤l1<...<lγiz−2v≤mlβ 6=i
γiz−2v∏
t=1g(Xlt
,Xi)=z
Xltz
2L2v+1
2v + 1
−Am∑
i=1
αi.Yi
n∑
k=1
1− (−1)γik−1
2.c(γik) +
E
(γik−1
2
)
∑
q=0(−1)
γik−2q
∑
1≤l1<...<lγik−2q≤mlβ 6=i
γik−2q∏
t=1g(Xlt
,Xi)=k
Xltk
c(2q)
.
n∏
z=1z 6=k
Lγiz+1 − (−L)γiz+1
γiz + 1+
E
(γiz−1
2
)
∑
v=0(−1)
γiz−2v
∑
1≤l1<...<lγiz−2v≤mlβ 6=i
γiz−2v∏
t=1g(Xlt
,Xi)=z
Xltz
2L2v+1
2v + 1
avec
c(j) =j∑
k=0
(−1)E( j−k2 ) 1ωj−k+1
.j!k!.((
1− (−1)j−k+1).Lk.sin(ω.L) +
(1− (−1)j−k
).Lk.cos(ω.L)
)
et
αi =n∏
l=1
m∏
j=1j 6=i
g(Xi,Xj)=l
1Xil −Xjl
– Le calcul dans le paragraphe 3.3 en page xiv de l’annexe nous donne :∫
Xr(x)
2dx =
m∑
i=1
Y2i αi
n∏
l=1
2γil∑
j=0
(−1)2γil−j
∑
1≤k1<...<k2γil−j≤m
∏
g(Xi,Xks )=l
Xks
Lj+1 − (−L)j+1
j + 1
+2∑
1≤u<v≤mYu.Yv.αujl.αvzk
n∏
l=1
γul+γvl∑
j=0
(−1)γul+γvl−j
∑
1≤k1<...<kγul+γvl−j≤m
∏
g(Xu,Xks )=lou g(Xv,Xks )=l
Xks
Lj+1 − (−L)j+1
j + 1
avec
αi =n∏
l=1
m∏
j=1j 6=i
g(Xi,Xj)=l
1Xil −Xjl
9

L’erreur quadratique de la fonction de Rastrigin est donc donnee par la formule suivante :
eRMS =
√1|X|
∫
X[f(x)− r(x)]2 dx
ou f est la fonction de Rastrigin et ou r est un polynome de regression. Pour obtenir la valeurde cette erreur il faut d’abord faire la somme des 3 termes calcules precedemment assortis deleur coefficient. Ensuite, il faut diviser cette somme par |X| et enfin prendre la racine carreede cette derniere valeur.
2.1.3 Calcul de l’erreur quadratique pour la fonction de Griewank
On rappelle que la fonction de Griewank est definie de la maniere suivante :
f(x) = 1 +n∑
i=1
x2i
4000−
n∏
i=1
cos
(xi√i
), xi ∈ [−600; 600]
On prend X = [−L;L]n, un intervalle symetrique avec L ∈ [0, 600]. Ainsi X ⊂ [−600; 600]n.
Or :– Le calcul dans le paragraphe 4.1 en page xvii de l’annexe nous donne :
∫
X
f(x)2 dx
=
∫
X
[1 +
n∑
i=1
x2i
4000−
n∏
i=1
cos
(xi√
i
)]2
dx
= (2L)n + n.2n+1Ln+2
12000+
2nLn+4
16000.
[n
5+
1
9
(n−1∑
i=0
2i
)]− 2n+1
(n∏
i=1
√i.sin
(L√i
))
− 1
4000.2n+1
(n∏
i=1
√i
)
n∑
i=1
n∏
j=1j 6=i
sin
(L√j
)(
L2.sin
(L√i
)+ 2L.
√i.cos
(L√i
)− 2i.sin
(L√i
))
+
n∏
i=1
[L +
√i
2.sin
(2L√
i
)]
– Le calcul dans le paragraphe 4.2 en page xxiv de l’annexe nous donne :∫
Xf(x).r(x) dx =
m∑
i=1
Yi.αi
n∏
l=1
Lγil+1 − (−L)γil+1
γil + 1+
E
(γil−1
2
)
∑
q=0(−1)
γil−2q
∑
1≤l1<...<lγil−2q≤mlβ 6=i
γil−2q∏
t=1g(Xlt
,Xi)=l
Xltl
2L2q+1
2q + 1
+1
4000
m∑
i=1
αi.Yi
n∑
k=1
Lγik+3 − (−L)γik+3
γik + 3+
E
(γik−1
2
)
∑
q=0(−1)
γik−2q
∑
1≤l1<...<lγik−2q≤mlβ 6=i
γik−2q∏
t=1g(Xlt
,Xi)=k
Xltk
2L2q+3
2q + 3
.
n∏
z=1z 6=k
Lγiz+1 − (−L)γiz+1
γiz + 1+
E
(γiz−1
2
)
∑
v=0(−1)
γiz−2v
∑
1≤l1<...<lγiz−2v≤mlβ 6=i
γiz−2v∏
t=1g(Xlt
,Xi)=z
Xltz
2L2v+1
2v + 1
10

−m∑
i=1
Yi.αi
n∏
l=1
1− (−1)γil−1
2c(γil, i) +
E
(γil−1
2
)
∑
q=0(−1)
γil−2q
∑
1≤l1<...<lγil−2q≤mlβ 6=i
γil−2q∏
t=1g(Xlt
,Xi)=l
Xltl
.c(2q, i)
avec
c(j, i) =j∑
k=0
(−1)E( j−k2 ) 1(
1√i
)j−k+1.j!k!.
((1− (−1)j−k+1
).Lk.sin
(L√i
)+(
1− (−1)j−k).Lk.cos
(L√i
))
et
αi =n∏
l=1
m∏
j=1j 6=i
g(Xi,Xj)=l
1Xil −Xjl
– Le calcul dans le paragraphe 3.3 en page xiv de l’annexe nous donne :∫
Xr(x)
2dx =
m∑
i=1
Y2i αi
n∏
l=1
2γil∑
j=0
(−1)2γil−j
∑
1≤k1<...<k2γil−j≤m
∏
g(Xi,Xks )=l
Xks
Lj+1 − (−L)j+1
j + 1
+2∑
1≤u<v≤mYu.Yv.αujl.αvzk
n∏
l=1
γul+γvl∑
j=0
(−1)γul+γvl−j
∑
1≤k1<...<kγul+γvl−j≤m
∏
g(Xu,Xks )=lou g(Xv,Xks )=l
Xks
Lj+1 − (−L)j+1
j + 1
avec
αi =n∏
l=1
m∏
j=1j 6=i
g(Xi,Xj)=l
1Xil −Xjl
L’erreur quadratique de la fonction de Griewank est donc donnee par la formule suivante :
eRMS =
√1|X|
∫
X[f(x)− r(x)]2 dx
ou f est la fonction de Griewank et r est un polynome de regression. Pour obtenir la valeur decette erreur il faut d’abord faire la somme des trois termes calcules precedemment assortis deleur coefficient. Ensuite, il faut diviser cette somme par |X| et enfin prendre la racine carreede cette derniere valeur.
2.2 Demarche informatique
Dans cette partie, nous developperons l’etude relative a l’implementation du calcul deserreurs quadratiques.
2.2.1 Diagramme de classe
La premiere phase de l’etude consiste a determiner les classes necessaires pour l’imple-mentation en Java. En effet, il apparaıt que certains objets ont des proprietes et des carac-teristiques communes. De plus, il faut penser a organiser les classes de maniere a ce que l’onpuisse facilement en rajouter a l’avenir.
11

Il y a ainsi 4 classes qui s’imposent d’elles-memes. La premiere est une classe ”Echantillon-nage”. En effet, nous devons comparer deux methodes d’echantillonnage qui ont la proprietecommune de fournir des echantillons. Il apparaıt donc necessaire de creer une classe abstraitequi factorise ces methodes. Cette classe se derivera notamment en methode d’echantillonnageLHS et en celle faite avec une grille reguliere. Cette classe est utile car si l’on veut etudierune autre methode d’echantillonnage, il suffit d’integrer celle-ci dans cette classe abstraite.
Une autre classe qui s’impose naturellement est la classe abstraite ”Benchmark” qui fac-torise les fonctions de Benchmark. En effet, cette classe contient les fonctions de test qui sontutilisees de maniere similaire dans le programme. Dans notre etude, ce sont les fonctions deRastrigin et de Griewank qui sont derivees des fonctions de Benchmark. Cette classe pourraservir pour d’autres fonctions de Benchmark, notamment celles citees dans la partie dediee ace type de fonctions.
La troisieme classe est la classe des polynomes. En effet, nous avons choisi d’utiliser unpolynome de regression mais nous aurions pu utiliser la methode des moindres carres ou bienles B-splines. Ainsi, nous aurions pu directement creer une classe non abstraite ”Regression”mais cela n’aurait pas ete judicieux pour une extension future. C’est pourquoi nous avonsdecide de creer une classe abstraite ”Polynome” afin de pouvoir ajouter aisement d’eventuellesmethodes.
Enfin, la derniere classe est la classe d’indicateur d’erreur. Une fois encore, nous avonsdecide de creer une classe abstraite nommee ”Indicateur”. L’indicateur que nous utilisons estl’erreur quadratique (eRMS). Cependant, nous aurions pu utiliser egalement la valeur absoluede la difference entre la fonction et le polynome ou d’autres indicateurs. Cette classe abstraitea donc ete creee dans l’eventuel ajout de nouveaux indicateurs.
Il reste maintenant a etablir les relations qui existent entre ces differentes classes. Onremarque naturellement que les relations qui peuvent exister entre ces classes sont des com-positions. En effet, si l’on supprime une de ces classes, alors le probleme n’existe plus. Premie-rement, il apparaıt que la classe indicateur est liee aux classes ”Benchmark” et ”Polynome”.En effet, pour calculer l’erreur, il est necessaire de connaıtre la fonction de Benchmark et lepolynome utilises. Ensuite, la classe ”Polynome” est liee a l’echantillonnage car celui-ci estcalcule grace aux echantillons effectues. Enfin, la classe ”Echantillonnage” (Sample) est liee ala classe ”Benchmark” car on a besoin de connaıtre la fonction de Benchmark afin d’evaluerles valeurs par f des points de l’echantillonnage.
Le diagramme de classes ainsi obtenu est en figure 4 :
Les classes dont le nom est en gris sont des classes que l’on pourrait ajouter a l’avenirdans la continuite de ce projet.
2.2.2 Enchaınement des processus
Dans cette partie, nous decrirons l’ordre dans lequel s’enchaınent les processus. En entreedu probleme, nous avons donc les donnees relatives au probleme qui sont la dimension danslaquelle nous travaillons (n), le nombre de points d’echantillonnage desires (m) ainsi que lamethode d’echantillonnage utilisee (Ech). Avec toutes ces donnees on peut determiner lespoints de l’echantillonnage selon la methode souhaitee. Cet echantillonnage nous fournit untableau de vecteurs contenant les coordonnees des points de l’echantillonnage. Ensuite, il fautevaluer les valeurs des points obtenus par la fonction de Benchmark f . A la sortie de cetteetape, nous avons donc les points de l’echantillonnage ainsi que leurs valeurs obtenues par
12

Figure 4 – Diagramme de classes
la fonction a l’etape precedente. A partir de ce moment, la construction du polynome deregression devient possible. C’est ce que l’on effectue a la troisieme etape. A la fin de celle-ci,nous avons donc le polynome de regression (r) ainsi que la fonction de Benchmark. Le dernierprocessus de la chaıne consiste alors a calculer l’erreur quadratique, valeur que l’on attendaitpour comparer les methodes d’echantillonnage. L’enchaınement des processus est resume surla figure 5 :
2.2.3 Protocoles de tests
Des tests ont ete effectues afin d’etre certains que les fonctions de Benchmark ainsi quele polynome de regression ont bien ete codes. Par consequent, nous avons effectue un testpour verifier l’exactitude du codage de la fonction de Rastrigin. Il s’agissait de calculer ma-nuellement la valeur par la fonction de Rastrigin d’un point predefini en dimension 2, parexemple. Pour savoir si le test est concluant, on compare cette valeur avec celle calculee parle programme pour le meme point. On peut effectuer cela avec plusieurs points et si les testspour ces points sont concluants, on peut supposer que la fonction de Rastrigin est bien codee.Ce principe de test peut etre egalement applique a la fonction de Griewank et a la premiereforme du polynome de regression.
De plus, nous avons vu que deux formes du polynome de regression ont ete utilisees. Apresavoir verifie que la premiere forme du polynome nous donnait les bonnes valeurs, il fallait etrecertains que la deuxieme valeur etait egalement correcte. Le principe de test est alors identiqueau precedent, c’est-a-dire qu’il consiste a comparer la valeur retournee par la premiere formedu polynome avec celle retournee par la deuxieme forme.
2.2.4 Problemes rencontres
Dans la demarche initiale, nous devions coder les formules generales de l’eRMS trouveemanuellement. Cependant, ces formules posent un probleme puisqu’il faut calculer les per-
13

Figure 5 – Enchaınement des processus
mutations de k elements parmi m, ou m est le nombre de points d’echantillonnage souhaite.Nous avons des lors code une fonction afin de calculer ces permutations. La premiere versionde cette fonction etait batie sur une definition recursive. Cependant, celle-ci ne s’averait pastres efficace car nous nous heurtions rapidement a des problemes de piles. Cette fonction avaitegalement une version iterative. Cependant, l’usage de celle-ci etait lui aussi limite car noussommes confrontes a un probleme de taille en memoire. En effet, avec cette version, on stocketoutes les permutations possibles, ce qui prend beaucoup de memoire. La troisieme versiona alors consiste a trouver un element de la permutation a partir de son predecesseur. Pourcela, les iterateurs ont ete utilises. En theorie, cette version ne se heurte pas aux problemesde memoire et de piles mais il faut un tres grand temps de calcul des que le nombre de pointsdans l’echantillon devient eleve. De plus, l’implementation de cette methode pour le calculde l’eRMS s’avere complexe et couteuse car il faut calculer ces permutations plusieurs fois.C’est pourquoi nous avons decide d’utiliser les sommes de Riemann afin de calculer l’eRMS .Cependant, les formules generales trouvees par les calculs peuvent etre reprises a l’avenir pourle calcul de l’eRMS . Le calcul des permutations par les iterateurs est egalement une methodequi pourra etre developpee par la suite.
14
3 Resultats et discussion
Dans cette partie, nous presenterons et commenterons les resultats obtenus.
3.1 Resultats
3.1.1 Observations sur le polynome de regression
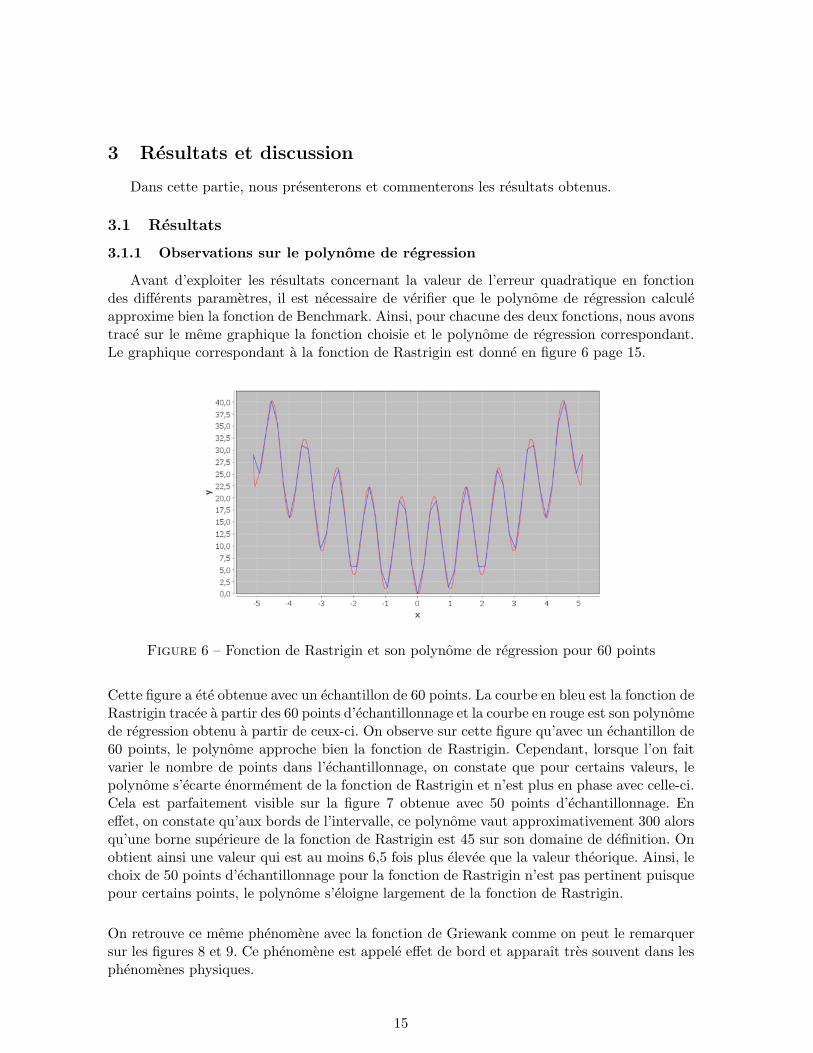
Avant d’exploiter les resultats concernant la valeur de l’erreur quadratique en fonctiondes differents parametres, il est necessaire de verifier que le polynome de regression calculeapproxime bien la fonction de Benchmark. Ainsi, pour chacune des deux fonctions, nous avonstrace sur le meme graphique la fonction choisie et le polynome de regression correspondant.Le graphique correspondant a la fonction de Rastrigin est donne en figure 6 page 15.
Figure 6 – Fonction de Rastrigin et son polynome de regression pour 60 points
Cette figure a ete obtenue avec un echantillon de 60 points. La courbe en bleu est la fonction deRastrigin tracee a partir des 60 points d’echantillonnage et la courbe en rouge est son polynomede regression obtenu a partir de ceux-ci. On observe sur cette figure qu’avec un echantillon de60 points, le polynome approche bien la fonction de Rastrigin. Cependant, lorsque l’on faitvarier le nombre de points dans l’echantillonnage, on constate que pour certains valeurs, lepolynome s’ecarte enormement de la fonction de Rastrigin et n’est plus en phase avec celle-ci.Cela est parfaitement visible sur la figure 7 obtenue avec 50 points d’echantillonnage. Eneffet, on constate qu’aux bords de l’intervalle, ce polynome vaut approximativement 300 alorsqu’une borne superieure de la fonction de Rastrigin est 45 sur son domaine de definition. Onobtient ainsi une valeur qui est au moins 6,5 fois plus elevee que la valeur theorique. Ainsi, lechoix de 50 points d’echantillonnage pour la fonction de Rastrigin n’est pas pertinent puisquepour certains points, le polynome s’eloigne largement de la fonction de Rastrigin.
On retrouve ce meme phenomene avec la fonction de Griewank comme on peut le remarquersur les figures 8 et 9. Ce phenomene est appele effet de bord et apparaıt tres souvent dans lesphenomenes physiques.
15
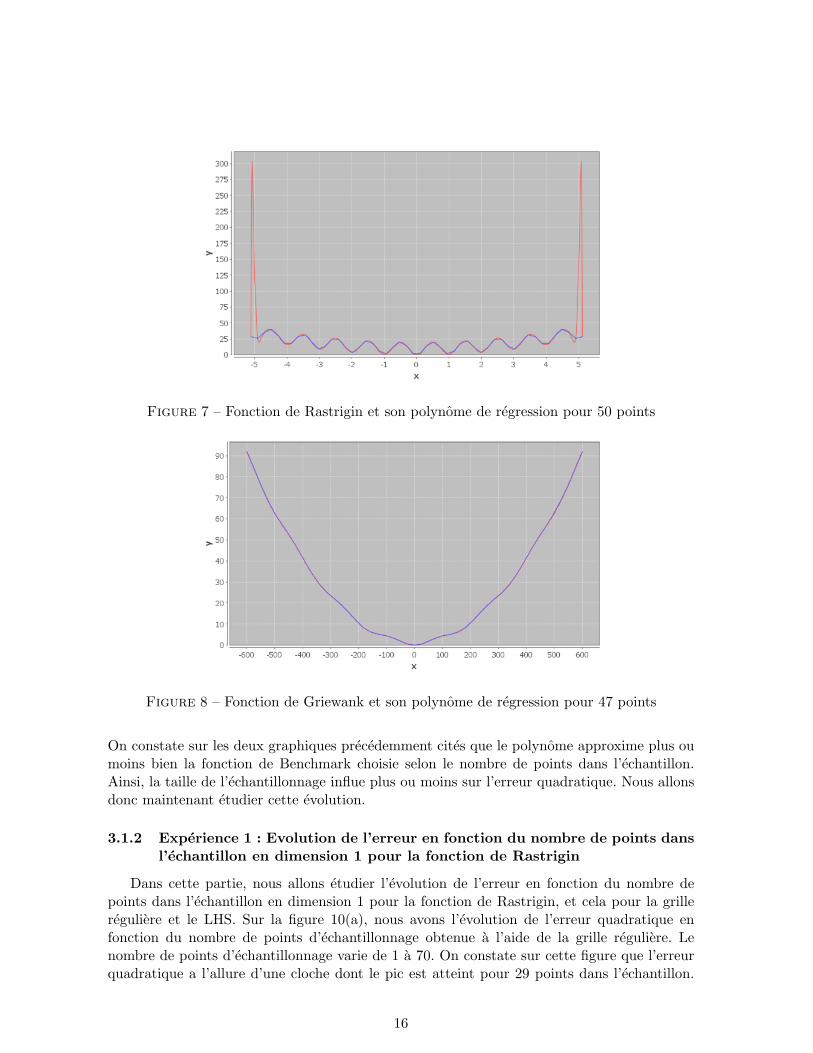
Figure 7 – Fonction de Rastrigin et son polynome de regression pour 50 points
Figure 8 – Fonction de Griewank et son polynome de regression pour 47 points
On constate sur les deux graphiques precedemment cites que le polynome approxime plus oumoins bien la fonction de Benchmark choisie selon le nombre de points dans l’echantillon.Ainsi, la taille de l’echantillonnage influe plus ou moins sur l’erreur quadratique. Nous allonsdonc maintenant etudier cette evolution.
3.1.2 Experience 1 : Evolution de l’erreur en fonction du nombre de points dansl’echantillon en dimension 1 pour la fonction de Rastrigin
Dans cette partie, nous allons etudier l’evolution de l’erreur en fonction du nombre depoints dans l’echantillon en dimension 1 pour la fonction de Rastrigin, et cela pour la grillereguliere et le LHS. Sur la figure 10(a), nous avons l’evolution de l’erreur quadratique enfonction du nombre de points d’echantillonnage obtenue a l’aide de la grille reguliere. Lenombre de points d’echantillonnage varie de 1 a 70. On constate sur cette figure que l’erreurquadratique a l’allure d’une cloche dont le pic est atteint pour 29 points dans l’echantillon.
16
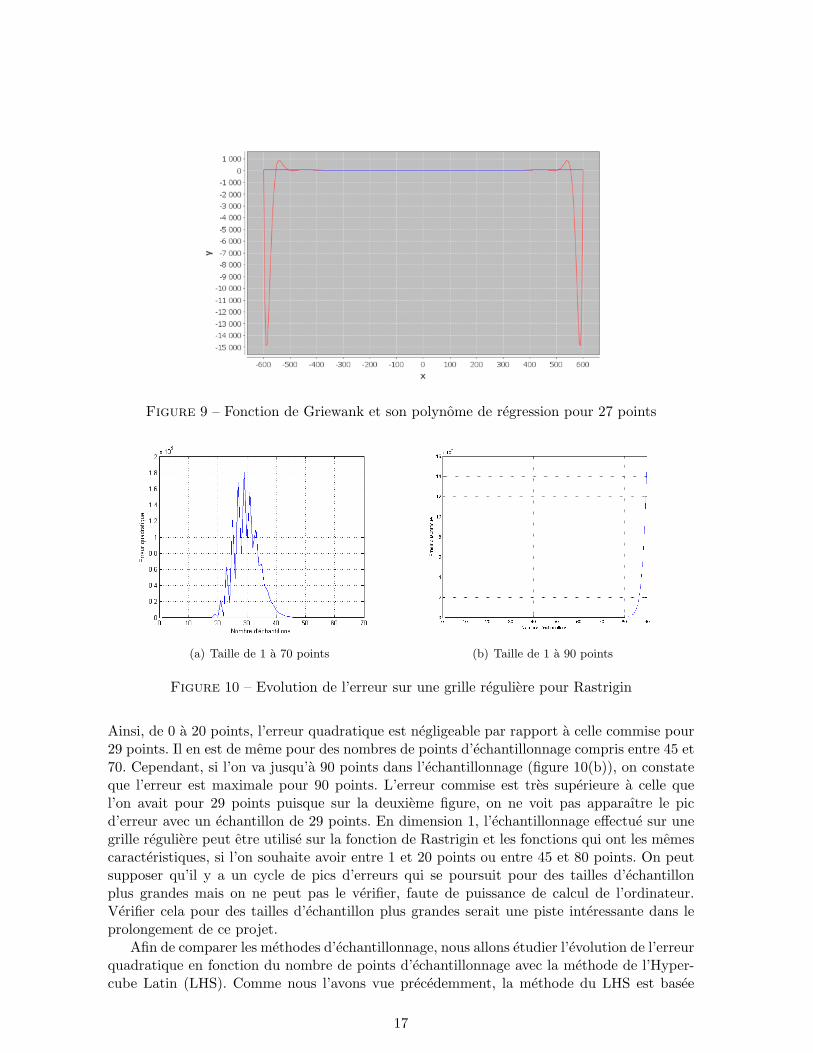
Figure 9 – Fonction de Griewank et son polynome de regression pour 27 points
(a) Taille de 1 a 70 points (b) Taille de 1 a 90 points
Figure 10 – Evolution de l’erreur sur une grille reguliere pour Rastrigin
Ainsi, de 0 a 20 points, l’erreur quadratique est negligeable par rapport a celle commise pour29 points. Il en est de meme pour des nombres de points d’echantillonnage compris entre 45 et70. Cependant, si l’on va jusqu’a 90 points dans l’echantillonnage (figure 10(b)), on constateque l’erreur est maximale pour 90 points. L’erreur commise est tres superieure a celle quel’on avait pour 29 points puisque sur la deuxieme figure, on ne voit pas apparaıtre le picd’erreur avec un echantillon de 29 points. En dimension 1, l’echantillonnage effectue sur unegrille reguliere peut etre utilise sur la fonction de Rastrigin et les fonctions qui ont les memescaracteristiques, si l’on souhaite avoir entre 1 et 20 points ou entre 45 et 80 points. On peutsupposer qu’il y a un cycle de pics d’erreurs qui se poursuit pour des tailles d’echantillonplus grandes mais on ne peut pas le verifier, faute de puissance de calcul de l’ordinateur.Verifier cela pour des tailles d’echantillon plus grandes serait une piste interessante dans leprolongement de ce projet.
Afin de comparer les methodes d’echantillonnage, nous allons etudier l’evolution de l’erreurquadratique en fonction du nombre de points d’echantillonnage avec la methode de l’Hyper-cube Latin (LHS). Comme nous l’avons vue precedemment, la methode du LHS est basee
17
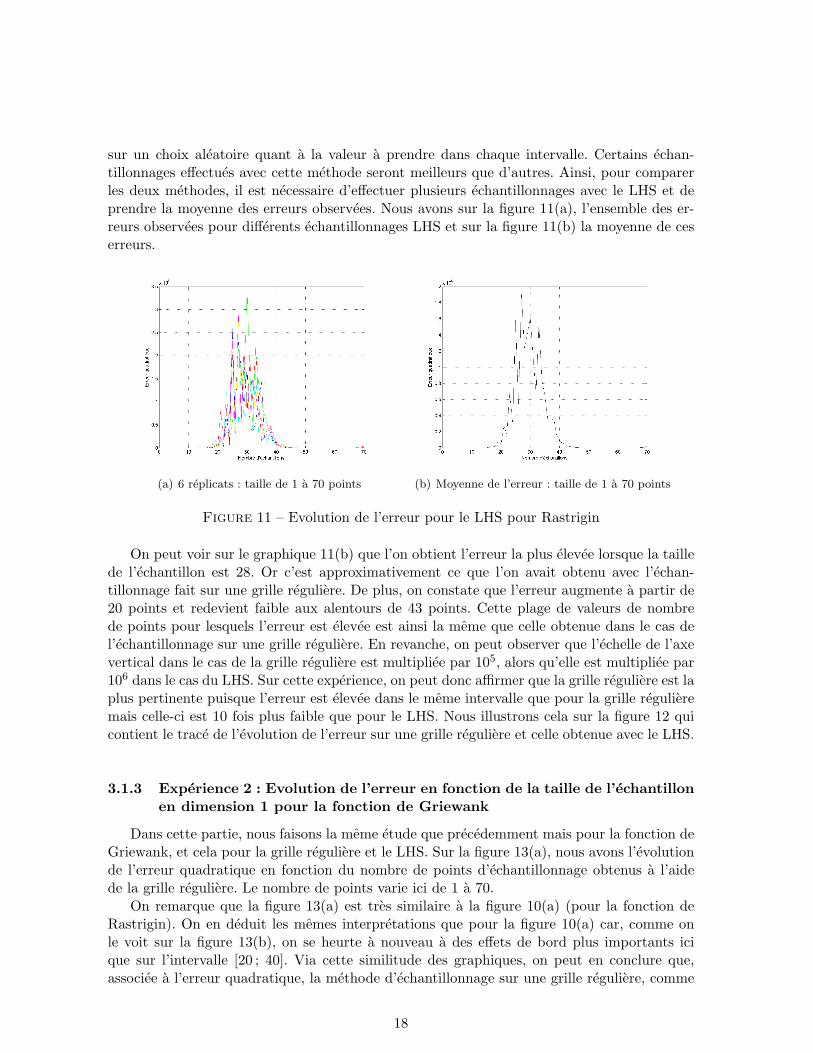
sur un choix aleatoire quant a la valeur a prendre dans chaque intervalle. Certains echan-tillonnages effectues avec cette methode seront meilleurs que d’autres. Ainsi, pour comparerles deux methodes, il est necessaire d’effectuer plusieurs echantillonnages avec le LHS et deprendre la moyenne des erreurs observees. Nous avons sur la figure 11(a), l’ensemble des er-reurs observees pour differents echantillonnages LHS et sur la figure 11(b) la moyenne de ceserreurs.
(a) 6 replicats : taille de 1 a 70 points (b) Moyenne de l’erreur : taille de 1 a 70 points
Figure 11 – Evolution de l’erreur pour le LHS pour Rastrigin
On peut voir sur le graphique 11(b) que l’on obtient l’erreur la plus elevee lorsque la taillede l’echantillon est 28. Or c’est approximativement ce que l’on avait obtenu avec l’echan-tillonnage fait sur une grille reguliere. De plus, on constate que l’erreur augmente a partir de20 points et redevient faible aux alentours de 43 points. Cette plage de valeurs de nombrede points pour lesquels l’erreur est elevee est ainsi la meme que celle obtenue dans le cas del’echantillonnage sur une grille reguliere. En revanche, on peut observer que l’echelle de l’axevertical dans le cas de la grille reguliere est multipliee par 105, alors qu’elle est multipliee par106 dans le cas du LHS. Sur cette experience, on peut donc affirmer que la grille reguliere est laplus pertinente puisque l’erreur est elevee dans le meme intervalle que pour la grille regulieremais celle-ci est 10 fois plus faible que pour le LHS. Nous illustrons cela sur la figure 12 quicontient le trace de l’evolution de l’erreur sur une grille reguliere et celle obtenue avec le LHS.
3.1.3 Experience 2 : Evolution de l’erreur en fonction de la taille de l’echantillonen dimension 1 pour la fonction de Griewank
Dans cette partie, nous faisons la meme etude que precedemment mais pour la fonction deGriewank, et cela pour la grille reguliere et le LHS. Sur la figure 13(a), nous avons l’evolutionde l’erreur quadratique en fonction du nombre de points d’echantillonnage obtenus a l’aidede la grille reguliere. Le nombre de points varie ici de 1 a 70.
On remarque que la figure 13(a) est tres similaire a la figure 10(a) (pour la fonction deRastrigin). On en deduit les memes interpretations que pour la figure 10(a) car, comme onle voit sur la figure 13(b), on se heurte a nouveau a des effets de bord plus importants icique sur l’intervalle [20 ; 40]. Via cette similitude des graphiques, on peut en conclure que,associee a l’erreur quadratique, la methode d’echantillonnage sur une grille reguliere, comme
18
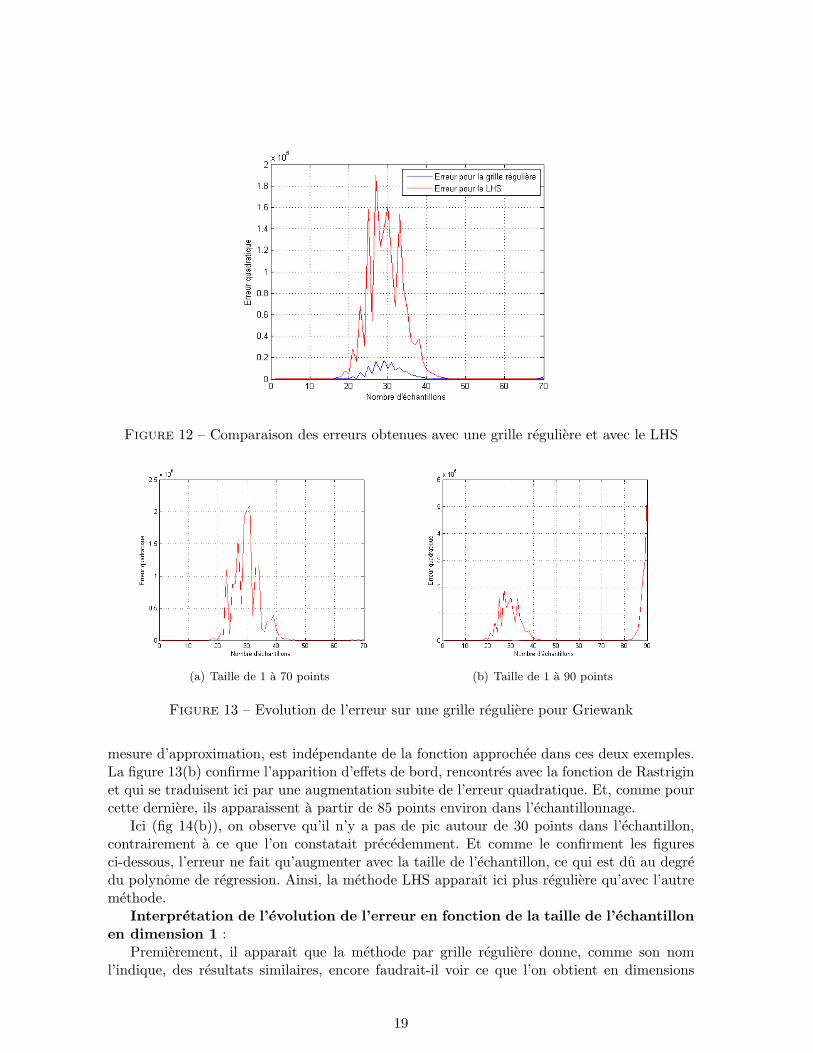
Figure 12 – Comparaison des erreurs obtenues avec une grille reguliere et avec le LHS
(a) Taille de 1 a 70 points (b) Taille de 1 a 90 points
Figure 13 – Evolution de l’erreur sur une grille reguliere pour Griewank
mesure d’approximation, est independante de la fonction approchee dans ces deux exemples.La figure 13(b) confirme l’apparition d’effets de bord, rencontres avec la fonction de Rastriginet qui se traduisent ici par une augmentation subite de l’erreur quadratique. Et, comme pourcette derniere, ils apparaissent a partir de 85 points environ dans l’echantillonnage.
Ici (fig 14(b)), on observe qu’il n’y a pas de pic autour de 30 points dans l’echantillon,contrairement a ce que l’on constatait precedemment. Et comme le confirment les figuresci-dessous, l’erreur ne fait qu’augmenter avec la taille de l’echantillon, ce qui est du au degredu polynome de regression. Ainsi, la methode LHS apparaıt ici plus reguliere qu’avec l’autremethode.
Interpretation de l’evolution de l’erreur en fonction de la taille de l’echantillonen dimension 1 :
Premierement, il apparaıt que la methode par grille reguliere donne, comme son noml’indique, des resultats similaires, encore faudrait-il voir ce que l’on obtient en dimensions
19
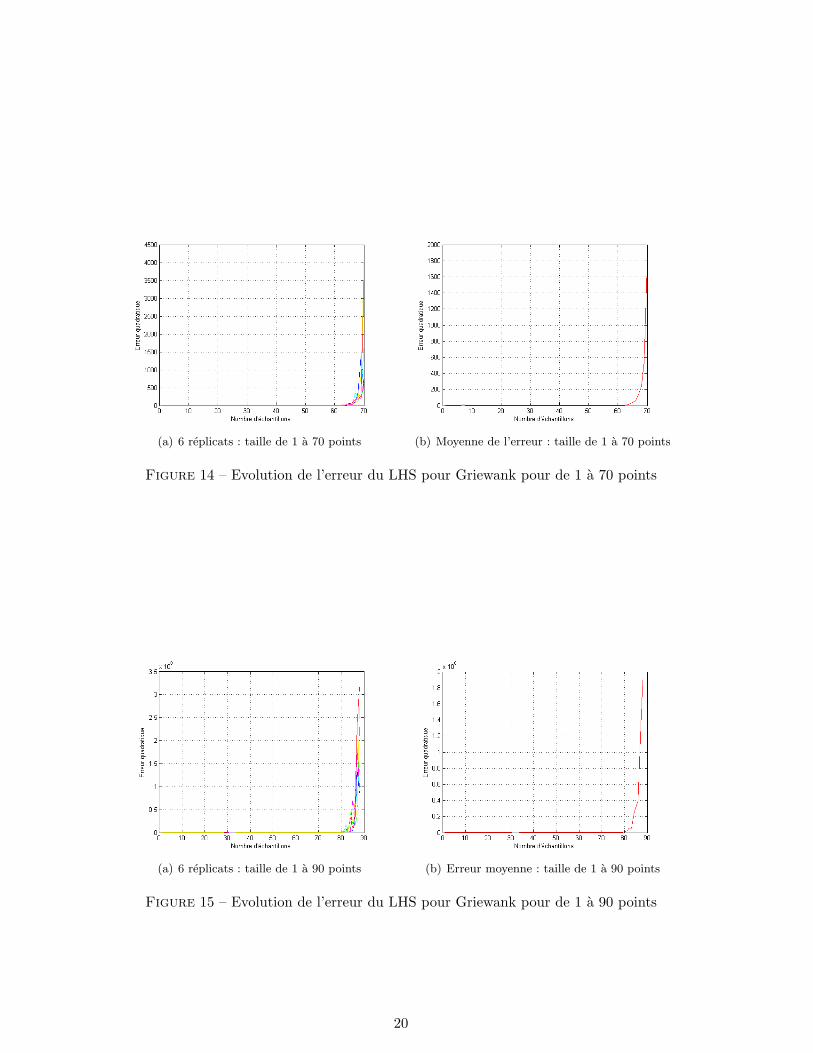
(a) 6 replicats : taille de 1 a 70 points (b) Moyenne de l’erreur : taille de 1 a 70 points
Figure 14 – Evolution de l’erreur du LHS pour Griewank pour de 1 a 70 points
(a) 6 replicats : taille de 1 a 90 points (b) Erreur moyenne : taille de 1 a 90 points
Figure 15 – Evolution de l’erreur du LHS pour Griewank pour de 1 a 90 points
20

superieures. C’est ce que nous ferons par la suite. En revanche, les graphiques correspondantpresentent des irregularites qui, par ailleurs, pourraient etre pseudo-periodiques mais ce n’estqu’une conjecture.
Ensuite, la methode LHS qui, par definition, utilise l’alea fournit des resultats differents.Ainsi, pour la fonction de Rastrigin, les deux methodes conduisent a des graphiques analogues,alors que pour l’autre fonction, le pic intermediaire n’apparaıt pas par la methode LHS. Pourminimiser l’effet aleatoire du LHS, il faudrait moyenner sur beaucoup de graphiques et celanous permettrait, a priori, de se rapprocher du resultat avec la grille reguliere.
Enfin, en dimension 1, on remarque que la methode LHS est beaucoup moins preciseque celle avec la grille reguliere. En effet avec 90 points, par exemple, et avec la fonction deGriewank, on a environ un rapport de (2.108)/(6.106)' 33.3 entre les methodes LHS et avecla grille reguliere.
3.1.4 Experience 3 : Evolution de l’erreur en fonction du nombre de la taille del’echantillon en dimension 2 pour la fonction de Rastrigin
Pour des raisons de temps de calcul, nous avons du nous limiter a un echantillon de taille16 en dimension 2. Malgre ce faible nombre de points, nous avons tout de meme d’interessantesinformations. En effet, on constate que l’erreur quadratique pour la fonction de Rastrigin variede 0,76 a 52,9 pour la grille reguliere. La valeur maximale est atteinte pour 16 points. Dansle meme temps, l’erreur quadratique varie de 2,9 a 8, 1.1074 pour des tailles d’echantilloncomprises entre 1 et 16 pour le LHS. On constate que l’erreur commise par le LHS surla fonction de Rastrigin en dimension 2 est tres elevee alors qu’elle reste moderee pour lagrille reguliere. Cela confirme l’observation faite pour l’experience 1, a savoir que la methoded’echantillonnage la plus adaptee pour la fonction de Rastrigin est la grille reguliere. De plus,on peut affirmer qu’en dimension 2, la methode d’echantillonnage la plus performante pourla fonction de Rastrigin est la grille reguliere.
3.1.5 Experience 4 : Evolution de l’erreur en fonction de la taille de l’echantillonen dimension 2 pour la fonction de Griewank
Comme pour l’experience 2, nous avons du limiter le nombre de points a 16 en dimension 2pour la fonction de Griewank. Cependant, on en deduit de nouvelles informations pertinentes.En effet, on constate que l’erreur quadratique maximale obtenue avec une grille reguliere estde 0,1. Dans le meme temps, l’erreur quadratique atteint la valeur de 2, 1.1056 pour 16 pointsavec le LHS. Cette valeur est tres elevee et surtout 1057 fois plus grande que celle obtenueavec la grille reguliere. Cela consolide l’observation faite avec l’experience 2, a savoir que lamethode d’echantillonnage la plus pertinente en dimension 2 est la grille reguliere.
3.2 Discussion des resultats
A travers les experiences realisees precedemment, il en resulte que les deux methodesd’echantillonnage etudiees ont des caracteristiques communes. Tout d’abord, il s’avere qu’au-cune de ces deux methodes n’approxime parfaitement la fonction de Benchmark. En effet, ilexiste toujours des tailles d’echantillon pour lesquelles l’erreur reste elevee. De plus, cet inter-valle est le meme pour les deux methodes d’echantillonnage, ce qui montre qu’elles reagissentde la meme maniere aux modulations de la fonction de Benchmark. Neanmoins, on constateque l’erreur obtenue avec une grille reguliere est souvent moins elevee que celle obtenue avec le
21

LHS. La grille reguliere est donc une meilleure methode pour l’echantillonnage de la fonctionde Rastrigin et pour la fonction de Griewank en dimension 2. Enfin, il est a noter qu’aucunede ces deux methodes ne permet d’avoir une bonne approximation de la courbe dans le cas oula taille de l’echantillon est dans un intervalle pour lequel l’erreur est elevee. C’est notammentle cas pour la fonction de Rastrigin en 1D pour laquelle aucune des 2 methodes ne permet del’approximer correctement pour des tailles d’echantillon comprises entre 20 et 45.
22

Conclusion
Ce projet a permis d’apporter des reponses a la problematique de l’evaluation de differentesmethodes d’echantillonnage. Au debut du projet, il s’agissait de comparer deux methodesd’echantillonnage, a savoir l’Hypercube Latin(LHS) et celle basee sur une grille reguliere.L’ensemble du projet a donc consiste a mettre en oeuvre un protocole experimental afin decomparer ces deux methodes. Pour cela, une partie du projet a ete consacree a la comprehen-sion des principes des methodes d’echantillonnage ainsi que de celui de l’indicateur d’erreur.La phase suivante du projet a ete l’implementation en Java du calcul d’erreur en fonctionde la dimension, de la methode d’echantillonnage, du nombre de points et de la fonction deBenchmark. Pour effectuer ce calcul, nous avons calcule les formules exactes de ces erreurspour les fonctions de Rastrigin et de Griewank afin de les implementer. Cependant, nousavons ete rapidement confrontes a differents problemes. Ainsi, l’implementation des formulesobtenues s’est averee plus difficile que prevue du fait de leur complexite. De plus, apres laresolution de ce probleme, il est apparu que certaines erreurs etaient incalculables pour causede depassement de pile ou de memoire insuffisante. Un autre algorithme a alors ete concuafin de resoudre ces problemes mais celui-ci avait egalement un defaut qui etait son temps decalcul. Ainsi, avec ce dernier, le nombre de points d’echantillonnage disponibles n’etait quede 25. C’est pourquoi nous avons decide d’effectuer le calcul des integrales par les sommes deRiemann.
D’apres les observations, il apparaıt qu’en dimension 1, la grille reguliere est a preconiserpour des fonctions similaires a la fonction de Rastrigin alors qu’il est preferable d’utiliserle LHS pour des fonctions similaires a la fonction de Griewank. De plus, il est a noter qu’endimension 2, la methode d’echantillonnage la plus pertinente est la grille reguliere. Cependant,nous avons ete limites sur le nombre d’experiences a effectuer. En effet, notre etude a du selimiter aux dimensions 1 et 2 a cause des temps de calcul et en dimension 2, nous n’avons puutiliser que 16 points. Ainsi, pour avoir une reponse plus precise concernant l’evaluation desmethodes d’echantillonnage, il serait interessant d’utiliser des machines ayant des puissancesde calcul plus elevees. Ceci nous permettrait d’obtenir des resultats pour des dimensions et destailles d’echantillon plus elevees. Ce projet peut se prolonger dans l’etude de l’implementationdes formules exactes afin de ne plus utiliser les sommes de Riemann qui ne fournissent qu’uneapproximation de cette erreur.
Enfin, ce projet nous a permis d’acquerir des connaissances en marge des cours dispenses al’ISIMA. Nous avons ete amenes a verifier que les formules obtenues et que le codage effectueetaient bien corrects. Nous avons donc imagine divers tests afin d’atteindre cet objectif. Ceprojet nous a egalement permis d’acquerir des connaissances techniques. En effet, pour realiserce rapport, nous avons ete amenes a apprendre l’utilisation de LATEX, un editeur de textefrequemment utilise pour la redaction d’articles scientifiques. De plus, le codage du calculdes erreurs quadratiques a ete effectue en Java. Nous avons donc pu decouvrir ce langage deprogrammation qui est tres frequemment utilise dans le monde de l’industrie.
23

Bibliographie
[1] BOYER D., MARTINEZ C. et PEDRAJAS N., A Crossover Operator for Evo-lutionary Algorithms Based on Population Features, Cordoba, 2005
[2] CHUFFART F., Evaluating Sampling Method Efficiency, Clermont-Ferrand, 2008
[3] SWILER L. et WYSS G., A User’s Guide to Sandia’s Latin Hypercube SamplingSoftware, Albuquerque, 2004
[4] www.tuteurs.ens.fr/logiciels/latex/ : Guide d’utilisation de l’editeur Latex

Glossaire
Classe : En programmation orientee objet, une classe declare des proprietes communesa un ensemble d’objets.
Diagramme de classe : Schema utilise en genie logiciel pour representer les classes, lesinterfaces d’un systemes ainsi que les differentes relations entre celles-ci.
Echantillon : Ensemble d’individus extraits d’une population etudiee de maniere a cequ’il soit representatif de cette population.
Erreur quadratique moyenne : Mesure permettant de comparer la fonction de Bench-mark choisie et son polynome de regression.
Fonction de Benchmark : Fonction concue pour l’elaboration de tests.
Grille reguliere : Methode d’echantillonnage basee sur un quadrillage regulier de pasconstant.
LHS : Abreviation de Latin Hypercube Sampling. C’est une methode d’echantillonnagebasee sur un choix aleatoire des points de l’echantillon.
Polynome de regression : Polynome calcule a partir d’un echantillon approchant lafonction echantillonnee.

Table des figures
1 Grille reguliere en 2D . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22 Exemple d’echantillonnage LHS pour 6 points en dimension 2 . . . . . . . . . . 43 Fonctions de Rastrigin et de Griewank en dimension 3 . . . . . . . . . . . . . . 54 Diagramme de classes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135 Enchaınement des processus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 146 Fonction de Rastrigin et son polynome de regression pour 60 points . . . . . . 157 Fonction de Rastrigin et son polynome de regression pour 50 points . . . . . . 168 Fonction de Griewank et son polynome de regression pour 47 points . . . . . . 169 Fonction de Griewank et son polynome de regression pour 27 points . . . . . . 1710 Evolution de l’erreur sur une grille reguliere pour Rastrigin . . . . . . . . . . . 1711 Evolution de l’erreur pour le LHS pour Rastrigin . . . . . . . . . . . . . . . . . 1812 Comparaison des erreurs obtenues avec une grille reguliere et avec le LHS . . . 1913 Evolution de l’erreur sur une grille reguliere pour Griewank . . . . . . . . . . . 1914 Evolution de l’erreur du LHS pour Griewank pour de 1 a 70 points . . . . . . . 2015 Evolution de l’erreur du LHS pour Griewank pour de 1 a 90 points . . . . . . . 20

Institut Supérieur Cemagref de Clermont-Ferrand d’Informatique de Modélisation et de Campus universitaire des Cézeaux leurs Applications BP50085 24 avenue des Landais Complexe des Cézeaux 63172 Aubière cedex BP 125 63 173 Aubière Cedex
Rapport d’ingénieur Projet de 2ème année
Filière 4
Mise en place d’un protocole d’évaluation de différentes méthodes d’échantillonnage
ANNEXES
TOME II
Présenté par : Anthony Ricochon
Nathanaël Le Dantec Responsable ISIMA : Vincent Barra Mardi 24 mars 2009 Chef de projet : Florent Chuffart Durée : 100 heures

Table des matieres
Introduction 1
1 Analyse du projet 21.1 Les methodes d’echantillonnage . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.1.1 Grille reguliere . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.1.2 Methode d’echantillonnage de l’Hypercube Latin (LHS) . . . . . . . . . 3
1.2 Les fonctions de ”Benchmark” . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.3 L’erreur quadratique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Demarche pour la construction du programme 72.1 Calculs des erreurs quadratiques . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.1 Modification de l’ecriture du polynome de regression . . . . . . . . . . . 82.1.2 Calcul de l’erreur quadratique pour la fonction de Rastrigin . . . . . . . 82.1.3 Calcul de l’erreur quadratique pour la fonction de Griewank . . . . . . . 10
2.2 Demarche informatique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.2.1 Diagramme de classe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.2.2 Enchaınement des processus . . . . . . . . . . . . . . . . . . . . . . . . . 122.2.3 Protocoles de tests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.2.4 Problemes rencontres . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3 Resultats et discussion 153.1 Resultats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.1.1 Observations sur le polynome de regression . . . . . . . . . . . . . . . . 153.1.2 Experience 1 : Evolution de l’erreur en fonction du nombre de points
dans l’echantillon en dimension 1 pour la fonction de Rastrigin . . . . . 163.1.3 Experience 2 : Evolution de l’erreur en fonction de la taille de l’echan-
tillon en dimension 1 pour la fonction de Griewank . . . . . . . . . . . . 183.1.4 Experience 3 : Evolution de l’erreur en fonction du nombre de la taille
de l’echantillon en dimension 2 pour la fonction de Rastrigin . . . . . . 213.1.5 Experience 4 : Evolution de l’erreur en fonction de la taille de l’echan-
tillon en dimension 2 pour la fonction de Griewank . . . . . . . . . . . . 213.2 Discussion des resultats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
Conclusion 23

Table des matieres
1 Calculs de la modification de la forme du polynome de Lagrange i
2 Theoreme de Fubini-Tonelli : i
3 Calculs de l’eRMS pour la fonction de Rastrigin ii3.1 Calcul de l’integrale de la fonction de Rastrigin au carre . . . . . . . . . . . . . . . ii
3.1.1 Calcul de la premiere integrale . . . . . . . . . . . . . . . . . . . . . . . . . ii3.1.2 Calcul de la seconde integrale . . . . . . . . . . . . . . . . . . . . . . . . . . iii3.1.3 Calcul de la derniere integrale . . . . . . . . . . . . . . . . . . . . . . . . . . iv3.1.4 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . vii
3.2 Calcul du terme croise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . vii3.2.1 Calcul de la premiere integrale . . . . . . . . . . . . . . . . . . . . . . . . . vii3.2.2 Calcul de la seconde integrale . . . . . . . . . . . . . . . . . . . . . . . . . . viii3.2.3 Calcul de la derniere integrale . . . . . . . . . . . . . . . . . . . . . . . . . . x3.2.4 Conclusion pour le terme croise . . . . . . . . . . . . . . . . . . . . . . . . . xiii
3.3 Calcul de l’integrale du polynome de Lagrange au carre . . . . . . . . . . . . . . . xiv3.4 Conclusion pour le eRMS pour la fonction de Rastrigin . . . . . . . . . . . . . . . . xv
4 Calculs de l’eRMS pour la fonction de Griewank xvi4.1 Calcul de l’integrale de la fonction de Griewank au carre . . . . . . . . . . . . . . . xvii
4.1.1 Calcul de la premiere integrale . . . . . . . . . . . . . . . . . . . . . . . . . xvii4.1.2 Calcul de la deuxieme integrale . . . . . . . . . . . . . . . . . . . . . . . . . xviii4.1.3 Calcul de la troisieme integrale . . . . . . . . . . . . . . . . . . . . . . . . . xviii4.1.4 Calcul de la quatrieme integrale . . . . . . . . . . . . . . . . . . . . . . . . xix4.1.5 Calcul de la cinquieme integrale . . . . . . . . . . . . . . . . . . . . . . . . xx4.1.6 Calcul de la sixieme integrale . . . . . . . . . . . . . . . . . . . . . . . . . . xxii4.1.7 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xxiii
4.2 Calcul du terme croise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xxiv4.2.1 Calcul de la premiere integrale . . . . . . . . . . . . . . . . . . . . . . . . . xxiv4.2.2 Calcul de la deuxieme integrale . . . . . . . . . . . . . . . . . . . . . . . . . xxiv4.2.3 Calcul de la troisieme integrale . . . . . . . . . . . . . . . . . . . . . . . . . xxv4.2.4 Conclusion pour le terme croise . . . . . . . . . . . . . . . . . . . . . . . . . xxvi
4.3 Calcul de l’integrale du polynome de Lagrange au carre . . . . . . . . . . . . . . . xxvii4.4 Conclusion pour le eRMS pour la fonction de Griewank . . . . . . . . . . . . . . . xxvii

1 Calculs de la modification de la forme du polynome deLagrange
Dans cette partie, nous detaillons le calcul concernant la modification du polynome de regres-sion.
r(x) =m∑
i=1
Yi
n∏
l=1
m∏
j=1j 6=i
g(Xi,Xj)=l
xl −Xjl
Xil −Xjl
=m∑
i=1
Yi
n∏
l=1
m∏
j=1j 6=i
g(Xi,Xj)=l
1Xil −Xjl
n∏
l=1
m∏
j=1j 6=i
g(Xi,Xj)=l
(xl −Xjl)
Orm∏
i=1
(x− αi) = xm +m−1∑
u=0
(−1)m−u
∑
1≤j1<...<jm−u≤m
(m−u∏
k=1
αjk
)xu
et nous avons alors
m∏
j=1j 6=i
g(Xi,Xj)=l
(xl −Xjl) = xγill +γil−1∑
u=0
(−1)γil−u
∑
1≤l1<...<lγil−u≤mlβ 6=i
γil−u∏
t=1g(Xlt
,Xi)=l
Xltl
xul
avec γil = Card{j/f(Xi, Xj) = l}Nous avons donc
r(x) =m∑
i=1
Yi
n∏
l=1
m∏
j=1j 6=i
g(Xi,Xj)=l
1Xil −Xjl
n∏
l=1
x
γill +
γil−1∑
u=0
(−1)γil−u
∑
1≤l1<...<lγil−u≤mlβ 6=i
γil−u∏
t=1g(Xlt
,Xi)=l
Xltl
xul
On pose
αi =n∏
l=1
m∏
j=1j 6=i
g(Xi,Xj)=l
1Xil −Xjl
et nous avons alors
r(x) =m∑
i=1
Yi.αi
n∏
l=1
x
γill +
γil−1∑
u=0
(−1)γil−u
∑
1≤l1<...<lγil−u≤mlβ 6=i
γil−u∏
t=1g(Xlt
,Xi)=l
Xltl
xul
2 Theoreme de Fubini-Tonelli :
Dans les calculs des erreurs quadratiques moyennes (eRMS), nous citons frequemment le theo-reme de Fubini. Voici l’enonce de ce theoreme :
i

Soient (X,A, µ) et (Y,B, ν) deux espaces mesures tels que les deux mesures soient σ-finies. Sif : X×Y → R+ est mesurable pour A
⊗B et positive sur X×Y , alors les applications x 7→ f(x, .)
et y 7→ f(., y) ainsi que les applications
x 7→∫
Y
f(x, y) dν(y) et y 7→∫
X
f(x, y) dµ(x)
sont mesurables positives. On a de plus∫ ∫
X×Yf(x, y) dζ(x, y) =
∫
X
[∫
Y
f(x, y) dν(y)]dµ(x) =
∫
Y
[∫
X
f(x, y) dµ(x)]dν(y)
ou on a note ξ la mesure produit sur (X × Y,A⊗B).
3 Calculs de l’eRMS pour la fonction de Rastrigin
3.1 Calcul de l’integrale de la fonction de Rastrigin au carre
On prend X = [−L;L]n, un intervalle symetrique avec L ∈ [0; 5, 12]. Ainsi X ⊂ [−5, 12; 5, 12]n.
∫
X
[A · n+
n∑
i=1
x2i −A · cos(ω · xi)
]2
dx
=∫
X
A2.n2 + 2A.n
(n∑
i=1
x2i −A.cos(ω.xi)
)+
(n∑
i=1
x2i −A.cos(ω.xi)
)2
dx
Par linearite de l’integrale, nous pouvons ecrire l’egalite suivante :
=∫
X
A2.n2 dx+∫
X
2A.n
(n∑
i=1
x2i −A.cos(ω.xi)
)dx+
∫
X
(n∑
i=1
x2i −A.cos(ω.xi)
)2
dx
3.1.1 Calcul de la premiere integrale
Calcul de ∫
X
A2.n2 dx
Prouvons que
∀n ∈ N∗∫
X
A2.n2 dx = A2.n2
∫
X
1 dx = (2L)nA2.n2
Preuve : Nous allons montrer cette formule par recurrence.
Initialisation : n=1 ∫
X
A2.n2 dx =∫ L
−LA2 dx = 2L.A2
La formule est donc vraie au rang 1.
ii

Passage au rang suivant : On suppose que la formule est vraie a un rang n. Montronsalors qu’elle est vraie au rang n+ 1.
On prend Γ = [−L;L]n+1 = [−L;L]n × [−L;L] = X × [−L;L]
Nous avons alors∫
Γ
A2.(n+ 1)2 dΓ = A2.(n+ 1)2
∫
Γ
1 dΓ = A2.(n+ 1)2
∫ L
−L
∫
X
1 dx dxn+1
= A2.(n+ 1)2
(∫ L
−L1 dxn+1
).
(∫
X
1 dx)
= A2.(n+ 1)2.2L.(2L)n = (2L)n+1.(n+ 1)2.A2
Ceci est effectivement vrai d’apres l’hypothese de recurrence et le theoreme de Fubini. Nous avonsla formule qui est vraie au rang n+ 1 donc nous avons :
∀n ∈ N∗∫
X
A2.n2 dx = (2L)nA2.n2
3.1.2 Calcul de la seconde integrale
Calcul de ∫
X
(n∑
i=1
x2i −A.cos(ω.xi)
)dx
Prouvons que
∀n ∈ N∗∫
X
(n∑
i=1
x2i −A.cos(ω.xi)
)dx = 2n.n
(Ln+2
3− A.Ln−1
ω.sin(ω.L)
)
Preuve : Nous allons montrer cette formule par recurrence.
Initialisation : n=1∫ L
−Lx2 −A.cos(ω.x) dx =
[x3
3− A
ω.sin(ω.x)
]L
−L
=L3
3− A
ω.sin(ω.L) +
L3
3− A
ω.sin(ω.L)
= 2(L3
3− A
ω.sin(ω.L)
)
La formule est vraie pour n=1.
Passage au rang suivant : On suppose que la formule est vraie pour un entier n. Montronsque cette formule est vraie au rang n+ 1.
On prend Γ = X × [−L;L] = [−L;L]n × [−L;L]
J =∫
Γ
n+1∑
i=1
x2i −A.cos(ω.xi) dΓ =
∫
Γ
(n∑
i=1
x2i −A.cos(ω.xi)
)+ x2
n+1 −A.cos(ω.xn+1) dΓ
=∫
Γ
n∑
i=1
x2i −A.cos(ω.xi) dΓ +
∫
Γ
x2n+1 −A.cos(ω.xn+1) dΓ par linearite de l’integrale.
iii

=∫ L
−L
(∫
X
n∑
i=1
x2i −A.cos(ω.xi) dx
)dxn+1 +
∫ L
−L
(∫
X
(x2n+1 −A.cos(ω.xn+1) dx
))dxn+1
=∫ L
−L2n.n
(Ln+2
3− A.Ln−1
ω.sin(ω.L)
)dxn+1 + (2L)n
∫ L
−Lx2n+1 −A.cos(ω.xn+1) dxxn+1
d’apres l’hypothese de recurrence.
= 2n+1.n
(Ln+3
3− A.Ln
ω.sin(ω.L)
)+ (2L)n
(2L3
3− 2A
ω.sin(ω.L)
)
= 2n+1.n
(Ln+3
3− A.Ln
ω.sin(ω.L)
)+ 2n+1
(Ln+3
3− ALn
ω.sin(ω.L)
)
= 2n+1.(n+ 1)(Ln+3
3− A.Ln
ω.sin(ω.L)
)
La formule est vraie au rang n+ 1 donc
∫
X
(n∑
i=1
x2i −A.cos(ω.xi)
)dx = 2n.n
(Ln+2
3− A.Ln−1
ω.sin(ω.L)
)
∀n ∈ N∗; ∀i ∈ [1..n]; x = (xi)i∈1,...,n, xi ∈ [−5, 12; 5, 12]; A = 10; ω = 2π; L ∈ [0; 5, 12]
3.1.3 Calcul de la derniere integrale
Calcul de ∫
X
(n∑
i=1
x2i −A.cos(ω.xi)
)2
dx
Prouvons que
∀n ∈ N∗,∫
X
(n∑
i=1
x2i −A.cos(ω.xi)
)2
dx
=
(2L)n−1.n
[2L5
5− 4A
ω
(L2.sin(ω.L) +
2Lω.cos(ω.L)− 2
(ω)2.sin(ω.L)
)+A2
(L+
12.ω
.sin(2.ω.L))]
+(2L)n−2
(n−1∑
i=1
2i
)(23L3 − 2A
ω.sin(ω.L)
)2
Preuve :Nous allons montrer cette formule par recurrence.
Initialisation : n=1
K =∫ L
−L
(x2
1 −A.cos(ω.x1))2dx1 =
∫ L
−Lx4
1 − 2A.cos(ω.x1).x21 +A2.cos2(w.x1) dx1
Par linearite de l’integrale, nous avons :
=∫ L
−Lx4
1 dx1 − 2A∫ L
−Lcos(ω.x1).x2
1 dx1 +A2
∫ L
−Lcos2(w.x1) dx1
Or,
•∫ L
−Lx4
1 dx1 =[x5
1
5
]L
−L=
2L5
5
iv
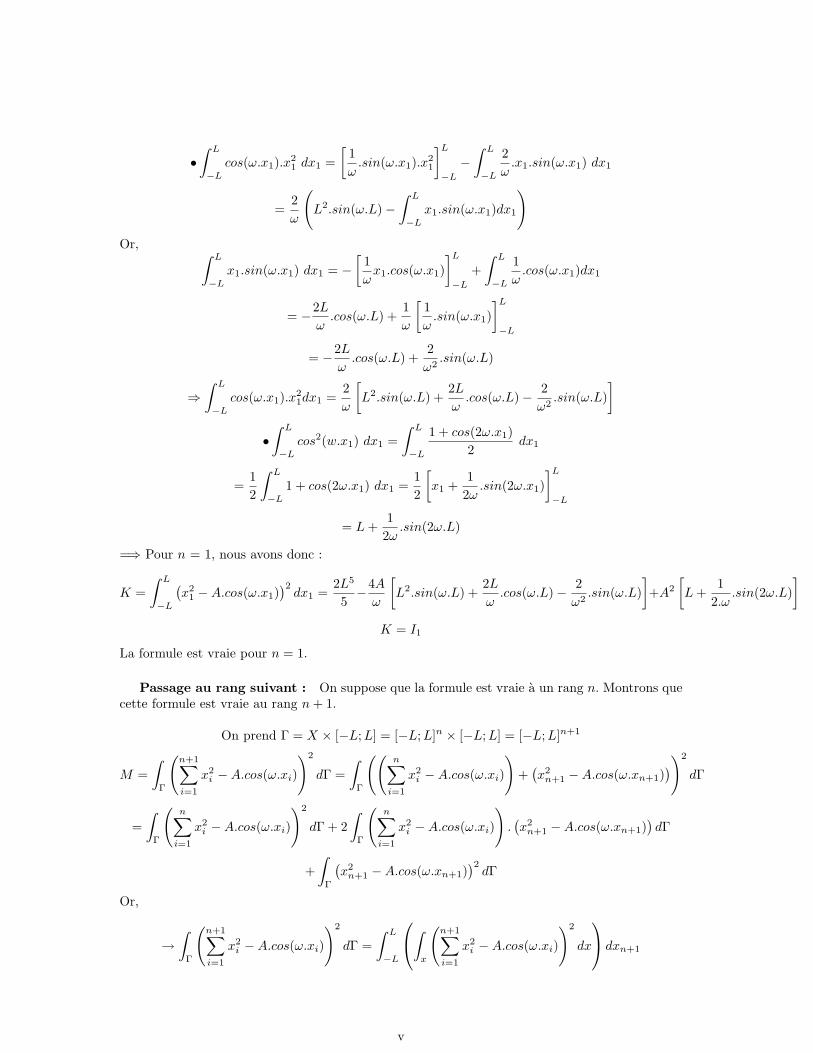
•∫ L
−Lcos(ω.x1).x2
1 dx1 =[
1ω.sin(ω.x1).x2
1
]L
−L−∫ L
−L
2ω.x1.sin(ω.x1) dx1
=2ω
(L2.sin(ω.L)−
∫ L
−Lx1.sin(ω.x1)dx1
)
Or, ∫ L
−Lx1.sin(ω.x1) dx1 = −
[1ωx1.cos(ω.x1)
]L
−L+∫ L
−L
1ω.cos(ω.x1)dx1
= −2Lω.cos(ω.L) +
1ω
[1ω.sin(ω.x1)
]L
−L
= −2Lω.cos(ω.L) +
2ω2.sin(ω.L)
⇒∫ L
−Lcos(ω.x1).x2
1dx1 =2ω
[L2.sin(ω.L) +
2Lω.cos(ω.L)− 2
ω2.sin(ω.L)
]
•∫ L
−Lcos2(w.x1) dx1 =
∫ L
−L
1 + cos(2ω.x1)2
dx1
=12
∫ L
−L1 + cos(2ω.x1) dx1 =
12
[x1 +
12ω.sin(2ω.x1)
]L
−L
= L+1
2ω.sin(2ω.L)
=⇒ Pour n = 1, nous avons donc :
K =∫ L
−L
(x2
1 −A.cos(ω.x1))2dx1 =
2L5
5−4Aω
[L2.sin(ω.L) +
2Lω.cos(ω.L)− 2
ω2.sin(ω.L)
]+A2
[L+
12.ω
.sin(2ω.L)]
K = I1
La formule est vraie pour n = 1.
Passage au rang suivant : On suppose que la formule est vraie a un rang n. Montrons quecette formule est vraie au rang n+ 1.
On prend Γ = X × [−L;L] = [−L;L]n × [−L;L] = [−L;L]n+1
M =∫
Γ
(n+1∑
i=1
x2i −A.cos(ω.xi)
)2
dΓ =∫
Γ
((n∑
i=1
x2i −A.cos(ω.xi)
)+(x2n+1 −A.cos(ω.xn+1)
))2
dΓ
=∫
Γ
(n∑
i=1
x2i −A.cos(ω.xi)
)2
dΓ + 2∫
Γ
(n∑
i=1
x2i −A.cos(ω.xi)
).(x2n+1 −A.cos(ω.xn+1)
)dΓ
+∫
Γ
(x2n+1 −A.cos(ω.xn+1)
)2dΓ
Or,
→∫
Γ
(n+1∑
i=1
x2i −A.cos(ω.xi)
)2
dΓ =∫ L
−L
∫
x
(n+1∑
i=1
x2i −A.cos(ω.xi)
)2
dx
dxn+1
v

Par l’hypothese de recurrence, nous avons :
=∫ L
−Ln.(2L)n−1.I1 + (2L)n−2
(n−1∑
i=0
2i
)(23L3 − 2A
ω.sin(ω.L)
)2
dxn+1
= n.(2L)n.I1 + (2L)n−1
(n−1∑
i=0
2i
)(23L3 − 2A
ω.sin(ω.L)
)2
→ 2∫
Γ
(n∑
i=1
x2i −A.cos(ω.xi)
).(x2n+1 −A.cos(ω.xn+1)
)dΓ
= 2∫ L
−L
(∫
X
(n∑
i=1
x2i −A.cos(ω.xi)
).(x2n+1 −A.cos(ω.xn+1)
)dx
)dxn+1
Par le theoreme de Fubini nous pouvonst ecrire l’egalite suivante :
= 2
(∫
X
n∑
i=1
x2i −A.cos(ω.xi) dx
).
(∫ L
−Lx2n+1 −A.cos(ω.xn+1) dxn+1
)
= 2n.(2L)n−1
(2L3
3− 2A
ω.sin(ω.L)
)2
→∫ L
−L
(x2n+1 −A.cos(ω.xn+1)
)2dxn+1 = (2L)nI1
⇒M = n.(2L)nI1+(2L)n−1
(n−1∑
i=0
2i
)(23L3 − 2A
ω.sin(ω.L)
)2
+2n.(2L)n−1
(2L3
3− 2A
ω.sin(ω.L)
)2
+(2L)nI1
J = (n+ 1).(2L)nI1 + (2L)n−1
(23L3 − 2A
ω.sin(ω.L)
)2[(
n−1∑
i=0
2i
)+ 2n
]
= (n+ 1).(2L)nI1 + (2L)n−1
(23L3 − 2A
ω.sin(ω.L)
)2(
n∑
i=0
2i
)
= (n+1).(2L)n(
2L5
5− 4A
ω
[L2.sin(ω.L) +
2Lω.cos(ω.L)− 2
ω2.sin(ω.L)
]+A2
[L+
12.ω
.sin(2.ω.L)])
+(2L)n−1
(23L3 − 2A
ω.sin(ω.L)
)2(
n∑
i=0
2i
)
= In+1
La formule est vraie au rang n+ 1 donc
∫
X
(n∑
i=1
x2i −A.cos(ω.xi)
)2
dx
=
(2L)n−1.n
[2L5
5− 4A
ω
(L2.sin(ω.L) +
2Lω.cos(ω.L)− 2
ω2.sin(ω.L)
)+A2
(L+
12ω.sin(2ω.L)
)]
+(2L)n−2
(n−1∑
i=1
2i
)(23L3 − 2A
ω.sin(ω.L)
)2
∀n ∈ N∗; ∀i ∈ [1..n]; x = (xi)i∈1,...,n, xi ∈ [−5, 12; 5, 12]; A = 10; ω = 2π; L = 5, 12
vi

3.1.4 Conclusion
Pour l’integrale de la fonction de Rastrigin au carre, nous avons
∫
X
[A · n+
n∑
i=1
x2i −A · cos(ω · xi)
]2
dx
=
(2L)nA2.n2 + 2n+1.A.n2
(Ln+2
3− A.Ln−1
ω.sin(ω.L)
)
+(2L)n−1.n
[2L5
5− 4A
ω
(L2.sin(ω.L) +
2Lω.cos(ω.L)− 2
ω2.sin(ω.L)
)+A2
(L+
12ω.sin(2− ω.L)
)]
+(2L)n−2
(n−1∑
i=1
2i
)(23L3 − 2A
ω.sin(ω.L)
)2
3.2 Calcul du terme croise
On prend X = [−L;L]n
Nous avons a calculer∫
X
r(x).
[A.n+
(n∑
k=1
x2k −A.cos(ω.xk)
)]dx
n ∈ N∗; A = 10; ω = 2π; x = (xi)i∈1,...,n, xi ∈ [−5, 12; 5, 12]
ou m est le nombre de points dans l’echantillonnage.
∫
X
r(x)
[A.n+
(n∑
k=1
x2k −A.cos(ω.xk)
)]dx
=∫
X
A.n.r(x) dx+∫
X
r(x).
(n∑
k=1
x2k
)dx
−∫
X
r(x)
(n∑
k=1
A.cos(ω.xk)
)dx
3.2.1 Calcul de la premiere integrale
Calcul de ∫
X
A.n.r(x) dx
Prouvons que
∀n ∈ N∗,∫
X
A.n.r(x) dx
=
∫
X
A.n
m∑
i=1
Yi.αi
n∏
l=1
x
γill +
γil−1∑
u=0
(−1)γil−u
∑
1≤l1<...<lγil−u≤mlβ 6=i
γil−u∏
t=1g(Xlt
,Xi)=l
Xltl
xul
dx
=
vii

A.n
m∑
i=1
Yi.αi
n∏
l=1
Lγil+1 − (−L)γil+1
γil + 1+
E(γil−1
2
)
∑
q=0
(−1)γil−2q
∑
1≤l1<...<lγil−2q≤mlβ 6=i
γil−2q∏
t=1g(Xlt
,Xi)=l
Xltl
2L2q+1
2q + 1
avec αi =n∏
l=1
m∏
j=1j 6=i
g(Xi,Xj)=l
1Xil −Xjl
Preuve : ∫
X
A.n.r(x) dx
∫
X
A.nm∑
i=1
Yi.αi
n∏
l=1
x
γill +
γil−1∑
u=0
(−1)γil−u
∑
1≤l1<...<lγil−u≤mlβ 6=i
γil−u∏
t=1g(Xlt
,Xi)=l
Xltl
xul
dx
Par linearite de l’integrale, nous avons :
A.nm∑
i=1
Yi.αi
∫
X
n∏
l=1
x
γill +
γil−1∑
u=0
(−1)γil−u
∑
1≤l1<...<lγil−u≤mlβ 6=i
γil−u∏
t=1g(Xlt
,Xi)=l
Xltl
xul
dx
Il vient par le theoreme de Fubini :
A.n
m∑
i=1
Yi.αi
n∏
l=1
∫ L
−Lxγill dxl +
γil−1∑
u=0
(−1)γil−u
∑
1≤l1<...<lγil−u≤mlβ 6=i
γil−u∏
t=1g(Xlt
,Xi)=l
Xltl
∫ L
−Lxul dxl
= A.n
m∑
i=1
Yi.αi
n∏
l=1
Lγil+1 − (−L)γil+1
γil + 1+
γil−1∑
u=0
(−1)γil−u
∑
1≤l1<...<lγil−u≤mlβ 6=i
γil−u∏
t=1g(Xlt
,Xi)=l
Xltl
∫ L
−Lxul dxl
Si u est impair alors l’integrale est nulle donc nous prendrons u pair. On pose alors u = 2q avecq ∈ N.
= A.n
m∑
i=1
Yi.αi
n∏
l=1
Lγil+1 − (−L)γil+1
γil + 1+
E(γil−1
2
)
∑
q=0
(−1)γil−2q
∑
1≤l1<...<lγil−2q≤mlβ 6=i
γil−2q∏
t=1g(Xlt
,Xi)=l
Xltl
∫ L
−Lx2ql dxl
= A.n
m∑
i=1
Yi.αi
n∏
l=1
Lγil+1 − (−L)γil+1
γil + 1+
E(γil−1
2
)
∑
q=0
(−1)γil−2q
∑
1≤l1<...<lγil−2q≤mlβ 6=i
γil−2q∏
t=1g(Xlt
,Xi)=l
Xltl
2L2q+1
2q + 1
3.2.2 Calcul de la seconde integrale
Calcul de ∫
X
r(x).
(n∑
k=1
x2k
)dx
viii

Prouvons que ∀n ∈ N∗ : ∫
X
r(x).
(n∑
k=1
x2k
)dx
=
m∑
i=1
αi.Yi
n∑
k=1
Lγik+3 − (−L)γik+3
γik + 3+
E(γik−1
2
)
∑
q=0
(−1)γik−2q
∑
1≤l1<...<lγik−2q≤mlβ 6=i
γik−2q∏
t=1g(Xlt
,Xi)=k
Xltk
2L2q+3
2q + 3
.
n∏
z=1z 6=k
Lγiz+1 − (−L)γiz+1
γiz + 1+E( γiz−1
2 )∑
v=0
(−1)γiz−2v
∑
1≤l1<...<lγiz−2v≤mlβ 6=i
γiz−2v∏
t=1g(Xlt
,Xi)=z
Xltz
2L2v+1
2v + 1
Preuve :
∫
X
(n∑
k=1
x2k
).r(x) dx
=∫
X
(n∑
k=1
x2k
).
m∑
i=1
Yi.αi
n∏
l=1
x
γill +
γil−1∑
u=0
(−1)γil−u
∑
1≤l1<...<lγil−u≤mlβ 6=i
γil−u∏
t=1g(Xlt
,Xi)=l
Xltl
xul
dx
=∫
X
m∑
i=1
αi.Yi
n∑
k=1
x
γik+2k +
γik−1∑
u=0
(−1)γik−u
∑
1≤l1<...<lγik−u≤mlβ 6=i
γik−u∏
t=1g(Xlt
,Xi)=k
Xltk
xu+2
k
.
n∏
v=1v 6=k
x
γivv +
γiv−1∑
u=0
(−1)γiv−u
∑
1≤l1<...<lγiv−u≤mlβ 6=i
γiv−u∏
t=1g(Xlt
,Xi)=v
Xltv
xuv
dx
Par linearite de l’integrale, nous avons :
=m∑
i=1
αi.Yi
∫
X
n∑
k=1
x
γik+2k +
γik−1∑
u=0
(−1)γik−u
∑
1≤l1<...<lγik−u≤mlβ 6=i
γik−u∏
t=1g(Xlt
,Xi)=k
Xltk
xu+2
k
.
n∏
v=1v 6=k
x
γivv +
γiv−1∑
u=0
(−1)γiv−u
∑
1≤l1<...<lγiv−u≤mlβ 6=i
γiv−u∏
t=1g(Xlt
,Xi)=v
Xltv
xuv
dx
Par linearite de l’integrale et par le theoreme de Fubini, nous avons :
=m∑
i=1
αi.Yi
n∑
k=1
∫ L
−Lxγik+2k dxk +
γik−1∑
u=0
(−1)γik−u
∑
1≤l1<...<lγik−u≤mlβ 6=i
γik−u∏
t=1g(Xlt
,Xi)=k
Xltk
∫ L
−Lxu+2k dxk
.
ix

n∏
v=1v 6=k
∫ L
−Lxγivv dxv +
γiv−1∑
u=0
(−1)γiv−u
∑
1≤l1<...<lγiv−u≤mlβ 6=i
γiv−u∏
t=1g(Xlt
,Xi)=v
Xltv
∫ L
−Lxuv dxv
Comme precedemment, on ne garde que les termes pour lesquels u est pair :
m∑
i=1
αi.Yi
n∑
k=1
Lγik+3 − (−L)γik+3
γik + 3+
E(γik−1
2
)
∑
q=0
(−1)γik−2q
∑
1≤l1<...<lγik−2q≤mlβ 6=i
γik−2q∏
t=1g(Xlt
,Xi)=k
Xltk
2L2q+3
2q + 3
.
n∏
z=1z 6=k
Lγiz+1 − (−L)γiz+1
γiz + 1+E( γiz−1
2 )∑
v=0
(−1)γiz−2v
∑
1≤l1<...<lγiz−2v≤mlβ 6=i
γiz−2v∏
t=1g(Xlt
,Xi)=z
Xltz
2L2v+1
2v + 1
3.2.3 Calcul de la derniere integrale
Nous avons a calculer l’integrale suivante :
∫
X
(n∑
i=1
A.cos(ω.xi)
).r(x) dx = A
∫
X
(n∑
i=1
cos(ω.xi)
).r(x) dx
Montrons l’egalite suivante : ∫
X
(n∑
i=1
A.cos(ω.xi)
).r(x) dx
=
Am∑
i=1
αi.Yi
n∑
k=1
1− (−1)γik−1
2.c(γik)+
E(γik−1
2
)
∑
q=0
(−1)γik−2q
∑
1≤l1<...<lγik−2q≤mlβ 6=i
γik−2q∏
t=1g(Xlt
,Xi)=k
Xltk
c(2q)
.
n∏
z=1z 6=k
Lγiz+1 − (−L)γiz+1
γiz + 1+E( γiz−1
2 )∑
v=0
(−1)γiz−2v
∑
1≤l1<...<lγiz−2v≤mlβ 6=i
γiz−2v∏
t=1g(Xlt
,Xi)=z
Xltz
2L2v+1
2v + 1
Pour montrer cette formule nous aurons besoin de calculer∫ L
−Lxj .cos(ω.x) dx
Nous voyons que pour j impair, cette integrale est nulle. En effet, le cosinus est une fonction paireet xj est une fonction impaire pour j impair. Le produit de ces 2 fonctions est alors une fonctionimpaire et son integrale sur un intervalle symetrique est donc nulle. Nous allons prouver que pourj pair, nous avons :
Ij =∫ L
−Lxj .cos(ω.x) dx =
j∑
k=0
(−1)E( j−k2 ) 1ωj−k+1
.j!k!.((
1− (−1)j−k+1).Lk.sin(ω.L) +
(1− (−1)j−k
).Lk.cos(ω.L)
)
Preuve :
x

Initialisation : j = 0
I0 =∫ L
−Lcos(ω.x) dx =
[1ω.sin(ω.x)
]L
−L=
2ω.sin(ω.L)
La formule est donc vraie pour j=0.
Passage a l’entier pair suivant : On suppose que la formule est vraie pour un entier pairj. Montrons que cette formule est encore vraie pour l’entier pair suivant.
Ij+2 =∫ L
−Lxj+2.cos(ω.x) dx
=[xj+2
ω.sin(ω.x)
]L
−L− j + 2
ω.
∫ L
−Lxj+1.sin(ω.x) dx
=2.Lj+2
ω.sin(ω.L)− j + 2
ω
([−xj+1
ω.cos(ω.x)
]L
−L+j + 1ω
∫ L
−Lxj .cos(ω.x) dx
)
=2.Lj+2
ω.sin(ω.L)− j + 2
ω.−2Lj+1
ω.cos(ω.L)
− (j + 2)(j + 1)ω2
[j∑
k=0
(−1)E( j−k2 ) 1ωj−k+1
.j!k!.((
1− (−1)j−k+1).Lk.sin(ω.L) +
(1− (−1)j−k
).Lk.cos(ω.L)
)]
=2.Lj+2
ω.sin(ω.L) +
2(j + 2).Lj+1
ω2.cos(ω.L)
−j∑
k=0
(−1)E( j−k2 ) 1ωj+3−k .
(j + 2)!k!
.((
1− (−1)j−k+1).Lk.sin(ω.L) +
(1− (−1)j−k
).Lk.cos(ω.L)
)
Or (−1)j+1−k = (−1)j+3−k et (−1)j−k = (−1)j+2−k
Le (j + 1)me terme de la somme vaut donc
(−1)E( j+2−j−12 ) 1
ω2.(j + 2).2Lj+1cos(ω.L)
et le (j + 2)me terme de la somme vaut
(−1)E( j+2−j−22 ) 1
ω2.Lj+2.sin(ω.L)
Or ce sont les 2 termes que nous avons devant la somme. Nous allons donc rentrer ces 2 termesdans la somme.
=j+2∑
k=0
(−1)E( j+2−k2 ) 1
ωj+3−k .(j + 2)!k!
.((
1− (−1)j+3−k) .Lk.sin(ω.L) +(1− (−1)j+2−k) .Lk.cos(ω.L)
)
La formule est vraie pour l’entier pair suivant donc la formule est vraie pour tous les entiers pairs.Montrons par recurrence la formule de la derniere integrale.
I =∫
X
(n∑
i=1
A.cos(ω.xi)
).r(x) dx = A
∫
X
(n∑
i=1
cos(ω.xi)
).r(x) dx
I = A
∫
X
(n∑
i=1
cos(ω.xi)
).
m∑
i=1
Yi.αi
n∏
l=1
x
γill +
γil−1∑
u=0
(−1)γil−u
∑
1≤l1<...<lγil−u≤mlβ 6=i
γil−u∏
t=1g(Xlt
,Xi)=l
Xltl
xul
dx
xi

I = A
∫
X
m∑
i=1
αi.Yi
n∑
k=1
x
γikk .cos(ω.xk) +
γik−1∑
u=0
(−1)γik−u
∑
1≤l1<...<lγik−u≤mlβ 6=i
γik−u∏
t=1g(Xlt
,Xi)=k
Xltk
xuk .cos(ω.xk)
.
n∏
v=1v 6=k
x
γivv +
γiv−1∑
u=0
(−1)γiv−u
∑
1≤l1<...<lγiv−u≤mlβ 6=i
γiv−u∏
t=1g(Xlt
,Xi)=v
Xltv
xuv
dx
Par linearite de l’integrale, nous avons :
I = Am∑
i=1
αi.Yi
∫
X
n∑
k=1
x
γikk .cos(ω.xk) +
γik−1∑
u=0
(−1)γik−u
∑
1≤l1<...<lγik−u≤mlβ 6=i
γik−u∏
t=1g(Xlt
,Xi)=k
Xltk
xuk .cos(ω.xk)
.
n∏
v=1v 6=k
x
γivv +
γiv−1∑
u=0
(−1)γiv−u
∑
1≤l1<...<lγiv−u≤mlβ 6=i
γiv−u∏
t=1g(Xlt
,Xi)=v
Xltv
xuv
dx
Par le theoreme de Fubini et par linearite de l’integrale, nous avons :
I = Am∑
i=1
αi.Yi
n∑
k=1
∫ L
−Lxγikk .cos(ω.xk) dxk +
γik−1∑
u=0
(−1)γik−u
∑
1≤l1<...<lγik−u≤mlβ 6=i
γik−u∏
t=1g(Xlt
,Xi)=l
Xltk
∫ L
−Lxuk .cos(ω.xk) dxk
.
n∏
v=1v 6=k
∫ L
−Lxγivv dxv +
γiv−1∑
u=0
(−1)γiv−u
∑
1≤l1<...<lγiv−u≤mlβ 6=i
γiv−u∏
t=1g(Xlt
,Xi)=v
Xltv
∫ L
−Lxuv dxv
On ne garde que les termes pour lesquels u est pair :
I = Am∑
i=1
αi.Yi
n∑
k=1
∫ L
−Lxγikk .cos(ω.xk) dxk +
E(γik−1
2
)
∑
q=0
(−1)γik−2q
∑
1≤l1<...<lγik−2q≤mlβ 6=i
γik−2q∏
t=1g(Xlt
,Xi)=k
Xltk
.
∫ L
−Lx2qk .cos(ω.xk) dxk
.
n∏
v=1v 6=k
∫ L
−Lxγivv dxv +
E(γiv−1
2
)
∑
q=0
(−1)γiv−2q
∑
1≤l1<...<lγiv−2q≤mlβ 6=i
γiv−2q∏
t=1g(Xlt
,Xi)=v
Xltv
∫ L
−Lx2qv dxv
Nous avons vu, pour j pair :
∫ L
−Lxj .cos(ω.x) dx =
j∑
k=0
(−1)E( j−k2 ) 1ωj−k+1
.j!k!.((
1− (−1)j−k+1).Lk.sin(ω.L) +
(1− (−1)j−k
).Lk.cos(ω.L)
)
On pose
c(j) =j∑
k=0
(−1)E( j−k2 ) 1ωj−k+1
.j!k!.((
1− (−1)j−k+1).Lk.sin(ω.L) +
(1− (−1)j−k
).Lk.cos(ω.L)
)
d’ou ∫ L
−Lxj .cos(ω.x) dx = c(j)
xii

Nous avons alors :
I = Am∑
i=1
αi.Yi
n∑
k=1
1− (−1)γik−1
2.c(γik)+
E(γik−1
2
)
∑
q=0
(−1)γik−2q
∑
1≤l1<...<lγik−2q≤mlβ 6=i
γik−2q∏
t=1g(Xlt
,Xi)=k
Xltk
c(2q)
.
n∏
z=1z 6=k
Lγiz+1 − (−L)γiz+1
γiz + 1+E( γiz−1
2 )∑
v=0
(−1)γiz−2v
∑
1≤l1<...<lγiz−2v≤mlβ 6=i
γiz−2v∏
t=1g(Xlt
,Xi)=z
Xltz
2L2v+1
2v + 1
= Am∑
i=1
αi.Yi
n∑
k=1
1− (−1)γik−1
2.c(γik)+
E(γik−1
2
)
∑
q=0
(−1)γik−2q
∑
1≤l1<...<lγik−2q≤mlβ 6=i
γik−2q∏
t=1g(Xlt
,Xi)=k
Xltk
c(2q)
.
n∏
z=1z 6=k
Lγiz+1 − (−L)γiz+1
γiz + 1+E( γiz−1
2 )∑
v=0
(−1)γiz−2v
∑
1≤l1<...<lγiz−2v≤mlβ 6=i
γiz−2v∏
t=1g(Xlt
,Xi)=z
Xltz
2L2v+1
2v + 1
3.2.4 Conclusion pour le terme croise
Pour l’integrale de la fonction de Rastrigin multipliee par le polynome (terme croise), nousavons : ∫
X
f(x).r(x) dx
=
A.nm∑
i=1
Yi.αi
n∏
l=1
Lγil+1 − (−L)γil+1
γil + 1+
E(γil−1
2
)
∑
q=0
(−1)γil−2q
∑
1≤l1<...<lγil−2q≤mlβ 6=i
γil−2q∏
t=1g(Xlt
,Xi)=l
Xltl
2L2q+1
2q + 1
+m∑
i=1
αi.Yi
n∑
k=1
1− (−1)γik−1
2.c(γik)+
E(γik−1
2
)
∑
q=0
(−1)γik−2q
∑
1≤l1<...<lγik−2q≤mlβ 6=i
γik−2q∏
t=1g(Xlt
,Xi)=k
Xltk
c(2q)
.
n∏
z=1z 6=k
Lγiz+1 − (−L)γiz+1
γiz + 1+E( γiz−1
2 )∑
v=0
(−1)γiz−2v
∑
1≤l1<...<lγiz−2v≤mlβ 6=i
γiz−2v∏
t=1g(Xlt
,Xi)=z
Xltz
2L2v+1
2v + 1
−Am∑
i=1
αi.Yi
n∑
k=1
1− (−1)γik−1
2.c(γik)+
E(γik−1
2
)
∑
q=0
(−1)γik−2q
∑
1≤l1<...<lγik−2q≤mlβ 6=i
γik−2q∏
t=1g(Xlt
,Xi)=k
Xltk
c(2q)
.
n∏
z=1z 6=k
Lγiz+1 − (−L)γiz+1
γiz + 1+E( γiz−1
2 )∑
v=0
(−1)γiz−2v
∑
1≤l1<...<lγiz−2v≤mlβ 6=i
γiz−2v∏
t=1g(Xlt
,Xi)=z
Xltz
2L2v+1
2v + 1
xiii

3.3 Calcul de l’integrale du polynome de Lagrange au carre
On prend X = [−L;L]n avec L ∈ [0; 5, 12]
Prouvons que :
∫
X
r2(x) dx =∫
X
m∑
i=1
Yi
n∏
l=1
m∏
j=1j 6=i
g(Xi,Xj)=l
xl −Xjl
Xil −Xjl
2
dx
=m∑
i=1
Y 2i αi
n∏
l=1
2γil∑
j=0
(−1)2γil−j
∑
1≤k1<...<k2γil−j≤m
∏
g(Xi,Xks )=l
Xks
L
j+1 − (−L)j+1
j + 1
+2∑
1≤u<v≤mYu.Yv.αujl.αvzk
n∏
l=1
γul+γvl∑
j=0
(−1)γul+γvl−j
∑
1≤k1<...<kγul+γvl−j≤m
∏
g(Xu,Xks )=lou g(Xv,Xks )=l
Xks
Lj+1 − (−L)j+1
j + 1
Preuve : On sait que
n∑
j=1
aj
2
=n∑
j=1
a2j + 2
∑
1≤j<k≤naj .ak
Nous avons donc
r(x)2 =m∑
i=1
Y 2i
n∏
l=1
m∏
j=1j 6=i
g(Xi,Xj)=l
(xl −Xjl
Xil −Xjl
)2
+2∑
1≤u<v≤mYu.Yv
n∏
l=1
m∏
j=1j 6=u
g(Xu,Xj)=l
(xl −Xjl
Xul −Xjl
).n∏
k=1
m∏
z=1z 6=v
g(Xv,Xz)=k
(xk −Xzk
Xvk −Xzk
)
On pose
αi =n∏
l=1
m∏
j=1j 6=i
g(Xi,Xj)=l
(1
Xil −Xjl
)
Nous avons alors
r(x)2 =m∑
i=1
Y 2i αi
n∏
l=1
m∏
j=1j 6=i
g(Xi,Xj)=l
(xl −Xjl)2
+2∑
1≤u<v≤mYu.Yv.αujl.αvzk
n∏
l=1
γul+γvl∑
j=0
(−1)γul+γvl−j
∑
1≤k1<...<kγul+γvl−j≤m
∏
g(Xu,Xks )=lou g(Xv,Xks )=l
Xks
x
jl
=m∑
i=1
Y 2i αi
n∏
l=1
2γil∑
j=0
(−1)2γil−j
∑
1≤k1<...<k2γil−j≤m
∏
g(Xi,Xks )=l
Xks
xjl
+2∫
X
∑
1≤u<v≤mYu.Yv.αujl.αvzk
n∏
l=1
γul+γvl∑
j=0
(−1)γul+γvl−j
∑
1≤k1<...<kγul+γvl−j≤m
∏
g(Xu,Xks )=lou g(Xv,Xks )=l
Xks
x
jl dx
xiv

D’ou ∫
X
r(x)2 dx
=∫
X
m∑
i=1
Y 2i αi
n∏
l=1
2γil∑
j=0
(−1)2γil−j
∑
1≤k1<...<k2γil−j≤m
∏
g(Xi,Xks )=l
Xks
xjl dx
+2∫
X
∑
1≤u<v≤mYu.Yv.αujl.αvzk
n∏
l=1
γul+γvl∑
j=0
(−1)γul+γvl−j
∑
1≤k1<...<kγul+γvl−j≤m
∏
g(Xu,Xks )=lou g(Xv,Xks )=l
Xks
x
jl dx
Par le theoreme de Fubini, il vient : ∫
X
r(x)2 dx
=m∑
i=1
Y 2i αi
n∏
l=1
2γil∑
j=0
(−1)2γil−j
∑
1≤k1<...<k2γil−j≤m
∏
g(Xi,Xks )=l
Xks
∫ L
−Lxjl dx
+2∑
1≤u<v≤mYu.Yv.αujl.αvzk
n∏
l=1
γul+γvl∑
j=0
(−1)γul+γvl−j
∑
1≤k1<...<kγul+γvl−j≤m
∏
g(Xu,Xks )=lou g(Xv,Xks )=l
Xks
∫ L
−Lxjl dx
En resume, ∫
X
r(x)2 dx
=m∑
i=1
Y 2i αi
n∏
l=1
2γil∑
j=0
(−1)2γil−j
∑
1≤k1<...<k2γil−j≤m
∏
g(Xi,Xks )=l
Xks
L
j+1 − (−L)j+1
j + 1
+2∑
1≤u<v≤mYu.Yv.αujl.αvzk
n∏
l=1
γul+γvl∑
j=0
(−1)γul+γvl−j
∑
1≤k1<...<kγul+γvl−j≤m
∏
g(Xu,Xks )=lou g(Xv,Xks )=l
Xks
Lj+1 − (−L)j+1
j + 1
3.4 Conclusion pour le eRMS pour la fonction de Rastrigin
Nous avons, pour la fonction de Rastrigin, l’erreur quadratique moyenne suivante :
eRMS =
√1|X|
∫
X
[f(x)− r(x)]2 dx
ou f est la fonction de Rastrigin et r un polynome de regression. Nous aurons la valeur de l’ eRMS
en divisant la formule suivante par le cardinal de X puis en prenant ensuite la racine carree del’expression suivante.
(2L)nA2.n2 + 2n+1.A.n2
(Ln+2
3− A.Ln−1
ω.sin(ω.L)
)
+(2L)n−1.n
[2L5
5− 4A
ω
(L2.sin(ω.L) +
2Lω.cos(ω.L)− 2
ω2.sin(ω.L)
)+A2
(L+
12ω.sin(2− ω.L)
)]
xv

+(2L)n−2
(n−1∑
i=1
2i
)(23L3 − 2A
ω.sin(ω.L)
)2
−2.A.nm∑
i=1
Yi.αi
n∏
l=1
Lγil+1 − (−L)γil+1
γil + 1+
E(γil−1
2
)
∑
q=0
(−1)γil−2q
∑
1≤l1<...<lγil−2q≤mlβ 6=i
γil−2q∏
t=1g(Xlt
,Xi)=l
Xltl
2L2q+1
2q + 1
−2m∑
i=1
αi.Yi
n∑
k=1
1− (−1)γik−1
2.c(γik)−2
E(γik−1
2
)
∑
q=0
(−1)γik−2q
∑
1≤l1<...<lγik−2q≤mlβ 6=i
γik−2q∏
t=1g(Xlt
,Xi)=k
Xltk
c(2q)
.
n∏
z=1z 6=k
Lγiz+1 − (−L)γiz+1
γiz + 1+E( γiz−1
2 )∑
v=0
(−1)γiz−2v
∑
1≤l1<...<lγiz−2v≤mlβ 6=i
γiz−2v∏
t=1g(Xlt
,Xi)=l
Xltz
2L2v+1
2v + 1
+2.Am∑
i=1
αi.Yi
n∑
k=1
1− (−1)γik−1
2.c(γik)−2
E(γik−1
2
)
∑
q=0
(−1)γik−2q
∑
1≤l1<...<lγik−2q≤mlβ 6=i
γik−2q∏
t=1g(Xlt
,Xi)=k
Xltk
c(2q)
.
n∏
z=1z 6=k
Lγiz+1 − (−L)γiz+1
γiz + 1+E( γiz−1
2 )∑
v=0
(−1)γiz−2v
∑
1≤l1<...<lγiz−2v≤mlβ 6=i
γiz−2v∏
t=1g(Xlt
,Xi)=z
Xltz
2L2v+1
2v + 1
+m∑
i=1
Y 2i αi
n∏
l=1
2γil∑
j=0
(−1)2γil−j
∑
1≤k1<...<k2γil−j≤m
∏
g(Xi,Xks )=l
Xks
L
j+1 − (−L)j+1
j + 1
+2∑
1≤u<v≤mYu.Yv.αujl.αvzk
n∏
l=1
γul+γvl∑
j=0
(−1)γul+γvl−j
∑
1≤k1<...<kγul+γvl−j≤m
∏
g(Xu,Xks )=lou g(Xv,Xks )=l
Xks
Lj+1 − (−L)j+1
j + 1
4 Calculs de l’eRMS pour la fonction de Griewank
f(x) = 1 +n∑
i=1
x2i
4000−
n∏
i=1
cos
(xi√i
)
Nous avons donc pour la fonction de Griewank, l’erreur quadratique moyenne suivante :
eRMS =
√1|X|
∫
X
[f(x)− r(x)]2 dx
=
√√√√√ 1|X|
∫
X
1 +
n∑
i=1
x2i
4000−
n∏
i=1
cos
(xi√i
)−
n∏
i=1
m−1∑
j=0
αij .xji
2
dx
xi ∈ [−600; 600]
xvi

Pour cela, nous allons d’abord calculer
∫
X
[1 +
n∑
i=1
x2i
4000−
n∏
i=1
cos
(xi√i
)]2
dx =∫
X
f2(x) dx
puis
∫
X
[1 +
n∑
i=1
x2i
4000−
n∏
i=1
cos
(xi√i
)].
n∏
i=1
m−1∑
j=0
αij .xji
dx =
∫
X
f(x).r(x) dx
et enfin∫
X
n∏
i=1
m−1∑
j=0
αij .xji
2
dx =∫
X
r2(x) dx
4.1 Calcul de l’integrale de la fonction de Griewank au carre
On prend X = [−L;L]n avec L ∈ [0; 600]
∫
X
f2(x) dx =∫
X
[1 +
n∑
i=1
x2i
4000−
n∏
i=1
cos
(xi√i
)]2
dx
=∫
X
[(1 +
n∑
i=1
x2i
4000
)−(
n∏
i=1
cos
(xi√i
))]2
dx
=∫
X
(1 +
n∑
i=1
x2i
4000
)2
− 2
(1 +
n∑
i=1
x2i
4000
).
(n∏
i=1
cos
(xi√i
))+
(n∏
i=1
cos
(xi√i
))2
dx
=∫
X
1+2n∑
i=1
x2i
4000+
(n∑
i=1
x2i
4000
)2
−2n∏
i=1
cos
(xi√i
)−2.
(n∑
i=1
x2i
4000
).
(n∏
i=1
cos
(xi√i
))+
n∏
i=1
cos2
(xi√i
)dx
Par linearite de l’integrale, nous avons :
=∫
X
1 dx + 2∫
X
n∑
i=1
x2i
4000dx +
∫
X
(n∑
i=1
x2i
4000
)2
dx− 2∫
X
n∏
i=1
cos
(xi√i
)dx
−2∫
X
(n∑
i=1
x2i
4000
).
(n∏
i=1
cos
(xi√i
))dx +
∫
X
n∏
i=1
cos2
(xi√i
)dx
4.1.1 Calcul de la premiere integrale
Calcul de ∫
X
1 dx
Nous avons ∫
X
1 dx = (2L)n
xvii

4.1.2 Calcul de la deuxieme integrale
Calcul de ∫
X
2n∑
i=1
x2i
4000dx
Nous avons ∫
X
2n∑
i=1
x2i
4000dx = n.
2n+1Ln+2
12000
Ce calcul a ete realise precedemment pour la fonction de Rastrigin.
4.1.3 Calcul de la troisieme integrale
Calcul de ∫
X
(n∑
i=1
x2i
4000
)2
dx
Nous allons prouver que
∫
X
(n∑
i=1
x2i
4000
)2
dx =2nLn+4
16.106.
[n
5+
19
(n−1∑
i=0
2i
)]
Preuve Nous allons montrer cette formule par recurrence :
Initialisation : n = 1
∫
X
(1∑
i=1
x2i
4000
)2
dx =∫ L
−L
x41
16.106dx1 =
2L5
5.16.106
La formule est vraie pour n = 1.
Passage au rang suivant : On suppose que la formule est vraie pour un entier n. Montronsque cette formule est vraie au rang n+ 1.
On prend Γ = X×[-L ; L] = [−L;L]n×[-L ; L]
K =∫
Γ
(n+1∑
i=1
x2i
4000
)2
dΓ =∫
Γ
(n∑
i=1
x2i
4000+x2n+1
4000
)2
dΓ
=∫
Γ
(n∑
i=1
x2i
4000
)2
dΓ
︸ ︷︷ ︸a
+ 2∫
Γ
(n∑
i=1
x2i
4000
)(x2n+1
4000
)dΓ
︸ ︷︷ ︸b
+∫
Γ
x4n+1
16.106dΓ
︸ ︷︷ ︸c
→ a :∫
Γ
(n∑
i=1
x2i
4000
)2
dΓ =∫ L
−L
∫
X
(n∑
i=1
x2i
4000
)2
dx dxn+1
=∫ L
−L
116.106
.2n.Ln+4
[n
5+
19.
(n−1∑
i=0
2i
)]dxn+1
=1
16.1062n+1Ln+5
[n
5+
19.
(n−1∑
i=0
2i
)]
xviii

→ b : 2∫
Γ
(n∑
i=1
x2i
4000
)(x2n+1
4000
)dΓ =
216.106
∫ L
−L
∫
X
(n∑
i=1
x2i
).x2n+1 dx dxn+1
=2
16.106
(∫
X
n∑
i=1
x2i dx
).
(∫ L
−Lx2n+1 dxn+1
)
=1
16.106
(2n+1.n.Ln+2
3
)(23L3
)
Le calcul de l’integrale de la somme a ete effectue dans le calcul de la seconde integrale.
=1
16.106.2n+1.(2n).Ln+5
9
→ c :∫
Γ
x4n+1
16.106dΓ =
(∫ L
−L
x4n+1
16.106dxn+1
)(∫
X
dx
)
=2L5
5.16.106.(2L)n
=2n+1Ln+5
5.16.106
⇒ K =1
16.106.
[2n+1.Ln+5
(n
5+
19
(n−1∑
i=0
2i
))+
(2n).2n+1.Ln+5
9+
2n+1.Ln+5
5
]
=1
16.106.2n+1.Ln+5
[n
5+
19.
(n−1∑
i=0
2i
)+
2n9
+15
]
=1
16.106.2n+1.Ln+5
[n+ 1
5+
19.
(n∑
i=0
2i
)]= In+1
Conclusion :
∀n ∈ N∗∫
X
(n∑
i=1
x2i
4000
)2
dx =1
16.1062nLn+4
[n
5+
19.
(n−1∑
i=0
2i
)]
4.1.4 Calcul de la quatrieme integrale
Calcul de ∫
X
n∏
i=1
cos
(xi√i
)dx
Prouvons que ∫
X
n∏
i=1
cos
(xi√i
)dx = 2n
(n∏
i=1
√i.sin
(L√i
))
Preuve : Montrons cette formule par recurrence.
Initialisation : n = 1∫ L
−Lcos
(x1√
1
)dx1 =
∫ L
−Lcos(x1) dx1
= [sin(x1)]L−L = 2.sin(L)
La formule est donc vraie pour n = 1.
xix

Passage au rang suivant : On suppose que la formule est vraie pour un entier n. Montronsque cette formule est vraie au rang n+ 1.
On prend Γ = X×[-L ; L] = [−L;L]n×[-L ; L]∫
Γ
n+1∏
i=1
cos
(xi√i
)dΓ =
∫ L
−L
(∫
X
n+1∏
i=1
cos
(xi√i
)dx
)dxn+1
Par le theoreme de Fubini, on peut ecrire :
=
[∫ L
−Lcos
(xn+1√n+ 1
)dxn+1
].
[∫
X
n∏
i=1
cos
(xi√i
)dx
]
d’ou, par l’hypothese de recurrence
=
[∫ L
−Lcos
(xn+1√n+ 1
)dxn+1
].
[2n(
n∏
i=1
√i.sin
(L√i
))]
=[√
n+ 1.sin(
xn+1√n+ 1
)]L
−L.
[2n(
n∏
i=1
√i.sin
(L√i
))]
= 2.√n+ 1.sin
(L√n+ 1
).
[2n(
n∏
i=1
√i.sin
(L√i
))]
= 2n+1
(n+1∏
i=1
√i.sin
(L√i
))
Conclusion : ∫
X
n∏
i=1
cos
(xi√i
)dx = 2n
(n∏
i=1
√i.sin
(L√i
))
4.1.5 Calcul de la cinquieme integrale
Calcul de ∫
X
(n∑
i=1
x2i
4000
)(n∏
i=1
cos
(xi√i
))dx
Prouvons que ∫
X
(n∑
i=1
x2i
4000
)(n∏
i=1
cos
(xi√i
))dx
=1
4000.2n(
n∏
i=1
√i
)
n∑
i=1
n∏
j=1j 6=i
sin
(L√i
)(L2.sin
(L√i
)+ 2L.
√i.cos
(L√i
)− 2i.sin
(L√i
))
Preuve : Montrons cette formule par recurrence :
Initialisation : n = 1
J =∫
X
(1∑
i=1
x2i
4000
)(1∏
i=1
cos
(xi√i
))dx
=∫ L
−L
x21
4000.cos(x1) dx1 =
14000
∫ L
−Lx2
1.cos(x1) dx1
=1
4000.2[L2.sin(L) + 2L.
√1.cos(L)− 2.sin(L)
]
La formule est vraie pour n = 1.
xx

Passage au rang suivant : On suppose que la formule est vraie pour un entier n. Montronsqu’elle est vraie au rang n+ 1.
On prend Γ = X×[-L ; L] = [−L;L]n×[-L ; L]
K =∫
Γ
(n+1∑
i=1
x2i
4000
)(n+1∏
i=1
cos
(xi√i
))dx
=1
4000
∫
Γ
(n∑
i=1
x2i + x2
n+1
)[n∏
i=1
cos
(xi√i
).cos
(xn+1√n+ 1
)]dΓ
=1
4000
∫
Γ
(n∑
i=1
x2i
)(n∏
i=1
cos
(xi√i
)).cos
(xn+1√n+ 1
)dΓ
︸ ︷︷ ︸a
+∫
Γ
x2n+1.cos
(xn+1√n+ 1
)( n∏
i=1
cos
(xi√i
))dΓ
︸ ︷︷ ︸b
→ Calcul de a :
a =∫
Γ
(n∑
i=1
x2i
)(n∏
i=1
cos
(xi√i
)).cos
(xn+1√n+ 1
)dΓ
Par le theoreme de Fubini, nous avons :
=
(∫ L
−Lcos
(xn+1√n+ 1
)dxn+1
).
(∫
X
(n∑
i=1
x2i
)(n∏
i=1
cos
(xi√i
))dx
)
=
(∫ L
−Lcos
(xn+1√n+ 1
)dxn+1
).2n(
n∏
i=1
√i
)
.
n∑
i=1
n∏
j=1j 6=i
sin
(L√i
)(L2.sin
(L√i
)+ 2L.
√i.cos
(L√i
)− 2i.sin
(L√i
))
= 2.√n+ 1.sin
(L√n+ 1
).2n(
n∏
i=1
√i
)
n∑
i=1
n∏
j=1j 6=i
sin
(L√i
)(L2.sin
(L√i
)+ 2L.
√i.cos
(L√i
)− 2i.sin
(L√i
))
= 2n+1
(n+1∏
i=1
√i
)
n∑
i=1
n+1∏
j=1j 6=i
sin
(L√i
)(L2.sin
(L√i
)+ 2L.
√i.cos
(L√i
)− 2i.sin
(L√i
))
→ Calcul de b :
b =∫
Γ
(n∏
i=1
cos
(xi√i
)).x2n+1.cos
(xn+1√n+ 1
)dΓ
=
(∫
X
(n∏
i=1
cos
(xi√i
))dx
).
(∫ L
−Lx2n+1.cos
(xn+1√n+ 1
)dxn+1
)
= 2n(
n∏
i=1
√i
)(n∏
i=1
sin
(L√i
)).
(∫ L
−Lx2n+1.cos
(xn+1√n+ 1
)dxn+1
)d’apres ce que l’on a calcule en 4
xxi

= 2n(
n∏
i=1
√i
)(n∏
i=1
sin
(L√i
))
.2√n+ 1
[L2.sin
(L√n+ 1
)− 2L.
√n+ 1.cos
(L√i
)− 2(n+ 1).sin
(L√i
)]
Calcul deja realise precedemment
Orn∏
i=1
sin
(L√i
)=n+1∏
j=1j 6=i
sin
(L√j
)
En effet, on rajoute le (n+1)me terme a la somme et nous avons bien l’egalite entre ces 2 produitscar nous avons alors i = n+ 1.
b = 2n+1
(n+1∏
i=1
√i
)
n+1∏
j=1j 6=n+1
sin
(L√j
)
[L2.sin
(L√n+ 1
)− 2L.
√n+ 1.cos
(L√i
)− 2(n+ 1).sin
(L√i
)]
⇒ K =1
4000.2n+1
(n+1∏
i=1
√i
)
n+1∑
i=1
n+1∏
j=1j 6=i
sin
(L√j
)(L2.sin
(L√i
)+ 2L.
√i.cos
(L√i
)− 2i.sin
(L√i
))
⇒ K = In+1
Conclusion :
∀n ≥ 1,∫
X
(n∑
i=1
x2i
4000
)(n∏
i=1
cos
(xi√i
))dx
=1
4000.2n(
n∏
i=1
√i
)
n∑
i=1
n∏
j=1j 6=i
sin
(L√j
)(L2.sin
(L√i
)+ 2L.
√i.cos
(L√i
)− 2i.sin
(L√i
))
4.1.6 Calcul de la sixieme integrale
Calcul de ∫
X
(n∏
i=1
cos2
(xi√i
))dx
Prouvons que ∫
X
(n∏
i=1
cos2
(xi√i
))dx =
n∏
i=1
[L+
√i
2.sin
(2L√i
)]
Preuve Montrons cette formule par recurrence :
Initialisation : n = 1∫
X
(1∏
i=1
cos2
(xi√i
))dx =
∫ L
−Lcos2(x1) dx1
=12
∫ L
−L1 + cos(2x1) dx1
= L+12.sin(2L)
La formule est vraie pour n = 1.
xxii

Passage au rang suivant On suppose que la formule est vraie pour un entier n. Montronsque cette formule est vraie au rang n+ 1.
On prend Γ = X×[-L ; L] = [−L;L]n×[-L ; L]
K =∫
Γ
n+1∏
i=1
cos2
(xi√i
)dΓ
Par le theoreme de Fubini, nous avons :
=
(∫
X
n∏
i=1
cos2
(xi√i
)dx
).
(∫ L
−Lcos2
(xn+1√n+ 1
)dxn+1
)
=n∏
i=1
[L+
√i
2.sin
(2L√i
)].
[12
∫ L
−L1 + cos
(2xn+1√n+ 1
)dxn+1
]
=n∏
i=1
[L+
√i
2.sin
(2L√i
)].12.
[2L+
√n+ 1.sin
(2L√n+ 1
)]
n∏
i=1
[L+
√i
2.sin
(2L√i
)].
[L+
√n+ 12
.sin
(2L√n+ 1
)]
=n+1∏
i=1
[L+
√i
2.sin
(2L√i
)]
La formule est donc vraie au rang n+ 1.
Conclusion : ∫
X
(n∏
i=1
cos2
(xi√i
))dx =
n∏
i=1
[L+
√i
2.sin
(2L√i
)]
4.1.7 Conclusion
Pour l’integrale de la fonction de Griewank au carre, nous avons
∫
X
[1 +
n∑
i=1
x2i
4000−
n∏
i=1
cos
(xi√i
)]2
dx
=
(2L)n + n.2n+1Ln+2
12000+
2nLn+4
16000.
[n
5+
19
(n−1∑
i=0
2i
)]− 2n+1
(n∏
i=1
√i.sin
(L√i
))
− 14000
.2n+1
(n∏
i=1
√i
)
n∑
i=1
n∏
j=1j 6=i
sin
(L√j
)(L2.sin
(L√i
)+ 2L.
√i.cos
(L√i
)− 2i.sin
(L√i
))
+n∏
i=1
[L+
√i
2.sin
(2L√i
)]
xxiii

4.2 Calcul du terme croise
On prend X = [−L;L]n
Nous avons a calculer ∫
X
[1 +
n∑
i=1
x2i
4000−
n∏
i=1
cos
(xi√i
)].r(x) dx
ou m est le nombre de points dans l’echantillon.
=∫
X
r(x) +
(n∑
k=1
x2k
4000
).r(x)−
[n∏
k=1
cos
(xk√k
)].r(x) dx
=∫
X
r(x) dx+∫
X
(n∑
k=1
x2k
4000
).r(x) dx−
∫
X
[n∏
k=1
cos
(xk√k
)].r(x) dx
4.2.1 Calcul de la premiere integrale
Calcul de ∫
X
r(x) dx
Prouvons que ∫
X
r(x) dx
=
=m∑
i=1
Yi.αi
n∏
l=1
Lγil+1 − (−L)γil+1
γil + 1+
E(γil−1
2
)
∑
q=0
(−1)γil−2q
∑
1≤l1<...<lγil−2q≤mlβ 6=i
γil−2q∏
t=1g(Xlt
,Xi)=l
Xltl
2L2q+1
2q + 1
Preuve : La demonstration de cette formule a deja ete effectuee pour la fonction de Rastrigin.
4.2.2 Calcul de la deuxieme integrale
Calcul de
∫
X
(n∑
k=1
x2k
4000
).
m∑
i=1
Yi.αi
n∏
l=1
x
γill +
γil−1∑
u=0
(−1)γil−u
∑
1≤l1<...<lγil−u≤mlβ 6=i
γil−u∏
t=1g(Xlt
,Xi)=l
Xltl
xul
dx
Prouvons que
∫
X
(n∑
k=1
x2k
4000
).
m∑
i=1
Yi.αi
n∏
l=1
x
γljl +
γil−1∑
u=0
(−1)γil−u
∑
1≤l1<...<lγil−u≤mlβ 6=i
γil−u∏
t=1g(Xlt
,Xi)=l
Xltl
xul
dx
=
14000
m∑
i=1
αi.Yi
n∑
k=1
Lγik+3 − (−L)γik+3
γik + 3+
E(γik−1
2
)
∑
q=0
(−1)γik−2q
∑
1≤l1<...<lγik−2q≤mlβ 6=i
γik−2q∏
t=1g(Xlt
,Xi)=k
Xltk
2L2q+3
2q + 3
.
xxiv

n∏
z=1z 6=k
Lγiz+1 − (−L)γiz+1
γiz + 1+E( γiz−1
2 )∑
v=0
(−1)γiz−2v
∑
1≤l1<...<lγiz−2v≤mlβ 6=i
γiz−2v∏
t=1g(Xlt
,Xi)=z
Xltz
2L2v+1
2v + 1
Preuve : ∫
X
(n∑
k=1
x2k
4000
).r(x) dx
=1
4000
∫
X
(n∑
k=1
x2k
).r(x) dx
La suite de la preuve a ete realisee dans le calcul de la deuxieme integrale du terme croise pour lafonction de Rastrigin.
4.2.3 Calcul de la troisieme integrale
Calcul de ∫
X
[n∏
i=1
cos
(xi√i
)].r(x) dx
=∫
X
[n∏
i=1
cos
(xi√i
)].
m∑
i=1
Yi.αi
n∏
l=1
x
γill +
γil−1∑
u=0
(−1)γil−u
∑
1≤l1<...<lγil−u≤mlβ 6=i
γil−u∏
t=1g(Xlt
,Xi)=l
Xltl
xul
dx
Prouvons que ∫
X
[n∏
i=1
cos
(xi√i
)].r(x) dx
=
m∑
i=1
Yi.αi
n∏
l=1
1− (−1)γil−1
2c(γil, i) +
E(γil−1
2
)
∑
q=0
(−1)γil−2q
∑
1≤l1<...<lγil−2q≤mlβ 6=i
γil−2q∏
t=1g(Xlt
,Xi)=l
Xltl
.c(2q, i)
avec
c(j, i) =j∑
k=0
(−1)E( j−k2 ) 1(
1√i
)j−k+1.j!k!.
((1− (−1)j−k+1
).Lk.sin
(L√i
)+(1− (−1)j−k
).Lk.cos
(L√i
))
Preuve : ∫
X
[n∏
i=1
cos
(xi√i
)].r(x) dx
=∫
X
[n∏
i=1
cos
(xi√i
)].
m∑
i=1
Yi.αi
n∏
l=1
x
γill +
γil−1∑
u=0
(−1)γil−u
∑
1≤l1<...<lγil−u≤mlβ 6=i
γil−u∏
t=1g(Xlt
,Xi)=l
Xltl
xul
dx
=∫
X
m∑
i=1
Yi.αi
n∏
l=1
cos
(xl√l
)xγill +
γil−1∑
u=0
(−1)γil−u
∑
1≤l1<...<lγil−u≤mlβ 6=i
γil−u∏
t=1g(Xlt
,Xi)=l
Xltl
cos
(xl√l
)xul
dx
xxv

Par linearite de l’integrale, nous pouvons ecrire l’equation suivante :
=m∑
i=1
Yi.αi
∫ L
−L
n∏
l=1
cos
(xl√l
)xγill +
γil−1∑
u=0
(−1)γil−u
∑
1≤l1<...<lγil−u≤mlβ 6=i
γil−u∏
t=1g(Xlt
,Xi)=l
Xltl
cos
(xl√l
)xul
dxl
Nous pouvons ecrire, par le theoreme de Fubini :
=m∑
i=1
Yi.αi
n∏
l=1
∫ L
−L
cos
(xl√l
)xγill +
γil−1∑
u=0
(−1)γil−u
∑
1≤l1<...<lγil−u≤mlβ 6=i
γil−u∏
t=1g(Xlt
,Xi)=l
Xltl
cos
(xl√l
)xul
dxl
=
m∑
i=1
Yi.αi
n∏
l=1
∫ L
−Lcos
(xl√l
)xγill dxl +
γil−1∑
u=0
(−1)γil−u
∑
1≤l1<...<lγil−u≤mlβ 6=i
γil−u∏
t=1g(Xlt
,Xi)=l
Xltl
∫ L
−Lcos
(xl√l
)xul dxl
Comme precedemment, on ne garde que les termes pour lesquels u est pair :
=
m∑
i=1
Yi.αi
n∏
l=1
∫ L
−Lcos
(xl√l
)xγill dxl +
E(γil−1
2
)
∑
q=0
(−1)γil−2q
∑
1≤l1<...<lγil−2q≤mlβ 6=i
γil−2q∏
t=1g(Xlt
,Xi)=l
Xltl
∫ L
−Lcos
(xl√l
)x2ql dxl
On pose
c(j, i) =j∑
k=0
(−1)E( j−k2 ) 1(
1√i
)j−k+1.j!k!.
((1− (−1)j−k+1
).Lk.sin
(L√i
)+(1− (−1)j−k
).Lk.cos
(L√i
))
Nous avons alors
=m∑
i=1
Yi.αi
n∏
l=1
1− (−1)γil−1
2c(γil, i) +
E(γil−1
2
)
∑
q=0
(−1)γil−2q
∑
1≤l1<...<lγil−2q≤mlβ 6=i
γil−2q∏
t=1g(Xlt
,Xi)=l
Xltl
.c(2q, i)
4.2.4 Conclusion pour le terme croise
Pour l’integrale de la fonction de Griewank multipliee par le polynome (terme croise), nousavons : ∫
X
f(x).r(x) dx
=
m∑
i=1
Yi.αi
n∏
l=1
Lγil+1 − (−L)γil+1
γil + 1+
E(γil−1
2
)
∑
q=0
(−1)γil−2q
∑
1≤l1<...<lγil−2q≤mlβ 6=i
γil−2q∏
t=1g(Xlt
,Xi)=l
Xltl
2L2q+1
2q + 1
+1
4000
m∑
i=1
αi.Yi
n∑
k=1
Lγik+3 − (−L)γik+3
γik + 3+
E(γik−1
2
)
∑
q=0
(−1)γik−2q
∑
1≤l1<...<lγik−2q≤mlβ 6=i
γik−2q∏
t=1g(Xlt
,Xi)=k
Xltk
2L2q+3
2q + 3
.
xxvi

n∏
z=1z 6=k
Lγiz+1 − (−L)γiz+1
γiz + 1+E( γiz−1
2 )∑
v=0
(−1)γiz−2v
∑
1≤l1<...<lγiz−2v≤mlβ 6=i
γiz−2v∏
t=1g(Xlt
,Xi)=z
Xltz
2L2v+1
2v + 1
−m∑
i=1
Yi.αi
n∏
l=1
1− (−1)γil−1
2c(γil, i) +
E(γil−1
2
)
∑
q=0
(−1)γil−2q
∑
1≤l1<...<lγil−2q≤mlβ 6=i
γil−2q∏
t=1g(Xlt
,Xi)=l
Xltl
.c(2q, i)
avec
c(j, i) =j∑
k=0
(−1)E( j−k2 ) 1(
1√i
)j−k+1.j!k!.
((1− (−1)j−k+1
).Lk.sin
(L√i
)+(1− (−1)j−k
).Lk.cos
(L√i
))
et
αi =n∏
l=1
m∏
j=1j 6=i
g(Xi,Xj)=l
1Xil −Xjl
4.3 Calcul de l’integrale du polynome de Lagrange au carre
Ce calcul a deja ete effectue dans la cas de la fonction de Rastrigin.
4.4 Conclusion pour le eRMS pour la fonction de Griewank
Nous avons, pour la fonction de Griewank,
eRMS =
√1|X|
∫
X
[f(x)− r(x)]2 dx
ou f est la fonction de Griewank et r un polynome de regression. Nous aurons la valeur de l’ eRMS
en divisant la formule suivante par le cardinal de X puis en prenant ensuite la racine carree del’expression suivante.
(2L)n + n.2n+1Ln+2
12000+
2nLn+4
16000.
[n
5+
19
(n−1∑
i=0
2i
)]− 2n+1
(n∏
i=1
√i.sin
(L√i
))
− 14000
.2n+1
(n∏
i=1
√i
)
n∑
i=1
n∏
j=1j 6=i
sin
(L√j
)(L2.sin
(L√i
)+ 2L.
√i.cos
(L√i
)− 2i.sin
(L√i
))
+n∏
i=1
[L+
√i
2.sin
(2L√i
)]
−2m∑
i=1
Yi.αi
n∏
l=1
Lγil+1 − (−L)γil+1
γil + 1+
E(γil−1
2
)
∑
q=0
(−1)γil−2q
∑
1≤l1<...<lγil−2q≤mlβ 6=i
γil−2q∏
t=1g(Xlt
,Xi)=l
Xltl
2L2q+1
2q + 1
−21
4000
m∑
i=1
αi.Yi
n∑
k=1
Lγik+3 − (−L)γik+3
γik + 3+
E(γik−1
2
)
∑
q=0
(−1)γik−2q
∑
1≤l1<...<lγik−2q≤mlβ 6=i
γik−2q∏
t=1g(Xlt
,Xi)=k
Xltk
2L2q+3
2q + 3
.
xxvii

n∏
z=1z 6=k
Lγiz+1 − (−L)γiz+1
γiz + 1+E( γiz−1
2 )∑
v=0
(−1)γiz−2v
∑
1≤l1<...<lγiz−2v≤mlβ 6=i
γiz−2v∏
t=1g(Xlt
,Xi)=z
Xltz
2L2v+1
2v + 1
+2m∑
i=1
Yi.αi
n∏
l=1
1− (−1)γil−1
2c(γil, i) +
E(γil−1
2
)
∑
q=0
(−1)γil−2q
∑
1≤l1<...<lγil−2q≤mlβ 6=i
γil−2q∏
t=1g(Xlt
,Xi)=l
Xltl
.c(2q, i)
+m∑
i=1
Y 2i αi
n∏
l=1
2γil∑
j=0
(−1)2γil−j
∑
1≤k1<...<k2γil−j≤m
∏
g(Xi,Xks )=l
Xks
L
j+1 − (−L)j+1
j + 1
+2∑
1≤u<v≤mYu.Yv.αujl.αvzk
n∏
l=1
γul+γvl∑
j=0
(−1)γul+γvl−j
∑
1≤k1<...<kγul+γvl−j≤m
∏
g(Xu,Xks )=lou g(Xv,Xks )=l
Xks
Lj+1 − (−L)j+1
j + 1
xxviii