Embed Size (px)
Citation preview

Notice
Joël FALCOUDocteur en Vision pour la Robotique
Université Blaise Pascal – Clermont-Ferrand



Notice
Table des matièresTable des matières.....................................................................................................................2
1. Curriculum Vitae ....................................................................................................................... 3 Etat civil.................................................................................................................................... 3Position actuelle........................................................................................................................ 3Formation.................................................................................................................................. 4Recherche.................................................................................................................................. 5Activités d’enseignement.......................................................................................................... 5Langues étrangères....................................................................................................................6Compétences techniques........................................................................................................... 6Réalisations informatiques........................................................................................................ 6
2. Enseignement ............................................................................................................................ 7 Liste des enseignements ........................................................................................................... 7
2007-2008 – Vacataire : 96 heures .......................................................................................72006-2007 – ATER (poste à temps plein) à l’ISIMA : 192 heures ......................................72003-2006 – Moniteur à l’Université d’Auvergne : 192 heures........................................... 8
Détails des enseignements ........................................................................................................9Récapitulatif............................................................................................................................ 12
3. Recherche ................................................................................................................................ 13 Introduction............................................................................................................................. 13Un langage spécifique pour un problème spécifique.............................................................. 14Méta-programmation et Domain Specific Language.............................................................. 15Le C++ comme système d'évaluation partielle ...................................................................... 16Des DSL pour la programmation parallèle............................................................................. 17
NT2 : Calculs scientifique optimisés :................................................................................ 17QUAFF : Déploiement de code sur machine MIMD..........................................................18
Application à la vision artificielle........................................................................................... 20Conclusion et Perspectives......................................................................................................22Publications et conférences..................................................................................................... 23
4. Charges collectives .................................................................................................................. 25 Charges administratives.......................................................................................................... 25Recherche................................................................................................................................ 25
2/25

Notice
1.Curriculum Vitae
Etat civil
Falcou JoëlNé le 02 mai 1980 à Sarlat (Dordogne, 24)Nationalité : françaiseSituation familiale : marié
Coordonnées personnelles : 8 Grande rue, 91940 Saint Jean de Beauregard [email protected] (+33/0) 6 15 07 71 37
Coordonnées professionnelles : IEF, Université Paris-Sud, 91405 Orsay CEDEX [email protected]@ http://www.ief.u-psud.fr/~falcou (+33/0) 1 69 15 41 18
Position actuellePost-doctorant du groupe AXIS de l'IEF affecté aux projets OCELLE et TERAOPS.
Activité : Génération et déploiement automatique de code de traitement d'image sur machines parallèles de type Cell, GPU et Ter@ops.
3/25

Notice
Formation
2006 - Thèse de Doctorat de l’Université Blaise Pascal (Clermont II)Titre : Un Cluster pour la Vision Temps Réel : Architecture, Outils et ApplicationsDirecteur de thèse : Jocelyn SérotÉcole doctorale : Sciences Pour l’Ingénieur (SPI) de Clermont-FerrandSoutenue le : 1er décembre 2006 à l’Université Blaise PascalMention : Très Honorable
Composition du jury : Jean Thierry Lapresté (Président du jury – Professeur à l’Université Blaise Pascal) Jocelyn Sérot (Directeur de Thèse – Professeur à l’Université Blaise Pascal) Daniel Etiemble (Rapporteur – Professeur à l’Université Paris Sud) Frédéric Loulergue (Rapporteur – Professeur à l’Université d’Orléans) Franck Cappello (Examinateur – Directeur de Recherche INRIAFuturs) Thierry Chateau (Examinateur – Maître de conférence à l’Université Blaise Pascal)
2003 - Diplôme d’Etudes Approfondies en Composants et Systèmes pour le Traitement de l’Information de l’Université Blaise Pascal (Clermont II)Titre du mémoire : Développement d’une bibliothèque de calcul SIMD – Application au traitement d’image.Spécialité : Vision pour la RobotiqueMention : BienLaboratoire : LASMEA, Université Blaise PascalResponsable de stage : Jocelyn Sérot
2000-2003 - Diplôme d’ingénieur en Informatique de l’Institut Supérieur en Informatique, Modélisation et de leurs Applications (ISIMA – Clermont-Ferrand)Spécialité : Génie Logiciel , Systèmes et Réseaux.Stage de troisième année commun au DEA
2000 - Classes préparatoires aux grandes écoles : Section PCSI et PSI*. au lycée Pierre de Fermat (Toulouse, Haute-Garonne)
1998 - Baccalauréat série S Mathématiqueau lycée Pré de Cordy (Sarlat, Dordogne)Mention : Bien
4/25

Notice
Recherche
Thèmes de recherche : Programmation générative pour le développement d’outils de
parallèlisation et de déploiement automatique de code de traitement d'image sur des architectures haute performance (cluster, multiprocesseurs, multi-core, CELL, GPU).
Adéquation Algorithme-Architecture : optimisation de code de traitement d’image et de vision artificielle.
Définitions d'outils de méta programmation pour la génération automatique de bibliothèques actives (optimisation inter et intra-procédurale automatique).
Bilan Scientifique : 2 revues internationales avec comité de lecture. 6 manifestations internationales avec comité de lecture. 2 manifestations nationales avec comité de lecture.
Publications clés : QUAFF : Efficient C++ Design for Parallel Skeletons
Joël Falcou, Jocelyn Sérot, Thierry Chateau, Jean-Thierry Lapresté.Parallel Computing , vol. 32 (7-8), Sept 2006, pg 604-615.
Application of template-based meta-programming compilation techniques to the efficient implementation of image processing algorithms on SIMD-capable processors.Joël Falcou, Jocelyn Sérot. ACIVS, Sept.. 2005
Activités d’enseignement2007-2008 : Vacataire à l'Université Paris-Sud et à l'Ecole Polytechnique. 96H équivalents TD.
2006 – 2007 : Attaché Temporaire à l’Enseignement et à la Recherche (ATER) à l’ISIMA. 192 heures équivalent TD.
2003 – 2006 : Moniteur à la Faculté de médecine de Clermont-Ferrand (Université d’Auvergne) : 192 heures équivalent TD.
Bilan : 480 heures équivalent TD
5/25

Notice
Langues étrangères
Anglais Courant. Lu, écrit, parlé.Allemand Niveau Intermédiaire. Lu, écrit, parlé.
Compétences techniques
Génie LogicielDesign Pattern, programmation parallèle, UML, Extreme Programming.
LangagesC, C++, intrinsics Altivec et SSE2, Java, C#, LISP, Objective Caml.
Systèmes d'exploitationWindows, unix, linux, Mac OS X.
DiversLaTeX, SVN, HTML, XML, JavaScript, LAMP, Eclipse.
Réalisations informatiques
QUAFF : Une bibliothèque de programmation parallèle par squelettes algorithmiques (structures similaires au Design Pattern) et de déploiement automatique sur cibles compatibles MPI : Applications au traitement d'image et au calcul scientifique. Disponible en Open Source sur : http://quaff.sourceforge.net
NT2 : Une bibliothèque pour le calcul parallèle haute-performance sur machines SIMD et/ou SMP, ciblée calcul algébrique et traitement d'image permettant de déployer du code MATLAB automatiquement. Utilisé au sein du projet Systematic LoVE. Disponible en Open Source sur : http://nt2.sourceforge.net
C+FOX : Pilote pour l’acquisition d'image en provenance de cameras Firewire sous MAC OS X ainsi qu'un mécanisme de broadcast FireWire. Disponible en Open Source sur http://cfox.sourceforge.net
CamlG4 : Une bibliothèque de calcul SIMD en Objective CAMLDisponible en Open Source sur : http://www.ief.u-psud.fr/~falcou/camlg4.html
6/25
Notice
2.Enseignement
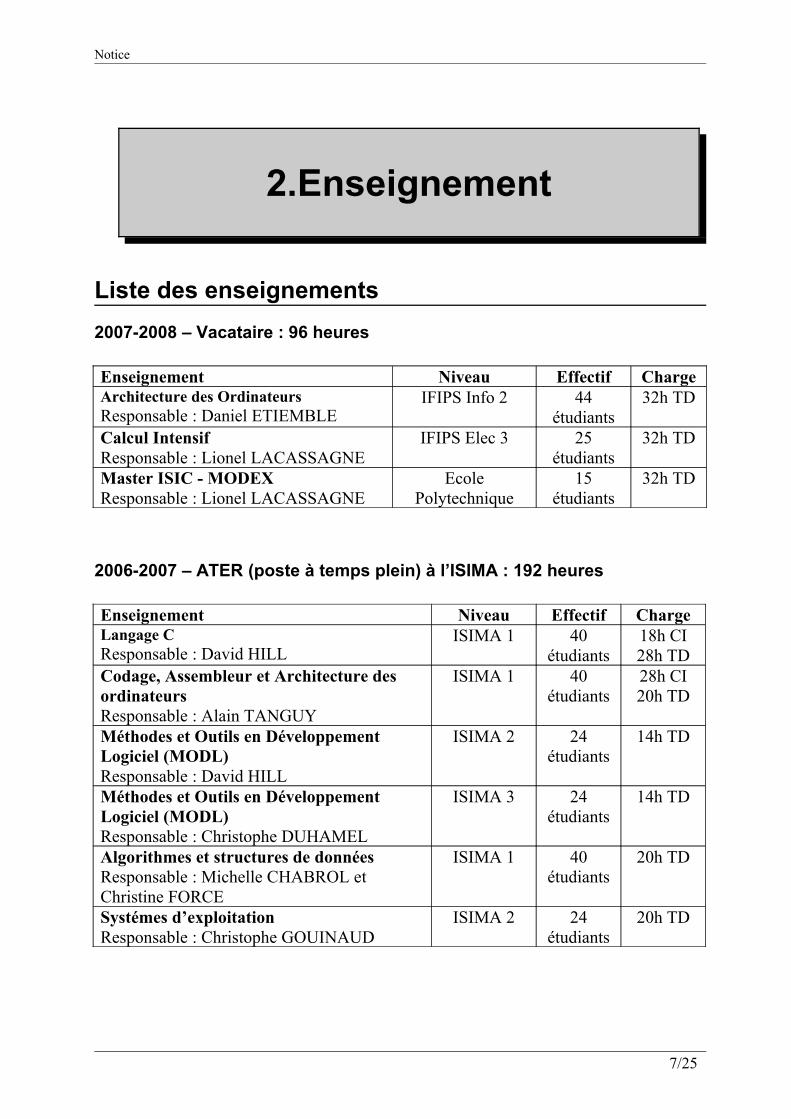
Liste des enseignements 2007-2008 – Vacataire : 96 heures
Enseignement Niveau Effectif ChargeArchitecture des OrdinateursResponsable : Daniel ETIEMBLE
IFIPS Info 2 44 étudiants
32h TD
Calcul IntensifResponsable : Lionel LACASSAGNE
IFIPS Elec 3 25 étudiants
32h TD
Master ISIC - MODEXResponsable : Lionel LACASSAGNE
Ecole Polytechnique
15 étudiants
32h TD
2006-2007 – ATER (poste à temps plein) à l’ISIMA : 192 heures
Enseignement Niveau Effectif ChargeLangage CResponsable : David HILL
ISIMA 1 40 étudiants
18h CI28h TD
Codage, Assembleur et Architecture des ordinateursResponsable : Alain TANGUY
ISIMA 1 40 étudiants
28h CI20h TD
Méthodes et Outils en Développement Logiciel (MODL)Responsable : David HILL
ISIMA 2 24 étudiants
14h TD
Méthodes et Outils en Développement Logiciel (MODL)Responsable : Christophe DUHAMEL
ISIMA 3 24 étudiants
14h TD
Algorithmes et structures de donnéesResponsable : Michelle CHABROL et Christine FORCE
ISIMA 1 40 étudiants
20h TD
Systémes d’exploitationResponsable : Christophe GOUINAUD
ISIMA 2 24 étudiants
20h TD
7/25
Notice
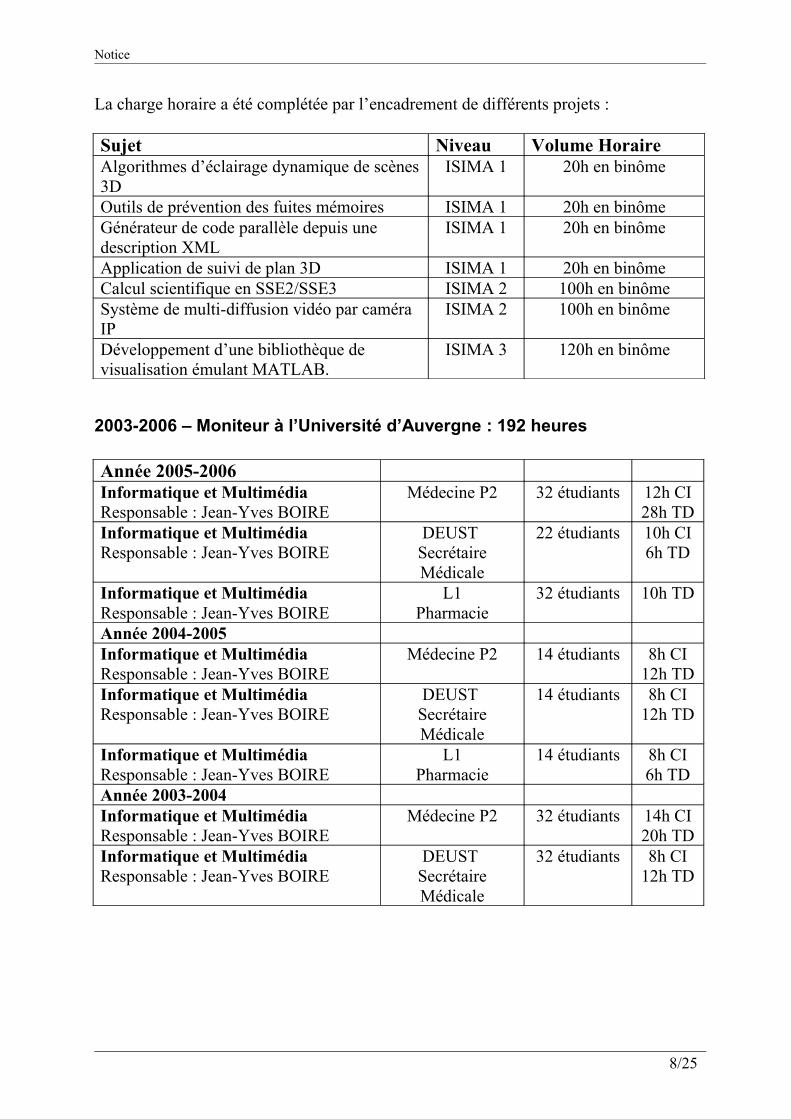
La charge horaire a été complétée par l’encadrement de différents projets :
Sujet Niveau Volume HoraireAlgorithmes d’éclairage dynamique de scènes 3D
ISIMA 1 20h en binôme
Outils de prévention des fuites mémoires ISIMA 1 20h en binômeGénérateur de code parallèle depuis une description XML
ISIMA 1 20h en binôme
Application de suivi de plan 3D ISIMA 1 20h en binômeCalcul scientifique en SSE2/SSE3 ISIMA 2 100h en binômeSystème de multi-diffusion vidéo par caméra IP
ISIMA 2 100h en binôme
Développement d’une bibliothèque de visualisation émulant MATLAB.
ISIMA 3 120h en binôme
2003-2006 – Moniteur à l’Université d’Auvergne : 192 heures
Année 2005-2006Informatique et Multimédia Responsable : Jean-Yves BOIRE
Médecine P2 32 étudiants 12h CI28h TD
Informatique et Multimédia Responsable : Jean-Yves BOIRE
DEUST Secrétaire Médicale
22 étudiants 10h CI6h TD
Informatique et Multimédia Responsable : Jean-Yves BOIRE
L1Pharmacie
32 étudiants 10h TD
Année 2004-2005Informatique et Multimédia Responsable : Jean-Yves BOIRE
Médecine P2 14 étudiants 8h CI12h TD
Informatique et Multimédia Responsable : Jean-Yves BOIRE
DEUST Secrétaire Médicale
14 étudiants 8h CI12h TD
Informatique et Multimédia Responsable : Jean-Yves BOIRE
L1Pharmacie
14 étudiants 8h CI6h TD
Année 2003-2004Informatique et Multimédia Responsable : Jean-Yves BOIRE
Médecine P2 32 étudiants 14h CI20h TD
Informatique et Multimédia Responsable : Jean-Yves BOIRE
DEUST Secrétaire Médicale
32 étudiants 8h CI12h TD
8/25

Notice
Au cours de ce service d’enseignement, j’ai en outre co-encadré plusieurs projets et stages ingénieurs.
Sujet Niveau EncadrementEtude et mise en oeuvre de solutions pour le contrôle d'un robot mobile par vision sur une architecture déportée*
Stage Ingénieur CNAM
50%
Portage d'une application de débogage parallèle (XMPI) sous environnement QT
Projet IngénieurISIMA 2
50%
Implantation et optimisation d'une classe de matrice creuse.
Projet IngénieurISIMA 2
50%
Détection et suivi d’objet temps réel sur séquence vidéos
Stage IngénieurISIMA 3
50%
Acquisition et commande à distance de caméras IP
Stage Licence Pro.Réseaux & Télécom
50%
* J’ai en outre fait partie du jury d’attribution du diplôme d’ingénieur CNAM de cet étudiant.
Détails des enseignements
Architecture des Ordinateurs (2007)Audience : IFIPS Informatique 2e année – groupes de 22 étudiants environResponsable : Daniel ETIEMBLE32h TD
Ces travaux pratiques sont une application des éléments vus en cours tels que : les critères de performances, les jeux d'instructions et leur relations avec les langages de haut niveau, la structure interne du processeur (chemin de données et partie contrôle, notion de pipeline), et les problématiques liées à la hiérarchie mémoire (caches, mémoire virtuelle et interface avec le système d'exploitation).
Calcul intensif – Master ISICAudience : IFIPS 3e année, Ecole PolytechniqueResponsable : Lionel LACASSAGNE64h TD
Ces travaux pratiques initient les étudiants à l'utilisation des instructions multimédia comme SSE2 ou AltiVec dans le cadre d’applications de Traitement du Signal, du Traitement d'Images ou de vision par ordinateur. Plus spécifiquement, les points abordés concernent l’expression via ces extensions d’algorithmes de calcul matriciel, de filtrage et d’applications classiques comme la détection de mouvement ou la détection de contours.
9/25

Notice
Langage C (2006)Audience : ISIMA 1 – groupe de 40 étudiantsResponsable : David HILL18h CI + 20h TD
Ce cours de programmation en langage C est dispensé à une promotion d’environ 120 étudiants divisée en trois groupes. Je suis chargé d’un de ces groupes en cours et d’un groupe de travaux pratiques (20h TD). Il s’agit d’aborder les notions « avancées » en C, les bases étant déjà supposées connues. Les étudiants bénéficient d’une remise à niveau les deux premières semaines de leur cursus.
Les sujets abordés sont les suivants : pointeurs (de variables et de fonctions), les structures (les enregistrements classiques, les structures auto-référentielles, les champs de bits, les énumérations et les unions), les macro-commandes (constantes et « fonctions »), la compilation séparée (gardiens, dépendances et makefile), les fichiers (textes et binaires), le système (processus, ligne de commande, entrées-sorties de bas niveau), les fonctions à nombre d’arguments variable et la librairie graphique Xlib.
Méthodes et Outils de Développement Logiciel : travaux pratiques (2006)Audience : ISIMA 2 et ISIMA 3 – groupes de 24 étudiants environResponsables : David HILL et Christophe DUHAMEL16h TD (ISIMA 2) et 14h TD (ISIMA 3)
Ces travaux pratiques permettent aux élèves ingénieurs de maîtriser le langage C++. En deuxième année, ils sont sensibilisés aux particularités du modèle Objet et du langage : héritage, polymorphisme, surcharge d’opérateurs simples, patrons (template).
En troisième année, l’accent est porté sur les techniques de Génie Logiciel avancées. Le but est de permettre aux étudiants de prendre du recul vis-à-vis du langage et d’appréhender des problématiques de design et de développement réalistes. Les points abordés sont : les patrons de conception usuels (Singleton, Abstract Factory, Iterator, Composite) et leurs interactions et différentes implantations classiques, les techniques usuelles de méta-programmation template comme les Traits, les listes statiques de types, l’arithmétique statique et les techniques de spécialisations partielles avancées. L’ensemble de ces travaux pratiques consiste en un sujet relativement vaste (réalisation d’un simulateur de système d’exploitation) dont le rythme d’avancement et le découpage permet de confronter les élèves à des problèmes de design non triviaux, les solutions classiques mais non pertinentes de ces problèmes et enfin des solutions plus élégantes à base de patrons de conceptions. La dernière partie de ces travaux pratiques aborde les techniques de conception d’interface graphique via la bibliothèque QT. Une introduction à des bibliothèques annexes comme BOOST est envisagée. J’ai activement participé à l’élaboration de cette série de travaux pratiques et un support de cours reprenant les concepts abordés est en cours de rédaction. Codage, assembleur et architecture des ordinateurs (2006)Audience : ISIMA 1 – groupe de 40 étudiantsResponsable : Alain TANGUY28h CI + 20h TD
Ce cours aborde les notions théoriques concernant la représentation et le codage de l’information avec, comme application, l’étude de la représentation des nombres entiers
10/25

Notice
naturels, les nombres réels simple et double précision et le codage des caractères. Il se poursuit par une introduction à l’algèbre de Boole et son application. Une deuxième partie se propose de présenter la structure classique des machines actuelles (processeurs, bus, cache, mémoire) afin d’amener les problématiques de la programmation en assembleur, qui constitue la troisième partie de cet enseignement. Une série de travaux pratique en assembleur x86 est proposé aux étudiants et recouvrent des sujets comme des algorithmes de cryptage, l’implantation de procédures graphiques (tracé de segments et de cercles) et l’émulation d'un terminal de communication série.
Systèmes d’exploitation (2006)Audience : ISIMA 2 – 2 groupes de 20 étudiantsResponsable : Christophe GOUINAUD20h TD
Ce cours a pour but de permettre aux étudiants d’avoir les bases nécessaires à la prise en charge d'un parc informatique, de comprendre les conséquences pratiques d'un choix de plate-forme et d’augmenter leurs capacités à réagir face à des pannes matérielles. Les parties théoriques présentent la gestion de parcs, l'informatique de l'entreprise (nommage et ressource) et les techniques nécessaires à l'ingénieur système (stratégie de déploiement, technique de sauvegarde, organisation pratique de l’accès aux ressources). Les TP abordent les thèmes de la gestion des utilisateurs et des droit d’accès, la sauvegarde des données, le dépannage de stations, la gestion des espaces disque, la surveillance, le déploiement de logiciels et la sécurité.L'ensemble est réalisé sur des plates-formes de type PC, pour les systèmes Linux et Windows. Lors des ces TP, les binômes disposent de deux PC reliés par un réseau local privé. Algorithmes et Structures de données (2006)Audience : ISIMA 1 – groupes de 24 étudiantsResponsable : Michelle CHABROL et Christine FORCE20h TD
Cet enseignement constitue une sérieuse introduction à la démarche d’analyse structurée et aux structures de données usuelles comme les listes, les tables associatives, les arbres et les B-Arbres. Une large partie du cours aborde aussi les problématiques de la gestion d’une mémoire adressable et les algorithmes de tri. Une série de travaux pratiques permet de mettre en œuvre les structures et méthodes abordées en cours au sein d’applications complexes.
Informatique et multimédia (de 2003 à 2006)Audience : Deuxième année Médecine – groupe de 32 étudiants
DEUST Secrétaire médicale – groupe de 14 étudiantsL1 Pharmacie – groupe de 14 étudiants
Responsable : Jean-Yves BOIRE34h CI + 34h TD par an
Les enseignements que j’ai assuré avaient pour but de reprendre et d'étendre le module "Informatique et Multimédia" dispensé en parallèle aux élèves de 2e année médecine, de DEUG Pharmacie et de DEUST Délégué médicale. L’ancienne version de ce module comprenait une large part à la prise en main des outils de bureautique de types Excel et Word. Afin de donner une profondeur supplémentaire à ce module, j’ai décidé de le remanier afin d’y inclure les éléments précurseurs des enseignements nécessaires à l'incorporation du C2i (Certificat Informatique et Internet) au sein de ces cursus. Le C2i est la concrétisation de la
11/25

Notice
volonté de l'Éducation nationale de valoriser une pratique raisonnée des TICE vu l'importance de l'outil informatique et du développement des réseaux et de l'Internet. Il spécifie les compétences qu'un élève peut acquérir dans le cadre des activités ordinaires des disciplines enseignées tout au long de sa scolarité. Ainsi, le C2i atteste de la maîtrise d'un ensemble de compétences nécessaires à l'étudiant pour mener les activités qu'exige un cursus d'enseignement supérieur. En outre, il me semblait important de démystifier l'outil informatique afin de permettre aux étudiants d’appréhender cette formation avec un esprit critique et ouvert aux diverses problématiques des TICE. Il était bien sur impossible de fournir une formation exhaustive à ces compétences dans le créneau de temps imparti. J’ai donc décider de focaliser cet enseignement sur quatre axes distincts :
Première approche de l'outil informatique. Prise en main du Système. Premier contact avec Internet. Prise en main des outils bureautiques.
À partir de ces points-clés, j’ai mis en place un enseignement de type cours intégré qui visait à fournir aux étudiants les connaissances à la fois théoriques et pratiques nécessaires à une prise en main et une maîtrise efficace de l'outil informatique au sein de leur cursus. En outre, une courte initiation à des outils dédiés comme PubMed était adjointe à ce programme et permettait de mettre en œuvre l’ensemble des connaissances assimilées jusqu’alors.
Récapitulatif
12/25
MatièreCours TD Total
Informatique et Multimédia 68 100 202Langage C 18 28 55Assembleur/Codage 28 20 62Structures de données 20 20Système d'exploitation 20 20C++ 28 28Architecture des Ordinateurs 32 32Programmation SIMD 64 64Encadrements de projets 7 7Total 114 319 490

Notice
3.Recherche
IntroductionL’augmentation des performances des processeurs, longtemps prédite avec succès
par la loi de Moore, est depuis quelques années mise à mal par plusieurs facteurs :
L’augmentation, à un rythme bien plus soutenue, des besoins en puissances de calcul dans de nombreux domaines (physique, finance, traitement du signal et de l'image);
Les contraintes physiques (échauffement, finesse de la gravure,courant de fuite) qui s'opposent au développement de processeurs plus complexes et plus puissants.
Pour néanmoins répondre aux besoins exprimées par un public de plus en plus large et de plus en plus exigeant, une solution fut d'investir dans le développement d’architecture parallèle comme les clusters, les processeurs équipés d'extension de calcul SIMD, les processeurs multi-core voire many-core ou les cartes d’accélérations graphiques.
D'un point de vue puissance, ces architectures ont su répondre avec une grande efficacité aux desiderata des utilisateurs, qu'ils s’agissent de la communauté scientifique – avec le succès des clusters et, plus récemment, de la Grille – ou du particulier – grâce à la démocratisation grandissante des machines multi-core. Malheureusement, si le problème de la puissance est résolu, les difficultés se sont progressivement déportés au niveau de développement. En effet, si concevoir une application de calcul efficace sur une architecture classique était une tâche réalisable par un spécialiste du domaine, la conception d'une application sur une machine parallèle nécessite des compétences bien spécifiques.
Pendant un temps, des outils de parallélisation explicites (MPI, OpenMP et bien d’autre) ont permis de profiter de la puissance de machines parallèles de petite taille (typiquement, de l'ordre de quatre à six éléments de calculs). Mais, les architectures émergentes, comme le processeur CELL ou les cartes graphiques, mettent en jeu plusieurs dizaines d'éléments de calcul, chacun disposant d'unités d’accélération intégrées, et contraignent les développeurs à utiliser des outils toujours plus complexes et peu adaptés à un tel changement d'échelle.
13/25

Notice
Une des causes de ces limitations est que la programmation parallèle est encore de nos jours largement basée sur l’utilisation d’outils bas niveaux alors que de nombreux modèles de haut niveau sont disponibles et permettent de masquer à l’utilisateur final les détails techniques nécessaires au bon déroulement de l’application. De nombreuses bibliothèques ont ainsi été proposées afin de fournir des interfaces simples d’utilisation pour de nombreux modèles de programmation pour des architectures multi-processeurs ou, pour l’écriture de code de calcul scientifique sur des machines équipées d’extension SIMD. La difficulté principale dans la définition et l’implantation de ces bibliothèques et de trouver l’équilibre entre l’expressivité, i.e. la possibilité d’exprimer le parallélisme sous-jacent de l’application sans se soucier des détails d’implantations et l’efficacité, i.e. le fait que les performances de l’exécutable final reste comparable à celle d’un code équivalent développé et optimisé par un expert. Ces deux caractéristiques sont malheureusement souvent inconciliables, rendant l’utilisation de tels outils peu intéressante. Un autre écueil s’ajoute à ces considérations purement techniques. En effet, les utilisateurs qui expriment un besoin en puissance de calcul et fournissent les applications à paralléliser sont rarement des experts en parallélisme ou en programmation. Il est alors nécessaire que les outils fournis soit largement accessibles, c’est à dire qu’ils s’intègrent de manière la plus complète possible aux outils habituels des utilisateurs.
L'objet de mes travaux est donc de définir et implanter des outils de haut niveau qui permettent à la fois d’exprimer aisément l’ensemble des constructions nécessaire pour définir une application parallèle, de garantir des performances équivalentes à celle d’un code écrit à la main tout en s’insérant de manière transparente dans une chaîne de développement classique.
Un langage spécifique pour un problème spécifiqueUne approche efficace pour le développement de bibliothèques présentant à la
fois un niveau d’abstraction élevé et des performances satisfaisantes consiste à définir une bibliothèque active. Ce type de bibliothèque met en oeuvre une phase d’optimisation haut niveau dépendant du modèle de programmation, laissant le compilateur effectuer les optimisations bas niveau usuelles (ordonnancement des communications et fusion d’étapes se déroulant sur un même processeur par exemple). Pour réaliser de telles bibliothèques, plusieurs systèmes de méta-définition ont été proposés. Ces systèmes permettent d’injecter au sein de compilateurs des extensions qui permettent de fournir à ce dernier les indications sémantiques nécessaires à une compilation efficace. L’utilisation de ces outils reste néanmoins difficile et il est nécessaire de chercher une alternative intégrable directement au sein d’un langage hôte sans nécessiter d’outils externes.
Cette autre approche consiste à définir un langage orientés domaine (ou Domain Specific Language), fournissant une sémantique adaptée au modèle et une syntaxe concise permettant d’exprimer un large éventail de programme en adéquation avec le problème considéré. En effet, force est de constater que les tentatives de créations de compilateurs parallèlisants génériques capables d'optimiser efficacement un
14/25

Notice
code quelconque pour un large panel d’architectures parallèles différentes restent lettre morte. L’approche préconisée ici repose sur la définition de DSL répondant à un sous-problème restreint de la programmation parallèle – utilisation des extensions SIMD, déploiement sur cible MIMD, etc. . Dans un tel contexte, la définition de modèles et de solutions ad hoc permet de répondre de façon pertinente au problème considéré, répondant ainsi à la contrainte d'expressivité exprimée plus avant. Reste à satisfaire les contraintes d’accessibilité et d'efficacité.
Méta-programmation et Domain Specific LanguageSi une technique classique pour permettre l’utilisation de DSL consiste à
développer un compilateur ou un interpréteur, des travaux récents montrent qu’il est possible d’inclure ces DSL directement au sein de langages existants. Actuellement, Template Haskell et MetaOCaml proposent d’utiliser une approche basée sur la programmation générative et, plus spécifiquement, sur le mécanisme de méta-programmation afin de permettre le développement de DSL au sein des langages Haskell et OCaml.
On peut défini la méta-programmation comme étant l’écriture de programme, plus exactement des méta-programmes, capables au sein d’un système adéquat d’extraire, transformer et générer des fragments de code afin de produire de nouveau codes répondant à un besoin précis. L’exemple le plus simple de méta-programme est le compilateur qui, à partir de fragments de code dans un langage donné, est capable d’extraire des informations et de générer un nouveau code, cette fois en langage machine, qui sera plus tard exécuté par le processeur. De manière plus formelle, on distingue deux types de système de méta-programmation :
les analyseurs de programmes qui utilise la structure et l’environnement d’un programme afin de calculer un nouveau fragment de programme. On retrouve dans cette catégorie des outils comme des optimisateurs de code hors-ligne;
les générateurs de programmes dont l’utilisation première est de résoudre une famille de problèmes connexes dont les solutions sont souvent des variations d’un modèle connu. Dans ce dessein, ces systèmes engendrent un nouveau programme capable de résoudre une instance particulière de ces problèmes et optimisé pour cette résolution. On distingue plus précisément les générateurs statiques qui génèrent un code nécessitant une phase de compilation classique – comme YACC – et les générateurs capables de construire des programmes et de les exécuter à la volée. On parle alors de multi-stage programming.
Si les résultats obtenus dans le cadre de Template Haskell et MetaOCaml sont extrêmement prometteurs, l’utilisation de langage fonctionnel pour développer des applications parallèles complexes et réutilisant une large quantité de code existant reste une gageur dans de nombreux domaines. Je me suis donc tourné vers l'implantation de telles solutions au sein d'un langage plus à même d'être utilisé de manière régulière par des développeurs d'origines diverses et permettant de répondre à la contrainte d'expressivité.
15/25

Notice
Le C++ comme système d'évaluation partielle La solution au problème d'expressivité est résolue par l'utilisation d'un
mécanisme d'évaluation partielle, une technique de méta-programmation qui consiste à discerner les parties statiques du programme – c’est-à-dire les parties du code calculable à la compilation – des parties dynamiques – calculables à l’exécution. Le compilateur est alors conduit à évaluer cette partie statique et à générer un code – dit code résiduel – ne contenant plus que les parties dynamiques prêtes à être compilées classiquement. Afin de déterminer les portions de code à évaluer statiquement, un évaluateur partiel doit analyser le code source original pour y détecter des structures et des données statiques. Cette détection permet par la suite de spécialiser les fragments de code. Ceci nécessite un langage à deux niveaux dans lequel il est possible de manipuler de tels marqueurs.
C++ s’avére fournir un tel système de marquage au travers des templates. Leur but principal est de fournir un support pour la programmation dites «générique», favorisant ainsi la réutilisation de code. Un template définit une famille de classes ou de fonctions paramétrées par une liste de valeurs ou de types. Fixer les paramètres d’une classe ou d’une fonction template permet de l’instancier et donc de fournir au compilateur un fragment de code complet et compilable. Une autre fonctionnalité est de permettre la spécialisation partielle d’un template. Le résultat d’une telle spécialisation est alors non pas un fragment de code compilable mais un nouveau template devant lui-même être instancier. Ainsi, il devient possible de fournir des templates dépendant de certaines caractéristiques de ces paramètres et d’optimiser le code ainsi généré en fonction de ces caractéristiques. Lorsque le compilateur tente de résoudre un type template, il commence par chercher la spécialisation la plus complète et remonte la liste des spécialisations partielles jusqu’à trouver un cas valide. Nous retrouvons donc ici, la définition même de l’évaluation partielle : la programmation par spécialisation. On démontre aisément – par construction ou par analogie avec le lambda-calcul – que les templates forment un sous-langage Turing-complet, assurant ainsi l'expressivité nécessaire pour décrire des programmes complexes.
A partir de ces constatations, on montre que les templates C++ supporte une grande partie des fonctionnalités des langages fonctionnels à même de fournir les bases d'un évaluateur partiel de DSL. Ainsi, on retrouve l'équivalent template du Pattern Matching, de la spécification de structures de données abstraites ainsi qu'un support limité de l'inspection de code. Des outils comme les bibliothèques LOKI ou BOOST::MPL fournissent d’ailleurs des implantations standard de ces constructions, mettant à disposition de véritables boîtes à outils de méta-programmes.
16/25

Notice
Des DSL pour la programmation parallèleCes bases théoriques m'ont permis de mettre au point deux outils pour la
programmation parallèle prenant respectivement en charge l’expression du parallélisme de type SIMD et l’expression du parallélisme MIMD via un modèle fondé sur les squelettes algorithmiques.
NT2 : Calculs scientifique optimisés :Les applications de vision artificielle complexes sont habituellement développées
à partir d’un formalisme mathématique adéquat et implantées dans un langage de haut niveau qui prend en charge les éléments classiques du calcul matriciel, de l’algèbre linéaire ou du traitement d’image. Des outils comme MATLAB sont régulièrement utilisés par les développeurs de la communauté Vision car ils permettent d’exprimer de manière directe des expressions mathématiques complexes et proposent un large panel de fonctionnalités au sein d’un modèle de programmation procédural classique. Mais il s’avère que certaines applications nécessitent d’être porté vers des langages plus performants en termes de temps de calcul. Un processus de réécriture vers des langages comme C ou FORTRAN est souvent envisagé, mais implique un surcroît de travail non négligeable compte tenu du faible niveau d’expressivité de ces langages.
NT2 a été conçue afin de permettre la gestion performante de matrices numériques. Son originalité réside principalement en trois points :
L’utilisation des techniques d'inspection de code et d'évaluation partielle[2] permettant d’obtenir des temps d’exécutions équivalents (à 10% prés) de ceux obtenus avec un code C équivalent;
L’utilisation transparente des caractéristiques architecturales disponibles sur une large gamme de machines : extension SIMD AltiVec, SSE2 ou support des machines SMP;
Un large panel d'optimisations annexes pour contrôler finement la qualité du code généré : déroulage de boucles, stratégie de partage de données, copy on write, etc...
La reproduction la plus fidèle possible des fonctionnalités et de la syntaxe de MATLAB, permettant ainsi un portage rapide de code MATLAB en C++.
Le principal apport de NT2 est donc de faciliter le portage de code MATLAB en C++ par un simple copier-coller de source à source. L’interface de NT2 est construite de manière à masquer le plus possibles les options d’optimisations à l’utilisateur peu averti, tout en laissant au développeur plus aguerri la possibilité d’optimiser finement son code.
17/25

Notice
QUAFF : Déploiement de code sur machine MIMDLa programmation parallèle de machine MIMD (comme les clusters par
exemple) est traditionnellement effectuée grâce à des outils tels que MPI ou PVM. L'utilisation de tels frameworks est assez peu productive car elle nécessite une attention toute particulière au déploiement du code et à la planification des communications entre les éléments de calculs. De nombreux modèles de programmations de plus haut niveaux ont été proposés. Parmi ceux-ci, j’ai décidé de m'intéresser plus particulièrement aux squelettes algorithmiques.
Le concept de squelette algorithmique est basé sur le fait que la mise en oeuvre du parallélisme dans les applications se fait très fréquemment en utilisant un nombre restreint de schémas récurrents. Ces schémas explicitent les calculs menés en parallèle et les interactions entre ces calculs. La notion de squelette correspond alors à tout ce qui, dans ces schémas, permet de contrôler les activités de calcul. Un squelette algorithmique prend donc en charge un schéma de parallélisation précis. Ainsi, toutes les opérations bas niveau nécessaires à la mise en oeuvre de la forme de parallélisme choisie sont contenues dans le code du squelette. L’utilisateur paramètre ce squelette en fournissant les fonctions de calcul de son algorithme. Ces fonctions seront alors exécutées en parallèle et les données transiteront entre elles selon le schéma que représente le squelette. Les squelettes algorithmiques rendent donc compte d’une volonté de structurer la programmation parallèle comme les Design Patterns le furent pour la programmation séquentielle. La complexité de la programmation parallèle étant alors restreinte par la limitation délibérée de l’expression du parallélisme à des formes clairement identifiées et dépendantes du domaine d’application considéré et particulièrement bien adapté au traitement d'image bas et moyen niveau.
Dans le cadre de ces travaux et de leurs applications, on dénombre quatre structures de squelettes pertinentes [1]:
Le squelette «seq», qui transforme une fonction utilisateur en fonction utilisable au sein d'un squelette;
Le squelette « pipe », qui encapsule un parallélisme de type flux dans lequel N étapes de calcul sont enchaînées, chaque étape pouvant s’exécuter en parallèle sur des données distinctes;
Le squelette « pardo », qui encapsule un parallélisme de type tâche : N opérations sont appliquées en parallèle sur chaque données d’entrée ;
Le squelette « farm », qui encapsule un parallélisme de données : une même opération est appliquée à l’ensemble des données d’entrées; le modèle d’exécution sous-jacent est celui dit en “ferme de processus”, où un processus “maître” distribue dynamiquement les données à traiter à un ensemble de processus esclaves et collecte les résultats, afin de réaliser un équilibre de charge.
Le squelette « scatter-compute-merge » (ou SCM), qui encapsule un parallélisme de type flux dans lequel la donnée d'entrée est découper en N données
18/25

Notice
intermédiaires distribuées à N processus esclaves dont les résultats sont fusionnées avant d'êtres transmises au processus suivant.
Dans ce modèle, les « étapes » sont soient des fonctions séquentielles définies par l'utilisateur, soit des squelettes complets. L'instanciation de squelettes et leur imbrications permet donc au final de construire des applications d'une complexité arbitraire. L'idée sous-jacente de QUAFF est alors de considérer ces structures comme les éléments de base d'un langage dont la syntaxe abstraite est la suivante :
∑ ::= Seq f| Pipe ∑1 ... ∑n| Pardo ∑1 ... ∑n| Farm n ∑| SCM n fs fc fm
f ::= Fonction séquentielle définie par l'utilisateur.n ::= Valeur entière supérieure ou égale à 1.
Imaginons par exemple un programme se décomposant en trois étapes : une étape de production de données (réalisée par une fonction f ), une étape de traitement de ces données en parallèle à l’aide d’une ferme à trois esclaves (chacun exécutant la même fonction g ), une étape de traitement des résultats (réalisée par une fonction h). Ce programme se définit alors simplement de la manière suivante :
A = Pipe(Seq f, Farm(3, Seq g), Seq h)
On définit ensuite une série de règles de sémantique formelle qui transforme cette définition en un Réseau de Processus Séquentiels Communiquant contenant au sein de ces noeuds l'ensemble du macro-code nécessaire à son déploiement sur une machine MIMD [3]. Ces règles de sémantiques sont implantées sous forme de méta-programmes qui, lors de la compilation d'une application QUAFF, vont générer le code C MPI strictement nécessaire et suffisant à l'exécution de l'application ainsi définie. Si l'on reprend l'exemple de l'application A,son code C++ est le suivant :
int main(int argc, char** argv){ QUAFF::Init(argc,argv);
run( pipe( seq(f), farm<3>(seq(g)), seq(h) ) ); QUAFF::Finalize();}
En termes de performance, le code produit par QUAFF s'exécute avec un surcoût moyen inférieur à 5% par rapport à un code C MPI écrit à la main, garantissant ainsi les performances globales de l'application.
19/25

Notice
Application à la vision artificielleAfin de valider ces outils, j’ai implanté des applications de vision artificielle de complexité réaliste sur un cluster dédié à la vision artificielle – la machine Babylon [6]– composé de quinze PowerPC G5 dual core.
Cette machine met en oeuvre :
Une architecture hybride à trois niveaux de parallélisme : SIMD intégré au processeur via l'extension AltiVec d’IBM/Motorola, SMP et MIMD. Ce type d’architecture permet d’augmenter de manière significative le rapport performance/coût d'une telle machine.
Un double réseau de communication. Ce double réseau permet de limiter l'impact du transfert vidéo entre chaque nœud et donc d’augmenter le temps processeur effectivement disponible pour les calculs. Le premier réseau de communication est constitué d'un réseau Ethernet Gigabit entièrement dédié à la synchronisation des nœuds, l'échange de messages spécifiques à l’application et à la récupération des résultats. Le deuxième réseau est dédié au transfert des images en provenance des caméras vers les nœuds de calcul et est constitué d'un bus FireWire IEEE 1394b à 800Mo/s.
Les applications implantées sont :
Une application de reconstruction 3D éparse [5]. Cette application a pour but de reconstruire une vue tridimensionnelle d’une scène à partir de la triangulation de la position de points d’intérêts détectés dans un flux vidéo stéréoscopique.
20/25

Notice
Une application de suivi de piéton par filtrage particulaire [4]. Cette application se propose d’utiliser des techniques probabilistes pour suivre la position 3D d’un piéton au sein d’une séquence vidéo stéréoscopique. L’originalité de cette application réside dans l’utilisation d’un filtre à particule et d’un classifieur composite basé sur des techniques de BOOSTING.
Pour ces deux applications, des accélérations de l'ordre de 40 à 100 ont été obtenues avec seulement 28 processeurs, ramenant ainsi le temps d'exécutions de ces applications dans une fenêtre compatible avec le temps réel vidéo (soit 25 images/secondes).
21/25

Notice
Conclusion et PerspectivesMes travaux ont permis de mettre en avant la pertinence des approches
d'évaluation partielle à base de template comme solution de développement de Domain Specific Languages pour la programmation parallèle. Ils démontrent aussi que le développement d'outils ciblés sur des problématiques restreintes (traitement d'image, vision artificielle, High Performance Computing) et leur interopérabilité est une solution plus à même de résoudre le problème de la parallélisation automatique que les approches classiques à bases de compilateurs dédiés.
Les perspectives de ces travaux sont multiples. De manière très pragmatique, la définition et le développement de DSL répondant aux challenges posés par les architectures émergentes constituent une voie qui, à court terme, permettra de solutionner le problème de programmabilité de ces machines. Si NT2 et QUAFF ont montré qu'il était possible de fournir des solutions logicielles efficaces, expressives et accessibles, leurs potentiels successeurs pourront répondre, en utilisant un cadre identique, aux problématiques de la programmation d’architectures aussi variées que le CELL, le TILE64 ou les futurs multi-cores comportant un grand nombre de coeur. Les cibles de types FPGA sont aussi à considérer à la fois comme cible de déploiement d’applications et comme support pour un outil de méta-programmation pour l’optimisation disjointe. De tels travaux sont actuellement en cours au sein des projets OCELLE et TER@OPS.
Au plan méthodologique, l'utilisation de la programmation générative et de l'évaluation partielle permet de réutiliser au sein de composant logiciels l'ensemble de l'expertise concernant une architecture tout en limitant l’effort initial de développement. Ainsi, l’implantation d’une bibliothèque classique proposant N algorithmes optimisés pour P plateformes nécessite l’écriture de NxP algorithmes. Pour une bibliothèque active, il suffit d’expliciter les relations de compositions entre algorithme et optimisation, de définir les N+P fragments de codes strictement nécessaires et de laisser le compilateur exécuter les méta-programmes permettant, à la volée, d’instancier le meilleur couple (N,P) pour une situation donnée.
Au plan théorique, la définition de DSL enfouies au sein de langage comme le C++ s’avère être une passerelle de choix pour permettre l’utilisation au sein d’outils efficaces de modèles de programmation ou de modèles d’exécutions complexes longtemps délaissés à cause de la complexité de leur mise en œuvre. Les liens existant entre la méta-programmation et la programmation fonctionnelle amènent à penser que de nombreux modèles (comme celui d’APL par exemple) sont à même d’être réinjecter au sein d’un langage plus largement accessible tout en conservant l’apport de leur sémantique et de leur syntaxe.
22/25

Notice
Publications et conférences
Revues d’audience internationale avec comité
[1] QUAFF : Efficient C++ Design for Parallel Skeletons Joël FALCOU, Jocelyn SEROT, Thierry CHATEAU, Jean Thierry LAPRESTE, Parallel Computing, Volume 32, Issues 7-8, Septembre 2006, Pages 604-615.
[2] E.V.E., An Object Oriented SIMD Library. Joël FALCOU, Jocelyn SEROT, Scalable Computing: Practice and Experience, Volume 6, Issues 4, Décembre 2005, Pages 31-41.
Conférences d’audience internationale avec comité et publicationLe nom de l’orateur apparaît en souligné.
[3] ParCo 2007 – (Aachen, Allemagne) Formal semantics applied to the implementation of a skeleton-based parallel programming libraryJoël Falcou, Jocelyn SEROT, Septembre 2007, à paraître.
[4] CIMCV 2006 (Workshop d’ECCV 2006) – (Graz, Autriche) Real Time Parallel Implementation of a Particle Filter Based Visual Tracking Joël Falcou, Jocelyn SEROT, Thierry CHATEAU, Jean-Thierry LAPRESTE, 7 – 13 Mai 2006, actes sur CD-ROM.
[5] ParCo 2005 – (Malaga, Espagne) A Parallel Implementation of a 3D Reconstruction Algorithm for Real-Time VisionJoël FALCOU, Jocelyn SEROT, Thierry CHATEAU, Frédéric JURIE, Septembre 2005, p. 663-670
[6] GRETSI 2005 (Louvain-la-Neuve, Belgique) Un cluster de calcul hybride pour les applications de vision temps réelJoël Falcou, Jocelyn SEROT, Thierry CHATEAU, Frédéric JURIE, Septembre 2005, actes sur CD-ROM.
[7] PAPP 2004 (Cracovie, Pologne) E.V.E., An Object Oriented SIMD LibraryJoël Falcou, Jocelyn SEROT, Juin 2004, p 323-330
[8] ACIVS 2004 (Bruxelles, Belgique) Application of template-based meta-programming compilation techniques to the efficient implementation of image processing algorithms on SIMD-capable processorsJoël Falcou, Jocelyn SEROT, Septembre 2005, p 130
23/25

Notice
Conférences d’audience nationale avec comité et publication
[9] ORASIS 2007 (Aubernai, France) NT2 : Une bibliothèque haute-performance pour la vision artificielleJoël Falcou, Jean-Thierry Lapresté, Jocelyn Serot, Thierry Chateau
[10] JFLA 2003 (Chamrousse, France) CamlG4: une bibliothèque de calcul de parallèle pour Objective CamlJoël Falcou, Jocelyn Sérot, Janvier 2003, p. 139-152
Autres communications
[11] 9ème Journée École Doctorale SPI (Clermont-Ferrand, France) Un cluster hybride MIMD/SMP/SIMD pour la vision temps réelJoël Falcou, Juin 2005
24/25

Notice
4.Charges collectives
Charges administratives Coresponsable de l’organisation d’une journée de l’école doctorale SPI, Clermont-
Ferrand (en 2005).
Représentant des doctorants au sein du conseil de l’école doctorale SPI, Clermont-Ferrand (en 2005)
Recherche
Membre des projets de recherche OCELLE et TER@OPS. Définition et implantation d'outils de déploiement automatique sur architecture multi-core.
Membre du projet de recherche LoVE. Aide à l'interfacage des modules logiciels écrits via NT2 au sein du progiciel LoVE et de RTMAPS.
Membre du comité d’organisation du congrès ORASIS des jeunes chercheurs en vision par ordinateur, mai 2005, Fournol.
Relecteur pour la revue Parallel Computing,
Relecteur pour le workshop ICCS-PAPP 2007,
Administrateur et coresponsable technique du serveur de gestion de version (SVN) du LASMEA.
25/25